


1. Introduction
Although misinformation is nothing new, the topic has gained prominence in recent years due to the widespread circulation of entirely fabricated stories (presented as legitimate news) about broad-interest topics, such as the COVID-19 pandemic, election fraud, civil war, and foreign interference in US presidential elections. Misinformation is dangerous because it leads to inaccurate beliefs and creates partisan disagreements over basic facts. Given that social media has become a hub for misinformation and the fact that more than half of US adults get their news from social media (Shearer, Reference Shearer2021), tackling misinformation on social media is now more important than ever.
Researchers have developed a variety of policy recommendations that could reduce the amount of sharing and believing of misinformation on social media. Some of these recommendations include providing fact-checked information related to news articles (Lazer et al., Reference Lazer, Baum, Benkler, Berinsky, Greenhill, Menczer, Metzger, Nyhan, Pennycook and Rothschild2018; Graves, Reference Graves2016; Kriplean et al., Reference Kriplean, Bonnar, Borning, Kinney and Gill2014; Pennycook et al., Reference Pennycook, Bear, Collins and Rand2020; Yaqub et al., Reference Yaqub, Kakhidze, Brockman, Memon and Patil2020), nudging people to think about accuracy as they decide whether to share a news article on social media (Pennycook et al., Reference Pennycook, Epstein, Mosleh, Arechar, Eckles and Rand2021; Jahanbakhsh et al., Reference Jahanbakhsh, Zhang, Berinsky, Pennycook, Rand and Karger2021), increasing competition among media firms (Mullainathan & Shleifer, Reference Mullainathan and Shleifer2005; Blasco & Sobbrio, Reference Blasco and Sobbrio2012; Gentzkow & Shapiro, Reference Gentzkow and Shapiro2008), and detecting false articles using machine learning algorithms (Tacchini et al., Reference Tacchini, Ballarin, Della Vedova, Moret and De Alfaro2017; Wang, Reference Wang2017).
In this study, we evaluate the effectiveness of two such policy interventions, namely competition among media firms and third-party fact-checking, on misinformation. We present a theoretical model that captures the interaction between a rational media firm and a representative consumer who is solely interested in learning the truth. We model the interaction as a sequential game in which a media firm first chooses a costly action (e.g., how many journalists to hire) that determines the accuracy of the news it will produce. After a news article is published, a consumer decides whether or not to share this news article on social media. The consumer makes this decision knowing only the probability that the news article is true. However, his payoff depends on whether the article is actually true (in realization). If he shares the news article, he gets a positive payoff if it is true and a negative payoff if it is false. Not sharing the news article results in zero payoff. The media firm receives a positive payoff if the consumer chooses to share its news article on social media and receives a zero payoff if the consumer does not share its news article on social media.
The rationale behind these payoffs relies on the assumption that social media users are interested in sharing the truth. When someone shares a true news article, they build a reputation for reliability and gain followers. Conversely, sharing false news can damage their reputation and lead to a loss of followers. Additionally, some users may have an intrinsic preference for sharing truthful information. Our model focuses on people who have an incentive to share the truth, whether due to reputational concerns or innate preferences. In reality, sharing decisions are more complex, with some people sharing content to advance specific agendas and others sharing what they think their audience wants to see. We discuss these limitations and their implications for interpreting our results in Section 5.
We implement this model at the Utah State University Experimental Economics Lab using a 2x2 design. In a base treatment, we ask subjects to play a two-player game in which a sender (who is meant to represent the media firm) first chooses an accuracy level between 50 and 100 percent such that higher accuracy levels cost more money. Based on that accuracy, the computer sends a true or false message to a receiver (who is meant to represent the news consumer). The higher the accuracy chosen by the sender, the more likely that the receiver sees a true message. The receiver observes the accuracy level and the message generated and then decides whether or not to affirm the message. If the receiver affirms, then he earns $10 if the message turns out to be true and loses $10 if the message turns out to be false. If the receiver does not affirm, his payoff is $0. The sender earns $10 if the receiver affirms or $0 if the receiver does not affirm.
To complete the 2x2 design, we add three more treatments, namely a competition treatment, a fact-checking treatment, and a competition plus fact-checking treatment. Each treatment involves exactly one modification to the game. In the competition treatment, we add another sender to the game so that the receiver now sees two messages and two accuracy levels and can affirm, at most, one of them. In the fact-checking treatment, all messages must go through a fact-checking process before being sent to the receiver. The fact-checking process lets true messages pass with certainty and lets false messages pass with a 75 percent chance—with the remaining 25 percent chance, the false message is deleted and the sender is asked to choose a new accuracy, based on which a new message gets generated. In the competition plus fact-checking treatment, we combine both features mentioned above so that there are two senders and each sender’s message goes through the fact-checking process before being sent to the receiver.
We find that senders in the competition treatment choose a much higher accuracy, on average, than senders in the base treatment. Senders in the fact-checking treatment, however, do not choose any higher (or lower) accuracy than do senders in the base treatment. This finding suggests that, in this type of environment, competition among media firms is highly effective at reducing misinformation, whereas fact-checking is not.
This study contributes to both the theoretical and experimental strands of the misinformation literature. Most experimental work on misinformation interventions lacks strong theoretical foundations to analyze the underlying strategic interactions (e.g., Pennycook et al., Reference Pennycook, McPhetres, Zhang, Lu and Rand2020; Pennycook et al., Reference Pennycook, Epstein, Mosleh, Arechar, Eckles and Rand2021; Hameleers, Reference Hameleers2022; Ceylan et al., Reference Ceylan, Anderson and Wood2023). At the same time, theoretical models of misinformation and information transmission have rarely been subjected to rigorous empirical testing (e.g., Gentzkow & Shapiro, Reference Gentzkow and Shapiro2006; Zhu & Dukes, Reference Zhu and Dukes2015; Acemoglu et al., Reference Acemoglu, Ozdaglar and Siderius2024; Amini et al., Reference Amini, Bayiz, Lee, Somer-Topcu, Marculescu and Topcu2025). This disconnect between theory and evidence makes it difficult to develop reliable policy guidance for addressing misinformation. We address this gap by combining theoretical modeling with controlled experimental testing, providing the first comprehensive comparison of media competition and fact-checking as countermeasures for misinformation.
Our study also fills an important gap in the misinformation literature: existing studies typically evaluate interventions in isolation and do not examine how different interventions might interact when implemented simultaneously, which can be a crucial consideration for policy design. Our 2 $\times$2 design helps us evaluate the effects of media competition and fact-checking both individually and jointly. This design not only allows direct comparison of the two interventions, but also enables us to identify whether their combination produces reinforcing, neutral, or conflicting effects.
$\times$2 design helps us evaluate the effects of media competition and fact-checking both individually and jointly. This design not only allows direct comparison of the two interventions, but also enables us to identify whether their combination produces reinforcing, neutral, or conflicting effects.
2. Model
We develop a sequential game played between a media firm and a news consumer. We first provide a motivating example to illustrate the type of situation this theoretical game attempts to simulate. Next, we describe the game and create multiple environments—where each environment is essentially a different game—to test the effects of specific policy interventions.
In a base environment, i.e., the game that is played in the absence of any policy intervention, a media firm decides how much money to invest toward increasing its news accuracy in the first stage. In the second stage, a news article gets published based on the accuracy chosen by the media firm, and a news consumer decides whether or not to share this article on social media. The consumer makes this decision knowing the probability that the article is true but without knowing whether it is actually true. The media firm is incentivized to invest the lowest amount at which the consumer would share the article on social media, and the consumer is incentivized to share a true article and is disincentivized to share a false article. We develop two more games that are slight modifications of the base environment to capture the effect of two policy interventions.
To evaluate the effect of media competition on equilibrium outcomes, we develop another game, namely a competition environment, in which we add another media firm and let the two firms and one consumer play a three-player sequential game. In this environment, both firms simultaneously choose their investments in accuracy in the first stage. In the second stage, the news consumer decides which firm’s article, if any, to share on social media. We then develop a fact-checking environment, wherein we modify the base environment by adding an exogenous fact-checker, played by Nature for the purposes of the game. This fact-checker plays after the firm chooses its investment and a news article gets published but before the consumer learns that an article has been published. The fact-checker either deletes the article or allows the article to pass. More precisely, if the published news article is true, the fact-checker allows the article to pass and lets the consumer learn about it, but if it is false, then there is a 25 percent chance that the fact-checker deletes it—in which case the firm must make a new investment and publish a new article—and a 75 percent chance that the fact-checker lets the article pass and reach the consumer. The consumer, who does not know whether he is seeing the first or second (or  $n$th) article published by the firm, decides, as before, whether or not to share the article on social media.
$n$th) article published by the firm, decides, as before, whether or not to share the article on social media.
2.1. Base environment
2.1.1. Setup
There are two players, a sender ( $S$) and a receiver (
$S$) and a receiver ( $R$), and a state of the world that can be either red or blue,
$R$), and a state of the world that can be either red or blue,  $w\in\{red,blue\}$. While it is common knowledge that both states are equally likely, i.e.,
$w\in\{red,blue\}$. While it is common knowledge that both states are equally likely, i.e.,  $Pr(blue) = Pr(red) = 0.5$, neither player knows the actual realization of
$Pr(blue) = Pr(red) = 0.5$, neither player knows the actual realization of  $w$. A message,
$w$. A message,  $m\in \{red,blue\}$, informs the receiver about the realized state of the world. We define accuracy of the message,
$m\in \{red,blue\}$, informs the receiver about the realized state of the world. We define accuracy of the message,  $q$, as the probability with which the message is correct given the state of the world. That is,
$q$, as the probability with which the message is correct given the state of the world. That is,  $q:=\text{Pr}(m=w) $ and
$q:=\text{Pr}(m=w) $ and  $1-q=\text{Pr}(m \neq w) $. In other words,
$1-q=\text{Pr}(m \neq w) $. In other words,  $m|w\sim Ber(q)$.
$m|w\sim Ber(q)$.
