


Introduction
Maize (Zea mays L.) is the second most cultivated crop in the world, and together with rice (Oryza sativa L.) and wheat (Triticum aestivum L.), it is one of the three major cereal crops, being the staple crop for one-third of the world's population in the developing countries (Tanumihardjo et al., Reference Tanumihardjo, McCulley, Roh, Lopez-Ridaura, Palacios-Rojas and Gunaratna2020). It is employed as food, livestock feed and biofuels worldwide (Shiferaw et al., Reference Shiferaw, Prasanna, Hellin and Bänziger2011). Latin America is the centre of origin and diversity of maize (Gotor et al., Reference Gotor, Bellon, Polar and Caracciolo2017). In Peru, maize is cultivated from sea level, at the coastal area, up to above 3800 m above sea level, in the surrounding of the Titicaca Lake, and at the highlands area (Salhuana, Reference Salhuana2004; García Mendoza, Reference García Mendoza2017; Ministerio del Ambiente, 2018).
The greatest diversity and specialization of maize of the floury group (soft endosperm) took place in Peru, generating a diverse group in morphological and biological traits (Ministerio del Ambiente, 2018). Peru is pointed as a secondary centre of genetic diversity and has an important food culture associated with maize, characterized by multiple uses and forms of consumption (Stromberg et al., Reference Stromberg, Pascual and Bellon2010). The extreme variety of ecological conditions in which maize grows in Peru, together with the combination of other factors, such as mutation, hybridization and selection, has resulted in the production of a high number of races, giving rise to the great diversity that exists in the Andean region (Salhuana, Reference Salhuana2004). Despite government support to grow improved maize, farmers prefer to cultivate their landraces because of cultural reasons. In fact, maize is one of the main components of Andean cuisine, as there are races very much preferred for special dishes. Thus, some are eaten mainly toasted (races chullpi, paru), others boiled (race starch white) or in soups with beef and cattle viscera (race starch white) and so on. On the other hand, improved maize is grown only in the coast and used mainly for livestock. Another key reason for this preference is the lack of alternatives in the highlands. The only organization developing improved maize for the Peruvian highlands is the National Institute of Agrarian Innovation (INIA in Spanish), which has developed all the known cultivars of different starch-type maize, especially purple maize, which is open-pollinated (OP). However, in the case of Huancavelica, there is not a maize breeding programme, making it difficult to develop improved varieties for this production area. This is why the Universidad Nacional Autónoma de Tayacaja is working on a project aimed at conserving crop biodiversity in the region and developing improved maize cultivars specifically adapted to the conditions of the Tayacaja province. Furthermore, national and multinational seed companies are not focused to invest in developing hybrid cultivars for these maize types because local farmers are unlikely to pay for seeds. This is largely due to their small plot sizes, often 1 ha or less, and low level of technological advancement. Tayacaja province is located in the geographical department of Huancavelica in Peru and possesses an agricultural area of 104,872 ha, which represents 35% of the agricultural area of Huancavelica (estimated at 292,245 ha) (Ministerio de Desarrollo Agrario y Riego, 2021). A total area of 9071 ha in Tayacaja is cultivated with maize (Dirección Regional Agraria de Huancavelica, pers. commun.). In order of importance Colcabamba, Salcahuasi, Salcabamba, San Marcos de Rocchac, Daniel Hernández, Pampas, Surcabamba, Tintaypunco, Huaribamba, Huachocolpa and Quichuas are the main maize producing provinces in Huancavelica, comprising a little more than 90% of the cultivated area, with an average of about 750 ha per district. Maize production of the Peruvian highlands like in Huancavelica and Cajamarca is characterized by the use of landraces, low technological level agronomic management, scarce marketing capacity and in general, low levels of productivity.
Genotyping-by-sequencing (GBS), a next-generation sequencing technology, has emerged as a powerful tool for different genetic applications, such as genetic diversity analysis, linkage mapping, association mapping and genomic selection (Poland and Rife, Reference Poland and Rife2012; Crossa et al., Reference Crossa, Beyene, Semagn, Pérez, Hickey, Chen, Campos, Burgueño, Windhausen, Buckler, Jannink, Cruz and Babu2013; Romay et al., Reference Romay, Millard, Glaubitz, Peiffer, Swarts, Casstevens, Elshire, Acharya, Mitchell, Flint-Garcia, McMullen, Holland, Buckler and Gardner2013; Zhang et al., Reference Zhang, Pérez-Rodríguez, Semagn, Beyene, Babu, López-Cruz, San Vicente, Olsen, Buckler, Jannink, Prasanna and Crossa2015). Peru and the Latin American region have a great morphological diversity of native maize, which has not yet been fully studied using molecular tools. Also, it is not known exactly how many landraces of maize are stored under in situ or ex situ conditions, or the population structures of these maize collections. There have not been yet any comprehensive studies that have involved genotyping of large numbers of landraces from Huancavelica and Cajamarca using a technology that guarantees wide coverage of the species genome. In this sense, Grobman et al. (Reference Grobman, Salhuana, Sevilla and Mangelsdorf1961) referred that at least 52 maize races have been defined in Peru based on morphological descriptors, of the 180 races present in the Central Andes region that encompasses the Inca territory, whose genetic diversity and population structure are not yet known exactly.
