


Highlights
What is already known?
-
• Network meta-analysis extends conventional pairwise meta-analysis by simultaneously synthesizing multiple interventions in a single integrated analysis.
-
• A significant challenge in network meta-analysis is the lack of reported within-study correlations among treatment comparisons in published studies.
What is new?
-
• We propose a new method for network meta-analysis that ensures valid statistical inference without the need for knowledge of within-study correlations.
-
• The proposed method employs a composite likelihood and a sandwich-type robust variance estimator, offering a computationally efficient and scalable solution, particularly for network meta-analysis involving a large number of treatments and studies.
Potential impact for Research Synthesis Methods readers
-
• The proposed method can be easily applied to any univariate network meta-analysis project without requiring knowledge of within-study correlations among treatment comparisons.
1 Introduction
Meta-analysis is a widely used tool in systematic reviews for combining and contrasting multiple studies to obtain overall estimates of the relative effects in the target population.Reference Higgins, Thompson and Spiegelhalter 1 , Reference Borenstein, Hedges, Higgins and Rothstein 2 The methodology of pairwise meta-analysis, which focuses solely on comparing an intervention with a reference (e.g., control or placebo), has been well developed.Reference DerSimonian and Laird 3 , Reference Egger, Smith and Altman 4 For many medical conditions, there are often more than two interventions of interest. In such situations, performing isolated pairwise meta-analysis might neither adequately represent the comprehensive landscape of interventions nor guide the selection of optimal treatment to maximize patient benefits.Reference Salanti 5 , Reference Dias and Caldwell 6 Furthermore, it is often unrealistic to anticipate that there will be at least a head-to-head trial comparing any two interventions of interest.
Network meta-analysis (NMA), coined by Lumley back in 2002,Reference Lumley 7 also known as multiple treatment meta-analysis or mixed treatment comparison, is a state-of-the-science technique for making inferences about multiple treatments. This approach enables the comparison of diverse treatment subsets across various trials. A notable application of NMA is the comparison of treatment options for depression conducted by Cipriani and his colleagues,Reference Cipriani, Furukawa and Salanti 8 which provided a comprehensive summary of the relative efficacy and safety of 21 antidepressant drugs based on all available studies to date. Their insights have the potential to influence clinical practices, impacting millions of individuals who suffer from depression globally. Essentially, the rationale of NMA is to expand pairwise meta-analysis to simultaneously compare multiple treatments and produce consistent estimates of relative treatment effects by synthesizing both direct and indirect clinical evidence in a single integrated analysis.Reference Dias and Caldwell 6
Over the last two decades, a plethora of methodological developments in NMA has emerged, mostly focusing on meta-regression and Bayesian hierarchical models, among others.Reference Salanti, Dias and Welton 9 – Reference Jackson, Law and Barrett 12 For instance, the estimation of indirect evidence in NMAs was first derived through a meta-regression model,Reference Lumley 7 , Reference Salanti, Higgins, Ades and Ioannidis 13 wherein various treatment comparisons were treated as covariates in a model. Yet, such an approach can be challenging to estimate between-study variance, especially for sparse networks, so that the between-study heterogeneity variance is often assumed to be common across all treatment comparisons in a network.Reference Lumley 7 , Reference Salanti, Higgins, Ades and Ioannidis 13 , Reference Higgins and Whitehead 14 On the other hand, the assumption of common between-study heterogeneity variance can lead to inaccurate estimates.Reference Brignardello-Petersen, Murad and Walter 15 A shift toward the Bayesian hierarchical model, pioneered by Lu and his colleagues,Reference Lu and Ades 16 , Reference Lu and Ades 17 has received significant interest. Their subsequent workReference Lu and Ades 18 further discussed how the consistency equations imposed restrictions on between-study heterogeneity of each treatment comparison and used the spherical parameterization based on Cholesky decomposition to implement the constraints.
In addition to the contrast-based NMA (CB-NMA), which focuses on the (weighted) average of study-specific relative effects by assuming fixed study-specific intercepts, arm-based NMA (AB-NMA) models assess study-specific absolute effects and assume random intercepts. This offers greater flexibility in estimands, including both population-averaged absolute and relative effects.Reference Lin, Zhang, Hodges and Chu 19 – Reference Wang, Lin, Murray, Hodges and Chu 23 Alternatively, NMAs can be conceptualized as a multivariate meta-analysis.Reference White, Barrett, Jackson and Higgins 24 Other existing models for implementing NMAs include electrical networks and graph-theoretical methodsReference Rücker 25 , Reference Rücker and Schwarzer 26 under fixed-effects or random-effects models. In addition to the classical framework of synthesizing point estimates, a novel confidence distribution framework, based on a sample-dependent distribution function, has been proposed.Reference Yang, Liu, Liu, Xie and Hoaglin 27
Despite the popularity of NMAs, an important challenge has not been fully addressed: the unknown or unreported within-study correlations. Specifically, estimates of contrasts between each pair of treatment comparisons are correlated within a multi-arm study when these contrasts involve a common comparator. On the other hand, within-study correlations are rarely reported in published trials.Reference Riley 28 When conducting an NMA, ignoring within-study correlations can lead to biased estimates of relative treatment effects; particularly, these estimates were also found to have increased mean-square errors and standard errors.Reference Riley 28 , Reference Chen, Hong and Riley 29
When the impact of within-study correlations is non-ignorable, several methods have been proposed and used to obtain estimates of within-study correlations. First, the availability of individual participant-level data allows to compute the within-study correlations directly between treatment comparisons in each trial;Reference Riley, Lambert and Staessen 30 however, it is uncommon in meta-analysis to have individual participant-level data for all trials. Study investigators are often unable to provide information about within-study correlations even if we make requests directly.Reference Jackson, Riley and White 31 Second, an alternative method, known as the Pearson correlation method, proposed by Kirkham et al.,Reference Kirkham, Riley and Williamson 32 can be implemented in multivariate meta-analysis. Third, Riley et al.Reference Riley, Thompson and Abrams 33 proposed a single correlation parameter to capture both within-study and between-study correlations in the setting of multivariate meta-analysis. As pointed out by Riley et al.,Reference Riley 28 the impact of within-study correlations is relative to the magnitude of between-study variation. In other words, when total variation in estimated effect sizes across studies, as the sum of within-study and between-study covariance, is dominated by within-study variation, the impact of within-study correlations can be substantial. Ignoring the unknown within-study correlations can lead to misleading results.Reference Riley, Thompson and Abrams 33 Other methods, such as Bayesian approaches,Reference Wei and Higgins 34 have also been proposed.
Even though the within-study correlations can be estimated by the abovementioned methods, each of them requires additional assumptions and constraints, along with high computational complexity, to ensure that the estimated within-study variance–covariance matrices are valid and positive definite, particularly for Bayesian methods using Markov chain Monte Carlo algorithms. One of the existing methods to resolve such an issue is to restrict the range of correlation coefficients in each study from a truncated prior distribution so that the positive definiteness of the variance–covariance matrix is guaranteed.Reference Efthimiou, Mavridis, Riley, Cipriani and Salanti 35 Other alternatives, such as Cholesky parameterization and spherical decomposition,Reference Wei and Higgins 36 have been employed to ensure positive-definite variance–covariance matrices for meta-analysis and NMA under a Bayesian framework. These methods, however, may be more difficult to implement in NMAs as the number of studies and treatments in a network grows.
To overcome the aforementioned challenges, we propose a new method without imposing any additional assumptions beyond those in a standard NMA. Compared to the conventional approach implementing NMAs with the standard full likelihood, our proposed method does not require knowledge of the typically unreported within-study correlations among treatment comparisons. Using composite likelihoodReference Lindsay 37 , Reference Varin, Reid and Firth 38 and the finite-sample corrected variance estimator,Reference Pustejovsky 39 , Reference Pustejovsky and Tipton 40 our proposed method can lead to valid effect size estimates with coverage probabilities close to the nominal level. We also derived the corresponding algorithm which is computationally efficient and scalable to a large number of treatments in NMAs. Unlike the state-of-the-art methods, whose computational time increases exponentially with respect to the number of treatments and studies, the computational time of our algorithm increases linearly with the number of treatments and remains nearly invariant with respect to the number of studies. Further, our algorithm avoids the issue of singular covariance estimates, which is a known practical issue when conducting multivariate meta-analysis or NMA.Reference Chen, Hong and Riley 29 , Reference Jackson, Riley and White 31 , Reference Chen, Liu, Ning, Cormier and Chu 41 – Reference Ma, Lian, Chu, Ibrahim and Chen 44
The rest of the article is organized as follows. In Section 2, we give an overview of the two motivating examples, namely, an NMA comparing interventions for primary open-angle glaucoma, and an NMA comparing treatments for chronic prostatitis and chronic pelvic pain syndrome. In Section 3, we formulate the proposed method and introduce a treatment ranking procedure, while in Section 4, we describe a series of simulation studies to illustrate the limitations of conventional NMA models, and to examine the statistical properties of the proposed method. In Section 5, we present the applications of the proposed method to the two motivating examples. We conclude with a discussion and key messages in Section 6.
2 Two motivating examples
2.1 Comparison of interventions for primary open-angle glaucoma
Li et al.Reference Li, Lindsley and Rouse 45 and Wang et al.Reference Wang, Rouse and Marks-Anglin 46 conducted an NMA to compare all first-line treatments for primary open-angle glaucoma or ocular hypertension. Glaucoma is a disease of the optic nerve characterized by optic nerve head changes and associated visual field defects.Reference Boland, Ervin and Friedman 47 This NMA consisted of 125 trials comparing 14 active drugs and a placebo in subjects with primary open-angle glaucoma or ocular hypertension. The studies were collected from 1983 to 2016 through the Cochrane Register of Controlled Trials, Drugs@FDA, and ClinicalTrials.gov;Reference Wang, Rouse and Marks-Anglin 46 a total of 22,656 participants were included in these studies.
Figure 1(a) visualizes the data structure. Specifically, the 14 active drugs were divided into four major drug classes, including
 $\alpha $
-2 adrenergic agonists,
$\alpha $
-2 adrenergic agonists,
 $\beta $
-blockers, carbonic anhydrase inhibitors, and prostaglandin analogs. This network consisted of 114 two-arm studies, 10 three-arm studies, and 1 four-arm study. The primary outcome of interest was the difference in mean increased intraocular pressure (IOP) measured by any method at 3 months in continuous millimeters of mercury (mmHg). The original NMA analysisReference Li, Lindsley and Rouse
45
employed a Bayesian hierarchical model with the Markov chain Monte Carlo technique.Reference Lu and Ades
16
,
Reference Lu and Ades
17
Their analysis focused on modeling the between-study variance–covariance matrix, assuming either a homogeneous or heterogeneous structure, rather than the within-study variance–covariance matrix. A ranking of treatments was produced through the surface under the cumulative ranking curve.Reference Salanti, Ades and Ioannidis
48
The study found that all active drugs were clinically effective in reducing IOP at 3 months compared with placebo, with bimatoprost, latanoprost, and travoprost ranked as the first, second, and third most efficacious drugs, respectively, in lowering IOP.
