


1. Introduction
We introduce here the Phonomaton, a public web-facing facility (https://www.kratylos.org/ph) designed to assist students in introductory phonology courses as well as more advanced phonologists in modeling and comparing complex derivations. The program produces step-by-step derivations based on user-provided representations and rules that can make full use of features and autosegmental tiers.Footnote 1 We then discuss an implementation of this tool in a semester-long trial and consider the ways in which such tools can facilitate the instruction of theoretical linguistics more generally.
The Phonomaton aims both to be powerful enough to model the full phonology of any language and also to serve as a pedagogical tool for introducing fundamental notions of phonology in an interactive manner that encourages exploration. The tool facilitates teaching underlying representations, rule notation (including alpha notation, segment indexing, and regular expressions), feature systems, natural classes, serial derivations, morphological levels, and autosegmental phonology. The Phonomaton allows a user to formulate hypotheses and immediately test them by manipulating an analysis and seeing its output. We also envision the tool as a gateway to computer science. It instantiates a high-level programming language (albeit one that looks nearly identical to familiar rule formalism) and brings to life the procedural algorithms that have been kept until now in the province of the written page, even among introductions with a strong focus on formalization (e.g. Bale & Reiss Reference Bale and Reiss2018).
In the following subsection, we contextualize the program in the current landscape of linguistic software for professional and pedagogical use. In Section 2, we give an overview of the core functions of the software, focusing on how it handles segments and features (Section 2.1) and phonological rules (Section 2.2). This latter section aims to give a feel of what the program is capable of by examining not only the basic rule formalism (Section 2.3), but also underspecification (Section 2.4), alpha notation (Section 2.5), morphological boundaries (Section 2.6), segment indexing (Section 2.7), quantifiers and regular expressions (Section 2.8), types of rule application (Section 2.9), and morphological paradigms (Section 2.10). In Section 3, we discuss how we have employed the program in the classroom and the results of a student survey on its implementation. We conclude in Section 4 with a note on future pedagogical and technological prospects. Readers who are less interested in the mechanics of the program and more concerned with its pedagogical application should be able to skip to Section 3 without getting lost.
1.1. The state of the field
At present, few computational tools are available for teaching phonology. Pheatures Spreadsheet (van Vugt Reference van Vugt2012), which supersedes the earlier FeaturePad (Zuraw Reference Zuraw2004) and PhonologyPad (Albro Reference Albro1999), allows users to explore natural classes within inventories. The program also shows the result of altering a phonological feature and can check answers to questions involving natural classes. Given its narrower focus, however, Pheatures Spreadsheet lacks the power to model phonological derivations/evaluations. Phonology Assistant (Summer Institute of Linguistics (SIL) 2005) is even more distant, as it is aimed not at students but rather at linguists seeking to describe a phonological system. Phonology Assistant works in tandem with other software produced by SIL (FLEx and Toolbox) to help the user derive as many phonological generalizations as possible from the lexicon (including stochastic tendencies). But like the previous programs, it lacks the ability to model alternations and more resembles a corpus tool. The program closest to the one presented here is Derive! (Steel & Jurgec Reference Steel and Jurgec2017), an interactive browser-based program that calculates serial derivations using SPE-style rules (Sound pattern of English; Chomsky & Halle Reference Chomsky and Halle1968) and a customizable set of features. Despite these similarities, the Phonomaton is, to our knowledge, the first publicly available program designed to model derivational phonology in its full breadth, using feature geometry, underspecification, autosegmental representations, and morphological categorization, and including as well as the ability to download and upload analyses.Footnote 2
We believe that formalization has broader implications from a field-wide perspective and that our efforts address two unfortunate trends: increasing incommensurability across analyses and frameworks, and the marginalization of theoretical linguistics in applied fields. With the proliferation of theories, frameworks, and proposals, the field has reached a point where no two linguists play by all the same rules, with disagreements both in details and fundamental concepts. One factor in this trend, we believe, has been the informal nature in which arguments and analyses are customarily presented. Generative linguistics was long distinguished by a solid mathematical foundation with a paradoxical antagonism toward computational implementation, especially puzzling considering the early and widespread recognition that generative linguistics shares much with the algorithmic style of programming.Footnote 3 Halle had already stated in the forward to his 1959 The sound pattern of Russian,
I have assumed that an adequate description of a language can take the form of a set of rules—analogous perhaps to a program of an electronic computing machine—which when provided with further special instructions, could in principle produce all and only well-formed (grammatical) utterances in the language in question. (Halle Reference Halle1971 [1959]:12)
By the early 1970s, however, much of the substantive formal foundations of Chomsky’s earliest work, including SPE (Chomsky & Halle Reference Chomsky and Halle1968), had largely fallen away, leaving a residue of what critics often refer to as ‘pseudomath’.Footnote 4 The consequences of this aversion have been both scientific and sociological. First, practical applications of computational linguistics are now dominated by statisticians and engineers rather than experts in language structure. Consequently, the field of theoretical linguistics has boxed itself out of what could have been its most lucrative applications.Footnote 5 This is not to say that a field devoted to understanding the human cognitive system should be driven by economic concerns, but now, in the eighth decade of generative linguistics, it seems quite likely that the intuition-based (and, arguably, compuphobic) approach that has defined mainstream linguistics in the US has made pursuing a profession in the field a gamble that only few can afford. Put more bluntly, a field of study that should have wide-ranging practical applications throughout society has largely settled for reproducing linguists.Footnote 6 Given the persistent socioeconomic inequities along racial and ethnic lines in the US and elsewhere, the field’s long-standing inclination toward ‘pure’ theory could have only negative implications for diversity by narrowing practical applications and career paths.Footnote 7 Needless to say, the promotion of diversity and equity faces multiple obstacles requiring multiple solutions; here, we only seek to nudge linguistics pedagogy toward a formal rigor with wider application.
Within the pedagogical context, the Phonomaton aims to promote computational thinking more generally, that is, to develop algorithmic problem-solving techniques that a computer can carry out (Papert Reference Papert1990, Wing Reference Wing2006) and that are generalizable to any number of professional fields. Computational thinking is often defined as having the following steps.Footnote 8
-
• Decomposition: reducing complex problems to simpler components
-
• Pattern recognition: identifying similarities within and between problems
-
• Abstraction: using idealized, abstract representations to simplify patterns
-
• Designing algorithms: creating a sequence of instructions to solve a problem
-
• Evaluation: comparing the advantages and disadvantages of alternative solutions
Any linguist will likely recognize that these are precisely the steps taken implicitly or explicitly in the analysis of natural language. Considering that problem solving in computer science is so naturally akin to problem solving in linguistics, it appears as even more of a lost opportunity that formal links between the two fields have until recently been restricted to computational linguistics proper and have not permeated significantly into the core subdisciplines of phonology, morphology, syntax, and semantics.Footnote 9 One of the pedagogical goals of the Phonomaton is thus to make explicit the very steps laid out above by presenting phonology as coding. Although we believe this approach provides transferable skills, we emphasize that the aim is not to train students to become programmers; it is to use the computer to improve our own understanding of a phenomenon. In the words of Alan Perlis, ‘Whereas we think we know something when we learn it, and are convinced we know it when we can teach it, the fact is that we don’t really know it until we can code it for an automatic computer!’ (quoted by George Forsythe in his 1958 address to the Mathematical Association of America; see e.g. Denning & Tedre Reference Denning and Tedre2019).
In the following, we introduce the main features of the Phonomaton in some detail but refer the reader to the documentation for a more complete description of all of the program’s possibilities. For reasons of space and scope, we do not discuss autosegmental phonology or the use of the morphological tier.
2. Creating a derivation in the Phonomaton
Upon opening the Phonomaton in a web browser, we see the three fields that contain the principle components of an analysis:
-
• Phonological rules: Contains a preamble, where the user can declare an inventory, custom phonemes, custom feature geometries, and (inviolable) surface filters, followed by a series of SPE-style phonological rules, which comprise the derivation proper.
-
• Underlying representations (URs): A set of abstract phonological forms (provided by the user in IPA), which will serve as the input to the serial rules in the previous field. This field may optionally contain the output target for each UR, which the program will use to check against the actual output as derived by the user’s rules.
-
• Morphological rules: An optional field containing morphological rules written in the same style as phonological ones (e.g. ∅ → -ɪŋ / _>), but with a different application. Each rule in this field applies to each UR independently to create a new stem that is then fed into the phonological rules. For example, if there are three rules in this field, three additional derivational columns will be created for each UR, representing three morphological derivations. This feature is designed for solving problems that involve morphological paradigms.
In addition to the above fields, we find the following ancillary fields:
-
• Metadata: Contains subfields for the provenance of the data, author of the analysis, and analysis version, among other types of information. This metadata, supplied by the user, is meant to organize downloaded analyses and to make analyses easily searchable if they are uploaded to the Phonomaton’s library.
-
• Sample rules: A set of sample phonological rules that can be inserted into a derivation with a click of a button.
-
• Library: A collection of implemented analyses and classic phonology problems, which the user can open and experiment with.
-
• Historical data sets: Contains two large data sets of Austronesian historical data: Blust et al.’s (Reference Blust, Trussel and Smith2023) Austronesian comparative dictionary, and Edwards’s (Reference Edwards2021a,Reference Edwardsb) Rote-Meto comparative dictionary. Clicking on a particular language from one of these resources sets the user up to derive attested forms in that language from reconstructed etyma.
-
• IPA chart: A full IPA chart that displays associated feature sets for each segment and allows the user to compare segments and test for natural classes.
-
• Segments and features: Contains the full feature matrix for each IPA segment, following Hayes (Reference Hayes2009). As in the IPA chart, clicking on multiple segments highlights their similarities and differences.
2.1. Segments, features, and inventories
Figure 1 shows the use of the interactive IPA chart. Here, the user has clicked on four IPA symbols [θ s ʃ ʂ], which are now highlighted, and the program displays their differences in the matrix shown in the lavender pop-out window. In this case, the segments differ only in the features [anterior], [distributed], and [strident], so only these features are presented in the matrix. Below that, it lists all of the features these segments have in common. By default, the Phonomaton employs the feature set of Hayes Reference Hayes2009, although the user can modify the feature sets of segments as well as introduce new segments (see Section 2.1).
Comparison of segments without an inventory.

