
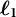


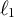
Multidimensional item response theory (MIRT) provides a framework in which responses to a set of items are explained by the items’ relation to a number of latent traits (Reckase, Reference Reckase2009). We assume that person i’s response to item j is influenced by L latent traits
 $\theta _{1i}, \dots , \theta _{Li}$
, where the influence strength is determined by discrimination parameters
$\theta _{1i}, \dots , \theta _{Li}$
, where the influence strength is determined by discrimination parameters
 $\alpha _{j1}, \dots , \alpha _{jL}$
similar to factor loadings in linear factor analysis. The discrimination parameters for all items and all traits are contained in the discrimination matrix
$\alpha _{j1}, \dots , \alpha _{jL}$
similar to factor loadings in linear factor analysis. The discrimination parameters for all items and all traits are contained in the discrimination matrix
 $\boldsymbol {\alpha }$
. The assumption of a number of latent traits—rather than just one, as in more traditional unidimensional item response models—is often considered more realistic in psychological research. Psychological constructs are often by definition composed of multiple subcomponents, or response behavior is assumed to be complex and multifactorial.
$\boldsymbol {\alpha }$
. The assumption of a number of latent traits—rather than just one, as in more traditional unidimensional item response models—is often considered more realistic in psychological research. Psychological constructs are often by definition composed of multiple subcomponents, or response behavior is assumed to be complex and multifactorial.
Multidimensional item response models can be divided into confirmatory and exploratory models, analogous to the factor analytical tradition (McDonald, Reference McDonald1999). While confirmatory models test the fit of a prespecified item–trait relationship structure to the data, exploratory models aim to determine which items stand in relation to which factors, for instance through rotation of the discrimination (or factor loadings) matrix
 $\boldsymbol {\alpha }$
. A common goal of this popular method is to find a simple structure, that is, an item–trait relationship structure where each item loads primarily onto one factor and not (or only to a small extent) on the remaining factors (Browne, Reference Browne2001; Thurstone, Reference Thurstone1947). An alternative strategy to this end—which has only recently gained popularity in the context of MIRT—is regularization (Cho et al., Reference Cho, Xiao, Wang and Xu2022; Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). Regularization includes techniques often originally developed for variable selection in (generalized) linear models (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). By including a penalty term in the model likelihood, sparse parameter estimates with many zeroes can be enforced. In comparison to unpenalized estimation, parameter values are shrunken toward 0, often improving predictive performance and model interpretation. In the context of MIRT, this leads to more parsimonious estimates of discrimination matrices
$\boldsymbol {\alpha }$
. A common goal of this popular method is to find a simple structure, that is, an item–trait relationship structure where each item loads primarily onto one factor and not (or only to a small extent) on the remaining factors (Browne, Reference Browne2001; Thurstone, Reference Thurstone1947). An alternative strategy to this end—which has only recently gained popularity in the context of MIRT—is regularization (Cho et al., Reference Cho, Xiao, Wang and Xu2022; Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). Regularization includes techniques often originally developed for variable selection in (generalized) linear models (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). By including a penalty term in the model likelihood, sparse parameter estimates with many zeroes can be enforced. In comparison to unpenalized estimation, parameter values are shrunken toward 0, often improving predictive performance and model interpretation. In the context of MIRT, this leads to more parsimonious estimates of discrimination matrices
 $\boldsymbol {\alpha }$
by selecting only notable item-trait relationships and shrinking the rest toward 0 (see also Trendafilov, Reference Trendafilov2014).
$\boldsymbol {\alpha }$
by selecting only notable item-trait relationships and shrinking the rest toward 0 (see also Trendafilov, Reference Trendafilov2014).
Research into regularization as a tool to find simply structured discrimination matrices
 $\boldsymbol {\alpha }$
in MIRT models has so far focused on models for binary and ordinal response data. But some psychometric tests and self-reports generate another type of response data: counts. For instance, divergent thinking and verbal fluency tasks (Myszkowski & Storme, Reference Myszkowski and Storme2021), or processing speed tasks (e.g., Doebler & Holling, Reference Doebler and Holling2016). Psychological count responses also occur among self-reports (e.g., in clinical psychology; Magnus & Thissen, Reference Magnus and Thissen2017; Wang, Reference Wang2010), or as biometric indicators (e.g., number of fixations in eye-tracking; Man & Harring, Reference Man and Harring2019). Count data naturally occur in text data analysis (Proksch & Slapin, Reference Proksch and Slapin2009). Corresponding count data item response models have received increasingly more attention in the psychometric literature in recent years (e.g., Beisemann, Reference Beisemann2022; Forthmann et al., Reference Forthmann, Gühne and Doebler2020; Graßhoff et al., Reference Graßhoff, Holling and Schwabe2020; Man & Harring, Reference Man and Harring2019).
$\boldsymbol {\alpha }$
in MIRT models has so far focused on models for binary and ordinal response data. But some psychometric tests and self-reports generate another type of response data: counts. For instance, divergent thinking and verbal fluency tasks (Myszkowski & Storme, Reference Myszkowski and Storme2021), or processing speed tasks (e.g., Doebler & Holling, Reference Doebler and Holling2016). Psychological count responses also occur among self-reports (e.g., in clinical psychology; Magnus & Thissen, Reference Magnus and Thissen2017; Wang, Reference Wang2010), or as biometric indicators (e.g., number of fixations in eye-tracking; Man & Harring, Reference Man and Harring2019). Count data naturally occur in text data analysis (Proksch & Slapin, Reference Proksch and Slapin2009). Corresponding count data item response models have received increasingly more attention in the psychometric literature in recent years (e.g., Beisemann, Reference Beisemann2022; Forthmann et al., Reference Forthmann, Gühne and Doebler2020; Graßhoff et al., Reference Graßhoff, Holling and Schwabe2020; Man & Harring, Reference Man and Harring2019).
The simplest count data item response model, Rasch’s Poisson Counts Model (RPCM; Rasch, Reference Rasch1960; see also, e.g., Holling et al., Reference Holling, Böhning and Böhning2015; Jansen, Reference Jansen1995; Jansen & van Duijn, Reference Jansen and van Duijn1992), models the expected count response
 $\mu _{ij}$
for person i to item j as
$\mu _{ij}$
for person i to item j as
 $\mu _{ij} = \exp (\delta _j + \theta _i)$
, where
$\mu _{ij} = \exp (\delta _j + \theta _i)$
, where
 $\delta _j$
is the item easiness and
$\delta _j$
is the item easiness and
 $\theta _i$
is the sole latent trait.Footnote 1 Conditional (upon
$\theta _i$
is the sole latent trait.Footnote 1 Conditional (upon
 $\theta _i$
) responses are assumed to follow a Poisson distribution. Extensions of the RPCM provided more general models, for example, by substituting the log-linear relationship in the RPCM by a sigmoid curve (Doebler et al., Reference Doebler, Doebler and Holling2014), or by addressing the conditional equidispersion implied by the Poisson distribution. Conditional equidispersion leads to the strong assumption that
$\theta _i$
) responses are assumed to follow a Poisson distribution. Extensions of the RPCM provided more general models, for example, by substituting the log-linear relationship in the RPCM by a sigmoid curve (Doebler et al., Reference Doebler, Doebler and Holling2014), or by addressing the conditional equidispersion implied by the Poisson distribution. Conditional equidispersion leads to the strong assumption that
 $\mathbb {E}(X_{ij} | \theta _i) = \mathbb {V}\text {ar}(X_{ij} | \theta _i)$
. Early extensions of the RPCM allowed overdispersed (i.e.,
$\mathbb {E}(X_{ij} | \theta _i) = \mathbb {V}\text {ar}(X_{ij} | \theta _i)$
. Early extensions of the RPCM allowed overdispersed (i.e.,
 $\mathbb {E}(X_{ij} | \theta _i) < \mathbb {V}\text {ar}(X_{ij} | \theta _i)$
) conditional response distributions (e.g., Hung, Reference Hung2012; Wang, Reference Wang2010). More recently, models for item-specific conditional equi-, over-, or underdispersion (i.e.,
$\mathbb {E}(X_{ij} | \theta _i) < \mathbb {V}\text {ar}(X_{ij} | \theta _i)$
) conditional response distributions (e.g., Hung, Reference Hung2012; Wang, Reference Wang2010). More recently, models for item-specific conditional equi-, over-, or underdispersion (i.e.,
 $\mathbb {E}(X_{ij} | \theta _i)> \mathbb {V}\text {ar}(X_{ij} | \theta _i)$
) were proposed by employing the more general Conway–Maxwell–Poisson (CMP) distribution (Conway & Maxwell, Reference Conway and Maxwell1962; Huang, Reference Huang2017; Shmueli et al., Reference Shmueli, Minka, Kadane, Borle and Boatwright2005). The Conway Maxwell Poisson Model (CMPCM; Forthmann et al., Reference Forthmann, Gühne and Doebler2020) has no discrimination parameters like a Rasch model, while the Two Parameter Conway Maxwell Poisson Model (2PCMPCM; Beisemann, Reference Beisemann2022) includes discrimination parameters. Qiao et al. (Reference Qiao, Jiao and He2023) propose a CMP-based joint modeling approach. Tutz (Reference Tutz2022) provides an alternative approach all together for dispersion handling. Regardless of the approach, the adequate consideration of dispersion for count data is important to ensure proper uncertainty quantification, i.e., correct standard errors and model-implied reliability (Forthmann et al., Reference Forthmann, Gühne and Doebler2020).
$\mathbb {E}(X_{ij} | \theta _i)> \mathbb {V}\text {ar}(X_{ij} | \theta _i)$
) were proposed by employing the more general Conway–Maxwell–Poisson (CMP) distribution (Conway & Maxwell, Reference Conway and Maxwell1962; Huang, Reference Huang2017; Shmueli et al., Reference Shmueli, Minka, Kadane, Borle and Boatwright2005). The Conway Maxwell Poisson Model (CMPCM; Forthmann et al., Reference Forthmann, Gühne and Doebler2020) has no discrimination parameters like a Rasch model, while the Two Parameter Conway Maxwell Poisson Model (2PCMPCM; Beisemann, Reference Beisemann2022) includes discrimination parameters. Qiao et al. (Reference Qiao, Jiao and He2023) propose a CMP-based joint modeling approach. Tutz (Reference Tutz2022) provides an alternative approach all together for dispersion handling. Regardless of the approach, the adequate consideration of dispersion for count data is important to ensure proper uncertainty quantification, i.e., correct standard errors and model-implied reliability (Forthmann et al., Reference Forthmann, Gühne and Doebler2020).
These generalizations have focused on unidimensional count item response models. Apart from bidimensional extensions of RPCM (Forthmann et al., Reference Forthmann, Çelik, Holling, Storme and Lubart2018, for a model without discrimination parameters, and Myszkowski & Storme, Reference Myszkowski and Storme2021, for a two-parameter Poisson model), multidimensional count data models have mostly been developed within the frameworks of generalized linear latent and mixed models (GLLAMM; Skrondal & Rabe-Hesketh, Reference Skrondal and Rabe-Hesketh2004) or factor analysis (Wedel et al., Reference Wedel, Böckenholt and Kamakura2003) rather than within MIRT. These works have primarily relied on the Poisson distribution, with Wedel et al. (Reference Wedel, Böckenholt and Kamakura2003) accomodating some flexibility through truncation of the Poisson distribution leading to underdispersion, and allowing different link functions.
With the present work, we aim to generalize the 2PCMPM (Beisemann, Reference Beisemann2022) to a multidimensional count data item response model framework which offers the advantages of multidimensional item response modeling for count data in conjunction with the dispersion flexibility of the CMP distribution. The framework contains a number of existing count data item response models as special cases, allowing for easy testing of assumptions by means of model comparisons. Our goal is further to provide marginal maximum likelihood estimation methods for the framework, with a focus on exploratory models. For these, interpretability of the discrimination matrix
 $\boldsymbol {\alpha }$
is a crucial goal and is aided by pursuing a simple structure for
$\boldsymbol {\alpha }$
is a crucial goal and is aided by pursuing a simple structure for
 $\boldsymbol {\alpha }$
. To this end, we explore both traditional rotation techniques (Browne, Reference Browne2001), and more novel regularization approaches (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). The remainder of the paper is structured as follows: In the next section, we introduce and formulate the proposed multidimensional count data item response model framework. We proceed to present marginal maximum likelihood estimation methods for the framework, based on the expectation-maximization (EM) algorithm (Dempster et al., Reference Dempster, Laird and Rubin1977). We present both unpenalized and penalized estimation methods. Afterward, we assess the proposed models and algorithms in a simulation study and illustrate the framework with a real-world application example. Finally, a discussion of the presented work is provided.
$\boldsymbol {\alpha }$
. To this end, we explore both traditional rotation techniques (Browne, Reference Browne2001), and more novel regularization approaches (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). The remainder of the paper is structured as follows: In the next section, we introduce and formulate the proposed multidimensional count data item response model framework. We proceed to present marginal maximum likelihood estimation methods for the framework, based on the expectation-maximization (EM) algorithm (Dempster et al., Reference Dempster, Laird and Rubin1977). We present both unpenalized and penalized estimation methods. Afterward, we assess the proposed models and algorithms in a simulation study and illustrate the framework with a real-world application example. Finally, a discussion of the presented work is provided.
1 Multidimensional Two-Parameter Conway–Maxwell–Poisson models
The tests and self-reports for which methods are developed in this article consist of count data items. Item scores are calculated by counting events or by aggregating across a large number of tasks each with a binary score. From each participant
 $i \in \{1, \dots , N\}$
, we obtain a response
$i \in \{1, \dots , N\}$
, we obtain a response
 $x_{ij}$
to each item
$x_{ij}$
to each item
 $j \in \{1, \dots , M\}$
, where
$j \in \{1, \dots , M\}$
, where
 $x_{ij} \in \mathbb {N}_0$
,
$x_{ij} \in \mathbb {N}_0$
,
 $\forall i \in \{1, \dots , N\}$
,
$\forall i \in \{1, \dots , N\}$
,
 $\forall j \in \{1, \dots , M\}$
. An example of such count data tests in the psychological literature are tests in the creative thinking literature which ask participants for different associations in response to items (e.g., the alternate uses task, AUT, to assess divergent thinking; see e.g., Forthmann et al., Reference Forthmann, Gühne and Doebler2020; Myszkowski & Storme, Reference Myszkowski and Storme2021 for psychometric analyses of AUT items). The associations given by each person i to each item j can be counted, resulting in the count response
$\forall j \in \{1, \dots , M\}$
. An example of such count data tests in the psychological literature are tests in the creative thinking literature which ask participants for different associations in response to items (e.g., the alternate uses task, AUT, to assess divergent thinking; see e.g., Forthmann et al., Reference Forthmann, Gühne and Doebler2020; Myszkowski & Storme, Reference Myszkowski and Storme2021 for psychometric analyses of AUT items). The associations given by each person i to each item j can be counted, resulting in the count response
 $x_{ij}$
.
$x_{ij}$
.
To model these count responses in an item response theory framework, we assume that the responses depend on item characteristics and L different latent traits
 $\theta _{li}$
for person i and trait
$\theta _{li}$
for person i and trait
 $l \in \{1, \dots , L\}$
. When
$l \in \{1, \dots , L\}$
. When
 $L> 1$
, the model is multidimensional. This assumption grants more flexibility as (1) unidimensional models are contained as special cases (for
$L> 1$
, the model is multidimensional. This assumption grants more flexibility as (1) unidimensional models are contained as special cases (for
 $L = 1$
) and (2) the assumption of more than one latent trait is often frequently more realistic and is often empirically supported. An overarching latent trait can be made up of different subdomains that influence item responses differently. Items may also share commonalities beyond the main unidimensional trait they measure, violating the local independence assumption in unidimensional models (in the AUT example, this could be different domains the items tap into like figural or verbal; Forthmann et al., Reference Forthmann, Çelik, Holling, Storme and Lubart2018; Myszkowski & Storme, Reference Myszkowski and Storme2021). In a multidimensional framework, this can be accounted for by modeling the item domains as different latent traits.
