


1. Introduction
Over the past decade, neural networks have found wide adoption in a range of musical contexts, primarily focused on the symbolic and digital domains (Briot Reference Briot2021; Wang et al. Reference Wang, Zhao, Liu, Pang, Qin and Wu2024), but there are comparatively few documented examples of their use within electromechanical sound-producing systems. Recent works illustrate this practice, from Gardener and Debicki’s Empty Vessels (2019), in which mechatronic cellos perform generated MIDI (Musical Instrument Digital Interface) sequences, to Quadrature’s Fantasie#4 (2019), which used radio wave data as a seed for generative models and player piano. To document artistic approaches in this emerging field, this article presents a practice review of works from the past decade, identifying how physical constraints shape the design of these systems and discussing the varied forms of interaction that arise.
The review reveals that while audio classification and MIDI generation are relatively common, the use of natural language processing (NLP) in a musical context remains underexplored. In response, the article documents the creation of a do-it-yourself (DIY) motor-driven instrument, embedding a small language model to generate syntax sequences. The project, Seven Studies for Electric Motors, maps the resulting sequences to motors and found objects, demonstrating how linguistic structures can be translated into physical sound and exploring the strategies for improvisational interaction that result.
This paper was guided by three questions:
-
1. How are neural networks currently used in electromechanical music and sound art, and which areas remain underexplored?
-
2. How do material constraints shape the design and function of these systems?
-
3. What approaches to interaction are employed in these systems, and how can they inform new modes of creative practice?
Related work in this field includes Parkinson and Dunning’s taxonomy of improvisational interaction with musical machines (Parkinson and Dunning Reference Parkinson and Dunning2024) and broader surveys of robotic musicianship (Bretan and Weinberg Reference Bretan and Weinberg2016). Several frameworks have emphasised the artistic dimensions of combining computational and material processes, including Valle’s description of acoustic computer music in which the limitations of found objects and actuators are seen as a creative affordance (Valle Reference Valle2013), and Pigott’s emphasis on the electromechanical mechanism itself as central to creative exploration (Pigott Reference Pigott2017). Zareei’s Audiovisual Materialism argues that the visual and material aspects of this practice are inseparable from the sonic (Zareei Reference Zareei2020), connecting with a broader field of practice, including kinetic sound art and sculpture.
This article contributes a practice review of neural network applications in electromechanical sound art and insights into artistic practice in machine learning through reflections on creative work. The following section outlines the broader context, tracing a renewed interest in mechanically-produced sound and its relevance to current forms of machine learning-based musical systems.
1.1. Electromechanical music
In recent years, composers and sound artists have made increasing use of motors, solenoids, and other electromechanical devices to enact computational processes through physical sound-producing bodies. This is driven in part by increased accessibility to hardware – actuators, sensors, and microcontrollers – and software – a variety of open-source tools, educational resources, and forums (Flø Reference Flø2018; Zareei Reference Zareei2020).
Current practitioners are drawing on a history of kinetic sound art and mechanical music, with automatic instruments paired with algorithmic procedures as early as Winkel’s Reference Winkel1821 Componium, a self-playing organ capable of generating variations on a theme (Zemanek Reference Zemanek1966). The late twentieth-century resurgence of interest in mechanical instruments saw the expressive potential of the player piano expanded notably by Nancarrow and later by Peter Ablinger and others (Drott Reference Drott2004; Barrett Reference Barrett2009). Mechatronic ensembles including LEMUR (League of Electronic Musical Urban Robots), Machine Orchestra, and SolidNoise Ensemble represent a growing interest in the expressive potential of automated instruments, computational control, and DIY methods, alongside a recognition of the unique character and qualities of acoustic sound (Harriman et al. Reference Harriman, Bethancourt, Narula, Theodore and Gross2016; Kapur et al. Reference Kapur, Darling, Diakopoulos, Murphy, Hochenbaum, Vallis and Bahn2011; Oh et al. Reference Oh, Harriman, Narula, Gross, Eisenberg and Hsi2016).
At the same time, kinetic sculpture and electromechanical sound art have been developing throughout the late twentieth and early twenty-first centuries, with notable examples including Trimpin’s interactive sculptures and installations (Leitman Reference Leitman2011). Other artists working in this field include Peter Vogel, Pe Lang, Zimoun, and Marianthi Papalexandri, among many others.
Despite the widespread use of algorithmic control in electromechanical musical systems, the incorporation of machine learning into this field is a relatively recent practice, with exceptions including Baginsky’s self-learning robotic rock band, The Three Sirens (1992-) (Audry et al. Reference Audry, Drouin-Trempe and Siebert2022). Unlike purely electronic systems, electromechanical systems introduce a materiality that shapes both the sound produced and the conceptual approach taken by the artist. These systems present a particularly compelling case for exploring machine learning algorithms through their acoustic and material properties, requiring consideration of the instruments’ physical constraints and sonic affordances, from actuation mechanisms to the resonant properties of materials. At the same time, machine learning applications can extend approaches to interaction by allowing features to be learned from data rather than being explicitly programmed, as well as facilitating novel generative behaviours. To understand how artists are working within this space, the following section outlines the methodology used to survey existing works and structure a review of current approaches.
2. Methodology
This research was conducted in three stages: a review of the field, identification of a research gap, and a practice-based exploration in response to that gap.
First, a review of existing works from 2015 to the present was undertaken to provide a survey of the field over the past decade. The search began with academic databases,Footnote 1 journals,Footnote 2 and conference proceedings.Footnote 3 Terms covered three areas: machine learning, mechatronic music, and sound art, combining at least one machine learning term (such as ‘AI’ or ‘neural network’) with at least one mechatronic term (such as ‘robotic’, ‘solenoid’, or ‘kinetic’) and one sound art or music term (such as ‘sound art’ or ‘installation’). To reduce the results to a manageable size, limitations were applied to the subject area or relevant keywords. This approach highlighted the limitations of keyword search strategies, e.g., kinetic is a common musical metaphor, which can obscure results. Results were supplemented with a search of gallery archives, artist websites, and repositories to identify further artistic projects and performances not otherwise documented.Footnote 4 This survey is partial and reflects available documentation rather than an exhaustive catalogue.
The discussion addresses the research questions on emerging applications, material constraints, and strategies for interaction. This revealed the application of NLP within electromechanical music as a comparatively underexplored area. While a few works were found to use NLP for narrative or conceptual purposes, its potential for generating abstract musical material – building on compositional approaches such as those developed by Clarence Barlow (Barlow Reference Barlow2021) – remained largely unaddressed.
