


1. Introduction
In insurance and reinsurance business, a large amount of unstructured data is generated and needs processing and analyzing. In contrast to structured data, which are typically represented in tabular form, unstructured data encompass information that lacks a pre-defined format, such as text and images. Common unstructured data in (re)insurance business include insurance policies, claim reports, and emails. The processing of unstructured data comprises a broad variety of tasks, ranging from fundamental operations to sophisticated analysis. At the fundamental level, this includes entity extraction (e.g., policy details from documents) and classification (e.g., claim reason classification into a list of given options). More advanced processes involve synthesizing information into summaries and applying logical reasoning, such as evaluating the appropriateness of claim payments based on policy terms. The traditional approach to such unstructured data has been to deal with it by hand, which is both inefficient and time-consuming. The development of natural language processing (NLP) provides an automated solution for unstructured data processing. The evolution of language models originates from the statistical models in the 1990s (Jelinek, Reference Jelinek1990; Waibel & Kai-Fu, Reference Waibel and Kai-Fu1990; Jelinek et al., Reference Jelinek, Lafferty and Mercer1992; Brown et al., Reference Brown, Cocke, Della Pietra, Della Pietra, Jelinek, Lafferty and Roossin1990; Brown et al., Reference Brown, Della Pietra, Della Pietra and Mercer1993; Brown, Reference Brown1990; Jelinek, Reference Jelinek1998; Rosenfeld, Reference Rosenfeld2000; Stolcke, Reference Stolcke2002; Gao & Lin, Reference Gao and Lin2004), which are developed under the Markov assumption that the probabilistic inference of the (k + 1)st word is dependent on its preceding k words. Subsequently, neural-network-based language models were introduced to handle sequential data effectively, including recurrent neural networks and its variants, e.g., gated recurrent unit and long-short term memory (Rumelhart et al., Reference Rumelhart, Hinton and Williams1986; Chung et al., Reference Chung, Gulcehre, Cho and Bengio2014; Hochreiter & Schmidhuber, Reference Hochreiter and Schmidhuber1997). The models mentioned above are relatively small language models, which perform well in specific tasks such as extraction and classification, but exhibit restricted capabilities in reasoning. The integration of these models into the (re)insurance sector could facilitate the automation of business processes, such as claim classification and fraud detection, thereby enhancing operational efficiency (Lee et al., Reference Lee, Manski and Maiti2020; Saddi et al., Reference Saddi, Gnanapa, Boddu and Logeshwaran2023).
The transformer architecture led a breakthrough enabling more scalable training and better model performance through self-attention mechanism (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez and Polosukhin2017). Based on this architecture, the BERT (Bidirectional Encoder Representations from Transformers) model was released by pre-training on large-scale unlabeled text data (Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019). Subsequently, the rise of ChatGPT (OpenAI, 2022) and other large language models (LLMs) has significantly changed the paradigm of NLP, marking a substantial leap toward achieving artificial general intelligence. With the increase of model and data sizes of pre-trained language models, some emergent abilities have been found, leading to the term LLM (Wei et al., Reference Wei, Wang, Schuurmans, Bosma, Ichter, Xia and Zhou2022). These emergent abilities include in-context learning, instruction following and step-by-step reasoning, making it possible for language models to solve more complicated problems. For example, GPT-3 demonstrated few-shot learning capabilities, unlike its predecessor GPT-2 (Brown et al., Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal and Amodei2020). These pre-trained LLMs are considered storing a wide range of knowledge and common sense with advanced reasoning capabilities. Recently, ChatGPT resulted from aligning the LLMs from the GPT series for dialogue, which presents an exceptional conversational ability with humans (OpenAI, 2022). In addition to enhanced performance on conventional NLP tasks such as extraction and classification, the emerging capabilities of LLMs demonstrate the potential of AI assistants for employees in the (re)insurance sector (Balona, Reference Balona2023). As AI assistants, LLMs could be used to improve efficiency, streamline operations, and support decision-making in a variety of ways. For example, they can analyze and summarize long documents, highlighting key information and saving significant reading time. Another potential scenario is preliminary assessments in claims processing, where LLM can compile relevant policy and claim reports to suggest an initial decision to accept or reject a claim, subject to human review.
However, challenges remain in the use of LLMs in (re)insurance sector. While LLMs are designed to have broad knowledge, they may struggle with domain-specific tasks due to the overrepresentation of popular topics and underrepresentation of niche subjects. This can lead to inconsistent or inaccurate responses when dealing with complex domain-specific concepts and terminology. The domain specialization of LLMs is a critical yet demanding problem. To narrow the divide between general LLMs and domain-specific requirements, there are two prevalent methods, namely prompt engineering and fine-tuning, which involve the integration of proprietary and domain-specific data into LLMs. The two methods offer varying levels of computational efficiency, ease of deployment, and adaptability. Prompt engineering is resource-efficient, yet its capacity to enhance the performance of LLMs in domain-specific tasks is limited. It could leverage the inherent language capabilities of LLMs without altering the model parameters, making them ideal for tasks such as information extraction and text generation (Dodson, Reference Dodson2023). In contrast, it has been shown that fine-tuning can significantly improve the inference of LLMs, especially for tasks demanding complex reasoning (Singhal et al., Reference Singhal, Tu, Gottweis, Sayres, Wulczyn, Hou and Natarajan2025; Chung et al., Reference Chung, Hou, Longpre, Zoph, Tay, Fedus and Wei2024). While there have been reports of LLMs being specialized in sectors such as medicine, finance, investment, and law through fine-tuning techniques (Singhal et al., Reference Singhal, Tu, Gottweis, Sayres, Wulczyn, Hou and Natarajan2025; Yang et al., Reference Yang, Liu and Wang2023; Yang et al., Reference Yang, Tang and Tam2023; Cui et al., Reference Cui, Li, Yan, Chen and Yuan2023), the (re)insurance domain has not yet been explored in this context. Additionally, many tasks within the (re)insurance domain rely on the ability to perform complex quantitative reasoning, such as the calculation of premiums and loss payments. However, many fine-tuned models have been applied to text-heavy tasks, indicating a research gap for those that require quantitative reasoning performed frequently in the (re)insurance workflow.
This study assesses the capability of LLMs to perform reasoning tasks within the (re)insurance sector. We utilize reinsurance training materials to create quantitative question-answer pairs that test the models’ ability to calculate and allocate liabilities, premiums, and claims between the reinsured and the reinsurer. While these test cases may not fully replicate real-world business scenarios, they serve as a valuable benchmark to evaluate LLMs’ potential for executing reasoning tasks in the reinsurance domain. The open-source Llama 2-Chat models of sizes 7B, 13B, and 70B are adopted as our baseline with prompt engineering based on one-shot learning and fine-tuning with various datasets applied subsequently to further augment the model performance. As a benchmark for comparison, we also evaluated the performance of GPT 4, a close-source model released around the same time as Llama 2. Our findings can be summarized as follows:
-
• By using one-shot learning, the Llama 2-Chat 70B model demonstrates notable performance improvement, while the 7B and 13B models encounter difficulties. Fine-tuning with the calculation dataset increases evaluation metric from around 15 points to nearly 80 points, yielding a five-to-six-fold enhancement and outperforming larger pre-trained LLMs, which underscores the importance and efficacy of fine-tuning for reasoning-intensive tasks.
-
• When task-specific calculation dataset is limited, supplementing LLMs with more accessible domain-specific knowledge data can markedly improve performance, achieving results comparable to models fine-tuned on extensive calculation datasets. Even without calculation data, employing background knowledge for fine-tuning with one-shot prompting can significantly elevate model capabilities.
-
• There is a positive correlation between the model performance and its capacity for reasoning, with deductions due to computational errors comprising a minimal fraction of the overall performance metrics. Consequently, enhancing reasoning capability stands as the principal focus for optimizing LLMs in quantitative tasks. Furthermore, the fine-tuned model maintains its proficiency in common sense reasoning and factual knowledge, suggesting retention of acquired knowledge post-fine-tuning, according to their performance on public benchmarks.
The paper is organized as follows. Section 2 offers an overview of related work for reader reference. Section 3 details our experiment set-up, including evaluation data, training data, prompt engineering, and fine-tuning techniques employed in this work, and evaluation metric. In Section 4, we present our findings from experiments and auxiliary assessments, including error analysis and the model evaluation on public benchmarks. The concluding remarks can be found in Section 5.
2. Related works
In this section, we present prior work related to our study. Section 2.1 provides an overview of existing literature on the application of NLP techniques in (re)insurance problems, covering both traditional language models and LLMs. Section 2.2 delves into an introduction of open-source LLMs and domain-specification techniques, including prompt engineering and fine-tuning, as well as examples of domain-specification of LLMs.
2.1 NLP techniques in (re)insurance sector
2.1.1 Traditional language models
