




Highlights
What is already known?
-
• Moderator analyses are a crucial step in a meta-analysis, although they are often underpowered.
-
• In the presence of multiple effect sizes within studies, various methods are available for analyzing moderator variables through meta-regression, including multivariate models, multilevel models, robust variance estimation, and combinations of the first two methods with robust variance estimation.
-
• Some simulation studies have compared the performance of these methods. The results indicate that all of them achieve adequate Type I error rates with a large number of studies and that a posterior robust variance correction addresses model mis-specification.
-
• Despite this, some questions remain: The statistical power of these methods has never been directly compared, nor have Type I error rates or power been evaluated when the moderator variable pertains to study characteristics.
What is new?
-
• This article provides a comprehensive comparison of the statistical properties of methods for conducting meta-regressions when multiple effect sizes are present within studies and binary variables are analyzed, related to either study-level or within-study characteristics.
-
• We focus on a common scenario in this context: studies or effect sizes are often highly imbalanced across the categories of the categorical moderator variable.
-
• The results show that the properties of these methods vary depending on whether moderator variables refer to study-level or effect size-level characteristics: Statistical power is negatively affected by the imbalanced distribution of effect sizes, and it is generally higher when the moderator variable pertains to within-study characteristics.
-
• Multilevel models alone can lead to inflated Type I error rates when moderator variables refer to within-study characteristics, but this inflation may be corrected using robust variance estimation.
Potential impact for RSM readers
-
• The results of this study will help applied meta-analysts select the most suitable methods for conducting meta-regression.
In meta-analysis, findings from studies investigating the same research question are aggregated quantitatively to provide a comprehensive overview of the available evidence pertaining to that specific topic. The unit of analysis is typically an effect size, which is a number that summarizes the strength of the association between the variables of interest. Following the compilation of this evidence summary, the next step commonly involves checking whether there is statistical heterogeneity among the effect sizes, and if that is the case, exploring whether the characteristics of the studies have an impact on the observed effect sizes.Reference Thompson 1 For example, in Yan and colleagues’ meta-analysisReference Yan, Lao, Panadero, Fernández-Castilla, Yang and Yang 2 examining the influence of peer assessment on academic outcomes, the researchers explored whether studies that incorporated online technology in their procedures yielded larger effect sizes compared to those that did not. Their findings revealed that, indeed, the overall effect size was greater for the former (g = 0.78) than for the latter (g = 0.44). This procedure of using study characteristics to predict study results is known as moderator analyses and is commonly carried out through the implementation of a mixed-effects model, also known as meta-regression.Reference Thompson and Higgins 3
Moderator analyses play an important role in advancing scientific understanding by uncovering how different study characteristics might affect the results obtained. These analyses are crucial because they direct researchers’ attention to factors that might have been previously overlooked. When significant moderator effects are observed, these previously ignored factors become salient, leading to a more refined picture of the phenomena being studied. This process enriches the overall understanding and interpretation of research findings, ultimately contributing to more robust and comprehensive scientific insights.
Moderator analyses are commonly conducted through statistical regression models known as meta-regressions. In these models, a study characteristic either categorical (e.g., type of design) or quantitative (e.g., mean age of the sample) is used as a predictor variable in a regression where the dependent variables are the effect sizes extracted from primary studies. Given the important role of moderator analyses in scientific advancement, it is crucial to ensure that the estimates derived from meta-regression models are unbiased, effectively control Type I errors, and maintain robust statistical power to detect an effect.
Numerous studies have focused on these aspects of meta-regression analysis in situations where only one effect size could be extracted per study.Reference Berkey, Hoaglin, Mosteller and Colditz 4 – Reference Viechtbauer, López-López, Sánchez-Meca and Marín-Martínez 13 However, studies incorporated into meta-analyses often report multiple results, frequently supplying data that allows the calculation of several effect sizes.Reference López-López, Page, Lipsey and Higgins 14 For example, when different questionnaires are used to measure different aspects of a psychological construct (e.g., to measure anxiety, different facets of the construct can be measured, such as motor, cognitive, or physiological anxiety), measurements are made on different subsamples, or the same sample is measured at different time points. These effect sizes are more closely related to each other because they stem from the same study and therefore share underlying methodological characteristics, or because they are derived from the same individuals, making them statistically dependent. This dependency must be considered in the statistical model of the meta-analysis to avoid a Type I error rate higher than the nominal value.Reference Becker, Tinsley and Brown 15
Three primary methods are used to model the dependence between effect sizes: the multivariate method,Reference Kalaian and Raudenbush 16 , Reference Raudenbush, Becker and Kalaian 17 three-level models,Reference Van den Noortgate, López-López, Marín-Martínez and Sánchez-Meca 18 , Reference Van den Noortgate, López-López, Marín-Martínez and Sánchez-Meca 19 and correlated-effects models using the robust variance estimation (RVE) inference method.Reference Hedges, Tipton and Johnson 20 , Reference Tipton 21 Recently, a combination of three-level models with RVE method has been proposed to ensure nominal Type I errors.Reference Fernandez-Castilla, Aloe and Declercq 22 – Reference Tipton, Pustejovsky and Ahmadi 25 Last, to enhance the power to detect moderator effects, a new inferential technique called cluster wild bootstrapping (CWB) has been proposed within the correlated-effects model with RVE framework.Reference Joshi, Pustejovsky and Beretvas 26 The technical details of these methods will be introduced in the upcoming sections.
All these methods can accommodate moderator variables to explain the variability observed in effect sizes both across studies and within studies. Moderator variables can reflect study characteristics (e.g., the country where the study is conducted) or within-study characteristics (e.g., instruments used to measure multiple dependent variables reported within studies). Throughout this text, we will refer to these two types of characteristics as study-level variables and effect size-level variables, respectively. Although not addressed in the present manuscript, it is important to consider centering these moderator variables (both continuous and categorical) to disentangle level-specific effects.Reference Yaremych, Preacher and Hedeker 27 , Footnote 1
Several studies have investigated or compared the effectiveness of the aforementioned methods in the context of meta-regression, examining both quantitative and categorical study-level and effect size-level characteristics.Reference López-López, Van den Noortgate, Tanner-Smith, Wilson and Lipsey 9 , Reference Tipton 21 , Reference Fernandez-Castilla, Aloe and Declercq 22 , Reference Joshi, Pustejovsky and Beretvas 26 , Reference Park and Beretvas 28 López-López et al.Reference López-López, Van den Noortgate, Tanner-Smith, Wilson and Lipsey 9 compared the power and Type I error of three-level models and correlated-effects models with RVE inference method in meta-regressions with a single quantitative moderator variable that could describe a study or an effect size characteristic. Results showed that the three-level multilevel model had higher power but poorer control of Type I error, while the correlated-effects models with RVE method provided correct Type I error rates but had low statistical power. Unfortunately, this research focused exclusively on quantitative moderator variables, whereas many times moderator variables are categorical, such as the educational level of the sample (primary, secondary, and university) or the type of design (experimental, quasi-experimental, and observational).
Regarding the performance of meta-regressions with categorical variables, TiptonReference Tipton 21 found that applying the RVE inference method to a correlated-effects model with different small-sample adjustments, such as the bias-reduced linearization correction proposed by Bell and McCaffreyReference Bell and McCaffrey 29 combined with the Satterthwaite approximation for estimating degrees of freedom,Reference Satterthwaite 30 provided the best tradeoff between Type I error and statistical power when analyzing unbalanced dichotomous variables. This was particularly true when the number of studies was 40, the between-study heterogeneity was small or moderate, and the effect size difference between categories was large (i.e., 0.40). However, in other simulated conditions, statistical power was very low. A limitation of this study is that the performance of the correlated-effects model with RVE and small-sample adjustments was not compared to other methods, such as three-level models or three-level models with RVE.
This limitation is also present in the simulation study conducted by Joshi et al.,Reference Joshi, Pustejovsky and Beretvas 26 who examined the Type I error and power of the CWB method applied to a correlated-effects model with RVE using various types of variables (i.e., quantitative and categorical, both at study and at effect size level). This method is very promising, as it was found to adequately control Type I error while showing higher statistical power than the correlated-effects model with RVE and small-sample correction, particularly when hypothesis tests involved multiple contrasts, with as few as 10 studies. However, the authors did not compare the performance of CWB with other alternative methods.
Two existing simulation studies have compared the performance of the three-level model and the correlated-effects model with RVE inference in meta-regressions with categorical moderator variables.Reference Fernandez-Castilla, Aloe and Declercq 22 , Reference Park and Beretvas 28 Park and BeretvasReference Park and Beretvas 28 found that the three-level model had convergence issues and underestimated standard errors under unfavorable conditions (i.e., a small number of studies, high heterogeneity, and an uneven distribution of effect sizes across moderator categories). In contrast, the correlated-effects model with RVE showed better performance. In a subsequent study, Fernández-Castilla et al.Reference Fernandez-Castilla, Aloe and Declercq 22 extended this research by incorporating additional simulation conditions, testing alternative three-level model specifications (i.e., a three-level model that allows estimating different between-studies residual variance estimates for each category of the moderator) and evaluating hybrid approaches that combined three-level models with RVE. They concluded that all methods provided adequate estimates when at least 40 studies are available. Additionally, they found that applying three-level models with RVE generally maintained appropriate Type I error rates, even when the three-level model was mis-specified and the number of studies was as low as 20. Lastly, they observed that an imbalance in the number of effect sizes across categorical moderator categories negatively impacted results.
Despite the advancements made by these studies, a critical gap remains. Neither of these studies examined or compared the statistical power and Type I error ratesFootnote 2 of the methods for detecting differences in overall effects across categorical moderator categories. Additionally, both studies focused on moderator variables that represented effect size-level characteristics, but not on study-level characteristics. Addressing these gaps is the primary motivation for the present study.
1 The present study
Categorical variables are of special interest from a methodological perspective because, in meta-analysis, effect sizes are often disproportionately distributed across categories (see example provided in Table 1). This imbalanced distribution is known to affect the properties of methods commonly used in meta-regressions.Reference Tipton 21 , Reference Fernandez-Castilla, Aloe and Declercq 22 Beyond the type of variable used in a meta-regression, when a variable describes an effect size-level characteristic, different three-level model specifications can be applied, and choosing an incorrect specification can significantly underestimate standard errors associated with the moderator effect,Reference Fernandez-Castilla, Aloe and Declercq 22 leading to inflated Type I error rates.
Results from meta-regressions carried out with different methods

Note:
 ${\widehat{\sigma}}_{u_{res}}^2$
= residual between-studies variance;
${\widehat{\sigma}}_{u_{res}}^2$
= residual between-studies variance;
 ${\widehat{\sigma}}_{w_{res}}^2$
= residual within-study variance; RVE = robust variance estimation; CWB = cluster wild bootstrapping; SE = standard error. To fit the multivariate model, an imputed variance–covariance matrix was used, using a correlation of 0.6.
${\widehat{\sigma}}_{w_{res}}^2$
= residual within-study variance; RVE = robust variance estimation; CWB = cluster wild bootstrapping; SE = standard error. To fit the multivariate model, an imputed variance–covariance matrix was used, using a correlation of 0.6.
To date, no study has conducted an integrative analysis comparing Type I error rates and statistical power across various methods (and their specifications) for meta-regression with binary variables, which can represent study- or effect size-level characteristics, in the presence of dependent effect sizes. This research gap serves as the primary motivation for the present simulation study. The results of this study will help meta-analysts determine which method exhibits better properties under different conditions when analyzing categorical moderator variables. Additionally, it will enable them to make more informed decisions regarding the inclusion (or exclusion) of meta-regression analyses involving binary variables with a high imbalance across categories. Finally, this article aims to clarify the different three-level model specifications that can be implemented when effect size-level moderators are present, along with their respective pros and cons.
2 Methods for meta-regression
In this section, we introduce the meta-regression models that will be tested in the present simulation study: three-level models, correlated-effects model with RVE inference, their combination (three-level models with RVE), and correlated-effects models with RVE and CWB as inferential methods. For clarity, we will explain the different terms in the equations using an applied example. Yan et al.Reference Yan, Lao, Panadero, Fernández-Castilla, Yang and Yang 2 published a meta-analysis on the effect of peer assessment (compared to teacher assessment) on academic outcomes. A relevant (binary) moderator variable was whether students received feedback from their peer assessments (coded as 0 – No and 1 – Yes).
2.1 Three-level models
A traditional random-effects model can be seen as a two-level model, where effect sizes are nested within studies. In the presence of multiple effect sizes, an additional level (or random effect) can be added to account for the dependency among these effects, which are often extracted from the same sample or following identical procedures.
The three-level model employed to estimate an overall effect size as well as the variability within and across studies, along with its advantages and disadvantages, has been thoroughly described in previous manuscripts.Reference Van den Noortgate, López-López, Marín-Martínez and Sánchez-Meca 18 , Reference Van den Noortgate, López-López, Marín-Martínez and Sánchez-Meca 19 , Reference Moeyaert, Ugille, Beretvas, Ferron, Bunuan and Van den Noortgate 31 In general, the primary advantage of this approach is that it does not require knowledge of the covariances among effect sizes, unlike the multivariate approach. Additionally, it treats different outcomes (i.e., various effect sizes within studies) as a random sample from a population of outcomes, rather than a fixed set of outcomes identical from study to study, which might not be realistic in many contexts.
In the following lines, we delineate two types of three-level mixed-effects models applicable for conducting moderator analyses. Initially, we elaborate on the mixed-effects model integrating a binary moderator variable denoting a characteristic of the studies. Subsequently, we discuss a mixed-effects model encompassing a categorical moderator variable reflecting characteristics of the outcomes within studies (e.g., at the effect size level). These models are expounded separately due to the latter’s potential specification in two distinct manners, but in practice, it is possible to incorporate moderator variables at both levels at the same time.
