


In factor analysis and related models of ordinal observed variables, we commonly assume that latent variables follow a normal distribution with mean 0 and variance 1. These constraints have computational advantages that can lead to efficiency in model estimation. Separately from identification constraints, it is common practice for applied researchers to ignore that their observed variables are ordinal, summing or averaging the variables as though they are continuous (e.g., Liddell & Kruschke, Reference Liddell and Kruschke2018; Sijtsma et al., Reference Sijtsma, Ellis and Borsboom2024a). In this article, we propose identification constraints that are related to averaging ordinal variables as though they are continuous. This can make the model parameters more intuitive to applied researchers, as compared to the usual identification constraints.
Many researchers have studied when and whether we can treat ordinal variables as continuous (e.g., Bollen & Barb, Reference Bollen and Barb1981; Bürkner & Vuorre, Reference Bürkner and Vuorre2019; Liddell & Kruschke, Reference Liddell and Kruschke2018; McNeish & Wolf, Reference McNeish and Wolf2020; Rhemtulla et al., Reference Rhemtulla, Brosseau-Liard and Savalei2012; Winship & Mare, Reference Winship and Mare1984). Perhaps the most famous work on this topic is Stevens’ scales of measurement (e.g., Stevens, Reference Stevens1946). In distinguishing between ordinal scales and interval scales, Stevens notes that “means and standard deviations computed on an ordinal scale are in error to the extent that the successive intervals on the scale are unequal in size” (p. 679). Our results below involve the idea of equal intervals in ordinal CFA models, providing minimal identification constraints that are related to equal intervals. Our results are also related to those of Kruschke and colleagues (Kruschke, Reference Kruschke2014, Reference Kruschke2015; Liddell & Kruschke Reference Liddell and Kruschke2018), who considered identification constraints for univariate, ordinal regression models. They reasoned that, because applied researchers are accustomed to treating ordinal variables as continuous, we should seek to identify the ordinal regression model so that the underlying continuous variable is on the scale of the ordinal variable. For example, if we have an ordinal variable with five categories, then the ordinal regression model should generally predict values between 1 and 5 on the latent continuous scale, which are then converted to probabilities of assuming each ordered category.
In the pages below, we formalize the above arguments by first providing background on the specific models and identification constraints that we consider. We then study how ordinal CFA models can be constrained so that the latent variable predictions equal the average of the ordinal variables (where we treat the ordinal variables as continuous). Next, we propose minimal identification constraints related to these ideas and illustrate them via example and simulation. Finally, we consider limitations and future directions. The supplementary material includes code showing how our proposed integer constraints can be implemented in lavaan (Rosseel, Reference Rosseel2012) and in mirt (Chalmers, Reference Chalmers2012).
1 Theoretical background
We assume data vectors
 $\boldsymbol {y}_i$
of length p,
$\boldsymbol {y}_i$
of length p,
 $i=1,\ldots ,n$
, where all p variables are ordinal with K categories. Under the traditional probit link function, we can conceptualize continuous, latent data vectors
$i=1,\ldots ,n$
, where all p variables are ordinal with K categories. Under the traditional probit link function, we can conceptualize continuous, latent data vectors
 $\boldsymbol {y}^\ast _i$
that are chopped to yield the observed, ordinal data. For example, for
$\boldsymbol {y}^\ast _i$
that are chopped to yield the observed, ordinal data. For example, for
 $K=4$
, the chopping can be written as
$K=4$
, the chopping can be written as
 $$ \begin{align*} y_{ij} = 1 &\text{ if }-\infty <\ y^*_{ij} < \tau_{j1} \\ y_{ij} = 2 &\text{ if }\tau_{j1} <\ y^*_{ij} < \tau_{j2} \\ y_{ij} = 3 &\text{ if }\tau_{j2} <\ y^*_{ij} < \tau_{j3} \\ y_{ij} = 4 &\text{ if }\tau_{j3} <\ y_{ij}^* <\ \infty, \end{align*} $$
$$ \begin{align*} y_{ij} = 1 &\text{ if }-\infty <\ y^*_{ij} < \tau_{j1} \\ y_{ij} = 2 &\text{ if }\tau_{j1} <\ y^*_{ij} < \tau_{j2} \\ y_{ij} = 3 &\text{ if }\tau_{j2} <\ y^*_{ij} < \tau_{j3} \\ y_{ij} = 4 &\text{ if }\tau_{j3} <\ y_{ij}^* <\ \infty, \end{align*} $$
where
 $\tau _{j1} < \tau _{j2} < \tau _{j3}$
are the threshold parameters for item j.
$\tau _{j1} < \tau _{j2} < \tau _{j3}$
are the threshold parameters for item j.
The CFA model is placed on the
 $\boldsymbol {y}^\ast _i$
as if we had observed, continuous data:
$\boldsymbol {y}^\ast _i$
as if we had observed, continuous data:
 $$ \begin{align} \boldsymbol{y}^\ast_i &= \boldsymbol{\nu} + \boldsymbol{\Lambda} \boldsymbol{\eta}_i + \boldsymbol{\delta}_i \end{align} $$
$$ \begin{align} \boldsymbol{y}^\ast_i &= \boldsymbol{\nu} + \boldsymbol{\Lambda} \boldsymbol{\eta}_i + \boldsymbol{\delta}_i \end{align} $$
 $$ \begin{align} \boldsymbol{\eta}_i &\sim \text{N}(\boldsymbol{\kappa}, \boldsymbol{\Phi}) \end{align} $$
$$ \begin{align} \boldsymbol{\eta}_i &\sim \text{N}(\boldsymbol{\kappa}, \boldsymbol{\Phi}) \end{align} $$
 $$ \begin{align} \boldsymbol{\delta}_i &\sim \text{N}(\boldsymbol{0}, \boldsymbol{\Theta}), \end{align} $$
$$ \begin{align} \boldsymbol{\delta}_i &\sim \text{N}(\boldsymbol{0}, \boldsymbol{\Theta}), \end{align} $$
where
 $\boldsymbol {\nu }$
is
$\boldsymbol {\nu }$
is
 $p \times 1$
,
$p \times 1$
,
 $\boldsymbol {\Lambda }$
is
$\boldsymbol {\Lambda }$
is
 $p \times m$
,
$p \times m$
,
 $\boldsymbol {\eta }_i$
is
$\boldsymbol {\eta }_i$
is
 $m \times 1$
, and
$m \times 1$
, and
 $\boldsymbol {\delta }_i$
is
$\boldsymbol {\delta }_i$
is
 $p \times 1$
. We further assume that
$p \times 1$
. We further assume that
 $\boldsymbol {\Theta }$
is diagonal and that
$\boldsymbol {\Theta }$
is diagonal and that
 $\boldsymbol {\Lambda }$
has a clustered structure, i.e., that each observed variable only loads on one factor. Regarding the latter assumption, we could alternatively say that the factor complexity of each observed variable equals 1 or that each row of
$\boldsymbol {\Lambda }$
has a clustered structure, i.e., that each observed variable only loads on one factor. Regarding the latter assumption, we could alternatively say that the factor complexity of each observed variable equals 1 or that each row of
 $\boldsymbol {\Lambda }$
has only one nonzero entry.
$\boldsymbol {\Lambda }$
has only one nonzero entry.
Given
 $\boldsymbol {\eta }_i$
, the probability that
$\boldsymbol {\eta }_i$
, the probability that
 $Y_{ij}$
assumes each category is the area of the normal distribution between two thresholds, i.e.,
$Y_{ij}$
assumes each category is the area of the normal distribution between two thresholds, i.e.,
 $$ \begin{align} P(Y_{ij} = y_{ij} \mid \boldsymbol{\eta}_i, \boldsymbol{\xi}) = \Phi \left (\frac{\tau_{j,y_{ij}} - (\nu_j + \boldsymbol{J}_j \boldsymbol{\Lambda} \boldsymbol{\eta}_i)}{\theta_{ii}} \right ) - \Phi \left (\frac{\tau_{j,(y_{ij}-1)} - (\nu_j + \boldsymbol{J}_j \boldsymbol{\Lambda} \boldsymbol{\eta}_i)}{\theta_{ii}} \right ), \end{align} $$
$$ \begin{align} P(Y_{ij} = y_{ij} \mid \boldsymbol{\eta}_i, \boldsymbol{\xi}) = \Phi \left (\frac{\tau_{j,y_{ij}} - (\nu_j + \boldsymbol{J}_j \boldsymbol{\Lambda} \boldsymbol{\eta}_i)}{\theta_{ii}} \right ) - \Phi \left (\frac{\tau_{j,(y_{ij}-1)} - (\nu_j + \boldsymbol{J}_j \boldsymbol{\Lambda} \boldsymbol{\eta}_i)}{\theta_{ii}} \right ), \end{align} $$
where
 $\Phi ()$
is the standard normal cumulative distribution function,
$\Phi ()$
is the standard normal cumulative distribution function,
 $\boldsymbol {J}_j$
is a
$\boldsymbol {J}_j$
is a
 $1 \times p$
vector with an entry of 1 in position j and 0 elsewhere,
$1 \times p$
vector with an entry of 1 in position j and 0 elsewhere,
 $\boldsymbol {\xi }$
is a vector of item parameters, and
$\boldsymbol {\xi }$
is a vector of item parameters, and
 $\tau _{j0} = -\infty $
and
$\tau _{j0} = -\infty $
and
 $\tau _{jK} = \infty $
for all j. The conditional model likelihood for respondent i (conditioned on the latent variables
$\tau _{jK} = \infty $
for all j. The conditional model likelihood for respondent i (conditioned on the latent variables
 $\boldsymbol {\eta }_i$
) can then be written as
$\boldsymbol {\eta }_i$
) can then be written as
 $$ \begin{align} L(\boldsymbol{\xi} | \boldsymbol{y}_i, \boldsymbol{\eta}_i) = \prod_{j=1}^p \prod_{k=1}^K P(Y_{ij} = k \mid \boldsymbol{\eta}_i, \boldsymbol{\xi})^{u_{ijk}}, \end{align} $$
$$ \begin{align} L(\boldsymbol{\xi} | \boldsymbol{y}_i, \boldsymbol{\eta}_i) = \prod_{j=1}^p \prod_{k=1}^K P(Y_{ij} = k \mid \boldsymbol{\eta}_i, \boldsymbol{\xi})^{u_{ijk}}, \end{align} $$
where
 $u_{ijk}$
equals 1 if person i responded to question j with the kth ordered category and 0 otherwise. For model estimation, the marginal likelihood is often used instead of the above likelihood, where the
$u_{ijk}$
equals 1 if person i responded to question j with the kth ordered category and 0 otherwise. For model estimation, the marginal likelihood is often used instead of the above likelihood, where the
 $\boldsymbol {\eta }_i$
are integrated out. This integration requires approximation via quadrature or other numerical methods (e.g., Tuerlinckx et al., Reference Tuerlinckx, Rijmen, Verbeke and De Boeck2006). Alternatively, researchers often obtain the polychoric correlations between ordinal variables and fit the traditional CFA model via weighted least squares (e.g., Muthén, Reference Muthén1984). The latter approach is fast because it avoids numerical integration, capitalizing on the equivalence between IRT and CFA (e.g., Takane & de Leeuw, Reference Takane and de Leeuw1987).
$\boldsymbol {\eta }_i$
are integrated out. This integration requires approximation via quadrature or other numerical methods (e.g., Tuerlinckx et al., Reference Tuerlinckx, Rijmen, Verbeke and De Boeck2006). Alternatively, researchers often obtain the polychoric correlations between ordinal variables and fit the traditional CFA model via weighted least squares (e.g., Muthén, Reference Muthén1984). The latter approach is fast because it avoids numerical integration, capitalizing on the equivalence between IRT and CFA (e.g., Takane & de Leeuw, Reference Takane and de Leeuw1987).
1.1 Identification constraints
Additional constraints are necessary to identify model parameters. For example, a common set of constraints is
 $$ \begin{align} \text{diag}(\boldsymbol{\Phi}) = \boldsymbol{1},\ \boldsymbol{\kappa} = \boldsymbol{0},\ \boldsymbol{\nu} = \boldsymbol{0},\ \boldsymbol{\Theta} = \boldsymbol{I}, \end{align} $$
$$ \begin{align} \text{diag}(\boldsymbol{\Phi}) = \boldsymbol{1},\ \boldsymbol{\kappa} = \boldsymbol{0},\ \boldsymbol{\nu} = \boldsymbol{0},\ \boldsymbol{\Theta} = \boldsymbol{I}, \end{align} $$
where the restriction on
 $\boldsymbol {\Phi }$
is sometimes called a “unit variance constraint.” A variation involves fixing one loading per latent variable to 1, instead of fixing each diagonal entry of
$\boldsymbol {\Phi }$
is sometimes called a “unit variance constraint.” A variation involves fixing one loading per latent variable to 1, instead of fixing each diagonal entry of
 $\boldsymbol {\Phi }$
to be 1. This shifts the constraints on
$\boldsymbol {\Phi }$
to be 1. This shifts the constraints on
 $\boldsymbol {\Phi }$
to constraints on
$\boldsymbol {\Phi }$
to constraints on
 $\boldsymbol {\Lambda }$
, and is sometimes called a “reference indicator constraint.” Another variation for ordinal CFA involves the so-called “delta parameterization,” where the constraints on
$\boldsymbol {\Lambda }$
, and is sometimes called a “reference indicator constraint.” Another variation for ordinal CFA involves the so-called “delta parameterization,” where the constraints on
 $\boldsymbol {\Theta }$
are replaced with constraints on the model-implied covariance matrix of
$\boldsymbol {\Theta }$
are replaced with constraints on the model-implied covariance matrix of
 $\boldsymbol {y}^\ast $
:
$\boldsymbol {y}^\ast $
:
 $$ \begin{align} \text{diag}(\boldsymbol{\Lambda \Phi \Lambda}^\prime + \boldsymbol{\Theta}) = \boldsymbol{1}. \end{align} $$
$$ \begin{align} \text{diag}(\boldsymbol{\Lambda \Phi \Lambda}^\prime + \boldsymbol{\Theta}) = \boldsymbol{1}. \end{align} $$
These sets of constraints lead to equivalent, equal-fitting models whose parameter estimates can be transformed to one another. While the specific choice of constraints is often regarded as arbitrary (e.g., Bollen et al., Reference Bollen, Lilly and Luo2024), it is worth mentioning that different sets of constraints sometimes lead to differing conclusions regarding parameter equality (Klopp & Klößner, Reference Klopp and Klößner2023; Klößner & Klopp, Reference Klößner and Klopp2018; Steiger, Reference Steiger2002) and regarding Bayesian model selection (Graves & Merkle, Reference Graves and Merkle2022).
1.2 Latent variable prediction
Following model estimation via marginal maximum likelihood or weighted least squares, researchers may optionally request latent variable predictions that serve as scores for each individual i. There is a large history of literature discussing the indeterminacy of factor scores (see, e.g., Waller, Reference Waller2022, for a summary), where the indeterminacy is discussed in the context of estimating the
 $\boldsymbol {\eta }_i$
jointly with the
$\boldsymbol {\eta }_i$
jointly with the
 $\boldsymbol {\delta }_i$
. To obtain unique predictions of the
$\boldsymbol {\delta }_i$
. To obtain unique predictions of the
 $\boldsymbol {\eta }_i$
, a reasonable thing to do (which is also common practice) is to marginalize over the
$\boldsymbol {\eta }_i$
, a reasonable thing to do (which is also common practice) is to marginalize over the
 $\boldsymbol {\delta }_i$
while addressing sign indeterminacy and rotational indeterminacy via parameter constraints. This is similar to the situation that Rhemtulla and Savalei (Reference Rhemtulla and Savalei2025) recently considered for continuous
$\boldsymbol {\delta }_i$
while addressing sign indeterminacy and rotational indeterminacy via parameter constraints. This is similar to the situation that Rhemtulla and Savalei (Reference Rhemtulla and Savalei2025) recently considered for continuous
 $\boldsymbol {y}_i$
.
$\boldsymbol {y}_i$
.
For ordinal factor analysis, we can obtain latent variable predictions by maximizing the likelihood function
 $L(\boldsymbol {\eta }_i \mid \boldsymbol {y}_i, \boldsymbol {\xi })$
for all i, where the likelihood function has the same form as the right side of Equation (5). As compared to Equation (5), we now estimate
$L(\boldsymbol {\eta }_i \mid \boldsymbol {y}_i, \boldsymbol {\xi })$
for all i, where the likelihood function has the same form as the right side of Equation (5). As compared to Equation (5), we now estimate
 $\boldsymbol {\eta }_i$
and condition on
$\boldsymbol {\eta }_i$
and condition on
 $\boldsymbol {\xi }$
, whereas we previously did the opposite. Maximization of this function requires numerical methods because it involves the normal CDF.
$\boldsymbol {\xi }$
, whereas we previously did the opposite. Maximization of this function requires numerical methods because it involves the normal CDF.
Maximum likelihood estimates of the
 $\boldsymbol {\eta }_i$
do not exist for extreme response patterns consisting of all 1s or Ks. Consequently, it is common practice (for IRT as well as generalized linear mixed models) to multiply the likelihood function by the “prior” distribution from Equation (2), which leads us to maximize the posterior distribution of each
$\boldsymbol {\eta }_i$
do not exist for extreme response patterns consisting of all 1s or Ks. Consequently, it is common practice (for IRT as well as generalized linear mixed models) to multiply the likelihood function by the “prior” distribution from Equation (2), which leads us to maximize the posterior distribution of each
 $\boldsymbol {\eta }_i$
. The resulting estimates of the
$\boldsymbol {\eta }_i$
. The resulting estimates of the
 $\boldsymbol {\eta }_i$
are called the maximum a posteriori (MAP) estimates. In situations where we have already estimated the Equation (2) parameters and hold them fixed, we may also refer to our estimates of the
$\boldsymbol {\eta }_i$
are called the maximum a posteriori (MAP) estimates. In situations where we have already estimated the Equation (2) parameters and hold them fixed, we may also refer to our estimates of the
 $\boldsymbol {\eta }_i$
as empirical Bayes estimates. Further detail about these procedures can be found in, e.g., Baker and Kim (Reference Baker and Kim2004).
$\boldsymbol {\eta }_i$
as empirical Bayes estimates. Further detail about these procedures can be found in, e.g., Baker and Kim (Reference Baker and Kim2004).
2 Parameter constraints and sum scores
It is customary for applied researchers to ignore the fact that their variables are ordinal and to sum or average the ordinal variables associated with each latent variable. This commonly happens by assigning the lowest category a value of 1 and the highest category a value of K, then averaging. The average serves as a summary score for each participant that can be used in regressions and other models. We now discuss how the latent variable predictions from an ordinal CFA model can mimic the average of observed ordinal variables. This will lead us to develop alternative identification constraints in later sections.
2.1 Constraints
Consider the ordinal CFA model from the previous section, where all free loadings are fixed at 1,
 $\boldsymbol {\kappa } = (\frac {K + 1}{2}) \boldsymbol {1}$
, where
$\boldsymbol {\kappa } = (\frac {K + 1}{2}) \boldsymbol {1}$
, where
 $\boldsymbol {1}$
is an
$\boldsymbol {1}$
is an
 $m \times 1$
vector, and
$m \times 1$
vector, and
 $( \tau _{j1}, \tau _{j2}, \ldots , \tau _{j(K-1)}) = (1.5,\ 2.5,\ \ldots ,\ (K - .5))$
. Under these constraints, we have a Rasch-like model, and the items are interchangeable because the loadings and thresholds are identical across items. For such a model, Andersen (Reference Andersen1977) shows that the sum of individual i’s responses is a sufficient statistic for
$( \tau _{j1}, \tau _{j2}, \ldots , \tau _{j(K-1)}) = (1.5,\ 2.5,\ \ldots ,\ (K - .5))$
. Under these constraints, we have a Rasch-like model, and the items are interchangeable because the loadings and thresholds are identical across items. For such a model, Andersen (Reference Andersen1977) shows that the sum of individual i’s responses is a sufficient statistic for
 $\boldsymbol {\eta }_i$
(also see Andrich, Reference Andrich1978; Lord, Reference Lord1953). Samejima (Reference Samejima1969) additionally shows that the maximum of the item response function for response category k occurs at the midpoint between that category’s threshold parameters (see her Equation 5.6), for
$\boldsymbol {\eta }_i$
(also see Andrich, Reference Andrich1978; Lord, Reference Lord1953). Samejima (Reference Samejima1969) additionally shows that the maximum of the item response function for response category k occurs at the midpoint between that category’s threshold parameters (see her Equation 5.6), for
 $k = 2, \ldots , (K-1)$
. Our restrictions on thresholds imply that the mode occurs at the integer value that applied researchers often assign to ordinal variables. Thus, we claim that the MAP estimates of the
$k = 2, \ldots , (K-1)$
. Our restrictions on thresholds imply that the mode occurs at the integer value that applied researchers often assign to ordinal variables. Thus, we claim that the MAP estimates of the
 $\boldsymbol {\eta }_i$
are equal to the average of observed ordinal responses (where the responses are coded as integers starting from 1). But further clarification is needed for the extreme categories of 1 and K, which we provide in the next section.
$\boldsymbol {\eta }_i$
are equal to the average of observed ordinal responses (where the responses are coded as integers starting from 1). But further clarification is needed for the extreme categories of 1 and K, which we provide in the next section.
2.2 Empirical results
As described previously, the latent variable predictions involve maximization of Equation (5), which is now a function of
 $\boldsymbol {\eta }_i$
and is conditioned on
$\boldsymbol {\eta }_i$
and is conditioned on
 $\boldsymbol {\xi }$
along with
$\boldsymbol {\xi }$
along with
 $\boldsymbol {y}_i$
. To show that the model constraints from the previous section lead to latent variable predictions equaling the average of observed variables, we consider here a one-factor model with values of p from 2 to 10 and
$\boldsymbol {y}_i$
. To show that the model constraints from the previous section lead to latent variable predictions equaling the average of observed variables, we consider here a one-factor model with values of p from 2 to 10 and
 $K=5$
. For each value of p, we generate all possible response patterns and calculate the MAP prediction of the latent variable for each response pattern. We do not estimate any item parameters here: in addition to the constraints on the loadings, thresholds, and latent means from the previous section, we fixed
$K=5$
. For each value of p, we generate all possible response patterns and calculate the MAP prediction of the latent variable for each response pattern. We do not estimate any item parameters here: in addition to the constraints on the loadings, thresholds, and latent means from the previous section, we fixed
 $\boldsymbol {\nu } = \boldsymbol {0}$
,
$\boldsymbol {\nu } = \boldsymbol {0}$
,
 $\boldsymbol {\Phi } = p$
, and
$\boldsymbol {\Phi } = p$
, and
 $\boldsymbol {\Theta } = \boldsymbol {I}$
.
$\boldsymbol {\Theta } = \boldsymbol {I}$
.
Figure 1 shows scatter plots of the average observed response (x-axis) versus MAP latent variable prediction for all possible response patterns. Each red point is a response pattern that does not include an extreme response of 1 or 5, while each blue point is a response pattern that does include an extreme. The figure shows that the points generally fall along the diagonal, with some differences at the far left and far right sides of each panel. This provides some evidence that latent variable predictions under our model constraints remain close to the average of observed variables for all response patterns. The supplementary materials include additional code that considers additional values of p and K. It shows that the gradient of the likelihood function is always close to 0 at the mean of observed variables, so long as the response pattern does not include extreme responses of 1 or K. The code also considers maximum likelihood estimates of the latent variables, in addition to MAP predictions.
Observed averages versus MAP latent variable estimates for
 $K=5$
and
$K=5$
and
 $p=2$
to 10. Each point represents a response pattern. Red points are response patterns that do not include a response of 1 or 5, and blue points are response patterns that do include a response of 1 and/or 5.
$p=2$
to 10. Each point represents a response pattern. Red points are response patterns that do not include a response of 1 or 5, and blue points are response patterns that do include a response of 1 and/or 5.

