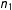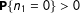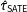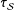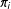1 Introduction
Population-based survey experiments have become increasingly common in political science in recent decades (Gaines, Kuklinski, and Quirk Reference Gaines, Kuklinski and Quirk2007; Mutz Reference Mutz2011; Sniderman Reference Sniderman, Druckman, Green, Kuklinski and Lupia2011). However, practical advice remains limited in the literature and uncertainty persists among scholars regarding the role of weights that capture differing probabilities of eventual inclusion across units in the analysis of survey experiments (Franco et al. Reference Franco, Simonovits, Malhotra and Zigerell2017). Should they be used or ignored? If they are to be used, which estimators are to be preferred? As Mutz (Reference Mutz2011, 113–120) notes,
“there has been no systematic treatment of this topic to date, and some scholars have used weights while others have not …the practice of weighting was developed as a survey research tool—that is, for use in observational settings. The use of experimental methodology with representative samples is not yet sufficiently common for the analogous issue to have been explored in the statistical literature”
We seek to fill this void with a systematic evaluation of using weights, based on sound statistical principles rooted in the Neyman–Rubin model, to obtain practical advice for scholars seeking to make the best possible decisions when using (or electing not to use) weights in their analysis of survey experiments. We explore the topic through a combination of mathematical analysis, simulation, and examination of real data.
Taken together, these explorations lead to the conclusion that, for scholars examining population treatment effects using the high-quality, broadly representative samples recruited and delivered by top online survey firms, sample quantities, which do not rely on weights, are often sufficient. Sample average treatment effect (SATE) estimates tend not to differ substantially from their weighted counterparts, and they avoid the statistical power loss that accompanies weighting. When precise estimates of population average treatment effects (PATE) are essential, we find that a “double-Hàjek” weighted estimator is a very straightforward and reliable option in many cases. We also analytically show that poststratifying on survey weights and/or covariates highly correlated with the outcome is a conservative choice for precision improvement, because it is unlikely to do harm and could be quite beneficial in certain circumstances.
The greater prevalence of online surveys has gone hand-in-hand with the boom in survey experiments. Firms such as YouGov (formerly Polimetrix) and Knowledge Networks (now owned by GfK) provide researchers platforms through which to run experiments. The firms offer representative samples generated through extensive panel recruitment efforts and sophisticated sample matching and weighting procedures. By reducing or eliminating costs, subsidized, grant-based and collective programs such as Time-Sharing Experiments for the Social Sciences (TESS), the Cooperative Congressional Election Study (CCES), and Cooperative Campaign Analysis Project (CCAP) have further facilitated researchers’ access to time on high-end online surveys. Other firms and platforms, such as Survey Sampling International, Google Consumer Surveys (Santoso, Stein, and Stevenson Reference Santoso, Stein and Stevenson2016), and Amazon’s Mechanical Turk (Berinsky, Huber, and Lenz Reference Berinsky, Huber and Lenz2012), offer even less costly access to large and diverse convenience samples on which researchers can also conduct survey experiments. Researchers using these sometimes generate their own weights to improve representativeness. However, because we view population inferences with such convenience samples as rather tenuous, our primary interest is in methods for analysis of data from sources, such as YouGov and Knowledge Networks, that actively recruit subjects and provide the researcher with weights.
Survey experiments are a two-step process where a sample is first obtained from a parent population, and then that sample is randomized into different treatment arms. The sample selection and treatment assignment processes are generally independent of each other. Sampling procedures have changed in recent years because of increasing rates of nonresponse and new technologies. As a result, weights can vary substantially across units, with some units having only a small probability of being in the sample. In contrast, the treatment assignment mechanisms are usually simple and relatively balanced, rendering the SATE straightforward to estimate. Estimating the PATE, however, is less so because these estimates need to incorporate the weights, which introduces additional variance as well as a host of complexities.
In this work we assume the weights are known, and further assume that they incorporate both sampling probabilities and nonresponse. In particular, if there is nonresponse, and the nonresponse is correctly modeled as a function of some set of covariates, the overall weight would then be the product of being included in the sample and of responding conditional on that inclusion. We use weight rather than sampling weight to indicate this more general view. In fact, for our primary type of data targeted by this work, typically the weights are calculated by the survey firms to represent the relative chances that a newly arrived recruit would get selected into the survey; as volunteering is in part self-selection, the nonresponse is built into the final weight calculations automatically. We believe the findings based on these assumptions are nevertheless informative, but we also discuss the additional complications of weight uncertainty in the body of this paper.
Overall, we encourage researchers choosing between these approaches to first give serious thought to the types of inferences they will make. Do they simply wish to establish the presence or absence of an effect in a given population? If so, the SATE may suffice. Or do they hope to measure the magnitude of an effect that may not already be documented? In this case, the scholar should possibly consider her options for weighted estimators.
In Section 2, we overview general survey methodology. In Section 3, we formally consider survey experiments and relate them to the SATE. We formally define the PATE and some estimators of it in Section 4, where we also discuss weights and uncertainty in weights in more detail, and we introduce a poststratification estimator in Section 4.3. We then investigate the performance of these estimators through simulation studies in Section 5, and analyze trends and features of real survey experimental data collected through YouGov in Section 6. We conclude with an extended discussion, providing some advice and high-level pointers to applied practitioners.
2 Surveys and Survey Experiments through the Lens of Potential Outcomes
We formalize surveys and survey experiments in terms of the Neyman–Rubin model of potential outcomes (Splawa-Neyman, Dabrowska, and Speed Reference Splawa-Neyman, Dabrowska and Speed1990). Assume we have a population of
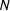 $N$
units indexed as
$N$
units indexed as
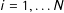 $i=1,\ldots N$
. We take a sample from this population using a sample selection mechanism, and we then randomly assign treatment in this sample using a treatment assignment mechanism. Both mechanisms will be formally defined in subsequent sections. Each unit
$i=1,\ldots N$
. We take a sample from this population using a sample selection mechanism, and we then randomly assign treatment in this sample using a treatment assignment mechanism. Both mechanisms will be formally defined in subsequent sections. Each unit
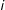 $i$
in the population has a pair of values,
$i$
in the population has a pair of values,
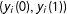 $(y_{i}(0),y_{i}(1))$
, called its potential outcomes. Let
$(y_{i}(0),y_{i}(1))$
, called its potential outcomes. Let
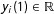 $y_{i}(1)\in \mathbb{R}$
be unit
$y_{i}(1)\in \mathbb{R}$
be unit
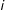 $i$
’s outcome if it were treated, and
$i$
’s outcome if it were treated, and
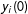 $y_{i}(0)$
its outcome if it were not. For each selected unit, we observe either
$y_{i}(0)$
its outcome if it were not. For each selected unit, we observe either
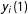 $y_{i}(1)$
or
$y_{i}(1)$
or
 $y_{i}(0)$
depending on whether we treat it or not. For any unselected unit, we observe neither.
$y_{i}(0)$
depending on whether we treat it or not. For any unselected unit, we observe neither.
We make the usual no-interference assumption that implies that treatment assignment for any particular unit has no impact on the potential outcomes of any other unit. This assumption is natural in survey experiments. The treatment effect
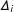 $\unicode[STIX]{x1D6E5}_{i}$
for unit
$\unicode[STIX]{x1D6E5}_{i}$
for unit
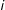 $i$
is then the difference in potential outcomes,
$i$
is then the difference in potential outcomes,
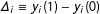 $\unicode[STIX]{x1D6E5}_{i}\equiv y_{i}(1)-y_{i}(0)$
. These individual treatment effects are deterministic, pretreatment quantities.
$\unicode[STIX]{x1D6E5}_{i}\equiv y_{i}(1)-y_{i}(0)$
. These individual treatment effects are deterministic, pretreatment quantities.
Let
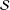 ${\mathcal{S}}$
be our sample of
${\mathcal{S}}$
be our sample of
 $n$
units. Then the SATE is the mean treatment effect over the sample:
$n$
units. Then the SATE is the mean treatment effect over the sample:
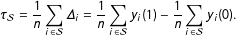 $$\begin{eqnarray}\unicode[STIX]{x1D70F}_{{\mathcal{S}}}=\frac{1}{n}\mathop{\sum }_{i\in {\mathcal{S}}}\unicode[STIX]{x1D6E5}_{i}=\frac{1}{n}\mathop{\sum }_{i\in {\mathcal{S}}}y_{i}(1)-\frac{1}{n}\mathop{\sum }_{i\in {\mathcal{S}}}y_{i}(0).\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D70F}_{{\mathcal{S}}}=\frac{1}{n}\mathop{\sum }_{i\in {\mathcal{S}}}\unicode[STIX]{x1D6E5}_{i}=\frac{1}{n}\mathop{\sum }_{i\in {\mathcal{S}}}y_{i}(1)-\frac{1}{n}\mathop{\sum }_{i\in {\mathcal{S}}}y_{i}(0).\end{eqnarray}$$
This is a parameter for the sample at hand, but is random in its own right if we view the sample as a draw from the larger population. By comparison, a parameter of interest in the population is the PATE defined as
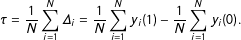 $$\begin{eqnarray}\unicode[STIX]{x1D70F}=\frac{1}{N}\mathop{\sum }_{i=1}^{N}\unicode[STIX]{x1D6E5}_{i}=\frac{1}{N}\mathop{\sum }_{i=1}^{N}y_{i}(1)-\frac{1}{N}\mathop{\sum }_{i=1}^{N}y_{i}(0).\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D70F}=\frac{1}{N}\mathop{\sum }_{i=1}^{N}\unicode[STIX]{x1D6E5}_{i}=\frac{1}{N}\mathop{\sum }_{i=1}^{N}y_{i}(1)-\frac{1}{N}\mathop{\sum }_{i=1}^{N}y_{i}(0).\end{eqnarray}$$
In general
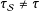 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}\neq \unicode[STIX]{x1D70F}$
, and if the sampling scheme is not simple (e.g., some types of units are more likely to be selected), then potentially
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}\neq \unicode[STIX]{x1D70F}$
, and if the sampling scheme is not simple (e.g., some types of units are more likely to be selected), then potentially
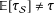 $\mathbb{E}[\unicode[STIX]{x1D70F}_{{\mathcal{S}}}]\neq \unicode[STIX]{x1D70F}$
.
$\mathbb{E}[\unicode[STIX]{x1D70F}_{{\mathcal{S}}}]\neq \unicode[STIX]{x1D70F}$
.
We discuss some results concerning the sample selection mechanism in the next section. After that, we will combine the sample selection with the treatment assignment process.
