

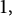
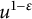
1 Introduction
1.1 Background
The purpose of this note is to study the distribution of large prime factors of elements in sequences which satisfy only a few minimal conditions.
Let us recall the classical theory and notation: let
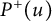 $P^+(u)$
be the largest prime factor of a positive integer u. It is a consequence of a result of Dickman [Reference Dickman13] that for any fixed
$P^+(u)$
be the largest prime factor of a positive integer u. It is a consequence of a result of Dickman [Reference Dickman13] that for any fixed
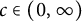 $c \in (0,\infty )$
,
$c \in (0,\infty )$
,
 $$ \begin{align*}\frac{1}{x}|\{u\leq x:\, P^+(u) \leq u^c\}| \sim \rho(1/c), \end{align*} $$
$$ \begin{align*}\frac{1}{x}|\{u\leq x:\, P^+(u) \leq u^c\}| \sim \rho(1/c), \end{align*} $$
as
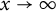 $x\rightarrow \infty $
, where
$x\rightarrow \infty $
, where
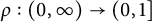 $\rho :(0,\infty ) \rightarrow (0,1]$
is a continuous function called the Dickman function. (See, e.g., [Reference Montgomery and Vaughan33, Chapter 7.1] for a modern account.)
$\rho :(0,\infty ) \rightarrow (0,1]$
is a continuous function called the Dickman function. (See, e.g., [Reference Montgomery and Vaughan33, Chapter 7.1] for a modern account.)
This result was generalized and given a probabilistic interpretation by Billingsley [Reference Billingsley4] (and independently Knuth and Trabb Pardo [Reference Knuth and Trabb Pardo29] and Vershik [Reference Vershik41]). Let u be chosen randomly and uniformly from the integers from
 $1$
to x. Then the above result says that
$1$
to x. Then the above result says that
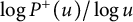 $\log P^+(u)/\log u$
tends in distribution to a nonnegative random variable
$\log P^+(u)/\log u$
tends in distribution to a nonnegative random variable
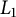 $L_1$
with cumulative distribution function
$L_1$
with cumulative distribution function
 $\mathbb {P}(L_1\leq c) = \rho (1/c)$
. Moreover, let
$\mathbb {P}(L_1\leq c) = \rho (1/c)$
. Moreover, let
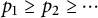 $p_1 \geq p_2 \geq \cdots $
be the prime factors of u listed with multiplicity, with the convention that
$p_1 \geq p_2 \geq \cdots $
be the prime factors of u listed with multiplicity, with the convention that
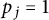 $p_j = 1$
if u has fewer than j prime factors (so that
$p_j = 1$
if u has fewer than j prime factors (so that
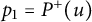 $p_1 = P^+(u)$
and
$p_1 = P^+(u)$
and
 $u = p_1p_2\dots $
). Billingsley showed that there is a sequence of (dependent) random variables
$u = p_1p_2\dots $
). Billingsley showed that there is a sequence of (dependent) random variables
 $L_1, L_2,\ldots $
such that for any
$L_1, L_2,\ldots $
such that for any
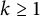 $k \geq 1$
, and any fixed constants
$k \geq 1$
, and any fixed constants
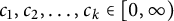 $c_1,c_2,\ldots ,c_k \in [0,\infty )$
,
$c_1,c_2,\ldots ,c_k \in [0,\infty )$
,
 $$ \begin{align*}\mathbb{P}\Big(\frac{\log p_1}{\log u} \leq c_1,\dots, \frac{\log p_k}{\log u} \leq c_k\Big) \rightarrow \mathbb{P}(L_1 \leq c_1,\ldots,L_k \leq c_k), \end{align*} $$
$$ \begin{align*}\mathbb{P}\Big(\frac{\log p_1}{\log u} \leq c_1,\dots, \frac{\log p_k}{\log u} \leq c_k\Big) \rightarrow \mathbb{P}(L_1 \leq c_1,\ldots,L_k \leq c_k), \end{align*} $$
as
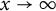 $x\rightarrow \infty $
. That is, the process
$x\rightarrow \infty $
. That is, the process
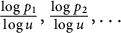 $\tfrac {\log p_1}{\log u}, \tfrac {\log p_2}{\log u},\ldots $
tends in distribution to
$\tfrac {\log p_1}{\log u}, \tfrac {\log p_2}{\log u},\ldots $
tends in distribution to
 $L_1, L_2,\ldots $
. (See, e.g., [Reference Billingsley5] for a modern probabilistic account. Here and in what follows, we discard with the case
$L_1, L_2,\ldots $
. (See, e.g., [Reference Billingsley5] for a modern probabilistic account. Here and in what follows, we discard with the case
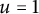 $u=1$
by adopting the formal convention
$u=1$
by adopting the formal convention
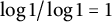 $\log 1 / \log 1 = 1$
.)
$\log 1 / \log 1 = 1$
.)
For each k, an explicit formula for
 $\mathbb {P}(L_1 \leq c_1,\ldots ,L_k \leq c_k)$
can be written down (see [Reference Billingsley5, Theorem 4.4] for a density formula), but the formula is somewhat complicated. The following characterization is simpler: let
$\mathbb {P}(L_1 \leq c_1,\ldots ,L_k \leq c_k)$
can be written down (see [Reference Billingsley5, Theorem 4.4] for a density formula), but the formula is somewhat complicated. The following characterization is simpler: let
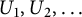 $U_1, U_2, \ldots $
be independent and identically distributed uniform random variables on the interval
$U_1, U_2, \ldots $
be independent and identically distributed uniform random variables on the interval
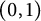 $(0,1)$
, and define random variables
$(0,1)$
, and define random variables
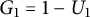 $G_1 = 1- U_1$
,
$G_1 = 1- U_1$
,
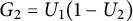 $G_2 = U_1(1-U_2)$
,
$G_2 = U_1(1-U_2)$
,
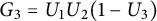 $G_3 = U_1 U_2 (1-U_3)$
, …. Then
$G_3 = U_1 U_2 (1-U_3)$
, …. Then
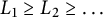 $L_1 \geq L_2 \geq \dots $
may be defined as the outcome of sorting
$L_1 \geq L_2 \geq \dots $
may be defined as the outcome of sorting
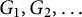 $G_1, G_2,\ldots $
into nonincreasing order.
$G_1, G_2,\ldots $
into nonincreasing order.
The sequence of random variables
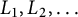 $L_1, L_2, \ldots $
is known as the Poisson–Dirichlet process with parameter
$L_1, L_2, \ldots $
is known as the Poisson–Dirichlet process with parameter
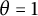 $\theta = 1$
. As the name suggests, there are Poisson–Dirichlet processes with
$\theta = 1$
. As the name suggests, there are Poisson–Dirichlet processes with
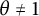 $\theta \neq 1$
, but in this article, we will only deal with
$\theta \neq 1$
, but in this article, we will only deal with
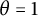 $\theta = 1$
, and so if there is no risk of confusion, we refer to
$\theta = 1$
, and so if there is no risk of confusion, we refer to
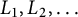 $L_1, L_2, \ldots $
as simply the Poisson–Dirichlet process. (See [Reference Billingsley5, Reference Kingman28] for an account of general
$L_1, L_2, \ldots $
as simply the Poisson–Dirichlet process. (See [Reference Billingsley5, Reference Kingman28] for an account of general
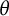 $\theta $
, along with a more detailed introduction to the case
$\theta $
, along with a more detailed introduction to the case
 $\theta = 1$
.)
$\theta = 1$
.)
We note that
 $\tfrac {\log p_1}{\log u} + \tfrac {\log p_2}{\log u} + \cdots = 1$
, and likewise
$\tfrac {\log p_1}{\log u} + \tfrac {\log p_2}{\log u} + \cdots = 1$
, and likewise
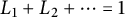 $L_1 + L_2 + \cdots = 1$
almost surely.
$L_1 + L_2 + \cdots = 1$
almost surely.
1.2 Some well-distributed arithmetic sequences
It is natural to wonder whether this statistical pattern governing the distribution of large prime factors of random integers extends to other arithmetic sequences. Some cases which have been studied extensively include shifted primes [Reference Baker and Harman2, Reference Banks and Shparlinski3, Reference Ding14, Reference Feng and Wu17, Reference Fouvry18, Reference Goldfeld21, Reference Hooley25, Reference Wu43] – that is, the sequence
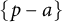 $\{p-a\}$
for a constant
$\{p-a\}$
for a constant
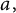 $a,$
where p ranges over the primes – and the values of irreducible polynomials [Reference Dartyge7–Reference Deshouillers and Iwaniec12, Reference Heath-Brown23, Reference Hooley24, Reference Irving27, Reference Merikoski32, Reference Tenenbaum40] – that is, the sequence
$a,$
where p ranges over the primes – and the values of irreducible polynomials [Reference Dartyge7–Reference Deshouillers and Iwaniec12, Reference Heath-Brown23, Reference Hooley24, Reference Irving27, Reference Merikoski32, Reference Tenenbaum40] – that is, the sequence
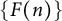 $\{F(n)\}$
, where F is an irreducible polynomial with integer coefficients and a positive leading coefficient and n ranges over the integers.
$\{F(n)\}$
, where F is an irreducible polynomial with integer coefficients and a positive leading coefficient and n ranges over the integers.
In this article, we study a quite general class of arithmetic sequences. Let
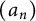 $(a_n)$
be a sequence of nonnegative numbers. Define the quantities
$(a_n)$
be a sequence of nonnegative numbers. Define the quantities
 $$ \begin{align} N(x) = \sum_{n\leq x} a_n, \quad\quad N_d(x) = \sum_{\substack{n\leq x \\ n \equiv 0 \ (\mathrm{mod}\ d)}} a_n. \end{align} $$
$$ \begin{align} N(x) = \sum_{n\leq x} a_n, \quad\quad N_d(x) = \sum_{\substack{n\leq x \\ n \equiv 0 \ (\mathrm{mod}\ d)}} a_n. \end{align} $$
We say that the sequence
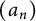 $(a_n)$
:
$(a_n)$
:
-
(A) Has index
 $\alpha $
if for some
$\alpha> 0$
,
$$ \begin{align*}N(x) = x^{\alpha+o(1)}, \end{align*} $$
$\alpha $
if for some
$\alpha> 0$
,
$$ \begin{align*}N(x) = x^{\alpha+o(1)}, \end{align*} $$
-
(B) Has a level of distribution
$\vartheta $
if for any
$0 < c < \vartheta $
and any
$A> 0$
, (2)where
$$ \begin{align} \sum_{d\leq x^c} |N_d(x) - g(d) N(x)| \ll_{c,A} \frac{1}{(\log x)^A} N(x), \end{align} $$
$g(d)$
is a multiplicative function with
$g(d) \in [0,1]$
for all
$d\geq 1$
, and (3)for some constant
$$ \begin{align} \sum_{p \leq x} g(p) \log p = \log x + O(1), \quad \quad g(d) = O(C^{\Omega(d)}/d), \end{align} $$
$C \geq 1$
.
