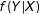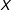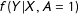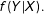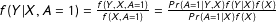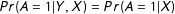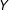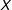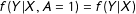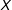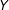Observational data in the social sciences are often incomplete. The most common approach for dealing with missing data is complete case analysis (or listwise deletion), but this strategy has important shortcomings: it ignores the valuable information carried by partially observed units, and it can introduce bias in regression coefficient estimates.
In a recent Political Analysis article, Lall (Reference Lall2016) adds to a body of work making a powerful case for an alternative: multiple imputation (MI). The author argues that listwise deletion (LWD) often introduces severe bias in regression estimates, and he applies a popular imputation routine (Honaker, King, and Blackwell Reference Honaker, King and Blackwell2011) to show that several published results are affected by the way analysts handle missing data.
Here, we clear up a common misunderstanding about LWD: this approach does not introduce bias in regression estimates, as long as the dependent variable is conditionally independent of the missingness mechanism, or when the analyst can control for the determinants of missingness.
We highlight the conditions under which MI is most likely to improve the accuracy and precision of regression results, and propose a set of best practices for empiricists dealing with missing data. The premise underlying these best practices is that while complete case analysis can be problematic, MI is no panacea: the range of circumstances under which this approach guarantees bias reduction relative to LWD is limited, and results may be sensitive to violations of the imputation model’s assumptions. When results under MI and LWD diverge, analysts can make no a priori claim that one set of results is more credible than the other, and access to imputation software does not absolve researchers of their responsibility to know the data.Footnote 1
1 When Does Listwise Deletion Introduce Bias in Regression Estimates?
After Rubin (Reference Rubin1976), it has become standard practice to distinguish between three missingness generation mechanisms.Footnote 2 Data are said to be missing completely at random (MCAR) if the pattern of missingness is independent of both the observed and unobserved data. Data are called missing at random (MAR) if missingness depends only on observables. Data are not missing at random (NMAR) when missingness depends on unobservables.
Based on this typology, Lall (Reference Lall2016, 416) writes:
“Listwise deletion is unbiased only when the restrictive MCAR assumption holds—that is, when omitting incomplete observations leaves a random sample of the data. Under MAR or [NMAR], deleting such observations produces samples that are skewed away from units with characteristics that increase their probability of having incomplete data.”
This echoes King et al. (Reference King, Honaker, Joseph and Scheve2001, 51), who argue that
“inferences from analyses using listwise deletion are relatively inefficient, no matter which assumption characterizes the missingness, and they are also biased unless MCAR holds.”
It is true that MI allows us to leverage more information than LWD, and that it could thus improve the efficiency of our analyses. However, the claim that LWD always introduces bias unless data are MCAR is erroneous. To demonstrate,Footnote
3
let
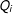 $Q_{i}$
