


Introduction
Although the contrast between subject-extracted relative clauses (SRs) like (1a) and object-extracted relative clauses (ORs) like (1b) is one of the most investigated areas in sentence processing, language acquisition, and theoretical syntax studies, the source of the object disadvantage, namely the fact that ORs are more challenging, is still very controversial.
-
(1a) The employee that insulted the manager left the room abruptly.
-
(1b) The employee that the manager insulted left the room abruptly.
An object-relative (OR) disadvantage in language acquisition has been consistently reported: ORs such as (1b) are comprehended and produced later than their SR counterparts like (1a) (e.g., Adani, Reference Adani2011; Arosio et al., Reference Arosio, Adani, Guasti, Brucart, Gavarró and Solà2009; Cilibrasi et al., Reference Cilibrasi, Adani and Tsimpli2019; Friedmann et al., Reference Friedmann, Belletti and Rizzi2009; Guasti et al., Reference Guasti, Vernice and Franck2018; Kidd & Bavin, Reference Kidd and Bavin2002). Comparable asymmetries have been documented in clinical populations, notably in individuals with agrammatism, who exhibit reduced comprehension and production of ORs compared to SRs (e.g., Adelt et al., Reference Adelt, Stadie, Lassotta, Adani and Burchert2017; Friedmann, Reference Friedmann2008; Friedmann et al., Reference Friedmann, Reznick, Dolinski-Nuger and Soboleva2010; Garraffa & Grillo, Reference Garraffa and Grillo2008; Grodzinsky, Reference Grodzinsky2000; Varlokosta et al., Reference Varlokosta, Nerantzini, Papadopoulou, Bastiaanse and Beretta2014). However, these studies mainly used offline comprehension and production tasks, which cannot directly reveal the incremental source of the OR disadvantage. The present study addresses this gap by examining online sentence processing of relatives within the broader psycholinguistic literature on this topic.
Since a full review of all proposed explanations lies beyond the scope of this study, we focus in the following sections on those accounts that have received the most sustained attention, have generated substantial theoretical debate, and are most relevant to our experimental investigation.
The surprisal account
According to the surprisal account (cf. Hale, Reference Hale2001; Levi, Reference Levy2008; MacDonald, Reference MacDonald2013; Reali & Christiansen, Reference Reali and Christiansen2007), the difficulty of a word in a structure depends on how unexpected it is in this structure. High-surprisal (low-predictability) words cause more processing effort, while low-surprisal (highly predictable) words are processed more easily. When applied to our domain of investigation, surprisal’s starting point is the assumption that SRs are more common than ORs; therefore, while reading or listening to the sentences in (1), after the word “that,” the comprehender will expect a verb and not an NP. The cost of ORs comes from the violation of the expectation. This violation is predicted to trigger a slowdown in reading, specifically on the subject of ORs, where the unexpected input occurs. A big advantage of this account is that in principle it allows precise numerical predictions on the comprehender’s behavior on a given construction once the probability of that construction is established in the relevant corpus.
Two critical points can be advanced, though. The first is the need to give a precise definition of the theoretical construct whose frequency must be measured. To be concrete, although it is very likely that sentences like (1a) are generally more frequent than sentences like (1b), ORs with a personal pronoun in subject position like (2) are much more frequent, possibly as frequent as the corresponding SR, depending on the corpus considered.
-
(2) The employee that I insulted left the room abruptly.
In null subject languages like Italian, the counterpart of (2) with a null subject is also very productive.
What is the right theoretical construct whose frequency should be measured? All ORs or subtypes of ORs according to the (null or overt) category that occupies their subject position?
A second problem is more conceptual. The surprisal account is not built to explain why a certain construction is less frequent and therefore more difficult. Any attempt to answer “the why question” in this framework risks being circular (ORs are difficult because they are rare, and they are rare because they are difficult).
The integration account
The critical assumption of the integration account (Gibson, Reference Gibson1998; Grodner & Gibson, Reference Grodner and Gibson2005) is that the head of the relative clause (“the employee”) must be maintained in the memory buffer for a longer time in ORs than in SRs; therefore, a difficulty emerges when the NP “the employee” must be retrieved and integrated with the verb “insulted” in (1b). According to this account, the difficulty is modulated by the distance between the filler and its gap and by the number of NPs that need to be processed before the gap is met (in 1b the filler is more distant than in 1a, and the NP “the manager” must be kept in the memory buffer until the gap is identified). The integration account explicitly measures distance in linear terms; therefore, it makes the cross-linguistic prediction that in languages in which the filler and the gap are linearly closer in ORs than in SRs (say Mandarin Chinese, Korean, and Japanese), the former should become easier, in stark contrast with languages like English. Whether this prediction is correct or not is controversial, though (cf. Jäger et al., Reference Jäger, Chen, Li, Lin and Vasishth2015; Kwon et al., Reference Kwon, Gordon, Lee, Kluender and Polinsky2010; Miyamoto & Nakamura, Reference Miyamoto and Nakamura2013).
The intervention/interference account
This family of accounts has been independently proposed in different forms in the theoretical syntax (cf. Biondo et al., Reference Biondo, Pagliarini, Moscati, Rizzi and Belletti2023; Friedmann et al., Reference Friedmann, Belletti and Rizzi2009) and in the processing (Gordon et al., Reference Gordon, Hendrick and Johnson2001, Reference Gordon, Hendrick and Johnson2004; Van Dyke & Lewis, Reference Van Dyke and Lewis2003; Van Dyke, Reference Van Dyke2007) literature, and it postulates that a dependency is harder when an element, which is similar to the filler, intervenes/interferes in the filler-gap dependency. Specifically, ORs are challenging because they contain a competitor for the filler position, namely the NP in the subject position of the relative: by the moment the object of the verb “insulted” must be identified, the NP “the employee” and the NP “the manager” compete, and this creates an intervention/interference.
Although the basic intuition is very similar, the notion of similarity is operationalized differently. In interference accounts, such as the cue-based retrieval (CBR) model (Engelmann et al., Reference Engelmann, Jäger and Vasishth2019; Lewis & Vasishth, Reference Lewis and Vasishth2005; Lewis et al., Reference Lewis, Vasishth and Van Dyke2006), all features impacting on working memory load are relevant at encoding. However, retrieval interference is predicted only when the filler and the competitor share features that are cued at retrieval. By contrast, in intervention accounts, such as featural relativized minimality (Biondo et al., Reference Biondo, Pagliarini, Moscati, Rizzi and Belletti2023; Friedmann et al., Reference Friedmann, Belletti and Rizzi2009), the only relevant features are those active in the syntactic structure. As we explain in the Discussion section, the notions of being cued at retrieval and of being grammatically active overlap in most cases, but they are not identical and may yield divergent predictions in specific contexts.
Another difference lies in the configuration that is assumed to trigger intervention/interference. The interference account (Gordon et al., Reference Gordon, Hendrick and Johnson2001, Reference Gordon, Hendrick and Johnson2004; Van Dyke & Lewis, Reference Van Dyke and Lewis2003; Van Dyke, Reference Van Dyke2007) maintains that interference is established among categories that are linearly ordered without looking at the abstract structure that underlies this linear sequence. Conversely, in intervention accounts (cf. Biondo et al., Reference Biondo, Pagliarini, Moscati, Rizzi and Belletti2023; Friedmann et al., Reference Friedmann, Belletti and Rizzi2009), intervention is formally defined by the notion of c-command: roughly speaking, a category intervenes if it is immediately attached to the line that connects filler and gap in the syntactic tree.
Predictions of different accounts and previous experimental investigations
Although there are different ways to compare these three families of explanations, in this paper, we follow a recent trend that compares these approaches based on the predictions they make about the specific moment in sentence processing in which the processing difficulty should arise (cf. Staub, Reference Staub2010, for a thorough application of this approach). Let us see this prediction in turn by taking (3) as the base of the discussion. The example is divided into five regions, following the partitioning used in most of the experiments that are going to be presented in this section.
-
(3)

