


1 Introduction
Exploratory factor analysis has been widely used in social sciences and beyond to measure unobserved constructs of interest, such as ability, attitudes, and behaviors, and for dimensionality reduction. It has been noted early on in the factor analysis literature, particularly with the development of the more precise computational frameworks for maximum likelihood (ML) estimation in Jöreskog (Reference Jöreskog1967) and Jöreskog and Lawley (Reference Jöreskog and Lawley1968), that the estimation of factor analysis models often results in improper solutions. Such improper solutions involve zero or negative estimates for error variances, and often correlation estimates greater than one in absolute value. Such occurrences are typically referred to as Heywood cases (Heywood, Reference Heywood1931). Martin and McDonald (Reference Martin and McDonald1975) distinguish between an exact Heywood case in which at least one of the estimates of the error variances is zero but none are negative, and an ultra-Heywood case, in which at least one estimate of the error variances is negative. A zero error variance implies that there is no measurement error, and the factors fully explain the observed variable. That is rare in real applications but, at the same time, does not pose as much concern as negative estimates for error variances do. Causes of Heywood cases that have been reported in the literature are model and data dependent and include outliers, non-convergence of associated optimization procedures, under-identification, model misspecification, missing data, and sampling fluctuations combined with a true value close to the boundary for the parameter, small sample sizes, poorly defined factors, and factor over-extraction (see, e.g., Chen et al., Reference Chen, Bollen, Paxton, Curran and Kirby2001; Cooperman & Waller, Reference Cooperman and Waller2022; Dillon et al., Reference Dillon, Kumar and Mulani1987; Kano, Reference Kano, Rizzi, Vichi and Bock1998; van Driel, Reference van Driel1978; and the references therein). Cooperman and Waller (Reference Cooperman and Waller2022) provide an up-to-date review of the causes, effects, and solutions to Heywood cases in confirmatory and exploratory factor analysis.
The presence of Heywood cases in factor analysis has practical implications. It can produce parameter estimates, standard errors, factor scores, and goodness-of-fit test statistics that cannot be trusted. Cooperman and Waller (Reference Cooperman and Waller2022) found, through a simulation study, that Heywood cases increase the standard errors of factor loadings and bias the factor scores upward. Eliminating items that correspond to estimates which display a Heywood case often moves the Heywood problem to one of the remaining items.
An approach to handle Heywood cases, especially when they are suspected to be due to sampling fluctuations, is by restricting the estimates of the error variances to
 $[0, \infty )$
either explicitly or by setting negative estimates to zero (see Gerbing & Anderson, Reference Gerbing and Anderson1987 for a discussion). However, this violates regularity conditions of ML estimation, leading to estimators and testing procedures with properties that are hard to evaluate. Another common approach is to impose priors on the loadings, error variances, or both to avoid improper solutions. Estimation, then, proceeds either using a likelihood-based approach with the prior information incorporated via a penalty term (see, e.g., Akaike, Reference Akaike1987; Hirose et al., Reference Hirose, Kawano, Konishi and Ichikawa2011; Lee, Reference Lee1981; Martin & McDonald, Reference Martin and McDonald1975) or by posterior sampling through MCMC (see, e.g., Lee & Song, Reference Lee and Song2002). For example, Martin and McDonald (Reference Martin and McDonald1975) proposed a Bayesian estimation framework in which they maximize not the likelihood but the posterior density, using a prior distribution for the error covariance matrix that assigns zero probability to negative values. They assume a prior distribution that is almost uniform, except that it decreases to zero at the point where an error variance is equal to zero. Lee (Reference Lee1981) also investigated the form of the posterior density under different informative prior distributions, some of which have been designed to deal with Heywood cases. Akaike (Reference Akaike1987), in the process of developing a model selection criterion for factor analysis, also encountered the problem of improper solutions and proposed a standard spherical prior distribution of factor loadings and a uniform distribution for the error variances. Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) build on Akaike’s work by imposing a prior distribution only on the error variances, where the inverse of the diagonal elements of the error covariance matrix has exponential distributions. To the best of our knowledge, there has been no formal proof that such penalties prevent Heywood cases. Furthermore, naive penalization can introduce considerable finite sample bias in the estimation of the factor loadings and error variances, as illustrated in the simulation studies of Section 7.
$[0, \infty )$
either explicitly or by setting negative estimates to zero (see Gerbing & Anderson, Reference Gerbing and Anderson1987 for a discussion). However, this violates regularity conditions of ML estimation, leading to estimators and testing procedures with properties that are hard to evaluate. Another common approach is to impose priors on the loadings, error variances, or both to avoid improper solutions. Estimation, then, proceeds either using a likelihood-based approach with the prior information incorporated via a penalty term (see, e.g., Akaike, Reference Akaike1987; Hirose et al., Reference Hirose, Kawano, Konishi and Ichikawa2011; Lee, Reference Lee1981; Martin & McDonald, Reference Martin and McDonald1975) or by posterior sampling through MCMC (see, e.g., Lee & Song, Reference Lee and Song2002). For example, Martin and McDonald (Reference Martin and McDonald1975) proposed a Bayesian estimation framework in which they maximize not the likelihood but the posterior density, using a prior distribution for the error covariance matrix that assigns zero probability to negative values. They assume a prior distribution that is almost uniform, except that it decreases to zero at the point where an error variance is equal to zero. Lee (Reference Lee1981) also investigated the form of the posterior density under different informative prior distributions, some of which have been designed to deal with Heywood cases. Akaike (Reference Akaike1987), in the process of developing a model selection criterion for factor analysis, also encountered the problem of improper solutions and proposed a standard spherical prior distribution of factor loadings and a uniform distribution for the error variances. Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) build on Akaike’s work by imposing a prior distribution only on the error variances, where the inverse of the diagonal elements of the error covariance matrix has exponential distributions. To the best of our knowledge, there has been no formal proof that such penalties prevent Heywood cases. Furthermore, naive penalization can introduce considerable finite sample bias in the estimation of the factor loadings and error variances, as illustrated in the simulation studies of Section 7.
This article introduces a maximum softly penalized likelihood (MSPL) framework for factor models. Specifically, we derive sufficient conditions on an arbitrary penalty to the log-likelihood function that guarantee that maximum penalized likelihood (MPL) estimation never results in the occurrence of Heywood cases. Furthermore, we show that the penalties proposed in Akaike (Reference Akaike1987) and Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) satisfy those conditions, while guaranteeing key equivariance properties for factor analysis, namely, equivariance under arbitrary scaling of the data and under factor rotations. To our knowledge, this is the first proof that those two penalties can effectively deal with Heywood cases. We, then, present conditions, under which MPL estimators have the desirable asymptotic properties expected from the ML estimator, namely, consistency and asymptotic normality, under the assumption that the limit of the estimator of the variance–covariance matrix decomposes in an exploratory factor analysis fashion. In particular, we show that this is achieved by requiring that the penalization is soft enough, in a way that adapts to how information about the model parameters accumulates. We also discuss how the Akaike (Reference Akaike1987) and Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) penalties can be adapted for soft penalization. Although our asymptotic results assume correct specification, in which case Heywood cases are sampling artifacts, our simulation studies about model selection performance in Section 7 suggest that under factor number misspecification, MSPL estimation continues to exhibit the least-false behavior expected by the ML estimator (see, e.g., White, Reference White1982).
The remainder of this article is organized as follows. Section 2 briefly presents the factor analysis model. The proposed MPL framework is introduced in Section 3. Section 4 states our existence result of MPL estimates, which rules out the occurrence of Heywood cases, and Section 5 provides the asymptotic behavior of MPL estimators. Section 6 discusses the scaling factors for our MSPL estimators, and Section 7 provides a series of simulation studies that investigate the finite sample performance of MSPL-based estimation and inference and compares them to existing Bayesian approaches. Section 8 gives real data examples and final remarks are provided in Section 9. Proofs of all theoretical results and additional materials are provided in the Supplementary Material.
2 Exploratory factor analysis
The factor analysis model for a random vector of observed variables
 $\boldsymbol {x}$
and q factors
$\boldsymbol {x}$
and q factors
 $(q < p)$
is
$(q < p)$
is
 $$ \begin{align} \boldsymbol{x} = \boldsymbol{\mu} + \boldsymbol{\Lambda} \boldsymbol{z} +\boldsymbol{\epsilon} \,, \end{align} $$
$$ \begin{align} \boldsymbol{x} = \boldsymbol{\mu} + \boldsymbol{\Lambda} \boldsymbol{z} +\boldsymbol{\epsilon} \,, \end{align} $$
where
 $\boldsymbol {\mu } = (\mu _1, \ldots , \mu _p)^\top \in \Re ^p$
,
$\boldsymbol {\mu } = (\mu _1, \ldots , \mu _p)^\top \in \Re ^p$
,
 $\boldsymbol {\Lambda }$
is a
$\boldsymbol {\Lambda }$
is a
 $p \times q$
real matrix of factor loadings,
$p \times q$
real matrix of factor loadings,
 $\boldsymbol {z} \sim \operatorname {\mathrm {N}}(\boldsymbol {0}_q, \boldsymbol {I}_q)$
,
$\boldsymbol {z} \sim \operatorname {\mathrm {N}}(\boldsymbol {0}_q, \boldsymbol {I}_q)$
,
 $\boldsymbol {\epsilon } \sim \operatorname {\mathrm {N}}(\boldsymbol {0}_p, \boldsymbol {\Psi })$
, and
$\boldsymbol {\epsilon } \sim \operatorname {\mathrm {N}}(\boldsymbol {0}_p, \boldsymbol {\Psi })$
, and
 $\boldsymbol {z}$
is independent of
$\boldsymbol {z}$
is independent of
 $\boldsymbol {\epsilon }$
. In the latter expressions,
$\boldsymbol {\epsilon }$
. In the latter expressions,
 $\boldsymbol {\Psi }$
is a
$\boldsymbol {\Psi }$
is a
 $p \times p$
diagonal matrix with jth diagonal element
$p \times p$
diagonal matrix with jth diagonal element
 $\psi _{j}> 0$
, and
$\psi _{j}> 0$
, and
 $\boldsymbol {0}_q$
is a vector of q zeros, and
$\boldsymbol {0}_q$
is a vector of q zeros, and
 $\boldsymbol {I}_q$
is the
$\boldsymbol {I}_q$
is the
 $q \times q$
identity matrix. It follows that
$q \times q$
identity matrix. It follows that
 $\operatorname {\mathrm {E}}(\boldsymbol {x}) = \boldsymbol {\mu }$
and
$\operatorname {\mathrm {E}}(\boldsymbol {x}) = \boldsymbol {\mu }$
and
 $\operatorname {\mathrm {var}} (\boldsymbol {x}) = \boldsymbol {\Sigma } = \boldsymbol {\Lambda }\boldsymbol {\Lambda }^\top + \boldsymbol {\Psi }$
. The exploratory factor analysis model is identifiable only up to orthogonal rotations of the factor loadings matrix
$\operatorname {\mathrm {var}} (\boldsymbol {x}) = \boldsymbol {\Sigma } = \boldsymbol {\Lambda }\boldsymbol {\Lambda }^\top + \boldsymbol {\Psi }$
. The exploratory factor analysis model is identifiable only up to orthogonal rotations of the factor loadings matrix
 $\boldsymbol {\Lambda }$
. Bartholomew et al. (Reference Bartholomew, Knott and Moustaki2011, Chapter 3) discuss approaches that resolve unidentifiability.
$\boldsymbol {\Lambda }$
. Bartholomew et al. (Reference Bartholomew, Knott and Moustaki2011, Chapter 3) discuss approaches that resolve unidentifiability.
In the presence of realizations of n independent random vectors
 $\boldsymbol {x}_1, \ldots , \boldsymbol {x}_n$
, the log-likelihood function about the parameters
$\boldsymbol {x}_1, \ldots , \boldsymbol {x}_n$
, the log-likelihood function about the parameters
 $\boldsymbol {\mu }$
and
$\boldsymbol {\mu }$
and
 $\boldsymbol {\Sigma }$
of the exploratory factor analysis model is
$\boldsymbol {\Sigma }$
of the exploratory factor analysis model is
 $$ \begin{align} C - \frac{n}{2} \left[ \log \det \left( \boldsymbol{\Sigma} \right) + \operatorname{\mathrm{tr}} \left(\boldsymbol{\Sigma}^{-1} \boldsymbol{S} \right) + \sum_{i=1}^{n} ( \bar{\boldsymbol{x}} - \boldsymbol{\mu})^\top \boldsymbol{\Sigma}^{-1} (\bar{\boldsymbol{x}} - \boldsymbol{\mu})\right] \,, \end{align} $$
$$ \begin{align} C - \frac{n}{2} \left[ \log \det \left( \boldsymbol{\Sigma} \right) + \operatorname{\mathrm{tr}} \left(\boldsymbol{\Sigma}^{-1} \boldsymbol{S} \right) + \sum_{i=1}^{n} ( \bar{\boldsymbol{x}} - \boldsymbol{\mu})^\top \boldsymbol{\Sigma}^{-1} (\bar{\boldsymbol{x}} - \boldsymbol{\mu})\right] \,, \end{align} $$
where
 $C = -np \log (2 \pi )/2$
,
$C = -np \log (2 \pi )/2$
,
 $\bar {\boldsymbol {x}} = \sum _{i=1}^n \boldsymbol {x}_i /n$
and
$\bar {\boldsymbol {x}} = \sum _{i=1}^n \boldsymbol {x}_i /n$
and
 $\boldsymbol {S} = \sum _{i=1}^n (\boldsymbol {x}_i - \bar {\boldsymbol {x}})(\boldsymbol {x}_i -\bar {\boldsymbol {x}} )^\top / n$
is the sample covariance matrix, assumed to be full rank. Clearly, the maximizer of (2.2) with respect to
$\boldsymbol {S} = \sum _{i=1}^n (\boldsymbol {x}_i - \bar {\boldsymbol {x}})(\boldsymbol {x}_i -\bar {\boldsymbol {x}} )^\top / n$
is the sample covariance matrix, assumed to be full rank. Clearly, the maximizer of (2.2) with respect to
 $\boldsymbol {\mu }$
is
$\boldsymbol {\mu }$
is
 $\bar {\boldsymbol {x}}$
, and at that point the quadratic term in (2.2) involving
$\bar {\boldsymbol {x}}$
, and at that point the quadratic term in (2.2) involving