To explore this application in greater depth, Seven Studies for Electric Motors was developed: a DIY motor-driven device that integrates a small language model for linguistic syntax-based sequence generation. The project serves as an exploratory case study for embedding language models in electromechanical instruments. Reflections on this practice aim to clarify insights emerging from the practical activity of developing new work – what Barbara Bolt describes as a ‘reflexive knowing that imbricates and follows on from handling’ (Bolt Reference Bolt, Barrett and Bolt2007).
3. Results
Surveyed works were manually organised into categories reflecting the function of a neural network. Many of the most prominent applications involve models that are highly specialised in their domain; MIDI generation models depend on the structure of symbolic music, and speech-to-text models are designed to process phonetic and linguistic data. In these cases, the categories are partly defined by the data itself (e.g., MIDI generation, speech transcription). However, a flexible tool like Wekinator is not defined by a specific domain, and so the category Live Parameter Mapping is used to describe its role in creating real-time, learned connections between input and output.
3.1. Audio classification
Software libraries for machine learning-based audio classification are becoming increasingly accessible, including Flucoma (Tremblay et al. Reference Tremblay, Roma and Green2021) and MLStar (Kopito et al. Reference Kopito, Schwartz, Amblard, Filman and Rabern2023). While neural networks have been applied to audio classification since the late 1990s, these recent tools allow practitioners without expert knowledge to train a neural network on a dataset of categorised sounds, using a set of user-defined audio features to teach the model to distinguish between different sound classes. These features can describe timbral characteristics, such as Mel-frequency cepstral coefficients (MFCCs), brightness, or roughness, or rhythmic qualities.
In practice, audio classification is often combined with acoustic instruments in performer-responsive works, with two works in this category exploring parallel human-robotic configurations.
-
Ben Eyes’ Ghost in the Piano (Eyes Reference Eyes2024) augments a piano with motors, solenoids, actuators, and loudspeakers, analysing live guitar audio using FluCoMa to classify playing techniques, which then inform a wavetable-based sequencer and synthesiser. The resulting accompaniment is projected through the piano’s acoustic resonance via synthesised sound and motor-driven actuators.
-
Gioti’s Imitation Game (Gioti Reference Gioti2019) paired a human percussionist with a robotic counterpart, controlled by a feed-forward neural network trained to classify the rhythms, instruments, and playing techniques of the human performer in three modes of interaction: repeat, imitate, and initiate.
-
Franklin’s Robo-Cajon (Franklin Reference Franklin2024) also features a parallel configuration, pairing a solenoid-actuated cajon with a human-played cajon equipped with a contact microphone, classifying rhythmic data from the human performer using a neural network in MLStar, with a hidden Markov model (HMM) used to predict and generate rhythmic patterns.
3.2. MIDI generation
Machine learning-based MIDI generation typically involves training a neural network, such as a recurrent neural network (RNN) or a transformer, on a large dataset of existing MIDI. Once trained, the models can generate new sequences that reproduce the stylistic and structural features of the source material, though challenges remain in capturing long-term form and expression (Mitra and Zualkernan Reference Mitra and Zualkernan2025).
These applications are well-suited to existing mechanical instruments such as the Disklavier due to their compatibility with MIDI control and the availability of extensive training datasets (Wang et al. Reference Wang, Zhao, Liu, Pang, Qin and Wu2024), while projects involving custom-built instruments often require the creation of new datasets that reflect the specific affordances of the instrument. However, both approaches often feature other statistical or rule-based methods in tandem with generative models.
-
Quadrature’s Fantasie#4 (Quadrature 2021) mapped live radio telescope signals to player piano, generating MIDI using Piano Genie (Donahue et al. Reference Donahue, Simon and Dieleman2019), and Magenta’s Polyphony-RNN was trained on twentieth-century piano music. The work presents a gradual divergence of machine learning responses from direct mappings of the radio signals, as the models elaborate on the data.
-
Nikrang’s Absolute Hallucination (Nikrang Reference Nikrang2024) used Ricercar, a collaborative software trained on public domain classical works, to control a self-playing piano. The work explores random compositional paths through the ‘creative space’ of the model.
-
Thompson IV (Thompson IV Reference Thompson2022) created duets for Disklavier and human performer, training Polyphony-RNN on MIDI transcribed from speech and piano music from Thelonious Monk to Mara Gibson.
-
Refree’s Interleggere ad affectum (2025) repurposed GrooveTransformer, a transformer-based model for real-time drum accompaniment generation, to produce a rhythmic and harmonic accompaniment in a work for multiple pipe organs. The work used a Markov-based process to generate harmonic content and note durations, with a second performer supervising the generative accompaniment (Evans et al. Reference Evans, Haki and Jordà2025).
-
Arca, Armitage, and Shepardson’s The Light Comes in the Name of the Voice (Shepardson and Armitage Reference Shepardson and Armitage2024) employed a generative system built around the Notochord MIDI model to extend Arca’s improvisations on the Magnetic Resonator Piano, an electromagnetically augmented grand piano (McPherson Reference McPherson2010), into ‘uncanny’ reinterpretations.
-
Gardener and Debicki’s Empty Vessels (Debicki and Gardener Reference Debicki and Gardener2019) features a mechatronic cello trio performing generated MIDI sequences, using an HMM to generate melody parts from the MIDI model’s harmonic output.
-
Benjamin Bacon’s Little Sound Machines (Bacon Reference Bacon2018) consists of multiple devices constructed from salvaged and repurposed objects. The work used separate Tensorflow models for rhythm, harmony, and melody construction, followed by stochastic parameter generation in Max-MSP. Throughout the installation, the models learn from and influence each other in a ‘purely machine-made performance’.
3.3. Live parameter mapping
Mapping non-musical data streams to control mechanical actions is a common strategy in electromechanical sound art. In works not using machine learning, this is often achieved using rule-based systems, from Zareei’s mapping of cellular automata to motor frequencies and light-emitting diode (LED) patterns in Noise Square (Zareei et al. Reference Zareei, Carnegie and Kapur2015) to the mapping of a dancer’s movement to mechanically actuated percussion in Hsu and Kemper’s Why Should Our Bodies End at the Skin? (Hsu and Kemper Reference Hsu and Kemper2019), and Eacott’s submerged sensor in Floodtide (2008) for translating tidal data into parameters for a mechanical organ.
