


1. Introduction
There is a ghost in the room: when artists describe their work with artificial intelligence, terms like ‘haunted’, ‘uncanny’ or ‘otherworldly’ abound (Broad et al. Reference Broad, Leymarie and Grierson2020; Grba Reference Grba2022; Halperin et al. Reference Halperin, Jones and Rosner2023; Roberts Reference Roberts2023; Privato and Magnusson Reference Privato and Magnusson2024). WeFootnote 1 might ask then whether these terms pertain to qualities inherent to these algorithms, or whether they reflect on how we conceptualise and give meaning to the aesthetics of AI-generated media. In the context of musical practice, this paper argues the latter: when practitioners work with AI, they engage not just with algorithms and datasets but with a rich cultural imaginary of popular narratives of ghosts in the machine, of autonomous machines in science fiction and of spectral presences in analogue media. Our premise is that these associations shape our sonic aesthetic expectations and actively influence design decisions, from system architectures to signal processing choices. In this sense, the ghostly presence we hear in AI-generated sound may be something we engineer into existence rather than organically discover.
While existing research has addressed how music-making tools embed ‘paths of least resistance’ toward certain aesthetics (Magnusson Reference Magnusson2019; McPherson and Tahıroğlu Reference McPherson, Lepri, Morreale, Harrison, Morrison and Davison2020; Snape and Born Reference Snape, Born and Born2022), less attention has been paid to the reverse direction: how the aesthetic expectations that practitioners bring to technology-mediated musical practice, based on cultural narratives and conceptual associations, actively steer design decisions and sonic aesthetic outcomes. This point is illustrated by our reconstruction of events of the Surfing Hyperparameters project, a performance system involving an ensemble of AI models and a feedback-actuated augmented bass (FAAB). In this account, we collect the mismatches between our sonic aesthetic expectations – haunted, uncanny, otherworldly – and the system’s sonic outputs. Through this narrative exercise, we identified that the haunted sonic aesthetics of the system were inspired rather than directly caused by the AI component of the system.
This paper proceeds through interconnected investigations on the topic of how aesthetics are constructed in technology-mediated musical practice. In Section 2, we first examine the aesthetic associations that cluster around AI in experimental music contexts, particularly the prevalence of ghostly and haunted aesthetics. We then explore, in Section 3, how these associations function as a form of aesthetic expectation that shapes creative practice, a theme which is illustrated later in our reconstruction of the Surfing Hyperparameters project in Section 4. Drawing from this story, in Section 5, we discuss the important role of narrative in mediating between aesthetics and technology, issues of accountability when speculating about the behaviour of AI systems, and the further implications of this work for practice-based research. Finally, we collect our conclusions in Section 6.
2. How does AI sound?
Before we dive into the question of how AI sounds, we need to first problematise the term ‘AI’ itself. In The uncontroversial ‘thingness’ of AI (2023), Suchman argues that ‘AI’ functions as what Lévi-Strauss has called a ‘floating signifier’ (Reference Lévi-Strauss1987) – a term that seems to reference something specific while remaining ambiguous enough to absorb many meanings. According to Suchman, critical scholars further crystallise these suggestive powers when their critique fails to destabilise its object of study. In this paper, we attempt to destabilise the term ‘AI’ by precisely addressing how this floatiness allows it to absorb certain aesthetic qualities that do not necessarily relate to specific technical implementations.
We acknowledge this vagueness yet deliberately retain the term ‘AI’ throughout the paper, as replacing it with technical specifics would lose the very ambiguity that allows the term to absorb aesthetic qualities. Our use of ‘AI’ is thus intentional: rather than sidelining the term’s vagueness, we examine how this ‘floating’ quality shapes the assumptions and expectations we bring to technology-mediated musical practice. When we ask ‘how does AI sound?’, we are not asking only how a specific sound-generating model sounds, but rather about the expectations practitioners hold of how AI – in its ambiguous form – should sound, particularly within the experimental music technology practice and research community. While our perspectives are necessarily situated within this context, other researchers working with AI and musical practice may recognise similar aesthetic frameworks in their own practice.
2.1. Making sound with latent spaces
In the 2010s, the usage of machine learning (ML) techniques in experimental music performance was primarily in the form of supervised classification and regression models for mapping gesture (or generally, an input) to sound (Schnell et al. Reference Schnell, Röbel, Schwarz, Peeters and Borghesi2009; Caramiaux and Tanaka Reference Caramiaux and Tanaka2013; Bullock and Momeni Reference Bullock and Momeni2015), at least in the digital musical instrument research space. As Jourdan and Caramiaux (Reference Caramiaux2023) report, from 2017 and with the popularisation of unsupervised deep learning techniques, researchers in this field have increasingly focused on audio generation tasks through the usage of Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), Recurrent Neural Networks (RNNs) and variants.
Currently, latent space manipulation is perhaps the most common technique to make sound with AI models (Tahiroǧlu et al. Reference Tahiroǧlu, Kastemaa and Koli2021; Scurto and Postel Reference Scurto and Postel2023; Privato et al. Reference Privato, Magnusson, Shepardson, Lepri and Magnusson2024; Shaheed and Wang Reference Shaheed and Wang2024; Schroeder and Reuben Reference Schroeder, Reuben, Massi, Prokůpek, Ricci and Ostillio2025). Latent spaces are generated by training models such as VAEs or GANs. For instance, VAEs are trained to encode the input data into a continuous latent space, and then decode samples from this latent space back into data resembling the original inputs. A common approach to making music with latent spaces is to use some sort of interface to ‘navigate’ the latent space. Examples of this approach include Stacco, which uses magnets and magnetic sensors to sample the latent space of RAVE models (Caillon and Esling Reference Caillon and Esling2021), models which are based on VAEs and in this particular project are trained on different instruments such as guitar, saxophone or organ (Privato et al. Reference Privato, Magnusson, Shepardson, Lepri and Magnusson2024); or AI-terity, which uses a non-rigid 3D printed structure with embedded capacitive sensors to sample the latent space of a GAN model trained on electronic and downtempo ambient tracks (Tahiroǧlu et al. Reference Tahiroǧlu, Kastemaa and Koli2021). Alternatively, VAE models trained on a particular instrument’s sounds can be used for timbre transfer by processing audio input from a different instrument, e.g. transforming voice into drums (Caspe et al. Reference Caspe, McPherson and Sandler2025).