Prior to the appearance of LLMs, traditional NLP techniques, such as statistical models and neural-network-based models, have offered effective tools for processing unstructured data. By extracting information from raw text data and transforming it into structured numerical or categorical data, these language models could generate additional variables for further analysis. For example, the utilization of rule-based NLP algorithms or sentence embeddings could help with the recognition of fraudulent patterns from the contents of claims, thereby facilitating the detection of insurance fraud through machine learning techniques (Saddi et al., Reference Saddi, Gnanapa, Boddu and Logeshwaran2023). Word embedding models could be used for claim classification, and new features could be generated to provide additional information for claim analysis and loss amount prediction through actuarial models such as generalized linear model (Lee et al., Reference Lee, Manski and Maiti2020). The deployment of these NLP models can reduce the time and human effort required for manual review by automating the processing of unstructured data, thereby enhancing overall efficiency. Furthermore, NLP techniques offer the potential to utilize a broader range of data source for modelling purposes beyond structured data. This could facilitate the generation of insights and enhance the performance of (re)insurance models.
2.1.2 Large language models
With the extensive knowledge foundation and emerging reasoning capabilities, LLMs present the potential of the application in the (re)insurance sector through two ways: directly contributing to modelling and serving as workflow assistant (Balona, Reference Balona2023). The first application involves solving the same tasks as the traditional language models. For example, ChatGPT can be used to extract information from accident reports, achieving a higher accuracy than traditional small language models (Troxler & Schelldorfer, Reference Troxler and Schelldorfer2024). The utilization of LLMs for NLP tasks shows several advantages. Firstly, LLMs are trained on a large corpus with a deeper understanding of fundamental and expert knowledge, which enables them to perform better than traditional language models. Secondly, the pre-processing of raw data can be simplified. For example, there is no need to translate the input text into the same language when dealing with multilingual tasks. Thirdly, some less complex tasks can be solved by LLMs in an unsupervised approach, saving the effort required for data annotation and model training, which are necessary in machine learning. The second application involves assisting in the daily work of employees in the (re)insurance sector by providing documentation summarization and generation, automatic data analysis, coding assistance, and other problem-solving services (Balona, Reference Balona2023). The potential of incorporating LLMs into routine work is guaranteed by their emerging capabilities. However, this application has not been sufficiently explored in previous literature and is likely to become a valuable area of interest in future research.
2.2 LLM and domain-specialization
2.2.1 Open-source LLM and Llama2
Developing an LLM from scratch is a resource-intensive endeavor. Therefore, it is common practice to use existing publicly available models, which can be divided into two categories, i.e., close-source and open-source LLMs (Zhao et al., Reference Zhao, Zhou, Li, Tang, Wang, Hou and Wen2023). Compared to the close-source LLMs, such as ChatGPT by OpenAI, offering access through APIs or user interfaces without the need for local deployment, open-source LLMs provide downloadable model checkpoints, enabling local deployment, further training, or fine-tuning. These models ensure great transparency, permit full control, and are often released with different options of model sizes, allowing for flexible customization.
Among the open-source LLMs, Llama, a suite of models, has been broadly used in academic research and commercial applications, demonstrating robust performance across numerous benchmarks (Beeching et al., Reference Beeching, Fourrier, Habib, Han, Lambert, Rajani and Wolf2023). Following an initial release of Llama from Meta AI in February 2023, Llama 2 and Llama 2-Chat were introduced in July 2023 with further training on new public datasets and various model sizes of 7B, 13B, and 70B parameters. Compared with the pre-trained Llama 2, the Llama 2-Chat models were optimized for following instructions and dialogue use cases (Touvron et al., Reference Touvron, Martin, Stone, Albert, Almahairi, Babaei and Scialom2023). Subsequent developments have built upon these models, e.g., Llama 2-Instruct was tailored for long-text chat, and Llava was adapted for multimodal instruction-following tasks (Together, 2023; Liu, Reference Liu2023).
2.2.2 Prompt engineering
Despite the capabilities of LLMs, a persistent gap exists between their general knowledges and domain-specific tasks. Prompt engineering is a relatively new discipline for developing and optimizing prompts to effectively use LLMs without altering the model parameters. There have been reports indicating that LLMs show improved capacity on downstream tasks when properly prompted (Radford et al., Reference Radford, Wu, Child, Luan, Amodei and Sutskever2019; Wei et al., Reference Wei, Wang, Schuurmans, Bosma, Ichter, Xia and Zhou2022).
Among the approaches in prompt engineering, few-shot prompting enables in-context learning to steer the models by providing demonstration examples (Brown et al., Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal and Amodei2020). It has been evident that the LLMs can acquire proficiency for common tasks through the provision of one single example, referred to as one-shot prompting. Besides, various techniques have emerged for reasoning-intensive tasks (Saravia, Reference Saravia2022). For example, Chain-of-Thought (CoT) prompting enhances the complex reasoning capabilities of LLMs by presenting a sequence of smaller reasoning steps, aiding the model with comprehension of the task (Wei et al., Reference Wei, Wang, Schuurmans, Bosma, Ichter, Xia and Zhou2022). This can be coupled with one-shot or few-shot prompting to further amplify model performance. Tree-of-Thoughts prompting provides a framework for tasks demanding exploration or strategic reasoning, resembling an expanded version of CoT with multiple nodes and branches (Yao et al., Reference Yao, Yu, Zhao, Shafran, Griffiths, Cao and Narasimhan2023).
2.2.3 Fine-tuning
Fine-tuning is a process where a pre-trained model is further trained on a smaller and domain-specific dataset. This process adjusts the model parameters to specialize its knowledge and improve its performance on tasks within the specific domain. However, fine-tuning large models with billions to trillions of parameters poses practical challenges due to high computational costs and single-GPU RAM limitations. To address this, parameter-efficient fine-tuning (PEFT) methods have been developed, training a limited number of parameters instead of full parameter fine-tuning. Existing PEFT methods could be categorized into several groups: addition-based PEFT fine-tune newly introduced parameters, selection-based PEFT fine-tune a subset of existing parameters, and reparametrization-based PEFT fine-tune a low-rank representation of full parameters (Lialin et al., Reference Lialin, Deshpande and Rumshisky2023).
Among the reparametrization-based methods , Low-Rank Adaptation (LoRA) and its variants, such as Quantized Low-Rank Adaptation (QLoRA), are the most prominent PEFT techniques for fine-tuning LLMs. LoRA decomposes the updates of weight matrix into products of two low-rank matrices, which efficiently reduces training parameters, enables pretrained models to be shared across multiple tasks, and incurs no inference latency (Hu et al., Reference Hu, Shen, Wallis, Allen-Zhu, Li, Wang and Chen2022). This approach has led to the development of numerous open-source models with outstanding performance (Cui et al., Reference Cui, Li, Yan, Chen and Yuan2023; Yang et al., Reference Yang, Tang and Tam2023). QLoRA extends LoRA by introducing quantization to enhance parameter efficiency during fine-tuning (Dettmers et al., Reference Dettmers, Pagnoni, Holtzman and Zettlemoyer2023). It combines LoRA principles with 4-bit NormalFloat quantization and double quantization techniques. Studies demonstrate that both LoRA and QLoRA achieve performances comparable to full parameter tuning across models of various sizes (Patel, Reference Patel2023; Google, 2023). QLoRA consumes approximately 75% less peak GPU memory than LoRA, yet LoRA demonstrates a 66% improvement in speed and is 40% more cost-efficient than QLoRA (Google, 2023). Thus, LoRA is preferred when GPU memory is sufficient for fine-tuning tasks, while QLoRA is recommended when memory constraint is a concern.
2.2.4 Domain specialization of LLMs
Several studies have leveraged LLMs in various domains by employing prompt engineering and fine-tuning techniques according to survey (Zhao et al., Reference Zhao, Zhou, Li, Tang, Wang, Hou and Wen2023). For instance, in the legal domain, ChatLaw utilized Q&A pairs derived from news, exam questions, and legal documents to fine-tune open-source LLMs for legal inquiries (Cui et al., Reference Cui, Li, Yan, Chen and Yuan2023). Similarly, DISC-LawLLM prepared diverse training datasets, including multi-choice questions, law retrieval, legal consultation, and agreement writing (Yue et al., Reference Yue, Chen, Wang, Li, Shen, Liu and Zhou2023). In finance, FinGPT fine-tuned LLMs with news, reports, and social media data for sentiment analysis, relation extraction, headline analysis, and more (Yang et al., Reference Yang, Liu and Wang2023). InvestLM curated instructions from various sources for tasks like sentiment analysis and document classification focusing on the investment industry (Yang et al., Reference Yang, Tang and Tam2023). In the medical domain, Med-PaLM focused on medical Q&A datasets for high-quality medical answers (Singhal et al., Reference Singhal, Azizi, Tu, Mahdavi, Wei, Chung and Natarajan2023), while HuaTuo trained on real or ChatGPT-generated conversations for medical consultations (Wang et al., Reference Wang, Liu, Xi, Qiang, Zhao, Qin and Liu2023). These studies underscore the potential of LLMs for fine-tuning in diverse domains.
Despite the proliferation of the above domain-specific models, there remains a notable absence of LLMs with expertise in (re)insurance sector. One of the quantitative reasoning tasks in this domain involves calculating the allocations of liabilities, premiums, and claims between reinsured and reinsurer, which requires a profound understanding of (re)insurance and mathematical principles. In this work, we evaluate the development of domain-specific language model tailored to this task by implementing prompt engineering and fine-tuning techniques on existing open-source LLMs.
3. Methodology
In this section, we detail the experiment set-up for the evaluation of domain-specific LLMs on the calculation task of (re)insurance allocation, as shown in Fig. 1. The data used in the experiment are presented in Section 3.1. In Section 3.2, we focus on the implementation details and computational aspects of the LLMs and associated prompt engineering and fine-tuning techniques. The evaluation metric is discussed in Section 3.3.
Illustration of experiment set-up. The evaluation framework incorporates human assessment, using open source LLMs as base models and benchmarks. We employ prompt engineering and fine-tuning to achieve domain specialization. Recognizing the challenges of gathering extensive task-specific training data (calculation dataset), we further examine the impact of fine-tuning with background knowledge (knowledge dataset).