The advantage of machine learning in this context is the ease with which complex and high-dimensional mappings can be created, with the relationships learned from examples provided by the user. Wekinator is a prominent tool for real-time model training, supporting a range of algorithms – from neural networks to decision trees and support vector machines – and has found wide applications in interactive music (Fiebrink and Sonami Reference Fiebrink and Sonami2020), as well as the single example identified below in the electromechanical domain.
-
Macionis and Kapur’s Where is the Quiet (Macionis and Kapur Reference Macionis and Kapur2019) used Wekinator to analyse EEG data (Muse headband), mapping alpha waves to solenoid-actuated singing bowls in response to a calm state of the participant.
3.4. System modelling
System modelling involves training a model to reproduce the dynamics of a complex system. Unlike direct parameter mapping, where an input is directly mapped to an output, this method uses a neural network to generate data that simulates or predicts a system’s behaviour. The underlying process is often similar to MIDI generation, in that a model learns sequential patterns from a dataset and is then used to make predictions – but the prevalence and specific focus of MIDI generation warrant a separate category.
-
In Supraorganism (Emard Reference Emard2020), Justine Emard trained a neural network on data from a honeybee colony. The network’s predictions of the colony’s behaviour are embodied by robotic glass and light sculptures that produce sound by rotating wires against their surfaces.
3.5. Analogue neural networks
Some artists have used analogue models of neural networks as the basis for physical installation works. This approach can be seen in analogue electronic works such as Wolfgang Spahn’s Echo State Network (Spahn Reference Spahn2019) and with sound enacted through motors in Faubel’s generation of emergent rhythmic patterns using ‘neurally inspired’ analogue oscillators (Faubel Reference Faubel2021).
-
Spahn and Faubel’s Symbolic Grounding (Faubel and Spahn Reference Faubel and Spahn2018) is an installation work in which kinetic sound and light patterns emerge from an analogue network of artificial neurons – a process the artists describe as rendering the emergent ‘temporal structures and functions tangible’. The work’s use of neural oscillators makes this a distinct approach to the algorithmic machine learning strategies discussed elsewhere.
3.6. Speech transcription
The transcription of speech to generate musical material has been widely used in the broader electromechanical field. Many works, from Peter Ablinger’s Quadraturen series to Canuto’s stepper motor-driven Talking Motors (Canuto Reference Canuto2023), focus on spectral features, mapping the acoustic properties of the voice to automatic instruments or motors. Other approaches include physical models of the acoustic vocal tract, as found in the resonators of Ali Miharbi’s Whispering series (Miharbi Reference Miharbi2016).
A different approach has emerged with the development of speech-to-text systems. They function by using an acoustic model to analyse an audio signal and map its sound features to phonemes. A language model then processes this sequence, statistically determining the most probable series of words. Artistic works using text transcription often centre around the misinterpretation or fragmentation of meaning.
-
Benjamin Bacon’s PROBE II, Subaudition (Bacon Reference Bacon2021) used DeepSpeech to transcribe audience speech, transmitted to a second machine which translates the data to a mirrored zoetrope projection. The work focuses on the ‘translation, degradation, and misinterpretation of meaning’.
3.7. Text and language generation
Modern neural network models for text generation use an encoder-decoder framework to map an input sequence into low-dimensional vectors called embeddings. A decoder then uses these embeddings to generate new text (Li et al. Reference Li, Tang, Zhao, Nie and Wen2024).
Text generation has found artistic uses across music and sound art to generate musical forms, from Walshe’s Text Score Dataset (Walshe Reference Walshe2021) to the deliberate undertraining of models in Kıratlı’s Cacaphonic Choir (Kıratlı et al. Reference Kıratlı, Wolfe and Bundy2020). In the material domain, these models can be used to imbue physical objects with personality and narrative and model non-human forms of communication.
-
Jan Zuiderveld’s Conversations beyond the ordinary (Zuiderveld Reference Zuiderveld2024) embedded large language models in appliances – a coffee machine, a microwave, and a photocopier – giving the devices specific personalities; the coffee machine requires the audience’s sincere desire for a coffee in order to produce one.
-
Savery developed singing capabilities for the robotic marimba player, Shimon (Savery et al. Reference Savery, Zahray, Weinberg and Miranda2021), generating lyrics with a combination of WordNet to provide synonyms and antonyms from user-defined keywords, a Long Short-Term Memory network (LSTM) for text generation, and a Markov model to refine the generated rhymes. The authors synchronise the robot’s physical gestures with the lyrics, including ‘emotion-conveying eyebrow movements’.
-
Thomas Grill’s Mutual Understanding installation (Grill Reference Grill2019) uses two agents communicating via horn loudspeakers, inspired by an experiment in which chatbots were directed to optimise their language for negotiation. The agents develop a vocabulary independent from human language with a goal to ‘maximise the beauty of their own vocal expression’.