2.2. Ghosts in the machine
In texts discussing musical practice with latent spaces, what’s typically emphasised is the ‘novelty’ aspect: since the latent space is continuous, it can be sampled to generate sounds that are a statistical interpolation between sounds rather than a mere recombination of them (Cádiz et al. Reference Cádiz, Macaya, Cartagena and Parra2021; Tahiroğlu and Wyse Reference Tahiroğlu and Wyse2024). However, creating new and as-of-yet-unheard sounds is easier than it might seem: any sounds created through random processes will be novel in some trivial way. Non-trivial novelty occurs when, as listeners, we can ascribe some meaning to it (Dahlstedt Reference Dahlstedt and Reck Miranda2021). In this sense, what’s interesting about these new sounds is not their unprecedented nature but rather that the process that produced them is neither obvious (e.g. a simple transposition) nor random, but rather obscure yet still perceived as aesthetically intentional.
Along these lines, Dahlstedt asks: ‘what comes from the algorithm, and not from the human designers and operators behind it? […] what influence cannot be referenced back to a human?’ (Dahlstedt Reference Dahlstedt and Reck Miranda2021: 883). This obscure agency of AI generative systems is often perceived as what Fisher (Reference Fisher2016) would call the eerie: ‘The eerie concerns the most fundamental metaphysical questions one could pose, questions to do with existence and non-existence: Why is there something here when there should be nothing? Why is there nothing here when there should be something?’ (Fisher Reference Fisher2016: 10, italics in original).
2.2.1. Strange presences in media and sonic hauntology
Strange presences inside algorithms and machines in general have been extensively explored in popular culture as ‘the ghost in the machine’. The phrase has inspired a variety of cultural manifestations from cyberpunk manga (Shirow [Reference Shirow1991] 2009) to sonic hauntology (Fisher Reference Fisher2012).Footnote 2 Media technologies have also popularly been haunted by ghosts of the past in the event of interference and degradation, especially in the context of analogue media. Tape noise or analogue video degradation has often been associated with the ghosts of previous audiences, whose use of such technologies produced such degradation (Hilderbrand Reference Hilderbrand2009; Sexton Reference Sexton2012).
How the past infiltrates the present is indeed the trope of the 2000s sonic hauntology movement, with the Ghost Box label and artists such as Burial (2006) or The Caretaker (2009) (Fisher Reference Fisher2012). The term hauntology is borrowed from Derrida’s critique of Western thought as a succession of repeating ideas, i.e., the ‘spectrality’ of Western thought, particularly in Marxism (Derrida [Reference Derrida1993] 2006; Reynolds [Reference Reynolds2006] 2012); although in the sonic movement the political or philosophical connotations have been downplayed to focus on ‘the more ontological sense of hauntology: that being is itself haunted, constituted from a number of hidden traces whose presence is felt but often unacknowledged’ (Sexton Reference Sexton2012: 562). Sonic hauntologists made this presence audible by mixing digital and analogue technologies: often by foregrounding recording noises signalling decay and deterioration, motifs inspired by film scores (particularly science fiction and horror), sampling and adding reverberation to evoke ‘eerie dead presences’, and weaving these with industrial drones, abstract noise, spoken word and found sounds (Sexton Reference Sexton2012; Reynolds [Reference Reynolds2006] 2012).
2.2.2. Ghosts in the AI
Several authors have traced parallels between the sonic hauntology movement and AI-generated sound (Rubinstein Reference Rubinstein2020; Privato and Magnusson Reference Privato and Magnusson2024; Sturm et al. Reference Sturm, Amerotti, Dalmazzo, Cros Vila, Casini and Kanhov2024). Along these lines, we could ask whether there are technical aspects in AI-generated music that give rise to the sonic hauntology characteristic aesthetics. Well aware that ‘making music with AI’ escapes lazy generalisations, we are referring in particular to latent space exploration, which is a broad practice encompassing varied forms of experimental music-making (Tahiroǧlu et al. Reference Tahiroǧlu, Kastemaa and Koli2021; Scurto and Postel Reference Scurto and Postel2023; Privato and Magnusson Reference Privato and Magnusson2024; Shier and Yi Reference Shier and Yi2025). Early architectures that could produce raw audio, such as Wavenet (van den Oord et al. Reference van den Oord, Dieleman, Zen, Simonyan, Vinyals and Graves2016), did so at a low fidelity and could generate nonsensical yet plausible speech, causing their outputs to be easily associated with ghosts in the machine.Footnote 3 Other approaches rely on spectral representations of sound, which can introduce artefacts like phase discontinuities that contribute to an uncanny or degraded quality. More recent neural audio synthesis architectures, such as RAVE (Caillon and Esling Reference Caillon and Esling2021), have improved sound quality while running in real-time, yet the eeriness might still persist in other forms: impossible timbres (e.g. timbre transfer between drums and flute), superhuman ways of playing instruments (a feature shared with music by artists such as Squarepusher (1996)), or simply, the inherent latency between encoder and decoder, causing a shadowing effect during real-time interaction with the model.
However, the association between AI and sonic hauntologists is more often argued from a conceptual perspective. While sonic hauntologists achieve a ghostly and eerie aesthetic through an intentional ‘plundering of the recorded past’ (Rubinstein Reference Rubinstein2020: 78), large generative AI systems engage in their own form of archival haunting: they systematically plunder vast datasets of recorded media and resituate them within drastically different contexts (Rubinstein Reference Rubinstein2020: 83). These associations between AI-generated music and sonic hauntology and ghostly aesthetics are conceptual rather than based on a sonic aesthetic – that AI-generated music contains ‘traces of the past’ does not intrinsically mean that the generated sound will render similar aesthetics as those of sonic hauntologists.
3. How do we make aesthetics with technology?
We have seen that ‘ghostly’, ‘uncanny’ and ‘eerie’ are common associations with AI-generated sounds, at least in those generated by latent-space manipulation systems. While some of these associations are grounded in technical phenomena (e.g. glitch, noise), others rely on conceptual links (e.g. by relating to the ghost in the machine tropes). As Science and Technology Studies (STS) scholars remind us, tools are inscribed with their designer’s worldviews (Akrich Reference Akrich, Wiebe and Law1992), an argument which can be easily extended to how particular musical aesthetics are inscribed in musical instruments (Magnusson Reference Magnusson2009; McPherson and Lepri Reference McPherson and Lepri2020). What has been given less attention is how technology might inspire certain aesthetic and musical ideas without relying on technical grounds – i.e. through a conceptual or imaginary route.
