

23.1 Time, Rhythm and Register
Reality is a function of the methods used to observe events in space and time. Based on this pragmatic postulate, and concentrating on the temporal dimension, in the present study a novel signal-processing framework is developed in order to analyse the speech rhythm of selected authentic data types, as opposed to the intuited and constructed formal data that are used in the description of ‘linguistic rhythm’ (advisedly thus named by Liberman and Prince, Reference Liberman and Prince1977). In the present context, ‘authentic’ means that the data were not invented for the purpose of scientific study but are, in traditional terms, usage-based data recorded in independently motivated scenarios. The study relies extensively on graph illustrations of acoustic phonetic analyses. Approximately half of the contribution is devoted to theoretical issues, and the other half is concerned with exploratory case studies of rhythm in six different speech registers.
Time is a basic parameter in the analysis of speech utterances, along an extensive timescale. The scale spans the range from phones, with tens of milliseconds, through larger grammatical units of several seconds and discourse linguistic units of several minutes, to much longer time spans: the acquisition of first and second languages, dialect, and register, then across generations to historical language change and language evolution. One of the shorter span regions on the timescale is that of real-time speech rhythms: perceived regular, strong–weak alternations of beats and inter-beat intervals, which appear in the infrasound frequency domain as low-frequency (LF) oscillations between 0.1 Hz and 10 Hz in the long-term spectrum of the speech signal; see also Chapters 10 and 14. These oscillations are treated here within the modulation-theoretic framework of rhythm formant theory (RFT) for speech stylometry, and rhythm formant analysis (RFA), its associated methodology (Gibbon and Li, Reference Gibbon and Li2019; Gibbon, Reference Gibbon2021, Reference Gibbon2022, Reference Gibbon2023).
The study is based on an inhomogeneity assumption: the speech of individuals and communities is not homogeneous, and different registers, styles and genres used by speakers and hearers differ in many properties, including prosody, understood informally as the rhythms and melodies of speech. A null hypothesis would be that all these varieties have the same rhythms. A more realistic set of hypotheses is that speech is more or differently rhythmical in some registers than others, that differences can be detected, and if rhythms are not found in speech data, then maybe the wrong data have been selected. Conversely, if rhythms are detected in one speech register, they may not necessarily be found in all registers. Results of rhythm analyses depend, for example, on whether selected data are from the formal metalinguistic register of traditional linguistic and phonetic analysis, or whether they are foraged from speech ‘in the wild’.
The aim is to investigate whether the interplay of rhythm and function in different kinds of oral narrative can be described and distinguished using the RFT/RFA framework. To this end, the study focuses on small exploratory case studies of a selection of speech registers and starts with a detailed discussion of the theoretical background. The study deals with oral narratives as registers (Section 23.2), rhythms and their functions (Section 23.3), approaches to speech rhythm analysis (Section 23.4), the heuristic use of the annotation-mining method (Section 23.5), the RFT/RFA framework (Section 23.6), RFA analyses of different kinds of oral narrative register (Section 23.7), a comparison of rhythms in different registers by means of unsupervised clustering (Section 23.8), and results and conclusions (Section 23.9).
23.2 Oral Narratives as Registers
Six specific registers are analysed in the present study and represent oral narratives of different kinds: toddler dialogue at an early stage in first-language acquisition, the narrative genre of African village communities, fluency of reading aloud in English as a second language (L2), a comparison between newsreading and poetry reading in English, and a comparison of recitations of different Chinese poetry genres. The prediction is that rhythms in these registers are physically distinguishable and that the differences can be detected with RFT/RFA.
The traditional term ‘register’ and related terms such as ‘genre’, ‘style’ and ‘functional style’ have been used in too many different ways in the literature to be reviewed here (but see Gibbon, Reference Gibbon1981, Reference Gibbon1985). The term is used in the present contribution for family resemblances of text and speech usage in task-oriented contexts such as spontaneous conversation, verbal coordination, storytelling, reading aloud, child and mother speech or the metalinguistic formal register of traditional linguistic data.
The term ‘register’ is closely related to Wittgenstein’s ‘language game’ (Reference Wittgenstein1953:5, §7), referring to language usage in specific contexts, such as bricklayers using language as a work tool or children learning a language, which he calls (without negative associations) ‘primitive languages’: ‘Ich will diese Spiele “Sprachspiele” nennen, und von einer primitiven Sprache manchmal als einem Sprachspiel reden.’ (‘I will call these games ‘language games’ and will sometimes speak of a primitive language as a language game.’) This philosophical perspective implies that the language usage of an individual or community can be seen as an inhomogeneous set of overlapping registers, styles, genres and language games, with virtuoso register-hopping, style-shifting and code-switching between language and speech varieties by community members.
Registers are usually described in terms of specific vocabularies and specific preferences for grammatical and word formation rules (Biber and Conrad, Reference Biber and Conrad2019). In spoken registers, criteria such as clear or fast-speech enunciation, as defined in hyperarticulation and hypoarticulation theory (Lindblom, Reference Lindblom, Hardcastle and Marchal1990), and speech rhythm and melody are equally relevant (Crystal and Davy, Reference Crystal and Davy1969).
A basic functional space for registers can be defined. First, modality ranges from oral–auditory, unidirectional–multidirectional, through face-to-face conversation to teleglossic (communication at a distance), and to subtypes of teleglossia in many kinds of electronic or other medium. Second, topic relates, for example, to domestic or professional, private or public, or task-oriented (teaching, carpentry, sport, conversation …). Third, style covers language features of formal–informal, polite–impolite communication.
The registers discussed here are in the oral–auditory modality, with varying topics, from the impenetrable conversation of toddlers talking with single-syllable vocabulary on the one hand, to broadcast news or conventional poetry on the other. The data are recordings of authentic natural real-time data, partly from public sources.
23.3 Rhythms and Their Metalocutionary Functions
Rhythms and speech registers have been rare companions in phonological and phonetic studies, while in discourse studies there is a history of interactionist discussion of rhythm in different speech varieties (Brazil, Reference Brazil1985; Couper-Kuhlen, Reference Couper-Kuhlen1993; Couper-Kuhlen and Selting, Reference Couper-Kuhlen and Selting2018). From a functional point of view, natural speech rhythms are metalocutions with emotional and rhetorical functions, but also with a metalocutionary indexical cohesive function, such as head-nodding, finger-pointing and beat gestures (McNeill, Reference McNeill1992). Prosodic beats literally point (during utterance time and at utterance place) at constituents of the lexico-syntactic locution that they accompany.
From a functional perspective, an inheritance hierarchy of increasing specificity can be defined for directly observable rhythms: physical rhythms (ocean waves, ripples, branches in the breeze), physiological rhythms (heartbeats, blinking, brain frequencies), behavioural rhythms (walking, chewing), bonding rhythms (dancing, handshaking, intimate interaction), communication rhythms (gesture, writing, speech) and speech rhythms.
Intuitively, rhythms are sequences (sometimes different sequences in parallel, as in music) of regular waves and beats in the speech signal at similar intervals in time, where beats and inter-beat intervals are related to stronger and weaker values of some audible parameter ranging around one second in duration. When are beat sequences rhythms? An individual beat is not a rhythm, nor is a sequence of two beats, but a sequence of at least three beats permits the two inter-beat intervals to be compared in terms of duration equality and thus for a rhythm to be identified (Nakamura and Sagisaka, Reference Nakamura and Sagisaka2011). Syllable rhythms alternate between vocalic beats and consonantal inter-beat intervals. Word-level foot beats alternate between stronger syllables as beats and sequences of weaker syllables as inter-beat intervals. Phrasal-level ‘nuclear accent’ beats in major intonation sequences or ‘paratones’ alternate with minor intonation sequences with less prominent nuclear accents. Even longer duration, slower rhythms occur in read-aloud texts and in rhetorical and poetic discourse.
From a physical point of view, speech rhythms are oscillations of parameter values in the acoustic signal (Barbosa, Reference Barbosa2002), such as the amplitude of speech at a particular frequency, for example 5 Hz for syllables of average duration of 200 ms, or about 1.25 Hz for accented words at intervals of about 800 ms, depending on the speech register (see Sections 23.7 and 23.8). Rhythms may be considerably longer than this, particularly in carefully crafted speeches or in poetry and song (see Chapter 26; Daikoku and Goswami, Reference Daikoku and Goswami2022).
A ‘golden fleece’ that has haunted the search for speech rhythm in phonetics for decades is the ideal timing property of isochrony – equal timing in a succession of similar events. The isochrony property is not found as absolute duration equality, however, but as a scale of duration similarity of different phonetic event types such as mora, syllable and stress group (Dauer, Reference Dauer1983, Reference Dauer1987). Several scales based on descriptive statistics have been proposed as a basis for a rhythm typology of languages (e.g., Grabe and Low, Reference Grabe, Low, Gussenhoven and Warner2002). These approaches have been critically discussed by Gibbon and Fernandes (Reference Gibbon and Fernandes2005), Gibbon (Reference Gibbon, Sudhoff, Lenertova and Meyer2006) and Arvaniti (Reference Arvaniti2009), among others.
Whichever domain is inspected, rhythms are periodic time functions – that is, they have a frequency. A rhythmic beat has a magnitude. Rhythms have a property of resonance, the constancy of frequency, and of bandwidth, the frequency range within which a varying rhythm remains a rhythm, and they have persistence in time: rhythms require at least three component beats and thus at least two inter-beat intervals, as already noted. Speech rhythms may co-occur (Barbosa, Reference Barbosa2002; Asu and Nolan, Reference Asu and Nolan2006; Inden et al., Reference Inden, Zofia, Wagner, Wachsmuth, Miyake, Peebles and Cooper2012) in a hierarchy, as in music (see Section 23.7.2), and may also be shared with other interlocutors when their behaviour is mutually entrained and they adapt to each other (Chapter 29; Cummins and Port, Reference Cummins and Port1998), as in the dialogue case studies in Sections 23.7.1 and 23.7.2.
23.4 Approaches to Speech Rhythm Analysis
The study of speech rhythm dates back to antiquity, and rhythm has traditionally been seen as a poetic or rhetorical device. Since the mid-twentieth century, phonological accounts of rhythms applied a metaphorical concept of structure as rhythm (‘linguistic rhythm’; Liberman and Prince, Reference Liberman and Prince1977) using intuited and constructed data, along with other categories that are labelled with metaphors from poetics (e.g., ‘metrical phonology’, ‘trochaic’, ‘iambic’, ‘foot’). In poetics itself, distinctions are made between metrical frameworks, such as the iambic pentameter, on the one hand, and grammatical stress patterns on the other, and between these structural concepts and performed rhythms in poetry readings; see also rhetorical rhythms in public speeches (Gibbon and Li, Reference Gibbon and Li2019).
The main approaches to speech rhythm in acoustic phonetics are listed here in approximate historical chronological order of appearance, as context for the present approach:
1. Qualitative linguistic and applied linguistic models, typically related to pronunciation teaching, from Sweet (Reference Sweet1908) through Pike (Reference Pike1945), Jassem (Reference Jassem1952) to Abercrombie (Reference Abercrombie1967) and many textbooks; see Gibbon (Reference Gibbon1976) for an overview of these traditional approaches.
2. Qualitative algebraic models in universalist theories, from Chomsky et al. (Reference Chomsky, Halle, Lukoff, Halle, Lunt, McLean and van Schooneveld1956) through metrical theories originating with Liberman and Prince (Reference Liberman and Prince1977) and the prosodic hierarchy of Selkirk (Reference Selkirk1984) to search-theoretic optimality theories originating with Prince and Smolensky (Reference Prince, Smolensky and McCarthy2004).
3. Annotation mining in descriptive phonetics with hybrid qualitative and quantitative signal-symbol mappings based on annotated speech, from Lehiste (Reference Lehiste1970) and Jassem et al. (Reference Jassem, Hill, Witten, Gibbon and Richter1984) to Asu and Nolan (Reference Asu and Nolan2006) and many others; see Section 23.5.
4. Modulation-theoretic analysis in experimental and clinical acoustic phonetics, with concepts derived from radio engineering: demodulation and spectral analysis of meaningful information signals from the acoustic speech signal, from Ohala (Reference Ohala1992), Todd and Brown (Reference Todd and Brown1994), Traunmüller (Reference Traunmüller1994), Greenberg and Kingsbury (Reference Greenberg and Kingsbury1997) to Barbosa (Reference Barbosa2002), Tilsen and Johnson (Reference Tilsen and Johnson2008) and several later studies; see the overviews included in Gibbon (Reference Gibbon2021), Chapters 8 and 10, and Section 23.6.
Annotation mining and RFT/RFA are described in the following two sections, and annotation mining is used in two of the case studies in Sections 23.7 and 23.8 as a heuristic source of predictions for further analysis with RFT/RFA.
23.5 Annotation Mining: Theory and Practice
The earliest and most popular family of methods for measuring rhythms in the physical speech signal is annotation mining, which inspects the duration relations between speech units such as vocalic or consonantal segments, syllables, feet and so on. The assumption that rhythm is solely a function of speech unit durations is an oversimplification, however, since the prominent beats or waves of a rhythm may also involve other parameters such as pitch patterns (Lehiste, Reference Lehiste1970).
Annotation mining has a broader and a narrower sense. In the broader sense, it has six steps. The first step includes recording the speech signal and visualising properties such as the waveform (oscillogram), the fundamental frequency (F0) estimation (‘pitch’ track), the intensity curve and the spectrogram. The next step is labelling (segmentation and classification) of the speech signal by the assignment of categorial linguistic labels to intervals or points in the signal by close listening and by inspection of the display. The annotations are <startpoint, endpoint, label> triples for intervals, or <midpoint, label> pairs for points. In any given annotation sequence (tier), labels denote units of a particular linguistic category: phonetic (e.g., phones, syllables, larger units), structural (e.g., words, phrases) or functional (e.g., focus, question, parenthesis). The parallel annotation tiers implicitly define time-synchronised mappings between tiers.
An example of phonetic annotation with parallel tiers using the Praat phonetic workbench software (Boersma, Reference Boersma2001) is shown in Figure 23.1 (see Tracy and Gibbon, Reference Tracy, Gibbon, Beißwenger, Gredel, Lemnitzer and Schneider2023, for data description). The annotations are in parallel horizontal tiers, with annotation segments marked by vertical lines. From top to bottom, the tiers are of syllables, of syllables without hesitation particles, of sentence transcripts and of coordinating conjunctions and hesitation phenomena.
Annotation with the Praat phonetic workbench software (German spontaneous report, illustrating hesitatons).
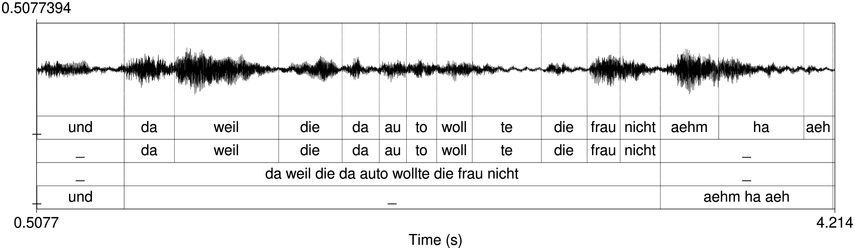
Figure 23.1 Long description
The annotation below the oscillogram has four tiers: 1. All syllables. 2. All syllables without conjunctions and hesitation particles. 3. Whole utterance without conjunctions and hesitation particles. The text of the annotation is informal spontaneous German: da weil die da auto wollte die frau nicht.
The final step, annotation mining in the narrow sense (Gibbon and Fernandes, Reference Gibbon and Fernandes2005), is statistical analysis of sequences of annotated interval durations and their relations, often in an attempt to discover the isochronicity (degree of isochrony) of the sequence. Visual inspection of similarly spaced labels in Figure 23.1 gives an initial indication of possibly rhythmical sections in the recording.
Annotation mining traditionally involves descriptive statistics such as the mean together with dispersion measures (standard deviation, coefficient of variation), to provide an index of duration regularity (see the overview and comparison in Gibbon and Fernandes, Reference Gibbon and Fernandes2005). These methods are useful, but problematic as rhythm measures for several reasons in addition to concentration on the duration parameter alone: (1) descriptive statistics apply to static populations, not to dynamic time functions such as the speech signal; (2) taking squared or absolute values ignores the key alternation property of rhythms, and thus the same index may refer to alternating or non-alternating sequences; (3) the ‘rhythm metrics’ are not metrics in the mathematical sense: they do not compare vectors of length n in an n-dimensional metric space (the triangle inequality criterion).
The pairwise variability (PVI) metrics are an exception and also overcome the disadvantage of unsuitability for time series. However, they retain the second disadvantage of ignoring alternations by using absolute differences. The PVI metrics also introduce a further assumption of binarity: the subtraction operation implies that rhythms are binary. This may be true on average (Nolan and Jeon, Reference Nolan and Jeon2014), but in reality three or more neighbouring units may be involved, as in the ‘triple time’ of Everly Blenkinsop worried a lot about allergies. The heuristic is saved by the de facto preponderance of binary rhythms.
The PVI metrics apply to sequences of interval durations and have non-normalised (‘raw’) and normalised versions, the rPVI and the nPVI (Grabe and Low, Reference Grabe, Low, Gussenhoven and Warner2002; Asu and Nolan, Reference Asu and Nolan2006):
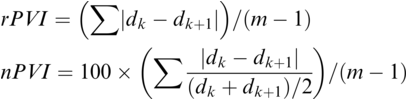
Formally, the PVI measures are metrics: they are derivable directly from Manhattan distance and normalised Manhattan distance (Canberra distance), respectively, which are known metrics. The PVI metrics measure the average ‘next-door-neighbour distance’ between adjacent durations dk, dk+1 of neighbouring intervals in the annotation. A duration sequence d1, …, dm is essentially treated as two overlapping vectors, d1, …, dm-1 and d2, …, dm, and the element-wise absolute difference (distance) between these two vectors is calculated. Manhattan distance, normalised Manhattan distance and similar distance metrics yield comparable results to the PVI metrics.
The irregularity measures have been successfully used as heuristics to show systematic regularity differences between formal register data in different languages. The graphs in Figure 23.2 illustrate properties of the two metrics, measured with story readings in different languages. The two metrics yield the same ordering and demonstrate that with both PVI variants, the languages that are considered to tend towards so-called syllable timing, such as Mandarin, Tem (ISO 639-3 kdh) and Farsi, have considerably lower irregularity values than English, with so-called word, foot or stress timing. In Sections 23.7.1 and 23.8.2 the PVI metrics are used as heuristic sources of predictions for RFT/RFA measurements.
The rPVI and nPVI for different languages, showing linear and non-linear properties for the two metrics.
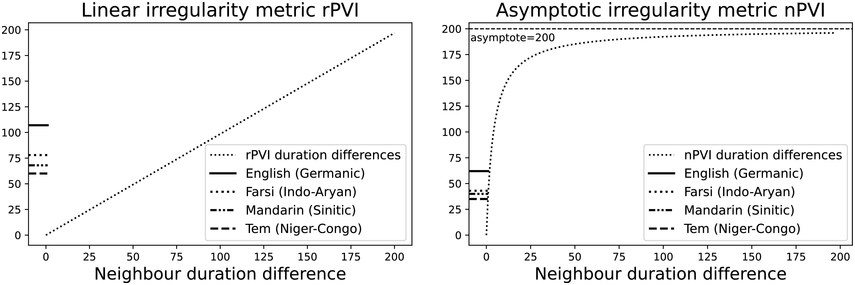
Figure 23.2 Long description
The measures are the raw Pairwise Variability Index (usually used for consonant sequences) and the normalised Pairwise Variability Index (usually used for vocalic sequences).The left-hand graph plots the measured r P V I indices for the four languages along the y axis. The x axis is labelled in steps of 25 from 0 to 200, each step representing a consistent difference level between neighbours in an alternating idealised syllable sequence. The resulting r P V I index is shown on the y axis, and the function is illustrated by a linear diagonal line. Similarly, the right-hand graph for the n P V I has the same structure as the left-hand graph, except that the function shown by the plotted curve is asymptotic, with an asymptote of 200.
23.6 Rhythm Formants: Theory and Practice
23.6.1 Speech Modulation Theory
The approaches that enable analysis of the regularly alternating properties of real-time rhythms in authentic data, such as frequency, magnitude, resonance, bandwidth and persistence, are applications to speech of a signal-processing theory that is as old as radio: speech modulation theory (SMT) (Chapters 8 and 10; Ohala, Reference Ohala1992; Todd and Brown, Reference Todd and Brown1994; Traunmüller, Reference Traunmüller1994; Cummins and Port, Reference Cummins and Port1998; O’Dell and Nieminen, Reference O’Dell and Nieminen1999; Barbosa, Reference Barbosa2002; Galves et al., Reference Galves, Garcia, Duarte and Galves2002; Tilsen and Johnson, Reference Tilsen and Johnson2008; Inden et al., Reference Inden, Zofia, Wagner, Wachsmuth, Miyake, Peebles and Cooper2012; Tilsen and Arvaniti, Reference Tilsen and Arvaniti2013; Gibbon, Reference Gibbon2021, Reference Gibbon2022, Reference Gibbon2023; Frota et al., Reference Frota, Vigário, Cruz, Hohl and Braun2022). Neighbouring disciplines, particularly neurology and neurolinguistics, have applied similar methods (Chapter 5; Meyer, Reference Meyer2018). The RFT/RFA framework is a further development of SMT, introducing the phonetic concept rhythm formant and using the semantic concept of metalocution for the indexical cohesion-marking functions of rhythm.
In SMT the speech signal is modelled as a carrier wave that is modulated by information signals: frequency modulation (FM) relating to intonation, pitch accent and tone, and amplitude modulation (AM) relating to the sonority curve shaped by phonotactics, word formation, grammar and patterns of discourse (Ohala, Reference Ohala1992; Galves et al., Reference Galves, Garcia, Duarte and Galves2002). Simplifying the speech production process, the carrier wave is the complex sawtooth-like wave generated in the larynx, with an F0 and a series of harmonics (overtones) as multiples of the F0. The carrier can be imagined as a monotone ‘Ah!’ As in radio frequency technology, the carrier can be represented in stylised form (A: amplitude, f: frequency, t: time; phase is not included):
FM (variable phonation):

