


Plain language summary
This article proposes a framework for analyzing narrative structures in film and video that addresses a key limitation in current digital humanities research. Although recent computational advances have enabled large-scale analysis of audiovisual media, most existing methods focus on low-level technical features, such as shot length, camera angles or color. As a result, there remains a gap between what computational tools can readily measure and what humanities scholars seek to understand: how narratives generate meaning, guide interpretation and produce social or ideological effects.
To bridge this gap, we develop a multi-layered model that connects technical features to higher-level storytelling strategies. We conceptualize films and videos as structured systems of meaning designed to shape audience attention, emotion and interpretation. At the lowest level, the model captures concrete audiovisual features, which are combined into recurring film editing and discourse patterns, such as shot alternation in dialogue scenes. These patterns, in turn, support broader narrative strategies – such as fragmentation, where continuity is disrupted to create tension or disorientation – that can be used to probe ideological positions, including political and cultural orientations.
We implement this framework using state-of-the-art computational methods to automatically detect audio, visual and linguistic features, alongside an interactive tool that allows researchers to search large video collections for narrative patterns. This enables movement between large-scale quantitative analysis and close reading of specific segments. We demonstrate the approach on a corpus of over 1,000 German news videos, showing that outlets associated with different political and journalistic ideologies employ narrative strategies to varying degrees. Our findings show that storytelling strategies can be formalized and detected computationally, and that they reveal meaningful differences across media sources. By linking technical analysis with narrative interpretation, this work opens new directions for digital film and media studies and contributes to computational narratology by extending narrative analysis beyond text to audiovisual media.
Introduction
In recent years, digital humanities (DH) research has evolved from its textual origins to encompass film and video studies as critical areas of inquiry as well. Historically, DH’s initial focus on textual analysis has been gradually complemented by computational approaches to visual media, enabling what has been termed “distant viewing” (Arnold and Tilton Reference Arnold and Tilton2019) and “deep watching” (Howanitz et al. Reference Howanitz, Bermeitinger, Radisch, Gassner, Rehbein and Handschuh2019). These approaches represent a shift toward engaging with large-scale, non-textual datasets in ways that blend both quantitative and qualitative analysis. Such advances have already spurred extensive research into formal and aesthetic aspects of film, including color analysis (e.g., Flückiger Reference Flückiger2020), shot structure (Heftberger Reference Heftberger2018; Salt Reference Salt2007) and stylistic attributes (Redfern Reference Redfern2022), all facilitated by tools and methods tailored to multimodal data (cf. Arnold and Tilton Reference Arnold and Tilton2020; Burghardt et al. Reference Burghardt, Bateman, Müller-Budack, Ewerth, Nunn and Oorschot2024; Pustu-Iren et al. Reference Pustu-Iren, Sittel, Mauer, Bulgakowa and Ewerth2020; Redfern Reference Redfern2022). While these computational approaches are already contributing greatly to our understanding of the more formal features of film, they are not yet able to engage with many of the more abstract narrative dimensions that play a crucial role in film analysis more generally (Bordwell Reference Bordwell and Ryan2004, Reference Bordwell2006; Müller and Kappelhoff Reference Müller and Kappelhoff2018). This leaves a gap between treatments in terms of formal technical features and the concerns of many researchers involved in film analysis at more qualitative, interpretative levels, in effect reiterating the classic tension within DH as such: that is, how to establish levels of description that are “computable” but also responsive to traditional humanities-oriented research questions.
Our goal in this article is to address this gap by proposing a digital multimodal approach to investigating the narrative techniques applied in audiovisual media, such as film. In contrast to previous work that has often focused on more surface aesthetics properties, we set out a general method by which more abstract audiovisual patterns that shape meaning, drive plot and engage viewers in story arcs can begin to be made accessible for larger-scale investigation. In doing so, we align our work with the emerging field of computational narratology, which has begun to extend its research focus beyond written texts to the analysis of narrative structures in multimodal and large-scale audiovisual corpora. Taking the perspective of narratology allows us to reconceptualize film not merely as a sequence of images, but as a complex system of narration(s) that can be studied through computational means.
Our approach combines both a theoretical understanding of how meanings can be made in audiovisual media based in current work on multimodal semiotics (Bateman Reference Bateman2017; Bateman, Wildfeuer, and Hiippala Reference Bateman2017) and recent advances in deep learning and multimodal analysis which allow us to search for and retrieve complex narrative structures across large video corpora with new levels of specificity and accuracy. This then contributes to the trend identified by DH scholars as the “digital visual turn” (Wevers and Smits Reference Wevers and Smits2019), but goes further than applying machine learning to extract, analyze and visualize large amounts of visual information. In addition, we expand the scope of inquiry beyond visual content to include language, audio, movement and other expressive forms to articulate an extensible and multi-layered framework for multimodal narrative analysis in general. As part of this work, we have developed an interactive information retrieval system, called Narrascope, that is designed to identify, explore and visualize discovered narrative patterns in an interactive way. This tool is not only innovative in its capability to handle multimodal data, but also allows researchers to engage with video content on an exploratory basis applying a scalable viewing approach (Burghardt, Pause, and Walkowski Reference Burghardt, Pause and Walkowski2019; Ruth, Liebl, and Burghardt Reference Ruth, Liebl and Burghardt2023), thereby supporting the iterative refinement of our understanding of narrative strategies.
The article makes several novel contributions. First, we set out more precisely how we are using the concept of “narrative” as an organizational scaffold and how we break the concept down into multi-layered components essential for formalization and computational tasks. For this, we deploy a framework building on multimodal semiotics to theorize the links across these different analytical layers to perform digital multimodal narrative analysis. Second, we show how we implement this theoretical framework for extracting narrative patterns in a manner that can be computationally formalized, leveraging advanced deep learning frameworks for multimodal information extraction. Finally, we illustrate several applications of the framework. Specifically, we show the framework in use for the detection of potentially problematic narrative patterns in news videos through an examination of a relatively large sample of German news videos, thereby offering a new set of tools for analyzing news narratives in the context of disinformation addressing various facets of media manipulation and narrative construction in the digital age.
Narrative and narrative strategies in film and video
Since the term “narrative” is subject to a wide range of definitions across diverse areas, it is particularly important right at the outset of our discussion to clarify our use of the term. In this section, therefore, we characterize our use of both “narrative” and “narrative strategies,” and then relate these to our broader multi-layered semiotic account of meaning making.
Formalization of narratives
Definitions for “narrative” range over diverse units and phenomena, stretching from a simple “single event” on the one hand to complex arcs of story phases and transitions on the other (cf., e.g., Fludernik Reference Fludernik1996; Forster Reference Forster2005 [1927]; Genette Reference Genette1980). Often, collections of temporally organized events contributing to causal networks of contingency, cause and effect are considered necessary as well (Porzel et al. Reference Porzel, Pomarlan, Spillner, Rockstroh, Bateman, Marenzi, Gottschalk, Müller-Budack, Tadić and Winters2025; Winer Reference Winer, Dershowitz and Nissan2014). Most of these constructs are also regularly applied in the specific context of film analysis in one form or another and so are all potentially relevant (e.g., Black Reference Black1986; Bordwell Reference Bordwell1985; Griem and Voigts-Virchow Reference Griem and Voigts-Virchow2002; Heinen and Sommer Reference Heinen and Sommer2009; Kuhn Reference Kuhn2011; Wulff Reference Wulff1999). To do justice to this diversity, our goal in the present article will not be to favor any one interpretation of “narrative” over others. Our aim is rather to provide a flexible framework that can help support investigations of a “narrative” nature for audiovisual media no matter the choice of definition.
The notion of narrative we pursue in the article will therefore refer to:
any methods used to structure, develop and shape audiovisual materials so as to increase the engagement, emotional arousal and emotional responses of audiences, as well as directing spectators to most plausible interpretations.
This means that we will not restrict what will be considered “narrative” and what not, but seek instead to provide a general means for exploring, capturing and then explaining how designed sequences of audiovisual material have reliable and consistent effects on their viewer-listeners that may be applied in many research contexts.
The range of phenomena that we will be concerned with below is consequently broader than those often seen as directly “narrative” in nature, and includes aspects regularly treated in film studies under poetics, aesthetics and similar. This then also accommodates quite abstract interpretations and ideological orientations of the kinds discussed in film genre theory (e.g., Altman Reference Altman1999; Grant Reference Grant2007; Tudor Reference Tudor1974) and well-known critical positions such as Mulvey’s (Reference Mulvey1975; Reference Mulvey1989) “male gaze” central to much feminist film theory. In most such cases, we find interpretations that pick out selected technical features of film as being indicative of particular kinds of ideological effects or orientations – for example, styles of hats and reoccurring landscapes for genres, such as the Western or, in Mulvey’s case, fragmented and fragmenting views of the female body and lack of female agency. The problem of establishing linkages between such abstract categories and the concrete features of film so that they can be subjected to empirical investigation has long been discussed. Buckland (Reference Buckland2026), for example, attempts a closer operationalization of features that could be indicative of Mulvey’s “male gaze,” including framed visuals, enclosed spaces, close-ups, lack of screen depth, fragmentation and more, as well as certain properties of the story more broadly. This moves in a direction compatible with that set out here by combining various levels of abstraction, but the patterns proposed are still only informally described. Conversely, current approaches to fully automatic multimodal classification of film genre draw on an increasingly broad range of technical features (cf. Moreno-Galván et al. Reference Moreno-Galván, López-Santillán, González-Gurrola, Montes-Y-Gómez, Sánchez-Vega and López-Monroy2025), but nevertheless focus on assigning classificatory labels rather than revealing the critical audiovisual strategies constitutive of narrative.
To address these limitations, we draw here on current results in multimodal semiotics, using these to construct a theoretical foundation for our approach. Through these means, we consider it possible to relate computational approaches to more abstract kinds of narrative interpretation formerly excluded from DH. To begin, we briefly introduce this semiotic foundation and then sketch its relation to film and audiovisual media analysis.
A semiotics-based multi-layered framework
Research topics on abstract themes in film and video, such as ideologies, character traits or information authenticity and values in news or documentary videos, have primarily been based hitherto on top-down analysis. This is because it is never possible to directly “read off” such interpretations from formal film features alone. Conversely, computational approaches to audiovisual analysis have typically explored low-level detection of measurable film technical features, such as shot durations, image color and color balance, shot sizes and camera angles (Benini, Canini, and Leonardi Reference Benini, Canini and Leonardi2010; Cutting et al. Reference Cutting, Brunick, DeLong and Iricinschi2011; Cutting, DeLong, and Brunick Reference Cutting, DeLong and Brunick2011; Cutting, DeLong, and Nothelfer Reference Cutting, DeLong and Nothelfer2010; Flückiger Reference Flückiger2020; Savardi et al. Reference Savardi, Kovács, Signoroni and Benini2023) precisely because these can be read off the technical attributes of the medium. Interconnecting the two extreme ends of this spectrum in order to systematically contrast how narrative themes and ideologies might shape the adoption of particular formal properties in film and vice versa is then highly challenging.
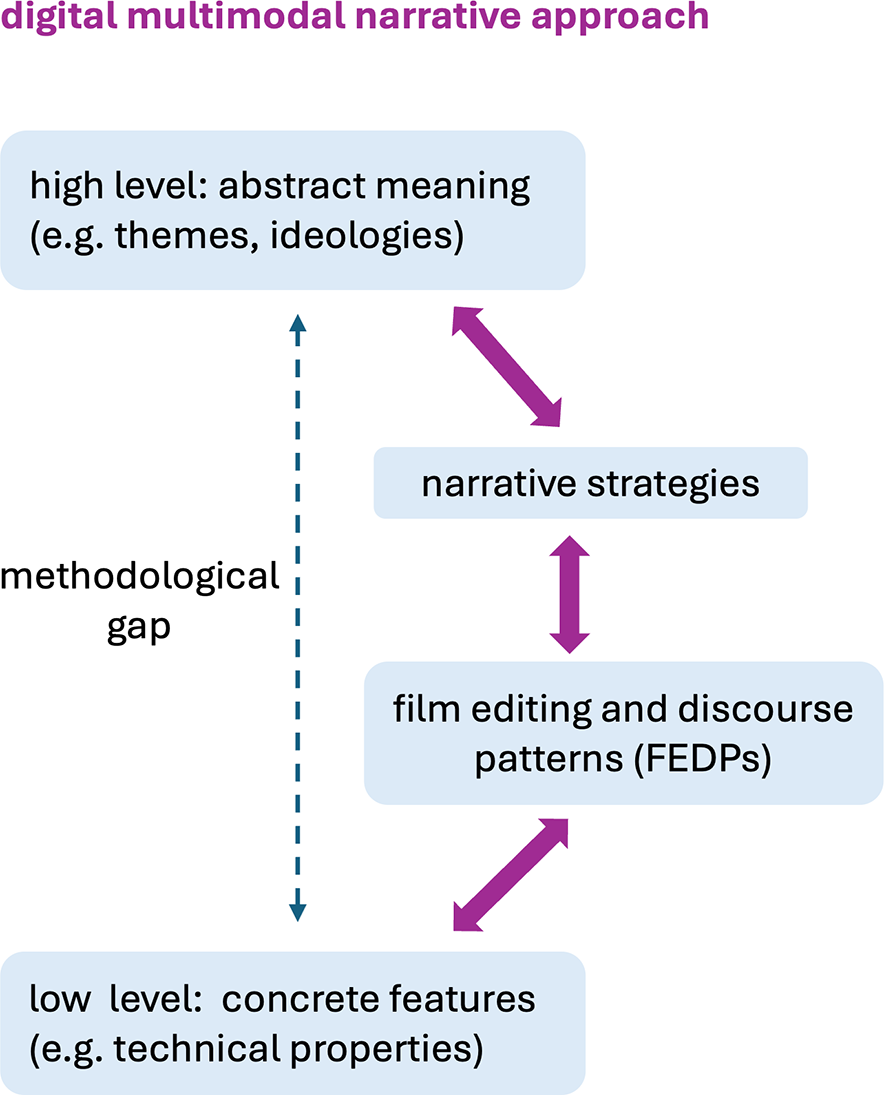
Our approach to this is to decompose the large theoretical and methodological “gap” between technical features and abstract interpretations across several intermediate layers of descriptive abstraction, each anchored above and below and allowing analysis to move progressively from patterns of descriptions at lower levels of abstraction to descriptions at higher levels. This framework is motivated in some detail in Tseng (Reference Tseng2013, Reference Black12). Figure 1 suggests the approach graphically, setting out how the methodological gap between technical attributes of the medium and abstract meanings can be bridged, integrating top-down and bottom-up analyses of audiovisual media in a layered fashion. We will illustrate each of the layers in this architecture as we proceed, showing both what they involve and how they can receive computational instantiation to support larger-scale DH research on audiovisual media.