In this section, we investigate how musical aesthetics are made in technology-mediated music making. We explore how sonic aesthetics might not only be caused by a technology but also inspired by it, and the relevance of narrative in mediating between the material constraints of a technology and our evolving imagination of it.
3.1. The idiomaticity of tools
Utopian yet persistent marketing slogans claiming that new music technology will be able to generate any imaginable sound have accompanied the introduction of many novel musical instruments and interfaces (Théberge Reference Théberge1997). In these bold claims, music technology is marketed as a neutral mediator of musical ideas, avoiding making any assumptions about the musical preferences of potential buyers to attract a broader range of customers (McPherson et al. Reference McPherson, Lepri, Morreale, Harrison, Holland, Mudd, Wilkie-McKenna, McPherson and Marcelo2019). In contrast, a non-neutrality view of technology acknowledges that designers inscribe their values into the technologies they build (Akrich Reference Akrich, Wiebe and Law1992). In music technology, a way in which this materialises is by facilitating certain musical aesthetics over others; Magnusson illustrates this with the piano, which ‘“tells us” that microtonality is of little importance’, and the drum-sequencer, which assures us that ‘4/4 rhythms and semiquavers are more natural than other types’ (Magnusson Reference Magnusson2009: 171).
Indeed, ‘[t]echnology embodies theory and this affects the music, as much as our musical ideas are written into our software and hardware’ (Magnusson Reference Magnusson2019: 67). Even in the blank canvases of computer music languages such as Max or PureData (Pd), McPherson and Tahıroğlu find salient idiomaticity: ‘patterns […] which are particularly easy or natural to execute in comparison to others’ (McPherson and Tahıroğlu Reference McPherson, Lepri, Morreale, Harrison, Morrison and Davison2020: 53). McPherson and Lepri (Reference McPherson and Lepri2020) study Pd patching practices through a compositional game with several participants, and find that most of the produced patches showed a 1-to-1 relationship between the current value of a sensor and a parameter value, i.e., a memoryless control relationship, and that fundamental sound synthesis elements such as sine and sawtooth oscillators, white noise and filters appeared straightforwardly in the final output (McPherson and Lepri Reference McPherson and Lepri2020: 4–5). These idiomatic patterns are what Snape and Born have called ‘paths of least resistance’ in their study of MaxMSP patching practices, where they identify ‘collagist coding’ practices in which users repurpose code from Max help files and tutorials rather than writing their patches from scratch, which leads to characteristic sounds, a ‘sense of “Maxness”’. In particular, they point towards Max’s temporal paradigm as a strong aesthetic force which favours musics involving live processing, material generation and physical computing elements:
When practitioners and critics describe something as “sounding like Max”, they articulate a sensitivity not so much to an actual sound, or a sonic marker of style or genre, but to something at once subtler and broader: the prevalence of aesthetic figures – sonic, material, visual or formal – that stem from paths of least resistance to the ways of working with time peculiar to Max. (Snape and Born Reference Snape, Born and Born2022: 246)
3.2. The paths of least resistance in AI-generated sound
It could be tempting to assume that, given that AI is fundamentally a set of computational techniques rather than a concrete piece of software, it is generally free of the influence of intrinsic idiomatic patterns or musical assumptions. Indeed, one should be careful when generalising about AI, so narrowing down the scope to latent space manipulation in a musical context, we can identify at least an obvious source of aesthetic influence: the training data. Because music is not just sound (Born Reference Born, Clayton, Herbert and Middleton2012), and sound is not just an audio signal, any computational representation of music incurs some assumption about its nature. The problem is similar to that of projecting an Earth globe map onto a flat map. The two-dimensional map can preserve one or more of the following characteristics: directions, distances, areas or shapes – yet never all of them, as one would require the three dimensions of a globe map. As it is well known, the Mercator projection relies on this mathematical impossibility to represent countries in the Global South as being minuscule in comparison to countries in the Global North (Henrikson Reference Henrikson1979; Barney Reference Barney2014).Footnote 4 In music, the issue is no less complex, as some of its features do not even have a concrete, orthogonal, quantifiable and unambiguous representation (e.g. pitch, timbre) (McPherson et al. Reference McPherson, Lepri, Morreale, Harrison, Morrison, Davison and Wanderley2024; Reed et al. Reference Reed, Benito, Caspe and McPherson2024). Crystallising music into a given representation implies making choices to disambiguate said features – choices that, like the Mercator projection, privilege certain musical traditions while marginalising others (e.g. MIDI’s assumption of equal temperament and discrete pitches disadvantages music with microtones or continuous pitch variation). If using an off-the-shelf dataset – and the availability of certain musics over others will also exert its aesthetic influence – the choice of music representation will be left to the creator of said dataset (Salamon Reference Salamon2019). Moreover, off-the-shelf datasets are typically released with a task in mind (e.g. genre classification, piano performance generation), which in turn points to how popular music-related tasks in AI research influence the music representation and musical content of said datasets.
We have seen, then, that music technologies facilitate some compositional paths over others, both through their inner workings (e.g. choice of music representation), as well as through the specific practices they enable (e.g. collagist coding), which have aesthetic consequences. On the issue of how musical aesthetics are made with technology, another relevant aspect that we need to consider is the associations with technology that are not rooted in some technical or material reality but rather in conceptual or imagined grounds. As we discussed in Section 2.2.2, AI-generated sound is often regarded as haunted, ghostly, eerie, and such characteristics have been represented in media through certain sonic resources (analogue reproduction sounds, glitch, interference, crackle, spoken word). However, there is no obvious technical reason or causal chain establishing that AI-generated sound needs to follow that ghostly and eerie aesthetic. Such aesthetics might be instead inspired by cultural narratives surrounding the technology, reflected in sonic design choices such as input signal selection, audio effects or digital signal processing tricks. The paths of least resistance in AI music systems are thus both technical, stemming from software and hardware constraints as well as the practices they enable, and conceptual, emerging from cultural associations and imagined qualities we project onto these technologies.
3.3. The importance of narrative
The main consequence of these paths of least resistance is that practitioners gravitate toward certain sonic aesthetics when using a particular technology – e.g. the ‘Maxness’ of Max (Snape and Born Reference Snape, Born and Born2022). This influence extends beyond the moment of creation itself: our associations between technologies and their characteristic sounds shape how we imagine future instruments and compositions. When these sonic expectations align with actual technical phenomena, they create a feedback loop that reinforces these aesthetic tendencies. However, when sonic expectations rely mostly on conceptual associations – such as the notion that AI-generated sounds should be haunted – there is a clash between sonic expectation and technical reality.