Therefore, the main objectives of this study were to: (1) understand the genetic diversity of 25 accessions of starchy maize from Huancavelica and Cajamarca, (2) investigate the population structure of these accessions using genome-wide single-nucleotide polymorphism (SNP) markers and (3) estimate the genetic relationships among these accessions. Here, we determined the number of different alleles, allelic richness, observed and expected heterozygosity, Shannon–Wiener index and inbreeding coefficient. In addition, we inferred population differentiation fixation index. A number of evolutionary processes such as (i) isolation, (ii) mutation, (iii) selection (adaptation, yield, utilitarian reasons) and (iv) hybridization undergo by maize in Peru resulting in an increase of phenotypic and genotypic variation (Grobman et al., Reference Grobman, Salhuana, Sevilla and Mangelsdorf1961). The results of this work will provide basic information for the genetic improvement of Peruvian starchy maize in the future, and to establish strategies for adequate conservation of this germplasm.
Materials and methods
Experimental genotypes and DNA extraction
A total of 100–150 ears of maize were collected for each accession of the landraces found in the field in 2018. Nineteen experimental genotypes of maize were collected from farms located in the main maize-producing districts of the province of Tayacaja, Huancavelica, Peru. This province encompasses 23 districts, of which 14 are considered the main maize producers, according to the Agricultural Agency of Tayacaja (verbal communication). A total of eight districts out of the 14 were considered for collecting maize due to access difficulties for the remaining six districts. In addition, six OP cultivars provided by Baños del Inca Agricultural Research Station of the INIA located in the department of Cajamarca were requested. The largest maize germplasm collection is maintained by Universidad Nacional Agraria la Molina, which is located in Lima. Unfortunately, it was not possible to have access to this collection. Full details of the accessions examined in this work are provided in online Supplementary Table S1. Detailed morphological characteristics of most of these accessions were reported in a previous study (García-Mendoza et al., Reference García-Mendoza, Pérez-Almeida, Prieto-Rosales, Medina-Castro, Manayay-Sánchez, Marín-Rodríguez, Ortecho-Llanos and Taramona-Ruíz2023).
Maize accessions were sown into soil in germination trays. A sample of fresh tissue from 50 seedlings per accession at the stage of three to four leaflets was used for DNA isolation, using the cetyltrimethylammonium bromide method employed by Saldaña et al. (Reference Saldaña, Cancan, Cruz, Correa, Ramos, Cuellar and Arbizu2021) and adapted for this species. We used 100 mg of maize tissue with liquid nitrogen to ground them. DNA purity was assessed by a NanoDrop spectrophotometer (Thermo Scientific, Massachusetts, USA), by reading the absorbance of the maize samples at 260 and 280 nm. The evaluation of the DNA quantity and quality was performed by using a Qubit4 Fluorometer (Invitrogen, Waltham, MA, USA), according to the Qubit 4 Quick Reference Guide, and agarose gel (1%), respectively.
Genotyping-by-sequencing
DNA samples were sent to the University of Minnesota Genomics Center (UMGC) for DNA sequencing. A GBS protocol was followed, according to Elshire et al. (Reference Elshire, Glaubitz, Sun, Poland, Kawamoto, Buckler and Mitchell2011) and Wu et al. (Reference Wu, San Vicente, Huang, Dhliwayo, Costich, Semagn, Sudha, Olsen, Prasanna, Zhang and Babu2016). We employed restriction enzyme ApeKI as employed by a previous study on maize (Wang et al., Reference Wang, Yuan, Wang, Yu, Liu, Zhang, Gowda, Nair, Hao, Lu, San Vicente, Prasanna, Li and Zhang2020), and used the methodology proposed by Bradbury et al. (Reference Bradbury, Zhang, Kroon, Casstevens, Ramdoss and Buckler2007) and Glaubitz et al. (Reference Glaubitz, Casstevens, Lu, Harriman, Elshire, Sun and Buckler2014). GBS library was prepared following the methodology reported by Huaringa-Joaquin et al. (Reference Huaringa-Joaquin, Saldaña, Saravia, García-Bendezú, Rodriguez-Grados, Salazar, Camarena, Injante and Arbizu2023) and Arbizu et al. (Reference Arbizu, Ellison, Senalik, Simon and Spooner2016). Flow cells were sequenced by using 100 bp single-end reads on a NovaSeq 6000 sequencer. Raw data quality control was conducted with FastQC software (https://www.bioinformatics.babraham.ac.uk/projects/fastqc/, accessed on July 2022). Then, we used the TASSEL-5 GBS v2 pipeline (Bradbury et al., Reference Bradbury, Zhang, Kroon, Casstevens, Ramdoss and Buckler2007; Glaubitz et al., Reference Glaubitz, Casstevens, Lu, Harriman, Elshire, Sun and Buckler2014) to analyse raw data. The available reference genome of Zea maize was also employed (Zm-B73-REFERENCE-NAM-5.0, https://www.maizegdb.org/genome/assembly/Zm-B73-REFERENCE-NAM-5.0).
Tags in the FASTQ files indicate that the restriction enzyme used was ApeKI and the barcode for each sample was used for sample identification. Then, we used the GBSSeqToTagDBPlugin argument with the default parameter and minimum base quality score of 20 to identify GBS tags in the raw database. Then, TagExportToFastqPlugin was used to index unique tags of each sequence to produce a FASTQ text file. The Burrows–Wheeler Aligner (BWA) v.0.7.17 program (Li and Durbin, Reference Li and Durbin2009) was employed to align all the tags with the reference genome (Zm-B73-REFERENCE-NAM-5.0). SAM output file format was transformed into a binary file by using SAMToGBSdbPluginn, and DiscoverySNPCallerPluginV2 was used to identify SNPs from the aligned tags. The SNPQualityProfilerPlugin was employed to score all SNPs, and the ProductionSNPCallerPluginV2 allowed us to convert data from fastq and keyfiles to genotypes.