 $\bar {\boldsymbol {x}}$
and
$\bar {\boldsymbol {x}}$
and
 $\boldsymbol {\mu }$
vanishes. Then, the profile log-likelihood about
$\boldsymbol {\mu }$
vanishes. Then, the profile log-likelihood about
 $\boldsymbol {\Psi }$
and
$\boldsymbol {\Psi }$
and
 $\boldsymbol {\Lambda }$
is
$\boldsymbol {\Lambda }$
is
 $$ \begin{align} \ell(\boldsymbol{\theta}; \boldsymbol{S}) = C - \frac{n}{2} \left[ \log \det \left( \boldsymbol{\Lambda} \boldsymbol{\Lambda}^\top + \boldsymbol{\Psi} \right) + \operatorname{\mathrm{tr}} \left\{ \left(\boldsymbol{\Lambda}\boldsymbol{\Lambda}^\top + \boldsymbol{\Psi}\right)^{-1} \boldsymbol{S} \right\} \right] \, \end{align} $$
$$ \begin{align} \ell(\boldsymbol{\theta}; \boldsymbol{S}) = C - \frac{n}{2} \left[ \log \det \left( \boldsymbol{\Lambda} \boldsymbol{\Lambda}^\top + \boldsymbol{\Psi} \right) + \operatorname{\mathrm{tr}} \left\{ \left(\boldsymbol{\Lambda}\boldsymbol{\Lambda}^\top + \boldsymbol{\Psi}\right)^{-1} \boldsymbol{S} \right\} \right] \, \end{align} $$
with
 $\boldsymbol {\theta } = (\theta _1, \ldots , \theta _{p(q + 1)})^\top = (\lambda _{11}, \ldots , \lambda _{pq}, \psi _{1}, \ldots , \psi _{p})^\top $
, where
$\boldsymbol {\theta } = (\theta _1, \ldots , \theta _{p(q + 1)})^\top = (\lambda _{11}, \ldots , \lambda _{pq}, \psi _{1}, \ldots , \psi _{p})^\top $
, where
 $\lambda _{jk}$
and
$\lambda _{jk}$
and
 $\psi _{j}$
are the
$\psi _{j}$
are the
 $(j, k)$
th and
$(j, k)$
th and
 $(j, j)$
th elements of
$(j, j)$
th elements of
 $\boldsymbol {\Lambda }$
and
$\boldsymbol {\Lambda }$
and
 $\boldsymbol {\Psi }$
, respectively,
$\boldsymbol {\Psi }$
, respectively,
 $(j = 1, \ldots , p; k = 1, \ldots , q)$
. Heywood cases correspond to directions
$(j = 1, \ldots , p; k = 1, \ldots , q)$
. Heywood cases correspond to directions
 $\{\boldsymbol {\theta }(r)\}_{r \in \mathbb {N}}$
such that the value of
$\{\boldsymbol {\theta }(r)\}_{r \in \mathbb {N}}$
such that the value of
 $\ell (\boldsymbol {\theta }(r); \boldsymbol {S})$
increases but
$\ell (\boldsymbol {\theta }(r); \boldsymbol {S})$
increases but
 $\lim \limits _{r \to \infty }\boldsymbol {\Psi }(\boldsymbol {\theta }(r))$
is no longer positive definite. Ultra-Heywood cases, that is, maxima of (2.3) with some of the variances negative, can, of course, be prevented by maximizing the log-likelihood under the constraint that
$\lim \limits _{r \to \infty }\boldsymbol {\Psi }(\boldsymbol {\theta }(r))$
is no longer positive definite. Ultra-Heywood cases, that is, maxima of (2.3) with some of the variances negative, can, of course, be prevented by maximizing the log-likelihood under the constraint that
 $\psi _{j}> 0$
. Nevertheless, this does not eliminate the possibility of at least one of the ML estimates of
$\psi _{j}> 0$
. Nevertheless, this does not eliminate the possibility of at least one of the ML estimates of
 $\psi _{11}, \ldots , \psi _{pp}$
being exactly zero.
$\psi _{11}, \ldots , \psi _{pp}$
being exactly zero.
3 Maximum penalized likelihood for handling Heywood cases
A straightforward way to avoid Heywood cases is to employ an MPL estimator
 $$ \begin{align} \tilde{\boldsymbol{\theta}} \in \arg \underset{\boldsymbol{\theta} \in \boldsymbol{\Theta}}{\max} \, \ell^{\ast}(\boldsymbol{\theta}; \boldsymbol{S}) \,, \end{align} $$
$$ \begin{align} \tilde{\boldsymbol{\theta}} \in \arg \underset{\boldsymbol{\theta} \in \boldsymbol{\Theta}}{\max} \, \ell^{\ast}(\boldsymbol{\theta}; \boldsymbol{S}) \,, \end{align} $$
where
 $\ell ^{\ast}(\boldsymbol {\theta }; \boldsymbol {S}) = \ell (\boldsymbol {\theta }; \boldsymbol {S}) + P^{\ast}(\boldsymbol {\theta }; \boldsymbol {S})$
and
$\ell ^{\ast}(\boldsymbol {\theta }; \boldsymbol {S}) = \ell (\boldsymbol {\theta }; \boldsymbol {S}) + P^{\ast}(\boldsymbol {\theta }; \boldsymbol {S})$
and
 $\boldsymbol {\Theta } = \left \{\boldsymbol {\theta } \in \Re ^{p (q + 1)}: \theta _m> 0, m > pq \right \}$
, with a penalty function
$\boldsymbol {\Theta } = \left \{\boldsymbol {\theta } \in \Re ^{p (q + 1)}: \theta _m> 0, m > pq \right \}$
, with a penalty function
 $P^{\ast}(\boldsymbol {\theta })$
that discourages estimates of
$P^{\ast}(\boldsymbol {\theta })$
that discourages estimates of
 $\psi _{ii}$
being zero, so that the set
$\psi _{ii}$
being zero, so that the set
 $$ \begin{align*}\arg \underset{\boldsymbol{\theta} \in \boldsymbol{\Theta}}{\max} \, \ell^{\ast}(\boldsymbol{\theta}; \boldsymbol{S}) = \left\{\bar{\boldsymbol{\theta}}\in \boldsymbol{\Theta}: \ell^{\ast}(\bar{\boldsymbol{\theta}}; \boldsymbol{S}) = \underset{\boldsymbol{\theta} \in \boldsymbol{\Theta}}{\sup} \, \ell^{\ast}(\boldsymbol{\theta}; \boldsymbol{S}) \right\}, \end{align*} $$
$$ \begin{align*}\arg \underset{\boldsymbol{\theta} \in \boldsymbol{\Theta}}{\max} \, \ell^{\ast}(\boldsymbol{\theta}; \boldsymbol{S}) = \left\{\bar{\boldsymbol{\theta}}\in \boldsymbol{\Theta}: \ell^{\ast}(\bar{\boldsymbol{\theta}}; \boldsymbol{S}) = \underset{\boldsymbol{\theta} \in \boldsymbol{\Theta}}{\sup} \, \ell^{\ast}(\boldsymbol{\theta}; \boldsymbol{S}) \right\}, \end{align*} $$
is nonempty. Toward constructing an MPL estimator that always exists, Akaike (Reference Akaike1987) and Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) proposed the penalties
 $$ \begin{align} P^{\ast}(\boldsymbol{\theta}) = -\frac{\rho n}{2} \operatorname{\mathrm{tr}}\left(\boldsymbol{\Psi}^{-1/2} \boldsymbol{\Lambda} \boldsymbol{\Lambda}^\top \boldsymbol{\Psi}^{-1/2}\right) \,, \quad \text{and} \quad P^{\ast}(\boldsymbol{\theta}) = -\frac{\rho n}{2} \operatorname{\mathrm{tr}}\left(\boldsymbol{\Psi}^{-1/2} \boldsymbol{S} \boldsymbol{\Psi}^{-1/2}\right) \,, \end{align} $$
$$ \begin{align} P^{\ast}(\boldsymbol{\theta}) = -\frac{\rho n}{2} \operatorname{\mathrm{tr}}\left(\boldsymbol{\Psi}^{-1/2} \boldsymbol{\Lambda} \boldsymbol{\Lambda}^\top \boldsymbol{\Psi}^{-1/2}\right) \,, \quad \text{and} \quad P^{\ast}(\boldsymbol{\theta}) = -\frac{\rho n}{2} \operatorname{\mathrm{tr}}\left(\boldsymbol{\Psi}^{-1/2} \boldsymbol{S} \boldsymbol{\Psi}^{-1/2}\right) \,, \end{align} $$
respectively, for
 $\rho> 0$
. The penalties in (3.2) are attractive because the MPL estimates preserve two particular equivariance properties that the ML estimator has, namely, equivariance under rescaling of the response vectors and equivariance under rotations of the factor loadings. The former is desirable to justify the common practice in factor analysis of setting
$\rho> 0$
. The penalties in (3.2) are attractive because the MPL estimates preserve two particular equivariance properties that the ML estimator has, namely, equivariance under rescaling of the response vectors and equivariance under rotations of the factor loadings. The former is desirable to justify the common practice in factor analysis of setting
 $\boldsymbol {S}$
in (2.3) to the sample correlation matrix, and the latter is desirable because it ensures that any post-fit rotation of the factors is still the ML estimate of the rotated factors.
$\boldsymbol {S}$
in (2.3) to the sample correlation matrix, and the latter is desirable because it ensures that any post-fit rotation of the factors is still the ML estimate of the rotated factors.
To see the equivariance under rescaling of the response vectors, let
 $\dot {\boldsymbol {x}}_i = \boldsymbol {L} \boldsymbol {x}_i$
, for a known, diagonal, invertible
$\dot {\boldsymbol {x}}_i = \boldsymbol {L} \boldsymbol {x}_i$
, for a known, diagonal, invertible
 $p \times p$
matrix
$p \times p$
matrix
 $\boldsymbol {L}$
. Then,
$\boldsymbol {L}$
. Then,
 $\dot {\boldsymbol {\Sigma }} = \operatorname {\mathrm {var}}(\dot {\boldsymbol {x}}_i) = \dot {\boldsymbol {\Lambda }} \dot {\boldsymbol {\Lambda }}^\top + \dot {\boldsymbol {\Psi }}$
, with
$\dot {\boldsymbol {\Sigma }} = \operatorname {\mathrm {var}}(\dot {\boldsymbol {x}}_i) = \dot {\boldsymbol {\Lambda }} \dot {\boldsymbol {\Lambda }}^\top + \dot {\boldsymbol {\Psi }}$
, with
 $\dot {\boldsymbol {\Lambda }} = \boldsymbol {L} \boldsymbol {\Lambda }$
and
$\dot {\boldsymbol {\Lambda }} = \boldsymbol {L} \boldsymbol {\Lambda }$
and
 $\dot {\boldsymbol {\Psi }} = \boldsymbol {L} \boldsymbol {\Psi } \boldsymbol {L}^\top $
, and the sample variance–covariance matrix based on
$\dot {\boldsymbol {\Psi }} = \boldsymbol {L} \boldsymbol {\Psi } \boldsymbol {L}^\top $
, and the sample variance–covariance matrix based on
 $\dot {\boldsymbol {x}}_1, \ldots , \dot {\boldsymbol {x}}_n$
is
$\dot {\boldsymbol {x}}_1, \ldots , \dot {\boldsymbol {x}}_n$
is
 $\dot {\boldsymbol {S}} = \boldsymbol {L} \boldsymbol {S} \boldsymbol {L}^\top $
. Denoting
$\dot {\boldsymbol {S}} = \boldsymbol {L} \boldsymbol {S} \boldsymbol {L}^\top $
. Denoting
 $\dot {\boldsymbol {\theta }} = (\dot \lambda _{11}, \ldots , \dot \lambda _{pq}, \dot \psi _{1}, \ldots , \dot \psi _{p})^\top $
, the cyclic property of the trace operator and properties of the determinant for products of invertible matrices can be used to show that
$\dot {\boldsymbol {\theta }} = (\dot \lambda _{11}, \ldots , \dot \lambda _{pq}, \dot \psi _{1}, \ldots , \dot \psi _{p})^\top $
, the cyclic property of the trace operator and properties of the determinant for products of invertible matrices can be used to show that
 $\ell (\dot {\boldsymbol {\theta }}; \dot {\boldsymbol {S}}) = \ell (\boldsymbol {\theta }; \boldsymbol {S}) + \dot {c}$
, where
$\ell (\dot {\boldsymbol {\theta }}; \dot {\boldsymbol {S}}) = \ell (\boldsymbol {\theta }; \boldsymbol {S}) + \dot {c}$
, where
 $\dot {c}$
does not depend on
$\dot {c}$
does not depend on
 $\dot {\boldsymbol {\theta }}$
. Hence, if
$\dot {\boldsymbol {\theta }}$
. Hence, if
 $\hat {\boldsymbol {\Lambda }}$
and
$\hat {\boldsymbol {\Lambda }}$
and
 $\hat {\boldsymbol {\Psi }}$
are the maximizers of
$\hat {\boldsymbol {\Psi }}$
are the maximizers of
 $\ell (\boldsymbol {\theta }; \boldsymbol {S})$
, the maximizers of
$\ell (\boldsymbol {\theta }; \boldsymbol {S})$
, the maximizers of
 $\ell (\dot {\boldsymbol {\theta }}; \dot {\boldsymbol {S}})$
are
$\ell (\dot {\boldsymbol {\theta }}; \dot {\boldsymbol {S}})$
are
 $\boldsymbol {L} \hat {\boldsymbol {\Lambda }}$
and
$\boldsymbol {L} \hat {\boldsymbol {\Lambda }}$
and
 $\boldsymbol {L} \hat {\boldsymbol {\Psi }} \boldsymbol {L}^\top $
, respectively. Similar calculations show that, for both penalties in (3.2),
$\boldsymbol {L} \hat {\boldsymbol {\Psi }} \boldsymbol {L}^\top $
, respectively. Similar calculations show that, for both penalties in (3.2),
 $P^{\ast}(\dot {\boldsymbol {\theta }}) = P^{\ast}(\boldsymbol {\theta }) + \dot {d}$
for a known constant
$P^{\ast}(\dot {\boldsymbol {\theta }}) = P^{\ast}(\boldsymbol {\theta }) + \dot {d}$
for a known constant
 $\dot {d}$
that does not depend on
$\dot {d}$
that does not depend on
 $\dot {\boldsymbol {\theta }}$
. Hence, if
$\dot {\boldsymbol {\theta }}$
. Hence, if
 $\tilde {\boldsymbol {\Lambda }}$
and
$\tilde {\boldsymbol {\Lambda }}$
and
 $\tilde {\boldsymbol {\Psi }}$
are the maximizers of
$\tilde {\boldsymbol {\Psi }}$
are the maximizers of
 $\ell ^{\ast}(\boldsymbol {\theta }; \boldsymbol {S})$
, the maximizers of
$\ell ^{\ast}(\boldsymbol {\theta }; \boldsymbol {S})$
, the maximizers of
 $\ell ^{\ast}(\dot {\boldsymbol {\theta }}; \dot {\boldsymbol {S}})$
are
$\ell ^{\ast}(\dot {\boldsymbol {\theta }}; \dot {\boldsymbol {S}})$
are
 $\boldsymbol {L} \tilde {\boldsymbol {\Lambda }}$
and
$\boldsymbol {L} \tilde {\boldsymbol {\Lambda }}$
and
 $\boldsymbol {L} \tilde {\boldsymbol {\Psi }} \boldsymbol {L}^\top $
, respectively. The equivariance under rotations of the factors is a direct consequence of the invariance of both
$\boldsymbol {L} \tilde {\boldsymbol {\Psi }} \boldsymbol {L}^\top $
, respectively. The equivariance under rotations of the factors is a direct consequence of the invariance of both
 $\ell (\boldsymbol {\theta }; \boldsymbol {S})$
and the penalties in (3.2), when
$\ell (\boldsymbol {\theta }; \boldsymbol {S})$
and the penalties in (3.2), when
 $\boldsymbol {\Lambda }$
is replaced by
$\boldsymbol {\Lambda }$
is replaced by
 $\boldsymbol {\Lambda } \boldsymbol {Q}$
, for an orthogonal
$\boldsymbol {\Lambda } \boldsymbol {Q}$
, for an orthogonal
 $q \times q$
matrix
$q \times q$
matrix
 $\boldsymbol {Q}$
.
$\boldsymbol {Q}$
.
Despite the above attractive equivariance properties, to our knowledge, there has been no formal proof that penalties (3.2) resolve Heywood cases. Furthermore, naive choice of
 $\rho $
can introduce considerable finite-sample bias in the estimation of
$\rho $
can introduce considerable finite-sample bias in the estimation of
 $\boldsymbol {\theta }$
, as it is illustrated later in the simulations of Section 7.
$\boldsymbol {\theta }$
, as it is illustrated later in the simulations of Section 7.
4 Existence of maximum penalized likelihood estimates
Theorem 4.1 provides general conditions that ensure the existence of MPL estimates and uses them to examine the properties of the penalties (3.2).
Theorem 4.1 (Existence of MPL estimates in factor analysis).
Let
 $\boldsymbol {\Theta } = \left \{\boldsymbol {\theta } \in \Re ^{p (q + 1)}: \theta _m> 0, m > pq \right \}$
and
$\boldsymbol {\Theta } = \left \{\boldsymbol {\theta } \in \Re ^{p (q + 1)}: \theta _m> 0, m > pq \right \}$
and
 $\partial \boldsymbol {\Theta } = \{\boldsymbol {\theta } \in \Re ^{p(q + 1)}: \exists m> pq, \theta _m = 0 \}$
and
$\partial \boldsymbol {\Theta } = \{\boldsymbol {\theta } \in \Re ^{p(q + 1)}: \exists m> pq, \theta _m = 0 \}$
and
 $\boldsymbol {\Sigma }(\boldsymbol {\theta }) = \boldsymbol {\Lambda }(\boldsymbol {\theta })\boldsymbol {\Lambda }(\boldsymbol {\theta })^\top + \boldsymbol {\Psi }(\boldsymbol {\theta })$
. Assume that
$\boldsymbol {\Sigma }(\boldsymbol {\theta }) = \boldsymbol {\Lambda }(\boldsymbol {\theta })\boldsymbol {\Lambda }(\boldsymbol {\theta })^\top + \boldsymbol {\Psi }(\boldsymbol {\theta })$
. Assume that
 $\boldsymbol {S}$
has full rank and that the penalty function
$\boldsymbol {S}$
has full rank and that the penalty function
 $P^{\ast}(\boldsymbol {\theta }): \boldsymbol {\Theta } \to \Re :$
$P^{\ast}(\boldsymbol {\theta }): \boldsymbol {\Theta } \to \Re :$
-
(E1) is continuous on
 $\boldsymbol {\Theta }$
;
$\boldsymbol {\Theta }$
; -
(E2) is bounded from above on
$\boldsymbol {\Theta }$
, that is,
$\underset {\boldsymbol {\theta } \in \boldsymbol {\Theta }}{\sup } \, P^{\ast}(\boldsymbol {\theta }) < \infty $
; -
(E3) diverges to
$-\infty $
for any sequence
$\{\boldsymbol {\theta }(r)\}_{r \in \mathbb{N}}$
such that
$\lim _{r \to \infty }\boldsymbol {\theta }(r) \in \partial \boldsymbol {\Theta }$
and
$\lim _{r \to \infty }\lambda _{\min } (\boldsymbol {\Sigma }(\boldsymbol {\theta }(r)))> 0$
, where
$\lambda _{\min }(\boldsymbol {A})$
is the minimum eigenvalue of a matrix
$\boldsymbol {A}$
.