$\beta $
-blockers, carbonic anhydrase inhibitors, and prostaglandin analogs. This network consisted of 114 two-arm studies, 10 three-arm studies, and 1 four-arm study. The primary outcome of interest was the difference in mean increased intraocular pressure (IOP) measured by any method at 3 months in continuous millimeters of mercury (mmHg). The original NMA analysisReference Li, Lindsley and Rouse
45
employed a Bayesian hierarchical model with the Markov chain Monte Carlo technique.Reference Lu and Ades
16
,
Reference Lu and Ades
17
Their analysis focused on modeling the between-study variance–covariance matrix, assuming either a homogeneous or heterogeneous structure, rather than the within-study variance–covariance matrix. A ranking of treatments was produced through the surface under the cumulative ranking curve.Reference Salanti, Ades and Ioannidis
48
The study found that all active drugs were clinically effective in reducing IOP at 3 months compared with placebo, with bimatoprost, latanoprost, and travoprost ranked as the first, second, and third most efficacious drugs, respectively, in lowering IOP.
Illustration of evidence network diagrams. The size of each node is proportional to the number of participants assigned to each treatment. Solid lines represent direct comparisons between treatments in trials, with line thickness proportional to the number of trials directly comparing each pair of treatments.
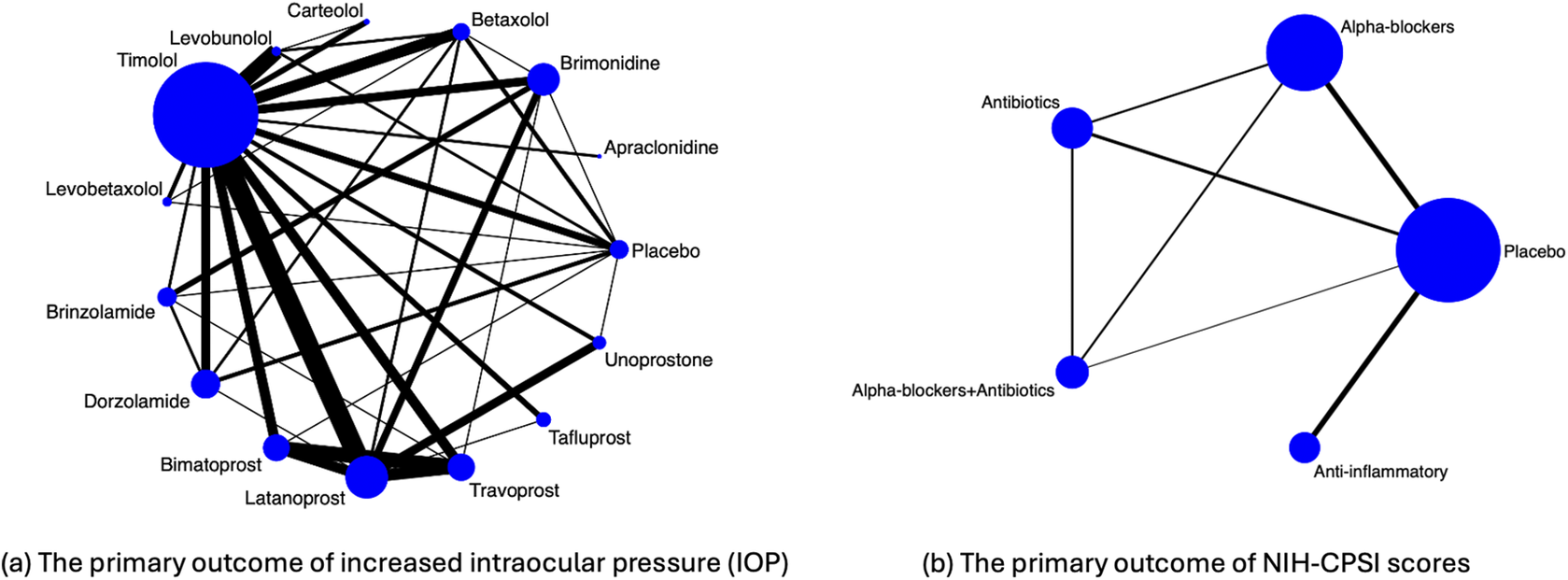
As described in the Introduction section, an important limitation of this motivating example is the unknown or unreported within-study correlations. Specifically, contrast treatment estimates for the IOP outcome may be potentially correlated within a trial; for example, in five studies, both bimatoprost and travoprost were compared against latanoprost within the same trial.Reference Parrish, Palmberg and Sheu 49 – Reference Traverso, Ropo, Papadia and Uusitalo 53 These within-study correlations among treatment comparisons were not reported, and individual participant-level data were unavailable for computing such correlations.
2.2 Comparison of treatments for the chronic prostatitis and chronic pelvic pain syndrome
Thakkinstian et al.Reference Thakkinstian, Attia, Anothaisintawee and Nickel 54 performed an NMA to determine the effectiveness of multiple pharmacological therapies in improving chronic prostatitis symptoms in patients with chronic prostatitis and chronic pelvic pain syndrome (CP/CPPS). CP/CPPS is a common disorder characterized by two major clinical manifestations: pelvic pain and lower urinary tract symptoms.Reference Polackwich and Shoskes 55 The identified studies were collected from the MEDLINE and EMBASE databases up to January 13, 2011, and included a total of 1,669 participants.
Figure 1(b) visualizes the data structure. The primary outcome of interest was the symptom score measured by the National Institutes of Health Chronic Prostatitis Symptom Index (NIH-CPSI), which consists of total symptoms, pain, voiding, and quality of life scores.Reference Litwin, McNaughton-Collins and Fowler
56
The dataset consisted of 19 published trials comparing five treatment regimens, including: placebo, any
 $\alpha $
-blockers (terazosin, doxazosin, tamsulosin, alfuzosin, silodosin), any antibiotics (ciprofloxacin, levofloxacin, tetracycline), anti-inflammatory/immune modulatory agents (steroidal and non-steroidal anti-inflammatory drugs, glycosaminoglycans, phytotherapy, and tanezumab), and a combination of antibiotics and
$\alpha $
-blockers (terazosin, doxazosin, tamsulosin, alfuzosin, silodosin), any antibiotics (ciprofloxacin, levofloxacin, tetracycline), anti-inflammatory/immune modulatory agents (steroidal and non-steroidal anti-inflammatory drugs, glycosaminoglycans, phytotherapy, and tanezumab), and a combination of antibiotics and
 $\alpha $
-blockers. Treatment comparisons among the five treatments were conducted by Thakkinstian et al.Reference Thakkinstian, Attia, Anothaisintawee and Nickel
54
using an NMA approach. Their findings suggested that
$\alpha $
-blockers. Treatment comparisons among the five treatments were conducted by Thakkinstian et al.Reference Thakkinstian, Attia, Anothaisintawee and Nickel
54
using an NMA approach. Their findings suggested that
 $\alpha $
-blockers, antibiotics, and/or anti-inflammatory/immune modulatory agents were more efficacious in improving the total NIH-CPSI symptom scores compared to placebo. In this example, within-study correlations among treatment comparisons were not available for any of the included studies.
$\alpha $
-blockers, antibiotics, and/or anti-inflammatory/immune modulatory agents were more efficacious in improving the total NIH-CPSI symptom scores compared to placebo. In this example, within-study correlations among treatment comparisons were not available for any of the included studies.
3 Methods
In this section, we introduce the proposed composite likelihood-based method for conducting NMA without the need for knowledge of within-study correlations. Throughout this article, we focus on the contrast-based model,Reference Salanti, Higgins, Ades and Ioannidis 13 although our method can be extended to arm-based models.Reference Hong, Chu, Zhang and Carlin 11 , Reference Wang, Lin, Hodges and Chu 21 – Reference Wang, Lin, Murray, Hodges and Chu 23 The contrast-based model employs a two-stage estimation approach: in the first stage, the estimated effects comparing all possible intervention options in studies are computed, along with their associated standard errors from the contrast-level data, and in the second stage, the effect estimates are analyzed using a normal likelihood approximation.
3.1 Notations and model specification
Suppose that a network consists of m studies (
 $i=1,\ldots , m$
) comparing a set of treatment options
$i=1,\ldots , m$
) comparing a set of treatment options
 $\mathscr {K} = \{0, 1, 2, \dots ,K\}$
for (
$\mathscr {K} = \{0, 1, 2, \dots ,K\}$
for (
 $K+1$
) treatments. Each design (
$K+1$
) treatments. Each design (
 $d=1,\ldots , D$
) corresponds to a subset of treatments
$d=1,\ldots , D$
) corresponds to a subset of treatments
 $\mathscr {K}_{d}$
, i.e.,
$\mathscr {K}_{d}$
, i.e.,
 $\mathscr {K}_d \in \mathscr {K}$
, and let
$\mathscr {K}_d \in \mathscr {K}$
, and let
 $m_d$
be the number of studies in design d. Under the assumptions of consistency, a network with (
$m_d$
be the number of studies in design d. Under the assumptions of consistency, a network with (
 $K+1$
) treatments contains K basic parameters. These parameters are frequently taken to be the relative effects of each treatment versus a reference (or common comparator). In this article, we do not assume that all studies utilize the same reference treatment. Instead, our proposed method incorporates all observed treatment comparisons, ensuring that reported treatment effects and standard errors contribute to the estimation of objective parameters in the proposed composite likelihood function. Moreover, the estimation does not depend on the choice of a common reference.
$K+1$
) treatments contains K basic parameters. These parameters are frequently taken to be the relative effects of each treatment versus a reference (or common comparator). In this article, we do not assume that all studies utilize the same reference treatment. Instead, our proposed method incorporates all observed treatment comparisons, ensuring that reported treatment effects and standard errors contribute to the estimation of objective parameters in the proposed composite likelihood function. Moreover, the estimation does not depend on the choice of a common reference.
