


A. Background
The rapid development of generative artificial intelligence technology presents significant challenges to existing copyright frameworks. As large AI models require vast amounts of data for training, copyrighted works often serve as essential sources of high-quality training material. Whether the reproduction and use of such works in AI model training constitute fair use under copyright law has become a critical issue of concern at the intersection of law and technology.
Legal disputes concerning AI model training have emerged globally, reflecting divergent legal interpretations and the absence of a clear consensus. In December 2023, the New York Times sued Microsoft and OpenAI for allegedly training AI models on millions of its articles without permission. OpenAI countered that such use constitutes “fair use” under U.S. copyright law,Footnote 1 and the case remains ongoing. Similarly, in June 2024, leading record labels—including the Recording Industry Association of America (RIAA), UMG Records, Sony Music, and Warner Records—filed lawsuits against AI companies Suno and Udio, accusing them of unlawfully using copyrighted sound recordings in training their models.Footnote 2 In February 2025, the U.S. District Court for the District of Delaware ruled against Ross Intelligence in Thomson Reuters v. Ross Intelligence,Footnote 3 rejecting its fair use defense and finding it liable for direct copyright infringement. While the decision is limited to non-generative AI, it marks the first U.S. case to establish that unauthorized use of copyrighted works for AI training constitutes infringement. Similar disputes have emerged in other jurisdictions. In April 2023, the French Competition Authority imposed a $250 million fine on Google, in part for using copyrighted content to train its chatbot “Gemini” without authorization from French publishers.Footnote 4 On September 7, 2024, the German District Court of Hamburg ruled that the reproduction of copyrighted works fell under the text and data mining exception to fair use, setting a significant precedent in AI copyright law.Footnote 5 In November 2023, in China, a lawsuit filed by several painters against the AI model Trik is currently being heard by the Beijing Internet Court, making it one of the country’s first legal challenges concerning AI training.Footnote 6 These issues highlight the growing focus of both the technology and legal communities on this topic.
In addition to litigation, various jurisdictions have begun addressing AI training through legislation. The European Union, through Article 3 and 4 of the Digital Single Market Copyright Directive (2019), introduced a text and data mining exception,Footnote 7 which was later reinforced by Article 53(1)(c) of the Artificial Intelligence Act (2024), requiring general-purpose AI models to comply with the text and data mining provisions.Footnote 8 The United States, while lacking explicit legislation on AI training, has relied on judicial precedents such as the Authors Guild, Inc. v Google, Inc.Footnote 9 and Anderson v. Stability Footnote 10 to evaluate fair use. Although the U.S. lacks direct legislation on this issue, the flexible and adaptable four-factor fair use test—along with certain precedents—leaves room for considering model training as fair use. This flexibility offers a potential pathway for resolving the controversy, even as the Westlaw ruling has emphasized that training foundation models do not qualify as fair use. Meanwhile, in July 2024, Japan’s Checklist and Guidance Related to AI and Copyrights suggested that copyrighted works may be used without permission during AI training for non-commercial purposes, but that the commercial production and sale of AI-generated works of art will be subject to standard copyright infringement laws,Footnote 11 thereby emphasizing the need to balance AI protection and development.
China has yet to establish clear legislative guidance on copyright issues related to AI model training. The Copyright Law of the People’s Republic of China (“Copyright Law”) does not directly address such disputes. While its third amendment introduced provisions like the “three-step test” and the “underpinning clause” for fair use, these do not explicitly resolve issues concerning AI training. Recent developments, including the Interim Measures for the Management of Generative Artificial Intelligence Services (“Interim Measures”) have further fueled discussions on how AI training should be treated under Chinese copyright law. The issue of fair use in model training has gained increasing attention within the context of AI legislation—with provisions addressing it appearing not only in the interim measures—but also in draft proposals by two scholars within the broader AI legislative framework. In China, following the release of the Model AI Law 1.0 (Expert Proposal) by Professor Zhou Hui’s team in August 2023, Professor Zhang Linghan’s team published the Artificial Intelligence Law of the People’s Republic of China (Scholarly Proposal) in March 2024. Both proposals include provisions on the fair use of model training—reflecting the growing recognition of the need to resolve this issue—which stems from unclear copyright rules and the importance of AI development. As a result, both the copyright and AI communities are actively exploring solutions.
This Article evaluates the legal landscape surrounding AI training in China, explores potential fair use approaches, and offers practical solutions to the challenges of copyright issues in this evolving field.
In Section B, this Article critically examines China’s evolving legal landscape regarding copyright controversies surrounding AI training—reviewing legislative discussions during the third revision of Copyright Law and the Interim Measures. To explore potential developments in AI-related copyright legislation, the Article also analyzes two academic proposals for China’s Artificial Intelligence Law by Zhou Hui and Zhang Linghan, identifying key areas of divergence and consensus within the academic community on this issue.
In Section C, this Article analyzes the core legal disputes, explores the theoretical basis for fair use, and anticipates potential developments in this dispute. It then compares three different legal approaches to the copyright issues in AI training, the statutory license approach—which addresses market failure and protects copyright holders’ interests, but incurs high implementation costs. The second approach—which excludes the use of copyrighted works from the reproduction right—offers a low-cost solution but may limit the scope of copyright protection. Drawing on empirical research on AI model outputs, the Article argues that recognizing AI model training as fair use better aligns with China’s legal framework and technological needs. The use of copyrighted material in the training phase qualifies as incidental reproduction and transformative use, balancing copyright holders’ interests while resolving licensing market failures.
In Section D, based on these insights, the Article proposes a practical solution to the copyright controversies surrounding AI model training within the context of China’s generative AI development, while also encouraging the international community to reach a consensus on AI copyright issues.
B. Relevant Legislative and Judicial Developments in China
This section reviews the legislative and judicial developments of fair use provisions in China, with a particular emphasis on AI-related legislation concerning intellectual property protection. The first part of this section examines the evolution of fair use provisions, focusing on the third revision of Copyright Law and the expanded application of fair use in judicial practice. The second part delves into the legislative process concerning artificial intelligence, highlighting the model training-related IP provisions in the Interim Measures for the Management of Generative Artificial Intelligence Services and analyzing the scholarly draft proposals for the Artificial Intelligence Law by two prominent scholars.
I. Changes to the Fair Use Provisions in the Copyright Law
Fair use refers to the lawful act of permitting others to use a copyrighted work without seeking permission from the right holder under specific circumstances. Copyright laws worldwide can be broadly categorized into two systems: The copyright system and the authorship system, which are based on distinct legal philosophies and exhibit significant historical differences in the construction of fair use frameworks.
From an instrumentalism perspective, countries following the copyright system view restrictions on copyright as a normal means of balancing interests. They adopt affirmative expressions such as “fair use” or “fair dealing,” allowing for more flexible legislation and granting judges broader discretion in determining copyright limitations. In contrast, countries adhering to the authorship system are grounded in natural rights theory, considering copyright limitations as exceptional cases. These jurisdictions use the term “exception of right,” employ a closed list of specific exceptions, and do not permit expanded judicial interpretation.Footnote 12
China’s copyright regime is a hybrid of the copyright system and the authorship system, primarily adopting the theory of limitation of rights for fair use. Historically, China’s copyright system employed a closed-ended legislative model for fair use provisions, specifying twelve exceptions, including personal study, reasonable citation, news reporting, teaching and research, and free performance. The purpose of fair use is to promote the advancement of social science and cultural undertakings through balanced protection, and fair use provisions have evolved alongside shifts in copyright interests.
1. Expansion of Fair Use Application in Judicial Practice
Since its enactment in 1990, the Copyright Law has undergone two amendments, in 2001 and 2010. However, it still largely reflects the legal framework of the traditional printing era—with the provisions on fair use remaining substantially unchanged. With the advent of the digital technology era, globalization has become an irreversible trend, leading to the expansion of copyright-related industries and increasingly complex economic relationships.Footnote 13 The closed-ended fair use provisions have gradually struggled to address the challenges posed by new technologies, particularly the emerging situations and evolving dynamics in judicial practice.
