


1. Introduction
This manuscript demonstrates that multi-state models provide a natural framework for modeling the cost of individual claims in an individual reserving application. Our approach builds upon the findings presented in a recent paper (Bladt and Furrer, Reference Bladt and Furrer2023b), which introduces the conditional Aalen–Johansen estimator. This estimator is a versatile, non-parametric tool for estimating state occupation probabilities conditioned on specific features, and it also discusses its key properties. Note that Aalen–Johansen-type estimators have traditionally found applications in life insurance. However, in this work, we demonstrate how these estimators can also be applied to non-life insurance for reserving purposes.
As mentioned earlier, multi-state models have found widespread use in the domain of life insurance. In the works of Hoem (Reference Hoem1969, Reference Hoem1972), they introduce a by-now standard approach, representing biometric states (active, deceased, etc.) as finite states within a spatial model. However, to the best of our knowledge, these models have seen less frequent application in non-life insurance literature. Notable exceptions can be found in the work of Hesselager (Reference Hesselager1994) and Maciak et al. (Reference Maciak, Mizera and Pešta2022). In Hesselager (Reference Hesselager1994), the authors model outstanding claim amounts conditionally on the current state, such as incurred but not reported (IBNR), reported but not settled (RBNS), and settled. In this context, the time variable corresponds to calendar time, similar to that in life insurance. In contrast, our approach in this paper takes a different perspective, replacing time with payments as the fundamental evolution variable. In Maciak et al. (Reference Maciak, Mizera and Pešta2022), the authors propose modeling the incremental paid amounts as outcomes of a homogeneous Markov chain on a finite state space, though only for aggregated data and in discrete time.
In this manuscript, we propose an individual claims reserving model based on a continuous-time non-explosive pure jump process denoted by J on a finite state space,
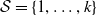 $\mathcal{S} = \{1, \ldots, k\}$
,
$\mathcal{S} = \{1, \ldots, k\}$
,
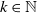 $k\in\mathbb{N}$
, where states correspond to the development periods (DPs) within a development triangle, and the “time spent” between state transitions corresponds to the claim size growth between DP’s. The state k serves as an absorbing state, representing claim closure. It is worth noting that, in practice, DPs have a stochastic behavior that leads to variation in the state space dimension across individual claim histories. However, for simplicity, we address this by collapsing long claim developments into a single state, as the specific details are not of primary importance in this context.
$k\in\mathbb{N}$
, where states correspond to the development periods (DPs) within a development triangle, and the “time spent” between state transitions corresponds to the claim size growth between DP’s. The state k serves as an absorbing state, representing claim closure. It is worth noting that, in practice, DPs have a stochastic behavior that leads to variation in the state space dimension across individual claim histories. However, for simplicity, we address this by collapsing long claim developments into a single state, as the specific details are not of primary importance in this context.
In a broader context, the application of counting processes to individual reserving has been a subject of research since the seminal contributions (Arjas, Reference Arjas1989; Norberg, Reference Norberg1993, Reference Norberg1997), with subsequent refinements and practical considerations detailed in the work of Haastrup and Arjas (Reference Haastrup and Arjas1996) and Antonio and Plat (Reference Antonio and Plat2014). In the study of Antonio and Plat (Reference Antonio and Plat2014), they assume a framework where claims are generated by a position-dependent marked Poisson process, and they incorporate a severity modelling approach within the mark.
The primary contribution of this manuscript lies in presenting a novel interpretation of state spaces, which enables us to approach the claims reserving problem from a fresh perspective, using a non-parametric estimator from survival analysis. We denote state process by
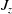 $J_z$
when the cumulative claim size of an individual reaches z, where
$J_z$
when the cumulative claim size of an individual reaches z, where
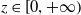 $z \in \left[0,+\infty\right)$
. Note that in this approach, the fundamental variable of interest is the claim size itself, rather than time. The transition probabilities leading to the absorbing state k represent the cumulative distribution of individual claim sizes. In other words, as individuals progress through the states, their observations accumulate claim size, reflecting the evolution of their claims. Upon reaching the absorbing state, a claim is considered settled, and no further payments are possible.
$z \in \left[0,+\infty\right)$
. Note that in this approach, the fundamental variable of interest is the claim size itself, rather than time. The transition probabilities leading to the absorbing state k represent the cumulative distribution of individual claim sizes. In other words, as individuals progress through the states, their observations accumulate claim size, reflecting the evolution of their claims. Upon reaching the absorbing state, a claim is considered settled, and no further payments are possible.
Recent literature on individual reserving has focused on decomposing individual reserving data into different modules that describe the micro-level structure of the portfolio, for example, payment delay, settlement delay and payment size. By doing so, Huang et al. (Reference Huang, Qiu, Wu and Zhou2015) and Wang et al. (Reference Wang, Wu and Qiu2021) extended the discrete model for predicting IBNR claims in Norberg (Reference Norberg1986) to a model for RBNS and IBNR claims that discusses, theoretically and with empirical studies, the beneficial effect of including individual information in reserving models. An interesting approach to modelling the joint distribution of reporting delays and claim sizes of RBNS claims under censoring can be found in Lopez (Reference Lopez2019). The work in Crevecoeur et al. (Reference Crevecoeur, Antonio, Desmedt and Masquelein2023) embeds Crevecoeur et al. (Reference Crevecoeur, Robben and Antonio2022) in a more general context and illustrates how pricing and reserving can be modelled under a unified framework and severity is modelled conditionally on the previous modules. A similar approach has been proposed in Delong et al. (2022), wherein the authors incorporate a gamma-distributed severity component into a neural network-based methodology.
In contrast to the aforementioned works, which rely on likelihood-based estimation or parametric assumptions on the claim size distribution, we propose a fully non-parametric estimation of the full cumulative distribution function of claim sizes, building on the results of Bladt and Furrer (Reference Bladt and Furrer2023b). The latter reference proposes a conditional version of the classic Aalen–Johansen estimator, which allows for continuous or discrete covariates, and where minimal assumptions on the process J are imposed, that is no Markov assumption is required. In particular, such lax probabilistic framework is desirable when it is unclear whether there exist duration effects in each state, as is the case for claim development processes.
Finally, we also propose a solution for modelling the IBNR and RBNS reserves separately. Our model is compared with the chain ladder in two case studies, one using simulated data and the other using a recent dataset from a Danish non-life insurer. In both the simulation case study and the real data case application, we have access to the total future claims costs and can thus compare the predicted amount with the target amount. The predicted curve for the cumulative density function of claims size is compared with the empirical cumulative density function using the continuously ranked probability score (CRPS), first proposed in Gneiting and Raftery (Reference Gneiting and Raftery2007). Interestingly, we show how the CRPS can be used to perform model selection by answering the natural question of how to select the number of states in the state space
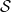 $\mathcal{S}$
.
$\mathcal{S}$
.
This manuscript is organised as follows. In Section 2, we introduce the conditional Aalen–Johansen estimator after a discussion on the probabilistic setup and we explain how to reinterpret a state space
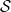 $\mathcal{S}$
to set up our reserving model. In Section 3, we connect our framework to development triangles and after a discussion on the current literature in reserving, we illustrate how to estimate of the final cost of the claims. Section 4 will demonstrate the effectiveness of our approach through a comprehensive case study using simulated data. Recent contributions to the literature have provided various algorithms for generating individual loss reserve datasets (Gabrielli and Wüthrich, Reference Gabrielli and Wüthrich2018; Avanzi et al., Reference Avanzi, Taylor, Wang and Wong2021, Reference Avanzi, Taylor and Wang2023; Wang and Wüthrich, Reference Wang and Wüthrich2022). Once reporting delays become available, it is possible to simulate both incurred but not settled (IBNR) claims and reported but not settled (RBNS) claims. We have chosen to focus on the exploration of RBNS claims in the next section, deliberately avoiding additional assumptions about the claims generation process (see for example Avanzi et al., Reference Avanzi, Taylor, Wang and Wong2021). This approach aims to draw the attention of the reader to the applicability of our models in different scenarios. We showcase the application of our IBNR modeling strategy in the section Section 5, where we rigorously test our models using a recent real individual data portfolio from a Danish insurer. Finally, Section 6 concludes.
$\mathcal{S}$
to set up our reserving model. In Section 3, we connect our framework to development triangles and after a discussion on the current literature in reserving, we illustrate how to estimate of the final cost of the claims. Section 4 will demonstrate the effectiveness of our approach through a comprehensive case study using simulated data. Recent contributions to the literature have provided various algorithms for generating individual loss reserve datasets (Gabrielli and Wüthrich, Reference Gabrielli and Wüthrich2018; Avanzi et al., Reference Avanzi, Taylor, Wang and Wong2021, Reference Avanzi, Taylor and Wang2023; Wang and Wüthrich, Reference Wang and Wüthrich2022). Once reporting delays become available, it is possible to simulate both incurred but not settled (IBNR) claims and reported but not settled (RBNS) claims. We have chosen to focus on the exploration of RBNS claims in the next section, deliberately avoiding additional assumptions about the claims generation process (see for example Avanzi et al., Reference Avanzi, Taylor, Wang and Wong2021). This approach aims to draw the attention of the reader to the applicability of our models in different scenarios. We showcase the application of our IBNR modeling strategy in the section Section 5, where we rigorously test our models using a recent real individual data portfolio from a Danish insurer. Finally, Section 6 concludes.
2. The conditional Aalen–Johansen estimator
In this section, we introduce our statistical framework, the quantities of interest, and the conditional occupation probabilities. We present the conditional Aalen–Johansen estimator (Bladt and Furrer, Reference Bladt and Furrer2023b), a non-parametric estimator for the conditional occupation probabilities of an arbitrary jump process. Note that the conditional Aalen–Johansen estimator is closely linked with the literature streams on kernel-based estimation for survival and semi-Markov processes (McKeague and Utikal, Reference McKeague and Utikal1990; Nielsen and Linton, Reference Nielsen and Linton1995; Dabrowska, Reference Dabrowska1997), as well as landmarking (Van Houwelingen, Reference Van Houwelingen2007). We conclude the section with some remarks on the interpretation of multi-state models for reserving. As we explain in the next paragraphs, this is a fundamental step to construct our reserving model.
2.1. The probabilistic setup
Let
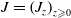 $J=\left(J_z\right)_{z \geqslant 0}$
be a non-explosive pure jump process on a finite state space
$J=\left(J_z\right)_{z \geqslant 0}$
be a non-explosive pure jump process on a finite state space
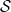 $\mathcal{S}$
and take
$\mathcal{S}$
and take
 $(\Omega, \mathcal{F}, \mathbb{P})$
to be the underlying probability space. Here, we let
$(\Omega, \mathcal{F}, \mathbb{P})$
to be the underlying probability space. Here, we let
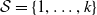 $\mathcal{S}=\{1, \ldots, k\}$
, with
$\mathcal{S}=\{1, \ldots, k\}$
, with
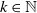 $k\in \mathbb{N}$
. Denote by Y the possibly infinite absorption time of J. Let X be a random variable with values in
$k\in \mathbb{N}$
. Denote by Y the possibly infinite absorption time of J. Let X be a random variable with values in
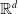 $\mathbb{R}^d$
equipped with the Borel
$\mathbb{R}^d$
equipped with the Borel
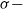 $\sigma-$
algebra. We assume that the distribution of X admits a density g with respect to the Lebesgue measure
$\sigma-$
algebra. We assume that the distribution of X admits a density g with respect to the Lebesgue measure
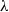 $\lambda$
. Absolute continuity in case of known atoms may be relaxed as discussed in Bladt and Furrer (Reference Bladt and Furrer2023b).
$\lambda$
. Absolute continuity in case of known atoms may be relaxed as discussed in Bladt and Furrer (Reference Bladt and Furrer2023b).
We introduce a multivariate counting process N with components
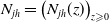 $N_{j h}=\left(N_{j h}(z)\right)_{z \geqslant 0}$
given by
$N_{j h}=\left(N_{j h}(z)\right)_{z \geqslant 0}$
given by
 \begin{align*}N_{j h}(z)=\#\left\{s \in(0, z]: J_{s-}=j, J_s=h\right\}, \quad z \geqslant 0,\end{align*}
\begin{align*}N_{j h}(z)=\#\left\{s \in(0, z]: J_{s-}=j, J_s=h\right\}, \quad z \geqslant 0,\end{align*}
for
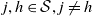 $j, h \in \mathcal{S}, j \neq h$
. Let us introduce the following assumption.
$j, h \in \mathcal{S}, j \neq h$
. Let us introduce the following assumption.
Assumption 1. For every
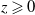 $z\geqslant 0$
and
$z\geqslant 0$
and
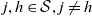 $j,h\in\mathcal{S},j\neq h$
there exists some
$j,h\in\mathcal{S},j\neq h$
there exists some
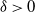 $\delta > 0$
such that
$\delta > 0$
such that
 \begin{align*}\mathbb{E}\left[N_{jh}(z)^{1+\delta}\right]< \infty.\end{align*}
\begin{align*}\mathbb{E}\left[N_{jh}(z)^{1+\delta}\right]< \infty.\end{align*}
Taking the largest z and the minimum across the whole states provides a delta which is independent of j,h,z.
For any x in the support of X define the conditional occupation probabilities according to
 \begin{align*}p_j(z \mid x)=\mathbb{E}\left[\unicode{x1D7D9}_{\left\{J_z=j\right\}} \mid X=x\right] .\end{align*}
\begin{align*}p_j(z \mid x)=\mathbb{E}\left[\unicode{x1D7D9}_{\left\{J_z=j\right\}} \mid X=x\right] .\end{align*}
We denote by
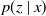 $p(z \mid x)$
the row vector with elements
$p(z \mid x)$
the row vector with elements
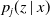 $p_j(z \mid x)$
. We now introduce the cumulative conditional transition rates and cast the conditional occupation probabilities as a product integral of these cumulative rates. To this end, let
$p_j(z \mid x)$
. We now introduce the cumulative conditional transition rates and cast the conditional occupation probabilities as a product integral of these cumulative rates. To this end, let
 \begin{align*}p_{j h}(z \mid x)=\mathbb{E}\left[N_{j h}(z) \mid X=x\right],\end{align*}
\begin{align*}p_{j h}(z \mid x)=\mathbb{E}\left[N_{j h}(z) \mid X=x\right],\end{align*}
and define the cumulative conditional transition rates via
 \begin{align*}\Lambda_{j h}(z \mid x)=\int_0^z \frac{1}{p_j(s-\mid x)} p_{j h}(\mathrm{d} s \mid x).\end{align*}
\begin{align*}\Lambda_{j h}(z \mid x)=\int_0^z \frac{1}{p_j(s-\mid x)} p_{j h}(\mathrm{d} s \mid x).\end{align*}
A cumulative transition hazard matrix is defined by having the j,j entry
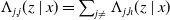 $\Lambda_{j,j}(z \mid x)=\sum_{j\neq}\Lambda_{j,h}(z \mid x)$
for
$\Lambda_{j,j}(z \mid x)=\sum_{j\neq}\Lambda_{j,h}(z \mid x)$
for
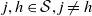 $j, h \in \mathcal{S}, j \neq h$
.
$j, h \in \mathcal{S}, j \neq h$
.
Let
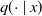 $q(\cdot \mid x)$
be the interval function associated with the conditional transition probabilities:
$q(\cdot \mid x)$
be the interval function associated with the conditional transition probabilities:
 \begin{align*}q_{j h}(s, z \mid x)=\unicode{x1D7D9}_{\left\{p_j(s|x)> 0\right\}} \frac{\mathbb{E}\left[\unicode{x1D7D9}_{\left\{J_z=h\right\}} \unicode{x1D7D9}_{\left\{J_s=j\right\}} \mid X=x\right]}{p_j(s|x)}+\unicode{x1D7D9}_{\left\{p_j(s|x)=0\right\}} \unicode{x1D7D9}_{\{j=h\}}.\end{align*}
\begin{align*}q_{j h}(s, z \mid x)=\unicode{x1D7D9}_{\left\{p_j(s|x)> 0\right\}} \frac{\mathbb{E}\left[\unicode{x1D7D9}_{\left\{J_z=h\right\}} \unicode{x1D7D9}_{\left\{J_s=j\right\}} \mid X=x\right]}{p_j(s|x)}+\unicode{x1D7D9}_{\left\{p_j(s|x)=0\right\}} \unicode{x1D7D9}_{\{j=h\}}.\end{align*}
In Overgaard (Reference Overgaard2019), it is shown that this assumption ensures that the product integral
is well defined. Therefore,