Suppose
 $\mathscr {T}=\{jj'\}_{j,j'\in \mathscr {K}, j'\neq j}=\{01,02,\dots ,(K-1)K\}$
is the set of N observed treatment comparisons. Let
$\mathscr {T}=\{jj'\}_{j,j'\in \mathscr {K}, j'\neq j}=\{01,02,\dots ,(K-1)K\}$
is the set of N observed treatment comparisons. Let
 $y_{i,jj'}$
be an observed treatment effect comparing treatment j to treatment
$y_{i,jj'}$
be an observed treatment effect comparing treatment j to treatment
 $j'$
in the i-th study. Let
$j'$
in the i-th study. Let
 $\mathbf {{y}}_{i}=\left \{y_{i,jj'} \right \}_{jj'\in \mathscr {T}}^{T} = (y_{i,01}, y_{i,02}, \ldots , y_{i,(K-1)K})^{T}$
be the vector of observed contrasts of treatments, along with the vector of associated standard errors
$\mathbf {{y}}_{i}=\left \{y_{i,jj'} \right \}_{jj'\in \mathscr {T}}^{T} = (y_{i,01}, y_{i,02}, \ldots , y_{i,(K-1)K})^{T}$
be the vector of observed contrasts of treatments, along with the vector of associated standard errors
 ${\mathbf {s}}_i = \left \{ s_{i,jj'} \right \}_{jj'\in \mathscr {T}}^{T} = (s_{i,01}, s_{i,02}, \ldots , s_{i,(K-1)K})^{T}$
. The observed relative treatment effects in an NMA are modeled via a random-effects framework,
${\mathbf {s}}_i = \left \{ s_{i,jj'} \right \}_{jj'\in \mathscr {T}}^{T} = (s_{i,01}, s_{i,02}, \ldots , s_{i,(K-1)K})^{T}$
. The observed relative treatment effects in an NMA are modeled via a random-effects framework,
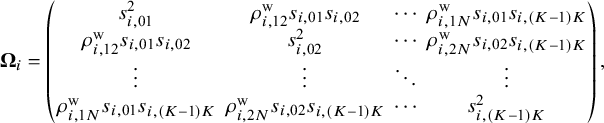
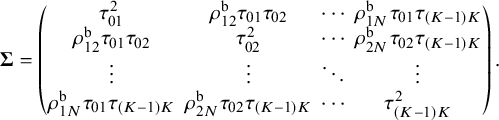
Here, ![]() represents a vector of true population relative treatment effect sizes. The
represents a vector of true population relative treatment effect sizes. The ![]() matrix indicates that the total variability affecting summary measures in each study is the sum of both within-study and between-study variance–covariance matrices. For the within-study variance–covariance
matrix indicates that the total variability affecting summary measures in each study is the sum of both within-study and between-study variance–covariance matrices. For the within-study variance–covariance ![]() ,
,
 $\rho ^{\text {w}}_{i,st}$
(for
$\rho ^{\text {w}}_{i,st}$
(for
 $1\le s<t \le N$
) refers to the within-study correlation, which is rarely reported in published literature or even calculated in individual studies. We assume that
$1\le s<t \le N$
) refers to the within-study correlation, which is rarely reported in published literature or even calculated in individual studies. We assume that ![]() is the within-study correlation matrix, where the diagonal elements are equal to
is the within-study correlation matrix, where the diagonal elements are equal to
 $1$
and the off-diagonal elements are
$1$
and the off-diagonal elements are
 $\rho _{i,st}^{\text {w}}$
for
$\rho _{i,st}^{\text {w}}$
for
 $1\le s<t \le N$
. For the between-study variance–covariance matrix
$1\le s<t \le N$
. For the between-study variance–covariance matrix ![]() ,
,
 $\tau _{jj'}^{2}$
represents the heterogeneity variance of the outcome comparing treatment j and treatment
$\tau _{jj'}^{2}$
represents the heterogeneity variance of the outcome comparing treatment j and treatment
 $j'$
, and
$j'$
, and
 $\rho ^{\text {b}}_{st}$
denotes the between-study correlation for
$\rho ^{\text {b}}_{st}$
denotes the between-study correlation for
 $1\le s<t \le N$
. We assume that
$1\le s<t \le N$
. We assume that ![]() is the between-study correlation matrix, where the diagonal elements are equal to
is the between-study correlation matrix, where the diagonal elements are equal to
 $1$
and the off-diagonal elements are
$1$
and the off-diagonal elements are
 $\rho _{st}^{\text {b}}$
for
$\rho _{st}^{\text {b}}$
for
 $1\le s<t \le N$
.
$1\le s<t \le N$
.
3.2 Proposed method
Let
 $\mathscr {M}_{jj'}$
be the subset of studies that report effect sizes and standard errors for the outcome in the treatment comparison between j and
$\mathscr {M}_{jj'}$
be the subset of studies that report effect sizes and standard errors for the outcome in the treatment comparison between j and
 $j'$
. Let
$j'$
. Let ![]() be the log composite likelihood function of the model defined in Equation (1), given the observed data
be the log composite likelihood function of the model defined in Equation (1), given the observed data
 $(\mathbf {y}_i,\mathbf {s}_i)$
. We have
$(\mathbf {y}_i,\mathbf {s}_i)$
. We have
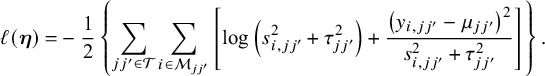
In order to fit an NMA, it is indispensable that the consistency equation is satisfied as follows,
 $\mu _{jj'} = \mu _{jk}-\mu _{j'k}$
,
$\mu _{jj'} = \mu _{jk}-\mu _{j'k}$
,
 $\forall k\neq j,j'$
. Throughout this section, we choose treatment ‘0’ as a common reference. Then, in Equation (2), we only need to estimate the parameters
$\forall k\neq j,j'$
. Throughout this section, we choose treatment ‘0’ as a common reference. Then, in Equation (2), we only need to estimate the parameters ![]() , where
, where ![]() and
and ![]() . We obtain the estimates of these parameters by maximizing the log composite likelihood function,
. We obtain the estimates of these parameters by maximizing the log composite likelihood function,
where the estimator ![]() is asymptotically normal as
is asymptotically normal as
 $m\to \infty $
. The asymptotic variance–covariance matrix of
$m\to \infty $
. The asymptotic variance–covariance matrix of ![]() can be estimated by a sandwich-type estimator of form
can be estimated by a sandwich-type estimator of form ![]() , with
, with ![]() and
and  Here, we opted for a sandwich-type variance estimator, which offers two key advantages in NMAs. First, it is robust to dependence. Even though the composite likelihood method assumes independence between treatment effects within a study, the sandwich estimator can partially account for this dependence. It achieves this by incorporating additional information during variance–covariance estimation, leading to more accurate standard errors for treatment effects. Second, the sandwich-type estimator is generally robust to misspecification of covariance structures. This robustness is particularly beneficial for handling complex data structures often encountered in NMAs. However, it is important to note that the underlying marginal model itself cannot be misspecified. We also note that the restricted maximum likelihood (REML) estimator produces the same asymptotic distribution as the maximum likelihood estimator by incorporating the extra term of
Here, we opted for a sandwich-type variance estimator, which offers two key advantages in NMAs. First, it is robust to dependence. Even though the composite likelihood method assumes independence between treatment effects within a study, the sandwich estimator can partially account for this dependence. It achieves this by incorporating additional information during variance–covariance estimation, leading to more accurate standard errors for treatment effects. Second, the sandwich-type estimator is generally robust to misspecification of covariance structures. This robustness is particularly beneficial for handling complex data structures often encountered in NMAs. However, it is important to note that the underlying marginal model itself cannot be misspecified. We also note that the restricted maximum likelihood (REML) estimator produces the same asymptotic distribution as the maximum likelihood estimator by incorporating the extra term of
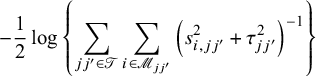 $$\begin{align*}-\frac{1}{2}\log\left\{\sum_{{jj'}\in\mathscr{T}}\sum_{i \in \mathscr{M}_{jj'}} \left(s_{i,jj'}^2 + \tau_{jj'}^2\right)^{-1}\right\} \end{align*}$$
$$\begin{align*}-\frac{1}{2}\log\left\{\sum_{{jj'}\in\mathscr{T}}\sum_{i \in \mathscr{M}_{jj'}} \left(s_{i,jj'}^2 + \tau_{jj'}^2\right)^{-1}\right\} \end{align*}$$
in Equation (2). Additionally, we notice that ![]() is information-orthogonal to
is information-orthogonal to ![]() . Assuming the information matrix is
. Assuming the information matrix is  with
with ![]()
![]() and
and ![]() The off-diagonal element of the information matrix,
The off-diagonal element of the information matrix, ![]() , satisfies
, satisfies ![]() , implying that
, implying that ![]() and
and ![]() are information-orthogonal. Under this information-orthogonality property, the variance–covariance matrix of
are information-orthogonal. Under this information-orthogonality property, the variance–covariance matrix of ![]() involves the information of
involves the information of ![]() alone and can be simplified as
alone and can be simplified as ![]() , with
, with  The asymptotic variance–covariance matrix is estimated by its empirical variance–covariance matrix
The asymptotic variance–covariance matrix is estimated by its empirical variance–covariance matrix ![]() , where
, where ![]() and
and ![]() are the submatrices of
are the submatrices of ![]() and
and ![]() , respectively. As elucidated by Liang and Zeger,Reference Liang and Zeger
57
the information-orthogonality property implies that the between-study variance estimates have a limited impact on the estimation of effect sizes
, respectively. As elucidated by Liang and Zeger,Reference Liang and Zeger
57
the information-orthogonality property implies that the between-study variance estimates have a limited impact on the estimation of effect sizes ![]() . A detailed description of robust sandwich-type variance estimation is provided in Appendices 1 and 2 of the Supplementary Material.
. A detailed description of robust sandwich-type variance estimation is provided in Appendices 1 and 2 of the Supplementary Material.
The efficient and iterative algorithm for parameter estimation can be implemented by maximizing the log composite likelihood function in Equation (2), as described in Algorithm 1. More specifically, when ![]() is fixed at some value of
is fixed at some value of ![]() , the parameters
, the parameters ![]() can be estimated by solving a system of linear equations. In other words, maximizing
can be estimated by solving a system of linear equations. In other words, maximizing ![]() over
over ![]() yields
yields
where ![]() is the solution of the above system of linear equations, and
is the solution of the above system of linear equations, and
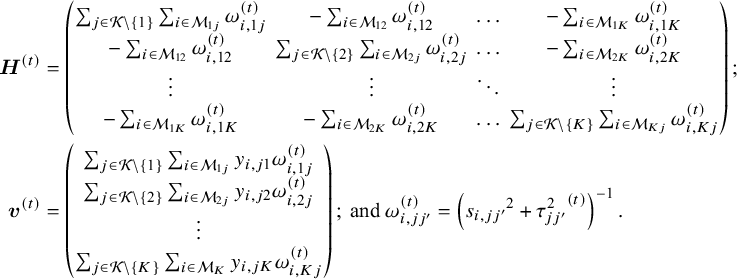
The proof of convergence for Algorithm 1 is provided in Appendix 3 of the Supplementary Material. Additionally, a detailed description of testing for inconsistency can be found in Appendix 4 of the Supplementary Material. The R code for the 3-arm study is publicly available on GitHub: https://github.com/Penncil/xmeta/tree/master/R/CLNMA.equal.tau.R.