$L = 1$
) and (2) the assumption of more than one latent trait is often frequently more realistic and is often empirically supported. An overarching latent trait can be made up of different subdomains that influence item responses differently. Items may also share commonalities beyond the main unidimensional trait they measure, violating the local independence assumption in unidimensional models (in the AUT example, this could be different domains the items tap into like figural or verbal; Forthmann et al., Reference Forthmann, Çelik, Holling, Storme and Lubart2018; Myszkowski & Storme, Reference Myszkowski and Storme2021). In a multidimensional framework, this can be accounted for by modeling the item domains as different latent traits.
We propose to extend the recently proposed two-parameter Conway–Maxwell–Poisson model (2PCMPM; Beisemann, Reference Beisemann2022)—which models differing item discriminations and dispersions in a unidimensional model—to the multidimensional case. The proposed Multidimensional Two-Parameter Conway–Maxwell–Poisson Models (M2PCMPM) assumes a log-linear factor model for the expected count response:
 $\mu _{ij}$
$\mu _{ij}$
 $$ \begin{align} \mu_{ij} = \exp \left( \alpha_{j1} \theta_{1i} + \dots + \alpha_{jL} \theta_{Li} + \delta_j \right) = \exp \left( \sum_{l = 1}^L \alpha_{jl} \theta_{li} + \delta_j \right). \end{align} $$
$$ \begin{align} \mu_{ij} = \exp \left( \alpha_{j1} \theta_{1i} + \dots + \alpha_{jL} \theta_{Li} + \delta_j \right) = \exp \left( \sum_{l = 1}^L \alpha_{jl} \theta_{li} + \delta_j \right). \end{align} $$
In this extension of the slope-intercept parametrized 2PCMPM, we denote by
 $\alpha _{jl}$
the slope for item j and trait l, which quantifies the extent to which differences in the latent trait l are reflected in the expected responses to item j. The parameter
$\alpha _{jl}$
the slope for item j and trait l, which quantifies the extent to which differences in the latent trait l are reflected in the expected responses to item j. The parameter
 $\delta _j$
is the intercept for item j, which is related to—but does not directly correspond to—item j’s easiness. Analogously to the 2PCMPM, we then assume that responses follow a Conway–Maxwell–Poisson (CMP) distribution conditional on the L latent traits. We use the mean parameterization of the CMP distribution (Huang, Reference Huang2017), denoted as
$\delta _j$
is the intercept for item j, which is related to—but does not directly correspond to—item j’s easiness. Analogously to the 2PCMPM, we then assume that responses follow a Conway–Maxwell–Poisson (CMP) distribution conditional on the L latent traits. We use the mean parameterization of the CMP distribution (Huang, Reference Huang2017), denoted as
 $\text {CMP}_{\mu }$
. Thus, we assume that
$\text {CMP}_{\mu }$
. Thus, we assume that
 $$ \begin{align} P(x_{ij}; \boldsymbol{\theta}_i, \boldsymbol{\zeta}_j) = \text{CMP}_{\mu}(x_{ij}; \mu_{ij}, \nu_j) = \frac{\lambda(\mu_{ij}, \nu_j)^{x_{ij}}}{(x_{ij}!)^{\nu_j}} \frac{1}{Z(\lambda(\mu_{ij}, \nu_j), \nu_j)}, \end{align} $$
$$ \begin{align} P(x_{ij}; \boldsymbol{\theta}_i, \boldsymbol{\zeta}_j) = \text{CMP}_{\mu}(x_{ij}; \mu_{ij}, \nu_j) = \frac{\lambda(\mu_{ij}, \nu_j)^{x_{ij}}}{(x_{ij}!)^{\nu_j}} \frac{1}{Z(\lambda(\mu_{ij}, \nu_j), \nu_j)}, \end{align} $$
with
 $\boldsymbol {\theta }_i = (\theta _{1i}, \dots , \theta _{Li})^T$
denoting the L latent traits of person i,
$\boldsymbol {\theta }_i = (\theta _{1i}, \dots , \theta _{Li})^T$
denoting the L latent traits of person i,
 $\mu _{ij}$
as in Equation (1) and
$\mu _{ij}$
as in Equation (1) and
 $\nu _j$
as the item-specific dispersion parameter (
$\nu _j$
as the item-specific dispersion parameter (
 $\nu _j < 1$
implies overdispersed,
$\nu _j < 1$
implies overdispersed,
 $\nu _j> 1$
underdispersed, and
$\nu _j> 1$
underdispersed, and
 $\nu _j = 1$
equidispersed conditional responses). In Equation (2), the expression
$\nu _j = 1$
equidispersed conditional responses). In Equation (2), the expression
 $Z(\lambda (\mu _{ij}, \nu _j), \nu _j) = \sum _{x = 0}^{\infty } \lambda (\mu _{ij}, \nu _j)^x / (x!)^{\nu _j}$
is the normalizing constant of the
$Z(\lambda (\mu _{ij}, \nu _j), \nu _j) = \sum _{x = 0}^{\infty } \lambda (\mu _{ij}, \nu _j)^x / (x!)^{\nu _j}$
is the normalizing constant of the
 $\text {CMP}_{\mu }$
distribution (Huang, Reference Huang2017). For simpler notation, we denote all item parameters
$\text {CMP}_{\mu }$
distribution (Huang, Reference Huang2017). For simpler notation, we denote all item parameters
 $\alpha _{jl}$
,
$\alpha _{jl}$
,
 $\forall l$
,
$\forall l$
,
 $\delta _j$
, and
$\delta _j$
, and
 $\nu _j$
, for one item j concatenated in one vector with
$\nu _j$
, for one item j concatenated in one vector with
 $\boldsymbol {\zeta }_j$
. As Huang (Reference Huang2017) showed, we obtain the rate
$\boldsymbol {\zeta }_j$
. As Huang (Reference Huang2017) showed, we obtain the rate
 $\lambda (\mu _{ij}, \nu _j)$
by solving
$\lambda (\mu _{ij}, \nu _j)$
by solving
 $$ \begin{align} 0 = \sum_{x = 0}^{\infty} (x - \mu_{ij}) \frac{\lambda^{x}}{(x!)^{\nu_j}} \end{align} $$
$$ \begin{align} 0 = \sum_{x = 0}^{\infty} (x - \mu_{ij}) \frac{\lambda^{x}}{(x!)^{\nu_j}} \end{align} $$
for
 $\lambda$
.
$\lambda$
.
With the assumption of conditional independence given all L latent traits, the probability of the response vector
 $\textbf {x}_i = (x_{i1}, \dots , x_{iM})^T$
of person i is the product of Equation (2) for each item. The L latent traits
$\textbf {x}_i = (x_{i1}, \dots , x_{iM})^T$
of person i is the product of Equation (2) for each item. The L latent traits
 $\boldsymbol {\theta }_i$
for each person i jointly follow a multivariate normal distribution with mean vector
$\boldsymbol {\theta }_i$
for each person i jointly follow a multivariate normal distribution with mean vector
 $\boldsymbol {\mu }_{\theta } = \boldsymbol {0} \in \mathbb {R}^L$
and covariance matrix
$\boldsymbol {\mu }_{\theta } = \boldsymbol {0} \in \mathbb {R}^L$
and covariance matrix
 $\boldsymbol {\Sigma }_{\theta }$
, where
$\boldsymbol {\Sigma }_{\theta }$
, where
 $\boldsymbol {\Sigma }_{\theta }$
is a full rank
$\boldsymbol {\Sigma }_{\theta }$
is a full rank
 $L \times L$
matrix with all diagonal entries equal to 1 for model identification purposes (more details on assumptions for
$L \times L$
matrix with all diagonal entries equal to 1 for model identification purposes (more details on assumptions for
 $\boldsymbol {\Sigma }_{\theta }$
follow in section Latent Trait Covariance Matrix). Assuming that persons respond independently of each other, we obtain
$\boldsymbol {\Sigma }_{\theta }$
follow in section Latent Trait Covariance Matrix). Assuming that persons respond independently of each other, we obtain
 $$ \begin{align} L_m(\boldsymbol{\zeta}; \mathbf{x}) = \prod_{i = 1}^{N} \int \dots \int \prod_{j=1}^M P(x_{ij}; \boldsymbol{\theta}_i, \boldsymbol{\zeta}_j) \Psi(\boldsymbol{\theta}_i; \boldsymbol{\mu}_{\theta}, \boldsymbol{\Sigma}_{\theta}) d \theta_{1i} \dots d \theta_{Li}, \end{align} $$
$$ \begin{align} L_m(\boldsymbol{\zeta}; \mathbf{x}) = \prod_{i = 1}^{N} \int \dots \int \prod_{j=1}^M P(x_{ij}; \boldsymbol{\theta}_i, \boldsymbol{\zeta}_j) \Psi(\boldsymbol{\theta}_i; \boldsymbol{\mu}_{\theta}, \boldsymbol{\Sigma}_{\theta}) d \theta_{1i} \dots d \theta_{Li}, \end{align} $$
as the marginal likelihood for the data
 $\textbf {x}$
of all N respondents, where
$\textbf {x}$
of all N respondents, where
 $\Psi $
denotes the density of the multivariate normal distribution and
$\Psi $
denotes the density of the multivariate normal distribution and
 $\boldsymbol {\zeta }$
denotes the item parameters
$\boldsymbol {\zeta }$
denotes the item parameters
 $\{\boldsymbol {\zeta }_1, \dots , \boldsymbol {\zeta }_M\}$
for all M items. The M2PCMPM contains a number of count data item response models as special cases which we list in Appendix C. In the following, we focus on exploratory M2PCMPMs, but see Appendix C for a note on confirmatory M2PCMPM within this framework.
$\{\boldsymbol {\zeta }_1, \dots , \boldsymbol {\zeta }_M\}$
for all M items. The M2PCMPM contains a number of count data item response models as special cases which we list in Appendix C. In the following, we focus on exploratory M2PCMPMs, but see Appendix C for a note on confirmatory M2PCMPM within this framework.
1.1 Model identification
The full M2PCMPM as presented in Equation (1) constitutes an exploratory multidimensional item response model: Any item can be associated by any degree with any latent trait. For this reason, the full M2PCMPM as in Equation (1) is not uniquely identified; it is rotationally indeterminate. To enable estimation, we thus need to impose identification constraints on the discrimination matrix
 $\boldsymbol {\alpha }$
. A common constraint is a triangular
$\boldsymbol {\alpha }$
. A common constraint is a triangular
 $(L-1) \times (L-1)$
submatrix of zeroes in the discrimination matrix (as we believe is, for example, implemented in the mirt package; Chalmers, Reference Chalmers2012), i.e., we impose constraints to
$(L-1) \times (L-1)$
submatrix of zeroes in the discrimination matrix (as we believe is, for example, implemented in the mirt package; Chalmers, Reference Chalmers2012), i.e., we impose constraints to
 $L-1$
out of the M items to fix rotational indeterminacy. W.l.o.g., let these be the first
$L-1$
out of the M items to fix rotational indeterminacy. W.l.o.g., let these be the first
 $L-1$
items.
$L-1$
items.
 $\alpha _{j1}$
on the first trait is estimated freely and
$\alpha _{j1}$
on the first trait is estimated freely and
 $\forall \alpha _{jl'} = 0, l' \in \{2, \dots , L\}$
. For the following items
$\forall \alpha _{jl'} = 0, l' \in \{2, \dots , L\}$
. For the following items
 $j \in \{2, \dots , L-1\}$
, the first j discriminations are free and we constrain
$j \in \{2, \dots , L-1\}$
, the first j discriminations are free and we constrain
 $\forall \alpha _{jl'} = 0, l' \in \{j+1, \dots , L\}$
. In the following, this constraint will be referred to as the upper-triangle identification constraint. See, e.g., Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016, for examples, of alternative constraints. Note that imposing too strong or empirically insensible constraints may impact the model fit (negatively) (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). Identification constraints are imposed upon initial estimation to enable finding a likelihood mode. When rotating the initial solution, constraints are lifted, and the discrimination matrix
$\forall \alpha _{jl'} = 0, l' \in \{j+1, \dots , L\}$
. In the following, this constraint will be referred to as the upper-triangle identification constraint. See, e.g., Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016, for examples, of alternative constraints. Note that imposing too strong or empirically insensible constraints may impact the model fit (negatively) (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). Identification constraints are imposed upon initial estimation to enable finding a likelihood mode. When rotating the initial solution, constraints are lifted, and the discrimination matrix
 $\boldsymbol {\alpha }$
is rotated freely.
$\boldsymbol {\alpha }$
is rotated freely.
2 Marginal maximum likelihood estimation methods for the M2PCMPM
The goal of (frequentist) model estimation of the M2PCMPM is to maximize the model’s marginal likelihood (Equation (4)) in terms of item parameters
 $\boldsymbol {\zeta }$
. An elegant and popular approach to marginal likelihood estimation in the context of item response models is the EM algorithm (Dempster et al., Reference Dempster, Laird and Rubin1977; for an introduction see McLachlan & Krishnan, Reference McLachlan and Krishnan2007; see Bock & Aitkin, Reference Bock and Aitkin1981 for the first IRT application). The expected complete-data likelihood—rather than the observed marginal likelihood—is determined in each expectation (E) step. It includes unobservable parameters, i.e., the latent traits. The expected complete-data likelihood is maximized in each maximization (M) step. E and M steps are repeated until a convergence criterion is met.
$\boldsymbol {\zeta }$
. An elegant and popular approach to marginal likelihood estimation in the context of item response models is the EM algorithm (Dempster et al., Reference Dempster, Laird and Rubin1977; for an introduction see McLachlan & Krishnan, Reference McLachlan and Krishnan2007; see Bock & Aitkin, Reference Bock and Aitkin1981 for the first IRT application). The expected complete-data likelihood—rather than the observed marginal likelihood—is determined in each expectation (E) step. It includes unobservable parameters, i.e., the latent traits. The expected complete-data likelihood is maximized in each maximization (M) step. E and M steps are repeated until a convergence criterion is met.