Figure 1. Long description
The table arranges consonants by place of articulation from bilabial on the left to glottal on the right, and by manner from plosive at the top to lateral approximant at the bottom. The fricative row contains highlighted cells for theta, s, esh, and esh with tail under dental, alveolar, post alveolar, and retroflex columns. To the right, a feature box lists these four sounds and compares them for anterior, distributed, and strident features, using plus and minus signs. Below, shared features are listed, including minus syllabic, plus consonantal, minus sonorant, plus continuant, plus delayed release, minus approximant, minus tap, minus trill, minus nasal, minus voice, minus spread glottis, minus constricted glottis, minus labial, minus round, minus labiodental, plus coronal, minus lateral, minus dorsal, high, low, front, back, tense.
The Phonomaton can also compare segments in conjunction with an inventory. An inventory is declared by listing a set of phones in the preamble (e.g. ‘Inventory: a i u p t k’) or simply by selecting segments in the IPA chart and clicking the ‘Make inventory’ button.
When an inventory has been declared, the segments it contains are highlighted in the chart with a blue outline, as seen in Figure 2. At this point, clicking any group of segments shows their distinctive features if they constitute a natural class within the inventory, in addition to the standard feature comparison. In Figure 2, the user has clicked three segments, [t θ s], and the lavender window shows that this is a natural class within the inventory with distinctive features [−voice, +anterior].
Comparing segments within an inventory that form a natural class.

Figure 2. Long description
The main panel is a consonant chart with columns for place of articulation: bilabial, labiodental, dental, alveolar, post alveolar, retroflex, palatal, velar, uvular, pharyngeal. Rows represent manner: plosive, implosive, nasal, trill, tap or flap, fricative, lateral fricative, approximant, lateral approximant. Segments t, d, s, z, theta, eth, and g are boxed in blue. t, theta, and s are shaded yellow. To the right, a vertical list details features for t, theta, s: continuant plus plus plus, delayed release plus plus plus, distributed minus plus minus, strident minus plus. Features in common are listed: plus syllabic, plus consonantal, minus sonorant, minus approximant, minus tap, minus trill, minus nasal, minus voice, minus spread glottis, minus constricted glottis, labial, round, labiodental, coronal, plus anterior, lateral, dorsal, high, low, front, back, tense. Distinctive features are bracketed: minus voice, plus anterior.
If no set of features uniquely distinguishes the group of selected segments, the software notes that fact and suggests the closest match containing all of the selected segments. For instance, given the same inventory as in Figure 2, the user has clicked [d n θ ð s] in Figure 3. The lavender box now informs us that this collection of segments does not form a natural class and suggests the closest match, which in this case involves adding [z] to the set.
Comparing segments within an inventory that do not form a natural class.

Figure 3. Long description
The main chart is a grid with columns labeled Bilabial, Labiodental, Dental, Alveolar, Post alveolar, Retroflex, Palatal, Velar, Uvular, Pharyngeal, and rows for Plosive, Implosive, Nasal, Trill, Tap or Flap, Fricative, Lateral fricative, Approximant, and Lateral approximant. Blue boxes outline the following segments: b, d, n, θ, ð, s, z. The segments d, n, θ, ð, s, z are also shaded yellow. To the right, a feature matrix lists sonorant, continuant, delayed release, nasal, voice, distributed, strident, with plus or minus values for d, n, θ, ð, s, z. Below, a note states no set of features distinguishes the selected set, and that plus anterior selects d, n, θ, ð, s, z. Additional shared features are listed, including syllabic, consonantal, approximant, tap, trill, spread glottis, constricted glottis, labial, round, labiodental, coronal, anterior, lateral, dorsal, high, low, back, tense.
In addition to selecting segments directly on the IPA chart, the user can select segments by their features using the interface shown in Figure 4. Upon selection of a set of feature specifications, the relevant segments are highlighted in the IPA chart.
Selecting segments by feature.