equal 1 if the
$Q_{i}$
equal 1 if the
 $i$
th observation is fully observed, and 0 otherwise. A simple complete case model can be represented as:
$i$
th observation is fully observed, and 0 otherwise. A simple complete case model can be represented as:
 $$\begin{eqnarray}\mathbf{QY}=\mathbf{QX}\boldsymbol{\unicode[STIX]{x1D6FD}}_{c}+\mathbf{Q}\boldsymbol{\unicode[STIX]{x1D700}},\quad \text{with }\mathbf{Q}=\text{diag}(Q_{1},\ldots ,Q_{n}).\end{eqnarray}$$
$$\begin{eqnarray}\mathbf{QY}=\mathbf{QX}\boldsymbol{\unicode[STIX]{x1D6FD}}_{c}+\mathbf{Q}\boldsymbol{\unicode[STIX]{x1D700}},\quad \text{with }\mathbf{Q}=\text{diag}(Q_{1},\ldots ,Q_{n}).\end{eqnarray}$$
Defining
 $\mathbf{X}_{c}=\mathbf{QX}$
and
$\mathbf{X}_{c}=\mathbf{QX}$
and
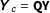 $\mathbf{Y}_{c}=\mathbf{QY}$
, the least squares complete case estimator becomes:
$\mathbf{Y}_{c}=\mathbf{QY}$
, the least squares complete case estimator becomes:
 $$\begin{eqnarray}\displaystyle \hat{\boldsymbol{\unicode[STIX]{x1D6FD}}}_{c} & = & \displaystyle (\mathbf{X}_{c}^{\prime }\mathbf{X}_{c})^{-1}\mathbf{X}_{c}^{\prime }\mathbf{Y}_{c}\nonumber\\ \displaystyle & = & \displaystyle (\mathbf{X}^{\prime }\mathbf{QX})^{-1}\mathbf{X}^{\prime }\mathbf{QY}\nonumber\\ \displaystyle & = & \displaystyle (\mathbf{X}^{\prime }\mathbf{QX})^{-1}\mathbf{X}^{\prime }\mathbf{Q}(\mathbf{X}\boldsymbol{\unicode[STIX]{x1D6FD}}+\boldsymbol{\unicode[STIX]{x1D700}})\nonumber\\ \displaystyle & = & \displaystyle \boldsymbol{\unicode[STIX]{x1D6FD}}+(\mathbf{X}^{\prime }\mathbf{QX})^{-1}\mathbf{X}^{\prime }\mathbf{Q}\boldsymbol{\unicode[STIX]{x1D700}}.\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \hat{\boldsymbol{\unicode[STIX]{x1D6FD}}}_{c} & = & \displaystyle (\mathbf{X}_{c}^{\prime }\mathbf{X}_{c})^{-1}\mathbf{X}_{c}^{\prime }\mathbf{Y}_{c}\nonumber\\ \displaystyle & = & \displaystyle (\mathbf{X}^{\prime }\mathbf{QX})^{-1}\mathbf{X}^{\prime }\mathbf{QY}\nonumber\\ \displaystyle & = & \displaystyle (\mathbf{X}^{\prime }\mathbf{QX})^{-1}\mathbf{X}^{\prime }\mathbf{Q}(\mathbf{X}\boldsymbol{\unicode[STIX]{x1D6FD}}+\boldsymbol{\unicode[STIX]{x1D700}})\nonumber\\ \displaystyle & = & \displaystyle \boldsymbol{\unicode[STIX]{x1D6FD}}+(\mathbf{X}^{\prime }\mathbf{QX})^{-1}\mathbf{X}^{\prime }\mathbf{Q}\boldsymbol{\unicode[STIX]{x1D700}}.\end{eqnarray}$$
Clearly, if
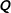 $\mathbf{Q}$
is independent of
$\mathbf{Q}$
is independent of
 $\boldsymbol{\unicode[STIX]{x1D700}}$
, and if the usual assumptions of the classical linear model hold, the complete case estimator is unbiased.Footnote
4
More loosely, Equation (1) shows that the OLS estimator with LWD is unbiased in the MAR cases where the pattern of missingness is unrelated to values of the dependent variable, or where we can control for the determinants of missingness.
$\boldsymbol{\unicode[STIX]{x1D700}}$
, and if the usual assumptions of the classical linear model hold, the complete case estimator is unbiased.Footnote
4
More loosely, Equation (1) shows that the OLS estimator with LWD is unbiased in the MAR cases where the pattern of missingness is unrelated to values of the dependent variable, or where we can control for the determinants of missingness.
Equation (1) also implies that complete case coefficient estimates are unbiased in the NMAR case “where the probability that a covariate is missing depends on the value of that covariate”, as long as “the probability of being a complete case depends on
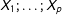 $X_{1};\ldots ;X_{p}$
but not on
$X_{1};\ldots ;X_{p}$
but not on
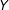 $Y$
” (Little and Rubin Reference Little and Rubin2002, 43).
$Y$
” (Little and Rubin Reference Little and Rubin2002, 43).