3.1 Data
The data utilized in this work are sourced from reinsurance training materials, which contain a general overview of reinsurance business, as well as a detailed introduction to common types of reinsurance treaties, including proportional reinsurance and non-proportional reinsurance. They are used to construct evaluation and training datasets described in the following subsections.
3.1.1 Evaluation dataset
The evaluation dataset comprises the calculations of (re)insurance allocation in the form of question and answering (Q&A) extracted from the aforementioned training materials. The dataset consists of 100 questions across 25 different types, with each type featuring multiple scenarios. For instance, questions involving reinsurer payment calculations may vary based on factors such as deductible levels and loss amounts, or the treatment of underwritten buildings as single or separate risks.
3.1.2 Training dataset
The training dataset is customized to evaluate fine-tuning effects on model performance, consisting of two subsets: task-specific data and background knowledge data. Task-specific data encompass calculation Q&A pairs similar to those in the evaluation dataset. Recognizing the challenges of gathering comprehensive task-specific data, background knowledge data are included to assess the impact of fine-tuning using broader domain knowledge.
(i) Task-specific data: calculation dataset
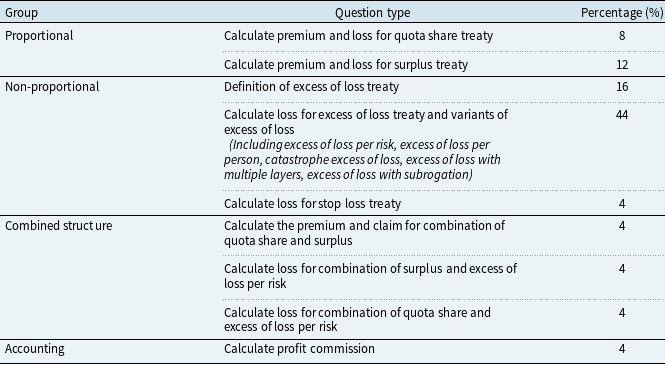
The calculation dataset consists of questions with various reinsurance types and difficulty levels. Proportional reinsurance questions constitute 20%, non-proportional reinsurance questions 64%, while 12% involve combined structures, and 4% are accounting calculations. Tasks range from simple deductions to complex computations involving multiple treaty types, reflecting the intricacies of reinsurance financial calculations. Each question specifies the desired answer, background, and conditions, with clear explanations provided in the answer to facilitate model comprehension. For multi-step reasoning and calculation tasks, CoT methodology is employed to guide the model. The dataset contains 25 types, with experiments conducted on different training data sizes to gauge performance improvements, with a maximum of 1150 questions, averaging 46 questions per type. The types of questions in the calculation dataset and the percentage of each type are shown in Table 1. There are several examples of the calculation dataset shown in Appendix A. Calculation dataset.
Type of questions in the calculation dataset

