Introduction
Scholarly editions of texts are an integral part of the academic world of literary critics and historians, so much so that we take them for granted. The modern critical edition, the one referenced in footnotes, is broadly speaking an invention of the twentieth century: in the English-speaking world, modern theories of editing were developed intensively from the 1920s, in response to the particular challenges of editing Shakespeare, while in France, it was Gustave Lanson who pioneered the idea of critical editing at the Sorbonne in the early years of the century, with his exemplary edition of Voltaire’s Lettres philosophiques (1909). University presses continue to invest significant sums in new critical editions: Edinburgh University Press, for example, having completed the Edinburgh Edition of the Waverley Novels in thirty volumes, has now embarked on the ten-volume Edinburgh Edition of Walter Scott’s Poetry: such landmark editions play a dynamic role in our research culture.
How do these publishing initiatives figure in the present context of the turn to digital publishing? Digital editions of one sort or another have existed now for almost forty years, though there is widespread variation in terms of quality and functionality, and at times there is confusion between the simply digitised products which are little more than scanned versions of print books, and editions that are truly ‘born digital’. Some publishers produce digital versions of their existing print critical editions, the most ambitious example being Oxford Scholarly Editions Online, which brings together on one platform over 1,750 print critical editions published by Oxford University Press. Then there are stand-alone scholarly editions, of widely ranging ambition: Patrick Sahle’s Catalogue of Digital Scholarly Editions gives an overview of what has already been achieved, listing some 714 editions in six different languages, on topics ranging from history and literature to music and history of art.Footnote 1 Likewise, Greta Franzini’s Catalogue of Digital Editions has been gathering digital editions in an attempt to survey and identify best practices in the field of digital scholarly editing since 2012 (Franzini et al. Reference Franzini, Terras, Mahony, Driscoll and Pierazzo2016). Some of these editions, like The Blake Digital Text Project, are remarkable for the large number of high-quality images that they contain; others are particularly attractive because they include large numbers of manuscript images, for example, The Walt Whitman Archive, the Samuel Beckett Digital Manuscript Project, Jane Austen’s Fiction Manuscripts, or Nietzsche Source. It is entirely understandable that digital scholarly editions (or DSEs), in the early phase of digital publication, chose to focus on what we might term ‘documentary’ editions (Pierazzo Reference Pierazzo2015, pp. 74–83). Clearly, however, we have not yet exploited anything like the full potential of the digital medium for producing scholarly editions more generally. The situation has not changed radically since Peter Shillingsburg, in 2006, remarked of the digital editions then available that, ‘Yes they are better. No, they are not good enough’ (Shillingsburg Reference Shillingsburg2006, p. 111).
The challenge is clear. Rather than regard DSEs as derivatives of a print object, how might we rethink from first principles what a digital edition might look like, exploiting to the full the potential for critical editing in the digital medium? This raises many questions, beginning with the business model. There are strong pressures now for academic work to be available on open access, but scholarly editing in particular is a costly business, and financial sustainability is crucial, in particular for work that needs to be available over the long term, serving as a reference resource. We also have to consider the views and habits of the users. Even when researchers use digital editions, they are sometimes reluctant to quote them as the authoritative source of reference, so we should find ways of presenting digital editions as authoritative and easily referenceable. A print edition, with all its merits, is a static work of reference; digital editions, on the other hand, have the potential to be much more than that, to engage their readers by being tools of research and even to serve as platforms on which research can be published. These are exciting possibilities, and the creators of new digital resources need to enthuse and engage their users, and even encourage them to be demanding of the resource presented to them.
Faced by this ambitious agenda, the aim of the present volume is modest, taking as a case study one particular project that has been grappling with these questions. The three authors have all played roles in the planning and building of Oxford University Voltaire, a digital edition of the complete writings of Voltaire, launched commercially in January 2026 and distributed by Liverpool University Press [see Fig. 1].
Oxford University Voltaire Logo

This resource has been (re)created from the authoritative print edition of the Complete Works of Voltaire, produced in 205 volumes over nearly half a century, and published by the Voltaire Foundation in Oxford. We tell the story of that transformation here, in the hope that this case study will interest other creators and users of scholarly digital editions, and perhaps even influence future thinking about their development.
1 The State of the Art in Digital Scholarly Editing
1.1 Introduction
The constant evolution of scholarly editing reflects the profound transformations that have over the centuries affected the ways in which texts are produced, preserved, analysed, and disseminated. Rooted in the philological traditions of textual criticism, scholarly editions have long served as essential tools for understanding the cultural, historical, and linguistic contexts of written works. From the painstakingly crafted manuscript copies of antiquity to the authoritative critical editions of the print era, these endeavours have continuously adapted to address the challenges of textual preservation and interpretation. Today, we stand at the threshold of a new paradigm, shaped by the integration of digital technologies into the field.
Digital scholarly editions (DSEs) represent a convergence of traditional critical editing methodologies and contemporary technological innovation. These editions harness the power of digital tools to expand the possibilities of textual scholarship, enabling the representation of texts in new and previously unimaginable ways. By incorporating dynamic features such as hypertextual linking, multimedia integration, and other interactive functionalities, DSEs transcend the static limitations of print and have the capacity to foster deeper engagement with textual materials and their historical contexts.Footnote 2
The significance of DSEs extends well beyond their technical capabilities. They address enduring challenges in the field, such as the accessibility and preservation of texts. In doing so, they democratise access to cultural heritage, enabling scholars, students, and the general public to engage with primary sources and scholarly commentary from virtually anywhere in the world. Furthermore, DSEs facilitate collaborative and interdisciplinary approaches to text analysis, forming a core element of the digital humanities research community (Sahle Reference Sahle, Driscoll and Pierazzo2016).
This chapter aims to provide a comprehensive examination of the state of the art in digital scholarly editing. It begins with an exploration of the historical foundations of scholarly editions, tracing their evolution from manuscript traditions to the advent of digital methodologies. Following Paul Eggert’s recent work, we also highlight the dual impulses guiding today’s scholarly editions: the archival, which focuses on preserving the historical integrity of texts, and the editorial, which curates and interprets texts for modern audiences (Eggert Reference Eggert2019). The combination of these perspectives in the development of the Oxford University Voltaire allows us to examine how DSEs might negotiate the balance between historical fidelity and contemporary relevance in the future, addressing both the practical and theoretical dimensions of their creation.
1.2 A Brief History of Scholarly Editions
1.2.1 Origins and Early Practices
Scholarly editions have played a pivotal role in the preservation and dissemination of our cultural and textual heritage throughout history. The primary purpose of these editions is to provide an authoritative and reliable version of a text, often accompanied by critical apparatus, annotations, and commentary. These elements enable scholars to engage with texts in a way that contextualises their historical, cultural, and linguistic significance. The history of scholarly editions is thus deeply intertwined with the development of written culture itself. In antiquity, the first ‘scholarly’ efforts were devoted to preserving oral traditions and sacred texts, often through laborious manuscript copying. The first textual scholars, belonging to the Alexandrian school, included figures such as Zenodotus and Aristarchus, who were notable for their early editorial endeavours in standardising the Homeric epics (Nagy Reference Nagy1994). These editors sought not only to preserve the text in its ‘original’ form, but also to interpret and resolve inconsistencies in the manuscript tradition, thus laying the theoretical and practical groundwork for textual criticism as a discipline for the next two millennia.
The modern need for scholarly editions arose from the inherent variability of textual witnesses, especially before the advent of the printing press. Medieval manuscripts were copied by hand, often introducing errors, omissions, and variations (Love Reference Love, Kaylor and Philips2012). These differences necessitated a systematic approach to collating and evaluating textual evidence to produce editions that reflected the closest approximation of the original text. As the field of textual criticism developed in the early-modern period, scholarly editions evolved to incorporate methodologies that addressed these challenges. Editors began to rely on comparative analysis, using multiple manuscript sources to identify and correct errors, while also documenting significant variants (D’Amico Reference D’Amico1988). This approach became a hallmark of scholarly philology, ensuring that texts could be studied and interpreted with confidence both in terms of authenticity and fidelity.
The emergence of the printing press in the fifteenth century marked a significant turning point in the history of scholarly editions. For the first time, texts could be reproduced on a large scale with consistent quality, allowing for broader dissemination and access (Eisenstein Reference Eisenstein1980). This technological advancement also facilitated the development of proto-scholarly editions, such as those by the Renaissance publisher Aldus Manutius, which emphasised textual accuracy and often included paratextual elements like annotations and commentaries (Margolis Reference Margolis2023). These works represent an early intersection of editorial labour and intellectual interpretation, reflecting the dual objectives of preserving and elucidating texts.
1.2.2 Scholarly Editions in the Modern Era
By the nineteenth century, scholarly editions had become central to academic inquiry, especially in the context of literary and historical studies. The rise of philology as a scientific discipline, exemplified by figures such as Karl Lachmann, emphasised the rigorous comparison of manuscript variants to reconstruct authorial intent (Fornaro Reference Fornaro2011). This period also marked the ascendancy of what Paul Eggert terms the ‘capital-R Romantic author’, whose intentions were seen as the definitive guide to textual authority (Eggert Reference Eggert2019, p. 5). Scholarly editions were imbued with a sense of finality, presenting a single, authoritative version of a text that sought to encapsulate its essential meaning as that intended by its author. However, this approach often sidelined the material and social dimensions of textual production. The literary work was treated as an idealised entity, detached from its historical and material contexts. This limitation would later be challenged by the emergence of book history and social-text theories, which emphasised the collaborative and contingent nature of textual production.
The latter half of the twentieth century witnessed significant shifts in the theory and practice of scholarly editing. Influenced by post-structuralist critiques, scholars began to question the privileging of authorial intent and the notion of a definitive text. Key contributions from Jerome McGann and D. F. McKenzie, who argued for a ‘social-text’ approach that acknowledged the multiple agencies involved in textual production, broadened the interests and actors of scholarly editions to include publishers, typesetters, and readers, among others (McGann Reference McGann1983, Reference McGann1991; McKenzie Reference McKenzie1986). This perspective redefined the scholarly edition as a dynamic interplay of textual, material, and social elements, rather than a fixed repository of meaning. Paul Eggert’s earlier work advances this dialogue by proposing the concept of ‘textual agency’, which encompasses the intentions and actions of all contributors to a text’s life cycle, from authors to readers (Eggert Reference Eggert2009). Eggert, following Peter Robinson (Reference Robinson2013a), further emphasises the need for scholarly editions to address these complexities, presenting the text as both a historical artifact and a living work that continues to evolve through its interactions with readers (2019).
The transition to DSEs represents a continuation of these theoretical developments, while also introducing new possibilities and challenges. The digital medium enables editions to function simultaneously as archives and arguments, integrating vast amounts of data while foregrounding editorial decisions (Eggert Reference Eggert2016). This dual role aligns with his broader vision of the scholarly edition as an active mediator between past and present, materiality and meaning.
Digital editions also offer unprecedented opportunities for interactivity and accessibility. By incorporating tools for searching, linking, and annotating, they invite users to engage with texts in ways that transcend the linear constraints of print. Yet, the digital turn also demands a renewed commitment to editorial rigour and sustainability, ensuring that these innovations serve the enduring goals of textual scholarship (Robinson Reference Robinson2013b; Pierazzo Reference Pierazzo2015). In this evolving landscape, the history of scholarly editions serves as both a foundation and a guide. By understanding the principles and practices that have shaped the field, we can better navigate the complexities of its digital future, preserving the richness of textual heritage while embracing the transformative potential of new technologies.
1.2.3 Methodologies
The methodologies underpinning traditional scholarly editions have been shaped by centuries of practice and refinement, with textual criticism at their core. One key approach is stemmatics, developed by Karl Lachmann in the nineteenth century, which aims to reconstruct the ‘archetype’ or the earliest recoverable form of a text by analysing patterns of variation across surviving manuscripts. This involves constructing a ‘stemma codicum’, a family tree that traces the relationships between different manuscript witnesses (Roelli Reference Roelli and Roelli2020).
Another approach is the creation of diplomatic editions, which faithfully reproduce a specific manuscript, including its idiosyncrasies such as spelling variations, marginalia, and scribal errors. These editions prioritise historical authenticity over editorial correction and are often used for manuscripts with significant historical or cultural value. On the other hand, so-called ‘eclectic’ editing represents a more interpretive methodology, where editors select the ‘best’ readings from various manuscript sources to construct an ideal text. This method is common in critical editions of literary and religious texts, where the goal is to present a version that aligns with the editor’s judgment of authorial intent (Sahle Reference Sahle, Driscoll and Pierazzo2016).
A critical apparatus, integral to many traditional editions, documents the editorial decisions and variant readings across sources. This allows readers to trace the editor’s reasoning and engage with the textual evidence directly. The apparatus serves as both a record of textual variants and a tool for scholarly debate.
Traditional methodologies have also been shaped by the goals of the editions themselves. For instance, variorum editions compile a comprehensive record of commentary, interpretations, and textual variants, making them valuable resources for understanding the reception history of a text. Meanwhile, facsimile editions provide high-quality reproductions of manuscripts, offering visual access to their original form.
While these methodologies laid the foundation for modern scholarly practice, they were not without limitations. Editors often grappled with incomplete or conflicting evidence, and their subjective decisions could introduce biases into the editions. Moreover, the constraints of print technologies meant that the rich interconnections between textual variants and commentary often had to be simplified, resulting in a loss of nuance. These foundational methodologies continue to inform the development of DSEs, which aim to overcome the limitations of print by leveraging the dynamic capabilities of the digital medium.
1.2.4 Challenges
Traditional scholarly editions, while invaluable, encountered significant challenges that hindered their effectiveness in representing and preserving complex texts. One of the foremost limitations was the linear format of print media. Texts with extensive variations, interlinear glosses, or marginal annotations were often simplified or truncated to fit the constraints of a printed page. This reduction compromised the ability of editions to fully represent the richness and complexity of source materials.
The reliance on physical archives created additional barriers to reproducibility and comparison. Scholars frequently had to travel to specific locations to consult rare manuscripts or editions, which not only required significant resources but also introduced geographical inequalities in research opportunities. Moreover, physical editions were vulnerable to environmental degradation, loss, and damage, further jeopardising the longevity of scholarly efforts (Baillot & Busch Reference Baillot and Busch2021).
Another persistent issue was the subjectivity of editorial decisions. The interpretative nature of constructing critical editions meant that editors often had to make subjective choices about which variants to include, how to resolve discrepancies, and which annotations to prioritise. These decisions, while necessary, introduced biases that could skew the representation of a text and its historical context. The lack of transparency in some editorial processes exacerbated this problem, leaving readers without a clear understanding of the rationale behind key decisions.
Accessibility and dissemination posed another major challenge. High-quality scholarly editions were often produced in limited print runs, making them accessible only to researchers with access to specialised libraries. This exclusivity limited broader engagement with the texts, curbing their potential influence and scholarly utility. Furthermore, the prohibitive costs of production and acquisition meant that such editions were often financially inaccessible to smaller institutions and independent scholars.
Finally, traditional editions struggled with the fragmentation of resources. Related materials, such as commentary, facsimiles, and critical analyses, were often dispersed across multiple publications, requiring scholars to piece together information from disparate sources. This disjointed approach hindered a comprehensive study and made it challenging to engage with a text holistically. These challenges underscored the need for innovative methodologies that could address the limitations of traditional practices. The advent of digital technologies promised solutions to many of these issues, paving the way for more accessible, dynamic, and integrated approaches to scholarly editing.
1.3 Current Trends in Digital Scholarly Editions
1.3.1 Towards the Digital
The transition from traditional scholarly editions to their digital counterparts began in the late twentieth century, fuelled by advancements in computing and information technology. One of the earliest steps in this evolution was the use of computer-assisted collation tools, which automated the labour-intensive process of comparing textual variants. This innovation allowed scholars to analyse large corpora of manuscripts more efficiently and with greater precision (Gilbert Reference Gilbert1973).
Digital repositories emerged as another critical development in this transition. Projects like the Thesaurus Linguae Graecae (TLG) and the Perseus Digital Library provided scholars with centralised platforms for accessing and studying digitised texts.Footnote 3 These repositories not only enhanced accessibility but also facilitated comparative research by integrating tools for textual analysis.
The rise of the Text Encoding Initiative (TEI) in the 1980s marked a watershed moment in the evolution of DSEs.Footnote 4 The TEI provided a standardised framework for encoding textual data – first in SGML markup, and then, finally from 2002, in XML – enabling the consistent and interoperable representation of texts. This standardisation was crucial for ensuring that digital editions could be preserved, shared, and utilised across different platforms and research contexts (Burnard Reference Burnard2014).
Multimedia integration further distinguished digital editions from their print predecessors. High-resolution images of manuscripts, interactive annotations, and hypertextual links allowed users to engage with texts in new and dynamic ways. These features made it possible to represent complex textual relationships, such as parallel narratives or intertextual references, with greater clarity and depth (Van Mierlo Reference Van Mierlo2022).
The shift towards digital editions was not without challenges, however. Ensuring the long-term preservation of digital resources such as DSEs required robust archival strategies, including the use of redundant storage systems and migration to newer formats as technology evolved. Additionally, the reliance on proprietary software and platforms raised concerns about sustainability and accessibility (Oltmanns et al. Reference Oltmanns, Hasler, Peters-Kottig and Kuper2019). Despite these issues, the evolution towards the digital has fundamentally reshaped the landscape of textual scholarship and publishing.
1.3.2 Digital Scholarly Editions Today
Over the past two decades, DSEs have become central to contemporary textual scholarship, presenting significant opportunities and challenges as they adapt to both analogue and born-digital materials. Drawing on the foundational work of Peter Shillingsburg (Reference Shillingsburg1996), Hans Walter Gabler (Reference Gabler2010), Amy Earhart (Reference Earhart2012), Peter Robinson (2013), Elena Pierazzo (2016), Patrick Sahle (Reference Sahle, Driscoll and Pierazzo2016), and Paul Eggert (Reference Eggert2019), as well as recent discussions by James O’Sullivan and Michael Pidd (Reference O’Sullivan and Pidd2023), this section examines how DSEs can address current cultural, technical, and methodological demands while exploring future-oriented possibilities.
Sahle’s assertion that a true digital edition must utilise the unique affordances of the digital medium remains a cornerstone of scholarly discourse. A merely ‘digitised’ edition – that is, a static reproduction of a print artefact – is insufficient to capture the dynamism of digital scholarship. Instead, DSEs must go beyond remediation, becoming tools for interactivity, collaboration, and interpretation. As Sahle notes, a digital edition should be unprintable without losing significant functionality, underscoring its reliance on digital technology to reveal multiple textual dimensions (2017). Digital editions should also embrace the possibilities of hypertextuality, multimedia integration, and algorithmic manipulation, creating interactive environments that transcend the limitations of paper editions. This paradigm shift moves away from static representations towards dynamic, modular structures that facilitate continuous revision and reinterpretation (Earhart Reference Earhart2012).