3.8. Current and emerging applications
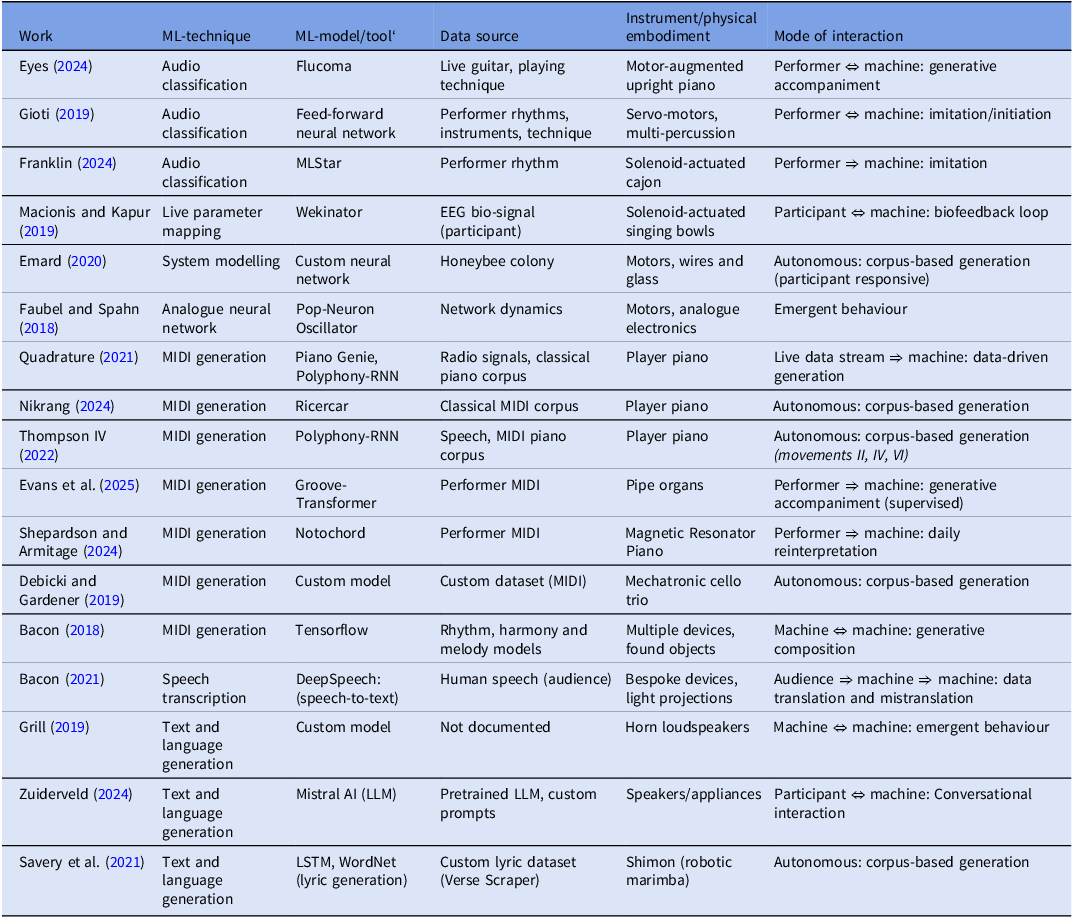
Table 1 provides a summary of the key works identified. The seventeen works included are those which use a documented machine learning technique and in which a physical component is central to their realisation. The table categorises each work according to its technique and tool, instrument or physical embodiment, and mode of interaction, providing an overview that informs the following practice-based work and later discussion.
Summary of surveyed works

The ‘Mode of Interaction’ column considers the agents involved, whether an interaction is directional or reciprocal, and the primary artistic purpose (imitative, responsive, generative, etc.). This practical approach was chosen over more formal frameworks, such as those by Jung (Jung Reference Jung2023) or Vear (Vear et al. Reference Vear, Benford, Avila and Moroz2023), to accommodate the diversity of the works, which range from human-machine collaborations to autonomous systems.
MIDI generation was the most widespread application. These works used a range of approaches, from creating custom models (Empty Vessels) to fine-tuning existing models (Fantasie#4, The Light Comes…). Generative MIDI models were often paired with player pianos, likely reflecting the availability of datasets and the compatibility of models with MIDI-enabled instruments. Some works in this category used non-musical data such as transcribed speech as input (Seven Piano Etudes Speaks…) but the majority used existing piano datasets. Custom-built instruments often repurpose or combine models (Little Sound Machines) for the particular affordances of the instrument.
A smaller number of works turned to alternative generative strategies. These included the modelling of environmental systems, as found in Emard’s Supraorganism, where a neural network’s predictions of a honeybee colony dictated the behaviour of the installation. In a distinct approach, the emergent behaviour of an analogue neural network was embodied in Spahn and Faubel’s Symbolic Grounding, based on the spontaneous self-organising properties of such networks (Amari Reference Amari1977).
Five works used neural networks for data interpretation, with sources ranging from audio to EEG streams. Here, the main affordance of machine learning (ML) is its ease of use and robustness relative to other algorithmic approaches. Audio classification was implemented with existing software libraries (FluCoMa, MLStar), while live parameter mapping often relied on flexible tools such as Wekinator (Where is the Quiet). These models typically formed part of larger algorithmic systems, incorporating performer-machine feedback loops (Imitation Game) and stochastic elements to generate electromechanical responses. While the role of the models themselves in these works was largely functional, Bacon’s PROBE II used errors in the speech-to-text process as a central theme of the work.
NLP is an emerging area, with four works using models ranging from speech-to-text to large language models. Text generation strategies were used to explore machine personality (Conversations beyond…) or model non-human forms of communication (Mutual Understanding). These focus on language as a narrative or conceptual medium rather than as a structural source for composition, which suggests opportunities for further work in this area. One such approach is explored through the following practice-based case study.
Other notable gaps include machine vision, which, despite the maturity of tools in adjacent fields, remains underexplored in this domain. Similarly, while the potential for embedding inference directly onto microcontrollers is growing with frameworks like TensorFlow Lite and Edge Impulse, few works currently take advantage of completely embedded ML processes.
4. Discussion
The following discussion considers the second and third guiding questions of this article: how material constraints shape the design and function of electromechanical systems, and what approaches to interaction are employed within them.
4.1. Material constraints
Zareei’s Audiovisual Materialism (Zareei Reference Zareei2020) points to the inseparability of the material, visual, and audible aspects of a work. This can be seen clearly in the alien forms of Bacon’s Probe II, which are themselves the sound-producing bodies. Likewise, the light and sound patterns of Emard’s Supraorganism are a direct visualisation of an emergent system, and in player piano works, the physical action of keys and hammers is a central part of the aesthetic.
Pigott, in foregrounding the electromechanical mechanism, distinguishes between works which celebrate the unpredictable qualities of materials and those which prioritise fine, expressive control (Pigott Reference Pigott2017). The most common approach was the latter, with existing instruments including the player piano and MIDI-enabled pipe organ and new augmented instruments such as the Magnetic Resonator Piano (MRP). The constraints of these systems often influenced the implementation of the machine learning system: in Empty Vessels, Gardener and Debicki created a dataset tailored to the unique affordances of the mechatronic cello trio, finding that existing datasets did not suit the capabilities of the instrument. In Arca, Armitage, and Shepardson’s The Light Comes in the Name of the Voice, the particular timbral and dynamic affordances of the MRP required a custom approach to model training, reusing aspects of the original performance to map between the expression of the instrument and the velocity values expected by the model.