AM (variable oral-nasal filter) & FM:
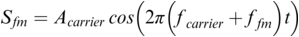
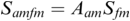
Both the FM and the AM information signals are normalised relative to the frequency and the amplitude of the carrier before modulation. The AM and FM frequencies that are relevant for speech rhythms, between about 10 Hz and 0.1 Hz, are between about 10 and 1,000 times lower than the carrier frequency.
Figure 23.3 shows the three main frequency zones that enter into FM and AM speech signals from a modulation-theoretic perspective. The carrier signal is in the central area of the logarithmic scale between about 70 Hz and 500 Hz (depending on sex, age, conventions and individual factors). The harmonics are amplitude modulated as high-frequency (HF) carriers for phone formants.
Speech modulation frequency scale.
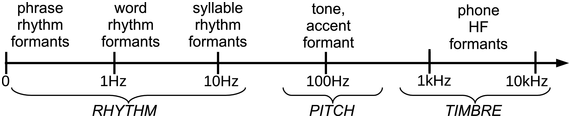
Figure 23.3 Long description
The arrow has regular logarithmically ordered ticks at 0, 1, 10, 100 Hertz and at 1 kiloHertz and 10 kiloHertz. The ticks provide a general orientation for identifying approximate functional frequency ranges in speech: below 15 kHz for speech rhythms, around 100 Hertz and above for fundamental frequency, corresponding to intonation, tone and pitch accents, and three ranges around 500 Hertz for F 1, 1500 Hertz for F 2 and 2500 Hertz for F 3, the three main speech sound formants.
The term rhythm formant is used for LF magnitude peaks in the spectrum, by analogy with HF phone formants, which are also defined acoustically as magnitude peaks in the spectrum. Definitions of LF formants and HF formants differ when based on production and perception rather than transmission of speech.
23.6.2 Demodulation in the RFT/RTA Framework
In speech analysis (and in speech perception), the FM and AM components of the composite carrier wave are demodulated in order to extract the signals representing structural and semantic information. Low-pass-filtered FM demodulation corresponds to F0 estimation (‘pitch’ tracking) in conventional terminology, and the resulting F0 track is interpreted in terms of tones, pitch accents and intonations. Demodulated low-pass-filtered AM approximates to the sonority curve of phonology and provides the acoustic grounding for speech rhythms. In the present study the FM signal is only discussed in passing (Section 23.8.3). RFT adds the following postulate to SMT:
Magnitude peaks in the spectra of the LF FM and AM information signals function as rhythm formants determined by utterance categories from phone and syllable to longer discourse units, and indicate properties of rhythms in the frequency domain: frequency (comparable with speech rate in the time domain), magnitude (how prominent the beats are), resonance (constancy of frequency), bandwidth (the frequency range covered by the rhythm) and persistence (the duration of the rhythmic sequence).
RFA is the methodology associated with RFT. Figure 23.4 illustrates the data flow: inputs and outputs are stored; inputs are demodulated in order to estimate the FM (F0) and AM information signals; fast Fourier transform (FFT) is applied and sets of spectral properties are analysed and compared.
Rhythm formant analysis data flow.
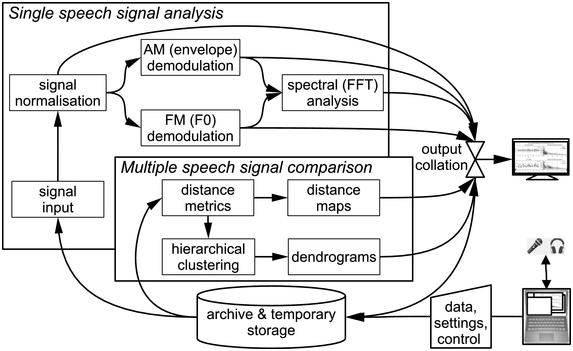
Figure 23.4 Long description
The system begins with an input speech signal. The signal is normalized, which is followed by A M demodulation, F M demodulation, and spectral analysis, from which properties such as spectral variance are derived. Multiple speech signals are compared, based on the spectral properties using metrics such as Euclidean Distance, which are used for the generation of the distance maps. The distances are also used together with linkage criteria in hierarchical clustering. The cluster hierarchies are represented as dendrograms. The results of the output are then collated and the collated results are then displayed on the monitor and stored.
For FM demodulation (see Section 23.8.3), a modified time domain algorithm is used, AMDF (average magnitude difference function) with preprocessing and post-filtering. AM demodulation is performed by obtaining the absolute values of the low-pass-filtered waveforms and smoothing the resulting amplitude envelope (see figures in Sections 23.7 and 23.8). The absolute Hilbert transform (He and Dellwo, Reference He and Dellwo2016) and other techniques are also used for AM demodulation.
In RFA the demodulated FM and AM signals are analysed holistically by applying an FFT to the entire recording, or to a selected long stretch of the recording, with transform windows of several seconds. The LF spectrum shows frequency × magnitude, with no temporal information.
To regain temporal information, an LF spectrogram is calculated with overlapping spectral slices (time × frequency × magnitude). The spectrogram allows detection of rhythm resonance, bandwidth and persistence as well as frequency. Several property vectors and variance values, for example, the ten most prominent well-defined peaks or the entire LF spectrum (Section 23.7), are then compared using unsupervised cluster analysis (Section 23.8).
23.7 Exploratory Case Studies of Spoken Registers
23.7.1 An Interactive Protodialogue Register: Talking Twin Babies
A well-known YouTube meme is ‘Talking Twin Babies’, showing video recordings of the ‘communicative babbling’ of 17-month-old American twins in a kitchen, holding a prosodically very fluent-sounding conversation with each other, using only iterations of the single-syllable ‘da’.Footnote 1 The children are apparently imitating conversations between older children or adults. The overall duration of the selected dialogue is 112.41 seconds. In the present context the dialogue is a minimal interactive speech register, and a true ‘language game’ (see also Daikoku and Goswami, Reference Daikoku and Goswami2022; Chapter 38 on infant speech registers).
The dialogue grammar is iterative and has two iteration levels: the utterance cycle enclosing the cycle with the syllable ‘da’. Iteration cycles are easily modelled in a finite state machine, which requires only linear processing time and finite working memory, a realistic assumption. This contrasts with recursive grammars, which, an unrealistic assumption, in principle require non-linear processing time and non-finite working memory, though they are often used as a convenience. The finite state grammar also relates easily to rhythms as beat iterations (see Pierrehumbert, Reference Pierrehumbert1980, whose finite state intonation grammar can also be interpreted as a rhythm machine). The grammar is rendered here as a regular expression: a disjunction of at least one utterance by a twin of at least one ‘da’ syllable:
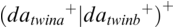
Annotation mining is used to predict values for possible confirmation in the follow-up RFA analysis (see Figure 23.5 (top)). Table 23.1 lists a selection of descriptive statisticsFootnote 2 for syllable and interpausal unit (IPU) annotation. There are 147 syllables with mean syllable durations of 346.38 ms, a relatively slow rate of about 2.89 syll/s. For comparison, syllable rates in adult reading aloud and conversation in the Aix-MARSEC database (Auran et al., Reference Auran, Bouzon and Hirst2004) were measured as reference values, finding tempo variation between about four syll/s for religious readings and poetry readings, and almost six syll/s for radio news. The nPVI metric for syllables yields an average ‘next-door neighbour distance’ of 23, a highly regular pattern, in contrast to values near 40 for Standard Mandarin (often said to have syllable timing) and near 50 for English (often said to have foot, word or stress group timing). The intra-IPU duration slope is 0.401, indicating tempo deceleration.
Dialogue registers: top, 20 s, toddlers (Section 23.7.1); bottom, 18 s, caller–choir exchange (Section 23.7.2).
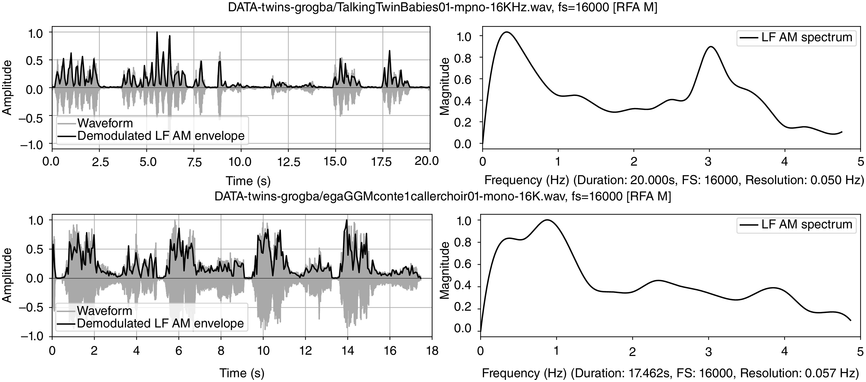
Figure 23.5 Long description
The top two panels show time-domain and frequency domain visualisations of data from a 20 second monosyllabic conversation between two American toddlers. The bottom two panels show time domain and frequency domain visualisations of 20 seconds of data from interactive choral storytelling in the Niger-Congo language Ega. The left-hand top and bottom panels show amplitude of the waveform and superimposed amplitude modulation envelope as a function of time. The right-hand panels represent demodulation of the A M envelope as a low frequency spectrum below 5 Hertz. Peaks in the spectrum show different speech rhythms and are termed rhythm formants. In the toddler spectrum, there are two prominent peaks, one at about 0.3 Hertz representing utterance repetition rate and one at about 3 Hertz representing syllable rate. In the Ega choral narrative data there are four main peaks, at about 0.25 Hertz representing utterance rate, 1 Hertz representing phrase rate, 2.25 Hertz representing word rate and 4 Hertz representing syllable rate. Both the toddler utterances and the choral narrative are syllable-timed, and the latter has a higher degree of rhythmic complexity above the syllable level.
| Syllable durations (N: 197) | Interpausal unit (IPU) durations (N: 37) | ||||||
|---|---|---|---|---|---|---|---|
| min: | 147 | max: | 1033 | min: | 751 | max: | 7265 |
| total: | 68237 | range: | 886 | total: | 113419 | range: | 6514 |
| mean: | 346.38 | mean rate/s: | 2.89 | mean: | 3065.38 | mean rate/s | 0.33 |
| median: | 325.0 | median rates/s: | 3.08 | median: | 2782.0 | median rate/s | 0.36 |
| intercept: | 307.088 | slope: | 0.401 | intercept: | 3281.105 | slope: | ‒11.985 |
| std: | 111.937 | coeff var (%): | 32.316 | std: | 1490.889 | coeff var (%): | 48.636 |
| nPVI: | 23 | rPVI: | 85 | nPVI: | 53 | rPVI | 1582 |
Each IPU is measured with the following pause. The mean IPU duration of 3.065 s and the 0.33 IPU/sec rate, with an nPVI distance of 53, is quite irregular. The slope of ‒11.985 for IPU duration sequences is negative, indicating shorter IPUs as the utterance proceeds. The toddler syllable sequences are synchronised with dance-like arm and leg movements.
The mean syllable rate of 2.89 syll/s suggests that a spectral magnitude peak at around 2.89 Hz will be found as a syllable rhythm formant. Similarly, the IPU rate of 0.33 IPU/sec suggests that a spectral magnitude peak of around 0.33 Hz will be found as an IPU rhythm formant. These values are taken as predictions for the RFA analysis.
Figure 23.5 (top) visualises the RFA measurements of the twin toddler dialogue. The left panel shows the waveform (grey values) and the demodulated amplitude envelope (dark positive values). The right subpanel shows a representation of the LF spectrum, smoothed with a moving median filter and spline interpolation. The spectrum of the toddler dialogue shows two very well-defined peaks, one at 0.3 Hz (IPU rhythm formant) and one at 3 Hz (syllable rhythm formant), as predicted by the annotation mining, showing superposed IPU and syllable rhythms as metalocutionary pointers to the dual patterning of the dialogue grammar. The extreme regularity is generated jointly by both toddlers and can thus be seen as evidence for rhythm entrainment (Chapter 29; Cummins and Port, Reference Cummins and Port1998; Inden et al., Reference Inden, Zofia, Wagner, Wachsmuth, Miyake, Peebles and Cooper2012; Rathcke et al., Reference Rathcke, Lin, Falk and Dalla Bella2021) in natural speech.
23.7.2 A Poetic Interactive Dialogue Register: Ega Orature
23.7.2.1 Structure and Spectrum
Part of an interactive orature session is analysed: a story in Ega, an endangered Niger–Congo language with agglutinative tonal morphology, spoken in South Central Ivory Coast (ISO 639-3 ega; Gibbon, Reference Gibbon2023). The selected session segment consists of a chanted caller–choir exchange (adjacency pairs) between the narrator and the audience. The dialogue grammar for the orature session as a whole can be modelled as a finite state machine (as already noted, an appropriate formalism for rhythm iteration), here in transition network format (Figure 23.6) with four iterating cycles: narrative-pause; narrative-pause-backchannel-pause; call-response chant; overall narrative-chant.
State machine (finite transition network) representing Ega orature dialogue grammar.
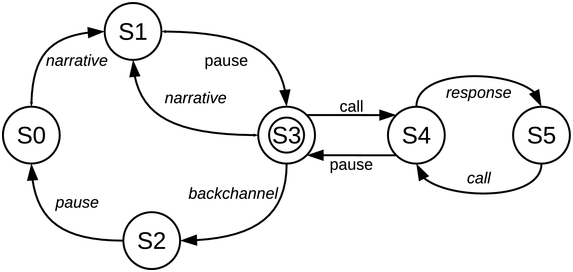
Figure 23.6 Long description
From the start state a narrative transition initiates a narrative-pause cycle, and may branch to a call-response cycle returning to the narrative-pause cycle or to a backchannel cycle leading back to the start state. The figure represents a finite state transition network as a model of dialogue flow in Ega interactive choral narrative. The full definition for each state and transition in the state machine is: Start state: S 0. Terminal state: S 3. States: S 0, S 1, S 2, S 3, S 4, S 5. Vocabulary: narrative, pause, call, response, backchannel. Transitions: S 0 narrative to S 1, S 1 pause to S 3, S 3 narrative to S 1, S 3 call to S 4, S 3 backchannel to S 2, S 2 pause to S 0, S 4 response to S 5, S 4 pause to S 3, S 5 call to S 4.
23.7.2.2 Resonance, Persistence: The LF Spectrogram
Figure 23.5 (bottom) shows the waveform, amplitude envelope and LF spectrum of one of the chant exchanges. The peaks below 1 Hz, at 0.25 Hz and an octave higher at 0.5 Hz reflect the overall two cycle levels of caller–choir and caller and choir, respectively. The example illustrates metalocutionary cohesive functions of multiple rhythms as markers of locutionary patterns.
The atemporality deficit of the spectrum is remedied by using an LF spectrogram (Figure 23.7) to show the resonance and persistence of rhythms (see Todd and Brown, Reference Todd and Brown1994; Greenberg and Kingsbury, Reference Greenberg and Kingsbury1997). The spectrogram frequency and temporal resolutions are low because of the Küpfmüller time-frequency uncertainty principle 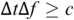 (meaning that time windows and frequency ranges cannot both be arbitrarily reduced), and therefore a long FFT window is needed in order to capture the low frequencies. The low temporal resolution is partly compensated for by overlapping the spectral slices.
(meaning that time windows and frequency ranges cannot both be arbitrarily reduced), and therefore a long FFT window is needed in order to capture the low frequencies. The low temporal resolution is partly compensated for by overlapping the spectral slices.
Low-frequency spectrogram: first chant section of the orature session.
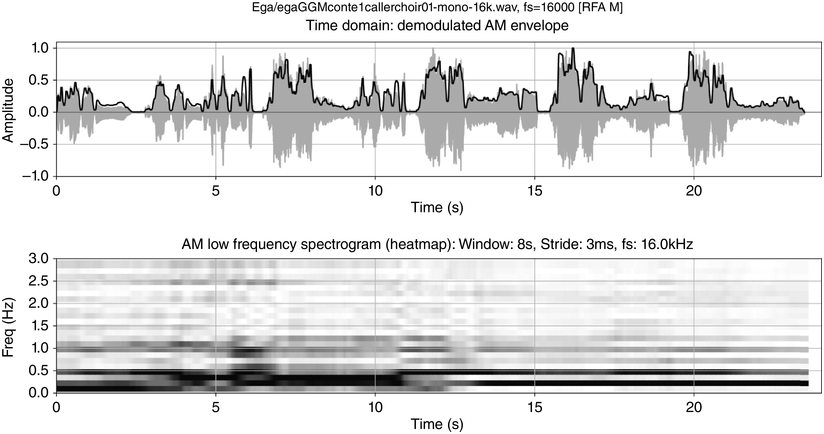
Figure 23.7 Long description
The top plot shows the time domain waveform with superimposed amplitude modulation envelope. The bottom plot shows the demodulation of the A M envelope as a low frequency spectrogram. Frequencies of speech rhythm formants are clearly visible as rhythm bars in the spectrogram. The plots have representations whose x axes are time-aligned with each other, with time steps from 0 to 20 seconds. The y axis of the top plot shows signal and envelope amplitude as a function of time. The y axis of the bottom plot shows the changing spectrogram frequencies as functions of time. As a third dimension, the magnitudes of frequencies at different points in time are represented by grey shading: the stronger the darker. Formant-like horizontal bars in the spectrogram show time intervals where the same frequency is maintained at high magnitude. These bars are referred to as rhythm bars.
The chant rhythms appear in the spectrogram as rhythm formant bars an octave apart, at 0.25 Hz and 0.5 Hz, as in the spectrum, starting at about 12 s. In addition to frequency, rhythm bars have temporal properties of resonance and persistence and point to dialogue sections, showing the metalocutionary cohesive function of discourse rhythms. Since the rhythm formants are jointly supplied by audience members, together with their shared metalocutionary function, they can be seen as further evidence for natural speech–song entrainment.
23.7.3 A Practical Register: L2-Reading Aloud
The text prompt is the IPA benchmark text, an English translation of Aesop’s fable The North Wind and the Sun, which has been used in previous rhythm studies to compare language varieties (e.g., Tilsen and Arvaniti, Reference Tilsen and Arvaniti2013; Gibbon, Reference Gibbon2021). For present purposes, reading aloud in a second language (L2) is regarded as a different register from reading aloud in the first language (L1).
There have been many descriptions of L2 fluency in the time domain in relation to the rhythms of partially automatised production skills: syllable rate and reduction, mean run (IPU) duration, filled and unfilled pause ratio, and expert ratings (see overviews in Thomson, Reference Thomson, Reed and Levis2015; Trouvain and Braun, Reference Trouvain, Braun, Gussenhoven and Chen2020). The use of frequency domain spectral parameters for L2 fluency assessment was introduced by Gibbon and Lin (Reference Gibbon and Li2019) and Gibbon (Reference Gibbon2023), showing that RFA can be used to distinguish between three speaker types: British native speakers as readers, a fluent Chinese speaker of L2 English and a class of intermediate-level L2 students of English.
Visual inspection of the LF spectra in Figure 23.8 reveals conspicuous differences between speaker types. The top panel (male British native speaker, reading duration 40 s) shows a clear sentence rate at 0.3 Hz and a foot (pitch accent) rate between 2 and 3 Hz. The middle panel (accented though fluent female Chinese university teacher of L2 English, reading duration 60 s) shows IPU peaks at 0.2 and 0.8 Hz, and foot peaks around 1.5 Hz, indicating less regular IPUs and a slower foot rate than the native speaker. The bottom panel (intermediate-level male Chinese student of English, Tongji corpus, Yu, Reference Yu, Bigi and Hirst2013, reading duration 55 s) shows a very scattered distribution of peaks, a possible indicator of uncertainty and lower fluency. The comparison indicates that metalocutionary cohesion marking can be a component of fluency evaluation, and that RFT/RFA analysis can help to identify these markers.
English: top, L1 male, South-Eastern British English; middle: Chinese L2 female (fluent); bottom, Chinese L2 male (less fluent).
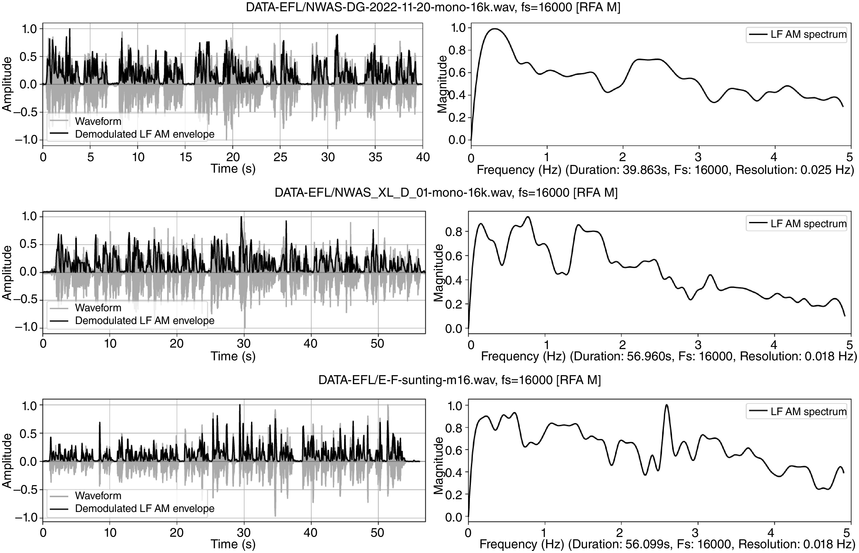
Figure 23.8 Long description
Each row shows story-telling data from readers of English with different degrees of fluency: English native readers in the top row, Mandarin Chinese female readers in the centre row and Mandarin Chinese male readers in the bottom row, showing decreasing degrees of spectral regularity, representing fluency. The left-hand top and bottom panels show amplitude of the waveform and of the superimposed amplitude modulation envelope as a function of time. The right-hand panels represent demodulation of the A M envelope as a low frequency spectrum below 5 Hertz. Peaks in the spectrum show different speech rhythms and are termed rhythm formants. The results show relatively even frequency distribution in the English native reader spectrum, somewhat more irregular frequency distribution in the Mandarin Chinese female spectrum and even more irregular frequency distribution in the Mandarin Chinese male spectrum. The degrees of irregularity are interpreted as degrees of fluency.
23.8 Stylometric Rhythm Comparison with RFT/RFA
23.8.1 Comparison Methods
Having analysed different kinds of data, RFA results from different data samples can be compared. RFA output is a set of vectors of spectral parameters that are relevant for rhythm analysis. The values include frequency and amplitude envelopes; spectra and trajectories of highest-magnitude frequencies in the spectral slices of spectrograms; FM and AM magnitude peaks; and vector variance.
Unsupervised clustering algorithms are used to compare rhythms of different speakers as an alternative to classical difference testing. In Section 23.8.2 k-means clustering is shown as a scatter plot with marked clusters. Vector pairs can also be compared using distance metrics and display of the resulting distance network. Another method is to use the values from a distance network together with a clustering criterion to calculate a hierarchical dendrogram (Section 23.8.3).
23.8.2 Comparison of Newsreading and Poetry Reading
The data compared in this section are from the Aix-MARSEC database (Auran et al., Reference Auran, Bouzon and Hirst2004) and are identified by ID in the figures: newsreadings and poetry readings (Gibbon, Reference Gibbon2022), with mainly male readers. Excerpts from the selected recordings are as follows (shorter pauses are marked ‘|’ in the newsreading transcript, longer pauses as ‘||’; rhyming lines are marked ‘||’ and half-lines ‘|’ in the transcript of the poetry reading):
BBC news extract: A thousand people were led to safety | after being trapped by a fire | in the London underground last night. || Many had to walk along the track to the nearest station.||
Poem Eunice, written and read by John Betjeman, first stanza: With her latest roses | happily encumbered || Tunbridge Wells Central | takes her from the night, || Sweet second bloomings | frost has faintly umbered || And some double dahlias | waxy red and white.||
The annotation-mining results in Table 23.2 show that syllable and word rates are faster for the newsreading (‘B’) than for the poetry reading (‘H’): 5.53 syll/s versus 3.89 syll/s, and 3.68 word/s versus 2.65 word/s. The IPU rate for the newsreadings is slower mainly because the utterances are longer than the lines of the poetry readings. Despite these differences, the nPVI values for syllables (51:53) and words (68:69) are almost the same in the two cases. The IPUs (77:31) show a striking but expected difference: the newsreading IPUs are very irregular while the poetry reading IPUs are very regular. Standard deviation and coefficient of variation confirm the difference, suggesting that automatic comparison may be possible.
| Category | File | n | Mean (ms) | Rate/s | SD | CoVx100 | nPVI |
|---|---|---|---|---|---|---|---|
| Syllables | B0101B (news) | 242 | 180.78 | 5.53 | 89.763 | 49.65 | 51 |
| H0101B (poetry) | 189 | 257.24 | 3.89 | 127.018 | 49.38 | 53 | |
| Words | B0101B (news) | 161 | 271.73 | 3.68 | 141.663 | 52.13 | 68 |
| H0101B (poetry) | 129 | 376.88 | 2.65 | 208.762 | 55.39 | 69 | |
| IPUs | B0101B (news) | 16 | 2734.31 | 0.37 | 1655.932 | 60.56 | 77 |
| H0101B (poetry) | 22 | 2209.91 | 0.45 | 793.455 | 35.90 | 31 |
An RFA analysis of 20 s of each recording was made, from 15 s to 35 s into the recording. The results are shown in Figure 23.9, with the demodulated AM envelopes of selected intervals of the newsreading (upper row) and the poetry reading (lower row) – in the left-hand panels – in the time domain, and the holistic LF spectra of these intervals – in the right-hand panels – in the frequency domain. The demodulated envelopes have very different amplitude distributions.
RFA demodulation and LF spectrum outputs for a newsreading (top) and a poetry reading (bottom).
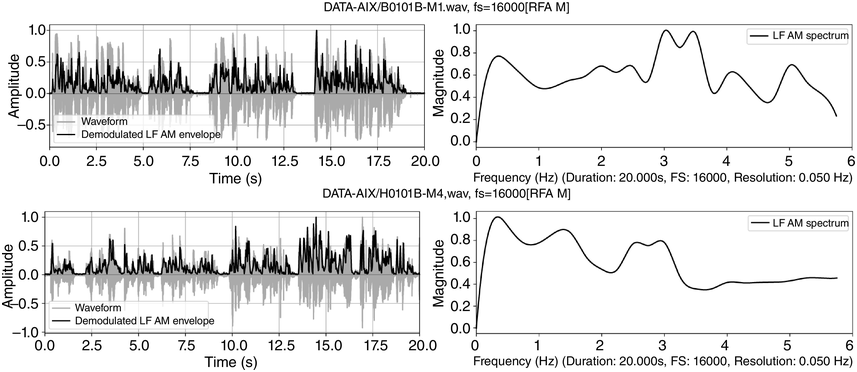
Figure 23.9 Long description
The top two panels show time-domain and frequency domain visualisations of data from a 20 second radio news reading. The bottom two panels show time domain and frequency domain visualisations of 20 seconds of data from the poet John Betjeman reading his poem Eunice.
The LF spectral differences correspond to the annotation-mining results. The left-hand rhythm formant of the newsreading (about 0.3 Hz) corresponds approximately to the mean IPU rate (0.37 IPU/s). The peaks between 3 and 4 Hz approximate to the mean annotated word rate of 3.68 syll/s, and the peak at about 5.2 Hz approximates to the mean annotated syllable rate of 5.53 Hz. Different syllable types and small variations in timing account for the bandwidth of frequency variation within the different spectral regions.
So far, the broad peak at 1.5 Hz and the peak at 5 Hz in the poetry readings are unaccounted for. The situation is quite complicated because the fourfold structure of the poem (syllable, word, half-line, line) does not easily match the three phonetic categories of syllable, word and IPU. The broad peak at 1.5 Hz may mean somewhat variable half-line durations, and the broad peak at 5 Hz may denote weak, unstressed syllables. The LF spectrum of the poetry reading (lower right) differs: the IPU rate (lines of the poem) was measured at 0.45 Hz, and a peak is observed at approximately 0.4 Hz. There are also peaks at 1.5 Hz and 3 Hz, and at just under 4 Hz, and at 5 Hz. The small 4 Hz peaks relate to the 3.89 syll/s measured syllable rate, and the 2.65 word/s rate relates to the frequency peak at about 2.7 Hz.
Ten examples each from these two reading registers are compared using k-means clustering, k=2. The graphs in Figure 23.10 show the AM spectrogram trajectory on the x-axis. The left-hand graph has the FM spectrogram trajectory of highest-magnitude frequencies on the y-axis, and the right-hand graph y-axis shows F0 variance (newsreading: ‘B’, poetry reading: ‘H’; male: ‘M’, female: ‘F’; speaker index: numbers; centroids as stars). The x-axes show a near-partition between the registers, with just one ‘H’ outlier. The FM spectrogram trajectory (y-axis) does not show clear category separation, while F0 variance (relating to linear F0 range) shows higher values for female readers.
Comparison of variances of newsreadings (B) and poetry readings (H).
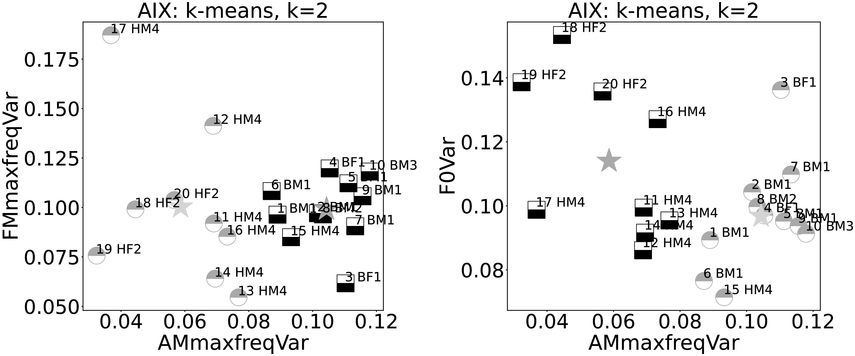
Figure 23.10 Long description
Each plot shows the relationship between two variables. The left-hand plot shows variance of amplitude modulation on the x axis and variance of frequency modulation on the y axis. The distribution of the two data types shows a clear separation according to data type and k-means cluster along the x axis but random distribution along the y axis. The right-hand plot shows the distribution of the two data types according to A M maximum frequency variance and fundamental frequency variance. The data types are assigned accurately to clusters on the x axis but are randomly distributed on the y axis.
When distances between the AM spectrogram trajectories (paths of frequencies with highest magnitude in each spectral slice) are compared with an additional criterion of agglomerative hierarchical clustering, a clear partition between the two registers emerges (see Figure 23.11); the length of the branches indicates the size of the inter-cluster difference. This result is obtained reliably with different common distance metrics (Chebyshev, Euclidean, Manhattan) and all available clustering criteria (including farthest neighbour, nearest neighbour, mean, median and variance minimisation). It is not obtained with Cosine and Pearson distance, showing the relevance of absolute difference, not trajectory shape.
Hierarchical clustering of newsreading and poetry reading (Euclidean distance and farthest neighbour clustering).
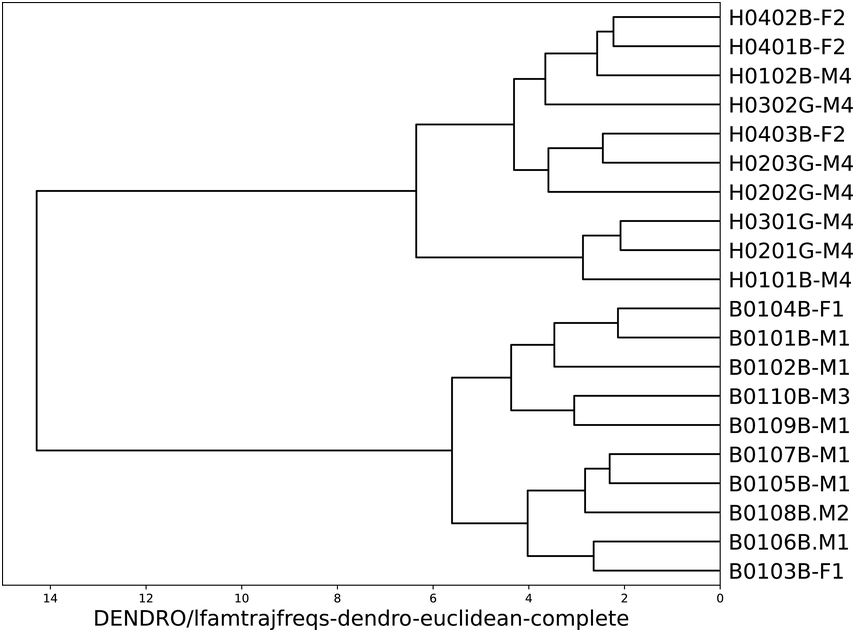
Figure 23.11 Long description
The major branch shows a perfect partition between the two data types. The subgroups in each data type are not further investigated. The comparison criterion is the low frequency spectrum trajectory derived from the amplitude modulation envelope, and the data are compared using Euclidean distance and complete linkage, also known as farthest neighbour linkage.
23.8.3 Comparison of Poetry Genres
In a cooperative ventureFootnote 3 with a specialist in Chinese–English literary translation, two types of poetry were examined, not in contemporary languages but in a hybrid scenario: Tang dynasty Chinese poetry from the seventh and eighth centuries CE in modern recitations from the early-twenty-first century CE (see also Gibbon, Reference Gibbon2022).
The types of poem to be compared are the five-character line and seven-character line genres, with 11 poems of each type, including rhythm influences from different conventional tonal patterns. Intuitively, it is expected that the rhythms of the two genres differ at the level of line-length rhythms. The demodulated signals were duration-normalised and the spectrum shapes, rather than distance, were compared using a Pearson distance measure, for example 1-abs(r). The resulting network is shown in Figure 23.12. An exact partition was found at a distance limit of 0.47 (the range is 0 … 1): the five-syllable (‘B’) poems are on the left in the figure, and the seven-syllable (‘F’) poems are on the right. There is sufficient distance between B and F genres and sufficient intra-genre proximity to yield separate B and F graphs.
Distance network with modern recitations of two genres of Tang dynasty poetry.
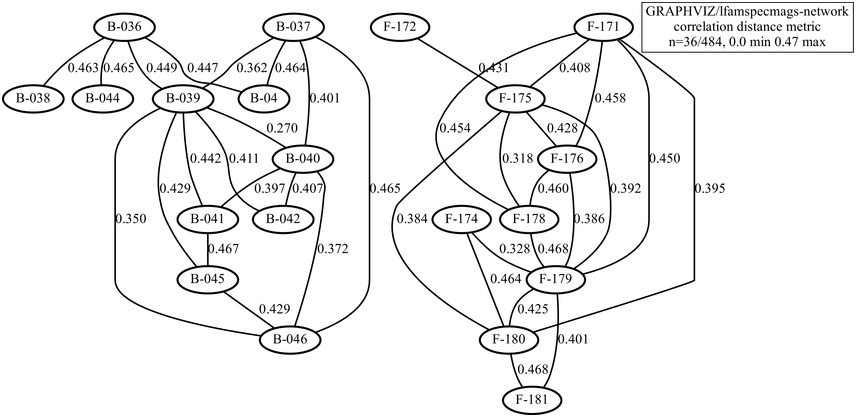
Figure 23.12 Long description
The nodes represent different readings, and the partition between the two networks represents a partition between two different poetry genres. The edges between the nodes represent the numerical distances or differences between the readings.
23.9 Results and Conclusions
In preparation for the rhythm analyses and comparisons, close attention was paid to methodological assumptions about register, rhythm and phonetic analysis as determinants of models of the physical reality of rhythm, in the sense noted at the beginning of the Introduction. Exploratory case studies of six different register scenarios and their dynamic rhythm formant properties were carried out, and unsupervised cluster comparisons were conducted with RFT and RFA, a recently developed modulation-theoretic signal-processing framework, using annotation mining as a heuristic source of hypotheses for these analyses. The analyses demonstrated distinctive rhythms in authentic natural data from spoken registers and their metalocutionary functions as indexical markers of locutionary cohesion.
The case study datasets are very small, so the results, though clear, may not be fully generalisable. Nevertheless, exploratory case studies of this kind are useful sources of hypotheses for future research. Further exact numerical modelling of rhythm formant properties of frequency, magnitude, resonance, bandwidth and persistence remains to be done. The important point to be retained, however, is the proposition that natural real-time rhythms with long-term LF acoustic properties can distinguish between speech registers, styles or genres.
Open issues for future work concern more detailed rhythm properties that can be found in the natural performance of speech, as in musical performances, such as syncopation, attack and decay, or sustain and release. Some of these properties depend on the phonotactics of languages (for example, a preponderance of voiceless fricatives as opposed to sonorants may relate to an ‘attack’ category), as in the well-known pair takete–maluma (Köhler, Reference Köhler1929) with voiceless obstruents in the first word and nasal sonorants in the second. Such properties may be relevant for explaining subjective attractiveness or unpleasantness judgments of rhythms and musicality in typologically different languages.
The results indicate that there are ‘real-time rhythms’ beyond the abstract ‘linguistic rhythm’ domain that can be captured by means of physically grounded empirical analysis, and that have identifiable metalocutionary functionality, marking meaningful cohesive locutions. Applications are anticipated not only in acoustic phonetic speech stylometry, as in the present study, but in speaker, language and register identification and search, including forensic search, pertaining to other categories and dimensions of speech in and beyond the acoustic domain.
Summary
Spectral properties of amplitude and frequency modulation of speech are cues to physical correlates of speech rhythms. Low frequency spectral differences approximate to annotation-mining results and correspondences between rhythm formants in the frequency domain, and word, phrase and discourse units can be established. Rhythm comparisons are visualised using the distance networks and hierarchical clustering that characterise text stylometry and dialectometry.
Implications
Spectral analysis shows that the term ‘linguistic rhythm’ for numerical encoding of grammatical structure is far from providing a general rhythm theory with empirical grounding of speech rhythms. Measurable spectral properties of spoken language relate to linguistic units as well as to the rhetorical and poetic patterns of speech, and also extend stylometric and dialectometric studies into the real-time physical domain of speech. The RFT/RFA framework provides a path towards more detailed investigation of the prosodic correlates of linguistic categories and an acoustic grounding for studies of neural oscillations.
Gains
The novel concept of rhythm formant advances modulation-theoretic comparison of speech rhythms by setting specific spectral properties in relation to linguistic units. Further, the formal semantics of rhythm, defined as metalocutionary indexical pointers to cohesive patterns in the lexico-syntactic utterance patterns, here defined with finite state machines, represents a step towards a formal semantics of prosody. Practical uses in speech classification, self-taught language-learning applications and language fluency evaluation are anticipated.
24.1 Introduction
The present study belongs to a line of research that examines on experimental grounds established claims and methods of rhetoric and media training. Many of such claims and methods have emerged from a combination of experience, intuition, and practical work with coaches. They are implemented on an everyday basis without understanding in detail whether, how, for whom, and under what circumstances they unfold their intended positive effects. By positive effects, we mean that they help learners of public speaking enhance their level of perceived charisma. Charisma is the result of an “emotion-laden leader signaling” (Antonakis et al., Reference Antonakis, Bastardoz and Jacquart2016), or, more specifically, of a signal-based, balanced transmission of competence, self-confidence, and passion, which respectively create trust, motivation, and commitment in people. Based on that, charisma helps speakers gain attention or inspire audiences to take desired actions or opinions (see Michalsky and Niebuhr, Reference Michalsky and Niebuhr2019). The range of signals that can contribute are diverse and include clothing and posture, choice of words and gestures, as well as pronunciation and nonverbal speech characteristics. Our study is about the latter signals and speech prosody in particular – see Arvaniti (Reference Arvaniti2020) for a recent definition of prosody.
So far, previous studies have cast a rather critical light on the validity of established claims and methods of rhetoric and media training. For example, a frequent claim is that rhetorical questions have a positive effect on their users’ charisma. Neitsch and Niebuhr (Reference Neitsch and Niebuhr2022) were able to corroborate this claim for oral presentations (like Tur et al., Reference Tur, Harstad and Antonakis2022, did for written language), however, only in connection with the prototypical prosody of real information-seeking questions. Using the normal prosody of rhetorical questions can even backfire to speakers, according to Neitsch and Niebuhr. A further example is the study of Tschinse et al. (Reference Tschinse, Asadi, Gutnyk and Niebuhr2022), who investigated the claim that smiling boosts a speaker’s perceived charisma and should therefore be applied as often as possible. Tschinse et al. found initial experimental evidence that smiling speech indeed makes speakers more charismatic. However, they also found an overdose threshold for smiling in public speeches that was sex-specific and considerably lower for female than for male speakers. An example for an established method of rhetoric and media training is the much-praised and often time-consumingly trained abdominal “belly” breathing. Niebuhr and Barbosa (Reference Berger, Zellers and Niebuhr2023) investigated whether this actually brings the promised charisma benefits (compared to the typical chest-dominated way of breathing). While their results showed that voices were perceived as more resonant under abdominal breathing, they could not find evidence that abdominal breathing has a positive effect on the perception of speaker charisma. By contrast, charisma increased perceptually only under chest breathing.
Continuing this line of research, the present study is about the so-called cork exercise (CE). The key concept of this exercise is that a wine bottle cork is clamped at about one-third of its length between the upper and lower incisors and held in place by gently biting down. Now the speaker starts reading out loud a specific training text, articulating as clearly as possible “around the cork” (e.g., Alburger, Reference Alburger2014). According to guidebooks on rhetoric and leadership, performing this exercise gives speakers a more “open and vivid articulation” (Khidr, Reference Khidr2017) and, moreover, causes a “remarkable difference in the sound of your voice” (Alburger, Reference Alburger2014). According to Knoppers et al. (Reference Knoppers, Obdeijn and Giessner2021:249), the voice becomes “deeper and fuller” after the CE. Schinko-Fischli (Reference Schinko-Fischli2019) additionally stresses the immediate and robust effect of the exercise by stating that it “is excellent for improving the clarity of your pronunciation in a short time.” More than a hundred years ago already, Rice (Reference Rice1920) had pointed out the effectiveness of the CE (see also Timmermans et al., Reference Timmermans, Coveliers, Wuyts and Van Looy2012).
Unlike for many other claims and methods, there is some experimental evidence to support the guidebook quotations. Timmermans et al. (Reference Timmermans, Coveliers, Wuyts and Van Looy2012), for example, conducted a perception experiment based on a within-subjects before–after comparison with one control group and two test groups of normal and dysarthric speakers. They found that, after the exercise, the non-dysarthric test group was rated to speak more clearly and intelligibly than the control group. Timmermans et al. (Reference Timmermans, De Bodt and Ysenbaert2015) later replicated the positive perceptual effect of the CE with media representatives, that is, journalists and radio hosts. However, they could not find any acoustic correlates of that perceptual improvement, such as changes in the levels of the first- and/or second-formant frequency (F1, F2). Such correlates were found by Leyns et al. (Reference Leyns, Corthals and Cosyns2021), though, who showed that the CE makes third-formant (F3) frequencies increase, albeit not for all vowels and speakers. Yet, these authors reported a robust effect of the exercise on intelligibility.
In summary, the CE has so far been primarily examined with regard to its effect on articulation and intelligibility. If the CE has any effects on prosody is unknown. It is claimed, for example, by Alburger (Reference Alburger2014) and Knoppers et al. (Reference Knoppers, Obdeijn and Giessner2021) that speakers’ vocal (i.e., prosodic) performances also benefit from the CE. Our study addresses this gap. We tested what effect the CE has on vocal performance, specifically on speech rhythm, intonation, timbre, timing, and loudness. Rhythm is operationalized here in terms of both established acoustic measures and a new instrument for measuring jaw-lowering patterns: the MARRYS cap (Erickson et al., Reference Erickson, Niebuhr, Gu, Huang and Geng2021). Jaw-lowering patterns were repeatedly shown across languages to be closely related to degrees of sentence stress (Erickson et al., Reference Erickson, Niebuhr, Gu, Huang and Geng2021), which are a major source of perceived speech rhythm (Kohler, Reference Kohler2009).
Thus, unlike previous studies, our study focuses on the CE’s acoustic rather than perceptual effects. However, the latter can, to some extent, be inferred from the former. It is well known from previous studies that virtually all acoustic vocal-performance measures are positively correlated with perceived charisma and/or related traits (charm, persuasiveness, trustworthiness, enthusiasm, and so on; e.g., Strangert and Gustafson, Reference Strangert and Gustafson2008; Rosenberg and Hirschberg, Reference Rosenberg and Hirschberg2009; Niebuhr and Skarnitzl, Reference Niebuhr and Skarnitzl2019, Reference Niebuhr and Skarnitzl2021). For example, being a more charismatic speaker means to have a higher pitch level, a larger pitch range, a higher tempo, a higher loudness level, and so on (see Rosenberg and Hirschberg, Reference Rosenberg and Hirschberg2009). In addition, Berger et al. (Reference Berger, Zellers and Niebuhr2023) found in accord with Niebuhr et al. (Reference Niebuhr, Brem, Michalsky and Neitsch2020) that the range of the F1 is positively correlated with perceived charisma. The larger the F1 ranges, the more charismatic speech sounds. And since “a lowering of the jaw causes an increased F1” (Mooshammer et al., Reference Mooshammer, Hoole and Geumann2007:171), larger F1 ranges mean more pronounced jaw lowering or, to put it in the words of Erickson and Niebuhr (Reference Niebuhr, Barbosa, Rüdiger and Drayter2023), more pronounced “jaw dancing.”
Thus, if systematic effects of the CE on prosodic acoustics emerge, and if these effects are to be positive for vocal charisma, they must manifest in the form of prosodic-parameter increases and, in the case of rhythm, additionally in increased jaw lowering. Testing this assumption is the main goal of our study.
There are many differences concerning how exactly the CE is implemented. This applies, for example, to the duration of the exercise (see Timmermans et al., Reference Timmermans, Coveliers, Wuyts and Van Looy2012). Instructions also vary considerably. However, many instructions have in common that they raise high expectations among speakers. The speakers are told how much their speech production will improve and how traditional and effective the exercise is (see the guidebook quotations above [Alburger, Reference Alburger2014; Khidr, Reference Khidr2017; Schinko-Fischli, Reference Schinko-Fischli2019; Knoppers et al., Reference Knoppers, Obdeijn and Giessner2021]). In such a setting, it cannot be ruled out that post-exercise changes are only the result of a placebo effect, caused by the praising, effect-oriented instruction. Furthermore, effects of the CE have so far only been found for speech recorded immediately after the CE. Although guidebooks promise a sustainable effect, this sustainability has not been empirically supported up until now.
As a supplement, we include these two open questions as secondary goals. We address them by (1) testing two different instruction videos, a neutral instruction-oriented one and a praising, effect-oriented one that emulates typical guidebook-style instructions and (2) comparing speakers’ pre- and post-exercise performance.
To summarize, the research questions are therefore: Are there significant effects of the CE in the form of differences in the participants’ rhythms and prosodies between pre- and post-exercise vocal performances? If so, (a) is there a significant interaction of these effects with the type of video instruction and (b) do these significant effects persist also after a distractor task?
We explored these questions with an eye to speaker sex. This was primarily because it is well documented that men and women tend to exhibit distinct levels of public-speaking anxiety and display different behavioral responses to such anxiety (Carrillo et al., Reference Carrillo, Moya-Albiol and Gonzalez-Bono2001). Additionally, prior research has identified sex-related variances in articulatory movements and dynamics of lips, jaw, and tongue (Tang et al., Reference Tang, Hannah and Jongman2015; Weirich et al., Reference Weirich, Fuchs, Simpson, Winkler and Perrier2016). This is relevant insofar as a CE intervention could interfere differently with these sex-related variances.
24.2 Method
24.2.1 Participants
A total of 16 participants took part in our experiment. They were randomly assigned to two test conditions, an effect-oriented condition and an instruction-oriented condition – see Section 24.2.2 below. Table 24.1 gives an overview. Participants were German native speakers. All gave formal written consent to participate in the study. (Due to a number of previous related experiments, a separate ethical approval from SDU’s Research Ethics Committee was not required for this study.) None of the participants had heard of the CE before or had any other experience with rhetoric or media training. Thus, they were completely naïve to public-speaking practices.
| Sample | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| Effect-oriented condition | ID | EF1 | EF2 | EF3 | EM1 | EM2 | EM3 | EM4 | EM5 |
| Sex | female | female | female | male | male | male | male | male | |
| Age | 30–40 | 20–30 | 40–50 | 40–50 | 20–30 | 20–30 | 20–30 | 30–40 | |
| Instruc.-oriented condition | ID | IF1 | IF2 | IF3 | IF4 | IM1 | IM2 | IM3 | IM4 |
| Sex | female | female | female | female | male | male | male | male | |
| Age | 30–40 | 20–30 | 40–50 | 20–30 | 20–30 | 20–30 | 20–30 | 20–30 |
24.2.2 Test Conditions
One goal was to test the extent to which the CE relies on a placebo effect – caused by the fact that books and coaches emphasize how established and successful the exercise is when introducing it to participants. To address that, the sample was divided into two test conditions with eight participants each: the effect-oriented condition and the instruction-oriented condition (see Table 24.1 in Section 24.2.1).
Both conditions were represented by videos kindly produced for us by a professional rhetoric and media trainer, Dr. Katrin Prüfig (KP) – see Figure 24.1. KP recorded the videos while speaking in front of a neutral background.
Individual example frames from the instruction-oriented video produced by KP for the purpose of this study.

The instruction-oriented video was 1:15 minutes long. It introduced the term cork exercise, showed the cork, and illustrated the method with a short example text that KP performed first with and then without the cork in her mouth. As part of this contrastive performance, KP informed her viewers that the goal should be to articulate clearly and elaborately “around the cork” – and that the method can basically be combined with any text. The video ended with a call to action that encouraged viewers to try out the CE themselves.
The effect-oriented video was about one minute longer, that is, 2:14 minutes in total. It contained exactly the same content. However, in the video’s additional 60 seconds, KP praised the method. She stressed that the CE would be an established, tried-and-trusted exercise among rhetorical trainers and media coaches like herself, and that successful professional keynote speakers and actors would value this exercise for a long time, and they like to apply it right before their performances “on stage.” Moreover, after having read the example text with and without the cork in the mouth, KP explicitly described the beneficial effect on its users, for example, in the form of clearer and more forceful speech production. The video ended in the same call to action as the instruction-oriented video.
24.2.3 Reading Material
For comparing CE effects on participants’ prosodies, we chose the German version of Aesop’s fable North Wind and the Sun. The text was selected for two reasons. First, it is well established in the speech sciences, is repeatedly used for analyzing both sound segments and prosodies, and it represents a standard text for the phonetic documentation of languages by the International Phonetic Association (IPA) (Baird et al., Reference Baird, Evans and Greenhill2022).
Second, and more importantly, it is known from previous studies that North Wind and the Sun can be fluently produced by native speakers of German. It is also roughly known which phrasings (i.e., pause locations) are to be expected – and that the text is basically capable of eliciting a rich, melodic prosody as well as clearly pronounced sentence stresses (pitch-accented words) and speech rhythms (e.g., Trouvain and Grice, Reference Trouvain and Grice1999; Braun et al., Reference Braun and Künzel2003; Andreeva and Dimitrova, Reference Andreeva and Dimitrova2022).
Besides North Wind and the Sun, another elicitation text was used in this study: the German poem “Der Zwölf Elf” (the 12th elf), written by Christian Morgenstern between 1887 and 1914. It consists of 139 words, 12 stanzas, and 24 verses. We used a poem on the assumption that this type of text would particularly well support the CE with regard to prosodic factors such as rhythm, intonation, and melody. Public-speaking trainers such as Bernhardt (Reference Bernhardt2022) explicitly recommend using poems in connection with the CE. Consistent with such recommendations, Rodero et al. (Reference Rodero, Diaz-Rodriguez and Larrea2018) show, for example, that poetry triggers stronger and more frequent stresses, phrasings, and loudness contrasts during public-speaking training compared to normal prose texts. Furthermore, poetry is also known for effectively teaching adult language learners the prosody of a foreign language or for improving children’s reading and speaking fluency (Miccinati, Reference Miccinati1985).
Among suitable poems, we chose “Der Zwölf Elf” for two reasons. Firstly, it represented one of two official cork-speaking exercises in the book by Meisner (Reference Meisner2010). Meisner’s exercises are aimed at Parkinson’s patients. Thus, the exercises should be at least as effective with non-pathological speakers such as our 16 participants. Secondly, “Der Zwölf Elf” resulted in an exercise duration that was similar to those used in previous scientific CE studies (see Timmermans et al., Reference Timmermans, Coveliers, Wuyts and Van Looy2012).
24.2.4 Procedure
The experiment was carried out based on a mixed-design framework. That is, it included a within-subjects factor and a between-subjects factor – see Figure 24.2, whose images are used here under CC licenses from the following sources: Project Gutenberg (license: public domain, CC0): https://picryl.com/media/the-north-wind-and-the-sun-sun-project-gutenberg-etext-19994-821bd3, corks (license public domain, CC0), www.rawpixel.com/image/6020053/wooden-wine-cork-free-public-domaincc0-photo, survey icon (license public domain, CC0) https://commons.wikimedia.org/wiki/File:Online_Survey_Icon_or_logo.svg. The within-subjects factor was the comparison of North Wind and the Sun reading performances before versus after the CE intervention, henceforth referred to as PRE versus POST1. The factor itself is referred to as SEQUENCE. The factor SEQUENCE also included a distractor task and a further reading task POST2. The rationale for their inclusion is explained below. The two video conditions of the effect-oriented and instruction-oriented videos represented the between-subjects factor VIDEO.
Overview of the experimental procedure and the material provided in each step.

The participants were invited individually to the experiment that took place in the sound-treated recording booth of the CIE Acoustics Lab of the University of Southern Denmark (SDU). Upon arrival, they were only informed that they would take part in a speech-production experiment and that their speech signals and jaw movements during speech production would be recorded to that end. Furthermore, the participants were told that their speech-production data would be collected on the basis of two reading texts.
After participants had given consent, they were asked to take a seat in the sound-treated booth. The MARRYS cap was put on to record jaw movements in parallel to audio – see Figure 24.3.Footnote 1 The MARRYS cap is, in short, a new phonetic device that can record jaw lowering via sensor straps on both sides of the head that converge on the chin (see, for further details, Niebuhr and Gutnyk, Reference Niebuhr and Gutnyk2021). The cap achieves a similar precision and resolution as the current gold standard of electro-magnetic articulography, or EMA (Svensson Lundmark et al., Reference Svensson Lundmark, Ericksson, Niebuhr, Tiede and Wei-Rong2023). However, unlike EMA, the MARRYS cap is easy to use and portable, and even allows the recording and analysis of asymmetries in vertical jaw lowering (Niebuhr and Gutnyk, Reference Niebuhr and Gutnyk2021).
Illustration of the recording setting inside the sound-treated booth of the CIE Acoustics Lab.

The speech-production experiment began with the participants having to read North Wind and the Sun twice. The first run was a dummy run, designed to familiarize the participants with the recording situation and the reading text. The second run was used as the baseline production PRE (Figure 24.2).
After the two rounds, participants saw the respective video by KP and were asked to do the CE themselves based on the poem “Der Zwölf Elf.” A cork was handed out to them while they received this instruction (Figure 24.2).
After participants had finished reading the poem, they were asked to remove the cork and read the North Wind and the Sun fable again. Then, they were given a nonverbal task. They were instructed to fill out the Smalley–Trent five-minute personality test on the screen in front of them. The personality test was integrated into the experiment as a distractor element (Figure 24.2). It temporarily distracted participants from the CE and prevented them from internally rehearsing and retaining their immediate experiences and motor memories gained through the exercise.
The Smalley–Trent test is also known as the four-animal personality test (Liu et al., Reference Liu, Niu and Carassai2017). It consists of a small set of 18 questions based on which the test gives a graded assessment of the participants’ strengths, weaknesses, and natural inclinations, represented by four animal characters: lion, otter, beaver, and golden retriever – see the example in Figure 24.4.
Illustration of the Smalley–Trent five-minute personality test result.