As discussed by its proponents, the surprisal account makes the prediction that the processing difficulty should arise in the moment in which the expectation concerning the SR occurrence is not met, namely in the region immediately following “that” (W1 region). On the contrary, banning spillover effects (in the present work we use this term to define all possible delayed effects of the relevant manipulation), no special processing difficulties are expected in later regions, since the surprisal effect will have already been dealt with.
The predictions of the integration account are quite different, because the difficulty is expected at the moment in which the filler must be retrieved and integrated with the relative clause verb, namely in the W2 region.
Similarly to the intervention/interference account, this approach predicts an effect in the W2 region when the filler must be retrieved, and the effect of the intervening NP “the manager” is expected to arise (cf. Biondo et al., Reference Biondo, Pagliarini, Moscati, Rizzi and Belletti2023 for an explicit discussion). We discuss in the Discussion section if further effects can be hypothesized in W1.
As for the Post region, the matrix predicate needs to be integrated with the matrix subject “the employee,” and in principle, in this case as well, the linear intervention by the NP “the manager” might create an interference. However, while W2 is involved in the resolution of a filler gap dependency, Post is involved in the resolution of a subject-predicate dependency, and these two grammatical dependencies might have different behavioral effects. More critically, the same type of linear intervention occurs in the corresponding SR (“the employee that insulted the manager left the room abruptly”). Therefore, no additional processing cost for SRs or ORs is predicted in this region. However, in ORs, like (1b), the NP “the employee” that needs to be reactivated for subject-verb agreement in Post has just been reactivated as the antecedent of the gap in W2. The reactivation of the same NP in two consecutive positions and for two different dependencies could trigger an additional processing cost in Post for ORs, as discussed by Staub et al. (Reference Staub, Dillon and Clifton2017) and by Concetti and Moscati (Reference Concetti and Moscati2023).
Turning to the existing experimental research on these predictions, the effects appear to be strongly task-dependent. Three main methodologies have been used to investigate the online processing of relative clauses: self-paced reading, maze tasks, and eye-tracking. We discuss each in turn.
Overall, the findings from self-paced reading studies are prima facie inconsistent with the surprisal account. In Grodner and Gibson’s (Reference Grodner and Gibson2005) study, for example, the NP inside the relative (“the manager” in 1) is not read more slowly in ORs than in SRs, as the surprisal account would predict. As this finding depends on the comparison of the same NP in different positions in the sentence, Grodner and Gibson also compare RTs (adjusted for word length) in the region following the relative pronoun (this contains the verb in SRs and the subject in ORs) and in the following region (this contains the object in SRs and the verb in ORs) and conclude that the latter region, but not the former, was significantly more difficult to process in ORs than in SRs.
The expected effect in the W1 region is generally not found. On the contrary, the verb is read more slowly in the OR than in the SR, so the effect emerges in W2. Some effect emerges in Post as well, but it disappears when W2 and Post are set apart by inserting a prepositional phrase, and this suggests that any effect at Post is the spillover effect of the main effect in the previous region.
A possible criticism of this interpretation is that the self-paced reading task is prone to elicit spillover effects; therefore, one cannot exclude that the late effects do result from a surprisal effect in the W1 region, which manifests only later. For this reason, other techniques have been used, including the maze task. In this task, the participant is presented with pairs of words, and they must press a button to select the only member of the pair that continues the sentence in a sensible manner. For example, after reading the initial word “the,” both the target word “employee” and an unacceptable foil appear, and the word “employee” must be selected. This forced choice continues until the end of the sentence. According to different versions of the maze task, the foil can either be a pseudoword (lexical maze) or an existing word that, however, is not a grammatical continuation (grammatical maze). Although the maze task can be criticized for not being ecological and for relying on metalinguistic reasoning that does not necessarily reflect normal online processing, it is known to dramatically reduce spillover effects, as the forced choice obliges the comprehender to fully analyze the incoming string prior to moving forward. In fact, processing times for maze data have been shown to appear on the target word itself and not in downstream spillover regions (cf. Boyce et al., Reference Boyce, Futrell and Levy2020).
Interestingly, in a series of experiments involving different types of maze tasks (lexical maze and grammatical maze, cf. Forster et al., Reference Forster, Guerrera and Elliot2009, and a mixed maze task, cf. Vani et al., Reference Vani, Wilcox and Levy2021), the picture that emerges is that the processing difficulty arises in the region following “that” with no (or negligible) late effects. This is in agreement with the surprisal account and inconsistent with the other accounts.
Finally, eye tracking has been used to study online processing of SRs and ORs. Staub (Reference Staub2010) unveils a complex pattern that can be summarized as follows: both early effects (in the W1 region) and late effects (in W2) emerge, but they take a different form. Disruption in W1 takes the form of regressive saccades (regression from the same NP is more likely when it is the subject of the OR than when it appears in the corresponding SR). Disruption in W2 takes the form of longer reading time on the verb “insulted” in ORs than in SRs.
Staub’s interpretation is that both the surprisal account and the accounts that posit a problem at retrieval are needed, since the difficulty with ORs is due to two distinct sources, which have qualitatively distinct behavioral consequences in normal reading: regression signals surprisal, and longer reading times signal integration/intervention costs.
Aim of the study
In this paper, we address some questions that the current literature leaves open. Notably, if Staub et al. are right and integration/intervention costs are real, although they are not the only explicative factor, why does the maze task hide them? In order to tackle this question, in Experiment 1, we designed a modified maze task in which the forced choice is restricted to the relative clause regions. This is intended to maintain the advantages of the maze, but at the same time, we eliminate the processing load introduced by the forced choice when this is not informative. As the specific maze task used in Experiment 1 is novel, in Experiment 2, the very same grammatical stimuli used in Experiment 1 were used in a self-paced reading task to double-check whether the reading time patterns match qualitatively in the two distinct experimental techniques.
Material and methods
The study included two experiments adopting different methodologies: Experiment 1 used a modified maze task, and Experiment 2 a self-paced reading task. No participant undertook both experiments since they employed the same stimuli. The study was approved by the Ethics Committee of the Department of Psychology of the University Milano-Bicocca, Milan, Italy (Prot. No. RM-2023-694).
Experiment 1—Modified maze task
We developed a novel mixed methodology based on a lexical maze task (i.e., forced choice) in the critical part of the sentence (relative clause) embedded in a self-paced reading task (matrix clause).
Stimuli
We prepared 40 pairs of center-embedded relative clauses. Each pair included a subject relative (SR) and its corresponding object relative (OR). Each sentence was segmented into five regions, as illustrated in Table 1.
Structure of the stimuli used in the modified maze task.

