

9.1 Introduction
Doctrinal research in European Union (EU) law engages in the analysis and critique of law found in the judgments of the Court of Justice of the European Union (CJEU) and the legislative texts issued by the EU’s political institutions. Through its critical reflections on what are typically landmark judgments or pieces of legislation, the discipline illuminates the underlying principles and values of the EU’s legal system. Empirical legal studies in EU law, on the other hand, aims to identify patterns and relationships among the often-abstract phenomena that characterise the EU’s legal system. In other words, ELS in EU law relies on empirical evidence to uncover what the law obscures through abstract legal concepts.Footnote 1 Has the CJEU’s jurisprudence become more deferential towards national authorities in the EU’s Member States over time? Is judicial independence declining in some Member States, and if so, how are the EU’s institutions responding to this trend? Are Member State governments able to shape the CJEU’s jurisprudence by signalling their positions on important legal questions? Empirical legal scholars – irrespective of their research focus or differences in approach and methodology – have in common that they use data, that is, facts about the world, to answer the questions that motivate their research.Footnote 2
The sources of such data are generally diverse, ranging from expert interviews to publicly available documents, academic literature, archival material, social media accounts, online surveys, and more. In ELS in EU law in particular, text plays a prominent role as a source of data. It is the primary medium through which EU law is communicated, for instance via directives and regulations drafted by the EU’s political institutions, the CJEU’s jurisprudence, preliminary references submitted by national courts, and observations filed by Member State governments. We can reasonably assume that most scholars wishing to study EU law empirically find it helpful to turn to text as a source of data to answer their research questions. Sometimes, the required information for their research projects exists in the shape of already compiled datasets. Single-user databases are tailored to serve the narrowly defined purposes of a specific research project, whereas multi-user databases allow several individuals to access the data at the same time and for different research purposes.Footnote 3 However, oftentimes researchers do not have the luxury of being handed a dataset that is ready for use for their particular study. In most instances, they will have to collect (at least some of) the relevant evidence for their research projects themselves. For empirical legal scholars of EU law, this typically involves ‘processing’ legal text, that is, converting unstructured information found in texts into a format that is useful for the researcher and conducive to subsequent empirical analyses.Footnote 4
Extracting useful information from text requires several steps. First, researchers must think carefully about how to render abstract phenomena measurable. For instance, what do researchers mean when they refer to ‘deference’ or ‘judicial independence’, and how can they identify their absence or presence? Put simply, researchers must conceptualise a phenomenon of interest and develop an instrument allowing them to measure variation in that phenomenon. Second, researchers need to implement their measurement instruments and systematically record the desired data for each unit of analysis (e.g., a sample of CJEU judgments) in their study, a process commonly referred to as coding. Finally, researchers need to evaluate their measurement instruments, engaging in a process of critical self-reflection to ensure that the measures they put forward do not fall short of reflecting the true meaning of the concept under examination, and that the instruments produce the same results regardless of who is carrying out the measurements.Footnote 5
In this chapter, we describe each of these steps in greater detail and provide practical guidance on how empirical legal scholars should approach them. Along the way, we highlight challenges that are particular to empirical legal research in EU law. We begin by discussing how researchers should conceptualise abstract phenomena and offer guidance on the development of instruments that allow researchers to measure them. We then discuss key considerations that researchers should be mindful of during the coding process. The chapter’s final section then centres on evaluating measurement instruments, specifically discussing ways to improve an instrument’s validity and reliability.
