

Mental health clinicians treat patients who are at much greater risk of suicide, suicide attempts or non-fatal self-harm than the general population. Reference Meehan, Kapur, Hunt, Turnbull, Robinson and Bickley1,Reference Owens, Horrocks and House2 Clinicians would like to be able to predict with acceptable accuracy, for a clinically meaningful time frame, which individual patients will subsequently die by suicide or have a further episode of non-fatal self-harm so that preventive interventions can be preferentially allocated to those classified as ‘high risk’ for those outcomes. Reference Berman and Silverman3 Historically, there have been three generations of prediction approaches: unassisted clinician prediction (first), standardised scales or biological tests (second) and scales derived from statistical modelling (third). Many clinical instruments have been utilised for prediction including: psychological scales such as versions of the Beck Depression Inventory (BDI) Reference Beck, Ward, Mendelson, Mock and Erbaugh4 or the SADPERSONS scale; Reference Patterson, Dohn, Bird and Patterson5 biological tests such as the dexamethasone suppression test (DST) Reference Carroll6 and the cerebrospinal fluid (CSF) 5-hydroxyindoleacetic acid (5-HIAA) concentration test; Reference Carroll, Greden, Feinberg, Angrist, Burrows, Lader, Lingjaerde, Sedvall and Wheatley7 and scales derived from statistical models such as the ReACT Self-Harm Rule Reference Cooper, Kapur, Dunning, Guthrie, Appleby and Mackway-Jones8 and the Repeated Episodes of Self-Harm (RESH) score. Reference Spittal, Pirkis, Miller, Carter and Studdert9
At the policy level, the use of risk assessment classification to determine treatment allocation has been strongly endorsed in the USA. The (US) National Action Alliance for Suicide Prevention's Research Prioritization Task Force has made a recommendation to ‘find ways to assess who is at risk for attempting suicide in the immediate future’. This recommendation is specifically ‘related to the task of identifying and predicting near-term suicide risk at the individual patient level’. Reference Claassen, Harvilchuck-Laurenson and Fawcett10 Similarly, the (US) National Strategy for Suicide Prevention stated the need to ‘Fund the development of suicide screening and assessment tools that will be non-proprietary and widely available’ (Objective 7.4); and ‘Develop standardized protocols for use within emergency departments based on common clinical presentation to allow for more differentiated responses based on risk profiles and assessed clinical needs’ (Objective 9.6). 11 There have been clear objections about the clinical utility of this approach, based on the inaccuracy of predictive ‘tests’ used as the basis for allocation of treatment. Reference Ryan and Large12 In the UK, the National Institute for Health and Care Excellence (NICE) guidelines have instead suggested ‘Do not use risk assessment tools and scales to predict future suicide or repetition of self-harm’ and emphasised a shift in recommendations from ‘risk assessment’ to ‘needs assessment’ to determine allocation of clinical aftercare. 13 The relevant accuracy statistics for clinicians are the positive predictive value (PPV) and the negative predictive value (NPV) of a test; and as a basis for allocation of treatment, the PPV is the key statistic. Simply put: ‘The positive predictive value … expresses the proportion of those with positive test results who truly have disease’. Reference Attia14 Unlike sensitivity and specificity, the PPV and NPV are highly dependent on the prevalence of the outcome of interest, which means that the values for these measures are not simply transferable from one clinical population to another with different prevalence of disease. Reference Attia14 A few systematic reviews of predictive instruments have reported sensitivity and specificity ranges for specific tests or scales. Reference Freedenthal15,Reference Warden, Spiwak, Sareen and Bolton16 A recent review explored a wide range of diagnostic accuracy measures for a small number of risk scales used to assess patients after presentation for self-harm. Reference Quinlivan, Cooper, Davies, Hawton, Gunnell and Kapur17 However, there have been no meta-analyses to produce pooled estimates for the PPV for predictive instruments in mental health patient populations.
Method
Key questions
Our key question for the review was: is the classification of mental health patients as being ‘high risk’ for subsequent suicide death or self-harm (for example non-fatal self-harm, deliberate self-harm, self-harm, suicide attempt or parasuicide), by risk assessment, using either psychological scales, biological tests or third-generation scales, sufficiently accurate for clinical use? Our subquestion was: what are the pooled estimates for PPV of those clinical risk assessments in clinical populations?
Databases and search terms used
The systematic review was conducted using the PRISMA statement and associated set of instructions. Reference Liberati, Altman, Tetzlaff, Mulrow, Gotzsche and Ioannidis18 The search terms used were selected from past reviews and included: synonyms for suicidal behaviours including suicide and non-fatal self-harm (for example “self$harm”, “attempted suicide”, “parasuicide”, “self$injur*”, “self$poison*”, “suicide*”), synonyms for repetition (for example “repeat*”, “recur*”, “re$present*”, “recidiv*”) and synonyms for cohort study (for example “follow$up”, “retrospective”, “predict*”, “prospect*”, “longitudinal”). The databases used for the search included Medline, PsychInfo, Embase, CINHAL, Web of Science, Cochrane trials and Scopus. No time limits were used. We also hand searched key journals in the field; reviewed the reference lists of each paper retrieved; and used the ‘find similar’ and ‘find citing’ functions for seminal papers in Web of Science and PubMed. We contacted corresponding authors to provide clarification of results when these were unclear.