We are interested in the situation where the observation of J is right-censored. To this end, we introduce a strictly positive random variable W describing right censoring, so that we actually observe the triplet
 \begin{align*}\left(X,\left(J_z\right)_{0 \leqslant z \leqslant W}, Y \wedge W \right) .\end{align*}
\begin{align*}\left(X,\left(J_z\right)_{0 \leqslant z \leqslant W}, Y \wedge W \right) .\end{align*}
Whenever the Markov property fails for the jump process J, the following assumption is key for our estimation procedure.
Assumption 2. Right censoring is conditionally entirely random:
 \begin{align*} W {\perp \!\!\! \perp}\ J \mid X.\end{align*}
\begin{align*} W {\perp \!\!\! \perp}\ J \mid X.\end{align*}
Other censoring schemes are possible if J is Markovian, though we do not make that assumption in the sequel.
Remark 1. From a reserving perspective, the above assumption amounts to stating that, conditional on covariates, closure of a claim is simply specified through an independent random mechanism. One should note that this assumption is not verifiable, despite its widespread use in survival analysis.
We introduce
 \begin{align*}p_j^c(z \mid x) =\mathbb{E}\left[\unicode{x1D7D9}_{\left\{J_z=j\right\}} \unicode{x1D7D9}_{\{z< W\}} \mid X=x\right],\end{align*}
\begin{align*}p_j^c(z \mid x) =\mathbb{E}\left[\unicode{x1D7D9}_{\left\{J_z=j\right\}} \unicode{x1D7D9}_{\{z< W\}} \mid X=x\right],\end{align*}
and
 \begin{align*}p_{j h}^c(z \mid x) =\mathbb{E}\left[N_{j h}(z \wedge W) \mid X=x\right] .\end{align*}
\begin{align*}p_{j h}^c(z \mid x) =\mathbb{E}\left[N_{j h}(z \wedge W) \mid X=x\right] .\end{align*}
from which we may conclude that
 \begin{equation}\Lambda_{j h}(z \mid x)=\int_0^z \frac{1}{p_j^c(s-\mid x)} p_{j h}^c(\mathrm{d} s \mid x),\end{equation}
\begin{equation}\Lambda_{j h}(z \mid x)=\int_0^z \frac{1}{p_j^c(s-\mid x)} p_{j h}^c(\mathrm{d} s \mid x),\end{equation}
within the interior of the support of W.
2.1.1. Estimators
Consider the i.i.d. replicates
 $\left(X^{i},\left(J_z^{i}\right)_{0 \leqslant z \leqslant W^{i}}, Y^{i} \wedge W^{i}\right)_{i=1}^n$
. Define
$\left(X^{i},\left(J_z^{i}\right)_{0 \leqslant z \leqslant W^{i}}, Y^{i} \wedge W^{i}\right)_{i=1}^n$
. Define
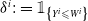 $\delta^i:=\unicode{x1D7D9}_{\left\{Y^i\leqslant W^i\right\}}$
, which equals 1 when the observation is absorbed (closed claim), and zero otherwise. In a reserving context, this distinction is usually reflected by specifying two types of claims: closed claims and RBNS (open) claims, and we write, respectively,
$\delta^i:=\unicode{x1D7D9}_{\left\{Y^i\leqslant W^i\right\}}$
, which equals 1 when the observation is absorbed (closed claim), and zero otherwise. In a reserving context, this distinction is usually reflected by specifying two types of claims: closed claims and RBNS (open) claims, and we write, respectively,
 $n=n^{\texttt{Closed}}+n^{\texttt{RBNS}}$
.
$n=n^{\texttt{Closed}}+n^{\texttt{RBNS}}$
.
We now construct an estimator for the conditional occupation probabilities
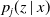 $p_j(z\mid x)$
, but from Equation (2.1), it essentially suffices to estimate the cumulative conditional transition rates
$p_j(z\mid x)$
, but from Equation (2.1), it essentially suffices to estimate the cumulative conditional transition rates
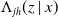 $\Lambda_{j h}(z \mid x)$
, which we do using Equation (2.2), Let
$\Lambda_{j h}(z \mid x)$
, which we do using Equation (2.2), Let
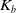 $K_b$
be kernel functions of bounded variation and bounded support, with
$K_b$
be kernel functions of bounded variation and bounded support, with
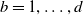 $b=1,\ldots,d$
and let
$b=1,\ldots,d$
and let
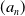 $(a_n)$
be a bandwidth sequence. We impose the following standard assumption, confering with Stute (Reference Stute1986).
$(a_n)$
be a bandwidth sequence. We impose the following standard assumption, confering with Stute (Reference Stute1986).
Assumption 3. The band sequence satisfies:
-
1.
 $a_n \rightarrow 0$
as
$n \rightarrow \infty$
.
$a_n \rightarrow 0$
as
$n \rightarrow \infty$
. -
2.
$n a_n^d \rightarrow \infty$
as
$n \rightarrow \infty$
. -
3.
$\sum_{n=1}^{\infty} c_n^r< \infty$
for some
$r \in(1,1+\delta)$
where
$c_n:=\left(n a_n^d\right)^{-1} \log n$
.
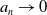
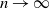
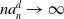
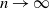
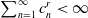
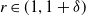
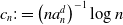
For instance, one may take, for
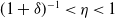 $(1+\delta)^{-1}< \eta< 1$
, any sequence satisfying
$(1+\delta)^{-1}< \eta< 1$
, any sequence satisfying
 \begin{align*}a_n^d \sim \frac{\log n}{n^{1-\eta}}.\end{align*}
\begin{align*}a_n^d \sim \frac{\log n}{n^{1-\eta}}.\end{align*}
We introduce the usual kernel estimator for the density g:
 \begin{align*}{\unicode{x1D558}}^{(n)}(x)=\frac{1}{n} \sum_{i=1}^n {\unicode{x1D558}}^{(n, i)}(x)=\frac{1}{n} \sum_{i=1}^n \prod_{b=1}^d \frac{1}{a_n} K_b\left(\frac{x_b-X_b^{i}}{a_n}\right) .\end{align*}
\begin{align*}{\unicode{x1D558}}^{(n)}(x)=\frac{1}{n} \sum_{i=1}^n {\unicode{x1D558}}^{(n, i)}(x)=\frac{1}{n} \sum_{i=1}^n \prod_{b=1}^d \frac{1}{a_n} K_b\left(\frac{x_b-X_b^{i}}{a_n}\right) .\end{align*}
It is well-known (cf. Ghosh, Reference Ghosh2018, Ch. 1.4) that
 \begin{align*}{\unicode{x1D558}}^{(n)}(x) \stackrel{\text { a.s. }}{\rightarrow} g(x), \quad n \rightarrow \infty,\end{align*}
\begin{align*}{\unicode{x1D558}}^{(n)}(x) \stackrel{\text { a.s. }}{\rightarrow} g(x), \quad n \rightarrow \infty,\end{align*}
and, for any random variable V with i.i.d. replicates
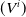 $(V^i)$
satisfying
$(V^i)$
satisfying
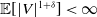 $\mathbb{E}[|V|^{1+\delta}]< \infty$
that
$\mathbb{E}[|V|^{1+\delta}]< \infty$
that
 \begin{align}\frac{1}{n} \frac{\sum_{i=1}^n V^{i} {\unicode{x1D558}}^{(n, i)}(x)}{{\unicode{x1D558}}^{(n)}(x)} \stackrel{\operatorname{a.s.}}{\rightarrow} \mathbb{E}[V \mid X=x], \quad n \rightarrow \infty .\end{align}
\begin{align}\frac{1}{n} \frac{\sum_{i=1}^n V^{i} {\unicode{x1D558}}^{(n, i)}(x)}{{\unicode{x1D558}}^{(n)}(x)} \stackrel{\operatorname{a.s.}}{\rightarrow} \mathbb{E}[V \mid X=x], \quad n \rightarrow \infty .\end{align}
Based on the kernel estimator for g, we form the following Nadaraya–Watson type kernel estimators:
 \begin{align}& \mathbb{N}_{j h}^{(n)}(z \mid x)=\frac{1}{n} \sum_{i=1}^n \mathbb{N}_{j h}^{(n, i)}(z \mid x)=\frac{1}{n} \sum_{i=1}^n \frac{N_{j h}^{i}\left(z \wedge W^i\right) {\unicode{x1D558}}^{(n, i)}(x)}{{\unicode{x1D558}}^{(n)}(x)} \end{align}
\begin{align}& \mathbb{N}_{j h}^{(n)}(z \mid x)=\frac{1}{n} \sum_{i=1}^n \mathbb{N}_{j h}^{(n, i)}(z \mid x)=\frac{1}{n} \sum_{i=1}^n \frac{N_{j h}^{i}\left(z \wedge W^i\right) {\unicode{x1D558}}^{(n, i)}(x)}{{\unicode{x1D558}}^{(n)}(x)} \end{align}
 \begin{align}& \mathbb{I}_j^{(n)}(z \mid x)=\frac{1}{n} \sum_{i=1}^n \mathbb{I}_j^{(n, i)}(z \mid x)=\frac{1}{n} \sum_{i=1}^n \frac{\unicode{x1D7D9}_{\left\{z< W^{i}\right\}} \unicode{x1D7D9}_{\left\{J_z^{i}=j\right\} }{\unicode{x1D558}}^{(n, i)}(x)}{{\unicode{x1D558}}^{(n)}(x)} \end{align}
\begin{align}& \mathbb{I}_j^{(n)}(z \mid x)=\frac{1}{n} \sum_{i=1}^n \mathbb{I}_j^{(n, i)}(z \mid x)=\frac{1}{n} \sum_{i=1}^n \frac{\unicode{x1D7D9}_{\left\{z< W^{i}\right\}} \unicode{x1D7D9}_{\left\{J_z^{i}=j\right\} }{\unicode{x1D558}}^{(n, i)}(x)}{{\unicode{x1D558}}^{(n)}(x)} \end{align}
Remark 2. Due to Assumption 1, it follows from Equation (2.3) that
 \begin{align*}\mathbb{N}_{j h}^{(n)}(z \mid x) \stackrel{\text { a.s. }}{\rightarrow} p_{j h}^c(z \mid x), \quad n \rightarrow \infty.\end{align*}
\begin{align*}\mathbb{N}_{j h}^{(n)}(z \mid x) \stackrel{\text { a.s. }}{\rightarrow} p_{j h}^c(z \mid x), \quad n \rightarrow \infty.\end{align*}
Furthermore, it holds that
 \begin{align*}\mathbb{I}_j^{(n)}(z \mid x) \stackrel{\text { a.s. }}{\rightarrow} p_j^c(z \mid x), \quad n \rightarrow \infty .\end{align*}
\begin{align*}\mathbb{I}_j^{(n)}(z \mid x) \stackrel{\text { a.s. }}{\rightarrow} p_j^c(z \mid x), \quad n \rightarrow \infty .\end{align*}
Definition 1. The conditional Nelson–Aalen estimator for the cumulative conditional transition rates is defined as
 \begin{align*}\mathbb{\Lambda}_{j h}^{(n)}(z \mid x)=\int_0^z \frac{1}{\mathbb{I}_j^{(n)}(s-\mid x)} \mathbb{N}_{j h}^{(n)}(\mathrm{d} s \mid x) .\end{align*}
\begin{align*}\mathbb{\Lambda}_{j h}^{(n)}(z \mid x)=\int_0^z \frac{1}{\mathbb{I}_j^{(n)}(s-\mid x)} \mathbb{N}_{j h}^{(n)}(\mathrm{d} s \mid x) .\end{align*}
Definition 2. The conditional Aalen–Johansen estimator for the conditional occupation probabilities is defined according Equation (2.1), but with the cumulative conditional transition rates replaced by the conditional Nelson–Aalen estimator, that is,

