


Introduction
Research on second language (L2) practice has shown that practice conditions significantly affect L2 learning. In a seminal paper, Suzuki et al. (Reference Suzuki, Nakata and Dekeyser2019) connected the desirable difficulties framework from cognitive psychology (Bjork, Reference Bjork, Metcalfe and Shimamura1994) to L2 learning, claiming that optimal L2 practice should consider potential sources of L2 learning difficulty. In addition to the linguistic difficulty of the target feature and learner-related factors, the authors acknowledge that the conditions under which L2 learning occurs are a potential source of difficulty. Some conditions that affect the degree of difficulty during the learning process include the contexts in which the target L2 items appear, as well as the spacing between learning episodes. While some degree of difficulty is desirable for L2 learning, difficulties coming from multiple sources might hinder learning (Serfaty & Serrano, Reference Serfaty and Serrano2022; Suzuki, Reference Suzuki and Suzuki2024; Suzuki et al., Reference Suzuki, Nakata and Dekeyser2019).
Research in cognitive psychology has demonstrated that distributed repetitions benefit learning and retention more than massed (or consecutive) practice, a phenomenon which is referred to as the spacing effect. Various theories attempt to explain this effect, most of which suggest that processing is more difficult when repetitions are spaced, as previous presentations are not as readily accessible and cannot be easily retrieved from memory. This increased difficulty in the processing of information during learning leads to stronger memory representations, making spacing a “desirable difficulty” (Murphy et al., Reference Murphy, Bjork and Bjork2023; Suzuki et al., Reference Suzuki, Nakata and Dekeyser2019).
Suzuki (Reference Suzuki and Suzuki2024) and Suzuki et al. (Reference Suzuki, Nakata and Dekeyser2019) claim that not only spacing but also increased variation in L2 practice conditions add difficulty to the learning process. When repetitions are exact, the learners do the same activity multiple times, for instance, practicing oral skills by speaking about one topic three times as opposed to speaking about three different topics. Although some studies have found that “same” repetitions lead to greater L2 gains (de Jong & Perfetti, Reference de Jong and Perfetti2011), others have highlighted the positive effect of variable practice (Jones et al., Reference Jones, Dye, Johns and Ross2017). Therefore, more research is needed to examine the impact of variation in repeated L2 practice conditions. In the cognitive psychology literature, some findings suggest that the positive effect of spacing is more pronounced when there are no contextual changes during practice (e.g., Bercovitz et al., Reference Bercovitz, Bell, Simone and Wiseheart2017), further emphasizing the need for research in SLA on the role of context in L2 learning under different practice schedules.
Crucially, beyond examining learning outcomes on L2 tests, more research is needed that includes processing measures to obtain objective indications of difficulty (Suzuki et al., Reference Suzuki, Nakata and Dekeyser2019). There is evidence that when learners experience difficulties in processing the input, for instance, because it involves an unknown word, an increased number of eye fixations and longer fixation durations are typical (see Elgort & Beyersmann, Reference Elgort and Beyersmann2024 for a discussion). Therefore, eye-tracking is a promising technique to investigate potential difficulties in processing when L2 practice involves different spacing and contextual conditions.
The aim of the present study is to further examine the role of spacing by comparing massed versus spaced repetitions in conditions involving identical versus varied contexts in vocabulary learning through reading of full texts. This research represents a unique contribution to studies on optimal L2 practice conditions, as it combines both spacing and context diversity. To our knowledge, these factors have not been analyzed together in our field as potential challenges in the learning process that could lead to differing learning outcomes. Given that our primary contribution lies in advancing research on L2 practice conditions, with a focus on spacing and its interaction with contextual variability, the literature review is structured to first address research on the spacing effect, followed by work on context and spacing, and finally on repeated reading as the area in which these variables are explored in the domain of incidental vocabulary learning.
Literature review
Spacing effect in L2 vocabulary learning
Existing evidence indicates that repetition plays a pivotal role in general L2 development (DeKeyser, Reference DeKeyser2007; Suzuki, Reference Suzuki and Suzuki2024) and in vocabulary development in particular (Webb, Reference Webb2007). Acknowledging the importance of repeated encounters with unknown vocabulary has led to interest in determining the optimal interval between those repetitions, i.e., the role of spacing. Research studies in cognitive psychology have examined spacing through different perspectives: some have focused on spaced versus massed practice (i.e., the spacing effect), whereas others have examined different degrees of spacing in spaced practice by comparing shorter versus longer lags (i.e., the lag effect) (Toppino & Gerbier, Reference Toppino, Gerbier and Ross2014).
Although most research on spacing in SLA has focused on vocabulary learning, a small but growing body of work investigates its role in other areas of L2 development, with most studies examining the lag effect rather than the spacing effect. The meta-analysis by Kim and Webb (Reference Kim and Webb2022), which included both spacing and lag effects, found that longer spacing generally benefited L2 learning, although the benefit was more robust for vocabulary than for other areas, such as grammar and pronunciation.
In L2 vocabulary learning, studies comparing massed and spaced repetitions have typically focused on inter-stimulus spacing within a single session, showing benefits of spaced repetitions for intentional paired-associate learning, consistent with findings in cognitive psychology (Koval, Reference Koval2022; Nakata, Reference Nakata2015; see Serrano, Reference Serrano2022, for a review).
Single-session experiments have also examined the spacing effect in contextual word learning, where target words appear in different sentences rather than as repeated paired associates. Koval (Reference Koval2019) examined the learning of 40 Finnish words, each of which was inserted in four different English sentences. The study also used eye-tracking to examine processing under the two differently spaced conditions. Her results showed that massed items received fewer fixations and were learned less successfully than spaced repetitions, in line with the deficient processing hypothesis of the spacing effect (Cuddy & Jacoby, Reference Cuddy and Jacoby1982).
In conclusion, existing evidence suggests that spaced practice benefits L2 learning, particularly intentional vocabulary learning in single-session experiments. When new words are repeated consecutively, learning tends to be less successful than when other items intervene between repetitions. However, it remains unclear whether similar benefits occur when spacing is examined across multiple sessions with delays of several days, rather than just intervening items, and when learning is incidental and takes place within the context of reading.
Contextual variability and spacing
As Suzuki (Reference Suzuki and Suzuki2024) notes, there is limited research comparing varied versus consistent L2 practice in L2 learning, with the former often considered a more challenging practice condition. Furthermore, within the SLA literature, there is a lack of previous research investigating how context variability might influence the spacing effect, which is one of the primary objectives of the present study. In cognitive psychology, however, there are some studies examining the role of environmental/external context (room, background presentation) that offer interesting insights.
In two different one-session experiments, Verkoeijen et al. (Reference Verkoeijen, Rikers and Schmidt2004) presented Dutch L1 speakers with a list of words in their native language. The authors examined (1) the role of context by comparing same and different, operationalized as word presentation background color or design; and (2) spacing of repetitions (massed vs. spaced) on the free recall of the target words. The authors found a significant spacing effect, a non-significant effect of context, and an interesting interaction between context and spacing, in which context variability benefitted massed presentations but was detrimental for spaced repetitions.
Verkoeijen et al. (Reference Verkoeijen, Rikers and Schmidt2004) interpret their findings through two accounts of the spacing effect: contextual variability (Melton, Reference Melton1970) and study-phase retrieval (Greene, Reference Greene1989). The former attributes the effect to diverse contextual cues enhancing retrieval, while the latter emphasizes the importance of successful retrieval of prior presentations, which excessive spacing can hinder. Verkoeijen et al. (Reference Verkoeijen, Rikers and Schmidt2004) argue that contextual diversity aids massed repetitions by enriching retrieval cues but complicates retrieval in spaced repetitions, making learning more challenging. Similarly, Bercovitz et al. (Reference Bercovitz, Bell, Simone and Wiseheart2017) found a spacing effect for Swahili-English word pair learning when study and practice occurred in the same room, but this effect disappeared when the context changed between sessions.
In SLA, vocabulary research has focused on the role of the linguistic context in which novel words appear—such as sentences or texts—in facilitating word learning (e.g., Webb, Reference Webb2008; Yi & DeKeyser, Reference Yi and DeKeyser2022). However, little is known about how context type and spacing conditions interact to influence vocabulary learning.
In the study by Pagan and Nation (Reference Pagán and Nation2019), context for vocabulary learning was operationalized as the number of different sentences in which the target words appeared. In one experimental session using eye-tracking technology, English L1 speakers were exposed to 42 rare words in English in two different contextual conditions: same (a single sentence repeated four times) or different (four different sentences). Additionally, the authors compared massed versus spaced distributions. The eye-tracking results showed that during the learning phase, massed and same conditions led to shorter fixations than spaced and different. The posttests involved processing of the target words in new sentences, and results showed that the two conditions that led to more effortful processing during the learning phase (spaced and different) led to more fluent performance in the testing phase.
While Pagan and Nation’s study sheds light on L1 novel word processing, its applicability to L2 learners remains uncertain. It also lacks offline vocabulary tests that could strengthen evidence of acquisition. Moreover, the study’s one-session design assesses learning only minutes after exposure. Finally, though it supports the benefits of contextual diversity in sentence-level vocabulary learning (Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008; Ferreira & Ellis, Reference Ferreira and Ellis2016), its relevance to incidental learning from longer texts is unclear.
Repeated reading
Repeated encounters with novel words are widely recognized as crucial for vocabulary acquisition, as vocabulary learning is an incremental process that often requires multiple exposures before new words are fully mastered (Webb, Reference Webb2007; Yi, Reference Yi2022; Yi & DeKeyser, Reference Yi and DeKeyser2022).
The term repeated reading is normally used to describe an approach to L1 literacy that involves reading the same short text multiple times with the aim of increasing readers’ accuracy and fluency (Samuels, Reference Samuels1979). In the L2 context, it has also been used to foster L2 reading fluency (Nation, Reference Nation2009) and as a form of deliberate L2 practice that can help establish a foundation for later communicative use (Suzuki, Reference Suzuki and Suzuki2024). Importantly, rereading the same text can also ensure repeated exposure to unfamiliar vocabulary, which has been shown to support incidental vocabulary learning (e.g., Serrano & Pellicer-Sánchez, Reference Serrano and Pellicer-Sánchez2024; Webb & Chang, Reference Webb and Chang2012).
However, while repeated reading increases exposure to unfamiliar words, it limits contextual diversity. According to Jones et al. (Reference Jones, Dye, Johns and Ross2017), more than repetition, it is contextual diversity that determines lexical organization. Following the principle of likely need, the authors claim that “the key prediction of semantic diversity is that repetition of a word in distinct documents will increase its likely need to a greater extent than an equal number of repetitions in redundant documents.” (p. 261). The authors also suggest that when words appear in contexts that are “incongruent” or different from previously encountered and stored contexts, they are more strongly encoded in memory.
On the other hand, repeated readings of the same text can also be predicted to positively impact incidental vocabulary learning if we consider the importance of content familiarity for inferring the meaning of unknown words (Johns et al., Reference Johns, Dye and Jones2016). Pulido (Reference Pulido2004; Reference Pulido2007) found that topic familiarity had a positive effect on comprehension, which in turn predicted vocabulary learning.
Liu and Todd (Reference Liu and Todd2016) compared incidental vocabulary learning from reading the same text seven times versus seven different texts in one session. Different texts showed slightly greater gains (10.59 vs. 10.34), although the advantage was statistically significant. Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2024) conducted a similar study, with fewer repetitions (three vs. seven) and shorter texts, along with eye-tracking. Their findings showed that repeated reading of the same text enhanced both online processing and vocabulary learning, challenging Liu and Todd’s conclusions.
Repeated reading is also well-suited for investigating spacing effects in incidental vocabulary learning, particularly in determining optimal repetition intervals. Findings from our previous research comparing massed and spaced repeated reading of the same text indicate little difference in learning new English words or eye fixations on these novel words between the two conditions (Serrano & Pellicer-Sánchez, Reference Serrano and Pellicer-Sánchez2024), contrasting with studies using sentence-level repetitions (Koval, Reference Koval2019; Pagan & Nation, Reference Pagán and Nation2019). However, whether these findings extend to different-text repetitions remains unclear.
In sum, the few existing studies comparing repeated reading of same texts versus different texts in a single session have yielded conflicting findings, with some studies pointing to an advantage of different texts (Liu & Todd, Reference Liu and Todd2016) and others to same-text conditions (Chandy et al., Reference Chandy, Serrano and Pellicer-Sánchez2024). While previous studies have also explored the role of spacing in the context of repeatedly reading the same text (Serrano & Pellicer-Sánchez, Reference Serrano and Pellicer-Sánchez2024), no previous research has examined the effect of spacing in different-text repetitions. Crucially, while L1 research has shown the importance of examining spacing in relation to contextual diversity (Pagan & Nation, Reference Pagán and Nation2019), similar studies in the L2 context are yet to be conducted.
To address these gaps, the present study builds on Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2024) by incorporating new data on spaced repeated reading to examine the effect of spacing in connection with contextual diversity. In both studies, the materials and target words are different from Serrano and Pellicer-Sánchez (Reference Serrano and Pellicer-Sánchez2024), with the goal of providing new evidence on the role of spacing in incidental vocabulary learning through repeated reading in various contextual conditions.
The present study
The present study addresses several gaps in the SLA literature, including the examination of the spacing effect by comparing massed practice in one day versus spaced practice over several days, and the investigation of spacing in incidental L2 vocabulary learning and processing through repeated reading. Most importantly, it contributes to an underexplored area by examining how contextual diversity may shape the effects of spacing on both learning outcomes and processing. Specifically, it compares massed (a single session) and spaced (three weekly sessions) schedules for the incidental learning of novel vocabulary when it appears in the same text read three times or in three different texts. Additionally, it examines how processing might differ across spacing and contextual conditions. The specific questions that guide this study are the following:
-
1. To what extent does spacing (massed vs. spaced schedules) and context (same vs. different texts) affect incidental vocabulary learning through reading?
-
2. Does processing of novel words, as examined through eye-tracking, change across readings when learners read the same text versus different texts under massed versus spaced conditions?
Following the desirable difficulties hypothesis, as well as prior empirical studies on sentence reading (Pagan & Nation, Reference Pagán and Nation2019; Suzuki, Reference Suzuki and Suzuki2024), we expect that the massed and same conditions would be facilitative during the learning phase, leading to less effortful processing, as evidenced through fewer and shorter eye fixations and, possibly, better short-term retention of vocabulary knowledge. More challenging conditions, such as spaced and different, might be desirably difficult during reading but might lead to better long-term retention. On the other hand, combining two sources of difficulty might lead to undesirable difficulties, and thus we expect the combination different-spaced to be the most challenging during the reading process and possibly the least conducive to learning.
Method
Design
The study used a pretest-treatment-posttest design. The treatment lasted either two or three sessions—depending on whether it was massed or spaced—and involved repeated reading of texts that included 20 novel words encountered six times. There was one between-participant factor, namely, spacing (massed vs. spaced), and one within-participant factor, which was contextual variability (same vs. different texts). The dependent variables concerned vocabulary learning gains—assessed through form and meaning recognition tests and a meaning recall test—and online processing, analyzed through eye-movement measures.
The data presented here extend the dataset reported in Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2024). While Chandy et al. ( Reference Chandy, Serrano and Pellicer-Sánchez2024) examined the effect of contextual diversity on massed repeated reading, the present study includes both massed and spaced repeated reading and investigates the interaction between spacing and contextual diversity. The instruments and materials are the same as those used in Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2024).
Participants
The participants were recruited from an English Applied Linguistics undergraduate class at a university in Spain. The students were offered course credit in exchange for their voluntary participation in the study. A total of 100 students initially signed up, but data from eight students were excluded: five were native English speakers and three had a vocabulary size of fewer than 4,000 words according to the V_YesNo test (Meara & Miralpeix, Reference Meara and Miralpeix2017), which we considered a requirement for adequate comprehension of the target texts. The V_YesNo test was used because it is less cognitively demanding and less time-consuming than other vocabulary tests. This was particularly important in our study, as participants were already engaged in several other tasks. The test has been shown to provide reliable estimates of vocabulary size (e.g., Meara & Miralpeix, Reference Meara and Miralpeix2017). The final set of participants consisted of 92 students (81 female, reflecting the typical demographic profile of English Studies students). Eye-movement data were available for 86 participants. Due to technical issues with the eye-tracker, proper calibration was not possible for some participants because of excessive glasses reflection and/or eye makeup.
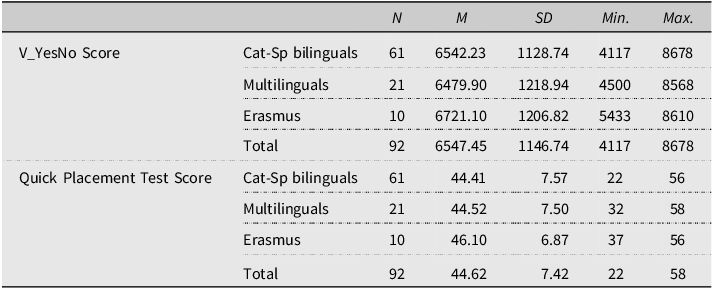
Among the 92 students, 61 were Catalan-Spanish bilinguals, 21 were also raised in Catalonia but were heritage speakers of other languages (including Urdu, Punjabi, Amazigh, Arabic, and Romanian), and 10 were exchange students from other parts of Europe (Italy, Poland, the Netherlands, and Germany) and China. Although the participants had different L1s, the L1 groups did not differ significantly in their English vocabulary size (F(2, 91) = .149, p = .862) or general proficiency (F(2, 91) = .221, p = .802), as evaluated by the Oxford Quick Placement Test, QPT (see Table 1).
Descriptive statistics V_YesNo and QPT (quick placement test) scores by L1

