

Introduction
The landscape of translational science and research in the United States has been significantly shaped by several major federal funding initiatives designed to accelerate the translation of scientific discoveries into improved health outcomes. The Clinical and Translational Science Awards (CTSA) Program, managed by NCATS, supports over 60 academic hubs that aim to accelerate research translation from bench to bedside through enhanced infrastructure, training, and collaboration [1]. Complementing the CTSA Program, the IDeA Networks for Clinical and Translational Research (IDeA-CTR) extend capacity to 23 historically underfunded states and Puerto Rico, emphasizing health conditions in rural and underserved communities [2].
Together, such initiatives form a distributed national ecosystem that advances translational science by generating and evaluating the impact of innovations in research processes and methods. As demands grow for demonstrable impact, efficiency, and return on investment (ROI), evaluators across these networks require robust frameworks and tools to assess both local and system-wide outcomes.
Evaluation methodologies, when applied systematically and with scientific rigor, represent a form of translational science in their own right. Just as translational science aims to translate research discoveries into improved health outcomes, evaluation science in this context translates relevant organizational practices and research processes into continuous improvement and demonstrated impact. By applying systematic approaches, replication strategies, and evidence-based methods to assess and improve health research processes, evaluators contribute directly to advancing the translation pipeline and strengthening the scientific foundation of translational research itself.
The Evaluation Special Interest Group (SIG) meeting held during the Association for Clinical and Translational Science (ACTS) annual conference in Washington, D.C. on April 14, 2025, brought together over 50 translational science evaluators and other professionals working in CTSAs and IDeA-CTRs to share best practices, address persistent challenges, and explore emerging evaluation needs. This paper summarizes the key presentations, discussions, and implications from this meeting, highlighting insights relevant to the broader CTS community.
Meeting components and topics
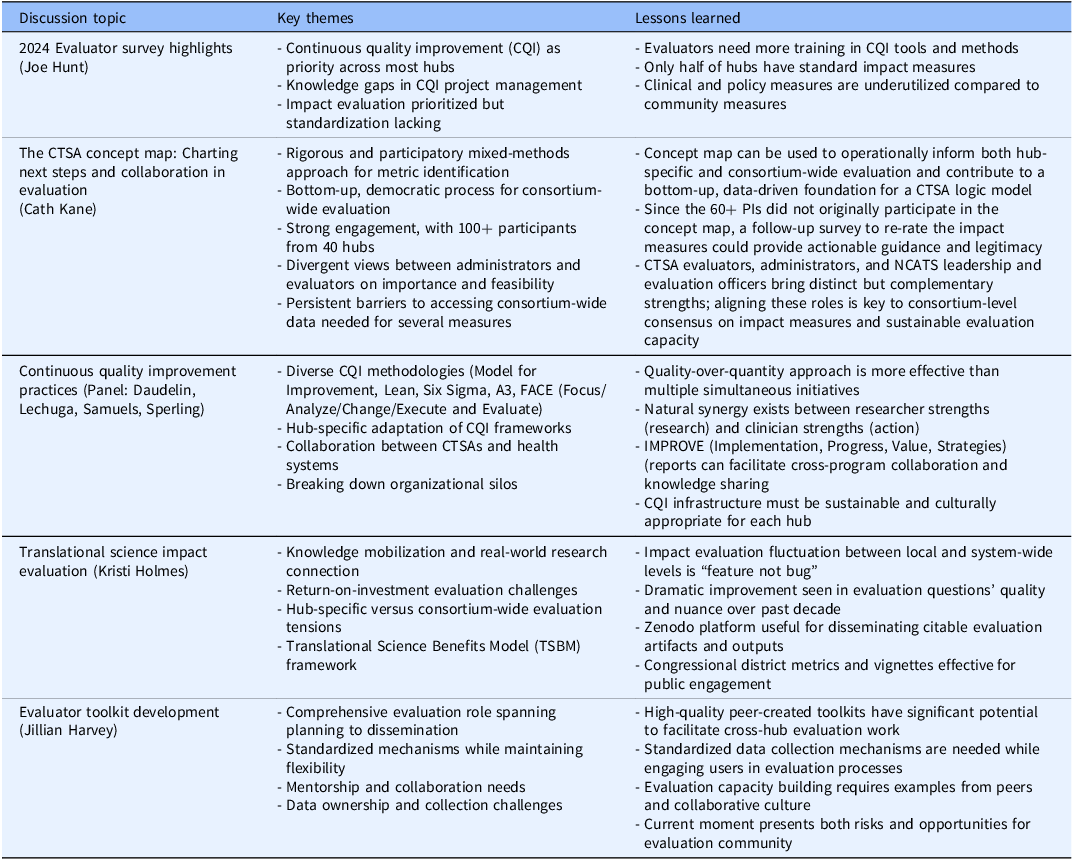
The Evaluation SIG has over 100 members representing more than 50 translational science/research organizations, including 45 CTSAs. The 4-hour meeting included brief SIG business updates followed by four substantive presentations with integrated discussions. The meeting also featured updates on collaborations with the ACTS Team Science SIG and the formation of a new CTSA Program working group focused on learning health systems, demonstrating the interconnected nature of evaluation across different domains of translational science. See Table 1 for a summary of key topics, themes, and lessons learned emerged in the Evaluation SIG Meeting presentations and discussions – described in more detail in the consequent sections.