(ii) Background knowledge data: knowledge dataset
The knowledge dataset is derived from the aforementioned materials, comprising questions and corresponding text paragraphs structured into Q&A pairs. For instance, paragraphs detailing the advantages of quota share reinsurance are transformed into Q&A pairs with corresponding questions and answers. Examples of this dataset are provided in Appendix B. Knowledge dataset. We manually extract 600 questions from the training materials as the base data. To augment the dataset, we utilize the open-source Llama 2-Chat 70B model to rewrite Q&A pairs in varied phrases, resulting in a total of 1200 pairs in the knowledge dataset.
3.2 Computational details
In this experiment, Llama 2-Chat models of various sizes are adopted as the base models and the baseline for evaluation. The models are accessed from the model catalog in Azure Machine Learning Studio. We employ one-shot prompting and LoRA as the prompt engineering and fine-tuning techniques for domain specialization, respectively. The example provided to the models is selected from the training dataset, which follows the CoT methodology with detailed reasoning steps for model comprehension. Examples of the prompts are presented in Appendix C. One-shot prompt. With sufficient GPU memory, LoRA is applied for fine-tuning, with a rank of 8, target modules of four weight matrices in the self-attention module (q_proj, k_proj, v_proj, and o_proj) and two in the multilayer perceptron module (up_proj and down_proj), and optimizer of AdamW. A learning rate of 3e-4 with warm-up and linear decay schedule is applied in the training process. The batch size is 128 and the micro batch size is 4. The number of epochs is determined based on the training loss and evaluation loss, while model checkpoints are saved along the training process. The fine-tuning is conducted on two A100 (80G) GPUs, with training time varying based on number of epochs, data size, and model size. For instance, fine-tuning the Llama 2-Chat 7B model with calculation datasets (1150 calculations) under 5 epochs required 8 minutes, while the Llama 2-Chat 13B model required 14 minutes. For Llama 2-Chat 70B models, we encountered resource limitations preventing us from fine-tuning on two A100 GPUs. On the one hand, utilizing more computational resources would significantly increase costs. On the other hand, loading the model in 8-bit precision for fine-tuning would result in reduced model performance. Given these considerations, we employ 70B models only for generation problems without fine-tuning.
3.3 Evaluation metric
Given the quantitative reasoning-intensive nature of the task, necessitating multiple steps of reasoning to obtain a conclusive answer, model performance evaluation is conducted through human assessment. The evaluation dataset comprises 100 questions, each carrying a maximum score of 1 point, totaling 100 points overall. Model outputs are graded on a scale of 0–1, depending on their proficiency in problem-solving, as delineated in Table 2.
Score deduction criteria for model outputs in the evaluation dataset, with each question assigned a maximum score of 1 point out of 100