Then, the set of MPL estimates
 $\displaystyle \arg \max _{\boldsymbol {\theta } \in \boldsymbol {\Theta }} \ell ^{\ast}(\boldsymbol {\theta }; \boldsymbol {S})$
is non-empty.
$\displaystyle \arg \max _{\boldsymbol {\theta } \in \boldsymbol {\Theta }} \ell ^{\ast}(\boldsymbol {\theta }; \boldsymbol {S})$
is non-empty.
The proof of Theorem 4.1 is in Section S2.2 of the Supplementary Material. The theorem is model-agnostic in that it only requires
 $\boldsymbol {S}$
to have full rank and that parameter estimation is conducted using the penalized log-likelihood function of (3.1); no assumptions about the true data generating process are made. Theorem 4.1 establishes that under conditions E1–E3 for the penalty to the log-likelihood, MPL estimation always results in estimates that are not Heywood cases, in the sense that
$\boldsymbol {S}$
to have full rank and that parameter estimation is conducted using the penalized log-likelihood function of (3.1); no assumptions about the true data generating process are made. Theorem 4.1 establishes that under conditions E1–E3 for the penalty to the log-likelihood, MPL estimation always results in estimates that are not Heywood cases, in the sense that
 $\tilde {\boldsymbol {\theta }}$
has
$\tilde {\boldsymbol {\theta }}$
has
 $\tilde {\psi }_{j}> 0 (j = 1, \ldots , p)$
.
$\tilde {\psi }_{j}> 0 (j = 1, \ldots , p)$
.
The penalties by Akaike (Reference Akaike1987) and Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) in (3.2) satisfy assumptions E1–E3 for
 ${\rho> 0}$
, and, hence, MPL estimation using either of those results in no Heywood cases. To see that, note that matrix inversion, matrix multiplication, and trace are all continuous operations on
${\rho> 0}$
, and, hence, MPL estimation using either of those results in no Heywood cases. To see that, note that matrix inversion, matrix multiplication, and trace are all continuous operations on
 $\boldsymbol {\Theta }$
. As a result, the penalties in (3.2) are continuous and assumption E1 is satisfied. The penalties in (3.2) can be re-expressed as
$\boldsymbol {\Theta }$
. As a result, the penalties in (3.2) are continuous and assumption E1 is satisfied. The penalties in (3.2) can be re-expressed as
 $$ \begin{align} P^{\ast}(\boldsymbol{\theta}) = - \frac{\rho n}{2} \sum_{j = 1}^p \frac{\boldsymbol{A}_{jj}(\boldsymbol{\theta})}{\boldsymbol{\Psi}_{jj}(\boldsymbol{\theta})} \, , \end{align} $$
$$ \begin{align} P^{\ast}(\boldsymbol{\theta}) = - \frac{\rho n}{2} \sum_{j = 1}^p \frac{\boldsymbol{A}_{jj}(\boldsymbol{\theta})}{\boldsymbol{\Psi}_{jj}(\boldsymbol{\theta})} \, , \end{align} $$
where
 $\boldsymbol {A}_{jj}(\boldsymbol {\theta }) = \boldsymbol {S}_{jj}$
for the Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) penalty, and
$\boldsymbol {A}_{jj}(\boldsymbol {\theta }) = \boldsymbol {S}_{jj}$
for the Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) penalty, and
 $\boldsymbol {A}_{jj}(\boldsymbol {\theta }) = \boldsymbol {\lambda }_j(\boldsymbol {\theta })^\top \boldsymbol {\lambda }_j(\boldsymbol {\theta })$
for the Akaike (Reference Akaike1987) penalty, where
$\boldsymbol {A}_{jj}(\boldsymbol {\theta }) = \boldsymbol {\lambda }_j(\boldsymbol {\theta })^\top \boldsymbol {\lambda }_j(\boldsymbol {\theta })$
for the Akaike (Reference Akaike1987) penalty, where
 $\boldsymbol {\lambda }_j(\boldsymbol {\theta })$
is the jth row of
$\boldsymbol {\lambda }_j(\boldsymbol {\theta })$
is the jth row of
 $\boldsymbol {\Lambda }(\boldsymbol {\theta })$
, and
$\boldsymbol {\Lambda }(\boldsymbol {\theta })$
, and
 $\boldsymbol {C}_{jk}$
denotes the
$\boldsymbol {C}_{jk}$
denotes the
 $(j, k)$
th element of the matrix
$(j, k)$
th element of the matrix
 $\boldsymbol {C}$
. Note that
$\boldsymbol {C}$
. Note that
 $\boldsymbol {A}_{jj}(\boldsymbol {\theta }) / \boldsymbol {\Psi }_{jj}(\boldsymbol {\theta }) \ge 0$
for both penalties. Hence, (4.1) is bounded above by zero for
$\boldsymbol {A}_{jj}(\boldsymbol {\theta }) / \boldsymbol {\Psi }_{jj}(\boldsymbol {\theta }) \ge 0$
for both penalties. Hence, (4.1) is bounded above by zero for
 $\rho> 0$
, and E2 is satisfied. Now, consider a sequence
$\rho> 0$
, and E2 is satisfied. Now, consider a sequence
 $\{\boldsymbol {\theta }(r)\}_{r \in \mathbb {N}}$
such that
$\{\boldsymbol {\theta }(r)\}_{r \in \mathbb {N}}$
such that
 $\lim _{r \to \infty }\boldsymbol {\theta }(r) \in \partial \boldsymbol {\Theta }$
and
$\lim _{r \to \infty }\boldsymbol {\theta }(r) \in \partial \boldsymbol {\Theta }$
and
 $\lim _{r \to \infty }\lambda _{\min }(\boldsymbol {\Sigma }(\boldsymbol {\theta }(r)))> 0$
. Then, there exists at least one
$\lim _{r \to \infty }\lambda _{\min }(\boldsymbol {\Sigma }(\boldsymbol {\theta }(r)))> 0$
. Then, there exists at least one
 $j \in \{1, \ldots , p\}$
such that
$j \in \{1, \ldots , p\}$
such that
 $\boldsymbol {\Psi }_{jj}(\boldsymbol {\theta }(r)) \to 0$
. For
$\boldsymbol {\Psi }_{jj}(\boldsymbol {\theta }(r)) \to 0$
. For
 $\boldsymbol {A}(\boldsymbol {\theta }) = \boldsymbol {S}$
, the penalty (4.1) diverges to
$\boldsymbol {A}(\boldsymbol {\theta }) = \boldsymbol {S}$
, the penalty (4.1) diverges to
 $-\infty $
as
$-\infty $
as
 $\boldsymbol {\Psi }_{jj}(\boldsymbol {\theta }) \to 0$
. For the Akaike (Reference Akaike1987) version,
$\boldsymbol {\Psi }_{jj}(\boldsymbol {\theta }) \to 0$
. For the Akaike (Reference Akaike1987) version,
 $\boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))^\top \boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))$
can either diverge to
$\boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))^\top \boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))$
can either diverge to
 $\infty $
or converge to a constant
$\infty $
or converge to a constant
 $c_j> 0$
. Only the former can happen for the chosen sequence
$c_j> 0$
. Only the former can happen for the chosen sequence
 $\{\boldsymbol {\theta }(r)\}_{r \in \mathbb {N}}$
, because, for the latter,
$\{\boldsymbol {\theta }(r)\}_{r \in \mathbb {N}}$
, because, for the latter,
 $\boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))^\top \boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))$
would need to converge to zero at an appropriate rate, in which case
$\boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))^\top \boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))$
would need to converge to zero at an appropriate rate, in which case
 $\boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))^\top \boldsymbol {\lambda }_j(\boldsymbol {\theta }(r)) + \boldsymbol {\Psi }_{jj}(\boldsymbol {\theta })$
converges to zero, resulting in
$\boldsymbol {\lambda }_j(\boldsymbol {\theta }(r))^\top \boldsymbol {\lambda }_j(\boldsymbol {\theta }(r)) + \boldsymbol {\Psi }_{jj}(\boldsymbol {\theta })$
converges to zero, resulting in
 $\boldsymbol {\Sigma }(\boldsymbol {\theta }(r))$
having at least one zero eigenvalue. Hence, E3 is satisfied for both the Akaike (Reference Akaike1987) and Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) penalties.
$\boldsymbol {\Sigma }(\boldsymbol {\theta }(r))$
having at least one zero eigenvalue. Hence, E3 is satisfied for both the Akaike (Reference Akaike1987) and Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011) penalties.
Theorem A2 in the Supplementary Material provides an existence result under more general parameterizations of the factor analysis model, which is used for proving the consistency results in Section 5.2, and which might be useful if one wishes to impose further restrictions on the structure of
 $\boldsymbol {\Sigma }$
, as is being done, for example, in confirmatory factor analysis (see, e.g., Bartholomew et al., Reference Bartholomew, Knott and Moustaki2011, Chapter 8).
$\boldsymbol {\Sigma }$
, as is being done, for example, in confirmatory factor analysis (see, e.g., Bartholomew et al., Reference Bartholomew, Knott and Moustaki2011, Chapter 8).
5 Asymptotics for maximum penalized likelihood
5.1 Consistency
To discuss the consistency of estimates for
 $\boldsymbol {\Lambda }, \boldsymbol {\Psi }$
in factor analysis models, we must i) define the estimands
$\boldsymbol {\Lambda }, \boldsymbol {\Psi }$
in factor analysis models, we must i) define the estimands
 $\boldsymbol {\Lambda }_0, \boldsymbol {\Psi }_0$
, and
$\boldsymbol {\Lambda }_0, \boldsymbol {\Psi }_0$
, and
 $\boldsymbol {\Sigma }_0 = \boldsymbol {\Lambda }_0\boldsymbol {\Lambda }_0^\top + \boldsymbol {\Psi }_0$
and ii) ensure identifiability.
$\boldsymbol {\Sigma }_0 = \boldsymbol {\Lambda }_0\boldsymbol {\Lambda }_0^\top + \boldsymbol {\Psi }_0$
and ii) ensure identifiability.
If the modeling assumption of Section 2 is met for matrices
 $\boldsymbol {\Lambda }_0$
and
$\boldsymbol {\Lambda }_0$
and
 $\boldsymbol {\Psi }_0$
, then the latter are the parameter values that identify the data-generating process. This is the viewpoint taken in Kano (Reference Kano1983) in their consistency proofs, where they introduce and use the concept of strong identifiability.
$\boldsymbol {\Psi }_0$
, then the latter are the parameter values that identify the data-generating process. This is the viewpoint taken in Kano (Reference Kano1983) in their consistency proofs, where they introduce and use the concept of strong identifiability.
Let
 $\boldsymbol {B}$
be any
$\boldsymbol {B}$
be any
 $p \times q$
matrix and
$p \times q$
matrix and
 $\boldsymbol {V} $
be any positive-definite
$\boldsymbol {V} $
be any positive-definite
 $p \times p$
diagonal matrix and define
$p \times p$
diagonal matrix and define
 $\boldsymbol {\Sigma } = \boldsymbol {B} \boldsymbol {B}^\top + \boldsymbol {V}$
. A factor model is said to be strongly identifiable if and only if, for any
$\boldsymbol {\Sigma } = \boldsymbol {B} \boldsymbol {B}^\top + \boldsymbol {V}$
. A factor model is said to be strongly identifiable if and only if, for any
 $\epsilon> 0$
, there exists a
$\epsilon> 0$
, there exists a
 $\delta> 0$
such that
$\delta> 0$
such that
for some orthogonal matrix
 $\boldsymbol {Q}$
of order q and where
$\boldsymbol {Q}$
of order q and where ![]() is some matrix norm. Since our results are derived in a fixed p and fixed q asymptotic regime, the particular choice of matrix and vector norm is irrelevant for the developments (see Horn & Johnson, Reference Horn and Johnson2012, Corollary 5.4.5 and Section S2.1 of the Supplementary Material for details). Hence, throughout, let
is some matrix norm. Since our results are derived in a fixed p and fixed q asymptotic regime, the particular choice of matrix and vector norm is irrelevant for the developments (see Horn & Johnson, Reference Horn and Johnson2012, Corollary 5.4.5 and Section S2.1 of the Supplementary Material for details). Hence, throughout, let ![]() and
and ![]() denote any vector and matrix norm, respectively.
denote any vector and matrix norm, respectively.
Theorem 5.1. Assume that
-
(C1) the factor model is strongly identifiable;
-
(C2) the set of MPL estimates
$\arg \max _{\boldsymbol {\theta } \in \boldsymbol {\Theta }} \ell ^{\ast}(\boldsymbol {\theta }; \boldsymbol {S}) $
is non-empty; -
(C3)
$P^{\ast}(\boldsymbol {\theta }) \leq 0$
for all
$\boldsymbol {\theta } \in \boldsymbol {\Theta }$
.