9.2 Developing Concepts and Measurement Instruments
While the measurement of physical properties such as length, time, or velocity is expressed in standardised units of measurement such as metres, seconds, and metres per second, measuring legal concepts is likely to be a more complicated matter. This is mainly because legal concepts are theoretical, latent constructs that can assume a variety of different meanings depending on the contextual circumstances. The main task of the empirically minded researcher thus consists in building a bridge between these unobservable constructs and empirical facts by identifying observable indicators that can serve as their concrete manifestations.Footnote 6
However, identifying indicators that capture the correct and full sense of a legal concept will be difficult when the meaning of that concept itself is shrouded in uncertainty. One of the particularities of the EU legal system is that it operates with a plethora of vaguely framed terms that are inconclusive and inherently value-laden, which renders their interpretation susceptible to divergent views and subject to ongoing academic controversy. This is particularly true in the case of general principles of EU law. With respect to their recognition and interpretation, Advocate General Mazák once remarked that it is ‘the nature of general principles of law, which are to be sought rather in the Platonic heaven of law than in the law books, that both their existence and their substantive content are marked by uncertainty’.Footnote 7 As prescribed in Article 19 (1) TEU it is the task of the CJEU to develop the law and clarify its meaning through interpretation. In doing so, it has frequently relied on the teleological method as the interpretation of the Treaty provisions is entirely grounded in the idea that there are objectives of pivotal constitutional importance the Union must achieve.Footnote 8 It becomes evident that EU law is a discipline that is characterised by purpose-driven functionalism.Footnote 9
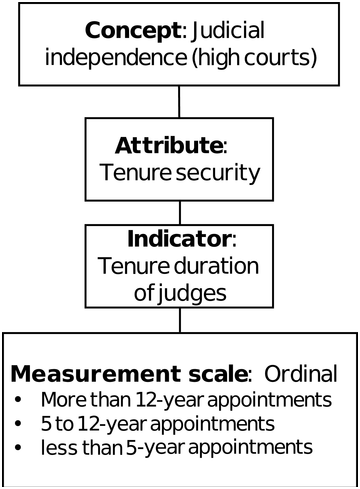
For better illustration, take the legal concept of ‘judicial independence’, which most people will associate with safeguarding the judicial branch from any form of external political interference.Footnote 10 In search of what judicial independence means in the EU context, it makes sense to scrutinise the case law of the CJEU. In its recent case law, the Court has made use of the teleological method of interpretation to clarify what it perceives to be minimum common standards for ensuring the independence of European judges. Relying on common values such as effective judicial protection, the right to a fair trial, and the rule of law, the Court has reminded the Member States of their duty to fulfil the commitments they had made upon joining the Union. Based on this line of case law, potential attributes of the concept of judicial independence could be, for example, freedom from any constraints influencing the (re)appointment and promotion of judges,Footnote 11 the security of judges’ tenure,Footnote 12 or insulation from budgetary pressuresFootnote 13 exerted by the executive and legislative branches to control the judiciary’s performance. If we focus solely on the attribute of tenure security, an observable indicator that immediately comes to mind is the duration of the judges’ tenure of office in high courts across different Member States of the EU, assuming that longer terms in office foster judges’ independence and vice versa (see Figure 9.1). A researcher may distinguish between appointments that allow judges to serve for more than twelve years on a court, appointments for five to twelve-year terms, and finally, any appointments lasting under five years. Assuming that rules concerning the security of judges’ tenure are a valid attribute of the concept of judicial independence (see our discussion below on validity), and that the duration of judges’ tenure is a sensible indicator for this attribute, a researcher may then conclude that systems providing judges with more than twelve years of tenure are characterised by higher levels of judicial independence than systems providing five to twelve-year terms, while the lowest level of judicial independence is found in systems providing judges with terms that last less than five years.
An example of an attribute and indicator for the concept of judicial independence.

Figure 9.1 Long description
The following are labeled from top to bottom in order. Concept, judicial independence, high courts. Attribute, tenure security. Indicator, tenure duration of judges. Measurement scale, ordinal, with more than 12-year appointments, 5 to 12-year appointments, and less than 5-year appointments.
Identifying appropriate attributes of a concept and their observable indicators, however, is not always as straightforward as our example of judicial independence suggests. The concepts typically examined by scholars conducting empirical legal studies in EU law are often complex and characterised by more than one attribute. Recently, scholars working in the field of ELS have turned to large language models (LLMs) to summarise legal documents or retrieve information from legal texts (see Ovádek’s Chapter on machine learning and large language models in this volume). Given that the performance and accuracy of LLMs is only going to improve, much of the time- and resource-intensive collection of data currently carried out by human coders will likely be outsourced to machines (see also our discussion in Section 9.4 below). The formation of concepts and the development of instruments measuring them, however, requires conscious choices from researchers themselves, who should have explanations at hand for why they picked a particular conceptual attribute or selected a particular indicator.
