


Overview on the TwinLife Core Project
TwinLife is the first twin family panel in Germany that implemented a population register-based sampling design (for a detailed description see Lang & Kottwitz, Reference Lang and Kottwitz2020), collecting data from same-sex twin pairs reared together in families with good proficiency of the German language. Its main aim is to investigate mechanisms of gene-environment interplay driving social inequalities and processes leading to individual differences in life outcomes (Mönkediek et al., Reference Mönkediek, Lang, Weigel, Baum, Eifler, Hahn, Hufer, Klatzka, Kottwitz, Krell, Nikstat, Diewald, Riemann and Spinath2019; Rohm et al., Reference Rohm, Andreas, Deppe, Eichhorn, Instinske, Klatzka, Kottwitz, Krell, Mönkediek, Paulus, Piesch, Ruks, Starr, Weigel, Diewald, Kandler, Riemann and Spinath2023). For this purpose, the TwinLife data enables researchers to investigate biological, psychological, and social origins of social inequalities and life outcomes in six broad areas: (1) skill formation and education, (2) career and labor market attainment, (3) social integration and participation, (4) subjective perception of quality of life, (5) physical and psychological health, and (6) deviant behavior and behavioral problems. Individual differences in these broad areas were assessed in various data collections (see Figure 1) based on a cross-sequential design, including four age cohorts of twins who were about 5, 11, 17, and 23 years old at the time of the first survey in 2014 and 2015. Based on this design, the TwinLife data covers developmental trajectories from childhood to young adulthood and enables longitudinal analyses of developmental mechanisms associated with social inequalities and life outcomes. For example, utilizing longitudinal biometric twin models, the data offers a unique opportunity to disentangle genetic and environmental factors underlying inter-individual differences in intra-individual developmental changes (see Starr et al., Reference Starr, Ruks, Weigel and Riemann2023, for an application).
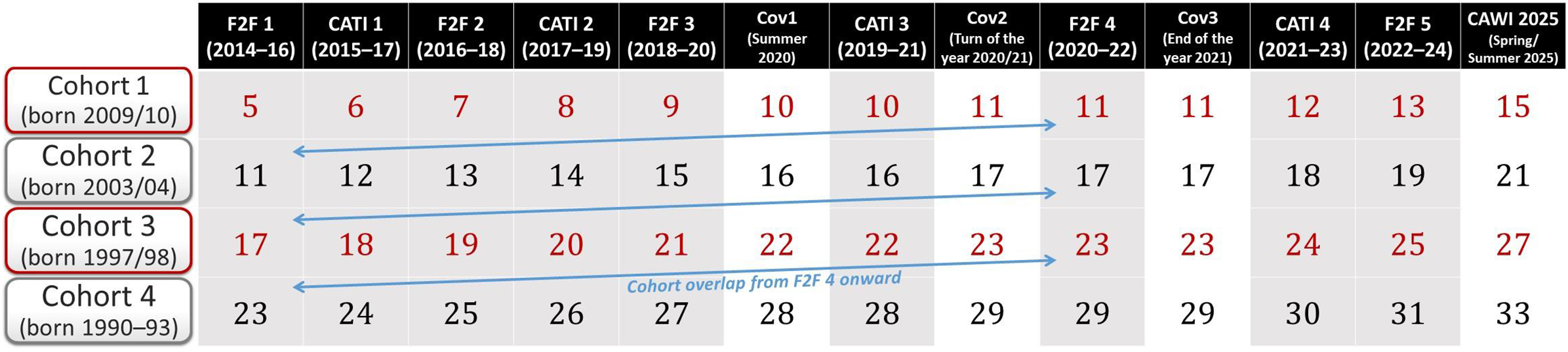
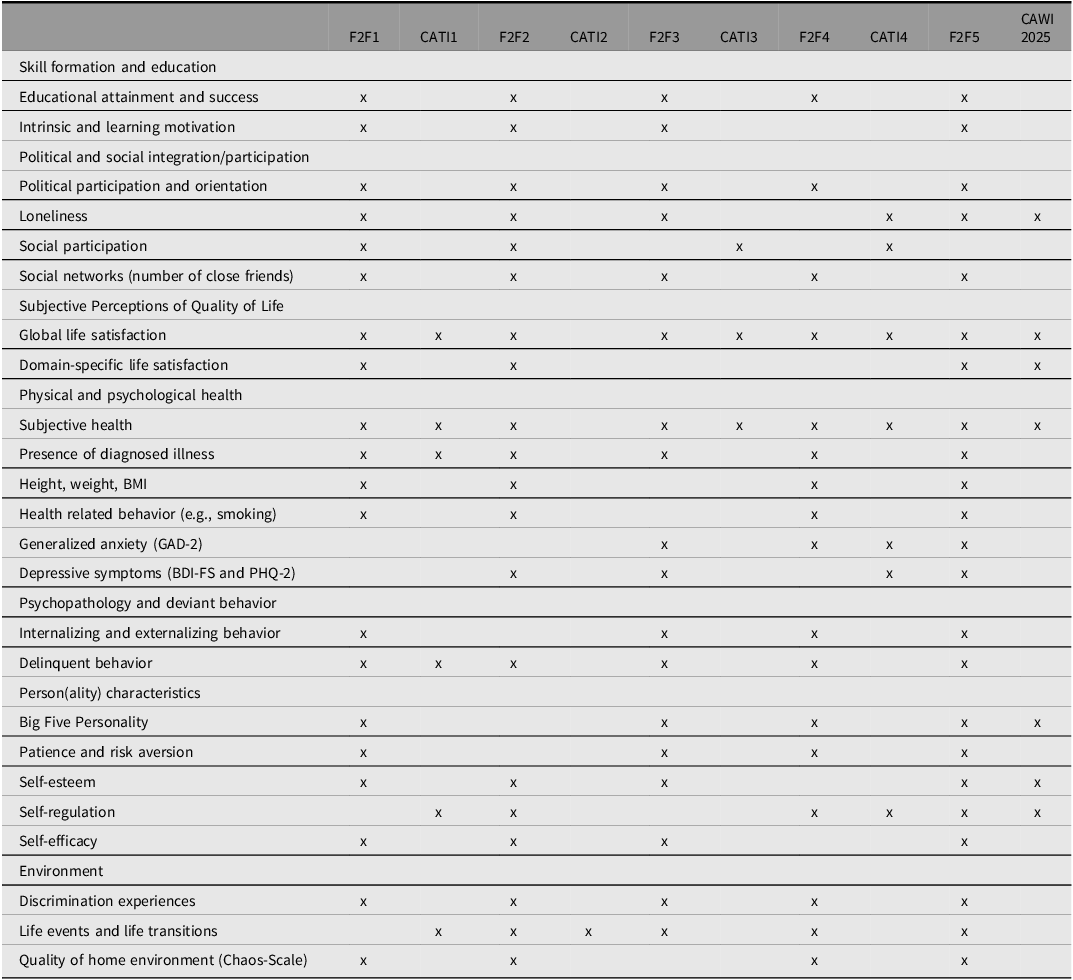
Overview of the TwinLife Panel Design.
Note: This figure is an extension of Figure 2 in Rohm et al. (Reference Rohm, Andreas, Deppe, Eichhorn, Instinske, Klatzka, Kottwitz, Krell, Mönkediek, Paulus, Piesch, Ruks, Starr, Weigel, Diewald, Kandler, Riemann and Spinath2023). F2F, face-to-face interviews; CATI, computer-assisted telephone interviews; Saliva,: collection of saliva via self-collection kit (Oragene kit); 1. strict lockdown and 2. strict lockdown: contact restrictions in private life, travel restrictions, closure of schools, gastronomy, retail, service sector, cultural institutions (e.g., museums, cinema, concerts) and social sports activities; lighter lockdown measures: contact restrictions in private life and closure of gastronomy, cultural institutions and social sports activities. Yellow boxes (Cov, Corona-based inventories; CAWI, computer-assisted web-based interviews) indicate additional data collections that were not planned to be carried out at the beginning of TwinLife data collection in 2014. *Due to the COVID-19 pandemic, face-to-face interviews needed to be substituted with computer-assisted telephone and computer assisted web interviews. **Due to the COVID-19 pandemic, collection of saliva samples took place between September 2021 and May 2022. Most of the samples were collected in 2021 during Cov 3.

Data Collection and Cross-Sequential Twin Design
To date, there is neither a central population register nor a health or disease register in Germany. To establish a register-based longitudinal panel, the TwinLife project had to implement an innovative sampling strategy and obtain addresses directly from the many residents’ registration offices located at community level in Germany. Here, twin families were identified through a multistage process. In a first step, a sample of about 500 communities (with more than 5000 inhabitants) was drawn where residents’ registration offices were asked to identify potential twins in four target birth cohort groups: 2009−2010 (cohort 1), 2003−2004 (cohort 2), 1997−1998 (cohort 3), and 1990−1993 (cohort 4) (Mönkediek et al., Reference Mönkediek, Lang, Weigel, Baum, Eifler, Hahn, Hufer, Klatzka, Kottwitz, Krell, Nikstat, Diewald, Riemann and Spinath2019). The twins were then identified by locating children registered as currently living in the same household, having the same sex, and birth dates. By limiting the study to same-sex twins, the costs of reaching the required total sample size for fraternal twins were reduced, and it was easier to find a sufficient number of twin families with a balanced ratio of identical and fraternal twins. To facilitate the identification of a sufficient number of twin families in the targeted birth cohorts (about 1000; i.e., up to 5% of all twin births in Germany), TwinLife includes twins from subsequent birth years (subsamples A and B) per cohort. For cohort 4, a restriction to only children currently living in the same household was not possible, due to some of the twins potentially no longer living with their parents. Therefore, twins of cohort 4 were identified by utilizing registries of residents that lived under the same address dating several years back (Lang & Kottwitz, Reference Lang and Kottwitz2020). After the residents’ registration offices provided a gross sample of around 19,000 addresses, in a final step, 13,359 addresses (families) were sampled and contacted until about 1000 twin families per birth cohorts agreed to take part in the first data collection in 2014−15 (Brix et al., Reference Brix, Pupeter, Rysina, Steinacker, Schneekloth, Baier, Gottschling, Hahn, Hufer, Kaempfert, Kornadt, Krell, Lang, Lenau, Mattheus, Nikstat, Peters, Schulz, Schunck, Starr, Witt, Diewald, Riemann and Spinath2017; Lang & Kottwitz, Reference Lang and Kottwitz2020). The original sample consisted of 4096 twin families (36%), who were subsequently observed and surveyed annually.
