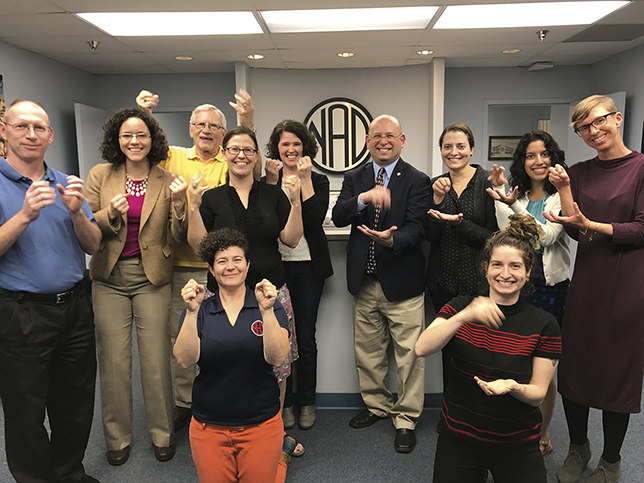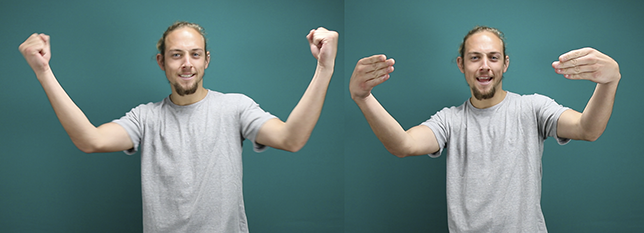1 About This Element
“Kira: What’s writing? Jen: Words that stay”
Humans have known for thousands of years that we need to turn to technology to make our words stay, whether they’re spoken, signed, or felt. There are well-known written orthographies or systems for spoken languages like the one you’re reading now for English. But there aren’t any conventionalized systems for signed languages. I’ve thought a lot about how to make signed words stay and I share one of those ways with you in this Element.
ASL SignbankFootnote 1 is a digital tool that stores data such as American Sign Language (ASL) videos, photos, and text, all connected with individual ASL signs for the purpose of annotating ASL videos. The logo, shown in Figure 1, honors both our name sign and iconic teal background used to film signs for ASL Signbank.
ASL Signbank logo designed by deaf designer Silvia Palmieri (2023).

Section 1.1 is an introduction and a preface in which I describe my personal motivations for creating and maintaining ASL Signbank. It is also where I acknowledge where I am most at ease – with the practice of data documentation or annotating and organizing bits of data, rather than writing. Section 2 describes what the ASL Signbank is, along with a history of signbanks and what kind of data have been used to build the resource. I also describe our ASL Signbank name sign. Section 3 dives into why signbanks exist – the need for textual representation, using ID glosses for corpora and language documentation, and annotation software used with signbanks. Section 4 is a close look at lemmatization and the principles we used to develop textual labels in ASL Signbank. Section 5 walks the reader through a single entry with detailed descriptions for each entry and possible values. Section 6 briefly describes how to use ASL Signbank with a specific set of annotation conventions with a description of an ELAN template file (.etf) associated with ASL Signbank as an External Controlled Vocabulary (ECV). Finally, Section 7 wraps up with some concluding reflections.
1.1 Introduction
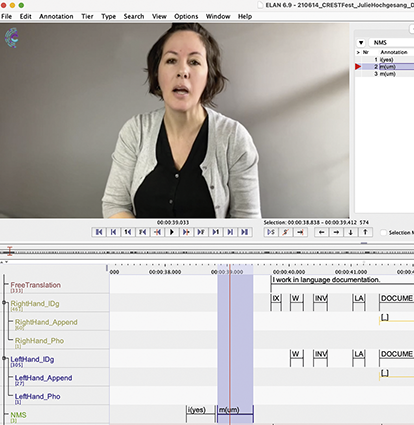
I’m a documenter and a maintainer. That’s what I do – create and maintain records that can be digitally shared. I’ve been documenting signed languages, especially the one I grew up with – ASL – for a while now. As part of this practice, I spend quite a bit of time pondering how to document ASL signs in use, as shown in Figure 2, to be shared in ways the ASL communities appreciate.

Figure 2 Long description
From left to right: Felicia Williams signing automatic, Nayo Franck signing drive, Paige Hawkins signing last part of inform, Renca Dunn signing quote, Mari Klassen signing sign, Franklin Jones Junior signing F S (short for fingerspell), April Jackson-Woodard signing instagram, Conrad Baer signing to sign, Norma Moran signing first, Yvans Cator Junior signing I X (index, pointing to camera), Raychelle Harris signing cat, Gabriel Arellano signing category, Andrew Morrill signing match, Debbie Colbert signing scratch, Leticia Arellano signing why, Debbie Peterson signing 8-weeks, Carmelina Kennedy signing where, Jonathan McMillan signing art, Brenda Perrodin signing love, Lourdes Valenzuela signing community, Miranda Medugno producing N M S hey, Lettie Nazloo signing signature, Kurt Gagne signing to stick, Cody Pederson signing research, Arlene B. Kelly signing soon, LeeAnn Tang signing wow, Nageena Ahmadzai signing borderline, Giovanni Maucere signing deaf, Ashley Clark signing year, Wink signing dissertation, Kelly Lenis signing that's sick, Felicia Williams (filmed again) signing close, Conrad Baer (filmed again) signing bye), Julie A. Hochgesang signing corpus, A S L Signbank logo.
I invite you to ponder this work with me. How could we document ASL like spoken languages are recorded in text? ASL and other signed languages currently have no conventionalized written systems. Imagine, for example, searching for signs across ASL videos. What would this work entail? Like we see with YouTube videos or social media posts, you might recommend adding captions or a bunch of hashtags, likely using English words that correspond to the meaning of relevant ASL signs. To search across videos, these captions or hashtags need to be consistent. If you search for “mom,” your results may not show others that you know to be relevant such as “mother,” “mama,” or “mommy”; so to be searchable, you need to use the same choice. To remember those choices, a list of some kind needs to be maintained. It’s going to get long quickly. And you might want to connect them to other signs to help find them easily or point out other kinds of connections like how they look alike or have similar meanings. That’s hard to do with a list. You may be thinking okay, let’s build a database and put them there. Great, good idea. What do we put in it? And what about when we come across new signs? And what about preparing shareable videos of the signs? You might be thinking, this is going to take me some time and resources. Yes, it will. I’ve been thinking about how to represent ASL video data since I started graduate school in 2005 and have been working on ASL Signbank properly since 2015. And I’m still thinking about all of this.
ASL Signbank is an old friend of mine. In its various incarnations, it has kept me company for many years. We’ve grappled with many issues together. It is hard to tell its story because it’s rather complicated and it’s not easy to know where to start. I’ve ended up with an Element that not only tells you a bit about how to do this work but also reflects on it all. ASL Signbank (Hochgesang et al. Reference Hochgesang, Crasborn and Lillo-Martin2025) may appear to be a straightforward product with well-defined edges but is the ongoing result of research processes that I and other researchers undertake daily. It’s also a reflection of how I do research, which is tied to centering deaf signers of all kinds contributing meaningfully to knowledge. These contributions must happen in ways that acknowledge and represent language use as embodied processes and making space for different kinds of signers in a balanced manner. I practice “slow science,” meaning I do science in a way where I value working with collaborators and enjoy the processes themselves. ASL Signbank is also a demonstration of a signing deaf linguist doing work in a mostly hearing space (Hochgesang Reference Hochgesang, Bono, Efthimiou and Fotinea2018, Reference Hochgesang2022a).
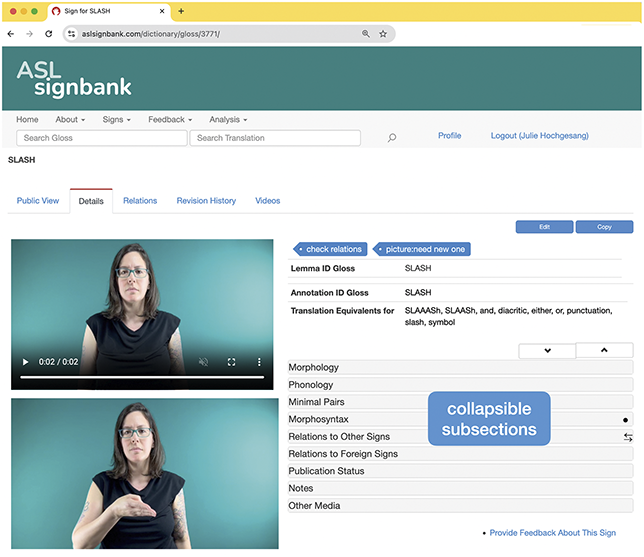
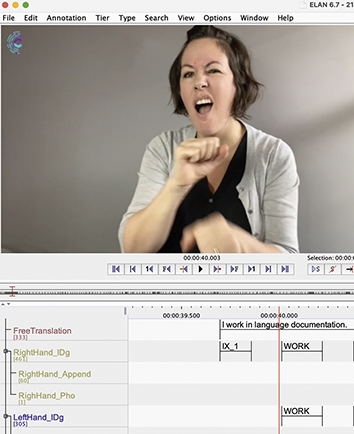
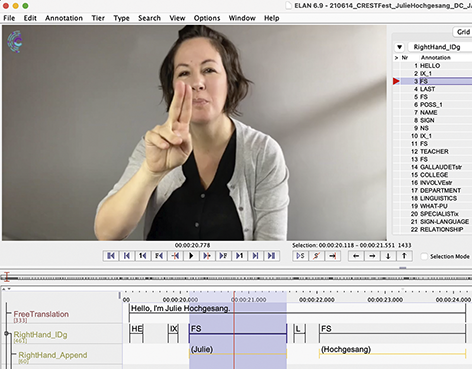
In short, I am interested in the use of ASL because, among a great number of reasons, I’m Deaf and it’s been my primary language since I was one year old along with English (preferably written). I am a linguist, and my interest is in signed languages and how the communities use and talk about them. Video is essential for my work as well as technology such as ELANFootnote 3 (Crasborn & Sloetjes Reference Crasborn, Sloetjes, Crasborn, Efthimiou and Hanke2008) or iLex (Hanke Reference Hanke, Rodríguez and Araujo2002) as annotation software to reduce the labor of finding things again in videos instead of rewatching them in real time. This software allows me to time-link annotations, or textual notes, to videos, which enables finding things in the data. As someone who grew up constantly browsing dictionaries, this has been a source of immense joy and fascination. As a research assistant for Deborah Chen Pichler and Diane Lillo-Martin for ASL acquisition projects (Hochgesang Reference Hochgesang, Berez-Kroeker, McDonnell, Koller and Collister2022b), I started organizing and labeling signs in 2006 and have since created thousands of notes, photos, and videos in ways that can be reused for annotation and sharing. As a maintainer of ASL Signbank, I’ve curated or created relevant (meta)data, such as original source videos and screenshots of signs, refilmed sign videos and screenshots, and sign entry information, as demonstrated in Figure 3.
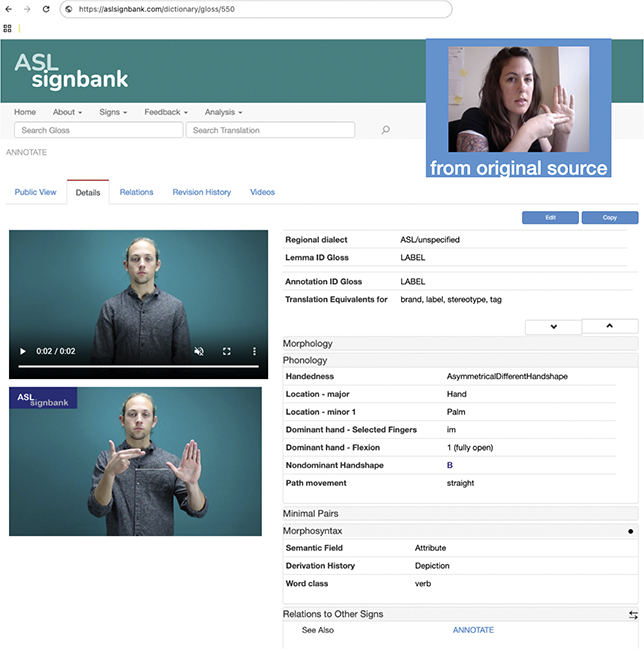
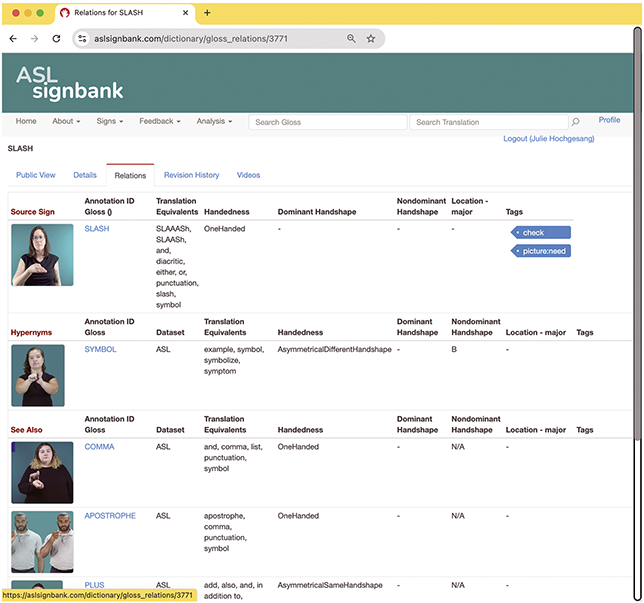
ASL Signbank entry for “label” with source (top right).
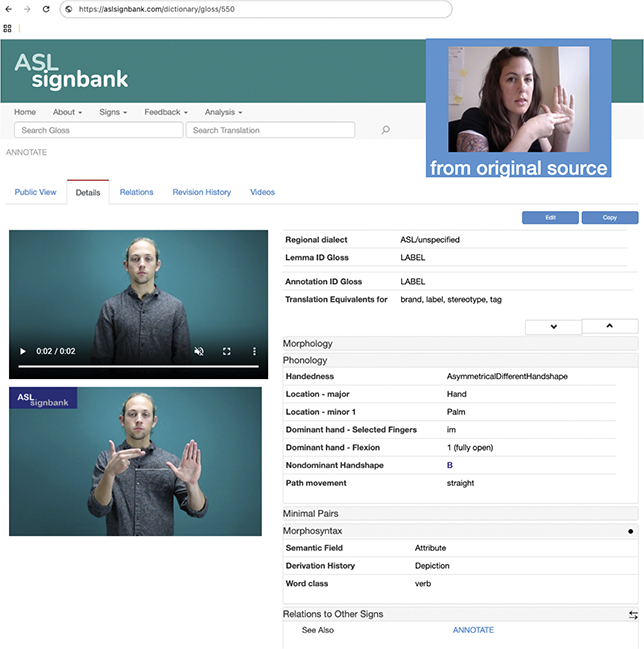
Figure 3 Long description
The two images on the left are of the same man - white with blond hair - signing label in A S L. Image on the right, in front of a blue box with text from the original source, is of Julie - a white woman with long brown hair, tattooed arms, sitting in her office, and signing label. Text on right is entry information - regional dialect A S L or unspecified, Lemma I D gloss LABEL, Annotation I D gloss LABEL, Translation Equivalents for brand, label, stereotype, tag. There are several gray bars with text: Morphology, Phonology, Minimal Pairs, Morphosyntax, Relations to Other Signs, Relations to Foreign Signs, Publication Status, Notes, Other media. Phonology and Relations to Other Signs subsections are expanded with additional text - https://aslsignbank.com/dictionary/gloss/550/.
Figure 3 is an example of an ASL Signbank entry I created for the ASL sign “to label,”Footnote 4 where the English word (or “label”) serves as the sign’s identifying “ID” gloss, a consistent and unique textual label (Johnston Reference Johnston2010) to enable searching and the like. In my work, I create ID glosses for signs in videos that need to be textually represented in annotation, as indicated by the “draft” version of the sign in front of the top right box in Figure 3.
As an academic, I could have started this introduction with the seemingly objective statement: “ASL Signbank is a lexical database that stores ID glosses, unique textual labels, that use English text linked to ASL signs, in order to annotate ASL videos. It has been built upon the template of other signbanks developed by those working with signed language corpora.” That statement may be accurate but is devoid of oft messy and ongoing questions and processes that come with developing and maintaining any scientific product. We created ASL Signbank to represent the signed data we had and wanted to use for our research. We also wanted to make it useful to the signing communities. Along the way, I used what I know about ASL as a Deaf signer and as a signed language linguist with an interest in phonetics and phonology to develop an annotation tool that could be used with ELAN, which is well-used among signed language researchers.
1.2 Writing about This Resource and Reflection
This Element was hard to write. Not just the typical writer’s block and the anxious procrastination that comes with it. Not just the apocarevolutiondemic days (Hochgesang Reference Hochgesang2022a) and imposter syndrome (Chua et al. Reference Chua, De Meulder, Geer, Addison, Breeze and Taylor2022). But because resources like dictionaries and databases can be a source of violence (Craft et al. Reference Craft, Wright, Weissler and Queen2020), including gatekeeping or discrimination. Researchers working with sociolinguistic (Bucholtz Reference Bucholtz2000), raciolinguistic (Rosa & Flores Reference Rosa and Flores2017), educational (Charity Hudley & Mallinson Reference Charity Hudley and Mallinson2018), and crip linguistic (Henner & Robinson Reference Henner and Robinson2023) perspectives have noted that linguistic resources, and the idea of “Linguistics,” are often used to push a specific linguistic, teaching, or cultural agenda. One only has to look at the long, extractive, and colonial history of museums or even the practice of collecting to see the harms that have been done by imposing a narrow set of experiences on what is actually a wide-ranging set of bodies of knowledge.Footnote 5 And this has persisted in how we process and store knowledge digitally as digital archivistsFootnote 6 or librarians know all too well (Reidsma Reference Reidsma2019).
Linguistic disciplines, including language documentation, share the same issues (Leonard Reference Leonard, McDonnell, Berez-Kroeker and Holton2018). While we have FAIRFootnote 7 guidelines (Wilkinson et al. Reference Wilkinson, Dumontier and Aalbersberg2016) to help us consider how to responsibly process and share data openly, we also have the CAREFootnote 8 guidelines (Carroll et al. Reference Carroll, Garba and Figueroa-Rodríguez2020) to remind us that these data come from people and should be treated with utmost respect and care. Management of that data, both primary and meta, is essential for citation and subsequent accountability (Berez-Kroeker et al. Reference Berez-Kroeker, McDonnell, Koller and Collister2022).
And we have considered what it means to work with the signed communities when doing research (Harris et al. Reference Harris, Holmes and Mertens2009; McCaskill et al., Reference McCaskill, Lucas, Bayley and Hill2011; Kusters Reference Kusters, Zeshan and de Vos2012; Lucas Reference Lucas, Meurant, Mieke and Vermeerbergen2013; Singleton et al. Reference Singleton, Martin, Morgan, Orfanidou, Woll and Morgan2015; Moriarty Reference Moriarty2020; Hochgesang & Palfreyman Reference Hochgesang, Palfreyman, Fenlon and Hochgesang2022; Hochgesang Reference Hochgesang2023; Hou & Ali Reference Hou, Ali, Charity Hudley, Mallinson and Bucholtz2024). There are many claims that have been made in early signed language research – often based on data of a small number of signing consultants and not openly shared – that have shaped much of our working methodological and theoretical assumptions today. They need to be revisited and evaluated. This work cannot be done without revisiting accessible data and has not been done much for signed languages (Bennett Reference Bennett2024). Even if ASL is one of the most studied signed languages out there, there remains much we do not know or have not asked.
I have been thinking about the lessons shared by all of who I just mentioned and have reflected on how to do the work I do. And because I know my work cannot, and should not, represent all the ASL communities (Henner & Robinson Reference Henner and Robinson2023; Hou & Namboodiripad Reference Hou and Namboodiripad2025), I work to create resources that do not center or privilege a specific group as language resources often do, for example, “White Deaf native signerism” (Lim and Hou (Lim Reference Lim2025)). I have tried to ensure that the signers seen in ASL Signbank videos represent a wide variety of signing experiences tied to different kinds of embodied socio-identities. Even with its limitations, I propose that continually maintained signbanks, with some flexibility and constant reflection in design and care, are useful strategies for archiving contemporary language use – eventually becoming historical sources.
Historically, the work of developing a language resource has usually meant that one person or a small group of people make decisions about a language that belongs to millions. Language description requires entering a conversation that is decades old and rife with theoretical assumptions, such as considering native speakers as ideal sources of data although they aren’t (Cheng et al. Reference Cheng, Burgess and Vernooij2021), that were made by hearing nonsigners who barely consulted deaf ones, who, if they were lucky, were the assistants or lab managers.
And it irks me to no end that we rely on glosses from ambient spoken languages to represent signed languages, like English glosses for ASL (”tyranny of glossing” (Slobin Reference Slobin2008; Hochgesang Reference Hochgesang2019)). But to draw upon an experience that the modern person can perhaps relate to, glosses are like passwords. People hardly want to use them. They’re a pain to remember. It takes convoluted methods to use them, but they’re necessary for access to tools and information. And to serve that purpose, they – both the passwords and the glosses – need to be consistent and shared. And with glosses, that work should be done with reflection while operationalizing CARE FAIRly.
I hope readers of this Element exercise the same kind of care. In these days of so-called Artificial Intelligence (AI) and oft-extractive natural language processing (NLP) (Bender & Friedman Reference Bender and Friedman2018; Bender & Hanna Reference Bender and Hanna2025), it is even more essential. While on the topic of “AI,” please note that signers should always accompany ASL Signbank use whether it’s browsing, annotating, or teaching. It was entirely made with them in mind (Section 1.4). There are plenty of resources out there for ASL learners, very few for those who already use them as their daily primary language. As for what I write about in this Element, I can only be explicit and reflective. I may offend people who say that science is supposed to be neutral and objective. That’s just untrue. Science has been led by those with power who have decisions about what is “neutral” and “objective” and want you to believe it is so (e.g., Clemons Reference Clemons, Hudley, Mallinson and Bucholtz2024).
As will be clear here, I don’t see myself as a traditional academic. As I thought about how to write this, I found myself thinking what do readers want me to say? What is the “right” way to do this, but then I realized that’s not what I can write about. I’m a Deaf ASL community member trained in linguistics. I see the beauty and importance of practices and feel the shapes of things better as I do them, as I interact with them and reflect on the process. That’s what I write about. This Element will not be a “traditional academic” product, a decision I have made precisely because I question the label “traditional academic.” It will be what I would have liked to see when I was a young scholar. It’s for deaf people. It’s for people who don’t see themselves as traditional academics but have the knowledge although they haven’t seen themselves as having authority for constructing and sharing that knowledge.
1.3 Whose Story and for What Purpose?
As Roberts (Reference Roberts1997) wrote: “every decision about how to transcribe tells a story. The question is, whose story and for what purpose?” (p. 169). I started working on my dissertation in 2008. When I first started out, I decided that its title would be “whose story and for what purpose?” When I finished in 2013, the title was completely different (Hochgesang Reference Hochgesang2013) although the “why” driving my work was still the same. I wanted to do a dissertation focused on representation of data. Dear-well-meaning-but-naive-2008-Julie imagined she’d do each chapter focusing on different levels of representation in signed language research – from phonetic to morphological, syntactic to discourse level – and dive into the histories of representational choices and practical demonstrations using actual signed language data from different signed languages. From this work, surely, I’d be able to examine the different stories of signed language researchers and the purposes they had.
Luckily, Bob Johnson, my dissertation chair, counseled me to make it smaller, much smaller. I ended up focusing on phonological representation of the handshape in ASL using child acquisition data consisting of one child’s set of signs over two years and examining how four notation systems did the job. While the focus was narrow, the work was intensive and consuming. I was able to focus on “the small bits” of language use, and in the small things, I could still see the big. And the big with that work was realizing how nuanced the transcription process is, and how difficult it is to identify the one system that will solve all our problems.Footnote 9 The other members of my dissertation committee also helped me realize this, especially Onno Crasborn. In describing his work for a phonological database for signed languages, Crasborn discussed the “database paradox” (Crasborn, van der Hulst & van der Kooij Reference Crasborn, van der Hulst and van der Kooij2001) where one needs to make decisions about what to represent while also doing the representation which is quite the metalinguistic (read: mind-boggling) task!
I’ll admit. … I started my dissertation thinking I’d find the one system to rule all, the one system that would be best for anything. I quickly realized that was foolish and impossible. This would be like saying there should be only one kind of kitchen utensil. Tools for language representation vary because they must – people have different preferences, goals, and skill sets. Their access to resources like funding, colleagues, students, research assistants, and tools will always vary based on where they work and with whom. I’ve given up on finding the one answer. But I haven’t given up on wondering about the work that goes into it, why, and by whom. “Whose story and for what purpose?” are important questions. What is considered data? (Finnegan Reference Finnegan and Austin2008). How do people perceive, collect, represent, share, use, analyze, and cite the data? What motivates them? This matters because these ways have the potential of becoming other people’s ways. While shaped by knowledge, our practices, and our choices, our representation in return shapes knowledge (Ochs Reference Ochs1979; Edwards Reference Edwards, Edwards and Lampert1993; Murphy Reference Murphy2021).
Since I’ve been at Gallaudet, both as a graduate student and a professor in the linguistics department, I’ve worked with data representation. I’ve taught phonology and field methods. I’ve trained students in the use of notation systems for signed languages and annotation software linked to videos. As described in Hochgesang (Reference Hochgesang, Berez-Kroeker, McDonnell, Koller and Collister2022b), I’ve been considering how to represent signs – usually produced by one or two hands/arms in front of the signer, along with considerable information on the face, torso, and even the rest of the body. I’ve thought endlessly about how to capture what I observe about signers languaging – from the small to the big, keeping in mind how design choices shape the representation and subsequent use of. As Roberts (Reference Roberts1997) writes:
If talk is a social act, then so is transcription. As transcribers fix the fleeting moment of words as marks on the page, they call up the social roles and relations constituted in language … transcribers bring their own language ideology to the task. In other words, all transcription is representation, and there is no natural or objective way in which talk can be written.
As a signing deaf person from a midwestern middle-class hearing family who grew up in mainstreamed educational environments with frequent deaf socialization through deaf friends and deaf events with signing deaf adults, I have seen firsthand the intense and complicated language attitudes regarding English and ASL, not to mention other spoken and signed languages. I’ve battled with them myself. Like most work for spoken language linguistics, English is the dominant form of textual representation for signed languages, especially ASL, for both transcription and dissemination. I’ve explored this in previous work, where I advocate for prioritizing visual representation for visual signed data (#Glossgesang)Footnote 10 (Hochgesang Reference Hochgesang2019, Reference Hochgesang2022b). What’s especially important to note here is that this practice of using English as our main form of representation, often leaving out the original data (the signed data), has deeply shaped our current knowledge of signed language research. For example, representing 👉 with English “he,” “she,” or “it” means there’s also the senses associated with those English pronouns – gender, third person, and singular – that could be carried over.
Some linguists are now pushing for language data to be shared publicly or as open access (e.g., Seyfeddinipur et al. (Reference Seyfeddinipur, Ameka and Bolton2019) citing Christen (Reference Christen2012)). Under these research models, research should then be freely accessible and available. Ironically, this free access is not cheap in terms of resources. Resources include immense people power, stable technological infrastructure, and ongoing institutional support (Hochgesang et al. Reference Hochgesang, Lepic, Shaw and Wehrmeyer2023). It also includes the power of language representation, such as who can “decide” what kind of knowledge to include. I know firsthand that many signed language researchers either don’t know how to sign or cannot sign much. I also know that some researchers can be extractive and exploitative. This makes it difficult to trust their “read” of the data, a problem that is compounded when the data is not available. I share work because I want to see the data firsthand and make sure others in the signing communities can access this tool (Berez-Kroeker et al. Reference Berez-Kroeker, McDonnell, Koller and Collister2022). To make sure we are accountable by ensuring knowledge is accurately represented while acknowledging that “accurate” is subjective.
While I will be writing about ASL Signbank in this Element to explain the tool so others may use it for their own purposes, I will also be reflecting on choices that I made. The care I took while building and maintaining this resource. Language use is not to be distilled into simple labels devoid of interaction and studied on their own. But rather the labels along with recorded language use helps us make sense of it all.
Lest I make maintaining the ASL Signbank seem like a chore, let me be perfectly clear – working on ASL Signbank is a joy for quite a few reasons. Among them, celebrating the variation and actual language use of signers in North America. I loved dictionaries as a child and still do. While ASL Signbank is not a dictionary, there are processes that are like making a dictionary. There is joy in cataloging our language use for the use of others. When I annotate videos, I see many things that make me go VEE: The sign choices people make. The certain signs of places, identities, or situations. The ways bodies move to articulate signs. For example, people love fingerspelling on the way to the next sign. No wonder learners or algorithms have a hard time with fingerspelling! But I love it – they’re sneaky little words born on the go and disappear upon arrival but still manage to contribute to the message overall. All of this is fascinating to me as a linguist observing and documenting people doing language. That’s the whole point of observing language – to see how people move their bodies to communicate, perform, express identity, and so on. It puzzles me that we’d outsource this “labor” to algorithms. I enjoy sharing these observations with my communities in nontraditional ways that are more accessible to people such as VEEing emboxed discourse, that is, signing while using video-mediated communication like Zoom or Facetime, during the early days of the COVID-19 pandemic in 2020 (Hochgesang Reference Hochgesang2025b) and doing language documentation projects (Hochgesang Reference Hochgesang2023).Footnote 11 I often share them on social media or my own website, which allows me to take advantage of digital tools to express my ideas in a multimodal manner – with written English, emojis, signs in photos, gifs or videos, and links to ASL Signbank entries.
1.4 ASL Signbank Is Not for “AI” Extraction
ASL Signbank is not intended for “AI” extraction. My objections to this practice are numerous and include skepticism about how “AI” researchers view data, acknowledgement for attribution and authority of knowledge, recognition that tech “fixes” are usually not designed by disabled users, and care for the process of linguistic analysis.
I caution the reader that ASL Signbank, which can enable (semi)automated tasks for annotation, is not considered “ideal” for machine learning (or “AI”) as some researchers would like. Natural language processing researchers have stated that human-made labeling is too inaccurate and inconsistent for developing models they can use (Bragg et al. Reference Bragg, Caselli and Hochgesang2021). I find this interesting because for me the work with ASL Signbank is not so much about making a computational model but making primary data accessible for others. In my own view, it’s not ideal for machines anyway because language use is not about producing signs in isolation as many current technical applications claiming to teach signed languages will show – especially with fingerspelling. Language use is, instead, words in messy sequence with one another and, more importantly, in interaction with other signers.
Furthermore, I do not want ASL Signbank to be extracted for machine learning where sources are not credited and data are not treated with care as they should be since they come from real people and their rich lives (Bender & Friedman Reference Bender and Friedman2018; Gallaudet Linguistics Department 2025a). I also do not see this information as a way of “fixing” issues with communication or access because, as disabled people have shown time and time again, they are the experts at adapting in an able-bodied world that was not built with them in mind (Erard Reference Erard2017; Hill Reference Hill2020; Jackson et al. Reference Jackson, Haagaard and Williams2022; Börstell Reference Börstell2023; Desai et al. Reference Desai, De Meulder, Hochgesang, Kocab, Lu, Efthimiou, Fotinea and Hanke2024). They know the fixes that they want to see or whether anything needs to be fixed at all.
For those going “but what about ‘AI’? It’s everywhere.” I truly enjoy the process of annotating data – from observing people languaging to deciding what to focus on to choosing a way to represent that act then actually committing it to the digital page and sharing it with others. Yes, annotation is a time-consuming act. I often tell my students it takes about an hour for an experienced annotator to process about a minute of video data for the first pass (free translation, tokenization of units like utterances and words, and labeling of those units). It’s tempting to recommend automation,Footnote 12 but to me that’s the whole point – looking at language use with my own eyes and thinking about how to represent it all because representation is theoretical and rooted in what we think is essential. I don’t want any “artificial” things in my way when I’m doing that. Research about language, a very human act, should be done by humans themselves.
When I analyze data, I am labeling things I find important and interesting for the questions I am asking. It’s almost as if the act of it is more important than the actual labels themselves. Usually, these questions are related to language documentation, the use of language as used by different members of ASL communities, language ideologies, and phonetics and phonology (especially phonological processes). But I also acknowledge that it is what I see and what I am interested in. I find the act of making this explicit as a way of being accountable, as a (sorta)reliable way of sharing how I have come to my conclusions, and, most of all, as entering a conversation with others who can bring their own views and interpretations to the data. That I believe adds value to the corpora – messy but real and nuanced views by humans about human data. That’s why we’re doing the work we’re doing and asking the questions we’re asking.
2 What ASL Signbank Is
ASL Signbank is an online database that maintains ID glosses for ASL. It’s like a password manager storing those passwords that are hard to remember. A signbank is an online lexical database for a signed language, usually developed by linguists working with signed language corpora or those who are interested in modeling some aspect of language. Starting with the signed language of the Australian Deaf community (Johnston Reference Johnston2001), signbanks have been created for several signed languages, including British Sign Language (BSL) (Fenlon et al. Reference Fenlon, Cormier and Rentelis2014) and Nederlandse Gebarentaal (NGT) (Crasborn & Zwitserlood Reference Crasborn and Zwitserlood2008).
Although we have been working on developing consistent annotation guidelines for the acquisition projects since 2006 (Chen Pichler et al. Reference Chen Pichler, Hochgesang, Lillo-Martin and Quadros2010; Hochgesang Reference Hochgesang2025c), it wasn’t until Reference Hochgesang, Cooper and Rashid2015 that we (Diane Lillo-Martin, Onno Crasborn and myself) started creating a signbank for ASL by building on the previously developed NGT Signbank and Global Signbank (Cassidy et al. Reference Cassidy, Crasborn and Nieminen2018). ASL Signbank has been publicly available since 2017 and is being used for the Sign Language Acquisition, Annotation, Archiving, and Sharing (SLAAASh) project, an ongoing effort to prepare corpora of sign language acquisition to share with the research communities, including projects annotating ASL data. I have used it throughout documentation projects and teaching linguistics at Gallaudet. I refer to that effort and set of shared protocols as Collections of ASL for Research and Documentation (CARD). CARD is also a collection of video collections, as described in Section 2.4.1. It is in this sense, among other choices, that ASL Signbank is unique in that it is tied to multiple corpora. Other signbanks grow mainly with one specific corpus. Early on, we also collaborated with ASL-LEX to share coding and to increase interoperability should researchers or others choose to use both databases (Becker et al. Reference Becker, Catt, Hochgesang, Efthimiou, Fotinea and Hanke2020; Sehyr et al. Reference Sehyr, Caselli, Cohen-Goldberg and Emmorey2021), which we discuss briefly in Section 2.3.
2.1 Practical Example: Finding Signs in Video
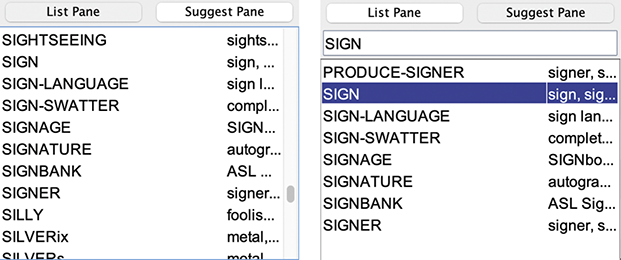
We pondered the issue of finding signs in video briefly in Section 1.1, but let me give you a real-life example using this video.Footnote 13 If you know ASL, you were able to follow along and maybe can remember some signs now that you’re back here reading this – “rocket,” “funny,” “bae,” and so on. Imagine trying to go back to the video and finding those signs you remember. It’s unlikely you remember the precise timestamp. You would need to scroll the video to manually search for them. To be more efficient or quicker, we’d need a digital searching method. But first we’d need to render the data searchable. That you must manually scroll the video means it’s not.Footnote 14
To be searchable, these signs need to be in some kind of textual form like “rocket,” “funny,” and “bae.” Although we’re quite good at perceiving language on the go, it’s difficult to study language in its raw form – as sound or light waves through the air or vibrations on the skin. To observe language over time, to count, to share, or to cite, we need to freeze that linguistic behavior somehow. Videos are a good start, but they aren’t usable if we must rewatch the videos in real time every time. Again, we need to tag (or label) units with machine-readable text. Spoken languages, especially those that are well-resourced like English, have a long history of writing systems that have led to text corpora that support these kinds of searches (McEnery & Hardie Reference McEnery and Hardie2011). For signed languages, we are unable to rely on already-conventionalized writing systems like there are for English or other well-resourced languages or even the International Phonetic Alphabet (IPA) (International Phonetic Association 1999), a conventionalized and familiar notation system that linguists can use to represent the form of any spoken language.
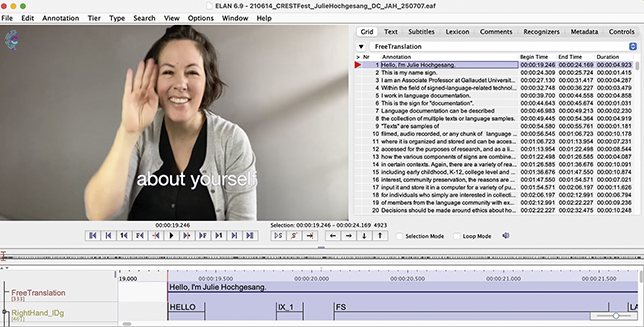
So, with that limitation, if we want to have a maintained digital list of labels for ASL signs in videos, we need some kind of textual representation. Since ASL and other signed languages are not standardly written, researchers have been using glosses (Comrie et al. Reference Comrie, Haspelmath and Bickel2015) in both research records for analysis and in publication to share their research. For ASL, using glosses means the selection of particular English words that are close to ASL signs in meaning and written in all caps (Figure 4).
Example of glossing with translation.