The 92 participants were randomly assigned to two spacing groups, with 45 in the massed condition and 47 in the spaced condition. There was no significant difference in vocabulary size between the massed (M = 6611, SD = 1170.43) and the spaced group (M = 6486.60, SD = 1132.86): t(90) = .518, p = .606. However, given that the p-value for the comparison between the massed (M = 46.11, SD = 6.30) and spaced groups (M = 43.19, SD = 8.18) on the general proficiency test approached the commonly accepted threshold for statistical significance (t(90) = 1.91, p = .059), we opted to include these scores as covariates in the analyses.
Materials
Target vocabulary
The target vocabulary included 20 pseudowords. The decision to use pseudowords was driven by the need to control for participants’ prior knowledge and, more importantly, for learning outside of the treatment—a common limitation in previous studies (e.g., Serrano & Pellicer-Sánchez, Reference Serrano and Pellicer-Sánchez2024).
The pseudowords were created using the ARC Nonword Database (Rastle, Harrington, & Coltheart, Reference Rastle, Harrington and Coltheart2002) and taken from the norming data generated by Pellicer-Sánchez et al. (Reference Pellicer-Sánchez, Siyanova-Chanturia and Parente2022). They were selected based on neighborhood size (1–5), number of body neighbors (1–5), and number of phonological neighbors (1–5). No pseudo homophones were used, and only nonwords with valid orthographic onsets and bodies, as well as legal bigrams, were selected.
As reported in Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2024), 63 pseudowords were piloted with L1 English speakers, who rated them on a six-point Likert scale (1 = unlikely, 6 = likely to be an English word) alongside 12 low-frequency real words. We selected 20 pseudowords with a mean score of at least 4. These replaced concrete, high-frequency nouns (within the first 1K-2K frequency bands). All items were 4–7 letters long, with a mean length of 5.60 for both sets. See Appendix A for the target items and their characteristics.
Reading materials
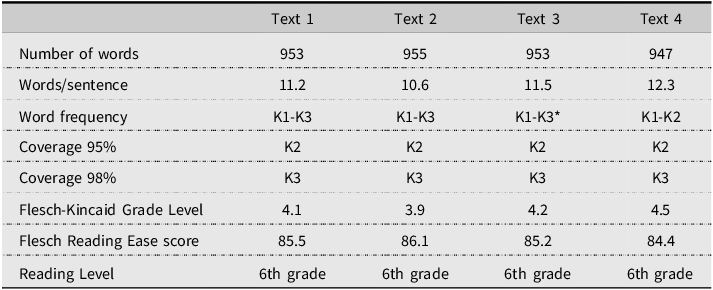
The target vocabulary was embedded in four different texts, which participants read under two conditions. Text 1, adapted from Pellicer-Sánchez (Reference Pellicer-Sánchez2016), was assigned to the same condition and read three times, following Lynn’s (Reference Lynn2021) finding that three repetitions are more effective than additional exposures. The text had 954 words, including 10 pseudowords, and was a simple narrative in the past tense, containing high-frequency vocabulary (from the first 3K word families).
Texts 2–4, also including 10 pseudowords, were read only once in the different conditions. These texts were written in a similar style to Text 1 and had similar characteristics in terms of readability, length, lexical coverage, etc. See Table 2 for details and Appendix B for the actual texts. All materials will be made available in an online repository upon publication.
Text characteristics