Inclusion and exclusion criteria
Studies were eligible for inclusion if: (a) they used a longitudinal cohort design; (b) they reported on a psychological scale, a biological test or a third-generation scale; (c) the scale was used as a risk assessment tool by using a cut-off score to classify participants as being at ‘high risk’ for subsequent suicidal behaviour; and (d) they reported data for suicide or self-harm outcomes during a follow-up period. There was no restriction based on study population, setting or age group. Only studies published in English were included. There was no restriction based on the time period when the study was conducted.
Studies were excluded if they did not: (a) use a clinical predictive scale of some type (for example unassisted clinician opinion) to ‘predict’ suicidal behaviours; (b) provide the minimum necessary extractable data for the meta-analyses; (c) did not have information for suicidal behaviour outcomes during a specified follow-up period; or (d) reported data from subsamples reported in other studies.
Data collection process
Three of the authors (K.M., A.M., M.J.S.) extracted descriptive information for each study. Individual studies could report on more than one scale, so we extracted the name of each scale and the cut-point used to predict outcomes (suicide, self-harm or self-harm plus suicide). For the meta-analyses, for each scale we used the 2 × 2 contingency tables or, if not available, we used the reported sensitivity, specificity and prevalence to calculate the values of interest using Bayes' rule. These data were recorded on forms, which were piloted on five evaluations and then modified before final use by four authors working in pairs (G.L.C.–K.M., A.M.–M.J.S.). Data were extracted by two independent raters, non-agreement was settled by discussion and consensus and reviewed by a third rater if needed.
Ratings of bias
We used the QUADAS-2 tool (QUality Assessment of Diagnostic Accuracy Studies – version 2) to assess risk of bias in four domains: patient selection (two items: participant selection (random or consecutive) and exclusions less than 15% of population), index test (two items: masking to outcome and pre-specified cut-points), reference standard (two items: classification of outcomes and masking of rating), and flow and timing (3 items: duration of follow-up 1 year or less, same outcome measurement for all, drop-out less than 15%). Reference Whiting, Rutjes, Westwood, Mallett, Deeks and Reitsma19
The QUADAS-2 forms were piloted on five evaluations and then modified before final use by two of the authors (G.L.C., A.M.) for each scale evaluation. Each item was phrased as a question requiring a rating of ‘yes’, ‘no’ or ‘unclear’ and each domain was then rated for risk of bias, classified as ‘low’, ‘high’ or ‘unclear’. The ratings of risk of bias for the four domains were used to provide a pooled rating of risk of bias for all the scales included in the meta-analyses. A subgroup of scale evaluations were classified as high quality (i.e. low risk of bias) if the ratings in the two most important domains (patient selection and flow and timing) were rated as low risk; and this subgroup was used for meta-analysis.
Data analysis
We classified studies as reporting biological scales or psychological scales (including third-generation scales) or both. We reported study-specific descriptive results using the n = 70 studies as the unit of analysis and scale-specific descriptive and meta-analysis results using the k = 128 study-outcome-sample-scales as the unit of analysis (online Table DS1). This latter unit of analysis reflects the different levels of information within each study – information on the study itself, the outcomes explored within each study, any subsamples that were used (whole sample, training sample, validation sample), and finally information on each scale that was evaluated. We therefore refer to this unit of analysis as the scale. Because scale-specific PPV values are proportions, we used the binomial-normal model to estimate the pooled PPV. Reference Stijnen, Hamza and Ozdemir20 This is a random-effects logistic regression model. The pooled PPV and the confidence intervals are estimated on the logit scale and then back transformed to a proportion for interpretation.
For the high-quality studies, third-generation studies, studies in hospital settings and studies of single psychological scales, there were a smaller number of studies, and so we combined self-harm and self-harm plus suicide outcomes (since the additional suicide events did not substantially inflate the prevalence of the self-harm outcome) as a composite outcome. The combined outcome of self-harm plus suicide can be interpreted as a self-harm outcome for the purposes of the estimated PPV.
We grouped scale evaluations by type and completed meta-analyses for: all scales combined (any suicidal behaviour, self-harm, self-harm plus suicide and suicide), high-quality evaluations (self-harm and self-harm plus suicide combined), all psychological scales (any suicidal behaviour, self-harm, self-harm plus suicide and suicide), all biological tests (any suicidal behaviour, self-harm, self-harm plus suicide and suicide) and third-generation scales (self-harm and self-harm plus suicide combined).
We also completed meta-analyses for individual scales where there were three or more evaluations available. These included biological tests, DST and CFS 5-HIAA levels (suicide); psychological scales, Buglass and Horton, SADPERSONS, Beck Hopelessness Scale (BHS), Beck Depression Inventory (BDI); and third-generation scales, Manchester Self-Harm Rule (MSHR), Edinburgh Risk Rating Scale (ERRS) (self-harm and self-harm plus suicide combined).
Publication bias was assessed using funnel plots for all studies and all scales combined, although it is acknowledged that this may be of limited usefulness in the meta-analyses of predictive studies. All meta-analyses were performed using the metafor package Reference Viechtbauer21 in R (version 3.20). 22
Results
The search produced 32 166 articles (including duplicates). Keyword screening in title and abstract identified 1076. We removed 355 duplicates. We screened the abstracts of the remaining 721 articles, removed 510 and included a further 93 from other sources. We then assessed 304 articles by reading the full text (including one study that was reviewed twice because it reported on a psychological and a biological scale). A total of 233 articles were excluded from this set (135 did not predict suicidal behaviour or were not longitudinal and 98 had no extractable data); leaving 70 articles for analysis (Fig. 1).