The twin families were invited by mail to participate in the study before they were visited by an interviewer for a face-to-face interview (for a detailed description, see Brix et al., Reference Brix, Pupeter, Rysina, Steinacker, Schneekloth, Baier, Gottschling, Hahn, Hufer, Kaempfert, Kornadt, Krell, Lang, Lenau, Mattheus, Nikstat, Peters, Schulz, Schunck, Starr, Witt, Diewald, Riemann and Spinath2017, and Lang & Kottwitz, Reference Lang and Kottwitz2020). In addition to the twins, data were collected from the twins’ parents (biological and step-parents), a nontwin sibling (the one closest in age to the twins and at least 5 years old, if available), and partners of adult twins (if available). In the first wave, siblings and partners were only interviewed if they lived in the same household as one of the twins. From wave 2 on, participants who left the household (e.g., due to separation of parents, or due to siblings or twins moving out of the parental home) and other target people who moved into the household (e.g., partners of twins) were tracked, contacted and surveyed as part of their new households. While respondents were offered multiple opportunities to self-update their addresses in the address database (study’s hotline, email address, online address portal), address tracking was conducted via the ADDRESSFACTORY database of Deutsche Post AG. In addition, during the field phase, residents’ registration offices were contacted for individual inquiries about changed addresses (Lesaar et al., Reference Lesaar, Prussog-Wagner and Hess2020). These measures were conducted each month throughout the entire fieldwork phase and after. Starting with the fourth wave, twins were asked to provide information on their children.
The collection mode alternated between face-to-face interviews (F2F) at the respondents’ homes and computer-assisted telephone interviews (CATI) across survey waves (see Figure 1). To limit the time interviewers spent in the household during the F2F interviews, computer-assisted self-interviews, and paper and pencil interviews were implemented in addition to the computer-assisted personal interviews (e.g., Brix et al. Reference Brix, Pupeter, Rysina, Steinacker, Schneekloth, Baier, Gottschling, Hahn, Hufer, Kaempfert, Kornadt, Krell, Lang, Lenau, Mattheus, Nikstat, Peters, Schulz, Schunck, Starr, Witt, Diewald, Riemann and Spinath2017). Alternatively, computer-assisted web-based interviews (CAWI) were also offered to respondents in the later waves. For example, the interviews of the fourth F2F wave, which were originally planned as household interviews, had to be substituted with CATI and CAWI interviews due to contact restrictions during the COVID-19 pandemic. In order to assess the impact of the pandemic on respondents, between 2020 to 2024, additional information was collected in four COVID-19 supplementary surveys (Cov 1–Cov 4 in Figure 1).
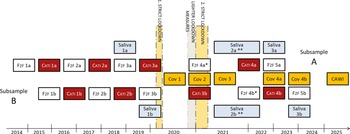
Starting with the fourth wave of the F2F survey, the cohorts overlap in terms of age, making it possible to combine the data. For example, in the fourth F2F wave, the youngest twins (cohort 1), aged 11 years old, were of the same age as the second cohort when they were first interviewed (see Figure 2). As of 2025, five F2F interviews and four CATI interviews have been conducted. While the originally planned observation period covers 10 years (between 2014 and 2024), the panel was extended in spring 2025 to include a further CAWI follow-up survey. Together, the established cohort-sequential design covers an age range of up to 28 years, from age 5 to age 33 (see Figure 2). This cross-sequential twin design allows to separate the effects of age, time, and cohort on genetic, environmental, and phenotypic differences in several characteristics that were measured repeatedly over time.
Age overlaps between the TwinLife cohorts.
Note: Age refers to mean age during each survey. F2F, face-to-face interviews; CATI, computer-assisted telephone interviews; Cov, Corona-based inventories; CAWI, computer-assisted web-based interviews.
Source: TwinLife homepage (own depiction).
All participants were informed in writing prior to the surveys about the aims of the study, incentives, and that their participation was voluntary and could be withdrawn at any time. In all F2F surveys, participants received a two-page leaflet summarizing the procedures concerning data processing, protection and privacy, and informing them about their rights and how to exercise them in accordance with applicable data protection laws. At the beginning of each F2F interview, informed verbal consent was obtained from participants, or the participants’ legal guardians when the participants were underage, and documented. When the study started, written informed consent was not required, in line with German national legislation and the institutional requirements. Nevertheless, for all supplementary online surveys, written informed consent was obtained from all participants.
Panel Stability and Sample Weights
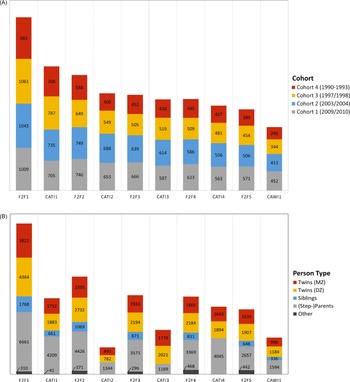
In total, 16,951 individuals from 4096 twin families participated in the first wave of TwinLife. The complete sample comprises data on 19,152 individuals, including the twins, their parents, partners, and a sibling of the twins (if available). Figure 3A shows the development of the sample sizes in the F2F and CATI surveys by cohorts. For simplicity, all sample sizes and participation rates are calculated based on at least one family member participating in the respective survey. As shown in Figure 3A, there was a substantive drop in the number of participating families from the first home interview (F2F 1) to later participation in the panel (CATI 1). Participation rates of the families were around 70% in all cohorts in CATI 1 and in the younger two cohorts in F2F 2. For the older two cohorts, the participation rates fell to around 60% in F2F 2 which corresponds to the third survey wave. This drop is not unusual in the context of panel studies with register-based sampling designs (e.g., in comparison to opt-in studies, where individuals proactively choose to participate), as it takes time for participants to feel committed to a study. Furthermore, Figure 3A shows that the number of participating families stabilized across panel waves, particularly in the younger two cohorts from the second wave of home interviews onward. The decline in the number of participating families across waves can be particularly observed in the oldest twin cohort due to the twins’ age and living situations (e.g., twins leaving the parental home), which made it harder to reach and interview them. The participation rates of the twins and their families are comparable to other large German panel studies with register-based sampling of families, such as the German Socio-Economic Panel (SOEP, Kroh et al., Reference Kroh, Kühne, Siegers and Belcheva2018) or the adult cohort of the National Educational Panel Study (NEPS; Zinn et al., Reference Zinn, Würbach, Steinhauer and Hammon2020).
Numbers of (A) families by twin cohort and (B) twin family members in the home and telephone interviews of TwinLife.
Note: Reported sample sizes and participation rates are defined by at least one family member participating in the respective survey. MZ, monozygotic; DZ, dizygotic; N = 6 cases of twins with unknown zygosity. F2F, face-to-face interviews; CATI, computer-assisted telephone interviews; CAWI, computer-assisted web-based interviews.
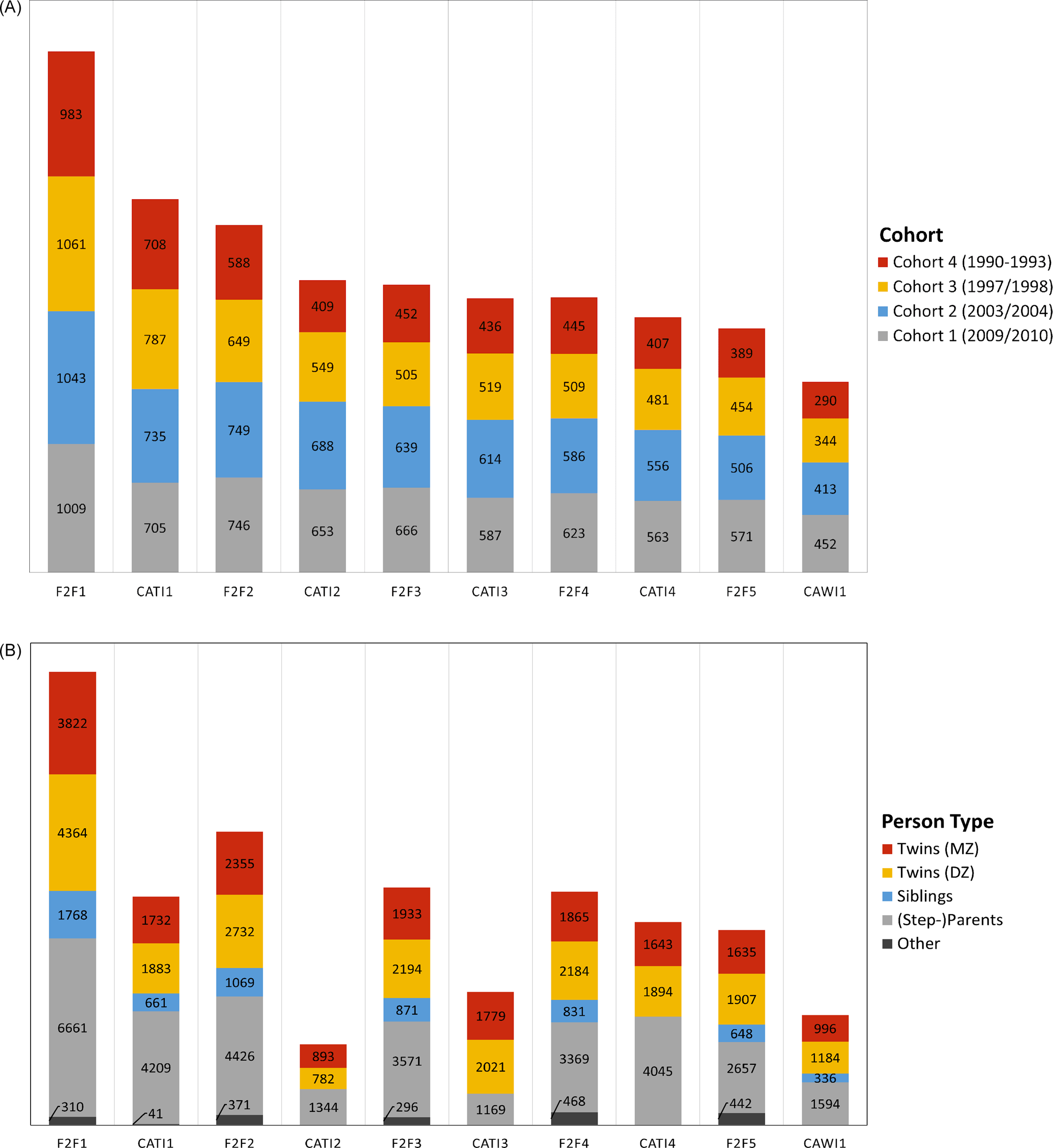
Figure 3B shows the development of sample sizes at the level of family members. As the figure illustrates, fewer family members were surveyed in CATI waves one to three. This was due to the following reasons: Due to their young age (<10 years old), the twins of the youngest cohort could not be interviewed in CATI 1 and CATI 2. Here, only parental reports about the children were available. In addition, in CATI 2 the twins in cohort 2 were not interviewed as the scope of the survey had to be reduced in this wave to reduce costs (see also Figure 4A and 4B). For the same reason, in CATI 2 and CATI 3 only one adult person was interviewed to collect important household information as well as information on the children.