Figure 4 Long description
Julie is signing in A S L with English glosses overlaid on each sign in white boxes, black text - SIGNBANK FOR SEARCH LABEL FOR POSS (audience) PRODUCE-SIGN. On the bottom left is an English translation: The ASL Signbank is for searching labels for your signs - black text on white background.
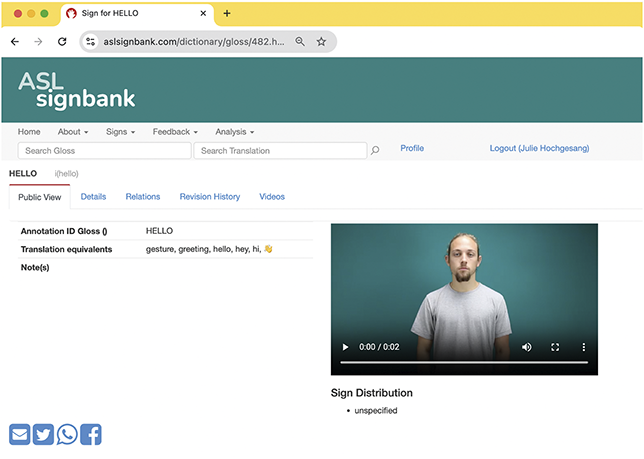
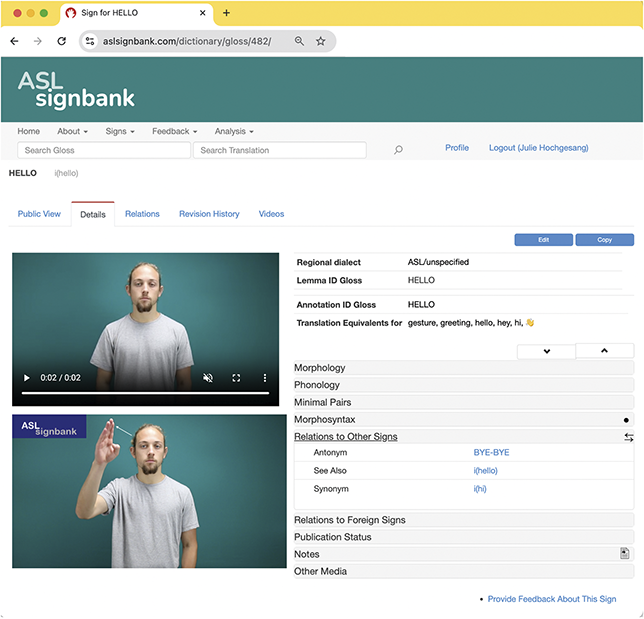
To make them machine-readable, glosses need to be unique for different signs. These are known as “identifying glosses” or “ID glosses” (Johnston Reference Johnston2010). ID glosses facilitate consistent, systematic annotation of sign usage. Further expanded in Section 3.2.1, ID glosses are essentially the same English text used as consistent labels of the same signs. For example, HELLOFootnote 15 is the same text used to label the same ASL form and the annotator does not alternate between different textual choices that would work as well such as “hi” or “yo.” In ASL Signbank, “HELLO” has been chosen as the ID gloss for the ASL sign and is meant to represent different productions associated to this form in annotation even if there is a bit of phonetic variability (Figure 5).
Different productions of ASL signs labeled as HELLO taken from CARD, original source noted at top or bottom