Figure 24.4 Long description
The components are as follows. Top. A graphical representation of a waveform of the sound's amplitude over time. Darker areas indicate louder sound. Middle. A visual representation of a spectrogram of the sound's frequency content over time. Bottom. A textual representation of the speech sounds including symbols like "sil" represent silent, "v" represents a voiced sound, and "c" represents a consonant sound.
After completing the personality test, participants were asked to read the North Wind and the Sun a third time.
So, while there was only one PRE performance of the fable per speaker in the experiment, we included two POST performances, one directly after the CE and one after the distractor (POST1 and POST2; Figure 24.2). While POST1 was to examine whether the CE would have any immediate effects on jaw movements, rhythm, and prosody, POST2 was to investigate whether CE-intervention effects would be robust enough not to disappear after a short distraction. Like PRE and POST1, POST2 is also a part of the within-subjects factor SEQUENCE.
In a final debriefing, the participants were informed about the objectives of the study, including the existence of two video conditions and the condition they had been assigned to. Most of the participants stated that they found the CE exciting and unfamiliar, but also a little strenuous. The majority of participants also estimated that the cork had had no significant effects on their speech production or, if at all, only short-term effects.
A complete experiment session lasted about 15 minutes. Note that the participants were always alone in the sound-treated booth during the individual reading performances. The experimenter only came in to initiate the next step and then left the booth again. Also note that the participants were generally and repeatedly instructed before each North Wind and the Sun round not just to read the text but rather to perform it, for example, as if they were reading it for an audience.
24.2.5 Data Analysis
24.2.5.1 Speech-Rhythm Analysis
We used the Munich automatic segmentation system (MAUS; Kisler et al., Reference Kisler, Reichel and Schiel2017) with its German linguistic rule set to create Praat TextGrid files in which the North Wind and the Sun readings were broken down into seven types of time-interval tiers. These ranged from a “Segment” tier with individual consonant and vowel boundaries, to a “Syllable” tier with syllable boundaries, and finally to a “Sentence” tier where the beginnings and ends of the text?s six sentences were marked. (see Figure 24.5). All automatically created boundaries were manually checked and, if required, corrected, taking into account the criteria of phonetic segmentation summarized in Machač and Skarnitzl (Reference Machač and Skarnitzl2009).
Example of a Praat TextGrid file in combination with its corresponding sound file.
The figure shows sentence 2 of the fable uttered by the female speaker KF (“Sie wurden einig, dass derjenige für den Stärkeren gelten sollte, der den Wanderer zwingen würde, seinen Mantel abzunehmen”). Vertical bars mark landmarks in the speech signal at six levels, from acoustic energy peaks (level 6) to syllable and individual sound-segment boundaries (levels 5 and 1). The dark gray curve in the spectrogram shows the f0 contour (100–400 Hz); “sil” labels indicate silent (nonspeech) intervals.
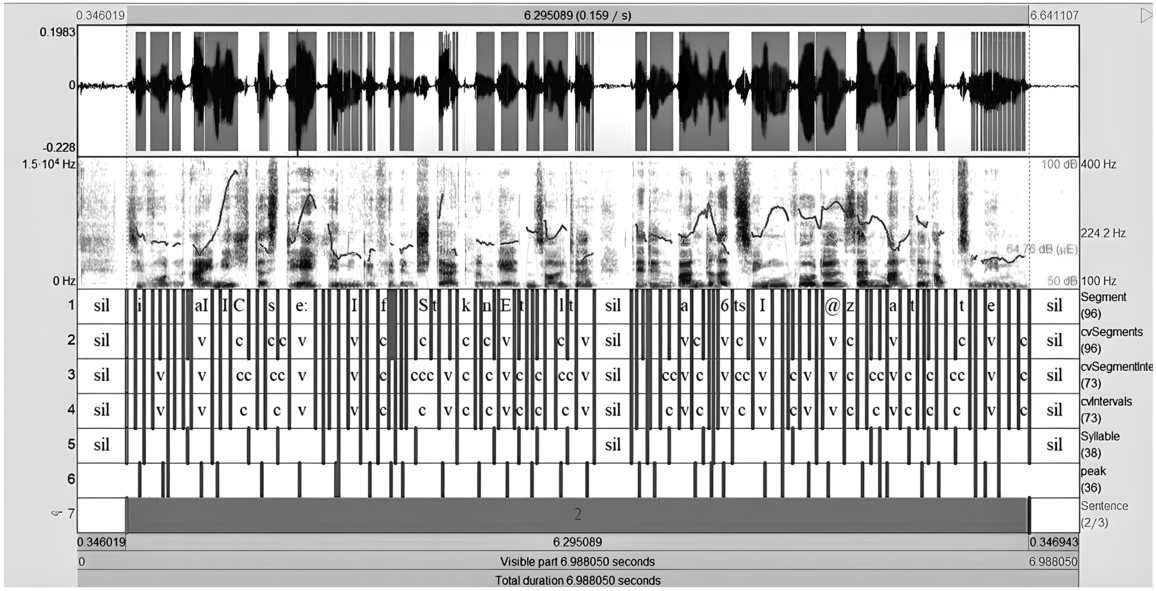
Figure 24.5 Long description
The horizontal axis represents pre, post 1, and post 2. The vertical axis represents the estimated marginal means for male and female speakers. The maximum to minimum mean values of estimated marginal means for female speakers are as follows. Set a. Top. Effect-oriented video; 550, 510, and 500. Instruction-oriented video; 510, 500, and 500. Bottom. Effect-oriented video; 500, 500, and 450. Instruction-oriented video; 510, 500, and 500. Set b. Top. Effect-oriented video; 13, 12, and 12. Instruction-oriented video; 12, 12, and 12. Bottom. Effect-oriented video; 13, 12 and 11. Instruction-oriented video; 11, 10 and 10. The values are estimated.
We used a script written for Praat (Boersma, Reference Boersma, Durand, Gut and Kristoffersen2014) by Volker Dellwo (see Taghva et al., Reference Taghva, Moloodi, Abolhasanizadeh and Tabei2023) to measure, based on the TextGrid files, the most widely employed speech-rhythm parameters proposed by previous works (Ramus et al., Reference Ramus, Nespor and Mehler1999; Grabe and Low, Reference Grabe and Low2002; Dellwo et al., Reference Dellwo, Leemann and Kolly2015). Three types of parameters were measured, all related to the time-interval structures realized by the speakers: (1) mean measures refer to the average duration of a unit’s time interval; (2) delta (∆) measures show the standard deviation of the time-interval durations of a unit; and (3) rPVI (raw pairwise variability index) measures represent the sum of the absolute differences between pairs of consecutive time intervals (either vocalic or consonantal) divided by the number of pairs in the speech sample. Following the argument of Bertini et al. (Reference Bertini, Bertinetto and Zhi2011), we refrained from normalizing these rPVI values (to nPVI values), also for vowels, in order to allow stress or pitch-accent duration changes to show up clearly in PVI values. The three types of measures were taken for the following five units: syllables, consonants, vowels, as well as voiced and unvoiced speech sections as a whole, that is, for example, clusters of unvoiced consonants or sequences of vowels and adjacent sonorant consonants.
24.2.5.2 Analysis of Intonation, Timbre, Timing, and Loudness
Rhythm is an integral part of speech prosody – see Arvaniti (Reference Arvaniti2020). The fact that we have separated the rhythmic-acoustic parameters in Section 24.2.5.1 from the other speech prosody parameters in this section only serves to provide a clearer description. The acoustic analysis of these other prosodic parameters included measures related to intonation, timbre, timing, and loudness. Measurements were taken automatically by means of ProsodyPro (Xu, Reference Xu2013), using the default (recommended) sex-specific analysis settings. All obtained values were manually cross-checked. Implausible values (such as zeros) were either removed or replaced by manually measured values. The following parameters were measured:
Intonation: mean f0 (fundamental frequency) level (Hz), mean f0 minimum (Hz), mean f0 maximum (Hz), and f0 range (difference between minimum and maximum, Hz). The latter three f0 measures were based on values of the 90th percentile in order to exclude measurement outliers.
Timbre: harmonic-amplitude difference h1–h2 (i.e., a source spectral tilt measure, f0-corrected, dB), amplitude differences between the first harmonic and the harmonic closest to the third formant h1–A3 (i.e., spectral tilt measure, f0-corrected, dB), and the mean formant levels (Hz) of F1, F2, and F3.
Timing: pause count, mean pause duration (in ms), and mean speaking rate (syll/s)
Loudness: mean RMS (root mean squared) (dB) and RMS variability (standard deviation, dB)
Note that all acoustic-prosodic measures were taken per sentence. Each speaker was, thus, represented by six measurements per PRE, POST1, and POST2 performance.
24.2.5.3 Analysis of MARRYS Cap Signals
The MARRYS signals were transferred to Audacity for post-processing (Audacity, Reference Audacity2017). For the analysis of the jaw movements, we applied the “MARRYS-Amplitude” script written for Praat by Svensson Lundmark to the TextGrids’ sentence-interval tiers (Svensson Lundmark et al., Reference Svensson Lundmark, Ericksson, Niebuhr, Tiede and Wei-Rong2023). Minimum and maximum amplitudes (in Pascal) were measured on that basis. Amplitude is the stretch of the belt in the MARRYS cap; hence, a higher amplitude equals a bigger displacement of the jaw. As each North Wind and the Sun reading included six sentences, a total of 18 minimum and maximum amplitude measurements were taken per speaker across all three SEQUENCE conditions (PRE, POST1, and POST2). Furthermore, we collected, as reference values, the maximum and minimum amplitudes of the initial sentence of the poem read during the CE with the cork in the mouth. All sentence intervals were manually checked and adjusted prior to running the Praat script to not include any nonspeech jaw movements made prior or after each read sentence.
Furthermore, we used the minimum and maximum amplitude of each sentence to calculate the amplitude range. The range estimated differences in jaw movement within the sentence. Besides the raw values of maximum amplitude and amplitude range, we used the CE reference-amplitude values to normalize the raw measurements such that a 0 measurement would mean that the speaker’s mouth was opened during a North Wind and the Sun sentence just as much as during the CE with the cork inside the mouth. Finally, based on all minimum and maximum values, the average amplitude per sentence was calculated.
24.2.5.4 Inferential Statistics
The measurements were statistically analyzed in terms of mixed-model multivariate analyses of variance (MM-MANOVAs), using SPSS v.28.0. Three MM-MANOVAs were conducted: one on the rhythm measures, one on the (other) prosody measures, and one on the MARRYS cap measures. All three statistical models had a similar makeup. The measures listed in Sections 24.2.5.1, 24.2.5.2, and 24.2.5.3 were the respective dependent variables. The within-subjects independent variable was SEQUENCE. It included the three levels PRE, POST1, and POST2. The between-subjects independent variable was VIDEO with its effect-oriented or instruction-oriented conditions – see Figure 24.2. Speaker SEX was included as an additional between-subject independent variable.
The test statistics reported in the results sections below include partial eta-squared effect-size values. Moreover, if a measure’s results violated the sphericity criterion, we report test statistics based on Greenhouse–Geisser corrections. Multiple-comparisons tests between the three levels of SEQUENCE were conducted. Due to the high number of these pairwise comparisons, the basic risk that one of these tests comes out statistically significant by chance increases. In order to reduce this risk, we corrected p-values and confidence intervals according to Šidák. For our data, in which we can, if at all, assume positively correlated tests, the correction procedure named after the Czech statistician Zbyněk Šidák is considered conservative.
24.3 Results
24.3.1 Rhythm Characteristics
The MM-MANOVA on rhythm characteristics resulted in a significant main effect of SEQUENCE (i.e., PRE versus POST1 versus POST2: F[50,320]= 2.896, p<0.001,  = 0.312). In addition, there were significant interactions of SEQUENCE with both VIDEO (F[50,320] = 1.522, p=0.018,
= 0.312). In addition, there were significant interactions of SEQUENCE with both VIDEO (F[50,320] = 1.522, p=0.018,  = 0.192) and SEX (F[50,320]= 1.419, p=0.040,
= 0.192) and SEX (F[50,320]= 1.419, p=0.040, 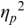 = 0.181). The three-way interaction SEQUENCE*VIDEO*SEX was not significant.
= 0.181). The three-way interaction SEQUENCE*VIDEO*SEX was not significant.
Breaking down the overall statistical model into its univariate elements (and conducting multiple-comparisons tests, with Šidák corrections, between the levels of SEQUENCE) revealed further details that we address below separately for each of the three types of rhythm measures: mean, delta, and rPVI; see also the examples in Figures 24.6(a) and (b).
The CE significantly changed the speakers’ mean duration patterns of all rhythm units, that is, syllables (F[2,184]= 27.635, p<0.001, 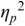 = 0.231), consonants (F[2,184]= 7.572, p<0.001,
= 0.231), consonants (F[2,184]= 7.572, p<0.001, 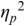 = 0.076), vowels (F[2,184]= 19.211, p<0.001,
= 0.076), vowels (F[2,184]= 19.211, p<0.001, 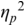 = 0.173), voiced intervals (F[2,184]= 12.543, p<0.001,
= 0.173), voiced intervals (F[2,184]= 12.543, p<0.001, 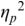 = 0.120), and unvoiced intervals (F[2,184]= 7.150, p=0.001,
= 0.120), and unvoiced intervals (F[2,184]= 7.150, p=0.001, 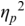 = 0.072). The overall effect pattern was the same for all units: Mean durations significantly increased from PRE to POST1, but then significantly decreased again in POST2 to a level that was statistically identical to that of PRE. That is, the mean segmental duration patterns in POST2 were as if the CE intervention had never happened.
= 0.072). The overall effect pattern was the same for all units: Mean durations significantly increased from PRE to POST1, but then significantly decreased again in POST2 to a level that was statistically identical to that of PRE. That is, the mean segmental duration patterns in POST2 were as if the CE intervention had never happened.
Furthermore, significant SEQUENCE*VIDEO interactions were found for the syllables (F[2,184]= 11.042, p<0.001, 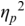 = 0.107), for the vowels (F[2,184]= 6.795, p=0.002,
= 0.107), for the vowels (F[2,184]= 6.795, p=0.002, 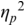 = 0.069), as well as for the voiced intervals as a whole (F[2,184]= 6.173, p=0.003,
= 0.069), as well as for the voiced intervals as a whole (F[2,184]= 6.173, p=0.003, 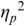 = 0.063). These interactions reflect that the temporary increases of mean durations in the POST1 performances occurred only in combination with the effect-oriented video. The instruction-oriented video did not associate with significant changes in mean duration patterns. An example can be found in the rPVI syllable patterns in Figure 24.6(b).
= 0.063). These interactions reflect that the temporary increases of mean durations in the POST1 performances occurred only in combination with the effect-oriented video. The instruction-oriented video did not associate with significant changes in mean duration patterns. An example can be found in the rPVI syllable patterns in Figure 24.6(b).
Results on rhythm characteristics illustrated by two time-interval parameters.
Estimated marginal means and error bars (95% CI) for (a) the delta V and (b) the syllable-based rPVI. Dark gray bars indicate the effect-oriented and light-gray bars the instruction-oriented video conditions. Top panels show the female speakers’ and bottom panels the male speakers’ results.
Figure 24.6 Long description
The horizontal axis represents pre, post 1, and post 2. The vertical axis represents the estimated marginal means for male and female speakers. The maximum to minimum mean values of estimated marginal means for female speakers are as follows. Set a. Top. Effect-oriented video; 210 for post 1, 200 for pre, and 202 for post 2. Instruction-oriented video; 180 for post 2, 180 for post 1, and 170 for pre. Bottom. Effect-oriented video; 125 for post 2, 125 for post 1, and 125 for pre. Instruction-oriented video; 125 for pre, 125 for post 1, and 124 for post 2. Set b. Top. Effect-oriented video; 510 for post 1, 510 for post 2, and 510 for pre. Instruction-oriented video; 500 for post 1, 480 for post 2 and 480 for pre. Bottom. Effect-oriented video; 480 for pre, 480 for post 1, and 480 for post 2. Instruction-oriented video; 480 for post 1, 480 for post 2, and 470 for pre. The bars depict similar values in sets c and d. The values are estimated.
As for the second type, that is, the delta measures, we also found significant changes induced by the CE intervention on all rhythm units, that is, syllables (F[2,184]= 4.272, p=0.016,  = 0.045), consonants (F[2,184]= 7.572, p<0.001,
= 0.045), consonants (F[2,184]= 7.572, p<0.001,  = 0.076), vowels (F[2,184]= 3.617, p=0.029,
= 0.076), vowels (F[2,184]= 3.617, p=0.029, 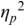 = 0.038), voiced intervals (F[2,184]= 3.950, p=0.021,
= 0.038), voiced intervals (F[2,184]= 3.950, p=0.021, 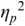 = 0.041), and unvoiced intervals (F[2,184]= 6.373, p=0.002,
= 0.041), and unvoiced intervals (F[2,184]= 6.373, p=0.002, 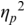 = 0.065). The nature of these effects is overall similar to that of the mean durations. That is, the delta measurements increased from PRE to POST1, but then decreased again after the distractor task from POST1 to POST2. However, unlike for the mean measures, this decrease did not in most cases lead all the way down again to the delta levels of PRE. Thus, POST2 delta values were, by majority, still significantly higher than their PRE counterparts. This depended on the factors VIDEO and SEX. In the case of the syllable-based delta values, for example, we found significant SEQUENCE*VIDEO (F[2,184]= 3.369, p=0.039,
= 0.065). The nature of these effects is overall similar to that of the mean durations. That is, the delta measurements increased from PRE to POST1, but then decreased again after the distractor task from POST1 to POST2. However, unlike for the mean measures, this decrease did not in most cases lead all the way down again to the delta levels of PRE. Thus, POST2 delta values were, by majority, still significantly higher than their PRE counterparts. This depended on the factors VIDEO and SEX. In the case of the syllable-based delta values, for example, we found significant SEQUENCE*VIDEO (F[2,184]= 3.369, p=0.039, 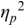 = 0.036) and SEQUENCE*SEX interactions (F[2,184]= 4.757, p=0.011,
= 0.036) and SEQUENCE*SEX interactions (F[2,184]= 4.757, p=0.011, 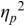 = 0.049), reflecting that the increases from PRE to POST1 as well as the degree of maintenance of that POST1 level in POST2 performances were more strongly pronounced both in the effect-oriented video conditions as well as for the male participants. Similarly, for the delta values of consonants and vowels, it was mainly the effect-oriented video condition (consonants: F[2,184]= 3.353, p=0.041,
= 0.049), reflecting that the increases from PRE to POST1 as well as the degree of maintenance of that POST1 level in POST2 performances were more strongly pronounced both in the effect-oriented video conditions as well as for the male participants. Similarly, for the delta values of consonants and vowels, it was mainly the effect-oriented video condition (consonants: F[2,184]= 3.353, p=0.041, 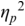 = 0.029; vowels: F[2,184]= 3.245, p=0.045,
= 0.029; vowels: F[2,184]= 3.245, p=0.045, 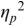 = 0.027) and the male speaker group (consonants: F[2,184]= 3.412, p=0.033,
= 0.027) and the male speaker group (consonants: F[2,184]= 3.412, p=0.033, 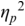 = 0.038; vowels: F[2,184]= 3.769, p=0.027,
= 0.038; vowels: F[2,184]= 3.769, p=0.027, 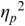 = 0.040) for which an increase from PRE to POST1 occurred; and only for the male speakers, the delta values at POST2 still remained significantly above those of PRE – see Figure 24.6(a). The same applied to the voiced and unvoiced intervals (voiced: F[2,184]= 4.443, p=0.012,
= 0.040) for which an increase from PRE to POST1 occurred; and only for the male speakers, the delta values at POST2 still remained significantly above those of PRE – see Figure 24.6(a). The same applied to the voiced and unvoiced intervals (voiced: F[2,184]= 4.443, p=0.012, 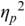 = 0.048; unvoiced: F[2,184]= 3.688, p=0.028,
= 0.048; unvoiced: F[2,184]= 3.688, p=0.028, 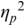 = 0.038). For the female speakers, there were no delta increases in connection with the instruction-oriented video; and their delta values decreased rather than increased in POST2 relative to the level of PRE.
= 0.038). For the female speakers, there were no delta increases in connection with the instruction-oriented video; and their delta values decreased rather than increased in POST2 relative to the level of PRE.
The rPVI measures also yielded significant effects of SEQUENCE on all rhythm units, that is, syllables (F[2,184]= 6.331, p=0.002, 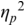 = 0.064), consonants (F[2,184]= 4.842, p=0.009,
= 0.064), consonants (F[2,184]= 4.842, p=0.009, 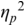 = 0.050), vowels (F[2,184]= 13.981, p<0.001,
= 0.050), vowels (F[2,184]= 13.981, p<0.001, 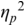 = 0.132), voiced intervals (F[2,184]= 12.543, p<0.001,
= 0.132), voiced intervals (F[2,184]= 12.543, p<0.001, 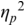 = 0.120), and unvoiced intervals (F[2,184]= 3.763, p=0.025,
= 0.120), and unvoiced intervals (F[2,184]= 3.763, p=0.025, 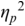 = 0.039). However, compared to the mean and delta measures above, these rPVI effects proved still more sensitive to the SEX and VIDEO conditions. For example, for the syllable-based rPVI, we found an increase after the CE intervention, that is, from PRE to POST1. But this only applied to the effect-oriented video (SEQUENCE*VIDEO: F[2,184]= 3.279, p=0.040,
= 0.039). However, compared to the mean and delta measures above, these rPVI effects proved still more sensitive to the SEX and VIDEO conditions. For example, for the syllable-based rPVI, we found an increase after the CE intervention, that is, from PRE to POST1. But this only applied to the effect-oriented video (SEQUENCE*VIDEO: F[2,184]= 3.279, p=0.040, 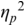 = 0.035), and only male speakers were able to preserve this increase in their POST2 performances (SEQUENCE*SEX: F[2,184]= 3.155, p=0.045,
= 0.035), and only male speakers were able to preserve this increase in their POST2 performances (SEQUENCE*SEX: F[2,184]= 3.155, p=0.045, 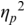 = 0.033) – see Figure 24.6(b). That is, the instruction-oriented video was not able to trigger a significant rPVI increase, and, for female speakers, this increase was not robust enough to be carried over from POST1 to POST2 performances (i.e., the PRE versus POST2 difference was not significant).
= 0.033) – see Figure 24.6(b). That is, the instruction-oriented video was not able to trigger a significant rPVI increase, and, for female speakers, this increase was not robust enough to be carried over from POST1 to POST2 performances (i.e., the PRE versus POST2 difference was not significant).
For the vowel-based rPVI, both sexes behaved similarly. Results showed an increase from the PRE rPVI to the POST1 rPVI, but again only in connection with the effect-oriented video (SEQUENCE*VIDEO: F[2,184]= 7.095, p=0.001, 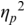 = 0.072), and at POST2 the increase returned again to the lower rPVI level of the PRE performance. That is, the vowel-based rPVI increase was not robust enough to be preserved until after the distractor task.
= 0.072), and at POST2 the increase returned again to the lower rPVI level of the PRE performance. That is, the vowel-based rPVI increase was not robust enough to be preserved until after the distractor task.
For the consonant-based rPVI, results showed a significant increase, but only for the male participants in the effect-oriented video condition (SEQUENCE*SEX: F[2,184]= 2.996, p=0.049, 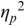 = 0.028; SEQUENCE*VIDEO: F[2,184]= 3.068, p=0.047,
= 0.028; SEQUENCE*VIDEO: F[2,184]= 3.068, p=0.047, 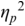 = 0.030). Neither did the female speakers show a similar consonant-based rPVI increase, nor was the instruction-oriented video able to trigger such an increase.
= 0.030). Neither did the female speakers show a similar consonant-based rPVI increase, nor was the instruction-oriented video able to trigger such an increase.
For the voiced and unvoiced speech units, the results patterns were overall similar to those of the vowels and consonants, respectively (voiced intervals: SEQUENCE*VIDEO: F[2,184]= 4.202, p=0.016, 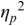 = 0.044; unvoiced intervals: SEQUENCE*SEX: F[2,184]= 3.012, p=0.048,
= 0.044; unvoiced intervals: SEQUENCE*SEX: F[2,184]= 3.012, p=0.048, 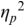 = 0.029; SEQUENCE*VIDEO: F[2,184]= 3.113, p=0.044,
= 0.029; SEQUENCE*VIDEO: F[2,184]= 3.113, p=0.044, 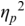 = 0.032).
= 0.032).
24.3.2 Intonation, Timbre, Timing, and Loudness
The MM-MANOVA on intonation, timbre, timing, and loudness yielded, overall, a significant main effect of SEQUENCE (i.e., PRE versus POST1 versus POST2: F[46,324]= 2.449, p<0.001, 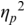 = 0.258) as well as a significant interaction of SEQUENCE and VIDEO (F[46,324]= 1.166, p= 0.018,
= 0.258) as well as a significant interaction of SEQUENCE and VIDEO (F[46,324]= 1.166, p= 0.018, 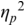 = 0.179). The factor SEX was not significant, but there was a three-way interaction SEQUENCE*VIDEO*SEX (F[46,324]= 2.162, p<0.001,
= 0.179). The factor SEX was not significant, but there was a three-way interaction SEQUENCE*VIDEO*SEX (F[46,324]= 2.162, p<0.001, 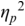 = 0.235).
= 0.235).
Like for the rhythm results, the effect pattern created by the CE intervention was complex. Moreover, the nature of the effects differed between male and female speakers (i.e., as a function of SEX) as well as between the two VIDEO conditions. We will summarize the overall pattern by addressing the four types of measures one by one below. Figures 24.7(a) and (d) show example results patterns for each type of measurement.
First, as regards intonation, we obtained significant effects of SEQUENCE on mean f0 level (F[2,184]= 10.014, p<0.001, 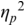 = 0.098) as well as on f0 minimum (F[2,184]= 5.465, p=0.009,
= 0.098) as well as on f0 minimum (F[2,184]= 5.465, p=0.009, 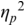 = 0.056) and f0 maximum (F[2,184]= 6.329, p=0.003,
= 0.056) and f0 maximum (F[2,184]= 6.329, p=0.003, 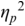 = 0.064). For all measures, the effects of SEQUENCE manifested themselves as an increase in f0, particularly from PRE to POST1 (see Figure 24.6(a) for mean f0). Furthermore, in terms of effect sizes, the increase was stronger for the instruction-oriented VIDEO condition. It was also more robust in this VIDEO condition in the sense that the increase from PRE to POST 1 also remained significant in the PRE versus POST2 comparison, especially for the f0 minimum (mean f0 level: F[2,184]= 2.752, p=0.069,
= 0.064). For all measures, the effects of SEQUENCE manifested themselves as an increase in f0, particularly from PRE to POST1 (see Figure 24.6(a) for mean f0). Furthermore, in terms of effect sizes, the increase was stronger for the instruction-oriented VIDEO condition. It was also more robust in this VIDEO condition in the sense that the increase from PRE to POST 1 also remained significant in the PRE versus POST2 comparison, especially for the f0 minimum (mean f0 level: F[2,184]= 2.752, p=0.069, 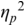 = 0.029; f0 minimum: F[2,184]= 3.772, p=0.034,
= 0.029; f0 minimum: F[2,184]= 3.772, p=0.034,  = 0.039). Finally, we saw SEQUENCE*SEX interactions for the mean f0 and the minimum f0 (mean f0 level: F[2,184]= 3.962, p=0.022,
= 0.039). Finally, we saw SEQUENCE*SEX interactions for the mean f0 and the minimum f0 (mean f0 level: F[2,184]= 3.962, p=0.022, 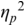 = 0.041; f0 minimum: F[2,184]= 4.800, p=0.015,
= 0.041; f0 minimum: F[2,184]= 4.800, p=0.015, 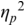 = 0.050). The interactions reflected that the f0 increases induced by the CE were overall more pronounced and robust for the male than for the female speakers (Figure 24.7a).
= 0.050). The interactions reflected that the f0 increases induced by the CE were overall more pronounced and robust for the male than for the female speakers (Figure 24.7a).
The results for timbre were in many respects similar to those of intonation. For example, the CE associated with a significant effect of SEQUENCE in the form of an increase in the voice quality measure h1–h2 (F[2,184]= 4.170, p=0.017, 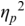 = 0.043). However, the increase mainly relied on one speaker SEX, that is, females (SEQUENCE*SEX: F[2,84]= 3.662, p=0.035,
= 0.043). However, the increase mainly relied on one speaker SEX, that is, females (SEQUENCE*SEX: F[2,84]= 3.662, p=0.035, 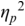 = 0.037), and it was more strongly pronounced for the instruction-oriented VIDEO condition (SEQUENCE*VIDEO: F[2,84]= 4.987, p=0.008,
= 0.037), and it was more strongly pronounced for the instruction-oriented VIDEO condition (SEQUENCE*VIDEO: F[2,84]= 4.987, p=0.008, 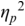 = 0.051). Likewise, we found increases in the mean levels of the F1 and the F3. These increases were more strongly pronounced for the instruction-oriented VIDEO condition – see Figure 24.7(b) (F1, SEQUENCE*VIDEO: F[2,184]= 3.497, p=0.032,
= 0.051). Likewise, we found increases in the mean levels of the F1 and the F3. These increases were more strongly pronounced for the instruction-oriented VIDEO condition – see Figure 24.7(b) (F1, SEQUENCE*VIDEO: F[2,184]= 3.497, p=0.032, 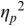 = 0.037; F3, SEQUENCE*VIDEO: F[2,184]= 3.006, p=0.050,
= 0.037; F3, SEQUENCE*VIDEO: F[2,184]= 3.006, p=0.050, 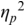 = 0.032). Moreover, the F1 and F3 increases came out significant only for one speaker SEX. Unlike for h1–h2, it was the male speaker group that showed F1 and F3 increases from before to after the CE (F1, SEQUENCE*SEX: F[2,184]= 3.772, p=0.025,
= 0.032). Moreover, the F1 and F3 increases came out significant only for one speaker SEX. Unlike for h1–h2, it was the male speaker group that showed F1 and F3 increases from before to after the CE (F1, SEQUENCE*SEX: F[2,184]= 3.772, p=0.025, 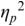 = 0.039; F3, SEQUENCE*VIDEO: F[2,184]= 5.886, p=0.003,
= 0.039; F3, SEQUENCE*VIDEO: F[2,184]= 5.886, p=0.003, 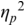 = 0.060). This included that the F1 and F3 increases produced after the CE were maintained by male speakers also after the distractor task in the POST2 condition. This was not true for the female speakers.
= 0.060). This included that the F1 and F3 increases produced after the CE were maintained by male speakers also after the distractor task in the POST2 condition. This was not true for the female speakers.
Results on intonation, timbre, timing, and loudness illustrated by one parameter each.
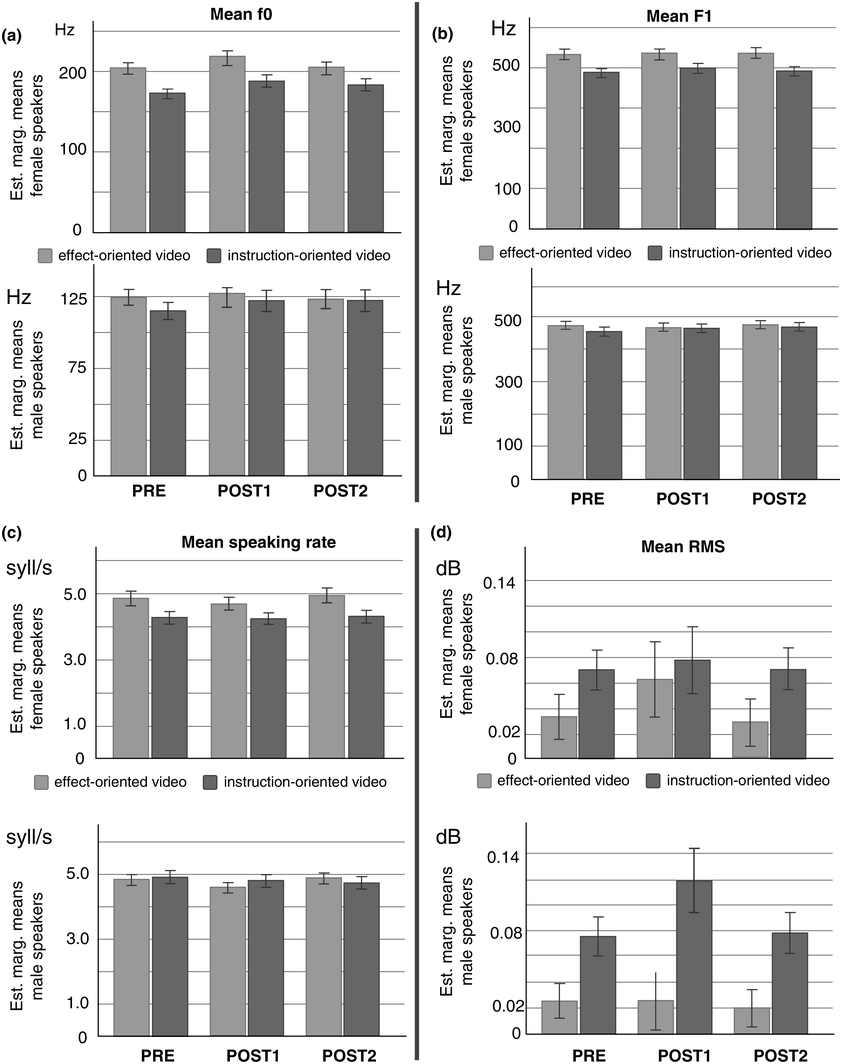
Figure 24.7 Long description
Panel A depicts two bar graphs with error bars. The mean values of estimated marginal means for female speakers are as follows. Set a: Top. Effect-oriented video; 6.5 for post 1, 5.9 for post 2, and 4.8 for pre. Instruction-oriented video; 6.0 for post 1, 4.8 for post 2, and 4.8 for pre. Bottom. Effect-oriented video; 5.0 for post 1, 5.0 for post 2, and 4.5 for pre. Instruction-oriented video; 4.4 for post 1, 4.0 for post 2 and 3.9 for pre. Panel B depicts a bi-directional and an upside-down bar graph with error bars. The mean values of estimated marginal means for female speakers are as follows. Set b: Top. Effect-oriented video; 0.2 for post 2, 0.1 for post 1 and minus 0.5 for pre. Instruction-oriented video; minus 0.5 for pre. minus 0.4 for post 1 and minus 0.38. Bottom. Effect-oriented video; minus 0.58 for pre, minus 0.45 for post 1 and minus 0.4 for post 2. Instruction-oriented video; minus 0.58 for pre, minus 0.44 for post 1 and minus 04 for post 2. The values are estimated.
Timing characteristics were also significantly affected by SEQUENCE, that is, the CE intervention. The effects were restricted to two features: pause count (F[2,184]= 5.989, p=0.003, 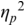 = 0.061) and speaking rate (F[2,184]= 3.987, p=0.020,
= 0.061) and speaking rate (F[2,184]= 3.987, p=0.020, 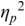 = 0.041); and, unlike for intonation and timbre, there were no significant interactions between the CE effects (i.e., the factor SEQUENCE) and SEX. That is, both male and female participants changed speaking in the same way from before to after the CE. Specifically, the pause count increased from PRE to POST1. In POST2 the pause count decreased again to the same level as in PRE. This up-and-down occurred in both the instruction-oriented and the effect-oriented VIDEO condition. Like a mirror image of the number of pauses, participants’ speaking rates decreased significantly from PRE to POST1, but then also increased significantly again in POST2 to the same level as in PRE. The only difference to the pause count effect was that this slowing down and speeding up was more strongly pronounced for the effect-oriented VIDEO condition, in that way creating a significant SEQUENCE*VIDEO interaction (F[2,184]= 3.885, p=0.022,
= 0.041); and, unlike for intonation and timbre, there were no significant interactions between the CE effects (i.e., the factor SEQUENCE) and SEX. That is, both male and female participants changed speaking in the same way from before to after the CE. Specifically, the pause count increased from PRE to POST1. In POST2 the pause count decreased again to the same level as in PRE. This up-and-down occurred in both the instruction-oriented and the effect-oriented VIDEO condition. Like a mirror image of the number of pauses, participants’ speaking rates decreased significantly from PRE to POST1, but then also increased significantly again in POST2 to the same level as in PRE. The only difference to the pause count effect was that this slowing down and speeding up was more strongly pronounced for the effect-oriented VIDEO condition, in that way creating a significant SEQUENCE*VIDEO interaction (F[2,184]= 3.885, p=0.022, 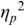 = 0.040) – see Figure 24.7(c).
= 0.040) – see Figure 24.7(c).
Finally, the results on loudness also show an up-and-down change in speaking behavior from PRE to POST1 to POST2. This effect of SEQUENCE emerged for both mean RMS (F[2,184]= 12.869, p<0.001, 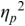 = 0.123) and RMS variability (F[2,184]= 5.790, p=0.004,
= 0.123) and RMS variability (F[2,184]= 5.790, p=0.004, 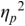 = 0.059). Unlike for pause count and speaking rate, however, there was a three-way interaction of SEQUENCE, SEX, and VIDEO (mean RMS: F[2,184]= 7.363, p<0.001,
= 0.059). Unlike for pause count and speaking rate, however, there was a three-way interaction of SEQUENCE, SEX, and VIDEO (mean RMS: F[2,184]= 7.363, p<0.001, 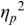 = 0.074; RMS variability: F[2,184]= 4.796, p=0.009,
= 0.074; RMS variability: F[2,184]= 4.796, p=0.009, 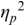 = 0.050). That is, the higher and more variable loudness levels in POST1 (as compared to both PRE and POST2) occurred for female speakers only in connection with the effect-oriented video condition, and for male speakers only in connection with the instruction-oriented video condition – see Figure 24.7(d).
= 0.050). That is, the higher and more variable loudness levels in POST1 (as compared to both PRE and POST2) occurred for female speakers only in connection with the effect-oriented video condition, and for male speakers only in connection with the instruction-oriented video condition – see Figure 24.7(d).
24.3.3 Jaw Lowering
The MM-MANOVA on the jaw-lowering data of the MARRYS cap showed a main effect of SEQUENCE (F[6,340]= 3.533, p=0.002, 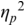 = 0.059) as well as an interaction of SEQUENCE with VIDEO (F[6,340]= 4.336, p<0.001,
= 0.059) as well as an interaction of SEQUENCE with VIDEO (F[6,340]= 4.336, p<0.001, 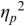 = 0.071). There was no significant SEQUENCE*SEX interaction and also no significant three-way interaction.
= 0.071). There was no significant SEQUENCE*SEX interaction and also no significant three-way interaction.
On this basis, the following results pattern emerged, illustrated by two examples in Figures 24.8(a) and (b) of the minimum jaw-lowering amplitude on the one hand and the cork-normalized jaw-lowering range on the other.
Results on jaw lowering represented by absolute minimum and normalized range.
Estimated marginal means and error bars (95% CI) for (a) the minimum jaw-lowering amplitude and (b) the normalized jaw-lowering range, where values below zero indicate that speakers opened their mouth less than in the CE condition. Dark gray bars indicate the effect-oriented and light-gray bars the instruction-oriented video conditions. Top panels show the female speakers’ and bottom panels the male speakers’ results. Note that the male display of jaw-lowering amplitude shows dB*10 to account for the head-size differences between male and female speakers on absolute amplitude offset levels (Alam et al., Reference Alam, Mohd Noor, Basri, Yew and Wen2015).
Figure 24.8 Long description
The illustration is in a tabular form. It has six columns and two rows. The column is titled Sequence, N equals 16, Pre versus Post 1 versus Post 2 performances of North Wind and the Sun. The column headers are as follows. Text reading dummy run, Text reading baseline pre, C E intervention, text reading after C E post 1, Distractor pers test survey and text reading after C E P O S T 2.
The average jaw-lowering amplitude measure resulted in no separate significant main effect of SEQUENCE, but we found a significant SEQUENCE*VIDEO interaction (F[2,172]= 5.387, p=0.006, 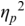 = 0.061). The interaction reflects that the instruction-oriented video condition brought about an increase in jaw-lowering amplitude, in particular from PRE to POST2. This increase occurred similarly for male and female speakers and was equally absent for both sexes in the effect-oriented video condition. The SEQUENCE*SEX interaction was thus not significant.
= 0.061). The interaction reflects that the instruction-oriented video condition brought about an increase in jaw-lowering amplitude, in particular from PRE to POST2. This increase occurred similarly for male and female speakers and was equally absent for both sexes in the effect-oriented video condition. The SEQUENCE*SEX interaction was thus not significant.
The three jaw-lowering measures of minimum amplitude, maximum amplitude, and amplitude range were all significantly affected by the CE intervention (SEQUENCE). The effects were such that the minimum amplitude became successively lower (F[2,172]= 3.725, p=0.026, 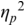 = 0.042 – see Figure 24.8(a)) and the maximum amplitude successively higher (F[2,172]= 3.869, p=0.023,
= 0.042 – see Figure 24.8(a)) and the maximum amplitude successively higher (F[2,172]= 3.869, p=0.023, 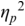 = 0.043) from PRE to POST1 to POST2. The combination of these two effects, that is, a more contrastive jaw-lowering pattern within sentences, made the amplitude range increase from PRE to POST1 to POST2, with an effect size stronger than those of minimum and maximum amplitude (F[2,172]= 8.924, p<0.001,
= 0.043) from PRE to POST1 to POST2. The combination of these two effects, that is, a more contrastive jaw-lowering pattern within sentences, made the amplitude range increase from PRE to POST1 to POST2, with an effect size stronger than those of minimum and maximum amplitude (F[2,172]= 8.924, p<0.001, 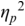 = 0.094). There was a tendency of these individual and combined jaw-movement changes to be more pronounced in the instruction-oriented video condition. However, the interaction SEQUENCE*VIDEO did not reach significance; neither did the SEQUENCE*SEX interaction.
= 0.094). There was a tendency of these individual and combined jaw-movement changes to be more pronounced in the instruction-oriented video condition. However, the interaction SEQUENCE*VIDEO did not reach significance; neither did the SEQUENCE*SEX interaction.
Finally, the cork-normalized main measures both showed significant main effects of SEQUENCE (F[2,172]= 3.869, p=0.023,  = 0.043; F[2,172]= 8.924, p<0.001,
= 0.043; F[2,172]= 8.924, p<0.001,  = 0.094) – see Figure 24.8(b). Recall from Section 24.2.5.3 that we normalized the amplitude values per speaker to those that were measured during the CE intervention. Thus, measurements of 0 or higher (i.e., positive values) indicate that the speakers opened their mouths and lowered their jaws more during the North Wind and the Sun performances than during the actual CE. Measurements below 0 mean the opposite.
= 0.094) – see Figure 24.8(b). Recall from Section 24.2.5.3 that we normalized the amplitude values per speaker to those that were measured during the CE intervention. Thus, measurements of 0 or higher (i.e., positive values) indicate that the speakers opened their mouths and lowered their jaws more during the North Wind and the Sun performances than during the actual CE. Measurements below 0 mean the opposite.
Based on that, we can see in Figure 24.8(b) that, unlike the male speakers, the female speakers showed mouth openings or jaw lowerings in POST1 and POST2 that were on average larger than those caused by the cork inside their mouth. We can also see that the mouth openings or jaw lowerings were more pronounced and similar to those caused by the cork inside the mouth in the effect-oriented video condition (the corresponding SEQUENCE*VIDEO interaction showed a significant trend: F[2,172]= 2.622, p=0.076,  = 0.030), and that the biggest changes towards stronger mouth openings/jaw lowerings occurred from POST1 to POST2, not from PRE to POST1. However, as we only have a few speakers per gender and video condition, these results should be taken with caution.
= 0.030), and that the biggest changes towards stronger mouth openings/jaw lowerings occurred from POST1 to POST2, not from PRE to POST1. However, as we only have a few speakers per gender and video condition, these results should be taken with caution.
24.3.4 Results Summary
Table 24.2 provides an overview of the results. We have counted the number of measures (dependent variables) for which a significant effect of the CE emerged in the PRE versus POST1 comparisons. Because of the multitude of individual measures, we have summed up these significant effects per measurement type. This is what the column “change” shows. Additionally, we have specified in Table 24.2 if these significant CE effects were found in the effect-oriented video condition – “V-eff” – or in the instruction-oriented video condition – “V-ins.” The column named “robust” specifies how many of the PRE-to-POST1 “changes” persisted also in the POST2 performances. The percentages “Tot” put the absolute numbers in relation to the total number of measures (dependent variables) for which a CE effect could have potentially occurred. All this data is separately presented for the male and the female speaker samples.
Absolute frequencies of changes induced by the CE per measure or type of measure as well as in % across a whole set of measures, displayed separately for the (m)ale and (f)emale speaker groups. V-eff and V-ins refer to the effect- and instruction-oriented video conditions; “robust” refers to significant PRE-to-POST2 differences. Note that Max amplitude and Range amplitude include the normalized and non-normalized MARRYS cap measurements.
| Measure | Sex | change | V-eff | V-ins | robust |
|---|---|---|---|---|---|
| Acoustic rhythm features | |||||
| Mean measures | m | 5 | 5 | 0 | 0 |
| f | 5 | 5 | 2 | 0 | |
| Delta measures | m | 5 | 5 | 0 | 4 |
| f | 2 | 2 | 0 | 0 | |
| rPVI measures | m | 5 | 5 | 0 | 2 |
| f | 3 | 2 | 0 | 0 | |
| Tot % | m | 100.0 | 100.0 | 0 | 33.3 |
| Tot % | f | 66.7 | 81.2 | 18.2 | 0 |
| Acoustic prosody features | |||||
| Pitch | m | 4 | 2 | 2 | 2 |
| f | 4 | 2 | 4 | 0 | |
| Timbre | m | 2 | 0 | 2 | 2 |
| f | 4 | 0 | 4 | 2 | |
| Timing | m | 3 | 3 | 2 | 0 |
| f | 3 | 1 | 2 | 0 | |
| Loudness | m | 2 | 1 | 1 | 0 |
| f | 2 | 1 | 1 | 0 | |
| Tot % | m | 71.4 | 46.2 | 53.8 | 26.7 |
| Tot % | f | 85.7 | 36.4 | 63.8 | 13.3 |
| MARRYS cap jaw-lowering features | |||||
| Mean amplitude | m | 1 | 0 | 1 | 1 |
| f | 1 | 0 | 1 | 1 | |
| Min amplitude | m | 1 | 0 | 1 | 1 |
| f | 1 | 1 | 1 | 1 | |
| Max amplitude | m | 2 | 2 | 2 | 2 |
| f | 2 | 0 | 2 | 2 | |
| Range amplitude | m | 2 | 2 | 2 | 2 |
| f | 2 | 2 | 2 | 2 | |
| Tot % | m | 100.0 | 50.0 | 50.0 | 100.0 |
| Tot % | f | 100.0 | 33.3 | 66.7 | 100.0 |
Here is an example: For the delta type of rhythm measures, there were five significant CE effects from PRE to POST1 for the male speakers (“change” = 5), and for the female speakers there were two significant CE effects (“change” = 2). All of these effects emerged in the effect-oriented video condition “V-eff,” and for the male speakers, four of the five effects persisted in the POST2 condition (“robust” = 4). In contrast, for the female speakers, the two significant CE effects disappeared again in the POST2 condition (“robust” = 0). For the delta measures, the maximum number of effects that could show a significant CE effect was five. The same applied to the mean and rPVI types of measures. For the male speakers, 15 of 15 possible effects occurred from PRE to POST1 across all three measurement types, therefore the Tot % of “change” is 100%; for the female speakers, it was 10 out of 15 measures, that is, 66.7%.
According to Table 24.2, the CE had a significant effect on the acoustic rhythm measures. For the male participants, CE affected all measures (100%); for the female participants, changes still extended over the majority of measures (66.7%). For both speaker groups, the changes were primarily triggered by the effect-oriented video, and almost none of the changes proved robust enough to be carried over from POST1 into POST2 performances. On the whole, the CE had a more comprehensive and robust effect on the acoustic rhythm structures of male than of female speakers.
This higher robustness of cork effects for male speakers also applied to the other measures of acoustic prosody. With 26.7%, almost twice as many cork effects remained in the male speakers’ POST2 performances than in the female speakers’ performances (13.3%). In terms of the number of changed parameters, the CE affected male and female speakers’ prosodies to similar degrees, that is, 71.4% versus 85.7%. That is, not every measured parameter was changed, especially not in the domains of intonation and timbre. For timing and loudness parameters, however, the percentage was 100% for both sexes. In contrast to the rhythm measures, prosodic changes were mainly triggered by the instruction-oriented video condition – for women even more so than for men. In addition, all robust effects go back to the instruction-oriented video condition.
As regards the jaw-lowering signals, we found a similar advantage of the instruction-oriented video in triggering significant PRE-to-POST effects in speakers – and in triggering effects that remain robust in POST2 performances. It is noteworthy that the robustness of the triggered effects was 100% – for male and female participants. The percentage of CE-affected jaw-lowering parameters was also 100% for both sexes. So, the CE clearly had the strongest and most robust effects on articulation patterns (jaw-lowering amplitudes) – and less strong and robust effects on acoustic patterns of rhythm and prosody.
24.4 Discussion
In guidebooks and seminars on public speaking, it is not uncommon that recommendations and methods are passed on to learners without these recommendations and methods having ever been subjected to scientific testing. In this way, a knowledge base is created that gains credibility through tradition and at some point is no longer critically questioned. The present study is part of a line of research that is meant to tackle this issue. We analyze central claims of rhetoric and media training using experimental means.
The present study was on the CE, a very popular method in rhetoric and media training. Based on a within-subjects before–after comparison and an additional between-subjects difference between instruction-oriented and effect-oriented video conditions, the following questions were asked: Are there significant differences in the participants’ vocal performances between PRE and POST? If so, (a) is there a significant interaction of these PRE-to-POST effects with the video condition and (b) do these significant differences persist also in POST2 performances?
Three main conclusions can be drawn from the results summary (see Table 24.2). First, the CE indeed has a significant and sustained effect on mouth-opening (i.e., jaw-lowering) patterns in speech. Rhetoric and media trainers are right when stating that the exercise changes the way participants speak afterwards (see Khidr, Reference Khidr2017; Knoppers et al., Reference Knoppers, Obdeijn and Giessner2021; Bernhardt, Reference Bernhardt2022). Second, however, our data also suggest that these articulatory effects are not consistently and sustainably reflected in the acoustics of rhythm and prosody. On the contrary, after only a short distractor element such as a five-minute personality test, most of the induced rhythmic and prosodic cork effects disappear to the extent that they are no longer detectable in POST2-performance signals (in terms of significant differences relative to PRE signals). This applies in particular to female participants. Finally, it seems that male participants benefit more from the CE than female participants.
These sex-related findings are consistent with Tang et al. (Reference Tang, Hannah and Jongman2015), who reported based on a contrastive analysis of plain versus clear speeches “that male speakers often show greater clear speech effects than female speakers, particularly involving greater degrees of horizontal lip stretch and jaw movement” (p. 10). Our findings also fit in with Weirich et al. (Reference Weirich, Fuchs, Simpson, Winkler and Perrier2016). They showed that male speakers produce, in plain speech, by default less jaw lowering (i.e., a smaller mouth opening) than female speakers. So, after a CE stimulation of clear speech, male speakers should have a greater potential to enhance their movements and prosodies than female speakers, which corresponds to what we found. The underlying reason for these differences between male and female speakers is still largely unknown, and our results are not suitable to shed further light on existing explanatory approaches. Tang et al. (Reference Tang, Hannah and Jongman2015) speculate that the male speakers’ greater articulatory movements in clear speech could be attributed to their larger-size articulators relative to females’, which allow more room for variability and more extreme speech articulation, given that movement displacement is generally positively correlated with the size of the vocal tract and its articulators. In our opinion, this is a plausible idea, which can be combined with the sex differences in public-speaking anxiety to account for the male–female robustness differences in Table 24.2. Yet, further research is required to test these assumptions.
How exactly does the CE change the rhythmic and general prosodic acoustics of speech? To put it briefly and descriptively, the speaking rate decreases, causing the sound-segment durations to increase, especially those of vowels and voiced intervals. Thus, the speech becomes on the whole more sonorous. At the same time, duration structures become richer and more contrasty. For example, short, unstressed syllables become even shorter; and long, stressed syllables become even longer. This also increases loudness level and loudness variability. Together with the increase in loudness level, the voice becomes more high-pitched overall, but not more melodious, for example, in the form of an increased f0 range. The timbre of the voice changes in the form of higher F1 and F3 values and, for female speakers, also in the form of higher h1–h2 and h1–A3 values, which is indicative of a clearer (less breathy) and more powerful voice, produced with more vocal effort. Pauses become more frequent and longer, resulting in a more structured speaking performance of both sexes.
It is well known that F1 is the acoustic mirror image of jaw lowering; that is, there is a negative correlation of F1 values with jaw-lowering amplitudes (Traunmüller, Reference Traunmüller1984). The increase in F1 we found is therefore generally consistent with the larger range and maximum amplitude of jaw lowering observed in the MARRYS cap signals – even though the stronger jaw lowering has proven to be more robust than the acoustic F1 increase (in terms of a PRE versus POST2 significance), especially for female participants. This sex-specific finding is interesting and should be further investigated insofar as it seems to match with physiological studies showing that although women have smaller maximum jaw-lowering amplitudes than men, they can produce a larger jaw-lowering range relative to the movement angle (Pullinger et al., Reference Pullinger, Liu, Low and Tay1987).
The rise in F3 is harder to link to articulatory patterns. In our view, the most plausible explanation for the F3 increase is as follows. The CE not only caused the participants’ mouths to open but also spread their lips. F3 is strongly correlated with speakers’ lip configuration. Lip rounding leads to lower F3 values and lip spreading, that is, smiling, to higher F3 values (Fagel, Reference Fagel, Esposito, Campbell, Vogel, Hussain and Nijholt2010). Thus, given that we found F3 increases, it is plausible to assume – and consistent with our visual observations during the experiment – that the CE resulted in a more smiling way of speaking in POST1 and POST2 performances.
With the increases in F3, we replicated the results of Leyns et al. (Reference Leyns, Corthals and Cosyns2021) as well as their finding that these increases vary across speakers. In contrast to Timmermans et al. (Reference Timmermans, Coveliers, Wuyts and Van Looy2012), we were for the first time also able to find articulatory effects of CE interventions, and unlike in all previous studies, we show for the first time here that CE effects extend beyond pronunciation and the acoustics of a particular formant frequency. Rather, our findings support the previously unproven claims of rhetorical guidebooks and media trainers that the CE affects the voice (Alburger, Reference Alburger2014). That the voice gets “deeper and fuller” after the CE, as claimed by Knoppers et al. (Reference Knoppers, Obdeijn and Giessner2021), is not perfectly in line with our data, though, as the f0 mean actually increased rather than decreased from PRE to POST performances. However, given that loudness increased as well and it is known that a higher loudness level can bias humans to perceive a lower pitch level (Cohen, Reference Cohen1961), perhaps the effect described by Knoppers et al. is a psychoacoustic rather than a purely acoustic one. That voices can get “fuller” is consistent with the h1–h2 and h1–A3 increases we found as well as with the increases in vowel and sonorant-interval durations. Furthermore, the more “open and vivid articulation” that Khidr (Reference Khidr2017) holds out in prospect for CE users is met by our results on jaw-lowering and acoustic rhythm structure.
Regarding these comparisons, what are the practical implications of our results? Based on the known correlations between acoustic parameters and perceived speaker charisma (for Western cultures and/or Western Germanic languages, see, for example, Strangert and Gustafson, Reference Strangert and Gustafson2008; Rosenberg and Hirschberg, Reference Rosenberg and Hirschberg2009; Niebuhr and Skarnitzl, Reference Niebuhr and Skarnitzl2019, Reference Niebuhr and Skarnitzl2021), we can conclude that only a few parameters, such as the speaking rate, were changed by the CE to the detriment of speakers (the rate is positively correlated with charisma but decreased rather than increased after the exercise). Some parameters such as the f0 range remained unaffected. However, the majority of the acoustic parameters were favorably changed by the CE, which is why we can assume that the exercise is basically capable of increasing perceived speaker charisma, at least temporarily. The findings of our present study thus speak in favor of continuing to use the CE in rhetoric and media training.
From a practical viewpoint, it is also noteworthy that type, magnitude, and robustness of the cork-induced effects depended on the type of video presented. In order to achieve rhythmic-acoustic effects, the effect-oriented video seemed to be better suited. For general prosodic effects, on the other hand, the instruction-oriented video was the better trigger. These asymmetrical findings must be examined, replicated, and understood in follow-up studies. For now, the conclusion can only be that the instruction can have a significant effect on how – and how robustly – the CE affects the subsequent speech performances of its users. Rhetoric and media trainers should therefore instruct their participants carefully, monitor changes following the CE, and control and support them in a targeted manner, until more detailed insights are available on how specific instructions affect post-exercise performances. One thing is clear, though: The cork-induced changes on rhythm and prosody seem to be more than simple placebo effects caused by coaches and trainers praising the exercise’s tradition and effectiveness. If this were the case, then we would not have found any PRE-to-POST1/2 effects in the instruction-oriented video condition. Rather, all effects would have been concentrated in the effect-oriented video condition. By contrast, in our data, numerous CE effects emerged after the instruction-oriented video. Praising the CE in advance does not make it more effective; in fact, it can prevent some effects (especially of the vocal performance) from occurring.
Of course, our conclusions are also subject to a number of limitations. The most important one is certainly the small sample. Assuming that the effect of the CE has an individual component, it is quite possible that the differences related to the video and sex conditions are partly caused by individual speakers. This is especially true for the factor of speaker sex. An important task of subsequent studies is therefore to replicate and further differentiate the results using a larger sample. In addition, such a larger sample should also include a control-group condition. Since our study lacked such a condition, we cannot completely rule out that (some of) the CE effects were mere training or familiarization artifacts of a repeated performance of the North Wind and the Sun text. In general, however, the results speak against such an overinterpretation of repetition artifacts as CE intervention effects. First, such artifacts would have had a homogeneous impact on speakers’ performances. Thus, measures would have either increased or decreased continuously from PRE to POST1 to POST2, whereas most of our results showed bidirectional changes from PRE to POST2. Second, we had included a dummy text performance at the beginning of the experiment; and three–four readings of only six sentences hardly seem sufficient to produce a fatigue effect from PRE to POST2. Furthermore, the interactions of the CE effects with speaker sex and video condition speak against pure repetition artifacts, but point to real behavioral patterns owed to the intervention conditions.
A further limitation concerns the jaw measurements. We used the KTH RespTrack system (Heldner et al., Reference Heldner, Włodarczak, Branderud and Stark2019) in an innovative way to implement the MARRYS cap concept in the current study. To that end, the RespTrack stretching belt was attached under the speaker’s chin and then ran along both sides of the cheeks to the cap on the head. Speakers were able to adjust the tension of the belt according to their individual comfort level. Since signal offsets due to speaker-individual tension levels were set to 0 prior to recording, the belt adjustment was not able to affect the measured values per se. What we could not rule out, however, was that the tension of the stretching belt exerted an individual degree of counter-pressure on the speaker’s jaw-lowering movements. Therefore, follow-up studies should use the genuine MARRYS system, which has been optimized to largely avoid such counter-pressure biases (Svensson Lundmark et al., Reference Svensson Lundmark, Ericksson, Niebuhr, Tiede and Wei-Rong2023).
A further limitation concerns the fact that there is a wide range of options in how to apply the CE. One of our reviewers, for example, asked what would have happened if we had used North Wind and the Sun (rather than “Der Zwölf Elf”) also for the CE intervention. We can only speculate about an answer, but we assume that the results might have come out clearer and more robust in that case (in the sense of higher percentages in Table 24.2), due to better motor learning and a more direct motor transfer from the CE to POST1/2 performances. We decided against this option because it does not correspond to common practice. For one thing, learners of public speaking hardly ever have a text that they want to specifically prepare during rhetoric or media training (such training is more about acquiring general, transferable skills); and, for another thing, trainers like to use special texts that require very extensive (compensatory) articulation movements during a CE intervention and that have an inherently regular rhythmic structure, such as “Der Zwölf Elf.” In view of this, the results we obtained here are perhaps more conservative than necessary, but probably also characterized by a higher level of ecological validity.
Further CE options concern the following questions: How often is the exercise used and for how long do the participants train with the cork? How often is the exercise repeated? How long are the breaks between exercises? Which speaking tasks/texts are used? In this experiment, we tested only one single setting from this (non-exhaustive) range of options. It is possible that other settings would have yielded different results. On the other hand, we have certainly tested a minimal setting – and have, based on that, already found supporting evidence for the effectiveness of the CE, especially on rhythm, timing, and loudness measures. It is reasonable to assume that more intensive training settings would yield even clearer and inter-individually more consistent CE effects. Especially since rhetorical coaches and media trainers often stress that the CE unfolds its full potential “if done regularly” (Bernhardt, Reference Bernhardt2022:318), investigating effects of training time and/or training intensity is an obvious task of follow-up studies, in particular with regard to the question of if the CE effects can consolidate (in terms of a higher level of robustness – see Table 24.2), and if so, when and under what conditions.
Answers to such questions can also be useful if the CE is to be used beyond rhetoric and media training. We primarily think of educational (e.g., language teaching) or therapeutic applications, for example, to fight monotonous voices (due to Parkinson’s disease), or to learn or relearn a certain speaking rhythm – see the experiences of Erickson and Niebuhr (Reference Niebuhr, Barbosa, Rüdiger and Drayter2023) with teaching “jaw dancing” across languages. Especially in speech pathology, there seem to be hardly any modern cork studies (see Froeschels, Reference Froeschels1943; Perlstein and Shere, Reference Perlstein and Shere1946), which suggests that the potential of CE is hardly being exploited in that area. Over and above those applied contexts, the CE could also become a powerful stimulation and elicitation tool in linguistic research to better understand the production and perception (and underlying cognitive processes) of speech rhythm – see the critical discussion of speech rhythm in Nolan and Jeon (Reference Nolan and Jeon2014) on the one hand and the summary of the nested neural oscillation idea in Erickson and Niebuhr (Reference Niebuhr, Barbosa, Rüdiger and Drayter2023) on the other.
Summary
The conducted speech-production experiment tested for the first time the effectiveness of the CE, which is a popular technique in public-speaking and media training. We provided supporting evidence that the exercise is able to change users’ rhythm and prosody patterns – mostly temporarily – towards more sonorous and contrasty structures that, when interpreted in the context of known correlations, should be associated with a higher level of perceived speaker charisma.
Implications
First, interventions such as the CE have systematic effects on articulatory and acoustic rhythm patterns that can be used for educational or therapeutic purposes and, if necessary, further refined for these applications. Second, in line with previous findings, articulatory changes do not necessarily have specific acoustic consequences. Both are avenues for follow-up studies.
Gains
CE effects only proved robust for some parameters that varied with speaker sex and instruction. This raises questions about the implicit, individual learning of speech-production/rhythm patterns. Furthermore, the exercise intervention is suitable to create natural, contrastive, within-speaker stimuli with which the contribution of rhythm to perceived speaker charisma can be examined.
24.5 Acknowledgments
The authors are greatly indebted to Rongjie Shi and Katrina Norah Nabunjo for their assistance in recruiting participants and carrying out the experiment. We are also very grateful to Katrin Prüfig for recording the CE videos for us. Furthermore, we would like to thank our two reviewers, Laura Verga and Anna Fiveash, for their many insightful comments and questions on an earlier draft of this chapter as well as our editors Caroline Duchow, Lars Meyer, and Antje Strauss for patience, guidance, and feedback on style and title. Finally, note the first author (Oliver Niebuhr) is the founder and CEO of the speech-technology company AllGoodSpeakers ApS. Please visit the following link for a conflict-of-interest statement: https://oliverniebuhr.com/conflict-of-interest.html.
25.1 Introduction
Recent research discusses relationships between language processing and musical rhythm processing. The ability to synchronise to an external rhythm links to phonological skills in preschool children, while the ability to discriminate rhythmic structure correlates with morphosyntactic production and comprehension in school-age children (Gordon et al., Reference Gordon, Shivers and Wieland2015; Lee et al., Reference Lee, Ahn, Holt and Schellenberg2020; Woodruff Carr et al., Reference Woodruff Carr, White-Schwoch, Tierney, Strait and Kraus2014). Moreover, children with developmental language disorders show impaired performance in synchronising with a metronome, rhythm discrimination, or rhythm reproduction (Corriveau and Goswami, Reference Corriveau and Goswami2009; Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2014). In typical adults, percussionists with exceptional rhythmic skills show better performance than vocalists or non-musicians in sentence-in-noise perception (Slater and Kraus, Reference Slater and Kraus2016; Yates et al., Reference Yates, Moore, Amitay and Barry2019). At the brain level, overlapping regions involved in rhythm and syntax processing have been identified in a recent activation likelihood estimation (ALE) meta-analysis (Heard and Lee, Reference Heard and Lee2020). Experimental data further show comparable event-related potentials evoked by rhythmic and syntactic violations, both of which are altered in patients with lesions or neurodegenerative diseases to the basal ganglia (Kotz and Schmidt-Kassow, Reference Kotz and Schmidt-Kassow2015; Schmidt-Kassow and Kotz, Reference Schmidt-Kassow and Kotz2009). While there is convincing evidence of a relationship between musical rhythm and language processing, overlap between the music and language processing systems remains hotly debated (Chen et al., Reference Chen, Affourtit and Ryskin2023). Numerous studies have shown that rhythmic stimulation can also influence performance in linguistic tasks. The key manipulations in these experiments include 1) imposing a metrical structure on the speech stimuli, 2) creating an alignment or lack thereof between the metrical structures of musical and linguistic stimuli, or 3) manipulating the structural regularity of the musical stimuli independently of the linguistic stimuli. We will provide a review and novel characterisation of these effects later in this chapter.
Several theories account for the behavioural and neural links reported between rhythm and language processing. Generally, these accounts focus on the precise localisation of rhythm processing and its interactions with language processing networks, the precise nature of internal oscillations, and their role in rhythm and language processing (Fiveash et al., Reference Fiveash, Bedoin, Gordon and Tillmann2021; Kotz et al., Reference Kotz, Stockert and Schwartze2014; Ladányi et al., Reference Ladányi, Persici, Fiveash, Tillmann and Gordon2020; Large et al., Reference Large, Herrera and Velasco2015; Large and Jones, Reference Large and Jones1999; Patel and Iversen, Reference Patel and Iversen2014). One line of research proposed that the processing of hierarchical structures might be a crucial overlap between rhythm and language processing (Fitch and Martins, Reference Fitch and Martins2014). Various frameworks have characterised music and language based on their hierarchical organisation (Lerdahl and Jackendoff, Reference Lerdahl and Jackendoff1983; Patel, Reference Patel2008, Reference Patel2011). Here, we will explain to what extent musical rhythm and linguistic syntax (and prosody) can be considered hierarchical structures, highlighting empirical evidence supporting hierarchical structure building in both domains. Next, we will review the effects of rhythmic stimulation on language processing and provide a novel characterisation of these effects. Finally, we will present some theories proposed to account for these rhythmic stimulation effects and evaluate to what extent hierarchical structure processing as a shared cognitive component between rhythm and language processing may provide further insight into the precise nature of rhythmic stimulation effects.
25.2 Hierarchical Structure in Rhythm and Language
Language and music are both considered hierarchical sequences, that is, ordered arrangements of unique elements that can be represented in a tree-like structure in which multiple levels of lower-level units and groups of units are combined into higher-level constituents (Fitch and Martins, Reference Fitch and Martins2014; Patel, Reference Patel2008). Consequently, several recent studies suggested a domain-general cognitive system to be responsible for coding hierarchical structure (Martins et al., Reference Martins, Gingras, Puig-Waldmueller and Fitch2017, Reference Martins, Fischmeister and Gingras2020). Hierarchies appear to be omnipresent in human cognition and culture, as we are able to generate hierarchies in a wide range of domains including metrical, linguistic, visual, action, and social hierarchies (Altmann et al., Reference Altmann, Bülthoff and Kourtzi2003; Fitch and Martins, Reference Fitch and Martins2014; Hauser et al., Reference Hauser, Chomsky and Fitch2010; Jackendoff, Reference Jackendoff2009; Martins et al., Reference Martins, Gingras, Puig-Waldmueller and Fitch2017; Schmid et al., Reference Schmid, Saddy and Franck2023; Tecumseh Fitch and Friederici, Reference Tecumseh Fitch and Friederici2012; Vender et al., Reference Vender, Krivochen and Compostella2020; Zink et al., Reference Zink, Tong and Chen2008). Recent evidence from musical rhythm and language processing suggests that human participants show a tendency to infer hierarchical structures even if overt cues to such structures are not acoustically present in the input (Criscuolo et al., Reference Criscuolo, Schwartze, Henry, Obermeier and Kotz2023; Ding et al., Reference Ding, Melloni, Zhang, Tian and Poeppel2016; Kaufeld et al., Reference Kaufeld, Bosker, Alday, Meyer and Martin2020; Large et al., Reference Large, Herrera and Velasco2015; Nozaradan et al., Reference Nozaradan, Mouraux and Jonas2017; Poudrier, Reference Poudrier2020; Schmidt-Kassow and Kotz, Reference Schmidt-Kassow and Kotz2009; Tal et al., Reference Tal, Large and Rabinovitch2017).
In rhythm, meter refers to the hierarchical structuring of a series of events in time into higher-order groupings (Kotz et al., Reference Kotz, Ravignani and Fitch2018). This metrical structure is built from temporal units and enables the system to make precise temporal predictions as to when the next event, such as a tone onset or beat, is expected to occur. In music, subjective rhythmisation experiments showed that listeners tend to perceive equitone isochronous sequences in groups of elements (Criscuolo et al., Reference Criscuolo, Schwartze, Henry, Obermeier and Kotz2023; Poudrier, Reference Poudrier2020). Despite the stimulus itself being a metronome, participants report that the first unit of each group is more salient than the rest or that a pause between the last element of a group and the first element of a new group is longer. Rhythmic grouping biases have also been described in the iambic–trochaic law, according to which sounds varying in intensity are more likely to be perceived as trochees (strong–weak), while those varying in duration are more often perceived as iambs (weak–strong, Bolton, Reference Bolton1984; Hayes, Reference Hayes1995). These grouping biases have been proposed to play a crucial role in language acquisition (Langus et al., Reference Langus, Mehler and Nespor2017). Recent studies have shown that if a metronome of identical tones is presented at a sufficient rate (e.g., 5 Hz), a large number of participants perceive groups of tones rather than an equitone isochronous sequence, and that these groupings are reflected in neural responses to isochronous tone sequences (Criscuolo et al., Reference Criscuolo, Schwartze, Henry, Obermeier and Kotz2023; Poudrier, Reference Poudrier2020). Results from studies focusing on ‘missing pulse’ phenomena provide further behavioural and neural evidence for the tendency to build a metrical hierarchy even if it is not acoustically present in the input. Participants listening to syncopated rhythms reportedly perceive a pulse frequency that is absent from the acoustic stimulus. In one key experiment that investigated neural entrainment to metrical groupings in musical rhythm, the authors constructed 11 rhythms, ranging from isochronous to highly complex rhythms that did not contain any spectral energy at the pulse frequency. Even in the most complex rhythms containing no overt pulse frequency, participants tapped in phase or anti-phase to a constant pulse frequency that was not present in the acoustic signal (Large et al., Reference Large, Herrera and Velasco2015). Similar observations have also been made at the brain level. In a recent study, participants passively listened to rhythms containing no spectral energy at the pulse frequency while their brain responses were recorded in magnetoencephalography (MEG). Neural oscillations corresponding to the acoustically missing pulse frequency were identified and taken as evidence for a non-stimulus-driven, internally generated neural representation of the pulse frequency, a crucial component of metrical hierarchy (Tal et al., Reference Tal, Large and Rabinovitch2017).
In linguistic syntax, words group into phrases that combine into higher-order phrases, clauses, and sentences. As syntactic structure is based on formal rules (Chomsky, Reference Chomsky1965), the parser generates discrete rule-based predictions (such as expecting a noun after a determiner). In prosody, syllables combine into feet that group into phonological words, phonological phrases, intonation phrases, and utterances (Nespor and Vogel, Reference Nespor and Vogel1986; Selkirk, Reference Selkirk1984). While the precise nature of hierarchy in prosody and syntax is not the same, a range of evidence suggests that they can both be characterised as hierarchical sequences (for a detailed overview of hierarchy in prosody and syntax, please refer to Kotz et al., Reference Kotz, Schwartze and Schmidt-Kassow2009; for an ongoing debate on linguistic syntax and neural oscillations, please see Lo et al., Reference Lo, Henke, Martorell and Meyer2023 and Kazanina and Tavano, Reference Kazanina and Tavano2023). It has been proposed that prosodic regularities are actively exploited during speech perception and production (Cutler, Reference Cutler, Sundberg, Nord and Carlson1991, Reference Cutler1994). Empirical evidence shows that the expectation of these regularities can even drive typical adults to erroneously produce lexical words by inserting prosodic boundaries before strong syllables and grammatical words by deleting boundaries before weak syllables (Cutler and Butterfield, Reference Cutler and Butterfield1992). More recent neurolinguistics findings show remarkably similar results to missing pulse experiments. In one such experiment, participants listened to speech stimuli in Mandarin in which syllable onsets were clearly marked but which contained no overt cues of phrase or sentence boundaries. Materials were constructed such that every sentence (1,000 ms) was built up of one noun phrase (500 ms) and one verb phrase (500 ms), each containing two monosyllabic words (250 ms each). Sentences were presented auditorily in immediate succession and no pauses such that the input sequence contained clear acoustic cues to syllables but no acoustic cues of phrase and sentence boundaries. Mandarin-speaking participants showed neural oscillations corresponding to the frequencies of syllables (4 Hz), phrases (2 Hz), and sentences (1 Hz), while participants with no knowledge of Mandarin only showed oscillations at the acoustically present syllable frequency (Ding et al., Reference Ding, Melloni, Zhang, Tian and Poeppel2016). A recent criticism of this study has remarked that syntactic phrase and sentence boundaries corresponded with (acoustically missing) prosodic boundaries in these materials (Glushko et al., Reference Glushko, Poeppel and Steinhauer2022). Replicating the original study with prosodic and syntactic boundaries distinguished, the authors suggest that these oscillations are more likely to reflect (covert) prosodic boundaries or an interaction between prosodic and syntactic boundaries than purely syntactic boundaries (Glushko et al., Reference Glushko, Poeppel and Steinhauer2022). Nevertheless, these studies provide evidence that neural entrainment to spoken language goes beyond stimulus acoustics and reflects top-down processes of internal hierarchical structure building in the absence of direct structural information in the input (Meyer et al., Reference Meyer, Sun and Martin2019).
25.3 Reviewing and Categorising Rhythmic Stimulation Effects
Several studies showed that rhythmic stimulation, that is, exposure to a rhythm prior to or during a linguistic task, can influence linguistic performance. All of the rhythmic stimulation studies reviewed here show short-term effects on subsequent language processing. Most of these studies are based on one of three manipulations: imposing a regular metrical structure on speech stimuli, creating an alignment between the rhythmicity of music and the linguistic stimulus (rhythmic cueing), or manipulating the structural regularity of the musical stimulus irrespective of the linguistic stimulus (rhythmic priming). A more detailed description of these paradigms as well as a summary of evidence from each will be elaborated in the following paragraphs.
In studies imposing a rhythm on speech stimuli, experimental sentences are created by manipulating the alternation of strong and weak syllables to create either a highly regular trochaic (strong–weak) or a less regular pattern. To our knowledge, all of these experiments have been conducted in German. These studies report that sentences with a regular metrical pattern are processed more easily than less regular sentences. In typical speakers, event-related potentials typically evoked by unexpected semantic (N400) and syntactic (P600) events show a lower amplitude in metrically regular than irregular sentences (Kotz and Schmidt-Kassow, Reference Kotz and Schmidt-Kassow2015; Roncaglia-Denissen et al., Reference Roncaglia-Denissen, Schmidt-Kassow and Kotz2013, Reference Roncaglia-Denissen, Schmidt-Kassow, Heine and Kotz2015; Rothermich et al., Reference Rothermich, Schmidt-Kassow and Kotz2012; Rothermich and Kotz, Reference Rothermich and Kotz2013). This finding is interpreted as a facilitation effect stemming from the interface between metric and syntactic expectancies. Highly regular sentences are also highly predictable and provide a clear metrical grid as reliable cues when the next strong syllable is expected to arrive. These temporal predictions of when a next event will occur could facilitate syntactic expectations of what will occur. Unlike typical adults, speakers with neurodegenerative diseases or focal lesions to the basal ganglia normally show no P600 in response to syntactic expectancy violations. However, when these violations are embedded in metrically regular sentences, the P600 is restored. This finding is taken as evidence that the syntactic deficit in these patients stems from an underlying temporal processing deficit, which can be compensated by the regular metrical structure of the target sentences (Kotz and Gunter, Reference Kotz and Gunter2015; Kotz and Schmidt-Kassow, Reference Kotz and Schmidt-Kassow2015).
Unlike these prior studies, rhythmic cueing experiments manipulate both musical and speech rhythm. Here, rhythmic stimuli precede the linguistic stimulus and the key variable is the alignment between the stress pattern of the musical rhythm preceding an utterance and that of the utterance itself. Typical adult speakers show faster detection of a target phoneme in speech stimuli, while children with cochlear implants show more accurate phonological reproduction of the target speech stimulus when it is preceded by a cue with a matching rather than a mismatching stress pattern (Cason et al., Reference Cason, Astésano and Schön2015a, Reference Cason, Hidalgo, Isoard, Roman and Schön2015b; Cason and Schön, Reference Cason and Schön2012). These findings are usually interpreted within the framework of the dynamic attending theory (DAT, Large and Jones, Reference Large and Jones1999). Originally proposed to explain how listeners process systematic changes in events, DAT proposes that attention is not distributed evenly over time but fluctuates in an oscillatory manner. Internal oscillators can entrain to the rhythmicity of an external stimulus such that attentional peaks correspond to when predictable stimuli are expected. In rhythmic cueing experiments, if the stress pattern of the preceding musical rhythm matches that of the target utterance, some of the attentional oscillations might entrain to this stress pattern and will orient attention to stressed syllables in a speech stimulus. This results in better performance when the cueing and target rhythms match.
Rhythmic priming studies manipulate the musical rhythm preceding a linguistic stimulus irrespective of the rhythm of the speech stimulus itself. Here, the key variable is the regularity of the musical prime, defined as the ease with which the prime allows listeners to extract its underlying metrical structure. Results show that typical children and adults, as well as children with developmental language disorder and developmental dyslexia, show improved grammaticality judgement after a regular prime than an irregular prime or after a rhythmically neutral or silent baseline (Bedoin et al., Reference Bedoin, Brisseau, Molinier, Roch and Tillmann2016; Canette et al., Reference Canette, Bedoin and Lalitte2020a, Reference Canette, Fiveash and Krzonowski2020b, Reference Canette, Lalitte and Bedoin2020c; Chern et al., Reference Chern, Tillmann, Vaughan and Gordon2018; Fiveash et al., Reference Fiveash, Bedoin, Lalitte and Tillmann2020; György et al., Reference György, Saddy, Kotz and Franck2024; Ladányi et al., Reference Ladányi, Lukács and Gervain2021; Przybylski et al., Reference Przybylski, Bedoin and Krifi-Papoz2013). The rhythmic priming effect may be specific to language processing, not affecting mathematics or visuo-spatial control tasks in English children, semantic fluency in French children, and picture naming and Stroop tasks in Hungarian children (Chern et al., Reference Chern, Tillmann, Vaughan and Gordon2018; Ladányi et al., Reference Ladányi, Lukács and Gervain2021). Rhythmic priming studies are frequently interpreted in the framework of DAT. Here, if the metrical structure of the external stimulus is regular and allows for reliable predictions of when the next key event will occur, listeners’ attention will focus on the target event, facilitating sequencing and predictive mechanisms. Accordingly, as syntactic processing also relies on sequencing and (syntactic) predictive mechanisms, it is argued that entrainment to rhythmically regular musical stimuli could benefit subsequent syntactic processing (Bedoin et al., Reference Bedoin, Brisseau, Molinier, Roch and Tillmann2016; Canette et al., Reference Canette, Bedoin and Lalitte2020a; Przybylski et al., Reference Przybylski, Bedoin and Krifi-Papoz2013).
Given the growing number and variety of rhythmic stimulation studies, we suggest that it may be relevant to refine our characterisation of rhythmic stimulation effects on language processing. These effects differ in two key dimensions: the temporal relationship between the rhythmic stimulation and the test stimulus (i.e., whether linguistic stimuli are presented in synchrony with or shortly after rhythmic stimulation), and the language component affected by the rhythmic stimulation (i.e., whether the linguistic task taps into a more perceptual or more abstract component of language processing).
Temporality varies such that the two stimuli can either be presented simultaneously or after a short delay. In synchronous presentation, the rhythmic stimulus falls at a particular time point of the test linguistic stimulus corresponding to enhanced (attentional) sensitivity. Such rhythmic manipulations facilitate the processing of a target stimulus when it falls on beat, on a strong beat, or on a temporally predicted event due to the temporal structure of the rhythmic stimulus. In the case of a short delay (cueing or priming), the test stimuli are presented immediately or a very short time after rhythmic stimulation. In rhythmic cueing experiments, facilitatory effects can be observed when there is a match (versus mismatch) between the metrical structure of the rhythmic stimulation and the prosodic structure of the test stimuli. In other words, the rhythmic and test stimuli are structurally aligned. In rhythmic priming experiments, facilitation effects are observed following the presentation of a musical prime with a regular (versus irregular or neutral) metrical structure even though there is no direct alignment between the metrical structure of the musical prime and the prosodic structure of the linguistic stimuli.
It seems important to distinguish between tasks that involve the processing of linguistic units grounded in perception (e.g., phoneme detection), on which the rhythmic stimulation may have a direct effect, and the processing of more abstract aspects of language that have no direct anchoring in perception (e.g., grammaticality judgement).
The studies reported in the literature appear to cover nearly all possible combinations of the temporality of the stimuli and the nature of the linguistic task: synchronised effects have been found for grammatical and semantic tasks (Kotz and Schmidt-Kassow, Reference Kotz and Schmidt-Kassow2015; Roncaglia-Denissen et al., Reference Roncaglia-Denissen, Schmidt-Kassow and Kotz2013, Reference Roncaglia-Denissen, Schmidt-Kassow, Heine and Kotz2015; Rothermich et al., Reference Rothermich, Schmidt-Kassow and Kotz2012; Rothermich and Kotz, Reference Rothermich and Kotz2013), while short-delay effects were found in the domains of phonology (Cason et al., Reference Cason, Astésano and Schön2015a, Reference Cason, Hidalgo, Isoard, Roman and Schön2015b; Cason and Schön, Reference Cason and Schön2012) and syntax (Bedoin et al., Reference Bedoin, Brisseau, Molinier, Roch and Tillmann2016; Canette et al., Reference Canette, Bedoin and Lalitte2020a, Reference Canette, Fiveash and Krzonowski2020b, Reference Canette, Lalitte and Bedoin2020c; Chern et al., Reference Chern, Tillmann, Vaughan and Gordon2018; Fiveash et al., Reference Fiveash, Bedoin, Lalitte and Tillmann2020; György et al., Reference György, Saddy, Kotz and Franck2024; Ladányi et al., Reference Ladányi, Lukács and Gervain2021; Przybylski et al., Reference Przybylski, Bedoin and Krifi-Papoz2013). However, as discussed above, two kinds of short-delay studies can be distinguished based on a direct structural alignment or lack thereof between the rhythmic and linguistic stimuli. To our knowledge, short-delay phonological effects were only found when the alignment between the rhythmic and test stimuli was manipulated (Cason et al., Reference Cason, Astésano and Schön2015a, Reference Cason, Hidalgo, Isoard, Roman and Schön2015b; Cason and Schön, Reference Cason and Schön2012), while short-delay syntactic effects were only found in experiments where there was no direct alignment between the two structures (Bedoin et al., Reference Bedoin, Brisseau, Molinier, Roch and Tillmann2016; Canette et al., Reference Canette, Bedoin and Lalitte2020a, Reference Canette, Fiveash and Krzonowski2020b, Reference Canette, Lalitte and Bedoin2020c; Chern et al., Reference Chern, Tillmann, Vaughan and Gordon2018; Fiveash et al., Reference Fiveash, Bedoin, Lalitte and Tillmann2020; György et al., Reference György, Saddy, Kotz and Franck2024; Ladányi et al., Reference Ladányi, Lukács and Gervain2021; Przybylski et al., Reference Przybylski, Bedoin and Krifi-Papoz2013).
25.4 Accounting for Rhythmic Stimulation Effects: Insights from Hierarchical Structure Processing
Numerous theories aim to account for the behavioural and neural links between rhythm and language processing. Some of these accounts focus more on the precise localisation of rhythm processing and its interaction with language processing networks (Kotz et al., Reference Kotz, Schwartze and Schmidt-Kassow2009, Reference Kotz, Stockert and Schwartze2014, Reference Kotz, Brown and Schwartze2016; Kotz and Schwartze, Reference Kotz and Schwartze2010; Patel, Reference Patel2011, Reference Patel2012). Other frameworks concentrate more on the precise nature of internal oscillations and their role in rhythm and language processing (Giraud and Poeppel, Reference Giraud and Poeppel2012; Goswami, Reference Goswami2011; please also refer to Chapters 5 and 35). The two approaches are not mutually exclusive as several accounts touch on both key brain regions and the role of neural oscillations (Fujii and Wan, Reference Fujii and Wan2014; Large and Snyder, Reference Large and Snyder2009; Tierney and Kraus, Reference Tierney and Kraus2014). The recently proposed processing rhythm in speech and music (PRISM, Fiveash et al., 2021; please also see Chapter 28) framework has attempted to synthesise several accounts proposing shared mechanisms between musical rhythm and speech processing and identified three key shared components: 1) the precise encoding of low-level information in the acoustic signal; 2) internal oscillations that entrain to external oscillations playing an important role in structural processing, temporal integration, and generating predictions; and 3) coupling between sensory and motor regions involved in music and speech perception (see Fiveash et al., Reference Fiveash, Bedoin, Gordon and Tillmann2021, and Ladányi et al., Reference Ladányi, Persici, Fiveash, Tillmann and Gordon2020, for detailed reviews). In the following paragraphs, we will focus on explanations proposed for the above-presented rhythmic stimulation effects. Referring back to our previous categorisation of rhythmic stimulation effects, we will review the proposed accounts and evaluate to what extent hierarchical structure processing may provide further insight into the rhythmic priming effect.
To account for cases where the language task is presented synchronously with rhythmic stimulation, several studies have relied on DAT (Large and Jones, Reference Large and Jones1999). In these accounts, rhythm could serve as a temporal framework for the language task as the key manipulation is whether the target stimulus falls on a temporally predicted event. A framework suggesting enhanced attentional focus on the target stimulus resulting from entrainment to a regular temporal structure of the rhythmic stimulus provides an adequate explanation. Regardless of whether the task drives the focus on perceptual or abstract components of language processing, providing a directly relevant language-external or language-internal cue to the temporal location of the target stimulus should lead to faster processing. The predictive mechanisms at play are proposed to be subserved by subcortico-cortical networks involving the basal ganglia, the cerebellum, as well as auditory and motor regions (Kotz et al., Reference Kotz, Stockert and Schwartze2014, Reference Kotz, Brown and Schwartze2016; Kotz and Schwartze, Reference Kotz and Schwartze2010). Another key element in some proposed accounts is the interface between syntactic and temporal predictions. Specifically, discrete predictions (e.g., predicting a noun after a determiner) are proposed to interface with temporal predictions based on a specific metrical structure (allowing the parser to predict the beat of a rhythm or to predict when the next strong beat or syllable is expected). However, the precise nature of this interaction is yet to be established.
In cases where the language task is presented immediately or shortly after a rhythmic stimulation, DAT is often cited as the key account for the effects of rhythmic stimulation. Such an explanation appears rather intuitive in rhythmic cueing studies, where the manipulation of interest is the alignment between the metrical structures of the rhythmic and linguistic stimuli, and the language task is often grounded in perception. If the metrical structures of the rhythmic and linguistic stimuli align, internal oscillations, having entrained to the phase or period properties of the rhythmic stimulus, will have also entrained to those of the language stimulus.
A purely DAT-based account may appear less straightforward in rhythmic priming studies, where the key manipulation is the metrical regularity of the prime rhythm with no direct relation to that of the language stimulus, and the language task is based on a more abstract component of language processing. The explanation in these studies is that the temporal cues provided by a regular rhythm enable internal oscillators to more easily entrain to the input and generate temporal expectations based on its metrical structure. As speech and language processing also rely on entrainment and temporal attention, entrained internal oscillators may benefit subsequent language processing (Bedoin et al., Reference Bedoin, Brisseau, Molinier, Roch and Tillmann2016; Canette et al., Reference Canette, Bedoin and Lalitte2020a; Przybylski et al., Reference Przybylski, Bedoin and Krifi-Papoz2013). As outlined above, there appears to be no direct correspondence between the metrical structure of the prime rhythm and that of the language stimuli used in these studies, and the language task relies on a more abstract (syntactic) component of language processing. Therefore, precisely how entrainment to a regular rhythmic prime benefits grammatical processing in a purely DAT-based framework is not fully understood. Furthermore, rhythmic priming effects identified in populations with typically developing speech/language processing and limited attentional capacities (typical infants) also suggest that a purely attention-based account cannot fully explain the priming effect (please also refer to Chapter 18).
A recent account proposes hierarchical cognitive control as a shared mechanism that might better explain the rhythmic priming effect (Asano et al., Reference Asano, Boeckx and Seifert2021). This explanation is two-fold. First, a regular rhythm provides an easily extractable metrical structure that can be constructed by highly automatic processes to construct its metrical representation. Therefore, fewer resources responsible for hierarchical control are necessary for metrical structure building and more of these resources can be used for subsequent syntax processing during regular rhythmic priming, while the opposite is true when the parser is exposed to the irregular rhythm (Asano et al., Reference Asano, Boeckx and Seifert2021). Second, the highly predictable structure of the regular rhythmic prime could also actively support syntactic structure building by providing a predictable metrical grid, thus improving syntactic performance (Asano et al., Reference Asano, Boeckx and Seifert2021; Kotz et al., Reference Kotz, Schwartze and Schmidt-Kassow2009). As mentioned earlier, it has been proposed that rule-based syntactic predictions can interface with temporally predictable cues during language processing (Kotz et al., Reference Kotz, Schwartze and Schmidt-Kassow2009; Kotz and Schmidt-Kassow, Reference Kotz and Schmidt-Kassow2015; Kotz and Schwartze, Reference Kotz and Schwartze2010). One possibility is that rather than establishing a direct link between temporal and syntactic processing, the two systems communicate through a shared system responsible for the internal construction and representation of complex hierarchical structures (György et al., Reference György, Saddy, Kotz and Franck2024). If this were the case, the regular temporal structure of a musical prime might activate this shared network, which, in turn, would facilitate the internal construction of the upcoming hierarchical (prosodic and syntactic) structure due to having already been activated by the hierarchical (temporal) structure of the preceding prime. A structure-based approach, which does not need to be mutually exclusive to other accounts such as dynamic attending or predictive coding, may better explain some of the rhythmic effects reviewed in this chapter. Specifically, observations where there is no clear alignment between the rhythmic stimulus and the target-language stimulus, and the effects reported lie in more abstract structural properties rather than more perceptual features of language processing, might find a more substantial explanation in a complex account based on hierarchical structure building in rhythm and syntax.
25.5 Conclusion
This chapter began with an examination of hierarchical structures where lower-level units are combined into higher-level constituents in language (syntax or prosody) and rhythm processing. It went on to review and present a novel characterisation of rhythmic stimulation effects in language processing based on the temporality of rhythmic stimulation and the nature of the language task used. This characterisation allowed us to isolate a number of short-delay rhythmic stimulation studies where the lack of alignment between the rhythmic and linguistic stimuli and the abstract nature of the linguistic component measured might necessitate a structure-based explanation. Hierarchical structure processing as a shared system between rhythm and language processing may present one, but not the only, potential account for these effects. Further research should seek to systematically evaluate the role of hierarchical structure processing and other proposed shared mechanisms between rhythm and language in the rhythmic stimulation effects reviewed here. More insight into the precise role of each of these mechanisms could pave the way for the development of rhythm-based, non-linguistic diagnostic and therapeutic tools for language disorders. However, before these potential tools could become valid and reliable in clinical practice, it is essential to acquire a more complete theoretical understanding of the rhythm–language interface.
Summary
This chapter aimed to examine rhythm and language processing from the perspective of hierarchical structure building. First, we presented hierarchical structural processing in both domains. Next, we reviewed and characterised rhythmic stimulation effects in language processing. Finally, we isolated effects that could benefit from a hierarchical structure-based explanation.
Implications
This chapter provides a novel classification of rhythmic stimulation effects, highlighting gaps in the literature where further research is needed. It also provides a possible reinterpretation of rhythmic priming effects, which further research could test empirically.
Gains
This chapter provides a novel classification of reported rhythmic stimulation effects, as well as possible interpretations. This might provide more insight into the precise mechanism underlying them. A more complete understanding of these effects could benefit our theoretical knowledge of the rhythm–language interface and pave the way for concrete applications.
26.1 What Is Rhythmic about Speech and Song?
Rhythms surround us: from footsteps in the hallway to the blinking red of a traffic signal. Although rhythms are a pervasive part of daily life, they play an important role in vocal communication for humans and a range of species (Honing, Reference Honing2012; Merchant and Honing, Reference Merchant and Honing2014; Patel, Reference Patel2010; Ravignani and Madison, Reference Ravignani and Madison2017). In humans, rhythms are present in two primary means of communication: speech and song. People perceive rhythms in speech from prosodic and linguistic stress patterns of syllables, and perceive rhythms in song from notes as they unfold in time (Patel, Reference Patel2010). Although the definition of rhythm can vary considerably, here we adopt a music cognition perspective and describe rhythm in its broadest sense as a pattern of events unfolding in time (McAuley, Reference McAuley, Riess Jones, Fay and Popper2010; Ravignani and Madison, Reference Ravignani and Madison2017). As such, speech events are typically syllables and song events are notes. This definition is inclusive of many different types of repeating sounds, such as cricket chirps, waves crashing on the beach, chewing food, and even a dough hook smacking around the bowl of an electric mixer.
Speech and song are both rhythmic, but a key difference between the two domains is how events relate to one another. In song, and music more generally, rhythms are organized around perceptually strong events, called a beat or pulse (Povel and Essens, Reference Povel and Essens1985). The alternation of strong and weak beats in music occurs at roughly equal intervals, which gives rise to the perception of isochrony (i.e., “iso” meaning “same” and “chronos” meaning “time”) despite considerable variation in note lengths or timing of note onsets relative to the beat. In many cases, a physical event is not always present on the beat and yet listeners perceive a strong pulse in that location (London, Reference London2004; Nave et al., Reference Nave, Snyder and Hannon2023; Parncutt, Reference Parncutt1994; Snyder and Krumhansl, Reference Snyder and Krumhansl2001; Temperley, Reference Temperley2004). When rhythms are structured around the beat, note durations are related by integer multiples with small integer ratios. That means that a long note in a piece of music is one, two, three, or four times the duration of a short note in the sequence (e.g., quarter versus half note; Jacoby and McDermott, Reference Jacoby and McDermott2017; Roeske et al., Reference Roeske, Tchernichovski, Poeppel and Jacoby2020). In contrast, speech rhythms are dictated by the word length, syntactic structure, and prosodic emphasis of the specific utterance (Patel, Reference Patel2010; Selkirk, Reference Selkirk1980; Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2013). For instance, stressed syllables are often longer than unstressed syllables (Cutler and Foss, Reference Cutler and Foss1977; Fry, Reference Fry1955, Reference Fry1958; Seidl et al., Reference Seidl, French, Wang and Cristia2014). Articles, such as a, an, and the, occur in fixed positions relative to content words in English, and are unstressed, monosyllabic, and shorter than many content words, creating an unstressed-stressed rhythm (Andreou et al., Reference Andreou, Kashino and Chait2011; Hayes, Reference Hayes1985). Words at the end of a phrase are lengthened (Klatt, Reference Klatt1975), words that receive prosodic emphasis for effect are also held out longer (Selkirk, Reference Selkirk1995), and different languages have different stress patterns or a lack of stress at all (Cutler and Clifton, Reference Cutler, Clifton, Bouma and Bouwhuis1984; Peperkamp et al., Reference Peperkamp, Vendelin and Dupoux2010). The rhythmic patterns of speech can be predictable and repeating, sometimes even alternating between stressed and unstressed syllables much like the definition of a beat above (Breen and Clifton Jr, Reference Breen and Clifton2011; Cutler and Foss, Reference Cutler and Foss1977; Levey and Raphael, Reference Levey and Raphael2002; Patel, Reference Patel2010). However, syllable durations do not relate to one another by consistent integer relationships, which means that there is no regular pulse or beat in speech.
We present two additional terms, periodicity and rhythmic regularity, to carefully differentiate how rhythmic events relate to each other in speech and song. Periodicity is defined as a pattern repeating in time (Patel, Reference Patel2010) and is traditionally related to a fixed interval or period with which the pattern repeats. However, speech research has long used the term periodicity to mean repeating patterns, such as alternations of stressed and unstressed syllables, that do not have a fixed period (Beier and Ferreira, Reference Beier and Ferreira2018). So here we use this term in that sense of a repeating pattern that does not repeat at a fixed interval, but instead at some variable period (e.g., like the meaning of periodic). To illustrate this notion, imagine an auditory notification played to alert travelers that a subway train is about to arrive (a quick sequential ascending major chord: G-B-D-G) and a new train comes every four to six minutes (see Figure 26.1A). This musical alert is periodic – it occurs repeatedly whenever a train arrives – and is also rhythmic – the four-note chord has a short-short-short-long pattern of note events – but it does not give rise to the perception of a regular pulse. Rhythmic regularity is when an alternation between strong and weak events gives rise to a beat (i.e., a series of perceptually strong events; Large, Reference Large and Grondin2008) and the intervals between strong events occur at roughly equal intervals (Ravignani and Madison, Reference Ravignani and Madison2017; Ravignani and Norton, Reference Ravignani and Norton2017). Think again of the train arrival notification. If the train arrived every 2,400 ms and the musical alert itself was composed of three 200 ms intervals followed by one 600 ms interval, then it would give rise to a regular pulse, or a beat in music. Specifically, the first and last notes would become strong beats because the (implausible) 2,400 ms train arrival window would suggest two 600 ms silent beats, making the whole sequence a cycle of four beats (see Figure 26.1B). In everyday English speech, an individual phrase provides a rhythm of stressed and unstressed syllables, and, when we speak in longer utterances, new rhythmic patterns with similar properties repeat at irregularly spaced phrasal and prosodic intervals. As such, speech is considered periodic: It is a repeating rhythmic pattern of events, but it is not rhythmically regular. In contrast, song is rhythmically regular, where a repeating pattern occurs at intervals of the same duration and gives rise to the perception of an underlying pulse or beat. In music, these beats are grouped into a hierarchy of strong and weak beats (e.g., groups of three or four beats per measure; Jones, Reference Jones1985; Lerdahl and Jackendoff, Reference Lerdahl and Jackendoff1983) called meter. Although speech has also been described as having meter (e.g., Selkirk, Reference Selkirk1984), metricality in speech is the alternation of strong and weak syllables without a fixed integer-related interval relative to previous syllables. Speech, even at the metrical level, is more about the recurrence of a particular pattern (periodicity) instead of the presence of an underlying beat occurring at isochronous intervals.
Illustrating rhythmic regularity as different from periodic.
Illustration of the difference between a signal that is A) periodic and rhythmic compared to one that is B) rhythmically regular and gives rise to the percept of a beat.