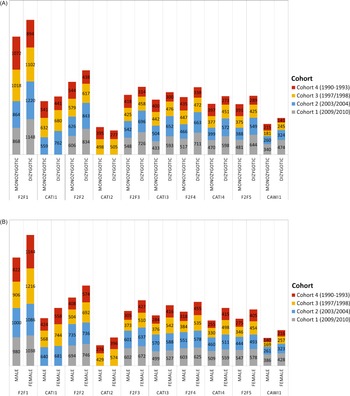
Number of (A) monozygotic and dizygotic twins as well as (B) male and female twins who participated in the home and telephone interviews of TwinLife by cohort.
Note: Twins in Cohort 1 were not included in the telephone interviews in CATI 1 and CATI 2 due to their young age. Twins in Cohort 2 were not interviewed in CATI 2. For cost reasons, the scope of the survey had to be reduced in this wave. F2F, face-to-face interviews; CATI, computer-assisted telephone interviews; CAWI: computer-assisted web-based interviews.
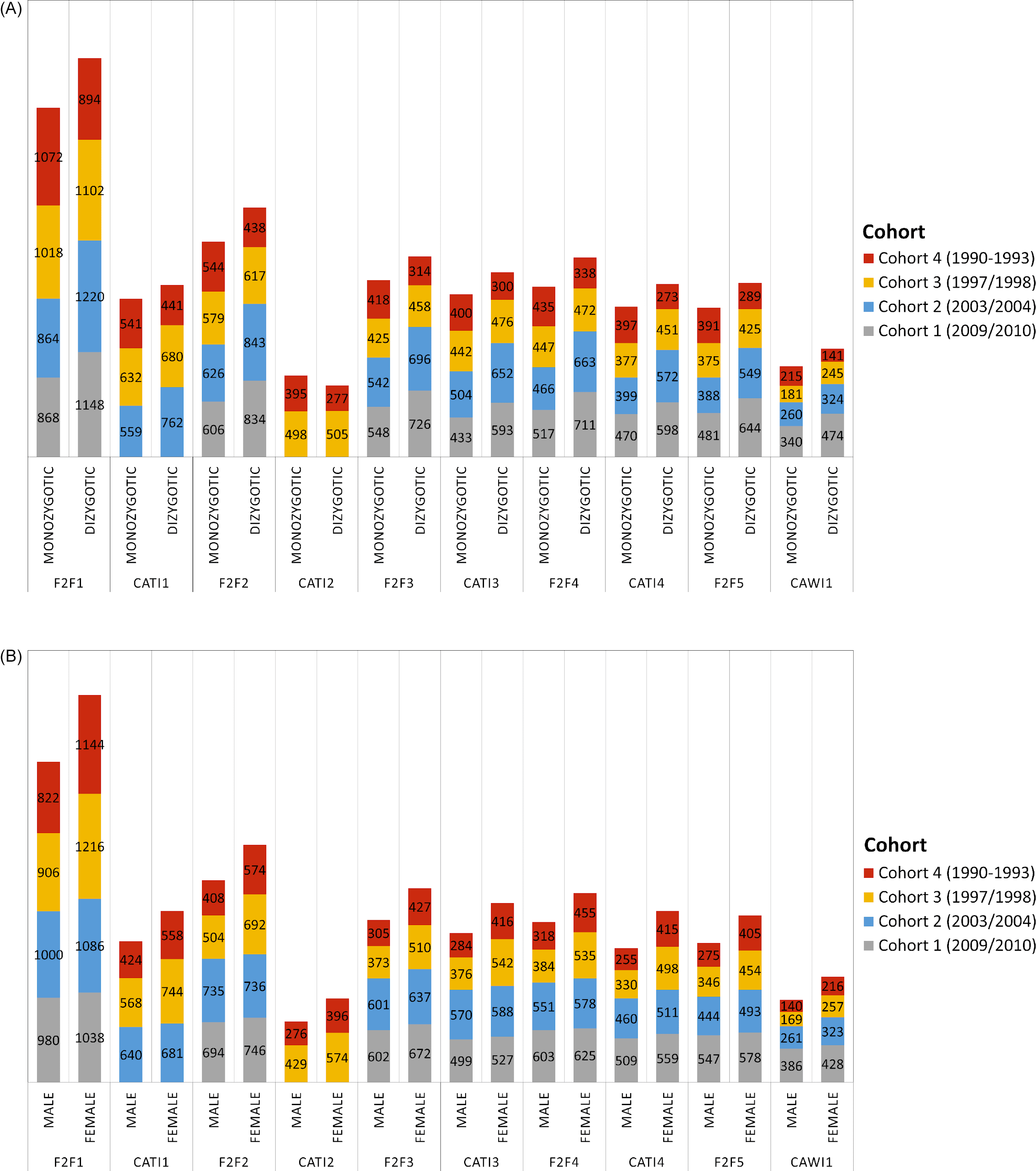
In TwinLife, the applied probabilistic sampling method (see section on data collection) has proven effective in counteracting the possible overrepresentation of monozygotic (MZ) twin pairs, which is a common problem in twin studies based on self-recruitment (for a discussion see: Lykken et al., Reference Lykken, McGue and Tellegen1987). Except for the oldest cohort, dizygotic (DZ) twins were slightly overrepresented in the different survey waves (compare Figure 4A): in cohorts 1 and 2, about 58%, and in cohort 3, about 52%. In the fourth cohort, however, depending on the survey wave, only 41% to 45% were DZ twin pairs. Furthermore, as described before, due to their young age, no twins were interviewed in the youngest cohort in CATI 1 and CATI 2, and twins in cohort 2 were not interviewed in CATI 2 to reduce the costs of the survey.
Similarly, the applied probability-based sampling design resulted in a relatively balanced sample with regard to the sex-ratio of the twins (compare Figure 4B). While TwinLife only includes same-sex DZ twins, across survey waves, about 51% to 53% of the twins in the two younger cohorts were female. In the two older cohorts, about 57% to 60% of the twins were female.
For the TwinLife data, several sample weights on the family level were calculated. To address unequal sampling probabilities of the twin families, design weights were calculated for F2F1 wave. To address nonresponse bias due to selective survey participation in F2F1, nonresponse weights were calculated. Finally, to address biased estimates due to selective panel drop out, panel weights were calculated for all subsequent waves (CATI1-F2F5). For more information on the survey weights, see Krell and Ruks (Reference Krell and Ruks2023).
Extended Twin Family Design
Using extended twin family data in TwinLife can provide more comprehensive insights into the sources of variance in various phenotypes. As classical twin models (CTM) rely on data from twins only, they rely on various assumptions (such as the absence of assortative mating) that do not always reflect the actual processes giving rise to individual differences (cf. Coventry & Keller, Reference Coventry and Keller2005). Through the inclusion of data from twins’ biological parents and, if available, also twins’ siblings in nuclear twin family models (NTFMs; Keller et al., Reference Keller, Medland, Duncan, Hatemi, Neale, Maes and Eaves2009), some of these assumptions can be relaxed. As a consequence, NTFMs provide more accurate estimates of heritability and environmental variance components under various conditions (Instinske & Kandler, Reference Instinske and Kandler2024). In particular, involving parental data allows to study mating patterns; for example, whether individuals select their spouses based on certain similarities in some characteristics (Horwitz et al., Reference Horwitz, Balbona, Paulich and Keller2023). Such assortative mating affects the genetic correlation between parents, which might increase the genetic relatedness within their offspring (except for already genetically identical MZ twins) and thereby affect estimates of genetic and environmental variance components in CTMs (e.g., Gonggrijp et al., Reference Gonggrijp, Silventoinen, Dolan, Boomsma, Kaprio and Willemsen2023).
Furthermore, utilizing data from additional relatives of twins, the simplifying assumption of CTMs that either nonadditive genetic effects or environmental influences shared by twins approach zero can be relaxed. Due to the additional information, additional sources that contribute to phenotypic variance can be considered (Keller et al., Reference Keller, Medland, Duncan, Hatemi, Neale, Maes and Eaves2009). For instance, the additional consideration of parents and nontwin siblings of twins allows to distinguish between different types of environmental sources shared by family members, such as those shared across generations, only by siblings of a descendant generation, or only by twins (Bleidorn et al., Reference Bleidorn, Hufer, Kandler, Hopwood and Riemann2018; Hufer et al., Reference Hufer, Kornadt, Kandler and Riemann2020; Kandler et al., Reference Kandler, Instinske and Bell2025).
Moreover, NTFMs are based on information from individuals from two generations. Therefore, they enable examining whether intergenerational transmission of certain characteristics occurs due to genetic or environmental factors (e.g., Wolfram et al., Reference Wolfram, Ruks and Spinath2024). NTFMs allow to consider that parents may provide rearing environments that are influenced by their own genetic predisposition and thus associated with their children’s genetic predisposition (Briley et al., Reference Briley, Livengood and Derringer2018; Plomin et al., Reference Plomin, DeFries and Loehlin1977). This form of passive gene-environment covariance allows to study the extent to which socio-environmental circumstances shared by siblings reared together correspond to genetic differences (Kandler et al., Reference Kandler, Kühn, Mönkediek, Forstner and Bleidorn2024).
Drawing on data from the partners of twins, which is across waves available for 1142 participants of the older TwinLife cohorts, the TwinLife data can be used to study how aspects related to partnership (e.g., partnership quality), life events experienced by partners (e.g., severe illness), and partners’ characteristics (e.g., partner’s personality) can shape developmental mechanisms associated with social inequalities and life outcomes. Even though we do not have information on the exact timeline of the partnership duration, the data allow for a detailed examination of the circumstances under which partnerships are formed or dissolved. Since the twins and their partners are key components of their respective social environments, combining interviews from both parties provides more detailed insights into the specific reasons for the similarities between the partners, and thus also into the sources of individual differences. Specifically, partner similarity can be either due to genetic factors (i.e., genetic homogamy), due to a shared social background (i.e., social homogamy) or due to partner-specific interactions that increase their similarity over time (i.e., convergence; e.g., Luo, Reference Luo2017). As all these different causes underlying partner similarity may have different consequences for the genetic and environmental variance in a certain construct. The use of spouses-of-twin models (e.g., Kandler et al., Reference Kandler, Lewis, Feldhaus and Riemann2015) constitutes one way to derive more detailed conclusions on the sources of individual differences in this regard.
Certainly, the NTFM or spouses-of-twin model outlined here rely on simplified assumptions as well. Some of these assumptions and the requirements of NTFM or spouses-of-twin models are discussed in Keller et al. (Reference Keller, Medland, Duncan, Hatemi, Neale, Maes and Eaves2009) and Keller et al. (Reference Keller, Medland and Duncan2010). Even more complex models can be used to account for these limitations. However, these models require substantial sample sizes that are rarely accomplished (e.g., Keller et al., Reference Keller, Medland and Duncan2010). This emphasizes the potential of combining data from different empirical studies utilizing an extended twin family design.
TwinLife Satellite Projects
Over the years, the core TwinLife project has been expanded by several satellite projects, whose data can be linked using the available identifiers (person IDs). This was done to more comprehensively examine the interplay between genes and environments in shaping differences in life chances.