According to Sahle, good DSEs often navigate between two editorial roles that exist in tension, one of representation and the other of critical engagement. Representation involves reproducing documents visually or textually, while critical engagement entails applying scholarly methods to enhance accessibility and usability. Historically, as we have seen previously, these practices were rooted in philological traditions, focusing on reconstructing authorial intention or ‘original’ versions of texts. Paul Eggert’s distinction between the ‘archival’ and ‘editorial’ impulses in scholarly editing functions in much the same way but provides perhaps a more nuanced framework for understanding DSEs today. Archival activities focus on the faithful recording and preservation of materials (Sahle’s ‘representation’), while editorial efforts mediate these materials for audience consumption (i.e., ‘critical engagement’). Eggert’s proposed ‘slider’ model for DSEs emphasises the interconnectedness of these roles, suggesting that DSEs must balance fidelity to source materials with accessibility and usability for diverse audiences on a continuum rather than in a linear fashion (Reference Eggert2019, pp. 83–89).
The interplay between the archival and editorial impulses highlights the complexity of DSEs and their intended readerships. Archival editions are document-facing, ensuring a faithful transcription of source materials and unhindered access to originals. Editorial texts, in contrast, are audience-facing, seeking to interpret and contextualise materials for usability and clarity. This distinction is fluid, with projects often integrating both impulses to varying degrees. For example, the Rossetti Archive and the Walt Whitman Archive demonstrate how archival fidelity can coexist with reader-oriented interactivity, creating hybrid models that enrich scholarly engagement.Footnote 5
Another critical characteristic of DSEs is their customisability. Users can interact with the text in ways that suit their specific research needs. For instance, scholars can toggle between different textual layers, such as diplomatic transcriptions and critical editions, or view textual variants and annotations in parallel (Ohge Reference Ohge2021). This flexibility makes DSEs versatile tools for a wide range of academic inquiries. Certain DSEs can furthermore expand this interactivity to emphasise collaboration and crowdsourcing, leveraging digital platforms to involve broader communities in the editorial process (Terras Reference Terras, Schreibman, Siemens and Unsworth2016). Tools such as MediaWiki, Zooniverse, and GitHub, or bespoke platforms for crowdsourced transcription, allow researchers, students, and even non-specialist enthusiasts to contribute to the creation and enhancement of digital editions.Footnote 6 This participatory approach not only democratises access to scholarly work but also accelerates the completion of large-scale editorial projects.
Finally, DSEs should prioritise accessibility and sustainability. By making texts available online, they reach a global audience, breaking down geographical and financial barriers to scholarly resources. Many digital editions are open access, aligning with the growing emphasis on equitable access to knowledge and publicly funded research outputs. Furthermore, efforts to ensure the long-term preservation of DSEs, such as adherence to open standards like TEI-XML and partnerships with digital archives, seek to address concerns about the ephemeral nature of digital technologies.Footnote 7
1.3.3 Technological Foundations
The backbone of DSEs is built upon robust technological frameworks that facilitate their dynamic and interactive nature. Among the most important of these frameworks is the TEI, which has become the standard for encoding texts in a structured and machine-readable format. Text encoding is foundational to DSEs, and the TEI has become the lingua franca for encoding textual materials, enabling both interoperability and preservation. The TEI schemas capture the physical, logical, and semantic structures of texts, accommodating various editorial approaches (Burnard Reference Burnard2014). However, the reliance on TEI has also reinforced book-oriented tropes, limiting the exploration of born-digital materials that challenge traditional textual hierarchies (O’Sullivan & Pidd Reference O’Sullivan and Pidd2023).
Automated collation tools, such as Collate, CollateX, and HyperCollate, have become essential components in the modern editorial workflow.Footnote 8 These tools facilitate the comparison of multiple textual witnesses, automating the process of identifying textual variants and generating alignment visualisations (Haentjens Dekker et al. Reference Haentjens Dekker, Van Hulle, Middell, Neyt and Van Zundert2015). This not only saves scholars considerable time compared to traditional manual collation but also ensures precision and repeatability in results. As highlighted by Robinson (2013), such tools represent a shift in scholarly editing towards computational efficiency, enabling editors to focus on interpretative tasks rather than repetitive technical labour.
More recently, the International Image Interoperability Framework (IIIF) has become indispensable for DSEs incorporating high-resolution manuscript images.Footnote 9 The IIIF provides a standardised protocol for accessing, annotating, and manipulating visual materials, ensuring compatibility across platforms. Features such as deep zooming, annotation layers, and comparative views allow users to closely examine the intricate details of digitised artefacts.
Open-source platforms such as Omeka, Scalar, EVT (Edition Visualisation Technology), and TEI-Publisher empower scholars to develop customised digital editions without requiring extensive technical expertise.Footnote 10 These platforms offer modular features for embedding multimedia, linking external datasets, and designing user-centric interfaces. Their adaptability allows projects to cater to diverse audiences, from academic researchers to public users, ensuring that DSEs remain inclusive and accessible. By democratising the technical aspects of digital editing, these tools have expanded the range of participants who can contribute to the creation of scholarly editions.
High-performance computing solutions have further transformed the scalability and reach of DSEs over the past several years. These technologies enable projects to handle large datasets, and implement advanced features such as machine learning-driven text analysis. As the demand for interactivity, responsiveness, and data-intensive features grows, computationally heavy solutions will be needed to provide the infrastructural backbone necessary to support cutting-edge digital editions. Moreover, advances in data visualisation and user interaction have introduced new dimensions to DSEs. From dynamic mapping tools to interactive timelines, these innovations enhance the interpretative possibilities of digital texts. They also address the above-mentioned tension between the archival and editorial impulses by presenting data in ways that serve both preservationist and interpretative goals.
Digital scholarly editions are also beginning to explore the potential of augmented reality (AR) and virtual reality (VR) to create immersive experiences. These technologies allow users to engage with texts and historical contexts in entirely new ways. For example, a virtual reconstruction of a medieval scriptorium might enable users to ‘walk through’ the environment where manuscripts were created, while VR annotations provide a spatial and interactive approach to textual commentary. These applications are still emerging, but they represent an exciting frontier for experiential and contextual scholarship (O’Sullivan & Pidd Reference O’Sullivan and Pidd2023).
Digital editions are increasingly prioritising inclusive and accessible design, ensuring that their resources reach diverse audiences. Features such as text-to-speech functionality, multilingual interfaces, colour-contrast adjustments, and keyboard navigability ensure that digital editions accommodate users with varying needs, including those with disabilities. By adopting inclusive practices, DSEs extend the impact and usability of their work to a global audience (Martinez et al. Reference Martinez, Dillen, Bleeker, Sichani and Kelly2019).Footnote 11 These innovative practices highlight how DSEs are not merely digital reproductions of print editions but complex scholarly objects in their own right.
1.3.4 Challenges and Critiques
Despite the significant advancements in DSEs, several challenges and critiques have emerged, reflecting both technical and conceptual issues. These challenges underscore the need for thoughtful innovation, critical reflection, and interdisciplinary collaboration. For example, while many DSEs have successfully reimagined their analogue sources, they have largely retained book-like structures and methodologies. O’Sullivan and Pidd argue that this conservatism limits DSEs’ potential, particularly when dealing with born-digital materials such as social media posts, digital fiction, and video games (2023). These materials demand a rethinking of editorial practices to reflect their non-linear, multimodal, and platform-dependent characteristics (Bekius & Van Hulle Reference Bekius, Van Hulle, Beloborodova and Van Hulle2024). Born-digital texts often lack fixed boundaries, for example, existing as fluid and interactive entities that challenge traditional notions of textual stability.
The integration of these born-digital materials – content created and consumed entirely within digital ecosystems – is one of the most pressing challenges for DSEs. Tweets, blogs, and e-literature defy conventional editorial frameworks, requiring tools and methods that can address temporality, interactivity, and contextuality. Projects like Digital Fiction Curios and Pathfinders exemplify innovative approaches to editing born-digital texts.Footnote 12 Digital Fiction Curios creates immersive virtual environments to showcase early e-literature, while Pathfinders records the traversal of hypertext works on legacy systems. These models highlight the necessity of embracing impermanence and fluidity, acknowledging that some aspects of digital materials – such as their original interactive platforms – may be irretrievable (O’Sullivan & Pidd Reference O’Sullivan and Pidd2023).
Digital scholarly editions, as with all digital resources, face the persistent challenge of long-term preservation. Unlike printed editions, digital formats are vulnerable to technological obsolescence, requiring continuous updates and migrations to new platforms. The lack of standardised strategies for archiving DSEs exacerbates this problem, as projects often rely on temporary funding and institution-specific infrastructures. Ensuring the longevity of DSEs demands robust and scalable preservation strategies, including partnerships with digital repositories and adherence to open standards such as XML-TEI.Footnote 13 Similarly, IIIF protocols have been instrumental in addressing some of these issues, but broader institutional and financial commitments are necessary to secure our growing digital heritage (Orlandi & Marsili Reference Orlandi and Marsili2019).
While DSEs aim to enhance access to scholarly materials, global disparities still persist in terms of technological infrastructure and digital literacy. Scholars and institutions in resource-limited settings often struggle to access high-resolution images or advanced functionalities due to bandwidth limitations or lack of access to modern devices (Ragnedda & Gladkova Reference Ragnedda and Gladkova2020). Furthermore, the dominance of English-language interfaces and metadata tends to marginalise non-English-speaking users, restricting global engagement with DSEs. Addressing these inequities requires multilingual interfaces, localised resources, and open-access policies that can further democratise digital scholarship.Footnote 14
The reliance on advanced technical skills, such as XML encoding, digital collation, and data visualisation, also creates barriers for scholars trained in traditional methodologies. Many researchers lack the resources or time to acquire these skills, limiting their ability to contribute to or benefit from DSEs fully. This issue underscores the importance of developing user-friendly tools and platforms that minimise the technical burden (Franzini et al. Reference Franzini, Terras and Mahony2019). For instance, platforms like TEI-Publisher have made strides in enabling non-technical users to create and manage digital editions, but more accessible solutions are needed to bridge the gap further.
The massive digitisation of texts raises complex questions about intellectual property rights, particularly for modern works or texts under copyright. Navigating these legal frameworks can be cumbersome and often restricts the scope of what can be included in a DSE. Open-access initiatives help alleviate some of these issues, but they also face resistance from publishers and other stakeholders. Crowdsourcing transcription and annotation has also introduced ethical questions about labour and attribution (Terras Reference Terras, Schreibman, Siemens and Unsworth2016). Contributors, particularly non-specialists, may not receive adequate recognition or compensation for their work. Furthermore, digitising sensitive or culturally significant texts demands careful consideration of the communities and traditions associated with those materials to avoid exploitation or misrepresentation (Risam Reference Risam2018).
Finally, some critics argue that DSEs, despite their technological advantages, often fail to capture the tactile and material qualities of physical texts. Elements such as paper texture, ink composition, and marginal annotations carry significant scholarly value that digital representations may overlook or inadequately replicate. While high-resolution imaging and interactive tools can approximate these qualities, the sensory experience of engaging with a physical artifact remains difficult to reproduce. These various challenges highlight the need for ongoing innovation and critical reflection within the field of digital scholarly editing. Addressing these issues will ensure that DSEs continue to serve as transformative tools for textual scholarship, balancing the preservation of cultural heritage with the demands of a rapidly evolving digital landscape.
1.4 Future Directions in Digital Scholarly Editions
1.4.1 AI and Machine Learning
Artificial intelligence (AI) and machine learning (ML) are increasingly central to the future of the digital humanities and, by extension, DSEs, offering new techniques and approaches for the digitisation, analysis, and dissemination of texts and text traditions. These technologies have begun to revolutionise the way scholars approach traditional problems in textual studies, including transcription, collation, and annotation (Jannidis Reference Jannidis, Cohen, Price and Bernardini2025).
One of the most impactful applications of AI lies in automating the transcription of historical documents. Tools such as Transkribus leverage neural networks trained on diverse handwriting styles to convert manuscripts into digital text with remarkable accuracy.Footnote 15 These tools dramatically reduce the time and labour required to transcribe large collections, while their adaptive algorithms improve continuously as they process more data. For instance, early trials with Transkribus demonstrated its ability to transcribe seventeenth-century handwritten texts with over 90 per cent accuracy, a result that has since been refined with larger datasets and more sophisticated models (Nockels et al. Reference Nockels, Gooding and Terras2024). Such advancements make it feasible to work with previously inaccessible or underexplored archives.
AI also plays a critical role in the collation of textual variants. Machine learning algorithms can identify and align variations across multiple manuscript witnesses, providing comprehensive visualisations of textual relationships. This capability supports more precise reconstructions of original texts and offers new insights into the evolution of works over time (Camps et al. Reference Camps, Clérice and Pinche2021). CollateX, for example, an advanced collation tool mentioned earlier, has been integrated with some rudimentary machine-learning capacities to improve its ability to handle complex textual traditions, such as those found in medieval European literature, early biblical manuscripts, or even modern genetic editions (Van Hulle Reference Van Hulle2016; Whittle et al. Reference Whittle, O’Sullivan, Pidd and Hegland2023).
Beyond transcription and collation, AI enhances the semantic analysis of texts through Natural Language Processing. These technologies allow researchers to extract themes, map relationships, and analyse stylistic changes across extensive corpora (Janke et al. Reference Jänicke, Franzini, Cheema and Scheuermann2017). For instance, sentiment analysis and topic modelling have been applied to large datasets, revealing patterns of cultural and linguistic evolution that would be difficult to detect manually (Galleron et al. Reference Galleron, Patras, Arias and Tanasescu2024). Natural Language Processing also facilitates multilingual studies, enabling the alignment and comparison of texts across different languages and scripts (Levchenko Reference Levchenko2024).
The annotation of texts has also benefited significantly from AI-driven tools. Automated systems can identify and tag entities such as names, dates, and places, linking them to relevant databases or external resources (Humbel et al. Reference Humbel, Nyhan, Vlachidis, Sloan and Ortolja-Baird2021). This not only streamlines the editorial process but also enriches the contextual layers of DSEs, offering users a deeper understanding of the material. For example, projects such as the Recogito platform have employed AI to annotate geographical and historical references in ancient texts, making them accessible to both scholars and the general public.Footnote 16
Another frontier for AI in DSEs is predictive restoration. By training algorithms on extensive datasets of similar texts, AI can reconstruct missing or damaged sections of manuscripts with high degrees of probability (Humbel et al. Reference Humbel, Nyhan, Vlachidis, Sloan and Ortolja-Baird2021). This technique has already been applied to fragmentary papyri and inscriptions, where it has provided reconstructions that align closely with scholarly expectations (Sommerschield Reference Sommerschield, Assael and Pavlopoulos2023). The implications for archaeology and palaeography are profound, as these tools extend the reach of traditional methods.
Artificial intelligence and ML also support collaborative and participatory models in digital scholarship. Tools that validate crowdsourced data or assist non-experts in contributing to DSE projects are becoming more common. For example, AI-driven quality control systems ensure the accuracy of community-generated transcriptions and annotations, allowing large-scale projects to harness the collective efforts of diverse participants without compromising scholarly standards (Mahotra Reference Mahotra and Majchrzak2024).
As AI and ML continue to evolve, their integration into DSEs promises to redefine the landscape of textual scholarship. These technologies not only accelerate traditional workflows but also open entirely new avenues for exploration and interpretation, offering tools that were unimaginable even a decade ago. The ethical and methodological implications of these advancements, however, warrant careful consideration, ensuring that the use of AI aligns with the principles of transparency, inclusivity, and scholarly rigour.
1.4.2 Interdisciplinary Collaboration
The future of scholarly editing thus lies in fostering interdisciplinary collaborations that bridge the gap between textual studies, computer science, design, and the wider digital humanities. Such collaborations enable the integration of expertise from diverse fields to address the multifaceted challenges of creating and sustaining the next generation of DSEs. Textual criticism can benefit from advanced computational methods such as machine learning algorithms for textual analysis, while computer scientists can gain access to complex, real-world datasets to refine their tools and techniques (Van Hulle Reference Van Hulle, Eliot and Rose2019). This reciprocal relationship not only enhances the capabilities of DSEs but also drives research in computational linguistics and AI (Van Zundert Reference Van Zundert, Driscoll and Pierazzo2016).
Another crucial collaboration needs to be established between digital designers and humanities scholars. User experience (UX) design and interface development play an essential role in ensuring that DSEs are accessible and intuitive for a broad audience (Andrews & Van Zundert Reference Andrews, Van Zundert, Bleier, Bürgermeister, Klug, Neuber and Schneider2018). By integrating feedback from textual scholars and end-users, designers can create platforms that balance aesthetic appeal with functional precision (Wheeles Reference Wheeles2010). Such designs encourage engagement and enable users to explore texts in innovative ways (Schofield et al. Reference Schofield, Whitelaw and Kirk2017). The involvement of historians and cultural theorists further enriches the development of DSEs. These experts provide critical insights into the context and interpretation of historical texts, ensuring that digital representations honour the cultural significance of the originals. Collaborative projects often benefit from ethnographic and historiographic perspectives, which guide the ethical curation of sensitive materials and marginalised voices.
Moreover, interdisciplinary collaborations extend to the preservation and dissemination of digital editions. Archivists, librarians, and information scientists contribute essential expertise in metadata standards, cataloguing, and digital preservation strategies. Their involvement ensures that DSEs remain accessible and viable for future generations, addressing concerns about technological obsolescence and data decay. The success of interdisciplinary collaboration also depends on effective project management and communication strategies. Shared digital platforms, regular cross-disciplinary workshops, and open-access publications foster a culture of transparency and inclusivity. Funding agencies increasingly recognise the value of interdisciplinary research, encouraging projects that bring together diverse perspectives to tackle complex problems.
1.4.3 Sustainability
As mentioned, the sustainability of DSEs is one of the most pressing challenges facing the field. Unlike traditional print editions, DSEs require continuous technical maintenance, software updates, and server hosting to remain accessible over time. Ensuring that these projects are not only initiated but also maintained for future generations demands innovative funding models and institutional support (Barats et al. Reference Barats, Schafer and Fickers2020).
One key approach to sustainability is the adoption of open standards and interoperable formats, such as TEI-XML for text encoding and IIIF for image delivery. These standards ensure that DSEs are not tied to proprietary systems, reducing the risk of obsolescence as technologies evolve. Collaborative efforts to establish and adhere to such standards across institutions can help create a more sustainable ecosystem for digital scholarship. Notably, tools like EditionCrafter combine IIIF and static site generation to create lightweight, flexible, and maintainable digital editions, reflecting broader interest in minimal computing strategies.Footnote 17
Minimal computing has emerged as a particularly relevant trend, emphasising low-tech, sustainable approaches to digital scholarship that minimise environmental impact and dependence on complex infrastructure. This movement, promoted by groups like the Digital Humanities Climate Coalition and the Software Sustainability Institute, highlights the ethical dimensions of digital production and maintenance, encouraging projects to adopt efficient, resource-conscious methods.Footnote 18
Institutional partnerships are another critical component of sustainability. Universities, libraries, and cultural heritage organisations play a vital role in providing the infrastructure and expertise needed to support DSEs. Long-term agreements between these institutions and project teams can ensure the continuity of resources and knowledge transfer. In some cases, digital preservation initiatives, such as LOCKSS (Lots of Copies Keep Stuff Safe), provide distributed storage solutions that safeguard against data loss.Footnote 19
Funding models for DSEs must also evolve to address their unique requirements. Traditional grants, often limited in duration, are insufficient for the ongoing maintenance of digital projects (VandeCreek Reference VandeCreek2022). Instead, hybrid funding models that combine public grants, private sponsorships, and crowdfunding initiatives offer a more sustainable solution. Public–private partnerships, where corporations provide financial or technical support in exchange for visibility or collaboration opportunities, have also proven effective in sustaining large-scale projects.
