


Introduction
English native speakers are more likely to say salt and pepper rather than pepper and salt, even though both phrases are grammatically acceptable and convey the same meaning. Lexical patterns, such as salt and pepper, are referred to as formulaic language and are ubiquitous in language, accounting for up to 50% of language use (e.g., Erman & Warren, Reference Erman and Warren2000). Previous research has demonstrated, using different methodologies, that English native speakers process formulaic language faster than novel language (e.g., Arnon & Snider, Reference Arnon and Snider2010; Carrol & Conklin, Reference Carrol and Conklin2020; Siyanova-Chanturia et al., Reference Siyanova-Chanturia, Conklin, Caffarra, Kaan and van Heuven2017; Tremblay et al., Reference Tremblay, Derwing, Libben and Westbury2011). This processing advantage has been attributed to the relative frequency of formulaic sequences (compared to novel combinations), leading to their entrenchment in memory. The processing advantage observed for formulaic language in native speakers is not always evident in non-native speakers (e.g., Carrol & Conklin, Reference Carrol and Conklin2014, Reference Carrol and Conklin2017; Siyanova-Chanturia et al., Reference Siyanova-Chanturia, Conklin and Van Heuven2011), and this has been attributed to their insufficient L2 (second language) exposure. Put another way, if repeated occurrences are needed to entrench a sequence in memory, non-natives may not have had sufficient exposure for this to occur.
Frequency of exposure has received increasing attention in vocabulary research. Previous research has demonstrated that frequency of exposure plays an important role in the development of L2 vocabulary knowledge (e.g., Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Laufer & Rozovski-Roitblat, Reference Laufer and Rozovski-Roitblat2011; Pellicer-Sánchez & Schmitt, Reference Pellicer-Sánchez and Schmitt2010). However, the majority of studies have focused on single words, whereas comparatively fewer studies have examined formulaic sequences. The existing studies suggest that more exposure enhances the learning gains of L2 formulaic language, although most research has been carried out on collocations (Durrant & Schmitt, Reference Durrant and Schmitt2010; Majuddin et al., Reference Majuddin, Siyanova-Chanturia and Boers2022; Webb et al., Reference Webb, Newton and Chang2013). The aim of the present study is to investigate the role of exposure in the learning and processing of a less investigated type of formulaic language: binomials.
Binomials are defined as “phrases formed by two content words from the same lexical class connected by a conjunction, where one word order is more frequent than the other (bride and groom/groom and bride)” (Siyanova-Chanturia et al., Reference Siyanova-Chanturia, Conklin and Van Heuven2011, p. 2). They differ from other types of formulaic sequences in several ways. For one, while binomials exhibit a preferred word order, altering the word order does not typically lead to changes in meaning or syntactic irregularity. This unique property, where word order can be reversed without creating ungrammatical formulations or introducing confounds (e.g., individual word frequency differences, syntactic and semantic oddities), makes binomials an ideal choice for examining the effect of phrasal frequency. Additionally, binomials allow the investigation of two key properties: co-occurrence restrictions (the combination of specific words) and configuration restrictions (the order of specific words).
Previous research on binomials has demonstrated a processing advantage for the conventionalized binomial form (e.g., time and money) relative to its reversed form (e.g., money and time) in online eye-tracking experiments (Siyanova-Chanturia et al., Reference Siyanova-Chanturia, Conklin and Van Heuven2011). Sensitivity to the configuration restrictions of binomials has also been observed for novel binomials. Native speakers developed a processing advantage for novel binomials (e.g., wires and pipes) over their reversed forms (pipes and wires) after as few as four to five exposures (Conklin & Carrol, Reference Conklin and Carrol2021) but this was not the case for non-native speakers (Sonbul et al., Reference Sonbul, El-Dakhs, Conklin and Carrol2023). Research on binomial acquisition employing offline measures, on the other hand, has shown that non-native speakers can acquire knowledge of the preferred order of binomials after only two to six exposures (Alotaibi et al., Reference Alotaibi, Pellicer-Sánchez and Conklin2022; Altamimi & Conklin, Reference Altamimi and Conklin2024b).
As can be seen above, studies on binomials have relied on either online measures (eye-tracking) to capture real-time processing (Siyanova-Chanturia et al., Reference Siyanova-Chanturia, Conklin and Van Heuven2011; Sonbul et al., Reference Sonbul, El-Dakhs, Conklin and Carrol2023) or offline measures to assess declarative knowledge (Alotaibi et al., Reference Alotaibi, Pellicer-Sánchez and Conklin2022) but rarely incorporated both within a single design. Crucially, research on formulaic language has demonstrated a dissociation between online and offline measures, suggesting that these measures tap into different knowledge systems (e.g., Sonbul & El-Dakhs, Reference Sonbul and El-Dakhs2020; Sonbul & Schmitt, Reference Sonbul and Schmitt2013; Sonbul, Reference Sonbul2015). Another limitation of previous research on binomials is that the cross-language congruency effect has not been controlled in most previous studies (e.g., Sonbul et al., Reference Sonbul, El-Dakhs, Conklin and Carrol2023).
The present study aims to contribute to research on the processing and learning of binomials by addressing these limitations and extending the work of Conklin and Carrol (Reference Conklin and Carrol2021) and Sonbul et al. (Reference Sonbul, El-Dakhs, Conklin and Carrol2023). More specifically, it examines both the learning and processing of binomials by incorporating online (eye-movements) and offline (familiarity rating) measures to determine whether sensitivity to the configuration of L2 binomials emerges incidentally during online reading as well as in offline post-test.
Literature review
Offline and online vocabulary measures
Most studies on the incidental acquisition of L2 vocabulary have focused on the acquisition of single words from reading exposure (e.g., Pellicer-Sánchez & Schmitt, Reference Pellicer-Sánchez and Schmitt2010; Pitts et al., Reference Pitts, White and Krashen1989; Waring & Takaki, Reference Waring and Takaki2003; Webb, Reference Webb2007). These studies used offline post-tests to measure learning outcomes that are reported as gains in declarative knowledge as a result of increased exposure. Although offline measures have been commonly used in previous research, they have some key limitations. One concern is that they do not capture the “partial and incremental growth in knowledge occurring as a function of an individual’s experience with each word” (Joseph et al., Reference Joseph, Wonnacott, Forber and Nation2014, p. 245). To address this, some recent studies have started to explore vocabulary acquisition through online measures, such as eye-tracking. These methods allow for the examination of online processing as it unfolds in real time, offering insights into the incremental development of vocabulary knowledge with each repeated encounter during reading. Previous eye-tracking research suggests a link between eye-tracking patterns and vocabulary gains (e.g., Godfroid et al., Reference Godfroid, Boers and Housen2013; Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Mohamed, Reference Mohamed2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016). These studies combined offline measures (paper-and-pencil post-tests) and online measures (eye-tracking) to investigate the incidental acquisition of L2 vocabulary. Godfroid et al. (Reference Godfroid, Boers and Housen2013) found that pseudowords (i.e., words that would be unknown to readers) had longer fixation times than known words for non-native learners. Further, longer fixations to the pseudowords were predictive of successful word recognition in a post-test. Later research by Godfroid et al. (Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018) suggested that both the number of exposures and total reading time contributed to vocabulary learning and that reading times decreased as a result of increased exposure. Similarly, Pellicer-Sánchez (Reference Pellicer-Sánchez2016) showed that there was a positive relationship between total reading time and successful recall of pseudowords. In addition, the pseudowords elicited significantly faster reading times after three encounters, and by the eighth encounter, they were read in a similar manner to real words.
Other studies on formulaic language have revealed inconsistent findings in offline and online measures (e.g., Sonbul & El-Dakhs, Reference Sonbul and El-Dakhs2020; Sonbul & Schmitt, Reference Sonbul and Schmitt2013). Sonbul and Schmitt (Reference Sonbul and Schmitt2013) used both offline (i.e., form recall and recognition tasks) and online measures (i.e., a priming paradigm in a lexical decision task) to examine the learning of collocations. The offline measures indicated that all learning conditions enhanced knowledge of collocations for native and non-native speakers. In contrast, the online measure did not demonstrate a processing advantage for the target collocations. Sonbul and El-Dakhs (Reference Sonbul and El-Dakhs2020) employed both offline (i.e., a multiple-choice form recognition task) and online (i.e., a timed acceptability judgment task) measures to examine the recognition of two types of collocations: congruent (i.e., matching in form and meaning in English and Arabic) and incongruent collocations (e.g., existing only in English). Results from the offline task showed that Arabic-L1 learners of English-L2 recognized congruent collocations more accurately than incongruent ones. However, the online task revealed that response times were similar for both collocation types, with a modulating effect of proficiency whereby the difference was clearer for lower proficiency non-natives than higher proficiency ones. In a later eye-tracking experiment, El-Dakhs et al. (Reference El-Dakhs, Sonbul and Masrai2024) found that non-natives process congruent and incongruent collocations similarly. In addition, a dissociation between online and offline measures was observed in Sonbul (Reference Sonbul2015), where sensitivity to collocational frequency appeared in offline measures (i.e., a rating task of how typical the collocations were in English). Online in an eye-tracking experiment, however, the effect was only evident in an early reading measure (first pass reading time) but not later in processing (i.e., total reading time and fixation count) for both native and non-native speakers.
One explanation for the discrepancy between offline and online measures is that they likely tap into different constructs. Offline measures assess declarative knowledge, whereas online measures reflect implicit processing. The findings from these studies suggest that even after declarative knowledge is acquired, it may not be accessible quickly enough to be detected during implicit processing tasks. It may be that more exposures to a lexical pattern are necessary before declarative knowledge is accessed automatically and can be detected by online measures.