The game is played in two stages. In the first stage, the sender chooses  $q\in[0.5,1]$. In the second stage, the receiver observes
$q\in[0.5,1]$. In the second stage, the receiver observes  $q$ and the realization of
$q$ and the realization of  $m$ and then decides whether or not to affirm the message, a decision denoted by
$m$ and then decides whether or not to affirm the message, a decision denoted by  $a\in \{0,1\}$. The sender also has to pay an accuracy cost that is determined by an increasing convex function
$a\in \{0,1\}$. The sender also has to pay an accuracy cost that is determined by an increasing convex function  $c(q)$ that has the following properties:
$c(q)$ that has the following properties:  $c^{\prime} (q) \gt 0, c^{\prime\prime} (q) \gt 0$, and
$c^{\prime} (q) \gt 0, c^{\prime\prime} (q) \gt 0$, and  $c(0.5)=0$. The last property implies that a completely uninformative message requires zero investment. The sender pays this accuracy cost at the time of choosing an accuracy level, so this cost is incurred even if the receiver does not affirm the message.
$c(0.5)=0$. The last property implies that a completely uninformative message requires zero investment. The sender pays this accuracy cost at the time of choosing an accuracy level, so this cost is incurred even if the receiver does not affirm the message.
The sender’s payoff is entirely dependent on the receiver’s action. If the receiver affirms the message, the sender earns a high revenue that we normalize to $1, resulting in a net payoff of  $1-c(q)$. If the receiver does not affirm the message, the sender earns $0.5, resulting in a net payoff of
$1-c(q)$. If the receiver does not affirm the message, the sender earns $0.5, resulting in a net payoff of  $0.5-c(q)$. The receiver’s payoff depends on his own action as well on whether the message is true. If the receiver affirms the message and the message is true, then the receiver’s payoff is $1. If the receiver affirms the message and the message is false, then the receiver’s payoff is zero (although the sender would still earn $1 in this case). If the receiver does not affirm the message, the receiver’s payoff is 0.5. Figure 1 presents the extensive form of this game.
$0.5-c(q)$. The receiver’s payoff depends on his own action as well on whether the message is true. If the receiver affirms the message and the message is true, then the receiver’s payoff is $1. If the receiver affirms the message and the message is false, then the receiver’s payoff is zero (although the sender would still earn $1 in this case). If the receiver does not affirm the message, the receiver’s payoff is 0.5. Figure 1 presents the extensive form of this game.
Illustration of Base Environment

Figure 1 Long description
A decision tree diagram with three main nodes: Sender, Nature and Receiver. The Sender node branches to the Nature node with probabilities q and 0.5. The Nature node further branches into true (q) and false (1 minus q) paths. Each path leads to the Receiver node, which has options to affirm or not affirm. The outcomes for each decision are shown: if the message is true and affirmed, the Sender's payoff is 1 minus c(q) and the Receiver's payoff is 1; if not affirmed, the Sender's payoff is 0.5 minus c(q) and the Receiver's payoff is 0.5. If the message is false and affirmed, the Sender's payoff is 1 minus c(q) and the Receiver's payoff is 0; if not affirmed, the Sender's payoff is 0.5 minus c(q) and the Receiver's payoff is 0.5.
To focus on nontrivial cases, we make two further assumptions. First,  $c(1)=0.5$ so that the cost of sending a 100 percent accurate message completely nullifies the sender’s additional payoff from affirming. Second, we assume that the sender is risk-neutral while the receiver is risk-averse.Footnote 1 Specifically, the sender’s and the receiver’s utility functions are
$c(1)=0.5$ so that the cost of sending a 100 percent accurate message completely nullifies the sender’s additional payoff from affirming. Second, we assume that the sender is risk-neutral while the receiver is risk-averse.Footnote 1 Specifically, the sender’s and the receiver’s utility functions are
 \begin{equation*}
U_S (q;a) =
\begin{cases}
1 - c(q) & \text{if } a=1 \\
0.5 - c(q) & \text{if } a=0,
\end{cases} \end{equation*}
\begin{equation*}
U_S (q;a) =
\begin{cases}
1 - c(q) & \text{if } a=1 \\
0.5 - c(q) & \text{if } a=0,
\end{cases} \end{equation*} \begin{equation*}
U_R (a;m(q),w) =
\begin{cases}
v(1) &\text{if } a=1 \text{ and } m=w \\
v(0) &\text{if } a=1 \text{ and } m \neq w \\
v(0.5) & \text{if } a=0,
\end{cases}
\end{equation*}
\begin{equation*}
U_R (a;m(q),w) =
\begin{cases}
v(1) &\text{if } a=1 \text{ and } m=w \\
v(0) &\text{if } a=1 \text{ and } m \neq w \\
v(0.5) & \text{if } a=0,
\end{cases}
\end{equation*} where  $v(x)$ is a continuous function that transforms monetary payoffs into utility for the receiver. This function has the following properties:
$v(x)$ is a continuous function that transforms monetary payoffs into utility for the receiver. This function has the following properties:  $v^\prime (x) \gt 0$,
$v^\prime (x) \gt 0$,  $v^{\prime \prime} (x) \lt 0$, and
$v^{\prime \prime} (x) \lt 0$, and  $v(0)=0$. The concavity of
$v(0)=0$. The concavity of  $v(x)$ captures the receiver’s risk aversion when deciding whether to affirm messages of uncertain accuracy. Given that
$v(x)$ captures the receiver’s risk aversion when deciding whether to affirm messages of uncertain accuracy. Given that  $\text{Pr}(m=w)=q$, the receiver’s expected utility from affirming is
$\text{Pr}(m=w)=q$, the receiver’s expected utility from affirming is  $\mathbb{E}U_R(a=1)= q v(1) + (1-q)v(0)$.
$\mathbb{E}U_R(a=1)= q v(1) + (1-q)v(0)$.
2.1.2. Equilibrium
To arrive at the subgame perfect Nash equilibrium (SPNE), we solve the game through backward induction, first deriving the receiver’s optimal strategy given  $q$ and then deriving the sender’s best response to the receiver’s strategy. Proposition 1 provides the receiver’s optimal strategy. All proofs are in Appendix A.
$q$ and then deriving the sender’s best response to the receiver’s strategy. Proposition 1 provides the receiver’s optimal strategy. All proofs are in Appendix A.
(i) There exists a unique
 $q^B\in (0.5,1) $ s.t.
$\mathbb{E}U_R (a=1) = U_R (a=0)$.
$q^B\in (0.5,1) $ s.t.
$\mathbb{E}U_R (a=1) = U_R (a=0)$.(ii) The receiver’s optimal strategy is
a(q) =
\begin{cases}
1 &\text{if } q\geq q^B \\
0 &\text{if } q \lt q^B.
\end{cases}



Proposition 1 states that there is some threshold value of  $q^B$ such that the receiver finds it profitable to affirm the message for accuracy levels greater than
$q^B$ such that the receiver finds it profitable to affirm the message for accuracy levels greater than  $q^B$ and finds it not profitable for accuracy levels less than
$q^B$ and finds it not profitable for accuracy levels less than  $q^B$. Intuitively, if the sender chooses
$q^B$. Intuitively, if the sender chooses  $q=1$, then there would be no risk involved, and therefore any risk-averse receiver would strictly prefer to affirm. On the other extreme, if the sender chooses
$q=1$, then there would be no risk involved, and therefore any risk-averse receiver would strictly prefer to affirm. On the other extreme, if the sender chooses  $q=0.5$, then no receiver would want to affirm. Somewhere in between these two extremes, there has to be a point where the receiver is indifferent between affirming and not affirming.
$q=0.5$, then no receiver would want to affirm. Somewhere in between these two extremes, there has to be a point where the receiver is indifferent between affirming and not affirming.
Proposition 2. The sender’s optimal strategy is  $q=q^B$, resulting in the following SPNE:
$q=q^B$, resulting in the following SPNE:  \begin{pmatrix}
q^B\\
\mathbb{1}\cdot (q\geq q^B)
\end{pmatrix}.
\begin{pmatrix}
q^B\\
\mathbb{1}\cdot (q\geq q^B)
\end{pmatrix}.
Proposition 2 states that the sender will choose the minimum accuracy level that he believes will get the message affirmed. For further illustration, we provide some examples in Appendix A that highlight the differences in each environment.
2.2. Competition environment
2.2.1. Setup
We construct a competition environment by adding another sender to the game presented in the base environment, which results in a new game played between three players: Sender 1 ( $S_1$), Sender 2 (
$S_1$), Sender 2 ( $S_2$), and Receiver (
$S_2$), and Receiver ( $R$). As before, the game is played in two stages. In the first stage, each sender
$R$). As before, the game is played in two stages. In the first stage, each sender  $S_i$, for
$S_i$, for  $i\in\{1,2\}$, simultaneously and independently chooses
$i\in\{1,2\}$, simultaneously and independently chooses  $q_i\in[0.5,1]$ and incurs a cost of
$q_i\in[0.5,1]$ and incurs a cost of  $c(q_i)$. In the second stage, the receiver observes
$c(q_i)$. In the second stage, the receiver observes  $q_1$ and
$q_1$ and  $q_2$ along with realizations of
$q_2$ along with realizations of  $m_1$ and
$m_1$ and  $m_2$, where
$m_2$, where  $m_i \in \{\hat{r},\hat{b}\} \sim Ber(q_i)$, for
$m_i \in \{\hat{r},\hat{b}\} \sim Ber(q_i)$, for  $i\in\{1,2\}$. The receiver’s choice is denoted by
$i\in\{1,2\}$. The receiver’s choice is denoted by  $a\in\{0,1,2\}$, where
$a\in\{0,1,2\}$, where  $a=1$ represents the decision to affirm
$a=1$ represents the decision to affirm  $m_1$,
$m_1$,  $a=2$ represents the decision to affirm
$a=2$ represents the decision to affirm  $m_2$, and
$m_2$, and  $a=0$ represents the decision to affirm neither message. We do not allow receivers to affirm both messages because this restriction captures several realistic aspects of social media behavior. First, users typically read only one article when encountering multiple stories on the same topic due to time and attention constraints. Second, even if both articles are read, sharing multiple stories about the same event would be redundant and potentially confusing to their followers. Third, if two news articles contradict each other, sharing both of them would undermine the user’s credibility.