2.1 Simple surveys (no experiments)
Let
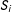 $S_{i}$
be a dummy variable indicating selection of unit
$S_{i}$
be a dummy variable indicating selection of unit
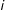 $i$
into the sample, with
$i$
into the sample, with
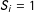 $S_{i}=1$
if unit
$S_{i}=1$
if unit
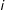 $i$
is in the sample, and 0 if not. Let
$i$
is in the sample, and 0 if not. Let
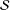 ${\mathcal{S}}$
be
${\mathcal{S}}$
be
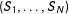 $(S_{1},\ldots ,S_{N})$
, the vector of selections. In a slight abuse of notation, let
$(S_{1},\ldots ,S_{N})$
, the vector of selections. In a slight abuse of notation, let
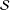 ${\mathcal{S}}$
also denote the random sample. Thus, for example,
${\mathcal{S}}$
also denote the random sample. Thus, for example,
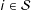 $i\in {\mathcal{S}}$
would mean unit
$i\in {\mathcal{S}}$
would mean unit
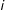 $i$
was selected into sample
$i$
was selected into sample
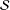 ${\mathcal{S}}$
. Finally let the overall selection probability or sampling probability for unit
${\mathcal{S}}$
. Finally let the overall selection probability or sampling probability for unit
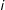 $i$
be
$i$
be
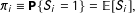 $$\begin{eqnarray}\unicode[STIX]{x1D70B}_{i}\equiv \mathbf{P}\!\left\{S_{i}=1\right\}=\mathbb{E}[S_{i}],\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D70B}_{i}\equiv \mathbf{P}\!\left\{S_{i}=1\right\}=\mathbb{E}[S_{i}],\end{eqnarray}$$
which is the probability of unit
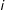 $i$
being included in the sample. The more the
$i$
being included in the sample. The more the
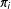 $\unicode[STIX]{x1D70B}_{i}$
vary, the more the sample could be unrepresentative of the population. We assume
$\unicode[STIX]{x1D70B}_{i}$
vary, the more the sample could be unrepresentative of the population. We assume
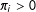 $\unicode[STIX]{x1D70B}_{i}>0$
for all
$\unicode[STIX]{x1D70B}_{i}>0$
for all
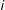 $i$
, meaning every unit has some chance of being selected into
$i$
, meaning every unit has some chance of being selected into
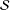 ${\mathcal{S}}$
. The
${\mathcal{S}}$
. The
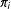 $\unicode[STIX]{x1D70B}_{i}$
depend, among other things, on the desired size of sample
$\unicode[STIX]{x1D70B}_{i}$
depend, among other things, on the desired size of sample
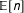 $\mathbb{E}[n]$
. We assume the
$\mathbb{E}[n]$
. We assume the
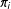 $\unicode[STIX]{x1D70B}_{i}$
are fixed and known and incorporate nonresponse; we discuss uncertainty in them in Section 4.2.
$\unicode[STIX]{x1D70B}_{i}$
are fixed and known and incorporate nonresponse; we discuss uncertainty in them in Section 4.2.
Consider the case where we have no treatment and we see
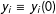 $y_{i}\equiv y_{i}(0)$
for any selected unit. Our task is to estimate the mean of the population,
$y_{i}\equiv y_{i}(0)$
for any selected unit. Our task is to estimate the mean of the population,
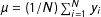 $\unicode[STIX]{x1D707}=(1/N)\sum _{i=1}^{N}y_{i}$
. Estimating the mean of a population under a sampling framework has a long, rich history. We base our work on two estimators from that history here.
$\unicode[STIX]{x1D707}=(1/N)\sum _{i=1}^{N}y_{i}$
. Estimating the mean of a population under a sampling framework has a long, rich history. We base our work on two estimators from that history here.
Let
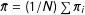 $\bar{\unicode[STIX]{x1D70B}}=(1/N)\sum \unicode[STIX]{x1D70B}_{i}$
be the average selection probability in the population and
$\bar{\unicode[STIX]{x1D70B}}=(1/N)\sum \unicode[STIX]{x1D70B}_{i}$
be the average selection probability in the population and
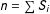 $n=\sum S_{i}$
be the realized sample size for sample
$n=\sum S_{i}$
be the realized sample size for sample
 ${\mathcal{S}}$
, with
${\mathcal{S}}$
, with
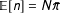 $\mathbb{E}[n]=N\bar{\unicode[STIX]{x1D70B}}$
. Then let
$\mathbb{E}[n]=N\bar{\unicode[STIX]{x1D70B}}$
. Then let
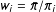 $w_{i}=\bar{\unicode[STIX]{x1D70B}}/\unicode[STIX]{x1D70B}_{i}$
be the weight. These weights
$w_{i}=\bar{\unicode[STIX]{x1D70B}}/\unicode[STIX]{x1D70B}_{i}$
be the weight. These weights
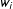 $w_{i}$
are relative to a baseline of 1, which eases interpretability due to removing dependence on
$w_{i}$
are relative to a baseline of 1, which eases interpretability due to removing dependence on
 $n$
. A weight of 1 means the unit stands for itself, a weight of 2 means the unit “counts” as 2 units, a weight of 0.5 means units of this type tend to be overrepresented and so this unit counts as half, and so forth. The total weight of our sample is then
$n$
. A weight of 1 means the unit stands for itself, a weight of 2 means the unit “counts” as 2 units, a weight of 0.5 means units of this type tend to be overrepresented and so this unit counts as half, and so forth. The total weight of our sample is then
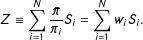 $$\begin{eqnarray}Z\equiv \mathop{\sum }_{i=1}^{N}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}S_{i}=\mathop{\sum }_{i=1}^{N}w_{i}S_{i}.\end{eqnarray}$$
$$\begin{eqnarray}Z\equiv \mathop{\sum }_{i=1}^{N}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}S_{i}=\mathop{\sum }_{i=1}^{N}w_{i}S_{i}.\end{eqnarray}$$
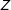 $Z$
is random, but
$Z$
is random, but
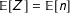 $\mathbb{E}[Z]=\mathbb{E}[n]$
.
$\mathbb{E}[Z]=\mathbb{E}[n]$
.
The Horvitz–Thompson estimator (Horvitz and Thompson Reference Horvitz and Thompson1952), an inverse probability weighting estimator, is then
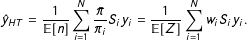 $$\begin{eqnarray}{\hat{y}}_{HT}=\frac{1}{\mathbb{E}[n]}\mathop{\sum }_{i=1}^{N}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}S_{i}y_{i}=\frac{1}{\mathbb{E}[Z]}\mathop{\sum }_{i=1}^{N}w_{i}S_{i}y_{i}.\end{eqnarray}$$
$$\begin{eqnarray}{\hat{y}}_{HT}=\frac{1}{\mathbb{E}[n]}\mathop{\sum }_{i=1}^{N}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}S_{i}y_{i}=\frac{1}{\mathbb{E}[Z]}\mathop{\sum }_{i=1}^{N}w_{i}S_{i}y_{i}.\end{eqnarray}$$
Although unbiased, the Horvitz–Thompson estimator is well known to be highly variable. This variability comes from the weights; if you randomly get too many rare units in the sample, the inverse of their weights will inflate
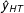 ${\hat{y}}_{HT}$
, even if all
${\hat{y}}_{HT}$
, even if all
 $y_{i}$
are the same. We are not controlling for the realized size of the sample. This is reparable by normalizing by the realized weight of the sample rather than the expected.
$y_{i}$
are the same. We are not controlling for the realized size of the sample. This is reparable by normalizing by the realized weight of the sample rather than the expected.
This gives the Hàjek estimator, which is the usual weighted average of the selected units, and which likely reflects the approach used by most scholars:
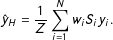 $$\begin{eqnarray}{\hat{y}}_{H}=\frac{1}{Z}\mathop{\sum }_{i=1}^{N}w_{i}S_{i}y_{i}.\end{eqnarray}$$
$$\begin{eqnarray}{\hat{y}}_{H}=\frac{1}{Z}\mathop{\sum }_{i=1}^{N}w_{i}S_{i}y_{i}.\end{eqnarray}$$
The Hàjek estimator is not unbiased, but it often has smaller MSE than Horvitz–Thompson (Hàjek Reference Hàjek1958; Särndal, Swensson, and Wretman Reference Särndal, Swensson and Wretman2003). The bias, however, will tend to be negligible, as shown by the following lemma:
Lemma 2.1 (A variation on Result 6.34 of Cochran (Reference Cochran1977)).
Under a Poisson selection scheme, i.e. units sampled independently with individual probability
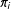 $\unicode[STIX]{x1D70B}_{i}$
, the bias of the Hàjek estimator is
$\unicode[STIX]{x1D70B}_{i}$
, the bias of the Hàjek estimator is
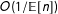 $O(1/\mathbb{E}[n])$
. In particular, the bias can be approximated as
$O(1/\mathbb{E}[n])$
. In particular, the bias can be approximated as
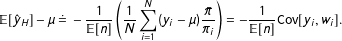 $$\begin{eqnarray}\mathbb{E}[{\hat{y}}_{H}]-\unicode[STIX]{x1D707}\,\dot{=}\,-\frac{1}{\mathbb{E}[n]}\left(\frac{1}{N}\mathop{\sum }_{i=1}^{N}(y_{i}-\unicode[STIX]{x1D707})\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}\right)=-\frac{1}{\mathbb{E}[n]}\text{Cov}[y_{i},w_{i}].\end{eqnarray}$$
$$\begin{eqnarray}\mathbb{E}[{\hat{y}}_{H}]-\unicode[STIX]{x1D707}\,\dot{=}\,-\frac{1}{\mathbb{E}[n]}\left(\frac{1}{N}\mathop{\sum }_{i=1}^{N}(y_{i}-\unicode[STIX]{x1D707})\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}\right)=-\frac{1}{\mathbb{E}[n]}\text{Cov}[y_{i},w_{i}].\end{eqnarray}$$
See Appendix C for proof. The above shows that, for a fixed population, the bias decreases rapidly as sample size increases. If we sample with equal probability or if the outcomes are constant, the bias is 0. However, if the covariance between the weights and
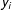 $y_{i}$
is large, the bias could potentially be large also. In particular, the covariance will be large if rare units (those with small
$y_{i}$
is large, the bias could potentially be large also. In particular, the covariance will be large if rare units (those with small
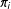 $\unicode[STIX]{x1D70B}_{i}$
) systematically tend to be outliers with large
$\unicode[STIX]{x1D70B}_{i}$
) systematically tend to be outliers with large
 $y_{i}-\unicode[STIX]{x1D707}$
because, as weights are nonnegative inverses of the
$y_{i}-\unicode[STIX]{x1D707}$
because, as weights are nonnegative inverses of the
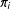 $\unicode[STIX]{x1D70B}_{i}$
, their distribution can feature a long right tail that drives the covariance.
$\unicode[STIX]{x1D70B}_{i}$
, their distribution can feature a long right tail that drives the covariance.
3 Survey Experiments and SATE
Survey experiments are surveys with an additional treatment assigned at random to all selected units. Independent of
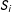 $S_{i}$
let
$S_{i}$
let
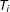 $T_{i}$
be a treatment assignment, with
$T_{i}$
be a treatment assignment, with
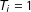 $T_{i}=1$
if unit
$T_{i}=1$
if unit
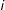 $i$
is treated, 0 otherwise. The most natural such assignment mechanism for our context is Bernoulli assignment, where each responding unit
$i$
is treated, 0 otherwise. The most natural such assignment mechanism for our context is Bernoulli assignment, where each responding unit
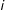 $i$
is treated independently with probability
$i$
is treated independently with probability
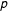 $p$
for some
$p$
for some
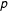 $p$
. Another common mechanism is the classic complete randomization, when a
$p$
. Another common mechanism is the classic complete randomization, when a
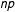 $np$
-sized simple random sample of the
$np$
-sized simple random sample of the
 $n$
units is treated. Regardless, we assume randomization is a separate process from selection. In particular, we assume that randomization does not depend on the weights.
$n$
units is treated. Regardless, we assume randomization is a separate process from selection. In particular, we assume that randomization does not depend on the weights.
If our interest is in the SATE, then a natural estimator is Neyman’s difference-in-means estimator of
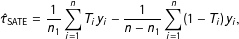 $$\begin{eqnarray}\displaystyle \hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}=\frac{1}{n_{1}}\mathop{\sum }_{i=1}^{n}T_{i}y_{i}-\frac{1}{n-n_{1}}\mathop{\sum }_{i=1}^{n}(1-T_{i})y_{i}, & & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}=\frac{1}{n_{1}}\mathop{\sum }_{i=1}^{n}T_{i}y_{i}-\frac{1}{n-n_{1}}\mathop{\sum }_{i=1}^{n}(1-T_{i})y_{i}, & & \displaystyle\end{eqnarray}$$
with
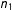 $n_{1}$
the (possibly random) number of treated units (see Splawa-Neyman, Dabrowska, and Speed Reference Splawa-Neyman, Dabrowska and Speed1990).