-
(C) Is congruence uniform if there are constants
$B\geq 0$
,
$C \geq 1$
such that
$$ \begin{align*}N_d(x) \ll \Big(\frac{C^{\Omega(d)}}{d} N(x) + C^{\Omega(d)} \Big) (\log x)^B,\quad \textrm{for}\; d\leq x. \end{align*} $$
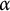
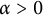

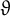
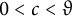
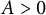


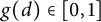
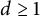


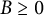
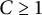

Additionally, we say the sequence
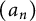 $(a_n)$
:
$(a_n)$
:
-
• Is
$\sigma $
well-distributed if
$(a_n)$
satisfies each of (A)–(C) and
$\sigma $
is any positive number less than or equal to
$\alpha $
and
$\vartheta $
.
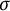
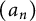
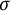
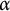
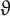
Here, as usual,
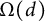 $\Omega (d)$
is the number of prime factors of d counted with multiplicity. Note that (3) implies that
$\Omega (d)$
is the number of prime factors of d counted with multiplicity. Note that (3) implies that
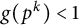 $g(p^k) < 1$
except for finitely many primes p.
$g(p^k) < 1$
except for finitely many primes p.
Likewise note that we trivially have
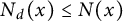 $N_d(x) \leq N(x)$
, so that the condition for congruence uniformity is only meaningful for those integers d with prime factors
$N_d(x) \leq N(x)$
, so that the condition for congruence uniformity is only meaningful for those integers d with prime factors
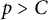 $p> C$
.
$p> C$
.
It will typically be the case that
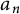 $a_n$
is the indicator function of n belonging to some subset of the integers, and in that case, we will also describe that subset by the above terminology as long as there is no chance for confusion.
$a_n$
is the indicator function of n belonging to some subset of the integers, and in that case, we will also describe that subset by the above terminology as long as there is no chance for confusion.
Remark 1 Let us explain some intuition for these conditions. (A) is self-explanatory; in (B), one may keep in mind the examples
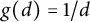 $g(d) = 1/d$
or
$g(d) = 1/d$
or
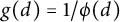 $g(d) = 1/\phi (d)$
; and (C) may be thought of as a more technical condition – the reader may check that it is trivially satisfied if the sequence
$g(d) = 1/\phi (d)$
; and (C) may be thought of as a more technical condition – the reader may check that it is trivially satisfied if the sequence
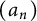 $(a_n)$
is bounded and
$(a_n)$
is bounded and
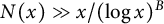 $N(x) \gg x/(\log x)^B$
for some B.
$N(x) \gg x/(\log x)^B$
for some B.
Examples of sequences satisfying these conditions are described by the following propositions. Throughout the article, for a proposition
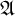 $\mathfrak {A}$
, we use the notation
$\mathfrak {A}$
, we use the notation
 $\mathbf {1}[\mathfrak {A}]$
to be
$\mathbf {1}[\mathfrak {A}]$
to be
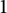 $1$
if
$1$
if
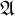 $\mathfrak {A}$
is true and
$\mathfrak {A}$
is true and
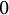 $0$
otherwise.
$0$
otherwise.
Proposition 2 Shifted primes are
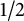 $1/2$
well-distributed. That is, for a fixed integer a, consider the set
$1/2$
well-distributed. That is, for a fixed integer a, consider the set
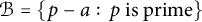 $\mathcal {B} = \{p-a:\, p\; \textrm {is prime}\}$
and let
$\mathcal {B} = \{p-a:\, p\; \textrm {is prime}\}$
and let
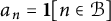 $a_n = \mathbf {1}[n \in \mathcal {B}]$
. Then
$a_n = \mathbf {1}[n \in \mathcal {B}]$
. Then
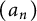 $(a_n)$
has index
$(a_n)$
has index
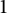 $1$
, has level of distribution
$1$
, has level of distribution
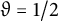 $\vartheta = 1/2$
, and is congruence uniform.
$\vartheta = 1/2$
, and is congruence uniform.
Proof That the sequence has index
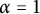 $\alpha = 1$
follows from the prime number theorem (or indeed Chebyshev’s bounds). By Remark 1, congruence uniformity also follows from Chebyshev’s lower bound
$\alpha = 1$
follows from the prime number theorem (or indeed Chebyshev’s bounds). By Remark 1, congruence uniformity also follows from Chebyshev’s lower bound
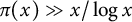 $\pi (x) \gg x/\log x$
. The level of distribution
$\pi (x) \gg x/\log x$
. The level of distribution
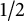 $1/2$
follows from the Bombieri–Vinogradov theorem [Reference Cojocaru and Murty6, Theorem 9.2.1], with
$1/2$
follows from the Bombieri–Vinogradov theorem [Reference Cojocaru and Murty6, Theorem 9.2.1], with
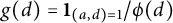 $g(d) = \mathbf {1}_{(a,d)=1}/\phi (d)$
, where
$g(d) = \mathbf {1}_{(a,d)=1}/\phi (d)$
, where
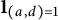 $\mathbf {1}_{(a,d)=1}$
is
$\mathbf {1}_{(a,d)=1}$
is
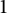 $1$
when d is coprime to a and
$1$
when d is coprime to a and
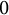 $0$
otherwise.
$0$
otherwise.
Proposition 3 The values of irreducible polynomials of degree D are
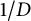 $1/D$
well-distributed. That is, for a polynomial
$1/D$
well-distributed. That is, for a polynomial
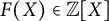 $F(X) \in \mathbb {Z}[X]$
of degree
$F(X) \in \mathbb {Z}[X]$
of degree
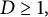 $D\geq 1,$
which is irreducible with positive leading coefficient, consider the set
$D\geq 1,$
which is irreducible with positive leading coefficient, consider the set
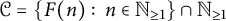 $\mathcal {C} = \{ F(n):\, n \in \mathbb {N}_{\geq 1} \} \cap \mathbb {N}_{\geq 1}$
and let
$\mathcal {C} = \{ F(n):\, n \in \mathbb {N}_{\geq 1} \} \cap \mathbb {N}_{\geq 1}$
and let
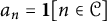 $a_n = \mathbf {1}[n \in \mathcal {C}]$
. Then
$a_n = \mathbf {1}[n \in \mathcal {C}]$
. Then
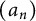 $(a_n)$
has index
$(a_n)$
has index
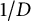 $1/D$
, has level of distribution
$1/D$
, has level of distribution
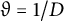 $\vartheta = 1/D$
, and is congruence uniform.
$\vartheta = 1/D$
, and is congruence uniform.
Proof That the index is
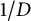 $1/D$
follows from the fact that
$1/D$
follows from the fact that
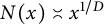 $N(x) \asymp x^{1/D}$
.
$N(x) \asymp x^{1/D}$
.
We see that the level of distribution is
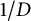 $1/D$
in the following way. For a natural number d, let
$1/D$
in the following way. For a natural number d, let
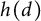 $h(d)$
be the number of distinct roots of F modulo d. By the Chinese Remainder Theorem (see [Reference Nagell36, Theorem 46]), we note that h is multiplicative. Set
$h(d)$
be the number of distinct roots of F modulo d. By the Chinese Remainder Theorem (see [Reference Nagell36, Theorem 46]), we note that h is multiplicative. Set
 $g(d) = h(d)/d$
and note g is multiplicative also.
$g(d) = h(d)/d$
and note g is multiplicative also.
Obviously
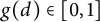 $g(d) \in [0,1]$
. We will show that (2) and (3) are satisfied for this function g. Let us show that (3) holds first. It is known that
$g(d) \in [0,1]$
. We will show that (2) and (3) are satisfied for this function g. Let us show that (3) holds first. It is known that
 $\sum _{p\leq x} g(p) \log p = \log x + O(1)$
; this is just a weak claim that F will on average have one root modulo a prime (see, e.g., [Reference Nagel35, Equation (4), p. 352] or [Reference Lee30, Corollary 4] for a more modern statement).
$\sum _{p\leq x} g(p) \log p = \log x + O(1)$
; this is just a weak claim that F will on average have one root modulo a prime (see, e.g., [Reference Nagel35, Equation (4), p. 352] or [Reference Lee30, Corollary 4] for a more modern statement).
The second claim in (3) is just the claim that
 $h(d) \ll C^{\Omega (d)}$
for some constant
$h(d) \ll C^{\Omega (d)}$
for some constant
 $C> 1$
. This follows from the multiplicativity of h and [Reference Nagell36, Theorem 54] by taking
$C> 1$
. This follows from the multiplicativity of h and [Reference Nagell36, Theorem 54] by taking
 $C=D \cdot \mathrm {disc}(F)^2$
.
$C=D \cdot \mathrm {disc}(F)^2$
.
Now, let us now prove (2). We first establish that
 $$ \begin{align} |N_d(x) - g(d)N(x)| \ll h(d), \end{align} $$
$$ \begin{align} |N_d(x) - g(d)N(x)| \ll h(d), \end{align} $$
where the implicit constant depends only on F.
To see this, note that since
 $F(n+d) \equiv F(n) \bmod d$
, in every interval of length
$F(n+d) \equiv F(n) \bmod d$
, in every interval of length
 $d,$
we will have
$d,$
we will have
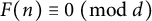 $F(n) \equiv 0 \ (\mathrm {mod}\ d)$
for
$F(n) \equiv 0 \ (\mathrm {mod}\ d)$
for
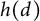 $h(d)$
values of n. In particular, since F is eventually increasing, there is some sufficiently large
$h(d)$
values of n. In particular, since F is eventually increasing, there is some sufficiently large
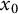 $x_0$
(depending on F) such that whenever
$x_0$
(depending on F) such that whenever
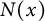 $N(x)$
increases by d on an interval to the right of
$N(x)$
increases by d on an interval to the right of
 $x_0$
,
$x_0$
,
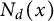 $N_d(x)$
will increase by
$N_d(x)$
will increase by
 $h(d)$
on the same interval. Therefore,
$h(d)$
on the same interval. Therefore,
 $$ \begin{align*}|N_d(x) - g(d)N(x)| \leq h(d) + |N_d(x_0) - g(d)N(x_0)| = h(d) + O(1) \end{align*} $$
$$ \begin{align*}|N_d(x) - g(d)N(x)| \leq h(d) + |N_d(x_0) - g(d)N(x_0)| = h(d) + O(1) \end{align*} $$
with the
 $O(1)$
term present to account for behavior of this quantity for
$O(1)$
term present to account for behavior of this quantity for
 $x \leq x_0$
.
$x \leq x_0$
.
If
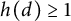 $h(d) \geq 1$
, this verifies (4). On the other hand, if
$h(d) \geq 1$
, this verifies (4). On the other hand, if
 $h(d) = 0$
, we have
$h(d) = 0$
, we have
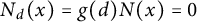 $N_d(x) = g(d) N(x) = 0$
for all x, so (4) is verified in this case also.
$N_d(x) = g(d) N(x) = 0$
for all x, so (4) is verified in this case also.
Hence, from (4),
 $$ \begin{align} \sum_{d \le x^c} |N_d(x) - g(d)N(x)| \ll \sum_{d \le x^c}h(d) \ll_{c} x^c (\log x)^A, \end{align} $$
$$ \begin{align} \sum_{d \le x^c} |N_d(x) - g(d)N(x)| \ll \sum_{d \le x^c}h(d) \ll_{c} x^c (\log x)^A, \end{align} $$
where we use Lemma 4, proved below, in the last estimate. As
 $N(x) \asymp x^{1/D}$
, we see (2) is satisfied as long as
$N(x) \asymp x^{1/D}$
, we see (2) is satisfied as long as
 $c < 1/D$
.
