


1 Introduction
Stance detection is a natural language processing technique that analyzes a segment of text to estimate the emotive tone expressed in regards to a specific topic, building on sentiment analysis methods (AlDayel and Magdy Reference AlDayel and Magdy2021; Bestvater and Monroe Reference Bestvater and Monroe2023; Mohammad, Sobhani, and Kiritchenko Reference Mohammad, Sobhani and Kiritchenko2017) which simply gauge the overall sentiment of the text. Sentiment analysis methods have been used for a diverse range of tasks within social science and political science research. These techniques have been used to measure media tone (Boukes et al. Reference Boukes, van de Velde, Araujo and Vliegenthart2020), public opinions (Ceron et al. Reference Ceron, Curini, Iacus and Porro2014), political polarization (Yarchi, Baden, and Kligler-Vilenchik Reference Yarchi, Baden and Kligler-Vilenchik2021), politician favorability (Nasukawa and Yi Reference Nasukawa and Yi2003), medical patient experiences (Greaves et al. Reference Greaves, Ramirez-Cano, Millett, Darzi and Donaldson2013), disaster relief (Beigi et al. Reference Beigi, Hu, Maciejewski, Liu, Pedrycz and Chen2016) and mis- and disinformation detection (Alonso et al. Reference Alonso, Vilares, Gómez-Rodríguez and Vilares2021; Hardalov et al. Reference Hardalov, Arora, Nakov and Augenstein2022). More recent work has discussed how stance expressed toward specific subjects within texts is often distinct from general sentiment (Bestvater and Monroe Reference Bestvater and Monroe2023), leading to the development of new approaches to improve methods for stance detection (Burnham Reference Burnham2024; Zhang et al. Reference Zhang, Dai, Niu, Yin, Fan and Huang2024). Stance detection has subsequently been used for a variety of purposes, including annotation of political messages (Törnberg Reference Törnberg2023), assessing views on COVID-19 health mandates (Alizadeh et al. Reference Alizadeh2025), and tracking news media stance on political topics (Mets et al. Reference Mets, Karjus, Ibrus and Schich2024).
A variety of methods have been used to estimate stance, broadly falling into three categories: (1) lexicon-based approaches (LBAs), which assign sentiment scores to texts by aggregating predefined word-level values; (2) supervised language models (SLMs), which are models pretrained on large corpora and fine-tuned for specific classification tasks, including stance detection and natural language inference; and (3) generative large language models (LLMs), which generate text in response to a provided task description (Alturayeif, Luqman, and Ahmed Reference Alturayeif, Luqman and Ahmed2023; Burnham Reference Burnham2024; Zhang et al. Reference Zhang2024).
Previous work has found that fine-tuning SLMs and LLMs can improve stance detection. (Alizadeh et al. Reference Alizadeh2024; Bestvater and Monroe Reference Bestvater and Monroe2023; Laurer et al. Reference Laurer, van Atteveldt, Casas and Welbers2024b). There are multiple approaches to finetuning, including: in-target tuning, which uses annotated text specific to the stance detection task to refine model performance (Zhang et al. Reference Zhang, Deng, Liu, Pan, Bing, Duh, Gomez and Bethard2024); cross-target tuning, which leverages annotated data from related tasks or domains to improve performance on a target task (Osnabrügge, Ash, and Morelli Reference Osnabrügge, Ash and Morelli2023; Xu et al. Reference Xu, Paris, Nepal, Sparks, Gurevych and Miyao2018); and for LLMs, prompt engineering techniques such as few-shot prompting, where a small number of labeled examples are included in the task description, and chain-of-thought prompting, which guides the model through intermediate reasoning steps on an example to enhance task comprehension and accuracy (Wei et al. Reference Wei2022).
Across methods and tuning approaches, there has been mixed evidence on which strategies are most effective for improving stance detection. While some work has found that LLMs typically outperform SLMs (Burnham Reference Burnham2024; Maia and da Silva Reference Maia and da Silva2024; Mets et al. Reference Mets, Karjus, Ibrus and Schich2024), other studies have found that LLMs can vary widely in performance (Cruickshank and Ng Reference Cruickshank and Ng2024; Kristensen-McLachlan et al. Reference Kristensen-McLachlan, Canavan, Kardos, Jacobsen and Aarøe2023; Mu et al. Reference Mu2024). There is also been mixed evidence on few-shot prompting (Gül, Lebret, and Aberer Reference Gül, Lebret and Aberer2024; Perez, Kiela, and Cho Reference Perez, Kiela and Cho2021) and cross-target tuning performance (Li et al. Reference Li, Sosea, Sawant, Nair, Inkpen, Caragea, Zong, Xia, Li and Navigli2021; Ng and Carley Reference Ng and Carley2022).
Additionally, prior research has highlighted the potential for LLMs to produce unreliable estimates due to factors, such as data contamination across model versions (Aiyappa et al. Reference Aiyappa, An, Kwak and Ahn2024), prompting choices (Cruickshank and Ng Reference Cruickshank and Ng2024), and biases embedded in training data (Gover Reference Gover2023; Motoki, Neto, and Rodrigues Reference Motoki, Neto and Rodrigues2024; Rozado 2024). However, less applied work has systematically compared the performance of different fine-tuning approaches and prompting strategies, particularly in contexts involving multiple target subjects or continuous measures of stance (Zhang et al. Reference Zhang, Dai, Niu, Yin, Fan and Huang2024).
Existing research primarily benchmarks stance detection methods using binary or categorical measures, which limits the ability to compare variations in sentiment intensity (Alturayeif et al. Reference Alturayeif, Luqman and Ahmed2023; Schiller, Daxenberger, and Gurevych Reference Schiller, Daxenberger and Gurevych2021; Zhang et al. Reference Zhang, Dai, Niu, Yin, Fan and Huang2024). However, several existing stance evaluation benchmarks have used continuous stance scores to capture polarity scales (Saif et al. Reference Saif, Fernandez, He and Alani2013; Thelwall, Buckley, and Paltoglou Reference Thelwall, Buckley and Paltoglou2012), emotional intensity (Mohammad and Bravo-Marquez Reference Mohammad and Bravo-Marquez2017; Mohammad et al. Reference Mohammad, Bravo-Marquez, Salameh and Kiritchenko2018), or aspect-based sentiment (Dai et al. Reference Dai, Kong, Shang, Feng, Jiaji and Tan2025). Further, more recent work has begun to explore continuous stance estimation, either by annotating stance scores on a continuous scale (Li and Conrad Reference Li and Conrad2024) or by positioning political texts along continuous dimensions (Bergam, Allaway, and Mckeown Reference Bergam, Allaway and Mckeown2022; Le Mens and Gallego Reference Mets, Karjus, Ibrus and Schich2024). Evaluating stance with continuous measures is valuable for many political questions, as it allows for a more nuanced expression of stance, enables ranking of statements by intensity, and facilitates richer statistical comparisons across groups. However, there remains limited evidence comparing the performance of stance detection methods using continuous measures.
This article compares the performance of lexicon-based methods, SLMs, and LLMs in detecting stance. We evaluate model performance across two datasets of statements about major U.S. presidential candidates posted on Twitter (now X) before and after the 2020 U.S. Presidential Election. We also assess the impact of three fine-tuning approaches: cross-target tuning (using models trained on a politician’s party affiliation), in-target tuning (using models trained on hand-coded stance scores), and prompt engineering. Our results show that while cross-target tuning and prompt engineering improve performance, in-target tuning consistently produces the most accurate models. Notably, in-target tuning is especially important when analyzing statements that reference multiple target subjects, where it significantly outperforms other approaches.
2 Methods Considered
We estimated sentiment scores using six candidate models: two LBAs, VADER (Valence Aware Dictionary for Sentiment Reasoning) (Hutto and Gilbert Reference Hutto and Gilbert2014) and EmoLex (NRC Word-Emotion Association Lexicon) (Mohammad and Turney Reference Mohammad, Turney, Inkpen and Strapparava2010); two SLMs: SiEBERT, which classifies stance using categorical sentiment scores (Hartmann et al. Reference Hartmann, Heitmann, Siebert and Schamp2023), and DeBERTa, which uses natural language inference to categorize stance (He et al. Reference He, Liu, Gao and Chen2020; Laurer et al. Reference Laurer, van Atteveldt, Casas and Welbers2024a); and two LLMs, GPT-3.5 Turbo and GPT-4 Omni (Brown et al. Reference Brown2020).
We present results using a limited selection of methods, though we consider a wider range of approaches in the Supplementary Material.Footnote 1 We prioritized evaluating SLMs over other supervised methods, as previous research has shown SLMs consistently outperform approaches, such as support vector machines, naive Bayes, logistic regression, and long short-term memory models (Hartmann et al. Reference Hartmann, Heitmann, Siebert and Schamp2023).
We provide a brief description of each model in the following sections, along with a summary of all included methods in Table A.1 in the Supplemental Material. Code for this project is available through GitHub, along with the input data, estimates, and summary result tables at the Harvard Dataverse. All models were trained and deployed on a vast.ai instance with an RTX A4000 GPU and an Xeon W-2175 CPU, using Python 3.11 and R 4.2.2.
2.1 LBAs
LBAs assign sentiment values to words in sentences using predefined dictionaries. These dictionaries are typically created by either assigning scores to words based on qualitative judgments of their polarity (e.g., the word “good” might have a sentiment score of 0.7, while “great” scores 0.8) or by using models to derive latent sentiment scores from human-coded texts (Pang, Lee, and Vaithyanathan Reference Pang, Lee and Vaithyanathan2002). Each word in the text is scored, and the overall sentiment score is the average of these values. LBAs can vary depending on the method used to construct the dictionary or the specific domain considered for sentiment scoring. For instance, some dictionaries are based on researchers evaluating word sentiment within specialized corpora, such as political speeches or news articles (Deng and Wiebe Reference Deng, Wiebe, Mihalcea, Chai and Sarkar2015).