$a=0$ represents the decision to affirm neither message. We do not allow receivers to affirm both messages because this restriction captures several realistic aspects of social media behavior. First, users typically read only one article when encountering multiple stories on the same topic due to time and attention constraints. Second, even if both articles are read, sharing multiple stories about the same event would be redundant and potentially confusing to their followers. Third, if two news articles contradict each other, sharing both of them would undermine the user’s credibility.
Players’ payoffs are as follows:
 \begin{equation*}
U_{S_i} (q_i;a) =
\begin{cases}
1 - c(q_i) & \text{if } a=i \\
0.5 - c(q_i) & \text{if } a \neq i,
\end{cases} \end{equation*}
\begin{equation*}
U_{S_i} (q_i;a) =
\begin{cases}
1 - c(q_i) & \text{if } a=i \\
0.5 - c(q_i) & \text{if } a \neq i,
\end{cases} \end{equation*} \begin{equation*}
U_R (a;m_i,w) =
\begin{cases}
v(1) &\text{if } a= i \text{ and } m_i=w \\
v(0) &\text{if } a= i \text{ and } m_i \neq w \\
v(0.5) &\text{if } a=0.
\end{cases}
\end{equation*}
\begin{equation*}
U_R (a;m_i,w) =
\begin{cases}
v(1) &\text{if } a= i \text{ and } m_i=w \\
v(0) &\text{if } a= i \text{ and } m_i \neq w \\
v(0.5) &\text{if } a=0.
\end{cases}
\end{equation*}2.2.2. Equilibrium
We first derive the receiver’s optimal strategy.
Proposition 3. The receiver’s optimal strategy is
 \begin{equation*} a=
\begin{cases}
0 &\text{if } q_1 \lt q^B \text{ and } q_2 \lt q^B \\
1 &\text{if } q_1 \gt q_2 \text{ and } q_1 \geq q^B \\
2 &\text{if } q_2 \gt q_1 \text{ and } q_2 \geq q^B \\
1 \text{ or } 2 &\text{if } q_1 = q_2 \geq q^B.
\end{cases}
\end{equation*}
\begin{equation*} a=
\begin{cases}
0 &\text{if } q_1 \lt q^B \text{ and } q_2 \lt q^B \\
1 &\text{if } q_1 \gt q_2 \text{ and } q_1 \geq q^B \\
2 &\text{if } q_2 \gt q_1 \text{ and } q_2 \geq q^B \\
1 \text{ or } 2 &\text{if } q_1 = q_2 \geq q^B.
\end{cases}
\end{equation*} Proposition 3 states that the receiver will affirm the message that has a higher accuracy as long as that accuracy is greater than his threshold of  $q^B$. If both messages have the same accuracy and that accuracy is greater than
$q^B$. If both messages have the same accuracy and that accuracy is greater than  $q^B$, then the receiver is indifferent between affirming either of the two messages and resolves this indifference by randomly choosing one message.
$q^B$, then the receiver is indifferent between affirming either of the two messages and resolves this indifference by randomly choosing one message.
Next, we derive the optimal strategy for each sender. The senders in this environment are essentially bidders in a symmetric first-price all-pay auction (FPAA) with complete information, because sender  $S_i$ “bids”
$S_i$ “bids”  $c(q_i)$ and pays this bid regardless of which message gets affirmed. The “winning” sender receives an additional payoff of $0.5. Therefore, to determine each sender’s optimal strategy, we apply the unique equilibrium of an FPAA with convex costs and a reservation price of
$c(q_i)$ and pays this bid regardless of which message gets affirmed. The “winning” sender receives an additional payoff of $0.5. Therefore, to determine each sender’s optimal strategy, we apply the unique equilibrium of an FPAA with convex costs and a reservation price of  $q^B$.Footnote 2
$q^B$.Footnote 2
Proposition 4. There is a unique equilibrium in which each sender continuously randomizes over the range  $q \in [q^B,1]$ using the distribution function
$q \in [q^B,1]$ using the distribution function  $F(q) = 2c(q) $.
$F(q) = 2c(q) $.
Proposition 4 states that senders play a mixed strategy over the continuous range  $[q^B,1]$ and choose probabilities according to the distribution
$[q^B,1]$ and choose probabilities according to the distribution  $F(q)$.Footnote 3 Example 2 (in Appendix A) presents a numerical example of the equilibrium in this environment.
$F(q)$.Footnote 3 Example 2 (in Appendix A) presents a numerical example of the equilibrium in this environment.
2.3. Fact-checking environment
2.3.1. Setup
We construct a fact-checking environment by modifying the base environment to include a fact-checking process. As in the base environment, the sender chooses an accuracy level and the computer chooses the true message with that much probability. However, before the message is shown to the receiver, it gets randomly selected, with probability  $p \in [0,1]$, of getting checked.Footnote 4 A message that gets checked either proceeds as normal or gets deleted, depending on whether it is true or false. If a message is false, then it gets deleted and the sender is asked to choose a new accuracy, based on which a new message is randomly chosen. While the receiver is aware of the fact-checking process, he cannot tell whether the message he sees got checked. We assume that fact-checking has a constant marginal cost of
$p \in [0,1]$, of getting checked.Footnote 4 A message that gets checked either proceeds as normal or gets deleted, depending on whether it is true or false. If a message is false, then it gets deleted and the sender is asked to choose a new accuracy, based on which a new message is randomly chosen. While the receiver is aware of the fact-checking process, he cannot tell whether the message he sees got checked. We assume that fact-checking has a constant marginal cost of  $c_F \gt 0$ per message checked.
$c_F \gt 0$ per message checked.
In this environment, the sender faces a game that could potentially (although with diminishing probability) go on forever. This is because with a probability of  $p(1-q)$, the message will get deleted and the sender will be asked to choose a new accuracy. With the remaining probability,
$p(1-q)$, the message will get deleted and the sender will be asked to choose a new accuracy. With the remaining probability,  $1-p(1-q)$, the message passes through the fact-checking process and goes to the receiver.
$1-p(1-q)$, the message passes through the fact-checking process and goes to the receiver.
In the event that a message gets deleted, the sender would face the exact same game that he faced earlier: he would need to choose an accuracy  $q\in [0.5,1]$, and the new message would have the same probability of clearing the fact-checking process. Therefore, the sender’s optimal choice of
$q\in [0.5,1]$, and the new message would have the same probability of clearing the fact-checking process. Therefore, the sender’s optimal choice of  $q$ would remain the same each time he is asked regardless of how many previous messages got deleted. In this environment, the sender’s expected utility is:
$q$ would remain the same each time he is asked regardless of how many previous messages got deleted. In this environment, the sender’s expected utility is:
 \begin{equation*} \mathbb{E}U_S =
\begin{cases}
1 -\mathbb{E}[c (q)] & \text{if } a=1 \\
0.5 - \mathbb{E}[c (q)] & \text{if } a =0,
\end{cases} \end{equation*}
\begin{equation*} \mathbb{E}U_S =
\begin{cases}
1 -\mathbb{E}[c (q)] & \text{if } a=1 \\
0.5 - \mathbb{E}[c (q)] & \text{if } a =0,
\end{cases} \end{equation*}where, assuming the sender chooses the same accuracy each time he is asked,
 \begin{align*}
\mathbb{E}[c (q)] &= c(q) + p(1-q)c(q) + p^2(1-q)^2 c(q) + ... \\
&= \frac{c(q)}{1-p(1-q)}
\end{align*}
\begin{align*}
\mathbb{E}[c (q)] &= c(q) + p(1-q)c(q) + p^2(1-q)^2 c(q) + ... \\
&= \frac{c(q)}{1-p(1-q)}
\end{align*}The receiver’s utility function is the same as in the base environment; i.e.,
 \begin{equation*} U_R =
\begin{cases}
v(1) &\text{if } a=1 \text{ and } m=w \\
v(0) &\text{if } a=1 \text{ and } m \neq w \\
v(0.5) & \text{if } a=0
\end{cases} \end{equation*}
\begin{equation*} U_R =
\begin{cases}
v(1) &\text{if } a=1 \text{ and } m=w \\
v(0) &\text{if } a=1 \text{ and } m \neq w \\
v(0.5) & \text{if } a=0
\end{cases} \end{equation*}2.3.2. Equilibrium
Since some messages get deleted, the mere fact that the receiver sees a message tells the receiver that it is not among those that got deleted. The receiver would be interested in the effective (or posterior) probability that the message is true, i.e., the probability that a message is true conditional on the fact that it gets seen by the receiver. We can derive this using Bayes’ rule, as follows:
 \begin{align*}
\text{Pr(true|seen)} &= \frac{\text{Pr(seen|true)Pr(true)}}{\text{Pr(seen|true)Pr(true)+ Pr(seen|false)Pr(false)}} \\
&= \frac{q}{q + (1-p)(1-q) } \\
&= \frac{q}{1-p+pq}.
\end{align*}
\begin{align*}
\text{Pr(true|seen)} &= \frac{\text{Pr(seen|true)Pr(true)}}{\text{Pr(seen|true)Pr(true)+ Pr(seen|false)Pr(false)}} \\
&= \frac{q}{q + (1-p)(1-q) } \\
&= \frac{q}{1-p+pq}.