When addressing how aesthetics are constructed in the creative process with technology, the paths of least resistance are only a part of the story – equally relevant are the practitioners’ sonic expectations, the actual technical qualities of the system, and the ongoing negotiation between these items as the creative practice unfolds. Capturing this dynamic interaction requires a methodological approach that can document this negotiation as it happens, rather than through a reconstruction after the fact, which will inevitably be biased by the experience of later iterations of the system design. Our approach to address aesthetics in technology-mediated musical practice, which we will describe in the next section, centres on the evolving narratives that practitioners construct about their work as it happens. Indeed, the stories practitioners tell about technology are performative (Haraway Reference Haraway1988; Traweek Reference Traweek and Pickering1992; Law Reference Law2000), not merely innocent articulations of reality but reality-producers. What actually happens technically in technology-mediated music making often matters less than the narrative practitioners construct around it. Through these stories, practitioners mediate between sonic expectations and material encounters with technology, articulating an aesthetic for their creative projects (Green Reference Green2014).
4. The Surfing Hyperparameters project
In this section, we retell the story of the Surfing Hyperparameters project. The repetition prefix (the re- in retell) is to emphasise that we are reconstructing the narrative from documentation captured as the project unfolded, following the approach we outlined in a previous publication (Pelinski et al. Reference Pelinski, McPherson and Fiebrink2024): written notes from practice sessions and the reflexive journal thereafter, GitHub commit historyFootnote 5 and audiovisual material.
In Section 4.1, we begin by describing the project context, motivation, and initial design and expectations. Since this early development focused on implementing the system infrastructure, and we did not interact with the system musically, we present a condensed account of this stage, as our aesthetic expectations during this time remained largely unchanged. We then reconstruct the narrative in the project through two subsequent iterations in Section 4.2, foregrounding the elements that shaped the sonic aesthetics of the system.
4.1. Project background
4.1.1. Context and motivation
The motivation for this project was to explore using deep learning models as design materials in creative practice. While the latest trends in music AI research focus on the application of large language models (LLMs) to audio tasks (Latif et al. Reference Latif, Shoukat, Shamshad, Usama, Ren and Cuayáhuitl2023; Ma et al. Reference Ma, Øland, Ragni, Sette, Saitis, Donahue and Lin2024), alternative creative AI practices work with small custom datasets (Vigliensoni and Fiebrink Reference Vigliensoni and Fiebrink2024), exploring the models’ idiosyncratic behaviours rather than pursuing model generalisation (Vigliensoni et al. Reference Vigliensoni, Fiebrink, Perry and Fiebrink2022; Jourdan and Caramiaux Reference Jourdan and Baptiste2024; Sappho et al. Reference Sappho, MacDonald, O’Hear, Ponlot and Frank2025, Schroeder and Reuben Reference Schroeder, Reuben, Massi, Prokůpek, Ricci and Ostillio2025). This emphasis on custom small datasets contrasts with author #1’s previous experience in the field of Music Information Retrieval (MIR) research, where the focus is on the optimisation of models for specific tasks. A way in which this optimisation is done is by tuning the models’ hyperparameters, i.e., the parameters that are fixed during training, such as the number of layers or the learning rate. The typical approach involves training many variations of the same architecture with different hyperparameter configurations, ranking these models according to some performance metric, and discarding all but the best-performing one. Motivated by ‘recycling’ those discarded models, we were interested in exploring how variations of the same architecture, trained with the same data but different training hyperparameters, could potentially produce different sound worlds – each exhibiting its own properties as artistic material. Along these lines, an inspiration for this project was Caramiaux’s work in interactive ML for creative practice, where he argues for ‘enabling materiality through interactivity’ (Caramiaux Reference Caramiaux2023: 43–45).
The intention was to design such a system as a sort of augmentation or ‘something to play with’ for author #2 with their FAAB. The FAAB is a double bass repurposed as a feedback instrument and was built by author #2 in collaboration with Halldòr Ùlfarsson. The FAAB has individual pickups placed under each string, whose signals are processed in a Bela microprocessor and then sent to an amplifier driving a speaker embedded in the back of the instrument. As the system’s amplitude increases, this results in a feedback loop in which the speaker mechanically vibrates the instrument’s body and consequently the strings, causing the instrument to enter self-oscillationFootnote 6 (Melbye and Úlfarsson Reference Melbye and Úlfarsson2020; Melbye Reference Melbye2021, Reference Melbye2023).
4.1.2. Core system design
The central project ambition was to navigate between different models during live performance, each producing distinct sonic profiles given their different hyperparameter configurations. Below, we discuss the core elements of the system design. Since the initial development phase focused on implementation rather than sonic experimentation, instead of providing an elaborate narrative for this part, in the following section, we summarise our early expectations before diving into our retelling of the project narrative.