On December 16, 2011, to address the contradiction between slow legislative processes and practical needs, the Supreme People’s Court issued the Opinions on Issues Concerning Maximizing the Role of Intellectual Property Right Trials in Boosting the Great Development and Great Prosperity of Socialist Culture and Promoting the Independent and Coordinated Development of Economy (the “Opinions”).Footnote 14 Article 8 of this document explicitly states:
In cases of special circumstances where it is genuinely necessary to promote technological innovation and commercial development, considering the nature and purpose of the act of using the work, the nature of the work being used, the quantity and quality of the part being used, and the effect of the use on the potential market or value of the work, if the act of use neither conflicts with the normal exploitation of the work nor unreasonably prejudices the legitimate interests of the author, the use may be deemed fair use.
This document clearly demonstrates that courts may reference the four factors of the U.S. fair use doctrine and combine them with the three-step test to determine fair use. If the relevant act satisfies the four factors and also meets the requirements of the latter two steps of the three-step test, it may qualify as fair use. By issuing judicial interpretative documents, the Supreme People’s Court has recognized the innovative application of the three-step test by some courts, thereby partially alleviating the limitations of the closed-ended fair use clause and further refining and clarifying the core elements of fair use determinations.
Under the guidance of this document, the courts in China have expanded the application of the fair use provision in practice, with some acts of exploitation of works in the context of new technologies being recognized as fair use. One approach is to expand the interpretation of the “appropriate citation” provision in Article 24(2) of the Copyright LawFootnote 15 to apply the theory of “transformative use.” In the “Huluwa and Black Cat Sheriff Artwork Copyright Infringement Dispute Case”Footnote 16, the court found that the movie poster appropriately incorporated iconic characters such as “Calabash Brothers” and “Black Cat Detective” as background elements to illustrate the era-specific characteristics of the 1980s. The court held that this use was not a mere display of the works’ artistic beauty; instead, its value and function had undergone a transformation. Therefore, it constituted transformative use and did not unreasonably harm the legitimate interests of the copyright holder. In contrast, in “Li Xianghui and Guangzhou Huaduo Network Technology Co.,”Footnote 17 the court declined to find fair use. It determined that the infringing image, although reduced in scale and resolution, was directly incorporated into the webpage text rather than being used as a thumbnail. This allowed users to directly grasp the ideas expressed in the original work. Furthermore, aside from a broad shared theme, there was no substantive connection between the image and the article, and the use failed to produce any new meaning. Since the use was also commercial in nature, it did not constitute fair use.
Another approach is to break through the closed-ended provisions of the Copyright Law on limitations and exceptions, and directly determine whether “transformative use” is constituted according to the three-step test stipulated in Article 21 of the Regulations for the Implementation of the Copyright Law (“Implementation Regulations”) or the U.S. “four-factor test” to fair use. In 2013, a Chinese writer claimed that the Google digital book search provided by Google China’s website infringed his copyright on his book The Hydrochloric Acid Lover. The Beijing Municipal Higher People’s Court ruled in the final hearing that the act of providing a fragment of a work in Google’s digital book search was fair use, but the act of electronically uploading the full text of the book infringed on copyright.Footnote 18 The judgment was in line with the copyright law at the time, as the act of digitizing the work was not included in the fair use provision, and the act of reproducing the full text of the book could hardly fall into the “other circumstances” in the fair use provision. This reflects that—in the judicial practice at that time—although the courts attempted to expand the application of the fair use clause to the technical utilization of works, they remained cautious about the full-text reproduction of works.
2. The Third Revision of Copyright Law
2.1. Background of the Amendment to the Fair Use Clause
With the rapid development of information technology worldwide, countries such as Europe and Japan have revised their copyright fair use provisions. In 2018, Japan amended its Copyright Law, introducing exceptions under Article 30-4, which does not aim to enjoy the thoughts and feelings expressed in the work, and further stipulating exceptions for data analysis and computer data processing. Articles 47-4 and 47-5 provide exceptions for the incidental use of computers and minor uses of information processing, respectively, aiming to promote the development of the information industry while safeguarding the legitimate rights of copyright holders.Footnote 19 In 2019, the European Union’s Copyright Directive for the Digital Single Market introduced an limitation for text and data mining, distinguishing between scientific research purposes and general purposes. This exception applies to research organizations and cultural heritage institutions based on the purpose of scientific research. For general purposes, the exception is subject to a reservation clause, meaning it applies only if the right holder has not expressly reserved the use of the work or other content in an appropriate manner.Footnote 20
In 2020, the third revision of Copyright Law occurred at a critical time, sparking widespread attention and heated discussions across society, particularly within the academic community.Footnote 21 One major debate focused on whether technological innovations, which change the way works are utilized, necessitate adjustments to the fair use provisions. This raised the question of whether the fair use system should remain closed-ended or be made more flexible.Footnote 22 Additionally, there was considerable discussion regarding the expansion of specific circumstances under fair use. Professor Wu Handong argued that the amendment should include the three-step test as a determining factor for fair use and provide specific provisions for the fair use of computer programs.Footnote 23 Professor Tao Qian also proposed that the amendment should address the fair use of computer programs, particularly by including research-based data mining within the scope of fair use.Footnote 24
2.2. Amended Fair Use Provisions in the Copyright Law
The third revision of the Copyright Law was influenced by the international context of economic globalization, the reality of scientific and technological modernization, and China’s vision of building a strong cultural nation.Footnote 25 In July 2011, the National Copyright Administration (NCCA) initiated the third revision of the Copyright Law. On November 11, 2020, the Twenty-third Meeting of the Standing Committee of the Thirteenth National People’s Congress voted to adopt the Decision on the Revision of the Copyright Law.
After the third amendment, Article 24 of the Copyright Law on fair use incorporated the relevant provisions from Article 21 of the Implementation Regulations concerning the three-step test. The revised text also added the phrase “shall not harm the normal exploitation of the work concerned and shall not unreasonably prejudice the legitimate interests of the copyright owner” at the beginning of the first paragraph, strengthening the connection between the Copyright Law and the Berne Convention. Additionally, minor adjustments were made to the language of the legislation concerning some of the circumstances listed under fair use.
Moreover, the phrase “other circumstances stipulated by laws and administrative regulations” was added to the end of Article 24(1), aiming to provide sufficient flexibility to accommodate the changes in interests driven by technological advancements. Although the revised fair use provision remains a “semi-closed” model of limitations and exceptions, it does not fully address the needs arising from the development of artificial intelligence technology, given the limited scope of the provision.Footnote 26
2.3. Reasons for Not Adding a Specific Provision
After the third amendment, the Copyright Law did not modify the fair use provisions to meet the needs of technological development for the following reasons.
First, there is a certain degree of ambiguity in the judicial application standard of the multi-factor dynamic judgment method for fair use. The U.S. Copyright Act of 1976 stipulates the four-factor test for determining fair use,Footnote 27 further clarifying the specific circumstances constituting fair use through judicial cases, including the digitization of large volumes of books for analysis and retrieval.Footnote 28 After the Campbell case, “transformative use” gradually became a key element in the application of fair use in U.S. law. Particularly when assessing the first factor of the four-factor test, “transformative use” not only formally diluted the significance of “commercial or non-profit educational nature,” but also substantially overshadowed the other three elements, becoming the “dominant factor” in the fair use analysis.Footnote 29
However, as a civil law country, China’s copyright system does not explicitly adopt the four-factor analysis or “transformative use” as statutory law. Consequently, these concepts cannot be directly applied as the basis for judicial decisions. Moreover, in the judicial application of the multi-factor dynamic judgment of fair use, while courts have expansively interpreted the fair use provision and innovatively applied the “transformative use” theory, there has not been a consistent understanding of the guiding rules and application standards for fair use determinations.Footnote 30 For example, different courts may make opposite judgments in the face of similar cases.Footnote 31 The absence of a shared understanding of the rules and standards of fair use means that delegating such judgments to the judiciary could grant judges excessive discretionary power, which is highly controversial. Given the lack of sufficient consensus, the four-factor test was ultimately not incorporated into the fair use provision.