Our data set with VCFtools v.0.1.15 (Danecek et al., Reference Danecek, Auton, Abecasis, Albers, Banks, DePristo, Handsaker, Lunter, Marth, Sherry, McVean and Durbin2011) was curated with the following parameters: (i) minimum minor allele frequency of 0.1, (ii) maximum minor allele frequency of 1, (iii) number of alleles two and (iv) maximum missing data of 0.9.
Population structure and genetic diversity analysis
To estimate the maize population structure, we employed STRUCTURE program v.2.3.4 (Pritchard et al., Reference Pritchard, Stephens and Donnelly2000) with populations ranging from 1 to 15 and 10 runs for each one and a burn-in length of 50,000 Monte Carlo iterations, followed by 150,000 iterations. All parameters were set to default except that we considered an admixture model with no previous population information. The most likely number of clusters was inferred by the Evanno method (Evanno et al., Reference Evanno, Regnaut and Goudet2005), and we considered a membership probability ⩾0.75 to divide the maize accessions into different clusters. Package pophelper v.2.3.1 (Francis, Reference Francis2017) in R program v.4.4.0 (R Core Team, 2024) was employed to generate population structure plots.
An analysis of molecular variance (AMOVA) was performed with the poppr package, and in R program we estimated the (i) number of different alleles, (ii) allelic richness, (iii) observed heterozygosity, (iv) expected heterozygosity, (v) Shannon–Wiener index and (vi) inbreeding coefficient. Finally, the population differentiation due to genetic structure (F ST) was calculated with the hierfstat v.0.5-11 package (Goudet, Reference Goudet2005) in R. An F ST value greater than 0.15 is considered as significant in differentiating populations (Frankham et al., Reference Frankham, Ballou, Briscoe and McInnes2002).
Phylogenetic analyses
Genetic distances were calculated based on Provesti's coefficient (Prevosti et al., Reference Prevosti, Ocaña and Alonso1975) in R software v4.3.2 (R Core Team, 2024), and then a dendrogram was constructed using the UPGMA clustering algorithm with 1000 bootstrap replicates in the poppr package v.2.9.4 (Kamvar et al., Reference Kamvar, Tabima and Grünwald2014). A principal coordinate analysis (PCoA) was conducted with the dudi.pco argument of the ade4 v1.7-22 package (Dray and Dufour, Reference Dray and Dufour2007). The resulting tree was viewed in FigTree v.1.4.4 (http://tree.bio.ed.ac.uk/software/figtree/).
Results
Sequencing analysis and SNP distribution
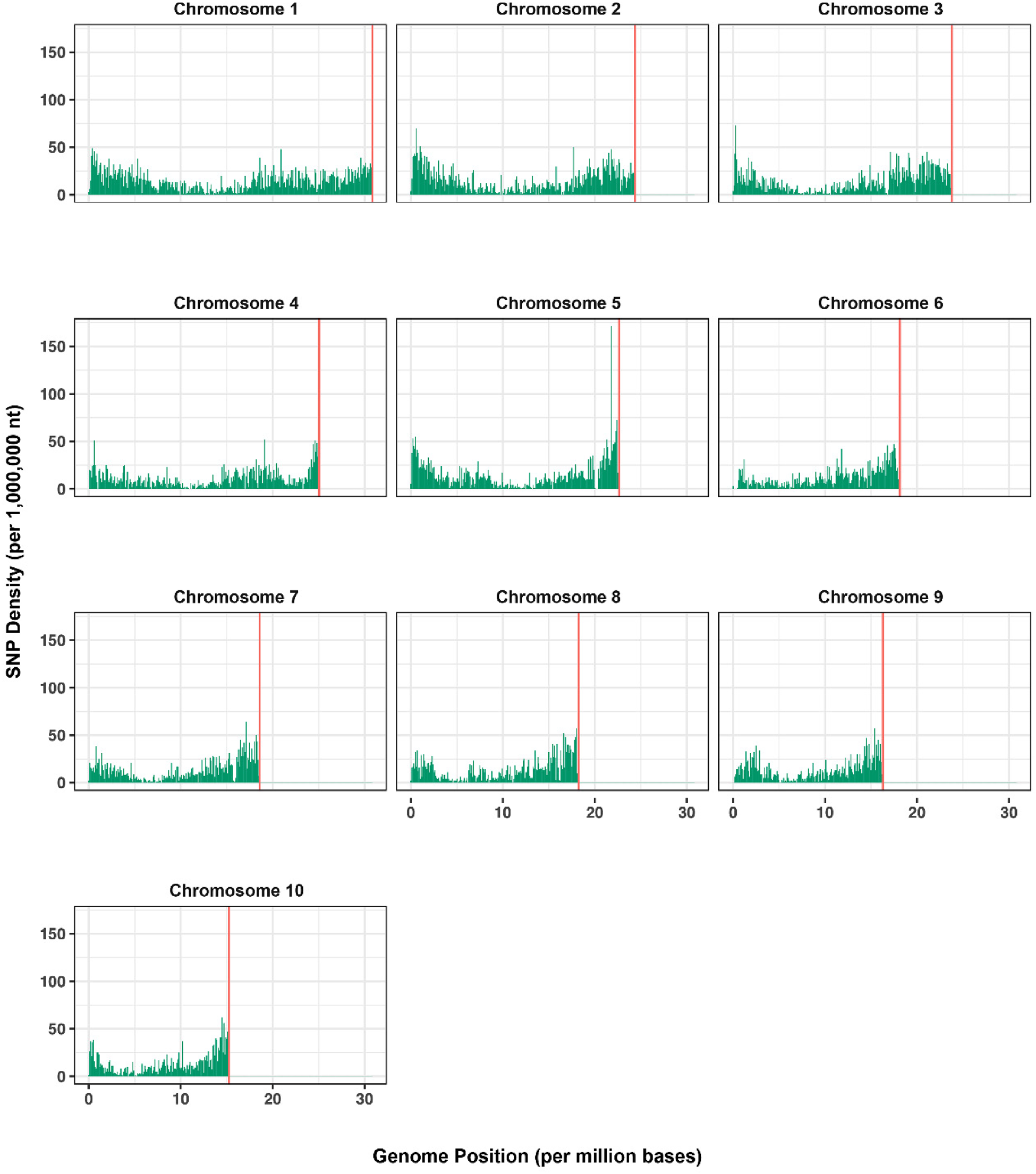
Total demultiplexed reads was 93.6M, with good barcoded reads representing 99.9%; and the average reads per each of the 25 maize accessions was 3.7M. We obtained 1,227,622 tags, of which 88.8% uniquely aligned to the Z.mays genome. Following the approach of Arbizu et al. (Reference Arbizu, Ellison, Senalik, Simon and Spooner2016), a total of 122,025 raw SNPs were detected, and after filtering a total of 29,332 SNPs were retained across the 10 chromosomes of maize with an average SNP density of 73.92 kb (online Supplementary Fig. S1, Table S2). Chromosome 1 presented the highest number of physically mapped SNPs (15.91%, 4668 SNPs). The highest and lowest marker densities were reported for chromosomes 4 (91.33 kb) and 2, respectively (online Supplementary Table S2).