The Molecular Genetic Extension TwinSNPs
An important extension of the core project and a further strength of TwinLife is the collection of saliva samples, from which molecular genetic data is obtained as part of the accompanying satellite project TwinSNPs. Written informed consent was obtained from participants who provided saliva samples. Here, each respondent received an information booklet about the goals of the extension projects, the processing of the saliva samples, the genotyping profiling, the future use of the data, data protection and their rights, and how to exercise them in accordance with applicable data protection laws. All materials were also made available on the TwinLife website (www.twin-life.de) so that they could be accessed at any time. If a participant was underage, a legal guardian gave written informed consent.
Based on saliva samples collected from TwinLife participants via self-collection kits (Oragene), DNA was extracted and respondents were genotyped (Illumina Global Screening Arrays, GSA+MD-24v3.0-Psych-24v1.1, Illumina, San Diego, CA, USA). Details on the processing of genotype data in TwinSNPs can be found in the cohort profile (Frach et al., Reference Frach, Disselkamp, Schowe, Andreas, Deppe, Maj, Rohm, Ruks, Wiesmann, Kandler, Mönkediek, Spinath, Nöthen, Binder, Czamara and Forstner2026). The TwinSNPs project enables the combination of the twin family design with genome-wide genetic variations based on single nucleotide polymorphisms (SNPs), which makes it possible, for example, to calculate and take into account polygenic scores (PGS). Besides the general incorporation of PGS in analytic approaches (for an overview, see Pingault et al., Reference Pingault, Allegrini, Odigie, Frach, Baldwin, Rijsdijk and Dudbridge2022), TwinLife offers the opportunity to combine genetically informative analyses based on PGS with twin-based analyses. PGS can be conceptualized as summary measures of (additive) genetic effects on a certain trait or disorder (e.g., Dudbridge, Reference Dudbridge2013; Harden & Koellinger, Reference Harden and Koellinger2020). This information can be considered beyond the covariance structure of MZ and DZ twins to estimate the extent to which phenotypic differences are attributable to genetic differences (e.g., Dolan et al., Reference Dolan, Huijskens, Minică, Neale and Boomsma2021). As such, the entire genetic variance can be decomposed into variance due to the common genetic variants incorporated in the PGS and the remaining genetic variance derived from the ratios of MZ and DZ twin similarity (e.g., Bruins et al., Reference Bruins, Dolan and Boomsma2020).
An overview of available PGS in TwinLife can be found in the download section on the TwinLife documentation website (www.twin-life.de/documentation/downloads) and in the cohort profile (Frach et al., Reference Frach, Disselkamp, Schowe, Andreas, Deppe, Maj, Rohm, Ruks, Wiesmann, Kandler, Mönkediek, Spinath, Nöthen, Binder, Czamara and Forstner2026). First publications based on the molecular genetic data from TwinLife addressed topics such as the PGS prediction of education (Starr et al., Reference Starr, Ruks, Giannelis, Willoughby, Pettersson, Pahnke, Maj, Andreas, Ahlskog, Arseneault, Fisher, Forstner, Kandler, McGue, Nöthen, Oskarsson, Spinath, Vrieze, Wertz and von Stumm2026), the associations of subjective well-being with personality traits (Deppe et al., Reference Deppe, Disselkamp, Maj, Aldisi, Nöthen, Diewald, Spinath, Forstner and Kandler2026), and neighborhood deprivation (Harerimana et al., Reference Harerimana, Liu and Ruks2025).
Due to the extended family design, TwinLife also allows testing for direct and indirect genetic effects in a within-sibship (e.g., Howe et al., Reference Howe, Nivard, Morris, Hansen, Rasheed, Cho, Chittoor, Ahlskog, Lind, Palviainen, van der Zee, Cheesman, Mangino, Wang, Li, Klaric, Ratliff, Bielak, Nygaard and Davies2022) or trio-design (e.g., Balbona et al., Reference Balbona, Kim and Keller2022). This structure makes it well suited for applying methodological innovations in family-based genomewide association studies (GWAS) and other genetically informed designs; for example, those proposed by Bates et al. (Reference Bates, Sesia, Sabatti and Candès2020) and Balbona et al. (Reference Balbona, Kim and Keller2021) based on PGS. Utilizing the existing data on the twins and their parents, it is possible to contribute to research on indirect genetic effects, such as genetic nurture, that is, the indirect effects of parental genotypes on offspring outcomes via environmental pathways rather than direct genetic transmission (Kong et al., Reference Kong, Thorleifsson, Frigge, Vilhjalmsson, Young, Thorgeirsson, Benonisdottir, Oddsson, Halldorsson, Masson, Gudbjartsson, Helgason, Bjornsdottir, Thorsteinsdottir and Stefansson2018), on a wide range of outcomes. However, indirect genetic effects can also arise due to assortative mating and population stratification (e.g., Young et al., Reference Young, Benonisdottir, Przeworski and Kong2019). From a methodological perspective, genetic nurture, also known as passive rGE, as well as other sources of indirect genetic effects, can confound direct genetic effect estimates. Thus, incorporating genetic data from related individuals reduces bias in estimates of direct genetic effects (e.g., Young et al., Reference Young, Benonisdottir, Przeworski and Kong2019).
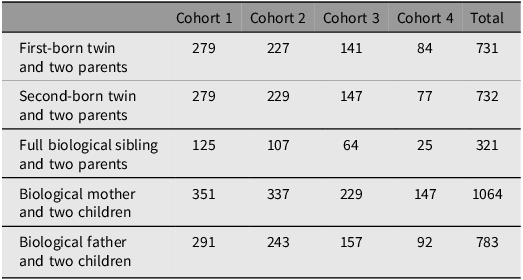
Based on its family design, TwinLife currently offers genotype data (including PGS) for different combinations of parent-offspring trios, where valid PGS information for either the biological mother, the biological father and at least one biological child is available (see Table 1 for further information on available person types and cases per cohort).
Cases of individuals per TwinLife cohort with valid trio PGS data, by person type

Note: Full biological siblings: both parents are the same as twins’ parents.
The Epigenetic Extension TECS
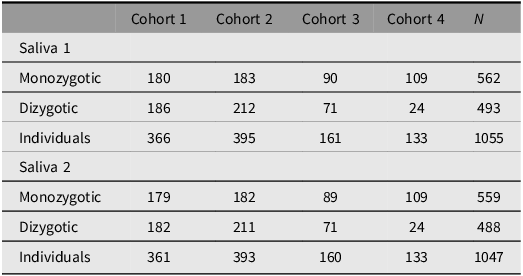
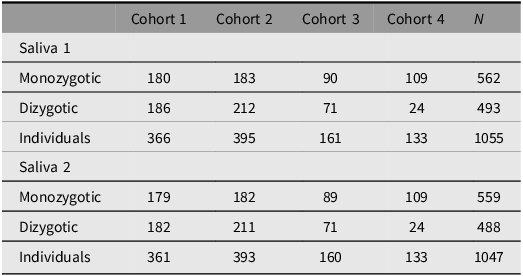
The aim of the TwinLife Epigenetic Change Satellite (TECS) project was to assess epigenetic changes in relation to the COVID-19 pandemic. For this purpose, DNA methylation (DNAm) data was obtained from the first two saliva samples (see Saliva 1a to 2b in Figure 1) for a selected group of twin participants using the Infinium MethylationEPIC BeadChip array (v1.0, Illumina, San Diego, CA, USA). Specifically, complete twin pairs with saliva samples collected at both timepoints, before and during the pandemic (see Figure 1), a valid consent form (signed by children and parents for those under 18 years of age), and participation in both the Cov 2 and Cov 3 surveys (see Figure 1) were prioritized for the assessment (n = 505 complete twin pairs). In addition, remaining slots on the arrays (n = 2128, two measures per participant) were used for individual twins (n = 54) that fulfilled these criteria.
For all twins with valid DNAm data after quality control (see Table 2), several epigenetic aging estimators were calculated, such as the Horvath clock (Horvath, Reference Horvath2013), the PedBE clock (McEwen et al., Reference McEwen, O’Donnell, McGill, Edgar, Jones, MacIsaac, Lin, Ramadori, Morin, Gladish, Garg, Unternaehrer, Pokhvisneva, Karnani, Kee, Klengel, Adler, Barr, Letourneau and Kobor2020), GrimAge2 (Lu et al., Reference Lu, Binder, Zhang, Yan, Reiner, Cox, Corley, Harris, Kuo, Moore, Bandinelli, Stewart, Wang, Hamlat, Epel, Schwartz, Whitsel, Correa, Ferrucci and Horvath2022), and DunedinPACE (Belsky et al., Reference Belsky, Caspi, Corcoran, Sugden, Poulton, Arseneault, Baccarelli, Chamarti, Gao, Hannon, Harrington, Houts, Kothari, Kwon, Mill, Schwartz, Vokonas, Wang, Williams and Moffitt2022). In addition, new epigenetic scores are continuously computed as they become available. To date, these include, for example, the epigenetic score for CRP (C-reactive protein, Barker et al., Reference Barker, Cecil, Walton, Houtepen, O’Connor, Danese, Jaffee, Jensen, Pariante, McArdle, Gaunt, Relton and Roberts2018) and BMI (Do et al., Reference Do, Sun, Meeks, Dugué, Demerath, Guan, Li, Chen, Milne, Adeyemo, Agyemang, Nassir, Manson, Shadyab, Hou, Horvath, Assimes, Bhatti, Jordahl and Conneely2023). First studies utilizing epigenetic clocks examined the genetic and environmental contributions to differences in epigenetic aging and how these vary across age and time (Kuznetsov et al., Reference Kuznetsov, Liu, Schowe, Czamara, Instinske, Pahnke, Nöthen, Spinath, Binder, Diewald, Forstner, Kandler and Mönkediek2025) and linked to personality differences (Instinske et al., Reference Instinske, Schowe, Czamara, Kuznetsov, Mönkediek and Kandler2026). An overview of all currently available epigenetic aging estimators and other derived scores from the DNAm data can be found on the TwinLife documentation website (www.twin-life.de/documentation/downloads). Detailed descriptions of the DNAm data generation, preprocessing, and epigenetic age score computations are provided in Frach et al. (Reference Frach, Disselkamp, Schowe, Andreas, Deppe, Maj, Rohm, Ruks, Wiesmann, Kandler, Mönkediek, Spinath, Nöthen, Binder, Czamara and Forstner2026).
Cases per TwinLife cohort with valid epigenetic data, by DNA-validated zygosity
Further Satellite Projects
There are several other satellite projects that have already begun or have even been completed. These projects are based on collaborations with colleagues from different research institutions that collected more specific data beyond the actual TwinLife survey and that tackle more specific research questions.