Notes: SR = subject relatives; OR = object relatives; Start = subject of the matrix clause and complementizer; W1 = first critical region of the relative clause (verb for SRs and subject DP for ORs); W2 = second critical region of the relative clause (object DP for SRs and verb for ORs); Post = verb of the matrix clause; End = end of the matrix clause with a direct object, an indirect object, or an adjunct.
The Start, Post, and End regions were presented in a self-paced reading task. The W1 and W2 regions, which correspond to the relative clause subject and verb, were presented as a forced-choice task. In these regions, participants selected between a target word or phrase and a pseudoword presented simultaneously. The pseudowords were generated by making minimal phonological modifications to the target word of the opposite relative clause type (SR or OR) in the same region. For example, the subject of the OR in Table 1 (la cameriera, “the waitress”) competed with the pseudoword offenfilava, which phonologically resembles the verb offendeva (“offended”) that appears in the corresponding SR. This design, which creates a competition in the subject position of the OR between an NP and a pseudoverb, aimed to magnify any interference on the processing of the target OR by the alternative (easier) SR parse induced by the pseudowords. The same logic applies in the SR in Table 1, although the interference by the OR parse activated by the pseudoword is not expected to arise here.
In order to avoid any possible confounding due to adjacent verbs with the same morphology (as in the English OR “the waitress that that the manager scolded abandoned the job”), the verb in the relative clause and the matrix verb had different tense/aspect morphology (i.e., imperfetto—“imperfect” in the relative clause and passato prossimo—“present perfect” in the main clause).
As shown in the example, each target-pseudoword pair had the same character length (excluding spaces). The average character lengths (excluding spaces) for each region were as follows: 13.2 for Start (SD = 2.28, range: 9–18), 9.90 for W1 (SD = 1.47, range: 6–13), 9.97 for W2 (SD = 1.47, range: 6–13), 9.94 for Post (SD = 1.66, range: 7–13), and 10.7 for End (SD = 2.98, range: 6–18). All nouns used in the stimuli were animate, and we selected transitive verbs that allowed for full syntactic and semantic reversibility of the sentences. The 80 experimental sentences (40 SRs and 40 ORs) were divided into two equivalent lists (List A and List B), such that each participant saw only one version of each pair, for a total of 20 subject relatives and 20 object relatives per participant.
Both lists also included 20 filler sentences featuring noun complement clauses (e.g., “The hope that kittens will be born is shared by the parents”). Half of the fillers used this word order, while the other half employed a postverbal subject in the complement clause, a structure permitted in Italian. To distract from the main task, we varied the tense and mood of the verbs in the complement clauses (e.g., present and imperfect indicative, present and imperfect subjunctive, and present conditional), yielding a range of grammatical acceptability: from fully standard Italian to colloquial and ungrammatical constructions.
The complete list of stimuli and fillers is provided in Appendix A in Supplementary Materials.
Participants and procedures
Forty-two adult native Italian speakers (age range: 18–65; 52% female) participated in the experiment. Each participant was presented with 60 sentences (40 experimental items and 20 fillers), shown incrementally in written form and in randomized order. Participants advanced through each region by pressing a key.
After reading the Start region, they completed a forced-choice task in the W1 region, selecting between the target word and the pseudoword using a keypress. Immediately afterward, the same task was administered for the W2 region. The vertical position of the target and pseudoword (top vs. bottom) was randomized across both stimuli and participants while maintaining a balanced proportion across the experiment. Following the forced-choice tasks, participants read the verb of the matrix clause (Post region) and the conclusion of the sentence (End region). Before proceeding to the next item, they provided an acceptability judgment of the sentence using a 7-point Likert scale (1 = completely unacceptable to 7 = fully acceptable).
Participants completed four practice items before beginning the experiment to familiarize themselves with the procedure. The experiment was conducted in person in a quiet environment, using E-Prime 3 software, under the silent supervision of a researcher.
We collected the following data:
-
• Reading/reaction times (RTs) for all sentence regions (Start to End) and the acceptability rating task in milliseconds.
-
• Accuracy in the maze task (W1 and W2 regions).
-
• Acceptability judgment scores (1 to 7).
Analyses
Descriptive statistics were computed for all variables. Acceptability ratings from the filler items were used to verify that participants engaged with the full range of the 7-point Likert scale. However, results from fillers were not included in further analyses.
Accuracy in the maze task (W1 and W2 regions) was analyzed using logistic mixed-effects models. Only trials with correct responses were retained for subsequent analyses of reading/reaction times (RTs).
For RT data, outliers were excluded based on a threshold defined as the mean plus two standard deviations (mean + 2SD) considering the total time for trial (i.e., the sum of the RTs in each region).
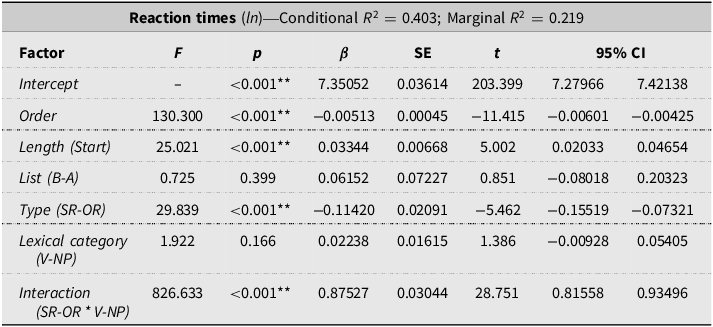
RTs were analyzed using linear mixed-effects models, after transforming the raw RTs using the natural logarithm (ln) to normalize the distribution. Sentence type (SR vs. OR) and list (A vs. B) were treated as fixed factors; stimulus length and presentation order were included as covariates; and participants and items were included as random factors. Likert scores were analyzed using an ordinal mixed-effects model with the same fixed and random structure. To disentangle the effect of lexical category from that of linear position on processing costs in the relative clause, we conducted an additional analysis in which the two critical regions (W1 and W2) were modeled jointly rather than analyzed separately. We fitted a linear mixed-effects model to log-transformed RTs, including all observations from both regions. Sentence type (SR vs. OR) and lexical category (verbal: reported as V vs. nominal: reported as NP) were entered as fixed effects, along with their interaction, which indexes differences associated with the position in the clause (W1 vs. W2). The model further included list (A vs. B) as a fixed factor and stimulus length and presentation order as covariates. Random intercepts for participants and items were specified. All analyses were conducted using Jamovi 2.6.
Experiment 2—Self-paced reading task
The same stimuli and fillers, distributed into the same two equivalent lists, were used in Experiment 2, which employed a self-paced reading task across all five regions (Start to End). No pseudowords were presented; only the correct alternatives for W1 and W2 from Experiment 1 were shown.
Forty adult native Italian speakers (age range: 18–65; 63% female) participated (different from those in Experiment 1). Participants pressed a key to advance through each region and, as in Experiment 1, provided an acceptability judgment on a 7-point Likert scale after each sentence. The experiment was implemented via E-Prime 3 under supervision.
We collected reading times (RTs) for all regions and the acceptability task (in milliseconds), along with acceptability scores (1–7). Outlier removal and statistical analyses were conducted following the same procedures as in Experiment 1.
Results
Experiment 1—Modified maze task
Data from all 42 participants of Experiment 1 were retained for analysis. Acceptability ratings for the filler items confirmed that participants made use of the full Likert scale, successfully distinguishing among different levels of acceptability (see Supplementary Figure 1). Acceptability ratings for subject and object relatives (SRs and ORs), both fully grammatical in Italian, were skewed toward the higher end of the scale, as presented below. The removal of outliers resulted in a 4% reduction in the number of observations.
Accuracy
Accuracy in the selection of the target word during the maze task was overall very high in both the forced-choice regions (W1: 97.3% for SRs, 88.5% for ORs; W2: 97.3% for SRs, 89.5% for ORs). Results from the logistic mixed-effects models confirmed a significant effect of sentence type on accuracy, with SRs associated with higher accuracy in both regions (ps < 0.001). In the W1 region only, the order of presentation also had a significant effect, with accuracy increasing progressively over the course of the experiment (p = 0.007).
Reaction and reading times
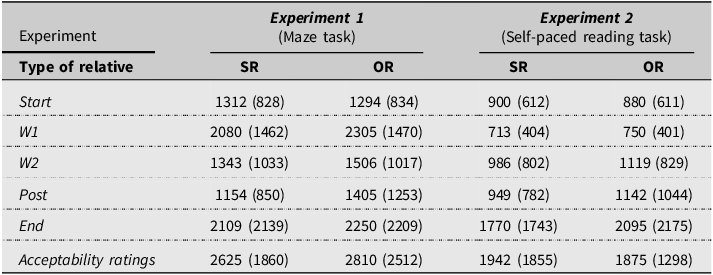
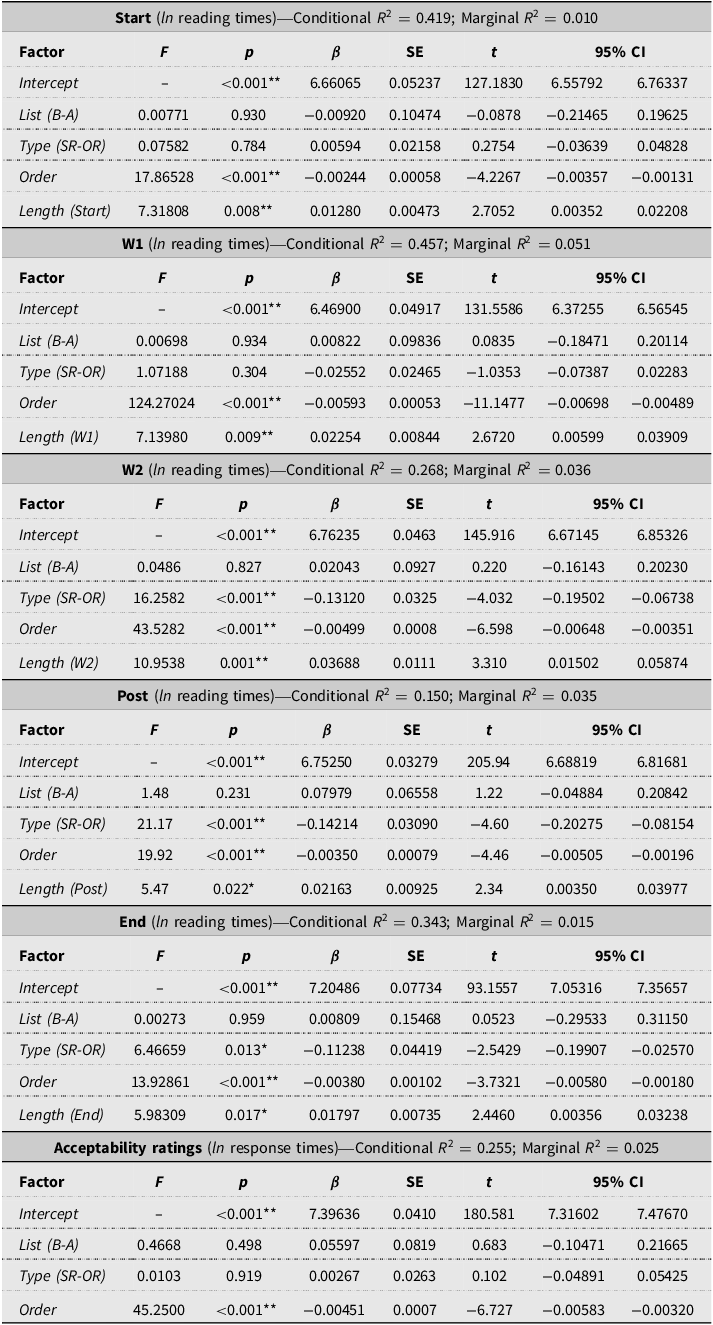
Descriptive statistics for the reading and reaction times are reported in Table 2. The fixed effects results (omnibus F tests and parameter estimates) from the linear mixed-effects models for all sentence regions (Start to End) are presented in Table 3. Visual representations of the contrast between subject relatives (SRs) and object relatives (ORs) across the five regions are shown in Figure 1 (panels a–e).
Descriptive statistics of reading and reaction times in the two experiments by type of relative across the regions (Start, W1, W2, Post, and End) and for acceptability ratings.