\end{align*}Proposition 5. The receiver’s optimal strategy in the fact-checking environment is
 \begin{equation*} a(q) =
\begin{cases}
0 &\text{if } q \lt q^F(p) \\
1 &\text{if } q \geq q^F(p)
\end{cases} \text{, where } q^F(p) = \frac{(1-p)q^B}{1-pq^B}.\end{equation*}
\begin{equation*} a(q) =
\begin{cases}
0 &\text{if } q \lt q^F(p) \\
1 &\text{if } q \geq q^F(p)
\end{cases} \text{, where } q^F(p) = \frac{(1-p)q^B}{1-pq^B}.\end{equation*} The receiver affirms if and only if  $\mathbb{E}U_R(a=1) \geq \mathbb{E}U_R(a=0) $, which occurs when the posterior probability that the message is true exceeds the threshold accuracy
$\mathbb{E}U_R(a=1) \geq \mathbb{E}U_R(a=0) $, which occurs when the posterior probability that the message is true exceeds the threshold accuracy  $q^B$ from the base environment. That is, the receiver affirms when
$q^B$ from the base environment. That is, the receiver affirms when  $\frac{q}{1-p+pq} \geq q^B$, which simplifies to
$\frac{q}{1-p+pq} \geq q^B$, which simplifies to  $q \geq q^F(p)$.
$q \geq q^F(p)$.
Proposition 6. The sender’s optimal strategy is  $q=q^F(p)$, resulting in the SPNE
$q=q^F(p)$, resulting in the SPNE  $\{q^F(p), \mathbb{1}\cdot (q\geq q^F(p)) \} $
$\{q^F(p), \mathbb{1}\cdot (q\geq q^F(p)) \} $
As in the base environment, the sender’s best response is to choose the lowest accuracy at which the receiver would affirm (see Proposition 2). Note that  $q^F(p) \lt q^B$
$q^F(p) \lt q^B$  $\forall \ p \gt 0$, which means that senders invest in a lower accuracy level in the presence of fact-checking. This is because the fact-checking process improves the receiver’s posterior about the message being true, allowing the senders to get away with a lower initial accuracy level.
$\forall \ p \gt 0$, which means that senders invest in a lower accuracy level in the presence of fact-checking. This is because the fact-checking process improves the receiver’s posterior about the message being true, allowing the senders to get away with a lower initial accuracy level.
2.3.3. Social welfare analysis
We can analyze the social welfare implications of different levels of fact-checking by considering the total welfare of all participants. The social welfare function can be defined as:
 \begin{equation*}SW(p) = U_S(q^F(p)) + U_R(q^F(p)) - C(p)\end{equation*}
\begin{equation*}SW(p) = U_S(q^F(p)) + U_R(q^F(p)) - C(p)\end{equation*}where  $C(p)$ is a monotonically increasing function that represents cost of implementing and maintaining a fact-checking system with intensity
$C(p)$ is a monotonically increasing function that represents cost of implementing and maintaining a fact-checking system with intensity  $p$.
$p$.
The socially optimal level of fact-checking,  $p^*$, depends on the specific functional forms of
$p^*$, depends on the specific functional forms of  $v(x)$,
$v(x)$,  $c(q)$, and
$c(q)$, and  $C(p)$. In general,
$C(p)$. In general,  $p^* \in (0,1)$ when the marginal benefit of fact-checking at low levels exceeds its marginal cost, but the marginal benefit eventually diminishes while costs continue to rise. If
$p^* \in (0,1)$ when the marginal benefit of fact-checking at low levels exceeds its marginal cost, but the marginal benefit eventually diminishes while costs continue to rise. If  $C(p)$ is very high for all
$C(p)$ is very high for all  $p$,
$p$,  $p^* = 0$ (no fact-checking is optimal), and when the cost function is relatively flat,
$p^* = 0$ (no fact-checking is optimal), and when the cost function is relatively flat,  $p^*$ approaches higher values.
$p^*$ approaches higher values.
As an example, suppose the sender’s accuracy cost is  $c(q)=2(q-0.5)^2$, the receiver’s utility from a monetary payoff of
$c(q)=2(q-0.5)^2$, the receiver’s utility from a monetary payoff of  $x$ dollars is
$x$ dollars is  $v(x)=\sqrt{x}$, and the cost of fact-checking is given by
$v(x)=\sqrt{x}$, and the cost of fact-checking is given by  $C(p)=0.5p^2$. In equilibrium, the sender chooses
$C(p)=0.5p^2$. In equilibrium, the sender chooses  $q^F(p)=\frac{\sqrt{2}(1-p)}{1-\sqrt{2}p}$ and the receiver affirms, yielding expected utilities:
$q^F(p)=\frac{\sqrt{2}(1-p)}{1-\sqrt{2}p}$ and the receiver affirms, yielding expected utilities:
 \begin{equation*} \mathbb{E}U_S(p) = 1- \frac{2[q^F(p)-0.5]^2}{1-p[1-q^F(p)]} \qquad \qquad \mathbb{E}U_R(p)= \frac{q^F(p)}{1-p[1-q^F(p)]} \end{equation*}
\begin{equation*} \mathbb{E}U_S(p) = 1- \frac{2[q^F(p)-0.5]^2}{1-p[1-q^F(p)]} \qquad \qquad \mathbb{E}U_R(p)= \frac{q^F(p)}{1-p[1-q^F(p)]} \end{equation*}The social welfare function is
 \begin{equation*}SW(p)=1 + \frac{q^F(p)-2[q^F(p)-0.5]^2}{1-p[1-q^F(p)]}-0.5p^2\end{equation*}
\begin{equation*}SW(p)=1 + \frac{q^F(p)-2[q^F(p)-0.5]^2}{1-p[1-q^F(p)]}-0.5p^2\end{equation*}where  $q^F(p)=\frac{\sqrt{2}(1-p)}{1-\sqrt{2}p}$. The first order condition of this function results in a socially optimal fact-checking probability of
$q^F(p)=\frac{\sqrt{2}(1-p)}{1-\sqrt{2}p}$. The first order condition of this function results in a socially optimal fact-checking probability of  $p^* \approx 0.17$.
$p^* \approx 0.17$.
2.4. Competition and fact-checking environment
2.4.1. Setup
Last, we construct a competition and fact-checking environment by adding both modifications, i.e., fact-checking and competition, to the base environment. In this environment, there are two senders who simultaneously choose their respective accuracy levels. Each sender’s message gets selected for fact-checking with a probability of  $p$. When both senders’ messages successfully go through the fact-checking process explained earlier, the receiver sees both messages along with the accuracy of each message. If a message gets deleted during the fact-checking process, only the sender whose message it is gets informed about it.
$p$. When both senders’ messages successfully go through the fact-checking process explained earlier, the receiver sees both messages along with the accuracy of each message. If a message gets deleted during the fact-checking process, only the sender whose message it is gets informed about it.
In this environment, for  $i\in {1,2}$, Sender
$i\in {1,2}$, Sender  $i$’s utility function is
$i$’s utility function is
 \begin{equation*} U_{S_i} (q_i;a) =
\begin{cases}
1 -\mathbb{E}[c (q_i)] & \text{if } a=i \\
0.5 - \mathbb{E}[c (q_i)] & \text{if } a \neq i,
\end{cases} \end{equation*}
\begin{equation*} U_{S_i} (q_i;a) =
\begin{cases}
1 -\mathbb{E}[c (q_i)] & \text{if } a=i \\
0.5 - \mathbb{E}[c (q_i)] & \text{if } a \neq i,
\end{cases} \end{equation*}where
 \begin{align*}
\mathbb{E}[c (q_i)] &= c(q_i) + p(1-q_i)c(q_i) + p^2(1-q_i)^2 c(q_i) + ... \\
&= \frac{c(q_i)}{1-p(1-q_i)}.
\end{align*}
\begin{align*}
\mathbb{E}[c (q_i)] &= c(q_i) + p(1-q_i)c(q_i) + p^2(1-q_i)^2 c(q_i) + ... \\
&= \frac{c(q_i)}{1-p(1-q_i)}.
\end{align*}The receiver’s utility is
 \begin{equation*}
U_R (a;m_i,w) =
\begin{cases}
v(1) &\text{if } a= i \text{ and } m_i=w \\
v(0) &\text{if } a= i \text{ and } m_i \neq w \\
v(0.5) &\text{if } a=0.
\end{cases}
\end{equation*}
\begin{equation*}
U_R (a;m_i,w) =
\begin{cases}
v(1) &\text{if } a= i \text{ and } m_i=w \\
v(0) &\text{if } a= i \text{ and } m_i \neq w \\
v(0.5) &\text{if } a=0.
\end{cases}
\end{equation*} The receiver’s expected utility from affirming message  $i\in\{1,2\}$ is
$i\in\{1,2\}$ is
 \begin{equation*}\mathbb{E}U_R (a=i)= \widetilde{q_i} v(1) + (1-\widetilde{q_i})v(0), \end{equation*}
\begin{equation*}\mathbb{E}U_R (a=i)= \widetilde{q_i} v(1) + (1-\widetilde{q_i})v(0), \end{equation*}where  $\widetilde{q_i} = \text{Pr(true|seen)} = \frac{q_i}{1-p+pq_i}$.
$\widetilde{q_i} = \text{Pr(true|seen)} = \frac{q_i}{1-p+pq_i}$.
2.4.2. Equilibrium
Proposition 7. The receiver’s optimal strategy in the competition and fact-checking environment is
 \begin{equation*}a=
\begin{cases}
0 &\text{if } q_1,q_2 \lt q^F(p) \\
1 &\text{if } q_1 \gt q_2 \text{ and } q_1 \geq q^F(p) \\
2 &\text{if } q_1 \lt q_2 \text{ and } q_2 \geq q^F(p) \\
1 \text{ or } 2 &\text{if } q_1 = q_2 \text{ and } q_1, q_2 \geq q^F(p) \\
\end{cases} \end{equation*}
\begin{equation*}a=
\begin{cases}
0 &\text{if } q_1,q_2 \lt q^F(p) \\
1 &\text{if } q_1 \gt q_2 \text{ and } q_1 \geq q^F(p) \\
2 &\text{if } q_1 \lt q_2 \text{ and } q_2 \geq q^F(p) \\
1 \text{ or } 2 &\text{if } q_1 = q_2 \text{ and } q_1, q_2 \geq q^F(p) \\
\end{cases} \end{equation*} That is, the receiver will affirm the message that has the higher accuracy as long as that accuracy is at least as much as  $q^F(p)$.
$q^F(p)$.