Study-level characteristics. When a meta-analyst aims to test the impact of study characteristics on the observed effect sizes, they can implement the following three-level model. At Level 1, the term
 ${t}_{ij}$
refers to the ith effect size observed in study j:
${t}_{ij}$
refers to the ith effect size observed in study j:
 $$\begin{align}{t}_{ij}={\beta}_{ij}+{e}_{ij}.\kern0.48em \left(\mathrm{Level}\;1\right)\end{align}$$
$$\begin{align}{t}_{ij}={\beta}_{ij}+{e}_{ij}.\kern0.48em \left(\mathrm{Level}\;1\right)\end{align}$$
Following the example introduced before,
 ${t}_{ij}$
would be the standardized mean difference that indicates the difference between the group that received peer assessment and the group that received teacher assessment in academic performance, measured with outcome i (e.g., math exam, science exam, English assignment, etc.) in study j. This observed effect size is not exactly equal to its population effect,
${t}_{ij}$
would be the standardized mean difference that indicates the difference between the group that received peer assessment and the group that received teacher assessment in academic performance, measured with outcome i (e.g., math exam, science exam, English assignment, etc.) in study j. This observed effect size is not exactly equal to its population effect,
 ${\beta}_{ij}$
, due to a random deviation,
${\beta}_{ij}$
, due to a random deviation,
 ${e}_{ij}$
, that emerges due to the use of different samples across outcomesFootnote
3
and studies. These deviations are assumed to be normally distributed with mean 0 and variance
${e}_{ij}$
, that emerges due to the use of different samples across outcomesFootnote
3
and studies. These deviations are assumed to be normally distributed with mean 0 and variance
 ${\sigma}_{e_{ij}}^2$
, typically known as the sampling variance, which is often estimated before conducting the meta-analysis.
${\sigma}_{e_{ij}}^2$
, typically known as the sampling variance, which is often estimated before conducting the meta-analysis.
At Level 2, the population effect
 ${\beta}_{ij}$
equals the population mean for study j,
${\beta}_{ij}$
equals the population mean for study j,
 ${\theta}_{0j}$
, plus a random deviation,
${\theta}_{0j}$
, plus a random deviation,
 ${w}_{ij}$
, whose variance (
${w}_{ij}$
, whose variance (
 ${\sigma}_w^2$
) would be interpreted as the within-study variance:
${\sigma}_w^2$
) would be interpreted as the within-study variance:
 $$\begin{align}{\beta}_{ij}={\theta}_{0j}+{w}_{ij}.\kern0.6em \left(\mathrm{Level}\;2\right)\end{align}$$
$$\begin{align}{\beta}_{ij}={\theta}_{0j}+{w}_{ij}.\kern0.6em \left(\mathrm{Level}\;2\right)\end{align}$$
Following the example, the population effect size reflecting the difference between the peer-assessment group and the teacher-assessment group in outcome i within study j (
 ${\beta}_{ij}$
) equals the mean of the population effect of study j,
${\beta}_{ij}$
) equals the mean of the population effect of study j,
 ${\theta}_{0j}$
, plus a random deviation
${\theta}_{0j}$
, plus a random deviation
 ${w}_{ij}$
that emerges due to the fact that the outcomes used to measure academic performance may differ within studies: maybe authors used both a math and a reading assignment. The variance of
${w}_{ij}$
that emerges due to the fact that the outcomes used to measure academic performance may differ within studies: maybe authors used both a math and a reading assignment. The variance of
 ${w}_{ij}$
,
${w}_{ij}$
,
 ${\sigma}_w^2$
, reflects the variability in the population effects around the study-specific mean
${\sigma}_w^2$
, reflects the variability in the population effects around the study-specific mean
 ${\theta}_{0j},$
that is, the within-study variance.
${\theta}_{0j},$
that is, the within-study variance.
Lastly, at Level 3, the mean population effect for study j,
 ${\theta}_{0j}$
, may vary either randomly or in relation to the characteristics of the study:
${\theta}_{0j}$
, may vary either randomly or in relation to the characteristics of the study:
 $$\begin{align}{\theta}_{0j}={\gamma}_{00}+{\gamma}_{01}{Z}_{1j}+{u}_{0j}.\kern0.6em \left(\mathrm{Level}\;3\right)\end{align}$$
$$\begin{align}{\theta}_{0j}={\gamma}_{00}+{\gamma}_{01}{Z}_{1j}+{u}_{0j}.\kern0.6em \left(\mathrm{Level}\;3\right)\end{align}$$
The term
 ${Z}_{1j}$
of Equation (3) refers to any characteristic of study j. If this characteristic is categorical such as study design (e.g., experimental or quasi-experimental), or whether the students received feedback from their assessments (e.g., yes or no), the term
${Z}_{1j}$
of Equation (3) refers to any characteristic of study j. If this characteristic is categorical such as study design (e.g., experimental or quasi-experimental), or whether the students received feedback from their assessments (e.g., yes or no), the term
 ${\gamma}_{00}$
would refer to the overall effect size for the reference category. For instance, if the “feedback” variable was dummy coded in 1s and 0s,
${\gamma}_{00}$
would refer to the overall effect size for the reference category. For instance, if the “feedback” variable was dummy coded in 1s and 0s,
 ${\gamma}_{00}$
would represent the overall standard mean difference for those studies where the students did not receive feedback on their assessments. The term
${\gamma}_{00}$
would represent the overall standard mean difference for those studies where the students did not receive feedback on their assessments. The term
 ${\gamma}_{01}$
would represent the difference between the pooled standardized mean differences of both categories, and therefore,
${\gamma}_{01}$
would represent the difference between the pooled standardized mean differences of both categories, and therefore,
 ${\gamma}_{00}$
+
${\gamma}_{00}$
+
 ${\gamma}_{01}$
would equal the pooled standardized mean difference for those studies where the students did receive feedback of their assessments. Finally, the random effect
${\gamma}_{01}$
would equal the pooled standardized mean difference for those studies where the students did receive feedback of their assessments. Finally, the random effect
 ${u}_{0j}$
, assumed to be normally distributed with mean 0 and variance
${u}_{0j}$
, assumed to be normally distributed with mean 0 and variance
 ${\sigma}_{u_{res}}^2$
, is the residual between-studies variance after accounting for the effect of
${\sigma}_{u_{res}}^2$
, is the residual between-studies variance after accounting for the effect of
 ${Z}_{1j}$
.
${Z}_{1j}$
.
Effect size-level characteristics. Moderator variables can also pertain to characteristics of effect sizes within studies. For example, if some studies include two conditions: one where feedback was not provided to students and another where feedback was provided, different effect sizes could emerge within a study depending on the presence or absence of feedback. Therefore, this variable now describes an effect size-level characteristic. If this categorical moderator was analyzed with a three-level meta-regression model, the first level (Equation (1)) would remain the same. However, at Level 2, the population outcome-specific effect
 ${\beta}_{ij}$
would exhibit variability, stemming from both random factors and the attributes of the outcomes:
${\beta}_{ij}$
would exhibit variability, stemming from both random factors and the attributes of the outcomes:
 $$\begin{align}{\beta}_{ij}={\theta}_{0j}+{\theta}_{1j}{X}_{1 ij}+{w}_{ij}.\kern0.72em \left(\mathrm{Level}\;2\right)\end{align}$$
$$\begin{align}{\beta}_{ij}={\theta}_{0j}+{\theta}_{1j}{X}_{1 ij}+{w}_{ij}.\kern0.72em \left(\mathrm{Level}\;2\right)\end{align}$$
The term
 ${X}_{1 ij}$
represents a characteristic of outcome i within study j (e.g., absence or presence of feedback), and the term
${X}_{1 ij}$
represents a characteristic of outcome i within study j (e.g., absence or presence of feedback), and the term
 ${\theta}_{1j}$
is the effect of
${\theta}_{1j}$
is the effect of
 ${X}_{1 ij}$
on the population outcome effects
${X}_{1 ij}$
on the population outcome effects
 ${\beta}_{ij}$
within study j. Importantly, at Level 3, we can make two assumptions regarding the within-study effect
${\beta}_{ij}$
within study j. Importantly, at Level 3, we can make two assumptions regarding the within-study effect
 ${\theta}_{1j}$
: either it remains constant across studies (e.g., the presence of feedback systematically improves or worsens the assessment of academic performance to the same extent across studies) or it varies across studies (e.g., the presence of feedback on academic performance differs between studies). In practice, meta-analysts often apply the first model specification, where at the study level (Level 3), the effect
${\theta}_{1j}$
: either it remains constant across studies (e.g., the presence of feedback systematically improves or worsens the assessment of academic performance to the same extent across studies) or it varies across studies (e.g., the presence of feedback on academic performance differs between studies). In practice, meta-analysts often apply the first model specification, where at the study level (Level 3), the effect
 ${\theta}_{1j}$
remains constant across studies (
${\theta}_{1j}$
remains constant across studies (
 ${\gamma}_{10}$
):
${\gamma}_{10}$
):
 $$\begin{align}\left\{{}_{\theta_{1j}={\gamma}_{10}}^{\theta_{0j}={\gamma}_{00}+{u}_{0j}}\right.\kern1em \left(\mathrm{Level}\;3\right).\end{align}$$
$$\begin{align}\left\{{}_{\theta_{1j}={\gamma}_{10}}^{\theta_{0j}={\gamma}_{00}+{u}_{0j}}\right.\kern1em \left(\mathrm{Level}\;3\right).\end{align}$$
The term
 ${\gamma}_{00}$
represents the overall effect size in the reference category. Following our example,
${\gamma}_{00}$
represents the overall effect size in the reference category. Following our example,
 ${\gamma}_{00}$
would denote the overall standardized mean difference for those outcomes where feedback was absent. Unlike the moderator effect
${\gamma}_{00}$
would denote the overall standardized mean difference for those outcomes where feedback was absent. Unlike the moderator effect
 ${\gamma}_{10}$
, the effect
${\gamma}_{10}$
, the effect
 ${\gamma}_{00}$
is typically allowed to vary across studies (the random effect
${\gamma}_{00}$
is typically allowed to vary across studies (the random effect
 ${u}_{0j}$
is assumed to be normally distributed with mean 0 and variance
${u}_{0j}$
is assumed to be normally distributed with mean 0 and variance
 ${\sigma}_{u_0}^2$
, which is the between-studies variance of the overall effect size for the reference category). An important implication of the model is precisely the assumption that the effect
${\sigma}_{u_0}^2$
, which is the between-studies variance of the overall effect size for the reference category). An important implication of the model is precisely the assumption that the effect
 ${\gamma}_{10}$
(i.e., the difference between the overall effect across categories) is the same or stable across studies. If
${\gamma}_{10}$
(i.e., the difference between the overall effect across categories) is the same or stable across studies. If
 ${\gamma}_{10}$
did vary across studies, that is, if the effect of feedback on academic performance differed between studies, the model in Equation (5) would be mis-specified, and that can have important implications on the parameter estimates.Reference Fernandez-Castilla, Aloe and Declercq
22
Alternatively,
${\gamma}_{10}$
did vary across studies, that is, if the effect of feedback on academic performance differed between studies, the model in Equation (5) would be mis-specified, and that can have important implications on the parameter estimates.Reference Fernandez-Castilla, Aloe and Declercq
22
Alternatively,
 ${\gamma}_{10}$
could be allowed to vary across studies:
${\gamma}_{10}$
could be allowed to vary across studies:
 $$\begin{align}\left\{{}_{\theta_{1j}={\gamma}_{10}+{u}_{1j}}^{\theta_{0j}={\gamma}_{00}+{u}_{0j}}\right.\kern1em \mathrm{Level}\;3.\end{align}$$
$$\begin{align}\left\{{}_{\theta_{1j}={\gamma}_{10}+{u}_{1j}}^{\theta_{0j}={\gamma}_{00}+{u}_{0j}}\right.\kern1em \mathrm{Level}\;3.\end{align}$$
Under this model, the moderator effect of variable
 ${X}_{1 ij}$
on the outcome effects within study j (
${X}_{1 ij}$
on the outcome effects within study j (
 ${\theta}_{1j})$
would equal an overall moderator effect,
${\theta}_{1j})$
would equal an overall moderator effect,
 ${\gamma}_{10}$
, plus a random deviation,
${\gamma}_{10}$
, plus a random deviation,
 ${u}_{1j}.$
The variance of
${u}_{1j}.$
The variance of
 ${u}_{1j}$
is
${u}_{1j}$
is
 ${\sigma}_{u_1}^2$
, which would represent the heterogeneity of
${\sigma}_{u_1}^2$
, which would represent the heterogeneity of
 ${\gamma}_{10}$
across studies.
${\gamma}_{10}$
across studies.
To assess the statistical significance of the moderator effect (
 ${\gamma}_{01}$
or
${\gamma}_{01}$
or
 ${\gamma}_{10}$
) which represents the difference between categories, Wald tests are commonly employed, with a significance level of 0.05. Alternatively, likelihood ratio tests (LRTs) can be used to compare the fit of a null model to that of a model incorporating the moderator variable. If the model with the moderator variable shows a significantly better fit (
${\gamma}_{10}$
) which represents the difference between categories, Wald tests are commonly employed, with a significance level of 0.05. Alternatively, likelihood ratio tests (LRTs) can be used to compare the fit of a null model to that of a model incorporating the moderator variable. If the model with the moderator variable shows a significantly better fit (
 $\alpha$
= 0.05), it can be concluded that the moderator variable is statistically significant.
$\alpha$
= 0.05), it can be concluded that the moderator variable is statistically significant.
Recently, a method using three-level models in combination with RVE inference method has been proposed. This method consists of applying first a three-level meta-regression, then extracting the variance–covariance matrix from the three-level model results, and then correcting this matrix using a sandwich estimator, including the bias-reduced linearization adjustment of Bell and McCaffrey.Reference Bell and McCaffrey 29 Also, hypothesis tests using Satterthwaite degrees of freedom are conducted. This posterior application of RVE ensures that inferences are correct in terms of Type I error, even if the three-level model is mis-specified.Reference Fernandez-Castilla, Aloe and Declercq 22 , Reference Pustejovsky and Tipton 24
2.2 Correlated-effects model with RVE inference
This method involves the specification of a working model that accounts for the correlation between effect sizes within studies. It builds on the random-effects model but includes a sandwich-type adjustment to the standard errors of the regression coefficients. This adjustment helps to prevent underestimation of standard errors due to statistical dependence among effect sizes.Reference Hedges, Tipton and Johnson 20 A great advantage of this method is that there is no need to estimate covariances between effect sizes, because it relies on a working model that involves making general, approximate assumptions about the dependence structure. Additionally, this method does not make distribution assumptions, as opposed to the three-level model which requires the sampling distribution of the effect sizes to be normal.