Closing the theoretical, analytic and methodological gap between form and interpretation.
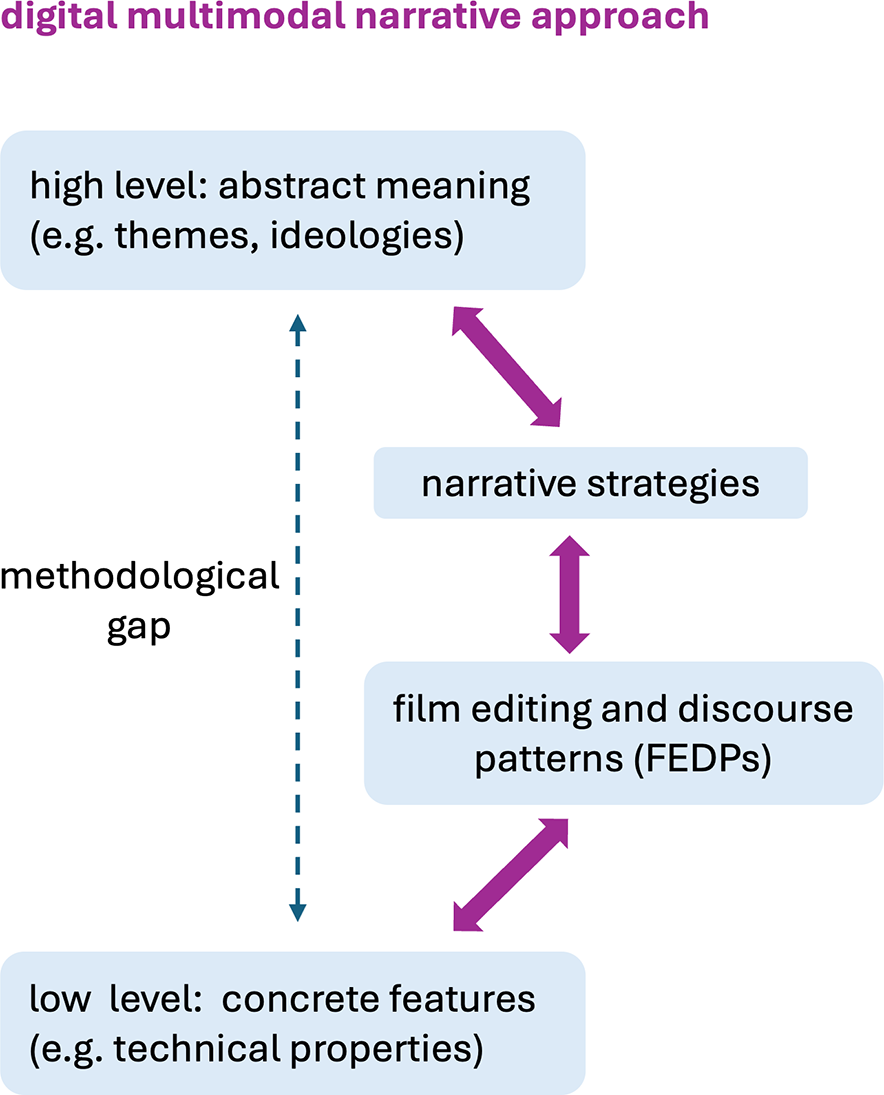
At the lowest level we place concrete, technical features of the medium which are measurable and relatively straightforward to derive computationally; in “the Computational approaches to film and video analysis” section, we give an overview of the current state of this part of our framework. Subsequently, building on the descriptions made possible at that level, we introduce a further level of patterning that we term film editing and discourse patterns (FEDPs). This level relates directly to traditional film practice and education, where it is still commonplace to consider established “solutions” to frequently encountered filming situations, such as dialogues between several people, perhaps standing or sitting around a table or scene introductions, where overviews are first given followed by details of the situation, and so on. Practical film guides set out lists of such techniques and a substantial part of learning practical film skills is becoming familiar with these for constructing sequences for particular, reoccurring effects (cf. Arijon Reference Arijon1976; Spottiswoode Reference Spottiswoode1935; Thompson and Bowen Reference Thompson and Bowen2009a, Reference Thompson and Bowen2009b). Analogously to the use of set patterns in language, these film templates have often been termed film idioms:
“A single idiom encodes the expertise to capture a particular type of situation, such as a conversation between two actors, or the motion of a single actor from one point to another. The idiom is responsible for deciding which shot types are appropriate and under what conditions one shot should transition to another. The idiom also encodes when the situation has moved outside the idiom’s domain of expertise – for example, when a third actor joins a two-person conversation.” (He, Cohen, and Salesin Reference He, Cohen and Salesin1996, 4)
Our new level of description captures this kind of very practical filmmaking knowledge by providing a specification language for incorporating multimodal “idioms” formally and computationally within our overall framework. In the “Formalization of film editing and discourse patterns” section, we show how this has been achieved drawing directly on an approach to constraining decisions in virtual cinematography for automated visual storytelling developed by Wu et al. (Reference Wu, Galvane, Lino, Christie, Bares, Gandhi, Galvane and Ronfard2017).
The patterns of this level operate by grouping formal technical features of film into specific structural organizations that are considered relevant for guiding interpretation. In the case of audiovisual media, these generally involve patterns of traditional cinematic features of any kind that may be hypothesized as having narrative consequences. Such FEDPs do not need necessarily to be narrative in their own right, but are adopted in our framework as the basic building blocks, or constitutive elements, by which narratives of any kind can be constructed. As we move higher in abstraction, particular combinations and structures defined over FEDPs then come to identify explicitly narrative strategies capable of building more extended communicative structures; we consider the assembly of a catalog of such extended “arcs” as primarily an empirical issue to be filled during the kind of explorative empirical research that our framework supports and which we illustrate below.
The final move upwards in abstraction is to our targeted accounts of potential ideological differences. The key to this analytic step lies in considering variations across usages of lower-level patterns. Theoretically, this draws on more variationist accounts of social meanings as pursued in several branches of linguistics, particularly functional and sociolinguistics, whereby variations in usage patterns have been found to reliably correlate with social configurations, such as class, gender and various other contextual and power relationships (cf. Halliday Reference Halliday1978; Labov Reference Labov2001; Martin and Rose Reference Martin and Rose2008). We extend this view to the multimodal case and examine differences in the use of narrative patterns at lower levels of abstraction as potential symptoms of differences in broad “ideological” positioning as well. We illustrate this concretely below by contrasting the narrative strategies employed in news channels that are commonly assumed to be adopting contrasting political ideologies.
Formally specifying each of these levels of description then allows us to deploy a multi-layered semiotic framework that interlinks:
-
• concrete features, such as technical properties,
-
• FEDPs defined over those features,
-
• narrative strategies defined over FEDPs and
-
• abstract themes and ideologies manifested in variations in the applications of those strategies,
all situated within a general framework supporting digital multimodal narrative research.
In the remainder of this article, therefore, we follow the right-hand path shown in Figure 1 and show the forms taken by each layer of description in more detail, motivating our modeling decisions and demonstrating their application through film and video examples. More specifically, our digital multimodal narrative approach allows for: (1) the use of computational tools to analyze an extensive set of technical and formal film features; (2) the identification of narrative strategies composed of multiple FEDPs; and (3) the specification of relationships between FEDPs, narrative strategies, ideological and other abstract themes. To demonstrate these cross-level relationships, we present in the later sections several use cases focused on news videos.
Formalization of film editing and discourse patterns
In the previous section, we set out a multilayered architecture for pursuing more abstract interpretations of audiovisual materials. In this section, we begin by setting out the development of a formal account of FEDPs that can be employed directly in computational exploration of audiovisual data. We then clarify and exemplify the types of narrative strategies we wish to capture.
Capturing and formalizing narrative strategies through FEDPs
Our starting point for the development of the level of FEDPs is drawn quite directly from the notion of film editing patterns (FEPs) introduced by Wu and Christie (Reference Wu, Christie, Christie, Galvane, Jhala and Ronfard2016) as well as Wu et al. (Reference Wu, Galvane, Lino, Christie, Bares, Gandhi, Galvane and Ronfard2017, Reference Wu, Palù, Ranon and Christie2018). FEPs are one of the most recent and flexible characterizations of “filmic idioms” as introduced in the previous section. Wu et al. (Reference Wu, Galvane, Lino, Christie, Bares, Gandhi, Galvane and Ronfard2017) develop FEPs both for controlling virtual cinematographical processes and for performing analysis of film segments and it is essentially the latter possibility that we build on here.
FEPs, and our extensions of FEPs below, are largely concerned with the lower level of interpretation set out in Figure 1 and are consequently defined in terms of rather concrete filmic technical features. They therefore take the critical first step in connecting technical feature of camera positions, framing and so on with the more general interpretations that may be employed subsequently in larger-scale narrative organizations. We can see the basic use of FEPs in the following simple example of using FEPs for film analysis offered by Wu et al. (Reference Wu, Galvane, Lino, Christie, Bares, Gandhi, Galvane and Ronfard2017) and reproduced here in Figure 2. This shows eight consecutive shots taken from Gary Ross’ (2012) film The Hunger Games in which the initial interpersonal relationships between the two main protagonists of the film are established.
Wu et al.’s (Reference Wu, Galvane, Lino, Christie, Bares, Gandhi, Galvane and Ronfard2017) example of multiple FEPs applying simultaneously across a sequence of shots from Gary Ross’ The Hunger Games (2012).

Formerly, each FEP defines constraints that have to be met by some sequence of shots for that sequence to be classified as instantiating the FEP in question. In the case shown in the figure, therefore, the FEPs “Intensify,” “Opposition,” “Frameshare,” “Same-size” and “Shot-reverse-shot” are found to apply to subsequences of shots as indicated. This means, for example, that the formal filmic properties of shots 1–3 match the formal pattern given for the FEP “Intensify,” and so on. Each of these patterns relates both “downwards” to particular configurations of formal features and “upwards” to narrative functions, such as showing antagonism, shared positions or emotions, dialogic interaction and so on; various further kinds of FEPs that Wu et al. (Reference Wu, Galvane, Lino, Christie, Bares, Gandhi, Galvane and Ronfard2017) address include alternating editing and cut-ins.
When guiding virtual cinematography, all such FEPs place constraints on the technical properties of shots and frames, such as camera distances, angles, etc., which can then be translated to both virtual and real filming scenarios. When used for analysis, the same technical properties serve as identification criteria. Considered most generally, therefore, these criteria specify:
-
• constraints on the technical features of sequences of shots,
-
• particular kinds of relations holding across shots and
-
• constraints on shot sequences, for example, restricting the length of shot sequences or requiring the presence of certain subsequences.
This framework proved itself effective for characterizing an interesting range of filmic constructions, but remained limited. As Wu et al. concluded:
“The Film Editing Patterns language provides a simple way to define complex editing constraints for automatic detection and enforcement of cinematographic patterns. However, the visual features currently available in the vocabulary are limited to the size, position, angle and number of actors on-screen, and there are many other features that are essential to cinematographic storytelling, including lighting, sound, and staging, that we currently do not take into account when defining patterns.” (Wu et al. Reference Wu, Galvane, Lino, Christie, Bares, Gandhi, Galvane and Ronfard2017, 0:21)
This is what we now develop further, expanding FEPs to include both a broader (and in principle open) range of formal properties as well as larger-scale structures appropriate for picking out discourse patterns and capturing stylistic and discourse choices found in films as well. To mark this expansion, we term the resulting patterns FEDPs reflecting their broader scope.
FEDPs consequently specify constraints of the kind found in FEPs augmented by both technical and discourse features of sequences of shots. Examples of such discourse-relevant constraints used below include specific relations among actors, objects, places and sounds. In addition, strategies may be defined drawing on particular discourse cohesive relations of re-occurrence and co-reference as proposed in the multimodal discourse approach to film analysis set out in Tseng (Reference Tseng2013) and Tseng, Laubrock, and Bateman (Reference Tseng, Laubrock and Bateman2021). We also use FEDPs to specify targets for analysis that might not yet be achievable fully automatically by incorporating features that require manual analysis. Audiovisual sequences can then be “marked up” as instantiating further FEDPs that then stand as ground truth annotation sets for training further recognizers.
In our multi-layered framework, therefore, FEDPs constitute crucial building blocks for gradually raising levels of descriptive abstraction toward narrative strategies as suggested in Figure 1. As explained above, we can then use the term narrative strategies to refer technically to any methods employed to structure, develop and shape a coherent filmic story. These strategies serve as communicative tools that enhance audience engagement, evoke emotional responses and direct interpretations. Common narrative strategies long identified in filmic storytelling include, for instance, emotionalization, individualization of characters, fragmentation of continuous events, flashback to childhood, confrontation, revelation of identities and so on. In film studies, these strategies are generally considered to involve a sophisticated synthesis of multimodal features, including filmic editing, technical properties, character actions and interactions, spatiotemporal structures, causal relationships between events and overarching story arcs (Kuhn and Schmidt Reference Kuhn, Schmidt, Hühn, Pier, Schmid and Schönert2014; O’Connell Reference O’Connell2010), all of which we now seek to bring within the remit of FEDPs and their combinations.
Fragmentation in an audiovisual news report taken from our corpus. Extract from news report on Covid-19 protest by CompactTV on 07.01.2022.

As an illustration of how narrative strategies can be captured by combinations of FEPDs, we briefly consider the formalization of one particular narrative strategy, that of fragmentation. This strategy characterizes a storytelling method where the narrative is presented in a disjointed manner, often breaking the space and/or time continuity of events. Constructing a narrative in this way readily creates a sense of disorientation and pushes viewers to actively engage with the material as they are required to piece together clues to achieve narrative coherence. The use of this narrative strategy may evoke audience’s feelings of tension, enhance emotional engagement with the characters and challenge the more commonly unreflected narrative coherence of these patterns to facilitate a different kind of embodied-cognitive resonance in the film viewer (Coëgnarts Reference Coëgnarts, Steven and Miklós2022). Furthermore, the use of this strategy is by no means restricted to narrative film, demonstrating the value of generalization across medial variants of audiovisual communication as a whole. In particular, fragmentation is also nowadays found in audiovisual news reporting, particularly in private or commercial news channels which often target viewers’ emotional engagement and create tension.
Figure 3, for example, shows an extract from a news report by CompactTV, a German news channel which produces daily news commonly seen as being more aligned with populist, right-wing political parties in Germany. This particular extract depicts an interview of a politician from the far-right, political party AfD. The interview takes place in a protest against Covid policies in 2022. The interview is spatially fragmented by inserting clips of the demonstration from an earlier time point. In other words, although the speaker is talking continuously throughout, shots 2 and 4 insert non-continuous demonstration clips with unclear spatial and temporal relations to the interview event that then serves as a narrative “scaffold.”