The differences between periodicity and rhythmic regularity may seem subtle, but the ramifications of the presence or absence of rhythmic regularity are anything but subtle. Musical behaviors such as dancing, singing, and playing an instrument all depend on the presence of rhythmic regularity to allow an individual or multiple individuals to move or play together in an ensemble or to play with music (Hannon et al., Reference Hannon, Nave‐Blodgett and Nave2018; Honing, Reference Honing2012; Nave-Blodgett et al., Reference Nave-Blodgett, Snyder and Hannon2021). Even the survival of the human species has been related back to rhythmic coordination and its importance for social bonding, especially through coordination with a beat as in music-making (Savage et al., Reference Savage, Loui and Tarr2021; Trainor and Cirelli, Reference Trainor and Cirelli2015).
Music is not the only stimulus that has rhythmic regularity, even if it is the strongest naturally occurring example of it. For instance, our heartbeat is perhaps the first regular beat we hear, with a weak-strong alternation in the lub-dub-lub-drub of a normal heartbeat cycle (De Meo et al., Reference De Meo, Matusz and Knebel2016; Ullal-Gupta et al., Reference Ullal-Gupta, Vanden Bosch der Nederlanden, Tichko, Lahav and Hannon2013). Even speech can have a beat, exemplified through the uncharacteristically regular alternation of unstressed and stressed syllables in iambic pentameter (e.g., “the rose is bright and shines a beam of light”) and other forms of poetry. When speech has a beat, that type of speech arguably plays a qualitatively different functional role than speech without a beat. Instead of a speech versus song dichotomy based on the presence or absence of rhythmic regularity, it is more likely that a communicative continuum exists with speech and song as the endpoints and several different types of vocalizations falling between, including poetry, rap, sprechstimme, public speeches, emotional speech, acting, infant-directed speech, and more (Vanden Bosch der Nederlanden et al., Reference Vanden Bosch der Nederlanden, Qi and Sequeira2022b). There are many acoustic features that move a stimulus along the speech-to-song continuum (Albouy et al., Reference Albouy, Mehr, Hoyer, Ginzburg and Zatorre2024; Brown, Reference Brown, Wallin, Merker and Brown2000; Fitch, Reference Fitch2006; Ozaki et al., Reference Ozaki, Tierney and Pfordresher2024; Vanden Bosch der Nederlanden et al., Reference Vanden Bosch der Nederlanden, Qi and Sequeira2022b), but rhythmic regularity is key to differentiating the endpoints of this continuum (see Chapters 11, 32, and 35).
26.2 Examining Acoustic Features of Rhythmic Regularity in Speech and Song
When adults describe acoustic differences between speech and song, they tend to focus on the different uses of pitch, while younger children (4–11 years of age) describe differences based on acoustic timing (Vanden Bosch der Nederlanden et al., Reference Vanden Bosch der Nederlanden, Qi and Sequeira2022b). Our previous qualitative work simply asked children and adults to describe the difference between speech and song in their own words, and we reported themes from their responses binned across all temporal acoustic features and other features (melodic, spectral, loudness). Here, we provide a reanalysis of these themes (data here: https://osf.io/xar3c/) to examine how children and adults describe different temporal features, such as the presence of a beat, throughout development. As is clear from Table 26.1, temporal characteristics were mentioned infrequently for describing the differences between speech and song (5–30% of participants depending on the age group: N=19, 4–7-year-olds; N=16, 8–11-year-olds; N=16, 12–17-year-olds; and N=47, 18–24-year-olds). Children and adults mentioned tempo at similar rates (reporting that song is faster than speech for children, but that speech is faster than song for adults); smoothness or flow (song is more smooth than speech) – which could be related to temporal and/or spectral features – increased with age; and adults mentioned beat or rhythm (lumped together because children’s definitions did not necessarily mention beat but talked about rhythm in a beat-like manner) more often than children overall (reporting more beat/rhythm in song than speech). Although these qualitative data suggest that rhythmic regularity is not the first thing people focus on in their verbal or written descriptions, perceptual judgments reported by our group (Vanden Bosch der Nederlanden et al., Reference Vanden Bosch der Nederlanden, Qi and Sequeira2022b) suggest otherwise: Adults rank the presence of a beat and rhythmic regularity in the top three characteristics that distinguish speech from song, and children of all ages agree that song has a beat.
Reanalysis of the qualitative data of Vanden Bosch der Nederlanden et al. (Reference Vanden Bosch der Nederlanden, Qi and Sequeira2022b) illustrating that individual participants’ spontaneous descriptions of the differences between speech and song infrequently describe beat or rhythm as a key differentiator compared to pitch or melody. Values are the proportion of participants endorsing each acoustic feature by age group.
| Age group | Beat/rhythm | Tempo | Flow |
|---|---|---|---|
| 4–7 | 0.11 | 0.11 | 0.05 |
| 8–11 | 0.13 | 0.13 | 0.19 |
| 12–17 | 0.06 | 0.13 | 0.19 |
| 18–24 | 0.23 | 0.09 | 0.30 |
Since rhythmic regularity is important for distinguishing speech from song, how is the degree of rhythmic regularity measured across these domains? Many studies characterize the strength of a beat in music (Alluri and Toiviainen, Reference Alluri and Toiviainen2010; Burger et al., Reference Burger, Thompson, Luck, Saarikallio and Toiviainen2013, Reference Burger, Thompson, Luck, Saarikallio and Toiviainen2014; De Gregorio et al., Reference De Gregorio, Valente and Raimondi2021; Henry et al., Reference Henry, Herrmann and Grahn2017; Lartillot et al., Reference Lartillot, Eerola, Toiviainen and Fornari2008; Matthews et al., Reference Matthews, Witek, Heggli, Penhune and Vuust2019; Roeske et al., Reference Roeske, Tchernichovski, Poeppel and Jacoby2020) and the degree of durational contrastiveness in speech (i.e., short–long) (Arvaniti, Reference Arvaniti2012; Grabe and Low, Reference Grabe and Low2002; Jadoul et al., Reference Jadoul, Ravignani, Thompson, Filippi and De Boer2016; Nolan and Jeon, Reference Nolan and Jeon2014; White and Mattys, Reference White and Mattys2007; Wiget et al., Reference Wiget, White and Schuppler2010), but few compare the degree of rhythmic regularity across speech and song. Our recent study (Yu et al., Reference Yu, Cabildo, Grahn and Vanden Bosch der Nederlanden2023) illustrated that subjective ratings of regularity reliably differentiated speech from song, when regularity was operationalized as how easy it would be to tap or clap along with the stimulus. Regularity ratings were also predicted by the acoustic features of spectral flux and syllable duration, which meant that less moment-to-moment change in the spectrum (i.e., spectral flux) and longer durations were associated with higher regularity ratings (Yu et al., Reference Yu, Cabildo, Grahn and Vanden Bosch der Nederlanden2023). This finding held true even after controlling for modality (speech and song), suggesting that these features predicted regularity ratings for both speech and song. Other studies that examine what features listeners use to differentiate speech and song can also shed light on key temporal characteristics. Speech and song are differentiated by their temporal modulation rates (e.g., song is slower than speech; Ding et al., Reference Ding, Patel and Chen2017), spectro-temporal modulation rates (co-occurrence of high-frequency spectral modulation with low-frequency temporal modulation for song relative to speech; Albouy et al., Reference Albouy, Mehr, Hoyer, Ginzburg and Zatorre2024), pulse clarity (Hilton et al., Reference Hilton, Moser and Bertolo2022), tempo (Ozaki et al., Reference Ozaki, Tierney and Pfordresher2024), and rhythmic regularity (Ozaki et al., Reference Ozaki, Tierney and Pfordresher2024; see their exploratory analyses). These features, including spectral flux and duration mentioned above, are certainly dependent on temporal dynamics, but nearly all fail to capture the integer-multiple relationships that characterize song’s alignment with a beat. It is still an open question what features listeners use to perceive rhythmic regularity in speech and song and whether the features reported here are merely a byproduct of the integer relationships in sounds with a beat.
One issue with the practice of relating acoustic features in speech and song to subjective ratings of regularity is the influence human perception has in altering the incoming signal. For instance, naturally occurring music does not have strictly equal durations between beats because of motor output delays, micro-timing deviations, or expressive timing (Appen et al., Reference Appen, Doehring and Moore2015; Danielsen et al., Reference Danielsen, Haugen and Jensenius2015; Datseris et al., Reference Datseris, Ziereis and Albrecht2019; Drake and Palmer, Reference Drake and Palmer1993; Rasch, Reference Rasch and Sloboda1988; Senn et al., Reference Senn, Kilchenmann, Von Georgi and Bullerjahn2016). People perceptually regularize, or quantize, the signal to make it sound more rhythmically regular than the physical signal would suggest. It is also likely that people perceive the moment of the beat in natural stimuli later than the sound’s physical onset. In musical timbres, people report that the perceptual occurrence of an event, or p-center, is delayed relative to the physical onset of the sound (see Chapter 11). Fast attack time sounds (e.g., percussion) have p-centers with shorter delays relative to the onset than slow attack time sounds (e.g., violin), and longer notes have p-centers with longer delays relative to onsets compared to shorter notes (Danielsen et al., Reference Danielsen, Nymoen and Anderson2019). The timing of the p-center is also dependent on the experience or expertise of the listener, which leads researchers to describe p-centers in music as “beat bins,” or windows of time, in which people are most likely to hear a beat (Speich et al., Reference Spiech, Endestad, Laeng, Danielsen and Haghish2023).
The concept of the p-center originates from speech studies (Morton et al., Reference Morton, Marcus and Frankish1976), but this literature is quite mixed as to the acoustic correlates of the p-center (Villing, Reference Villing2010). The most consistent finding relates the p-center to a window of time near the vowel onset (Fox and Lehiste, Reference Fox and Lehiste1987; Marcus, Reference Marcus1981). Like music, the p-center in speech is dependent on the “attack” of the consonants preceding the vowel onset (Cooper et al., Reference Cooper, Whalen and Fowler1986; Pompino-Marschall, Reference Pompino-Marschall1989). More recent studies have used sensorimotor synchronization tasks such as tapping to looped speech to characterize that the vowel onset is a strong attractor of taps in speech and music (Lidji et al., Reference Lidji, Palmer, Peretz and Morningstar2011; Rathcke et al., Reference Rathcke, Lin, Falk and Dalla Bella2021). More work is needed to characterize what acoustic factors contribute to the perceptual location of a beat in speech, song, and a range of natural environmental stimuli. If beat bins can be used to calculate integer-multiple relationships from stimulus features in complex stimuli such as speech and song, then beat bins could also be used to calculate integer-multiple relationships in a range of naturally occurring stimuli.
In summary, rhythmic regularity is an important feature for differentiating speech and song, children are sensitive to temporal features, but beat/rhythm are not critical for differentiating speech and song until later in development (see Section 6 for more about development). Finally, subjective ratings of rhythmic regularity reliably differentiate speech from song, although acoustic features (i.e., spectral flux, duration) that predict regularity ratings do not capture the integer relationships inherent to stimuli with a hierarchical beat structure. As outlined above, next steps include determining if psychologically informed metrics of rhythmic regularity are stronger predictors of regularity than easily extracted acoustic features, such as spectral flux or syllable duration. The long-term goal of this work is to characterize the degree of regularity in all sounds, including those beyond human communicative contexts, such as dog barks, typing, bird calls, water droplets, and sneezes. As such, acoustic metrics of regularity should be general enough to be applied in non-communicative contexts.
So why is it important to characterize the degree of regularity in speech, song, and environmental sounds? We now turn to the existing literature on neural and perceptual dynamics of rhythm to provide rationale for the important functions rhythmic regularity plays in attention, learning, and memory.
26.3 Attention Is Rhythmic
Already 60 years ago, Mari Reiss Jones outlined her work on dynamic attending theory (DAT) (Jones, Reference Jones1976), which proposed that attention is not constant but cyclical, with alternations between moments of focused attention followed by inattention (Large and Jones, Reference Large and Jones1999). In this theory, external stimulation, such as music, can guide attention toward moments in time when important information or events have a high likelihood of occurrence. In a musical sequence, attention would be allocated to the strong beats, when important melodic or metrical information is likely to occur, and attention would wane on weaker or off-beat positions. If attention is allocated more often to the strong than to the weak beats, this should be evident as better processing and sequencing of information occurring on the beat than off. Indeed, people are better at remembering faces when they are presented on the beat of a musical rhythm compared to when they are presented off the beat or in silence (Johndro et al., Reference Johndro, Jacobs, Patel and Race2019).
A stronger test of rhythmic facilitation through DAT is whether an external rhythm can start a cycle of focused attention and inattention at the rate of the rhythmic stimulus that continues even when the rhythm is no longer present. Several studies have shown that after a rhythmically regular prime, participants have better memory for information played after the prime, such as speech (Canette et al., Reference Canette, Fiveash and Krzonowski2020a; Cason and Schön, Reference Cason and Schön2012; Cason et al., Reference Cason, Astésano and Schön2015; Chern et al., Reference Chern, Tillmann, Vaughan and Gordon2018; Przybylski et al., Reference Przybylski, Bedoin and Krifi-Papoz2013) and visual information (Plancher et al., Reference Plancher, Lévêque, Fanuel, Piquandet and Tillmann2018), compared to an irregular prime or silence. Rhythmic attention may improve working memory performance by freeing up attentional resources by processing fewer, but highly relevant, elements in an ongoing stream of sensory input (Johndro et al., Reference Johndro, Jacobs, Patel and Race2019). Music and speech signals themselves are designed to provide key details at rhythmically salient moments in time. Speech stress typically highlights semantically meaningful elements in a sentence (Mattys, Reference Mattys1997; Pitt and Samuel, Reference Pitt and Samuel1990), and strong beats in music are more often populated with pitches that are crucial to the tonality of a piece of music (Prince and Schmuckler, Reference Prince and Schmuckler2014; Prince et al., Reference Prince, Tan and Schmuckler2020). Thus, not only do perceptual and attentional systems sample sensory input in a rhythmic manner, but the stimulus streams themselves are optimized for the listener. It remains to be seen whether human communicative sounds are uniquely structured to capitalize on information transfer at rhythmic moments in time or whether other animal vocalizations or environmental sounds are structured similarly (but see De Gregorio et al., Reference De Gregorio, Valente and Raimondi2021; Roeske et al., Reference Roeske, Tchernichovski, Poeppel and Jacoby2020).
26.4 Neural Correlates of Rhythmic Regularity
The type of rhythmic attention described in DAT is predicted by the cyclical excitatory-inhibitory oscillations for populations of neurons in the brain (Lakatos et al., Reference Lakatos, Karmos, Mehta, Ulbert and Schroeder2008; Large and Jones, Reference Large and Jones1999). A period of heightened sensitivity at the peak of an excitatory phase of a neural oscillation would explain better perceptual or memory outcomes described in the studies reported above (see also Henry and Herrmann, Reference Henry and Herrmann2014). Indeed, change sensitivity is related to the phase of oscillations aligned with the external rhythmic sensory input (e.g., Henry and Obleser, Reference Henry and Obleser2012). Not all neural tracking of sensory input can be described as neural entrainment (Haegens, Reference Haegens2018; Haegens and Golumbic, Reference Haegens and Golumbic2018; Kösem et al., Reference Kösem, Bosker and Takashima2018; Obleser and Kayser, Reference Obleser and Kayser2019; Zoefel et al., Reference Zoefel, Archer-Boyd and Davis2018), as neural tracking of stimulus rhythms could be evidence of true neural entrainment (e.g., oscillations continue even in the absence of stimulation) or stimulus-driven responses to sound onsets (e.g., N1-P2 onset responses). Regardless, the degree of phase alignment between brain and stimulus rhythms predicts behavioral performance, including speech comprehension (Peelle, Reference Peelle2012), attention (Zion-Golumbic and Schroeder, Reference Zion-Golumbic and Schroeder2012), and expertise (Doelling and Poeppel, Reference Doelling and Poeppel2015; Harding et al., Reference Harding, Sammler, Henry, Large and Kotz2019). For more on this topic, see Chapters 3 and 5.
Neural oscillations are described as inherently rhythmically regular, ascribing to a single frequency of oscillation (e.g., Zoefel et al., Reference Zoefel, Archer-Boyd and Davis2018; but see Haas and Kubin, Reference Haas and Kubin1998, for nonlinear multi-frequency oscillators capable of entraining to the irregularities of speech). If oscillators are biased toward isochrony, then the alignment of ongoing neural oscillations should be better for a stimulus that is also rhythmically regular (e.g., less phase resetting of ongoing oscillations to match the incoming stimulus). Since song is more rhythmically regular than speech (Yu et al., Reference Yu, Cabildo, Grahn and Vanden Bosch der Nederlanden2023), it follows that song should garner greater alignment with ongoing neural activity – greater neural tracking – than speech. Consistent with this assertion, neural tracking is reduced when speech rhythms are made less regular by inserting pauses (delta band; Kayser et al., Reference Kayser, Ince, Gross and Kayser2015), and neural tracking is increased when words are sung over spoken (theta band; Vanden Bosch der Nederlanden et al., Reference Vanden Bosch der Nederlanden, Joanisse and Grahn2020, Reference Vanden Bosch der Nederlanden, Joanisse, Grahn, Snijders and Schoffelen2022a). Thus, it is possible that neural tracking increases linearly with the degree of regularity (see Section 6 chapters for more about rhythm and learning).
Here, we report a reanalysis that characterizes how subjective rhythmic regularity relates to neural tracking. We reanalyzed magnetoencephalography (MEG) data from the Vanden Bosch der Nederlanden et al. (Reference Vanden Bosch der Nederlanden, Joanisse, Grahn, Snijders and Schoffelen2022a) dataset (available here: https://data.donders.ru.nl/) and related it with the regularity ratings of the same stimulus set of Yu et al. (Reference Yu, Cabildo, Grahn and Vanden Bosch der Nederlanden2023) (available here: https://osf.io/hnw5t/) to elucidate whether the degree of regularity predicts neural tracking at the syllable rate across both spoken and sung utterances. The MEG data was collected as part of the melody familiarity study, where participants listened to 96 stimuli (presented four times) and rated whether the melody of the spoken or sung stimulus was one they had learned during their training sessions (they learned half of the sung melodies without lyrics). We used a jackknifing technique (Richter et al., Reference Richter, Thompson, Bosman and Fries2015) to extract single-trial estimates of neural tracking for each stimulus (96 stimuli, four presentations) presented to each of their 32 participants and related these stimulus-level data with the average regularity rating (see Section 26.2 – subjective ratings of ease of clapping or tapping to the stimulus) provided for each stimulus by 51 participants. Jackknifing estimates use a leave-one-out approach, so if a particular stimulus contributed strongly to the overall estimate of neural tracking, there would be a large reduction in the jackknifed neural tracking estimate when the stimulus was left out. If that same stimulus was also rated high in rhythmic regularity, then a significant negative correlation between neural tracking and rhythmic regularity would mean that greater neural tracking is related to increases in subjective experiences of rhythmic regularity.
We used a linear mixed-effects model (R, lmer package; stimulus and participant as random effects) to predict neural tracking based on acoustic features and subjective regularity ratings described in Yu et al. (Reference Yu, Cabildo, Grahn and Vanden Bosch der Nederlanden2023). We found that after controlling for utterance type (speech versus song), neural tracking was predicted by subjective rhythmic regularity ratings and pulse clarity (minimum value, MIR Toolbox; see Figure 26.2). Interestingly, although spectral flux is a stronger predictor of neural tracking than amplitude envelope measures (Weineck et al., Reference Weineck, Wen and Henry2022), it did not explain unique variance beyond rhythmic regularity ratings (see Table 26.2). This reanalysis suggests that the degree of rhythmic regularity in a stimulus is a strong driver of neural tracking, even beyond acoustic features that are highly predictive of rhythmic regularity (i.e., spectral flux).
Results from the linear mixed-effects regression models predicting average theta-band cerebro-acoustic phase coherence (raw values), with stimulus and participant as random effects. Statistically significant variables in each model are highlighted in bold.
| Model | Variable | Estimate | t-value | p |
|---|---|---|---|---|
| Model 1 | Regularity | −0.191 | −4.145 | <.001 |
| X2(5, N=3072) = 16.113, p<.001, AIC = 8159.3 (compared to random intercept model) | ||||
| Model 2 | Regularity | −0.142 | −2.821 | 0.006 |
| Song | −0.220 | −2.183 | 0.032 | |
| X2(6, N=3072) = 4.798, p=.0285, AIC = 8156.5 (compared to Model 1) | ||||
| Model 3 | Regularity | −0.138 | −2.703 | 0.036 |
| Song | −0.365 | −2.496 | 0.008 | |
| Spectral flux | 0.052 | 0.693 | 0.490 | |
| F0 stability | −0.098 | −1.251 | 0.215 | |
| Pulse clarity | −0.116 | −2.528 | 0.013 | |
| Syllable duration | 0.031 | 0.507 | 0.613 | |
| Prop. small integer ratio | 0.034 | 0.729 | 0.468 | |
| Consonant PVI | −0.034 | −0.641 | 0.523 | |
| % vocalic | 0.083 | 1.468 | 0.146 | |
| X2(13, N=3072) = 11.662, p=.1122 AIC = 8158.8 (compared to Model 2) | ||||
| Model 4 | Regularity | −0.146 | −2.974 | 0.004 |
| Song | −0.203 | −2.077 | 0.041 | |
| Pulse clarity | −0.113 | −2.568 | 0.012 | |
| X2(7, N=3072) = 6.648, p=.0099, AIC = 8151.8 (compared to Model 2) | ||||
Linear mixed-effects regression results for neural and acoustic data.
Neural tracking (speech-brain coherence in the theta band – 4–8 Hz) is related to rhythmic regularity and pulse clarity, even after controlling for utterance type.
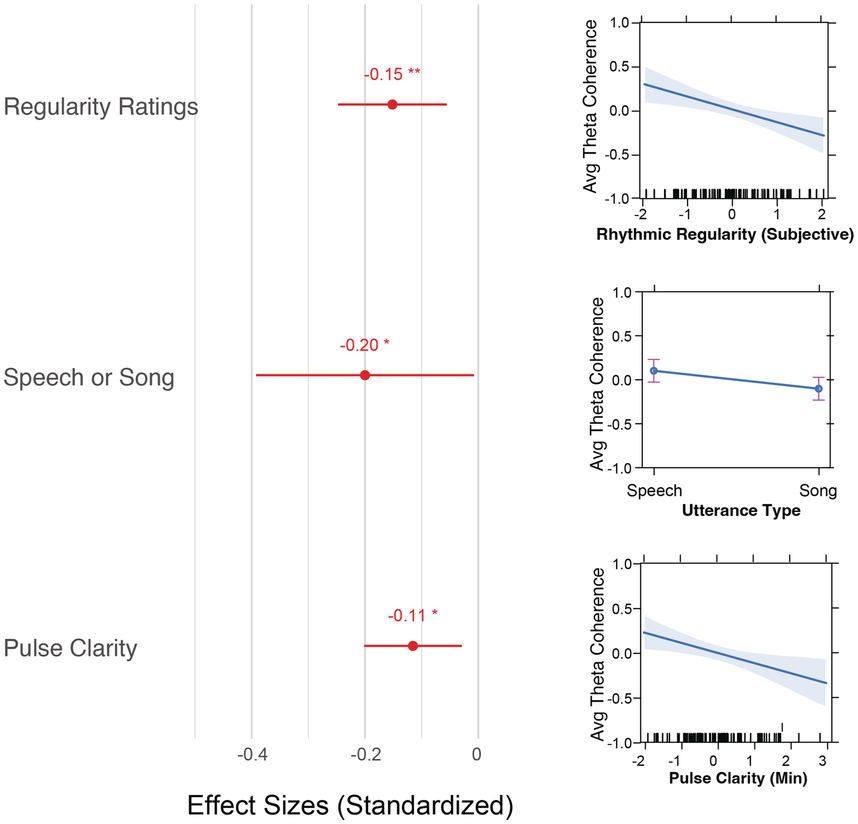
Figure 26.2 Long description
Left. An error bar graph of regularity ratings, speech or song and pulse clarity with effect sizes. The data points are as follows. Speech or song, minus 0.20. Regularity ratings, minus 0.15. Pulse Clarity, minus 0.11. Right. Two line graphs and one error bar graph plot the average theta coherence with the rhythmic regularity, utterance type and pulse clarity, respectively. Top: The line originates at (minus 2, 0.4) and terminates at (2, minus 0.3). Center: The error bars are plotted at 0.0 for Speech and at minus 0.1 for Song. Bottom: The line originates at (minus 2, 0.3) and terminates at (3, minus 0.5). The values are estimated.
These results may lend a neural explanation for recent studies showing that attention is biased toward rhythmic regularity, in both auditory (Andreou et al., Reference Andreou, Kashino and Chait2011) and visual domains (Zhao et al., Reference Zhao, Al-Aidroos and Turk-Browne2013), even without explicit awareness (Zhao et al., Reference Zhao, Al-Aidroos and Turk-Browne2013). Perhaps, stimuli that capture attention are those with greater rhythmic regularity because they are easier to process neurally than less regular or irregular stimuli. Further, if regular stimuli capture attention, then the regularity of the stimulus would also make it more likely that important moments in time align with moments of high neural excitability, resulting in better memory or comprehension. Although speech is not rhythmically regular, like music, it likely has a higher degree of regularity than other real-world sounds, such as a babbling brook. While regularity may move stimuli from one side of the speech–song continuum to the other, regularity may be critical for a broader range of noncommunicative stimuli forming a much larger acoustic continuum. The periodicity of speech may also underlie why people of all ages are nearly perfect at detecting when a human voice changes in a complex scene compared to musical instrument sounds, environmental sounds, or animal vocalizations (Vanden Bosch der Nederlanden et al., Reference Vanden Bosch der Nederlanden, Snyder and Hannon2016, Reference Vanden Bosch der Nederlanden, Zaragoza, Rubio-Garcia, Clarkson and Snyder2018; Vanden Bosch der Nederlanden and Vouloumanos et al., Reference Vanden Bosch der Nederlanden and Vouloumanos2021). Future work should examine whether attentional biases toward real-world sounds could be predicted based on the degree of regularity in the signal, such that the stimulus with the highest degree of regularity is the one that captures attention. Together, this review and reanalysis suggest that the human brain is endowed with neural mechanisms specialized to process rhythmic regularities across multiple domains.
26.5 Leveraging Rhythmic Regularity in Music
A growing number of studies show relationships between musical rhythmic processing and language (e.g., Gordon et al., Reference Gordon, Shivers and Wieland2015; Kertész and Honbolygó, Reference Kertész and Honbolygó2023; Ozernov-Palchik and Patel, Reference Ozernov‐Palchik and Patel2018; Woodruff Carr et al., Reference Woodruff Carr, White-Schwoch, Tierney, Strait and Kraus2014). They show, for instance, that kindergarteners’ rhythmic discrimination skills and letter-sound knowledge – an early predictor of reading development – are highly correlated (Ozernov-Palchik and Patel, Reference Ozernov‐Palchik and Patel2018), that drumming consistency relates to language outcomes (Woodruff Carr et al., Reference Woodruff Carr, White-Schwoch, Tierney, Strait and Kraus2014), and that rhythm perception in elementary school-aged children predicts expressive grammar skills (Nitin et al., Reference Nitin, Gustavson and Aaron2023). Deficits in rhythmic processing abilities have also been connected to a wide range of developmental disorders, including dyslexia, ADHD, autism, motor coordination disorders, and stuttering (Fiveash et al., Reference Fiveash, Bedoin, Gordon and Tillmann2021; Garnett et al., Reference Garnett, Chow, Limb, Liu and Chang2022; Hannon et al., Reference Hannon, Nave‐Blodgett and Nave2018; Ladanyi et al., Reference Ladányi, Persici, Fiveash, Tillmann and Gordon2020; Lense et al., Reference Lense, Ladányi, Rabinowitch, Trainor and Gordon2021). Compared to typically developing children, those with reading disorders and language impairment struggle to synchronize their movements to a metronome or musical rhythm (Corriveau and Goswami, Reference Corriveau and Goswami2009). The ability to extract a stable pulse or perceive rhythmic regularity may be crucial to successful language processing (Bekius et al., Reference Bekius, Cope and Grube2016; Centanni et al., Reference Centanni, Pantazis and Truong2018, Reference Centanni, Beach and Ozernov-Palchik2022).
Given that language deficits are related to musical beat processing, music-based interventions that help people pick up on rhythmic regularity can complement existing therapies to increase the positive impact on language outcomes. As described above, rhythmic priming studies successfully use musical primes to entrain neural activity and facilitate the extraction of relevant information from subsequently presented speech stimuli (Canette et al., Reference Canette, Lalitte and Bedoin2020b; Chern et al., Reference Chern, Tillmann, Vaughan and Gordon2018). Extra scaffolding and priming of rhythmic attention through music may be particularly beneficial for children with developmental disorders who struggle to create internal representations of salient moments in ongoing speech streams. This is consistent with reports that rhythm-based musical training can benefit reading and phonological processes in dyslexic children (Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2015) and speech processing for children with cochlear implants (Bedoin et al., Reference Bedoin, Besombes and Escande2018). Beyond the potential benefits in language processing, rhythm in music is also tightly related to the experience of pleasure and reward (Fiveash et al., Reference Fiveash, Ferreri and Bouwer2023; Todd and Lee, Reference Todd and Lee2015; Zatorre, Reference Zatorre2015). This makes musical interventions focused on rhythmic regularity especially fruitful for improving perceptual as well as socio-emotional outcomes across the lifespan. Musical features such as rhythmic regularity can be leveraged to improve neural tracking and downstream behavioral outcomes, such as comprehension or engagement.
Summary
Rhythmic regularity is a key differentiator of speech and song, but how it is measured in the acoustic signal is not trivial. Listeners subjectively report rhythmic regularity in song, but the acoustic features that are consistent with regularity do not correspond with the small integer ratios of events that align with a beat. Rhythmic regularity is a significant modulator of neural tracking in speech and song, suggesting regularity likely plays a crucial role in guiding other behavioral outcomes related to neural tracking, such as attention, memory, engagement, and even comprehension.
Implications
Our work suggests that regularity drives neural tracking and is a key factor differentiating speech and song. Given the neural tracking findings, would regularizing the speech signal to be more music-like improve intelligibility and comprehension compared to typical, irregular, speech rhythms? If this is the case, then why did humans evolve two distinct systems of communication that differ in the degree of regularity and their functional goals: speech for transaction of meaning, and song for conveying or regulating emotion? That is, why do we not exclusively sing to one another? Future work should characterize the role of rhythmic regularity across multiple domains, including speech, song, and other everyday sounds.
Gains
This chapter presents a first step toward understanding the role of regularity across communicative modalities and characterizing its impact on neural processing. We highlight the necessity for a good metric of the degree of regularity that can characterize a range of naturally occurring stimuli. Such a metric has the potential to have broad impact, for example on the best practices for teaching and learning in the classroom to improve retention, or in high-risk situations to grab listeners’ attention, as in hospital-alert settings.
27.1 Introduction
Spoken language unfolds in time, just as music. Consequently, both of these two major communicative sound systems encode structures in temporal relations. However, this ontologically anchored possibility of encoding structural relations is only addressed peripherally and unsystematically in linguistic theory formation. The bulk of work in structural phonology is centered around the abstract systemic values of the spectral qualities (represented as discrete phonemes) and fundamental frequencies (represented as discrete tonal categories) of acoustic events. As we shall see, time appears only occasionally as a distinctive feature of phonemes in structuralist phonology, as an abstract feature of moraic structure in metrical phonology (Liberman and Prince, Reference Liberman and Prince1977; Hayes, Reference Hayes1995), as a feature of pitch accents in intonational phonology, or as a delimitative property of phrase edges in prosodic phonology. Our contribution intends to sketch possible ways to conceive of time as a theoretical primitive of phonological structure, informed not only by linguistics but also by music-theoretical research, where time and the relation between meter and rhythm are fundamental but different concepts for any structural representation of music.
We understand music and language as communicative sound systems that rely on cognitive faculties shared by all human beings (Patel, Reference Patel2008; Rebuschat et al., Reference Rebuschat, Rohrmeier, Hawkins and Cross2012; Arbib, Reference Arbib2013). In a first approximation, it appears fairly safe to say that language organizes sound events primarily to express meaning, while the organizing principles of music are directed primarily to the external form of sound events.Footnote 1 At a closer look, however, such a clear-cut differentiation is problematic, since music is meaningful in many ways that are observable also in language (Sloboda, Reference Sloboda1998; Koelsch, Reference Koelsch2011; Reich, Reference Reich2011; Schlenker, Reference Schlenker2022). In language, on the other hand, the external form of expression (Saussure’s signifiant) also follows principles that do not contribute to the construction of propositional meaning but to the optimization of itself. In establishing a single and integrative form of representation, we hope to expose more clearly which principles of construction may be claimed to rely on shared cognitive resources and which are particular to language or music.
A caveat is necessary right from the start. Time is a far less stable object to study than our omnipresent watches want to make us believe. The Greek rhetorical tradition knew the difference between chronos and kairos, the latter being conceived as the subjectively perceived time with relation to a meaningful moment. In a similar conception, Husserl (1928) rejects the objective, “vulgar” time and investigates the inneres Zeitbewußtsein (‘consciousness of internal time’). The difference between chronological time and kairotic time may be illustrated with John Cage’s famous piece 4’33 (composed in 1952), in which a pianist or any other musician or group of musicians enter the stage of a concert hall and play during four minutes and 33 seconds nothing. These 4’33 minutes of silence may be perceived infinitely longer than the chronologically same 4’33 minutes in a concert with real music. We believe that the cognitive representation of time in both language and music must be at least partly kairotic, and that is one of the reasons why we face many methodological problems, because kairotic time escapes from approximation with objective instruments (see White and Malisz, Reference White, Malisz, Gussenhoven and Chen2020, for a similar view on time in language).
To understand structural parallels and divergences between linguistic and musical timing, we will have to consider forms and their functions at different levels of organization. In language, this may relate to the construction of morphemes by phonemic features, the metrical construction of feet, or the delimitation of words and phrases. These forms are related to systemic functions such as distinctivity, delimitativity, culminativity – and rhythmicity, to add a fourth to Trubetzkoy’s (Reference Trubetzkoy1939) three core functions in phonology. Many scholars hesitate to accept rhythmicity as part of the linguistic system proper, while others readily posit a “rhythm rule” to project alternating strength to subsequent syllables (Hayes, Reference Hayes1995; Kager, Reference Kager1999). We believe that we need a principled representation of timing in phonological theory, since linguistic rhythm draws core distinctions between languages (see Chapters 32 and 34). In our view, however, not only in music but also in language, rhythm is fundamentally different from metrical projection. Rather, rhythm characterizes how events are placed in time in terms of their onsets and durations, and, in terms of performance, the way speakers or musicians behave towards an abstract metrical grid in time. As rhythm places events onto positions provided by the metrical grid, an acoustic linguistic or musical event may be placed at prominent or less prominent positions at different levels of the metrical grid. In subsymbolic time structure, events may further occur just before, right at, or a little after a prominent position, enabling further ways of subtle expressive differences. In music, creative play with establishing and breaking the metrical grid leads to interesting expressive and perceptual phenomena, for instance, groove (Witek et al., Reference Witek, Clarke, Wallentin, Kringelbach and Vuust2014), while in language, it may serve to encode subtle pragmatic modifications of meaning or just simply correspond to prosodic routines of a given speech community.
Accordingly, this chapter is concerned with prominence and timing and their functions in language and music. First, we review the core characteristics of musical rhythm; second, we turn to review a range of linguistic configurations of time and prominence; third, we propose a new autosegmental-metrical account across music and language; and fourth, we conclude with a discussion of cognitive implications and the identification of some research topics that we hope to clarify in our theoretical perspective.
27.2 Beats and Timing in Music
Time is a central category in music since music unfolds in its temporal order to combine various pitch and other sonic events. The foundation of temporal organization in music is based on an underlying beat structure, which defines the tempo of a musical piece and constitutes a quasi-universal across musical cultures (Patel, Reference Patel2008).Footnote 2 The beat defines two interrelated time structures: a symbolic time structure and a subsymbolic time structure (see Figure 27.1, which only focuses on the beat level in both time structures; hierarchical metrical structure is explained in Figure 27.2). The following text describes symbolic time structure first; the subsymbolic structure is characterized in detail at the end of the chapter.
The relationship between symbolic time structure (beat time) and subsymbolic time structure (real time).
The relationship between both time structures is characterized by their mapping of the reference beat. In other words, the idealized isochronic beat in beat time is distorted in subsymbolic real time.