The role of frequency in the learning and processing of vocabulary
Of all the factors that influence the learning and processing of single words, frequency of exposure has received the most attention in vocabulary research (Pellicer-Sánchez & Boers, Reference Pellicer-Sánchez, Boers, Siyanova-Chanturia and Pellicer-Sánchez2019). Both offline and online measures have provided evidence for the role of frequency in learning. For example, previous studies using form recall and recognition post-tests have shown that frequency of exposure plays an important role in developing L2 vocabulary knowledge (e.g., Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Laufer & Rozovski-Roitblat, Reference Laufer and Rozovski-Roitblat2011; Pellicer-Sánchez & Schmitt, Reference Pellicer-Sánchez and Schmitt2010), such that repeated contextual encounters with unknown L2 words contribute to learning gains. In addition, online measures have revealed that word frequency is one of the strongest predictors of response times, with more frequent words eliciting shorter response times than infrequent ones (Brysbaert et al., Reference Brysbaert, Mandera and Keuleers2018). Important for the current study, eye-tracking research demonstrates that as learners encounter unknown words through repeated exposures during reading, these words elicit fewer and shorter fixations (e.g., Elgort et al., Reference Elgort, Brysbaert, Stevens and Van Assche2018; Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016). Thus, across repeated exposures (i.e., increasing frequency), reading times to new words become more like those of already known words, which is taken as an indication that the words are being learned.
In addition to its effect on single words, the role of frequency of exposure has also been shown to play an important role in the learning and processing of formulaic sequences. When measuring frequency effects, studies usually manipulate text-based frequency (i.e., the number of occurrences participants encounter) while controlling for corpus-based frequency. Research using offline measures indicates that number of encounters in a text contributes significantly to the acquisition of formulaic sequences from reading. Durrant and Schmitt (Reference Durrant and Schmitt2010), for example, found that two exposures to a collocation led to better form recall by non-native learners than a single exposure. Webb et al. (Reference Webb, Newton and Chang2013) presented non-native learners with multiple instances (1-15 repetitions) of the same collocation in a text and found that the number of encounters positively influenced the incidental learning of collocations. More recently, Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2022) exposed non-native learners to audiovisual input that was seeded with different types of formulaic sequences. Results showed that formulaic sequences that appeared twice yielded better recall than those that appeared only once. However, other studies have shown that increasing the number of exposures does not always lead to better learning gains. For example, Pellicer-Sánchez (Reference Pellicer-Sánchez2017) compared the acquisition of adjective-pseudoword collocations during reading under two exposure conditions: four versus eight times. Post-test results indicated incidental learning gains but revealed no significant effect based on the number of exposures.
Akin to what has been found for single words, we would expect that with repeated exposure to unknown formulaic language, processing will become more like that elicited by known formulaic sequences. Pellicer-Sánchez et al. (Reference Pellicer-Sánchez, Siyanova-Chanturia and Parente2022) investigated how frequency of exposure influences the processing of novel collocations. English native and non-native speakers read a story in which novel (adjective-pseudoword) collocations were presented either four or eight times, and known collocations were presented eight times. Results demonstrated an effect of frequency of exposure on collocation processing, with a decrease in both the number and duration of fixations across repeated exposures. Processing for novel collocations was comparable to that of known collocations after eight exposures for both native and non-native speakers. In another eye-tracking study, Altamimi and Conklin (Reference Altamimi and Conklin2024a) replicated Pellicer-Sánchez et al.’s (Reference Pellicer-Sánchez, Siyanova-Chanturia and Parente2022) findings, demonstrating faster processing of novel collocations with repeated exposures among both native and non-native speakers.
The learning and processing of binomials by natives and non-natives
Most research on formulaic language has focused on either collocations or idioms, with comparatively fewer studies investigating the processing and acquisition of binomials. Binomials and collocations are similar in that learning them involves acquiring knowledge of the co-occurrences of words (e.g., strong wind, salt and pepper). However, they are different in that binomials require acquiring the additional knowledge of their specific configuration: developing a sensitivity to the word order preference (i.e., the forward form salt and pepper is much more frequent and natural sounding to a native speaker than the reversed form pepper and salt). In contrast, syntax dictates word order in collocations.
Phonological and semantic constraints have been proposed to account for why one word order is preferred in binomials (Benor & Levy Reference Benor and Levy2006; Mollin, Reference Mollin2012). However, such accounts do not provide a complete explanation, as many counterexamples exist for each constraint (e.g., the male-before-female constraint as in men and women is violated in bride and groom) (Conklin & Carrol, Reference Conklin and Carrol2021). Further, frequency was found to be a stronger predictor of word order preference than abstract constraints (Morgan & Levy, Reference Morgan and Levy2016). Thus, Conklin and Carrol (Reference Conklin and Carrol2021) suggest that the preferred word order of binomials is likely shaped by repeated usage, which leads to entrenchment of a particular order in memory, ultimately resulting in its conventionalization over time.
Previous research on binomial processing has capitalized on the syntactically permittable flexibility of word order for these sequences, demonstrating a processing advantage for the frequent conventionalized binomial form (time and money) relative to its reversed form (money and time), which differ only in phrasal frequency (e.g., Siyanova-Chanturia et al., Reference Siyanova-Chanturia, Conklin and Van Heuven2011; Reference Siyanova-Chanturia, Conklin, Caffarra, Kaan and van Heuven2017). Moreover, Siyanova-Chanturia et al. (Reference Siyanova-Chanturia, Conklin and Van Heuven2011) showed evidence that for non-native speakers of English, this sensitivity is modulated by L2 proficiency, with clearer effects as proficiency increases. The processing advantage for binomials over their reversed forms has been attributed to the entrenchment of the conventional pattern in memory.
More recently, studies have started to explore the processing of novel binomials. Conklin and Carrol (Reference Conklin and Carrol2021) used eye-tracking to investigate the processing of novel binomials among native speakers. Participants read short stories in which existing binomials were presented once in their conventional form (e.g., time and money), and novel binomials were presented one to five times in an experimentally defined forward form (e.g., wires and pipes). Subsequently, items were presented in their reversed forms (e.g., money and time, pipes and wires). Results demonstrated that, similar to existing binomials (which were always read more quickly than their reversed forms), novel binomials developed a processing advantage over their reversed forms after only four to five exposures. This suggests that sensitivity to the sequential order of binomials emerges rapidly during reading. Sonbul et al. (Reference Sonbul, El-Dakhs, Conklin and Carrol2023) replicated Conklin and Carrol’s (Reference Conklin and Carrol2021) study with non-native learners (Arabic L1). They found no processing advantage for existing binomials over their reversed forms. In contrast to the original study, after either two or four repetitions of a novel binomial, the reversed forms were processed faster than their forward forms. This suggests that non-native speakers treated the reversed forms as another encounter of the same binomials, ignoring the configuration violation. That is, non-native speakers were able to register the co-occurrence restriction for novel binomials in memory but did not develop sensitivity to their sequential order (configuration) as quickly as native speakers.
Altamimi and Conklin (Reference Altamimi and Conklin2024b) investigated the effects of congruency and frequency of exposure on the learning of binomials on self-paced reading and a timed word order recognition task. Arabic second language learners of English and native English speakers read a text in which three types of binomials were presented either two or five times: English-only, Arabic-only, and congruent (occurring in both English and Arabic). Results from the word order task showed that participants acquired recognition knowledge of the preferred order of binomials after only two exposures, with no effect of frequency of exposure. Analysis of response times showed that native English speakers recognized congruent and English-only items faster than Arabic-only items, while Arabic L2 learners recognized congruent items faster than both English-only and Arabic-only items. In terms of self-paced reading, there was a processing advantage across repeated exposures for both groups and under all item types.
Alotaibi et al. (Reference Alotaibi, Pellicer-Sánchez and Conklin2022) investigated the effects of the number of exposure (2, 4, 5, and 6 occurrences) and different input modes (reading-only, listening-only, and reading-while-listening) on the learning of binomials by non-native speakers. Post-test results (familiarity ratings) indicated that both reading-only and reading-while-listening were more effective for enhancing declarative knowledge of binomials than listening-only. There was also an effect of frequency: novel binomials encountered six times yielded familiarity ratings similar to existing binomials.
In sum, previous studies have shown that English native speakers demonstrate a clear sensitivity to the specific configuration of binomials. However, this is not always evident among non-native speakers. Further, the role of frequency of exposure on the learning and processing of binomials is still not fully understood.
The present study
Previous research suggests that frequency of exposure facilitates the learning and processing of formulaic sequences. The limited research on binomials has revealed discrepancies between native and non-native speakers’ performance: for novel binomials, native speakers exhibit a sensitivity to both the co-occurrence of words and their configuration after repeated encounters—four to five exposures (Conklin & Carrol, Reference Conklin and Carrol2021)—while non-native speakers seem to register the co-occurrence of words but not their configuration (Sonbul et al., Reference Sonbul, El-Dakhs, Conklin and Carrol2023). The limitations in the Sonbul et al.’s (Reference Sonbul, El-Dakhs, Conklin and Carrol2023) study might account for such discrepancies. Sonbul et al. (Reference Sonbul, El-Dakhs, Conklin and Carrol2023) did not fully account for a cross-language congruency effect, which has been shown to influence the processing of formulaic sequences, particularly collocations and idioms (for an overview, see Conklin & Carrol, Reference Conklin, Carrol, Siyanova-Chanturia and Pellicer-Sánchez2019). As indicated above, in addition to co-occurrence restrictions, which is a common feature of different types of formulaic sequences, binomials have a distinctive quality, that is, configuration restrictions. Hence, in binomials, congruency may have a different effect to other types of formulaic sequences. Additionally, Sonbul et al. (Reference Sonbul, El-Dakhs, Conklin and Carrol2023) included a limited range of repetitions: two versus four. As speculated by Sonbul et al. knowledge of configuration restrictions may be developed later than knowledge of co-occurrence restrictions, and thus, non-native speakers might require more exposures for sensitivity to configuration restrictions to emerge.