2.1.1. Custom segments
The Phonomaton also allows the user to create new segments based on a custom set of feature specifications. This facility can also be used to create segments that are underspecified for particular features. To take a concrete example, obstruent voicing in Turkish suggests an analysis in which stops in the underlying stratum are underspecified for voice, whereas those in loan strata are specified. Inkelas (Reference Inkelas1995) posits the set of stops in 1, where the ‘archiphonemes’ in 1a lack a voice feature altogether, and the fully specified sets in 1b and 1c have a negative and positive value for the [voice] feature, respectively.
(1)
a.
/P T K/
[ ]
b.
/p t k/
[−voice]
c.
/b d ɡ/
[+voice]
The user can define segments in the preamble of the rules using the syntax shown in 2.Footnote
10
(2)
Define: T[-syllabic,+consonantal,-sonorant,-continuant,-delayed_release,-approximant,-tap,-trill,-nasal,-spread_gl,-constr_gl,-labial,-round,-labiodental,+coronal,+anterior,-distributed,-strident,-lateral,-dorsal,0high,0low,0front,0back,0tense]
The declaration in 2 creates a new segment /T/ that is identical to /t/ except that it lacks the [voice] feature. ‘Define’ can create completely novel segments with any feature set, and one can also redefine the feature sets of existing segments by using ‘Redefine’. For a language without contrastive voicing in stops, we could thus redefine stops such as /p t k/ as lacking a [voice] feature entirely.Footnote 11 As discussed below in Section 2.4, ‘feature-filling’ rules can subsequently target segments with underspecified features to provide them with a value in a particular environment.Footnote 12
2.2. Phonological rules
Beyond functioning as a feature calculator, the strength of the Phonomaton lies in its ability to execute ordered rules and to derive surface forms from underlying representations. Phonological rules are written in the traditional SPE notation: target → change / environment (optionally preceded by a rule name), and the software executes them in the order they are written. The user can type rules from scratch in the phonological rules field or make use of the sample rules, shown in Figure 5, which are automatically pasted into a derivation when clicked and can be modified manually from there. The sample rule collection contains simple segmental rules as well as more complex ones for syllabification, mora assignment, footing, and stress, which can be experimented with freely.
The library of sample rules.

Figure 5. Long description
At the top, phonological rules are listed as green buttons, including affrication, apheresis, apocope, C-epenthesis, cluster simplification, final deletion, final devoicing, fortition, gemination, intervocalic lenition, local metathesis, long-distance metathesis, nasal spread, paragogue, syncope, V-epenthesis, V-epenthesis in C dot C, voice assimilation, and vowel lengthening. Below, secondary articulation rules are grouped, such as labialization, delabialization, palatalization, depalatalization, pharyngealization, depharyngealization, velarization, and develarization. Next, syllabification rules are shown, including simple onset, simple coda, complex onset, and complex coda, each with exclusive conditions. Mora assignment rules follow, listing long V mora and moraic coda. Footing rules are next, with head foot L, head foot L allowing 1 feet, head foot R, head foot R allowing 1 feet, iterative L-R and R-L footing, and moraic footing, each with iterative or exclusive conditions. Stress rules are grouped below, including trochaic primary, iambic primary, trochaic secondary, iambic secondary, and weight-sensitive stress. At the bottom, morphological rules are shown, with plural as the only listed rule. All rules are presented as green buttons with white text, organized in horizontal rows under each category heading.
A simple derivation with two of the sample rules applying to user-generated representations is shown in Figure 6.
A sample derivation.

Figure 6. Long description
The table has four horizontal rows and three vertical columns. The top row, labeled underlying representation in orange, lists balg, tala, talg. The second row, labeled Final Deletion in blue, shows bal, tal, and an empty cell. The third row, labeled Paragogue in purple, shows balə, tala, and tala. The bottom row, labeled surface form in green, repeats balə, tala, tala. The transformation applies two phonological rules: Final Deletion removes final consonants, and Paragogue adds a schwa after a final consonant. The right panel contains editable fields for phonological rules, morphological rules, and underlying representations, with balg, tala, talg entered. Below are buttons for Submit, Refresh-submit, Clear, Download, and Browse.
Figure 6 shows two ordered rules that operate on the right edge of the word (symbolized by ‘>’; see Section 2.6 for the full set of boundary symbols), with three underlying representations. The resulting derivation is shown at the top, where light blue cells show intermediate representations and blank cells represent the failure of a rule to apply.
2.3. The target and change
The user can specify the target, change, and environment of a rule directly in IPA symbols and the common abbreviations C (for [−syllabic] segments), V (for [+syllabic] segments), and X (for all segments, excluding boundary symbols), as in 3a. All parts of a rule can also refer to features, as in 3b.
(3)
a.
k → ɣ / Vː_V
b.
[-continuant,-voice] → [+continuant,+voice,+delayed_release] / [+syllabic,+long]_[+syllabic]
Rules can make use of traditional feature notation, exemplified in 3b, but the Phonomaton also introduces several novel methods for relating to features that go beyond textbook treatments. The symbol ± for a feature in the change means ‘change only if necessary to match a phone in the inventory’ (or, if there is no specified inventory, in the entire IPA). This specification is useful in cases in which a single phonological process affecting one or more features implies an incidental change in a different feature only in a subset of the target segments. For instance, a process of intervocalic lenition may effect the following set of changes: p → ɸ, t → s, k → x. Such lenition in featural terms is a change to [+continuant, +delayed_release]. However, for the second segment, /t/, there is an additional change from [−strident] to [+strident], a feature that is incompatible with the bilabial and velar places of articulation. In this situation, we could write the rule as in 4a, which produces the derivation in 4b.
(4)
a.
Intervocalic lenition: C → [+continuant,+delayed_release,±strident] / V_V
b.
Underlying representation
/apa/
/ata/
/aka/
/aqa/
Intervocalic lenition
aɸa
asa
axa
aχa
Surface form
[aɸa]
[asa]
[axa]
[aχa]
The change to [+strident] is necessary only in the case of /t/, because no segment differs from /t/ only in being [+continuant, +delayed_release] without also being [+strident]. (The other candidate for a continuant here is [θ], but this segment differs in being [+distributed].)
Although ± causes a change only when necessary, a feature change can also be defeasible, taking place only when possible, given a particular inventory. Defeasible changes are signaled by the symbols ⊕ and ⊖ preceding a feature, which mean ‘change to plus or minus, respectively, if the resulting segment is contained in the inventory’.Footnote
13 This restriction is the default behavior when a rule makes reference to only a single feature. For instance, the rule in 5a affects only the segments /s/ and /t/ in 5b because the other segments targeted have no counterpart differing only in being [−anterior]. We do not expect the change to create an impossible segment in these other cases; rather, we expect that the rule simply fails to apply.
(5)
a.
Retroflex assimilation: C → [-anterior] / _[-anterior]
b.
Underlying representation
/apʂa/
/aθʂa/
/asʂa/
/atʂa/
/akʂa/
/aqʂa/
Retroflex assimilation
aʂʂa
aʈʂa
Surface form
[apʂa]
[aθʂa]
[aʂʂa]
[aʈʂa]
[akʂa]
[aqʂa]
However, asserting a defeasible change becomes useful when some partial set of specified changes still takes place even when the full set of changes invoked cannot apply to all of the relevant segments. For instance, a process of lenition turns voiceless stops into voiced fricatives, as shown in 6, but if the inventory language lacks a voiced uvular fricative [ʁ], lenition to a fricative takes place without voicing when applying to uvular stops.
(6)
/p/ → [β]
/k/ → [ɣ]
/q/ → [χ]
Such a process can often be modeled by two rules, in this case, a spirantization rule and a subsequent voicing rule, the second of which would not apply to the uvular because of the gap in the inventory. But such a two-step approach can fail by incorrectly merging segments that should remain distinct. For instance, the language may have underlying /ɸ/ and /x/, which do not voice intervocalically under the same process, yet the underlying spirants would not be differentiated from derived ones after the spirantization rule. In this scenario, the rule in 7 obtains exactly the correct result for 6, effecting the change from stops to fricatives across the board but adding [+voice] only when possible, as signaled by [⊕voice] in the change.
(7)
Lenition: C → [+continuant,+delayed_release,⊕voice] / V_V
Another approach to facts such as these makes use of feature deletion. Noncontrastive features can be removed from the calculation entirely using the ‘Delete’ command, as in 8. Here, surface segments may differ in [voice], but rules cannot refer to this feature, nor are differences in [voice] visible to the grammar.
(8)
Inventory: a p β k ɣ q χ
Delete: [voice]
Lenition: C → [+continuant,+delayed_release] / V_V
Although there are both voiced and voiceless segments in the surface inventory in 8, noncontrastive voicing can now be treated as simply being concomitant with [+continuant] or [+delayed release]. Deleting the voice feature can therefore also derive the alternation in 6 above. This case exemplifies one way in which the Phonomaton facilitates comparison between competing solutions.
2.4. Underspecification and feature-filling rules
As discussed in Section 2.1 above, the user can declare underspecified segments as part of the preamble. Now we demonstrate how rules can target underspecified values so that they provide feature values only where none previously exist. First, we introduce an underspecified segment using Define, as shown in 9a, by copying the features of /t/ and deleting the voice specification. In 9b, we formulate a rule that is strictly ‘feature filling’, as signaled by ⊗ in the target.Footnote
14 The polarity ⊗ matches only an underspecified feature value (that is, neither + nor −).
(9)
a.
Define: T[-syllabic,+consonantal,-sonorant,-continuant,-delayed_release,-approximant,-tap,-trill,-nasal,-spread_gl,-constr_gl,-labial,-round,-labiodental,+coronal,+anterior,-distributed,-strident,-lateral,-dorsal,0high,0low,0front,0back,0tense]
b.
Intervocalic voicing: [-syllabic,⊗voice] → [+voice] / V_V
Final devoicing: [-syllabic,⊗voice] → [-voice] / _>
Figure 7 shows a derivation based on 9. Here, intervocalic voicing applies only to /T/, which is underspecified for [voice], and not to its voiceless counterpart /t/. Similarly, final devoicing applies only to /T/, and not to its voiced counterpart /d/. Underspecification in conjunction with ⊗ provides us with an elegant way to model alternations of the type seen in Turkish voicing, discussed in Section 2.1, where loan strata contain the contrastively voiced stops /t/ and /d/, but where voicing is underspecified (and therefore predictable) in /T/.
Derivation with a feature-filling rule.