SNP-based genetic diversity analysis
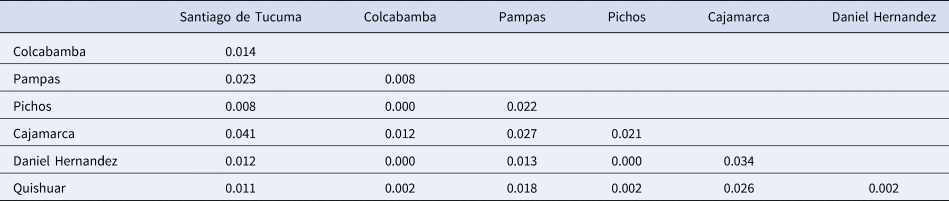
Diversity analysis showed different values among the seven populations (Table 1). The analysis of allelic patterns (N A) ranged from 1.55 (Pichos) to 1.91 (Cajamarca). The allelic richness (i.e. number of alleles per locus), which is a strong indication for the evolutionary potential of a population (Caballero and García-Dorado, Reference Caballero and García-Dorado2013), varied from 1.32 (Pichos) to 1.38 (Cajamarca). The frequency of heterozygous maize individuals (H O) ranged from 0.25 (Cajamarca) to 0.29 (Santiago de Tucuma and Colcabamba), respectively. Genetic diversity index (i.e. expected heterozygosity) varied from 0.33 (Pichos) to 0.38 (Cajamarca). Shannon–Wiener index allowed to distinguish the variation level between populations of maize and varied from 0.69 (Colcabamba and Pichos) to 1.79 (Cajamarca). Inbreeding coefficients (F IS) exhibited high values (0.21–0.38) (Table 1), indicating inbreeding for the maize populations. In general, fixation indices (F ST) were very low in general, suggesting a limited degree of differentiation among maize populations. A value of zero was observed between the populations of Colcabamba versus Pichos and Colcabamba versus Daniel Hernandez. Population divergence between population Santiago de Tucuma and Cajamarca revealed the highest genetic difference (0.041) (Table 2).
Indices of genetic diversity of 25 Peruvian starchy maize accessions based on 29,332 SNPs
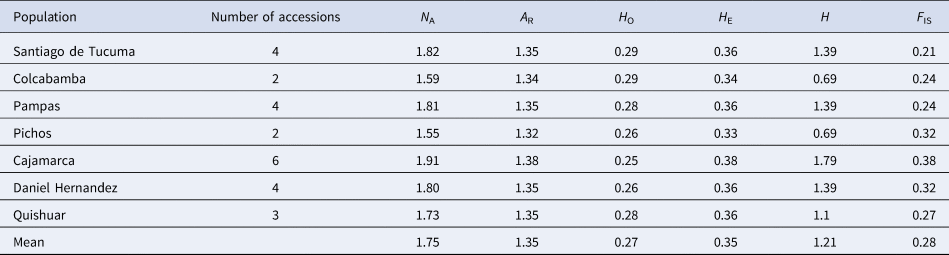
N A, number of different alleles; A R, allelic richness; H O, observed heterozygosity; H E, expected heterozygosity; H, Shannon–Wiener index; F IS, inbreeding coefficient.
