


1. Introduction
As is often the case for concepts in statistics, the term “conditional likelihood” has many meanings. It has, for instance, been used to refer to likelihoods where conditioning is on (1) exogenous explanatory variables (e.g., Gourieroux & Monfort, Reference Gourieroux and Monfort1995), (2) latent variables (e.g., Aigner et al., Reference Aigner, Hsiao, Kapteyn, Wansbeek, Griliches and Intriligator1984), (3) the outcome variable, for instance in capture-recapture modeling of population size (e.g., Sanathanan, Reference Sanathanan1972) and ascertainment correction in biometrical genetics (e.g., Pfeiffer et al., Reference Pfeiffer, Gail and Pee2001), (4) previous outcomes, for instance in autoregressive time-series models (e.g., Box & Jenkins, Reference Box and Jenkins1976) and peeling in phylogenetics (e.g., Felsenstein, Reference Felsenstein1981), (5) order statistics (e.g., Kalbfleisch, Reference Kalbfleisch1978), or (6) sufficient statistics.
In this address we follow the seminal theoretical work of Andersen (Reference Andersen1970, Reference Andersen1973a) and Kalbfleisch and Sprott (Reference Kalbfleisch and Sprott1970) and let a conditional likelihood be obtained by conditioning on sufficient statistics for incidental parameters in order to eliminate these parameters. In the context of latent variable or mixed effects modeling, the incidental parameters are the values taken by latent variables for a set of clusters, for example individuals or organizational units.
In psychometrics, the canonical use of conditional likelihoods is in measurement relying on the Rasch model (Rasch, Reference Rasch1960) and its extensions. As demonstrated by Rasch, estimation of item parameters can in this case be based on a conditional likelihood where the person parameters are eliminated by conditioning on their sufficient statistics. It is often argued that Rasch models and conditional maximum likelihood (CML) estimation are advantageous in measurement (e.g., Fischer, Reference Fischer, Fischer and Molenaar1995a). Indeed, Molenaar (Reference Molenaar1995) closes his excellent overview of estimation of Rasch models in the following way:
“Unless there are clear reasons for a different decision, the present author would recommend to use CML estimates.”
Conditional likelihoods have been used for a variety of problems in measurement; see Fischer (Reference Fischer, Fischer and Molenaar1995b; Reference Fischerc), Formann (Reference Formann1995), Maris and Bechger (Reference Maris and Bechger2007), Verhelst (Reference Verhelst, Veldkamp and Sluijter2019), von Davier and Rost (Reference von Davier and Rost1995), and Zwitser and Maris (Reference Zwitser and Maris2015) for a small selected sample.
We are certainly not disputing the utility of CML estimation in measurement. However, we will argue that conditional likelihoods perhaps have a more important role to play in addressing endogeneity problems in psychometrics. Focus will be on cluster-level endogeneity, where covariates and latent variables are dependent, a problem ignored by popular methods which can therefore produce severely inconsistent estimates. Fortunately, CML estimation, an instance of what is referred to as “fixed-effects estimation” in econometrics, can rectify this problem.
Our plan is as follows. First we introduce some latent variable models and discuss the cluster-level endogeneity problem whose origins, effects and alleviation we will examine. We proceed to delineate the ideas of protective and mitigating estimation of target parameters before describing the incidental parameter problem of joint maximum likelihood (JML) estimation. Two approaches that address that problem are discussed: marginal maximum likelihood (MML) and conditional maximum likelihood (CML) estimation. We demonstrate that CML estimation, in contrast to MML estimation, handles cluster-level endogeneity, and describe an endogeneity-correcting feature of MML estimation for large clusters. The scope of CML estimation is then extended followed by a discussion of MML estimation of augmented models that can accommodate cluster-level endogeneity. Several reasons for cluster-level endogeneity are investigated (unobserved cluster-level confounding of causal effects, cluster-specific measurement error, retrospective sampling, informative cluster sizes, missing data, and heteroskedasticity) and we show how different estimators perform in these situations. Thereafter, we discuss latent variable scoring before closing the paper with some concluding remarks.
2. Clustered Data
We consider data consisting of clusters j (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\ldots ,N$$\end{document} ) that contain units ij (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\ldots ,n_{j}$$\end{document}
) that contain units ij (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\ldots ,n_{j}$$\end{document} ). Units are typically exchangeable within clusters in cross-sectional multilevel designs. An example is students ij nested in schools j, where the index i associated with the students within a school is arbitrary.
). Units are typically exchangeable within clusters in cross-sectional multilevel designs. An example is students ij nested in schools j, where the index i associated with the students within a school is arbitrary.
Units are non-exchangeable within clusters in two settings: (a) longitudinal designs where i is the chronological sequence number of the time-point when a subject was observed and (b) measurement designs where i is the item (or question) responded to by a subject. In the non-exchangeable case, when i corresponds to the same time-point or item across subjects j, we will refer to i as an “item.” The different kinds of clustered data are illustrated in Fig. 1.
Illustration of clustered data for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N=3$$\end{document} clusters and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=2$$\end{document}
clusters and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=2$$\end{document} units per cluster. Exchangeable units (upper panel) and non-exchangeable units (lower panel).
units per cluster. Exchangeable units (upper panel) and non-exchangeable units (lower panel).

3. Latent Variable Model
We consider generalized linear mixed models (GLMMs) with canonical link functions (see, e.g., Rabe-Hesketh & Skrondal, Reference Rabe-Hesketh and Skrondal2009). Given the cluster-specific latent variables or random effects
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\zeta }}_{j}$$\end{document} , the model for an outcome
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
, the model for an outcome
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} is a generalized linear model (GLM) with three components (e.g., Nelder & Wedderburn, Reference Nelder and Wedderburn1972): a linear predictor
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\nu _{ij}$$\end{document}
is a generalized linear model (GLM) with three components (e.g., Nelder & Wedderburn, Reference Nelder and Wedderburn1972): a linear predictor
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\nu _{ij}$$\end{document} , a link function
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\mu _{ij})=\nu _{ij}$$\end{document}
, a link function
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\mu _{ij})=\nu _{ij}$$\end{document} that links the linear predictor to the conditional expectation
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _{ij}$$\end{document}
that links the linear predictor to the conditional expectation
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _{ij}$$\end{document} of the outcome, and a conditional outcome distribution from the exponential family.
of the outcome, and a conditional outcome distribution from the exponential family.
For a GLMM, we express the linear predictor as

where:
-
• \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\beta }}$$\end{document}
 is a vector of parameters for the unit-specific vector
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}. For exchangeable units
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} are regression coefficients for unit-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}. For non-exchangeable units
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} contains a vector of item-specific intercepts and a vector of regression coefficients. Correspondingly,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} includes an elementary vector (where one of the elements is 1 and the other elements are 0) that picks out the intercept for item i, and item-specific and/or unit-specific covariates.
is a vector of parameters for the unit-specific vector
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}. For exchangeable units
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} are regression coefficients for unit-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}. For non-exchangeable units
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} contains a vector of item-specific intercepts and a vector of regression coefficients. Correspondingly,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} includes an elementary vector (where one of the elements is 1 and the other elements are 0) that picks out the intercept for item i, and item-specific and/or unit-specific covariates. -
• \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\gamma }}$$\end{document}
is a vector of parameters for the cluster-specific vector
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document}. For non-exchangeable units
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} are regression coefficients for cluster-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document}. For exchangeable units
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} includes an overall intercept and regression coefficients for the cluster-specific covariates in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document}, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document} includes a 1 and cluster-specific covariates. -
• \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\zeta }}_{j}$$\end{document}
is a vector of cluster-specific latent variables or random intercept and possibly random coefficients for the vector
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {z}}}_{ij}$$\end{document} of item-specific and/or unit-specific covariates (that are often partly overlapping with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document})
















The conditional expectation of the outcome, given the covariates and latent variables, is

and the conditional outcome distribution can be written as

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\phi $$\end{document} is the scale or dispersion parameter, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b(\cdot )$$\end{document}
is the scale or dispersion parameter, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$b(\cdot )$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c(\cdot )$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c(\cdot )$$\end{document} are functions depending on the member of the exponential family.
are functions depending on the member of the exponential family.
We confine our treatment to three GLMs:
-
(i) Normal distribution (where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi \! = \! \sigma ^2$$\end{document}
) and identity link for continuous outcomes,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(y_{ij}|{\mathbf {x}}_{ij},{{\mathbf {z}}}_{ij},{{\mathbf {v}}}_{j},{\varvec{\zeta }}_j) = (\sigma \sqrt{2\pi })^{-1} \exp \{-\frac{1}{2\sigma ^2} (y_{ij}-\nu _{ij})^2 \}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\mu _{ij})=\mu _{ij}$$\end{document} -
(ii) Bernoulli distribution and logit link for binary outcomes,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(y_{ij}|{\mathbf {x}}_{ij},{{\mathbf {z}}}_{ij},{{\mathbf {v}}}_{j},{\varvec{\zeta }}_j) = \mu _{ij}^{y_{ij}} (1 - \mu _{ij})^{1-y_{ij}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\mu _{ij}) = \log \Bigg \{\frac{\mu _{ij}}{1-\mu _{ij}}\Bigg \}$$\end{document} -
(iii) Poisson distribution and log link for counts,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(y_{ij}|{\mathbf {x}}_{ij},{{\mathbf {z}}}_{ij},{{\mathbf {v}}}_{j},{\varvec{\zeta }}_j) = \exp [-\exp (\nu _{ij})]\exp (\nu _{ij})^{y_{ij}}/y_{ij}!$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$g(\mu _{ij}) = \log (\mu _{ij})$$\end{document}







Other members of the exponential family include the gamma and inverse-Gaussian distributions.
For simplicity we concentrate on a special case of (1) with linear predictor

It should be emphasized that this model encompasses popular latent variable or mixed models, such as generalized linear random-intercept (multilevel or hierarchical) models, and Rasch models (Rasch, Reference Rasch1960) and their extensions such as “explanatory” IRT (De Boeck & Wilson, Reference De Boeck and Wilson2004).
We will in the sequel also use extensions of GLMMs such as generalized linear latent and mixed models (GLLAMMs) of Rabe-Hesketh et al. (Reference Rabe-Hesketh, Skrondal and Pickles2004) and Skrondal and Rabe-Hesketh (Reference Skrondal and Rabe-Hesketh2004).
4. Cluster-Level Exogeneity and Endogeneity
Our focus is on the challenges that arise in estimation of latent variable models when there is cluster-level endogeneity. Before embarking on the challenges we must explicitly define what we mean by this term. Let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_{j}$$\end{document} represent all observed covariates for cluster j. We say that there is cluster-level exogeneity if all covariates are independent of the cluster-specific intercepts;
represent all observed covariates for cluster j. We say that there is cluster-level exogeneity if all covariates are independent of the cluster-specific intercepts; ![]() . In contrast, cluster-level endogeneity occurs if at least one covariate in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_{j}$$\end{document}
. In contrast, cluster-level endogeneity occurs if at least one covariate in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_{j}$$\end{document} is not independent of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
is not independent of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} ;
; ![]() .
.
The definitions of cluster-level exogeneity and cluster-level endogeneity are represented in the graphs in the left and right panels of Fig. 2, respectively. This kind of graph, which we find useful and will use throughout, resembles traditional directed acyclic graphs (DAGs) but nodes can represent vectors of random variables here. An arrow between two nodes means that the probability distribution of the node that the arrow points to depends on the value taken by the emanating node. The undirected arc between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document} in the right panel indicates that there is dependence between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
in the right panel indicates that there is dependence between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and at least one element of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}
and at least one element of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document} .
.
Cluster-level exogeneity (left panel) and cluster-level endogeneity (right panel).

When exploring reasons for cluster-level endogeneity in Section 12 we will rather informally rely on the d-separation criterion (e.g., Verma & Pearl, Reference Verma and Pearl1988) and the equivalent moralization criterion (Lauritzen et al., Reference Lauritzen, Dawid, Larsen and Leimer1990) to infer cluster-level endogeneity from graphs of latent variable models, assuming “stability” or “faithfulness” to preclude dependence paths cancelling out. Sometimes we will examine likelihood contributions to show how cluster-level endogeneity arises and the consequences.
5. Protective and Mitigating Estimation of Target Parameters
In this address we will focus on the performance of point estimators under cluster-level endogeneity as the number of clusters N becomes large, whereas the cluster sizes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} are fixed and could be small. A classical goal in statistical modeling is (weak) consistency of estimators for all model parameters as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \, \rightarrow \, \infty $$\end{document}
are fixed and could be small. A classical goal in statistical modeling is (weak) consistency of estimators for all model parameters as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \, \rightarrow \, \infty $$\end{document} . However, this typically requires a correctly specified model, an assumption that we often deem to be naive.
. However, this typically requires a correctly specified model, an assumption that we often deem to be naive.
A less ambitious but more realistic goal is protective estimation which is consistent for target parameters but possibly inconsistent for other parameters (Skrondal & Rabe-Hesketh, Reference Skrondal and Rabe-Hesketh2014). Our target parameters throughout will be the subset of coefficients in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} corresponding to the unit-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
corresponding to the unit-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} in (3). These covariates could be time-varying variables in a longitudinal study, characteristics of units ij in a multilevel study, or attributes of items i or item-subject combinations ij in measurement.
in (3). These covariates could be time-varying variables in a longitudinal study, characteristics of units ij in a multilevel study, or attributes of items i or item-subject combinations ij in measurement.
An even less ambitious goal is what we will refer to as mitigating estimation where it is likely (but not guaranteed) that estimation of the target parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} is less inconsistent than conventional estimation that ignores misspecification. Although mitigation in this sense cannot be formally proved, it can be made plausible by theoretical arguments and based on evidence from simulations. The hope is that “almost consistent” estimators (e.g., Laisney & Lechner, Reference Laisney and Lechner2003) can be obtained. In reality, mitigating estimation will sometimes be the most realistic goal.
is less inconsistent than conventional estimation that ignores misspecification. Although mitigation in this sense cannot be formally proved, it can be made plausible by theoretical arguments and based on evidence from simulations. The hope is that “almost consistent” estimators (e.g., Laisney & Lechner, Reference Laisney and Lechner2003) can be obtained. In reality, mitigating estimation will sometimes be the most realistic goal.
6. Incidental Parameter Problems and Their Solutions
The distinction between structural parameters and incidental parameters was introduced in a seminal paper by Neyman and Scott (Reference Neyman and Scott1948). For linear predictor (3), the structural parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document} include
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
include
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} (and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document}
(and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document} if relevant), whereas the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
if relevant), whereas the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} are incidental parameters because their number increases in tandem with the number of clusters N. In econometrics a structural parameter is usually a causal parameter and for this reason Lancaster (Reference Lancaster2000) used the term “common parameter”.
are incidental parameters because their number increases in tandem with the number of clusters N. In econometrics a structural parameter is usually a causal parameter and for this reason Lancaster (Reference Lancaster2000) used the term “common parameter”.
Let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}$$\end{document} denote all outcomes and covariates for the sample, respectively. Assume that the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document}
denote all outcomes and covariates for the sample, respectively. Assume that the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document} for the clusters are conditionally independent across clusters and the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
for the clusters are conditionally independent across clusters and the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} for cluster j are conditionally independent, given the covariates and latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
for cluster j are conditionally independent, given the covariates and latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} . The joint likelihood for the structural parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document}
. The joint likelihood for the structural parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document} and the latent variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _1,\ldots ,\zeta _N$$\end{document}
and the latent variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _1,\ldots ,\zeta _N$$\end{document} (here treated as unknown parameters) becomes
(here treated as unknown parameters) becomes