3.3 Treatment ranking
The hierarchy of comparable interventions can be computed by incorporating the NMA estimates obtained from the proposed composite likelihood-based method. Among various approaches to treatment ranking, the most commonly employed method relies on ranking probabilities; the probabilities for each treatment can be placed at a specific ranking position, e.g., best, second best, third best treatment, and so forth, in comparison to all other treatments in a network. These approaches for treatment ranking include the surface under the cumulative ranking curve (SUCRA)Reference Salanti, Ades and Ioannidis
48
and P-score techniques,Reference Rücker and Schwarzer
58
among others. In this article, we adopted the SUCRA method.Reference Salanti, Ades and Ioannidis
48
By incorporating the NMA estimates obtained from our proposed method into SUCRA, we can properly account for uncertainty in the estimates of relative treatment ranking. Specifically, for each treatment j out of the (
 $K+1$
) competing treatments, SUCRA is calculated as follows:
$K+1$
) competing treatments, SUCRA is calculated as follows:
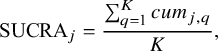 $$ \begin{align*}\text{SUCRA}_{j} = \frac{\sum_{q=1}^{K}{cum}_{j,q}}{K}, \end{align*} $$
$$ \begin{align*}\text{SUCRA}_{j} = \frac{\sum_{q=1}^{K}{cum}_{j,q}}{K}, \end{align*} $$
where
 ${cum}_{j,q}$
refers to the cumulative probability of being among the q-best treatments
${cum}_{j,q}$
refers to the cumulative probability of being among the q-best treatments
 $(q=1,2,\ldots , K+1)$
. A SUCRA value of
$(q=1,2,\ldots , K+1)$
. A SUCRA value of
 $1$
indicates that the treatment is ranked as the best, while a value of
$1$
indicates that the treatment is ranked as the best, while a value of
 $0$
indicates the treatment is ranked as the worst.
$0$
indicates the treatment is ranked as the worst.
4 Simulation study
In this section, our objective is to assess the impact of within-study correlations on pooled estimates when employing the proposed composite likelihood-based method. We conducted extensive simulation studies to evaluate the performance of the proposed method across various scenarios, varying factors such as the within-study correlations, between-study heterogeneity variance, and the number of studies. Furthermore, we compared the computational time of the proposed method with existing NMA methods implemented in the R packages.
4.1 Data-generating mechanisms
For the simulation study, we considered a contrast-based NMA consisting of a three-arm design (i.e., A, B, and C, where A is treated as the reference) for a single continuous outcome of primary interest. The simulated data were generated using the following model:
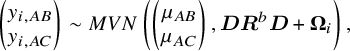
where 
![]() represents the
represents the
 $2\times 2$
between-study correlation matrix, and
$2\times 2$
between-study correlation matrix, and ![]() denotes the
denotes the
 $2\times 2$
within-study variance–covariance matrix. Within the simulated network, we assumed the consistency equation, in terms of
$2\times 2$
within-study variance–covariance matrix. Within the simulated network, we assumed the consistency equation, in terms of
 $\mu _{BC}=\mu _{AC}-\mu _{AB}$
. As suggested by Lu and Ades,Reference Lu and Ades
17
the between-study heterogeneity variance
$\mu _{BC}=\mu _{AC}-\mu _{AB}$
. As suggested by Lu and Ades,Reference Lu and Ades
17
the between-study heterogeneity variance
 $\tau _{AB}^{2}$
can be defined by the following relationship:
$\tau _{AB}^{2}$
can be defined by the following relationship: ![]() , where
, where
 $\tau _{AB}^{2}$
and
$\tau _{AB}^{2}$
and
 $\tau _{AC}^{2}$
are the variances of random quantities
$\tau _{AC}^{2}$
are the variances of random quantities
 $\mu _{AB}$
and
$\mu _{AB}$
and
 $\mu _{AC}$
, respectively. These variances are interpreted as the random effects of treatment B and C relative to a common comparator A.
$\mu _{AC}$
, respectively. These variances are interpreted as the random effects of treatment B and C relative to a common comparator A.
The model parameters described above varied during simulations and were as follows. Two scenarios were considered. The first scenario used a common between-study heterogeneity variance for all treatment comparisons with
 $\tau _{AB}=\tau _{AC}=0.5$
, and the off-diagonal elements of
$\tau _{AB}=\tau _{AC}=0.5$
, and the off-diagonal elements of ![]() were set to
were set to
 $0.1$
, in which
$0.1$
, in which ![]() was guaranteed to be positive semi-definite. Despite the assumption of a common between-study heterogeneity variance being widely used in practice, it remains a strong assumption. Thus, we relaxed the assumption of a common between-study heterogeneity variance. Instead, in the second scenario, unequal between-study heterogeneity variances were considered with
was guaranteed to be positive semi-definite. Despite the assumption of a common between-study heterogeneity variance being widely used in practice, it remains a strong assumption. Thus, we relaxed the assumption of a common between-study heterogeneity variance. Instead, in the second scenario, unequal between-study heterogeneity variances were considered with
 $\tau _{AB}=0.7$
and
$\tau _{AB}=0.7$
and
 $\tau _{AC}=0.5$
, respectively, and the off-diagonal elements of
$\tau _{AC}=0.5$
, respectively, and the off-diagonal elements of ![]() were again set to
were again set to
 $0.1$
. Under both scenarios, within-study correlations were set at small (
$0.1$
. Under both scenarios, within-study correlations were set at small (
 $0.2$
) and medium (
$0.2$
) and medium (
 $0.5$
) magnitudes to explore their impact. Both scenarios reflected a low-to-moderate level of heterogeneity, ranging between 20% and 35% of the total variance; in other words, between-study variance was not large enough to completely dominate within-study variance. We generated closed loops with equal two-arm and three-arm studies into the desired network of studies, with
$0.5$
) magnitudes to explore their impact. Both scenarios reflected a low-to-moderate level of heterogeneity, ranging between 20% and 35% of the total variance; in other words, between-study variance was not large enough to completely dominate within-study variance. We generated closed loops with equal two-arm and three-arm studies into the desired network of studies, with
 $m_{AB}=m_{AC}=m_{BC}=m_{ABC}=m$
. The true treatment effects for
$m_{AB}=m_{AC}=m_{BC}=m_{ABC}=m$
. The true treatment effects for
 $AB$
and
$AB$
and
 $AC$
comparisons were mimicked by the IOP data as described in Section 2 and set as
$AC$
comparisons were mimicked by the IOP data as described in Section 2 and set as
 $\mu _{AB}=-2$
and
$\mu _{AB}=-2$
and
 $\mu _{AC}=-4$
, and
$\mu _{AC}=-4$
, and
 $\mu _{BC}$
was obtained through the equation:
$\mu _{BC}$
was obtained through the equation:
 $\mu _{BC}=\mu _{AB}-\mu _{AC}$
. The simulated study sizes for NMAs were set to
$\mu _{BC}=\mu _{AB}-\mu _{AC}$
. The simulated study sizes for NMAs were set to
 $m=5, 10, 15, 20, 25$
, and
$m=5, 10, 15, 20, 25$
, and
 $50$
. For each simulation setting,
$50$
. For each simulation setting,
 $1,000$
NMA datasets were generated. Using the model parameters described above, continuous data were generated from the multivariate normal distribution in Equation (3). The simulation study was conducted using R software, version 4.2.1.
$1,000$
NMA datasets were generated. Using the model parameters described above, continuous data were generated from the multivariate normal distribution in Equation (3). The simulation study was conducted using R software, version 4.2.1.
4.2 Simulation results
We evaluated the performance of our proposed method by examining treatment effect estimates, in terms of bias, empirical standard error (ESE), model-based standard error (MBSE), as well as coverage of 95% confidence intervals.
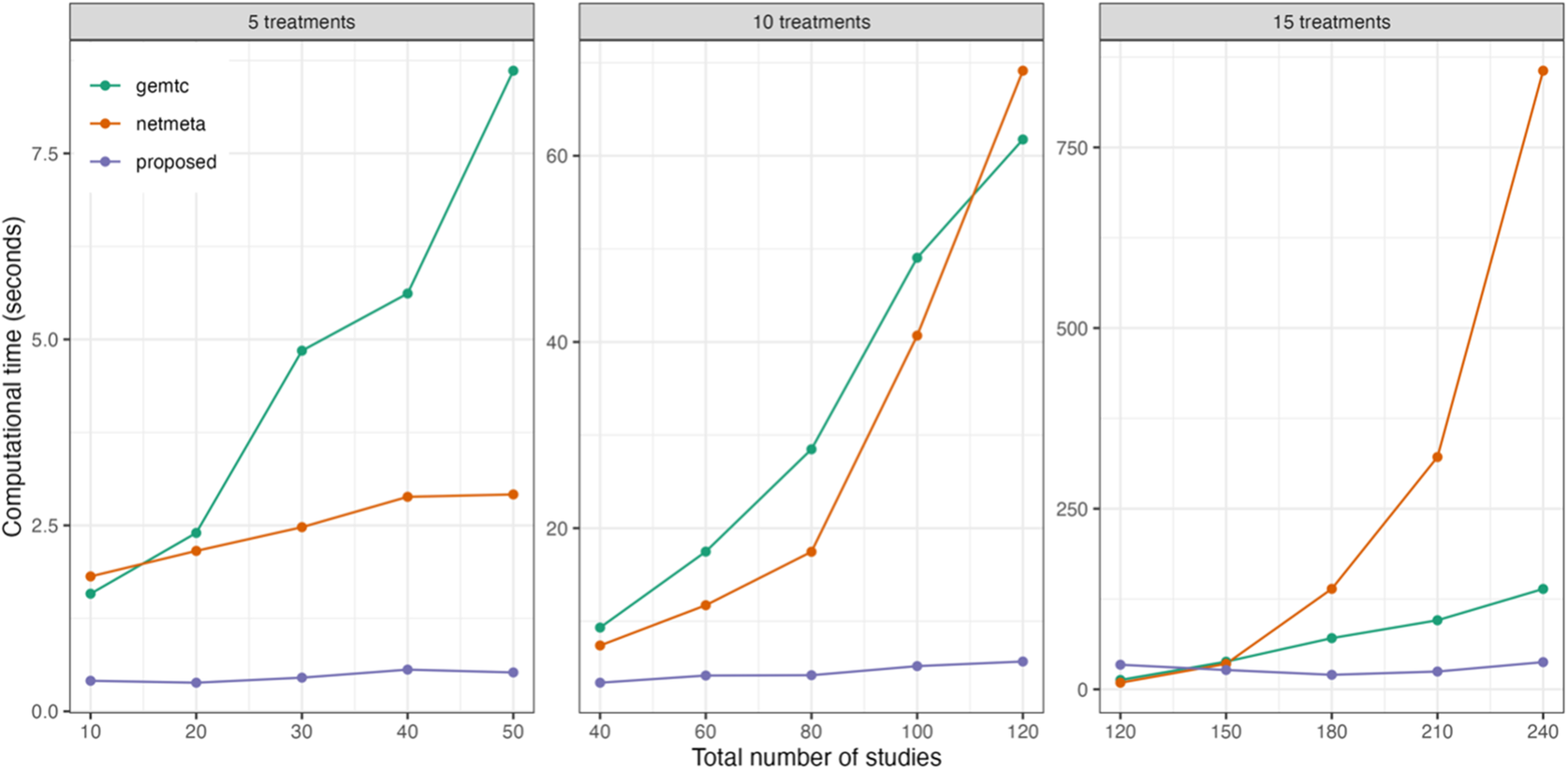
Figure 2 displays the computational time for various NMA approaches. The currently available R packages include ‘gemtc’Reference Valkenhoef, Kuiper and Valkenhoef 59 and ‘netmeta’,Reference Balduzzi, Rücker, Nikolakopoulou, Papakonstantinou, Salanti, Efthimiou and Schwarzer 60 in which the ‘gemtc’ package employs Bayesian NMA with Markov chain Monte Carlo (MCMC), while ‘netmeta’ is designed based on a frequentist random-effects NMA model. We found that initial values could significantly impact the execution time of both ‘gemtc’ and the proposed method, whereas ‘netmeta’ was less affected by this issue. As the number of treatment comparisons and studies increased, differences in computational time among the three methods became more pronounced. Even though ‘gemtc’ and ‘netmeta’ required minimal computational time for the scenarios with fewer studies, their computational time increased dramatically as the number of treatment comparisons and studies grew. Conversely, the proposed method generally yielded consistent performance in computational time, irrespective of the number of treatment comparisons or studies. Detailed computational time results are summarized in Table S1 of the Supplementary Material.