Figure 5 Long description
HELLO text in the middle. The top or bottom of each image has small text indicating the source of the sign. Top left to bottom right: White woman with medium-length brown hair, glasses and blue top; Asian woman with long black hair, glasses and maroon top; Light-skinned woman with medium-length curly black hair and green tank top; White woman with short blonde hair, glasses and red blazer; Light-skinned man with short brown hair, mask and black top; White woman with blonde hair pulled back and tan shirt with Hu logo. All are in different environments, signing A S L.
This practice of linking unique English labels to certain signs is laborious, a minimum of five minutes per entry not including refilming shareable videos or images. Using a single computer to maintain this is work enough, but sharing it across a single research project or multiple projects over time is even more, hence the allure of a signbank. Not to mention the ability to link to other entries through different kinds of relationships, thus improving the ability to search. The use of a database also allows for us to reduce the reliance on English glosses as representation when we can use other descriptive criteria to identify and search for sign entries. These criteria are described in depth in Section 5.
Any user can search for a sign using different aspects of the entries, even within a transcript. And these aspects can also be automatically added to the transcripts as a kind of semiautomatic tagging although they would need to be cleaned up by a human annotator. For example, entries are tagged with grammatical categories such as nouns, verbs, and adjectives. These tags can be automatically added to the transcript with the relevant ID glosses. Using a signbank with transcripts linked to videos permits annotators to view the signbank entries for potential glosses in-line while producing their annotation files, which increases the accessibility of annotated video data.
As the work goes on, the actual annotation process continues to inform the signbank, from the most basic questions (which signs to include) to refinement of the postulated linguistic features. Again, the categories of information about each sign used in ASL Signbank have been derived from prior signbanks (most immediately NGT Signbank (Crasborn & Zwitserlood Reference Crasborn and Zwitserlood2008)) and the SLAASh annotation conventions (Hochgesang Reference Hochgesang2025c). Although we have been working with specific annotation conventions for some time (Chen Pichler et al. Reference Chen Pichler, Hochgesang, Lillo-Martin and Quadros2010), our conventions have recently evolved to accommodate the lemmatization principles as described in Fenlon et al. (Reference Fenlon, Cormier and Schembri2015).
2.2 What Is a Signbank Anyway? And Some Other Relevant Concepts
A lexical database is a digital organization of meaningful units organized in ways creators think the represented language works. Database design is full of decisions in which database makers decide what they’re focusing on, choose what information they will include, and determine how that information is encoded. Then they build the structure based on what they want to do – annotate videos, search for entries, and connect to other entries. It is essential for data processing, sharing, and citation.
A lexical database organizes linguistic units in ways useful to building dictionaries and corpora to study lexicons and grammars (Fenlon et al. Reference Fenlon, Cormier and Schembri2015). Lexical databases attempt to structure entries around supposed relationships between units. WordNetFootnote 16 is a well-known and large lexical database for English that refers to itself as an “on-line lexical reference system whose design is inspired by current psycholinguistic theories of human lexical memory” (Miller et al. Reference Miller, Beckwith, Fellbaum, Gross and Miller1990, abstract). WordNet organizes English words through synonymy and these groups of synonyms are further connected through other semantic associations such as antonymy, hyponymy, and hypernymy. Often in signed language corpora, lexical databases are developed closely linked to corpora so they can feed one another in structure and data. Quite a few of them have been referred to as “signbanks,” which refers to both the concept of a signed language lexical database and the set of software (Cassidy et al. Reference Cassidy, Crasborn and Nieminen2018) to build them.
A corpus is a collection of texts (written, audio, or video recordings with relevant metadata about sessions and participants) that have been made machine-readable through consistent annotation with explicit conventions (Johnston Reference Johnston, Crasborn, Efthimiou and Hanke2008; Fenlon & Hochgesang Reference Hochgesang2022). Furthermore, a corpus can be used to extract information and is reusable and multifunctional (McEnery et al. Reference McEnery, Garside and Leech1997).
A meaningful or “linguistic” unit depends on the researcher, their language experiences, and their theoretical frameworks. What is considered to be linguistic is not straightforward, as I discuss next. My underlying principle as I’ve maintained ASL Signbank is that any signs I come across in the video data or are suggested by others doing the same are represented somehow. Our primary goal is to have machine-readable labels ready for any instance considered meaningful in the video data because we are working to make these videos accessible for our multipurpose uses. But determining what is “linguistic” in videos and should be annotated and added to signbanks is difficult to determine (Liddell Reference Liddell2003; Kusters & Sahasrabudhe Reference Kusters and Sahasrabudhe2018; Kusters & Hou Reference Kusters and Hou2020; Hodge & Ferrara Reference Hodge and Ferrara2022). What even is a “word” (or “sign”)? This relatively simple question is impossible to answer straightforwardly.
“Instances” are examples of a specific category or type, which, with signbanks or corpora, are signs. For example, HAPPY is a sign type and has its own entry. When browsing videos and seeing different productions that could be appropriately labeled by HAPPY, these are all instances of HAPPY. A “token” is the same as an instance. Annotators have to decide whether an instance is an instance of a type and determining the boundaries of that type. We do that to a certain degree in ASL Signbank, but not fully.
A lexical database is typically thought of as a model of the lexicon of a language. The lexicon is a theoretically thorny concept. It is thought of as the vocabulary of a language, in opposition to the grammar. For example, Johnston and Schembri (Reference Johnston and Schembri1999) define lexemes, the entries in a lexicon, as linguistic units “with a ‘given’ rather than a ‘generated’ meaning” (p. 115). They have distinguished between units that are “fully lexical,” “partly lexical,” and “non-lexical.” The vocabulary of a language can also be split in different ways. Padden (Reference Padden1998) suggested that the ASL lexicon contains native vocabulary and foreign vocabulary. Native items include nouns and verbs of all kinds, including classifier predicates. The foreign items are derived from fingerspelling, including loan signs and initialized signs.
In the necessary process of making decisions as we record (or essentially “freeze”) language in a way we can share and examine it, we engage in analytical traditions we have inherited where we impose narrow categorical decisions on fluid, everyday language in rich contexts. Database design requires categorical decisions, and so theoretical assumptions can get baked into the structure of the database and sometimes become overly constraining. Consider ongoing discussions in library science (Drabinski Reference Drabinski2013; Howard & Knowlton Reference Howard and Knowlton2018) and development of large language models for machine learning (e.g., Bender & Hanna Reference Bender and Hanna2025) about resulting systemic biases because of the categorical choices we make. Furthermore, the practice of separating and labeling language data is rooted in traditions of taxonomic sciences, which have shaped linguistics like many disciplines, and are further rooted in imperialistic and colonial practicesFootnote 17 (Leonard Reference Leonard, McDonnell, Berez-Kroeker and Holton2018; Charity Hudley et al. Reference Charity Hudley, Mallinson and Bucholtz2024). I also often lament how odd signs look when they are produced alone as entries for the ASL Signbank (Figure 3 for example). It is not the most representative model of a signing human interacting with other signing humans. Signs in these entries remind me of pinned butterflies – you can recognize them and even name them – but they’re not really the butterflies we know. Those are the ones out in nature flying about. The same can be said for signs. We get a better sense of signs when they’re out in nature flying about.
The usage-based view also challenges the idea that there is a clean division between vocabulary and grammar. For example, Lepic (Reference Lepic2019) argues that the idea of the “lexicon” has its roots in structuralism, which emphasizes structure over use. Lepic suggests a usage-based alternative to the structural notions of lexicon and lexicalization, which is to note that linguistic constructions (of all sizes) become fixed, conventional pairings of form and meaning through language use. This aligns with the broader usage-based approach, the perspective that values frequency of use and how patterns revolve around such use (Bybee Reference Bybee, Díaz-Campos and Balasch2023). A useful example can be found in Wilkinson et al.’s (Reference Wilkinson, Lepic, Hou, Janzen and Shaffer2023) example of the “bent-V” schema, in which signed forms with the same hand configurationFootnote 18 occur with some frequency in a video.Footnote 19 For example, this handshape is often used to represent varied movement of animals and people raising the question of how to best label them. Wilkinson et al. argue that actual use involves “recycled utterances that encompass many unit types, including fused, fixed, and flexible constructions … emerg[ing] from each signer’s experience with ASL” (p. 381), which isn’t easily captured through textual labels themselves. Imposing a category on signs is a necessary analytic step, but it is also a theoretical move. Though a lexical database is designed to capture individual words, when they are tied to corpora, they can start to push against this baked-in theoretical constraint, especially when focusing on the functional goal of annotation for potential multipurpose use.
Since we are working with a database that needs structure and we are working with linguistic units, we need some kind of organizing principle. For dictionaries and lexical databases, that is known as lemmatization, further expanded in Section 4. But simply put for now, lemmatization is the act of deciding the most basic or unmarked phonological variant of a concept – a lemma – and deciding what other variants belong in the same lemma group and what should be categorized as different. This too is highly theoretically thorny, and it also makes for long conversations between those who would split and those who would lump (Hodge & Crasborn Reference Crasborn, Berez-Kroeker, McDonnell, Koller and Collister2022; Palfreyman & Schembri Reference Palfreyman and Schembri2022). Splitters prefer more distinct subcategories within a larger category, while lumpers are generally happy with that large category alone. When using any linguistic tools, researchers of different research projects will have to keep in mind what their theoretical principles and goals are. For example, fellow faculty member Ryan Lepic, a lumper, would prefer to use lemmas as annotations (e.g., MOTHER and DEAF) instead of the more fine-grained annotation ID glosses (e.g., MOTHERwig and DEAFixdown) that I, the splitter, prefer to use. For now, it is important to know that lemmatization is used for the organization of lexical databases.
In databases, we often see what is considered the “citation form” or what many researchers equate with the “dictionary form” or “reference form.” The citation form is the basic, unmarked isolated form – or the form that is in the minds of those who know the language. The citation form is rarely produced – often only as reference forms in resources like ASL Signbank.
2.3 History of Signbanks and the Beginning of ASL Signbank
As discussed so far, signbanks are lexical databases that have been created for several signed languages (see Kopf et al. (Reference Kopf, Schulder, Hanke, Efthimiou, Fotinea and Hanke2022) for a detailed list). Many of these databases, not all called “signbanks,” feed online dictionaries and are populated from annotation files from signed language datasets. Such databases store ID glosses (standardized textual labels) for sign forms. Signbank 2.0 (Quadros et al. Reference Quadros, Rathmann, Romanek, Fernandes, Condé, Efthimiou, Fotinea and Hanke2024) is a current effort to build database(s) of comparable signs from different signed languages associated with corpora.
It is not a small task to host a signbank or any language resource. It requires coordination of ongoing resources, including people who can develop and maintain the software as well as the content. It’s meant to be an ongoing effort (Fenlon & Hochgesang Reference Hochgesang2022; Hochgesang et al. Reference Hochgesang, Lepic, Shaw and Wehrmeyer2023; Quadros et al. Reference Quadros, Rathmann, Romanek, Fernandes, Condé, Efthimiou, Fotinea and Hanke2024).
Made possible through a grant and coordination of several institutions, the ASL Signbank web application is modeled on the NGT Signbank or Global Signbank (1.0), which in turn is based on Auslan Signbank software (Cassidy et al. Reference Cassidy, Crasborn and Nieminen2018), written in Python using Django web application framework. The code is available for developers under a public license at www.github.com/Signbank/Global-Signbank/. The ASL Signbank infrastructure has been developed and maintained by Radboud University in the Netherlands, but it was hosted by Haskins Laboratories and Yale University in the United States from 2015 to 2025. In 2025, it was moved to University of Connecticut and a new domain – https://aslsignbank.com/. As of 2025, Wessel Stoop and Rob Dowden are the tech developers, helping keep the tech magic humming along.
When we created ASL Signbank for SLAAASh, we knew ASL Signbank could be useful to other researchers and ASL communities themselves, so we made it open access.Footnote 20 We also created a set of annotation conventions (Hochgesang 2025) since ASL Signbank alone cannot represent all of language use. ASL Signbank and the annotation conventions together as a protocol to process ASL videos for sharing is known as SLAASh (minus the A for “acquisition”). SLAASh can be used for any ASL research, even when not focused on acquisition, such as variation, language documentation, and corpora of ASL communities.
SLAAASh is preparing a digital video corpus of deaf children’s use of ASL, specifically four deaf children aged one to four of deaf parents (Lillo-Martin & Pichler Reference Liddell and Johnson2008). With ASL Signbank and the SLAASh annotation conventions, the primary data has been consistently annotated. Work is underway to share it online along with other signed language data. ASL Signbank entry content has been mostly produced by researchers and research assistants at Gallaudet.
Given the high-resource demand of maintaining ASL Signbank, we initially collaborated with the creators of ASL-LEX,Footnote 21 a publicly available database that includes subjective frequency and iconicity judgments for ASL signs (Caselli et al. Reference Caselli, Sehyr, Cohen-Goldberg and Emmorey2016; Sehyr et al. Reference Sehyr, Caselli, Cohen-Goldberg and Emmorey2021) to share the coding of sign entry content, especially sharing lemma glosses and phonological coding (Section 5). The goals of ASL Signbank and ASL-LEX are different. ASL Signbank is based on usage data (e.g., ID glosses for signs are created as they occur in our ASL video data), while ASL-LEX was designed to include elicited signs to represent the full range from high to low frequency and high to low iconicity, for use in psycholinguistic experiments. As described in Becker et al. (Reference Becker, Catt, Hochgesang, Efthimiou, Fotinea and Hanke2020), projects are linked together by the alignment of glosses in which we use the same lemmas, although sometimes different annotation ID glosses, and shared phonological coding derived from a simplified version of the Prosodic Model (PM) (Brentari Reference Brentari1998). There were some annotation ID glosses where our labeling preferences diverged, that is, we preferred more mnemonic labels for annotation ID glosses such as lower-case tags that indicated some aspect of the sign form.
I would describe the ASL Signbank as three stages at this point. The first two are described in depth in Hochgesang (Reference Hochgesang, Berez-Kroeker, McDonnell, Koller and Collister2022b). The first stage is from 2006 to 2015, in which we kept track of unique ID glosses for ASL signs and cycled through different sharing methods (a single computer, Dropbox, Google Drive, a homegrown database (Fanghella et al. Reference Fanghella, Geer, Henner and Crasborn2012)). During this stage, generative linguists interested in signed language acquisition and wanting to compare with spoken language child acquisition led the work and I worked as a research assistant and then lab manager (Chen Pichler et al. Reference Chen Pichler, Hochgesang, Lillo-Martin and Quadros2010), and even participant with my firstborn. The second stage is from 2015 to 2020-ish, in which we transitioned to using a signbank and inherited the structures and principles of existing ones. The theoretical and methodological fingerprints here are more rooted in functional frameworks or purported to be “framework-free” (Haspelmath (Reference Haspelmath2007), cited in Hodge & Crasborn Reference Crasborn, Berez-Kroeker, McDonnell, Koller and Collister2022) but still essentialist and structuralist in many ways. The third stage is from 2020-ish and on as I grapple with the static and essential nature of signbanks while I do descriptive and usage-based linguistics with like-minded collaborators. In 2017, I was invited by Ronice de Quadros to present at SIGN8 about my work on ASL Signbank in which I explored the idea of usage-based approaches, which are ideal for corpus research given the focus on frequency and how that shapes use. Through it all, the ultimate goal of ASL Signbank is to store glosses, or textual labels, linked with videos and photos of the ASL variants themselves along with additional information to reduce the reliance on English as representation, keeping best practices of data management in mind (Bird & Simons Reference Bird and Simons2003; Wilkinson et al. Reference Wilkinson, Dumontier and Aalbersberg2016; Berez-Kroeker et al. Reference Berez-Kroeker, McDonnell, Koller and Collister2022) while keeping ASL communities centered (Carroll et al. Reference Carroll, Garba and Figueroa-Rodríguez2020; Hochgesang & Palfreyman Reference Hochgesang, Palfreyman, Fenlon and Hochgesang2022).
2.4 Data Sources for ASL Signbank
2.4.1 Signed Data Sources
ASL Signbank is full of entries headed by ID glosses. Those ID glosses identify signs that come from ASL video data from multiple sources. As described in Section 2.3, most of the early signs come from acquisition data (Chen Pichler et al. Reference Chen Pichler, Hochgesang, Lillo-Martin and Quadros2010; Hochgesang Reference Hochgesang, Berez-Kroeker, McDonnell, Koller and Collister2022b), which, of course, includes plenty of ASL signs used by ASL communities in general.
Many subsequent ASL signs come from my work as a documenter. Since 2010, I have worked on other projects involving the language use of ASL communities, which I collectively refer to as CARD. As I described in Occhino et al. (Reference Occhino, Fisher, Hill, Hochgesang, Shaw and Tamminga2021)Footnote 22 and our website,Footnote 23 CARD describes both the philosophy of the work (deaf-centric care of open-access ASL data) and the protocols to do the work. It also serves as a landing site for multiple projects created with CARD in mind, such as O5S5: Documenting the experiences of the ASL communities in the time of COVID-19 (Hochgesang Reference Hochgesang2021b), Motivated Look at Indicating Verbs in ASL (MoLo) (Hochgesang et al. Reference Hochgesang, Lepic, Dudis, Shaw and Villanueva2022), and Social Media ASL (SoMe ASL) (Hochgesang & Occhino Reference Hochgesang and Occhino2024). There are also CARD-friendly projects that refer to projects that may not have been created with CARD protocols in mind but are mostly aligned with the processing protocols (especially the use of ASL Signbank and SLAASh conventions with ELAN) such as the Philadelphia Signs Project (Fisher et al. Reference Fisher, Tamminga and Hochgesang2020). I also work with collaborators who have created their projects using CARD protocols and/or ASL Signbank, for example, some of my colleagues are examining the family of WHAT signs in ASL.Footnote 24 Finally, there are projects that existed before CARD was even conceptualized but we have inherited the datasets, for example, Sociolinguistic Variation of ASL (Lucas et al. Reference Lucas, Bayley and Valli2001), or are supporting current collaborations, for example, Black ASL (McCaskill et al. Reference McCaskill, Lucas, Bayley and Hill2011). ID glosses for any sign that appeared in the video data from these projects are added to ASL Signbank.
Even more data has come from my work as a professor in the linguistics department at Gallaudet where I have taught data-centric courses – phonology of ASL, Field Methods, and Linguistic Data Management. I’ve also trained doctoral students, faculty, and researchers in using ELAN and ASL Signbank. I collaborate with Emily Shaw in the Department of Interpretation and Translation for Translation Lab, in which interpreting students are trained in translator work using ELAN and CARD files.
People using ASL Signbank for annotation can make ID gloss suggestions and share them with me. People who use ASL Signbank can, of course, make recommendations for additional signs using the online feedback form on the website.Footnote 25 I get community suggestions in this way, even through social media such as Twitter (2012 – 23), Instagram, or Bluesky.
Finally, the actors I have filmed for the videos and photos posted on ASL Signbank with the teal background have often contributed their own signs – from schooling experiences, where they’ve lived, their work, their hobbies, their favorite slang. Next, we discuss their backgrounds a bit and the type of data we generated.
2.4.2 ASL Signbank Footage and Actors
The SLAASh teamFootnote 26 has filmed several sessions from 2016 through 2025 and is anticipated to keep on filming as long as variants are being added to ASL Signbank. We have created content using Canon DSLR or iPhone Pro cameras. The videos have been edited using iMovie and compressed with Compressor. The high-quality videos are saved via personal folders, and the compressed videos are available on the site. The most central keyframe is automatically generated as the photo on ASL Signbank when posted. We later create watermarked images through Keynote and save them via screenshot at the highest resolution possible to be saved internally, recompressing as smaller jpeg files for the website.
All the ASL Signbank actors to date (thirty-four at time of writing; Figure 2) consider ASL as their primary language and have used it daily for most if not all of their lives. This was the only requirement for ASL Signbank – that they consider ASL one of their primary languages and have used it most of their lives.
They all identifyFootnote 27 as deaf or a child of deaf adults (CODA). At the time of filming, the actors ranged in age from sixty-three to twenty-five (most were in their twenties or thirties at the time of filming). Twenty-one identify as female or woman, and thirteen identify as male. Among our actors are those who identify as White, Black, Afro-Latinx, Asian-American, and more. While it was not a requirement for filming with ASL Signbank, about twenty-five actors have one or more deaf members in their family who also use ASL. Others have stated that their families, although hearing, also use ASL to some degree. About half shared that they had some experience with a signing system like Signed Exact English (SEE). They also know other languages – signed, spoken and/or written – such as English, French Creole, Lengua de Señas Mexicana (LSM), Spanish, Vietnamese, Kenyan Sign Language (KSL), Brazilian Portuguese, and Danish. Most have been using ASL since birth or, as one participant said, “in my mom’s tummy :)” (about twenty-four). The rest of the actors shared that they acquired ASL from between the ages of two to three (three), five (one), eight (two), and college (two).Footnote 28 There’s a roughly equal mix of school experiences from fully residential to fully mainstreamed (inclusion or solo) or a mixture of the two. Our actors have lived in over thirty states across the United States and a few provinces in Canada, and among the most represented are the DC area (Washington, DC, Maryland and Virginia), New York, and California. Five actors share that they have lived in countries outside of the United States – Finland, Italy, and Kenya.
2.5 ASL Signbank as an Identification Guide
People often think of the dictionary as a reference to search when they want to learn the meaning of a word or the “standard” pronunciation, usage, and so on. This classic notion of a dictionary, such as the Oxford English Dictionary (OED),Footnote 29 is the monolingual version where there are definitions for each word provided in the same language. Words are organized by headwords (lemmas) and usually accompanied by usage information such as pronunciation guides, grammatical categories, and other notes regarding usage (e.g., slang, offensive). Monolingual dictionaries are rich resources about their own language use.
Dictionaries can be descriptions about how a linguistic community uses their language (Stokoe et al. Reference Stokoe, Casterline and Croneberg1965). While dictionaries may, although not always, be based on language use, they also often become tools in language standardization. I cannot count how many times I’ve seen “that word’s not in the dictionary!” while playing Boggle or Scrabble.
While there are bilingual dictionaries (translations of words in one language to another language, for example, English to Kiswahili), ASL Signbank does not provide definitions (translations to English are not definitions) in either mode. There are no written English or signed ASL definitions. I, along with cocreator Diane Lillo-Martin, prefer that ASL Signbank not be considered a dictionary, especially in the sense of standardization. We did not set out to create a resource for language learners – of which there is plenty, especially for ASL. Instead, our initial and ongoing intent is to support ongoing research of ASL. The information included in ASL Signbank could contribute to building monolingual ASL dictionaries. Some other signbanks have indeed been used for dictionary creation (Johnston Reference Johnston, Crasborn, Efthimiou and Hanke2008).
Instead, let me detail what I’d like users to imagine ASL Signbank as. I refer to it as a label maker (or storage, rather) of a kind that can be used to tag signs in videos. The appeal for me is, when using it with ELAN, ASL Signbank accompanies the glosses themselves, which are time-linked to the videos – the ASL usage itself. The text labels are just that – labels. They’re secondary pointing to the ASL signs themselves.
ASL Signbank is more like an identification guide than a dictionary. Think of those you see for identifying insects, trees, birds, and the like. Each of those identification guides is full of entries with additional information in each entry to help with identifying them. ASL Signbank is useful in that it can serve as a citation guide and as an open-access resource for making representation of ASL visual in sharing (such as presentations or published materials).
I’ve always found it odd that we rely so heavily on written English as our primary mode of representing the work about ASL research. Citing or linking to ASL Signbank allows us to return to the source material as recommended by data accessibility guidelines like the Austin Principles of Data Citation.Footnote 30 Such a practice is important for signed language linguistics, which has a history of relying solely on English glosses without any pictures or videos, although unsurprisingly so because of technological limitations and the lack of a conventional written system to represent ASL signs. Hodge and Crasborn (Reference Crasborn, Berez-Kroeker, McDonnell, Koller and Collister2022) also point out that the form-based nature of signbanks (describing signs by their articulatory or formational features) allows us to search for signs through their forms, much like Stokoe et al. (Reference Stokoe, Casterline and Croneberg1965) set out to do, rather than written translations into another language and another modality.
2.6 ASL Signbank and Its Name Sign
ASL Signbank has a name sign of its own and here I explain how it came to be. At a guest lecture for the National Association of the Deaf in 2017, I introduced ASL Signbank to the headquarters staff and demonstrated the name sign that was current then – a combination of SIGN and fingerspelling “bank.” It was what we used to record our end-of-session gifs after filming with an ASL Signbank actor (Figure 6).
SIGN and FS (bank).