The incidental parameter problem (Neyman & Scott, Reference Neyman and Scott1948; see also Lancaster, Reference Lancaster2000) refers to the fact that joint maximum likelihood (JML) estimation of both structural and incidental parameters need not be consistent for the structural parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document} as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} for fixed cluster sizes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
for fixed cluster sizes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} . The problem arises because estimation of each
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
. The problem arises because estimation of each
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} must often rely on a small number of units
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
must often rely on a small number of units
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} in the cluster. Viewing the cluster sizes as produced by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j = n \times m_j$$\end{document}
in the cluster. Viewing the cluster sizes as produced by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j = n \times m_j$$\end{document} , where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_j$$\end{document}
, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_j$$\end{document} has a mean of 1, the inconsistency in estimating
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document}
has a mean of 1, the inconsistency in estimating
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document} for the models considered here is of order
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n^{-1}$$\end{document}
for the models considered here is of order
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n^{-1}$$\end{document} (e.g., Arellano & Hahn, Reference Arellano, Hahn, Blundell, Newey and Persson2007). Note that JML estimation has also been referred to as unconditional maximum likelihood estimation (e.g., Wright & Douglas, Reference Wright and Douglas1977) and unconstrained maximum likelihood estimation (e.g., de Leeuw & Verhelst, Reference de Leeuw and Verhelst1986) in psychometrics.
(e.g., Arellano & Hahn, Reference Arellano, Hahn, Blundell, Newey and Persson2007). Note that JML estimation has also been referred to as unconditional maximum likelihood estimation (e.g., Wright & Douglas, Reference Wright and Douglas1977) and unconstrained maximum likelihood estimation (e.g., de Leeuw & Verhelst, Reference de Leeuw and Verhelst1986) in psychometrics.
There is no incidental parameter problem when the joint likelihood can be factorized into two components, one just containing structural parameters and the other just incidental parameters. Such likelihood orthogonality (e.g., Lancaster, Reference Lancaster2000) occurs for linear predictor (3) with (a) identity link and normal conditional distribution (e.g., Chamberlain, Reference Chamberlain1980) and (b) log link and Poisson conditional distribution (e.g., Cameron & Trivedi, Reference Cameron and Trivedi1999). For these models JML estimation is consistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} for fixed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_{j}$$\end{document}
for fixed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_{j}$$\end{document} .
.
In general, consistent JML estimation can be achieved under a double-asymptotic scheme where both the number of units per cluster increases
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n \rightarrow \infty $$\end{document} and the number of clusters increases
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
and the number of clusters increases
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} . In psychometrics, a classical result is that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML}$$\end{document}
. In psychometrics, a classical result is that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML}$$\end{document} is consistent for the Rasch model in this case if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{N}{n} \rightarrow \infty $$\end{document}
is consistent for the Rasch model in this case if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{N}{n} \rightarrow \infty $$\end{document} (Haberman, Reference Haberman1977). Based on simulation evidence, Greene (Reference Greene2004) observed that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML}$$\end{document}
(Haberman, Reference Haberman1977). Based on simulation evidence, Greene (Reference Greene2004) observed that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML}$$\end{document} appears to be consistent for many latent variable models used in econometrics under double asymptotics. However, appealing to double asymptotics is unconvincing when n is not large.
appears to be consistent for many latent variable models used in econometrics under double asymptotics. However, appealing to double asymptotics is unconvincing when n is not large.
For the simple Rasch model, the inconsistency of JML estimation can be derived and corrected. When
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=2$$\end{document} , Andersen (Reference Andersen1973a) showed that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p\text{ lim } \ {\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML} = 2{\varvec{\beta }}$$\end{document}
, Andersen (Reference Andersen1973a) showed that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p\text{ lim } \ {\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML} = 2{\varvec{\beta }}$$\end{document} as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} , so
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{1}{2} \, {\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML}$$\end{document}
, so
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{1}{2} \, {\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML}$$\end{document} is consistent. For general n, Wright and Douglas (Reference Wright and Douglas1977) observed that the finite sample bias is approximately
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{1}{n-1} \, {{\varvec{\beta }}}^{}$$\end{document}
is consistent. For general n, Wright and Douglas (Reference Wright and Douglas1977) observed that the finite sample bias is approximately
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{1}{n-1} \, {{\varvec{\beta }}}^{}$$\end{document} and discussed the bias correction
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{n-1}{n} \, {\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML}$$\end{document}
and discussed the bias correction
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{n-1}{n} \, {\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML}$$\end{document} . Andersen (Reference Andersen1980, Theorem 6.1) stated the same result for inconsistency. For more complex models, methods that reduce inconsistency from order
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n^{-1}$$\end{document}
. Andersen (Reference Andersen1980, Theorem 6.1) stated the same result for inconsistency. For more complex models, methods that reduce inconsistency from order
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n^{-1}$$\end{document} to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n^{-2}$$\end{document}
to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n^{-2}$$\end{document} are discussed in Arellano and Hahn (Reference Arellano, Hahn, Blundell, Newey and Persson2007). For instance, a modified profile likelihood where the incidental parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document}
are discussed in Arellano and Hahn (Reference Arellano, Hahn, Blundell, Newey and Persson2007). For instance, a modified profile likelihood where the incidental parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document} are “profiled out” of the joint likelihood has been used for models with linear predictors such as (3) by Bellio and Sartori (Reference Bellio and Sartori2006) and Bartolucci et al. (Reference Bartolucci, Bellio, Salvan and Sartori2016). This approach can produce mitigating estimation.
are “profiled out” of the joint likelihood has been used for models with linear predictors such as (3) by Bellio and Sartori (Reference Bellio and Sartori2006) and Bartolucci et al. (Reference Bartolucci, Bellio, Salvan and Sartori2016). This approach can produce mitigating estimation.
An approach usually called marginal maximum likelihood (MML) estimation in psychometrics is the most popular for linear predictor (3). Here,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document} is treated as a random variable and “integrated out” of the joint likelihood, as proposed in early work by Kiefer and Wolfowitz (Reference Kiefer and Wolfowitz1956). Note that the statistical literature typically refers to this likelihood as integrated and that their marginal likelihood “transforms away” incidental parameters (e.g., Kalbfleisch & Sprott, Reference Kalbfleisch and Sprott1970). The terms unconditional maximum likelihood estimation (e.g., Bock & Lieberman, Reference Bock and Lieberman1970) and, simply, maximum likelihood estimation (e.g., Holland, Reference Holland1990) have also been used in psychometrics. Under assumptions including cluster-level exogeneity, MML is consistent for all model parameters.
is treated as a random variable and “integrated out” of the joint likelihood, as proposed in early work by Kiefer and Wolfowitz (Reference Kiefer and Wolfowitz1956). Note that the statistical literature typically refers to this likelihood as integrated and that their marginal likelihood “transforms away” incidental parameters (e.g., Kalbfleisch & Sprott, Reference Kalbfleisch and Sprott1970). The terms unconditional maximum likelihood estimation (e.g., Bock & Lieberman, Reference Bock and Lieberman1970) and, simply, maximum likelihood estimation (e.g., Holland, Reference Holland1990) have also been used in psychometrics. Under assumptions including cluster-level exogeneity, MML is consistent for all model parameters.
Alternatively, conditional maximum likelihood (CML) estimation can be used where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document} is treated as a fixed parameter and “conditioned out” of the joint likelihood. The idea of CML estimation was discussed already by Bartlett (Reference Bartlett1936, Reference Bartlett1937a), the eminent British statistician whose name is associated with factor scores in psychometrics (e.g., Bartlett, Reference Bartlett1937b). We will see that CML can yield protective estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
is treated as a fixed parameter and “conditioned out” of the joint likelihood. The idea of CML estimation was discussed already by Bartlett (Reference Bartlett1936, Reference Bartlett1937a), the eminent British statistician whose name is associated with factor scores in psychometrics (e.g., Bartlett, Reference Bartlett1937b). We will see that CML can yield protective estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} under cluster-level endogeneity.
under cluster-level endogeneity.
7. Marginal Maximum Likelihood (MML) Estimation
In marginal maximum likelihood (MML) estimation the cluster-specific intercept
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document} is treated as a random variable in estimation. The following assumptions are usually made:
is treated as a random variable in estimation. The following assumptions are usually made:
-
• [A.1] Cluster independence: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p({{\mathbf {y}}}|{{\mathbf {w}}},\zeta _1,\ldots ,\zeta _N; {{\varvec{\vartheta }}}) \ = \ \prod _{j=1}^{N} p({{\mathbf {y}}}_{j}|{{\mathbf {w}}}_{j},\zeta _j; {{\varvec{\vartheta }}})$$\end{document}
-
• [A.2] Conditional unit independence: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p({{\mathbf {y}}}_{j}|{{\mathbf {w}}}_j,\zeta _j; {{\varvec{\vartheta }}}) \ = \ \prod _{i=1}^{n_j} p(y_{ij}|{{\mathbf {w}}}_{j},\zeta _j; {{\varvec{\vartheta }}})$$\end{document}
-
• [A.3] Strict exogeneity conditional on the latent variable: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(y_{ij}|{{\mathbf {w}}}_{j},\zeta _{j}; {{\varvec{\vartheta }}}) = \ p(y_{ij}|{\mathbf {x}}_{ij},{{\mathbf {v}}}_{j},\zeta _{j}; {{\varvec{\vartheta }}})$$\end{document}
; i.e., given the latent variable, the outcome for a unit only depends on covariates for that unit -
• [A.4] Correct conditional distribution: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(y_{ij}|{\mathbf {x}}_{ij},{{\mathbf {v}}}_{j},\zeta _{j}; {{\varvec{\vartheta }}})$$\end{document}
follows (2) and (3) -
• [A.5] Cluster-level exogeneity: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\zeta _{j}|{{\mathbf {w}}}_{j}) \ = \ p(\zeta _{j})$$\end{document}
-
• [A.6] Latent variable normality: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\zeta _j) \ = \ \phi (\zeta _j;0,\psi )$$\end{document}
; a normal density with zero expectation and variance
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi $$\end{document}







Using [A.2]-[A.6], the marginal likelihood contribution of cluster j simplifies in the following way:

where we see that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} is marginalized over or integrated out of the joint likelihood.
is marginalized over or integrated out of the joint likelihood.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\phi (\zeta _j;0,\psi )$$\end{document} can be interpreted as the density of a cluster-specific disturbance in a data-generating mechanism or as a superpopulation density of clusters in survey sampling. That the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
can be interpreted as the density of a cluster-specific disturbance in a data-generating mechanism or as a superpopulation density of clusters in survey sampling. That the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} are independently and identically distributed random variables can be motivated by exchangeability of the clusters (e.g., Draper, Reference Draper1995).
are independently and identically distributed random variables can be motivated by exchangeability of the clusters (e.g., Draper, Reference Draper1995).
Using [A.1], MML estimation proceeds by maximizing the likelihood
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{MML}} = \prod _{j=1}^{N} {{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{MML}}$$\end{document} w.r.t.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
w.r.t.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi $$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi $$\end{document} (and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document}
(and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document} if relevant). If the above assumptions are satisfied, MML estimators are consistent as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
if relevant). If the above assumptions are satisfied, MML estimators are consistent as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} for fixed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_{j}$$\end{document}
for fixed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_{j}$$\end{document} for all parameters under appropriate regularity conditions (e.g., Butler & Louis, Reference Butler and Louis1997). Importantly, standard MML estimation becomes inconsistent, possibly severely, for all link functions when the exogeneity assumptions are violated. As we will see momentarily, inconsistency due to violation of [A.5] can arise because MML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
for all parameters under appropriate regularity conditions (e.g., Butler & Louis, Reference Butler and Louis1997). Importantly, standard MML estimation becomes inconsistent, possibly severely, for all link functions when the exogeneity assumptions are violated. As we will see momentarily, inconsistency due to violation of [A.5] can arise because MML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} exploits both within-cluster and between-cluster information, and the latter can be contaminated by cluster-level endogeneity.
exploits both within-cluster and between-cluster information, and the latter can be contaminated by cluster-level endogeneity.
7.1. MML Estimation for Identity Link and Normal Distribution
It is instructive to consider the linear predictor (3) with an identity link and a normal conditional distribution that can be written as

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\epsilon _{ij}$$\end{document} is an additive normally distributed unit-level error term,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\epsilon _{ij}|{\mathbf {x}}_{ij},{{\mathbf {v}}}_{j},\zeta _{j}) = \phi (\epsilon _{ij}; 0,\sigma ^2)$$\end{document}
is an additive normally distributed unit-level error term,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\epsilon _{ij}|{\mathbf {x}}_{ij},{{\mathbf {v}}}_{j},\zeta _{j}) = \phi (\epsilon _{ij}; 0,\sigma ^2)$$\end{document} .
.
For identity links the assumptions given above are stricter than necessary for consistent MML estimation. First, for identity and log links, [A.4] can be replaced by the more lenient assumption that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _{ij}$$\end{document} is correctly specified (and the domain of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
is correctly specified (and the domain of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} for the assumed exponential family distribution encompasses the domain of the correct distribution). This extends the idea of pseudo maximum likelihood (PML) estimation (Gourieroux et al., Reference Gourieroux, Monfort and Trognon1984) to what we may call pseudo marginal maximum likelihood estimation in the latent variable setting. For the identity link, [A.3], [A.4], and [A.5] can be replaced by (5) with a weaker set of assumptions where normality is relaxed for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document}
for the assumed exponential family distribution encompasses the domain of the correct distribution). This extends the idea of pseudo maximum likelihood (PML) estimation (Gourieroux et al., Reference Gourieroux, Monfort and Trognon1984) to what we may call pseudo marginal maximum likelihood estimation in the latent variable setting. For the identity link, [A.3], [A.4], and [A.5] can be replaced by (5) with a weaker set of assumptions where normality is relaxed for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\epsilon _{ij}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\epsilon _{ij}$$\end{document} ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{E}(\epsilon _{ij}| {{\mathbf {w}}}_{j}, \zeta _{j}) = 0$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{E}(\epsilon _{ij}| {{\mathbf {w}}}_{j}, \zeta _{j}) = 0$$\end{document} (a mean-independence version of “unit-level exogeneity”), and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{E}(\zeta _{j}| {{\mathbf {w}}}_{j}) = 0$$\end{document}
(a mean-independence version of “unit-level exogeneity”), and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{E}(\zeta _{j}| {{\mathbf {w}}}_{j}) = 0$$\end{document} (e.g., Wooldridge, Reference Wooldridge2010, p. 292). Second, for the identity link, consistent estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
(e.g., Wooldridge, Reference Wooldridge2010, p. 292). Second, for the identity link, consistent estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} neither requires assumption [A.2], see Zeger et al. (Reference Zeger, Liang and Albert1988), nor assumption [A.6], see Verbeke and Lesaffre (Reference Verbeke and Lesaffre1997).
neither requires assumption [A.2], see Zeger et al. (Reference Zeger, Liang and Albert1988), nor assumption [A.6], see Verbeke and Lesaffre (Reference Verbeke and Lesaffre1997).
We now outline how MML estimation relies on both between-cluster and within-cluster information, for simplicity omitting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document} from model (5) and letting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_{j}=n$$\end{document}
from model (5) and letting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_{j}=n$$\end{document} . The total sum of squares of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
. The total sum of squares of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} can then be decomposed into two contributions:
can then be decomposed into two contributions:

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$W_{yy}$$\end{document} represents the within-cluster variation and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$B_{yy}$$\end{document}
represents the within-cluster variation and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$B_{yy}$$\end{document} the between-cluster variation. We use similar decompositions of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_{{\mathbf {x}}{\mathbf {x}}}$$\end{document}
the between-cluster variation. We use similar decompositions of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_{{\mathbf {x}}{\mathbf {x}}}$$\end{document} into
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$W_{{\mathbf {x}}{\mathbf {x}}}$$\end{document}
into
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$W_{{\mathbf {x}}{\mathbf {x}}}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$B_{{\mathbf {x}}{\mathbf {x}}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$B_{{\mathbf {x}}{\mathbf {x}}}$$\end{document} , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_{{{\mathbf {x}}} y}$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_{{{\mathbf {x}}} y}$$\end{document} into
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$W_{{{\mathbf {x}}} y}$$\end{document}
into
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$W_{{{\mathbf {x}}} y}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$B_{{{\mathbf {x}}} y}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$B_{{{\mathbf {x}}} y}$$\end{document} . For known variance components
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi $$\end{document}
. For known variance components
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi $$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document} , the MML estimator is the generalized least squares (GLS) estimator that Maddala (Reference Maddala1971) shows can be expressed as
, the MML estimator is the generalized least squares (GLS) estimator that Maddala (Reference Maddala1971) shows can be expressed as

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\omega \equiv \frac{\sigma ^2}{\sigma ^2+ n \psi }$$\end{document} is the weight given to the between-cluster variation. The GLS estimator in essence combines the between-cluster and within-cluster estimators of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
is the weight given to the between-cluster variation. The GLS estimator in essence combines the between-cluster and within-cluster estimators of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} by weighting them in inverse proportion to their respective variances. Fuller and Battese (Reference Fuller and Battese1973) demonstrate that the GLS estimator can be obtained by using ordinary least squares (OLS) for the transformed data
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widetilde{y}}_{ij} = y_{ij} - \theta {\overline{y}}_{\cdot j}$$\end{document}
by weighting them in inverse proportion to their respective variances. Fuller and Battese (Reference Fuller and Battese1973) demonstrate that the GLS estimator can be obtained by using ordinary least squares (OLS) for the transformed data
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widetilde{y}}_{ij} = y_{ij} - \theta {\overline{y}}_{\cdot j}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widetilde{{\mathbf {x}}}}_{ij} = {\mathbf {x}}_{ij} - \theta {\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widetilde{{\mathbf {x}}}}_{ij} = {\mathbf {x}}_{ij} - \theta {\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document} , where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta = 1-\sqrt{\omega }$$\end{document}
, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\theta = 1-\sqrt{\omega }$$\end{document} . The probability limit of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm{GLS}}$$\end{document}
. The probability limit of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm{GLS}}$$\end{document} as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} can be expressed as
can be expressed as