Open-access publishing models have emerged as both an ethical imperative and a practical strategy for sustainability. By making DSEs freely available, creators can attract a larger user base, which in turn generates more opportunities for collaborative input and potential funding. However, open access requires alternative revenue streams, such as institutional support or subscription-based premium features for advanced tools. Ethical considerations also extend to issues of data governance and representation. The CARE principles, for example, advocate for collective benefit, authority to control, responsibility, and ethics in relation to Indigenous data – principles that may be productively applied to DSE design and management.Footnote 20
Finally, integrating sustainability planning into the early stages of project design is essential. Grant applications and project proposals should include detailed plans for long-term funding, preservation strategies, and scalability. By proactively addressing these issues, project teams can mitigate the risks associated with funding gaps or technological obsolescence. The sustainability of DSEs ultimately depends on the collective efforts of scholars, institutions, funders, and users. By embracing innovative funding models and prioritising open standards and collaborative practices, the field can ensure that DSEs remain vibrant and accessible resources well into the future.
With these issues and future directions in mind, we turn now from the general to the particular, exploring how the Oxford University Voltaire project encapsulates and addresses many of the methodological and technical challenges outlined above.
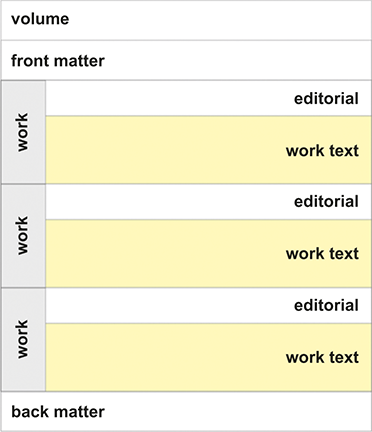
2 Making the Corpus: From Print to Digital
If we want a ‘complete’ Voltaire, it seems obvious that we gather together everything he wrote. But the task is by no means as simple as it might at first appear. To begin with, how do we define the corpus of any writer? Are there items that should be excluded? Then in the case of Voltaire in particular, there are two major complicating factors. Firstly, Voltaire wrote an enormous amount: he was a literary celebrity who held his reading public for a period of sixty years, from his first play Œdipe, published in 1718, until his death in 1778. His 2,000 or so published works total around fifteen million words. The sheer quantity of his writings presents a challenge. Secondly, Voltaire was constantly embroiled in controversy and subject to political and religious censorship: it is much harder to pin down a corpus that has become slippery and fragmented through being argued about over a lengthy period. In the face of such an enormous body of controversial writings, it is difficult not to be influenced by the weight of tradition, and difficult also to imagine how it might be shaped differently.
2.1 Collecting Voltaire’s Works in Print
Voltaire published a number of ‘collected’ editions of his writings, but these were never complete in the modern sense of aiming to include every single work: it was normal practice in the eighteenth century for a well-known author to put together an authorised edition that established the corpus that they wished to pass on to posterity; and this might well exclude so-called minor works, or works that for one reason or another were deemed to be compromising for the author’s posthumous reputation (Cronk Reference Cronk, Didier, Neefs and Rolet2012b; Cronk Reference Cronk2023).
The first serious attempt to bring together all of Voltaire’s works took place a few years after his death. This edition, managed under the editorial direction of the philosopher Condorcet and financed by the playwright Beaumarchais, was published between 1784 and 1789 in seventy volumes at Kehl, a small German town just across the Rhine from Strasbourg – for political reasons, the books could not be printed on French soil. The so-called ‘Kehl edition’ was an ambitious undertaking, and it constituted a serious attempt to establish a ‘canonical’ Voltaire. It grouped the works by genre, and for the first time collected a corpus of some 4,500 letters, in effect inventing Voltaire’s correspondence (he had never in his lifetime systematically published his letters together). The result of enormous labour and conceived deliberately as a monument to the celebrity author, this is still not quite a complete edition in the modern sense: certain works, such as an early poem ‘tainted’ with Christian belief, are omitted because they do not fit the ideological narrative that the editors wished to present. More importantly, the very large number of short prose ‘chapters’ published in various collections – in many ways Voltaire’s most characteristic polemical works – are grouped together in one long alphabetical sequence, obscuring the integrity of their original publication in different forms and at different times. Some texts are seriously deformed in the Kehl edition, while others are simply missing; works from different periods are mixed together; many texts are undated or are dated inaccurately. Most importantly, this is not a critical or scholarly edition in the modern sense: the text is not established on the basis of a specific edition, explanatory notes are minimal, and very few variants to the text are recorded (and in the case of Voltaire, whose works regularly appeared in multiple editions, variants are often numerous, long and important).
The Kehl edition is a remarkable cultural object and an extraordinary publishing achievement. The edition necessarily reflects the editing practices of its period, so it would be pointless to complain that it lacks the qualities of a modern critical edition. It proved to be hugely influential, for good and for ill. The Kehl edition in effect created the Voltaire that was known to the generation of the French Revolution. Later, in the nineteenth century, there was huge demand for editions of Voltaire, yet publishers understandably recoiled at the cost of reorganising such an enormous corpus, and inevitably they preferred to follow the Kehl edition, in the process recycling its assumptions without questioning them. During the period of the Restoration (1815–1830), the name of Voltaire enjoyed iconic importance in the new political landscape, and there were several dozen complete editions of Voltaire. These editions each added newly found letters, along with a few other minor texts that had turned up in manuscript, but fundamentally they all followed the Kehl template. The one editor of this period to try to impose a new order on the inherited Voltairean corpus was Adrien Beuchot, who made some modest improvements to the Kehl edition, for example, by establishing the Lettres philosophiques as a free-standing text.
After the collective editions of Voltaire’s lifetime, which were deliberately not complete, the collective editions that appeared following his death, from Kehl onwards, were ever-expanding, as more manuscripts, in particular letters, came to light. The last complete edition of the nineteenth century was edited by Louis Moland and appeared in fifty-two volumes in the early years of the Third Republic (1877–1885), at a time when Voltairean values were key to the fledgling French Republic, which had come into being following the defeat at the hands of the Prussians in 1870. The Moland edition significantly increased the number of known Voltaire letters, but in other respects, it again largely followed the pattern of the Kehl edition as revised by Beuchot in the 1830s. Throughout the twentieth century, the Moland edition remained, faute de mieux, the standard edition of reference.
2.2 The Complete Works of Voltaire/Œuvres complètes de Voltaire (1968–2022)
There were many oddities and eccentricities about the way in which Voltaire’s texts were handled, and mishandled, over the years in these collective editions. From the early twentieth century, when Voltaire began to be taught in universities, there began to appear scholarly editions of individual texts, such as the Lettres philosophiques (edited by Gustave Lanson, 1909) and Candide (edited by André Morize, 1913). But Voltaire scholars who wanted to venture beyond this narrow selection were still obliged to use the Moland edition, and given the imposing bulk of the corpus, it was immensely difficult to avoid earlier editorial choices, and all but impossible to challenge the traditional Voltairean canon, which in its essentials had remained unchanged since the Kehl edition in the late eighteenth century.
What was needed was a completely new edition, built on first principles, but this posed formidable challenges. Firstly, the work involved, therefore the cost, would be considerable; and secondly, even in the twentieth century, Voltaire remained an awkward and controversial figure in France, especially for Catholics. It is not surprising then that when finally, in the 1960s, plans were laid to produce a completely new edition of the totality of Voltaire’s writings, the initiative did not originate in France. It was two English academics, W. H. Barber and O. R. Taylor, both distinguished specialists of Voltaire in the University of London, who in 1967 approached Theodore Besterman (1904–1976), a Voltaire scholar of independent means, and asked for his support in launching a new edition. Besterman himself had recently produced a 118-volume edition of Voltaire’s correspondence (1953–64), a pioneering achievement that had been widely acclaimed, and he agreed to finance a new Complete Works of Voltaire and to become its general editor. The volumes of the new edition began to appear from 1968, and when Besterman died in 1976, he left a bequest enabling the project to continue at the Voltaire Foundation at the University of Oxford. Work on the so-called Oxford edition, now usually referred to by its acronym OCV, involved over 200 collaborators and was finally brought to completion in 2022, in 205 volumes.
The Oxford edition was the first edition to go back to the drawing board and to construct an edition of Voltaire’s collected works from scratch, without being influenced either by what Voltaire had done in his lifetime, or by the powerful posthumous editorial tradition created by the Kehl editors. It was also the first complete full-scale critical edition, and this is important, given that Voltaire repeatedly revised and rewrote his texts, so that many works exist in multiple versions. For each work, it was necessary to draw up, in so far as possible, a full list of known manuscripts, and a full description of all known print editions dating from Voltaire’s lifetime, identifying those that seem to have been published with his approval (although this is by no means always clear). Given that no library in the world has anything approaching all the editions of Voltaire’s writings, this was an enormous undertaking; the work became somewhat easier in later years, as digitised library catalogues became increasingly common. A copy text was selected for each work, that is to say, one of the versions thought to best represent the work in question, and then all the significant variants drawn from the other witnesses supposedly overseen by Voltaire were carefully noted. This gives readers access to the full extent of a work in all its permutations and allows them to understand how a given text evolved over time. In addition, the editor often provides extensive explanatory notes to the text. Preceding the text, there is a scholarly introduction to the work, placing it in its broader literary and cultural context, and also a full list of manuscripts and printed editions, including full bibliographical descriptions and appendices. Following the text, there is typically a list of works cited and a detailed index of names.
With such a large corpus, the question of how to order the texts is a challenging one. In all the complete editions of Voltaire from Kehl to Moland, the practice had been the same: to group the works by genre. The editions would routinely begin with volumes dedicated to theatre and to epic poetry, then followed the histories, other miscellaneous prose works, the shorter verse and finally, always at the end, the correspondence. This arrangement had the advantage of familiarity and apparent simplicity, but the disadvantage of rather downplaying the importance of the shorter prose works, which do not easily fit into preconceived generic categories (which is one reason of course why we now admire them). Any classification that ends up with so many of the most significant works clustered in some sort of ill-defined ‘miscellany’ looks suspiciously inadequate. The founding editors of the Oxford edition decided to try something different, and to arrange the texts, regardless of genre, by date; to be precise, by the date when the work was thought to have been substantially composed, rather than by the date of first publication (which can be stated with greater reliability). This bold innovation had important practical consequences: by including in a single volume works of different genres, the preparation of the volumes turned out to be slower than might otherwise have been the case, because numerous editors were contributing to the same volume. Academically, however, this was a significant advance: the arrangement of works within the Oxford edition shows clearly how Voltaire worked on different projects simultaneously, a phenomenon that has been called ‘creative concurrence’ (Van Hulle Reference Van Hulle2021); and such an arrangement further avoids the trap of separating writings into ‘major’ and ‘minor’ categories, especially important with this author, where it is the seemingly lesser works, like Candide, that posterity has judged to be among the most important in his œuvre.
The Oxford editors resolved, of course, to include in the edition everything that Voltaire wrote, and that list of works was largely established before they began their work. There could no longer be any question, for example, of quietly suppressing writings that were for whatever reason found to be embarrassing, as had happened in the early editions. In his edition of the correspondence, Besterman had preferred maximal inclusion: he rightly included letters addressed to Voltaire (often essential for understanding replies) and even letters written by third parties containing significant information about Voltaire. There are many quasi-legal documents and financial papers that are not strictly letters but still of interest in charting Voltaire’s life, and these Besterman includes in a long series of appendices to the correspondence.
In English studies, the term ‘unediting’ is sometimes used to describe how editorial choices and procedures in the early-modern period that result from ideological or cultural prejudice can often stifle significant or innovative aspects of the text (Marcus Reference Marcus1996); we can find clear parallels to this phenomenon in early editions of Voltaire. In one key respect, the new Oxford corpus differs from its predecessors, for the simple reason that a number of works published in Voltaire’s lifetime – and significant works at that – quite simply ‘disappeared’ in the Kehl edition, including individual works such as the Lettres philosophiques (1733/1734) or the Questions sur l’Encyclopédie (1770–1772), both of which were dismantled by the Kehl editors and broken down into their constituent chapters which were then absorbed into a larger whole. The Commentaire historique sur les œuvres de l’auteur de La Henriade, published in 1776, is another striking example of this phenomenon. The work has a curious structure, being made up of three unequal parts: an oddly flat and highly selective third-person account of Voltaire’s life, then a dossier of letters, and in conclusion a short poem. This is in fact a rather creative experiment in autobiography, or what we would now term life-writing, but it was not understood as such when it first appeared; the Kehl editors broke up the work, publishing its constituent parts in different volumes of the edition – with the result that the work in effect vanished from sight, even if its various parts were still in print. Thus the edition of the Commentaire historique in the Oxford edition is the first integral publication of the text since 1777, and it is a revelation of an aspect of Voltaire’s writing that was long neglected and misunderstood. Simply by dint of producing the first ever critical edition, therefore, whereby each text is traced back to its first printing, the corpus of the Oxford edition looks radically different from the corpus put together by the Kehl editors.
There were a small number of manuscripts, such as the ‘Chapitre des arts’, an incomplete draft chapter describing the history of the arts, originally destined for the Essai sur les mœurs but subsequently abandoned, that were included in the corpus for the first time. And while wishing to be as complete as possible, it is also necessary to draw the line somewhere: what to do, for example, with the household accounts of the château de Ferney? These manuscript accounts provide an interesting resource for research into material culture, telling us, for example what Voltaire ate, and how much he spent on his servants, and Besterman did publish a facsimile printing of the manuscript. This is obviously not a work by Voltaire, however, even though the manuscript does contain traces of his hand, and it was decided not to include it in the Complete Works. In the case of a corpus as large and complex as Voltaire’s, there is certainly a temptation to keep adding, a temptation that has sometimes to be resisted.
Many eighteenth-century editions of Voltaire contain prefaces and the like, and these paratexts pose an interesting challenge to the editors of a complete edition. If such prefaces are signed by Voltaire, there is no argument, but mostly they are anonymous, and sometimes they are signed with a pseudonym. We may very often surmise that these prefaces were in all probability written either by Voltaire or under his instruction; and whether composed directly by him or not, these are crucial texts for understanding the publishing strategy of a given publication. The Oxford editors tended, and increasingly as the years went on, to include these paratexts. An interesting example of the phenomenon is the subscriber’s list which prefaces the 1728 quarto edition of La Henriade published in London: the list of names of the great and the good that subscribed to the edition is clearly not a work ‘by’ Voltaire, though it is an intrinsic part of the edition which Voltaire corrected in proof, and the list is of course fascinating testimony to Voltaire’s ruthless networking on behalf of his poem. In this case, the original editor of La Henriade in 1970 chose not to include the list of subscribers in his edition, but the text was later included as an appendix to another edition published in 2022:Footnote 21 in the intervening half century, book historians had changed the way we use this type of document for studying the social networks that underlie the subscription sales of books in Britain and Ireland.
One significant addition to the OCV corpus, agreed only in the course of publication, was the inclusion of the marginalia found in the books of Voltaire’s library, now in Russia. The project to edit what was called the Corpus des notes marginales was initiated by the National Library of Russia in St Petersburg, but it sadly came to a halt in 1994, when it had reached the halfway point at volume 5. In 2002 the Voltaire Foundation negotiated with the library in St Petersburg to take over the publication of the Corpus and to reprint the earlier volumes; it was then decided, rather than publish these as a stand-alone collection, as had been initially intended, to incorporate the volumes of marginalia within the Compete Works,Footnote 22 and it was later decided to devote a further volume to the marginalia found in books outside the National Library of Russia.Footnote 23 It seemed a bold decision at the time to include such seemingly ephemeral writing in the corpus (though the Bollingen edition of Coleridge, which includes six volumes of marginalia, provided a distinguished precedent), but with hindsight, this was a sound move. The publication of Voltaire’s marginalia has stimulated renewed interest in the subject and opened up a fresh field of research (Pink Reference Pink2018); furthermore, its inclusion within the corpus had a dynamic effect on the edition itself, as editors were increasingly able to use the evidence of Voltaire’s library and the marginalia within its books to better understand Voltaire’s use of sources and the genesis of certain of his works.
2.3 From Paper to Digital: From OCV to OV
The publication of the Complete Works of Voltaire has been described by the book historian Robert Darnton as ‘a great trek, the greatest ever in the history of scholarly publishing’.Footnote 24 It now stands beyond doubt as the edition of reference for Voltaire, and that in itself poses something of a challenge: how can the edition maintain that standing as scholarship advances and as new discoveries are made? The sheer time and expense of producing a 205-volume paper edition means that we can say with certainty that there will never be a new edition of the complete works published in print. Everything points to a digital edition, but a digital edition of what sort?
As we have seen, digital editions can be archival (derived from print) or born-digital, and it would be possible, in theory at least, to imagine a wholly new born-digital edition of the complete works of Voltaire, one that would be conceived specifically for the digital medium and that would be entirely unconstrained by the necessities of print. But even if this might in theory be our ideal solution, it would be unworkable and unaffordable in practice. Given the enormity of the undertaking, given the vast quantity of information, much of it new research, already contained in OCV, it would not make practical sense to ignore the OCV print edition. So, if OCV is necessarily our starting point, the question becomes a different one: how should we digitise the OCV paper edition to achieve the best possible results? Here, the distinction between a digitised and a digital edition is crucial. The individual print volumes have already been digitised (and are sold both as print-on-demand volumes and as e-books); it would be a relatively simple operation to make a digitised edition by combining the volume files and making them cross-searchable. Elena Pierazzo makes a good argument against over-complication: texts can be simply digitised, and tools are increasingly available to search those texts (Pierazzo Reference Pierazzo2015, p. 2). The result of such an undertaking would be hugely convenient, it would save on shelf-space, but it would not in the end be radically different from the collection of printed books. Such digitised texts, containing the electronic reproductions of paper pages, are not true digital editions.
The Voltaire Foundation has a world-wide reputation as an academic publisher of ‘definitive’ scholarly editions; and it is a timely endeavour to seek to transfer that know-how from paper to the realm of the digital, and so rethink the critical edition in a new medium. Scholars of literature have long been familiar with critical editions in the form of print volumes, so it requires quite a leap to wonder how they might be conceived differently. How might we imagine the modern digital equivalent of what we used to call a ‘definitive’ edition? The very term ‘definitive’ is anachronistic, anchored to the age of print and of texts that were fixed (Shillingsburg Reference Shillingsburg2025). In truth, no scholarly edition ever says the last word, and we should rather speak of an ‘authoritative’ edition, one that is also ‘referenceable’, the edition of reference that scholars are expected to quote in their footnotes. The new digital edition that we are imagining will in addition be expandable and updatable, aiming to include and digest the latest critical thinking.