$n_{1}$
the (possibly random) number of treated units (see Splawa-Neyman, Dabrowska, and Speed Reference Splawa-Neyman, Dabrowska and Speed1990).
This estimator is essentially unbiased for the SATE (
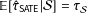 $\mathbb{E}[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}|{\mathcal{S}}]=\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
), but unfortunately, the SATE is not generally the same as the PATE and
$\mathbb{E}[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}|{\mathcal{S}}]=\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
), but unfortunately, the SATE is not generally the same as the PATE and
 $\mathbb{E}[\unicode[STIX]{x1D70F}_{{\mathcal{S}}}]\neq \unicode[STIX]{x1D70F}$
in general. The bias, for fixed
$\mathbb{E}[\unicode[STIX]{x1D70F}_{{\mathcal{S}}}]\neq \unicode[STIX]{x1D70F}$
in general. The bias, for fixed
 $n$
, is
$n$
, is
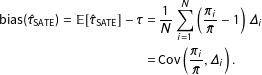 $$\begin{eqnarray}\displaystyle \text{bias}(\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}})=\mathbb{E}[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}]-\unicode[STIX]{x1D70F} & = & \displaystyle \frac{1}{N}\mathop{\sum }_{i=1}^{N}\left(\frac{\unicode[STIX]{x1D70B}_{i}}{\bar{\unicode[STIX]{x1D70B}}}-1\right)\unicode[STIX]{x1D6E5}_{i}\nonumber\\ \displaystyle & = & \displaystyle \text{Cov}\left(\frac{\unicode[STIX]{x1D70B}_{i}}{\bar{\unicode[STIX]{x1D70B}}},\unicode[STIX]{x1D6E5}_{i}\right).\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \text{bias}(\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}})=\mathbb{E}[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}]-\unicode[STIX]{x1D70F} & = & \displaystyle \frac{1}{N}\mathop{\sum }_{i=1}^{N}\left(\frac{\unicode[STIX]{x1D70B}_{i}}{\bar{\unicode[STIX]{x1D70B}}}-1\right)\unicode[STIX]{x1D6E5}_{i}\nonumber\\ \displaystyle & = & \displaystyle \text{Cov}\left(\frac{\unicode[STIX]{x1D70B}_{i}}{\bar{\unicode[STIX]{x1D70B}}},\unicode[STIX]{x1D6E5}_{i}\right).\end{eqnarray}$$
See Appendix C for derivation. As units with higher
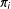 $\unicode[STIX]{x1D70B}_{i}$
will be more likely to be selected into
$\unicode[STIX]{x1D70B}_{i}$
will be more likely to be selected into
 ${\mathcal{S}}$
, the estimator will be biased toward the treatment effect of these units. Equation (3) shows an important fact: if the treatment impacts are not correlated with the weights, then there will be no bias. In particular, if the selection probabilities are all the same, or there is no treatment effect heterogeneity, then the bias of
${\mathcal{S}}$
, the estimator will be biased toward the treatment effect of these units. Equation (3) shows an important fact: if the treatment impacts are not correlated with the weights, then there will be no bias. In particular, if the selection probabilities are all the same, or there is no treatment effect heterogeneity, then the bias of
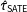 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
for estimating the PATE will be 0.
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
for estimating the PATE will be 0.
The variance of
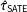 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
, conditional on the sample
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
, conditional on the sample
 ${\mathcal{S}}$
, is well known, but we include it here as we use it extensively.
${\mathcal{S}}$
, is well known, but we include it here as we use it extensively.
Theorem 3.1. Let sample
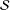 ${\mathcal{S}}$
be randomly assigned to treatment and control with
${\mathcal{S}}$
be randomly assigned to treatment and control with
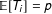 $\mathbb{E}[T_{i}]=p$
for all
$\mathbb{E}[T_{i}]=p$
for all
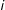 $i$
with either a complete randomization or Bernoulli assignment mechanism. The unadjusted simple-difference estimator
$i$
with either a complete randomization or Bernoulli assignment mechanism. The unadjusted simple-difference estimator
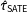 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
is unbiasedFootnote
1
for the SATE, i.e.
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
is unbiasedFootnote
1
for the SATE, i.e.
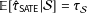 $\mathbb{E}[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}|{\mathcal{S}}]=\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
. Its variance is
$\mathbb{E}[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}|{\mathcal{S}}]=\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
. Its variance is
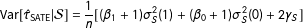 $$\begin{eqnarray}\displaystyle \text{Var}\!\left[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}|{\mathcal{S}}\right] & = & \displaystyle \frac{1}{n}[(\unicode[STIX]{x1D6FD}_{1}+1)\unicode[STIX]{x1D70E}_{S}^{2}(1)+(\unicode[STIX]{x1D6FD}_{0}+1)\unicode[STIX]{x1D70E}_{S}^{2}(0)+2\unicode[STIX]{x1D6FE}_{S}]\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \text{Var}\!\left[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}|{\mathcal{S}}\right] & = & \displaystyle \frac{1}{n}[(\unicode[STIX]{x1D6FD}_{1}+1)\unicode[STIX]{x1D70E}_{S}^{2}(1)+(\unicode[STIX]{x1D6FD}_{0}+1)\unicode[STIX]{x1D70E}_{S}^{2}(0)+2\unicode[STIX]{x1D6FE}_{S}]\end{eqnarray}$$
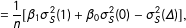 $$\begin{eqnarray}\displaystyle & = & \displaystyle \frac{1}{n}[\unicode[STIX]{x1D6FD}_{1}\unicode[STIX]{x1D70E}_{S}^{2}(1)+\unicode[STIX]{x1D6FD}_{0}\unicode[STIX]{x1D70E}_{S}^{2}(0)-\unicode[STIX]{x1D70E}_{S}^{2}(\unicode[STIX]{x1D6E5})],\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & = & \displaystyle \frac{1}{n}[\unicode[STIX]{x1D6FD}_{1}\unicode[STIX]{x1D70E}_{S}^{2}(1)+\unicode[STIX]{x1D6FD}_{0}\unicode[STIX]{x1D70E}_{S}^{2}(0)-\unicode[STIX]{x1D70E}_{S}^{2}(\unicode[STIX]{x1D6E5})],\end{eqnarray}$$
where
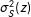 $\unicode[STIX]{x1D70E}_{S}^{2}(z)$
and
$\unicode[STIX]{x1D70E}_{S}^{2}(z)$
and
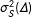 $\unicode[STIX]{x1D70E}_{S}^{2}(\unicode[STIX]{x1D6E5})$
are the variances of the individual potential outcomes and treatment effects for the sample, and
$\unicode[STIX]{x1D70E}_{S}^{2}(\unicode[STIX]{x1D6E5})$
are the variances of the individual potential outcomes and treatment effects for the sample, and
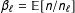 $\unicode[STIX]{x1D6FD}_{\ell }=\mathbb{E}[n/n_{\ell }]$
are the expectations (across randomizations) of the inverses of the proportion of units in the two treatment arms.
$\unicode[STIX]{x1D6FD}_{\ell }=\mathbb{E}[n/n_{\ell }]$
are the expectations (across randomizations) of the inverses of the proportion of units in the two treatment arms.
If
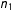 $n_{1}$
is fixed, such as with a completely randomized experiment, then
$n_{1}$
is fixed, such as with a completely randomized experiment, then
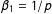 $\unicode[STIX]{x1D6FD}_{1}=1/p$
,
$\unicode[STIX]{x1D6FD}_{1}=1/p$
,
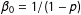 $\unicode[STIX]{x1D6FD}_{0}=1/(1-p)$
and the above simplifies to Neyman’s result of
$\unicode[STIX]{x1D6FD}_{0}=1/(1-p)$
and the above simplifies to Neyman’s result of
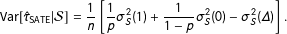 $$\begin{eqnarray}\text{Var}\!\left[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}|{\mathcal{S}}\right]=\frac{1}{n}\left[\frac{1}{p}\unicode[STIX]{x1D70E}_{S}^{2}(1)+\frac{1}{1-p}\unicode[STIX]{x1D70E}_{S}^{2}(0)-\unicode[STIX]{x1D70E}_{S}^{2}(\unicode[STIX]{x1D6E5})\right].\end{eqnarray}$$
$$\begin{eqnarray}\text{Var}\!\left[\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}|{\mathcal{S}}\right]=\frac{1}{n}\left[\frac{1}{p}\unicode[STIX]{x1D70E}_{S}^{2}(1)+\frac{1}{1-p}\unicode[STIX]{x1D70E}_{S}^{2}(0)-\unicode[STIX]{x1D70E}_{S}^{2}(\unicode[STIX]{x1D6E5})\right].\end{eqnarray}$$
For Bernoulli assignment, the
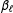 $\unicode[STIX]{x1D6FD}_{\ell }$
are complicated because of the expectation of the random denominator, and there are mild technical issues because the estimator is undefined when, for example,
$\unicode[STIX]{x1D6FD}_{\ell }$
are complicated because of the expectation of the random denominator, and there are mild technical issues because the estimator is undefined when, for example,
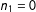 $n_{1}=0$
. One approach is to use
$n_{1}=0$
. One approach is to use
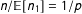 $n/\mathbb{E}[n_{1}]=1/p$
as an approximation for
$n/\mathbb{E}[n_{1}]=1/p$
as an approximation for
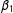 $\unicode[STIX]{x1D6FD}_{1}$
. This approximation is quite good; the bias is of high order for the same reasons as the bias for the Hàjek estimator (see Lemma 2.1). Furthermore, the undefined issue is of small concern as the chance of
$\unicode[STIX]{x1D6FD}_{1}$
. This approximation is quite good; the bias is of high order for the same reasons as the bias for the Hàjek estimator (see Lemma 2.1). Furthermore, the undefined issue is of small concern as the chance of
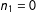 $n_{1}=0$
is exponentially small; giving the estimator an arbitrary value (e.g., 0) if this rare event occurs, introduces only a small bias. An alternate approach is to condition on the number of units treated: set
$n_{1}=0$
is exponentially small; giving the estimator an arbitrary value (e.g., 0) if this rare event occurs, introduces only a small bias. An alternate approach is to condition on the number of units treated: set
 $p=n_{1}/n$
and use Neyman’s results. Conditioning is a reasonable choice that we prefer. It leads to a more accurate (and more readable) formula. For details, including formal definitions and the derivations, see Miratrix, Sekhon, and Yu (Reference Miratrix, Sekhon and Yu2013).
$p=n_{1}/n$
and use Neyman’s results. Conditioning is a reasonable choice that we prefer. It leads to a more accurate (and more readable) formula. For details, including formal definitions and the derivations, see Miratrix, Sekhon, and Yu (Reference Miratrix, Sekhon and Yu2013).
It is important to underscore that any SATE analysis on the sample, given a truly modeled treatment assignment mechanism, is valid. That is, such an analysis is estimating a true treatment effect parameter, the SATE. If
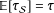 $\mathbb{E}[\unicode[STIX]{x1D70F}_{{\mathcal{S}}}]=\unicode[STIX]{x1D70F}$
, then any SATE analysis will be correct for PATE as well (although estimates of uncertainty may be too low if they do not account for variability in
$\mathbb{E}[\unicode[STIX]{x1D70F}_{{\mathcal{S}}}]=\unicode[STIX]{x1D70F}$
, then any SATE analysis will be correct for PATE as well (although estimates of uncertainty may be too low if they do not account for variability in
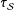 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
). In particular, if there is a constant treatment effect, then
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
). In particular, if there is a constant treatment effect, then
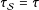 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}=\unicode[STIX]{x1D70F}$
for any sample, and the SATE will be the PATE, and all uncertainty estimates for the SATE will be the same as for the PATE.Footnote
2
But a constant treatment effect is a large assumption.