Some lexicon-based methods use expanded approaches that include features like valence shifting and semantic contexts, such as the approach VADER. Valence shifting involves assigning a multiplicative value to words which modify sentiment scores in the included text. Valence shifting assigns a multiplicative factor to words that modify the sentiment of other words in the text. These shifters are pre-specified by the researcher and are typically adjectives that alter the sentiment of nearby words. For example, the word “very” might increase the sentiment value of the next word by a factor of 1.15. In a sentence like “Spot is a very good boy,” if the word “good” is assigned a sentiment score of 0.7, the bigram “very good” would receive a sentiment score of
$1.15 \times 0.7 = 0.805$
 .
.
We estimated stance scores using all LBAs discussed in Section A.1 of the Supplementary Material. We implemented these approaches using the R packages sentimentr v2.9.0. and vader v1.2.1. Results can be found in Section A.10 of the Supplementary Material.
2.2 SLMs
Supervised models have long been used to estimate text sentiment, including approaches, such as Naive Bayes, support vector machines, logistic regression, decision trees, and neural networks (Wankhade, Rao, and Kulkarni Reference Wankhade, Rao and Kulkarni2022). In this article, we evaluate the performance of SLMs, which previous research has shown to outperform traditional supervised models in sentiment analysis and stance detection tasks (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019; Hartmann et al. Reference Hartmann, Heitmann, Siebert and Schamp2023).
SLMs leverage transfer learning, beginning with a transformer-based model that predicts masked words based on context-dependent vectors (Vaswani et al. Reference Vaswani2017). The model’s parameters are then updated through fine-tuning on a classification task, typically using a binary or categorical outcome variable (Hartmann et al. Reference Hartmann, Heitmann, Siebert and Schamp2023; Loureiro et al. Reference Loureiro, Barbieri, Neves, Anke and Camacho-Collados2022).
In this analysis, we examine two approaches to SLMs: pretrained transformers and paired-sequence entailment classification. Specifically, we evaluate the performance of SieBERT, a fine-tuned version of the RoBERTa model trained on sentiment datasets from 217 academic publications (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019; Hartmann et al. Reference Hartmann, Heitmann, Siebert and Schamp2023; Liu et al. Reference Liu2019), and BERT-NLI, a fine-tuned version of the DeBERTa-V3 model trained on various additional datasets (He et al. Reference He, Liu, Gao and Chen2020; Laurer et al. Reference Laurer, van Atteveldt, Casas and Welbers2024a, Reference Laurer, van Atteveldt, Casas and Welbers2024b). These models differ in their classification approaches. Pretrained transformers, such as SieBERT, are first trained using masked language modeling and then fine-tuned on domain-specific tasks (in this case, stance detection) to predict labels (Hartmann et al. Reference Hartmann, Heitmann, Siebert and Schamp2023). In contrast, paired-sequence entailment models, like BERT-NLI, use natural language inference to perform universal classification tasks, determining whether input text entails a given hypothesis (in this case, a hypothesis related to the stance of the text) (Laurer et al. Reference Laurer, van Atteveldt, Casas and Welbers2024a).
We implemented these approaches using the Python packages Transformers and Torch. Additional details on the implementation of these methods are available in Section A.3 of the Supplementary Material.
2.3 Generative LLMs
Generative LLMs leverage advanced architectures to understand language in context, building on transformer models and incorporating much larger datasets than SLMs. These models are further refined through reinforcement learning, based on human–AI interactions. The most widely used approach in large language modeling is generative pre-trained transformers (GPTs), which generate text based on human-written prompts (OpenAI 2022; Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018). In this study, we used two versions of GPT: ChatGPT-3.5 Turbo (v. 0125) and ChatGPT-4 Omni (v. 2024-08-06) to estimate stance. All models were set with a temperature hyperparameter of zero to produce more deterministic outputs (Alizadeh et al. Reference Alizadeh2024; Burnham Reference Burnham2024). Across multiple runs, we found that a temperature of zero allowed us to reproduce evaluation metrics consistently, though we observed slight fluctuations in the estimated scores on specific tasks, typically within a 0.1-point margin.
2.3.1 Prompts
For LLMs, we used four prompts to estimate stance scores:
-
• A sentiment prompt, which tasked the model with estimating a continuous sentiment score of the provided text.
-
• A stance prompt, which tasked the model with estimating a continuous stance score of the provided text.
-
• A few-shot prompt, which tasked the model with estimating a continuous stance score of the provided text, including four examples of existing tweets along with an associated stance score.
-
• A chain-of-thought prompt, which used three successive prompts to estimate continuous stance, using prompt (2) first, then tasking the model to explain the reasoning behind the estimated score, then including this reasoning in a final prompt as an example (. He et al. Reference He2024; Kojima et al. Reference Kojima, Gu, Reid, Matsuo and Iwasawa2022; Wei et al. Reference Wei2022).
For each prompt, we appended text from tweets to the end of the prompt input. For prompts 2–4, we included information on whether the target subject was “Biden” or “Trump.” All calls to the GPT API were made in separate sessions to ensure independence in model responses, and the temperature parameter was set to zero to ensure less stochastic responses (Alizadeh et al. Reference Alizadeh2024; Burnham Reference Burnham2024).
In addition to these prompts, we tested two alternative formulations of prompt (2): one which changed the prompt language slightly and a separate prompt which used the same language but tasked the model with generating a binary stance score (
$-$
 1 or 1). Section A.8 of the Supplementary Material includes all prompt language and additional details on prompting strategies. After receiving responses from the GPT API, we did additional post-processing to ensure results were in a vector format by using regular expressions on the obtained responses to extract stance scores.
1 or 1). Section A.8 of the Supplementary Material includes all prompt language and additional details on prompting strategies. After receiving responses from the GPT API, we did additional post-processing to ensure results were in a vector format by using regular expressions on the obtained responses to extract stance scores.
3 Datasets
We obtained two corpuses of data containing texts posted to Twitter (i.e., tweets), which we used to evaluate the performance of each candidate method. Note that such texts are brief, containing no more than 280 characters each. Providing additional details on each corpus:
Politicians: First, we assembled a “politician dataset” which contains all tweets posted by sitting members of the U.S. Congress (Senate and House of Representatives) during the 2020 U.S. Presidential election, between September 20, 2020 and January 21, 2021. We further narrowed the set of tweets to those that referenced either Joseph Biden or Donald Trump. We ultimately compiled 20,442 texts, composed of 5,508 tweets referencing Biden (3,902 from Democrats and 1,606 from Republicans), in addition to 14,934 tweets referencing Trump (4,109 from Republicans and 10,825 from Democrats). From this set of tweets, we randomly sampled 100 tweets concerning Biden and 100 tweets concerning Trump, which were scored by the study team and used to investigate how well party affiliation correlated with human-coded stance scores (we discuss this further in Section A.4 of the Supplementary Material).
Users: Second, we assembled a “user dataset” which contained tweets from the 1% sample of Twitter users. To assemble the list of users, we collected all available tweets from the 1% Twitter Firehose API between January 5, 2020 and August 15, 2022. We note that the resulting user list was skewed toward high-volume users. For users on this list, we collected tweets posted during the study period from September 20, 2020 to January 21, 2021. We then narrowed the included texts to those containing either the word “Trump” or “Biden,” then sampled 250 texts from this narrowed set to those that mentioned Joe Biden alone (and not Donald Trump), 250 texts that mentioned Donald Trump alone (and not Joe Biden), and an additional 126 texts that mentioned both Joe Biden and Donald Trump. Each sampled text was produced by a different Twitter user. We also sampled an additional 250 tweets mentioning Joe Biden (and not Donald Trump) and 250 tweets mentioning Donald Trump (and not Joe Biden), which were used exclusively for model tuning.
In addition to these two datasets, we applied models and estimated stance scores using data available in two previous studies: Li et al. Reference Li, Sosea, Sawant, Nair, Inkpen, Caragea, Zong, Xia, Li and Navigli2021 and Kawintiranon and Singh Reference Kawintiranon, Singh and Toutanova2021. We provide additional analyses regarding these studies in Section A.5 of the Supplementary Material.
For texts obtained by the study team, we collected information on the date the text was posted, IDs for the author, a tweet ID, and a binary indicator determining if the text was a retweet (i.e., one user sharing another user’s tweet). We replaced any letters containing accents with an ASCII equivalent letter without an accent. We also processed texts to remove any emoticons (e.g., “;)”), website addresses, HTML code, images, or emojis.
3.1 Benchmark and Training Data
We evaluated methods’ performance in each datset by comparing estimated stance scores with benchmark scores. We used different benchmark scores in the politician dataset and the user dataset.
In the politician dataset, we used the political affiliation of each Congress person to develop a benchmark score. Specifically, for each text, we set a benchmark score to equal 1 if the party affiliation (Democrat or Republican) of a representative aligned with the party affiliation of a given subject (“Biden” or “Trump”) and
$-$
 1 if otherwise. This coding was meant to replicate an assumption that a member of Congress will speak positively concerning presidential candidates who belong to the same party and negatively of candidates belonging to the opposing party.Footnote
2
For example, a tweet posted by Nancy Pelosi (a Democrat) containing “Biden” was assigned a benchmark score of 1, whereas a text by Nancy Pelosi containing “Trump” was assigned a score of
$-$
1 if otherwise. This coding was meant to replicate an assumption that a member of Congress will speak positively concerning presidential candidates who belong to the same party and negatively of candidates belonging to the opposing party.Footnote
2
For example, a tweet posted by Nancy Pelosi (a Democrat) containing “Biden” was assigned a benchmark score of 1, whereas a text by Nancy Pelosi containing “Trump” was assigned a score of
$-$
 1.
1.
For the user dataset, we developed stance scores by having two human coders review each text and assign a continuous stance value between
$-$
 1 and 1 concerning each subject. We then averaged the human-coded stance scores to obtain a benchmark score. We evaluated inter-rater reliability across the two coders, finding high agreement in coded scores, with an intraclass correlation of 0.85 (95% CI: 0.835, 0.864). More details on inter-rater reliability can be found in Section A.2 of the Supplementary Material.