Proposition 8. Each sender’s optimal strategy is to continuously randomize using  $F(q) = 2c(q) $ over the support
$F(q) = 2c(q) $ over the support  $[q^F(p),1]$
$[q^F(p),1]$
This is a straightforward extension of Proposition 4, where senders compete in a first-price all-pay auction but now face the lower threshold  $q^F(p)$ instead of
$q^F(p)$ instead of  $q^B$.
$q^B$.
2.5. Summary of results and testable hypotheses
The environments described earlier are designed specifically to evaluate the impact of media competition and fact-checking on the amount of misinformation shared on social media. All environments simulate situations where media firms decide how much money to invest toward increasing their news accuracy, and news consumers decide whether or not to share the firm’s news article on social media. That is,  $q$ represents news accuracy, while
$q$ represents news accuracy, while  $c(q)$ represents the amount invested by the firm toward news accuracy. Table 1 summarizes the equilibrium strategies in all four environments.
$c(q)$ represents the amount invested by the firm toward news accuracy. Table 1 summarizes the equilibrium strategies in all four environments.
Equilibrium Predictions

Table 1 Long description
The table compares sender and receiver strategies across four environments: Base, Fact-Checking, Competition, and Competition with Fact-Checking. In the Base environment, the sender's strategy is denoted by q^B, while the receiver's strategy is a function of whether q meets or exceeds q^B. Fact-Checking modifies the sender's strategy to q^F(p), dependent on probability p, and adjusts the receiver's strategy accordingly. In the Competition environment, sender strategies are defined by F_i(q)=2c(q) over the range [q^B,1], with receivers choosing the sender i whose quality q_i is highest. The Competition with Fact-Checking environment further refines sender strategies over [q^F(p),1], with receivers selecting based on the highest quality q_i relative to q^F(p). The table highlights how sender strategies are influenced by external factors like fact-checking and competition, impacting receiver decision-making.
Notes: See Propositions 1-8 for derivations of these results. For the experimental implementation, we set  $p=0.25$, which yields
$p=0.25$, which yields  $q^{F} = \frac{3q^{B}}{{4}-q^{B}}$.
$q^{F} = \frac{3q^{B}}{{4}-q^{B}}$.
Our theoretical predictions lead to the following testable hypotheses.
Hypothesis 1. Media competition provides the strongest incentives for accuracy investment, followed in descending order by competition plus fact-checking, base, and fact-checking environments.
In the base and fact-checking environments of our model, where the sender has a monopoly position, the sender chooses the lowest accuracy at which the receiver would be willing to affirm the message. These accuracy levels are  $q^B$ and
$q^B$ and  $q^F(p)$ for the base and fact-checking environments, respectively, with
$q^F(p)$ for the base and fact-checking environments, respectively, with  $q^F(p) \lt q^B$. In the other environments, where there are two senders, each sender’s best response is to continuously randomize over some range
$q^F(p) \lt q^B$. In the other environments, where there are two senders, each sender’s best response is to continuously randomize over some range  $[q,1]$ using some probability distribution function
$[q,1]$ using some probability distribution function  $f(q)$. In the competition environment, the average accuracy level chosen by senders is
$f(q)$. In the competition environment, the average accuracy level chosen by senders is  $q^C= E[q]=\int^1_{q^B} q\,f(q)dq $, whereas in the competition plus fact-checking environment, it is
$q^C= E[q]=\int^1_{q^B} q\,f(q)dq $, whereas in the competition plus fact-checking environment, it is  $q^{CF}= E[q]=\int^1_{q^F} q\,f(q)dq $. Given that
$q^{CF}= E[q]=\int^1_{q^F} q\,f(q)dq $. Given that  $q^F \lt q^B$ (
$q^F \lt q^B$ ( $\forall p \gt 0 $), this results in
$\forall p \gt 0 $), this results in  $q^{CF} \lt q^C$. Therefore, the (average) accuracy levels chosen by firms in all four environments can be ranked as:
$q^{CF} \lt q^C$. Therefore, the (average) accuracy levels chosen by firms in all four environments can be ranked as:  $q^F \lt q^B \lt q^{CF} \lt q^C. $ We test this hypothesis by comparing mean accuracy levels chosen by senders across treatments using t-tests and regression analysis.
$q^F \lt q^B \lt q^{CF} \lt q^C. $ We test this hypothesis by comparing mean accuracy levels chosen by senders across treatments using t-tests and regression analysis.
Hypothesis 2. Off the equilibrium path, fact-checking lowers the accuracy levels that receivers require to affirm messages, consistent with posterior belief updating.
This hypothesis tests whether receivers behave as rational Bayesian updaters when facing off-equilibrium sender behavior. In equilibrium, receivers always affirm messages because senders optimally choose accuracy levels that meet receivers’ decision thresholds. However, when senders deviate from equilibrium, we can observe how receivers incorporate the informational value of fact-checking into their decisions.
The key insight is that fact-checking provides receivers with additional information: a message that reaches them has survived the screening process. Rational receivers should update their posterior beliefs accordingly, lowering their accuracy requirements. Specifically, while receivers in the base environment require accuracy  $q^B$ to affirm, those in the fact-checking environment should require only
$q^B$ to affirm, those in the fact-checking environment should require only  $q^F(p) = \frac{(1-p)q^B}{1-pq^B} \lt q^B$ (where
$q^F(p) = \frac{(1-p)q^B}{1-pq^B} \lt q^B$ (where  $p$ is the probability of fact-checking).
$p$ is the probability of fact-checking).
Our experimental design naturally generates the off-equilibrium variation needed to test this hypothesis. Random rematching across rounds, one-shot interactions, and the learning environment mean that senders do not immediately converge to equilibrium strategies, creating meaningful variation in accuracy choices that allows us to observe receiver responses across different accuracy levels. We test this hypothesis by comparing receiver affirmation rates conditional on accuracy levels across treatments. This allows us to examine whether receivers require lower accuracy thresholds to affirm messages in the fact-checking treatment compared to the base treatment.
3. Experiment design
We now explain our experimental procedures and treatment designs. We develop four experimental treatments, each of which implements one of the environments described in the model section. We call these the base treatment, competition treatment, fact-checking treatment, and competition plus fact-checking treatment. Given that each treatment differs from the others in terms of only one feature, a comparison across these four treatments gives us a clean and robust way to evaluate the effect of that single feature and allows us to answer several important policy questions. For example, does media competition incentivize firms to improve the accuracy of their news? What about fact-checking? Moreover, do these interventions interact with one another, or are their effects entirely independent?
3.1. Experimental procedures
This study was approved by the Utah State University Institutional Review Board (Protocol # 12520). We conducted this experiment at the Experimental Economics Laboratory at Utah State University in Spring 2022. All subjects were university students and were recruited using Sona Systems. We recruited 201 subjects, who were divided across treatments as follows: 52 subjects participated in the base treatment, 51 in the competition treatment, 50 in the fact-checking treatment, and the remaining 48 in the competition plus fact-checking treatment.Footnote 5 We conducted these four treatments over 13 sessions (four sessions for the fact-checking treatment and three sessions for each of the other treatments). All interaction between subjects took place anonymously through computers, and the experiment was coded using oTree (Chen et al., Reference Chen, Schonger and Wickens2016). All subjects received a $7 show-up fee in addition to their earnings from the experiment. Each session took approximately 45 minutes, and average subject earnings were $21, including the show-up fee.
At the start of a session, subjects were asked to take a seat in a computer lab and were provided instructions and guidance by the software. First, subjects were asked to read through a detailed description of a game and were given an opportunity to ask questions. Next, they played an unpaid practice round in which they played as both the sender and the receiver. After the practice round, subjects were required to answer some understanding questions based on their choices in the practice round. They could only proceed to the main experiment upon answering all questions correctly.
After demonstrating a good understanding of the game, subjects played 20 rounds of a sender-receiver game. At the end, one of these rounds was randomly selected for payment. In each round, subjects were randomly reassigned the role of a sender or receiver and were randomly re-matched with another participant.Footnote 6 Thus, we obtained 1,680 unique sender-receiver interactions across the four treatments.
After playing these 20 rounds, subjects completed a questionnaire that elicited their demographic information as well as their preferences regarding risk, time, altruism, trust, and reciprocity. To elicit these preferences, we used questions from the Global Preferences Survey (Falk et al., Reference Falk, Becker, Dohmen, Enke, Huffman and Sunde2018). However, instead of using their sequence of hypothetical questions about choosing between an uncertain option and a certain option, we asked them to participate in an incentivized and paid bomb risk elicitation task (Crosetto & Filippin, Reference Crosetto and Filippin2013). In this task, subjects are incentivized to collect a greater number of boxes, but the more boxes they collect, the greater the chance that they might lose all their earnings.Footnote 7 The demographic questions collected information related to subjects’ age, gender, race, education, income, and religiousness. We elicit these preferences and demographic characteristics primarily for exploratory purposes, to examine whether any of them correlate with subjects’ behavior in the experiment. We do not find any such correlations (see Appendix B.1 for more details).
The experiment instructions, round screenshots, and questionnaire are all provided in Appendix C.
Several experimental design choices deserve emphasis. First, we use random rematching and role reassignment across rounds to generate independent observations. This is consistent with our theoretical focus on one-shot interactions rather than repeated game dynamics. Second, our choice to round accuracy levels to the nearest five percentage points in the analysis (Section 4.2) reflects an emergent pattern in subject behavior rather than an imposed constraint—subjects naturally gravitated toward multiples of five when choosing accuracy levels. Third, the 25 percent fact-checking probability represents a moderate intervention intensity. Our theoretical framework allows for any value of  $p \in [0,1]$, but we choose this level to balance meaningful impact with realistic implementation constraints, while leaving room for future studies to explore different intensities.
$p \in [0,1]$, but we choose this level to balance meaningful impact with realistic implementation constraints, while leaving room for future studies to explore different intensities.