The NAD office staff were not keen on having fingerspelling as part of the name sign so they offered their own version (Figure 7).
NAD suggestion for ASL Signbank name sign.
What the NAD staff suggested was another ASL version of the concept “to sign”Footnote 31 since they viewed the “sign” variant in Figure 5 as a more noun-y version referring to the general ability to sign or the modality itself. The NAD suggestion uses a variant that they perceived as more associated with the sense of using a word (or sign) itself and is often used to identify people who can sign fluently or are “closer to ASL communities” than others. They then chose a more depictive-like sign to represent “bank” in a way they perceived objects could be put in a repository, rather than the financial institutions they associated with FS(bank).
Afterward, when I shared this new name sign with yet other audiences, they seemed to like it for the artistry or novelty of this expression alone and for using it to describe ASL Signbank more like a process. But for using it as a name, there seemed to be a preference for a more reduced form as a name sign than a phrase. The name sign suggested by NAD was altered so that the first word (“to sign”) became a one-handed version (although the sign usually resists weak hand drop) and combined with a one-handed depicting sign that indicates a list.Footnote 32 This newer name sign, shown in Figure 8, can be reproduced as two-handed or just one-handed, ideal for plain reference.
Conrad Baer signing the name sign for ASL Signbank.
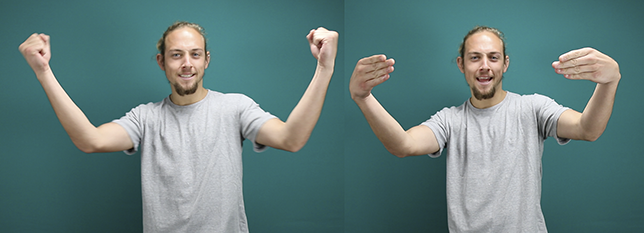
This name sign has the added accidental bonus of resembling the letters S (“s”) and B (“b”) in the manual alphabet used in ASL. It’s become a favorite for shooting the traditional gif at the end of each ASL Signbank filming session. Those gifs are shared online via social media as a way of sharing our work with the ASL (and research) communities. This ongoing conversation regarding the name sign illustrates the principle that signing communities should have authority over their terms of reference (Harris et al. Reference Harris, Holmes and Mertens2009). This process is unfortunately rare in practicing signed language research.
3 Why ASL Signbank Exists
There has been little descriptive work done for ASL or other signed languages. Much of the early research done in the 1960s through early 2000s were often done with a small group of signing consultants and often were White, Deaf “native” signers (Hochgesang et al. Reference Hochgesang, Lepic, Shaw and Wehrmeyer2023). And in sharing this research, often through traditional research products such as conference presentations, articles, or books, information about ASL is largely through English and a smattering of drawings or photos of ASL signs. In other words, the primary data – ASL usage – was largely invisible. This is mostly because of technological limitations. Prior to the 2000s, it was not easy to capture and share language use – either through audio or video recording. It also was rooted in academic traditions that valued “theoretical” work – explaining data in light of theoretical frameworks that claim how language itself works. It’s also often separated from language users or people themselves.
While descriptive linguistics has existed since the early 1900s, products were often dictionaries or reference grammars, which rarely linked or referred to the primary data itself (Himmelmann Reference Himmelmann, Gippert, Himmelmann and Mosel2006). In the later 1900s, along with technological advances, more disciplines working with language use wanted to highlight or directly include primary data – language documentation, corpus linguistics, sociolinguistics, language acquisition, and linguistic ethnography (Berez-Kroeker et al. Reference Berez-Kroeker, McDonnell, Koller and Collister2022). As outlined by Bird and Simons (Reference Bird and Simons2003), who cautioned against “digital detritus” (p. 562), working to share primary data involves several considerations to make it “portable,” transcendent over time and reusable across projects, platforms, and people. It takes work to maintain and ensure lasting digital data.
3.1 Writing or Textual Representation
Making words stay has been accomplished by writing, which, for a long time, has consisted of using some kind of writing implement to make marks on surfaces, from sticks on clay (cuneiform) to pen on paper. Linguists have listed over 7,000 languages (Hammarström et al. Reference Hammarström, Forkel, Haspelmath and Bank2024). And for those languages, there are about 200–300 orthographies or writing systems (Coulmas Reference Coulmas2002). I am using the Latin or Roman alphabet here to capture English to share all this information with the reader.
Writing is used by people for different purposes – to write lists for grocery shopping, letters to their loved ones, notes about what they’ve learned in class, texts filled with memes and books about something they’ve been working on for years (Crystal Reference Crystal2018; McCulloch Reference McCulloch2019). These writing systems and traditions reflect practices of sharing information that have evolved over time. They are good but imperfect systems for capturing meaning and intent (think about that paper where you had ideas but words wouldn’t come).Footnote 33
In the last century or so, we’ve turned to shiny boxes that create digital representations of text. Unicode is a universal standard format encoding characters for many writing systems and even emoji (Unicode Consortium 2024). What’s crucial about Unicode is that it encodes digital characters – what we use to type, search, or count – in consistent ways. “Unicode allows computers to reliably store, exchange and display textual material in nearly all of the writing systems of the world, both current and extinct” (McEnery & Hardie Reference McEnery and Hardie2011, pp. 3–4). Text on the computer needs to be searchable and for that to happen, it must consistently match form with reference, such as symbols we see/feel on the screen with a consistent reference.
Researchers also need ways to capture data in a format ideal for their work. Transcription refers to the act of representing information for the purpose of research analysis. Researchers using transcription can focus on specific kinds of language use or aspects. For the phonologist, they can use a technical written system known as a notation system to represent the forms of spoken or signed words such as the IPA (International Phonetic Association 1999) or Stokoe notation (Stokoe et al. Reference Stokoe, Casterline and Croneberg1965). The spoken language linguist representing a spoken English production of “tree” could represent it like using IPA /tri/, and the signed language linguist representing a signed ASL production of “tree” could represent it in Stokoe notation,Footnote 34 as shown in Figure 9.
ASL variant for “tree” and Stokoe notation of the signed production.

Notation systems are designed to represent what researchers think are important about the phonological form – signed, spoken, or felt. There are yet other transcription systems that have different analytical goals – to explore patterns in discourse, to represent meaningful components for morphosyntax, and so on. Outside of writing systems, people using languages themselves are probably not as invested in the systems themselves but may be interested in how researchers reflect their own experiences with language use through textual representation.
Consistency is important in the relationship between form and reference. What I mean by the relationship between form and reference is something like how “0” is associated with the digit meaning “zero” and the uppercase “O” is associated with the letter “o” in written English and other related languages that use the same orthography. Humans are good at understanding when slight changes in the form mean the same or different reference, machines less so. For research, making sure the connection between form and reference is stable is vital because these symbols are used to record data in research that are then used in analyses and generalization and then shared in publication and persist in foundational assumptions. Some researchers have discussed the methodological importance of thinking about how their chosen representational systems represent information (and what they leave out) along with design principles (Ochs Reference Ochs1979; Edwards Reference Edwards, Edwards and Lampert1993; Bucholtz Reference Bucholtz2000; Hochgesang Reference Hochgesang2014; Murphy Reference Murphy2021).
3.2 Why Transcribe or Annotate?
Many reading this Element will connect with the experience of writing notes in the margins of their books. It’s such an established practice that we even have digital applications that allow us to continue doing so. This is perhaps the more traditional view of annotation for many people but it’s the same process – adding additional information to the original text or source.
A more relevant example lies in our social media – many of us upload our videos or photos to a sharing platform like YouTube or Instagram. When we do so, the platform usually automatically adds metadata like upload date, time of media, owner handle, and URL. And the platform allows the uploader to add more information like title, captions, alt text, and hashtags. This is also a form of annotation akin to cataloging information like we would see with archives or libraries. This is annotation about the media themselves. It helps us search for them and even organize them like in YouTube playlists or Instagram collections.
Much of signed language research consisted of watching people sign either in real time or on video and entering notes about those observations on paper or in some separate digital document. This results in separation of the original (primary) act from its representation. This persists throughout analysis and dissemination. From a representational perspective, the chosen written conventions then serve as the primary representation of the signed data. From an analytic perspective, this can mean that the experiences with the written conventions can bleed over to signed language, for example, the analysis of ASL pronouns can be skewed when representing them with written pronouns from English (Hochgesang Reference Hochgesang, Berez-Kroeker, McDonnell, Koller and Collister2022b).
Even though I am not enthusiastic about glosses alone as a representation device, they have persisted as a best practice in language documentation and corpora as a way of tagging the signed data in technical software like ELAN (Crasborn & Sloetjes Reference Crasborn, Sloetjes, Crasborn, Efthimiou and Hanke2008). And when used with primary data, the issues of the representational problems outlined throughout the Element are reduced (although not fully gone). This tagging of primary data with software is known as annotation.
3.2.1 Glossing or, Rather, ID Glossing
Earlier I introduced glossing as the practice of using text from written systems to represent uttered forms. It can be used for any mode – spoken, written, or tactile. In the absence of a conventionalized orthography, signed languages have often relied on glossing as the main, if not sole, representational system in research and sharing (Hochgesang Reference Hochgesang, Berez-Kroeker, McDonnell, Koller and Collister2022b). Since we need to be consistent about our representation to make our video data machine-readable (searchable and shareable), signed language linguists working with documentation and corpora have started using “identifying glosses” (or ID glosses) (Johnston Reference Johnston2010), which makes signs searchable. Recall that video data is not inherently searchable (Section 2.1). If we want to find similar instances in the video data, it is up to us to code the data consistently to search for them. ID glosses are not intended to be translations but ways of finding signs.
ID glosses are used to identify “lexical signs,” which are relatively conventional stable forms that a user may expect to find in a dictionary. Signs that are highly contextual and require immediate context are identified using unique codes. Some examples are pointing, fingerspelling, sign names, and depicting signs (Section 4.2). We will define what ID glosses mean and then discuss readability principles that influence how we select ID glosses.
3.2.2 ID Glosses Defined for ASL Signbank
We use a headword or lemma as an ID gloss in ASL Signbank. A headword is a basic and unmarked form. For example, the root form of the English verb “see” has the following inflected forms: “sees,” “saw,” “seen,” and “seeing.” “See” is considered the headword in this set of related terms. Similarly, the headwords in English will be used as sources for ID glosses in ASL Signbank. That is, the ASL sign that can be translated to “see” will be glossed as SEE.
Also, the ID glosses will be treated as lemmata (sets of words related to the same basic forms). So, while the ID glosses will draw upon basic forms in English, the ID gloss itself is also a headword. Signs that are derived from a basic form and morphologically modified will still be glossed with the same ID gloss. For example, if the sign SEE is modified for temporal aspect (in which the form is repeated with additional nonmanual signals), it still receives the same ID gloss – SEE. Such modification can be captured by a separate pass of annotations in the transcript (i.e., on further analysis of the data, the annotator can add tags specifically for any morphological modification).
The physical (or phonological) forms of signs will be used to guide the annotator’s decisions in choosing what English words will serve as ID glosses. This means the annotator sometimes ignores what spoken-language-influenced word (in this case, English) is produced on the mouth along with the manual articulation of the sign. Basically, to enhance searchability, the same form gets the same English word regardless (to a degree) of the contextual meaning.
3.3 Design or Readability Principles to Consider
When we represent something, it isn’t enough to consider the form of the representation but how it is designed or formatted. As you read this page, you are likely going from top to bottom and left to right as you read. You may be on the watch for specific formatting conventions that highlight certain types of information – font size, numbering, or small text at the bottom of a page. Like any human interaction, certain aspects of formatting are associated with specific meaning. Text in smaller font on the bottom of the page as in footnotes is considered to be less significant and could be safely ignored. This is why there are graphic designers,Footnote 35 artists, editors, and people who think about design as full-time jobs.Footnote 36
For my dissertation, I considered theoretical choices and design principles of different notation systems while representing handshapes of signs in a young child acquiring ASL. I discussed certain design principles I considered relevant for the act of representing form for research or transcription – specificity, category design, transparency, economy, conventionality, and familiarity (Hochgesang Reference Hochgesang2014). Hodge and Crasborn (Reference Crasborn, Berez-Kroeker, McDonnell, Koller and Collister2022) cite the following as “key principles that define good annotation practices: consistency, transparency, comparability and vitality” (46). Transcription is highly subjective, no matter how conventionalized a system is. Linguists have talked about the theoretical consequences of their choices for as long as they’ve had to represent data (Ochs Reference Ochs1979; Edwards Reference Edwards, Edwards and Lampert1993; Roberts Reference Roberts1997; McEnery et al. Reference McCulloch1997; Bucholtz Reference Bucholtz2000; Hochgesang Reference Hochgesang2014; Murphy Reference Murphy2021; Hodge & Crasborn Reference Crasborn, Berez-Kroeker, McDonnell, Koller and Collister2022). Such considerations have stayed with me as I maintain ASL Signbank. Here, I’ll focus on a couple of broad concerns – machine-readability and human-readability – because they are the most relevant for anyone who wants to use ASL Signbank to annotate their video data.
3.3.1 Machine-Readability
Machine-readability, also known as computational tractability, simply put, means to render items in a way that can be “read” by the computers or in a way that allows users to search for them. This is essential if we want to render (ASL) videos searchable. Machine-readability occurs when the same data are represented in the same way (Edwards Reference Edwards, Schiffrin, Tannen and Hamilton2003). With ASL Signbank (and other signbanks), machine-readability is accomplished through assigning signs with unique glosses or ID glosses. This conventional pairing of data and labels (also known as “tags”) allows for searching, counting, and sorting. In other words, the computer can be asked to find all instances of the same sign using the “find” feature and their designated ID gloss.
Again, ID glosses are not direct representations of the signs themselves but textual labels or tags that allow us to find their entries again in the transcripts or in a linked database like ASL Signbank. For example, the sign produced by the signer in Figure 10 can be labeled by “now,” “presently, or “currently.”
ASL sign labeled as NOW in ASL Signbank.

As stated in Section 2.1, there are multiple possibilities for glosses. This can lead to inconsistency in glosses for the same sign, which is problematic and should be avoided since this will negatively impact machine-readability (i.e., the computer will not be able to find all instances of the same sign when they are glossed differently). If we don’t have a system for linking labels with signs, glosses can then conjure other (unrelated) sign forms. The same textual label needs to be used for the same sign throughout the transcripts for identification. In addition to using conventionalized ID glosses to make the data machine-readable, the annotator needs to use symbols traditionally targeted by text search features, which are often symbols themselves, rather than formatting such as bolding or italicization.
3.3.2 Human-Readability
In addition to machine-readability, in which the same information is encoded in the same way, we also should consider “human-readability,” which has to do with making the data easier to process or scan from a human perspective. This is where formatting choices come into play, like bold or italicized font and use of punctuation (e.g., parenthetical marks). Specially formatted textual items signify aspects, such as bold for emphasis or parentheses () for side comments. Even when working with machine-readable text, human-readability is still important because human annotators are encoding the data and humans are scanning the transcripts along with video data.
To that end, the annotations (here, the ID glosses) should be relatively easy for the annotator to retrieve while annotating. And when done, the annotated transcript should be readable.
When deciding upon ID glosses, human-readability is enhanced by choosing everyday English words that are commonly used for the same concept expressed in signs. For example, the ASL sign for “arm” could be coded as B-5 because of the handshapes in the sign or it could be coded as “@#%$” as a randomly selected series of symbols used to represent the sign; or it could be coded as “a long body part that protrudes from the torso,” which we could argue is an acceptable translation. But those codes are hard to remember and, for the second code “@#%$,” arbitrary (given no obvious link between the sign and label), or for the third code “a long body part …, ” lengthy. Instead, it is arguably more effective to use the English translation commonly used. Specifically, here that is the word “arm,” as gloss for ARM. Although that is where we need to be careful about letting biases from English bleed through to the glosses, and makes it even more vital to remain linked to the primary data.
3.4 ELAN: A Quick Introduction
I’d be remiss if I didn’t provide a brief introduction to the software that ASL Signbank is tied to. My annotation experience is entirely bound to the experience of using ELANFootnote 37 (Crasborn & Sloetjes Reference Crasborn, Sloetjes, Crasborn, Efthimiou and Hanke2008) and I’ve been using it since 2006. It’s precisely that process that made me realize the importance of machine-readable textual labels and wanting a tool like ASL Signbank.
ELAN is a freely available annotation tool that links videos to time-aligned transcripts. It was first developed in the early 2000s by researchers working at the Max Planck Institute for Psycholinguistics. It is widely used by signed language researchers and those working with spoken languages, gesture, or multimodal language use. It is not the only annotation program (Hodge & Crasborn Reference Crasborn, Berez-Kroeker, McDonnell, Koller and Collister2022), but it is widely used because it is freely available, continuously updated, well-supported, documented, and portable.
I provide a brief example of how ELAN is used with ASL Signbank and the SLAASh annotation conventions in Section 6. Johnston (Reference Johnston2014) and Börstell (Reference Börstell, Fenlon and Hochgesang2022) provide excellent and comprehensive discussions of how to use and search ELAN annotation files (.eafs) and there is also a brief guide in Crasborn (Reference Crasborn, Berez-Kroeker, McDonnell, Koller and Collister2022). They highlight processes that are ideal for corpus research such as frequency and concordance. We also have an external controlled vocabulary (ECV) set up for ASL Signbank.Footnote 38 An ECV is a list of ID glosses directly linked to ASL Signbank that can directly show up in ELAN for annotation of videos.
4 Lemmatization
As discussed in Section 2.2, a lexical database is structured to reflect a theory of how languages work. For a signbank, clearly the organization will center signs, but which ones? Deciding all this for the act of transcription or annotation for research is a complex process that cannot be removed from theory (Ochs Reference Ochs1979) nor use. When I first started annotating signs in ELAN, I realized that I needed conventionalized labels along with a resource to manage that across project(s) members and over time. I saw that lexical resources like signbanks were ideal for that goal. Lemmatization is the process to determine headwords of entries and further structure the rest of the database.
4.1 Adopting Lemmas
Contemporary corpora are collections of machine-readable texts that have been tokenized, labeled, and translated as well as continually enriched via additional annotation passes. Such work of rendering language usage machine-readable “should not only be informed by linguistic theory but also that tags appended to these annotations should be used consistently and systematically” (Johnston Reference Johnston, Crasborn, Efthimiou and Hanke2008, p. 82), hence lemmatization. ASL Signbank treats ID glosses as lemmas. This requires instances of “the same sign” to be annotated with the same ID gloss. The benefit, in practical terms, is that using standard glosses across annotation files facilitates machine-readability. As discussed in Section 3.2, a lemma is a unit of organization where inflected forms are grouped together as a single entry. Fenlon et al. (Reference Fenlon, Cormier and Schembri2015) working on the BSL corpus and signbank developed a set of lemmatization principles they recommend as a guide to others doing similar work along with regular discussions with the relevant signing communities.
When we undertook the work of developing ASL Signbank in 2015, we adopted the practice of lemmatization for the practical reason of using the open-access software already available through Global Signbank and to align with current practices valued by signed corpus researchers (Cormier et al. Reference Cormier, Crasborn, Bank, Efthimiou, Fotinea and Hanke2016; Fenlon & Hochgesang Reference Hochgesang2022). Also, as one of the initial creators of ASL Signbank, I worked closely with Onno Crasborn to build ASL Signbank. Since he was maintaining the NGT Signbank at that time and we wanted to use the same tech developers, it was easiest to inherit mostly the same structure (lemmas and all). It’s also a meaningful step in either making comparable datasets for typologists or those interested in crosslinguistic studies, for example, Börstell et al. (Reference Börstell, Schembri and Crasborn2024). This desire to collaborate in a way to share data can also be seen in the shared lemmas and phonological coding with ASL-LEX. Schembri (Reference Schembri2010) noted that the BSL group had to do their lemmatization work “on the fly” (p. 138), as did we. Both of our groups did not have predetermined word lists beforehand. In this aspect, we both avoided the “lemma dilemma” (Brien & Turner Reference Brien, Turner, Ahlgren, Bergman and Brennan1994) of relying on spoken languages to shape our work.Footnote 39 This meant we had to continually feed the signbanks as we came across unique items in the video data we were annotating (Figure 11).
Diagram of adding to ASL Signbank (designed by Oswald V. Cameron).
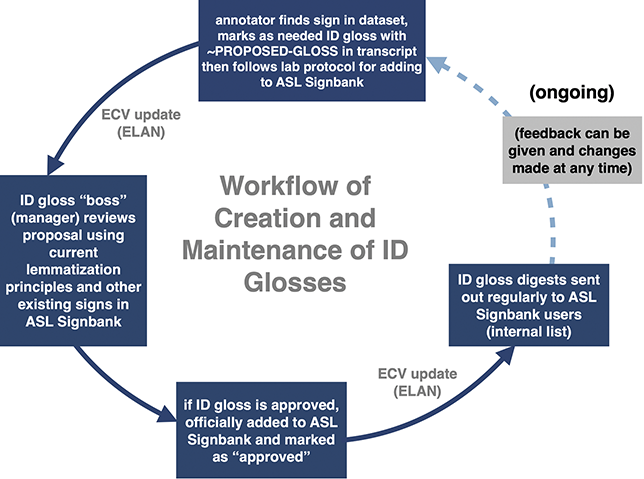
Figure 11 Long description
The center has text: Workflow of creation and maintenance of I D glosses, in gray and bold. Boxes in blue with white text are placed at circles around the centered text. Arrows indicate direction (leftward). First box annotator finds sign in dataset, marks as needed ID gloss with PROPOSED-GLOSS in transcript then follows lab protocol for adding to A S L Signbank, text by arrow E C V update (ELAN), second box I D gloss boss (manager) reviews proposal using current lemmatization principles and other existing signs in ASL Signbank, third box if I D gloss is approved, officially added to A S L Signbank and marked as approved, text by arrow E C V update (ELAN), fourth box I D gloss digests sent out regularly to A S L Signbank users (internal list), fifth and last box in gray (feedback can be given and changes made at any time), text by arrow ongoing.
Fortunately, Fenlon et al. (Reference Fenlon, Cormier and Schembri2015) published their lemmatization principles the same year we started work on ASL Signbank and we were able to use their work as a guide for ours. They refer to the process of lemmatization as the “grouping together of phonetic, phonological and morphological variants and distinguishing these from lexical variants” (p. 202). They also distinguish between “sign modification” and “sign formation,” which align with “inflectional” and “derivational” processes which they discuss as contentious among signed language researchers (e.g., Liddell (Reference Liddell2003) suggests that ASL has no inflectional processes).
As discussed in Section 2.1, the “lexicon” has been problematized by usage-based sign linguists (Wilkinson et al. Reference Wilkinson, Lepic, Hou, Janzen and Shaffer2023). Like they point out, words are not used alone (like “structuralist building blocks”) but in interaction with one another such as NOT in WHY NOT and WHY-NOT and NOT UNDERSTAND (Wilkinson Reference Wilkinson2016), pointing in Japanese Sign Language in one man’s translation over time (Tomita Reference Tomita2021), LOOK (Hou Reference Hou2022), ASL [N+N] compounds (Lepic Reference Lepic2023), idioms such as KEEP-QUIET HARD, and other constructionsFootnote 40 such as [THINK-X] (Lepic Reference Lepic2025).Footnote 41 This calls into question whether a true division can be made between “given” and “derived” meanings (Johnston and Schembri Reference Johnston and Schembri1999). As Wilkinson et al. (Reference Wilkinson, Lepic, Hou, Janzen and Shaffer2023) say: “These categories are often assumed as objective realities, but they are constructs that are imposed by linguists, and may or may not align with the category judgments that individual language users may make” (358). These words and collocations or (multi-word) constructionsFootnote 42 are where we can observe language use at work, in examining their production and reuse in interaction.
I also subscribe to the idea that usage-based views of language use and corpus resources are ideal for this kind of work if we build them accordingly. Johnston (Reference Johnston2010) states that lemmatization is essential for representation of signs for research. I do agree we need to be mindful of theory and how it shapes our work, since being “framework-free” is practically impossible. That said, I am skeptical of how a database divorced from interaction can equate, or be representative of, a lexicon as claimed by some (Johnston Reference Johnston2010; Fenlon et al. Reference Fenlon, Cormier and Schembri2015). In any case, I’m more interested in examination of connecting primary data of language use in interaction since it’s in the embodied interaction where interesting connections lie. Tagged datasets using conventionalized textual labels from databases allow us access to interactions themselves. My primary goal is to be able to represent signs in video but be informed by current theories and practices as well as mindful of my own biases as an ASL signer/linguist/annotator.
4.2 Lemmatization Principles for ASL Signbank
Using lemmatization principles outlined in Fenlon et al. (Reference Fenlon, Cormier and Schembri2015), ASL Signbank has a lemma ID gloss for each unique unmodified sign and an annotation ID gloss which will be slightly different if there are more than one sign in that lemma group. We generally follow the same principles as laid out in Fenlon et al. (Reference Fenlon, Cormier and Schembri2015) to determine lemmas. The lemmatization principles are simple at first glance (Figure 12).
Visualization of lemmatization for ASL Signbank.