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{{\widetilde{{\mathbf {x}}}}}$$\end{document} is the covariance matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widetilde{{\mathbf {x}}}}_{ij}$$\end{document}
is the covariance matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widetilde{{\mathbf {x}}}}_{ij}$$\end{document} , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{{{\mathbf {x}}} \zeta }$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{{{\mathbf {x}}} \zeta }$$\end{document} is the covariance matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
is the covariance matrix of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document}
with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document} . Importantly, the estimator is inconsistent if cluster-level exogeneity [A.5] is violated because this implies that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{{{\mathbf {x}}} \zeta } \ne {{\mathbf {0}}}$$\end{document}
. Importantly, the estimator is inconsistent if cluster-level exogeneity [A.5] is violated because this implies that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Sigma _{{{\mathbf {x}}} \zeta } \ne {{\mathbf {0}}}$$\end{document} .
.
Analytical integration is trivial for models with conjugate latent variable densities for which
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{MML}}$$\end{document} can be written in closed form. For a GLMM with linear predictor (3) and identity link,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{MML}}$$\end{document}
can be written in closed form. For a GLMM with linear predictor (3) and identity link,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{MML}}$$\end{document} simply takes the form of the (ordinary) likelihood of a multivariate normal regression model with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{E}({{\mathbf {y}}}_j \! \mid \! {{\mathbf {w}}}_j) = {\mathbf {X}}_{j}{\varvec{\beta }}+ ({{\mathbf {1}}}_{n_{j}} \! \otimes {{\mathbf {v}}}_{j}^{\prime }){\varvec{\gamma }}$$\end{document}
simply takes the form of the (ordinary) likelihood of a multivariate normal regression model with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{E}({{\mathbf {y}}}_j \! \mid \! {{\mathbf {w}}}_j) = {\mathbf {X}}_{j}{\varvec{\beta }}+ ({{\mathbf {1}}}_{n_{j}} \! \otimes {{\mathbf {v}}}_{j}^{\prime }){\varvec{\gamma }}$$\end{document} (where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{1j}^{\prime },\ldots ,{\mathbf {x}}_{n_{j}j}^{\prime }$$\end{document}
(where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{1j}^{\prime },\ldots ,{\mathbf {x}}_{n_{j}j}^{\prime }$$\end{document} are the rows of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {X}}_{j}$$\end{document}
are the rows of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {X}}_{j}$$\end{document} ) and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Var}({{\mathbf {y}}}_j \! \mid \! {{\mathbf {w}}}_j) = \psi {{\mathbf {1}}}_{n_{j}}{{\mathbf {1}}}_{n_{j}}^{\prime } + \sigma {{\mathbf {I}}}_{n_{j}}$$\end{document}
) and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Var}({{\mathbf {y}}}_j \! \mid \! {{\mathbf {w}}}_j) = \psi {{\mathbf {1}}}_{n_{j}}{{\mathbf {1}}}_{n_{j}}^{\prime } + \sigma {{\mathbf {I}}}_{n_{j}}$$\end{document} . MML estimation of linear mixed models when variance components are unknown is discussed by Laird and Ware (Reference Laird and Ware1982) using the EM algorithm and by Goldstein (Reference Goldstein1986) using iterative generalized least squares (IGLS).
. MML estimation of linear mixed models when variance components are unknown is discussed by Laird and Ware (Reference Laird and Ware1982) using the EM algorithm and by Goldstein (Reference Goldstein1986) using iterative generalized least squares (IGLS).
7.2. MML Estimation for Logit Link and Bernoulli Distribution or Log Link and Poisson Distribution
Because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _{ij}$$\end{document} is nonlinear in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document}
is nonlinear in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{j}$$\end{document} for log and logit links,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{MML}}$$\end{document}
for log and logit links,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{MML}}$$\end{document} cannot be expressed in closed form and maximization is usually based on numerical integration (e.g., Rabe-Hesketh et al., Reference Rabe-Hesketh, Skrondal and Pickles2005) or Monte Carlo integration (e.g., Booth & Hobert, Reference Booth and Hobert1999).
cannot be expressed in closed form and maximization is usually based on numerical integration (e.g., Rabe-Hesketh et al., Reference Rabe-Hesketh, Skrondal and Pickles2005) or Monte Carlo integration (e.g., Booth & Hobert, Reference Booth and Hobert1999).
Unfortunately, it is difficult to assess the normality assumption for the latent variables [A.6] for logit links. However, MML estimators for regression coefficients are almost consistent if [A.6] is violated, whereas estimators for intercepts and random effect variances can be severely inconsistent if the correct latent variable density is highly skewed (e.g., Neuhaus et al., Reference Neuhaus, Hauck and Kalbfleisch1992). The threats posed by violation of the cluster-level exogeneity assumption [A.5] persist.
8. Conditional Maximum Likelihood (CML) Estimation
We retain assumptions [A.1]-[A.4] stated for MML estimation but now relax assumptions [A.5] and [A.6] regarding the latent variable distribution.
Using the exponential family distribution (2) in conjunction with linear predictor (3), we obtain

It follows from the Neyman-Fisher factorization theorem (e.g., Pawitan, Reference Pawitan2001, Theorem 3.1) that for known
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} , the cluster-specific sumscore of the outcomes,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} y_{ij}$$\end{document}
, the cluster-specific sumscore of the outcomes,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} y_{ij}$$\end{document} , is a sufficient statistic for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j + {\varvec{\gamma }}^{\prime }{{\mathbf {v}}}_{j}$$\end{document}
, is a sufficient statistic for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j + {\varvec{\gamma }}^{\prime }{{\mathbf {v}}}_{j}$$\end{document} (and that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} {\mathbf {x}}_{ij}y_{ij}$$\end{document}
(and that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} {\mathbf {x}}_{ij}y_{ij}$$\end{document} is a sufficient statistic for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
is a sufficient statistic for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} ).
).
The conditional likelihood contribution of cluster j, given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tau _j \equiv \sum _{i=1}^{n_j} y_{ij}$$\end{document} , can be expressed as
, can be expressed as

Importantly, the cluster-specific term
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j + {{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document} cancels out of the numerator and denominator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
cancels out of the numerator and denominator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} and the latent variable assumptions [A.5] and [A.6] are therefore no longer required.
and the latent variable assumptions [A.5] and [A.6] are therefore no longer required.
CML estimation proceeds by maximizing the conditional likelihood
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{CML}} = \prod _{j=1}^{N} {{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} w.r.t.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document}
w.r.t.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document} , where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document}
, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\vartheta }}}$$\end{document} is a vector containing
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
is a vector containing
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} (and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document}
(and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document} if relevant) here. If the above assumptions are satisfied together with appropriate regularity conditions, CML estimators are consistent as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
if relevant) here. If the above assumptions are satisfied together with appropriate regularity conditions, CML estimators are consistent as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} for fixed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
for fixed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} (e.g., Andersen, Reference Andersen1970, Reference Andersen1973a).
(e.g., Andersen, Reference Andersen1970, Reference Andersen1973a).
The conditional likelihood
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{CML}}$$\end{document} is almost invariably derived by treating the cluster-specific latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
is almost invariably derived by treating the cluster-specific latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} as a fixed parameter, although Sartori and Severini (Reference Sartori and Severini2004) show that the same
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
as a fixed parameter, although Sartori and Severini (Reference Sartori and Severini2004) show that the same
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}^{\scriptscriptstyle \mathrm{CML}}$$\end{document} results if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
results if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} is treated as a random variable.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
is treated as a random variable.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} is usually interpreted as fixed when using CML estimation in psychometrics (e.g., Holland, Reference Holland1990), whereas the “fixed effects framework” of econometrics interprets
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
is usually interpreted as fixed when using CML estimation in psychometrics (e.g., Holland, Reference Holland1990), whereas the “fixed effects framework” of econometrics interprets
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} as a random variable that can have arbitrary dependence with the covariates (e.g., Wooldridge, Reference Wooldridge2010, p. 286).
as a random variable that can have arbitrary dependence with the covariates (e.g., Wooldridge, Reference Wooldridge2010, p. 286).
In contrast to MML estimation, CML estimation is based on solely within-cluster information. A great advantage of CML estimation is therefore that it is protective for the target parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} if [A.1]-[A.4] are satisfied, regardless of the latent variable distribution and even if there is cluster-level endogeneity. It is usually not recognized that CML estimation also has a role to play under exogeneity because performance does not rely on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document}
if [A.1]-[A.4] are satisfied, regardless of the latent variable distribution and even if there is cluster-level endogeneity. It is usually not recognized that CML estimation also has a role to play under exogeneity because performance does not rely on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document} being the correct specification of the functional form for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
being the correct specification of the functional form for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} .
.
A cost of CML estimation is that it can be inefficient because it just exploits within-cluster information. Inefficiency is particularly acute when there is little within-cluster variation in the unit-specific covariates. Hence, CML estimation may have larger mean squared errors for estimating
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} than MML estimation, even under cluster-level endogeneity (e.g., Palta & Yao, Reference Palta and Yao1991). Also, using CML estimation to remove cluster-specific slopes can lead to pronounced inefficiency.
than MML estimation, even under cluster-level endogeneity (e.g., Palta & Yao, Reference Palta and Yao1991). Also, using CML estimation to remove cluster-specific slopes can lead to pronounced inefficiency.
CML estimation is primarily useful if the coefficients
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} of unit-specific covariates are the target parameters because the coefficients
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
of unit-specific covariates are the target parameters because the coefficients
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} of cluster-specific covariates and the covariance parameters of random effects cannot be estimated. In our view, this may actually be beneficial because these parameters are inconsistently estimated by standard MML if there is cluster-level endogeneity.
of cluster-specific covariates and the covariance parameters of random effects cannot be estimated. In our view, this may actually be beneficial because these parameters are inconsistently estimated by standard MML if there is cluster-level endogeneity.
Interactions between cluster-specific and unit-specific covariates become elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} and can be estimated by CML for models with cluster-specific intercepts. For instance, the treatment-by-time interaction is often the target parameter in longitudinal data with time-invariant treatments. In models with cluster-specific random coefficients, the vectors
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
and can be estimated by CML for models with cluster-specific intercepts. For instance, the treatment-by-time interaction is often the target parameter in longitudinal data with time-invariant treatments. In models with cluster-specific random coefficients, the vectors
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {z}}}_{ij}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {z}}}_{ij}$$\end{document} often include common variables and the corresponding elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
often include common variables and the corresponding elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} are conditioned away by CML. Hence, the treatment-by-time interaction parameter cannot be estimated by CML in a model with cluster-specific slopes of time (e.g., Liang & Zeger, Reference Liang and Zeger2000).
are conditioned away by CML. Hence, the treatment-by-time interaction parameter cannot be estimated by CML in a model with cluster-specific slopes of time (e.g., Liang & Zeger, Reference Liang and Zeger2000).
In some situations covariate measurement error or misclassification problems can be more serious for CML than MML estimation (e.g., Griliches & Hausman, Reference Griliches and Hausman1986; Frisell et al., Reference Frisell, Öberg, Kuja-Halkola and Sjölander2012). However, CML estimation is immune to such problems for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} and we will later show that cluster-specific covariate measurement error for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
and we will later show that cluster-specific covariate measurement error for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} is handled.
is handled.
We now show the form taken by the conditional likelihood contribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} for identity, logit and log links.
for identity, logit and log links.
8.1. CML Estimation for Identity Link and Normal Distribution
Using that the sum of conditionally independent normally distributed random variables has a normal distribution, the conditional likelihood contribution for cluster j in model (5) becomes (e.g., Chamberlain, Reference Chamberlain1980)

We see that the cluster-level component
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j \! + \! {{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document} has cancelled out of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
has cancelled out of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} and that a cluster does not contribute to estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
and that a cluster does not contribute to estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} if the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
if the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} do not vary within the cluster.
do not vary within the cluster.
For the identity link, assumption [A.2] is not required for consistent estimation, and [A.4] can be replaced by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}[({\mathbf {x}}_{ij} \! - \! {\overline{{\mathbf {x}}}}_{\cdot j}),(\epsilon _{ij} \! - \! {\overline{\epsilon }}_{\cdot j})]={{\mathbf {0}}}$$\end{document} . The effects of violating this zero-correlation assumption can in some cases be more severe for CML than MML estimation (e.g., Bound & Solon, Reference Bound and Solon1999; Frisell et al., Reference Frisell, Öberg, Kuja-Halkola and Sjölander2012). This can be addressed by using instrumental variables (IV) estimation if plausible instruments are available (e.g., Ebbes et al., Reference Ebbes, Böckenholt and Wedel2004). Chamberlain (Reference Chamberlain, Griliches and Intriligator1984, Reference Chamberlain, Heckman and Singer1985) proposes tests of [A.3] for the identity link (and the probit link) and Sjölander et al. (Reference Sjölander, Frisell, Kuja-Halkola, Öberg and Zetterquist2016) derive the inconsistency produced by various violations of [A.2] and [A.3] for the identity link (and the logit link for some instances) in sibling designs.
. The effects of violating this zero-correlation assumption can in some cases be more severe for CML than MML estimation (e.g., Bound & Solon, Reference Bound and Solon1999; Frisell et al., Reference Frisell, Öberg, Kuja-Halkola and Sjölander2012). This can be addressed by using instrumental variables (IV) estimation if plausible instruments are available (e.g., Ebbes et al., Reference Ebbes, Böckenholt and Wedel2004). Chamberlain (Reference Chamberlain, Griliches and Intriligator1984, Reference Chamberlain, Heckman and Singer1985) proposes tests of [A.3] for the identity link (and the probit link) and Sjölander et al. (Reference Sjölander, Frisell, Kuja-Halkola, Öberg and Zetterquist2016) derive the inconsistency produced by various violations of [A.2] and [A.3] for the identity link (and the logit link for some instances) in sibling designs.
For the identity link there are several alternative ways of implementing CML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . We will briefly describe them below because they provide insight into basic features of CML estimation and its connection to other estimation methods in this particular case.
. We will briefly describe them below because they provide insight into basic features of CML estimation and its connection to other estimation methods in this particular case.
8.1.1. Cluster-Mean Centering and Maximum “Marginal” Likelihood Estimation in Statistics
Consider the cluster-mean centered or within-cluster model

which is an example of a “working model” derived from the assumed data-generating mechanism. We see that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} is swept out of the model and any misspecification related to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
is swept out of the model and any misspecification related to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} is therefore immaterial. However,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document}
is therefore immaterial. However,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document} (and actually any cluster-specific function of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
(and actually any cluster-specific function of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} ) is also swept out which precludes estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
) is also swept out which precludes estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} . On the other hand, MML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
. On the other hand, MML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} is inconsistent if either
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
is inconsistent if either
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} or
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
or
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} are cluster-level endogenous as is estimation of both
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
are cluster-level endogenous as is estimation of both
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} if the functional form
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document}
if the functional form
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document} is incorrect.
is incorrect.
The maximum likelihood (ML) estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} in this model coincides with the CML estimator, which it not surprising given the resemblance of (9) with the argument of the exponential function in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
in this model coincides with the CML estimator, which it not surprising given the resemblance of (9) with the argument of the exponential function in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} . Furthermore, the CML estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
. Furthermore, the CML estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} is the within-cluster ordinary least squares (OLS) estimator
is the within-cluster ordinary least squares (OLS) estimator

which is the special case of (7) where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\omega =0$$\end{document} and between-cluster information is hence ignored.
and between-cluster information is hence ignored.
Using standard terminology in statistics (e.g., Pawitan, Reference Pawitan2001), the likelihood based on (9) can be viewed as a marginal likelihood that “transforms away” the nuisance parameters (here the incidental parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} ) by considering the implied model for the deviations from cluster means
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij} - {\overline{y}}_{\cdot j}$$\end{document}
) by considering the implied model for the deviations from cluster means
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij} - {\overline{y}}_{\cdot j}$$\end{document} . The canonical example of a marginal likelihood in the statistical sense is the restricted or residual likelihood of Patterson and Thompson (Reference Patterson and Thompson1971) for variance components in linear mixed models, where regression coefficients are nuisance parameters. Recall that this meaning of “marginal” is different from that in psychometrics where it refers to a likelihood where random
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
. The canonical example of a marginal likelihood in the statistical sense is the restricted or residual likelihood of Patterson and Thompson (Reference Patterson and Thompson1971) for variance components in linear mixed models, where regression coefficients are nuisance parameters. Recall that this meaning of “marginal” is different from that in psychometrics where it refers to a likelihood where random
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} are “integrated out”.
are “integrated out”.
Goetgeluk and Vansteelandt (Reference Goetgeluk and Vansteelandt2008) use cluster-mean centering to consistently estimate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} under cluster-level endogeneity by conditional generalized estimating equations (CGEE), an estimator that can also be used for log links.
under cluster-level endogeneity by conditional generalized estimating equations (CGEE), an estimator that can also be used for log links.
8.1.2. Cluster-Specific Dummy Variables and JML Estimation
Alternatively, we can use JML estimation for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} in a working model that includes dummy or indicator variables with fixed cluster-specific coefficients
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
in a working model that includes dummy or indicator variables with fixed cluster-specific coefficients
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}

where the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$d_{rj}$$\end{document} take the value 1 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r\!=\!j$$\end{document}
take the value 1 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$r\!=\!j$$\end{document} and 0 otherwise. Note that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document}
and 0 otherwise. Note that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document} is omitted because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
is omitted because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} is collinear with the dummy variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$d_{rj}$$\end{document}
is collinear with the dummy variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$d_{rj}$$\end{document} . JML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
. JML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} can simply proceed by using OLS to estimate (10).
can simply proceed by using OLS to estimate (10).
The use of a fixed parameter for each cluster explains why CML and related estimators are often referred to as fixed-effects estimators in econometrics. In that literature, MML and related estimators that assume cluster-level exogeneity are referred to as random-effects estimators, although the estimands are not the random effects.
By explicitly controlling for clusters in this way we are estimating pure within-cluster effects. The clusters are said to act as their own controls, and estimation is therefore immune to cluster-level endogeneity. As mentioned earlier, there is no incidental parameter problem in this case and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm JML} = {\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm CML}$$\end{document} is consistent as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
is consistent as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} for fixed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
for fixed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} . Consistency of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{\zeta }}_j^{\scriptscriptstyle \mathrm JML}$$\end{document}
. Consistency of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{\zeta }}_j^{\scriptscriptstyle \mathrm JML}$$\end{document} requires a double-asymptotic scheme where both
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j \rightarrow \infty $$\end{document}
requires a double-asymptotic scheme where both
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j \rightarrow \infty $$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} .
.
8.1.3. Auxiliary Linear Projection and MML Estimation
In the Mundlak-device (Mundlak, Reference Mundlak1978) the cluster means
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document} of the unit-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
of the unit-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} are included in the model. This can be viewed as handling violation of [A.5] by considering an auxiliary linear projection
are included in the model. This can be viewed as handling violation of [A.5] by considering an auxiliary linear projection

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cov}({\overline{{\mathbf {x}}}}_{\cdot j},u_j)={{\mathbf {0}}}$$\end{document} per construction. Substituting the linear projection in (5), we obtain
per construction. Substituting the linear projection in (5), we obtain

which can be expressed as the following model that is estimated in the “hybrid method” of Allison (Reference Allison2009):