3.2. Description of treatments
Our experimental implementation translates the theoretical environments described in Section 2 into laboratory treatments using concrete parameters and simplified language accessible to a general student population. This results in a 2x2 design that allows us to vary the two interventions of interest: media competition and third-party fact-checking. The competition treatment includes two senders and one receiver; the fact-checking treatment includes a bot that probabilistically checks messages for accuracy; and the competition and fact-checking treatment consists of two senders and the fact-checking bot. As Table 2 illustrates, this results in a total of four treatments. We describe each treatment in more detail below. The complete instructions provided to the subjects are available in Appendix C.
Experimental Treatments

Table 2 Long description
The table examines the impact of fact-checking and competition on outcomes. It presents four scenarios: no fact-checking or competition, only competition, only fact-checking, and both fact-checking and competition. The base scenario involves neither fact-checking nor competition. Introducing competition alone changes the outcome to 'Competition,' while adding fact-checking alone results in 'Fact-checking.' The combination of both factors leads to 'Competition plus fact-checking,' indicating that the joint application of these strategies produces the most comprehensive effect. This suggests that while each factor individually influences outcomes, their combined effect is more significant.
3.2.1. Base treatment
The base treatment implements the theoretical base environment using concrete numerical parameters. Subjects are told that a ball is drawn at random from an urn containing one red ball and one blue ball, with neither player observing the color of the ball drawn. This setup provides an intuitive way for subjects to understand the 50-50 prior probability assumption from our model. For the accuracy cost function, we use  $c(q)=10(2q-1)^2$, which satisfies all the theoretical requirements: It is increasing and convex in
$c(q)=10(2q-1)^2$, which satisfies all the theoretical requirements: It is increasing and convex in  $q$, equals zero when
$q$, equals zero when  $q=0.5$, and reaches
$q=0.5$, and reaches  $c(1)=10$ when accuracy is perfect. To help subjects understand this convex relationship without mathematical notation, we use an interactive graph where moving a slider updates both the accuracy level and associated cost in real time (see Figure 7 in the Appendix). The sender’s task is to choose
$c(1)=10$ when accuracy is perfect. To help subjects understand this convex relationship without mathematical notation, we use an interactive graph where moving a slider updates both the accuracy level and associated cost in real time (see Figure 7 in the Appendix). The sender’s task is to choose  $q\in [0.5,1]$, knowing that it will result in a cost of
$q\in [0.5,1]$, knowing that it will result in a cost of  $c(q)=10(2q-1)^2$.
$c(q)=10(2q-1)^2$.
We show the receiver the accuracy chosen by the sender along with a message, explaining that the accuracy represents the probability that the given message is true (see Figure 8 in the Appendix). We emphasize that the receiver cannot know with certainty whether the message is true as that depends on the color of the ball drawn, which is unknown to the receiver. Lastly, the experimental payoffs are simple transformations of our theoretical utility functions into dollar amounts. Specifically, receivers earn $10 for affirming a true message, lose $10 for affirming a false message, and earn $0 for not affirming. Senders earn $10 if their message is affirmed (regardless of whether it is true), implementing the assumption that media firms care primarily about engagement.
3.2.2. Competition treatment
We implement the competition treatment by adding an extra sender to the base treatment, turning it into a three-player game. The senders face identical cost functions,  $c(q)=10(2q-1)^2$, and choose the accuracy of their respective messages,
$c(q)=10(2q-1)^2$, and choose the accuracy of their respective messages,  $q_1$ and
$q_1$ and  $q_2$, simultaneously. The receiver sees two messages and two accuracy levels, and decides which, if any, to affirm. The first-price-all-pay auction structure emerges naturally: Both senders pay their accuracy costs regardless of which message gets affirmed, but only the sender whose message is affirmed earns $10. The receiver, as before, earns $10 if he affirms a true message, loses $10 if he affirms a false message, and earns nothing if he chooses not to affirm.
$q_2$, simultaneously. The receiver sees two messages and two accuracy levels, and decides which, if any, to affirm. The first-price-all-pay auction structure emerges naturally: Both senders pay their accuracy costs regardless of which message gets affirmed, but only the sender whose message is affirmed earns $10. The receiver, as before, earns $10 if he affirms a true message, loses $10 if he affirms a false message, and earns nothing if he chooses not to affirm.
3.2.3. Fact-checking treatment
The fact-checking treatment implements the theoretical fact-checking environment using a 25 percent probability of message verification, which we describe to subjects as messages having a “25 percent chance of going through a filter.” This language avoids potentially loaded terminology while clearly conveying the random selection process. Although receivers are not explicitly told the posterior probability that the message is true conditional on reaching them, they are fully informed about the fact-checking process and can theoretically compute the posterior probability themselves using this information.
The key implementation challenge is managing the potentially infinite game structure from our theory, where false messages can be repeatedly deleted. We handle this by programming the system to automatically restart the sender’s decision process whenever a false message gets deleted, but with the sender paying accuracy costs for each attempt. This preserves the theoretical insight that expected costs increase when fact-checking is present. While we explain the fact-checking process to receivers, we do not tell them whether the message they see went through fact-checking. This allows receivers to infer (heuristically) the posterior probability that a message is true conditional on it reaching them.
A comparison between the base and fact-checking treatments allows us to see the effect of fact-checking on firms’ decision to invest in accuracy as well as on consumers’ decision to share a news article.
3.2.4. Competition plus fact-checking treatment
This treatment combines both modifications to implement our most complex environment. The main experimental challenge is coordinating the fact-checking process across multiple senders while maintaining the random assignment assumption. We implement this by having each sender’s message independently face a 25 percent fact-checking probability. When a message gets deleted, only the affected sender is notified and asked to choose a new accuracy level, while the other sender’s message waits (assuming it cleared the fact-checking process).
The receiver’s decision process remains similar to the competition treatment, i.e., receivers see two messages and two accuracy levels, but now the messages implicitly carry the additional information value that they survived the fact-checking process.
4. Results
4.1. Data
Our final data consist of 1,680 unique sender-receiver interactions that took place among 201 subjects over four treatments. These interactions are distributed as follows: 520 interactions in the base treatment, 500 in the fact-checking treatment, 340 in the competition treatment, and 320 in the competition plus fact-checking treatment. Despite having approximately the same number of subjects in each treatment, we observe fewer interactions in the latter two treatments because each interaction consists of three people, two senders and one receiver. We also collected a variety of subject-level characteristics, and a closer look at the distribution of these characteristics suggests that subject assignment to treatment was indeed random. See Appendix B.1 for detailed statistics on subject-level characteristics by treatment.
4.2. Treatment effects on senders’ choice
To analyze accuracy levels chosen by senders, we use all sender decisions from each round, clustering standard errors at the subject level to account for within-subject correlation across rounds. Our analysis includes 2,340 sender accuracy choices across the four treatments: 520 in the base treatment, 500 in the fact-checking treatment, 680 in the competition treatment (340 interactions with 2 senders each), and 640 in the competition plus fact-checking treatment (320 interactions with 2 senders each). Although the competition treatment contains two senders in each interaction, we treat each sender’s choice as a separate unit of observation for this analysis because the two senders make their decisions simultaneously and independently.
Figure 2 graphically presents senders’ choices. The left panel of the Figure shows the average accuracy levels chosen by senders in each treatment, while the right panel shows their kernel distributions. In the base treatment, senders chose an average accuracy level of 74.3 percent. In the fact-checking treatment, this is slightly higher at 75.4 percent. In the competition treatment, the average accuracy chosen is the highest, at 81.1 percent. Consistent with our theoretical prediction, the average accuracy level in the competition plus fact-checking treatment, at 78.7 percent, is lower than the competition treatment, as the presence of fact-checking lowers the threshold accuracy required for receiver acceptance, which in turn reduces the range over which competing senders randomize. For robustness, we conduct a regression analysis controlling for various subject-level characteristics. Our results (shown in Appendix B) confirm these treatment effects, with competition increasing accuracy by 7.2 percentage points ( $p \lt 0.001$), the combined treatment increasing accuracy by 5.39 percentage points (
$p \lt 0.001$), the combined treatment increasing accuracy by 5.39 percentage points ( $p \lt 0.001$) relative to the base treatment, and the fact-checking treatment showing no significant effect (
$p \lt 0.001$) relative to the base treatment, and the fact-checking treatment showing no significant effect ( $p=0.16$).
$p=0.16$).
Accuracy Levels Chosen by Senders

Figure 2 Long description
The left graph is a bar graph showing accuracy levels chosen by senders across four treatments: Base, Competition, Fact Check and Competition plus Fact Check. The accuracy levels are 74.3 percent for Base, 81.1 percent for Competition, 75.4 percent for Fact Check and 78.7 percent for Competition plus Fact Check. The right graph is a line graph showing kernel density distributions of accuracy chosen in each treatment. The x-axis is labeled 'Accuracy Chosen (percent)' ranging from 0 to 100 and the y-axis is labeled 'Density'. The graph includes four curves labeled Base, Fact Checking, Competition and Competition plus Fact Check, each showing different distributions of accuracy levels chosen by senders.
To establish the complete statistical ranking predicted by Hypothesis 1, we conduct pairwise comparisons between all treatment pairs (Table 3). Based on statistically significant differences, the results indicate the order of accuracy levels:  $q^F \approx q^B \lt q^{CF} \lt q^C$. This is very close to the ordering predicted by Hypothesis 1,
$q^F \approx q^B \lt q^{CF} \lt q^C$. This is very close to the ordering predicted by Hypothesis 1,  $q^F \lt q^B \lt q^{CF} \lt q^C$. Competition produces significantly higher accuracy than all other treatments: 6.53 percentage points higher than Base (
$q^F \lt q^B \lt q^{CF} \lt q^C$. Competition produces significantly higher accuracy than all other treatments: 6.53 percentage points higher than Base ( $p \lt 0.001$), 5.45 percentage points higher than Fact-checking (
$p \lt 0.001$), 5.45 percentage points higher than Fact-checking ( $p = 0.001$), and 2.06 percentage points higher than Competition plus fact-checking (
$p = 0.001$), and 2.06 percentage points higher than Competition plus fact-checking ( $p = 0.012$). The Competition plus fact-checking treatment significantly outperforms Base (+4.47 pp,
$p = 0.012$). The Competition plus fact-checking treatment significantly outperforms Base (+4.47 pp,  $p = 0.001$) but the difference with Fact-checking, while in the predicted direction (+3.38 pp), is not statistically significant (
$p = 0.001$) but the difference with Fact-checking, while in the predicted direction (+3.38 pp), is not statistically significant ( $p=0.189$). The Fact-checking versus Base comparison shows minimal difference (+1.08 pp,
$p=0.189$). The Fact-checking versus Base comparison shows minimal difference (+1.08 pp,  $p = 0.386$), consistent with our theoretical prediction that fact-checking has minimal impact on firms’ accuracy investments in isolation. This complete pattern of results provides strong confirmation of Hypothesis 1’s prediction that competition creates the strongest incentives for accuracy investment.