Figure 1 Long description
Starting from the top-left, each panel represents a value of p from 2 to 10, increasing left to right and top to bottom. The x axis is labeled observed average, ranging from 1 to 5. The y axis is labeled M A P estimate, ranging from 0 to 6. Each panel contains a diagonal black line from the lower left to upper right, indicating the identity line. Data points are plotted as circles, with blue points representing response patterns that include a response of 1 or 5, and red points representing patterns without a response of 1 or 5. As p increases, the number of data points increases and the spread along the axes becomes denser. Most points cluster near the diagonal, indicating close agreement between observed averages and M A P estimates, with some outliers deviating above or below the line, especially at higher p values.
When an individual’s response pattern does include the extremes of 1 or K, the
 $\boldsymbol {\eta }_i$
predictions are pulled toward
$\boldsymbol {\eta }_i$
predictions are pulled toward
 $-\infty $
or
$-\infty $
or
 $+\infty $
, respectively, so that they no longer equal the average of the observed variables. This can be observed on the left and right sides of each panel of Figure 1. A similar phenomenon happens for large values of K (say 8 or more) when responses are near the extremes (e.g., 2 or
$+\infty $
, respectively, so that they no longer equal the average of the observed variables. This can be observed on the left and right sides of each panel of Figure 1. A similar phenomenon happens for large values of K (say 8 or more) when responses are near the extremes (e.g., 2 or
 $(K-1)$
). In the MAP case, the prior distribution from (2) helps keep the predictions from straying too far from the observed average. We fixed the prior variance,
$(K-1)$
). In the MAP case, the prior distribution from (2) helps keep the predictions from straying too far from the observed average. We fixed the prior variance,
 $\boldsymbol {\Phi }$
, to equal p in each panel of these results. This may appear to be an odd choice, but it is used here to demonstrate the robustness of our result. This is because a prior variance of p is weaker than the traditional prior variance of 1. Were we to fix
$\boldsymbol {\Phi }$
, to equal p in each panel of these results. This may appear to be an odd choice, but it is used here to demonstrate the robustness of our result. This is because a prior variance of p is weaker than the traditional prior variance of 1. Were we to fix
 $\boldsymbol {\Phi }$
to 1, our points would be even closer to the diagonal. And in the maximum likelihood case, an ad hoc, vague prior distribution is often used to ensure that latent variable predictions exist for extreme response patterns. In each case, the resulting latent variable predictions are close to the means of the integer-coded ordinal variables.
$\boldsymbol {\Phi }$
to 1, our points would be even closer to the diagonal. And in the maximum likelihood case, an ad hoc, vague prior distribution is often used to ensure that latent variable predictions exist for extreme response patterns. In each case, the resulting latent variable predictions are close to the means of the integer-coded ordinal variables.
2.3 Summary
We have shown that under a highly-constrained ordinal CFA model, the MAP predictions of the latent variables are highly related to the integer-coded average of observed variables. This was anticipated by Andersen (Reference Andersen1977) and Samejima (Reference Samejima1969), though the connection to treating ordinal variables as continuous was perhaps not fully clarified or appreciated. For example, about 20 years after these works, Steiger (Reference Steiger, Borg and Mohler1994) states, “My strong hunch is that, if scales were developed using unit weighting on the basis of ordinary component analysis, and these scale scores were used instead of individual items, that there would be no need for special techniques for categorical variables, because the resulting scores would be ‘close enough’ to continuous variates” (p. 218). Our result is also similar to the results of Foldnes and Grønneberg (Reference Foldnes and Grønneberg2022), who show that equally-spaced thresholds can lead integer-coded correlations to match polychoric correlations (especially see their Corollary 1). But the model described in this section is too highly constrained to be useful in many practical situations, so we next consider minimal identification constraints.
3 Minimal identification constraints in ordinal CFA
Although researchers nearly always identify ordinal CFA models via some variation of the constraints in (6), there exists an infinite number of possible identification constraints. We would like a set of identification constraints that get us closer to the highly-constrained model from the previous section, where latent variable predictions are averages of observed variables.
To move in this direction, we consider the Wu and Estabrook (Reference Wu and Estabrook2016) matrix expressions that transform parameter estimates under one set of constraints to parameter estimates under another set of constraints. Their expressions are
 $$ \begin{align} \widetilde{\boldsymbol{T}} &= \boldsymbol{\gamma 1}^\prime + \boldsymbol{\Delta}^{-1}\boldsymbol{T} \end{align} $$
$$ \begin{align} \widetilde{\boldsymbol{T}} &= \boldsymbol{\gamma 1}^\prime + \boldsymbol{\Delta}^{-1}\boldsymbol{T} \end{align} $$
 $$ \begin{align} \widetilde{\boldsymbol{\Lambda}} &= \boldsymbol{\Delta}^{-1}\boldsymbol{\Lambda D} \end{align} $$
$$ \begin{align} \widetilde{\boldsymbol{\Lambda}} &= \boldsymbol{\Delta}^{-1}\boldsymbol{\Lambda D} \end{align} $$
 $$ \begin{align} \widetilde{\boldsymbol{\nu}} &= \boldsymbol{\Delta}^{-1}\boldsymbol{\nu} + \boldsymbol{\Delta}^{-1}\boldsymbol{\Lambda \beta} + \boldsymbol{\gamma} \end{align} $$
$$ \begin{align} \widetilde{\boldsymbol{\nu}} &= \boldsymbol{\Delta}^{-1}\boldsymbol{\nu} + \boldsymbol{\Delta}^{-1}\boldsymbol{\Lambda \beta} + \boldsymbol{\gamma} \end{align} $$
 $$ \begin{align} \widetilde{\boldsymbol{\Theta}} &= \boldsymbol{\Delta}^{-1} \boldsymbol{\Theta} \boldsymbol{\Delta}^{-1} \end{align} $$
$$ \begin{align} \widetilde{\boldsymbol{\Theta}} &= \boldsymbol{\Delta}^{-1} \boldsymbol{\Theta} \boldsymbol{\Delta}^{-1} \end{align} $$
 $$ \begin{align} \widetilde{\boldsymbol{\kappa}} &= \boldsymbol{D}^{-1} (\boldsymbol{\kappa} - \boldsymbol{\beta}) \end{align} $$
$$ \begin{align} \widetilde{\boldsymbol{\kappa}} &= \boldsymbol{D}^{-1} (\boldsymbol{\kappa} - \boldsymbol{\beta}) \end{align} $$
 $$ \begin{align} \widetilde{\boldsymbol{\Phi}} &= \boldsymbol{D}^{-1} \boldsymbol{\Phi} \boldsymbol{D}^{-1}, \end{align} $$
$$ \begin{align} \widetilde{\boldsymbol{\Phi}} &= \boldsymbol{D}^{-1} \boldsymbol{\Phi} \boldsymbol{D}^{-1}, \end{align} $$
where
 $\boldsymbol {T}$
is a
$\boldsymbol {T}$
is a
 $p \times (K-1)$
matrix whose rows each contain the thresholds for one observed variable, and
$p \times (K-1)$
matrix whose rows each contain the thresholds for one observed variable, and
 $\boldsymbol {D}$
,
$\boldsymbol {D}$
,
 $\boldsymbol {\Delta }$
,
$\boldsymbol {\Delta }$
,
 $\boldsymbol {\beta }$
, and
$\boldsymbol {\beta }$
, and
 $\boldsymbol {\gamma }$
are the transformation matrices and vectors. The
$\boldsymbol {\gamma }$
are the transformation matrices and vectors. The
 $\boldsymbol {D}$
and
$\boldsymbol {D}$
and
 $\boldsymbol {\Delta }$
matrices are positive, diagonal matrices of dimension
$\boldsymbol {\Delta }$
matrices are positive, diagonal matrices of dimension
 $m \times m$
and
$m \times m$
and
 $p \times p$
, respectively. The
$p \times p$
, respectively. The
 $\boldsymbol {\beta }$
and
$\boldsymbol {\beta }$
and
 $\boldsymbol {\gamma }$
vectors are of dimension
$\boldsymbol {\gamma }$
vectors are of dimension
 $m \times 1$
and
$m \times 1$
and
 $p \times 1$
, respectively.
$p \times 1$
, respectively.
Ordinal CFA parameter identification amounts to defining a minimal set of parameter constraints that fix the four transformation matrices and vectors described above, such that the constraints hold on both the left and right sides of Equations (8)–(13) (also see Wu & Estabrook, Reference Wu and Estabrook2016, Proposition 1). For example, consider the identification constraints from (6). These constraints require that
 $\boldsymbol {D} = \boldsymbol {I}$
,
$\boldsymbol {D} = \boldsymbol {I}$
,
 $\boldsymbol {\beta } = \boldsymbol {0}$
,
$\boldsymbol {\beta } = \boldsymbol {0}$
,
 $\boldsymbol {\gamma } = \boldsymbol {0}$
, and
$\boldsymbol {\gamma } = \boldsymbol {0}$
, and
 $\boldsymbol {\Delta } = \boldsymbol {I}$
. Below, we use the transformation matrices to develop alternative constraints.
$\boldsymbol {\Delta } = \boldsymbol {I}$
. Below, we use the transformation matrices to develop alternative constraints.
4 Alternative identification constraints
Instead of fixing parameters to 0 or 1, we seek identification constraints that put the latent variable close to the integer scale of the ordinal variable. As we mentioned earlier, such constraints can be helpful to applied researchers who are working with ordinal data, because they are accustomed to thinking on the scale of the ordinal variable and to treating the ordinal variables as if they are continuous.
The constraints that we study are related to the constraints that led to factor scores mimicking observed averages. Instead of fixing
 $\boldsymbol {\nu }$
to
$\boldsymbol {\nu }$
to
 $\boldsymbol {0}$
, we require that the
$\boldsymbol {0}$
, we require that the
 $\nu $
parameters associated with each latent variable sum to 0. Relatedly, instead of fixing a single loading to 1 or fixing the latent variance to 1, we constrain the loadings associated with each latent variable to average 1. This is reminiscent of the Little et al. (Reference Little, Slegers and Card2006) effect coding approach for continuous data. Finally, we fix the lower and upper thresholds of each observed variable to 1.5 and
$\nu $
parameters associated with each latent variable sum to 0. Relatedly, instead of fixing a single loading to 1 or fixing the latent variance to 1, we constrain the loadings associated with each latent variable to average 1. This is reminiscent of the Little et al. (Reference Little, Slegers and Card2006) effect coding approach for continuous data. Finally, we fix the lower and upper thresholds of each observed variable to 1.5 and
 $K - 0.5$
, respectively.
$K - 0.5$
, respectively.
To formally describe the constraints, let
 $\mathcal {S}_q$
be the set of observed variables whose loadings in the qth column of
$\mathcal {S}_q$
be the set of observed variables whose loadings in the qth column of
 $\Lambda $
are not fixed to 0 (i.e., the set of observed variables that “load” on latent variable q). Let
$\Lambda $
are not fixed to 0 (i.e., the set of observed variables that “load” on latent variable q). Let
 $n_q$
be the cardinality of
$n_q$
be the cardinality of
 $\mathcal {S}_q$
. Then, our identification constraints can be written as
$\mathcal {S}_q$
. Then, our identification constraints can be written as
 $$ \begin{align*} \displaystyle \sum_{j \in \mathcal{S}_q} \nu_j = 0\ \ \forall\ q &= 1, \ldots, m \\ \frac{1}{n_q} \displaystyle \sum_{j \in \mathcal{S}_q} \lambda_{jq} = 1\ \ \forall\ q &= 1, \ldots, m \\ \tau_{j1} = 1.5\ \ \forall\ j &= 1, \ldots, p \\ \tau_{j(K-1)} = K - 0.5\ \ \forall\ j &= 1, \ldots, p. \end{align*} $$
$$ \begin{align*} \displaystyle \sum_{j \in \mathcal{S}_q} \nu_j = 0\ \ \forall\ q &= 1, \ldots, m \\ \frac{1}{n_q} \displaystyle \sum_{j \in \mathcal{S}_q} \lambda_{jq} = 1\ \ \forall\ q &= 1, \ldots, m \\ \tau_{j1} = 1.5\ \ \forall\ j &= 1, \ldots, p \\ \tau_{j(K-1)} = K - 0.5\ \ \forall\ j &= 1, \ldots, p. \end{align*} $$
Based on our previous arguments, these threshold restrictions help ensure that the scale of each latent variable is similar to that of the integer-coded ordinal items. Additionally, the latent variable means and variances are freely estimated, reflecting the standing of each latent variable on the ordinal scale. This helps applied researchers to understand and interpret the latent variable predictions, as well as other model parameters.
To show that the above constraints are minimal identification constraints, we first note that we have
 $2(p + m)$
individual constraints, which matches the number that was established by Wu and Estabrook (Reference Wu and Estabrook2016). To further establish these constraints, we make use of the Wu and Estabrook transformation matrices in the following proposition.
$2(p + m)$
individual constraints, which matches the number that was established by Wu and Estabrook (Reference Wu and Estabrook2016). To further establish these constraints, we make use of the Wu and Estabrook transformation matrices in the following proposition.
Proposition 1. Let
 $\mathcal {S}_q$
be the set of observed variables whose loadings in the qth column of
$\mathcal {S}_q$
be the set of observed variables whose loadings in the qth column of
 $\Lambda $
are not fixed to 0. Let
$\Lambda $
are not fixed to 0. Let
 $n_q$
be the cardinality of
$n_q$
be the cardinality of
 $\mathcal {S}_q$
. Then, the following are minimal identification constraints for an ordinal CFA model with clustered structure:
$\mathcal {S}_q$
. Then, the following are minimal identification constraints for an ordinal CFA model with clustered structure:
 $$ \begin{align*} \displaystyle \sum_{j \in \mathcal{S}_q} \nu_j = 0\ \ \forall\ q &= 1, \ldots, m \\ \frac{1}{n_q} \displaystyle \sum_{j \in \mathcal{S}_q} \lambda_{jq} = 1\ \ \forall\ q &= 1, \ldots, m \\ \tau_{j1} = 1.5\ \ \forall\ j &= 1, \ldots, p \\ \tau_{j(K-1)} = K - 0.5\ \ \forall\ j &= 1, \ldots, p. \end{align*} $$
$$ \begin{align*} \displaystyle \sum_{j \in \mathcal{S}_q} \nu_j = 0\ \ \forall\ q &= 1, \ldots, m \\ \frac{1}{n_q} \displaystyle \sum_{j \in \mathcal{S}_q} \lambda_{jq} = 1\ \ \forall\ q &= 1, \ldots, m \\ \tau_{j1} = 1.5\ \ \forall\ j &= 1, \ldots, p \\ \tau_{j(K-1)} = K - 0.5\ \ \forall\ j &= 1, \ldots, p. \end{align*} $$
Proof. By Proposition 1 of Wu and Estabrook (Reference Wu and Estabrook2016), we first show that the proposed constraints fix the transformation matrices from Equations (8)–(13). We then show that these constraints do not add additional parameter restrictions.
For a particular observed variable j, the right side of Equation (8) involves scaling its thresholds by a positive constant
 $\delta _{jj}$
and then adding a constant
$\delta _{jj}$
and then adding a constant
 $\gamma _j$
. Considering these transformations, we must set
$\gamma _j$
. Considering these transformations, we must set
 $\gamma _j=0$
and
$\gamma _j=0$
and
 $\delta _{jj}=1$
to maintain lower and upper threshold values of 1.5 and
$\delta _{jj}=1$
to maintain lower and upper threshold values of 1.5 and
 $(K-0.5)$
, respectively. This holds for all j, so we have
$(K-0.5)$
, respectively. This holds for all j, so we have
 $\boldsymbol {\gamma } = \boldsymbol {0}$
and
$\boldsymbol {\gamma } = \boldsymbol {0}$
and
 $\boldsymbol {\Delta } = \boldsymbol {I}$
.
$\boldsymbol {\Delta } = \boldsymbol {I}$
.
Next, we examine (9) with
 $\boldsymbol {\Delta } = \boldsymbol {I}$
. The right side of this equation scales each column of
$\boldsymbol {\Delta } = \boldsymbol {I}$
. The right side of this equation scales each column of
 $\boldsymbol {\Lambda }$
by a positive, diagonal entry of
$\boldsymbol {\Lambda }$
by a positive, diagonal entry of
 $\boldsymbol {D}$
. But we already constrained the free entries in each column of
$\boldsymbol {D}$
. But we already constrained the free entries in each column of
 $\boldsymbol {\Lambda }$
to average 1. The only way to maintain this constraint is to set
$\boldsymbol {\Lambda }$
to average 1. The only way to maintain this constraint is to set
 $\boldsymbol {D} = \boldsymbol {I}$
.
$\boldsymbol {D} = \boldsymbol {I}$
.
Finally, we examine (10) with
 $\boldsymbol {\Delta } = \boldsymbol {I}$
and
$\boldsymbol {\Delta } = \boldsymbol {I}$
and
 $\boldsymbol {\gamma } = \boldsymbol {0}$
and consider a particular latent variable q. To maintain the requirement that
$\boldsymbol {\gamma } = \boldsymbol {0}$
and consider a particular latent variable q. To maintain the requirement that
 $\displaystyle \sum\nolimits _{j \in \mathcal {S}_q} \widetilde {\nu }_j = 0$
, we require that
$\displaystyle \sum\nolimits _{j \in \mathcal {S}_q} \widetilde {\nu }_j = 0$
, we require that
 $$ \begin{align*} \displaystyle \sum_{j \in \mathcal{S}_q} \lambda_{jq} \beta_q = - \displaystyle \sum_{j \in \mathcal{S}_q} \nu_j. \end{align*} $$
$$ \begin{align*} \displaystyle \sum_{j \in \mathcal{S}_q} \lambda_{jq} \beta_q = - \displaystyle \sum_{j \in \mathcal{S}_q} \nu_j. \end{align*} $$
But we also have the restriction that
 $\displaystyle \sum\nolimits _{j \in \mathcal {S}_q} \nu _j = 0$
. So we must fix
$\displaystyle \sum\nolimits _{j \in \mathcal {S}_q} \nu _j = 0$
. So we must fix
 $\beta _q = 0$
for all q, i.e.,
$\beta _q = 0$
for all q, i.e.,
 $\boldsymbol {\beta } = \boldsymbol {0}$
. Now, all four transformation matrices are fixed, establishing that these constraints resolve parameter indeterminacy.
$\boldsymbol {\beta } = \boldsymbol {0}$
. Now, all four transformation matrices are fixed, establishing that these constraints resolve parameter indeterminacy.
To show that the proposed constraints are minimal constraints required to identify the model parameters, we note that parameters identified under traditional constraints can be transformed to the proposed constraints. This is achieved via the following set of transformation matrices:
 $$ \begin{align*} \boldsymbol{\Delta}_{jj} &= (\tau_{j(K-1)} - \tau_{j1})/(K - 2) \ \ \forall\ j \\ \boldsymbol{D}_{kk} &= n_k \left ( \sum_{j \in \mathcal{S}_k} \delta^{-1}_{jj} \lambda_{jk} \right )^{-1} \ \ \forall\ k \\ \boldsymbol{\beta}_k &= -\left ( \displaystyle \sum_{j \in \mathcal{S}_k} \delta^{-1}_{jj} \lambda_{jk} \right )^{-1} \sum_{j \in \mathcal{S}_k} \left ( 1.5 + \delta^{-1}_{jj}(\nu_j - \tau_{j1}) \right ) \ \ \forall\ k \\ \boldsymbol{\gamma}_j &= 1.5 - \delta^{-1}_{jj} \tau_{j1} \ \ \forall\ j.\\[-34pt] \end{align*} $$
$$ \begin{align*} \boldsymbol{\Delta}_{jj} &= (\tau_{j(K-1)} - \tau_{j1})/(K - 2) \ \ \forall\ j \\ \boldsymbol{D}_{kk} &= n_k \left ( \sum_{j \in \mathcal{S}_k} \delta^{-1}_{jj} \lambda_{jk} \right )^{-1} \ \ \forall\ k \\ \boldsymbol{\beta}_k &= -\left ( \displaystyle \sum_{j \in \mathcal{S}_k} \delta^{-1}_{jj} \lambda_{jk} \right )^{-1} \sum_{j \in \mathcal{S}_k} \left ( 1.5 + \delta^{-1}_{jj}(\nu_j - \tau_{j1}) \right ) \ \ \forall\ k \\ \boldsymbol{\gamma}_j &= 1.5 - \delta^{-1}_{jj} \tau_{j1} \ \ \forall\ j.\\[-34pt] \end{align*} $$
The identification constraints proposed here are not the only ones that could be used. Following tradition, we could fix one loading per latent variable instead of requiring that loadings average 1. We could also add constraints on
 $\boldsymbol {\nu }$
and/or on
$\boldsymbol {\nu }$
and/or on
 $\boldsymbol {\Theta }$
and reduce the constraints on thresholds. We further discuss some of these alternatives in Appendix A. Our focal constraints appear to lead to the closest correspondence between integer-coded averages and latent variable predictions.
$\boldsymbol {\Theta }$
and reduce the constraints on thresholds. We further discuss some of these alternatives in Appendix A. Our focal constraints appear to lead to the closest correspondence between integer-coded averages and latent variable predictions.
Lee et al. (Reference Lee, Poon and Bentler1990) discuss ideas related to our proposed constraints, identifying ordinal CFA models via constraints on thresholds (also see Lee, Reference Lee2007; Shi & Lee, Reference Shi and Lee1998). However, they do not consider the idea of placing the latent variables on the scale of the ordinal variables. In their example, they fix some thresholds to the maximum likelihood estimates of a previous study, where those estimates come from a model whose latent variables follow a standard normal distribution.
We now discuss some additional issues related to our proposed constraints.
Remark 1. The proposed identification constraints are minimal identification constraints. This means that, as compared to traditional identification constraints, the model fit and many other model summaries remain the same. In particular, standardized coefficients under the proposed constraints are equal to those obtained under traditional constraints.
Remark 1 is especially noteworthy because some researchers are accustomed to reporting standardized coefficients. The proposed constraints have no impact on standardized coefficients, and it remains precarious to compare estimated coefficients across groups, standardized or otherwise. For example, although the latent variable means and variances are free under integer constraints, some of the thresholds are held equal across groups. Additionally, because we are not changing the fit of the model, model misfit and model misspecification are concerns for models with our proposed constraints, just as they are for models with traditional constraints. For example, Grønneberg and Foldnes (Reference Grønneberg and Foldnes2024) recently considered how assumed nonnormality of the
 $\boldsymbol {y}_i^\ast $
can bias the polychoric correlations that are used for weighted least squares estimation.
$\boldsymbol {y}_i^\ast $
can bias the polychoric correlations that are used for weighted least squares estimation.
Remark 2. To convert parameter estimates under alternative constraints (e.g., those from Proposition 1) to parameter estimates under the traditional constraints from Equation (6), the transformation matrices are
 $$ \begin{align*} \text{diag}(\boldsymbol{D}) &= \text{diag}(\boldsymbol{\Phi})^{1/2} \\ \text{diag}(\boldsymbol{\Delta}) &= \text{diag}(\boldsymbol{I}) \\ \boldsymbol{\beta} &= \boldsymbol{\kappa} \\ \boldsymbol{\gamma} &= - \boldsymbol{\Theta}^{-1} (\boldsymbol{\nu} + \boldsymbol{\Lambda \kappa}). \end{align*} $$
$$ \begin{align*} \text{diag}(\boldsymbol{D}) &= \text{diag}(\boldsymbol{\Phi})^{1/2} \\ \text{diag}(\boldsymbol{\Delta}) &= \text{diag}(\boldsymbol{I}) \\ \boldsymbol{\beta} &= \boldsymbol{\kappa} \\ \boldsymbol{\gamma} &= - \boldsymbol{\Theta}^{-1} (\boldsymbol{\nu} + \boldsymbol{\Lambda \kappa}). \end{align*} $$
This result is similar to the results of Klopp and Klößner (Reference Klopp and Klößner2021) for models of continuous variables, except that they are for models of ordinal variables.
In summary, Proposition 1 establishes that our proposed constraints address the model’s parameter indeterminacy without introducing further restrictions. In the sections below, we first study whether the constraints cause problems with the convergence of model estimation algorithms. We then illustrate how the proposed constraints work in two applied examples.
5 Simulation study
We used a Monte Carlo simulation to ascertain that the proposed identification constraints do not affect model convergence, admissibility, or quality (as defined by the value of the model discrepancy function at the optimal estimates). We fit a variety of ordinal factor analysis models in lavaan using default options, to examine whether researchers using integer constraints are likely to encounter problems with model estimation.
5.1 Method
In the simulation study, we compared the proposed integer constraints to reference-marker constraints and to unit-variance constraints using a population model with three correlated factors. We varied attributes that are often included in latent variable simulation designs (e.g., Flora & Curran, Reference Flora and Curran2004; Gagné & Hancock, Reference Gagné and Hancock2006; Rhemtulla et al., Reference Rhemtulla, Brosseau-Liard and Savalei2012): number of indicators per factor (3 or 6), standardized factor loading magnitude (0.4, 0.6, 0.8), number of response categories (3, 4, 5), and response distribution (symmetric, skewed, or middling). In the skewed conditions, the response probability of the highest option was 0.04 (and in conditions with
 $>$
2 response options, the response probability of the second highest option was set to 0.06). In the middling conditions, the response probability of the lowest and highest response options was 0.05 (where this condition was not included for 2 response options). For conditions with sparse response distributions, we manipulated the proportion of indicators per latent factor affected by that sparse pattern (0.33, 0.66, 1). For proportions less than 1, the remaining items had a symmetric response distribution.
$>$
2 response options, the response probability of the second highest option was set to 0.06). In the middling conditions, the response probability of the lowest and highest response options was 0.05 (where this condition was not included for 2 response options). For conditions with sparse response distributions, we manipulated the proportion of indicators per latent factor affected by that sparse pattern (0.33, 0.66, 1). For proportions less than 1, the remaining items had a symmetric response distribution.
In addition to these population model conditions, we also compared the two starting value options offered by lavaan: simple and default. With simple starting values, all parameter values are set to zero, except the factor loadings, which are set to 0.7, and (residual) variances, which are set to one. The default starting values are more involved. First, the factor loadings are estimated per factor using a two-stage least squares estimator. Second, the residual variances of observed variables are set to half the observed variance, and all other (residual) variances are set to 0.05. Third, thresholds are set to the standard normal distribution variates that match the (cumulative) response probabilities. The remaining parameters (regression coefficients and covariances) are set to zero.
We used lavaan (Rosseel, Reference Rosseel2012) to simulate 500 datasets for each fully crossed condition. Next, we used lavaan to fit the ordinal CFA model to each dataset, using each of the three identification constraints. These estimations used the default lavaan three-stage DWLS algorithm with “theta” parameterization. The sum constraints involved in our integer coding are handled in lavaan by projecting the full parameter vector to a reduced vector with nonredundant entries, then estimating this reduced parameter vector. See Rosseel (Reference Rosseel2015) for further details.
The simulation outcomes of interest were convergence rate, admissible results rates (e.g., non-negative variance estimates and positive definite covariance matrices), and
 $\chi ^2$
model fit estimates. We evaluated the impact of the conditions with a fixed-effects ANOVA, focusing on the partial Eta-squared (
$\chi ^2$
model fit estimates. We evaluated the impact of the conditions with a fixed-effects ANOVA, focusing on the partial Eta-squared (
 $\eta ^{2}_{p}$
) estimates, which were computed using effectsize (Ben-Shachar et al., Reference Ben-Shachar, Lüdecke and Makowski2020).
$\eta ^{2}_{p}$
) estimates, which were computed using effectsize (Ben-Shachar et al., Reference Ben-Shachar, Lüdecke and Makowski2020).
5.2 Results
We did not find much evidence that the integer constraints had estimation differences as compared to alternative identification constraint methods. Minor differences in convergence rates existed, but these were balanced out by differences in admissible result rates, resulting in almost identical converged and admissible (i.e., valid) result rates. Results of an ANOVA with converged and admissible result rates as the outcome variable indicated that the identification constraint had a negligible effect (
 $\eta ^{2}_{p} = 0.001$
). Similarly, starting values also minimally affected converged and admissible result rates (
$\eta ^{2}_{p} = 0.001$
). Similarly, starting values also minimally affected converged and admissible result rates (
 $\eta ^{2}_{p} =~0$
). Other simulation factors had a larger impact, ranging from
$\eta ^{2}_{p} =~0$
). Other simulation factors had a larger impact, ranging from
 $\eta ^{2}_{p} = 0.088$
for response distribution to
$\eta ^{2}_{p} = 0.088$
for response distribution to
 $\eta ^{2}_{p} = 0.238$
for factor loading magnitude. Given the minimal impact of starting values, we will focus on the results when using simple starting values. Results for default starting values are presented in Appendix B.
$\eta ^{2}_{p} = 0.238$
for factor loading magnitude. Given the minimal impact of starting values, we will focus on the results when using simple starting values. Results for default starting values are presented in Appendix B.
5.2.1 Convergence by condition
To provide further insight into these findings, we depict a subset of conditions in Figure 2. Within this figure, the y-axis shows the proportion of replications that converged and were admissible. Different factor loading magnitudes are shown on the x-axis, panel rows represent the number of indicators per factor, and panel columns represent the number of response categories. Within each plot, the three identification constraints are defined by different shapes and colors, and different response distributions are separated by line type. For the skewed and middling response distributions, we included results in which all indicators follow this pattern. We focus on these conditions because we found that results increasingly resembled the symmetric response distribution as the proportion of indicators with the skewed or middling response distributions decreased. Thus, the results in Figure 2 represent the most challenging conditions.
Proportion of converged and admissible replications across simulation conditions when all indicators have a balanced, skewed, or middling response distribution.