Summary of key presentations*/discussions at the 2025 ACTS evaluation SIG meeting

Note: *Powerpoint presentation slides are available upon request from the presenters.
CTSA evaluator survey highlights
Joe Hunt (Indiana University) presented findings from the 2024 CTSA Evaluator Survey, which assessed the evaluation landscape across CTSA Program hubs. Key findings revealed that while continuous quality improvement (CQI) is a priority at most hubs, with most evaluation programs involved in consulting or supporting CQI efforts, there remains a significant need for more knowledge about managing CQI projects, tools, and methods. Impact evaluation was also identified as a priority, though only half of the respondents reported having standard impact measures. Community impact measures were most frequently used to demonstrate impact, while clinical and policy measures were less commonly employed.
Concept mapping for consortium-wide evaluation
Cath Kane (NYU Langone) presented a comprehensive review of a consortium-wide concept mapping effort that engaged over 100 stakeholders from 40 CTSA hubs in identifying and assessing CTSA measures for evaluation with practical implications for use at both the hub and consortium levels. Using a participatory mixed-methods approach, the process surfaced more than 80 measures organized into thematic clusters, allowing for an actionable taxonomy of metrics. Strong engagement across roles highlighted the value of this rigorous and democratic process, where evaluators, administrators, and other stakeholders contributed to shaping these potential frameworks for both hub-level and consortium-wide evaluation.
The findings revealed important tensions and opportunities. For some participants, long-term impact measures, particularly those linked to the Translational Science Benefits Model (TSBM) [3], were rated as highly important but less feasible to implement. Another persistent barrier identified was the absence of organizational mechanisms enabling individual CTSA evaluators to inform, design, or conduct evaluation work that leverages the strength of or the data from the CTSA Program Consortium. The discussion highlighted the tension between local hub needs and consortium-wide evaluation goals, with participants noting the pressing need for collaboration and for accessing consortium-wide data to conduct meaningful evaluative work.
Kane emphasized the need for making use of the concept map via additional bottom-up approaches by suggesting concrete next steps, such as using the concept map as a foundation for the development of a consortium-wide logic model and/or engaging CTSA PIs through a targeted follow-up survey to validate and refine the highest-priority impact measures from the map.
Continuous quality improvement practices
A panel featuring Denise Daudelin (Tufts University), Claudia Lechuga (Albert Einstein College of Medicine and Montefiore Health System), Elias Samuels (University of Michigan), and Jessica Sperling (Duke University) presented diverse approaches to implementing CQI within CTSA hubs. The presentations demonstrated the flexibility of CQI methodologies and their adaptation to different hub contexts.
