


Randomised controlled trials relevant to people with schizophrenia are often small and of short duration. Reference Cure and Adams1,Reference Thornley and Adams2 Attrition rates from these studies can be considerable (Table 1). Whatever the reason for the loss of trial sample to follow-up, whether it is because the participant requests it or because trial protocol necessitates withdrawal from the study, these people often are not able to provide, or are not available for, final outcome scores. Although some complete information may still be obtained from routine data, this loss to follow-up does mean that many scale-derived outcomes reflect the condition of only a proportion of participants. As scale data are so commonly the primary outcomes in trials relevant to mental healthcare, Reference Thornley and Adams2 this leaves these studies vulnerable to the many biases introduced by not undertaking an intention-to-treat analysis. Reference Hollis and Campbell3 Statistical techniques have evolved to rebuild a semblance of the complete data-set but all such devices are imperfect and are based on assumptions that are difficult or impossible to substantiate. Reference Dunn, Maracy and Tomenson4,Reference Leucht, Engel, Bauml and Davis5
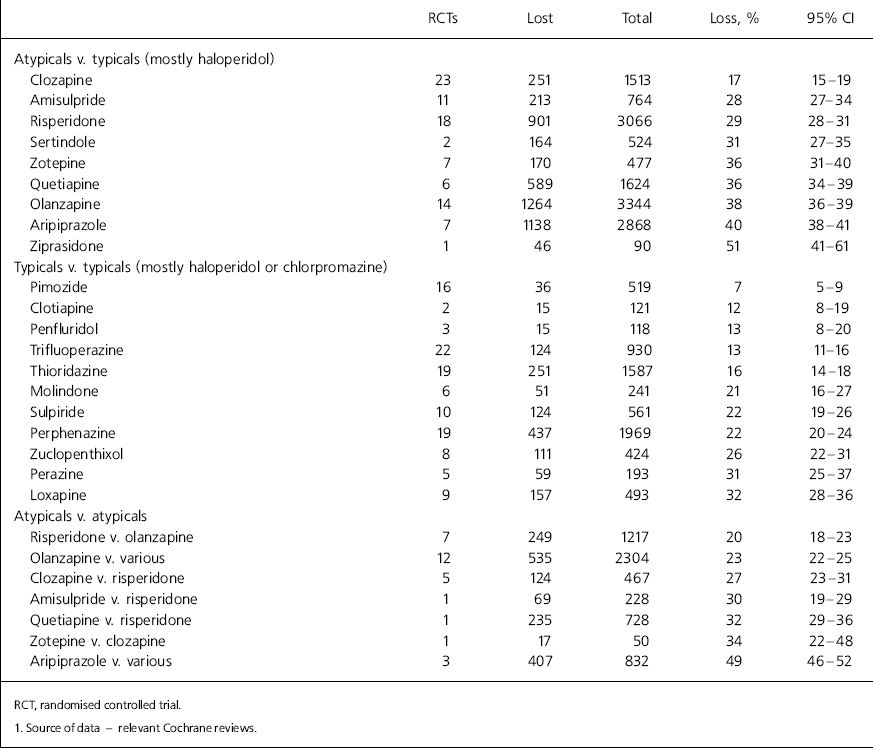
Table 1. Total lost to follow-up by about 10–12 weeks in drug trials1
| RCTs | Lost | Total | Loss, % | 95% CI | |
|---|---|---|---|---|---|
| Atypicals v. typicals (mostly haloperidol) | |||||
| Clozapine | 23 | 251 | 1513 | 17 | 15–19 |
| Amisulpride | 11 | 213 | 764 | 28 | 27–34 |
| Risperidone | 18 | 901 | 3066 | 29 | 28–31 |
| Sertindole | 2 | 164 | 524 | 31 | 27–35 |
| Zotepine | 7 | 170 | 477 | 36 | 31–40 |
| Quetiapine | 6 | 589 | 1624 | 36 | 34–39 |
| Olanzapine | 14 | 1264 | 3344 | 38 | 36–39 |
| Aripiprazole | 7 | 1138 | 2868 | 40 | 38–41 |
| Ziprasidone | 1 | 46 | 90 | 51 | 41–61 |
| Typicals v. typicals (mostly haloperidol or chlorpromazine) | |||||
| Pimozide | 16 | 36 | 519 | 7 | 5–9 |
| Clotiapine | 2 | 15 | 121 | 12 | 8–19 |
| Penfluridol | 3 | 15 | 118 | 13 | 8–20 |
| Trifluoperazine | 22 | 124 | 930 | 13 | 11–16 |
| Thioridazine | 19 | 251 | 1587 | 16 | 14–18 |
| Molindone | 6 | 51 | 241 | 21 | 16–27 |
| Sulpiride | 10 | 124 | 561 | 22 | 19–26 |
| Perphenazine | 19 | 437 | 1969 | 22 | 20–24 |
| Zuclopenthixol | 8 | 111 | 424 | 26 | 22–31 |
| Perazine | 5 | 59 | 193 | 31 | 25–37 |
| Loxapine | 9 | 157 | 493 | 32 | 28–36 |
| Atypicals v. atypicals | |||||
| Risperidone v. olanzapine | 7 | 249 | 1217 | 20 | 18–23 |
| Olanzapine v. various | 12 | 535 | 2304 | 23 | 22–25 |
| Clozapine v. risperidone | 5 | 124 | 467 | 27 | 23–31 |
| Amisulpride v. risperidone | 1 | 69 | 228 | 30 | 19–29 |
| Quetiapine v. risperidone | 1 | 235 | 728 | 32 | 29–36 |
| Zotepine v. clozapine | 1 | 17 | 50 | 34 | 22–48 |
| Aripiprazole v. various | 3 | 407 | 832 | 49 | 46–52 |
We aimed to gauge the attrition level at which results of drug trials for people with schizophrenia lose enough credibility to be mistrusted by three relevant groups of stakeholders.
