


1. Introduction
In acquiring a syntax for their native language, children infer a system that specifies ways of combining expressions in hierarchical structures and defines dependencies over those structures. These dependencies encode abstract grammatical relations, determined not by the specific form of any particular expression, but rather by the syntactic properties of expressions and their structural positions relative to each other.
For instance, the predicate-argument dependency between a verb and its direct object is established through a particular structural configuration in 1a, and it is the same regardless of the particular verb or the particular object noun phrase (in bold). And whereas in English this dependency is often established locally, between two adjacent expressions, the same abstract dependency can also be established nonlocally, across potentially large amounts of linguistic material. In each of the sentences in 1b–d, a fronted phrase bears the same object relation to the verb fix as does the corresponding phrase (a toy) in 1a, despite appearing in a nonadjacent position.
(1)
a.
David is fixing a toy. Amy is buying a plane ticket.
b.
What did David fix?
c.
What did the girl who we saw at the park say that David fixed?
d.
I found the toy that David fixed.
These examples show us that syntactic dependencies are highly abstract in relation to the specific forms that express them. The same verb-object dependency can be satisfied by phrases with very different surface forms, appearing in very different positions in a sentence. And these dependencies take still different forms in other languages. This tension between the abstract nature of syntactic dependencies and the variability of surface forms that realize them presents a challenge for theories of how this central domain of syntax is acquired (Chomsky Reference Chomsky1965, Reference Chomsky and Piatelli-Palmarini1980, Fodor Reference Fodor1998, Lidz & Gagliardi Reference Lidz and Gagliardi2015, Pinker Reference Pinker1984, Valian Reference Valian, Frazier and de Villiers1990). How do language learners come to identify abstract structural relations in the face of such great variety in surface expression?
Prior accounts of dependency acquisition have largely focused on dependencies that are morphologically marked, such as the relation between the auxiliary verb is and the -ing form of the verb in 1a. Young children show awareness of the cooccurrence patterns of nonadjacent sounds and morphemes in their input, statistical sensitivities that may allow them to discover morphosyntactic dependencies at early ages (Gómez Reference Gómez2002, Gómez & Maye Reference Gómez and Maye2005, Höhle et al. Reference Höhle, Schmitz, Santelmann and Weissenborn2006, Nazzi et al. Reference Nazzi, Barrière, Goyet, Kresh and Legendre2011, Santelmann & Jusczyk Reference Santelmann and Jusczyk1998, Tincoff et al. Reference Tincoff, Santelmann and Jusczyk2000, van Heugten & Shi Reference van Heugten and Shi2010). But this represents only a narrow corner of the dependencies that learners must acquire. Here, we turn our attention to the sorts of dependencies illustrated in 1b–d, in which an object is moved from its canonical position after the verb.Footnote 1 The abstract nature of movement dependencies poses a challenging learning problem. Identifying that the same verb-object dependency is present in 1a and 1b–d requires tracking the cooccurrences not only of specific surface forms, but also of abstract syntactic categories and positions. Learners must become aware that a fronted noun phrase is standing in a nonlocal relation to something that has no overt phonological form: the ‘gap’ associated with the verb, in canonical direct object position, where it is thematically interpreted.
In this article, we argue that identifying abstract syntactic dependencies requires statistical inference over both overt and hidden grammatical structure. We pursue the hypothesis, consistent with a broader literature on the role of expectation violation in development (Denison & Xu Reference Denison, Xu, Kushnir, Benson and Xu2012, Kouider et al. Reference Kouider, Long, Le Stanc, Charron, Fievet, Barbosa and Gelskov2015, Stahl & Feigenson Reference Stahl and Feigenson2015, Reference Stahl and Feigenson2017, Téglás et al. Reference Téglás, Vul, Girotto, Gonzalez, Tenenbaum and Bonatti2011), that children learn from unsatisfied grammatical predictions. Our case study is the role of verb argument-structure knowledge in the acquisition of argument movement. In their second year of life, children begin to identify subjects and objects in their canonical positions, and to learn which verbs require objects (Fisher et al. Reference Fisher, Jin and Scott2019, Jin & Fisher Reference Jin and Fisher2014, Lidz et al. Reference Lidz, White and Baier2017, White & Lidz Reference White and Lidz2022, Yuan et al. Reference Yuan, Fisher and Snedeker2012). Movement dependencies are acquired only after local argument-structure knowledge has emerged (Gagliardi et al. Reference Gagliardi, Mease and Lidz2016, Perkins & Lidz Reference Perkins and Lidz2020, Reference Perkins and Lidz2021). This developmental trajectory points toward a particular learning mechanism: knowledge of local argument dependencies may help learners identify when arguments have been moved. If children notice when a predicted argument for a verb is missing in its expected position, this may compel them to search for that argument nonlocally, and thereby learn the morphosyntactic footprints of particular movement dependencies in their language (Gagliardi et al. Reference Gagliardi, Mease and Lidz2016, Perkins Reference Perkins2019, Perkins & Lidz Reference Perkins and Lidz2020, Stromswold Reference Stromswold1995).
We provide computational support for this proposal. We develop a learner that identifies which surface morphosyntactic properties of sentences are correlated with expected but missing direct objects of verbs. In simulations on child-directed English, our model successfully identifies the majority of sentences with object movement in its input. Moreover, we show that prior argument-structure knowledge plays a substantial role in the success of this distributional learning mechanism: knowledge of which verbs require objects provides an important guide for identifying which surface distributions characterize object movement. These findings provide insight into how learning from expected grammatical structure can work in concert with statistical learning to enable syntactic dependency acquisition in early development.
2. Acquiring nonlocal syntactic dependencies
A large body of literature finds that sensitivity to dependencies between nonadjacent sounds and morphemes develops in an infant’s second year of life (Gómez Reference Gómez2002, Gómez & Maye Reference Gómez and Maye2005, Höhle et al. Reference Höhle, Schmitz, Santelmann and Weissenborn2006, Nazzi et al. Reference Nazzi, Barrière, Goyet, Kresh and Legendre2011, Santelmann & Jusczyk Reference Santelmann and Jusczyk1998, Tincoff et al. Reference Tincoff, Santelmann and Jusczyk2000, van Heugten & Shi Reference van Heugten and Shi2010). For instance, Santelmann & Jusczyk Reference Santelmann and Jusczyk1998 showed that eighteen-month-old English learners are aware of the dependency between is and ‑ing in sentences like Everybody is baking bread. Because these types of nonadjacent dependencies are morphologically marked, they leave detectable evidence on the surface forms of sentences that learners hear. That is, to identify that there is a dependency between is and -ing, learners need only notice that these sounds cooccur in their input with unusual regularity—although this still leaves open the question of how learners identify that this surface-level cooccurrence is marking a particular grammatical dependency, namely the relation between the auxiliary be and a verb in the progressive aspect (Höhle et al. Reference Höhle, Schmitz, Santelmann and Weissenborn2006, Nazzi et al. Reference Nazzi, Barrière, Goyet, Kresh and Legendre2011, Santelmann & Jusczyk Reference Santelmann and Jusczyk1998, Tincoff et al. Reference Tincoff, Santelmann and Jusczyk2000).
Other types of nonlocal syntactic dependencies, such as the argument movement dependencies in wh-questions, have received much less attention in prior work. These also pose a more substantial learning challenge. English wh-phrases have different surface forms from clause arguments in their canonical positions and have different distributions: they overwhelmingly occur clause-initially. Therefore, recognizing that the same verb-object dependency is present in the wh-question in 1b and in the basic transitive clause in 1a requires abstracting away from these surface properties. Infants cannot merely track the cooccurrences of specific sounds or lexical items; they must represent the dependency abstractly, as an instance of the same dependency that is typically established locally between a verb and its direct object.
Prior experimental work has found that infants as young as fifteen months sometimes respond appropriately to wh-questions (Gagliardi et al. Reference Gagliardi, Mease and Lidz2016, Perkins & Lidz Reference Perkins and Lidz2020, Seidl et al. Reference Seidl, Hollich and Jusczyk2003). But Gagliardi et al. (Reference Gagliardi, Mease and Lidz2016) and Perkins and Lidz (Reference Perkins and Lidz2020) argue that infants’ success on these tasks may reflect an interpretive heuristic based on knowledge of local argument dependencies in combination with pragmatic reasoning, rather than syntactic representations of the nonlocal dependencies in these questions. This argument is motivated by earlier findings that children at fifteen to sixteen months show sensitivity to lexical and clause transitivity (Jin & Fisher Reference Jin and Fisher2014, Lidz et al. Reference Lidz, White and Baier2017). Learners at this age are beginning to identify which verbs require direct objects (Lidz et al. Reference Lidz, White and Baier2017), and in the following months they gain facility in using this knowledge to predict upcoming direct objects during on-line sentence processing (Hirzel et al. Reference Hirzel, Perkins and Lidz2020, Lidz et al. Reference Lidz, White and Baier2017, White & Lidz Reference White and Lidz2022). Infants in this age range also use subjects and objects to draw inferences about verb meaning, interpreting verbs with both subjects and objects as labels for causal events (Jin & Fisher Reference Jin and Fisher2014). This early knowledge of local subject and object dependencies may lead to the appearance of wh-question comprehension in prior preferential looking tasks, even without representing wh-dependencies syntactically. Such tasks typically presented infants with wh-questions with transitive verbs, such as Which dog did the cat bump?, in the context of events in which, for example, a dog bumps a cat, and the cat bumps a different dog. A fifteen-month-old who can identify that the cat is the subject in this question, and who knows that bump typically requires a direct object, may be inclined on the basis of that knowledge to look at an individual who got bumped by a cat—appearing to understand the question without necessarily representing which dog as a nonlocal object of the verb. In support of this account, Perkins & Lidz Reference Perkins and Lidz2020 found that fifteen-month-olds’ performance on this task depended on their vocabulary, a likely index of their verb knowledge.
Perkins & Lidz Reference Perkins and Lidz2021 provided a more rigorous test of wh-dependency representations by asking when infants register the complementarity between a local direct object and an object wh-phrase. If infants represent the wh-phrase in a sentence like 1b as expressing the same grammatical relation as the local direct object in 1a, then they should be aware that the wh-phrase cannot cooccur with a local object: *What did David fix a toy? is ungrammatical. In a listening preference task, infants were presented with both wh-questions and basic declarative clauses with transitive verbs, with and without local direct objects. Eighteen-month-olds listened longer to basic declarative sentences with local objects versus without (e.g. A dog! The cat should bump him! > *A dog! The cat should bump!), but displayed the opposite pattern of preference for wh-questions (e.g. Which dog should the cat bump? > *Which dog should the cat bump him?). That is, eighteen-month-olds showed a consistent preference for grammatical sentences of each type. However, fourteen- and fifteen-month-olds did not differentiate between these sentence types. These results suggest that infants represent the wh-phrase as a nonlocal object of the verb at eighteen months, but not before.
2.1. Learning mechanisms
The experimental results surveyed above point toward the following developmental trajectory. Basic verb argument-structure knowledge appears to develop early, at fifteen to sixteen months for English learners, and emerges before infants identify moved arguments, such as those in wh-questions. What learning mechanisms might allow learners to identify these nonlocal argument dependencies in their input? This is not a trivial task. Movement dependencies are not always marked with consistent morphology: for instance, English wh-phrases take a variety of different forms. The class of wh-elements in any language will distribute in specific ways in the surface forms of sentences: for instance, English wh-words are clause-initial and frequently occur in questions. However, even if a learner can identify a word class with these particular surface distributional properties, it does not necessarily follow that these are wh-elements. Many languages have question particles that can appear at sentence boundaries in both wh- and polar questions. An example is the particle la in Tz’utujil Mayan, as in 2. A Tz’utujil learner needs a way to tell that la is a question particle and not a wh-word, and conversely an English learner needs a way to tell that what is a wh-word and not a question particle.
(2)
Tz’utujil Mayan (Dayley Reference Dayley1981)
La
xwari
ja
ch’uuch’?
q
slept
the
baby
‘Did the baby sleep?’
Moreover, in many languages, wh-phrases do not appear clause-initially. In wh-in-situ languages like Chinese, Japanese, and Korean, wh-phrases are pronounced in their thematic position local to the verb, but still take interrogative scope in a higher clausal position, as in 3. Learners of these languages must identify when an expression is in a nonlocal wh-dependency with a higher clausal node, even when it has not overtly moved to this position.Footnote 2
(3)
Mandarin Chinese (Cheng Reference Cheng2003)
Hufei
mai-le
shenme?
Hufei
buy-prf
what
‘What did Hufei buy?’
Thus, in order to identify wh-dependencies in their language, children must solve multiple problems. They need to learn whether their language fronts wh-phrases, and if so, which surface forms signal that this movement has occurred. In a language with wh-fronting, they also must identify the thematic position where the wh-phrase should be interpreted in relation to the verb. As noted above, wh-in-situ poses a different learning problem from wh-fronting: in wh-fronting, a wh-phrase is pronounced in the position where it takes interrogative scope, and learners must identify a nonlocal dependency with its thematic position, whereas in wh-in-situ, the wh-phrase is pronounced in its thematic position, and learners must identify a nonlocal dependency with its scope position. We focus here on the problem posed by wh-fronting, but return to consider wh-in-situ in the general discussion in Section 5.
In English, surface signals for wh-movement include not only wh-words, but also a variety of other reflexes of movement, such as prosodic marking and, in questions where the moved constituent is not a subject, subject-auxiliary inversion and do-support. Mature speakers of a language make efficient use of these signals in sentence processing to identify moved arguments and predict upcoming ‘gaps’ where they should be interpreted (Aoshima et al. Reference Aoshima, Phillips and Weinberg2004, Crain & Fodor Reference Crain, Fodor, Dowty, Karttunen and Zwicky1985, Frazier & Clifton Reference Frazier and Clifton1989, Frazier & Flores d’Arcais Reference Frazier and Flores d’Arcais1989, Sussman & Sedivy Reference Sussman and Sedivy2003, Traxler & Pickering Reference Traxler and Pickering1996). But children must first learn these signals in order to use them in parsing wh-dependencies. In languages like English, identifying the tails of these dependencies is particularly challenging, because the thematic positions of moved elements are phonologically null. How do learners identify a nonadjacent dependency where only one element appears overtly?
One possible piece of the puzzle comes from the literature on ‘expectation violation’ or ‘error-driven learning’ in other areas of cognitive development. A large body of work finds that infants use knowledge about the physical and social properties of objects and agents, alone or in combination with learned statistical contingencies, to make predictions about upcoming events (Denison & Xu Reference Denison, Xu, Kushnir, Benson and Xu2012, Kouider et al. Reference Kouider, Long, Le Stanc, Charron, Fievet, Barbosa and Gelskov2015, Stahl & Feigenson Reference Stahl and Feigenson2015, Reference Stahl and Feigenson2017, Téglás et al. Reference Téglás, Vul, Girotto, Gonzalez, Tenenbaum and Bonatti2011). Violations of these predictions may provide valuable opportunities for learning (Stahl & Feigenson Reference Stahl and Feigenson2015, Reference Stahl and Feigenson2017). For instance, an experiment in Stahl & Feigenson Reference Stahl and Feigenson2015 presented eleven-month-olds with events that either conformed with or violated object solidity. In one such event, a ball rolled down a ramp toward a solid wall, stopping behind an occluder. When the occluder was lifted, one group of infants saw that the ball had been stopped by the wall, while a second group of infants saw that the ball had apparently passed through the wall, violating their predictions about object solidity. After this event, both groups of infants were tested on their ability to map a novel property (e.g. squeaking) to the previously observed toy. Infants who had observed the prediction-violating event showed significantly greater learning than infants who had not. In a further experiment, infants who viewed these events were then given a choice to explore the ball or a novel object. Infants who had viewed the prediction-violating event chose to explore the ball more than infants who had not. Moreover, their exploration was consistent with testing the object’s solidity properties: they banged the ball against the table to a greater extent than infants who had seen a different event type. These results suggest that even very young learners are sensitive to inconsistency between their own predictions and observed events, and when they observe a situation where their predictions are violated, they exploit this opportunity to learn, explore, and test hypotheses about the potential cause of that violation.
We pursue the hypothesis that a similar form of expectation violation may underlie infants’ discovery of argument movement dependencies in languages like English. Here, it is not predictions about physical events that drive learning, but rather predictions about grammatical structure. On this hypothesis, verb argument-structure knowledge developmentally precedes argument movement acquisition because the former provides the basis for generating structural predictions—specifically, predictions about upcoming arguments of verbs. When infants encounter a case where an expected argument does not appear in its local position, they exploit this expectation violation to learn about the cause of the locally missing argument, scaffolding their identification of movement dependencies (Gagliardi et al. Reference Gagliardi, Mease and Lidz2016, Perkins Reference Perkins2019, Perkins & Lidz Reference Perkins and Lidz2020, Stromswold Reference Stromswold1995). For example, learners who know that a verb like fix requires a direct object might register that it is unexpectedly missing after the verb in a question like What did David fix?. This unsatisfied structural prediction may provide the basis of inferring the tail of a nonlocal argument dependency—a ‘gap’ of argument movement—even though it is silent. And it may compel learners to search the rest of the sentence for the cause of the missing argument, eventually identifying that another expression in the sentence (what) is satisfying the verb’s transitivity requirement nonlocally. This would allow them both to assign an appropriate parse to the sentence and to begin to learn how various types of nonlocal dependencies are realized: that is, that this question contains a wh-dependency, which is marked in English by various surface signals, such as what, do-support, and subject-auxiliary inversion.
In sum, we propose that the process of acquiring nonlocal dependencies follows three logically independent steps, which we together call Gap-Driven Learning (Perkins Reference Perkins2019, Perkins & Lidz Reference Perkins and Lidz2020):
-
(i) using knowledge of verb argument structure to detect argument gaps: predicted arguments that are unexpectedly missing in their local positions;
-
(ii) identifying what surface forms are correlated with these argument gaps; and
-
(iii) inferring what types of syntactic dependencies are responsible for those correlations.
Here, we investigate the gap-driven learning hypothesis specifically in the domain of direct object gaps. This decision is motivated by empirical evidence for early knowledge of verb transitivity (Jin & Fisher Reference Jin and Fisher2014, Lidz et al. Reference Lidz, White and Baier2017), making it plausible that direct object gaps are the type of argument gap that learners may be able to detect readily at the relevant stage of development. But how this knowledge is in place by this age raises its own learning problem, which must be addressed in order for gap-driven learning to be possible. Before children can identify when arguments have been moved, they cannot identify all instances of direct objects in sentences containing transitive verbs. How, then, do they arrive at the appropriate expectations that some verbs obligatorily require objects, such that they will be surprised when those objects are missing? Perkins et al. (Reference Perkins, Feldman and Lidz2022) investigate this question computationally and show that it is feasible for children to find their way around this learning problem. The learner in Perkins et al. Reference Perkins, Feldman and Lidz2022 assumes that it occasionally represents sentences erroneously and learns what portion of its input representations to treat as signal versus noise for the purpose of learning verb transitivity. When tested on the distributions of direct objects that a child at this age could identify in child-directed English, the model learned how to filter its data to correctly assign transitivity properties to the majority of the most frequent verbs in its input. This tells us that it is in principle possible for children to identify verb transitivity without accurately parsing argument movement, thereby providing a way for gap-driven learning to get started.
In this article, we present a computational model that instantiates the first two steps of learning under the gap-driven learning hypothesis. The learner builds off of the model in Perkins et al. Reference Perkins, Feldman and Lidz2022, using the approximate verb transitivity knowledge identified by that learner. Our model tracks statistical regularities in the surface morphosyntactic features of sentences in order to identify clusters of sentences that share distributional properties. At the same time, it tracks when its expectations of upcoming direct objects are violated, in order to infer which clusters of properties are correlated with potential direct object gaps. When tested on child-directed speech, we find that the model identifies the large majority of sentences with object movement. Furthermore, we show that prior knowledge of verb transitivity, even if rough and approximate, is important for this distributional learning process to be successful. The learner performs better if it uses transitivity knowledge to infer likely object gaps, rather than clustering sentences on the basis of their overt surface features alone. These findings demonstrate that a learner could in principle identify object movement dependencies in English by using unsatisfied structural predictions to guide distributional learning. As verb transitivity knowledge forms the basis for generating these structural predictions, this provides an account for the empirically attested order of argument structure and argument movement acquisition in early development.
3. Model
We present a Bayesian model that simultaneously tracks the statistical distributions of surface morphosyntactic features in sentences and applies its knowledge of verb transitivity in order to infer which distributional properties are correlated with locally missing direct objects. This distributional learning takes the form of categorization: the learner infers ‘categories’ of sentences according to their feature distributions, and infers which sentence categories likely contain direct object gaps. When the learner sees a sentence that violates its expectations about verb transitivity, the learner infers that this sentence contains a direct object gap and that all other sentences in the distributionally defined category do so as well. This allows the learner to generalize across sentences that share similar surface features, and to infer which of those shared features signal object movement dependencies.
This distributional learning mechanism follows prior computational work that has proposed similar mechanisms for the acquisition of phonetic categories in infancy and for category learning domain-generally (Anderson & Matessa Reference Anderson and Matessa1990, Feldman et al. Reference Feldman, Griffiths, Goldwater and Morgan2013, Maye et al. Reference Maye, Werker and Gerken2002, McMurray et al. Reference McMurray, Aslin and Toscano2009, Sanborn et al. Reference Sanborn, Griffiths and Shiffrin2010). Similar to these previous models, the current account envisions the learning task as requiring two simultaneous inferences: discovering the underlying system of categories that give rise to distributions of surface features that a learner observes, and identifying which observations belong to which category. However, it departs from previous literature by envisioning this categorization process as merely a means to an end. Whereas the phonetic learning literature has traditionally assumed that there is a set of phonetic categories to be acquired (but see Feldman et al. Reference Feldman, Goldwater, Dupoux and Schatz2021), here we do not assume that adult grammars necessarily represent ‘categories’ of sentences in any meaningful way. Instead, the categories inferred by this learner are an intermediate step of learning: they enable further inference about the underlying properties of sentences that are formally similar. When the learner infers that one sentence in a category likely contains an object gap, it then infers that this property holds of other sentences in the category as well. In doing so, it identifies which surface features are correlated with object gaps and therefore may be the footprints of movement.
Our computational approach falls under the paradigm of Bayesian cognitive modeling. A cognitive model formalizes a hypothesis about the knowledge that a learner brings to a particular learning task (the learner’s hypothesis space, containing assumptions about how its data are generated), along with the mechanisms that a learner uses to update that knowledge on the basis of new data. Bayesian approaches characterize learners’ beliefs as probability distributions over hypotheses, which are updated using rational probabilistic inference: the posterior probability of a hypothesis given observed data is calculated by combining the learner’s prior beliefs with the likelihood of the data under each hypothesis. The learner that we present in the current work is a Bayesian model that is ‘nonparametric’ in the sense that the size of its parameters (the number of latent sentence categories to be acquired) is unknown in advance. The approach taken in Bayesian cognitive modeling differs from the statistical approach of hypothesis testing through Bayesian regression: in the cognitive modeling paradigm, the model itself is the hypothesis being tested, rather than a tool for assessing which of several hypotheses provides the best fit for data. Such a model can take many different forms, depending on the theoretical assumptions of the modeler, and typically assumes a complex, nonlinear relationship between variables and data. The current approach uses some of the same techniques from the machine learning literature, but differs from supervised machine learning in that the model is not fit on the learning objective that it is tested on, so its data need not be split between training and test sets to avoid overfitting. For a detailed tutorial introduction on Bayesian cognitive methods and further examples of how this paradigm has been applied, see Griffiths et al. Reference Griffiths, Chater and Tenenbaum2024 and the citations therein.
Following a rich tradition in the language acquisition literature (e.g. Abend et al. Reference Abend, Kwiatkowski, Smith, Goldwater and Steedman2017, Alishahi & Stevenson Reference Alishahi and Stevenson2008, Berwick Reference Berwick1985, Dillon et al. Reference Dillon, Dunbar and Idsardi2013, Elman Reference Elman1990, Frank et al. Reference Frank, Goodman and Tenenbaum2009, Goldwater et al. Reference Goldwater, Griffiths and Johnson2009, Pearl & Sprouse Reference Pearl and Sprouse2019, Perfors et al. Reference Perfors, Tenenbaum and Wonnacott2010, Perfors et al. Reference Perfors, Tenenbaum and Regier2011, Perkins et al. Reference Perkins, Feldman and Lidz2022, Sakas & Fodor Reference Sakas, Fodor and Bertolo2001, Reference Sakas and Fodor2012, Vallabha et al. Reference Vallabha, McClelland, Pons, Werker and Amano2007, Wexler & Culicover Reference Wexler and Culicover1980, Yang Reference Yang2002), our model is framed at Marr’s (Reference Marr1982) computational level. We aim to characterize a particular type of mental computation that could give rise to successful learning given the information available in children’s data and a set of hypotheses about their knowledge at the relevant developmental stage. This model therefore represents an idealization of learners’ actual inference processes, but an idealization that is nonetheless grounded in empirical data about their grammatical knowledge and representational abilities in development, described in more detail below. It also provides a measure of how much information is available in the child’s representation of the input (at a particular stage of development) to support the hypothesized inferences. The results of our simulations open the door for further algorithmic questions concerning learners’ abilities to access and use the information available in their environment, and whether their learning processes resemble this idealized mechanism.
In this section, we (i) specify the generative model, encoding the learner’s assumptions about how its observations of sentence features are generated, and (ii) specify how the learner jointly infers sentence categories and object gaps, given its data and its knowledge of verb transitivity. The following sections present simulations demonstrating that this joint inference allows the learner to successfully identify features that characterize object movement dependencies in English, when tested on child-directed speech.
3.1. Generative model
The data that our learner observes consists of the morphosyntactic features of sentences containing transitive, intransitive, or alternating verbs. The learner builds off of a first step of learning modeled in Perkins et al. Reference Perkins, Feldman and Lidz2022, which shows how some initial knowledge of verb transitivity properties might be acquired before a child can identify moved objects. That learner assumed that there are three transitivity categories to be identified—transitive verbs that require direct objects, intransitive verbs that disallow them, and alternating verbs that optionally allow them—and assigned verbs in its input to these three categories based on their distributions with direct objects in canonical postverbal positions, which English-learning infants can identify prior to eighteen months (Gagliardi et al. Reference Gagliardi, Mease and Lidz2016, Hirsh-Pasek & Golinkoff Reference Hirsh-Pasek, Golinkoff, McDaniel, McKee and Cairns1996, Jin & Fisher Reference Jin and Fisher2014, Lidz et al. Reference Lidz, White and Baier2017, Perkins & Lidz Reference Perkins and Lidz2020, Seidl et al. Reference Seidl, Hollich and Jusczyk2003). These initial transitivity assignments are imperfect, modeling the realistic assumption that a child’s knowledge of verb transitivity is likely to be approximate at this stage of development.
The current learner now assumes that there are two reasons why it might observe canonical direct objects or no direct objects after the verbs in the sentences that it observes. On the one hand, the transitivity of that verb determines whether it should always, never, or sometimes occur with a direct object. On the other hand, there may be a separate grammatical process, such as argument movement, that results in an apparent transitivity violation. The learner assumes that these transitivity violations are governed by latent ‘categories’ of sentences with shared grammatical properties. Each category has a particular parameter governing whether it produces object gaps: if it does, then observations of canonical direct objects in that category may no longer reflect the transitivity properties of these verbs, but may instead be due to other grammatical properties that produce ‘nonbasic’ word orders. These properties also give rise to the distributions of other morphosyntactic features of sentences in a particular category.
For instance, the learner might identify that a sentence like What did David fix? belongs to a category of other sentences that have object gaps and also tend to be questions with subject-auxiliary inversion, a form of do, and an unknown functional element sentence-initially (e.g. what). On the other hand, the learner might identify that a sentence like Your toy got broken belongs to another category of sentences that also have object gaps, but different morphosyntactic features: here, a form of get and the verbal suffix -en. The distributional features of the first sentence category are the footprints of object wh-questions in English; the features of the second category are the footprints of get-passives.
The learner does not know ahead of time how many sentence categories there will be or what the properties of those categories are. Using the distributions of direct objects and the other observed sentence features in its data, the learner infers what categories of sentences are present, what their distributional properties are, and which categories produce object gaps. This allows the learner to identify specific clusters of morphosyntactic features that are correlated with object gaps in different clause types, which may be candidates for entering into nonlocal movement dependencies.
More formally, we provide the graphical model for the learner in Figure 1. A graphical model provides a visual representation of the process by which the learner assumes its data are generated. Circular nodes represent random variables, and arrows represent conditioning relationships between variables. Shaded nodes represent variables with observed/known values; unshaded nodes represent variables whose values are unknown and must be inferred. Rectangular ‘plates’ indicate when a portion of the model is repeated over a particular range, denoted by the superscript in the right corner. See Griffiths et al. Reference Griffiths, Chater and Tenenbaum2024 for more information.
Graphical model for Joint Inference Learner. Nodes correspond to random variables: the observed direct objects X and other features F in each sentence, the transitivity category T and rate of direct objects θ for each verb, the latent ‘category’ c of each sentence, the rate of direct objects δ (X) and other sentence features δ (F) produced by each category, and whether each category produces a transitivity violation e. Arrows denote conditioning relationships between variables.