where
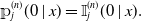 ${\unicode{x1D561}}_j^{(n)}(0 \mid x)=\mathbb{I}_j^{(n)}(0 \mid x).$
The estimator
${\unicode{x1D561}}_j^{(n)}(0 \mid x)=\mathbb{I}_j^{(n)}(0 \mid x).$
The estimator
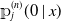 ${\unicode{x1D561}}_j^{(n)}(0 \mid x)$
for the occupation probabilities
${\unicode{x1D561}}_j^{(n)}(0 \mid x)$
for the occupation probabilities
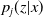 $p_j(z|x)$
denotes the jth entry of the row vector
$p_j(z|x)$
denotes the jth entry of the row vector
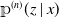 ${\unicode{x1D561}}^{(n)}(z \mid x)$
, an estimator for
${\unicode{x1D561}}^{(n)}(z \mid x)$
, an estimator for
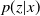 $p(z|x)$
.
$p(z|x)$
.
Remark 3. We refer to Bladt and Furrer (Reference Bladt and Furrer2023b) for the proof that the estimators are pathwise strongly consistent and asymptotically Gaussian distributed.
When all the subjects start in state 1 at inception, we can use the estimator of the occupation probabilities of the absorbing state k,
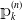 ${\unicode{x1D561}}_k^{(n)}$
to model the cumulative density function of the individual claim size.
${\unicode{x1D561}}_k^{(n)}$
to model the cumulative density function of the individual claim size.
Remark 4. The Volterra integral equation defines the product integral of the matrix function
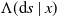 $\Lambda(\mathrm{d} s \mid x)$
as the unique solution
$\Lambda(\mathrm{d} s \mid x)$
as the unique solution
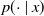 $p(\cdot \mid x)$
to the equation
$p(\cdot \mid x)$
to the equation
 \begin{align*} p(t \mid x)=\operatorname{Id}+\int_{(0,t]}p(s-\mid x) \Lambda(\mathrm{d} s \mid x). \end{align*}
\begin{align*} p(t \mid x)=\operatorname{Id}+\int_{(0,t]}p(s-\mid x) \Lambda(\mathrm{d} s \mid x). \end{align*}
However, when a piecewise constant estimator of
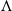 $\Lambda$
is given by
$\Lambda$
is given by
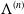 $\mathbb{\Lambda}^{(n)}$
, as is described in detail in the previous section, the computation of the product integral simplifies. More precisely, denote
$\mathbb{\Lambda}^{(n)}$
, as is described in detail in the previous section, the computation of the product integral simplifies. More precisely, denote
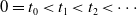 $0=t_0< t_1< t_2< \cdots$
the sequence of time points describing all observed jump times in the sample. Then the recursion
$0=t_0< t_1< t_2< \cdots$
the sequence of time points describing all observed jump times in the sample. Then the recursion
 \begin{align*}{\unicode{x1D561}}^{(n)}_j(t_{\ell+1} |x)-{\unicode{x1D561}}^{(n)}_j(t_{\ell} |x)=\sum_{\substack{k \in \mathcal{Z} \\ k \neq j}} {\unicode{x1D561}}^{(n)}_k(t_{\ell} | x)\Delta\mathbb{\Lambda}_{kj}^{(n)}(t_{\ell +1} | x) -{\unicode{x1D561}}^{(n)}_j(t_{\ell} | x) \sum_{\substack{k \in \mathcal{Z} \\ k \neq j}} \Delta\mathbb{\Lambda}_{jk}^{(n)}(t_{\ell +1} | x)\end{align*}
\begin{align*}{\unicode{x1D561}}^{(n)}_j(t_{\ell+1} |x)-{\unicode{x1D561}}^{(n)}_j(t_{\ell} |x)=\sum_{\substack{k \in \mathcal{Z} \\ k \neq j}} {\unicode{x1D561}}^{(n)}_k(t_{\ell} | x)\Delta\mathbb{\Lambda}_{kj}^{(n)}(t_{\ell +1} | x) -{\unicode{x1D561}}^{(n)}_j(t_{\ell} | x) \sum_{\substack{k \in \mathcal{Z} \\ k \neq j}} \Delta\mathbb{\Lambda}_{jk}^{(n)}(t_{\ell +1} | x)\end{align*}
and starting value
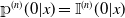 ${\unicode{x1D561}}^{(n)}(0 | x) = \mathbb{I}^{(n)}(0 | x)$
completely characterize the product integral
${\unicode{x1D561}}^{(n)}(0 | x) = \mathbb{I}^{(n)}(0 | x)$
completely characterize the product integral
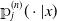 ${\unicode{x1D561}}^{(n)}_j(\cdot |x)$
at jump times (and constant otherwise).
${\unicode{x1D561}}^{(n)}_j(\cdot |x)$
at jump times (and constant otherwise).
2.2. Practical considerations for claims development
In this section, we offer practical insights into our modeling approach, with the aim of assisting the reader in understanding our multi-state setup for claims reserving. Refer to Figure 1, which conceptually illustrates our model featuring a state space
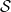 $\mathcal{S}$
with
$\mathcal{S}$
with
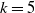 $k=5$
states.
$k=5$
states.
Example of multi-state model for claims reserving, with
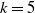 $k=5$
. We interpret time spent in each state as increasing claims size clock, instead of calendar time. The states represent the development periods (DP’s) of the individual claims.
$k=5$
. We interpret time spent in each state as increasing claims size clock, instead of calendar time. The states represent the development periods (DP’s) of the individual claims.