The aim of the present study is to address the limitations in Sonbul et al. (Reference Sonbul, El-Dakhs, Conklin and Carrol2023) and to extend its scope by accounting for the congruency effect, increasing the number of exposures, and including an offline post-exposure measure to assess declarative knowledge. This study seeks to answer the following research questions:
-
RQ1: Do non-native speakers demonstrate online sensitivity to the configuration (i.e., word order) of existing congruent binomials and novel binomials encountered in context?
-
RQ2: How does the processing of novel binomials alter as a function of frequency of exposure (1 to 6 exposures)?
-
RQ3: Do non-native speakers exhibit offline sensitivity to the configuration of L1–L2 congruent existing binomials and novel binomials encountered in context?
Methods
Participants
A total of 61 participants (L1-Arabic L2-English) took part in the study. At the time of study, they worked or studied at a university in Saudi Arabia. One participant was excluded due to track failure during the experiment. Thus, we considered the data of 60 participants (Female = 39) who ranged in age between 18 and 42 (Mean = 23.58, SD = 5.39). Their self-rated L2 proficiency scores (out of five) in the four skills were as follows: speaking (Mean = 4.42, SD = 0.70), reading (Mean = 4.57, SD = 0.56), writing (Mean = 4.17, SD = 0.78), and listening (Mean = 4.18, SD = 0.70).
As an approximate objective measure of their proficiency in English, the participants completed the V_YesNo online vocabulary test (Meara & Miralpeix, Reference Meara and Miralpeix2017) with a maximum score of 10,000. Their average score was 6288,87 (SD = 1261.53, Minimum = 4092, Maximum = 9564). It should be noted that the vocabulary score was employed as a screening procedure in the present study whereby only participants who scored 4,000 or above completed the eye-tracking experiment and the offline task (see Procedures below). This was important to ensure that the materials (target/control items and passages, see below) were suitable for the participants and that they were not likely to experience any difficulty understanding them.
Since the study employed a three-version counter-balanced design (see Materials below), each participant was assigned one of the three versions: Version 1 (N = 20), Version 2 (N = 20), and Version 3 (N = 20). The analysis of a one-way ANOVA showed that participants reading the three versions did not differ in their vocabulary score: Version 1 (Mean = 7148.62, SD = 1560.59), Version 2 (Mean = 7018, SD = 1676.29), Version 3 (Mean = 6980.77, SD = 1514.12); (df = 2, F = 0.09, p =.91).
Items
The study set out to examine non-native learners’ processing of existing English binomials that were congruent with Arabic and their processing/learning of novel English binomials. Hence, two sets of items were developed: existing English-Arabic binomials (same configuration) and novel binomials which do not exist in either language. All component words in the target and control binomials (existing and novel) belonged to the most frequent 4,000 word families in English (Nation, Reference Nation2012). This helped to ensure that our participants, who all scored above 4,000 in the vocabulary test (see above), would be familiar with binomials’ constituent words.
The existing binomials were developed based on extensive research in the literature (e.g., Altamimi, Reference Altamimi2021; Benor & Levy, Reference Benor and Levy2006; Conklin & Carrol, Reference Conklin and Carrol2021; Gorgis & Al-Tamimi, Reference Gorgis and Al-Tamimi2005; Morgan & Levy, Reference Morgan and Levy2016). Selection of the items involved three steps. First, the frequency of the forward and backward forms of each potential binomial was checked in the NOW (News on the Web) corpus (Davies, Reference Davies2016) with over 20 billion words. The NOW corpus is best suited to the purposes of the present study due to its considerable size (cf. the Corpus of Contemporary American English or COCA with just over a billion words). Bigger corpora allow for more accurate frequency counts for less frequent items, with binomials being less frequent in language use relative to other formulaic sequences such as collocations. Only items where one direction of the binomial was more frequent than the other with a minimum of 3:1 ratio (minimum forward raw frequency = 4,000) were included in the initial pool. This ensured that the binomial existed in English with a preferred direction. Second, two of the co-authors (proficient Arabic-English speakers) independently rated each of the 44 potential items for (1) whether the binomial is used in Arabic, and (2) whether the word order is the same in both English and Arabic. This resulted in a reduced list of 34 potential binomials, including only items that existed in Arabic and judged to be used in the same preferred direction as English. The next step was to check the Arabic frequency of the potential items in the 6.5-billion-word Arabic Web Corpus or “arTenTen” (Arts et al., Reference Arts, Belinkov, Habash, Kilgarriff and Suchomel2014, available on Sketch Engine). Only items (N = 21) where the forward frequency was higher than the reversed frequency with a minimum ratio of 3:1 were included in the final pool of items (minimum forward raw frequency = 600).Footnote 1, Footnote 2 Thus, the final list of existing binomials included 21 items with an average ratio of 31.04 to 1 in Arabic (SD = 52.28) and average ratio of 93.40 to 1 in English (SD = 211.67). The items had a word order preference that was significantly preferred and congruent in both languages: English (Mean forward = 67892.81, SD = 95767.75; Mean backward = 3850.81, SD = 8627.84; t = 3.05, p = 0.006) and Arabic (Mean forward = 15910.76, SD = 19522.45; Mean backward = 2214.48, SD = 4005.86; t = 3.15, p = 0.005). These items were divided into two categories: target items included in the reading texts (N = 12) and control items included in the offline rating task only (N = 9).
For novel binomials, similar procedures were followed. Some of the items were borrowed from Conklin and Carrol (Reference Conklin and Carrol2021), and additional items were constructed following the same procedures. “Noun and noun” word pairs were selected from the same semantic field with no clear order preference (e.g., castle and tower). The component words were selected in a way that none of them formed part of an existing frequent binomial. We ended up with an initial list of 44 items. First, we checked the potential novel binomials for their English frequency in NOW. Only items with a low frequency in either direction (fewer than 2,000 raw occurrences) and no preferred word order in English (forward-to-backward ratio of less than 2 to 1) were selected. This resulted in a reduced list of 40 items. Finally, we checked the Arabic frequency of the novel binomials in both directions in the “arTenTen” Corpus and only included items where the frequency was very low (less than 500 occurrences with a forward-backward and backward-forward ratio of less than 2:1).Footnote 3 For the final list of novel items, one direction was specified as the experimentally defined forward direction and the other one was operationalized as the backward form. The novel items did not differ in the forward or backward direction either in English (Mean forward = 321.33, SD = 341.87; Mean backward = 313.14, SD = 269.51; t = 0.09, p =.93) or Arabic (Mean forward = 82.52, SD = 181.57; Mean backward = 158.86, SD = 450.06; t = −0.72, p =0.48). Appendix S1 in the online supplementary material presents the existing and novel binomials and their properties. The items were divided into three sets (A, B, C) counter-balanced across the three conditions: One occurrence in the reading texts (1-rep henceforth), six occurrences in the reading texts (6-rep henceforth), and no occurrences in the reading texts (control henceforth) (see Figure 1). The no-occurrence items will be included in an offline rating task following the eye-tracking experiment as control items (see further below).
Counterbalancing under the three versions of the experiment.

Reading texts
Six stories were developed by the second author (a native speaker of English) to reflect the counter-balanced versions presented in Figure 1. Items were distributed proportionally across the six stories as follows:
-
1. For the existing binomials, the forward and reversed forms of each binomial appeared in consecutive stories (e.g., forward in Story 1 and reversed in Story 2; forward in Story 2 and reversed in Story 3, etc.).
-
2. For the novel binomials which appeared only once (1-rep condition), the forward and reversed forms appeared in consecutive stories in the same way as for existing binomials.
-
3. For the novel binomials which appeared six times (6-rep condition), the six forward forms appeared in four consecutive stories in a 2-1-2-1 design (e.g., two occurrences in Story 1—1 occurrence in Story 2—2 occurrences in Story 3—1 occurrence in Story 4). This was finally followed by the reversed form in the next story (e.g., Story 5). All 6-rep items therefore began in either Story 1 or 2 and ended in Story 5 or 6.
-
4. For the novel binomials in the control condition, these did not appear at all in the reading passages.
Following the recommendations of Arai and Takizawa (Reference Arai and Takizawa2024), we checked the lexical coverage of the passages using the VocabProfiler Tool on LexTutor.com. Results showed that 99% of the words in the texts belonged to the most frequent 4,000 word families in English, which our participants were familiar with (see Participants above).
For each story, three yes/no comprehension questions were created to ensure that participants were reading for comprehension (Total = 18 questions). The full passages, comprehension questions, data files, and codes are available on OSF through the following link: https://osf.io/x4whb.
Familiarity rating task
As a measure of offline processing (declarative knowledge) of the existing and novel binomials, participants completed a familiarity rating task. In this task, the items (Existing = 21, Novel = 21, Total = 42) were randomly presented in their forward and reversed forms to participants in two counter-balanced lists with a balanced number of items in both directions under each list. No item was presented in its forward and reversed forms in the same list. The items belonged to one of the following categories:
-
1- Existing binomials which were presented during the eye-tracking experiment (N = 12).