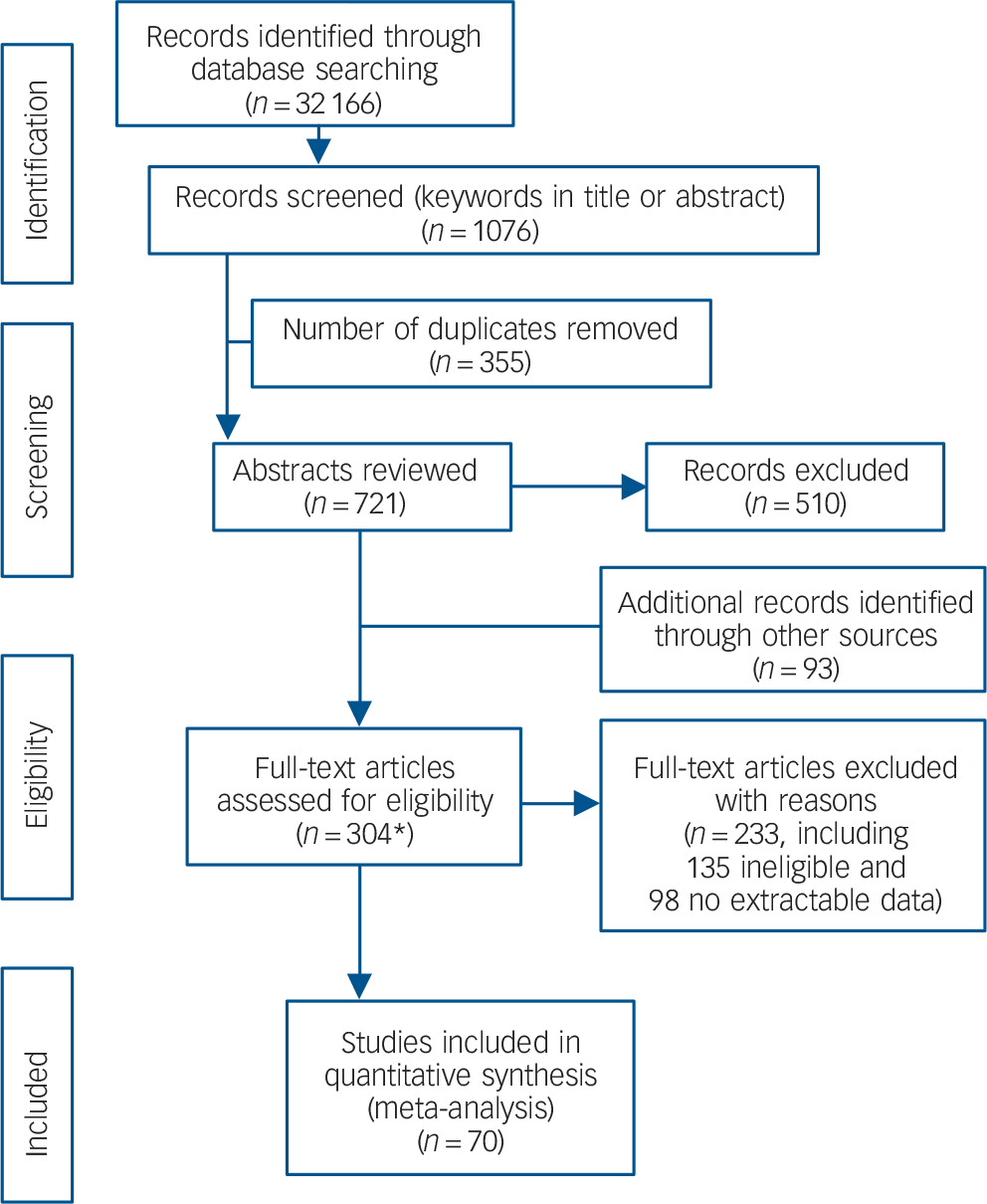
Fig. 1 PRISMA flow diagram.
*Includes one study that was assessed twice as it held data relevant to both a clinical and biological scale.
Overview of studies and scales
From the 70 selected studies, 52 assessed psychological scales, Reference Cooper, Kapur, Dunning, Guthrie, Appleby and Mackway-Jones8,Reference Spittal, Pirkis, Miller, Carter and Studdert9,Reference Beck, Steer, Kovacs and Garrison23–Reference Yen, Shea, Walsh, Edelen, Hopwood and Markowitz72 17 biological measures Reference Carroll, Greden, Feinberg, Angrist, Burrows, Lader, Lingjaerde, Sedvall and Wheatley7,Reference Asberg, Traskman and Thoren73–Reference Yerevanian, Feusner, Koek and Mintz88 and one reported on both. Reference Samuelsson, Jokinen, Nordstrom and Nordstrom89 An overview of the studies is shown in online Tables DS1 and DS2. Studies came from North America (psychological n = 24, biological n = 9), UK (psychological n = 13), Europe (psychological n = 12, biological n = 7, both n = 1), Australia and New Zealand (psychological n = 3) and one where the country was not reported (biological n = 1). The earliest study was published in 1966 Reference Cohen, Motto and Seiden34 and the latest in 2014. Reference Yaseen, Kopeykina, Gutkovich, Bassirnia, Cohen and Galynker71 Publication of articles over time show a phasic distribution with peaks in the 1980s (n = 18), 2000s (n = 19) and a further peak since 2010 (n = 17 currently).