Then, for any
 $\epsilon> 0$
, there exists a
$\epsilon> 0$
, there exists a
 $\delta>0$
such that
$\delta>0$
such that
for some orthogonal
 $q \times q$
matrix
$q \times q$
matrix
 $\boldsymbol {Q}$
.
$\boldsymbol {Q}$
.
The proof of Theorem 5.1 is in Section S2.3 of the Supplementary Material. Theorem 5.1 shows that if
 $\boldsymbol {S} \to \boldsymbol {\Sigma }_0$
and
$\boldsymbol {S} \to \boldsymbol {\Sigma }_0$
and
 $n^{-1} P^{\ast}(\boldsymbol {\theta }_0) \to 0$
either in probability or almost surely, then the MPL estimates
$n^{-1} P^{\ast}(\boldsymbol {\theta }_0) \to 0$
either in probability or almost surely, then the MPL estimates
 $\boldsymbol {\Lambda }(\tilde {\boldsymbol {\theta }})$
,
$\boldsymbol {\Lambda }(\tilde {\boldsymbol {\theta }})$
,
 $\boldsymbol {\Psi }(\tilde {\boldsymbol {\theta }})$
converge to
$\boldsymbol {\Psi }(\tilde {\boldsymbol {\theta }})$
converge to
 $\boldsymbol {\Lambda }_0$
,
$\boldsymbol {\Lambda }_0$
,
 $\boldsymbol {\Psi }_0$
, respectively, in probability or almost surely, up to orthogonal rotations of
$\boldsymbol {\Psi }_0$
, respectively, in probability or almost surely, up to orthogonal rotations of
 $\boldsymbol {\Lambda }(\tilde {\boldsymbol {\theta }})$
. Note that the conditions that we require of the penalty function are mild;
$\boldsymbol {\Lambda }(\tilde {\boldsymbol {\theta }})$
. Note that the conditions that we require of the penalty function are mild;
 $P^{\ast}(\boldsymbol {\theta })$
can be deterministic or depend on the responses, as long as it is pointwise
$P^{\ast}(\boldsymbol {\theta })$
can be deterministic or depend on the responses, as long as it is pointwise
 $o_p(n)$
.
$o_p(n)$
.
5.2
$\sqrt {n}$
-consistency and asymptotic distribution

Results on the rate of consistency and the asymptotic distribution of the MPL estimator can be derived under a stronger condition on the order of the penalty than that of Theorem 5.1. In particular, we are interested in
 $\sqrt {n}$
-consistency of the MPL estimates, that is,
$\sqrt {n}$
-consistency of the MPL estimates, that is,
where
 $\tilde {\boldsymbol {\theta }}$
and
$\tilde {\boldsymbol {\theta }}$
and
 $\hat {\boldsymbol {\theta }}$
denote the MPL and ML estimates, respectively, and
$\hat {\boldsymbol {\theta }}$
denote the MPL and ML estimates, respectively, and
 $\boldsymbol {Q}_1, \boldsymbol {Q}_2$
are appropriate sequences of orthogonal rotation matrices. Under stronger identification conditions, we can also establish results on the asymptotic distribution of
$\boldsymbol {Q}_1, \boldsymbol {Q}_2$
are appropriate sequences of orthogonal rotation matrices. Under stronger identification conditions, we can also establish results on the asymptotic distribution of
 $\tilde {\boldsymbol {\theta }}$
and
$\tilde {\boldsymbol {\theta }}$
and
 $\hat {\boldsymbol {\theta }}$
.
$\hat {\boldsymbol {\theta }}$
.
Central to such results is the local identification restriction that the Jacobian of
 $\operatorname {\mathrm {vec}}(\boldsymbol {\Sigma }(\boldsymbol {\theta }))$
has full column rank at the parameter of interest
$\operatorname {\mathrm {vec}}(\boldsymbol {\Sigma }(\boldsymbol {\theta }))$
has full column rank at the parameter of interest
 $\boldsymbol {\theta }_{0}$
. If the map
$\boldsymbol {\theta }_{0}$
. If the map
 $\boldsymbol {\theta } \mapsto \operatorname {\mathrm {vec}}(\boldsymbol {\Sigma }(\boldsymbol {\theta }))$
is continuously differentiable with full column rank Jacobian at
$\boldsymbol {\theta } \mapsto \operatorname {\mathrm {vec}}(\boldsymbol {\Sigma }(\boldsymbol {\theta }))$
is continuously differentiable with full column rank Jacobian at
 $\boldsymbol {\theta }_{0}$
, then there exists an open neighborhood
$\boldsymbol {\theta }_{0}$
, then there exists an open neighborhood
 $\mathcal {U}_0$
around
$\mathcal {U}_0$
around
 $\boldsymbol {\theta }_{0}$
, such that for any
$\boldsymbol {\theta }_{0}$
, such that for any
 $\varepsilon> 0$
, there exists a
$\varepsilon> 0$
, there exists a
 $\delta> 0$
, with
$\delta> 0$
, with
for all
 $\boldsymbol {\theta } \in \mathcal {U}_0$
. This assumption ensures that the information matrix is invertible, which is required for
$\boldsymbol {\theta } \in \mathcal {U}_0$
. This assumption ensures that the information matrix is invertible, which is required for
 $\sqrt {n}$
-asymptotics. The full column rank condition N2 in Theorem 5.2 is, for example, also present in Anderson and Amemiya (Reference Anderson and Amemiya1988, Theorems 2 and 3), who establish the asymptotic normal distribution of the
$\sqrt {n}$
-asymptotics. The full column rank condition N2 in Theorem 5.2 is, for example, also present in Anderson and Amemiya (Reference Anderson and Amemiya1988, Theorems 2 and 3), who establish the asymptotic normal distribution of the
 $\sqrt {n} (\hat {\boldsymbol {\theta }} - \boldsymbol {\theta }_0)$
in factor analysis models under that and additional conditions.
$\sqrt {n} (\hat {\boldsymbol {\theta }} - \boldsymbol {\theta }_0)$
in factor analysis models under that and additional conditions.
In the unrestricted model, where
 $\boldsymbol {\Theta } = \{\boldsymbol {\theta } \in \Re ^{p(q + 1)}: \theta _m> 0, m > pq\}$
, this full rank condition does not hold due to the invariance of the variance–covariance matrix under orthogonal rotations of
$\boldsymbol {\Theta } = \{\boldsymbol {\theta } \in \Re ^{p(q + 1)}: \theta _m> 0, m > pq\}$
, this full rank condition does not hold due to the invariance of the variance–covariance matrix under orthogonal rotations of
 $\boldsymbol {\Lambda }$
. Thus, henceforth, we focus on a restricted parameter space
$\boldsymbol {\Lambda }$
. Thus, henceforth, we focus on a restricted parameter space
 $\bar {\boldsymbol {\Theta }} \subseteq \Re ^d$
with covariance mapping
$\bar {\boldsymbol {\Theta }} \subseteq \Re ^d$
with covariance mapping
 $\boldsymbol {\Sigma }(\boldsymbol {\theta }) = \boldsymbol {\Lambda }(\boldsymbol {\theta }) \boldsymbol {\Lambda }(\boldsymbol {\theta })^\top + \boldsymbol {\Psi }(\boldsymbol {\theta })$
that does not allow for a rank-deficient Jacobian. We further assume that
$\boldsymbol {\Sigma }(\boldsymbol {\theta }) = \boldsymbol {\Lambda }(\boldsymbol {\theta }) \boldsymbol {\Lambda }(\boldsymbol {\theta })^\top + \boldsymbol {\Psi }(\boldsymbol {\theta })$
that does not allow for a rank-deficient Jacobian. We further assume that
 $\bar {\boldsymbol {\Theta }}$
is contained in
$\bar {\boldsymbol {\Theta }}$
is contained in
 $\boldsymbol {\Theta }$
in the sense that for every
$\boldsymbol {\Theta }$
in the sense that for every
 $\boldsymbol {\theta } \in \boldsymbol {\Theta }$
, there exists a
$\boldsymbol {\theta } \in \boldsymbol {\Theta }$
, there exists a
 $\bar {\boldsymbol {\theta }} \in \bar {\boldsymbol {\Theta }}$
and an orthogonal rotation
$\bar {\boldsymbol {\theta }} \in \bar {\boldsymbol {\Theta }}$
and an orthogonal rotation
 $\boldsymbol Q$
, such that
$\boldsymbol Q$
, such that
 $\boldsymbol {\Lambda }(\boldsymbol {\theta })\boldsymbol {Q} = \boldsymbol {\Lambda }(\bar {\boldsymbol {\theta }})$
and
$\boldsymbol {\Lambda }(\boldsymbol {\theta })\boldsymbol {Q} = \boldsymbol {\Lambda }(\bar {\boldsymbol {\theta }})$
and
 $\boldsymbol {\Psi }(\boldsymbol {\theta }) = \boldsymbol {\Psi }(\bar {\boldsymbol {\theta }})$
. Common parameter restrictions encountered in practice, that accommodate this requirement include requiring
$\boldsymbol {\Psi }(\boldsymbol {\theta }) = \boldsymbol {\Psi }(\bar {\boldsymbol {\theta }})$
. Common parameter restrictions encountered in practice, that accommodate this requirement include requiring
 $\boldsymbol {\Lambda }$
to be upper-triangular, or requiring
$\boldsymbol {\Lambda }$
to be upper-triangular, or requiring
 $\boldsymbol {\Lambda }^\top \boldsymbol {\Psi }^{-1} \boldsymbol {\Lambda }$
to be diagonal (see, e.g., Bartholomew et al., Reference Bartholomew, Knott and Moustaki2011, Chapter 3).
$\boldsymbol {\Lambda }^\top \boldsymbol {\Psi }^{-1} \boldsymbol {\Lambda }$
to be diagonal (see, e.g., Bartholomew et al., Reference Bartholomew, Knott and Moustaki2011, Chapter 3).
Note that the parameter vector defining the matrices
 $\boldsymbol {\Lambda }_0$
and
$\boldsymbol {\Lambda }_0$
and
 $\boldsymbol {\Psi }_0$
need not itself be in
$\boldsymbol {\Psi }_0$
need not itself be in
 $\bar {\boldsymbol {\Theta }}$
. Rather, we assume that
$\bar {\boldsymbol {\Theta }}$
. Rather, we assume that
 $\bar {\boldsymbol {\Theta }}$
contains a parameter vector that corresponds to a loading matrix that can be appropriately rotated to give
$\bar {\boldsymbol {\Theta }}$
contains a parameter vector that corresponds to a loading matrix that can be appropriately rotated to give
 $\boldsymbol {\Lambda }_0$
. Unless
$\boldsymbol {\Lambda }_0$
. Unless
 $\boldsymbol {\Lambda }_0$
and
$\boldsymbol {\Lambda }_0$
and
 $\boldsymbol {\Psi }_0$
correspond to a parameter vector in
$\boldsymbol {\Psi }_0$
correspond to a parameter vector in
 $\bar {\boldsymbol {\Theta }}$
, convergence of loading matrices is therefore naturally stated after appropriate rotation.
$\bar {\boldsymbol {\Theta }}$
, convergence of loading matrices is therefore naturally stated after appropriate rotation.
Theorem 5.2. Assume that
-
(N1) there exists a
$\boldsymbol {\theta }_0 \in \bar {\boldsymbol {\Theta }}$
such that
$\boldsymbol {S} \overset {p}{\longrightarrow } \boldsymbol {\Sigma }(\boldsymbol {\theta }_0)$
as
$n \to \infty $
; -
(N2)
$\boldsymbol {\Sigma }(\boldsymbol {\theta }_{0})$
is strongly identifiable in
$\bar {\boldsymbol {\Theta }}$
and the Jacobian of
$\textrm {vec}(\boldsymbol {\Sigma }(\boldsymbol {\theta }))$
with respect to
$\boldsymbol {\theta }$
has full column rank at
$\boldsymbol {\theta }_{0}$
; -
(N3) the set of MPL estimates
$\arg \underset {\boldsymbol {\theta } \in \bar {\boldsymbol {\Theta }}}{\max } \, \{ \ell ^{\ast}(\boldsymbol {\theta }; \boldsymbol {S}) \}$
is not empty; -
(N4)
$P^{\ast}(\boldsymbol {\theta }) = c_n P(\boldsymbol {\theta })$
, where
$P(\boldsymbol {\theta })$
is nonpositive, deterministic, invariant under orthogonal rotations of
$\boldsymbol {\Lambda }$
, and continuously differentiable on
$\bar {\boldsymbol {\Theta }}$
, with
$c_n = o_p(\sqrt {n})$
positive.