Population differentiation depicted by fixation index (F ST) analysis of starchy Peruvian maize from Cajamarca and Huancavelica based on 29,332 SNPs
Genetic structure and inter-relationship
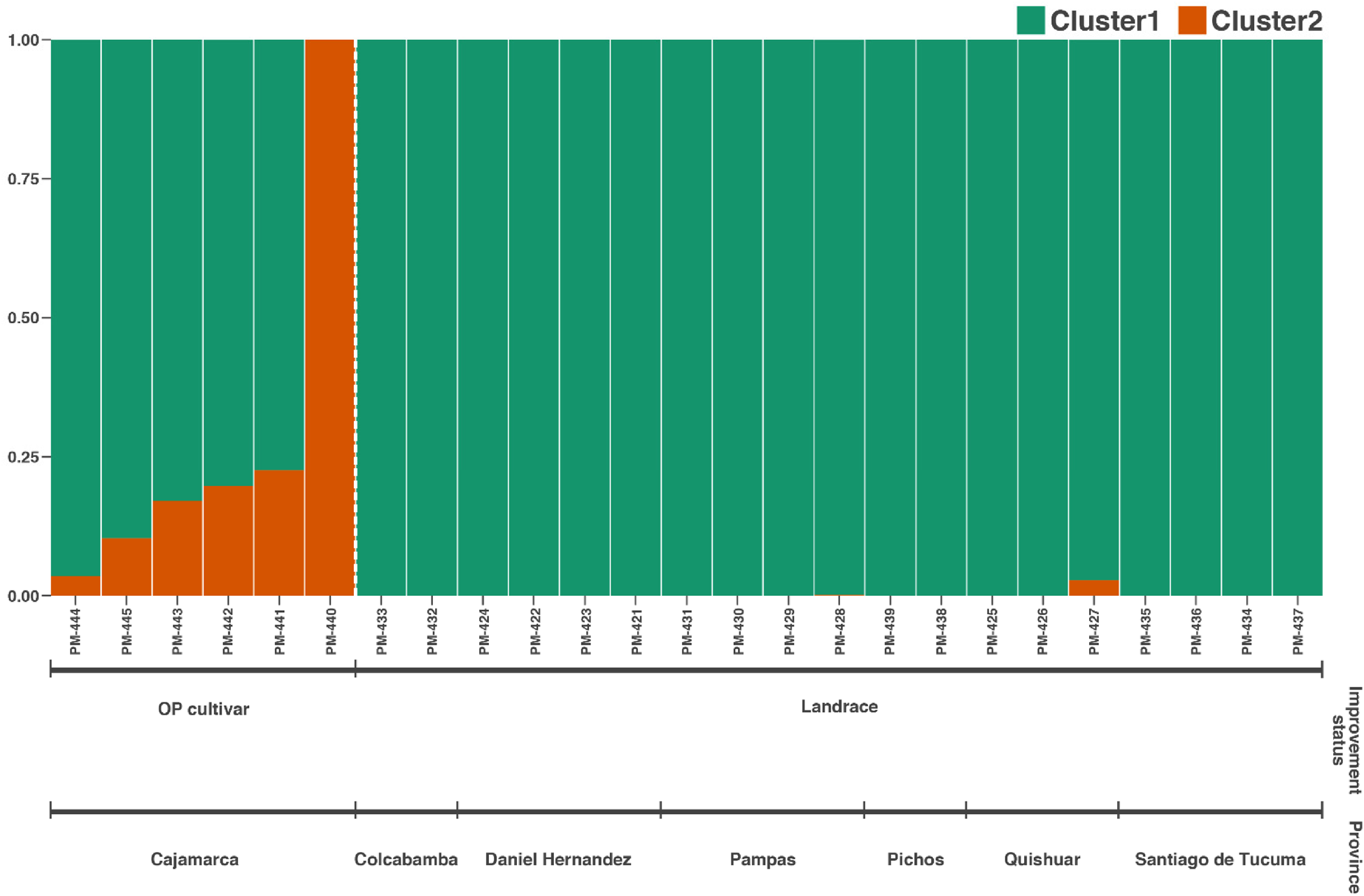
The Evanno method identified the best K value (number of populations) is two for our data set (online Supplementary Fig. S2). Maize accessions did not cluster according to their geographic origin (Fig. 1, online Supplementary Table S3). Interestingly, all landraces of starchy corn correspond to cluster 1. On the other hand, accession PM-440 which is an OP cultivar is the only material that belongs to cluster 2; the other OP cultivars present admixture (Fig. 1).
Genome density plot of 29,332 SNPs in the maize genome.
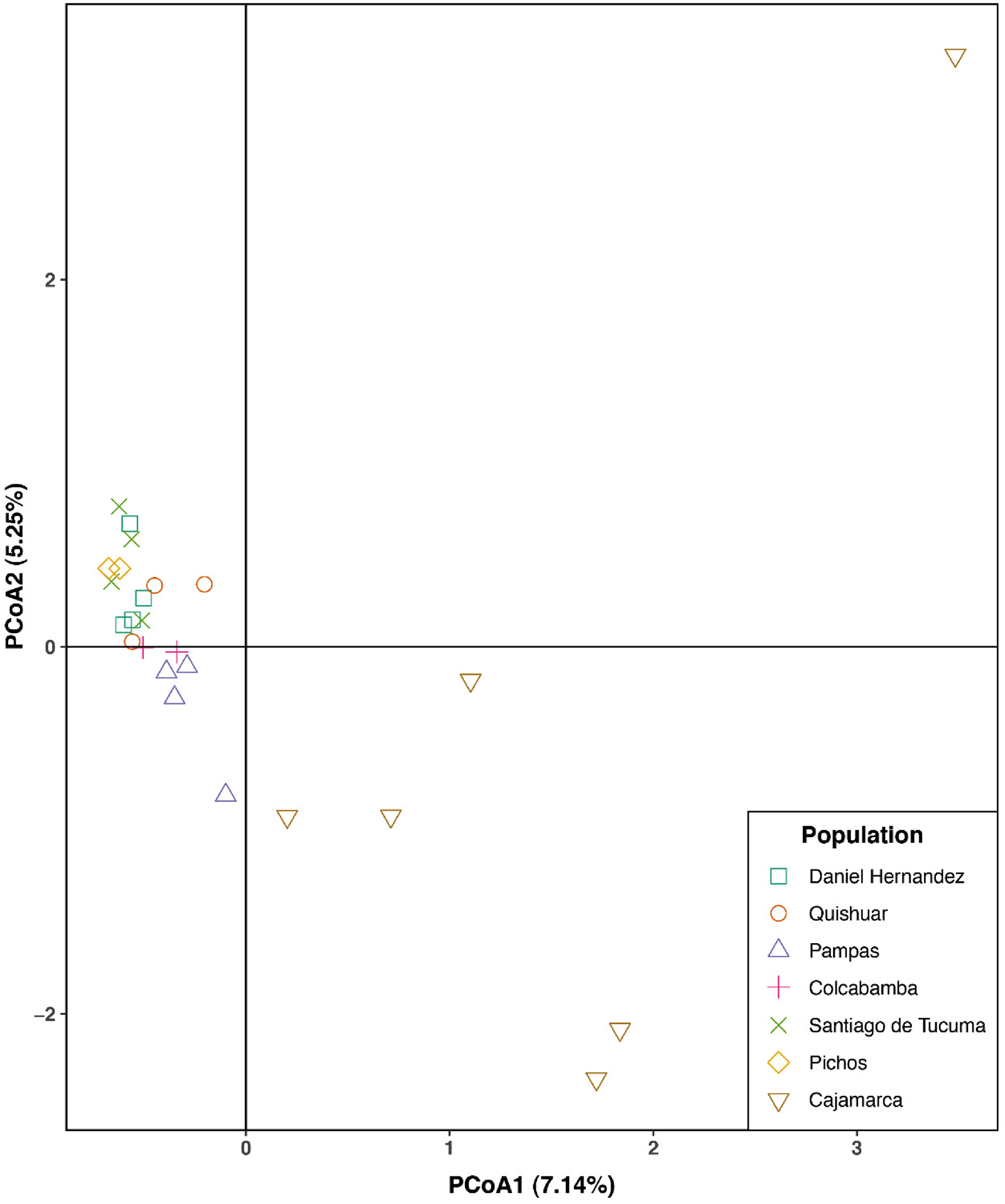
Our PCoA showed the first and second axis explained 7.14 and 5.25% of the variance, respectively, and concordant to our STRUCTURE results, PCoA resolved two clusters based on Provesti's genetic distance among all the 25 maize accessions of starchy maize (Fig. 2). All landrace accessions of starchy maize are grouped together, except for one from Pampas. Interestingly, all maize individuals from Cajamarca, which are OP cultivars are not grouping with the maize landraces. That is, grouping is based on the improvement status of these starchy maize. The phylogenetic tree constructed on the UPGMA algorithm depicted two main clades. Clade 1 contains landrace accessions from six locations (Daniel Hernandez, Quishuar, Pampas, Colcabamba, Santiago de Tucuma, Pichos and Cajamarca) (one accession only, PM-444), while clade 2 consists only of OP cultivars from Cajamarca (online Supplementary Fig. S3).
Population structure of 25 Peruvian accessions of starchy maize showed by the STRUCTURE analysis using 29,332 SNP markers. Each vertical bar represents a maize individual and numbers on the y-axis correspond to the membership probability in each cluster.
According to the AMOVA results, the greatest genetic variation was observed within populations (97.15%), while 2.85% was reported for between populations (Table 3).
AMOVA between and within the populations of starchy maize

df, degree of freedom; SS, sum of squares; MS, mean squares; Est. Var., estimated variance; %, percentage of genetic variation.
Discussion