Detailed examples are available in Appendix D. Marking examples.
4. Results
In this section, we provide an in-depth analysis of our experimental findings. Section 4.1 details the evaluation of the baseline models and their enhanced performance through the application of prompt engineering. Notably, the implementation of one-shot prompting has yielded a significant performance boost, especially for the 70B model. Section 4.2 presents the outcomes of fine-tuning, demonstrating that this method surpasses one-shot prompting in terms of performance improvement. Furthermore, Section 4.3 explores the influence of background knowledge, revealing that models reap the greatest benefits when task-specific datasets are limited. In the final analysis, Sections 4.4 and 4.5 examine the model performance before and after fine-tuning. It is evident that reasoning capability is the key determinant in enhancing model performance on quantitative calculation tasks. The general proficiency of baseline models is well-maintained after fine-tuning, as evidenced by their performance in public benchmarks.
4.1 Baseline and prompt engineering
We first evaluate the Llama 2-Chat models of 7B, 13B, and 70B parameters with and without the application of one-shot prompting using the evaluation dataset described in Section 3.1.1, which includes calculation questions of (re)insurance allocation of varying complexity, ranging from simple to intricate. We also evaluate GPT 4, which was released in March 2023, on the same test dataset as a benchmark. We calculate a score out of 100 for each model employing the evaluation metric in Section 3.3.
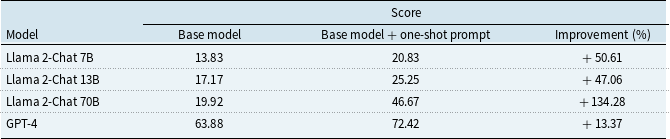
The performance comparison of Llama 2-Chat models with and without one-shot prompting

The findings, summarized in Table 3, reveal anticipated outcomes. (1) The Llama 2-Chat models demonstrate unsatisfactory performance in addressing reinsurance calculation tasks, primarily due to their lack of specialized domain knowledge. Despite a maximum score of 100 points, all three models score below 20 points. The 70B model outperforms its smaller counterparts, indicating a positive correlation between model size and knowledge retention in model pre-training. Meanwhile, GPT 4 yields 63.88 without further prompting or fine-tuning. (2) The integration of prompt engineering, i.e., one-shot prompting with CoT presented in Section 3.2, leads to improvements in model performance. Most notably, larger models, characterized by enhanced reasoning abilities and proficiency in following instructions, experience more benefits from prompt engineering interventions. This is demonstrated by the score of 70B model, which more than doubles from 19.92 to 46.67 points by using one-shot prompting. However, the improvements through prompt engineering are generally limited, e.g., the 7B and 13B models encounter difficulties. While this approach enables models to improve on easy-to-moderate-level problems, the complexity of certain tasks underscores the essential requirement for infusing domain-specific data via fine-tuning.
It is worth noting that in the one-shot prompt experiment, we provided examples of the same question type as prompts, which would overestimate the effectiveness of prompt engineering. In practice, it is impractical or laborious to feed the LLM with appropriate examples.
The percentages of improvement are also presented. The Llama 2-Chat models exhibit limited efficacy in addressing reinsurance calculation tasks, primarily due to their lack of specialized domain knowledge. It can be seen that the application of one-shot prompting results in a performance increase, particularly for the 70B model.
4.2 Fine-tuning with task-specific data
The findings in the previous subsection reveal challenges faced by models when addressing quantitative calculations on (re)insurance allocation, particularly noticeable in smaller models, despite the supplementary aid provided by one-shot prompts. In this subsection, we examine the efficacy of fine-tuning models using task-specific data contained in the calculation dataset described in Section 3.1.2. Due to the constraint of the computational resource, we only fine-tune the Llama 2-Chat 7B and 13B models.
The effect of fine-tuning with different sizes of the calculation dataset, Llama 2-Chat 7B and 13B models. Fine-tuning smaller LLMs can achieve significantly better performance. The larger the amount of training data, the higher the performance. Determining the optimal size of the training data is crucial for achieving peak performance in practical applications.