Figure 1. Long description
At the top, a shaded node labeled T is enclosed in a large rectangle labeled V. Below T, an unshaded node labeled theta is connected by a downward arrow. Theta points downward to two shaded nodes, X on the left and F on the right, both inside a medium rectangle labeled m. X and F are horizontally aligned. X and F each have upward arrows from an unshaded node c below them, which sits at the base of the m rectangle. F is also inside a smaller rectangle labeled n, nested within m. X and F each have additional arrows pointing downward and leftward to three unshaded nodes at the bottom: e sub c, delta sub c superscript X, and delta sub c superscript F. These three nodes are enclosed in a horizontal rectangle at the bottom, with delta sub c superscript F inside a smaller rectangle labeled infinity. All arrows indicate conditional relationships between variables. The diagram visually encodes the dependencies among observed variables X and F, latent category c, transitivity T, and rate parameters theta, delta sub c superscript X, and delta sub c superscript F, as well as the transitivity violation e sub c.
Observations of direct objects are formalized as the Bernoulli random variable X. This variable encodes direct object data for each of the m sentences containing each of the V verbs in the model’s input, with a value of 1 if the sentence contains a direct object following the verb, and 0 if it does not. The model’s observations of the other n relevant morphosyntactic features of the sentence are represented by the vector of Bernoulli random variables
 $ \overrightarrow{F} $
. Specific details of this feature set are discussed in the next section.
$ \overrightarrow{F} $
. Specific details of this feature set are discussed in the next section.
The direct object observations X (v) for a given verb v can be generated by two processes: the transitivity of verb v, represented by the variables T and θ in the upper half of the model, or the other grammatical properties of the category that the sentence belongs to, represented by the variables c, e, and δ (X) in the lower half of the model. We describe each of these generative processes in turn.
In the upper part of the model, each observation X (v) of a direct object for a particular verb is conditioned on the parameter θ (v), a continuous random variable that controls the probability that verb v will be used with a direct object. θ (v) is conditioned on the variable T (v), a discrete random variable that can take on three values corresponding to transitive, intransitive, or alternating verbs. In order to model the hypothesis that learners are using prior knowledge of verb transitivity properties, we assume that the learner has approximate knowledge of these values of T for the set of verbs in the learner’s data, as acquired by the model in Perkins et al. Reference Perkins, Feldman and Lidz2022. This means that the learner knows some of the values of θ as well. If verb v is fully transitive, then the learner assumes that θ (v) = 1: the verb should always occur with a direct object. If the verb is fully intransitive, then θ (v) = 0: the verb should never occur with a direct object. If the verb belongs to the alternating category of T, then θ (v) takes an unknown value between 0 and 1 inclusive. The prior probability over θ in this case is a Beta(α,β) distribution, where the parameters α and β are counts of direct objects and no direct objects for verb v in sentence categories without transitivity violations, excluding the current category.
In the lower part of the model, each X (v) is conditioned on the discrete random variable c, defined for all positive integers, which represents the category that the sentence belongs to. These sentence categories also condition the other morphosyntactic features in the sentence, encoded in the vector
 $ \overrightarrow{F} $
. Each category c is assumed to reflect a particular set of underlying grammatical properties that give rise to the distributions of direct objects and other features of a sentence. The number and properties of these categories are a priori unknown, and the learner infers the properties that will allow it to explain the distributions of features and direct objects that it observes. Returning to our earlier examples, the learner might infer a value of c that encodes English wh-object questions, giving high probability to sentence-initial function words (i.e. wh-words), subject-auxiliary inversion, forms of do, and direct object gaps. Another inferred value of c might encode English get-passives, giving high probability to direct object gaps, forms of get, and the -en verbal suffix. The prior probability over c is a Dirichlet process (Ferguson Reference Ferguson1973), which gives a particular category prior probability proportional to the number of sentence observations already assigned to that category. This process also reserves a small nonzero probability for new categories, allowing the model to flexibly converge on the number of sentence categories that best explains the distributions in its data. By allowing the model to explore a potentially unbounded number of categories, this prior builds in the fewest possible assumptions about the number of categories required to explain the distributions in a given language or data set; however, this form of prior also biases the model to reuse categories whenever possible, and thus to keep the total number of categories small.Footnote 3 See Appendix A for details.
$ \overrightarrow{F} $
. Each category c is assumed to reflect a particular set of underlying grammatical properties that give rise to the distributions of direct objects and other features of a sentence. The number and properties of these categories are a priori unknown, and the learner infers the properties that will allow it to explain the distributions of features and direct objects that it observes. Returning to our earlier examples, the learner might infer a value of c that encodes English wh-object questions, giving high probability to sentence-initial function words (i.e. wh-words), subject-auxiliary inversion, forms of do, and direct object gaps. Another inferred value of c might encode English get-passives, giving high probability to direct object gaps, forms of get, and the -en verbal suffix. The prior probability over c is a Dirichlet process (Ferguson Reference Ferguson1973), which gives a particular category prior probability proportional to the number of sentence observations already assigned to that category. This process also reserves a small nonzero probability for new categories, allowing the model to flexibly converge on the number of sentence categories that best explains the distributions in its data. By allowing the model to explore a potentially unbounded number of categories, this prior builds in the fewest possible assumptions about the number of categories required to explain the distributions in a given language or data set; however, this form of prior also biases the model to reuse categories whenever possible, and thus to keep the total number of categories small.Footnote 3 See Appendix A for details.
The random variables e, δ (X), and δ (F) represent the parameters of each of the sentence categories. The Bernoulli random variable ec encodes whether a given category c produces transitivity violations. If ec = 0, then the category does not produce transitivity violations, and all observations of a direct object in X (v) were generated by the transitivity properties of verb v. But if ec = 1, then the category does produce transitivity violations, and the observations of direct objects X (v) were generated by a particular grammatical property of category c. The learner in Perkins et al. Reference Perkins, Feldman and Lidz2022 inferred that transitivity violations occurred approximately 19% of the time in sentences containing this same set of verbs in child-directed speech. In order to model the hypothesis that the current learner builds off of the knowledge gained in that previous stage of learning, our learner assumes that 19% is the prior probability that ec = 1.Footnote 4
The random variable
 $ {\delta}_c^{(X)} $
represents the probability of observing a direct object in a category with transitivity violations—that is, whether the particular violation in that category produces object gaps, or whether it adds an apparent extra object that is not licensed by the verb. Intuitively, we can think of the probability that a sentence contains a direct object as depending on one of two biased coins. If ec = 0 and the observation was generated by the verb’s transitivity properties, then one biased coin is flipped and the sentence contains a direct object with probability θ (v). But if ec = 1 and the observation was generated by the grammatical properties of category c, then a different biased coin is flipped and the sentence contains a direct object with probability
$ {\delta}_c^{(X)} $
represents the probability of observing a direct object in a category with transitivity violations—that is, whether the particular violation in that category produces object gaps, or whether it adds an apparent extra object that is not licensed by the verb. Intuitively, we can think of the probability that a sentence contains a direct object as depending on one of two biased coins. If ec = 0 and the observation was generated by the verb’s transitivity properties, then one biased coin is flipped and the sentence contains a direct object with probability θ (v). But if ec = 1 and the observation was generated by the grammatical properties of category c, then a different biased coin is flipped and the sentence contains a direct object with probability
 $ {\delta}_c^{(X)} $
. The parameter
$ {\delta}_c^{(X)} $
. The parameter
 $ {\delta}_c^{(X)} $
is assumed to have a uniform Beta(1,1) prior distribution. This uniform prior means that it is equally likely a priori for a sentence category to create object gaps as it is to add extra objects. This form of prior builds in the fewest possible assumptions about the probability of observing a direct object versus an object gap within a sentence category. Analogous to
$ {\delta}_c^{(X)} $
is assumed to have a uniform Beta(1,1) prior distribution. This uniform prior means that it is equally likely a priori for a sentence category to create object gaps as it is to add extra objects. This form of prior builds in the fewest possible assumptions about the probability of observing a direct object versus an object gap within a sentence category. Analogous to
 $ {\delta}_c^{(X)} $
, the random variables in
$ {\delta}_c^{(X)} $
, the random variables in
 $ {\overrightarrow{\delta}}_c^{(F)} $
represent the probabilities of observing the other morphosyntactic features in a given sentence category. Each
$ {\overrightarrow{\delta}}_c^{(F)} $
represent the probabilities of observing the other morphosyntactic features in a given sentence category. Each
 $ {\delta}_c^{(F)} $
is also assumed to have a uniform Beta(1,1) prior distribution, meaning that all features are equally likely a priori to be present as they are to be absent; this likewise builds in the fewest possible assumptions about the distributions of features within sentence categories.
$ {\delta}_c^{(F)} $
is also assumed to have a uniform Beta(1,1) prior distribution, meaning that all features are equally likely a priori to be present as they are to be absent; this likewise builds in the fewest possible assumptions about the distributions of features within sentence categories.
3.2. Inference
The learner uses component-wise Gibbs sampling (Geman & Geman Reference Geman and Geman1984) to jointly infer the category of each observed sentence (c) and whether each category contains transitivity violations (
 $ e $
). We first initialize values of c and e for each sentence. Then, for each sentence, we calculate a posterior probability distribution over new category assignments given the observed data in X and F, the known verb transitivity properties T, and the other sentence category assignments and properties. We resample new values of c for each sentence sequentially from this posterior probability distribution. Finally, we use the new category values to resample values of e for each category from its posterior probability distribution, given the other model parameters. This cycle is repeated over many iterations until the model converges to a stable distribution over c and e. Details of the initialization and sampling procedure are provided in Appendix A.
$ e $
). We first initialize values of c and e for each sentence. Then, for each sentence, we calculate a posterior probability distribution over new category assignments given the observed data in X and F, the known verb transitivity properties T, and the other sentence category assignments and properties. We resample new values of c for each sentence sequentially from this posterior probability distribution. Finally, we use the new category values to resample values of e for each category from its posterior probability distribution, given the other model parameters. This cycle is repeated over many iterations until the model converges to a stable distribution over c and e. Details of the initialization and sampling procedure are provided in Appendix A.
4. Simulations
We tested our learner on a data set of child-directed English. As described above, our model performs two steps of inference: it jointly categorizes sentences according to their surface feature distributions, and infers which sentence categories have direct object gaps. In order to evaluate its performance and assess the importance of each of these inference steps, we compared it to a baseline model that lacks one of these steps. The first baseline model uses verb transitivity knowledge to identify object gaps, but does not categorize sentences based on their feature distributions. The second baseline model categorizes sentences based on their feature distributions, but lacks verb transitivity knowledge and the ability to identify object gaps. We ask two primary questions: (i) how well can our learner identify instances of object movement in English, in comparison to these baselines? and (ii) how informative are the specific features of the model’s categories for isolating movement dependencies from other grammatical processes?
4.1. Data
We prepared a data set from four parsed corpora in the CHILDES Treebank (Pearl & Sprouse Reference Pearl and Sprouse2013), which contains parse trees for child-directed English corpora on CHILDES (MacWhinney Reference MacWhinney2000). Details of these corpora are provided in Table 1. From these corpora, we selected sentences containing the verbs whose transitivity properties are known by our learner. Because a child’s knowledge of verb transitivity is likely to be imperfect before eighteen months of age, we base our learner’s knowledge on the transitivity classes inferred by the learner in Perkins et al. Reference Perkins, Feldman and Lidz2022, which provides a model of the previous stage of learning that our current model builds off of. We selected 18,503 sentences containing the verbs whose transitivity properties were inferred by the previous learner: these are the fifty most frequent transitive, intransitive, and alternating action verbs in these corpora. Because the previous learner assigned only 66% of these verbs to the correct transitivity category as specified in Perkins et al. Reference Perkins, Feldman and Lidz2022, this provides a noisy and imperfect source of knowledge for the current learner.Footnote 5 Table 2 provides the frequencies of these verbs, along with the transitivity categories assumed by our model.
Corpora of child-directed speech.