Figure 2 Long description
There are eight panels, arranged in two rows and four columns. The x axis in each panel is labeled Loading magnitude, ranging from 0.4 to 0.8. The y axis is labeled Proportion converged and admissible, ranging from 0 to 1. The columns are labeled at the top as Response categories: 2, 3, 4, and 5. The rows are labeled at the right as Number of indicators per factor: 3 (top row) and 6 (bottom row). Each panel contains three line types: solid for Symmetric, dashed for Skewed, and dotted for Middling response patterns. Three identification methods are shown: circles for Integer, triangles for Unit–Variance, and squares for Reference–Indicator. Across all panels, the Reference–Indicator method (square markers) consistently achieves the highest proportion, especially at higher loading magnitudes and more response categories. The Skewed and Middling patterns show lower proportions, particularly for fewer response categories and lower loading magnitudes. Increasing the number of indicators per factor improves convergence and admissibility for all methods. The legend below the panels clarifies marker shapes and line types.
Figure 2 demonstrates that converged and admissible result rates are higher for models with more indicators, better measurement quality (i.e., higher factor loadings), items with more response categories, and symmetric response distributions. However, within a specific combination of these factors, the three identification constraint methods performed similarly (i.e., lines of matching type have near perfect overlap).
There were two exceptions to the finding that identification constraints performed similarly. These exceptions are both shown in row 2, column 1 of Figure 2. First, for models with six indicators per factor, 0.4 factor loading magnitude, and items with three response categories which followed a skewed response distribution (dashed lines), the reference-indicator constraints resulted in lower converged and admissible result rates (
 $0.74$
) compared to the other two identification constraint methods (
$0.74$
) compared to the other two identification constraint methods (
 $0.81$
). Second, for the middling response distribution (dotted lines), model estimation was often problematic. For example, when the loading magnitude was 0.4, the reference-indicator constraints had a “converged and admissible rate” of
$0.81$
). Second, for the middling response distribution (dotted lines), model estimation was often problematic. For example, when the loading magnitude was 0.4, the reference-indicator constraints had a “converged and admissible rate” of
 $0.13$
, with the proposed integer constraints having a rate of
$0.13$
, with the proposed integer constraints having a rate of
 $0.32$
and the unit-variance constraints having a rate of
$0.32$
and the unit-variance constraints having a rate of
 $0.4$
. These rates increase and become more similar as the loading magnitude increases. The conditions appear especially difficult because there are two thresholds per item, but nearly all the responses are in the middle category. This leads to considerable uncertainty in the thresholds, which is magnified by small loadings.
$0.4$
. These rates increase and become more similar as the loading magnitude increases. The conditions appear especially difficult because there are two thresholds per item, but nearly all the responses are in the middle category. This leads to considerable uncertainty in the thresholds, which is magnified by small loadings.
5.2.2 Estimation quality
For those replications where all identification constraint methods converged and were admissible, we examined the quality of estimation using the
 $\chi ^2$
statistics of model fit (rounded to three decimal points). Similar to the convergence results from the previous paragraph, we observed differences in
$\chi ^2$
statistics of model fit (rounded to three decimal points). Similar to the convergence results from the previous paragraph, we observed differences in
 $\chi ^2$
statistics under middling response distributions and three response categories (see Table 1). Differences decreased as the factor loading magnitude increased. A closer inspection of the differences in
$\chi ^2$
statistics under middling response distributions and three response categories (see Table 1). Differences decreased as the factor loading magnitude increased. A closer inspection of the differences in
 $\chi ^2$
-values across all conditions shows that the integer identification constraints most often resulted in a different
$\chi ^2$
-values across all conditions shows that the integer identification constraints most often resulted in a different
 $\chi ^2$
-value (
$\chi ^2$
-value (
 $56$
%), followed by unit-variance (
$56$
%), followed by unit-variance (
 $20$
%), reference-marker (
$20$
%), reference-marker (
 $19$
%), and replications where all three identification constraint methods produced different
$19$
%), and replications where all three identification constraint methods produced different
 $\chi ^2$
-values (
$\chi ^2$
-values (
 $6$
%). When response distributions were symmetric or skewed,
$6$
%). When response distributions were symmetric or skewed,
 $\chi ^2$
-values were identical for the vast majority of replications (see Appendix B).
$\chi ^2$
-values were identical for the vast majority of replications (see Appendix B).
Proportion replications with middling response pattern resulting in identical fit across identification constraint methods