Voltaire provides an excellent subject for this experiment, firstly on account of the sheer size of the corpus of writings, and secondly because of their unparalleled variety. Voltaire composes in just about every known literary genre, and in addition there is his correspondence (over 21,000 letters), his working notebooks, and the marginalia: few writers offer more complex challenges. The aim to produce an authoritative digital edition of Voltaire’s collected writings is nothing if not ambitious.
An important question before we go any further: the name! What do we call the digital reinvention of the Complete Works of Voltaire? During the early development of the project, the research team referred to it as Digital Voltaire. However, in discussion with two British university presses who were both potential distributors of the product, we were told the same thing: if we wished the name of the digital product to convey a sense of heft and authority, it would be best to avoid altogether the word ‘digital’ and synonyms like ‘electronic’. To use the name of the publisher, Voltaire Foundation, would have created a clumsy and repetitive title, so in the end the research team chose Oxford University Voltaire, to be known also by its abbreviation, OV.
The literary corpus of Voltaire, once it is transformed into a digital object, becomes something different. Print is static, where digital is (or should be) dynamic, and this transforms how we think about the corpus, and about the scholarly edition generally. Elena Pierazzo asks an important question: ‘Are digital editions texts to be read or objects to be used?’ (Pierazzo Reference Pierazzo2015, p. 147). The OCV is principally designed to be consulted; its digital successor OV will be, in addition, an object to be used. So the digital version must not (only) be an enhanced and revised version of the print edition, though it will be that; it must be rethought from the inside out, and try not to be confined by the limitations of the paper edition. The modelling of the content has the power to generate new knowledge, a subject to which we return in the next chapter.
It is a nice paradox that after spending half a century producing a ‘definitive’ print edition of Voltaire, our central aim now is that the digital edition should replace the print version as the authoritative source of reference for this author. But where the print edition was designed primarily as an object to be read, the digital successor will have a triple function:
(1) to be read, and to be cited as the version of reference;
(2) to be used as a research tool, enabling scholars to conduct research; and
(3) to be a platform enabling the publication of that research.
2.3.1 Updating Material in the Digital Edition
The first challenge then is to think about how the material contained in the print volumes might be supplemented, adapted or reworked. At the simplest level, the digital edition provides an opportunity to correct mistakes, make revisions, add recent discoveries, and so forth. Firstly, we can carry out simple updating, such as replacing references to other works of Voltaire, currently a mixture of Moland and OCV references, with hyperlinks. Secondly, we can make minor corrections: there are typographical errors to be corrected, and more importantly, omissions in lists of editions or in sources in the text which can be rectified. In recent years, the availability of online texts has greatly facilitated research into, for example, rare print editions, the location of manuscripts, or the source of quotations. Such resources were not available to earlier editors in the 1970s and 80s, and useful complementary information can and should now be added to the editions published in earlier years. Thirdly, we can make minor additions, and the edition can be updated, to take account of new research as it is published. For example, the edition of the opera libretto Le Temple de la gloire records that we do not know the music of the first (1745) performance; a manuscript of this score was subsequently unearthed in the university library at Berkeley, and it is clearly desirable to include in the edition a reference to this new discovery.
It is unlikely, though not impossible, that new Voltaire works will come to light, but one area in which new material is being constantly discovered is that of the correspondence. Voltaire was prodigiously active as a correspondent, and manuscripts of new letters regularly surface in archives or appear in sale rooms: it is clearly desirable to be able to add to the edition new letters, and unknown manuscripts of known letters, as they are discovered. In editing Voltaire’s correspondence, Besterman took the decision to stop in 1778, at the moment of Voltaire’s death. Ralph Leigh who during the same years was editing the comparably monumental correspondence of Jean-Jacques Rousseau, took the different decision to include letters written about Rousseau in the years immediately following his death: these are fascinating testimony to the reception of the writer’s ideas and values. It might well be valuable to extend the Voltaire correspondence in the same way. The digital version of OCV needs to be updatable, so as to remain, always, the authoritative point of reference for this author.
2.3.2 Adding Material to the Digital Edition: The Voltaire Studio
Beyond updating the material already contained within the print corpus, it has been decided to create a certain number of entirely new resources, supplements to the corpus, that will be grouped under the umbrella title of the ‘Voltaire Studio’, and that will be made freely available. Firstly, the Voltaire Studio will include the Compendium, discussed below, a collection of highly curated entity pages based on names, places and events, designed to facilitate searching and providing a multiplicity of entry points into this rich and complex resource. In addition we will include newly built resources that will stand alone, while also enriching OV. The first of these, due to be published in 2026, is an iconography of Voltaire; as arguably the first literary celebrity in Europe, depictions of the writer (both favourable and hostile) proliferated in his lifetime and thereafter, playing a key role in how he came to be read and understood. This material, highly attractive in its own right, will also provide a significant complement to the literary works in providing important evidence for their reception. Two other projects that are envisaged are a catalogue of Voltaire’s personal library and a catalogue of his manuscripts. The Library of Voltaire represents the most complete dataset regarding the books that Voltaire was known to have owned and used: a total of around 6,000 volumes and approximately 1,000 manuscripts. Begun in 2021, the database makes these items searchable and therefore more widely accessible to scholars. The Catalogue of Manuscripts Relating to Voltaire/Catalogue des Manuscrits relatifs à Voltaire (CMV), meanwhile, is a digital union catalogue which brings together global collections of Voltaire manuscripts in one place for the first time. Begun in 2022, CMV contains approximately 20,000 entries for manuscripts produced by, or relating to, Voltaire, allowing users to search across international archival collections. The beta versions of both these databases were launched in March 2024, and currently function as stand-alone resources; we plan to incorporate them into the Voltaire Studio, making them fully inter-connected with OV. The inclusion of these catalogues will further enhance the research enabled by OV, especially in the analysis of sources and in the genetic study of texts.
Further additions to the Voltaire Studio will be made as time and finances permit. Reference was made above to Voltaire’s Household Accounts: this manuscript was not edited as part of OCV, but there would be a good case for including it here. There are many other items that might be considered for inclusion in the Voltaire Studio: a biography, timelines, maps (especially important for understanding Voltaire’s historical works) are all under consideration, we could also investigate the addition of musical examples from the operas based on Voltaire’s libretti or from songs set to his poems. An important focus for future research could be in the area of the illustration of Voltaire’s works. The number of plates in OCV was necessarily limited, for the most part images of title pages and of manuscripts; these are useful and informative, and their number could usefully be expanded. In addition, the editions that make up OCV say little about book illustration, an area in which book historians have become more keenly interested in recent decades. Some illustrated editions, such as the 1728 London quarto edition of La Henriade, were published with Voltaire’s approval, and deserve more critical attention. Even the illustrated editions that appeared without his approval are important for the influence they may have had on reception (Cronk Reference Cronk2002). Moreau le jeune’s illustration of Candide meeting an enslaved man, added in 1787 after Voltaire’s death, has been widely reproduced and has had a huge impact on how we think about Voltaire’s role in the slavery debate.
The quantity of material that could be added is limitless, and this is both an advantage and a potential danger. We need to bear in mind that the scholarly edition of a text is always at root an interpretation, in which the editor presents an argument and makes choices to guide the reader. An edition may legitimately choose to include certain materials at the expense of others in order to underscore its core arguments. We need perhaps to be wary of the desire to include absolutely everything, or we should at least be very disciplined about how additional information is prioritised within the hierarchy of the edition: selectivity is a positive virtue in a critical edition. More is not always better, and a digital edition, with no constraints of space, could become unwieldy and less user-friendly, unless the information is structured with care. Secondly, all additions and emendations to the base print editions will be signed and dated, and subject to peer review before publication. The Voltaire Studio is not envisaged as a crowd-sourced activity, but as a carefully curated publication, in keeping with the practice of the traditional scholarly edition.
The types of material included in the Voltaire Studio exist of course in the case of many writers. We believe however that the Studio breaks new ground in important ways. Firstly, the material is being gathered together under a single umbrella, so as to be fully interconnected with the works themselves: this will enable users to make discoveries and will generate new knowledge. Secondly, in making this material available on Open Access, we hope to draw readers to the resource. And thirdly, we would like (some of) the readers of OV to become contributors to the resource, publishing their findings on the platform. Moving beyond the old idea of a ‘definitive’ (print) edition, the Voltaire Studio enables OV to become an authoritative and referenceable (digital) edition, which reflects the current trends in scholarship, and permits its users to become contributors to it.
2.3.3 Readership
The triple function of OV as a resource for reading, for research and for publication, encourages us to think afresh about who its users will be. We (think we) know the traditional readership of OCV: the print edition of the Œuvres complètes de Voltaire was purchased in the main by university libraries and by a small number of individual scholars; the target readership in this case is made up of ‘professional’ scholars and researchers, many of whom may already be to some extent familiar with Voltaire and his writings.
OV will certainly aim to retain these readers, those who currently cite OCV as the edition of reference in their scholarly publications. There is not yet in the scholarly community widespread general acceptance of the idea that a digital edition might have the same heft as an authoritative ‘university press’ edition of reference – the one which is systematically quoted in the footnotes of scholarly articles and books. In the late twentieth century, Peter Shillingsburg deplored the fact that ‘only one tenth of one per cent of the available texts on the Internet were reliable for scholarly work – 99.9% of the texts were who knows what’ (Shillingsburg Reference Shillingsburg1996, p. 138). It is not clear that the situation has improved so very much in the thirty years since he wrote these words. The print OCV edition is currently regarded as the ‘definitive’ work of reference for quoting Voltaire, and looking to the future, we aim to establish OV as the new reference edition of Voltaire, the one to which scholars refer as a matter of course. We need therefore to explore ways of ‘hallmarking’ the edition so that it is, and feels, authoritative.
In addition, the high-quality content of OV will potentially be able to reach and appeal to wholly new audiences. Potentially varying levels of readership could be anticipated, for example by providing different and/or additional annotation for certain categories of reader, as was done with Candide 2:0: l’édition enrichie, the Candide App designed by the Voltaire Foundation and the Bibliothèque nationale de France and launched in 2012. We might imagine different paths through the resource for various categories of reader: university students; school students, including francophone students outside Europe, in, say, North Africa; a reading-public broader than the traditional scholarly readership; and so forth.
The recent marked improvement in automatic translation also opens up new opportunities. Voltaire’s texts are of course edited in the language in which he wrote, which is French (and a small number of writings in English, Italian, and Latin), and this inevitably limits the potential readership of OCV. It remains the case that the overwhelming majority of Voltaire’s works remain untranslated: a future project should be to explore the possibilities of using machine learning to provide high-quality translations of Voltaire into other languages. Translations of individual texts might also be invited. In the shorter term, automatic translation is already good enough to translate the scholarly apparatus in OCV (introductions, notes, etc.), that are given currently in either French or English, depending on the individual editor’s preference: this is potentially a powerful way of communicating OV’s scholarly content to a far wider audience.
2.3.4 Publishing Research
OV will appeal to researchers not just as a research resource of reference, but also as a platform on which they will be able to publish their findings based on their research using the resource. We imagine three different avenues of publication:
(1) Supplementary notes. These will be brief corrections or additions to the apparatus in the critical editions in OV.
(2) New material in the Voltaire Studio. These will be new open-access resources, as described above, that will stand alone but also be fully integrated into the OV ecosystem.
(3) Articles in a new blog/journal, which will be incorporated into the Voltaire Studio. This will be an open access journal, on a blog-style platform, containing short articles developing research conducted in part or wholly with OV. There are models for this, though they are few in number: Nietzsche Source, for example, which began as a documentary edition of Nietzsche’s manuscripts, has included, since 2014, Studia Nietzscheana, an international online, peer-reviewed digital-only scholarly journal, publishing research on Nietzsche.
In all cases, these contributions will be assessed by an editorial board and peer-reviewed before being published in OV. The various possibilities of scholarly intervention and contribution remain to be developed, and while we are not considering crowd-sourced projects, there are other models of scholarly collaboration with which we can experiment. Suda On Line, a Byzantine lexicography, is an example of a resource where more than two hundred people worldwide submitted translated or editorial material that was progressively ‘vetted’ to a usable standard by an editorial board. The OV exists to stimulate research and to encourage scholarly engagement.
2.4 Sustainability and Open Access: The Business Model
A scholarly digital edition as large and ambitious as the one sketched here poses obvious challenges. Firstly, how do we pay for it? And secondly, equally importantly, how do we ensure that it reaches all the readers that it deserves to, now and in the future? The advantages of open access (OA) seem self-evident, and Peter Baldwin is a passionate advocate of this principle: ‘Open access hinges on flipping the funding stream from consumer to producer. Whether the dissemination is paid for directly by authors, or indirectly by funders or some third party, including governments, is less important than shifting the cost away from consumers. This core tenet of open access is what allows us to envisage the global availability of all (scholarly) content’ (Baldwin Reference Baldwin2023, p. 5). It is hard to resist this rallying cry for the global availability of scholarly content. But nothing is free: someone, at some stage in the publishing process, has to pay, and therein lies the dilemma. We are beginning now to have some successful models for making journals open access, and Liverpool University Press is currently one of several presses exploring innovative ways of achieving this, in particular adopting the Subscribe to Open model (S2O), whereby an existing subscriber base for a print publication is used to underwrite, at no increased cost to the libraries, the ‘flipping’ of a journal to OA.
However, finding an OA solution for long-form scholarly work, such as the monograph, and in particular the scholarly edition, is proving to be a far greater challenge. In an article of 2024 in Times Higher Education, Anthony Cond and Jane Bunker (the heads of Liverpool and Cornell university presses respectively) are critical of what was then a REF draft proposal in the UK to require monographs being made available by depositing a book’s ‘author accepted manuscript’ (AAM): such a scheme undervalues the input of the publisher, they argue, and it also creates a divide between different institutions, those that rely on green access to an inferior version, and those that can afford to buy the finished product, the published book. Cond and Bunker conclude, thinking no doubt of the success of the S2O model for journals, that collective action in the shape of library subscriptions is the way forward also for monographs (Cond and Bunker Reference Cond and Bunker2024). A symposium held in April 2024 in Liverpool, Opening the Monograph: Its Future within an Open Scholarly Landscape, similarly suggested a leaning among funders (and perhaps academics and publishers too?) towards a collective subvention rather than a Book Publishing Charge.
If monographs pose a challenge, scholarly editions pose an even greater one. These are explicitly exempted from the UKRI’s policy on open access, as revised in November 2023: this is seemingly a recognition of the difficulties we have in coming up with any viable model. The UKRI has launched a fund to support OA for what they call ‘long-form outputs’, but in the guidelines, as updated on 18 March 2024, long-form outputs refer only to monographs – the scholarly edition is simply not mentioned. The four UK funding bodies produced a consultation document concerning OA policy for the 2029 REF concerning long-form scholarship that again contained no mention of scholarly editions whatsoever; and in the event, long-form scholarship, in all its forms, will not need to be OA for 2029. The UKRI clearly recognises that we have a problem, and an OA policy for scholarly editions remains unfinished business.
It is important to lay out the particular challenges posed by the scholarly edition that make it unlike other types of long-form scholarship.
(1) Traditional university presses and their equivalents are often criticised by OA enthusiasts for being profit-driven enterprises, but good publishers play a vital role in the preparation of high-quality scholarly editions, which are by nature complex publications, containing intricate bibliographical details. In such cases, the processes of peer review, copy-editing, and proof-reading are essential in ensuring a good outcome, and in-house editors make a key contribution to ensuring the consistency and excellence of the final product. The use of an ‘author accepted manuscript’ (AAM) to provide green open access, already of doubtful use for the monograph, would clearly be entirely inappropriate in the case of the scholarly edition, even one that was published in print only.
(2) Sustainability of any digital resource requires a robust technical infrastructure and adequate ongoing funding to maintain it. In the case of a scholarly edition, its text may well not be fixed like that of a monograph; we may have the ambition to create a flexible resource that can update its contents and evolve by incorporating the new research that it engenders. Such a dynamic resource, making the fullest use of the digital medium, will require even greater funding to remain sustainable.
(3) Sustainability depends not only on funding, but also on a sound communications policy ensuring outreach, and for this, we also need the professional skills of the traditional publisher. We authors all have a touching belief that once our work is freely available, the whole world will rush to read us – and sadly, that is not always the case. An OA DSE, in addition to sustainability, also needs discoverability (including, e.g., the production of MARC records). Traditional publishers have sales and marketing teams, and if OA means we can dispense with the sales force, we still do need a sustained and dynamic communications strategy to ensure that our resource reaches its intended users, along with an ongoing strategy to increase our reader base.
(4) Digital editions in the future need to have the same heft as the ‘definitive’ paper editions of the past: there is a paradox that editions made freely available are not always appreciated as much as editions that have to be paid for, so we have to work even harder to ensure that OA digital editions have the appropriate authority.
Turning now to OV, the ideal, of course, would be to make the new resource fully available on OA, like, for example, the Stanford Encyclopedia of Philosophy. To sustain such a high-level, evolving resource as OV will require, however, significant capital investment, and fundraising for that will present a challenge. In the meantime, in the absence of such financial support, the only viable option for the Voltaire Foundation is to partner with a publisher, and it is Liverpool University Press who will market and sell OV on subscription or with perpetual access. This solution has the obvious advantage of generating a modest regular income that will contribute towards sustaining the resource. But this is not an easy option. It will limit access to the resource, especially as library budgets in all countries are under pressure, and humanities librarians in particular struggle to compete for central resources. There are also some interesting cultural assumptions to negotiate in selling a French-language resource in the UK: universities in the English-speaking world are prepared to buy or subscribe to datasets, though they tend to be wary of products in ‘foreign’ languages; libraries in the French-speaking world are sometimes less open to paying for electronic editions at all, especially if they are in French and produced ‘abroad’.
While we are not able to offer the entire resource on OA at present, we have imagined a hybrid model. The core of the scholarly edition (the texts, with their annotation and introductions) will be behind the paywall, while the resources of the Voltaire Studio and the blog/journal will all be freely available on OA. Although falling far short of complete OA, this compromise at least strives to combine some of the benefits of OA with the partial financial sustainability of the subscription model. It is also important to remember the needs of digital humanities researchers who want to use highly curated data for their own experiments, and we will make available the raw data free of charge, by special agreement, to all bona fide researchers. The OV is not just an authoritative resource of reference; it is equally importantly a research tool, and more than that a research laboratory. To guarantee the long-term independence and development of such a dynamic resource, it needs to be self-sustaining, even while we hold to the long-term ideal of full open access.
The Voltaire Foundation is a university-based, but entirely self-financing, research team, dedicated to research into Voltaire (and other Enlightenment authors) and into digital publishing. Working with the ARTFL Project (University of Chicago), we have already made available on open access Tout Voltaire, a digital edition containing a plain text version of the entirety of Voltaire’s writings (apart from the correspondence). The OV is something different: a research project that tries to imagine what a DSE of a canonical single author might potentially look like. This of course, is not as it stands, a model that would be viable for many other editorial projects; Voltaire’s writings are exceptionally prolific and remarkably complex, and our project requires a level of investment that is similarly out of the ordinary. We hope however, that OV in addition to advancing research in Voltaire studies, may perhaps influence the planning of other editorial projects and also contribute to the current debate about the sustainability of DSEs on the one hand, and the need for referenceable digital editions on the other.