Daudelin presented the fundamentals of CQI, highlighting three major methods: Model for Improvement, Lean, and Six Sigma [Reference Barr and Brannan4]. At Tufts, collaboration between the health system and CTSA focused on improving patient engagement in research using tools including fish-bone diagrams, prioritization matrices, and process mapping. Samuels described U-M CTSI’s use of the A3 template [Reference Myers, Kin, Billi, Burke and Van Harrison5] to guide several internal CQI initiatives led by CTSI programs, noting the synergies yielded by the common use of this and other quality improvement frameworks by other groups within U-M’s academic medical center.
Lechuga presented the FACE model (Focus, Analyze, Change Planning, Execute, and Evaluate), emphasizing collaborative approaches and the importance of logic models in structuring CQI initiatives. The 12-week process involves staggered cycles with structured meetings where modules present their CQI focus through the FACE cycle and receive feedback from peers throughout the process. Sperling described the development of IMPROVE [Implementation, Progress, Value, Strategies] reports, three-page documents summarizing key successes, challenges, and opportunities for collaboration, developed through focus groups to address the limitations of traditional spreadsheet-based tracking systems.
The panel discussion revealed both facilitators and barriers to CQI implementation. Facilitators included the flexibility of CQI approaches, peer-to-peer learning opportunities, and the ability to break down organizational silos. Key barriers included establishing clear responsibilities across multiple programs, resistance to perceived evaluation or judgment, and the challenge of balancing quality with quantity in CQI initiatives.
Translational science impact evaluation
Kristi Holmes (Northwestern University) addressed the complex challenges of defining and measuring translational science impact. While acknowledging that no single definitive definition exists, one adapted from Bayley [Reference Bayley6] was presented: “Impact is the provable effects of our work in the real world. Impact is the changes we can see (demonstrate, measure, capture) in society, economy, and the environment which happens because of our work.”
Holmes emphasized the importance of knowledge mobilization [Reference Karcher, Cvitanovic and Shellock7], the process by which research connects to the real world. She highlighted an increasing focus on ROI evaluations, which can be challenging to conduct due to difficulties with measuring actual costs. The presentation also addressed unintended and less visible forms of impact, including increased capacity of study teams and the public, which traditional metrics like bibliometrics may not capture.
A central theme in the discussion was the relationship between hub-specific evaluation goals and consortium-wide evaluation objectives. Holmes noted that this fluctuation between local and system-level impact evaluation “seems to be a feature and not a bug” of CTSA evaluation, reflecting the reactive nature of evaluation practice and the need for hub evaluation efforts to reflect a range of local nuances and considerations. Despite this inherent tension, Holmes observed dramatic improvements over the past decade in the quality and nuance of research questions being addressed by CTSA evaluators.
Holmes also presented the work of the Translational Impact Working Group, which aims to transform the discussion on translational impact into practical, actionable strategies through a community of practice that can work together to identify key challenges and share best practices and resources to communicate impact across CTSA hubs. Deliverables include development of impact instruments, creation of a publicly accessible repository in Zenodo, and planning for a Translational Science Impact summit scheduled for Spring 2026.
Evaluator toolkit development
Jillian Harvey’s (Medical University of South Carolina) presentation focused on the development of a comprehensive toolkit created by and for CTSA evaluators. The presentation detailed the broad scope of evaluator responsibilities, including planning, conducting, synthesizing, and disseminating evaluation results. Harvey identified several critical barriers to effective evaluation: limited staffing capacity, inefficiencies in data collection, and ambiguous ownership of data, and the need for more rigorous research on causal mechanisms linking CTSA activities to hub-level impacts.
Harvey emphasized the importance of establishing standardized evaluation mechanisms while maintaining flexibility for local adaptation. The toolkit development process revealed evaluator needs including examples of tools used by others, mentorship and collaboration opportunities, and orientation resources that vary by experience level.
Discussion participants validated the potential value of a high-quality, evaluator-created toolkit for facilitating work within and across CTSA hubs. Key challenges discussed included engaging users in data entry, addressing missing data, and the need for substantive conversations with leadership and other interested parties who may have limited time for sustained evaluation discussions.