Figure 7. Long description
The table has four rows and six columns. The top row lists underlying representations: ata, ada, aTa, at, ad, aT. The second row, labeled intervocalic voicing, shows only ada under aTa. The third row, labeled final devoicing, shows at under aT. The bottom row, labeled surface form, lists ata, ada, ada, at, ad, at, corresponding to each underlying representation.
2.5. Alpha notation and abbreviations
Alpha notation is available through the use of three Greek letters α, γ, and δ, which may also be specified negatively. (We omit β because it is identical to the IPA symbol for the bilabial fricative.) A simple example is given in 10, with a resulting derivation shown in Figure 8. The rule in 10 uses the variable α to assert that a consonant should match the voicing of an immediately following consonant.Footnote
15 The result is that the /ɡ/ in /aɡta/ assimilates in voice to the following /t/ to yield [akta] and the /p/ in /apdu/ assimilates in the same way to yield [abdu]. Alpha notation is thus able to express feature assimilation as a single process, whether it involves a change to a positive or negative specification of a feature.
(10)
Voice assimilation: C → [αvoice] / _[-syllabic,αvoice]
Voice assimilation.

Figure 8. Long description
The top row labels four columns as agta, apdu, agda, aptu under underlying representation. The second row, labeled Voice assimilation alpha plus, has abdu under apdu. The third row, labeled Voice assimilation alpha minus, has akta under agta. The bottom row, labeled surface form, lists akta, abdu, agda, aptu in bold under their respective columns. The table shows that agta changes to akta, apdu to abdu, agda and aptu remain unchanged.
We can also use variables to enforce agreement between the target and the environment. For instance, 11 asserts that a vowel should agree with the following vowel in the feature [round] when both vowels match for height features [high] and [low]. Here we explicitly state the labial feature as ± in the target, so the target’s [labial] value can change if necessary to satisfy rounding assimilation.
(11)
Rounding assimilation: [+syllabic,γhigh] → [αround,±labial] / _[+syllabic,αround,γhigh]
Figure 9 shows a derivation resulting from this rule. Because the derivation is decomposed into subrules containing all of the combinatorial possibilities, the exact condition under which the change takes place is displayed clearly. In the first subrule, all instances of α and γ (in the target, change, and environment) are replaced by +; in the second subrule, all instances of α are replaced by +, all instances of γ are replaced by −, and so forth.
Variables in the target and environment.

Figure 9. Long description
The top row lists underlying representations: bui, biu, bue, beu. Four rows below show voice assimilation conditions labeled with alpha and gamma values. The first condition (alpha plus gamma plus) yields byu for biu. The second (alpha plus gamma minus) has no outputs. The third (alpha minus gamma plus) yields bui for bui. The fourth (alpha minus gamma minus) has no outputs. The bottom row labeled surface form shows bui, byu, bue, beu under their respective columns.
The first two forms in Figure 9, /bui/ and /biu/, trigger regressive assimilation because the two adjacent vowels are of similar height. The last two forms, /bue/ and /beu/, however, do not undergo rounding harmony, because the adjacent vowels are of different heights.
2.6. Morphological boundaries
The Phonomaton recognizes several morphological boundaries in the underlying forms, employing the standard symbolic notation of the Leipzig Glossing Rules: - for prefix and suffix boundaries, ~ for reduplicant boundaries, ⟨ ⟩ for infix boundaries, = for clitic boundaries, and white space for word boundaries. Departing from tradition, we provide a boundary symbol ⇒ when an analysis needs to differentiate prefix or proclitic boundaries from suffix or enclitic boundaries. The symbol ≣ is also provided for indicating special morphosyntactic junctures.Footnote
16 Phonological rules can reference generic word boundaries by # and left and right word boundaries by < and >, respectively. Therefore, one can write a word-final devoicing rule as in 12.
(12)
Final devoicing: [-syllabic] → [-voice] / _>
A rule that raises mid vowels before enclitic boundaries and word-finally can be written as in 13. Disjunction is written with the elements separated by the vertical bar character and enclosed in parentheses (see Section 2.8 below).
(13)
Final raising: [+syllabic,-low] → [+high] / _(=|>)
2.7. Segment indexing
Certain processes, like metathesis, require indexing segments in a rule’s target and change. The Phonomaton employs superscripts (from ¹ to ⁴) to index segments. The rule in 14 matches a sequence of two consonants in which the first is coronal and the second is labial. The rule defines variables by labeling the relevant segments with a superscript; these indices appear again in the change but without any preceding features or segments. That is, instead of repeating redundant information in the change, as in the common notation C¹C² → C²C¹ for metathesis, the Phonomaton expects C¹C² → ²¹, with the redundancy removed (but see 18 below for an example where features modify an indexed segment).
(14)
metathesis: [-syllabic,+coronal]¹[-syllabic,+labial]² → ²¹
The result of 14 is to swap a coronal consonant with a following labial consonant, as shown in Figure 10.
A derivation showing metathesis of coronal and labial stops.