Table 1. Long description
From top to bottom, the first row lists Brown—Adam, Eve, and Sarah (Brown 1973) with 3 children aged 1;6 to 5;1, 391,848 words, and 87,473 utterances. The second row is Soderstrom (Soderstrom et al. 2008) with 2 children aged 0;6 to 1;0, 90,608 words, and 24,130 utterances. The third row is Suppes (Suppes 1974) with 1 child aged 1;11 to 3;11, 197,620 words, and 35,904 utterances. The fourth row is Valian (Valian 1991) with 21 children aged 1;9 to 2;8, 123,112 words, and 25,551 utterances. Columns from left to right are Corpus, number of children, ages, number of words, and number of utterances.
Known verbs and transitivity categories assumed by learner

Table 2. Long description
Beginning at the top, the table is divided into three main categories: Transitive, Alternating, and Intransitive. Under Transitive, verbs listed are feed (220, 93 percent), fix (337, 91 percent), pick (331, 90 percent), bring (605, 89 percent), drop (169, 88 percent), throw (312, 88 percent), hit (214, 87 percent), lose (185, 86 percent), close (166, 85 percent), buy (358, 84 percent), touch (183, 84 percent), leave (356, 83 percent), and wash (195, 83 percent). The Alternating category follows, with pull (331, 81 percent), push (352, 78 percent), open (342, 77 percent), catch (185, 76 percent), cut (263, 75 percent), bite (191, 73 percent), turn (485, 72 percent), build (299, 72 percent), knock (160, 72 percent), hold (579, 70 percent), read (509, 69 percent), break (550, 63 percent), drink (366, 60 percent), wear (477, 60 percent), eat (1,318, 59 percent), sing (306, 53 percent), blow (255, 52 percent), draw (375, 51 percent), move (238, 47 percent), ride (281, 41 percent), hang (151, 35 percent), stick (192, 29 percent), write (583, 27 percent), fit (227, 22 percent), play (1,568, 19 percent), wait (383, 15 percent), and stand (294, 7 percent). The final section, Intransitive, includes run (228, 6 percent), walk (253, 4 percent), jump (197, 4 percent), swim (180, 4 percent), work (256, 4 percent), cry (275, 3 percent), sleep (451, 3 percent), sit (859, 1 percent), stay (308, 1 percent), and fall (605, 0 percent). Each verb is accompanied by its total count and the percentage of instances with direct objects, illustrating the learner's assumptions about verb transitivity.
We conducted an automated search over the Treebank trees for overt direct objects following each verb, as well as the morphosyntactic features of each sentence that our model observes. We assume that the learner’s inference is driven by information relevant to the predicate-argument structure of a sentence: morphosyntactic features pertaining to subjects, objects, and verbs. These features are listed in Table 3.
Direct objects and morphosyntactic features observed by learner (X and F). The presence of a direct object is the sole feature encoded by X. The remaining twenty-one features are encoded within the feature vector
 $ \overrightarrow{F} $
.
$ \overrightarrow{F} $
.

Table 3. Long description
The table has two columns labeled Type and Features. The first row under Type is Object, with Features stating direct object of known verb is overt in canonical object position as right noun phrase sister of verb. The next row is Subject, with Features listing subject of known verb is overt in canonical subject position as left noun phrase sister of verb phrase, sentence-initial, preceded by an auxiliary, or preceded by another noun. The following row is Verb, with Features stating known verb is first verb in sentence, followed by a preposition or particle, or has -ed, -en, -ing, -s, or irregular morphology. The next row is Tense and auxiliaries, with Features stating verb is preceded by to, be, have, get, or occurs with do. The final row is Other, with Features listing question, unknown function word sentence-initially, sentence-medially before verb, sentence-medially after verb, or sentence-finally.
In selecting these features, we model a learner with the representational abilities of an infant between the ages of fifteen and eighteen months. Prior behavioral evidence finds that infants at these ages can use the word-order properties of their language to identify clause subjects and objects in their canonical positions (Gagliardi et al. Reference Gagliardi, Mease and Lidz2016, Hirsh-Pasek & Golinkoff Reference Hirsh-Pasek, Golinkoff, McDaniel, McKee and Cairns1996, Jin & Fisher Reference Jin and Fisher2014, Lidz et al. Reference Lidz, White and Baier2017, Perkins & Lidz Reference Perkins and Lidz2020, Seidl et al. Reference Seidl, Hollich and Jusczyk2003). They attend to auxiliaries and can detect when the order of a subject and auxiliary is inverted (Geffen & Mintz Reference Geffen and Mintz2015). They are able to segment a variety of verbal suffixes in English and other languages (Figueroa & Gerken Reference Figueroa and Gerken2019, Höhle et al. Reference Höhle, Schmitz, Santelmann and Weissenborn2006, Kim & Sundara Reference Kim and Sundara2021, Mintz Reference Mintz2013, Nazzi et al. Reference Nazzi, Barrière, Goyet, Kresh and Legendre2011, Santelmann & Jusczyk Reference Santelmann and Jusczyk1998, Soderstrom et al. Reference Soderstrom, Wexler and Jusczyk2002, Soderstrom et al. Reference Soderstrom, White, Conwell and Morgan2007, van Heugten & Shi Reference van Heugten and Shi2010). In addition to auxiliaries and verbal affixes, infants at these ages are sensitive to the syntactic properties of a handful of other functional categories: determiners (Cauvet et al. Reference Cauvet, Limissuri, Millotte, Skoruppa, Cabrol and Christophe2014, Hicks et al. Reference Hicks, Maye and Lidz2007, Höhle et al. Reference Höhle, Weissenborn, Kiefer, Schulz and Schmitz2004, Shi & Melançon Reference Shi and Melançon2010), pronouns (Cauvet et al. Reference Cauvet, Limissuri, Millotte, Skoruppa, Cabrol and Christophe2014), prepositions (Lidz et al. Reference Lidz, White and Baier2017), and negators (de Carvalho et al. Reference de Carvalho, Crimon, Barrault, Trueswell and Christophe2021). Although they may not know the categories of other functional elements, they are able to recognize them as functional as opposed to lexical on the basis of their phonetic and prosodic properties (Monaghan et al. Reference Monaghan, Chater and Christiansen2005, Shi et al. Reference Shi, Morgan and Allopenna1998, Shi et al. Reference Shi, Werker and Morgan1999).
In coding for the features in Table 3, we model an infant who can identify objects locally after verbs, but cannot yet identify nonlocal objects, such as fronted wh-phrases in wh-questions (Perkins & Lidz Reference Perkins and Lidz2021). This means that sentences like You’re eating and What are you eating? were both coded as not having a direct object from our learner’s perspective, even though the wh-word what acts as a nonlocal object in the second sentence of this pair. Instead, wh-words are coded as ‘unknown function words’, a hypercategory that includes all functional elements assumed to be unknown at this age: wh-words, complementizers, quantifiers, focus particles, and conjunctions other than and.
We also code for the pragmatic feature ‘question’, which represents whether an utterance has interrogative force. Empirical evidence suggests that infants in their second year of life understand when a speaker is seeking information (Casillas & Frank Reference Casillas and Frank2017, Goodhue et al. Reference Goodhue, Hacquard and Lidz2023, Luchkina et al. Reference Luchkina, Sobel and Morgan2018); see Carruthers Reference Carruthers2018 on ‘questioning attitudes’ as a basic component of human minds. They do so likely on the basis of distributional, prosodic, and sociopragmatic cues (such as pauses and eye gaze) that differentiate questions from assertions in child-directed speech (Yang Reference Yang2022). Young infants are sensitive to the prosodic and distributional differences between declaratives and polar questions (Frota et al. Reference Frota, Butler and Vigário2014, Geffen & Mintz Reference Geffen and Mintz2015, Soderstrom et al. Reference Soderstrom, Ko and Nevzorova2011). Although wh-questions differ from polar questions in their prosody (Geffen & Mintz Reference Geffen and Mintz2017), it is possible that infants may know that these sentences are interrogatives, even before they are aware that they contain wh-dependencies (Gagliardi et al. Reference Gagliardi, Mease and Lidz2016, Perkins & Lidz Reference Perkins and Lidz2020, Seidl et al. Reference Seidl, Hollich and Jusczyk2003). Questions were identified by the presence of a question mark in the transcription; this does not distinguish constituent questions from polar questions.
In coding for the feature ‘question’, we abstract away from the specific prosodic features that learners might rely on to distinguish interrogatives from declaratives, and wh-questions from polar interrogatives (Frota et al. Reference Frota, Butler and Vigário2014, Geffen & Mintz Reference Geffen and Mintz2015, Gryllia et al. Reference Gryllia, Doetjes, Yang and Cheng2020, Soderstrom et al. Reference Soderstrom, Ko and Nevzorova2011, Yang Reference Yang2022), which were not available in the corpora of child-directed speech used for our model’s data set. In abstracting away from the prosodic signal, we ask how far a learner might get on the basis of distributional morphosyntactic information. However, we do not intend this as a claim that children cannot or do not additionally attend to this richer prosodic information, and further work might extend the current model to operate over a prosodically enriched data set.
To verify the accuracy of our automated coding, a random sample of 500 sentences from the data set were separately hand-coded by two trained researchers. Percentage agreement between the hand-coding and automated coding ranged from 87–100% across the twenty-one features; interrater reliability was also 87–100%. See Appendix B for more detail.
The sentences in the data set were also coded for their underlying clause types,Footnote 6 listed in Table 4. These annotations were used as a gold standard to evaluate our model and were not part of the model’s data set. These clause types included three with movement: wh-questions, passives, and relative clauses. A given clause might be coded as multiple types: for example, as both a question and a passive. For sentences with multiple clauses, coding was conducted for the clause containing the verb of interest. Accuracy of clause-type coding was again evaluated by comparing against a 500-sentence sample hand-coded by two researchers. Percentage agreement between the hand-coding and automated coding ranged from 84–99% across the nine clause types (interrater reliability 87–99%); see Appendix B. Additional hand-coding was conducted for wh-questions and relative clauses in order to annotate the gap site in these sentences, which could not be reliably identified automatically for the entire data set.
Distribution of underlying clause types in data set.

Table 4. Long description
From the top row downward, the table lists clause types in the leftmost column: Basic transitive, Basic intransitive, W h-question, Polar question, Other question, Passive, Relative clause, Other embedded clause, and Imperative. The next two columns display the number of clauses and their percentage of the dataset for each type: Basic transitive 2,855 (15 percent), Basic intransitive 2,704 (15 percent), W h-question 2,336 (13 percent), Polar question 3,641 (20 percent), Other question 1,922 (10 percent), Passive 268 (1 percent), Relative clause 298 (2 percent), Other embedded clause 4,905 (27 percent), Imperative 2,176 (12 percent). The rightmost column provides descriptions: Basic transitive is a matrix, finite, declarative clause with overt direct object following known verb; Basic intransitive is matrix, finite, declarative clause without overt direct object following known verb; W h-question has canonical syntactic form of a W h-question with W h-element in dependency with known verb; Polar question has canonical syntactic form of a polar question; Other question includes tag, fragment, echo questions, and rising-intonation declaratives not in canonical W h or polar form; Passive is a passivized known verb excluding adjectival forms; Relative clause is a known verb in a full or reduced relative clause; Other embedded clause is a known verb in a finite or nonfinite embedded, nonrelative clause; Imperative has canonical syntactic form of an imperative.
4.2. Results
4.2.1. Sentence category distributions
Our joint inference model inferred thirty-nine total sentence categories, sixteen with transitivity violations and twenty-three without. To determine which of the model’s inferred transitivity-violating categories were ones that contained object gaps (versus other types of transitivity violations), we calculated the odds ratio of direct objects appearing in these categories. This measure divides the odds of observing a feature in a given category by the odds of observing that feature outside of that category; an odds ratio significantly greater than 1 indicates that a feature is more likely to be present within than outside of the category, and an odds ratio significantly less than 1 indicates that a feature is more likely to be absent. Significance was calculated using a Fisher’s exact test with a Bonferroni correction for multiple comparisons. See Appendix C for full details.
Of the sixteen transitivity-violating categories, fifteen had significantly lower odds (odds ratio less than 1) of producing direct objects; we call these ‘object gap’ categories. For each of the model’s categories, Figure 2 displays the proportion of the category made up of each underlying clause type. Note that these proportions do not necessarily sum to 1 because a single clause might be of multiple types. For example, the sentences in the model’s category 1 are entirely (1.00) wh-questions; this means that a given sentence in category 1 has a 100% probability of being tagged with the wh-question type in the gold-standard annotation. However, in category 2, a given sentence has a 95% probability of being a wh-question and also a 99% probability of being an embedded clause: this is a category that is predominantly long wh-questions, that is, those with wh-dependencies into embedded clauses.
Proportions of clause types in inferred sentence categories, joint inference model.

Figure 2. Long description
The top heatmap, labeled Object gap, displays clause types as rows: Wh-question, Passive, Relative clause, Embedded clause, Polar question, Other question, Imperative, and Basic. Columns are numbered 1 to 16. The highest values, shown in dark blue, are for Wh-question (1.00 at category 1), Passive (0.89 at category 5), and Embedded clause (0.99 at category 4). Basic clauses, in yellow, have higher proportions in categories 11 to 16, peaking at 0.69 in category 15. The legend indicates Movement (dark blue), Other nonbasic (light blue), and Basic (yellow). The bottom heatmap, labeled Non-transitivity-violating, uses the same row labels and columns numbered 17 to 39. Highest values are for Embedded clause (0.98 at category 21), Wh-question (0.89 at category 17), and Imperative (0.95 at category 33). Basic clauses again show higher proportions in later categories, peaking at 0.88 in category 32. Color intensity corresponds to the proportion value in each cell.
In order to see whether the sentences in a given category predominantly belong to a particular clause type, versus being spread out among many different clause types, we calculated the purity of these categories when compared to the true underlying clause types in the corpora. Purity was calculated by counting the total number of sentences that belong to the predominant clause type in each category and dividing by the total number of sentences in the data set (Manning et al. Reference Manning, Raghavan and Schütze2008). Because a given sentence could belong to more than one clause type (i.e. both a wh-question and an embedded clause), we counted it as belonging to the predominant type in the category if that type was among those that the sentence belongs to. We note that this is a coarse approach and intend it only as a descriptive measure; our goal is not to evaluate the model on its clustering, but rather to evaluate it on whether it is able to find movement in its data, which we report in the following section. Given this approach, this measure has a minimum value of 0 if clusters are made up of a mixture of clause types, and a maximum value of 1 if clusters are made up of a single clause type. Our model’s overall cluster purity is 0.76, which tells us that the model’s categories were more likely to track one underlying clause type rather than a mixture.
The model inferred many more categories than necessary to identify the set of underlying clause types that it is being evaluated against. This is unsurprising: the learner was not given any information about how many clause-type categories were present, nor the grain size at which to perform its categorization. Instead, it was given leeway to posit as many categories as needed to explain the distributions of features and transitivity violations in its data. The model divided wh-questions among seven different categories: five transitivity-violating categories and two with no transitivity violations. These categories differentiate monoclausal from biclausal questions (e.g. What does he eat? vs. What would you like to read?), questions in the progressive aspect (e.g. What are you bringing?) from those in other aspects, and questions where the wh-word is sentence-initial from those where it is not (e.g. And what is he wearing?). The model also categorized subject questions separately from object and adjunct questions, and correctly identified subject questions as non-transitivity-violating. These distinctions may have implications for the learner’s ability to generalize about the surface forms that are distinctive of different types of movement dependencies, a point we return to in the following sections.
4.2.2. Accuracy on identifying object movement
Here, we ask how well our learner can identify instances of object movement in its data. Visually, we can see from Figure 2 that clause types with movement were more likely to be categorized in object-gap categories than in non-object-gap categories. To ask how well the model identified cases of object movement specifically, we compared its object-gap categories against the sentences that were coded as actually having object gaps in the corpus. The model’s accuracy is displayed in Figure 3 using three metrics. Precision measures the proportion of sentences in the model’s object-gap categories that contained object movement according to our gold standard—that is, the proportion of these categories made up of object wh-questions, object relative clauses, or passives. Recall measures the proportion of sentences with object movement in the corpus overall that were identified as belonging to one of the model’s object-gap categories. These metrics are not always aligned: it would be possible to achieve perfect recall by identifying all sentences as having object movement, but this would result in very poor precision. The F1 score, the harmonic mean of precision and recall, reflects the model’s overall accuracy by taking into account both of these metrics. For each of these metrics, we compare the model’s performance to a chance baseline, indicated by the dashed horizontal line. This represents the expected performance of a learner that randomly categorizes sentences as having transitivity violations that cause direct object gaps, by flipping a coin with weight 0.19, which is the probability of transitivity violations encoded in our learner’s prior.
Accuracy on identifying sentences with object movement in three metrics: precision (proportion of model’s object-gap categories that contain object movement), recall (proportion of object movement in corpus identified by model), and F1 (harmonic mean of precision and recall).

Figure 3. Long description
The x-axis lists three metrics from left to right: Precision, Recall, F1. For each metric, three vertical bars represent the No-category model (dark blue), No-transitivity model (teal), and Joint inference model (gold). For Precision, values are 0.23 for No-category, 0.15 for No-transitivity, and 0.37 for Joint inference. For Recall, values are 0.43 for No-category, 0.87 for No-transitivity, and 0.8 for Joint inference. For F1, values are 0.25 for No-category, 0.3 for No-transitivity, and 0.5 for Joint inference. A dashed horizontal line at 0.2 crosses all bars. The legend at the right matches colors to model names.
The model achieved an F1 score of 0.50. Its recall was 0.80, indicating that it identified 80% of sentences with object movement in its data. This accuracy rate is substantially above chance performance. Its precision was 0.37, indicating that on average, 37% of the sentences within its object-gap categories had instances of object movement. This precision rate is also above chance, but shows us that the model did not always manage to isolate object movement from other clause types in its data. To examine this further, we plotted the distribution of movement and nonmovement types in the model’s object-gap categories in Figure 4. Object movement was the predominant clause type in 60% of these categories, but occurred alongside other movement types as well, particularly adjunct movement. The model appears to categorize adjunct movement together with object movement based on some surface distributional similarities: unlike subject movement, both object and adjunct movement contain subject-auxiliary inversion and can trigger do-support, even though adjunct movement does not tend to produce transitivity violations. The other 40% of the model’s object-gap categories predominantly comprised sentences without movement. Thus, while the learner achieved high accuracy in identifying sentences with object movement as such, in certain cases it categorized sentences with object movement together with other clause types.
Distribution of movement types in model’s object-gap categories.