Then, there exist sequences of orthogonal rotation matrices
 $\boldsymbol {Q}_1, \boldsymbol {Q}_2$
such that:
$\boldsymbol {Q}_1, \boldsymbol {Q}_2$
such that:
and
where
 $\hat {\boldsymbol {\theta }}$
and
$\hat {\boldsymbol {\theta }}$
and
 $\tilde {\boldsymbol {\theta }}$
denote two sequences of the ML and MPL estimates, respectively.
$\tilde {\boldsymbol {\theta }}$
denote two sequences of the ML and MPL estimates, respectively.
The proof of Theorem 5.2 is in Section S2.4 of the Supplementary Material. Theorem 5.2 as presented above gives conditions about the consistency of ML and MPL estimators, as well as the rate of convergence to one another. If one is interested in establishing the asymptotic distribution of the MPL estimator
 $\tilde {\boldsymbol {\theta }}$
based on the limiting distribution of the ML estimator
$\tilde {\boldsymbol {\theta }}$
based on the limiting distribution of the ML estimator
 $\hat {\boldsymbol {\theta }}$
, one can replace the strong identifiability condition on
$\hat {\boldsymbol {\theta }}$
, one can replace the strong identifiability condition on
 $\boldsymbol {\Lambda }_0, \boldsymbol {\Psi }_0$
with a more stringent point-identification condition on
$\boldsymbol {\Lambda }_0, \boldsymbol {\Psi }_0$
with a more stringent point-identification condition on
 $\boldsymbol {\theta }_0$
:
$\boldsymbol {\theta }_0$
:
-
N2*) for any
$\epsilon>0$
, there exists a
$\delta>0$
such that for all
$\boldsymbol {\theta } \in \bar {\boldsymbol {\Theta }}$
, implies that and the Jacobian of
$\textrm {vec}(\boldsymbol {\Sigma }(\boldsymbol {\theta }))$
with respect to
$\boldsymbol {\theta }$
has full column rank at
$\boldsymbol {\theta }_{0}$
.






In this instance, the conclusion of Theorem 5.2 is that
 $\tilde {\boldsymbol {\theta }} \overset {p}{\longrightarrow } \boldsymbol {\theta }_{0}$
and
$\tilde {\boldsymbol {\theta }} \overset {p}{\longrightarrow } \boldsymbol {\theta }_{0}$
and ![]() . This stronger identification condition may be required when one wishes to establish the asymptotic distribution of
. This stronger identification condition may be required when one wishes to establish the asymptotic distribution of
 $\tilde {\boldsymbol {\theta }}, \hat {\boldsymbol {\theta }}$
. Slutsky’s lemma then implies that if
$\tilde {\boldsymbol {\theta }}, \hat {\boldsymbol {\theta }}$
. Slutsky’s lemma then implies that if
 $\sqrt {n} (\hat {\boldsymbol {\theta }} - \boldsymbol {\theta }_0)$
has a normal distribution asymptotically, then
$\sqrt {n} (\hat {\boldsymbol {\theta }} - \boldsymbol {\theta }_0)$
has a normal distribution asymptotically, then
 $\sqrt {n} (\tilde {\boldsymbol {\theta }} - \boldsymbol {\theta }_0)$
with a penalty scaled as in N4 has the same asymptotic distribution.
$\sqrt {n} (\tilde {\boldsymbol {\theta }} - \boldsymbol {\theta }_0)$
with a penalty scaled as in N4 has the same asymptotic distribution.
Note that the conditions of Theorems 5.1 and 5.2 only require that the limit of the estimator of the variance–covariance matrix
 $\boldsymbol {S}$
decomposes in an exploratory factor analysis fashion, and normality of errors is not essential.
$\boldsymbol {S}$
decomposes in an exploratory factor analysis fashion, and normality of errors is not essential.
6 Maximum softly penalized likelihood
Theorem 4.1 establishes conditions on
 $P^{\ast}(\boldsymbol {\theta })$
that ensure the existence of the MPL estimates. On the other hand, Theorems 5.1 and 5.2 involve sufficient conditions on the order of the penalty
$P^{\ast}(\boldsymbol {\theta })$
that ensure the existence of the MPL estimates. On the other hand, Theorems 5.1 and 5.2 involve sufficient conditions on the order of the penalty
 $P^{\ast}(\boldsymbol {\theta })$
for the consistency of the MPL estimator. Specifically, if
$P^{\ast}(\boldsymbol {\theta })$
for the consistency of the MPL estimator. Specifically, if
 $P^{\ast}(\boldsymbol {\theta }) = o_p(\sqrt {n})$
, the respective order conditions in Theorems 5.1 and 5.2 are satisfied.
$P^{\ast}(\boldsymbol {\theta }) = o_p(\sqrt {n})$
, the respective order conditions in Theorems 5.1 and 5.2 are satisfied.
Suppose that
 $P^{\ast}(\boldsymbol {\theta }) = c_n P(\boldsymbol {\theta })$
, where the functional part
$P^{\ast}(\boldsymbol {\theta }) = c_n P(\boldsymbol {\theta })$
, where the functional part
 $P(\boldsymbol {\theta })$
satisfies the conditions of Theorem 4.1 for the existence of MPL estimates, and where
$P(\boldsymbol {\theta })$
satisfies the conditions of Theorem 4.1 for the existence of MPL estimates, and where
 $c_n> 0$
is a scaling factor. One way to derive a suitable scaling factor is to consider how information about the model parameters accumulates as n increases. For example, we can derive a principled heuristic for
$c_n> 0$
is a scaling factor. One way to derive a suitable scaling factor is to consider how information about the model parameters accumulates as n increases. For example, we can derive a principled heuristic for
 $c_n$
by considering the exploratory factor analysis model in (2.3) under independence (i.e.,
$c_n$
by considering the exploratory factor analysis model in (2.3) under independence (i.e.,
 $\boldsymbol {\Lambda }$
is a matrix of zeros). The unknown parameters are the vector of variances
$\boldsymbol {\Lambda }$
is a matrix of zeros). The unknown parameters are the vector of variances
 $\sigma _1^2, \ldots \sigma _p^2$
, and the information matrix about those parameters is a diagonal matrix with jth diagonal element
$\sigma _1^2, \ldots \sigma _p^2$
, and the information matrix about those parameters is a diagonal matrix with jth diagonal element
 $n / (2 \sigma ^4_j)$
. Standard results on the asymptotic distribution of the ML estimator give that
$n / (2 \sigma ^4_j)$
. Standard results on the asymptotic distribution of the ML estimator give that
 $\sqrt {n / 2} (s_j^2 / \sigma _j^2 - 1)$
converges in distribution to a standard normal random variable for all
$\sqrt {n / 2} (s_j^2 / \sigma _j^2 - 1)$
converges in distribution to a standard normal random variable for all
 $j \in \{1, \ldots , p\}$
. The rate of information accumulation for each coordinate is
$j \in \{1, \ldots , p\}$
. The rate of information accumulation for each coordinate is
 $\sqrt {n / 2}$
and, hence, we can choose
$\sqrt {n / 2}$
and, hence, we can choose
 $c_n = \sqrt {2 / n}$
. This choice is in line with the requirements of Theorems 5.1 and 5.2 for any exploratory factor analysis model, while ensuring that the penalization strength is asymptotically negligible. We call MSPL estimation, MPL estimation with asymptotically negligible penalties that guarantee existence and
$c_n = \sqrt {2 / n}$
. This choice is in line with the requirements of Theorems 5.1 and 5.2 for any exploratory factor analysis model, while ensuring that the penalization strength is asymptotically negligible. We call MSPL estimation, MPL estimation with asymptotically negligible penalties that guarantee existence and
 $\sqrt {n}$
-consistency. In Section 4, we showed that the conditions for the existence of the MPL estimates are satisfied for the penalties (3.2) in Akaike (Reference Akaike1987) and Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011). In particular, both penalties have the form
$\sqrt {n}$
-consistency. In Section 4, we showed that the conditions for the existence of the MPL estimates are satisfied for the penalties (3.2) in Akaike (Reference Akaike1987) and Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011). In particular, both penalties have the form
 $P^{\ast}(\boldsymbol {\theta }) = \rho n P(\boldsymbol {\theta }) / 2$
,
$P^{\ast}(\boldsymbol {\theta }) = \rho n P(\boldsymbol {\theta }) / 2$
,
 $\rho> 0$
,
$\rho> 0$
,
 $P(\boldsymbol {\theta }) \le 0,$
and
$P(\boldsymbol {\theta }) \le 0,$
and
 $P(\boldsymbol {\theta }) = O(1)$
. Both penalties can be adapted for MSPL estimation by setting
$P(\boldsymbol {\theta }) = O(1)$
. Both penalties can be adapted for MSPL estimation by setting
 $\rho = 2 \sqrt {2 / n^{3}}$
.
$\rho = 2 \sqrt {2 / n^{3}}$
.
7 Simulation studies
We conduct a series of simulation experiments to compare the performance of ML estimation, MPL estimation based on the penalties (3.2) with vanilla choices of
 $\rho $
, and MSPL estimation. The methods are compared in terms of their ability to handle Heywood cases, frequentist properties of the estimators, and selection of the number of factors when Heywood cases are present.
$\rho $
, and MSPL estimation. The methods are compared in terms of their ability to handle Heywood cases, frequentist properties of the estimators, and selection of the number of factors when Heywood cases are present.
Our simulation settings have been informed by the simulation-based results reported in Cooperman and Waller (Reference Cooperman and Waller2022). Specifically, Cooperman and Waller (Reference Cooperman and Waller2022) identified, through an extensive simulation study, the following causes of Heywood cases in order of importance: item-to-factor ratio, model specification (correct, fitting one factor less than the actual number, and fitting one extra factor than the actual number), sample size, and loading matrix pattern (low against high loadings on the same factor, and factors with all low loadings against factors with all high loadings).
We fix the number of factors to
 $q = 3$
. We then consider sample sizes
$q = 3$
. We then consider sample sizes
 $n \in \left \{50, 100, 400 \right \}$
and the item-to-factor ratios 3:1, 5:1, and 8:1, and let the loading matrix
$n \in \left \{50, 100, 400 \right \}$
and the item-to-factor ratios 3:1, 5:1, and 8:1, and let the loading matrix
 $\boldsymbol {\Lambda }$
vary across experimental settings. Specifically, for the loading matrix with item-to-factor ratio 3:1, we use the matrices in settings
$\boldsymbol {\Lambda }$
vary across experimental settings. Specifically, for the loading matrix with item-to-factor ratio 3:1, we use the matrices in settings
 $A_3$
and
$A_3$
and
 $B_3$
in Table 1, which are motivated from the settings of Cooperman and Waller (Reference Cooperman and Waller2022, Table 2). Setting
$B_3$
in Table 1, which are motivated from the settings of Cooperman and Waller (Reference Cooperman and Waller2022, Table 2). Setting
 $A_3$
decreases the factor loadings sequentially, while setting
$A_3$
decreases the factor loadings sequentially, while setting
 $B_3$
assumes two strong and one weak factor. Setting
$B_3$
assumes two strong and one weak factor. Setting
 $A_5$
for the 5:1 ratio and setting
$A_5$
for the 5:1 ratio and setting
 $A_8$
for the 8:1 ratio are defined correspondingly to
$A_8$
for the 8:1 ratio are defined correspondingly to
 $A_3$
, where we choose the nonzero column blocks to be
$A_3$
, where we choose the nonzero column blocks to be
 $(0.80, 0.65, 0.50, 0.35, 0.20)$
and
$(0.80, 0.65, 0.50, 0.35, 0.20)$
and
 $(0.80, 0.70, 0.60, 0.50, 0.40, 0.30, 0.20, 0.10)$
, respectively. For settings
$(0.80, 0.70, 0.60, 0.50, 0.40, 0.30, 0.20, 0.10)$
, respectively. For settings
 $B_5$
for the 5:1 ratio and
$B_5$
for the 5:1 ratio and
 $B_8$
for the 8:1 ratio, we simply repeat the non-zero loadings in Table 1 according to the item-to-factor ratio. The specific variances
$B_8$
for the 8:1 ratio, we simply repeat the non-zero loadings in Table 1 according to the item-to-factor ratio. The specific variances
 $\boldsymbol {\Psi }$
are set so that the diagonal elements of
$\boldsymbol {\Psi }$
are set so that the diagonal elements of
 $\boldsymbol {\Sigma } = \boldsymbol {\Lambda }\boldsymbol {\Lambda }^\top + \boldsymbol {\Psi }$
are all one.
$\boldsymbol {\Sigma } = \boldsymbol {\Lambda }\boldsymbol {\Lambda }^\top + \boldsymbol {\Psi }$
are all one.
Loading matrix settings
 $A_3$
and
$A_3$
and
 $B_3$
$B_3$