4.1.2.1. Signal flow
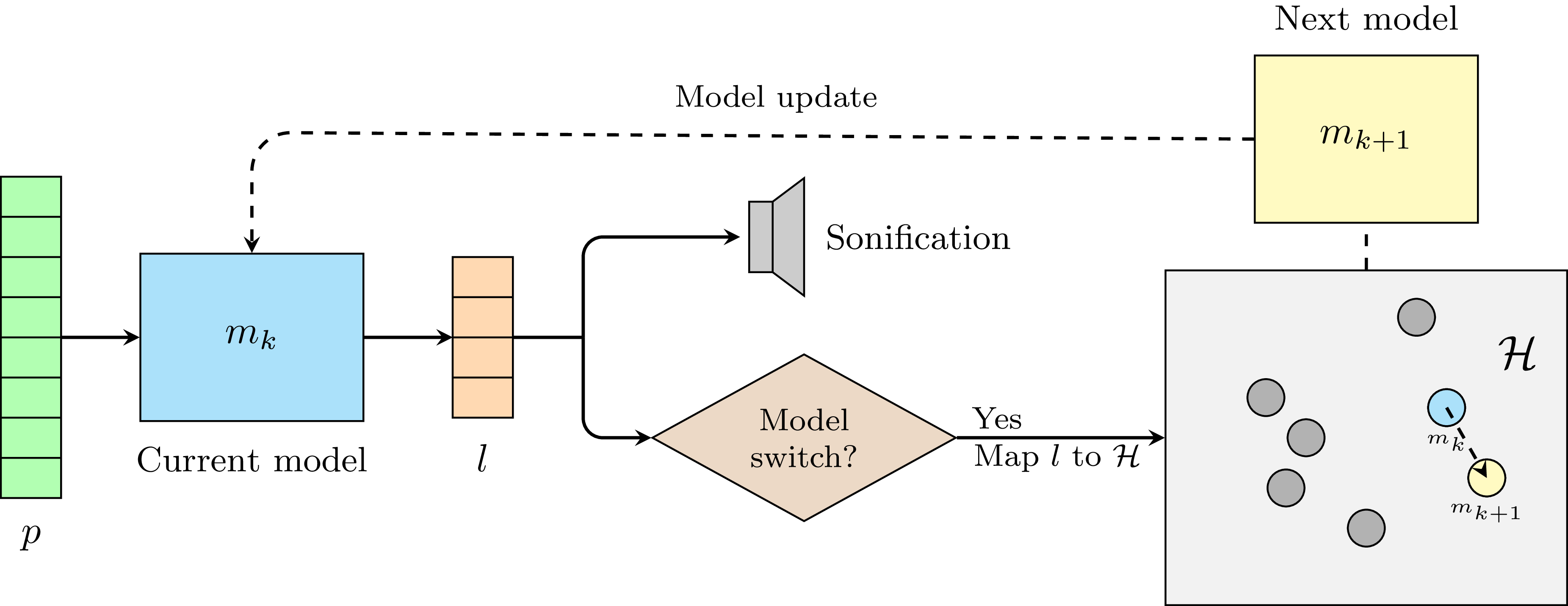
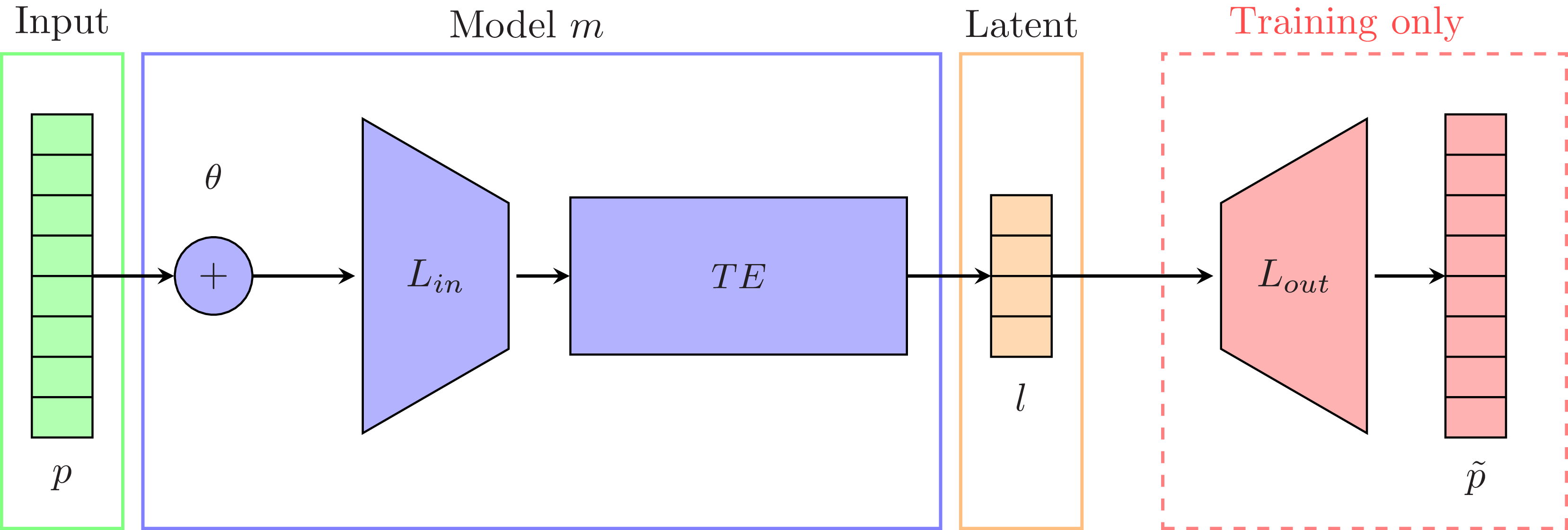
The basic system architecture (see Figure 1) remained largely the same throughout the project. We attached eight piezo sensors (contact microphones) to different parts of the FAAB (see Figure 2), and captured their signals at 22,050 Hz using Bela (McPherson and Zappi Reference McPherson, Lepri, Morreale, Harrison and Zappi2015), which sent the data to a laptop computer running Python via the pybela library (Pelinski et al. Reference Pelinski, McPherson, Fiebrink, Moro and McPherson2025). These signals were processed in windows of 1,024 samples by a lightweight autoencoder based on the Transformer architecture (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones and Gomez2017). The network consisted of a stack of Transformer encoder layersFootnote 7 that compressed the eight piezo signals into four latent signals, and a simple linear layer decoder that was only used during training (see Figure 3). The output signals were sonified through different techniques as the project unfolded, so we will discuss these later as we present the project narrative.
Core system architecture. Eight piezo signals
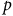 $p$
are processed by the current model
$p$
are processed by the current model
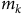 ${m_k}$
to produce latent outputs
${m_k}$
to produce latent outputs
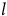 $l$
, which are then sonified. When the switching model algorithm triggers a model switch, the current latent values
$l$
, which are then sonified. When the switching model algorithm triggers a model switch, the current latent values
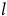 $l$
are mapped to coordinates in the hyperparameter space
$l$
are mapped to coordinates in the hyperparameter space
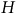 $H$
, and the nearest model
$H$
, and the nearest model
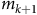 ${m_{k + 1}}$
becomes the new active model.
${m_{k + 1}}$
becomes the new active model.

Piezo contact microphones attached at the front, tailpiece, bridge and inside the F-holes of the doublebass. The piezos at the back and on the scroll are not shown in the picture. The faders and knobs visible on the FAAB are used for individual string gain and effects blend (Melbye Reference Melbye2023: 81), respectively, for the FAAB’s own signal processing. In the supplementary video and audio materials, no effects were used.

Autoencoder architecture based on the Transformer encoder. Eight piezo signals (
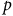 $p$
, 8 × 1,024 samples) are combined with positional encodings
$p$
, 8 × 1,024 samples) are combined with positional encodings
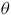 $\theta$
, compressed to four channels via linear layer
$\theta$
, compressed to four channels via linear layer
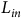 ${L_{in}}$
processed through Transformer encoder
${L_{in}}$
processed through Transformer encoder
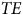 $TE$
to produce latent representation
$TE$
to produce latent representation
 $l$
(4 × 1,024), then reconstructed to original dimensions
$l$
(4 × 1,024), then reconstructed to original dimensions
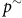 ${p^ \sim }$
(8 × 1,024) via output layer
${p^ \sim }$
(8 × 1,024) via output layer
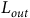 ${L_{out}}$
during training. During performance, the
${L_{out}}$
during training. During performance, the
 ${L_{out}}$
layer is dropped and the
${L_{out}}$
layer is dropped and the
 $l$
latents are directly used as output.