1 and 1 concerning each subject. We then averaged the human-coded stance scores to obtain a benchmark score. We evaluated inter-rater reliability across the two coders, finding high agreement in coded scores, with an intraclass correlation of 0.85 (95% CI: 0.835, 0.864). More details on inter-rater reliability can be found in Section A.2 of the Supplementary Material.
To facilitate evaluations with binary estimated and benchmark scores, all benchmark scores were also reformulated as binary by setting values below zero to “Negative” and values above zero to “Positive.”
We hypothesize that hand-coded scores are a better representation of true stance than our party affiliation proxy. Accordingly, our primary conclusions are based on evaluating performance using the users dataset. However, we also evaluate performance using the politician dataset, which provides a robustness check for the performance of cross-target tuning.
These benchmarks also provide a means by which to fine-tune the methods. In particular, the party affiliation benchmarks are used for in-target tuning of the politicians dataset and cross-target tuning of the users dataset, whereas the human-coded benchmarks are used for cross-target tuning of the politicians dataset and in-target tuning of the users dataset. We provide more details on tuning in the following section.
In Section A.4 of the Supplementary Material, we evaluate the validity of using party affiliation as a measure of stance by comparing it to human-coded stance scores in the politician dataset. In summary, we found that political affiliation was highly correlated with human-coded stance scores (
$r = 0.87$
 ). We also investigate using DW-Nominate scores as a proxy measure (Carroll et al. Reference Carroll, Lewis, Lo, Poole and Rosenthal2009; Poole and Rosenthal Reference Poole and Rosenthal1985), though we find this measure does not exhibit as strong a correlation with human-coded stance scores.
). We also investigate using DW-Nominate scores as a proxy measure (Carroll et al. Reference Carroll, Lewis, Lo, Poole and Rosenthal2009; Poole and Rosenthal Reference Poole and Rosenthal1985), though we find this measure does not exhibit as strong a correlation with human-coded stance scores.
Note that all analyses presented in the results section (Section 6) involve comparisons using continuous or binary benchmark scores. In Section A.6 of the Supplementary Material, we also consider performance using categorical (ordinal) benchmark scores.
4 Model Tuning
We tuned SLMs and LLMs models using data from both the politician dataset (using a party affiliation proxy) and the user dataset (using human-coded stance scores). Each of these models was then applied to both datasets, yielding a set of in-target tuned models and a set of cross-target tuned models for each of the two data sources.
The benchmark scores from each respective dataset were used as the outcome variable for tuning models. Note that tuned models were constructed independently for each target (“Biden” or “Trump”). For both datasets, we split available data for each subject into a tuning sample, separated further into a training, test, and evaluation set.
For the politician dataset, 80% of the texts for each subject were used for tuning (further separating into 80% for training and 20% for testing), and the remaining 20% was withheld for out-of-sample evaluation. For the user dataset, 250 texts mentioning only “Trump” and 250 texts mentioning only “Biden” were used as the tuning samples (200 in the training set and 50 in the test set), and an additional 250 texts mentioning only “Trump” and 250 texts mentioning only “Biden” were withheld for evaluation.Footnote 3 The 126 user texts mentioning both subjects was used only for evaluation—we applied the subject-specific tuned models separately to each of these texts (to generate two scores for the text—one for each subject).
The models tuned using party affiliation were applied to estimate stance scores on both the politician dataset (to evaluate in-target tuning performance on the party affiliation measure) and user datasets (to evaluate cross-target tuning performance). Likewise, the models tuned using the user dataset were applied to estimate stance scores on the politician dataset (to evaluate cross-target tuning performance on a party affiliation classifier) and the user evaluation sample (to evaluate in-target tuning on the hand-coded stance scores).
Conventionally, researchers have used fivefold or tenfold cross-validation to evaluate model accuracy under slightly different samples. We were limited to a single fold for cross-validation due to the costs involved in tuning GPT models. We discuss this limitation further in Section 7.1.
Lastly, we also tested tuned models using the politician dataset and DW-Nominate as a proxy measure but found these models underperformed models tuned using political affiliation as a proxy (more details on these results can be found in Section A.4 of the Supplementary Material). We also provide some additional details on tuning SLMs in Section A.3 of the Supplementary Material.
5 Evaluation Metrics
We summarize model performance primarily by calculating Pearson correlations between the estimated scores and the benchmark scores. The Pearson correlation is used to measure the association between continuous variables. However, we are also interested in assessing the models’ ability to quantify stance using binary (positive/negative) or categorical (e.g., positive/neutral/negative) measures. To make these comparisons, we transform the estimated scores to the desired scale and then apply Matthews’ correlation coefficient (phi) (Matthews Reference Matthews1975) for binary scores and Cramér’s V (Cramér Reference Cramér1999) for categorical scores. Additionally, we use the point-biserial correlation (Sheskin Reference Sheskin2003) when measuring the association between binary and continuous scores.Footnote 4 Results for binary and categorical scores are provided in the Supplementary Material.
The Pearson correlation is used because of its advantages in assessing model performance. Specifically, Pearson correlations are invariant to the labeling of positive and negative classes and are less sensitive to class imbalances, unlike metrics such as the F1-score, which can be influenced by class distribution (Baldi et al. Reference Baldi, Brunak, Chauvin, Andersen and Nielsen2000; Chicco and Jurman Reference Chicco and Jurman2020, Reference Chicco and Jurman2023).
We also evaluated model performance using root mean squared error (RMSE) and mean squared error (MSE) for continuous benchmark scores, and F1-score, accuracy, precision, and recall for binary benchmark scores. However, it is important to note that these metrics are not suitable for comparing results across different types of data. For instance, RMSE should not be used to compare continuously estimated scores with binary benchmarks, such as the party affiliation metric in the politician dataset.
Across datasets, summary statistics are reported separately for “Biden” and “Trump” as a target subject. For the user dataset, we also separated out texts by the number of subjects, with results indicating whether a text mentioned a single subject or both subjects.
6 Results
In the following sections, we detail method performance. In Section 6.1, we report results using the politician dataset and show how methods without additional tuning distinguish stance across party affiliation. Then, in Section 6.2, we compare method performance without additional tuning on hand-coded stance scores within the user dataset, comparing results across texts that contain a single subject or multiple subjects. Section 6.3 then compares method performance after tuning, showing cross-target and in-target tuning performance using the party affiliation and hand-coded stance score benchmarks. We further compare performance when benchmarks are measured as a binary variable. Lastly, we compare LLM results across several different prompting strategies in Section 6.4. We also provide example texts from each dataset, along with estimated stance scores by method, in Section A.9 of the Supplementary Material.
6.1 Do Stance Scores Align With Party Affiliation Without Tuning?
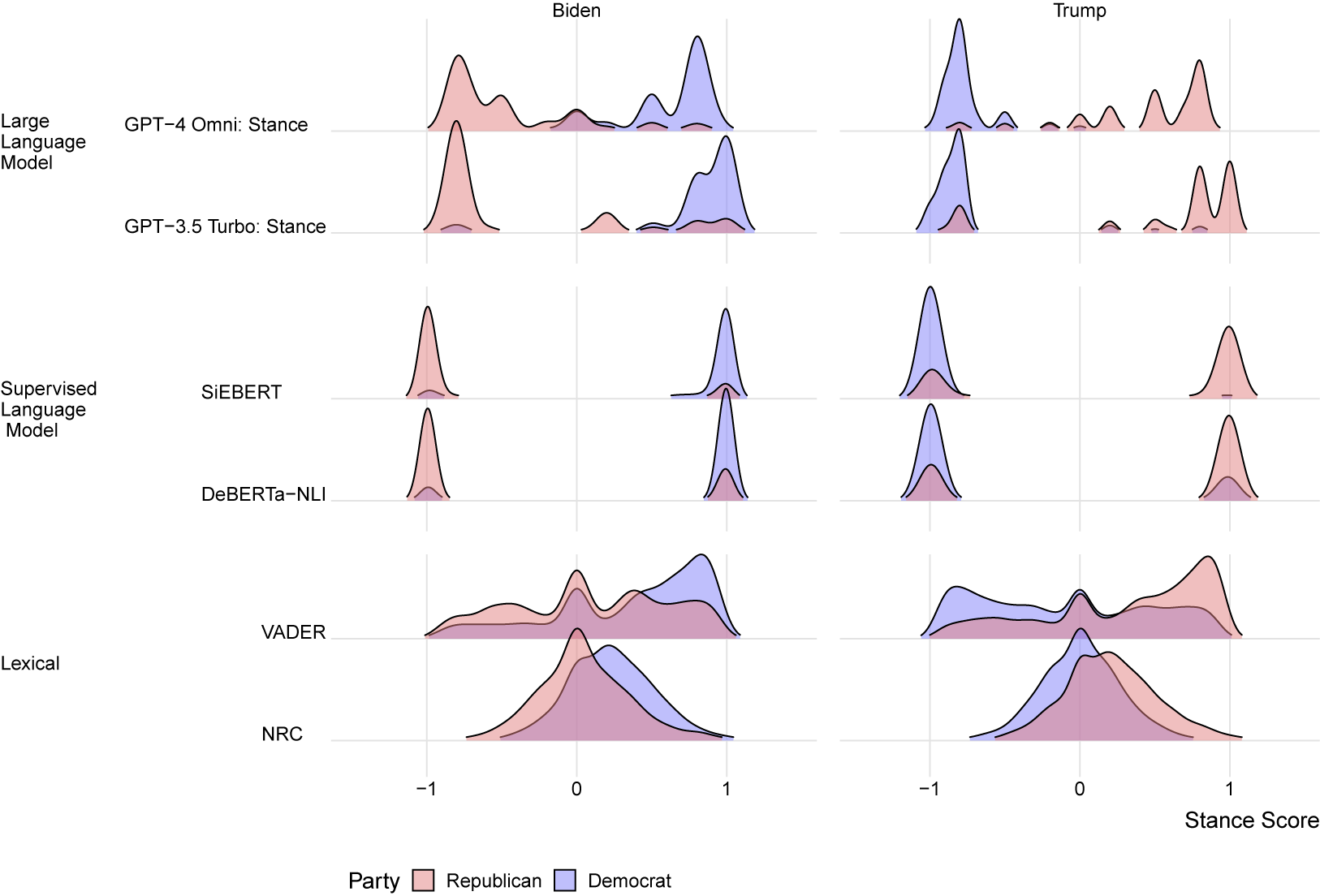
Figure 1 displays the distribution of estimated stance scores across political affiliations. We assume that public statements by legislators will express positive stance concerning a political candidate who belongs to their own political party and negative sentiment concerning candidates from the opposing party (see Section A.4 of the Supplementary Material discussing this assumption). In short, results are expected to show separation of stance scores based on party affiliation.