$c < 1/D$
.
To prove congruence uniformity, we use the bound
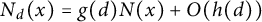 $ N_d(x) = g(d)N(x) + O(h(d))$
. Consequently, for a constant
$ N_d(x) = g(d)N(x) + O(h(d))$
. Consequently, for a constant
 $C> 1$
as above, we see that
$C> 1$
as above, we see that
 $N_d(x) \ll \frac {C^{\Omega (d)}}{d} N(x) + C^{\Omega (d)}$
, for all
$N_d(x) \ll \frac {C^{\Omega (d)}}{d} N(x) + C^{\Omega (d)}$
, for all
 $d \leq x$
.
$d \leq x$
.
We have used one of the following results above and we will need them later as well.
Lemma 4 Suppose
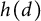 $h(d)$
is a multiplicative function and
$h(d)$
is a multiplicative function and
 $g(d) = h(d)/d$
satisfies
$g(d) = h(d)/d$
satisfies
 $g(d) \in [0,1]$
for all d and
$g(d) \in [0,1]$
for all d and
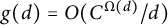 $g(d) = O(C^{\Omega (d)}/d)$
for some constant
$g(d) = O(C^{\Omega (d)}/d)$
for some constant
 $C \geq 1$
. Then for some constant
$C \geq 1$
. Then for some constant
 $A> 0$
,
$A> 0$
,
 $$ \begin{align*}\sum_{n \le x} g(n) \ll (\log x)^A \end{align*} $$
$$ \begin{align*}\sum_{n \le x} g(n) \ll (\log x)^A \end{align*} $$
and
 $$ \begin{align*}\sum_{n \le x} h(n) \ll x (\log x)^A. \end{align*} $$
$$ \begin{align*}\sum_{n \le x} h(n) \ll x (\log x)^A. \end{align*} $$
Proof Let
 $p_1,\ldots ,p_\ell $
be the finite set of primes less than
$p_1,\ldots ,p_\ell $
be the finite set of primes less than
 $2C$
, and set
$2C$
, and set
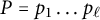 $P = p_1\dots p_\ell $
. Then
$P = p_1\dots p_\ell $
. Then
 $$ \begin{align*} \sum_{\substack{n\leq x \\ (n,P)=1}} g(n) \ll \sum_{\substack{n\leq x \\ (n,P)=1}} C^{\Omega(n)}/n \leq \prod_{\substack{p \leq x \\ (p,P)=1}} \Big(1 + \frac{C}{p} + \frac{C^2}{p^2}+\cdots\Big) \\ = \exp\Big(\sum_{p\leq x} \frac{C}{p} + O(1)\Big) \ll (\log x)^C, \end{align*} $$
$$ \begin{align*} \sum_{\substack{n\leq x \\ (n,P)=1}} g(n) \ll \sum_{\substack{n\leq x \\ (n,P)=1}} C^{\Omega(n)}/n \leq \prod_{\substack{p \leq x \\ (p,P)=1}} \Big(1 + \frac{C}{p} + \frac{C^2}{p^2}+\cdots\Big) \\ = \exp\Big(\sum_{p\leq x} \frac{C}{p} + O(1)\Big) \ll (\log x)^C, \end{align*} $$
where we have used the fact that
 $C/p$
in the product above is no more than
$C/p$
in the product above is no more than
 $1/2$
in order to sum the series. Using multiplicativity and
$1/2$
in order to sum the series. Using multiplicativity and
 $g(p_i^{e_i}) \in [0,1]$
for
$g(p_i^{e_i}) \in [0,1]$
for
 $1\leq i \leq \ell $
, we have from a crude bound
$1\leq i \leq \ell $
, we have from a crude bound
 $$ \begin{align*} \sum_{n\leq x} g(n) \le \sum_{p_1^{e_1}\dots p_\ell^{e_\ell} \leq x} \;& \sum_{\substack{m \leq x/p_1^{e_1}\dots p_\ell^{e_\ell}\\ (m,P)=1}}g(m) \\ &\ll (\log x)^C \Big(\sum_{e_1:\; p_1^{e_1}\leq x} 1\Big) \dots \Big(\sum_{e_\ell:\; p_\ell^{e_\ell}\leq x} 1\Big) \ll (\log x)^{C+\ell}. \end{align*} $$
$$ \begin{align*} \sum_{n\leq x} g(n) \le \sum_{p_1^{e_1}\dots p_\ell^{e_\ell} \leq x} \;& \sum_{\substack{m \leq x/p_1^{e_1}\dots p_\ell^{e_\ell}\\ (m,P)=1}}g(m) \\ &\ll (\log x)^C \Big(\sum_{e_1:\; p_1^{e_1}\leq x} 1\Big) \dots \Big(\sum_{e_\ell:\; p_\ell^{e_\ell}\leq x} 1\Big) \ll (\log x)^{C+\ell}. \end{align*} $$
This proves the first estimate. For the second, we have
 $$ \begin{align*}\sum_{n\leq x} h(n) \leq x \sum_{n\leq x} g(n), \end{align*} $$
$$ \begin{align*}\sum_{n\leq x} h(n) \leq x \sum_{n\leq x} g(n), \end{align*} $$
which implies the claim.
Regarding the level of distribution of shifted primes, one expects more can be said.
Conjecture 5 The shifted primes have level of distribution
 $\vartheta = 1$
.
$\vartheta = 1$
.
Indeed this is a slightly weaker version of the Elliott–Halberstam conjecture [Reference Cojocaru and Murty6, Chapter 9.2].
On the other hand, it does not seem that the values of irreducible polynomials of degree
 $2$
or greater have level of distribution
$2$
or greater have level of distribution
 $1$
.
$1$
.
Some interesting arithmetic sequences are known to have level of distribution
 $1,$
however, for instance, those positive integers
$1,$
however, for instance, those positive integers
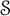 $\mathcal {S}$
which indicate a 0 in the Thue–Morse sequence [Reference Spiegelhofer38].
$\mathcal {S}$
which indicate a 0 in the Thue–Morse sequence [Reference Spiegelhofer38].
 $\mathcal {S}$
may be characterized in the following way: it is the collection of positive integers n, where n has an even number of 1s in its binary expansion.
$\mathcal {S}$
may be characterized in the following way: it is the collection of positive integers n, where n has an even number of 1s in its binary expansion.
Proposition 6 The values of the Thue–Morse sequence are
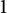 $1$
well-distributed. That is, let
$1$
well-distributed. That is, let
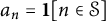 $a_n = \mathbf {1}[n \in \mathcal {S}]$
. Then
$a_n = \mathbf {1}[n \in \mathcal {S}]$
. Then
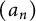 $(a_n)$
has index 1, has level of distribution
$(a_n)$
has index 1, has level of distribution
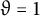 $\vartheta = 1$
, and is congruence uniform.
$\vartheta = 1$
, and is congruence uniform.
Proof The claim that the sequence has index 1 follows from classical results of Gelfond [Reference Gelfond20] which implies
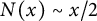 $N(x) \sim x/2$
(see Theorem A in [Reference Spiegelhofer38]). The claim that the sequence has level of distribution
$N(x) \sim x/2$
(see Theorem A in [Reference Spiegelhofer38]). The claim that the sequence has level of distribution
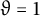 $\vartheta = 1$
follows from Theorem 1.1 of [Reference Spiegelhofer38]. And again by Remark 1, congruence uniformity is trivial.
$\vartheta = 1$
follows from Theorem 1.1 of [Reference Spiegelhofer38]. And again by Remark 1, congruence uniformity is trivial.
1.3 Main results
Our main results depend on the following setup. As above, we let
 $(a_n)$
be a sequence of nonnegative numbers, and for a parameter
$(a_n)$
be a sequence of nonnegative numbers, and for a parameter
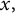 $x,$
we let u be a random integer such that
$x,$
we let u be a random integer such that
 $$ \begin{align*}\mathbb{P}(u = m) = \frac{a_m}{N(x)} \mathbf{1}[1 \leq m \leq x]. \end{align*} $$
$$ \begin{align*}\mathbb{P}(u = m) = \frac{a_m}{N(x)} \mathbf{1}[1 \leq m \leq x]. \end{align*} $$
In the case that
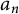 $a_n$
is the indicator function of a subset of natural numbers, u is uniformly distributed on elements of the set no more than x. As before, we let
$a_n$
is the indicator function of a subset of natural numbers, u is uniformly distributed on elements of the set no more than x. As before, we let
 $p_1 \geq p_2 \geq \cdots $
be the prime factors of u listed with multiplicity, with the convention that
$p_1 \geq p_2 \geq \cdots $
be the prime factors of u listed with multiplicity, with the convention that
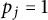 $p_j = 1$
if n has fewer than j prime factors.
$p_j = 1$
if n has fewer than j prime factors.
We will prove results comparing the distribution of
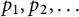 $p_1,p_2,\ldots $
to a Poisson–Dirichlet process (Theorem 7 and Lemma 8) and also an upper bound for the likelihood that
$p_1,p_2,\ldots $
to a Poisson–Dirichlet process (Theorem 7 and Lemma 8) and also an upper bound for the likelihood that
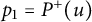 $p_1 = P^+(u)$
is exceptionally large (Theorem 11). These results are related in that they use almost the same information, but because they may be of independent interest, we have written this note so that their proofs may be read independently.
$p_1 = P^+(u)$
is exceptionally large (Theorem 11). These results are related in that they use almost the same information, but because they may be of independent interest, we have written this note so that their proofs may be read independently.
Theorem 7 If
 $(a_n)$
is
$(a_n)$
is
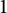 $1$
well-distributed, then
$1$
well-distributed, then
 $$ \begin{align*}\mathbb{P}\Big(\frac{\log p_1}{\log u} \leq c_1,\dots, \frac{\log p_k}{\log u} \leq c_k\Big) \rightarrow \mathbb{P}(L_1 \leq c_1,\ldots,L_k \leq c_k), \end{align*} $$
$$ \begin{align*}\mathbb{P}\Big(\frac{\log p_1}{\log u} \leq c_1,\dots, \frac{\log p_k}{\log u} \leq c_k\Big) \rightarrow \mathbb{P}(L_1 \leq c_1,\ldots,L_k \leq c_k), \end{align*} $$
as
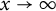 $x\rightarrow \infty $
. That is, the process
$x\rightarrow \infty $
. That is, the process
 $\tfrac {\log p_1}{\log u}, \tfrac {\log p_2}{\log u},\ldots $
tends in distribution to the Poisson–Dirichlet process
$\tfrac {\log p_1}{\log u}, \tfrac {\log p_2}{\log u},\ldots $
tends in distribution to the Poisson–Dirichlet process
 $L_1, L_2,\ldots $
.
$L_1, L_2,\ldots $
.
This generalizes to multiple prime factors a result noted by Granville [Reference Granville22] (with details of the proof provided by Wang [Reference Wang42]) that for shifted primes the Elliott–Halberstam conjecture implies the distribution of the largest prime divisor is governed by the Dickman function (a phenomenon first conjectured by Pomerance [Reference Pomerance37]). And this result proves unconditionally that large prime factors of the Thue–Morse tend to a Poisson–Dirichlet distribution.