2.1 Expectation-maximization algorithm
As the M2PCMPM is an extension of the 2PCMPM, estimation methods for the 2PCMPM can be extended to develop estimation methods for the M2PCMPM. Beisemann (Reference Beisemann2022) provided an EM algorithm for the 2PCMPM which we use as the basis for proposing EM algorithms for the M2PCMPM. The integral in Equation (4) does not exist in closed form and thus has to be approximated in estimation, for example, by Gauss–Hermite quadrature with fixed quadrature points. Relying on such a Gauss–Hermite quadrature for the integral approximation with
 $K^L$
quadrature points, we generalize the expected complete-data log likelihood of the 2PCMPM (Beisemann, Reference Beisemann2022) to
$K^L$
quadrature points, we generalize the expected complete-data log likelihood of the 2PCMPM (Beisemann, Reference Beisemann2022) to
 $L \geq 1$
latent traits for the expected complete-data log likelihood of the M2PCMPM:
$L \geq 1$
latent traits for the expected complete-data log likelihood of the M2PCMPM:
 $$ \begin{align} \mathbb{E}(LL_c) \propto \sum_{k_L = 1}^{K} \dots &\sum_{k_2 = 1}^{K} \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \sum_{j = 1}^{M} ( x_{ij} \log(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j)) - \nu_j \log(x_{ij}!)\notag \\ &- \log (Z(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j), \nu_j)) ) P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}'), \end{align} $$
$$ \begin{align} \mathbb{E}(LL_c) \propto \sum_{k_L = 1}^{K} \dots &\sum_{k_2 = 1}^{K} \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \sum_{j = 1}^{M} ( x_{ij} \log(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j)) - \nu_j \log(x_{ij}!)\notag \\ &- \log (Z(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j), \nu_j)) ) P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}'), \end{align} $$
where
 $LL_c$
denotes the complete-data log likelihood, and
$LL_c$
denotes the complete-data log likelihood, and
 $$ \begin{align} \mu_{jk_1,\dots,k_L} = \exp(\alpha_{j1} q_{k_1} + \dots + \alpha_{jl} q_{k_l} + \dots + \alpha_{jL} q_{k_L} + \delta_j), \end{align} $$
$$ \begin{align} \mu_{jk_1,\dots,k_L} = \exp(\alpha_{j1} q_{k_1} + \dots + \alpha_{jl} q_{k_l} + \dots + \alpha_{jL} q_{k_L} + \delta_j), \end{align} $$
with
 $k_l \in \{1, \dots , K\}$
as the node index for trait l. Here, the joint posterior probability of the multidimensional quadrature point
$k_l \in \{1, \dots , K\}$
as the node index for trait l. Here, the joint posterior probability of the multidimensional quadrature point
 $(q_{k_1}, \dots , q_{k_L})$
is given by
$(q_{k_1}, \dots , q_{k_L})$
is given by
 $$ \begin{align} P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}') = \frac{\prod_{j = 1}^M \text{CMP}_{\mu}(x_{ij} | q_{k_1}, \dots, q_{k_L}, \boldsymbol{\zeta}_j^{\prime}) w_{k_1} \dots w_{k_L}}{\sum_{{k^{\prime}_1} = 1}^K \dots \sum_{{k^{\prime}_L} = 1}^K \prod_{j = 1}^M \text{CMP}_{\mu}(x_{ij} | q_{k^{\prime}_1}, \dots, q_{k^{\prime}_L}, \boldsymbol{\zeta}_j^{\prime}) w_{k^{\prime}_1} \dots w_{k^{\prime}_L} }, \end{align} $$
$$ \begin{align} P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}') = \frac{\prod_{j = 1}^M \text{CMP}_{\mu}(x_{ij} | q_{k_1}, \dots, q_{k_L}, \boldsymbol{\zeta}_j^{\prime}) w_{k_1} \dots w_{k_L}}{\sum_{{k^{\prime}_1} = 1}^K \dots \sum_{{k^{\prime}_L} = 1}^K \prod_{j = 1}^M \text{CMP}_{\mu}(x_{ij} | q_{k^{\prime}_1}, \dots, q_{k^{\prime}_L}, \boldsymbol{\zeta}_j^{\prime}) w_{k^{\prime}_1} \dots w_{k^{\prime}_L} }, \end{align} $$
where with
 $w_{k_l}$
$w_{k_l}$
 $k_l \in \{1, \dots , K\}$
denote the nodes’ quadrature weights. The E step consists of computing Equation (7). In the subsequent M step, we maximize Equation (5) iteratively as a function of the item parameters
$k_l \in \{1, \dots , K\}$
denote the nodes’ quadrature weights. The E step consists of computing Equation (7). In the subsequent M step, we maximize Equation (5) iteratively as a function of the item parameters
 $\boldsymbol {\zeta }$
. To this end, we need to take the derivatives of Equation (5) with respect to the item parameters. We optimize in
$\boldsymbol {\zeta }$
. To this end, we need to take the derivatives of Equation (5) with respect to the item parameters. We optimize in
 $\log \nu _j$
rather than
$\log \nu _j$
rather than
 $\nu _j$
to search on an unconstrained parameter space (compare Beisemann, Reference Beisemann2022). Similar to the techniques in Beisemann (Reference Beisemann2022) and Huang (Reference Huang2017), we form derivatives (using some results from Huang, Reference Huang2017), resulting in gradients
$\nu _j$
to search on an unconstrained parameter space (compare Beisemann, Reference Beisemann2022). Similar to the techniques in Beisemann (Reference Beisemann2022) and Huang (Reference Huang2017), we form derivatives (using some results from Huang, Reference Huang2017), resulting in gradients
 $$ \begin{align} \frac{\partial \mathbb{E}(LL_c)}{\partial \alpha_{jl}} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \frac{q_{k_l} \mu_{jk_1,\dots,k_L}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} (x_{ij} - \mu_{jk_1,\dots,k_L}) P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}'), \end{align} $$
$$ \begin{align} \frac{\partial \mathbb{E}(LL_c)}{\partial \alpha_{jl}} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \frac{q_{k_l} \mu_{jk_1,\dots,k_L}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} (x_{ij} - \mu_{jk_1,\dots,k_L}) P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}'), \end{align} $$
for slopes
 $\alpha _{jl}$
(note that
$\alpha _{jl}$
(note that
 $q_{k_l}$
in the numerator of the fraction does not loop over all trait dimensions
$q_{k_l}$
in the numerator of the fraction does not loop over all trait dimensions
 $1$
to L, but instead is specific to dimension
$1$
to L, but instead is specific to dimension
 $l \in \{1, \dots , L\}$
for the slope
$l \in \{1, \dots , L\}$
for the slope
 $\alpha _{il}$
we are considering),
$\alpha _{il}$
we are considering),
 $$ \begin{align} \frac{\partial \mathbb{E}(LL_c)}{\partial \delta_j} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \frac{\mu_{jk_1,\dots,k_L}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} (x_{ij} - \mu_{jk_1,\dots,k_L}) P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}'), \end{align} $$
$$ \begin{align} \frac{\partial \mathbb{E}(LL_c)}{\partial \delta_j} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \frac{\mu_{jk_1,\dots,k_L}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} (x_{ij} - \mu_{jk_1,\dots,k_L}) P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}'), \end{align} $$
for intercepts
 $\delta _j$
, and
$\delta _j$
, and
 $$ \begin{align} \frac{\partial \mathbb{E}(LL_c)}{\partial \log \nu_j} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \nu_j &\left( A(\mu_{jk_1,\dots,k_L}, \nu_j) \frac{x_{ij} - \mu_{jk_1,\dots,k_L}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} - (\log(x_{ij}!) - B(\mu_{jk_1,\dots,k_L}, \nu_j)) \right)\notag \\ &\times P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}'), \end{align} $$
$$ \begin{align} \frac{\partial \mathbb{E}(LL_c)}{\partial \log \nu_j} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \nu_j &\left( A(\mu_{jk_1,\dots,k_L}, \nu_j) \frac{x_{ij} - \mu_{jk_1,\dots,k_L}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} - (\log(x_{ij}!) - B(\mu_{jk_1,\dots,k_L}, \nu_j)) \right)\notag \\ &\times P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}'), \end{align} $$
for log dispersions
 $\log \nu _j$
, with
$\log \nu _j$
, with
 $A(\mu _{jk_1,\dots ,k_L}, \nu _j) = \mathbb {E}_{X_j} (\log (X_j!)(X_j-\mu _{kj}))$
and
$A(\mu _{jk_1,\dots ,k_L}, \nu _j) = \mathbb {E}_{X_j} (\log (X_j!)(X_j-\mu _{kj}))$
and
 $B(\mu _{jk_1,\dots ,k_L}, \nu _j)) = \mathbb {E}_{X_j} (\log (X_j!))$
(Huang, Reference Huang2017). Furthermore,
$B(\mu _{jk_1,\dots ,k_L}, \nu _j)) = \mathbb {E}_{X_j} (\log (X_j!))$
(Huang, Reference Huang2017). Furthermore,
 $$ \begin{align} V(\mu_{jk_1,\dots,k_L}, \nu_j) = \sum_{x = 0}^{\infty} \frac{(x - \mu_{jk_1,\dots,k_L})^2\lambda(\mu_{jk_1,\dots,k_L}, \nu_j)^x}{(x!)^{\nu_j}Z(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j), \nu_j)}, \end{align} $$
$$ \begin{align} V(\mu_{jk_1,\dots,k_L}, \nu_j) = \sum_{x = 0}^{\infty} \frac{(x - \mu_{jk_1,\dots,k_L})^2\lambda(\mu_{jk_1,\dots,k_L}, \nu_j)^x}{(x!)^{\nu_j}Z(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j), \nu_j)}, \end{align} $$
(Huang, Reference Huang2017) is the variance of the
 $\text {CMP}_{\mu }$
distribution which depends on
$\text {CMP}_{\mu }$
distribution which depends on
 $\mu _{jk_1,\dots ,k_L}$
and
$\mu _{jk_1,\dots ,k_L}$
and
 $\nu _j$
.
$\nu _j$
.
A known limitation of quadrature is its poor scaling to high dimensions (McLachlan & Krishnan, Reference McLachlan and Krishnan2007); that is, in the context of the M2PCMPM, settings with greater numbers of latent traits. However, as illustrated with our example, in count data item response settings a smaller number of latent traits is frequently realistic.
2.2 Simple structure via rotation
After obtaining an initial solution with the EM algorithm described above, the classical approach for interpretable results is to apply a rotation to the discrimination parameters. Lifting the identification constraints after the initial solution is obtained, we have an infinite number of alternative solutions that can be obtained via rotation (i.e., rotational indeterminancy) (Scharf & Nestler, Reference Scharf and Nestler2019). That is, there is an infinite number of rotation matrices
 $V \in \mathbb {R}^{L \times L}$
for which
$V \in \mathbb {R}^{L \times L}$
for which
 $\boldsymbol {\alpha } \boldsymbol {\Theta }^T = \boldsymbol {\alpha } V V^{-1} \boldsymbol {\Theta }^T = (\boldsymbol {\alpha } V) (V^{-1} \boldsymbol {\Theta }^T)$
, where
$\boldsymbol {\alpha } \boldsymbol {\Theta }^T = \boldsymbol {\alpha } V V^{-1} \boldsymbol {\Theta }^T = (\boldsymbol {\alpha } V) (V^{-1} \boldsymbol {\Theta }^T)$
, where
 $\boldsymbol {\alpha } \in \mathbb {R}^{M \times L}$
is the discrimination matrix and
$\boldsymbol {\alpha } \in \mathbb {R}^{M \times L}$
is the discrimination matrix and
 $\boldsymbol {\Theta } \in \mathbb {R}^{N \times L}$
the latent trait matrix (Scharf & Nestler, Reference Scharf and Nestler2019; Trendafilov, Reference Trendafilov2014). A preferred rotation matrix V has to be selected, usually one optimizing a specific criterion such as indicating a simple structure (Browne, Reference Browne2001; Thurstone, Reference Thurstone1947) of
$\boldsymbol {\Theta } \in \mathbb {R}^{N \times L}$
the latent trait matrix (Scharf & Nestler, Reference Scharf and Nestler2019; Trendafilov, Reference Trendafilov2014). A preferred rotation matrix V has to be selected, usually one optimizing a specific criterion such as indicating a simple structure (Browne, Reference Browne2001; Thurstone, Reference Thurstone1947) of
 $\boldsymbol {\alpha }$
(Scharf & Nestler, Reference Scharf and Nestler2019). Rotation techniques differ in the employed criterion and in whether they allow latent traits to be correlated (i.e., oblique methods) or not (i.e., orthogonal methods) (Scharf & Nestler, Reference Scharf and Nestler2019; Trendafilov, Reference Trendafilov2014). Popular rotation techniques are for instance varimax (Kaiser, Reference Kaiser1958, Reference Kaiser1959), which is an orthogonal rotation method, and oblimin (Carroll, Reference Carroll1957; Clarkson & Jennrich, Reference Clarkson and Jennrich1988), which is an oblique rotation method.
$\boldsymbol {\alpha }$
(Scharf & Nestler, Reference Scharf and Nestler2019). Rotation techniques differ in the employed criterion and in whether they allow latent traits to be correlated (i.e., oblique methods) or not (i.e., orthogonal methods) (Scharf & Nestler, Reference Scharf and Nestler2019; Trendafilov, Reference Trendafilov2014). Popular rotation techniques are for instance varimax (Kaiser, Reference Kaiser1958, Reference Kaiser1959), which is an orthogonal rotation method, and oblimin (Carroll, Reference Carroll1957; Clarkson & Jennrich, Reference Clarkson and Jennrich1988), which is an oblique rotation method.
2.3 Simple structure via regularization
Recently, a simple structure has also been obtained with regularization techniques (Cho et al., Reference Cho, Xiao, Wang and Xu2022; Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016; Trendafilov, Reference Trendafilov2014). A perfect simple structure is a sparse matrix: Each item loads on exactly one latent trait, and the other loadings are zero (Scharf & Nestler, Reference Scharf and Nestler2019; Trendafilov, Reference Trendafilov2014). Finding a sparse solution to an optimization problem is one aim of regularization (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). By imposing a penalty term R onto the likelihood, regularization methods shrink parameter estimates toward
 $0$
(Hastie et al., Reference Hastie, Tibshirani and Friedman2009). R is a function of all parameters to be regularized and grows as the absolute value of each parameter estimate grows (Scharf & Nestler, Reference Scharf and Nestler2019). As a result, only substantial parameters (in our case, loadings or discriminations) remain notably different from
$0$
(Hastie et al., Reference Hastie, Tibshirani and Friedman2009). R is a function of all parameters to be regularized and grows as the absolute value of each parameter estimate grows (Scharf & Nestler, Reference Scharf and Nestler2019). As a result, only substantial parameters (in our case, loadings or discriminations) remain notably different from
 $0$
, essentially encouraging a (more) simple structure of the discrimination matrix
$0$
, essentially encouraging a (more) simple structure of the discrimination matrix
 $\boldsymbol {\alpha }$
(Scharf & Nestler, Reference Scharf and Nestler2019). As opposed to rotation methods, which are implemented after finding an initial estimate with the M2PCMPM EM algorithm, regularization methods modify the likelihood and have to be integrated into the EM algorithm. In general, the regularized estimates cannot be rotated without changing the value of R; they are hence rotationally determined in this sense.
$\boldsymbol {\alpha }$
(Scharf & Nestler, Reference Scharf and Nestler2019). As opposed to rotation methods, which are implemented after finding an initial estimate with the M2PCMPM EM algorithm, regularization methods modify the likelihood and have to be integrated into the EM algorithm. In general, the regularized estimates cannot be rotated without changing the value of R; they are hence rotationally determined in this sense.
As we maximize the expected complete-data log likelihood in each M step, we subtract the penalty term
 $R \geq 0$
from it, weighted with a hyperparameter
$R \geq 0$
from it, weighted with a hyperparameter
 $\eta $
(notation here inspired by Scharf & Nestler, Reference Scharf and Nestler2019; Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016 and in line with Beisemann, Reference Beisemann2022). The penalty term R is a function of all slopes
$\eta $
(notation here inspired by Scharf & Nestler, Reference Scharf and Nestler2019; Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016 and in line with Beisemann, Reference Beisemann2022). The penalty term R is a function of all slopes
 $\alpha _{11}, \dots , \alpha _{jl}, \dots , \alpha _{ML}$
, as contained in
$\alpha _{11}, \dots , \alpha _{jl}, \dots , \alpha _{ML}$
, as contained in
 $\boldsymbol {\alpha }$
. We aim for a sparse solution specifically for
$\boldsymbol {\alpha }$
. We aim for a sparse solution specifically for
 $\boldsymbol {\alpha }$
(ideally a simple structure), which is why we only impose the penalty term over
$\boldsymbol {\alpha }$
(ideally a simple structure), which is why we only impose the penalty term over
 $\boldsymbol {\alpha }$
. We obtain
$\boldsymbol {\alpha }$
. We obtain
 $$ \begin{align} \mathbb{E}(LL_c)_{\text{reg}} \propto \sum_{k_L = 1}^{K} \dots &\sum_{k_2 = 1}^{K} \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \sum_{j = 1}^{M} ( x_{ij} \log(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j)) - \nu_j \log(x_{ij}!)\notag \\ &- \log (Z(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j), \nu_j)) ) P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}') - \eta R(\boldsymbol{\alpha}), \end{align} $$
$$ \begin{align} \mathbb{E}(LL_c)_{\text{reg}} \propto \sum_{k_L = 1}^{K} \dots &\sum_{k_2 = 1}^{K} \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \sum_{j = 1}^{M} ( x_{ij} \log(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j)) - \nu_j \log(x_{ij}!)\notag \\ &- \log (Z(\lambda(\mu_{jk_1,\dots,k_L}, \nu_j), \nu_j)) ) P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}') - \eta R(\boldsymbol{\alpha}), \end{align} $$
with
 $P(q_{k_1}, \dots , q_{k_L} | \mathbf {x}_{i}, \boldsymbol {\zeta }')$
as in Equation (7). We can immediately see that for
$P(q_{k_1}, \dots , q_{k_L} | \mathbf {x}_{i}, \boldsymbol {\zeta }')$
as in Equation (7). We can immediately see that for
 $\eta = 0$
, the unregularized maximum likelihood estimate is optimal. The hyperparameter
$\eta = 0$
, the unregularized maximum likelihood estimate is optimal. The hyperparameter
 $\eta \geq 0 $
should be tuned, i.e., selected from a grid of possible values to provide the best result in terms of a tuning criterion (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). We are going to return to this point further below.