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}=\unicode[STIX]{x1D70F}$
for any sample, and the SATE will be the PATE, and all uncertainty estimates for the SATE will be the same as for the PATE.Footnote
2
But a constant treatment effect is a large assumption.
4 Estimating the PATE
Imagine we had both potential outcomes
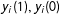 $y_{i}(1),y_{i}(0)$
for all the sampled
$y_{i}(1),y_{i}(0)$
for all the sampled
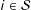 $i\in {\mathcal{S}}$
. These would give us exact knowledge of the SATE, and we could also use this information, coupled with the weights, to estimate the PATE. In particular, with knowledge of the
$i\in {\mathcal{S}}$
. These would give us exact knowledge of the SATE, and we could also use this information, coupled with the weights, to estimate the PATE. In particular, with knowledge of the
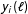 $y_{i}(\ell )$
we have a sample of treatment effects:
$y_{i}(\ell )$
we have a sample of treatment effects:
 $$\begin{eqnarray}\unicode[STIX]{x1D6E5}_{i}=y_{i}(1)-y_{i}(0)\quad \text{for }i\in {\mathcal{S}}.\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D6E5}_{i}=y_{i}(1)-y_{i}(0)\quad \text{for }i\in {\mathcal{S}}.\end{eqnarray}$$
We can use these
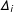 $\unicode[STIX]{x1D6E5}_{i}$
to estimate the PATE,
$\unicode[STIX]{x1D6E5}_{i}$
to estimate the PATE,
 $\unicode[STIX]{x1D70F}$
, with, for example, a Hàjek estimator:
$\unicode[STIX]{x1D70F}$
, with, for example, a Hàjek estimator:
 $$\begin{eqnarray}\unicode[STIX]{x1D708}_{{\mathcal{S}}}=\frac{1}{Z}\sum S_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}\unicode[STIX]{x1D6E5}_{i}=\frac{1}{Z}\sum S_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}y_{i}(1)-\frac{1}{Z}\sum S_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}y_{i}(0).\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D708}_{{\mathcal{S}}}=\frac{1}{Z}\sum S_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}\unicode[STIX]{x1D6E5}_{i}=\frac{1}{Z}\sum S_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}y_{i}(1)-\frac{1}{Z}\sum S_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}y_{i}(0).\end{eqnarray}$$
This oracle estimator
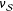 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
is slightly biased, but the bias is small, giving
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
is slightly biased, but the bias is small, giving
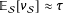 $\mathbb{E}_{{\mathcal{S}}}[\unicode[STIX]{x1D708}_{{\mathcal{S}}}]\approx \unicode[STIX]{x1D70F}$
. If we wanted an unbiased estimator, we could use a Horvitz–Thompson estimator by replacing
$\mathbb{E}_{{\mathcal{S}}}[\unicode[STIX]{x1D708}_{{\mathcal{S}}}]\approx \unicode[STIX]{x1D70F}$
. If we wanted an unbiased estimator, we could use a Horvitz–Thompson estimator by replacing
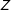 $Z$
with
$Z$
with
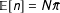 $\mathbb{E}[n]=N\bar{\unicode[STIX]{x1D70B}}$
, the expected sample size.
$\mathbb{E}[n]=N\bar{\unicode[STIX]{x1D70B}}$
, the expected sample size.
Unfortunately, we do not, for a given sample
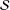 ${\mathcal{S}}$
, observe
${\mathcal{S}}$
, observe
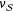 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
. We can, however, estimate it given the randomization and partially observed potential outcomes. Estimating the PATE is now implicitly a two-step process: estimate the sample-dependent
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
. We can, however, estimate it given the randomization and partially observed potential outcomes. Estimating the PATE is now implicitly a two-step process: estimate the sample-dependent
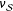 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, which in turn estimates the population parameter
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, which in turn estimates the population parameter
 $\unicode[STIX]{x1D70F}$
. Under this view, we have two concerns. First, we have to accurately estimate
$\unicode[STIX]{x1D70F}$
. Under this view, we have two concerns. First, we have to accurately estimate
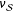 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, using all the tools available, by simple randomized experiments such as adjustment methods or, if we can control the randomization, blocking. Second, we have to focus on a sample parameter
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, using all the tools available, by simple randomized experiments such as adjustment methods or, if we can control the randomization, blocking. Second, we have to focus on a sample parameter
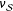 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, that is itself a good estimator of
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, that is itself a good estimator of
 $\unicode[STIX]{x1D70F}$
. See Appendix A for further discussion.
$\unicode[STIX]{x1D70F}$
. See Appendix A for further discussion.
4.1 Estimating
 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
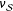
Equation (6) shows that our estimator is the difference in weighted means of our treatment potential outcomes and our control potential outcomes. This immediately motivates estimating these means with the units randomized to each arm of our study, as with the following “double-Hàjek” estimator
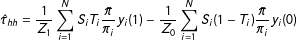 $$\begin{eqnarray}\displaystyle \hat{\unicode[STIX]{x1D70F}}_{hh}=\frac{1}{Z_{1}}\mathop{\sum }_{i=1}^{N}S_{i}T_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}y_{i}(1)-\frac{1}{Z_{0}}\mathop{\sum }_{i=1}^{N}S_{i}(1-T_{i})\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}y_{i}(0) & & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \hat{\unicode[STIX]{x1D70F}}_{hh}=\frac{1}{Z_{1}}\mathop{\sum }_{i=1}^{N}S_{i}T_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}y_{i}(1)-\frac{1}{Z_{0}}\mathop{\sum }_{i=1}^{N}S_{i}(1-T_{i})\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}y_{i}(0) & & \displaystyle\end{eqnarray}$$
with
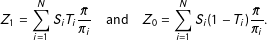 $$\begin{eqnarray}Z_{1}=\mathop{\sum }_{i=1}^{N}S_{i}T_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}\quad \text{and}\quad Z_{0}=\mathop{\sum }_{i=1}^{N}S_{i}(1-T_{i})\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}.\end{eqnarray}$$
$$\begin{eqnarray}Z_{1}=\mathop{\sum }_{i=1}^{N}S_{i}T_{i}\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}\quad \text{and}\quad Z_{0}=\mathop{\sum }_{i=1}^{N}S_{i}(1-T_{i})\frac{\bar{\unicode[STIX]{x1D70B}}}{\unicode[STIX]{x1D70B}_{i}}.\end{eqnarray}$$
The
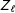 $Z_{\ell }$
are the total sample masses in each treatment arm.
$Z_{\ell }$
are the total sample masses in each treatment arm.
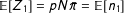 $\mathbb{E}[Z_{1}]=pN\bar{\unicode[STIX]{x1D70B}}=\mathbb{E}[n_{1}]$
, the expected number of units that will land in treatment (similarly for control).
$\mathbb{E}[Z_{1}]=pN\bar{\unicode[STIX]{x1D70B}}=\mathbb{E}[n_{1}]$
, the expected number of units that will land in treatment (similarly for control).
This estimator is two separate Hàjek estimators, one for the mean treatment outcome and one for the mean control. Each estimator adjusts for the total mass selected into that condition. This difference of weighted means is the one naturally seen in the field. It corresponds to the weighted OLS estimate from regressing the observed outcomes
 $Y^{\text{obs}}$
on the treatment indicators
$Y^{\text{obs}}$
on the treatment indicators
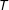 $T$
with weights
$T$
with weights
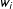 $w_{i}$
. This equivalence is shown in Appendix C.
$w_{i}$
. This equivalence is shown in Appendix C.
Because this is a Hàjek estimator, there is bias for
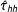 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
in the randomization step as well as the selection step because the
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
in the randomization step as well as the selection step because the
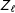 $Z_{\ell }$
depend on the realized randomization. Again, this bias is small, which means the expected value of our actual estimator, conditional on the sample, is approximately
$Z_{\ell }$
depend on the realized randomization. Again, this bias is small, which means the expected value of our actual estimator, conditional on the sample, is approximately
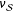 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, our Hàjek “estimator” of the population
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, our Hàjek “estimator” of the population
 $\unicode[STIX]{x1D70F}$
:
$\unicode[STIX]{x1D70F}$
:
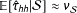 $\mathbb{E}[\hat{\unicode[STIX]{x1D70F}}_{hh}|{\mathcal{S}}]\approx \unicode[STIX]{x1D708}_{{\mathcal{S}}}$
. (For unbiased versions, see Appendix A.)
$\mathbb{E}[\hat{\unicode[STIX]{x1D70F}}_{hh}|{\mathcal{S}}]\approx \unicode[STIX]{x1D708}_{{\mathcal{S}}}$
. (For unbiased versions, see Appendix A.)
We can obtain approximate results for the population variance of
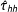 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
if we view the entire selection-and-assignment process as drawing two samples from a larger population. We ignore the finite-sample issues of no unit being able to appear in both treatment arms (i.e., we assume a large population) and use approximate formula based on sampling theory. For a Poisson selection scheme and Bernoulli assignment mechanism we then have:
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
if we view the entire selection-and-assignment process as drawing two samples from a larger population. We ignore the finite-sample issues of no unit being able to appear in both treatment arms (i.e., we assume a large population) and use approximate formula based on sampling theory. For a Poisson selection scheme and Bernoulli assignment mechanism we then have:
Theorem 4.1. The approximate variance (AV) of
 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
is
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
is
 $$\begin{eqnarray}AV(\hat{\unicode[STIX]{x1D70F}}_{hh})\approx \frac{1}{p\mathbb{E}[n]}\frac{1}{N}\mathop{\sum }_{j=1}^{N}w_{j}(y_{j}(1)-\unicode[STIX]{x1D707}(1))^{2}+\frac{1}{(1-p)\mathbb{E}[n]}\frac{1}{N}\mathop{\sum }_{j=1}^{N}w_{j}(y_{j}(0)-\unicode[STIX]{x1D707}(0))^{2},\end{eqnarray}$$
$$\begin{eqnarray}AV(\hat{\unicode[STIX]{x1D70F}}_{hh})\approx \frac{1}{p\mathbb{E}[n]}\frac{1}{N}\mathop{\sum }_{j=1}^{N}w_{j}(y_{j}(1)-\unicode[STIX]{x1D707}(1))^{2}+\frac{1}{(1-p)\mathbb{E}[n]}\frac{1}{N}\mathop{\sum }_{j=1}^{N}w_{j}(y_{j}(0)-\unicode[STIX]{x1D707}(0))^{2},\end{eqnarray}$$
with
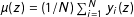 $\unicode[STIX]{x1D707}(z)=(1/N)\sum _{i=1}^{N}y_{i}(z)$
. This formula assumes the
$\unicode[STIX]{x1D707}(z)=(1/N)\sum _{i=1}^{N}y_{i}(z)$
. This formula assumes the
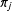 $\unicode[STIX]{x1D70B}_{j}$
are small; see Appendix C for a more exact form. This variance can be estimated by
$\unicode[STIX]{x1D70B}_{j}$
are small; see Appendix C for a more exact form. This variance can be estimated by
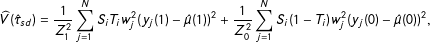 $$\begin{eqnarray}\widehat{V}(\hat{\unicode[STIX]{x1D70F}}_{sd})=\frac{1}{Z_{1}^{2}}\mathop{\sum }_{j=1}^{N}S_{i}T_{i}w_{j}^{2}(y_{j}(1)-\hat{\unicode[STIX]{x1D707}}(1))^{2}+\frac{1}{Z_{0}^{2}}\mathop{\sum }_{j=1}^{N}S_{i}(1-T_{i})w_{j}^{2}(y_{j}(0)-\hat{\unicode[STIX]{x1D707}}(0))^{2},\end{eqnarray}$$
$$\begin{eqnarray}\widehat{V}(\hat{\unicode[STIX]{x1D70F}}_{sd})=\frac{1}{Z_{1}^{2}}\mathop{\sum }_{j=1}^{N}S_{i}T_{i}w_{j}^{2}(y_{j}(1)-\hat{\unicode[STIX]{x1D707}}(1))^{2}+\frac{1}{Z_{0}^{2}}\mathop{\sum }_{j=1}^{N}S_{i}(1-T_{i})w_{j}^{2}(y_{j}(0)-\hat{\unicode[STIX]{x1D707}}(0))^{2},\end{eqnarray}$$
where
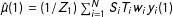 $\hat{\unicode[STIX]{x1D707}}(1)=(1/Z_{1})\sum _{i=1}^{N}S_{i}T_{i}w_{i}y_{i}(1)$
and
$\hat{\unicode[STIX]{x1D707}}(1)=(1/Z_{1})\sum _{i=1}^{N}S_{i}T_{i}w_{i}y_{i}(1)$
and
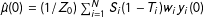 $\hat{\unicode[STIX]{x1D707}}(0)=(1/Z_{0})\sum _{i=1}^{N}S_{i}(1-T_{i})w_{i}y_{i}(0)$
.