$l$
latents are directly used as output.

Model variations and navigation
Using the W&B sweep tool,Footnote 8 we trained twenty model variations with different hyperparameter configurations. Based on these configurations, we assigned coordinates to each model in a four-dimensional space, which we call the hyperparameter space. The four dimensions of this space correspond to a selection of the model’s hyperparameters.Footnote 9
Model switching
During performance, only one of the twenty trained models runs at a time, while a model switching algorithm determines when to switch models. The implementation of this algorithm was one of the key aspects addressed during our practice sessions. Because it directly influenced the aesthetics, we will discuss the algorithm specifics in the narrative section. Once the model switching algorithm switches to a new model, the current model’s four latent outputs are mapped to coordinates in the hyperparameter space,Footnote 10 and the closest model in the space is selected to run next (see Figure 1). In this way, author #2’s playing influences both the immediate sonic output and the trajectory through different models.
4.1.3. Initial expectations
We placed the eight piezos across the FAAB – on the front, back, inside the F-holes, and on the bridge, tailpiece and scroll. Our goal was to capture variations in the instrument’s resonance from multiple listening perspectives (points in the instrument’s body). We expected the autoencoder would integrate this spatial information into a rich representation of the instrument’s behaviour, compressing the eight signals into four fundamental, orthogonal dimensions of sound – a ‘disentangled’ representation of the sound across the instrument. In retrospect, this is a questionable expectation – as we will see in the next section, it proved incorrect – yet we are presenting it here as it framed our initial design decisions.
We imagined that these disentangled dimensions would behave as slowly changing (relatively to audio) control signals that would respond to changes in author #2’s playing of the FAAB. To us, musically, this suggested modulated sinusoidal oscillators and ambient synth music, similar to the sound the FAAB produces when entering self-oscillation produced by feedback. Our listening habits at the time – ambient and electroacoustic organ music by composer Kali Malone (Reference Malone2019) for author #1 and the duo emptyset (2015) for author #2 – undoubtedly also contributed to shaping our expectations.
4.2. Retelling the story
In this section, we present an account of the Surfing Hyperparameters project, reconstructed through the documentation we collected as the project unfolded. We present this account through radical transparency, embarrassing at times given some of the – in retrospect obvious – mismatches between our expectations and the system behaviour. We choose to present them here as they remain relevant in how they contributed to shaping the sonic aesthetics of the system.
Because of the radical transparency approach, this account will differ from a more standard report of development. We are relaying the narratives we told as the process unfolded, focusing on the paths we took to construct the system aesthetics, rather than on only the decisions which were successful in how they directly affected the final version of the system. In Section 5, we will reflect on these narratives and connect them with our previous discussion on aesthetics in technology-mediated musical practice.
4.2.1. Iteration A
In this first iteration, we expected the latent signals to behave like slowly changing control signals, so we used them to control oscillators in a modular synth. We mounted the Bela in a Eurorack system using the Pepper cape kit,Footnote 11 which routed the eight piezo signals to the laptop for processing through one of the 20 models. The four latent outputs were then sent back to the Pepper, which converted them to CV (control voltage). We then used these four CV signals to control the width, centre and harmonic tilt of a Verbos Oscillator,Footnote 12 and the wavefolding parameter of a Make Noise Dual Primary Oscillator.Footnote 13 Our aim here was to create a droning bass layer to accompany the FAAB with overlying textures that would reflect the dynamic changes in the control signals.
This first version of the model switching algorithm was the simplest: it averaged the amplitude of the four latent signals over five windows (0.23 seconds), mapped these values to the four-dimensional hyperparameter space, and selected the closest model. The algorithm triggered every five windows regardless of performance dynamics. We expected a relatively continuous trajectory through the hyperparameter space, with the system staying on the same model unless the playing style changed significantly. Instead, the model switched every 0.23 seconds without fail, creating a rigid periodicity where the dominant audible feature became the switching rate itself rather than the models’ distinct characteristics;Footnote 14 a musical character which, to our disappointment, was not related to our conceptual idea of using models as artistic materials. We also discovered that the hyperparameter space trajectory gravitated toward three particular models, rather than venturing into the other 17 models. In order to prevent rapid switching, we used the ratio between the standard deviation and amplitude average as input to a trigger with hysteresis, delaying state change with dynamically changing leaky thresholds. We additionally forced model change on switching to prevent repetition of models.
Still, the synth did not sound like the drony bass we envisioned but rather like pitched noise, and often the only explanation for a model switch was that the leaky thresholds were so low that any signal could cross them. We therefore disabled the model switching algorithm to focus on adjusting the synth parameters. During a moment in which author #2 was not playing but speaking while holding the bass, we realised we could hear their voice through the loudspeakers connected to the synth.Footnote 15 At this stage, it became clear that the four latent signals were not disentangled representations of the eight input piezo signals but rather a rough compression of the audio input (obvious in retrospect!). This explained why they behaved as ‘noise’ when used as control signals. If previously we had been disappointed by periodicity-driven sonic phenomena (caused by constant model switching), we were now even more discouraged by the fact that the musical output we were expecting to hear was simply bad audio compression.
Having arranged a performance in the coming week,Footnote 16 we stuck with the system and spent time tuning the model switching algorithm parameters and working on the sound design. We found that the system mainly reacted to amplitude, behaving in practice like an overly complex amplitude follower. Nevertheless, we still found it engaging to listen to, and according to author #2, to play with; although, as reported by them, it often did some ‘aesthetically indefensible’ model switches because of the leaky thresholds in the model switching algorithm.
4.2.2. Iteration B
Iteration A took place during a one-month residency in author #2’s studio in Berlin. To enable remote collaboration after author #1 returned to London, we moved the output sound processing from the modular synth to the laptop. We built a PCB cape for the Bela with voltage dividers to centre each piezo signal within the Bela’s analogue range (0–5 V). In this process, we realised that our modular setup had clipped the piezo signals, so we recorded a new dataset, added appropriate DC filtering and trained a new set of models.