Describing a narrative strategy in such terms remains quite abstract and is consequently located at a considerable distance from measurable formal features. Following the modeling architecture of Figure 1, however, we now break down this general strategy of fragmentation into a collection of lower-level patterns that can regularly serve as indications that fragmentation is occurring. Quite specifically, in the context of news video, fragmentation appears to be established through FEDPs that intertwine fragmented space by means of the editing technique of alternating shots combined with a discourse pattern of a single speaker and reoccurring places and spoken language.
We summarize this lower level patterning abstractly in Figure 4 and will return to its more formal definition below. We also see here the particular role of multimodality in our account: what makes a segment fragmented is not restricted to any single expressive modality, such as the visual effects, but freely combines visuals, sound and spoken language. In our examples below, we make frequent use of this capability to combine clues from different modalities.
Film editing and discourse patterns combined to support an interpretation of fragmentation.

When a complex narrative strategy has been defined in this way, our architecture and its computational instantiation allow us to query larger data sets to find instances of subsequences that meet the specified constraints. This then serves as the basis for the final step of analysis suggested in Figure 1 and the move up toward ideological configurations and abstract themes. In terms of the functional semiotic approach that we adopt and as noted above, ideological configurations often reveal themselves through differences and contrasts in how particular communicative goals are framed and then pursued (Martin and Rose Reference Martin and Rose2008; Tseng Reference Tseng2013). Since, as is usual in corpus-based work, our data includes a range of “metadata” indicating sources, dates of production, topics and so on, it is then straightforward to explore whether the instances retrieved for some narrative strategies are unevenly distributed according to those metadata categories. When we find uneven distributions, this provides the grounds for hypotheses that differing ideological orientations may be at work. We provide specific examples of this with respect to our news report corpus below.
Defining, modeling and operationalization of FEDPs
We turn now to the formalization of FEDPs to achieve the goal of our framework of providing computationally supported analysis. For this, we construct an abstract query language for defining and operating with FEDPs and narrative strategies that can then be used in empirical audiovisual studies more broadly. This draws closely on the account of multimodal meaning making set out in Bateman, Wildfeuer, and Hiippala (Reference Bateman, Wildfeuer and Hiippala2017) so as to define filmic patterns both across modalities and across longer extents as useful for discourse analysis; these are also directly related to the notion of multi-layered annotations in multimodal corpus work (cf. Bateman Reference Bateman2022, 73).
The development of query languages for interrogating multimodal corpora is an active area of research in its own right. Approaches building on techniques for working with linguistic data tend to be the most sophisticated among these because of the combined need to deal with properties, such as structure, sequence, dependency relations and mutual constraints within and across these dimensions. A still very relevant review of types of approach is given by Clematide (Reference Clematide, Gintare, Clematide, Utka and Volk2015). Experience in this line of development has led to most such query languages aiming to be open with respect to the particular units and properties they provide for building query patterns, setting out an overall logical structure that can be used for composing structural patterns with additional relational and property constraints.
We follow this strategy in our own approach as well and set out in the current section how we define queries first at an “abstract” level that is largely independent of specific implementations. In general, there will be many ways in which the necessary query mechanisms can be implemented, ranging over database techniques, graph matching, path-based matching and more. A recent description of options taken up can be found, for example, in Graën et al. (Reference Graën, Schaber, McDonald, Mustač, Rajovič, Schneider, Vukovič, Zehr, Bubenhofer, Lindén, Kontino and Niemi2023). We will focus here, however, on just the specific details relevant for our use cases, adopting directly the notation for FEPs proposed by Wu et al. (Reference Wu, Galvane, Lino, Christie, Bares, Gandhi, Galvane and Ronfard2017) and, in particular, their formal specification in terms of embedded constraint Ppatterns (ECPs) in Wu and Christie (Reference Wu, Christie, Christie, Galvane, Jhala and Ronfard2016). In the use cases we present below, these abstract queries then receive an implementation at the concrete level actually supported by our exploration tool.
ECPs are essentially recursive attribute–value pairs and so are straightforward to interpret. Using them provides a transparent way of capturing constraints over shots, subsequences and their relations. We consequently adopt this general strategy, extending it further to capture our notion of multimodal FEDPs as introduced above. These retain the recursive specification of filmic practices, while also incorporating properties designed for discourse-sensitive analysis and automatic processing. As an example, Listing 1 shows our FEDP definition of intensification (same actor). This builds on Wu et al.’s original intensification pattern (see Wu et al. Reference Wu, Palù, Ranon and Christie2018, 9) of progressively moving the camera “closer” by adding an additional discourse “cohesion” constraint that the same actor is depicted across shots. Consequently, our specification recursively defines just those patterns of sequences and sub-sequences that are to count as an instance of the pattern.

Following the pattern, the entire intensification (same actor) sequence has to include three or more shots (line 2) as in the original pattern, but with a new constraint specifying that all shots must involve the same actor (line 4). Over this sequence, a size relationship holds whereby each shot must be classifiable as being “closer” than the previous one (line 6). Again following Wu et al., the definition also allows for sub-sequences in which shot size remains constant (lines 8–13), which can themselves contain any number of shots (line 9), provided those shots are of the same size (line 11). This flexibility reflects the fact that, in film-theoretic terms, intensification is not invalidated by occasional repetitions of the same shot size. When translated into the concrete query form of our tools, applying the pattern to a corpus then supports retrieval of any sequences that match for purposes of further exploration as we illustrate below. Beyond the actor relation illustrated in this example, FEDPs incorporate a variety of further discourse-based relations. Those that will be particularly relevant below include:
-
• object relation;
-
• location relation;
-
• action relation.
Finally, drawing on the view of multimodal discourse underlying our account theoretically, we also add a more multimodally discriminating notion of formal units that moves us beyond Wu et al.’s focus on shots. Since, as we have seen, it is often the case that constraints may operate both within distinct modalities (e.g., within the sound stream, verbal language or features within a shot) and across modalities, we need to add such combinations of constraints to the pattern language as well. For this, we define additional unit types alongside shots and shot sequences which can be included in the abstract patterns defined so as to pick out different kinds of sequences. In our use cases below, we will make most use of units that indicate speaker turns as extracted from the audio channel.
Defining more abstract pattern combinations
We then use combinations of FEDPs to define higher-level narrative strategies as explained above in the “Capturing and formalizing narrative strategies through FEDPs” section. For example, we specify the higher-level narrative strategy of fragmentation by systematically formalizing its constituent components. This first step then also involves specifying the FEDP of alternating shots, which we formalize as shown in Listing 2.

This operates in the same way as the example query patterns given above, but includes a richer collection of relational discoursal constraints binding the various contributing shots together. As previously discussed, the alternating shot pattern involves a visual exchange between two actors and/or objects across a sequence of shots. To capture this, the pattern specifies that we require a sequence of at least four shots (line 2) made up of an alternating sequence where shots 1 and 3 share a particular framing size and shots 2 and 4 similarly also share a common framing size (line 4). The framing sizes of the two-shot pairs need not be the same, however. In addition, the pair of shots 1 and 3 need to depict the same actor or object (line 6), as do the pair of shots 2 and 4 (line 7). Moreover, these need to be mutually different actors or objects as indicated by the difference constraint given in line 9. This formalization then captures the core alternating structure with paired repetition both in visual framing and in the actors/objects featured, reflecting a back-and-forth dynamic that is a characteristic discourse organization of many film editing sequences.
Moving on to the second constituent of the fragmentation strategy, the FEDP of continuity of talk/dialogue is formalized in Listing 3. This pattern defines a continuation of talk or dialogue across a sequence of speaker turns made up of at least two speaker turns (line 2). The condition in line 4 then ensures that the dialogue flows continuously across all the speaker turns of the sequence, capturing the ongoing verbal interaction regardless of any visual cuts that may co-occur. We spell out further how the information from the audio track and the visual shot information are combined formally in our concrete instantiations of such queries discussed in the use cases below.

Finally, to produce the fragmentation strategy, we combine these two FEDPs as shown in Listing 4. Here, we see the constraints for the alternating shot FEDP mirrored in lines 4–9 and the constraint for continuity of talk/dialogue included in line 11. Together they capture the fragmentation strategy discussed in the “Capturing and formalizing narrative strategies through FEDPs” section, covering visual cuts while nevertheless maintaining the flow of the same talk or dialogue as required.

Once defined, such patterns are typically grouped into yet larger and more abstract structures by referencing them by name. This allows us to construct catalogs of larger-scale units that can also have properties and attributes specified for them and, consequently, be grouped into further sequences as motivated by empirical studies. Larger-scale patterns usually involve smaller-scale FEDPs such as intensification in this way. The smaller-scale patterns then serve as components within broader strategies. This helps establish several empirically interesting tasks whose investigation is now ongoing. For example, broader, more abstract patterns also exhibit variations in the make-up of their internal components and so are not simply bound to single lower-level structures. However, the range and conditions for such variation remain to be determined.
Feature extraction and computational instantiations
In this section, we have seen how we have defined an abstract query language that allows us to formally specify multimodal patterns at various levels of abstraction as required for addressing narrative. This language plays several distinct roles in our general approach. One usage that we mentioned briefly above, for example, is to provide targets for manual annotation of data. When exploring audiovisual narrative constructions, it is often useful to test out hypotheses of recurring structural organizations by hand. The query language patterns are then interpreted as coding instructions for use with standard audiovisual annotation tools such as ELAN (Wittenburg et al. Reference Wittenburg, Brugman, Russel, Klassmann and Sloetjes2006). When such patterns have been found to be sufficiently reliable, we can then also take the resulting annotations as ground truth training data for building automatic recognizers for those patterns. Several of our more specialized extraction components were trained and evaluated in this way.
Most central for our concerns in this article, however, is the use of the query language to explore narrative patterning in larger bodies of audiovisual data. As set out in “A semiotics-based multi-layered framework” section, we consider variations in narrative patterns as an important indicator of ideological orientations and such variations can only be found when examining data at scale. To support this functionality, it is necessary to provide computational instantiations of all aspects of the query language so that data can be interrogated, automatically retrieving examples of patterns directly from raw audiovisual data. We thus link the abstract predicates of the query language to an extensive library of automatic feature extraction components drawing on the current state-of-the art in audiovisual processing. We characterize these capabilities in detail in the next section.
This modular architecture has important benefits for working with complex data in a highly dynamic field. The predicates and attributes used in the query language can receive multiple implementations on the computational side, allowing users without knowledge of the computational techniques employed to use both FEDPs and narrative structures for empirical investigations. As computational processing techniques improve in functionality, these can be incorporated on the computational side of our framework leaving the abstract queries mostly unchanged and oriented more to narrative and filmic concerns as appropriate. We will see several of the benefits of this organization in our use case studies below. Probing data at scale without needing the explicit computational skills that manage feature extraction is a major step forward for making this kind of analysis more broadly accessible.
Beginning in the section following, therefore, we describe the processing pipeline we use for automatically annotating raw audiovisual data with the necessary units, attributes and values that later support interrogation via FEDP and narrative queries. Following this, we present our selected use cases showing all of the components at work.
Computational approaches to film and video analysis
Videos are inherently multimodal incorporating multiple forms of expression, including images (static and dynamic), audio (speech, music and noise) and overlaid text. Manual film studies require analysis of all these modalities, making it a very time-consuming and tedious task. Thus, AI methods for automatic film and video analysis are essential for studying large video corpora. In the following, we summarize the main developments in computer vision, audio analysis and natural language processing (NLP) based on a structured workflow for video analysis comprising three key steps:
-
1. Temporal video segmentation to transform a continuous video stream into discrete units (e.g., shots, scenes and speaker turns).
-
2. Audio-visual content analysis to identify topics, settings, objects, emotions, entities, etc.
-
3. Coherence analysis to measure the visual, auditory and textual similarity (for speech and overlaid text) across temporal units in the video.
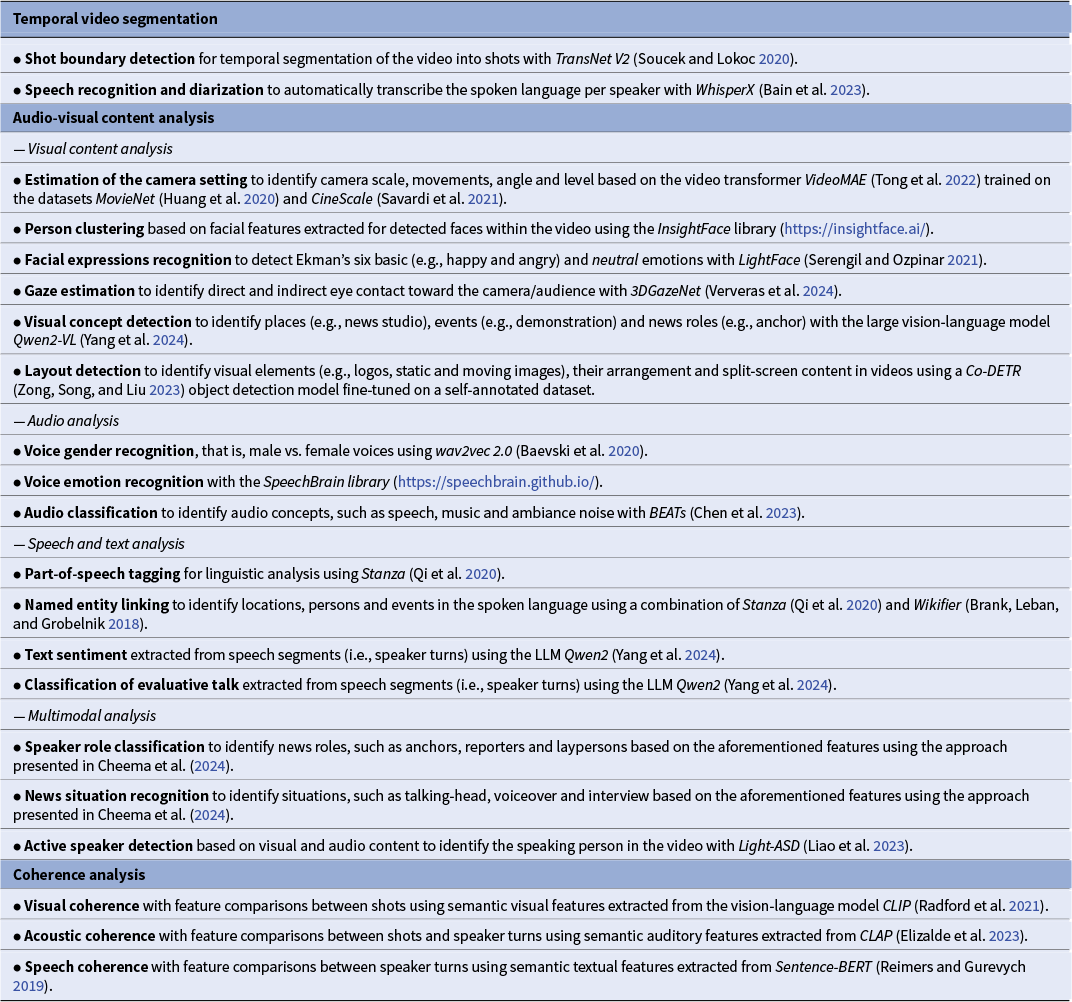
An overview of features that we extract specifically for analyzing the FEDPs and narrative patterns in films and news is presented in Table 1. We also refer to the overview in Burghardt et al. (Reference Burghardt, Bateman, Müller-Budack, Ewerth, Nunn and Oorschot2024) for further details on film analysis in the DH.