Table 1 Long description
The table has three main column groups: loading magnitude, proportion sparse, and response options. Response options are subdivided into 3 indicators and 6 indicators, each with 3, 4, or 5 response options. For loading magnitude 0.4 and proportion sparse 0.33, proportions are 0.99, 1.00, 1.00 for 3 indicators and 0.87, 0.99, 0.99 for 6 indicators. For 0.4 and 0.67, values are 0.94, 1.00, 1.00 for 3 indicators and 0.65, 0.98, 0.99 for 6 indicators. For 0.4 and 1.00, values are 0.93, 1.00, 1.00 for 3 indicators and 0.51, 0.99, 0.99 for 6 indicators. For loading magnitude 0.6 and proportion sparse 0.33, values are 1.00, 1.00, 1.00 for 3 indicators and 0.92, 1.00, 1.00 for 6 indicators. For 0.6 and 0.67, values are 0.98, 1.00, 1.00 for 3 indicators and 0.75, 0.99, 1.00 for 6 indicators. For 0.6 and 1.00, values are 0.93, 1.00, 1.00 for 3 indicators and 0.56, 1.00, 1.00 for 6 indicators. For loading magnitude 0.8 and proportion sparse 0.33, values are 1.00, 1.00, 1.00 for 3 indicators and 0.99, 1.00, 1.00 for 6 indicators. For 0.8 and 0.67, values are 1.00, 1.00, 1.00 for 3 indicators and 0.97, 1.00, 1.00 for 6 indicators. For 0.8 and 1.00, values are 1.00, 1.00, 1.00 for 3 indicators and 0.95, 1.00, 1.00 for 6 indicators. Across all loading magnitudes and proportions sparse, proportions for 3 indicators are consistently high, while for 6 indicators, proportions decrease as proportion sparse increases.
To better understand the differences in
 $\chi ^2$
-values that occurred with the middling response distribution, we focused on the most problematic conditions with six indicators per factor that had three response options. Table 2 shows that, when differences across identification methods arose, the reference-marker identification method was somewhat more likely to result in the best fit (i.e., lowest
$\chi ^2$
-values that occurred with the middling response distribution, we focused on the most problematic conditions with six indicators per factor that had three response options. Table 2 shows that, when differences across identification methods arose, the reference-marker identification method was somewhat more likely to result in the best fit (i.e., lowest
 $\chi ^2$
-value), in some cases together with a second identification method. This pattern was more apparent when the middling response distribution was applied to all indicators and the loading magnitude was lowest. Full results for all middling response distribution conditions are included in Appendix B.
$\chi ^2$
-value), in some cases together with a second identification method. This pattern was more apparent when the middling response distribution was applied to all indicators and the loading magnitude was lowest. Full results for all middling response distribution conditions are included in Appendix B.
Proportion replications with middling response pattern, six indicators, and three response categories resulting in best fit across identification constraint methods

Table 2 Long description
The table has seven rows and ten columns. The first column lists identification constraint methods: All, Reference-Indicator, Unit-Variance, Integer, R I and U V, R I and I, U V and I. The next nine columns are grouped under three loading values: 0.4, 0.6, and 0.8. Each loading group has columns for sparse indicator proportions 0.33, 0.67, and 1.00. For ‘All’, proportions decrease as sparse indicator proportion increases within each loading: for 0.4, values are 0.87, 0.65, 0.51; for 0.6, 0.92, 0.75, 0.56; for 0.8, 0.99, 0.97, 0.95. Other methods show much lower proportions, mostly below 0.10, with Reference-Indicator and combinations involving it showing the lowest values. The highest proportions overall are for the ‘All’ method at higher loadings and lower sparse indicator proportions.
5.2.3 Summary
The simulation study showed that the proposed integer identification constraints do not meaningfully affect estimation admissibility, convergence, or quality. When differences do emerge, the proposed integer identification constraints are more similar to the unit-variance identification constraint method, and both perform better than the reference-indicator identification method. Problems can arise when there are few ordinal categories, and the bulk of responses are in a single middle category. In this case, estimation is more difficult regardless of the identification constraint, and integer coding does not necessarily perform best. But integer coding also does not consistently perform worse than other sets of constraints in those situations.
6 Example 1: Comparison to traditional estimates
To build intuition for how the constraints work in practice, we use real data to compare a model with traditional identification constraints to a model with our proposed integer constraints. We use a 7-item survey of attitudes toward science and technology (Reif and Melich, Reference Reif and Melich2015), where each item has the ordered categories of “strongly disagree,” “disagree,” “agree,” and “strongly agree.” The dataset includes responses from 392 individuals, with no missing values. It is available via the ltm R package (Rizopoulos, Reference Rizopoulos2006), with item response frequencies being shown in Table 3.
Item response frequencies of the attitudes toward science dataset

Table 3 Long description
The table has seven columns labeled Comfort, Environment, Work, Future, Technology, Industry, and Benefit. Four rows represent response levels 1 to 4. For Comfort, frequencies are 5, 32, 266, 89. For Environment, 29, 90, 145, 128. For Work, 33, 98, 206, 55. For Future, 14, 72, 210, 96. For Technology, 18, 91, 157, 126. For Industry, 10, 47, 173, 162. For Benefit, 21, 100, 193, 78. The highest frequency in each category is at response level 3 except for Industry, where level 4 is nearly as high as level 3.
6.1 Method
We used lavaan (Rosseel, Reference Rosseel2012) to fit a 1-factor, ordinal CFA model to the 7 items via the default DWLS algorithm (obtained via the argument ordered = TRUE). We first fit the model using the traditional constraints from Equation (6) (i.e., using the “theta” parameterization), and we then fit the model using the alternative constraints of:
 $$ \begin{align*} \displaystyle \sum_{j=1}^7 \nu_j &= 0 \\ \frac{1}{7} \displaystyle \sum_{j=1}^7 \lambda_j &= 1 \\ \tau_{j1} = 1.5\ &\text{for }j=1, \ldots, 7 \\ \tau_{j3} = 3.5\ &\text{for }j=1, \ldots, 7. \end{align*} $$
$$ \begin{align*} \displaystyle \sum_{j=1}^7 \nu_j &= 0 \\ \frac{1}{7} \displaystyle \sum_{j=1}^7 \lambda_j &= 1 \\ \tau_{j1} = 1.5\ &\text{for }j=1, \ldots, 7 \\ \tau_{j3} = 3.5\ &\text{for }j=1, \ldots, 7. \end{align*} $$
After model estimation, we obtained MAP estimates of the latent variable for each respondent.
6.2 Results
As expected, the discrepancy function and
 $\chi ^2$
statistic were identical for the estimated model with traditional identification constraints as compared to the estimated model with the alternative identification constraints. The models do not fit well by any of the traditional fit metrics (e.g.,
$\chi ^2$
statistic were identical for the estimated model with traditional identification constraints as compared to the estimated model with the alternative identification constraints. The models do not fit well by any of the traditional fit metrics (e.g.,
 $\chi ^2_{14} = 322, p < 0.01$
; RMSEA = 0.24), and poor model fit as well as model misspecifications can lead to questionable parameter interpretations. But because fit is held constant across identification constraints, we proceed with comparing parameter estimates across the two sets of identification constraints.
$\chi ^2_{14} = 322, p < 0.01$
; RMSEA = 0.24), and poor model fit as well as model misspecifications can lead to questionable parameter interpretations. But because fit is held constant across identification constraints, we proceed with comparing parameter estimates across the two sets of identification constraints.
We begin by comparing estimates of parameters that are shared across the two models. Table 4 compares estimated loadings and standard errors under the traditional and alternative constraints, while Table 5 does the same for thresholds. Examining Table 4, we see that the loadings and standard errors are larger under the alternative constraints because they are constrained to average 1. The alternative constraints provide a basis for interpreting loadings: values above 1 are larger than average, and values below 1 are smaller than average. The “work” item stands out as having the smallest loading under both sets of constraints.
Comparison of loading estimates and SEs under traditional constraints and under integer constraints