Settings and samples
Most studies recruited adults (psychological n = 29, biological n = 13, both n = 1), others combined youth and adults (psychological n = 9) or adolescents only (psychological n = 4) and some did not report ages (psychological n = 10, biological n = 4). The samples were typically drawn from patients with recent self-harm or suicide ideation (psychological n = 33, biological n = 3, both n = 1) or from psychiatric populations (psychological n = 15, biological n = 14) with a minority from other populations (psychological n = 4). For psychiatric populations, the specific disorders (where reported) were mood disorders (psychological n = 1, biological n = 11), first-episode psychosis or schizophrenia (psychological n = 2, biological n = 1), post-traumatic stress disorder (clinical n = 1) and personality disorder (biological n = 1). Other populations were military veterans (psychological n = 1, biological n = 1) and prisoners (psychological n = 2).
Follow-up time points
The follow-up periods varied from 6 months or less (psychological n = 17, biological n = 1) to more than 10 years (psychological n = 3, biological n = 2). The most common length of follow-up was 1 year (psychological n = 13, biological n = 5, both n = 1).
QUADAS quality ratings
In total, 17% of scales were judged as having low risk of bias for patient selection (k = 22), 49% for choice of index test (k = 63), 59% for the reference standard (k = 76) and 34% for flow and timing of patients (k = 44) (online Fig. DS1). In all, 16 scales were judged as high quality overall because of low risk of bias in patient selection and flow and timing. Details can be seen in online Fig. DS1.
Pooled estimates of PPV
The forest plots of the study-specific PPVs for all scales and for each suicidal behaviour are contained in the online Fig. DS2. For all scales and any suicidal behaviour combined (k = 128), the overall pooled estimate PPV was 16.0%; for self-harm, (k = 62) 26.3%; for self-harm or self-harm and suicide combined (k = 15) 35.9%; and for suicide (k = 51) 5.5% (Fig. 2).
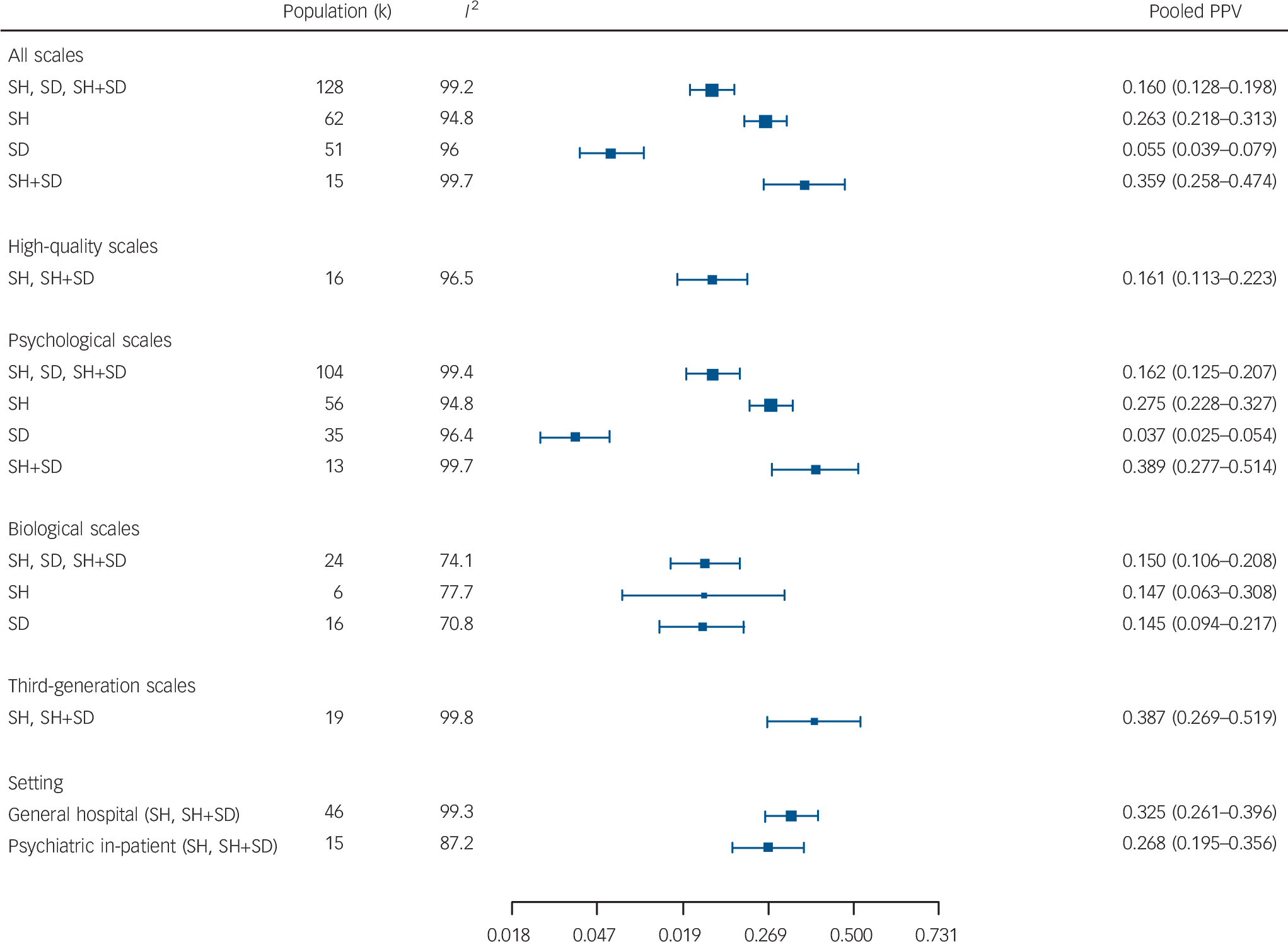
Fig. 2 Summary pooled positive predictive values (PPVs) from meta-analyses of all scales, psychological, biological, high-quality, third-generation scales and general hospital and psychiatric in-patient settings.