For the identity link, MML estimation (or ML/OLS estimation treating the composite error terms
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j + \epsilon _{ij}$$\end{document} as independent) of these working models produces the consistent CML estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
as independent) of these working models produces the consistent CML estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} , even if the linear projection does not coincide with the correct auxiliary statistical model or “data-generating mechanism”. Contrary to common belief (e.g., Allison, Reference Allison2009), the hybrid method is inconsistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
, even if the linear projection does not coincide with the correct auxiliary statistical model or “data-generating mechanism”. Contrary to common belief (e.g., Allison, Reference Allison2009), the hybrid method is inconsistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} (and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi $$\end{document}
(and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi $$\end{document} ) even if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document}
) even if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document} is cluster-level exogenous because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\delta }}}$$\end{document}
is cluster-level exogenous because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{\delta }}}$$\end{document} absorbs some of the effects of the cluster-level covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document}
absorbs some of the effects of the cluster-level covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document} (Castellano et al., Reference Castellano, Rabe-Hesketh and Skrondal2014).
(Castellano et al., Reference Castellano, Rabe-Hesketh and Skrondal2014).
8.1.4. Including Deviations from Cluster Means and E-Estimation
In the vector version of (12) for cluster j, the matrix of cluster mean deviations
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {X}}_j - {{\mathbf {1}}}_{n_j} \! \otimes {\overline{{\mathbf {x}}}}_{\cdot j}^{\prime }$$\end{document} is orthogonal to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {1}}}_{n_j} \! \otimes {{\mathbf {v}}}_{j}^{\prime }$$\end{document}
is orthogonal to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {1}}}_{n_j} \! \otimes {{\mathbf {v}}}_{j}^{\prime }$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {1}}}_{n_j}\zeta _j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {1}}}_{n_j}\zeta _j$$\end{document} , so the CML estimator for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
, so the CML estimator for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} is obtained by estimating the simplified working model
is obtained by estimating the simplified working model

by ML/OLS.
This can be viewed as a variant of E-estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} (e.g., Robins et al., Reference Robins, Mark and Newey1992). Here, specification of a correct model for the association between the outcome and possibly unknown cluster-level covariates in the “outcome model” is avoided by breaking the correlation between the unit-level covariates (“exposures”
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
(e.g., Robins et al., Reference Robins, Mark and Newey1992). Here, specification of a correct model for the association between the outcome and possibly unknown cluster-level covariates in the “outcome model” is avoided by breaking the correlation between the unit-level covariates (“exposures”
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} ) and cluster-level variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
) and cluster-level variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} in the “exposure model” through the inclusion of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document}
in the “exposure model” through the inclusion of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document} (see also Goetgeluk & Vansteelandt, Reference Goetgeluk and Vansteelandt2008).
(see also Goetgeluk & Vansteelandt, Reference Goetgeluk and Vansteelandt2008).
8.1.5. Using Deviations from Cluster Means as Instrumental Variables
Because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}-{\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document} is correlated with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
is correlated with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} whereas
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {X}}_j - {{\mathbf {1}}}_{n_j} \! \otimes {\overline{{\mathbf {x}}}}_{\cdot j}^{\prime }$$\end{document}
whereas
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {X}}_j - {{\mathbf {1}}}_{n_j} \! \otimes {\overline{{\mathbf {x}}}}_{\cdot j}^{\prime }$$\end{document} is orthogonal to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {1}}}_{n_j}\zeta _j$$\end{document}
is orthogonal to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {1}}}_{n_j}\zeta _j$$\end{document} by construction,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}-{\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document}
by construction,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}-{\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document} can serve as instrumental variable for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
can serve as instrumental variable for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} in the outcome model (5). Instrumental variables (IV) estimators, such as two-stage least squares (2SLS), are then identical to the CML estimator for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
in the outcome model (5). Instrumental variables (IV) estimators, such as two-stage least squares (2SLS), are then identical to the CML estimator for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} .
.
8.2. CML Estimation for Logit Link and Bernoulli Distribution
We now consider linear predictor (3) with a logit link and a Bernoulli conditional distribution. The conditional likelihood contribution for cluster j can be expressed as (e.g., Chamberlain, Reference Chamberlain1980)

Here,

is the set of all
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j \atopwithdelims ()\tau _j$$\end{document} permutations of zeros and ones whose sum equals
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tau _{j}$$\end{document}
permutations of zeros and ones whose sum equals
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tau _{j}$$\end{document} , the observed value of the sufficient statistic for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
, the observed value of the sufficient statistic for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} .
.
We note that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j \! + \! {{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document} has cancelled out of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
has cancelled out of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} . Also, a cluster does not contribute to the conditional likelihood if its outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
. Also, a cluster does not contribute to the conditional likelihood if its outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} are all 0 or all 1, or
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
are all 0 or all 1, or
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} does not vary in the cluster. CML estimation appears computationally demanding but is feasible even for large
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
does not vary in the cluster. CML estimation appears computationally demanding but is feasible even for large
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} by using recursive algorithms (e.g., Howard, Reference Howard1972; Gustafsson, Reference Gustafsson1980) or Markov chain Monte Carlo (e.g., Rice, Reference Rice2004). For very large
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
by using recursive algorithms (e.g., Howard, Reference Howard1972; Gustafsson, Reference Gustafsson1980) or Markov chain Monte Carlo (e.g., Rice, Reference Rice2004). For very large
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} , approximations can be based on composite conditional likelihoods (e.g., Liang, Reference Liang1987) or random sampling of permutations in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {B}}}}_j$$\end{document}
, approximations can be based on composite conditional likelihoods (e.g., Liang, Reference Liang1987) or random sampling of permutations in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {B}}}}_j$$\end{document} (e.g., D’Haultfæuille & Iaria, Reference D’Haultfæuille and Iaria2016). For
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n \! = \! 2$$\end{document}
(e.g., D’Haultfæuille & Iaria, Reference D’Haultfæuille and Iaria2016). For
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n \! = \! 2$$\end{document} ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} simplifies to the standard likelihood contribution of a logistic regression model with binary outcome equal to 1 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{1j} \! = \! 0, y_{2j} \! = \! 1)$$\end{document}
simplifies to the standard likelihood contribution of a logistic regression model with binary outcome equal to 1 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{1j} \! = \! 0, y_{2j} \! = \! 1)$$\end{document} and equal to 0 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{1j} \! = \! 1, y_{2j} \! = \! 0)$$\end{document}
and equal to 0 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{1j} \! = \! 1, y_{2j} \! = \! 0)$$\end{document} , and with covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{2j} \! - \! {\mathbf {x}}_{1j}$$\end{document}
, and with covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{2j} \! - \! {\mathbf {x}}_{1j}$$\end{document} .
.
Several other models have likelihood contributions that take a similar form as (13):
-
(i) Case-control studies: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
corresponds to the conditional likelihood contribution for matched set j in conditional logistic regression for matched retrospective case-control designs, were the indicator
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} takes the value 1 if unit i is one of a fixed number of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tau _{j}$$\end{document} cases and 0 if unit i is one of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j-\tau _{j}$$\end{document} controls.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} then represents the conditional probability of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} observed covariate vectors in set j, given all potential allocations of the covariate vectors to cases and controls (e.g., Prentice & Breslow, Reference Prentice and Breslow1978). -
(ii) Survival analysis with ties: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
corresponds to the “discrete” or “exact” partial likelihood contribution for the jth ordered survival time in a Cox proportional-hazards model with tied survival times (Cox, Reference Cox1972). At the jth survival time, the indicator
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} takes the value 1 if unit i is one of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\tau _{j}$$\end{document} units in the risk set who experienced the event and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {B}}}}_j$$\end{document} is defined as in (14) for the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} units in the risk set. When there are no ties, the standard partial likelihood contribution for an event occurring at the jth survival time can be expressed as
(15) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{ \exp ( {\mathbf {x}}_{i}^{\prime }{\varvec{\beta }}) }{ \sum _{d \in {{{\mathcal {R}}}}_j} \exp ( {\mathbf {x}}_{d}^{\prime }{\varvec{\beta }})}, \end{aligned}$$\end{document}the conditional probability that a particular unit i experiences the event at the jth survival time, given that exactly one unit in the risk set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal {R}}}}_j$$\end{document}
experiences the event. The risk sets are not disjoint because a unit in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {R}}}}_j$$\end{document} belongs to all risk sets for earlier events and the term “partial likelihood” is used (Cox, Reference Cox1975). -
(iii) Discrete choice: The conditional likelihood contribution for individual j in the conditional logit model for discrete choice takes the form of the standard partial likelihood contribution (15). Here, the likelihood contribution is the conditional probability that a particular alternative i is chosen by individual j, given that exactly one alternative is chosen from the individual-specific alternative set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{{\mathcal {R}}}}_j$$\end{document}
(e.g., McFadden, Reference McFadden1974).















We also note that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} is identical to the conditional likelihood contribution produced by instead conditioning on the order statistic
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{(1)j},\ldots ,y_{(n_j)j}$$\end{document}
is identical to the conditional likelihood contribution produced by instead conditioning on the order statistic
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{(1)j},\ldots ,y_{(n_j)j}$$\end{document} (e.g., Chen, Reference Chen2007).
(e.g., Chen, Reference Chen2007).
The basic idea of standard CML estimation is extended in exact conditional logistic regression (e.g., Cox, Reference Cox1970; Mehta et al., Reference Mehta and Patel1995) with linear predictor (3). Here, each element in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} is estimated by conditioning on sufficient statistics for not just
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
is estimated by conditioning on sufficient statistics for not just
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} (as in standard CML estimation) but also for the remaining elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
(as in standard CML estimation) but also for the remaining elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . For small or unbalanced datasets this approach can mitigate separation problems where outcomes are perfectly predicted and standard conditional likelihoods therefore do not exist (e.g., Albert & Anderson, Reference Albert and Anderson1984). Moreover, inferences for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
. For small or unbalanced datasets this approach can mitigate separation problems where outcomes are perfectly predicted and standard conditional likelihoods therefore do not exist (e.g., Albert & Anderson, Reference Albert and Anderson1984). Moreover, inferences for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} are based on permutation distributions of the sufficient statistics that do not rely on asymptotics.
are based on permutation distributions of the sufficient statistics that do not rely on asymptotics.
Nonparametric marginal maximum likelihood (NPMML) estimation (e.g., de Leuuw & Verhelst, 1986) leaves the latent variable distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document} unspecified. NPMML estimation can be implemented by treating the latent variable as discrete and choosing the number of mass points to yield the highest likelihood. For concordant Rasch models that fit the observed sumscore distribution exactly, Lindsay et al. (Reference Lindsay, Clogg and Grego1991) show that NPMML and CML estimation produce identical estimates of the item parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
unspecified. NPMML estimation can be implemented by treating the latent variable as discrete and choosing the number of mass points to yield the highest likelihood. For concordant Rasch models that fit the observed sumscore distribution exactly, Lindsay et al. (Reference Lindsay, Clogg and Grego1991) show that NPMML and CML estimation produce identical estimates of the item parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . Rice (Reference Rice2004) provides conditions ensuring that marginal and conditional likelihoods are equal. We note that standard NPMML estimation does not address the cluster-level endogeneity problem.
. Rice (Reference Rice2004) provides conditions ensuring that marginal and conditional likelihoods are equal. We note that standard NPMML estimation does not address the cluster-level endogeneity problem.
For a GLMM with linear predictor (1), the sufficient statistic for the latent variable vector
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\zeta }}_j$$\end{document} is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} {{\mathbf {z}}}_{ij}y_{ij}$$\end{document}
is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} {{\mathbf {z}}}_{ij}y_{ij}$$\end{document} . For the logit link and the Bernoulli distribution, the conditional likelihood contribution then takes the same form as (13), with the difference that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} {{\mathbf {z}}}_{ij}d_{i}=\sum _{i=1}^{n_j} {{\mathbf {z}}}_{ij}y_{ij}$$\end{document}
. For the logit link and the Bernoulli distribution, the conditional likelihood contribution then takes the same form as (13), with the difference that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} {{\mathbf {z}}}_{ij}d_{i}=\sum _{i=1}^{n_j} {{\mathbf {z}}}_{ij}y_{ij}$$\end{document} now replaces
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} d_{i} = \sum _{i=1}^{n_j} y_{ij}$$\end{document}
now replaces
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j} d_{i} = \sum _{i=1}^{n_j} y_{ij}$$\end{document} in the definition of the permutation set. In a panel data setting, Thomas (Reference Thomas2006) considered the special case of a logit model with a cluster-specific intercept and a cluster-specific slope of time.
in the definition of the permutation set. In a panel data setting, Thomas (Reference Thomas2006) considered the special case of a logit model with a cluster-specific intercept and a cluster-specific slope of time.
8.3. CML Estimation for Log Link and Poisson Distribution
Consider linear predictor (3) with a log link and a Poisson conditional distribution. Using that the sum of conditionally independent Poisson random variables has a Poisson distribution, the conditional likelihood contribution for cluster j becomes (e.g., Hausman et al., Reference Hausman, Hall and Griliches1984)

Again
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j \! + \! {{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}$$\end{document} has cancelled out of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
has cancelled out of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} . We see that the product in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document}
. We see that the product in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{{\mathcal {L}}}}_j^{\scriptscriptstyle \mathrm{CML}}$$\end{document} that contains
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
that contains
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} is identical to the likelihood contribution for a unit j in a standard multinomial logit model with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
is identical to the likelihood contribution for a unit j in a standard multinomial logit model with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} alternatives, except that it is not required that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij} \in \{0,1\}$$\end{document}
alternatives, except that it is not required that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij} \in \{0,1\}$$\end{document} or
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j}y_{ij}=1$$\end{document}
or
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sum _{i=1}^{n_j}y_{ij}=1$$\end{document} here.
here.
Recall that there is no incidental parameter problem for the model with log link and a Poisson conditional distribution, and CML estimation and JML estimation with dummy variables for clusters produce identical estimates of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . For the log link, assumption [A.2] is not required for consistent estimation and [A.4] can be relaxed by assuming that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _{ij}$$\end{document}
. For the log link, assumption [A.2] is not required for consistent estimation and [A.4] can be relaxed by assuming that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _{ij}$$\end{document} is correctly specified (e.g., Wooldridge, Reference Wooldridge1999).
is correctly specified (e.g., Wooldridge, Reference Wooldridge1999).
Thomas (Reference Thomas2006) derived the CML estimator for a Poisson regression model with a cluster-specific intercept and a cluster-specific slope of time, and pointed out that there is no incidental parameter problem in this case either.
8.4. CML Estimation Beyond GLM Link Functions
It is worth noting that CML estimation can be used not just for GLMMs with continuous, binary, and count outcomes that we have investigated so far but also for other combinations of outcomes and latent variable models.
-
(a) Binary \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{ij} \in \{0,1\}$$\end{document}
: Stratified linear odds-ratio models with cluster-specific parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} (e.g., Storer et al., Reference Storer, Wacholder and Breslow1983)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} p(y_{ij}=1|{\mathbf {x}}_{ij},{{\mathbf {v}}}_{j};{{\varvec{\vartheta }}},\zeta _j) \ = \ \frac{\exp \{\zeta _j\} (1 + {\mathbf {x}}_{ij}^{\prime }{\varvec{\beta }}+ {{\mathbf {v}}}_j^{\prime }{\varvec{\gamma }})}{1 + \exp \{\zeta _j\} (1 + {\mathbf {x}}_{ij}^{\prime }{\varvec{\beta }}+ {{\mathbf {v}}}_j^{\prime }{\varvec{\gamma }})}. \end{aligned}$$\end{document}
-
(b) Ordinal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{ij} \in \{0,\ldots , K\}$$\end{document}
: Adjacent category logit models with cluster-specific parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} (e.g., Heinen, Reference Heinen1996, p.124)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} p(y_{ij}=k|{\mathbf {x}}_{ij},{{\mathbf {v}}}_{j};{{\varvec{\vartheta }}},\zeta _j) \ = \ \frac{ \exp \{ \alpha _{ki} + {\mathbf {x}}_{ij}^{\prime }{\varvec{\beta }}+ {{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}+ k\zeta _j \} }{\sum _{c=0}^{K} \exp \{ \alpha _{ci} + {\mathbf {x}}_{ij}^{\prime }{\varvec{\beta }}+ {{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}+ c\zeta _j \} }, \end{aligned}$$\end{document}where we explicitly let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _{ki}$$\end{document}
denote unit and category-specific intercepts (no intercepts in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} here), with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{0i} \! = \! 0$$\end{document}. Seminal special cases in psychometrics include the partial credit model (Masters, Reference Masters1982) that has no covariates, and the rating scale model (Andrich, Reference Andrich1978) where additionally the item parameters are decomposed as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{ki}=\alpha _{i}+\kappa _{k}$$\end{document}. For the exchangeable case,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{ki}$$\end{document} is replaced by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{k}$$\end{document} with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{0} \! = \! 0$$\end{document}.
Approximate CML estimation can be obtained via data expansion for cumulative logit models (Mukherjee et al., Reference Mukherjee, Ahn, Liu, Rathouz and Sanchez2008), of which the logistic graded response model of Samejima (Reference Samejima1969) is a special case, and for continuation-ratio logit models, as shown for sequential item response models by Tutz (Reference Tutz1990).
Kelderman and Rijkes (Reference Kelderman and Rijkes1994) discuss CML estimation for a range of Rasch-type item response models for ordinal responses.
-
(c) Nominal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{ij} \in \{0,\ldots , K\}$$\end{document}
: Multinomial logit models with cluster and category specific parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _{kj}$$\end{document} (e.g., Chamberlain, Reference Chamberlain1980; Conaway, Reference Conaway1989; Lee, Reference Lee2002)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} p(y_{ij}=k|{\mathbf {x}}_{0ij},\ldots ,{\mathbf {x}}_{Kij},{\mathbf {x}}_{ij},{{\mathbf {v}}}_j;{{\varvec{\vartheta }}},\zeta _{0j},\ldots ,\zeta _{Kj}) \ = \ \frac{ \exp \{\alpha _{ki} + {\mathbf {x}}_{kij}^{\prime }{\varvec{\beta }}+ {\mathbf {x}}_{ij}^{\prime }{\varvec{\beta }}_k + {{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}_k + \zeta _{kj}\} }{\sum _{c=0}^{K} \exp \{\alpha _{ci} + {\mathbf {x}}_{cij}^{\prime }{\varvec{\beta }}+ {\mathbf {x}}_{ij}^{\prime }{\varvec{\beta }}_c + {{\mathbf {v}}}_{j}^{\prime }{\varvec{\gamma }}_c + \zeta _{cj}\} }, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _{ki}$$\end{document}
are item and category-specific intercepts (no intercepts in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} or
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_k$$\end{document} here), with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{0i} \! = \! 0$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{k1} \! = \! 0$$\end{document}, and we let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_0 \! = \! {{\mathbf {0}}}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}_0 \! = \! {{\mathbf {0}}}$$\end{document}. Special cases in psychometrics (e.g., Rasch, Reference Rasch and Neyman1961; Andersen, Reference Andersen1973b) do not include covariates. For the exchangeable case,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{ki}$$\end{document} is replaced by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{k}$$\end{document} with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _{0} \! = \! 0$$\end{document}. -
(d) Survival times t: Stratified Cox-regression with cluster-specific baseline hazard function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_{j}^{0}(t)$$\end{document}
(e.g., Chamberlain, Reference Chamberlain, Heckman and Singer1985; Lancaster, Reference Lancaster1990; Ridder & Tunali, Reference Ridder and Tunali1999)
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h_{ij}(t) \ = \ h_{j}^{0}(t) \exp \{ {\mathbf {x}}_{ij}^{\prime }{\varvec{\beta }}+ {{\mathbf {v}}}_j^{\prime }{\varvec{\gamma }}\}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_{ij}(t)$$\end{document}
is the continuous time hazard function for unit i in cluster j. Estimating the models by maximum partial likelihood yields fixed-effects estimators in the spirit of CML estimation.





