-
2- Existing binomials which were not presented during the eye-tracking experiment (N = 9).
-
3- Novel binomials presented during the eye-tracking experiment once (1-rep type) (N = 7)
-
4- Novel binomials presented during the eye-tracking experiment six times (6-rep type) (N = 7)
-
5- Novel binomials not presented during the eye-tracking experiment (control type) (N = 7)
The instructions were as follows:
In this task, you will see a set of English phrases in isolation, for example “black and white.” You need to decide on a scale of 1 to 7 how familiar each is. On this scale, 1 = very unfamiliar and 7 = very familiar. For example, for the phrase “gold and silver,” I would circle “7” because I have heard this phrase a lot of times. However, “silver and gold,” although using the same words would be much less familiar so would receive lower ratings, probably around 1 to 3.
Procedure
The participants were invited to the eye-tracking lab, and informed consent was obtained. The study started with the V_YesNo online vocabulary test as a rough measure of proficiency (15 minutes). Participants who crossed the threshold score of 4,000 in this test were invited to complete the eye-tracking experiment. Next, the eye-tracking experiment started with a practice story, and then, the six main stories appeared sequentially, each followed by three comprehension questions. Finally, the participants completed the rating task and answered some questions about their language background.
The eye-tracking experiment was run on SR Research Eye-link 1000+ eye-tracker in monocular mode at 500Hz with a desk-mounted chin rest to minimize movement. A 9-point grid calibration was conducted before each story and whenever it was deemed necessary during the experiment, and a fixation point preceded each screen for drift checking. The stories were presented in 18-point Courier New font, double-spaced. The task was to read the stories as naturally as possible for comprehension and to answer the questions that followed each story. Target binomials did not appear in the beginning or end of lines or at line breaks. Results of the comprehension questions showed that participants did not have any issues understanding the stories (Mean = 88.43%, SD = 10.64, Minimum = 61.11%, Maximum = 100%).
Analysis
The analysis was performed using linear mixed-effects models in R 4.4.2 (R Core Team, 2024). We carried out four analyses to answer the three research questions: Analysis 1 (RQ1) and Analysis 2 (RQ2) analyzed online eye-tracking data while Analysis 3 and Analysis 4 examined offline familiarity ratings (RQ3). All analyses were run using the lmer4 and lmerTest functions. For the eye movement data (Analysis 1 and Analysis 2), we examined first-pass reading time (FPRT) and total reading time (TRT) as measures of early and late processing, respectively. These two measures are often employed in research on formulaic language (e.g., Conklin & Carrol, Reference Conklin and Carrol2021) as they can be viewed as being complementary. While FPRT exhibits lexical-level processing of the target items, TRT incorporates textual integration considering the wider context (including regressions to the target items). Two regions of interest were examined: Word 3, and whole phrase.Footnote 4 Since the word “and” was skipped more than 60% of the time, it was not considered as an individual region of analysis.
We started by cleaning the eye-tracking data using the four-step procedure; fixations shorter than 100 ms and longer than 800 ms were removed (4.2% of all fixations). We excluded trials that were discontinued or where track failure was experienced. Also, a phrase that was completely skipped was also excluded from the analysis. In such cases, all subsequent occurrences of the item, including the reversed form, were also removed. This resulted in loss of 14.6% of data points in both Analysis 1 and Analysis 2.Footnote 5 Both reading time measures (TRT and FPRT) were log-transformed prior to the analysis to reduce skewness in the data.
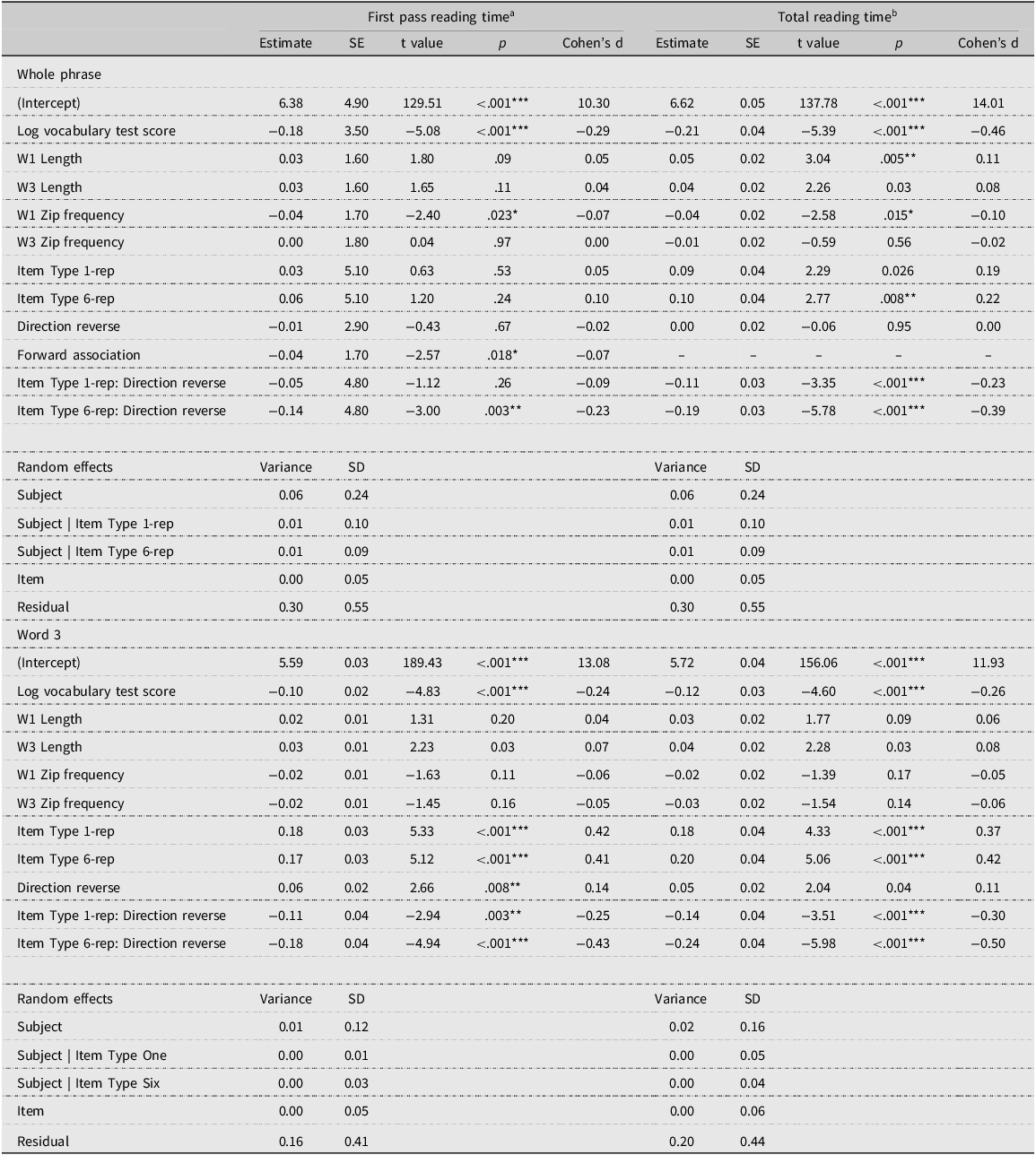
Analysis 1 examined the eye-movement data for the forward (first occurrence) and reversed forms of both the existing and novel binomials to answer RQ 1 (Do non-native speakers demonstrate online sensitivity to the configuration (i.e., word order) of existing congruent binomials and novel binomials encountered in context?). The outcome variables were FPRT and TRT for the two main regions of interest; hence, four models were fitted. The analysis used the maximal model justified by the research design. Fixed effects included Item Type (existing, 1-rep, and 6-rep) and Direction (forward versus reversed), and the interaction between them. We controlled for several variables to partial out their effect, and these included vocabulary size, Word 1 frequency, Word 3 frequency, Word 1 length, and Word 3 length. Frequency was based on the NOW Corpus and was expressed on the Zipf scale (van Heuven et al., Reference Van Heuven, Mandera, Keuleers and Brysbaert2014), and length was counted in characters. Then, we added several factors to examine their contribution to the model fit: forward association strength (Kiss et al., Reference Kiss, Armstrong, Milroy, Piper, Aitken, Bailey and Hamilton-Smith1973), phrasal frequency, and the Item Type x Direction x Vocabulary score interaction. Only variables that significantly improved the model fit (with lower AIC values) were retained. Following von der Malsburg and Angele’s (Reference von der Malsburg and Angele2017) suggestions for corrections in eye-tracking experiments that include more than one measure, we divided the .05 threshold by the number of measures (i.e., two: FPRT and TRT), and only treated a variable as significant if it reached the adjusted threshold of .025. By-participant slopes for Item Type and Direction were initially added. However, including them both resulted in convergence issues, so only Item Type was included as a slope. When the Item Type x Direction was significant, pairwise comparisons were conducted using the emmeans function in the emmeans package. A significant difference between the forward and reversed forms under one of the three item types (existing, 1-rep, and 6-rep) was taken as evidence for sensitivity to binomial configuration.
Analysis 2 focused on the 6-rep novel items only to answer RQ2 (How does the processing of novel binomials alter as a function of frequency of exposure (1 to 6 exposures)?). The main fixed factor in this analysis was occurrence (first, second, third, fourth, fifth, sixth, and reversed). The covariates were the same as Analysis 1, with the addition of Item Set which was included to account for the effect of counterbalancing. Similar to Analysis 1, we examined the contribution of forward association, phrasal frequency, and the Vocabulary score x Occurrence interaction. Only factors that significantly improved the model fit were included in the final model.