Second, the third revision primarily addresses several issues, such as the creation of rights, the utilization of rights, and the improvement of the mechanism for the redress of rights. However, the focus of the revision is somewhat dispersed and does not specifically address the challenges posed by the development of new technologies in relation to fair use. The inclusion of the three-step test and the “other circumstances” clause could better accommodate emerging situations arising from technological advancements. The three-step test could address the lack of criteria for determining fair use and its incorporation into the fair use provision would further define the conditions for applying fair use.Footnote 32 The “other circumstances” provision also allows for flexibility, leaving room for future revisions of the fair use provisions to better respond to challenges brought by technological development. Additionally, the Regulation for the Implementation of the Copyright Law, which is currently being revised, could further clarify the specific judgment standards for fair use in the future. Therefore, the third revision has effectively reserved substantial institutional space and flexibility within the fair use provision to prepare the law for new situations that may arise.
3. The Revision of the Implementation Regulations Remains Unsolved
Compared to revising the Copyright Law itself, revising the Implementing Regulations of the Copyright Law (“Implementing Regulations”) can more directly address the issue of unclear standards for the judicial application of fair use. In recent years, the academic community has increasingly discussed the need for revisions to the Implementing Regulations. Professor Li Mingde proposed that the revision should explicitly define the limitation of rights under “other circumstances stipulated by laws and administrative regulations,” and further emphasized that that the regulation should address copyright issues arising from the extraction of text data during AI model training, particularly highlighting its use for non-commercial text and data mining.Footnote 33
Against the backdrop of the rapid development of AI technology, the application of rights restrictions will have a significant influence on copyright holders, with varying interests among different stakeholder groups. Consequently, the NCCA must carefully consider the needs of copyright holders, collective management organizations, and the broader industry in revising the Implementing Regulations. As a result, the revision process has been relatively slow. As of the time of writing, the revision of the Implementing Regulations remains incomplete, making it difficult to address copyright disputes related to model training through the Implementing Regulations.
In summary, the amendment of the fair use provision in the third revision of the Copyright Law and the evolving application of fair use in practice reveal the broader changes in social dynamics. As technological developments significantly affect the use of works, both legislation and practice have gradually expanded the application of fair use. Through the amendment, the Copyright Law retains a certain level of flexibility by incorporating the three-step test and the underpinning clause. However, it does not leave the judgment of fair use entirely to the judiciary. This decision is rooted not only in China’s national context but also in a desire to maintain consistency in the application of legal rules. Although the issue of AI model training has garnered substantial attention from various sectors, and the NCCA has been revising the Implementing Regulations, resistance has emerged regarding the creation of specialized provisions due to ongoing consultations with copyright holders’ groups.
II. Changes in Provisions for the Protection of Intellectual Property Rights in the Context of AI Legislation
The process of revising the fair use provisions in the Copyright Law has not been without its challenges. Given the rapid development of generative AI technology, and in order to maintain the stability and authority of legal norms, the three revisions of the Copyright Law since its enactment have occurred at long intervals. As a result, the likelihood of a near-term revision of the Copyright Law to incorporate new fair use cases is relatively low. In accordance with the relevant provisions of legal hierarchy, defining the nature of model training using copyrighted works in AI legislation would not conflict with the existing provisions of the Copyright Law. Consequently, academics have shifted their focus to the realm of artificial intelligence legislation, aiming to address the fair use controversy surrounding model training. In this context, scholars have also explored the issue of incorporating intellectual property protection provisions related to data training. This section will summarize the evolution of intellectual property protection provisions in the development of artificial intelligence legislation.
1. Process of Establishing the Intellectual Property Provisions of the Interim Measures for the Management of Generative Artificial Intelligence Services
In July 2023, China’s National Internet Information Office (NIIO), in collaboration with the National Development and Reform Commission (NDRC), Ministry of Education (MOE), Ministry of Science and Technology (MOST), Ministry of Industry and Information Technology (MIIT), Ministry of Public Security (MPS), and the General Administration of Radio, Film, and Television (SARFT) announced the Interim Measures for the Management of Generative Artificial Intelligence Services (“Interim Measures”), which took effect on August 15, 2023. The document emphasizes the concept of promoting AI development in parallel with safety, rather than solely focusing on the protection of intellectual property rights. Article 7 of the Interim Measures addresses the protection of intellectual property rights, while Articles 5 and 6 highlight the importance of encouraging the independent and innovative application of AI technology and fostering the generation of quality content.
The process of finalizing the intellectual property rights provisions reflects changes in the understanding of the relationship between property rights protection and scientific and technological development, both in the scientific and technological community and the legal field. Compared to the Interim Measures (Draft for Public Comments) published in April 2023, the official provisions differ in the formulation of certain articles. The second paragraph of Article 7 in the “Exposure Draft” stipulates:
Providers shall be responsible for the legitimacy of the sources of pre-training data and optimized training data for generative artificial intelligence products. The pre-training and optimization training data used for generative AI products shall meet the following requirements: … “(ii) They shall not contain content that infringes intellectual property rights.Footnote 34
In contrast, the final formulation of the clause in the Interim Measures states:
Generative AI service providers shall, in accordance with the law, carry out pre-training, optimization training, and other training data processing activities, and comply with the following requirements: … (ii) Where intellectual property rights are involved, they shall not infringe on the intellectual property rights of others in accordance with the law.
This provision has sparked significant discussion among both academia and industry.Footnote 35 The intellectual property provision in the Interim Measures (Draft for Public Comments) primarily focuses on works protected by copyright from a results-oriented perspective, stipulating that training data shall not contain copyright-protected works. However, it does not address whether the utilization of these works complies with Copyright Law from a behavioral perspective. In fact, the use of copyrighted works under certain conditions may not infringe copyright if it aligns with the limitations regulated in Copyright Law. Thus, the original expression, “shall not contain content that infringes intellectual property rights,” is not sufficiently precise.
Following the revision, the official provision now states that, “[i]f intellectual property is involved, it shall not infringe on the intellectual property lawfully enjoyed by others,” emphasizing the legitimacy of utilizing the works. Additionally, the source of the works affects the legitimacy of data training. The official text shifts the focus of regulation from the legitimacy of the data source to the legitimacy of the data processing activities. For instance, if works are stored in the database and provided to the public without authorization, their use as training data would typically violate copyright. However, if legally obtained works are used for model training, there is room to interpret this as fair use. Accordingly, the official text of the Interim Measures introduces the concept of “use of legally sourced data,” which is central to this regulation. As a result, the expression “using data with legitimate sources” has been included in the official text, and China has retained the institutional interface within the fair use provisions of the Copyright Law.
Although the legislative status of the Interim Measures is that of a departmental regulation, the process of formulating its intellectual property provisions demonstrates a shift in the relevant departments’ understanding of the nature of using copyrighted materials to train AI models. While incorporating input from both academia and industry, the legal interpretation of the act has gradually transitioned from one of infringement to fair use. However, given the limitations of its position within the legislative hierarchy, the Interim Measures do not directly address whether the use of works for model training constitutes fair use. This, in turn, reflects a respect for the dynamic evolution of the Copyright Law, where the flexible nature of the fair use provisions allows for more room to accommodate the development of artificial intelligence.
2. Intellectual Property Protection Provisions in the Scholar’s Draft Proposals of the AI Act
Under the fundamental principle of equally emphasizing the regulation and development of artificial intelligence established in the Interim Measures, both The Model Artificial Intelligence Law 2.0 (Expert Proposal) Footnote 36and the Artificial Intelligence Law of the People’s Republic of China (Scholarly Proposal),Footnote 37 drafted respectively by the teams of Professors Zhou Hui and Zhang Linghan, contain provisions limiting copyright protection. These proposals reflect the academic community’s growing consensus on the copyright issues surrounding model training, specifically that the adjustment and improvement of the intellectual property legal framework should align with the development of artificial intelligence, and the intellectual property-related provisions in AI legislation should be effectively aligned with the intellectual property legal framework.