SD, suicide death, SH, self-harm.
When restricted to high-quality evaluations (k = 16) for self-harm or self-harm plus suicide combined, the pooled PPV estimate was 16.1%. For the psychological instruments the pooled PPV was highest for self-harm plus suicide (k = 13) 38.9%, followed by self-harm alone (k = 56) 27.5% and suicide (k = 35) 3.7%. For the biological measures, for any outcome (k = 24) the pooled PPV was 15.0%, for self-harm (k = 6) 14.7% and suicide (k = 16) 14.5%. For the third-generation scales (k = 19) the pooled PPV for self-harm or self-harm plus suicide was 38.7%; for general hospital populations (k = 46) it was 32.5% and for psychiatric hospital in-patients (k = 15) it was 26.8% (Fig. 2).
For the individual biological tests predicting suicide, the best pooled PPV was for CSF 5-HIAA (k = 6) 21.1%; for individual psychological scales predicting self-harm or self-harm plus suicide combined, the BHS (k = 4), 29.1% or the Buglass and Horton scale (k = 9) 28.8% were equal; and for third-generation scales the ERRS (k = 3) 27.6% was best (Fig. 3).
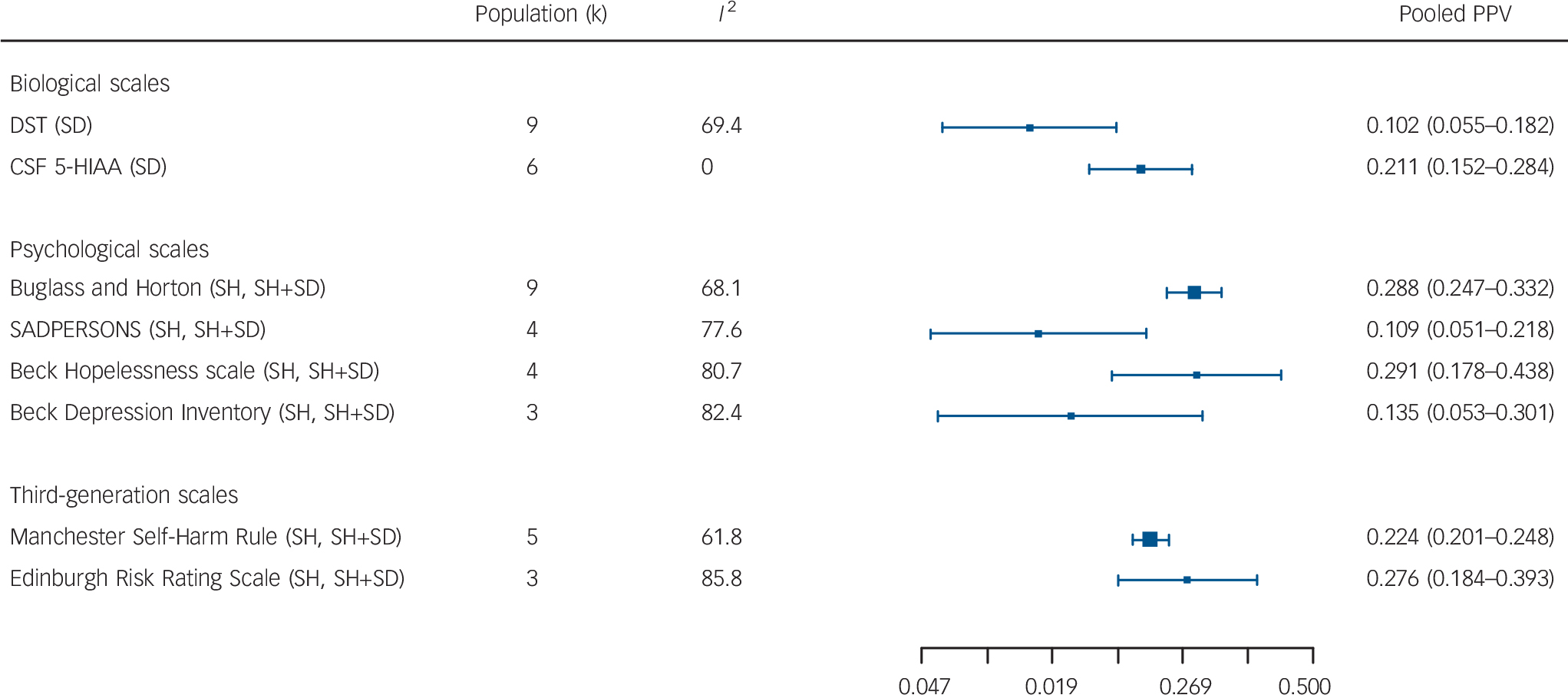
Fig. 3 Summary pooled positive predictive values (PPVs) from meta-analyses of specific biological scales, psychological scales and third-generation scales.
DST, Dexamethasone Suppression Test; CSF 5-HIAA, cerebrospinal fluid 5-hydroxyindoleacetic acid; SD, suicide death, SH, self-harm.