Indexing also assists in rules for total assimilation, reduplication, gemination, and degemination. The Phonomaton requires that indices be associated with a segment or class of segments before they are used as referents. For example, the rule of total assimilation in 15a associates the superscripted index 1 with a segment that matches [+consonantal] in the target and then refers back to that segment in the change with the plain superscript numeral. This would have the effect of changing /nk/ to [kk], /mb/ to [bb], and so forth. A formulation of the same rule as in 15b would fail because it invalidly employs an index in the change before the environment where it is defined.
(15)
Total assimilation of a nasal to a following consonant
a.
✓ [+nasal][+consonantal]¹ → ¹¹
b.
✗ [+nasal] → ¹ / _[+consonantal]¹
Similarly, a rule of vowel copying, often written in a form like 16b, runs afoul of the requirement that the target define each index. Such rules can easily be reformulated as in 16a, where the entire environment is targeted and copied with a modification. Despite being common practice, it is redundant, and thus disallowed, to repeat the Cs and Vs in the change.
(16)
Vowel copying
a.
✓ V¹C²C³ → ¹²¹³ /_#
b.
✗ ∅ → ¹ / V¹C_C#
One can write complex rules of reduplication (a morphological operation) using indices in conjunction with simple regular expressions. The rule in 17 reduplicates a word-initial onset followed by the vowel /a/, an example of reduplication with ‘fixed segmentalism’. Figure 11 shows the resulting derivation for three underlying forms.Footnote
17
(17)
Reduplication: C¹V² → ¹a¹² / <_
A derivation showing reduplication with fixed segmentalism.

Figure 11. Long description
The top row has four columns labeled from left to right as underlying representation, binsu, tuka, koko. The second row, labeled Reduplication, contains babinsu under binsu, tatuka under tuka, and kakoko under koko. The third row, labeled surface form, repeats babinsu, tatuka, and kakoko under their respective columns. The leftmost column labels the process for each row.
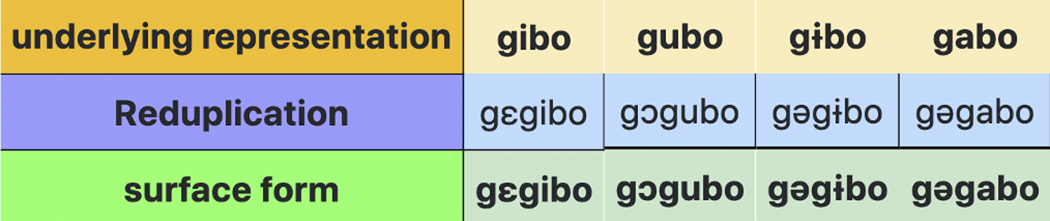
Indexed segments can also undergo featural modifications. Any features specified before an index in the change component of a rule apply to the indexed segment in the output. In 18, the features [−high, −low, −tense] apply to the first instance of a segment indexed by ², that is, the first vowel in the stem. Figure 12 shows sample derivations.
(18)
Reduplication: C¹V² → ¹[-high,-low,-tense]²¹² / <_
Reduplication with partial neutralization.

Figure 12. Long description
The table has three rows and four columns. The top row, labeled underlying representation, lists gibo, gubo, giɡbo, and gabo. The middle row, labeled Reduplication, lists gegibo, gəgubo, gəgiɡbo, and gægabo. The bottom row, labeled surface form, lists gegibo, gəgubo, gəgiɡbo, and gægabo. Each column shows how the base form changes through reduplication and surface realization, with the vowel in the reduplicated syllable partially neutralized to schwa in three cases.
2.8. Regular expression syntax
The Phonomaton allows regular expressions in the target and environment of a rule, the most important component of which are quantifiers. In 19 we present a comparison between the regular expressions for quantifiers used by the Phonomaton (based on Perl’s regex notation) and the familiar SPE notation (Chomsky & Halle Reference Chomsky and Halle1968).
(19)
Quantifier
Example
SPE
*
zero or more
C*
 $ {C}_0 $
$ {C}_0 $
?
zero or one
C?
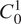 $ {C}_0^1 $
or (C)
$ {C}_0^1 $
or (C)
+
one or more
C+
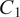 $ {C}_1 $
$ {C}_1 $
{x,y}
range min to max
C{2,4}
 $ {C}_2^4 $
(from 2 to 4)
$ {C}_2^4 $
(from 2 to 4)
Thus, a rule of vowel lowering that applies at the end of the word can be specified to occur regardless of the presence of a word-final coda, as in 20a, with either a simple word-final coda or no coda at all, as in 20b, with a simple or complex coda, as in 20c, or with a complex coda of two to four consonants, as in the unlikely case of 20d.
(20)
a.
V → [-high] / _C*>
b.
V → [-high] / _C?>
c.
V → [-high] / _C+>
d.
V → [-high] / _C{2,4}>
These quantifiers can combine with indices to handle complex cases of reduplication. In 21a, we see word-initial CV-reduplication. In 21b, we see reduplication of a word-initial unit containing two vowels and their preceding consonants (a disyllable, in the common case). The index in the target captures the entire expression within the parenthesized group, which is then duplicated in the change. The environment ensures that this process is anchored to the left edge of the word.Footnote
18
(21)
a.
(C*V)¹ → ¹¹ / <_
b.
(C*VC*V)¹ → ¹¹ / <_
Regular expressions also work in conjunction with various feature specifications and underspecification to model locality and blocking effects. Consider the case of retroflex harmony, where /ʃ/ assimilates to the [−distributed] feature of a retroflex when the retroflex precedes it. We can model this process as in 22, which says that a [−anterior] consonant becomes [−distributed] (retroflex) when preceded anywhere in the word by a [−distributed, −anterior] segment. The symbol X stands for any segment and X* stands for zero or more segments, so the process operates long-distance.
(22)
Retroflex assimilation: [-syllabic,-anterior] → [-distributed] / [-distributed,-anterior]X*_
We can also model blocking effects for rules such as these. If we modify the above environment as in 23, the rule will now apply only when the segments intervening between the target and the preceding trigger are [−coronal].
(23)
… / [-distributed,-anterior][-coronal]*_
Figure 13 shows a derivation based on this rule; the dorsal consonant /k/ in the first form is transparent for retroflex harmony, but the intervening /s/ in the second form, being coronal, is opaque and thus blocks assimilation.
Retroflex harmony blocking.