Overview of tasks (bold) and corresponding approaches (italics) used for feature extraction in this work to model the film editing and discourse patterns (FEDPs) and narrative patterns
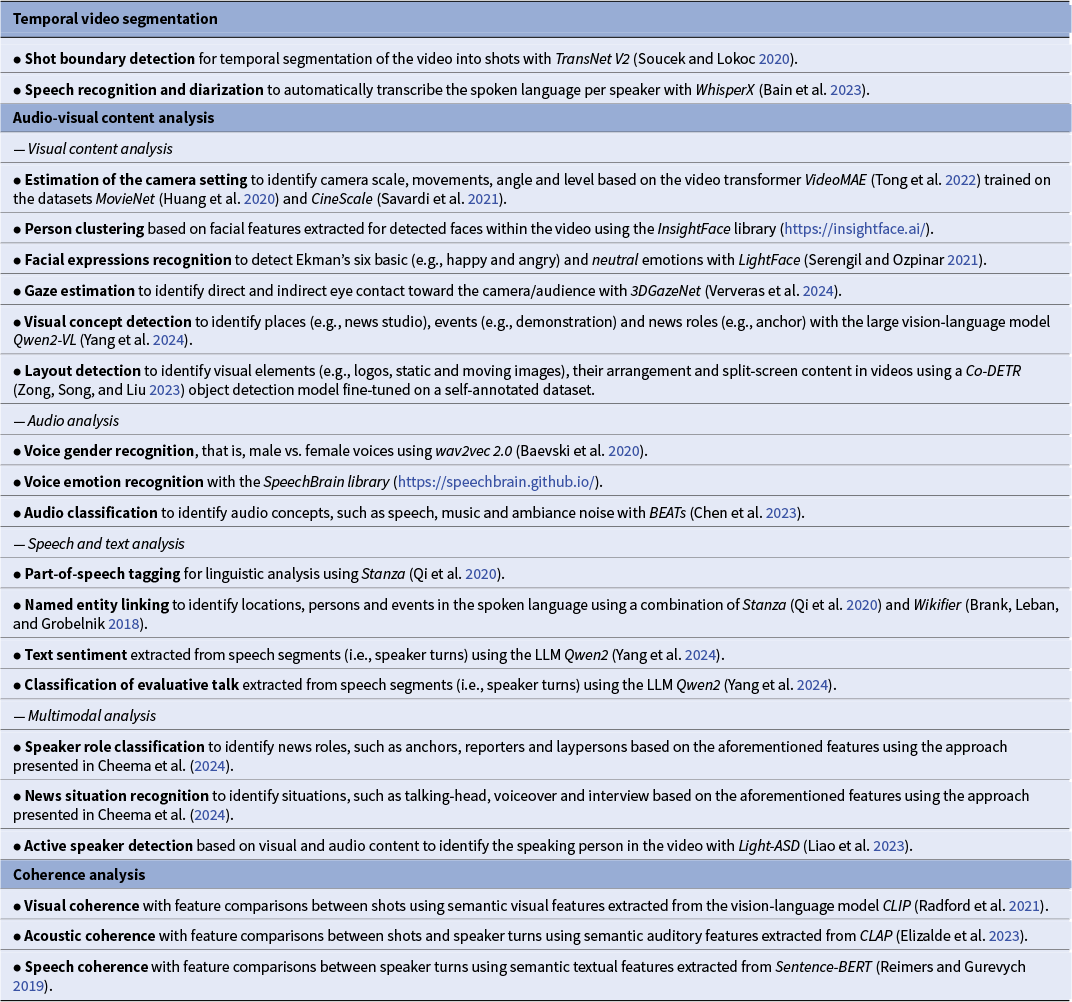
Temporal video segmentation
The segmentation of videos into meaningful temporal units is a fundamental step in video analysis. It transforms a continuous video stream into discrete units allowing the extraction and aggregation of features that align with temporal or narrative structures, such as shots, scenes or speaker turns.
To segment videos based on the visual content, methods for shot boundary detection (e.g., Soucek and Lokoc Reference Soucek and Lokoc2020) identify shot transitions, such as hard cuts or gradual transitions (fades) across camera frames. These shots can be further grouped, for example, into scenes, chapters or news stories based on their spatiotemporal or semantic relationships (Wu et al. Reference Wu, Chen, Liu, Zhuge, Li, Qiao, Shu, Gan, Xu, Ren, Xu, Zhang, Ramachandra, Lin and Ghanem2023). Similarly, methods for audio-based speaker diarization (e.g., Bain et al. Reference Bain, Huh, Han and Zisserman2023) automatically detect and transcribe consecutive speech segments in the audio signal and assign them to the corresponding speakers. This enables the analysis of speech for individual characters as well as continuous dialogues with standard methods from NLP.
Audio-visual content analysis
Once the video is segmented, the next stage involves extracting features from each modality. Recent advancements in AI have revolutionized the analysis of audio-visual content in videos, enabling the extraction of rich semantic features across visual, auditory and textual (i.e., speech and overlaid text) expressive modalities. These developments, driven by innovations in deep learning and multimodal modeling, have expanded the possibilities for understanding narrative structures, character dynamics and cinematic techniques at scale. Below, we provide a selection of key tasks enabled by these advancements in each domain.
Visual content analysis: Progress in computer vision, particularly through vision transformers (ViT; Dosovitskiy et al. Reference Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, Uszkoreit and Houlsby2021) and large vision-language models (LVLMs) like CLIP (Radford et al. Reference Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, Sutskever, Meila and Zhang2021) and Qwen2-VL (Yang et al. Reference Yang, Yang, Hui, Zheng, Yu, Zhou, Li, Li, Liu, Huang, Dong, Wei, Lin, Tang, Wang, Yang, Tu, Zhang, Ma and Fan2024), has enabled robust semantic classification of visual content. For example, these models can recognize visual concepts and contextual settings, such as physical objects, events and scenes (environments) to ground narratives. LVLMs can identify arbitrary visual concepts, such as “news studio” or “demonstration” given a textual description, that is, a prompt. Furthermore, specialized approaches for face detection and facial analysis available in Python libraries, such as InsightFace (https://insightface.ai/), can automatically identify individuals and recognize emotions (e.g., happiness and anger) as well as gaze direction (Ververas et al. Reference Ververas, Gkagkos, Deng, Doukas, Guo and Zafeiriou2024) to infer interpersonal dynamics or audience engagement. Layout and composition analysis examine spatial arrangements (e.g., split-screens) and camera settings (e.g., camera scale and movement) to provide insights into visual storytelling techniques.
Audio content analysis: Besides accurate transcription of speech (see the “Temporal video segmentation” section 7), powerful audio analysis approaches and tools, such as SpeechBrain (https://speechbrain.github.io/), wav2vec 2.0 (Baevski et al. Reference Baevski, Zhou, Mohamed and Auli2020), CLAP (Elizalde et al. Reference Elizalde, Deshmukh, Al Ismail and Wang2023) and BEATs (Chen et al. Reference Chen, Wu, Wang, Liu, Tompkins, Chen, Che, Yu, Wei, Krause, Brunskill, Cho, Engelhardt, Sabato and Scarlett2023), can classify audio concepts, for example, to distinguish between dialogue, voiceovers and background ambience, as well as vocal attributes like gender and emotional tone. These methods support tasks, such as speaker identification, emotional tone analysis and audio role classification, revealing how auditory elements contribute to narrative pacing and emotional resonance.
Speech and text analysis: Advances in NLP have enabled the extraction of linguistic and semantic patterns from transcribed speech and overlaid text. Tools like Stanza (Qi et al. Reference Qi, Zhang, Zhang, Bolton, Manning, Celikyilmaz and Wen2020) and Wikifier (Brank, Leban, and Grobelnik Reference Brank, Leban and Grobelnik2018) facilitate part-of-speech tagging and named entity linking, mapping grammatical structures and contextual references (e.g., persons, locations and events) to narrative themes. Classification approaches based on language models like Sentence-BERT (Reimers and Gurevych Reference Reimers and Gurevych2019), or more recently, generative large language models (LLMs), such as Qwen2 (Yang et al. Reference Yang, Yang, Hui, Zheng, Yu, Zhou, Li, Li, Liu, Huang, Dong, Wei, Lin, Tang, Wang, Yang, Tu, Zhang, Ma and Fan2024), further enhance topic modeling and the analysis of textual content, for example, by classifying sentiment and evaluative language, identifying persuasive strategies or character-specific discourse patterns.
Multimodal analysis: The integration of visual, audio and textual data and novel vision-language models (VLMs, e.g., Radford et al. Reference Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, Sutskever, Meila and Zhang2021; Yang et al. Reference Yang, Yang, Hui, Zheng, Yu, Zhou, Li, Li, Liu, Huang, Dong, Wei, Lin, Tang, Wang, Yang, Tu, Zhang, Ma and Fan2024) have unlocked new possibilities for multimodal analysis. Moreover, approaches like Light-ASD (Liao et al. Reference Liao, Duan, Feng, Zhao, Yang and Chen2023) align visual and audio cues to detect active speakers in the visual content, while multimodal approaches (e.g., Cheema et al. Reference Cheema, Arafat, Tseng, Bateman, Ewerth and Müller-Budack2024) identify speaker roles (e.g., anchors and reporters) and contextual situations (e.g., interviews and voiceovers). These approaches combine features across modalities to uncover how audio-visual elements collectively shape storytelling, such as distinguishing between narrative-driven dialogue and ambient soundscapes.
Coherence analysis: Finding patterns across shots
Encoder models can be used to generate semantic, numerical representation for visual, auditory and textual content, such as speech, which can be used to measure the similarity between temporal units, such as shots and speaker turns (see the “Temporal video segmentation” section) within a video. This comparison helps reveal the coherence of settings or concepts across temporal units, which is crucial for establishing FEPs and narrative strategies (see the “Narrative and narrative strategies in film and video” section) – such as the use of shot reverse-shot in dialogue scenes, fragmentation with incoherent content or cut-ins to emphasize key details. For this purpose, well-generalizable foundation models trained on large-scale datasets (see the “audio-visual content analysis” section) are typically used as encoder models, for example:
-
• image transformers (e.g., Dosovitskiy et al. Reference Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, Uszkoreit and Houlsby2021) or LVLMs such as CLIP (Radford et al. Reference Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, Sutskever, Meila and Zhang2021) or SigLIP (Zhai et al. Reference Zhai, Mustafa, Kolesnikov and Beyer2023) for visual content;
-
• audio transformers such as CLAP (Elizalde et al. Reference Elizalde, Deshmukh, Al Ismail and Wang2023) or BEATs (Chen et al. Reference Chen, Wu, Wang, Liu, Tompkins, Chen, Che, Yu, Wei, Krause, Brunskill, Cho, Engelhardt, Sabato and Scarlett2023);
-
• sentence transformers such as variations of BERT (e.g., Reimers and Gurevych Reference Reimers and Gurevych2019) for textual content in the form of speech or overlaid text.
Figure 5.Predefined patterns in Narrascope and the advanced query builder view.


Case studies on audio-visual narrative – Exploring news videos with the Narrascope tool
This section brings together the formalization and modeling of FEDPs and more complex narrative strategies (see the “Narrative and narrative strategies in film and video” and “Formalization of film editing and discourse patterns” sections) with the extraction of multimodal information from audio-visual sources through the computational methods introduced in the “Computational approaches to film and video analysis” section. Once patterns have been formalized and their features extracted, it becomes possible to conduct empirical analyses of large video collections. To facilitate such analyses in the style of an interactive information retrieval system, we developed the Narrascope tool, which is the tool applied in the following case studies. All examples presented here come from German news videos studied in the context of the project FakeNarratives (2022-2024). The basic idea of Narrascope is to enable researchers to search for any type of narrative pattern – or combinations of patterns – using a query language specifically designed to express FEDPs and related narrative configurations.Footnote 1 When a query is submitted, Narrascope searches the underlying video collection for matching instances and returns a list of results. These can then be visualized and exported for further processing in various formats.
The current collection comprises more than 1,000 videos (approximately 250 hours of material) from five German news channels. These include the established formats Tagesschau and ZDFheute as well as the more alternative sources BildTV, CompactTV and Welt. Narrascope comes with an open-ended catalog of named predefined patterns that can be searched directly as shown in Figure 5. At the same time, each pattern can be displayed in the underlying query language and adjusted as needed. New patterns can also be formulated within the expressive scope of the query language, ensuring both flexibility and transparency in empirical research. As noted above, it is often the case that patterns can be implemented in various ways. We use this flexibility both to mitigate gaps or weaknesses in concrete coverage and to explore the effectiveness of alternative versions of FEPs/FEDPs – as shown in the figure, variants are already available for several of the patterns listed.