Finally, Analysis 3 and Analysis 4 examined the rating data from the familiarity task for the existing and novel binomials, respectively, to answer RQ3 (Do non-native speakers exhibit offline sensitivity to the configuration of L1-L2 congruent existing binomials and novel binomials encountered in context?). For offline results, the significance threshold was set at 0.05. The fixed factors in Analysis 3 for existing binomials included Condition (target versus control), Direction (forward versus reversed), and the interaction between them. When a significant difference emerges between the forward and reversed forms under either condition, this can be taken as evidence of offline sensitivity to the configuration of existing binomials. An additional aim here was to compare targets seen during the eye-tracking experiment with those that were not (controls), to establish any differences in ratings as a result of exposure during reading.
For Analysis 4, the fixed factors included Condition (1-rep, 6-rep, and control), Direction (forward versus reversed), and the interaction between them. Significant differences between the forward and reversed forms under any of the conditions were taken as evidence of non-natives’ developing offline sensitivity to novel binomials after exposure. Covariates were the same as those examined in the previous analyses, including the Condition x Direction x Vocabulary score interaction. By-participant slopes for Condition and Direction were included in both analyses, but this resulted in convergence issues, so only Condition was included in the final models.
For all models that were fitted, we checked for collinearity using the VIF (variance inflation factor) values and no issues emerged (all VIF values < 7).
Results
Analysis 1: RQ1 (Do non-native speakers demonstrate online sensitivity to the configuration (i.e., word order) of existing congruent binomials and novel binomials encountered in context?)
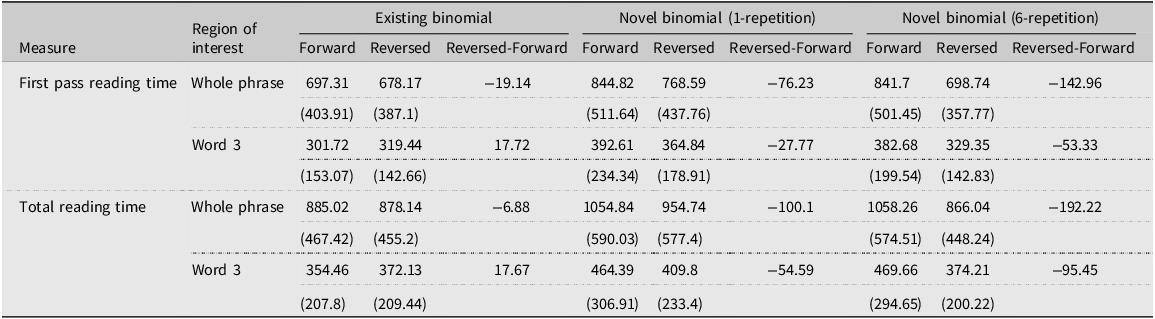
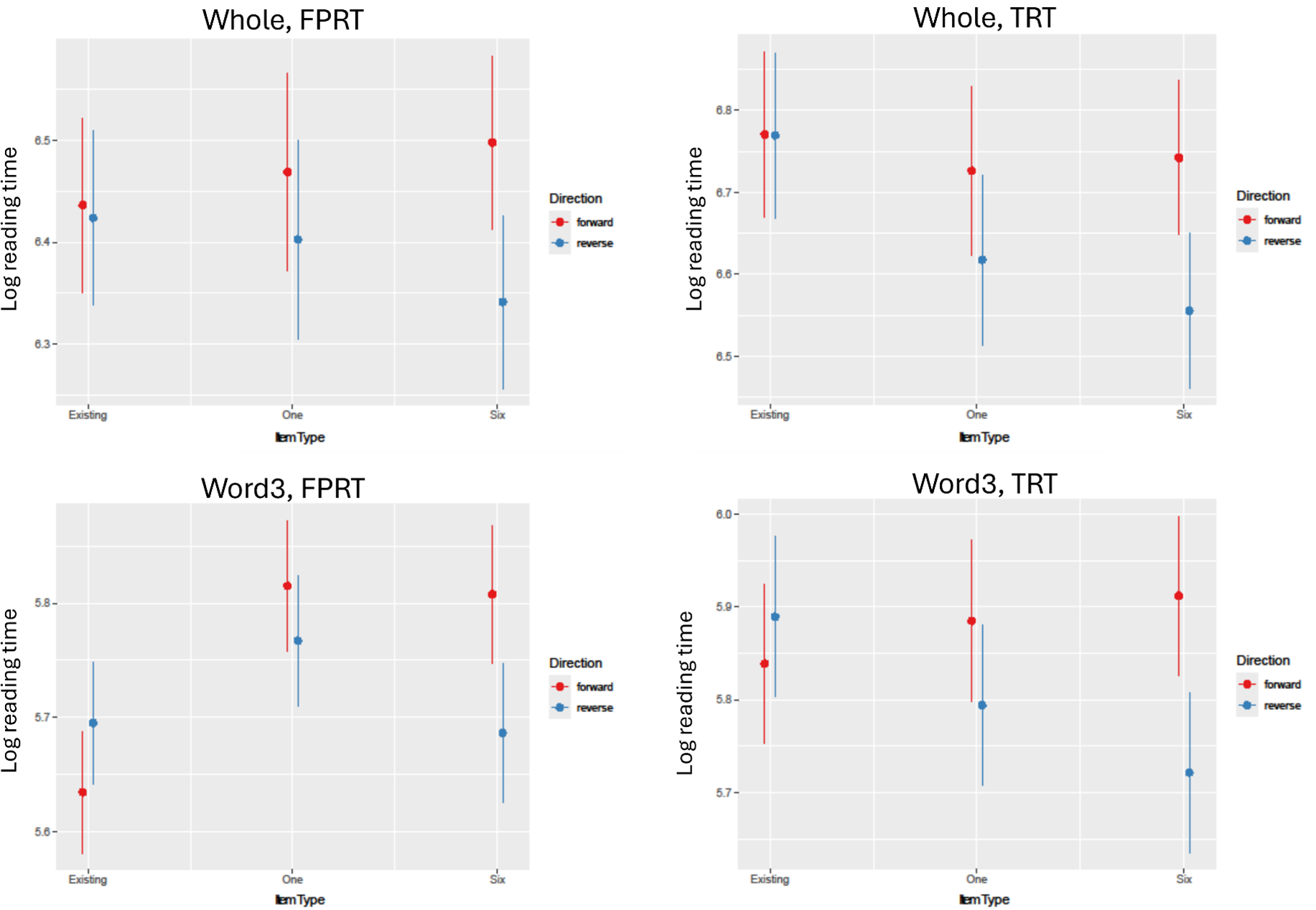
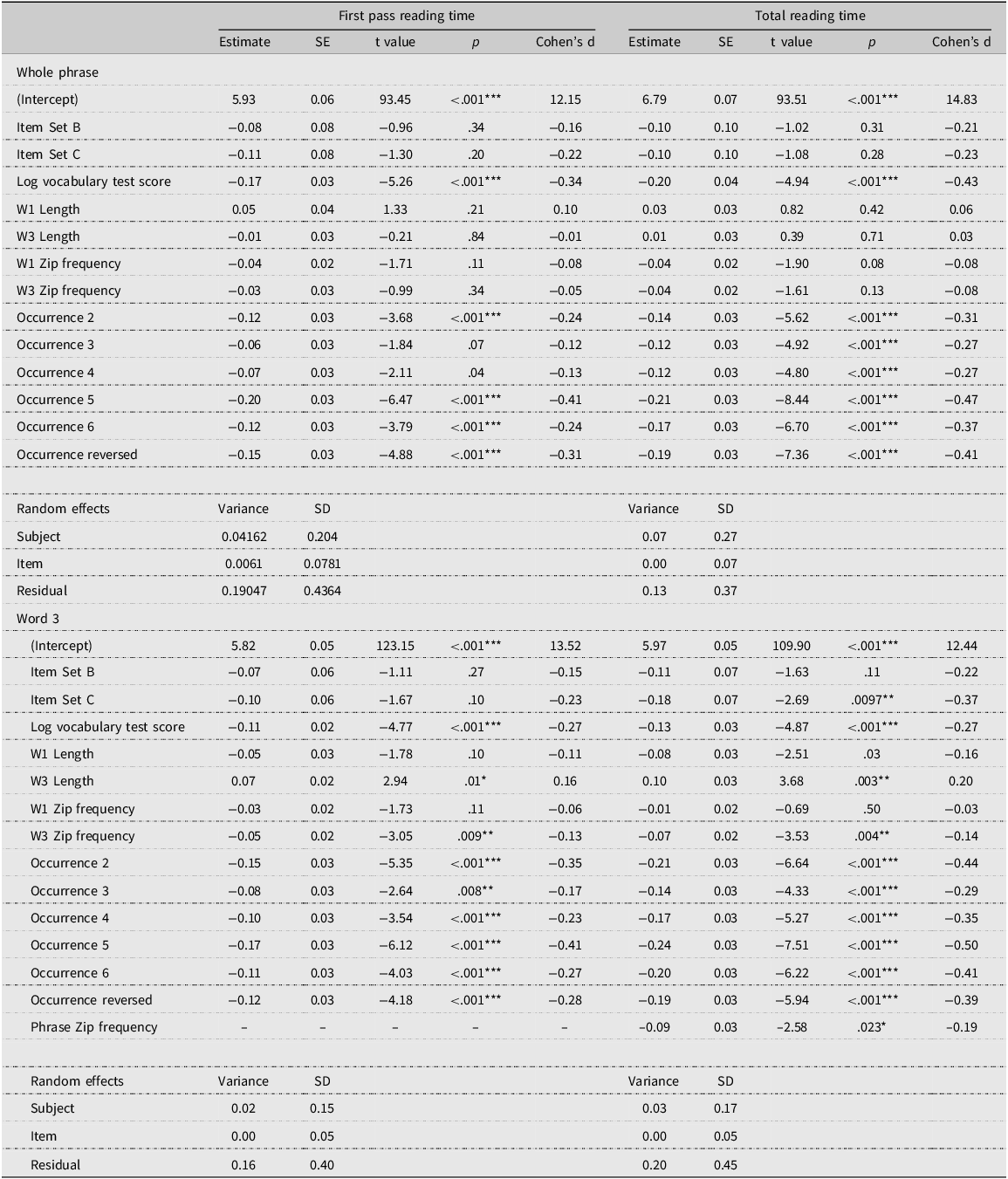
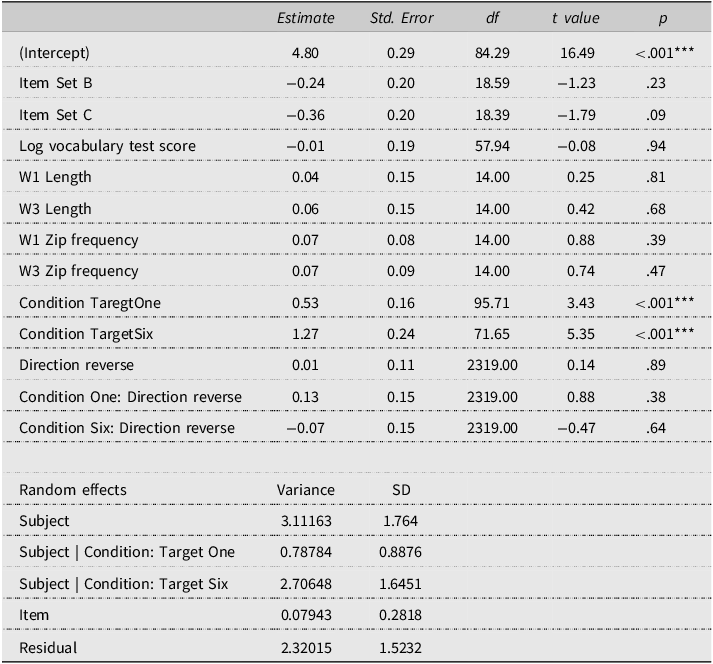
Table 1 presents the average FPRT and TRT (raw data) for existing and novel binomials in the forward (first occurrence) and reversed forms. The best-fit models for Analysis 1 (based on log-transformed data) are presented in Table 2. Results showed that the Item Type x Direction interaction was significant for both measures and for all interest areas. Pairwise comparisons (see Appendix S2, online supplementary material, and Figure 2) showed that the reversed form