

1. Introduction
Sound change and analogy are widely regarded as two of the main drivers of language change. They have been understood as opposing forces in the evolution of inflectional paradigms at least since the time of the Neogrammarians. In his Prinzipien der Sprachgeschichte (see also the discussion in Fertig Reference Fertig2013:95–99), Paul (Reference Paul1880) described sound change as a force that wreaks havoc in paradigms. The accumulation of irregularity caused by sound change would over time render forms completely irregular and an inflectional system unusable, he argues, were it not for the counterbalancing effect of analogical change. Analogy keeps the ravages under control by getting rid of exceptional forms and maintaining morphological oppositions more or less predictable. This relationship was formulated most succinctly by Sturtevant (Reference Sturtevant1947), whose renowned paradox states that sound change is regular but generates irregularity, while analogy is irregular but generates regularity.
This overall story has been presented as a fact to generations of students and historical linguists, most often through concrete local examples where a phonologically conditioned sound change introduces stem allomorphy into a paradigm, and analogical change levels it sometime thereafter. Typical examples (see e.g. Millar Reference Millar2015:101) are the /s/-/r/ alternations in Archaic Latin declension resulting from rhotacism of /s/ between vowels (e.g. honōs /*honōsis > honōs /honōris > honōr /honōris), or the stress-related stem-vowel alternations in Old French verbs, ironed out in Modern French (e.g. a.ˈmer/*ˈ a.me > a.ˈmer/ˈ ai.me > aimer/ aime). These examples are selected to illustrate what is assumed to be an overall trend. Sound change, however, can also eliminate morphological complexity, for example, by eroding inflectional endings and thus generating syncretisms. Many cases can also be found of analogical changes introducing, rather than eliminating, stem allomorphy or other seemingly irregular traits (e.g. Eng. dived > dove) or simply changing one type of (ir)regularity for another.
For illustration, Table 1 shows all of these possibilities in the history of Spanish verbs. The first four rows show the effect of some sound changes on regularly developing lexemes. The key sound changes are the Romance palatalizations that gave rise to stem alternations such as dig-o [diɣo] ‘I say’ vs. dic-es [diθes] ‘you say’; see Maiden Reference Maiden2018:85–91. The bottom eight rows show the expected effects of the same set of sound changes on the first- and second-person singular present indicative of four illustrative verbs. The first verb, partir ‘split’, should have developed a stem alternation /θ/-/t/ through regular sound change (cf. Lat. púteum, Sp. pó[θ]o ‘well’) but does not have one in modern Spanish. Perhaps as expected, analogical change must have leveled the allomorphy, in this case by extending the stem with /t/. The second verb, hacer ‘do’, would have first developed, and then lost, stem alternation through regular sound change. This is so because the alternating segments (which would have become /s/ and /z/ in medieval Spanish; cf. Portuguese ˈfasu vs. ˈfazɨʃ) merged in the language in the sixteenth century (notice in Table 1 how /tʃː/, /tsː/, and /ts/ in ‘arm’, ‘well’, and ‘hundred’, respectively, all eventually became /θ/ in modern Spanish). Analogical change, however, introduced a segment /ɡ/ into this verb (already before the tenth century) and has hence acted as a complexifying force historically in this paradigm. The third verb, salir ‘exit’, is expected to develop /x/-/l/ stem alternation through regular sound change (cf. Latin álium, Sp. á[x]o ‘garlic’), but this has been analogically altered into a different pattern of stem alternation /lɡ/-/l/. The last verb, decir ‘say’, acquired a stem alternation /ɡ/-/θ/ through regular sound change, and analogy has not (yet) intervened.
Morphological effects of sound change vs. analogy (with gray shading) in the history of Spanish.

Table 1. Long description
Beginning at the top row, the table lists Latin forms in the first column, followed by columns for phonological changes: i or e yields j before vowels, t j yields ts long, vowel long yields vowel, k j yields t sh long, l j yields l long, k yields ts before e or i, and an ellipsis column. The next columns show the expected Spanish form, the actual Spanish form, and the gloss. For example, bráːkium transforms through bráːkju, bráːkjo, brátʃːo, and bráθo, resulting in bráθo meaning ‘arm’. Other rows show similar stepwise changes for álium (‘garlic’), púteum (‘well’), kéntum (‘hundred’), partioː (‘I split’), partiːs (‘you split’), fákioː (‘I do’), fákis (‘you do’), sálioː (‘I exit’), sáliːs (‘you exit’), díːkoː (‘I say’), and díːkis (‘you say’). Gray shading marks cells where analogy overrides expected sound change, such as in the Spanish forms pánto, ágo, and salgo. Each row traces the evolution from Latin through intermediate phonological stages to modern Spanish, with glosses clarifying the meaning.
Given the potential of both sound change and analogy to both increase and decrease morphological complexity within inflectional paradigms, what we are missing is a thorough analysis of their overall long-term effects. General trends or laws of analogy have been thoughtfully discussed qualitatively for over a century (see e.g. Kuryłowicz Reference Kuryłowicz1945, Mańczak Reference Mańczak1957), and different types of analogy (e.g. proportional vs. nonproportional) have been carefully classified (Hill Reference Hill2007, Fertig Reference Fertig2013). It seems uncontroversial that the challenge of learning language from a finite input must favor more easily learnable relations and generalizations, that is, simplicity, when relevant input is less frequently provided (Kirby & Hurford Reference Kirby, Hurford, Cangelosi and Parisi2002, Milizia Reference Milizia2014, Blevins et al. Reference Blevins, Milin, Ramscar, Kiefer, Blevins and Bartos2017). At the same time, it has sometimes been argued that morphological change can also irregularize high-frequency items to increase the discriminability of forms (see Nübling Reference Nübling1999, Reference Nübling2011, contra Gaeta Reference Gaeta2007), or that analogy tends to operate in such a local domain (e.g. English dive-dived becoming dive-dove through analogy with drive-drove) that it can engender complexification at the global level (Joseph Reference Joseph, Spencer and Zwicky2017:356–57).
While qualitative literature has provided many empirical findings and an increased understanding of the history of many languages, the logical next step is to conduct a large-scale quantitative analysis of the cumulative effects of sound change and analogical change in an inflectional system as a whole, across thousands of years and across thousands of items. This is the goal of the present article, which looks in detail at the evolution of morphological complexity from Latin to French verbs, and at the predictors of analogical change. Section 2 gives a brief introduction to the methods we employ, involving computerized forward reconstruction and the calculation of cell-to-cell conditional entropy and related morphological complexity measures. We present the data we rely on in Section 3: verbal inflected lexicons of Latin and French, with etymological annotation of cell-to-cell and lemma-to-lemma cognacy relations. Our operationalization of variables (historical analogical change, token frequency, regularity, and sound changes) is presented and motivated in full detail in Section 4. Section 5 presents statistical models and results. In variables like the number of inflectional classes or the degree of allomorphy, sound change was found to increase complexity, while analogy reduces it. This does not seem to be the case, however, when it comes to average conditional entropy. Concerning the predictors of analogical change, morphological regularity and frequency have been confirmed to matter, as does the amount of sound change, while no effect was detectable for markedness. We discuss the relevance of the findings and their implications in Section 6, with special attention given to the more unexpected results. Finally, Section 7 summarizes the article and outlines avenues for future research.
2. Computational approaches to morphological complexity and sound change
The reason traditional research on analogy and sound change has relied on selected examples and impressionistic accounts, rather than on the exhaustive evaluation of these forces over whole inflectional systems, is simply that the latter was prohibitively difficult and time consuming until quite recently. Accurately deriving by hand the effect of dozens or hundreds of ordered sound changes over thousands of words (i.e. a greatly expanded Table 1) would constitute a lifetime achievement. Similarly, codifying the morphological differences and similarities between every pair of cells in the paradigms of hundreds or thousands of lexemes would be close to impossible by hand. Tackling both problems together would have been highly prone to mistakes and ultimately unfeasible in terms of time required. This has fortunately changed quite radically over the last twenty years, through the increase in computing power and the development of methods and tools to perform these analyses automatically.
Regarding automated explorations in historical phonology, the application of regular Neogrammarian sound changes over large lexicons is computationally straightforward, as it consists essentially of ordered find-and-replace regular-expression changes over segment strings. This approach, known as Computerized Forward Reconstruction (CFR), was pursued at the beginning of the computer age (Burton-Hunter Reference Burton-Hunter1976, Eastlack Reference Eastlack1977, Maniet Reference Maniet1985) and has recently experienced renewed interest (Sims-Williams Reference Sims‐Williams2018, Piwowarczyk Reference Piwowarczyk and Olander2022, Marr & Mortensen Reference Marr and Mortensen2023, List Reference List2024). CFR so far has been employed as a means for testing hypotheses about sound changes in a language’s history and for investigating and revising their relative chronologies. DiaSim (Marr & Mortensen Reference Marr and Mortensen2020), for example, is an interface that simulates the ordered operations of such relative chronologies (cascades) upon a lexicon. Through the accuracy metrics and diagnostics it provides, CFR-based ‘rule-debugging’ can be performed as well. Marr and Mortensen (Reference Marr and Mortensen2023) used this to improve Latin-to-French reflex prediction from a 3.2% baseline cascade based on the work of Pope (Reference Pope1934) up to 84.9%. The fixes produced by ‘debugging’ this relative chronology included both cases where proposals already made in the literature could be independently arrived at and the likely discovery of a hitherto missed sound law in Old French (Marr Reference Marr2024).
Regarding the quantitative assessment of the morphological complexity of inflectional systems, Information Theory and Shannon’s (Reference Shannon1948) entropy set the basis for a true quantitative turn in the synchronic analyses of inflectional systems over the last decades. Data sets and software have been developed that now allow for accurate and replicable assessments of the morphological complexity of whole systems within hours or minutes. The challenge speakers of highly inflecting languages face in predicting some inflected forms from other forms (e.g. the 1sg.prs from the 2sg.prs in Table 1 or vice versa) has come to be known as the Paradigm Cell Filling Problem (PCFP; Ackerman et al. Reference Ackerman, Blevins, Malouf, Blevins and Blevins2009) and constitutes a very active area of research in the field. Multiple measures of complexity have been developed and applied to inflectional systems crosslinguistically (e.g. conditional entropies, principal parts), and various hypotheses have been proposed regarding possible universal principles or trends of paradigmatic structure in human languages (e.g. the Low Conditional Entropy Conjecture of Ackerman and Malouf (Reference Ackerman and Malouf2013) and the Marginal Detraction Hypothesis of Stump and Finkel (Reference Stump and Finkel2013)). Some current software (see Beniamine’s (Reference Beniamine2018) Qumin) can also sidestep the problem of segmentation (see e.g. Gundersen Reference Gundersen, Simonsen and Endresen2001, Goldsmith Reference Goldsmith, Clark, Fox and Lappin2010), thus solving one of the last obstacles on the way to full replicability and theoretical neutrality.
Thanks to the aforementioned methods and tools, the opportunity has now emerged to pursue a quantitative exploration of the paradigmatic effects of sound change and analogy over whole inflectional systems. As an easily accessible additional object of analysis, this approach also allows us to explore the predictors of morphological change at a larger scale (both by timespan and by number of items) than has ever been possible. Most extant quantitative work on this topic has been based on small set of documented analogical changes (generally a few dozen; see Gaglia Reference Gaglia2020, Sims-Williams Reference Sims-Williams2022). A much larger data set containing thousands of items, and both analogically changed and unchanged words, must lead to more reliable assessments of the role of frequently discussed predictors like frequency, semantic similarity, markedness, and/or irregularity.
3. Data sets: inflected lexicons of Latin and French verbs with cognacy information
With the increase of computing power, data sets have also become larger over the last decades. Inflected lexicons (i.e. databases with the complete paradigms of thousands of lexemes) have been assembled for many of the world’s major languages (see e.g. Unimorph; Kirov et al. Reference Kirov, Cotterell, Sylak-Glassman, Walther, Vylomova, Xia and Faruqui2018). These have played a primary role in the investigation of morphological complexity. However, they have so far been used chiefly for synchronic and typological research (e.g. Ackerman & Malouf Reference Ackerman and Malouf2013, Stump & Finkel Reference Stump and Finkel2013, Beniamine Reference Beniamine2018, Cotterell et al. Reference Cotterell, Kirov, Hulden and Eisner2019). For the diachronization of this research, the ideal starting point would involve large inflected lexicons of a contemporary language and of a direct ancestor. Latin represents the optimal candidate in this respect, as it has evolved into a large family of well-described modern languages. Its verbal system is the best inflectional system for the task, due to its large and multifaceted paradigms (i.e. various conjugations and tenses, stem alternations, irregular forms, etc.) and due to the comparatively faithful preservation of verbal inflection in modern Romance compared to nominal inflection. We are fortunate to have a large inflected lexicon of Classical Latin verbs (LatInfLexi; Pellegrini & Passarotti Reference Pellegrini and Passarotti2018), which includes all forms of 3,348 verbs and their frequencies.Footnote 1 This is the first resource we build on. The second is Vlexique (Bonami et al. Reference Bonami, Caron and Plancq2013), an inflected lexicon of French verbs that includes all inflected forms of 4,987 verbs in phonological form. This has been recently supplemented with frequency information (see Beniamine et al. Reference Beniamine, Coavoux and Bonami2024).
We choose French because of the availability, through the work of Marr and Mortensen (Reference Marr and Mortensen2023), of DiaCLEF, a computationally implementable sound change cascade containing all regular sound changes from Latin to French. For the purposes of this investigation, a modified version of the cascade DiaCLEF was used, which has been named DiaCLEF2024. Modifications were largely to prevent a cascading error effect due to the emergence of secondary phonemic sequences that were unforeseen (an artifact of how DiaCLEF was constructed and optimized over a mostly nominal data set FLLex, largely drawn from examples used by Pope Reference Pope1934). The fixes made, largely consisting of generalizations to existing rules, can be consulted in the supplementary information accompanying this article at https://osf.io/5yr6m/?view_only=cf589970acc04d0c98050f0b0ac59c04.
The inflected lexicons we rely on are not etymologically annotated or linked in any way. It thus becomes necessary to incorporate cognacy information from other sources. We therefore automatically extracted from Wiktionary (10 April 2023) the etymological entries of every lemma in our French lexicon (see Table 2). While Wiktionary is a crowd-sourced collaborative effort, and hence not peer reviewed, we have found the etymological information it contains to often be accurate for French and organized in a systematic-enough way that allows for the automated extraction of information (e.g. ‘borrowed’ words and ‘inherited’ words are quite consistently flagged as such through the use of these terms; see the entries in Table 2). The broad coverage and digital format of Wiktionary constitute further advantages. In French verbs of Latin pedigree (see abdiquer and accoter in Table 2), the ancestral Latin lemmas (or rather their citation forms) were extracted automatically from these entries. French verbs originating through derivation and those borrowed from other languages (see accréditer and actionner in Table 2) were ignored. All of the etymological information extracted automatically was manually checked for accuracy. For this, we relied on the Französisches etymologisches Wörterbuch (FEW; von Wartburg Reference von Wartburg1948, Renders Reference Renders2015), on the Dictionnaire etymologique de l’ancien francais (DEAF; Baldinger et al. Reference Baldinger, Gendron, Straka, Fietz-Beck, Möhren, Tittel and Städtler1974), and on our knowledge of French historical phonology.
Illustrative Wiktionary entries, with etymological information automatically extracted.