The statistical model for meta-regression is the following:
where
 $\mathbf{T}$
is a stacked vector containing the i effect sizes within the m studies, and X is a design matrix constructed so that its rows correspond to the total number of effect sizes, while its columns represent the number of covariates examined in the meta-regression analysis (plus the intercept, if desired). These covariates can refer to characteristics of the studies or of the outcomes. Moreover,
$\mathbf{T}$
is a stacked vector containing the i effect sizes within the m studies, and X is a design matrix constructed so that its rows correspond to the total number of effect sizes, while its columns represent the number of covariates examined in the meta-regression analysis (plus the intercept, if desired). These covariates can refer to characteristics of the studies or of the outcomes. Moreover,
 $\boldsymbol{\unicode{x3b3}}$
represents a vector containing the regression coefficients (i.e., moderator effects) that need to be estimated, and
$\boldsymbol{\unicode{x3b3}}$
represents a vector containing the regression coefficients (i.e., moderator effects) that need to be estimated, and ![]() is a stacked vector with the residuals of each of the k effect sizes within the m studies. To estimate the vector
is a stacked vector with the residuals of each of the k effect sizes within the m studies. To estimate the vector
 $\boldsymbol{\unicode{x3b3}}$
of regression coefficients, weighted least squares estimation method is used:
$\boldsymbol{\unicode{x3b3}}$
of regression coefficients, weighted least squares estimation method is used:
 $$\begin{align}\widehat{\boldsymbol{\unicode{x3b3}}}={\left(\sum_{j=1}^m\mathbf{X}^{\prime}_{\boldsymbol{j}}{\mathbf{W}}_{\boldsymbol{j}}{\mathbf{X}}_{\boldsymbol{j}}\right)}^{-\mathbf{1}}\left(\sum_{j=1}^m\mathbf{X}^{\prime}_{\boldsymbol{j}}{\mathbf{W}}_{\boldsymbol{j}}{\mathbf{T}}_{\boldsymbol{j}}\right),\end{align}$$
$$\begin{align}\widehat{\boldsymbol{\unicode{x3b3}}}={\left(\sum_{j=1}^m\mathbf{X}^{\prime}_{\boldsymbol{j}}{\mathbf{W}}_{\boldsymbol{j}}{\mathbf{X}}_{\boldsymbol{j}}\right)}^{-\mathbf{1}}\left(\sum_{j=1}^m\mathbf{X}^{\prime}_{\boldsymbol{j}}{\mathbf{W}}_{\boldsymbol{j}}{\mathbf{T}}_{\boldsymbol{j}}\right),\end{align}$$
where
 ${\mathbf{W}}_{\boldsymbol{j}}$
is a diagonal matrix containing the weights assigned to the effects of study j. In the classical application of the RVE inference method, weights (
${\mathbf{W}}_{\boldsymbol{j}}$
is a diagonal matrix containing the weights assigned to the effects of study j. In the classical application of the RVE inference method, weights (
 ${\mathbf{W}}_{\boldsymbol{j}}$
) can be approximated by either assuming that effect sizes are correlated because they have been calculated on the same sample (i.e., correlated effects) or assuming that effect sizes covary because they have been obtained under similar conditions: similar research groups, similar instruments and procedures, etc. (i.e., hierarchical effects). Formulas to obtain each of these types of weights can be found elsewhere.Reference Hedges, Tipton and Johnson
20
It should be noted that new approaches have been recently proposed where both types of dependency can be simultaneously modeled.Reference Pustejovsky and Tipton
24
${\mathbf{W}}_{\boldsymbol{j}}$
) can be approximated by either assuming that effect sizes are correlated because they have been calculated on the same sample (i.e., correlated effects) or assuming that effect sizes covary because they have been obtained under similar conditions: similar research groups, similar instruments and procedures, etc. (i.e., hierarchical effects). Formulas to obtain each of these types of weights can be found elsewhere.Reference Hedges, Tipton and Johnson
20
It should be noted that new approaches have been recently proposed where both types of dependency can be simultaneously modeled.Reference Pustejovsky and Tipton
24
After estimating the vector of moderator effects
 $\widehat{\boldsymbol{\unicode{x3b3}}}$
, their sampling variances (i.e., standard errors) are given by
$\widehat{\boldsymbol{\unicode{x3b3}}}$
, their sampling variances (i.e., standard errors) are given by
 $$\begin{align}\mathbf{V}\left(\widehat{\unicode{x3b3}}\right)={\left(\sum_{j=1}^m{\mathbf{X}}_{\boldsymbol{j}}^{\prime }{\mathbf{W}}_{\boldsymbol{j}}{\mathbf{X}}_{\boldsymbol{j}}\right)}^{-\mathbf{1}}\left(\sum_{j=1}^m{\mathbf{X}}_j^{\prime }{\mathbf{W}}_j{\mathbf{e}}_j{\mathbf{e}}_j^{\prime }{\mathbf{W}}_j{\mathbf{X}}_j\right){\left(\sum_{\boldsymbol{j}=1}^m{\mathbf{X}}_j^{\prime }{\mathbf{W}}_j{\mathbf{X}}_j\right)}^{-\mathbf{1}},\end{align}$$
$$\begin{align}\mathbf{V}\left(\widehat{\unicode{x3b3}}\right)={\left(\sum_{j=1}^m{\mathbf{X}}_{\boldsymbol{j}}^{\prime }{\mathbf{W}}_{\boldsymbol{j}}{\mathbf{X}}_{\boldsymbol{j}}\right)}^{-\mathbf{1}}\left(\sum_{j=1}^m{\mathbf{X}}_j^{\prime }{\mathbf{W}}_j{\mathbf{e}}_j{\mathbf{e}}_j^{\prime }{\mathbf{W}}_j{\mathbf{X}}_j\right){\left(\sum_{\boldsymbol{j}=1}^m{\mathbf{X}}_j^{\prime }{\mathbf{W}}_j{\mathbf{X}}_j\right)}^{-\mathbf{1}},\end{align}$$
where
 ${\mathbf{e}}_j$
is the observed vector of residuals of the jth study. In subsequent developments of this approach, TiptonReference Tipton
21
and Pustejovsky and TiptonReference Pustejovsky and Tipton
23
explored ways of further adjusting the estimated variances of the regression coefficients,
${\mathbf{e}}_j$
is the observed vector of residuals of the jth study. In subsequent developments of this approach, TiptonReference Tipton
21
and Pustejovsky and TiptonReference Pustejovsky and Tipton
23
explored ways of further adjusting the estimated variances of the regression coefficients,
 $\mathbf{V}\left(\widehat{\unicode{x3b3}}\right),$
to keep the Type I error at the nominal level, especially when the number of studies synthesized is small (i.e., less than 40). In this regard, TiptonReference Tipton
21
found a good performance for a combination of two small-sample corrections, namely the bias-reduced linearization adjustment proposed by Bell and McCaffreyReference Bell and McCaffrey
29
applied on
$\mathbf{V}\left(\widehat{\unicode{x3b3}}\right),$
to keep the Type I error at the nominal level, especially when the number of studies synthesized is small (i.e., less than 40). In this regard, TiptonReference Tipton
21
found a good performance for a combination of two small-sample corrections, namely the bias-reduced linearization adjustment proposed by Bell and McCaffreyReference Bell and McCaffrey
29
applied on
 $\mathbf{V}\left(\widehat{\unicode{x3b3}}\right)$
, along with the Satterthwaite correction to the degrees of freedom of the t-distribution used to test the estimated regression coefficient.Reference Satterthwaite
30
Specifically, TiptonReference Tipton
21
proposed adding an adjustment matrix
$\mathbf{V}\left(\widehat{\unicode{x3b3}}\right)$
, along with the Satterthwaite correction to the degrees of freedom of the t-distribution used to test the estimated regression coefficient.Reference Satterthwaite
30
Specifically, TiptonReference Tipton
21
proposed adding an adjustment matrix
 ${\mathbf{A}}_j$
next to the cross-product of residuals:
${\mathbf{A}}_j$
next to the cross-product of residuals:
 $$\begin{align}\mathbf{V}\left(\widehat{\unicode{x3b3}}\right)={\left(\sum_{j=1}^m{\mathbf{X}}_{\boldsymbol{j}}^{\prime }{\mathbf{W}}_{\boldsymbol{j}}{\mathbf{X}}_{\boldsymbol{j}}\right)}^{-\mathbf{1}}\left(\sum_{j=1}^m{\mathbf{X}}_j^{\prime }{\mathbf{W}}_j{\mathbf{A}}_j{\mathbf{e}}_j{\mathbf{e}}_j^{\prime }{\mathbf{A}}_j{\mathbf{W}}_j{\mathbf{X}}_j\right){\left(\sum_{\boldsymbol{j}=1}^m{\mathbf{X}}_j^{\prime }{\mathbf{W}}_j{\mathbf{X}}_j\right)}^{-\mathbf{1}}.\end{align}$$
$$\begin{align}\mathbf{V}\left(\widehat{\unicode{x3b3}}\right)={\left(\sum_{j=1}^m{\mathbf{X}}_{\boldsymbol{j}}^{\prime }{\mathbf{W}}_{\boldsymbol{j}}{\mathbf{X}}_{\boldsymbol{j}}\right)}^{-\mathbf{1}}\left(\sum_{j=1}^m{\mathbf{X}}_j^{\prime }{\mathbf{W}}_j{\mathbf{A}}_j{\mathbf{e}}_j{\mathbf{e}}_j^{\prime }{\mathbf{A}}_j{\mathbf{W}}_j{\mathbf{X}}_j\right){\left(\sum_{\boldsymbol{j}=1}^m{\mathbf{X}}_j^{\prime }{\mathbf{W}}_j{\mathbf{X}}_j\right)}^{-\mathbf{1}}.\end{align}$$
For a full description of the bias-reduced linearization adjustment (i.e., matrix
 ${\mathbf{A}}_j$
) and the Satterthwaite correlation to the degrees of freedom, we refer to the works of Tipton,Reference Tipton
21
Tipton and Pustejovsky,Reference Tipton and Pustejovsky
32
and Pustejovsky and Tipton.Reference Pustejovsky and Tipton
23
It should be noted that the Satterthwaite degrees of freedom are particularly sensitive to the unbalanced distribution of effect sizes across the categories of a categorical variable, especially in study-level covariates. Specifically, TiptonReference Tipton
21
found that when the Satterthwaite degrees of freedom are smaller than 4, the Type I error rate can be inflated, making p-values unreliable.
${\mathbf{A}}_j$
) and the Satterthwaite correlation to the degrees of freedom, we refer to the works of Tipton,Reference Tipton
21
Tipton and Pustejovsky,Reference Tipton and Pustejovsky
32
and Pustejovsky and Tipton.Reference Pustejovsky and Tipton
23
It should be noted that the Satterthwaite degrees of freedom are particularly sensitive to the unbalanced distribution of effect sizes across the categories of a categorical variable, especially in study-level covariates. Specifically, TiptonReference Tipton
21
found that when the Satterthwaite degrees of freedom are smaller than 4, the Type I error rate can be inflated, making p-values unreliable.
Recently, Joshi et al.Reference Joshi, Pustejovsky and Beretvas 26 proposed combining the correlated-effects models with RVE method with bootstrapping techniques to enhance the power for detecting moderator effects while maintaining the Type I error rate at the nominal level. Among the various bootstrapping methods, Joshi et al.Reference Joshi, Pustejovsky and Beretvas 26 recommend using CWB,Reference Cameron, Gelbach and Miller 33 which accounts for the clustered structure of effect sizes within studies. This approach begins by fitting two models to the meta-analytic data: a null model, typically a standard random-effects model excluding moderator variables, and a full model that incorporates a moderator variable. A test statistic is then derived from the full model. Residual vectors from the null model are subsequently obtained, clustered by study. Then, for each bootstrap iteration, a random value (with mean 0 and variance 1) is generated for each study, and the corresponding residual vector is multiplied by this value. These modified residuals are added to the predicted values from the null model to create a new set of bootstrapped outcome scores. The full model is subsequently refitted using these scores, and a new test statistic is computed.
This process yields a p-value, calculated as the proportion of bootstrap test statistics that exceed the test statistic obtained from the original data analysis. This value is then used to determine whether the effect of the moderator variable is statistically different from zero. Technical details of this method, as well as relevant R code for its implementation, can be found in Joshi et al.Reference Joshi, Pustejovsky and Beretvas 26
3 Empirical example
To illustrate the properties of the methods discussed above, we use real meta-analytic data from the previously mentioned study by Yan et al.Reference Yan, Lao, Panadero, Fernández-Castilla, Yang and Yang 2 In this meta-analysis, the authors compared peer assessment with teacher assessment in enhancing academic performance. As previously presented, one potential moderator explored was whether students received feedback following their self-assessments. The results presented in Table 1 are based on a meta-regression in which the binary variable “feedback” (coded as 0 = no feedback; 1 = feedback) was included as a predictor of the standardized mean differences, which represent the relative efficacy of peer assessment compared to teacher assessment. It is important to note that this variable reflects a characteristic at the effect size level; that is, within a single study, some effect sizes were drawn from contexts where students received feedback on their peer assessments, while others came from contexts where no feedback was provided. Additionally, the distribution of effect sizes across the two categories was highly unbalanced: 259 effect sizes were drawn from scenarios where no feedback was provided to students, while only 78 effect sizes fell into the category where feedback was given.
The differences in p-values and estimates across methods are noteworthy. The multivariate approach indicates a statistically significant difference between categories, while the three-level model yields results approaching significance. In contrast, the three-level model with RVE and the version including an additional random effect both produce non-significant results. Moreover, the correlated-effects models with RVE and with RVE and CWB appear more conservative in this example. Overall, this brief illustration highlights how the choice of analytical method can influence meta-regression outcomes, with different approaches potentially leading to different conclusions. The data for this example and the R code used to generate the results in Table 1 are available at https://osf.io/czwtp/overview.
4 Method
4.1 Data generation
The R code to run the simulation studies and supplementary results are available at https://osf.io/czwtp/overview.