Distribution of estimated stance scores by subject for politician texts.

Figure 1 Long description
The visualization is organized into a grid with two columns labeled Biden and Trump. The vertical axis groups models into three categories: Large Language Model (G P T 4 Omni: Stance and G P T 3.5 Turbo: Stance), Supervised Language Model (SiEBERT and DeBERTa N L I), and Lexical (VADER and N R C). The horizontal axis represents Stance Score ranging from negative 1 to 1. Data is color-coded by party: Republican in red and Democrat in blue.
* Large Language Models: For Biden, G P T 4 Omni shows a multi-modal distribution with a prominent red peak near negative 0.8 and a blue peak near 1. G P T 3.5 Turbo shows a sharp red peak at negative 0.8 and a blue peak at 1. For Trump, both models show a sharp blue peak at negative 0.8 and a red peak at 1.
* Supervised Language Models: SiEBERT and DeBERTa N L I show nearly identical bimodal distributions. For Biden, there is a small red peak at negative 1 and a sharp blue peak at 1. For Trump, there is a sharp blue peak at negative 1 and a sharp red peak at 1.
* Lexical Models: VADER shows broad, overlapping distributions for both politicians. N R C shows the most centralized distributions, with both parties peaking near 0 for both Biden and Trump, though the Democrat blue curve is slightly shifted toward 1 for Biden and toward negative 1 for Trump.
The left facet of this figure displays scores for texts containing the subject “Biden,” while the right facet displays scores for texts concerning the subject “Trump.” The blue density shows estimated scores for Democrat members, while the red density shows estimated scores for Republican members. The purple density shows the overlap in the two empirical distributions.
As shown in Figure 1, the LBAs—VADER and NRC—estimate a similar distribution of scores across political affiliations and target subject, showing little separation based on the author’s party affiliation. Conversely, SLMs and LLMs produce more divergent scores between the two political parties. We observe that SLMs produce scores clustered around
$-$
 1 and
$+$
1 and
$+$
 1, which is a consequence of these methods classifying texts as a binary variable. The LLMs produce continuous-valued scores; however, there remain few neutral-valued scores for either subject or political party.
1, which is a consequence of these methods classifying texts as a binary variable. The LLMs produce continuous-valued scores; however, there remain few neutral-valued scores for either subject or political party.
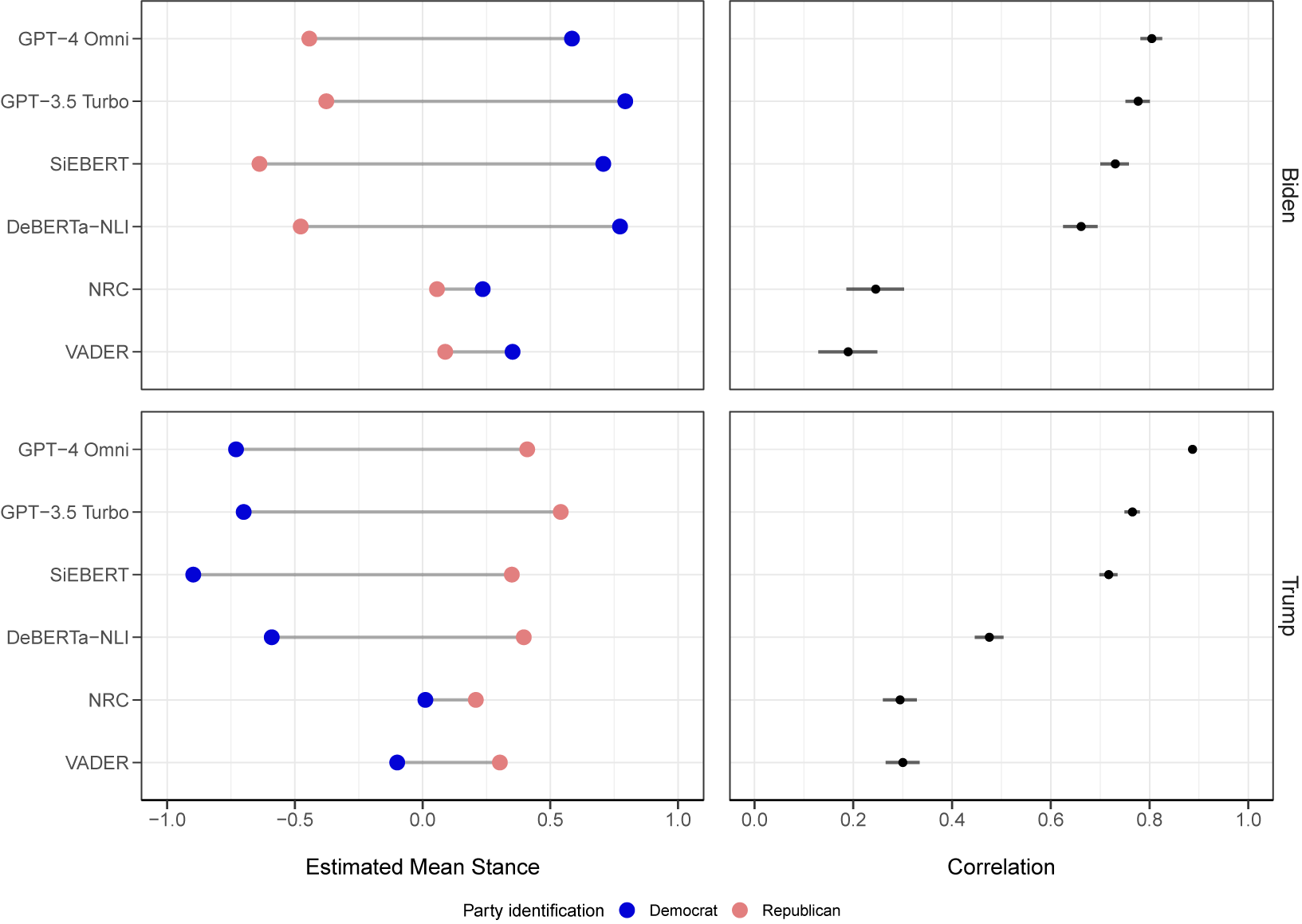
To further determine if estimated scores align party affiliation, we display the mean of estimated stance scores by party affiliation and target subject in Figure 2, along with the Pearson correlation (and the 95% confidence interval for the correlation) between estimated scores and party affiliation. Lexicon-based methods do not estimate a meaningful difference in scores between the political parties for either subject, and exhibit a small correlation between estimated scores and the benchmark.
Estimated mean stance score by political affiliation and target subject (left) and correlation between party affiliation and estimated stance scores by target subject (right).

Figure 2 Long description
The multi-panel plot is organized into a two-by-two grid. The top row focuses on Biden and the bottom row on Trump. The left column displays Estimated Mean Stance on an X axis from negative 1.0 to 1.0. The right column displays Correlation on an X axis from 0.0 to 1.0. The Y axis for all panels lists six models: G P T dash 4 Omni, G P T dash 3.5 Turbo, Si E B E R T, De B E R T a dash N L I, N R C, and V A D E R.
Top-Left Panel (Biden Stance): Blue dots (Democrat) are consistently to the right of red dots (Republican). For G P T dash 4 Omni, G P T dash 3.5 Turbo, Si E B E R T, and De B E R T a dash N L I, the blue dots are near 0.75 while red dots are between negative 0.5 and negative 0.75. N R C and V A D E R show much smaller gaps near the 0.0 center line.
Top-Right Panel (Biden Correlation): Black dots with horizontal error bars show a downward trend in correlation. G P T dash 4 Omni is highest at approximately 0.8, while V A D E R is lowest at approximately 0.2.
Bottom-Left Panel (Trump Stance): The positions are reversed. Red dots (Republican) are to the right of blue dots (Democrat). For the top four models, red dots are near 0.5 while blue dots range from negative 0.6 to negative 0.9. N R C and V A D E R again show smaller gaps closer to 0.0.
Bottom-Right Panel (Trump Correlation): Similar to the Biden panel, correlation decreases from top to bottom. G P T dash 4 Omni is near 0.9, while N R C and V A D E R are both near 0.3.
SLMs and LLMs produce more divergent mean scores between the parties for both subjects, with the SiEBERT model having the widest difference between the parties of 1.35 for the subject “Biden” and 1.24 for the subject “Trump.” For all methods displayed in Figure 2, we find the difference between the two parties is significant (using an unpaired t-test with unequal variance for the mean difference).
However, despite the size of mean differences being comparable across SLMs and LLMs, there is a wide range of correlations between estimated scores and party affiliation. LLM models have the highest correlations for both subjects, with GPT-4 Omni having a correlation of 0.80 (0.78, 0.83) and 0.89 (0.87, 0.89) for texts with “Biden” and “Trump,” respectively. Lexicon-based models display the lowest correlation with the benchmark, with VADER having a correlation of 0.19 (0.13, 0.25) for “Biden” texts and NRC having a correlation of 0.29 (0.26, 0.32) for “Trump” texts.