9. MML Becomes CML for Large Clusters
Increasing the sample size usually does not improve estimation of misspecified models. However, standard MML estimation that ignores cluster-level endogeneity approaches CML estimation, and hence becomes more robust against cluster-level endogeneity, as the cluster sizes increase.
We first consider linear predictor (3) with an identity link. For known variance components, the generalized least squares (GLS) estimator is the MML estimator. Maddala (Reference Maddala1971) showed that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lim _{n \rightarrow \infty }{\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm GLS} = {\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm CML}$$\end{document} for fixed N, see also (6) where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\omega \! \equiv \! \frac{\sigma ^2}{\sigma ^2+n\psi } \rightarrow 0$$\end{document}
for fixed N, see also (6) where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\omega \! \equiv \! \frac{\sigma ^2}{\sigma ^2+n\psi } \rightarrow 0$$\end{document} when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n \rightarrow \infty $$\end{document}
when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n \rightarrow \infty $$\end{document} . Hence, GLS approaches CML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
. Hence, GLS approaches CML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} as the cluster sizes increase, making GLS estimation robust against cluster-level endogeneity without any ameliorating model extensions. Moreover,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
as the cluster sizes increase, making GLS estimation robust against cluster-level endogeneity without any ameliorating model extensions. Moreover,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} can in this case be consistently estimated if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
can in this case be consistently estimated if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} is exogenous. It is clear from the IGLS formulae in Breusch (Reference Breusch1987) that large-cluster robustness also applies to MML estimation.
is exogenous. It is clear from the IGLS formulae in Breusch (Reference Breusch1987) that large-cluster robustness also applies to MML estimation.
Does the robustness extend beyond identity links? To shed some light on this, we performed a simulation study with exchangeable units to investigate the behaviour of MML estimation under cluster-level endogeneity for binary outcomes with a logit link and a normal latent variable distribution. For
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \! = \! 1,\!000,\!000$$\end{document} clusters, we gradually increased the cluster sizes n from 2 to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$1,\!000$$\end{document}
clusters, we gradually increased the cluster sizes n from 2 to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$1,\!000$$\end{document} . We simulated multivariate normal
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(x_{1j},x_{2j},x_{3j},x_{4j},\zeta _j)$$\end{document}
. We simulated multivariate normal
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(x_{1j},x_{2j},x_{3j},x_{4j},\zeta _j)$$\end{document} with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Var}(x_{ij})=1$$\end{document}
with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Var}(x_{ij})=1$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},x_{i^{\prime }j})=0.2$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},x_{i^{\prime }j})=0.2$$\end{document} and parameter values
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma =0$$\end{document}
and parameter values
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma =0$$\end{document} ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta =1$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta =1$$\end{document} ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi =1$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi =1$$\end{document} .
.
In Fig. 3 we show the similarity of the MML estimator and the consistent (as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} ) CML estimator by plotting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{{\widehat{\beta }}^{\scriptscriptstyle \mathrm MML}}{{\widehat{\beta }}^{\scriptscriptstyle \mathrm CML}}$$\end{document}
) CML estimator by plotting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{{\widehat{\beta }}^{\scriptscriptstyle \mathrm MML}}{{\widehat{\beta }}^{\scriptscriptstyle \mathrm CML}}$$\end{document} against n for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(\zeta _j,x_{ij}) \! = \! 0.4$$\end{document}
against n for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(\zeta _j,x_{ij}) \! = \! 0.4$$\end{document} (solid curve) and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(\zeta _j,x_{ij}) \! = \! 0.2$$\end{document}
(solid curve) and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(\zeta _j,x_{ij}) \! = \! 0.2$$\end{document} (dashed curve). We see that the large-cluster robustness of MML estimation extends to the logit link and that larger cluster sizes are required to approach consistency when the cluster-level endogeneity is more severe.
(dashed curve). We see that the large-cluster robustness of MML estimation extends to the logit link and that larger cluster sizes are required to approach consistency when the cluster-level endogeneity is more severe.
Automatic inconsistency correction of MML estimation for logistic random-intercept model as a function of cluster size n.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(\zeta _j,x_{ij}) = .4$$\end{document} (solid curve) and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(\zeta _j,x_{ij}) = .2$$\end{document}
(solid curve) and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(\zeta _j,x_{ij}) = .2$$\end{document} (dashed curve) for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N=1{,}000{,}000$$\end{document}
(dashed curve) for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N=1{,}000{,}000$$\end{document} clusters.
clusters.

10. Extending the Scope of CML Estimation
For non-exchangeable data it is often plausible that the coefficients of the covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} are item-specific. Considering small to moderate cluster sizes, we now propose a useful extension of the model class for which CML estimation is applicable. Specifically, we generalize the GLMM in (1) by replacing
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
are item-specific. Considering small to moderate cluster sizes, we now propose a useful extension of the model class for which CML estimation is applicable. Specifically, we generalize the GLMM in (1) by replacing
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} by item-specific coefficients
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_i$$\end{document}
by item-specific coefficients
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_i$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}_i$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}_i$$\end{document}

Letting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n^{\mathrm{max}}$$\end{document} denote the maximum cluster size, the linear predictor (16) can be re-expressed as
denote the maximum cluster size, the linear predictor (16) can be re-expressed as

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{rj}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document} are now defined as in the exchangeable case. We see that this model includes solely unit-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$d_{ri}{\mathbf {x}}_{rj}$$\end{document}
are now defined as in the exchangeable case. We see that this model includes solely unit-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$d_{ri}{\mathbf {x}}_{rj}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$d_{ri}{{\mathbf {v}}}_{j}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$d_{ri}{{\mathbf {v}}}_{j}$$\end{document} and that both variable types have item-invariant coefficients. This is exactly the situation for GLMMs where CML estimation is traditionally employed, and CML estimation can therefore also be used for model (16) in a straightforward manner. Consistent estimation results for the regression coefficients in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_i$$\end{document}
and that both variable types have item-invariant coefficients. This is exactly the situation for GLMMs where CML estimation is traditionally employed, and CML estimation can therefore also be used for model (16) in a straightforward manner. Consistent estimation results for the regression coefficients in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_i$$\end{document} and the differences
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}_i - {\varvec{\gamma }}_{i^{\prime }}$$\end{document}
and the differences
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}_i - {\varvec{\gamma }}_{i^{\prime }}$$\end{document} for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i^{\prime } \! \ne \! i$$\end{document}
for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i^{\prime } \! \ne \! i$$\end{document} .
.
The validity of the traditional and rather restrictive model with invariant coefficients
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} can now be investigated by contrasting it with the more general model (16), for instance by using conditional likelihood-ratio tests (Andersen, Reference Andersen1971) and fit measures based on conditional likelihoods. We refer to Maris (Reference Maris1998) for an insightful discussion of confidence intervals and hypothesis testing based on CML estimation.
can now be investigated by contrasting it with the more general model (16), for instance by using conditional likelihood-ratio tests (Andersen, Reference Andersen1971) and fit measures based on conditional likelihoods. We refer to Maris (Reference Maris1998) for an insightful discussion of confidence intervals and hypothesis testing based on CML estimation.
CML estimation can also be used for models with crossed latent variables, such as panel models with both individual and year effects. For the identity link, Balazsi et al. (Reference Balazsi, Matyas, Wansbeek and Matyas2017) review fixed-effects approaches, and for the logit link, Charbonneau (Reference Charbonneau2017) and Kertesz (Reference Kertesz and Matyas2017) use CML estimation by repeatedly conditioning on sufficient statistics to eliminate crossed latent variables one at a time. Generalized additive mixed models (GAMMs) with cluster-specific intercepts were estimated using CML by Zhang and Davidian (Reference Zhang and Davidian2004).
For models with several levels of nested latent variables, CML estimation is simply implemented by conditioning on the sufficient statistics for the latent variables at the lowest level.
11. Mimicking CML by MML Estimation of Augmented Models
How can we proceed if CML estimation is not possible for the model of interest? A subset of the parameters can in some instances be treated as known to produce a model that lends itself to CML estimation. Verhelst and Glas (Reference Verhelst, Glas, Fischer and Molenaar1995) proposed the one parameter logistic model (OPLM) where discrimination parameters are taken to be “fixed constants supplied by hypothesis”, making CML estimation feasible for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . However, we usually prefer approaches that can provide protective or mitigating estimation in general settings without treating parameters as known.
. However, we usually prefer approaches that can provide protective or mitigating estimation in general settings without treating parameters as known.
A model closely resembling that of interest can sometimes be found. The most obvious example is use of the logit link instead of the very similar probit link which cannot be used in CML estimation. Another example is dynamic (or autoregressive) logit models with cluster-specific intercepts for binary binary outcomes. In this case Bartolucci and Nigro (Reference Bartolucci and Nigro2010) used a quadratic exponential model (Cox & Wermuth, Reference Cox and Wermuth1994) to address the limitations of the CML estimator of Honoré and Kyriazidou (Reference Honoré and Kyriazidou2000).
In this section we consider a general approach where we mimick CML estimation by MML estimation of augmented models that can handle cluster-level endogeneity. The first variant uses an auxiliary model that specifies how the latent variable depends on the endogenous covariates and the second variant uses a joint model where the endogenous covariates are treated as outcomes. Both variants can accommodate multidimensional latent variables and, in contrast to CML, models with factor loadings or discrimination parameters and non-canonical link functions. For notational simplicity, we henceforth omit reference to parameters in all distributions.
11.1. Auxiliary Modeling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} Given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}


Cluster-level endogeneity can be addressed by using an auxiliary statistical model for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {w}}}_j)$$\end{document} . We describe two alternative methods: using a GLLAMM and using a reduced-form GLMM.
. We describe two alternative methods: using a GLLAMM and using a reduced-form GLMM.
11.1.1. Using GLLAMM
A GLLAMM (e.g., Rabe-Hesketh et al., Reference Rabe-Hesketh, Skrondal and Pickles2004; Skrondal & Rabe-Hesketh, Reference Skrondal and Rabe-Hesketh2004) is composed of a response model for the outcomes given the covariates and latent variables and a structural model for the latent variables given the covariates. Conditional on latent variables, the response model is an extended GLM that accommodates more outcome types and different outcome types for different units. The linear predictor generalizes that of the GLMM in (1) by, for instance, allowing factor loadings or discrimination parameters for the latent variables. Conditional on observed covariates, the structural model is a multilevel structural equation model for the latent variables with normally distributed disturbance terms.
In the present setting, we can use a simple special case of a GLLAMM where the linear predictor of the response model is specified as (3) and the structural model is specified as the chosen auxiliary model. A Mundlak-inspired auxiliary model is

and for non-exchangeable units we can use the more flexible Chamberlain auxiliary model (Chamberlain, Reference Chamberlain1980, Reference Chamberlain, Griliches and Intriligator1984)

In (17) it is assumed that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{E}(\zeta _j|{{\mathbf {w}}}_{j})= {\overline{{\mathbf {x}}}}_{\cdot j}^{\prime } {{\varvec{\delta }}}$$\end{document} , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j$$\end{document} is homoskedastic, normal and independent of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document}
is homoskedastic, normal and independent of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\overline{{\mathbf {x}}}}_{\cdot j}$$\end{document} , and in (18) we assume that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{E}(\zeta _j|{{\mathbf {w}}}_{j})= \sum _{r=1}^{n_j} {{\mathbf {x}}}_{r j}^{\prime } {{\varvec{\delta }}}_r$$\end{document}
, and in (18) we assume that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{E}(\zeta _j|{{\mathbf {w}}}_{j})= \sum _{r=1}^{n_j} {{\mathbf {x}}}_{r j}^{\prime } {{\varvec{\delta }}}_r$$\end{document} , and that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j$$\end{document}
, and that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j$$\end{document} is homoskedastic, normal and independent of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {x}}}_{ij}$$\end{document}
is homoskedastic, normal and independent of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {x}}}_{ij}$$\end{document} (Chamberlain, Reference Chamberlain, Griliches and Intriligator1984).
(Chamberlain, Reference Chamberlain, Griliches and Intriligator1984).
Estimating the GLLAMM by MML provides consistent estimators for all parameters if the auxiliary and outcome models are correctly specified. MML estimation is mitigating for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} if the auxiliary model is a reasonable approximation of the correct model. Note that the assumed auxiliary models can be viewed as linear projections for the identity link (see Sect. 8.1.3).
if the auxiliary model is a reasonable approximation of the correct model. Note that the assumed auxiliary models can be viewed as linear projections for the identity link (see Sect. 8.1.3).
Invoking the GLLAMM framework makes it straightforward to consider useful model extensions. For non-exchangeable units, it may be plausible that the observed covariates have item-specific coefficients
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_i$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}_i$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}_i$$\end{document} , and that the latent variable has item-specific factor loadings or discrimination parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _i$$\end{document}
, and that the latent variable has item-specific factor loadings or discrimination parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _i$$\end{document} . We can then use the following linear predictor for the response model:
. We can then use the following linear predictor for the response model:

The model can, for instance, be extended to include multidimensional latent variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\zeta }}_j$$\end{document} and ultimately extended to the full GLLAMM response model (see e.g., Rabe-Hesketh et al., Reference Rabe-Hesketh, Skrondal and Pickles2004).
and ultimately extended to the full GLLAMM response model (see e.g., Rabe-Hesketh et al., Reference Rabe-Hesketh, Skrondal and Pickles2004).
11.1.2. Using Reduced-Form GLMM
Alternatively, the auxiliary model can be substituted into (3) to yield a reduced-form working GLMM. Substituting model (17), we obtain

which can be rearranged to get

In general, MML estimation of these models produces mitigating estimation for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} , with the exception of identity links where we have pointed out that the consistent CML estimator is obtained.
, with the exception of identity links where we have pointed out that the consistent CML estimator is obtained.
Neuhaus and McCulloch (Reference Neuhaus and McCulloch2006) considered (20) without cluster-level covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document} and called it a “between-within model”. They referred to MML estimation of (20) as the “poor-man’s approximation to the conditional likelihood approach” because it is straightforward to implement in practice. Brumback et al. (Reference Brumback, Dailey, Brumback, Livingston and He2010) extended the poor-man’s approximation by considering nonlinear functions of the cluster-means. Note that, although
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {X}}_j - {{\mathbf {1}}}_{n_j} \! \otimes {\overline{{\mathbf {x}}}}_{\cdot j}^{\prime }$$\end{document}
and called it a “between-within model”. They referred to MML estimation of (20) as the “poor-man’s approximation to the conditional likelihood approach” because it is straightforward to implement in practice. Brumback et al. (Reference Brumback, Dailey, Brumback, Livingston and He2010) extended the poor-man’s approximation by considering nonlinear functions of the cluster-means. Note that, although
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {X}}_j - {{\mathbf {1}}}_{n_j} \! \otimes {\overline{{\mathbf {x}}}}_{\cdot j}^{\prime }$$\end{document} is orthogonal to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {1}}}_{n_j} \! \otimes {{\mathbf {v}}}_{j}^{\prime }$$\end{document}
is orthogonal to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {1}}}_{n_j} \! \otimes {{\mathbf {v}}}_{j}^{\prime }$$\end{document} , omitting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document}
, omitting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document} if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}\! \ne \! {{\mathbf {0}}}$$\end{document}
if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}\! \ne \! {{\mathbf {0}}}$$\end{document} is likely to produce some additional inconsistency for models with logit links because odds ratios are not collapsible (e.g., Gail et al., Reference Gail, Wieand and Piantadosi1984).
is likely to produce some additional inconsistency for models with logit links because odds ratios are not collapsible (e.g., Gail et al., Reference Gail, Wieand and Piantadosi1984).
For non-exchangeable units, we can substitute model (18) in (19) with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _i=1$$\end{document} to obtain
to obtain

In contrast to the GLLAMM approach, factor loadings or discrimination parameters are not accommodated.
We conducted a Monte Carlo experiment to study the performance of MML estimation for a random-intercept binary logit model with a correctly specified auxiliary model for exchangeable data. To investigate consistency as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N\rightarrow \infty $$\end{document} for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=4$$\end{document}
for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=4$$\end{document} , we simulated multivariate normal
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(x_{1j},x_{2j},x_{3j},x_{4j},\zeta _j)$$\end{document}
, we simulated multivariate normal
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(x_{1j},x_{2j},x_{3j},x_{4j},\zeta _j)$$\end{document} with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Var}(x_{ij})=1$$\end{document}
with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Var}(x_{ij})=1$$\end{document} ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},x_{i^{\prime }j})=0.2$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},x_{i^{\prime }j})=0.2$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},\zeta _j)=0.4$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},\zeta _j)=0.4$$\end{document} for all i and parameter values
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma =0$$\end{document}
for all i and parameter values
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\gamma =0$$\end{document} ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta =1$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta =1$$\end{document} , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi =1$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\psi =1$$\end{document} . The cluster mean
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\overline{x}}_{\cdot j}$$\end{document}
. The cluster mean
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\overline{x}}_{\cdot j}$$\end{document} was used in the auxiliary model.
was used in the auxiliary model.
Figure 4 plots the ratio of estimates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\frac{{\widehat{\beta }}^{\scriptscriptstyle \mathrm MML}}{{\widehat{\beta }}^{\scriptscriptstyle \mathrm CML}}$$\end{document} against N. Because this ratio seems to converge to 1 as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document}
against N. Because this ratio seems to converge to 1 as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N \rightarrow \infty $$\end{document} for fixed n and we know that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm CML}$$\end{document}
for fixed n and we know that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm CML}$$\end{document} is consistent, we conclude that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm MML}$$\end{document}
is consistent, we conclude that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm MML}$$\end{document} also appears to be consistent. MML estimation using a correct auxiliary model is therefore protective in this case.
also appears to be consistent. MML estimation using a correct auxiliary model is therefore protective in this case.
Protective MML estimate for simulated data with correct auxiliary model for logit link as a function of N.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},\zeta _j)=0.4$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=4$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=4$$\end{document} .
.