Table 1 Long description
The table has nine rows for items 1 to 9. For setting A sub 3, columns show values for each item in three positions. Items 1 to 3 have nonzero values only in the first position: 0.80, 0.65, 0.45. Items 4 to 6 have nonzero values only in the second position: 0.80, 0.65, 0.45. Items 7 to 9 have nonzero values only in the third position: 0.80, 0.65, 0.45. For setting B sub 3, items 1 to 3 have 0.80 in the first position, items 4 to 6 have 0.80 in the second position, and items 7 to 9 have 0.30 in the third position. All other values are zero. The structure highlights that for A sub 3, the nonzero values decrease from item 1 to 3 and 4 to 6, while for B sub 3, the first six items have 0.80 and the last three have 0.30 in the third position.
We compare the ML estimator with the MSPL estimators using appropriately scaled versions of the penalties (3.2) with
 $\rho = 2\sqrt {2 / n^{3}}$
based on the discussion in Section 6. We refer to those penalties as “Akaike[
$\rho = 2\sqrt {2 / n^{3}}$
based on the discussion in Section 6. We refer to those penalties as “Akaike[
 $n^{-1/2}$
]” and “Hirose[
$n^{-1/2}$
]” and “Hirose[
 $n^{-1/2}$
].” We also consider MPL with the non-decaying scaling
$n^{-1/2}$
].” We also consider MPL with the non-decaying scaling
 $\rho = 1$
, which was also used in Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011). We refer to those penalties as “Akaike[n]” and “Hirose[n].”
$\rho = 1$
, which was also used in Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011). We refer to those penalties as “Akaike[n]” and “Hirose[n].”
For each combination of loading matrix, sample size, and item-to-factor ratio, we draw
 $1,000$
independent samples according to the factor analysis model (2.1) and, for each sample, we compute the estimates of (3.1). The estimates are computed by first getting MPL estimates from
$1,000$
independent samples according to the factor analysis model (2.1) and, for each sample, we compute the estimates of (3.1). The estimates are computed by first getting MPL estimates from
 $100$
iterations of an EM-maximization of the penalized log-likelihood, which we then use as starting values for a Newton–Raphson optimization routine. We identify Heywood cases heuristically, when at least one of the following occurs: the estimation procedure fails, the normalized gradient
$100$
iterations of an EM-maximization of the penalized log-likelihood, which we then use as starting values for a Newton–Raphson optimization routine. We identify Heywood cases heuristically, when at least one of the following occurs: the estimation procedure fails, the normalized gradient
 $\{\nabla \nabla ^\top \ell ^{\ast}(\boldsymbol {\theta })\}^{-1} \nabla \ell ^{\ast}(\boldsymbol {\theta })$
has at least one element with absolute value greater than
$\{\nabla \nabla ^\top \ell ^{\ast}(\boldsymbol {\theta })\}^{-1} \nabla \ell ^{\ast}(\boldsymbol {\theta })$
has at least one element with absolute value greater than
 $10^{-4}$
, and at least one of the estimates of
$10^{-4}$
, and at least one of the estimates of
 $\psi _{1}, \ldots , \psi _{p}$
is less than
$\psi _{1}, \ldots , \psi _{p}$
is less than
 $10^{-4}$
.
$10^{-4}$
.
Figure 1 shows the percentage of samples that have been identified as Heywood cases. It is evident that ML estimation results in a considerable number of Heywood cases across experimental settings, while, as expected from Theorem 4.1, MPL and MSPL estimation are effective in dealing with them. The negligible fraction of estimates that are identified as Heywood cases for MPL and MSPL estimation are attributable to the heuristics we use for the identification of Heywood cases and can be eliminated by less stringent heuristics.
Percentage of samples (out of
 $1,000$
) that have been identified as Heywood cases for ML (“None”), MPL with Akaike[n] and Hirose[n] penalties, and MSPL with Akaike[
$1,000$
) that have been identified as Heywood cases for ML (“None”), MPL with Akaike[n] and Hirose[n] penalties, and MSPL with Akaike[
 $n^{-1/2}$
] and Hirose[
$n^{-1/2}$
] and Hirose[
 $n^{-1/2}$
] penalties,
$n^{-1/2}$
] penalties,
 $n \in \left \{50,100,400\right \}$
, and loading matrix settings
$n \in \left \{50,100,400\right \}$
, and loading matrix settings
 $A_3$
,
$A_3$
,
 $B_3$
,
$B_3$
,
 $A_5$
,
$A_5$
,
 $B_5$
,
$B_5$
,
 $A_8$
, and
$A_8$
, and
 $B_8$
.
$B_8$
.

Figure 1 Long description
From left to right, each panel represents a sample size: n equals 50, n equals 100, n equals 400. The y axis shows percent Heywood cases, ranging from 0 to 80. The x axis lists settings A sub 3, A sub 5, A sub 8, B sub 3, B sub 5, B sub 8. For each setting, five colored bars represent None (dark purple), Akaike open bracket n close bracket (blue), Hirose open bracket n close bracket (teal), Akaike open bracket n to the negative one half power close bracket (green), Hirose open bracket n to the negative one half power close bracket (yellow). Across all panels, the None penalty consistently yields the highest Heywood case percentages, often above 75 percent for A sub 3 and B sub 3. Penalties with Akaike and Hirose, especially with n to the negative one half power, show much lower percentages, typically below 10 percent. As n increases, the frequency of Heywood cases decreases for all penalty types, with the lowest values observed at n equals 400. The legend at the top identifies each penalty type by color.
We evaluate the finite-sample performance of ML, MPL, and MSPL estimators in terms of bias, probability of underestimation, and root mean-squared error (RMSE), estimated excluding the samples that have been identified as Heywood cases.
Figure 2 shows violin plots of coordinatewise estimates of the logarithm of the absolute bias, the logarithm of the RMSE, and the probability of underestimation of the unique elements of
 $\boldsymbol {\Lambda }\boldsymbol {\Lambda }^\top $
, for each estimator,
$\boldsymbol {\Lambda }\boldsymbol {\Lambda }^\top $
, for each estimator,
 $n \in \left \{50, 100, 400\right \}$
, and loading matrix settings
$n \in \left \{50, 100, 400\right \}$
, and loading matrix settings
 $A_3$
and
$A_3$
and
 $B_3$
. A black dot indicates the average over all coordinates in each specification. The MSPL estimates, with soft scaling of order
$B_3$
. A black dot indicates the average over all coordinates in each specification. The MSPL estimates, with soft scaling of order
 $n^{-1/2}$
, exhibit the smallest or close to the smallest bias across all methods and a rate of decay that is in line with Theorem 5.2. Notably, the Akaike[n] and Hirose[n] penalized estimators exhibit large finite sample bias. We also see that the MSPL estimators are well calibrated, with a probability of underestimation close to
$n^{-1/2}$
, exhibit the smallest or close to the smallest bias across all methods and a rate of decay that is in line with Theorem 5.2. Notably, the Akaike[n] and Hirose[n] penalized estimators exhibit large finite sample bias. We also see that the MSPL estimators are well calibrated, with a probability of underestimation close to
 $1/2$
across all settings. In contrast, the Akaike[n] and Hirose[n] estimators consistently underestimate the elements of
$1/2$
across all settings. In contrast, the Akaike[n] and Hirose[n] estimators consistently underestimate the elements of
 $\boldsymbol {\Lambda } \boldsymbol {\Lambda }^\top $
. This underestimation is expected from the excessive penalization that results from using a scaling factor of order n. Similarly to bias, the RMSE of the MSPL estimates is the lowest or close to the minimal RMSE across all methods. The coordinatewise estimates of the logarithm of absolute bias, the logarithm of RMSE, and probability of underestimation for loading matrix settings
$\boldsymbol {\Lambda } \boldsymbol {\Lambda }^\top $
. This underestimation is expected from the excessive penalization that results from using a scaling factor of order n. Similarly to bias, the RMSE of the MSPL estimates is the lowest or close to the minimal RMSE across all methods. The coordinatewise estimates of the logarithm of absolute bias, the logarithm of RMSE, and probability of underestimation for loading matrix settings
 $A_5$
and
$A_5$
and
 $B_5$
, and
$B_5$
, and
 $A_8$
and
$A_8$
and
 $B_8$
are shown in Figures S1 and S2 in the Supplementary Material, respectively. The findings are the same as above for
$B_8$
are shown in Figures S1 and S2 in the Supplementary Material, respectively. The findings are the same as above for
 $A_3$
and
$A_3$
and
 $B_3$
.
$B_3$
.
Violin plots of estimates of
 $\log (|\mathrm {Bias}|)$
(top panel),
$\log (|\mathrm {Bias}|)$
(top panel),
 $\log (\mathrm {RMSE})$
(middle panel), and probability of underestimation (bottom panel) for the elements of
$\log (\mathrm {RMSE})$
(middle panel), and probability of underestimation (bottom panel) for the elements of
 $\boldsymbol {\Lambda }\boldsymbol {\Lambda }^\top $
, for each estimator,
$\boldsymbol {\Lambda }\boldsymbol {\Lambda }^\top $
, for each estimator,
 $n \in \left \{50,100,400\right \}$
, and loading matrix settings
$n \in \left \{50,100,400\right \}$
, and loading matrix settings
 $A_3$
and
$A_3$
and
 $B_3$
. The average over all elements for each setting is noted with a dot.
$B_3$
. The average over all elements for each setting is noted with a dot.

Figure 2 Long description
From top-left to bottom-right, the panels are organized by loading matrix settings A sub 3 and B sub 3. Each column corresponds to a setting, with three rows for log absolute bias, log R M S E, and probability of underestimation. The x-axis in all panels is sample size n with values 50, 100, and 400. The y-axis is log absolute bias in the top row, log R M S E in the middle row, and probability of underestimation in the bottom row. Each panel contains five colored violin plots per sample size, corresponding to estimators None (purple), Akaike open bracket n close bracket (blue), Hirose open bracket n close bracket (teal), Akaike open bracket n to the negative one half power close bracket (green), and Hirose open bracket n to the negative one half power close bracket (yellow), as indicated in the legend above. Black dots mark the average over all elements for each setting. In both settings, as n increases, log absolute bias and log R M S E decrease for all estimators. Probability of underestimation centers near 0.5 for most estimators and sample sizes, with some variation. The spread of violin plots narrows with increasing n, indicating reduced variability. The dashed line at 0.5 in the bottom panels marks the reference for probability of underestimation.
We also assess the performance of AIC and BIC selection of the number of factors based on each estimator (see Akaike, Reference Akaike1987 and Hirose et al., Reference Hirose, Kawano, Konishi and Ichikawa2011 for details on these criteria for factor models) for item-to-factor ratio 3:1 with settings
 $A_3$
and
$A_3$
and
 $B_3$
for the loading matrix, and
$B_3$
for the loading matrix, and
 $n \in \{50, 400, 1,000, 5,000\}$
. We note that when fitting models with
$n \in \{50, 400, 1,000, 5,000\}$
. We note that when fitting models with
 $q \in \{1,2\}$
, the model is misspecified and the assumptions of Theorems 5.1 and 5.2 do not apply. This design choice mirrors common practitioner behavior in factor selection and motivates our inclusion of this scenario. We fit the factor analysis model (2.1) for
$q \in \{1,2\}$
, the model is misspecified and the assumptions of Theorems 5.1 and 5.2 do not apply. This design choice mirrors common practitioner behavior in factor selection and motivates our inclusion of this scenario. We fit the factor analysis model (2.1) for
 $q \in \{1, \ldots , 5\}$
. The AIC and BIC are computed from the unpenalized log-likelihood evaluated at the ML and MSPL estimates, respectively. We use all the samples, including those that have been identified as leading to Heywood cases, for computing AIC and BIC. Figure 3 shows the percentage of times that the model with three factors was selected with AIC and BIC at each estimator and
$q \in \{1, \ldots , 5\}$
. The AIC and BIC are computed from the unpenalized log-likelihood evaluated at the ML and MSPL estimates, respectively. We use all the samples, including those that have been identified as leading to Heywood cases, for computing AIC and BIC. Figure 3 shows the percentage of times that the model with three factors was selected with AIC and BIC at each estimator and
 $n \in \left \{50, 400, 1,000, 5,000\right \}$
. We note that AIC- and BIC-based model selection performs as expected with the MSPL estimators with Akaike[
$n \in \left \{50, 400, 1,000, 5,000\right \}$
. We note that AIC- and BIC-based model selection performs as expected with the MSPL estimators with Akaike[
 $n^{-1/2}$
] and Hirose[
$n^{-1/2}$
] and Hirose[
 $n^{-1/2}$
] penalties. BIC-based model selection selects the correct model with increasing probability as n increases, which is the result of the consistency of BIC-based model selection (see, e.g., Claeskens & Hjort, Reference Claeskens and Hjort2008, Chapter 4). For
$n^{-1/2}$
] penalties. BIC-based model selection selects the correct model with increasing probability as n increases, which is the result of the consistency of BIC-based model selection (see, e.g., Claeskens & Hjort, Reference Claeskens and Hjort2008, Chapter 4). For
 $n = 50$
, model selection based on MSPL estimators is also found to outperform that based on the ML estimator, most probably due to the strong handling of Heywood cases, even in small samples. On the other hand, the MPL estimators with Akaike[n] and Hirose[n] penalties result in poor performance in both AIC- and BIC-based model selection, mainly due to the strength of the penalty.
$n = 50$
, model selection based on MSPL estimators is also found to outperform that based on the ML estimator, most probably due to the strong handling of Heywood cases, even in small samples. On the other hand, the MPL estimators with Akaike[n] and Hirose[n] penalties result in poor performance in both AIC- and BIC-based model selection, mainly due to the strength of the penalty.
Percentage of times the model with
 $three$
factors is selected for each estimator,
$three$
factors is selected for each estimator,
 $n \in \{50, 400, 1000, 5000 \}$
, and loading matrix settings
$n \in \{50, 400, 1000, 5000 \}$
, and loading matrix settings
 $A_3$
and
$A_3$
and
 $B_3$
, using AIC and BIC. The absence of vertical bars pertaining to the Akaike[n]- and Hirose[n]-based model selection procedures indicate that these methods have never selected the correct model.
$B_3$
, using AIC and BIC. The absence of vertical bars pertaining to the Akaike[n]- and Hirose[n]-based model selection procedures indicate that these methods have never selected the correct model.