In our framework, we represent the active state as IBNR claims, while we treat RBNS claims as transitioning through intermediate states. Any claim that reaches state k is considered closed in our system due to the presence of an absorbing state. Consequently, we do not allow claims to reopen in our framework. Notably, unlike a traditional survival study, we do not explicitly model the time component, and the number of IBNR claims, along with their characteristics, remains unknown at the time of evaluation. In Section 3, we delve into how to model RBNS and IBNR claims, showcasing how our model can accommodate such scenarios. Furthermore, we have designed our state space so that state DP3+ at step
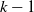 $k-1$
in Figure 1 is the final relevant DP that we explicitly model.
$k-1$
in Figure 1 is the final relevant DP that we explicitly model.
Finally, it is worth mentioning that we have not introduced development triangles yet, which are the standard aggregate datasets commonly used in claims reserving applications. The choice of parameter k aligns with the data that, in a conventional modelling approach, would be aggregated into development triangles of varying sizes. Since our proposed framework does not explicitly model the time component, we assume that payments close at the development year following the last payment. This assumption results in a development triangle with
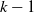 $k-1$
development times. This aspect will be particularly relevant for our data application, where we compare our model to the benchmark chain ladder method outlined in Mack (Reference Mack1993), and we need to construct a development triangle for this purpose.
$k-1$
development times. This aspect will be particularly relevant for our data application, where we compare our model to the benchmark chain ladder method outlined in Mack (Reference Mack1993), and we need to construct a development triangle for this purpose.
Remark 5. By changing the multi-state model in Figure 1, our approach can be modified to take into account additional domain-specific aspects of reserving data. For instance, if we allow transitions back from the state k (closed) to states
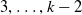 $3, \dots, k-2$
(DP 2,
$3, \dots, k-2$
(DP 2,
 $\dots$
), our framework can be modified to take into account reopenings.
$\dots$
), our framework can be modified to take into account reopenings.
3. Claims reserving
In this section, we will introduce the definitions of final cost of the claims and of the claims reserve and provide a notation for development triangles, an aggregated representation of the reserving data. We then connect the multi-state model that we introduced in the previous section to the actuarial literature in reserving, with a comparative literature review that distinguishes between the approaches that rely on aggregated data and those that rely on individual data, as the methodology outlined in this manuscript. We remark that aggregated data are a known data representation in survival studies when the individual data are not available, Andersen et al. (Reference Andersen, Borgan, Gill and Keiding1993, p. 168) and Gill (Reference Gill1986). We conclude this section with a discussion on the numerical estimation of the total final cost of the claims using the conditional Aalen–Johansen estimator
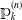 ${\unicode{x1D561}}_k^{(n)}$
of
${\unicode{x1D561}}_k^{(n)}$
of
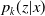 $p_k(z|x)$
.
$p_k(z|x)$
.
Notation. Together with our sample, which is composed of n i.i.d. observations generated from J and its covariates (refer to the previous section), we additionally observe the following quantities that are not related to
 $J^1, \ldots, J^n$
:
$J^1, \ldots, J^n$
:
 \begin{align*}\left\{T^i, U^i \right\}_{i=1}^n.\end{align*}
\begin{align*}\left\{T^i, U^i \right\}_{i=1}^n.\end{align*}
In detail,
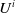 $U^i$
and
$U^i$
and
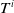 $T^i$
represent the accident period and the reporting delay of the ith claim, with
$T^i$
represent the accident period and the reporting delay of the ith claim, with
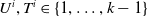 $U^i, T^i \in \left\{1, \ldots, k-1 \right\}$
. Let us also define the development triangle of the reporting delays as the set
$U^i, T^i \in \left\{1, \ldots, k-1 \right\}$
. Let us also define the development triangle of the reporting delays as the set
 \begin{align*}\mathcal{D}^{(k-1)} = \left\{ d_{\ell,j} : \ell + j \leqslant k; \ell,j = 1, \ldots, k-1 \right\},\end{align*}
\begin{align*}\mathcal{D}^{(k-1)} = \left\{ d_{\ell,j} : \ell + j \leqslant k; \ell,j = 1, \ldots, k-1 \right\},\end{align*}
with
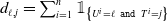 $ d_{\ell,j} = \sum^{n}_{i=1} \unicode{x1D7D9}_{\left\{U^i = \ell \texttt{ and } T^i = j\right\}}$
denoting the total claims reported in accident period
$ d_{\ell,j} = \sum^{n}_{i=1} \unicode{x1D7D9}_{\left\{U^i = \ell \texttt{ and } T^i = j\right\}}$
denoting the total claims reported in accident period
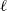 $\ell$
with delay j. In a similar fashion, we can define the development triangle of cumulative payments,
$\ell$
with delay j. In a similar fashion, we can define the development triangle of cumulative payments,
 \begin{align*}\mathcal{C}^{(k-1)} = \left\{ C_{\ell,j} : \ell + j \leqslant k; \ell,j = 1, \ldots, k-1 \right\},\end{align*}
\begin{align*}\mathcal{C}^{(k-1)} = \left\{ C_{\ell,j} : \ell + j \leqslant k; \ell,j = 1, \ldots, k-1 \right\},\end{align*}
where
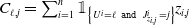 $C_{\ell,j}= \sum^n_{i=1}\unicode{x1D7D9}_{\left\{U^i = \ell \texttt{ and } J^i_{z_{i,j}} = j\right\}} z_{i,j}$
, with
$C_{\ell,j}= \sum^n_{i=1}\unicode{x1D7D9}_{\left\{U^i = \ell \texttt{ and } J^i_{z_{i,j}} = j\right\}} z_{i,j}$
, with
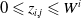 $0\leqslant z_{i,j}\leqslant W^{i}$
such that
$0\leqslant z_{i,j}\leqslant W^{i}$
such that
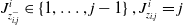 $J^i_{z^-_{i,j}}\in \left\{1, \ldots, j-1\right\}, J^i_{z_{i,j}}=j $
denoting the total cumulative amount paid in accident period
$J^i_{z^-_{i,j}}\in \left\{1, \ldots, j-1\right\}, J^i_{z_{i,j}}=j $
denoting the total cumulative amount paid in accident period
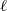 $\ell$
and DP j.
$\ell$
and DP j.
We are presently interested forecasting the ultimate cost of our claims,
 \begin{align*}Y^{\texttt{Closed}}+Y^{\texttt{RBNS}}:=\sum_{i=1}^n \delta^i Y^i+\sum_{i=1}^n (1-\delta^i) Y^i=\sum^{k-1}_{\ell=1} C_{\ell,k-1},\end{align*}
\begin{align*}Y^{\texttt{Closed}}+Y^{\texttt{RBNS}}:=\sum_{i=1}^n \delta^i Y^i+\sum_{i=1}^n (1-\delta^i) Y^i=\sum^{k-1}_{\ell=1} C_{\ell,k-1},\end{align*}
The claims reserve is simply
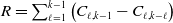 $R= \sum^{k-1}_{\ell=1} \left(C_{\ell,k-1}- C_{\ell,k-\ell}\right)$
.
$R= \sum^{k-1}_{\ell=1} \left(C_{\ell,k-1}- C_{\ell,k-\ell}\right)$
.
3.1. A comparative literature review
Research papers on loss reserving can be broadly categorized into two main streams of research: models based on development triangles (aggregate loss reserving models) and models based on individual data (individual loss reserving models). The relationship between individual data and aggregate modelling has been extensively studied in Miranda et al. (Reference Miranda, Nielsen and Verrall2012), Hiabu (Reference Hiabu2017), and Bischofberger et al. (Reference Bischofberger, Hiabu and Isakson2020), utilizing different survival analysis tools.
The existing body of literature on aggregate reserving has already provided the building blocks for predicting the distribution of loss reserves, with a specific emphasis on models that seek to emulate the empirical chain-ladder algorithm. In this section, we briefly mention some of these models and defer to the comprehensive discussion in Hess and Schmidt (Reference Hess and Schmidt2002) for their detailed categorization. For a distribution-independent approach to computing the mean squared prediction error of the loss reserve, one can refer to Mack (Reference Mack1993), where the author decomposes the prediction error of the loss reserve into its elemental components, namely process variance and estimation variance, as expressed by
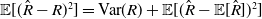 $\mathbb{E}[(\hat R- R)^2]=\mathrm{Var}(R)+\mathbb{E}[(\hat R- \mathbb{E} [\hat R])^2]$
. The model has received several statistical critiques through the years but remains one of the best-performing reserving models in an actuary’s toolkit.
$\mathbb{E}[(\hat R- R)^2]=\mathrm{Var}(R)+\mathbb{E}[(\hat R- \mathbb{E} [\hat R])^2]$
. The model has received several statistical critiques through the years but remains one of the best-performing reserving models in an actuary’s toolkit.
In England and Verrall (Reference England and Verrall1999), the authors replicate the point estimates of the chain-ladder method and ingeniously employ bootstrap and generalized linear models (GLM) to compute
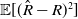 $\mathbb{E}[(\hat R- R)^2]$
. For an extension of the model, allowing for negative payments as well as an exploration of the model assumptions underpinning it, one may consult Verrall (Reference Verrall2000). An interesting comparison of the fundamental assumptions underpinning the aforementioned models is presented in Mack and Venter (Reference Mack and Venter2000), where the authors conclude that only the approach outlined in Mack (Reference Mack1993) is the true underlying model of the chain-ladder algorithm. In a more recent development, in Al-Mudafer et al. (Reference Al-Mudafer, Avanzi, Taylor and Wong2022), the approach in England and Verrall (Reference England and Verrall1999) is integrated into the framework of mixture density networks (Bishop, Reference Bishop1994).
$\mathbb{E}[(\hat R- R)^2]$
. For an extension of the model, allowing for negative payments as well as an exploration of the model assumptions underpinning it, one may consult Verrall (Reference Verrall2000). An interesting comparison of the fundamental assumptions underpinning the aforementioned models is presented in Mack and Venter (Reference Mack and Venter2000), where the authors conclude that only the approach outlined in Mack (Reference Mack1993) is the true underlying model of the chain-ladder algorithm. In a more recent development, in Al-Mudafer et al. (Reference Al-Mudafer, Avanzi, Taylor and Wong2022), the approach in England and Verrall (Reference England and Verrall1999) is integrated into the framework of mixture density networks (Bishop, Reference Bishop1994).
Shifting our focus to non-parametric models for individual reserving, the current discussion primarily centers on providing precise point forecasts for the loss reserve. In contrast, Delong and Wüthrich (2023) discuss the role of the variance function in regression problems for pricing.
In another recent development, Wüthrich (Reference Wüthrich2018) incorporates neural networks into the chain-ladder model, introducing features to the existing methodology. Further related work can be found in Lopez et al. (Reference Lopez, Milhaud and Thérond2019) and Lopez and Milhaud (Reference Lopez and Milhaud2021), where the authors employ a tree-based algorithm for modeling RBNS claims using censored data. In particular, in Lopez and Milhaud (Reference Lopez and Milhaud2021), the use of bootstrapping for estimating the uncertainty in the claims reserve is discussed.
Our manuscript introduces a novel approach to the individual reserving problem, allowing us to explicitly model curves of individual claim sizes denoted as
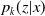 $p_k(z|x)$
within our framework.
$p_k(z|x)$
within our framework.
3.2. Prediction of RBNS and IBNR claim costs
We can calculate the final cost of RBNS claims numerically using the conditional Aalen–Johansen estimate
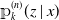 ${\unicode{x1D561}}_k^{(n)}(z \mid x)$
for
${\unicode{x1D561}}_k^{(n)}(z \mid x)$
for
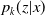 $p_k(z|x)$
. The predictor of the final total cost of RBNS claims is defined by
$p_k(z|x)$
. The predictor of the final total cost of RBNS claims is defined by
 \begin{equation*}\hat Y^{\texttt{RBNS}}=\sum^n_i\unicode{x1D7D9}_{\left\{\delta^i = 0\right\}} \left(W^{i} + \widehat{\mathbb{E}[Y| Y> W^{i}, X=x]}\right)\end{equation*}
\begin{equation*}\hat Y^{\texttt{RBNS}}=\sum^n_i\unicode{x1D7D9}_{\left\{\delta^i = 0\right\}} \left(W^{i} + \widehat{\mathbb{E}[Y| Y> W^{i}, X=x]}\right)\end{equation*}
with
 \begin{equation}\widehat{\mathbb{E}\left[Y| Y> W^{i}, X=x\right]} = \frac{1}{1-{\unicode{x1D561}}_k^{(n)}(W^i \mid x)}\int^{+\infty}_{W^{i}} (1-{\unicode{x1D561}}_k^{(n)}(y \mid x)) \mathrm{d} y.\end{equation}
\begin{equation}\widehat{\mathbb{E}\left[Y| Y> W^{i}, X=x\right]} = \frac{1}{1-{\unicode{x1D561}}_k^{(n)}(W^i \mid x)}\int^{+\infty}_{W^{i}} (1-{\unicode{x1D561}}_k^{(n)}(y \mid x)) \mathrm{d} y.\end{equation}
We remark that the general formula for the mth moment is explicitly given by
 \begin{align*}\widehat{\mathbb{E}\left[Y^m| Y> W^{i}, X=x\right]} = \frac{1}{1-{\unicode{x1D561}}_k^{(n)}(W^{i} \mid x)} \int_{W^{i}}^{+\infty} m y^{m-1}(1-{\unicode{x1D561}}_k^{(n)}(y \mid x)) \mathrm{d} y.\end{align*}
\begin{align*}\widehat{\mathbb{E}\left[Y^m| Y> W^{i}, X=x\right]} = \frac{1}{1-{\unicode{x1D561}}_k^{(n)}(W^{i} \mid x)} \int_{W^{i}}^{+\infty} m y^{m-1}(1-{\unicode{x1D561}}_k^{(n)}(y \mid x)) \mathrm{d} y.\end{align*}
Remark 6. Relatable approaches to the predictor in Equation (3.1) can be found in the survival literature on censored regression. For instance, similar techniques were presented for the estimation of the linear model in Buckley and James (Reference Buckley and James1979) and for the construction of the artificial data points in Heuchenne and Van Keilegom (Reference Heuchenne and Van Keilegom2007).
Strictly speaking, from a reserving standpoint, we also need to propose a strategy for reserving for the (unknown) IBNR claims. We denote the total number of IBNR claims by
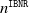 $n^{\texttt{IBNR}}$
, which is a random variable with values in
$n^{\texttt{IBNR}}$
, which is a random variable with values in
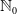 $\mathbb{N}_0$
. The individual cost of the IBNR claims is described by a sequence of iid copies of the random variable
$\mathbb{N}_0$
. The individual cost of the IBNR claims is described by a sequence of iid copies of the random variable
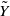 $\tilde Y$
, namely
$\tilde Y$
, namely
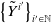 $\left\{ \tilde Y^{i^\prime} \right\}_{i^\prime \in \mathbb{N}}$
. Under the framework of Bladt and Furrer (Reference Bladt and Furrer2023b),
$\left\{ \tilde Y^{i^\prime} \right\}_{i^\prime \in \mathbb{N}}$
. Under the framework of Bladt and Furrer (Reference Bladt and Furrer2023b),
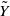 $\tilde Y$
has cumulative distribution function
$\tilde Y$
has cumulative distribution function
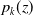 $p_k(z)$
. As we will describe shortly, we specify a model that does not consider the features, since in this case we do not have access to future exposures by feature. We propose to correct the model for the random presence of IBNR using a compound distribution, under the assumptions in Klugman et al. (Reference Klugman, Panjer and Willmot2012, p. 148). We describe the total cost of IBNR claims as follows:
$p_k(z)$
. As we will describe shortly, we specify a model that does not consider the features, since in this case we do not have access to future exposures by feature. We propose to correct the model for the random presence of IBNR using a compound distribution, under the assumptions in Klugman et al. (Reference Klugman, Panjer and Willmot2012, p. 148). We describe the total cost of IBNR claims as follows:
 \begin{align*}Y^{\texttt{IBNR}}=\sum^{n^{\texttt{IBNR}}}_{i^\prime=1} \tilde Y^{i^\prime}.\end{align*}
\begin{align*}Y^{\texttt{IBNR}}=\sum^{n^{\texttt{IBNR}}}_{i^\prime=1} \tilde Y^{i^\prime}.\end{align*}
The expression for
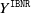 $Y^{\texttt{IBNR}}$
is well known in non-life mathematics and is often referred to as the collective risk model, Parodi (Reference Parodi2014). The moments of
$Y^{\texttt{IBNR}}$
is well known in non-life mathematics and is often referred to as the collective risk model, Parodi (Reference Parodi2014). The moments of
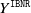 $Y^{\texttt{IBNR}}$
can be calculated in closed form. In particular, the expected cost of IBNR claims is predicted by
$Y^{\texttt{IBNR}}$
can be calculated in closed form. In particular, the expected cost of IBNR claims is predicted by
 \begin{align*}\hat Y^{\texttt{IBNR}} = \widehat{\mathbb E[Y^{\texttt{IBNR}}]}= \hat n^{\texttt{IBNR}}\widehat{\mathbb{E} [\tilde Y]}, \end{align*}
\begin{align*}\hat Y^{\texttt{IBNR}} = \widehat{\mathbb E[Y^{\texttt{IBNR}}]}= \hat n^{\texttt{IBNR}}\widehat{\mathbb{E} [\tilde Y]}, \end{align*}
with the m-th moment of
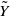 $\tilde Y$
predicted by
$\tilde Y$
predicted by
 \begin{align*}\widehat{ \mathbb{E} [\tilde Y^m]} = \int^{\infty}_0 m y^{m-1}(1-{\unicode{x1D561}}_k^{(n)}(y)) \mathrm{d} y,\end{align*}
\begin{align*}\widehat{ \mathbb{E} [\tilde Y^m]} = \int^{\infty}_0 m y^{m-1}(1-{\unicode{x1D561}}_k^{(n)}(y)) \mathrm{d} y,\end{align*}
fitting the unconditional Aalen–Johansen to the sample n to obtain
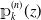 ${\unicode{x1D561}}_k^{(n)}(z)$
. To project the number of IBNR claims, we simply use the chain ladder model on the triangle of reporting delays
${\unicode{x1D561}}_k^{(n)}(z)$
. To project the number of IBNR claims, we simply use the chain ladder model on the triangle of reporting delays
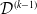 $\mathcal{D}^{(k-1)}$
and obtain
$\mathcal{D}^{(k-1)}$
and obtain
 $\hat n^{\texttt{IBNR}}$
.
$\hat n^{\texttt{IBNR}}$
.
Similarly, the variance of the IBNR claims is predicted by
 \begin{align*}\widehat {\mbox{Var}( Y^{\texttt{IBNR}})}= \hat n^{\texttt{IBNR}} \left[\widehat{\mathbb{E} [\tilde Y^2]}- \widehat{\mathbb{E} [\tilde Y]}^2\right]+\widehat{\mathbb{E} [\tilde Y]}^2 \widehat{\mbox{Var}(n^{\texttt{IBNR}})}.\end{align*}
\begin{align*}\widehat {\mbox{Var}( Y^{\texttt{IBNR}})}= \hat n^{\texttt{IBNR}} \left[\widehat{\mathbb{E} [\tilde Y^2]}- \widehat{\mathbb{E} [\tilde Y]}^2\right]+\widehat{\mathbb{E} [\tilde Y]}^2 \widehat{\mbox{Var}(n^{\texttt{IBNR}})}.\end{align*}
We denote by
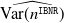 $\widehat{\mbox{Var}(n^{\texttt{IBNR}})}$
a predictor for the variance of
$\widehat{\mbox{Var}(n^{\texttt{IBNR}})}$
a predictor for the variance of
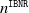 $n^{\texttt{IBNR}}$
. In this manuscript, we consider the predictor for the process variance discussed in Mack (Reference Mack1993).
$n^{\texttt{IBNR}}$
. In this manuscript, we consider the predictor for the process variance discussed in Mack (Reference Mack1993).
The total size of claims is
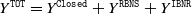 $Y^{\texttt{TOT}}= Y^{\texttt{Closed}}+Y^{\texttt{RBNS}}+Y^{\texttt{IBNR}}$
and we estimate it with
$Y^{\texttt{TOT}}= Y^{\texttt{Closed}}+Y^{\texttt{RBNS}}+Y^{\texttt{IBNR}}$
and we estimate it with
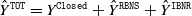 $\hat Y^{\texttt{TOT}}= Y^{\texttt{Closed}} + \hat Y^{\texttt{RBNS}}+\hat Y^{\texttt{IBNR}}$
. We remark that in several lines of business the contribution of the true cost of IBNR claims (
$\hat Y^{\texttt{TOT}}= Y^{\texttt{Closed}} + \hat Y^{\texttt{RBNS}}+\hat Y^{\texttt{IBNR}}$
. We remark that in several lines of business the contribution of the true cost of IBNR claims (
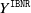 $ Y^{\texttt{IBNR}}$
) to
$ Y^{\texttt{IBNR}}$
) to
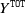 $Y^{\texttt{TOT}}$
is minor compared to the cost of RBNS claims (
$Y^{\texttt{TOT}}$
is minor compared to the cost of RBNS claims (
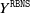 $ Y^{\texttt{RBNS}}$
). This is the case for those lines of business that have data with mostly single payments and a short time lag between reporting and settlement. See for instance the results presented in Friedland (Reference Friedland2010, p. 80) on the US market data, comparing for different lines of insurance the size of the estimated cost of IBNR claims to paid and outstanding claims. As we will show in Section 5, our real dataset exhibits exactly this behaviour and the IBNR correction will have a minor impact on the estimated final cost.
$ Y^{\texttt{RBNS}}$
). This is the case for those lines of business that have data with mostly single payments and a short time lag between reporting and settlement. See for instance the results presented in Friedland (Reference Friedland2010, p. 80) on the US market data, comparing for different lines of insurance the size of the estimated cost of IBNR claims to paid and outstanding claims. As we will show in Section 5, our real dataset exhibits exactly this behaviour and the IBNR correction will have a minor impact on the estimated final cost.
4. Simulation of RBNS claims
In this section, we perform two simulation studies to provide numerical evidence of the applicability of our models to claims reserving. To demonstrate the potential benefits to actuaries of using our modeling approach, we first compare our results with the chain ladder model (Mack, Reference Mack1993). A second comparison with the hierarchical reserving model in Crevecoeur et al. (Reference Crevecoeur, Antonio, Desmedt and Masquelein2023) can be found in Appendix A. To facilitate the presentation of our results, we refer to our model as AJ, the chain ladder model in Mack (Reference Mack1993) as as CL, and the hierarchical reserving model as hirem.
4.1. Implementation
It is possible to simulate observations from a jump-process model using the function sim_path from the R package AalenJohansen (Bladt and Furrer, Reference Bladt and Furrer2023a), by introducing a matrix of transition intensities. Markov and semi-Markov models are allowed. To obtain a realistic set of examples for the simulation study, we used the Nelson–Aalen implementation of the R package survival (Therneau, Reference Therneau2023) to estimate the (unconditional) cumulative transition intensities
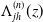 $\mathbb{\Lambda}_{j h}^{(n)}(z)$
for different choices of
$\mathbb{\Lambda}_{j h}^{(n)}(z)$
for different choices of
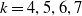 $k=4,5,6,7$
on the real dataset available to us for writing this manuscript. Then, similar choices of parameters were employed for the present section. See Table 3 for the description of the real data. The matrix of intensities can be obtained from the cumulative intensities
$k=4,5,6,7$
on the real dataset available to us for writing this manuscript. Then, similar choices of parameters were employed for the present section. See Table 3 for the description of the real data. The matrix of intensities can be obtained from the cumulative intensities
 $\mathbb{\Lambda}_{j h}^{(n)}(z)$
. Simulation by knowing the data generation process underlying the data is important to understand model performance compared to the true estimation target. For example, in Figure 2, we show an example of the fitted
$\mathbb{\Lambda}_{j h}^{(n)}(z)$
. Simulation by knowing the data generation process underlying the data is important to understand model performance compared to the true estimation target. For example, in Figure 2, we show an example of the fitted
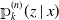 ${\unicode{x1D561}}_k^{(n)}(z \mid x)$
on datasets simulated directly with
${\unicode{x1D561}}_k^{(n)}(z \mid x)$
on datasets simulated directly with
 $\mathbb{\Lambda}$
without any feature effect. For each choice of k we simulated two datasets. The first dataset contains
$\mathbb{\Lambda}$
without any feature effect. For each choice of k we simulated two datasets. The first dataset contains
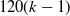 $120 (k-1)$
observations. The second dataset contains
$120 (k-1)$
observations. The second dataset contains
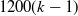 $1200 (k-1)$
observations. By comparing the
$1200 (k-1)$
observations. By comparing the
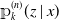 ${\unicode{x1D561}}_k^{(n)}(z \mid x)$
fitted to the smallest sample (red) with the curve fitted to the largest sample (blue), we observe that increasing the sample size yields fits that are closer to the true
${\unicode{x1D561}}_k^{(n)}(z \mid x)$
fitted to the smallest sample (red) with the curve fitted to the largest sample (blue), we observe that increasing the sample size yields fits that are closer to the true
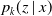 $p_k(z\mid x)$
, empirically validating the consistency of the Aalen–Johansen estimator with claim size as operational time.
$p_k(z\mid x)$
, empirically validating the consistency of the Aalen–Johansen estimator with claim size as operational time.
In particular, we have presented a model that can take into account the individual feature information. In the case studies that we present in the next section, we treat the accident period as a feature and add an effect by simply specifying
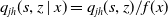 $q_{j h}(s, z \mid x) = q_{j h}(s, z)/f(x)$
, where f(x) is a function of some feature x and we can derive
$q_{j h}(s, z \mid x) = q_{j h}(s, z)/f(x)$
, where f(x) is a function of some feature x and we can derive
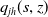 $q_{j h}(s, z)$
from the cumulative transition matrix obtained with the survival package. In the simulations we present, we assume that observations are generated from
$q_{j h}(s, z)$
from the cumulative transition matrix obtained with the survival package. In the simulations we present, we assume that observations are generated from
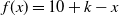 $f(x)= {10+k-x}$
, where in place of x we use the accident period, namely
$f(x)= {10+k-x}$
, where in place of x we use the accident period, namely
 $U^i$
introduced in the previous sections. For the simulation of the reserving datasets, we decide arbitrarily the number of observations in each accident period
$U^i$
introduced in the previous sections. For the simulation of the reserving datasets, we decide arbitrarily the number of observations in each accident period
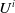 $U^i$
. Each claimant is then associated with a numeric variable representing the accident period
$U^i$
. Each claimant is then associated with a numeric variable representing the accident period
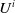 $U^i$
, taking values in
$U^i$
, taking values in
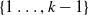 $\left\{1 \ldots, k-1\right\}$
, from which we can calculate the effect
$\left\{1 \ldots, k-1\right\}$
, from which we can calculate the effect
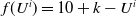 $f(U^i)= {10+k-U^i}$
. We also add an effect on the volumes, and generate fewer observations in most recent accident period. Generating decreasing volumes resembles cycles in the underwriting, a case study of an insurer that underwrites less policies in the more recent accident periods, resulting in less claims. In particular, we generated 1200 observations in the first accident period
$f(U^i)= {10+k-U^i}$
. We also add an effect on the volumes, and generate fewer observations in most recent accident period. Generating decreasing volumes resembles cycles in the underwriting, a case study of an insurer that underwrites less policies in the more recent accident periods, resulting in less claims. In particular, we generated 1200 observations in the first accident period
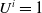 $U^i = 1$
and decreased by 100 the number of observations every accident periods. For instance, we have 1100 observations with
$U^i = 1$
and decreased by 100 the number of observations every accident periods. For instance, we have 1100 observations with
 $U^i=2$
and 1000 observations with
$U^i=2$
and 1000 observations with
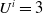 $U^i=3$
.
$U^i=3$
.
Comparison of the true severity curve (dark grey dotted line) to the fitted severity curve for different data sizes in the 4 simulated scenarios. The red curve is fitted on
 $120 (k-1)$
RBNS claims, the blue curve is fitted on 1200 RBNS claims. Z is rounded by millions.
$120 (k-1)$
RBNS claims, the blue curve is fitted on 1200 RBNS claims. Z is rounded by millions.