*There was one K5 word, jealous, which is a cognate with Catalan/Spanish gelós/celoso and was assumed to be known by the target participants.
Considering text characteristics, we can confidently conclude that the target texts did not pose comprehension difficulties for participants, which is crucial for inferring the meaning of novel words (Laufer, Reference Laufer2005). Four learners of similar characteristics also read the texts and confirmed their ease of understanding.
As explained in the previous section, we carefully selected 20 target pseudowords and assigned them to two sets (Set 1 and Set 2) for reading under the two contextual conditions (same vs. different). To control for the potential effect of the pseudowords, we used a Latin square design: half of the participants read Text 1 with Set 1 and Texts 2–4 with Set 2, while the other half read Text 1 with Set 2 and Texts 2–4 with Set 1. Each target word appeared twice in each text, resulting in six exposures overall, a frequency regarded as sufficient for incidental vocabulary learning (Rott, Reference Rott1999) and adopted in previous studies on incidental vocabulary learning through reading (e.g., Yi, Reference Yi2022; Yi & DeKeyser, Reference Yi and DeKeyser2022).
It is known that meaning inference is easier when the context in which the word appears provides clues (Webb, Reference Webb2008). In order to control for the potential effect of the immediate contexts (i.e., sentences) in which the pseudowords appeared in the target texts, a group of L1 English speakers (N = 75) were asked to evaluate the possibility of meaning inference of each target word from its immediate context by using a 4-point scale, as the approach has been successfully implemented in prior studies (Webb, Reference Webb2008). As reported in Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2024), no significant differences were found between words in the same (Text 1) and different (Texts 2–4) conditions (t(38) = .636, p = .528).
Vocabulary tests
Three vocabulary tests were used to assess participants’ vocabulary learning. The first one was a form recognition test, which included the target pseudowords as well as 20 other pseudowords with similar characteristics, also selected from the ARC Nonword Database (see Appendix C for the list). The participants were instructed to select the words they remembered from the texts.
Additionally, the students performed a meaning recall test, where they were asked to translate, define, or write anything they remembered about the target words. Finally, a multiple-choice test was also used to examine whether the learners were capable of recognizing the meaning of the target words. They had three options plus an “I don’t know” option to minimize guessing. The learners were presented with the target words in isolation and were given three meanings: one was the meaning of the target word they replaced, and the other two included meanings related to the words included in the stories where the pseudowords appeared (see Appendix D for the full tests and reliability estimates based on Cronbach’s alpha).
Procedure
All the sessions were conducted in a quiet lab, either individually or in small groups of 2–3 students. Before the first session, the participants had been informed about the general aim of the study and had completed the consent form and a short background questionnaire, including questions about their age, gender, and language-related practices.
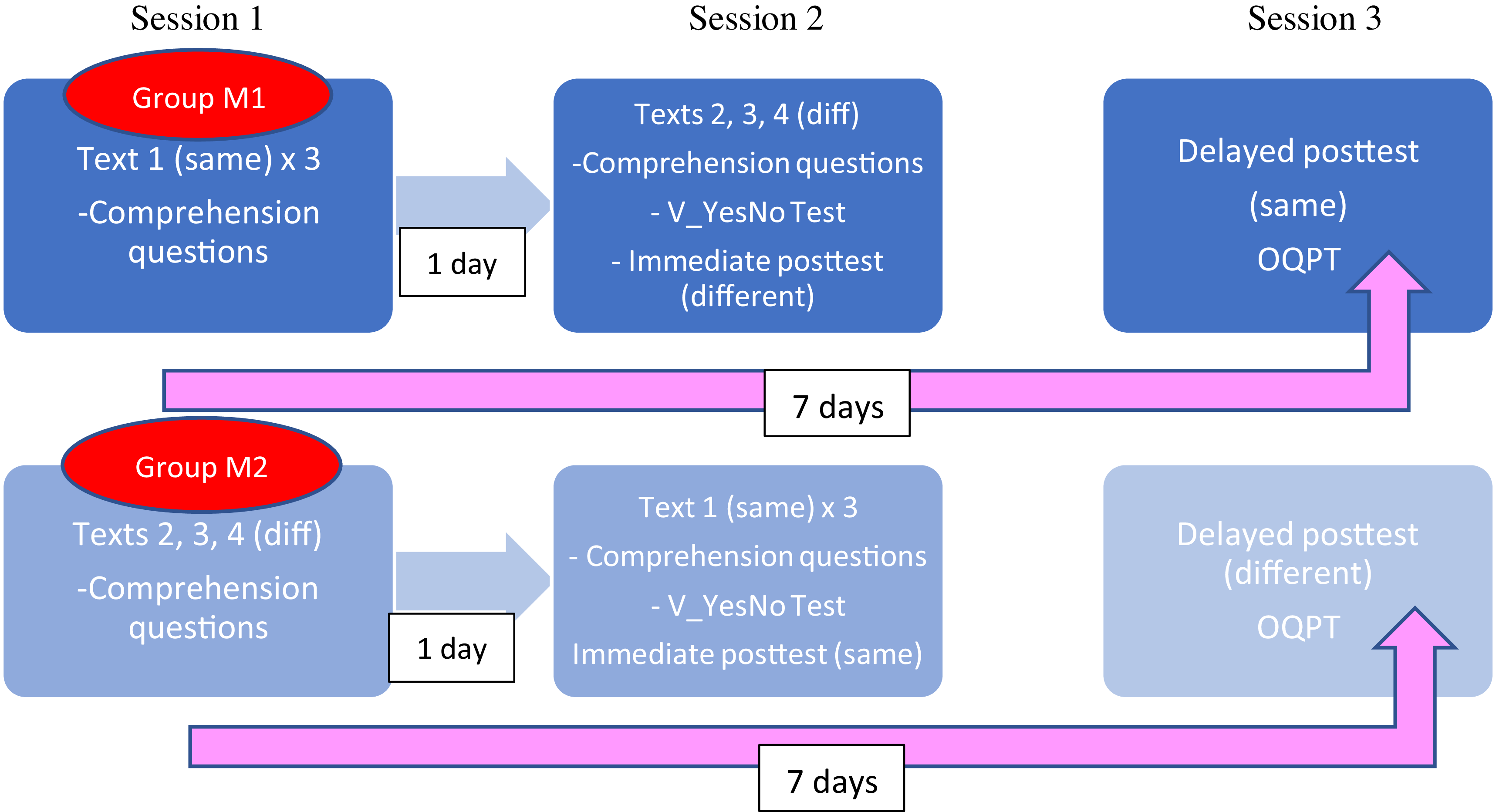
There was a total of three sessions for the massed group. The first two (spaced over one day) were devoted to repeated reading. In one session, participants read the same text (Text 1) three times, and in the other session, they read the three different texts (Texts 2–4) consecutively. Half of the participants started with the same text, and the other half with the different texts (see Figure 1). The participants were asked to read the texts for meaning in order to complete some comprehension questions related to their content. They read the texts on the desktop-based Tobii Pro Spectrum eye-tracking monitor (23.8” diagonally, 1920 x 1080 pixel resolution), sampling data at 1200 Hz. The text was presented using black Courier New font, size 18 and double spacing. Participants were seated 55–75 cm from the monitor and were instructed to avoid unnecessary head movement. Accuracy was checked before each reading using a five-point calibration, which was performed until calibration values were > 0.5º.
Procedure for the massed condition.
*OQPT = Oxford Quick Placement Test