Table 2. Long description
The table has five columns labeled French lexeme, Wiktionary entry, Latin, Borrowed, and Cognate lemma. Row 1: abdiquer, Wiktionary entry states Borrowed from Latin abdicāre, Latin column shows Latin, Borrowed column shows borrowed, Cognate lemma is abdicāre. Row 2: accoter, Wiktionary entry states Inherited from Late Latin accubitāre with influence of Old French acoster, Latin column shows Latin, Borrowed column shows inherited, Cognate lemma is accubitāre. Row 3: accréditer, Wiktionary entry states Borrowed from Spanish acreditar, Latin and Borrowed columns are blank, Cognate lemma is N/A. Row 4: actionner, Wiktionary entry states From action plus -er, Latin and Borrowed columns are blank, Cognate lemma is N/A.
To pair Latin and French verbal forms automatically from the respective inflected lexicons, we also needed to incorporate the information on paradigm-cell-level ancestry. Most word forms in the Classical Latin verbal paradigm have been lost in French and other Romance languages (for example, the old synthetic futures or passives). Conversely, some French verbal forms, namely the new Romance futures and conditionals, are not descendants of any inflected form in Classical Latin (these famously developed from the univerbation of former periphrases involving inflected forms of the verb ‘have’ and the infinitive; see e.g. Valesio Reference Valesio1968, Roberts Reference Roberts1992). A total of thirty-eight French verbal forms have been found to continue a Classical Latin form, and these constitute our focus in this article.
Because we are exploring open word classes, no inflected lexicon is or arguably can be complete. Although the lexicons we chose are the largest ones that are phonologically transcribed in their respective languages, they are not exhaustive by any means. While Vlexique, for example, contains close to 5,000 verbal lemmas, more quantity-focused sources (see e.g. Bescherelle Reference Bescherelle2006, Sagot Reference Sagot2010) achieve much higher numbers, sometimes exceeding 10,000. In Latin, of course, the lemma coverage is further restricted by the limits imposed by the surviving corpus of the language. It is often the case, therefore, that a French verb of Latin pedigree does not match any of the documented verbs in LatInfLexi. Less commonly, the French reflex of a Latin verb in LatInfLexi is not among the verbs documented in Vlexique. In either case the etymological matching of Latin/LatInfLexi to French/Vlexique forms cannot occur, which reduces our available data set.
The final overlap between the two lexicons (see Figure 1) constitutes the main data set on which the rest of this article relies. It includes 310 inherited cognate verbs and 11,593 total cognate inflected forms. Given the 100-lexeme threshold for whole-system representative accuracy identified by Malouf et al. (Reference Malouf, Ackerman and Semenuks2020), this size would be enough to allow us to make reliable quantitative assessments about morphological complexity. While they are not explored in this article, an additional 490 verbs and 18,925 pairs of forms have been tagged as borrowed from Latin, which includes those that are unattested in intermediate periods (i.e. were not present in the vernacular speech of Old French) and those with noticeable learnèd influence. As additional variables we included the token frequencies associated to every Latin and French form, which are kept from the original sources. To these etymologically arranged pairs of Latin vs. French forms we added, based on the aforementioned DiaCLEF2024 sound change cascade, expected French forms. These are computerized-forward-reconstructed (CFR) forms of what the forms ought to have been in modern French in the absence of analogy.
Venn diagrams displaying graphically the intersection between the inflected lexicons of Latin and French, in terms of either shared cognate cells (left) or shared cognate lexical items (right). Shaded areas indicate our final data set for this article.

Figure 1. Long description
The left diagram has two circles. The left circle is labeled French with 51 cells, the right circle is Latin with 254 cells. Their overlap is shaded and labeled Inherited 38 cells. The right diagram has two overlapping circles. The left circle is French (Flexique) with 4965 verbs, the right is Latin (LatInfLexi) with 3348 verbs. Their overlap is divided into two regions: a smaller upper shaded area labeled Inherited 310 verbs, and a lower unshaded area labeled Borrowed 490 verbs. The shaded regions in both diagrams indicate the final dataset used.
Table 3 illustrates the data structure through the present indicative forms of three verbs. Some expected forms in the CFR column (those in shaded rows) perfectly match the modern French forms (e.g. the FinIndPresAct2Sing of amare ‘love’, /amaːs/, is expected to become /ɛm/ through regular sound change). This is identical to the modern French form and hence the edit distance (ED) is 0. This suggests that this form likely developed regularly, that is, without analogical change, in its evolution from Latin. Other forms show a different picture. The FinIndPresAct2Plur of the same verb, /amaːtis/, should have developed into modern French /ame/ through regular sound change. The observed modern French form, however, is /ɛme/, which suggests that this form underwent analogical change in its stem vowel (ED = 1) at some point in history.
An outline of the structure of the final data set.Footnote 2

Table 3. Long description
Starting from the top row, columns are: Cognate cell, Cognate lemma, Latin form, Frequency in Latin, French form, Frequency in French, CFR, and ED. For amare, FinIndPresAct1Plur shows ama mus with frequency 510, French ɛ m ɔ̃ at 3,387, CFR am ɑ̃, ED 2. FinIndPresAct1Sing has amo with 784, French ɛ m at 135,171, CFR ɛ̃, ED 2. FinIndPresAct2Plur is ama tis at 148, French ɛ me at 18,587, CFR ame, ED 1. FinIndPresAct2Sing is ama s at 863, French ɛ m at 38,097, CFR ɛ m, ED 0. FinIndPresAct3Plur is amant at 1,175, French ɛ m at 17,986, CFR ɛ m, ED 0. FinIndPresAct3Sing is amat at 3,566, French ɛ m at 62,488, CFR ɛ m, ED 0. For attendere, FinIndPresAct1Plur is attendimus at 178, French at ̪ ɑ̃ d ̪ ɔ̃ at 2,861, CFR at ̪ ɑ̃ m, ED 3. FinIndPresAct1Sing is attendo at 102, French at ̪ ɑ̃ at 18,900, CFR at ̪ ɑ̃, ED 0. FinIndPresAct2Plur is attenditis at 61, French at ̪ ɑ̃ d ̪ e at 4,540, CFR at ̪ ɑ̃, ED 2. FinIndPresAct2Sing is attendis at 195, French at ̪ ɑ̃ at 6,046, CFR at ̪ ɑ̃, ED 0. FinIndPresAct3Plur is attendunt at 271, French at ̪ ɑ̃ d ̪ at 10,640, CFR at ̪ ɑ̃ d ̪, ED 0. FinIndPresAct3Sing is attendit at 683, French at ̪ ɑ̃ at 40,169, CFR at ̪ ɑ̃, ED 0. For auscultare, FinIndPresAct1Plur is awskulta mus at 1, French ɛ kut ̪ ɔ̃ at 326, CFR ɑ kut ̪ ɑ̃, ED 2. FinIndPresAct1Sing is awskulto at 26, French ɛ kut ̪ at 5,814, CFR ɑ ku, ED 2. FinIndPresAct2Plur is awskulta tis at 4, French ɛ kut ̪ e at 2,602, CFR ɑ kut ̪ e, ED 1. FinIndPresAct2Sing is awskulta s at 9, French ɛ kut ̪ at 4,013, CFR ɑ kut ̪, ED 1. FinIndPresAct3Plur is awskultant at 70, French ɛ kut ̪ at 1,698, CFR ɑ kut ̪, ED 1. FinIndPresAct3Sing is awskultat at 33, French ɛ kut ̪ at 5,879, CFR ɑ kut ̪, ED 1. Each row details the Latin and French forms, their frequencies, and phonetic correspondences, with ED values ranging from 0 to 3.
The differences between predicted and observed French can thus be used as a proxy for the incidence of analogical change historically in different forms. We believe noise will be low, given that we already discount the effect of the other major forces of language change by using etymologically paired words and excluding borrowings. However, these residual differences between expected and observed forms cannot be understood as a direct observation of analogical change either. Given that different original sequences can converge on the same result after accumulated sound changes (e.g. amaːs and amat both regularly become ɛm; see Table 3), some historical analogical changes (e.g. a change amaːs > amas) escape detection in the present method inasmuch as the regular downstream outcome would be the same (i.e. ama:s > ɛm; amas > ɛm). Conversely, a distortion operating in the opposite direction is that quite minor analogical changes (e.g. changes in the placement of stress, as in 2pl.prs.ind of ‘drink’ /bˈibitis/ > /bibˈitis/) can sometimes snowball into quite large differences (e.g. /be/ vs. /byve/) due to the accumulation of sound changes. Notwithstanding these distortions, we believe that quantifying the large-scale outcomes of analogical processes through this method provides a novel picture that is both nuanced and comprehensive with regard to the role played by analogy.
We should also note that we employ the term ‘analogical change’ in a broad sense here to refer to any kind of morphological change, regardless of whether this might be derived strictly from a (four-part) proportional relation to other forms. Thus, for example, while the change of /a/ into /ɛ/ in amare is plausibly based on such a relation, a change from /ɑ/ into /ɛ/ in all forms of auscultare ‘listen’ is not likely due to a comparable proportional relation. Given the presence of /e/ in this verb in other Western Romance languages, like Catalan escoltar and Spanish escuchar (but cf. Italian ascoltare), it seems likely that this morphological change was quite ancient. It might be linked to the spread of a phonotactic structure /esk/ or /esC/ that would have become very widespread in the lexicon as a result of the regular introduction of an epenthetic vowel /e/ before Western Romance word-initial consonant clusters starting with /s/ (e.g. Latin /skuːtum/ ‘shield’ > /eskuto/, whence Old French escut, Spanish escudo). A similar nonproportional morphological change is found from Latin aperire ‘open’ to French ouvrir, rather than expected ** avrir,Footnote 3 which occurred probably due to the influence of the semantically similar verb ‘cover’ (Latin cooperire, whence French couvrir). These types of morphological changes, involving nonproportional analogies (Fertig Reference Fertig2013:57–70), folk etymologies (Rundblad & Kronenfeld Reference Rundblad, Kronenfeld, Coleman and Kay2000, Maiden Reference Maiden and Eythórsson2008), lexical contaminations (Malkiel Reference Malkiel1951, Maiden Reference Maiden2020), and so forth, all fall under our purview.
4. Methods and metrics
The methodology of CFR applied to large data sets of inflectional paradigms provides a novel way to separate the effects of sound change and morphological change in the long-term evolution of inflectional systems. This allows us to test empirically, on the basis of real and plentiful natural language data, many hypotheses regarding the dynamics of morphological change. At the level of the individual form, we can ask what the best predictors are of whether a form will undergo morphological change: frequency, regularity, or other factors. At the level of whole inflectional systems, by comparing the Latin inflectional system to the expected French inflectional system we can assess the effect of sound change: does it complexify the inflectional system? And if so, how and which precise aspects of complexity? By comparing the expected and observed French inflectional systems, in turn, we can assess the long-term effect of morphological analogy: does it simplify the system? Which aspects exactly? What forms are most likely to undergo analogical change? To be able to answer these questions, we need to add more (predictor) variables to our data, and we need to adapt some others to increase their fit to the phenomena we want to measure.
Regarding our proxy metric for analogical change, the edit distance between expected and observed French forms constitutes only a crude first approximation to the measure we would like. First, we need to address the fact that there are more and less radical morphological changes. The FinImpPresAct2Plur form of adnūntiāre ‘announce’, /adnuːntiaːte/, for example, is predicted by our sound change cascade to become /anœ̃se/ through regular sound change, while its observed form in French is /anɔ̃se/. The FinIndPresAct1Sing form of peccāre ‘sin’, /pˈekkoː/, is predicted to become /pɛk/ but is actually /pɛʃ/. The similarity of the segments /œ̃/ and /ɔ̃/ is greater than that between the segments /k/ and /ʃ/. If there was a morphological change from the former to the latter in both of these pairs of sounds, we should say it was a more radical one in the case of /k/ to /ʃ/ for peccāre. Given that CFR is not infallible, differences between more similar segments are more likely to result from inexactitudes in our sound change cascade, rather than from actual irregular development. More radical differences are also more likely to result from multiple developments, rather than a single historical morphological change. These factors call for a finer-grained measure than raw edit distance if we want to employ such a measure as a proxy for the amount of historical morphological change that has occurred in a form. We hence report feature edit distance (FED) (Kondrak Reference Kondrak2003, Mortensen et al. Reference Mortensen, Littell, Bharadwaj, Goyal, Dyer and Levin2016), which is calculated via a minimal alignment edit distance backtrace algorithm, whereby the distance between two aligned phones (i.e. replacements, e.g. /k/ vs. /ʃ/) is determined by the proportion of phonetic features (e.g. +/− coronal, +/− plosive) that have different values. Another aspect that we need to adjust for is the fact that longer forms have a potential to be more different from each other than shorter forms (e.g. /anœ̃se/ compared to /nave/). That is, a pair of forms such as /ɛme/ and /ame/ as in Table 3 can be maximally wrong by (all the features of) only three segments, while the forms /anœ̃se/ and /anɔ̃se/ could be wrong by five. We thus need to normalize these distances (whether ED or FED), which we do by dividing by the segmental length of the longest word in the pair. By doing so, the measure becomes confined to the interval [0, 1] and can be interpreted as a proportion (as done elsewhere in computational historical phonological work; see e.g. Dekker & Zuidema Reference Dekker and Zuidema2020).
Regarding form frequency, we would like to model the factor that might play the most direct role in whether a form has or has not undergone analogy historically: the average use frequency of each form during the last 2,000 years. We have data only for frequencies at the beginning of that period (Latin) and at the end (modern French). One important observation, however, is that the Latin and French frequencies are strongly correlated (r = 0.78) in our data set, which suggests that the frequencies of lexical items and paradigm cells are quite stable and that averaging modern and ancient frequencies will constitute a good proxy for the average frequencies across the whole timespan. Another limitation of the available data is the genre of the corpora from which frequencies were extracted. While the French data is well balanced, the available Latin corpus (Delatte et al. Reference Delatte, Evrard, Govaerts and Denooz1981) is of necessity suboptimal in that the prevalence of (historical) narrative leads to the overrepresentation of perfective (these represent 16% in the Latin corpus, 11% in the French corpus) and third-person forms (these represent 63% in the Latin corpus, 40% in the French corpus). To counteract this genre-driven skew, we apply a corrective coefficient to forms in Latin that doubles the token frequencies of nonperfective and non-third-person forms. While the total amount of data is different in the two languages (around four times as many tokens in French), this is irrelevant if we calculate an average between the Latin and French counts.Footnote 4 This average between the French frequencies and the adjusted Latin frequencies (freq) hence represents the variable of historical token frequency in all future analyses. Note, however, that alternative operationalizations (e.g. separate consideration of Latin and French frequencies, or no adjustment of the Latin frequencies) do not affect our results in any significant way.
The morphological regularity of a form is another aspect that is frequently mentioned in relation to analogical change. Other senses of the term notwithstanding (see Herce Reference Herce2019), this usually refers to the type frequency of a class or pattern. Thus, most times (see Table 4), the 3sg.prs form of an English verb differs from its prs form through the addition or subtraction of a word-final /z/, which is why this (∅ ⇌ _z in Table 4) is considered the most regular formation. A reasonable way to operationalize regularity, thus, is to count how many times a morphological alternation is found across the lexicon. Among the forms in Table 4, ∅ ⇌ _z appears three times, while _v ⇌ _z and _u ⇌ _ʌz appear only one time. Since we are discussing historical analogical change, however, we cannot lose sight of the fact that it is the expected historical regularity that can logically play a role. That is, it is not the regularity of modern French forms (see the ‘French form’ column in Table 3) that we should use to check if regularity predicts analogy, because many synchronically regular forms are so due to analogical change. Rather, it is the regularity of expected French forms (‘CFR’ in Table 3) that might logically act as a predictor or trigger of historical analogical change. To calculate the regularity of individual forms we need to calculate, as in a greatly expanded Table 4, whole-system patterns and their counts, which we can do for the CFRed inflected lexicon just as easily as for the Latin and French cognate lexicons.
Morphological regularity (degree of gray shading corresponds to the number in parentheses) in partial paradigms of five English verbs, as measured from the type frequency of alternations.