3 Modelling Voltaire
3.1 Beyond the Bounds of the Paper Edition
The concept of ‘remediation’, as elaborated by Bolter and Grusin (Reference Bolter and Grusin1999), describes the movement of content from one medium to another as a process of translation, in which there are losses as well as gains. Remediation, they argue, depends on two basic impulses: immediacy, which is the attempt to eliminate or minimise the mediating function and present the illusion of directly-represented reality; and hypermediacy, the attempt to foreground the mediating function, so emphasising the impossibility of direct representation. Voltaire produced a complex body of work that can be accommodated only with great difficulty within the bounds of a traditional print edition; and this opens up the possibility that a future digital edition, a different remediation, will be able to model the Voltaire material to achieve greater immediacy and so come closer to the complexity of his writing.
It is never simple for a print volume to present clearly all the information that is required about a writer in a scholarly edition. Take, for example, Emily Dickinson. Her poetry is available in a modern variorum edition (1998), and in addition there is another edition, Emily Dickinson’s Poems: As She Preserved Them (2016), aimed, says the editor, at ‘the scholar, student and general reader’, which presents and annotates facsimile copies of the poems that Dickinson retained for herself during her lifetime. This interestingly conceived volume is designed to bring the reader closer to the processes of poetic creation and to enable what we now call a genetic study of the poetry; furthermore, both Harvard University and Amherst College, whose libraries between then have the major manuscript holdings, have each produced online digital versions of images of the Dickinson manuscripts. It would be a challenge to imagine a single print edition that could bring together all these different materials and cater for all these different categories of reader.
It is not uncommon for critical editions that aim at completeness to struggle with the constraints of the two-dimensional page layout. There is a constant tension between the demands of precision and exhaustivity, and the need for legibility and accessibility. In a chapter entitled ‘Editing as a theoretical pursuit’, Jerome McGann considers classic scholarly editions like Lachmann’s Lucretius, Bower’s Dekker and the Kane-Donaldson Piers Plowman, whose intellectual ambition breaks the bounds of the conventional scholarly edition: ‘They also seek discoveries that stand beyond the purposes of customary scholarly practices’ (McGann Reference McGann2001, p. 79). In McGann’s view, a great edition is a contribution to scholarly understanding, and in exceptional cases such as these, the critical edition makes a scholarly contribution that would not be possible in a conventional article or monograph:
[Projects like these] call attention to the theoretical opportunities involved in making an edition. The totalized factive commitments and obligations of an editorial project open into a theoretical privilege unavailable to the speculative or interpretive essay or monograph. For what these kinds of works know (and don’t know) will be carried to the limit of their capabilities and beyond – “beyond” because they are forced by their obligation to documentary completeness to expose their own fault lines.
In cases of such textual complexity, the material seems to explode the form of the printed book, and for critical editions attempting to impose system or structure on seemingly intractable materials, the digital edition has an obvious advantage in its ability to transcend the limits of the two-dimensional page and to be more supple in dealing with textual complexity. McGann discusses The Rossetti Archive as an example of a digital edition that was transformative in this way:
Electronic texts have a special virtue that paper-based texts do not have. They can be designed for complex interactive transformations. Thus, the general theoretical significance of editorial projects – once scarcely regarded – grows more clear than ever when they are drawn into the orbit of an encompassing innovation: digital textuality. In that context, the aspiration of works like the Kane-Donaldson seem more challenging than ever. They become stimulants to the pursuit of new – now imaginably more adequate – editorial tools. These would be tools with far greater powers of critical reflection and analysis because they would be capable of integrating documentary corpora that were larger and more diverse than one had ever thought possible.
The challenges over recent decades of attempting to tame Voltaire’s works for print publication in OCV have brought to the fore the multiple complexities of his works, and focussed our attention in a new way on the nature of Voltaire’s writing. In addition, therefore, to stimulating new research in particular areas that can be defined in advance, a digital edition has the potential to ‘open up’ Voltaire, and to allow us to examine the singularities of this corpus of writing in ways previously unimagined and unimaginable.
3.2 Theories of Editing
Scholarly editing played an important role in English studies during the twentieth century, and there was, for a long time, a broad consensus around a model of editing deriving from the work of Greg and Bowers. There is not space here to discuss their approach in detail, save to say that it assumed a theory of the text which gave absolute primacy to authorial intention. Jerome McGann produced a powerful attack on this position in his Critique of Modern Textual Criticism. He demonstrated the difficulty of identifying and isolating final authorial intentions, and most crucially, he suggested that the production of a text needs to be seen in a historical and social dynamic:
Furthermore, just as literary works are narrowly identified with an author, the ‘identity’ of the author with respect to the work is critically simplified through this process of individualization. The result is that the dynamic social relations which always exist in literary production – the dialectic between the historically located individual author and the historically developing institutions of literary production – tends to become obscured in criticism. Authors lose their lives as they gain such critical identities, and their works suffer a similar fate by being divorced from the social relationships which gave them their lives (including their ‘textual’ lives) in the first place, and which sustain them through their future life in society.
In other words, the traditional separation in literary research between textual study and interpretation is neither desirable nor viable. The study of textuality is fully part of literary hermeneutics.
In the late twentieth century, at about the same time as digital editions first began to appear, literary theorists were reconceptualising questions of textuality. Roland Barthes was not particularly interested in matters of textual philology (which had never been as prominent in the French literary tradition as they had in other European countries), but his influential essay on ‘the death of the author’ (Barthes Reference Barthes1977) anticipates of McGann’s critique of the Greg-Bowers’ tradition of editing. Don McKenzie did not have digital editions in mind when he spoke about the sociology of texts (McKenzie Reference McKenzie1986), but the evolution of his thinking clearly parallels the way in which McGann has theorised the ‘social edition’. It is not entirely clear here what is cause and what is effect: but the digital edition has clearly been a powerful stimulus for rethinking questions of textuality (Deegan and Sutherland Reference Deegan and Sutherland2009, p. 64; Pierazzo Reference Pierazzo2015, pp. 79–80).
In The Textual Condition, Jerome McGann extends his consideration of the social theory of editing and the socialisation of texts. One theme of this work is his continuing attack on final intentions, or as he puts it, ‘the problematic character of the concept of final intentions, which has become so important in twentieth-century editorial theory’ (McGann Reference McGann1991, p. 61). The position of OCV in this respect is interesting: the early general editors, Theodore Besterman and William Barber, followed what was in the 1960s and 1970s the standard editing practice, opting to choose a single copy text, and to provide in full ‘significant’ variants from that base text occurring in the other authorised editions and manuscripts produced in Voltaire’s lifetime: they properly eschewed the idea of producing an eclectic text amalgamating parts of different editions. But the concern with authorial intentions still weighed heavily on their practice. They often chose as base text the so-called ‘Leningrad copy’ of the encadrée edition of 1775, which contains autograph additions and so is thought to represent Voltaire’s ‘last word’ (although it was never published); they chose variants only from editions ‘authorised’ by Voltaire, something which is not always easy to determine, given that he sometimes passed variant versions of a text to an ‘unauthorised’ printer behind the back of the first chosen publisher; and they ordered the texts in OCV according to their assumed date of (substantial) composition, and not that of their date of publication. This approach, which seemed innovative in the 1960s, has the double disadvantage of giving too much importance to authorial intention (in trying to interpret La Pucelle, written and revised over a long period, the public response to this bawdy epic matters more than when it was first written) and of relying on surmise for much of the dating (we cannot be absolutely sure when Voltaire began to compose certain of his works).
There are some works by Voltaire where an early version of the text is more appropriate as base text. Le Mondain is a poem about the ethics of luxury. The first edition (1736) caused a scandal, not least on account of a lurid description of the love-making of Adam and Eve, writhing around in mud in the Garden of Eden; in later editions, at a time when Voltaire needed to avoid causing needless controversy, he cleaned up, literally, this scene which had caused so much offence (and amusement). If we want to understand the poem, and why it caused such controversy, we clearly need the early version in all its muddy obscenity. The concept of final intentions is of no relevance here; or to put it another way, Voltaire’s true intentions in this case are probably contained in the first edition, and not the last. There are other instances where the adoption of a late edition as base text has been the pragmatic choice: in the case of a work of history, where the text typically grew by constant accretion, it is easier for the reader to be given the full text, with an apparatus at the foot of the page explaining when a given paragraph was first added, than to adopt an earlier text, which would involve large quantities of additional text included in a smaller type-size among the ‘variants’. The choice of a later edition in this case is less about authorial intention than the practical demands of a reader-friendly page layout. In a digital edition, such spatial considerations are no longer relevant, and we might choose to design the edition so that the readers could choose which base text they wished to read (as in The Van Gogh Letters, where readers are able to switch on and off features of the original layout). On the other hand, a digital edition that simply provides the reader with every single version of a text is, in a sense, leaving the reader to do all the work; in the name of completeness, such an edition might be anything but reader-friendly. A scholarly edition is properly an interpretation of the text that guides its readers through the textual intricacies, making all variant readings findable where necessary, but that remains ‘readable’.
The Textual Condition considers texts as material and social phenomena, and a central preoccupation concerns the presence of ‘bibliographic’ codes alongside the familiar linguistic ones: Literary works are coded bibliographically as well as linguistically. In the case of the bibliographical codes, ‘author’s intentions’ rarely control the state or the transmission of the text. In this sense literary texts and their meanings are collaborative events. (McGann Reference McGann1991, p. 60)
This is an idea that Don McKenzie also pondered, especially in his pioneering work on the plays of William Congreve in which he demonstrated how aspects of typographic presentation were crucial to our interpretation of the text (McKenzie Reference McKenzie2002, pp. 198–236). What McGann does is to emphasise the structural function of these codes:
Every literary work that descends to us operates through the deployment of a double helix of perceptual codes: the linguistic codes, on the one hand, and the bibliographical codes on the other.…Textual and editorial theory has heretofore concerned itself almost exclusively with the linguistic codes. The time has come, however, when we have to take greater theoretical account of the other coding network which operates at the documentary and bibliographical level of literary works.
This argument is all the more important in the case of Voltaire because he was a writer who knew intimately the workings of the print trade; we have substantial examples of his correspondence with printers, notably the Cramer brothers in Geneva, and Voltaire’s insistent requests to them regarding cancels, alterations to the running heads, the insertion of marginal notes, changes to the typeface, all display an unusual familiarity with the technical detail of printing in the hand-press period. Voltaire, perhaps more than any other of the philosophes, understood the bibliographic codes that operated in the print world of his day.
This insight has great importance for our modelling of a critical edition:
Precisely because the bibliographical codes of books have not been customarily imagined as part of the critical editor’s project, scholarly editions have rarely expressed the hidden ideological histories which are embedded in the documentary forms of transmitted texts, including the documentary form […] called the critical edition.
Let us try to imagine, says McGann, a critical edition that gave equal importance to the historical analysis of the bibliographical codes as to the analysis of the linguistic codes in the apparatus:
This would be a major new undertaking for textual scholars. Indeed, it would involve, I believe, a project of greater critical significance for textual scholarship than anything we have seen since the even more epochal breakthroughs of the late eighteenth century.
In OCV, individual editions are fully described, but of course, more explanation is always possible. Voltaire had a habit of adding footnotes to his own text (in some cases even signed by a pseudonym, to ‘separate’ them from the body of the text): OCV respects Voltaire’s practice by setting his footnotes separately, and not conflating them with the modern annotation, as other editions had previously done. Yet the OCV edition still does not take account of, for example, the font size of the footnotes, which in certain cases turns out to be of importance (Cronk Reference Cronk and Cronk2000); this question could easily be addressed in a digital edition by the inclusion of appropriate links to page images of different editions.
Another problem is posed by Voltaire’s use of italics. The OCV ‘modernises’ usage in this respect, removing the use of italics in the case of proper names, and occasionally of other substantives. This seemed a reasonable practice in the mid twentieth century, but more recent research has shown that the use of italics in first editions whose printing was overseen by Voltaire is, at times, systematic and therefore potentially of semantic importance. In the case of the Traité sur la tolérance, for example, italics constitute a clear code by which Voltaire is able to underline certain key thematic clusters (Cronk Reference Cronk and Cronk2000).
There are further issues concerned with book design and format, and its relationship to the public, the role of publishers, book designers, typographers … McGann takes as an example a poem by Byron, ‘Fare Thee Well!’: three versions of the work circulated in 1816, all with the same text: a private printing by the author, an unauthorised publication in a newspaper, and finally an authorised publication in book form (McGann Reference McGann1991, pp. 58–59): the same work, produced in three different formats aimed at three distinct readerships, is not really the ‘same’ work at all. Such questions are highly relevant to the way in which Voltaire positioned himself before his public(s), and they are questions which are insufficiently studied and which critical editions hitherto have not really addressed. Different forms of publication are vital for Voltaire, for example, in the way in which he clearly distinguishes between public (that is, printed) poetry, and private poetry, designed to circulate in manuscript (and perhaps unauthorised printings). McGann is primarily concerned with printed books, but similar issues arise with manuscripts, and in this case, the term ‘bibliographical’ code is not appropriate; Elena Pierazzo has proposed the term ‘codicological code’ to cover this case (Pierazzo Reference Pierazzo2015, p. 81, note 24). It would certainly be useful to extend this analysis to Voltaire’s manuscripts.
3.3 Voltaire’s Open Text
Underlying all of McGann’s writing in The Textual Condition is a theory of textuality rooted in reading rather than writing, where texts are material and social phenomena. At root, what he demonstrates is the fundamental instability of physical text. We might add that the text of the hand-press period (approximately 1450–1800), corresponding broadly to what historians think of as the early-modern period, is intrinsically more unstable than the text produced by the machine press after 1800.
Critical editions on paper tend naturally to ‘solidify’ our sense of the physical text as object, and the challenge then is to ask how a digital critical edition can more accurately convey a sense of unstable text. The problem is a crucial one for Voltaire, whose texts are so often open and in flux. Returning to the question about the nature of the corpus asked at the start of the last chapter, ‘What did Voltaire write?’, we see that this is a more complex question that might appear. The OV provides an opportunity to rethink Voltaire radically as a writer by examining more closely than hitherto the very nature of his texts. This is a process that will open up many new research questions.
Voltaire’s thinking and writing are characterised by extraordinary fluidity: he comes back time and time again to the same themes, and he often repeats himself, or nearly repeats himself. The fluidity of his thought and ideas means that the same idea often appears in many different places, and if we want, for example, to understand what Voltaire thinks about religious toleration, one of his major articles of faith, it is not sufficient to look at his Traité sur la tolérance, we need also to look at poems, plays, stories, and so forth. The editors of the Kehl edition tried to assist the reader by grouping the texts thematically, so for example, there is a cluster of volumes collecting together the separate writings devoted to political thought. But precisely because Voltaire’s writing is so wide-ranging, and individual works often range across multiple topics, these divisions are never satisfactory; in fact, they give the Kehl edition a rather spurious sense of order which in the end distorts the true nature of Voltaire’s writing. Some of the most interesting commentary on political questions is to be found in the short fictions, for example, rather than in separate essays.
The way that scholarly editions have traditionally opened up an author’s œuvre is by way of the index; the two-volume index of names and themes that comes at the end of the Moland edition, prepared in the 1880s, is outstanding and has never been bettered; it remains, after 150 years, a valuable research tool. How can OV compete with this? Individual print volumes all have name and place indexes, and some of the volumes also have thematic indexes. It is vital now to explore how we might create an index to the digital edition. Searching for names and places is easy, given the quality of the metadata; and OV proposes to create pages for named entities, so that the reader will be able to consult an article on, say, Jean-Jacques Rousseau or Lisbon, that brings together in an attractive and structured way the large number of references to be found in the secondary material as well as in the primary texts. These entity pages will be gathered together into what we are calling the Compendium, which will be freely available, outside the paywall, and will provide attractive and well-documented pathways into the material. Thematic searching remains the great goal. It might be possible to use or adapt in some way the index of the Moland edition, and there are several digital tools for creating thematic indexes. This is a research project in progress, and it will prove crucial for opening up Voltaire’s writings, for finding what is not there as well as what is, and for seeing how his thinking is inflected depending on the date he was writing and the literary form he was employing.
This sense of fluidity affects not just Voltaire’s thinking, but also the writing itself. Voltaire wrote a lot, he also rewrote a lot, and as the years passed, self-quotation became a very marked feature of his writing. Sometimes this amounted to the simple retelling of a sentence or an anecdote, at other times Voltaire would recycle a paragraph or two, on occasion he would transplant wholesale a chapter from one book into another. Occasionally this borrowing is hinted at in the new text (‘As a great man has written … ’), but often Voltaire remains silent about his self-quotation. At other moments, Voltaire is defiant, telling his reader that important truths need to be hammered home by being repeated … The editors of the Kehl edition were perfectly aware of this self-borrowing, but also slightly embarrassed by it – whereas we today may think of self-quotation as an interesting literary device, there were those in the eighteenth century who judged this as somehow blameworthy. In consequence, the Kehl editors silently excised many of the more flagrant repetitions, and in the process, they butchered the integrity of the texts they were editing and altered, sometimes profoundly, the work as Voltaire was presenting it to his readers. If at the end of the eighteenth century, editors were embarrassed by a writer who relished quoting himself, at the beginning of the twenty-first century we can now warm to a writer who savours the fluidity of his own texts and who enjoys teasing his readers with a tantalising mixture of the familiar and the unfamiliar. John Bryant has talked of ‘the fluid text’ to describe the way in which literary works exist in multiple versions that change over time through revision, adaptation and editing (Bryant Reference Bryant2002), and Voltaire takes this inherent instability one step further by incorporating self-quotation into the initial conception of many of his works (especially his later ones). There is a strong imperative, aesthetic as well as editorial, to present Voltaire’s texts as he wrote them, and to preserve the integrity of his texts as they were published and read in his lifetime. As works and titles of works change and evolve, sections of text can get lost, and modern editors need to track all these variations, small and large. The OCV does this, in many cases for the first time, and in cases of rewriting or self-quotation, we hope that this was noticed and signalled in the annotation. But there are sure to be cases that have been missed. A future research project will be to investigate the Voltaire digital corpus using techniques of sequence alignment to detect text-reuse, whether direct quotation or approximate rewriting, and then to add annotation accordingly.
The extraordinary fluidity of Voltaire’s writing goes far beyond his penchant for self-quotation. His works proliferate, they appear in different formats, under different names, and as one work morphs into another, it is hard to know sometimes where one work ends and another begins. The frontiers between different works become blurred, and the corpus of Voltaire’s writing risks merging into one textual whole. This happens in different ways. Firstly, there are single texts that are continually reconfigured. Le Fanatisme, ou Mahomet le prophet, first performed in 1741, is a tragedy that deals with the theme of religious fanaticism. Popular on stage, this work also enjoyed success as a book ‘to be read’, and it must have been a best-seller, to judge from the large number of editions that were published. These are not simply reprints of the first edition, as Voltaire contrives to change the text constantly, not so much by changing the text of the play (though he does that too) as by changing the paratexts that precede the text of the drama. For example, in 1745, he wrote (in Italian) to the liberal pope Benedict XIV, recommending this work to him, and the pope – rashly perhaps – replied without hostility. A (seeming) endorsement from the Pope of a play which by implication criticised the Catholic Church was more than Voltaire could have hoped for, and from 1745, editions of Mahomet include among the prefatory material the exchange of letters between Voltaire and the pope (who does not seem to have given permission for his private correspondence to be aired in this way). Later editions included other prefatory material: the text of this single tragedy is never stable.