$\hat{\unicode[STIX]{x1D707}}(0)=(1/Z_{0})\sum _{i=1}^{N}S_{i}(1-T_{i})w_{i}y_{i}(0)$
.
See Appendix C for the derivation, which also gives more general formulas that can be adapted for other selection mechanisms. For related work and similar derivations, see Wood (Reference Wood2008) and Aronow and Middleton (Reference Aronow and Middleton2013).
4.2 Uncertain and misspecified weights
Following the survey sampling literature, this paper assumes the weights are exact, correct, and known. They are considered to be the total chance of selection into the sample. In particular, again following standard practice, the
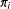 $\unicode[STIX]{x1D70B}_{i}$
are the product of any original sampling weights and any nonresponse weights, given a classic sampling context (Groves et al.
Reference Groves, Fowler, Couper, Lepkowski, Singer and Tourangeau2009). By contrast, for surveys such as YouGov the nonresponse is built in, as the recruited panels are in effect self-selected, so we get the overall weights (which they call propensity or case weights) directly. Our results are regarding these total weights.
$\unicode[STIX]{x1D70B}_{i}$
are the product of any original sampling weights and any nonresponse weights, given a classic sampling context (Groves et al.
Reference Groves, Fowler, Couper, Lepkowski, Singer and Tourangeau2009). By contrast, for surveys such as YouGov the nonresponse is built in, as the recruited panels are in effect self-selected, so we get the overall weights (which they call propensity or case weights) directly. Our results are regarding these total weights.
Of course, especially when considering nonresponse, weights are not known but instead estimated using a model and, ideally, a rich set of covariates. This raises two concerns. The first is if the weights are systematically inaccurate due to some selection mechanism that has not been correctly captured. In this case, as the weights are independent of the assignment mechanism, the SATE estimates are still valid and unbiased. The PATE estimates, however, can be arbitrarily biased, and this bias is not necessarily detectable. For example, if only those susceptible to treatment join the study, the PATE estimate will be too high, and there may be no measured covariate that allows for detection of this.
The second concern is whether there is additional uncertainty that needs to be accounted for, given the estimated weights, when doing inference for the PATE. There is, although we believe this uncertainty can often be much smaller than the uncertainty in the randomized experiment itself.Footnote 3 While this uncertainty could be taken into account, much of the literature does not tend to do so. Interestingly, it is not obvious whether estimating the weights given the sample could actually improve PATE precision similar to using estimated propensity scores instead of known propensity scores—see, for example, Hirano, Imbens, and Ridder (Reference Hirano, Imbens and Ridder2000). We leave this as an area for future investigation.
For further thoughts on concerns regarding uncertainty in the weights, we point to the literature on generalizing randomized trials to wider populations, such as discussed in Hartman et al. (Reference Hartman, Grieve, Ramsahai and Sekhon2015) and Imai, King, and Stuart (Reference Imai, King and Stuart2008). Here, the approach is generally to estimate units’ propensity for inclusion into the experiment, and then weight units by these quantities in order to estimate population characteristics. These propensities of inclusion are usually estimated by borrowing from the propensity score literature for observational studies (Cole and Stuart Reference Cole and Stuart2010). One nice aspect of this approach is it provides diagnostics in the form of a placebo test. In particular, the characteristics of the reweighted control group of the randomized experiment should match the characteristics of the target population of interest (see Stuart et al. (Reference Stuart, Cole, Bradshaw and Leaf2010) for a discussion).
Relatedly, O’Muircheartaigh and Hedges (Reference O’Muircheartaigh and Hedges2014) and Tipton (Reference Tipton2013) propose poststratified estimators, stratifying on these estimated weights. In their case, however, they also have the population proportions of the strata as given, which allows for simpler variance expressions and arguably less sensitivity to error in the weights themselves. Furthermore, they do not incorporate the unit-level weights once they stratify. Tipton (Reference Tipton2013) investigates the associated bias-variance trade-offs due to stratification, and gives advice as to when stratification will be effective.
Generalization assumes we know the assignment mechanism, but not necessarily the sampling mechanism. There is some work on the reverse case, with estimated propensity scores of treatment and known weights, see DuGoff, Schuler, and Stuart (Reference DuGoff, Schuler and Stuart2013). Here the final propensity weights are also treated as fixed for inference.
4.3 Poststratification to improve precision
One can improve the precision of an experiment by adjusting for covariates. For an examination of this under the potential outcome framework, see, for example, Lin (Reference Lin2013). We use poststratification for this adjustment. In poststratification, treatment effects are first estimated within each of a series of specified strata of the data and then averaged together with weights proportional to strata size (Miratrix, Sekhon, and Yu Reference Miratrix, Sekhon and Yu2013).
We use poststratification because it relies on very weak modeling assumptions and naturally connects with the weighting involved in estimating the PATE. See Appendix B for the overall framework and associated estimators. Other estimators that rely on regression and other forms of modeling are also possible; see Zheng and Little (Reference Zheng and Little2003) or, more recently, Si, Pillai, and Gelman (Reference Si, Pillai and Gelman2015). For poststratification, the more the mean potential outcomes vary between strata, the greater the gain in precision. And given that it is precisely when the weights and outcomes are correlated that we must worry about the weights, poststratifying on them is a natural choice. Such stratification is easy to implement: simply build
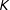 $K$
strata prerandomization (but not necessarily presampling) by, e.g., taking the
$K$
strata prerandomization (but not necessarily presampling) by, e.g., taking the
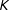 $K$
-weighted quantiles of the
$K$
-weighted quantiles of the
 $1/\unicode[STIX]{x1D70B}_{i}$
as the strata.
$1/\unicode[STIX]{x1D70B}_{i}$
as the strata.
When the units are divided into
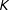 $K$
quantiles by survey weight, the cut points of those quantiles depend on the realized weights of the sample. Because this is still prerandomization, this does not impact the validity of the variance and variance-estimation formulas of the SATE estimate of
$K$
quantiles by survey weight, the cut points of those quantiles depend on the realized weights of the sample. Because this is still prerandomization, this does not impact the validity of the variance and variance-estimation formulas of the SATE estimate of
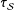 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
. It does, however, make generating appropriate population variance formulas difficult. Given this, we propose using the bootstrap, incorporating the variable definition of strata to take this stage being sample-dependent into account. Bootstrap is natural in that for survey experiments we are pulling units from a large population, and so simulating independent draws is reasonable. While a technical analysis of this approach is beyond the scope of this paper, we discuss some particulars of implementation in Appendix B. Reassuringly, our simulation studies in the next section show excellent coverage rates.
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
. It does, however, make generating appropriate population variance formulas difficult. Given this, we propose using the bootstrap, incorporating the variable definition of strata to take this stage being sample-dependent into account. Bootstrap is natural in that for survey experiments we are pulling units from a large population, and so simulating independent draws is reasonable. While a technical analysis of this approach is beyond the scope of this paper, we discuss some particulars of implementation in Appendix B. Reassuringly, our simulation studies in the next section show excellent coverage rates.
5 Simulation Studies
We here present a series of simulation studies to assess the relative performance of the respective estimators. We also assess the performance of the bootstrap estimates of the standard errors.
Our simulation studies are as follows: we generate a large population of size
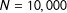 $N=10,000$
with the two potential outcomes and a selection probability for each unit. Using this fixed population, we repeatedly take a sample and run a subsequent experiment, recording the treatment effect estimates for the different estimators. In particular, we first select a sample of size
$N=10,000$
with the two potential outcomes and a selection probability for each unit. Using this fixed population, we repeatedly take a sample and run a subsequent experiment, recording the treatment effect estimates for the different estimators. In particular, we first select a sample of size
 $n$
, sampling without replacement but with probabilities of selection inversely proportional to the weights.Footnote
4
Once we have obtained the final sample, we randomly assign treatment and estimate the treatment effect. After doing this 10,000 times we estimate the overall mean, variance, and MSE of the different estimators to compare their performance to the PATE. We also calculate bootstrap standard error estimates for all the estimators using the case-wise bootstrap scheme discussed in Appendix B.
$n$
, sampling without replacement but with probabilities of selection inversely proportional to the weights.Footnote
4
Once we have obtained the final sample, we randomly assign treatment and estimate the treatment effect. After doing this 10,000 times we estimate the overall mean, variance, and MSE of the different estimators to compare their performance to the PATE. We also calculate bootstrap standard error estimates for all the estimators using the case-wise bootstrap scheme discussed in Appendix B.
Table 1. Simulations A & B. Performance of different estimators as estimators for the PATE for (A) a heterogeneous treatment effect scenario with
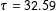 $\unicode[STIX]{x1D70F}=32.59$
and (B) a constant treatment effect of
$\unicode[STIX]{x1D70F}=32.59$
and (B) a constant treatment effect of
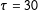 $\unicode[STIX]{x1D70F}=30$
. For each estimator, we have, from left to right, its expected value, bias, standard error, root mean squared error, average bootstrap SE estimate, and coverage across 10,000 trials.
$\unicode[STIX]{x1D70F}=30$
. For each estimator, we have, from left to right, its expected value, bias, standard error, root mean squared error, average bootstrap SE estimate, and coverage across 10,000 trials.
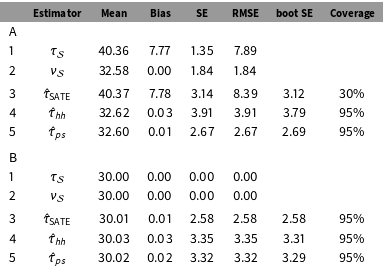
5.1 Simulation A
Our first simulation is for a population with a heterogeneous treatment effect that varies in connection to the weight. See Appendix D for some simple plots showing the structure of the population and a single sample. Our treatment effect, outcomes, and sampling probabilities are all strongly related. We then took samples of a specified size from this fixed population, and examined the performance of our estimators as estimators for the PATE.