4.1.1 Study-level moderator
Cohen’s d effect sizes were directly generated from a multivariate two-level model:
 $$\begin{align}{d}_{ij}={\beta}_{0j}+{e}_{ij}\end{align} $$
$$\begin{align}{d}_{ij}={\beta}_{0j}+{e}_{ij}\end{align} $$
where
 ${d}_{ij}$
refers to the observed effect size i reported in study j, and
${d}_{ij}$
refers to the observed effect size i reported in study j, and
 ${\beta}_{0j}$
represents the overall population effect size of study j. The term
${\beta}_{0j}$
represents the overall population effect size of study j. The term
 ${e}_{ij}$
represents the random deviation of
${e}_{ij}$
represents the random deviation of
 ${d}_{ij}$
from
${d}_{ij}$
from
 ${\beta}_{0j}$
due to the use of a sample of participants (e.g., random sampling error). The estimation procedure typically used in this model, namely ML or REML, assumes that the vector of residuals
${\beta}_{0j}$
due to the use of a sample of participants (e.g., random sampling error). The estimation procedure typically used in this model, namely ML or REML, assumes that the vector of residuals
 $\mathbf{e}$
within study j follows a multivariate normal distribution with mean 0 and with the following I × I variance–covariance matrix (V), with I being the total number of effect sizes within a study, so that
$\mathbf{e}$
within study j follows a multivariate normal distribution with mean 0 and with the following I × I variance–covariance matrix (V), with I being the total number of effect sizes within a study, so that
 $$\begin{align*}\left[\begin{array}{c}{e}_{1j}\\ {}\begin{array}{c}{e}_{2j}\\ {}\begin{array}{c}\vdots \\ {}{e}_{Ij}\end{array}\end{array}\end{array}\right]\sim MVN\left(\left[\begin{array}{c}0\\ {}\begin{array}{c}0\\ {}\begin{array}{c}\vdots \\ {}0\end{array}\end{array}\end{array}\right],\left[\begin{array}{ccc}{\sigma^2}_{e_1}& & \kern0.5em \\ {}{\sigma}_{e_1{e}_2}& {\sigma^2}_{e_2}& \begin{array}{cc}& \end{array}\\ {}\begin{array}{c}\vdots \\ {}{\sigma}_{e_1{e}_I}\end{array}& \begin{array}{c}\vdots \\ {}{\sigma}_{e_2{e}_I}\end{array}& \begin{array}{c}\begin{array}{cc}\ddots & \end{array}\\ {}\begin{array}{cc}\dots & {\sigma^2}_{e_I}\end{array}\end{array}\end{array}\right]\right).\end{align*}$$
$$\begin{align*}\left[\begin{array}{c}{e}_{1j}\\ {}\begin{array}{c}{e}_{2j}\\ {}\begin{array}{c}\vdots \\ {}{e}_{Ij}\end{array}\end{array}\end{array}\right]\sim MVN\left(\left[\begin{array}{c}0\\ {}\begin{array}{c}0\\ {}\begin{array}{c}\vdots \\ {}0\end{array}\end{array}\end{array}\right],\left[\begin{array}{ccc}{\sigma^2}_{e_1}& & \kern0.5em \\ {}{\sigma}_{e_1{e}_2}& {\sigma^2}_{e_2}& \begin{array}{cc}& \end{array}\\ {}\begin{array}{c}\vdots \\ {}{\sigma}_{e_1{e}_I}\end{array}& \begin{array}{c}\vdots \\ {}{\sigma}_{e_2{e}_I}\end{array}& \begin{array}{c}\begin{array}{cc}\ddots & \end{array}\\ {}\begin{array}{cc}\dots & {\sigma^2}_{e_I}\end{array}\end{array}\end{array}\right]\right).\end{align*}$$
In the main diagonal of the variance–covariance matrix, we find the sampling variance of each effect size, which was calculated following the formula provided by Gleser and OlkinReference Gleser, Olkin, Cooper and Hedges 34 :
 $$\begin{align}{\sigma}_{e_{ij}}^2=\frac{n_1+{n}_2}{n_1{n}_2}+\frac{\delta_{ij}^2}{2\left({n}_1+{n}_2\right)},\end{align}$$
$$\begin{align}{\sigma}_{e_{ij}}^2=\frac{n_1+{n}_2}{n_1{n}_2}+\frac{\delta_{ij}^2}{2\left({n}_1+{n}_2\right)},\end{align}$$
where
 ${n}_1$
and
${n}_1$
and
 ${n}_2$
represent the sample sizes of the experimental and control groups, and
${n}_2$
represent the sample sizes of the experimental and control groups, and
 ${\delta}_{ij}$
refers to the population effect of effect size i within study j. Moreover, covariances between effect sizes (e.g.,
${\delta}_{ij}$
refers to the population effect of effect size i within study j. Moreover, covariances between effect sizes (e.g.,
 ${\sigma}_{e_1{e}_2}$
) are specified outside the main diagonal. For this study, we have assumed that effect sizes reported in the same study referred to different types of outcomes. Therefore, the covariances were computed using the formulas established by Gleser and OlkinReference Gleser, Olkin, Cooper and Hedges
34
for Cohen’s d effect sizes for this scenario:
${\sigma}_{e_1{e}_2}$
) are specified outside the main diagonal. For this study, we have assumed that effect sizes reported in the same study referred to different types of outcomes. Therefore, the covariances were computed using the formulas established by Gleser and OlkinReference Gleser, Olkin, Cooper and Hedges
34
for Cohen’s d effect sizes for this scenario:
 $$\begin{align}{\sigma}_{e_{ij}{e}_{ij\prime }}=\frac{n_1+{n}_2}{n_1{n}_2}{\rho}_{ij ij\prime }+\frac{\delta_{ij}{\delta}_{ij\prime }{\rho}_{ij\; ij\prime}^2}{2\;\left({n}_1+{n}_2\right)}\end{align}$$
$$\begin{align}{\sigma}_{e_{ij}{e}_{ij\prime }}=\frac{n_1+{n}_2}{n_1{n}_2}{\rho}_{ij ij\prime }+\frac{\delta_{ij}{\delta}_{ij\prime }{\rho}_{ij\; ij\prime}^2}{2\;\left({n}_1+{n}_2\right)}\end{align}$$
where
 ${\delta}_{ij}$
and
${\delta}_{ij}$
and
 ${\delta}_{ij\prime }$
refer to the population effects of two different effect sizes reported within study j, and
${\delta}_{ij\prime }$
refer to the population effects of two different effect sizes reported within study j, and
 ${\rho}_{ij\; ij\prime }$
refers to the correlation between outcome variables.
${\rho}_{ij\; ij\prime }$
refers to the correlation between outcome variables.
At Level 2, the study-specific population effects
 ${\beta}_{0j}$
is a function of a study-dummy (moderator) variable
${\beta}_{0j}$
is a function of a study-dummy (moderator) variable
 ${X}_{1j}$
:
${X}_{1j}$
:
 $$\begin{align}{\beta}_{0j}={\gamma}_{00}+{\gamma}_{01}{X}_{1j}+{u}_{0j},\end{align}$$
$$\begin{align}{\beta}_{0j}={\gamma}_{00}+{\gamma}_{01}{X}_{1j}+{u}_{0j},\end{align}$$
where
 ${\gamma}_{00}$
represents the overall effect size for category 0 of the moderator variable
${\gamma}_{00}$
represents the overall effect size for category 0 of the moderator variable
 ${X}_{1j}$
,
${X}_{1j}$
,
 ${\gamma}_{01}$
is the difference between the overall effects from both categories, and
${\gamma}_{01}$
is the difference between the overall effects from both categories, and
 ${\gamma}_{00}+{\gamma}_{01}$
is the overall effect size for category
${\gamma}_{00}+{\gamma}_{01}$
is the overall effect size for category
 ${X}_{1j}$
= 1. The study-specific random effects,
${X}_{1j}$
= 1. The study-specific random effects,
 ${u}_{0j}$
, represent the random deviation of
${u}_{0j}$
, represent the random deviation of
 ${\beta}_{0j}$
from the overall effect size
${\beta}_{0j}$
from the overall effect size
 ${\gamma}_{00}$
due to between-studies variation. The random effect
${\gamma}_{00}$
due to between-studies variation. The random effect
 ${u}_{0j}$
is normally distributed with mean zero and variance
${u}_{0j}$
is normally distributed with mean zero and variance
 ${\sigma}_{u_0}^2$
, which stands for the (residual) between-studies variance around the effect of
${\sigma}_{u_0}^2$
, which stands for the (residual) between-studies variance around the effect of
 ${\gamma}_{00}$
once the effect of
${\gamma}_{00}$
once the effect of
 ${X}_{1j}$
has been taken into account. Note that in this model, it is assumed that outcomes of the same type share a common population effect size.
${X}_{1j}$
has been taken into account. Note that in this model, it is assumed that outcomes of the same type share a common population effect size.
Cohen’s d was not corrected to Hedges’ g, as Lin and AloeReference Lin and Aloe
35
found that using Cohen’s d as an estimator of population effect delta generally leads to less bias in the meta-analytic results than Hedges’ g. Also, following the recommendations of Lin and Aloe,Reference Lin and Aloe
35
the formula to calculate the sampling variance of Cohen’s d was the one in Equation (3) but replacing the population term
 ${\delta}_{ij}^2$
with
${\delta}_{ij}^2$
with
 ${d}_{ij}^2$
. Finally, it should be noted that by generating Cohen’s d directly, the results of this simulation can be generalized to effect sizes that are approximately normally distributed (e.g., Fisher’s Z or log-transformed odds ratio).
${d}_{ij}^2$
. Finally, it should be noted that by generating Cohen’s d directly, the results of this simulation can be generalized to effect sizes that are approximately normally distributed (e.g., Fisher’s Z or log-transformed odds ratio).
4.1.2 Effect size-level moderator
Cohen’s d effect sizes were directly generated from a multivariate two-level model:
 $$\begin{align}{d}_{ij}={\beta}_{0j}{X}_{0 ij}+{\beta}_{1j}{X}_{1 ij}+{e}_{ij},\end{align}$$
$$\begin{align}{d}_{ij}={\beta}_{0j}{X}_{0 ij}+{\beta}_{1j}{X}_{1 ij}+{e}_{ij},\end{align}$$
where
 ${X}_{0 ij}$
and
${X}_{0 ij}$
and
 ${X}_{1 ij}$
are dummy-coded variables indicating the category of the moderator variable to which the effect size pertains (coded as 1), and
${X}_{1 ij}$
are dummy-coded variables indicating the category of the moderator variable to which the effect size pertains (coded as 1), and
 ${e}_{ij}$
is a vector of residuals with I × I variance–covariance matrix. At the second level:
${e}_{ij}$
is a vector of residuals with I × I variance–covariance matrix. At the second level:
 $$\begin{align}\begin{cases}\beta_{0j} = \gamma_{00} + u_{0j} \\\beta_{1j} = \gamma_{10} + u_{1j},\end{cases}\end{align}$$
$$\begin{align}\begin{cases}\beta_{0j} = \gamma_{00} + u_{0j} \\\beta_{1j} = \gamma_{10} + u_{1j},\end{cases}\end{align}$$
where
 ${\gamma}_{00}$
and
${\gamma}_{00}$
and
 ${\gamma}_{10}$
represent, respectively, the overall effect for category 0 and the overall effect for category 1. The study-specific random effects,
${\gamma}_{10}$
represent, respectively, the overall effect for category 0 and the overall effect for category 1. The study-specific random effects,
 ${u}_{0j}$
and
${u}_{0j}$
and
 ${u}_{1j}$
, are assumed to follow a bivariate normal distribution:
${u}_{1j}$
, are assumed to follow a bivariate normal distribution:
 $$\begin{align*}\left[\begin{array}{c}{u}_{0j}\\ {}{u}_{1j}\end{array}\right]\sim MVN\;\left(\left[\begin{array}{c}0\\ {}0\end{array}\right],\left[\begin{array}{cc}{\sigma}_{u_0}^2& \\ {}{\sigma}_{u_0{u}_1}& {\sigma}_{u_1}^2\end{array}\right]\right)\nonumber,\end{align*}$$
$$\begin{align*}\left[\begin{array}{c}{u}_{0j}\\ {}{u}_{1j}\end{array}\right]\sim MVN\;\left(\left[\begin{array}{c}0\\ {}0\end{array}\right],\left[\begin{array}{cc}{\sigma}_{u_0}^2& \\ {}{\sigma}_{u_0{u}_1}& {\sigma}_{u_1}^2\end{array}\right]\right)\nonumber,\end{align*}$$
where the variances
 ${\sigma}_{u_0}^2$
and
${\sigma}_{u_0}^2$
and
 ${\sigma}_{u_1}^2$
stand for the between-studies variances of the population effect sizes
${\sigma}_{u_1}^2$
stand for the between-studies variances of the population effect sizes
 ${\gamma}_{00}$
and of the differences between effects,
${\gamma}_{00}$
and of the differences between effects,
 ${\gamma}_{10}$
, respectively. These between-studies variances were always equal, meaning that the assumption of homoscedasticity was satisfied. Additionally, it is important to note that this model operates under the assumption that differences between categories may vary across studies. This implies that while one study may show no differences between categories, another may indeed reveal variations. We adopt this approach because there is no compelling reason to assume that overall effects within categories of a moderator remain consistent across studies. Similar to how a random-effects model allows the overall effect to randomly vary across studies, the effects within a moderator category can also exhibit variability across studies. In cases where such variation occurs, we must acknowledge that the differences between effects, denoted as
${\gamma}_{10}$
, respectively. These between-studies variances were always equal, meaning that the assumption of homoscedasticity was satisfied. Additionally, it is important to note that this model operates under the assumption that differences between categories may vary across studies. This implies that while one study may show no differences between categories, another may indeed reveal variations. We adopt this approach because there is no compelling reason to assume that overall effects within categories of a moderator remain consistent across studies. Similar to how a random-effects model allows the overall effect to randomly vary across studies, the effects within a moderator category can also exhibit variability across studies. In cases where such variation occurs, we must acknowledge that the differences between effects, denoted as
 ${\gamma}_{10}$
, can also vary across studies.
${\gamma}_{10}$
, can also vary across studies.
The correlation selected to calculate the covariances for between-study residuals (
 ${\sigma}_{u_0{u}_1}$
) was set to 0.4, which is an intermediate value.Reference Fernandez-Castilla, Aloe and Declercq
22
,
Reference Park and Beretvas
28
This correlation was not varied in the present simulation because these two previous studies have found no effect of this factor on simulation results.
${\sigma}_{u_0{u}_1}$
) was set to 0.4, which is an intermediate value.Reference Fernandez-Castilla, Aloe and Declercq
22
,
Reference Park and Beretvas
28
This correlation was not varied in the present simulation because these two previous studies have found no effect of this factor on simulation results.
The difference in overall effects across categories is represented by
 ${\gamma}_{01}$
when the moderator effect is at the study level, and by
${\gamma}_{01}$
when the moderator effect is at the study level, and by
 $\left({\gamma}_{10}-{\gamma}_{00}\right)$
when it operates at the effect size level. To avoid confusion, for the remainder of the article, we will refer to the overall effect of the first category as
$\left({\gamma}_{10}-{\gamma}_{00}\right)$
when it operates at the effect size level. To avoid confusion, for the remainder of the article, we will refer to the overall effect of the first category as
 ${\gamma}_0$
, and to the moderator effect of the second category as
${\gamma}_0$
, and to the moderator effect of the second category as
 ${\gamma}_1$
, regardless of whether it pertains to a study-level or effect size-level characteristic.