Even after these significant changes, aside from a loud pop caused by DC filter discontinuities when switching models, we experienced far too little noticeable difference between the output of individual models to make an impact in a performance situation. We decided to shift focus to the compression loss between input and compressed signals, inspired by two works: Tom Maguire’s (Reference Maguire2014) track moDernisT, which comprises the audio lost when compressing Suzanne Vega’s Tom’s Diner (Reference Vega1987) to mp3; and Robson et al. (Reference Robson, McPherson and Bryan-Kinns2025) installation, where participants experience exaggerated Doppler Effects caused by subtle body movements. Inspired by the Multi-scale Spectrogram Distance function (Turian and Henry Reference Turian and Henry2020), we sonified the spectral difference between inputs and outputs using what we call the Multi-Scale Spectral Difference (MSSD). To implement the MSSD, we computed the STFTs of inputs and outputs at multiple window and hop sizes, took the differences between corresponding spectrograms, mapped each to the original scale (1,024), and finally summed all difference spectrograms. For sonification, we used an oscillator bank with one oscillator per frequency bin, where amplitudes were modulated by the difference spectrogram and phases were randomly initialised.Footnote 17
At this stage, the MSSD produced a metallic, filtered quality, as if played underwater. While this sound no longer resembled a compressed version of the audio input, we were still not satisfied with the sonic aesthetic.Footnote 18 However, the MSSD exhibited a fast periodic sound – a ‘brbrbr’ – which we attributed to an unidentified issue with the MSSD. A smoothing average and an envelope follower masked this sound. Another artefact at this stage was the discontinuity of the filters when switching models. We added a long crossfade between models (six-windows, 2.8 seconds) using a 6th-power function (y = x 6) as the crossfade curve, which delayed the entrance of the new model after a switch long enough to reproduce only a damped tail of the discontinuity. This delayed entrance, combined with the damped noise and the smoothing average, gave a certain elegance and intention to the change between models.Footnote 19
At this point, the differences between models were noticeable but subtle. We opted for recording shorter datasets (5 minutes each versus the previously 30-minute-long datasets), with each focusing on a different restricted range of playing techniques. We recorded five of these mini-datasets and trained five models on each. In this scenario, when a new model is selected, it not only has different hyperparameters but might also have been trained on a different dataset. Finally, model differences became audible: some sounded grainier with distinct frequency ranges, and quiet moments were sometimes interrupted by switching to a louder model. In conversation, author #2 expressed their feeling that the sound of the MSSD at its current stage was not dissimilar to what they imagined the models to sound like when the project was initiated. The final performance uses this version of the system.Footnote 20
5. Discussion
5.1. Getting the story straight
Initially, we framed this project as an exploration of AI models as design materials, expecting our conceptual idea (on AI model materiality) and its implementation (navigating a hyperparameter space in performance) would render aesthetics often associated with AI – ghostly, eerie and uncanny. However, as Section 4 has illustrated, we experienced an ongoing tension between our intended narrative and the system’s actual behaviour. For instance, in iteration A, it made us uncomfortable that the musical outputs’ characteristic features were attributed to something unrelated to our concept of AI materiality (such as model switching periodicity). Along with the realisation that the latent signals were trivial compressions of the input audio, these factors debunked our intended narrative.
We then focused on exploiting the fact that even though the models merely compressed the input signals, they did so in idiosyncratic ways. We implemented the MSSD with the expectation that by amplifying this difference we could hear each model’s distinct sonic properties (materialities). In retrospect, it seems clear that we were trying to bend the system to accommodate our desired narrative, as if the difference spectrograms could somehow ‘prove’ that AI models as design materials produce ghostly aesthetics. We finally achieved an aesthetic we felt satisfied with, insofar as it approximated that envisioned ghostly sound, yet through engineering the sound rather than the AI models themselves, whose main contribution was simply being slightly different from one another. The MSSD process – sonifying difference spectrograms through oscillator banks – became the salient aspect of the audio output. Unable to rely on the models directly for our desired sonic aesthetic, we added engineering tweaks such as long crossfades and moving averages to achieve the intended sound.
On the topic of aesthetics in technology-mediated musical practice, we can extract two complementary conclusions here: first, that in the Surfing Hyperparameters project, rather than open-ended exploration, the driving force was to accommodate a certain story we wanted to tell about an AI system and its sonic aesthetics. And second, that, along these lines, in this project, the aesthetic expectations we had about AI sound being ghostly, haunted and uncanny played a role at least as relevant as our actual usage of AI.
The point here is not that it is wrong in any way to ‘engineer’ aesthetics – making music with (and about) a certain technology does not automatically outlaw adding effects and decorations to achieve a desired sound. Our point relates to how our initial narratives around the project attempted to justify the system’s sonic aesthetic on its usage of AI models, and how this expectation was in tension with our actual experience of the system and its behaviour. We felt that the system’s aesthetics were somehow ‘insincere’ if we could not justify them by the system’s usage of AI. We develop this point further in the next section.
5.2. Accountability and horses
The Clever Hans Effect, or ‘being right for the wrong reasons’, is named after Hans, a horse that at the beginning of the 20th century was claimed to be able to solve arithmetic problems. After an investigation, it was found that Hans would start tapping the floor when the questioner unconsciously tilted their head and only stop when the questioner turned their head straight after the right number of taps, thus tapping the correct answer (Pfungst [Reference Pfungst1911] 2010, cited in Sturm Reference Sturm2014). Various researchers have identified the Clever Hans Effect in AI systems. For instance, in the field of MIR, Sturm (Reference Sturm2014) finds that various ‘horse’ genre classification systems rely on characteristics confounded with the genre ground truth label; he does so by applying ‘irrelevant’ transformations to the training datasets – transformations that should not alter the genre classification result (e.g. equalisation, subtle time stretching, reverberation) yet do. Similar conclusions have been drawn for AI systems in other domains (Lapuschkin et al. Reference Lapuschkin, Wäldchen, Binder, Montavon, Samek and Müller2019; Kauffmann et al. Reference Kauffmann, Dippel, Ruff, Samek, Müller and Montavon2025).
Speculating about a model’s inner workings is not uncommon, as understanding how a model is actually processing data requires active investigation. While misalignment between speculation and reality can have catastrophic consequences in technoscientific domains, in creative practices, the stakes are different, although we still argue for accountability to the chosen narrative: presenting horse Hans as capable of doing arithmetic once we know he cannot, would be problematic. With this, we are not claiming that all should conduct detailed analyses of their narratives and their alignment with the technical realities of their systems. The question is rather: to what extent are we relying on the ambiguity of AI systems (the floatiness of the term ‘AI’) to grant some credibility or novelty to a project story that might align poorly with reality?