Results for
 $n=500$
are on Table 1. Other sample sizes such as
$n=500$
are on Table 1. Other sample sizes such as
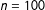 $n=100$
, not shown, are substantively the same. The first two lines of the table show the performance of the two “oracle” estimators
$n=100$
, not shown, are substantively the same. The first two lines of the table show the performance of the two “oracle” estimators
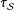 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
(Equation (1)) and
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
(Equation (1)) and
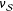 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
(Equation (6)), which we could use if all of the potential outcomes were known. For
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
(Equation (6)), which we could use if all of the potential outcomes were known. For
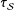 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
there is bias because the treatment effect of a sample is not generally the same as the treatment effect of the population. The Hàjek approach of
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
there is bias because the treatment effect of a sample is not generally the same as the treatment effect of the population. The Hàjek approach of
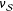 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, second line, is therefore superior despite the larger SE. Line 3 is the simple estimate of the SATE from Equation (2). Because it is estimating
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, second line, is therefore superior despite the larger SE. Line 3 is the simple estimate of the SATE from Equation (2). Because it is estimating
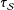 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
, it has the same bias as line 1, but because it only uses observed outcomes, the SE is larger. Line 4 uses the “double-Hàjek” estimator shown in Equation (7). This estimator is targeting
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
, it has the same bias as line 1, but because it only uses observed outcomes, the SE is larger. Line 4 uses the “double-Hàjek” estimator shown in Equation (7). This estimator is targeting
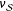 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, reducing bias, but has a larger SE relative to line 3 due to the fact that we are incorporating weights. Line 5 is the poststratified “double Hàjek” given in Appendix B. Units were stratified by their survey weight, with
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, reducing bias, but has a larger SE relative to line 3 due to the fact that we are incorporating weights. Line 5 is the poststratified “double Hàjek” given in Appendix B. Units were stratified by their survey weight, with
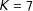 $K=7$
equally sized (by weight) strata. For this scenario, poststratifying helps, as illustrated by the smaller SE and RMSE, compared to
$K=7$
equally sized (by weight) strata. For this scenario, poststratifying helps, as illustrated by the smaller SE and RMSE, compared to
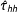 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
.
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
.
An inspection of the coverage rates reflects what we have already discussed: the estimate
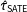 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
does not target the PATE while the other two sample estimates,
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
does not target the PATE while the other two sample estimates,
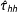 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
and
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
and
 $\hat{\unicode[STIX]{x1D70F}}_{ps}$
, do. Therefore, it has terrible coverage. Furthermore, the latter two estimates give correct coverage, which is reflective of the bootstrap SE estimates hitting their mark.
$\hat{\unicode[STIX]{x1D70F}}_{ps}$
, do. Therefore, it has terrible coverage. Furthermore, the latter two estimates give correct coverage, which is reflective of the bootstrap SE estimates hitting their mark.
5.2 Simulation B
As a second simulation we kept the original structure between
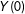 $Y(0)$
and
$Y(0)$
and
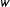 $w$
, but set a constant treatment effect of 30 for all units. Results are on the bottom half of Table 1. Here,
$w$
, but set a constant treatment effect of 30 for all units. Results are on the bottom half of Table 1. Here,
 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}=\unicode[STIX]{x1D70F}$
for any sample
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}=\unicode[STIX]{x1D70F}$
for any sample
 ${\mathcal{S}}$
, so there is no error in either estimate with known potential outcomes (lines 1–2). This also means that
${\mathcal{S}}$
, so there is no error in either estimate with known potential outcomes (lines 1–2). This also means that
 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
is a valid estimate of the PATE and this is reflected in the lack of bias and nominal coverage rate (line 3). The increase of SE of the weighted and poststratified estimators (lines 4–5) reflects the use of weights when they are in fact unnecessary. Overall, the SATE estimate is the best, as expected in this situation.
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
is a valid estimate of the PATE and this is reflected in the lack of bias and nominal coverage rate (line 3). The increase of SE of the weighted and poststratified estimators (lines 4–5) reflects the use of weights when they are in fact unnecessary. Overall, the SATE estimate is the best, as expected in this situation.
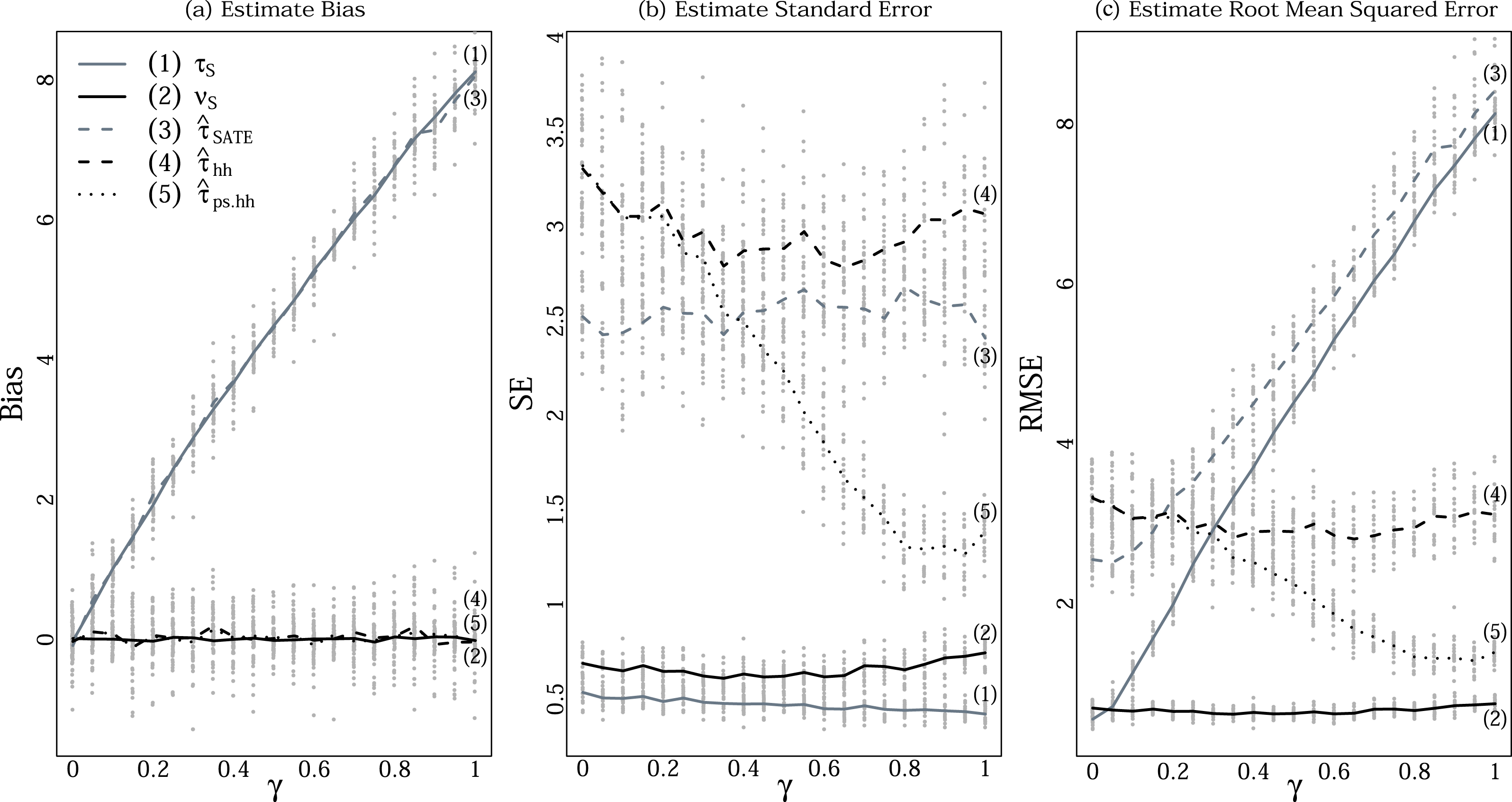
Figure 1. (a) Bias, (b) standard error, and (c) root mean squared error of estimates when selection probability is increasingly related to the potential outcomes (Simulation C). The horizontal axis,
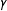 $\unicode[STIX]{x1D6FE}$
, varies the strength of the relationship between outcome and weight. Gray are SATE-targeting, black PATE-targeting. Solid are oracle estimators using all potential outcomes of the sample, dashed are actual estimators. The thicker lines are averages over the 20 simulated populations in light gray dots.
$\unicode[STIX]{x1D6FE}$
, varies the strength of the relationship between outcome and weight. Gray are SATE-targeting, black PATE-targeting. Solid are oracle estimators using all potential outcomes of the sample, dashed are actual estimators. The thicker lines are averages over the 20 simulated populations in light gray dots.
5.3 Simulation C
In our final simulation, we systematically varied the relationship between selection probability and outcomes while maintaining the same marginal distributions in order to examine the benefits poststratification.
In our data generating process (DGP) we first generate a bivariate normal pair of latent variables with correlation
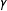 $\unicode[STIX]{x1D6FE}$
, and then generate the weights as a function of the first variable and the outcomes as a function of the second. Then, by varying
$\unicode[STIX]{x1D6FE}$
, and then generate the weights as a function of the first variable and the outcomes as a function of the second. Then, by varying
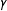 $\unicode[STIX]{x1D6FE}$
we can vary the strength of the relationship between outcome and weight. (See Appendix D for the particulars.) When
$\unicode[STIX]{x1D6FE}$
we can vary the strength of the relationship between outcome and weight. (See Appendix D for the particulars.) When
 $\unicode[STIX]{x1D6FE}=1$
, which corresponds to Simulation A,
$\unicode[STIX]{x1D6FE}=1$
, which corresponds to Simulation A,
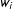 $w_{i}$
and
$w_{i}$
and
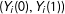 $(Y_{i}(0),Y_{i}(1))$
have a very strong relationship and we benefit greatly from poststratification. Conversely when
$(Y_{i}(0),Y_{i}(1))$
have a very strong relationship and we benefit greatly from poststratification. Conversely when
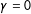 $\unicode[STIX]{x1D6FE}=0$
,
$\unicode[STIX]{x1D6FE}=0$
,
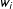 $w_{i}$
and
$w_{i}$
and
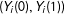 $(Y_{i}(0),Y_{i}(1))$
are unrelated and there will be no such benefit.
$(Y_{i}(0),Y_{i}(1))$
are unrelated and there will be no such benefit.
For each
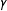 $\unicode[STIX]{x1D6FE}$
we generated 20 populations, conducting a simulation study within each population. We then averaged the results and plotted the averages against
$\unicode[STIX]{x1D6FE}$
we generated 20 populations, conducting a simulation study within each population. We then averaged the results and plotted the averages against
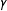 $\unicode[STIX]{x1D6FE}$
on Figure 1. The solid lines give the performance of the oracle estimators
$\unicode[STIX]{x1D6FE}$
on Figure 1. The solid lines give the performance of the oracle estimators
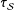 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
and
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
and
 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, and the nonsolid lines are the estimators. The gray lines are estimators that do not incorporate the weights, and the black lines are estimators that do. The light gray points show the individual population simulation studies; they vary due to the variation in the finite populations.
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, and the nonsolid lines are the estimators. The gray lines are estimators that do not incorporate the weights, and the black lines are estimators that do. The light gray points show the individual population simulation studies; they vary due to the variation in the finite populations.
We first see that, because both the double Hàjek and its poststratified version are targeting
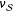 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, which in turn estimates the PATE, they remain unbiased regardless of the latent correlation. On the other hand, the SATE and its estimator,
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
, which in turn estimates the PATE, they remain unbiased regardless of the latent correlation. On the other hand, the SATE and its estimator,
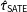 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
, are affected. The bias continually increases as the relationship between weight and treatment effect increases.
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
, are affected. The bias continually increases as the relationship between weight and treatment effect increases.