$p = 0.386$), consistent with our theoretical prediction that fact-checking has minimal impact on firms’ accuracy investments in isolation. This complete pattern of results provides strong confirmation of Hypothesis 1’s prediction that competition creates the strongest incentives for accuracy investment.
Pairwise Comparisons of Mean Accuracy Levels

Table 3 Long description
The table compares mean accuracy levels across different conditions: Base, Competition, Fact-checking, and a combination of Competition and Fact-checking (Comp+FC). The largest mean difference is observed between Competition and Base, with an increase of 6.53 percentage points and a highly significant p-value of less than 0.001. In contrast, the comparison between Fact-checking and Base shows a small, non-significant increase of 1.08 percentage points with a p-value of 0.386. Other notable comparisons include Competition vs. Fact-checking, which shows a significant decrease of 5.45 percentage points (p = 0.001), and Fact-checking vs. Comp+FC, which shows a significant increase of 3.38 percentage points (p = 0.012). The data suggests that Competition alone significantly improves accuracy compared to Base, while Fact-checking alone does not show a significant effect.
Notes: P-values are from two-tailed t-tests with standard errors clustered at the subject level. pp = percentage points.
4.3. Treatment effects on receivers’ choice
Unlike senders, receivers face a new decision in every interaction—because they are responding to an accuracy chosen by a different sender each time. For example, a receiver who sees an accuracy level of 50 percent in one round and 80 percent in the next round faces two entirely different decisions in each round. Therefore, we use the interaction-level data to calculate the average number of times receivers affirm for a given accuracy level. Specifically, we take averages at the interaction level to calculate  $L(q)=\text{Pr}(a=1|q)$, the likelihood of affirming for a given value of
$L(q)=\text{Pr}(a=1|q)$, the likelihood of affirming for a given value of  $q$. Since messages with higher accuracy levels are more likely to get affirmed, we expect this function to be increasing in
$q$. Since messages with higher accuracy levels are more likely to get affirmed, we expect this function to be increasing in  $q$.Footnote 8
$q$.Footnote 8
Estimating this likelihood function using experimental data poses one problem in particular, which is that some accuracy levels were more popular among subjects than others. For example, accuracy levels of 54 percent and 56 percent were each chosen only once out of 2,340 accuracy choices made in the entire experiment. We resolve this issue by grouping accuracy choices into multiples of five, by rounding each accuracy to the nearest five. Hence, we use experimental data to estimate 11 points of the likelihood function, i.e.,  $L(q)$ for
$L(q)$ for  $q\in \{0.50, 0.55, 0.60, ...,1\}$. Interestingly, subjects revealed a preference for choosing accuracy levels that are multiples of five (see Figure 4 in Appendix B), making this approach almost a natural solution. Further, given that we are mostly interested in the general relationship between the probability of affirming and accuracy levels, and not the precise marginal effect of each accuracy level, we find this to be a very reasonable solution.
$q\in \{0.50, 0.55, 0.60, ...,1\}$. Interestingly, subjects revealed a preference for choosing accuracy levels that are multiples of five (see Figure 4 in Appendix B), making this approach almost a natural solution. Further, given that we are mostly interested in the general relationship between the probability of affirming and accuracy levels, and not the precise marginal effect of each accuracy level, we find this to be a very reasonable solution.
Figure 3 presents this likelihood function for the base treatment, the competition treatment, and the fact-checking treatment. To allow for easier comparison with the base treatment, we show the likelihood functions for the base and the competition treatments in the left panel and the likelihood functions for the base and the fact-checking treatments in the right panel. As expected, the likelihood function appears to be generally upward sloping in all three treatments. One notable observation in the base treatment is that the probability of affirming makes a considerable jump between the accuracy levels of 65 and 70 percent. This suggests that many receivers use 70 percent as a threshold below which they are not willing to affirm. A sizable jump can also be observed between these values in the fact-checking treatment. For the competition treatment, however, we do not have sufficient data to check if receivers adopt a similar strategy because they almost always saw at least one message with an accuracy of at least 75 percent.
Likelihood of Affirming

Figure 3 Long description
The image contains two line graphs. The first graph, labeled 'Base vs. Competition', shows the fraction of messages affirmed on the y-axis and accuracy level in percent on the x-axis, ranging from 50 to 100. The base line increases from 0.10 at 55 percent accuracy to 1.00 at 95 percent accuracy. The competition line starts at 0.20 at 65 percent accuracy and reaches 0.95 at 100 percent accuracy. The second graph, labeled 'Base vs. Fact-Checking', also plots the fraction of messages affirmed against accuracy level. The base line follows a similar pattern as in the first graph. The fact-checking line starts at 0.10 at 55 percent accuracy, dips slightly and then rises to 0.95 at 95 percent accuracy. Both graphs include data points with sample sizes indicated by 'n equals' followed by numbers at each point.
The left panel of Figure 3 shows that for any given accuracy level, receivers in the competition treatment are less likely to affirm messages than receivers in the base treatment. In other words, receivers require higher accuracy levels in the competition treatment. This finding holds true regardless of whether the two messages seen by receivers are the same or different. That is, receivers are equally selective when both messages are the same as when they are different, ruling out the possibility that contradictory messages per se drive the increased selectivity (see Appendix B.3 for details). Given that message disagreement does not drive the effect, the increased selectivity appears to stem from the presence of choice itself. Having multiple sources to evaluate makes receivers more discerning about which messages to affirm.
In the fact-checking treatment, receivers are more likely to affirm a message than those in the base treatment when accuracy is 60 percent or lower. For accuracy levels above 60 percent, the pattern reverses: Receivers in the fact-checking treatment are less likely to affirm the message. However, pairwise t-tests comparing the fraction of messages affirmed at each accuracy level reveal no statistically significant differences between the base and fact-checking treatments (all  $p \gt 0.10$). Thus, we cannot conclude that fact-checking has an effect, in either direction, on the likelihood of affirming a message.
$p \gt 0.10$). Thus, we cannot conclude that fact-checking has an effect, in either direction, on the likelihood of affirming a message.
To formally test Hypothesis 2, we estimate linear probability models of the receiver’s affirming decision with accuracy as the independent variable, interacted with indicators for the presence of fact-checking. Results of these regressions are reported in the Appendix in Table 9. Across all specifications, we find a positive and statistically significant effect of accuracy on affirmation, confirming that receivers are more likely to share higher-accuracy messages. The accuracy coefficient is larger in the absence of competition (approximately 2.1 percentage points) compared to the treatments with competition (approximately 1.2 percentage points), consistent with our earlier finding that competition makes receivers more selective.
However, the results provide no support for Hypothesis 2’s prediction that fact-checking lowers receivers’ accuracy thresholds. The interaction terms between fact-checking and accuracy are consistently small in magnitude (around -0.001 to -0.003) and statistically insignificant across all specifications. This indicates that receivers do not systematically adjust their accuracy requirements in response to the presence of fact-checking, contrary to the theoretical prediction that they should become more willing to affirm messages at lower accuracy levels after accounting for the informational value of the screening process.
4.4. Impact on misinformation
To assess the effectiveness of each policy intervention in reducing misinformation shared on social media, we examine the fraction of false messages among those interactions in which the receiver chose to affirm. Since our experimental decision to affirm a message represents the decision to share an article on social media, this conditional probability directly measures how much misinformation would flow through social platforms in each treatment. Table 4 presents these results, with the fourth row showing the key metric: the fraction of affirmed messages that were false, calculated by dividing the third row (affirmed and false messages) by the first row (total affirmed messages). The table also displays the breakdown of affirmed messages into true and false categories, with p-values indicating whether treatment effects differ significantly from the base treatment using two-sided t-tests.
Fraction of Affirmed Messages

Table 4 Long description
The table measures the fraction of messages affirmed under different treatments: Base, Competition, Fact-checking, and Competition plus Fact-checking (Comp + FC). The 'Comp + FC' treatment has the highest fraction of affirmed messages at 0.919, significantly higher than the base treatment (p < 0.001). In terms of affirmed messages that are true, 'Comp + FC' also leads with 0.775, again significantly different from the base (p < 0.001). The fraction of affirmed messages that are false is lowest in the 'Comp + FC' and Fact-checking treatments, both at 0.144. The fraction of true messages that are affirmed is highest in the Fact-checking treatment at 0.815, with a significant difference from the base (p = 0.030). These results suggest that the combination of competition and fact-checking is most effective in affirming true messages.
Notes: Parentheses show p-values resulting from two-tailed t-tests comparing each treatment’s mean to that of the base treatment. The fourth row shows the fraction of messages that were true, conditional on being affirmed, i.e., (Affirmed  $\cap$ True)/Affirmed.
$\cap$ True)/Affirmed.