Table 4. Long description
The table has seven columns and five rows. The first column lists verbs: team, lean, lead, have, do. The next three columns show forms: present, third person singular present, and past, each with a phonological form and a number in parentheses indicating type frequency. For ‘team’: present is tim (5), third person singular present is timz (6), past is timd (5). For ‘lean’: lin (5), linz (6), lind (5). For ‘lead’: lid (4), lidz (4), led (2). For ‘have’: h a e v (2), h a e z (4), h a e d (4). For ‘do’: d u (2), d turned v z (2), d small capital i d (2). The last three columns show alternation types with arrows and numbers in brackets. For ‘team’ and ‘lean’, present to third person singular present is empty set double-headed arrow underscore z [3], present to past is empty set double-headed arrow underscore d [2], third person singular present to past is underscore z double-headed arrow underscore d [3]. For ‘lead’, present to third person singular present is empty set double-headed arrow underscore z [3], present to past is underscore i underscore double-headed arrow underscore e underscore [1], third person singular present to past is underscore i z double-headed arrow underscore e underscore [1]. For ‘have’, present to third person singular present is underscore v double-headed arrow underscore z [1], present to past is underscore v double-headed arrow underscore d [1], third person singular present to past is underscore z double-headed arrow underscore d [3]. For ‘do’, present to third person singular present is underscore u double-headed arrow underscore turned v z [1], present to past is underscore u double-headed arrow underscore small capital i d [1], third person singular present to past is underscore turned v z double-headed arrow underscore small capital i d [1]. Degree of gray shading in each cell corresponds to the frequency number in parentheses.
Software is available nowadays to address these matters computationally over large data sets. Here we use Beniamine’s (Reference Beniamine2018) Qumin scripts to extract morphological alternations (such as _u ⇌ _ʌz) from whole unsegmented inflected forms. This way we avoid having to choose between different theoretically motivated options of stem-suffix segmentation, and we make calculations replicable. Qumin’s algorithm works in terms of pairs of forms, as displayed in Table 4. For every pair of forms across all lexemes (e.g. in Table 3, FinIndPresAct2Plur /ame/ and FinIndPresAct2Sing /ɛm/, or FinIndPresAct2Sing /ɛm/ and FinIndPresAct3Plur /ɛm/), it calculates the shortest and most generalizable way to transform one form into the other. This would be ɛ_ ⇌ a_e and ∅ ⇌ ∅, respectively, in the aforementioned pairs of forms from amare. The former alternation occurs in five verbs in our lexicon, the latter in 253. The former alternation can hence be said to be much less regular than the latter. To obtain a measure of regularity per form, rather than per pair of forms, we simply add the type frequency of all the pairs of cells in which a given form is involved. In our toy example from English verbs in Table 4, this would quantify the regularity of teams /timz/ as 3 + 3 = 6, that of had /hæd/ as 1 + 3 = 4, and that of does /dʌz/ as 1 + 1 = 2. Turning to our more complex expected-French data set, the regularity of FinIndPresAct2Plur /ame/ will be determined by the average regularity of its alternations with all other word forms in its paradigm: with FinIndPresAct2Sing /ɛm/ (as above), and with the other thirty-six cells in its paradigm. The resulting metric (the sum of all by-pair type frequencies) must vary in our lexicon between 11,285Footnote 5 and 37, and can be transformed into and understood as a 0 to 1 metric by dividing by the former number. That is, the regularity of a form will be operationalized here as the proportion of all equivalent forms from other verbs that behave like it against other forms.
Regarding whole-system complexity, the aforementioned Qumin (Beniamine Reference Beniamine2018) allows us to also calculate predictive uncertainties such as the conditional entropies associated with predicting each form from every other form in the paradigm. Just as this software’s output can be used to calculate form-level regularity, it can also be used to calculate whole-system properties and averages. When it comes to complexity, the emergent consensus in the field is that pursuit of a single unified measure of morphological complexity (let alone whole-language complexity; see Miestamo Reference Miestamo2008, Deutscher Reference Deutscher, Sampson, Gil and Trudgill2009) is something of a wild goose chase. Different aspects of complexity can vary independently and have to be measured accordingly (see e.g. Stump & Finkel Reference Stump and Finkel2013). Here we analyze the following aspects in our Latin, expected French, and observed French inflected lexicons.
-
(i) Average conditional entropy, which is equated with ‘integrative’ complexity by Ackerman and Malouf (Reference Ackerman and Malouf2013), informs us about what the average uncertainty is of predicting the form of one cell given knowledge of another cell, and given knowledge of the language’s inflectional system. Given the paradigm size we work with (see Figure 1, left) we obtain a matrix with 38*37 conditional entropies, whose average and distribution we can analyze.
-
(ii) Concerning the distribution of conditional entropies, one of the aspects we can examine is the number of interpredictability areas within the paradigm (a.k.a. ‘distillations’ in Stump & Finkel Reference Stump and Finkel2013). These are all those (groups of) cells that behave differently in their allomorphic relation to other cells. In the three partial subparadigms in Table 3, for example, FinIndPresAct2Sing and FinIndPresAct3Sing are always predictable from each other (they are syncretic, and hence always have an alternation ∅ ⇌ ∅, while other pairs of cells contrast in different ways in different verbs.
-
(iii) Number of inflectional (micro)classes is the number of (classes of) verbs that are morphologically different in at least one alternation in their inflectional paradigm. Going back to the verbs in Table 3, for example, the alternation between the observed French FinIndPresAct3Plur /ɛm/ and FinIndPresAct2Plur /ɛme/ is the same as between the equivalent forms of the verb attendere, that is, /at̪ɑ̃d̪/ and /at̪ɑ̃d̪e/. The alternation between FinIndPresAct3Plur and FinIndPresAct3Sing, however, is different in the two verbs: /ɛm/-/ɛm/ vs. /at̪ɑ̃d̪/-/at̪ɑ̃/. Along with providing the overall number of classes, we can also, as before, analyze distributional properties of allomorphy, for example, measuring the morphological similarity between classes, by counting the number of pairs of cells in which they behave differently.
-
(iv) The average prevalence of allomorphy in an inflectional system can be measured through the difference between the morphological alternations (see Table 4) of different lexemes. The morphological difference between two lexemes can be measured by counting the number of times they have different alternations. The verbs ‘team’ and ‘lean’ in Table 4, for example, always have the same alternations and their distance is hence zero, while ‘lean’ and ‘lead’ differ in two alternations, and ‘lead’ and ‘have’ differ in all three of them. In our French data set this will be a count measure from 0 to 703, which is the total number of cell-to-cell pairs in our paradigms ((38*37)/2). We are hence able to express this measure as a percentage, and average across all lexeme pairs to obtain a whole-system average.
-
(v) Although patterns of allomorphy have been much more prominent in the study of morphological complexity, syncretism and expressivity provide a complementary dimension of complexity to explore. The average number of distinct word forms per verb, for example, is an easily accessible metric of the ‘enumerative’ complexity (Ackerman & Malouf Reference Ackerman and Malouf2013) of different systems. Notice how expected amare and auscultare in Table 3 have one additional morphologically distinct word form compared to attendere. The number of patterns of syncretism provides an alternative, easily accessible metric of whole-system complexity. In relationship with debates regarding the autonomy of morphology (Luís & Bermúdez-Otero Reference Luís and Bermúdez-Otero2016), it could also be interesting to calculate the degree of semantic and morphosyntactic affinity (i.e. number of shared morphosyntactic values) of syncretic vs. nonsyncretic forms.
5. Results
5.1. Predictors of morphological change
Linguists have long explored which aspects explain the timing and direction of analogical changes in paradigms (Kuryłowicz Reference Kuryłowicz1945, Mańczak Reference Mańczak1957). It is well established that the FinIndPresAct2Plur form of amare in French, for example, underwent analogical change historically (see the difference between expected /ame/ and observed /ɛme/ in Table 3). Plausible motivations can almost always be found for such changes. In this case, change from /a/ to /ɛ/ might have occurred through analogy with other forms in the paradigm (e.g. 3sg /ɛm/) that had the latter stem vowel, and on the basis of verbs (e.g. attendere and auscultare in Table 3) that had the same stem vowel across the paradigm. Multiple other unattested changes, however, would have been possible given this same configuration; for example, a spread of stem vowel /a/ to /ɛm/ (instead of the other way around), or a spread of /a/-/ɛ/ stem-vowel alternation to other verbs (instead of the disappearance of the alternation from the verbs where it emerged). Morphological change need not have occurred at all, of course, as the preservation of stem alternations and irregularities is also perfectly possible and not uncommon. Thus, although some dissenting voices can be found,Footnote 6 analogy is widely believed to be a capricious, relatively unpredictable force (cf. Sturtevant’s Reference Sturtevant1947 paradox) for which only tendencies can be identified.
Frequency and morphological irregularity have been widely claimed to be among the main factors that drive analogical change (Lieberman et al. Reference Lieberman, Michel, Jackson, Tang and Nowak2007, Carroll et al. Reference Carroll, Svare and Salmons2012, Sims-Williams Reference Sims-Williams2022). However, their strength as predictors has never been analyzed quantitatively in large data sets. Furthermore, while plausibly all languages display an inverse correlation between frequency and morphological irregularity (Wu et al. Reference Wu, Cotterell and O’Donnell2019), disagreement exists concerning the evolutionary dynamics that create or maintain this configuration. While the preferential morphological regularization of low-frequency items is widely acknowledged, some authors believe that irregularization of very high-frequency items also plays a role (see Nübling Reference Nübling2011, Juge Reference Juge2013). Extremely high-frequency forms, for example, seem to often be irregularly shortened (see Dahl Reference Dahl2004:157, Bybee et al. Reference Bybee, File-Muriel and de Souza2016, Herce & Cathcart Reference Herce and Cathcart2024). Short irregular forms could have cognitive advantages in high-frequency environments, for example, due to their faster processing because of earlier uniqueness points (see Luce Reference Luce1986, Balling & Baayen Reference Balling and Baayen2012). Through our present data set, we could check if the likelihood of historical analogical change decreases monotonically with frequency, or whether this proportion is lowest in mid or mid-high frequencies instead, and rises again for extremely-high-frequency items.
In addition to frequency and morphological regularity, other factors may plausibly play a role and can be investigated as predictors. Markedness (see Jakobson Reference Jakobson1941, Tiersma Reference Tiersma1982, Andrews Reference Andrews1990, Battistella Reference Battistella1990, Andersen Reference Andersen and Andersen2001, Reference Andersen and Andersen2011), for example, has been argued to favor some values as pivots of morphological change. Watkins (Reference Watkins1962:96), most famously, argued that analogical morphological changes often have worked in a way that the third-person (singular) form has provided a basis for analogical change in other persons. In Polish, for example, Proto-Indo-European *h₁ésmi ‘I am’, *h₁ési ‘you are’, and *h₁ésti ‘(s)he is’ have developed into jestem, jesteś, and jest, respectively. The /t/ that used to be a mark of just the third person has spread analogically to other forms, and third person has become zero-marked. Similar developments are reported in other languages. If the third person is conceptualized as the ‘nonperson’, singular as the ‘nonnumber’, present as the ‘nontense’, and so forth, different values might be inherently more or less likely to undergo analogical restructuring by virtue of their semantic elaboration. Alternatively (see Haspelmath Reference Haspelmath2006), such trends could be accounted for through the higher frequency of third person, singular, or present compared to other values. Here we explore the possible role of markedness by exploring ‘third’, ‘singular’, and ‘present’ values (i.e. the unmarked values of person, number, and tense, respectively; see Tiersma Reference Tiersma1982) as predictors of analogical change.
One last factor we would like to explore as a possible predictor of analogical change is, perhaps counterintuitively, sound change. In their evolution from Latin to French, different word forms have undergone a different number of modifications due to regular sound change (ranging from six to fifty-one in our data set). There are various reasons to explore this as a possible predictor of analogy. The first is the possibility that there is a genuine causal association by which more sound changes lead to more analogical changes. If, as sometimes portrayed, analogy is a reactive force that cleans up the ravages of sound change (Paul Reference Paul1880, McMahon Reference McMahon1994:70), sound change could play a direct/causal role. A related reason is the possibility of paradigmatic resistance to sound change (see e.g. Malkiel Reference Malkiel1960, Reference Malkiel1976, Anttila Reference Anttila1989:77–84, Campbell Reference Campbell, Durie and Ross1996, Blevins & Wedel Reference Blevins and Wedel2009, Hill Reference Hill2014, Pierce Reference Pierce2016). This is a much-discussed phenomenon whereby a sound change can be resisted when morphological structure clashes with it.Footnote 7 Such analogical resistance, the same as change, would also cause a divergence between expected and observed forms in our method. If we understand every sound change as a hurdle against which a form may occasionally stumble, more hurdles will correspond to more divergences between predicted and observed forms. A final reason to add the number of historical sound changes that a word has undergone as a predictor of historical analogy would be to absorb/control for the effect of possible mistakes in our sound change cascade. Although 1,000+ items were used in its set-up and calibration (see Marr & Mortensen Reference Marr and Mortensen2023), the possibility remains that some regular sound changes have been missed or incorrectly posited. A more complex phonological history makes mistakes, and hence discrepancies between expected and observed forms, more likely.
To analyze whether all of these predictors (i.e. token frequency, regularity, sound changes, and markedness) have an effect on the likelihood of historical analogical change, we fit a Bayesian beta regression model using the brms interface (Bürkner Reference Bürkner2018) in R to Stan (Carpenter et al. Reference Carpenter, Gelman, Hoffman, Lee, Goodrich, Betancourt, Brubaker, Guo, Li and Riddell2017). Zero inflated beta regression was chosen due to its suitability when the predicted variable is a proportion (as is our proxy for historical analogical change, normalized FED) but contains many zeros. We use a logit link for the mean (mu) and an identity link for the precision parameter (phi). To account for hierarchical structure in the data, we include random effects (random intercepts and slopes) for both cell and lemma.Footnote 8 We ran four Markov chain Monte Carlo (MCMC) chains, each running for 4,000 iterations with a 1,000-iteration warmup. Convergence diagnostics indicated that the model converged successfully (all R̂ = 1.00). Results are reported in Table 5, with main effects for which a decisive effect has been found in bold. These are also displayed visually in Figure 2.
Results of the model analogy ~ freq + regul + sound + third + singular + pres + (1 + freq + regul + sound | cell) + (1 + freq + regul + sound | lemma).