Material constraints are, however, more immediately visible in Pigott’s description of unpredictable sound materials. This approach, which Valle terms ‘semi-random variations…in the electromechanical environment’ (Valle Reference Valle2013), typically features DIY instruments built from motors, servos, solenoids, and found objects. Here, the inherent limitations and erratic nature of the materials act as both affordance and constraint; the unpredictability of Emard’s glass-enclosed wires or ringing school bell of Bacon’s Little Sound Machines is central to those works, but the model and electromechanical mechanism are often less tightly integrated, with the model’s output serving as a trigger for an action rather than a detailed performance instruction (as in the MRP). This can be seen in Seven Studies, where the sequences produced by the language model were mapped to precomputed grid sequences as an intermediate stage between the model and motors. Where instrumental affordances were particularly constrained – such as the solenoid-actuated singing bowls (Where is the Quiet) – a threshold was used to map complex data to physical action. This strategy occurs frequently in wider electromechanical sound art, such as Greg Kress’ Brain Noise Machine (Kress Reference Kress2010), which uses a threshold on the participant’s level of mental focus to control a single DC motor.
A third distinct approach was the augmentation of existing non-musical appliances, with Zuiderveld embedding personality and narrative into coffee machines, microwaves, and other devices. Here, the object’s pre-existing function shapes the artistic statement. This is an idea widely explored in electromechanical sound art outside of ML approaches: for example, Dunham’s CLICK::TWEET (Dunham Reference Dunham2021), which draws comparisons between modern and past methods of communication through pairing telegraph keys with social media feeds.
4.2. Interaction
The nature of interaction ranged across the surveyed works, from human-machine dialogue to fully autonomous systems. In directional (performer ⇒ machine) interactions, a performer’s audio or MIDI data served as a one-way input to the system. The purpose of one-way interactions in the surveyed works ranged from direct imitation to using performance data as a seed for a generative MIDI model. While most works in this category involved live interaction, Arca, Armitage, and Shepardson’s The Light Comes in the Name of the Voice presented a delayed interaction in which Arca’s improvisations were reinterpreted by the model in an installation setting.
Reciprocal (performer ⇔ machine) interactions involved feedback loops. In Parkinson and Dunning’s Improvising with Machines (Parkinson and Dunning Reference Parkinson and Dunning2024), these systems could be described as collaborative works in which a human performer responds to the output of the machine and, in turn, influences the machine. This dynamic is central to creating what Vear describes as liveness, ‘a sensation that something is co-operating in the real-time flow, or not’ (Vear et al. Reference Vear, Benford, Avila and Moroz2023). Gioti, in Imitation Game, describes balancing this real-time interaction with aspects of compositional control by using a naïve rehearsal format, in which a human improviser has no preconception of how the system will respond.
Other works minimised or removed the human from the interactive loop, focusing instead on data-driven or emergent behaviours. Autonomous systems (Empty Vessels, Absolute Hallucination) operated without direct human input during the performance. Quadrature’s Fantasie#4 presented an interaction between a non-human data source (live radio waves) and a non-human musical agent (generative model, player piano), with the creative act as the machine interpretation of data streams. Emard’s Supraorganism combined both dataset-based generation and responsive approaches through a largely autonomous system, but with audiences influencing the installation’s behaviour through their presence.
Machine-to-machine approaches explored emergent behaviour between multiple machine agents, as in Bacon’s Little Sound Machines, where three models ‘learn from and influence each other’. Grill’s Mutual Understanding focused specifically on the outcomes of these machine-to-machine interactions in language processing, and Bacon’s PROBE II examined interaction through the translation and mistranslation of information passed between human and machine and between machines themselves.
Jung proposes a three-axis model for intelligent music performance system design (IMPS) comprised of embodiment, participation, and autonomy – described as the ‘extent to which non-human agents are integrated into a system, and… the autonomous contributions within a system’. The surveyed works as material objects demonstrate high levels of physical embodiment but vary widely in autonomy and participation. Performer-machine works such as Gioti’s Imitation Game featured high participation with autonomy moderated through performer control or predefined modes of interaction. Corpus-based systems like Nikrang’s Absolute Hallucination demonstrate a high degree of autonomy by eliminating the human from the immediate interactive loop, even while their output is shaped by a human-curated dataset.
From an audience’s perspective, it may not be clear to what extent a work is autonomous (Couchot Reference Couchot2019: 243). This is examined in Anna Savery’s work for the robot musician Kierzo, where an audience survey revealed questions about whether the device was pre-programmed or responding randomly to the performer – and suggests explaining the technologies before performances as a possible approach (Savery and Savery Reference Savery and Savery2024). A degree of misinterpretation can also happen in the opposite context: in Stapleton and Davis’ networked performance piece Ambiguous Devices, pre-concert talks explained that the devices were not autonomous but performed remotely by a human collaborator (Stapleton and Davis Reference Stapleton and Davis2012).
5. Seven studies for electric motors
5.1. Overview
The practice review identified natural language processing as an underexplored application within musical systems. To explore this further, the following sections outline a practice-based approach through the design of a DIY electromechanical instrument, using a small language model to produce syntax sequences for musical output.
Syntax patterns as the basis for musical structure occur in several existing works. Barlow’s Progéthal Percussian for Advanced Beginners (Barlow Reference Barlow2003) computationally mapped parts of speech to a musical score for six percussionists, framed as a course in this new language. More recently, Ko et al.’s Harmonic Words, Narrative Chords (Ko et al. Reference Ko, Choi and Lee2024) outlines a process of deriving harmonic sequences from parts of speech, word length, and sentiment. Other artists have explored formal grammar as a generative technique, such as Clemens Gadenstätter’s Semantical Investigations II (Gadenstätter et al. Reference Gadenstätter, Mayer, Eder, Nierhaus and Nierhaus2015).
Seven Studies for Electric Motors develops Barlow’s approach in Progéthal Percussian through the embedding of a small language model in a DIY motor-driven improvisation device (Figure 1). The work is built around the generation of sentences and the extraction of dependency relations, structures that describe the syntactic connections between words. These patterns are then mapped to sequences of motor and light activity. Motors are used in this realisation for three reasons: first, the algorithmic process of generation, parsing, and mapping is central to the work, providing a means to create structured sequences that would be impractical to compose or realise manually. Second, these devices allow testing of a mapping method with instant audible feedback. And finally, the use of found and recycled objects is an important part of this practice; as with the use of speech, this involves placing ordinary objects in a musical context, with their imperfections and limitations drawn out through the mapping. There is no requirement for the objects to be drawn from the text or designed to imitate any aspect of human vocal production – in fact, it is only through the difference between the source and material realisation that new and surprising musical material emerges.
The seven studies for the electric motor device, showing the perspex surface, 16 DC motors, and an arrangement of found objects and actuators (copper, springs, plastic, and wood).