Our results, depicted in Fig. 2, highlight a substantial increase in scores post fine-tuning with the calculation dataset. Prior to fine-tuning, the 7B model achieves 13.83 points based on the evaluation dataset, while the 13B model attains 17.17 points. Following fine-tuning with the complete calculation dataset, their performances improve significantly to 76.58 and 83.08 points, representing 521% and 382% improvements, respectively, outperforming GPT 4. Furthermore, the performance achieved through fine-tuning significantly surpasses that obtained from the one-shot prompting. Notably, the fine-tuned 7B and 13B models outperform the 70B model by a considerable margin. This outcome aligns with previous reports indicating that fine-tuning can customize LLMs to domain-specific requirements (Cui et al., Reference Cui, Li, Yan, Chen and Yuan2023; Yang et al., Reference Yang, Tang and Tam2023). Moreover, a discernible trend is observed wherein model performance improves with an increase in the size of the training data. The 7B model shows rapid improvement upon reaching 500–600 calculation Q&A pairs, while the 13B model exhibits a similar trend at 400–500 calculation Q&A pairs. Identifying the optimal point at which model performance peaks is crucial for practical applications, as it enables the attainment of optimal results with minimal resources. As depicted in the figure, the 13B model marginally outperforms the 7B model, although the difference is not statistically significant.
Fine-tuning the Llama 2-Chat models with 1150 calculation samples, but with explanations at different level of details: (a) base model. (b) Only numerical results are included in the training data. (c) Text expressions and numerical results are contained in the training data. (d) Text expressions, numerical results, and math formula achieving results are all provided in the training data. This figure shows that the more detailed the explanation provided in the training data, the better the models perform.

These results underscore the significant performance enhancements achievable through fine-tuning pre-trained language models using task-specific data, especially in complex tasks involving reasoning and calculation steps. This has significant implications for the development of conversational LLMs, suggesting that fine-tuning smaller models on task-specific datasets may be more effective and performant than relying solely on large pre-trained models.
Given that our evaluation dataset comprises problems necessitating reasoning and calculation steps, we further explored the influence of CoT in the training data on model performance. Three types of training datasets are constructed and compared: (1) Only numerical results are included. (2) Text expressions and numerical results are contained. (3) Text expressions, numerical results, and mathematical formulas achieving results are all provided. An example is presented in Appendix E. CoT test training data. Scores of the 7B and 13B models fine-tuned using the aforementioned datasets are evaluated and compared in Fig. 3.
The models fine-tuned with detailed CoT processes outperform the others. Notably, the more detailed the explanation provided in the training data, the better the model performs, consistent with human intuition. However, the observed differences between the various datasets in this experiment are not statistically significant. This could be attributed to the availability of a sufficiently large dataset, enabling the model to discern patterns and learn effectively. Additionally, our evaluation dataset comprises both simple questions, easily solved without detailed explanations, and complex questions, challenging to solve even with detailed explanations, potentially contributing to similar scores among different training data formats.
4.3 Fine-tuning with background knowledge data
In the realm of LLM fine-tuning, the acquisition of task-specific data has been recognized as a pivotal factor in enhancing the performance of LLMs on downstream tasks, as evidenced in prior research and corroborated by our own findings (Yue et al., Reference Yue, Chen, Wang, Li, Shen, Liu and Zhou2023; Yang et al., Reference Yang, Liu and Wang2023). However, the endeavor of amassing comprehensive task-specific datasets is often fraught with challenges, such as time constraints and inherent complexities. This issue becomes particularly pronounced within domains hosting numerous downstream tasks, where the sheer volume of data required for each task may be insufficient for robust model tuning. On the other hand, the reservoir of background knowledge in related domains is often abundant and readily accessible. In this subsection, we examine the effect of fine-tuning with background knowledge data.
We embark on fine-tuning the 7B and 13B Llama 2-Chat models using the knowledge dataset presented in Section 3.1.2. The performance of these fine-tuned models is first evaluated in conjunction with one-shot prompting. Subsequently, we explore the synergistic effects of combining the knowledge dataset with the calculation dataset during fine-tuning to comprehensively analyze the impact of both datasets.
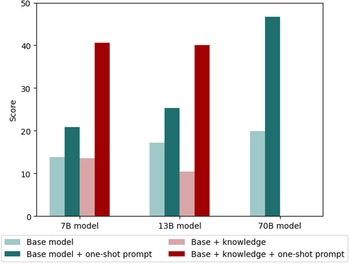
The results of fine-tuning with background knowledge, both individually and in conjunction with one-shot prompts, are depicted in Fig. 4. Notably, our observations suggest that fine-tuning with the knowledge dataset alone does not significantly boost the ability of model in addressing calculation tasks. There exists a discernible decline in performance, particularly for the 13B model. It appears that the models fine-tuned with background knowledge tend to provide interpretations and descriptions of the problem rather than offering the final answer through calculations. This phenomenon could be attributed to the discrepancy between the nature of the training knowledge, which primarily comprises descriptive texts on (re)insurance topics, and the calculation tasks, which necessitate quantitative reasoning and calculation based on these concepts. However, when augmented with one-shot prompting, the integration of domain knowledge into smaller LLMs yields a substantial enhancement in performance. Remarkably, the 13B model fine-tuned with background knowledge, when coupled with the one-shot prompt, achieves a performance level comparable to that of the 70B model. This is attributed to the one-shot prompt provided, effectively bridging the divide between the training data and the specific task. Consequently, the model is better equipped to follow instructions on tackling calculations, together with the knowledge injected into it enhances its understanding and reasoning capabilities.
The impact of fine-tuning utilizing a knowledge dataset and a one-shot prompt on the Llama 2-Chat 7B, 13B, and 70B models. The numbers for base model and base model + one-shot prompt are sourced directly from Section 4.1. Fine-tuning the LLM solely with background knowledge does not help with its ability to solve specific tasks in the domain. However, when combined with one-shot prompt, injecting domain knowledge into smaller LLMs results in a significant increase in model performance. This increase is comparable to that of larger LLMs without domain knowledge.