Table 5. Long description
From the top row downward, the predictors are cell and lemma, both categorical random effects with intercept estimates of 0.54 (confidence interval 0.42 to 0.70) and 0.84 (confidence interval 0.75 to 0.94), respectively. The next three rows highlight fixed effects: frequency, regularity, and sound change. Frequency is measured as log historical token frequency of a word form, estimate minus 0.02, confidence interval minus 0.04 to minus 0.01. Regularity is the proportion of lexicon with same morphology, estimate minus 2.02, confidence interval minus 2.80 to minus 1.21. Sound change is the number of historical sound changes undergone, estimate 0.02, confidence interval 0.01 to 0.02. The final three rows are dichotomic predictors: third person (estimate 0.00, confidence interval minus 0.25 to 0.25), singular number (estimate minus 0.01, confidence interval minus 0.21 to 0.19), and present tense (estimate minus 0.09, confidence interval minus 0.39 to 0.21). Significant effects are observed for frequency, regularity, and sound change, with regularity showing the strongest negative association.
Model predictions: likelihood of analogical change (y-axis) as a function of log frequency, regularity, and the number of sound changes (x-axis of each panel).

Figure 2. Long description
The left panel plots ANALOGY on the y-axis against FREQ on the x-axis, showing a downward-sloping blue line with a shaded confidence band, indicating that higher frequency corresponds to lower likelihood of analogical change. The middle panel plots ANALOGY versus REGUL, also showing a downward-sloping blue line with a shaded band, indicating that higher regularity is associated with lower likelihood of analogical change. The right panel plots ANALOGY versus SOUND, showing an upward-sloping blue line with a shaded band, indicating that a greater number of sound changes corresponds to a higher likelihood of analogical change. All axes are labeled in uppercase. The shaded regions represent confidence intervals around the model predictions.
As Table 5 shows, the 95% highest (posterior) density intervals of frequency, regularity, and sound change do not overlap with zero, suggesting that these factors are significant predictors of historical analogical change on a given word form. The effects of the main variables are largely as expected from previous literature: more token frequency correlates with less historical analogical change (see left panel of Figure 2). This appears to be a monotonic effect across all frequencies. Some researchers (most notably Nübling Reference Nübling1999, Reference Nübling2011) have argued that irregularization, often associated with shortening (see Herce & Cathcart Reference Herce and Cathcart2024), might be common in extremely-high-frequency words and morphemes (see also Dahl Reference Dahl2004:157, Bybee et al. Reference Bybee, File-Muriel and de Souza2016). This would translate into a U-shaped distribution by which intermediate frequencies disfavor analogy, but both very low and very high frequencies are associated with more change. This is not what we find in our current data set (see Figure 3, left). Although the effect of frequency does level off at the highest-frequency ranges, higher frequency seems to always (i.e. at all ranges) be associated with less analogical change.
Observed relationship between analogy and frequency, regularity, and sound changes.

Figure 3. Long description
From left to right, the first panel plots Analogy on the y-axis from 0.00 to 0.15 against Frequency on the x-axis from 0 to 15. Data points are densely clustered at low frequency, with a blue trend line showing analogy decreases as frequency increases, then slightly rises at the highest frequencies. The second panel plots Analogy versus Regularity from 0.00 to 0.35. Data points are spread across the range, with the blue trend line showing analogy decreases as regularity increases. The third panel plots Analogy versus Sound changes from 0 to 50. Data points are distributed throughout, with the blue trend line showing analogy increases as sound changes increase. All panels include a shaded confidence interval around the trend line.
The general effect of regularity is also supported by our present results. More regularity—in other words, higher type frequency—decreases the probability of analogical change (see the middle panel of Figure 2). This makes sense if we think of analogical change as an overwhelmingly regularizing force. When an irregular word form (e.g. Eng. holp) fails to be memorized and is produced by rule, change ensues (i.e. helped), but when a regular word form (e.g. started) fails to be learned by rote and is produced by rule (i.e. analogically), this results in no change to its original form (i.e. started). The overwhelmingly regularizing effect of analogy must hence be the reason for our present results that more irregular words undergo more analogical change, as well as for the general correlation of regularity and frequency in language (see Lieberman et al. Reference Lieberman, Michel, Jackson, Tang and Nowak2007, Wu et al. Reference Wu, Cotterell and O’Donnell2019).
Besides these most frequently discussed predictors, we also observe a significant effect of historical sound change in our data set. That is, the more sound changes are predicted to affect a word historically, the more likely it is for this word to undergo historical analogical change. This effect is displayed in the third panel of Figure 2. The interpretation of this result is quite complicated. As advanced in Section 5.1, there could be various compatible reasons for this result, which are discussed in Section 6.
In contrast to the aforementioned predictors, morphosyntactic ones (i.e. value ‘markedness’) have not been observed to significantly impact historical analogical change. Thus, the unmarked value (i.e. 3, sg, prs) has not been found to be less prone to analogical change once other predictors like frequency are taken into account. Properties like markedness, therefore, do not seem to significantly predict the direction of analogical change. Morphosyntactic values and cells, the same as lexemes, matter (note that the two random effects of our model have been found to have decisive effects). This is expected because analogical changes of course tend to be sensitive to them. The onset replacement to esk- in auscultare (see Table 3), or from aper- to oper- in aperire, happened within the confines of particular lexemes. Similarly, the analogical spread of inflectional markers (e.g. -ɔ̃ for the 1pl) tends to be similarly confined to a particular morphosyntactic value or set of values. However, concrete values such as (un)marked ones have not been observed here to consistently promote or inhibit analogy.
5.2. Complexity effects of sound change and analogy
Sound change and analogical change are generally considered forces with opposite effects regarding the evolution of morphological complexity in paradigms. Sound change is phonologically regular but generates irregularity at the morphological level. Conditioned sound changes in particular generate unpredictable allomorphy and lexeme-specific patterns that increase the overall irregularity and complexity of an inflectional system. Analogical change, by contrast, is morphologically motivated and is thought to work generally toward the elimination of exceptions and the extension of more generally applicable morphological patterns, hence increasing the regularity of an inflectional system over time. There has been a basic agreement over this matter at least since Neogrammarian times, but there has never been a large-scale empirical investigation of these supposedly general trends over long periods of time. Furthermore, as explained in Section 4, we tend to distinguish different types of morphological complexity nowadays. Exploring the effect of different forces over different aspects of complexity, and doing so with real language data rather than with artificial language experiments or simulations, constitutes a necessary step forward in the study of morphological diachrony. In this section we measure the effects of these forces on the measures described in Section 4. For the calculation of morphological complexity measures we chiefly rely on Beniamine’s (Reference Beniamine2018) software Qumin.
Table 6 shows the whole-system complexity as measured in our inflected lexicons for Latin, expected French, and observed French. Our method allows us to interpret the differences between Latin and expected French as the product of sound change, and the differences between expected and observed French as the product of analogical change.
Complexifying (gray) vs. simplifying (white) effect of historical sound change and analogical change on various morphological aspects of the French verbal inflectional system.

Table 6. Long description
Starting from the top row, the table lists five complexity metrics in the leftmost column: inflection classes, interpredictability areas, prevalence of allomorphy, forms per verb, and conditional entropy. For each metric, values are given for Latin, expected French, and observed French. The next two columns show the effect of sound change and the effect of analogy, with gray cells indicating complexifying effects and white cells indicating simplifying effects. Inflection classes: Latin 107, expected French 239, observed French 65, sound change plus 123 percent, analogy minus 73 percent. Interpredictability areas: Latin 14, expected French 27, observed French 14, sound change plus 93 percent, analogy minus 48 percent. Prevalence of allomorphy: Latin 62.3 percent, expected French 85.5 percent, observed French 60.3 percent, sound change plus 37.3 percent, analogy minus 29.5 percent. Forms per verb: Latin 37.86, expected French 18.75, observed French 14.5, sound change minus 50 percent, analogy minus 23 percent. Conditional entropy: Latin 0.218, expected French 0.235, observed French 0.276, sound change plus 8 percent, analogy plus 15 percent. The table visually distinguishes complexifying effects (gray) from simplifying effects (white) in the last two columns.
Concerning the number of inflectional (micro)classes, among the verbs and cells in our data set we have 107 different inflectional microclasses in Latin, 239 in expected French, and sixty-five in observed French. Sound change has hence increased the number of classes (e.g. through conditioned sound changes that create lexeme-to-lexeme morphological differences), while analogical change has starkly counteracted the complexifying effect of sound change and has reduced the number of classes dramatically. A similar result is found concerning the number of predictability areas or distillations in Romance, as Latin had fourteen, expected French has twenty-seven, and observed French has fourteen. Regarding the degree of allomorphy, we again obtain a similar picture. The average morphological distance between lexemes was 438 in Latin, 601 in expected French, and 424 in observed French. Expressed as a percentage of the 703 total cell-to-cell pairs in our paradigms, we obtain 62.3% allomorphy in Latin vs. 85.5% in expected French vs. 60.3% in observed French. Regarding the related matter of syncretism, we find that both sound change and analogy reduce the average number of distinct word forms per verb, which was 37.86 in Latin, 18.75 in expected French, and 14.5 in observed French. Finally, concerning average conditional entropy, the role of sound change and analogical change seems modest at best. The average conditional entropy between the Latin verbal forms in our data set is 0.218 bits, while this is 0.235 in expected French and 0.276 in observed French.
Based on these results, the traditional intuition (Paul Reference Paul1880, Sturtevant Reference Sturtevant1947) that sound change complexifies inflectional paradigms while analogy simplifies them holds true for multiple aspects of complexity. The number of inflection classes, the number of morphological interpredictability areas within the paradigm, and the degree of allomorphy all increase (i.e. complexify) substantially through the application of regular sound changes, and decrease substantially (i.e. simplify) through the effect of analogical morphological change. Given the logically maximum number of inflectional classes (310, the number of lemmas) and interpredictability areas (thirty-eight, the number of cells), the differences between Latin and expected French (i.e. the effect of sound change), and between expected French and observed French (i.e. the effect of analogical change), are statistically significant (p < 0.01) according to a chi-square test. When it comes to the prevalence of allomorphy, a chi-square test on the underlying proportions shows that these differences are also statistically highly significant (p < 0.0001).Footnote 9 This therefore constitutes an empirical quantitative validation of qualitatively and impressionistically deduced tendencies that are almost as old as the discipline. After two millennia of historical sound changes and morphological analogy, French has ended up with similar levels of complexity as Latin on its inherited lexicon, but this is only because, in most aspects, the complexifying impact of sound change was neutralized by the simplifying effect of analogy.
While the traditional insights of historical linguists have been confirmed for some types of complexity, this does not apply to all types. The expressivity of an inflectional system, that is, the number of distinct word forms in the paradigm, for example, is a variable on which both sound change and analogy have been found to operate in the same direction in the history of French: toward simplification. This is the only possible effect for sound change, as only mergers, and not unconditioned splits, are possible through regular sound change. That is, while two formerly different words can merge due to regular sound change, two identical words can never become different. This means that a reduction in the number of distinct word forms is the only possible outcome of sound change. Our data also show, however, the very much nontrivial fact that analogical change has ‘played along’ and contributed a further reduction in the number of different word forms in the French verbal paradigm. This finding is discussed in more detail in Section 6.3.
The last, and possibly most striking, result displayed in Table 6, however, is that sound change and analogy do not seem to have a robust effect upon complexity as measured by conditional entropy. A Bayesian Gaussian regression with random effects (intercepts) for predictor and predicted cell fit with brms finds that differences in conditional entropies between Latin and expected French (i.e. sound change), and between expected and observed French (i.e. analogy), were not significantly different from zero. This finding and its possible explanations and implications are further discussed in Section 6.3.
6. Discussion
6.1. Discussion of methodology
This article has presented a novel method to explore morphological and paradigmatic diachrony. It is a method, we believe, that harnesses the best qualities of the approaches currently most prevalent in the field. It combines the use of actual historical language data that traditional approaches have generally relied on with the large (potentially exhaustive) data quantity and replicability that modern experimental methods afford. Our method could be thought of as intermediate between two previously irreconcilable alternatives, the first involving the analysis (quantitative or qualitative) of a comparatively small set of observed historical analogical changes (Fertig Reference Fertig2000, Lieberman et al. Reference Lieberman, Michel, Jackson, Tang and Nowak2007, Sims-Williams Reference Sims-Williams2022), and the second relying on the analysis (usually quantitative) of large volumes of artificial, simulated, or experimentally produced analogical changes (e.g. Reali & Griffiths Reference Reali and Griffiths2009, Atkinson et al. Reference Atkinson, Smith and Kirby2018, Round et al. Reference Round, Esher and Beniamine2025). In this article, by contrast, we employ large/exhaustive volumes of inferred historical analogical changes.
For this inference we require documented ancestral and modern cognate word forms and a sound change cascade that recapitulates the effect of regular historical sound change between the two points in time. As described in Section 4, morphological differences between the expected (e.g. 2pl.prs ‘love’ /ame/) and the observed modern forms (e.g. /ɛme/) should correspond to historical analogical change. While this inference is certainly not perfect (we cannot discard, for example, inexactitudes in our cascade, or the existence of historical analogical changes that generate no differences in morphological outcome), we are confident that our method approximates actual historical analogical change enough to observe broad long-term evolutionary tendencies and test diachronic hypotheses on sound change and analogy. The added data volume, automation, and tractability that this method affords compensates the reduction in granularity with respect to traditional approaches. This is particularly so because the limited amount of historical linguistic data has been one of the main bottlenecks curtailing robust empirical findings in the field of morphological diachrony and language change more generally. Relative to simulations and artificial language learning experiments, in turn, the present approach has the advantage of exploring actual language data, with the corresponding gain in ecological validity and interpretability.
In this article we focus on the evolution of verbal inflection from Classical Latin to modern French. We annotated the most complete extant inflected lexicons of Latin and French verbs for the etymological relations between paradigm cells and lemmas in the two languages. This allowed us to obtain a large number of Latin-French word pairs. Focusing on the directly inherited sublexicon only, we obtained over 300 complete verbal paradigms and over 11,000 word forms. Form-to-form and system-to-system differences between these cognate paradigms will be due to the combined effect of both (i) sound change and (ii) analogical change.Footnote 10 To be able to separate the effects of these two forces, we make use of computerized forward reconstruction; that is, we apply to the Latin forms a sequence of Latin-to-French regular sound changes (also known as a ‘cascade’) arrived at independently for the exploration of historical phonology (Marr & Mortensen Reference Marr and Mortensen2023). This leaves us with a triad of forms for each of our 11,000+ data points, where the observed Latin and French forms (e.g. Latin /amaːtis/ and French /ɛme/) can be compared with the expected French forms (e.g. **/ame/).
As Figure 4 illustrates, the contrast between observed Latin and expected French forms will approximate the effect of historical sound change, either at the level of concrete forms or at the level of the inflectional system. Comparing expected French forms and observed French forms, in turn, will approximate the effect of historical analogical change. This allows us to investigate the accumulated effects of both forces over paradigmatic morphology and morphological complexity over long periods of time.
Key rationale of our change-inference method.