Figure 13. Long description
The table has three horizontal rows. The top row, labeled underlying representation, contains two cells: the first cell shows 'ʂakaʂa’ and the second shows 'ʂasaʂa’. The middle row, labeled Retroflex assimilation, has 'ʂakaʂa’ under the first column and the second column is blank. The bottom row, labeled surface form, repeats 'ʂakaʂa’ in the first cell and 'ʂasaʂa’ in the second. This layout demonstrates that retroflex assimilation occurs in the first word but is blocked in the second, so only the first word changes in the assimilation row.
Another relevant feature of regular expressions is grouping and alternation (signaled by brace notation in SPE). If a rule must make reference to segments that cannot be generalized by features, it can express alternation by the vertical bar symbol. For instance, a change that takes place only before the phonemes /s d ɣ/ at the end of a word is expressed as in 24.
(24)
a → ə / _(s|d|ɣ)>
2.9. Types of rule application and a brief look at syllabification
The Phonomaton allows for four flavors of rule application. The default is for a rule to apply wherever it can, scanning an underlying or intermediate representation from left to right. But rules can also apply iteratively, in which case the output of the rule can feed another application of the same rule. The default application of a nasalization rule is shown in 26a, while its iterative counterpart is shown in 25b.
(25)
a.
V → [+nasal] / _C*[+nasal]
b.
V → [+nasal] / _C*[+nasal] // iterate
The rule in 25a would apply to a representation like /balabon/ to derive [balabõn], whereas that in 25b would derive [bãlãbõn]. The iterative rule in 25b takes the output of its application as its input until no more changes can be made, at which point the derivation proceeds to the next rule.
Other cases require a rule to apply only to its maximal environment, as per the Pāṇini principle (also known as the ‘subset principle’ or ‘elsewhere condition’). Among other cases, this is crucial for syllabifying strings algorithmically, by rules that insert onset and coda boundaries, as exemplified in 26.
(26)
Onset: ∅ → ⟨ / _(([-sonorant]?[+approximant,-syllabic]?)|C)V // exclusive
Coda: ∅ → ⟨ / VC?_ // exclusive
The onset rule in 26 states: insert an onset boundary (⟨) preceding a vowel, optionally preceded by (i) an approximant (i.e. trills, taps, laterals, glides), in turn optionally preceded by a nonsonorant, or (ii) a singleton consonant of any type. The embedded parenthesis group captures certain types of CC clusters, such as the ones listed below option I in 27, while excluding others (e.g. ml, rl, nt) that do not fit this template.
(27)
Option I
Option II
( ([-sonorant]?[+approximant,-syllabic]?)
| C )
t
r
t
p
j
r
k
l
n
s
w
m
Because each part of the embedded group is optional, this part of the pattern could also capture singleton onsets that fit the given feature specifications. However, we would still need option II for a C of any type if there are singleton onsets that do not participate in clusters. For instance, our onset rule in 26 describes a language that allows nasal onsets but does not allow nasals in either component of a CC cluster, because a [+sonorant, −approximant] segment such as m, n, ŋ is not captured by either component of option I.
The coda rule in 26 is simpler and allows for a singleton coda consonant of any type. Crucially, the specification ‘exclusive’ at the end of both rules ensures that the boundaries will be inserted only once at the edge of the maximal string containing the optional segments rather than at every possible point. Otherwise, a UR such as /blabla/ would result in ⟨b⟨l⟨a⟩⟨b⟨l⟨a⟩ instead of the correct ⟨bla⟩⟨bla⟩.Footnote 19
2.10. Morphological rules
Exercises in phonology courses commonly present a paradigm, which the student must analyze into a set of roots and affixes or other morphophonological processes. One example of such an exercise, based on Serbo-Croatian adjectives, is shown in Table 1 (Kenstowicz & Kisseberth Reference Kenstowicz and Kisseberth1979:74).
Serbo-Croatian adjective paradigm.

Table 1. Long description
Starting from the top row, each adjective is presented in four grammatical forms: masculine, feminine, neuter, and plural. The first row shows mlád, mladá, mladó, mladí for ‘young’. The second row lists zelén, zelená, zelenó, zelení for ‘green’. The third row has púst, pustá, pustó, pustí for ‘empty’. The fourth row presents léden, ledná, lednó, lední for ‘frozen’. The fifth row displays dóbar, dobrá, dobró, dobrí for ‘good’. The sixth row shows jásan, jasná, jasnó, jasní for ‘clear’. The seventh row lists debéo, debelá, debeló, debelí for ‘fat’. The eighth row has béo, belá, beló, belí for ‘white’. The ninth row presents mío, milá, miló, milí for ‘dear’. The tenth row displays nágao, naglá, nagló, naglí for ‘abrupt’. The eleventh row shows óbao, oblá, obló, oblí for ‘round’. The twelfth row lists pódao, podlá, podló, podlí for ‘base’. Each row ends with the English gloss corresponding to the adjective.
Coopting for simplicity’s sake the [tone_high] feature to indicate stress (as the Phonomaton does not treat stress as a segmental feature), we can derive the forms in Table 1 with the phonological rules in 28a and the morphological rules in 28b.
(28)
a.
Phonological rules
Stress assignment: V → [+tone_high] / _C*>
Epenthesis: ∅ → a / C_C>
L-vocalization: l → o / _>
b.
Morphological rules
FEM: 0 → a / _>
NEUT: 0 → o / _>
PL: 0 → i / _>
The Phonomaton applies each morphological rule to each underlying representation to create an input form, as shown in Figure 14 for the underlying representations /ledn/, /debel/, and /naɡl/. We see the bare underlying representation, as well, preceding the forms that have undergone morphological rules.Footnote 20
Serbo-Croatian derivation with morphological rules.

Figure 14. Long description
The table has five rows and ten columns. The top row, labeled underlying representation, lists ledn, ledna, ledno, ledni, debel, debela, debelo, debeli, nagl, nagla, naglo, nagli. The next row, Stress Assignment, shows accents: lédn, ledná, lednó, lední, debél, debelá, debeló, debelí, nágl, naglá, nagló, naglí. The Epenthesis row adds a vowel to some forms: léden, ledná, lednó, lední, debél, debelá, debeló, debelí, nágal, naglá, nagló, naglí. The L-vocalization row applies only to debel and nagl forms, yielding debéo, nágao. The bottom row, surface form, shows the final outputs: léden, ledná, lednó, lední, debéo, debelá, debeló, debelí, nágao, naglá, nagló, naglí. Each process is applied sequentially down the rows, with some cells left blank where no change occurs.
The Phonomaton accepts morphological rules in the same format as phonological rules. For instance, a rule introducing a simple affix converts a null to the phonological form of the affix in a word-edge environment, namely <_ for prefixes and _> for suffixes. This approach also facilitates modeling nonconcatenative processes such as lenition, ablaut, and infixation, as any process that can be written as a phonological rule can be treated as a morphological rule.
With this, we conclude our review of the program’s features and proceed to how it has been implemented in the classroom.
3. The Phonomaton as a teaching tool
3.1. Pedagogically oriented features
Crucial to its pedagogical function is the Phonomaton’s ability to save and upload analyses. Saving an analysis downloads the data found in each component (underlying representation, phonological rules, and morphological rules) as a single, human-readable text file, with all of the contents of the analysis appearing precisely as in the web interface. Analyses are downloaded and uploaded with a single click without any need to log in or register. Students can use these downloaded analyses as submissions to class exercises for the instructor to check.
An advantage to treating phonological derivations as code is that an analysis can be interspersed with comments that are not executed by the program, following Knuth’s (Reference Knuth1992) popular concept of ‘literate programming’, whereby the programmer writes code as an expository text for a human audience interspersed with executable lines directed at the software. The program explains itself as it goes, preceding the expository comments with a character that tells the program not to execute that particular line. This approach has become routine in reproducible research and can be easily applied to executable linguistic analysis of the type presented here. The following brief example demonstrates the idea with the complex vowel-length alternations of Chimwiini (Kisseberth & Abasheik Reference Kisseberth and Abasheik1974). The comments, not executed by the program, are preceded by %.
% Epenthesize a vowel to stems ending in a consonant:
Final vowel attachment: ∅ → a / C_>
% Lengthen all word-final vowels:
Word final lengthening: V → [+long] / _>
% Shorten all vowels that precede the third syllable from the end. This is implemented here by referring to vowels rather than syllables. The following rule’s environment looks for three vowels in the forward context that can be interrupted by any number of segments or boundary symbols (word boundaries, in this case):
Preantepenultimate shortening: V → [-long] / _.*V.*V.*V
% Shorten a vowel at the end of a phrase, represented by the end of the line $:
Phrase final shortening: V → [-long] / _$
% Shorten a vowel that precedes a long vowel. The environment specifies that any number of consonants (C*) can intervene between the long vowel trigger and the target:
Pre-long shortening: V → [-long] / _C*[+syllabic, +long]
When the code above is executed it yields the derivation shown in Figure 15, with the given underlying representations.
Chimwiini vowel alternations.