The evaluation scores of the Llama 2-Chat 7B (a) and 13B (b) models fine-tuned on various sizes of calculation dataset. The solid lines represent models initially fine-tuned using knowledge dataset and calculation dataset, while the dotted lines indicate models with only calculation dataset. It can be seen that the model performance remains the same irrespective of domain knowledge infusion, with the 13B model exhibiting slightly better score using fewer calculation Q&A pairs. Yet, when fine-tuned with knowledge dataset, the model performance escalates more rapidly with increases in the size of calculation dataset, indicating an alternative approach when constructing task-specific datasets is challenging and resource-intensive.

Second, we further fine-tune the models using the knowledge dataset as well as various sizes of calculation dataset and examine their respective performance. As depicted in Fig. 5, the peak performance attainable by the models remains consistent irrespective of the inclusion of background knowledge, approximately at 75 and 80 points for the 7B and 13B models, respectively. Notably, the addition of the knowledge dataset to the training data facilitates reaching maximum performance levels with a reduced amount of calculation Q&A pairs. For instance, optimal performance for the 7B model is achieved with 600 calculation Q&A pairs, whereas incorporating the background knowledge dataset enables peak performance with only 400 calculation Q&A pairs. We also notice distinct performance trends with and without the use of knowledge dataset. While performance improvement based on fine-tuning with calculation dataset alone follows a convex curve, the integration of knowledge data yields a concave curve, indicating more rapid performance gains. In the case of the 13B model fine-tuned with only 200 calculation Q&A pairs, the performance of model remains almost the same as that of the base model. However, augmenting the training data with the knowledge dataset and 200 calculation Q&A pairs results in a substantial performance boost, with the score escalating to 60.67 points, representing a 4-fold increase. These findings are consistent with prior research (Aracena et al., Reference Aracena, Rodríguez, Rocco and Dunstan2023), which demonstrates the effectiveness of incorporating knowledge dataset and indicates an alternative approach when constructing task-specific datasets is challenging and resource-intensive.
4.4 Error analysis
In this subsection, we provide an analysis of the calculation tasks that are not correctly solved by the LLMs. Our evaluation criteria reveal that LLMs often exhibit deficiencies in reinsurance calculation, attributable to two primary factors. Firstly, insufficient knowledge or weak reasoning abilities make it difficult for models to understand and solve problems. Secondly, while the models may possess the necessary procedural knowledge, deficiencies in calculation accuracy lead to incorrect responses. These inaccuracies may stem from rounding errors inherent in floating-point data formats or from the complexity of computation processes, where intricate operations such as A * B/C increase the likelihood of errors. Currently, the internal mechanisms through which LLMs perform such computations remain poorly understood. A recent study by Anthropic has indicated that transformers are not performing the calculation; rather, they are estimating the answer by memorizing frequently used calculation results. While a step-by-step CoT chain could be provided by LLM, it is not representative of the model’s actual mechanisms (Lindsey et al., Reference Lindsey, Gurnee, Ameisen, Chen, Pearce, Turner and McDougall2025). Addressing these challenges may necessitate the integration of external calculators alongside LLMs. We have visualized the average of scores obtained or deducted resulting from deficient reasoning and calculation abilities in different performance ranges in Fig. 6, providing further insights into model performance.
The average score obtained and deducted in different performance ranges of all 38 experiments in this study. The scores are deducted for two reasons: lack of reasoning ability and miscalculation, in which reasoning ability is the dominant factor. Fine-tuning can enhance the reasoning abilities, as evidenced by the correlation between improved model performance and reduced scores deducted due to reasoning errors.

Our investigation reveals a correlation between enhanced model performance and a reduction in lost scores attributable to deficient reasoning capabilities, indicating an improvement in the reasoning prowess of the models concerning quantitative tasks in the reinsurance domain. Conversely, an increase in model performance correlates with a rise in lost scores due to miscalculation. The average of scores deducted due to miscalculation ranges from 1.5 to 2.5, with higher model performance resulting in greater deductions. Although initially counterintuitive, this trend aligns with our definition of miscalculation. The likelihood of miscalculation is contingent upon the model’s mastery of problem-solving steps and accurate presentation of relevant formulas, which are enhanced as reasoning abilities improve. Overall, lack of reasoning abilities accounts for most of the reasons for score deductions, where emphasis needs to be placed to improve model performance. In addition, for a given model, the marginal improvement in model performance decreases as the score increases and eventually converges to a certain level. If higher performance is required, a larger model would be an option, such as the Llama 2-Chat 70B model.
Our study underscores those errors in reinsurance quantitative tasks by LLMs stem from deficiencies in knowledge, reasoning, and calculation abilities. Fine-tuning LLMs on reinsurance calculation datasets enhances their reasoning capabilities. To address miscalculation, integrating an external calculator with LLMs can mitigate this issue and improve model performance by 1.5–2.5 points. These findings carry significant implications for leveraging LLMs in quantitative reasoning-intensive tasks within the (re)insurance industry.
4.5 Public benchmark
In order to assess the catastrophic forgetting phenomenon in LLMs following fine-tuning, i.e. LLMs might completely or substantially forget the information related to previously learned tasks after being trained on a new task, we investigate the performance of both base models and fine-tuned models on general knowledge and calculation tasks. Our evaluation encompasses several widely recognized benchmark datasets, including Hellaswag, ARC, and Winogrande, which gauge common sense reasoning abilities, MMLU and TruthfulQ&A, assessing knowledge across various subjects, and GSM8K, measuring arithmetic reasoning skills. The outcomes from these benchmark assessments are depicted in Fig. 7. Notably, the fine-tuned model maintains its proficiency in common sense reasoning, professional knowledge, and arithmetic reasoning tasks, suggesting retention of acquired knowledge post-fine-tuning.
The evaluation of base models and fine-tuned models, augmented with both knowledge and calculation datasets, on publicly available benchmark assessments. After fine-tuning the Llama 2-Chat models with background knowledge and task-specific data, their knowledge in common sense, professional expertise, and arithmetic reasoning remains.