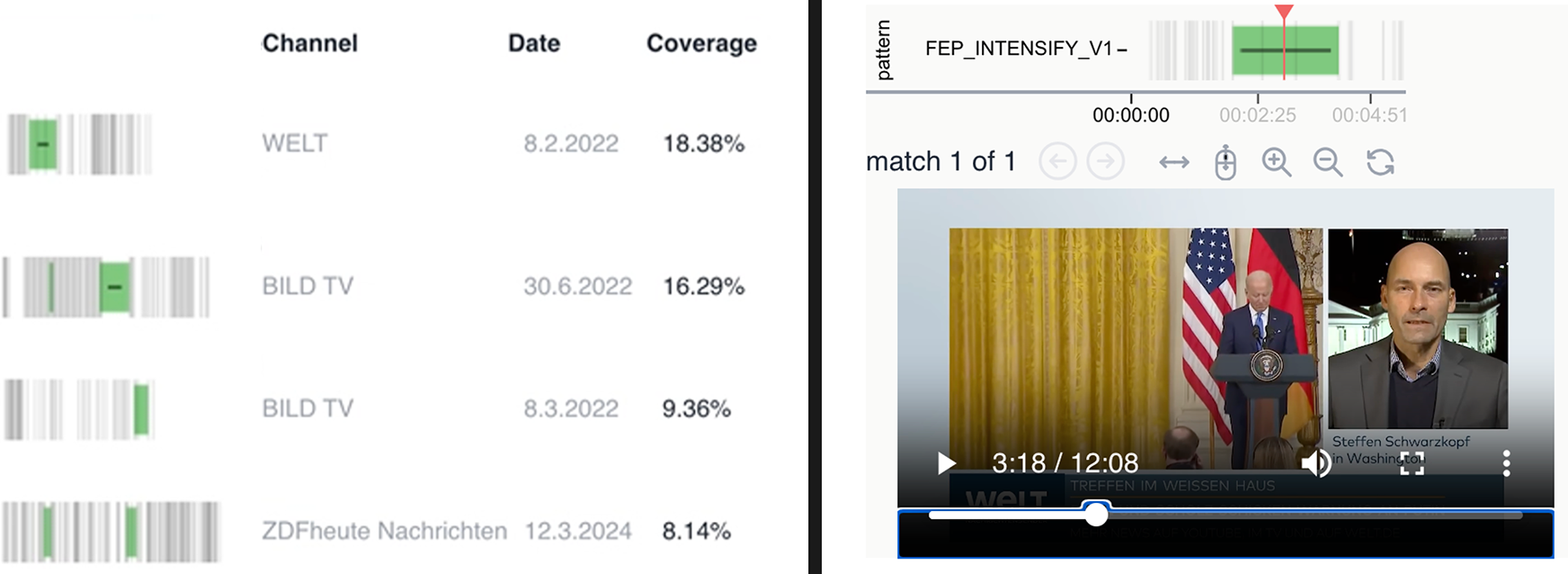
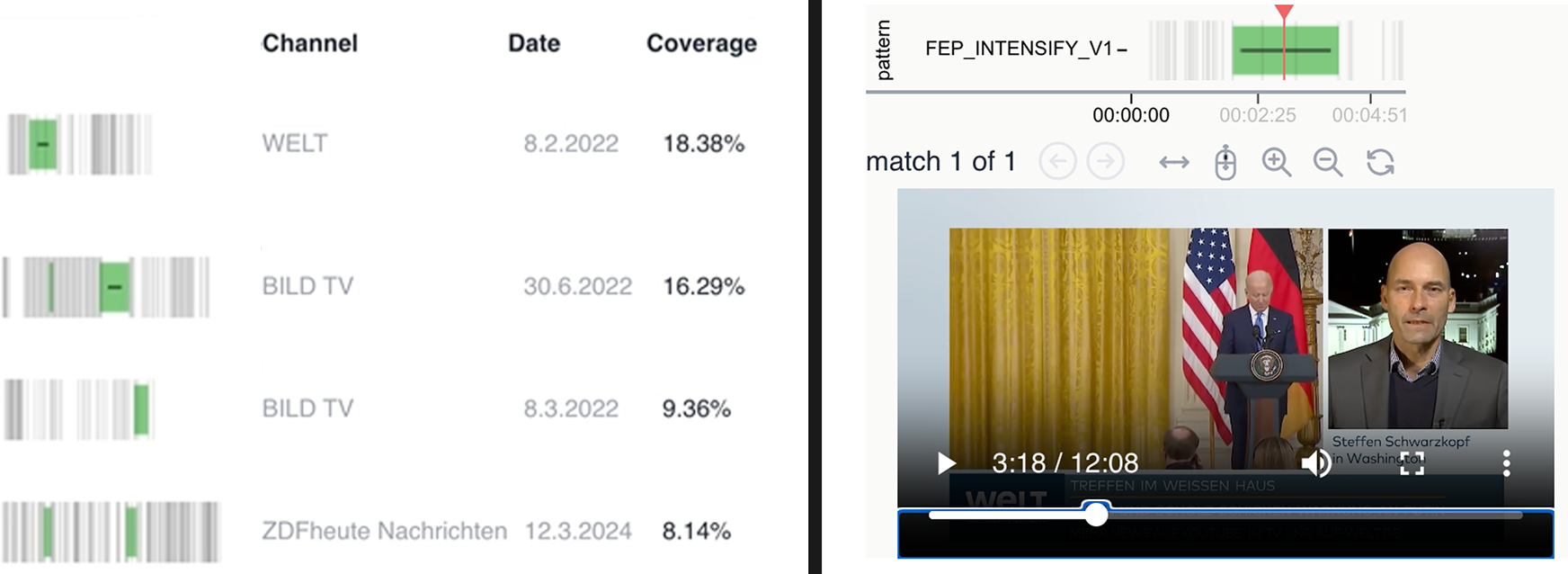
The visualization of search results for any applied pattern is illustrated on the left-hand side of Figure 6. Each row represents a video in which the queried pattern was detected. Vertical grey lines indicate shot boundaries, while green highlights mark those sequences that match the query. By clicking on a result, users can open an interactive video player, which is displayed on the right-hand part of Figure 6. Here, the red playhead can be moved to any position, enabling researchers to view the video segments in detail and reconstruct the identified narrative pattern within its media context. This combination of large-scale retrieval and interactive close analysis makes Narrascope a versatile tool for multimodal narrative research.
Example for results screen in Narrascope. The left-hand side shows all the videos in the collection that contain the searched for pattern (highlighted in green). Upon clicking a video in the result list, an interactive video player opens (right-hand side).
Example 1: Intensification in news videos
In this first example, we apply the FEDP of intensification of a single actor as formalized in the “Defining, modeling and operationalization of FEDPs” section to our news video corpus in Narrascope. Thus, in this section, we present how to query a sequence of shots that visually “tracks” the same actor through progressively enlarging shot sizes. This pattern may prove useful in large-scale studies aiming to examine the functions and contexts in which such intensification is employed within the news genre.
Formally, in an intensification pattern, we instantiate the abstract query pattern described above with the Narrascope query shown in Listing 5. Rendered as natural language, lines 1–3 look at all triples of consecutive shots, s1–s3 (line 2). In line 4, the query then groups the actor instances in those shots by their id (i.e., in the present case, their facial identity). If an actor occurs in n of these shots, this operation will result in a list of n actor instances. Looking at all actor lists produced by this operation, the query then asks if there is some (i.e., at least one) triple of actor instances [a, b, c], which indicates one actor who occurred in all three shots. In addition, line 5 adds the requirement that the actor’s size on screen must grow across instances of occurrence from a to b and from b to c.

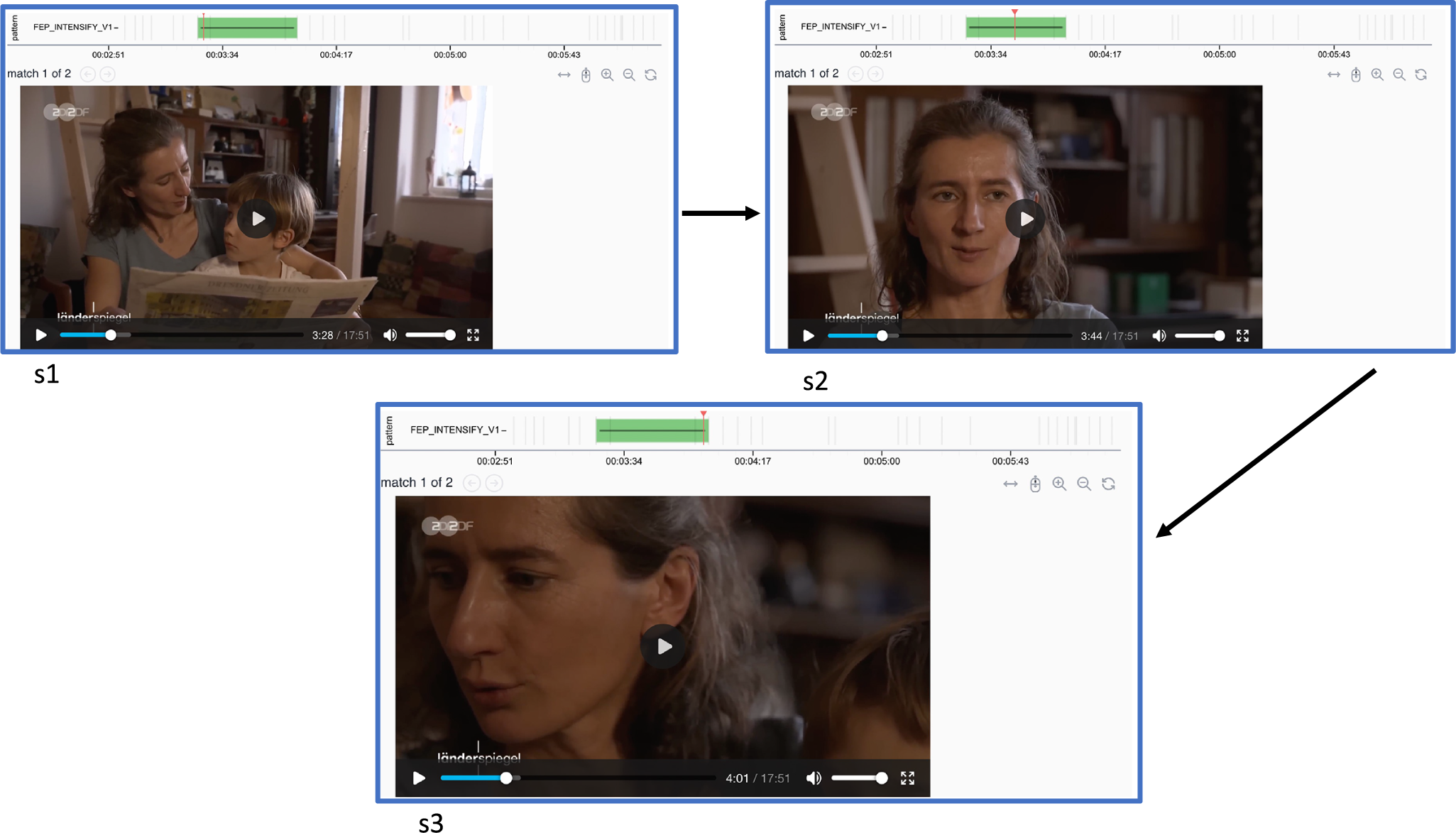
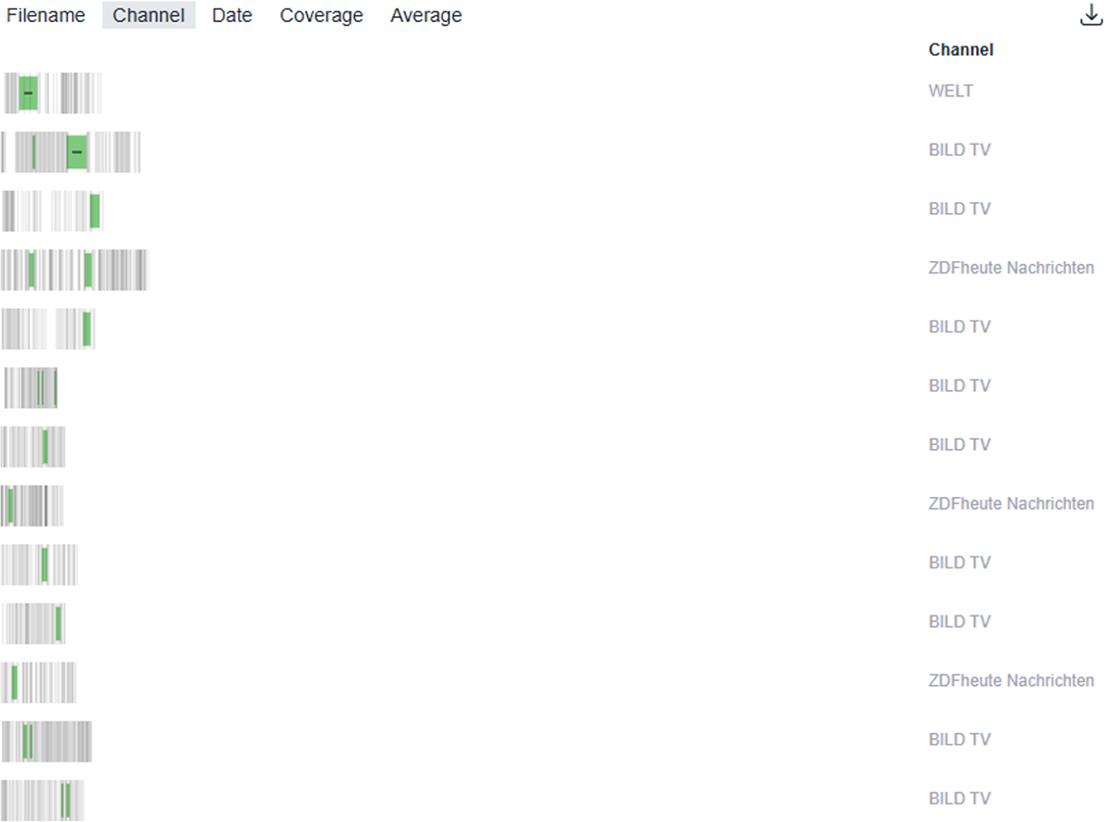
Figure 7 displays the immediate list of results obtained when running the query. Figure 8 then highlights one of these entries as an illustrative example of a top hit returned by the pattern search in Narrascope. In this case, we observe a sequence of three shots (s1–s3) from a ZDFheute clip, where the shot size progressively increases across the sequence.
Returned result list in Narrascope for the intensification of same actor query.