On the other hand, while the values of irreducible polynomials do not appear to have level of distribution
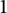 $1$
, it is reasonable to believe that their prime factors tend to a Poisson–Dirichlet distribution. That the distribution of the largest prime factor is governed by the Dickman function was given a conditional proof by Martin [Reference Martin31] on the assumption of a prime number theorem for polynomial sequences. It may be possible to formulate a relaxed version of level of distribution
$1$
, it is reasonable to believe that their prime factors tend to a Poisson–Dirichlet distribution. That the distribution of the largest prime factor is governed by the Dickman function was given a conditional proof by Martin [Reference Martin31] on the assumption of a prime number theorem for polynomial sequences. It may be possible to formulate a relaxed version of level of distribution
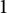 $1$
which applies to the values of irreducible polynomials and which also implies a Poisson–Dirichlet distribution for large prime factors, but we do not pursue this further here. (Indeed the condition
$1$
which applies to the values of irreducible polynomials and which also implies a Poisson–Dirichlet distribution for large prime factors, but we do not pursue this further here. (Indeed the condition
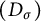 $(D_\sigma )$
in the very recent preprint [Reference Mounier34] might be a correct starting point.)
$(D_\sigma )$
in the very recent preprint [Reference Mounier34] might be a correct starting point.)
Even for a sequence with level of distribution less than 1, one may still compare the correlation functions of its large prime factors to those of the Poisson–Dirichlet process, at least against test functions with restricted support.
Lemma 8 If
 $(a_n)$
is
$(a_n)$
is
 $\sigma $
well-distributed, then for any
$\sigma $
well-distributed, then for any
 ${k \geq 1}$
and any continuous
${k \geq 1}$
and any continuous
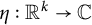 ${\eta : \mathbb {R}^k \rightarrow \mathbb {C}}$
with
${\eta : \mathbb {R}^k \rightarrow \mathbb {C}}$
with
 $\operatorname {\mathrm {supp}} \eta \subset \{y \in \mathbb {R}_+^k:\, y_1 + \cdots + y_k < \sigma \}$
(so, in particular,
$\operatorname {\mathrm {supp}} \eta \subset \{y \in \mathbb {R}_+^k:\, y_1 + \cdots + y_k < \sigma \}$
(so, in particular,
 $\eta $
is compactly supported),
$\eta $
is compactly supported),
 $$ \begin{align} \mathbb{E} \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log u},\dots, \frac{\log p_{j_k}}{\log u}\Big) \rightarrow \mathbb{E} \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta(L_{j_1},\ldots,L_{j_k}), \end{align} $$
$$ \begin{align} \mathbb{E} \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log u},\dots, \frac{\log p_{j_k}}{\log u}\Big) \rightarrow \mathbb{E} \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta(L_{j_1},\ldots,L_{j_k}), \end{align} $$
as
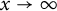 $x\rightarrow \infty $
.
$x\rightarrow \infty $
.
Here and throughout the article, we adopt the convention that
 $\mathbb {R}_+ = (0,\infty )$
. So
$\mathbb {R}_+ = (0,\infty )$
. So
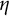 $\eta $
being supported in
$\eta $
being supported in
 $\mathbb {R}_+^k$
means that
$\mathbb {R}_+^k$
means that
 $\eta (y_1,\ldots ,y_k)$
will vanish when any
$\eta (y_1,\ldots ,y_k)$
will vanish when any
 $y_i$
is sufficiently close to
$y_i$
is sufficiently close to
 $0$
. (Recall that the support of a function is the closure of the set on which it does not vanish.)
$0$
. (Recall that the support of a function is the closure of the set on which it does not vanish.)
Remark 9 In Theorem 7 and Lemma 8 and in other places in this article, it should be possible to adopt a weaker definition of level of distribution, in which the bound (2) need only hold for sums over d in which
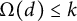 $\Omega (d) \leq k$
and all prime factors of d are larger than
$\Omega (d) \leq k$
and all prime factors of d are larger than
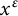 $x^\epsilon $
, with implicit constants depending on k and
$x^\epsilon $
, with implicit constants depending on k and
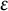 $\epsilon $
, for all
$\epsilon $
, for all
 $k \geq 1$
and
$k \geq 1$
and
 $\epsilon> 0$
, but we do not pursue this generalization here.
$\epsilon> 0$
, but we do not pursue this generalization here.
In fact, the right-hand side in (6) has a simple evaluation in general: for any continuous
 $\eta $
with compact support in
$\eta $
with compact support in
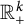 $\mathbb {R}_+^k$
,
$\mathbb {R}_+^k$
,
 $$ \begin{align} \mathbb{E} \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta(L_{j_1},\ldots,L_{j_k}) = \int_{\mathbb{R}_+^k} \frac{\mathbf{1}[t_1+\cdots + t_k \leq 1]}{t_1\dots t_k} \eta(t)\, d^kt. \end{align} $$
$$ \begin{align} \mathbb{E} \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta(L_{j_1},\ldots,L_{j_k}) = \int_{\mathbb{R}_+^k} \frac{\mathbf{1}[t_1+\cdots + t_k \leq 1]}{t_1\dots t_k} \eta(t)\, d^kt. \end{align} $$
This is [Reference Vershik41, Equation (4)] (see also the closely related [Reference Arratia, Kochman and Miller1, Equation (14)]).
Theorem 7 will be seen to follow from Lemma 8 and a characterization of the Poisson–Dirichlet process due to Arratia–Kochman–Miller [Reference Arratia, Kochman and Miller1].
Remark 10 It may be worthwhile for number theorists unfamiliar with correlation sums to write out an explicit example of the sort of sum which appears on the left-hand side of (6). For instance, if
 $u = p_1 p_2 p_3$
with
$u = p_1 p_2 p_3$
with
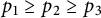 $p_1 \geq p_2 \geq p_3$
all primes, then we have for the
$p_1 \geq p_2 \geq p_3$
all primes, then we have for the
 $2$
-point correlation sum,
$2$
-point correlation sum,
 $$ \begin{align*} \sum_{\substack{j_1,j_2 \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log u}, \frac{\log p_{j_2}}{\log u}\Big) =\ &\eta\Big(\frac{\log p_1}{\log u}, \frac{\log p_2}{\log u}\Big) + \eta\Big(\frac{\log p_1}{\log u}, \frac{\log p_3}{\log u}\Big) \\ &+\eta\Big(\frac{\log p_2}{\log u}, \frac{\log p_1}{\log u}\Big)+ \eta\Big(\frac{\log p_2}{\log u}, \frac{\log p_3}{\log u}\Big)\\ &+ \eta\Big(\frac{\log p_3}{\log u}, \frac{\log p_1}{\log u}\Big) + \eta\Big(\frac{\log p_3}{\log u}, \frac{\log p_2}{\log u}\Big). \end{align*} $$
$$ \begin{align*} \sum_{\substack{j_1,j_2 \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log u}, \frac{\log p_{j_2}}{\log u}\Big) =\ &\eta\Big(\frac{\log p_1}{\log u}, \frac{\log p_2}{\log u}\Big) + \eta\Big(\frac{\log p_1}{\log u}, \frac{\log p_3}{\log u}\Big) \\ &+\eta\Big(\frac{\log p_2}{\log u}, \frac{\log p_1}{\log u}\Big)+ \eta\Big(\frac{\log p_2}{\log u}, \frac{\log p_3}{\log u}\Big)\\ &+ \eta\Big(\frac{\log p_3}{\log u}, \frac{\log p_1}{\log u}\Big) + \eta\Big(\frac{\log p_3}{\log u}, \frac{\log p_2}{\log u}\Big). \end{align*} $$
We have adopted the convention for such a u that
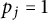 $p_j=1$
for
$p_j=1$
for
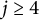 $j\geq 4$
, but because of the support of
$j\geq 4$
, but because of the support of
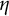 $\eta $
such terms do not appear in this sum. Note that the sum is symmetric in
$\eta $
such terms do not appear in this sum. Note that the sum is symmetric in
 $p_1, p_2$
, and
$p_1, p_2$
, and
 $p_3$
.
$p_3$
.
The left-hand side of (6) will then be an average over u of sums of this type.
Lemma 8 has a surface-level resemblance to results that can be proven about zeros of L-functions. The reader unfamiliar with correlation sums as occur in the lemma may consult [Reference Hough, Krishnapur, Peres and Virág26, Chapter 1] for a general introduction and further information.
Lemma 8 gives information about prime divisors of intermediate size, but because of restrictions on the support of
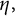 $\eta ,$
it does not entail an asymptotic formula for the distribution of the largest prime factor of u. Our last result shows that even this partial information about the level of distribution entails an upper bound for how often the largest prime factor can be especially large.
$\eta ,$
it does not entail an asymptotic formula for the distribution of the largest prime factor of u. Our last result shows that even this partial information about the level of distribution entails an upper bound for how often the largest prime factor can be especially large.
Theorem 11 If
 $(a_n)$
is
$(a_n)$
is
 $\sigma $
well-distributed for some
$\sigma $
well-distributed for some
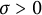 $\sigma> 0$
, then for any
$\sigma> 0$
, then for any
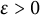 $\epsilon> 0$
,
$\epsilon> 0$
,
 $$ \begin{align*}\limsup_{x\rightarrow\infty}\mathbb{P}(P^+(u) \geq u^{1-\epsilon}) \ll \epsilon, \end{align*} $$
$$ \begin{align*}\limsup_{x\rightarrow\infty}\mathbb{P}(P^+(u) \geq u^{1-\epsilon}) \ll \epsilon, \end{align*} $$
where the implicit constant depends on the sequence
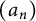 $(a_n)$
.
$(a_n)$
.
We note that this is an essentially optimal result, since for sequences with level of distribution
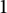 $1$
by Theorem 7, we have
$1$
by Theorem 7, we have
 $\mathbb {P}(P^+(u) \geq u^{1-\epsilon }) \sim 1- \rho (1/(1-\epsilon ))$
, and for
$\mathbb {P}(P^+(u) \geq u^{1-\epsilon }) \sim 1- \rho (1/(1-\epsilon ))$
, and for
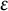 $\epsilon $
small enough that
$\epsilon $
small enough that
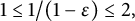 $1\leq 1/(1-\epsilon ) \leq 2,$
we have
$1\leq 1/(1-\epsilon ) \leq 2,$
we have
 $1- \rho (1/(1-\epsilon )) = \log (1/(1-\epsilon )) \approx \epsilon $
(see [Reference Montgomery and Vaughan33, Equation (7.10)] for the evaluation of
$1- \rho (1/(1-\epsilon )) = \log (1/(1-\epsilon )) \approx \epsilon $
(see [Reference Montgomery and Vaughan33, Equation (7.10)] for the evaluation of
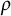 $\rho $
in this range).
$\rho $
in this range).
In the case of sampling shifted primes
 $p-1 \leq x$
, Theorem 11 recovers the following corollary.
$p-1 \leq x$
, Theorem 11 recovers the following corollary.