Figure 12 Long description
The top group labels different signs (different form and meaning), different lemmas with two images of ASL signs with glosses TYPE and WORD. Latina woman with black curly hair, red glasses, and blue top signing type; Black man with short black hair and goatee in gray polo shirt signing word. On the right is a box with a different gloss text; the center group label phonological variants (similar form, similar meaning), same lemma with two images of ASL signs with glosses SOONns and SOONch. Same white woman with long blonde hair pulled in a side ponytail and wearing a dark gray shirt signing in A S L. On the right is a box with an add gloss-tag text; bottom group label different signs (different form, similiar meaning), different lemmas with two images of ASL signs with glosses SOONns and TEMPORARY. Same white woman with long blonde hair pulled in side ponlytail and wearing a dark gray shirt signing in ASL. On the right is a box with a different English gloss; mark as related text.
We refer to differences in form and meaning to decide whether sign lemmas are separate. That is, if the meaning and the form of two entries are different, they are different lemmas and get different ID glosses. If the meaning is similar and there are one or two phonological differences, they are under the same lemma and get the same annotation ID glosses, with the difference indicated by lowercase tags that identify the particular formational aspect responsible. There are different placements, handshapes, path movements, handedness, contact, and other formational features characterizing each sign (Occhino & Hochgesang, Reference Occhino and Hochgesangforthcoming). As much as possible, lemmas in ASL Signbank match the lemmas of ASL-LEX (Caselli et al. Reference Caselli, Sehyr, Cohen-Goldberg and Emmorey2016) to facilitate shared coding and useability of both datasets if needed for research.
4.2.1 Signs with Different Forms and Meanings = Different Lemmas
In short, ASL signs with different phonological forms and meanings are deemed different lemmas and accordingly get unique glosses. For example, the ASL signs for “give” and “believe” (Figure 13) are clearly different forms with distinct meaning. One is two-handed, whereas the other is one-handed. They have different placements, path movements, and handshapes along with patterns of contact.
Two separate ASL signs treated as lemmas “give” and “believe” with their ID glosses.

Figure 13 Long description
White text boxes with black text show glosses for GIVE and BELIEVE in the images themselves. The top image has a white man with short blond hair, glassees and a gray top signing give in A S L; the bottom image has a white woman with blonde hair pulled back and a gray tank signing believe in A S L.
Different lemmas are also generated through sign formation processes. For example, the verb TEACH and the noun TEACHER, which is derived from TEACH through the addition of PERSONb. They fall under separate lemmas. Similarly, signs like WANT and DON’T-WANT fall under separate lemmas.
4.2.2 Signs Modified but Roughly Same Root Meaning = Same Lemmas
As Fenlon et al. (Reference Fenlon, Cormier and Schembri2015) recommend, we group together productions that share meaning but may slightly differ in phonological form under the same lemma because of sign modification processes such as aspect, directionality, and intensification. We can repetitively sign “give” from Figure 14 with different kinds of paths and repetition to indicate different kinds of aspect such as “continuously” or “from time to time” as well as change its ending point to indicate different referents, even more than one.
Different productions of “give” because of sign modification.

Figure 14 Long description
The signer is a white woman with medium-length brown hair, blue glasses in a black top with tattoos showing on arms. She's standing in front of a teal background. The top 2 images are single images. The bottom is a series of 5 combined into 1, with most of the right opaque and the last on the left fully shown.
Any sign signed with modification falls under the same lemma and would be labeled with the same annotation ID gloss.
4.2.3 Signs with Slightly Different Forms and Same Meanings = Phonological Variants of Same Lemma
On the other hand, signs with stable and mostly similar forms and meaning are considered phonological variants of the same lemma. In Figure 15, two forms for “believe” are similar but clearly different in one formational aspect, such as the initial handshape for the dominant hand.
Phonological variants of the same lemma BELIEVEnoix and BELIEVEix.

Figure 15 Long description
The top image has a Black man with short black dreadlocks and a gray top signing believe in A S L; the bottom image has a white woman with blonde hair pulled back and a gray tank signing believe in A S L - the variant where the extended index finger first contacts the forehead then changes to full hand as it moves down to contact weak hand.
Their meaning, however, is the same.Footnote 43 We then treat them as phonological variants linked to the same lemmaFootnote 44 but with unique annotation ID glosses (marked by the lowercase tags, that is, “noix” and “ix”) to enable searching for them in annotated datasets.
Tagging this phonological variation difference with lowercase text is a departure from the BSL lemmatization principles and a reflection of my interest in phonetics and language use. Phonological variants of the same lemma are also marked as “variants” in “sign relations.”Footnote 45 Note that productions are considered phonological variants when these variants are conventionalized among signers in the ASL communities. If you ask a signer the difference between the two BELIEVE variants mentioned in this section earlier, they’ll likely tell you that they tend to use one variant but have seen others.
Note that using a stable phonological variant (e.g., BELIEVEix) is somewhat different from variability that you will see with any word in everyday language use because of phonological processes or variability in bodies (Occhino & Hochgesang, Reference Occhino and Hochgesangforthcoming). My favorite example is the first-person singular pronoun in ASL for which the citation form is shown in Figure 16.
IX_1.

But we very rarely see that same form shown in Figure 16 in everyday language as can be observed in the video I compiled from the O5S5 ASL project. In Figure 17, I include two instances for each signer taken from this video compilationFootnote 46 to show how pervasive the pointing to self can vary even across the same person.
The first-person singular pronoun produced by ASL users in O5S5 ASL.Footnote 47

Figure 17 Long description
There are two pictures per signer, with various appearances and backgrounds. Different signers sign differently - with different placements, handshapes, and even sometimes two-handed (those are circled in white).
Instead, we see variation in handshape (especially with the thumb being extended), in location (especially to the side of the chest), and in path movement (usually reduced). These varied productions still get labeled with the same annotation ID gloss – IX_1 – to enable searching for them in the dataset. This is what is meant by labeling the same instances of a type in order to make them machine-readable or searchable. If any phonetic variability persists and seems to lead to a new construction, it could then be labeled with a new ID gloss in ASL Signbank.
Annotators are expected to use the labels that correspond to phonological productions within acceptable ranges still associated with the reference forms in the ASL Signbank videos and photos in the entries. For example, one could sign FAMOUS slowly or quickly, smaller or larger, softly or tensely, and so on, referred to as “phonetic embellishment” in Fenlon et al. (Reference Fenlon, Cormier and Schembri2015). These kinds of changes are usually more for “effect,” or prosodic changes, due to the environment (audience is further away, closer; signing event is formal or informal, etc.). All these productions are labeled with the same ID gloss. We assume that people using ASL Signbank will report variants they consider to be phonologically different enough to warrant its own ID gloss label – either as a phonological variant within the same lemma or as a separate lemma but related somehow (Section 5.10).
4.2.4 Signs with Different Forms but Similar Meanings = Different Lemmas, Marked as Synonyms
Signs that have clearly distinct phonological forms but related meanings are considered different lemmas but marked as synonyms in “related signs” (Section 5.10). The signs in Figure 18 are examples of ASL synonyms under different lemmas.
ASL signs for “speechless” and “acquiesce” with their ID glosses.

Figure 18 Long description
The top image has a white woman with medium-length brown hair, blue glasses, and a black top revealing tattoos on arms, signing speechless in A S L; the bottom image has a Black man with short black hair and a goatee wearing a gray polo shirt, signing acquiesce in A S L.
The signs for “speechless” and “acquiesce” receive unique ID glosses but are marked as “related” as synonyms in ASL Signbank.
4.2.5 Lemmatization Principles in Practice
In practice, this adherence to lemmatization requires continual discussion among researchers and members of ASL communities. One such discussion regards deciding the boundaries of variation. For instance, the ASL sign for “equal” (Figure 19) can have a single set of movements (bent hands move together to touch) or repeated sets.
ASL sign for “equal.”

Productions of ASL “equal” forms will, of course, vary in form based on use, intended meaning, and individual style. Are they of a single lemma with one of the forms a modification of the lemma? Or are they two separate lemmas with conventionalized separate meanings? Is this distinction stable across the ASL communities? We have tentatively left this example as a single lemma with one annotation ID gloss. We will revisit it once we have a sufficient number of examples in the corpora that use ASL Signbank.
On the other hand, the ASL signs for “show” and “example” are produced similarly but one (“show”) has one set of movements and the other (“example”) has shorter and repeated movements (Figure 20). With this conventionalized slightly different phonological form and different meanings in usage (e.g., the form for “show” is often directed while “example” isn’t), they are separate lemmas.

These lemmatization decisions are made both by observing how these signs behave in the dataset and how they are understood by the researchers. Regular lab meetings are held to discuss sign lemmas. Frequently the discussion involves reviewing multiple instances of related forms and meanings and then producing them further in various modifications.
4.2.6 Lemmatization Principles in Practice
For signs that may not be as lexically fixed but are specific types of signs, we use regular codes to annotate them, for example, DS for “depicting sign,” NS for “name sign,” and IX for “index” or pointing sign. Then, specific referents are added to related tiers in the annotation files (as explained in Section 6.3.1). It is often challenging to decide which of those types are not “conventional” enough to warrant their own ID gloss. In general, I defer to this “rule of thumb” – if it can be represented by an ID gloss of some type, I leave it alone as is and allow research projects to decide what works for them. If I get a request to add something, I will if it’s aligned with the principles outlined here. The actual usage of each sign in the communities informs ASL Signbank, from the most basic questions (which signs to include) to refinement of the descriptive linguistic features. As our datasets grow, our ability to address these kinds of questions will grow. Lemmatization of ASL signs has never been done on a scale like this before – one that has been continually refreshed by actual usage data.
4.3 ID Glosses: How We Choose English Textual Labels
Although we’re trying to reduce the effect of English on our representation of signed data, we’re still using it as our source for textual labels. For each sign, the most unmarked and common English translation is selected as the ID gloss. This helps annotators retrieve and scan them in the transcripts. Often, the lemma ID and annotation ID gloss will be the same. If there are phonological variants, the annotation ID gloss will change somewhat, while the lemma ID remains the same.
The following signs are stable phonological variants for the same concept “apple.” They are assigned the same lemma ID gloss APPLEFootnote 48 but are appended with lowercase tags in their annotation ID gloss to identify the phonological form of the signs themselves – APPLEx, APPLEa, and APPLEck. That is, each form receives the lemma gloss APPLE because they share the same meaning, but each gets a different tag appended to the gloss for their slightly different phonological forms (“x” for the handshape, “a” for the handshape again; “ck” indicates the location of where the hand is located – here, the cheek). This will also serve as a quick way of observing how many variants exist in the language.
Note that variants often differ by region or other socially defined group distinctions (age, race and ethnicity, and gender identity). For example, in contrast, it seems that SWEETCAKE is mostly only used by signers from Philadelphia, whereas a signer from elsewhere might sign CAKEdown. In contrast, an individual signer may use multiple variants depending on the social situation, while others may use only a single variant in their own signing. One example that I have observed is LANGUAGEl and LANGUAGEf, where some individuals will use both signs in the same video. Determining whether they’re of the same lemma in cases like these can be tricky. It may be considered so for some groups, and yet others, they are not. This is precisely why I am not comfortable with the claim that a lexical database or signbank can represent “the lexicon” but am more comfortable with using it as a machine-readable annotation tool (i.e., label maker/holder) of signs to further observe and describe language use of the signing communities.
Arbitrarily chosen numbers or alphabetic symbols as used by other teams are avoided as tags in our project because these are more difficult for the transcriber (or analyst) to remember. As discussed in Section 3.3, a key design consideration is human-readability. Tags that refer to phonological form are preferred because they are easier to retrieve (or recall) when annotating and scan when reviewing the annotated data.
Sometimes there are ASL signs that could be labeled by the same English translation such as these signs – PLANT, HOUSEPLANT, PUT-IN, which could all be fairly labeled as PLANT but are different forms and/or mean different things in ASL, thus they get unique English text labels as ID glosses. I take care in these situations to use a different English textual label and often can use English synonyms for different related concepts in ASL as well. But as I described in the beginning, I also use choosing ID glosses as an opportunity to weirdify the labels to signify the act of glossing is not ASL itself. I cannot emphasize this enough. ID glosses are NOT signs. They are textual labels to allow us to access the original signed forms. English text cannot fully represent ASL signs but they can facilitate searches for them. One consistent practice I have done to make this clear throughout ASL Signbank is to weirdify the glosses themselves.
For example, English has just the one word “picnic” for that concept. ASL Signbank lists eight ASL variantsFootnote 49 related to “picnic” in meaning but with different forms. Lowercase tags cannot be used here since they’re meant to distinguish between phonological variants of the same lemma. Instead, uppercase text with some kind of referent to form or meaning is used, for example, PICNIC-CLAP or PICNIC-SAUSAGE. These are not references to clapping or eating sausage during picnics but something about their form is reminiscent of those concepts in English. We also have the challenge caused by signs that are ASL synonyms (as linked in “related signs” (Section 5.10)), meaning they are different words but would receive the same English translation. Sometimes they read a bit strangely from an English textual perspective – they may have uppercase text with lowercase text (CUTEnoth) or they may have words that seem like English but don’t perfectly match the meaning (PICNIC-CHEST3) (Section 5.3.1 has more about tags).
When signs have the same form but different meanings (homonyms), we provide them with different English glosses but mark them as homonyms in “related signs” (Section 5.10). For example, SOMETHING and ALWAYS are homonymsFootnote 50 in ASL.
Sometimes there are homonyms in English but they are distinct signs (different forms) in ASL such as “right” and the earlier example with “plant.” In English, “right” is used to refer to multiple concepts. In ASL, the signs to express those concepts are different in form – LEGAL-RIGHT, RIGHT, and RIGHT-HAND; therefore they will receive different ID glosses even if they can share the same written translation. Sometimes it is difficult to find a different English translation to use as a separate gloss. Since it is difficult to label them uniquely, we will use meaning in the multiple words separated by hyphens in the glosses themselves.
When new entries are added to ASL Signbank, a list of possible English words that come to mind is added to the translation equivalents field. This field is used to list possible translations or keywords to help searchability (Section 5.4). Thanks to Unicode, even emojis can be added to help with searching. Users are encouraged to share their preferred search terms with us to improve searchability. They can also be used to find ID glosses during the annotation process in ELAN files.
ASL Signbank contains annotation ID glosses for a few different types of signs, including DS (depicting sign), FS (fingerspelling), POSS (possessive), NS (name sign), IX (index), and NUM (number). They can be searched for by entering “annotation convention” in the “translation” search box. We do not provide specific labels for certain constructions that could be categorized as any of these types here unless requested. This is not a theoretical statement on saying they are not lexical or linguistically significant but a reduction of labor on our part. There are some highly conventionalized types that have been added directly such as name signs like OBAMA or HERSEY-SCHOOLFootnote 51 and frequent collocations such as SIGN-LANGUAGE, WHY-NOT, and even including some that are fingerspelled like BACK-TO. To add a single entry to ASL Signbank takes several minutesFootnote 52 – even for the experienced annotator – because of the work it takes to create the videos and photos (often both the draft version and the professional recreated ones) and to determine the appropriate entry information for each (e.g., grammatical category, usage notes). This reflects heeding usage patterns in ASL.
4.4 Workflow of Creation and Maintenance of ID Glosses
The workflow of creating and maintaining ID glosses has been detailed in Hochgesang (Reference Hochgesang, Berez-Kroeker, McDonnell, Koller and Collister2022b). In short, the maintenance of the ID glosses is under the supervision of one person, currently me. Sometimes annotators will come across a sign not yet represented in ASL Signbank and need to suggest it be added.
All the annotators working with me on research projects that use ASL Signbank are required to follow a specific protocol for when the sign they need to annotate is not in the database. After ensuring that they have exhausted all possibilities by searching translation equivalents on ASL Signbank, they then draft a temporary ID gloss using their understanding of ASL Signbank lemmatization principles. When following preferred annotation conventions, they prefix their suggestion with ~, for example, ~STAR-TREK (although they can use ~NEED-ID-GLOSS,Footnote 53 already listed in ASL Signbank). While doing this, annotators will break free from the ECV. Since the eafs are directly linked to the ASL Signbank ECV list, the annotators need to force the annotation field to escape the list to enter new entries. They can also create this annotation on another field and drag it to the ID gloss tier while holding down the “option” key.Footnote 54 Researchers who choose to use their own labels can also use this method to break free from the ASL Signbank ID glosses.
Annotators then take a video of themselves producing the sign and share it with me. Or if they have edit access, they click “proposed new sign” in ASL Signbank (under “publication status”) and add the tag “proposed new ID gloss needs review.”
I review the suggestions and ensure that the additions are not duplicates of already existing signs and are consistent with existing conventions. The sign is then marked as approved and tagged to be refilmed. We then produce professional filmed signs (every few months or, even, years) that are later published in ASL Signbank. Changes to ASL Signbank (additions or changes of ID glosses) are tracked in ID gloss digests that are internally shared. Connecting to ASL Signbank via ECV ensures access to the latest ID glosses.Footnote 55 This work is ongoing as we come across unique signs in the video datasets and receive suggestions from members of ASL communities.
5 Walking Through an Entry
ASL Signbank is structured to show different views structured around signs and their ID glosses along with formational and usage information (Figure 21).
Screenshots of different views of ASL SignbankFootnote 56 – (a) home page, (b) all signs, (c) search, and a single entry, (d) public, and (e) registered.
home page,
Figure 21a Long description
The menu of different options directly below - Home, About, Sign, Feedback, Analysis, with arrows pointing down to indicate they're collapsible. Search boxes directly below next to Profile and Logout (Julie Hochgesang). Welcome text in bold above some hyperlinked text and a logo A S L Signbank on a teal background with outline of hands showing s and b. Full text available: https://aslsignbank.com/.
all signs,
Figure 21b Long description
Same banners at top with A S L Signbank info on teal background, as well as search options with a menu bar. The signs are shown in a spreadsheet view with a series of images on the far left, then I D glosses, translation equivalents or keywords, phonological information like handedness and location, and tags such as check phonology in blue for the CASTLE entry.
search, and a single entry,
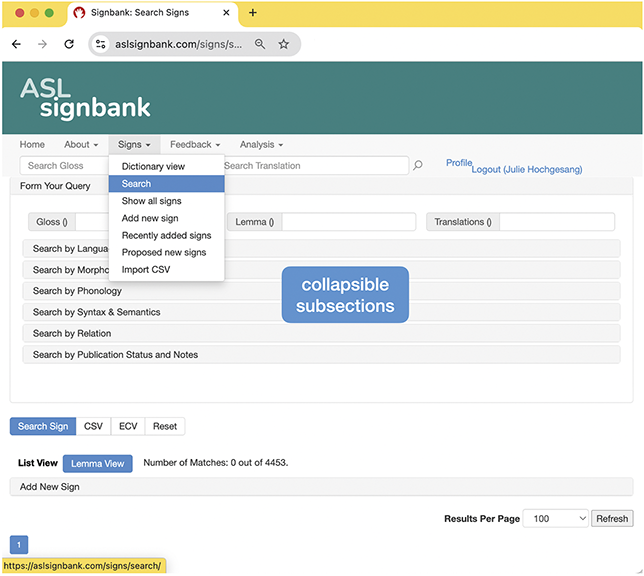
Figure 21c Long description
Same banners at top with A S L Signbank info on a teal background, as well as search options with a menu bar. There are different options for search with collapsible subsections in a blue curved box overlaid on the image. Full text available here: https://aslsignbank.com/signs/search/.
public, and
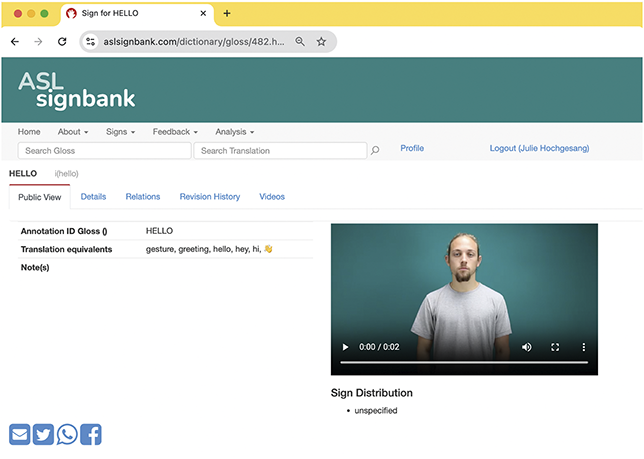
Figure 21d Long description
Same banners at top with A S L Signbank info on a teal background, as well as search options with a menu bar. There are different options for viewing the entry: public view (shown in this figure), details, relations, revision history, and video. Full text available here: https://aslsignbank.com/dictionary/gloss/482.html.
registered.
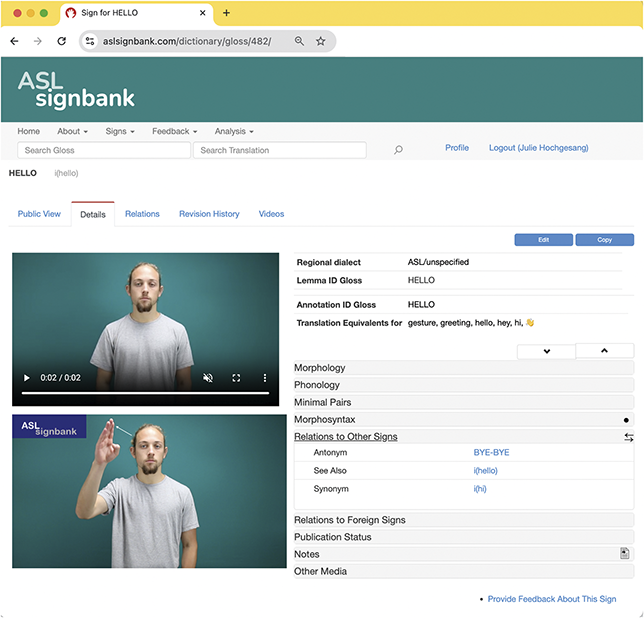
Figure 21e Long description
Same banners at top with A S L Signbank info on a teal background, as well as search options with a menu bar. There are different subsections providing more information about the entry: regional dialect, lemma I D gloss, Annotation I D gloss, translation equivalents, subsections: morphology, phonology, minimal pairs, morphosyntax, relations to other signs (which is shown in full here), relations to foreign signs, publication status, notes, and other media. Full text available here: https://aslsignbank.com/dictionary/gloss/482.
When first visiting the site, we are at the home page with introductory information about the site (Figure 21(a)). When clicking on “all signs” or search for a specific sign, we are taken to a list of entries which provides limited formational information about signs and tags in a spreadsheet view (Figure 21(b)). The search fields for finding signs, which are always visible on the top of the page, are either “search gloss,” when one knows the precise ID gloss label they want, or “search translation,” when one is not sure of the label. There is also an advanced search page with collapsible subsections to fine-tune searches (Figure 21(c)). After searching, the resulting list of entries includes a photo of the sign, a video when hovering over it, the annotation ID gloss, some phonological information, and any tags that may be associated with that entry. When clicking on any one of the results, we’re taken to the entry for that sign, with a list of related search results just below the search boxes (“HELLO” and “i(hello)” in Figures 21(d) and (e). If the user is not registered, a public view with limited information about each entry is shown (Figure 21(d)) – annotation ID gloss (Section 5.3), translation equivalents (Section 5.4), and usage notes (Section 5.13). I recommend that users register for a free account so that they have access to comprehensive information. Registered users can access entries with expanded information available via collapsible subsections (Figure 21(e)). There are even more views than shown here such as resources listed under “About” (copyright, manual, conditions of use, contact us, FAQs), more entry views such as “relations” or “revision history” views, multiple options for viewing signs or adding them (reserved for registered users that can edit the site), and feedback pages for visitors to share overall feedback or suggest signs.
This sectionFootnote 57 describes each field in any registered-view entry for ASL Signbank, which revolves around the sign visually represented by the video and photo and textually labeled by the annotation ID gloss (Figure 22).
A screenshot of an entry in ASL Signbank.
Figure 22 Long description
Julie (white woman with brown hair) in a black top, signing. Same banners at top with A S L Signbank info on a teal background, as well as search options with a menu bar. There are different subsections providing more information about the entry: regional dialect, lemma ID gloss, Annotation ID gloss, translation equivalents, subsections: morphology, phonology, minimal pairs, morphosyntax, relations to other signs, relations to foreign signs, publication status, notes, and other media. Full text available here: https://aslsignbank.com/dictionary/gloss/3771/.
Each field, organized by collapsible subsections, provides linguistic and usage information for each entry and also serves as a way to search for entries using the “search” page (Figure 21(c)). Data entry is ongoing, and some fields may be better populated than others throughout the database. I define each possible value, along with a few examples. These ID glosses included here as examples reflect ASL Signbank at the time of writing (the summer of 2025). Occasionally, ID gloss labels are changed to continue following conventions as more signs are added to the database. For example, a tag may be added to an annotation ID gloss if a phonological variant is added (e.g., SOON with “ch” and “ns”). When changes are made to labels, earlier annotation ID glosses will be preserved in the translation equivalents field and an accompanying note documenting the change under “notes” field subsection.
Each entry has an URL that looks like: aslsignbank.com/dictionary/gloss/###/, such as aslsignbank.com/dictionary/gloss/3771/ for SLASH. The number stands for the number of the entry in the order it was created starting with 1 or 3771 for SLASH. Note that the total number of current entries does not match the number of the most recent entry because some entries have been totally deleted. Deletion of entries occurs because they were set up as test entries, mistakenly added, or not needed any longer.
The following subsections are ordered in the same order as seen in any ASL Signbank entry and again have largely been inherited by previous signbanks. As I am interested in phonetics and a usage-based approach, I have devoted more energy to some fields, and less to others.Footnote 58 Throughout, I will comment on the fields that have been used more or less. In many cases, the fields that are less active could be used or even repurposed for study by a future student or collaborator. All the values entered in these fields can be used to searchFootnote 59 for ASL signs.
5.1 Regional Dialect
If a sign is known to be associated with a particular regional dialect, that information is given here (Figure 23, editor-only view).
Screenshot of regional dialect field.
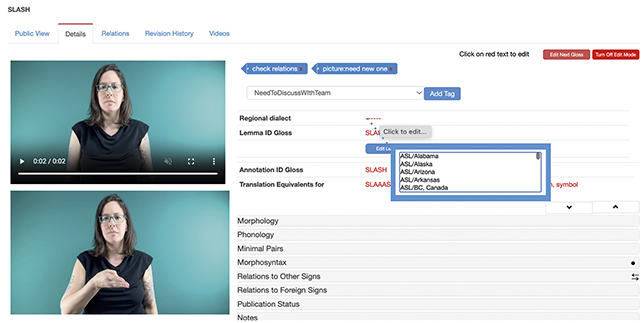
Figure 23 Long description
Next to regional dialect is a series of red dashes, a gray box click to edit, and then blue dots lead to a blue box with white text listing options: A S L/Alabama, A S L/Alaska, etc., with an option to scroll for more.
Possible values in this field include each state in the United States and some cities like Philadelphia, PA, or Washington, DC, Canada, and an “ASL/unspecified” value. Information documented in this field often comes from the source videos themselves, the actors who filmed our reference videos or comments written by the signing communities on the ASL Signbank Instagram account. Multiple regions may be indicated here, and signs that are regionally specific but also more widely known may be listed as belonging to a specific region(s) or “ASL/unspecified.” This information has not been added for SLASH since it seems to be widespread across North America and/or we do not know the bounds of its usage.
5.2 Lemma ID Gloss
A lemma ID gloss is a unique identifier for an abstract category of signs. A sign or a group of signs may share the same lemma in ASL Signbank as shown in Figure 24. If there are more than one sign in a lemma category, unique labels are provided through the annotation ID glosses (Section 5.3).
Screenshot of Lemma ID and annotation ID gloss fields.