In the second paragraph of Article 10, “Principles of Promoting Development and Innovation” of Professor Zhou Hui’s The Model Artificial Intelligence Law 2.0 (Expert Proposal), it is clearly stated that “establish a statutory licensing and/or fair use system for intellectual property rights that is compatible with the development of artificial intelligence, and support scientific research and cultural creative activities utilizing AI-generated works.” The Article suggests that, during the research and development stage, AI legislation can make special provisions for the use of data for training purposes and explicitly establish a statutory licensing and fair use system of intellectual property rights, one that is appropriate to the development of AI, to support the supply of data elements in the AI field.Footnote 38 This also emphasizes that the intellectual property legal framework should align with the development of artificial intelligence and should not hinder the industrial advancement of AI.
In Article 24 “Fair Use of Data,” of Chapter 2, “Development and Promotion” of Professor Zhang Linghan Team’s Artificial Intelligence Law of the People’s Republic of China (Draft for Suggestions from Scholars), it is clearly stated that the use of copyrighted data for model training constitutes a “different purpose or function of use,” and it should be determined that such use qualifies as fair if it complies with the last two steps of the three-step test. This provision adopts the criteria of “transformative use” and the three-step test, aligning with the fair use provisions of the Copyright Law, which offers significant efficiency advantages.Footnote 39 This system design specifies that model training meets the requirements of “fair use,” which facilitates the liberalization of data resources, such as intellectual property works, and accelerates the development of high-quality datasets in China. Professor Xu Xiaoben also emphasized that the Artificial Intelligence Law (Scholar’s Proposal) addresses the intellectual property issues arising in the development, provision, and use of artificial intelligence products or services, and seeks to explore institutional arrangements within the existing legal framework that support the healthy development of artificial intelligence.Footnote 40
Compared to the revision process in the field of copyright, the legislative process in the field of artificial intelligence reflects that the state’s greater focus on the practical needs and feedback from the AI industry. The two versions of China’s Artificial Intelligence Law Proposals are grounded in the development needs of the AI industry, reflecting a consensus within the academic community that the use of works for model training should be governed by the copyright limitation system. It is explicitly stated that fair use should be prioritized, with the statutory licensing system considered as a secondary option to facilitate the availability of high-quality training data for AI models and promote industrial development.
Following the emergence of copyright disputes related to artificial intelligence, it is evident that the focus has shifted from the technology community to the copyright community. The technological community began to recognize the potential profound influence of this issue on the innovation and development of AI technology, actively proposing corresponding measures during the third revision of the Copyright Law and the consultation period of the Interim Measures. This raised significant concern over the copyright issues accompanying technological advancements and had a major influence on the revision of the fair use provisions of the Copyright Law and the establishment of intellectual property provisions in the Interim Measures. Traditionally centered on the fields of literature and art, the Copyright Law has now started to focus more on science and technology, reflecting the growing recognition of the role technological development plays in driving innovation. The fair use provision has garnered considerable attention as it addresses the misalignment between current legal frameworks and technological advancements, offering irreplaceable value in fostering the innovative development of AI technology. This also reflects that, in today’s increasingly intertwined legal and technological landscape, the revision and interpretation of Copyright Law must carefully consider the distinctions between the fields of literature and art and science and technology. It also emphasizes the importance of actively incorporating the views of the technological community and conducting an in-depth analysis of the dynamic interaction between legal copyright protection and technological innovation in order to build a comprehensive and effective legal framework.
C. Analysis of the Main Academic Perspectives
The process of three revisions to the Copyright Law and the establishment of intellectual property provisions in the Interim Measures reveal the complex controversies surrounding the use of copyrighted material for model training. The industrial development of artificial intelligence urgently requires legal clarity and access to high-quality data resources. To address the legal challenges faced by this industry, clear rules on copyright exceptions must be established. In recent years, scholars have conducted continuous and in-depth research on this issue, leading to the emergence of three primary perspectives: Statutory licensing, fair use,Footnote 41 and non-expressive use. These views have gradually formed a spectrum of copyright limitation tools, ranging from strict to broad. This section will examine these three mainstream perspectives and provide a detailed analysis.
I. Perspective 1: The Use of Works in Model Training Constitutes Statutory License
As one of the limitations on copyright rights, the statutory license system allows a user to directly use a work without prior permission from the copyright holder, provided that reasonable remuneration is paid to the right holder. Granting absolute exclusive rights to the copyright owner may hinder important societal uses of the work, while permitting certain behaviors under fair use could undermine the economic benefits that the copyright owner is entitled to receive.Footnote 42 As a middle ground to protect both the rights of copyright holders and the public’s fair use, scholars have proposed that the statutory license system can address the issue of copyright infringement in machine learning, while balancing the protection of works with the demands of technological development.Footnote 43 Under the appropriate technical and institutional conditions, the statutory license system can safeguard the interests of copyright holders without unduly restricting AI companies’ access to data. Moreover, AI companies could be required to register the acquired works, compensate right holders, and ensure that the provenance of the acquired works is preserved through blockchain technology to prevent tampering or elimination of usage traces.
In terms of institutional implementation, in addition to the four existing types of statutory licenses in China, consideration should be given to adding a new type of statutory license to the Copyright Law and establishing efficient, reasonable procedures to clarify the mechanism for distributing remuneration to right holders, thereby providing the necessary legal support.Footnote 44
1. Legitimacy Analysis
According to this perspective, the use of copyrighted works in the training of generative artificial intelligence models does not align with the legislative intent and application standards of the fair use system. The fair use system adheres to the value of “fairness” and is primarily concerned with the public interest, emphasizing the realization of social justice and the fulfillment of public functions by the copyright law. Applying fair use to expressive machine learning, however, would undermine the legitimate gains of the right holders.Footnote 45 Model training predominantly serves the profit-driven objectives of AI products or services, which is inconsistent with the public interest purpose of the fair use system. For example, although generative AI products or services released in the market provide free usage quotas to users, full functionality typically requires the purchase of a membership. Currently, only a limited number of model training activities—those based on scientific research and meeting restrictions on subject, mode, and proportion of use—might qualify as fair use under circumstances like “classroom teaching or scientific research” regulated in Article 24 of Copyright Law. AI companies, however, do not satisfy the subjective conditions outlined in the fair use clause, making it difficult for such activities to pass the first and third steps of the three-step test.Footnote 46
Moreover, the copyright crisis in model training essentially reflects a market failure arising from the high costs associated with negotiating large-scale commercial exploitation of works. While both fair use and statutory licenses can reduce negotiation costs between copyright holders and AI companies, they can have different effects on copyright holders’ incentives. The application of fair use raises concerns that the legal rights of copyright owners’ may be unduly restricted. In contrast, the statutory license system, which is centered on the principle of “compulsory transactions for consideration,” prioritizes efficiency. Its aim is to reconcile conflicts between different transaction parties, enhance transaction efficiency, and replace prior negotiations with post-transaction license fee payments, thereby promoting the commercial exploitation of works.Footnote 47 The statutory license system can safeguard the basic interests of right holders and support their creative incentives. Consequently, this view argues that the application of a statutory licensing system is the most effective model for sustaining creativity incentives, mitigating industrial conflicts, and addressing market failures.Footnote 48
2. Potential Issues
However, there are potential issues with this approach, particularly the high costs associated with the statutory licensing system and the challenges of implementing the necessary technical and legal support.
First, the implementation cost of a statutory licensing mechanism for model training is significant. In terms of transaction costs, there exists a contradiction between the “one-size-fits-all” licensing fee structure of statutory licenses and the market standard,Footnote 49 and the unilateral pricing mechanism of statutory licenses may harm the interests of rights holders.Footnote 50 Furthermore, designing an effective remuneration distribution mechanism poses challenges. Excessive pricing could diminish AI companies’ incentives to use copyrighted materials for model training, while low pricing would make it difficult to adequately compensate right holders, in addition to failing to cover the costs of operating the statutory licensing mechanism. To resolve this contradiction, a scientifically designed statutory license payment scheme is necessary, with fee structures tailored to different types of works and the extent of their use, ensuring that the license fee is as close as possible to the actual market value of the works. Given that a model training data set may contain over 100,000 works,Footnote 51 higher legislative and coordination costs between management organizations are inevitable, potentially reducing transaction efficiency and undermining the practical feasibility of this approach.