Corollary 12 (Erdős)
For any
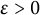 $\epsilon> 0$
,
$\epsilon> 0$
,
 $$ \begin{align*}\limsup_{x\rightarrow\infty} \frac{1}{\pi(x)}|\{p \leq x: P^+(p-1) \geq p^{1-\epsilon}\}| \ll \epsilon. \end{align*} $$
$$ \begin{align*}\limsup_{x\rightarrow\infty} \frac{1}{\pi(x)}|\{p \leq x: P^+(p-1) \geq p^{1-\epsilon}\}| \ll \epsilon. \end{align*} $$
This result appears implicitly, though somewhat obscurely, in a paper of Erdős (see the line beginning with “the sum in a is less than” in [Reference Erdős16, p. 213]). A recent paper of Ding [Reference Ding15] gives a proof with explicit constants and explains some of the history around this estimate.
As in these other proofs of Corollary 12, the proof of Theorem 11 relies on an upper bound sieve.
2 Resemblance to Poisson–Dirichlet: A proof of Theorem 7 and Lemma 8
Proof of Lemma 8
Let us rewrite the left-hand side of (6) as
 $$ \begin{align} \frac{1}{N(x)} \sum_{n\leq x} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log n},\ldots, \frac{\log p_{j_k}}{\log n}\Big), \end{align} $$
$$ \begin{align} \frac{1}{N(x)} \sum_{n\leq x} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log n},\ldots, \frac{\log p_{j_k}}{\log n}\Big), \end{align} $$
where in the inner sum,
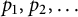 $p_1, p_2,\ldots $
are the prime factors of n listed according to multiplicity. We have given an expression for the right-hand side of (6) in the evaluation (7). We will show convergence to this expression in the following steps: first, we show that
$p_1, p_2,\ldots $
are the prime factors of n listed according to multiplicity. We have given an expression for the right-hand side of (6) in the evaluation (7). We will show convergence to this expression in the following steps: first, we show that
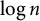 $\log n$
can be replaced by
$\log n$
can be replaced by
 $\log x$
in the denominators above; second, we show that those n with repeated large prime factors contribute only a negligible amount to the sum; and third, we show that the resulting expression can be expressed in more conventional language of analytic number theory and in that way easily evaluated.
$\log x$
in the denominators above; second, we show that those n with repeated large prime factors contribute only a negligible amount to the sum; and third, we show that the resulting expression can be expressed in more conventional language of analytic number theory and in that way easily evaluated.
Let us note from the start there are constants
 $a> 0$
and
$a> 0$
and
 $c < \sigma $
such that
$c < \sigma $
such that
 $\eta (y_1,\ldots ,y_k)$
vanishes whenever
$\eta (y_1,\ldots ,y_k)$
vanishes whenever
 $y_i \leq a$
or
$y_i \leq a$
or
 $y_1+\cdots +y_k \geq c$
; this is because of the restricted support of
$y_1+\cdots +y_k \geq c$
; this is because of the restricted support of
 $\eta $
.
$\eta $
.
Thus, in our first step, we show that (8) is
 $$ \begin{align} =\frac{1}{N(x)} \sum_{n\leq x} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align} $$
$$ \begin{align} =\frac{1}{N(x)} \sum_{n\leq x} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align} $$
To see this, note that in (8) for each tuple
 $j_1,\ldots ,j_k$
for which the summand is non-vanishing,
$j_1,\ldots ,j_k$
for which the summand is non-vanishing,
 $p_{j_1},\ldots ,p_{j_k} \geq n^a$
. But n can have no more than
$p_{j_1},\ldots ,p_{j_k} \geq n^a$
. But n can have no more than
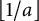 $\lfloor 1/a \rfloor $
prime factors
$\lfloor 1/a \rfloor $
prime factors
 $p_j \geq n^a$
. Thus, we have the following crude bound: for any n,
$p_j \geq n^a$
. Thus, we have the following crude bound: for any n,
 $$ \begin{align} \Big| \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log n},\dots, \frac{\log p_{j_k}}{\log n}\Big) \Big| \leq \max(|\eta|) \cdot k! \binom{\lfloor 1/a \rfloor}{k} = O(1), \end{align} $$
$$ \begin{align} \Big| \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log n},\dots, \frac{\log p_{j_k}}{\log n}\Big) \Big| \leq \max(|\eta|) \cdot k! \binom{\lfloor 1/a \rfloor}{k} = O(1), \end{align} $$
where the implicit constant depends on k and
 $\eta $
but does not depend on n.
$\eta $
but does not depend on n.
Hence, for arbitrary
 $\varepsilon> 0$
, the left-hand side of (8) is
$\varepsilon> 0$
, the left-hand side of (8) is
 $$ \begin{align} = \frac{1}{N(x)}\sum_{x^{1-\epsilon} < n \leq x} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log n},\dots, \frac{\log p_{j_k}}{\log n}\Big) + O\Big(\frac{N(x^{1-\epsilon})}{N(x)}\Big). \end{align} $$
$$ \begin{align} = \frac{1}{N(x)}\sum_{x^{1-\epsilon} < n \leq x} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log n},\dots, \frac{\log p_{j_k}}{\log n}\Big) + O\Big(\frac{N(x^{1-\epsilon})}{N(x)}\Big). \end{align} $$
Due to continuity and compact support,
 $\eta $
is uniformly continuous. Hence, for any
$\eta $
is uniformly continuous. Hence, for any
 $p_{j_1},\ldots ,p_{j_k}$
in the sum above, for
$p_{j_1},\ldots ,p_{j_k}$
in the sum above, for
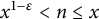 $x^{1-\epsilon } < n \leq x$
,
$x^{1-\epsilon } < n \leq x$
,
 $$ \begin{align*} \eta\Big(\frac{\log p_{j_1}}{\log n},\dots, \frac{\log p_{j_k}}{\log n}\Big) &= \eta\Big(\frac{\log p_{j_1}}{\log x} +O(\epsilon),\dots, \frac{\log p_{j_k}}{\log x} +O(\epsilon)\Big) \\ &=\eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) + O(\delta(\epsilon)), \end{align*} $$
$$ \begin{align*} \eta\Big(\frac{\log p_{j_1}}{\log n},\dots, \frac{\log p_{j_k}}{\log n}\Big) &= \eta\Big(\frac{\log p_{j_1}}{\log x} +O(\epsilon),\dots, \frac{\log p_{j_k}}{\log x} +O(\epsilon)\Big) \\ &=\eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) + O(\delta(\epsilon)), \end{align*} $$
for a quantity
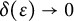 $\delta (\epsilon ) \rightarrow 0$
as
$\delta (\epsilon ) \rightarrow 0$
as
 $\epsilon \rightarrow 0$
. Thus, (11) is
$\epsilon \rightarrow 0$
. Thus, (11) is
 $$ \begin{align} = \frac{1}{N(x)}\sum_{x^{1-\epsilon} < n \leq x} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} &\eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) \nonumber\\ &+ O\Big(\delta(\epsilon)\cdot\frac{N(x)-N(x^{1-\epsilon})}{N(x)}\Big) + O\Big(\frac{N(x^{1-\epsilon})}{N(x)}\Big). \end{align} $$
$$ \begin{align} = \frac{1}{N(x)}\sum_{x^{1-\epsilon} < n \leq x} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} &\eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) \nonumber\\ &+ O\Big(\delta(\epsilon)\cdot\frac{N(x)-N(x^{1-\epsilon})}{N(x)}\Big) + O\Big(\frac{N(x^{1-\epsilon})}{N(x)}\Big). \end{align} $$
This is because in both (11) and (12), for each
 $n,$
only a bounded number of tuples
$n,$
only a bounded number of tuples
 $j_1,\ldots ,j_k$
will give rise to a nonzero summand (there will be at most
$j_1,\ldots ,j_k$
will give rise to a nonzero summand (there will be at most
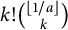 $k! \binom {\lfloor 1/a \rfloor }{k}$
such tuples, as in (10)), and in the difference between such summands in (11) and (12) will be
$k! \binom {\lfloor 1/a \rfloor }{k}$
such tuples, as in (10)), and in the difference between such summands in (11) and (12) will be
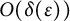 $O(\delta (\epsilon ))$
always.
$O(\delta (\epsilon ))$
always.
An index
 $\alpha \geq \sigma> 0$
implies that the error terms in (12) are
$\alpha \geq \sigma> 0$
implies that the error terms in (12) are
 $O(\delta (\epsilon ))+ o_{x\rightarrow \infty }(1)$
, and because
$O(\delta (\epsilon ))+ o_{x\rightarrow \infty }(1)$
, and because
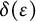 $\delta (\epsilon )$
can be taken arbitrarily small, this implies (9).
$\delta (\epsilon )$
can be taken arbitrarily small, this implies (9).
In our second step, we show that in (9), the sum over n can be replaced by a sum only over those n which have no repeated large prime factors. Let us consider the complementary set of n which do have a repeated large prime factor; define
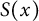 $S(x)$
to be the set of positive integers
$S(x)$
to be the set of positive integers
 $n \leq x$
such that in the prime factorization
$n \leq x$
such that in the prime factorization
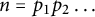 $n = p_1 p_2 \dots $
some
$n = p_1 p_2 \dots $
some
 $p_i \in [x^a, x^c]$
occurs with multiplicity at least
$p_i \in [x^a, x^c]$
occurs with multiplicity at least
 $2$
. We have
$2$
. We have
 $$ \begin{align} \sum_{n\in S(x)} a_n \leq &\sum_{n\leq x} a_n \sum_{x^a \leq p \leq x^c} \mathbf{1}[\,p^2|n\,] = \sum_{x^a \leq p \leq x^c} N_{p^2}(x) \nonumber\\ &\quad\ll N(x) \sum_{x^a \leq p \leq x^c} \frac{1}{p^2} (\log x)^B + \log(x)^B \sum_{x^a \leq p \leq x^c} 1 \nonumber\\ &\quad= N(x) \log(x)^B \sum_{x^a \leq p \leq x^c} \frac{1}{p^2} + O_B\Big(x^c(\log x)^B\Big) = o(N(x)), \end{align} $$
$$ \begin{align} \sum_{n\in S(x)} a_n \leq &\sum_{n\leq x} a_n \sum_{x^a \leq p \leq x^c} \mathbf{1}[\,p^2|n\,] = \sum_{x^a \leq p \leq x^c} N_{p^2}(x) \nonumber\\ &\quad\ll N(x) \sum_{x^a \leq p \leq x^c} \frac{1}{p^2} (\log x)^B + \log(x)^B \sum_{x^a \leq p \leq x^c} 1 \nonumber\\ &\quad= N(x) \log(x)^B \sum_{x^a \leq p \leq x^c} \frac{1}{p^2} + O_B\Big(x^c(\log x)^B\Big) = o(N(x)), \end{align} $$
where the second to last equation holds for some
 $B>0$
and follows from the congruence uniformity property (C), and the last line follows from the prime number theorem and the assumption (A) that the sequence has an index satisfying
$B>0$
and follows from the congruence uniformity property (C), and the last line follows from the prime number theorem and the assumption (A) that the sequence has an index satisfying
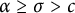 $\alpha \geq \sigma> c$
.
$\alpha \geq \sigma> c$
.