Figure 4. Long description
The chart displays fifteen vertical bars, each representing an object-gap category numbered 1 to 15 along the x-axis. The y-axis shows proportion from 0.0 to 1.0. Each bar is divided into five colored segments: gray for No movement, green for Prep object movement, light blue for Adjunct movement, dark blue for Subject movement, and purple for Object movement. From category 1 to 7, Object movement (purple) is the largest segment, decreasing gradually. Adjunct movement (light blue) and Subject movement (dark blue) appear mainly in categories 2 to 6. Prep object movement (green) is present in categories 1, 4, 5, 10, and 12. No movement (gray) increases steadily from category 6 onward, becoming the dominant segment in categories 8 to 15, where other movement types are minimal or absent. The legend on the right matches each color to its movement type.
The model achieves this performance despite several factors that limit its accuracy. First, the model does not receive credit for identifying cases of movement other than wh-questions, passives, and relative clauses; other rarer cases of movement were more difficult to code automatically, and thus were not annotated in the gold-standard labels.Footnote 7 Second, the model infers object movement only from sentences that it believes violate verb transitivity: sentences with missing direct objects for verbs that it considers fully transitive. This means that the current evaluation measures how well the model was able to generalize from fully transitive verbs to verbs that also allow intransitive uses. Table 5 displays the proportions of sentences with object movement that the model correctly identified as having object gaps, broken down by the verb classes that comprised the model’s prior transitivity knowledge. The model achieved high recall even though the majority of sentences with object movement occurred with verbs that it believed to be alternating, rather than obligatorily transitive. Of the 1,369 sentences coded as having object movement in the corpus, only 299 contained known transitive verbs, compared to 1,055 containing known alternating verbs.Footnote 8 Nonetheless, the model achieved high accuracy across both the transitive and alternating verb classes. This tells us that it was able to generalize effectively: it used the presence of object gaps with known transitive verbs to identify the forms that object movement takes in its data, even with verbs that do not obligatorily require objects.Footnote 9
Proportion of object-movement sentences identified, by verb type.

Table 5. Long description
From top to bottom, the table has four rows and three columns. The first column lists verb classes: Transitives, Intransitives, Alternators, and Total. The second column shows the number of object-movement sentences: 299 for Transitives, 15 for Intransitives, 1,055 for Alternators, and 1,369 as the total. The third column gives the proportion identified: 0.75 for Transitives, 0.60 for Intransitives, 0.82 for Alternators, and 0.80 as the total. All values are aligned by row, with the total row italicized.
In summary, our joint inference model performed significantly higher than chance in categorizing sentences with object movement in its data. It achieved a high recall rate, indicating that it was correctly able to identify the large majority of sentences with object movement that it encountered. Its accuracy was high for both transitive and alternating verbs, indicating that it was able to use the presence of transitivity violations with fully transitive verbs to identify direct object gaps with verbs that do not require objects. However, this object-gap inference produced a mixture of signal and noise: the sentences that the model categorized together with object movement also contained a variety of other movement and nonmovement clause types. This has potential implications for how informative the learner’s categories are for isolating object movement from other syntactic dependencies, a question we turn to next.
4.2.3. Identifying distinctive features of object movement
Under our hypothesis, the sentence categories inferred by the joint inference model are an intermediate step of learning. Jointly inferring how to categorize sentences according to their surface features, and which sentence categories contain object gaps, helps a learner identify the particular forms that characterize different types of object movement in the target language. Here, we ask how well the model identified which specific surface features are the footprints of object movement. To do this, we assessed which surface features are most distinctive in the categories that the model inferred to have object gaps. If these include the characteristic forms of English object movement dependencies, then the model’s sentence categories contain helpful information for identifying the ways that object movement can be realized in English.
To assess feature distinctiveness, we again calculated the odds ratio of each surface feature in the model’s argument-gap categories. Table 6 reports the features with odds ratios significantly greater than 1 for each of the model’s object-gap categories; full details are provided in Appendix C. Among these features are the characteristic forms of object movement dependencies in English. The categories that are predominantly wh-questions have greater odds of including subject-auxiliary inversion, do, and unknown function words sentence-initially or sentence-medially before the verb: these are wh-words. The categories predominantly made of passives have greater odds of including get or be, and -en, -ed, or irregular verbal morphology.
Features with significantly higher odds in object-gap categories.

Table 6. Long description
The table has three columns: Category, Primary clause type, and Distinctive features. Row 1: Category 1, wh-question, subject is overt and preceded by an auxiliary, verb is first in sentence, has -ing and is preceded by be, sentence-initial function word, question. Row 2: Category 2, wh-question and embedded, verb is preceded by to, sentence-initial function word, question. Row 3: Category 3, wh-question, subject is overt and preceded by an auxiliary, verb is first in sentence and occurs with do, sentence-initial function word, question. Row 4: Category 4, wh-question, subject is overt and preceded by an auxiliary, verb is first in sentence, has -ing and is preceded by be, sentence-medial function word before verb, question. Row 5: Category 5, passive, verb has -ed, -en, or irregular form and is preceded by get. Row 6: Category 6, passive, verb has -ed or irregular form and is preceded by to and be. Row 7: Category 7, passive, subject (when overt) is sentence-initial, verb is first in sentence, has irregular form and is preceded by be or have. Row 8: Category 8, passive, subject is overt and sentence-initial, verb is first in sentence, has -en form and is preceded by be or have. Row 9: Category 9, passive, subject is overt and preceded by a noun phrase, verb has -en or irregular form and is preceded by be or have. Row 10: Category 10, passive, subject (when overt) is sentence-initial, verb is first in sentence, has -ed form and is preceded by be or have. Row 11: Category 11, embedded, verb is preceded by to, sentence-medial function word before verb. Row 12: Category 12, embedded, subject is overt and preceded by a noun phrase, verb has -ed, -s, or irregular form, sentence-medial function word before or after verb. Row 13: Category 13, imperative, verb is first in sentence. Row 14: Category 14, basic, subject is overt and sentence-initial, verb is first in sentence, has -ed, -s, or irregular form, function word sentence-finally or sentence-medially after verb. Row 15: Category 15, basic, subject is overt and preceded by a noun phrase, verb has -ing and is preceded by be, sentence-medial function word before verb.
However, the distinctive features of object-gap categories also include forms that are irrelevant to movement dependencies. These include many positional characteristics of subjects and verbs, but also some specific morphemes. For instance, be and -ing are distinctive of two of the model’s wh-question categories, and have is distinctive of several of the model’s passive categories. These features mark the realization of aspectual dependencies: be and -ing mark the progressive aspect, and have together with -ed or -en marks the perfect aspect. Thus, the model’s categories contain both signal and noise for learning which surface features are the footprints of movement rather than other syntactic dependencies.
In summary, the current learner successfully identified the forms that characterize the most frequent types of movement in English, but it also identified some irrelevant features that are accidentally correlated with these forms. This invites the question of how a learner could effectively use this information for further steps of learning—how a learner could separate signal from noise by explaining some correlations as movement and others as different dependencies. It is possible that the model’s ability to posit a potentially unbounded number of categories pushed it toward categories that are overly specific. Future work might test hypotheses about limits on the number of categories that a learner can posit, relaxing the ideal-learner assumption of this model in favor of one that more closely reflects the cognitive constraints that a child is operating within. It is unknown, however, whether this would lead the learner away from the accidental correlations that it identifies when its number of categories is unconstrained. Alternatively, it is also possible that a more sophisticated distributional learning mechanism might perform better. Further investigation is needed to determine whether the signal-to-noise ratio in the model’s categories improves if it infers argument gaps using not only missing direct objects, but also other required but missing arguments (subjects and prepositional objects). This would give the learner the opportunity to identify nonobject movement; it is an open question whether this could make its inference about categories with argument gaps more precise.
4.3. Model comparisons
Our model achieves above-chance performance on identifying sentences with object movement by jointly inferring two properties: how sentences should be categorized together according to their surface feature distributions, and which sentence categories violate expectations about verb transitivity. To evaluate how important this joint inference is, we compare our model to baseline learners that perform only one step of inference at a time.
4.3.1. No-Category baseline
If it did not matter that our learner categorized sentences according to their surface features, then a learner should do just as well at identifying object movement on a sentence-by-sentence basis, by noting when objects are unexpectedly missing for known transitive verbs. To test whether the model’s categorization process matters, we compared our model against a baseline learner that used only the presence or absence of direct objects in individual sentences, together with its knowledge of the transitivity properties of verbs in these sentences, to infer which sentences likely contain object gaps. Like our learner, this baseline model infers that an object gap is present when a transitive verb is unexpectedly missing its object. Unlike our learner, this model does not cluster sentences into categories according to their surface features, so it cannot draw inferences about which features are likely to be distinctive of sentences with object movement and cannot generalize the likely presence of an object gap from one sentence to another based on the similarity of their features.
This baseline learner has the architecture of the filtering model in Perkins et al. Reference Perkins, Feldman and Lidz2022, shown in Figure 5a. This is similar to the generative model in Figure 1, but omits the variables c, F, and δ (F). With the variable c omitted, the learner does not assume that its direct object observations are partially governed by latent categories of sentences; with F and δ (F) omitted, the learner does not observe or draw any inferences about the distributions of other surface features of sentences. Here, the variables e and δ (X) are not indexed by sentence category: e represents whether an individual sentence (rather than a sentence category) contains a transitivity violation, and δ (X) represents the rate of direct objects in individual sentences (rather than sentence categories) where transitivity violations are present. The learner’s inference procedure consists of learning which sentences contain transitivity violations given its assumptions about verb transitivity and the rate of violations, but no joint learning about sentence categories on the basis of their distributional features. We fixed the transitivity properties T of each verb and the parameter δ (X) to the values inferred by the learner in Perkins et al. Reference Perkins, Feldman and Lidz2022. We then sampled transitivity violations for each sentence in the corpus from the posterior probability distribution over e given X, T, and δ (X), integrating over θ. See Appendix A for details.
Graphical models for (a) no-category baseline and (b) no-transitivity baseline.

Figure 5. Long description
Panel A, anchored at the outer box labeled V, contains a vertical sequence: at the top is a shaded circle T, arrow to white circle theta, arrow to shaded circle X inside a smaller box m, arrow to white circle e. X has an arrow to a shaded circle delta super X outside m. A callout box at the bottom right reads No sentence categories or surface features. Panel B, anchored at the outer box V, contains a large box with a nested box m, which itself contains a smaller box n. Inside n are shaded circles X and F, with arrows from X and F to a white circle c below. X and F each have arrows to shaded circles delta sub c super X and delta sub c super F, both outside the main boxes. A callout box at the top reads No verb transitivity knowledge. All arrows indicate dependency relationships among variables.
To determine how well this ‘no-category baseline’ identified movement, we compared the sentences without direct objects that it inferred to have transitivity violations against the actual cases of object movement in the corpus. Its precision, recall, and F1 score are reported in Figure 3 above. The model achieved above-chance accuracy overall, but scored substantially lower than the joint inference model on all three metrics. This is because the baseline model’s only source of reliable information for object gaps comes from the small percentage of verbs that it believes to be obligatorily transitive; it uses no other features in the sentences to inform this inference. If we examine its identification of object movement across verb classes, we find that it achieved high accuracy (74%) on identifying object movement with fully transitive verbs. But for the much larger percentage of verbs that are alternating, it can only guess which sentences contain gaps, identifying only 34% of object movement with these verbs. Thus, our joint inference model’s ability to categorize sentences using a wide range of surface morphosyntactic features, and to generalize across sentences in a category, results in substantially better performance than inferring movement on a sentence-by-sentence basis from transitivity violations alone.
4.3.2. No-Transitivity baseline
Our second baseline comparison investigates how much prior verb transitivity knowledge constrains the learner’s identification of movement—specifically, how important it is that our learner uses transitivity violations in the process of categorizing sentences by their surface morphosyntactic features. We compare our model against a learner that performs this categorization without knowing which verbs require direct objects. Like our learner, this baseline model uses the surface features of sentences to cluster sentences into categories. Unlike our learner, this baseline model does not have any knowledge of which verbs are transitive, so it cannot track transitivity violations in order to infer that object gaps are present in some of its sentence categories. Instead, it treats direct object observations identically to other surface features: for this learner, all direct objects are governed by the grammatical properties of a sentence category, not by the transitivity classes of verbs in the sentences. This learner therefore runs the risk of inferring categories that mix together sentences with movement and sentences without.
The architecture of this ‘no-transitivity baseline’ is shown in Figure 5b. This assumes the lowest portion of the generative model in Figure 1, omitting the variables T, θ, and e. When the variables T and θ are omitted, the learner now assumes that all direct object observations X are generated by
 $ {\delta}_c^{(X)} $
, the grammatical properties of each sentence category, rather than by any properties of the verbs in these sentences. When the variable e is omitted, the learner no longer assumes that certain sentence categories contain transitivity violations. This means that its inference procedure consists of learning which sentence categories are present and which sentences belong to those categories, but no joint learning about transitivity violations in these categories. We sample category values for each sentence in the corpus from the posterior probability distribution over c given X and F, integrating over δ (X) and δ (F). See Appendix A for details.
$ {\delta}_c^{(X)} $
, the grammatical properties of each sentence category, rather than by any properties of the verbs in these sentences. When the variable e is omitted, the learner no longer assumes that certain sentence categories contain transitivity violations. This means that its inference procedure consists of learning which sentence categories are present and which sentences belong to those categories, but no joint learning about transitivity violations in these categories. We sample category values for each sentence in the corpus from the posterior probability distribution over c given X and F, integrating over δ (X) and δ (F). See Appendix A for details.
Like our learner, the no-transitivity baseline inferred thirty-nine total categories. Of these, twenty-two had significantly lower odds of producing direct objects; we call these ‘object-gap’ categories, under the assumption that these are the learner’s candidate categories for object movement. Full details are provided in Appendix C. The proportions of underlying clause types in the learner’s categories are reported in Figure 6. These categories have similarly high purity to those inferred by the joint inference model: the baseline model’s overall cluster purity is 0.77, compared to 0.76 for the joint inference model. This shows that the morphosyntactic features being tracked by both learners are informative for differentiating the various underlying clause types in the corpus, even without knowledge of which verbs require objects.
Proportions of clause types in sentence categories, no-transitivity baseline.

Figure 6. Long description
The top heatmap, labeled Object gap, has rows for Wh-question, Passive, Relative clause, Embedded clause, Polar question, Other question, Imperative, and Basic. Columns are numbered 1 to 22. Highest values are in the Wh-question row for categories 1 to 3 (0.98, 0.96, 0.90, dark purple for Movement), and Passive row for categories 4 to 7 (0.91, 0.86, 0.70, 0.61, also Movement). Embedded clause shows a peak at category 11 (0.97, blue for Other nonbasic). Basic row has high values from category 15 to 22 (0.94 to 0.46, yellow for Basic). The bottom heatmap, labeled Other violation, has the same row labels and columns numbered 23 to 39. Wh-question row peaks at category 23 (0.92, Movement). Embedded clause row peaks at category 28 (0.99, Other nonbasic). Basic row shows high values from category 35 to 39 (0.83 to 0.49, Basic). Color legend at right: Movement (dark purple), Other nonbasic (blue), Basic (yellow).
However, the baseline model’s categories did not successfully differentiate sentences with movement from sentences without. The learner inferred many more sentence categories that were candidates for object movement, leading to slightly higher recall than our joint inference learner (Figure 3 above). But its precision was quite poor, leading to a substantially worse F1 score. To examine the source of this worse precision, we plotted the distribution of movement and nonmovement types in the model’s object-gap categories in Figure 7. We find that object movement is the predominant clause type in only 27% of the learner’s object-gap categories, compared to 60% in our joint inference learner. This tells us that our learner’s ability to track transitivity violations is important for identifying categories of sentences with and without movement. While the distributions of morphosyntactic surface features of sentences convey a certain amount of information about the distinctions among different clause types, learning which of these distinctions signal movement, and which do not, requires the use of verb transitivity knowledge during distributional analysis.
Distribution of movement types in object-gap categories, no-transitivity baseline.