Both competition and fact-checking interventions prove effective at reducing misinformation on social media, with the combined treatment showing the strongest performance. Under baseline conditions, approximately one in four (24.8 percent) news articles shared on social media would constitute misinformation. The competition treatment reduces this rate by 7.2 percentage points while fact-checking treatment achieves a similar reduction of 6.3 percentage points. The combined competition plus fact-checking treatment yields the largest reduction, bringing the misinformation rate down by 9.1 percentage points from the base treatment. While the combined treatment significantly outperforms the base condition ( $p=0.003$), it does not differ significantly from either individual intervention (
$p=0.003$), it does not differ significantly from either individual intervention ( $p=0.521$ for competition comparison,
$p=0.521$ for competition comparison,  $p=0.328$ for fact-checking comparison), suggesting that the interventions may not provide substantial additional benefits when implemented together.
$p=0.328$ for fact-checking comparison), suggesting that the interventions may not provide substantial additional benefits when implemented together.
5. Discussion
The goal of this study is to evaluate the effect of two policies for tackling misinformation, namely media competition and third-party fact-checking. Specifically, we examine the effect of each policy on (i) how much money media firms invest toward their news accuracy, (ii) the willingness of consumers to share articles on social media, and (iii) the proportion of false news articles that ultimately make their way to social media. Our base treatment provides baseline values for each dependent variable that is used for comparison with other treatments.
Our experiment shows that that media competition has the strongest effect on all three measures while fact-checking has no significant effect. Our first main finding, that competition incentivizes media firms to devote more resources to news accuracy, is consistent with the theoretical prediction made in Hypothesis 1. We also find that in the presence of media competition, consumers are less willing to share news on social media for the same accuracy levels. Intuitively, this is because exposure to multiple news sources increases consumers’ standards of accuracy, causing them to become more selective about which articles to share on social media. Finally, we find that the fraction of false news articles shared on social media is the lowest in the competition and competition plus fact-checking treatments.
An important limitation of our study is the assumption that consumers are motivated solely by accuracy when deciding whether to share news content. Recent research indicates that people sometimes share news based on what they believe others want to see, even when they suspect the information may be inaccurate. Our policy recommendations are most applicable to contexts where accuracy concerns dominate sharing decisions. In environments where strategic considerations or partisan motivations drive sharing behavior, different interventions targeting social incentives rather than information quality may be more effective.
Another limitation of our theoretical framework is the use of one-shot (rather than repeated) interactions between media firms and consumers. In reality, consumers rely heavily on media firms’ reputations when deciding whether to read and share news articles, and this reputation building depends on consumers’ ability to observe firms’ track records with false news. A repeated interaction framework, where trust is built over time through consistent performance, could alter our conclusions about the effectiveness of competition and fact-checking interventions. We expect competition would have stronger effects in a repeated interaction framework because firms would consider both immediate and long-term reputational benefits of investing in accuracy. At the same time, fact-checking is likely to cause an improvement in news accuracy in a repeated interaction framework due to reputation concerns, unlike our one-shot framework where the mechanism operates differently and may not provide realistic incentives. Future research extending our model to incorporate reputation dynamics would provide valuable insights into how these policy interventions perform in settings where trust-building is central to media firms’ strategies.
Moreover, the simplistic assumptions of our theoretical model provide an excellent starting point and ample room for adding various types of real-world complexities. Thus, the model can serve as a valuable guide for future work in this area. For example, our model assumes that social media consumers are only interested in truth whereas in reality, people are interested in spreading news that aligns with their preexisting beliefs and preferences. Future studies could make this model more realistic by allowing consumers to have a preference for sharing a particular message even if that message is the less accurate one. Another example is that our model assumes that media firms only care about viewership, while in reality, we find that some firms have their own political agendas they try to promote. Future studies can incorporate media firms’ preferences more accurately by giving senders in the experiment an additional reward if their preferred message gets shared on social media.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/eec.2026.10040.
Replication material
The replication material for this study is available at https://doi.org/10.3886/E240630V2.















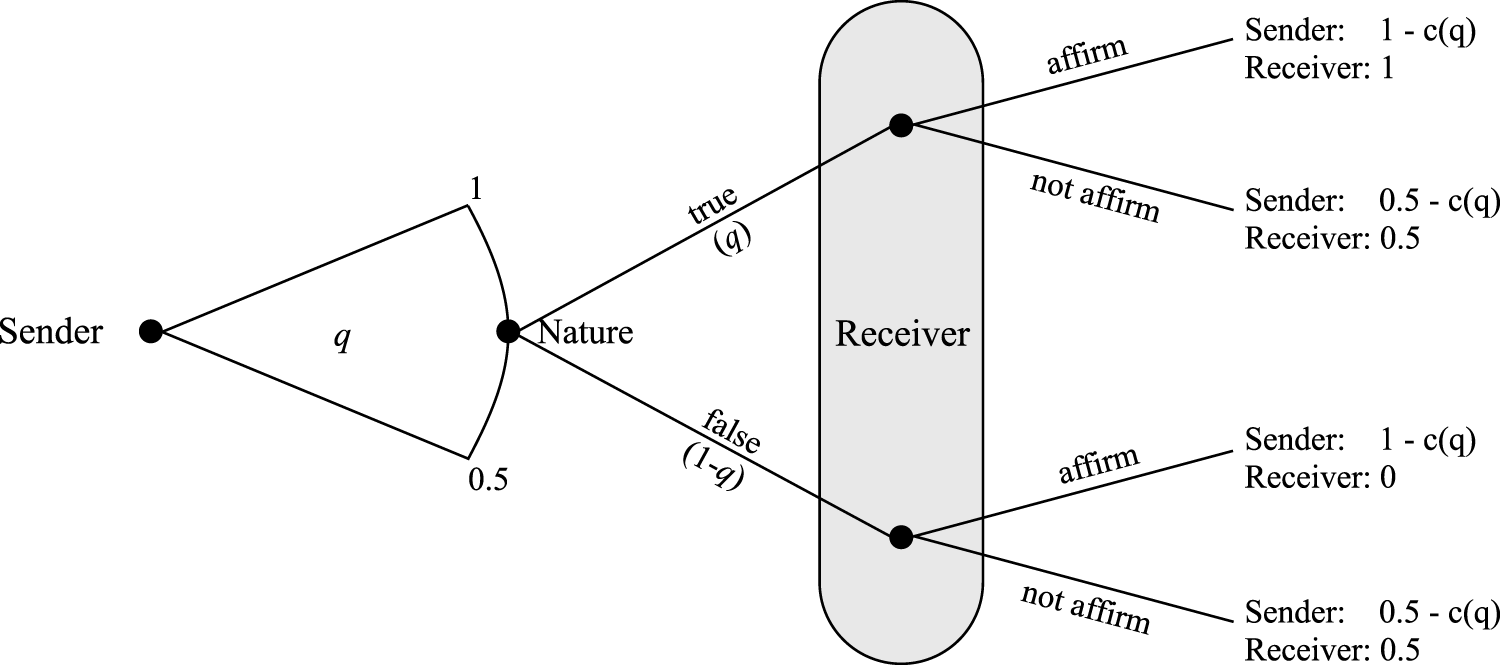


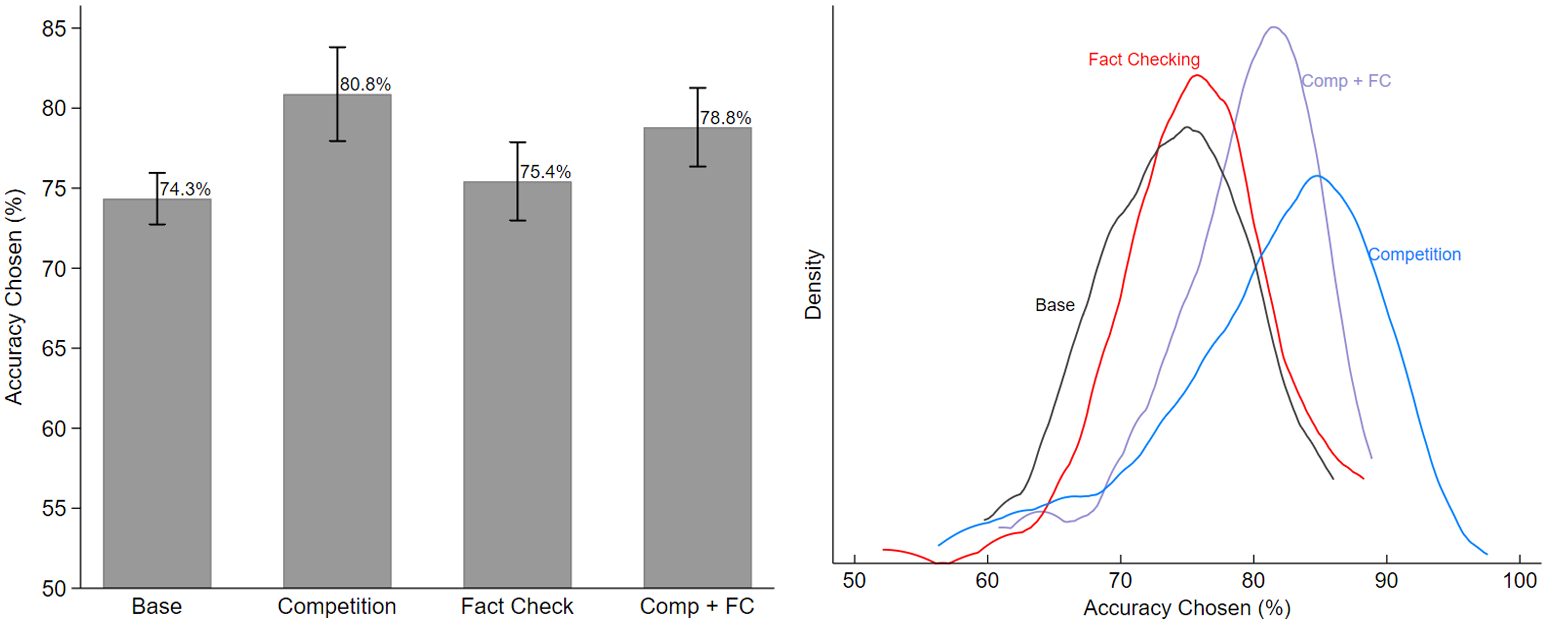




 Open access
Open access