Secondly, there is the case of anthologies and ‘miscellaneous’ volumes. Voltaire specialised in short polemical texts – his ‘little chapters’ (‘petits chapitres’) as he called them by – which he sometimes published in collected volumes. We may take the example of Le Philosophe ignorant (1766): we know this work today in all modern editions as a single text, but the original edition contained five works in all, the main text with which we are familiar being followed by two short contes, a short chapter on persecution, and a dialogue, André Destouches à Siam, on the theme of justice (Cronk Reference Cronk2006; Cronk Reference Cronk2008). In other words, the first edition of Le Philosophe ignorant is in fact an anthology of five texts, on different but interrelated topics, and it is left to the reader to work through the implications of this structure, as Voltaire grouped, and regrouped his texts, to create a ‘book’. All paper editions, including OCV, have separated this collection into its constituent elements and edited them separately. The OV will be able, for the first time, to reproduce Le Philosophe ignorant as Voltaire intended it should first appear, helping the reader to appreciate the complex interchanges between the five constituent texts of the first edition.
Thirdly, there are the longer works which grow and evolve. If the shorter works are unstable because of the way Voltaire moves them around to publish them in different configurations, some of the longer works are unstable for the way in which they stubbornly remain open, unfinished. This is particularly the case with Voltaire’s Essai sur les mœurs, a universal history which Voltaire began writing in the 1740s. The first full edition was a best-seller when it appeared in 1756, and the revision and completion of the work occupied Voltaire for the remainder of his life. As the Essai moved forward in time, he eventually reached the seventeenth century, so that after 1768, the Siècle de Louis XIV (and its sequel, the Précis du siècle Louis XV) were placed after the Essai, so that his three great historical projects merged seamlessly into one. Meanwhile, La Philosophie de l’histoire, a polemical account of ancient history, published in 1765 as a separate work dedicated to Catherine the Great, becomes from 1769 the ‘Discours préliminaire’ of the enlarged Essai. The fluctuating nature of this work can be seen from the evolving titles – and titles were something to which Voltaire paid close attention. The Abrégé de l’histoire universelle of 1753 becomes in 1754 the Essai sur l’histoire universelle, and then, in 1756, the Essai sur l’histoire générale et sur les mœurs et l’esprit des nations, depuis Charlemagne jusqu’à nos jours (1756). Only in 1771 does the work acquire the title by which it is now known, Essai sur les mœurs et l’esprit des nations et sur les principaux faits de l’Histoire depuis Charlemagne jusqu’à Louis XIII. Voltaire’s writing is a writing in movement, and a work like the Essai is in perpetual evolution.
In cases such as this, the notion of ‘final intention’ has little sense: Voltaire produces texts which are in flux, open, never stable. Critical editions however, stabilise in order to record, and in so doing, perhaps they run the risk of betraying the objects they represent. This is well understood as a consequence of what we can call remediation. McGann talks of Piers Plowman as the example of a complex text that bursts out of the constraints of a paper critical edition, and in like fashion, Voltaire can be seen as an author whose entire œuvre defies and expands the conventional limits of print. The fluidity of this writing derives fundamentally from Voltaire’s engagement with the world of publishing. Voltaire was a master of the media necessary to spread his message, and the most powerful medium of communication in his day was the hand press. But publication was changing fast in the eighteenth century: improved communications due to better roads, slowly increasing levels of literacy across Europe, the general absence of legal copyright, all these factors led to an explosion in the number of printed items across Europe. Increasing numbers of books appeared in smaller, cheaper formats, and publishers began to build effective circuits of circulation.
Some writers looked with disdain at the emergence of what, in London, was called Grub Street, though Voltaire seems to have relished the freedoms it permitted. In so many ways, Voltaire was a cultural conservative, but he understood the book trade of his day, and his adroit handling of the publication of his works meant that editions proliferated. He even deliberately colluded in destabilising his own texts, for example, by sending ‘variants’ of a text to one publisher behind the back of another publisher who mistakenly believed he had an exclusive text. Voltaire was wealthy enough not to need to be concerned about earnings from royalties; what mattered most to him was that his books would appear in the greatest possible numbers, to reach the widest readership. The name of Voltaire sold books – even when he published them anonymously – and his celebrity profile turned ‘Voltaire’ into a brand name. Nor was his celebrity confined to France. His works were quickly translated into many European languages, and the spread of his publications is a European publishing phenomenon in itself. It became increasingly hard for governments and the church to censor Voltaire: his books were everywhere, and if one edition was seized by the police, then another would immediately spring up in another town. As Voltaire liked to point out, a strongly worded edict of censorship was always good for sales. Keen book-collectors were known to complain about the ever-shifting nature of Voltaire’s books, because no publication was ever definitive. In January 1778, when the rumour of Voltaire’s death was (falsely) circulating in London, Horace Walpole wrote to a friend that ‘Now one may buy his works safely, as he cannot write them over and over again’.Footnote 25
3.4 Modelling a Corpus with No Boundaries
The OV, as a digital remediation of OCV, can already offer remarkable opportunities for new research, as we create connections across the vast corpus. And potentially, OV can do much more, as we strive to build a digital edition that reflects a sense of textual fluidity, of an œuvre always in movement. McGann’s idea that the complexity of certain textual objects simply defies a paper edition provides Voltaire editors with a great challenge. This comes down to a question of modelling and metadata architecture: we cannot at this stage foresee all the possible research avenues we may wish to explore in the future, but we can try to ‘future-proof’ the resource by imagining from the outset the possible searches we might want to undertake.
The correspondence provides a simple starting point. Voltaire’s epistolary network is unprecedented in the number of letters and number of correspondents, and to really delve into this complexity, we need to be able to identify quickly those letters which are replies to other letters, which also means identifying absences of letters, and then to be able to search sub-sets of these letters. With the appropriate metadata, this entire correspondence network can be opened up in a way that was simply not possible until now.
Another sense of the openness of Voltaire’s corpus is created by the variety of different forms in which he published his works. It is not just that Voltaire writes in many different literary genres; he published in many different formats, ranging from the very permanent to the purely ephemeral. So alongside the beautifully illustrated quarto editions, there are smaller octavo editions, even cheap and scruffy duodecimo editions: the format of the book would certainly have influenced the reader of the work in the eighteenth century. There are also pamphlets and newspaper articles, many of which were later gathered together in other, more permanent formats. The pamphlet provides an interesting example that merits further research: cheap and easy to produce, mostly anonymous, small and easy to circulate without arousing the interest of the police or the censor, pamphlets play an important role in the publishing economy of the Enlightenment. But how many of Voltaire’s works, later gathered into leather-bound volumes, first saw the light of day in pamphlet form? This simple question is important – yet still not entirely easy to answer. The inclusion in OV of appropriate metadata describing publication formats will be revelatory.
Another dimension of openness in the corpus is generated by the evanescent nature of Voltaire’s authorship. Today, when we know that Voltaire wrote a book, we put his name on the title page, but of course, that was not his practice. He wrote in multiple voices, using many different names. Voltaire will habitually sign his weightier works, such as his plays or works of history, with the name ‘Voltaire’, but in other cases he often publishes anonymously or with a fanciful pseudonym (‘the archbishop of Novgorod’), of which there exist several hundred. Sometimes the anonymity is deliberately transparent, though in a few cases, for example, his vicious attacks on Jean-Jacques Rousseau, the anonymity was designed to actually conceal his identity. For the most part, however, such is Voltaire’s fame, and so recognisable is his voice, that he doesn’t need to sign his books – everyone knew anyway (or thought they did). The advantage of not signing was obvious: if the police took an interest in some heterodox work, Voltaire could plausibly deny his authorship, and it would then be up to the police to disprove him. And Voltaire’s genius is to turn everything into a game: ‘God preserve me, my dear brother, from having anything to do with the Pocket Philosophical Dictionary! I have read some of it: it reeks horribly of heresy’, wrote Voltaire to a reliable friend in Paris, adding: ‘But since you are curious about these irreligious works and keen to refute them, I’ll look out for a few copies, and send them to you at the first opportunity’.Footnote 26 Voltaire turns the fact of his authorship into a great publishing game, and if we don’t want to miss the joke, we need metadata that records how Voltaire ‘signs’ his works, how he juggles and manipulates various names to simultaneously arouse the curiosity of the reader and the fury of the censor.
Voltaire’s fame was so great, and his style seemingly so inimitable, that many authors in the eighteenth century wrote works of pastiche that they published as being by Voltaire – it was an easy way to make money. These works attributed to Voltaire have caused a headache to editors of OCV, because it is sometimes hard to draw a clear line between true and fake – and Voltaire probably wanted it that way. Some works attributed to Voltaire, particularly poems, are already included in OCV, and there would be a case in the future for including more such would-be ‘Voltaire’ works. They are an interesting testimony to the publishing phenomenon that is Voltaire, and with digital techniques of author attribution becoming ever more reliable, it will be possible in years to come to admit some of these works into the Voltairean canon with greater certainty (and to exclude others).
The exciting challenge that we face with OV is to model and remodel the writings of Voltaire so as to recreate, in a new medium, the fundamental openness of his corpus. In so doing, we will be liberated to read Voltaire in a way that he would have intended if the digital medium had existed. We may say of the digital critical edition what Voltaire says of God: if it hadn’t existed, we would have had to invent it. Willard McCarty reminds us of what computers can be – and what they are not:
Although efficient access to data is an essential function of computing, the greater potential is for computers as modelling machines, not knowledge jukeboxes. To think of them as only the latter is profoundly to misunderstand human knowledge.
McCarty crucially emphasises the fundamental difference between modelling of and modelling for. The modelling of the contents of OCV will allow OV to model for the creation of new knowledge. More than that, even, it will reveal, for the first time, the complexities of what we may call, after McGann, Voltaire’s textual condition. Only the digital medium can hope to represent the fluidity of a corpus in constant movement, and OV has the potential not simply to be a stimulus to a better understanding of Voltaire’s œuvre but to create a new Voltaire.
4 OV: Designing and Constructing the Digital Edition
Any attempt to digitise something as large, varied, subtle, and – as we have seen – fluid as the complete works of Voltaire is one fraught with compromise. Not only do you have to account for a lifetime of learning and modification on the part of the philosopher, but you must also accommodate the necessarily variable and evolving editorial disciplines of a research and publishing project spanning more than half a century. It can at times feel like trying to fit a straight-jacket to a blancmange. It can, however, be done, as we are proving.
4.1 Purpose
A first and necessary question regarding the digitisation is: what is it for? What are we expecting the data to achieve? Are we intending solely to capture the text itself (the ‘words and spaces’)? Do we want to end up with something that could replicate the print edition exactly, including every nuance of rendering, alignment, and pagination? Or are we aiming for something more ambitious, something that will facilitate study and analysis beyond what is currently feasible with the print edition, and position the digital edition for further development in the future?
It will come as no surprise that the last of those is our chief aim, though of course the first is also present: every word in the print edition will be in the marked-up data set, though we have confined explicit declarations of rendering (typography, alignment) chiefly to the primary content where this cannot be deduced from the context. It follows from this, then, that the digital edition would not be able to replicate the print edition of OCV in every detail down to the last textual alignment, but this is not something we would expect to need to do – the digital edition will take us forward, without needing to take us back to the source.
4.2 Model and Digitisation
In its most basic form, the digital OCV consists of the source editions marked up in XML to the TEI model, with an attendant metadata set as a series of RDF (Resource Description Framework) triples. When we were planning the work, TEI was really the only model we considered to accomplish the task, given both its longevity and the number of projects that have contributed, through discussion and revision, to its current state, where almost everything we needed to describe can be achieved with markup ‘off the shelf’, so to speak. There is enormous reassurance in knowing that you are not the first to have to encode a multi-layered critical apparatus, for example. If we have tagged further, it is by standing on the shoulders of XML giants.
Having decided on TEI, our first task was to determine which parts of the model we wished to use, and how those components were to be assembled in our specific implementation to achieve the results we need. TEI is, amongst other things, comprehensive, both in the particular things about a text that it can describe, and in the general attributes it makes available to enhance that description. The development of this OCV-specific TEI model was a gradual process, informed both by careful study of a wide range of extracts from the print edition, and through queries and problems during the digitisation process itself. The data model specification was, and still is, a living document, and will only truly be ‘finished’ once there is no more content to mark up. With a corpus as broad and as dense as OCV, there is always the potential for surprise.
There is then the challenge of how to make the XML happen, of how to turn something in excess of one hundred thousand print pages into usable, reliable data. For this, we engaged the services of a data transformation company that had worked with the Voltaire Foundation on previous occasions, with a brief to provide one TEI-XML file per print edition volume. That brief was accompanied by the data model specification, whose many, many pages were absorbed into the digitisers’ processes.
To a certain extent, the digitisers were familiar with the type of task we needed completing, though the nature of the material and – crucially – its language (predominantly French) were new to them. We had therefore to gauge how much preparation, explanation, and even translation to provide in advance in order to gain the best possible results. A detailed handover document was provided for each volume to be digitised, containing details of basic metadata and collated witnesses, but inevitably details and nuances of how particular markup should be applied were often cued by source text in French, which meant a certain amount of analysis and correction has come once the TEI-XML has been delivered.
Despite the many decades over which OCV was produced, and the thousands of works it contains across multiple genres, the structure we needed to encode was largely consistent across the corpus. A volume consists of one or more works, all preceded by front matter and all followed by back matter. Each work consists of the primary text (or ‘work text’), accompanied by editorial material (see Fig. 2).
Logical volume structure for OV
Any given work may be followed by appendices, which from a data and metadata perspective are modelled in the same way as the works themselves (with editorial material and primary text), except that in the metadata they are marked as annexed to the main work. This allows us in a digital edition to control how appendices are discovered, and avoid their contributing too much ‘noise’ when a reader is browsing Voltaire’s works.
Levels within any body of text – whether explicit or implicit – are encoded by hierarchical divisions.
Pagination in this context is a curious beast. Given that we are not focusing primarily on a markup that is capable of replicating the print edition, it might seem evident that the pagination of that print edition need not be replicated in the XML, but we have to recognise that we need to produce a digital edition that is referenceable both in and of itself, and with regard to its sibling print edition. And where referencing is concerned, whether we like it or not, the reign of the page continues and shows no sign of ending.
We need to facilitate referencing traffic to and from the edition. We have therefore ensured that the start of every page from the print edition is marked up with TEI’s <pb/> element (which we have to remind ourselves at regular intervals represents in TEI a page beginning, and not a page break), so that:
any automated citation derived from a portion of the TEI-XML can also include a page reference derived from the data;
any external citation, including a page reference, can be used to take a user of an online edition using the TEI-XML to the precise point in the content.
4.3 Referenceability
We may regard pagination and its use in citation as a hangover from print days, but at the same time, as stated in a previous section, we would concede that, as a method of pinpointing a locus within a mass of content, it does – even in these digital and potentially paper-free days – have its uses. The page is, frankly, phenomenally convenient.
The corollary to the above is to recognise the challenge of referencing where the source edition is not a print volume, but is instead that fabled and revered beast, the born-digital edition. Without page breaks to start with, when your content flows unimpeded by the need to turn a piece of paper, how do you cite the edition? Part of the response to that conundrum is technical, and part is cultural.
The technical response is that, given the way in which we have constructed the OV data – where, for example, every element carries a unique identifier – and given that each point in an unchanging XML document can be reliably referenced in terms of its position in the document’s structure, it would be possible to produce a citation from a digital product that pinpointed the referenced text at, say, the paragraph level, and which would moreover bring a reader using that digital reference to the correct part of the text. Can we, therefore, say voilà?
Non. Or rather, probablement pas, and the reason for that is the degree of reassurance that current page-based references instil in the reader. They are, after all, how works have been cited for centuries, and as we have seen such a reference will be interoperable between OCV (print) and OV (online). One option to address this would be to add to the born-digital editions anchors placed at regular intervals in the same way as the <pb/> elements in the data derived from the print edition, to provide convenient markers in the text which can then be referenced in citations. The advantage of this approach would be to produce references for all digital material in a consistent and well-known syntax to take readers to the vicinity of the referenced material (as page references do), and this is what we intend to do for future born-digital editions.
4.4 Metadata
Although we are populating the TEI header with a certain amount of metadata, the real heavy lifting for OV is being done by a separate metadata set expressed as a flat sequence of RDF triples. It was decided to model the metadata in this way, and not rely solely on TEI’s capabilities in this area, since many of the entities that the metadata describes extend beyond a particular volume (and therefore beyond any one TEI-XML file). With RDF metadata we also have complete freedom in what we can express, and how semantically we relate one record to another. We can, for instance, model a person as a discrete entity, and describe their relation to other entities as the need arises – as the author of a creative work, as the editor of a critical edition, as the illustrator of a book, as the father of another person, for example. We are also making a clear distinction between creative works, critical editions, and published volumes so that we can describe each thing independently of the others, while also describing the relationships between them. In this way, we have developed a flexible and extensible semantic network which will be the backbone of the digital product bringing OV to readers.
A semantic network can only happen if its constituent entities have been reliably identified. Some of this was achieved at the initial digitisation stage, but for the reasons outlined above, our partners were not able to provide this markup to the degree that we needed, so another process was required. We developed this in-house, and it consists of an XSLT stylesheet that analyses the running text of the XML and – amongst other things – proposes proper nouns, which are then presented to editors in the form of spreadsheets where decisions can be recorded as to the markup to be applied (or not) to the identified entity.
Appropriately for a project developing a digital resource of eighteenth-century writing, the regular expression developed to tease out these proper nouns is deliciously rococo:
((([dl]’)?[A-ZŒ](\.|[\w\-’]+)| ?‘,(([1–9]+[ers][ert]?|et))?,‘(‘,(l’)?abbé|amiral|baron(ne)?|(arch)?bishop|cardinal|chancelier|chevalier|(vi)?comte(sse)?|czar(ina)?|(arch(i)?)?du[ck](e|hesse)?|earl|[eé]lect[o]u?er|empereur|(arch)?évêque|impératrice|landgrave|maréchale?|marquise?|ordonnance|p[ao]pe|père|prince(sse)?|patriarche|président|régente?|roi|reine|sainte?|sieur|sire|sophi|sultana?|tsar(ine)?,‘|‘,bataille|battle|cou?ncile?|défaite|[eé]dic?t|guerre|journée|ligue|paix|peace|si[eè]ge|tr[ae][ai]t[éy]|trêve|war,‘|‘,basilique|boulevard|château|mer|place|rue|sea,‘|‘,concile|parlement|ministère|monastère|université,‘|(‘,cantonales?|diplomatiques?|historiques?|françaises?|municipale?s?|nationales?|royales?|universitaires?,‘)?))((?[IVX]{1,5}[,\.:‘]| ?‘,(al|ben|d[aeou‘]s?|de[l‘]?(la)?|d(egl)?i|of| v[ao]n|y|the) (la)?,‘| d’| l[ae’]|\-sur\-| al\-))?[\-, ]?){1,6}
Even a non-technical reader will detect in this mass of characters things like titles (‘cardinal’), events (‘bataille’), institutions (‘parlement’), qualifiers (‘royale’), and prepositions (‘de’), in addition to the core pattern of a capitalised word. Using this regular expression we can, for instance, from the running text:
… en signant la révocation de l’édit de Nantes (ch.36, lignes 509–12 et …
propose the candidate:
édit de Nantes
and from the running text:
Anne Marie Louise d’Orléans, duchesse de Montpensier (1627–1693), cousine germaine de Louis XIV …
propose the candidates:
Anne Marie Louise d’Orléans, duchesse de Montpensier
Louis XIV
Once an editor has reviewed the spreadsheet and recorded their decision as to how the candidate is to be marked up (e.g. as a person, as a place, as an event), a separate XSLT process then reads that spreadsheet in parallel with the TEI-XML for the volume concerned and implements the requested tagging.