Figure 15. Long description
From the top row, the table lists five lexical items: kure:belan, xteka, bo:zəl, kuna kahawa, kama mpʰaka. Each subsequent row applies a phonological process: Final vowel attachment adds a vowel to bo:zəl, yielding bo:zəla. Word final lengthening adds a colon to vowels in xteka, bo:zəla, kuna kahawa, and kama mpʰaka. Preantepenultimate shortening shortens vowels in kurebelana and kuna kahawa. Phrase final shortening removes final vowels in xteka, bozela, kuna kahawa, and kama mpʰaka. Pre-long shortening is blank. The surface form row shows the resulting forms: kurebelana, xteka, bo:zela, kuna kahawa, kama mpʰaka. The expected row matches the surface forms, with length marks retained where appropriate.
Another pedagogically relevant feature of note in Figure 15 is the final row in the table headed by ‘expected’. In the field where underlying representations are entered, the user can optionally add the expected surface form following the representation separated by a double backslash (e.g. kama mpʰaka // kamaː mpʰaka). This inclusion has the effect of displaying the expected form at the bottom of each column and checking it against the actual derived form.Footnote 21 If the two match, the expected form is displayed in green, as seen in Figure 15. If they do not match, the expected form is highlighted in red. This feature is also convenient for creating problem sets, which an instructor can present as a blank Phonomaton analysis with expected surface forms; the students’ task is then to provide the underlying representations and rules.
3.2. Implementation
We have received constructive input from two introductory phonology courses where an earlier version of the Phonomaton was employed. We report here from a survey of nineteen students who used the program in the Spring 2024 semester at Queens College (City University of New York), where the first author was the instructor and the third author was the teaching assistant. In addition to the positive comments, we highlight here some of the critical ones as well, since we believe these uncover important issues in the use of technology in the classroom more broadly.
For context, Queens College is part of the City University of New York, a public university with a mission of making higher education accessible to all.Footnote 22 The campus is among the most diverse in the country, and over a third of the students are the first generation in their families to attend college. Within the undergraduate linguistics program, there is also a relatively wide range in the students’ levels of preparation. Some students could compete handily with their peers in the most prestigious departments, while others are not yet comfortable with the technical aspects of linguistic analysis. Optimally, the Phonomaton would lift all boats, aiding both advanced students and those who did not yet have a strong grasp of the fundamentals.
In the semester-long trial, the students submitted all of their work as Phonomaton analyses, so they already knew whether their solutions were formatted correctly and generated the desired results. The instructor’s role in evaluating assignments could then focus on questions of economy, insight, and naturalness, which are higher-level matters often occluded by the effort to get the mechanics right. The instructor also made frequent use of the Phonomaton during lectures in order to show the various effects of rules and their interactions. Overall, the majority of the students reported finding the Phonomaton helpful, as seen in Figure 16, although a considerable number of students had mixed feelings, and four students responded negatively.
Responses to ‘Was the Phonomaton helpful?’.

When asked about their favorite aspect of the program, eight students responded with reference to finding and calculating features, six students chose the Phonomaton’s ability to check their work, and another six students chose the ability to calculate and display derivations. Several remarks in response to the question, ‘Did you find the Phonomaton program helpful in learning how phonological rules and derivations work? Why or why not? What were the best and worst parts of it?’, made reference to verifying the output of rules and their interactions:
I found the Phonomaton helpful and the best part of the Phonomaton for me was seeing each rule in action. I could see exactly how each rule changed the underlying representation.
Seeing exactly how my rules affect the underlying forms helped me think of them algorithmically.
I really enjoyed how it showed how the UF [underlying forms] were changed step by step by the different rules. Having a program perform the rules for you was much more efficient, especially across large data sets. It was very salient to see where rules did and did not work to create a correct SF [surface form], and that was very helpful.
I really liked seeing you use it in class to demonstrate rule ordering. I found that very helpful to understand how underlying forms can change and how rules can feed/counterfeed/bleed other rules.
Other comments noted how the program helped them understand feature systems, which involve a steep learning curve, as students have to unlearn descriptive categories, such as stop, fricative, and affricate, in order to learn more abstract features that do not always have easily discernible physical or acoustic correlates (such as [distributed] and [dorsal]):
My favorite part of the phonomaton was showing how IPA sound[s] share certain features, as well as what features change as you go from one sound to another. It really helped me understand the concept of features to begin with, and how much languages tend to care more about features than individual phonemes.
As for the worst parts of the program, students largely referred to its sensitivity to small errors and the lack of helpful error messages. In the most critical remark to this effect, the student stated that the program actually detracted from their learning because they were so concerned about getting the program to work as they expected. We return to these points below.
During the course, early exercises on features and on the mechanics of rule writing were assigned in two stages. In the first stage, the assignment was to be done by hand and submitted in the normal manner. In the second stage, the students had to complete the same problem using the Phonomaton, from which they downloaded and submitted their analysis. The exercises were not discussed in class until after the second stage. In the exercise on applying rules, students were given a rule (e.g. ə → ∅ / VC _ CV) and asked to apply it to a number of underlying forms. In the exercise on writing rules, they were given three underlying forms with their corresponding surface forms and asked to devise a rule that accounted for the alternations. The before and after assessments for both assignments are shown in Figure 17, where the vertical axis represents the scores out of 100.
Assessment scores before and after using the Phonomaton.