Maize is a staple food in the world, and it is very likely the Andean region of Peru harbours the largest morphological diversity of maize races in the world (Grobman et al., Reference Grobman, Salhuana, Sevilla and Mangelsdorf1961; Ministerio del Ambiente, 2018; Salvador-Reyes and Silva Clerici, Reference Salvador-Reyes and Silva Clerici2020; Salvador-Reyes et al., Reference Salvador-Reyes, Rebellato, Lima Pallone, Ferrari and Clerici2021). Most studies on these Peruvian races were mainly focused on morphological and chemical parameters (see Ortiz et al., Reference Ortiz, Sevilla, Alvarado and Crossa2008; Salvador-Reyes et al., Reference Salvador-Reyes, Rebellato, Lima Pallone, Ferrari and Clerici2021; Fuentes-Cardenas et al., Reference Fuentes-Cardenas, Cuba-Puma, Marcilla-Truyenque, Begazo-Gutiérrez, Zolla, Fuentealba, Shetty and Ranilla2022; Gálvez Ranilla et al., Reference Gálvez Ranilla, Zolla, Afaray-Carazas, Vera-Vega, Huanuqueño, Begazo-Gutiérrez, Chirinos, Pedreschi and Shetty2023). In addition, the genetic and population parameters of these races in Peru remain largely unknown. Currently, SNP marker is the choice for genetic analysis due to the multiple advantages it possesses, such as the abundant number of markers at a low cost that can be generated (Close et al., Reference Close, Bhat, Lonardi, Wu, Rostoks, Ramsay, Druka, Stein, Svensson, Wanamaker, Bozdag, Roose, Moscou, Chao, Varshney, Szucs, Sato, Hayes, Matthews, Kleinhofs, Muehlbauer, DeYoung, Marshall, Madishetty, Fenton, Condamine, Graner and Waugh2009; Nantongo et al., Reference Nantongo, Odoi, Agaba and Gwali2022). Identification of SNP markers through the GBS protocol is currently conducted in the field of plant breeding (He et al., Reference He, Zhao, Laroche, Lu, Liu and Li2014). In fact, this GBS methodology has been widely applied successfully in genetic diversity studies such as switchgrass (Panicum virgatum L.) (Lu et al., Reference Lu, Lipka, Glaubitz, Elshire, Cherney, Casler, Buckler and Costich2013), yellow mustard (Sinapis alba L.) (Fu et al., Reference Fu, Cheng and Peterson2014), pepper (Capsicum spp.) (Pereira-Dias et al., Reference Pereira-Dias, Vilanova, Fita, Prohens and Rodríguez-Burruezo2019), tomato (Solanum lycopersicum Mill.) (Kandel et al., Reference Kandel, Bedre, Mandadi, Crosby and Avila2019), maize (Wang et al., Reference Wang, Yuan, Wang, Yu, Liu, Zhang, Gowda, Nair, Hao, Lu, San Vicente, Prasanna, Li and Zhang2020), potatoes (Solanum tuberosum L.) (Xiao et al., Reference Xiao, Zhang, Jin and Si2023) and tarwi (Lupinus mutabilis Sweet) (Huaringa-Joaquin et al., Reference Huaringa-Joaquin, Saldaña, Saravia, García-Bendezú, Rodriguez-Grados, Salazar, Camarena, Injante and Arbizu2023), among others. Here, we employed for the first time the GBS approach to infer the genetic structure and diversity of landraces of maize from two geographical regions of Peru, Cajamarca and Huancavelica.