In terms of implementation costs, AI companies seeking licenses from a large number of copyright holders may encounter varying levels of willingness to license works—for example, copyright holders may seek higher licensing fees for popular works. Additionally, overlapping copyright and neighboring rights associated with the works used for training further increase the costs of searching for and negotiating with right holders. The imposition of license fees on a large number of works could also lead to excessive fees, which may disproportionately burden AI companies, especially startups, compared to large corporationsthus hindering the innovation potential of the AI industry. While technologies such as blockchain have been suggested to track the use of works by AI companies and reduce enforcement costs, implementing blockchain and other technological solutions also entails substantial economic costs.
Second, copyright collective management organizations (CMOs) do not provide a perfect solution to statutory licensing costs. In China, these organizations have a certain administrative nature, which can lead to market monopolies and discriminatory licensing practices.Footnote 52 There has been considerable debate among scholars regarding the establishment of an involuntary copyright collective management model.Footnote 53 CMOs can usually only manage the works of the members who have joined, and cannot cover the vast amount of copyrighted works in model training. In the absence of clear legislative provisions on “involuntary collective management systems,” the de facto involuntary collective management of non-member works may constitute “ultra vires management.”Footnote 54
In terms of reducing transaction costs, CMOs still face significant challenges. They must negotiate licensing fees and cannot guarantee a reduction in search costs for right holders. For example, statutory licenses for reprinting in newspapers and periodicals often result in low fee collection rates due to difficulties in locating the authors, among other issues.Footnote 55 Although copyright collective management organizations were once an effective tool for advancing and balancing the public interest, their rationale is gradually being undermined by technological advancements.Footnote 56
Moreover, a significant conflict of interest exists between copyright owners and CMOs, highlighting the inefficiencies and irrationalities within the current system.Footnote 57 The majority of fees collected from AI companies are paid to the collective management organizations, leaving copyright owners with minimal financial support. The system of copyright CMOs offers limited assistance in resolving the statutory licensing issue for model training due to its inherent flaws.Footnote 58
Finally, the inclusion of model training within the statutory licenses of the Copyright Act will likely require a future revision of the Act. Unlike the fair use system, which retains an institutional interface for potential exploitation of works, current list of statutory licenses is closed and does not encompass the use of copyrighted works for model training. Consequently, the application of the statutory license system remains costly in terms of legal expenses, making it challenging to meet the data needs of the AI industry in the short term.
II. Perspective 2: The Use of Works in Model Training Does Not Constitute “Reproducing”
The concept of “reproduction” is one of the most complex in copyright law. Under the influence of “author-centrism,” the revision of the Berne Convention, and the legislative history of the WIPO Copyright Treaty and the WIPO Performances and Phonograms Treaty, the term “reproduction” has been broadly extended to include both known and unknown methods of reproduction.Footnote 59 Reproduction can be categorized into two types: “Reproduction in the sense of copyright law,” and “reproduction not in the sense of copyright law.” When new technologies emerge, the first thing to determine is whether the use of works made possible by the technology falls within the scope of the exclusive rights granted by copyright law, and only then should the issue of fair use be considered.Footnote 60 Perspective two argues that the use of a work in model training does not constitute an act of “use” as defined by copyright law. Therefore, it excludes such acts from the scope of copyright protection and asserts that they do not require exemption under the copyright restriction system.Footnote 61
1. Legitimacy and Benefits
There are two types of unauthorized but legal use of works: One is non-copyrightable use, and the other is fair use. “Non-copyrightable use” refers to the use of a work not in the sense or scope of copyright law.Footnote 62 In traditional contexts, this typically focuses on the personalized expression of a specific work. However, the use of works in the model training stage is “non-specific,” as it does not focus on the expression or function of any particular work. Specifically, the act of reproduction does not seek to appreciate the artistic value of the work or reproduce it in its original form for presentation to the user, but instead focuses on learning from and extracting the underlying principles and features of the work.Footnote 63 This extraction of meta-information for the purpose of learning does not fulfill the necessary conditions for copyright protection, namely, the use and enjoyment of the expressive value of the work, and is therefore excluded from copyright.Footnote 64 Consequently, model training involves large-scale collections of works, and individual works become highly interchangeable in data training, making it difficult to assess their independent value. The use of four million works in the Authors Guild, Inc. v. Google, Inc. case in the United States constitutes fair use, which can also be interpreted as “non-display use.”Footnote 65
The reproduction of a work during model training occurs only in the training phase, as an “incidental reproduction” or “intermediate reproduction.” It does not qualify as a “reproductive act in the sense of copyright law,” and falls outside the scope of work utilization originally envisaged by the Berne Convention.Footnote 66 Currently, there is a tendency for the concept of “reproduction” to expand with technological development, despite the author’s rights system supporting the “principle of extension of rights” of copyright, which asserts that the interests of copyright holders should be extended wherever new uses of works emerge. However, from copyright law theory, this approach risks disruption of the balance of interests between copyright owner and the public. If the reproduction conducted during model training was included within the scope of copyright, it could result in an imbalance between the rights of the copyright holder and the advancement of the industry under this new production model. Therefore, the reproduction right should not cover “incidental reproduction” in the context of model training. The evaluation of “incidental reproduction” should reject the “principle of extension of rights” and distinguish it from reproduction as defined by copyright law.
The perspective of excluding the use of works in the model training phase from the scope of copyright rights offers certain advantages. When new technologies significantly influence copyright interests, this approach demonstrates a high degree of adaptability allowing it to be applied flexibly to new situations without necessitating changes to existing legal rules. Unlike the approach to fair use, which first requires categorizing model training as a copyright-regulated use before it can be exempted, this approach excludes such uses from the outset. In light of the lack of specific legal provisions in China governing the use of works in model training, this approach can quickly and effectively address the copyright challenges posed by model training. To some extent, it offers advantages over the fair use framework.
2. Potential Problems
In the age of artificial intelligence, the potential uses of works are vast, often accompanied by various acts of reproduction enabled by new technologies. If the intermediary concept of “non-copyrightable use” is excluded from “reproduction,” the scope of the reproduction right may become too narrow to address future methods of utilizing works, potentially affecting the revenue of copyright owners. As a result, excluding “non-use” from the scope of copyright rights may be challenging to justify within the copyright owners’ community.
There is no international precedent for excluding reproduction from the scope of copyright. In 2001, the EU established the Information Society Copyright Directive to address the challenges posed by the expansion of reproduction rights. It regulates all acts of reproduction of works and provides for a series of exceptions, including a mandatory exception for temporary reproduction that member states are required to implement.Footnote 67 The U.S. Congress enacted Section 117(c) of the Copyright Act, which imposes limitations on the right of reproduction, affirming that temporary reproduction in computer memory is subject to the reproduction right under copyright law. However, an exception exists: The work must be embodied in a medium, that is, placed in a medium such that it can be perceived and reproduced from that medium—the “embodiment requirement”—and it must remain thus embodied “for a period of more than transitory duration”—the “duration requirement.”Footnote 68 In Japan, Article 30-4(iii) of the Copyright Act, as amended in 2018, introduced a new exception for data exploitation, allowing works to be “[e]xploited in a way that does not involve what is expressed in the work being perceived by the human senses.”Footnote 69 While this provision exempts model training issues, it also includes a provision ensuring that the interests of copyright holders are not unduly harmed.
In terms of international conventions, the Berne Convention—constrained by the historical context in which it was developed—adopts the broadest definition of the right of reproduction. The agreed statement in Article 1(4) of the WIPO Copyright Treaty clarifies that the machine exception to the right of reproduction—as established by the Berne Convention in the traditional technological environment—can also apply in the digital environment.Footnote 70 The WIPO Performances and Phonograms Treaty, an internet treaty as well, includes provisions similar to those of the WIPO Copyright Treaty, thereby extending the traditional concept of “reproduction” to the digital and online environments.Footnote 71 Therefore, international copyright conventions do not establish uniform legal rules for temporary reproduction, but instead allow national or regional copyright systems to design corresponding regulations. The idea of excluding reproduction from the scope of copyright law has not reached international consensus.