Comparison of computational time for the proposed method and two existing methods implemented in the R packages ‘gemtc’ and ‘netmeta’, with varying numbers of treatments and studies.
The upper panel of Table 1 summarizes simulation results for treatment comparisons
 $AB$
and
$AB$
and
 $AC$
in the scenario with common between-study heterogeneity. Overall, we observed that the proposed composite likelihood-based method yielded approximately unbiased pooled estimates for
$AC$
in the scenario with common between-study heterogeneity. Overall, we observed that the proposed composite likelihood-based method yielded approximately unbiased pooled estimates for
 $AB$
and
$AB$
and
 $AC$
treatment comparisons in most simulation settings. It did not exhibit discernible patterns in
$AC$
treatment comparisons in most simulation settings. It did not exhibit discernible patterns in
 $AB$
and
$AB$
and
 $AC$
treatment estimates across different magnitudes of within-study correlations (i.e.,
$AC$
treatment estimates across different magnitudes of within-study correlations (i.e.,
 $0.2$
and
$0.2$
and
 $0.5$
); in other words, the magnitude of within-study correlations appeared to have a limited impact on the pooled estimates. The confidence intervals computed using the robust sandwich-type variance method demonstrated acceptable coverage probabilities ranging from 88% to 94%, relying on the number of studies. Interestingly, the model-based standard errors appeared somewhat smaller than their empirical standard errors. One possible explanations for this phenomenon is that the proposed method based on composite likelihood provided more efficient inference in large sample settings. However, as widely acknowledged in the literature,Reference Gunsolley, Getchell and Chinchilli
61
–
Reference Li and Redden
66
the variance estimated using the sandwich-type method may be underestimated when the number of studies is below
$0.5$
); in other words, the magnitude of within-study correlations appeared to have a limited impact on the pooled estimates. The confidence intervals computed using the robust sandwich-type variance method demonstrated acceptable coverage probabilities ranging from 88% to 94%, relying on the number of studies. Interestingly, the model-based standard errors appeared somewhat smaller than their empirical standard errors. One possible explanations for this phenomenon is that the proposed method based on composite likelihood provided more efficient inference in large sample settings. However, as widely acknowledged in the literature,Reference Gunsolley, Getchell and Chinchilli
61
–
Reference Li and Redden
66
the variance estimated using the sandwich-type method may be underestimated when the number of studies is below
 $50$
for continuous outcomes.
$50$
for continuous outcomes.
Summary of 1,000 simulations with,
 $m = 5, 10, 15, 20, 25$
and
$m = 5, 10, 15, 20, 25$
and
 $50$
: bias (Bias), empirical standard error (ESE), model-based standard error (MBSE), and coverage probability (CP) of pooled estimates of
$50$
: bias (Bias), empirical standard error (ESE), model-based standard error (MBSE), and coverage probability (CP) of pooled estimates of
 $AB$
and
$AB$
and
 $AC$
treatment comparisons
$AC$
treatment comparisons
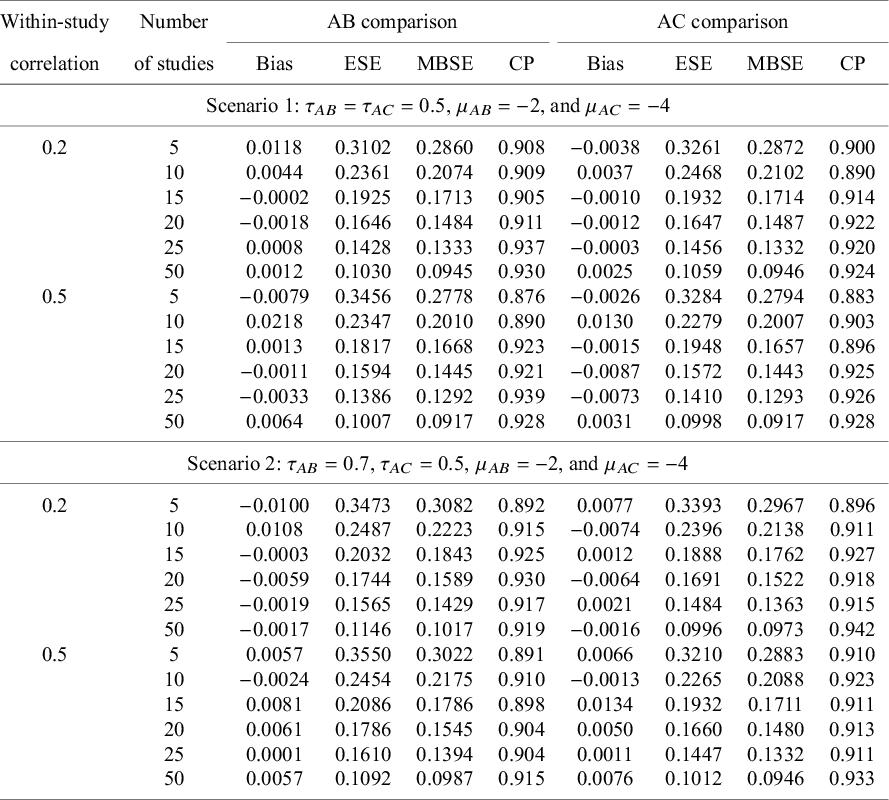
Note: Upper panel (Scenario 1): the data-generation mechanism assumes a common between-study heterogeneity variance. Lower panel (Scenario 2): the data-generation mechanism assumes an unequal between-study heterogeneity variance. All results were based on the proposed method without any corrections
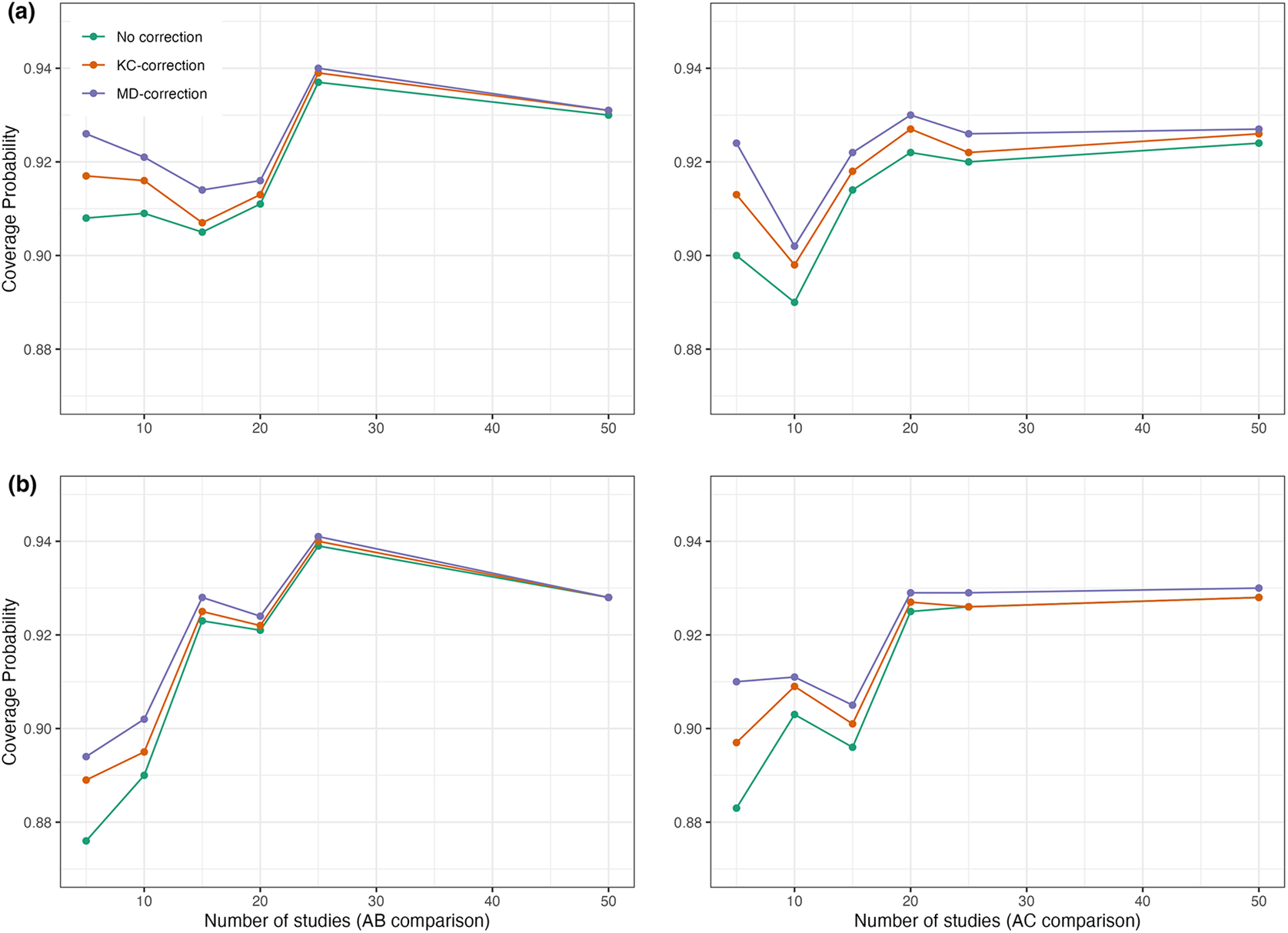
To resolve this issue, several alternative bias-corrected sandwich estimators have been proposed to improve a small-sample performance, such as the KC-corrected sandwich estimatorReference Kauermann and Carroll
67
and the MD-corrected sandwich estimator,Reference Mancl and DeRouen
63
among others. As indicated by Li and Redden,Reference Li and Redden
66
no single bias-corrected sandwich estimator is universally superior; however, a rule of thumb is to choose the KC-corrected method when the coefficient of variation is less than
 $0.6$
. Through simulation studies, we evaluated whether the coverage probabilities of 95% confidence intervals obtained by the proposed method improved after corrections. Figure 3 displays comparisons of coverage probabilities using the proposed method with and without the KC-corrected and MD-corrected techniques for situations where the number of studies was
$0.6$
. Through simulation studies, we evaluated whether the coverage probabilities of 95% confidence intervals obtained by the proposed method improved after corrections. Figure 3 displays comparisons of coverage probabilities using the proposed method with and without the KC-corrected and MD-corrected techniques for situations where the number of studies was
 $5$
,
$5$
,
 $10$
,
$10$
,
 $15$
,
$15$
,
 $20$
,
$20$
,
 $25$
(or even
$25$
(or even
 $50$
). We found that the proposed method with corrections exhibited higher coverage probabilities compared to the proposed method without any corrections, particularly when the number of studies was relatively small (e.g.,
$50$
). We found that the proposed method with corrections exhibited higher coverage probabilities compared to the proposed method without any corrections, particularly when the number of studies was relatively small (e.g.,
 $5$
,
$5$
,
 $10$
, and
$10$
, and
 $15$
studies). Detailed results with the KC-corrected and MD-corrected methods are provided in Tables S2 and S3 of the Supplementary Material, respectively.