Each text was presented over 16 different trials, corresponding to 16 paragraphs. There was an average of 63.53 words per trial. No more than two (different) target words were present on any one screen, and the target items were not placed at the beginning or end of a line or sentence. The participants controlled their own reading pace by clicking the mouse to move from one screen to the next, while being unable to go back to previous screens. On average, participants took around 4.8 minutes (SD = 1.06) to read each text.
After reading, the participants answered 16 true/false comprehension questions per text, one related to each of the paragraphs/slides. The comprehension questions were designed to tap the main ideas included in the paragraphs and were used to keep participants engaged in processing the meaning of the texts. The participants took around 5 minutes to answer these questions (see Appendix E for the questions and test reliability estimates).
In the second session, after the readings and comprehension questions, the participants performed the general vocabulary test (V_YesNo test) (around 10 mins) and the immediate vocabulary posttests of the pseudowords read that session (8–10 minutes) in the following order: form recognition, meaning recall, meaning recognition.
In session 3, one week after the first, the participants were tested on the words included in session 1 (7-day retention interval delayed posttest). This meant that participants completed an immediate test for half of the target items and a delayed test for the other half. Testing the items immediately after the first session would have alerted them about the focus of the study and would have resulted in unwanted testing effects. The design implemented allowed us to include both immediate and delayed tests while controlling for potential test effects. In this session, which took approximately 40 minutes, the participants also performed the general English proficiency test (Oxford Quick Placement test, QPT; Cronbach’s alpha = 0.86).
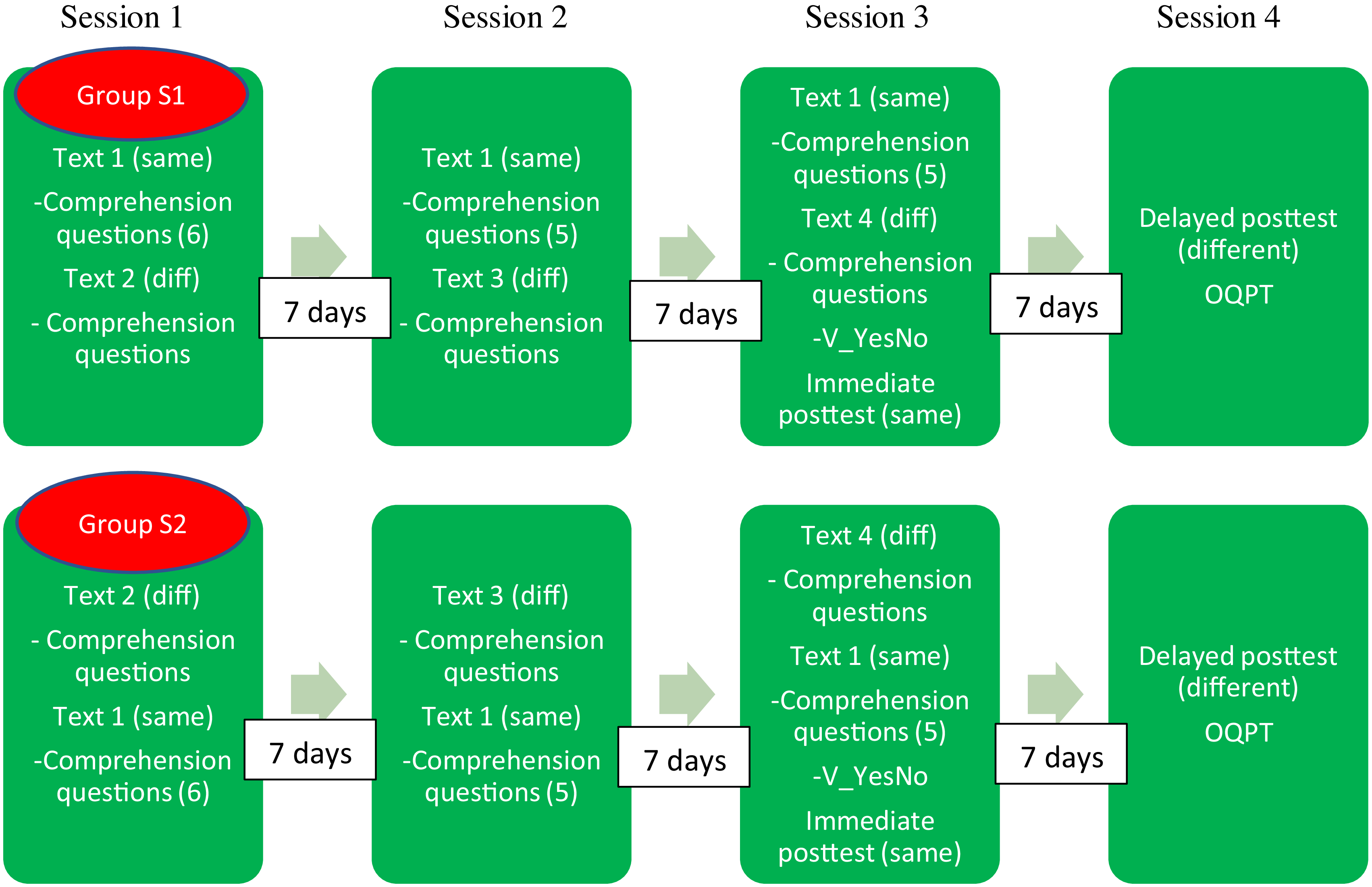
For the students in the spaced group, there were four sessions, since the repeated reading sessions were spaced over three different days across three weeks (see Figure 2). Sessions 1 and 2 were short and focused on reading: half of the participants started with the same condition and the other half with the different condition. After the readings, the students answered comprehension questions. In the case of the same condition, the participants answered 1/3 of the questions after each of the three readings. Sessions 3 and 4 were equivalent to sessions 2 and 3 in the massed condition: session 3 included readings, comprehension questions, the V_YesNo test, and immediate target vocabulary tests; while session 4 included the delayed target vocabulary posttest and the general proficiency test (QPT).
Procedure for the spaced condition.
*OQPT = Oxford Quick Placement Test.