III. Perspective 3: The Use of Works in Model Training Constitutes Fair Use
Perspective 3 asserts that the utilization of works in AI model training shall be recognized as fair use. Both Perspective 2 and Perspective 3 believe that the use of work in AI model training should not be considered as infringing copyright. Perspective 3 tries to establish certain preconditions for the legitimacy of using works in AI model training under the framework of fair use analysis, thereby allowing for flexibility in future legal interpretations.
1. Legitimacy Argument
1.1. Use of Works in Model Training Constitutes “Incidental Reproduction” and “Transformative Use”
As outlined in Perspective 2, model training takes place in a relatively closed internal computer environment, where copies of copyrighted works are made during the training process but are not directly incorporated into the final model. This process involves mere “incidental reproduction” of the work, which should qualify as fair use. The nature of this “incidental reproduction” is further clarified in EU legislation. The EU’s 2019 Digital Single Market Copyright Directive affirms that the temporary reproduction exception regulated in Article 5 of the 2001 Copyright Directive remains applicable to text and data mining, provided that the reproduction does not exceed the scope of the exception.Footnote 72
In addition, the exploitation of works in model training also constitutes “transformative use” under United States law. The theory of “transformative use” was proposed by Justice Leval in 1990 in his article On the Standard of Fair Use, and was subsequently adopted by the U.S. Supreme Court in 1994 in Campbell v. Acuff-Rose Music. This decision established the test for transformative use based on the first of the four fair use factors: “[T]he purpose and nature of the use.”Footnote 73 The specific meaning of transformative use is that the purpose of the work is not to simply reproduce the original literary or artistic value of the work or fulfill its intrinsic function or purpose. Instead, by adding new aesthetic content, perspectives, concepts, or through other means, the original work acquires new value, function, or nature in its use, thereby altering its original purpose or function.
In the era of text data mining, some scholars have introduced the concept of “machine reading,” which differs from “human reading,” and is considered “non-expressive reading,” qualifying as fair use of the work.Footnote 74 Similarly, the model training involves using a vast corpus of works to learn and derive patterns, such as grammatical structure and other non-expressive elements of the works, rather than utilizing the specific expression of a particular work. The “non-expressive use” of works constitutes transformative use of the works at the level of the purpose or function.Footnote 75 As in the Authors Guild, Inc. v. Google, Inc. case, the U.S. court ruled that the primary purpose of Google’s use of the works was “to enable the public to search and locate specific chapters of books,” which was entirely different from the purpose of appreciating the work itself or extracting the market value from the copyright owner, and thus constituted “transformative use.”Footnote 76
1.2. Market Failure in the AI Model Training Licensing Market
Market failures in licensing can justify the application of fair use. Professor Wendy Gordon has proposed a three-step test for fair use, under which the use of a work constitutes fair use if the following conditions are met: First, the market failure is real, and the market cannot address it spontaneously; second, the permitted use is of a more socially desirable character; and third, granting fair use does not substantially harm the copyright owner’s incentives.Footnote 77 An economic analysis of fair use suggests that it is often permitted when the market is unable to effectively acquire and use copyrighted works.
There are significant market failures in the licensing market for AI model training. AI companies require vast quantities of works to train their models but there is limited and inconsistent willingness to license these works. The process of identifying and negotiating with copyright holders involves high transaction costs, which are further exacerbated by the fragmentation of rights and the presence of a vast number of copyright holders, both of which contribute to the accumulation of licensing fees.Footnote 78 Furthermore, the permitted use has important social value for the long-term development of AI companies. The development of large models is highly dependent on access to large amounts of high-quality training data. Only at a certain scale can “intelligent emergence” of model capabilities occur.Footnote 79 The richness and diversity of data sources can reduce the bias and discrimination in large models, thereby ensuring the high quality of output content.
In the context of China’s national conditions, small and medium-sized enterprises (SMEs) or start-ups in the AI sector often lack the capital to afford these high transaction costs. The application of a statutory licensing system could therefore negatively affect market competition within the AI industry. As for whether the incentives of copyright owners would be substantially harmed, the empirical study below shows that the output of large models does not substantially resemble the prior works, and thus, does not significantly affect the market revenue of copyright owners.
1.3. No Unreasonable Damage to the Legitimate Rights and Interests of Copyright Holders
According to the three-step test, the first step in determining fair use is to assess whether the use of a work will “unreasonably harm the legitimate rights and interests of copyright owners.” This issue is central to the debate over the fair use of works in AI model training. This Article argues that the use of works in large AI models does not unreasonably harm the legitimate rights and interests of copyright holders. By learning from copyrighted works through machine learning, the model can internalize relevant language rules and capture the statistical patterns from a vast number of works, rather than being a collection of those works. The large model itself is a product of the technological domain and does not belong to the market of literature, art, and science where the works themselves reside. Also, the output of the large models does not directly reproduce the original works. Instead, the model may generate innovative uses of the statistical patterns of the works. The reproduction involved in model training occurs in the machine, akin to web scraping through crawler technology, and does not directly present the works to human readers.Footnote 80
Concerns raised by copyright holders and related groups center on the risk that AI models may generate content substantially similar to existing works, thereby affecting their market revenue. However, the possible risk of copyright infringement at the model output stage should not negate the fair use of the training process. These two stages are not directly causally linked. Even if we consider the two stages of large model training and subsequent content generation together, we should recognize that the normal use of large AI models is not to reproduce or plagiarize existing works. Although large AI models may generate content that is substantially similar to existing works, they are more likely to produce content that does not constitute substantial similarity in normal usage. Moreover, the models can be used in a wide range of fields and have a rich variety of functions beyond generating content similar to existing works. We should not limit the use of works during training, as this could affect the development capabilities of large models and fair competition in the market. Generating works for appreciation is just one part of the application prospects of large artificial intelligence models, which needs to be kept in mind when making legal judgments. For potential copyright infringement issues that may arise during usage, it is necessary to regulate the behavior of AI system or service providers and users at the usage stage. This includes reasonably determining liability for damages and requiring certain measures to avoid generating infringing content, thereby protecting the rights of copyright holders.
2. Empirical Study
To explore the legitimacy of the fair use of model training, it is necessary to understand the potential infringement risks posed by large AI models at the output stage, thus to have a better understanding of the potential influence to the market for copyright holders’ works. To this end, we conducted a copyright experiment, empirically examining whether the content generated by big-model-based AI services is more likely to be substantially similar to copyright-protected works. The experiment focuses on the influence of large language models for generative artificial intelligence on the market and examines whether copyright protection can be achieved through the service provider’s use of technical measures to control output. Due to the limited scope of the experiment, the results should be considered indicative.
From July 15 to July 30, 2024, we selected sixty literary works protected under Copyright LawFootnote 81 to test four generative AI service platforms that have been launched in China. The selection criteria prioritized popularity and genre diversity, referencing authoritative sources such as the Mao Dun Literature Prize winners, the Douban Top 250 Highest-Rated Books, and the WeChat Reading Top 200 General Ranking. This sample primarily consists of full-length novels—including classics and popular works like The Ordinary World, The Legend of the Condor Heroes, and The Sword Snow Stride, as well as select novellas such as At Middle Age and To Live. Prompting questions were designed to request the output of original content from specified chapters of the test works, and the corresponding responses were recorded. A total of 240 valid responses were collected. During the statistical analysis phase, the tf-idf algorithm was employed to calculate the overlap in character count between each response and the original text. Manual annotation was used to evaluate the degree of similarity between the responses and the original text to determine whether it constituted “substantial similarity.” This process allowed for the assessment of the copyright infringement risk of generative AI services from a copyright law perspective.
Figure 1 presents a scatter plot illustrating the distribution of overlapping characters between the output content and the original text across the four generative AI services. Specifically, Model W outputs up to 938 characters from the original text, with an average output of 77.8 characters. Model T has the highest number of overlapping original text characters at 48, with an average of only 2.05 characters. Model K outputs up to 40 original text characters, with an average output of 5.32 characters. Model D has the highest number of overlapping original text characters at 11, with an average output of only 0.67 characters.