$15$
studies). Detailed results with the KC-corrected and MD-corrected methods are provided in Tables S2 and S3 of the Supplementary Material, respectively.
Coverage probabilities of estimated pooled treatment effects for comparisons between treatments
 $AB$
and
$AB$
and
 $AC$
using the proposed method with and without the KC-corrected and MD-corrected sandwich variance estimators under (a) within-study correlation of
$AC$
using the proposed method with and without the KC-corrected and MD-corrected sandwich variance estimators under (a) within-study correlation of
 $0.2$
; and (b) within-study correlation of
$0.2$
; and (b) within-study correlation of
 $0.5$
.
$0.5$
.
On the other hand, results for the scenario with unequal between-study heterogeneity variance are provided in the lower panel of Table 1. The pooled estimates for
 $AB$
and
$AB$
and
 $AC$
treatment comparisons were generally unbiased. As presented in the lower panel of Table 1, coverage probabilities were acceptable to good across most configurations, yielding coverage probabilities close to the nominal level of 95% (ranging from 89% to 94%). Similarly, variance estimates were adjusted using the KC-corrected and MD-corrected sandwich estimator for smaller studies, as illustrated in Tables S4 and S5 in the Supplementary Material, respectively. As expected, coverage probabilities were slightly improved compared to results obtained from the proposed method without corrections. In summary, simulation results suggested that the proposed method is robust to the magnitude of within-study correlations, regardless of whether the between-study heterogeneity variance is equal or unequal.
$AC$
treatment comparisons were generally unbiased. As presented in the lower panel of Table 1, coverage probabilities were acceptable to good across most configurations, yielding coverage probabilities close to the nominal level of 95% (ranging from 89% to 94%). Similarly, variance estimates were adjusted using the KC-corrected and MD-corrected sandwich estimator for smaller studies, as illustrated in Tables S4 and S5 in the Supplementary Material, respectively. As expected, coverage probabilities were slightly improved compared to results obtained from the proposed method without corrections. In summary, simulation results suggested that the proposed method is robust to the magnitude of within-study correlations, regardless of whether the between-study heterogeneity variance is equal or unequal.
5 Data application
In this section, we present the results of applying the proposed method to the two published NMAs, primary open-angle glaucoma and chronic prostatitis and chronic pelvic pain syndrome (CP/CPPS), as introduced in Section 2.
5.1 Application to primary open-angle glaucoma
The primary outcome of interest, in terms of IOP, was reported in a total of 22,656 patients across 125 studies, evaluating four classes of interventions:
 $\alpha $
-2 adrenergic agonists,
$\alpha $
-2 adrenergic agonists,
 $\beta $
-blockers, carbonic anhydrase inhibitors, and prostaglandin analogs (PAGs). For the IOP outcome, the within-study variances were generally much larger than the between-study variances; the between-study variance was estimated at approximately
$\beta $
-blockers, carbonic anhydrase inhibitors, and prostaglandin analogs (PAGs). For the IOP outcome, the within-study variances were generally much larger than the between-study variances; the between-study variance was estimated at approximately
 $0.49$
using placebo as a reference. This was reflected by an
$0.49$
using placebo as a reference. This was reflected by an
 $I^2$
value of
$I^2$
value of
 $43\%$
, indicating that the total variation was not completely dominated by the between-study variation. Consequently, within-study correlations might lead to overestimated standard errors of pooled estimates for treatment comparisons if they were not properly accounted for in an NMA. The results of the standard NMA using the Lu and Ades’ approach (shown in the lower triangular matrix) and the proposed method (shown in the upper triangular matrix) without requiring knowledge of within-study correlations are presented in Figure S1 in the Supplementary Material. The results of pairwise meta-analysis are provided in Figure S2 in the Supplementary Material. As displayed in the upper triangular matrix of Figure S1 in the Supplementary Material, all active drugs were likely more effective in lowering IOP at 3 months compared to placebo, with mean differences in 3-month IOP ranging from
$43\%$
, indicating that the total variation was not completely dominated by the between-study variation. Consequently, within-study correlations might lead to overestimated standard errors of pooled estimates for treatment comparisons if they were not properly accounted for in an NMA. The results of the standard NMA using the Lu and Ades’ approach (shown in the lower triangular matrix) and the proposed method (shown in the upper triangular matrix) without requiring knowledge of within-study correlations are presented in Figure S1 in the Supplementary Material. The results of pairwise meta-analysis are provided in Figure S2 in the Supplementary Material. As displayed in the upper triangular matrix of Figure S1 in the Supplementary Material, all active drugs were likely more effective in lowering IOP at 3 months compared to placebo, with mean differences in 3-month IOP ranging from
 $-1.79$
mmHg (
$-1.79$
mmHg (
 $95\%$
CI,
$95\%$
CI,
 $-2.65$
to
$-2.65$
to
 $-0.94$
) to
$-0.94$
) to
 $-5.53$
mmHg (
$-5.53$
mmHg (
 $95\%$
CI,
$95\%$
CI,
 $-6.24$
to
$-6.24$
to
 $-4.82$
). Moreover, bimatoprost showed the greatest reduction in 3-month IOP compared to placebo (mean difference =
$-4.82$
). Moreover, bimatoprost showed the greatest reduction in 3-month IOP compared to placebo (mean difference =
 $-5.53$
;
$-5.53$
;
 $95\%$
CI,
$95\%$
CI,
 $-6.24$
to
$-6.24$
to
 $-4.82$
), followed by travoprost (mean difference =
$-4.82$
), followed by travoprost (mean difference =
 $-4.82$
;
$-4.82$
;
 $95\%$
CI,
$95\%$
CI,
 $-5.51$
to
$-5.51$
to
 $-4.12$
), latanoprost (mean difference =
$-4.12$
), latanoprost (mean difference =
 $-4.61$
;
$-4.61$
;
 $95\%$
CI,
$95\%$
CI,
 $-5.31$
to
$-5.31$
to
 $-3.92$
), levobunolol (mean difference =
$-3.92$
), levobunolol (mean difference =
 $-4.50$
;
$-4.50$
;
 $95\%$
CI,
$95\%$
CI,
 $-5.68$
to
$-5.68$
to
 $-3.32$
), taflurpost (mean difference =
$-3.32$
), taflurpost (mean difference =
 $-3.93$
;
$-3.93$
;
 $95\%$
CI,
$95\%$
CI,
 $-5.04$
to
$-5.04$
to
 $-2.81$
), and so on. We noted that drugs within the PAG class generally had similar effects on 3-month IOP reduction, except for unoprostone (mean difference =
$-2.81$
), and so on. We noted that drugs within the PAG class generally had similar effects on 3-month IOP reduction, except for unoprostone (mean difference =
 $-1.79$
;
$-1.79$
;
 $95\%$
CI,
$95\%$
CI,
 $-2.65$
to
$-2.65$
to
 $-0.94$
). Inconsistent results were found in several treatment comparisons when applying the standard NMA and the proposed method, including: brinzolamide versus betaxolol (the standard NMA: mean difference =
$-0.94$
). Inconsistent results were found in several treatment comparisons when applying the standard NMA and the proposed method, including: brinzolamide versus betaxolol (the standard NMA: mean difference =
 $-0.85$
with
$-0.85$
with
 $95\%$
CI,
$95\%$
CI,
 $-1.71$
to
$-1.71$
to
 $0.00$
; the proposed: mean difference =
$0.00$
; the proposed: mean difference =
 $-0.96$
with
$-0.96$
with
 $95\%$
CI,
$95\%$
CI,
 $-1.63$
to
$-1.63$
to
 $-0.29$
), carteolol versus apraclonidine (the standard NMA: mean difference =
$-0.29$
), carteolol versus apraclonidine (the standard NMA: mean difference =
 $-1.43$
with
$-1.43$
with
 $95\%$
CI,
$95\%$
CI,
 $-3.36$
to
$-3.36$
to
 $0.49$
; the proposed: mean difference =
$0.49$
; the proposed: mean difference =
 $-1.47$
with
$-1.47$
with
 $95\%$
CI,
$95\%$
CI,
 $-2.69$
to
$-2.69$
to
 $-0.24$
), tafluprost versus levobetaxolol (the standard NMA: mean difference =
$-0.24$
), tafluprost versus levobetaxolol (the standard NMA: mean difference =
 $-1.47$
with
$-1.47$
with
 $95\%$
CI,
$95\%$
CI,
 $-2.81$
to
$-2.81$
to
 $-0.12$
; the proposed: mean difference =
$-0.12$
; the proposed: mean difference =
 $-1.16$
with
$-1.16$
with
 $95\%$
CI,
$95\%$
CI,
 $-2.40$
to
$-2.40$
to
 $0.08$
), brinzolamide versus dorzolamide (the standard NMA: mean difference =
$0.08$
), brinzolamide versus dorzolamide (the standard NMA: mean difference =
 $-0.74$
with
$-0.74$
with
 $95\%$
CI,
$95\%$
CI,
 $-1.51$
to
$-1.51$
to
 $0.04$
; the proposed: mean difference =
$0.04$
; the proposed: mean difference =
 $-0.73$
with
$-0.73$
with
 $95\%$
CI,
$95\%$
CI,
 $-1.30$
to
$-1.30$
to
 $-0.16$
), and levobunolol versus carteolol (the standard NMA: mean difference =
$-0.16$
), and levobunolol versus carteolol (the standard NMA: mean difference =
 $-1.09$
with
$-1.09$
with
 $95\%$
CI,
$95\%$
CI,
 $-2.15$
to
$-2.15$
to
 $-0.03$
; the proposed: mean difference =
$-0.03$
; the proposed: mean difference =
 $-1.08$
with
$-1.08$
with
 $95\%$
CI,
$95\%$
CI,
 $-2.19$
to
$-2.19$
to
 $0.02$
).