Figure 7. Long description
The horizontal axis lists object-gap categories from 1 to 22. The vertical axis shows proportion from 0 to 1. Each bar is divided into five colored segments: grey for no movement, dark green for prep object movement, light blue for adjunct movement, dark blue for subject movement, and purple for object movement. Categories 1 to 8 have high proportions of object movement (purple) and subject movement (dark blue), with some adjunct (light blue) and prep object movement (dark green) in the lowest categories. From category 9 onward, grey (no movement) dominates, with only small segments of other movement types in categories 10 to 14, 18, 20, 21, and 22. Category 22 shows a notable increase in subject movement (dark blue) and prep object movement (dark green) compared to other high categories. The legend on the right matches colors to movement types.
4.4. Summary
In summary, our model identified 80% of sentences with object movement in child-directed speech, by tracking the surface morphosyntactic features of sentences that violate its expectations of verb transitivity. The model jointly infers how to categorize sentences according to their surface feature distributions and which of these sentence categories contain object gaps: unexpectedly missing objects of known verbs. This allowed the learner to generalize across sentences that share the same form and posit object gaps even for verbs that it does not know to be transitive. The learner performed substantially better than a baseline that relies only on known verb transitivity knowledge and does not categorize sentences on the basis of their surface feature distributions. This shows that the model’s categorization process is important. It also outperformed a baseline that categorizes sentences using their surface features alone, without knowing which verbs require objects. The baseline learner performed substantially worse at differentiating sentences with and without object movement, showing that verb knowledge is an important guide for identifying movement.
5. General discussion
In order to acquire the system of syntactic dependencies in their language, children must detect evidence for abstract structure that is realized in highly variable ways within and across languages. Prior work has focused on how learners leverage statistical sensitivities to identify dependencies that are morphologically marked in their language (Gómez Reference Gómez2002, Gómez & Maye Reference Gómez and Maye2005, Höhle et al. Reference Höhle, Schmitz, Santelmann and Weissenborn2006, Nazzi et al. Reference Nazzi, Barrière, Goyet, Kresh and Legendre2011, Santelmann & Jusczyk Reference Santelmann and Jusczyk1998, Tincoff et al. Reference Tincoff, Santelmann and Jusczyk2000, van Heugten & Shi Reference van Heugten and Shi2010). But these statistical learning mechanisms face challenges when encountering the fuller range of syntactic dependency types that learners must acquire. Movement dependencies provide an extreme example, both in their degree of abstraction and the degree of overt evidence available on the surface forms of sentences. How do learners identify a nonadjacent dependency between a fronted expression and the ‘gap’ of movement, which has no overt phonological form?
Here, we argue that solving this problem requires statistical learning not just over overt linguistic material, but also over hidden grammatical structure. Consistent with the literature on expectation violation in other domains of cognition (Denison & Xu Reference Denison, Xu, Kushnir, Benson and Xu2012, Kouider et al. Reference Kouider, Long, Le Stanc, Charron, Fievet, Barbosa and Gelskov2015, Stahl & Feigenson Reference Stahl and Feigenson2015, Reference Stahl and Feigenson2017, Téglás et al. Reference Téglás, Vul, Girotto, Gonzalez, Tenenbaum and Bonatti2011), we pursue the hypothesis that statistical learning is informed by unsatisfied grammatical predictions. When a learner encounters an unexpectedly missing predicted argument of a verb, this may serve as evidence for a gap of an argument movement dependency. By tracking the surface forms that cooccur with these posited gap sites, learners may come to identify the distributional signatures of argument movement in the target language, enabling further inference about which specific syntactic dependencies underlie these surface forms. This hypothesis is motivated by prior empirical findings that knowledge of verb transitivity emerges before the identification of movement dependencies in infancy (Gagliardi et al. Reference Gagliardi, Mease and Lidz2016, Jin & Fisher Reference Jin and Fisher2014, Lidz et al. Reference Lidz, White and Baier2017, Perkins & Lidz Reference Perkins and Lidz2020, Reference Perkins and Lidz2021).
Our findings demonstrate that this hypothesis is computationally feasible for the identification of object movement. Our learner jointly categorizes sentences according to similarities in their surface forms and infers which of these sentence categories violate its expectations about verb transitivity. This joint inference allows it to accurately identify the majority of object movement in child-directed speech and, in doing so, to identify the formal properties that are the footprints of object movement in English. It performs substantially better than baseline learners that rely on only one of these two sources of information: either learning from verb transitivity violations without using surface morphosyntactic features of sentences, or learning from distributions of surface features with no knowledge of verb transitivity. This shows that the learner’s expectations about hidden grammatical structure, coming from prior verb argument-structure knowledge, place important constraints on its distributional learning mechanism. It thereby provides a computational account for why verb argument-structure knowledge developmentally precedes the acquisition of movement in a language like English.
These findings raise three sorts of questions for future research. First, how does a learner take information about the formal correlates of object gaps in the language and identify whether a particular form is realizing a movement dependency, versus another syntactic dependency? Our learner’s inference yields both signal and noise for this next step of learning: the distinctive features of its object-gap categories include forms that characterize object movement in English, but also include forms that realize other nonmovement dependencies, such as aspectual dependencies. It is possible that children using this mechanism might be overly specific in the forms they associate with movement—for instance, inferring that progressive aspect is a hallmark of wh-questions, or perfect aspect is a hallmark of passives. Alternatively, perhaps a learner would identify fewer accidental correlations if the number of categories that it can posit for its data are limited, inviting further work exploring how children’s developing cognitive capacities might interact with this type of distributional learning at young ages. But the current findings also raise the possibility that this learning mechanism is not sufficient to allow children to determine which expressions in a sentence are participating in movement dependencies, and which are not. Separating signal from noise may require supplementing information from formal distributions with additional information about the likely dependencies in a given sentence and the ways that those dependencies can be realized, so that a learner can successfully factor out the features that realize other dependencies from those that realize movement.
Prosody and pragmatics might provide additional relevant sources of information that are likely available to a young infant. Infants are sensitive to prosodic patterns from their first weeks of life (e.g. Christophe et al. Reference Christophe, Dupoux, Bertoncini and Mehler1994, Christophe et al. Reference Christophe, Mehler and Sebastián-Gallés2001, Gerken et al. Reference Gerken, Jusczyk and Mandel1994, Jusczyk et al. Reference Jusczyk, Hirsh-Pasek, Kemler Nelson, Kennedy, Woodward and Piwoz1992, Nazzi et al. Reference Nazzi, Bertoncini and Mehler1998). Because prosodic breaks tend to fall at the edges of syntactic phrases, past work has argued that infants may be able to use this information to help identify some of the constituency structure of an utterance (Christophe et al. Reference Christophe, Millotte, Bernal and Lidz2008, de Carvalho et al. Reference de Carvalho, He, Lidz and Christophe2019, Gleitman et al. Reference Gleitman, Gleitman, Landau, Wanner and Newmeyer1988, Gout et al. Reference Gout, Christophe and Morgan2004, Morgan Reference Morgan1986, Morgan & Demuth Reference Morgan and Demuth1996). Languages also deploy various other prosodic features, such as pitch and durational differences, to differentiate interrogatives from declaratives and wh-interrogatives from polar interrogatives (Frota et al. Reference Frota, Butler and Vigário2014, Geffen & Mintz Reference Geffen and Mintz2015, Gryllia et al. Reference Gryllia, Doetjes, Yang and Cheng2020, Soderstrom et al. Reference Soderstrom, Ko and Nevzorova2011, Yang Reference Yang2022). Many of these features are language-specific and therefore must themselves be acquired, but it is possible that learners’ inferences about the features that realize movement could be made more precise by tracking prosodic information in tandem with the morphosyntactic information provided to our model.
Infants also show early abilities to track the communicative intent of speakers (Csibra Reference Csibra2010, Meltzoff Reference Meltzoff1995, Woodward Reference Woodward2009) and to identify the speech act of an utterance, at least at a coarse level of granularity (Casillas & Frank Reference Casillas and Frank2017, Goodhue et al. Reference Goodhue, Hacquard and Lidz2023, Grosse et al. Reference Grosse, Behne, Carpenter and Tomasello2010, Liszkowski Reference Liszkowski2005, Luchkina et al. Reference Luchkina, Sobel and Morgan2018). This speech-act information might also provide useful information about the syntactic dependencies in a given sentence. However, as argued by Yang (Reference Yang2022), it is likely that this speech-act information would need to work in tandem with the type of syntactically guided distributional analysis proposed in the current work. Even a small amount of information about a speaker’s communicative intent in using a particular sentence, along with the speaker’s prosody, may help constrain the structure and interpretation that a learner assigns to that sentence. But it is likely that this information is not by itself constraining enough to provide a complete parse. Yang Reference Yang2022 shows that it is computationally difficult to identify questions from child-directed speech using only pragmatic and prosodic information, and thus identifying which questions contain wh -dependencies would likely be even more challenging. This suggests that a learner might need to have available a partial syntactic representation for which this top-down information could be useful. This invites further investigation into how statistical learning might be supplemented both by a child’s developing knowledge of possible syntactic dependencies and by knowledge of how those dependencies relate to speakers’ goals in discourse.
A second important question for future research is how learners come to identify not only object wh-movement in their language, but also other types of movement dependencies. Our model uses only unexpectedly missing direct objects to infer when movement might be present, and therefore cannot identify subject, prepositional object, or adjunct movement. However, our model’s exclusive focus on object movement is not intended as a claim that this form of movement must developmentally precede all others. Instead, these results merely demonstrate that the proposed expectation-violation learning mechanism could allow a learner to identify one type of argument movement that is empirically attested at early stages of development, while leaving open the possibility that other types of movement might also be acquired in tandem. In particular, it is possible that this mechanism could generalize to other forms of argument movement: in addition to tracking object gaps, a child might track when expected subjects or prepositional objects are unexpectedly absent, thereby allowing simultaneous inferences about the presence of subject and prepositional object movement. However, these gaps will be less obvious in matrix subject questions than in embedded questions, raising questions about the amount of evidence available for a learner to detect subject movement at young ages. A different learning mechanism would be required for the acquisition of adjunct movement, where no missing argument will signal the tail of the dependency.Footnote 10 Although some work finds that infants comprehend and produce subject and certain adjunct questions at young ages (Gagliardi et al. Reference Gagliardi, Mease and Lidz2016, Perkins & Lidz Reference Perkins and Lidz2020, Seidl et al. Reference Seidl, Hollich and Jusczyk2003, Stromswold Reference Stromswold1995), further empirical work is needed to establish the developmental trajectory of infants’ syntactic representations of these other forms of wh-movement relative to object movement, and to investigate the mechanisms by which they are acquired.
A third future research direction is determining how the proposed learning mechanism might generalize crosslinguistically. Our learner uses expectations about the word order of English to detect when direct objects are missing in their canonical positions. This hinges on the assumption that learners at this stage of development have already acquired some knowledge of how their language marks canonical predicate-argument relations. Some computational support exists for this assumption (Maitra & Perkins Reference Maitra and Perkins2023, Perkins & Hunter Reference Perkins and Hunter2023, Reference Perkins and Hunter2026), but further empirical investigation is needed. In languages with a freer word order, other information, such as case morphology, may need to be recruited; see Fisher et al. Reference Fisher, Jin and Scott2019 and Suzuki & Kobayashi Reference Suzuki and Kobayashi2017 for evidence that Korean- and Japanese-learning two-year-olds are sensitive to this information in verb learning.
Moreover, using argument gaps as evidence for movement dependencies requires at least a reasonable correlation between empty arguments and movement in a language. This may be true for English (although see the caveat noted above for matrix subject questions), but this will be complicated in languages that allow syntactic null arguments or wh-in-situ. In languages like Korean and Japanese, learners must come to identify that many of the argument gaps they observe are null pronominals rather than the gaps of movement; conversely, English learners must rule out a null pronominal analysis in favor of movement. And learners of wh-in-situ languages will not be able to rely on argument gaps in order to identify wh-dependencies; instead, they must come to recognize such dependencies even when the wh-element has not overtly moved to the clause position where it takes scope (Aoun et al. Reference Aoun, Hornstein and Sportiche1981, Huang Reference Huang1982). It is possible that learners can more readily recognize when an in-situ wh-element bears a particular grammatical relation, but would need to use other formal, prosodic, or pragmatic information to recognize that this element is in a nonlocal dependency with a higher node in the clause, corresponding to the scope of the interrogative.
We suggest that the mechanism proposed here for English is one instance of a more general learning strategy that might be tailored to fit the evidence provided by a learner’s data. Crosslinguistically, identifying canonical argument dependencies may be a necessary precursor to identifying nonlocal dependencies such as movement. An English learner may identify that word order provides a strong signal for canonical argument relations, and disruptions to this expected canonical word order signal that movement may be present. A Japanese learner may identify that case morphology is a better signal for these argument relations, that argument ‘gaps’ occur with a frequency that is more easily attributed to null pronominals rather than movement, and that overt and covert movement dependencies may be instead signaled by additional formal, prosodic, or pragmatic properties. In both cases, it is plausible that a learner’s initial knowledge of the core predicate-argument structure of a clause provides an important grammatical scaffold for guiding future learning from the surface distributions in the data. This invites further empirical and computational work studying the developmental trajectory of argument structure and argument movement crosslinguistically.
More broadly, the current findings illustrate how two learning mechanisms with analogues in other areas of cognition—statistical learning and learning from expectation violation—can be combined to novel effect in the domain of language acquisition. On this proposal, prior grammatical knowledge creates expectations that, when violated, form the basis for inferring hidden grammatical structure. Statistical learning may then be conducted over this hidden structure as well as more observable forms in the data. Here, we suggest that this combination provides a powerful foothold into syntactic dependency learning in early language development. This may also provide new avenues for understanding how incremental learning proceeds in not only language acquisition but also other domains of cognition, where predictions generated from knowledge acquired earlier in development form part of the data that learners use to draw new generalizations.
Data availability statement
Code and data for the model and simulations reported in this article can be found at https://github.com/perkinsl/mind-the-gap/.
Acknowledgments
We thank Shounak Kuiry, Lillianna Righter, Jordan Schneider, and John-Paul Teti for assistance in coding and data preparation. We also thank Lisa Pearl, Alexander Williams, and audiences at BUCLD 2019 and the University of Maryland CNL Lab for their helpful feedback on earlier versions of this work. [Full editorial history: Received 01 June 2024; revision invited 05 April 2025; revision received 31 July 2025; accepted pending revisions 05 October 2025; revision received 09 January 2026; accepted 12 January 2026.]
Funding disclosure statement
This work was supported by the National Science Foundation (#BCS-1551629, Doctoral Dissertation Improvement grant #BCS-1827709, and NRT award #DGE-1449815), by the Division of Behavioral and Cognitive Sciences (#1551629, #1827709), and by the Division of Graduate Education (#1449815).
Conflict of interest
The authors declare no conflict of interest.
Ethics statement
None.
Appendix A: Details of Gibbs sampling
A1. Joint inference learner
We use Gibbs sampling (Geman & Geman Reference Geman and Geman1984) to jointly infer c and e, integrating over θ, δ (X), and δ (F).
A1.1. Sampling c
To begin, values of c for each sentence are initialized to one of three initial sentence categories: one category with transitivity violations and two without. These initial categories are sampled from the posterior probability distribution that a given sentence contains a transitivity violation under the model in Perkins et al. Reference Perkins, Feldman and Lidz2022. This uses the same sampling equations as for the no-category baseline, reported in Section A2. If a sentence is sampled as containing a transitivity violation under that model, it is initialized to the transitivity-violating category; if not, it is randomly initialized to one of the two nonviolating categories. We used two nonviolating categories rather than one because this improved the sampler’s convergence.
After initializing c, new values of c for each sentence are resampled sequentially. From observations of direct objects and other features in a sentence, and across other sentences in the model’s data, the model determines which previously seen or new value of c was most likely to have generated those observations. For direct object observation
 $ {X}_i^{(v)} $
and other feature observations
$ {X}_i^{(v)} $
and other feature observations
 $ {\overrightarrow{F}}_i^{(v)} $
in sentence i, together with all other direct object observations
$ {\overrightarrow{F}}_i^{(v)} $
in sentence i, together with all other direct object observations
 $ {\mathbf{X}}_{-i} $
, feature observations
$ {\mathbf{X}}_{-i} $
, feature observations
 $ {\overrightarrow{\mathbf{F}}}_{-i} $
, and sentence category assignments
$ {\overrightarrow{\mathbf{F}}}_{-i} $
, and sentence category assignments
 $ {\mathbf{c}}_{-i} $
for other sentences in the data set, we use Bayes’s rule to compute the posterior probability of each value for c.
$ {\mathbf{c}}_{-i} $
for other sentences in the data set, we use Bayes’s rule to compute the posterior probability of each value for c.
 $$ p\left({c}_i|{X}_i^{(v)},{\overrightarrow{F}}_i^{(v)},{T}^{(v)},{e}_c,{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)=\frac{p\left({X}_i^{(v)},{\overrightarrow{F}}_i^{(v)}|{c}_i,{e}_c,{T}^{(v)},{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)p({c}_i|{\mathbf{c}}_{-i})}{{\sum \limits}_{c_i^{\mathrm{\prime}}}p\left({X}_i^{(v)},{\overrightarrow{F}}_i^{(v)}|{c}_i^{\mathrm{\prime}},{e}_c,{T}^{(v)},{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)p({c}_i^{\mathrm{\prime}}|{\mathbf{c}}_{-i})} $$
$$ p\left({c}_i|{X}_i^{(v)},{\overrightarrow{F}}_i^{(v)},{T}^{(v)},{e}_c,{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)=\frac{p\left({X}_i^{(v)},{\overrightarrow{F}}_i^{(v)}|{c}_i,{e}_c,{T}^{(v)},{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)p({c}_i|{\mathbf{c}}_{-i})}{{\sum \limits}_{c_i^{\mathrm{\prime}}}p\left({X}_i^{(v)},{\overrightarrow{F}}_i^{(v)}|{c}_i^{\mathrm{\prime}},{e}_c,{T}^{(v)},{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)p({c}_i^{\mathrm{\prime}}|{\mathbf{c}}_{-i})} $$
The posterior probability of a particular value of c given the observed data, known transitivity categories, and other sentence category values is proportional to the likelihood, the probability of
 $ {X}_i^{(v)} $
and
$ {X}_i^{(v)} $
and
 $ {\overrightarrow{F}}_i^{(v)} $
given that value of c, other observed data and category values, and the prior probability of c. We assume that c is independent of all other model parameters. The prior probability of c is a Dirichlet process (Ferguson Reference Ferguson1973) with parameter α. In this process, each category value ci has prior probability proportional to the number of sentence observations already assigned to that category,
$ {\overrightarrow{F}}_i^{(v)} $
given that value of c, other observed data and category values, and the prior probability of c. We assume that c is independent of all other model parameters. The prior probability of c is a Dirichlet process (Ferguson Reference Ferguson1973) with parameter α. In this process, each category value ci has prior probability proportional to the number of sentence observations already assigned to that category,
 $ {n}_{c_i} $
. This process also reserves a small nonzero probability for new categories of c, determined by the parameter α, which we set equal to 1. The proportion of this extra probability that is reserved for new transitivity-violating categories is 0.19, the mean rate of transitivity violations inferred by the model in Perkins et al. Reference Perkins, Feldman and Lidz2022, and the proportion reserved for new categories without violations is set to 0.81. For n total observations of sentences across all categories, we define the prior on c.
$ {n}_{c_i} $
. This process also reserves a small nonzero probability for new categories of c, determined by the parameter α, which we set equal to 1. The proportion of this extra probability that is reserved for new transitivity-violating categories is 0.19, the mean rate of transitivity violations inferred by the model in Perkins et al. Reference Perkins, Feldman and Lidz2022, and the proportion reserved for new categories without violations is set to 0.81. For n total observations of sentences across all categories, we define the prior on c.
 $$ p\left({c}_i|{\mathbf{c}}_{-i}\right)=\{
\begin{array}{cc}\frac{n_{c_i}}{n+\alpha }& \quad \text{for previously seen values of }\quad c\\
{}\frac{0.19\alpha }{n+\alpha }& \text{for new values where } {e}_c=1\\
{}\frac{0.81\alpha }{n+\alpha }& \text{for new values where } {e}_c=0
\end{array} $$
$$ p\left({c}_i|{\mathbf{c}}_{-i}\right)=\{
\begin{array}{cc}\frac{n_{c_i}}{n+\alpha }& \quad \text{for previously seen values of }\quad c\\
{}\frac{0.19\alpha }{n+\alpha }& \text{for new values where } {e}_c=1\\
{}\frac{0.81\alpha }{n+\alpha }& \text{for new values where } {e}_c=0
\end{array} $$
Assuming independence between X and F, we calculate the likelihood as the product of the probabilities of observing
 $ {X}_i^{(v)} $
and
$ {X}_i^{(v)} $
and
 $ {\overrightarrow{F}}_i^{(v)} $
, given the other observations and model parameters.
$ {\overrightarrow{F}}_i^{(v)} $
, given the other observations and model parameters.
 $$ p\left({X}_i^{(v)},{\overrightarrow{F}}_i^{(v)}|{c}_i,{e}_c,{T}^{(v)},{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)=p\left({X}_i^{(v)}|{c}_i,{e}_c,{T}^{(v)},{\mathbf{X}}_{-i},{\mathbf{c}}_{-i}\right)p\left({\overrightarrow{F}}_i^{(v)}|{c}_i,{e}_c,{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right) $$
$$ p\left({X}_i^{(v)},{\overrightarrow{F}}_i^{(v)}|{c}_i,{e}_c,{T}^{(v)},{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)=p\left({X}_i^{(v)}|{c}_i,{e}_c,{T}^{(v)},{\mathbf{X}}_{-i},{\mathbf{c}}_{-i}\right)p\left({\overrightarrow{F}}_i^{(v)}|{c}_i,{e}_c,{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right) $$
The first term in this likelihood function is calculated differently depending on the value of ec for the current category ci. If ci is a transitivity-violating category (
 $ {e}_{c_i}=1 $
), then direct objects are generated by the grammatical property of that category
$ {e}_{c_i}=1 $
), then direct objects are generated by the grammatical property of that category
 $ {\delta}_{c_i}^{(X)} $
. We calculate the probability of a direct object by integrating over all possible values of
$ {\delta}_{c_i}^{(X)} $
. We calculate the probability of a direct object by integrating over all possible values of
 $ {\delta}_{c_i}^{(X)} $
, conditioning on other observations of sentences in this category.
$ {\delta}_{c_i}^{(X)} $
, conditioning on other observations of sentences in this category.
 $$ p\left({X}_i^{(v)}|{c}_i,{e}_i=1,{T}^{(v)},{\mathbf{X}}_{-i},{\mathbf{c}}_{-i}\right)=\int p\left({X}_i^{(v)}|{\delta}_{c_i}^{(X)}\right)p\left({\delta}_{c_i}^{(X)}|{c}_i,{\mathbf{X}}_{-i}\right)d{\delta}_{c_i}^{(X)} $$
$$ p\left({X}_i^{(v)}|{c}_i,{e}_i=1,{T}^{(v)},{\mathbf{X}}_{-i},{\mathbf{c}}_{-i}\right)=\int p\left({X}_i^{(v)}|{\delta}_{c_i}^{(X)}\right)p\left({\delta}_{c_i}^{(X)}|{c}_i,{\mathbf{X}}_{-i}\right)d{\delta}_{c_i}^{(X)} $$
The first term inside the integral is equal to
 $ {\delta}_{c_i}^{(X)} $
if
$ {\delta}_{c_i}^{(X)} $
if
 $ {X}_i^{(v)}=1 $
, or
$ {X}_i^{(v)}=1 $
, or
 $ 1-{\delta}_{c_i}^{(X)} $
if
$ 1-{\delta}_{c_i}^{(X)} $
if
 $ {X}_i^{(v)}=0 $
. We can use Bayes’s rule to compute the second term inside the integral, the probability of
$ {X}_i^{(v)}=0 $
. We can use Bayes’s rule to compute the second term inside the integral, the probability of
 $ {\delta}_{c_i}^{(X)} $
given all other observations within the category.
$ {\delta}_{c_i}^{(X)} $
given all other observations within the category.
 $$ p\left({\delta}_{c_i}^{(X)}|{c}_i,{\mathbf{X}}_{-i}\right)=\frac{p\left({\mathbf{X}}_{-i}|{\delta}_{c_i}^{(X)},{c}_i\right)p\left({\delta}_{c_i}^{(X)}|{c}_i\right)}{\int p\left({\mathbf{X}}_{-i}|{\delta}_{c_i}^{(X)},{c}_i\right)p\left({\delta}_{c_i}^{(X)}|{c}_i\right)d{\delta}_{c_i}^{(X)}} $$
$$ p\left({\delta}_{c_i}^{(X)}|{c}_i,{\mathbf{X}}_{-i}\right)=\frac{p\left({\mathbf{X}}_{-i}|{\delta}_{c_i}^{(X)},{c}_i\right)p\left({\delta}_{c_i}^{(X)}|{c}_i\right)}{\int p\left({\mathbf{X}}_{-i}|{\delta}_{c_i}^{(X)},{c}_i\right)p\left({\delta}_{c_i}^{(X)}|{c}_i\right)d{\delta}_{c_i}^{(X)}} $$
The prior probability
 $ p\left({\delta}_{c_i}^{(X)}|{c}_i\right) $
is assumed to follow a uniform Beta(1,1) distribution. Let
$ p\left({\delta}_{c_i}^{(X)}|{c}_i\right) $
is assumed to follow a uniform Beta(1,1) distribution. Let
 $ {n}_{c_i} $
be the total observations in category ci and
$ {n}_{c_i} $
be the total observations in category ci and
 $ {k}_{c_i} $
be the total direct object observations in this category. The likelihood term,
$ {k}_{c_i} $
be the total direct object observations in this category. The likelihood term,
 $ p\left({\mathbf{X}}_{-i}|{\delta}_{c_i}^{(X)},{c}_i\right) $
, is the probability of observing
$ p\left({\mathbf{X}}_{-i}|{\delta}_{c_i}^{(X)},{c}_i\right) $
, is the probability of observing
 $ {k}_{c_i} $
direct objects in
$ {k}_{c_i} $
direct objects in
 $ {n}_{c_i} $
total observations. This follows a binomial distribution with parameter
$ {n}_{c_i} $
total observations. This follows a binomial distribution with parameter
 $ {\delta}_{c_i}^{(X)} $
.
$ {\delta}_{c_i}^{(X)} $
.
 $$ p\left({\mathbf{X}}_{-i}|{\delta}_{c_{i}}^{(X)},{c}_{i}\right)=\begin{array}{c}
n_{c_{i}}\\
{k}_{c_{i}}
\end{array}
$$
$$ p\left({\mathbf{X}}_{-i}|{\delta}_{c_{i}}^{(X)},{c}_{i}\right)=\begin{array}{c}
n_{c_{i}}\\
{k}_{c_{i}}
\end{array}
$$
Solving the integral in equation A4, we calculate that
 $ {X}_i^{(v)} $
takes a value of 1 with probability
$ {X}_i^{(v)} $
takes a value of 1 with probability
 $ \frac{k_{c_i}+1}{n_{c_i}+2} $
, and 0 with probability
$ \frac{k_{c_i}+1}{n_{c_i}+2} $
, and 0 with probability
 $ \frac{n_{c_i}-{k}_{c_i}+1}{n_{c_i}+2} $
.
$ \frac{n_{c_i}-{k}_{c_i}+1}{n_{c_i}+2} $
.
If ci is not a transitivity-violating category (
 $ {e}_{c_i}=0 $
), then direct objects in this category are generated by the transitivity properties of each verb. The first term in the likelihood function in equation A3 thus depends on the known transitivity category T (v) and θ (v), the rate of direct objects under that transitivity category. If verb v is transitive or intransitive, then θ is known, and
$ {e}_{c_i}=0 $
), then direct objects in this category are generated by the transitivity properties of each verb. The first term in the likelihood function in equation A3 thus depends on the known transitivity category T (v) and θ (v), the rate of direct objects under that transitivity category. If verb v is transitive or intransitive, then θ is known, and
 $ {X}_i^{(v)} $
takes a value of 1 with probability θ, and 0 with probability 1 − θ. If verb v is alternating, we again integrate over all possible values of θ (v), conditioning on observations of this verb in other categories without argument gaps. This integral is analogous to the integral in equation A4. Here, let
$ {X}_i^{(v)} $
takes a value of 1 with probability θ, and 0 with probability 1 − θ. If verb v is alternating, we again integrate over all possible values of θ (v), conditioning on observations of this verb in other categories without argument gaps. This integral is analogous to the integral in equation A4. Here, let
 $ {n}_1^{(v)} $
be the total observations for verb v in categories where ec = 0, and
$ {n}_1^{(v)} $
be the total observations for verb v in categories where ec = 0, and
 $ {k}_1^{(v)} $
be the total direct object observations for verb v in these categories. Following equations analogous to A4–A6, we calculate that
$ {k}_1^{(v)} $
be the total direct object observations for verb v in these categories. Following equations analogous to A4–A6, we calculate that
 $ {X}_i^{(v)} $
takes a value of 1 with probability
$ {X}_i^{(v)} $
takes a value of 1 with probability
 $ \frac{k_1^{(v)}+1}{n_1^{(v)}+2} $
, and 0 with probability
$ \frac{k_1^{(v)}+1}{n_1^{(v)}+2} $
, and 0 with probability
 $ \frac{n_1^{(v)}-{k}_1^{(v)}+1}{n_1^{(v)}+2} $
.
$ \frac{n_1^{(v)}-{k}_1^{(v)}+1}{n_1^{(v)}+2} $
.
The second term in equation A3 is the probability of the other observed features occurring in the given category. Assuming independence among features, this is equivalent to the product over the probabilities of observing each feature in this category.
 $$ p\left({\overrightarrow{F}}_i^{(v)}|{c}_i,{e}_c,{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)={\prod}_{F_i^{\mathrm{\prime}(v)}}p\left({F}_i^{\mathrm{\prime}(v)}|{c}_i,{e}_c,{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right) $$
$$ p\left({\overrightarrow{F}}_i^{(v)}|{c}_i,{e}_c,{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)={\prod}_{F_i^{\mathrm{\prime}(v)}}p\left({F}_i^{\mathrm{\prime}(v)}|{c}_i,{e}_c,{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right) $$
The probability of observing a particular feature F in a category ci is given by
 $ {\delta}_{c_i}^{(F)} $
for that feature and that category. We integrate over all possible values of
$ {\delta}_{c_i}^{(F)} $
for that feature and that category. We integrate over all possible values of
 $ {\delta}_{c_i}^{(F)} $
, conditioning on other observations of feature F. Let
$ {\delta}_{c_i}^{(F)} $
, conditioning on other observations of feature F. Let
 $ {n}_{c_i} $
be the total observations in category ci and
$ {n}_{c_i} $
be the total observations in category ci and
 $ {k}_{c_i}^F $
be the total observations of feature F in this category. Following equations analogous to A4–A6, we calculate that
$ {k}_{c_i}^F $
be the total observations of feature F in this category. Following equations analogous to A4–A6, we calculate that
 $ {F}_i^{(v)} $
takes a value of 1 with probability
$ {F}_i^{(v)} $
takes a value of 1 with probability
 $ \frac{k_{c_i}^F+1}{n_{c_i}+2} $
, and 0 with probability
$ \frac{k_{c_i}^F+1}{n_{c_i}+2} $
, and 0 with probability
 $ \frac{n_{c_i}-{k}_{c_i}^F+1}{n_{c_i}+2} $
.
$ \frac{n_{c_i}-{k}_{c_i}^F+1}{n_{c_i}+2} $
.
A1.2. Sampling e
After sampling values for c for each sentence in the data set, we then sample new values of e for each category. We calculate the posterior probability of each value of ec for a category c given all of the direct object observations in that category X c and known verb transitivity properties T.
 $$ p\left({e}_c|c,{\mathbf{X}}_c,T\right)=\frac{p\left({\mathbf{X}}_c|{e}_c,c,T\right)p\left({e}_c\right)}{\sum_{e_c^{\prime }}p\left({\mathbf{X}}_c|{e}_c^{\prime },c,T\right)p\left({e}_c^{\prime}\right)} $$
$$ p\left({e}_c|c,{\mathbf{X}}_c,T\right)=\frac{p\left({\mathbf{X}}_c|{e}_c,c,T\right)p\left({e}_c\right)}{\sum_{e_c^{\prime }}p\left({\mathbf{X}}_c|{e}_c^{\prime },c,T\right)p\left({e}_c^{\prime}\right)} $$
We assume that ec is independent of T and c and that the prior probability p(ec) = 1 is again set to 0.19, the mean rate of transitivity violations inferred by the model in Perkins et al. Reference Perkins, Feldman and Lidz2022. In other words, the learner assumes that the prior probability of a transitivity-violating category is equivalent to the probability that any single sentence contains a transitivity violation, as inferred by the previous learner. This will be the case only if sentences are equally distributed among categories, a simplifying assumption of the learner’s prior that may be overridden if not supported by the data.
The likelihood term, p(X
c|ec, c, T), is the probability of seeing particular observations of direct objects for verbs in this category. If
 $ {e}_{c_i}=1 $
and ci is a transitivity-violating category, this probability is determined by
$ {e}_{c_i}=1 $
and ci is a transitivity-violating category, this probability is determined by
 $ {\delta}_{c_i}^{(X)} $
. We calculate the joint probability of the direct object observations for each verb in that category given
$ {\delta}_{c_i}^{(X)} $
. We calculate the joint probability of the direct object observations for each verb in that category given
 $ {\delta}_{c_i}^{(X)} $
, integrating across all possible values of
$ {\delta}_{c_i}^{(X)} $
, integrating across all possible values of
 $ {\delta}_{c_i}^{(X)} $
.
$ {\delta}_{c_i}^{(X)} $
.
 $$ p\left({\mathbf{X}}_c|{e}_c=1,c,T\right)=\int \prod \limits_{v^{\prime }}\left(p\left({\mathbf{X}}_c^{\left({v}^{\prime}\right)}|{\delta}_{c_i}^{(X)}\right)\right)p\left({\delta}_{c_i}^{(X)}|{c}_i\right)d{\delta}_{c_i}^{(X)} $$
$$ p\left({\mathbf{X}}_c|{e}_c=1,c,T\right)=\int \prod \limits_{v^{\prime }}\left(p\left({\mathbf{X}}_c^{\left({v}^{\prime}\right)}|{\delta}_{c_i}^{(X)}\right)\right)p\left({\delta}_{c_i}^{(X)}|{c}_i\right)d{\delta}_{c_i}^{(X)} $$
The first term inside the integral is the product across all verbs of probability of the direct observations for that verb
 $ {\mathbf{X}}_c^{(v)} $
in the category, given
$ {\mathbf{X}}_c^{(v)} $
in the category, given
 $ {\delta}_{c_i}^{(X)} $
. This probability is given in equation A6. We again assume that the prior probability
$ {\delta}_{c_i}^{(X)} $
. This probability is given in equation A6. We again assume that the prior probability
 $ p\left({\delta}_{c_i}^{(X)}|{c}_i\right) $
follows a uniform Beta(1,1) distribution. Let nc be the total observations in a particular category and kc be the total direct object observations in that category. Solving the integral in equation A9, we find the following.
$ p\left({\delta}_{c_i}^{(X)}|{c}_i\right) $
follows a uniform Beta(1,1) distribution. Let nc be the total observations in a particular category and kc be the total direct object observations in that category. Solving the integral in equation A9, we find the following.
 $$ p\left({\mathbf{X}}_c|{e}_c=1,c,T\right)=\frac{\varGamma \left({k}_c+1\right)\varGamma \left({n}_c-{k}_c+1\right)}{\varGamma \left({n}_c+2\right)}\left(\prod \limits_{v^{\prime }}\frac{\varGamma \left({n}_c^{\left({v}^{\prime}\right)}+1\right)}{\varGamma \left({k}_c^{\left({v}^{\prime}\right)}+1\right)\varGamma \left({n}_c^{\left({v}^{\prime}\right)}-{k}_c^{\left({v}^{\prime}\right)}+1\right)}\right) $$
$$ p\left({\mathbf{X}}_c|{e}_c=1,c,T\right)=\frac{\varGamma \left({k}_c+1\right)\varGamma \left({n}_c-{k}_c+1\right)}{\varGamma \left({n}_c+2\right)}\left(\prod \limits_{v^{\prime }}\frac{\varGamma \left({n}_c^{\left({v}^{\prime}\right)}+1\right)}{\varGamma \left({k}_c^{\left({v}^{\prime}\right)}+1\right)\varGamma \left({n}_c^{\left({v}^{\prime}\right)}-{k}_c^{\left({v}^{\prime}\right)}+1\right)}\right) $$
If
 $ {e}_{c_i}=0 $
and ci is not a transitivity-violating category, the likelihood term in equation A8 is determined by the known transitivity T (v) of each verb in the category. The probability of the particular direct object observations X
c in the category is the joint probability of seeing those direct object observations for each verb, given the transitivity of that verb.
$ {e}_{c_i}=0 $
and ci is not a transitivity-violating category, the likelihood term in equation A8 is determined by the known transitivity T (v) of each verb in the category. The probability of the particular direct object observations X
c in the category is the joint probability of seeing those direct object observations for each verb, given the transitivity of that verb.
 $$ p\left({\mathbf{X}}_c|{e}_c=0,c,T\right)=\prod \limits_{v^{\prime }}(p\left({\mathbf{X}}_c^{\left({v}^{\prime}\right)}|{T}^{\left({v}^{\prime}\right)}\right) $$
$$ p\left({\mathbf{X}}_c|{e}_c=0,c,T\right)=\prod \limits_{v^{\prime }}(p\left({\mathbf{X}}_c^{\left({v}^{\prime}\right)}|{T}^{\left({v}^{\prime}\right)}\right) $$
We can again rewrite
 $ {\mathbf{X}}_c^{(v)} $
as
$ {\mathbf{X}}_c^{(v)} $
as
 $ {k}_c^v $
direct object observations out of
$ {k}_c^v $
direct object observations out of
 $ {n}_c^v $
total observations for a given verb in a given category. The probability of observing
$ {n}_c^v $
total observations for a given verb in a given category. The probability of observing
 $ {k}_c^v $
direct objects out of
$ {k}_c^v $
direct objects out of
 $ {n}_c^v $
total observations of a verb follows a binomial distribution with parameter θ (v). Recall that θ (v) = 1 for transitive verbs and θ (v) = 0 for intransitive verbs. For alternating verbs, we must integrate across all possible values of θ (v).
$ {n}_c^v $
total observations of a verb follows a binomial distribution with parameter θ (v). Recall that θ (v) = 1 for transitive verbs and θ (v) = 0 for intransitive verbs. For alternating verbs, we must integrate across all possible values of θ (v).
 $$ p\left({\mathbf{X}}_c|{e}_c=0,c,T\right)=p\left({k}_c^{(v)}|{n}_c^{(v)},{T}^{(v)}\right)=\int p\left({k}_c^{(v)}|{n}_c^{(v)},{\theta}^{(v)}\right)p\left({\theta}^{(v)}|{T}^{(v)}\right)d{\theta}^{(v)} $$
$$ p\left({\mathbf{X}}_c|{e}_c=0,c,T\right)=p\left({k}_c^{(v)}|{n}_c^{(v)},{T}^{(v)}\right)=\int p\left({k}_c^{(v)}|{n}_c^{(v)},{\theta}^{(v)}\right)p\left({\theta}^{(v)}|{T}^{(v)}\right)d{\theta}^{(v)} $$
We assume that p(θ (v) | T (v)) follows a Beta(α,β) distribution, where the parameters α and β are counts of direct object observations and no direct object observations for verb v in other categories without argument gaps. Solving the integral in equation A12, we find as follows.
 $$ p\left({k}_c^{(v)}|{n}_c^{(v)},{T}^{(v)}\right)=\left(\frac{\varGamma \left({n}_c^{(v)}+1\right)}{\varGamma \left({k}_c^{(v)}+1\right)\varGamma ({n}_c^{(v)}-{k}_c^{(v)}+1}\right)\left(\frac{\varGamma \left(\alpha +\beta \right)}{\varGamma \left(\alpha \right)\varGamma \left(\beta \right)}\right)\left(\frac{\varGamma \left({k}_c^{(v)}+\alpha \right)\varGamma \left({n}_c^{(v)}-{k}_c^{(v)}+\beta \right)}{\varGamma \left({n}_c^{(v)}+\alpha +\beta \right)}\right) $$
$$ p\left({k}_c^{(v)}|{n}_c^{(v)},{T}^{(v)}\right)=\left(\frac{\varGamma \left({n}_c^{(v)}+1\right)}{\varGamma \left({k}_c^{(v)}+1\right)\varGamma ({n}_c^{(v)}-{k}_c^{(v)}+1}\right)\left(\frac{\varGamma \left(\alpha +\beta \right)}{\varGamma \left(\alpha \right)\varGamma \left(\beta \right)}\right)\left(\frac{\varGamma \left({k}_c^{(v)}+\alpha \right)\varGamma \left({n}_c^{(v)}-{k}_c^{(v)}+\beta \right)}{\varGamma \left({n}_c^{(v)}+\alpha +\beta \right)}\right) $$
A1.3. Sampling with annealing
The reported simulations used 5,000 total iterations of Gibbs sampling. This number was chosen to be the largest that could run within a feasible amount of time, and the model was run multiple times to assess convergence, with no substantive differences found across runs. To aid in the model’s search process, simulated annealing was used during the first 1,000 iterations. In this process, we raise the posterior probabilities of c and e to the power of an annealing constant defined as 1/t, where t is the current temperature. Then, we slowly lower the temperature (reduce t) until the annealing constant reaches 1. While the temperature is warm, the posterior probability distributions are flattened so the learner is able to explore more of its hypothesis space. After 1,000 iterations of Gibbs sampling with annealing, another 4,000 iterations were run without annealing. The final iteration was taken as a sample from the posterior distribution over c and e.
A2. Baseline models
A2.1. No-category baseline
Transitivity violations under the no-category baseline were sampled from the posterior probability distribution over the variable e in Perkins et al. Reference Perkins, Feldman and Lidz2022, given observed direct objects X and the values of T and δ (X) inferred by that model. Here, e is a random variable encoding whether an individual sentence contains a transitivity violation and δ (X) is the probability that a transitivity violation will produce a direct object in an individual sentence. Via Bayes’s rule, the posterior predictive probability for the value ei of a particular sentence i, given the direct object observation
 $ {X}_i^{(v)} $
for the verb v in that sentence, all other error values
$ {X}_i^{(v)} $
for the verb v in that sentence, all other error values
 $ {\mathbf{e}}_{-i} $
, other direct object observations
$ {\mathbf{e}}_{-i} $
, other direct object observations
 $ {\mathbf{X}}_{-i} $
, and other model parameters, is as follows.
$ {\mathbf{X}}_{-i} $
, and other model parameters, is as follows.
 $$ p\left({e}_i|{X}_i^{(v)},{T}^{(v)},{\delta}^{(X)},{\mathbf{e}}_{-i},{\mathbf{X}}_{-i}\right)=\frac{p\left({X}_i^{(v)}|{e}_i,{T}^{(v)},{\delta}^{(X)},{\mathbf{e}}_{-i},{\mathbf{X}}_{-i}\right)p\left({e}_i\right)}{\sum_{e_i^{\prime }}p\left({X}_i^{(v)}|{e}_i^{\prime },{T}^{(v)},{\delta}^{(X)},{\mathbf{e}}_{-i},{\mathbf{X}}_{-i}\right)p\left({e}_i^{\prime}\right)} $$
$$ p\left({e}_i|{X}_i^{(v)},{T}^{(v)},{\delta}^{(X)},{\mathbf{e}}_{-i},{\mathbf{X}}_{-i}\right)=\frac{p\left({X}_i^{(v)}|{e}_i,{T}^{(v)},{\delta}^{(X)},{\mathbf{e}}_{-i},{\mathbf{X}}_{-i}\right)p\left({e}_i\right)}{\sum_{e_i^{\prime }}p\left({X}_i^{(v)}|{e}_i^{\prime },{T}^{(v)},{\delta}^{(X)},{\mathbf{e}}_{-i},{\mathbf{X}}_{-i}\right)p\left({e}_i^{\prime}\right)} $$
For the prior probability that a sentence contains a transitivity violation p(ei), we again use 0.19, the mean rate of transitivity violations (the parameter ε) inferred by the learner in Perkins et al. Reference Perkins, Feldman and Lidz2022. If the sentence contains a transitivity violation (ei = 1), the likelihood
 $ p\left({X}_i^{(v)}|{e}_i=1,{T}^{(v)},\varepsilon, {\delta}^{(X)},{\mathbf{e}}_{-i},{\mathbf{X}}_{-i}\right) $
depends only on the value for δ (X), the probability that a transitivity violation produces a direct object:
$ p\left({X}_i^{(v)}|{e}_i=1,{T}^{(v)},\varepsilon, {\delta}^{(X)},{\mathbf{e}}_{-i},{\mathbf{X}}_{-i}\right) $
depends only on the value for δ (X), the probability that a transitivity violation produces a direct object:
 $ {X}_i^{(v)} $
takes a value of 1 with probability δ (X), and 0 with probability 1 − δ (X). If the sentence does not contain a transitivity violation (ei = 0), the likelihood depends on the probability that verb v occurs with a direct object, given by θ (v) for the verb’s transitivity category T (v). If the verb is transitive or intransitive, θ (v) is known;
$ {X}_i^{(v)} $
takes a value of 1 with probability δ (X), and 0 with probability 1 − δ (X). If the sentence does not contain a transitivity violation (ei = 0), the likelihood depends on the probability that verb v occurs with a direct object, given by θ (v) for the verb’s transitivity category T (v). If the verb is transitive or intransitive, θ (v) is known;
 $ {X}_i^{(v)} $
takes a value of 1 with probability θ, and 0 with probability 1 − θ. If the verb is alternating, we must again integrate over all possible values of θ (v), conditioning on other observations of this verb without transitivity violations. Let
$ {X}_i^{(v)} $
takes a value of 1 with probability θ, and 0 with probability 1 − θ. If the verb is alternating, we must again integrate over all possible values of θ (v), conditioning on other observations of this verb without transitivity violations. Let
 $ {n}_1^{(v)} $
be the total observations for verb v in sentences where e = 0, and
$ {n}_1^{(v)} $
be the total observations for verb v in sentences where e = 0, and
 $ {k}_1^{(v)} $
be the total direct object observations in those sentences. Again following equations analogous to A4–A6, we find that
$ {k}_1^{(v)} $
be the total direct object observations in those sentences. Again following equations analogous to A4–A6, we find that
 $ {X}_i^{(v)} $
takes a value of 1 with probability
$ {X}_i^{(v)} $
takes a value of 1 with probability
 $ \frac{k_1^{(v)}+1}{n_1^{(v)}+2} $
, and 0 with probability
$ \frac{k_1^{(v)}+1}{n_1^{(v)}+2} $
, and 0 with probability
 $ \frac{n_1^{(v)}-{k}_1^{(v)}+1}{n_1^{(v)}+2} $
.
$ \frac{n_1^{(v)}-{k}_1^{(v)}+1}{n_1^{(v)}+2} $
.
For the no-category baseline simulation, values of e were randomly initialized for each sentence and were then resampled sequentially from the posterior distribution over ei above, using the values for T and the mean value of δ (X) = 0.25 inferred by the model in Perkins et al. Reference Perkins, Feldman and Lidz2022. This process was repeated over 5,000 iterations of Gibbs sampling, and the final sample was used as a sample from model’s posterior distribution over e.
A2.2. No-transitivity baseline
Sentence categories for the no-transitivity baseline were sampled according to a subset of the equations in Section A1 for our joint inference learner, without conditioning on individual verbs, transitivity values, or transitivity violations. Given observations of direct objects Xi and other features
 $ {\overrightarrow{F}}_i $
in sentence i, together with other direct object and feature observations
$ {\overrightarrow{F}}_i $
in sentence i, together with other direct object and feature observations
 $ {\mathbf{X}}_{-i} $
and
$ {\mathbf{X}}_{-i} $
and
 $ {\mathbf{F}}_{-i} $
as well as other sentence category assignments
$ {\mathbf{F}}_{-i} $
as well as other sentence category assignments
 $ {\mathbf{c}}_{-i} $
, the posterior probability of ci is as follows.
$ {\mathbf{c}}_{-i} $
, the posterior probability of ci is as follows.
 $$ p\left({c}_i|{X}_i,{\overrightarrow{F}}_i,{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)=\frac{p\left({X}_i,{\overrightarrow{F}}_i|{c}_i,{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)p\left({c}_i|{\mathbf{c}}_{-i}\right)}{\sum_{c_i^{\prime }}p\left({X}_i,{\overrightarrow{F}}_i|{c}_i^{\prime },{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)p\left({c}_i^{\prime }|{\mathbf{c}}_{-i}\right)} $$
$$ p\left({c}_i|{X}_i,{\overrightarrow{F}}_i,{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)=\frac{p\left({X}_i,{\overrightarrow{F}}_i|{c}_i,{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)p\left({c}_i|{\mathbf{c}}_{-i}\right)}{\sum_{c_i^{\prime }}p\left({X}_i,{\overrightarrow{F}}_i|{c}_i^{\prime },{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right)p\left({c}_i^{\prime }|{\mathbf{c}}_{-i}\right)} $$
The prior probability of c is calculated just as in our joint inference learner, in equation A2. Again assuming independence between X and F, we calculate the likelihood
 $ p\left({X}_i,{\overrightarrow{F}}_i|{c}_i,{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right) $
as the product of the likelihoods of observing Xi and
$ p\left({X}_i,{\overrightarrow{F}}_i|{c}_i,{\mathbf{X}}_{-i},{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right) $
as the product of the likelihoods of observing Xi and
 $ {\overrightarrow{F}}_i $
given all other observations and sentence categories. Because the no-transitivity baseline assumes that a direct object observation Xi is generated directly by the sentence category ci and not by the transitivity properties of the verb in that sentence, the likelihood of a direct object
$ {\overrightarrow{F}}_i $
given all other observations and sentence categories. Because the no-transitivity baseline assumes that a direct object observation Xi is generated directly by the sentence category ci and not by the transitivity properties of the verb in that sentence, the likelihood of a direct object
 $ p\left({X}_i|{c}_i,{\mathbf{X}}_{-i},{\mathbf{c}}_{-i}\right) $
is calculated according to the equations for transitivity-violating categories under the joint inference learner (equations A4–A6). The likelihood of the features in a sentence
$ p\left({X}_i|{c}_i,{\mathbf{X}}_{-i},{\mathbf{c}}_{-i}\right) $
is calculated according to the equations for transitivity-violating categories under the joint inference learner (equations A4–A6). The likelihood of the features in a sentence
 $ p\left({\overrightarrow{F}}_i|{c}_i,{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right) $
is calculated in the same way as for our joint inference learner, in equation A7.
$ p\left({\overrightarrow{F}}_i|{c}_i,{\overrightarrow{\mathbf{F}}}_{-i},{\mathbf{c}}_{-i}\right) $
is calculated in the same way as for our joint inference learner, in equation A7.
The simulation for the no-transitivity baseline was conducted similarly to the simulation for our joint inference learner. Each value of c was first randomly initialized to one of three categories and then resampled over 5,000 iterations of Gibbs sampling, with simulated annealing used during the first 1,000 iterations. The final iteration was taken as a sample from the posterior distribution over c.
Appendix B: Accuracy of automated data set coding
Table A1 reports percentage agreement and Cohen’s kappa between two researchers’ hand-coding and the automated annotations, for each sentence feature and clause type in a random sample of 500 sentences from our data set. We also report the interrater reliability of the two researchers for the purposes of comparison. We note that Cohen’s kappa should be interpreted with caution, as each sentence feature and clause type was represented to different degrees within the 500-sentence sample.
Accuracy of sentence feature and clause-type coding.