K2ID Twins
The K2ID Twins project was the first satellite project of TwinLife and organized in collaboration with the Freie Universität Berlin and the German Institute for Economic Research (DIW Berlin). This project was aimed at analyzing the influences of the quality of early childhood education and care institutions on child development in association with the professional involvement and quality of life of the parents, taking socio-economic differences into account. Of particular interest was research into the extent to which high-quality daycare centers were able to compensate for stressful or resource-poor family environments, whether and under which conditions similar environments still contributed to differences in children’s development (e.g., based on individuals’ experiences), and what role genetic predispositions played in this (www.twin-life.de/satellitenprojekte/k2id). For this purpose, the youngest cohort from TwinLife (twins who were 5 years old and had not started school yet) and their families were surveyed with an additional parent questionnaire. In addition, the twins’ educators and the heads of the daycare centers were interviewed to gather detailed information about the situations in these approximately 360 daycare centers. The data of this satellite project is now available for the research community as a scientific use file. A detailed description of the survey can be found in Ruks et al. (Reference Ruks, Kottwitz, Weigel, Klatzka, Paulus and Deppe2025). A first publication with the K2ID Twins data examined whether certain quality characteristics of daycare centers that the twin experienced affected externalizing problems behaviors at a later age (Mönkediek et al., Reference Mönkediek, Schober, Diewald, Eichhorn and Spiess2024).
ImmunoTwin
The ImmunoTwin project is being conducted with partners at Luxembourg University and at the Luxembourg Institute of Health (www.twin-life.de/satellitenprojekte/immunotwin). The project focuses on the long-term immunological consequences in twins with different experiences of stress throughout their lives and examines the role of risk and protective factors. One of these consequences is immunological aging and its developmental conditions. Utilizing epigenetic clocks, for example, the question of the extent to which stress factors from social environments can lead to premature impairment of the immune system and cause chronic diseases that normally only occur in old age is addressed. To collect the necessary data, in a first step, adult twins from TwinLife were contacted and encouraged to take part in a screening interview, resulting in 2079 interviews. With the help of these interviews and existing TwinLife data, in a second step, twins who were discordant in their experiences were identified (144 MZ and 173 DZ twins). In a third step, the discordant twins were invited to take part in psychological interviews (72 MZ and 82 DZ twins). In addition, saliva and blood samples were collected from 63 MZ twins to derive genetic information and information on the immune system.
TwinLife environment
The TwinLife Environment project is being realized with partners at the Max Planck Institute for Human Development in Berlin and at the Max Planck Institute of Psychiatry in Munich (www.twin-life.de/satellitenprojekte/umwelt). The project investigates how changing characteristics of a person’s physical environment affect cognitive functions, behavior, and the brain. Accordingly, the project is interested in collecting detailed information about the environments and their changes from the study participants. Of particular interest here are those twin pairs who tend to experience different environments after moving out of their parents’ home. Comparing these discordant twins is the most straightforward way to investigate the influence of the (changing) environment on cognitive functions, behavior, and the brain. Data for the study is currently collected from a subsample of adult twins. After completing online questionnaires gathering data on the twins’ behavior, health status, and living environment, participants receive a smartphone for one week to answer a short daily questionnaire via an app and to conduct a geographical ecological momentary assessment (GEMA) of their environments. The app also tracks the location of the smartphones (geo-coordinates) and can link this information to other data provided by respondents as well as to additional location-based data. In addition, physical characteristics, such as pulse, are captured as well as movement and sleep patterns are recorded using a smartwatch provided for this purpose. Furthermore, air quality and temperature of the environments are measured via an extra device. Taken together, the gathered information will provide researchers with detailed information about the environments of the participating individuals. For a subgroup of MZ twins, next to a cognitive test and a clinical interview, magnetic resonance imaging (MRI) scans of the head are also taken to study their brain structure and functioning. In addition, these twins are asked to fill in questionnaires collecting information on, among other things, their home and working environment.
Basic Facts and Sample Statistics
Zygosity Determination and Genetic Similarity
Zygosity was assessed at baseline using physical similarity questionnaires (see Hill Goldsmith, Reference Hill Goldsmith1991; Oniszczenko et al., Reference Oniszczenko, Angleitner, Strelau and Angert1993), which were administered during the first household interview. For the two youngest age groups, questionnaires were completed by the twins’ parents, whereas the two oldest age groups provided self-reports. In an early genotyped validation sample, collected during F2F1 including 287 pairs of twins, analyses indicated high validity of the questionnaire-based zygosity assessments and a low misclassification rate of 4% on average (see Table 3 and Lenau & Hahn, Reference Lenau and Hahn2017).
Frequencies of monozygotic and dizygotic twin pairs depending on classification method and misclassification rates

Note: F2F, face-to-face interviews.