Analyses
Vocabulary tests
The form recognition test was scored dichotomously, with 1 point awarded for correctly identifying the target word forms and 0 for incorrect or missed responses.
The meaning recall test was scored as follows: 0 points were assigned for responses that differed from the target words, and 1 point was given if the student provided the correct target word, a synonym, an accurate translation, or a semantically related word that was contextually appropriate. For instance, in the case of the target word “criminal” in the same text (“They treated every boy there like a brald/nuse who had been locked up for committing a serious offence”), the following answers were also given 1 point: “prisoner,” “bad child,” “worker,” “slave.” Similarly, for the target word “house” (“One of the few buildings in the village was a glabe/droft for poor kids who had no money and nowhere to live”), “orphanage,” “building,” “prison,” and “basement” were also considered correct. Since most of the answers were either left blank or were inaccurate (90.90%), it was decided to give full credit (and not half credit) when students showed some knowledge of the target words. The meaning recall answers were evaluated by two raters, who reached 100% agreement after deciding on common guidelines for scoring.
Finally, the meaning recognition test also received binary scoring: 1 point for the correct meaning recognition in the multiple-choice question and 0 when the participant selected any of the distractors or the “I don’t know” option.
Eye-tracking measures
Online processing of the target words was examined through four different measures, as the combination of multiple measures is believed to better capture learners’ cognitive processes (Godfroid, Reference Godfroid2019). To capture the temporal dynamics of processing, our analyses differentiated between early-processing measures and late-processing measures, following common practices in eye-tracking-based vocabulary learning research (e.g., Elgort et al., Reference Elgort, Brysbaert, Stevens and Assche2018; Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Pellicer-Sánchez et al., Reference Pellicer-Sánchez, Siyanova-Chanturia and Parente2022; Yi, Reference Yi2022). First fixation duration (FFD) was used as an early measure to examine learners’ efforts in recognizing word forms; total fixation duration (TFD) and fixation count (FC) were used as late measures to investigate participants’ more controlled cognitive processes of lexical integration; average fixation duration (AFD) was included as it has been claimed to be useful in exploring how eye movements unfold over time (Conklin et al., Reference Conklin, Pellicer-Sánchez and Carrol2018).
Statistical analyses
Generalized linear mixed models (GLMMs) for repeated measures were conducted on the vocabulary scores using SPSS 27 (IBM, 2020). As the scores were binary (0 or 1), the binomial distribution with a logit link function was employed. Given the repeated nature of the measurements (multiple items per participant at multiple time points), the analysis accounted for within-subject correlation by specifying a repeated measures structure with compound symmetry.
In the case of the eye-tracking measures, which were continuous, a GLMM for repeated measures with normal distribution was used. Although the data were not normally distributed initially, a priori cleaning was conducted by removing all values more than 2.5 SD above the mean, as recommended by Godfroid (Reference Godfroid2019). The resulting data loss was as follows: TFD 2.52%, AFD 1.51%, FFD 1.85%, and FC 2.42%. The remaining data were normally distributed according to the skewness and kurtosis values, which were between −2 and 2 (Godfroid, Reference Godfroid2019) for all four measures. In these analyses, the repeated measures were item (each of the target words), reading time (1, 2, and 3), and encounter time (each appearance of the target word). Both reading time and encounter time were treated as categorical variables. In SPSS, the reference category is the last one, but the estimation of the effects for each group was obtained using the /EMMEANS instruction.
In all analyses, we were interested in the effects of spacing (massed vs. spaced) and context (same vs. different). In the case of vocabulary, we examined the effect of testing time (testing time 1: immediate posttest vs. testing time 2: delayed posttest). For the eye movement data, we considered the effect of reading time (1, 2, and 3). For all analyses, we considered the two- and three-way interactions (x) between the different main effects. The proficiency test scores (QPT) were included as a covariate to control for participants’ proficiency level. Alpha level was set at .05. Pairwise comparisons were performed using Bonferroni adjustment when effects were statistically significant.
We note that, in the main text, we report the fixed effects table as well as the graphs and pairwise comparisons as they appear in the SPSS output. For transparency and comparability with R-based reporting, we include the fixed coefficients tables—reporting B, SE, p-values, and 95% CIs—in Appendix F. The syntax, output, and SPSS data sets are available in an anonymous online repository and will be made available upon publication.
Results
To confirm that participants attended to the reading materials as instructed, we first examined their performance on the comprehension questions. The average score on the comprehension tests was 12.93 out of 16 (80.81%), suggesting that, overall, participants had little difficulty understanding the texts. Scores were similar between the massed and spaced groups (M = 13.48 and 12.40, respectively), while comprehension was higher when the same text was read three times compared to when three different texts were read once (M = 13.88 vs. 11.99 out of 16). The following sections address our research questions by focusing on vocabulary learning and online processing.
Vocabulary
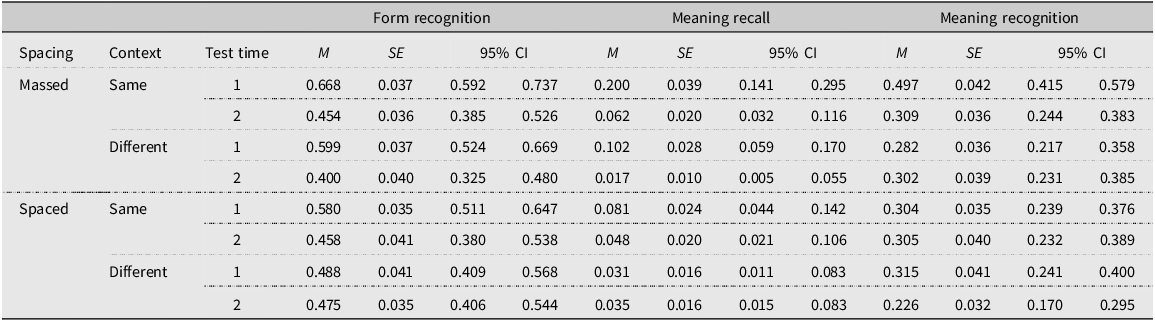
Table 3 shows the estimated means (M) and standard errors (SE) for all the vocabulary tests in the different conditions.
Descriptive statistics vocabulary test scores by condition

It can be observed that the easiest vocabulary test for the students was the form recognition test, followed by the meaning recognition test. The meaning recall test, as expected, was very difficult. The same condition seemed more beneficial than the different condition, and the massed group generally outperformed the spaced group, although the difference was more obvious on the immediate posttest. The results of the inferential statistics will be discussed for each test separately.
Form recognition
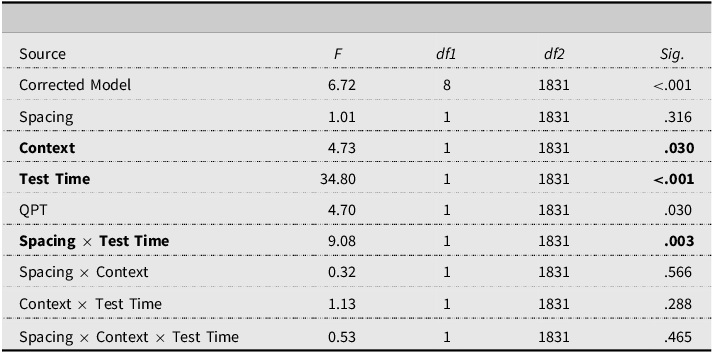
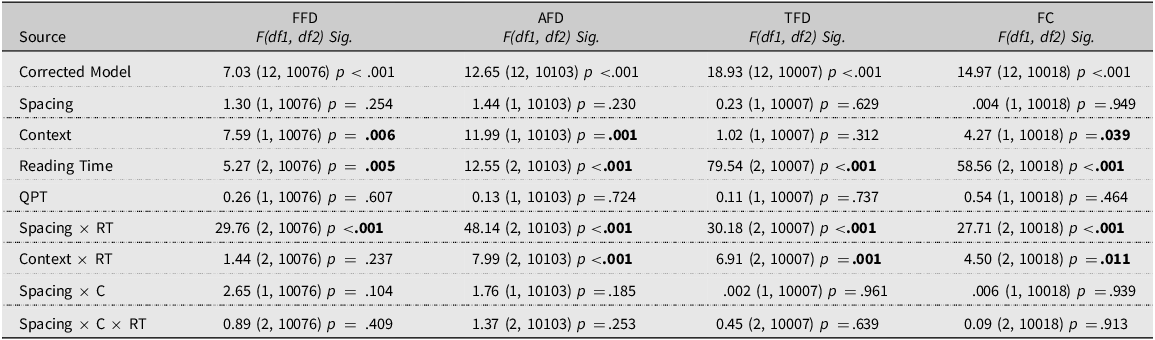
Starting with the form recognition test, the results of the GLMMs showed that the effect of context was statistically significant, as was the effect of test time. While the effect of spacing was not statistically significant, there was a significant interaction between spacing and test time (see Table 4 for all main effects, and Table A1, Appendix F for fixed coefficients).
Fixed effects vocabulary form recognition

Pairwise contrasts for the effect of context showed that the forms of the target words were better recognized when they appeared in the same text (M diff = 0.052, SE = 0.024, 95% CI [0.005, 0.010], p = .030). As for test time, the scores on the immediate posttest were significantly higher than on the delayed posttest: M diff = 0.140, SE = 0.023, 95% CI [0.09, 0.18], p < .001.
Regarding the interaction between spacing and test time (see Figure 3), the scores of the massed group were significantly higher than those of the spaced group on the immediate posttest (M diff = 0.10, SE = 0.04, 95% CI [0.02, 0.17], p = .009) but the difference disappeared on the delayed posttest (M diff = −0.04, SE = .004, 95% CI [−0.11, 0.04], p = .309).
Interaction spacing × test time form recognition (Left) and meaning recall (Right).

Meaning recall
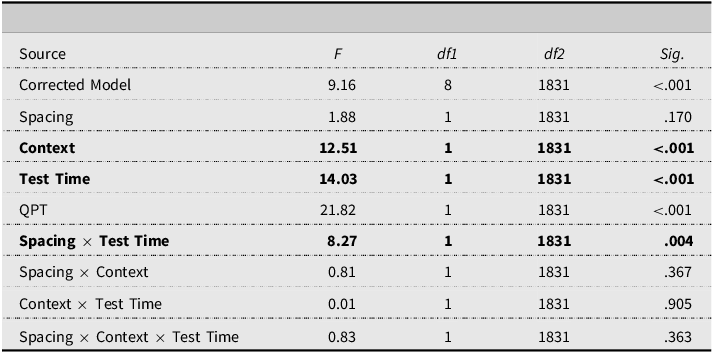
In the case of meaning recall, the results of the GLMMs, as shown in Table 5, replicate the ones reported for form recognition, with the same condition leading to significantly higher scores than the different condition (Mdiff = 0.48, SE = 0.01, 95% CI [0.02, 0.07], p < .001) and the scores of the immediate posttest being significantly higher than those on the delayed posttest (Mdiff = 0.05, SE = 0.01, 95% CI [0.02, 0.08], p < .001). See Table A2, Appendix F, for fixed coefficients.
Fixed effects vocabulary meaning recall