4.2. Evaluating the models performance
Using the approach introduced in Section 4.1, we present two simulated scenarios: Alpha and Beta. In scenario Alpha, we simulate directly with unconditional transition intensities that we have fitted to the real data. In the Beta scenario, we introduce the effect of the accident period characteristics and the occupation intensities. In each scenario we simulate, for the different choices of
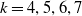 $k=4,5,6,7$
, a total number of 20 datasets to smooth possible fluctuations due to the random generator and report the average results that we obtain. Each dataset in scenario Alpha contains
$k=4,5,6,7$
, a total number of 20 datasets to smooth possible fluctuations due to the random generator and report the average results that we obtain. Each dataset in scenario Alpha contains
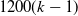 $1200(k-1)$
observations. The dataset in scenario Beta contains
$1200(k-1)$
observations. The dataset in scenario Beta contains
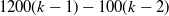 $1200(k-1)-100(k-2)$
observations. As motivated in Section 4.1, we let the volumes decrease in recent accident periods. We chose arbitrarily to decrease the volume by 100 in every accident period subsequent to the first one.
$1200(k-1)-100(k-2)$
observations. As motivated in Section 4.1, we let the volumes decrease in recent accident periods. We chose arbitrarily to decrease the volume by 100 in every accident period subsequent to the first one.
The choice of measure of model performance can be an ardouos task when models are very different, as are AJ and CL. The first performance measure that we propose is the error incidence,
 \begin{align*}\texttt{EI}= \frac{\hat Y^{\texttt{TOT}}}{Y^{\texttt{TOT}}}-1,\end{align*}
\begin{align*}\texttt{EI}= \frac{\hat Y^{\texttt{TOT}}}{Y^{\texttt{TOT}}}-1,\end{align*}
where
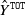 $\hat Y^{\texttt{TOT}} $
is the predicted final claim size and
$\hat Y^{\texttt{TOT}} $
is the predicted final claim size and
 $Y^{\texttt{TOT}}$
is the actual final claim size, which is available from the simulation. The EI is an interesting benchmark that provides insight into the relative accuracy of the AJ compared to the CL, though it does not highlight the fact that AJ provides a much more nuanced description of the claim size than point estimates. In Figure 3, we provide a box plot of the EI for the Alpha scenario (left side) and the Beta scenario (right side) for the different values of k. Compared to the CL, the AJ model performs favourably for each choice of k and in both scenarios.
$Y^{\texttt{TOT}}$
is the actual final claim size, which is available from the simulation. The EI is an interesting benchmark that provides insight into the relative accuracy of the AJ compared to the CL, though it does not highlight the fact that AJ provides a much more nuanced description of the claim size than point estimates. In Figure 3, we provide a box plot of the EI for the Alpha scenario (left side) and the Beta scenario (right side) for the different values of k. Compared to the CL, the AJ model performs favourably for each choice of k and in both scenarios.
Box plots of EI for AJ and CL over the 20 simulations, for each value of k, in the Alpha scenario (left column) and the Beta scenario (right column).