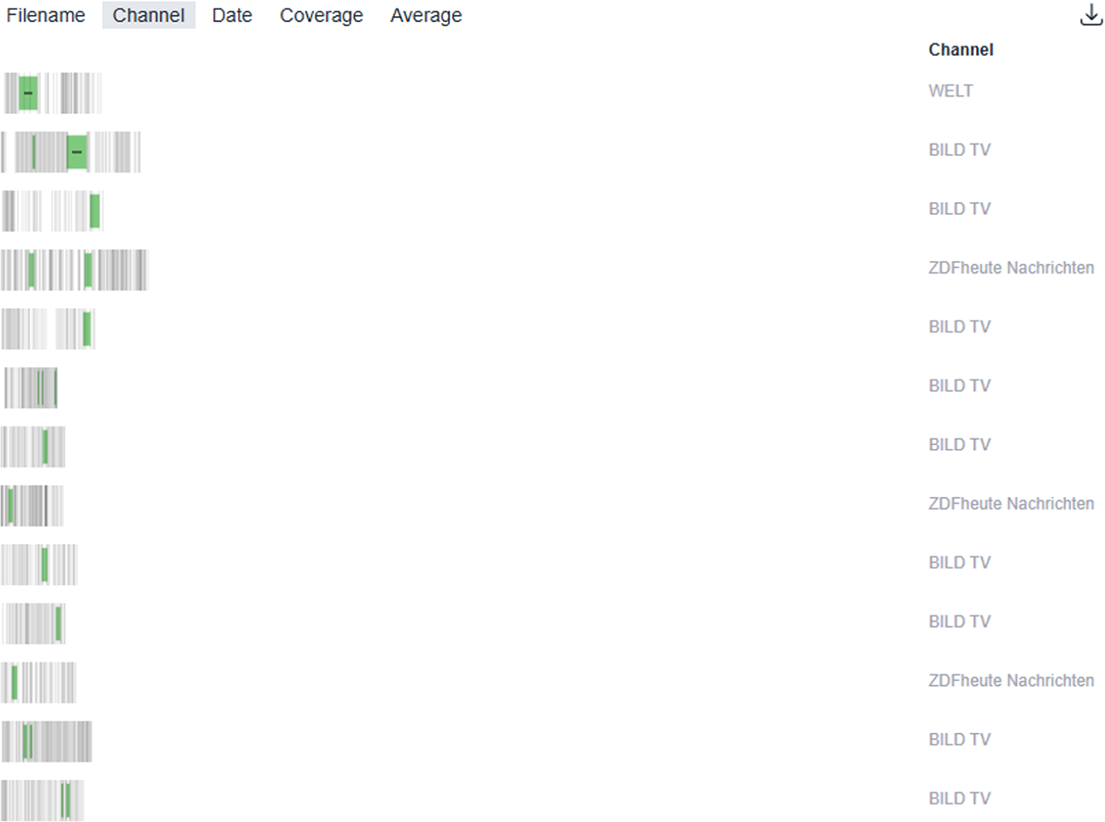
Example Narrascope hit for intensification of same actor query (hit shows a sequence from ZDFheute news).
Distribution of the intensification pattern (same actor) across different news channels produced by Narrascope, summing the proportions of matches per video within each channel.
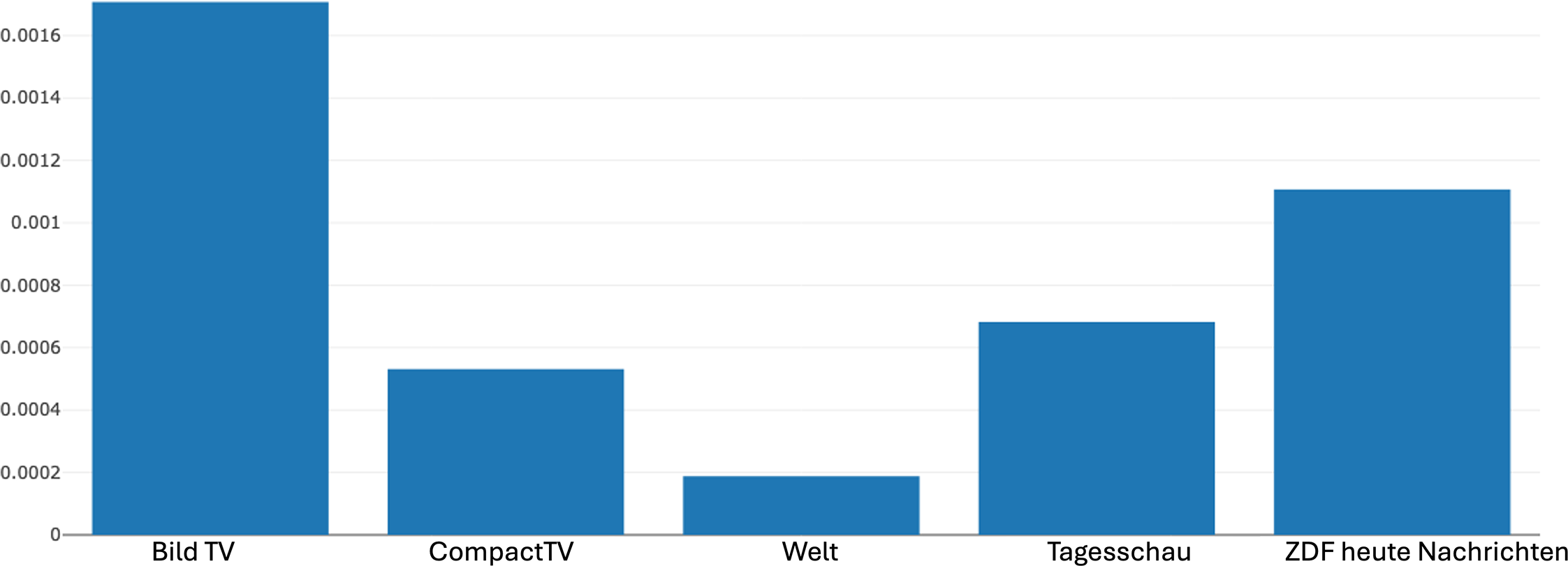
Narrascope also offers the functionality of showing distributions of FEDPs used across different sources such as news channels (or movies). Figure 9 shows the relative frequency of the given FEDP across the news channels included in our corpus in Narrascope, calculated on the basis of the number of matches found in proportion to the number of shots in each video. This then gives an indication of the probability that the pattern matches a random shot for a video from a certain channel. BildTV exhibits the highest frequency of the pattern and Welt the lowest, while the overall distribution shows that the use of intensification varies considerably between sources. Many other kinds of metrics could be explored for more fine-grained differentiation.
Returning to our digital multimodal narrative approach as presented in Figure 1, however, such differences are to be understood not only as technical or stylistic choices at the level of FEDPs, but also as part of broader narrative strategies that contribute to the construction of meaning. When related to the higher strata of the model, these patterned choices in FEDP usage can be seen as contributing to distinct ideological configurations as well because they reflect rather different strategies of news construction and presentation. Although the FEDP data presented here does not allow for definitive claims about the specific ideological orientations of the individual channels, the observed variation demonstrates how differences at the relatively concrete level of discourse patterns may align with far more abstract differences. Our results then scale upwards to the level of abstract meaning, contributing to our understanding of how themes and orientations may be shaped quite differently across different sources of multimodal news communication.
Example 2: Alternating shots in news videos
To demonstrate further how lower level FEDP can also be seen as parts of higher-level narrative strategies as introduced in the “Defining, modeling and operationalization of FEDPs” section, we demonstrate now the instantiation of our “fragmentation” example above. For this, we start by showing the instantiation of the FEDP of alternating shots (Figure 2), before merging it with the continuity of talk/dialogue FEDP to give the complete fragmentation query.

For illustration purposes, we concentrate here on the particular “actor–object–actor” form of alternation. The corresponding query in Listing 6 searches for a sequence of four shots s1–s4, where both s2 and s4 must not show any people (lines 1–6). Most of the further requirements of the relevant FEDP as described in “A semiotics-based multi-layered framework” section are then based on relational constraints holding over selected shots making up the pattern as a whole. These can be implemented in several ways as we will now briefly sketch.
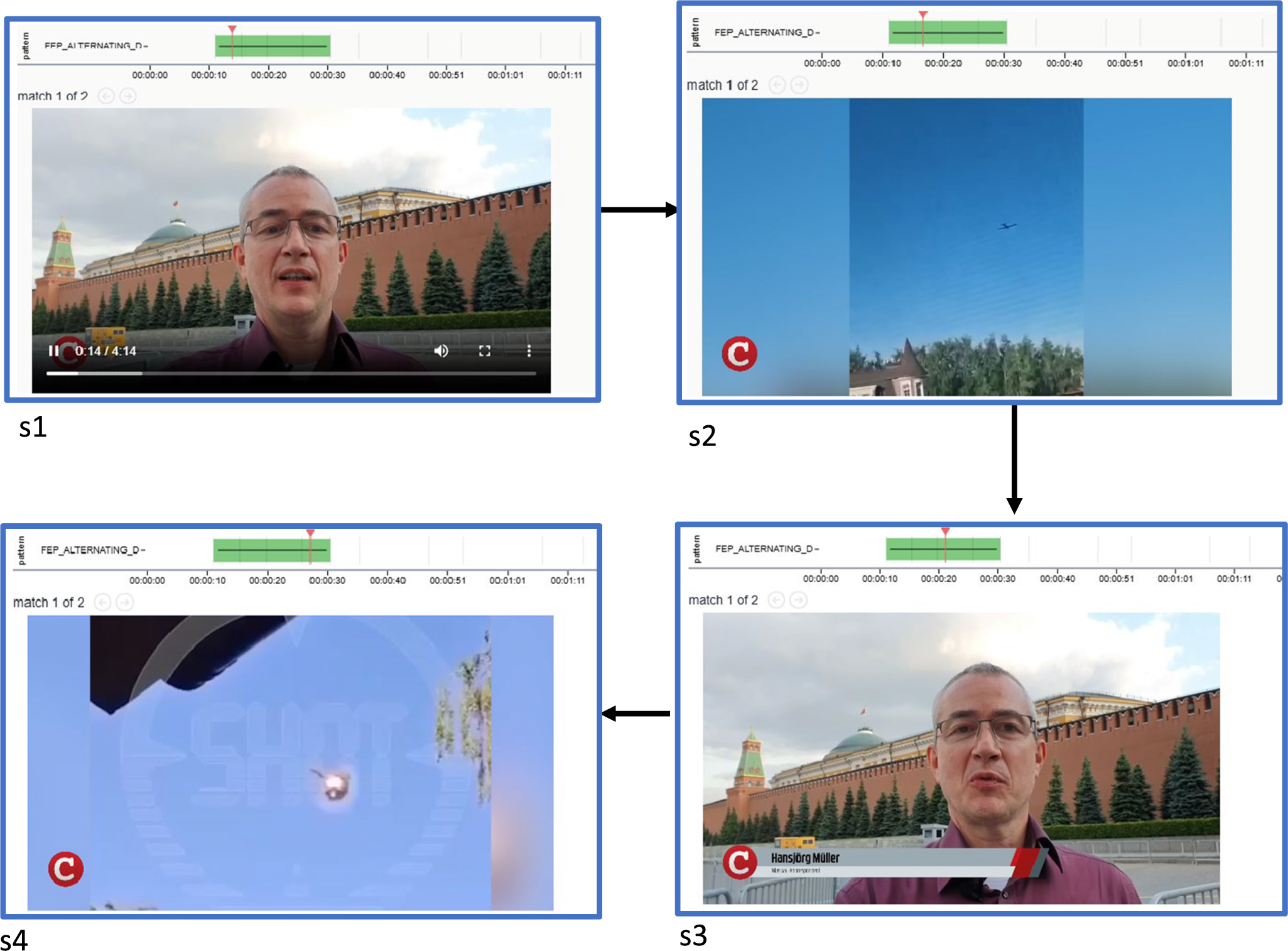
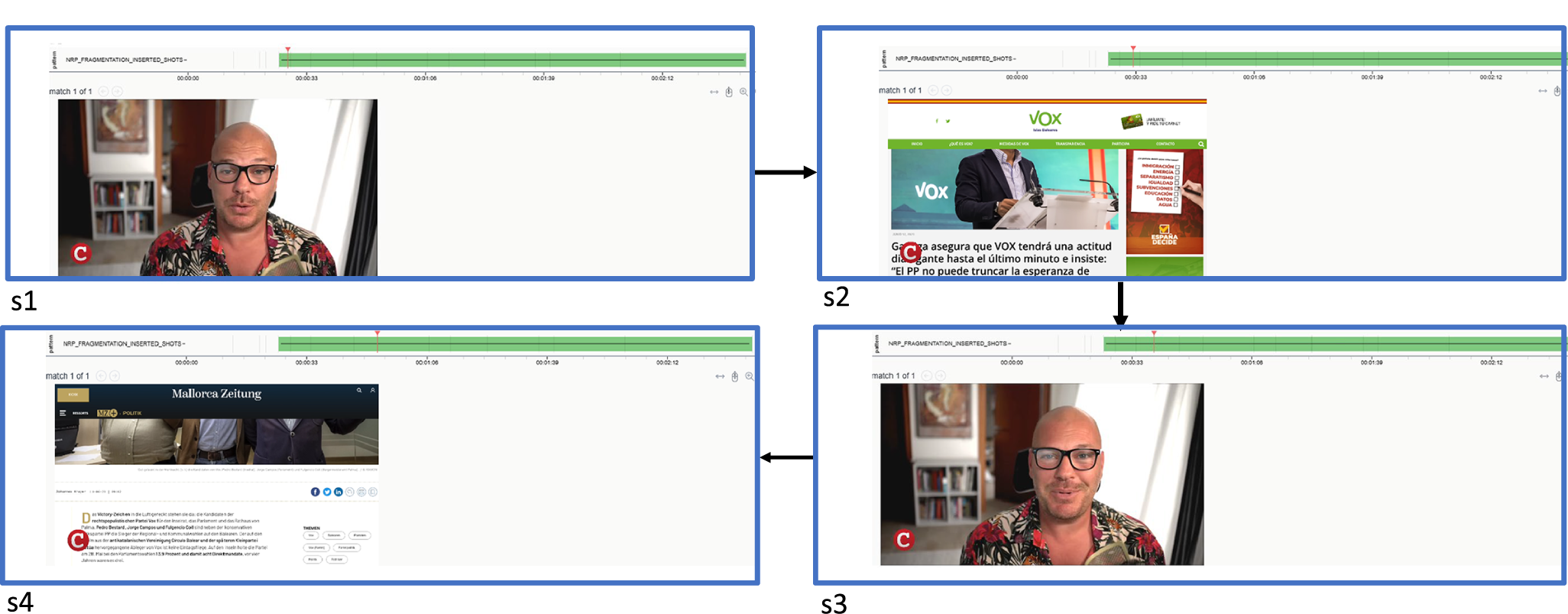
Example Narrascope hit for alternating shots query (hit shows a sequence from CompactTV news).