$\eta \geq 0 $
should be tuned, i.e., selected from a grid of possible values to provide the best result in terms of a tuning criterion (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). We are going to return to this point further below.
Depending on the penalty term R, different regularization methods are implemented (for an introduction and an overview, see Hastie et al., Reference Hastie, Tibshirani and Friedman2009). In this work, we employ the lasso (Tibshirani, Reference Tibshirani1996) penalty,
 $$ \begin{align} R_{\text{lasso}}(\boldsymbol{\alpha}) = {||\boldsymbol{\alpha}||}_{1} = \sum_{l=1}^L \sum_{j=1}^M |\alpha_{jl}|. \end{align} $$
$$ \begin{align} R_{\text{lasso}}(\boldsymbol{\alpha}) = {||\boldsymbol{\alpha}||}_{1} = \sum_{l=1}^L \sum_{j=1}^M |\alpha_{jl}|. \end{align} $$
For binary and polytomous MIRT models, the lasso penalty has yielded promising results as a method to find a well-fitting discrimination matrix
 $\boldsymbol {\alpha }$
with a (rather) simple structure (Cho et al., Reference Cho, Xiao, Wang and Xu2022; Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016).
$\boldsymbol {\alpha }$
with a (rather) simple structure (Cho et al., Reference Cho, Xiao, Wang and Xu2022; Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016).
2.4 Lasso penalty
Integrating the lasso penalty (Tibshirani, Reference Tibshirani1996) into the M2PCMPM EM algorithm requires an extension of the algorithm. We plug Equation (13) into Equation (12), and we observe that the E step of the M2PCMPM algorithm remains unaltered by the penalty term. In the M step, we are confronted with the problem that due to the
 $\ell _1$
norm, the gradient only exists for
$\ell _1$
norm, the gradient only exists for
 $\alpha _{jl} \neq 0$
. To solve this issue for binary and polytomous MIRT models, Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) employed the coordinate descent algorithm (Friedman et al., Reference Friedman, Hastie and Tibshirani2010) in the M step (see also Cho et al., Reference Cho, Xiao, Wang and Xu2022, for a related approach using variational estimation). Binary and polytomous MIRT models have an estimation advantage over count MIRT models in that they require only the estimation of discrimination and location parameters since the conditional variance is implied by these. The M2PCMPM additionally requires estimation of the dispersion parameters. A strategy in the context of (generalized) linear mixed models optimizing penalized (fixed) effects in one step, and then optimizing remaining model parameters in another step, alternating the steps until convergence (note that random effects are estimated in yet another step, but this is not of interest to us here; Nestler & Humberg, Reference Nestler and Humberg2022; Schelldorfer et al., Reference Schelldorfer, Meier and Bühlmann2014). Inspired by these approaches, we propose the M2PCMPM lasso-EM algorithm (see Algorithm 1) that—during each M step—first optimizes
$\alpha _{jl} \neq 0$
. To solve this issue for binary and polytomous MIRT models, Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) employed the coordinate descent algorithm (Friedman et al., Reference Friedman, Hastie and Tibshirani2010) in the M step (see also Cho et al., Reference Cho, Xiao, Wang and Xu2022, for a related approach using variational estimation). Binary and polytomous MIRT models have an estimation advantage over count MIRT models in that they require only the estimation of discrimination and location parameters since the conditional variance is implied by these. The M2PCMPM additionally requires estimation of the dispersion parameters. A strategy in the context of (generalized) linear mixed models optimizing penalized (fixed) effects in one step, and then optimizing remaining model parameters in another step, alternating the steps until convergence (note that random effects are estimated in yet another step, but this is not of interest to us here; Nestler & Humberg, Reference Nestler and Humberg2022; Schelldorfer et al., Reference Schelldorfer, Meier and Bühlmann2014). Inspired by these approaches, we propose the M2PCMPM lasso-EM algorithm (see Algorithm 1) that—during each M step—first optimizes
 $\alpha $
’s and
$\alpha $
’s and
 $\delta $
’s using item-blockwise coordinate descent, and then optimizes dispersion parameters using Equation (10).
$\delta $
’s using item-blockwise coordinate descent, and then optimizes dispersion parameters using Equation (10).
Taking an item-blockwise optimization approach as in Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), we exploit that the expected complete-data log likelihood decomposes into the sum of the item contributions (immediately observable in Equation (5)). During each M step of the EM algorithm, we further assume (as is common in EM algorithms) the posterior probabilities from the previous E step for latent traits to be known (via the quadrature approximation). Thus, the (penalized) optimization problem during each M step and for each item j is that of a generalized linear model (GLM) with intercept
 $\delta _j$
and (penalized) slopes
$\delta _j$
and (penalized) slopes
 $\boldsymbol {\alpha }_j$
. Note that CMP
$\boldsymbol {\alpha }_j$
. Note that CMP
 $_\mu $
-regression is a “bona fide GLM[…]” (Huang, Reference Huang2017, p. 365). This allows the use of algorithmic techniques developed for
$_\mu $
-regression is a “bona fide GLM[…]” (Huang, Reference Huang2017, p. 365). This allows the use of algorithmic techniques developed for
 $\ell _1$
-regularization in GLMs, such as coordinate descent (Friedman et al., Reference Friedman, Hastie and Tibshirani2010).
$\ell _1$
-regularization in GLMs, such as coordinate descent (Friedman et al., Reference Friedman, Hastie and Tibshirani2010).
As we can see in Algorithm 1 in Appendix B, we need updating rules for
 $\delta _j$
and the
$\delta _j$
and the
 $\boldsymbol {\alpha }_j$
within the blockwise coordinate descent during the M step. To this end, we follow Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016): They approximate the expected complete-data log likelihood for item j (i.e., item-specific increment in Equation (5) in our case) as a univariate function of each item parameter, respectively, with a local quadratic approximation. Using this approximation, the resulting lasso update (with tuning parameter
$\boldsymbol {\alpha }_j$
within the blockwise coordinate descent during the M step. To this end, we follow Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016): They approximate the expected complete-data log likelihood for item j (i.e., item-specific increment in Equation (5) in our case) as a univariate function of each item parameter, respectively, with a local quadratic approximation. Using this approximation, the resulting lasso update (with tuning parameter
 $\eta $
) takes the following shape (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016; adapted to our model and parameterization):
$\eta $
) takes the following shape (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016; adapted to our model and parameterization):
 $$ \begin{align} \hat{\delta}_j = \delta^{'}_j - \frac{\frac{\partial \mathbb{E}(LL_c)_j}{\partial \delta_{j}}}{\frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \delta_{j}^2}}, \end{align} $$
$$ \begin{align} \hat{\delta}_j = \delta^{'}_j - \frac{\frac{\partial \mathbb{E}(LL_c)_j}{\partial \delta_{j}}}{\frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \delta_{j}^2}}, \end{align} $$
(Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016) for each
 $\delta _j$
and
$\delta _j$
and
 $$ \begin{align} \hat{\alpha}_{jl} = - \frac{S\left(- \frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \alpha_{jl}^2} \alpha^{'}_{jl} + \frac{\partial \mathbb{E}(LL_c)_j}{\partial \alpha_{jl}}, \eta\right) }{\frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \alpha_{jl}^2}} \end{align} $$
$$ \begin{align} \hat{\alpha}_{jl} = - \frac{S\left(- \frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \alpha_{jl}^2} \alpha^{'}_{jl} + \frac{\partial \mathbb{E}(LL_c)_j}{\partial \alpha_{jl}}, \eta\right) }{\frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \alpha_{jl}^2}} \end{align} $$
(Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016) for each
 $\alpha _{jl}$
.Footnote 2 Here, S denotes the soft thresholding operator (Donoho & Johnstone, Reference Donoho and Johnstone1995), which is defined as
$\alpha _{jl}$
.Footnote 2 Here, S denotes the soft thresholding operator (Donoho & Johnstone, Reference Donoho and Johnstone1995), which is defined as
 $$ \begin{align} S(x, \eta) = \text{sign}(x)(|x| - \eta)_{+} = \begin{cases} x - \eta, \qquad &\text{if} \; x> 0 \; \text{ and } \; \eta < |x|, \\ x + \eta, \qquad &\text{if} \; x < 0 \; \text{ and } \; \eta < |x|,\\ 0 \qquad &\text{if} \; \eta \geq |x| \end{cases}, \end{align} $$
$$ \begin{align} S(x, \eta) = \text{sign}(x)(|x| - \eta)_{+} = \begin{cases} x - \eta, \qquad &\text{if} \; x> 0 \; \text{ and } \; \eta < |x|, \\ x + \eta, \qquad &\text{if} \; x < 0 \; \text{ and } \; \eta < |x|,\\ 0 \qquad &\text{if} \; \eta \geq |x| \end{cases}, \end{align} $$
(Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). We substitute the M2PCMPM-specific terms.
 $\partial \mathbb {E}(LL_c)_j/\partial \delta _{j}$
and
$\partial \mathbb {E}(LL_c)_j/\partial \delta _{j}$
and
 $\partial \mathbb {E}(LL_c)_j/\partial \alpha _{jl}$
are given in Equations (8) and (9). Using the second derivatives of the variance
$\partial \mathbb {E}(LL_c)_j/\partial \alpha _{jl}$
are given in Equations (8) and (9). Using the second derivatives of the variance
 $V(\mu _{jk_1,\dots ,k_L}, \nu _j)$
in terms of
$V(\mu _{jk_1,\dots ,k_L}, \nu _j)$
in terms of
 $\delta _j$
and
$\delta _j$
and
 $\alpha _{jl}$
(see Appendix A) and results from Huang (Reference Huang2017), we obtain the following second derivatives in terms of
$\alpha _{jl}$
(see Appendix A) and results from Huang (Reference Huang2017), we obtain the following second derivatives in terms of
 $\delta _j$
and
$\delta _j$
and
 $\alpha _{jl}$
,
$\alpha _{jl}$
,
 $$ \begin{align} \frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \alpha_{jl}^2} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \frac{q_{k_l}^2 \mu_{jk_1,\dots,k_L} P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}')}{V(\mu_{jk_1,\dots,k_L}, \nu_j)^2} C(\mu_{jk_1,\dots,k_L}, \nu_j), \end{align} $$
$$ \begin{align} \frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \alpha_{jl}^2} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \frac{q_{k_l}^2 \mu_{jk_1,\dots,k_L} P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}')}{V(\mu_{jk_1,\dots,k_L}, \nu_j)^2} C(\mu_{jk_1,\dots,k_L}, \nu_j), \end{align} $$
and
 $$ \begin{align} \frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \delta_{j}^2} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \frac{\mu_{jk_1,\dots,k_L} P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}')}{V(\mu_{jk_1,\dots,k_L}, \nu_j)^2} C(\mu_{jk_1,\dots,k_L}, \nu_j), \end{align} $$
$$ \begin{align} \frac{\partial^2 \mathbb{E}(LL_c)_j}{\partial \delta_{j}^2} = \sum_{k_L = 1}^{K} \dots \sum_{k_1 = 1}^{K} \sum_{i = 1}^{N} \frac{\mu_{jk_1,\dots,k_L} P(q_{k_1}, \dots, q_{k_L} | \mathbf{x}_{i}, \boldsymbol{\zeta}')}{V(\mu_{jk_1,\dots,k_L}, \nu_j)^2} C(\mu_{jk_1,\dots,k_L}, \nu_j), \end{align} $$
where
 $$ \begin{align} C(\mu_{jk_1,\dots,k_L}, \nu_j) = V&(\mu_{jk_1,\dots,k_L}, \nu_j) (x_{ij} - 2\mu_{jk_1,\dots,k_L})\notag \\ &- \mu_{jk_1,\dots,k_L}(x_{ij} - \mu_{jk_1,\dots,k_L}) \left(\frac{\mathbb{E}_X(X^3 - \mu_{jk_1,\dots,k_L} X^2)}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} - 2\mu_{jk_1,\dots,k_L} \right). \end{align} $$
$$ \begin{align} C(\mu_{jk_1,\dots,k_L}, \nu_j) = V&(\mu_{jk_1,\dots,k_L}, \nu_j) (x_{ij} - 2\mu_{jk_1,\dots,k_L})\notag \\ &- \mu_{jk_1,\dots,k_L}(x_{ij} - \mu_{jk_1,\dots,k_L}) \left(\frac{\mathbb{E}_X(X^3 - \mu_{jk_1,\dots,k_L} X^2)}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} - 2\mu_{jk_1,\dots,k_L} \right). \end{align} $$
2.5 Latent trait covariance matrix
In the M2PCMPM EM algorithm (including the regularized variants), we assume the latent trait covariance matrix,
 $\boldsymbol {\Sigma }_{\theta }$
, fixed. The diagonal of
$\boldsymbol {\Sigma }_{\theta }$
, fixed. The diagonal of
 $\boldsymbol {\Sigma }_{\theta }$
is fixed to the canonical value
$\boldsymbol {\Sigma }_{\theta }$
is fixed to the canonical value
 $\textbf {1} \in \mathbb {R}^L$
for identification purposes in this model with discrimination parameters—this is analogous to the identification assumption made in the unidimensional case in Beisemann (Reference Beisemann2022). A convenient choice for the off-diagonal is to assume orthogonal latent traits during estimation (i.e., fix all off-diagonal elements of
$\textbf {1} \in \mathbb {R}^L$
for identification purposes in this model with discrimination parameters—this is analogous to the identification assumption made in the unidimensional case in Beisemann (Reference Beisemann2022). A convenient choice for the off-diagonal is to assume orthogonal latent traits during estimation (i.e., fix all off-diagonal elements of
 $\boldsymbol {\Sigma }_{\theta }$
to 0). If the latent traits are in fact correlated, pronounced loadings of items on two or more factors can result. For the classical rotation approach, an oblique rotation can find a correlated solution with fewer items loading on two or more factors
$\boldsymbol {\Sigma }_{\theta }$
to 0). If the latent traits are in fact correlated, pronounced loadings of items on two or more factors can result. For the classical rotation approach, an oblique rotation can find a correlated solution with fewer items loading on two or more factors
In the case of strong(er) correlations between latent factors, this may put the regularized approach at a disadvantage as a sparse solution will not fit well when more than one loading is required to account for latent factor correlations. Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) approach this problem by first estimating an unpenalized MIRT model to obtain latent factor correlation estimates from this model, which they plug into
 $\boldsymbol {\Sigma }_{\theta }$
for the respective off-diagonal estimates. We use the same approach in this work, but we obtain the latent factor correlation from oblique rotation of the
$\boldsymbol {\Sigma }_{\theta }$
for the respective off-diagonal estimates. We use the same approach in this work, but we obtain the latent factor correlation from oblique rotation of the
 $\boldsymbol {\alpha }$
matrix. Note that an alternative would be to estimate the latent factor correlations within the EM algorithm, albeit this would require adjustments to the algorithm as well as the model identification constraints (compare Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016).