Table 4 Long description
The table has seven columns labeled Comfort, Environment, Work, Future, Technology, Industry, and Benefit. For each factor, the traditional estimate (Trad est) and its standard error (S E) are listed first, followed by the integer estimate (Int est) and its S E. Comfort: Trad est 0.60 (S E 0.09), Int est 0.89 (S E 0.10). Environment: Trad est 0.48 (S E 0.07), Int est 1.17 (S E 0.14). Work: Trad est 0.33 (S E 0.07), Int est 0.66 (S E 0.12). Future: Trad est 0.54 (S E 0.07), Int est 0.98 (S E 0.11). Technology: Trad est 0.50 (S E 0.07), Int est 1.07 (S E 0.13). Industry: Trad est 0.68 (S E 0.09), Int est 1.34 (S E 0.15). Benefit: Trad est 0.46 (S E 0.07), Int est 0.88 (S E 0.12). Integer estimates are consistently higher than traditional estimates across all factors, with standard errors also generally larger for integer constraints.
Comparison of threshold estimates and SEs under traditional constraints and under integer constraints

Table 5 Long description
The table has seven columns labeled Comfort, Environment, Work, Future, Technology, Industry, and Benefit. The first set of rows presents traditional estimates with standard errors. For Comfort: minus 2.61 (0.21), minus 1.54 (0.11), 0.87 (0.09). For Environment: minus 1.60 (0.11), minus 0.57 (0.07), 0.50 (0.07). For Work: minus 1.45 (0.10), minus 0.45 (0.07), 1.14 (0.08). For Future: minus 2.05 (0.14), minus 0.88 (0.08), 0.79 (0.08). For Technology: minus 1.88 (0.12), minus 0.66 (0.08), 0.52 (0.07). For Industry: minus 2.36 (0.17), minus 1.28 (0.10), 0.27 (0.08). For Benefit: minus 1.78 (0.12), minus 0.55 (0.07), 0.93 (0.08). The next set of rows presents integer estimates. For all columns, the first integer estimate is 1.50 (no standard error), followed by a value above 2: Comfort 2.12 (0.08), Environment 2.48 (0.06), Work 2.27 (0.05), Future 2.32 (0.06), Technology 2.52 (0.06), Industry 2.32 (0.08), Benefit 2.41 (0.06). The final integer estimate for all columns is 3.50 (no standard error).
Examining Table 5, many thresholds have no standard errors under the alternative constraints because they are fixed. The free thresholds have standard errors from 0.05 to 0.08, which are similar to the standard errors under traditional constraints. Additionally, the threshold estimates under the alternative constraints are intuitive because they can be compared to the 1.5–2.5–3.5 values that would help us to treat the observed variables as continuous. We see that the “environment” and “technology” items most closely correspond to this pattern, while the middle thresholds for “comfort” and “work” are noticeably smaller than 2.5. These thresholds interact with the estimated latent mean and variance, which we can freely estimate under the alternative constraints. The estimates are 3 and 0.15, respectively, suggesting that participants generally have high values of the latent variable (attitude toward science). Said differently, the midpoint of a 1–5 scale is 2.5, and the estimated mean of the latent variable is a half-point larger than this midpoint. This result corresponds to the observed response frequencies from Table 3.
Finally, Figure 3 compares the average of each participant’s ordinal variables to the MAP prediction of the latent variable under the alternative constraints. We see that the MAP predictions are similar to the averages, with some shrinkage whereby the extreme averages have less-extreme latent variable predictions. We also see that the averages and latent variable predictions differ the most for participants with low averages (below 2), reflecting the result that participants generally tended to respond with “agree” or “strongly agree” on the ordinal scale.
Average of observed variables versus MAP latent variable predictions for the attitudes toward science dataset.

7 Example 2: Item response application
To further illustrate how the integer constraints work in practice, we now consider a model estimated in an item response framework. We fit our model via marginal maximum likelihood, capitalizing on the flexibility of the mirt package (Chalmers, Reference Chalmers2012) to implement our constraints and to fit the model. In the language of IRT, we can say we are estimating a graded response model with a probit link function.
7.1 Method
We use data from a study of social media privacy (Dienlin and Metzger, Reference Dienlin and Metzger2016), where respondents completed scales related to their use of Facebook and their privacy concerns. We focus on a 5-item subscale of respondents’ perceived Facebook benefits that includes items such as “Facebook allows me to express my personality and feelings.” Each item contained 5 response categories from “strongly disagree” to “strongly agree.” The data are available at https://osf.io/e3j98/ and contain responses from 1,156 online participants, where the sampling scheme was designed to be representative of American adults (see Dienlin & Metzger, Reference Dienlin and Metzger2016). We model 1,057 participants who supplied complete data on the Facebook benefits scale, which allows for simpler model computations and summaries.
We fit the graded response model with integer constraints in mirt, making use of package functionality to define new item types and to implement parameter constraints. The mirt marginal maximum likelihood estimation algorithm involves rectangular quadrature with 61 nodes. The specific integer constraints for this example are:
 $$ \begin{align*} \displaystyle \sum_{j=1}^5 \nu_j &= 0 \\ \frac{1}{5} \displaystyle \sum_{j=1}^5 \lambda_j &= 1 \\ \tau_{j1} = 1.5\ &\text{for }j=1,\ldots,5 \\ \tau_{j4} = 4.5\ &\text{for }j=1,\ldots,5. \end{align*} $$
$$ \begin{align*} \displaystyle \sum_{j=1}^5 \nu_j &= 0 \\ \frac{1}{5} \displaystyle \sum_{j=1}^5 \lambda_j &= 1 \\ \tau_{j1} = 1.5\ &\text{for }j=1,\ldots,5 \\ \tau_{j4} = 4.5\ &\text{for }j=1,\ldots,5. \end{align*} $$
To estimate the model with sum constraints on the intercepts and loadings, mirt makes use of the optimizer from the package Rsolnp (Galanos and Ye, Reference Galanos and Ye2025). This includes a Lagrange multiplier method that can handle both linear and nonlinear parameter constraints.
7.2 Results
We first examine model fit, using mirt to obtain the C2 statistic of Cai and Monroe (Reference Cai and Monroe2014). This statistic rejects the hypothesis of exact fit (C2(df = 3) = 10.03, p = 0.02), which commonly happens in practice. The 90% confidence interval for RMSEA is (0.017, 0.081), providing some evidence that the model fit is adequate (e.g., Maydeu-Olivares, Reference Maydeu-Olivares2013; Maydeu-Olivares & Joe, Reference Maydeu-Olivares and Joe2014).
Item parameter estimates are shown in Table 6. The first two columns are the two free thresholds, followed by the loadings, intercepts, and residual variances (the Tau1 and Tau4 parameters are fixed to 1.5 and 4.5, respectively, for all items). In addition to these parameters, the latent variable mean and variance are estimated to be 2.9 and 0.53, respectively.
Item parameter estimates for Example 2

Table 6 Long description
The table header lists columns as Tau2, Tau3, Lambda, Nu, and Theta. For Item 1, values are 2.07, 3.05, 0.99, 0.20, and 0.34. Item 2 has 2.23, 3.27, 0.94, dash 0.00, and 0.31. Item 3 has 2.16, 3.11, 1.04, dash 0.05, and 0.27. Item 4 has 2.26, 3.24, 0.99, 0.09, and 0.29. Item 5 has 2.29, 3.31, 1.04, dash 0.24, and 0.24. Dashes indicate missing or inapplicable Nu values for Items 2, 3, and 5.
From the table, we see that the estimated thresholds for each item are lower than the benchmark values of 2.5 and 3.5. Combined with the fact that the latent variable mean is near the midpoint of 3, this suggests that participants avoided the “strongly disagree” option of the scale. The estimated loadings are all near the benchmark value of 1, and no items stand out as being exceptionally better or worse than the others.
Figure 4 is similar to Figure 3 from our previous example, showing the average score for each individual versus the MAP predictions from the integer-constrained model. We see close agreement here, with points falling slightly below the diagonal for average scores near 3 and larger. This is related to our observation that the thresholds for all items are below the benchmarks of 2.5 and 3.5: the model estimates that people tend to avoid the “strongly disagree” option, so lower values of the latent variable can still lead participants to select higher response options.
Average of observed variables versus MAP latent variable predictions for the social media dataset.

A common IRT model summary involves visualization of how the expected test score changes with the latent variable. For ordinal variables, the expected score is typically the sum of integer-coded responses. We consider a similar summary here, showing how the expected average score (the expected test score divided by the number of items) varies as a function of the latent variable. In the left panel of Figure 5, the solid line shows the expected average score (y-axis) for varying values of the latent variable (x-axis) under integer constraints. We see that the line is above the dashed diagonal on the left side of the panel, which is related to the idea that people avoided the “strongly disagree” option. That is, participants with low values of the latent variable are expected to have averages greater than 1. The solid line closely follows the diagonal for the rest of the figure, with a crossing near the maximal expected average of 5.
Latent variable values versus expected average score (left panel), with overlaid points of MAP latent variable estimates versus observed average scores (right panel).

Figure 5 Long description
The left panel plots Latent variable on the x axis from 1 to 5 and Expected average score on the y axis from 1 to 5. A solid curve rises nonlinearly from bottom left to top right, showing a positive but decelerating relationship. A dashed diagonal line marks the identity line where expected score equals latent variable. The right panel uses the same axes but the y axis is labeled Expected/observed average score. The same solid and dashed lines are present, but black dots are overlaid, representing MAP latent variable estimates versus observed average scores. The dots cluster closely around the solid curve, especially at lower values, and spread more at higher values, indicating the observed scores generally follow the expected trend but with increasing dispersion.
The right panel of Figure 5 contains the same expected average line, with points showing each person’s estimated latent variable (x-axis) versus their observed average (y-axis). We see that the points are similar to the expected average near the middle (latent variables of 2.5 to 3.5), and they stray from the expected average near the extremes. This difference is likely due to the boundaries of the expected average score. That is, the average score has a hard lower bound of 1 and a hard upper bound of 5, so the expected value will be pulled toward the center of the scale. The latent variables are unbounded, allowing us to observe predictions near the extremes of 1 and 5.
The mirt model estimation that we implemented here is not comprehensive. Most notably, we did not handle missing values, and we did not obtain standard errors of parameter estimates under integer constraints. The latter requires further analytical work on the Hessian under integer constraints, or a Jacobian so that we can apply the delta method to standard errors under traditional constraints. But we have illustrated that the constraints can be applied in traditional IRT settings, where latent variables are commonly used for scoring purposes.
8 General discussion
In this article, we first considered how constraints on an item factor analysis model can lead to latent variable predictions mimicking the average of observed ordinal variables, where the variables are coded as 1, 2, …, K. Based on these constraints, we then defined a set of minimal identification constraints (“integer constraints”) that puts the latent variable on the scale of the integer-coded ordinal variable. This is potentially worthwhile because applied researchers are accustomed to thinking on the scale of the ordinal variable and to treating ordinal variables as though they are continuous. Our simulation showed that the integer constraints did not meaningfully influence rates of model convergence or admissibility, at least for the conditions examined. Our examples showed specific uses of the constraints, including enhanced interpretation of parameter estimates, intuitive latent variable predictions, and application in traditional IRT settings. In the sections below, we consider additional uses of integer constraints and potential extensions of our results.
8.1 Additional applications
The integer constraints suggest a likelihood ratio test of whether or not the observed ordinal variables can be treated as continuous. That is, we can fit an ordinal CFA with our proposed minimal identification constraints, then conduct a likelihood ratio test comparing this model to the highly-constrained model whose latent variable predictions are the observed averages. If the likelihood ratio test suggests that the fit of the two models is equal, then researchers could feel more confident about treating their ordinal variables as continuous. We are doubtful that this likelihood ratio test will often indicate that the fit of the two models is equal.
Related to the likelihood ratio test, integer constraints could be further considered in the context of measurement invariance studies with multiple groups. Wu and Estabrook (Reference Wu and Estabrook2016) provide a comprehensive treatment of measurement invariance under traditional identification constraints, and we used some of their results in this article. Because we have defined transformation matrices to convert traditional constraints to integer constraints, much of the Wu and Estabrook results could be translated to testing measurement invariance under integer constraints. The integer constraints may help to make measurement invariance testing more interpretable and intuitive.
Finally, the integer constraints have potential uses in Bayesian modeling because they potentially make the specification of prior distributions more intuitive. For example, because loadings are constrained to average 1 under integer constraints, the priors for factor loadings would often have a mean of 1. And because the factor mean is related to the average of ordinal variables, researchers may more easily convert their prior expectations to prior distributions. On the other hand, the sum constraints on loadings can complicate the prior distributions of those parameters (e.g., Merkle et al., Reference Merkle, Ariyo, Winter and Garnier-Villarreal2023), so that Bayesian SEM software may not automatically handle the constraints. One possible solution involves discarding the sum constraints on loadings, replacing them with constraints on a single loading per factor.
If we are to maintain the sum constraints in a Bayesian context, another possible solution involves estimating the model using the traditional identification constraints (which are available in most software) while specifying priors for integer-constrained parameters. Then, we would additionally need the Jacobian for transforming the parameters under traditional constraints to the parameters under integer constraints, which involves the results from Remark 2. For many models, this Jacobian will involve the determinant of a large matrix, though the structure of the underlying matrix may allow for fast determinant computations. Further work is needed.
8.2 Differing numbers of categories per variable
The developments in this article relied on the assumption that the observed variables are all ordinal with K categories. In practice, it is common to have ordinal variables with differing numbers of categories, for example, two ordinal variables with three possible categories and three ordinal variables with five possible categories. In this case, we write that each ordinal variable j has
 $K_j$
response categories. It is more cumbersome to specify identification constraints here, because the differing number of thresholds per variable complicates matrix manipulations such as Equation (8).
$K_j$
response categories. It is more cumbersome to specify identification constraints here, because the differing number of thresholds per variable complicates matrix manipulations such as Equation (8).
Because integer constraints were designed to be close to the average of integer-coded variables, we should also consider whether it makes sense to take an average when variables have different numbers of categories. As an extreme example, consider a situation where two variables have three categories and a third variable has 50 categories. If we code each variable using integers starting at 1 and then average them, it is clear that the third variable will usually dominate the average. This suggests that we should view the 3-category variables as coarsened versions of the 50-category scale. That is, if we were to code the 3-category variables so that they assumed values on a scale from 1 to 50, then it would make more sense to average across the variables. In the context of our integer constraints, this amounts to fixing the thresholds of the 3-category variables to values other than 1.5 and 2.5. The thresholds should instead divide the 50-point scale into three equal segments, which here corresponds to a lower threshold of 17.17 and an upper threshold of 33.83.
In general terms, let
 $K_j$
be the number of categories for the ordinal variable j. For a specific latent variable k, let
$K_j$
be the number of categories for the ordinal variable j. For a specific latent variable k, let
 $K_{\text {max}} = \text {max}_{j \in \mathcal {S}_k} K_j$
. Then, for all observed variables that load on latent variable k (i.e., for all
$K_{\text {max}} = \text {max}_{j \in \mathcal {S}_k} K_j$
. Then, for all observed variables that load on latent variable k (i.e., for all
 $j \in \mathcal {S}_k$
), we should fix
$j \in \mathcal {S}_k$
), we should fix
 $$ \begin{align*} \tau_{j1} &= \frac{1}{2} + \frac{K_{\text{max}}}{K_j} \\ \tau_{j(K_j-1)} &= \frac{1}{2} + \frac{K_{\text{max}}(K_j - 1)}{K_j}. \end{align*} $$
$$ \begin{align*} \tau_{j1} &= \frac{1}{2} + \frac{K_{\text{max}}}{K_j} \\ \tau_{j(K_j-1)} &= \frac{1}{2} + \frac{K_{\text{max}}(K_j - 1)}{K_j}. \end{align*} $$
The other constraints on intercepts and loadings remain the same as before. A modification is additionally required for a binary variable j, which only has a single threshold parameter. For that case, we fix
 $\tau _{j1}$
in the above manner while also fixing the intercept
$\tau _{j1}$
in the above manner while also fixing the intercept
 $\nu _j$
to 0.
$\nu _j$
to 0.
8.3 Summary
The sum score is a major consideration in the historical development of psychometrics as well as in current developments (e.g., McNeish, Reference McNeish2024; Mislevy, Reference Mislevy2024; Sijtsma et al., Reference Sijtsma, Ellis and Borsboom2024b). In this article, we studied an integer identification constraint for ordinal CFA that has a direct relationship to the sum score, where we average the ordinal items as if they are continuous. These constraints might balance the concerns of those who view the sum score as unsophisticated with those who view the sum score as a benchmark. In drawing on the intuition of the sum score, we hope that the integer constraints will enable more researchers to meaningfully employ common psychometric models of ordinal data.
Data availability statement
All results were obtained using the R system for statistical computing (R Core Team, 2025), version 4.5.2, making use of the lavaan (Rosseel, Reference Rosseel2012), ggplot2 (Wickham, Reference Wickham2016), and xtable (Dahl et al., Reference Dahl, Scott, Roosen, Magnusson and Swinton2019) packages. Code for reproducing the results in this article and for applying integer constraints to other lavaan models is available at https://semtools.r-forge.r-project.org/.
Funding statement
This work was supported by the Institute of Education Sciences, U.S. Department of Education, Grant R305D210044.
Competing interests
The authors declare none.
Appendix
A Alternative integer constraints
We considered many variations of the integer constraints presented in this article. Our proposed constraints appear to get us close to the integer-coded average across a variety of scenarios. Below, we describe some variations that we considered, along with problems that we encountered.
A.1 Constrain one threshold per observed variable instead of two
We initially constrained each observed variable’s middle threshold to the middle of the integer scale. For example, for an observed variable j with
 $K_j = 4$
, we fixed
$K_j = 4$
, we fixed
 $\tau _{j2} = 2.5$
. For an observed variable j with
$\tau _{j2} = 2.5$
. For an observed variable j with
 $K_j = 5$
, we constrained the second and third thresholds to be symmetric around 3, i.e.,
$K_j = 5$
, we constrained the second and third thresholds to be symmetric around 3, i.e.,
 $3 - \tau _{j2} = \tau _{j3} - 3$
. Then, to make up for the lack of constraints on the second threshold, we either constrained
$3 - \tau _{j2} = \tau _{j3} - 3$
. Then, to make up for the lack of constraints on the second threshold, we either constrained
 $\theta _{jj} = 1$
or
$\theta _{jj} = 1$
or
 $\nu _j = 0$
. A problem with these constraints is that the outer thresholds
$\nu _j = 0$
. A problem with these constraints is that the outer thresholds
 $\tau _{j1}$
and
$\tau _{j1}$
and
 $\tau _{j(K_j-1)}$
were often estimated to be outside of
$\tau _{j(K_j-1)}$
were often estimated to be outside of
 $(1,K_j)$
, so that there was a larger mismatch between observed averages and latent variable predictions.
$(1,K_j)$
, so that there was a larger mismatch between observed averages and latent variable predictions.
A.2 Constrain two middle thresholds instead of two outer thresholds
We again observed that the outer thresholds would be estimated outside of
 $(1,K_j)$
, leading again to a larger mismatch between observed averages and latent variable predictions.
$(1,K_j)$
, leading again to a larger mismatch between observed averages and latent variable predictions.
A.3 Constrain the loadings’ geometric mean to equal 1, instead of the arithmetic mean
Under this constraint, we may experience inconsistent signs of individual loadings. For example, when we have an even number of loadings, the loadings can all be negative yet have a geometric mean of 1. This will not necessarily be problematic in situations where all loadings are expected to have the same sign, and where we use frequentist estimation. It may be more problematic for Bayesian models where some loadings’ posterior distributions overlap with 0. In that case, MCMC methods may experience problems because they will sometimes encounter loadings with differing signs.
B Additional figures and tables
The figures and tables below show results from additional simulation conditions. Specifically, Figure B1 and Tables B1 and Table B2 mimic the simulation study results presented in the main text of this article but focus on conditions when default starting values are used. In addition, Tables B3 and B4 present supplementary results on the proportion of replications with identical model fit across identification constraints for conditions using simple and default starting values, respectively. Similarly, Tables B5 and B6 present supplementary results for models with three indicators on the proportion of replications that resulted in best fit for each identification constraint for conditions using simple and default starting values, respectively. Finally, Tables B7 and B8 present supplementary results for models with six indicators on the proportion of replications that resulted in best fit for each identification constraint for conditions using simple and default starting values, respectively.
Proportion of converged and admissible replications across simulation conditions when all indicators have a balanced, skewed, or middling response distribution, using default starting values.