While in this article we have disregarded the emergence and extinction of inflectional forms and lexical items to focus on the effects of sound change and analogy upon cognate forms, the effect of these other processes (e.g. borrowing, grammaticalization, loss of inflection, word obsolescence) is likely to be just as important for understanding paradigmatic change. The etymological pairing of inflected lexicons and the quantification of the effects of sound change and analogy could be considered a first step toward the exploration of the predictors and effects of these other processes. For example, it is likely but yet unverified that borrowing, internal derivation, and grammaticalization mostly introduce regularity into the inflectional system. It is less clear what the effect might be of the loss of inflection or the obsolescence of lexemes. Although research is scarce, some (e.g. Prins Reference Prins1941, Elerick Reference Elerick2016) have argued that very short or highly homophonous words (e.g. Lat. eō ‘go’, ōs ‘mouth’) are more likely to be replaced by longer words (but see Wichmann & Holman Reference Wichmann, Holman, Borin and Saxena2013). Highly irregular lexemes (e.g. Lat. ferō ‘bear’) and word forms could also be more prone to being replaced (as well as more prone, of course, to being analogically reshaped).
Not much research has been conducted on the paradigmatic effects of sound change either, and as a result, few claims have been made about possible paradigmatic predictors or effects of sound change. This, along with the necessity to narrow down our domain of study in this article, is the reason why we have concentrated primarily on analogical change. We believe, however, that the relative absence of research on the paradigmatic effects of sound change is not due to the topic’s lack of interest. A possibility that has been occasionally mentioned, for example, is that sound changes, in inception or propagation, may be influenced by extra-phonetic factors like functional load or homophony (see Janda & Joseph Reference Janda, Joseph, Blake and Burridge2003, Wedel et al. Reference Wedel, Kaplan and Jackson2013, Ceolin Reference Ceolin2020, Round et al. Reference Round, Dockum and Ryder2022). Hence, it might be that the extant lexicon and paradigms influence the likelihood of sound changes, so that those which result in more (uncomfortable) homophony are less likely. Measuring the effects of observed historical sound changes compared to alternative randomized sound change cascades might be a way to explore in future work whether this is the case.
6.2. Discussion of the predictors of analogy
While other sources of change, and their predictors and repercussions, have been less extensively explored, abundant research has addressed morphological analogical change. Here we have analyzed the possible impact of the most frequently discussed predictors of analogy. Statistical analysis of analogical change in the diachrony of our 11,593 forms presents highly significant effects of token frequency, regularity, and sound changes. Token frequency has been a commonly discussed predictive factor, going back at least to Mańczak’s (Reference Mańczak1957) ‘fourth tendency’, but discussed also in abundant research thereafter (e.g. Bybee Reference Bybee1985, Lieberman et al. Reference Lieberman, Michel, Jackson, Tang and Nowak2007). Here, we have found that the (log) frequency of a word is negatively correlated with historical analogical change. The conserving effect of frequency appears to be stronger at the lower-frequency ranges and flattens at the higher-frequency ranges. That is, while extremely-high-frequency items are only a little less likely than very-high-frequency items to undergo analogical change, there is a substantial difference in the likelihood of analogy in extremely-low-frequency vs. low-frequency items. Despite some suggestions (e.g. Nübling Reference Nübling2011) that extremely high token frequency might promote analogical irregularization and shortening, this does not appear to be the case in our data set.
Regularity, or in other words type frequency, has also been a major factor discussed in the literature of analogical change (e.g. Hare & Elman Reference Hare and Elman1995, Cotterell et al. Reference Cotterell, Kirov, Hulden and Eisner2018). Here, we also found it to be a highly significant predictor of historical analogical change. More morphological regularity has been found to be associated with less analogical change. This is unsurprising, as most analogical changes are regularizations, that is, they involve replacing exceptional low-type-frequency forms (e.g. holp as the past of help in English) with unexceptional high-type-frequency forms (like helped). While analogical irregularization does occur (e.g. Eng. dived > dove), this seems generally limited to phonologically similar items (Prasada & Pinker Reference Prasada and Pinker1993, Albright Reference Albright2002a) and small morphological gangs (Herce Reference Herce2020). Our results that analogy and regularity are inversely correlated in the history of French suggest that analogical regularization must be much more frequent than analogical irregularization. Although the extant literature might overreport regularizations (and sometimes even incorrectly identify a form as the ancestral one simply because it is the irregular one; see Fertig Reference Fertig2013:80–83), our data suggest that analogical regularizations must decisively outnumber analogical irregularizations. Note, however, that the full role of morphological regularity as an inhibitor of analogical change emerges only once the effect of frequency is taken into account, since, as it is well known (see e.g. Wu et al. Reference Wu, Cotterell and O’Donnell2019), frequency and morphological regularity are inversely correlated in natural languages.
Given that, as our results suggest, analogical regularization (i.e. transfer from a smaller to a larger class) is more frequent than analogical irregularization, we must reflect on why more regular items are found to be targeted less by analogy. Fertig (Reference Fertig2013:77) and others have argued, and we agree, that this must be due to a greater chance of ‘analogical nonchange’ in items that are already regular. That is, speakers of English might well produce the past tenses of starve, belay, infer, and so forth analogically (i.e. by rule, rather than through retrieval of a memorized form). In verbs that are already inflected in the most common way, however, this analogical recreation of the past form would lead, in practice, to no surface change. That is, even if analogy, understood as rule-generation, were just a matter of token frequency (Stemberger & MacWhinney Reference Stemberger and MacWhinney1986), we would still find more analogical change in more irregular verbs due to the prevalence of analogical regularization.
Morphosyntactic markedness has also featured among the factors that have been claimed to influence the direction of analogical change (see e.g. Tiersma Reference Tiersma1982). Kuryłowicz’s (Reference Kuryłowicz1945) ‘second law’ claims that the least marked form in a morphosyntactic opposition is less prone to analogy. Here we did not find markedness to have a consistent effect, as values like third person or singular number were not less prone to analogy once the crucial confound of token frequency was taken into account. For full disclosure, a summary of the average amount of historical analogical change across French verb paradigm cells is shown in Table 7.
Average amount of analogical change in different paradigm cells.

Table 7. Long description
From top to bottom, the table lists seven rows for paradigm cells: 1 s g, 2 s g, 3 s g, 1 p l, 2 p l, 3 p l. Each row contains eight columns. The columns, from left to right, are Imp Pres, Ind Pres, Sub Pres, Ind Imp, Ind Past Perf, Sub Pqp Perf, an unlabeled column, and cell type. For 1 s g, values are dash, 0.040, 0.044, 0.091, 0.079, 0.091, 0.034, Gdv. For 2 s g, values are 0.029, 0.027, 0.050, 0.091, 0.086, 0.091, 0.031, Inf. For 3 s g, values are dash, 0.028, 0.049, 0.091, 0.081, 0.083, 0.038, Part Plur Fem. For 1 p l, values are dash, 0.059, 0.098, 0.096, 0.048, 0.136, 0.042, Part Plur Masc. For 2 p l, values are 0.052, 0.056, 0.060, 0.073, 0.094, 0.080, 0.038, Part Sing Fem. For 3 p l, values are dash, 0.035, 0.037, 0.091, 0.135, 0.086, 0.043, Part Sing Masc. Highest values are found in plural cells, especially in Sub Pqp Perf for 1 p l (0.136) and Ind Past Perf for 3 p l (0.135). Dashes indicate missing data in Imp Pres for all 1 s g, 3 s g, 1 p l, and 3 p l cells.
The idea of the existence of derivational bases in paradigms underlies some of these proposals that certain values could be preferred as models, rather than targets, of diachronic analogical change. While in word-based connectionist models of morphology all forms in a paradigm may have equal standing and exist in bidirectional relation to all other forms, in morpheme-based rule-based models it is often assumed that lexemes have a single stored underlying form from which the rest are derived. While some proposals, like those based on general markedness, argue for universal morphosyntactic bases across languages (e.g. Watkins Reference Watkins1962), others allow for language-specific preferences. Albright (Reference Albright2002b, Reference Albright2010), for example, argued for the central role of morphological predictability in how speakers ‘choose’ their bases within the paradigm. He claims that the most informative/predictive word form in an inflectional system, that which allows for better predictions about the forms/allomorphs of other cells, is usually privileged and left unchanged in processes of analogical change.
This line of thinking is quite compatible with contemporary Word and Paradigm approaches that see conditional entropy as the best measure for PCFP complexity (e.g. Ackerman & Malouf Reference Ackerman and Malouf2013) and as a key contributor to the difficulty of a system for speakers. One might hence expect that analogical change will tend to leave more predictive forms (e.g. ‘principal parts’; see Finkel & Stump Reference Finkel and Stump2007) unchanged and modify other forms instead to achieve a reduction in conditional entropies overall. In the PCFP literature, the predictiveness of a cell refers to how easy it is to guess other cells from it, while the predictability of a cell refers to how easy it is to predict that cell given others. As we measure both in bits here, higher values (i.e. more difficulty of prediction) correspond to less predictability or predictiveness. If Albright is on the right track, we should find a positive correlation between analogy and our operationalization of predictiveness in bits here: that is, all things being equal, cells that are better predictors of other cells should be more resistant to analogical change.
We fit a beta regression model in R (function betareg) to predict the proclivity to analogy of our thirty-eight paradigm cells (see Table 7) on the basis of their respective frequency and their expected predictability and predictiveness. The effect of cell frequency (z-value = −2.436) was found to be highly significant (p = 0.015). High-frequency cells appear consistently to be highly resistant to analogy (see Figure 5, left), although more unpredictable variation is found in the incidence of historical analogy among low-frequency cells. Even at the individual form level, forms belonging to high-frequency cells tend to exhibit decisively lower historical analogical change (see also Bybee & Brewer Reference Bybee and Brewer1980, Albright Reference Albright2010, Kapatsinski Reference Kapatsinski2022).
Correlation of analogical change to frequency (left) and predictiveness (right).