11.2. Joint Modeling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}


We can also handle cluster-level endogeneity by specifying a joint statistical model
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {y}}}_{j},{{\mathbf {w}}}_j)$$\end{document} for the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_{j}$$\end{document}
for the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_{j}$$\end{document} and covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}
and covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document} . For continuous outcomes we discuss joint modeling via conventional structural equation modeling (SEM) and for other outcome types we briefly describe joint modeling using GLLAMMs.
. For continuous outcomes we discuss joint modeling via conventional structural equation modeling (SEM) and for other outcome types we briefly describe joint modeling using GLLAMMs.
11.2.1. Using Conventional SEM
In conventional SEM with identity links and normal conditional distributions, analytic integration over the latent variables is straightforward. In this case joint models are usually expressed as

which requires specification of a model for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {w}}}_j,\zeta _j)$$\end{document} . Specifically, a SEM that includes covariances between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
. Specifically, a SEM that includes covariances between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} is specified and estimated by MML (e.g., Teachman et al., Reference Teachman, Duncan, Yeung and Levy2001; Bollen & Brand, Reference Bollen and Brand2010). In this case consistency requires a correctly specified covariance structure, but does not rely on normality (e.g., Browne, Reference Browne1974), and the approach can be viewed as an instance of pseudo maximum (marginal) likelihood estimation (e.g., Arminger & Schoenberg, Reference Arminger and Schoenberg1989).
is specified and estimated by MML (e.g., Teachman et al., Reference Teachman, Duncan, Yeung and Levy2001; Bollen & Brand, Reference Bollen and Brand2010). In this case consistency requires a correctly specified covariance structure, but does not rely on normality (e.g., Browne, Reference Browne1974), and the approach can be viewed as an instance of pseudo maximum (marginal) likelihood estimation (e.g., Arminger & Schoenberg, Reference Arminger and Schoenberg1989).
Figure 5 shows path diagrams for a SEM representation of a standard random-intercept model with exogenous unit-specific covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} and exogenous cluster-specific covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$v_j$$\end{document}
and exogenous cluster-specific covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$v_j$$\end{document} (left panel) and a joint SEM for the same model but allowing the random intercept to be correlated with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document}
(left panel) and a joint SEM for the same model but allowing the random intercept to be correlated with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} to accommodate cluster-level endogeneity (right panel).
to accommodate cluster-level endogeneity (right panel).
Joint modeling using SEM for identity link and normal conditional distribution. Path diagrams (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=3$$\end{document} ) for standard random-intercept model where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},\zeta _j) \! = \! 0$$\end{document}
) for standard random-intercept model where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},\zeta _j) \! = \! 0$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(v_{j},\zeta _j) \! = \! 0$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(v_{j},\zeta _j) \! = \! 0$$\end{document} (left panel) and joint SEM specifying
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},\zeta _j) \! \ne \! 0$$\end{document}
(left panel) and joint SEM specifying
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(x_{ij},\zeta _j) \! \ne \! 0$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(v_{j},\zeta _j) \! = \! 0$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathrm{Cor}(v_{j},\zeta _j) \! = \! 0$$\end{document} (right panel).
(right panel).

MML estimation of the joint model in the right panel produces CML estimates of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . In contrast to CML estimation, the joint MML approach is also consistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}
. In contrast to CML estimation, the joint MML approach is also consistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} is cluster-level exogenous (as in the figure). Because all the bells and whistles of SEMs are available, it is straightforward to include, for instance, factor loadings in the models. Note that appropriate parameter restrictions should be imposed for exchangeable data (Sim, Reference Sim2019).
is cluster-level exogenous (as in the figure). Because all the bells and whistles of SEMs are available, it is straightforward to include, for instance, factor loadings in the models. Note that appropriate parameter restrictions should be imposed for exchangeable data (Sim, Reference Sim2019).
11.2.2. Using GLLAMM
The SEM approach outlined above is not feasible beyond the identity link, and joint models in biometrics and statistics are typically formulated as (e.g., Neuhaus & McCulloch, Reference Neuhaus and McCulloch2006)

which requires specification of a model for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {w}}}_j|\zeta _j)$$\end{document} . In this case a GLLAMM response model such as (19) with different outcome types for different units is specified for both the outcome model
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {y}}}_j|{{\mathbf {w}}}_j,\zeta _j)$$\end{document}
. In this case a GLLAMM response model such as (19) with different outcome types for different units is specified for both the outcome model
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {y}}}_j|{{\mathbf {w}}}_j,\zeta _j)$$\end{document} and the covariate model
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {w}}}_j|\zeta _j)$$\end{document}
and the covariate model
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {w}}}_j|\zeta _j)$$\end{document} .
.
MML estimation for joint models is consistent for all model parameters if the model for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {w}}}_j|\zeta _j)$$\end{document} is correctly specified, in addition to a correct outcome model for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {y}}}_{j}|{{\mathbf {w}}}_j,\zeta _j)$$\end{document}
is correctly specified, in addition to a correct outcome model for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {y}}}_{j}|{{\mathbf {w}}}_j,\zeta _j)$$\end{document} and a correct
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document}
and a correct
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document} .
.
11.3. Auxiliary or Joint Modeling?
Both auxiliary and joint modeling are useful for mimicking protective CML estimation of the target parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} when there is cluster-level endogeneity. However, it seems unlikely that auxiliary models represent plausible data-generating mechanisms (e.g., Goetgeluk & Vansteelandt, Reference Goetgeluk and Vansteelandt2008), whereas joint models may do so, for instance when there is unobserved cluster-level confounding (see Sect. 12.1). In the unlikely event that the entire joint model is correctly specified, MML estimation will be consistent for all model parameters. Neuhaus and McCulloch (Reference Neuhaus and McCulloch2006) discuss conditions for consistent estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
when there is cluster-level endogeneity. However, it seems unlikely that auxiliary models represent plausible data-generating mechanisms (e.g., Goetgeluk & Vansteelandt, Reference Goetgeluk and Vansteelandt2008), whereas joint models may do so, for instance when there is unobserved cluster-level confounding (see Sect. 12.1). In the unlikely event that the entire joint model is correctly specified, MML estimation will be consistent for all model parameters. Neuhaus and McCulloch (Reference Neuhaus and McCulloch2006) discuss conditions for consistent estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} using auxiliary modeling when the data-generating mechanism is a joint model. Auxiliary modeling can be implemented in standard GLMM software, and very flexible nonlinear parametric models can be used for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {w}}}_j)$$\end{document}
using auxiliary modeling when the data-generating mechanism is a joint model. Auxiliary modeling can be implemented in standard GLMM software, and very flexible nonlinear parametric models can be used for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {w}}}_j)$$\end{document} , whereas modeling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {w}}}_j|\zeta _j)$$\end{document}
, whereas modeling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {w}}}_j|\zeta _j)$$\end{document} requires specification of an appropriate link function and conditional distribution for each covariate. Joint modeling in effect assumes a particular dependence structure for the covariates but accommodates covariates missing at random. We advocate performing sensitivity analysis by using both auxiliary and joint modeling.
requires specification of an appropriate link function and conditional distribution for each covariate. Joint modeling in effect assumes a particular dependence structure for the covariates but accommodates covariates missing at random. We advocate performing sensitivity analysis by using both auxiliary and joint modeling.
Finally, it should be kept in mind that the choice between CML estimation and MML estimation of augmented models may in practice involve a trade-off between inconsistencies due to CML estimation of overly simple models (e.g., without discrimination parameters) and misspecified endogeneity models.
12. Reasons for Cluster-Level Endogeneity
Cluster-level endogeneity can arise for a variety of reasons, including unobserved cluster-level confounding, covariate measurement error, retrospective sampling, informative cluster sizes, missing data, and heteroskedasticity.
12.1. Unobserved Cluster-Level Confounding of Causal Effects
Recall that consistent MML estimation in general requires cluster-level exogeneity as shown in the left panel of Fig. 2. Consider now the case where the data-generating mechanism contains an unobserved cluster-level confounder
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j$$\end{document} as in the left panel of Fig. 6 (where the cluster-level error term is now denoted
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j^*$$\end{document}
as in the left panel of Fig. 6 (where the cluster-level error term is now denoted
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j^*$$\end{document} ).
).
Unobserved cluster-level confounding. Cluster-level unobserved confounder
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j$$\end{document} (left panel) and resulting cluster-level endogeneity (right panel).
(left panel) and resulting cluster-level endogeneity (right panel).

In a statistical model with linear predictor such as (3), the unobserved cluster-level confounder
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j$$\end{document} becomes absorbed by the cluster-level error term
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j = \zeta _j^* + u_j$$\end{document}
becomes absorbed by the cluster-level error term
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j = \zeta _j^* + u_j$$\end{document} as displayed in the right panel of Fig. 6. It is evident that unobserved cluster-level confounding leads to cluster-level endogeneity.
as displayed in the right panel of Fig. 6. It is evident that unobserved cluster-level confounding leads to cluster-level endogeneity.
Use of the term confounding presupposes that regression coefficients represent causal effects that can be confounded. Lancaster (Reference Lancaster2000, p. 296) points out that econometricians emphasize that some or all covariates may be “chosen” by an individual j in light of his knowledge of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} (e.g., attending a training program,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}\!=\!1$$\end{document}
(e.g., attending a training program,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}\!=\!1$$\end{document} rather than
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}\!=\!0$$\end{document}
rather than
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}\!=\!0$$\end{document} , because ability
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
, because ability
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} is low). Hence, economic theory provides a presumption that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
is low). Hence, economic theory provides a presumption that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} are dependent in the population. Lancaster concludes that “This point plays absolutely no role in the statistics literature”, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
are dependent in the population. Lancaster concludes that “This point plays absolutely no role in the statistics literature”, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} is invariably, and usually implicitly, either assumed to be independent or uncorrelated with random covariates or assumed to not depend on the values taken by fixed covariates. Here, regression coefficients merely represent associations between included variables, or linear projections in the case of linear models, in which case the error terms are orthogonal to the covariates by construction. Spanos (Reference Spanos2006) contrasts the conventional meaning of models in econometrics and statistics.
is invariably, and usually implicitly, either assumed to be independent or uncorrelated with random covariates or assumed to not depend on the values taken by fixed covariates. Here, regression coefficients merely represent associations between included variables, or linear projections in the case of linear models, in which case the error terms are orthogonal to the covariates by construction. Spanos (Reference Spanos2006) contrasts the conventional meaning of models in econometrics and statistics.
Importantly, CML estimation can be consistent for causal effects even when there is unobserved cluster-level confounding. Under assumptions [A.1]-[A.4],
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{\beta }}^{\scriptscriptstyle \mathrm CML}$$\end{document} for a treatment
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document}
for a treatment
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} in (3) can be interpreted as estimating a causal effect that is homogeneous in the population. However, causal effects are usually viewed as heterogeneous and the estimand taken to be some average causal effect (ACE) in the modern literature on causal inference.
in (3) can be interpreted as estimating a causal effect that is homogeneous in the population. However, causal effects are usually viewed as heterogeneous and the estimand taken to be some average causal effect (ACE) in the modern literature on causal inference.
For the identity link,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{\beta }}^{\scriptscriptstyle \mathrm CML}$$\end{document} represents an estimated ACE for the subpopulation of clusters where the treatment varies between the units (e.g., Imai & Kim, Reference Imai and Kim2019; Petersen & Lange, Reference Petersen and Lange2020). Sobel (Reference Sobel2012) and Wooldridge (Reference Wooldridge2010: sect. 21.6.4) explore causal effects that can be estimated by fixed-effects methods for different treatment regimes and state assumptions required for identification. For the logit link, there is no simple interpretation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{\beta }}^{\scriptscriptstyle \mathrm CML}$$\end{document}
represents an estimated ACE for the subpopulation of clusters where the treatment varies between the units (e.g., Imai & Kim, Reference Imai and Kim2019; Petersen & Lange, Reference Petersen and Lange2020). Sobel (Reference Sobel2012) and Wooldridge (Reference Wooldridge2010: sect. 21.6.4) explore causal effects that can be estimated by fixed-effects methods for different treatment regimes and state assumptions required for identification. For the logit link, there is no simple interpretation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{\beta }}^{\scriptscriptstyle \mathrm CML}$$\end{document} when the causal odds ratio is heterogeneous (Sjölander et al., Reference Sjölander, Johansson, Lundholm, Altman, Almqvist and Pawitan2012; Petersen & Lange, Reference Petersen and Lange2020).
when the causal odds ratio is heterogeneous (Sjölander et al., Reference Sjölander, Johansson, Lundholm, Altman, Almqvist and Pawitan2012; Petersen & Lange, Reference Petersen and Lange2020).
12.2. Cluster-Specific Measurement Error
Sometimes variables are fallibly measured with cluster-specific measurement errors (e.g., Wang et al., Reference Wang, Flanders, Bostick and Long2012). Examples include teacher-specific bias in ratings of students and laboratory tests analyzed in batches.
12.2.1. Covariate Measurement Error
We now consider the following version of linear predictor (3):

where the unit-specific covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} is continuous.
is continuous.
If
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} were observed and cluster-level exogenous, consistent estimation of all model parameters could proceed by MML estimation. The new feature is that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document}
were observed and cluster-level exogenous, consistent estimation of all model parameters could proceed by MML estimation. The new feature is that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} is latent and fallibly measured by a continuous variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document}
is latent and fallibly measured by a continuous variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document} with additive cluster-specific covariate measurement error
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _{j}$$\end{document}
with additive cluster-specific covariate measurement error
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _{j}$$\end{document}

Rearranging this classical covariate measurement model as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij} = m_{ij} - \delta _{j}$$\end{document} , we substitute it in (21) to obtain a working model with linear predictor
, we substitute it in (21) to obtain a working model with linear predictor

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j^* \equiv \zeta _j - \beta \delta _{j}$$\end{document} . Having replaced the latent covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document}
. Having replaced the latent covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} by the fallibly observed covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document}
by the fallibly observed covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document} , we see that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
, we see that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} has been replaced by a composite cluster-specific error term. Unfortunately, even if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document}
has been replaced by a composite cluster-specific error term. Unfortunately, even if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} is cluster-level exogenous, the fallibly observed covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document}
is cluster-level exogenous, the fallibly observed covariate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document} becomes cluster-level endogenous. This is because the component
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta \delta _{j}$$\end{document}
becomes cluster-level endogenous. This is because the component
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta \delta _{j}$$\end{document} of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j^*$$\end{document}
of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j^*$$\end{document} is not independent of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document}
is not independent of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document} .
.
MML estimation would be inconsistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document} in the working model. Joint modeling of the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
in the working model. Joint modeling of the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} and measures
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document}
and measures
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$m_{ij}$$\end{document} would enable consistent MML estimation of all model parameters, but only if the entire model is correctly specified. In contrast, CML estimation is protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document}
would enable consistent MML estimation of all model parameters, but only if the entire model is correctly specified. In contrast, CML estimation is protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document} . In this case parametric assumptions are not required for the distributions of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
. In this case parametric assumptions are not required for the distributions of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} or
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _{j}$$\end{document}
or
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _{j}$$\end{document} , and these terms could even be dependent, producing a form of differential measurement error. Moreover,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document}
, and these terms could even be dependent, producing a form of differential measurement error. Moreover,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} could be cluster-level endogenous. CML estimation remains protective if several continuous unit-specific covariates are measured with covariate- and cluster-specific errors.
could be cluster-level endogenous. CML estimation remains protective if several continuous unit-specific covariates are measured with covariate- and cluster-specific errors.
12.2.2. Latent-Response Measurement Error
Consider now the class of GLMMs that can be expressed as latent response models