Notes: Data are reported as means (standard deviation). Reading and reaction times were measured in milliseconds.
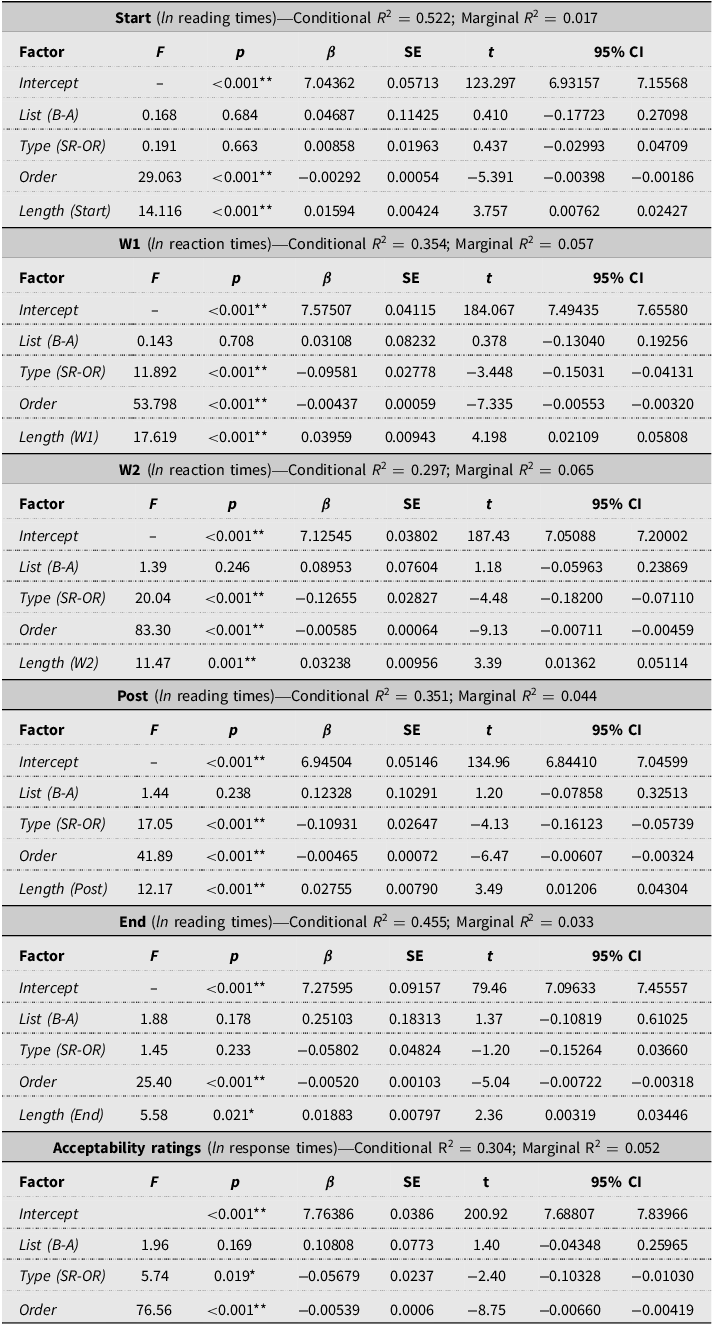
Fixed effects (omnibus F tests and parameter estimates) and model fit (R 2) for linear mixed models of reading and reaction times in the modified maze task across the regions: Start, W1, W2, Post, and End.