Figure 5. Long description
The left panel is titled Cell frequency and analogy. The x-axis is labeled Log frequency, ranging from 0 to 10. The y-axis is labeled Analogy, ranging from 0.00 to 0.10. A downward-sloping line with a shaded confidence band shows a negative correlation between log frequency and analogy. Data points are labeled with grammatical forms such as SubPqp1Plur, IndPast3Plur, SubPres1Plur, IndPast2Plur, IndPres2Sing, Imperative2Plur, PartPlurMasc, Gerund, Infinitive, and others. Higher analogy values are associated with lower log frequency, and vice versa. The right panel is titled Predictiveness and analogy. The x-axis is labeled Predictiveness, ranging from 0.0 to 0.3. The y-axis is labeled Analogy, also ranging from 0.00 to 0.10. An upward-sloping line with a shaded confidence band shows a positive correlation between predictiveness and analogy. The same set of grammatical form labels is distributed along the trend, with higher analogy values corresponding to higher predictiveness. The spatial arrangement of data points varies between panels, reflecting the different relationships.
The significant effect (z-value = 2.587, p = 0.01) of predictiveness also goes in the direction predicted by Albright: more informative cells were more resistant to change (i.e. lower entropies in the prediction of other cells are associated with lower incidence of historical analogical change). No statistically significant correlation (z-value = −0.322, p = 0.75) was found between predictability and analogy; that is, whether the morphology of a cell is easy or difficult to predict appears to play no role in the likelihood that it is analogically modified.
The last predictor of analogy that was tested in Section 5.1 was, perhaps counterintuitively, sound change. The number of historical sound changes that a word has or should have undergone in its evolution from Latin was found to be positively and significantly correlated with the amount of historical analogical change expected on that word. This finding is open to multiple interpretations. The first involves the greater likelihood of mistakes in the historical-phonological derivation of words through our cascade given greater numbers of historical sound changes. This would be somewhat trivial, and not relevant to understanding analogy per se (although still necessary to include in a complete statistical model to remove this possibly method-derived noise).
A second interpretation would be that more historical sound changes are indeed associated with greater chances and occurrences of historical analogical changes. This is also highly plausible. Every single form adopted by a word over the course of its history (i.e. /ɑmˈɑːte/, /ɑmˈɑːtɛ/, /ɑmˈɑtɛ/ …) existed in a systematic relation to other forms in its paradigm. It might hence be expected that if a word has historically had more different forms, it must be more likely to adopt one that is at odds with other words in its paradigm or dispreferred for any other reason, and hence analogized away. If one conceives of analogical morphological change as a reactive force against sound change, as in the work of Paul and others (more recently see Enger Reference Enger2013 and Adamczyk & Versloot Reference Adamczyk and Versloot2019), this association should not be a surprise. It also seems to hold impressionistically that Romance languages where less sound change has occurred are also more conservative with respect to analogical change, so one might expect the same to hold among different words within a single language.
A final possible interpretation is that not all sound changes are in fact perfectly regular. The phenomenon of ‘lexical diffusion’ is well known (e.g. Labov Reference Labov1981). Some sound changes are argued to occasionally ‘run out of steam’ before the entire lexicon is affected (Wang Reference Wang1969). Some changes might also be occasionally resisted ab initio in specific environments, for example, if the paradigmatic regularity they disrupt is ‘too powerful’ (see fn. Footnote 5) or if they give rise to dispreferred structures like pernicious homophony (Blevins & Wedel Reference Blevins and Wedel2009). No matter how seldom this happens, if it is at all possible it will lead to the presently observed result that there is a positive correlation between the number of historical sound changes and our proxy for historical analogical change, which is the divergence between expected and observed French forms. Under this interpretation, this would not represent analogical change strictly speaking, but analogical resistance to sound change.
We believe all three interpretations are compatible and probably play some role in the presently reported finding that the number of historical sound changes constitutes a powerful and decisive predictor of historical analogical change in our data set.
6.3. Discussion of the effect of analogy on morphological complexity
Turning to morphological complexity, this topic has recently become a focus of considerable discussion in the field, being the subject of numerous volumes and papers (e.g. Miestamo et al. Reference Miestamo, Sinnemäki and Karlsson2008, Stump & Finkel Reference Stump and Finkel2013, Arkadiev & Gardani Reference Arkadiev and Gardani2020). Most research has focused on the measurement and possible causes of differences in morphological complexity between languages. While the jury is still out regarding, for example, the role of societal factors (McWhorter Reference McWhorter2011, Shcherbakova et al. Reference Shcherbakova, Michaelis, Haynie, Passmore, Gast, Gray, Greenhill, Blasi and Skirgård2023), there seems to be an emerging consensus that complexity is a multidimensional concept, and hence that different ‘types’ of complexity need to be measured separately (see Ackerman & Malouf Reference Ackerman and Malouf2013, Stump & Finkel Reference Stump and Finkel2013, Audring Reference Audring2017, Cotterell et al. Reference Cotterell, Kirov, Hulden and Eisner2019, Arkadiev & Gardani Reference Arkadiev and Gardani2020, Kantarovich et al. Reference Kantarovich, Grenoble, Vinokurova and Nesterova2021, Herce Reference Herce, Arkadiev and Rainer2027). This is the approach we have adopted here, identifying various factors that contribute to different types of complexity in an inflectional system: the number of inflection classes in the lexicon, the number of interpredictability areas in the paradigm, the number of different word forms, the prevalence of allomorphy, and the average conditional entropy.
As explained in the introduction to this article, it is an established view in our field that, exceptions notwithstanding, sound change generates morphological and paradigmatic complexity while analogy generates simplicity (Paul Reference Paul1880, Sturtevant Reference Sturtevant1947). Our findings (reported in Table 6) support this assumption when it comes to the number of inflection classes, predictability domains, and the degree of allomorphy. Given the relatively uncontroversial nature of these findings, our main contribution when it comes to these measures is to have validated the core insight of Sturtevant’s paradox with a novel method and with a larger data set than ever used previously. Against this background of mostly agreeing results, two unexpected findings strike us as more surprising and therefore deserving of additional discussion: (i) the analogical spread of syncretism, and (ii) the apparent lack of sensitivity of average conditional entropies to analogy.
6.3.1. Analogical spread of syncretism in French verbs
While the spread of syncretism as a result of regular sound change is the only possibility, and hence a trivial result, our finding that analogical morphological change has contributed a further increase in syncretism in French verbs is a significant one. A finer-grained analysis of this analogically generated syncretism (see Table 8) reveals that it seems modulated by a preference to affect cells that share more values, and a preference to keep distinct cells that differ across multiple semantic or morphosyntactic dimensions (see also Saldana et al. Reference Saldana, Herce and Bickel2022). Due to preexisting morphological similarities in Latin, cells with similar values are expected to syncretize with each other more often through regular sound change. However, this tendency has been boosted significantly by analogical morphological change.
Proportion of syncretism between cells with different numbers of shared values.

Table 8. Long description
From left to right, columns are labeled 2 shared values, 1 shared value, and no shared values. The first row shows Expected French proportions: 0.143 for 2 shared values, 0.054 for 1 shared value, 0.050 for no shared values. The second row shows Observed French proportions: 0.217 for 2 shared values, 0.088 for 1 shared value, 0.052 for no shared values. The third row shows the difference between observed and expected: plus 7.4 percent for 2 shared values, plus 3.4 percent for 1 shared value, plus 0.2 percent for no shared values.
As Table 8 shows, historical morphological change has brought about very little additional syncretism between word forms with no shared values (e.g. 2pl.imp and 1sg.prs). A bootstrapping approach (10,000 samples of size 1,000) fails to reveal a statistically significant difference here (p = 0.41). By contrast, syncretism has spread significantly among forms with one shared value (e.g. 2pl.imp and 1sg.imp) and especially those with two shared values (e.g. 3pl.prs and 3sg.prs), with bootstrapping suggesting statistically highly significant differences in both cases (p = 0.0022 and p = 0, respectively). This is chiefly due to the generalization of syncretism among forms with the same tense-aspect-mood or number value (see e.g. the leveling of sg forms observed in amare (/ɛ̃/ vs. /ɛm/) and auscultare (/ɑku/ vs. /ɑkut̪/) in Table 3). While this is an aspect that tends to be neglected (or outright denied) in much of the Autonomous Morphology literature (e.g. Aronoff Reference Aronoff1994, Maiden Reference Maiden2018), semantic and morphosyntactic values can be seen to play a crucial role in the evolution of morphology and morphological oppositions within inflectional paradigms, and Romance languages are no exception to this (see also Bybee & Brewer Reference Bybee and Brewer1980, Herce Reference Herce2022, Reference Herce2023).
The analogical spread of syncretism in French that we observed in our data set can be interpreted in two compatible ways. The first is that syncretism—or in other words, a ∅ ⇌ ∅ alternation—is a morphological pattern among many others, which happened to become quite frequent in many environments due to regular sound change. Like any other common pattern, it tended to be generalized wherever it was the most common strategy or wherever it was more common than other morphological contrasts. The second way to interpret the analogical spread of syncretism in French is to note the possible relationship to the obligatorification of subject pronouns. That is, the loss of expressivity in the verbal paradigm, initially as a result of sound change, might have driven the obligatorification of pronouns (e.g. Barbosa et al. Reference Barbosa, Duarte and Kato2005, Fuß Reference Fuß, Wratil and Gallmann2011), which in turn allowed for more forms, particularly from the same tense, to become syncretic analogically without an increase in ambiguity.Footnote 11
6.3.2. Analogy does not decrease conditional entropy
Conditional entropy, which has become the most widespread metric in the exploration of the integrative morphological complexity of paradigms and the PCFP (see Ackerman et al. Reference Ackerman, Blevins, Malouf, Blevins and Blevins2009, Ackerman & Malouf Reference Ackerman and Malouf2013), captures the uncertainty that a speaker with a complete knowledge of an inflectional system would face if they had to predict the inflected forms of a newly encountered lexeme. In the illustrative subparadigms displayed in Table 9, for example, predicting an unknown 3sg.prs given a known inf (e.g. hervir ‘boil’) would represent a choice between two equiprobable alternatives. If the infinitive ends with form -er, this translates into a binary choice between diphthongization (-ie-) and no change (-e-) in the 3sg.prs stem vowel. If the infinitive ends with -ir, the choice is between diphthongization (-ie-) and raising (-i-). A choice between two equiprobable alternatives translates into 1 bit of entropy, and this is hence the conditional entropy of the 3sg.prs given the inf in our toy example. Doing the reverse, that is, predicting the inf given a 3sg.prs, is easier in our illustrative subparadigm because 3sg.prs -e- implies inf -er and 3sg.prs -i- implies inf -ir (i.e. entropy is 0), while a 3sg.prs in -ie- can be associated with both -er and -ir in the inf, another binary choice between equiprobable alternatives (i.e. entropy is 1). This means that the average conditional entropy of the inf given a 3sg.prs is 0.5 bits.
Illustrative subparadigms in Spanish. Different fonts and shades of gray indicate different allomorphy.

Table 9. Long description
Starting from the top row, each entry lists the English gloss, Spanish infinitive, and third person singular present form. The first four rows use regular font and lighter shading: ‘lose’ perd-er p-ie-rde, ‘have’ ten-er t-ie-ne, ‘put in’ met-er m-e-te, ‘weave’ tej-er t-e-je. The next five rows use bold font and darker shading, marking allomorphy: ‘lie’ ment-ir m-ie-nte, ‘hurt’ her-ir h-ie-re, ‘surrender’ rend-ir r-i-nde, ‘ask’ ped-ir p-i-de, ‘boil’ herv-ir with a bold question mark in the present form. The table visually differentiates verb classes and stem alternations.
If these complexity measures that have come to dominate quantitative research into paradigm structure translate into cognitive or user-based difficulty or cost, analogical change should probably be expected to tend toward the reduction of conditional entropies. This has been, in fact, quite generally assumed to be the case in quantitative simulations and experimental literature on analogical change (see e.g. Ackerman & Malouf Reference Ackerman and Malouf2015, Smith et al. Reference Smith, Ashton and Sims-Williams2023, Arnon & Kirby Reference Arnon and Kirby2024, Round et al. Reference Round, Esher and Beniamine2025).
Round et al. (Reference Round, Esher and Beniamine2025), for example, conducted simulations of analogical change in paradigms and flagged the fact that previous analogous simulations (e.g. Ackerman & Malouf Reference Ackerman and Malouf2015) yielded a reduction in conditional entropy only through the eradication of allomorphy and inflectional classes. Since we observe that inflectional classes and allomorphy persist over long periods of time (e.g. in Romance; see Maiden Reference Maiden2018), they argue that something must be wrong with the way analogical change has been conceptualized in these earlier models (and, we would argue, traditionally) through attraction only.Footnote 12 Round et al. discover that if one adds some repulsion to the attraction dynamics that characterized previous models, this will result in stable systems of inflectional classes (where all classes have different allomorphs across all cells). They believe this to match better the dynamics observed in natural inflectional systems and conclude that repulsion dynamics hence must play a role in analogical change. Speakers, they argue, might not only make a lexeme more similar to another one it resembles, but also make it more dissimilar from a lexeme that already is morphologically different in other aspects. Consider again the illustrative toy example from Table 9. If we wanted to analogically generate a 3sg.prs form for hervir ‘boil’ from its inf, we might look for evidence only at other verbs that have the same morphology in that cell (i.e. -ir) or also at verbs with different morphology (i.e. -er). In the latter case, the idea would be to analogically favor the morphological solutions observed in verbs with an infinitive in -ir like hervir, and to disfavor the morphological solutions observed in verbs with an infinitive in -er. This is what is referred to as ‘attraction-repulsion dynamics’ (cf. Round et al. Reference Round, Esher and Beniamine2025). Given the tie, in Table 9, between diphthongizing (e.g. m-ie-nte) and raising (e.g. r-i-nde) in the -ir conjugation, repulsion (i.e. the presence of diphthongization but not raising in the ‑er conjugation) would tilt the balance toward a form h-i-rve, rather than h-ie-rve.
While our results on allomorphy (see Table 6) indicate that it has been reduced on average as a result of analogy, the (re)distribution of allomorphy could provide additional evidence in relation to this disagreement surrounding attraction vs. attraction-repulsion dynamics. Attraction-repulsion dynamics predict that dissimilar inflectional classes should become more dissimilar over time as a result of analogical change. In other words, allomorphic distances between the most dissimilar classes should be lower in expected French than in observed French, that is, more similar before than after historical analogical changes, due to the prevalence of repulsion among the most distant inflectional classes. But this is not what we find. First, as Figure 6 suggests, we find a precipitous decline in average verb-to-verb morphological distances as a result of analogical change. If we observe how many pairs of cells (maximally (38*37)/2 = 703) behave differently in every possible pair of verbs ((306*305)/2 = 46,665), we see that, through the accumulation of sound changes, the vast majority of verbs would be expected to end up with different morphological alternations in most cell pairs (see in Figure 6 how most verbs cluster in expected French in the area between 620 and 680 different cell-to-cell alternations). Observed French, by contrast, shows many more verbs with completely identical inflectional behavior (i.e. distance = 0) and has more verbs in the intermediate-similarity ranges (most prominently 480 to 600) as a result of analogy.
Lemma-to-lemma morphological distances in expected vs. observed French.

Figure 6. Long description
The x-axis is labeled Morphological distance number of different cell pairs, ranging from 0 to over 600. The y-axis is labeled Density, ranging from 0.000 to 0.015. Two overlapping density curves are shown: expected French is shaded light gray, observed French is shaded dark gray. Both curves start near zero, with expected French showing a pronounced peak near 600, while observed French has a lower, broader peak in the same region and smaller peaks at lower distances. The legend at the right identifies the shading for each curve. The highest density for expected French is just above 0.015, while observed French remains below 0.010 throughout.
Looking at individual pairs of verbs, we find analogical dissimilation to be extremely uncommon. Only 1.93% show increased morphological distance from expected to observed French, and this is extremely uncommon (< 5%) everywhere, even among the most dissimilar verbs. While we did find evidence that the assimilatory effect of analogy is strongest between verbs that were already relatively similar morphologically (see Figure 7), we find no evidence for repulsion dynamics in historical analogical change. It thus seems to be a process different from analogy, namely sound change, that takes care of repulsion in the diachronic dynamics of natural inflectional systems.
Change in lemma-to-lemma morphological distance from expected to observed French. Negative values correspond to analogical morphological convergence (i.e. ‘attraction’), while positive values correspond to analogical divergence (i.e. ‘repulsion’).