${\gamma}_1$
, regardless of whether it pertains to a study-level or effect size-level characteristic.
4.2 Simulation factors
4.2.1 Number of studies (k)
In the review of multilevel meta-analyses carried out by Fernández-Castilla et al.,Reference Fernández-Castilla, Jamshidi and Declercq 36 the Q1, Q2, and Q3 number of studies in multilevel meta-analysis of different fields were around 18, 35, and 53. Previous simulation studies have found that 40 studies are normally enough to get unbiased estimates.Reference López-López, Van den Noortgate, Tanner-Smith, Wilson and Lipsey 9 , Reference Fernandez-Castilla, Aloe and Declercq 22 Therefore, also following the procedure of TiptonReference Tipton 21 and López-López et al.,Reference López-López, Van den Noortgate, Tanner-Smith, Wilson and Lipsey 9 we generated meta-analyses of 20 and 40 studies, corresponding to (approximately) Q1 and Q2.
4.2.2 Number of effect sizes within studies (m)
According to Fernández-Castilla et al.Reference Fernández-Castilla, Jamshidi and Declercq
36
primary studies reporting multiple results rarely include the same number of outcomes, and, on average, they include around 3 effect sizes. Tipton et al.Reference Tipton, Pustejovsky and Ahmadi
25
found that the average number of effect sizes per study was around 4.5 in meta-analysis in the psychology and education areas. These unbalanced distributions of effect sizes across studies were taken into account in the simulation by generating different number of effect sizes across studies. First, the average number of effect sizes per study was set to be 3 or 5 (
 $\overline{m}$
= {3, 5}). Then, a number was extracted from a Poisson distribution as
$\overline{m}$
= {3, 5}). Then, a number was extracted from a Poisson distribution as
 $$\begin{align*}{m}_j\sim \min \left\{1+ Poisson\left(\overline{m}-1\right),\left(\overline{m}\ast 2+1\right)\right\}.\end{align*}$$
$$\begin{align*}{m}_j\sim \min \left\{1+ Poisson\left(\overline{m}-1\right),\left(\overline{m}\ast 2+1\right)\right\}.\end{align*}$$
This approach is similar to the one Joshi et al.Reference Joshi, Pustejovsky and Beretvas
26
used to generate their data. When
 $\overline{m}=3$
, the number of effect sizes per study ranged between 1 and 6, and when
$\overline{m}=3$
, the number of effect sizes per study ranged between 1 and 6, and when
 $\overline{m}=5$
, the number of effect sizes per study ranged between 1 and 9.
$\overline{m}=5$
, the number of effect sizes per study ranged between 1 and 9.
4.2.3
Correlation between effect sizes (
 $\boldsymbol{\rho}$
)
$\boldsymbol{\rho}$
)

Effect sizes from the same study could be moderately (
 $\rho =0$
.4) or largely correlated (
$\rho =0$
.4) or largely correlated (
 $\rho =0$
.8). These values are consistent with those selected in previous simulation studies. For instance, López-López et al.Reference López-López, Van den Noortgate, Tanner-Smith, Wilson and Lipsey
9
chose an average correlation of 0.3 (moderate) or 0.7 (large), whereas Joshi et al.Reference Joshi, Pustejovsky and Beretvas
26
and TiptonReference Tipton
21
chose correlations of 0.5 and 0.8 for moderate and large correlations, respectively. Following the procedure of Joshi et al.,Reference Joshi, Pustejovsky and Beretvas
26
correlations were varied across studies by extracting a correlation value from a beta distribution as follows:
$\rho =0$
.8). These values are consistent with those selected in previous simulation studies. For instance, López-López et al.Reference López-López, Van den Noortgate, Tanner-Smith, Wilson and Lipsey
9
chose an average correlation of 0.3 (moderate) or 0.7 (large), whereas Joshi et al.Reference Joshi, Pustejovsky and Beretvas
26
and TiptonReference Tipton
21
chose correlations of 0.5 and 0.8 for moderate and large correlations, respectively. Following the procedure of Joshi et al.,Reference Joshi, Pustejovsky and Beretvas
26
correlations were varied across studies by extracting a correlation value from a beta distribution as follows:
 $$\begin{align*}{r}_j\sim Beta\left(\rho \upsilon, \left(1-\rho \right)\upsilon \right),\end{align*}$$
$$\begin{align*}{r}_j\sim Beta\left(\rho \upsilon, \left(1-\rho \right)\upsilon \right),\end{align*}$$
where
 $\upsilon$
was always set to 50 to generate moderate heterogeneity across correlations.
$\upsilon$
was always set to 50 to generate moderate heterogeneity across correlations.
4.2.4 Sample size (n)
In the review of multilevel meta-analyses carried out by Fernández-Castilla et al.,Reference Fernández-Castilla, Jamshidi and Declercq 36 the median sample size (n) in primary studies was around 100, with the first quartile being around 35.Footnote 4 As sample sizes tend to vary significantly among primary studies, we generated random numbers from a lognormal distribution, either LnN(3.91, 0.7) or LnN(4.61, 0.7), reproducing the sample sizes observed in the review. When the mean of the lognormal distribution was 3.91, the average total sample size was 45, and this value ranged from approximately 15 to 200. When the mean of the lognormal distribution was 4.61, the average total sample size was 100, and this value approximately ranged from 52 to 500.
4.2.5 Type of moderator variable
The binary moderator variable could explain characteristics of the studies (study-level moderator) or characteristics of the effect sizes within study (effect size-level moderator).
4.2.6 Overall effect of each category
The overall effect for the reference category (
 ${\gamma}_0$
) was always 0, and the difference between categories,
${\gamma}_0$
) was always 0, and the difference between categories,
 ${\gamma}_1$
, could be 0 as well (this condition serves to study Type I error), or 0.10, 0.30, and 0.50 (these conditions serve to study power). These values are similar to those selected in previous simulations; for instance, Rubio-Aparicio et al.Reference Rubio-Aparicio, López-López, Viechtbauer, Marín-Martínez, Botella and Sánchez-Meca
10
generated differences of 0.2, 0.4, and 0.6, whereas Joshi et al.Reference Joshi, Pustejovsky and Beretvas
26
generated differences of 0.1, 0.3, and 0.5. Also, these values represent a realistic range of Cohen’s d indices typically observed in meta-analyses from different fields.Reference Fernández-Castilla, Jamshidi and Declercq
36
Additionally, as described by Cafri et al.Reference Cafri, Kromrey and Brannick
5
according to a review of 81 meta-analysis, the median difference between overall effects of the two categories of a moderator is 0.16 (r = 0.08).
${\gamma}_1$
, could be 0 as well (this condition serves to study Type I error), or 0.10, 0.30, and 0.50 (these conditions serve to study power). These values are similar to those selected in previous simulations; for instance, Rubio-Aparicio et al.Reference Rubio-Aparicio, López-López, Viechtbauer, Marín-Martínez, Botella and Sánchez-Meca
10
generated differences of 0.2, 0.4, and 0.6, whereas Joshi et al.Reference Joshi, Pustejovsky and Beretvas
26
generated differences of 0.1, 0.3, and 0.5. Also, these values represent a realistic range of Cohen’s d indices typically observed in meta-analyses from different fields.Reference Fernández-Castilla, Jamshidi and Declercq
36
Additionally, as described by Cafri et al.Reference Cafri, Kromrey and Brannick
5
according to a review of 81 meta-analysis, the median difference between overall effects of the two categories of a moderator is 0.16 (r = 0.08).
4.2.7 Distribution of effects across the categories of the dummy moderator variable
A key focus of this study was to investigate how an uneven distribution of effect sizes across the categories of the moderator variable impacts parameter estimates, the Type I error rate, and statistical power. Three scenarios were examined: balanced (50%–50%), unbalanced (30%–70%), and very unbalanced (10%–90%) distributions of effect sizes across categories of the binary moderator variable. When the moderator variable was at the study level, entire studies were assigned to one category or the other based on the specified percentages. In contrast, when the moderator was at the effect size level, individual effect sizes within studies were randomly assigned to each category according to the same proportions.
4.2.8
(Residual) between-studies variance (
${\widehat{\boldsymbol{\sigma}}}_{{\boldsymbol{u}}_{\boldsymbol{res}}}^{\mathbf{2}}$
)

To simplify the analysis, we selected two values for between-studies variance representing moderate and high variability: 0.10 for moderate and 0.30 for high variability. These values align with those reported by Fernández-Castilla et al.Reference Fernández-Castilla, Jamshidi and Declercq
36
in multilevel meta-analyses across various fields and match conditions used in previous simulations.Reference López-López, Van den Noortgate, Tanner-Smith, Wilson and Lipsey
9
,
Reference Joshi, Pustejovsky and Beretvas
26
When the moderator variable was at the effect size level, the overall effects for each category could vary across studies (
 ${\sigma}_{u_{0j}}^2$
and
${\sigma}_{u_{0j}}^2$
and
 ${\sigma}_{u_{1j}}^2$
), with both variances set to 0.05 or 0.15 under an assumption of homoskedasticity. The correlation between random study effects was fixed at 0.4, based on prior simulationsReference Fernandez-Castilla, Aloe and Declercq
22
,
Reference Park and Beretvas
28
showing no significant impact of this correlation. We chose this intermediate value as representative of earlier studies. Please note that in the scenario where the moderator variable referred to an effect size-level characteristic, the total variance became slightly smaller, 0.24 and 0.08, respectively, due to the 0.4 correlation between study effects.
${\sigma}_{u_{1j}}^2$
), with both variances set to 0.05 or 0.15 under an assumption of homoskedasticity. The correlation between random study effects was fixed at 0.4, based on prior simulationsReference Fernandez-Castilla, Aloe and Declercq
22
,
Reference Park and Beretvas
28
showing no significant impact of this correlation. We chose this intermediate value as representative of earlier studies. Please note that in the scenario where the moderator variable referred to an effect size-level characteristic, the total variance became slightly smaller, 0.24 and 0.08, respectively, due to the 0.4 correlation between study effects.
All these settings resulted in a total of 768 scenarios, with 1,000 replications conducted for each of them.
4.3 Data analysis
In this section, we outline the statistical techniques that were applied to run the meta-regression models.
4.3.1 Multivariate method
Although this method is not central to the present study, primarily due to the frequent unavailability of the information needed to calculate the covariance among effect sizes within studies, we still find it valuable to explore its performance, as this approach has been increasingly implemented following the approximation of a variance–covariance matrix.Reference Assink and Wibbelink
37
When the moderator variable referred to study-level characteristics, the multivariate model implemented was the one specified in Equations (11) and (14), consistent with the data generation process. In this case, the variance–covariance matrix of the observed effect sizes was approximated using the same correlation value specified during data generation (either 0.4 or 0.8, depending on the simulation condition), with the data function impute_covariance_matrix() from the clubSandwich package.Reference Pustejovsky
38
When the moderator variable referred to effect size-level characteristics, we implemented a multivariate model similar to that specified in Equations (15) and (16), with a simplification applied to Equation 16. Specifically, we removed the term
 ${u}_{1j}$
, implying that the difference between moderator categories was assumed to be constant across studies. In this scenario, the approximate variance–covariance matrix was constructed using the average correlation between effect sizes within studies, which varied depending on whether the effect sizes belonged to the same moderator category. This modified multivariate model was used because, in practice, it is uncommon to specify a model that includes a random effect for the difference between moderator categories. It is also important to note that Assink and WibbelinkReference Assink and Wibbelink
37
proposed a more complex multivariate model with an additional (third) level. The significance of the moderator effect (
${u}_{1j}$
, implying that the difference between moderator categories was assumed to be constant across studies. In this scenario, the approximate variance–covariance matrix was constructed using the average correlation between effect sizes within studies, which varied depending on whether the effect sizes belonged to the same moderator category. This modified multivariate model was used because, in practice, it is uncommon to specify a model that includes a random effect for the difference between moderator categories. It is also important to note that Assink and WibbelinkReference Assink and Wibbelink
37
proposed a more complex multivariate model with an additional (third) level. The significance of the moderator effect (
 ${\unicode{x3b3}}_1$
) was evaluated using a Wald test.
${\unicode{x3b3}}_1$
) was evaluated using a Wald test.
4.3.2 Three-level models
When the moderator variable reflected study-level characteristics, we fitted the three-level model specified in Equations (1)–(3). For moderator variables that represented effect size-level characteristics, two versions of the three-level models were applied. The first corresponds to the model defined in Equations (1), (4), and (5), where the moderator effect is assumed to be constant across studies (a specification commonly used in published meta-analyses). The second model, defined in Equations (1), (4), and (6), allows the moderator effect to vary across studies, which more accurately reflects the data generation process.
In all these models, the statistical significance of the moderator effect
 ${\unicode{x3b3}}_1$
was evaluated using Wald tests (based on Z statistics) with a nominal level of 0.05. LRTs were only used for the traditional three-level model (using Equations (1)–(3) for study-level moderator, and Equations (1), (4), and (5) for effect size-level moderator) by comparing the deviance of the null model with that of the model including the moderator.
${\unicode{x3b3}}_1$
was evaluated using Wald tests (based on Z statistics) with a nominal level of 0.05. LRTs were only used for the traditional three-level model (using Equations (1)–(3) for study-level moderator, and Equations (1), (4), and (5) for effect size-level moderator) by comparing the deviance of the null model with that of the model including the moderator.
However, for the extended three-level model including an additional study-level random effect for the moderator, the significance of the moderator effect was assessed using only Wald tests. This is because comparing the null model to a model that includes both the moderator and its study-level random effect involves estimating three additional parameters: the fixed moderator effect, its variance, and the covariance between study-level random effects. As a result, a significant LRT result could reflect the influence of any of these components, making it difficult to isolate the specific contribution of the moderator effect. The metafor packageReference Viechtbauer 39 was used for these analyses.
Last, within this framework, we also implemented the combination of three-level models and RVE. To do this, we first fit the three-level model specified in Equations (1)–(3) (for study-level characteristics) or the model in Equations (1), (4), and (5) (for effect size-level characteristics). RVE inferential method was then applied to adjust the variance–covariance matrix obtained from the three-level model using a sandwich estimator. Inference in this case was based on t-tests with Satterthwaite-corrected degrees of freedom. These analyses were conducted using the metaforReference Viechtbauer 39 and clubSandwichReference Pustejovsky 38 R packages.