of novel binomials in the 6-rep condition was always read significantly faster than the forward form (between 53 and 192 ms difference). Additionally, for the 1-rep condition, the reversed form showed faster processing than the forward form during late processing (TRT) only for the whole phrase (100 ms difference). As for the existing binomials, the difference between the forward and reversed forms was never significant.Footnote 6
Analysis 2: RQ2 (How does the processing of novel binomials alter as a function of frequency of exposure (1 to 6 exposures)?)
Average reading times (and standard deviation) for existing and novel items in the forward and reversed directions

Model 1 for the difference between forward and reversed forms for existing and novel binomials

a Analysis models:Whole phrase: (lg_IA_FIRST_RUN_DWELL_TIME ∼ lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency + W3ZipFrequency + ItemType*Direction + ForwardAssociation+ (1+ItemType|Subject) + (1|Item)).
Word 3: (lg_IA_FIRST_RUN_DWELL_TIME ∼ lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency + W3ZipFrequency + ItemType*Direction + (1+ItemType|Subject) + (1|Item)).
b Analysis models:
Whole phrase: (lg_IA_DWELL_TIME ∼ lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency + W3ZipFrequency + ItemType*Direction + (1+ItemType|ParticipantCode) + (1|Item)).
Word 3: (lg_IA_DWELL_TIME ∼ lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency + W3ZipFrequency + ItemType*Direction + (1+ItemType|Subject) + (1|Item)).
A graphical presentation of the Item Type x Direction interaction (Analysis 1).

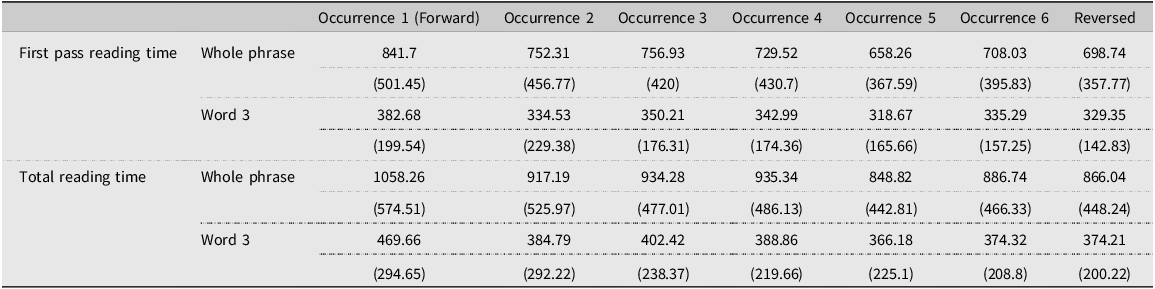
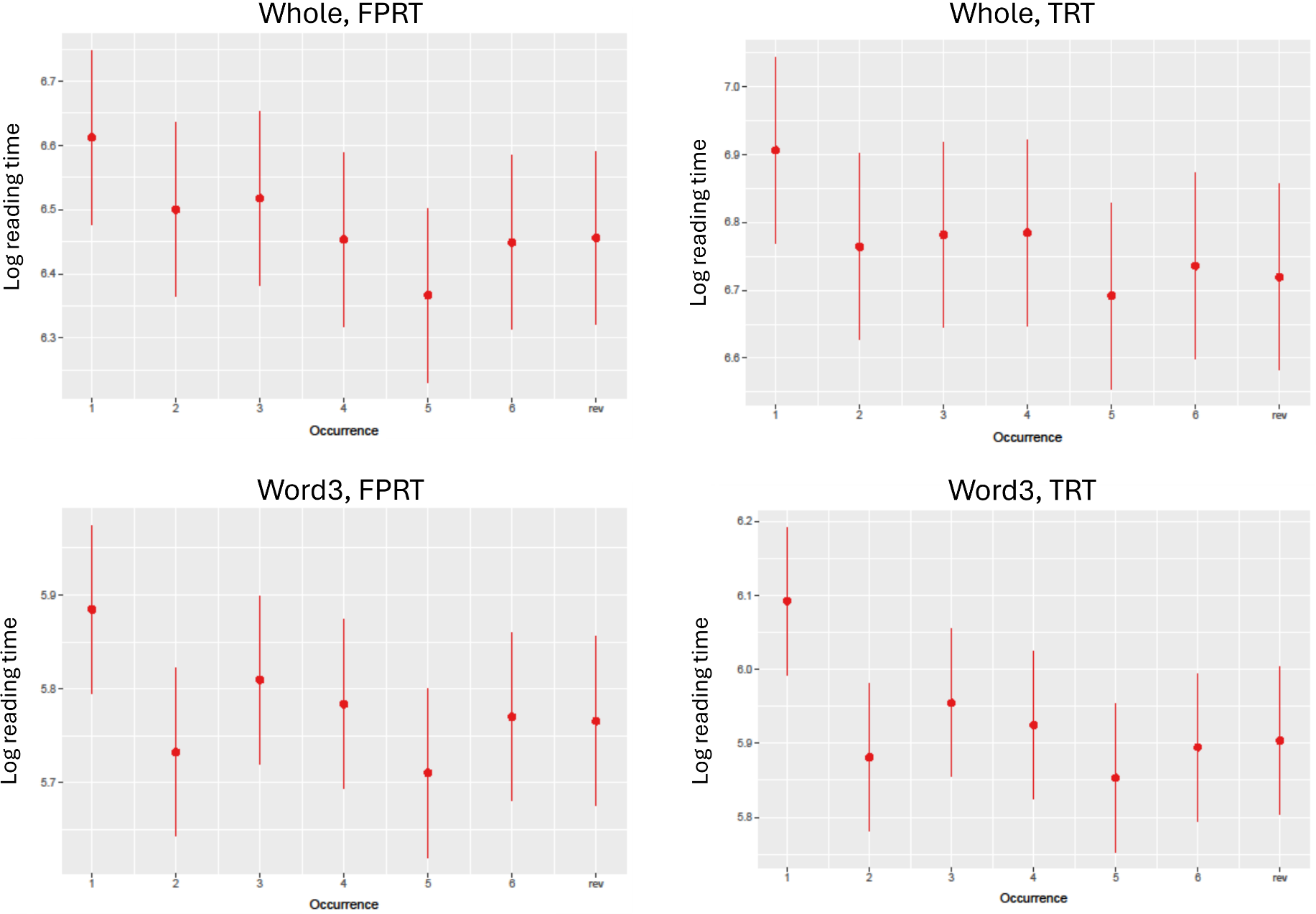
Analysis 2 examined the FPRT and TRT of the 6-rep novel items to understand the effect of frequency of exposure (1–6) on online processing. Mean reading times are presented in Table 3, and the models are presented in Table 4. Pairwise comparisons are included in Appendix S3 in the online supplementary material (see also Figure 3). Results showed that occurrence had a significant effect on reading times (early and late measures) for Word 3 and the whole phrase. Pairwise comparisons showed that the first occurrence of binomials was almost always read more slowly than all the other occurrences (including the reversed forms). This seems to suggest that reading a binomial multiple times led to a processing advantage. The fact that the reversed form was read faster than the initial one supports the finding in Analysis 1 whereby the reversed 6-rep forms were read faster than the initial forward exposure.