The scores improved significantly, especially in relation to rule writing, when the students had the opportunity to manipulate and check their analyses using the Phonomaton. Whereas many students struggled with consistent formalization of rules in the first stage, through experimenting with different possibilities, they were able to self-correct to a large extent during the second stage.
A different exercise, adapted from Hayes Reference Hayes2009:101, presented the students with statements like that in 29a, which they were expected to translate into feature-based rules like that in 29b, given a particular inventory of vowels and consonants.
(29)
a.
[i y ɯ u] become [e ø ɤ o] before [q ɴ].
b.
Vowel lowering: [+syllabic,+high] → [-high] / _[-continuant,+dorsal,-high]
The Phonomaton led to a 30% improvement in the second attempt over the first one, where students had the aid of only a static feature chart. In this case, however, it can be argued that the problem becomes trivial with the help of the Phonomaton, as the program calculates natural classes and featural differences within any subset of segments. The user must only enter the relevant inventory and check each pair to ensure that a particular change in features accounts for the entire alternation. To this point, an anonymous referee asks, ‘What happens if the student needs Phonomaton to identify a natural class? Do they learn this concept if the program does it for them?’. Overall improvements in classroom-based assessments, where the students did not have access to the program, suggest that the program helped them overcome the considerable initial difficulties that the stage-one scores revealed. However, our evaluation was not comprehensive enough to compare classroom-based assessments on exactly the same type of material before and after the students worked with the Phonomaton. Our future evaluations of the program will attempt to pinpoint how the Phonomaton aids progress in independent work, as opposed to overall improvements. We note, though, that the program does not aim to explain phonology any more than a calculator is meant to explain concepts in math.Footnote 23 For a well-motivated student who independently explores the various possibilities of rule formulation and interaction, we believe the program could serve a broader function, but the Phonomaton is not designed to replace instruction.Footnote 24 One student noted this explicitly in the survey:
I don’t know if I would say it was helpful for learning HOW rules and derivations work, it was helpful moreso for checking rules and derivations and also troubleshooting rules that were slightly wrong. I feel like the logic behind the rules had to be learned without the Phonomaton.
The two biggest challenges encountered in applying the software pedagogically were (i) the lack of guidance on malformed rules, and (ii) an unevenness in how the tool was taken up by students at different levels of proficiency. We believe these two challenges are linked. The most common complaint in the evaluations of the program had to do with the unhelpful error messages that malformed rules would trigger. Perhaps in our eagerness for the Phonomaton to handle as much phonological theory as possible, including autosegmental phonology and optimality theory (not discussed here for reasons of space), we skimped on what turned out to be the most important element for novices: detailed guidance on the mechanics of rule writing. Based on the evaluations, we have remedied this problem to a large extent. The program now pinpoints which rule and what part of that rule contains an error, calling out specific problems such as a missing underscore, a missing arrow, a missing bracket, or invoking a feature that doesn’t exist. Most likely as a result of this lacuna in the original trial semester, we found a strong correlation between the students’ overall grades in the course and their assessment of the Phonomaton. Those who achieved higher scores in assessments and in the course as a whole consistently reported finding the Phonomaton more useful. We address this problem with urgency because, if left untreated, it could yield precisely the opposite effect of what we had originally set out to do, namely, to lift all boats, and instead simply exacerbate the gap between those who are already comfortable with mathematical formalism and algorithmic thinking upon entering the course and those who are not. Now that the program offers friendly guidance in rule formulation and allows for a bit more flexibility, we expect a more even response across students at varying levels of proficiency. In particular, we aim for this aspect of the program to have a broader impact in opening the doors to computational thinking for those students who may not take naturally to rule syntax and mathematical formalization.Footnote 25
There are several facilities that have not yet been integrated into the Phonomaton but that would be useful to students in optimizing a working analysis. The program could check not only whether a derivation achieves its desired target, as it does now, but also whether there are redundancies in the rules (e.g. reference to features that do not need to be invoked, or overspecified rule environments). The program could also gauge the complexity of a given analysis and assign a numeric score based on the number of rules and specifications for each rule. Although formal economy metrics of this type have never been widely adopted in theoretical phonology, they could serve an important pedagogical function. We continue to explore these and other potential extensions of the program.
4. Conclusion
Bird (Reference Bird and Mitkov2005:45) outlines some of the challenges in producing a ‘phonologist’s workbench’ program:
A phonologist’s workbench should help people to ‘debug’ their analyses and spot errors before going to press with an analysis. Developing such tools is much more difficult than it might appear. First, there is no agreed method for modelling non-linear representations, and each proposal has shortcomings. Second, processing data sets presents its own set of problems, having to do with tokenization, symbols which are ambiguous as to their featural decomposition, symbols marked as uncertain or optional, and so on. Third, some innocuous looking rules and constraints may be surprisingly difficult to model, and it might only be possible to approximate the desired behavior. Additionally, certain universal principles and tendencies may be hard to express in a formal manner.
Similarly, Piwowarczyk (Reference Piwowarczyk and Olander2022:40) notes in his review of computational models of historical sound change that:
… very few have actually ventured to take historical sound change rules from textbooks of well studied languages and develop a working computer model. And anyone who HAS ventured into this territory has quickly realized that there is a world of difference between the rules as they are written in standard linguistic notation and as they need to be written in computer models.
The Phonomaton has taken up this challenge, and we can attest to all of the difficulties mentioned above. However, the value of a user-friendly phonological rule engine is well worth the trouble. Such a program can help students grasp the more daunting formal aspects of phonology by encouraging experimentation. Furthermore, the tool can serve as a bridge to precise thinking about language and an interactive proof that a theory produces the expected results, in contrast to the typically underformalized presentations found in textbooks. On a higher level, a program such as the one presented here leads the way to reconfiguring linguistics pedagogy as ‘contructionism’, in the sense of Papert (Reference Papert1990), in which students build concrete versions of abstract concepts and have the pleasure of seeing their creations produce results with novel input. In this scenario, students adopt precise formulations as they learn to communicate with the program, not simply because the instructor demands it. In other words, it is constructionism rather than instructionism that ultimately guides the students.
The rigor enforced by computability also pays dividends to professional linguists. The reader may have noticed that, despite our opening with a jeremiad on the fragmentation of linguistic theory, many of the Phonomaton’s capabilities presented here are novel (e.g. the use of ±, ⊕, ⊖, ⊗, feature deletion, and the use of phonetic inventories, discussed in Section 2.2). To a large extent, these innovations were brought about by our failure to implement solutions to classic problems as typically presented in textbooks. In this case, the standard of computability has suggested new ways of interacting with features and underspecification. The ethos of the project, however, aims to provide multiple strategies to solve problems, in the spirit of exploring advantages and drawbacks to different approaches. We now have a formal framework from which we can argue for or against such innovations.
In closing, we point out some further directions for the Phonomaton and their potential impacts. The current norm in teaching any introductory theoretical linguistics course, including Phonology, involves a rapidly moving semester-long carousel of concepts exemplified by disembodied snippets from a wide variety of languages. As theories have developed in their complexity, there has been a waning interest in producing works on the scale of the Sound pattern of English (Chomsky & Halle Reference Chomsky and Halle1968), the Sound pattern of Russian (Halle Reference Halle1971 [1959]), or Spanish phonology (Harris Reference Harris1969), among many others of that era, which attempt to tackle entire phonological grammars. We hope that the Phonomaton will rekindle an appetite for holistic projects of this nature by enforcing consistency and opening the analysis to public inspection and testing. The possibility of collaboration on a large-scale phonological grammar is even more tantalizing.Footnote 26
We see a certain urgency to the program presented here. In the foundational stories of the generative revolution, Chomsky’s algorithmic approach was built atop the ruins of structuralism and behaviorism. Ironically, seventy years after behaviorism had been all but vanquished in mainstream linguistics, it has made its return through the back door of natural language processing, to devastating effect. In particular, ChatGPT, the first publicly available language model to convincingly pass the Turing test, appears to make no use whatsoever of the facts, solutions, and general wisdom accumulated over nearly a century of generative explorations of the human language faculty.Footnote 27 Mainstream linguistics, having staked so much in abstract structure and symbolic manipulation, now appears to be in a pitched battle with a type of ‘deep learning’ that is largely opaque and illegible to human observers. So complete is the circle that Chomsky et al. (Reference Chomsky, Roberts and Watumull2023) rehearse many of the same arguments against ‘deep learning’ language models that Chomsky (Reference Chomsky1959) famously deployed against Skinner over sixty years earlier. Surely it will not be a phonological rule engine that saves algorithmic approaches from the depredations of ‘deep learning’, if that indeed materializes as an existential threat. We hope, however, that it can serve as a small bridge between computer science and the cognitive approaches to language that have come to define the field from Pāṇini to the present day. Most immediately, however, it is our aim to make these approaches more accessible and easier to learn for new generations of students and to help them pivot to broader applications by framing phonology as coding.
Data availability statement
All linguistic data herein has been previously published in the cited sources. The Phonomaton program is freely available for use at www.kratylos/ph. For access to the code, please contact the authors.
Acknowledgments
We thank the Computer Science Department of the University of Kentucky at Lexington for providing computing resources as well as the audiences at the University of Kentucky, CUNY Graduate Center, Cornell, and elsewhere for their feedback. We especially thank Kie Zuraw, Christian DiCanio, the section editors and anonymous referees, whose extensive comments led to significant revisions and improvements. All remaining errors are ours alone. [Full editorial history: Received 18 November 2022; revision invited 04 December 2022; revision received 14 July 2023; revision invited 21 December 2023; revision received 20 January 2025; accepted pending revisions 30 September 2025; revision received 12 October 2025; accepted 15 December 2025.]
Competing interests
The authors declare that they have no competing interests.
Ethics statement
The authors declare that this manuscript is original research, has not been published previously, and is not currently under consideration for publication elsewhere. All authors have read and approved the final manuscript and have no conflicts of interest to disclose. This article does not contain any studies with human or animal participants performed by any of the authors. Anonymized reviews of the software reported here were provided on an entirely voluntary basis by students at the first author’s institution.


















 Open access
Open access