Lemmatization is discussed in detail in Section 4.
5.3 Annotation ID Gloss
Each annotation ID gloss corresponds to an individual entry in ASL Signbank (Figure 22). Again, as introduced in Section 4.3, annotation ID glosses (often referred to simply as ID glosses or IDgs) are unique identifiers for individual citation forms. These machine-readable labels are used when annotating ASL signing video data, regardless of any changes to the form such as morphological processes, phonetic processes, or nonmanual signals that may occur during/with a given instance of a sign. Annotation ID Gloss assignment is discussed in detail in Section 4.3. ASL Signbank annotation ID glosses can be directly linked to ELAN transcripts (.eafs) through an ECVFootnote 60 and connected to specific tiers in ELAN through setting up a type associated with the ASL Signbank ECV.Footnote 61
5.3.1 Tags for Annotation ID glosses
Here is a description of categories of tags and the possible tags within each category. The annotation tags (or lowercase text appended to ID glosses) are unique to ASL Signbank. The general guidance provided here for applying each tag may not be reflected in every annotation ID gloss. The choice of an exact lemma and annotation ID gloss are secondary to the primary goals of ID glossing: maintaining a one-to-one relationship between lexical forms and annotation ID glosses and reflecting phonological variant relationships through shared lemma ID glosses. They are not fully consistently applied because their goal is not to systematically characterize phonological forms of signs – which are done by the phonological coding in other fields – or to make any kind of theoretical claim about phonological structure but to serve as a visual and mnemonic device for human annotators to better read the glosses and quickly associate them with the form of the signed production. Rather, the annotation tags serve as a flexible strategy to permit new categories as needed.
Handshape
Handshape tags mostly refer to handshapes associated with numbers or the manual alphabet. For the handshapes found in the signs TWO, THREE, and FOUR, tags are fully spelled out (e.g., WARfour). Handshapes corresponding to numbers above four can be indicated with a number (e.g., BALLOON5). Tags can also indicate handshapes that correspond to the manual alphabet. These are given as lower case letter tags after the uppercase portion of the annotation ID gloss (e.g., GENERATIONg). Note that these handshape tags are not intended to indicate initialization specifically, which is reflected in a “See Also” relationship with the manual alphabet sign (Section 5.10). The handshape found in the sign numeral ONE is often noted with the tag “ix” (for “index,” for example, FROWNix). The handshape tag “bo” is used for the “baby O” handshape (e.g., WRITEbo). The tag “claw” can indicate the “claw 5” handshape (e.g., DARKclaw). Other tags include “th” short for “thumb” (CUTEth), “noth” for “no thumb” (CUTEnoth), and “onex” for the hooked extended index finger (e.g., FASTonex).
Handedness
The tags “sym” (“symmetrical”) and “asym” (“asymmetrical”) are used in a few different ways with annotation ID glosses in ASL Signbank. The first is to distinguish between two-handed variants of a sign, where “sym” can denote a two-handed variant (e.g., REMEMBERsym versus REMEMBERfh) and “asym” can denote a one-handed variant (e.g., KINDERGARTENasym versus KINDERGARTENb). The question of whether a difference in only the weak handshape creates a distinct lexical item and therefore warrants a distinct annotation ID gloss is an ongoing discussion amongst ASL Signbank researchers. For this reason, there is variation in whether separate entries are created in these cases.
Orientation
A couple of tags are used for variants that differ in orientation of arm and palm. These tags are applied without regard to the joint at which the orientation is implemented (shoulder, elbow, or wrist).
sup (supine): arm facing upward
pro (pronated): arm facing downward
Placement
The following tags describe a sign’s placement (or part of) for cases where this description distinguishes variants. There may be contact but it is not required.
neut (neutral space)
fh (forehead)
ears
eye
ns (nose)
ck (cheek)
mo (mouth)
ch (chin)
hand
arm
pa (palm)
fa (forearm)
bk (back of hand or head)
ts (torso)
Movement
The tags listed here refer to both path movements and local or internal movements.
wig (wiggle)
up
down
alt (alternating movement between dominant and weak hands)
flex (wrist, elbow, or finger joint flexion)
rot (wrist, elbow, or shoulder rotation)
shake (wrist adduction)
tap (repeated contact)
ext (wrist or elbow extension)
arc (incomplete circular path)
cir ( circular path)
zig (quickly repeated back and forth movement)
str (straight path movement)
rep (repeated movement)
twist (twisting movement at the wrist)
Initial Index Handshape
There is a category of signs for which one variant begins with a component that appears to be derived from the sign THINK and/or MIND, with the extended “index” (“ix”) handshape at the forehead. The other variant begins with the same forehead location but has a single handshape (not the extended index handshape) that persists throughout the sign. In these cases, the tag “ix” usually marks the variant with the initial index handshape and “noix” (“no index”) for the variant without this component, for example, BELIEVEix and BELIEVEnoix.
5.4 Translation Equivalents
This field contains a list of possible English translations, related English words, and emojis for the sign in each entry. The annotation ID gloss is also included (including the tag, if applicable) in this field. For example, SLASH’s translation equivalents are “SLAAASh, SLAASh, and, diacritic, either, or, punctuation, slash, symbol.” They are not meant to serve as full translations of the ASL signs themselves but are meant to facilitate searching for entries without already knowing their ID glosses much like keywords. This list is not intended to be exhaustive, and users are encouraged to share their preferred translations with the maintainer of ASL Signbank to be added.
5.5 Semantic Field
The semantic field has a list of general meaning types and allows us to group similarly meaning signs together. For example, SLASH’s semantic field is “object.” This list has not been modified since the beginning of the project and we plan to revisit this in the future.
Animal
Attribute
Color
Discourse marker
Emotion
Event
Food
Locative
Number
People
Place
State
Variable (when an entry could be two or more of the above values)
N/A: when “not applicable” or “unsure”
5.6 Morphology
If a sign is multimorphemic, the component morphemes can be listed in this field. Given our priority in rendering signed ASL data machine-readable and not analyzing the ASL “lexicon,” this is the least developed aspect of ASL Signbank. See other signbanks for more developed aspects, for example, the Global Signbank Manual (Crasborn et al. Reference Crasborn, Zwitserlood, van der Kooij and Ormel2024).
5.6.1 Sequential Morphology
If a sign contains multiple morphemes which are combined sequentially, these sequential components are listed here. Two main types of sequential morphology have been observed for ASL: compounding and affixation. A compound is a complex construction consisting of two nominal signs (Lepic Reference Lepic2023), although many signs descend from combinations of signs; also see historical treatment of this process (Liddell & Johnson Reference Liddell and Johnson1986; Lepic Reference Lepic2019). For example, BOY and FRIEND are both listed in the compound BOYFRIEND. Affixation refers to the process of adding a prefix or suffix to a sign, resulting in a new sign with a distinct meaning from the original sign. TEACHER is a classic example of this process, combining TEACH and PERSON. At this time, these signs with apparent affixation are not well tracked in the database.
5.6.2 Simultaneous Morphology
Simultaneous morphology consists of changes to a sign’s form that are realized throughout the sign rather than before or after the base form. An example of simultaneous morphology is numeral incorporation. A sign like THREE-WEEKS, created through “incorporation” (see field “role in this sign”), is composed of a dominant handshape morpheme with the meaning “three” and a weak handshape and movement that contribute the meaning “week,” which is noted as the “blend gloss” in this entry. Again, given our preference to prioritize making signs machine-readable, this field has not been utilized in our data entry to date.
5.7 Phonology
In an effort to reduce labor, phonological coding added to entries in ASL Signbank uses the ASL-LEX coding (Sehyr et al. Reference Sehyr, Caselli, Cohen-Goldberg and Emmorey2021), which is a simplified version of the PM (Brentari Reference Brentari1998). Figure 25 shows the phonological coding details for SLASH.
The phonological coding for SLASH.
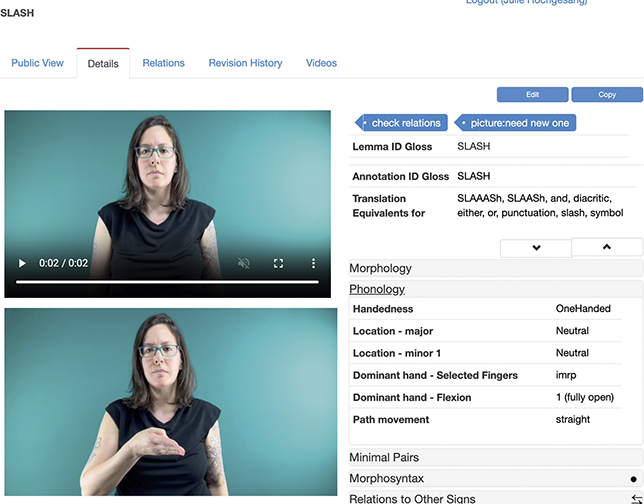
Figure 25 Long description
Entry view with video and photo on left. Entry text with subsections mostly collapsed except for Phonology. Text: Handedness: one-handed
Location - major: neutral.
Location - minor 1: neutral.
Dominant hand - Selected Fingers: i m r p.
Dominant hand - Flexion: 1 (fully open).
Path movement: straight.
The PM is a more abstract, theoretical, and categorical claim about how signs are structured. As a phonetician, I prefer a more articulatory-based and descriptive notation system such as the Signed Language Phonetic Annotation (SLPA) (Johnson & Liddell Reference Johnson and Liddell2010; Hochgesang Reference Hochgesang2014). Alas, such descriptive notation systems are better suited to actual tokens and not isolated reference forms as we see in ASL Signbank. The ASL-LEX coding system suits our purpose then in creating richer data for each sign entry in a way that enhances their searchability and reduces the tyrannical effect of English in being their only representation.
The phonological coding in ASL Signbank does not provide a complete phonological description of signs; there are contrastive elements that are not included for entries, for example, direction of movement. This leads to situations in which signs that are distinct in form and meaning are identically coded for phonology in ASL Signbank (e.g., ACT and AGGRESSIVE, which differ only in direction of movement, a characteristic which is not coded here). We have described the sharing of phonological coding across the two research teams of ASL Signbank and ASL-LEX in Becker et al. (Reference Becker, Catt, Hochgesang, Efthimiou, Fotinea and Hanke2020).
5.7.1 Handedness
ASL signs can be one- or two-handed. The possible values for handedness in ASL Signbank are as follows:
AsymmetricalDifferentHandshape
AsymmetricalSameHandshape
OneHanded
Other (violates sym/dom conditions)
SymmetricalOrAlternating
When two-handed, Symmetry and Dominance Conditions (Battison Reference Battison1978) have been used to categorize how the hands/arms behave. The Symmetry Condition holds that signs for which both hands move must have the same or mirroring placement and orientation, same handshape, and same (simultaneous or alternating) path movement. This type of sign is listed in ASL Signbank as “SymmetricalOrAlternating” (e.g., ACCEPT has symmetrical specifications and BICYCLE has alternating movement). Signs in which only one hand moves are referred to as “asymmetrical.” When the two handshapes are the same in an asymmetrical sign, these signs are coded in ASL Signbank as “AsymmetricalSameHandshape” (e.g., BELIEVEnoix). The Dominance Condition states that when a two-handed sign has different specifications for the two handshapes, the sign must be asymmetrical (i.e., only one hand can move), and the stationary hand is restricted to one of seven unmarked handshapes, coded in the “Nondominant handshape” field as 1, 5, A, B, C, O, and S. These signs are coded in ASL Signbank as “AsymmetricalDifferentHandshape” (e.g., COUNT). Finally, two-handed signs may be coded in ASL Signbank as “Other” when they apparently “violate” either the Symmetry or Dominance Condition. Signs that violate the Symmetry Condition are those for which both hands move but have different handshapes (e.g., SIM-COM). Signs that violate the Dominance Condition are those for which the stationary hand has a handshape other than the seven unmarked handshapes (e.g., CHERRY).
5.7.2 Location: Major
Each sign is specified for only one categorical location. The possible locations are next. Note that there does not need to be contact between the hand and location.
arm (including wrist)
body (signer’s torso)
hand
head (including face)
neutral (signing space in front of the signer’s body)
other
5.7.3 Location: Minor 1 and Location: Minor 2
Full description of a sign’s citation form sometimes requires specification of a more specific location within the major location. Minor locations can be contrastive (e.g., APPLEx and ONION are both specified for the head as major location but are distinguished by minor location: “CheekNose” and “Eye,” respectively). Minor location values are listed next under their respective major locations. “Minor 2” is intended for signs where there are second minor locations.
Arm
ElbowBack
ElbowFront
ForearmBack
ForearmFront
ForearmUlnar
UpperArm
Body
Clavicle
Hips
Neck
Shoulder
TorsoBottom
TorsoMid
TorsoTop
Waist
Hand
FingerBack
FingerFront
FingerRadial
FingerTip
FingerUlnar
Heel: (none yet)
Palm
PalmBack
WristBack
WristFront:
Head
CheekNose
Chin
Eye
ForeHead
HeadTop
Mouth
UnderChin
UpperLip
Neutral
Neutral
Other
Other
N/A
5.7.4 Dominant Hand: Selected Fingers
Some signed language phonologists suggest that signs have a “selection” of fingers in which certain fingers are prominent in a sign, in that they are the fingers that move, make contact, or are otherwise noticeable. This was first proposed by Mandel (Reference Mandel1981) as the “Finger Position Constraint,” which limits the number of categories a handshape can specify for finger configurations to two. One group of fingers or the selected fingers can be specified for any configuration possible in ASL. The other group, or the nonselected fingers, must be either fully extended or fully flexed/closed.
Since Mandel, various models have formalized this constraint in slightly different ways; all capture the notion that signs specify one category of phonologically salient fingers. ASL Signbank adopts ASL-LEX’s PM criteria for coding selected fingers. In signs with a handshape change or handshape-internal movement, the fingers that move are selected (e.g., index in QM). For signs without a handshape change or handshape-internal movement, if one set of fingers is partially flexed or partially extended (e.g., index in NEED), these fingers are considered selected and the set of fully flexed or fully extended fingers are considered nonselected. If neither of these criteria can be applied to distinguish between selected and nonselected fingers, the decision is made based on which fingers “appear foregrounded” (Caselli et al. Reference Caselli, Sehyr, Cohen-Goldberg and Emmorey2016). For example, in the sign ALONE, there is no handshape change or internal movement, one category of fingers (index) is fully extended, and the other category (middle, ring, and pinky) is fully flexed. Since neither group is partially extended/flexed, stacked, or crossed, applying these criteria does not differentiate selected from nonselected fingers in ALONE. However, the index finger appears foregrounded and is therefore coded as the selected finger. In ASL-LEX and ASL Signbank, the thumb is coded as selected only when it is the only selected finger. For example, in MOON, both index and thumb are partially extended and middle, ring, and pinky are fully flexed. In this case, only the index is coded as the selected finger. In the sign TEXT-PAGER, on the other hand, since the thumb is the only moving/salient finger while the others are fully flexed and nonmoving, the thumb is coded as the selected finger. In asymmetrical two-handed signs, selected fingers are coded only for the dominant hand (e.g., middle is selected for ADVANTAGE). The full word “thumb” labels the thumb as the selected finger. The codes for the remaining fingers are each one letter: i = index, m = middle, r = ring, and p = pinky. All possible combinations of the four fingers, including each finger individually, are possible in this field except for “ir” (index and ring), “mp” (middle and pinky), and “rp” (ring and pinky), which are unattested in ASL.
i
m
r
p
thumb
im
ip
mr
mrp
imr
imrp
5.7.5 Dominant Hand: Flexion
Following ASL-LEX and PM, flexion codes in ASL Signbank are categorical. That is, rather than providing a phonetic description of the flexion of individual joints, flexion codes describe nine categories of hand configurations that arise from combinations of flexion values of selected finger joints and configuration of the thumb in relation to the selected fingers. Selected finger joints may be “flat,” “bent,” or “curved.” In “flat” configurations, selected fingers are flexed at the metacarpal joints only. In “bent” configurations, the distal and proximal joints are flexed. “Curved” configurations are those in which the selected finger joints are partially flexed. The thumb can be either “closed,” in which case it contacts the fingers, or “open,” in which case it does not. These finger and thumb configurations combine to produce seven contrastive categories. Two additional joint configurations – crossing and stacking – provide the last two possible values in the Flexion field.
When flexion changes due to handshape change or handshape-internal movement, only the initial state is coded. For asymmetrical two-handed signs, the values given in this field reflect the dominant hand configuration only. Here, each contrastive category resulting from the finger and thumb configurations just presented is described. The first seven are coded in ASL Signbank by a numerical label, and the last two are simply named “Crossed” and “Stacked.”
1 (fully open) – finger joints fully extended and thumb unopposed, not contacting fingers
2 (bent or closed) – finger joints closed
3 (flat open) – metacarpal joints flexed, thumb not contacting fingers
4 (flat closed) – metacarpal joints fully flexed, thumb contacting selected or nonselected fingers
5 (curved open) – finger joints partially flexed, thumb not contacting fingers
6 (curved closed) – finger joints partially flexed, thumb contacting fingers
7 (fully closed) – finger joints fully flexed, thumb may or may not be contacting fingers
Crossed – selected fingers crossed over one another
Stacked – different flexion value for each selected finger
5.7.6 Abduction Change
For signs with a handshape change in which the selected fingers move toward or away from one another in a sideward motion, entries appear with the value “yes” in the abduction change field (e.g., HAIRCUT). Entries for signs that do not have abduction change simply lack this field (e.g., VEGGIE). On the search page, the value options are listed as “True,” corresponding to “yes,” and “False” (or “no”), which will return entries without this field. Abduction change is coded for the dominant hand only in asymmetrical two-handed signs.
5.7.7 Flexion Change
When a handshape change involves flexion or extension of the selected finger joints, the “Flexion change” field appears with the value “yes” (e.g., VLOG). When flexion remains the same, this field does not appear in the sign entry (e.g., SHINY). On the search page, the value options are listed as “True,” corresponding to “yes,” and “False” (or “no”), which will return entries without this field. In asymmetrical two-handed signs, flexion change is coded for the dominant hand only.
5.7.8 Nondominant Handshape
“Handedness” (Section 5.7.1) provides a description of the three types of two-handed signs and the Symmetry and Dominance Conditions. For one-handed signs, SymmetricalOrAlternating, and SymmetricalSameHandshape signs, the “Nondominant Handshape” field appears with the value “N/A.” For “AsymmetricalDifferentHandshape” entries that follow the Symmetry and Dominance Conditions, the nondominant handshape is limited to one of seven: 1, 5, A, B, C, O, S.
5.7.9 Path Movement
ASL signs can be specified for one of four possible path movements: “BackAndForth,” “Circular,” “Curved,” or “Straight.” Each of these corresponds to a trajectory of the hand(s). A description of each of these path movements is provided here. In addition to these four trajectories, the “Path movement” field can present two additional values: “None” and “Other.” These are also described here. Path movements can be implemented by any joint in citation form except for the finger/thumb joints, which implement handshape-internal movements.
BackAndForth – alternating movement along a straight trajectory
Circular – a complete circular trajectory
Curved – curved trajectory that doesn’t complete a circular path
Straight – non-alternating movement along a straight trajectory
None – no path movement; handshape-internal movement only or a change in orientation only
Other – multiple trajectories (for multisyllabic signs and/or signs with sequential morphology), which can be either consecutive or simultaneous
5.8 Minimal Pairs
This is left over from the Global Signbank (Crasborn et al. Reference Crasborn, Zwitserlood, van der Kooij and Ormel2024), the model we used to build ASL Signbank from, and has been inactive as long as ASL Signbank has been active.
5.9 Morphosyntax
5.9.1 Word Class
Precise definitions of word class (also known as lexical category or part of speech) differ by theory, but broadly it can be defined as a category that corresponds to a lexical item’s grammatical role in a sentence. Many signs can be categorized as members of multiple word classes depending on context. In these cases, ASL Signbank research assistants choose which category they feel describes the primary use of that sign. The following are the options for this field, briefly described.
Noun – signs that can be the subject or object of a sentence; often (but not always) refer to a person, place, thing, or idea
Adjective – signs that describe a property or attribute of a noun, such as color, size, or another characteristic
Minor – signs that are part of closed classes, including prepositions, pronouns, and conjunctions; prepositions express location or temporal relationships; pronouns are signs that refer to a person, thing, or concept that is already part of the discourse; conjunctions are signs that connect parts of sentences
Name – sign names for people or places
Noun/verb – When a sign’s usage seems evenly split between the noun and verb categories, it is coded as “noun/verb”