$0.02$
).
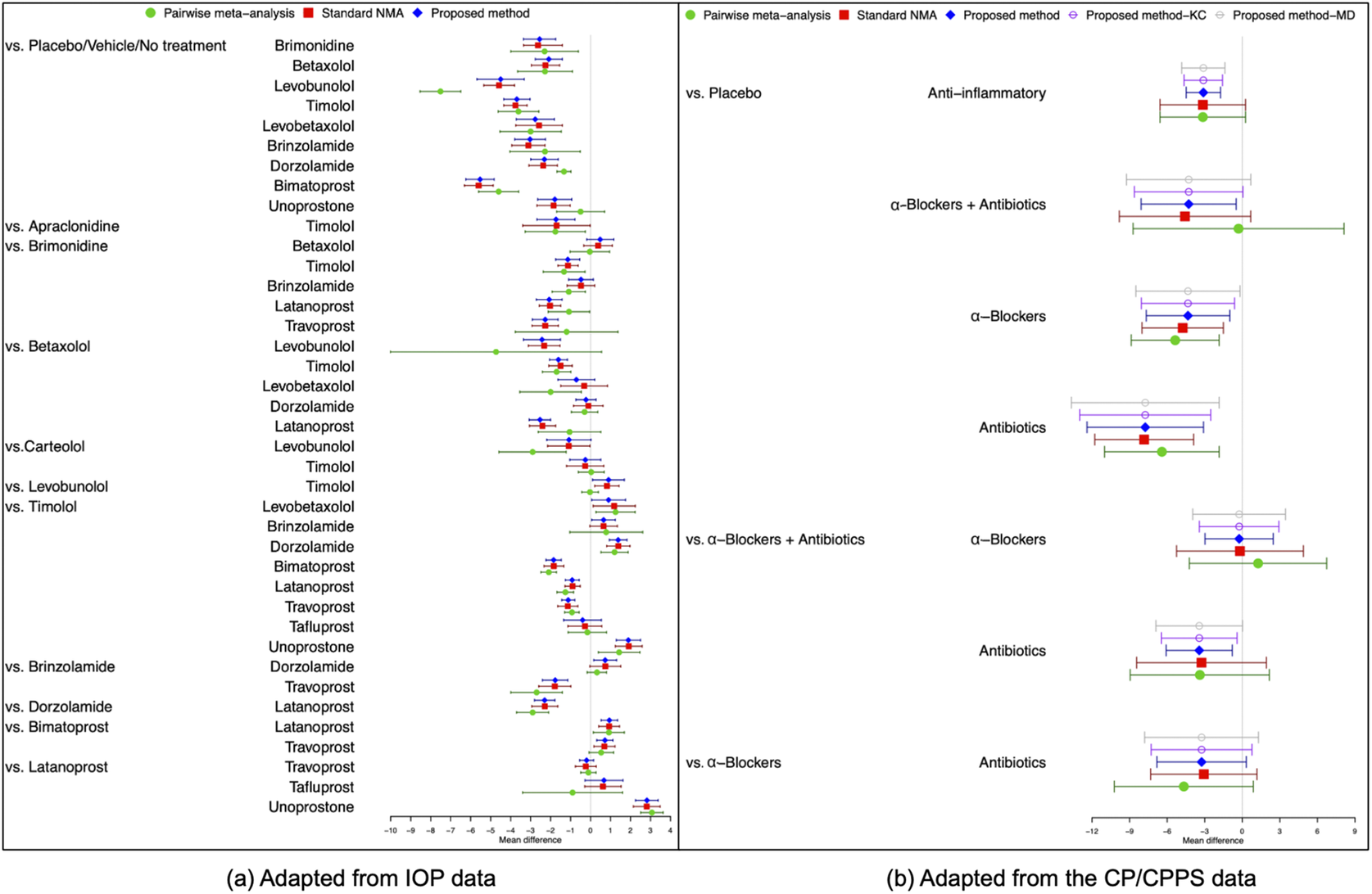
Figure 4(a) illustrates the pooled estimates with corresponding 95% confidence intervals for all treatment comparisons using three approaches: pairwise meta-analysis, the standard NMA based on the Lu and Ades’ approach, and the proposed method. The pairwise meta-analysis provided the direct estimates from all available head-to-head comparisons. As expected, it yielded wider 95% confidence intervals than the other two approaches due to that the indirect evidence was not incorporated into the analysis. The proposed method produced narrower 95% confidence intervals than the standard NMA approach for most treatment comparisons. Figure 5(a) displays a two-dimensional concordance plot of statistical significance, represented by the Z value for both the standard NMA approach and the proposed method, where a Z value less than
 $1.96$
corresponds to a p-value greater than
$1.96$
corresponds to a p-value greater than
 $0.05$
. A few points showed discordant evidence in treatment comparisons between the proposed method and the standard NMA. This discrepancy may be attributed to the fact that the proposed method accounts for non-ignorable effects of within-study correlations, which affect the standard errors of the estimated pooled treatment effects. Figure S3(a) in the Supplementary Material presents the treatment ranking based on the surface under the cumulative ranking curves (SUCRA),Reference Salanti, Ades and Ioannidis
48
as mentioned in Section 3.3. A higher SUCRA score indicates a superior ranking for 3-month IOP reduction. Consequently, bimatoprost (SUCRA = 98.7%) had the highest SUCRA value for 3-month IOP reduction, followed by travoprost (SUCRA = 66.5%), latanoprost (SUCRA = 51.5%), and levobunolol (SUCRA = 42.5%).
$0.05$
. A few points showed discordant evidence in treatment comparisons between the proposed method and the standard NMA. This discrepancy may be attributed to the fact that the proposed method accounts for non-ignorable effects of within-study correlations, which affect the standard errors of the estimated pooled treatment effects. Figure S3(a) in the Supplementary Material presents the treatment ranking based on the surface under the cumulative ranking curves (SUCRA),Reference Salanti, Ades and Ioannidis
48
as mentioned in Section 3.3. A higher SUCRA score indicates a superior ranking for 3-month IOP reduction. Consequently, bimatoprost (SUCRA = 98.7%) had the highest SUCRA value for 3-month IOP reduction, followed by travoprost (SUCRA = 66.5%), latanoprost (SUCRA = 51.5%), and levobunolol (SUCRA = 42.5%).
Comparisons of overall relative treatment estimates with 95
 $\%$
confidence intervals using pairwise meta-analysis approach, the standard NMA based on the Lu and Ades’ approach, the proposed method without any corrections, and the proposed method with KC-corrected or MD-corrected sandwich variance estimators. Each node represents the pooled mean difference for the outcomes of interest.
$\%$
confidence intervals using pairwise meta-analysis approach, the standard NMA based on the Lu and Ades’ approach, the proposed method without any corrections, and the proposed method with KC-corrected or MD-corrected sandwich variance estimators. Each node represents the pooled mean difference for the outcomes of interest.
Comparisons of Z values using the standard NMA based on the Lu and Ades’ approach, the proposed method without corrections, and the proposed method with KC-corrected or MD-corrected sandwich variance estimators, respectively
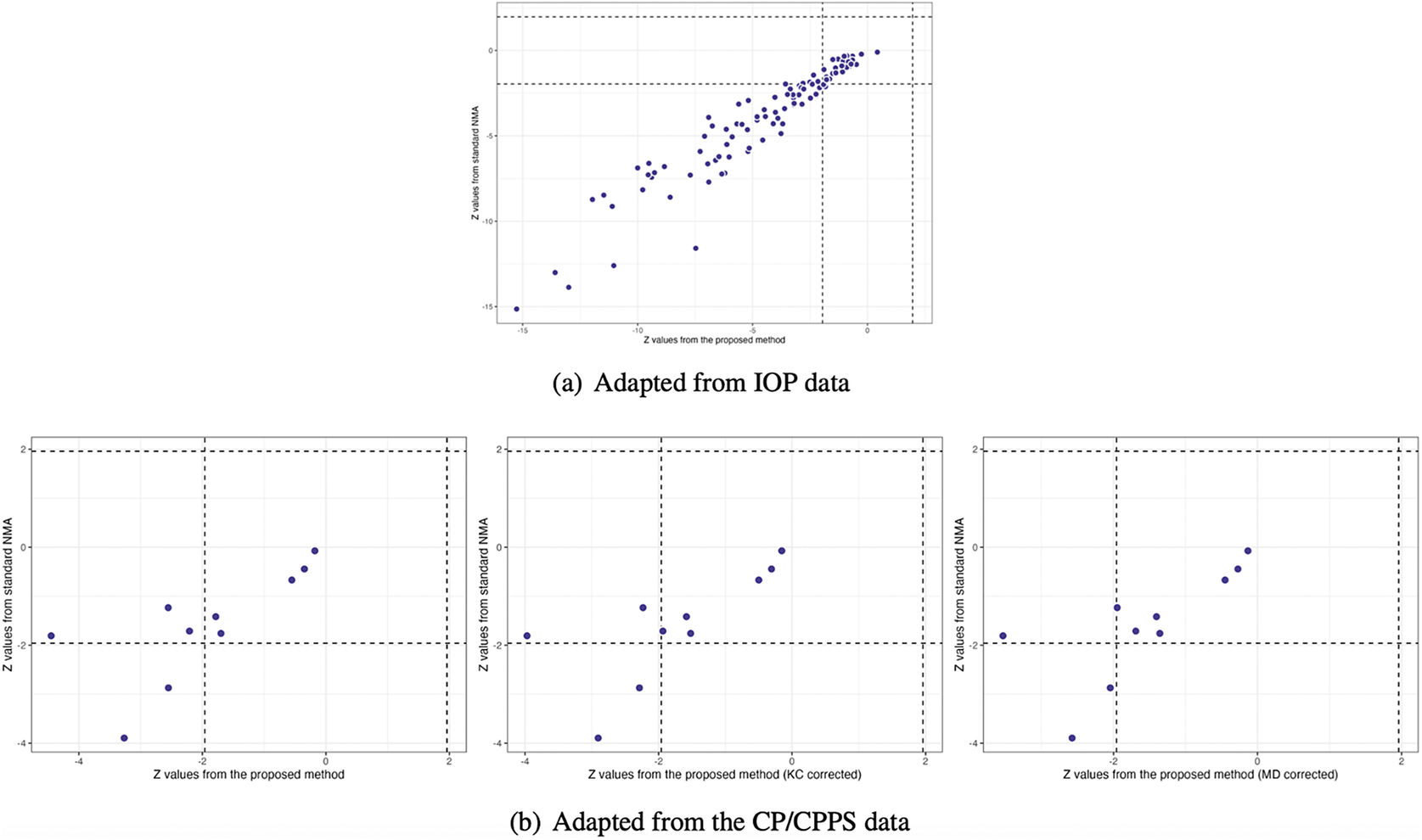
5.2 Application to chronic prostatitis and chronic pelvic pain syndrome
In this example, within-study variances are larger than between-study variances for the outcome of NIH-CPSI scores, and thus the effect of within-study correlations cannot be neglected. Due to the limited number of studies, we chose the KC-corrected and MD-corrected methods to adjust the sandwich-type variance estimations, following the rule of coefficient of variation
 $\leq $
0.6. The NMA results using Lu and Ades’ approach and the proposed method without knowing within-study correlations are presented in Figure S4 in the Supplementary Material. Upon re-analysis, in terms of NIH-CPSI scores, all active drugs showed a statistically significant improvement over placebo, with mean differences of NIH-CPSI scores ranged from
$\leq $
0.6. The NMA results using Lu and Ades’ approach and the proposed method without knowing within-study correlations are presented in Figure S4 in the Supplementary Material. Upon re-analysis, in terms of NIH-CPSI scores, all active drugs showed a statistically significant improvement over placebo, with mean differences of NIH-CPSI scores ranged from
 $-7.75$
(
$-7.75$
(
 $95\%$
CI,
$95\%$
CI,
 $-12.40$
to
$-12.40$
to
 $-3.10$
) to
$-3.10$
) to
 $-3.11$
(
$-3.11$
(
 $95\%$
CI,
$95\%$
CI,
 $-4.48$
to
$-4.48$
to
 $-1.74$
), as shown in Figure S4 in the Supplementary Material. We found inconsistent results between the proposed method and the standard NMA method. Specifically,
$-1.74$
), as shown in Figure S4 in the Supplementary Material. We found inconsistent results between the proposed method and the standard NMA method. Specifically,
 $\alpha $
-blockers plus antibiotics (mean difference =
$\alpha $
-blockers plus antibiotics (mean difference =
 $-4.58$
,
$-4.58$
,
 $95\%$
CI:
$95\%$
CI:
 $-9.82$
to
$-9.82$
to
 $0.67$
) and anti-inflammatory agents (mean difference =
$0.67$
) and anti-inflammatory agents (mean difference =
 $-3.15$
,
$-3.15$
,
 $95\%$
CI:
$95\%$
CI:
 $-6.57$
to
$-6.57$
to
 $0.26$
) did not exhibit significantly greater efficacy than placebo with respect to NIH-CPSI scores when the standard NMA method was applied. Moreover, the proposed method indicated that antibiotics alone were significantly more efficacious than
$0.26$
) did not exhibit significantly greater efficacy than placebo with respect to NIH-CPSI scores when the standard NMA method was applied. Moreover, the proposed method indicated that antibiotics alone were significantly more efficacious than
 $\alpha $
-blockers plus antibiotics (mean difference =
$\alpha $
-blockers plus antibiotics (mean difference =
 $-3.44$
;
$-3.44$
;
 $95\%$
CI,
$95\%$
CI,
 $-6.08$
to
$-6.08$
to
 $-0.80$
), a result not observed with the standard NMA method.