$\boldsymbol {\alpha }$
matrix. Note that an alternative would be to estimate the latent factor correlations within the EM algorithm, albeit this would require adjustments to the algorithm as well as the model identification constraints (compare Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016).
2.6 Computational aspects
The M2PCMPM EM algorithms are computationally expensive. Thus, we dedicated some effort to improving computational efficiency, as outlined below.
2.7 Start values
In line with the start value approach Beisemann (Reference Beisemann2022) uses for the 2PCMPM, we set starting values for the M2PCMPM by fitting multidimensional two-parameter Poisson models to the data and compute starting values for the dispersion parameters as described in Beisemann (Reference Beisemann2022). Fitting these Poisson variants first saves computation time as each Poisson iteration of the EM algorithm is much less expensive than a CMP iteration, the obtained start values are already quite close to the CMP solution for the
 $\alpha _{jl}$
and the
$\alpha _{jl}$
and the
 $\delta _j$
, and therewith reduce the number of required iterations of the M2PCMPM EM algorithm (compare Beisemann, Reference Beisemann2022).
$\delta _j$
, and therewith reduce the number of required iterations of the M2PCMPM EM algorithm (compare Beisemann, Reference Beisemann2022).
2.8 Regularization tuning and warm starts
For the lasso-penalized M2PCMPM EM algorithm, the hyperparameter
 $\eta $
requires tuning to be optimally chosen. To this end, we use a grid of
$\eta $
requires tuning to be optimally chosen. To this end, we use a grid of
 $\eta $
values to assess. Values of the grid are chosen equidistantly on the log scale (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). To increase computational efficiency when fitting a penalized M2PCMPM for each
$\eta $
values to assess. Values of the grid are chosen equidistantly on the log scale (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). To increase computational efficiency when fitting a penalized M2PCMPM for each
 $\eta $
value on the grid, we implemented warm starts (Hastie et al., Reference Hastie, Tibshirani and Friedman2009), that is, we used the model parameter estimates of the previous model as start values for the subsequent model. To select the optimal
$\eta $
value on the grid, we implemented warm starts (Hastie et al., Reference Hastie, Tibshirani and Friedman2009), that is, we used the model parameter estimates of the previous model as start values for the subsequent model. To select the optimal
 $\eta $
, one has to impose a criterion which
$\eta $
, one has to impose a criterion which
 $\eta $
has to optimize. Traditionally, one may use cross-validation and optimize the RMSE of model predictions (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). However, due to the high computational cost of the M2PCMPM EM algorithm and in line with prior research (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016), we opted to use the Bayesian information criterion (BIC) as a criterion to optimize instead. Following Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), for the lasso penalty, we computed the BIC (Schwarz, Reference Schwarz1978) dependent on
$\eta $
has to optimize. Traditionally, one may use cross-validation and optimize the RMSE of model predictions (Hastie et al., Reference Hastie, Tibshirani and Friedman2009). However, due to the high computational cost of the M2PCMPM EM algorithm and in line with prior research (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016), we opted to use the Bayesian information criterion (BIC) as a criterion to optimize instead. Following Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), for the lasso penalty, we computed the BIC (Schwarz, Reference Schwarz1978) dependent on
 $\eta $
as
$\eta $
as
 $$ \begin{align} \text{BIC}_{\eta} = p^* \log{N} - 2 LL_m(\boldsymbol{\hat{\zeta}_{\eta}}; \textbf{x}), \end{align} $$
$$ \begin{align} \text{BIC}_{\eta} = p^* \log{N} - 2 LL_m(\boldsymbol{\hat{\zeta}_{\eta}}; \textbf{x}), \end{align} $$
where
 $LL_m(\boldsymbol {\hat {\zeta }_{\eta }}; \textbf {x})$
is the unpenalized marginal log-likelihood for the penalized model parameter estimates (using hyperparameter value
$LL_m(\boldsymbol {\hat {\zeta }_{\eta }}; \textbf {x})$
is the unpenalized marginal log-likelihood for the penalized model parameter estimates (using hyperparameter value
 $\eta $
), and
$\eta $
), and
 $p^*$
is the number of parameters
$p^*$
is the number of parameters
 $\neq 0$
, i.e., the number of parameters for which the estimate is neither shrunken to 0 nor constrained to 0. We select the
$\neq 0$
, i.e., the number of parameters for which the estimate is neither shrunken to 0 nor constrained to 0. We select the
 $\eta $
value minimizing
$\eta $
value minimizing
 $\text {BIC}_{\eta }$
.
$\text {BIC}_{\eta }$
.
2.9 Implementation
We implemented M2PCMPM EM algorithm (with and without penalities) in the R package countirt ( https://github.com/doebler/countirt ; please consult the package’s GitHub page for more information on the implementation and its limitations)Footnote 3. For computational efficiency, the algorithm was implemented in R and C++, using among others the package GSL (Galassi et al., Reference Galassi, Davies, Theiler, Gough, Jungman, Alken and Rossi2010), tied into R using Rcpp (Eddelbuettel et al., Reference Eddelbuettel, François, Allaire, Ushey, Kou, Russel and Bates2011). Multidimensional Gauss–Hermite quadrature was implemented using MultiGHQuad (Kroeze, Reference Kroeze2016). For efficiency, quadrature grid truncation is used per default (i.e., quadrature points with very low quadrature weights are precluded from the grid).
3 Simulation study
In this small simulation study, we aimed to validate the proposed algorithms and illustrate the viability of their usage in different psychometric settings. The simulation study was run in R (R Core Team, Reference Team2023), using the package countirt to fit the M2PCMPMs. The code for the simulations and rds files of the saved simulation results are available at https://osf.io/n5792/?view_only=decbaf3ed16f4bac953ebc6be31c4859.
3.1 Design
In line with previous simulations regarding regularized item response models (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016), we varied the number of latent traits between
 $L = 3$
and
$L = 3$
and
 $L = 4$
. Further, we varied the correlation between these latent traits (
$L = 4$
. Further, we varied the correlation between these latent traits (
 $\rho = 0$
vs.
$\rho = 0$
vs.
 $\rho = .3$
). Choosing parameter values for a new class of count item response models is to a certain extent guess work and arbitrary. We tackled this issue by looking at what parameter value ranges occur at all for previously proposed and applied CMP-based count item response models (cf. Beisemann, Reference Beisemann2022; Beisemann et al., Reference Beisemann, Forthmann and Doebler2024; Forthmann et al., Reference Forthmann, Gühne and Doebler2020) and what sort of range we observed for the M2PCMPM on our example data. We did not use these exact values or any edge-case values from these studies and examples, but just used them to obtain a general feel for realistic parameter value ranges. The exact ranges and values were then chosen arbitrarily. For the model parameters, we used the same range of
$\rho = .3$
). Choosing parameter values for a new class of count item response models is to a certain extent guess work and arbitrary. We tackled this issue by looking at what parameter value ranges occur at all for previously proposed and applied CMP-based count item response models (cf. Beisemann, Reference Beisemann2022; Beisemann et al., Reference Beisemann, Forthmann and Doebler2024; Forthmann et al., Reference Forthmann, Gühne and Doebler2020) and what sort of range we observed for the M2PCMPM on our example data. We did not use these exact values or any edge-case values from these studies and examples, but just used them to obtain a general feel for realistic parameter value ranges. The exact ranges and values were then chosen arbitrarily. For the model parameters, we used the same range of
 $\delta _j$
and
$\delta _j$
and
 $\nu _j$
values across all conditions. For
$\nu _j$
values across all conditions. For
 $\delta _j$
, we used values between 1.5 and 3.5, and for
$\delta _j$
, we used values between 1.5 and 3.5, and for
 $\log \nu _j$
, we used values between
$\log \nu _j$
, we used values between
 $-$
0.8 and 0.8 (i.e., implying—not very large—over- and underdispersion of varying degree), assigned randomly to the items. The true
$-$
0.8 and 0.8 (i.e., implying—not very large—over- and underdispersion of varying degree), assigned randomly to the items. The true
 $\alpha _j$
values depended on the simulation condition: Apart from the number of latent traits, we also varied the number number of items per trait (
$\alpha _j$
values depended on the simulation condition: Apart from the number of latent traits, we also varied the number number of items per trait (
 $m = 3$
vs.
$m = 3$
vs.
 $m = 5$
). To the best of our knowledge, settings with small(er) numbers of items are realistic for count tests, with count tests often being comprised of less items than binary tests. We further varied the type of structure of the
$m = 5$
). To the best of our knowledge, settings with small(er) numbers of items are realistic for count tests, with count tests often being comprised of less items than binary tests. We further varied the type of structure of the
 $\boldsymbol {\alpha }$
matrix (simple vs. slightly complex). With regard to the
$\boldsymbol {\alpha }$
matrix (simple vs. slightly complex). With regard to the
 $\boldsymbol {\alpha }$
matrix structure, simple implies only single loadings of items on their assigned traits. The slightly complex structure implies in our simulation that a quarter of the items for each trait additionally—but to a lesser extent—load onto at least one of the other traits. We generated the
$\boldsymbol {\alpha }$
matrix structure, simple implies only single loadings of items on their assigned traits. The slightly complex structure implies in our simulation that a quarter of the items for each trait additionally—but to a lesser extent—load onto at least one of the other traits. We generated the
 $\boldsymbol {\alpha }$
matrices as follows: (1) For each number-of-latent-traits and items-per-trait combination, we first set up a simple structure discrimination matrix, where each item loads onto only one trait. For each trait, there were m items associated with the respective traits. Per trait, for the respective m items, we chose the discriminations equidistantly between 0.2 and 0.3 and remaining discriminations were set to 0. (2) We then used the simple structure discrimination matrix set up in (1) to build the slightly complex structure. To this end, we kept any nonzero loadings as they were in (1). For any zero-loadings from (1), we sampled out of the values
$\boldsymbol {\alpha }$
matrices as follows: (1) For each number-of-latent-traits and items-per-trait combination, we first set up a simple structure discrimination matrix, where each item loads onto only one trait. For each trait, there were m items associated with the respective traits. Per trait, for the respective m items, we chose the discriminations equidistantly between 0.2 and 0.3 and remaining discriminations were set to 0. (2) We then used the simple structure discrimination matrix set up in (1) to build the slightly complex structure. To this end, we kept any nonzero loadings as they were in (1). For any zero-loadings from (1), we sampled out of the values
 $\{0, 0.05, 0.1\}$
with probabilities
$\{0, 0.05, 0.1\}$
with probabilities
 $\{0.75, 0.125, 0.125\}$
, so that we obtained some cross loadings. All true parameter values are displayed in the Supplementary Material. The described design factors were fully crossed to yield 16 simulation conditions (see Table 1). We ran
$\{0.75, 0.125, 0.125\}$
, so that we obtained some cross loadings. All true parameter values are displayed in the Supplementary Material. The described design factors were fully crossed to yield 16 simulation conditions (see Table 1). We ran
 $T = 40$
simulation trials per condition.Footnote 4
$T = 40$
simulation trials per condition.Footnote 4
Overview of the 16 simulation conditions

3.2 Data generation and model fitting
In each trial in each respective condition, we generated (inspired by our application example)
 $N = 1200$
responses to
$N = 1200$
responses to
 $M = L \times m$
items under the M2PCMPM with the condition-specific model parameters. With regard to simulating item response data from the CMP distribution, we followed prior simulation studies on CMP-based item response models, using and adapting code from Forthmann et al. (Reference Forthmann, Gühne and Doebler2020) and Beisemann (Reference Beisemann2022). In each trial, we first fitted an exploratory M2PCMPM with upper-triangle identification constraint. The obtained solution was rotated once using the orthogonal varimax criterion(Kaiser, Reference Kaiser1958, Reference Kaiser1959) and once using the oblique oblimin (Clarkson & Jennrich, Reference Clarkson and Jennrich1988), relying on the GPArotation package (Bernaards & Jennrich, Reference Bernaards and Jennrich2005). Then, we fitted the lasso-penalized M2PCMPMs for hyperparameter tuning with regard to the BIC.Footnote 5 We used a 12-value penalization grid of
$M = L \times m$
items under the M2PCMPM with the condition-specific model parameters. With regard to simulating item response data from the CMP distribution, we followed prior simulation studies on CMP-based item response models, using and adapting code from Forthmann et al. (Reference Forthmann, Gühne and Doebler2020) and Beisemann (Reference Beisemann2022). In each trial, we first fitted an exploratory M2PCMPM with upper-triangle identification constraint. The obtained solution was rotated once using the orthogonal varimax criterion(Kaiser, Reference Kaiser1958, Reference Kaiser1959) and once using the oblique oblimin (Clarkson & Jennrich, Reference Clarkson and Jennrich1988), relying on the GPArotation package (Bernaards & Jennrich, Reference Bernaards and Jennrich2005). Then, we fitted the lasso-penalized M2PCMPMs for hyperparameter tuning with regard to the BIC.Footnote 5 We used a 12-value penalization grid of
 $[0,1000]$
with values chosen equidistantly on the log scale (compare Hastie et al., Reference Hastie, Tibshirani and Friedman2009). We tuned the lasso-penalized M2PCMPMs once with the orthogonal latent trait assumption and once with a latent trait covariance matrix which incorporates the latent traits correlations obtained from the obliquely rotated M2PCMPM (see Latent Trait Covariance Matrix). All M2PCMPMs were fitted using the countirt package (see Computational Aspects).
$[0,1000]$
with values chosen equidistantly on the log scale (compare Hastie et al., Reference Hastie, Tibshirani and Friedman2009). We tuned the lasso-penalized M2PCMPMs once with the orthogonal latent trait assumption and once with a latent trait covariance matrix which incorporates the latent traits correlations obtained from the obliquely rotated M2PCMPM (see Latent Trait Covariance Matrix). All M2PCMPMs were fitted using the countirt package (see Computational Aspects).
We enhanced computational efficiency through several techniques. First, we used warm starts in tuning
 $\eta $
with regard to the BIC for the penalized M2PCMPMs (see Computational Aspects). Second, we used the parameter estimates obtained from the unpenalized exploratory M2PCMPM as start values for
$\eta $
with regard to the BIC for the penalized M2PCMPMs (see Computational Aspects). Second, we used the parameter estimates obtained from the unpenalized exploratory M2PCMPM as start values for
 $\eta = 0$
(which should result in immediate convergence as
$\eta = 0$
(which should result in immediate convergence as
 $\eta = 0$
is the unpenalized case). Third, we adjusted the number of quadrature nodes per trait, in relation to the number of latent traits (with 10 nodes per trait for
$\eta = 0$
is the unpenalized case). Third, we adjusted the number of quadrature nodes per trait, in relation to the number of latent traits (with 10 nodes per trait for
 $L = 3$
, and 4 nodes per trait with
$L = 3$
, and 4 nodes per trait with
 $L = 4$
).
$L = 4$
).