Of course, researchers may find it challenging to determine whether they have identified every essential attribute to clearly communicate the sense or meaning of a concept. One way to ensure that the conceptual attributes identified by a researcher are collectively exhaustive (in other words, to ensure that no essential attributes are omitted from their concept) is to think of attributes as individually necessary and collectively sufficient conditions. To illustrate, consider again our earlier example of judicial independence. We can think of fixed tenure rules as an individually necessary condition for judicial independence. A legal system that does not provide fixed tenures for high-court judges cannot embody judicial independence. However, fixed tenure rules alone may not necessarily capture the meaning of judicial independence. For instance, existing literature has identified financial autonomy for high courts and governments’ consistent faithful implementation of high court judgments as additional essential attributes of judicial independence. Hence, judicial independence is then only given in systems where all three of these individually necessary attributes – fixed tenure, financial autonomy, and consistent implementation of judgments – are collectively present. We want to stress that there is no definitive answer to whether a particular attribute is individually necessary for a concept, and we expect these decisions to often be the subject of debate in the scholarly literature. We consider debates over the meaning of a concept to be necessary and fruitful, and we encourage scholars to articulate the attributes of their concepts in a transparent manner to facilitate such debates.
An issue when it comes to the selection of appropriate indicators for conceptual attributes that is specific to ELS in EU law is the veil of secrecy surrounding the decision-making process at the Court of Justice. The opaqueness of the decision-making process, non-disclosure of judicial votes, and restricted access to documents such as case files, the pleadings of the parties, and reports of the hearings are serious obstacles put in the way of anyone wishing to study the Court empirically. Thus, empirical legal scholars often have no other choice but to rely on publicly available sources when selecting indicators that could provide a glimpse into the decision-making process. The legal texts they will primarily consult are the Treaties, secondary legislation, national laws of the Member States, as well as the judgments of the CJEU. A major drawback is that the information gleaned from such publicly available texts often does not constitute a first-hand account of the discussions and events that took place behind closed doors.
In addition to institutional policies restricting access to documents, one of the EU’s founding Member States, France, has criminalised research on individual judicial behaviour, placing it under the looming threat of a maximum sentence of up to five years in prison.Footnote 14 Imagine some researcher finding unassailable proof for the fact that one particular judicial actor at the CJEU pursues a particularly neoliberal agenda and has exerted a remarkable influence on decisional outcomes. For fear of repercussions, the researcher may look for alternatives, replacing the identity of the judicial actor with a placeholder such as, for example, economic expertise when it is obvious that only certain actors, including that particular individual, possess such qualifications. Framing economic expertise as the driver of decisional outcomes would conceal the true nature of the relationship, leading to sub-standard theorisation and conceptualisation. It becomes evident that institutional practices restricting access or outright bans not only have a muting effect on intellectual innovation, but also impinge upon the ability of researchers to devise high-quality measurement instruments.
9.3 Implementing Measurement Instruments
Coding constitutes a central task for scholars of ELS, which, depending on the type of variable, can come with varying degrees of difficulty. In the following, we distinguish between textual and interpretive variables. Textual variables are simple to code as they allow researchers to assign values almost exclusively from reading the wording of the judgment or any other document. It is for this type of variable that machine learning classifiers and LLMs hold the greatest potential (see Chapter 10 by Ovádek in this volume). Machines can easily identify linguistic patterns and pick out words in context. For example, determining whether a free movement of services case explicitly mentions issues related to public procurement or not would be a textual variable.
In contrast to that, interpretive variables are more complex and typically require coders to assign values by interpreting the Court’s decision and reasoning against the body of case law and legal literature – a task that presupposes expert legal knowledge and familiarity with the jurisprudence of the Court. Further, the meaning of words or linguistic patterns may change over time, and it may make a difference whether we find a particular word in a judgment issued by the Court of Justice in the 1960s or in the late 2010s. An illustrative example is a variable we call ‘doctrinal outcome’.Footnote 15 The Court can entrench, strengthen, or expand existing doctrines, or create new concepts and principles. Such instances would be assigned the value ‘strong doctrinal outcome’. By contrast, the Court can soften its strong doctrinal positions or apply established doctrines, concepts, and principles, without further developing their scope. This would prompt the value ‘weak doctrinal outcome’. Interpretive variables strongly draw on prior knowledge of substantive EU law and coding them will be difficult to reproduce by non-lawyers, let alone machine-learning algorithms. Furthermore, interpretive variables are naturally context-dependent. New challenges arising from changing political and economic realities will require the Court to reconfigure its goals and sometimes to chart a new path. Due to the dynamic nature of EU law concepts, it is likely that measurement instruments considered appropriate for studying one particular issue will be of limited usefulness for other questions. Against this backdrop, data generated through the hand-coding of interpretive variables inevitably entails a trade-off: as these variables are highly complex, updating the data on a regular basis will prove challenging, leading to the risk that the compiled datasets become historical artefacts representing huge coding efforts with little increasing returns.