For instance, models with logit links for binary outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} arise if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\epsilon _{ij}$$\end{document}
arise if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\epsilon _{ij}$$\end{document} has a standard logistic density and the observed outcome is produced by thresholding the latent response
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}^*$$\end{document}
has a standard logistic density and the observed outcome is produced by thresholding the latent response
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}^*$$\end{document} as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij} = \text{ I }({y_{ij}^*>0})$$\end{document}
as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij} = \text{ I }({y_{ij}^*>0})$$\end{document} .
.
If
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}^*$$\end{document} is contaminated by cluster-specific additive error
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _j$$\end{document}
is contaminated by cluster-specific additive error
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _j$$\end{document} , we obtain
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}^{\bullet } = y_{ij}^* + \delta _j$$\end{document}
, we obtain
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}^{\bullet } = y_{ij}^* + \delta _j$$\end{document} yielding observed outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij} = \text{ I }({y_{ij}^{\bullet }>0})$$\end{document}
yielding observed outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij} = \text{ I }({y_{ij}^{\bullet }>0})$$\end{document} . Substituting the latent response model (22) we see that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
. Substituting the latent response model (22) we see that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} is replaced by a composite cluster-specific intercept
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j^{\bullet } = \zeta _j + \delta _j$$\end{document}
is replaced by a composite cluster-specific intercept
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j^{\bullet } = \zeta _j + \delta _j$$\end{document} .
.
Again, CML estimation is protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document} and parametric assumptions are not required for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
and parametric assumptions are not required for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _{j}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _{j}$$\end{document} . Moreover, differential measurement error, in the sense that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _j$$\end{document}
. Moreover, differential measurement error, in the sense that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\delta _j$$\end{document} depends on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document}
depends on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_{j}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} , is accommodated.
, is accommodated.
12.3. Retrospective Sampling
We will discuss two kinds of retrospective sampling schemes that produce cluster-level endogeneity, the first by sampling units and the second by sampling clusters.
12.3.1. Case-Control and Choice-Based Sampling of Units
Case-control sampling is very useful for rare binary outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document} when obtaining one or more of the covariates is expensive or invasive (e.g., Breslow, Reference Breslow1996). Examples include drawing blood samples from individuals and conducting comprehensive psychiatric interviews with patients.
when obtaining one or more of the covariates is expensive or invasive (e.g., Breslow, Reference Breslow1996). Examples include drawing blood samples from individuals and conducting comprehensive psychiatric interviews with patients.
The basic idea of case-control designs is to under-sample units i with outcome
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}=0$$\end{document} . This is an example of retrospective sampling because the probability of being sampled depends on the value taken by an outcome variable. Letting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}$$\end{document}
. This is an example of retrospective sampling because the probability of being sampled depends on the value taken by an outcome variable. Letting
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}$$\end{document} be an indicator variable for sampling unit i in cluster j, the probability of selecting the unit is then dependent on whether the unit is a case (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}=1$$\end{document}
be an indicator variable for sampling unit i in cluster j, the probability of selecting the unit is then dependent on whether the unit is a case (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}=1$$\end{document} ) or control (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}=0$$\end{document}
) or control (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}=0$$\end{document} ):
):

We assemble the selection indicators for the units in cluster j in the selection vector
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {s}}}_j$$\end{document} . In a cumulative case-control study (e.g., Rothman et al., Reference Rothman, Greenland and Lash2008, p. 125), the researcher samples all cases,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi (1) = 1$$\end{document}
. In a cumulative case-control study (e.g., Rothman et al., Reference Rothman, Greenland and Lash2008, p. 125), the researcher samples all cases,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi (1) = 1$$\end{document} , whereas
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi (0)$$\end{document}
, whereas
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi (0)$$\end{document} is small in order to under-sample controls.
is small in order to under-sample controls.
In choice-based sampling individuals are sampled retrospectively by stratifying on their individual choices (e.g., Manski, Reference Manski1981), in which case the marginal distribution of the choices in the selected sample typically differs from the corresponding population distribution. A canonical example is choice of transport mode (such as bus, plane or train) where travelers are interviewed at their chosen mode.
The anatomy of retrospective sampling of units is depicted in the left panel of Fig. 7, where we see that the probability of selecting a unit depends on the outcome of that particular unit. Importantly, the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_{j}$$\end{document} are colliders because they are affected by both
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
are colliders because they are affected by both
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document} . The elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {s}}}_j$$\end{document}
. The elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {s}}}_j$$\end{document} are descendants of the colliders in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document}
are descendants of the colliders in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document} and conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {s}}}_j$$\end{document}
and conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {s}}}_j$$\end{document} (performing selection) therefore induces cluster-level endogeneity as illustrated in the right panel of Fig. 7 (conditioning is henceforth signalled by placing variables in grey background in the figures). The produced dependence between the “parents”
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
(performing selection) therefore induces cluster-level endogeneity as illustrated in the right panel of Fig. 7 (conditioning is henceforth signalled by placing variables in grey background in the figures). The produced dependence between the “parents”
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document} is due to “moralization” according to the terminology of Lauritzen et al. (Reference Lauritzen, Dawid, Larsen and Leimer1990).
is due to “moralization” according to the terminology of Lauritzen et al. (Reference Lauritzen, Dawid, Larsen and Leimer1990).
Retrospective sampling of units. Unselected population (left panel) and selected sample (right panel).

Applications proceed with the logit link

where we temporarily denote the intercept for unit i as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _i$$\end{document} (no intercepts in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
(no intercepts in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} here).
here).
The model is often estimated by standard MML but the marginal likelihood contribution is misspecified for the selected sample (where we denote the outcome vector as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_{j}^{\scriptscriptstyle \mathrm sel}$$\end{document} )
)

We see that the correct contribution in the first line differs from the standard marginal likelihood contribution in the second line in two ways: (1) the correct conditional outcome distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(y_{ij}^{\scriptscriptstyle \mathrm sel}|S_{ij}\!=\!1,{\mathbf {x}}_{ij},{{\mathbf {v}}}_j,\zeta _j)$$\end{document} differs from the naive one
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(y_{ij}^{\scriptscriptstyle \mathrm sel}|{\mathbf {x}}_{ij},{{\mathbf {v}}}_j,\zeta _j)$$\end{document}
differs from the naive one
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(y_{ij}^{\scriptscriptstyle \mathrm sel}|{\mathbf {x}}_{ij},{{\mathbf {v}}}_j,\zeta _j)$$\end{document} and the correct latent variable distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {s}}}_j,{{\mathbf {w}}}_j)$$\end{document}
and the correct latent variable distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {s}}}_j,{{\mathbf {w}}}_j)$$\end{document} differs from the naive one
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document}
differs from the naive one
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document} . The fact that the correct latent variable distribution becomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {s}}}_j,{{\mathbf {w}}}_j)$$\end{document}
. The fact that the correct latent variable distribution becomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {s}}}_j,{{\mathbf {w}}}_j)$$\end{document} corresponds to the dependence between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
corresponds to the dependence between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document} seen in the right panel of Fig. 7. As a result, standard MML estimation leads to inconsistent estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
seen in the right panel of Fig. 7. As a result, standard MML estimation leads to inconsistent estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} , an instance of collider-stratification bias (e.g., Greenland et al., Reference Greenland, Pearl and Robins1999).
, an instance of collider-stratification bias (e.g., Greenland et al., Reference Greenland, Pearl and Robins1999).
It is important to note that the logit link is preserved in selected samples

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha _i^{\scriptscriptstyle \mathrm sel} = \alpha _i + \log [\pi (1)/\pi (0)]$$\end{document} . It follows that standard CML estimation is protective. Prentice (Reference Prentice1976) argues that protective estimation of the coefficient
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document}
. It follows that standard CML estimation is protective. Prentice (Reference Prentice1976) argues that protective estimation of the coefficient
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document} for a binary
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document}
for a binary
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} can alternatively be achieved by CML estimation of a retrospective logit model with cluster-specific effects where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document}
can alternatively be achieved by CML estimation of a retrospective logit model with cluster-specific effects where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} is the outcome and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document}
is the outcome and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document} is now the coefficient of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
is now the coefficient of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} . In contrast, MML estimation with an auxiliary model produces inconsistent estimation of the intercepts but protective or mitigating estimation of the coefficients of covariates, depending on whether the auxiliary model is correct or not.
. In contrast, MML estimation with an auxiliary model produces inconsistent estimation of the intercepts but protective or mitigating estimation of the coefficients of covariates, depending on whether the auxiliary model is correct or not.
12.3.2. Sumscore-Based Sampling of Clusters
For rare binary outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document} , clusters where many of the outcomes take the value zero are sometimes under-sampled. For instance, in a genetic study a family j could be more likely to be ascertained if one or more members of the family has a particular disease.
, clusters where many of the outcomes take the value zero are sometimes under-sampled. For instance, in a genetic study a family j could be more likely to be ascertained if one or more members of the family has a particular disease.
Here we consider the case where the probability of sampling a cluster j is a function of the sumscore or number of “successes” in the cluster (e.g., Neuhaus & Jewell, Reference Neuhaus and Jewell1990)

The structure of retrospective sumscore-based sampling is shown in the left panel of Fig. 8. Importantly, we see from the right panel that conditioning on the cluster-selection indicator
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_j$$\end{document} induces cluster-level endogeneity because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_j$$\end{document}
induces cluster-level endogeneity because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_j$$\end{document} is a descendant of the colliders in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document}
is a descendant of the colliders in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document} .
.
Retrospective sampling of clusters. Unselected population (left panel) and selected sample (right panel).

We proceed with a logit link as we did for retrospective sampling of units. The standard marginal likelihood contribution is now misspecified in the selected sample

which yields inconsistent MML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . In contrast to retrospective sampling of units,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {y}}}_{j}^{\scriptscriptstyle \mathrm sel}|S_j\!=\!1,{\mathbf {x}}_{ij},{{\mathbf {v}}}_j,\zeta _j)$$\end{document}
. In contrast to retrospective sampling of units,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {y}}}_{j}^{\scriptscriptstyle \mathrm sel}|S_j\!=\!1,{\mathbf {x}}_{ij},{{\mathbf {v}}}_j,\zeta _j)$$\end{document} is no longer a product of conditionally independent logit models, but rather corresponds to the Rosner (Reference Rosner1984) model for correlated data. MML estimation based on an auxiliary model therefore produces inconsistent estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
is no longer a product of conditionally independent logit models, but rather corresponds to the Rosner (Reference Rosner1984) model for correlated data. MML estimation based on an auxiliary model therefore produces inconsistent estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . Fortunately, standard CML estimation is once again protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
. Fortunately, standard CML estimation is once again protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} (Neuhaus & Jewell, Reference Neuhaus and Jewell1990).
(Neuhaus & Jewell, Reference Neuhaus and Jewell1990).
12.4. Informative Cluster Sizes
It is sometimes plausible that the cluster sizes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} depend on a cluster-specific latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
depend on a cluster-specific latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and cluster-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
and cluster-specific covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} . For example, for a clinical psychologist j, the patient volume
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
. For example, for a clinical psychologist j, the patient volume
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} may depend on his latent skill
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
may depend on his latent skill
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and whether he works in a public or private hospital
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_j$$\end{document}
and whether he works in a public or private hospital
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_j$$\end{document} . The patient outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document}
. The patient outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document} may depend on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
may depend on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_j$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_j$$\end{document} , and observed individual patient characteristics
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document}
, and observed individual patient characteristics
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document} . This situation is shown in Fig. 9, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {c}}}_j$$\end{document}
. This situation is shown in Fig. 9, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {c}}}_j$$\end{document} is included to signify that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document}
is included to signify that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} are typically dependent.
are typically dependent.
Informative cluster-sizes.

A joint model can be specified for the outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {y}}}_j$$\end{document} and cluster size
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
and cluster size
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} , the latter part typically a Poisson model with log link
, the latter part typically a Poisson model with log link

MML estimation of the joint model is consistent if the cluster-size model
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(n_j|{{\mathbf {v}}}_j,\zeta _j)$$\end{document} is correctly specified in addition to the outcome model
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(y_{ij}|{\mathbf {x}}_{ij},{{\mathbf {v}}}_j,\zeta _j)$$\end{document}
is correctly specified in addition to the outcome model
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(y_{ij}|{\mathbf {x}}_{ij},{{\mathbf {v}}}_j,\zeta _j)$$\end{document} and the mixing distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document}
and the mixing distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document} .
.
Researchers occasionally condition on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} by including it as a covariate in the model (e.g., Seaman et al., Reference Seaman, Pavlou and Copas2014). The standard marginal likelihood contribution in this case is misspecified
by including it as a covariate in the model (e.g., Seaman et al., Reference Seaman, Pavlou and Copas2014). The standard marginal likelihood contribution in this case is misspecified

It is evident from Fig. 9 that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} is a collider and that conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
is a collider and that conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} opens a confounding path between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
opens a confounding path between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document} that makes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document}
that makes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document} cluster-level endogenous. However, also conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
cluster-level endogenous. However, also conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} blocks this path, in which case
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document}
blocks this path, in which case
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document} remains cluster-level exogenous, whereas
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
remains cluster-level exogenous, whereas
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} becomes cluster-level endogenous. The latent-variable distribution becomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {v}}}_j,n_j)$$\end{document}
becomes cluster-level endogenous. The latent-variable distribution becomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {v}}}_j,n_j)$$\end{document} (shown in the second line of the likelihood contribution above), which differs from the assumed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document}
(shown in the second line of the likelihood contribution above), which differs from the assumed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document} in naive MML estimation.
in naive MML estimation.
For the identity link, MML estimation is consistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} under cluster-level exogeneity whatever the distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}
under cluster-level exogeneity whatever the distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} (e.g., Verbeke & Lesaffre, Reference Verbeke and Lesaffre1997), but this is not the case for other links. Naive MML estimation that includes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
(e.g., Verbeke & Lesaffre, Reference Verbeke and Lesaffre1997), but this is not the case for other links. Naive MML estimation that includes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} as a covariate therefore gives protective estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
as a covariate therefore gives protective estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} for the identity link, but otherwise inconsistent estimation, albeit mildly inconsistent according to simulations. Fortunately, standard CML estimation is protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
for the identity link, but otherwise inconsistent estimation, albeit mildly inconsistent according to simulations. Fortunately, standard CML estimation is protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} for all canonical links because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
for all canonical links because
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} is a cluster-level characteristic. Important advantages of this approach are that we neither need to know about the relevant
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
is a cluster-level characteristic. Important advantages of this approach are that we neither need to know about the relevant
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} nor specify a correct model for the dependence on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
nor specify a correct model for the dependence on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} .
.
In practice, the cluster size
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} is often ignored in the estimating model. From Fig. 9 we see that conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
is often ignored in the estimating model. From Fig. 9 we see that conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} makes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
makes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_j$$\end{document} conditionally independent. This implies that MML estimation for the identity link remains protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
conditionally independent. This implies that MML estimation for the identity link remains protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . For the logit link, the estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
. For the logit link, the estimator of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} for the model that ignores
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
for the model that ignores
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} has a probability limit that differs from the inconsistent MML estimator for the model where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
has a probability limit that differs from the inconsistent MML estimator for the model where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} is included as a covariate because odds-ratios are not collapsible (e.g., Gail et al., Reference Gail, Wieand and Piantadosi1984). It is extremely unlikely that this estimator is consistent. For the log link, the inconsistency is expected to be mild. Fortunately, standard CML estimation remains protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
is included as a covariate because odds-ratios are not collapsible (e.g., Gail et al., Reference Gail, Wieand and Piantadosi1984). It is extremely unlikely that this estimator is consistent. For the log link, the inconsistency is expected to be mild. Fortunately, standard CML estimation remains protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} for all canonical links.
for all canonical links.
Neuhaus and McCulloch (Reference Neuhaus and McCulloch2011) considered a restrictive version of the model in Fig. 9 where the cluster size just depends on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} . Here, there is no collider problem and the correct mixing distribution becomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|n_j)$$\end{document}
. Here, there is no collider problem and the correct mixing distribution becomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|n_j)$$\end{document} . The conclusions reported above for MML and CML estimation persist.
. The conclusions reported above for MML and CML estimation persist.
12.5. Data Missing Not at Random
12.5.1. Outcome-Dependent Missingness
Missingness of outcomes that depends on the values taken by the outcomes violates the missing at random assumption (e.g., Seaman et al., Reference Seaman, Galati, Jackson and Carlin2013) and is therefore referred to as not missing at random (NMAR).
In the longitudinal non-exchangeable setting, current-outcome dependent missingness occurs if the probability that an outcome is missing at an occasion i,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}=1$$\end{document} , depends on the value taken by the outcome for that particular occasion
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
, depends on the value taken by the outcome for that particular occasion
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} . An example would be when the outcome is a disease symptom that makes it more difficult to visit a clinic for an assessment. The structure of current-outcome dependent missingness is shown in the left panel of Fig. 10, which is identical to that previously shown for retrospective sampling of units in Fig. 7.
. An example would be when the outcome is a disease symptom that makes it more difficult to visit a clinic for an assessment. The structure of current-outcome dependent missingness is shown in the left panel of Fig. 10, which is identical to that previously shown for retrospective sampling of units in Fig. 7.
Outcome dependent missingness. Current outcome dependent missingness (left panel) and lag(1) dependent missingness for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=4$$\end{document} (right panel).
(right panel).