Two examples of the metrical grid.
The left, two bars from the old folk song “Scarborough Fair,” displays an instance of an isochronic meter (here, 6/8); the right, three bars from the song “Seven Days” by Sting, shows an instance of a non-isochronic meter (5/4); note that the beat level combines 3/8 + 3/8 + 2/8 + 2/8.

At the symbolic level, the beat defines an isochronic unit, and, subsequently, a metrical structure is defined as a grid of prominence patterns based on the isochronic beat unit (Lerdahl and Jackendoff, Reference Lerdahl and Jackendoff1983; London, Reference London2004). The following is a summary characterization of common notions of musical meter, largely following the previous two references (for more information, see Giger, Reference Giger1993, and Patel, Reference Patel2008). In most forms of Western music in the past and present, metrical structures prefer the subdivision of the grid in terms of perfectly regular groups of two or three beats, which continue throughout the entire piece (unless there is a comparably rare case of a change of meter). It is further possible to employ non-isochronic metrical structures (such as 5/8, 7/4, 11/8, 21/8) in which metrical units cannot be fully derived by the prime factors 2 or 3. In such cases, metrical structures are derived as additives from units of 2 or 3 (London, Reference London2004): for instance, 5/8 could be derived as (2+3)/8 or (3+2)/8 or 7/4 as (2+2+3)/4, (2+3+2)/4, (3+2+2)/4. In such cases, the regular 2 or 3 subdivision continues at the other levels below the bar or at the hypermetrical level (beyond the single bar). Finally, given the possibility of non-isochronous meters, regular units could also be subdivided in a non-isochronous way, for example, 9/8 = (2+2+2+3)/8 or 4/4 = (3+3+2)/8. Generally, such non-isochronous metrical structures occur commonly in non-Western music, such as Turkish, Balkan, Arab, or Indian musical traditions. Figure 27.2 displays examples comparing isochronous (6/8) and non-isochronous (5/4) meters.
Furthermore, rhythmic event structures in music are defined in reference to the metrical grid: Rhythmic events may derive from simple integer ratios from the beat unit (e.g., 2, 3, 3/2, 1/2, 1/3, 1/4, 3/4, etc.) and are placed at regular positions on the grid. Since the grid could be potentially unboundedly subdivided by regular subdivision, events never land between grid points at the symbolic level, and simple grid positions are always preferred. Moreover, rhythmic structure of musical events may not occur entirely freely but has been argued to be recursively hierarchically structured (Longuet-Higgins, Reference Longuet-Higgins1979; Rohrmeier, Reference Rohrmeier2020): This is derived from understanding rhythmic structure not in terms of a sequence of event onsets and durations but in terms of time-span subdivisions, insertions, and shifts. For instance, the time span of a half note may be subdivided into two quarter notes, inducing one additional event onset in the middle of the time span. Also, an event at a strong metrical position may be prepared by the insertion of one or more upbeat events at the preceding weak metrical position, leading up to and strengthening the prepared event (this may entail a shortening or elision of the previously preceding event). In the case of a syncopation, an event on a strong metrical position may be shifted to an adjacent weak position (usually by half its duration). Because of its hierarchical substructure, musical rhythm and grouping structure may be conceived of as one converging property (extending Lerdahl and Jackendoff, Reference Lerdahl and Jackendoff1983; see Rohrmeier, Reference Rohrmeier2020).
Figure 27.3 displays an example of metrical and rhythmic structure in music (reproduced from Rohrmeier, Reference Rohrmeier2020; see also Reich and Rohrmeier, Reference Reich, Rohrmeier, Reina and Szczepaniak2014). The staff lines display the melodic line and its rhythm. The grid below the staff line displays the metrical grid, following the convention by Lerdahl and Jackendoff (Reference Lerdahl and Jackendoff1983). In the case of this example, the beat level is the line second from top (quarter-note level, below eighth-note level). Notably, there are points in the grid without note onsets (such as bar 2, beat 2, bar 4, beats 2,3,4 in the upper example). Most rhythmic events in the melody reinforce the grid at the beat or stronger (i.e., graphically lower) levels. This is also reconfirmed by statistical note onset histograms (see Huron, Reference Huron2006). Note that the example also indicates two hypermetrical levels beyond the bar unit. Hypermeter characterizes relations with a longer time span such as strong and weak bars or groups of bars; in the example, for instance, the first events of bars 1 and 3 (and 5) receive even stronger prominence, with bar 1 (and 5) being even stronger. The diagram illustrates the difference between a 3/4 and 4/4 meter. Remarkably, the division into triplets happens only once in the 3/4 grid while all other divisions are duple. Finally, the diagram illustrates that the overarching rhythmic Gestalt of the entire phrase is different in the 3/4 and 4/4 case despite the melodic structure and, particularly, its temporal inter-onset intervals being fully identical. This implies that the entire Gestalt depends on the interrelation of rhythmic structure and the meter. In terms of musical performance, this implies that musicians who would convey one over the other interpretation to the listener would employ various forms of fine-tuned performance parameters to reinforce the sense of meter and metrical prominence: This may include note stress in terms of micro-timing, timbre, or loudness, or highlighting grouping in terms of exaggerated transitions or rests in micro-timing. Further note that metrical ambiguity as in Figure 27.3 is empirically rare in music and hard to construct artificially. In most cases, melodies or musical pieces clearly establish their metrical structure in terms of their rhythm, that is, mainly through note onsets and durations (see also Huron, Reference Huron2006, for further explanation).
The same set of onsets and durations placed on two different metrical grids.
The resulting rhythmic Gestalt is different for the two cases.