To be clear, the above conclusions do not depend on which variables are partially observed, but rather on the association between the values of those variables and the pattern of missingness. The outcome
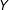 $Y$
may well be unobservable for the
$Y$
may well be unobservable for the
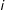 $i$
th individual, but as long as the reason why data are missing for that individual relates to the value of
$i$
th individual, but as long as the reason why data are missing for that individual relates to the value of
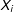 $X_{i}$
and not
$X_{i}$
and not
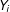 $Y_{i}$
(net of
$Y_{i}$
(net of
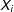 $X_{i}$
), then LWD does not introduce bias in regression estimates.
$X_{i}$
), then LWD does not introduce bias in regression estimates.
These results should not be surprising to political scientists, who have long been aware of the pitfalls of “selecting cases for study on the dependent variable” (Geddes Reference Geddes1990). To illustrate, Figure 1 shows two simulated samples where all observed units (black) fall below an arbitrary threshold, and all unobserved units (gray) fall above that threshold.Footnote 5 The gray lines show the result of a bivariate regression model using the full data, while the black lines show analogous results based on the observed data only. In the left panel of Figure 1, sample selection is based on the values of the independent variable, and the gray and black lines overlap (no bias). In the right panel of Figure 1, sample selection is based on the values of the dependent variables, and the two linear models diverge (bias).
The practical implications are considerable. In cross-national comparisons, for instance, more complete cases are typically available for advanced democracies than for developing countries. This has led analysts to worry that their estimates may suffer from an “advanced economies” or a “pro-democracy” bias (e.g., Lall Reference Lall2017, 1292).
We can distinguish between two interpretations of this problem. First, one could argue that the estimated slopes should be different in democratic and authoritarian countries, and that a full data estimate of the (“averaged”) marginal effect will be sensitive to sample composition. In that case, our recommendation is that researchers model heterogeneity explicitly (Brambor, Clark, and Golder Reference Brambor, Clark and Golder2006; Franzese and Kam Reference Franzese and Kam2009), or risk misspecification bias (but not necessarily selection bias).
Second, one could think about the issue not in terms of heterogeneous marginal effects, but directly in terms of a selection problem. In that case, analysts should reflect on the nature of the association between missingness and their dependent variable. If, as in the resource curse literature, the outcome of interest is “regime type”, and we suspect that this dependent variable directly affects transparency and observability (Hollyer, Rosendorff, and Vreeland Reference Hollyer, Rosendorff and Vreeland2011), then there are good reasons to worry. In contrast, when analysts can put the drivers of missingness on the right-hand side of their regression equations, LWD need not spoil the results.
Linear regression under two selection mechanisms.

2 When Can Multiple Imputation Improve Regression Estimates?
MI seems more likely to be beneficial in some contexts. First, as suggested by Equation (1), the use of LWD is largely unproblematic when data are MCAR, when missingness is solely a function of the regressors, or when control variables can purge the dependent variable of its association with the missingness generation mechanism. In those cases, MI does not reduce bias, but it could still improve efficiency.
Second, there are good reasons to expect that MI will be most effective where missingness affects auxiliary (or control) variables, rather than the main independent or dependent variablesof interest.Footnote
6
As Little (Reference Little1992, 1227) points out, if “the X’s are complete and the missing values of
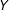 $Y$
are missing at random, then the incomplete cases contribute no information to the regression of
$Y$
are missing at random, then the incomplete cases contribute no information to the regression of
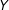 $Y$
on
$Y$
on
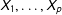 $X_{1},\ldots ,X_{p}$
.” Relatedly, White and Carlin (Reference White and Carlin2010, 2928) note that “MI is likely to be beneficial for the coefficient of a relatively complete covariate when other covariates are incomplete.”
$X_{1},\ldots ,X_{p}$
.” Relatedly, White and Carlin (Reference White and Carlin2010, 2928) note that “MI is likely to be beneficial for the coefficient of a relatively complete covariate when other covariates are incomplete.”