$-0.80$
), a result not observed with the standard NMA method.
Figure 4(b) illustrates the overall relative estimates with 95% confidence intervals for all treatment comparisons using five different approaches, including: pairwise meta-analysis, the standard NMA method, and the proposed method with and without corrections. The results obtained from pairwise meta-analysis yielded wider 95% confidence intervals compared to all other NMA approaches. As expected, the proposed method produced narrower 95% confidence intervals in contrast to the standard NMA using Lu and Ades’ approach. Furthermore, the proposed method without any corrections reported narrower 95% confidence intervals than the standard NMA approach. Corrections for the sandwich-type variance estimations using the KC-corrected and MD-corrected procedures resulted in slightly wider 95% confidence intervals than the proposed method without any corrections for some treatment comparisons. Figure 5(b) displays the concordance plot between the standard NMA approach and the proposed method with or without corrections. Several points showed discordant evidence in treatment comparisons between the proposed method and the standard NMA approach. This discrepancy may arise because the proposed method accounts for the unavailability of within-study correlations, which can affect the standard errors of estimated pooled treatment effects. Figure S3(b) in the Supplementary Material displays the treatment ranking using SUCRA. Overall, antibiotics (SUCRA = 94.6%) were ranked highest for the improvement of NIH-CPSI scores, followed by
 $\alpha $
-blockers plus antibiotics (SUCRA = 41.3%) and
$\alpha $
-blockers plus antibiotics (SUCRA = 41.3%) and
 $\alpha $
-blockers (SUCRA = 42.4%).
$\alpha $
-blockers (SUCRA = 42.4%).
6 Discussion
We propose a composite likelihood-based approach to model univariate outcomes in NMAs. The proposed method helps obtain the estimation of overall relative treatment effects in NMAs, even when within-study correlations are unavailable in the original articles. To the best of our knowledge, existing NMA approaches often make assumptions about within-study correlations (assuming them to be known or zero), which can introduce bias if the true within-study correlations are non-negligible. Obtaining within-study correlations typically necessitates a joint analysis of individual participant-level data, often using bootstrapping methods.Reference Ishak, Platt, Joseph and Hanley 68 , Reference Daniels and Hughes 69 However, this is seldom done unless specific questions about correlations between treatment comparisons are of interest in the included studies. Our proposed method has two key advantages. The first advantage is that the estimation and statistical inference of treatment effects remain valid even if the correlation structure is misspecified. Simulation studies have shown that the proposed method provides nearly unbiased estimates and maintains reasonable coverage rates for 95% confidence intervals across scenarios with common or unequal between-study heterogeneity variances for treatment comparisons. Additionally, as illustrated in two applications, the proposed method is less prone to variance estimation issues than the standard NMA approach when total variation is not dominated by between-study variation. The second advantage of the proposed method is its ability to reduce computational time by circumventing the need to estimate correlation parameters. This improvement is particularly evident when compared to currently available methods for NMAs, such as those implemented in the R packages ‘gemtc’ and ‘netmeta’ (see Figure 2 and Table S1 in the Supplementary Material).
Nevertheless, there are three potential limitations to the proposed method. First, the proposed method focuses on contrast-based models in NMAs. While NMAs can also be performed using an arm-based approach, there are ongoing debates in the literature regarding the differences between contrast-based and arm-based models.Reference White, Turner, Karahalios and Salanti 20 The arm-based approach offers a promising direction for future NMA modeling. It can potentially alleviate concerns about correlations among contrasts, especially in cases where treatment arm summaries are independent. Under these conditions, the arm-based approach yields the results consistent with the contrast-based method, requiring solely the standard errors of independent treatment summaries along with the inclusion of a fixed study main effect. Piepho and MaddenReference Piepho and Madden 70 demonstrated the practical application of an arm-based meta-analysis using the SAS procedures GLIMMIX and BGLMM. Their work highlighted the effectiveness of this approach in circumventing the complexities associated with correlations among contrasts while maintaining concurrent control. However, a key criticism of the arm-based approach is that it might not fully preserve randomization within trials under certain scenarios.Reference Chu, Lin, Wang, Wang, Chen and Cappelleri 71 This potential bias in the estimated relative effect is particularly concerning if the assumption of transportable relative treatment effects is violated. It is important to note that when a fixed study main effect is included in the linear predictor, the arm-based NMA utilizes only within-study information, thereby preserving randomization and mitigating this issueReference Piepho, Madden and Williams 72 Further research is needed to explore detailed formulations that can optimize the arm-based approach for NMAs. We also encourage researchers to report treatment arm summaries along with their associated standard errors, in addition to reporting contrasts, to provide a more comprehensive understanding of the data.
Second, our simulation studies revealed that the empirical coverage fell below 90% for the 95% nominal level, particularly in studies with limited sample sizes (e.g., 5 or 10 studies). This suggests a potential limitation of the proposed method when dealing with a small number of studies, as the asymptotic properties it relies upon may not fully manifest in such scenarios. Alternatively, the arm-based approach might be less susceptible to this limitation, offering a robust option for analyses involving fewer studies.
Third, because the proposed method is constructed using a composite likelihood-based approach, the variance is estimated through a sandwich-type estimator. This estimator tends to underestimate the true variance, especially when the number of studies is small. This underestimation exacerbates the issue of under-coverage of confidence intervals and inflated type I error rates.Reference Kauermann and Carroll 67 To improve finite-sample variance estimation, we have applied the KC-corrected and MD-corrected sandwich variance estimatorsReference Mancl and DeRouen 63 , Reference Kauermann and Carroll 67 in our simulation studies and the CP/CPPS application. As a result, the confidence intervals became slightly wider after applying these corrections, leading to improved coverage probabilities compared to the uncorrected method. It would be of interest to investigate how these variations of sandwich variance estimators would improve the coverage probability of the composite likelihood inference in multivariate NMA setting,Reference Duan, Tong, Lin, Levine, Sammel, Stoddard, Li, Schmid, Chu and Chen 73 and NMA for comparing diagnostic test setting.Reference Ma, Lian, Chu, Ibrahim and Chen 74
In conclusion, this work highlights the importance of considering non-ignorable within-study correlations in network meta-analyses. Ignoring these correlations, particularly when they are non-negligible, can lead to inaccurate standard errors for treatment effect estimates. The proposed composite likelihood-based approach offers an alternative for univariate NMAs when within-study correlation data are not available from original research articles. This method avoids the need for complex individual participant-level data analysis and maintains valid treatment effect estimation, even with misspecified correlation structures. Additionally, it delivers significant computational efficiency gains compared to existing NMA methods.
Acknowledgements
All statements in this report, including its findings and conclusions, are solely those of the authors and do not necessarily represent the views of the Patient-Centered Outcomes Research Institute (PCORI), its Board of Governors or Methodology Committee.
Author contributions
Conceptualization: Y.-L.L., B.Z., Y.C.; Data curation: Y.-L.L., B.Z.; Formal analysis: Y.-L.L., B.Z., Y.C.; Investigation: Y.-L.L., B.Z., H.C., Y.C.; Methodology: Y.-L.L., B.Z., H.C., Y.C.; Supervision: Y.C.; Writing—review and editing: Y.-L.L., B.Z., H.C., Y.C.
Competing interest statement
The authors declare that no competing interests exist.
Data availability statement
The network meta-analysis datasets described in Sections 2 and 5 were obtained from the following published studies: Li et al.,Reference Li, Lindsley and Rouse 45 Wang et al.,Reference Wang, Rouse and Marks-Anglin 46 and Thakkinstian et al.Reference Thakkinstian, Attia, Anothaisintawee and Nickel 54 The R code used for data analysis is available at: https://github.com/nbxszby416/uni-CLNMA/tree/main.
Funding statement
This work was partially supported by grants from the National Institutes of Health (R01DK128237, R01LM014344, R01LM013519, R01AG073435, R56AG074604, RF1AG077820, R21AI167418, R21EY034179, U24MH136069, and U01TR003709).
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/rsm.2024.12.



















 Open access
Open access