Similarly, while the scores on the immediate posttest were significantly higher for the massed group (M diff = 0.098, SE = 0.03, 95% CI [0.042, 0.152], p = .001), the difference disappeared on the delayed posttest. In fact, the massed group’s performance was significantly worse at the second testing time (M diff = 0.115, SE = 0.024, 95% CI [0.07, 0.16], p < .001) but that was not the case for the spaced group (M diff = 0.01, SE = 0.02, 95% CI [−0.02, 0.04], p = .546) (see Figure 3 for the interaction). However, it should be noted that the scores of the spaced group on the immediate posttest were already very low (Table 3).
Meaning recognition
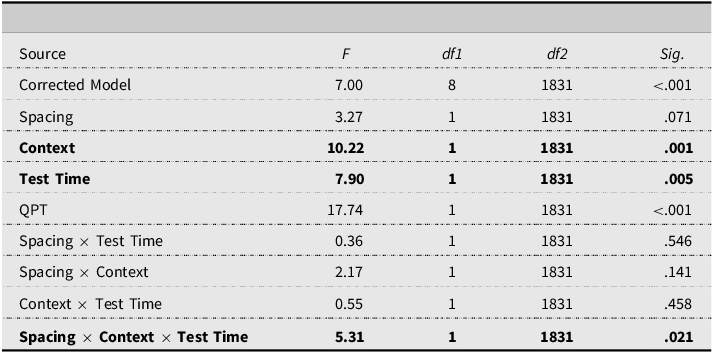
The results of the GLMMs with the meaning recognition scores as the dependent variable show the same results for context and test time, with the same condition and immediate posttest having significantly higher scores than the different condition and the delayed posttest respectively (context: M diff = 0.07, SE = 0.02, 95% CI [0.03, 0.11], p = .001; test time: (M diff = 0.06, SE = 0.02, 95% CI [0.02, 0.10], p = .005). In contrast to the form recognition and meaning recall tests, the interaction between spacing and time was not significant; however, there was an interesting three-way interaction between spacing, context, and time (see Table 6 for fixed effects, and Table A3, Appendix F for fixed coefficients).
Fixed effects vocabulary meaning recognition

Figure 4 illustrates the three-way interaction between spacing, context, and test time. When focusing on test time, the pairwise comparisons showed that in the massed group, the same condition led to significantly higher scores on the immediate posttest than on the delayed posttest (there was high attrition, but it should be emphasized that the massed-same-immediate obtained the highest scores of all conditions). No differences were observed for the massed reading of the different texts between the two testing times. In the case of the spaced group, while there were no differences for the same versus different texts on the immediate posttest, the scores on the delayed posttest were higher for the same condition, although the difference failed to reach statistical significance (M diff = 0.089, SE = 0.052, 95% CI [−0.013−.191], p = .087). See Appendix G for all the contrasts and pairwise comparisons regarding the three-way interaction.
Interaction spacing × context × test time meaning recognition.

Online processing as examined through eye-tracking
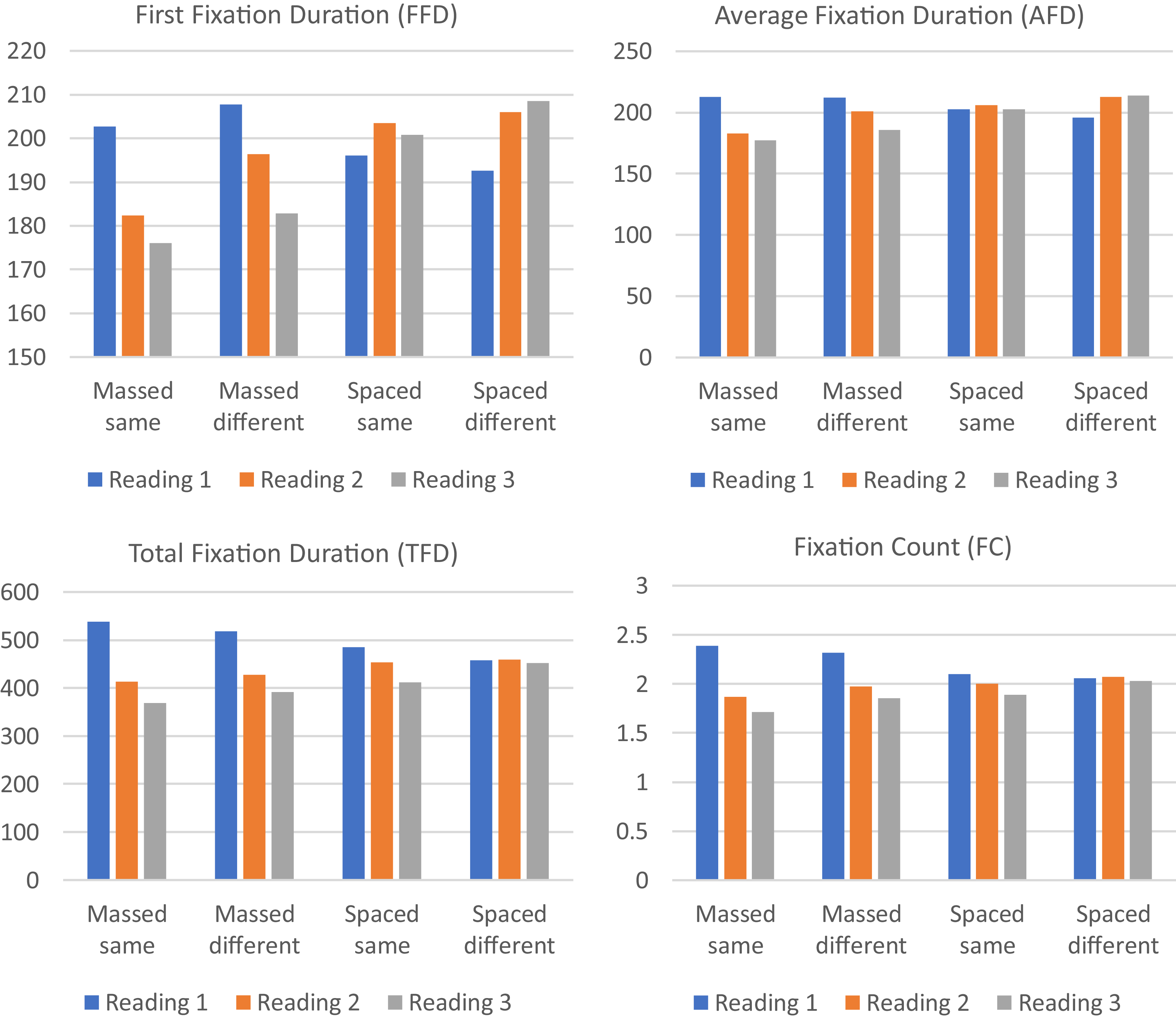
The table with the estimated Ms, SE and 95% CI is included in Appendix H. Figure 5 shows distinct patterns across the spacing and context conditions. In the massed group, particularly under the same-context condition, there is a clearer decrease across reading times in all measures compared to the spaced group. For the spaced same-context condition, no decrease is observed in FFD or AFD across readings; instead, FFD slightly increases during the second reading. TFD and FC show a slight decrease over reading times. In the spaced different-context condition, FFD and AFD exhibit an intriguing upward trend across readings, rather than a decrease, while TFD and FC remain relatively consistent.
Eye-movement patterns across reading times for different spacing and context conditions.

The results of the GLMMs for each variable of interest will be presented below. While the effect of reading time provides insight into how eye fixations change across readings, our main focus is on its interaction with spacing and context, as these reveal whether fixation patterns evolve differently across conditions. These interactions are explored in detail in the following subsections. The effect of reading time alone is less central to our discussion, but as a brief summary, we note that it was significant for all measures, consistently showing changes in eye fixations across readings—except for FFD, where only the first and third readings differed significantly. See Table 7 for all fixed effects and Appendix F for fixed coefficients (Tables A4-A7).
Fixed effects results for eye-tracking measures

QPT = Quick Placement Test; RT = reading time: C = context; FFD = first fixation duration; AFD = average fixation duration; TFD = total fixation duration; FC = fixation count.
Spacing
As reflected in Table 7, although the effect of spacing was not significant for any online processing measure, there was always a significant interaction between spacing and reading time. In the case of FFD, the interaction (F(2, 10076) = 29.78, p < .001) suggests that FFD on the target words was shorter for the massed group than for the spaced group during the third reading: Mdiff = −25.17, SE = 9.13, 95% CI [−43.06, −7.28], p = .006. No differences were registered between conditions in the first and second reading time (reading 1: Mdiff = 10.89, SE = 9.13, 95% CI [−7.01, 28.79], p = .233; reading 2: Mdiff = −15.45, SE = 9.12, 95% CI [−33.32, 2.44], p = .090). The pairwise contrasts exploring differences in reading time for each condition separately indicate that there was a significant decrease across reading times for the massed group (reading 1-reading 2: Mdiff = 15.85, SE = 3.49, 95% CI [8.02, 23.67], p < .001; reading 2-3: Mdiff = 9.91, SE = 3.47, 95% CI [3.10, 16.72], p = .004; reading 1-3: Mdiff = 25.76, SE = 3.48, 95% CI [17.41, 34.11], p < .001). The spaced group, on the other hand, significantly increased their FFD on the target words from the first to the second reading time (Mdiff = −10.49, SE = 3.33, 95% CI [−18.45, −2.52], p = .005), and from the first to the third reading time (Mdiff =-10.30, SE = 3.35, 95% CI [−17.99, −2.60], p = .005). There were no significant changes between the second and third reading time (Mdiff = −0.19, SE = 3.34, 95% CI [−6.36, 6.74], p = .955). See Figure 6 for a visual representation of the interaction.
Interactions spacing × reading time for FFD (Top Left), AFD (Top Right), TFD (Bottom Left), and FC (Bottom Right).