3.3 Evaluation criteria
For the penalized M2PCMPMs, we evaluated the models for the
 $\eta $
value selecting during hyperparameter tuning. Following Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), we evaluated the correct estimation rate (CER), which we adapted to the upper-triangle identification constraint used here. The CER (adapted from Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016) is defined here as
$\eta $
value selecting during hyperparameter tuning. Following Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), we evaluated the correct estimation rate (CER), which we adapted to the upper-triangle identification constraint used here. The CER (adapted from Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016) is defined here as
 $$ \begin{align} \text{CER} = \frac{\sum_{l=1}^L \sum_{j=1}^M \mathbb{I}(\hat{\lambda}_{jl} = \lambda_{jl}) - c}{L \times M - c}, \end{align} $$
$$ \begin{align} \text{CER} = \frac{\sum_{l=1}^L \sum_{j=1}^M \mathbb{I}(\hat{\lambda}_{jl} = \lambda_{jl}) - c}{L \times M - c}, \end{align} $$
with c is the number of constraints imposed on
 $\boldsymbol {\alpha }$
for identification,
$\boldsymbol {\alpha }$
for identification,
 $L \times M$
the number of elements in
$L \times M$
the number of elements in
 $\boldsymbol {\alpha }$
, and
$\boldsymbol {\alpha }$
, and
 $\lambda _{jl} = \mathbb {I}(\alpha _{jl} \neq 0)$
and
$\lambda _{jl} = \mathbb {I}(\alpha _{jl} \neq 0)$
and
 $\hat {\lambda }_{jl} = \mathbb {I}(\hat {\alpha }_{jl} \neq 0)$
, where
$\hat {\lambda }_{jl} = \mathbb {I}(\hat {\alpha }_{jl} \neq 0)$
, where
 $\mathbb {I}(.)$
denotes the indicator function. Note that we defined the CER slightly differently than Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) to better accommodate our identification constraint. The CER helps to assess whether the variable selection in the lasso-penalized models worked correctly, or to what extent. Performance of the BIC-based tuning for the lasso-penalized models was assessed by comparing the two
$\mathbb {I}(.)$
denotes the indicator function. Note that we defined the CER slightly differently than Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) to better accommodate our identification constraint. The CER helps to assess whether the variable selection in the lasso-penalized models worked correctly, or to what extent. Performance of the BIC-based tuning for the lasso-penalized models was assessed by comparing the two
 $\eta $
s selected by minimizing BIC and maximizing CER (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). We additionally report the number of elements in
$\eta $
s selected by minimizing BIC and maximizing CER (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). We additionally report the number of elements in
 $\boldsymbol {\alpha }$
that were estimated to be zero (i.e., shrunken to 0) for the penalized M2PCMPMs.
$\boldsymbol {\alpha }$
that were estimated to be zero (i.e., shrunken to 0) for the penalized M2PCMPMs.
Further, we assessed bias and RMSE for the intercept and (log-)dispersion parameters. As there are an infinite number of rotated solutions, bias and RMSE on each single discrimination parameter are less meaningful for rotated exploratory item response models. Based on the helpful suggestion of a reviewer, we evaluated the off-diagonal elements of
 $\hat {\boldsymbol \alpha }Cov(\boldsymbol \theta )\hat {\boldsymbol \alpha }^\top $
in terms of bias and RMSE (Battauz & Vidoni, Reference Battauz and Vidoni2022). This measure is identical for orthogonal and oblique rotations of loadings, so differences are only expected between the two lasso approaches and one of the rotations of the unpenalized models. The latter were indeed identical within numerical error.
$\hat {\boldsymbol \alpha }Cov(\boldsymbol \theta )\hat {\boldsymbol \alpha }^\top $
in terms of bias and RMSE (Battauz & Vidoni, Reference Battauz and Vidoni2022). This measure is identical for orthogonal and oblique rotations of loadings, so differences are only expected between the two lasso approaches and one of the rotations of the unpenalized models. The latter were indeed identical within numerical error.
3.4 Results
All trials were completed without any numerical instabilities and the EM algorithm(s) converged for all models in all trials and conditions. The average and median computation times across trials per condition are displayed in Table 2. Some of the conditions exceed 60h on the cluster available for this project, with some variance between randomly assigned computational nodes. We observed substantially lower times on an average laptop (up to several hours), so the computational times are provided for relative comparisons.
Average (mean) and median (med) computation times (in seconds) for the different models in the 16 conditions

Note: Note that the lasso models include hyperparameter tuning, and thus multiple model fits in one instance, but for the first hyperparameter grid value, the rotate fit parameter estimates were used as start values (yielding a 1-iteration run of the algorithm). obli = oblique (latent traits are a priori assumed to be correlated). ortho = orthogonal (latent traits are a priori assumed to be orthogonal). L = number of latent traits.
 $\rho $
= true latent trait correlation. m = number of items per trait.
$\rho $
= true latent trait correlation. m = number of items per trait.
Figure 1 shows the average CER per condition and per method or model used. In the first two rows of Figure 1, we see the results for the simple
 $\boldsymbol {\alpha }$
structure, and in the last two rows, the results for the complex
$\boldsymbol {\alpha }$
structure, and in the last two rows, the results for the complex
 $\boldsymbol {\alpha }$
structure are displayed. There was a clear difference in performance between the two different
$\boldsymbol {\alpha }$
structure are displayed. There was a clear difference in performance between the two different
 $\boldsymbol {\alpha }$
structures. For the simple
$\boldsymbol {\alpha }$
structures. For the simple
 $\boldsymbol {\alpha }$
structure, in line with expectations, we see poor performance of the rotation methods (which are not able to shrink estimates down to exactly 0, putting them at a disadvantage in general in terms of CER). In conditions with complex
$\boldsymbol {\alpha }$
structure, in line with expectations, we see poor performance of the rotation methods (which are not able to shrink estimates down to exactly 0, putting them at a disadvantage in general in terms of CER). In conditions with complex
 $\boldsymbol {\alpha }$
structure, the rotation methods performed better in these conditions as we would expect when there are fewer parameters that require shrinkage to exactly 0. In conditions with correlated latent traits, we can see that only the oblique lasso model showed decent performance (in most but not all conditions) in terms of CER. Especially for correlated latent traits, performance fell off for four latent traits in conjunction with five items per trait, even for the oblique lasso. For
$\boldsymbol {\alpha }$
structure, the rotation methods performed better in these conditions as we would expect when there are fewer parameters that require shrinkage to exactly 0. In conditions with correlated latent traits, we can see that only the oblique lasso model showed decent performance (in most but not all conditions) in terms of CER. Especially for correlated latent traits, performance fell off for four latent traits in conjunction with five items per trait, even for the oblique lasso. For
 $L = 3$
latent traits, more items per trait tended to increase performance (at least for complex
$L = 3$
latent traits, more items per trait tended to increase performance (at least for complex
 $\boldsymbol {\alpha }$
structure), but for
$\boldsymbol {\alpha }$
structure), but for
 $L = 4$
latent traits, more items tended to decrease performance (for both
$L = 4$
latent traits, more items tended to decrease performance (for both
 $\boldsymbol {\alpha }$
structures). One can again speculate that these last two observed patterns in the results might be due to the number of observations to number of parameters ratio which is considerably decreased for 4 traits and 5 items per trait.
$\boldsymbol {\alpha }$
structures). One can again speculate that these last two observed patterns in the results might be due to the number of observations to number of parameters ratio which is considerably decreased for 4 traits and 5 items per trait.
Mean Correct Estimation Rate (CER) estimates for each simulation condition. Estimates for the different model variants are shown on the x-axis and indicated by different shapes as detailed in the legend on the right-hand side. (L = number of latent tarits. r = true correlation between latent traits. m = number of items per trait. simple / complex = type of
 $\boldsymbol {\alpha }$
structure. Lasso / Rotate = model variant. ortho = orthogonal. obli = oblique.).
$\boldsymbol {\alpha }$
structure. Lasso / Rotate = model variant. ortho = orthogonal. obli = oblique.).

Figure 2 plots the (condition average) CER for the tuning parameter
 $\eta $
selected via the BIC (on the y axis) against the maximum (condition average) CER obtained by any of the models on the
$\eta $
selected via the BIC (on the y axis) against the maximum (condition average) CER obtained by any of the models on the
 $\eta $
grid, i.e., the model we would have selected based on the CER. Figure 2 shows the two different lasso models in two separate panels. Figure 2 describes how well the BIC performed in terms of parameter tuning (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). Ideally, the BIC-selected
$\eta $
grid, i.e., the model we would have selected based on the CER. Figure 2 shows the two different lasso models in two separate panels. Figure 2 describes how well the BIC performed in terms of parameter tuning (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). Ideally, the BIC-selected
 $\eta $
is the CER-selected
$\eta $
is the CER-selected
 $\eta $
which would mean that the condition’s point in Figure 2 would lie on the diagonal black line. In Figure 2, we can see that this is the case for one condition for the oblique lasso (
$\eta $
which would mean that the condition’s point in Figure 2 would lie on the diagonal black line. In Figure 2, we can see that this is the case for one condition for the oblique lasso (
 $L = 4, \rho = 0.3, m = 3$
with simple
$L = 4, \rho = 0.3, m = 3$
with simple
 $\boldsymbol {\alpha }$
structure), and for four conditions for the orthogonal lasso (
$\boldsymbol {\alpha }$
structure), and for four conditions for the orthogonal lasso (
 $L = 3, \rho = 0.3, m = 3$
,
$L = 3, \rho = 0.3, m = 3$
,
 $L = 3, \rho = 0.3, m = 5$
,
$L = 3, \rho = 0.3, m = 5$
,
 $L = 4, \rho = 0.3, m = 3$
, and
$L = 4, \rho = 0.3, m = 3$
, and
 $L = 4, \rho = 0.3, m = 5$
with simple
$L = 4, \rho = 0.3, m = 5$
with simple
 $\boldsymbol {\alpha }$
structure, and
$\boldsymbol {\alpha }$
structure, and
 $L = 3, \rho = 0.3, m = 5$
with complex
$L = 3, \rho = 0.3, m = 5$
with complex
 $\boldsymbol {\alpha }$
structure). For either method, conditions with simple
$\boldsymbol {\alpha }$
structure). For either method, conditions with simple
 $\boldsymbol {\alpha }$
structure, more items, and/or more traits tended to exhibit better accuracy of BIC-based
$\boldsymbol {\alpha }$
structure, more items, and/or more traits tended to exhibit better accuracy of BIC-based
 $\eta $
tuning with points in proximity of the line. For complex
$\eta $
tuning with points in proximity of the line. For complex
 $\boldsymbol {\alpha }$
structure (compared to the other conditions), the CER were lower even when
$\boldsymbol {\alpha }$
structure (compared to the other conditions), the CER were lower even when
 $\eta $
was selected based on the CER. Figure 2 shows here that for complex
$\eta $
was selected based on the CER. Figure 2 shows here that for complex
 $\boldsymbol {\alpha }$
structure (compared to the other conditions), BIC-based tuning works notably better (with points closer to the diagonal line) for more items per trait (and even better if that is in conjunction with more latent traits).
$\boldsymbol {\alpha }$
structure (compared to the other conditions), BIC-based tuning works notably better (with points closer to the diagonal line) for more items per trait (and even better if that is in conjunction with more latent traits).
Condition average CER for the BIC-selected model (y-axis) against condition average CER for the CER-selected model (x-axis), shown in two separate panels (lasso with oblique latent covariance matrix on the left and lasso with orthogonal latent covariance matrix on the right). Simulation conditions (in terms of number of latent traits (L), latent factor correlation (r), and number of items per trait (m)) are shown in different colours as indicated by the legend on the right-hand side (under “Condition”). Different
 $\boldsymbol {\alpha }$
structures are represented by different shapes as indicated by the legend on the right-hand side (under “Structure”).
$\boldsymbol {\alpha }$
structures are represented by different shapes as indicated by the legend on the right-hand side (under “Structure”).

Table 5 contains the average number and proportion of discrimination parameters shrunken to zero. Clearly, employing the
 $\ell _1$
-penalty enforces a simple structure with 9% to 59% zeroes among the estimated discrimination parameters. In most situations, the oblique Lasso model is sparser, with more zeroes than the orthogonal model. The only exceptions to this are the cases with a complex structure of
$\ell _1$
-penalty enforces a simple structure with 9% to 59% zeroes among the estimated discrimination parameters. In most situations, the oblique Lasso model is sparser, with more zeroes than the orthogonal model. The only exceptions to this are the cases with a complex structure of
 $m=5$
items per uncorrelated factor. These observations reinforce the conclusions based on the CER.
$m=5$
items per uncorrelated factor. These observations reinforce the conclusions based on the CER.
Average bias (between-item
 $SD$
in parentheses) and RMSE (between-item
$SD$
in parentheses) and RMSE (between-item
 $SD$
in parentheses) on
$SD$
in parentheses) on
 $\delta _j$
parameters across all items per condition
$\delta _j$
parameters across all items per condition

Note: Note that rotated models have the same
 $\delta _j$
estimates regardless of rotation methods as those only affect
$\delta _j$
estimates regardless of rotation methods as those only affect
 $\hat {\boldsymbol {\alpha }}$
. obli = oblique (latent traits are a priori assumed to be correlated). ortho = orthogonal (latent traits are a priori assumed to be orthogonal). L = number of latent traits.
$\hat {\boldsymbol {\alpha }}$
. obli = oblique (latent traits are a priori assumed to be correlated). ortho = orthogonal (latent traits are a priori assumed to be orthogonal). L = number of latent traits.
 $\rho $
= true latent trait correlation. m = number of items per trait.
$\rho $
= true latent trait correlation. m = number of items per trait.
Average bias (
 $SD$
in parentheses) and RMSE (
$SD$
in parentheses) and RMSE (
 $SD$
in parentheses) on
$SD$
in parentheses) on
 $\log \nu _j$
parameters across all items per condition
$\log \nu _j$
parameters across all items per condition

Note: Note that rotated models have the same
 $\delta _j$
estimates regardless of rotation methods as those only affect
$\delta _j$
estimates regardless of rotation methods as those only affect
 $\hat {\boldsymbol {\alpha }}$
. obli = oblique (latent traits are a priori assumed to be correlated). ortho = orthogonal (latent traits are a priori assumed to be orthogonal). L = number of latent traits.
$\hat {\boldsymbol {\alpha }}$
. obli = oblique (latent traits are a priori assumed to be correlated). ortho = orthogonal (latent traits are a priori assumed to be orthogonal). L = number of latent traits.
 $\rho $
= true latent trait correlation. m = number of items per trait.
$\rho $
= true latent trait correlation. m = number of items per trait.
Average number of discrimination parameters shrunken to zero by the
 $\ell _1$
-penalty
$\ell _1$
-penalty

Bias and RMSE estimates for the rotation-invariant item parameters (
 $\delta _j$
’s and
$\delta _j$
’s and
 $\log \nu _j$
’s) are shown in Tables 3 and 4, respectively. We can see that the intercept parameters can be estimated very well with very little bias (Table 3). For the dispersion parameters, we have (slightly) larger bias and RMSE estimates (Table 4), but overall still mostly satisfactory performance for a sample of
$\log \nu _j$
’s) are shown in Tables 3 and 4, respectively. We can see that the intercept parameters can be estimated very well with very little bias (Table 3). For the dispersion parameters, we have (slightly) larger bias and RMSE estimates (Table 4), but overall still mostly satisfactory performance for a sample of
 $N = 1200$
. In particular for
$N = 1200$
. In particular for
 $L = 4$
traits, performance is better for larger m, that is, for more items per trait. Settings with
$L = 4$
traits, performance is better for larger m, that is, for more items per trait. Settings with
 $L = 3$
traits yielded better performance than those with
$L = 3$
traits yielded better performance than those with
 $L = 4$
, likely as the number of observations to number of items ratio is smaller in the latter case for constant
$L = 4$
, likely as the number of observations to number of items ratio is smaller in the latter case for constant
 $N = 1200$
.
$N = 1200$
.