Average Output Word Length of Original Works

Based on these data, while Model W outputs relatively long excerpts of the original text in some cases, this is not a common occurrence. The proportion of original text in its overall output is low and does not pose a significant risk of copyright infringement. In contrast, the output from Model T, Model K, and Model D shows a very low number of characters overlapping with the original text, resulting in minimal reproduction of the original work’s content.
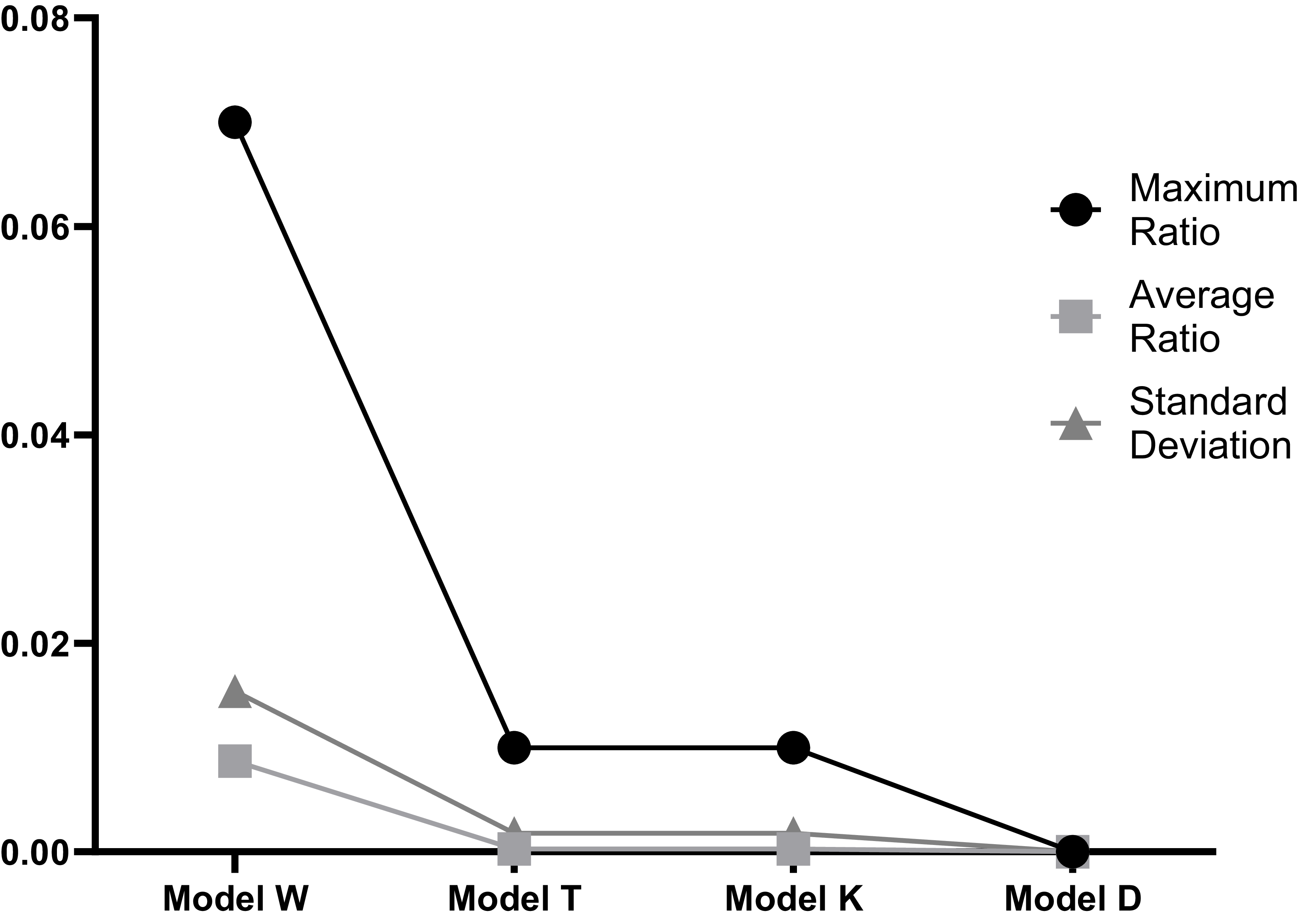
Figure 2 illustrates the distribution of original text in the output content of the four generative AI services. It presents the proportion of the original text to the corresponding chapters of the original work, along with the maximum value, mean, and standard deviation of these data. The statistical results reveal that the length of the original text output by Model W only constitutes at most 7% of the corresponding chapter of the work. For example, with a chapter length of 5,000 words, Model W can output a maximum of 350 words of the original text in a single response. This suggests that the high cost but low benefit of generating works using AI makes it difficult to produce high-quality and longer original texts. Therefore, it can be argued that the output of a generative AI service does not constitute a substantial replacement for the original work.
Average Original-to-Chapter Ratio of Large Models’ Output

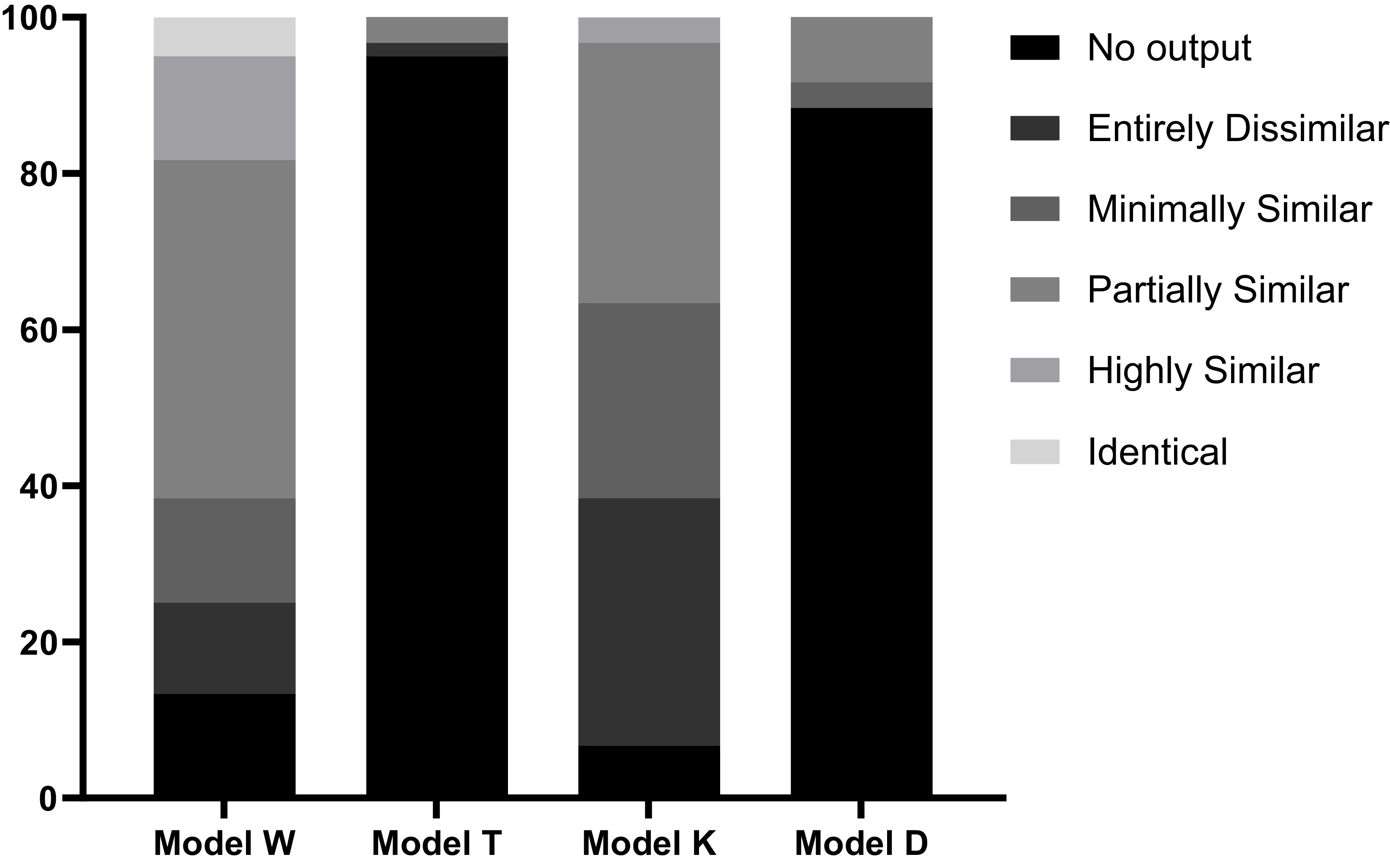
Figure 3 presents the results of the assessment of similarity between the output content and the original text in the initial response from four generative AI services. The assessment is categorized into five levels based on the degree of similarity: Entirely dissimilar, minimally similar, partially similar, highly similar, and identical. Among these, the levels “highly similar” and “identical” indicate a higher risk of copyright infringement. Specifically, Model W shows that 13.3% of its output is highly similar to the original content, and 5% directly replicates the original text. In contrast, Model K outputs highly similar content at 3.3% and does not replicate the original text (0%). Both Model T and Model D produce no highly similar or identical content (0%). Among the four generative AI services assessed, Model W exhibits the highest risk of copyright infringement at 18.3%, while Model K carries a relatively low risk of 3.3%. Model T and Model D did not produce any content posing a risk of infringement in this experiment.