Figure B1 Long description
There are eight panels, arranged in two rows and four columns. The x axis in each panel is labeled Loading magnitude with values 0.4, 0.6, and 0.8. The y axis is labeled Proportion converged and admissible, ranging from 0.25 to 1.00. Columns are labeled at the top as Response categories: 2, 3, 4, and 5. Rows are labeled at the right as Number of indicators per factor: 3 (top row) and 6 (bottom row). Each panel contains three line types: solid for Symmetric, dashed for Skewed, and dotted for Middling response patterns. Three identification methods are shown: circles for Integer, triangles for Unit–Variance, and squares for Reference–Indicator. Across all panels, the solid lines (Symmetric) consistently reach the highest proportion values, especially at higher loading magnitudes and response categories. Dashed and dotted lines (Skewed and Middling) show lower proportions, with more variation across identification methods. The Reference–Indicator method (squares) generally achieves higher proportions than Integer (circles) and Unit–Variance (triangles), particularly as the number of indicators and response categories increase.
Proportion replications with middling response pattern resulting in identical fit across identification constraint methods, using default starting values

Table B1 Long description
The table is organized with loading magnitude in the first column, proportion sparse in the second, and six columns for response options grouped by number of indicators. The response options columns are divided into two groups: three indicators (with three, four, and five response options) and six indicators (with three, four, and five response options). For loading magnitude 0.4, proportion sparse 0.33, the proportions are 0.99, 1.00, 1.00 for three indicators and 0.92, 0.99, 0.98 for six indicators. For 0.4, 0.67, values are 0.98, 1.00, 1.00 and 0.75, 0.98, 0.99. For 0.4, 1.00, values are 0.92, 1.00, 1.00 and 0.56, 0.99, 0.99. For loading magnitude 0.6, proportion sparse 0.33, values are 0.99, 1.00, 1.00 and 0.96, 1.00, 1.00. For 0.6, 0.67, values are 0.98, 1.00, 1.00 and 0.86, 1.00, 1.00. For 0.6, 1.00, values are 0.96, 1.00, 1.00 and 0.73, 1.00, 1.00. For loading magnitude 0.8, proportion sparse 0.33, values are 1.00, 1.00, 1.00 and 0.99, 1.00, 1.00. For 0.8, 0.67, values are 1.00, 1.00, 1.00 and 0.97, 1.00, 1.00. For 0.8, 1.00, values are 0.99, 1.00, 1.00 and 0.96, 1.00, 1.00. Across all conditions, proportions are highest for more response options and higher loading magnitudes, with lower values for higher sparsity and fewer indicators.
Proportion replications with middling response pattern, six indicators, and three response categories resulting in best fit across identification constraint methods, using default starting values

Table B2 Long description
The table has seven rows and ten columns. The first column lists identification constraint methods: All, Reference-Indicator, Unit-Variance, Integer, R I and U V, R I and I, U V and I. The next nine columns are grouped into three sets by loading values: 0.4, 0.6, and 0.8. Each set has columns for proportion sparse indicators 0.33, 0.67, and 1.00. For ‘All’, proportions decrease as sparse indicator proportion increases: at loading 0.4, values are 0.92, 0.75, 0.56; at 0.6, 0.96, 0.86, 0.73; at 0.8, 0.99, 0.97, 0.96. Other methods show much lower proportions, mostly near zero. Reference-Indicator and Unit-Variance have values ranging from 0.00 to 0.06 and 0.00 to 0.05 respectively. Integer method ranges from 0.02 to 0.17. Combined methods (R I and U V, R I and I, U V and I) have values between 0.00 and 0.10. The highest proportions are consistently found in the ‘All’ method, especially at higher loadings and lower sparse indicator proportions.
Proportion replications with symmetric or skewed response pattern resulting in identical fit across identification constraint methods, using simple starting values

Table B3 Long description
The table has three main columns for pattern, loading magnitude, and proportion sparse, followed by six columns for response options. The response options are grouped into two sets: three indicators and six indicators, each with three subcolumns for 3, 4, and 5 response options. For the symmetric pattern, with loading magnitudes 0.4, 0.6, and 0.8 and proportion sparse 0.00, all proportions are 1.00 except for 0.99 and 0.98 in the six-indicator group at 0.4 loading. For the skewed pattern, each loading magnitude (0.4, 0.6, 0.8) is subdivided by proportion sparse (0.33, 0.67, 1.00). For 0.4 loading, proportions range from 0.89 to 1.00, with lower values in the six-indicator group as proportion sparse increases. For 0.6 and 0.8 loading, proportions remain high, with minimum values of 0.94 and most values at or near 1.00. The lowest proportions occur for skewed patterns with higher proportion sparse and more indicators.
Proportion replications with symmetric or skewed response pattern resulting in identical fit across identification constraint methods, using default starting values

Table B4 Long description
The table is organized with rows grouped by response pattern: Symmetric and Skewed. The first three columns are Pattern, Loading magnitude, and Proportion sparse. The next six columns are grouped under Response options, split into two sets: 3 indicators and 6 indicators, each with three columns for 3, 4, and 5 response options. For Symmetric pattern, loading magnitudes are 0.4, 0.6, and 0.8, all with proportion sparse 0.00. All response option values are 1.00 except for 0.99 in the 6 indicators columns for 3 and 5 response options at loading 0.4. For Skewed pattern, loading magnitudes are 0.4, 0.6, and 0.8, each with proportion sparse values 0.33, 0.67, and 1.00. For 0.4 loading and 0.33 sparse, values range from 0.94 to 1.00. For 0.4 loading and 0.67 sparse, values are 0.91 to 1.00. For 0.4 loading and 1.00 sparse, values are 0.93 to 1.00. For 0.6 loading, values for 0.33 sparse are 0.96 to 1.00, for 0.67 sparse are 0.94 to 1.00, and for 1.00 sparse are 0.95 to 1.00. For 0.8 loading, values for 0.33 sparse are 0.98 to 1.00, for 0.67 sparse are 0.94 to 1.00, and for 1.00 sparse are 0.96 to 1.00. The highest proportions are consistently observed for symmetric patterns and higher loading magnitudes, with slightly lower values for skewed patterns and higher sparsity.
Proportion replications with middling response pattern and three indicators per factor resulting in best fit across identification constraint methods, using simple starting values

Table B5 Long description
Starting from the top row, the table is organized by response options (3, 4, 5) in the first column. For each response option, the second column lists identification constraint methods: All, Reference-Indicator, Unit-Variance, Integer, R I and U V, R I and I, U V and I. The next nine columns are grouped into three sets by loading values (0.4, 0.6, 0.8), each with sparse indicator proportions 0.33, 0.67, and 1.00. For response option 3, the ‘All’ method yields proportions from 0.93 to 1.00 across all loadings and sparse indicator levels. All other methods for option 3 have proportions between 0.00 and 0.02. For response options 4 and 5, the ‘All’ method yields 1.00 for every loading and sparse indicator combination, while all other methods yield 0.00. This pattern is consistent across all loading and sparse indicator combinations. The table demonstrates that the ‘All’ method consistently results in the best fit, regardless of loading or sparse indicator proportion, while alternative identification constraint methods rarely yield the best fit.
Proportion replications with middling response pattern and three indicators per factor resulting in best fit across identification constraint methods, using default starting values

Table B6 Long description
The table is organized by response options in the first column, with values 3, 4, and 5. For each, rows list best fit methods: All, Reference-Indicator, Unit-Variance, Integer, R I and U V, R I and I, U V and I. Columns to the right are grouped by loading values 0.4, 0.6, and 0.8, each subdivided into sparse indicator proportions 0.33, 0.67, and 1.00. For response option 3, the ‘All’ method yields high best fit proportions across all loadings and sparsity (0.92 to 1.00), while other methods show near-zero values. For response options 4 and 5, only the ‘All’ method yields 1.00 for all loadings and sparsity; all other methods are zero. This pattern indicates that the ‘All’ method consistently results in the best fit regardless of loading or sparsity, while other identification constraint methods rarely yield the best fit.
Proportion replications with middling response pattern and six indicators per factor resulting in best fit across identification constraint methods, using simple starting values

Table B7 Long description
Starting from the top row, columns are organized as follows: the first column is ‘Resp. options’ with values 3, 4, and 5. The second column is ‘Best fit’ with methods All, Reference-Indicator, Unit-Variance, Integer, RI and UV, RI and I, and UV and I. The next nine columns are grouped by loading levels 0.4, 0.6, and 0.8, each with sparse indicator proportions 0.33, 0.67, and 1.00. For Resp. option 3, the ‘All’ method yields proportions from left to right: 0.87, 0.65, 0.51, 0.92, 0.75, 0.56, 0.99, 0.97, 0.95. Other methods under option 3 show much lower proportions, mostly below 0.10. For Resp. option 4, the ‘All’ method shows proportions near or at 1.00 across all loading and sparse indicator combinations, while all other methods yield 0.00 or very close to zero. The same pattern holds for Resp. option 5. Across all response options, only the ‘All’ method consistently achieves high proportions of best fit, especially as the number of response options increases, while alternative identification constraint methods rarely yield best fit. The table demonstrates that the ‘All’ method is robust to changes in loading and sparse indicator proportions, while other methods are not.
Proportion replications with middling response pattern and six indicators per factor resulting in best fit across identification constraint methods, using simple starting values