4.3.3 Correlated-effects model with RVE inferential method
This method was implemented using correlated effects, and small-sample corrections were applied as recommended by TiptonReference Tipton
21
and Pustejovsky and Tipton,Reference Pustejovsky and Tipton
23
specifically the bias-reduced linearization adjustment and the Satterthwaite degrees of freedom correction. The t-statistic, along with the corrected degrees of freedom, was used to assess the significance of the regression coefficients (
 $\unicode{x3b1} =0.05)$
. These analyses were conducted using the robumeta package.Reference Fisher, Tipton and Huang
40
$\unicode{x3b1} =0.05)$
. These analyses were conducted using the robumeta package.Reference Fisher, Tipton and Huang
40
Finally, within this framework, we implemented this method followed by the application of CWB. This approach was applied both with and without the bias-reduced linearization adjustment. The method produces an F-statistic to evaluate the pre-specified hypothesis. All analyses were conducted using the wildmeta package R.Reference Joshi, Pustejovsky and Cappelli 41
4.4 Analysis of the simulation results
To identify the simulation conditions associated with different results (e.g., bias, mean squared error, Type I error, and power), we conducted analyses of variance (ANOVAs), where the independent variables were the simulation factors. We considered simulation factors with an eta squared (
 ${\eta}^2$
) value exceeding 0.14 as influential.Reference Cohen
42
${\eta}^2$
) value exceeding 0.14 as influential.Reference Cohen
42
4.4.1 Fixed effects
To assess the accuracy of the overall effects for each category of the binary variable
 $({\gamma}_0$
and
$({\gamma}_0$
and
 ${\gamma}_1$
), we calculated the bias (i.e., the observed estimate minus true value). Relative bias is not used here because the additive nature of the parameter makes absolute bias a more meaningful measure (the relative bias would be overly sensitive to shifts in scale) and because it cannot be calculated when the overall effect of the first category,
${\gamma}_1$
), we calculated the bias (i.e., the observed estimate minus true value). Relative bias is not used here because the additive nature of the parameter makes absolute bias a more meaningful measure (the relative bias would be overly sensitive to shifts in scale) and because it cannot be calculated when the overall effect of the first category,
 ${\gamma}_0$
, is set to zero. Additionally, the mean squared error (MSE) was calculated for the overall effects of each category of the categorical variable.
${\gamma}_0$
, is set to zero. Additionally, the mean squared error (MSE) was calculated for the overall effects of each category of the categorical variable.
4.4.2 Type I error
The Type I error was examined under the condition where the difference between the overall effects (
 ${\gamma}_1$
) was zero. Specifically, we calculated the proportion of iterations in which a significant difference between effects was detected, despite the true difference being zero. Due to simulation error, it is likely that the Type I error is not exactly 0.05 for each combination of conditions. To assess whether the Type I error falls within reasonable bounds given the simulation error, we constructed confidence intervals around the nominal value of
${\gamma}_1$
) was zero. Specifically, we calculated the proportion of iterations in which a significant difference between effects was detected, despite the true difference being zero. Due to simulation error, it is likely that the Type I error is not exactly 0.05 for each combination of conditions. To assess whether the Type I error falls within reasonable bounds given the simulation error, we constructed confidence intervals around the nominal value of
 $\alpha$
using the following formula:
$\alpha$
using the following formula:
 $$\begin{align*}CI=0.05\mp 1.96\,{{{{\bullet}}}}\, \sqrt{\frac{0.05\left(1-0.05\right)}{1000}\;}.\end{align*}$$
$$\begin{align*}CI=0.05\mp 1.96\,{{{{\bullet}}}}\, \sqrt{\frac{0.05\left(1-0.05\right)}{1000}\;}.\end{align*}$$
This resulted in a confidence interval ranging from 0.036 (lower bound) to 0.064 (upper bound).
4.4.3 Power
Statistical power was evaluated in those conditions where the difference between the overall effects of the moderator categories (
 ${\gamma}_1$
) was different from zero. Power was calculated as the percentage of iterations in which the p-value for the difference between effects was below the nominal level of 0.05.
${\gamma}_1$
) was different from zero. Power was calculated as the percentage of iterations in which the p-value for the difference between effects was below the nominal level of 0.05.
5 Results
Across all results, the correlated-effects models with RVE and CWB, both with and without the bias-reduced linearization adjustment, produced identical outcomes. Therefore, we report results for these methods without adjustment.
To describe results for non-convergence rates, fixed-effects bias, and MSE, we present only the results for the multivariate method, the three-level model, and the correlated-effects models with RVE, since the remaining methods (three-level models with RVE and correlated-effects models with RVE and CWB) affect only the inference provided by these methods, not the fixed-effect estimates.
5.1 Study-level moderator
5.1.1 Non-convergence
The three-level model failed to converge in 62 out of 384,000 iterations, whereas the multivariate method failed to converge in only 2 out of 384,000 iterations. In contrast, correlated-effects models with RVE method systematically converged across all conditions and iterations. Non-convergence in the three-level model was most frequent when sample size was large (85.48% of the non-convergence iterations), between-study variance was high (74.19%), the number of studies was small (69.34%), and within-study correlation was low (
 $\rho$
= 0.4, 66%).
$\rho$
= 0.4, 66%).
5.1.2 Bias of the fixed effects
The mean bias of
 ${\gamma}_0$
ranged from −0.032 to 0.021, and the mean bias of
${\gamma}_0$
ranged from −0.032 to 0.021, and the mean bias of
 ${\gamma}_1$
ranged from −0.027 and 0.013, indicating that both parameters were generally underestimated rather than overestimated under certain conditions. When running an ANOVA with the bias of
${\gamma}_1$
ranged from −0.027 and 0.013, indicating that both parameters were generally underestimated rather than overestimated under certain conditions. When running an ANOVA with the bias of
 ${\gamma}_0$
, no condition exhibited an η2
greater than 0.14. Nevertheless, the condition with the higher (though still low) η2
was the distribution of effect sizes, with a higher biased observed in
${\gamma}_0$
, no condition exhibited an η2
greater than 0.14. Nevertheless, the condition with the higher (though still low) η2
was the distribution of effect sizes, with a higher biased observed in
 ${\gamma}_0$
when effect sizes were very unbalanced distributed (mean bias of
${\gamma}_0$
when effect sizes were very unbalanced distributed (mean bias of
 ${\gamma}_0$
in this condition was 0.001). For the parameter
${\gamma}_0$
in this condition was 0.001). For the parameter
 ${\gamma}_1$
, the true value of
${\gamma}_1$
, the true value of
 ${\gamma}_1$
was the factor that most strongly affected its bias. The greater the value of
${\gamma}_1$
was the factor that most strongly affected its bias. The greater the value of
 ${\gamma}_1$
, the greater the underestimation of
${\gamma}_1$
, the greater the underestimation of
 ${\gamma}_1$
(the mean bias when
${\gamma}_1$
(the mean bias when
 ${\gamma}_1$
= 0.5 was −0.008).
${\gamma}_1$
= 0.5 was −0.008).
Figures representing the bias of
 ${\gamma}_0$
and
${\gamma}_0$
and
 ${\gamma}_1$
for each method can be found in the Supplementary Material (Figures S1 and S2, respectively), alongside a spreadsheet with the bias for each combination of conditions (
Study-level_bias and MSE.xlsx
).
${\gamma}_1$
for each method can be found in the Supplementary Material (Figures S1 and S2, respectively), alongside a spreadsheet with the bias for each combination of conditions (
Study-level_bias and MSE.xlsx
).
5.1.3 Mean squared error
To better understand these results, it is important to note that under unbalanced conditions, the category with fewer effect sizes was associated with
 ${\gamma}_0$
. Consequently, under these conditions, fewer effect sizes were available for estimating
${\gamma}_0$
. Consequently, under these conditions, fewer effect sizes were available for estimating
 ${\gamma}_0$
, which explains why MSE was systematically larger for this parameter.
${\gamma}_0$
, which explains why MSE was systematically larger for this parameter.
Both the three-level model and correlated-effects models with RVE led to similar average MSEs for both
 ${\gamma}_0$
(MSE = 0.046) and
${\gamma}_0$
(MSE = 0.046) and
 ${\gamma}_1$
(MSE = 0.014), while the multivariate method led to a slightly smaller MSE (MSE for
${\gamma}_1$
(MSE = 0.014), while the multivariate method led to a slightly smaller MSE (MSE for
 ${\gamma}_0$
= 0.045 and for
${\gamma}_0$
= 0.045 and for
 ${\gamma}_1$
= 0.013). Overall, the ANOVA analyses showed that for
${\gamma}_1$
= 0.013). Overall, the ANOVA analyses showed that for
 ${\gamma}_0$
and
${\gamma}_0$
and
 ${\gamma}_1,$
the MSE was lower when the variance between studies was small (η2 = 0.18 for
${\gamma}_1,$
the MSE was lower when the variance between studies was small (η2 = 0.18 for
 ${\gamma}_0$
and η2 = 0.43 for
${\gamma}_0$
and η2 = 0.43 for
 ${\gamma}_1$
) and the number of studies was large (η2 = 0.12 for
${\gamma}_1$
) and the number of studies was large (η2 = 0.12 for
 ${\gamma}_0$
, η2 = 0.30 for
${\gamma}_0$
, η2 = 0.30 for
 ${\gamma}_1$
; see Table S1 in the Supplementary Material). For all methods, the MSE of
${\gamma}_1$
; see Table S1 in the Supplementary Material). For all methods, the MSE of
 ${\gamma}_0$
was additionally affected by the uneven distribution of effect sizes across subgroups (η2 = 0.45), whereas this factor did not seem to affect the MSE of
${\gamma}_0$
was additionally affected by the uneven distribution of effect sizes across subgroups (η2 = 0.45), whereas this factor did not seem to affect the MSE of
 ${\gamma}_1$
(see Table S1 in the Supplementary Material). In the Supplementary Material, we provide the MSE for each method and combination of conditions (
Study-level_bias and MSE.xlsx
).
${\gamma}_1$
(see Table S1 in the Supplementary Material). In the Supplementary Material, we provide the MSE for each method and combination of conditions (
Study-level_bias and MSE.xlsx
).
5.1.4 Type I error
Table 2 provides the average Type I error rate observed for each method in each category of each simulation condition.
Mean Type I error rate disaggregated by method and simulation conditions

Note: LRT = likelihood ratio test; CE = correlated-effects models; RVE = robust variance estimation; CWB = cluster wild bootstrapping. Values in bold indicate Type I errors outside the confidence interval that accounts for simulation error.
As shown in Table 2, the multivariate method and three-level models (when not combined with RVE) led to slightly inflated Type I error rates, although these rates were mostly within the confidence interval for simulation error. The application of three-level models with RVE, the correlated-effects models with RVE, and correlated-effects models with RVE and CWB resulted in Type I error rates below the nominal level. An ANOVA conducted to determine which simulation conditions were associated with the Type I error indicated that, in addition to the type of method applied (η2 = 0.25), the distribution of effect sizes across categories also affected the Type I error rates (η2 = 0.10).
Figure 1 shows the distribution of Type I error rates by method for different distributions of effect sizes. The multivariate method and three-level models (with both Wald and LRT tests) led to slightly inflated Type I errors under some conditions, especially if effect sizes were very unbalanced distributed across the categories of the moderator variable, whereas the RVE-based methods showed good control of Type I error across most conditions. However, these methods became too conservative when effect sizes were very unevenly distributed across the categories of the moderator (90%–10%), especially three-level models with RVE and the correlated-effects model with RVE.
Type I error distribution across methods, disaggregated by the degree of imbalance in the distribution of effect sizes across the moderator categories.

As the next step, we focused specifically on the Type I error rates observed when applying a multivariate method or a three-level model (using both Wald and LRT tests). The number of studies included in the meta-analysis emerged as the most influential simulation factor for both methods. In multilevel models, the Type I error rate increased to 0.087 when k = 20, but remained within the expected range (0.036–0.064) when the number of studies was increased to 40. In the multivariate method, some inflation in the Type I error rate (up to 0.070) was observed, even with 40 studies, particularly when the sample size was small (n = 45). The Type I error rate disaggregated by each method and combination of conditions can be found in the Supplementary Material ( Study-level_Type I error.xlsx ).
5.1.5 Power
Table 3 provides the average power observed for each method in each category of each simulation condition. Some expected patterns are observed, such as an increase in power with a higher number of studies, a greater difference between categories, a decrease in total variability, and a more balanced distribution of effect sizes across the categories of the moderator. The rest of the simulation factors did not seem to substantially affect the power.
Power disaggregated by the simulated conditions and method

Note: LRT = likelihood ratio test; CE = correlated-effects models; RVE = robust variance estimation; CWB = cluster wild bootstrapping.
In general, the multivariate method and three-level models (using both Wald and LRT tests) exhibited slightly higher power rates. Interestingly, when RVE was applied in combination with three-level models, the power rates were only marginally affected, except in cases where effect sizes were very unevenly distributed across the categories of the moderator variable. This finding is important because it demonstrates that the combination of three-level models and RVE adequately controls Type I error while only minimally affecting power.
The most noticeable difference in power across methods occurs under the “distribution across categories” conditions. On average, when effect sizes were very unevenly distributed, the power rate of RVE-based methods was nearly one-third of that observed with multilevel approaches and with the multivariate method. Overall, the highest power observed for all methods (approximately 0.60) occurred when the difference between the overall effects across categories was large (0.5).
An ANOVA was conducted entering power rates as dependent variable. The simulation factors exerting a stronger effect on power were the difference between categories (η2 = 0.49) and the distribution of effect sizes across categories (η2 = 0.14). The distribution of power rates across these conditions is shown in Figure 2. The average power disaggregated by each method and combination of simulation factors can be found in the Supplementary Material ( Study-level_Power.xlsx ).
Statistical power across methods, disaggregated by the magnitude of differences between categories and the degree of imbalance in effect size distributions across moderator categories.

As shown in Figure 2, when the distribution of effect sizes was balanced across categories and the difference between categories is large (
 ${\gamma}_1$
= 0.5), all methods showed the highest power rates. However, as the distribution of effect sizes became more uneven, power decreased, particularly for the RVE-based methods, even when the difference between categories was substantial. Under these conditions (highly unbalanced effect size distribution across categories and a large difference between categories), multilevel approaches demonstrate higher power but remain insufficient. The lowest power across all methods was observed when the difference between categories was small, regardless of how effect sizes were distributed across categories.