As expected, the SE of the estimators that do not use weights,
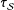 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
and
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
and
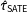 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
, stay the same regardless of
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
, stay the same regardless of
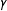 $\unicode[STIX]{x1D6FE}$
because the marginal distributions of the outcomes are the same across
$\unicode[STIX]{x1D6FE}$
because the marginal distributions of the outcomes are the same across
 $\unicode[STIX]{x1D6FE}$
. The estimators that only use weights to adjust for sampling differences,
$\unicode[STIX]{x1D6FE}$
. The estimators that only use weights to adjust for sampling differences,
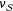 $\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
and
$\unicode[STIX]{x1D708}_{{\mathcal{S}}}$
and
 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
, also remain the same, although their SEs are larger than for
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
, also remain the same, although their SEs are larger than for
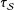 $\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
and
$\unicode[STIX]{x1D70F}_{{\mathcal{S}}}$
and
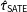 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
because of incorporating the weights. We pay for unbiasedness with greater variability. The poststratified estimator
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
because of incorporating the weights. We pay for unbiasedness with greater variability. The poststratified estimator
 $\hat{\unicode[STIX]{x1D70F}}_{ps}$
, however, sees continual precision gains as the weights are increasingly predictive of treatment effect. For low
$\hat{\unicode[STIX]{x1D70F}}_{ps}$
, however, sees continual precision gains as the weights are increasingly predictive of treatment effect. For low
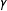 $\unicode[STIX]{x1D6FE}$
, it has roughly the same uncertainty as
$\unicode[STIX]{x1D6FE}$
, it has roughly the same uncertainty as
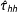 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
, but is soon the most precise of all (nonoracle) estimators.
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
, but is soon the most precise of all (nonoracle) estimators.
These conclusions are tied together in the rightmost panel of Figure 1, showing the RMSE, which gives the combined impact of bias and variance on performance. As
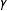 $\unicode[STIX]{x1D6FE}$
increases, the RMSE of
$\unicode[STIX]{x1D6FE}$
increases, the RMSE of
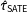 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
steadily climbs due to bias, eventually being the worst at
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
steadily climbs due to bias, eventually being the worst at
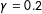 $\unicode[STIX]{x1D6FE}=0.2$
. Meanwhile, the poststratified estimator that exploits weights,
$\unicode[STIX]{x1D6FE}=0.2$
. Meanwhile, the poststratified estimator that exploits weights,
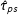 $\hat{\unicode[STIX]{x1D70F}}_{ps}$
, performs better and better. Overall, if weights are important then (1) the bias terms can be too large to be ignored, and (2) there is something to be gained by adjusting the estimates of treatment effects with those weights beyond simple reweighting. Otherwise, SATE estimators are superior, as incorporating weights can be costly.
$\hat{\unicode[STIX]{x1D70F}}_{ps}$
, performs better and better. Overall, if weights are important then (1) the bias terms can be too large to be ignored, and (2) there is something to be gained by adjusting the estimates of treatment effects with those weights beyond simple reweighting. Otherwise, SATE estimators are superior, as incorporating weights can be costly.
6 Real Data Application
To better understand the overall trade-offs involved in using weighted estimators of PATE versus simply estimating the SATE on actual survey experiments, we analyzed a set of survey experiments embedded in 7 separate surveys fielded by us though YouGov over the course of 5 years. Studies appeared in two modules of the 2010 CCES, one module each of the 2012 and 2014 CCES, a survey of Virginia voters run prior to the 2013 gubernatorial election in that state, and two other national YouGov surveys. Each survey had post hoc weights assigned by YouGov through that firm’s standard procedure. Across these surveys were 18 separate assignments of respondents to binary treatments. In several of these cases, multiple outcomes were measured, producing 46 randomization/outcome combinations.Footnote 5 All of the studies examined were conducted in the United States and focused on topics related to partisan political behavior.Footnote 6 As such, we make our comparisons of SATE and PATE by looking at Democratic and Republican respondents separately. This is because treatment effects for such studies are generally highly heterogeneous by respondent party identification. Our set of 46 randomization/outcome combinations produce 92 experiments (half among Democrats and half among Republicans). Sample sizes for the experiments analyzed range from 145 to 504.Footnote 7 Weights varied substantially in these samples, ranging from near 0 to around 8, when normalized to 1 across the sample (standard deviation of 1.04). Sixty five of them (70.7%) showed SATEs that were significantly different from zero. However, once the weights provided by YouGov were taken into account to estimate the PATE (via the double-Hàjek estimate) only 52 experiments (56.5%) had significant effects.
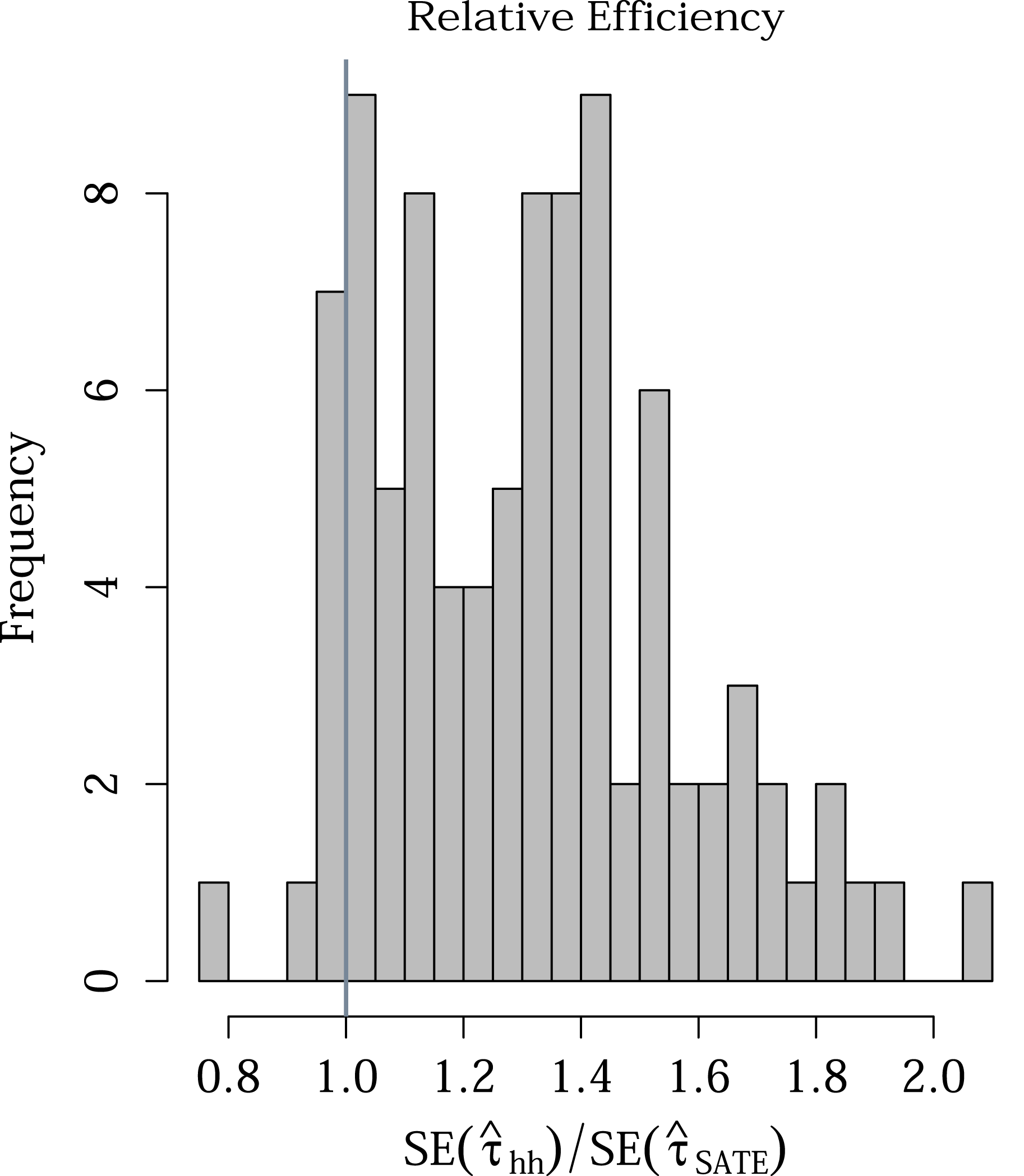
Figure 2. Relative efficiency of
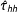 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
versus
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
versus
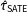 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
of the estimates for the 92 experiments.
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
of the estimates for the 92 experiments.
Our first finding is that incorporating weights substantially increased the standard errors. Figure 2 shows a 32.1% average increase in standard error estimates of
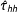 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
over
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
over
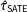 $\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
across experiments.
$\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}$
across experiments.
We next examined whether there is evidence of some experiments having a PATE substantially different from the SATE. To do this, we calculated bootstrap estimates of the standard error for the difference in the estimators, and calculated a standardized difference in estimates of
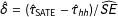 $\hat{\unicode[STIX]{x1D6FF}}=(\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}-\hat{\unicode[STIX]{x1D70F}}_{hh})/\widehat{SE}$
. If there were no difference between the SATE and the PATE, the
$\hat{\unicode[STIX]{x1D6FF}}=(\hat{\unicode[STIX]{x1D70F}}_{\text{SATE}}-\hat{\unicode[STIX]{x1D70F}}_{hh})/\widehat{SE}$
. If there were no difference between the SATE and the PATE, the
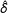 $\hat{\unicode[STIX]{x1D6FF}}$
s should be roughly distributed as a standard Normal. First, the average of these
$\hat{\unicode[STIX]{x1D6FF}}$
s should be roughly distributed as a standard Normal. First, the average of these
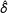 $\hat{\unicode[STIX]{x1D6FF}}$
is
$\hat{\unicode[STIX]{x1D6FF}}$
is
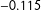 $-0.115$
, giving no evidence for any systematic trend of the PATE being larger or smaller than the SATE. Second, when we compared our
$-0.115$
, giving no evidence for any systematic trend of the PATE being larger or smaller than the SATE. Second, when we compared our
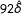 $92\hat{\unicode[STIX]{x1D6FF}}$
values to the standard normal with a qq-plot (Figure 3), we find excellent fit. While there is a somewhat suggestive tail departing from the expected line, the bulk of the experiments closely follow the standard normal distribution, suggesting that the SATE and PATE were generally quite similar relative to their estimation uncertainty. A test using q-statistics (modeled after Weiss et al.
Reference Weiss, Bloom, Verbitsky-Savitz, Gupta, Vigil and Cullinan2017) failed to reject the null of no differences across the experiments (
$92\hat{\unicode[STIX]{x1D6FF}}$
values to the standard normal with a qq-plot (Figure 3), we find excellent fit. While there is a somewhat suggestive tail departing from the expected line, the bulk of the experiments closely follow the standard normal distribution, suggesting that the SATE and PATE were generally quite similar relative to their estimation uncertainty. A test using q-statistics (modeled after Weiss et al.
Reference Weiss, Bloom, Verbitsky-Savitz, Gupta, Vigil and Cullinan2017) failed to reject the null of no differences across the experiments (
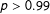 $p>0.99$
); especially considering the possible correlation of outcomes would make this test anticonservative, we have no evidence that the PATE and SATE estimates differ (see Appendix E for further investigation of this). An FDR test also showed no experiments with a significant difference.
$p>0.99$
); especially considering the possible correlation of outcomes would make this test anticonservative, we have no evidence that the PATE and SATE estimates differ (see Appendix E for further investigation of this). An FDR test also showed no experiments with a significant difference.