Based on molecular genetic data collected as part of the TwinSNPs satellite project, the zygosity of a substantial share of the twin pairs was further validated. Out of the initial 4096 twin pairs, 1323 complete twin pairs were genotyped based on saliva samples collected in F2F3 and subsequent waves (Table 3). Comparing the results from the larger genotyped sample with the zygosity variable based solely on questionnaire data indicated a misclassification rate of 5.6%, further strengthening the validity of the questionnaire-based method of zygosity determination. Misclassifications of twins zygosity were generally higher for DZ twin pairs than for MZ twins. A variable combining all information sources, prioritizing DNA-based zygosity when available, is available in the dataset (zyg0112).
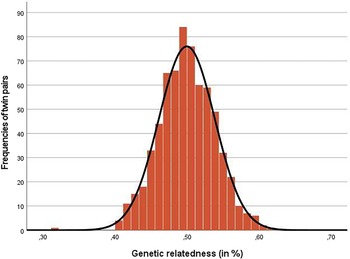
The available molecular genetic data allowed the calculation of the actual genetic similarity between siblings (i.e., their degree of relatedness or kinship). For DZ twins, this enables the use of empirically derived relatedness (or kinship) coefficients in twin models, rather than relying on the standard assumption of a genetic correlation in DZ pairs of r G = .50. While DZ twins share on average 50% of their genetic makeup, their actual genetic similarity may vary, and can be precisely determined with the use of the kinship coefficients. Their use can help to alleviate the potential over- or underestimation of genetic variance components (see Therneau, Reference Therneau2024, for an implementation in R, and Yang et al., Reference Yang, Lee, Goddard and Visscher2011, for an application) as, for example, in the case of assortative mating of the twins’ parents, which would increase the average genetic correlation of DZ twins in the presence of positive assortative mating (Instinske & Kandler, Reference Instinske and Kandler2024). Figure 5 shows the kinship distribution in TwinLife‘s DZ twin pairs with available molecular genetic data (N pairs = 665). The average genetic relatedness between DZ twins of a pair in TwinLife was 0.4997 with a standard deviation of 0.039. Thus, at least for the TwinLife data, the use of r G = .50, which reflects the genetic similarity of fraternal twins, can be considered valid.
Distribution of the genetic relatedness score.

Sample Representativeness
The TwinLife data is based on a national probability sample drawn from population registers. To assess the representativeness of the TwinLife sample with regard to the social stratification in Germany, Lang and Kottwitz (Reference Lang and Kottwitz2020) compared the distributions of several indicators in TwinLife with those of a proxy-twin sample based on the German Microcensus. The German Microcensus is a representative household register sample of 1% of the German households, carried out annually since 1957 (Destatis, 2026). Proxy twin pairs were identified as two children with the same year of birth living in the same household with at least one of their parents (Lang & Kottwitz, Reference Lang and Kottwitz2020). The analysis showed that the share of households with tertiary-educated parents was approximately 15% higher in TwinLife compared to the German Microcensus. Additionally, TwinLife households had a slightly higher median household income and about 10% fewer households without German citizenship. These results indicated that participation in TwinLife was, to some degree, selective, especially with respect to parental education. However, the analysis confirmed that the TwinLife sample covers the full range of key socioeconomic indicators, including both the lower and upper bounds. Capturing also the bounds of the resources’ distribution is essential for stratification research.
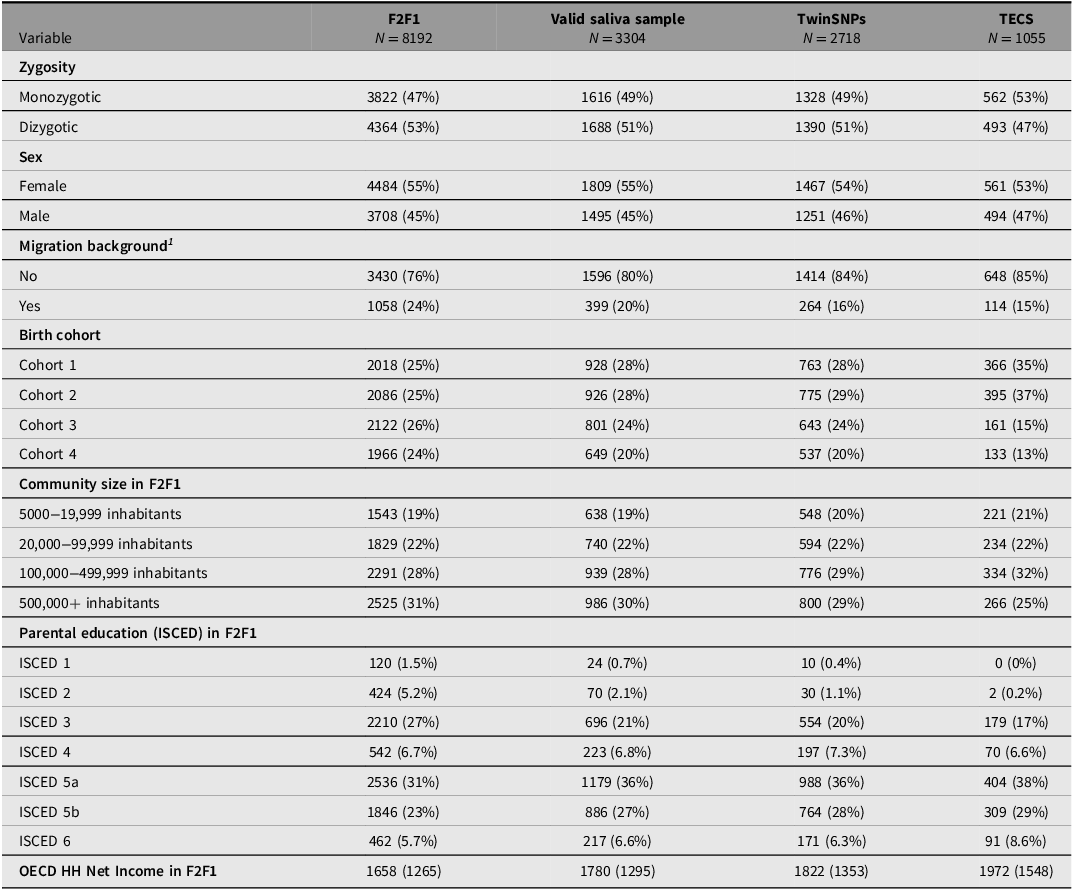
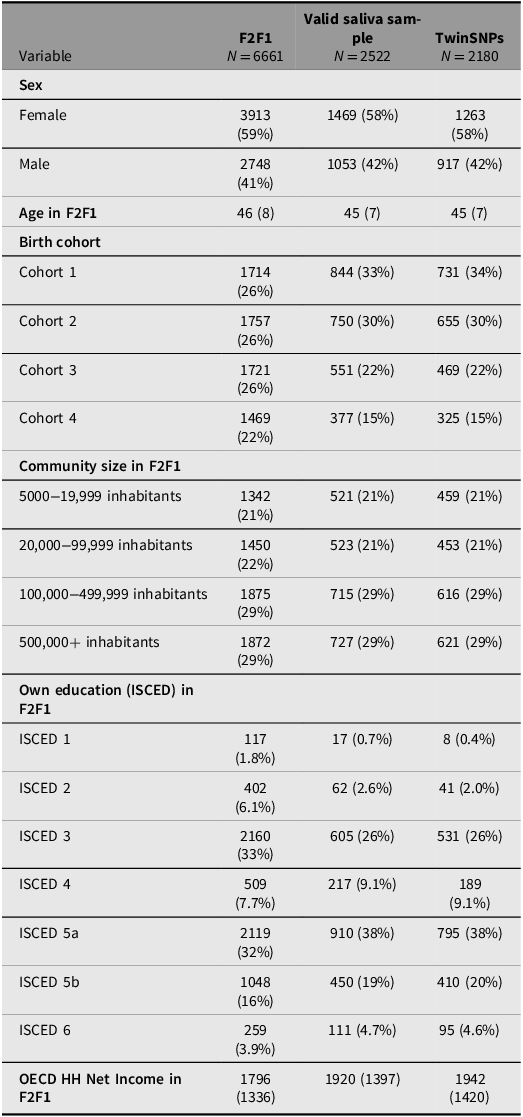
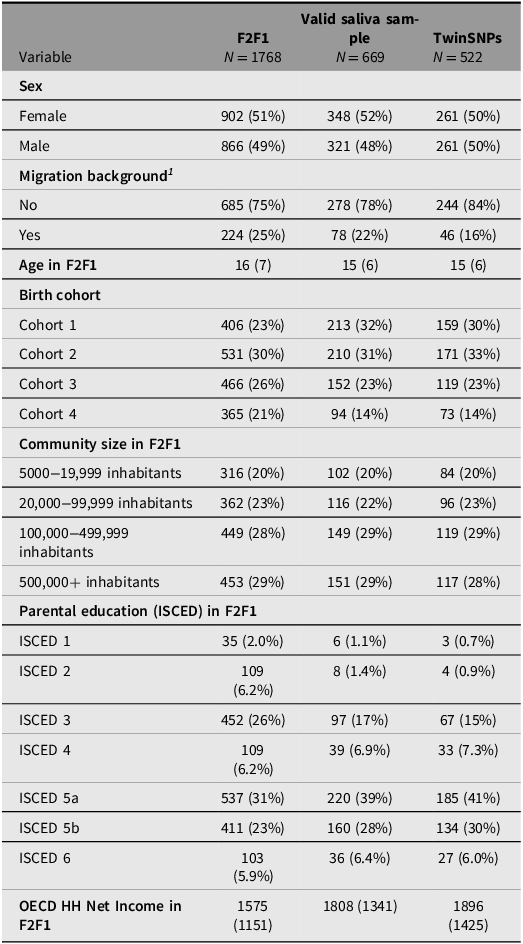
Saliva for genotyping the respondents was collected from the third household wave (F2F 3) onward including all participants who agreed to provide a sample (about 70%). Since additional selection criteria apply for the TECS sample (see above), several indicators across the genotyped subsamples were compared with the full TwinLife sample at F2F1 to evaluate their representativeness (see Tables 4 to 6). The three twin subsamples — Valid Saliva Sample, TwinSNPs, and TECS (with valid DNAm data) — showed similar distributions to the full twin sample at F2F1 (Table 4) in terms of zygosity, sex, and community size. All included a higher proportion of participants without a migration background and a greater share of younger birth cohorts (Cohorts 1 and 2). Parental education and household income were slightly higher across subsamples. The two parent subsamples — Valid Saliva Sample and TwinSNPs — showed similar distributions to the full parent sample at F2F1 in terms of sex and community size (Table 5). Both had a lower mean age than the full parent sample and a greater share of younger birth cohorts. Parents’ own education and household income were slightly higher. The two sibling subsamples — Valid Saliva Sample and TwinSNPs — showed similar distributions to the full sibling sample at F2F1 in terms of sex and community size (Table 6). Both had a lower mean age and a greater share of younger birth cohorts. Parental education and household income were slightly higher. For more details on the genotyping and differences in the characteristics of the participants compared to the initial core sample see Frach et al. (Reference Frach, Disselkamp, Schowe, Andreas, Deppe, Maj, Rohm, Ruks, Wiesmann, Kandler, Mönkediek, Spinath, Nöthen, Binder, Czamara and Forstner2026).
Comparison of sample characteristics between genotyped twin subsamples and all twins in the full TwinLife sample
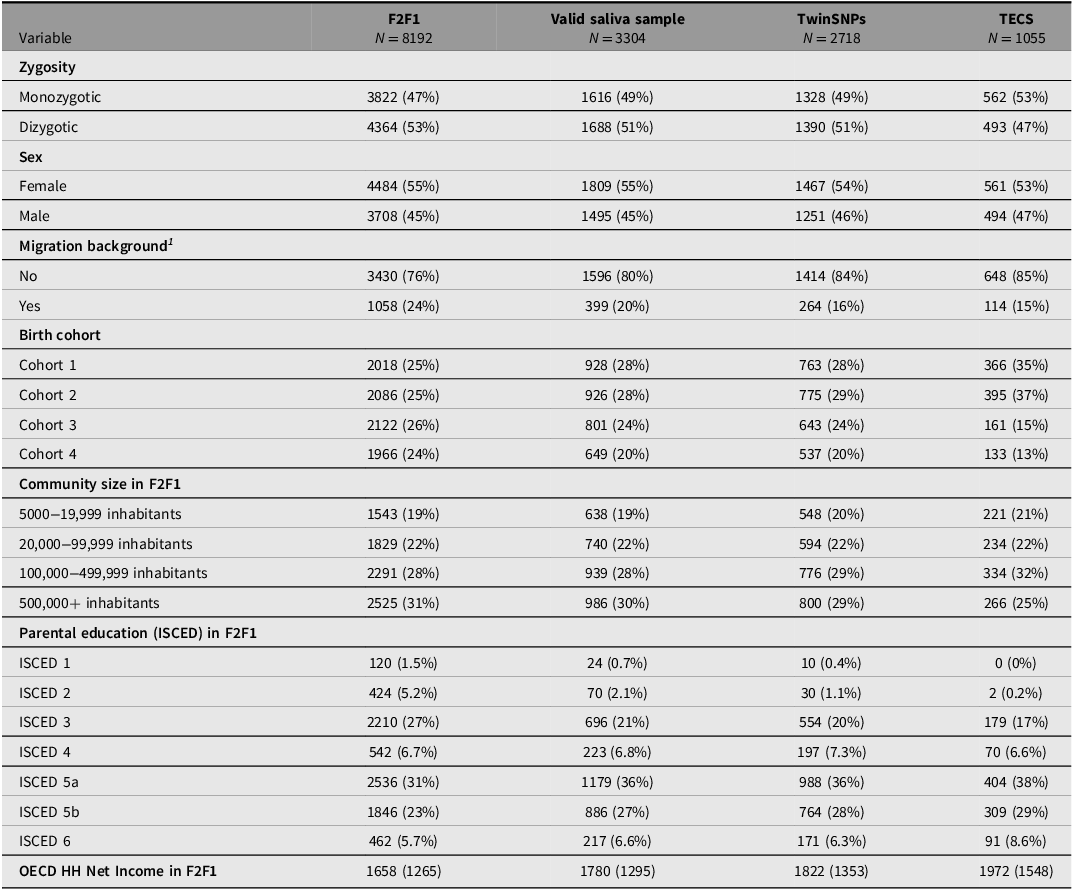
Note: For continuous variables: Mean (standard deviation); For categorical variables: Absolute frequencies (relative frequencies in %); ISCED, International Standard Classification of Education; OECD HH, net equivalent household income based on the modified OECD scale; F2F, face-to-face interviews.
1 Following the definition of the German federal statistical office, a person has a migration background if they or at least one parent were not born with German citizenship. Thus, migration background is only calculated for persons with valid information on citizenship for both themselves and their parents.
Comparison of sample characteristics between genotyped parent subsamples and all parents in the full TwinLife sample
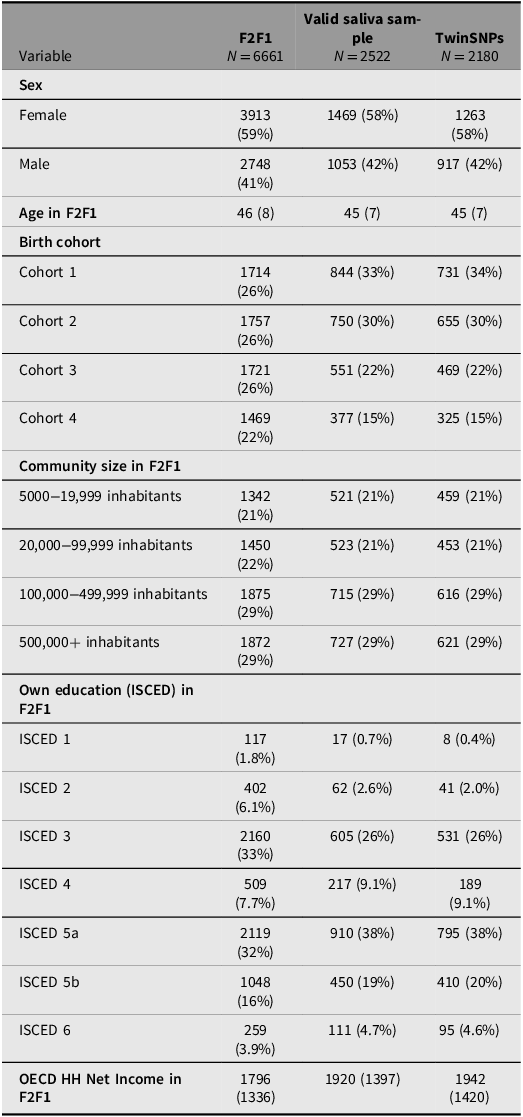
Note: For continuous variables: Mean (standard deviation); For categorical variables: Absolute frequencies (relative frequencies in %); ISCED, International Standard Classification of Education; OECD HH, net equivalent household income based on the modified OECD scale; F2F, face-to-face interviews.