While the EI is an interesting benchmark, to better understand the performance of the models compared to the data at hand, we would ideally like to use a proper scoring measure (Gneiting and Raftery, 2007). In principle, a scoring metric with the property of being proper is able to evaluate the better model by assigning better scores to better models. In this manuscript we consider the continuously ranked probability score (CRPS) as a proper scoring metric:
 \begin{align*}\operatorname{CRPS}\left({\unicode{x1D561}}_k^{(n)}(z \mid x), y\right) &= \int_{0}^{+\infty} \left({\unicode{x1D561}}_k^{(n)}(z \mid x) - \unicode{x1D7D9}_{\{y \leqslant z\}}\right)^2 \mathrm{d} z \\&= \int^{y}_0 \left({\unicode{x1D561}}_k^{(n)}(z \mid x)\right)^2 \mathrm{d}z + \int^{+\infty}_y \left(1-{\unicode{x1D561}}_k^{(n)}(z \mid x)\right)^2 \mathrm{d}z,\end{align*}
\begin{align*}\operatorname{CRPS}\left({\unicode{x1D561}}_k^{(n)}(z \mid x), y\right) &= \int_{0}^{+\infty} \left({\unicode{x1D561}}_k^{(n)}(z \mid x) - \unicode{x1D7D9}_{\{y \leqslant z\}}\right)^2 \mathrm{d} z \\&= \int^{y}_0 \left({\unicode{x1D561}}_k^{(n)}(z \mid x)\right)^2 \mathrm{d}z + \int^{+\infty}_y \left(1-{\unicode{x1D561}}_k^{(n)}(z \mid x)\right)^2 \mathrm{d}z,\end{align*}
where
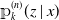 ${\unicode{x1D561}}_k^{(n)}(z \mid x)$
is the predicted curve of the individual claims sizes and
${\unicode{x1D561}}_k^{(n)}(z \mid x)$
is the predicted curve of the individual claims sizes and
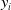 $y_i$
is the (true) value of the final claim size that is available from the simulation. The interested reader can refer to the established statistical literature on proper scoring for a detailed discussion on this topic Gneiting and Raftery, Reference Gneiting and Raftery2007; Gneiting and Ranjan, Reference Gneiting and Ranjan2011).
$y_i$
is the (true) value of the final claim size that is available from the simulation. The interested reader can refer to the established statistical literature on proper scoring for a detailed discussion on this topic Gneiting and Raftery, Reference Gneiting and Raftery2007; Gneiting and Ranjan, Reference Gneiting and Ranjan2011).
4.3. Empirical analysis
The average results of our 20 simulations for the Alpha scenario are reported in Table 1. Each column of the table represents one of the AJ models fitted for the different choices of k (column one). The target
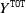 $Y^{\texttt{TOT}}$
(average simulated total cost) assuming
$Y^{\texttt{TOT}}$
(average simulated total cost) assuming
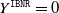 $Y^{\texttt{IBNR}}=0$
is in column four. The predicted final cost is
$Y^{\texttt{IBNR}}=0$
is in column four. The predicted final cost is
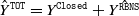 $\hat Y^{\texttt{TOT}} = Y^{\texttt{Closed}}+ \hat{Y^{\texttt{RBNS}}}$
. The EI results show that, on average, our models outperform the CL for every choice of k except
$\hat Y^{\texttt{TOT}} = Y^{\texttt{Closed}}+ \hat{Y^{\texttt{RBNS}}}$
. The EI results show that, on average, our models outperform the CL for every choice of k except
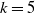 $k=5$
(columns five and six). For all choices of k, we find that the relative variability of our model is less than that provided by the CL (columns seven and eight). We compute
$k=5$
(columns five and six). For all choices of k, we find that the relative variability of our model is less than that provided by the CL (columns seven and eight). We compute
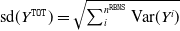 $\mbox{sd}(Y^{\texttt{TOT}})=\sqrt{\sum^{n^{\texttt{RBNS}}}_i \mbox{Var}(Y^i)}$
. In this manuscript, we will not discuss the estimation error, and the results we present with respect to the variability of the reserve refer only to the process variance. In column nine, we report the (average) CRPS.
$\mbox{sd}(Y^{\texttt{TOT}})=\sqrt{\sum^{n^{\texttt{RBNS}}}_i \mbox{Var}(Y^i)}$
. In this manuscript, we will not discuss the estimation error, and the results we present with respect to the variability of the reserve refer only to the process variance. In column nine, we report the (average) CRPS.
Results for scenario Alpha. For each value of k (column one) we present the average results over the 20 simulations. Each row of the table corresponds to a different AJ model specification (column three). The table includes the (average) actual Y
 $^{\texttt{TOT}}$
simulated total cost (column four) and the error incidence for the AJ and the CL (columns five and six). In columns seven and eight, we reported the coefficients of variation of Y
$^{\texttt{TOT}}$
simulated total cost (column four) and the error incidence for the AJ and the CL (columns five and six). In columns seven and eight, we reported the coefficients of variation of Y
 $^{\texttt{TOT}}$
. The results for the CRPS are reported in column nine.
$^{\texttt{TOT}}$
. The results for the CRPS are reported in column nine.

Results for scenario Beta. For each value of k (column one), we present the average results over the 20 simulations. Each row of the table corresponds to a different AJ model specification (column three). The table includes the (average) actual simulated total cost (column four) and the error incidence for the AJ and the CL (columns five and six). In columns seven and eight, we reported the coefficients of variation of Y
 $^{\texttt{TOT}}$
. The results for the CRPS, relative to the AJ model with features, are reported in column nine.
$^{\texttt{TOT}}$
. The results for the CRPS, relative to the AJ model with features, are reported in column nine.

Table 2 reports the average results for the 20 simulations of the Beta scenario. For each simulation, we fit two models, with and without the use of U as a feature (
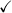 $\checkmark$
and ✗ in the table). The model with U is correctly specified assuming the Beta scenario. The aim of this experiment is to show that the CRPS is able to judge which is the better model in a context where we know the data generation process. As expected, we obtain a lower average CRPS for the models that include features. The CRPS results in Table 2 are relative to the AJ model with feature U. For example, for
$\checkmark$
and ✗ in the table). The model with U is correctly specified assuming the Beta scenario. The aim of this experiment is to show that the CRPS is able to judge which is the better model in a context where we know the data generation process. As expected, we obtain a lower average CRPS for the models that include features. The CRPS results in Table 2 are relative to the AJ model with feature U. For example, for
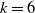 $k=6$
we see that the AJ model without the feature U shows (on average) a CRPS
$k=6$
we see that the AJ model without the feature U shows (on average) a CRPS
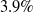 $3.9 \%$
higher than the CRPS of the AJ model with feature U. For the purpose of an easier interpretation, the CRPS results will be shown relative to the AJ with feature model also in the following tables. The (average) target
$3.9 \%$
higher than the CRPS of the AJ model with feature U. For the purpose of an easier interpretation, the CRPS results will be shown relative to the AJ with feature model also in the following tables. The (average) target
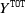 $Y^{\texttt{TOT}}$
is reported in the fourth column. The results for EI indicate that the AJ model generally outperforms the CL model. The relative variability results show comparable results for AJ and CL.
$Y^{\texttt{TOT}}$
is reported in the fourth column. The results for EI indicate that the AJ model generally outperforms the CL model. The relative variability results show comparable results for AJ and CL.
5. A data application on an insurance portfolio
In this section, we propose a case study on our model using real data. For this data application, we have at our disposal a recent real dataset from a Danish non-life insurer. The dataset is not publicly available (Table 3).
Description of the real dataset.

We provide additional insight in Figure 4. The exploratory analysis of the data shows that most of the records have a single payment (Figure 4(b)) and a very fast settlement (Figure 4 (d)). The data we present in this manuscript come from a very stable line of business. Interestingly, we show that we are able to outperform the CL on data where the CL is expected to behave as well as it can. Most of the datasets belong to claim_type 1, see Figure 4 (a).
Exploratory data analysis on the real dataset that we use in this section. We show the relative frequencies by type of claim Figure (a), the distribution of the number of payments Figure (b), the density plot of the total individual claim size Figure (c) and the distribution of the settlement delay from accident Figure (d).

Remark 7. Notice that the covariate in our application is discrete, which with a uniform kernel effectively amounts to subsampling of data. However, the estimators of the paper provide consistent and asymptotically normal estimators even when covariates are continuous. Nonetheless, kernel-based methods are prone to the curse of dimesionality, and hence our method provides the best results when covariate dimensions are small.
To analyse the real dataset, we propose two strategies that an actuary could follow to calculate the loss reserve. In Section 5.1, we show an example where we censor our data by different calendar periods and fit an AJ model for the maximum depth of data available. For example, for a model with
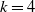 $k=4$
, we will have the individual data corresponding to a development triangle with 3 accident periods. The purpose of this application is to show the behaviour of our model compared to the CL on different datasets. In Section 5.2, we conclude with an application where we highlight the use of the CRPS measure to perform model selection, after having censored the data at an arbitrary calendar time, that is 5 calendar periods. Here we fit different models to the same datasets and select the best-performing model in terms of CRPS to calculate the loss reserve. The applications in this section also comprise the IBNR model that we have illustrated in the previous sections. In fact, we predict
$k=4$
, we will have the individual data corresponding to a development triangle with 3 accident periods. The purpose of this application is to show the behaviour of our model compared to the CL on different datasets. In Section 5.2, we conclude with an application where we highlight the use of the CRPS measure to perform model selection, after having censored the data at an arbitrary calendar time, that is 5 calendar periods. Here we fit different models to the same datasets and select the best-performing model in terms of CRPS to calculate the loss reserve. The applications in this section also comprise the IBNR model that we have illustrated in the previous sections. In fact, we predict
 $\hat Y^{\texttt{TOT}} = Y^{\texttt{Closed}}+ \hat{Y}^{\texttt{RBNS}}+\hat{Y}^{\texttt{IBNR}}$
and
$\hat Y^{\texttt{TOT}} = Y^{\texttt{Closed}}+ \hat{Y}^{\texttt{RBNS}}+\hat{Y}^{\texttt{IBNR}}$
and
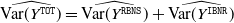 $\widehat{\mbox{Var}(Y^{\texttt{TOT}})}=\widehat{\mbox{Var}( Y^{\texttt{RBNS}})}+ \widehat{\mbox{Var}( Y^{\texttt{IBNR}})}$
.
$\widehat{\mbox{Var}(Y^{\texttt{TOT}})}=\widehat{\mbox{Var}( Y^{\texttt{RBNS}})}+ \widehat{\mbox{Var}( Y^{\texttt{IBNR}})}$
.
5.1. Model comparison on different datasets
Consider the first application, where we censor our data at different depths and fit an AJ model using the largest possible state space. Using our model, it is possible to explore and compare the individual claim size curves for the different values of claim_type, as shown in Figure 5.
The results are reported in Table 4, and they show that in general the AJ models outperform the CL in terms of EI, except for the scenario with
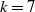 $k=7$
. For each scenario, we are able to select a model with or without features using the CRPS measure. The rows with a
$k=7$
. For each scenario, we are able to select a model with or without features using the CRPS measure. The rows with a
 $\checkmark$
(column two) refer to models that include the claim_type feature in the fit. The target
$\checkmark$
(column two) refer to models that include the claim_type feature in the fit. The target
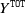 $Y^{\texttt{TOT}}$
is shown in column three. While in other scenarios, the CRPS for the AJ model that includes the claim_type feature is close to or better than the CRPS of the model without the feature, in
$Y^{\texttt{TOT}}$
is shown in column three. While in other scenarios, the CRPS for the AJ model that includes the claim_type feature is close to or better than the CRPS of the model without the feature, in
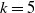 $k=5$
the model without the feature has a much lower CRPS. The relative variability results show that AJ and CL have comparable results. In fact, only for
$k=5$
the model without the feature has a much lower CRPS. The relative variability results show that AJ and CL have comparable results. In fact, only for
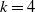 $k=4$
does CL have a lower relative variability.
$k=4$
does CL have a lower relative variability.
For different choices of k (column one), we fit a model with and without
 $\texttt{claim_type}$
(column two). The target Y
$\texttt{claim_type}$
(column two). The target Y
 $^{\texttt{TOT}}$
is shown in column three. The EI is shown in columns four and five. The CV of Y
$^{\texttt{TOT}}$
is shown in column three. The EI is shown in columns four and five. The CV of Y
 $^{\texttt{TOT}}$
are displayed in columns seven and eight for the AJ and CL respectively. The CRPS is shown in column nine.
$^{\texttt{TOT}}$
are displayed in columns seven and eight for the AJ and CL respectively. The CRPS is shown in column nine.

For each different dimension
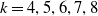 $k=4,5,6,7,8$
, we provide the individual claim size curves for our observations by covariate value
$k=4,5,6,7,8$
, we provide the individual claim size curves for our observations by covariate value
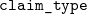 $\texttt{claim_type}$
. The x-axis represents Z and we scale it by
$\texttt{claim_type}$
. The x-axis represents Z and we scale it by
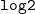 $\texttt{log2}$
to ease the plot visualization.
$\texttt{log2}$
to ease the plot visualization.