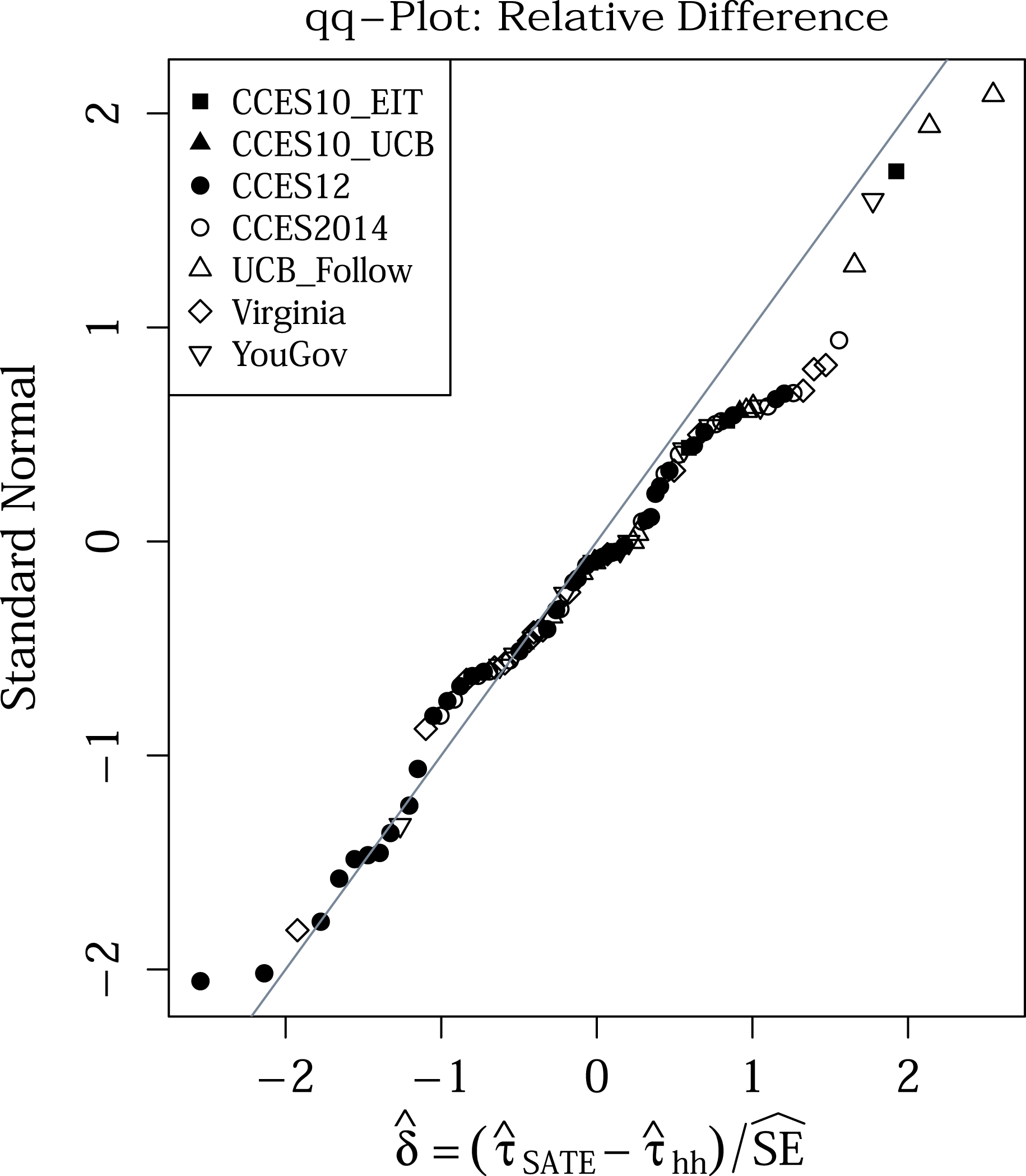
Figure 3. Quantile–quantile plot of the relative standardized differences
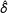 $\hat{\unicode[STIX]{x1D6FF}}$
of the estimates for the 92 experiments grouped into the larger surveys they are part of.
$\hat{\unicode[STIX]{x1D6FF}}$
of the estimates for the 92 experiments grouped into the larger surveys they are part of.
Finally, we consider whether poststratification on weights improved precision. Generally, it did not: the estimated SEs of
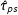 $\hat{\unicode[STIX]{x1D70F}}_{ps}$
are very similar to those for
$\hat{\unicode[STIX]{x1D70F}}_{ps}$
are very similar to those for
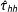 $\hat{\unicode[STIX]{x1D70F}}_{hh}$
, with an average increase of about 0.6%. Further examination offers a hint as to why poststratification did not yield benefits: the weights generated by YouGov for these samples do not correlate meaningfully with the outcomes of interest. In no case did the magnitude of the correlation between weights and outcome exceed 0.23. To further explore potential benefits of poststratification we examine the effects of adjusting for a covariate, respondent party identification, on the full experiments not separated by party ID. Relative to no stratification, if we poststratify on party ID, weighting the strata by the total sampled mass in both treatment and control, our PATE estimate shows an average reduction of 1.4% in estimated SEs across experiments with participants of both major parties. If we poststratify on both party ID and the weights, we see an average estimated SEs reduction of 1%. These reductions would in no way make up for the larger SEs from attempting to estimate the PATE.
$\hat{\unicode[STIX]{x1D70F}}_{hh}$
, with an average increase of about 0.6%. Further examination offers a hint as to why poststratification did not yield benefits: the weights generated by YouGov for these samples do not correlate meaningfully with the outcomes of interest. In no case did the magnitude of the correlation between weights and outcome exceed 0.23. To further explore potential benefits of poststratification we examine the effects of adjusting for a covariate, respondent party identification, on the full experiments not separated by party ID. Relative to no stratification, if we poststratify on party ID, weighting the strata by the total sampled mass in both treatment and control, our PATE estimate shows an average reduction of 1.4% in estimated SEs across experiments with participants of both major parties. If we poststratify on both party ID and the weights, we see an average estimated SEs reduction of 1%. These reductions would in no way make up for the larger SEs from attempting to estimate the PATE.
While this does not imply that scholars need not consider poststratifying on weights, it does show that outcomes of interest in political science studies are not necessarily going to be correlated with these weights. This makes clear the importance of researchers understanding, and reporting, the process used to generate weights and being aware of the covariates with which those weights are likely to be highly correlated (for online surveys, such a list would often includes certain racial and education-level categories).
6.1 Discussion
Overall, it appears that in this context and for these experiments, the survey weights significantly increase uncertainty, and that there is little evidence that the RMSE (which includes the SATE–PATE bias) for estimating the PATE is improved by estimators that include these weights. Furthermore, the weights are not predictive enough of outcome to help the poststratified estimator. With regard to poststratification, we note that in practice the analysis of any particular experiment would likely be improved by poststratifying on known covariates predictive of outcome rather than naïvely on the weights.
In understanding these findings, it is useful to consider the ways in which data from these leading online survey firms (in this case, YouGov) may differ from more convenience-based online samples. Even unweighted, datasets from these firms tend to be more representative. This is because they often engage in extensive panel recruitment and retention efforts and assign subjects from their panels to client samples through mechanisms such as block randomization. As a result, the unweighted data are often largely representative of the overall population along many relevant dimensions. Relatedly, firms may use a clean-up matching step, such as the one employed by YouGov, where they downsample their data to generate more uniform weights (Rivers Reference Rivers2006). This will likely increase the heterogeneity of the final sample, which could decrease precision.Footnote 8 We recommend that researchers request the original, preweighted data, in order to work with a larger and more homogeneous sample. For the SATE the gains are immediate. For the PATE, one might generate weights for the full sample by extrapolating from the weights assigned in the trimmed sample or by contracting with the survey firm to obtain weights for this full unmatched sample. Then, by poststratifying on the weights, the researcher can take advantage of the additional units to increase precision in some strata without increasing variability in the others. For both SATE and PATE estimation, power would be improved.
7 Discussion and Practical Guidance
We investigate incorporating weights in survey experiments under the potential outcomes framework. We focus on two styles of estimator, those that incorporate these weights to take any selection mechanisms into account, and those that ignore weights and instead focus on estimating the SATE. We primarily find that incorporating weights, even when they are exactly known, substantially decreases precision. Because of this, researchers are faced with a trade-off: more powerful estimates for the SATE, or more uncertain estimates of the PATE. We conclude with several observations that should inform how one navigates this trade-off.
The PATE can only be different from the SATE when two things hold: (1) there is meaningful variation in the treatment impact, and (2) that variation is correlated with the weights (see Equation (3)). Moreover, the random assignment of treatment protects inference for the weighted estimator, even if the weights are incorrect or known only approximately: because the randomization of units into treatment is independent of the (possibly incorrect) weights, any inference conditional on the sample and the weights is a valid inference. When PATE is the estimand, we are estimating the treatment effect for a hypothetical population defined by the weights and sample, even if it does not correspond to the actual population. For example, if we find a treatment effect in our weighted sample, we know the treatment does have an effect for at least some units. See Hartman et al. (Reference Hartman, Grieve, Ramsahai and Sekhon2015) for a discussion of this issue in the case of evaluating the external validity of an experiment.
It is important to compare the PATE and SATE estimates. A meaningful discrepancy between them is a signal to look for treatment effect heterogeneity and a flag that weight misspecification could be a real concern. If the estimates do not differ, however, and there is no other evidence of heterogeneity, then extrapolation is less of a concern—and furthermore the SATE is probably a sufficient estimate for the PATE. Of course, with misspecified weights if there is heterogeneity associated with being selected into the experiment that is not captured by the covariates, then PATE estimation can be undetectably biased. For more on assessing heterogeneity, see Ding, Feller, and Miratrix (Reference Ding, Feller and Miratrix2018).
Interestingly, our examination of real survey data found no strong connection between the weights and outcomes. The SATE and PATE estimators tended to be similar. Based on this, we have several general pieces of practical guidance: (1) When analyzing survey experiments using high-quality, broadly representative samples, such as those recruited and provided by firms like YouGov and Knowledge Networks, SATE estimates will generally be sufficient for most purposes. (2) If a particular research question calls for estimates of the PATE, a “double-Hàjek” estimator is probably the most straightforward (and a defensible) approach, unless weights are highly correlated with the outcomes variables. (3) If weights are strongly correlated with a study’s outcome(s) of interest, poststratification on the weights with bootstrap standard errors can help offset the cost of including weights for those seeking to draw population inferences.
This motivates a two-stage approach. First, focus on the SATE using the entire, unweighted sample and determine whether the treatment had impact. This will generally be the most powerful strategy for detecting an effect, as the weights, being set aside, will not inflate uncertainty estimates. Then, once a treatment effect is established, work on how to generalize it to the population. This second stage is an assessment of the magnitude of an effect in the population once an effect on at least some members of the population has been established. First estimate the PATE with the weights, and then compare it to the SATE estimate. If they differ, then consider working to explain any treatment effect heterogeneity with covariates, and think carefully about weight quality. Regardless, ensure that all analyses preserve the original strength of the assignment mechanism; the weights do not need to jeopardize valid assessment of the presence of causal effects. Part of preserving valid statistical inference would be to commit to a particular procedure before analyzing the given dataset. A preanalysis plan or sample splitting would help prevent a fishing expedition to find treatment effects.
Acknowledgements
For helpful and careful comments, we would like to thank Henry Brady, Devin Caughey, Christopher Fariss, Erin Hartman, Steve Nicholson, Liz Stuart, Chelsea Zhang, and participants of the ACIC 2015 and 2014 Society of Political Methodology Summer Meetings. We would also like to thank Guillaume Basse for his insights into the connection between weighted linear regression and the double-Hàjek estimator. We also thank the valuable feedback and commentary received from two anonymous reviewers and the Editor, who pushed us to clarify and refine our findings.
Supplementary material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2018.1.