Heterogeneity and risk of publication bias
The I 2 statistics (Figs 2 and 3) indicated a high degree of heterogeneity among scales, except for the CSF 5-HIAA. The funnel plots using all k = 128 scales for all outcomes also suggested heterogeneity is present. For scales with large sample sizes (Fig. 4, top half of the plot), the scale-specific PPVs fall evenly on either side of the pooled PPV (on the logit scale). However, for scales with smaller sample sizes (bottom half of the plot), more studies appear to have been published with high PPV values. However, it is unclear whether the pattern is indicative of heterogeneity or publication bias. Reference Lau, Ioannidis, Terrin, Schmid and Olkin90
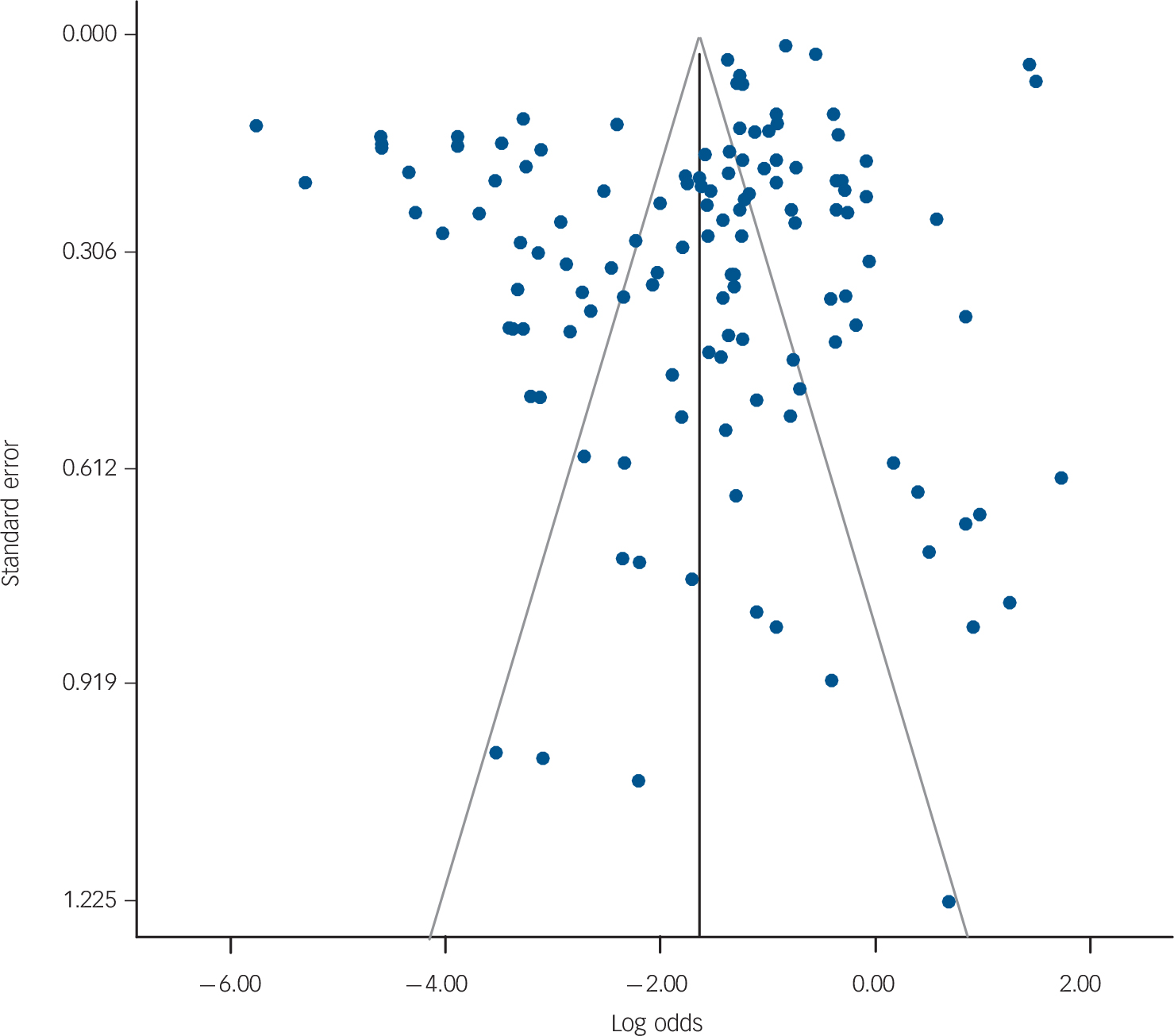
Fig. 4 Funnel plot for all scales and studies where the effect size of interest is positive predictive value (PPV).
Discussion
Prevalence rates and accuracy statistics
The PPV and NPV of all predictive instruments is limited by the prevalence of the outcome (i.e. ‘disease’) in the population of interest. This has been recognised in the prediction of suicide for over 60 years: ‘Suicide is an infrequent event and its prediction is subject to the limitations found in the prediction of any infrequent behavior or event’. Reference Rosen91 To illustrate, Pokorny presented a theoretical calculation, using a prevalence of suicide of 500/100 000/year (the suicide rate for psychiatric in-patients in Pokorny's unit) combined with a hypothetical predictive test having 99% sensitivity and 99% specificity. Reference Pokorny60 Under these idealised conditions the PPV was a modest 33%; and since 66% of positives would be false positives, the classification as ‘high risk’ was not useful to allocate intrusive and expensive treatment such as (involuntary) admission to hospital to prevent future suicide. Reference Pokorny60 Pokorny suggested that a test with a more realistic 50% sensitivity and 90% specificity would yield a PPV of only 2%, Reference Pokorny60 which is close to the pooled PPV estimates (range: 4–21%) from the current study.