Figure 3 Long description
From top left, the first panel shows A I C results for A sub 3. The x axis lists n values 50, 400, 1000, 5000. The y axis is percent samples from 0 to 100. For n equals 50, only the None estimator (purple) selects the correct model, at about 20 percent. For n equals 400, 1000, and 5000, Akaike open bracket n to the minus one half close bracket (green) and Hirose open bracket n to the minus one half close bracket (yellow) both reach about 75 percent, while None reaches 80 percent. Akaike open bracket n close bracket (blue) and Hirose open bracket n close bracket (teal) are absent. Top right, B I C for A sub 3: at n equals 50, all bars are near zero except None, which is about 5 percent. At n equals 400, None is about 20 percent, green and yellow are about 5 percent. For n equals 1000 and 5000, all three reach 100 percent. Bottom left, A I C for B sub 3: at n equals 50, None is about 15 percent, green and yellow about 10 percent. At n equals 400, None is about 50 percent, green and yellow about 55 percent. For n equals 1000 and 5000, all three are about 75 percent. Bottom right, B I C for B sub 3: all bars are near zero except at n equals 5000, where None, green, and yellow reach 100 percent. The legend above identifies colors for None (purple), Akaike open bracket n close bracket (blue), Hirose open bracket n close bracket (teal), Akaike open bracket n to the minus one half close bracket (green), and Hirose open bracket n to the minus one half close bracket (yellow).
For
 $n < 5,000$
, we observe the poor performance of BIC in selecting the correct number of factors in setting
$n < 5,000$
, we observe the poor performance of BIC in selecting the correct number of factors in setting
 $B_3$
across all estimators which we attribute to the two strong and one extremely weak factor (see Table 1). As Table 2 shows, BIC identifies the two strong factors in the majority of cases for small n, and starts identifying the weak factor more frequently slowly as n increases with ML or MSPL estimators.
$B_3$
across all estimators which we attribute to the two strong and one extremely weak factor (see Table 1). As Table 2 shows, BIC identifies the two strong factors in the majority of cases for small n, and starts identifying the weak factor more frequently slowly as n increases with ML or MSPL estimators.
Percentage of times each number of factors has been selected using minimum BIC, for ML and MSPL with Akaike[n], Hirose[n], Akaike[
 $n^{-1/2}$
], and Hirose[
$n^{-1/2}$
], and Hirose[
 $n^{-1/2}$
] penalties, under loading matrix setting
$n^{-1/2}$
] penalties, under loading matrix setting
 $B_3$
and
$B_3$
and
 $n \in \left \{50,400, 1000, 5000\right \}$
$n \in \left \{50,400, 1000, 5000\right \}$

Table 2 Long description
Starting from the top, the table is organized by sample size n in four blocks 50, 400, 1,000, and 5,000. Within each block, rows correspond to factor numbers q from 1 to 4. Columns list penalty methods None, Akaike n, Hirose n, Akaike n to the negative one half, and Hirose n to the negative one half. For n equals 50, None selects q equals 2 in 92.6 percent, Akaike n and Hirose n select q equals 1 in 100 percent, Akaike n to the negative one half and Hirose n to the negative one half select q equals 2 in 98.2 percent. For n equals 400, None selects q equals 2 in 99.5 percent, Akaike n in 95.3 percent, Hirose n in 34.9 percent, Akaike n to the negative one half and Hirose n to the negative one half in 99.5 percent. For n equals 1,000, None selects q equals 2 in 95.2 percent, Akaike n and Hirose n in 100 percent, Akaike n to the negative one half in 95.3 percent, Hirose n to the negative one half in 95.4 percent. For n equals 5,000, None selects q equals 3 in 100 percent, Akaike n and Hirose n select q equals 2 in 100 percent, Akaike n to the negative one half and Hirose n to the negative one half select q equals 3 in 100 percent. Across all n, selection is concentrated on q equals 2 or 3 depending on method and sample size, with Akaike n and Hirose n favoring lower q as n increases.
8 Real data examples
We estimate the factor model (2.1) using ML, and MSPL using the Akaike[
 $n^{-1/2}$
] and Hirose[
$n^{-1/2}$
] and Hirose[
 $n^{-1/2}$
] penalties for three data sets, where Heywood cases have been encountered in published work. The data sets are i) the Davis data (Rao, Reference Rao1955), which involve
$n^{-1/2}$
] penalties for three data sets, where Heywood cases have been encountered in published work. The data sets are i) the Davis data (Rao, Reference Rao1955), which involve
 $n = 421$
observations and
$n = 421$
observations and
 $p = 9$
items, ii) the Emmett data (Emmett, Reference Emmett1949; Lawley & Maxwell, Reference Lawley and Maxwell1971), which involve
$p = 9$
items, ii) the Emmett data (Emmett, Reference Emmett1949; Lawley & Maxwell, Reference Lawley and Maxwell1971), which involve
 $n = 211$
observations and
$n = 211$
observations and
 $p = 9$
items, and iii) the Maxwell data (Maxwell, Reference Maxwell1961, and Lawley & Maxwell, Reference Lawley and Maxwell1971, p. 44), which involve
$p = 9$
items, and iii) the Maxwell data (Maxwell, Reference Maxwell1961, and Lawley & Maxwell, Reference Lawley and Maxwell1971, p. 44), which involve
 $n = 810$
observations and
$n = 810$
observations and
 $p = 10$
items. Heywood cases result in the ML estimates of the factor model (2.1) with
$p = 10$
items. Heywood cases result in the ML estimates of the factor model (2.1) with
 $q = 2$
for the Davis data,
$q = 2$
for the Davis data,
 $q = 5$
for the Emmett data, and
$q = 5$
for the Emmett data, and
 $q = 4$
for the Maxwell data. The three data sets have also been analyzed in Akaike (Reference Akaike1987).
$q = 4$
for the Maxwell data. The three data sets have also been analyzed in Akaike (Reference Akaike1987).
Table 3 gives the estimates of the communalities
 $\sum _{k = 1}^q \lambda _{jk}^2 (j = 1, \ldots , p)$
using ML, and MSPL with Akaike
$\sum _{k = 1}^q \lambda _{jk}^2 (j = 1, \ldots , p)$
using ML, and MSPL with Akaike
 $[n^{-1/2}]$
and Hirose
$[n^{-1/2}]$
and Hirose
 $[n^{-1/2}]$
penalties, across different number of factors, along with the corresponding AIC and BIC values. As expected, ML estimation can lead to Heywood cases, which manifest as atypically large estimated communalities. In contrast, and as expected, there are no Heywood cases when MSPL estimation is used, and communality estimates are reasonable with no substantial impact on AIC and BIC values. Specifically, in the Davis data set, item
$[n^{-1/2}]$
penalties, across different number of factors, along with the corresponding AIC and BIC values. As expected, ML estimation can lead to Heywood cases, which manifest as atypically large estimated communalities. In contrast, and as expected, there are no Heywood cases when MSPL estimation is used, and communality estimates are reasonable with no substantial impact on AIC and BIC values. Specifically, in the Davis data set, item
 $1$
has an atypically large communality ML estimate for
$1$
has an atypically large communality ML estimate for
 $q = 2$
, while the MSPL estimates are all within reasonable ranges. MSPL estimation also resolves the Heywood cases that result in atypically large ML communality estimates for the Emmett data for
$q = 2$
, while the MSPL estimates are all within reasonable ranges. MSPL estimation also resolves the Heywood cases that result in atypically large ML communality estimates for the Emmett data for
 $q = 4$
and
$q = 4$
and
 $q = 5$
, and the Maxwell data for
$q = 5$
, and the Maxwell data for
 $q = 4$
. Tables S1–S3 in the Supplementary Material show the estimates of
$q = 4$
. Tables S1–S3 in the Supplementary Material show the estimates of
 $\boldsymbol {\Psi }$
and
$\boldsymbol {\Psi }$
and
 $\boldsymbol {\Lambda }$
for the Emmett data, for
$\boldsymbol {\Lambda }$
for the Emmett data, for
 $q \in \{1, \ldots , 5\}$
. As is apparent, the large ML estimated communalities for
$q \in \{1, \ldots , 5\}$
. As is apparent, the large ML estimated communalities for
 $q = 4$
and item 3, and
$q = 4$
and item 3, and
 $q = 5$
and item 4, correspond to negative ML variance estimates for those items. In contrast, and as expected all MSPL variance estimates are positive. Notably, due to soft penalization, the ML and MSPL estimates that do not correspond to Heywood cases are similar.
$q = 5$
and item 4, correspond to negative ML variance estimates for those items. In contrast, and as expected all MSPL variance estimates are positive. Notably, due to soft penalization, the ML and MSPL estimates that do not correspond to Heywood cases are similar.
Estimated communalities (
 $\times 10^3$
) for the Davis, Emmett, and Maxwell data, using ML, and MSPL with Akaike[
$\times 10^3$
) for the Davis, Emmett, and Maxwell data, using ML, and MSPL with Akaike[
 $n^{-1/2}$
] and Hirose[
$n^{-1/2}$
] and Hirose[
 $n^{-1/2}$
] penalties, for
$n^{-1/2}$
] penalties, for
 $q \in \{1, \ldots , 5\}$
, with AIC and BIC values
$q \in \{1, \ldots , 5\}$
, with AIC and BIC values

Table 3 Long description
The table is divided into three main sections: Davis data, Emmett data, and Maxwell data. Each section contains rows for three estimation methods: ML, Akaike with n to the minus one half penalty, and Hirose with n to the minus one half penalty. For each method, results are shown for q values from 1 to 5. Columns 3 to 12 list estimated communalities for items 1 to 10, scaled by 10 to the 3 power. The final two columns report AIC and BIC values. In the Davis data, for ML with q equals 2, item 1 shows a Heywood case with a value of 14,145. In Emmett data, ML with q equals 4, item 3 is a Heywood case at 14,307, and with q equals 5, item 4 is 8,877. In Maxwell data, ML with q equals 4, item 8 is a Heywood case at 27,024. Heywood cases are indicated in bold. For each method and q, AIC and BIC values are provided, showing model fit. Communality estimates and fit indices vary across methods and datasets, with Heywood cases marking problematic estimates.
Note: Heywood cases are shown in bold.
9 Concluding remarks
In this article, we introduced a novel MSPL framework for factor analysis models to address improper solutions known as Heywood cases that frequently occur in statistical practice. Heywood cases can lead to unstable and inconclusive results related to factor loading estimates and factor scores, as well as inaccurate inferences and model selection. Our approach provides a comprehensive blueprint for constructing penalties and scaling factors that ensure the existence of estimators within the admissible parameter space and avoid the proposed ad hoc solutions in the literature. Our work focuses on exploratory factor analysis, but the proposed estimator can also be applied in a confirmatory factor analysis setting by enforcing additional constraints that practitioners might wish to impose on the model (e.g., zero loadings, equal error variances, etc.).
We provide sufficient conditions for the existence of the MPL estimator in factor analysis, together with the asymptotic properties of consistency and asymptotic normality of the MPL estimators. Additionally, we derive decay rates for the scaling of the penalty function to ensure consistency and asymptotic normality of the MSPL estimators, thus preserving the favorable asymptotic properties expected by the ML estimator. Through extensive simulation studies, we compared MSPL with appropriately scaled versions of the penalties proposed by Hirose et al. (Reference Hirose, Kawano, Konishi and Ichikawa2011), which are derived from Bayesian considerations and thus lack soft penalization by default. The MSPL estimators are found to recover the performance expected from ML theory while resolving the issues related to Heywood cases, across various model specifications, sample sizes, and item-to-factor ratios, making them a valuable tool for practical applications in exploratory and potentially confirmatory factor analysis. Our findings further reveal that naive penalties not only can undermine frequentist properties, in terms of higher bias, RMSE, and probability of underestimation, but can also have a deteriorating effect on the performance of model selection procedures. Our framework enables hypothesis testing by ensuring the existence of interior estimates in finite samples, even when the ML estimator may fail to exist, while preserving standard ML asymptotic behavior.
A limitation of our results is that they assume the probability limit of the sample covariance lies within the exploratory factor analysis model class; extending the theory to a least-false interpretation under covariance misspecification, in the spirit of White (Reference White1982), is a natural and important direction for future work. Further research directions include exploring alternative penalty functions, within the MSPL framework, for the factor analysis model (2.1) and for related models such as logistic factor analysis (see Bartholomew et al., Reference Bartholomew, Knott and Moustaki2011, Chapter 4). For example, in the logistic model, steep item characteristic curves lead to infinite estimates of the loadings (see, e.g., Wang & Yotebieng, Reference Wang and Yotebieng2023 for a discussion of Heywood cases in item response models for binary data). MSPL can be readily extended to handle those cases, too.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/psy.2026.10092.
Data availability statement
The supplementary material is also available at https://github.com/psterzinger/FAPL, and consists of the three folders “code,” “results,” “figures,” and the Supplementary Material. The latter provides the proofs to our results and evidence from additional simulation studies and numerical examples to those presented in the main text. The “code” directory contains scripts to reproduce the numerical analyses, simulations, graphics, and tables in the main text and the Supplementary Material. The “results” and “figures” directories provide all results and figures from the numerical experiments and analyses in the main text and the Supplementary Material, respectively.
Author contributions
All authors contributed equally to this work.
Funding statement
This research received no specific grant funding from any funding agency, commercial, or not-for-profit sectors.
Competing interests
The authors declare none.
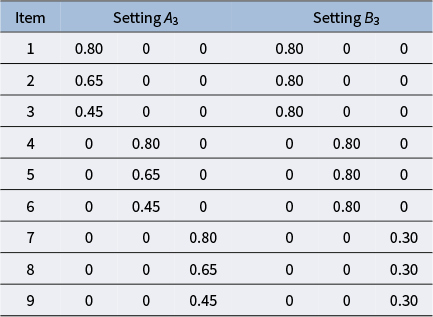