Table B8 Long description
The table is organized with response options in the first column, best fit method in the second, and nine columns grouped by loading values 0.4, 0.6, and 0.8, each with sparse indicator proportions 0.33, 0.67, and 1.00. For response option 3, the All method shows proportions from 0.92 to 0.99 across loadings and sparsity, while Reference-Indicator, Unit-Variance, Integer, RI and UV, RI and I, and UV and I methods have much lower proportions, mostly below 0.07. For response option 4, the All method yields proportions of 0.98 or higher for all loadings and sparsity, with other methods at or near zero. For response option 5, the All method remains at 0.98 or higher, others at or near zero. Across all response options, the All method consistently achieves the highest best fit proportions, especially as response options increase, while alternative methods rarely exceed 0.07. The trend is robust across all loading and sparsity combinations.
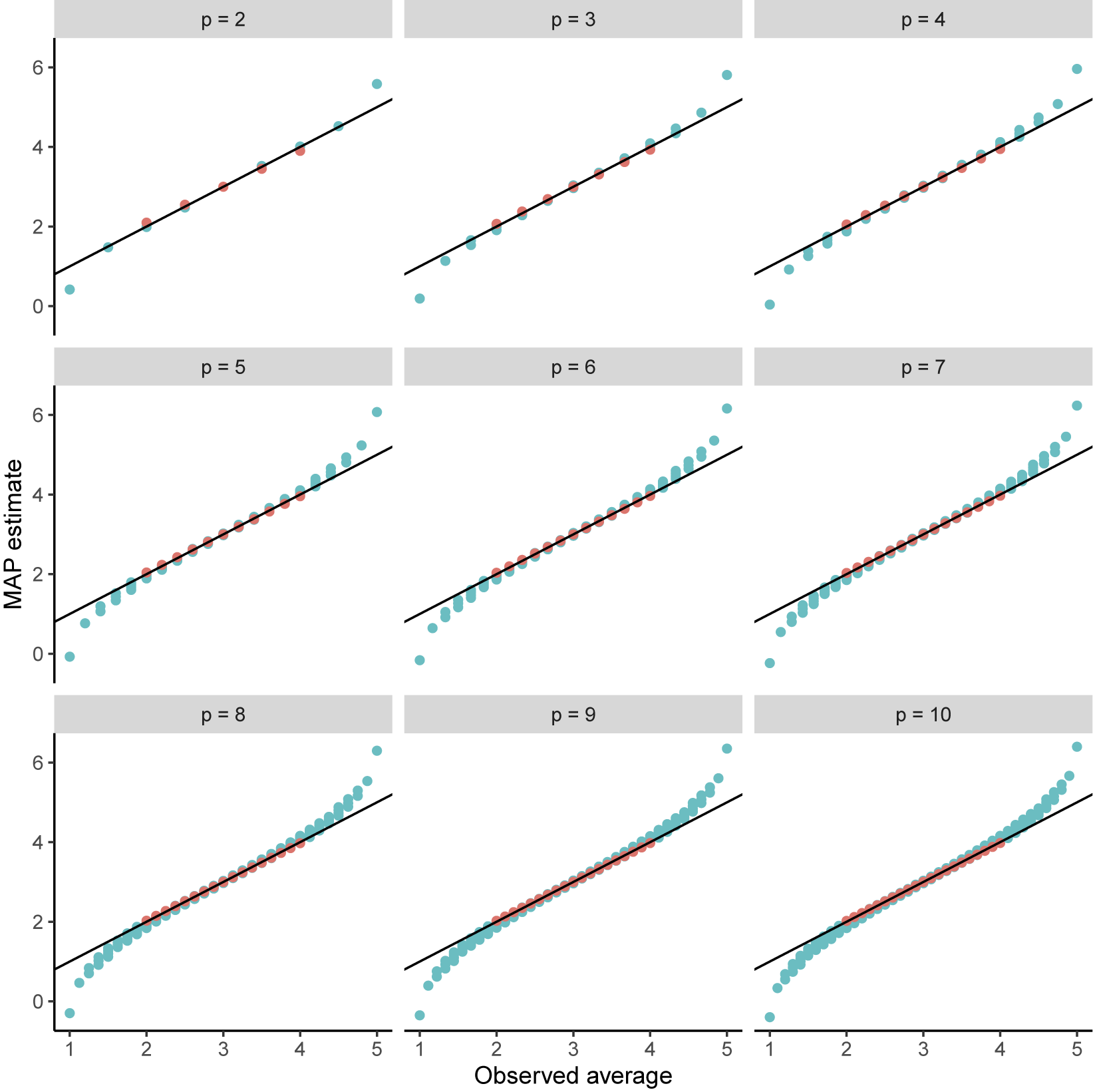