Overall, we find that SLMs and LLM models estimate stance scores which correlate well with party affiliation, while lexicon-based methods fail to produce separation in mean scores across parties.
6.2 Do Stance Scores Align With Human-Coded Stance Scores Without Tuning?
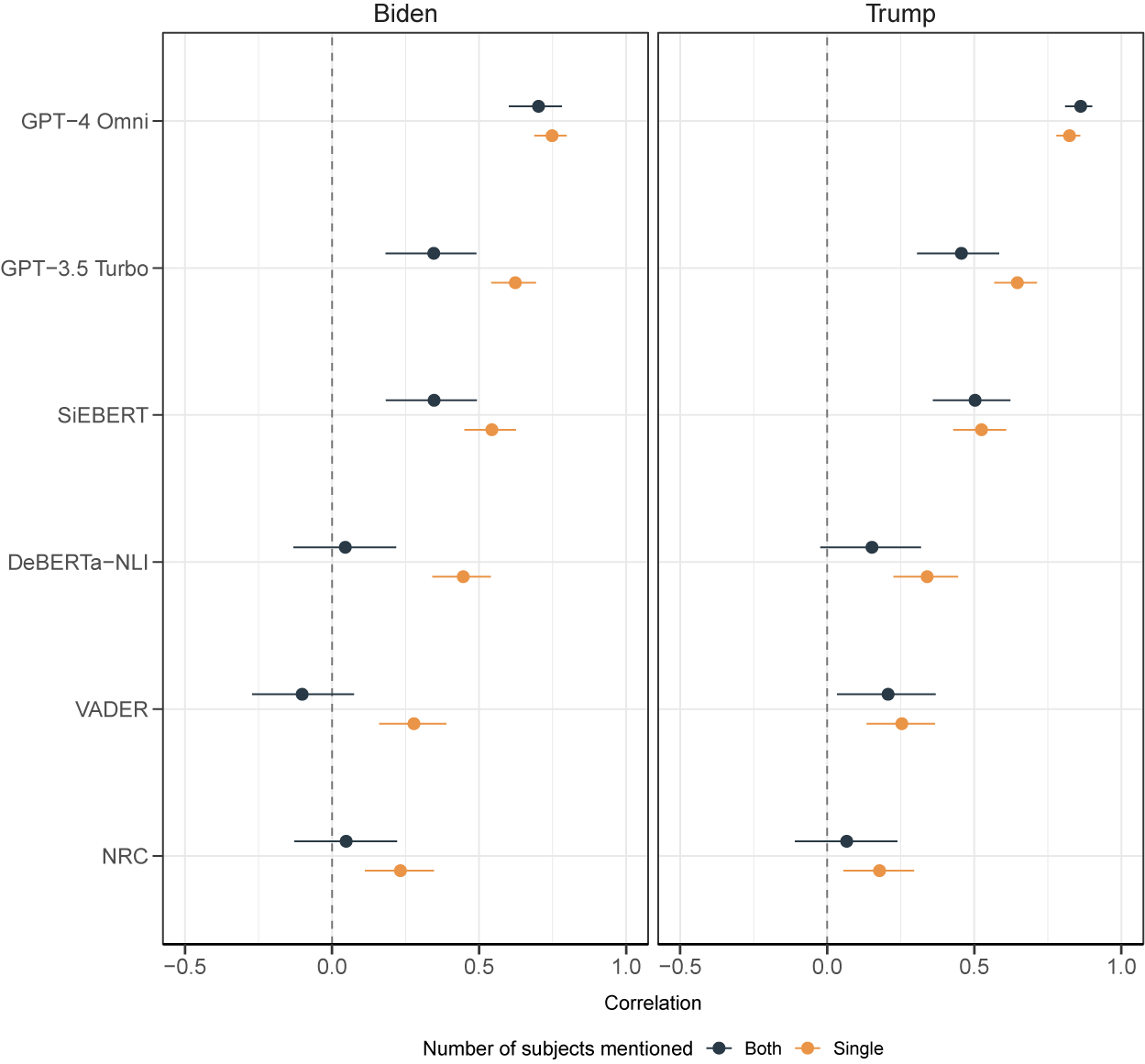
We next evaluated each method’s performance when estimating stance on user texts. We hypothesized that all approaches would struggle to recover stance without additional tuning (Bestvater and Monroe Reference Bestvater and Monroe2023), particularly when texts mention both subjects. Accordingly, we present results for user data separately by whether a text mentions a single subject or both subjects. In addition to these results, we also provide scatter plots of estimated scores compared to human-coded stance scores in Section A.11 of the Supplementary Material.Footnote 5
Figure 3 displays correlations between estimated scores and human-coded stance scores for each method. Facets in this figure show results stratified by the target subject (“Biden” or “Trump”), while color displays correlations separated by whether a text mentioned a single subject or both subjects. The figure shows that GPT-4 Omni has the highest correlation, 0.783 (0.777, 0.789), compared to alternative methods, across each subject and the number of subjects. For all methods, estimated correlations are lower when both subjects are mentioned in a text compared to a single subject, except GPT-4 Omni and the subject “Trump” (though this result is statistically non-significant).
Correlation of estimated stance scores with human-coded stance scores, by target subject and number of target subjects.

Figure 3 Long description
The two panels are titled Biden on the left and Trump on the right. The Y-axis lists six models from top to bottom: G P T-4 Omni, G P T-3.5 Turbo, SiEBERT, DeBERTa-N L I, V A D E R, and N R C. The X-axis represents Correlation ranging from -0.5 to 1.0 with a dashed vertical line at 0.0. Data points are color-coded: dark blue for Both subjects and orange for Single subject, each with horizontal error bars.
In the Biden panel:
* G P T-4 Omni shows the highest correlation, with Both near 0.7 and Single near 0.75.
* G P T-3.5 Turbo and SiEBERT show Both near 0.35 and Single near 0.55.
* DeBERTa-N L I shows Both near 0.05 and Single near 0.45.
* V A D E R shows Both at a negative correlation near -0.1 and Single near 0.25.
* N R C shows Both near 0.05 and Single near 0.25.
In the Trump panel:
* G P T-4 Omni shows the highest correlation, with Both near 0.85 and Single near 0.8.
* G P T-3.5 Turbo shows Both near 0.45 and Single near 0.65.
* SiEBERT shows Both near 0.5 and Single near 0.55.
* DeBERTa-N L I shows Both near 0.15 and Single near 0.35.
* V A D E R shows Both near 0.2 and Single near 0.25.
* N R C shows Both near 0.05 and Single near 0.2.
Across both panels, Single subject mentions generally result in higher correlation scores than Both subjects mentions, and G P T-4 Omni consistently outperforms all other models.
Estimates from the SLMs and LBAs show weak or inverse correlations with the benchmark scores, especially when the subject is “Biden.” Among the methods considered, VADER exhibits the weakest correlation, with an inverse correlation of
$-$
 0.1 (
$-$
0.1 (
$-$
 0.27, 0.075) when the text includes both subjects and scores are estimated for “Biden.” In contrast, SiEBERT achieves the highest correlation among the SLMs and LBAs, with a correlation of 0.54 (0.45, 0.62) for texts mentioning “Biden” as the sole subject. Overall, these results suggest that LLM models, particularly GPT-4 Omni, perform well in estimating scores without additional tuning. The performance gap between LLMs and other models is most pronounced when multiple subjects are mentioned, with SLMs and LBAs underperforming relative to when only a single target subject is present.
0.27, 0.075) when the text includes both subjects and scores are estimated for “Biden.” In contrast, SiEBERT achieves the highest correlation among the SLMs and LBAs, with a correlation of 0.54 (0.45, 0.62) for texts mentioning “Biden” as the sole subject. Overall, these results suggest that LLM models, particularly GPT-4 Omni, perform well in estimating scores without additional tuning. The performance gap between LLMs and other models is most pronounced when multiple subjects are mentioned, with SLMs and LBAs underperforming relative to when only a single target subject is present.