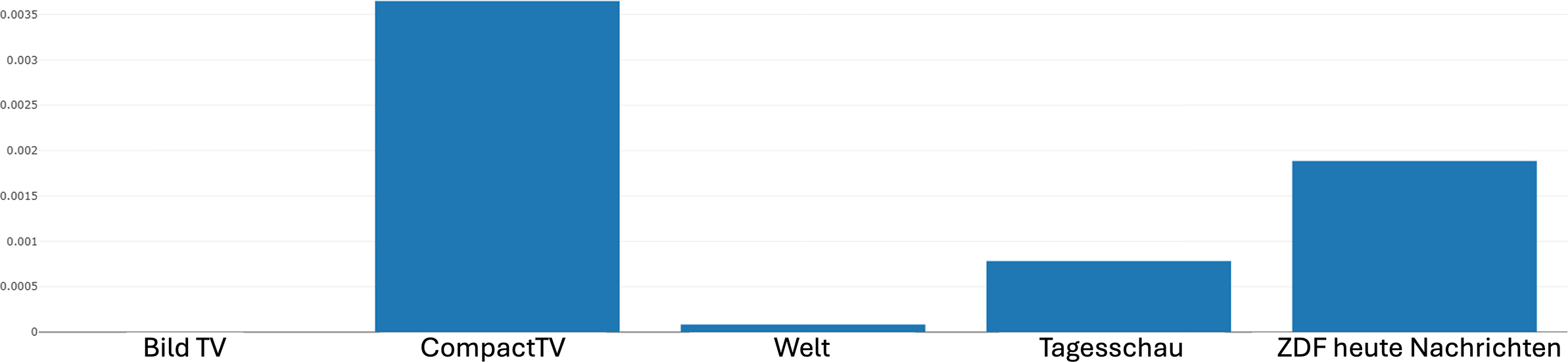
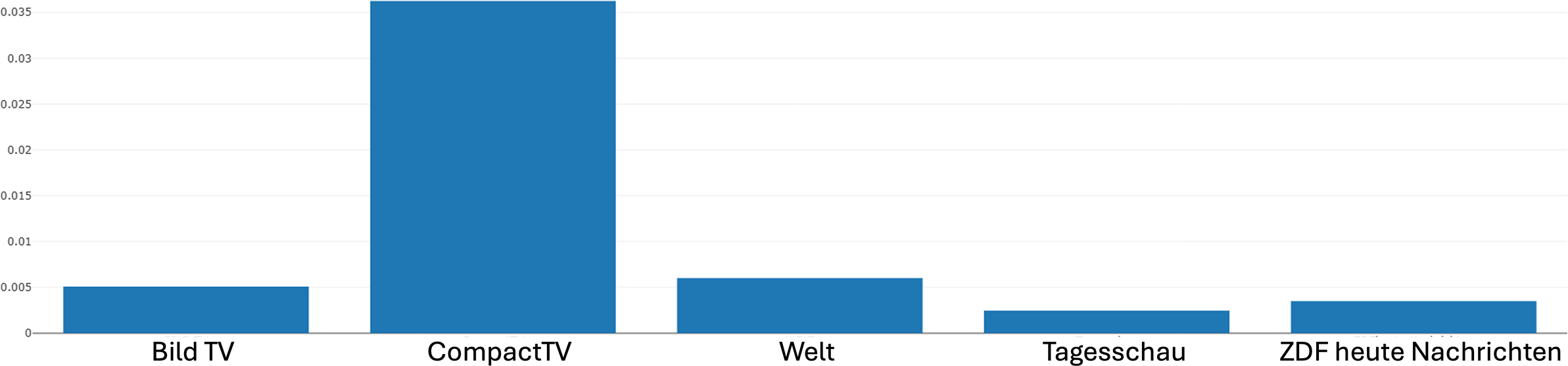
Distribution of the alternating shot pattern (actor–object–actor) across different news channels produced by Narrascope.
Whereas the abstract FEDPs introduced above generally specify binary distinctions that must hold for a pattern to apply – for example, in terms of same or different (Listing 2), most of the actual implementations of processing capabilities described in the “Computational approaches to film and video analysis” section return real number measurements of similarity, confidence, and so on. These must then first be discretized to match the FEDP specifications. This is performed by thresholding where particular values are set as boundaries for distinguishing binary (or other discrete sets of) results; it remains a largely empirical issue just which boundaries may prove most effective and under what conditions.
For each entity type, therefore, a corresponding measure function is defined that returns a numerical similarity measure of the specific relation holding between the identified entities of two given shots. Line 7, for example, states that a measure of the object relation between shots s1 and s3 should be returned based on image embeddings generated with the SigLIP model (Zhai et al. Reference Zhai, Mustafa, Kolesnikov and Beyer2023), which exhibits some improvements over the previous state-of-the-art model CLIP (see the “Computational approaches to film and video analysis” section). If this measure is greater than 0.8, then the object relation is discretized to “same” as specified in line 6 of Listing 2. In the same way, the visual_relation measure in line 8 builds on a general measure of visual similarity between the shots s1 and s2, but in this case matches when the visual similarity is low – corresponding to the “different” given in line 9 of Listing 2.
In the current implementation applied, both object_ relation and place:relation are in fact simply synonyms for visual_relation, since we do not yet compute object embeddings, and place embeddings were not performing well. This shows our general methodology in action, where gradual refinements are made as technical capabilities change and improve. Finally, the actor_relation in line 10 operates slightly differently in that the degree of overlap between the actors in the two shots s2 and s4 is calculated as a set-based measure of intersection (Jaccard index) that indicates the number of actors found present in both considered shots. This is again discretized to find pairs of shots sharing actors as required by line 7 in Listing 2.
Figure 10 displays one of the hits returned when applying the given query. In this example, shots 1 and 3 feature a reporter from the news channel CompactTV, alternating with shots 2 and 4, which depict drone footage. Here, we can readily see why shots s1 and s3 score highly on object and place similarity (lines 7 and 9 in Listing 6), while shots s1 and s2 conversely give low similarity ratings (line 8). Shots s2 and s4 also score highly as being similar on several counts (lines 10 and 11). These conditions taken together then trigger the match.
Figure 11 then shows the distribution of this alternating shot FEDP across the news channels included in the corpus as explained above. Examining this distribution diagram of the FEDP, we can observe the following: CompactTV makes the most frequent use of the pattern, while BildTV and Welt show the lowest usage. The distribution across Tagesschau and ZDFheute lies between these two extremes. In terms of our digital multimodal narrative approach, these findings can again be understood as reflecting differences at all levels of abstraction, potentially including certain ideological configurations as well. Again, it is worth emphasizing that the production of such information is where the analysis of potential differences and similarities across channels starts rather than being the end result in its own right. We can subject the distribution figures to a broad range of further visualization and statistical evaluations, detailed discussion of which is beyond the scope of the present article.
Example 3: From FEDP to narrative strategies: Fragmentation
To complete our examples, we now combine the alternating shots query with that of continuity of talk/dialogue, which then together constitute the narrative strategy of fragmentation as discussed in the “Capturing and formalizing narrative strategies through FEDPs” section. For this, we suggest the Narrascope instantiation in Listing 7, which searches for a sequence of shots where the first shot is called s1, the last shot s3 and the list of shots between s1 and s3 are s2 (lines 1–3). The syntax 1…10 indicates that s2 may consist of one to ten shots. The upper limit of 10 shots is useful to bound the runtime of the query matcher.

Several conditions hold over the full sequence. First, there has to be some speaking face in both s1 and s3 (lines 4 and 5). Moreover, there has to be exactly one speaker over the whole shot range (line 6) when looking at those speaker turns that overlap visual shots. This combination of modal domains is declared by the “join” in line 11, producing a genuinely multimodal query. As explained above, speaker turns are extracted automatically processing the audio channel in parallel to the shot boundary and visual feature extraction (see the “Computational approaches to film and video analysis” section). Finally, the visual similarity between s1 and the following shot has to exceed a threshold of 0.7 when measured under the SigLIP embedding (line 7), an actor relation with two given thresholds needs to exist between s1 and s3 (line 8) and the recognized place needs to be the same in s1 and s3 (line 9).
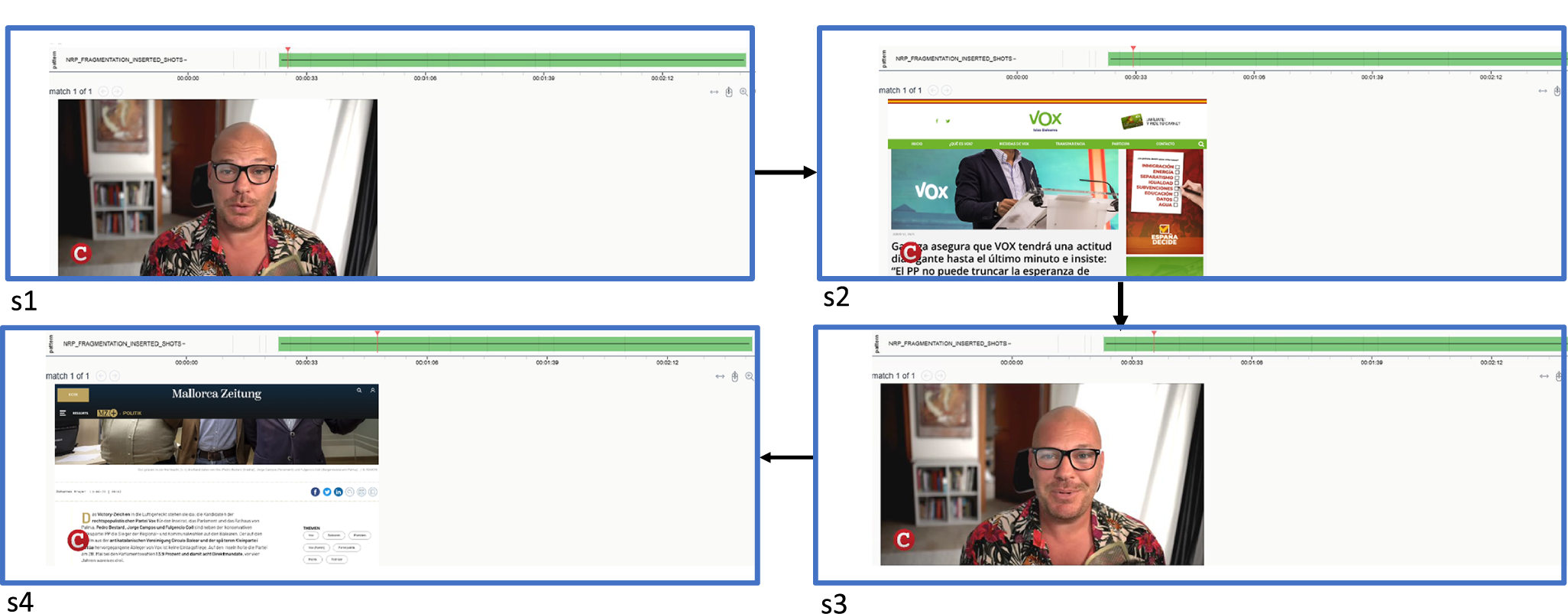
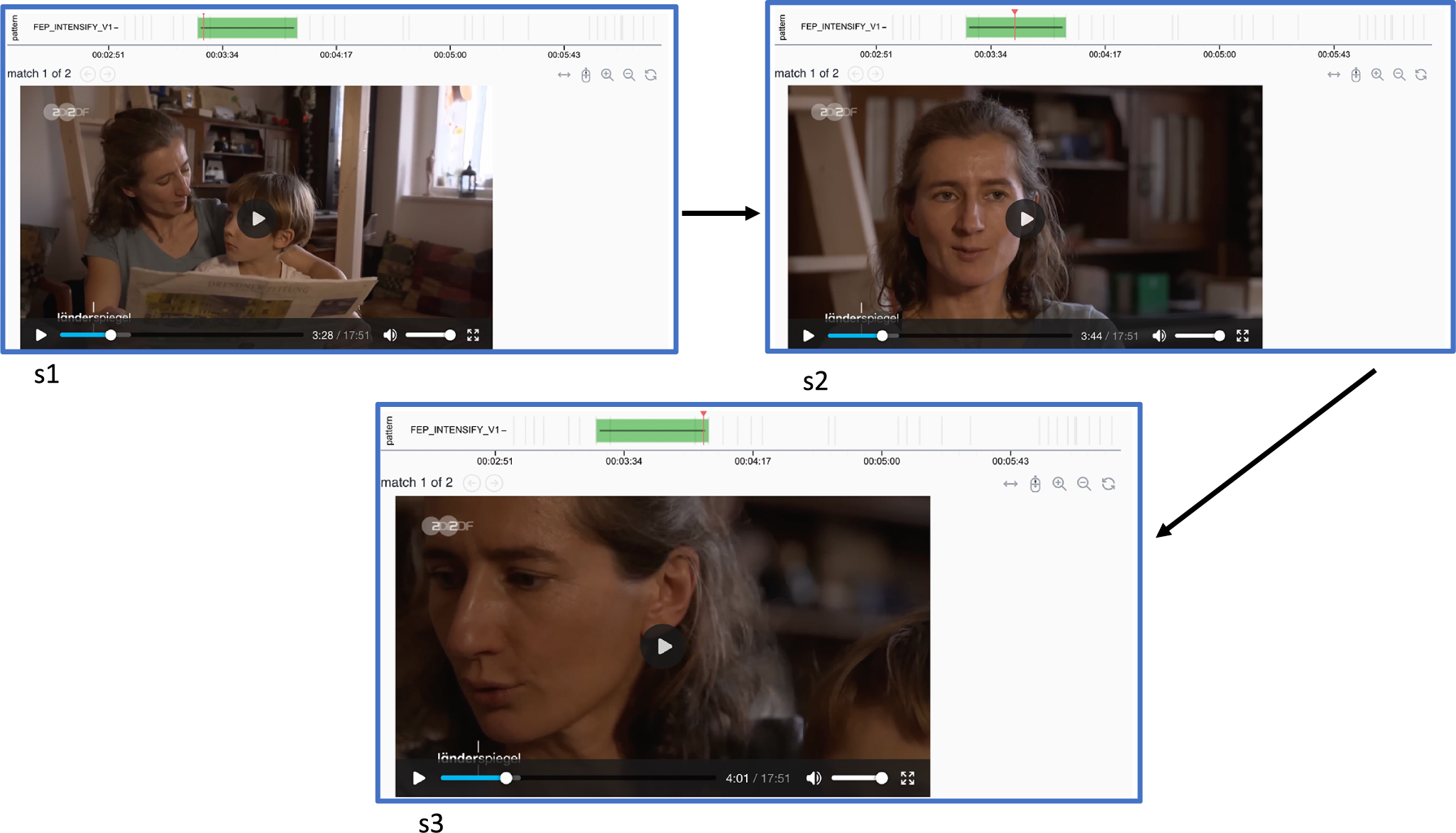
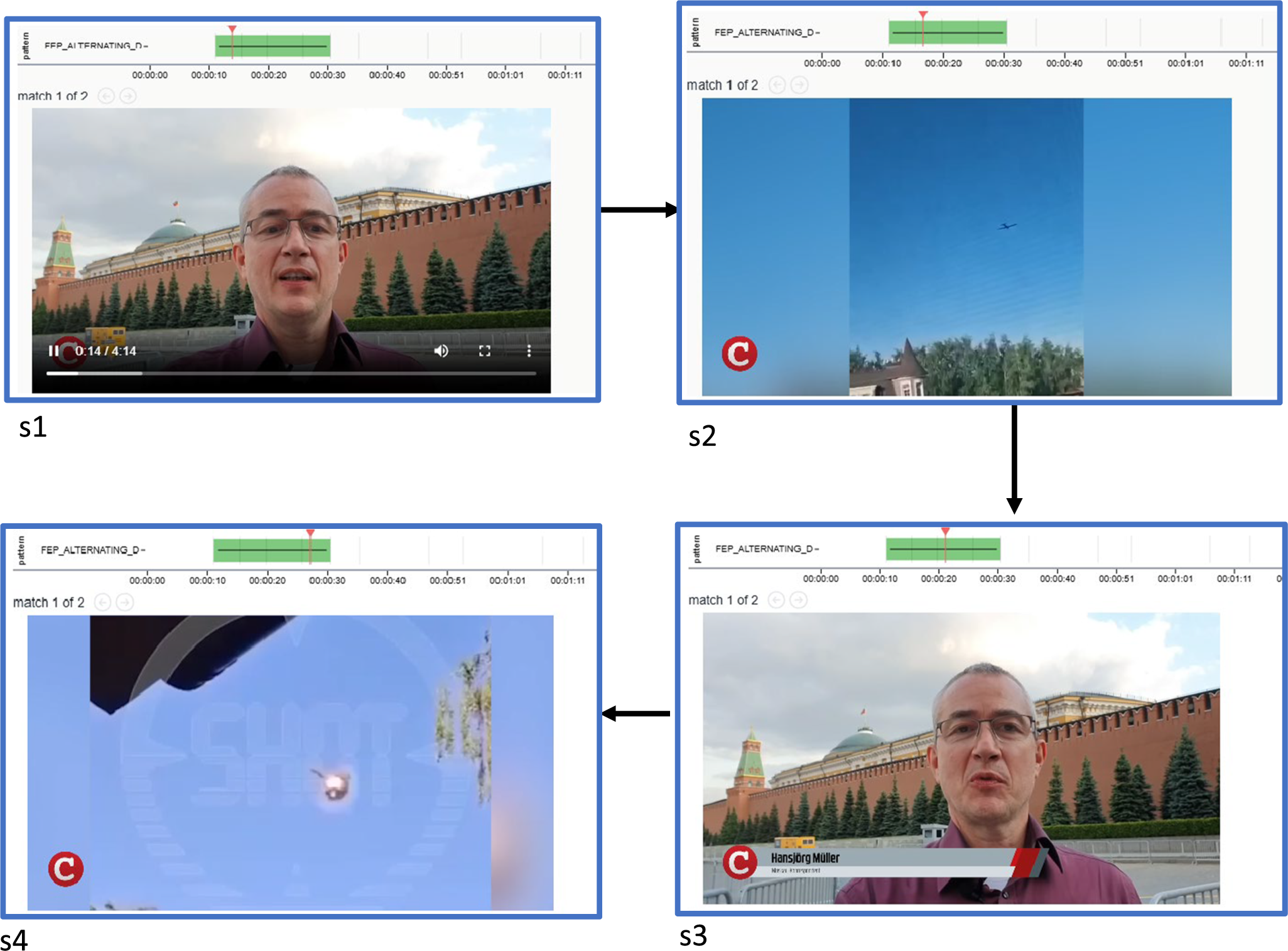
One of the returned hits for this query is shown in Figure 12. Here, we see a CompactTV sequence of four shots alternating between the speaker/commentator (shots 1 and 3) and website screenshots (shots 2 and 4). Although not visible in the stills, the speaker’s talk in shots 1 and 3 continues as a voice-over across shots 2 and 4, creating the characteristic fragmentation strategy. If we focus on the green bar at the top of each image and the positions indicated for the individual shots, it becomes clear that this example is part of a much longer sequence employing the same strategy, extending well beyond these four shots. For reasons of space, however, we have limited the illustration to the first four.