Furthermore, observe that the crude bound (10) remains true if
 $\log n$
is replaced by
$\log n$
is replaced by
 $\log x$
in the denominators, for all
$\log x$
in the denominators, for all
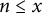 $n\leq x$
; the argument remains the same as in (10). Hence, using this estimate and (13), we see that (9) is
$n\leq x$
; the argument remains the same as in (10). Hence, using this estimate and (13), we see that (9) is
 $$ \begin{align} =\frac{1}{N(x)} \sum_{\substack{n\leq x \\ n \notin S(x)}} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align} $$
$$ \begin{align} =\frac{1}{N(x)} \sum_{\substack{n\leq x \\ n \notin S(x)}} a_n \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align} $$
Now coming to the third and final step, we observe that (14) can be rewritten:
 $$ \begin{align*}=\frac{1}{N(x)} \sum_{\substack{n\leq x \\ n \notin S(x)}} a_n \sum_{\substack{p_{j_1},\ldots,p_{j_k} \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align*} $$
$$ \begin{align*}=\frac{1}{N(x)} \sum_{\substack{n\leq x \\ n \notin S(x)}} a_n \sum_{\substack{p_{j_1},\ldots,p_{j_k} \\ \textrm{distinct}}} \eta\Big(\frac{\log p_{j_1}}{\log x},\dots, \frac{\log p_{j_k}}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align*} $$
The distinction between this sum and (14) is that now the prime factors
 $p_{j_1},\ldots ,p_{j_k}$
must be distinct, whereas before we needed only that the indices
$p_{j_1},\ldots ,p_{j_k}$
must be distinct, whereas before we needed only that the indices
 $j_1,\ldots ,j_k$
be distinct. But because
$j_1,\ldots ,j_k$
be distinct. But because
 $n\notin S(x)$
in the sum and because of the support of
$n\notin S(x)$
in the sum and because of the support of
 $\eta $
, these coincide whenever the inner summand is non-vanishing.
$\eta $
, these coincide whenever the inner summand is non-vanishing.
But there is a one-to-one correspondence between tuples
 $(p_{j_1},\ldots ,p_{j_k})$
of prime factors of n, all distinct, and tuples
$(p_{j_1},\ldots ,p_{j_k})$
of prime factors of n, all distinct, and tuples
 $(q_1,\ldots ,q_k)$
of distinct primes in which
$(q_1,\ldots ,q_k)$
of distinct primes in which
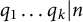 $q_1\dots q_k | n$
. So we can further rewrite the above as
$q_1\dots q_k | n$
. So we can further rewrite the above as
 $$ \begin{align} =\frac{1}{N(x)} \sum_{\substack{n\leq x \\ n \notin S(x)}} a_n \sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} \mathbf{1}\big[\,q_1\dots q_k | n\,\big] \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log {x}}\Big) +o_{x\rightarrow\infty}(1). \end{align} $$
$$ \begin{align} =\frac{1}{N(x)} \sum_{\substack{n\leq x \\ n \notin S(x)}} a_n \sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} \mathbf{1}\big[\,q_1\dots q_k | n\,\big] \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log {x}}\Big) +o_{x\rightarrow\infty}(1). \end{align} $$
By the same argument as in (10),
 $$ \begin{align*}\sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} \mathbf{1}\big[\,q_1\dots q_k | n\,\big] \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) = O(1) \end{align*} $$
$$ \begin{align*}\sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} \mathbf{1}\big[\,q_1\dots q_k | n\,\big] \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) = O(1) \end{align*} $$
uniformly in n. So we may use the bound (13) for contributions from
 $n\in S(x)$
to see that (15) is
$n\in S(x)$
to see that (15) is
 $$ \begin{align*}=\frac{1}{N(x)} \sum_{n\leq x } a_n \sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} \mathbf{1}\big[\,q_1\dots q_k | n\,\big] \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) +o_{x\rightarrow\infty}(1). \end{align*} $$
$$ \begin{align*}=\frac{1}{N(x)} \sum_{n\leq x } a_n \sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} \mathbf{1}\big[\,q_1\dots q_k | n\,\big] \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) +o_{x\rightarrow\infty}(1). \end{align*} $$
But this is
 $$ \begin{align*}= \frac{1}{N(x)} \sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} N_{q_1\dots q_k}(x) \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align*} $$
$$ \begin{align*}= \frac{1}{N(x)} \sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} N_{q_1\dots q_k}(x) \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align*} $$
We now simplify the above sum using that the level of distribution is
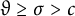 $\vartheta \geq \sigma> c$
. Note that the above sum can be rewritten as
$\vartheta \geq \sigma> c$
. Note that the above sum can be rewritten as
 $$ \begin{align*}= \frac{k!}{N(x)} \sum_{\substack{q_1<q_2<\dots<q_k \\ \textrm{prime, distinct}}} N_{q_1 \ldots q_k}(x) \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align*} $$
$$ \begin{align*}= \frac{k!}{N(x)} \sum_{\substack{q_1<q_2<\dots<q_k \\ \textrm{prime, distinct}}} N_{q_1 \ldots q_k}(x) \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align*} $$
Since
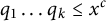 $q_1\ldots q_k \le x^c$
, one may think of the above sum as occurring over a subset of integers less than or equal to
$q_1\ldots q_k \le x^c$
, one may think of the above sum as occurring over a subset of integers less than or equal to
 $x^c$
, and using (2), this simplifies to
$x^c$
, and using (2), this simplifies to
 $$ \begin{align} =\sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct} }} g(q_1\dots q_k) \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align} $$
$$ \begin{align} =\sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct} }} g(q_1\dots q_k) \eta\Big(\frac{\log q_1}{\log x},\dots ,\frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align} $$
Observe that the upper bound in (3) implies that for any
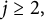 $j\geq 2,$
$j\geq 2,$
 $$ \begin{align*}\sum_{\substack{q\geq x^a \\ \textrm{prime}}} g(q)^j = o_{x\rightarrow\infty}(1). \end{align*} $$
$$ \begin{align*}\sum_{\substack{q\geq x^a \\ \textrm{prime}}} g(q)^j = o_{x\rightarrow\infty}(1). \end{align*} $$
Utilizing the multiplicativity of g and then this bound, we see that (16) is
 $$ \begin{align} =\sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} &g(q_1)\dots g(q_k) \eta\Big(\frac{\log q_1}{\log x},\dots,\frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1) \nonumber\\ &=\sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime}}} g(q_1)\dots g(q_k) \eta\Big(\frac{\log q_1}{\log x},\dots, \frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align} $$
$$ \begin{align} =\sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime, distinct}}} &g(q_1)\dots g(q_k) \eta\Big(\frac{\log q_1}{\log x},\dots,\frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1) \nonumber\\ &=\sum_{\substack{q_1,\ldots,q_k \\ \textrm{prime}}} g(q_1)\dots g(q_k) \eta\Big(\frac{\log q_1}{\log x},\dots, \frac{\log q_k}{\log x}\Big) + o_{x\rightarrow\infty}(1). \end{align} $$
But finally the asymptotic formula in (3) and partial summation implies that if
 $\nu $
is the indicator function of an interval
$\nu $
is the indicator function of an interval
 $[A,B] \subset (0,\infty )$
,
$[A,B] \subset (0,\infty )$
,
 $$ \begin{align*}\sum_{q\; \textrm{prime}} g(q)\, \nu\Big(\frac{\log q}{\log x}\Big) = \int_{\mathbb{R}_+} \frac{\nu(t)}{t}\, dt + {o_{x \to \infty}(1).} \end{align*} $$
$$ \begin{align*}\sum_{q\; \textrm{prime}} g(q)\, \nu\Big(\frac{\log q}{\log x}\Big) = \int_{\mathbb{R}_+} \frac{\nu(t)}{t}\, dt + {o_{x \to \infty}(1).} \end{align*} $$
This implies that if
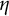 $\eta $
is the indicator function of a rectangle
$\eta $
is the indicator function of a rectangle
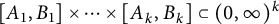 $[A_1,B_1]\times \cdots \times [A_k,B_k] \subset (0,\infty )^k$
, the right-hand side of (17) is
$[A_1,B_1]\times \cdots \times [A_k,B_k] \subset (0,\infty )^k$
, the right-hand side of (17) is
 $$ \begin{align} =\left(\sum_{q_1 \textrm{ prime}} g(q_1)\mathbf{1}_{[A_1,B_1]}\Big(\frac{\log q_1}{\log x}\Big)\right)\dots& \left(\sum_{q_k\textrm{ prime}} g(q_k) \mathbf{1}_{[A_k,B_k]}\Big(\frac{\log q_k}{\log x}\Big)\right) + o_{x \to \infty}(1)\nonumber\\ &\quad= \int_{\mathbb{R}_+^k} \frac{1}{t_1\dots t_k} \eta(t)\, d^kt + o_{x \to \infty}(1). \end{align} $$
$$ \begin{align} =\left(\sum_{q_1 \textrm{ prime}} g(q_1)\mathbf{1}_{[A_1,B_1]}\Big(\frac{\log q_1}{\log x}\Big)\right)\dots& \left(\sum_{q_k\textrm{ prime}} g(q_k) \mathbf{1}_{[A_k,B_k]}\Big(\frac{\log q_k}{\log x}\Big)\right) + o_{x \to \infty}(1)\nonumber\\ &\quad= \int_{\mathbb{R}_+^k} \frac{1}{t_1\dots t_k} \eta(t)\, d^kt + o_{x \to \infty}(1). \end{align} $$
But because linear combinations of such functions are dense in the space of continuous functions with compact support in
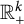 $\mathbb {R}_+^k$
, a standard approximation argument implies that (18) is true for this class of functions as well.
$\mathbb {R}_+^k$
, a standard approximation argument implies that (18) is true for this class of functions as well.
This gives an asymptotic evaluation of the left-hand side of (8). Due to the restricted support of
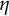 $\eta $
, the indicator function in the expression (7) for Poisson–Dirichlet plays no role here, and we have therefore that the left-hand side tends to the right-hand side of (8).
$\eta $
, the indicator function in the expression (7) for Poisson–Dirichlet plays no role here, and we have therefore that the left-hand side tends to the right-hand side of (8).
We will verify Theorem 7 using the above lemma and the following criterion, from [Reference Arratia, Kochman and Miller1, Lemma 2].
Lemma 13 (Arratia–Kochman–Miller)
If for each x,
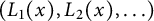 $(L_1(x),L_2(x),\ldots )$
is a random process with
$(L_1(x),L_2(x),\ldots )$
is a random process with
 $L_1(x) \geq L_2(x) \geq \cdots \geq 0$
satisfying
$L_1(x) \geq L_2(x) \geq \cdots \geq 0$
satisfying
 $\sum L_i(x) = 1$
, and if for any collection of disjoint intervals
$\sum L_i(x) = 1$
, and if for any collection of disjoint intervals
 $I_i = [a_i,b_i] \subset (0,1]$
with
$I_i = [a_i,b_i] \subset (0,1]$
with
 $b_1+\cdots + b_k < 1$
, we have
$b_1+\cdots + b_k < 1$
, we have
 $$ \begin{align} \liminf_{x\rightarrow\infty} \mathbb{E} \prod_{i=1}^k |\{j:\, L_j(x) \in I_i\}| \geq \prod_{i=1}^k \log(b_i/a_i) = \int _{I_1\times \cdots \times I_k} \frac{d^k t}{t_1\dots t_k}, \end{align} $$
$$ \begin{align} \liminf_{x\rightarrow\infty} \mathbb{E} \prod_{i=1}^k |\{j:\, L_j(x) \in I_i\}| \geq \prod_{i=1}^k \log(b_i/a_i) = \int _{I_1\times \cdots \times I_k} \frac{d^k t}{t_1\dots t_k}, \end{align} $$
then the process
 $L_1(x), L_2(x),\ldots $
tends in distribution to the Poisson–Dirichlet process
$L_1(x), L_2(x),\ldots $
tends in distribution to the Poisson–Dirichlet process
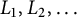 $L_1, L_2, \ldots $
as
$L_1, L_2, \ldots $
as
 $x\rightarrow \infty $
.