Genetic diversity of starchy maize of these two geographic locations is high, which is concordant with previous studies on races of maize. Reif et al. (Reference Reif, Warburton, Xia, Hoisington, Crossa, Taba, Muminović, Bohn, Frisch and Melchinger2006) employed 25 simple sequence repeat (SSR) markers to determine the genetic diversity and the relationship of 25 accessions of races of Mexico, and they found a high total number of alleles (7.84 alleles per locus) and an average gene diversity of 0.61. In a more comprehensive work, Vigouroux et al. (Reference Vigouroux, Glaubitz, Matsuoka, Goodman, Sánchez and Doebley2008) inferred the population genetic structure of 964 individuals that corresponded 350 maize races with 96 microsatellites, reporting a very high genetic diversity for the Andean maize (0.71). However, this is slightly lower than the value reported for races of maize from highland Mexico and Tropical lowland. Similarly, genetic diversity levels in Mexican maize populations were high based on the characterization conducted with 28 SSR markers (Bedoya et al., Reference Bedoya, Dreisigacker, Hearne, Franco, Mir, Prasanna, Taba, Charcosset and Warburton2017). On the contrary, molecular evaluation of the Peruvian starchy maize landraces is still very limited. Blas et al. (Reference Blas, Ribaut, Warburton, Chura and Sevilla2000) analysed 36 accessions of the Germplasm Bank of La Molina National Agrarian University (UNALM for its acronym in Spanish) with amplified fragment length polymorphism and SSR markers and concluded that race San Gerónimo and Piscorunto are very closely related. The most recent work at the molecular level of Peruvian maize included six races (83 accessions in total) from Cusco. Catalán et al. (Reference Catalán, Blas, Catalán, Pompeyo, Bazo, Catalán, Blas and Flores2019) employed eight SSR in their work and indicated those maize races present high levels of variability. In a more recent study, Arbizu et al. (Reference Arbizu, Soto, Flores, Ortiz, Blas, García-Mendoza, Sevilla, Crossa and Grobman2025) used about 14,000 SNPs and demonstrated that maize from the Andes of Peru possess very high genetic diversity (H E = 0.35), which is concordant with the present study.
Our study revealed a clear separation between landraces and OP cultivars of starchy Peruvian maize. Similarly, Warburton et al. (Reference Warburton, Reif, Frisch, Bohn, Bedoya, Xia, Crossa, Franco, Hoisington, Pixley, Taba and Melchinger2008), who used 25 SSR markers, reported PCoA separated the improved germplasm of CIMMYT maize breeding programme from the Mexican landraces. Gene differentiation (G ST) also showed tremendous difference in maize landraces compared to OP cultivars, which is explained by the breeding methodology followed by CIMMYT (Warburton et al., Reference Warburton, Reif, Frisch, Bohn, Bedoya, Xia, Crossa, Franco, Hoisington, Pixley, Taba and Melchinger2008). Furthermore, inbred lines of Chilean choclero maize were separated from landraces, according to the multivariate analysis with 10 SSR markers conducted by Salazar et al. (Reference Salazar, González, Araya, Mejía and Carrasco2017). They argued this separation is due to the selection pressure employed by farmers and by natural selection, and by maize breeders. Similarly, the separation found in the present work is very likely due to the intense of selection used by farmers in Peru. Landraces of starchy Peruvian maize were mainly developed following a low selection pressure while OP cultivars with a high selection intensity. Genetic drift may be another factor causing this distinction. Individuals from Cajamarca, which are OP cultivars presented the highest genetic diversity indices compared to the landraces of starchy maize, reflecting the breeding methodology employed by the INIA of Peru. That is, maize breeders from INIA commonly mix germplasm from different races known as ‘compuesto racial’ (Sevilla, Reference Sevilla, Johannessen and Hastorf1994) to develop breeding populations, creating an abundant amount of intra-population diversity. Then, INIA maize breeders conduct selection to develop OP cultivars of maize (López Alejandría, Reference López Alejandría2011; Zambrano et al., Reference Zambrano, Yánez and Sangoquiza2021). Similarly, Salazar et al. (Reference Salazar, González, Araya, Mejía and Carrasco2017) assessed the intra-racial genetic structure of 34 Chilean Choclero corn landraces and 22 inbred lines with 10 SSRs, and they reported inbred lines possessed higher gene diversity than the landraces. Moreover, they indicated most inbred lines are derived from Choclero landraces (Fig. 3).
Principal coordinate analysis (PCoA) of 25 starchy maize from seven provinces of Peru. Percentages of variance explained is in parentheses.