Cross-cutting themes and implications
Several themes emerged across presentations that have significant implications for the future of CTSA evaluation and the broader field of CTS.
Tension between local and consortium-wide evaluation: A persistent challenge identified across multiple presentations was balancing hub-specific evaluation needs with consortium-wide assessment goals. While individual hubs require locally relevant metrics and approaches, the consortium as a whole needs standardized and comprehensive measures to demonstrate collective impact and justify continued investment. This tension reflects the inherent complexity of evaluating a large, distributed network of research institutions with diverse local contexts and priorities [Reference Kane, Trochim and Bar8].
Evolution of evaluation frameworks: The meeting highlighted different evaluation frameworks and their ongoing development, particularly the growing adoption of the Translational Science Benefits Model [3] across CTSA programs and more broadly. The concept mapping work demonstrated that while consortium-wide measures are highly valued, their implementation remains challenging, suggesting the need for better integration of “unified, data-driven evaluation frameworks” [Reference Karcher, Cvitanovic and Shellock7].
Importance of collaborative approaches: All presentations and discussions emphasized the value of collaborative evaluation approaches, from the bottom-up concept mapping process to peer-to-peer learning in CQI initiatives. The sustained success of the Evaluation SIG itself demonstrates the value of cross-network collaboration in advancing evaluation practice.
Resource and capacity challenges: Limited staffing capacity and data management challenges were identified as critical barriers across multiple evaluation domains. These challenges are particularly relevant given increasing funding pressures and the evolving quality improvement and evaluation requirements specified in recent CTSA Program funding opportunity announcements.
Need for flexibility within structure: The diverse CQI approaches presented demonstrated that while standardized frameworks provide valuable structure, successful implementation requires adaptation to local contexts and organizational cultures. This principle applies broadly to evaluation practice in the CTS context.
Discussion and future directions
The 2025 Evaluation SIG meeting occurred during a period of significant change in the funding and political landscape for biomedical and health research. The emphasis on demonstrating impact, efficiency, and ROI reflects broader transparency, integrity, and accountability [9] pressures facing federally funded research programs. The meeting discussions highlighted both challenges and opportunities in this environment.
The system-wide concept mapping effort represents a significant step toward developing standardized evaluation approaches while maintaining local flexibility. However, the implementation gap between importance and feasibility for long-term impact measures suggests the need for additional leadership support and resources to operationalize these frameworks effectively.
The diversity of CQI approaches presented demonstrates the maturity of quality improvement practice within the CTSA program, fulfilling requirements established in recent funding announcements. The peer-to-peer learning and collaboration evident in the panel discussions suggest potential for broader dissemination of successful practices across the CTSA community.
The ongoing development of impact evaluation frameworks, including the TSBM and related tools, provides promise for more systematic assessment of translational science benefits. However, the challenges in defining and measuring impact, particularly at the consortium level, remain significant and require continued attention and collaboration.
Several specific recommendations emerge for consideration by translation science program evaluators, administrators, and leadership: (1) invest in skill development in emerging translational science evaluation; (2) document and share locally-developed evaluation approaches, tools, and lessons learned through appropriate channels to contribute to the field’s collective knowledge; (3) foster integration between evaluation practices and quality improvement initiatives, recognizing the inherent synergies between systematic evaluation and continuous improvement approaches; and (4) allocate sufficient resources to evaluation as a strategic function equivalent to other core hub operations.
The participant reaction to themes addressed in this meeting, including engagement and follow-on questions, have informed content foci for planned SIG webinars, conducted in conjunction with the CTSA Program Evaluators Group, the American Evaluation Association’s Translational Research Evaluation Topical Interest Group, and for future ACTS SIG meetings. The identified need for deeper integration between local evaluation efforts and consortium-level coordination suggests prioritizing future meetings and resources toward: (1) facilitating cross-hub learning on implementation of evaluation frameworks; (2) advancing the technical and governance infrastructure for consortium-level data collection and analysis; (3) continuing development of practitioner resources and communities of practice; and (4) positioning evaluation as a strategic function within CTSA hubs and the broader translational science enterprise.