$x\rightarrow \infty $
.
Proof of Theorem 7
Let
 $L_i(x) = \log p_i/\log u$
. If
$L_i(x) = \log p_i/\log u$
. If
 $\eta ^\ast = \mathbf {1}_{I_1\times \cdots \times I_k}$
were continuous this would be implied by Lemma 8, as
$\eta ^\ast = \mathbf {1}_{I_1\times \cdots \times I_k}$
were continuous this would be implied by Lemma 8, as
 $$ \begin{align*}\prod_{i=1}^k |\{j:\, L_j(x) \in I_i\}| = \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta^\ast\Big(\frac{\log p_{j_1}}{\log u},\dots, \frac{\log p_{j_k}}{\log u}\Big).\end{align*} $$
$$ \begin{align*}\prod_{i=1}^k |\{j:\, L_j(x) \in I_i\}| = \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta^\ast\Big(\frac{\log p_{j_1}}{\log u},\dots, \frac{\log p_{j_k}}{\log u}\Big).\end{align*} $$
But for any
 $\epsilon> 0$
, we can find a continuous function
$\epsilon> 0$
, we can find a continuous function
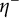 $\eta ^-$
with support in
$\eta ^-$
with support in
 $\{y\in \mathbb {R}_+^k:\, y_1 + \cdots + y_k < 1\}$
such that
$\{y\in \mathbb {R}_+^k:\, y_1 + \cdots + y_k < 1\}$
such that
 $$ \begin{align*}\eta^\ast \geq \eta^-\end{align*} $$
$$ \begin{align*}\eta^\ast \geq \eta^-\end{align*} $$
and
 $$ \begin{align*}\int_{\mathbb{R}_+^k} (\eta^\ast - \eta^-) \, \frac{d^k t}{t_1\dots t_k} \leq \epsilon.\end{align*} $$
$$ \begin{align*}\int_{\mathbb{R}_+^k} (\eta^\ast - \eta^-) \, \frac{d^k t}{t_1\dots t_k} \leq \epsilon.\end{align*} $$
(Indeed, if a box
 $I_1^-\times \cdots \times I_k^-$
is inside
$I_1^-\times \cdots \times I_k^-$
is inside
 $I_1\times \cdots \times I_k$
and only slightly smaller, a continuous function
$I_1\times \cdots \times I_k$
and only slightly smaller, a continuous function
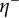 $\eta ^-$
sandwiched between indicator functions will satisfy these conditions.) Thus, lower-bounding
$\eta ^-$
sandwiched between indicator functions will satisfy these conditions.) Thus, lower-bounding
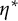 $\eta ^\ast $
by
$\eta ^\ast $
by
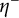 $\eta ^-$
, applying Lemma 8 for
$\eta ^-$
, applying Lemma 8 for
 $\eta ^-$
, and then using the correlation function formula (7), we have
$\eta ^-$
, and then using the correlation function formula (7), we have
 $$ \begin{align*}\liminf_{x\rightarrow\infty} \mathbb{E} \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta^\ast\Big(\frac{\log p_{j_1}}{\log u},\dots, \frac{\log p_{j_k}}{\log u}\Big) \geq \int_{\mathbb{R}_+^k} \eta^- \frac{d^k t}{t_1\dots t_k}.\end{align*} $$
$$ \begin{align*}\liminf_{x\rightarrow\infty} \mathbb{E} \sum_{\substack{j_1,\ldots,j_k \\ \textrm{distinct}}} \eta^\ast\Big(\frac{\log p_{j_1}}{\log u},\dots, \frac{\log p_{j_k}}{\log u}\Big) \geq \int_{\mathbb{R}_+^k} \eta^- \frac{d^k t}{t_1\dots t_k}.\end{align*} $$
But the right-hand side is within
 $\epsilon $
of
$\epsilon $
of
 $$ \begin{align*}\int \eta^\ast \frac{d^k t}{t_1\dots t_k} = \int_{I_1\times \dots I_k} \frac{d^kt}{t_1\dots t_k},\end{align*} $$
$$ \begin{align*}\int \eta^\ast \frac{d^k t}{t_1\dots t_k} = \int_{I_1\times \dots I_k} \frac{d^kt}{t_1\dots t_k},\end{align*} $$
and because
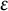 $\epsilon $
is arbitrary, this verifies that (19) is true in this case, and the result follows.
$\epsilon $
is arbitrary, this verifies that (19) is true in this case, and the result follows.
Remark 14 In effect, what Lemma 13 of Arratia–Kochman–Miller shows is that if the result of Lemma 8 holds for
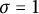 $\sigma = 1$
for some ordered process, then that process tends in distribution to the Poisson–Dirichlet process. That is, the convergence of correlation functions implies convergence in distribution in this context.
$\sigma = 1$
for some ordered process, then that process tends in distribution to the Poisson–Dirichlet process. That is, the convergence of correlation functions implies convergence in distribution in this context.
3 Upper bounds on largest primes: A proof of Theorem 11
In proving Theorem 11, we will use the Selberg upper bound sieve. We recall the setup from [Reference Friedlander and Iwaniec19].
Let
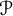 $\mathcal {P}$
be a finite set of primes, and define
$\mathcal {P}$
be a finite set of primes, and define
 $P = \prod _{p \in \mathcal {P}}p$
. Let
$P = \prod _{p \in \mathcal {P}}p$
. Let
 $g(d) \in [0,1)$
be defined for
$g(d) \in [0,1)$
be defined for
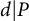 $d|P$
and be a multiplicative function for this set of d. In the notation (1) as before, define
$d|P$
and be a multiplicative function for this set of d. In the notation (1) as before, define
 $$ \begin{align*}r_d = N_d(x) - g(d)N(x), \end{align*} $$
$$ \begin{align*}r_d = N_d(x) - g(d)N(x), \end{align*} $$
and suppose there are constants
 $\kappa , K> 0$
such that
$\kappa , K> 0$
such that
 $$ \begin{align} \prod_{\substack{w \leq p < z \\ p \in \mathcal{P}}} \frac{1}{1-g(p)} \leq K \Big(\frac{\log z}{\log w}\Big)^\kappa, \end{align} $$
$$ \begin{align} \prod_{\substack{w \leq p < z \\ p \in \mathcal{P}}} \frac{1}{1-g(p)} \leq K \Big(\frac{\log z}{\log w}\Big)^\kappa, \end{align} $$
for all
 $z> w \geq 2$
.
$z> w \geq 2$
.
Theorem 15 (An explicit upper bound sieve)
For
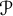 $\mathcal {P}$
, P,
$\mathcal {P}$
, P,
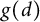 $g(d)$
, and
$g(d)$
, and
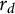 $r_d$
as just described, with g satisfying (20), define
$r_d$
as just described, with g satisfying (20), define
 $k = \kappa + \log K$
. If a parameter D is chosen such that all
$k = \kappa + \log K$
. If a parameter D is chosen such that all
 $p \in \mathcal {P}$
satisfy
$p \in \mathcal {P}$
satisfy
 $p < D^{1/(4k)}$
, then
$p < D^{1/(4k)}$
, then
 $$ \begin{align*}\sum_{\substack{n\leq x \\ (n,P)=1}} a_n \leq C\cdot V \cdot N(x) + \sum_{\substack{d|P \\ d < D}} \tau_3(d) |r_d|, \end{align*} $$
$$ \begin{align*}\sum_{\substack{n\leq x \\ (n,P)=1}} a_n \leq C\cdot V \cdot N(x) + \sum_{\substack{d|P \\ d < D}} \tau_3(d) |r_d|, \end{align*} $$
where
 $C> 0$
is a constant which depends only on k, we have defined
$C> 0$
is a constant which depends only on k, we have defined
 $$ \begin{align*}V = \prod_{p \in \mathcal{P}} (1-g(p)), \end{align*} $$
$$ \begin{align*}V = \prod_{p \in \mathcal{P}} (1-g(p)), \end{align*} $$
and
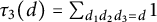 $\tau _3(d) = \sum _{d_1 d_2 d_3 = d} 1$
is the threefold divisor function.
$\tau _3(d) = \sum _{d_1 d_2 d_3 = d} 1$
is the threefold divisor function.
Proof This is Theorem 7.4 in [Reference Friedlander and Iwaniec19], where in their notation, we have taken
 $s = 4k$
and
$s = 4k$
and
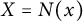 $X = N(x)$
. (Note that the hypothesis of their theorem requires
$X = N(x)$
. (Note that the hypothesis of their theorem requires
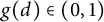 $g(d) \in (0,1)$
for
$g(d) \in (0,1)$
for
 $d|P$
, but one may check the proof works with no modification if
$d|P$
, but one may check the proof works with no modification if
 $g(d) \in [0,1)$
for
$g(d) \in [0,1)$
for
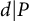 $d|P$
.)
$d|P$
.)
We now apply this result to get an upper bound on the frequency with which a number n has a prime factor larger than
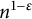 $n^{1-\epsilon }$
. It is only when
$n^{1-\epsilon }$
. It is only when
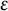 $\epsilon $
is small that Theorem 11 is nontrivial so we may suppose with no loss of generality that
$\epsilon $
is small that Theorem 11 is nontrivial so we may suppose with no loss of generality that
 $\epsilon < 1/2$
. The idea behind the proof is easy to state: if n has a prime factor larger than
$\epsilon < 1/2$
. The idea behind the proof is easy to state: if n has a prime factor larger than
 $n^{1-\epsilon }$
, it will have no prime factors in between
$n^{1-\epsilon }$
, it will have no prime factors in between
 $n^\epsilon $
and
$n^\epsilon $
and
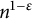 $n^{1-\epsilon }$
. (Since
$n^{1-\epsilon }$
. (Since
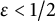 $\epsilon < 1/2$
, we have
$\epsilon < 1/2$
, we have
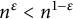 $n^\epsilon < n^{1-\epsilon }$
.) The upper bound is obtained by sieving by (a subset of) such primes.
$n^\epsilon < n^{1-\epsilon }$
.) The upper bound is obtained by sieving by (a subset of) such primes.
Proof of Theorem 11
Note that by (3), there is a constant
 $z_0$
such that
$z_0$
such that
 $g(p) \leq 1/2$
for all
$g(p) \leq 1/2$
for all
 $p \geq z_0$
. Further, by (3), we have
$p \geq z_0$
. Further, by (3), we have
 $$ \begin{align*}\prod_{z_0 \leq p < z}(1-g(p)) = \exp[-\log \log z + O(1)], \end{align*} $$
$$ \begin{align*}\prod_{z_0 \leq p < z}(1-g(p)) = \exp[-\log \log z + O(1)], \end{align*} $$
so that under the hypothesis of Theorem 11, we have that (20) is satisfied for any subset
 $\mathcal {P}$
of primes larger than
$\mathcal {P}$
of primes larger than
 $z_0$
, for
$z_0$
, for
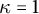 $\kappa = 1$
and some constant K. As in Theorem 15, define
$\kappa = 1$
and some constant K. As in Theorem 15, define
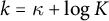 $k = \kappa + \log K$
.