For each choice of k, we can simply select the best-performing model in terms of CRPS and compute the claims reserve, the results are displayed in Table 5.
5.2. Model comparison on a single dataset
In the second application, we censor our data after 5 accident period and construct the AJ model for
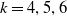 $k=4,5,6$
. For each choice of k, we fit a model both with and without the feature claim_type. Table 6 shows that in terms of CRPS, the model with
$k=4,5,6$
. For each choice of k, we fit a model both with and without the feature claim_type. Table 6 shows that in terms of CRPS, the model with
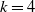 $k=4$
using the claim_type feature is the best model (minimum CRPS). This model is also the best in terms of EI.
$k=4$
using the claim_type feature is the best model (minimum CRPS). This model is also the best in terms of EI.
Using the CRPS, we are able to select the model with
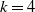 $k=4$
and that uses claim_type as a feature to compute the claims reserve. The model provides a reserve of
$k=4$
and that uses claim_type as a feature to compute the claims reserve. The model provides a reserve of
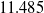 $11.485$
millions and a standard deviation of
$11.485$
millions and a standard deviation of
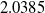 $ 2.0385$
millions. The strategy presented in this last section is of particular interest to reserving actuaries. While the empirical study in Section 5.1 is interesting for understanding the behaviour of our model on different data, in practice the maximum depth of the data is selected using indicators such as claims settlement speed or using the expert judgement of an experienced actuary Wüthrich and Merz (Reference Wüthrich and Merz2008, p. 12). The depth of the data is then known and the main interest is simply to select the best model, as shown here. Selecting the most appropriate model can be very difficult, see again Wüthrich and Merz (Reference Wüthrich and Merz2008, p. 13), and the strategy presented in this section provides a mathematically sound approach to doing so.
$ 2.0385$
millions. The strategy presented in this last section is of particular interest to reserving actuaries. While the empirical study in Section 5.1 is interesting for understanding the behaviour of our model on different data, in practice the maximum depth of the data is selected using indicators such as claims settlement speed or using the expert judgement of an experienced actuary Wüthrich and Merz (Reference Wüthrich and Merz2008, p. 12). The depth of the data is then known and the main interest is simply to select the best model, as shown here. Selecting the most appropriate model can be very difficult, see again Wüthrich and Merz (Reference Wüthrich and Merz2008, p. 13), and the strategy presented in this section provides a mathematically sound approach to doing so.
We selected for each data k (column one), the best-performing model in terms of CRPS and present the reserve (column one) and the standard deviation of the reserve (column two).

For the dataset with depth 5 accident periods, we fit the AJ model both including and excluding the
 $\texttt{claim_type}$
feature (column two). The target Y
$\texttt{claim_type}$
feature (column two). The target Y
 $^{\texttt{TOT}}$
is displayed in column three. The EI for the AJ and the CL can be found in columns four and five. The coefficient of variation of Y
$^{\texttt{TOT}}$
is displayed in column three. The EI for the AJ and the CL can be found in columns four and five. The coefficient of variation of Y
 $^{\texttt{TOT}}$
is displayed in columns six and seven. The CRPS is displayed in column eight.
$^{\texttt{TOT}}$
is displayed in columns six and seven. The CRPS is displayed in column eight.

6. Conclusion
The methodology described in this manuscript presents an improved approach for predicting loss reserves compared to commonly used aggregate loss reserving methods. We also introduce a comprehensive non-parametric estimator for the cumulative density function of individual claim sizes, distinguishing it from other individual loss reserving methods that mainly focus on point forecasts of claim reserves. While some questions remain open, particularly regarding the modeling of IBNR claims and their dependence on specific features, practical applications can address these issues by fitting our model with the chain ladder method for future reports and projecting their future costs using the unconditional curve of individual claim sizes. Furthermore, this methodology can be extended in various ways. One possibility is to explore the use of reverse time models, as described in Hiabu (Reference Hiabu2017), to project the future exposure of IBNR claims. In a broader context, future research could investigate how to model not only the size but also the frequency of individual claims.
Supplementary material
The code at https://github.com/gpitt71/conditional-aj-reserving complements the results of this manuscript. The folder was registered with unique Zenodo DOI 10.5281/zenodo.10118895.
Competing interests
The authors declare no competing interests of any kind.
Appendix
A Comparison with hirem
We perform a first comparison with the hirem model on the scenario Beta that we introduced in Section 4.3. The results are reported in Table A1. For the different values of k (column one), we compare the AJ model (with feature U) to the CL and hirem in terms of EI and CRPS. Each row corresponds to a different model (column two). The (average) target
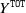 $Y^{\texttt{TOT}}$
is reported in column three. The EI (column four) shows that the AJ model is predicting the target
$Y^{\texttt{TOT}}$
is reported in column three. The EI (column four) shows that the AJ model is predicting the target
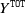 $Y^{\texttt{TOT}}$
more accurately than the CL and hirem. We also observe that the hirem model seems to be less accurate for higher values of k. Consistently with the data generating assumptions, the CRPS indicates that the AJ model better describes the curve of the claim size. The relative variation is reported from Table 2 the AJ model and the CL model (column five). We observe a similar relative variation of
$Y^{\texttt{TOT}}$
more accurately than the CL and hirem. We also observe that the hirem model seems to be less accurate for higher values of k. Consistently with the data generating assumptions, the CRPS indicates that the AJ model better describes the curve of the claim size. The relative variation is reported from Table 2 the AJ model and the CL model (column five). We observe a similar relative variation of
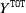 $Y^{\texttt{TOT}}$
on our models compared to hirem.
$Y^{\texttt{TOT}}$
on our models compared to hirem.
Results for scenario Beta. For each value of k (column one) we present the average results over the 20 simulations. Each row of the table corresponds to a different model (column two). The table includes the (average) actual simulated total cost (column three) and the error incidence for the AJ, the CL, and
 $\texttt{hirem}$
(columns four). In columns five we show the average relative variation and in column six we reported the average CRPS relative to the AJ CRPS.
$\texttt{hirem}$
(columns four). In columns five we show the average relative variation and in column six we reported the average CRPS relative to the AJ CRPS.

A second comparison is performed on synthetic data generated from the individual claims simulators available in the R package (Crevecoeur and Robben, Reference Crevecoeur and Robben2024). The package includes the hirem models implementation and four individual claims simulators for reported claims for
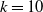 $k=10$
. While the four scenarios are briefly introduced in this section, we refer to the package documentation and the main manuscript for a detailed description. The generated features that are relevant for our application are reported in Table A2.
$k=10$
. While the four scenarios are briefly introduced in this section, we refer to the package documentation and the main manuscript for a detailed description. The generated features that are relevant for our application are reported in Table A2.
Description of the
 $\texttt{hirem}$
data.
$\texttt{hirem}$
data.

The data include one categorical feature, the type of claim (Type), which we use in our application and a hidden feature (Hidden) that is not known to the insurer at the evaluation. The package includes a baseline simulated scenario (Baseline) and three scenarios that include modifications compare to the Baseline. In the scenario Claim Mix, there is a change in the portfolio distribution with respect to the feature Type. In the scenario Extreme, a seasonality effect in calendar year 9 simulates an increase in the claim occurrences. Lastly, the Settlement scenario simulates a change of the claim settlement process to quicker settlement after calendar period 7.
The results of this second application are reported Table A3. We find that, both in terms of EI and CRPS and in the four simulated scenarios, our models always outperform the CL, while hirem performs better than the AJ (columns five and seven). The CRPS in column seven are relative to the CRPS of the AJ model with features. These results are expected, as the data are generated using assumptions that are consistent with the hirem model, see Appendix A of Crevecoeur et al. (Reference Crevecoeur, Antonio, Desmedt and Masquelein2023). Notwithstanding, the AJ model is performing comparatively well. The results are averaged over ten simulations.
We remark that the applications reported in Tables A1 and A3 indicate that, in general, for the scenarios that we inspected, individual models always outperform the chain ladder benchmark. However, as expected, the models perform best when the data generating process is consistent with the models assumptions.
The hirem package includes four data generators in four different scenarios with
 $k=10$
(column one). We compare our models (AJ with and without features, column two) to the model in Crevecoeur et al. (Reference Crevecoeur, Antonio, Desmedt and Masquelein2023) and the CL (column three). The actual Y
$k=10$
(column one). We compare our models (AJ with and without features, column two) to the model in Crevecoeur et al. (Reference Crevecoeur, Antonio, Desmedt and Masquelein2023) and the CL (column three). The actual Y
 $^{\texttt{TOT}}$
target is reported in column four. We show the EI and the CRPS results in columns five and seven, respectevely. The predicted relative variation of Y
$^{\texttt{TOT}}$
target is reported in column four. We show the EI and the CRPS results in columns five and seven, respectevely. The predicted relative variation of Y
 $^{\texttt{TOT}}$
is shown in column six.
$^{\texttt{TOT}}$
is shown in column six.