${\gamma}_1$
= 0.5), all methods showed the highest power rates. However, as the distribution of effect sizes became more uneven, power decreased, particularly for the RVE-based methods, even when the difference between categories was substantial. Under these conditions (highly unbalanced effect size distribution across categories and a large difference between categories), multilevel approaches demonstrate higher power but remain insufficient. The lowest power across all methods was observed when the difference between categories was small, regardless of how effect sizes were distributed across categories.
Other interesting results are that correlated-effects models with RVE and CWB only slightly improved power compared to traditional RVE, and that when using three-level models, the Wald and LRT tests showed similar power properties.
5.2 Effect size-level moderator
5.2.1 Non-convergence
Under this scenario, the three-level model did not converge in 161 out of the 384,000 iterations (0.04%), whereas the three-level model that allowed the moderator effect to vary across studies did not converge in 427 out of the 384,000 iterations (0.11%). The multivariate model experienced only a few convergence issues, with 86 non-converging iterations (0.02% of their respective iterations). The correlated-effects models with RVE method always converged.
A separate analysis of dataset characteristics associated with non-convergence rates revealed that, for both the multivariate method and multilevel models (with or without a random effect for the moderator effect), non-convergence was more likely when the number of studies was small (k = 20), effect sizes were highly unbalanced across moderator categories, and the average number of outcomes per study was low (m = 3).
5.2.2 Bias of the fixed effects
The mean bias of
 ${\gamma}_0$
ranged from −0.024 to 0.012, and the mean bias of
${\gamma}_0$
ranged from −0.024 to 0.012, and the mean bias of
 ${\gamma}_1$
ranged from −0.035 and 0.008, indicating that, as with study-level moderators, both parameters were generally underestimated rather than overestimated. The negative bias for
${\gamma}_1$
ranged from −0.035 and 0.008, indicating that, as with study-level moderators, both parameters were generally underestimated rather than overestimated. The negative bias for
 ${\gamma}_1$
was more pronounced than when the moderator variable referred to a study-level characteristic.
${\gamma}_1$
was more pronounced than when the moderator variable referred to a study-level characteristic.
ANOVAs performed on the bias of
 ${\gamma}_0$
and
${\gamma}_0$
and
 ${\gamma}_1$
showed that none of the conditions predicted these biases. Still, the factor that most strongly influenced the bias of
${\gamma}_1$
showed that none of the conditions predicted these biases. Still, the factor that most strongly influenced the bias of
 ${\gamma}_0$
was the type of method used: the largest mean bias for
${\gamma}_0$
was the type of method used: the largest mean bias for
 ${\gamma}_0$
was observed when the multivariate model was implemented (bias = −0.003). In contrast, the factor with the greatest influence on
${\gamma}_0$
was observed when the multivariate model was implemented (bias = −0.003). In contrast, the factor with the greatest influence on
 ${\gamma}_1$
was the true value of
${\gamma}_1$
was the true value of
 ${\gamma}_1$
: as the true value of
${\gamma}_1$
: as the true value of
 ${\gamma}_1$
increased, the bias also became larger in magnitude (mean bias when
${\gamma}_1$
increased, the bias also became larger in magnitude (mean bias when
 ${\gamma}_1=$
0.5 is −0.007).
${\gamma}_1=$
0.5 is −0.007).
Graphs illustrating the bias of
 ${\gamma}_0$
and
${\gamma}_0$
and
 ${\gamma}_1$
for each method are provided in the Supplementary Material (Figures S3 and S4, respectively), along with a spreadsheet detailing the bias and RB for every combination of conditions (Effect size-level_bias and MSE.xlsx).
${\gamma}_1$
for each method are provided in the Supplementary Material (Figures S3 and S4, respectively), along with a spreadsheet detailing the bias and RB for every combination of conditions (Effect size-level_bias and MSE.xlsx).
5.2.3 Mean squared error
The method that led to the highest efficiency when the moderator variable referred to a within-study characteristic was the three-level model allowing the moderator effect to vary across studies (MSE for
 ${\gamma}_0$
= 0.012 and for
${\gamma}_0$
= 0.012 and for
 ${\gamma}_1$
= 0.006). All the other methods led to similar MSEs (MSE for
${\gamma}_1$
= 0.006). All the other methods led to similar MSEs (MSE for
 ${\gamma}_0$
= 0.013 and for
${\gamma}_0$
= 0.013 and for
 ${\gamma}_1$
= 0.006). Results from an ANOVA showed that, similar to the results obtained for study-level moderators, the MSE peaked when the between-studies variance was low (
${\gamma}_1$
= 0.006). Results from an ANOVA showed that, similar to the results obtained for study-level moderators, the MSE peaked when the between-studies variance was low (
 ${\eta}^2$
= 0.17 for
${\eta}^2$
= 0.17 for
 ${\gamma}_0$
and
${\gamma}_0$
and
 ${\eta}^2$
= 0.45 for
${\eta}^2$
= 0.45 for
 ${\gamma}_1)$
, and when the number of studies was large (
${\gamma}_1)$
, and when the number of studies was large (
 ${\eta}^2$
= 0.16 for
${\eta}^2$
= 0.16 for
 ${\gamma}_0$
and
${\gamma}_0$
and
 ${\eta}^2$
= 0.39 for
${\eta}^2$
= 0.39 for
 ${\gamma}_1$
, see Table S1 in the Supplementary Material), and the MSE of
${\gamma}_1$
, see Table S1 in the Supplementary Material), and the MSE of
 ${\gamma}_0$
increased in conditions where effect sizes were unbalanced distributed across the categories of the moderator (
${\gamma}_0$
increased in conditions where effect sizes were unbalanced distributed across the categories of the moderator (
 ${\eta}^2$
= 0.34), whereas this factor did not affect MSE of
${\eta}^2$
= 0.34), whereas this factor did not affect MSE of
 ${\gamma}_1.$
${\gamma}_1.$
5.2.4 Type I error
Table 4 provides the average Type I error for each method and condition.
Average Type I error rates disaggregated by method and simulated conditions

Note: LRT = likelihood ratio test; CE = correlated-effects models; RVE = robust variance estimation; CWB = cluster wild bootstrapping. Values in bold indicate Type I errors outside the confidence interval that accounts for simulation error.
As shown, employing a three-level or a multivariate model assuming a common moderator effect across studies resulted in severely inflated Type I errors. This pattern was observed across all combinations of conditions when the categorical moderator described an effect size-level characteristic. The three-level model allowing the moderator effect to vary across studies led to much lower Type I error rates, though it remained overly liberal, especially under certain conditions.
To examine the factors influencing Type I error when the three-level model allowed the moderator effect to vary across studies, we isolated these results and conducted an ANOVA, using Type I error rates as the dependent variable and the simulation factors as independent variables. The distribution of effect sizes across the categories of the moderator variable (
 ${\eta}^2=$
0.33) and the number of studies (
${\eta}^2=$
0.33) and the number of studies (
 ${\eta}^2=$
0.13) were the most influential factors. When the number of studies was large (k = 40) and distribution of effects was even (50%–50%), the average Type I error was close to the nominal level (0.064). However, when the number of studies was small (k = 20) and the distribution of effects was very uneven (10%–90%), the Type I error rate was especially inflated (0.119).
${\eta}^2=$
0.13) were the most influential factors. When the number of studies was large (k = 40) and distribution of effects was even (50%–50%), the average Type I error was close to the nominal level (0.064). However, when the number of studies was small (k = 20) and the distribution of effects was very uneven (10%–90%), the Type I error rate was especially inflated (0.119).
Another important result is that three-level models with RVE led to average Type I errors that were practically at nominal level. The correlated-effects models with RVE, whether the traditional form or with CWB, resulted in Type I errors close to 0.05 and within the established confidence intervals across all 384 combinations of conditions. This indicates that implementing either the traditional RVE method or the CWB variant ensures adequate control of Type I error.
Table 4 shows that no simulation factor seemed to affect the Type I error of RVE-based approaches. However, the amount of variability among effect sizes did affect the Type I error of multilevel-based approaches: the larger the variability, the higher the Type I error. Other factors, including the distribution of effect sizes across the moderator categories, did not seem to influence the Type I error when the moderator variable referred to an effect size-level variable (see Figure S5 in the Supplementary Material). The Type I error rate disaggregated by each method and combination of conditions can be found in the Supplementary Material ( Effect size-level_Type I error.xlsx ).
5.2.5 Power
The mean power, segmented by method and simulation condition, is presented in Table 5. In this analysis, we excluded the power results from the three-level model assuming a constant moderator effect across studies, as well as from the multivariate method, due to the inflated Type I error rates observed in these models.
Mean power segmented by method and simulation condition

Note: LRT = likelihood ratio test; CE = correlated-effects models; RVE = Robust Variance Estimation method; CWB = Cluster wild bootstrapping.
Several anticipated trends are noted, including an increase in power with a greater number of studies, a larger difference between categories, reduced total variability, and a more balanced distribution of effect sizes across the moderator categories. Other factors, such as the correlation between outcome variables, did not appear to have a significant impact on power rates.
The power to detect an effect of an effect size-level variable was generally higher than the power to detect a study-level variable, often reaching relatively higher values across methods when the difference between categories was substantial (γ1 = 0.50). Among the methods, the three-level model that accounts for variability in the moderator effect across studies demonstrated the highest power rates. This was followed by the three-level model with RVE, which showed slightly greater power than both the correlated-effects models with RVE and with RVE and CWB approaches, while still adequately controlling for false positives.
Another important result is that RVE-based approaches were less affected by the uneven distribution of effect sizes across the moderator categories for effect size-level moderators (remember that when the characteristic was at the study level, the mean power for RVE-based methods was lower than 0.13, see Table 3). The ANOVA conducted on power rates revealed that the difference between categories was the most important factor (η2 = 0.63), with no other variables yielding substantial eta squared values (see Figure S6 in the Supplementary Material). The mean power disaggregated by each method and combination of conditions can be found in the Supplementary Material ( Effect size-level_Power.xlsx ).
6 Discussion
This study aimed to examine the Type I error rates and statistical power of methods available for conducting meta-regression with binary moderators in the presence of dependent effect sizes. In the following paragraphs, we summarize the key findings and provide practical recommendations for applied meta-analysts.
Regarding the moderator effect estimates, all methods generally performed well, although each showed a slight negative bias under certain conditions, specifically when the true effect was large and the effect sizes were very unbalanced distributed across the categories of the moderator. This latter condition (effect size distribution) also substantially reduced estimation efficiency (as reflected by the MSE), especially when the moderator corresponded to a study-level characteristic.
Perhaps the most relevant finding of this article is that using three-level models alone is not sufficient to ensure adequate control of Type I error, especially when the moderator variable represents a characteristic at the effect size level. Therefore, moving forward, if three-level models are used for meta-regression in meta-analyses, they should always be accompanied by RVE. This finding aligns with results reported by Fernández-Castilla and colleagues,Reference Fernandez-Castilla, Aloe and Declercq 22 where standard errors were significantly underestimated when a three-level model was applied without accounting for between-study variability in the moderator effect, which directly affected the Type I error. However, after the application of RVE, the Type I error was generally at the nominal level due to the small-sample corrections. This result is also consistent with the argument presented by Pustejovsky and TiptonReference Pustejovsky and Tipton 24 that RVE should not be viewed as a distinct method for meta-analysis, but rather as “a technique for guarding against model mis-specification” (p. 427).
In this simulation study, we considered a scenario in which the moderator effect, defined by a within-study (effect size level) characteristic, varied across studies. This assumption helps explain why the traditional three-level model, which does not account for between-study variability in the moderator effect, produced inflated Type I error rates. In this mis-specified model, the between-study variance is likely underestimated because the variability in the moderator effect is not incorporated. This underestimated variance is then used to calculate the standard errors of the fixed effects, resulting in artificially small standard errors and, consequently, an increased risk of detecting false positives.
While the extent to which within-study moderator effects vary across studies is not well established, it is reasonable to expect such variability. Just as random-effects models are widely used based on the assumption that studies originate from different populations, there is little justification for assuming that the effect of a within-study moderator (e.g., the difference between two categories) remains constant across all studies. An alternative and more complex specification of the three-level model, which accounts for between-study variability in the moderator effect, is possible and appears to provide better control of Type I error. However, some inflation remains, particularly when the number of studies is small and effect sizes are evenly distributed across the moderator categories. This model also shows higher statistical power to detect an effect compared to RVE-based approaches. Unfortunately, this study did not explore whether applying RVE to this more complex model would have effectively controlled Type I error while preserving statistical power. Although Fernández-Castilla et al.Reference Fernandez-Castilla, Aloe and Declercq 22 showed that applying RVE to this type of model successfully reduced Type I error to nominal levels, further research is needed to assess its impact on power. If an applied researcher wishes to use this more complex three-level model, we recommend first conducting a likelihood ratio test to determine whether a model that allows the moderator effect to vary across studies provides a better fit than the traditional three-level meta-regression model.
The second most relevant result of this investigation is that, either if the moderator refers to a study or to an effect size characteristic, the method showing the best tradeoff between Type I error and power is the combination of three-level models and RVE. Therefore, this is the approach that we recommend when performing meta-regression with a categorical moderator, keeping in mind that when effect sizes are very unevenly distributed across the categories of the moderator, the power to detect an effect reduces substantially. In this regard, it is relevant to emphasize the importance of conducting power analyses prior to performing moderator analyses. Recently, a study developed power approximations for methods that account for the presence of dependent effect sizes within studies,Reference Vembye, Pustejovsky and Pigott 43 , Reference Vembye, Pustejovsky and Pigott 44 extending those proposed by Hedges and Pigott.Reference Hedges and Pigott 7 It is anticipated that power analyses for meta-regressions involving dependent effect sizes will soon be available, allowing meta-analysts to quantify in advance the probability of detecting the smallest effect size of interest.Reference Anvari and Lakens 45
A third important result is that all RVE-based methods (correlated-effects models with RVE, and with RVE and CWB, and three-level models with RVE) effectively controlled Type I error across most combinations of conditions, regardless of whether the moderator pertained to a study or to an effect size-level characteristic. In contrast, three-level model approaches often led to inflated Type I error rates. Furthermore, when using RVE-based methods, the researcher does not need to worry about model specification (e.g., whether a moderator effect at the effect size level varies across studies). Additionally, the correlated-effects models with RVE and with RVE and CWB exhibited better convergence rates than multilevel and multivariate approaches, which aligns with the results observed by Park and Beretvas.Reference Park and Beretvas 28 However, this strong control of Type I error comes at the cost of power, which is lower for these methods compared to multilevel approaches. Additionally, correlated-effects models with CWB demonstrated higher power compared to the traditional application of RVE (with small-sample corrections), which is consistent with the findings of Joshi et al.Reference Joshi, Pustejovsky and Beretvas 26 However, the gain in power was relatively modest. Even so, it is important to note that Joshi et al.Reference Joshi, Pustejovsky and Beretvas 26 demonstrated that power gains with CWB are most significant for hypothesis tests involving multiple contrast hypotheses, that is, when analyzing categorical variables with more than two categories. Therefore, our results cannot be directly compared to those reported in their study.