Importantly, the meeting highlighted that evaluation capacity building is not a one-time initiative but an ongoing process requiring sustained attention, resources, and collaborative effort. The evaluation community’s ability to advance beyond current challenges – particularly those related to data access, staffing limitations, and framework implementation – will depend on whether CTSA hubs, NCATS, and the broader research community recognize evaluation as fundamental to research quality, impact, and scientific integrity.
Limitations
While this manuscript incorporates feedback and discussions of meeting attendees, the author group, consisting of meeting organizers and presenters, necessarily represents the views of only a subset of participants. The perspectives, emphasis, and conclusions presented reflect the authors’ interpretation of the meeting, and other attendees might prioritize different themes or draw different conclusions. In addition, while we utilized information from all meeting presentations and documentation of discussion during the meeting, the focus on presentations and formal discussions may not fully represent informal conversations and networking that occurred during the meeting. As a special communications paper, this manuscript is designed to summarize and synthesize meeting content rather than to provide a comprehensive, systematic review of the evaluation literature or a complete research synthesis.
Conclusion
The 2025 ACTS Evaluation SIG meeting demonstrated both the progress made and challenges remaining in CTSA evaluation practice. The consolidation of expert opinion around the value of diverse evaluation approaches, combined with the recognized need for consortium-wide coordination, reflects the maturation of the evaluation field within translational science. Key advances include the development of standardized frameworks like the CTSA Measures Concept Map and TSBM, the evolution of sophisticated CQI practices, and the growing emphasis on collaborative evaluation approaches.
Moving forward, success will depend on addressing persistent barriers including limited capacity, data management challenges, and the inherent tension between local and consortium-wide evaluation needs. The commitment to rigorous, reproducible evaluation made by meeting participants, combined with the collaborative interests evident throughout the discussions, provides a strong foundation for continued advancement of the field. As the political and funding environment continues to evolve, the evaluation community’s ability to demonstrate impact and facilitate continuous improvement will be critical to the continued success of translational science programs and their mission to improve human health.
Acknowledgements
The authors gratefully acknowledge the contributions of all participants of the 2025 Evaluation Special Interest Group meeting at the Association for Clinical and Translational Science annual conference. We thank the meeting planners, organizers, presenters, and notetakers. We also thank the Association for Clinical and Translational Science for providing the forum for this important dialogue on evaluation needs and challenges in clinical and translational science. The authors made use of AI to assist with the drafting of this article: Gemini 2.5 Pro was accessed on September 6, 2025, to extract and analyze insights from the meeting notes. This work was supported, in part, through the following National Institutes of Health (NIH) National Center for Advancing Translational Sciences (NCATS) grants: BV, UM1TR004405; ES, UM1TR004404; JS, UM1TR005436; DD, UM1TR004398; JH, UM1TR005294; KH, UM1TR005121; CK, UL1TR001445; CL, UM1TR004400; JH, UM1TR004402. The content is solely the responsibility of the authors and does not necessarily represent the official views of the contributors’ institutions, ACTS, NCATS or NIH.
Author contributions
Boris Volkov: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Resources, Supervision, Visualization, Writing-original draft, Writing-review and editing, Elias Samuels: Conceptualization, Data curation, Formal analysis, Investigation, Resources, Writing-original draft, Writing-review and editing, Jessica Sperling: Conceptualization, Investigation, Project administration, Supervision, Writing-original draft, Denise Daudelin: Conceptualization, Investigation, Project administration, Writing-review and editing, Jillian Harvey: Conceptualization, Data curation, Formal analysis, Project administration, Writing-review and editing, Kristi Holmes: Conceptualization, Writing-original draft, Writing-review and editing, Cathleen Kane: Conceptualization, Data curation, Formal analysis, Methodology, Writing-review and editing, Claudia Lechuga: Conceptualization, Writing-review and editing, Joe Hunt: Conceptualization, Investigation, Methodology, Project administration, Resources, Supervision, Writing-review and editing.
Competing interests
The authors have no conflicts of interest to declare.

 Open access
Open access