Since repetition of hospital-treated self-harm has higher prevalence, could this be more suitable for a risk classification approach? In our study, the high-quality studies yielded a pooled estimate for PPV of 16.1% (including self-harm plus suicide), which is no different to the pooled prevalence estimate found by Carroll and colleagues. Reference Carroll, Metcalfe and Gunnell92 The third-generation scales, most of which had a high risk of bias (inclined to maximise prevalence), had a pooled PPV of 38.7%, which appears to be an improvement over the pre-test probability of 16.3%. Could this be clinically useful? We address this question below.
Clinical utility of predictive tests
There are three methods used to determine the clinical utility of a predictive instrument: the PPV, the likelihood ratio (positive) (LR+) Reference Attia14 and the clinical utility index (positive) (CUI+). Reference Mitchell93 Similarly, there are three approaches to the question ‘what are the best ways to decide whether my patient does not need treatment (or is safe to send home) based on a negative predictive test (i.e. classification as low risk)?’, however, that question will need to be addressed in a separate study.
PPVs
The simplest is the PPV, the proportion of test-positive patients that will have the outcome; the balance being false positives. The clinician considers the available interventions, including efficacy, adverse effects and cost of administration and then makes a balanced judgement as to the usefulness of the positive test to allocate treatment. Involuntary admission to psychiatric hospital (to prevent suicide), which is highly intrusive, high cost, of unclear efficacy and with adverse effects on social standing, employment and health insurance status, would generally require a very high PPV to be considered useful. Conversely, an intervention which is effective (to prevent self-harm), brief, medium cost, delivered in the community, with low likelihood of adverse effects, Reference Guthrie, Kapur, Mackway-Jones, Chew-Graham, Moorey and Mendel94 when balanced against the false positive patients receiving a treatment they did not need but was unlikely to harm them, might require a lower PPV.
Pre-test probabilities, post-test probabilities, likelihood ratios and Fagan nomograms
Likelihood ratios are said to be independent of the underlying prevalence rate, while being applicable to an individual. Reference Attia14 Likelihood ratios that are close to 1.0 have no clinical usefulness and a LR+ of more than 10 is likely to be clinically useful. Likelihood ratios can be calculated, LR+ = sensitivity/(1–specificity), but in practice it is easier to use the Fagan's nomogram that graphically links pre-test probability, likelihood ratio and post-test probability. Online versions of these nomograms are freely available (for example http://araw.mede.uic.edu/cgi-bin/testcalc.pl).
Taking the repetition rate of hospital-treated self-harm (16.3% in 12 months) Reference Carroll, Metcalfe and Gunnell92 as the pre-test probability for any patient; the best case post-test probability was 29% for the Buglass and Horton Scale and the BHS (LR+ 2.1); and 39% for the third-generation scales (LR+ 3.3). Similarly for an in-patient in a psychiatric hospital (expected 6.5% self-harm in 12 months); Reference Gunnell, Hawton, Ho, Evans, O'Connor and Potokar95 the pooled estimate of 27% as the post-test probability (LR+ of 5.2), would appear to be possibly useful. However, these study populations actually had a mean prevalence of 17.9% (LR+ 1.68), in which case prediction would have little usefulness.
CUI+
The CUI+ = sensitivity × PPV and is graded for utility: excellent ⩾0.81, good ⩾0.64, satisfactory ⩾0.49 and poor <0.49. Reference Mitchell93 Even when using the strongest results, the CUI+ was of poor utility: all scales, PPV 35.9%, pooled sensitivity 67.3% (CUI+0.24); psychological scales, PPV 38.9%, pooled sensitivity 70.0% (CUI+0.27); and third-generation studies, PPV 38.7%, pooled sensitivity 84.0% (CUI+0.33).
Duration of follow-up and clinical assessment of future suicidal behaviour
We considered 12 months as the longest duration of meaningful follow-up for clinical relevance and service organisation planning. Randomised controlled trials of psychosocial interventions are usually evaluated over a period of 6 or 12 months for the repetition of self-harm outcome. Reference Hetrick, Robinson, Spittal and Carter96 Many of the primary studies identified in our review used much longer follow-up, with a resulting increased prevalence rate of the outcomes and hence improved PPV estimates. This can be seen in the biological scales predicting suicide; the best pooled PPV was for CSF 5-HIAA (k = 6) 21.1%. This result was strongly influenced by six studies Reference Asberg, Traskman and Thoren73,Reference Asberg, Nordstrom, Traskman-Bendz and Roy74,Reference Jokinen, Nordstrom and Nordstrom82,Reference Nordstrom, Samuelsson, Asberg, Traskman-Bendz, Aberg-Wistedt and Nordin83,Reference Roy, Agren, Pickar, Linnoila, Doran and Cutler85,Reference Samuelsson, Jokinen, Nordstrom and Nordstrom89 where the sample sizes were small, and the populations were psychiatric in-patients (mostly with a depression diagnosis). The risk of bias was high or unclear for patient selection and the follow-up period was longer than 12 months for five evaluations. The prevalence of suicide in these six studies ranged from 3 to 33% (mean 17%), which is many times the expected rate for unselected psychiatric in-patients of 0.5% at 12 months after discharge; Reference Goldacre, Seagroatt and Hawton97 and more similar to a 19% lifetime prevalence for in-patient-treated populations with depression. Reference Goodwin and Jamison98
Can risk assessment be used in clinical practice to determine allocation of intervention?