Table A1. Long description
Beginning at the top, the table lists sentence features such as subject overt, subject sentence-initial, subject follows auxiliary, subject follows noun phrase, verb is first in sentence, verb before preposition or particle, and verb forms including -ed, -en, -ing, -s, irregular, follows to, be, have, get, occurs with do, sentence-initial functor, sentence-medial functor pre-verb, sentence-medial functor post-verb, sentence-final functor, and question. For each feature, agreement and kappa values are provided for Rater 1 vs. Automated, Rater 2 vs. Automated, and Rater 1 vs. Rater 2. Agreement values are generally high, ranging from 0.84 to 1.00, while kappa values vary more, with some features like subject follows noun phrase and sentence-medial functor post-verb showing lower kappa (0.34 to 0.63). Verb forms and question features consistently show perfect agreement and kappa (1.00). Clause types are listed next, including basic transitive, basic intransitive, wh-question, polar question, other question, passive, relative clause, other embedded clause, and imperative. Agreement remains high (0.84 to 1.00), but kappa values are more variable, especially for relative clause (0.23 to 0.60) and passive (0.28 to 0.66). The table demonstrates strong inter-rater and automated agreement for most features, but highlights variability in kappa for certain clause types and complex sentence structures.
Appendix C: Details of odds ratio comparisons
To assess the featural makeup of the categories inferred by our model, we calculated the odds ratio (OR) for each feature in each of these categories. The odds of observing a feature in a particular category were divided by the odds of observing the feature outside of that category. For any given category c and feature F, let
 $ {n}_{F=1}^{(c)} $
be the number of times that feature was present within a category (had value 1) and
$ {n}_{F=1}^{(c)} $
be the number of times that feature was present within a category (had value 1) and
 $ {n}_{F=1}^{\left(-c\right)} $
be the number of times that feature was present outside of that category. Similarly, let
$ {n}_{F=1}^{\left(-c\right)} $
be the number of times that feature was present outside of that category. Similarly, let
 $ {n}_{F=0}^{(c)} $
be the number of times that feature was absent within a category (had value 0) and
$ {n}_{F=0}^{(c)} $
be the number of times that feature was absent within a category (had value 0) and
 $ {n}_{F=0}^{\left(-c\right)} $
be the number of times that feature was absent outside of that category. Then, the odds ratio is calculated as in equation A16.
$ {n}_{F=0}^{\left(-c\right)} $
be the number of times that feature was absent outside of that category. Then, the odds ratio is calculated as in equation A16.
 $$ \mathrm{O}{\mathrm{R}}_F^{(c)}=\frac{n_{F=1}^{(c)}\hskip0.33em /\hskip0.33em {n}_{F=1}^{\left(-c\right)}}{n_{F=0}^{(c)}\hskip0.33em /\hskip0.33em {n}_{F=0}^{\left(-c\right)}} $$
$$ \mathrm{O}{\mathrm{R}}_F^{(c)}=\frac{n_{F=1}^{(c)}\hskip0.33em /\hskip0.33em {n}_{F=1}^{\left(-c\right)}}{n_{F=0}^{(c)}\hskip0.33em /\hskip0.33em {n}_{F=0}^{\left(-c\right)}} $$
An odds ratio greater than 1 indicates that a feature has higher-than-usual odds inside a category; an odds ratio less than 1 indicates that a feature has lower-than-usual odds inside a category. An odds ratio of infinity can occur if a feature is always present inside a category, and an odds ratio of 0 can occur if a feature is never present.
A Fisher’s exact test was conducted to determine whether particular features had significantly higher or lower odds of occurring within a category. A Bonferroni correction was applied to correct for multiple comparisons: because twenty-two features were analyzed for each category (direct objects X plus all twenty-one features in
 $ \overrightarrow{F} $
), the critical value for each comparison was established by setting α equal to 0.05/22 = 0.002.
$ \overrightarrow{F} $
), the critical value for each comparison was established by setting α equal to 0.05/22 = 0.002.
C1. Determining object-gap categories
We first determined our model’s ‘object gap’ categories by calculating the odds of observing a direct object within each of the sixteen categories that the model inferred to have a transitivity violation. Table A2 reports the odds ratios (OR) for direct objects, along with their 95% confidence intervals (CIs) and p-values, in each of the model’s transitivity-violating categories. A transitivity-violating category was classified as an object-gap category if the odds ratio was significantly lower than 1 (at p < 0.002)—that is, if the category had significantly lower odds of producing direct objects. The threshold of significance was met in categories 1–15, which were therefore classified as object-gap categories; it was not met in category 16, which was therefore classified as ‘other’.
Odds ratios for direct objects within transitivity-violating categories, joint inference model.