6.3 How Does Tuning Change Performance?
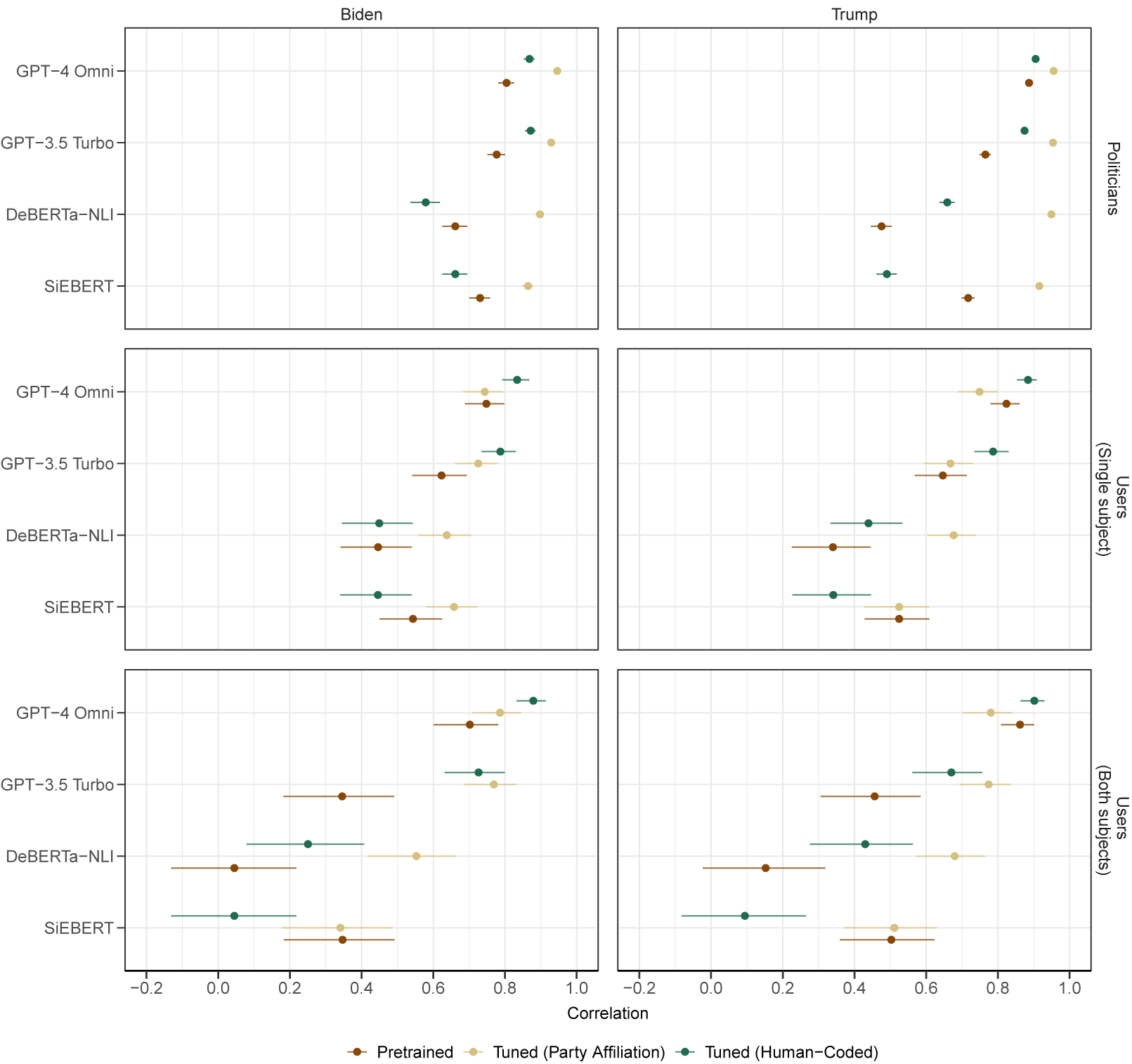
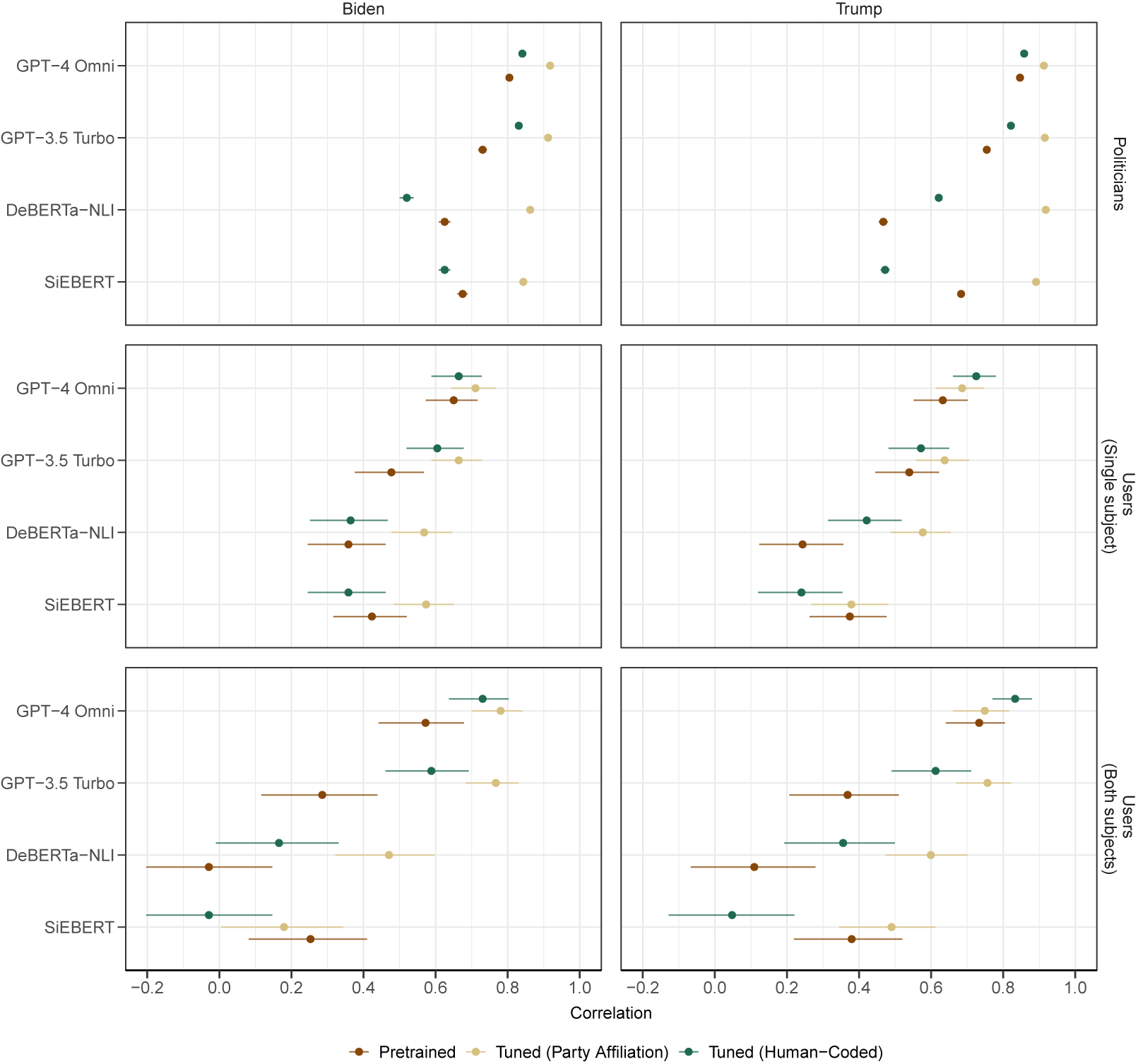
To improve the performance of supervised methods and LLM models, we attempted to tune these approaches using both in-target and cross-target tuning. We present the results of tuned models on out-of-sample politician data and user data in Figure 4.
Correlation of estimated stance scores with party affiliation (politician data) and human-coded stance scores (user data), by method, tuning approach, target subject, and number of subjects.

Figure 4 Long description
The multi-panel graph consists of three rows and two columns. The x-axis for all panels represents Correlation, ranging from negative 0.2 to 1.0. The y-axis lists four models: G P T-4 Omni, G P T-3.5 Turbo, De B E R T a-N L I, and S i E B E R T. Data points are color-coded: brown for Pretrained, light tan for Tuned Party Affiliation, and dark teal for Tuned Human-Coded.
* Top Row: Politicians. For both Biden (left) and Trump (right), Tuned Party Affiliation consistently shows the highest correlation, near 1.0. G P T models outperform De B E R T a and S i E B E R T in the Pretrained and Human-Coded categories.
* Middle Row: Users (Single subject). Correlation scores are generally lower than the politician data. G P T-4 Omni maintains the highest performance across all tuning types, while De B E R T a and S i E B E R T show wider error bars and lower correlations, particularly in the Pretrained category.
* Bottom Row: Users (Both subjects). This row shows the lowest overall correlations and the widest error bars. For Biden, S i E B E R T and De B E R T a Pretrained scores drop near 0.0. G P T-4 Omni remains the most stable, with correlations between 0.7 and 0.9.
Across all panels, tuning generally improves correlation compared to pretrained versions, with G P T-4 Omni consistently achieving the highest scores regardless of the target subject.
Note that for results in the politician data, the benchmark variable is party affiliation. Accordingly, models tuned using party affiliation would be an “in-target” approach, while those tuned using human-coded stance scores would be “cross-target.” Conversely, for the user data which uses human-coded stance scores as a benchmark variable, tuning using human-coded stance scores would be “in-target” while those tuned using party affiliation would be “cross-target.” We again separate user data into texts which mention either a single subject or both subjects.
Figure 4 shows correlations of estimated scores with each dataset’s respective benchmark: political affiliation and human-coded stance scores. We see that after some form of tuning, all methods improve in performance. Across datasets and target subjects, in-target tuned GPT-4 Omni models consistently perform the best. Some form of tuning leads to improvement over pretrained models for all methods (with the possible exception of SiEBERT), although the magnitude of this improvement is possibly smaller for GPT-4 Omni. Otherwise, specific model improvements vary depending on the tuning approach and benchmark variable.
In the politician dataset, we find that in-target tuning (with party affiliation) consistently leads to dramatic improvements in model performance (compared to pretrained models) across methods and subjects. Conversely, we see evidence that cross-target tuning (with human-coded stance scores) degrades the performance of the SLMs (DeBERTa NLI and SiEBERT) over pretrained analogs. For the LLMs (GPT), we see that cross-target tuning leads to a moderate improvement in model performance over the pretrained versions (while still under-performing compared to in-target tuning). Overall, these results indicate that (1) tuned models using the proxy measure reliably capture political affiliation, which provides evidence that the cross-target tuning models in the user dataset will reflect performance exclusively on the stance detection task (since the proxy measure appears to be well calibrate) and (2) cross-target tuned models using hand-coded scores lead to slight improvements in estimating party affiliation.
By contrast, the user dataset (which may be better suited to produce generalizable conclusions regarding estimation of stance since evaluations are based on human-coded benchmarks and not party affiliation) yields similar findings as well as additional nuance when evaluating performance. To start with the SLMs, in-target tuning (with human-coded stance scores) fails to yield statistically significant improvements over the pretrained models while potentially degrading performance in some cases (e.g., the SiEBERT model for Trump when both subjects are mentioned). However, cross-target tuning (with party affiliation) leads to statistically significant improvements over the pretrained versions of the DeBERTa-NLI models but fails to show similar improvement with the SiEBERT model. For the GPT models, both in-target and cross-target tuning improve performance over pretrained models; however, the benefits offered by in-target tuning are more substantial.