Notes: Reading and reaction times were measured in milliseconds and analyzed using the natural logarithm (ln) of the values. Length = number of characters in the tested sentence region (excluding spaces). SE = standard error; 95% CI = 95% confidence interval for β; SR = subject relatives; OR = object relatives. Statistical significance is indicated as p < 0.05 (*) and p < 0.01 (**).
Box plots showing reading and reaction times from the modified maze task for subject relatives and object relatives across the regions: Start (a), W1 (b), W2 (c), Post (d), End (e), and reaction times during acceptability ratings (f).
Notes: All times are reported in milliseconds. Each box represents the interquartile range (IQR), spanning from the first quartile (Q1) to the third quartile (Q3). The horizontal line inside the box indicates the median, while the cross (×) denotes the mean. Whiskers extend to the minimum and maximum values within 1.5 * IQR from the quartiles. SR = subject relatives (in blue); OR = object relatives (in orange).

The effect of the type of relative (SR vs. OR) was significant in W1 (F = 11.892, p < 0.001, SR: 2080 ± 1462 ms vs. OR: 2305 ± 1470 ms), W2 (F = 20.040, p < 0.001, SR: 1343 ± 1033 ms vs. OR: 1506 ± 1017 ms), and Post (F = 17.050, p = 0.011, SR: 1154 ± 850 ms vs. OR: 1405 ± 1253 ms) regions, with SRs associated with shorter reaction/reading times. No significant effects were found in Start or End regions (all ps > 0.05).
The factor related to list assignment (List A vs. B) was never significant (all ps > 0.05). In contrast, both the order of item presentation and the length of the stimuli (number of characters) consistently emerged as significant covariates across all five regions (ps < 0.05 in all cases). In particular, reading/reaction times decreased progressively over the course of the task, while longer stimuli (in terms of number of characters) were associated with longer reading/reaction times.
For the joint analysis of the critical region of the relative clause (W1 and W2), the model results are reported in Table 4. No main effect of lexical category (V vs. NP) was observed (p = 0.166), whereas the effect of the type of relative (SR vs. OR) was significant (F = 29.839, p < 0.001), as was the interaction between the two factors (F = 826.633, p < 0.001), which corresponds to the position in the clause (W1 vs. W2). Responses were slower in W1 than in W2, and ORs were consistently slower than SRs at both positions. A visual representation of the paired contrasts among type of relative, lexical category, and position is shown in Figure 2.
Fixed effects (omnibus F tests and parameter estimates) and model fit (R 2) for linear mixed models of reaction times in the relative clause regions of the modified maze task: analysis by type of relative, lexical category, and position (i.e., interaction between type of relative and lexical category).

Notes: Reaction times were measured in milliseconds and analyzed using the natural logarithm (ln) of the values. Length = number of characters in the tested sentence region (excluding spaces). SE = standard error; SR = subject relatives; OR = object relatives; V = verb; NP = noun phrase. Statistical significance is indicated as p < 0.05 (*) and p < 0.01 (**).
Bar chart of reaction times in the relative clause regions of the modified maze task by type of relative, lexical category, and position.
Notes: All times are reported in milliseconds. Each bar represents the mean of the condition, with whiskers marking ±1 standard deviation. SR = subject relatives; OR = object relatives; NP = noun phrase; V = verb; W1 = first region after the relative complementizer; W2 = second region of the relative clause.

Acceptability ratings
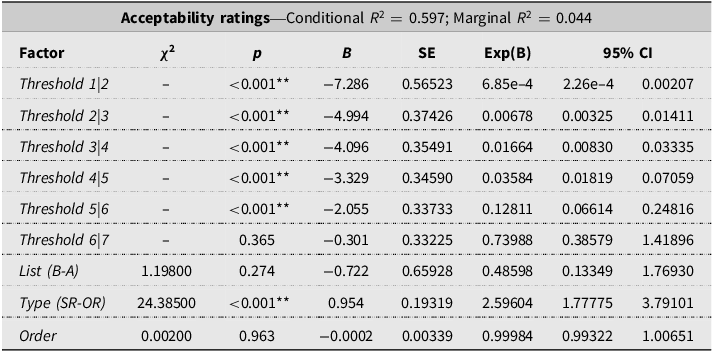
As mentioned above, acceptability ratings were generally high for both SRs and ORs, with 90% of responses scoring above 5 on the Likert scale. Results from the ordinal mixed-effects model (Table 5) revealed a significant effect of sentence type: participants were significantly more likely to give higher acceptability ratings to SRs than to ORs (odds ratio = 2.596, p < 0.001). Neither the order of presentation nor the list assignment had a significant effect (all ps > 0.05). The χ2-test further confirmed significant differences in the distribution of acceptability ratings between SRs and ORs (p < 0.001). Post-hoc analyses of adjusted residuals revealed that SRs received a significantly higher proportion of the maximum rating (score 7) compared with ORs. Table 6 presents these results and includes the corresponding descriptive statistics.
Fixed effects (omnibus χ2 tests and parameter estimates) and model fit (R 2) for the ordinal mixed model of acceptability ratings in Experiment 1.

Notes: Acceptability ratings were collected with a 7-point Likert scale. SE = Standard Error; Exp(B) = odds ratio; SR = subject relatives; OR = object relatives. Statistical significance is indicated as p < 0.05 (*) and p < 0.01 (**).
Contingency tables of the acceptability ratings in the two experiments (with X test and adjusted residuals).

Notes: Data are reported as absolute values and percentages within column (%). Statistical significance is indicated as p < 0.05 (*), p < 0.01 (**), and residuals (in italics) > |2| (*).
Regarding response times in the acceptability rating task, both sentence type and item order were significant factors in the linear mixed-effects model (Table 3). SRs were associated with shorter response times compared to ORs (p = 0.005; SR: 2360 ± 1091 ms vs. OR: 2505 ± 1172 ms), and participants became progressively faster at providing ratings as the task progressed (p < 0.001). The visual representation of the contrast between SRs and ORs is shown in Figure 1 (panel f.). The list assignment again did not have a significant effect (p > 0.05).
Experiment 2—Self-paced reading task
Data from all 40 participants were retained for analysis. As in Experiment 1, acceptability ratings for the filler items confirmed that participants made full use of the Likert scale (see Supplementary Figure 2). The removal of outliers resulted in a 4% reduction in the number of observations.
Reading times
Descriptive statistics for the reading and reaction times are reported in Table 2. The fixed effects results (omnibus F tests and parameter estimates) from the linear mixed-effects models for all sentence regions (Start to End) are presented in Table 7. Visual representations of the contrast between subject relatives (SRs) and object relatives (ORs) across the five regions are shown in Figure 3 (panels a–e).
Fixed effects (Omnibus F tests and parameter estimates) and model fit (R 2) for linear mixed models of reading times in the self-paced reading task across the regions: Start, W1, W2, Post, and End.

Notes: Reading times were measured in milliseconds and analyzed using the natural logarithm (ln) of the values. Length = number of characters in the tested sentence region (excluding spaces). SE = standard error; 95% CI = 95% confidence interval for β; SR = subject relatives; OR = object relatives. Statistical significance is indicated as p < 0.05 (*) and p < 0.01 (**).
Box plots showing reading times from the self-paced reading task for subject relatives and object relatives across the regions: Start (a), W1 (b), W2 (c), Post (d), End (e), and reaction times during acceptability ratings (f).
Notes: All times are reported in milliseconds. Each box represents the interquartile range (IQR), spanning from the first quartile (Q1) to the third quartile (Q3). The horizontal line inside the box indicates the median, while the cross (×) denotes the mean. Whiskers extend to the minimum and maximum values within 1.5 * IQR from the quartiles. SR = subject relatives (in blue); OR = object relatives (in orange).