Table A2. Long description
Beginning at the top row, the table lists sixteen categories in the leftmost column. For each category, the odds ratio is shown in the second column, the confidence interval in the third, and the p-value in the fourth. Category 1 has odds ratio 0.00, confidence interval 0.00 to 0.01, and p-value 4.97 E minus 129. Category 2 shows odds ratio 0.06, confidence interval 0.03 to 0.10, and p-value 8.70 E minus 56. Category 3 has odds ratio 0.28, confidence interval 0.22 to 0.35, and p-value 1.71 E minus 33. Category 4 displays odds ratio 0.13, confidence interval 0.06 to 0.25, and p-value 2.19 E minus 13. Category 5 has odds ratio 0.00, confidence interval 0.00 to 0.05, and p-value 5.47 E minus 22. Category 6 shows odds ratio 0.05, confidence interval 0.00 to 0.28, and p-value 3.35 E minus 06. Category 7 has odds ratio 0.28, confidence interval 0.14 to 0.53, and p-value 1.44 E minus 05. Category 8 displays odds ratio 0.13, confidence interval 0.06 to 0.27, and p-value 2.11 E minus 12. Category 9 has odds ratio 0.03, confidence interval 0.00 to 0.21, and p-value 3.64 E minus 08. Category 10 shows odds ratio 0.26, confidence interval 0.13 to 0.47, and p-value 5.36 E minus 07. Category 11 has odds ratio 0.32, confidence interval 0.26 to 0.40, and p-value 4.76 E minus 27. Category 12 displays odds ratio 0.10, confidence interval 0.06 to 0.15, and p-value 8.04 E minus 51. Category 13 has odds ratio 0.61, confidence interval 0.48 to 0.78, and p-value 4.01 E minus 05. Category 14 shows odds ratio 0.50, confidence interval 0.37 to 0.67, and p-value 2.01 E minus 06. Category 15 has odds ratio 0.11, confidence interval 0.06 to 0.19, and p-value 6.91 E minus 28. Category 16 displays odds ratio 0.60, confidence interval 0.39 to 0.90, and p-value 0.01. All values are presented in scientific notation where applicable.
We performed a similar calculation to determine the candidate object-gap categories for the no-transitivity baseline learner. Because this learner does not infer whether categories contain transitivity violations, we calculated the odds ratios for direct objects across all of the model’s categories, reported in Table A3. A category was classified as a candidate object-gap category if it had significantly lower odds of producing direct objects (OR < 1, p < 0.002); this criterion was met in categories 1–22. All other categories were classified as ‘no gap’.
Odds ratios for direct objects within sentence categories, no-transitivity baseline.

Table A3. Long description
The table is organized into two sets of columns per row. The left columns list categories 1 to 22, each with odds ratio, confidence interval, and p-value. The right columns list categories 23 to 39 with the same metrics. For categories 1 to 22: odds ratios range from 0.00 to 0.68, with most values below 1.00, indicating reduced odds for direct objects in these categories. Notable low odds ratios include category 4 at 0.00 with confidence interval [0.00, 0.05] and p-value 2.79 E minus 22, and category 13 at 0.00 with confidence interval [0.00, 0.01] and p-value 8.90 E minus 116. For categories 23 to 39: odds ratios vary more widely, with some above 1.00. Category 27 shows a high odds ratio of 57.05 with confidence interval [37.09, 92.92] and p-value 1.18 E minus 292, while category 30 has odds ratio 5.16 with confidence interval [4.43, 6.03] and p-value 6.86 E minus 130. Several categories, such as 24, 25, 26, 28, 29, 36, and 37, have odds ratios near or below 1.00 with non-significant p-values above 0.05. The table highlights both significant reductions and increases in odds for direct objects depending on sentence category, with statistical significance indicated by low p-values.
C2. Analyzing features of object-gap categories
To assess which surface features F were distinctive of the joint inference model’s fifteen object-gap categories, we calculated the odds ratios for each of the twenty-one features in each of these categories. Table A4 reports the odds ratio (OR), along with its 95% confidence interval (CI) and p-value, for each feature in each of the model’s object-gap categories. A feature was considered to be distinctive of a particular category if its odds ratio was significantly greater than 1 within that category (p < 0.002)—that is, if the category had significantly greater odds of producing that feature.
Odds ratios for features F within object-gap categories, joint inference model.

Table A4. Long description
Starting from the top, the table lists linguistic features in the leftmost column, with paired columns for odds ratio, confidence interval, and p-value for each object-gap category. The first header row introduces Category 1 and Category 2, followed by rows for features such as Subject overt, Subject sent-init, Subject follows aux, Subject follows N P, V is first in sentence, V before prep or particle, V has -ed, V has -en, V has -ing, V has -s, V irregular, V follows to, V follows be, V follows have, V follows get, V occurs with do, Sent-init functor, Sent-med functor pre-V, Sent-med functor post-V, Sent-fin functor, and Question. For each feature, the table provides odds ratio (including values such as infinity, zero, and large numbers), confidence intervals (e.g., [79.90, infinity], [0, 0.02]), and p-values (e.g., 5.00 E minus 97, 2.91 E minus 13) for both categories. This pattern repeats for subsequent pairs of categories, progressing left-to-right through Category 3 and Category 4, up to Category 15. Notable trends include frequent extreme odds ratios (infinity or zero), highly significant p-values, and wide confidence intervals for certain features. Some features, such as Subject overt and V has -ing, display consistently high or infinite odds ratios in specific categories, while others, like V has -ed or V irregular, show odds ratios near zero. The table structure allows comparison of statistical significance and effect size for each feature across all object-gap categories.
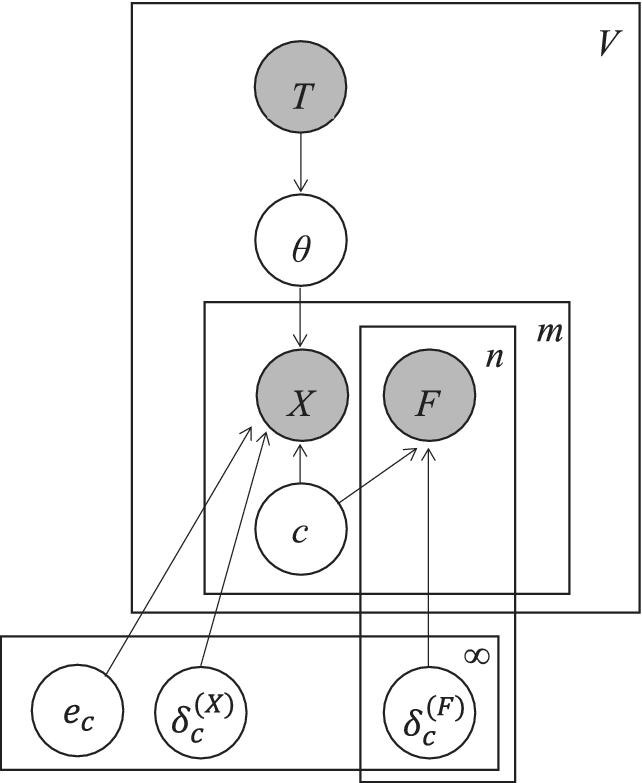