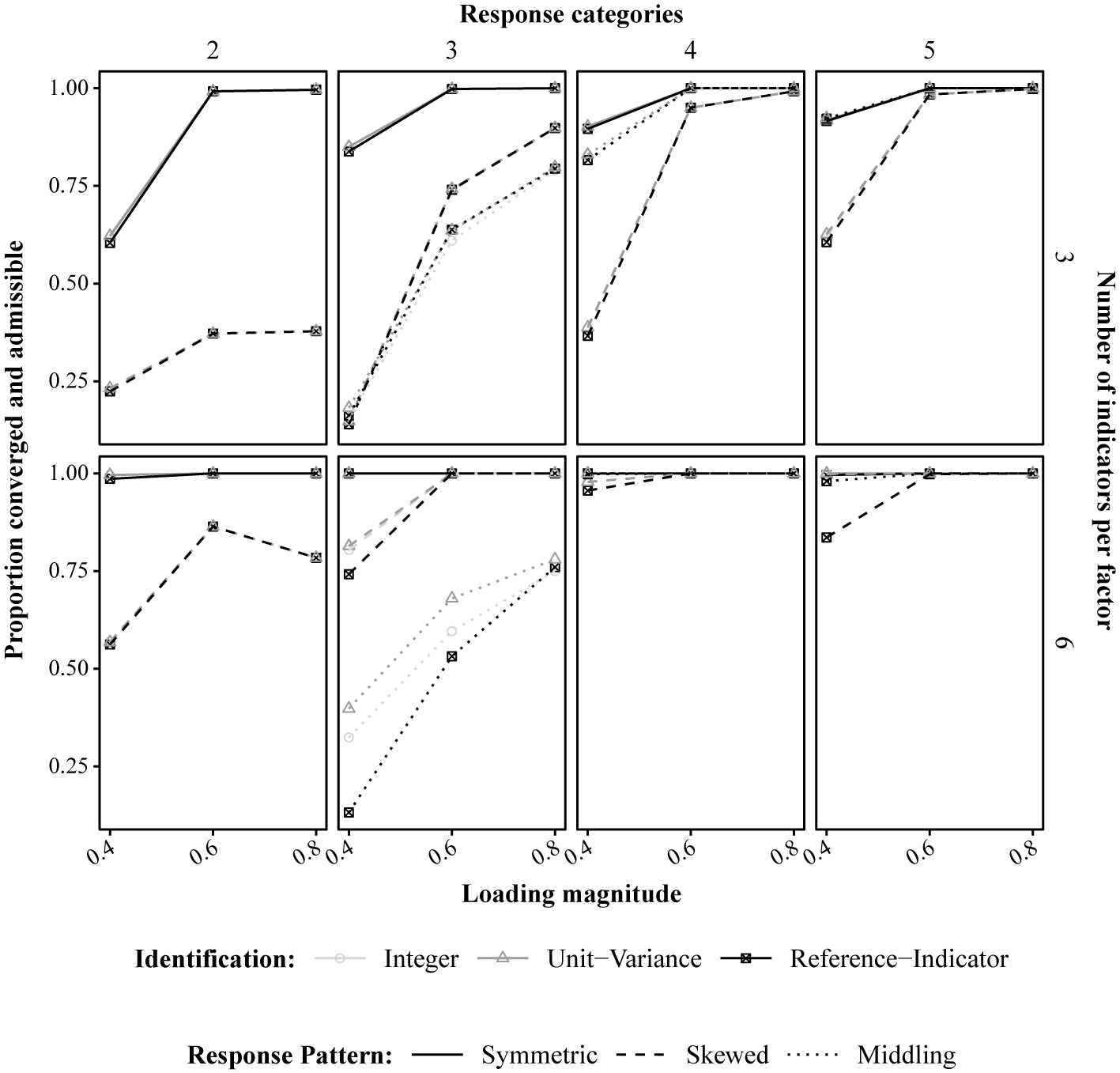
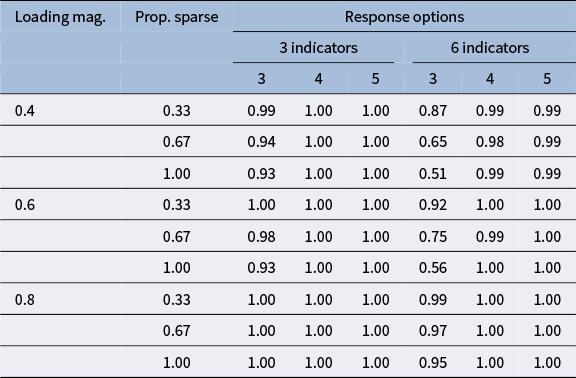
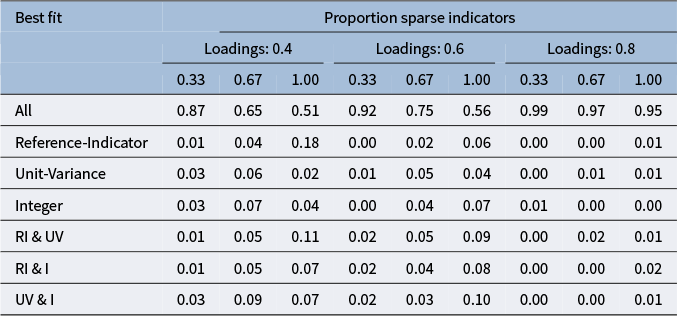
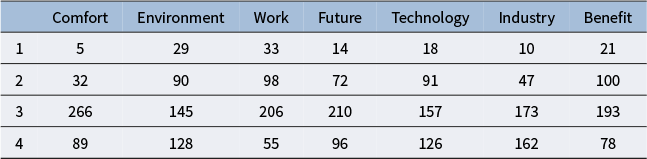
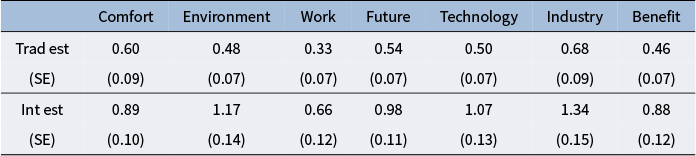
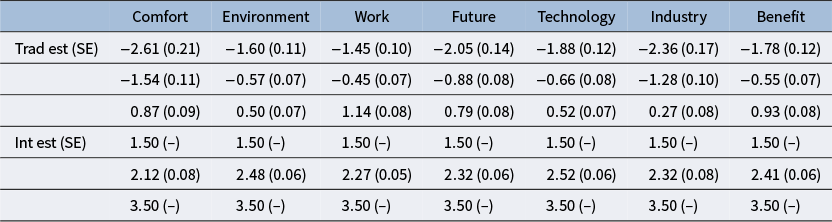
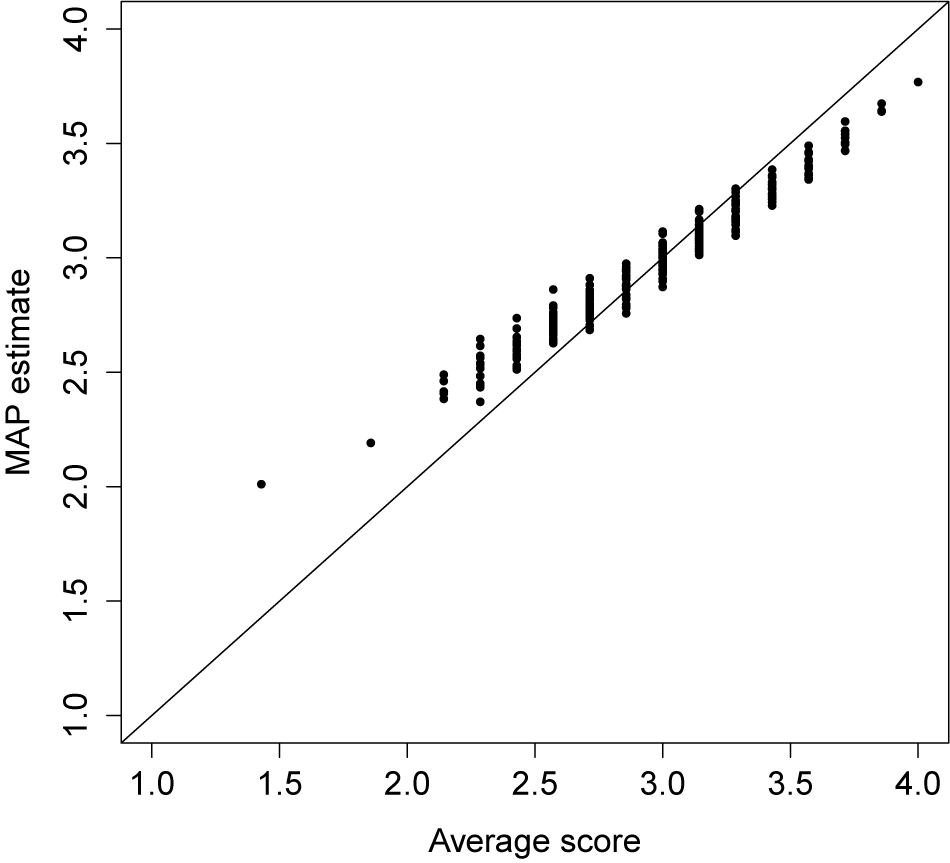
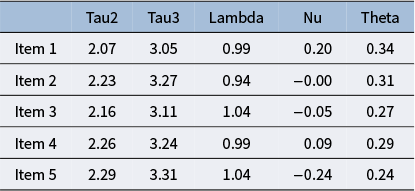
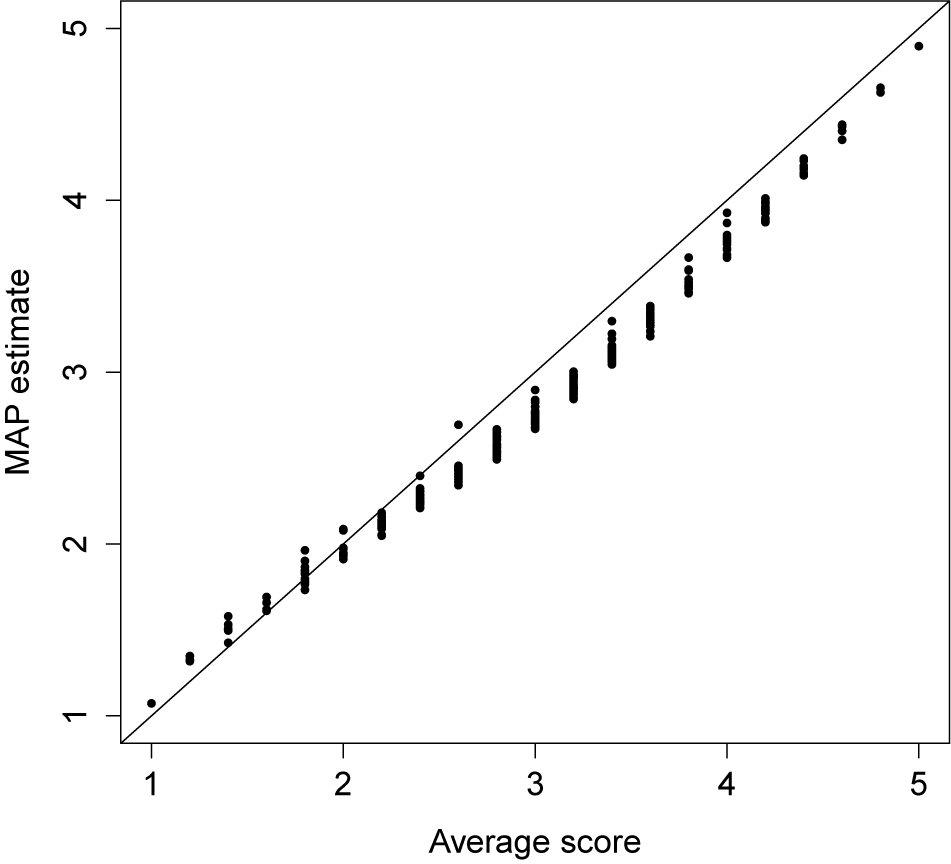
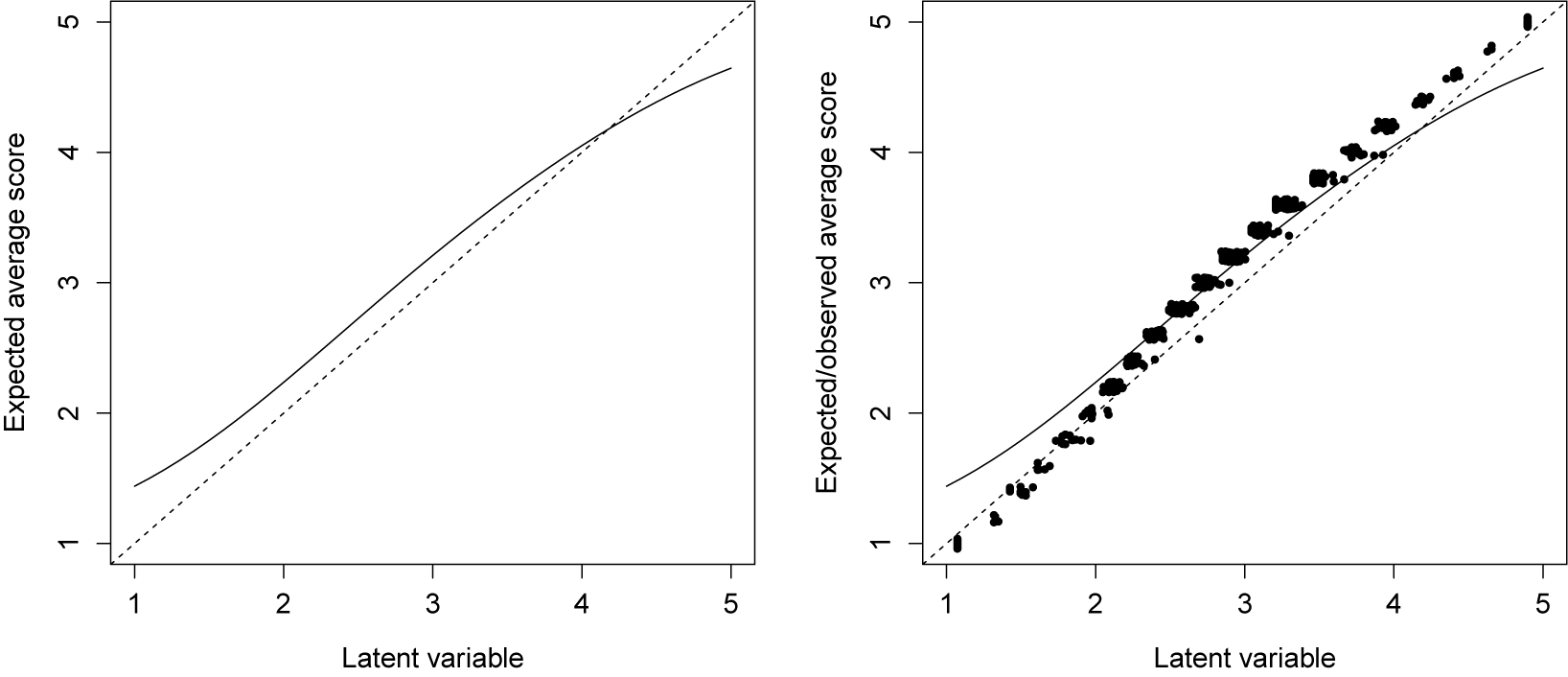
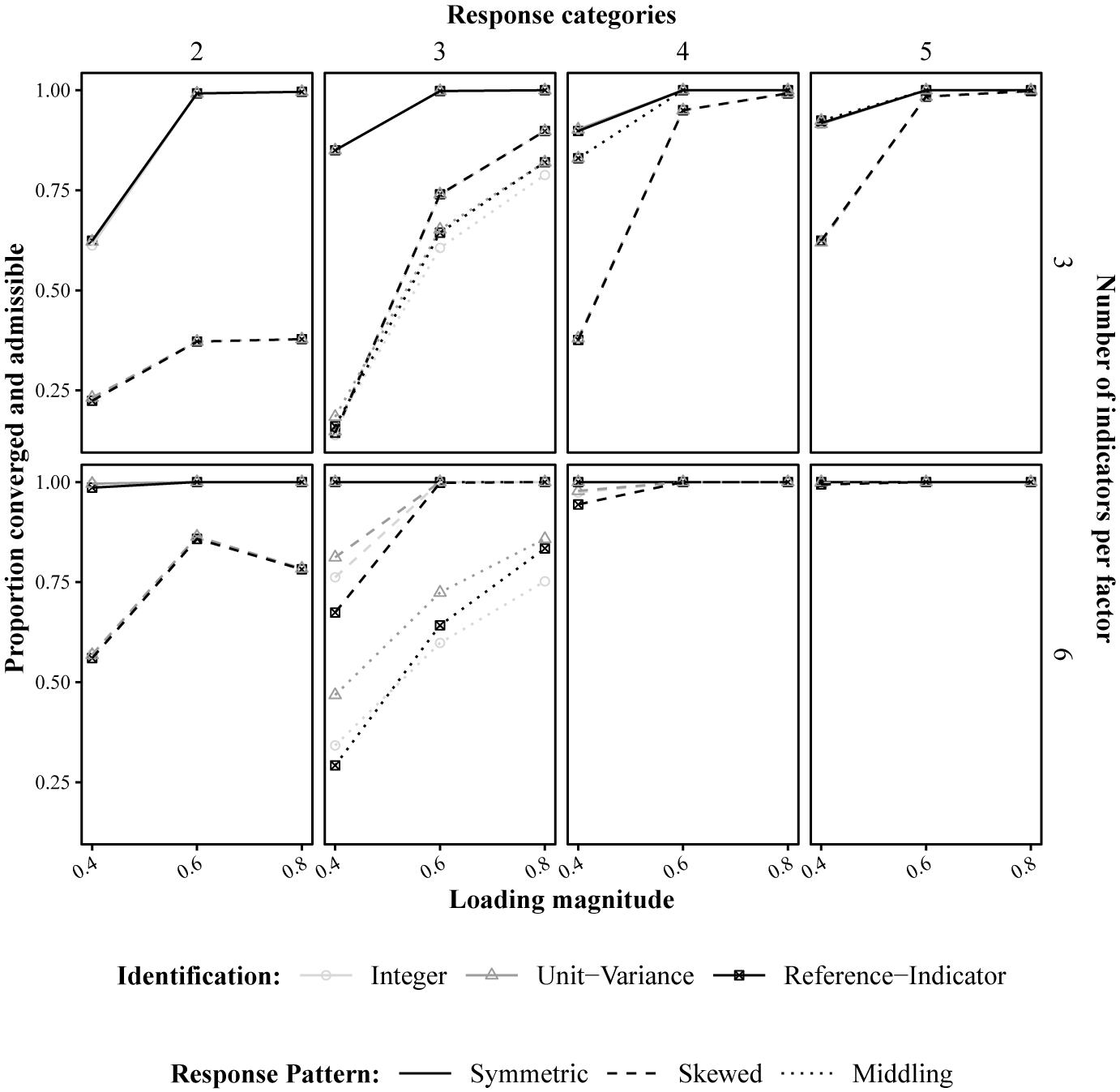
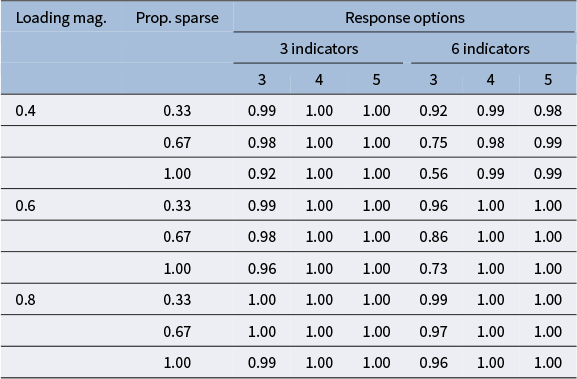
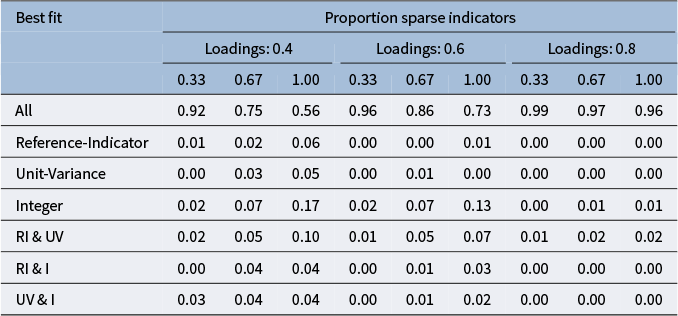
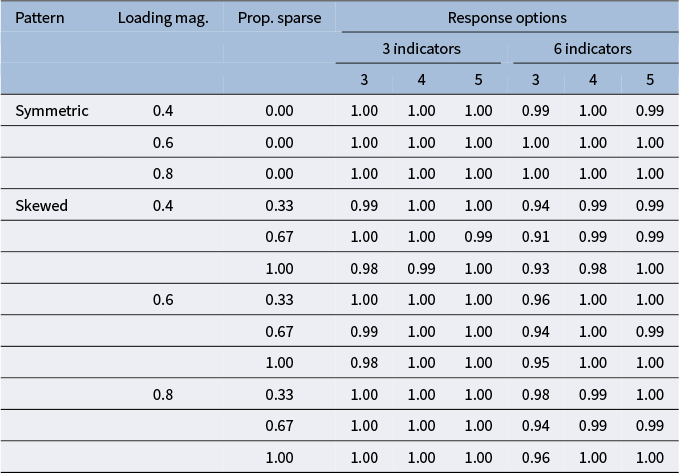
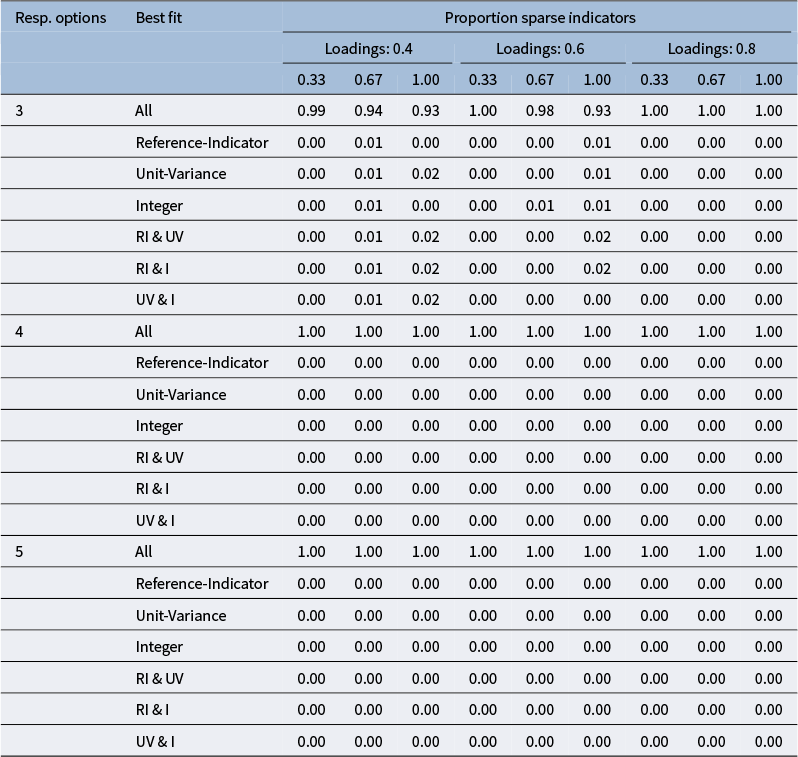
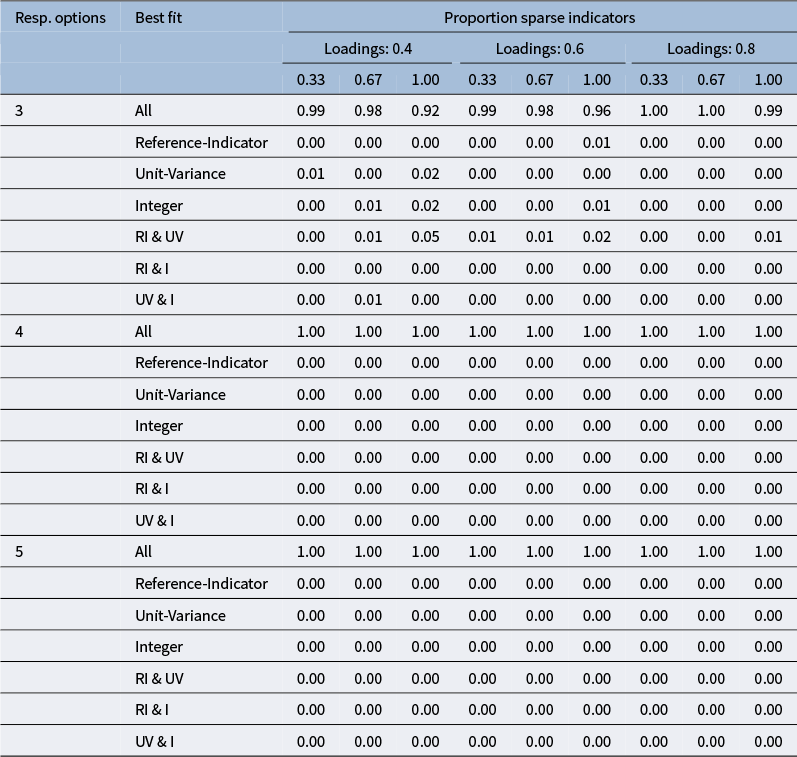
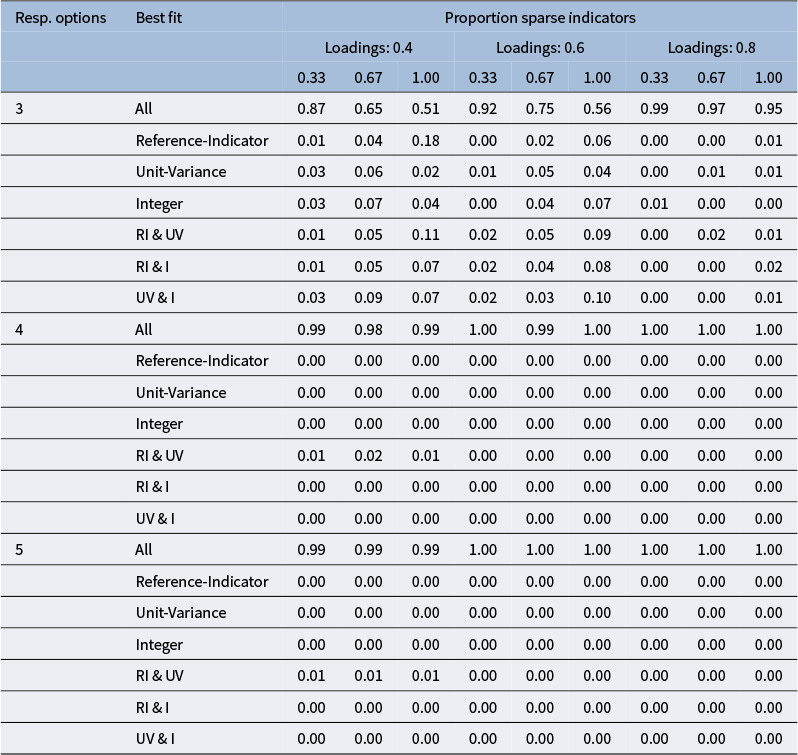
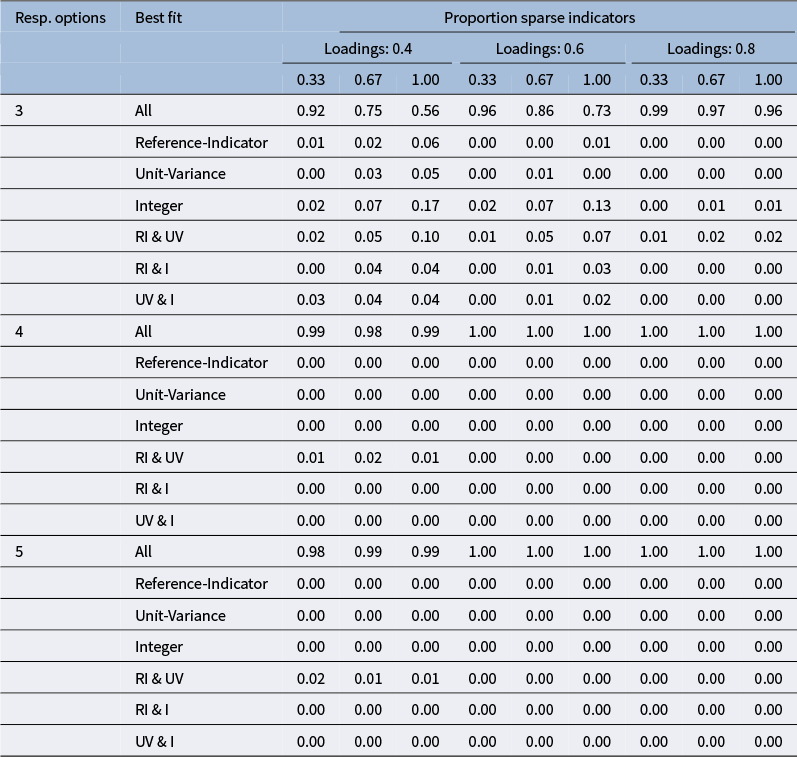

 Open access
Open access