The effect of the type of relative (SR vs. OR) was significant in the W2 (F = 16.258, p < 0.001, SR: 986 ± 802 ms vs. OR: 1119 ± 829 ms), Post (F = 21.170, p < 0.001, SR: 949 ± 782 ms vs. OR: 1142 ± 1044 ms), and End regions (F = 6.467, p = 0.013, SR: 1770 ± 1743 ms vs. OR: 2095 ± 2175 ms), with SRs associated with shorter reading times. No significant effects were found in the Start or W1 regions (all ps > 0.05).
The factor related to list assignment (List A vs. B) was never significant (all ps > 0.05). As in Experiment 1, both the order of item presentation and the length of the stimuli emerged as significant covariates across all five regions (ps < 0.05 in all cases): reading times decreased over the course of the task, while longer stimuli elicited longer reading times.
The results of the joint analysis for the critical region of the relative clause (W1 and W2) are reported in Table 8. Significant effects were found for lexical category (V vs. NP: F = 8.756, p = 0.003), for type of relative (SR vs. OR: F = 9.468, p = 0.003), and for the interaction between the two factors (F = 313.215, p < 0.001), which corresponds to the position in the clause (W1 vs. W2). No difference between NPs and Vs nor between SRs and ORs was found in W1, while, in W2, ORs (namely Vs) were associated with longer reading times than SRs (namely NPs). Consequently, in ORs, reading Vs was slower than reading NPs, while SRs presented the opposite pattern. A visual representation of the paired contrasts among type of relative, lexical category, and position is shown in Figure 4.
Fixed effects (omnibus F tests and parameter estimates) and model fit (R 2) for linear mixed models of reading times in the relative clause regions of the self-paced reading task: analysis by type of relative, lexical category, and position (i.e., interaction between type of relative and lexical category).

Notes: Reading times were measured in milliseconds and analyzed using the natural logarithm (ln) of the values. Length = number of characters in the tested sentence region (excluding spaces). SE = standard error; SR = subject relatives; OR = object relatives; V = verb; NP = noun phrase. Statistical significance is indicated as p < 0.05 (*) and p < 0.01 (**).
Bar chart of reading times in the relative clause regions of the self-paced reading task by type of relative, lexical category, and position.
Notes: All times are reported in milliseconds. Each bar represents the mean of the condition, with whiskers marking ± 1 standard deviation. SR = subject relatives; OR = object relatives; NP = noun phrase; V = verb; W1 = first region after the relative complementizer; W2 = second region of the relative clause.

Acceptability ratings
Acceptability ratings were generally high for both SRs and ORs, with 75.2% of responses scoring above 5 on the Likert scale. However, unlike in Experiment 1, results from the ordinal mixed-effects model (Table 9) revealed no significant effects of any of the factors considered, i.e., sentence type, list assignment, or order of presentation (all ps > 0.05). Conversely, the χ2-test identified significant differences in the distribution of acceptability ratings between SRs and ORs (p < 0.001). Post-hoc analyses of adjusted residuals revealed that SRs received a significantly higher proportion of the maximum rating (score 7) compared with ORs (see Table 6 for the details).
Fixed effects (omnibus χ2 tests and parameter estimates) and model fit (R 2) for ordinal mixed model of acceptability ratings in Experiment 2.