Example Narrascope hit for the fragmentation narrative strategy (hit shows a sequence from CompactTV news).
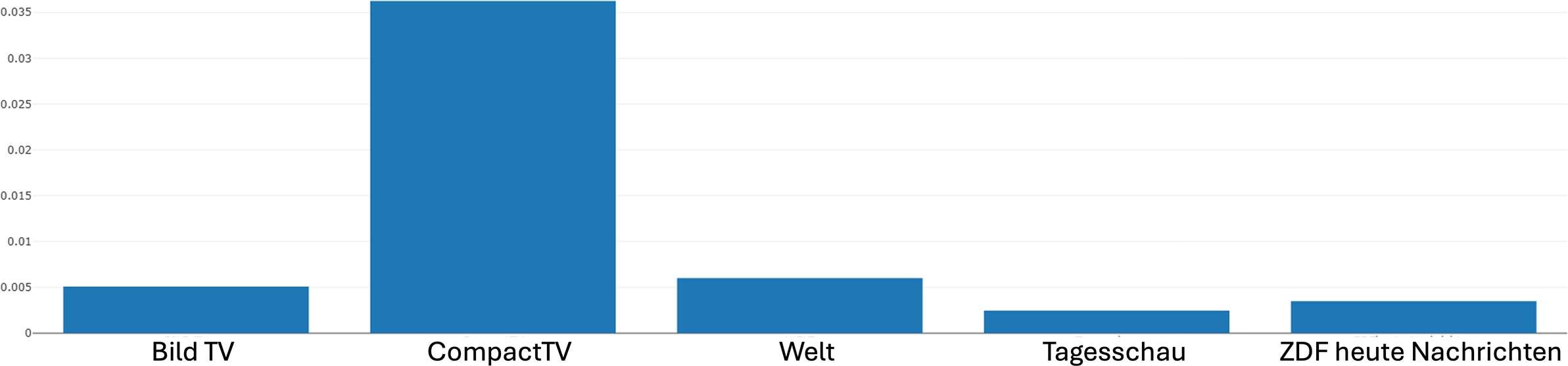
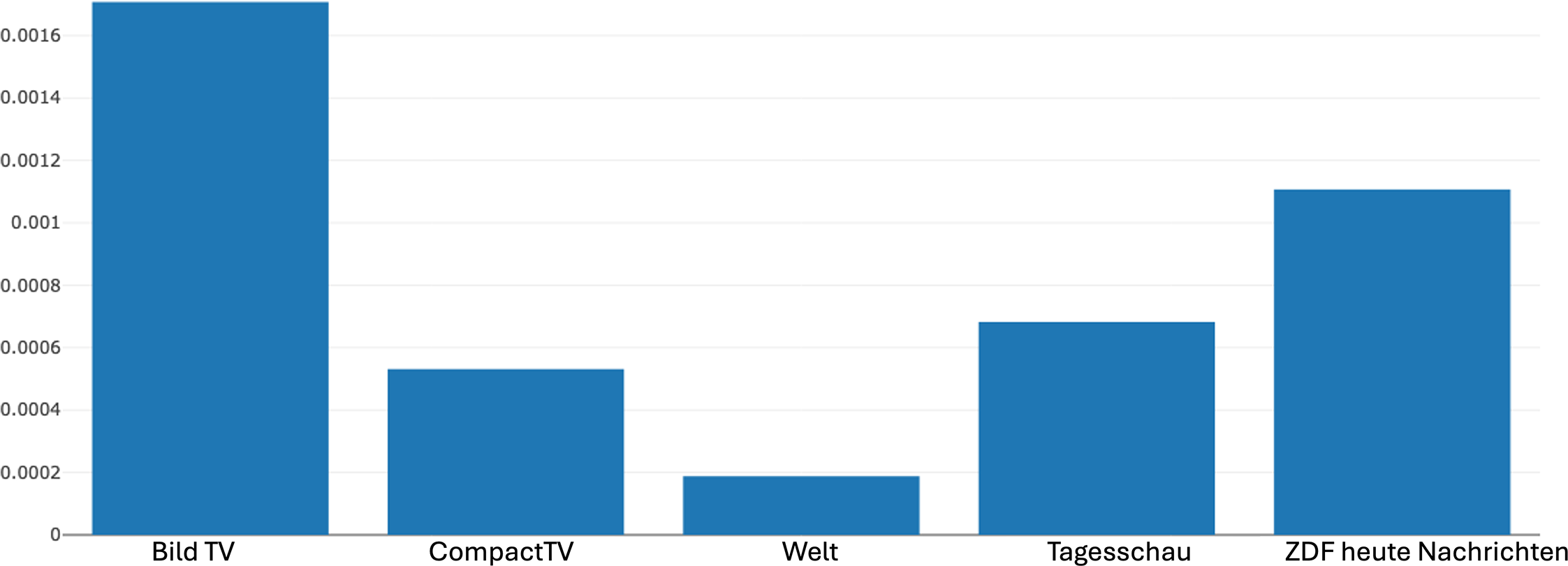
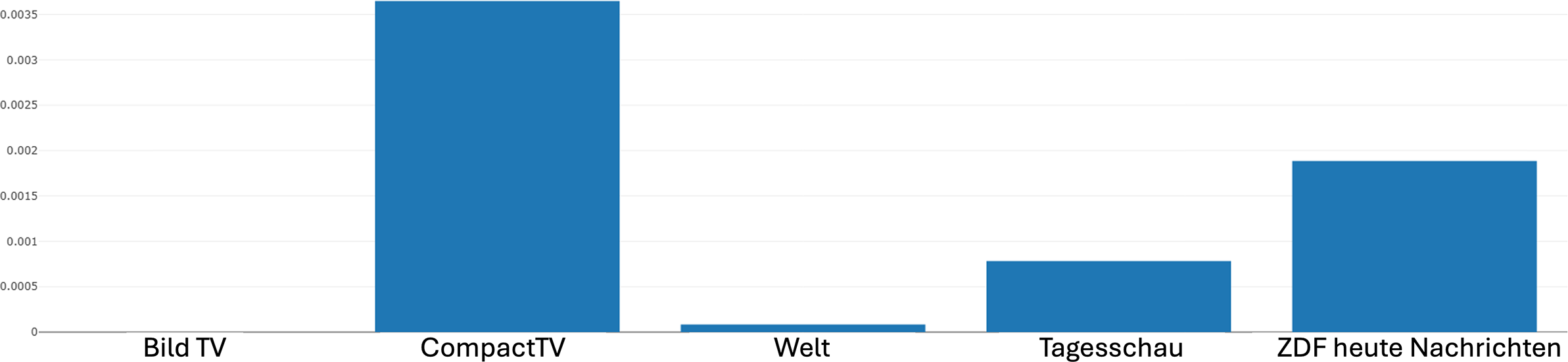
Returning to our bar charts of distribution for the strategy, Figure 13 shows that CompactTV indeed makes particularly strong use of Fragmentation, while the other channels employ it to a considerably lesser degree, with only marginal presence in Tagesschau and ZDFheute. As mentioned earlier, the strategy of fragmentation, by breaking up the spatiotemporal continuity of events, can encourage viewers to engage more actively in reconstructing coherence, a technique that can heighten tension, emotional involvement and interpretive effort depending on the topic being handled. It can thus be argued that its prevalence in CompactTV aligns with the tendency of commercial and alternative media outlets to foster audience engagement through heightened dramatic or disorienting effects, while the relative absence in public broadcasters suggests a stronger commitment to linear continuity and transparency in narrative construction. These findings, therefore, underscore again how differences at the level of narrative strategies can serve as important indicators of divergent communicative orientations in news reporting, which may in turn contribute to distinct ideological configurations at the more abstract level of meaning.
Distribution of the fragmentation strategy across different news channels produced by Narrascope.
Conclusion
In this article, we have introduced a digital multimodal framework for film and video analysis that bridges the current gap between computational analysis of formal features and the more interpretive study of narrative structures. By decomposing higher level narrative strategies into intermediate layers of FEDPs, we have shown how it now becomes possible to trace narrative architectures at scale and across large video corpora.
Looking ahead, we hope the approach outlined in this article will inspire a shift in digital film analysis, from studying how films are made (via technical or aesthetic features) toward also examining what they do narratively. By turning narrative into something that can be queried, retrieved and compared quantitatively, our framework opens the door to entirely new types of research questions, allowing us to investigate how narrative mechanisms vary across genres, historical periods, cultural contexts or ideological orientations. In this way, we hope our contribution marks a step toward a truly computational narratology of audiovisual media: one that embeds the interpretive richness of film studies within the quantitative scale and reproducibility of computational humanities.
Our approach, which already makes use of state-of-the-art machine learning models for multimodal information extraction, can be further advanced through recent developments in multimodal LLMs (MLLMs). These models combine visual and linguistic understanding, enabling them to generate rich textual descriptions from complex visual inputs and to reason jointly across modalities. While Arnold and Tilton (Reference Arnold and Tilton2024) demonstrate how this capability can transform the exploration of large visual collections, the same strengths can now be harnessed to move beyond surface features and toward the detection of higher-level narrative patterns within audiovisual media as well.
Data availability statement
This article primarily presents a conceptual and methodological framework. The empirical examples discussed are based on a video corpus that cannot be made publicly available due to copyright restrictions. All feature extraction is performed using established, publicly documented models, which are referenced in the text and can be accessed via their respective original publications and repositories. The Narrascope software itself is currently project-specific and not yet released as an open-access tool; however, a public release is planned. To support transparency and reproducibility at the methodological level, Narrascope’s complete query language grammar (BNF) and a standard library of functions are openly available in the repository referenced in the article.
Disclosure of use of AI tools
The use of Generative AI in our computational analysis of film and video was clearly specified in the method section. Otherwise, no AI tools were used outside of the methodology outlined in the paper.
Author contributions
Conceptualization: C.T., B.L., E.M.B., M.B., J.B. and R.E.; Data visualization: B.L.; Formal analysis: B.L., E.M.B., C.T., L.T. and G.C.; Funding acquisition: J.B., M.B. and R.E.; Methodology: C.T., B.L., E.M.B., M.B., J.B. and R.E.; Writing original draft: C.T., B.L., E.M.B., L.T., M.B. and J.B. All authors approved the final submitted draft.
Funding statement
This research was supported by grants from the German Ministry of Education and Research (BMBF; Award ID: 16KIS1515K).
Competing interests
The authors declare none.





 Open access
Open access
Rapid Responses
No Rapid Responses have been published for this article.