The found objects and actuators, including springs, copper foil, sticks, paper, plastic, and broken terracotta, are attached magnetically and rearranged between each study, introducing a degree of unpredictability. I currently work with around sixty objects, gradually adding new materials over time.
The objectives of the project were as follows:
-
Embedded text generation. The text was generated using a small language model running on a Raspberry Pi.
-
Extract dependency relations. These syntactical labels describe relationships between words in a sentence and were extracted from the generated text using spaCy.
-
Map dependency relations to musical sequences. A set of speech-derived sequence fragments was used as an analogue for dependency relation tokens.
-
Enact sequences through electric motors. Sixteen DC motors performed the generated sequences via found objects and actuators.
-
Modular objects and actuators. Found objects were mounted on magnets to allow easy adjustment and replacement during performance. Actuators were also removable to create a variety of sounds.
-
Amplification. Two contact microphones were used to amplify the sounds produced.
-
Lights. LEDs were used to make the resulting patterns and sequences visible.
-
Improvisation. To interact with the sequences performatively, an interface was developed using a MIDI controller to adjust the speed, amplitude, and other parameters in real time.
5.2. Embedded text generation
A key objective for Seven Studies was to create a self-contained, portable system so that I could travel and perform with the device in different locations. This required embedding the language generation process; the computational requirements of large language models make them unsuitable for this kind of local deployment, and the need for a stable internet connection would limit venues for performance. The selection of a specific small language model – Smollm2:135m (Allal et al. Reference Allal, Lozhkov, Bakouch, Blázquez and Penedo2025) – was led by this constraint. While small models lack the accuracy of their larger counterparts, their value in this project lies in their ability to efficiently generate novel, grammatically coherent sentences.
The model was prompted with the instruction ‘Generate a sentence about x’, where x is a random word supplied by the Wonderwords Python library. Each sentence is then parsed using the open-source spaCy library to extract the sequence of syntactic dependency relations, which form the input for the mapping process.
5.3. Mapping process
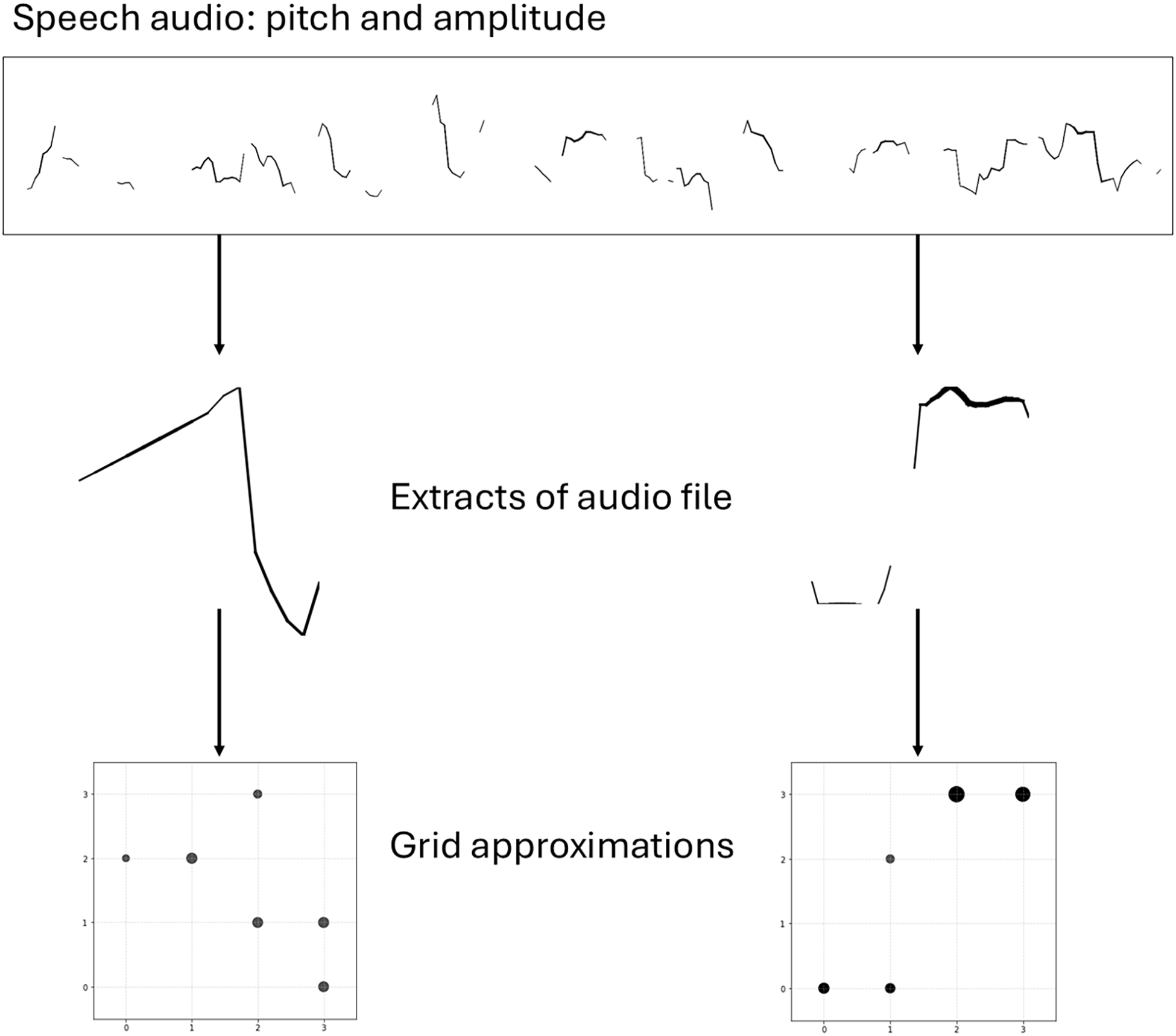
The mapping process converts the abstract syntactic structures from the language model into motion, sound, and light. This system was designed around an analogy: the machine-generated syntax provides the grammar to structure events in time, while approximations of human speech prosody provide the vocabulary for each event. To create this vocabulary, audio recordings of speech were segmented, analysed for pitch and amplitude, and translated into a set of over 250,000 4 × 4 motor activation grids, each representing a distinct sequence (Figure 2).
The mapping process: audio from speech recordings analysed for pitch and amplitude, translated into a 4 × 4 grid where point size represents motor speed.