Our meta-analysis shows that no instrument is sufficiently accurate as a basis to determine allocation to intervention. We would not recommend that ‘risk assessment’ be used to classify patients in order to allocate follow-up care, since most patients will be incorrectly classified (false positives) and directed to unnecessary treatment, whereas many patients will be classified as low risk (false negatives) and hence be denied necessary treatment. This is consistent with the NICE Clinical Guideline 133, which suggests that scales should not be used to predict future suicide or repetition of self-harm 13 and a recent review focused on a small number of predictive instruments. Reference Quinlivan, Cooper, Davies, Hawton, Gunnell and Kapur17
Alternatives to the risk assessment stratification approach to treatment allocation
Perhaps, the notion of ‘comprehensive risk assessment’ can be integrated into clinical practice with ‘comprehensive clinical assessment’, Reference Ryan and Large12 without the need to stratify patients into highly inaccurate risk categories. We would suggest that there are at least three alternative approaches to help determine treatment allocation.
First, clinical assessment can be used to identify any modifiable risk factors with follow-up care allocated to reduce exposure to those risks. Examples include: evidence-based treatments (for example for mood, substance use, psychotic or borderline personality disorders) or clinically accepted treatments (for example for relationship problems) or accepted standards of general care (for example individual and family support, social involvement, financial support, restriction of access to means). This approach is consistent with the ‘needs-based approach’ advocated by NICE 13 and with a public health approach that seeks to reduce exposure to known modifiable risk factors, in order to reduce prevalence and incidence of suicidal behaviours. This approach can be used for hospital-treated self-harm and for psychiatric in-patients at the time of discharge. Second, in subpopulations of patients who self-harm, for example patients meeting criteria for borderline personality disorder, there is proven efficacy for several psychological interventions specifically to reduce the number of self-harm events, 99 and these interventions are probably underutilised in clinical practice. Third, in unselected hospital-treated self-harm populations, cognitive–behavioural-based psychotherapy interventions have proven efficacy to reduce the proportion with any future self-harm; Reference Hetrick, Robinson, Spittal and Carter96,Reference Hawton, Witt, Taylor Salisbury, Arensman, Gunnell and Hazell100 and brief contact interventions may reduce the number of self-harm events. Reference Milner, Carter, Pirkis, Robinson and Spittal101 Patients who have self-harmed who are hospital treated could be allocated to these effective treatments without risk stratification. However, since 84% of patients will not repeat self-harm in 12 months, low-cost, short-term treatments with fewer adverse effects should be given higher priority. NICE guidelines suggest ‘Consider offering 3 to 12 sessions of a psychological intervention that is specifically structured for people who self-harm’. 13 Much less is known about interventions for the psychiatric in-patient population following discharge and these populations merit the development and evaluation of interventions to reduce subsequent self-harm.
Practice and policy implications
No individual predictive instrument or pooled subgroups of instruments were able to classify patients as being at high risk of suicidal behaviour with a level of accuracy suitable to be used to allocate treatment. Low prevalence outcomes, i.e. suicidal behaviours, are unlikely to be predicted by any instrument, even in key high-risk clinical populations, because of the statistical relationship of prevalence to PPV. The fairly steady increase in publication of papers arguing for the benefits of various risk assessment instruments and the parallel recommendations of prominent suicide prevention bodies to embrace the risk stratification approach for allocation of interventions has persisted despite the evidence against the clinical usefulness of this approach. Perhaps the evidence from this systematic review and meta-analysis will be used to mitigate these phenomena.
We would recommend three alternative approaches to a risk-based assessment to allocate intervention for high-risk clinical populations: first, an individual needs-based assessment followed by intervention to meet patient needs and to reduce exposure to modifiable risk factors; second, allocation of proven interventions for particular subpopulations; and third, the allocation of proven interventions that can be delivered to unselected clinical populations.
Limitations of the study
In any systematic review there is the danger of missing published studies because of incorrect selection of search terms or exclusion of studies based on assessment of titles and abstracts. Observational studies reporting accuracy of predictive instruments may be more difficult to identify than studies of recent randomised controlled trials, for which there are more established standards for titles and keywords. The risk of bias was high in some studies, particularly so for the studies of biological scales, which usually were much older studies and often capitalised on highly biased selection of participants and long follow-up times. Most studies of psychological scales examined hospital-treated self-harm populations and most biological tests were applied to in-patients in psychiatric hospitals with severe mood disorder, so generalisation of these findings to other populations should be done with caution. The meta-analysis of predictive studies differs from the meta-analysis of intervention studies in that heterogeneity is to be expected and hierarchical random-effects models are needed to estimate effect sizes. Reference Macaskill, Gatsonis, Deek, Harbord, Takwoingi, Deeks, Bossuyt and Gatsonis102 There was a high degree of heterogeneity for PPVs and in part this must be attributed to the differences in prevalence for three main outcomes: suicide, self-harm and self-harm plus suicide. These variations in prevalence can be seen in Tables DS1 and DS2. The I 2 statistic overestimates heterogeneity in meta-analyses of diagnostic tests. Reference Bossuyt, Davenport, Deeks, Hyde, Leeflang, Scholten, Deeks, Bossuyt and Gatsonis103 The further exploration of heterogeneity will require a series of meta-regressions, Reference Bossuyt, Davenport, Deeks, Hyde, Leeflang, Scholten, Deeks, Bossuyt and Gatsonis103 which could not be done in the current paper because of space restrictions. There will be other sources of heterogeneity, particularly arising from the populations selected, the predictor variables, the measurement of outcomes and the period of follow-up, which will be investigated further in a future paper.
Funding
K.M.'s position is funded by the Burdekin Suicide Prevention Program and administered by Hunter New England Mental Health Services.






eLetters
No eLetters have been published for this article.