Figure 7. Long description
The chart is a single boxplot graph. The x axis is labeled rank order by expected distance, binned by decile, running from left to right. The y axis is labeled change from expected to observed French, with values ranging from approximately minus 600 to plus 600. There are ten boxplots, one for each decile, arranged from left to right. The leftmost four boxplots show median values well below zero, with wide interquartile ranges and long whiskers, indicating large negative changes in morphological distance. The next two boxplots are closer to zero, with narrower ranges. The rightmost four boxplots are tightly clustered around zero, with very small interquartile ranges and short whiskers, indicating little change. The overall trend is that lower deciles (left) show greater negative change, while higher deciles (right) show minimal change.
This result matches our impression that most documented analogical changes work toward erasing morphological differences between classes (e.g. spreading so-called ‘superstable’ markers; see Wurzel Reference Wurzel, Dressler, Mayerthaler, Panagl and Wurzel1987, Dammel & Nübling Reference Dammel and Nübling2016) rather than toward reinforcing them (but see Enger Reference Enger2014). For example, the allomorphy of oblique plural suffixes was historically leveled in Russian (e.g. dat.pl -am/-om/-em > -am, ins.pl -ami/-i/-mi > -ami), and that of first-person preterite markers was leveled in Judeo-Spanish (e.g. 1sg -é/-í > -í, 1pl -amos/-imos > -imos; see Schwarzwald Reference Schwarzwald1993:32). This happened without a corresponding leveling in other parts of the paradigm, which would explain the aforementioned results by which analogical change has not decreased conditional entropies overall.
In summary, in models with only attraction dynamics (Ackerman & Malouf Reference Ackerman and Malouf2015), zero entropy is ultimately achieved through the complete loss of allomorphy. In those with attraction-repulsion dynamics (Round et al. Reference Round, Esher and Beniamine2025), it is achieved through the emergence of an extreme No-Blur configuration (Carstairs-McCarthy Reference Carstairs-McCarthy1994) in which every single allomorph is unique to a single inflectional class and hence allows one to predict the entire paradigm. In either case, analogical change causes reduction of conditional entropy. Despite the elegant simplicity and notional appeal of these models and their outcome, our results suggest that neither is correct. As discussed regarding Table 6, historical analogical change from Latin to French has not tended toward the reduction of conditional entropy. This is even more surprising considering that the number of interpredictability domains in the paradigm has been, in fact, greatly reduced due to analogy (from twenty-seven to fourteen). That means that many cell-to-cell conditional entropies that would have been positive have dropped to zero as an effect of analogy, which implies, given that the average entropy is not reduced, that many other conditional entropies must have increased through the effect of historical analogical change.
Looking at the distribution of cell-to-cell entropies, this is, in fact, what we find. Figure 8 shows the distribution of all 1,406 (37*38) cell-to-cell conditional entropies in our expected French and observed French inflected lexicons. Their difference, we reiterate, corresponds to the effect of historical analogical change in the language. The trend we find is that conditional entropies are much more homogeneous in expected than in observed French (variance 0.0307 vs. 0.0577). In expected French, almost all conditional entropies are found in the intermediate ranges, between 0.05 and 0.4 bits. In observed French, however, there are more perfectly predictable relations (i.e. 0 bits, hence the fewer predictability domains reported in Table 7) and also many more highly unpredictable relations, between 0.5 and 0.8 bits. Historical analogical change, thus, has been found here to result in polarization, rather than consistent overall lowering of conditional entropies. In other words, low entropies tend to get lower and high entropies tend to get higher. We fitted a Bayesian hierarchical model with a Gaussian distribution with a log link for the standard deviation, with random effects for predictor and predicted cell, and found a decisive (95% CI [0.42, 0.54]) increase in standard deviation of conditional entropies as a result of analogy.
Cell-to-cell conditional entropies in expected vs. observed French.

Figure 8. Long description
The x-axis is labeled Conditional Entropy, ranging from 0 to 1.25. The y-axis is labeled Density, ranging from 0 to 2.5. Two overlapping density curves are shown: Expected French is a lighter gray, peaking near 0.1 with a secondary peak near 0.35, then tapering off. Observed French is a darker gray, peaking near 0.05, with a smaller secondary peak near 0.3, and a third, lower peak near 0.65. Both curves decrease toward zero as conditional entropy increases. The legend at the right identifies the lighter curve as Expected French and the darker as Observed French.
Although a more thorough analysis that looks at morphological forms in detail would be desirable, we believe this is related to the loss of allomorphic diversity that we observed (Table 6) as one of the main complexity effects of analogy. Analogical change often results in the leveling of allomorphy, but this tends to happen in one cell or domain and not across the paradigm. Superstable markers for 1pl /ɔ̃/ or 2pl /e/ have been generalized across inflection classes in French, for example, while other parts of the paradigm (usually higher-frequency forms like the inf) preserve their allomorphy (in this case /e/, /waʁ/, /(d)ʁ/, or /iʁ/). The same applies to the leveling of unpredictable morphological contrasts between cells. Morphologically or morphosyntactically similar cells and tenses (e.g. 1sg.prs.sbjv and 2sg.prs.sbjv, or the simple past and the imperfect subjunctive) are more likely to analogically stay or become mutually predictable (either through syncretism, as in Table 8, or through a predictable morphological contrast, e.g. adding -ɔ̃) while entropies increase across these domains. The result of these dynamics is schematized in Table 10, in contraposition to the results expected from previous models and simulations of analogy.
Illustrative outcomes of analogical change under different models of analogy compared to a typical development. Different fonts and shades of gray indicate different allomorphy.

Table 10. Long description
Beginning at the leftmost column, glosses list eight verbs: lose, have, put in, weave, lie, hurt, surrender, ask. Each row presents three models: Attraction, Attraction-repulsion, and Typical outcome, each split into infinitive and third person singular present forms. Attraction model shows forms like perd-er and p-ie-rde for ‘lose’, ten-er and t-ie-ne for ‘have’, met-er and m-ie-te for ‘put in’, tej-er and t-ie-je for ‘weave’, ment-er and m-ie-nte for ‘lie’, her-er and h-ie-re for ‘hurt’, rend-er and r-ie-nde for ‘surrender’, ped-er and p-ie-de for ‘ask’. Attraction-repulsion model displays the infinitive forms as perd-er, ten-er, met-er, tej-er, but for ‘lie’, ‘hurt’, ‘surrender’, and ‘ask’, the infinitives are bolded as ment-ir, her-ir, rend-ir, ped-ir. Third person singular present forms in this model are p-e-rde, t-e-ne, m-e-te, t-e-je, m-i-nte, h-i-re, r-i-nde, p-i-de. Typical outcome model repeats the infinitive forms as perd-er, ten-er, met-er, tej-er, ment-er, her-er, rend-er, ped-er, and third person singular present forms as p-ie-rde, t-ie-ne, m-e-te, t-e-je, m-ie-nte, h-ie-re, r-i-nde, p-i-de. Font and shading differences visually mark allomorphy across models and forms.
While previous quantitative experimental approaches to historical analogical change produced a drop in conditional entropies (ultimately to zero), our French data suggest that a polarization of conditional entropies is the outcome observed in natural language change. While the illustrative subsystem in Table 9 had 0.5 bits of entropy in one direction and 1 bit in the other for 0.75 bits on average, the ‘typical outcome’ in Table 10 has 0 bits in one direction and 1.5 bits in the other for 0.75 bits of entropy on average. This might be naively thought of as a difficult system for a speaker to acquire or use, but we must consider that at least one form needs to be learned to even know about the existence of a lexeme. The allomorphic complexity in the 3sg.prs, therefore, might come at no real cognitive cost to the speaker if this is the default or citation form of the lexeme and a (or the most) frequently occurring form. The system after analogy has, after all, a single principal part, rather than two, and less allomorphy, despite the rise in average conditional entropy. Of course, in real inflectional systems, multiple forms could be stored, and different forms could act as bases of different subsets of the paradigm. In addition, because of the analogical consolidation of multiple forms into the same predictability domain (see Table 7), it could be groups of cells, rather than single cells, that behave as inf vs. 3sg.prs above.
Finally, going into the finest-grained detail, the analogical changes to expected conditional entropies in our French verbs can also be inspected for individual pairs of cells (Tables 11 and 12). Some regularities stand out here, notably the increase of conditional entropies between the former perfective tenses (IndPastPerf and SubPqpPerf in French) and the participles, on the one hand, and the rest of the paradigm, on the other. At the same time, historical analogical change has reduced the conditional entropies within this aforementioned paradigmatic domain, and between the gerund, the present subjunctive, and the imperfect tense forms. These developments could be understood as quantitative confirmation of some recurrent observations of the literature on Romance morphological change and so-called ‘morphomes’ over the last thirty years (Maiden Reference Maiden1992, Reference Maiden2018). Some domains within paradigms (e.g. the one called ‘PYTA’, which continues the former perfective tenses; see Maiden Reference Maiden2001) tend to preserve their allomorphic and morphological-predictive unity against disrupting sound changes and ‘push’ unpredictable allomorphic differences to their borders with other paradigmatic subdomains. The tendency for the PYTA/perfective domain to merge morphologically with the past participial domain has also been observed before, in Romance (see Wheeler Reference Wheeler, Maiden, Smith, Goldbach and Hinzelin2011, Badal Reference Badal2024) but also beyond (e.g. in Germanic; see Dammel et al. Reference Dammel, Nowak and Schmuck2010), and might have semantic motivations.
Change in cell-to-cell conditional entropies due to historical analogical change.

Table 11. Long description
Starting from the top row, each entry displays conditional entropy values for cell pairs, with column headers indicating target cells and row headers indicating source cells. Numerical values quantify the change in entropy due to historical analogical change. The table includes all cell combinations, with higher values highlighting greater entropy shifts. No graphical elements or color coding are present; all data is presented in numeric format.
Change in cell-to-cell conditional entropies due to historical analogical change.

Table 12. Long description
Starting from the top row, each entry lists cell pairs and their corresponding conditional entropy values. Columns display original entropy, entropy after analogical change, and the difference. Specific cell pairs are labeled, with numerical values provided for each condition. The table highlights which cell pairs experienced increases or decreases in conditional entropy due to historical analogical change, with some values marked as significant. The bottom rows summarize overall trends and aggregate statistics.
We can gain some final diachronic insight by noting that there are statistically significant correlations (as measured by the R coefficient) of 0.2267 (p < 0.001) between the conditional entropies of Latin and expected French (i.e. before and after regular sound change), 0.1098 (p < 0.001) between expected French and observed French (i.e. before and after analogical change), and 0.045 (p < 0.05) between Latin and observed French. We thus conclude that paradigmatic predictive structure can be inherited over long time periods even in the presence of very extensive analogical and sound changes (see also Herce & Bickel Reference Herce and Bickel2025). We also would like to point out that according to our current data, analogical change appears to be more disruptive to these predictive structures than regular sound change.
7. Conclusion
This article has presented a new method and data-generation process for the exploration of paradigm diachrony that offers important advantages compared to other frequently used ones. The use of exhaustive inflected lexicon data, that is, an entire inflectional system, allows us to operate with a much larger volume and variety of data than approaches that rely on a more direct ‘observation’ of changes (e.g. in historical corpora). The use of computerized forward reconstruction applied to large inflected lexicons allows us to separate phonological (e.g. /amaːtis/ > /ame/) from morphological analogical change (e.g. /ame/ > /ɛme/). While this inference of phonological and morphological changes must result, undoubtedly, in noisier data compared to an understanding obtained through direct observation, we believe that current understanding of etymological relations and historical phonology in some languages and families (like French, and Romance) has progressed enough to pursue the present quantitative automated approach to paradigm diachrony without jeopardizing the general validity of the resulting data. The possibility of analyzing data orders of magnitude larger than traditionally possible, including extremely infrequent word forms, is a significant step forward to test hypotheses of morphological change in statistically robust ways. This method also has important advantages, we believe, over approaches relying on simulations and artificial language experiments. Despite providing interesting conceptual clarity on frequently unstated assumptions about the dynamics of analogical change, the ecological limitations of that type of research make its findings very difficult to extrapolate to natural languages.Footnote 13 These limitations fortunately can be overcome with the present method, which allows us to use natural language data and morphological changes that are attested, or at least inferred, rather than simulated or experimentally generated.
Zooming into the present article’s findings on the diachrony of French verbs specifically, our data, representing sound change and analogical change over 2,000 years on 11,593 inflected forms from 310 verbs, allowed us to confirm the statistically significant role of frequency and regularity on analogical change. As most of the literature has claimed, higher frequency and regularity have been found to be associated with less analogical change. We did not observe any tendency toward the analogical irregularization of extremely-high-frequency items (see also Smith et al. Reference Smith, Ashton and Sims-Williams2023). We also did not observe any consistent effect of morphosyntactic values or markedness on the direction of analogy. Our model suggests that the tendency for unmarked values to be more resistant to change can be accounted for by the effect of frequency of the individual word and cell. We did find a novel significant predictor for analogy, never before explicitly discussed, to our knowledge: the amount of historical sound change. There are multiple ways to understand this finding, but explanation might boil down to the reactive role of analogy relative to sound change (i.e. more sound changes mean there is more for analogy to ‘clean up’) and to the possibility of morphological resistance to sound change.
Alongside the predictors of analogical change, the effect of sound change and analogy on inflectional system complexity was our second main object of analysis. The traditional story by which sound change complexifies the paradigm, while analogy simplifies it, has been quantitatively confirmed here for various aspects of morphological complexity, namely the number of inflectional classes, the number of interpredictability domains in the paradigm, and the prevalence of allomorphy. Other dimensions of paradigmatic complexity, however, have been found to be affected differently. Both sound change and analogy have contributed simplification when it comes to the number of morphologically distinct words in the paradigm (i.e. syncretism). Analogical change has spread syncretism, however, preferably among morphosyntactically similar forms, which highlights the importance of feature values, and meaning more generally, in the evolution of morphological paradigms.
The most surprising finding we report is that neither sound change nor analogical change seems to have a robust effect upon mean conditional entropies. Most of the recent literature on the PCFP has identified conditional entropies as possibly the most important measure for the integrative complexity of inflectional systems (Ackerman & Malouf Reference Ackerman and Malouf2013). It is generally assumed, directly or indirectly, that this objective complexity measure must translate into cognitive difficulty for speakers. It would hence be expected (and this has been consistently the result in computational modeling and simulations; see Ackerman & Malouf Reference Ackerman and Malouf2013, Round et al. Reference Round, Esher and Beniamine2025) that analogical morphological change should reduce conditional entropy. But this is not supported by the results of this paper. Historical analogical change has been found here to be neutral toward conditional entropies in the paradigm on average. What we do observe is a polarization, by which low entropies are reduced further while high entropies are increased. This occurs, we believe, due to (partial) leveling in some cell(s) and groups of cells but not others, a frequent outcome of analogical change in natural languages.
For reasons of space and focus, this article has analyzed sound change and, especially, analogy, in the inherited lexicon. Other diachronic forces (e.g. the borrowing or derivation of new lexical items, the grammaticalization of new inflected forms, and the loss of inflectional forms and lexemes) must also have a prominent role in determining the synchronic properties of inflectional systems, but these are much less well researched from a paradigmatic-complexity perspective. Future research should investigate the role of these other processes. Our method could be used to compare the expected morphological complexity of French with and without borrowings and newly derived verbs, and with and without novel inflected forms or loss of inflection. Further research should also be made in the domain of meaning. This article has made only a modest contribution to understanding how the semantics of paradigm cells influence the likelihood of analogical change generating syncretism or higher predictability. Much more can and should be done (e.g. using distributional-semantic quantitative methods; see e.g. Herce & Allassonière-Tang Reference Herce and Allassonnière-Tang2024) to investigate the effect of morphosyntactic and lexical-semantic similarity on analogical change (Bybee & Brewer Reference Bybee and Brewer1980, Nesset & Makarova Reference Nesset and Makarova2014). That is, in future research, we would like to check which specific word forms and lexemes have become more similar morphologically as a result of analogy, and whether this corresponds to semantically more similar lexemes and values. Future research could also build on the present method to look at factors like phonological neighborhood density, that is, phonological similarity to other verbs and forms, as a predictor of analogical change. It is well known, for example, that phonological similarity very strongly predicts how a wug form will be inflected (Albright Reference Albright2002a). Phonological neighborhood density has also been observed to predict mistakes and overgeneralizations in child language acquisition (see e.g. Engelmann et al. Reference Engelmann, Granlund, Kolak, Szreder, Ambridge, Pine, Theakston and Lieven2019) and would be expected to have an effect in language change as well. We hope that this work and its methodology can serve as a point of departure for investigating these various directions.
Data availability statement
All data and scripts are available at https://osf.io/5yr6m/?view_only=cf589970acc04d0c98050f0b0ac59c04.
Acknowledgments
B.H. would like to thank Chundra Cathcart for highlighting the potential of computerized forward reconstruction to analogical change, and for contributing ideas and literature on the role of irregularization in language change. We would also like to thank Erich Round for inspiring many aspects of this research and providing feedback, and Sacha Beniamine for creating and maintaining the Qumin software that we have relied on for much of the analysis. Finally, we would like to thank Language’s associate editor Morgan Sonderegger for his painstaking and patient advice regarding statistical analyses. Any remaining mistakes are, of course, our own. [Full editorial history: Received 14 May 2024; revision invited 20 January 2025; revision received 10 February 2025; accepted pending revisions 08 August 2025; revision received 26 December 2025; accepted 11 January 2026.]
Funding disclosure statement
This work was supported by the Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung (‘NCCR Evolving Language’, grant number 225146; ‘Spark’, grant number 220720) and by the Universität Zürich (UZH postdoc, grant number FK-24-077).
Competing interests
No competing interests to declare.