The choice between textual and interpretive variables will largely depend on the goals the researcher is pursuing. If the goal is to provide a qualitative empirical overview of the manifold approaches and interpretations put forward by the Court, designing extremely detailed instruments accounting for the smallest deviations in the case law may make sense. However, if the goal is to collect data for a quantitative analysis that allows researchers to draw generalisable inferences, a measurement instrument for a particular variable should capture values that occur frequently enough to be reasonably included in a statistical model. To illustrate, deference granted by the Court to the European Commission could be measured by distinguishing between different standards of review, equating a laxer review standard that only asks whether the Commission has committed any manifest error of assessment with more deference. Coding this interpretive variable will require a close reading of the text of the judgments, as there have been instances in which the Court formally recalled the manifest error test, but in fact, showed greater willingness to scrutinise the Commission’s analysis, concentrating on factual accuracy, consistency, reliability, and exhaustiveness of the Commission’s arguments.Footnote 16 Furthermore, the number of cases in which the Court explicitly used the doctrine of marginal review is relatively small, rendering it unsuitable for inclusion in statistical models. A simpler measure would be the rate at which the Court of Justice upholds Commission decisions in appeals cases, which could indicate the Court’s acknowledgement of the enforcer’s superior economic expertise.Footnote 17 Such a measure could serve as an outcome variable in a statistical model that seeks to explain variation in the Court’s showing of deference to the Commission over time. Arguably, the latter measure is quite crude as it exclusively focuses on the outcome as stated in the operative part, and not so much on the legal reasoning that has led to its adoption. For the purposes of conducting a quantitative analysis, however, it may be necessary to sacrifice the nuance of detail, albeit at the cost of simplifying. To reiterate, which of the two options outlined in this example is appropriate to capture deference is dependent on the researcher’s goal. Whichever choice a researcher makes while remaining within the realms of what is possible, it is important that they communicate this choice transparently to allow others to comprehend and possibly critique their reasoning.
Whether we formulate a variable as a textual or interpretive one will also have consequences for the choice of measurement scale. In our previous example (Figure 9.1), tenure duration was represented on an ordinal scale with three categories. It would also have been possible to opt for a ratio scale, discrete with whole numbers or continuous with fractional numbers. Scales that are quantitative in nature contain more information and allow researchers to appraise differences with great exactitude. However, this does not imply that researchers should always strive to measure their indicators on an interval or ratio scale. In most instances, the concepts subject to scholarly inquiry will be less conducive to being treated as interval or ratio scaled. Unlike with physical or chemical properties, we cannot assume that, for example, the distances between the values denoting different judicial attitudes are equal. Thus, opting for a nominal or ordinal one to measure a legal concept will often be the natural choice. Ultimately, researchers should carefully reflect on their specific research question and always select the measurement scale that fits the objectives of the study best, rather than simply refer to the superior information of certain scales when considered in the abstract.Footnote 18
To clarify any inconclusive points, researchers should compile a codebook containing clear coding instructions and annotations serving the disambiguation between outcomes as well as conceptually similar variables. Sometimes even variables that may appear simple at first glance can prove challenging to code. Take, for instance, the question of whether a case was decided for or against the Commission. Most appeals cases will invoke several grounds of appeal, and if an appeal is partly dismissed and partly upheld, determining who emerges as the winner of the proceedings can be difficult.Footnote 19 Carefully documenting each step along the way and spelling out the reasons behind the decisions made in the coding will allow researchers to revisit, reflect on, and sublimate the data generation process.
The codebook is a guide researchers can consult at any time to produce consistent and systematic data which also renders the coding process more transparent and reproducible. At which stage of the research process a codebook is assembled depends on the research design. Coding can be inductive, meaning that researchers start with an experimental sample to make some observations and then compile the codebook. This bottom-up approach derives the measurement instruments from the data, letting the narrative or theory emerge from it. Qualitative empirical work using interviews will most likely take the information gleaned from the interviews as a starting point for exploring possible themes, theories, and ideas. Deductive coding, on the other hand, refers to the top-down practice of having the theory and a codebook containing an intitial set of measurements first, and then coding the sample.Footnote 20 That said, inductive and deductive coding are not mutually exclusive, and most researchers will engage in an iterative process of review and refinement.