In terms of music perception and production, one of the main theories of metrical perception understands meter as instantiated in terms of coupled oscillators in the brain, which direct attentional focus to predictive time points in the future (Large and Palmer, Reference Large and Palmer2002; Merchant et al., Reference Merchant, Grahn, Trainor, Rohrmeier and Fitch2015). In this way, the metrical grid is directly linked to models of temporal musical expectancy (see also Huron, Reference Huron2006).
At the subsymbolic level, there are different ways in which the metrical grid may be distorted (and with it the rhythmic structures on top without distorting their simple duration ratios): (i) There may be overarching tempo variations, such as the music speeding up or slowing down (accelerando, ritardando); (ii) there may be timing variations within phrases to accentuate certain parts (rubato, or phrase-final lengthening); (iii) the grid may be systematically distorted, for instance, in the swing ratio in jazz; (iv) events may occur with a subtle anticipation or delay from their expected onset position – this may contribute to aesthetic effects such as event stress or groove; (v) events may occur at imprecise positions compared to the idealized grid because of precision limits of human instrumental or singing performance (even computationally generated music may include such effects as “humanizing”). While tempo variations may affect a musical piece at large, the other effects constitute deviations that are commonly referred to as micro-timing. Micro-timing is usually much smaller than the reference beat level. Micro-timing properties may be highly distinctive of a musical style; for instance, consider the timing properties of a Baroque church organ prelude, which commonly establishes a relatively strict stable beat with rich micro-timing variations to compensate missing dynamic (loudness) variability options, compared with a piano phrase by Chopin, which typically involves free stretching and distortion of the beat in real time (rubato) in order to achieve expressive richness, a bebop solo phrase, which establishes a strict sense of beat, yet a high degree of meter-violating (= obscuring) note onsets (called syncopations), which contribute to establishing groove, and a Cuban salsa phrase, which similarly establishes a systematic conflict between rhythm (note onsets) and metrical structure in terms of high levels of syncopation, which establish its danceability and groove. All of the aspects of subsymbolic time structure in music have in common that they constitute continuous distortions of the grid or the precise timing of events on the grid, while the symbolic relations of rhythmic events and their grid positions remain intact.
27.3 Beats and Timing in Language
While musical structures show rich, playful variations of the relation between symbolic beats in abstract time and sonic events in real time, much of what is perceived as rhythmic in language follows a different teleology: The construction of phonological word forms and their syntactic combination to complex utterances is bound to convey semantics, understood in linguistics as propositions and their modal and pragmatic embedding. However, the ways in which these meanings are encoded by temporal relations and some of the rhythmic preferences of languages, dialects, communities, styles, or individual speakers show clear parallelisms to music that allow for the assumption of shared cognitive resources of these two communicative sound systems.
A good orientation is offered by Dufter (Reference Dufter2003). Building on standard approaches to linguistic rhythm typology (Dauer, Reference Dauer1983; Auer, Reference Auer1993) and metrical phonology (Liberman and Prince, Reference Liberman and Prince1977; Hayes, Reference Hayes1995; see also Chapter 34 for a review of linguistic rhythm typology with illustrations from Romance languages, and Chapter 11 for a critical assessment of rhythmic classes), he assembles a quaternary typology of linguistic rhythm (1) on the grounds of the systematic pairing of prominence and timing to distinctivity:
(1) Dufter’s (Reference Dufter2003, 132) four types of linguistic rhythm:
1. distinctive duration in the lexical phonology – mora-based rhythm
2. distinctive duration in the sentence phonology – phrase-based rhythm
3. distinctive prominence (in words and/or sentences) – prominence-based rhythm
4. no contrasts in the rhythmic contour – alternating rhythm
All four typological possibilities are well documented in the literature and are exemplified below. In the conception of Dufter’s approach, linguistic rhythm is rhythmic mostly in the perception of acoustic events that are shaped by the requirements of distinctivity at different levels of the phonological structure in order to construct meaning. In this conception, only the fourth type corresponds to rhythmicity as a goal in production: If the phonological configuration of a language grammaticalizes neither timing nor prominence for distinctive or delimitative functions, these two major domains of prosody are available for processes that are directed to the rhythmic shape of an utterance itself.
While we readily agree with the major line of this conception, we believe that it requires further elaboration. Firstly, just like it is the case for other linguistic typologies, it is necessary to understand that types do not map directly to particular languages. Rather, languages may feature more than one of the possibilities above and show, for example, both distinctive duration and distinctive prominence (as in German; see Examples (2) and (4) below), alternating prominence besides a system with delimitative duration in sentence phonology, or distinctive segmental length and final lengthening (see Paschen et al., Reference Paschen, Fuchs and Seifart2022), and so on.
Furthermore, not only particular languages but also styles and dialects may show preferences for a certain cluster of form-function pairs. Thus, speakers may superimpose alternating prominence over distinctive prominence in poetic styles and songs, and different dialects of a given language may choose different rhythmic patterns or different degrees of their realizations (see Chapter 34 for rhythmic differences between Spanish and Portuguese that cannot be attributed to different systemic functions of time and prominence).
27.3.1 Distinctive Segmental Length
27.3.1.1 Restricted to Stressed Syllables
Just as its variation in pitch, the variation of the duration of any acoustic event may encode many different meanings and systemic functions in language in many different ways. Thus, the duration of a vowel or a consonant may be a distinctive feature for the phonological form of a morpheme and thus establish the meaning of an expression. As is well known, many languages exploit duration in their segmental phonology in this sense to establish phonological length (see Laver, Reference Laver1994, for many examples). The words with different meanings in (2a) and (2b) are segmentally identical; their only external contrasts are formed by the length of the stressed vowels:
(2) Contrastive vowel length in German
a. Hüte /yːtə/ “hats” vs. Hütte /ˈhytə/ “cottage”
b. Rate /ˈʁaːtə/ “rate” vs. Ratte /ˈʁatə/ “rat”
In German and many other languages, however, long vowels may occur only in stressed syllables (Moulton, Reference Moulton1962; Reis, Reference Reis1974; Wiese, Reference Wiese1996). Thus, there is a restriction to a structural position specified in the form of the phonological word, which, in German, is distinctive, too. In Example (3) we observe a minimal pair in which initial stress (3a) is opposed to penultimate (3b) and the long vowel /aː/ appears only in the stressed syllable (3b), while it is short in (3a). In (4) the vowel /o/ is short before the stressed syllable (4a) but long if stressed as in (4b):
a. umfahren /ˈumfaʁən/ “knock down driving” vs. b. umfahren /umˈfaːʁən/ “drive around”
a. Biologie /bioloˈgiː/ “biology” vs. b. Biologe /ˈbioˈloːgə/ “biologist”
Many languages show culminativity in this sense: Every word has one and only one stressed syllable (Hayes, Reference Hayes1995, 24–25). Moreover, stressed syllables often accumulate acoustic events that implement prominence in the speech signal, such as increased intensity, the location of turning points of tonal events, full sonority, and longer duration of segments.Footnote 3 However, while this configuration is the case in many European languages, it is far from universal.
27.3.1.2 Not Restricted to Stressed Syllables
More complex is the configuration of languages such as Wolof (North-Central Atlantic Congo, Senegal, wol) or Conchucos Quechua (Quechuan, Peru, qxo). In these languages, distinctive duration is not restricted to a culminative syllable that bears lexical stress but may occur more than once and on any of the syllables of a word.
In Wolof, for example, both vowels and consonants show distinctive lengthening. Consider the following minimal pairs for lexical (5) and morphological (6) contrasts:
a. fat (clean up) vs. faat (dead, kill)
b. tol (a fruit) vs. tool (garden)
a. nop (love) vs. nopp (ear)
b. gën (to be better) vs. gënn (Mortar)
c. lemi (to fold) vs. lemmi (to unfold)
Lengthening may appear on any (medial in 7a, right edge in 7b and 7h, left edge in 7e, 7f, 7g, second in 7c), on more than one (7d, 7e, 7f, 7g), and even on adjacent (7e) syllables:
(7)
a. ko.ˈmaa.se “to start” (< an obvious loan from French) b. xa.ˈndoor “to snore” c. wo.ˈyaa.na.ˌti “to beg once more” d. wax.ˈtáa.nu.kaay “place for conversation” e. ˈxáa.raa.nàat “to show up again unannounced” f. ˈfee.sa.lu.ˌkaay “instrument used to fill” g. ˈtoo.gan.di.ˌwaat “to stay again for a while” h. ˈdo.xa.ntu.ji.ˌwaat “to go for a walk again” (Ka, Reference Ka1994, 225–232; see also Reich, Reference Reich, Gabriel, Pešková and Selig2020)
Length is obviously not restricted to a stressed syllable in this language but specified freely as an important feature of phonological word forms. Terminlogically, we can differentiate between restricted length as in the examples in Section 27.3.1.1 and free length as in Wolof.
27.3.2 Delimitative Phrasal Length
Final lengthening is a property both of musical and linguistic phrases. For instance, final lengthening is a salient delimitative property of the last syllable of the phonological phrase in French. This prosodic domain is pivotal for this language, inasmuch as it is the domain for the application of many rules such as liaison and the epenthesis of glottal stops at its initial boundaries, as well as for all tonal modulations, which apply at initial and final boundaries of phonological phrases (Jun and Fougeron, Reference Jun, Fougeron and Botinis2000; Pagliano, Reference Pagliano2003; see Chapter 34 for an illustration). In a cross-linguistic perspective, however, length at phrasal boundaries may apply together with or without other demarcative prosodic events, just as segmental length at the level of words.
Note that, just as in music (see Figure 27.1), the real phonological length of any phonological domain in concrete utterances varies with the speech rate of the conversation under study and by no means may be stated in absolute values in chronological time. Distinctive phonological length is an abstract, relative feature of segments and phrases. The events in real time that correspond to it are subject to many factors in discourse, such as emotional arousal, time pressure in spontaneous dialogues, stylistic preferences of individual speakers, and preferred rhythmic patterns of speech communities. Thus, temporal structure behaves very much like intonational structure, in which the tonal categories are abstract targets that the concrete tunes of fundamental frequencies match more or less.
27.3.3 Moraic Structure: Time as a Property of Syllables
Timing as a property of phonological words is not restricted to distinctive functions. In many languages, timing is also an important feature for the assignment of prominence, and for processes such as compensatory lengthening, reduplication, and truncation. The subsyllabic unit mora (symbolized as μ) accounts both for syllabic complexity and for length in phonological representations, often grouped under the metaphoric label weight. Ladefoged and Johnson (Reference Ladefoged and Johnson2011, 251) take the mora as a unit of timing. In standard approaches to metrical phonology (Hayes, Reference Hayes1989, Reference Hayes1995; Hubbard, Reference Hubbard, Connell and Arvaniti1995), moras dominate segments, and are in turn dominated by syllables (Figure 27.4).
Association of segmental timing properties to syllables in moraic structure.
In this representation, length is treated just as a segment in the coda of the syllable: The long vowel [aː] is associated to two moras in (b), while in (c) it is the consonant in the coda that is associated with the second coda. As any other item in symbolic prosodic phonology, moraic structure must be motivated by the observation of processes and rules that take them as domains for their application. Thus, the status of the mora must be specified for each particular language or dialect separately (Hayes, Reference Hayes1989, Reference Hayes1995; Féry, Reference Féry, Féry and Vijver2003; among many others).
27.3.4 Timing of Pitch Accents
Pitch accents are phonologically specified excursions from the phonetic downtrend of fundamental frequency (F0) contours that construct the shape of an intonational tune together with events at the boundaries of these tunes. They are associated with lexical stresses (if the language has lexical stress) in a systematic, meaningful way that specifies the temporal distance of a peak or valley with respect to the stressed syllable. These temporal differences change the pragmatic interpretation according to the specifications of a particular grammar. For example, in German, following Niebuhr (Reference Niebuhr2007) (see also Kohler, Reference Kohler2005), the peaks of tonal events may occur early (the low tone L following the peak H is associated with the stressed syllable: HL* in ToBIFootnote 4), medial (the high tone is associated with the stressed syllable: LH*), or late (the low tone is associated with the stressed syllable and the peak is reached after this syllable: L*H) with respect to the stressed syllable, and convey pragmatic meanings such as given, new, and unexpected.Footnote 5 In Figure 27.5, we reproduce the three possible tunes of the example eine Malerin from Niebuhr (Reference Niebuhr2007, 176) in a schematic way. The dotted lines delimit the stressed syllable (ma) and the solid line represents the F0 that we perceive as intonation.
Early (A), medial (B), and late (C) peaks in German eine Malerin (a painter).
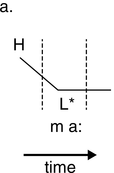
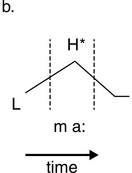
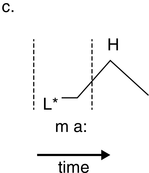
It is the temporal relation between an event and abstract knowledge about a prominent position that specifies the pitch accent in German. Many other, if not most, languages show such temporally specified pitch accents (see Moraes, Reference Moraes2008, for Brazilian Portuguese, and Estebas Vilaplana and Prieto, Reference Estebas Vilaplana, Prieto, Prieto and Roseano2010, for Castilian Spanish, among many others).
27.3.5 Iconic Lengthening
The need for a systematic representation of time becomes evident also in the observation of iconic timing, the manipulation of the length of the stressed syllable to express, for example, the extraordinarily long duration or size of a referred event (Schlenker, Reference Schlenker2018; Guerrini, Reference Guerrini2020). This expressive technique is available in many if not all languages. Interestingly, it is only possible in the stressed syllable, which is associated to a temporal representation that is clearly not derived from the phonological word form.Footnote 6
27.4 Representation of Time, Tone, and Prominence in an Autosegmental Model
27.4.1 Language
The temporal structures of linguistic forms outlined in Section 27.3 are comparable to the subtle temporal modulations we saw in Section 27.2, if we accept the necessary distinction between meter and rhythm also for language. The meaningful timing of events is possible because of an abstract metrical grid of prominences that are projected by the principle of alternating strength and at the speed entrained by the speech rate of an ongoing conversation. An event may occur early or late or be long only if there is a representation of when and how long it is expected to occur.
This argument relates to an important difference between the five structural timing specifications we presented in Section 27.3. Only the first two of them, segmental length and moraic structure, may be attributed to the phonological form of words. Let us call this level of timing intrinsic time. Final lengthening, relative timing of pitch accents, and iconic timing, however, cannot be derived from the lexicon. They must be associated to a level of time that is extrinsic to words. We believe that it is the very same level of time that forms the horizon for rhythmic patterns and subsymbolic timing in music: beats in time. It is the expectation created by the perceived periodic occurrence of sound events that models the metrical grid as a canvas for rhythmic events to be expected to occur. In music, metrical structure is induced by few note events or percussive events (or, externally, by counting in), while in language, what creates the temporal expectation of future events are the peaks of sonority reached in the nuclei of syllables.Footnote 7 Just as in music, speakers infer the speech rate that is expected in a given conversation by entrainment (see Jungers and Hupp, Reference Jungers and Hupp2009, for experimental evidence).
How should we model extrinsic time in phonology? Autosegmental phonology (Goldsmith, Reference Goldsmith1976; Yip, Reference Yip2002; Leben, Reference Leben and Aronoff2013) is a framework that was first developed to account for the independence of tones in tone languages, in which tones are associated to one or many tone-bearing units (TBUs) (moras, syllables, vowels, depending on the language) in a segmental string. In order to be realized as an acoustic event, a tone (T) must be associated with a TBU. If we take syllables (σ) as TBUs for illustration, different phonologies arise out of different association principles. Consider Figure 27.6: In (a) every tone is associated one to one with a particular TBU, in (b) many tones are associated with one TBU, in (c) one tone is associated with many syllables, and in (d) one tone is left without association as a so-called floating tone.
Possibilities for the association of tones to syllables.