It also records every implemented decision in the <revisionDesc/> part of the TEI header: this allows any subsequent processing to assess the status of any marked-up entity encountered in the file, and filter out those for which no decision has yet been recorded. In this way, only those approved entities make it through the distillation process to populate the RDF metadata.
Identifying a string as something to be marked up is one challenge; identifying it as a recognised entity, and enabling that entity to link to other recognitions of the same thing, is another. In some cases – ‘Voltaire’ being the very obvious example – we can be sufficiently certain about what is being referenced. In others, however, we need more information.
Take, for instance, ‘Choiseul’, which is a string that occurs several times in the complete works, and which could, depending on the context, refer to one of at least four individuals from French history:
César, duc de Choiseul (1598–1675), gentleman, soldier and Marshal of France
César Auguste de Choiseul de Plessis-Praslin (1637–1705), soldier
Claude de Choiseul-Francières (1633–1711), Marshal of France and governor of Langres, Saint-Omer and Valenciennes
Etienne François, duc de Choiseul (1719–1785), statesman and head of Louis XV’s government
How can we know when we encounter ‘Choiseul’ in the running text to which of these four the name refers? Well, we could leave it entirely to an editor to give us the answer, and she may be sufficiently au fait with the volume that the question is instantly resolved (and we are blessed with editors who do know the complete works in astonishing depth and with masterful recall). But multiply this question several hundred-fold since the two-hundred-plus volumes are, of course, replete with such names, and we can see that this route is impractical as a first step. It should, rather, be a move of last resort.
Fortunately, help is often at hand within the content in the form of the index. The index forms will usually give the full name together with the page reference (and remember we have retained the pagination from the print edition), so we can devise a process to find the corresponding index entry pointing to the page on which the string occurs, and attempt to determine a match from that.
The box into which to place any given named entity is usually uncontroversial – ‘Voltaire’ will always be a person, for instance, and ‘Lyon’ will always be a place. We did, however, find ourselves scratching our heads when it came to marking up figures from classical mythology (e.g. ‘Adonis’), from the more distant parts of the Bible (e.g. ‘Job’, ‘Moses’), and even, dare we confess, ‘God’. Does an entity have to be ‘real’ to earn the markup for a person, i.e. <persName/>? Do we have to be convinced of a figure’s historicity to be comfortable using that element? Should we find ourselves effectively pronouncing on the great theological conundrum of our species purely to decide on a tag?
Reader, we chose to do none of those things. Instead, we opted for a compromise which we hope represents no judgement on our part, and which we equally hope earns none on yours: for all of these entities, we mark them up as name[@type=”culturalBeing”], thus recognising the position these entities have in the cultures where they occur without encoding any creed.
A set of resolved named entities within the OCV dataset is all well and good, but that dataset and its attendant metadata needs to exist in the wider world, so in order to provide a fixed point outside our project we are including WikidataFootnote 27 IDs in the RDF records for each named entity, which can act as a wayfinder for future routes out to other authorities such as ISNI,Footnote 28 VIAF,Footnote 29 and so on. Where a given entity does not exist in Wikidata our next port of call is the data authority of the French national library, the Bibliothèque nationale de France.Footnote 30 With this two-step approach, nearly every named entity in our metadata will have an anchor in an external authority.
How to find those Wikidata IDs? Making this a purely manual task would, of course, be entirely impractical, so we have a process that assesses the best available form to use (e.g. the fuller index entry if a shorter name is used in the running text) and uses the Wikidata API to query the database to look for a match. We then present – via XSLT and another spreadsheet – candidate resolutions for editorial approval, and it is those subsequent decisions that control the distillation of the resolved entities from the TEI-XML to the RDF dataset.
It is undeniable with a project of the size and scope of OCV, merging them into OV, that it is for all concerned a learning experience. One cannot be exposed to such writing, and face the challenges of comprehending the material and then presenting it to its best effect, without deepening one’s own understanding and emerging better versed in how to tackle such problems. As it is with humans, so it is – we intend – with machines. We have described processes elsewhere in this chapter where editors are asked to make decisions based on material derived from the edition, and we are developing stages where those decisions are not only implemented in the data and the metadata, but where they can also on the basis of frequency and probability be used by those same processes to pre-empt decisions in future material, in order to streamline the workflow and ensure that editors’ time is used to best effect.
4.5 Bibliography
A core part of OV will be the bibliographic entities referenced and cited by its editors, and we are at pains to make these entities as useful to readers as possible. Part of the semantic decisions that the project editors provide is to approve, within a given volume, the proposed resolution from any given citation to the primary expression of that bibliographic entity. This may be as simple as linking a reference in the running text to the relevant entry in the formal list of works cited, or it may be in the absence of such an entry determining which is the fullest rendering of the available references, and link other references to that.
The purpose of this linking is not so much to plot a user’s journey within the volume, but rather to prepare the ground for the production of a consolidated bibliography across the entire resource, such that there can be a definitive entry for each referenced resource. Such an entry would serve both to provide the reader with the maximum amount of information, and – crucially – act as a springboard to journey beyond the digital product, be that via an encoded query to the user’s online library catalogue, or as the material for our own query to CrossRef’s metadata database for the purposes of garnering a digital object identifier (DOI) for the referenced resource. If we can find such a DOI, we can provide a route using it to an online instance of the referenced resource. Individually and in tandem, these approaches offer to bridge the gap between the citation and the thing.
4.6 Text and Language
In the TEI-XML, we are making a clear distinction between primary text (which, in the context of OV is Voltaire’s writing) and editorial material, for which there are multiple reasons. First, this enables each type of content to be presented differently in a digital product, which may allow the interface to convey a different sense of the material in each case through, for example, the choice of font and background colour. It also enables the reader to concentrate solely on one type of text without the distraction of the other – the primary text without the editorial notes, for example – if that is what she wishes.
Second, it could be a crucial distinction in the context of automated translation, where the editorial material could be considered appropriate text for this translation, whereas we might tread more carefully when considering machine translation of Voltaire’s works.
Talk of machine translation leads naturally to the topic of language markup, and this is a key part of the data model for OV. Our aim is for the language of every piece of text visible in the digital product to be known so that we can offer search filters and also provide translation where appropriate.
Those caveats regarding translation – and in this context we mean machine or automated translation – are important. Consider this passage (from volume 11a of OCV, in the editorial introduction to the Siècle de Louis XIV):
… à propos de l’Esprit des lois, il écrit étrangement qu’on doit ‘le mettre au rang des livres originaux qui ont illustré le siècle de Louis XIV’.
in which we have:
editorial text (“à propos de … ”);
a work title (“Esprit des lois”);
a quote (from Voltaire) (“le mettre au rang … ”).
all of which is in French. A blanket conversion of this paragraph into English regardless of the entities it contains could give us:
… regarding the Spirit of the Laws, he wrote strangely that one should ‘place it among the original books that illustrated the century of Louis XIV’.
which while being a competent, workaday translation is not necessarily the most appropriate or helpful thing to provide:
the referenced work is not called Spirit of the Laws;
the quoted words are not Voltaire’s.
A better treatment would be:
… regarding the Esprit des lois, he wrote strangely that one should ‘le mettre au rang des livres originaux qui ont illustré le siècle de Louis XIV’ [‘place it among the original books that illustrated the century of Louis XIV’].
This retains the original wording of both the title and the quote from Voltaire, but also provides a translation of the quote in addition, thereby making it clear that that translation is not the original quote.
We can consider doing this because of the markup that has been applied:à propos de l‘<title xml:id=“de-9780729411462-title-040146” level=“m”>Esprit des lois</title>, il écrit étrangement qu‘on doit <quote xml:id=“de-9780729411462-quote-040374”>le mettre au rang des livres originaux qui ont illustré le siècle de Louis XIV</quote>.This separates out both the title and the quote. It also tells us what language both of those entities are using, by virtue of there being no additional language attribute on each tag: each TEI-XML file declares an overall language for the volume by an @xml:lang attribute on the root <TEI/> element, and unless and until that declaration is superseded by an @xml:lang attribute lower down the hierarchy that language remains in force. So it is in this example – the declaration of French as the language of the text flagged by @xml:lang=“fr” at the root level has survived intact to this level, so the same applies to both title and quote in the example.
This markup can therefore help provide the best user experience with regard to translation:
titles can be regarded as ‘out of bounds’ and not to be translated, but rendered unchanged;
quotes need only be translated if their language differs from that called for in the translation, and any translation placed after the original so that the author’s words are retained.
A similarly structured extract, this time from volume 29b of OCV, in the editorial introduction to the Représentation aux Etats de l’Empire:
That Bussy similarly corrected the Représentation is testified by the aforementioned marginal note on the front page of one of the eight copies of the print edition that have been discovered: ‘cet écrit a été composé par le poète Voltaire, mais corrigé et rectifié par M. de Bussy’.
The markup here will now be familiar:
That Bussy similarly corrected the <title xml:id=“de-9780729412254-title-000190” xml:lang=“fr” level=“m”>Représentation</title> is testified by the aforementioned marginal note on the front page of one of the eight copies of the print edition that have been discovered: <quote xml:id=“de-9780729412254-quote-000015” xml:lang=“fr”>cet écrit a été composé par le poète Voltaire, mais corrigé et rectifié par M. de Bussy</quote>.If we were to summon an automated translation of this extract into French:
Le fait que Bussy ait également corrigé la Représentation est attesté par la note marginale susmentionnée figurant sur la première page de l’un des huit exemplaires de l’édition imprimée qui ont été découverts: ‘cet écrit a été composé par le poète Voltaire, mais corrigé et rectifié par M. de Bussy’.
the title and the quote remain untouched, and there is no need to provide a translation for the quote since its language (indicated by the @xml:lang=“fr” on <quote/>) equals that requested.
4.7 Variants
Variants – the ways in which the selected base text for a work differs from the other collated text witnesses – are a key part of OCV, and a particular challenge for OV. Their presentation at the base of a page of primary content, using the line numbers assigned to the base text as references and anchor words either side of the material change to pinpoint the affected text, was an innovation in the early days of OCV and one whose effect and value we were determined to emulate in a digital context.
TEI is, thankfully, already equipped to encode text witnesses and their variants. The witnesses themselves are marked up with the <witness/> element whose unique identifier – the @xml:id attribute – carries the siglum assigned by the editor of the work in question. Each variant uses a combination of the <app/>, <lem/>, and <rdg/> elements to encode the fact of there being a variant, the portion of material in the base text, and the variant reading respectively, and at its heart the approach and the markup are straightforward.
Let us take a very simple example, from volume 29a of OCV, in chapter 2 of the Précis du siècle de Louis XV. The base text is that found in a witness given the siglum W75G*, and one of the collated witnesses has the siglum K: both of these are detailed in the editorial introduction to the work:
W75G*
Some volumes of W75G contain handwritten corrections by Voltaire. See Samuel Taylor, ‘The definitive text of Voltaire’s works: the Leningrad …
K
Œuvres complètes de Voltaire. [Kehl,] Société littéraire-typographique, 1784–1789. 70 vol. (only vol.70 bears the date 1789). 8°.
<witness xml:id=“de-9780729411370-witness-W75 G_star” ana=“#de-9780729411370-interp-000001”> … </witness>
<witness xml:id=“de-9780729411370-witness-K”> … </witness>(The printed form of the siglum is also encoded as an <idno/> element within the witness description.)
At the end of one paragraph in the second chapter of the work, the source edition shows:
| … tant d’autres à la mendicité. Voici quelle fut l’origine de cette démence précédée et suivie de tant d’autres folies. | 70 |
| 71 K: tant de folies |
which tells us that in the witness K instead of ‘et suivie de tant d’autres folies.’ as shown in line 71 of the base text we find instead ‘et suivie de tant de folies.’ – the unvarying anchor words “tant” and ‘folies’ stand guard around the actual variant, ‘de’ instead of ‘d’autres’.
In the TEI-XML this is marked up as:… précédée et suivie de <app xml:id=“de-9780729411370-app-000049” type=“subs”><lem xml:id=“de-9780729411370-lem-000049” wit=“#de-9780729411370-witness-W75 G_star”>tant d‘autres folies.</lem><rdg xml:id=“de-9780729411370-rdg-000050” wit=“#de-9780729411370-witness-K84 #de-9780729411370-witness-K85 #de-9780729411370-witness-K12”>tant de folies.</rdg></app>with the base text contained within the <lem/> element, and the variant reading in the <rdg/> element.An editorial note relating to a specific reading can be included in the <app/> element, tying it unambiguously to that reading through a reference to its @xml:id attribute. For example:
<app>… <rdg xml:id=“de-9780729412254-rdg-000904” wit=“#de-9780729412254-witness-MS14” next=“#de-9780729412254-rdg-000909”>oser écrire de sa prison au roi même, et voici la lettre que Damiens dicta, et qu‘il signa.</rdg><note xml:id=“de-9780729412254-note-000106” corresp=“#de-9780729412254-rdg-000904”>A blank left in manuscript, presumably for the letter.</note></app>For simple substitutions, as in the example above, this approach works well. When the variant is more complex – when its start and end span structural containers such as scenes in a play, for example – the markup needs to be more elaborate. Something that can be expressed in print in a few numbers and words as, essentially, lines of text, needs to be present in the TEI-XML as discrete containers, with flags on the various components to indicate to a processor – a rendering engine to present the material via a digital interface, for example – that multiple tags constitute just one logical entity. Couple this with the potential for variants themselves to contain variants, and also the need to accommodate large amounts of structurally complex text in a reading, and the scene is set for unavoidably dense and elaborate tagging. Back to rococo.
A digital product offers the prospect of analysing variants in entirely new ways. It would in processing terms be fairly straightforward to show across an entire work how variants from a particular witness cluster in a particular part of the text. Couple that with date information for those witnesses, and a pattern might start to emerge about how across time a work evolved, particularly if there were more detailed analyses of the ways in which the collated witnesses vary from the base text (data on omissions and excisions, for instance). The OV as data offers much more potential for feasible research on criteria and patterns across the corpus than does OCV currently; a programmed search across multiple files and thousands of pages would take a fraction of the time equivalent analysis would require using the print edition.
4.8 Marginalia
Marginalia represents another area in which OV is breaking new ground. It is important to acknowledge other projects that have made authors’ (and anonymous readers’) marginalia available in different ways. These range from images of annotated pages that can be browsed to fully-fledged digital editions. On one end, we have resources such as the ‘Feuilletoirs’ section that forms part of the Université de Rouen’s extensive Gustave Flaubert website, and which includes transcriptions of marginalia, although these are not searchable and the digitised materials only represent a small part of the writer’s library. A step up from this is the Annotated Books Online project based at Utrecht University, in which the transcriptions of marginalia are searchable (and even often translated into English). The corpus here is somewhat haphazard, constructed by participating libraries and volunteers, and contains books annotated by known as well as unknown readers from the early-modern period. Non-verbal markings are visible in images but not explicitly recorded. At the other end are more sophisticated single-author databases and digital editions. Some are purely dedicated to marginalia, such as Schopenhauer’s Library: Annotations and marks in his Spanish books, which to date presents marginalia (verbal and non-verbal) on a single work only, albeit clearly presented and searchable, with editorial principles, and marked up in TEI-XML. Melville’s Marginalia Online is much more extensive, containing both verbal and non-verbal annotations relating to thirty-nine books. Its content is encoded in coordinate-based XML and can be browsed as well as searched, and submitted to various analyses (distribution, sentiment) using built-in tools. More comparable to the Voltaire edition are the Walt Whitman Archive and the Samuel Beckett Digital Manuscript Project insofar as they cover multiple types of works and written documents by their respective authors. Both are marked up using bespoke TEI-compliant XML. While the marginalia available from Whitman is limited, the Beckett resource contains digitised marginalia from over 800 volumes and allows the user to view non-verbal traces as well as textual notes. In places, editorial material links these annotations to other works or manuscripts edited on the site, making it the closest match to OV. Searches within the Beckett ‘Library’, however, do not distinguish between the printed text that Beckett was reading and his own scribbled words, and while one can browse and filter non-verbal ‘doodles’ within Beckett’s manuscripts, it seems not possible at present to do so in the ‘Library’.
In Voltaire’s complete works, out of a total of two hundred and five OCV volumes, thirteen are devoted to presenting Voltaire’s marginalia in roughly 1700 works (many of them multi-volume) from his library, as well as a handful held in other institutions today. Taking the form of textual notes as well as both simple and complex marks, the print edition strove to reproduce the original page as faithfully as possible with regard to the placement and extent of the marginalia.
When we digitise these volumes, therefore, we are necessarily producing an approximation of an approximation, and at the time of writing, the proof of the TEI-XML that has been created according to the model we devised for this type of material is yet to emerge. In essence, the marginalia fall into two types: (1) textual additions, usually in the margins of the printed volumes, and (2) graphical marks (some of which surely qualify as ‘doodles’) which can occur anywhere on the page.
The textual notes are relatively straightforward to encode. They typically sit in the margin, and we are able in the TEI-XML to link the first line of a note with a particular line in the text on which Voltaire is commenting. Where necessary we can indicate more precisely where a note was placed relative to the printed text, though much of this work is often done by accompanying editorial notes.
The marks present an altogether different challenge. To start with, there is the need simply to present them as part of the digital offering, and here we had to decide how much of the print edition’s fidelity to Voltaire’s handiwork we wanted to replicate. The production of the print editions entailed the drawing of each of the marks that Voltaire added, and if we were to produce an individual graphic for each one of these the numbers would run into the hundreds, if not thousands, each one of which would need to be accurately referenced.
We shrank from this approach and instead opted for something more abstract. While there is a great number of different symbols drawn by Voltaire, there is a much smaller number of types of symbol, so if we can encode based on type rather than each individual mark the process – both of markup and rendering – will become more manageable.
For example, Voltaire was extremely fond of crosses – there are over a thousand instances in the marginalia of this one type of mark. Some of them in the print edition of OCV are slightly larger than others, and some of them are, shall we say, scratchier than others, but essentially there are just over a thousand marks that look like this:
and some seven hundred or so that look like this:
so whenever a cross of either type occurs, we can indicate in the data ‘here is a one-of-those’.