5. Conclusions and future work
This study assesses the efficacy of LLMs via experiments on the calculation tasks within the (re)insurance domain. We evaluate the performance of open-source Llama 2-Chat models of 7B, 13B, and 70B sizes, with a blend of prompt engineering and fine-tuning with respect to both task-specific and background knowledge datasets.
Our empirical findings indicate that compared to prompt engineering, fine-tuning the 7B and 13B models with task-specific data engenders noteworthy enhancements in their capacity to tackle moderate to hard problems. Scores exhibit a remarkable leap, increasing from approximately 15 to nearly 80. In light of scenarios where the collection of task-specific data proves arduous, supplementing models with background knowledge is an effective alternative that achieves performance on par with models fine-tuned on extensive task-specific dataset. The model’s performance is limited by its reasoning and calculation abilities, with reasoning abilities being the main reason and can be improved by prompt engineering or fine-tuning. After fine-tuning, the model’s performance on specific tasks improves without forgetting common sense and professional knowledge.
Furthermore, the above insights can be used to select the optimal domain specialization technique for general LLMs. For tasks of simpler complexity with constrained data, prompt engineering may suffice. Conversely, tasks necessitating advanced reasoning and calculation proficiencies warrant fine-tuning with task-specific data. In cases where acquiring task-specific data pose challenges or is cost-prohibitive, fine-tuning LLMs with background knowledge emerges as a valuable adjunct. This method can enhance model performance without requiring extensive domain-specific datasets. Additionally, leveraging the same background knowledge through retrieval-augmented generation techniques may yield comparable improvements to those achieved through fine-tuning.
However, challenges remain in deploying LLMs in real-world (re)insurance applications. Data acquisition is a critical hurdle where fine-tuning is necessary. Obtaining sufficient, high-quality datasets is difficult, and labeling training data requires heavy human effort. Security concerns may arise due to the inclusion of personally identifiable information such as names, genders, and addresses in the input context. This could influence the selection of open-source or closed-source models. There may be a trade-off between performance and data protection risks. Furthermore, the potential impact of inaccurate or biased LLM outputs warrants careful consideration. In scenarios where erroneous outputs could lead to severe consequences, rigorous evaluation should be implemented prior to deployment. For business process automation, a hybrid approach involving human oversight may be more prudent, with LLMs serving either as reviewers subsequent to human input or as preliminary suggesters prior to human decisions. Lastly, the effort required for ongoing maintenance should not be underestimated. Close-source models often undergo frequent updates, while open-source models release new versions periodically. Consequently, previously selected models and prompts may no longer represent optimal choices, necessitating regular reassessment and potential adjustments to maintain system efficacy.
Representative examples of the training dataset in this study are provided in the Appendix to facilitate reproducibility. While the full proprietary datasets cannot be disclosed, these examples offer sufficient details to guide other researchers or institutions in constructing their domain-specific or task-specific corpora for fine-tuning. Consequently, other teams can replicate the experiments and evaluate the results in their own contexts, and refine or extend the approach for further applications within the reinsurance sector and related domains.
This study explores the potential for the application of LLMs in (re)insurance domain. The effectiveness of LLMs in handling unstructured data and their strong reasoning and calculation capabilities make them suitable candidates for utilization as AI assistants, with the potential to improve overall productivity and efficiency. However, the model and techniques need to be carefully chosen according to the task, in consideration of costs and the benefits. Meanwhile, data security, ethical, and regulatory considerations cannot be ignored when putting LLMs into use in order to avoid and mitigate potential risks.
Data availability statement
The data used in this study are internal training materials within Swiss Re and cannot be made publicly available.
Funding statement
This work received no specific grant from any funding agency, commercial, or not-for-profit sectors.
Competing interest
The authors declare none.
Disclaimer
The assessments and opinions expressed in this paper are the author’s personal assessments and opinions and should not be taken to reflect Swiss Re’s position on any issue. Further, Swiss Re disclaims any and all liability arising from the author’s contribution to this article.
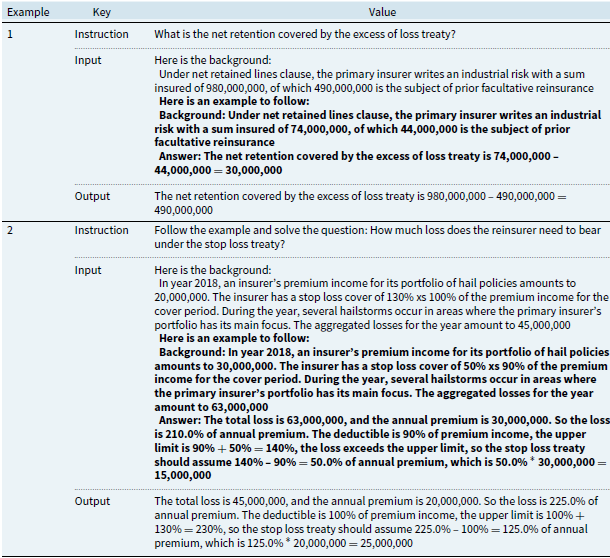
Appendix A. Calculation Dataset
Examples for data in calculation dataset

Appendix B. Knowledge Dataset
Examples for data in knowledge dataset

Appendix C. One-Shot Prompt
Examples for one-shot prompts

Appendix D. Marking Examples
Marking examples of partial deduction due to incorrect calculation

Marking examples of full deduction due to lack of reasoning capabilities

Appendix E. CoT Test Training Data
An example of training data for CoT test














 Open access
Open access