Thus, the association lines define the tonal grammar by specifying relations across different domains: Tones are seen as an independent layer of structure that is associated to the segmental string.Footnote 8
Autosegmental-metrical theory (AM) (Pierrehumbert, Reference Pierrehumbert1980; Ladd, Reference Ladd2008; Arvaniti, Reference Arvaniti, Barnes and Shattuck-Hufnagel2022; Grice, Reference Grice, Barnes and Shattuck-Hufnagel2022) takes the general principles further to intonation and metrical prominence. Pitch accents are associated with stressed syllables and boundary tones are associated with edges of (different instantiations of) phonological phrases. In this line of research, the representation of a segmental, a metrical (often reduced to lexical stress), and a tonal layer have proved to be a successful and elegant model for many linguistic phenomena (e.g., the shapes of pitch accents discussed in Section 27.3.3). It seems to us to be ideal for the modelling of complex relations between different structural domains, and we want to take it further by adding an additional independent layer for extrinsic, kairotic timing relations: beats in time.
Time appears in the analytic practice of AM:Footnote 9
(i) as a distinctive feature at the segmental level
(ii) as a correlate of phonological weight in the moraic structure
(iii) in the meaningful association of complex tones to lexical stress.
The third level is not well specified. Most scholars improvise an additional impressionistic diacritic (such as “>” for “late”) that may serve for preliminary differentiation of tonal categories, but it lacks precisely the representation of the extrinsic temporal anchors for the association of tones that we are trying to establish here. There must be a temporal layer that is not a property of word forms but serves as the horizon unto which prosodic events are projected in performance. We suggest to introduce an additional tier that represents these beats in extrinsic time.
Linguistic structure is bound to construct meaning in the first place, and the design of the phonological form itself is a subordinated, secondary function of linguistic phonology. These two different functional realms, however, work on the same substance: tones, time, and prominence. This is also the substance of temporal metrical organization of music, but genuine musical structure has nothing comparable to words. The level of comparison between music and language is to be found in the abstract temporal relations in the metrical grid, rather than in problematic direct analogies (e.g., words = tones, syllables = tones, etc.). In most musical traditions, the melodic, harmonic, and rhythmic structures are primarily organized to trigger aesthetic effects of different kinds, but less for the construction and modification of propositional and pragmatic meanings (Reich, Reference Reich2011). We argue that it is possible to represent both music and language in a unified representation along the main lines of AM, with the difference that in music (i) there are no morphemes and (ii) the inventory of tones is bigger and needs more information than just high (H) and low (L).Footnote 10
Just for the sake of illustration, we recorded the German utterance Sie fanden eine Lagune in der Wüste (‘They found a lagoon in the desert’) with a reading of unexpectedness and analyzed it in Praat (Boersma and Wennink, Reference Boersma and Weenink2023) to be able to show late peaks (see Figure 27.7). As Kohler (Reference Kohler2005) and Niebuhr (Reference Niebuhr2007) already demonstrated, the peak of the rising tone in Lagune occurs after the stressed syllable. Obviously, there is also a high boundary tone (H-) in the last syllable of the phrase Sie fanden eine Lagune, but the rise that begins with the associated low tone in the stressed syllable clearly reaches its peak also only in this syllable, thus forming a plateau. The following pitch accent is realized with a medial peak: The turning point of F0 occurs within the stressed syllable.
Intensity and F0 of an utterance with late peak in German.
Figure 27.7 Long description
The spectrogram shows the frequency in hertz and intensity in decibels of the sound over time. It depicts a solid line for the fundamental frequency, F 0 of the speech and a dotted line for the intensity of the sound. The text below the spectrogram shows the words of the phrase and their phonetic transcription. The row below the text shows the tone of the phrase. The symbols indicating the tones are as follows. L asterisk greater than H, H hyphen, L asterisk H and L.
A full-fledged representation of prosodic domains in autosegmental layers for this example is shown in Figure 27.8.
Inventory of prosodic domains association to beats for German eine Lagune in der Wüste.
Figure 27.8 Long description
Syllables are denoted by inverted alphabets. Moras are denoted by the symbol mu. Beats are denoted by x, while feets are denoted by either x or dot. Some segments consist of tones, p boundaries and lexical stress. Tones are denoted by L and H. P boundaries are denoted by the percent symbol. Lexical stress is denoted by the asterisk mark.
The phonological rules that construct the German utterance eine Lagune in der Wüste with the meaning of unexpectedness are the following, starting from the bottom line:
(i) The beats in time are entrained by the more or less periodic recurrence of peaks of sonority, the nuclei of syllables in the speech rate of a given conversation. The speech rate experienced in the conversation gives rise to their projection. These beats are not derived from the phonological word forms and are consequently independent from linguistic substance. Thus, they may be associated with iconic lengthening, compensatory lengthening (Hayes, Reference Hayes1989), or processes of catalexis (Jacobs, Reference Jacobs and Mazzola1994).
(ii) Feet are constructed by the assignment of alternating strength to the beats. This is the level of metrical grid construction that is in principle identical to the musical metrical grid, with the difference that it is restricted by the association to prosodic domains such as words or phrases.Footnote 11 Moras, then, are temporal representations of the segmental material in syllables and work as hinges between intrinsic and extrinsic time.
(iii) Stress is a feature of phonological word forms, projected by a morphological rule or derived by metrical algorithms, depending on the particular language (see van der Hulst, Reference van der Hulst1997, Reference van der Hulst2012; Hyman, Reference Hyman and van der Hulst2014). In German, stress is lexically or morphologically distinctive and must be kept salient for the processing of content. That is the reason why feet must align with stressed syllables and, consequently, some syllables remain metrically unparsed (as the first and the last syllable in Lagune).
(iv) The chains of segments construct the morphemes that encode lexical meanings (including their syntactic features).
(v) Pragmatics decides on the assignment of phrase boundaries and the form of pitch accents: The partitioning of utterances in background and focus projects phonological phrases delimited by boundary tones and shapes the form of pitch accents,Footnote 12 specified by their timing with respect to stressed syllables. In Figure 27.8, the pragmatics of the asserted unexpected event is expressed by the late timing of the high tone of the rising pitch accent: Its low tone is associated with the stressed syllable and its corresponding beat in time, while its high turning point is associated only with the beat in time that corresponds to the following syllable. This is an innovative aspect of our representation: Tones may feature an additional association with extrinsic representations of time, just as musical events.Footnote 13 This is where we find a clear parallelism to the expressive relation of real-time events to the beat time of the grid in music: Peaks need not occur where the symbolic beats project them but may surface in real time earlier or later. We model these relations by additional associations to beats in time.
27.4.2 Music
If we represent the musical pieces discussed in Section 27.2 and Figure 27.3 in an autosegmental model that specifies independent layers of structure and their association as in Figure 27.9, we find many comparable aspects to prosodic structures in linguistic utterances, but also many differences. In music, the layers of segments and words are absent since there are no words or morphemes. Tones are less directly organized with respect to semantics and pragmatics, but most directly with respect to other musical systems, such as melodic structure, voice-leading, and also harmony (in the case of Western tonal music); a majority of these systems are assumed to be hierarchical (Schenker, Reference Schenker1956; Lerdahl and Jackendoff, Reference Lerdahl and Jackendoff1983; Mukherji, Reference Mukherji2014; Clarke, Reference Clarke2017; Rohrmeier and Pearce, Reference Rohrmeier, Pearce and Bader2018; Finkensiep et al., Reference Finkensiep, Widdess and Rohrmeier2019). Thus, the musical case requires a much more elaborated inventory of tones and systematic pitch relations than just the relative categories High and Low. Notably, since there is no smallest metrical base level in music as the beat can be subdivided indefinitely, there may be levels below the beat level, as the musical score in analysis (Figure 27.10) indicates with the eighth-note level (binary subdivision of the beat).
A representation of the last two bars of the example in Figure 27.3, 4/4 version.
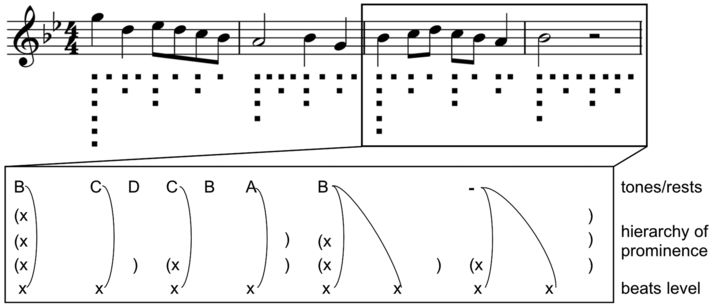
Figure 27.9 Long description
The musical notation consists of a treble clef, a time signature of 4 by 4, quarter notes and rests. There are dotted rhythms below the notation. A section of the notation is marked with a rectangular box and is expanded below to show the graphic representation. Below the notation, the graph consists of letters B, C, D, A and x, and parenthesis that correspond to tones or rests, hierarchy of prominence and beat levels.
A representation of the last two bars of the example in Figure 27.3, 3/4 version.
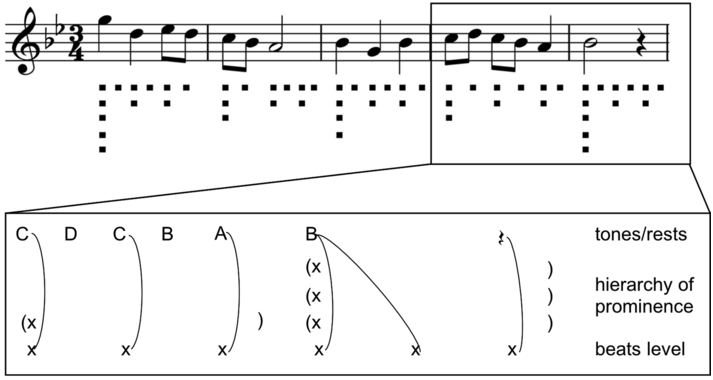
Figure 27.10 Long description
The musical notation consists of a treble clef, a time signature of 3 by 4, quarter notes and rests. There are dotted rhythms below the notation. A section of the notation is marked with a rectangular box and is expanded below to show the graphic representation. Below the notation, the graph consists of letters B, C, D, A and x, and parenthesis that correspond to tones or rests, hierarchy of prominence and beat levels.
The phonological rules that construct the musical utterances in Figures 27.9 and 27.10 are the following:
(i) A stable beat is entrained in musical performance (snapping, clapping, counting, playing) and defines a first, base (= reference) level of the metrical grid. By convention, beats in time are typically related to the temporal specifications of quarter notes. As the beat may be further subdivided, smaller units such as eighth notes may also be established in the metrical grid, as in the musical examples above. Since it is not central to our considerations, we skipped this level in the autosegmental representation.
(ii) The assignment of alternating strength to the beats in time creates a first level of the metrical grid. In a 4/4 or 2/4 meter (Figure 27.9), binary attribution of strength leads to one or two groups of prominence within each bar, which may be assigned additional prominence at higher levels. In a 3/4 system (Figure 27.10), the same tonal events (with the exception of the first B, which is parsed in the preceding bar) are bracketed in a ternary analysis.
(iii) Different to stress systems in language, all metrical groups commonly have their strongest stress come first rather than last, that is, they are left-headed (strong is initial), which is a direct consequence of the indefinite cyclic repetition of the metrical grid. Since musical events are not mapped to morphosyntactic categories such as words or phrases, they are in principle unbounded. The same holds for meter in poetry (Lerdahl and Halle, Reference Lerdahl and Halle1993; Lerdahl, Reference Lerdahl2001). Consequently, the decision of regarding a prominent event as initial or final is arbitrary. However, for the phenomenon of preparatory upbeats, partial grids before the prominent first stress are possible (see Lerdahl and Jackendoff, Reference Lerdahl and Jackendoff1983). This may be modelled with a set of offset values for each level of the metrical grid (see Rohrmeier, Reference Rohrmeier2020).
(iv) Notes at the beat level, that is, quarter notes and quarter rests, are associated with one beat in time, 1/2 notes and 1/2 rests are associated with two beats in time, and so on for more complex timing values. These associations specify the length of events, just as the intrinsic length of phonemes is represented as a secondary association of the moraic structure to beats in time. Tones may also land between beat positions, depending on their regular subdivision of the beat level.
(v) All other levels may reinforce the prominent positions of lower levels, at a regularity of two or three positions, and with a given offset that is smaller than their regularity. For complex non-isochronous meters, additive rules apply, as outlined above (Section 27.2, paragraph 2).
27.5 Conclusions and Perspectives
The unified form of representation for linguistic and musical timing that we introduced in this chapter made some important shared principles of structure building more transparent, but also showed some of the fundamental differences. In music, there is a fundamental distinction between idealized symbolic time structure established by an ideal isochronic beat and a subsymbolic time structure (real time), which governs distortions of the grid for expressive and stylistic purposes; we assume that the same distinction is equally fundamental in language, although it has not yet been postulated in linguistic research. Both music and language specify their temporal structure with respect to both the intrinsic length of individual events (notes or phonemes) and to extrinsic beats in time. Both music and language construct idealized hierarchical patterns of metrical prominence building on beats in time in symbolic time structure. Both music and language organize the temporal relation of real events with respect to the beats in time with which prominent positions are associated (this is further evident in text setting of songs to music: Lerdahl and Halle, Reference Lerdahl and Halle1993; Dell and Halle, Reference Dell, Halle, Aroui and Arleo2009).Footnote 14 Rhythm defines the placing of events on the metrical grid in both language and music. In music, subtle temporal specifications at the level of real time lead to expressive and potentially stylistic differentiation, while in many languages, the relative real-time timing of pitch events with respect to stress is grammaticalized to convey pragmatic meanings.
Our work also establishes a conceptual ground to establish notions of rhythm and meter in a joint common language, which have different traditions of use in music-theoretical and linguistic research. The word rhythm may be used to denote temporal phenomena as a whole; we refrain from this use and speak about time or temporal structure in music and language. In music, meter and metrical structure refer to an abstract hierarchical grid of time points that correspond at their psychological implementation with cyclical points of heightened psychological attention (London, Reference London2004), which may be reinforced by note onsets or expressive musical parameters. Following others (e.g., Patel, Reference Patel2008), we argue that, in principle, the same metrical structure is established in language and music. If meter establishes a white canvas of potential event positions, rhythm (in the narrow sense) characterizes the placing of events and their duration on the grid. Since music is not bound to words and their meaning, rhythmic structure in music may be extensively more complex than in language in terms of its phenomenological diversity as well as its potential construction principles (see, for example, Giger, Reference Giger1993; Nierhaus, Reference Nierhaus2009; Toussaint, Reference Toussaint2019).
Major differences between language and music arise from the grammaticalization of timing and prominence for the construction of the phonological form of morphemes, words, and phrases that carry semantic and pragmatic meaning. Thus, many of the cues for the perception of temporal structures and metrical patterns are derived in the lexicon and in the morphosyntactic structure that are absent in music. Consequently, the variation of temporal and metrical configurations is more varied and complex in music than in language.
Besides the principal goal to uncover the cognitive architecture of music and language, the establishment and further elaboration of a unified form of representation of timing and prominence across different domains of human behavior may contribute to address many important research questions. The coordination of gestures with linguistic utterances must specify a temporal anchor that is shared by both systems. Furthermore, the projection of linguistic onto musical forms will have to rely on the possibility of the association of both to a common cognitive representation. The same argument holds in principle also for other activities that are coordinated with musical forms, such as dance or even dynamic light installations. If we really want to understand the cognitive architecture of humans, we will need a common model for the representation of general and particular principles of structure building.
27.6 Acknowledgements
The contribution of Martin Rohrmeier has been in part funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (GA No 760081– PMSB). Martin Rohrmeier thanks Mr. Claude Latour for supporting this research through the Latour Chair in Digital Musicology.
Summary
Our contribution offers an overview of functions of timing and prominence in language and music. We argue that linguistic analysis should integrate a more systematic approach to temporal structures that cannot be derived from phonological word forms, and suggest a unified form of representation in the spirit of AM.
Implications
The suggested unified form of representation allows for a more systematic differentiation between metrics and rhythm in linguistic analysis. This form of representation should be available also for the multimodal analysis of speech and gestures or music and dance.
Gains
In comparing systematically the principles of structure building in music and language, we hope to contribute to the endeavor of disentangling shared and particular cognitive resources of language and music. This perspective is extendable also to research across species by identifying the timing relations that build up the structure of vocal communication in other animals.
28.1 Introduction
The current chapter focuses on potential connections between music and speech rhythm processing. Music and speech share a remarkable number of qualities, including acoustic features, temporal and sequence processing, and hierarchical structure building. Studying music and speech rhythm processing together provides broader insights into perception and cognition than when studying each domain separately. This chapter will outline similarities and differences between music and speech rhythm in relation to (1) acoustic elements and their perceptual and cognitive processing; (2) correlational links between the processing of rhythm in both domains; and (3) experimental studies showing effects of music rhythm training on language skills. It will then open out to what these links can suggest for (4) clinical research, and (5) future perspectives for both fundamental and applied research.
28.2 Acoustic and Cognitive Similarities between Music and Speech Rhythm
28.2.1 Acoustic Similarities between Music and Speech Rhythm
Music and speech are acoustic signals that are structured and delivered in time, containing frequency (pitch), intensity (loudness), timbre (sound quality), and duration (timing) information. For each domain, the ordering and duration of the events in time are referred to as rhythm (London, Reference London2012; McAuley, Reference McAuley and Jones2010). Importantly for the current discussion, a major difference between music and speech rhythm is that music is typically structured in time so that events occur regularly, and their onsets can be easily predicted by listeners (Jones, Reference Jones2018; Patel and Morgan, Reference Patel and Morgan2017). In most music, this regularity in rhythm gives rise to the perception of an underlying regular (isochronous) beat, which listeners are able to extract and to move along with (e.g., Repp and Su, Reference Repp and Su2013), and which drives auditory-motor activation and connection (Morillon and Baillet, Reference Morillon and Baillet2017; Zatorre et al., Reference Zatorre, Chen and Penhune2007). As has been noted throughout this book (see Chapter 26), speech rhythm does not contain this same kind of regularity, and intervals between speech elements (syllables, words) are not perfectly regular. There is a large discussion in the literature around whether speech can be considered rhythmic (Nolan and Jeon, Reference Nolan and Jeon2014; Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2013), and a long history of searching for periodicity in speech has proven difficult (i.e., searching for measures to categorize “stress-timed” versus “syllable-timed” languages; see Chapters 7 and 9). However, research has shown that speech rhythm emerges through the interaction of accentual, prosodic, and lexical factors, which create patterns of stress (Beier and Ferreira, Reference Beier and Ferreira2018; Goswami and Leong, Reference Goswami and Leong2013; Kohler, Reference Kohler2009) and prominence (see Kohler, Reference Kohler2009). These rhythmic patterns, which have also been referred to more globally as prosodic structure and surface speech timing (Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2013), have been shown to aid the segmentation of the acoustic signal into syllables, words, and phrases (Cutler, Reference Cutler1994; Spinelli et al., Reference Spinelli, Grimault, Meunier and Welby2010), allow for the prediction of upcoming information (Beier and Ferreira, Reference Beier and Ferreira2018), and facilitate turn-taking between speakers (see Pickering and Garrod, Reference Pickering and Garrod2013).
In both music and speech, the structuring of acoustic events in time can be described as creating a hierarchical structure, where smaller event units are embedded within larger event groups or chunks. In music, interacting acoustic and temporal patterns create – based on the underlying regular pulse – metrical structures with a metric hierarchy, leading to the perception of strong and weak beats (Lerdahl and Jackendoff, Reference Lerdahl and Jackendoff1983; London, Reference London2012; Povel and Essens, Reference Povel and Essens1985). In speech, the interacting acoustic and temporal patterns relate to the combination of phonemes, syllables, and words into phrases and sentences that can also be integrated within a rhythmic hierarchy of more and less prominently accented elements (Beier and Ferreira, Reference Beier and Ferreira2018). The similarities and differences in acoustic cues, regularity, and hierarchically structured events suggest that the combined or at least comparative investigation of music and speech rhythm processing can provide novel insights into perceptual and cognitive processing and sequencing, with potentially shared mechanisms.
28.2.2 Cognitive Similarities between Music and Speech Rhythm Processing
Empirical research has suggested that the acoustic and hierarchical features of music and speech may be processed by the brain in a similar way (Heard and Lee, Reference Heard and Lee2020; Patel, Reference Patel2008), and several theoretical frameworks have been proposed aiming to better understand cognitive connections between music and speech rhythm processing as well as their neural correlates (e.g., Fujii and Wan, Reference Fujii and Wan2014; Patel, Reference Patel2011; Tierney and Kraus, Reference Tierney and Kraus2014). Here, we will outline the Processing Rhythm in Speech and Music (PRISM) framework, which focuses on three mechanisms underlying speech and music rhythm processing: precise auditory processing, synchronization/entrainment of neural oscillations to an external rhythm, and sensorimotor coupling (Fiveash et al., Reference Fiveash, Bedoin, Gordon and Tillmann2021; see Figure 28.1). PRISM was developed on the basis of previous theoretical frameworks of music, speech, or music and speech processing that each discuss some of the individual mechanisms potentially involved in the processing of one or both domains. The goal of PRISM is to provide a larger perspective that traverses music and speech. PRISM extracts and combines the most central mechanisms discussed across different theories into a single framework, which can inform new research. In addition, PRISM also aims to provide future directions to identify specific mechanisms that could be underlying the effects of music rhythm training in the long term, and rhythmic stimulation in the short term, on speech and language processing.
The PRISM framework.
The three mechanisms proposed in the PRISM framework (Fiveash et al., Reference Fiveash, Bedoin, Gordon and Tillmann2021).
Figure 28.1 Long description
It shows three interconnected circles, reflecting three mechanism for rhythmic processing in music and speech: Precise Auditory Processing, Synchronization or Entrainment of Neural Oscillations, and Sensorimotor Coupling. The arrows show the connections between mechanisms.
Among the incorporated frameworks, the following three were the most influential when creating PRISM: the Sound Envelope Processing and Synchronization and Entrainment to Pulse (SEP) hypothesis (Fujii and Wan, Reference Fujii and Wan2014), the Precise Auditory Timing Hypothesis (PATH) (Tierney and Kraus, Reference Tierney and Kraus2014), and the Temporal Sampling Framework of developmental dyslexia (TSF) (Goswami, Reference Goswami2011). Larger theoretical frameworks including the Overlap, Precision, Emotion, Repetition, and Attention (OPERA) hypothesis (e.g., Patel, Reference Patel2014), the Dynamic Attending Theory (Jones, Reference Jones1976, Reference Jones2018; Jones and Boltz, Reference Jones and Boltz1989), and active sensing approaches (Morillon et al., Reference Morillon, Hackett, Kajikawa and Schroeder2015; Schroeder et al., Reference Schroeder, Wilson, Radman, Scharfman and Lakatos2010) also informed the current framework. Each of these frameworks point towards different, though partly overlapping, aspects of the music and speech/language connection, which PRISM aimed to combine with the proposition of three mechanisms, as presented below. Outlining these three mechanisms and their potential interactions – both for deficits and expertise – lead to new research perspectives for both fundamental and clinical research.
28.2.2.1 Precise Auditory Processing
Precise auditory processing is the basis for the processing of complex acoustic information carried in the music and speech signals, notably in relation to frequency, duration, and timbre. It is often tested by the investigation of the perception of just noticeable differences of variations between sounds (e.g., see Niebuhr et al., Reference Niebuhr, Reetz, Barnes, Yu, Gussenhoven and Chen2020, for the pitch dimension). Regarding the time dimension, the auditory system can discriminate millisecond-level timing deviations, and even timing deviations that are below the conscious change detection threshold (i.e., at 3 ms, Madison and Merker, 2004). This precise auditory timing has been suggested to underlie numerous beneficial effects of music training on speech and language processing (Fujii and Wan, Reference Fujii and Wan2014; Kraus and Chandrasekaran, Reference Kraus and Chandrasekaran2010; Patel, Reference Patel2014). Precise auditory timing is the foundation of the SEP, PATH, and TSF hypotheses, and is reflected in the precision element of OPERA. Both SEP and PATH (drawing on the OPERA hypothesis) suggest that the precision necessary for successful entrainment, which is enhanced by music training (see Section 28.3), underlies the benefits of music training on phonological processing and on the segmentation of the speech signal (Fujii and Wan, Reference Fujii and Wan2014; Tierney and Kraus, Reference Tierney and Kraus2014). In addition, the SEP hypothesis suggests that the enhanced precision to process the sound envelope of a music signal can also benefit processing of the speech envelope (in relation to the overlap element of the OPERA hypothesis). The TSF focuses on encoding of the speech envelope, and a role of potentially impaired encoding in pathology, notably in line with the findings that children with developmental dyslexia are impaired in precise tracking of the speech envelope (Goswami, Reference Goswami2011; Goswami et al., Reference Goswami, Power, Lallier and Facoetti2014). In particular, individuals with dyslexia are impaired in detecting the rise time (or onset) of incoming syllables in speech perception (Di Liberto et al., Reference Di Liberto, Peter and Kalashnikova2018; Goswami et al., Reference Goswami, Gerson and Astruc2010; Leong and Goswami, Reference Leong and Goswami2014; Power et al., Reference Power, Colling, Mead, Barnes and Goswami2016), which requires precise auditory processing and the synchronization/entrainment of neural oscillations (see Section 28.2.2.2). The different theoretical frameworks proposed earlier therefore point to a strong overlap between cognitive and neural correlates involved in music and speech rhythm processing in relation to precise auditory processing. This research suggests that music rhythm training can enhance the precision by which listeners process not only the music signal but also the speech signal.
28.2.2.2 Synchronization/Entrainment of Neural Oscillations to External Stimuli
Neural oscillations are endogenous rhythms of electrical activity that can be observed throughout the brain, and are hypothesized to support numerous cognitive processes (Buzsáki and Draguhn, Reference Buzsáki and Draguhn2004). Neuroscience research has shown that neural oscillations can support the perception of speech (Giraud and Poeppel, Reference Giraud and Poeppel2012; Kösem et al., Reference Kösem, Bosker and Takashima2018; Kösem and Wassenhove, Reference Kösem and van Wassenhove2017; see also Chapters 3 and 5) and of music (Fujioka et al., Reference Fujioka, Trainor, Large and Ross2012; Nozaradan et al., Reference Nozaradan, Peretz, Missal and Mouraux2011, Reference Nozaradan, Peretz and Mouraux2012) in a similar way (Harding et al., Reference Harding, Sammler, Henry, Large and Kotz2019). The role of neural oscillations is strongly developed in the TSF, briefly mentioned in PATH, and appears to be the neural basis of both sound envelope processing and synchronization and entrainment to pulse in the SEP hypothesis, though this is not explicitly stated. The role of neural oscillations is also essential to the dynamic attending theory (DAT). The DAT suggests that endogenous neural oscillations entrain to external rhythmic (or quasi-rhythmic) stimuli at multiple levels in a hierarchical fashion, resulting in levels of embedded neural oscillations that form nested oscillations (Jones, Reference Jones1976; see also Chapter 3). The entrainment of endogenous neural oscillations to external stimuli creates the foundation for hypotheses about how the brain predicts upcoming information, notably in time but also content (Arnal and Giraud, Reference Arnal and Giraud2012; Friston, Reference Friston2010; Friston and Buzsáki, Reference Friston and Buzsáki2016; Jones, Reference Jones2018). A more extended link has been further described between precise auditory processing and neural oscillations (Goswami, Reference Goswami2011; Poeppel, Reference Poeppel2003), as well as between neural oscillations and sensorimotor coupling (Morillon and Baillet, Reference Morillon and Baillet2017; van Wijk et al., Reference van Wijk, Beek and Daffertshofer2012).
28.2.2.3 Sensorimotor Coupling
Sensorimotor coupling refers to the connections between the auditory and motor cortices of the brain, and supports the perception and production of music and speech rhythm. The Action Simulation for Auditory Prediction hypothesis (ASAP) (Cannon and Patel, Reference Cannon and Patel2021; Patel and Iversen, Reference Patel and Iversen2014) and the active sensing framework (Morillon et al., Reference Morillon, Hackett, Kajikawa and Schroeder2015; Schroeder et al., Reference Schroeder, Wilson, Radman, Scharfman and Lakatos2010) suggest a tight connection between auditory and motor cortices, with the motor cortex implicated in generating precise auditory predictions (even in the absence of overt movement or movement preparation). The role of the motor system in generating auditory predictions could explain why motor cortex activation is routinely shown when just listening to music (Chen et al., Reference Chen, Penhune and Zatorre2008; Fujioka et al., Reference Fujioka, Trainor, Large and Ross2012; Gordon et al., Reference Gordon, Cobb and Balasubramaniam2018; Grahn and Brett, Reference Grahn and Brett2007) or to speech (Möttönen et al., Reference Möttönen, Dutton and Watkins2013; Wilson et al., Reference Wilson, Saygin, Sereno and Iacoboni2004). The role of the motor system in interaction with perception is illustrated by the human ability to seamlessly perceive and produce speech (e.g., turn-taking in conversations; Hidalgo et al., Reference Hidalgo, Falk and Schön2017; Pickering and Garrod, Reference Pickering and Garrod2013; see also Chapter 6), or to move in time with a song while on the dance floor (e.g., Janata et al., Reference Janata, Tomic and Haberman2012). Further, adding a motor component that is aligned with the regularity of the external stimulus can enhance the perception of that stimulus (Falk and Dalla Bella, Reference Falk and Dalla Bella2016). Both the SEP hypothesis and PATH focus on the role of the motor system in synchronizing and entraining the brain and body to an external stimulus. PATH suggests that motor entrainment (i.e., the act of aligning one’s movements with the onset of sound in a consistent way) satisfies all of the conditions laid out in the OPERA hypothesis, and could support transfer between music and speech processing abilities (in PATH, specifically phonological awareness), as well as enhance listeners’ precise auditory timing abilities.
28.3 Correlational Links between Music Rhythm and Speech Rhythm Processing
Similar acoustic and perceptual features (i.e., frequency/pitch, intensity/loudness, and timbre/sound quality), rhythmic structures (related to durational cues), as well as perceptual and cognitive processing mechanisms, including hierarchical structure processing, provide the basis for the investigation of potential transfer effects and connections between speech and music skills. This section will focus primarily on reported correlations between musical rhythm skills (measured mostly through rhythm production, rhythm perception, and synchronization to an external pulse) and various speech and language skills. One of the questions resulting from the observation of transfer or of correlations between music and speech/language processing is how to define the mechanisms that underlie these connections. Transfer effects and correlations have been observed for both (1) skills related to rhythm, temporal organization, and auditory discrimination (e.g., in word segmentation, word encoding, speech rhythm awareness, and phonological awareness, which could be considered as more low-level or direct transfer), and (2) literacy skills not necessarily related directly to rhythm processing per se (e.g., reading, syntactic processing, and spelling, which could be considered as more high-level or indirect transfer; see Besson et al., Reference Besson, Chobert and Marie2011; Bigand and Tillmann, Reference Bigand and Tillmann2022; Miendlarzewska and Trost, Reference Miendlarzewska and Trost2014). The low-level transfer effects might be based on improvement of fine-grained temporal processing and the synchronization of neural oscillations to external stimuli, which have been shown to be improved through musical training (Goswami, Reference Goswami2011; Tallal and Gaab, Reference Tallal and Gaab2006; Tierney and Kraus, Reference Tierney and Kraus2013). High-level language and literacy skills may develop from the more direct transfer, as the development of fine-grained temporal processing skills enhances sensitivity to speech rhythm, facilitating the processing of phonemes and syllables and in turn enhancing these higher-level language and literacy skills (Holliman et al., Reference Holliman, Wood and Sheehy2010; Tallal and Gaab, Reference Tallal and Gaab2006; Tierney and Kraus, Reference Tierney and Kraus2014). The review of the following correlational studies is presented with a couple of caveats. First, while correlational data are an important piece of the puzzle when understanding transfer effects, they should be interpreted with caution, and alongside longitudinal, experimental studies that consist of an experimental group and a control group that also receives some kind of nonmusical training (see Section 28.4). Second, correlational studies comparing musicians to nonmusicians cannot focus on music rhythm training specifically, as musicians are exposed to a large variety of musical training beyond only rhythm-focused aspects. In the following sections, we will first focus on potential beneficial effects of musical training on encoding, segmentation, and phonological awareness, before moving on to reading, syntax, and spelling.
28.3.1 Encoding, Segmentation, and Phonological Awareness
One link between musical rhythm skills and low-level speech processing is based on the processing of acoustic features. At the encoding stage of sound events (i.e., when acoustic features of a sound are first processed), musicians (compared to nonmusicians) show earlier and larger brainstem responses to the onset of both musical sounds and speech syllables (Musacchia et al., Reference Musacchia, Sams, Skoe and Kraus2007). Compared to nonmusicians, musicians also show enhanced syllable discrimination abilities based on amplitude rise time and voice onset time (Zuk et al., Reference Zuk, Ozernov-Palchik and Kim2013), perform better in speech-timing discrimination tasks (Sares et al., Reference Sares, Foster, Allen and Hyde2018), are quicker and more accurate at segmenting words in an artificial language (François et al., Reference François, Jaillet, Takerkart and Schön2014), and are more sensitive to metrically incongruous words (Marie et al., Reference Marie, Magne and Besson2011). Correlational studies have shown that (1) rhythm perception proficiency (as measured with a same-different rhythm task) is correlated with the amplitude of neural responses to violations in speech rhythm for nonmusicians (Magne et al., Reference Magne, Jordan and Gordon2016); (2) beat entrainment abilities in young children are correlated with more precise neural encoding of the speech envelope (Woodruff Carr et al., Reference Woodruff Carr, White-Schwoch, Tierney, Strait and Kraus2014); and (3) higher music rhythm perception abilities are correlated with more consistent grouping of speech rhythms in adults with varying musical ability (Boll-Avetisyan et al., Reference Boll-Avetisyan, Bhatara and Höhle2017). These rhythm-related skills as well as speech encoding and segmentation skills may contribute to phonological awareness abilities.
Phonological awareness is a central element of language learning and relates to the ability to manipulate and break up units of speech sounds, such as words, syllables, and phonemes (Ball, Reference Ball1993; Gordon et al., Reference Gordon, Fehd and McCandliss2015a). Several studies have shown links between phonological awareness and musical rhythm skills in school-aged children. For example, in typically developing children, phonological awareness measures correlate with performance in rhythmic discrimination tasks (Ozernov-Palchik et al., Reference Ozernov-Palchik, Wolf and Patel2018), as well as rhythm perception and production tasks (Degé et al., Reference Degé, Kubicek and Schwarzer2015), rhythm and melody repetition tasks (Cohrdes et al., Reference Cohrdes, Grolig and Schroeder2016), and rhythm production skills over development (David et al., Reference David, Wade-Woolley, Kirby and Smithrim2007). Links between rhythm perception and production skills and phonological awareness skills have also been shown in pathology, notably for children with dyslexia (Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2014; Huss et al., Reference Huss, Verney, Fosker, Mead and Goswami2011; Thomson and Goswami, Reference Thomson and Goswami2008) and developmental language disorder (Corriveau and Goswami, Reference Corriveau and Goswami2009). For example, Flaugnacco et al. (Reference Flaugnacco, Lopez and Terribili2014) showed that both rhythm reproduction and rhythm tapping correlated with phonological awareness in children with dyslexia (see also correlations with reading skills). Note that the potential relations between “phonological awareness” and “rhythm” abilities vary across studies, and that these patterns of correlation (versus noncorrelation) seem to be influenced by the types of tasks used to measure these broader constructs.Footnote 1
28.3.2 Reading, Syntax, and Spelling
Music rhythm skills have also been shown to correlate with reading, syntax, and spelling abilities. For example, music aptitude (especially music perception skills) and reading ability were shown to correlate with subcortical responses to predictable speech sounds, and these subcortical responses were reduced in poor readers (Strait et al., Reference Strait, Hornickel and Kraus2011). Groups with musical training also showed enhanced novel word learning (through picture–word associations) for children (Dittinger et al., Reference Dittinger, Chobert, Ziegler and Besson2017) and adults (Dittinger et al., Reference Dittinger, Barbaroux and D’Imperio2016). Further, rhythm perception abilities correlate with rapid word naming (Bekius et al., Reference Bekius, Cope and Grube2016), enhanced grammatical skills (Gordon et al., Reference Gordon, Shivers and Wieland2015b), and both reading and spelling skills while controlling for the effect of verbal ability (Douglas and Willatts, Reference Douglas and Willatts1994), and reading attainment (Holliman et al., Reference Holliman, Wood and Sheehy2010). Converging results have been reported for rhythm production abilities. For example, paced tapping performance correlates with word and nonword reading (González‐Trujillo et al., Reference González‐Trujillo, Defior and Gutiérrez‐Palma2014; Tierney and Kraus, Reference Tierney and Kraus2013), and rhythm production skills at school entry (~six years) predict: (1) reading and spelling at the end of the first year of school (Kertész and Honbolygó, Reference Kertész and Honbolygó2021; Lundetræ and Thomson, Reference Lundetræ and Thomson2018), (2) reading skills at the end of the second year of school (Dellatolas et al., Reference Dellatolas, Watier, Le Normand, Lubart and Chevrie-Muller2009), and (3) reading and spelling skills in the third year of school (in the same children as listed in (1): Kertész and Honbolygó, Reference Kertész and Honbolygó2023).
Links between rhythm perception and production and reading skills have also been shown in children with dyslexia (Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2014; Goswami et al., Reference Goswami, Thomson and Richardson2002; Huss et al., Reference Huss, Verney, Fosker, Mead and Goswami2011; Thomson and Goswami, Reference Thomson and Goswami2008) and developmental language disorder (Corriveau and Goswami, Reference Corriveau and Goswami2009). For example, Corriveau and Goswami (Reference Corriveau and Goswami2009) showed that children with developmental language disorder were impaired in paced tapping compared to age-matched control children, and that their paced tapping performance was related to reading and spelling measures.
28.4 Experimental Manipulations Investigating Links between Music and Speech Rhythm
28.4.1 Short-Term Rhythmic Stimulation
Experimental manipulations of music and speech materials have shown that rhythmic stimulation and entrainment to music can influence the subsequent processing of a speech signal – an experimental paradigm referred to as rhythmic cueing or rhythmic priming.
Rhythmic cueing studies involve a short rhythmic cue that matches one to one with the accents (stressed syllables) of a subsequent sentence.Footnote 2 These studies have shown that a matching rhythmic cue preceding a sentence enhances phoneme detection (Cason et al., Reference Cason, Astésano and Schön2015a; Cason and Schön, Reference Cason and Schön2012) and can enhance the neural response to a subsequent sentence (Falk et al., Reference Falk, Lanzilotti and Schön2017) compared to an irregular, mismatching cue. This effect can be boosted by simultaneous movement (e.g., tapping along; Falk and Dalla Bella, Reference Falk and Dalla Bella2016) and can also influence the sentence repetition performance of hearing-impaired children (Cason et al., Reference Cason, Hidalgo, Isoard, Roman and Schön2015b).
Rhythmic priming studies involve a longer rhythmic prime, typically 30 seconds, followed by a set of naturally spoken sentences. Such rhythmic priming experiments have shown that children and adults perform better at grammaticality judgments for auditorily presented sentences when presented after regular rhythmic primes compared to after irregular rhythmic primes or other control conditions (Canette et al., Reference Canette, Lalitte and Bedoin2020b; Chern et al., Reference Chern, Tillmann, Vaughan and Gordon2018; Fiveash et al., Reference Fiveash, Bedoin, Lalitte and Tillmann2020). This effect has also been observed for children with dyslexia and developmental language disorder (Bedoin et al., Reference Bedoin, Brisseau, Molinier, Roch and Tillmann2016; Ladányi et al., Reference Ladányi, Lukács and Gervain2021; Przybylski et al., Reference Przybylski, Bedoin and Krifi-Papoz2013), and can be seen in the brain response to syntax violations. The P600 neural response to grammatical errors increased after regular compared to irregular primes for adults with and without dyslexia (Canette et al., Reference Canette, Fiveash and Krzonowski2020a). Rhythmic priming also reinstated the P600 response for patients with basal ganglia lesions (Kotz et al., Reference Kotz, Gunter and Wonneberger2005), who typically do not show this response (Kotz et al., Reference Kotz, Frish, von Cramon and Friederici2003). In addition to grammatical error detection, recent research has shown a rhythmic priming effect for sentence repetition in children with and without developmental language disorder (Fiveash et al., Reference Fiveash, Ladányi and Camici2023b). These results show that in the short term, listening to a regular music rhythm with a strong metrical structure can improve the processing of the less regular speech signal in typically developing children and adults, as well as individuals with neurodevelopmental language disorders.
28.4.2 Long-Term Music (Rhythm) Training
Experimentally controlled music (rhythm) training studies have shown that speech and language abilities (especially speech rhythm processing and phonological awareness) can be enhanced following music training.Footnote 3 For example, Zhao and Kuhl (Reference Zhao and Kuhl2016) showed that musical activities focusing on temporal structures (12 sessions over a four-week period) enhanced nine-month-old infants’ sensitivity to the temporal structure of speech (and music), as measured by the neural response to rhythmic structural violations. A longitudinal study over two years showed that music training resulted in increased speech segmentation skills of eight-year-old children (François et al., Reference François, Chobert, Besson and Schön2013; see also Chobert et al., Reference Chobert, François, Velay and Besson2014, for a follow-up).
Other studies have reported that groups following experimentally implemented music training programs showed enhanced phonological awareness. For example, music training for 30 minutes a week over four months enhanced phoneme-segmentation fluency in kindergarten children (Gromko, Reference Gromko2005). In four- to six-year-old children, both music and phonological training, but not sports training, improved phonological awareness (Degé and Schwarzer, Reference Degé and Schwarzer2011; Patscheke et al., Reference Patscheke, Degé and Schwarzer2016). Several other studies have shown increased phonological awareness after music training (Bolduc and Lefebvre, Reference Bolduc and Lefebvre2012; Cogo-Moreira et al., Reference Cogo-Moreira, de Ávila, Ploubidis and Mari2013; Herrera et al., Reference Herrera, Lorenzo, Defior, Fernandez-Smith and Costa-Giomi2011; Moritz et al., Reference Moritz, Yampolsky, Papadelis, Thomson and Wolf2013). Phonological awareness has also been improved by music training (focusing specifically on rhythm) in dyslexic children (Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2015; see also Bonacina et al., Reference Bonacina, Cancer, Lanzi, Lorusso and Antonietti2015). These studies have also shown that the rhythmic training improved the dyslexic children’s reading performance, an effect that has been similarly shown in typically developing children.
Music (rhythm) training has also been shown to improve literacy skills. For example, Taub and Lazarus (Reference Taub and Lazarus2012) tested adolescents in Grades 9–10 (approximately 14–15 years old) and found that an experimental group who had 12 sessions of rhythm production training improved in their reading fluency and reading performance. Rautenberg (Reference Rautenberg2015) tested children in Grade 1 (approximately seven- to eight-years-old and showed that a group with eight months of music training (emphasizing both perception and production rhythmic skills) had enhanced reading accuracy. Further, eight-year-old children who underwent six months of music training (including rhythm, melody, harmony, and timbre training) showed improved reading performance (Moreno et al., Reference Moreno, Marques and Santos2009). In summary, music (rhythm) training programs have shown promising effects on different speech and language abilities, including improving speech rhythm processing, phonological awareness, and reading skills. Interestingly, the effect of the music training programs on phonological tasks, for example, can be similarly strong as that of specifically tailored language training programs (e.g., phonological training; see Bigand and Tillmann, Reference Bigand and Tillmann2022).
28.5 Clinical Perspectives
The link between rhythm and speech/language processing has been shown both in typically developing and clinical populations. Critically, research has revealed that processing music/rhythmic materials (perception and production) can improve speech/language processing through short-term stimulation (Bedoin et al., Reference Bedoin, Brisseau, Molinier, Roch and Tillmann2016; Fiveash et al., Reference Fiveash, Ladányi and Camici2023b; Ladányi et al., Reference Ladányi, Lukács and Gervain2021; Przybylski et al., Reference Przybylski, Bedoin and Krifi-Papoz2013) as well as long-term training (Bonacina et al., Reference Bonacina, Cancer, Lanzi, Lorusso and Antonietti2015; Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2015) for children with speech and language processing difficulties (see also Schön and Tillmann, Reference Schön and Tillmann2015, for a review). These beneficial effects of rhythmic stimulation and training are compelling considering the evidence that children with neurodevelopmental language disorders have difficulty with different types of rhythmic tasks. Timing deficits have been observed in rhythm perception and production tasks for individuals with dyslexia (e.g., Bégel et al., Reference Bégel, Dalla Bella and Devignes2022; Degé et al., Reference Degé, Kubicek and Schwarzer2015; Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2014; Overy et al., Reference Overy, Nicolson, Fawcett and Clarke2003; Thomson and Goswami, Reference Thomson and Goswami2008), developmental language disorder (Cumming et al., Reference Cumming, Wilson, Leong, Colling and Goswami2015; Sallat and Jentschke, Reference Sallat and Jentschke2015), and stuttering (Falk et al., Reference Falk, Müller and Dalla Bella2015; Olander et al., Reference Olander, Smith and Zelaznik2010; Wieland et al., Reference Wieland, McAuley, Dilley and Chang2015). Related timing deficits have also been shown in children with other pathologies where language processing is not the central deficit, such as children with developmental coordination disorder (Chang et al., Reference Chang, Li and Chan2021; Trainor et al., Reference Trainor, Chang, Cairney and Li2018), attention deficit hyperactivity disorder (Puyjarinet et al., Reference Puyjarinet, Bégel, Lopez, Dellacherie and Dalla Bella2017), and autism spectrum disorder (Dahary et al., Reference Dahary, Rimmer and Quintin2023; Isaksson et al., Reference Isaksson, Salomäki and Tuominen2018). Based on such evidence, the Atypical Rhythm Risk Hypothesis (ARRH) suggests that atypical rhythm processing can be considered as a risk factor for the potential development of later speech/language disorders (Ladányi et al., Reference Ladányi, Persici, Fiveash, Tillmann and Gordon2020; see also Lense et al., Reference Lense, Ladányi, Rabinowitch, Trainor and Gordon2021).
Rhythm and timing abilities are multifaceted (Bouwer et al., Reference Bouwer, Honing and Slagter2020; Fiveash et al., Reference Fiveash, Bella, Bigand, Gordon and Tillmann2022; Tierney and Kraus, Reference Tierney and Kraus2015). It is thus likely that impairments in different underlying mechanisms (and their combinations) could result in different types of timing impairments, having differential impacts on speech and language processing. For example, deficits in neural synchronization to the speech envelope have been reported for children with dyslexia (Molinaro et al., Reference Molinaro, Lizarazu, Lallier, Bourguignon and Carreiras2016; Power et al., Reference Power, Colling, Mead, Barnes and Goswami2016), whereas deficits in sensorimotor coupling (Chang et al., Reference Chang, Chow, Wieland and McAuley2016; Hickok et al., Reference Hickok, Houde and Rong2011) and disrupted timing cues produced from the basal ganglia (Alm, Reference Alm2004; Toyomura et al., Reference Toyomura, Fujii and Kuriki2011) have been reported for individuals who stutter. The PRISM framework proposes that designing training programs considering the three proposed underlying mechanisms (precise auditory processing, synchronization and entrainment to an external rhythm, and sensorimotor coupling) could have beneficial effects on speech and language processing in children with different developmental language disorders. This proposal is in line with the TSF (Goswami, Reference Goswami2011; Goswami et al., Reference Goswami, Power, Lallier and Facoetti2014) and the SEP hypothesis (Fujii and Wan, Reference Fujii and Wan2014). The TSF suggests that the regularity of music rhythm makes it a promising stimulus to train the tracking of hierarchical speech rhythm. Experimentally implemented training studies provide supportive data for this hypothesis, notably by showing that music rhythm training can improve tracking of the speech envelope, which should benefit phoneme perception and enhance phonological awareness (Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2015; Goswami, Reference Goswami2012). Administering tasks tapping specifically into each of the three mechanisms for each participant group and disorder should allow for creating a record of impairments and their potential relationships. This investigation may thus lead to an understanding of different patterns and potential weightings of impairments to specific mechanisms across disorders.
The SEP hypothesis has focused on applications of rhythm-based therapy to Parkinson’s disease (PD), stuttering, aphasia, and autism spectrum disorder. Short-term, direct stimulation interventions, such as auditory cueing and rhythmic stimulation, are effective in improving language processing in PD patients (Kotz and Gunter, Reference Kotz and Gunter2015) and enhance fluency in individuals who stutter (Toyomura et al., Reference Toyomura, Fujii and Kuriki2011). The rhythmic element of melodic intonation therapy has also been shown to be more effective than the melodic element for some aphasic patients (Stahl et al., Reference Stahl, Kotz, Henseler, Turner and Geyer2011), and providing an external auditory cue can improve gait in PD patients (Dalla Bella, Reference Dalla Bella2018; Dalla Bella et al., Reference Dalla Bella, Benoit and Farrugia2017). This research (see Fiveash et al., Reference Fiveash, Bedoin, Gordon and Tillmann2021, for an overview, and Section 7) suggests music rhythm training as an ideal tool to tap into the three proposed underlying mechanisms. One goal would be to enhance fine-grained auditory processing and sharpen the precision necessary to (1) process the speech signal, (2) enhance synchronization to process onset information more precisely in an unrolling sequence, as well as improve hierarchical processing and prediction of speech rhythm, and (3) strengthen auditory-motor networks in the brain, which are also shown to enhance predictive processing.
28.6 Future Perspectives
The three mechanisms highlighted by PRISM (i.e., precise auditory processing, synchronization and entrainment to an external rhythm, and sensorimotor coupling) have emerged from a combination of previously proposed theoretical frameworks. Now that these three mechanisms are clearly stated and combined, research can target each mechanism and/or their interactions to better understand their contribution to speech/language processing in both typically developing brains and pathological brains. PRISM predicts that (1) observed deficits within one of the underlying mechanisms proposed above should have consequences for both music and speech/language processing, (2) observed speech/language impairments across disorders should be related to impairments within one (or more) of the proposed mechanisms, and (3) training targeting the proposed mechanisms should enhance related skills across both speech/language and music processing.
This approach can be applied both at the fundamental research level as well as within training programs to better uncover links between neural mechanisms and their relation to music and speech/language processing abilities. Future research needs to better understand how these mechanisms (or their combinations) might be differently impaired across developmental disorders. This enhanced understanding would then provide the basis to develop and propose evidence-based training programs that aim to directly target specific impaired neural mechanisms.
The current chapter has focused on connections between music and speech rhythm, and has done so largely from a cognitive perspective. However, there are broader cognitive and biological connections between music and speech/language processing that should also be considered. In relation to rhythm specifically, the ARRH (Ladányi et al., Reference Ladányi, Persici, Fiveash, Tillmann and Gordon2020) has a strong focus on the genetic and biological factors that may underlie atypical rhythm processing and the connection to speech and language impairments (see Niarchou et al., Reference Niarchou, Gustavson and Sathirapongsasuti2022). Genetic building blocks may create the foundation by which joint deficits could occur within music and speech rhythm, and associated individual differences. As part of the PRISM hypothesis, Fiveash et al. (Reference Fiveash, Bedoin, Gordon and Tillmann2021) outline that in addition to the neural and cognitive factors covered by PRISM, future research should also incorporate the broader context (see Figure 28.2), including individual differences, atypical and disordered speech/language processing and related deficits in music rhythm, beneficial effects of rhythmic training in the long term and rhythmic priming in the short term on speech/language processing, and genetic influences (outlined further in Ladányi et al., Reference Ladányi, Persici, Fiveash, Tillmann and Gordon2020).
Broader cognitive and biological considerations.
In addition to the neural and cognitive considerations presented in the PRISM framework, there are broader cognitive and biological considerations to keep in mind when investigating speech and music connections.
Figure 28.2 Long description
The nodes represent different factors, and the dashed lines connecting them indicate relationships. The factors are as follows. Individual differences and development, atypical or disordered speech-language, rhythmic training or treatment, genetic and neural and cognitive.
Reward might also play an important role in the beneficial effects of rhythm on learning and memory and social connection (Fiveash et al., Reference Fiveash, Ferreri and Bouwer2023a). Intrinsic reward elicited through music (and in particular, the temporal dimension) might also be an important driving factor as to why music is particularly valuable within rehabilitation and training scenarios (e.g., Altenmüller and Schlaug, Reference Altenmüller and Schlaug2013). Therefore, optimizing musical reward should be considered when designing training experiments, in link with the groove literature (e.g., Matthews et al., Reference Matthews, Witek, Lund, Vuust and Penhune2020; Witek et al., Reference Witek, Clarke, Wallentin, Kringelbach and Vuust2014) and individual differences in sensitivity to music reward (Mas-Herrero et al., Reference Mas-Herrero, Marco-Pallares, Lorenzo-Seva, Zatorre and Rodriguez-Fornells2013). One could further extend this investigation by testing whether the beneficial effect of rhythm can be further boosted by social situations including joint action (see Fiveash et al., Reference Fiveash, Ferreri and Bouwer2023a).
Beyond the genetic and neural bases, referred to as internal factors, Nayak et al. (Reference Nayak, Coleman and Ladányi2022) also takes into account external factors (e.g., environment and experience) to explain music–language connections. Their Musical Abilities, Pleiotropy, Language, and Environment (MAPLE) framework considers studies supporting both rhythmic and tonal-melodic associations with speech perception, reading-related skills, and morphosyntactic skills (presented in their Tables 3, 4, and 5). It complements the more rhythm-specific links related to speech perception, phonological awareness, reading, and grammar (see supplementary material of Fiveash et al., Reference Fiveash, Bedoin, Gordon and Tillmann2021). Teasing apart the associations between rhythmic/tonal-melodic and speech/language abilities will shed light on which abilities might be supported by specific and shared underlying mechanisms.
These theories of music and speech/language processing (PRISM, ARRH, MAPLE) also underline the need to consider individual differences, both in typically developing and patient populations. The perception and production of music and speech/language involve numerous interacting elements that can be processed by the brain in different and widespread ways. Individual differences in genetic architecture, personality, musicality, musical training, musical reward sensitivity, and environmental influences (among others) may affect differently how music and speech/language are processed by the brain. This suggests that future research should also consider differences across individuals and across developmental disorders when investigating rhythm processing and potential effects of music training on language processing.
Summary
Music and speech rhythms display acoustic and structural similarities that are processed with shared cognitive and neural resources. The PRISM framework outlines perceptual and cognitive processes that could underlie the connections between music and speech/language processing observed in both correlational and experimental research. It provides perspectives and implications for clinical interventions, training, and future research.
Implications
The regularity of music rhythm provides a strong basis to better understand less regular speech signal processing. The proposed framework combines speech and music rhythm processing to facilitate future research investigating how the brain processes rhythm, and the mechanisms by which music training could be beneficial to speech processing.
Gains
We have presented a parsimonious framework to propel research in music and speech. Its goal is to better understand speech/music connections and how these could be used to help speech/language processing, even in pathological conditions.
29.1 Introduction
Interaction Phonology (Wagner et al., Reference Wagner and Niebuhr2013) postulates a process of rhythmic coordination based on entrainment processes that provide the temporal scaffold for higher-order adaptation among interlocutors in critical situations, and hence improves communication. Ten years after the publication of our framework, the time is more than ripe for its first evaluation and a thorough reassessment. To achieve this, I will first give an overview of the general assumptions and motivations underlying Interaction Phonology, and then describe its mechanism as a logistic, attention-guiding component in a model of speech processing in interaction. I will then derive a set of model predictions and evaluate them based on a thorough review of more recent empirical studies. In a last step, I will slightly modify our original model of Interaction Phonology (see Figure 29.1 for an overview of the original model; see Figure 29.2 for the adapted version), and list desiderata for its further testing in the future.
An overview of the processes and structures involved in Interaction Phonology.
The diagram depicts the processes in a listener who entrains to the rhythmic patterns of speech based on the expectations inherent in their language competence. The level of rhythmic-prosodic entrainment can be strengthened in difficult communicative situations. That way, the listener’s attention is guided to higher-order linguistic aspects connected to the rhythmic structures thus enhanced. This attentional process may alter the way that rhythmic-prosodic structures are connected to higher-order linguistic patterns, but also intensify the level of entrainment with an interlocutor. Taken together, these processes are expected to aid mutual understanding, particularly in “difficult” situations. The model relies on a set of modules, some of which are part of the speaker’s grammar. These encompass (1) an entrainment module, (2) an auditory analysis guided by it, which is also linked to (3) motor patterns, which automatically lead to convergence in speech production as an automatic by-product of entrainment, (4) a set of linguistic structures and expectations as part of a speaker’s grammar, which are linked to the levels of entrainment via their corresponding levels of prosodic organization, and (5) a monitoring of communication relevance, which estimates the need for entrainment (informed by the auditory and linguistic analysis) and adjusts the level of entrainment by modulating the coupling strength.
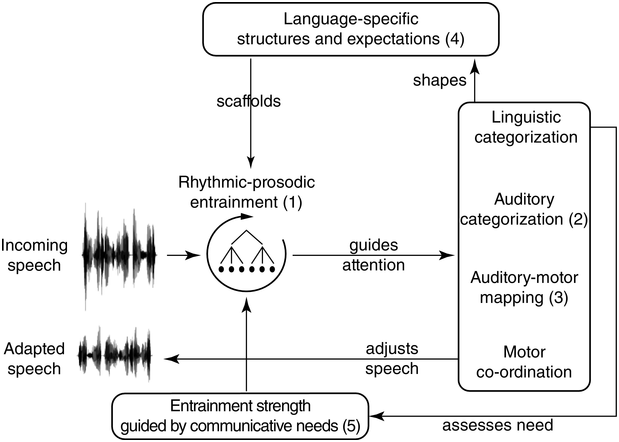
An adapted sketch of Interaction Phonology.
Those parts of Interaction Phonology that have received empirical support are indicated by check marks. Other parts are either commented as optional (auditory-motor mapping and speech adaptation) or have been modified/extended in line with empirical findings. In particular, the language-specific structures and expectations for which we have evidence to guide rhythmic-prosodic entrainment and to be shaped by it currently are restricted to phonetic-phonological ones. It remains unclear whether syntactic or lexical adaptations are connected with entrainment processes likewise.
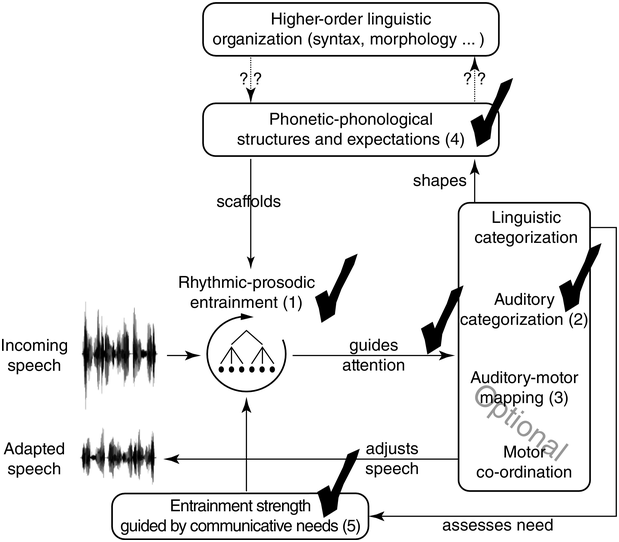
Figure 29.2 Long description
The diagram shows how incoming speech is processed through rhythmic-prosodic entrainment, phonetic-phonological structures, and linguistic categorization, ultimately leading to motor coordination and the assessment of communicative needs. Stages like rhythmic-prosodic entrainment, guides attention, auditory categorization, phonetic-phonological structures and expectations, entertainment strength guided by communicative needs are indicated with check marks.
29.2 A Sketch of Interaction Phonology
When two or more people communicate, they agree on a shared language system, with the ultimate goal to enable a common understanding with the help of an interactionally grounded, shared symbolic representation. However, assumptions about the shared symbol inventory may differ. For instance, whether you refer to certain vegetables as “potatoes,” “spuds,” “solanum tuberosum,” or “root vegetables” may depend on your individual assessment of the situation, individual preference, spoken variety, or linguistic context. It is likely that speakers will therefore negotiate the conditions of usage of a particular term to clarify reference or to signal mutual cooperativeness and perspective taking in a process called grounding (Clark and Brennan, Reference Clark, Brennan, Resnick, Levine and Teasley1991). During this process, it is not sufficient to agree on a shared inventory of symbols and grammatical constraints (e.g., “English”), because the way that abstract symbols are realized in the speech signal may differ, due to different speaking styles, varieties, registers, or external factors such as cognitive distraction or various types of “noise.” For this reason, sub-symbolic phonetic convergence has been claimed to be closely linked to the phenomenon of symbolic alignment, that is, the tendency of interlocutors to agree on a shared or similar inventory (Pickering and Garrod, Reference Pickering and Garrod2004).
So, agreeing on speaking the same “language” has something in common with two people agreeing on dancing a waltz. While the dance move sequences that qualify as “symbolic” figures of a waltz may be clear to both dancers, the velocity, amplitude, and detail of the pertaining movement trajectories need to be precisely negotiated, helped by an external pacemaker in the form of the rhythm of the accompanying music. In speech-based communication, it is likewise not sufficient to agree on an abstract set of phonemes, lexemes, and syntactic structures. Rather, speakers need to agree on a fine-grained execution of the shared movement patterns within their individual motor systems to achieve pronunciations that are mutually understood, for example, similar to the relative timing of articulators as expressed within articulatory phonology (Browman and Goldstein, Reference Browman and Goldstein1992).
So far, researchers have accumulated plenty of evidence for sub-symbolic coordination processes taking place between interlocutors: Speakers align their pronunciation patterns, speech tempo, and prosody (Bosch et al., Reference Bosch, Oostdijk and Boves2005; Gessinger et al., Reference Gessinger, Raveh, Steiner and Möbius2021; Levitan and Hirschberg, Reference Levitan and Hirschberg2011; Lewandowski and Jilka, Reference Lewandowski and Jilka2019; Pardo, Reference Pardo2006; inter alia), and occasionally even their conversational laughter (Ludusan and Wagner, Reference Ludusan and Wagner2022), but also on higher-order levels of linguistic organization such as lexical choice, syntactic structures, or referential gestures (Bergmann and Kopp, Reference Bergmann and Kopp2012; Brennan and Clark, Reference Brennan and Clark1996; inter alia). However, most studies find a lot of individual variation both in rhythmic-prosodic entrainment and higher-level linguistic alignment. Still, a key assumption of mechanistic accounts of interpersonal alignment (Pickering and Garrod, Reference Pickering and Garrod2004, Reference Pickering and Garrod2007) is that sub-symbolic, rhythmic-prosodic entrainment fosters symbolic alignment, and hence comprehension, on higher levels of grammatic organization.
To this day, speech processing architectures lack a unified account of whether and how any interaction between sub-symbolic and symbolic adaptation is actually achieved. In Wagner et al. (Reference Wagner and Niebuhr2013), we therefore argued for Interaction Phonology as a logistic, attention-guiding component that enables interlocutors to coordinate their articulatory movements on a low-signal level by a process of temporal entrainment. That way, listeners may guide their attention to crucial aspects of phonetic detail (Ghitza and Greenberg, Reference Ghitza and Greenberg2009; Ghitza, Reference Ghitza2012; Giraud and Poeppel, Reference Giraud and Poeppel2012; Chapters 12 and 19) that will permit an easier access to higher-level linguistic information. As a consequence, symbolic alignment should be fostered by temporal coordination in an automatic, bottom-up fashion. We use the term entrainment in a narrow sense (Obleser and Kayser, Reference Obleser and Kayser2019) where it describes a dynamic process of physically coupled oscillatory systems, which adapt their cycles both in period and phase, thereby ultimately achieving a fixed phase relationship. Humans are capable of interpersonal entrainment without an external, isochronous pacemaker, for example, when spontaneously synchronizing their clapping behavior in enthusiastic applause by period doubling (Néda et al., Reference Néda, Ravasz, Vicsek, Brechet and Barabási2000), or when speaking in synchrony (Cummins, Reference Cummins2009). Strikingly, humans have shown to synchronize their brain activities, strengthened by shared engagement and joint activity (Dikker et al., Reference Dikker, Michalareas and Oostrik2021).
In Interaction Phonology, the rhythmic properties of a language play a crucial role in this entrainment process. It has been noted that speech lacks the isochrony or regularity necessary for entrainment (Cummins, Reference Cummins2012). However, it may occasionally show fixed phase relationships or a high degree of regularity, at least in highly formalized speaking styles such as poetry (Wagner, Reference Wagner and Niebuhr2013), which may lend itself to rhythmic entrainment, even though we do not yet understand the exact mechanism behind this. While absolute coordination cannot be meaningfully expected between interlocutors at all times, there is some evidence in favor of entrainment: Across several languages, overlapping speech shows a preference for speakers being in phase with the interlocutor’s syllabic speech stream (Włodarczak et al., Reference Włodarczak, Šimko and Wagner2012). In line with entrainment models of attention (Lakatos et al., Reference Lakatos, Karmos, Mehta, Ulbert and Schroeder2008; Large and Jones, Reference Large and Jones1999), Interaction Phonology postulates that this process helps listeners gain access to language-specific phonological and higher-level properties of the utterance spoken.
Furthermore, we argued that rhythmic entrainment is a necessary prerequisite for the automaticity and swiftness of representational alignment in human interaction. While not excluding the possibility of a reductionist account of the phenomena described, we do not think it necessary for now to subscribe to this idea. Still, we argued for an inter-speaker coordination mechanism as being fundamental not only for speech perception but for communicative interaction, that is, the permanent active attuning to one another. Interaction Phonology can be preliminarily defined as taking care of the coordinative interactive processes that are strongly built on rhythmic-phonological structures.
Interaction Phonology furthermore postulates that there are universal and language-specific structures on which coordination takes place. In particular, it predicts that the rhythmic-prosodic organization of a language constrains the levels of temporal coordination between interlocutors. For a lack of better knowledge, these are assumed to be identical to the language-specific levels of prosodic organization (syllables, feet, prosodic phrases) and their internal metrical organization (Jun, Reference Jun2005). In other words, according to Interaction Phonology, the temporal coordination between interlocutors who speak varieties with a similar rhythmic-prosodic organization should be comparatively easy. However, Interaction Phonology also postulates that the mechanisms of temporal coordination are to some degree universal, based on syllabic structures that are grouped into larger units such as phrases or similar. Even though their regularity, function, and organization within the prosodic hierarchy may differ across languages, there is some space for rhythmic coordination even when interlocutors cannot rely on a large set of common temporal mechanisms that may serve as anchors to higher-level linguistic organization. An example would be an L2 (second-language) listener’s strategic reliance on prosodic universals as well as language-specific prosodic cues as indicators of lexical stress, which often is a useful approach to segment a speech stream into words (Endress and Hauser, Reference Endress and Hauser2010; Ordin and Nespor, Reference Ordin and Nespor2013; Tyler and Cutler, Reference Tyler and Cutler2009). The idea of rhythmic entrainment as a universal coordinative process underlying linguistic organization has received further support by developmental studies that described movement synchronization between neonates and their caregivers (Condon, Reference Condon1974; Jaffe et al., Reference Jaffe, Beebe and Feldstein2001), where a baby’s acquisition may be helped by anchoring into the universal prosodic properties of speech to pave the way for higher-order symbolic alignment (Chapters 35–37, 39, and 41). In fact, neonates are born with an ability to use prosodic strategies independently of segmental properties to identify word boundaries in their early language acquisition process (Fló et al., Reference Fló, Brusini and Macagno2019). An early alignment to the rhythmic-prosodic detail of a caregiver’s movements may therefore be a generally useful strategy in language acquisition. However, as prosodic and phonetic alignment has shown to be to some degree voluntary, situation-specific, and less strong in populations with autism spectrum disorder (Schweitzer and Lewandowski, Reference Schweitzer and Lewandowski2014; Schweitzer et al., Reference Schweitzer, Lewandowski and Duran2017; Wynn et al., Reference Wynn, Borrie and Sellers2018), Interaction Phonology allows for the modulation of underlying entrainment processes. That is, if conversational needs for mutual understanding and grounding are high, it predicts that entrainment can be willingly strengthened, thereby actively supporting mutual comprehension and conversational grounding.
29.3 The Mechanism of Interaction Phonology
Interaction Phonology postulates that the incoming speech signal is subject to a process of rhythmic-prosodic analysis that does the following:
Guides the listener’s attention to the fine phonetic detail of the speech signal that may be of particular relevance for a given language, which coincides with crucial boundaries of higher-level linguistic organization and therefore facilitates their prompt identification. For now, we believe that the levels of entrainment are identical to the levels of organization in the prosodic hierarchies of the different languages. It is possible that this language-specific coordination does not constitute an independent level of a language’s grammar but rather is a by-product of its morphosyntactic or phonological organization.
Is driven by a process of rhythmic entrainment, modulated according to communicative needs such as the overall level of “noise,” and informed by linguistic analyses of the ongoing interaction. Apart from objectively present external noise, this may also relate to the overall level of distraction, or the relevance of successful communication.
Is adaptive with respect to its level of entrainment, or coupling strength; these adaptations are strongly guided by the rhythmic-prosodic patterns of the language chosen to communicate but may also be subject to long-term entrainment between interlocutors, if these (initially) speak different languages or varieties.
Leads to an adaptation in speech production with respect to tempo and rhythmic modulation via perception–production coupling, and hence an improved attention to detail on the listener’s side and representational alignment in (adapted) speech production.
These analyses are organized within various model components, which are described in detail in Table 29.1 and are indicated by their respective numbers in Figure 29.1.
| Model component | Description |
|---|---|
| 1 | Entrainment module, guiding listener’s attention to points in the incoming speech signal that are crucially linked to higher-order linguistic organization |
| 2 | Entrained, or “guided,” auditory analysis of incoming speech input, which interfaces with subsequent linguistic analysis of input |
| 3 | Motor patterns mapped to incoming acoustic analysis, automatically leading to adapted speech output |
| 4 | Set of linguistic structures and expectations as part of a speaker’s grammar, which are linked to the levels of entrainment via their corresponding levels of prosodic organization, and which correspond to attractors in entrainment |
| 5 | A communication relevance monitor, which assesses the situation and ongoing communication (and with this, the need for entrainment), which may adapt the strength of necessary entrainment depending on present noise and the necessity of communicative success |
So far, Interaction Phonology has not yet spelled out connection or interface with existing models of speech production and perception. However, most of these models miss a link between symbolic and sub-symbolic processing, and Interaction Phonology may help improve our understanding of this interface. Given its focus on communication, Interaction Phonology can only be meaningfully integrated with architectures that account for both perception and production.
29.4 Predictions of Interaction Phonology
Here, we spell out a set of testable predictions by Interaction Phonology. The predictions are chosen as they all test crucial aspects of the model. Interaction phonology makes predictions beyond this list, especially with regards to prosodic universals and language-specific constraints. Also, given its current lack of formality and under-specification, it should be clear that this list is currently incomplete and lacks formal rigor.
Prediction 1: Speech rate adaptation should improve speech perception in similar communication settings.
Prediction 2: Entrainment should be visible across the levels of the prosodic hierarchy, in a language-specific fashion.
Prediction 3: The level of entrainment should be situation-specific, and vary within individuals across different situations.
Prediction 4: If rhythmic entrainment occurs, it should automatically result in symbolic alignment.
Prediction 1 falls out of the model, as the model postulates a positive effect of entrainment on speech perception by its guiding the listener’s attention to relevant phonetic detail using the entrainment module (see Figure 29.1, component 1). However, it needs to be taken into account that the model also predicts entrainment for those communicative situations in which perception may be impeded by various types of noise. Therefore, it is crucial for testing Prediction 1 that speech perception and entrainment are measured across similar settings, without added cognitive load or external noise. Speech rate is chosen mostly as a test (in favor of other potential features of rhythmic-prosodic entrainment) as there exists a considerable amount of empirical research on it. Prediction 2 falls out of the assumed link between levels of entrainment and language-specific structures (see Figure 29.1, component 4). That is, Interaction Phonology expects a certain language dependence with respect to the levels of entrainment that mirror the prosodic organization of the involved languages or varieties. Going back to speech rate entrainment, depending on the rhythmic-prosodic structure of the language to be entrained to, speech rate adaptation may concentrate on morae, syllables, prosodic feet, prosodic words, or even phrasal structures. Prediction 3 is derived from Interaction Phonology’s assumption that entrainment is to some degree deliberate and strategically chosen by interlocutors rather than a fully automatized process that will always be enabled (Figure 29.1, component 5). In other words, Interaction Phonology predicts the level of entrainment to a certain speech rate to be stronger in challenging communicative situations. Prediction 4 falls out of the assumed automatic link between sub-symbolic coordination and symbolic alignment (see Figure 29.1, connection between components 1 and 2). Here, the control mechanism that enables entrainment automatically takes into account higher-level similarities. If these two fail to be coupled, this would be a challenge for our control mechanism, and would point to a strongly strategic symbolic alignment that is not necessarily coupled to sub-symbolic, motor-level processes of articulation. In other words, an entrainment to speech rate ought to be also visible in the usage of more similar words, or syntagmatic structures.
29.5 Evaluating Interaction Phonology
Next, it will be determined whether more recent empirical research is in line with the assumptions and predictions of Interaction Phonology, or falsifies (aspects of) it. Where no research results lend themselves to model evaluation, suggestions for future studies will be made in order to better understand Interaction Phonology’s flaws, limitations, as well as strengths. The analysis will concentrate on the four main predictions of Interaction Phonology that have been spelled out above.
29.5.1 Prediction 1: Speech Rate Adaptation Helps Speech Perception
In incremental, online speech perception, listeners need to simultaneously pay attention to several levels of linguistic organization. The ability to do this may be enhanced by the different timescales underlying the spell-out of these levels (phones, syllables, words, phrases), which can be entrained to cortical rhythms working on similar timescales (Ghitza and Greenberg, Reference Ghitza and Greenberg2009; Ghitza, Reference Ghitza2012; Chapter 5). Much work around rhythmic entrainment during perception has concentrated on attentional selection, which ought to focus on crucial parts of the speech signal, for example, the initializations of syllables. There is converging evidence that some form of temporal entrainment indeed helps selectively attending to the incoming speech stream of a particular speaker among several concurrent speakers (Obleser and Kayser, Reference Obleser and Kayser2019). Also, neural entrainment processes have shown to (somewhat) aid speech perception and sentence comprehension (Lamekina and Meyer, Reference Lamekina and Meyer2022; Riecke et al., Reference Riecke, Formisano, Sorger, Başkent and Gaudrain2018; Wilsch et al., Reference Wilsch, Neuling, Obleser and Herrmann2018; Zoefel et al., Reference Zoefel, Archer-Boyd and Davis2018).
However, as speech tempos change dynamically in ongoing speech within the same speaker (Quené, Reference Quené2008), and speech is not isochronous like music (Cummins, Reference Cummins2012), for entrainment to be a successful tool for enhancing speech perception, listeners need to be able to swiftly adapt to these speech tempo changes. Speech rate convergence in production is a phenomenon largely supported by empirical research, appearing in both monological priming tasks (Jungers and Hupp, Reference Jungers and Hupp2009) and conversations (Cohen Priva et al., Reference Cohen Priva, Edelist and Gleason2017; Fuscone et al., Reference Fuscone, Favre and Prevot2021; Schultz et al., Reference Schultz, O’Brien and Philipps2016). For perception, Dilley and Pitt (Reference Dilley and Pitt2010) presented the first evidence for listeners indeed quickly adapting to the speech tempo of an incoming speech signal, leading them to perceptually insert additional syllables/words into a speech stream that was locally produced slowly; for example, “leisure time” was perceived as “leisure or time.” This effect, which they term LRE (lexical rate effect), is restricted to speech processing and does not generalize to tone perception (Pitt et al., Reference Pitt, Szostak and Dilley2016), but can be built up over longer stretches of time, thereby generating the expectations that drive selective attention (Baese-Berk et al., Reference Baese-Berk, Heffner and Dilley2014; Chapter 12). Bosker (Reference Bosker2017) showed in a series of experiments that it is the (isochronous) speech rate prior to a target that creates an anticipatory effect on perception. He interprets this as evidence for an underlying neural entrainment mechanism at play, which is not tied to the speech mode. What is not yet resolved is the question of whether entrainment is restricted to speech processing, or is a general monitoring and adaptation device. The studies reported here that have examined an impact of rhythmic entrainment on speech perception have done so in highly controlled laboratory settings. Thus, it can at least be said that in such contexts, an adaptation to speech tempo can be traced and appears to have a positive impact on speech perception. However, it still remains unclear how entrainment can actually be achieved given the intrinsic non-isochrony present in speech signals. Here, Bosker (Reference Bosker2017), Meyer et al. (Reference Meyer, Sun and Martin2020), and Obleser and Kayser (Reference Obleser and Kayser2019) claim that the – at best – pseudo-rhythmic acoustic properties of speech are sufficient to induce an entrainment mechanism that may lend itself to higher-order synchronicities in more abstract linguistic domains. For the moment, one can only speculate that highly adaptive (neural) oscillators with a fast reset should also be able to achieve a rapid entrainment to dynamically changing rhythms (Inden et al., Reference Inden, Malisz, Wagner and Wachsmuth2012).
29.5.2 Prediction 2: Entrainment Should Be Visible across Language-Specific Levels of the Prosodic Hierarchy
Building on the conspicuous similarities between the multi-timescales of cortical and speech rhythms (Ghitza and Greenberg, Reference Ghitza and Greenberg2009; Ghitza, Reference Ghitza2012), Interaction Phonology postulates that rhythmic entrainment should pertain to various timescales, and these timescales should reflect the rhythmic structure of the language(s) spoken. In particular, this should lead to language-specific rhythmic entrainment, as languages, language varieties, or speaking styles differ with respect to their prosodic organization, and this should be reflected in the long-term abilities of entrainment. For example, languages may differ vastly with respect to the length and complexity of syllable-sized units (Zec, Reference Zec and de Lacy2007). Interaction Phonology now predicts that speakers of languages with a higher degree of phonotactic complexity and variability are either more flexible in entraining to syllable streams or maybe make less use of syllable-level entrainment, as it is more often doomed to fail. Also, languages differ with respect to their higher-order prosodic organization, and may use different patterns of metrical organization (Jun, Reference Jun2005). Such differences should also show in language-selective rhythmic entrainment.
Currently, empirical evidence indeed points towards rhythmic entrainment being active on different timescales: The LRE (see above) has been shown to also apply for syllable-level speaking rate as well as rhythm, indicating a certain degree of higher-order entrainment on the foot or word level, where listeners modulate their perception based on whether they expect a stressed or unstressed syllable (Morrill et al., Reference Morrill, Dilley, McAuley and Pitt2014). Furthermore, the effect has shown to be additive, and listeners are more attentive when several rhythmic boundaries co-occur. However, despite considerable work on entrainment to pulse and higher-order meter in music (see the overview in Fitch, Reference Fitch2013), and despite a long tradition in research to hypothesize about similar processing mechanisms being at play in music and speech processing and organization (e.g., Lehrdahl and Jackendoff, Reference Lerdahl and Jackendoff1983; Wagner, Reference Wagner2008; Chapters 25–28), very little is actually known about language-specific entrainment, and most evidence remains speculative.
Some similarities between music and speech perception can be drawn from finger-tapping studies, a sensorimotor synchronization paradigm that is well established in music rhythm perception research (Repp, Reference Repp2005; Repp and Su, Reference Repp and Su2013). Finger tapping to music rhythms has been shown to help improve music time perception, similar to the perceptual benefits of entraining to speech rhythm (Manning and Schutz, Reference Manning and Schutz2013). In speech perception tasks, finger-tapping duration and intensity have likewise been shown to be sensitive to rhythmic structure linked to linguistic organization such as syllable onsets, lexical stress, sentence stress, or accent (Parrell et al., Reference Parrell, Goldstein, Lee and Byrd2014, Rathcke et al., Reference Rathcke, Lin, Falk and Dalla Bella2021). Another paradigm called speech cycling investigated rhythmic entrainment of repetitive short phrases to external high and low tones, and found cross-linguistic similarities in patterning speech to these external tones for Japanese and English, despite their different syllable structures (Tajima and Port, Reference Tajima, Port, Local, Ogden and Temple2003). While these studies point to a common sensorimotor entrainment mechanism, it should be noted that tapping in real time to an incoming speech signal is extremely difficult to do, and listening to or reproducing repetitive single phrases resembles music rather than speech processing (Anbari et al., Reference Anbari, Włodarczak and Wagner2013). An alternative methodological paradigm, in which listeners tapped a perceived rhythmic structure directly after perceiving an utterance, revealed an ability of listeners to encode language-specific rhythmic-prosodic features in tapping patterns as well, and showed a stronger reliance on acoustic-prosodic features as compared to non-motor prosody perception tasks (Bruggeman et al., Reference Bruggeman, Schade, Włodarczak and Wagner2022; Wagner et al., Reference Wagner, Ćwiek and Samlowski2019). However, it is yet unclear whether the results of tapping are indicative of sensorimotor entrainment proper or simply fall out of a general analysis of linguistic structure, integrating linguistic, acoustic-phonetic, and sensorimotor cues. Similar problems exist with studies on L2 acquisition that show that rhythmic priming has a beneficial effect on learning the target prosody in an L2, as they either rely on multimodal reproduction tasks or use musical (rather than speech) rhythms as priming materials (e.g., Baills and Prieto, Reference Baills and Prieto2021; Wang et al., Reference Wang, Mok and Meng2016) – neither is conclusive as to whether it really is rhythmic entrainment to speech that leads to the positive effects on mastering an L2 prosody. Overall, we have some empirical evidence pointing in the direction that rhythmic entrainment has long-term consequences, leading to long-term rhythmic expectations that result in an improved rhythmic entrainment performance in an L1 as compared to an L2, and that may result in better abilities of learning an L2 prosody in speakers with a high degree of rhythmic training. However, clear-cut evidence for this prediction of Interaction Phonology is still lacking.
29.5.3 Prediction 3: The Level of Entrainment Should Be Situation-Specific, and Vary within Individuals across Different Situations
Interaction Phonology postulates that interlocutors make a deliberate (though not necessarily conscious) choice in whether they employ prosodic entrainment or not, and it is expected that entrainment should be selectively activated in challenging communicative situations, in which the benefits of attention can be exploited best. As the vast majority of studies have been performed in laboratory conditions, often relying on short, highly controlled utterances that show little resemblance with everyday interactions, this has not been investigated in ecologically valid conditions. However, some first approaches do exist.
In a study that looked at rate-dependent adaptive listening in quiet and noisy conditions, Reinisch and Busker (Reference Reinisch and Bosker2022) could show that listeners dynamically adapt at a low level to challenging contexts, and can identify noisy target items more easily when these are preceded by coherently noisy signals. There is also increasing evidence that the selective attention to an individual speaker in a multi-party listening condition decreases entrainment to the ignored voices (e.g., Ding and Simon, Reference Ding and Simon2013; Fuglsang et al., Reference Fuglsang, Dau and Hjortkjær2017). This points towards the level of entrainment being to some degree adjustable according to situation-specific needs.
Several studies investigated the impact of acoustic manipulation (vocoded speech) on the level of entrainment, hypothesizing that vocoding would be detrimental to speech quality and therefore trigger higher entrainment. Peelle and Davis (Reference Peelle and Davis2012) and Peelle et al. (Reference Peelle, Gross and Davis2013) find evidence for neural entrainment to speech being higher when it is vocoded (more difficult to comprehend). While this may point to a direction of selective entrainment in the case of speech that is difficult to process, Baltzell et al. (Reference Baltzell, Srinivasan and Richards2017) showed that vocoded speech preceded by natural speech primes also aided the comprehension of vocoded speech. This is in line with findings on synchronous speech, where synchronization is not influenced by intelligibility but by rhythmic cues (Cummins, Reference Cummins2009).
Rather than manipulating the acoustics of their stimuli, Iverson et al. (Reference Iverson, Song and Bradley2018) and Song and Iverson (Reference Song and Iverson2018) tested the influence of overall intelligibility on neural entrainment by comparing the performance of L1 and L2 listeners when hearing L1 or L2 speech. Their results point to patterns of stronger neural entrainment when listening to the less familiar (L1 for L2 listeners, L2 for L1 listeners) and hence more challenging variety. However, the idea that any challenges to the ongoing communication success lead to an automatic increase in entrainment appears to be overly simplistic: A study by Hjortkjær et al. (Reference Hjortkjær, Märcher‐Rørsted, Fuglsang and Dau2020) indicates that a higher working memory load actively decreases the level of neural entrainment, and also Abel and Babel (Reference Abel and Babel2017) show lower phonetic convergence under high cognitive load. Interestingly, this effect was present both for a more difficult task as well as an increase in acoustic noise that had been tested for not being detrimental to speech intelligibility. These results indicate that entrainment needs cognitive resources by itself, possibly to uphold selective attention.
29.5.4 Prediction 4: If Entrainment Occurs, It Should Automatically Result in Symbolic Alignment between Interlocutors
By now, there is a long research tradition that has demonstrated adaptation between communication partners both on fine phonetic detail such as speech tempo, pause duration, intonation, or segmental articulation as well as more abstract linguistic representations such as the lexicon, syntactic structures, or referential gestures (see Section 29.2). What is unclear is whether low-level coordination on fine phonetic details indeed quasi-automatically triggers an agreement on higher-order linguistic concepts, as predicted by Interaction Phonology, and in line with models of interpersonal adaptation that link production and perception (Pickering and Garrod, Reference Pickering and Garrod2004, Reference Pickering and Garrod2007). However, clear-cut evidence for this idea appears to be difficult to come by, despite the undeniable benefit found for listening entrainment in speech perception (see above). Krivokapić (Reference Krivokapić2013) suggests that speech rate convergence between dialogue partners correlates with their alignment of variety-specific rhythmic patterns (Indian English and American English), indicating a certain automaticity in convergence across low-level and higher-level rhythmic-prosodic organization. Alternatively, this could be explained by falling out of inter-speaker entrainment in speech rate, as duration indicates both speech rate as well as rhythmic organization. One of the few studies that found evidence for a communicative benefit (beyond intelligibility) of speech rate adaptation is Manson et al. (Reference Manson, Bryant, Gervais and Kline2013), who reported an increase in cooperation between interlocutors when they also aligned in speech rate. Similarly, Lubold and Pon-Barry (Reference Lubold and Pon-Barry2014) report an increase in perceived rapport. These results may point to a higher degree of conversational grounding in situations where rhythmic-prosodic entrainment is evident, and may indicate a mechanistic link between low-level speech rate adaptation to higher-order linguistic processing. However, other interpersonal factors such as mutual likeability were not affected by an increase in entrainment (Manson et al., Reference Manson, Bryant, Gervais and Kline2013), which is further evidence that the underlying mechanism may be specialized to linguistic processing.
However, a clear-cut effect of entrainment on symbolic-linguistic alignment appears to be difficult to prove: Weise and Levitan (Reference Weise and Levitan2018) fail to find evidence for a link between acoustic-prosodic and symbolic alignment, while Rahimi et al. (Reference Rahimi, Kumar, Litman, Paletz and Yu2017) suggest that entrainment across different levels of linguistic organization can occur. Generally, most studies report a high degree of individual variation in entrainment, which seems to be at least to some degree driven by personal and interpersonal factors, for example, mutual likeability, perceived attractiveness, gender, as well as the power dynamics between interlocutors (Babel, Reference Babel2012; Michalsky and Schoormann, Reference Michalsky and Schoormann2017; Pardo, Reference Pardo2012; Reichel et al., Reference Reichel, Beňuš and Mády2018; Schweitzer and Lewandowski, Reference Schweitzer and Lewandowski2014; Schweitzer et al., Reference Schweitzer, Lewandowski and Duran2017).
29.6 Conclusion: An Adapted Sketch of Interaction Phonology
For some key predictions of Interaction Phonology, empirical evidence is growing stronger. In particular, we see that rhythmic entrainment does take place in speech tempo adaptations, and has a positive effect on intelligibility. While cross-linguistic studies on entrainment are very rare, there is evidence that it connects to the rhythmic-prosodic structure of individual languages, thereby probably also enhancing higher-level comprehension. Another key assumption of Interaction Phonology is that rhythmic-prosodic entrainment can be adjusted based on situative needs. Here, we indeed saw that listeners do adapt their entrainment to individual voices or increase entrainment in challenging listening situations. However, entrainment is not increased independently of the type of communicative challenge. Contrary to our prediction, working memory load seems to decrease entrainment, indicating that entrainment comes with a certain cognitive load of its own. Here, more research is necessary to better understand which type of situation triggers or decreases its effectiveness. Despite the positive effect entrainment has on intelligibility, when explicitly linking it to higher-level linguistic organization, there appears to be no automaticity in rhythmic-prosodic entrainment and higher-order symbolic alignment between interlocutors. At best, researchers find that this connection is not ruled out. In our account of Interaction Phonology, this connection is therefore removed for the time being, and the link between rhythmic-prosodic entrainment and symbolic-linguistic organization is limited to grammatical aspects of sound structure (phonology). From there, a connection to higher-order linguistic organization can be made as part of listening comprehension, but the connection to further symbolic entrainment needs to be questioned. For now, the results leave a question mark as to the exact nature of the interface between sound-related and higher-order linguistic processing in Interaction Phonology. As for the auditory-motor mapping, which predicts automatic convergence of rhythmic-prosodic patterns in speech-based interaction, it is left as optional in the model, as most data show high individual variation in speakers’ level of converging prosodic patterns, even though it seems to be to some degree automatized for speech tempo. Here, further empirical work is needed to highlight the level of automaticity or deliberate control, and how it covaries with other speaker traits, their level of neurocognitive alignment, or situative factors. Overall, it can be concluded that the model of Interaction Phonology can still be helpful to further inform psycholinguistic models of speech processing, to extend them to models of communicative interaction, and to improve and clarify the interface of symbolic and sub-symbolic processing in the models. Our adapted sketch of Interaction Phonology is illustrated in Figure 29.2.
Summary
Interaction Phonology explains symbolic and sub-symbolic inter-speaker adaptations using the mechanism of rhythmic-prosodic entrainment. Many key assumptions (rhythmic entrainment as an optional process that helps perception and is linked to grammar) are empirically supported. However, the original model was modified: Auditory-motor mapping is optional, entrainment can also be actively decreased under high cognitive load, and the assumed automaticity between entrainment and symbolic alignment is questioned.
Implications
Interaction Phonology provides a testable theoretical framework for evaluating language-specific and language-universal hypotheses related to rhythmic entrainment between interlocutors, and their relationship with higher-order alignment of abstract linguistic representations.
Gains
Interaction Phonology provides a theoretical framework that affords the necessary scaffold for enabling an inter-speaker alignment of phonetic-phonological, and potentially also higher-order, linguistic representations by a mechanism of rhythmic entrainment. Interaction Phonology extends existing speech processing models with an interface between symbolic and sub-symbolic processing, and integrating them into communication models.
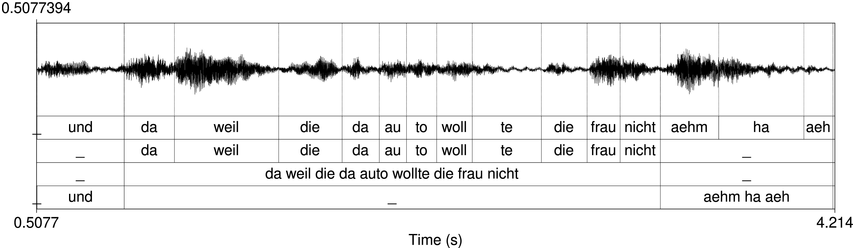
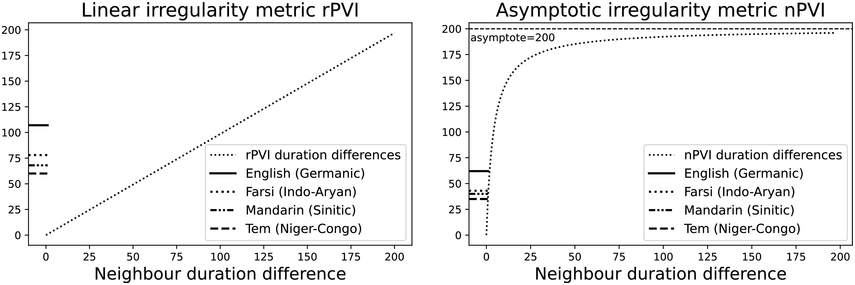
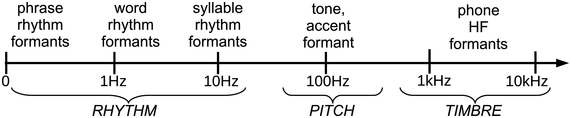
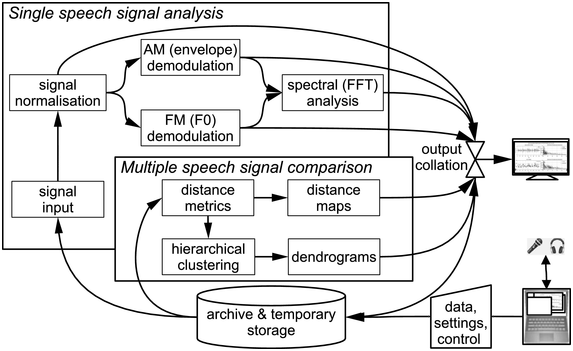
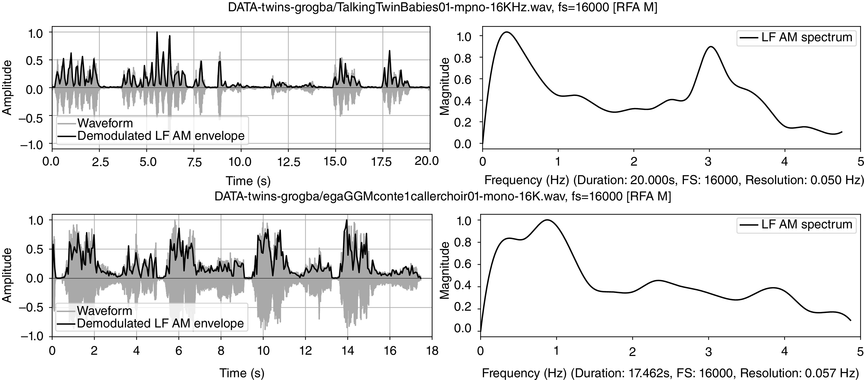
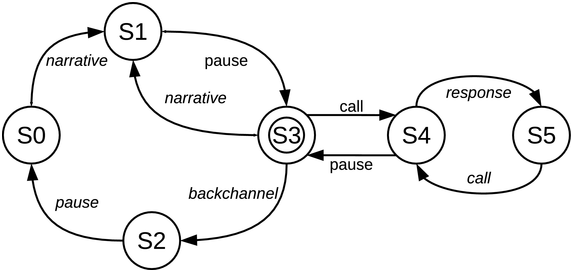
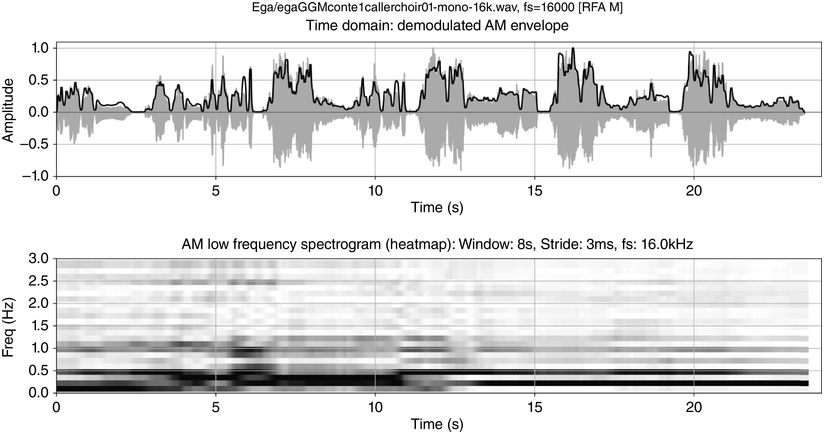
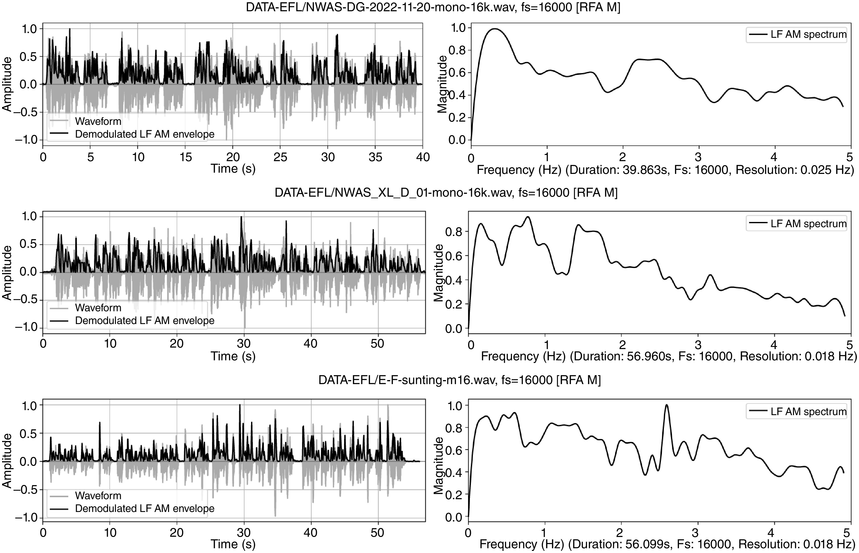
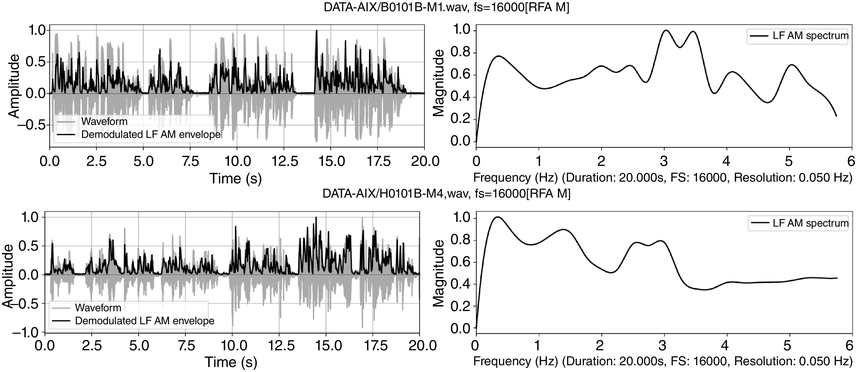
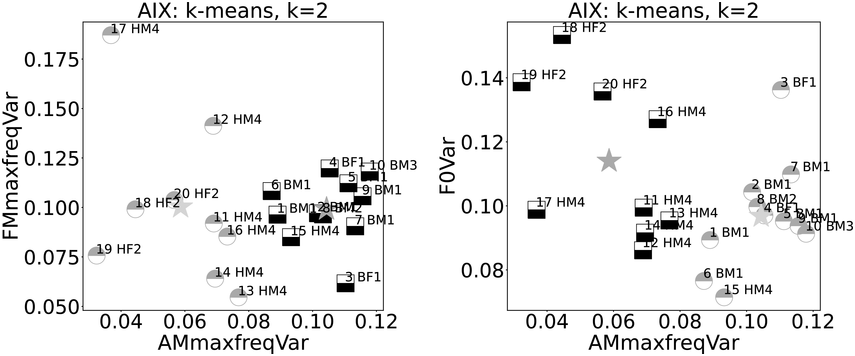
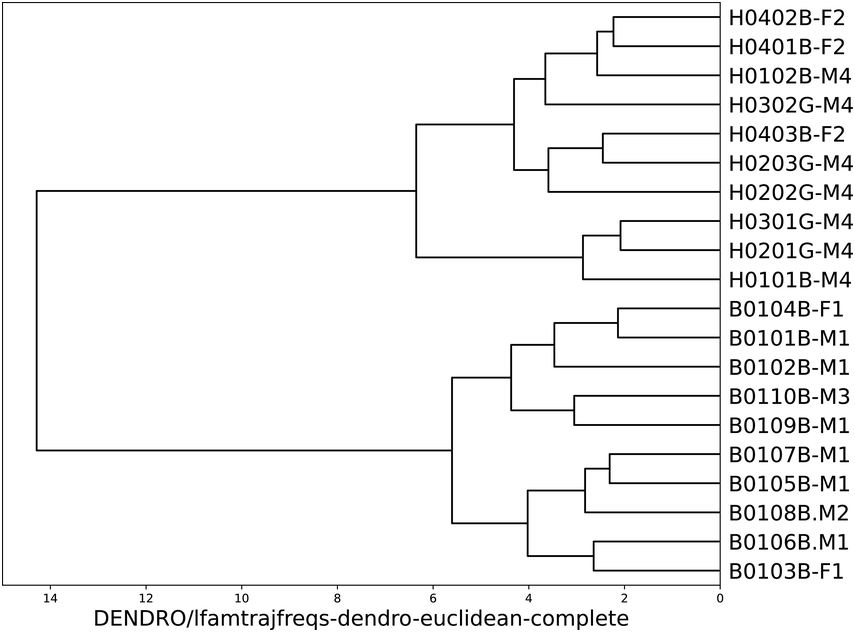
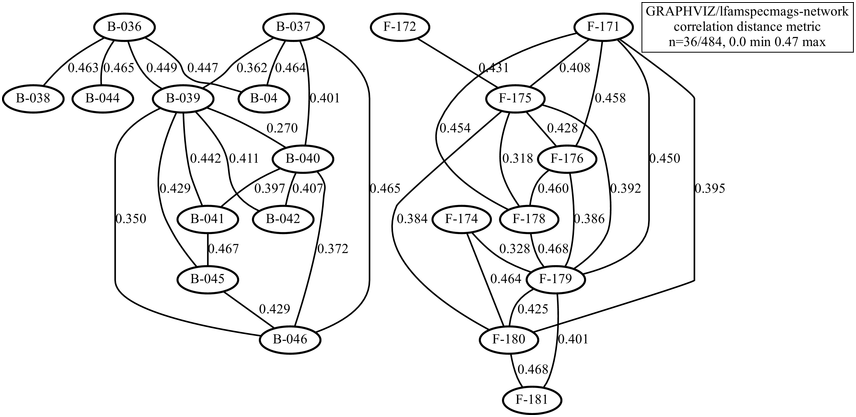