9.4 Evaluating Measurement Instruments
In this final section of the chapter, we offer guidance on how to evaluate the usefulness of the instruments that measure our concepts of interest. Our discussion revolves around two objectives. First, we want our measurement instruments to be valid, that is, the indicators we selected for our conceptual attributes should collectively capture the meaning of the relevant concept.Footnote 21 Second, we want our measurement instruments to be reliable. Following Hayes and Krippendorff, we think of measurement instruments as reliable if they, ‘serving as common instructions to different observers of the same set of phenomena, yield[s] the same data within a tolerable margin of error’.Footnote 22
9.4.1 Validity
Studying EU law empirically does not absolve researchers of analytical rigour and critical self-reflection. In selecting observable indicators for each conceptual attribute, researchers are advised to pay attention to content validity to ensure that those indicators capture the correct and full sense of the concept being measured.Footnote 23 In essence, researchers want to make sure that any indicator they select closely reflects the corresponding attribute of the concept. For example, identifying the duration of high court judges’ tenure allows us to conclude whether judges enjoy fixed tenures, which itself is an essential attribute of judicial independence. When defining the possible values for an indicator, researchers should make sure that these values are mutually exclusive and collectively exhaustive. As an illustration, consider our earlier example of high court judges’ tenure duration as an indicator. Had we only distinguished between high court judges’ appointments for five to twelve-year terms and appointments for five years or less, then the values on our indicator would have been neither mutually exclusive nor exhaustive. We simply would not know into which category we should sort a system that provides exactly five-year appointments for high court judges (the two categories are not mutually exclusive). Further, we would not know how to code systems that provide high court judges with lifetime tenure (the two categories are not exhaustive). To ensure that the values on indicators are mutually exclusive and exhaustive, it is advisable that researchers carry out a pilot study, or even engage in multiple rounds of coding to capture all relevant values for every indicator.Footnote 24
Second, new measurement instruments should generally produce results that converge with already existing, albeit possibly less fine-grained, measures of the same concept. Likewise, researchers should be sceptical if their own instruments suggest empirical patterns that starkly contrast with patterns identified in existing, well-established scholarship.Footnote 25 To illustrate, a researcher may develop a novel instrument to improve on the measurement of judicial independence, particularly with respect to capturing lacking judicial independence in what would otherwise be considered consolidated democracies. While some consolidated democracies may indeed fail to adequately protect the independence of their judiciaries, a measurement instrument suggesting that most states considered fully democratic in existing research lack judicial independence should be viewed with some scepticism. Of course, divergences between novel and existing measurement instruments may not necessarily mean that the former is doing a poor job. As Adcock and Collier point out, none of the existing indicators against which a researcher validates their own measurement instrument may be very good in capturing the systematised concept. Nonetheless, if researchers wish to introduce a novel way of measuring a particular concept, it is advisable that they submit their measurement instruments to various plausibility probes. As concepts are open to contestation, validity requires that only such concepts are included that can be justified on theoretical grounds. In this vein, it makes sense to triangulate the coded data with data from other sources or obtained by employing different data collection methods as a plausibility probe.Footnote 26
9.4.2 Reliability
We complement the advice on concept formation and the improvement of their validity with guidance on how the measurement of concepts should be carried out in practice, particularly with respect to research projects that rely on gathering information from texts and with a focus on improving the reliability of measurement instruments. Our discussion is structured around the following three guiding principles:
1. First, efforts to assess and monitor the reliability of measurement instruments should be made as early as possible in any research project that collects original data.
2. Second, researchers planning for a project that involves data collection should seek to reduce the number of steps that coders must perform in carrying out a coding task wherever possible.
3. Third, researchers should acknowledge that a measurement instrument’s reliability is decreasing with the complexity of the concept that coders are trying to measure, which has implications for the number of variables that can be measured by human coders.
Ensuring the reliability of measurement instruments is critical to the success or failure of any research project that gathers empirically novel data. Yet, developing reliable measurement instruments is difficult, particularly in the field of ELS in EU law where our research revolves around legal concepts that are difficult to grasp, let alone observe. However, we believe that careful planning can effectively mitigate the challenges faced by research projects that gather original data and that undertaking these projects is worth the risks.
9.4.2.1 Monitoring Reliability
Poor reliability of a measurement instrument comes with poor quality of the collected data.Footnote 27 Imagine two coders reading the same set of judgments issued by the CJEU to find out whether the Court showed deference to Member States’ national authorities in these judgments. If these two coders frequently arrived at different conclusions despite using the same measurement instrument, then researchers engaging with the collected data face a dilemma. Which of the two coders’ assessments should we trust and what inferences can we draw from the evidence they collected? Unfortunately, no measurement instrument applied by a human coder is perfectly reliable. In every instance of a coder using an instrument to measure the presence, absence, or degree of a concept, there is a chance that a different coder would arrive at a different conclusion. Even if the same coder would look at the same evidence twice, using the same measurement instrument, they may not perfectly replicate a measurement they had made previously.