This was a two-stage process: each speech audio file was represented as an F0 pitch and amplitude curve and segmented on silence. Each curve was then reduced to a sequence of points in a grid, where x represents time, y represents F0 pitch estimation, and point size corresponds to average amplitude. This extreme simplification is related to Ablinger’s grid-based Quadraturen method (Barrett Reference Barrett2009), applied here to generate a broad vocabulary of motor and light patterns. In performance, a randomised set of individual patterns corresponds to dependency relation labels, persisting until a remapping of the vocabulary (5.5).
This translation of a sentence to a motor sequence functions in the work as a hidden process. Its purpose is not for the audience to consciously decipher the linguistic source but to experience the material results of this process. The brightness of each LED was mapped directly to the speed of the adjacent motor, producing sound-accompanying gestures to make the resulting patterns more easily discernible (Jensenius and Wanderley Reference Jensenius, Wanderley, Godøy and Leman2010).
5.4. Material approach
The material approach for Seven Studies aligns with the tradition of electromechanical works that celebrate the unpredictable qualities of found materials (Valle Reference Valle2013; Pigott Reference Pigott2017). To facilitate this, the work uses a modular system, allowing objects and actuators to be added, removed, and reconfigured during performance.
Each object was mounted on a short wooden cylinder with a magnet at its base. This allowed for placement and adjustment on the perspex, with each object held in place by a second magnet from underneath. The material palette included porcelain, drum skin, thick copper foil, sticks, springs, stone, metal bells, and bars. Actuators were similarly designed for interchangeability. Each motor was fitted with a hexagonal shaft to hold carved wooden tops. These tops acted as mounts for a variety of striking and scraping implements fashioned from materials including plastic cable ties, springs, plastic bags, and brushes (Figure 3).
A selection of objects and actuators for seven studies for electric motors.

Amplification used two contact microphones, a preamp (metal marshmallow DIY phantom), and a Eurorack amplifier for high sensitivity and low noise. A perspex panel was used as the surface of the device, mounted on speaker spikes and rubber feet to reduce noise from the motors.
5.5. Interaction and improvisational control
Seven Studies was designed as an interaction between a generative system and a human improviser. While the system incorporates an autonomous process, it does not make musical decisions: the language model itself runs independently of the performer, generating sequences of dependency relations in response to random words. Instead, the interaction is built around the performer’s real-time response to the system’s output. Parkinson and Dunning describe this as a machine that plays rather than runs; this involves ‘some element of intervention, unpredictability or randomness’, and as a result, its ‘machine-personality begins to materialise in the sound’. This places the performer in a curatorial role, responsible for interpreting and shaping the machine’s output in real-time.
A rule-based interface was implemented using an ATOM MIDI controller, chosen for its combination of touch pads and rotary encoders. The 16 LED touch pads were configured as latching switches, allowing individual motors to be muted or unmuted. The four rotary encoders managed global parameters:
-
Overall speed by multiplying the overall durations
-
Quantisation allowing for rhythmic variation
-
Overall velocity set the mean intensity of the motor strikes while preserving local variation
-
Rest post-sentence allowing adjustment of the silence after sentences
-
Rest post-grid in combination with a button press, this introduced silence between each dependency label for textural control
A final button allowed the performer to instantly remap the dependency labels to new motor patterns. This control scheme established the machine as a content generator, offering a continuous stream of motor and light patterns, while the human acted as an interpreter, responsible for shaping phrasing, dynamics, tempo, and texture. Three programs were run simultaneously on the device: a Python script to generate sentences using the model (via Ollama), a Pure Data patch to handle timing and controller input, and a final Python script to control the motors and lights.
5.6. Output
The video work, Seven Studies for Electric Motors, documents the instrument, capturing seven configurations of objects and actuators in a real-time performance using the improvisational interface.
-
1 copper, springs (video example 1)
-
2 wood, springs, copper (video example 2)
-
3 plastic, paper
-
4 copper, springs (video example 3)
-
5 terracotta, paper, wood
-
6 springs, copper, paper
-
7 copper, springs
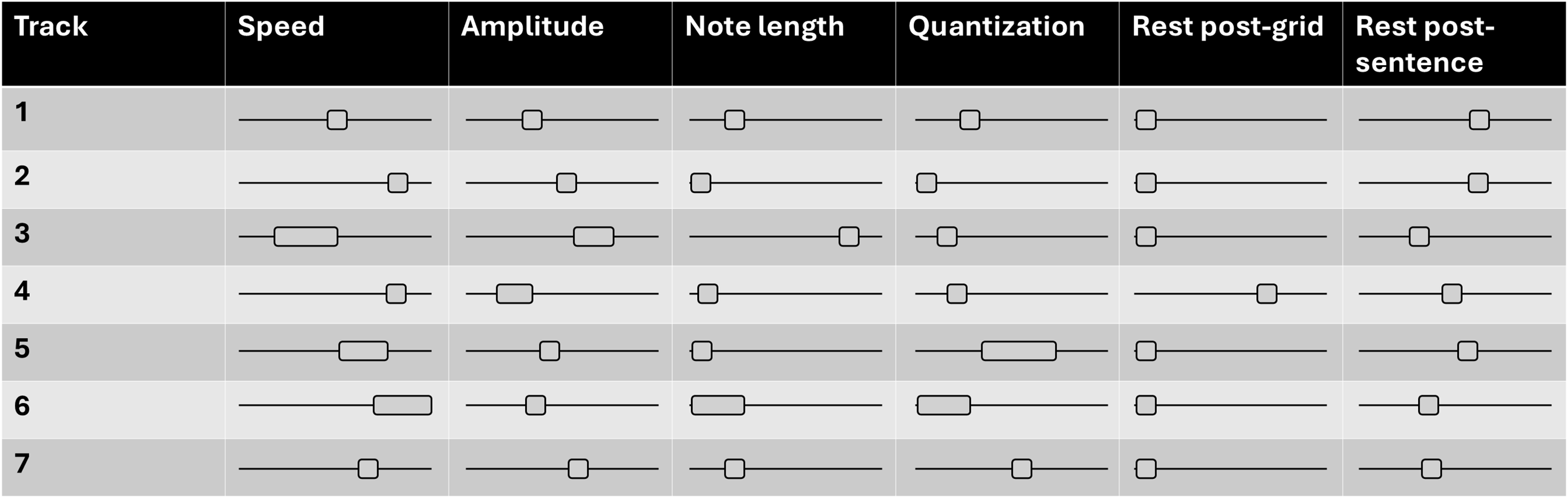
Videos of studies 1, 2, and 4 are provided as supplementary material and online.Footnote 5 To differentiate each study, specific controller positions were either unchanged or modulated within a small range (Figure 4). Each position was arrived at through improvisation with the interface and materials. Texts generated throughout each study are not saved: the musical patterns are defined by the grammar, and linguistic meaning is lost in the process.