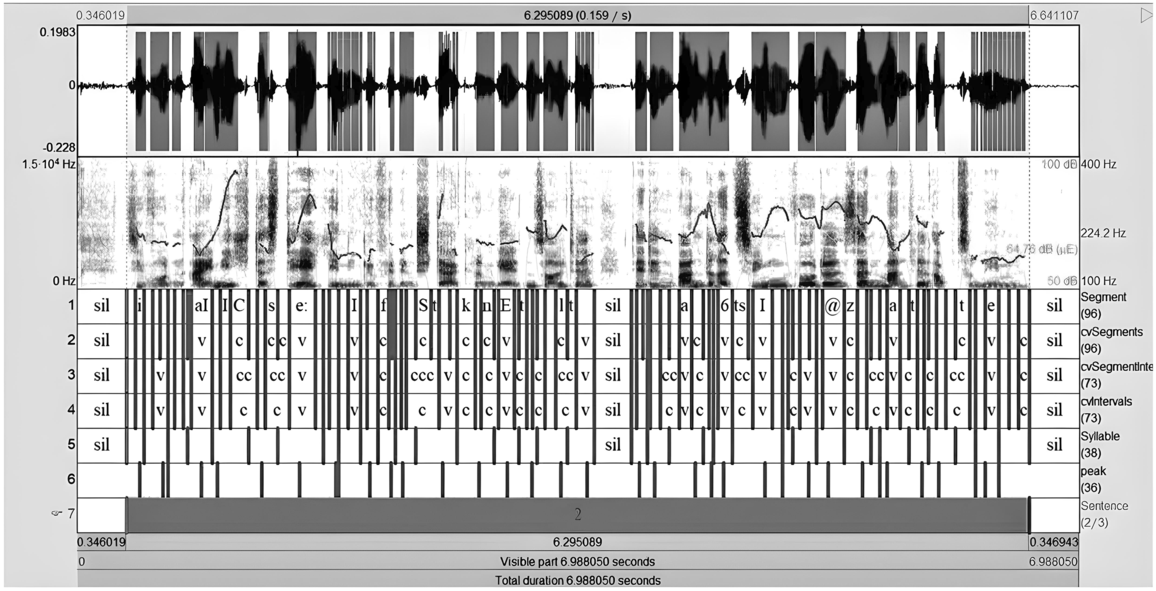
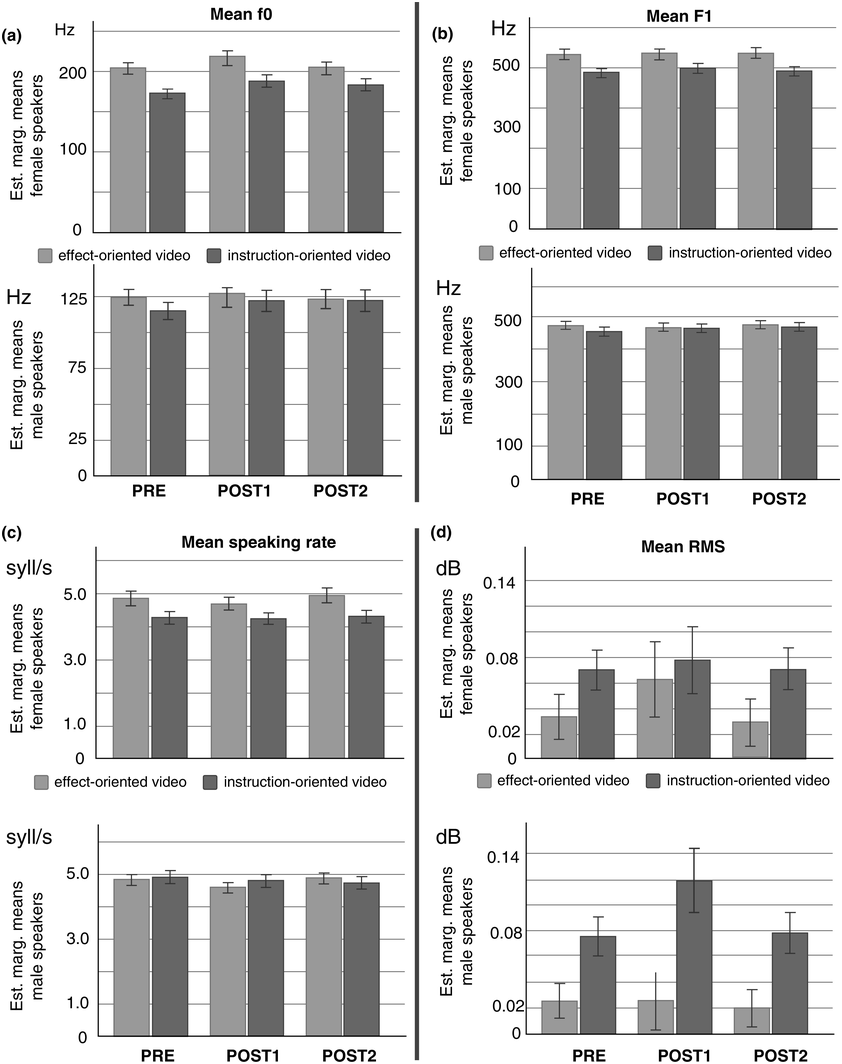
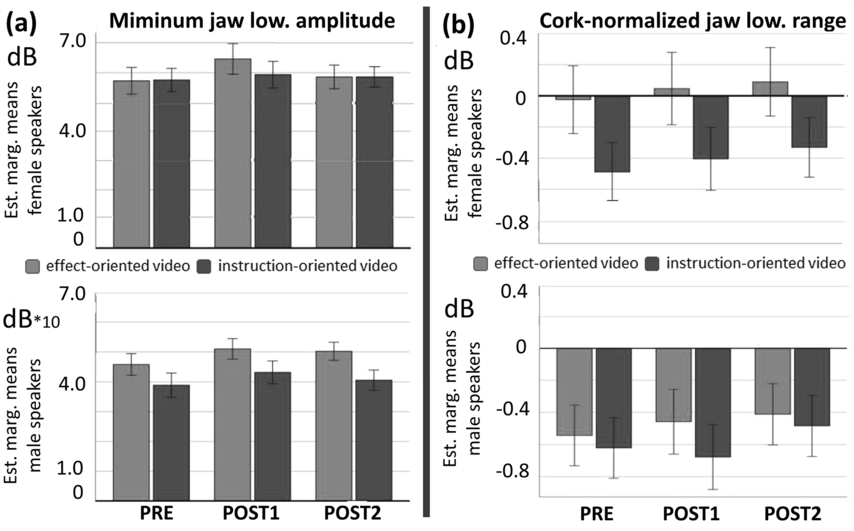




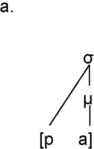
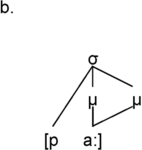
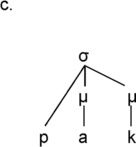
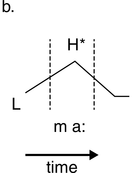
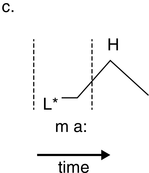

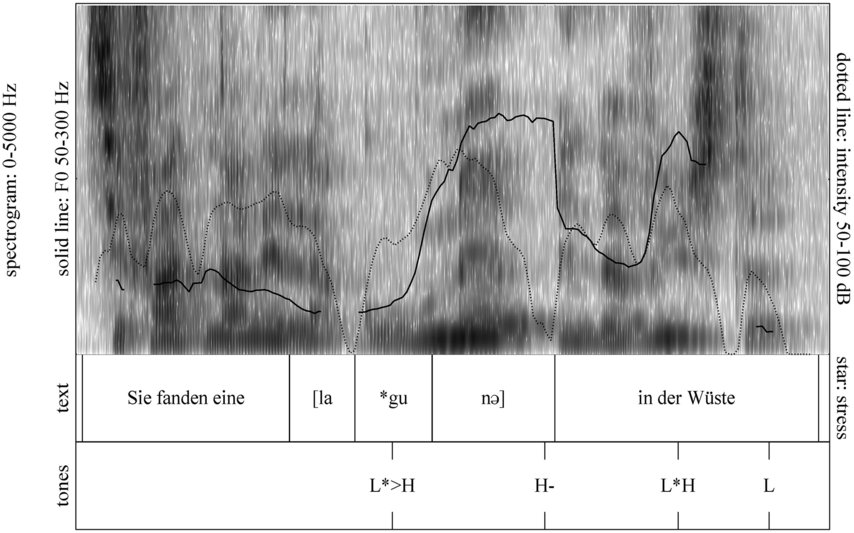
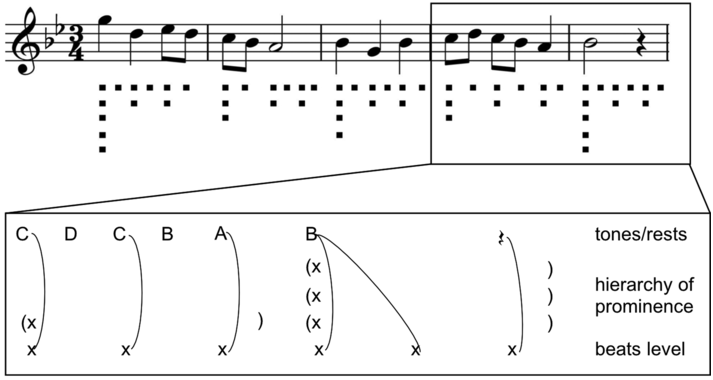
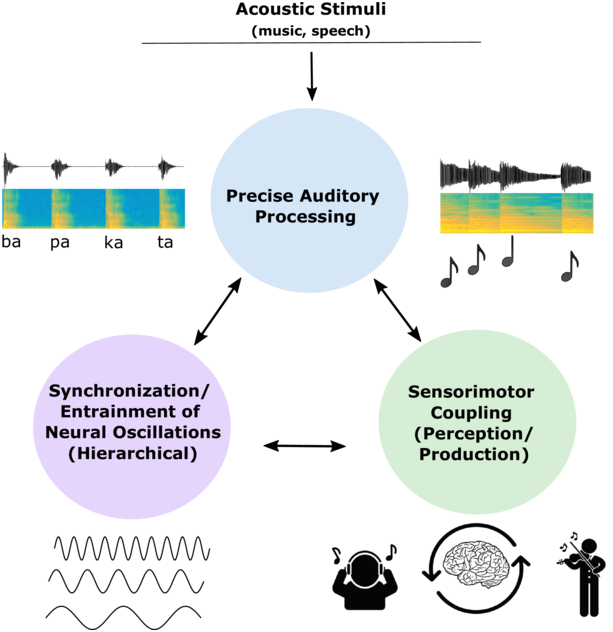

 Open access
Open access
{kind=link}