There are myriad reasons why coders may arrive at different measurements despite applying the same measurement instrument (e.g., personal biases, experience, or fatigue). Researchers should try to identify and address these issues as early as possible in their research projects, and concerns about the reliability of measurement instruments should already feature in their development. How complex are the instructions that are passed on to coders who are using the measurement instrument? How likely is it that coders will misunderstand (parts of) these instructions? How long will it take coders on average to code a single case?
Whether a measurement instrument is sufficiently reliable can only be answered by putting the instrument to the test. Researchers should allow for a testing phase as early as possible in their projects where multiple coders independently apply the measurement instrument to the same sample of cases to evaluate the instrument’s reliability. This sample should be sufficiently large as coding only a handful of cases is unlikely to yield any useful insights, and drawn at random. Researchers may feel inclined to assess a measurement instrument’s reliability for a hand-picked sample of well-known cases, such as landmark judgments of the CJEU. However, such landmark cases may systematically differ in many respects from the average case that coders will encounter most frequently in their work. Learning that an instrument proves reliable for landmark cases then tells us little about its reliability when it is used to measure a concept in the run-of-the-mill cases.
There is an extensive literature introducing coefficients that provide a numerical summary of the reliability of a measurement instrument. Prominent examples here are Krippendorff’s Alpha or Fleiss’s Kappa.Footnote 28 These coefficients account for the likelihood of agreement by chance between different coders and are therefore preferable over calculating the percentages of agreement between coders.Footnote 29 Researchers should select a reliability coefficient that is appropriate for the scale of their measurement instrument (e.g., some reliability coefficients are designed for ordered or unordered categorical measurement scales), and store the collected data in a spreadsheet format that easily lends itself for a reliability analysis using statistical software.Footnote 30 A debriefing with the coders about their experience using the instrument may also reveal typical sources of disagreement.
Whether a phase in which a sufficiently large sample of cases is assigned to multiple coders should be extended after an initial assessment of a measurement instrument’s reliability is an important judgment call. This decision is conditional on the instrument’s performance. This decision is conditional on the instrument’s performance (i.e., whether the recorded reliability was above an acceptable threshold for the reliability coefficient, acceptable, or poor) and the extent of any subsequent changes made to the coding instructions and procedure. In principle, the more significant the changes, the stronger the case for extending the phase. When significant changes were made, cases that had been coded using the original instructions should be coded again to ensure that all measurements were made following the same instructions. These can be difficult choices, given that coding even a limited sample of cases several times requires resources like time and money which are typically not available in abundance. Nonetheless, investing these resources early on is preferable to realising that a measurement instrument’s reliability is unacceptably poor only after every case has been coded.
Before we move on to the next guiding principle, we briefly reflect on the advice discussed above in the context of research projects that involve only one researcher, such as a dissertation project. How can a measurement instrument’s reliability be monitored if the coding is carried out by a single coder? First, coders themselves may simply code a sufficiently large sample of cases twice. The downside here is that coding decisions are not made independently from each other. A coder may remember their previous measurement which will influence their choice once a case is coded for the second time. Yet, observing poor reliability scores would still indicate issues with the coding instructions or the underlying concept being measured. For example, coding instructions may require attention to contextual details that can be easily missed when a coder becomes fatigued. Second, while the bulk of cases for a research project may be coded by a single coder, assistance of other coders may be enlisted only for evaluating an instrument’s reliability at the early stages of a research project. University departments and funding institutions often offer small grants that can be allocated to hire assistance for coding a sample of cases to assess the reliability of a measurement instrument. Finally, even if no other coder(s) are involved in the data collection, writing out the coding instructions, sharing them with academic peers or supervisors, and receiving feedback on these instructions prior to carrying out the coding is the minimum that researchers working individually can do to improve the reliability of their measurement instruments.
9.4.2.2 Reducing the Complexity of Coding Procedures
In most research projects that task human coders with extracting information from legal texts, coders are presented with a document and collect data based on the instructions of a codebook. Consider our earlier example of coders identifying whether the CJEU showed deference to national authorities in its preliminary rulings. Not every part of the CJEU’s preliminary rulings is relevant for this task. Coders looking for signs of the Court showing deference would search in vain in the judgment’s summary of the case in the national court and are best advised to focus their attention on the substantive parts of the Court’s answers to the referred questions. Even here, it is not a priori clear in which paragraph(s) the coder finds relevant evidence. The coder must first identify which paragraph(s) in the judgment contain the evidence, which then allows them to make a subsequent, second decision whether the Court showed deference to a national authority in the judgment. It may seem superfluous to distinguish between a coder deciding which segment of a document is relevant for a coding task and the coder deciding how to interpret the evidence in this segment. However, for the sake of improving the reliability of a measurement instrument, we believe it is important to acknowledge these two steps.