Number – numeral signs
Unsure – unclear
Verb – usually signs that refer to an action or event
5.9.2 Lexical Category 2
When an ASL Signbank research assistant feels that a sign is strongly associated with more than one word class, whichever the research assistant feels is more secondary (less frequent) is entered under “Lexical category 2.”
5.9.3 Lexical Category Notes
Notes are added as needed. This has been rarely used.
5.9.4 Derivation History
Derivation history describes a word’s development via morphological processes (e.g., compound, numeral incorporation) or other word-formation processes (e.g., fingerspelled loan signs, borrowing from a foreign signed language, initialization, depiction). Others can be listed and described in notes. This is not as well documented as I would like it to be but that’s because of lack of data as well as consensus on how to identify these forms (e.g., compounds as described in Lepic (Reference Lepic2023).)
5.9.5 Type of Iconicity
Like with other ASL Signbank fields, precise definitions of iconicity are theory-dependent (see Hodge and Ferrara Reference Hodge and Ferrara2022). In a very general way, iconicity can be defined as a resemblance between a sign’s form and an image to which it refers or otherwise there is some motivated relationship between the form and meaning (Dudis Reference Dudis and Roy2011). Because iconic signs differ in the exact component of the image that corresponds to aspects of the form, the values in the “type of iconicity” field indicate what aspect of the image is iconically represented.
This value list was inherited from our shared coding with ASL-LEX circa 2016 and has since been unused. We have not yet used this field for any ASL Signbank coding. If any project wishes to adopt this coding, we encourage them to determine project-specific criteria based on their preferred theoretical frameworks.
N/A – when entry is for a specific annotation convention and iconicity coding is “not applicable”
None – sign isn’t considered iconic
Mimetic – related to action (e.g., DRIVE is iconic in that hands are “holding” a steering wheel)
Mixed – both mimetic and perceptual (e.g., DRINK)
Perceptual – related to form (e.g., SCREWDRIVER indicates the shape of the tool along with a surface).
5.10 Relations to Other Signs
Signs can be related to one another in form, meaning, or both. Lemmatization reflects some of these relationships: signs with the same meaning that differ in one or two phonological aspects share a lemma and are differentiated by a tag in their annotation ID glosses (e.g., DOLPHINr and DOLPHINd). These are considered phonological variants, share a lemma, and are cross-listed in ASL Signbank entries by the “variant” relation. Other relationships between signs are not expressed by lemmatization, hence the need for the field “relations.” The following are the possible relations, their definitions, examples of each, and further explanations where needed.
Homonym – a lexical item with identical form but distinct meaning (separate lemmas)
Synonym – a lexical item with unrelated form (three or more phonological differences) but can have similar meaning
Variant – a lexical item with phonologically-related form (only one or two phonological differences) and identical meaning (same lemma, differentiated by tags)
Antonym – a lexical item with the opposite meaning
Hypernym – a lexical item that is the category head or names a category into which a given entry’s sign falls
Hyponym – a lexical item that belongs to a larger category
See also – this is a miscellaneous category. Signs listed as “See also” may fall into the following categories, or be otherwise related in ways not listed here.
easily confusable signs
signs that share iconic motivation
components of a construction
signs that otherwise have similar or related form and/or meaning but do not qualify for the other relations and may share the same semantic field
Handshape paradigm – signs that are part of a group of signs differentiated only by handshape, where the handshape often represents the first letter of an English translation of the represented concept.
Because the usage of signs shifts over time and can differ between individuals and contexts, defining relations between signs is not always straightforward, and the relation listed in an entry may not be true for all signers. We also are using relations that have been developed for spoken languages and do not entirely reflect signed language usage, hence heavy use of “see also” and a new value “handshape paradigm” (Hochgesang et al. Reference Hochgesang, Becker and Catt2020). SLASH has several relation types – hypernym is SYMBOL, and the other hyponyms of SYMBOL are listed as “see also” relations here.
Two signs may exist in multiple relations to one another. For example, the entry for WEEK is cross-listed as see also for the numeral incorporation signs ONE-WEEK, TWO-WEEKS, and so on. However, the form for WEEK and ONE-WEEK is identical, so these signs are also cross-listed through the “homonym” relation.
If there are any relations set, the “relations” view will provide a more structured view revolving around the relations themselves. Figure 26 shows SLASH as well as images of signs in other entries along with their ID glosses and type of relation, such as “source sign,” “hypernyms,” and “see also.”
Screenshot of relations view for SLASH.
Figure 26 Long description
Full text available: https://aslsignbank.com/dictionary/gloss_relations/3771.
While this section is well used, it has mostly been documented using annotator intuitions, lab discussions, and sporadic suggestions from ASL communities. Plans are underway to conduct more systematic investigation via surveys and focus group feedback. Even as is, it is a powerful way of searching ASL Signbank and seeing connections across ASL signs.
5.11 Relations to Foreign Signs
This has been entirely inherited from the Global Signbank and has not been used to date. It’s meant to document signs that are stated to be borrowed from foreign signed languages and needs to be linked to signbanks for other signed languages. This information hasn’t even been added yet for the manual to Global Signbank.
Under “loan,” if the sign is a “borrowed sign,” the value in this field is “True.” If not, the value in this field is “False.” Under “related language,” the relevant language is named. Under “gloss in related language,” the ID gloss from the relevant signbank is linked.
We haven’t used this feature but have left it intact in case people working with other signbanks want to connect to ASL Signbank.
5.12 Publication Status
This subsection includes metadata about the creation or contents of each entry.
Creation Date – month, day, and year the entry was first created
Creator – the researcher who first created the entry
In Web Dictionary – “yes” means entry is published (or visible in public version); “no” means entry is “unpublished” and restricted to registered users only.
Proposed new sign – “yes” means the entry has not yet been approved; “no” means approved.
Exclude from ECV – for purposes of annotation, there is an ECVFootnote 62 that lists values that can be entered in the ELAN transcript annotation fields linked to ID glosses listed in ASL Signbank. “yes” means the entry is included in the ECV; “no” means the entry is excluded from the ECV.
Note that only published entries can be publicly shared or reused in dissemination. ASL Signbank conditionsFootnote 63 has more information about how entries and content can be reused.
5.13 Notes
This section presents additional information about an entry that is not included in any of the above fields – to report ID gloss changes, to clarify information given in another field, to note usage information, or for researchers to discuss potential issues with an entry. Notes may be checked as “published,” meaning that they will appear in the publicly available web dictionary view of ASL Signbank. Published notes often provide information on usage (such as whether a sign is considered slang or offensive) or clarification on information in another field. Other notes, such as questions about a citation form, problems with an assigned IDgloss, or other issues that need to be addressed by the research team, are unpublished and appear only in the registered view, which requires a login. Notes are typically ended with the initials of the team member who added them, in case clarification is needed. If a tag is added (see section “tags” 5.15) to indicate a problem with an entry, a corresponding note is usually added to explain the reason for the tag. Depending on the topic of the note, it is categorized as one of the following:
N/A
About ID gloss
About entry content
Citation form issue
ID gloss change
Misc
Photo comment
Usage notes
Video comment
5.14 Other Media
Other media is another unutilized subsection in which alternate media could theoretically be added. It would not be available to the ECV when using a signbank as lexicon service,Footnote 64 in which the videos can be seen in the ELAN transcript.
5.15 Tags
Whole entries can be tagged. In “editing view” (available only to a handful researchers with editing access), tags appear at the very top of the entry and can be visible in the list of all signs. Our current tag list is as follows:
NeedToDiscussWIthTeam
check_phonology
check_relations
picture:need_new_one
sign:IDgloss_problematic_doesnotfollowconventions
sign:_approved
sign:_remove
sign:possibleduplicate
sign:proposedIDgloss_needsapproval
video:NeedToScrubSound
video:_missing
video:_refilm
video:_tech_problem
video:_wrong_sign
Tags are often used with suggested or new signs to mark that additional processing-like coding or filming needs to occur.
6 Using ASL Signbank with SLAASh Annotation Conventions in ELAN
From the start, ASL Signbank has been conceived and designed to work with ELAN with a specific set of annotation conventions developed by the SLAAASh project (Hochgesang Reference Hochgesang2025c) as well as processing and sharing protocols from CARD.Footnote 65 In this section, I demonstrate how to do all this with a video of a presentation I was invited to share for the CREST Fest 2021 (Hochgesang Reference Hochgesang2021a). My colleague, Ryan Lepic, and graduate students, Donovan Catt and Bonnie Barrett, started annotating it for their project examining the family of “what” signs.Footnote 66 It’s an ideal resource to useFootnote 67 because in the ASL videoFootnote 68 I share many of the ideas I discuss here in this Element.
Discussing the detailed processes of annotation and using ELAN is beyond the scope of this Element but can be found in discussions of signed language corpora development (Fenlon and Hochgesang Reference Hochgesang2022; Wehrmeyer 2023).Footnote 69 The annotation conventions specific to ASL Signbank are described in full elsewhere (Hochgesang Reference Hochgesang2025c) but I will walk you through some key points. I’ve also created a videoFootnote 70 demonstrating how I use ELAN with the CARD template, ASL Signbank, and SLAASh conventions.
6.1 CARD Template
The CARD ELAN template (.etf) follows the minimal requirements for the first pass of any corpus project which is to render the data machine-readable through adding translation, tokenization, and labeling. As Figure 27 shows, each transcript is linked to just one participant and filenames reflect metadata related to the movie name or session ID, relevant project, participant, annotator, and annotation status.
Screenshot of .eaf for my presentation.
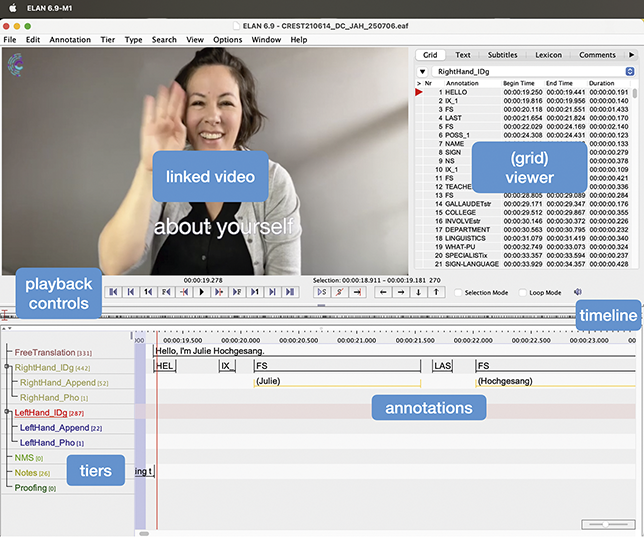
Figure 27 Long description
There are a few blue boxes with white text showing different parts of the ELAN file - linked video over Julie's video, (grid) viewer top left over a list of text for RightHand_I D g tier, playback controls by a set of buttons for playing the video, and timeline by a long thin box with many ticks in the middle. Tiers and annotations at the bottom. On the left is a list of categories of tiers - FreeTranslation, RightHand_I D g, RightHand_Append, RightHand_Pho (ditto Left), N M S, Notes, and Proofing. On the right are some short lines with text on top, for example, Hello I'm Julie Hochgesang next to FreeTranslation, etc.
The ELAN transcript (.eaf) consists of different elements – (top left) a linked video, (bottom half) tiers where time-linked annotations can be viewed and added, (center) playback controls and a timeline that shows ticks for all annotations added, and (top right) a viewer that shows different views of the annotations added or controls for the video. Providing a comprehensive tutorial to using ELAN is beyond the scope of this Element but the ELAN website has several resources to this endFootnote 71 and I have some resources, including ASL videos, on my personal website.Footnote 72
The tiers shown in Figure 28 are from an .etf that is already linked to ASL Signbank ECV (Hochgesang Reference Hochgesang2025a). That is, creating a new .eaf using this .etf will populate the transcript with these tiers. This template structure has been designed to work with ASL Signbank and SLAASh conventions.
Screenshot of tier names with function of each.
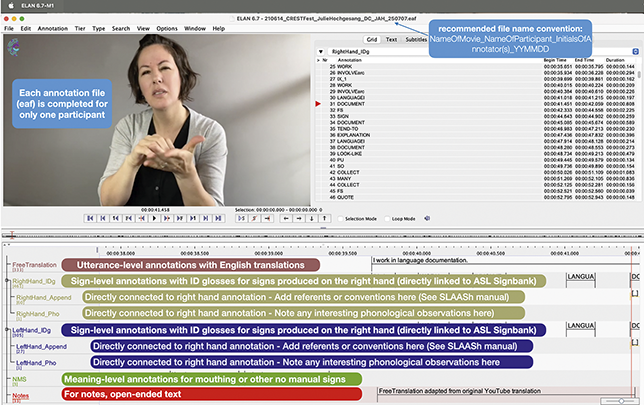
Figure 28 Long description
There are a couple of blue boxes on top pointing to the filename or over the video (top left). Corresponding with each tier are color-matched boxes with text describing the function of each. Full P D F with scannable text here: www.dropbox.com/scl/fi/y2qwoqc40xa7lgixya4q3/Screenshot-of-CARD-ELAN-template.pdf?rlkey=7t5kf3adx2i4c43fxhgk439s5&dl=0.
6.2 Using ASL Signbank as External Controlled Vocabulary
Again, the .eaf is directly linked to ASL Signbank through an ECV link.Footnote 73 Sign-length annotation fields should be created aligning with start and end times of individual signs produced by the right and left hands in the video. Following Johnson and Liddell (Reference Johnson and Liddell2011, pp. 412–413), signs, and corresponding annotation fields, start when all phonetic aspects (handshape, placement, etc.) are aligned and often change direction from previous sign or resting state. Signs end when one or more phonetic aspects change for the next sign or resting state. Figure 29 shows an example.
Start and end time of instance for WORK.
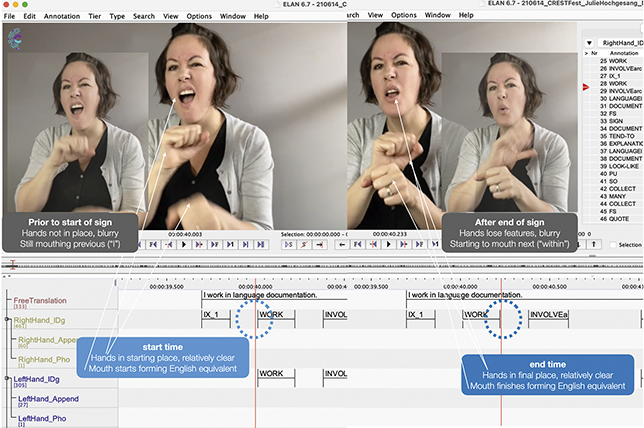
Figure 29 Long description
There are textual labels and arrows demonstrating different parts of the screen, meant to show how to determine the start and end times of annotation fields corresponding with the video. There are two screenshots of the ELAN file indicating the start time of WORK, then the end time, which are circled in dotted blue lines. Next to the circles are blue boxes with white text, start time: hands in starting place, relatively clear. Mouth starts forming English equivalent; end time: hands in final place, relatively clear, mouth finishes forming English equivalent. Above, near the video aspect of the screenshot, are 2 smaller and slightly opaque images of Julie signing, along with dark gray boxes with white text prior to the start of sign, hands not in place, blurry. Still mouthing previous (I), then After the end of sign, hands lose features, blurry. Starting to mouth next (within).
When adding annotations to the ID gloss tiers, “RightHand_IDg” and “LeftHand_IDg,” a list of ID glosses from ASL Signbank in the “list pane” appears (Figure 30(a)). Annotators can scroll to find labels, but I do not recommend that option since it’s over 4,000 entries long. Instead, the “suggest pane” (Figure 30(b)) allows annotators to type text to find the appropriate ID gloss.
Screenshots of editing panes in .eaf.
Figure 30 Long description
First is list pane of the annotation field in ELAN with options for S words: SIGHTSEEING, SIGN, SIGN-LANGUAGE, SIGN-SWATTER, SIGNAGE, SIGNATURE, SIGNBANK, SIGNER, SILLY, SILVERix. Second is suggest pane with SIGN typed in and options listed as: PRODUCE-SIGNER, SIGN, SIGN-LANGUAGE, SIGN-SWATTER, SIGNAGE, SIGNATURE, SIGNBANK, SIGNER.
The ECV option allows typing to search both the ID glosses and the translation equivalents. If using ASL Signbank as a lexicon service, the videos will play in ELAN (Figure 27). If not, annotators can visit ASL Signbank and find the glosses to ensure that the production played in the ID gloss video is an appropriate match for the signs being annotated. This is where annotator training and knowledge are essential – the annotator needs to decide which ID gloss labels are the best for the language produced in the videos. There will always be variability with language use and the annotator needs to decide how much variation warrants the use of a different ID gloss. Like described with the first-person singular pronoun, I almost never see the reference form shown on ASL Signbank but more like the forms shown in Figure 17. I still use IX_1 to label forms like these because they are still instances of the first-person singular pronoun in ASL use.
Given that there are over 4,000 entries in ASL Signbank, it can be difficult to locate the precise label sometimes, especially if the text label is short, like three letters long. In that case, using regular expressions (regex) on the website is helpful (Figure 31). Regular expressions are a series of characters that can refine searches such as this oft-used one of mine – ^exact$. For example, ^can$ will return that entry exactly instead of the twenty-four entries that have “can” somewhere in the ID gloss label.Footnote 74 Regex can often be used in many digital resources.
Screenshot of regex shortcuts in search field on ASL Signbank.
Figure 31 Long description
In many text fields, you can use patterns as follows: A contains A; hat A starts with A; Section A S ends with A; A B A or B; asterisk find all strings in this field use backslash to find special characters in field).
These can also be used in the search feature in ELAN (although not in the editing pane for the annotations).
6.3 First-Pass Annotation
The first pass for annotation is often to tokenize and label the data as well as add translation. It is an essential step in rendering texts of primary data machine- and human-readable.
6.3.1 ID Gloss and Append Tiers
Following current practices for signed language corpus and documentation projects, ID gloss labels are added to both right- and left-hand tiers (Figure 32). Annotating both hands allows me to represent when they are different in timing or production. Often one hand will not produce anything meaningful.
Screenshot of RH and LH.
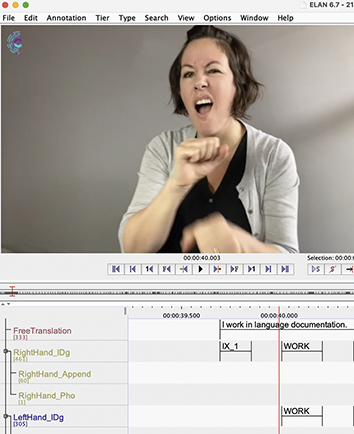
Recall that ASL Signbank is full of entries with relatively conventionalized items but in everyday language use, there’s much that’s either novel or highly specific. In those cases, we use codes that serve as ID gloss labels not for specific concepts but for sign types such as depicting signs, pointing (or index) signs, fingerspelling, and name signs. In those cases, the codes – such as DS, IX, FS, and NS – themselves are added to ID gloss tiers and the referents are added to relevant “append” tiers. The referents cannot be added directly to the ID gloss tiers because they are directly linked to the ASL Signbank ECV. Adding other information not in the ID gloss labels themselves will break that link (Section 4.4). In Figure 33, I show an example of adding a referent for FS – “Julie,” which is my name.
FS annotation with referent on “append” tier.
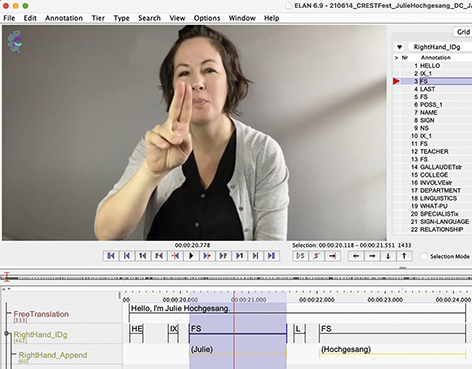
If annotators are using these codes (DS, FS, etc.) and do not know the referents, append tiers can be left blank. Also note that the DS labels have handshape tags. If annotators wish to code DS without handshape tags, they can simply choose DS. To search for all codes and other annotation conventions, annotators can type “annotation convention” in “search translation” on ASL Signbank.
There are also punctuation symbols that serve as annotation conventions. They have been mostly adopted from CHAT (MacWhinney Reference MacWhinney2000) to allow for comparable datasets across language modalities (Chen Pichler et al. Reference Chen Pichler, Hochgesang, Lillo-Martin and Quadros2010). The ones I use most often are [_], [?], and XXX. [_] signifies that signs have been held for longer than usually observed; [?] indicates uncertainty with choice of ID gloss label; XXX indicates that something cannot be observed. A visual and short guide to those conventions is available online (Hochgesang Reference Hochgesang2024) and a longer version (Hochgesang Reference Hochgesang2025c) also has a table of all the annotation conventions.
Note that referents have been enclosed in parentheses () and convention symbols in square brackets []. This is both human-readable, as a constant reminder of the type of data, and machine-readable in that you can search for them (although you may need to use the back slash \ to escape a character that has special meaning inside a regular expression).
6.3.2 No Manual Signals Tier
If something meaningful occurs but the hands are not producing that information, annotators use the NMS, “no manual signals,” tier. Figure 34 shows a couple of examples from my transcript with i(yes) and m(um), which are short for “interjection” and “mouthing,” respectively, following SLAASh conventions.
NMS tier.
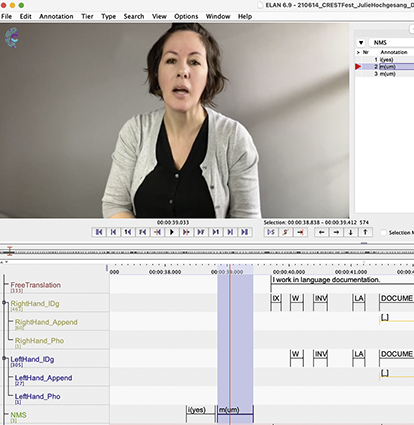
We have found that the NMS tier can be confusing, even for project veterans. This tier is a part of the first-pass annotation that renders the video data machine-readable. That data is anything signed meaningfully be it manual or nonmanual. If the hands are not producing something meaningful but the rest of the body is, the NMS tier is then used. This tier is not meant to be used with co-occurring nonmanual signals that we see with signs, for example, shifting our bodies to ask questions. Those are to be captured on later annotation passes as needed for individual research projects. There are also other tiers such as phonological notes (“_PHO”) and the more general “notes” which can be used to capture any observations regarding nonmanual signals, other aspects of the data, or even the annotation process itself.
Instead, the “no manual sign(al)s” tier is used to capture, for example, an ASL signer mouthing an English word, but this word does not correspond to any manual signing, such as if their hands are at rest. This tier is also not a comment on the “linguistic” status of co-occurring nonmanual signals. Far from it, NMS are interesting and important to consider in language use. Instead, here I am motivated from the perspective of an annotator preparing data to be used for multiple purposes. The resources of the annotator (their time, their attention, their skill) need to be practically balanced with what needs to be annotated. For that reason, making video data readable at minimum is prioritized because the video data will be linked with the annotation and together that serves as complete (and accessible) data.