Conditioning on the selection indicators
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}$$\end{document} leads to cluster-level endogeneity, as shown in the right panel of Fig. 7, because the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}$$\end{document}
leads to cluster-level endogeneity, as shown in the right panel of Fig. 7, because the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}$$\end{document} are decendants of the colliders
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
are decendants of the colliders
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} . For the non-exchangeable case, it is plausible that the missingness probabilities will differ between units i,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi _i(y_{ij})$$\end{document}
. For the non-exchangeable case, it is plausible that the missingness probabilities will differ between units i,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi _i(y_{ij})$$\end{document} .
.
For exchangable units, outcome-dependent missingness only makes sense if the probability that an outcome
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} is missing for a unit,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}=1$$\end{document}
is missing for a unit,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}=1$$\end{document} , depends on the value taken by the outcome for that particular unit. In contrast, for longitudinal data we can also consider lag(1) outcome-dependent missingness where the probability that an outcome is missing at an occasion,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}=1$$\end{document}
, depends on the value taken by the outcome for that particular unit. In contrast, for longitudinal data we can also consider lag(1) outcome-dependent missingness where the probability that an outcome is missing at an occasion,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$S_{ij}=1$$\end{document} , depends on the previous outcome
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{i-1,j}$$\end{document}
, depends on the previous outcome
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{i-1,j}$$\end{document} . Such a process is shown in the right panel of Fig. 10 for the case of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=4$$\end{document}
. Such a process is shown in the right panel of Fig. 10 for the case of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=4$$\end{document} . This can occur if an outcome, such as a diagnosis, only affects missingness after having been relayed to the subject. Again, missingness produces cluster-level endogeneity.
. This can occur if an outcome, such as a diagnosis, only affects missingness after having been relayed to the subject. Again, missingness produces cluster-level endogeneity.
Hausman and Wise (Reference Hausman and Wise1979) and Diggle and Kenward (Reference Diggle and Kenward1994) used MML to estimate joint models where linear predictor (3) with an identity link for the outcome is combined with probit/logit models for current-outcome dependent and current plus lag(1) outcome-dependent missingness, respectively. MML estimation is consistent for all parameters under correct model specification, but this approach has been criticized for relying heavily on unverifiable distributional assumptions (e.g., Little, Reference Little1985). Standard MML estimation (ignoring the missingness) suffers from collider-stratification bias and is inconsistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} .
.
Skrondal and Rabe-Hesketh (Reference Skrondal and Rabe-Hesketh2014) obtain several useful results for model (23). For current outcome-dependent missingness, CML estimation is protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . MML estimation using an auxiliary model yields protective estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
. MML estimation using an auxiliary model yields protective estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} if that model is correct and mitigating estimation otherwise. For lag(1) outcome-dependent missingness, CML estimation stratified on the missingness pattern is protective. If missingness depends on both the current and all lagged outcomes (whether observed or missing), CML estimation is protective only if complete data are analyzed stratified on judiciously chosen values of the sufficient statistic. Note that none of these results hinge on specification of a parametric or nonparametric model for missingness.
if that model is correct and mitigating estimation otherwise. For lag(1) outcome-dependent missingness, CML estimation stratified on the missingness pattern is protective. If missingness depends on both the current and all lagged outcomes (whether observed or missing), CML estimation is protective only if complete data are analyzed stratified on judiciously chosen values of the sufficient statistic. Note that none of these results hinge on specification of a parametric or nonparametric model for missingness.
12.5.2. Latent-Variable and Covariate Dependent Missingness
Missingness of outcomes can depend on the latent variable in addition to the covariates and is in this case also not missing at random (NMAR). For example, the probability of visiting a clinic/answering an item could depend on the unobserved frailty/ability
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} of the subject as well as his observed characteristics
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}
of the subject as well as his observed characteristics
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document} .
.
The structure shown in Fig. 11 is similar to that previously discussed for informative cluster-sizes but here
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {s}}}_{j}$$\end{document} could also depend on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{j}$$\end{document}
could also depend on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{j}$$\end{document} , so conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
, so conditioning on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} does not block the confounding path to give protective estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
does not block the confounding path to give protective estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} .
.
Latent-variable and covariate dependent missingness. Unselected population (left panel) and selected sample (right panel).

Joint modeling can be performed with “shared-parameter” models (e.g., Wu & Carroll, Reference Wu and Carroll1988; Ten Have et al., Reference Ten Have, Kunselman, Pulkstenis and Landis1998) where the outcome and missingness processes share latent variables in addition to observed covariates. MML estimation is consistent for all parameters if the joint model is correctly specified, but note that such models rely on unverifiable distributional assumptions (e.g., Little, Reference Little1985). Standard MML estimation that ignores missingness suffers from collider-stratification bias and is inconsistent. CML estimation is protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} for identity and log link functions because it can be cast as JML estimation of models with cluster-specific dummy variables.
for identity and log link functions because it can be cast as JML estimation of models with cluster-specific dummy variables.
For the logit link, Skrondal and Rabe-Hesketh (Reference Skrondal and Rabe-Hesketh2014) prove that CML estimation is protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} , even when missingness also depends on missing outcomes (in addition to the latent variable and covariates). Again, this does not require specification of a parametric or nonparametric missingness model.
, even when missingness also depends on missing outcomes (in addition to the latent variable and covariates). Again, this does not require specification of a parametric or nonparametric missingness model.
The case where missingness just depends on the latent variable is shown in Fig. 12. Here the shape of the latent variable distribution is changed from
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j)$$\end{document} to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {s}}}_j)$$\end{document}
to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(\zeta _j|{{\mathbf {s}}}_j)$$\end{document} but there is no collider problem. For the identity link, standard MML estimation is now protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
but there is no collider problem. For the identity link, standard MML estimation is now protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} . In contrast, standard MML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
. In contrast, standard MML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} for the logit link is just mitigating, but with mild inconsistency (e.g., Neuhaus et al., Reference Neuhaus, Hauck and Kalbfleisch1992). CML estimation remains protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}
for the logit link is just mitigating, but with mild inconsistency (e.g., Neuhaus et al., Reference Neuhaus, Hauck and Kalbfleisch1992). CML estimation remains protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} .
.
Latent-variable dependent missingness.

12.6. Heteroskedastic Latent Variable
Cluster-level endogeneity occurs if the variance of the latent variable distribution depends on cluster-level covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} . For example, Heagerty (Reference Heagerty1999) considered a longitudinal study of schizophrenia where the latent variable variance depends on gender. Such heteroskedasticity is illustrated in Fig. 13 where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document}
. For example, Heagerty (Reference Heagerty1999) considered a longitudinal study of schizophrenia where the latent variable variance depends on gender. Such heteroskedasticity is illustrated in Fig. 13 where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} is a subset of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document}
is a subset of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {w}}}_j$$\end{document} .
.
Heteroskedastic latent variable.

For the identity link, standard MML estimation remains consistent under this misspecification. For the logit link, Heagerty and Kurland (Reference Heagerty and Kurland2001) demonstrated that standard MML estimation becomes inconsistent for all parameters. If the structure of the heteroskedasticity is known, consistent MML estimation can be achieved if an appropriate heteroskedasticity model can be specified, for instance by using a GLLAMM. Fortunately, standard CML estimation is protective for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document} , and does not require additional modeling or even knowing the variables that induce heteroskedasticity.
, and does not require additional modeling or even knowing the variables that induce heteroskedasticity.
13. Latent Variable Scoring
When considering a latent variable model without an incidental parameters problem, it is straightforward to obtain estimates of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} by JML estimation using (4). In general, this scoring method can work well for large cluster sizes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document}
by JML estimation using (4). In general, this scoring method can work well for large cluster sizes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n_j$$\end{document} .
.
CML estimation is of limited value if the target of inference is the value of the latent variable
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} . However, we can estimate the cluster-specific component
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j \equiv \zeta _j + h({{\mathbf {v}}}_j)$$\end{document}
. However, we can estimate the cluster-specific component
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j \equiv \zeta _j + h({{\mathbf {v}}}_j)$$\end{document} that is eliminated in CML estimation by maximizing the scoring likelihood
that is eliminated in CML estimation by maximizing the scoring likelihood

with respect to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$u_j$$\end{document} . The estimated scores
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{u}}_j^{\mathrm{{\scriptscriptstyle ML}}}$$\end{document}
. The estimated scores
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{u}}_j^{\mathrm{{\scriptscriptstyle ML}}}$$\end{document} can then be plugged in to obtain predictions of outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(y_{ij}|{\mathbf {x}}_{ij}; {\widehat{{{\varvec{\vartheta }}}}}^{\mathrm{{\scriptscriptstyle CML}}}, {\widehat{u}}_j^{\mathrm{{\scriptscriptstyle ML}}})$$\end{document}
can then be plugged in to obtain predictions of outcomes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(y_{ij}|{\mathbf {x}}_{ij}; {\widehat{{{\varvec{\vartheta }}}}}^{\mathrm{{\scriptscriptstyle CML}}}, {\widehat{u}}_j^{\mathrm{{\scriptscriptstyle ML}}})$$\end{document} . Improvements of the ML estimator, such as variants of the weighted likelihood method of Warm (Reference Warm1989), can also be employed.
. Improvements of the ML estimator, such as variants of the weighted likelihood method of Warm (Reference Warm1989), can also be employed.
If CML estimation is mimicked by MML estimation of augmented models, we can use empirical Bayes (EB) prediction that performs partial pooling of information from other clusters and is therefore more precise. For instance, for joint modeling (see Sect. 11.2) the predictions can be obtained as:

The performance of EB prediction in this case also relies on correct specification of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p({{\mathbf {w}}}_j|\zeta _j; {{\varvec{\vartheta }}})$$\end{document} . Parametric assumptions are moreover made regarding the latent variable distribution unless nonparametric marginal maximum likelihood ((NPMML) is used (Rabe-Hesketh et al., Reference Rabe-Hesketh, Pickles and Skrondal2003). However, simulation studies suggest that violations of the distributional assumptions may have a modest impact on the mean squared error of prediction unless the assumed distribution has more limited support than the correct distribution, the latent variable variance is large, or the cluster sizes are large (e.g., McCulloch & Neuhaus, Reference McCulloch and Neuhaus2011a; Reference McCulloch and Neuhausb).
. Parametric assumptions are moreover made regarding the latent variable distribution unless nonparametric marginal maximum likelihood ((NPMML) is used (Rabe-Hesketh et al., Reference Rabe-Hesketh, Pickles and Skrondal2003). However, simulation studies suggest that violations of the distributional assumptions may have a modest impact on the mean squared error of prediction unless the assumed distribution has more limited support than the correct distribution, the latent variable variance is large, or the cluster sizes are large (e.g., McCulloch & Neuhaus, Reference McCulloch and Neuhaus2011a; Reference McCulloch and Neuhausb).
We refer to Skrondal and Rabe-Hesketh (Reference Skrondal and Rabe-Hesketh2009) for latent variable scoring and various kinds of prediction of outcomes in GLMMs and related models with multidimensional latent variables.
14. Concluding Remarks
We have demonstrated that conditional likelihoods have an important role to play in latent variable modeling that extends well beyond Rasch models for measurement. For the class of models considered here, a great advantage of CML estimation is that it can simultaneously handle cluster-level endogeneity problems induced by, for instance, unobserved cluster-level confounding of causal effects, cluster-specific measurement error, retrospective sampling, informative cluster sizes, missing data, and heteroskedasticity.
Although randomized experimental designs ensure that there is no confounding of treatment effects, there could be cluster-level endogeneity due to, for instance, covariate measurement error and data not missing at random. The famous Hausman (Reference Hausman1978) specification test that compares fixed-effect estimates (e.g., from CML estimation) with random-effects estimates (e.g., from MML estimation) is routinely used in the context of model (3). Contrary to common belief, a significant test cannot be interpreted as flagging unobserved confounding because cluster-level endogeneity can arise for a variety of reasons.
In psychology, split-plot analysis of variance (ANOVA) is sometimes used for repeated measures designs. The hypothesis test for a within-subject effect is in this case robust against cluster-level endogeneity. However, the focus is traditionally solely on hypothesis testing and not estimation of parameters or effect sizes. A very similar fixed-effects approach known as difference-in-differences in economics is popular for estimating effects in natural/quasi experiments (e.g., Angrist & Pischke, Reference Angrist and Pischke2009).
Hybrid estimation approaches can be obtained by combining CML with other estimation methods:
-
(a) CML and MML (and related) estimation: In a Rasch context, Andersen and Madsen (Reference Andersen and Madsen1977) used CML to estimate item parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\beta }}$$\end{document}
and subsequently MML to estimate the expectation and variance of a parametric person distribution, given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm CML}$$\end{document}. For a linear mixed model with random slopes, Verbeke et al. (Reference Verbeke, Spiessens and Lesaffre2001) used a conditional likelihood to eliminate the cluster-specific intercept
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document} (and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document}), and MML or restricted maximum likelihood (REML) to estimate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document},
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document} and the covariance matrix of the slopes in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\zeta }}_j$$\end{document}. Tibaldi et al. (Reference Tibaldi, Verbeke, Molenberghs, Renard, van den Noortgate and De Boeck2007) combined CML and composite-likelihood estimation of crossed random-effects models with identity and logit links. -
(b) CML and instrumental variables (IV) estimation:
For model (3) with identity link, Hausman and Taylor (Reference Hausman and Taylor1981) proposed a multi-stage estimation approach where CML is used to estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\beta }}$$\end{document}
(and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\sigma ^2$$\end{document}) followed by IV estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\gamma }}$$\end{document} (and the variance of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\zeta _j$$\end{document}) for given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\widehat{{\varvec{\beta }}}}^{\scriptscriptstyle \mathrm CML}$$\end{document}. The instruments are internal in the sense that they are constructed from the covariates
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbf {x}}_{ij}$$\end{document} and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\mathbf {v}}}_j$$\end{document} in the model. All parameters can be consistently estimated if one can correctly designate which unit- and cluster-specific covariates are cluster-level endogenous. In a panel data setting with identity link, Lee (Reference Lee2002) used first differencing to remove cluster-specific intercepts. Subsequently, he used IV methods to estimate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}$$\end{document}, where various exogeneity assumptions for the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\epsilon _{ij}$$\end{document} dictate if covariates at an occasion can serve as internal instruments for covariates at other occasions. -
(c) CML and Bayes estimation:
Conditional likelihoods have been used in conjunction with prior distributions for model parameters in Bayesian inference. This was motivated by Diggle et al. (Reference Diggle, Morris and Wakefield2000) to handle retrospective sampling and by Lancaster (Reference Lancaster2004) to handle unobserved confounding. It is worth pointing out that standard Bayesian inference that ignores cluster-level endogeneity performs similarly to standard MML estimation.
-
(d) Mixed-type ML estimation:
Cook and Farewell (Reference Cook and Farewell1999) discussed the construction of mixed-type likelihoods where the likelihood contributions are of different types for different clusters. They considered a version of linear predictor (3) with a logit link, where conditional likelihoods were used for small clusters whereas joint likelihoods were used for large clusters.
















An interesting recent development is the use of conditional likelihoods in double-robust estimation. Zetterquist et al. (Reference Zetterqvist, Vermeulen, Vansteelandt and Sjölander2019) consider model (3) with a logit link and a binary treatment
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} of interest. They argue that consistency for the corresponding
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document}
of interest. They argue that consistency for the corresponding
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document} can be achieved if at least one of the following approaches is consistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document}
can be achieved if at least one of the following approaches is consistent for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document} : i) CML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document}
: i) CML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document} in the prospective model (3) for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
in the prospective model (3) for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} or ii) CML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document}
or ii) CML estimation of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta $$\end{document} as the coefficient of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
as the coefficient of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document} in a retrospective logit model for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document}
in a retrospective logit model for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$x_{ij}$$\end{document} with a cluster-specific intercept. One need not know which of the models is correct so there are in this sense two opportunities of getting it right.
with a cluster-specific intercept. One need not know which of the models is correct so there are in this sense two opportunities of getting it right.
In closing, it is evident that we have drawn on and extended results not just from psychometrics but also from other “ics”, such as econometrics, biometrics and statistics, in this address. Unfortunately, progress in psychometrics has been hampered by a paucity of cross-fertilization from the other “ics” — but the opposite is certainly also true! A case in point is the extensive literature on covariate measurement error where the psychometric wheel is regularly reinvented, albeit often in a somewhat square fashion. We end with a perceptive citation from a Psychometrika article by the renowned econometrician Arthur Goldberger (Goldberger, Reference Goldberger1971, p. 83):
“Economists and psychologists have been developing their statistical techniques quite independently for many years. From time to time, a hardy soul strays across the frontier but is not met with cheers when he returns home.”


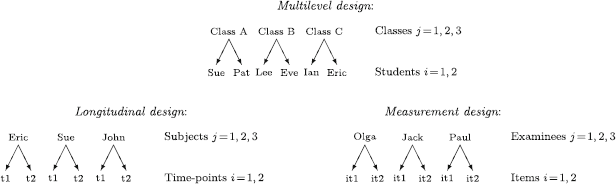


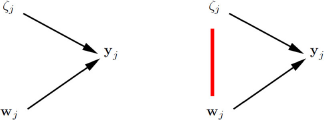
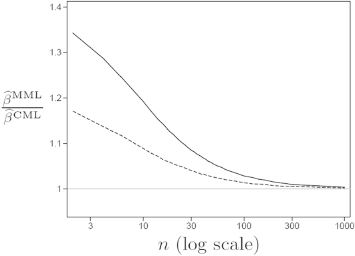



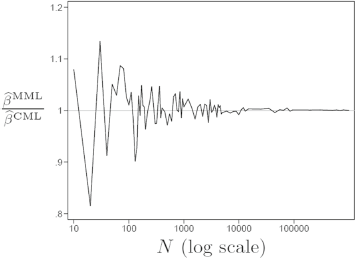


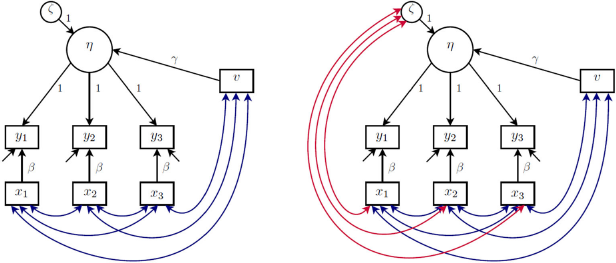





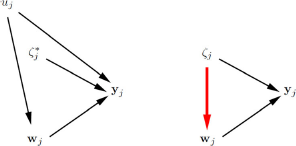

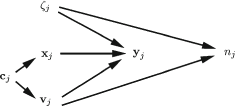


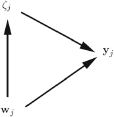

 Open access
Open access