Imagine a project leader setting up two tests to assess the reliability of a measurement instrument used in the coding task described above. In one of the tests, coders receive a set of unprocessed documents, for instance, complete CJEU judgments. In the other, coders receive only the paragraph(s) from each judgment that another researcher had previously identified as relevant. We can reasonably assume that coders involved in the second test are more likely to agree among each other, as they were able to focus their full attention on interpreting the substance of these paragraphs, while the coders working with complete documents not only had to read more text but also had to decide which of the paragraphs were relevant before proceeding to interpret the evidence from these paragraphs. Additional steps in the coding procedure allow for more room for error, and the likelihood that different coders arrive at different values increases with the procedural complexity of the task, a function of the number of steps a coder must complete before they can decide on how to code a particular case.
Supervised and unsupervised machine learning classifiers as well as LLMs can help researchers reduce the procedural complexity of coding tasks (see also Ovádek Chapter 10 in this volume). Fine-tuned machine learning models excel at classifying text based on recurring linguistic patterns, and we are optimistic that recent advances in tuning LLMs for text classification will improve classification performances even further. To illustrate, Schroeder and Lindholm programmed several classifiers to identify paragraphs in CJEU preliminary rulings that mark the beginning and end of each of the Court’s individual answers to national courts’ referred questions.Footnote 31 Drawing on common linguistic patterns in the CJEU’s judgments, classifiers were able to pick out these paragraphs with high accuracy and allowed the authors to split judgment texts into separate segments that only comprised the CJEU’s substantive answers to the referred questions. While such a classification does not tell us anything about the substance of the CJEU’s answers, it removes a step in a coding task that would ask coders to, for instance, identify the area of law that is dealt with in a particular answer.
9.4.2.3 Placing Priority on Conceptual Complexity
Complex concepts that require contextual knowledge to be accurately measured are often at the centre of our research. To illustrate, consider a task that requires coders to identify to what extent a CJEU preliminary ruling further restricts Member States’ future policy options.Footnote 32 To start with, coders would need to know the extent to which the CJEU’s jurisprudence had placed limitations on Member States’ policy-making prior to the judgment in question being issued. Second, while coders may find a paragraph in the judgment which suggests that the Court is tightening restrictions, the Court may have tied its ruling closely to the facts of the case heard by the referring national court. Hence, while the Court is indeed adding restrictions to Member States’ policy-making in scenarios that mirror the facts of the case heard by the referring national court, Member States could easily argue that these limitations do not apply in scenarios that differ, even slightly, from those facts.Footnote 33 Here, coders would not make their coding decisions based on a single paragraph alone, but in the context of other parts of the judgment, the CJEU’s previous decisions, and the likely responses of Member States in the future.
The complexity of a concept and the contextual knowledge required to accurately measure it are inversely related to the reliability of the instrument that is measuring the concept. This presents a challenge for project leaders, succinctly summarised by Mikhaylov, Laver, and Benoit: ‘Coding schemes must balance the researcher’s desire to reflect accurately the complexity of the reality represented by a text, with the practical requirements of keeping coding schemes simple enough that they can be implemented by human coders reliably.’Footnote 34 In order to balance the competing objectives of capturing complex realities and ensuring measurement reliability, coders should focus their attention on a limited number of variables that require detailed coding instructions and contextual knowledge. Any other variables can be coded with the assistance of or entirely by machines, making use of recurring linguistic or structural patterns in texts. For instance, information on variables such as the number of citations to CJEU case law in the Court’s own judgments can be fully coded by machines through pattern recognition techniques. To illustrate, using regular expressions, a machine can easily pick up citations following patterns like ‘C‑340/22’, which represents the code for an existing CJEU judgment. Here, apart from programming a machine to identify such patterns, no coder needs to be involved in collecting this information and their attention can be focused elsewhere.