Figure 3 investigates bias and RMSE in estimated item pair associations via the off-diagonal elements of
 $\hat {\boldsymbol \alpha }Cov(\boldsymbol \theta )\hat {\boldsymbol \alpha }^\top $
. Bias is negligible if
$\hat {\boldsymbol \alpha }Cov(\boldsymbol \theta )\hat {\boldsymbol \alpha }^\top $
. Bias is negligible if
 $\rho = 0$
, but for
$\rho = 0$
, but for
 $\rho = 0.3$
, slight biases become apparent, especially if the true discrimination parameter matrix is complex. As can be expected, the increase in Bias also increases the RMSE. In some scenarios (simple,
$\rho = 0.3$
, slight biases become apparent, especially if the true discrimination parameter matrix is complex. As can be expected, the increase in Bias also increases the RMSE. In some scenarios (simple,
 $L=4$
,
$L=4$
,
 $\rho =0.3$
,
$\rho =0.3$
,
 $m=3$
or
$m=3$
or
 $m=5$
), the oblique Lasso has somewhat lower Bias and RMSE.
$m=5$
), the oblique Lasso has somewhat lower Bias and RMSE.
Bias and RMSE of the off-diagonal elements of
 $\hat {\boldsymbol \alpha }Cov(\boldsymbol \theta )\hat {\boldsymbol \alpha }^\top $
, a measure of association of item pairs.
$\hat {\boldsymbol \alpha }Cov(\boldsymbol \theta )\hat {\boldsymbol \alpha }^\top $
, a measure of association of item pairs.

4 Application example
To illustrate the application of an exploratory M2PCMPM together with a comparison of the two regularization based approaches with the traditional rotation based approach, we reanalyze data (
 $N = 1318$
adolescents, including
$N = 1318$
adolescents, including
 $434$
adolescents diagnosed as highly gifted) from a German intelligence test (Berliner Intelligenzstrukturtest für Jugendliche: Begabungs- und Hochbegabungsdiagnostik, BIS-HB; Jäger et al., Reference Jäger, Holling, Preckel, Schulze, Vock, Süß and Beauducel2006). The BIS-HB is an operationalization of the Berlin model of intelligence structure (Jäger, Reference Jäger1967, Reference Jäger1982, Reference Jäger1984). In line with this model, the BIS-HB assesses intelligence across four operational abilities (each measured in three content domains: figural, verbal, and numerical): processing capacity, creativity, memory, and processing speed. We reanalyze the responses for the two operational abilities, creativity and processing speed, which generate count responses. Processing speed is assessed using nine items (also reanalyzed in Doebler et al., Reference Doebler, Doebler and Holling2014), creativity (in terms of idea flexibility) with five.
$434$
adolescents diagnosed as highly gifted) from a German intelligence test (Berliner Intelligenzstrukturtest für Jugendliche: Begabungs- und Hochbegabungsdiagnostik, BIS-HB; Jäger et al., Reference Jäger, Holling, Preckel, Schulze, Vock, Süß and Beauducel2006). The BIS-HB is an operationalization of the Berlin model of intelligence structure (Jäger, Reference Jäger1967, Reference Jäger1982, Reference Jäger1984). In line with this model, the BIS-HB assesses intelligence across four operational abilities (each measured in three content domains: figural, verbal, and numerical): processing capacity, creativity, memory, and processing speed. We reanalyze the responses for the two operational abilities, creativity and processing speed, which generate count responses. Processing speed is assessed using nine items (also reanalyzed in Doebler et al., Reference Doebler, Doebler and Holling2014), creativity (in terms of idea flexibility) with five.
In our re-analysis, we investigate in how far we can recover the theoretical factor structure of two latent traits in an exploratory M2PCMPM. We fit the two variants (i.e., lasso and rotation) of the exploratory two-factor M2PCMPM with the upper-triangle identification constraint to the data and 12 quadrature nodes per trait, using the countirt package (see Computational Aspects). For the M2PCMPM in conjunction with rotation, we used an orthogonal varimax (Kaiser, Reference Kaiser1958, Reference Kaiser1959) and an oblique oblimin rotation (Clarkson & Jennrich, Reference Clarkson and Jennrich1988). For the lasso-penalized M2PCMPM, we fitted one model with a priori orthogonal (i.e., uncorrelated) latent factors and one with a priori oblique (i.e., correlated) latent factors. For the latter, latent factor correlations obtained from the obliquely rotated M2PCMPM were used (compare Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). We tuned the lasso-penalized M2PCMPMs using a 20-value penalization grid of
 $[0,1000]$
with values chosen equidistantly on the log scale (cf. Hastie et al., Reference Hastie, Tibshirani and Friedman2009) and used warm starts in
$[0,1000]$
with values chosen equidistantly on the log scale (cf. Hastie et al., Reference Hastie, Tibshirani and Friedman2009) and used warm starts in
 $\eta $
-tuning (see Computational Aspects). As in the simulation study, start values for the first M2PCMPMs on the tuning grid (i.e., for
$\eta $
-tuning (see Computational Aspects). As in the simulation study, start values for the first M2PCMPMs on the tuning grid (i.e., for
 $\eta = 0$
) were the parameter estimates from the unpenalized M2PCMPM (before rotation).
$\eta = 0$
) were the parameter estimates from the unpenalized M2PCMPM (before rotation).
The results are shown in Table 6. While we do not obtain a pattern of perfect
 $\boldsymbol {\alpha }$
simple structure for any of the methods, we can see that in particular for the approaches with oblique latent traits, the estimates for the
$\boldsymbol {\alpha }$
simple structure for any of the methods, we can see that in particular for the approaches with oblique latent traits, the estimates for the
 $\boldsymbol {\alpha }$
matrix align well with theoretical considerations. That is, for the oblimin-rotated unpenalized M2PCMPM, we can see that the processing speed items load mostly on the first trait (i.e., processing speed), while the creative thinking items load mostly on the second trait (i.e., creative thinking). Only the processing speed items BD and OE load overall rather weakly onto either factor, with a small preference for the processing speed factor. A similar pattern of results emerged for the lasso-penalized M2PCMPM with oblique latent traits, with the penalty-imposed shrinkage amplifying the theoretically implied loading structure further. For the creative thinking items AM and ZF as well as for the processing speed item UW, the discrimination parameters were even shrunken to 0. We can see that the assumption that the latent traits are uncorrelated (i.e., varimax-rotated unpenalized M2PCMPM and lasso-penalized M2PCMPM with orthogonal latent traits) yielded a less differentiated loading structure, in particular for the creative thinking items which still load highest onto the second trait but also less negligibly onto the first, especially for the lasso-penalized M2PCMPM with orthogonal latent traits. Intercept (
$\boldsymbol {\alpha }$
matrix align well with theoretical considerations. That is, for the oblimin-rotated unpenalized M2PCMPM, we can see that the processing speed items load mostly on the first trait (i.e., processing speed), while the creative thinking items load mostly on the second trait (i.e., creative thinking). Only the processing speed items BD and OE load overall rather weakly onto either factor, with a small preference for the processing speed factor. A similar pattern of results emerged for the lasso-penalized M2PCMPM with oblique latent traits, with the penalty-imposed shrinkage amplifying the theoretically implied loading structure further. For the creative thinking items AM and ZF as well as for the processing speed item UW, the discrimination parameters were even shrunken to 0. We can see that the assumption that the latent traits are uncorrelated (i.e., varimax-rotated unpenalized M2PCMPM and lasso-penalized M2PCMPM with orthogonal latent traits) yielded a less differentiated loading structure, in particular for the creative thinking items which still load highest onto the second trait but also less negligibly onto the first, especially for the lasso-penalized M2PCMPM with orthogonal latent traits. Intercept (
 $\delta _j$
) and log-dispersion (
$\delta _j$
) and log-dispersion (
 $\log \nu _j$
) estimates were—as we would expect—very similar across methods. Note the rotated M2PCMPMs have only one set each as they are both based on the same unpenalized M2PCMPM for which we only rotate the
$\log \nu _j$
) estimates were—as we would expect—very similar across methods. Note the rotated M2PCMPMs have only one set each as they are both based on the same unpenalized M2PCMPM for which we only rotate the
 $\boldsymbol {\alpha }$
matrix, leaving the other parameters unchanged. Items exhibited a mix of over- and underdispersion, with some even close to equidispersion (i.e., 0 for
$\boldsymbol {\alpha }$
matrix, leaving the other parameters unchanged. Items exhibited a mix of over- and underdispersion, with some even close to equidispersion (i.e., 0 for
 $\log \nu _j$
as
$\log \nu _j$
as
 $\log (1) = 0$
), highlighting the strength of the CMP distribution to account for such a variation of dispersion across items.
$\log (1) = 0$
), highlighting the strength of the CMP distribution to account for such a variation of dispersion across items.
Results example (Processing speed (P) and creativity (C))

Note: Factor correlation from oblique rotation (oblimin):
 $r = .611$
. Identification constraints are printed in gray. obli = oblique (a priori correlated latent factors). ortho = orthogonal (a priori uncorrelated latent factors).
$r = .611$
. Identification constraints are printed in gray. obli = oblique (a priori correlated latent factors). ortho = orthogonal (a priori uncorrelated latent factors).
5 Discussion
This work proposes a novel multidimensional count item response model with flexible dispersion modeling: the multidimensional two-parameter Conway–Maxwell–Poisson model (M2PCMPM). A number of existing count item response models (Beisemann, Reference Beisemann2022; Forthmann et al., Reference Forthmann, Çelik, Holling, Storme and Lubart2018, Reference Forthmann, Gühne and Doebler2020; Myszkowski & Storme, Reference Myszkowski and Storme2021; Rasch, Reference Rasch1960) can be understood as special cases of the M2PCMPM, rendering the M2PCMPM a general overarching model class. The M2PCMPM can be employed in an exploratory manner—which this work primarily focused on—but also in a confirmatory manner by imposing constraints on model parameters. As a consequence, even more special cases of count item response models can be obtained and formulated as well as estimated within the M2PCMPM framework. We derived marginal maximum likelihood estimation methods based on the EM algorithm (Dempster et al., Reference Dempster, Laird and Rubin1977). For exploratory M2PCMPMs, we investigated using rotation methods (e.g., Carroll, Reference Carroll1957; Clarkson & Jennrich, Reference Clarkson and Jennrich1988; Kaiser, Reference Kaiser1958, Reference Kaiser1959) in conjunction with the proposed M2PCMPM-EM algorithm for obtaining a simple structure solution for the discrimination parameter matrix. Alternatively, we developed a
 $\ell _1$
-penalized (i.e., lasso-penalized; Tibshirani, Reference Tibshirani1996) variant of the M2PCMPM-EM algorithm, which can be used to the same end. We explored versions of this algorithm with a priori uncorrelated latent traits and with a priori correlated latent traits. In a simulation study and an application example, we assessed and compared the two proposed algorithms for fitting exploratory M2PCMPMs.
$\ell _1$
-penalized (i.e., lasso-penalized; Tibshirani, Reference Tibshirani1996) variant of the M2PCMPM-EM algorithm, which can be used to the same end. We explored versions of this algorithm with a priori uncorrelated latent traits and with a priori correlated latent traits. In a simulation study and an application example, we assessed and compared the two proposed algorithms for fitting exploratory M2PCMPMs.
5.1 Performance patterns from the simulation study
The conducted simulation study showed stable numerical performance for the developed algorithms in the investigated simulation settings. Bias and RMSE on the intercept and (log) dispersion parameters were overall satisfactory, with differences in performance between conditions in line with prior research on CMP-based count item response models (Beisemann, Reference Beisemann2022; Beisemann et al., Reference Beisemann, Forthmann and Doebler2024). In conditions with more latent traits, we tended to observe more bias, in particular for the (log) dispersion parameters. Due to rotational indeterminacy, we assessed bias and RMSE of discrimination parameter estimates with a measure of item level associations. For a number of the conditions, we observed decent performance, with the oblique lasso approaches slightly better. Conditions in which bias and RMSE were somewhat pronounced were those with correlated traits.
In terms of BIC-based hyperparameter tuning for the lasso-penalized M2PCMPM-EM algorithm (with either a priori correlated or a priori uncorrelated latent factors), we found performance differed notably depending on the condition. Assessing tuning performance following Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016), we found that performance was in general better for an underlying simple structure of the
 $\boldsymbol {\alpha }$
matrix. Unsurprisingly, more complex structures of the
$\boldsymbol {\alpha }$
matrix. Unsurprisingly, more complex structures of the
 $\boldsymbol {\alpha }$
matrix were more challenging as these are less clearly variable selection problems. With more items and/or more traits, the accuracy of the BIC-based hyperparameter tuning tended to improve. Compared to Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016)’s assessment of BIC-based hyperparameter tuning for lasso-penalized binary models, we observed overall (more or less pronounced) worse performance for count models (not just of the BIC tuning, but also of the CER-based tuning which is perhaps surprising at first glance). It is worth pointing out that the direct comparison to the models in Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) is not entirely appropriate as Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) defined the CER slightly differently to us (see above). The observed pattern may also be confounded with the number of penalized parameters—in our simulation, the smallest setting only included nine items, which leaves (with identification constraints) only six freely estimated, penalized parameters. In this instance, one misclassification already equates to a change of
$\boldsymbol {\alpha }$
matrix were more challenging as these are less clearly variable selection problems. With more items and/or more traits, the accuracy of the BIC-based hyperparameter tuning tended to improve. Compared to Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016)’s assessment of BIC-based hyperparameter tuning for lasso-penalized binary models, we observed overall (more or less pronounced) worse performance for count models (not just of the BIC tuning, but also of the CER-based tuning which is perhaps surprising at first glance). It is worth pointing out that the direct comparison to the models in Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) is not entirely appropriate as Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) defined the CER slightly differently to us (see above). The observed pattern may also be confounded with the number of penalized parameters—in our simulation, the smallest setting only included nine items, which leaves (with identification constraints) only six freely estimated, penalized parameters. In this instance, one misclassification already equates to a change of
 $\frac {1}{6}$
in the CER. As discussed further below, these results suggest that while the BIC-based hyperparameter tuning appears to work decently for some conditions, hyperparameter tuning for the lasso-penalized M2PCMPM-EM algorithm could still be improved by future research. These results also suggest that future research might wish to consider alternatives to the CER for performance evaluation. For example, one could extract the model-implied item covariance matrix and compare it to the observed item covariance matrix using matrix norms.
$\frac {1}{6}$
in the CER. As discussed further below, these results suggest that while the BIC-based hyperparameter tuning appears to work decently for some conditions, hyperparameter tuning for the lasso-penalized M2PCMPM-EM algorithm could still be improved by future research. These results also suggest that future research might wish to consider alternatives to the CER for performance evaluation. For example, one could extract the model-implied item covariance matrix and compare it to the observed item covariance matrix using matrix norms.
5.2 Limitations and further avenues for future research
Our simulation study was designed to provide a proof of concept for the proposed model and algorithms. It is important to note that it should only be regarded as such, and that it has severe limitations with regard to the number of simulation trials, the number of quadrature nodes per traits, and the sample size investigated. Please be aware that small numbers of simulation trials and low numbers of quadrature nodes per trait run the risk of yielding inaccurate or at least imprecise results. As a proof-of-concept type simulation, and as guided by previous research (Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016), it focused on scenarios with three or four latent traits. Future research could explore higher dimensional scenarios. In such settings, the Gauss-Hermite quadrature based M2PCMPM EM algorithm is likely going to reach its limitation, as Gauss-Hermite quadrature is known not to scale well to high-dimensional problems (Chalmers, Reference Chalmers2012). Thus, future research in this regard could explore alternative integral approximations, such as Monte Carlo based methods. Further, the maximum test length investigated in our simulation study was 20 items. Future research could investigate more extensive tests, including more items. This should assess the models’ viability for use with larger tests.