Third, MI may produce better results when analysts can build an imputation model that accurately predicts the values of missing data points. When missing values are difficult to predict, or when analysts cannot leverage relevant auxiliary variables to build their prediction model, we are more likely to see large differences in coefficient estimates across imputed datasets, which would reduce the precision of the combined estimates obtained by Rubin’s rules.
Fourth, an imputation routine is obviously more likely to be useful when its underlying statistical assumptions are satisfied. In particular, it is important to note that MI offers no guarantee of bias reduction unless data are MAR.Footnote 7 While we still lack systematic assessments, simple simulations have shown that LWD estimates can sometimes be less biased than MI estimates under NMAR (White and Carlin Reference White and Carlin2010; Pepinsky Reference Pepinsky2017).Footnote 8 MI performance can also be degraded when imputation routines make implausible distributional assumptions (e.g., multivariate normality) and data are not well-behaved.Footnote 9
Finally, it seems reasonable to expect that MI will bring about larger improvements to precision where the proportion of fully observed units is small (White and Carlin Reference White and Carlin2010).
In sum, MI can often improve regression estimates, but this is not always the case. Because some of the assumptions that underpin LWD and MI are untestable, analysts will typically be unable to make an a priori claim that either set of estimates is more credible than the other. When results under LWD and MI diverge, researchers will have to exercise case-specific judgement.
3 Best Practices
To exercise this kind of case-specific judgement, researchers should take to heart the repeated admonitions of MI advocates, by developing a deep knowledge of their datasets (King et al. Reference King, Honaker, Joseph and Scheve2001; van Buuren Reference van Buuren2012). They could also improve the credibility of their empirical work by following a set of simple best practices:
(1) Define the population of interest.
(2) Report the share of missing values for each variable and descriptive statistics for both complete and incomplete cases. Do fully observed units differ systematically from partially observed ones?
(3) Theorize the missingness mechanism. Is the pattern of missingness driven by (a) pure chance, (b) factors unrelated to the variables of interest, (c) values of the independent variables, (d) values of the dependent variable, or (e) unobservable factors? Under (a), (b), and (c), LWD can be used without fear that it will introduce bias in regression estimates. Under (d), MI can sometimes reduce bias, but it only offers guarantees if data are MAR and the imputation model’s assumptions are satisfied. Under (e) data are NMAR and neither LWD nor MI promise unbiased estimates.
(4) Check for divergence between LWD and MI results. If estimates do diverge, which “new” observations have a strong influence on the results? Are these observations theoretically distinct?
(5) Robustness checks. Do alternative imputation procedures or tuning parameters produce different results? Does the imputation model have good predictive power? Does it fill in reasonable values for missing observations?Footnote 10
In supplementary materials, we illustrate how these guidelines can improve statistical practice by revisiting one of the political-economy studies criticized in Lall (Reference Lall2016). The study we replicate meets some of the conditions listed above, and thus appears as a good prima facie candidate for MI. This replication exercise highlights some of the practical pitfalls of MI, and illustrates why researchers need to familiarize themselves with the data before deploying Amelia and concluding that MI results are more credible than LWD results.Footnote 11
4 Conclusion
Missing data are an inevitable problem in social science. The main shortcoming of the common way of dealing with these, through LWD, is that it is done in an unthinking manner. This is where the benefit of Lall’s article, and the literature to which it contributes, truly lies. We, as analysts, must show greater awareness of, and transparency about, the implications of missing data.
Unfortunately, MI is no panacea. In this note, we suggest that the range of circumstances under which this approach guarantees improvement relative to LWD is more narrow than is generally acknowledged by proponents of MI.
Taking the problem of missing data seriously means asking the type of questions raised above. Does the pattern of missingness suggest that LWD is biased, and that MI will be beneficial? What variables are truly unobserved, rather than nonexistent? Can we build an accurate prediction model to fill in missing values? And how does the expansion of the sample relate to the theory being tested? Multiple imputation requires a number of choices on the analyst’s part; these must be informed by knowledge of the data and of the theory being tested.
Supplementary material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2017.43.