6.3.3 Free Translation
Another tier that helps with readability in general is the “FreeTranslation” tier, which is meant for annotations aligned with utterances and populated with English translations. An utterance starts and ends with idea-like chunks following the ASL signs themselves. Research projects will have to determine criteria that work for them. For myself, I use the start and end of signs on the ID gloss tiers that correspond to a single idea. There are prosodic cues that I often rely on, such as eye blinks and head nods (Ormel & Crasborn Reference Ormel and Crasborn2011). The more cues there are, the more likely there’s an utterance break.Footnote 75 Annotations themselves will be English-like translations that translate the overall meaning of individual ASL utterances (Figure 35). This is perhaps a source of comfort for annotators who are not comfortable with how ID glosses can be such poor representatives of the actual meaning of signs.
FreeTranslation example.
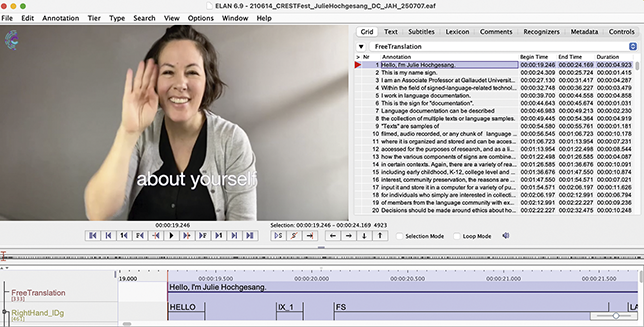
Figure 35 Long description
One part is highlighted in blue - Hello my name is Julie Hochgesang, on FreeTranslation tier, along with ID glosses below on Right I D g tier HELLO I X_1 F S.
The text in the FreeTranslation annotations can then be searched for specific meaning or interactions. For example, we used the SLAASh child transcripts to search for evidence of plural markers by using both the annotation convention [+] that marks repetition of signs on the append tiers and for common nouns that ended in -s on the translation tiers (Hochgesang & Becker Reference Hochgesang and Becker2019).
FreeTranslation annotations are meant to be faithful to the actual meaning, while understanding that translation (like annotation) is highly subjective and interpretative. It also relieves the ID glosses from the burden of carrying meaning (since they are quite poor at that job anyway). They also provide access to others who may not know ASL or the ASL of that time. The work we do with annotation is so time-consuming and highly detailed that it makes sense to have it serve other purposes.
Free translation is also not meant to be about “perfect” English. Since annotators vary in English fluency, we’re not too concerned about using “standard English” or even “academic English.” It’s meant to be a rough English approximation that captures the intended meaning. It’s also not about adding meaning that isn’t there, such as additional contextual information.
6.3.4 Notes
The “notes” tier can be used as annotators prefer. I do recommend that project members confer with one another about the purposes of their notes and to conventionalize any common observations so they can be easily found and reused for sharing. I often use the “notes” tier to note questions and choices regarding annotation, VEEing about language use in the video, and providing contextual information as needed.
7 Additional Reflections
My work maintaining ASL Signbank reflects how I perceive the way humans interact and process knowledge. Humans are categorical beings. Our brains need to categorize things – to help us process them, to recognize things for what they are, whether they’re of use to us, and how to use them. These categories can range from the big to the small or from very broad to rather specific. They all depend on our own experiences and ways of processing. With linguists, for example, we can start with specific theories which shape our categories and hence our labels and codes. These categories can be shared – and often are – colors, numbers, and political parties. They don’t exist apart from us, from our use, or our interactions. But we sometimes treat them as they are, often when they’re in resources removed from bodies like dictionaries and signbanks, hence the problem. But all systems have categories and labels. We just need to be careful not to let those become fixed and be-all-end-all but instead remain flexible, subject to reflection and interaction.
At the end of the day, ASL Signbank is an annotation tool, or as I like to say, a big label maker/holder. It is rooted in research and continually shaped by it. It is one resource that can be used, hopefully with care, with other research tools and methods.
It can also be used by those in the signing communities. I’ve received reports that it has been used by teachers and casual users to celebrate variation and different ways of languaging. For example, I’ve seen assignments that have users search for signs in different ways – translation equivalents, phonological aspects, or relations – allowing them to see the rich connections across signs. I’ve also often engaged in conversation with different ASL users about how to make ASL words stay and often incorporate their suggestions in our database via translation equivalents or usage notes.
7.1 Filming for ASL Signbank
At the time of writing, we have filmed almost thirty-five signers for ASL Signbank (Section 2.4). We film when we have enough draft videos that come up from the annotation process or suggestions by the communities. We compile those videos in a long list, usually slides, to be shown during the filming process. This is one way we escape the “lemma dilemma” (Section 4.1), that is, the effect of written languages on resource development. We are not relying on English word lists to create our entries. Instead, we are pulling from videos of ASL use and showing those videos themselves to our actors.
When we film (after first collecting consent and signer background information), we use a studio in the linguistics department of Gallaudet set up with a teal backgroundFootnote 76 and a DSLR camera or an iPhone. In the room is the actor producing the variants, an assistant showing the signs on a laptop, and me filming. Our filming sessions are a deaf and signing-centric space. Of course, we all use ASL the entire time. Because of that, spontaneous conversations in which actors share insights occur often. “Oh, that’s a cool variant!” “Oh yeah I’ve seen that before.” “Wow, I haven’t seen that one.” And lots of anecdotes – from funny to celebratory, uncomfortable, and sad – about their lives directly linked with the words we are documenting. It has been my privilege to witness these experiences.
Since we are creating a resource for annotating videos in which productions vary a great deal, we have instructed our actors to reproduce what they observe. Sometimes these variants aren’t considered to be their own. Often, it is not an issue for them to reproduce these signs. Sometimes, they don’t feel comfortable doing this, so we skip them and move on to the next. Actors are also instructed to produce them as “expression-less” as possible. They were also instructed to have their arms at rest by the torso, and then to pause briefly at the beginning and the ending of the production. Even though I do instruct them to try to reproduce them as observed in the original source, I also understand that the original source was an instance that is an example of everyday variation. So sometimes we adjust signs based on signers expressing how odd that production feels – either from an articulatory sense (it’s hard to sign that way) or usage sense (it doesn’t match their experience). And yet other times, we have to adjust them to be visible on camera (emboxed discourse). Sometimes playing around with the angle or handedness just to get the ideal view, which can be different from the original source. Signers also often tell us that their own variants are different and supply us with them as new entries for ASL Signbank.
There are plenty of items that clash with different preferences or ideologies. ASL Signbank contains signs that are considered slang, offensive, “not ASL,” “English,” outdated, and regional. We provide usage notes as much as possible to capture this but, of course, cannot capture every single ideology.
We need to be mindful because it’s hard to separate the person from the sign itself. This is one modality difference from the spoken language dictionaries we’re used to. We don’t see faces and bodies with the headwords we browse in dictionaries. But they’re forever linked to the entries in ASL Signbank. It’s also why I made an explicit choice to include different signers with socio-identities with a wide range like they are in the ASL communities. As one reviewer pointed out, this is also an ongoing concern in translation and interpreting work for Deaf communities. Many videos are online showing signers relaying messages that are not necessarily their own. We have a collective responsibility to remember to separate the messenger from the message when appropriate.
Finally, the way we produce signs for recording is also why ASL Signbank cannot represent ASL accurately. ASL isn’t a box of isolated forms with crisp beginnings and ends. It’s also odd to sign forms in isolation. Sometimes ASL Signbank productions look strange because of this fact alone. ASL languaging is embodied or emboxed and rooted in social use and interactions.
7.2 ASL Signbank on Social Media
As part of my research, I have practiced “science communication” (#SciComm), which is sharing of information from our research that is typically gate-kept through academic publishing hidden behind paywalls. I try to share my work in a citable manner by adding them to online repositories like Figshare or OSF whenever possible. I also add content to my website along with ASL videos that provide multimodal access to my work. This access is important because much research that has been done about them has been kept from the communities themselves.
To that end, I have made use of different sharing platforms such as YouTube,Footnote 77 Instagram,Footnote 78 and Twitter (when it was still Twitter) to share multimodal content with alt text, which is not easily added to our entries on ASL Signbank in its current form. Sharing on social media has been effective in making our information accessible to a wider audience, especially ASL communities (Hochgesang Reference Hochgesang, Bono, Efthimiou and Fotinea2018). It has also shown me that there is much out there made for the market of learning ASL. This means online content is often created with an assumed nonsigner audience and is shaped to fit their “hearing gaze.”
For a few years I posted daily to the ASL Signbank Instagram account as a way to share our work, increase awareness about representation of data, and engage in discussion about (ID) glossing and other representation methods and to celebrate variation in ASL communities. To some degree that did take place, albeit mostly in the form of English comments. For the most part, it was nonsigners commenting and asking questions like “can you slow down the videos? I can’t tell how to sign that concept,” “can you add voiceover/music?,” “can you tell us why you sign this way?.” I grew wary of yielding those comments and creating FAQs,Footnote 79 highlights,Footnote 80 and even videosFootnote 81 addressing these concerns and have stopped posting daily. This is unfortunate because those online sharing platforms with their ability to handle multimodal content are ideal for our sharing of science communication and engaging with the communities to continually refine our data and decisions, such as with documenting specific entry information as described in Section 5.
I see the hearing gaze everywhere while I search YouTube looking for ASL videos by those who use the language everyday but instead find ASL 101 assignments posted by new signers or interpreted content.Footnote 82 All these actions and questions are rooted in learning about ASL, and I welcome them. I would love for more people to sign ASL or other signed languages because I am delighted when I come across signers in everyday life. But in a space I’ve made to share research about and by ASL users, it would be good for primary ASL users themselves to be able to engage in this space. This is challenging when a space is overcrowded by those with different goals in mind.
I will continue to explore the digital spaces we have available to us in the signing communities and how to use these spaces with our communities in mind. I believe the open-access and signing-centric practices I mention in this Element will serve that goal well.
7.3 What Lies Ahead
As many know, the maintenance of technology and technical infrastructure, which includes ASL Signbank, is difficult (Information Maintainers et al. 2019; Chachra Reference Chachra2023). We may be wary of clicking a hyperlink in an article that is only five years old because it might be outdated. Maintenance is reliant on the upkeep of hardware (such as servers) and software (such as ELAN) and the institutions that make them possible to be active in the first place: namely, universities, tech companies, and governments (Bird & Simons Reference Bird and Simons2003; Mattern Reference Mattern, Berez-Kroeker, McDonnell, Koller and Collister2022; Berez-Kroeker et al. Reference Berez-Kroeker, McDonnell, Koller and Collister2022; Hochgesang et al. Reference Hochgesang, Lepic, Shaw and Wehrmeyer2023). Maintenance is also not “sexy” nor celebrated. It doesn’t usually get high prestige for faculty actions and citations of publications.
If by the time you read this, ASL Signbank is not active for reasons cited in Hochgesang et al. (Reference Hochgesang, Lepic, Shaw and Wehrmeyer2023), I hope you still can take away from this Element the importance of representation and the power it holds and find some of my lessons to be instructive. Like I have said, there is no one system to rule all. And there shouldn’t be. But there are practices that are conducive to processing and sharing ASL video data – or as I like to describe it, caring for our language data.
That said, there are continued funding attempts to maintain the database. We are always hoping to continue to improve on its design. I continue to accept more signs as we continue watching videos. I also would love to further explore socio-representation of North American ASL communities. There always remains data entry work such as phonological coding and other even-more neglected fields in ASL Signbank entries. We also need to continue evaluating the data input such as “related signs” (Section 5.10) through continued discussions with like-minded researchers, the communities, through surveys, and online sharing.
Since 2006, I have been using ASL Signbank in its various incarnations to provide a stable and citable version of signs in my work. Lexical resources like signbanks are meant to be tools for corpora and language documentation and to enable corpus methods such as looking at semantic networking or calculating frequency. We have yet to connect the signbank frequency script to any of the corpora we have developed using ASL Signbank. But a casual review of the CARD ELAN annotation files I have on my personal computer with a total of 60,571 annotationsFootnote 83 made possible through multiple file search reveals the most frequent signs and conventions in this dataset (see Tables 1 and 2).
| Annotation convention | Frequency |
|---|---|
| FS(fingerspelling) | 3,473 |
| IX(index) | 5,562 |
| DS(depicting-sign) | 1,811 |
| ~NEED-ID-GLOSS | 479 |
| POSS(possessive) | 472 |
| DS(ca) (constructed action) | 210 |
| &=activity | 200 |
| YYY(unclear) | 158 |
| NS(name-sign) | 68 |
| HONORIFIC | 52 |
Pointing signs (IX_1 and IX) are the most frequent with over 5,000 tokens. FS(fingerspelling), IX(index), and DS(depicting-sign) are the most used annotation conventions. With my colleagues in the Linguistics Department at Gallaudet, I’m working to use CARD data to further analyze the frequency of ASL constructions in usage data.
I love taking photos, writing notes, observing life through cameras, and love organizing all of those so they can be shared easily and carried on to others down the road. I often tell my students to care for their data by making it accessible and backing up everything as much as they can (Lots of Copies Keep Stuff Safe (LOCKSS)).Footnote 84 And because of all the labor it takes to do this work, I just can’t keep it locked up in a file cabinet in my office. That love and care for documentation has its fingerprints all over my maintenance of ASL Signbank. Open access THAT.
At the time of writing this, there are nearly 4,500 entries in ASL Signbank, and over 3,300 of them are publicly available. This living resource will grow as long as we work on it. I hope it grows well and continues to serve the documentation and celebration of the languaging practices of ASL communities. I will continue to reflect on the work I do and try to be accountable to shifting meaning and variation. After all, one person’s phonological variant is another person’s lemma. I also hope I demonstrated how research practices are shaped by the work as well as current traditions, values, and relevant ideologies. I ask you to use ASL Signbank with those who are fluent in ASL. Anyone doing signed language research must be doing the work with signing deaf people, preferably with them leading (Kusters et al. Reference Kusters, De Meulder and O’Brien2017; Hochgesang & Palfreyman Reference Hochgesang, Palfreyman, Fenlon and Hochgesang2022; Desai et al. Reference Desai, De Meulder, Hochgesang, Kocab, Lu, Efthimiou, Fotinea and Hanke2024). ASL Signbank alone does not and cannot represent all ASL use. But it can serve representation of how ASL is used across signing communities. May you see the benefit of ASL Signbank for your experiences and know just how it can be used or have gleaned useful lessons from processes such as representation and care for any kind of data.
Acknowledgments
The research reported here was supported in part by the National Institute on Deafness and Other Communication Disorders of the National Institutes of Health under award number R01DC013578, award number R01DC000183, and R01DC009263. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
ASL Signbank was developed at Radboud University by Onno Crasborn, Wessel Stoop, Micha Hulsbosch, and Susan Even. Wessel Stoop has been essential in keeping it up and running. We are also grateful to the tech staff at Yale and UConn, especially Kraig Eisenman and Robert Dowden.
Immense gratitude to Deborah Chen Pichler, Diane Lillo-Martin, and Ronice de Quadros for inviting me to work with them.
The work reported here would have not been possible without the original SLAAASh research team: Amelia Becker, Donovan Catt, Anna Lim Franck, Carmelina Kennedy, Ardavan Guity, and Lee Prunier. While writing this, Bonnie Barrett helped me film for ASL Signbank with the support of Joseph Hill’s start-up and Diane Lillo-Martin’s UConn internal grant.
All of the ASL Signbank actors (in chronological order of date of filming for us to date): Felicia Williams, Nayo Franck, Paige Hawkins, Renca Dunn, Mari Klassen, Franklin Jones Jr, April Jackson-Woodard, Conrad Baer, Norma Moran, Yvans Cator Jr, Raychelle Harris, Gabriel Arellano, Andrew Morrill, Debbie Colbert, Leticia Arellano, Debbie Peterson, Carmelina Kennedy, Jonathan McMillan, Brenda Perrodin, Lourdes Valenzuela, Miranda Medugno, Lettie Nazloo, Kurt Gagne, Cody Pederson, Arlene B. Kelly, LeeAnn Tang, Nageena Ahmadzai, Giovanni Maucere, Ashley Clark, Wink, Kelly Lenis, Julie A. Hochgesang
Gratitude to editors, Erin Wilkinson and David Quinto-Pozos, and the two anonymous reviewers along with Ryan Lepic and Diane Lillo-Martin’s support for helping get this in print!
Also gratitude to ASL communities, ASL Signbank staff, and users who’ve shaped the tool and the aims.
I would like to thank the students I’ve had over the years, especially doctoral students – Bonnie Barrett, Kiva Bennett, Donovan Catt, Ardavan Guity, Heather Hamilton, and Nozomi Tomita – whose questions and experiences about doing research and about language in general have simultaneously sharpened and softened my own thoughts.
I am grateful to my colleagues in the Gallaudet linguistics department for making work a wonderful place to be. I’ve engaged in countless discussions with my colleagues about annotation and what labels we should use for ID glosses. I would also like to thank my husband, Oz, and my boys, Ozzy and Oliver, who have been with me nearly as long as I’ve worked with ASL Signbank.
Thanks to my parents, Sandy and Jim, and my siblings, Jennifer and Jeff, for signing with me all my life.
Erin Wilkinson
University of New Mexico
Erin Wilkinson is Associate Professor in the Department of Linguistics at the University of New Mexico. She has broad research interests in bilingualism and multilingualism, language documentation and description, language change and variation, signed language typology, and language planning and policy in highly diverse signing communities. Her current studies in collaboration with other researchers examine cognitive and linguistic processing in signing bilingual populations. She also explores what linguistic structures are re-structured over time in signed languages and what are possible factors that contribute to language change and variation in signed languages in the lens of usage-based theory.
David Quinto-Pozos
University of Texas at Austin
David Quinto-Pozos is an Associate Professor in the Department of Linguistics at the University of Texas at Austin. His research interests include signed language contact and change, the interaction of language and gesture, L1 and L2 signed language acquisition, spoken-signed language interpretation, and vocabulary knowledge and literacy. He has served as an editor/co-editor of four volumes on signed language research, including Modality and Structure in Signed and Spoken Languages (Meier, Cormier, & Quinto-Pozos, eds. 2002; Cambridge University Press), Sign Languages in Contact (Quinto-Pozos, ed. 2007; Gallaudet University Press), Multilingual Aspects of Signed Language Communication and Disorder (Quinto-Pozos, 2014; Multilingual Matters), and Toward Effective Practice: Interpreting in Spanish-influenced Settings (Annarino, Aponte-Samalot, & Quinto-Pozos, 2014; National Consortium of Interpreter Education Centers).
About the Series
This Elements series covers a broad range of topics on signed language structure and use, describing dozens of different signed languages, along with accounts of signing (deaf and non-deaf) communities. The series is accessible (via print, electronic media, and video-based summaries) to a large deaf/signing-friendly audience.