Machines are most likely able to replace human coders for variables that require little to no contextual knowledge, such as citations, or simple counts of certain expressions in a judgment text. Even when some contextual knowledge is required, machines may significantly lighten the workload of coders. For instance, a researcher might explore the sentiment of paragraphs in preliminary rulings that include citations to existing case law, distinguishing, for example, between ‘positive’, ‘negative’, and ‘neutral’ sentiments. They may look for particular words or phrases that indicate that the referenced case law is useful for answering a national court’s question, or vice versa words and phrases which indicate that the Court believes the referenced case law does not help to answer the question. Recognising these patterns requires some contextual knowledge, and an off-the-shelf classifier using a dictionary of words for sentiment analysis is unlikely to suffice. Yet, coders’ annotations can be used to train a supervised classifier to capture sentiment in paragraphs that the coders have not yet reviewed. Programming a classifier reduces the workload of coders significantly, as they no longer have to code the bulk of cases themselves and instead only have to validate a sample of the machine’s classifications. However, researchers should be aware that any bias among coders who collected the data that is then used to train a machine learning classifier logically also affects the predictions made by that classifier. This reinforces the advice that researchers should debrief with coders early in the project to identify whether disagreements in measurements are, inter alia, caused by coders’ personal biases.
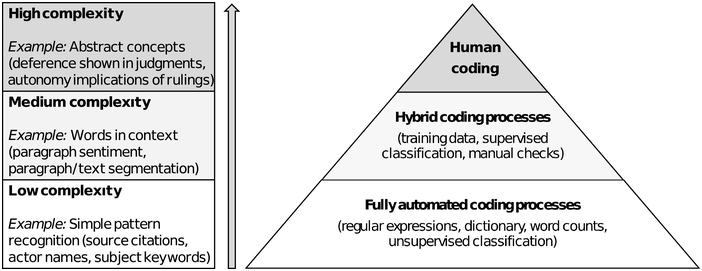
Figure 9.2 illustrates how the involvement of coders is tied to the complexity of a concept and the contextual knowledge that is required to make accurate measurement decisions. When context becomes more relevant for accurate measurement, the necessity to involve coders increases. The number of concepts coders must measure without the assistance of machines should be limited, so they can focus theit attention on fewer, more time-consuming, and error-prone tasks. At the other end of the spectrum, however, no such limitations exist for concepts that can be measured without having to interpret context. Adding concepts that can be easily measured by a machine, such as using a simple classifier working with regular expressions, requires minimal respources, apart from the initial programming effort, and places no additional burden on coders. We encourage researchers to carefully consider the portfolio of concepts that need to be measured in the context of their projects and avoid tasking coders with measuring several concepts that require highly contextual knowledge. Clearly, this also entails accepting trade-offs as the latter types of concepts are often the most central to research in the field of ELS in EU law. However, when faced with the choice between assigning coders the task of measuring several complex concepts with low reliability, and measuring a single concept with high reliability, we always favour the latter.
The extent to which contextual knowledge is required to make accurate coding decisions determines whether human coders need to be involved in the measurement of a concept. The number of concepts that need to be measured by human coders without the aid of machines should be limited.

Figure 9.2 Long description
The pyramid diagram has three sections from top to bottom. Human coding. Hybrid coding processes like training data, supervised classification, and manual checks. Fully automated coding processes such as regular expressions, dictionary, word counts, and unsupervised classification. An upward arrow on the left represents increasing complexity levels from bottom to top. Low complexity. Example, simple pattern recognition like source citations, actor names, and subject keywords. Medium complexity. Example, words in context like paragraph sentiment, and paragraph or text segmentation. High complexity. Example, abstract concepts like deference shown in judgements and autonomy implications of rulings.
9.5 Conclusion
In this chapter, we discussed how scholars in the field of ELS in EU law should conceptualise abstract phenomena and how they can develop measurement instruments that capture the meaning of these concepts. In essence, we believe that scholars should be transparent and explicit about the concepts they employ in their work. While many concepts in this field are characterised by complexity and are difficult to grasp, clearly identifying every attribute of a concept helps researchers to select appropriate observable indicators for these attributes. Further, we offered practical advice on the implementation of measurement instruments, including advice on how researchers can improve the reliability of their measurement instruments. The complexity of many concepts at the centre of empirical legal studies in EU law presents a challenge for researchers, specifically when it comes to developing reliable measurement instruments.
However, we believe that careful planning from project leaders, allowing for reliability evaluations early on in research projects and enabling coders to focus their attention on only a limited number of complex coding tasks, possibly through the use of deep learning classifiers, can effectively mitigate these challenges and significantly improve the quality of the data that is collected.

 Open access
Open access