Notes: Acceptability ratings were collected with a 7-point Likert scale. SE = standard error; Exp(B) = odds ratio; SR = subject relatives; OR = object relatives. Statistical significance is indicated as p < 0.05 (*) and p < 0.01 (**).
For response times in the acceptability rating task (Table 7), the only significant effect observed in the linear mixed-effects model was for the order of presentation, with response times decreasing as the task progressed (p < 0.001). Sentence type and list assignment did not show significant effects (all ps > 0.05). Although the difference between SRs and ORs was not statistically significant, a visual comparison is presented in Figure 2 (panel f.).
Discussion
In the present work, we run two different experiments to investigate the incremental processing of sentences with center-embedded subject and object relative clauses in Italian: a modified version of the maze task and a self-paced reading task, both using the same set of linguistic stimuli. Since object relatives are overall shown to be more challenging than correspondent subject relatives, the aims of the study were to localize the source of difficulty in object relatives (or object disadvantage) and to compare the two experimental procedures we adopted.
In summary, both experiments confirmed a higher processing load for object relative clauses, as expected. In the modified maze task (Experiment 1), this effect was reflected in significantly longer reaction/reading times in the region immediately following the complementizer (W1), in W2, and in Post (corresponding to the verb of the matrix clause). In the self-paced reading task (Experiment 2), longer reading times for object relatives emerged in W2, Post, and End regions, consistent with a spillover effect commonly associated with this experimental technique.
In our experimental design, we compare the same regions in ORs and SRs, but different words and foils occur in those regions in the two types of sentences. For example, W1 hosts a verb/pseudoverb pair in SRs but a NP/pseudoNP pair in ORs. However, we could control for this potential confounding factor. First, the lexical material that occurs in SRs in List A occurs in ORs in List B. If the effects are driven by the lexical material, reversal (or a significant modulation) of the findings should be observed in the two lists. This has not been observed.
Furthermore, the lexical category (nominal vs. verbal) itself does not appear to affect processing costs in either experiment. For the maze task, in the analysis modeling the two critical regions of the relative clause jointly, the lexical category was not a significant predictor. This finding confirms our interpretation of the results region by region. We maintain that the slowdown in W1 cannot be attributed to greater difficulty in making NP/pseudoNP decisions in comparison with verb/pseudoverb decisions, given that, at W2, verb/pseudoverb decisions were in fact slower than NP/pseudoNP decisions. In the joint analysis for the self-paced reading task, verbs were read more slowly than NPs overall. However, this slowdown is likely induced by their position in ORs, where Vs occur in W2, i.e., the region in which interference/intervention effects arise (as discussed below). Crucially, the absence of an intrinsic processing disadvantage for verbs in our materials is further supported by the complementary pattern observed in SRs, where verbs are read faster than NPs. Taken together, the two experiments converge on the conclusion that the asymmetry between ORs and SRs is not due to differential processing costs associated with the two lexical categories (verbs vs. nouns), but rather to their structural (or positional) configuration within the sentence.
Another interesting finding is that, in the modified maze task, reaction times at W1 were overall longer than at W2. This effect may be task-related, as W1 is the region where the participants must make an effort to shift from reading to a forced-choice task, whereas in W2, the task remains consistent with the preceding region. Another explanation concerns syntactic processing itself. At W1, participants must select either OR or SR parse, thereby projecting the corresponding syntactic structure (as discussed below). By contrast, at W2, participants need to integrate the lexical input into the already projected structure, possibly resulting in lower processing costs, i.e., shorter reaction times. This contrast appears specifically in the modified maze task, which enforces strictly incremental processing and is not subject to spillover effects.
Acceptability ratings were overall very high, confirming that both subject and object relatives are perceived as acceptable structures. The ordinal mixed models showed higher ratings for SRs than ORs, only in Experiment 1. We can tentatively propose that, as the maze task is more demanding since it requires a forced choice, it stresses the processing difficulties associated with ORs. Consequently, this could translate as a reduced perceived acceptability of ORs when compared to SRs. Nonetheless, a similar, albeit less robust, trend also emerged in Experiment 2: post-hoc χ2 analyses revealed a significantly higher proportion of maximum ratings (score 7) for SRs than for ORs.
In the introduction, we distinguished three main families of the accounts of the object disadvantage, and now, we compare the predictions of each of them with the results of our two experiments and with previous findings from the literature.
The surprisal account
The surprisal account predicts that the difficulty in incremental processing should arise in the first region where the incoming string must be assigned the less frequent OR interpretation, namely the region that immediately follows the Italian complementizer che (“that”). In our maze experiment, a slowdown does emerge in this region, consistent with the surprisal account. However, in the same experiment, the slowdown persists in the two subsequent regions, in which no effect of surprisal is expected since the explicit choice of the OR parse has already been done. The latter finding is important because it distinguishes our results from previous works adopting the maze task (both grammatical and lexical mazes), which found an effect only in the region following the complementizer (Vani et al., Reference Vani, Wilcox and Levy2021) and therefore suggested that surprisal alone might explain the object disadvantage. The slowdown in W2 and in the Post region, found in our experiment, might be due to the fact that we minimized the forced choice only to the critical regions and used pseudowords that possibly enhanced the competition between ORs and SRs processing. The standard lexical maze might be reduced to a lexical decision task without syntactic integration, while the standard grammatical task forces the syntactic integration at each step, without focusing on a specific contrast. In comparison, our task is suited to detect the processing costs specifically in the critical regions concerned by the manipulation. As in general, the maze task is not associated with spillover effects (Boyce et al., Reference Boyce, Futrell and Levy2020; Forster et al., Reference Forster, Guerrera and Elliot2009), and the late effect in W2 and in the Post region we found cannot be explained by surprisal.
Consistent with the previous literature, in the self-paced reading study, we found no effect in W1 (the one following the complementizer) and a slowdown in W2 (verb in the OR), in Post (main verb), and in End (sentence-final adverbial). However, since the self-paced reading task is prone to spillover effects, these results are less telling and do not challenge an explanation based uniquely on surprisal.
The integration account
As the integration account considers the distance between the filler and gap to be the source of the difficulty of ORs, it can explain the effects in W2 in both the maze task and in the self-paced reading task (as well as later effects in the latter task). However, it cannot explain the early effects in the region immediately following the complementizer, which was revealed by our maze experiment (in line with previous maze studies), since at this stage the gap has not been introduced yet and no distance can be computed.
A possible conclusion from these data is that both the explanation in terms of surprisal and the one in terms of integration are necessary, as suggested by Staub (Reference Staub2010) and Levy et al. (Reference Levy, Fedorenko and Gibson2013). The former is needed to explain the effect at W1; the latter is needed to explain later effects. However, a simple Occam’s razor consideration invites us to try to seek a single explanation for all the effects found in the incremental processing of relatives. This leads us to the third family of accounts.
The intervention/interference account
The core idea underlying these accounts is that a dependency between a filler and its gap is harder to process when an element similar enough to the filler interferes between them. In comparison with the integration account, the intervention/interference accounts have a special focus on the similarity between the filler and the interfering category.
Considering interference accounts, the CBR model (Engelmann et al., Reference Engelmann, Jäger and Vasishth2019; Lewis & Vasishth, Reference Lewis and Vasishth2005; Lewis et al., Reference Lewis, Vasishth and Van Dyke2006) proposes that nouns are stored in memory with syntactic (e.g., grammatical role), morphological (e.g., number), and semantic (e.g., animacy) features, while predicates or other dependency sites provide retrieval cues that guide which elements must be integrated. At a retrieval site, items in working memory are activated according to how well they match these cues, and the most highly activated noun is retrieved. Processing difficulties for ORs typically emerge at the retrieval site (i.e., W2 in our experiment) because interference occurs when the subject NP partially matches the retrieval cues, creating competition that slows selection. However, within this framework, it is less clear whether higher processing costs for ORs are expected to emerge before retrieval, namely at the encoding site (e.g., W1) as well. This early effect, if any, is due to the effort of preserving the full integrity of representations of the competing NPs, facilitating the choice of the target at retrieval (Hofmeister & Vasishth, Reference Hofmeister and Vasishth2014). However, experimental evidence of the effect at encoding is controversial (Saul et al., Reference Saul, Keshev and Meltzer-Asscher2025).
As for the intervention accounts, the theory called featural relativized minimality has been originally proposed to explain why object dependencies (including ORs) are comprehended and produced later in language acquisition (cf. Adani, Reference Adani2011; Arosio et al., Reference Arosio, Adani, Guasti, Brucart, Gavarró and Solà2009; Friedmann et al., Reference Friedmann, Belletti and Rizzi2009). This account, which has been more recently extended to sentence processing by Biondo and colleagues (Reference Biondo, Pagliarini, Moscati, Rizzi and Belletti2023), can be summarized as follows: for a category to qualify as an intervener, two conditions must be met. The first one is that the intervener must c-command the gap and must be c-commanded by the filler in the syntactic tree. Therefore, assuming featural relativized minimality, what counts is the hierarchical relation, not linear distance. The second condition to be met is that the intervener must share some relevant morphosyntactic (as opposed to generally semantic) features with the filler. For example, a full noun phrase counts as an intervener for another noun phrase, but a pronoun in the same position does not. Similarly, a mismatch in the number of features may modulate the intervention effect. A sentence like “The manager that the employees insulted left the room abruptly” is expected to be less challenging than the sentence “The manager that the employee insulted left the room abruptly” since the categories in bold in the former sentence are less similar (one being singular, the other being plural) than the categories in bold in the latter sentence. In fact, the notion of morphosyntactic features that count for intervention is more precise than that: only syntactically active features (i.e., those that are involved in the agreement relation between the subject and the verb, like the traits of person and number in English and Italian) count for the computation of the intervention. Biondo and colleagues (Reference Biondo, Pagliarini, Moscati, Rizzi and Belletti2023) support the featural relativized minimality account by showing that intervention defined in this way modulates the object disadvantage in relative clauses. In particular, they show that a number mismatch between the filler and the intervener significantly reduces the object disadvantage in the relative clause verb in a self-paced reading task.
Prima facie, the featural relativized minimality account can explain the slowdown effects in the region of the ORs verb (when the filler must be recovered and the intervening category can hinder the filler recuperation) but not in the early region following the complementizer, since the dependency is not resolved here.
However, when an NP is met in the position after the complementizer in the OR, the filler and the potential intervener are already present. If, as is standardly assumed, the comprehender builds a temporary parse and gradually adapts it to the incoming words, the presence of the complementizer followed by the subject NP leads to the projection of an OR syntactic tree, including its intervention configuration. This could allow featural relativized minimality to explain increased RTs for ORs at W1, in addition to later effects.
At this point, both intervention and interference accounts, as discussed above, have the potential to provide a unitary explanation for both early and late effects. Future research should determine which of the two competing approaches is the most adequate. Prima facie, both accounts predict facilitation in case of feature dissimilarities between the competing NPs in ORs.
Under the interference account, the relevant features are those that are cued at retrieval, namely the features overtly marked on the verb of the relative clause. Conversely, the intervention account predicts facilitation only when there is a mismatch in grammatically active morphosyntactic features. Generally, these two notions converge and thus identify the same set of relevant features. For instance, in Italian, as we said, number mismatch induces facilitation, since it is both grammatically active in subject-verb agreement and overtly marked on the verb.
There are, however, specific cases in which these two notions dissociate. In French, for example, number is grammatically active in subject-verb agreement, but the singular-plural contrast is not always phonologically marked in verbal inflection (e.g., an audible contrast for suivre “to chase”: 3SG /syi/ vs. 3PL /syiv/, but no audible contrast for pousser “to push”: 3SG = 3PL = /pus/). Consequently, in an auditory sentence-processing task, the interference account predicts facilitation due to number mismatch only for verbs with an audible plural marker and no facilitation in the case of verbs whose singular and plural forms are phonologically identical. In contrast, the intervention account predicts facilitation independently of phonological audibility, since number is grammatically active at an abstract level. More generally, the same logic extends to other instances of morphological syncretism; for example, further cases of third-person singular-plural syncretism that are not merely phonological and occur in verbal paradigms where number is grammatically active are attested in Lithuanian and Latvian, as well as in Estonian in the perfect tense.
Moreover, the interference account predicts that all features (syntactic, morphological, and semantic) may modulate processing at the encoding stage, since they all contribute to working memory load, independently of both grammatical activity and cueing at retrieval.
Another area where to compare the two approaches is cross-linguistic differences in the realization of relatives. In English, the subject of the OR is linearly closer to the filler than the gap; see (4). On the contrary, in languages like Chinese, Korean, and Japanese, since the RC precedes the noun it modifies, it is the object that is linearly closer to the gap in ORs; see (5), a Chinese OR in which the particle de can be considered functionally equivalent to “that” in English (cf. Huang et al., Reference Huang, Li and Li2009, chapter 6 for a more complete description of Chinese relatives).
-
(4) The child that [RC the grandma draws t the child]
‘the child that the grandma draws’
-
(5)