For models estimating stance, across models, subjects, and approaches to tuning (with the possible exception of GPT-4 Omni with Trump), the benefits of tuning appear to be most substantial when both subjects are mentioned, compared to single subjects. That is, we find that tuning narrows the performance gap for estimating stance between texts containing single or multiple subjects. This finding is most dramatic for both subject texts. Additionally, the tuning approach which most improves performance can differ by method.
While human-coded stance scores in the user data are continuous, estimated stance scores using the cross-target tuned model (based on party affiliation) are nearly binary. As such, it may be more feasible for in-target tuning (which is designed to yield continuous estimated scores) to maintain the distributional properties of the hand-coded benchmarks. Consequentially, findings could differ if the objective was to estimate binary stance (positive or negative), ignoring gradations.
To investigate this, we transformed the human-coded stance scores and all estimated scores to binary values which indicate “positive” or “negative” stance.Footnote 6 For this analysis, we used a modified prompt for GPT procedures, which specifically requests a binary output. Figure 5 shows results that are analogous to those in Figure 4 when binary benchmarks and estimated scores are used.
Correlation of binary stance scores with party affiliation (politicians dataset) and human-coded stance scores (users dataset), by method tuning approach, target subject, and number of subjects.

Figure 5 Long description
The grid consists of three rows and two columns. The x-axis for all panels represents Correlation ranging from negative 0.2 to 1.0. The y-axis lists four models: G P T dash 4 Omni, G P T dash 3 dot 5 Turbo, De B E R T a dash N L I, and Si E B E R T.
Columns are divided by target subject: Biden on the left and Trump on the right.
Rows are divided by dataset:
1. Top row: Politicians dataset.
2. Middle row: Users dataset (Single subject).
3. Bottom row: Users dataset (Both subjects).
Data points are color-coded by tuning approach:
- Brown dots: Pretrained.
- Tan dots: Tuned (Party Affiliation).
- Teal dots: Tuned (Human-Coded).
In the Politicians row, Tuned (Party Affiliation) consistently shows the highest correlation, often exceeding 0.8. In the Users rows, horizontal error bars are present. G P T dash 4 Omni generally maintains the highest correlation across all panels, typically between 0.6 and 0.9. The De B E R T a dash N L I and Si E B E R T models show significantly lower correlations in the Users (Both subjects) row, with some Pretrained and Tuned (Human-Coded) values falling near or below 0.2.
The results in Figure 5 are similar to those displayed in Figure 4. However, we find that overall performance tends to decrease when using binary values compared to the results shown in Figure 4. The results also show that GPT-3.5 Turbo and SLM models in the user dataset indicate cross-target tuning (with party affiliation) outperforms in-target tuning. For GPT-4 Omni for Biden, cross-target tuning offers the best performance for Biden, whereas for Trump, in-target tuning appears to be optimal (but note that the differences are not statistically significant in either case).
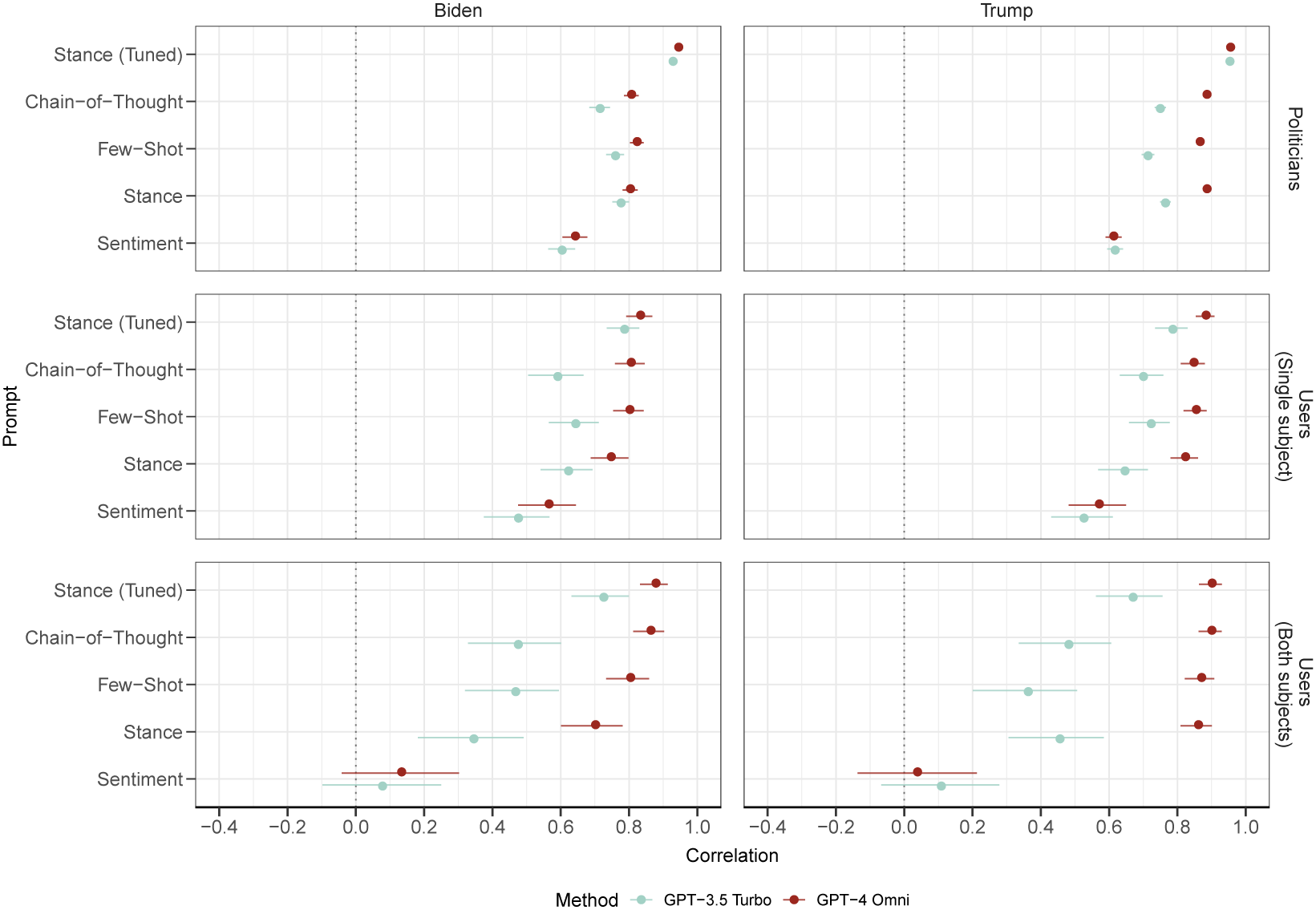
6.4 How Does Prompting Change Performance in LLMs?
LLMs have the added complexity of requiring a prompt which specifies a model task. In the previous section, we presented all results using a simple prompt which tasked the LLMs with providing a continuous (or for Figure 5, binary) stance score. Here, we present results across the wider array of prompts that were detailed in Section 2.3.1 and Section A.8 of the Supplementary Material. These are summarized as Chain-of-thought, Few-shot, Stance, and Sentiment.
The Stance prompt was used for all results presented in the previous sections. Complex prompting (Chain-of-thought and Few-shot) is often described as an alternative to tuning. As such, we compare these prompting strategies to in-target tuned models using the stance prompt.
Results for each prompt are provided in Figure 6, segmented by target subject, dataset (with user data also segmented by the number of subjects), and model (GPT-3.5 Turbo and GPT-4 Omni).
Correlation of continuous stance scores with party affiliation (politicians dataset) and hand-coded stance scores (user dataset), by prompt, method, target subject, and number of subjects.

Figure 6 Long description
The grid consists of three rows and two columns. The x-axis represents Correlation from negative 0.4 to 1.0. The y-axis lists prompt methods: Stance tuned, Chain-of-Thought, Few-Shot, Stance, and Sentiment. A legend at the bottom identifies light blue dots as G P T 3.5 Turbo and dark red dots as G P T 4 Omni.
* Top Row (Politicians): In both Biden and Trump columns, G P T 4 Omni consistently shows higher correlation than G P T 3.5 Turbo. Stance tuned has the highest correlation near 1.0, while Sentiment has the lowest near 0.6 for Biden and 0.5 for Trump.
* Middle Row (Users Single subject): Trends are similar to the first row but with wider error bars. G P T 4 Omni maintains a lead over G P T 3.5 Turbo. For Biden, correlations range from approximately 0.5 to 0.8. For Trump, they range from 0.6 to 0.9.
* Bottom Row (Users Both subjects): This row shows the lowest overall correlations and the widest error bars. In the Biden column, Sentiment drops significantly to near 0.1 for both models. In the Trump column, Sentiment is near 0.0. G P T 4 Omni remains more accurate than G P T 3.5 Turbo across all prompt types, with Stance tuned remaining the most effective method.
Overall, the evidence suggests that complex prompting strategies, such as chain-of-thought, may lead to improved model performance compared to simpler prompts. In several instances, most notably for GPT-4 Omni models, these prompting strategies lead to estimates which are comparable in performance to tuned model results. Nonetheless, the tuned models consistently yield the highest correlations; however, the differences between tuned models, chain-of-thought, and few-shot are not statistically significant in several cases when GPT-4-Omni is used (the difference is more distinct for GPT-3.5 Turbo). The improvements offered by tuning over alternative prompting strategies are largest when evaluating performance capturing the proxy measure of political affiliation, noting that the politician dataset had a greater sample size when conducting in-target tuning.
We see that a sentiment prompt performs relatively poorly, in particular for texts from the user dataset involving both subjects. This points to the benefits of directing the LLM toward a specific subject for stance detection and the sensitivity of models to prompting.
Pretrained models also tend to have higher performance when the subject target is Trump rather than Biden. Performance differences between subjects are non-significant in the user dataset but significant in the politician dataset. For example, the GPT-4 Omni Chain-of-Thought has a correlation of 0.8 (0.79, 0.83) for Biden texts and 0.88 (0.87, 0.89) for Trump, performing an average 9.7% worse.