MIDI controller settings for each of the seven studies.

5.7. Reflections
The primary affordance of embedding the language model was the ability to generate novel musical material that adhered to an internal logic in a self-contained and portable instrument. The trade-off was a limitation in generative complexity compared to larger models, but even a small model can produce syntactically rich structures sufficient for musical sequence generation. The choice to generate text live, rather than drawing from a static corpus, prioritised an in-the-moment unpredictability which was central to the work’s character. However, one limitation of the small model was the lack of control over sentence length, a feature often present in larger models (to a lesser extent) given the encoding of text (Fu et al. Reference Fu, Ferrando, Conde, Arriaga and Reviriego2024).
Reflecting on the ML aspects of the system, it is clear that the language model is not an agent but a tool for producing novel, syntactically consistent text – a function that has more in common with works employing models for data interpretation than symbolic composition. In this context, the main affordance is ease-of-use relative to algorithmic approaches. While the model’s ability to generate novel text drives the system’s improvisational behaviour, the level of autonomy is low: the device produces material within narrow generative bounds, modulated through the interface. This level of intervention introduced a tension between data and performance: manipulation through the interface often resulted in an aesthetic decoupling from the source. This occasionally masked the patterned character of the dependency-relation sequences and shifted the focus toward linguistic data as a generative seed and to the stand-alone material qualities of the device. The machine-personality is therefore not a result of the model’s creativity but an emergent property of the speech-analogy mapping and the translation of this logic into the physical domain.
This approach of repurposing a language model and dependency parser for musical generation aligned with the repurposing of materials. Because the translation from syntax to sound was a hidden process, the audience’s attention was directed away from the abstract grammar and towards its physical enactment. While the objects themselves had no specific conceptual significance, the aesthetic of reuse was a key feature. Objects were chosen for their sonic qualities, picked from materials to hand and kept or discarded through improvisation with the device. A broad aim was to create a varied palette of noise-based sounds, from the pitched qualities of metal springs to the dry clicking of paper and plastic. Another was to explore variation within each material; objects were repeated in different sizes – similar pieces of broken terracotta and sheets of copper of varying dimensions. Several introduced a degree of change into performance through the variable wobble of a spring or the position of a spinning wire. This physical unpredictability is also explored in Graham Dunning’s Mechanical Techno, in which he points to Ingold’s non-hylomorphic approach to making; this involves ‘collecting together raw materials and working with them’, rather than working towards a fixed goal (Ingold Reference Ingold2010).
The compositional experience was characterised by the ability to shape and respond to this generative stream in real-time, and while the unpredictability of the output prompted the use of certain objects or actuators in response, these objects and actuators did not influence the machine’s behaviour. The device could appear autonomous, generating a continuous stream of novel material without direct control. On the other hand, the rearranging of physical objects and occasional manipulations via a MIDI controller clearly shaped the musical qualities of the output. This is unresolved in its performance, leaving the audience to interpret the precise nature of the human-machine interaction. However, this one-way control contrasts with the reciprocal interaction seen in several surveyed works and could be addressed in the future by adding audio or visual input back into the system.
6. Conclusion
This article finds that the application of neural networks in electromechanical sound art has so far centred on symbolic generation, particularly through MIDI models paired with player pianos and other MIDI-enabled instruments. Beyond this, neural networks have been applied in more functional roles, such as audio or biosignal classification, and, in a smaller number of cases, to simulate environmental systems or emergent behaviours. Natural language processing, machine vision, and embedded inference remain underexplored in this domain. The case study in this article documents one possible approach to NLP and embedded inference, treating generated text as a structural grammar for physical sound production. In doing so, it extends earlier explorations of linguistic form in a live improvisation context.
Material constraints shaped the surveyed works both in terms of design and function. Those emphasising fine expressive control often adapt datasets or training methods to suit the specific affordances of the instrument, ensuring a close integration between model output and mechanical action. By contrast, DIY instruments often foreground the unpredictable qualities of materials, where limitations and irregularities become aesthetic features. The practice-based case study demonstrates one possibility in the latter approach, where modular objects and actuators allowed the improvisational shaping of a generative output. A further strand of practice augments existing appliances, where the pre-existing functions of objects shape the conceptual focus of the work.
Within these varied approaches to sound production, a range of interaction approaches were implemented, from directional performer-to-machine control through reciprocal feedback systems to autonomous and machine-to-machine interaction. Directional systems allow performers to seed or guide generative processes, as in Seven Studies, while reciprocal approaches involve feedback loops, where performers shape and are shaped by the machine’s behaviour. Autonomous systems minimise human input, drawing on a large corpus of non-human data sources, and machine-to-machine interactions explore emergent behaviours between non-human agents.
In the specific area of the case study, future work could integrate the modular approach to acoustic sound production with the inputs to a neural network, as seen in existing physical interfaces for audio synthesis (Fiebrink and Sonami Reference Fiebrink and Sonami2020; Privato et al. Reference Privato, Shepardson, Lepri and Magnusson2024). This approach could extend current improvisation practices with material objects. Other areas identified as underexplored through the survey include the area of machine vision, which, given the maturity of tools and approaches in adjacent fields (Ghelli Visi and Tanaka Reference Ghelli Visi, Tanaka and Miranda2021), suggests space for further work.
The survey was not exhaustive, and many other applications and approaches will be in use across the field. The search was limited by the terms and available documentation, with several existing works not including detailed processes. This could be addressed in the future through formal interviews with artists. The practice-based study developed in response to the survey represents only a single possible approach, and reflections on the methods used are written from an artist-performer perspective, with more work needed on an audience perspective for a full evaluation.
Overall, the survey and case study presented here offer a partial view of the field, but one that suggests scope for further exploration of how machine learning systems can intersect with electromechanical sound-making.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S1355771826101198.
Funding statement
This work was supported by the Arts & Humanities Research Council (grant number AH/R012733/1) through the White Rose College of the Arts & Humanities.





 Open access
Open access