In light of the limitations of the presented simulation study and upon a reviewer’s helpful suggestion, we attempted to conduct a more extensive simulation study, with
 $T = 50$
simulation trials per condition, setting the quadrature nodes per trait for conditions with
$T = 50$
simulation trials per condition, setting the quadrature nodes per trait for conditions with
 $L = 4$
traits up to
$L = 4$
traits up to
 $5$
, and including eight additional conditions with a sample size of
$5$
, and including eight additional conditions with a sample size of
 $N = 3000$
. A full overview of the design is available in the Supplementary Material. We ran into a computational issue: A number of conditions ran out of wall time (maximal wall time on the cluster used was 28 days) before they could be completed. This concerned primarily but not exclusively the conditions with
$N = 3000$
. A full overview of the design is available in the Supplementary Material. We ran into a computational issue: A number of conditions ran out of wall time (maximal wall time on the cluster used was 28 days) before they could be completed. This concerned primarily but not exclusively the conditions with
 $N = 3000$
. The Supplementary Material contains an overview over which conditions were completed. Results are very similar and suggest that the number of quadrature nodes was not too low to obtain meaningful results reported here. The additional results (for those conditions for which all 50 trials were completed within the maximum wall time) are depicted in the Supplementary Material. We encourage future research to attempt a more comprehensive simulation, including more simulation trials and higher numbers of quadrature nodes per trait, especially if they have access to more computation power. Any definitive recommendations on using the proposed models should be held off until such a comprehensive investigation has been conducted.
$N = 3000$
. The Supplementary Material contains an overview over which conditions were completed. Results are very similar and suggest that the number of quadrature nodes was not too low to obtain meaningful results reported here. The additional results (for those conditions for which all 50 trials were completed within the maximum wall time) are depicted in the Supplementary Material. We encourage future research to attempt a more comprehensive simulation, including more simulation trials and higher numbers of quadrature nodes per trait, especially if they have access to more computation power. Any definitive recommendations on using the proposed models should be held off until such a comprehensive investigation has been conducted.
We implemented the proposed algorithms in R and C++ within the countirt package. To this end, we built upon implementations of the 2PCMPM (Beisemann, Reference Beisemann2022) and related models (Beisemann et al., Reference Beisemann, Forthmann and Doebler2024) in countirt. These implementations all use a naive interpolation-from-grid approach for some of the CMP distribution-related quantities to stabilize, facilitate and fasten computations. This approach worked well in our simulation study and its settings, but can be expected to work less well in settings where the data do not align well with the interpolation grid (see https://github.com/doebler/countirt for details). In a regression framework, Philipson and Huang (Reference Philipson and Huang2023) developed a sophisticated and theory-based interpolation approach for CMP models, which allows not only inter- but also extrapolation from a specifically designed grid. Future research could aim to apply and extend their work to the (multidimensional) IRT context for CMP models.
In any case, our implementation in countirt can certainly be improved upon in terms of computational efficiency. We encourage future research to develop faster and more computationally efficient implementations of our proposed algorithms. We would expect that only such advances would allow the proposed models to be used in big data settings, such as big-data processing data applications. Future research could investigate what advances could make this possible to what extent.
For comparability with the rotation approach and for computational reasons, we did not tune our lasso penalty term on a training data set. However, for regularization methods that would be the recommended approach (Hastie et al., Reference Hastie, Tibshirani and Friedman2009) and is what we would recommend for high-stakes applications. This approach should prohibit overfitting to the data more aptly. In general, our tuning for the lasso penalty term simply used a grid with equidistant tuning parameter values on the log-value space (as is typically recommended; Hastie et al., Reference Hastie, Tibshirani and Friedman2009) and was based on the BIC. As we saw in the simulation study results, for certain settings, the selection of the tuning parameter could still be improved. In fact, sometimes the correct estimation rates were even low when they were used to choose the tuning parameter value. Future research might research how parameter tuning can be improved for the M2PCMPM lasso-EM algorithm and what computationally equally economical alternatives to the BIC as a tuning criterion could be used. Further, more investigation of tuning and the tuning grid used could also be interesting and helpful. Such investigations are going to have to face the computation time challenge that these computationally expensive models pose. Other than the warm starts already used in this work, other avenues such as EM algorithm accelerators might be explored (see Beisemann et al., Reference Beisemann, Wartlick and Doebler2020, for a recent overview of state-of-the-art methods).
For the penalization, we focused on the lasso (Tibshirani, Reference Tibshirani1996) which aligns with other research on penalization in item response models (Cho et al., Reference Cho, Xiao, Wang and Xu2022; Sun et al., Reference Sun, Chen, Liu, Ying and Xin2016). Future research could explore the relaxed lasso (Meinshausen, Reference Meinshausen2007) to avoid shrunken nonzero estimates. Lasso penalization is also known to perform less well in settings with correlated variables (Hastie et al., Reference Hastie, Tibshirani and Friedman2009), which corresponds to latent factor correlations in item response model settings. Future research could address such limitation by extending the lasso-penalized M2PCMPM EM algorithm to penalties such as the elastic net (Zou & Hastie, Reference Zou and Hastie2005), which adaptively combines properties of the lasso and the ridge (Hoerl & Kennard, Reference Hoerl and Kennard1970) penalty. Alternative penalties such as the smoothly clipped absolute deviation (SCAD; Fan & Li, Reference Fan and Li2001) could also be explored (for an application of SCAD in IRT, see e.g., Robitzsch, Reference Robitzsch2023). Other ways in which the penalized algorithms themselves could be extended by future research would be, for example, the incorporation of latent factor correlation estimation into the algorithm, rather than the two-step method by Sun et al. (Reference Sun, Chen, Liu, Ying and Xin2016) that we used here to have the algorithm account for correlated factors.
Finally, the M2PCMPM framework proposed in this work can also in itself be a stepping stone for future research. That is, the M2PCMPM framework offers researchers the opportunity to propose, fit, and investigate a number of new count item response models that can be accomodated by the M2PCMPM framework as special cases. This can be achieved by exploring the confirmatory side of the M2PCMPM framework which the present work only briefly touched on. Future research could suggest new constraints through which new count item response models can be obtained from the M2PCMPM. Furthermore, for the M2PCMPM framework to be complete and applicable in practice, it needs to be enriched in the future by developing multi-group and differential item functioning extensions within the framework as well as by deriving person parameter estimators, item fit, and person fit measures. We propose the following tentative recommendations for utilizing the M2PCMPM: (1) Unlike binary and ordinal IRT models, fewer items per factor are required, as item information can be substantially higher in the count data case (Beisemann et al., Reference Beisemann, Wartlick and Doebler2020).In fact, as few as three items per factor may suffice, particularly if a simple factor structure is plausible and the discrimination parameters are sufficiently large. Based on our experience with several authentic datasets, we suggest starting with a linear factor analysis of log-counts. (2) When computational resources permit, oblique or orthogonal Lasso methods should be considered, as the resulting zeroes in the discrimination parameter matrix facilitate interpretation. The BIC criterion is our recommended method for tuning the Lasso. (3) A limitation of the Lasso approach, however, is that the resulting models cannot be freely rotated. (4) If excess zeroes are observed in the count data (zero-inflation) the CMP distribution is not adequate. Similarly, once the counts are very large or the over- or underdispersion becomes too extreme, numerical problems can arise. More research on extensions to other distributions are needed for these cases.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/psy.2024.17.
Data availability statement
The algorithms developed in this work have been implemented in the R package countirt (https://github.com/mbsmn/countirt/tree/multidimensional). The R code for the simulation study and the R data files of the simulation results are available on OSF (https://osf.io/n5792/). The data set re-analyzed for the example could not be made publicly available as this was guaranteed to participants at the time of data collection during the original study.
Acknowledgments
The authors would like to thank two anonymous reviewers and the journal’s editors for their helpful and valuable feedback. M.B. would like to thank Paul Bürkner for the helpful discussions and his feedback during the process of working on this project. The authors gratefully acknowledge the computing time provided on the Linux HPC cluster at TU Dortmund University (LiDO3), partially funded by the Large-Scale Equipment Initiative by the German Research Foundation (DFG) as project 271512359.
Funding statement
This work was supported by research grant DO 1789/7-1 granted by the DFG (Deutsche Forschungsgemeinschaft) to P.D. M.B.’s work on this project was funded through this grant.
Competing interests
H.H. is co-author of the Berliner Intelligenzstruktur-Test für Jugendliche: Begabungs- und Hochbegabungsdiagnostik, the intelligence test used in the data example of this study. The remaining authors declare no competing interests.
Ethical standards
This work did not include data collection from human or animal participants. In this work, a pre-existing data set was re-analyzed to illustrate the developed method. The data set was collected by Heinz Holling and colleagues and originally published in Jäger et al. (2006). In Germany, where the data collection was conducted, ethical approval for the study by Jäger et al. (2006) was neither institutionally nor nationally obligatory at the time of data collection and thus no ethical approval was sought for the study at the time.
APPENDICES
A First derivative of the CMP variance
For the second derivatives in terms of
 $\delta _j$
and
$\delta _j$
and
 $\alpha _{jl}$
in Equations 17–18, we need the derivative of the variance V in terms of
$\alpha _{jl}$
in Equations 17–18, we need the derivative of the variance V in terms of
 $\delta _j$
and
$\delta _j$
and
 $\alpha _{jl}$
. That is,
$\alpha _{jl}$
. That is,
 $$ \begin{align} \frac{\partial V(\mu_{jk_1,\dots,k_L}, \nu_j)}{\partial \alpha_{jl}} &= \frac{\partial \mathbb{E}_X(X^2)}{\partial \alpha_{jl}} - \frac{\partial \mu_{jk_1,\dots,k_L}^2}{\partial \alpha_{jl}} \end{align} $$
$$ \begin{align} \frac{\partial V(\mu_{jk_1,\dots,k_L}, \nu_j)}{\partial \alpha_{jl}} &= \frac{\partial \mathbb{E}_X(X^2)}{\partial \alpha_{jl}} - \frac{\partial \mu_{jk_1,\dots,k_L}^2}{\partial \alpha_{jl}} \end{align} $$
 $$ \begin{align} &= \frac{\mu_{jk_1,\dots,k_L} q_{k_l}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} \mathbb{E}_X(X^3 - \mu_{jk_1,\dots,k_L} X^2) - 2 q_{k_l} \mu_{jk_1,\dots,k_L}^2, \end{align} $$
$$ \begin{align} &= \frac{\mu_{jk_1,\dots,k_L} q_{k_l}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} \mathbb{E}_X(X^3 - \mu_{jk_1,\dots,k_L} X^2) - 2 q_{k_l} \mu_{jk_1,\dots,k_L}^2, \end{align} $$
and
 $$ \begin{align} \frac{\partial V(\mu_{jk_1,\dots,k_L}, \nu_j)}{\partial \delta_{j}} &= \frac{\partial \mathbb{E}_X(X^2)}{\partial \delta_{j}} - \frac{\partial \mu_{jk_1,\dots,k_L}^2}{\partial \delta_{j}} \end{align} $$
$$ \begin{align} \frac{\partial V(\mu_{jk_1,\dots,k_L}, \nu_j)}{\partial \delta_{j}} &= \frac{\partial \mathbb{E}_X(X^2)}{\partial \delta_{j}} - \frac{\partial \mu_{jk_1,\dots,k_L}^2}{\partial \delta_{j}} \end{align} $$
 $$ \begin{align} &= \frac{\mu_{jk_1,\dots,k_L}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} \mathbb{E}_X(X^3 - \mu_{jk_1,\dots,k_L} X^2) - 2 \mu_{jk_1,\dots,k_L}^2. \end{align} $$
$$ \begin{align} &= \frac{\mu_{jk_1,\dots,k_L}}{V(\mu_{jk_1,\dots,k_L}, \nu_j)} \mathbb{E}_X(X^3 - \mu_{jk_1,\dots,k_L} X^2) - 2 \mu_{jk_1,\dots,k_L}^2. \end{align} $$
The first equality in both equation holds because for any random variable W it holds that
 $\mathbb {V}(W)= \mathbb {E}(W^2) - \mathbb {E}(W)^2$
. Taking the derivative of
$\mathbb {V}(W)= \mathbb {E}(W^2) - \mathbb {E}(W)^2$
. Taking the derivative of
 $\mu _{jk_1,\dots ,k_L}^2$
with regard to
$\mu _{jk_1,\dots ,k_L}^2$
with regard to
 $\alpha _{jl}$
and
$\alpha _{jl}$
and
 $\delta _{j}$
is trivial. To take the derivative of
$\delta _{j}$
is trivial. To take the derivative of
 $\mathbb {E}_X(X^2)$
with regard to
$\mathbb {E}_X(X^2)$
with regard to
 $\alpha _{jl}$
and
$\alpha _{jl}$
and
 $\delta _{j}$
, we used results provided in Huang (Reference Huang2017) and derivation rules.
$\delta _{j}$
, we used results provided in Huang (Reference Huang2017) and derivation rules.
B Lasso EM with blockwise coordinate descent during M step

C.1 Special cases
The M2PCMPM contains a number of count data item response models as special cases. For
 $L = 1$
, the M2PCMPM simplifies to the 2PCMPM (Beisemann, Reference Beisemann2022) and with the additional constraint that
$L = 1$
, the M2PCMPM simplifies to the 2PCMPM (Beisemann, Reference Beisemann2022) and with the additional constraint that
 $\alpha _{11} = \dots = \alpha _{1M}$
the model further simplifies to the Conway–Maxwell–Poisson Counts Model (CMPCM; Forthmann et al., Reference Forthmann, Gühne and Doebler2020). For
$\alpha _{11} = \dots = \alpha _{1M}$
the model further simplifies to the Conway–Maxwell–Poisson Counts Model (CMPCM; Forthmann et al., Reference Forthmann, Gühne and Doebler2020). For
 $L> 1$
, but equal slope parameters across items and traits, the M2PCMPM simplifies to a multidimensional CMPCM. Whenever all item-specific dispersions are fixed to be equal to 1 (i.e.,
$L> 1$
, but equal slope parameters across items and traits, the M2PCMPM simplifies to a multidimensional CMPCM. Whenever all item-specific dispersions are fixed to be equal to 1 (i.e.,
 $\forall j \in \{1, \dots , M \}: \nu _j = 1$
), the CMP density simplifies to the Poisson density. Consequently, the M2PCMPM also contains the RPCM (Rasch, Reference Rasch1960), the Two-Parameter Poisson Counts Model (2PPCM; Myszkowski & Storme, Reference Myszkowski and Storme2021), and multidimensional extensions of the RPCM and the 2PPCM (Forthmann et al., Reference Forthmann, Çelik, Holling, Storme and Lubart2018; Myszkowski & Storme, Reference Myszkowski and Storme2021). Thereby, the M2CMPM offers the possibility of a comprehensive framework for count data item response modeling which subsumes a number of existing count data item response models.
$\forall j \in \{1, \dots , M \}: \nu _j = 1$
), the CMP density simplifies to the Poisson density. Consequently, the M2PCMPM also contains the RPCM (Rasch, Reference Rasch1960), the Two-Parameter Poisson Counts Model (2PPCM; Myszkowski & Storme, Reference Myszkowski and Storme2021), and multidimensional extensions of the RPCM and the 2PPCM (Forthmann et al., Reference Forthmann, Çelik, Holling, Storme and Lubart2018; Myszkowski & Storme, Reference Myszkowski and Storme2021). Thereby, the M2CMPM offers the possibility of a comprehensive framework for count data item response modeling which subsumes a number of existing count data item response models.
C.2 Confirmatory models by imposing constraints
While not a focus of the present work, we wanted to note that with the M2PCMPM EM algorithm, one can also fit confirmatory multidimensional count data item response models. That is, one can impose constraints on the item parameters (in particular but not exclusively, the slope parameters) and evaluate the specified model’s fit to the data. Confirmatory models should be identified by the imposed constraints. For instance, the fit of a perfect simple structure to the data can be evaluated by imposing constraints which imply single loadings of each item onto only one trait l (for a fixed l) of the latent traits, respectively, and
 $\alpha _{jl'} = 0$
$\alpha _{jl'} = 0$
 $\forall l' \neq l$
.
$\forall l' \neq l$
.






























 Open access
Open access