Mean reading times (standard deviation) for the various repetitions of the novel items that were repeated six times

Model 2 for the difference between the various repetitions of the 6-repetition novel items

a Analysis models:Whole phrase: (lg_IA_FIRST_RUN_DWELL_TIME ∼ ItemSet + lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency + W3ZipFrequency + Occurrence + (1|Subject) + (1|Item)).
Word 3: (lg_IA_FIRST_RUN_DWELL_TIME ∼ ItemSet + lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency+ W3ZipFrequency + Occurrence + (1|Subject) + (1|Item)).
b Analysis models:
Whole phrase: (lg_IA_DWELL_TIME ∼ ItemSet + lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency + W3ZipFrequency + Occurrence + (1|Subject) + (1|Item)).
Word 3: (lg_IA_DWELL_TIME ∼ ItemSet + lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency + W3ZipFrequency + Occurrence + PhraseZipFrequency + (1|Subject) + (1|Item)).
A graphical presentation of “Occurrence” on reading times (Analysis 2).

It is evident that certain comparisons of the occurrences were significant (but not all) with a positive value, suggesting that more exposure (even the reversed form) led to faster reading, though not always significantly so. The overall downward trend in Figure 3 supports this finding.
Analysis 3 & Analysis 4: RQ3 (Do non-native speakers exhibit offline sensitivity to the configuration of L1-L2 congruent existing binomials and novel binomials encountered in context?)
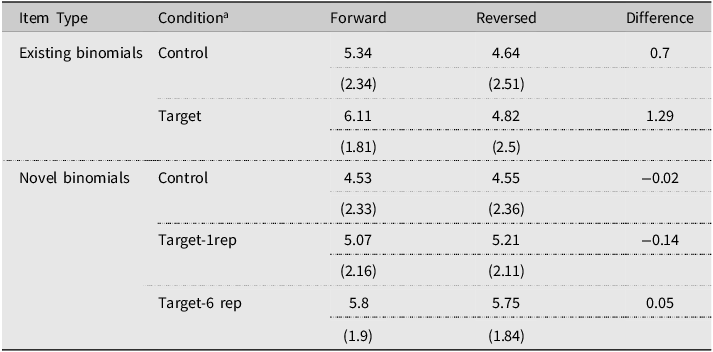
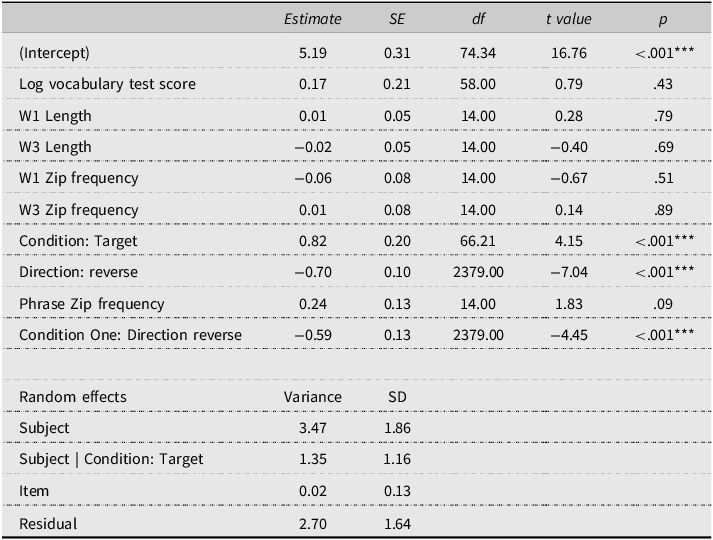
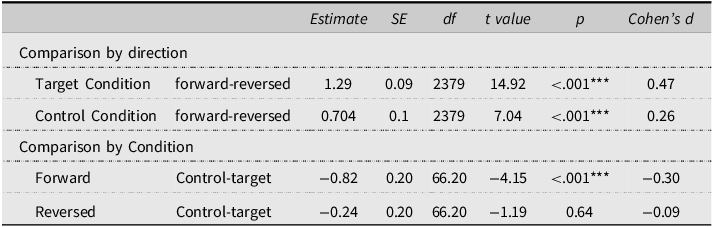
Mean rating scores for existing and novel binomials are presented in Table 5, and the best-fit model for existing binomials (Analysis 3) is presented in Table 6. Results showed a significant interaction between Condition and Direction. Pairwise comparisons (Table 7) indicated a significant increase in rating for the forward forms of binomials over their reversed forms for existing binomials under both the target (presented during reading, 1.29 difference) and control (not presented during reading, 0.7 difference) conditions. This suggests that L2 participants had declarative knowledge of the preferred word order of English binomials that are congruent with Arabic. Results also showed that the forward forms were rated higher for items presented during reading (target) than those that were not (control), but this was not the case for the reversed forms. This may represent a recency effect due to exposure during the reading task.
Means (standard deviation) for the rating (scale: 1 = very unfamiliar to 7 = very familiar) of existing and novel binomials under the various conditions

a Control items were not included in the reading passages, but target items were included in the reading passages.
Model for the difference between forward and reversed forms for the existing binomials (Analysis 3) in the offline rating task

Analysis model: (RatingScore ∼ lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency + W3ZipFrequency + Condition*Direction + PhraseZipFrequency + (1+Condition|Subject) + (1|Item)).
Pairwise comparison for the Condition x Direction interaction (Existing binomials – offline task)

Turning now to the novel binomials (Analysis 4), the best-fit model is presented in Table 8. Results showed a main effect of Condition but no effect of Direction and no interaction between the two factors. Thus, target novel binomials were rated higher in familiarity than control novel binomials. This result seems to suggest that regardless of direction, novel binomials that were presented during reading (once or six times) were rated higher than control items which were not included in the stories. Since Direction was not significant, it can be concluded that non-natives do not seem to have developed a sensitivity to novel binomials’ configuration restrictions after exposure. We also examined the 1-rep versus 6-rep difference and found that the former was rated lower than the latter (estimate = −0.63, t = −4.95, p <.001), indicating an overall increase in familiarity as a result of more exposures.
Model for the difference between forward and reversed forms for the novel binomials (Analysis 4) in the offline rating task

Analysis model: (RatingScore ∼ ItemSet + lg_VocabularyTestScore + W1Length + W3Length + W1ZipFrequency + W3ZipFrequency + Condition*Direction + (1+Condition|Subject) + (1|Item)).
Discussion
The primary goal of this study was to determine whether non-natives demonstrate an offline or online sensitivity to configuration constraints in novel binomials after six repetitions. The study combined an online measure (eye-tracking) with an offline measure (familiarity rating) to examine non-natives’ processing of existing (congruent with the participants’ L1, i.e., Arabic) and novel binomials during and after reading. Novel binomials were presented either once or six times in order to assess the effect of frequency on the learning of binomials. The aim was to address three research questions: (RQ1) Do non-native speakers demonstrate online sensitivity to the configuration (i.e., word order) of existing congruent binomials and novel binomials encountered in context?, (RQ2) How does the processing of novel binomials alter as a function of frequency of exposure (1 to 6 exposures)?, and (RQ3) Do non-native speakers exhibit offline sensitivity to the configuration of L1–L2 congruent existing binomials and novel binomials encountered in context?
Regarding RQ1, we found that Arabic non-native speakers of English did not exhibit sensitivity to the preferred word order of existing binomials. This finding is in line with Sonbul et al.’s (Reference Sonbul, El-Dakhs, Conklin and Carrol2023) study which showed no online sensitivity to existing binomials for a similar group of non-native speakers. It should be noted, though, that in the present study, we only included existing binomials which are congruent in word order with Arabic. Thus, it seems that Arabic speakers of English are not sensitive to established configuration restrictions in binomials even when these are consistent with the restrictions in their L1. The results are also in line with Siyanova-Chanturia et al. (Reference Siyanova-Chanturia, Conklin and Van Heuven2011) in that non-natives are not always sensitive to the direction of established binomials. It should be noted that Siyanova-Chanturia et al. (Reference Siyanova-Chanturia, Conklin and Van Heuven2011) found a modulating effect of L2 proficiency on the processing of L2 binomials, with clearer sensitivity as proficiency increases, but the present study did not find such an effect. The following offers some potential explanations for this discrepancy. First, the participants in the two studies likely differed in their L2 English proficiency. Although there are no objective measures that would allow a direct comparison between non-native participants in Siyanova-Chanturia et al. (Reference Siyanova-Chanturia, Conklin and Van Heuven2011) and the present study, there are major differences between them. Participants in the former study were students at a university in the UK and were thus ESL (English-as-a-second-language) users who had spent an average of 21 months in an English-speaking community and had passed the requirement for studying at a British university (minimum 6.00 in IELTS). In contrast, our participants were EFL (English-as-a-foreign-language) speakers at the time of study (although some of them had spent some time in an English-speaking country). Yamashita and Jiang (Reference Yamashita and Jiang2010) showed that EFL and ESL users process congruent/incongruent formulaic sequences (i.e., collocations) differently (with the effect of congruency diminishing for ESL users). Second, as discussed by Sonbul et al. (Reference Sonbul, El-Dakhs, Conklin and Carrol2023), the absence of a sensitivity in L1 Arabic speakers in L2 English might be related to the fact that binomials in Arabic are less fixed than those in English. Hence, if binomial word order is less fixed or biased in the L1, non-native speakers may be less attuned to this property in their L2. It would be interesting for future research to examine the effect of congruency on the processing of binomials by L1 Arabic-L2 English speakers in the EFL and ESL contexts.