Comparison of sample characteristics between genotyped sibling subsamples and all siblings in the full TwinLife sample
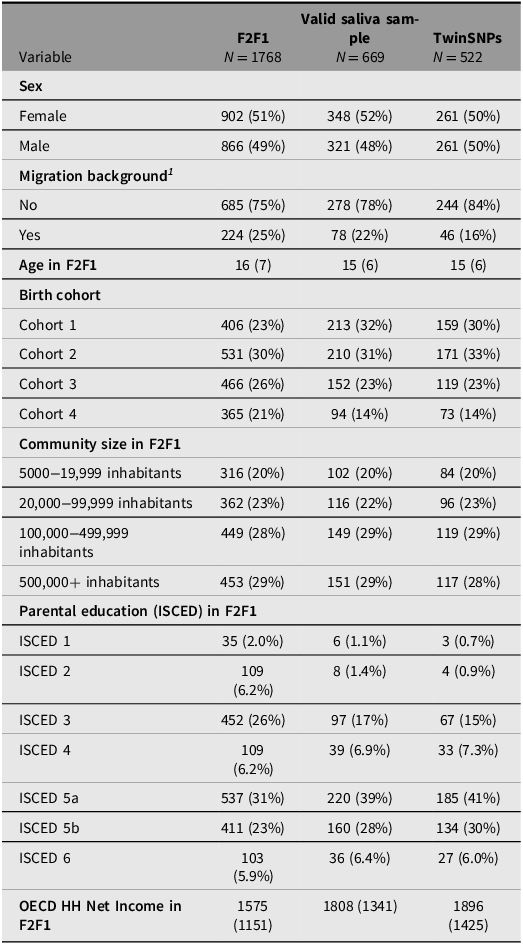
Note: For continuous variables: Mean (Standard Deviation); For categorical variables: Absolute frequencies (relative frequencies in %); ISCED, International Standard Classification of Education; OECD HH, net equivalent household income based on the modified OECD scale; F2F, face-to-face interviews.
1 Following the definition of the German federal statistical office, a person has a migration background if they or at least one parent was not born with German citizenship. Thus, migration background is only calculated for persons with valid information on citizenship for both themselves and their parents.
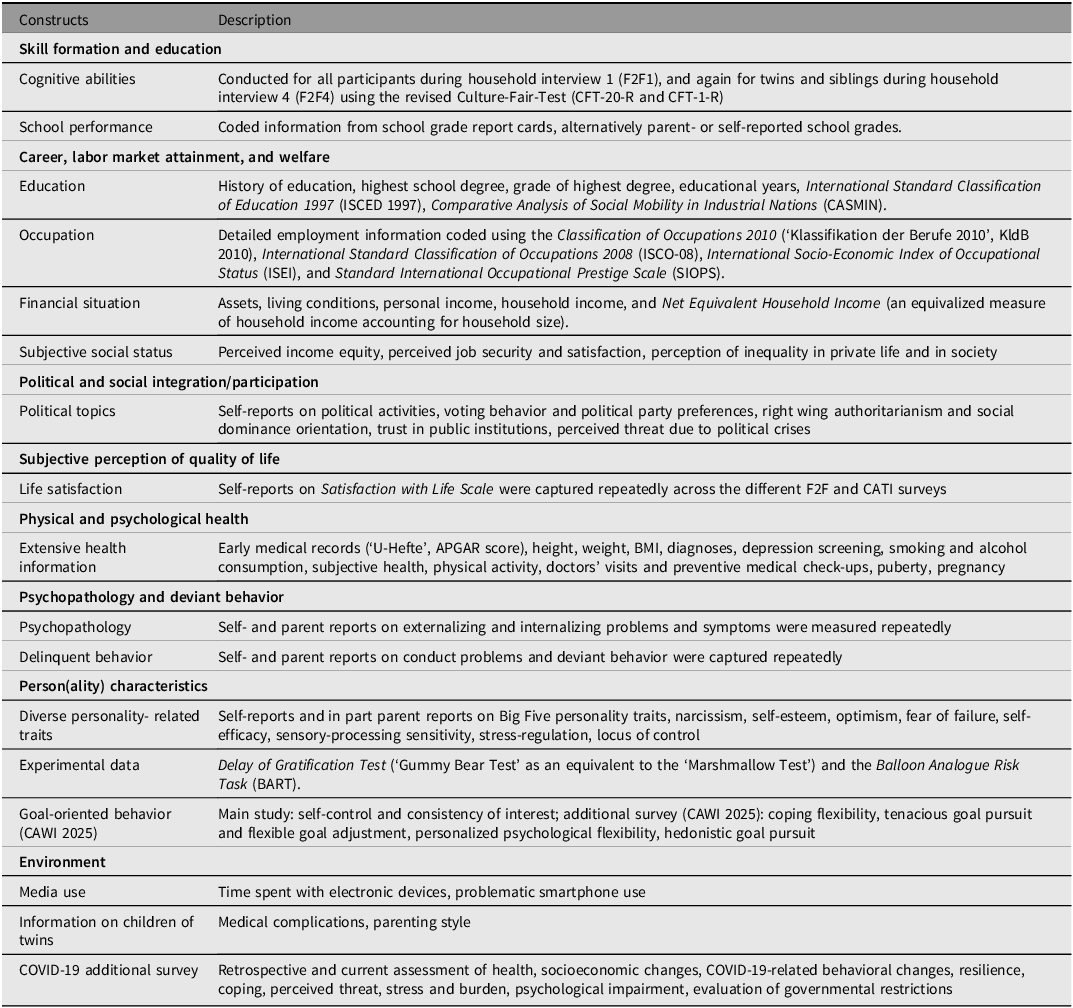
Overview of Constructs and Measurements
The TwinLife panel covers a broad range of constructs utilizing numerous items and scales from different disciplines including sociology, psychology, educational or political science. To facilitate comparisons with other major longitudinal studies, TwinLife frequently adopted constructs and measures used in large, representative family or household surveys without a twin family focus, such as the German Socio-Economic Panel (SOEP; Goebel et al., Reference Goebel, Grabka, Stefan, Martin, Richter, Schröder and Schupp2019) and the German Family Panel (Pairfam; Huinink et al., Reference Huinink, Brüderl, Nauck, Walper, Castiglioni and Feldhaus2011; Brüderl et al., Reference Brüderl, Drobnič, Hank, Neyer, Walper, Wolf, Alt, Bauer, Böhm, Borschel, Bozoyan, Christmann, Edinger, Eigenbrodt, Garrett, Geissler, Gonzalez Avilés, Gröpler, Gummer and Wetzel2018).
As TwinLife focuses on role of genetic and social factors as well as the complex person-environment interplay contributing to social inequality in six main areas (see Figure 6), it also covers a broad range of environmental measures, including a wide range of socioeconomic status constructs (see Table 7), as well as measures of individual differences, which can act as predictors, outcomes, mediators, and (or) moderators of social inequality.
TwinLife’s conceptual framework including domains and processes of interest.

Overview of selected constructs and exemplary measurements in TwinLife
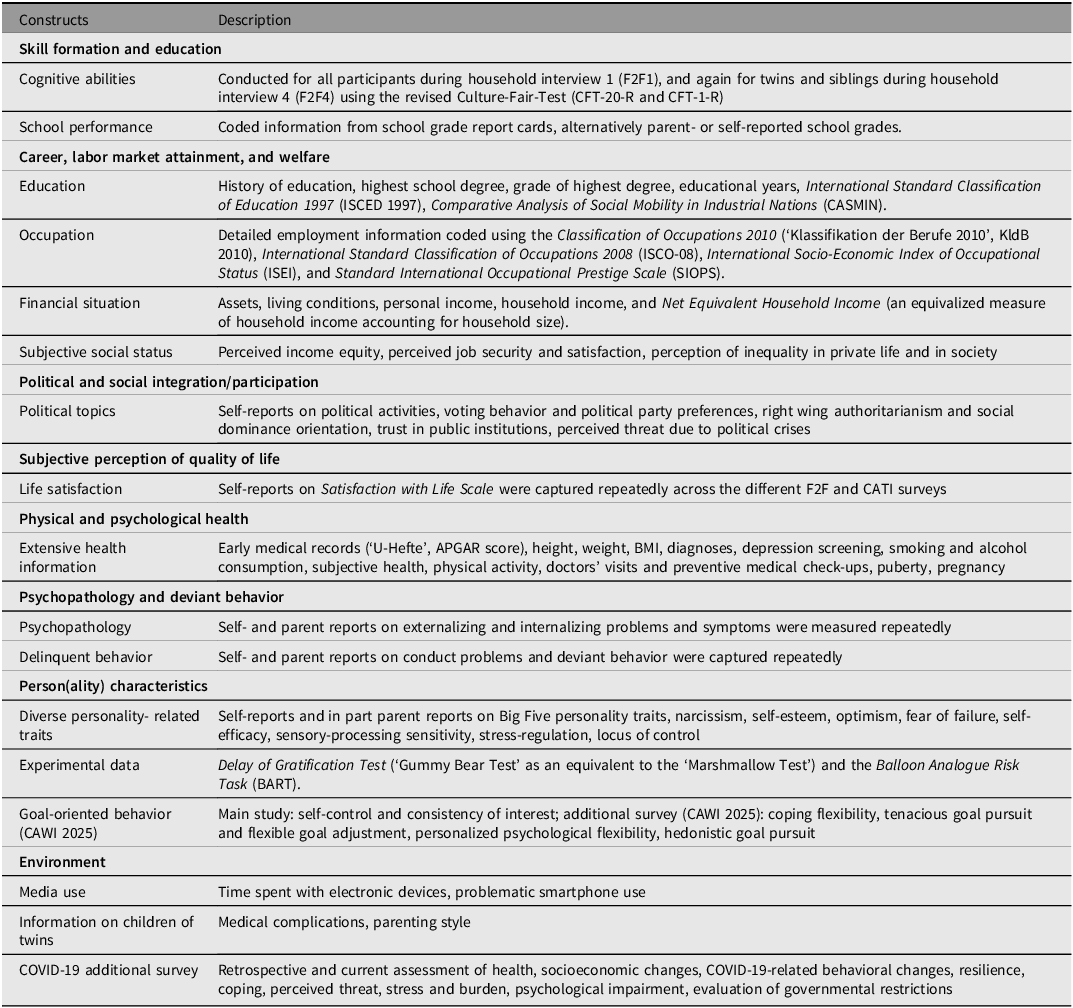
Note: For further information on the listed constructs and additional constructs captured in TwinLife as well as their sources, see the TwinLife Scales Manual (Klatzka et al., Reference Klatzka, Baum, Paulus, Nikstat, Dang, Andreas, Iser and Hahn2023) and the TwinLife data documentation website.