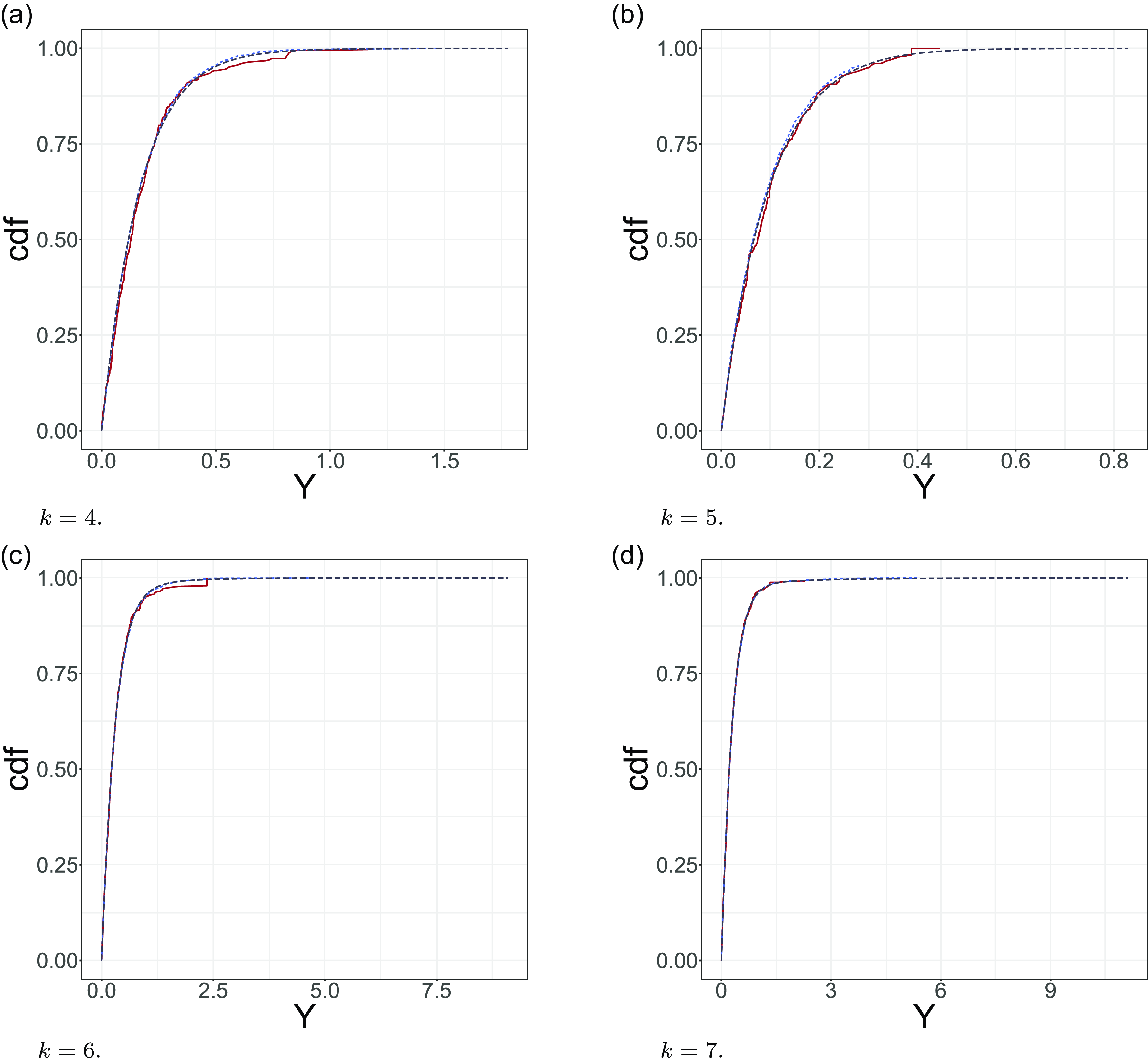

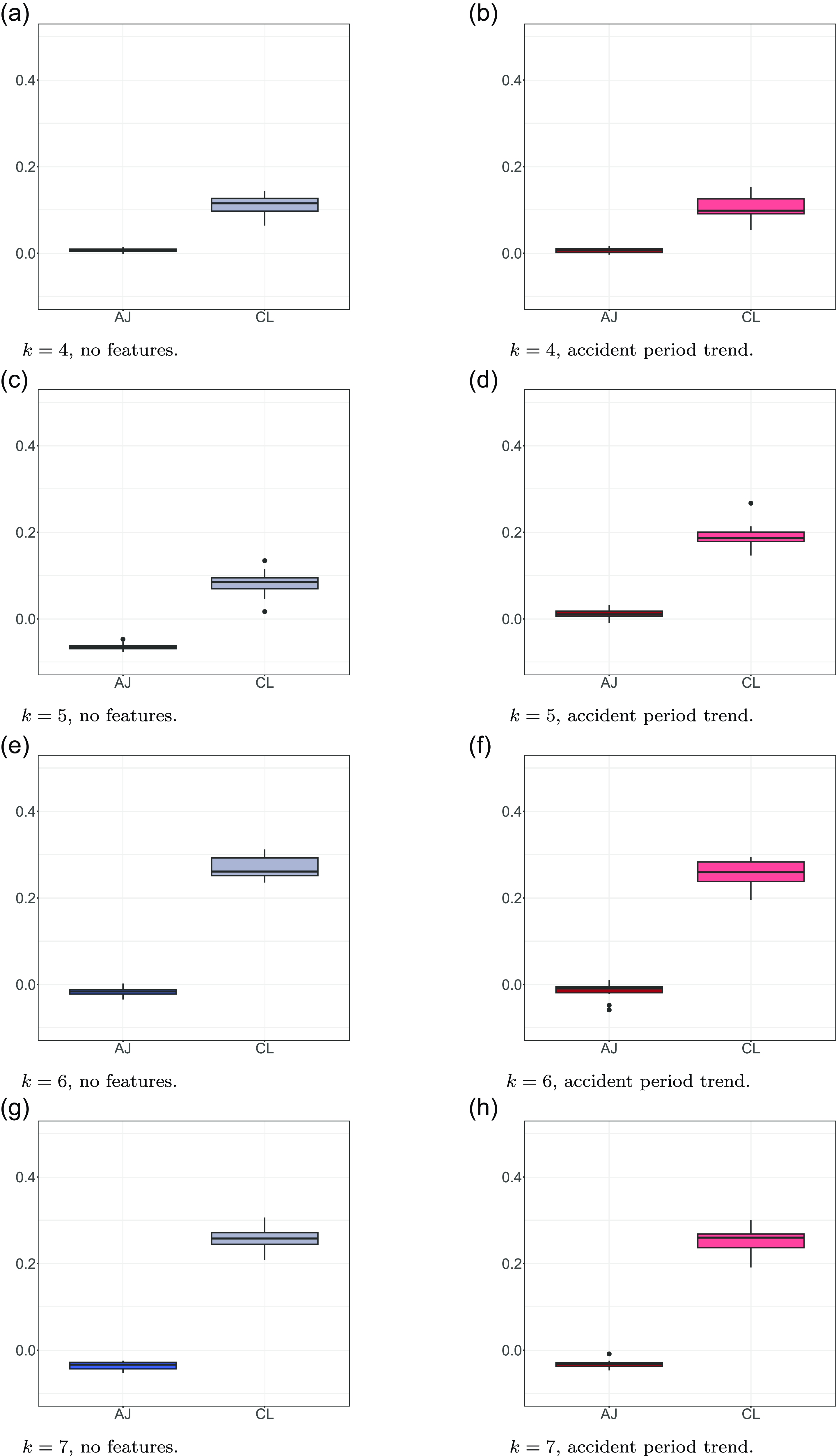
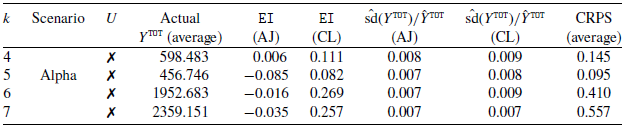


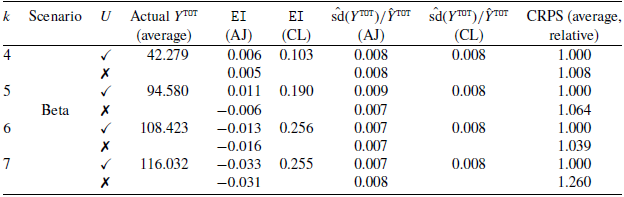

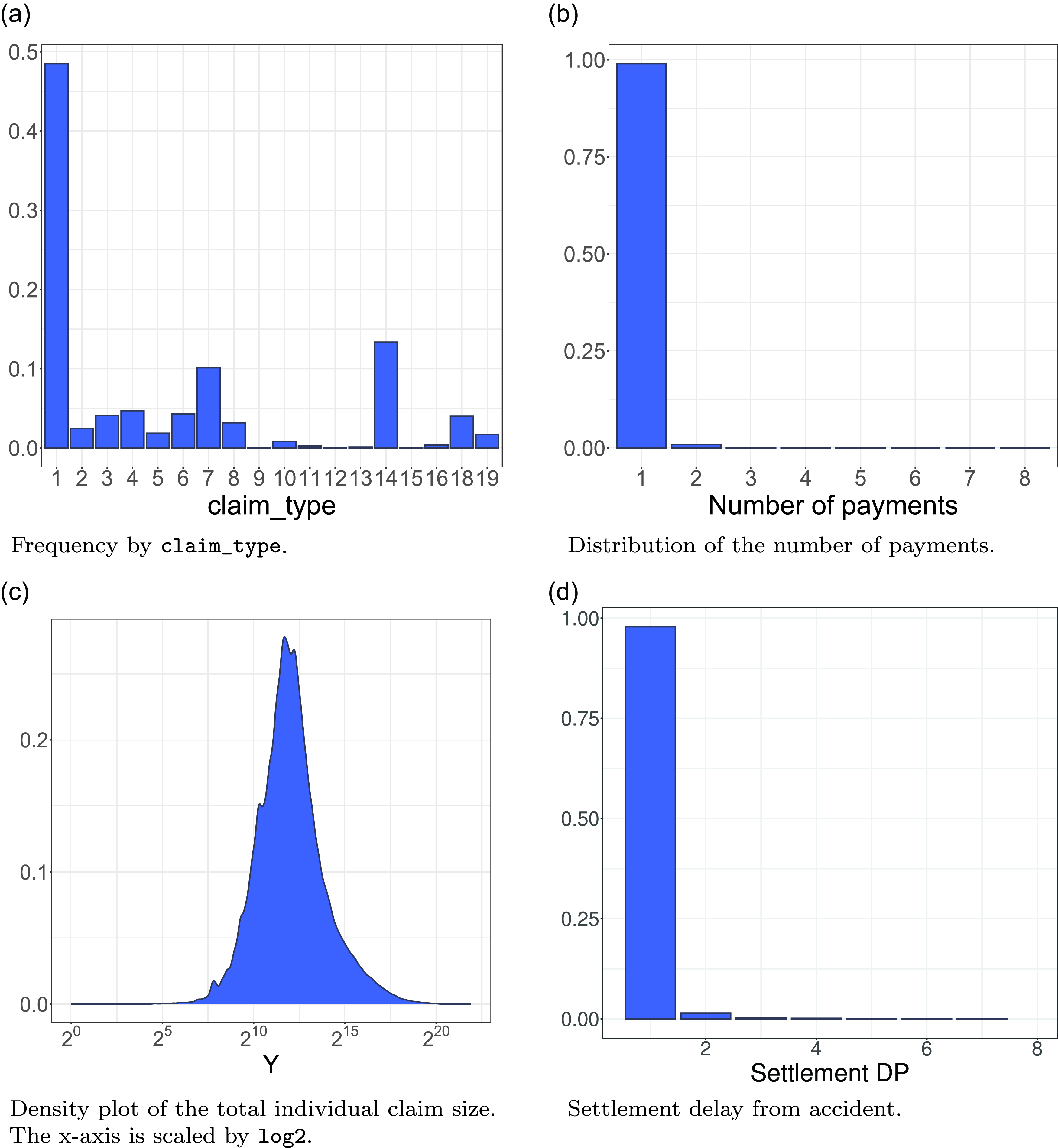
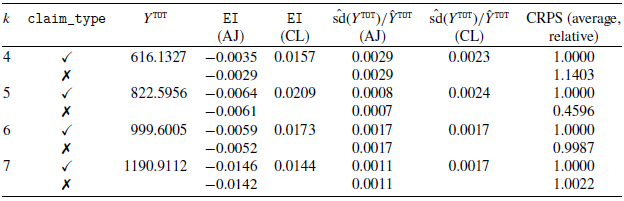



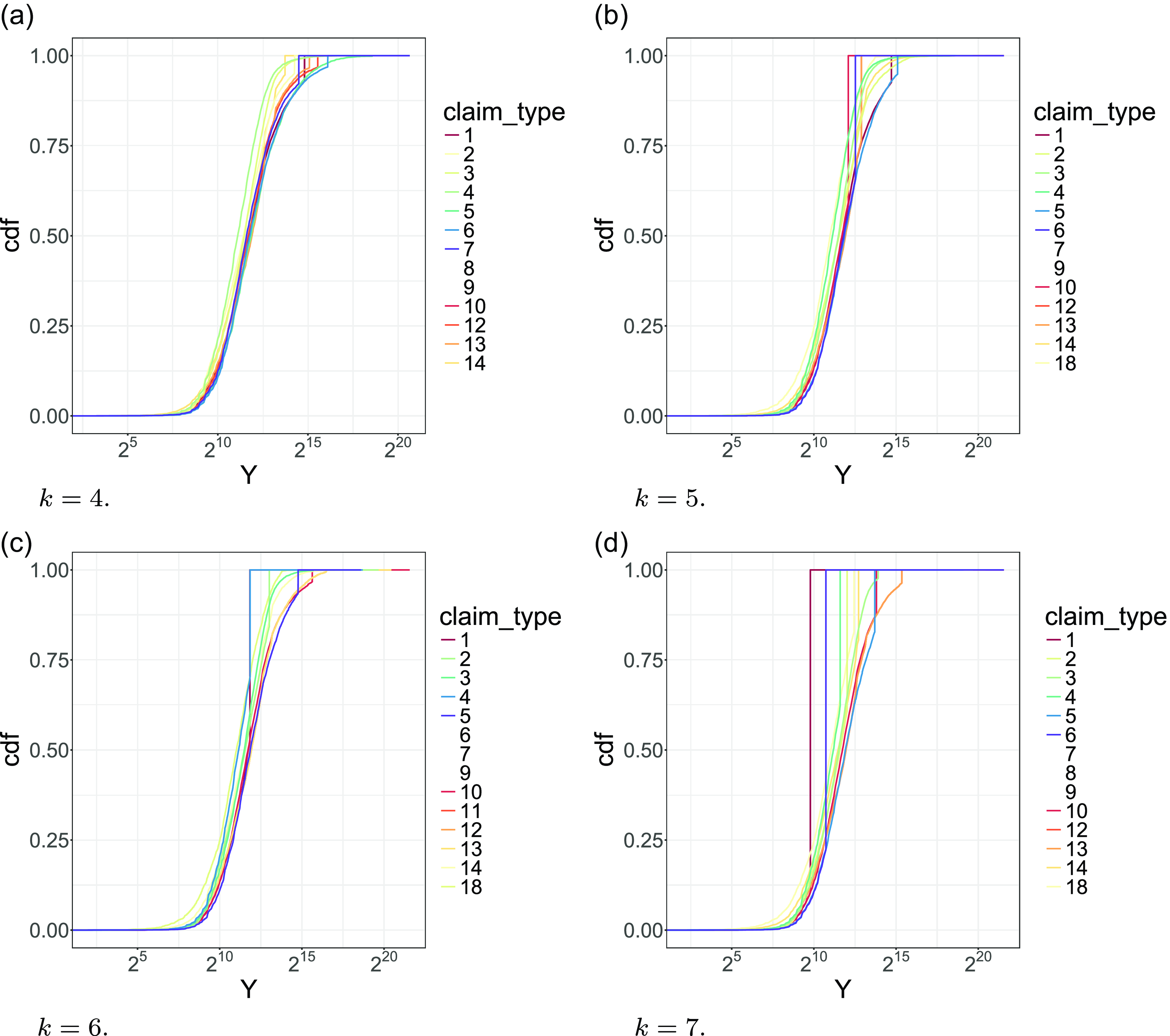



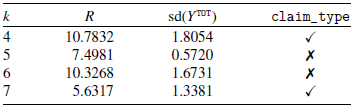
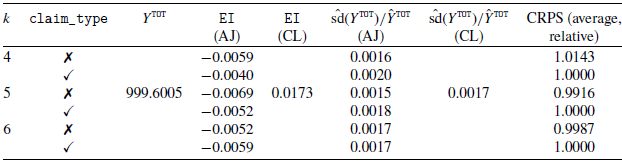



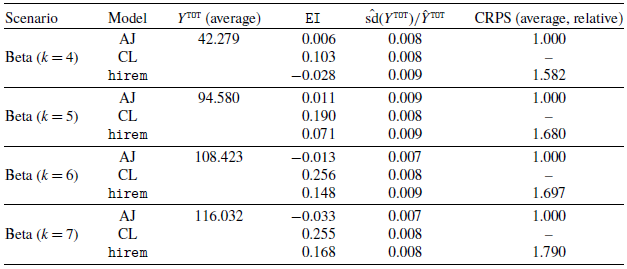


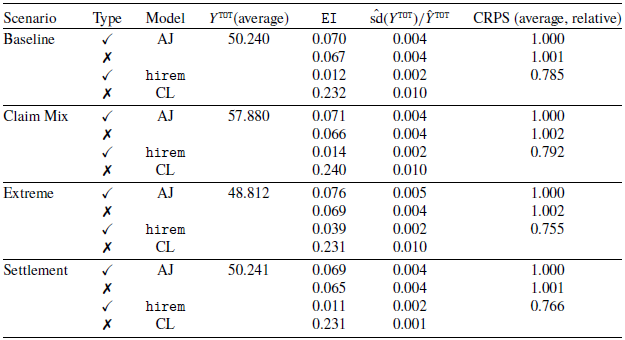




 Open access
Open access