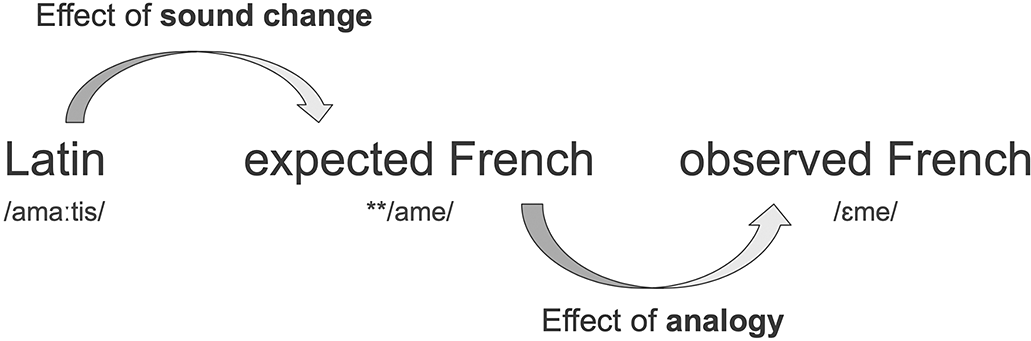




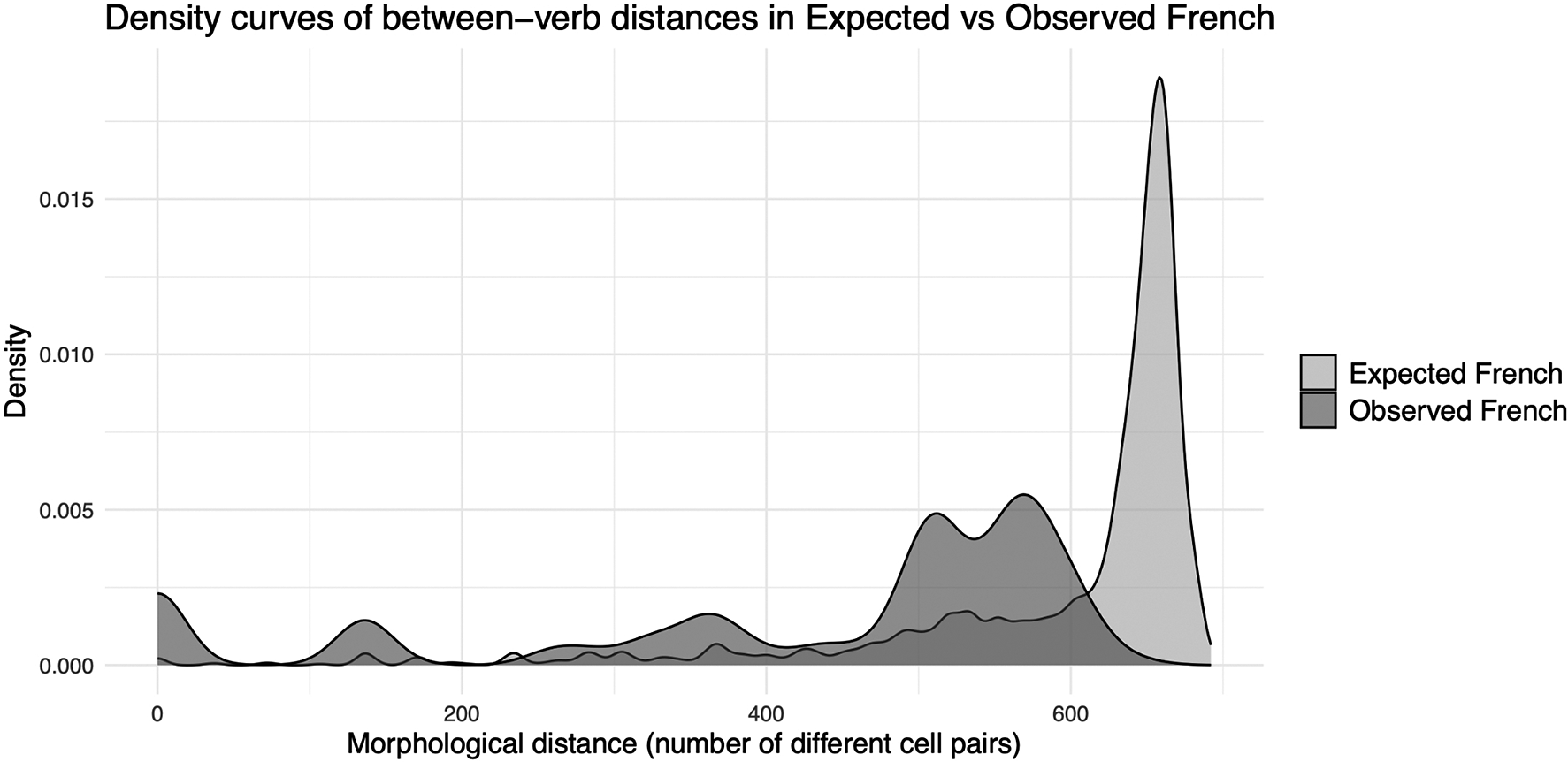
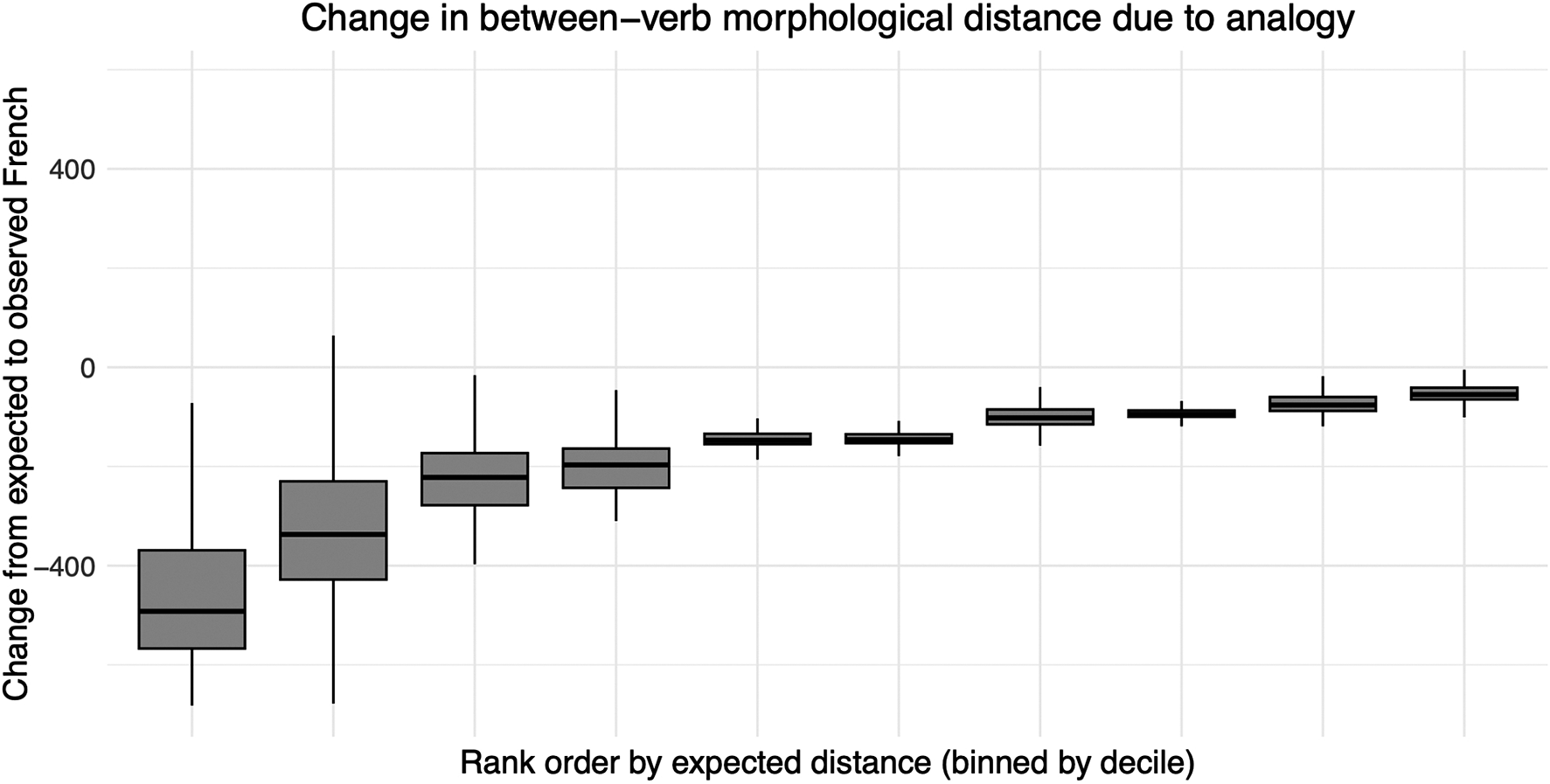
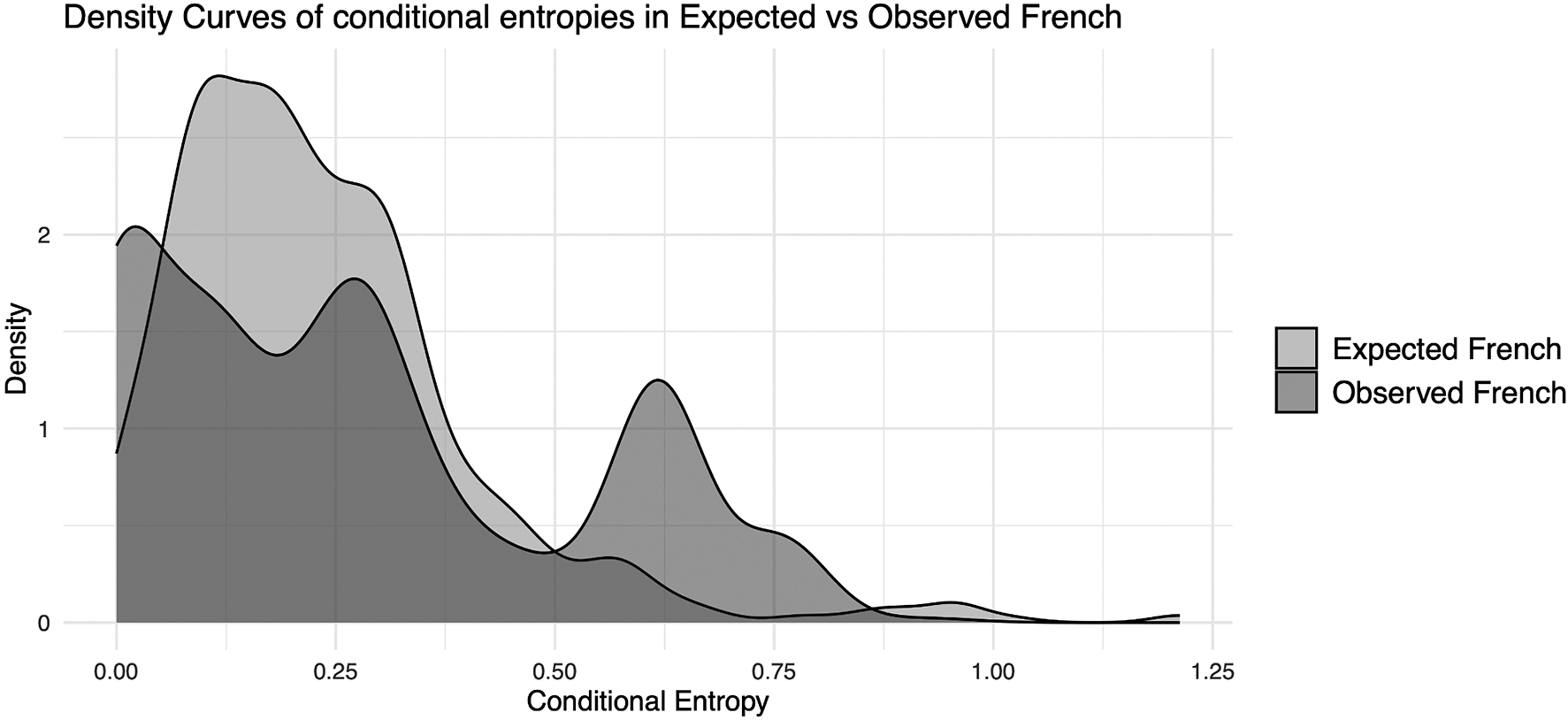




 Open access
Open access