A low degree of differentiation was observed between the populations of landraces from Huancavelica, indicating a low population structure, which is concordant with other studies for Mexican races of maize (McLean-Rodríguez et al., Reference McLean-Rodríguez, Costich, Camacho-Villa, Pè and Dell'Acqua2021). This may be explained by the levels of breeding as this plant species depends mainly on cross-pollination (Ma et al., Reference Ma, Subedi and Reid2004). In addition, the low F IS values reflected low degree of inbreeding that the starchy Peruvian landraces possess. Moreover, the greatest variation that is present within the population of these landraces may be explained by the gene flow among them as they are cultivated in a restricted geographical area, and also due to frequent seed exchange that growers usually perform.
Crop diversity is of vital importance for researchers, plant breeders and farmers (Dempewolf et al., Reference Dempewolf, Krishnan and Guarino2023). However, this variability has not been widely employed in breeding programmes as there is a lack of information on germplasm characterization and gene banks (McCouch et al., Reference McCouch, Navabi, Abberton, Anglin, Barbieri, Baum, Bett, Booker, Brown, Bryan, Cattivelli, Charest, Eversole, Freitas, Ghamkhar, Grattapaglia, Henry, Valadares Inglis, Islam, Kehel, Kersey, King, Kresovich, Marden, Mayes, Ndjiondjop, Nguyen, Paiva, Papa, Phillips, Rasheed, Richards, Rouard, Amstalden Sampaio, Scholz, Shaw, Sherman, Staton, Stein, Svensson, Tester, Montenegro Valls, Varshney, Visscher, von Wettberg, Waugh, Wenzl and Rieseberg2020). Currently, Peruvian maize landraces have not been fully exploited due to the lack of information of their potential. Previous work demonstrated maize landraces possess unique alleles that may be employed for maize improvement (Warburton et al., Reference Warburton, Reif, Frisch, Bohn, Bedoya, Xia, Crossa, Franco, Hoisington, Pixley, Taba and Melchinger2008; Salazar et al., Reference Salazar, González, Araya, Mejía and Carrasco2017) under the current climate change context. Here, we employed a reduced number of races and accessions of the Peruvian maize. However, our research group is expanding the Peruvian germplasm characterization and conservation of additional starchy maize races and accessions with genomic tools. This approach has been recognized as effective for plant biodiversity characterization and breeding (Abberton et al., Reference Abberton, Batley, Bentley, Bryant, Cai, Cockram, de Oliveira A, Cseke, Dempewolf, De Pace, Edwards, Gepts, Greenland, Hall, Henry, Hori, Howe, Hughes, Humphreys, Lightfoot, Marshall, Mayes, Nguyen, Ogbonnaya, Ortiz, Paterson, Tuberosa, Valliyodan, Varshney and Yano2016; Theissinger et al., Reference Theissinger, Fernandes, Formenti, Bista, Berg, Bleidorn, Bombarely, Crottini, Gallo, Godoy, Jentoft, Malukiewicz, Mouton, Oomen, Paez, Palsbøll, Pampoulie, Ruiz-López, Secomandi, Svardal, Theofanopoulou, de Vries, Waldvogel, Zhang, Jarvis, Bálint, Ciofi, Waterhouse, Mazzoni, Höglund, Aghayan, Alioto, Almudi, Alvarez, Alves, Amorim do Rosario, Antunes, Arribas, Baldrian, Bertorelle, Böhne, Bonisoli-Alquati, Boštjančić, Boussau, Breton, Buzan, Campos, Carreras, Castro, Chueca, Čiampor, Conti, Cook-Deegan, Croll, Cunha, Delsuc, Dennis, Dimitrov, Faria, Favre, Fedrigo, Fernández, Ficetola, Flot, Gabaldón, Agius, Giani, Gilbert, Grebenc, Guschanski, Guyot, Hausdorf, Hawlitschek, Heintzman, Heinze, Hiller, Husemann, Iannucci, Irisarri, Jakobsen, Klinga, Kloch, Kratochwil, Kusche, Layton, Leonard, Lerat, Liti, Manousaki, Marques-Bonet, Matos-Maraví, Matschiner, Maumus, Mc Cartney, Meiri, Melo-Ferreira, Mengual, Monaghan, Montagna, Mysłajek, Neiber, Nicolas, Novo, Ozretić, Palero, Pârvulescu, Pascual, Paulo, Pavlek, Pegueroles, Pellissier, Pesole, Primmer, Riesgo, Rüber, Rubolini, Salvi, Seehausen, Seidel, Studer, Theodoridis, Thines, Urban, Vasemägi, Vella, Vella, Vernes, Vernesi, Vieites, Wheat, Wörheide, Wurm and Zammit2023). Furthermore, future work may include the pangenomics of Peruvian maize from the highlands to capture the genetic variability through the whole genome assemblies and their comparative analysis from multiple maize accessions. We will also include genome-wide association analysis of the nutritional traits of the maize grain as some races are widely consumed across the Peruvian Andean population; however, the nutritional contributions in the human population are unknown. In addition, we expect this work will stimulate the use of modern molecular tools in favour of the study of the Peruvian native crops. This study could also contribute to guiding the use of the accessions evaluated in future plant breeding works with starchy corn.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S1479262125000024
Acknowledgements
We acknowledge the University of Minnesota Genomics Center for providing facilities and services. The authors also appreciate the Bioinformatics High-performance Computing server of Universidad Nacional Agraria la Molina (BioHPC-UNALM) for providing resources to perform the analyses. C. I. A. is grateful to Vicerrectorado de Investigación of UNTRM.









 Open access
Open access