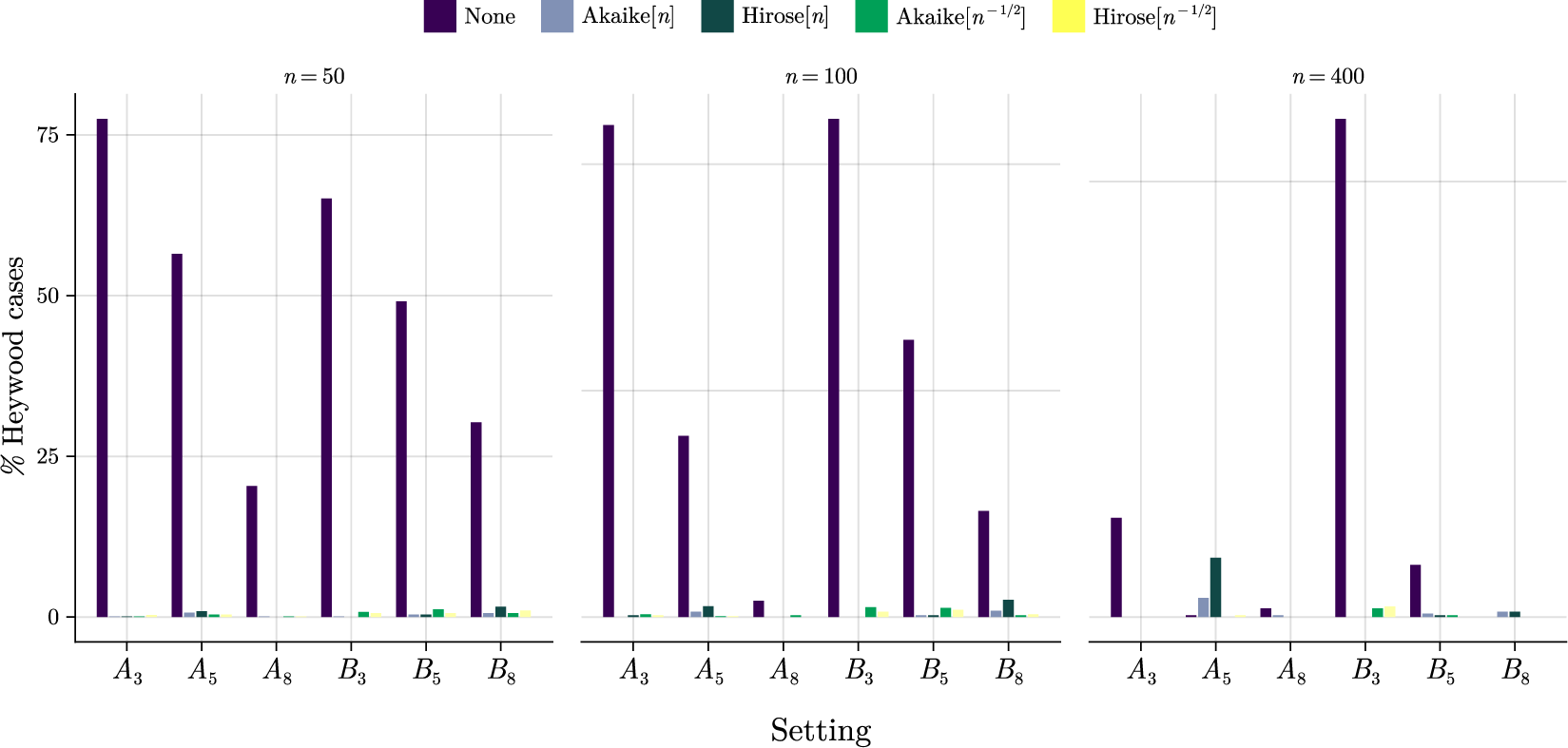










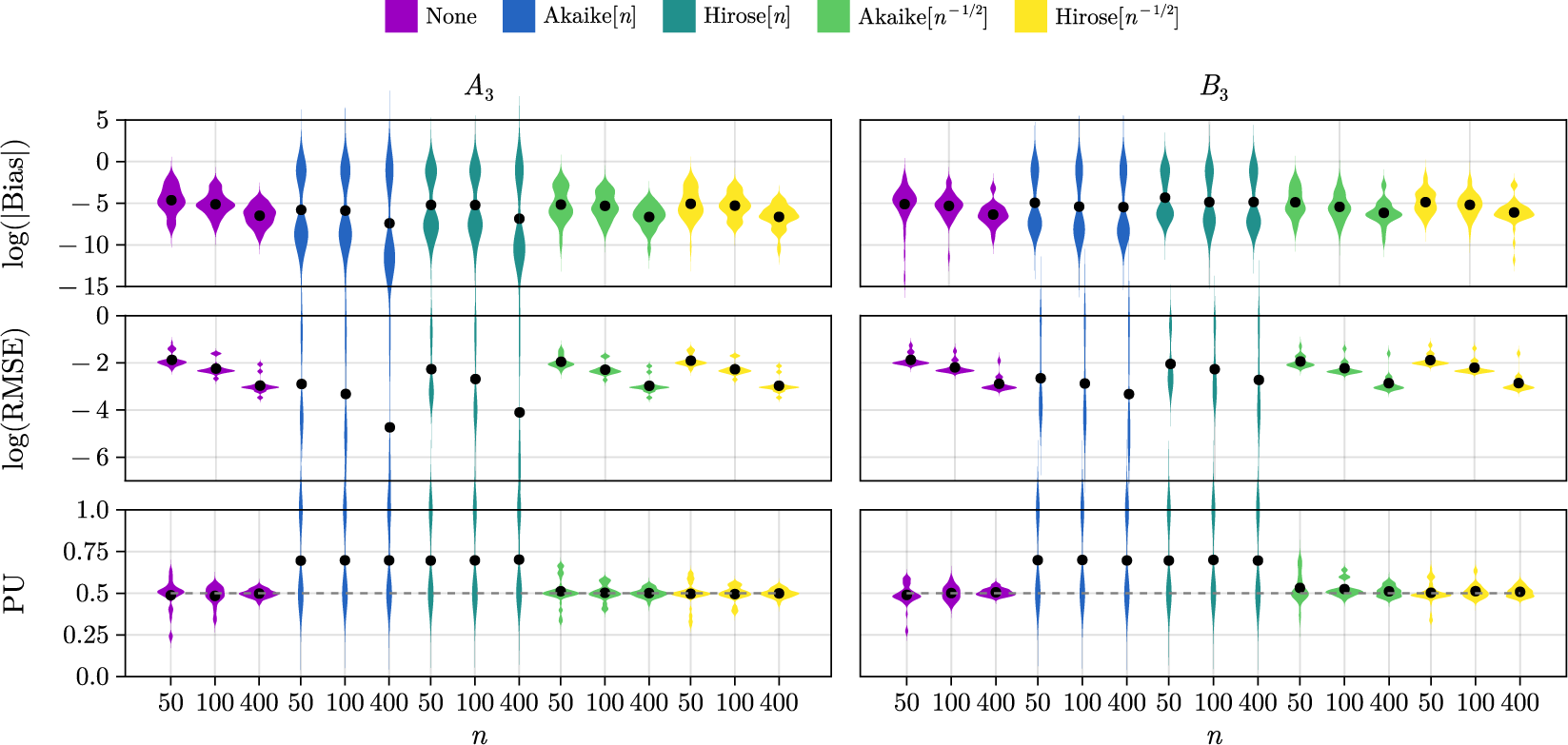






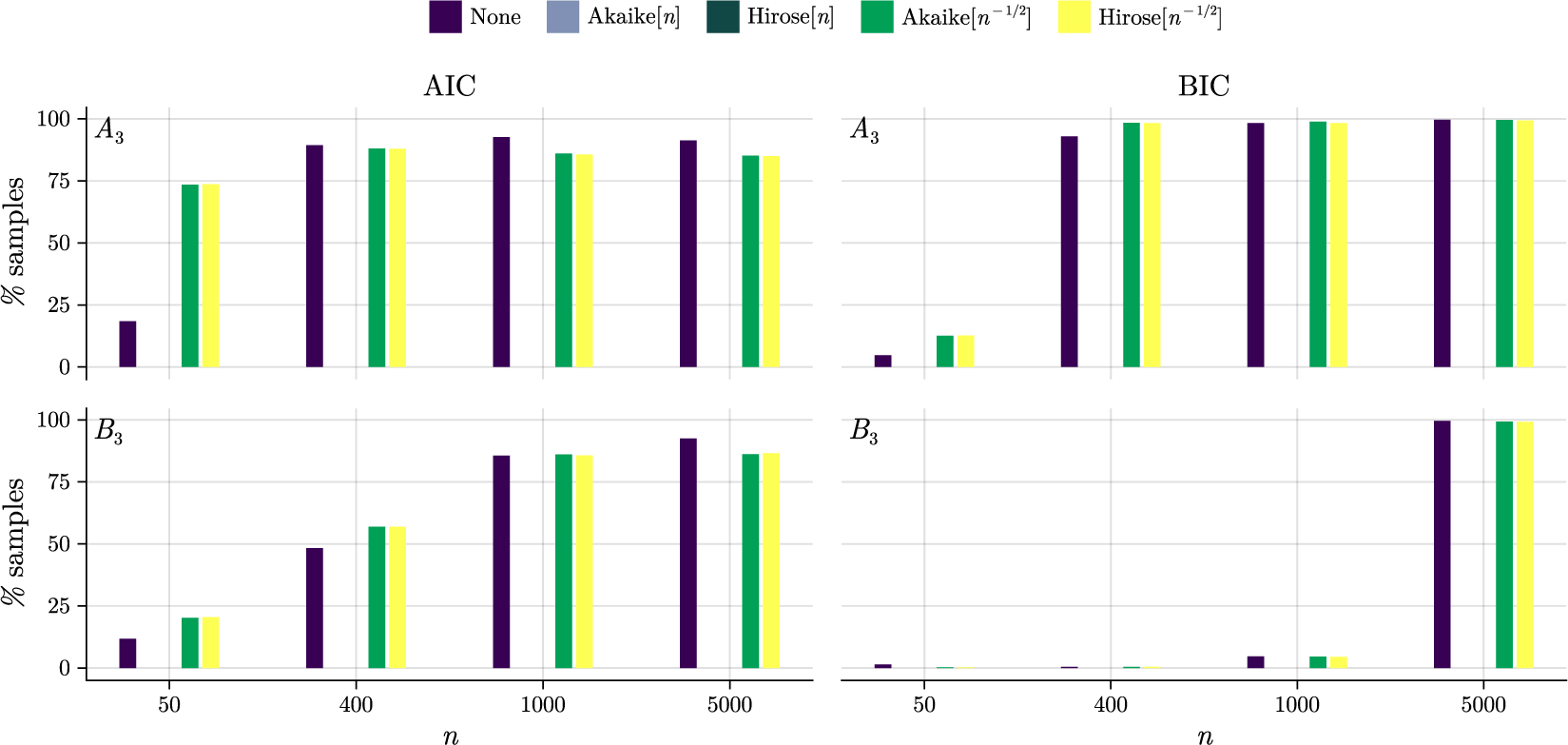




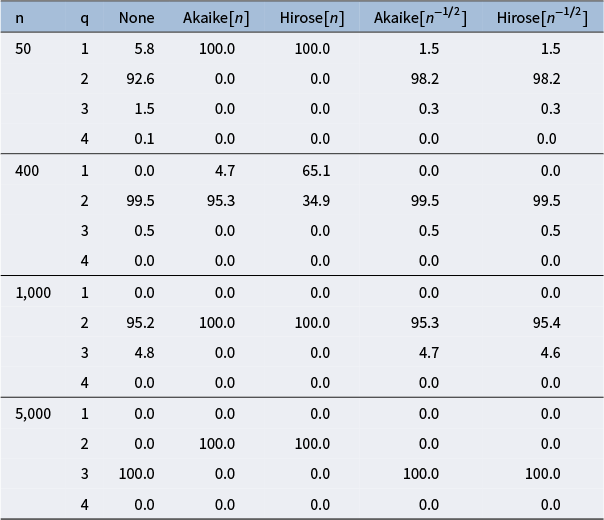




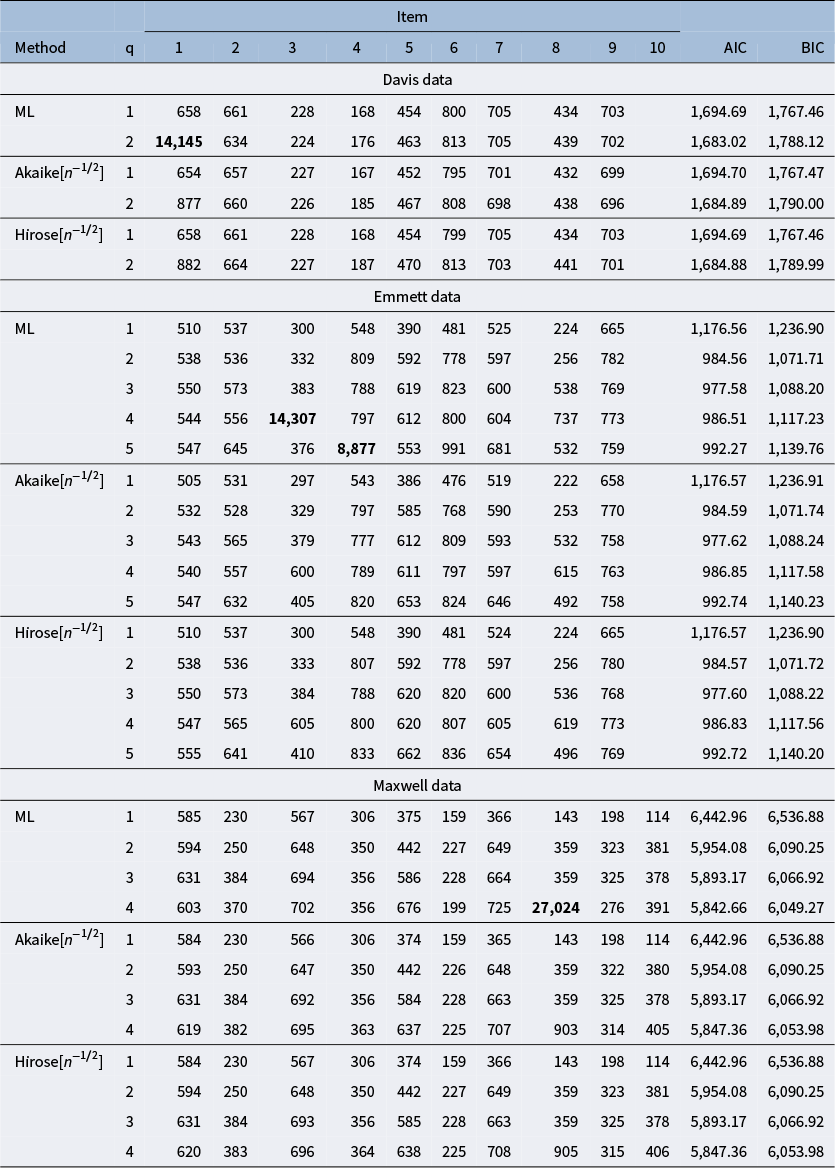







 Open access
Open access