There are then cross-like derivatives, such as:
and there are also marks right at the other end of the complexity spectrum, such as:
How then, can we encode this ‘one-of-those’-ness? Well, each type of mark needs a unique identifier, and we can use that identifier in the TEI-XML to indicate what type of mark needs to show in this place relative to the printed text. In order to derive these identifiers (remembering that XML identifiers cannot start with a number, so a simple incrementing integer would not have served) we derived a classification system based on the number of nodes (points where lines cross) and edges (continuous lines) in the mark, followed by a sequential number to make the identifier unique. So for the mark:

the number of nodes is zero (there are no intersections), and there is one edge, so this mark has the identifier n0e1-16 (it happened to be the sixteenth mark of this type to be classified). The mark:
however has four nodes (a T-junction counts as a node) and five edges – it has the identifier n4e5-03.
Using this approach, we have collated a library of Voltaire’s marginalia marks. To what end? Initially to be able to represent those marks as faithfully as practically possible in a digital interface, but further down the line to facilitate deeper analysis of the material than is feasible with the print edition. Which is the mark most frequently used? Which marks are used just once across the entire corpus? For any given mark, what is the spread across the corpus with regard to, say, author? Did he perhaps reserve his spikier glyphs for Jean-Jacques Rousseau? That last question is flippant, and the answer is unlikely to be ‘yes’, but it illustrates the sort of inquiry that this digitised treatment will facilitate.
The textual annotations, since in the markup they are clearly delineated from the text on which Voltaire is commenting, could also be the subject of linguistic analysis, which could help fuel research on Voltaire’s attitudes to particular authors beyond what is feasible with the current print edition.
We noted above that the marginalia in digital form are an approximation of an approximation, and so by definition, this presentation brings with it a degree of compromise. A counterpoint to this compromise could be to include in the digital edition facsimiles of the annotated pages so that the user can see precisely the position, scope, and ‘impression’ of the note or mark encoded in the data. This approach of leapfrogging the print edition to connect the reader with the original document (or at least an image of it) does not cancel the value of the digital encoding and rendering of the marginalia, for the reasons noted above. This would be one more tool for the reader to make the most of a digital edition.
4.9 Correspondence
Voltaire’s correspondence is a significant component of OCV – fully a quarter of the volumes in the set are home to more than twenty-one thousand letters in the founding editor Theodore Besterman’s second (so-called ‘definitive’) edition – and it will form a major part of OV, both in terms of quantity and functionality. It has already been digitised and formed into an online product, namely Electronic Enlightenment, which first saw the light of day in 2008. For its time a ground-breaking venture, developments since then in the field of epistolary studies and in digital product design mean we know we can now do much better.
Digitising the correspondence afresh provides us with the opportunity to conceptualise this content fully in an online edition, beyond simply showing letters on a screen. Any piece of correspondence exists in a wider context – it was written by (usually) one person, at a time and in a place, and intended to be read by one or more other people. On its own, therefore, it already forms a network that can then be related to those of other items along the various axes: What are the other letters than Voltaire wrote to this person? What are the other letters that Voltaire wrote on this date? How many letters were written in this place?
Equally important, if we wish to make the most of a digital edition will be to define the relationship between individual letters. At the most basic level this would describe a simple chronological sequence, but of more interest will be to encode the sequence of correspondence, as in, which letters respond or reply to which? This metadata will be a major task to produce, and we do not underestimate the time and effort involved, but the result will be of enormous value to researchers and will greatly enhance the network available for study.
One thing it is sure to produce is gaps, by which we mean letters that were definitely written, definitely received, and definitely read, but which are no longer extant. We can know this by virtue of the text in the letters we do have, and these gaps will take their place in the metadata alongside their material siblings, occupying vital points in the network.
Gaps are there to be filled. The corpus of correspondence in OCV is a snapshot – albeit an enormous one – of the letters that were known up to a certain point in time, but it is by no means fixed: although the original editor deemed his second edition ‘definitive’ it does not claim to be complete, and new Voltaire letters have a habit of surfacing from time to time through sales, auctions, and research. As each one comes to light, there will be the opportunity not only to edit it and incorporate it together with the editorial material into the digital edition, but also to see if it can find its place in one of the existing gaps, like a piece in a vast epistolary jigsaw. More than any other significant component of OV, the correspondence has the potential to be an ever-expanding – and ever-evolving – part of the digital edition, and one that sets the standard in supporting epistolary studies.
4.10 Quality
The TEI data model for OV is complex and dense. Take, for instance, this snapshot of the start of the second chapter of Voltaire’s best-known work Candide (see Fig. 3): One can just about make out the running text in amongst the morass of elements and attributes (the characters within the angle brackets), and this is by far not the most convoluted example in the corpus. We therefore have the challenge of marrying this highly marked-up and potentially confusing data set with the vital question we must ask of all XML we commission and put to use: How good is it?
Candide, chapter 2, in TEI-XML

That short and simple question breaks down practically into others, such as: When a tag is used, is it the correct tag for the content it contains? Is its scope correct? Are the attributes it carries correct with regard to its contents and to its context? Are the tags structured correctly? Are the characters used in the running text correct?
Each one of these questions has potentially a multitude of practical incarnations given the scope and variety of the markup we are using for OV, and the implications of having to check each condition manually across the entire set are truly terrifying, and in practical terms simply impossible. Help, however, is thankfully at hand.
An XML document is by definition a structured entity, in which it is possibly logically to travel the ‘family tree’, following branches, aware of ancestors, siblings, and descendants. While this can be done by the human eye, the XML standard includes an expression language, XPath, a standardised way of specifying one or more parts of an XML document based on structure and criteria, which can then be used by a process to locate those parts. Once at a defined location in the XML document certain tests can be applied to it, and the results of those tests analysed.
All of which – identification of a specific location in the data, assessment of specific criteria at that location, and information arising from that assessment – is bound up in the rule-based validation language Schematron,Footnote 31 which despite sounding like a 1960s B-movie villain is in fact an invaluable quality assurance tool, allowing us to cut through the fog of elements and attributes and know, quickly and in detail, what we have. It is our knight in parsing armour.
Using Schematron we have developed a battery of tests which we apply to our XML files, and the result is a series of messages telling us where in the file the software believes there to be a problem and what the problem is, and selecting the message takes us, helpfully, to the precise point in the mass of elements, attributes, and text where trouble lurks. This is speed and precision that would be utterly impossible working solely with the eye, and couple this with tailored transformation stylesheets that can correct known errors unearthed by Schematron, and we have at our disposal a library of detection and correction.
None of which is to denigrate the vital contribution that our people make to ensuring our data and metadata – and the digital products they power – are of the highest quality. There is no substitute for year upon year of deep editorial knowledge of Voltaire, of his writing, and of the principles and intricacies of the edition, and this expertise is particularly powerful in the context of a digital edition where the digitised material is rendered and brought to life. Flaws which might remain hidden in the depths of an XML file can be clear as day when presented via a digital interface to someone intimately familiar with the material, and investigating the cause of the effect will usually lead to an addition to our automated arsenal of quality control rules. This is undeniably a digital product, but we could not achieve anything without the human element.
5 Beyond the Digital Edition
The preceding chapters have traced the trajectory of digital scholarly editing, moving from broad methodological considerations to the specific case of Voltaire’s corpus and the design and construction of its digital edition. The evolution of this project reflects the broader trends and challenges in digital humanities, offering valuable insights into the strengths and limitations of current methodologies. As we conclude, it is necessary to widen the scope once more and reflect on the broader implications of this work. What does the case of Voltaire teach us about the future of digital editions? How can emerging technologies reshape textual scholarship? And what challenges must be addressed as digital editions become the norm in humanities research?
5.1 Big Data vs. Curated Data
One of the defining tensions in digital humanities today is the trade-off between big data approaches and the careful curation of textual materials. The digitisation of Voltaire’s Œuvres complètes exemplifies this dilemma. On the one hand, the sheer scale of his writings demands computational approaches that can analyse massive quantities of text, track intertextual references, and facilitate large-scale comparisons. On the other hand, the textual complexity and historical nuance of Voltaire’s works require meticulous editorial intervention to ensure accuracy, readability, and interpretability.
This trade-off is not unique to Voltaire. Across the wider community of digital scholarly editing, we should ask ourselves: To what extent should digital editions privilege comprehensiveness over selectivity? Large-scale text-mining and machine-learning models promise exciting new insights into authorship, style, and reception, but they risk obscuring the very material specificities that make a scholarly edition valuable (Tolonen, Mäkelä and Lahti Reference Tolonen, Mäkelä and Lahti2022). The ideal path forward likely involves hybrid models that integrate computational scalability with human expertise – leveraging AI tools for pattern recognition while maintaining editorial oversight in key areas. Moreover, this balance will need to consider audience engagement, ensuring that digital editions serve both specialised researchers and general readers.
Recent digital humanities projects have demonstrated both the strengths and challenges of large-scale text analysis. The HathiTrust Research Center, for example, enables computational text analysis on millions of digitised books, allowing researchers to trace linguistic patterns and thematic shifts across vast corpora. However, such large-scale approaches can overlook the nuances of individual texts, leading to generalisations that may not reflect the specificities of an author’s style or historical context (Underwood Reference Underwood2019). Conversely, curated digital editions, such as those established by the Samuel Beckett Digital Manuscript Project, for example, emphasise textual fidelity and critical annotations, ensuring a more detailed and interpretive reading experience. Finding a balance between these approaches is a central challenge for future digital scholarly editors.
Furthermore, as digital editions become more expensive, ethical considerations regarding data access and intellectual property rights must be addressed. Open-access models are increasingly favoured in the digital humanities, but they require sustainable funding mechanisms and institutional support (Eve & Gray Reference Eve and Gray2020; Baldwin Reference Baldwin2023). Digital projects must also navigate issues of copyright, particularly in cases where modern translations or annotations are involved. As the field evolves, developing best practices for balancing computational analysis with careful editorial curation will be essential to ensuring the continued success and relevance of DSEs.
5.2 Artificial Intelligence
As we have seen, artificial intelligence (AI) is rapidly reshaping textual scholarship, with profound implications for digital editions. In recent years, AI-powered tools have begun assisting scholars in tasks such as transcription, collation, variant detection, and text analysis. The development of machine-learning algorithms capable of recognising linguistic patterns and reconstructing damaged or incomplete texts presents new possibilities for digital scholarly editing. However, the integration of AI into editorial practice also raises significant challenges and ethical concerns.
One of the most immediate applications of AI in digital editing is automated text transcription. Optical Character Recognition (OCR) technology has evolved significantly over the past two decades, making it possible to digitise printed and handwritten texts with increasing accuracy. Projects such as Transkribus, which employs AI-powered handwriting recognition, have demonstrated how machine learning can be trained on historical scripts to produce reliable transcriptions (Muehlberger et al. Reference Muehlberger, Seaward and Terras2019). Despite these advancements, OCR and handwritten text recognition technologies remain imperfect. Variations in handwriting, faded manuscripts, and inconsistent print quality can lead to errors, necessitating human validation and correction. This highlights a fundamental principle in AI-assisted scholarly editing: while AI can automate repetitive tasks, it cannot fully replace human expertise. Editors must carefully review AI-generated transcriptions to ensure accuracy, contextual understanding, and proper editorial intervention (Pierazzo Reference Pierazzo2015).
As AI continues to play a greater role in digital editing, it is essential to consider the ethical and methodological implications of its use. AI models are only as reliable as the data on which they are trained. Biases in training datasets can lead to skewed results, particularly when dealing with historical texts that do not conform to modern linguistic norms. Additionally, the black-box nature of some machine-learning algorithms raises questions about transparency and interpretability: How do we ensure that AI-driven editorial decisions are explainable and justifiable?
There is also the issue of intellectual property. AI-generated transcriptions, collations, and annotations blur the lines of authorship and editorial contribution. Who owns an AI-generated scholarly edition? How should AI-assisted editorial work be credited in academic publishing? These questions must be addressed as AI becomes more integrated into textual scholarship. Looking ahead, the most promising approach to AI in digital scholarly editing is one of augmentation rather than replacement. AI should be viewed as a tool that enhances human expertise, not as a substitute for it. The future of digital editing will likely involve closer collaboration between scholars and technologists, ensuring that AI tools are designed with the specific needs of humanities research in mind. This requires ongoing dialogue between digital humanists, computer scientists, and editorial theorists to develop best practices for AI-assisted scholarship.
5.3 Sustainability, Open Access, and Community Outreach
As we have seen, the OV project raises critical questions about access and sustainability. The shift to digital offers unprecedented opportunities for democratising knowledge – scholarly editions, once locked in expensive print volumes, can now be freely available to a global audience. Open access (OA) has emerged as a guiding principle for digital humanities projects, but its implementation is not without complications, and it is anything but ‘free’. The long-term sustainability of digital projects requires continuous funding, infrastructure maintenance, and institutional support.
One of the most pressing concerns for DSEs is their longevity. Print editions, despite their costs and limitations, endure. Digital editions, by contrast, are vulnerable to technological obsolescence, shifting platform standards, and changing institutional priorities. The use of interoperable standards like TEI-XML helps mitigate some of these risks, but it does not fully address the issue of sustainability (Burnard Reference Burnard2014). Future editions must develop robust digital preservation strategies, ensuring that scholarly work remains accessible for generations to come. Additionally, funding models must evolve to support the ongoing curation and enhancement of digital projects, rather than relying solely on project-based grants with finite lifespans.
The evolution of DSEs suggests a move away from static representations of texts towards more dynamic, evolving models. Traditionally, print-based critical editions presented an authoritative, fixed text. Digital editions, however, allow for ongoing revision, annotation, and user engagement. The ability to incorporate new discoveries, update interpretations, and even crowdsource textual insights presents new opportunities for scholarly collaboration. This dynamism aligns with broader trends in the field of digital humanities, where knowledge is increasingly seen as iterative and interactive. As demonstrated in the case of Voltaire, future digital editions must strike a balance between stability and fluidity – offering authoritative texts while remaining adaptable to new research and methodologies. New publication models, including continuous peer review and community-driven annotations, could further enrich the digital scholarly landscape.
Another key development in digital scholarly editing is the increasing role of collaboration. Unlike print editions, which are typically produced by small teams of editors, digital editions have the potential to be ongoing, collaborative projects that incorporate contributions from scholars worldwide. Open annotation platforms, crowdsourced transcription projects, and user-driven metadata enhancements are becoming central to how digital editions evolve over time (Causer & Terras Reference Terras, Schreibman, Siemens and Unsworth2016). The shift towards open scholarly collaboration has the potential to transform academic publishing. However, this requires the establishment of clear editorial frameworks that balance openness with scholarly integrity. The role of peer review in digital editing must also be reconsidered, ensuring that collaborative contributions maintain high academic standards.
Additionally, public engagement with digital editions is an emerging area of interest. Many digital projects now aim to serve both scholarly audiences and the broader public. Voltaire’s works, for example, have significant cultural and historical importance beyond academia. Digital editions should therefore be designed with multiple audiences in mind, providing different levels of access and interpretive support to accommodate both specialised researchers and general readers (Fitzpatrick Reference Fitzpatrick2021).
5.4 The Future
As we look ahead, the key questions facing digital scholarly editing remain open-ended: How do we balance computational efficiency with humanistic inquiry? How can we ensure the long-term viability of digital projects? What new forms of scholarly engagement might digital editions enable? How can institutions create robust infrastructures that support digital scholarship over time?
The case of Voltaire underscores the potential of digital editions to revolutionise textual scholarship. Yet it also highlights the challenges that must be navigated – balancing technological advances with editorial principles, ensuring sustainability, and fostering collaborative research while maintaining rigorous scholarly standards. The answers to these questions will shape the future of scholarly editing in the digital age. If the case of Voltaire has shown us anything, it is that digital editions are not merely about preserving the past – they are about constructing new ways of understanding, interpreting, and engaging with texts in the present and future. The continued refinement of digital methodologies, coupled with thoughtful editorial oversight, will determine how successfully DSEs evolve to meet the needs of a changing academic and cultural landscape. Through collaboration, innovation, and institutional support, DSEs can serve as enduring resources that expand and enrich our understanding of historical texts for generations to come.
Abbreviations
- DSE
Digital Scholarly Edition.
- OCV
Complete Works of Voltaire / Œuvres complètes de Voltaire (205 vols, 1968–2022). Ed. Besterman, T, Cronk, N et al. Oxford: Voltaire Foundation.
- OV
Oxford University Voltaire (2006-). Voltaire Foundation. Distributed by Liverpool University Press.
Acknowledgements
The authors are deeply grateful to their Oxford University Voltaire colleagues, Alison Oliver and Gillian Pink, whose expertise and sustained contributions have been indispensable to the preparation of this book. We also warmly thank the two anonymous reviewers for their attentive reading and constructive suggestions, which have helped us to strengthen and clarify the manuscript. Our colleagues in the development team at Open Creative Communication (OCC) – including Sara Amirizad, Sean Curtis, Anselm Eustace, Alan Kazim, and Naomi Paulus – have been unfailingly resourceful in devising smart solutions to the many challenges we set before them. The realisation of the ambitions outlined in the following pages owes everything to their inventiveness, technical skill, and enthusiasm.
Series Editor
Samantha J. Rayner
University College London
Samantha J. Rayner is Professor of Publishing and Book Cultures at UCL. She is also Director of UCL’s Centre for Publishing, co-Director of the Bloomsbury CHAPTER (Communication History, Authorship, Publishing, Textual Editing and Reading) and co-Chair of the Bookselling Research Network.
Associate Editor
Leah Tether
University of Bristol
Leah Tether is Professor of Medieval Literature and Publishing at the University of Bristol. With an academic background in medieval French and English literature and a professional background in trade publishing, Leah has combined her expertise and developed an international research profile in book and publishing history from manuscript to digital.
Advisory Board
Simone Murray, Monash University
Claire Squires, University of Stirling
Andrew Nash, University of London
Leslie Howsam, Ryerson University
David Finkelstein, University of Edinburgh
Alexis Weedon, University of Bedfordshire
Alan Staton, Booksellers Association
Angus Phillips, Oxford International Centre for Publishing
Richard Fisher, Yale University Press
John Maxwell, Simon Fraser University
Shafquat Towheed, The Open University
Jen McCall, Central European University Press/Amsterdam University Press
About the Series
This series aims to fill the demand for easily accessible, quality texts available for teaching and research in the diverse and dynamic fields of Publishing and Book Culture. Rigorously researched and peer-reviewed Elements will be published under themes, or ‘Gatherings’. These Elements should be the first check point for researchers or students working on that area of publishing and book trade history and practice: we hope that, situated so logically at Cambridge University Press, where academic publishing in the UK began, it will develop to create an unrivalled space where these histories and practices can be investigated and preserved.
Academic Publishing and Book Culture
Gathering Editor: Jane Winters
Jane Winters is Professor of Digital Humanities at the School of Advanced Study, University of London. She is co-convenor of the Royal Historical Society’s open-access monographs series, New Historical Perspectives, and a member of the International Editorial Board of Internet Histories and the Academic Advisory Board of the Open Library of Humanities.