For AFD, the two spacing conditions differed significantly during the third reading, when the massed group showed significantly shorter AFD (M diff = 26.97, SE = 9.07, 95% CI [−44.45, −9.18], p = .003). The difference between conditions was not significant during the first reading (M diff = 13.19, SE = 9.07, 95% CI [−4.59, 30.97], p = .146) and it approached significance during the second (M diff = −17.63, SE = 9.07, 95% CI [−0.14, 35.41], p = .052).
Regarding TFD, the interaction between spacing and reading time shows that the massed group had significantly higher TFD on the target words during the first reading (M diff = 56.99, SE = 22.67, 95% CI [12.55, 101.42], p = .012), but significantly lower during the third reading than the spaced group (M diff = −51.71, SE = 22.63, 95% CI [−96.07, −7.35], p = .022). No differences were found between spacing conditions on the second reading (M diff = −35.62, SE = 22.63, 95% CI [−79.98, 8.75], p = .116).
In the same line, concerning FC, the massed group showed a significantly higher number of fixations on the target words during the first reading (M diff = 0.27, SE = 0.09, 95% CI [0.09, 0.45], p = .003) but significantly lower during the third reading (M diff = −0.18, SE = 0.09, 95% CI [−0.36, 0.00], p = .050), with no differences being registered between the two groups in the second reading (M diff = −0.11, SE = 0.09, 95% CI [−2.91, 0.68], p = .224).
Overall, the results suggest that the most significant difference between massed and spaced conditions occurred during the third reading. Specifically, when repeated reading was massed, there were fewer and shorter fixations compared to the spaced condition. Looking at each condition individually, it is interesting to note a general decrease in processing time during massed repeated reading, whereas, in the spaced condition, fixation durations increased across reading times.
Context
The effect of context was significant for FFD (M diff = −5.42, SE = 1.97, 95% CI [−9.28, −1.56], p = .006), AFD (M diff = −6.05, SE = 1.74, 95% CI [−9.47, −2.63], p = .001) and FC (M diff = −0.05, SE = 0.27, 95% CI [−0.11, −0.003], p = .039). In all cases, there were longer and more fixations on the target words when they appeared in different texts. For TFD, the effect of context was not statistically significant (See Table 7).
There was a significant interaction between context and reading time in all the eye-tracking measures, except for FFD (see Figure 7). For AFD, the interaction suggests that AFD was significantly lower in the same than in the different context during the second (Mdiff = −12.19, SE = 3.02, 95% CI [−18.11, −6.26], p < .001) and the third reading (Mdiff = −9.68, SE = 3.03, 95% CI [−15.62, −3.73], p = .001), while no differences were registered in the first reading (Mdiff = 3.71, SE = 3.02, 95% CI [−2.21, 9.64], p = .219). See Appendix I for the pairwise contrasts on the interactions focusing on reading time.
Context × Reading time interactions AFD (Top Left), TFD (Top Right), and FC (Bottom Center).

In the case of TFD, when words appeared in the same text, they received longer fixations during reading 1 than when they appeared in different texts (Mdiff = 23.75, SE = 10.70, 95% CI [2.77, 44.72], p = .026). In contrast, TFD to words on the different text was significantly higher during the third reading than to words on the same text (Mdiff = −31.79, SE = 10.62, 95% CI [−52.60, −10.98], p = .003). No differences were registered between same and different contexts during the second reading (Mdiff = −10.60, SE = 10.62, 95% CI [−31.41, 10.21], p = .318). See Appendix J for pairwise contrasts focusing on reading time in the interactions.
For FC, while there were no statistically significant differences between same and different conditions during the first and the second reading time (Mdiff = −0.05, SE = 0.05, 95% CI [−0.04, −0.15], p = .239 and Mdiff = −0.09, SE = 0.05, 95% CI [−0.18, 0.005], p = .064, respectively), there were significantly fewer fixations on the target words during the third reading in the same condition (Mdiff = −0.13, SE = 0.05, 95% CI [−0.23, −0.04], p = .004). See Appendix K for pairwise contrasts focusing on reading time for the two interactions.
The overall results indicate that encountering novel words in the same text read three times results in more fluent processing of those words compared to when they appear in three different texts. This effect mirrors the impact of spacing, with massed repeated reading leading to significantly more fluent processing of new words than spaced repetitions.
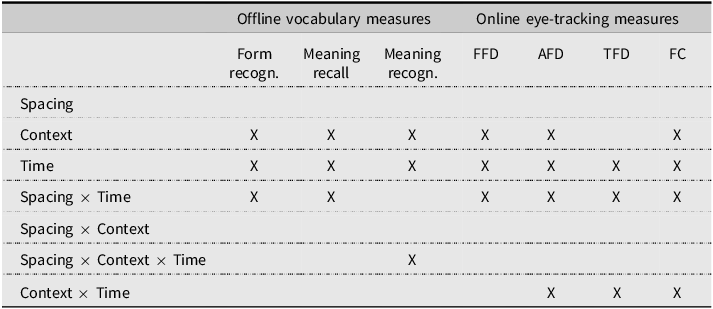
Importantly, as shown in Table 7, neither the spacing × context interaction nor the spacing × context × reading time interaction was significant for any eye-tracking measure. This suggests that spacing influenced the processing of novel words in a similar way, regardless of whether they appeared in the same or different texts. Table 8 provides an overview of all the results.
Results summary