Lastly, the results in Figure 6 indicate, similar to those shown in the previous sections, that more recent LLM models, specifically GPT-4 Omni, outperform older GPT models in both datasets. However, when evaluating results on hand-coded stance scores (users dataset), average differences are non-significant. This result suggests that for more recent LLMs, the relative benefit of tuning for estimating stance scores may be muted, compared to earlier model versions such as GPT 3.5 Turbo.
7 Conclusion
7.1 Limitations
These results carry several limitations. First, we used a limited number of out-of-sample cross-validation folds to evaluate model performance given computational costs. This also limited our ability to estimate replicate runs of LLMs. These models can exhibit variability in outputs from the same input (Aiyappa et al. Reference Aiyappa, An, Kwak and Ahn2024), though we aimed to minimize stochastic responses by setting a low value for the temperature hyperparameter. In addition, empirical work has found fewer folds may be preferable for method selection procedures, and results in Figure 4 display reasonably small uncertainty intervals on the test data (Zhang and Yang Reference Zhang and Yang2015). Also, many of our findings are based on comparisons of uncertainty intervals that did not overlap, indicating these findings would likely still hold with additional added cases.
Second, we did not include open-source large language architectures. Additional research should test whether these findings hold when using open-source LLM models. Previous evidence has suggested that SLMs and proprietary models may outperform fine-tuned open-source models (Alizadeh et al. Reference Alizadeh2024; Cruickshank and Ng Reference Cruickshank and Ng2024). However, there are notable research benefits to using open-source models beyond performance, such as better cost-effectiveness, transparency in the model parameters, and improved reproducibility (Alizadeh et al. Reference Alizadeh2024; Burnham Reference Burnham2024).
Third, researchers should also test additional LLMs for stance detection since LLMs can exhibit bias, which can vary across stance topics and model versions. For example, existing work has found LLMs can display political biases (Gover Reference Gover2023; Motoki et al. Reference Motoki, Neto and Rodrigues2024; Rozado 2024) and produce biased results on specific topics (Zhang et al. Reference Zhang2024). Certain prompting strategies, like chain-of-thought prompting, can further exacerbate existing model bias (Ng, Cruickshank, and Lee Reference Ng, Cruickshank and Lee2024), and later versions of a model can incorporate data leakage from previous user queries, leading to biased results (Aiyappa et al. Reference Aiyappa, An, Kwak and Ahn2024).
7.2 Discussion
In this article, we compared the performance of stance detection methods across tuning approaches and prompting strategies on multiple datasets, focusing on estimating stance regarding political candidates in the 2020 election. Overall, we find that tuned LLMs outperformed tuned SLMs and LBAs. This result was most significant when evaluating performance on texts that contained more than one subject.
Pretrained SLMs exhibited weak correlations with human-coded stance scores, indicating it is risky for researchers to use these methods without additional tuning. However, LLMs were able to identify stance scores with reasonable accuracy even without tuning, particularly when using strategies like few-shot prompting and chain-of-thought prompting, or the most recent available LLM. LBAs consistently, and dramatically, underperformed compared to other methods. In tandem, these results suggest that researchers should consider using LLMs to classify stance, particularly for more complex texts which contain multiple subjects. Additionally, researchers should avoid the use of LBAs in favor of state-of-the-art methods (Bestvater and Monroe Reference Bestvater and Monroe2023).
Most methods performed better when estimating stance scores on texts containing a single subject rather than multiple subjects. However, the gap in performance is much wider for SLMs and LBAs, which often fail to disambiguate stance when texts contain multiple subjects and can exhibit inverse correlations with human-coded stance scores. For SLMs, cross-target tuning led to a significantly narrowed gap in performance between single subject and multiple subject texts. Ultimately, the results suggest that for more complex texts with multiple subjects, researchers should use tuned models and consider using LLMs, along with tuning or prompting strategies.
We also found that methods had higher performance when using continuous measures of stance to tune models. Across multiple methods, we found that estimated correlations were larger when tuned using a continuuous measure and more reliably captured the distributional properties of human-coded stance scores. As such, we recommend researchers consider collecting continuous stance measures for tuning purposes, particularly since continuous measures are known to contain more statistical information than binary variables which can aid model performance (Altman and Royston Reference Altman and Royston2006; Cohen Reference Cohen1983).
Our work also illustrates throughout multiple analyses that both in-target and cross-target tuning led to improvements. Although in-target tuning is usually recommended in favor of cross-target tuning (Osnabrügge et al. Reference Osnabrügge, Ash and Morelli2023; Vamvas and Sennrich Reference Vamvas and Sennrich2020), our use of politicial affiliation to tune estimates of stance illustrates a circumstance where cross-target tuning may outperform in-target tuning across several methods. Our work suggests that researchers should consider additional opportunities to tune language models when the outcome (in this case, stance) is well correlated with a proxy measure. Researchers could also consider additional modeling strategies to leverage cross-target tuning, including multi-domain prompting strategies (Ding et al. Reference Ding2024; Khiabani and Zubiaga Reference Khiabani and Zubiaga2025) and ensemble models (Li and Caragea Reference Li and Caragea2021; Sobhani, Inkpen, and Zhu Reference Sobhani, Inkpen and Zhu2019).
Across datasets, more detailed prompting strategies tended to improve performance but often did not improve on in-target tuned model results. However, when using GPT-4 Omni, few-shot prompting led to performance which nearly matched tuned model results. This result suggests that more recent LLM architectures may benefit less from in-target tuning. This finding stands in contrast to existing work which has found few-shot prompting can have highly variable performance (Zhao et al. Reference Zhao, Wallace, Feng, Klein and Singh2021) and may not improve on simpler prompts (Burnham Reference Burnham2024). For older architectures—GPT-3.5 Turbo and GPT-4—prompting strategies exhibited much wider variation in performance across datasets (Zhu et al. Reference Zhu, Zhang, Haq, Pan and Tyson2023).
These results also show that pretrained LLMs tend to have higher performance when texts mention Trump rather than Biden, which may be reflective of data used to train foundational models. This observation held across methods, datasets, and prompts. This suggests researchers should exercise caution when using LLMs for stance detection, comparing and validating results across multiple approaches (Grimmer and Stewart Reference Grimmer and Stewart2013).
7.3 Future Directions
More work is needed to determine how prompting strategies might improve stance estimation. Burgeoning evidence indicates that conventional human-language prompts may not lead to the best performance. Instead, researchers may need to use additional modeling strategies to develop better prompts, such as reinforcement learning (Deng et al. Reference Deng2022), automated prompt generation (Gao, Fisch, and Chen Reference Gao, Fisch and Chen2021), or collaborative LLM models (Lan et al. Reference Lan, Gao, Jin and Li2024), which could differ lead to prompts which differ substantially from conventional language. As such, the findings in this article may underestimate the potential performance benefits of prompting strategies, since these prompts were not optimized.
It’s also worth noting that while LLMs led to better performance in the present study, researchers need to evaluate performance in context. For applied work, a model which classifies 99% of texts correctly might be useless if misclassification costs are sufficiently large (Elkan Reference Elkan2001; Hand Reference Hand2012). Accordingly, future work should consider comparing methods by incorporating classification costs into performance metrics, using approaches like weighting (Zadrozny, Langford, and Abe Reference Zadrozny, Langford and Abe2003). We also found in the present study that human-coded stance scores had high inter-rater reliability. Accordingly, additional work is needed to determine how models perform in settings where more disagreement occurs across annotators, which could impact method choices. We also did not systematically explore how models performed on more sarcastic texts within each dataset, which could be a useful extension to consider comparing method performance.
We found that for the most recent model architecture we considered, GPT-4 Omni, tuning led to only slight performance gains and in several instances, improvements were non-significant compared to prompting strategies. These results suggest that there may be contexts where fine tuning is not needed to achieve reliable performance. However, additional research is needed to determine the exact data settings and models where tuning may not be needed to achieve consistent performance.
Future work on stance detection should also prioritize collecting training data and estimating stance scores on a continuous scale. Our findings indicate that methods which performed best using continuous measures also performed well when measures were binary or categorical. This suggests that benchmarking stance models using continuous scores provides a more comprehensive assessment of performance. Moreover, continuous measures offer inherent flexibility, enabling binary or categorical transformations as needed, which is not possible when data is collected using alternative measures. Estimating stance continuously could also enhance downstream analyses, facilitate better comparisons across stratified groups, and capture variation in stance magnitude that may otherwise be overlooked.
7.4 Recommendations
We find that tuned LLMs consistently outperform lexical and SLM approaches in the critical task of stance detection, with the most significant advantages observed in texts containing multiple target subjects. Prompt engineering strategies, while nearly as effective as tuned models, exhibit variable performance depending on the target subject, highlighting the need for cautious application.
We recommend that researchers use tuned LLMs for stance detection tasks and adopt continuous stance measures to enable richer analysis. However, due to differences in performance across target subjects and methods, we strongly encourage analysts to validate results against human-coded benchmarks and test findings across multiple stance detection approaches to ensure robustness in findings.
Acknowledgements
We extend our gratitude to Eli Kohlenberg, Sascha Ishikawa, and J. C. Bartle for their assistance in accessing the databases and APIs used in this study.
Funding Statement
This research was supported by the National Science Foundation (IIS/BIGDATA) Award no. 1837959.
Data Availability Statement
Instructions for replication are available on GitHub at https://github.com/maxgriswold/Stay-Tuned---Improving-Sentiment-Analysis-and-Stance-Detection-Using-Large-Language-Models. Replication code and datasets for this article have also been published in the Political Analysis Harvard Dataverse at https://doi.org/10.7910/DVN/KHNBZL (Griswold, Robbins, and Pollard Reference Griswold, Robbins and Pollard2025).
Supplementary Material
The supplementary material for this article can be found at https://doi.org/10.1017/pan.2025.10023.



 Open access
Open access