For the novel binomials, the comparison between the first forward exposure and the reversed forms (for the 1-rep and 6-rep item types) consistently showed that the reversed form was processed faster than the forward form for the 6-rep items. This finding seems to suggest that when it comes to co-occurrence restrictions (e.g., wires used in combination with pipes regardless of the word order), seeing the binomials six times leads to a significant decrease in reading times. This finding is in line with previous research on non-natives’ online processing of collocations (Altamimi & Conklin, Reference Altamimi and Conklin2024a; Durrant & Schmitt, Reference Durrant and Schmitt2010; Pellicer-Sánchez, Reference Pellicer-Sánchez2017; Pellicer-Sánchez et al., Reference Pellicer-Sánchez, Siyanova-Chanturia and Parente2022) and binomials (Sonbul et al., Reference Sonbul, El-Dakhs, Conklin and Carrol2023) which showed that sensitivity to co-occurrence restrictions can be developed through repeated exposure in reading. This is also consistent with the findings of Sonbul et al. (Reference Sonbul, El-Dakhs, Conklin and Carrol2023) where more than one exposure (two or four) can lead to developing this co-occurrence restriction.
Turning now to RQ2, results comparing across the various occurrences of the 6-rep novel binomials (six forward and once reversed) showed no processing disadvantage for reversed forms in comparison to forward forms (as evident in Conklin & Carrol, Reference Conklin and Carrol2021 for natives). On the contrary, more exposure to the novel binomials (including the reversed form) generally led to a decrease in reading times (see Figure 3). As for the comparison between the various forward forms and the reversed form, our findings suggest that it is only the first exposure that was processed significantly more slowly than the reversed form, again stressing the finding reported above that non-natives in the present study were sensitive to co-occurrence restrictions rather than word order preference. Hence, similar to Sonbul et al. (Reference Sonbul, El-Dakhs, Conklin and Carrol2023), it can be concluded that the Arabic-English non-native speakers treated the reversed form as another occurrence of the same binomial regardless of word order. This is the case despite the fact that the present study added two more exposures to novel binomials (i.e., the maximum number of exposures was four in Sonbul et al. Reference Sonbul, El-Dakhs, Conklin and Carrol2023 but six in the present study). It seems that increasing exposure did not alter the tendency for non-natives to be unattuned to word order when processing L2 novel binomials. This is in contrast with the native speakers in Conklin and Carrol’s (Reference Conklin and Carrol2021) study who showed a processing advantage for novel binomials presented in the forward form over their reversed forms after four to five exposures. Thus, non-natives in the present study appear to perform differently than natives in that they do not seem to be sensitive to configuration restrictions when processing binomials online, possibly due to binomials being not as fixed in Arabic as they are in English (see above).
In addition to the online (eye-tracking) measure, the present study also included a post-exposure offline rating task to examine declarative knowledge of existing binomials (RQ3) and novel binomials after exposure (RQ4). For existing binomials which are congruent with the speakers’ L1 (Arabic), results showed higher ratings for the forward form over the reversed form for existing binomials (i.e., higher ratings) regardless of whether these were presented during the reading task or not. Thus, similar to Sonbul (Reference Sonbul2015) and Sonbul and El-Dakhs (Reference Sonbul and El-Dakhs2020) who showed dissociation between offline and online processing of collocations, the current study seems to suggest a similar dissociation between online (eye-movements) and offline (familiarity rating) processing of existing binomials. While offline, non-natives exhibited declarative knowledge of configuration restrictions congruent with their L1, they did not show such sensitivity online. Thus, declarative knowledge of formulaic sequences might develop earlier than online sensitivity which may require more exposure to be apparent (Sonbul, Reference Sonbul2015).
Turning to the findings of the familiarity rating task in relation to novel binomials, non-native speakers in the present study did not show sensitivity to configuration restrictions offline; the novel binomials were rated similarly in both directions. This finding stands in contrast with several previous studies such as Sonbul and Schmitt (Reference Sonbul and Schmitt2013), Altamimi and Conklin (Reference Altamimi and Conklin2024b) and Alotaibi et al. (Reference Alotaibi, Pellicer-Sánchez and Conklin2022). For example, in a study examining collocations, Sonbul and Schmitt (Reference Sonbul and Schmitt2013) found that non-native speakers developed declarative knowledge (recall and recognition) of unfamiliar, medical collocations after three exposures even though they did not manifest any online sensitivity. Similarly, previous research on binomials showed evidence for non-natives’ developing offline sensitivity to configuration restrictions after two exposures (Altamimi & Conklin, Reference Altamimi and Conklin2024b) and six exposures (Alotaibi et al., Reference Alotaibi, Pellicer-Sánchez and Conklin2022). It should be noted though that these previous studies on binomials used different forms of declarative measures than the present study. While in the present study, the items were presented in both the forward and reversed forms in the familiarity rating task to allow a direct comparison, Altamimi and Conklin (Reference Altamimi and Conklin2024b) used a forced-choice measure (Is it gold and silver or silver and gold) and Alotaibi et al. (Reference Alotaibi, Pellicer-Sánchez and Conklin2022) used a multiple-choice test and a familiarity rating task in the forward direction only. We argue that the offline measure employed in the present study might be more appropriate for detecting sensitivity to configuration restrictions through the direct comparison of the forward and reversed forms of the same binomial (although see below for a limitation in our offline task).
Overall, the results of the present study suggest that Arabic speakers of English are not sensitive to the preferred word order (i.e., configuration) for either existing or novel binomials online. Offline, they seem to be sensitive to binomials’ configuration restrictions for items that exist both in their L1 and L2 with the same preferred configuration (e.g., salt and pepper over pepper and salt). However, they do not develop such sensitivity to novel binomials after encountering them six times in a reading context.
Limitations and suggestions for future research
The study is limited in several ways. First, we only included existing binomials that have the same word order preference in L1 and L2 (i.e., congruent binomials). Future research on the processing of binomials could include both congruent and incongruent binomials and involve both offline and online measures. This would allow a more direct investigation of the effect of congruency on the processing of L2 binomials whether in real time during reading (eye-tracking) or after reading (declarative post-exposure tests).
Additionally, the offline measure employed in the present study was limited in that it presented both the forward and reversed forms to the participants without any counterbalancing (though in a balanced design), which might have resulted in them developing strategies in rating the binomials (the first presentation of the binomial—whether forward or reversed—might have an influence on the second one). Future research can attempt to develop counter-balanced lists to avoid such task-order effects on findings.
Third, and most importantly, the current research is limited in that it only included six exposures to the target novel binomials, which, based on the results, was not sufficient for the non-natives to develop an offline or online sensitivity to their configuration. Further research in this area will benefit from adding extra exposures to novel binomials in context. For example, Pellicer-Sánchez et al. (Reference Pellicer-Sánchez, Siyanova-Chanturia and Parente2022) found that the processing of novel collocations became similar to existing ones only after eight exposures. Thus, presenting novel binomials eight or even 10 times might help address the issue of how many exposures are needed before non-natives can develop sensitivity to novel binomials. Developing sensitivity to configuration restrictions might also pertain to longer-term, more consistent exposure, rather than several encounters in a short period of time. Hence, future research can adopt a longitudinal design where participants see the target binomial repeatedly in different contexts over a long period of time.
Another area for future research to consider is the inclusion of an explicit instruction or textual enhancement component instead of presenting binomials in normal font as was the case in most previous research on L2 binomials (Alotaibi et al., Reference Alotaibi, Pellicer-Sánchez and Conklin2022; Altamimi & Conklin, Reference Altamimi and Conklin2024b; Sonbul et al., Reference Sonbul, El-Dakhs, Conklin and Carrol2023). Previous research on the acquisition of collocational co-occurrence restrictions showed an advantage for textual enhancement and explicit instruction over natural exposure on offline measures (e.g., Sonbul & Schmitt, Reference Sonbul and Schmitt2013). Thus, future research can possibly examine the effect of such exposure conditions on the ability of non-natives to develop sensitivity to the configuration restrictions of novel binomials. This would have tangible implications for the teaching of binomials in L2 classes.
Finally, as indicated above, Arabic is less fixed than English when it comes to binomial configuration restrictions. Further research in the area can attempt to compare across non-native participants from various L1s—more or less fixed in the word order of binomial components. This would help address the issue of whether the current results are due to a transfer effect whereby certain L1s have less rigid word order preferences than others, and this is transferred into L2 processing. The question then is are non-natives better at watching out for L2 restrictions (e.g., “salt and pepper” being more acceptable than “pepper and salt”) to which they are attuned in their L1?
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0142716426100538
Replication package
Replication data and materials for this article can be found at https://osf.io/x4whb.
Acknowledgements
The researchers thank Prince Sultan University in Saudi Arabia for funding this research project through the grant SEED-CHS-2023-130.
Competing interests
The author(s) declare none.




 Open access
Open access