X indicates statistically significant effects.
Discussion
This study examined how spacing and context affect incidental learning and processing of novel words across three repeated readings of short texts. Overall, the results suggest that certain practice conditions were more beneficial for vocabulary learning than others, with same repetitions generally leading to better outcomes than different ones, and massed repetitions being more beneficial than spaced, but only on immediate posttests. The eye-tracking results showed that there were more and longer fixations when repetitions were spaced (vs. massed) and when words appeared in different contexts (vs. same) during the third reading.
The effects of the two main variables—spacing and context—across different reading and testing times are discussed separately. According to the desirable difficulties hypothesis, conditions like spaced practice and contextual variability may introduce challenges that enhance long-term learning (Murphy et al., Reference Murphy, Bjork and Bjork2023; Suzuki, Reference Suzuki and Suzuki2024). In this study, eye-tracking data helped capture these challenges, as longer fixations indicate greater cognitive effort (Rayner, Reference Rayner1998).
Spacing
Regarding spacing, our findings indicate that the massed group showed descriptively higher vocabulary scores than the spaced group; however, the difference between spacing conditions did not reach statistical significance. The lack of a significant advantage of the spaced condition contrasts with our prediction and with previous findings in the literature on vocabulary learning through sentence reading (Koval, Reference Koval2019; Pagán & Nation, Reference Pagán and Nation2019). This divergence likely stems from differences in methodology, particularly the spacing: previous studies spaced repetitions between items within the same session, whereas in the current study, spacing occurred between sessions.
In Koval’s (Reference Koval2019) experiment, participants learned Finnish words embedded in independent English sentences presented either consecutively or with 25 intervening sentences. Participants actively inferred meanings in concise, informative contexts and made less effort processing repeated items in the massed condition, as shown by eye-movement data (fewer and shorter fixations). These results align with both the deficient processing hypothesis (Cuddy & Jacoby, Reference Cuddy and Jacoby1982) and the desirable difficulties hypothesis (Bjork, Reference Bjork, Metcalfe and Shimamura1994). In contrast, participants in our study encountered pseudowords within longer texts, focusing on overall comprehension with no emphasis on the target vocabulary. Comparing descriptive statistics for FFD, FC, or TFD, our study shows lower means than Koval’s, likely due to the absence of a deliberate learning focus. While spacing effects are observed in both intentional and incidental learning, Verkoeijen et al. (Reference Verkoeijen, Rikers and Schmidt2005) found that long lags (8 intervening words versus 0, 2, or 5) yielded spacing effects in intentional learning but not in incidental learning.
Another key difference from sentence-based studies (e.g., Koval, Reference Koval2019; Nakata & Elgort, Reference Nakata and Elgort2021; Pagan & Nation, Reference Pagán and Nation2019) is that our participants read full texts rather than isolated sentences. Although the immediate context was informative, inferring word meanings was more challenging, as it required integrating information across sentences and paragraphs. Assuming participants knew all words except the pseudowords, they likely noticed the unfamiliar items across conditions—possibly explaining the similar results in form recognition and overall fixations in massed versus spaced repeated reading. However, mapping form to meaning was harder, as inferences relied on broader textual context, unlike the sentence-level context in prior studies. This difficulty likely increased under spaced conditions. According to study-phase retrieval theory (Greene, Reference Greene1989), effective learning from repeated exposure depends on the successful retrieval of prior encounters—something less likely with wider spacing, which may explain the absence of spacing benefits in this study.
The findings from the present study regarding spacing also contrast with results from a previous study on repeated reading, in which spaced repeated readings of the same text led to better meaning recognition of the target words overall, but especially on the delayed posttests (Serrano & Pellicer-Sánchez, Reference Serrano and Pellicer-Sánchez2024). The authors, however, recommended caution in interpreting these results, as the spaced group demonstrated substantial learning outside of the treatment context. The present study avoided this problem, as well as the potential test-retest effect, by including pseudowords and between-participant testing.
The absence of a spacing effect may also be linked to the fact that different degrees of spacing did not result in significant differences in overall processing time, as indicated by the lack of a main effect of spacing on the eye-tracking measures. Previous eye-tracking studies have demonstrated a relationship between processing time and vocabulary learning (Koval, Reference Koval2019; Pellicer-Sánchez, Reference Pellicer-Sánchez2016; Yi, Reference Yi2022; Yi & DeKeyser, Reference Yi and DeKeyser2022), suggesting that the lack of a spacing effect on vocabulary learning may be due to similar overall processing times across conditions.
There was, however, a significant interaction between reading time and spacing across all eye-tracking measures. This interaction indicated that, in the third reading, there were fewer fixations and shorter fixation durations in the massed condition, which aligns with previous vocabulary studies demonstrating a facilitative effect of repetition on processing (Pellicer-Sánchez, Reference Pellicer-Sánchez2016; Pellicer-Sánchez et al., Reference Pellicer-Sánchez, Siyanova-Chanturia and Parente2022; Yi, Reference Yi2022). In contrast, this facilitative effect was not observed in the spaced condition, particularly when context was different. In some measures (FFD and AFD), spaced repetitions even led to increased fixation durations across readings. This increase may indicate that learners recognized the form of some words but failed to recall previous encounters. In massed readings, words were more easily retrieved across repetitions, resulting in faster reading times by the third reading. This more fluent reading performance in the massed condition is in line with other studies that have found that massed repetitions enhance certain aspects of oral fluency (Bui et al., Reference Bui, Ahmadian and Hunter2019; Suzuki & Hanzawa, Reference Suzuki and Hanzawa2022).
However, this fluency did not support meaning inference or long-term retention, as shown by the interaction between spacing and testing time for meaning recall and recognition. While massed reading led to better immediate test performance, consistent with other studies (Pavlik & Anderson, Reference Pavlik and Anderson2005), this advantage disappeared after one week due to significant forgetting. The decline in fixation count and duration across readings also reflects reduced effort in forming durable form-meaning mappings for novel words. Following Soderstrom and Bjork (Reference Soderstrom and Bjork2015), the significantly higher scores in the massed condition on the immediate posttest may just reflect enhanced performance during acquisition rather than durable learning, which likely requires more cognitive investment.
Context
Regarding the role of context in vocabulary learning, the results of this study indicate that participants more easily recognized the form and meaning of the target words and recalled their meaning when the words appeared in the same text across three readings, rather than in three different texts. This advantage for repeated context was also found in a previous analysis that included only massed repeated reading, though the effect was limited to meaning recognition and did not extend to form recognition (Chandy et al., Reference Chandy, Serrano and Pellicer-Sánchez2024). As Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2024) suggested, form recognition may have been relatively easy regardless of contextual variation. However, that study only included massed repetitions, which, as discussed earlier, create more favorable learning conditions. The inclusion of both massed and spaced repetitions in the current study may help explain the differing results.
The findings showing an advantage for the same versus different conditions do not go in line with the prediction that context diversity would promote stronger memory representations (Jones et al., Reference Jones, Dye, Johns and Ross2017) or with previous findings that have examined the role of context in sentence reading. Pagan and Nation (Reference Pagán and Nation2019) found that although the same context made processing more fluent during the learning stage, as shown by shorter fixations and shorter reading times, memory representations were less consolidated, as evidenced by the more effortful processing when the words appeared in new sentences. Bolger et al. (Reference Bolger, Balass, Landen and Perfetti2008), as well as Ferreira and Ellis (Reference Ferreira and Ellis2016), also provided evidence for the benefits of contextual diversity for word learning.
However, encountering new words in the same context can also facilitate meaning inference by increasing familiarity with the surrounding words and sentences, especially when reading longer texts. Although the present study did not examine general reading fluency, other studies have reported fewer and shorter fixations across readings when learners read the same text multiple times (Serrano & Pellicer-Sánchez, Reference Serrano and Pellicer-Sánchez2024). Increased familiarity and content comprehension have been shown to predict vocabulary learning (Pulido, Reference Pulido2004, Reference Pulido2007). In the current study, participants who read the same text repeatedly were already familiar with the story’s content during their second reading, which facilitated comprehension. This familiarity may have enhanced their ability to notice and process new vocabulary. In contrast, participants who read three different texts needed to focus on understanding new content each time, which may have reduced the cognitive resources available for inferring the meanings of new words.
When examining number of fixations and fixation duration on the target words, it was observed that those that appeared in the same context received shorter FFD and AFD as well as fewer fixations (FC). There was also an interaction between context and reading time, in which the gap between the same and different contexts regarding AFD, TFD, and FC on the target words became wider in the third reading, with shorter reading times observed for words in the same condition. These findings are similar to those reported by Chandy et al. (Reference Chandy, Serrano and Pellicer-Sánchez2024) for massed repeated reading.
The fact that fewer and shorter fixations in the same context led to higher immediate vocabulary gains does not align with predictions suggesting that increased processing time would lead to greater noticing and learning (e.g., Koval, Reference Koval2019; Yi, Reference Yi2022). However, the larger differences between conditions in the third reading may indicate that, with repeated exposure to the same text, learners were already familiar with the new words after two previous encounters. In contrast, when words appeared in different texts, learners may have found it more challenging to recall them, leading to less fluent processing than in the same-context condition.
Interestingly, context diversity was found to be especially challenging in the spaced condition for delayed meaning recognition, as demonstrated by the three-way interaction between time, spacing, and context on the vocabulary test. In line with other studies in cognitive psychology (Bercovitz et al., Reference Bercovitz, Bell, Simone and Wiseheart2017; Verkoeijen et al., Reference Verkoeijen, Rikers and Schmidt2004), context diversity was especially detrimental in the spaced condition and especially for long-term retention. In other words, contextual diversity made retrieval of previous presentations more difficult in spaced practice, while it did not have such a negative effect in massed practice. This is also in line with the retrieval effort hypothesis (Pyc & Rawson, Reference Pyc and Rawson2009), which claims that effortful successful retrievals enhance memory more than “easy” successful retrievals, which would happen in the massed same condition at immediate testing. However, retrieval needs to be successful, which is probably what failed in the case of the spaced condition and especially when words appeared in different texts. As Appleton-Knapp et al. (Reference Appleton-Knapp, Bjork and Wickens2005) suggest, “up to a point, variation can make study-phase retrieval more effective my making it more difficult and involved -and, hence, more effective in supporting subsequent recall. For study-phase retrieval to be effective, however, retrieval must be possible, if effortful. At the point that induced variation results in a failure of retrieval, it becomes counterproductive” (p. 275).
Considering the overall results of this study, practice conditions that were theoretically more difficult (Suzuki, Reference Suzuki and Suzuki2024) and required more processing effort—as indicated by the eye-tracking measures—were not desirable. This may be because the task itself involved incidental vocabulary learning, and the focus on meaning comprehension might have made vocabulary learning more challenging. Additional difficulties introduced by conditions such as one-week spaced repetitions together with repetitions of novel words in different contexts may therefore be counterproductive, particularly when they occur simultaneously. The results also suggest that when conditions are too easy—as in massed-same repeated reading, which involved fewer and shorter fixations—they lead only to advantages on the immediate posttest. As Sonderstrom and Bjork (Reference Soderstrom and Bjork2015) suggest, this may simply reflect a performance advantage during training rather than genuine learning.
Limitations
The present study has some limitations. First, learners were exposed to the target words only six times under incidental learning conditions. Increasing the number of exposures or incorporating a deliberate learning component may lead to greater lexical gains and more pronounced differences between conditions (Koval, Reference Koval2019). Our analyses include offline vocabulary measures for learning outcomes and online measures for processing during the learning phase. Future studies should also examine processing differences in a posttest task to assess processing changes as a result of the treatment. This would provide valuable insight into how new words are integrated into participants’ lexicons, as in Pagan and Nation (Reference Pagán and Nation2019).
Conclusion
The present study is the first to examine the interaction between spacing and contextual diversity in L2 vocabulary learning, and it sheds light on the conditions that are more conducive to vocabulary learning through meaning-focused input. In general, one-week spaced repeated reading or presenting novel words in different texts seemed to encourage longer fixations, likely reflecting effortful retrieval of prior encounters. However, this did not benefit learning, possibly due to failed retrieval. Massed and same-text conditions led to more fluent reading and higher immediate gains, but not long-term retention, which is not unexpected considering that there were only a total of six encounters in incidental learning conditions. Our results are partly in line with Suzuki et al.’s (Reference Suzuki, Nakata and Dekeyser2019) claims that optimal L2 practice should consider difficulties coming from different sources.
Supplementary material
For supplementary material accompanying this paper visit https://doi.org/10.1017/S0142716425100283
Acknowledgements
This research was funded by grants PID2019-110536GB-I00, from the Spanish Ministry of Science and Innovation, and 2023SGR00303, from the Catalan Agency for Management of University and Research Grants (AGAUR). We thank Radha Chandy for assistance with data collection, and the Editor and anonymous reviewers for their insightful comments.







 Open access
Open access