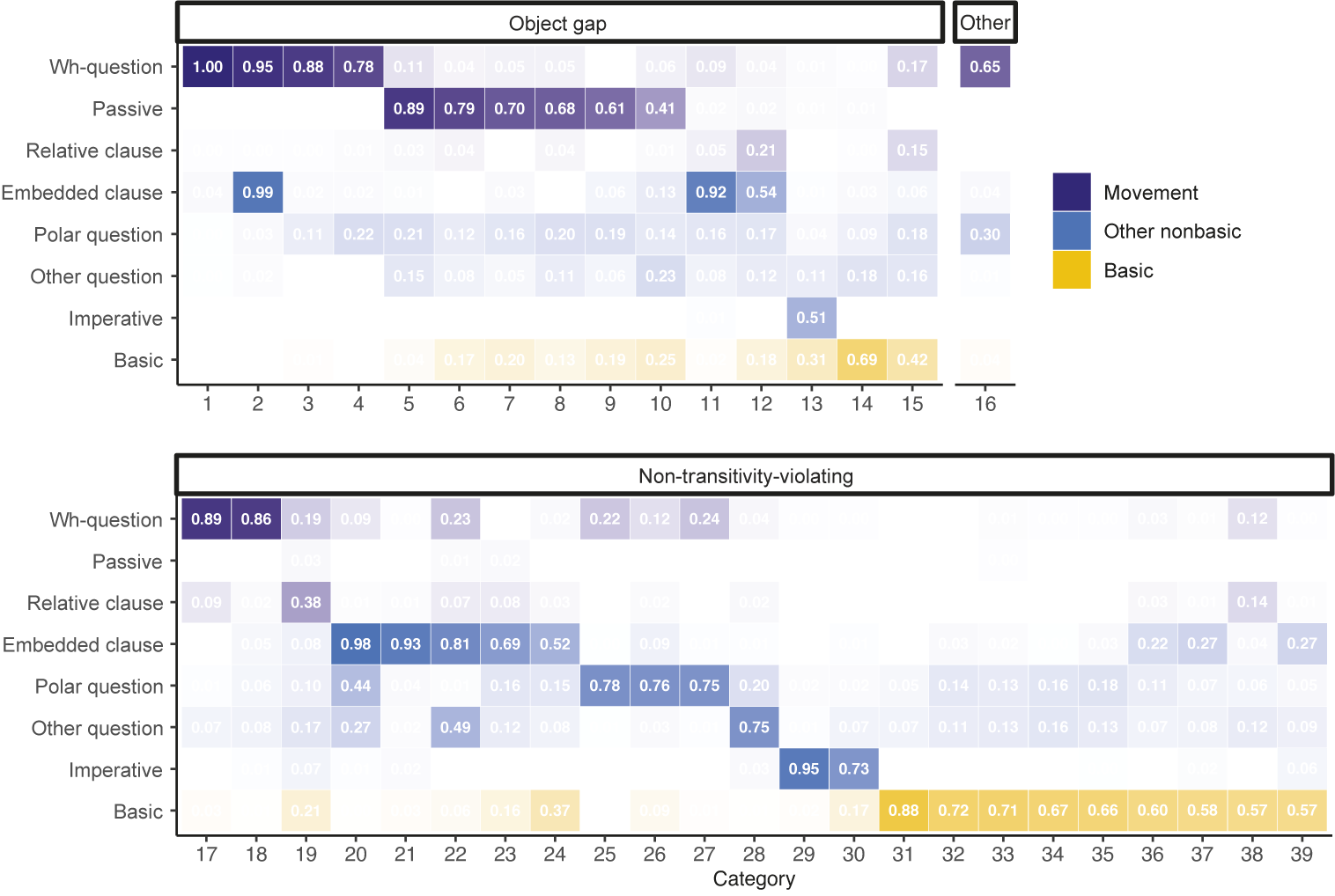
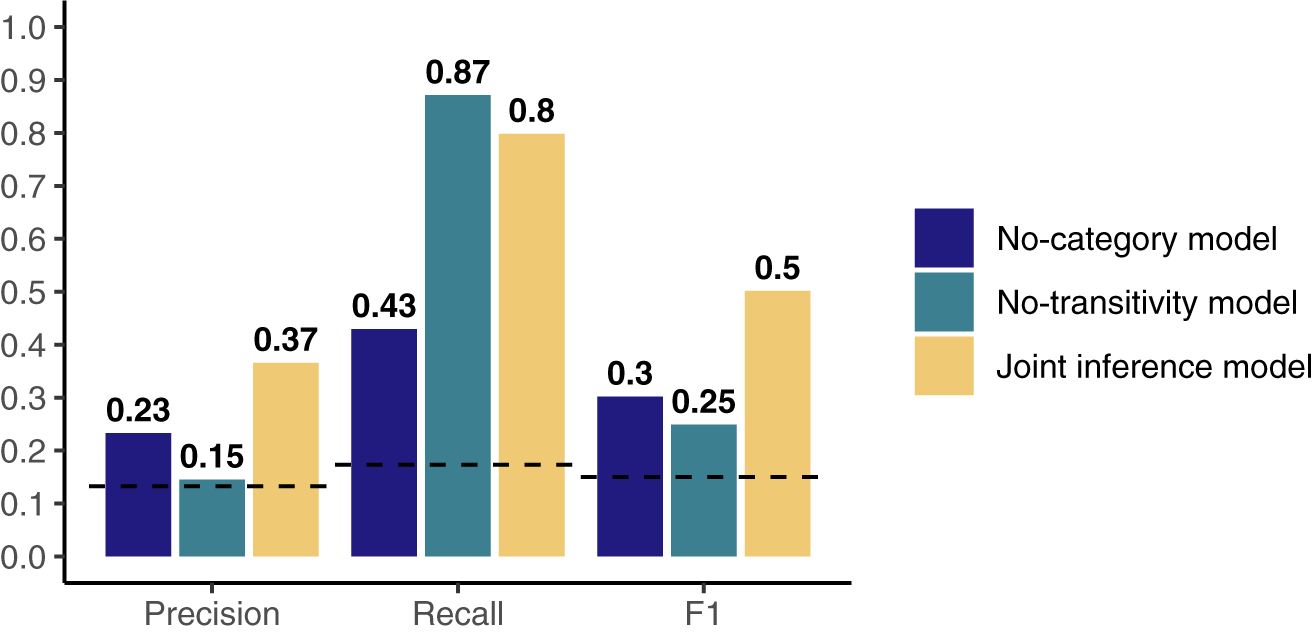
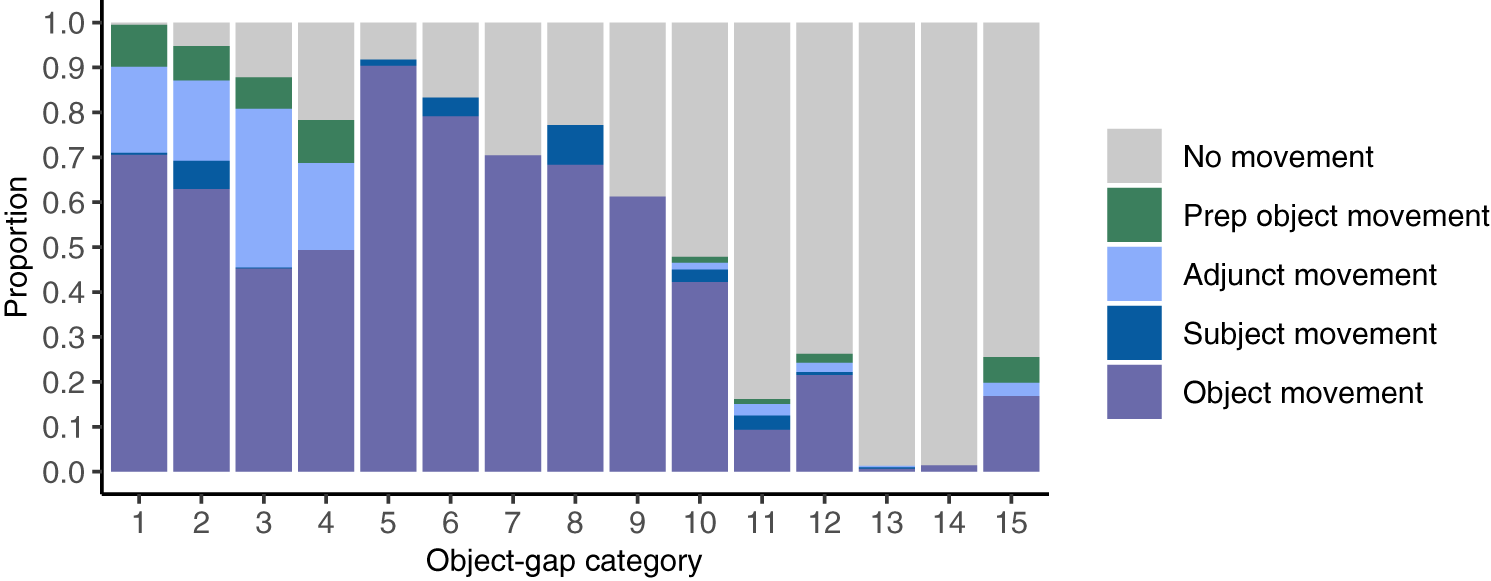


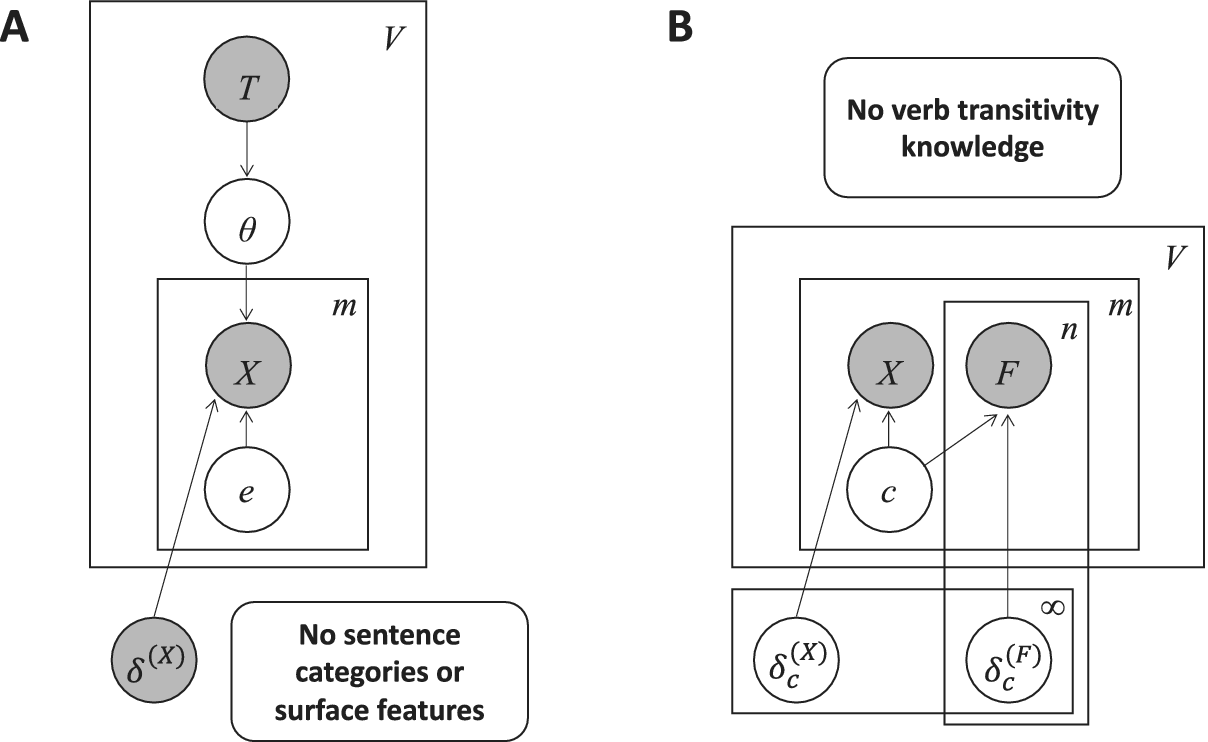
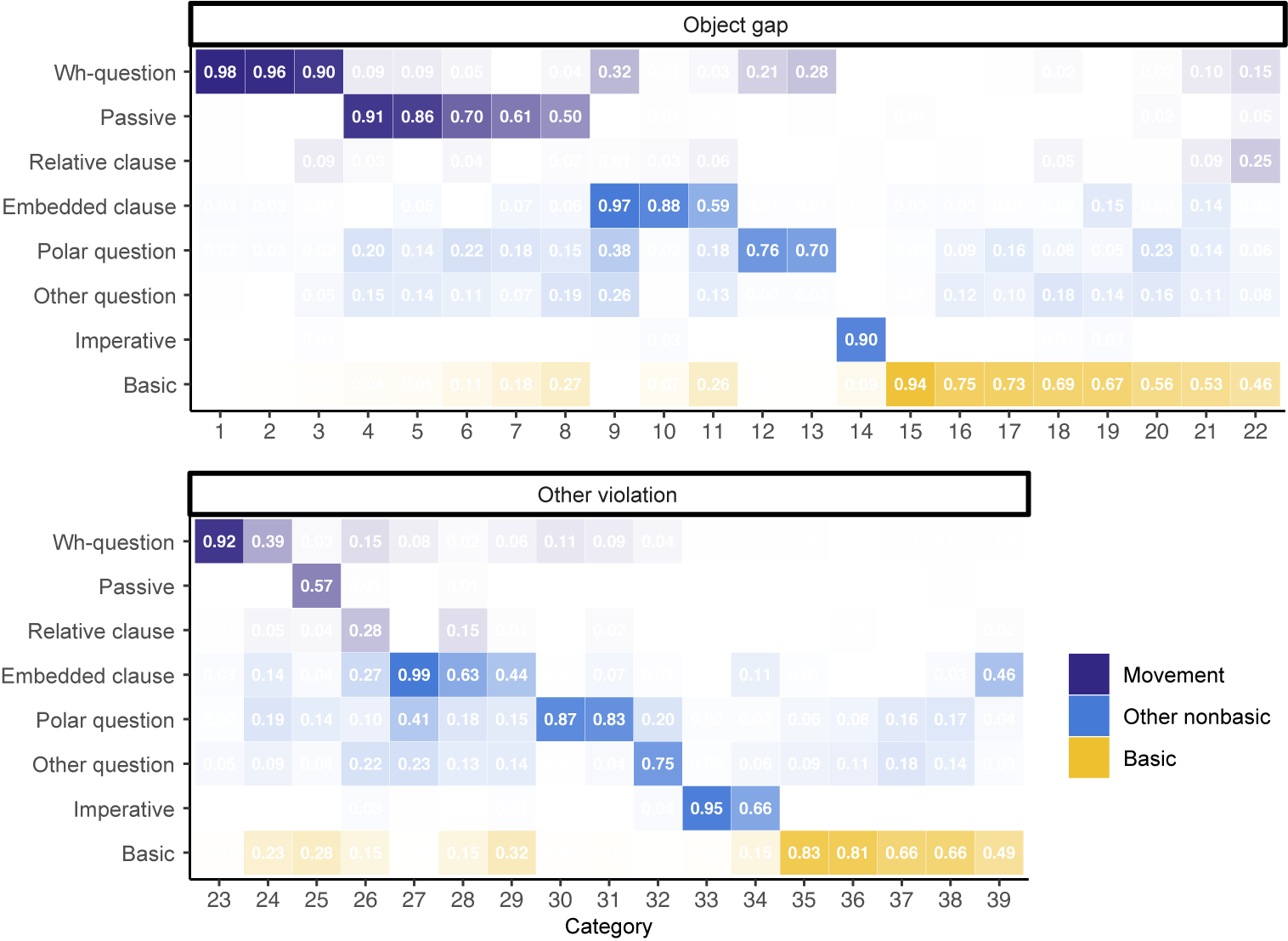
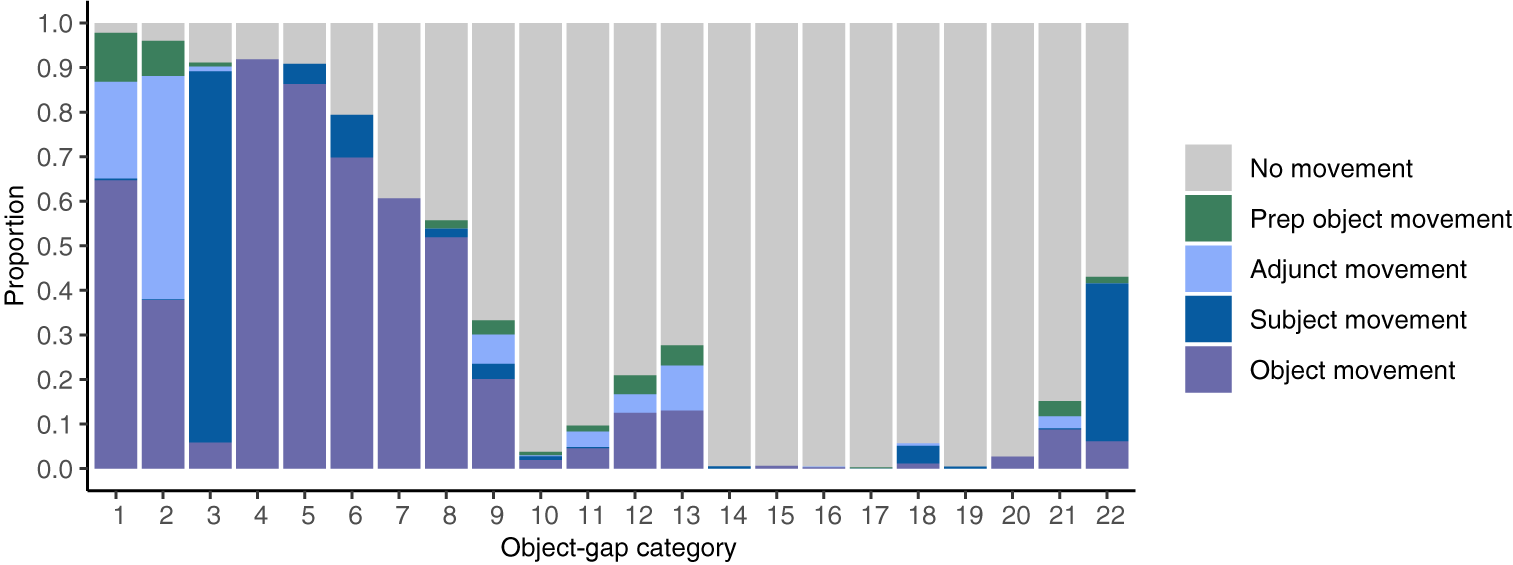

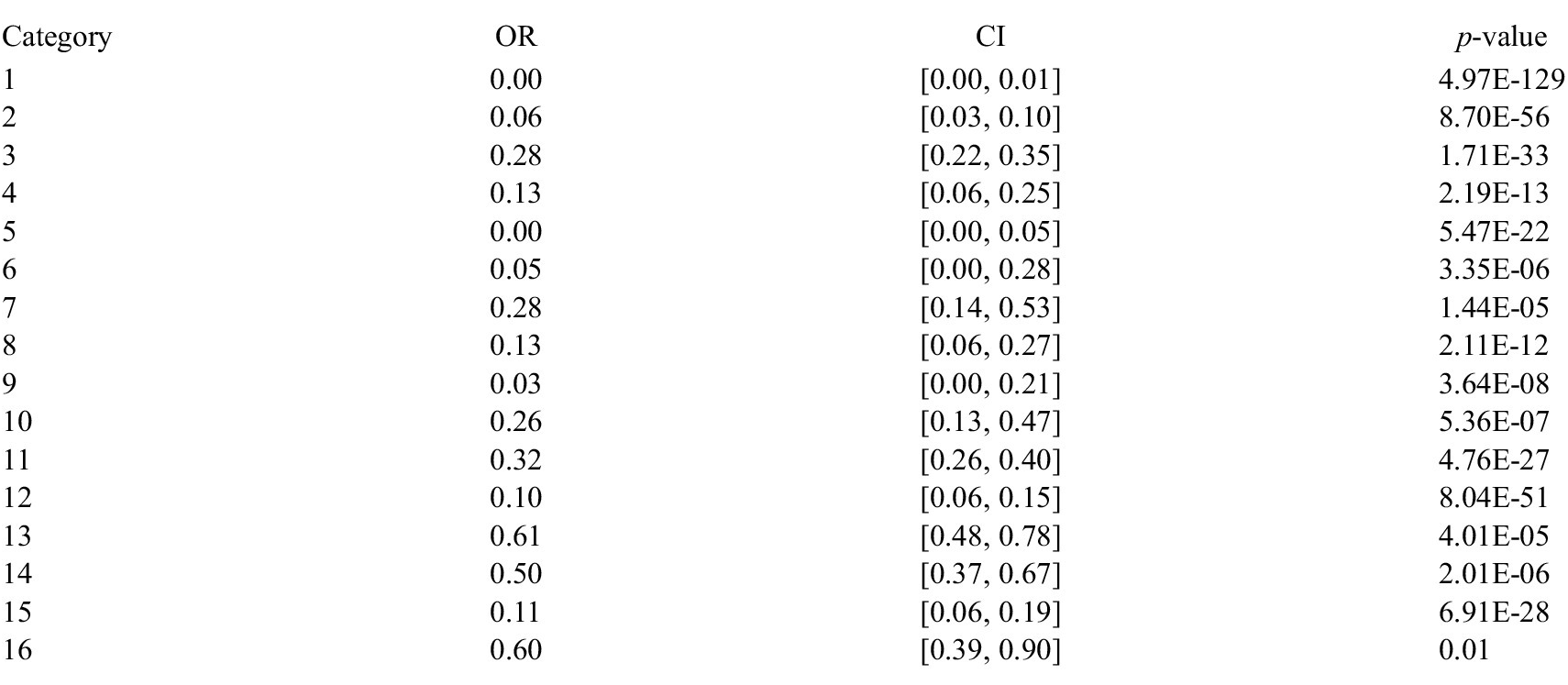



 Open access
Open access