$k = \kappa + \log K$
.
Let
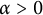 $\alpha> 0$
be the index. Using
$\alpha> 0$
be the index. Using
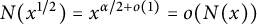 $N(x^{1/2}) = x^{\alpha /2 + o(1)} = o(N(x))$
, we have
$N(x^{1/2}) = x^{\alpha /2 + o(1)} = o(N(x))$
, we have
 $$ \begin{align} \sum_{n\leq x} a_n \mathbf{1}[P^+(n) \geq n^{1-\epsilon}] = \sum_{x^{1/2} < n\leq x} a_n \mathbf{1}[P^+(n) \geq n^{1-\epsilon}] + {o_{x\rightarrow\infty}(N(x))}. \end{align} $$
$$ \begin{align} \sum_{n\leq x} a_n \mathbf{1}[P^+(n) \geq n^{1-\epsilon}] = \sum_{x^{1/2} < n\leq x} a_n \mathbf{1}[P^+(n) \geq n^{1-\epsilon}] + {o_{x\rightarrow\infty}(N(x))}. \end{align} $$
But if
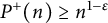 $P^+(n) \geq n^{1-\epsilon }$
, then n is not divisible by any primes strictly in between
$P^+(n) \geq n^{1-\epsilon }$
, then n is not divisible by any primes strictly in between
 $n^\epsilon $
and
$n^\epsilon $
and
 $n^{1-\epsilon }$
. If
$n^{1-\epsilon }$
. If
 $x^{1/2} < n \leq x$
, then this implies such n is not divisible by any primes strictly in between
$x^{1/2} < n \leq x$
, then this implies such n is not divisible by any primes strictly in between
 $x^\epsilon $
and
$x^\epsilon $
and
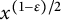 $x^{(1-\epsilon )/2}$
.
$x^{(1-\epsilon )/2}$
.
We will sieve out by a sparser set of primes even than these. Let
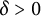 $\delta> 0$
be some number smaller than
$\delta> 0$
be some number smaller than
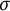 $\sigma $
. (So
$\sigma $
. (So
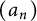 $(a_n)$
has level of distribution and index larger than
$(a_n)$
has level of distribution and index larger than
 $\delta $
.)
$\delta $
.)
Let
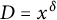 $D = x^\delta $
and then set
$D = x^\delta $
and then set
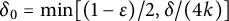 $\delta _0 = \min [(1-\epsilon )/2, \delta /(4k)]$
. Now define
$\delta _0 = \min [(1-\epsilon )/2, \delta /(4k)]$
. Now define
 $\mathcal {P}$
to be the primes larger than
$\mathcal {P}$
to be the primes larger than
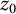 $z_0$
and strictly in between
$z_0$
and strictly in between
 $x^\epsilon $
and
$x^\epsilon $
and
 $x^{\delta _0}$
. (Let
$x^{\delta _0}$
. (Let
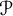 $\mathcal {P}$
be empty if there are no such primes.) We have
$\mathcal {P}$
be empty if there are no such primes.) We have
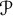 $\mathcal {P}$
is a subset of the primes in between
$\mathcal {P}$
is a subset of the primes in between
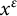 $x^\epsilon $
and
$x^\epsilon $
and
 $x^{(1-\epsilon )/2}$
, and also all
$x^{(1-\epsilon )/2}$
, and also all
 $p\in \mathcal {P}$
satisfy
$p\in \mathcal {P}$
satisfy
 $p < D^{1/4k}$
.
$p < D^{1/4k}$
.
Thus, if we set
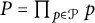 $P = \prod _{p\in \mathcal {P}}p$
, the right-hand side of (21) is
$P = \prod _{p\in \mathcal {P}}p$
, the right-hand side of (21) is
 $$ \begin{align*} &\leq \sum_{\substack{n\leq x \\ (n,P)=1}} a_n + o_{x\rightarrow\infty}(N(x)) \\ &\leq C' \cdot V \cdot N(x) + \sum_{\substack{d < D \\ d|P}} \tau_3(d)|r_d| + o_{x\rightarrow\infty}(N(x)), \end{align*} $$
$$ \begin{align*} &\leq \sum_{\substack{n\leq x \\ (n,P)=1}} a_n + o_{x\rightarrow\infty}(N(x)) \\ &\leq C' \cdot V \cdot N(x) + \sum_{\substack{d < D \\ d|P}} \tau_3(d)|r_d| + o_{x\rightarrow\infty}(N(x)), \end{align*} $$
where
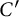 $C'$
is a constant which depends only on the sequence
$C'$
is a constant which depends only on the sequence
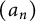 $(a_n)$
.
$(a_n)$
.
Now note that for sufficiently small
 $\epsilon $
, once x is sufficiently large, the set
$\epsilon $
, once x is sufficiently large, the set
 $\mathcal {P}$
will not be empty. Without loss of generality, we may assume that
$\mathcal {P}$
will not be empty. Without loss of generality, we may assume that
 $\epsilon $
is this small and x is at least this large in the remainder of the proof.
$\epsilon $
is this small and x is at least this large in the remainder of the proof.
We have
 $$ \begin{align*}V = \prod_{x^\epsilon < p < x^{\delta_0}} (1-g(p)) = \exp[-\log \log(x^{\delta_0}) + \log \log(x^\epsilon) + O(1)] \ll \epsilon. \end{align*} $$
$$ \begin{align*}V = \prod_{x^\epsilon < p < x^{\delta_0}} (1-g(p)) = \exp[-\log \log(x^{\delta_0}) + \log \log(x^\epsilon) + O(1)] \ll \epsilon. \end{align*} $$
Moreover, there are constants B and C such that
 $$ \begin{align} |r_d| \ll \frac{(\log x)^B C^{\Omega(d)}}{d} N(x) + (\log x)^B C^{\Omega(d)} \ll \frac{(\log x)^B C^{\Omega(d)}}{d} N(x) \end{align} $$
$$ \begin{align} |r_d| \ll \frac{(\log x)^B C^{\Omega(d)}}{d} N(x) + (\log x)^B C^{\Omega(d)} \ll \frac{(\log x)^B C^{\Omega(d)}}{d} N(x) \end{align} $$
for
 $d \leq D$
. (The first inequality follows from congruence uniformity, and the second from the index relation
$d \leq D$
. (The first inequality follows from congruence uniformity, and the second from the index relation
 $N(x)/d \gg x^{\alpha +o(1)}/x^\delta \gg 1$
.) Taking such a constant C, we note
$N(x)/d \gg x^{\alpha +o(1)}/x^\delta \gg 1$
.) Taking such a constant C, we note
 $$ \begin{align*} \sum_{\substack{d < D \\ d|P}} \tau_3(d) |r_d| \leq \Big( \sum_{\substack{d\leq x^\delta \\ d|P}} \frac{C^{\Omega(d)}\tau_3(d)^2}{d}\Big)^{1/2} \Big( \sum_{\substack{d\leq x^\delta \\ d|P}} \frac{d}{C^{\Omega(d)}} |r_d|^2\Big)^{1/2}. \end{align*} $$
$$ \begin{align*} \sum_{\substack{d < D \\ d|P}} \tau_3(d) |r_d| \leq \Big( \sum_{\substack{d\leq x^\delta \\ d|P}} \frac{C^{\Omega(d)}\tau_3(d)^2}{d}\Big)^{1/2} \Big( \sum_{\substack{d\leq x^\delta \\ d|P}} \frac{d}{C^{\Omega(d)}} |r_d|^2\Big)^{1/2}. \end{align*} $$
Note
 $\tau _3(n) \leq 3^{\Omega (n)}$
and for sufficiently large x, we have
$\tau _3(n) \leq 3^{\Omega (n)}$
and for sufficiently large x, we have
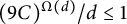 $(9C)^{\Omega (d)}/d \leq 1$
for all
$(9C)^{\Omega (d)}/d \leq 1$
for all
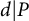 $d | P$
. So using Lemma 4 to estimate the first parentheses and (22) to estimate the second, for sufficiently large x, the above is
$d | P$
. So using Lemma 4 to estimate the first parentheses and (22) to estimate the second, for sufficiently large x, the above is
 $$ \begin{align*} \ll (\log x)^A \Big( (\log x)^B N(x) \sum_{d\leq x^\delta} |r_d|\Big)^{1/2} \end{align*} $$
$$ \begin{align*} \ll (\log x)^A \Big( (\log x)^B N(x) \sum_{d\leq x^\delta} |r_d|\Big)^{1/2} \end{align*} $$
for some constant
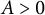 $A> 0$
.
$A> 0$
.
Using that
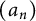 $(a_n)$
has level of distribution greater than
$(a_n)$
has level of distribution greater than
 $\delta $
, the above is
$\delta $
, the above is
 $$ \begin{align*} \ll N(x)/(\log x)^{A'} = o_{x\rightarrow\infty}(N(x)), \end{align*} $$
$$ \begin{align*} \ll N(x)/(\log x)^{A'} = o_{x\rightarrow\infty}(N(x)), \end{align*} $$
for any constant
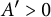 $A'> 0$
.
$A'> 0$
.
Putting matters together, we have
 $$ \begin{align*}\sum_{n\leq x} a_n \mathbf{1}[P^+(n) \geq n^{1-\epsilon}] \ll \epsilon N(x) + o_{x\rightarrow\infty}(N(x)), \end{align*} $$
$$ \begin{align*}\sum_{n\leq x} a_n \mathbf{1}[P^+(n) \geq n^{1-\epsilon}] \ll \epsilon N(x) + o_{x\rightarrow\infty}(N(x)), \end{align*} $$
where the implicit constant depends only on the sequence
 $(a_n)$
, which implies the theorem.
$(a_n)$
, which implies the theorem.
Remark 16 Theorem 11 says that the likelihood that
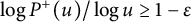 $\log P^+(u)/\log u\geq 1-\epsilon $
is
$\log P^+(u)/\log u\geq 1-\epsilon $
is
 $O(\epsilon )$
. Although in its proof, we have imported Theorem 15 directly from sieve theory, it is likely possible and would be interesting to abstract the combinatorial content of this sieve bound to prove a version of Theorem 11 for general point processes on the simplex with correlation functions known to agree with those of a Poisson–Dirichlet process against test functions with restricted support, in the sense of Lemma 8. We do not pursue this here however.
$O(\epsilon )$
. Although in its proof, we have imported Theorem 15 directly from sieve theory, it is likely possible and would be interesting to abstract the combinatorial content of this sieve bound to prove a version of Theorem 11 for general point processes on the simplex with correlation functions known to agree with those of a Poisson–Dirichlet process against test functions with restricted support, in the sense of Lemma 8. We do not pursue this here however.
Acknowledgments
We thank Yuchen Ding, Ofir Gorodetsky, Ram Murty, and anonymous referees for comments, suggestions, and corrections to earlier versions of this manuscript. We have used ChatGPT 5.2 to proofread a version of the manuscript and to help format references but no parts of the article were computer generated.










 Open access
Open access