Crucially, in both languages, the subject intervenes if intervention is defined in terms of c-command. Indeed, regardless of linear order, in the syntactic structures underlying both (4) and (5), the filler c-commands the subject of the relative clause, which in turn c-commands the gap.
Hence, the intervention account predicts that ORs should be more difficult than SRs both in languages like English, where the relative clause follows the noun, and in languages where the relative clause precedes the noun.
The prediction by the interference accounts is different. Interference can be triggered by a category that appears between the filler and the gap or by a category that is before both the filler and the gap (proactive interference, cf. Van Dyke & McElree, Reference Van Dyke and McElree2011). Conversely, a category that follows the gap cannot interfere because it has not been met by the time any effect emerges. For this reason, everything else being equal, only the intervention account predicts that the OR difficulties should be present also in languages in which the relative clause (including the gap) precedes the filler, like Japanese, Korean, and Mandarin Chinese. As mentioned in the Introduction, experimental data on subject/object asymmetry in these languages are controversial, though.
A last point to be discussed is that in both our experiments, we found that the object disadvantage extends at the matrix verb region (Post). This pattern does not straightforwardly follow from any of the presented accounts for subject-object asymmetries. While this effect may plausibly reflect a spillover from the early manipulation in the self-paced reading study, the same interpretation is not straightforward for the maze study. A more theoretically grounded explanation is therefore required. A possible explanatory factor is linked to thematic role assignment in these sentences: in Post, the matrix subject NP, which is also the head of the relative clause, must be reactivated in order to compute subject-verb agreement. In the SRs we examined, this NP corresponds to the subject gap, and it is assigned an agent thematic role in both the relative clause and the matrix clause. By contrast, in ORs, the matrix subject NP corresponds to the object gap. Incrementally, this NP is therefore reactivated and interpreted as the patient in W2 of the OR and, immediately afterwards (in Post), must be reassigned the agent role in the matrix clause. This rapid thematic-role shift may account for the object disadvantage we observed in the Post region. However, the effect at Post requires further exploration. This is particularly true because the existing evidence is inconclusive. Some previous studies (Gordon et al., Reference Gordon, Hendrick, Johnson and Lee2006; Traxler et al., 2002, Reference Traxler, Williams, Blozis and Morris2005) found an object disadvantage, in line with our results, but others (Concetti & Moscati, Reference Concetti and Moscati2023; Staub et al., Reference Staub, Dillon and Clifton2017) even found an object advantage.
Methodological considerations
From a methodological perspective, the comparison between our two experiments with the exact same stimuli supports the conclusion that the maze task provides a more precise measure of increased processing load during incremental sentence processing. In contrast, the self-paced reading task is prone to spillover effects, namely delayed effects of experimental manipulations (Boyce et al., Reference Boyce, Futrell and Levy2020; Forster et al., Reference Forster, Guerrera and Elliot2009; Vani et al., Reference Vani, Wilcox and Levy2021). These considerations are crucial for accurately localizing points of syntactic difficulty during online comprehension.
By adopting a modified maze task, we showed that hybrid paradigms can be sufficient for capturing fine-grained processing effects. The forced-choice design in the critical regions of the sentence allows for timely detection of processing difficulty, while the use of self-paced reading in the remaining regions reduces participant fatigue and simplifies experimental design, minimizing the risk of potential confounds that could obscure a genuine effect. For instance, a full lexical maze task entails the risk that participants focus solely on discriminating real words from pseudowords, without engaging in actual syntactic integration. Conversely, a grammatical maze task can be difficult to construct, especially in languages like Italian, where word order is relatively flexible. Crucially, in our case, the region immediately following the relative complementizer permits only a limited range of lexical categories that would result in ungrammatical continuations. We should nonetheless acknowledge that introducing pseudoword foils carries potential risks: it may elicit task-specific strategies, such as lexical-decision heuristics or metalinguistic reasoning, which could influence performance independently of syntactic processing. In principle, however, such risks would be expected to attenuate the relevant contrast, whereas in our experiment the effect emerged already in the first critical region. Moreover, our data suggest that there is no systematic bias associated with lexical category (i.e., no greater difficulty in choosing between NP/pseudoNP as opposed to verb/pseudoverb, or vice versa). Finally, although we have argued that there are good reasons to interpret the increased cost of ORs in the Post region as linguistically driven, we cannot rule out alternative explanations in terms of task-induced artifacts. For example, delayed effects of the slowdowns observed in earlier regions may also contribute to the Post-region pattern. In sum, we believe that this design choice was essential for amplifying the intended syntactic contrast between subject- and object-relative clause parsing, as it allowed us to exploit structural ambiguity through carefully constructed pseudowords that simulate the alternative structure.
Conclusions
The present study compared two experimental paradigms to investigate the processing of subject and object relatives in Italian, revealing a consistent object disadvantage across both tasks. Crucially, this disadvantage appeared already in the region immediately following the complementizer, but only in the modified maze task. This methodological difference between the two experiments highlights the greater sensitivity of the forced-choice paradigm in detecting early syntactic processing effects, which were not visible in the self-paced reading data due to spillover.
From a theoretical perspective, while surprisal may account only for the early slowdown and integration only for later effects, we claimed that possible extensions of the featural relativized minimality framework and of the cue-based retrieval model may offer a unified explanation both for early and late effects in OR processing. Further research is needed to compare our tentative incremental implementation in terms of structural intervention with possible explanations within the cue-based retrieval account, for instance, by testing the role of feature mismatch and considering the crosslinguistic dimension.
Acknowledgements
We thank Costanza Papagno for her contribution to the conception of the study and Riccardo Ferretti for his assistance with data collection.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0142716426100514.
Replication package
All research materials, data, and analysis code, alongside Supplementary Materials, are publicly available at https://osf.io/ukh6f/?view_only=2bdf1d0b7cf4419e8b3b1d47aca3a905.
Author contributions (CRediT taxonomy)
MV: conceptualization, data curation, formal analysis, investigation, methodology, writing—original draft, writing—review & editing.
CT: data curation, methodology, software.
CC: conceptualization, project administration, supervision, investigation, methodology, writing—original draft, writing—review & editing.











 Open access
Open access