This question becomes particularly relevant when the misalignment between speculation and reality becomes obvious. In iteration A, before realising that the system merely compressed the input signals rather than extracting disentangled representations we could use as control signals, we listened to the system trying to identify the system’s behaviour patterns and how they related to author #2’s playing. This way of listening, thinking of the model as an agent with aesthetic intentionality, crumbled when we discovered that our system was just compressing the audio signals. At this point, we could no longer listen to the system in the same way nor sustain, in good faith, the project narrative we had been sharing. We no longer heard that chaotic ‘agency’, just poor compression. At this stage, we were faced with two paths: to acknowledge that our usage of AI technology did not mystically produce the project aesthetics, or to maintain the misaligned narrative, in which case the system would become, as Sturm (Reference Sturm2014) would call it, a horse.
5.3. Situating practice research
Finally, a comment on the radical transparency approach. We thoroughly documented the Surfing Hyperparameters project process through in-situ note-taking, journaling and audiovisual recording as described in our previous work (Pelinski et al. Reference Pelinski, McPherson and Fiebrink2024), which builds on practice research methods (Bulley and Şahin Reference Bulley and Şahin2021) and Pickering’s (Reference Pickering1993) understanding of scientific practice as a dance of human and material agency. A similar framing, popular in research-through-design, is that of seeing design as a bricolage practice, ‘the result of careful negotiations in the making’, in which ‘the bricoleur does not plan ahead but develops the project in-situ with concerns of interaction, physical form, and behavior pattern not being hierarchically ordered a priori’ (Vallgårda and Fernaeus Reference Vallgårda and Fernaeus2015, 173).
When attempting to throw some light on how aesthetics are constructed when working with technology, such approaches are productive, for instance, in studying how the ‘paths of least resistance’ (Snape and Born Reference Snape, Born and Born2022) embedded in technology steer our aesthetic choices. However, an approach based solely on the in-situ interaction with materials can also be short-sighted insofar as it might miss the broader sociotechnical picture: factors we have discussed here, such as the influence of our aesthetic associations with certain technologies, but also other contextual aspects such as community expectations or, more mundanely, current listening habits. A purely practice-based or bricolage approach would perhaps assume that the sonic aesthetic for the Surfing Hyperparameters project ‘emerged’ in the making; however, looking back at the project narrative in Section 4, it becomes clear that we started this project with certain sonic expectations, and that the making process involved taking different paths to finally arrive at that intended aesthetic. In this project, it has become clear that practice-based approaches benefit from identifying our aesthetic expectations and preconceptions about the technologies involved, and question how these expectations shape project narratives and their aesthetic outcomes.
6. Conclusion
This paper examines how aesthetics are constructed in technology-mediated musical practice. We began by questioning whether the ghostly, eerie aesthetics that have often been associated with AI-generated music emerge from the technology itself or from our cultural expectations of it. Through reconstructing the story of the Surfing Hyperparameters project, we found that our aesthetic expectations about AI-generated sound played a role at least as relevant as our usage of said technology to shape the sonic aesthetics of the system.
While existing research has addressed how music-making tools embed ‘paths of least resistance’ toward certain aesthetics, our work shows another key aspect to consider: the aesthetic expectations practitioners bring to technology-mediated musical practice, based on cultural narratives and conceptual associations. These expectations do not merely influence how we interpret the systems’ sonic outcomes; they actively shape design decisions, from signal processing choices to system architectures. For practice-based research, this suggests the importance of documenting not just the project developments but also the aesthetic influences and the evolving narratives held as the process unfolds. Our radical transparency approach, presenting mismatches between expectations and reality (even if obvious in retrospect) reveals how these tensions actively contributed to shaping the sonic aesthetics of the system.
Through this story retelling, we identified that the sonic aesthetics of the project were inspired rather than directly caused by the usage of certain technologies. This distinction becomes particularly relevant in creative practice with AI: at this particular point in time, creative AI tools are becoming increasingly available to practitioners, yet these tools are novel enough to have not yet been assimilated. In this sense, many projects incorporating AI today are, fundamentally, about AI, explicitly exploring what it means to create with these technologies. That the aesthetics of many of these projects allude to some ghost in the machine may tell us more about our collective imagination of AI than about the algorithms themselves.
This work suggests that understanding how aesthetics are constructed in technology-mediated musical practice requires looking beyond technical specifications and in situ material interactions. Aesthetics are made through complex sociotechnical assemblages; in this work, we have addressed some of their elements: the popular narratives surrounding the given technology, the narratives and expectations we construct during development, and the ongoing mediation between what we imagine the technology to be and what it technically does. Acknowledging these multiple forces reveals the rich interplay between imagination, expectation and material reality through which technology-mediated musical practices come into being.
We acknowledge that this account only scratches the surface of the complexity involved in said interplay. Beyond our own expectations (conscious, as well as unconscious), each component in our system carries its own normative assumptions and intended uses as inscribed by its makers, alongside institutional forces such as funding calls, disciplinary norms and research evaluation frameworks (Hayes and Marquez-Borbon Reference Hayes and Marquez-Borbon2020). Navigating this dense network of intentions and expectations can be overwhelming, and future work could explore other corners of this network that are often paid less attention to, such as, for example, how communication protocols influence aesthetic outcomes in performance involving AI-generated sound.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S1355771826101228
Acknowledgements
We thank Adam Barkley for his valuable contribution in the first iteration of the project, where he took part as sound designer and synth performer. We would also like to thank Dr Federico Visi for his help in arranging the first author’s research visit to Universität der Kunste in July 2024, which facilitated the collaboration between the two first authors. We are thankful for the reviewers’ suggestions, which have greatly improved the quality of this paper. The first author is supported by the EPSRC UKRI Centre for Doctoral Training in Artificial Intelligence and Music (EP/S022694/1) and Bela (bela.io), and received travel funding from the Alan Turing Institute as part of the Enrichment Scheme Award 2023/2024. The second author was supported by STIP-4 – the Stipend for Artificial Intelligence, awarded by Musikfonds (Germany). The third author is supported by the Royal Academy of Engineering under the Research Chairs and Senior Research Fellowships scheme and by the UKRI Frontier Research grant EP/X023478/1.
Competing interests
The authors declare no competing interests.



















 Open access
Open access