A fourth finding is that the performance of these methods, in terms of Type I error and statistical power, varied depending on whether the moderator was a study-level or effect size-level characteristic. All methods that effectively controlled Type I error also demonstrated adequate power when the binary moderator referred to an effect size-level characteristic and the difference between categories was large. However, when the moderator represented a study-level characteristic, all methods showed lower power to detect an effect if the differences between overall effects across categories were small or moderate. Given that the average difference between categories is typically quite small (0.16, according to Cafri et al.Reference Cafri, Kromrey and Brannick 5 ), our study illustrates how unlikely it is for any method to detect such a difference. This result should also caution researchers about using meta-regression models to analyze study-level variables under unfavorable conditions (e.g., small differences between categories, a small number of studies, or highly unbalanced distributions of effect sizes).
When the difference between the study-level moderator categories was large, all methods showed improved power, except when effect sizes were highly unbalanced across moderator categories. This finding is important, because such imbalances are common in meta-analyses. Our study demonstrates that, under these conditions, the probability of detecting a true moderator effect remains lower across all methods when the moderator is at the study level. This reduction in power, particularly when effect sizes are unevenly distributed across moderator categories, was also observed by Cuijpers et al.Reference Cuijpers, Griffin and Furukawa 6 in simpler scenarios (i.e., when each study contributes only one effect size), and by TiptonReference Tipton 21 for correlated-effects models with RVE and small-sample corrections. In this situation (i.e., high imbalance and study-level covariate), conducting power analyses becomes even more important, as performing meta-regression with any method may not be meaningful given the expected low statistical power.
Last, it is important to examine the inflated Type I error rates produced by the multivariate method when the moderator variable refers to an effect size-level characteristic. The main reason for this inflation is the same as that observed in the traditional three-level model: The specification of the multivariate model did not align with the data-generating process; specifically, the applied multivariate model fails to account for between-study variability in the moderator effect, which ultimately results in underestimated standard errors. Recent proposals for applying the multivariate methodReference Assink and Wibbelink 37 suggest including an additional random effect (i.e., fitting a multivariate three-level model) to account not only for the dependency among effect sizes arising from shared samples but also for the clustering of effect sizes within the same study. Incorporating this extra random effect would likely have improved the performance of the multivariate method, as well as the combination with the RVE, which was not examined in the present study.
Another interesting result is that the performance of three-level models was very similar either using Wald test or LRT, despite previous studies found that LRTs had more power to detect an effect for a continuous moderator.Reference López-López, Van den Noortgate, Tanner-Smith, Wilson and Lipsey 9
This simulation study is not without limitations. First, we examined only a subset of models commonly used in practice. Additional model specifications could have been considered, for instance, a multivariate three-level model, a version incorporating a random effect for the moderator, versions of both models combined with the RVE, or versions of both models combined with CWB. Second, we did not include a simulation condition in which the moderator effect was constant across studies or where the between-study variance differed by category (i.e., heteroscedastic variances). Last, unlike studies by Pustejovsky and TiptonReference Pustejovsky and Tipton 23 or Joshi et al.,Reference Joshi, Pustejovsky and Beretvas 26 we did not explore more complex scenarios involving categorical moderators with more than two categories. Future research should investigate the power and Type I error properties of omnibus F-tests for comparing more than two groups, as well as the performance of multiple comparison corrections, such as Bonferroni or Tukey adjustments.
Supplementary material
To view supplementary material for this article, please visit http://doi.org/10.1017/rsm.2026.10092.
Competing interest statement
The authors declare that no competing interests exist.
Author contributions
Conceptualization: B.F.-C., M.R.-A.; Data curation: J.A.L.-L.; Formal analysis: J.A.L.-L., M.R.-A.; Methodology: B.F.-C., J.A.L.-L., M.R.-A.; Software: B.F.-C., J.A.L.-L.; Writing—original draft: B.F.-C.; Writing—review and editing: J.A.L.-L., M.R.-A.
Data availability statement
The code to run the simulation studies, the supplementary material, and some numerical results are available at https://osf.io/czwtp/overview.
Funding statement
This research has been supported by the University of Remote Teaching Education (Universidad Nacional de Educación a Distancia) and Banco Santander through Grant 2023-PUNED-0045 for Young Researchers, and also by the Region of Murcia (Spain) through the Regional Program for the Promotion of Scientific and Technical Research of Excellence (Action Plan 2022) of the Seneca Foundation – Science and Technology Agency of the Region of Murcia (Grant No. 22064/PI/22).
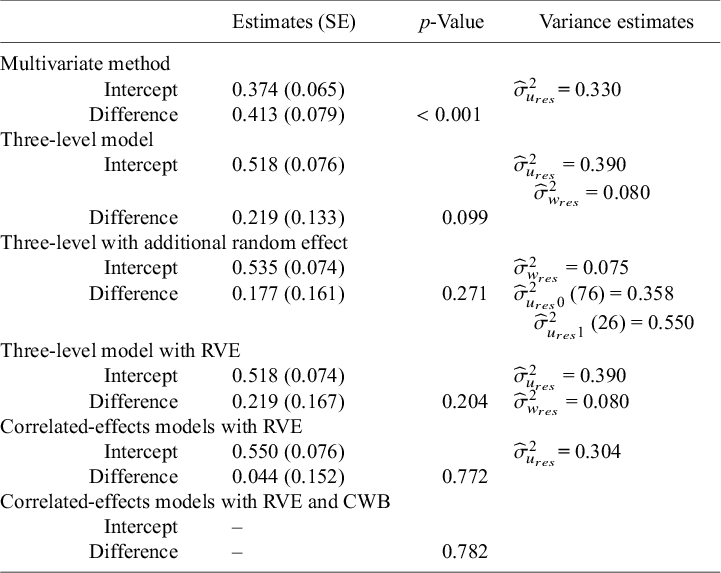
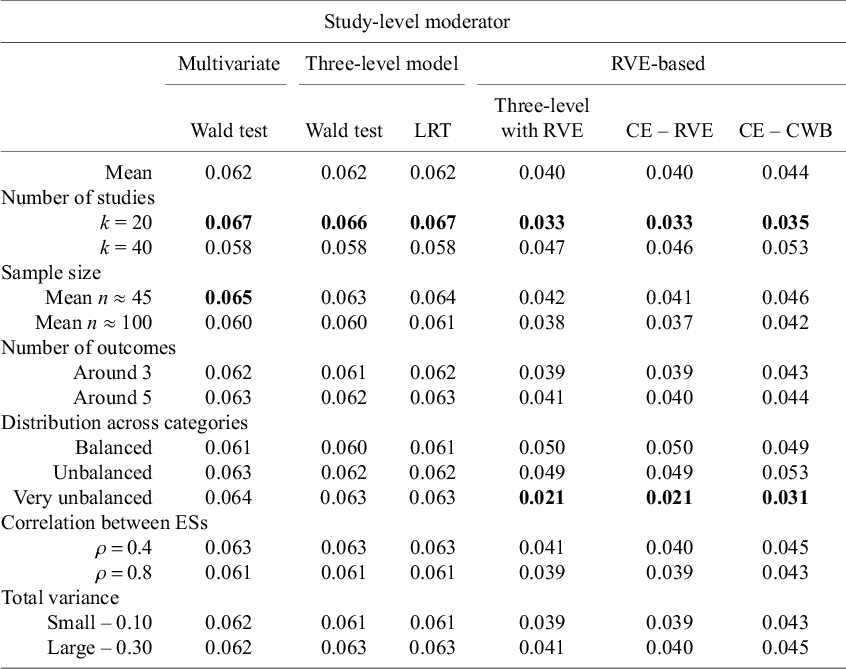

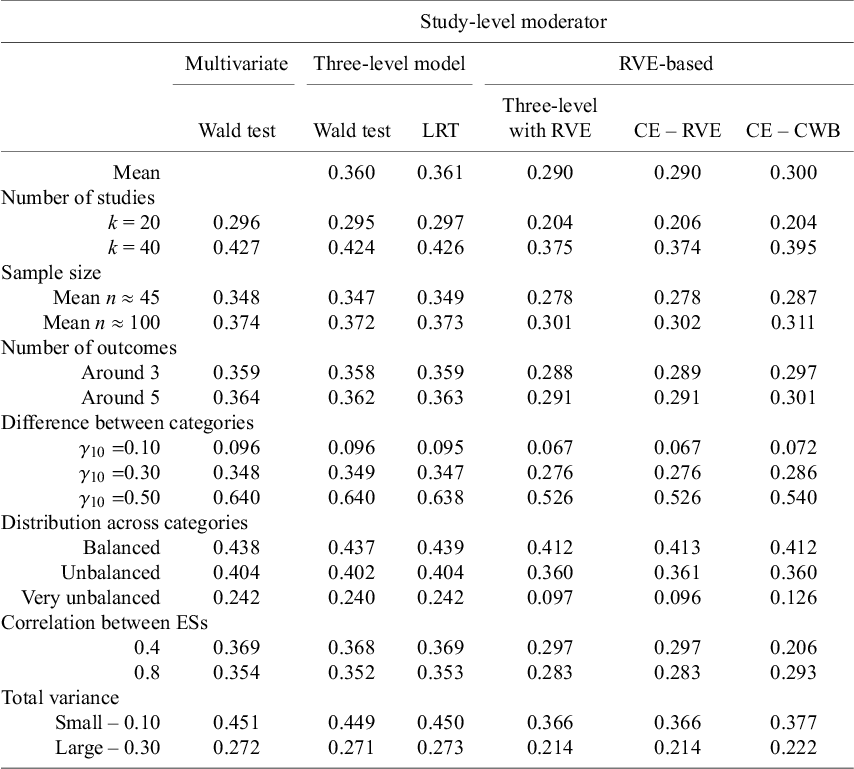

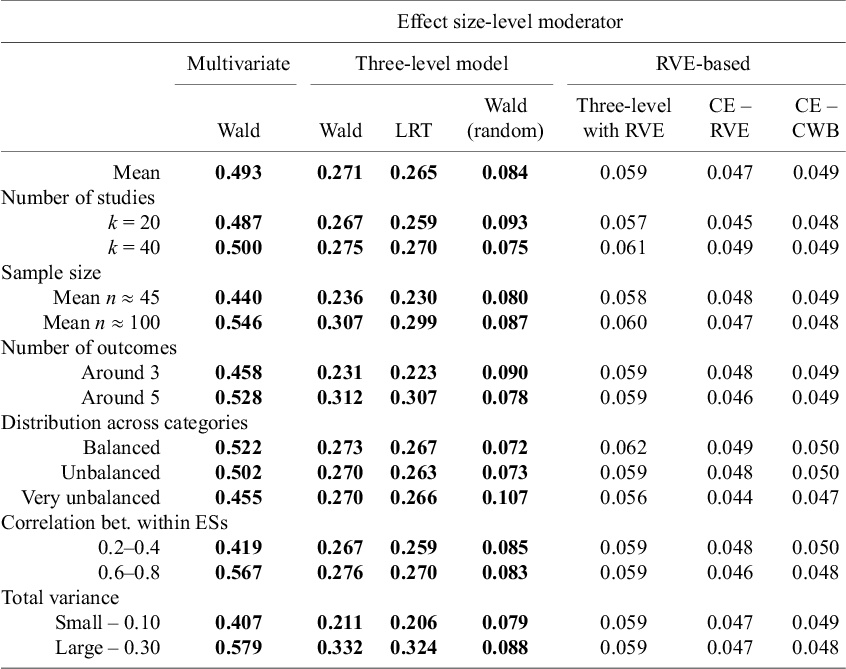
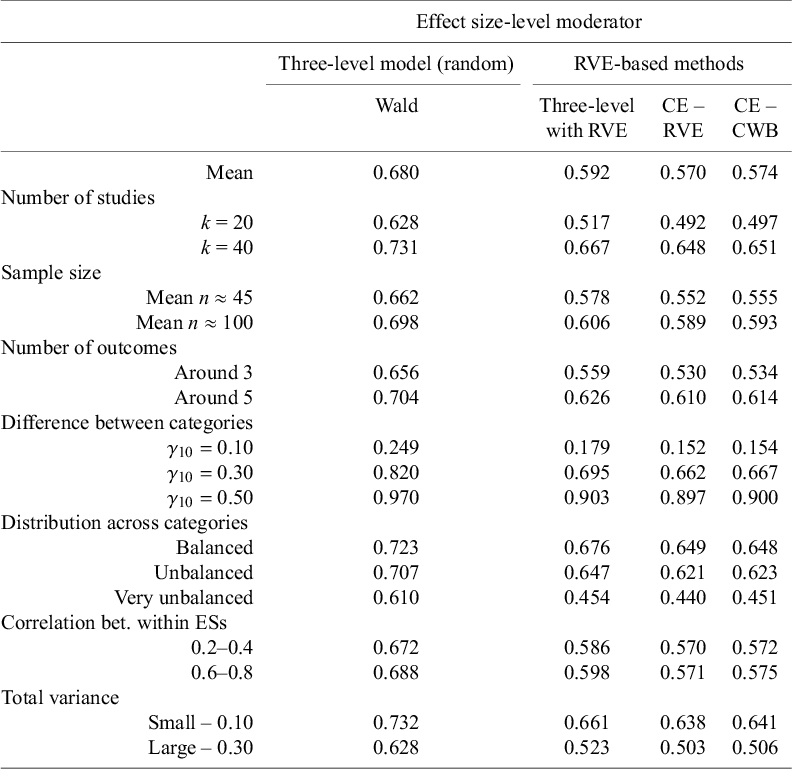



 Open access
Open access