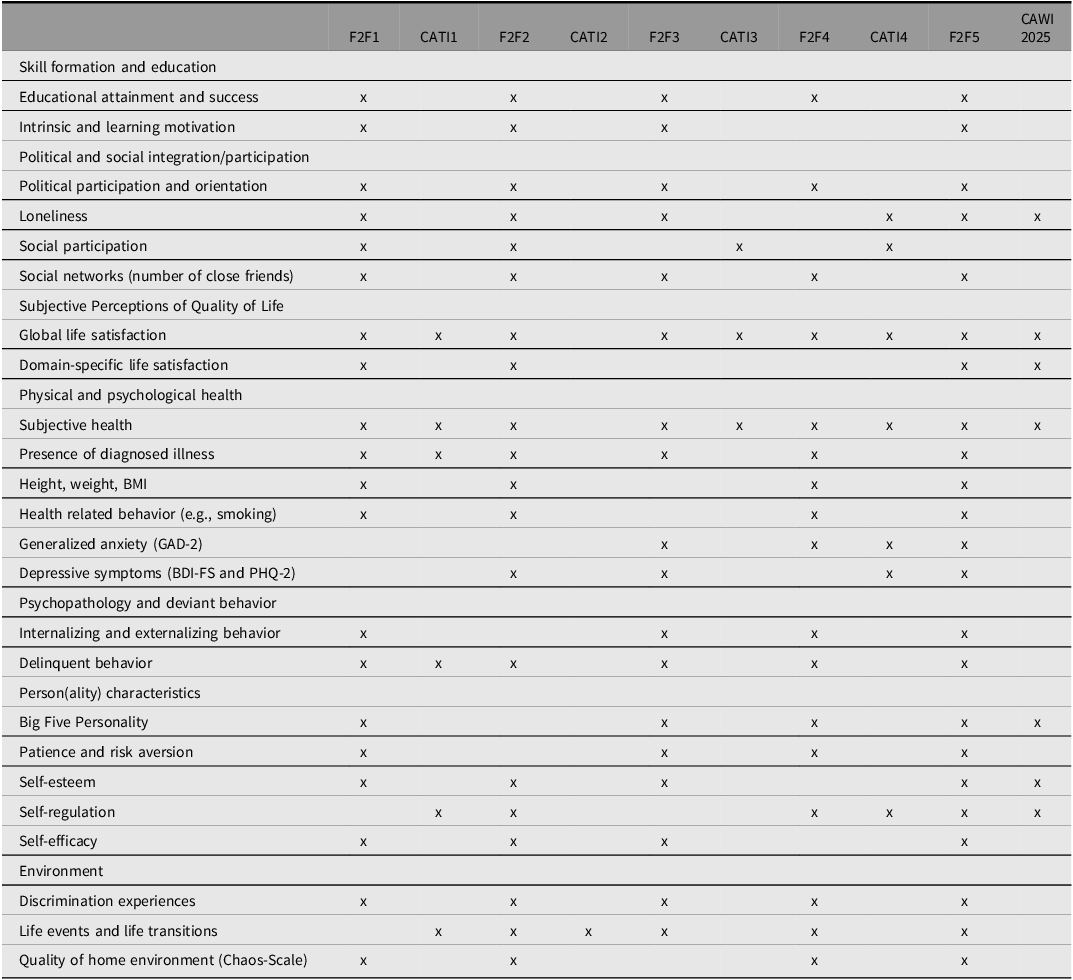
Over the course of the study, with its nine regular data collections, four supplementary COVID-19-questionnaires and the follow-up survey CAWI 2025, numerous constructs were assessed multiple times, enabling sophisticated longitudinal analyses. For a list of constructs that were assessed at least four times for many participants, please consult Table 8. Moreover, important information about different life course transitions ranging from school to labor market entry, and other important life course events, such as mating and starting a family, was collected across multiple waves. A detailed overview of all available constructs across all survey waves for all types of participants (e.g., twins, parents, partners), including self- and informant reports, is provided online at the TwinLife documentation page (www.twin-life.de/documentation/downloads). Sample size for a particular construct in a data collection may vary as some constructs were only assessed for a subset of participants (e.g., a particular twin cohort). Therefore, it is recommended to consult the overview at the TwinLife documentation page when planning research with the TwinLife data.
Constructs with at least four measurement time points
Note. Sample size for a particular construct in a data collection may vary as some constructs were only assessed for a subset of participants. For a full list of constructs captured in TwinLife, consult the website and item-level documentation. F2F, face-to-face interviews; CATI: computer-assisted telephone interviews; GAD-2, Generalized Anxiety Disorder 2-item; BDI-FS, Beck Depression Inventory-Fast Screen; PHQ-2, Patient Health Questionnaire-2.
The TwinLife data also contains geo-coordinates for the households of individuals (partly on street-level). Thus, for particular analyses, it is possible to match geo-coded information, such as satellite data or neighborhood related variables, to the TwinLife sample. In addition, TwinLife includes neighborhood-related information on spending power, type of building, type of roads, neighborhood age structure, Sinus-Geo-Milieus (reflecting dominant sociocultural diversity), phases of life, mobility, and Microm typologies. The variables were calculated based on data collected by the data research and marketing firm Microm.
Research Potential and Current Cutting-Edge Studies
The comprehensive data provided in TwinLife and its satellite projects, with its extensive measurements of environmental information, enables cutting-edge research in various fields, as evidenced by several recent publications. Particularly in combination with the (epi) genetic data TwinLife allows studying the role of gene-environment interplay in shaping the development of life chances in various areas of life.
For example, utilizing geolocated information in combination with polygenic scores, Harerimana and colleagues (2025) studied the link between genetic predispositions for subjective wellbeing and life satisfaction across levels of neighborhood deprivation. Their results showed that associations vary across areas and are strongest among individuals living in moderately deprived neighborhoods; thus, pointing to nonlinear gene-environment interaction patterns.
Deppe and colleagues (Reference Deppe, Disselkamp, Maj, Aldisi, Nöthen, Diewald, Spinath, Forstner and Kandler2026) investigated the phenotypic and genetic links between the Big Five personality traits and different facets of subjective wellbeing. They extended previous research in this field in multiple ways; among other things by examining age cohort differences. In addition, their work addressed the issue whether results from twin-based studies and from molecular genetic investigations correspond. Their results highlighted this correspondence and showed that genetic differences in wellbeing are associated with genetic differences in Big Five personality traits.
Based on samples of DZ twins, Starr and colleagues (Reference Starr, Ruks, Giannelis, Willoughby, Pettersson, Pahnke, Maj, Andreas, Ahlskog, Arseneault, Fisher, Forstner, Kandler, McGue, Nöthen, Oskarsson, Spinath, Vrieze, Wertz and von Stumm2026) studied the variability of PGS predictions of educational achievement in different national contexts and across ages to disentangle direct genetic effects captured by PGS from indirect genetic effects via environmental mediation. They observed considerable differences in the estimated PGS prediction of educational achievement across countries and age groups, with the relevance of indirect genetic effects largely explained by the socioeconomic status of families varying greatly.
Utilizing TECS-data, Kuznetsov and colleagues (Reference Kuznetsov, Liu, Schowe, Czamara, Instinske, Pahnke, Nöthen, Spinath, Binder, Diewald, Forstner, Kandler and Mönkediek2025) looked at the sources of differences in epigenetic aging. Here, they took advantage of the special possibilities offered by the data and decomposed the variance observed in different epigenetic clocks into genetic and (shared/nonshared) environmental variance components. Their results showed an increasing variance in epigenetic aging during the transition to adulthood that was mainly driven by increasing contributions of individual-specific environmental factors and, in part, the genetic component. However, the degree of genetic and environmental contributions varied systematically across the selected clocks, highlighting the need to consider the differences in how clocks were created and what they capture.
Finally, Schowe and colleagues (Reference Schowe, Ruks, Pahnke, Kuznetsov, Instinske, Mattingsdal, Forstner, Pahnke, Rohm, Kuznetsov, Bastian, Kandler, Czamara and Binder2025) investigated changes in epigenetic aging in reaction to psychological stress experienced during the COVID-19 pandemic, controlling for various other factors, including a polygenic score for wellbeing. They found a significant increase in epigenetic age acceleration in all age cohorts during the COVID-19 pandemic. Although this increase was related to physical health, socioeconomic background and genetic factors, only in adolescents did the perceived stress of the pandemic have an effect on pace of aging.
Taken together, the longitudinal panel combined with the extended twin family design, available genetic and epigenetic data, additional biological data, as well as the possibility of matching geographical data, provides a unique database with wide-ranging potential for research.
Data availability
The TwinLife data is available for academic research and teaching, after closing a data use contract (i.e., data recipients agree to follow legal and organizational requirements to ensure data confidentiality). The phenotypic data are available free of charge as a scientific use-file at the GESIS data archive via the Data Catalogue (for the current release see: https://doi.org/10.4232/1.14531). Genetic and epigenetic data is currently only available via signing an additional data use agreement. Due to the sensitivity of the data, geo-coded data and neighborhood related variables are only accessible at a secure work-place at Bielefeld University after concluding a special agreement. In each case, requests for data access must be sent to the official email of the study: twinlife@uni-bielefeld.de.
Funding
The TwinLife study was funded by the German Research Foundation (DFG) (Grant number 220286500). Funding was awarded to Martin Diewald, Christian Kandler, Frank M. Spinath, Bastian Mönkediek, and Rainer Riemann. The molecular genetic extension project of TwinLife was funded by the German Research Foundation (DFG; Grant number 428902522). Funding was awarded to Martin Diewald, Peter Krawitz, Markus M. Nöthen, Rainer Riemann, and Frank M. Spinath. The epigenetic change satellite project of TwinLife was funded by the German Research Foundation (DFG; Grant number 458609264). Funding was awarded to Elisabeth Binder, Martin Diewald, Andreas J. Forstner, Christian Kandler, Markus M. Nöthen, and Frank M. Spinath. The K2ID-Twins study was funded by the Jacobs Foundation (Project number 2014-11 23). Funding was awarded to Pia Schober, C. Katharina Spiess, and Martin Diewald. In none of the projects, funders had any role in the study design, data collection or analysis, the decision to publish, or the preparation of manuscripts.
Ethics approval
The TwinLife study was reviewed and approved by the German Psychological Society (Deutsche Gesellschaft für Psychologie; protocol numbers: RR 11.2009, RR 11.2009_amd_09.2013). The COVID-19 supplementary questionnaires were reviewed and approved by the Ethics Committee of the University of Bielefeld (Application No. 2020-106). The Ethics Committee of the Medical Faculty of the University of Bonn (No. 113/18) and the Ethics Committee of the University of Bielefeld (Application No. 2020-180) reviewed and approved the protocols for the (epi-)genetic analyses via saliva samples. Prior to the genetic sampling, the participants received extensive written information on, e.g., the sampling procedures, the scope of the study, their right to refuse participation, and their right to withdraw their consent at any given time. For sampling genetic data, written informed consent was obtained from all participants and the participant’s legal guardian (for minors).
Important researchers’ contributions
We would like to thank all the researchers who contributed to the TwinLife study and its extensions. Particularly we would like to thank Prof. Dr. Martin Diewald, Prof. Dr. Rainer Riemann, Prof. Dr. Pia S. Schober, Prof. Dr. C. Katharina Spieß, Prof. Dr. Yvonne Anders, Prof. Dr. David Richter, Prof. Dr. Claus Vögele, Prof. Dr. Conchita D’Ambrosio, Dr. Jonathan Turner, Prof. Dr. Simone Kühn, Prof. Dr. Elisabeth Binder, and Prof. Dr. Markus Nöthen.
Competing interests
All authors declared no conflicts of interest related to this manuscript.




 Open access
Open access