Method
A protocol was written and power calculations undertaken, suggesting that for what we thought would be a meaningful difference (20%) about 100 people in each of the groups would be necessary (α=0.05, power 80%). The questionnaire was drawn up and piloted in groups of clinicians, researchers and mental health service users (this led to refinement of the accompanying background information and of the final questionnaire question; see the online supplement to this paper). In March 2007, three groups of stakeholders were targeted. First, email contacts of all 128 general adult psychiatrists within the Yorkshire Deanery were obtained (the clinicians). Then a list of the first 100 most recently published email contacts from within the Cochrane Schizophrenia Group's Register of trials was generated (the researchers). Finally, 104 carers/service users from Rethink's regional groups across England were contacted (Rethink is a leading UK mental health membership charity, www.rethink.org). The trial gained approval from Leeds East Research Ethics Committee and one follow-up email was allowed should there be no response on first contact. On 23 March 2007, the question (see online supplement) was sent to the clinicians and researchers via email and followed up 2 months later. During this period, questionnaires were also sent out to carers and service users who attend Rethink's regional governance meetings.
Results
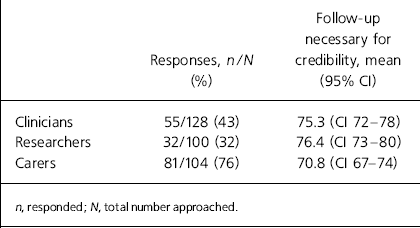
Response rates from clinicians and researchers were poor but all three stakeholder groups estimated the proportion of follow-up sample necessary at 12 weeks to generate a basic level of trust in the outcomes in drug trials relevant to schizophrenia to be about 70-80% (Table 2).
Table 2. Response rates and credibility rate as viewed by three groups of stakeholders
| Responses, n/N (%) | Follow-up necessary for credibility, mean (95% CI) | |
|---|---|---|
| Clinicians | 55/128 (43) | 75.3 (CI 72–78) |
| Researchers | 32/100 (32) | 76.4 (CI 73–80) |
| Carers | 81/104 (76) | 70.8 (CI 67–74) |
Discussion
This is the result of a survey with variable response rate to a question that forced a binary decision in a situation that, in reality, usually involves managing degrees of discomfort with research findings. It is also feasible that a question with well-tested psychometric properties may have generated different results. Nevertheless, we know of no study in any area of healthcare that has even attempted to investigate this limit of credibility in those for whom results of trials are important. Using 70-80% follow-up at 12 weeks as a broad estimate of the limit of credibility on the data derived from trials (Table 1) shows that the evidence on many commonly used drugs falls short of this standard.
To put this finding in context, schizophrenia drug trials are often short, involve participants who are so rigorously diagnosed as to be difficult to find in everyday practice, prescribe interventions that demand rigid adherence and measure outcomes on many scales of variable quality Reference Marshall, Lockwood, Bradley, Adams, Joy and Fenton6 that are often reported poorly and are problematic to interpret clinically. Reference Thornley and Adams2 These studies, nevertheless, are the well-established gold standard means by which mental health treatments are evaluated. 7 This simple survey asked participants to put aside all other worries about the design, conduct and reporting of these studies and to focus on attrition. Investigation of this single variable undermines the credibility of outcomes in most studies.
Drug trials, however, often report several outcomes. Attrition from one outcome may be large, whereas other outcome data from within the same study are almost complete. Often data on outcomes such as ‘loss to follow-up’, ‘hospitalised’ or ‘in contact with services/police/family’ are reasonably complete and it is not surprising that major trials are now beginning to use these as primary outcomes. Reference Lieberman, Stroup, McEvoy, Swartz, Rosenheck and Perkins8 This choice of simple routine outcomes, however, is still the exception rather than the rule. Most trials in this area focus on fine-grain, scale-derived outcomes. Scales, although greatly valued non-physiological measures, are mostly ordinal rather than continuous and face problems with validity, analysis and interpretation. They are further undermined by their association with incomplete data-sets. Often, however, trials generate binary outcomes such as ‘improved to an important degree’, but these are based on incomplete scale data and fail to directly ask the simple single question that would cover this outcome and for which it is likely that much more complete and credible data could be acquired.
Conclusions
Currently, clinicians, policy makers and consumers of care have to come to decisions about treatments based on information that is of questionable credibility. We believe that this allows many factors, such as fashion and advertising, to take priority over good evidence when it comes to making the difficult decisions about care. The loss of people from these studies is both an enormous opportunity and waste. One method used to give a semblance of end-point ratings is to carry forward the last observation of the person before they left. Ratings, even from the first few weeks into the trial, are carried forward to the end of the study, perhaps months later, often with the (unlikely) assumption that the person has been stable since the point of departure. If this technique remains acceptable to users of the findings, there will be little motivation for improvement. Last-observation-carried-forward is a flawed technique that depends on considerable assumptions and can lead to erroneous results. Reference Cotton, Yuen, Berger and McGorry9 The study design that wastes the resource of willing people ensures that most trials in schizophrenia remain small and difficult to apply clinically. There is now accumulating evidence that using more routine data can generate high-grade data-sets even on protracted follow-up. Reference Bain, Chalmers and Brewster10 Simpler pragmatic/real-world design could ensure that more studies were adequately powered for the more complete data-sets of clinically meaningful outcomes.
Declaration of interest
None.
Acknowledgements
The survey was supported by the National Health Service Priorities and Needs.





 Open access
Open access
eLetters
No eLetters have been published for this article.