Similarity of Large Model Output to Original Works

Based on the above results, the four services demonstrated greater caution in outputting copyrighted works, as evidenced by the lower percentage of original text in a single round of responses. This suggests that the relevant service providers have adopted a more stringent copyright protection strategy, possibly implementing technical measures to control the output of copyrighted materials. These measures effectively prevent users from substituting the consumption of original works by inducing the generative AI services to directly output the original text. Based on the experimental observations, it can be inferred that recognizing the use of works for model training as fair use is unlikely to infringe upon the legitimate interests of the rights holders.
D. Construction of Fair Use Rules in Model Training
Based on the preceding discussion, this Article argues that recognizing the use of works in model training as fair use aligns more closely with China’s legal framework and the practical needs of the industry. Article 24(1)(xiii) of the Copyright Law stipulates that fair use includes: “[O]ther circumstances provided for by laws and administrative regulations,” thereby offering a legal foundation and interface for expanding the fair use rule to specific contexts. Additionally, consideration may be given to amending the Implementation Regulations, or to adopting a fair use provision in legislation concerning artificial intelligence. Such a provision could read: “The incidental exploitation of a published work by another, through reproduction, adaptation, or other means, as necessitated by the technological processes of computer analysis, machine learning, and text data mining, shall constitute fair use.” Furthermore, the three-step test should be applied to assess fair use, ensuring that if the use of a particular work meets the above criteria but negatively affects its normal use or unreasonably harms the legitimate rights and interests of the copyright holder, it should not be deemed fair use.
Moreover, to prevent the output of copyright-infringing content by large models, AI service providers and users must take reasonable care to protect copyright. Service providers shall be required to fulfill their risk-alert obligations and encourage users to respect intellectual property rights when using their services. Providers can adopt strategies like value-alignment training to improve learning from human feedback, which can reduce the risk of copyright infringement caused by users’ prompts.Footnote 82 Additionally, they can implement technical measures, such as output-side filtering, to prevent the generation of infringing content. As the content generated by large models is probabilistic, service providers cannot fully predict or control the output. Therefore, it is necessary to further establish a conditional liability exemption rule for AI service providers, building upon the provisions of Article 14(1) of the Interim Measures. This rule can be guided by the “safe harbor” principle found in copyright law. Under this mechanism, service providers will not be held liable for infringement if they have exercised reasonable care and diligence. This includes, but is not limited to, fulfilling the risk-alert obligation, adopting necessary technical precautionary measures, and implementing timely removal or deletion of identifiable infringing content. The aim of this approach is to clearly define the responsibilities of relevant parties, effectively reduce the legal burden on AI enterprises, and promote the healthy and sustainable development of the AI industry.
E. Conclusions and Outlook
In reviewing the third revision of the Copyright Law and the legislative process of artificial intelligence, a distinction can be observed in the focus of attention between copyright law and AI law regarding copyright disputes over model training. The copyright law prioritizes balancing interests within traditional sectors and does not advocate for the establishment of technology-specific provisions in revising the fair use provisions. Moreover, it failed to take into account the changes in interests triggered by technological development, thus overlooking the reflection of technological advancements and their spillover effects. Similarly, the revision of the Implementation Regulations was constrained by the influence of traditional copyright holder groups, failing to address the aforementioned issues. In contrast, AI legislation places greater emphasis on the challenges and changes that technological advancement introduces to the existing legal framework, signaling a clear intent to reinforce technology-driven legislation. Given the complexity of the interests involved in copyright disputes related to model training, it is crucial to foster active exchanges and dialogue between the fields of copyright law and AI law. In the context of technological change—when formulating and refining the relevant legal system—it is essential to consider the influence of technological development, social welfare, and other factors, ensuring the legal framework effectively responds to the challenges posed by such change.
In addition to copyright legal rules, the industrial development of artificial intelligence is closely related to the data legal system. As one of the three key components of AI, the construction of the data system holds significant importance.Footnote 83 In the Resolution of CPC Central Committee on Further Deepening Reform Comprehensively to Advance Chinese Modernization from the Third Plenary Session of the 20th CPC Central Committee, it is stated that China will “[b]uild and put into operation national data infrastructure to promote data sharing, [work] faster to set up a system for data property rights concerning ownership determination, market transaction, proceeds distribution, and interests protection, and [boost] our governance and regulatory capabilities in relation to data security.” The Opinions of the CPC Central Committee and the State Council on Establishing a Data Base System to Maximize a Better Role of Data Elements emphasizes the structural separation system of data property rights in the construction of data ownership. The development of the artificial intelligence industry progress without the support of data resources, and enhancing the richness of training data can effectively reduce the potential for copyright infringement in generated content. It is important to note that copyright and data rights coexist concerning work-type data. Future data legislation may influence the rules governing the use of works, and the application of fair use in model training issues could face certain restrictions. Therefore, finding a balance of interests between copyright and data rights is a critical issue for future Chinese legislation to address.
To promote the development of the AI industry, countries have adopted various legal responses to copyright disputes over model training, including the EU’s text and dating mining model, Japan’s “non-appreciative use” model, and the “four-factor test and transformative use” model of the United States. While each of these models has distinct characteristics, there is a common trend toward applying copyright restrictions. Due to the transnational nature of AI technology and the highly internationalized legal and trade framework governing intellectual property, it is particularly crucial to establish a coordinated international governance system for AI. Since September 2019, WIPO has organized multiple dialogue sessions on IP and AI to explore the influence of AI on IP policies, effectively fostering communication between member states and stakeholders.Footnote 84 In the future, international discussions on AI-related IP issues within the WIPO framework should be intensified. Efforts should focus on advancing the harmonization of AI training copyright rules, fostering greater cooperation and consensus among countries in the AI and IP sectors, and promoting the development of a Memorandum of Understanding (MOU) on AI technologies. Simultaneously, it is essential to expedite the negotiation process of the relevant provisions under the Agreement on Trade-Related Aspects of Intellectual Property Rights (TRIPS) within the WTO framework, with the aim of improving the TRIPS Agreement in the context of the AI era. This will foster the robust development of the AI industry while promoting the innovation of global intellectual property governance rules and systems.
Acknowledgements
We gratefully acknowledge helpful comments from Profs. Gilad Abiri, Xin Dai, and Emanuel V. Towfigh. We also gratefully acknowledge the helpful work of the student editor Emma Gilliam. If there are any remaining problems, they are solely the responsibilities of the authors.
Competing Interests
The authors declare none.
Funding Statement
The work is supported by the Research Project on Rule of Law Construction and Legal Theory of the Ministry of Justice of the People’s Republic of China (Project No. 24SFB2003).


 Open access
Open access