


1 Introduction
Ordinal data are ubiquitous in psychology and related fields. With such data, e.g., arising from responses to rating scales, it is often recommended to estimate correlation matrices through polychoric correlation coefficients (e.g., Foldnes & Grønneberg, Reference Foldnes and Grønneberg2022; Garrido et al., Reference Garrido, Abad and Ponsoda2013; Holgado–Tello et al., Reference Holgado–Tello, Chacón–Moscoso, Barbero–Garcıa and Vila–Abad2010). The resulting polychoric correlation matrix is an important building block in subsequent multivariate models like factor analysis models and structural equation models (SEMs), as well as in exploratory methods like principal component analysis, multidimensional scaling, and clustering techniques (see, e.g., Mair (Reference Mair2018) for an overview). An individual polychoric correlation coefficient is the population correlation between two underlying latent variables that are postulated to have generated the observed categorical data through an unobserved discretization process. Traditionally, it is assumed that the two latent variables are standard bivariate normally distributed (Pearson, Reference Pearson1901) to estimate the polychoric correlation coefficient from observed ordinal data. Estimation of this latent normality model, called the polychoric model, is commonly carried out via maximum likelihood (ML) (Olsson, Reference Olsson1979). However, recent work has demonstrated that ML estimation of polychoric correlation is highly sensitive to violations of the assumption of underlying normality. Violations of this assumption result in a misspecified polychoric model, which can lead to substantially biased estimates of its parameters and those of subsequent multivariate models (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2019, Reference Foldnes and Grønneberg2020; Grønneberg & Foldnes, Reference Grønneberg and Foldnes2022; Jin & Yang-Wallentin, Reference Jin and Yang-Wallentin2017), particularly SEMs using diagonally weighted least squares (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2022), where the latter is based on weights derived under latent normality.
Motivated by the recent interest in non-robustness of ML, we study the estimation of the polychoric model under a misspecification framework stemming from the robust statistics literature (e.g., Huber & Ronchetti, Reference Huber and Ronchetti2009). In this setup, which we call partial misspecification here, the polychoric model is potentially misspecified for an unknown (and possibly zero-valued) fraction of observations. Heuristically, the model is misspecified such that the affected subset of observations contains little to no relevant information for the parameter of interest, the polychoric correlation coefficient. Examples of such uninformative observations include careless responses, misresponses, or responses due to item misunderstanding. Especially careless responding has been identified as a major threat to the validity of questionnaire-based research findings (e.g., Credé, Reference Credé2010; Huang, Liu, et al., Reference Huang, Liu and Bowling2015; Meade & Craig, Reference Meade and Craig2012; Welz et al., Reference Welz, Archimbaud and Alfons2024; Woods, Reference Woods2006). We demonstrate that already a small fraction of uninformative observations (such as careless respondents) can result in considerably biased ML estimates.
As a remedy and our main contribution, we propose a novel way to estimate the polychoric model that is robust to partial model misspecification. Essentially, the estimator poses the question “What is the best fit that can be achieved with the polychoric model for (the majority of) the data at hand?” The estimator compares the observed frequency of each contingency table cell with its expected frequency under the polychoric model, and automatically downweights cells whose observed frequencies cannot be fitted sufficiently well. As such, our estimator generalizes the ML estimator, but, in contrast to ML, does not crucially rely on the correct specification of the model. Specifically, our estimator allows the model to be misspecified for an unknown fraction of uninformative responses in a sample, but makes no assumption on the type, magnitude, or location of potential misspecification. The estimator is designed to identify such responses and to simultaneously reduce their influence so that the polychoric model can be accurately estimated from the remaining responses generated by latent normality. Conversely, if the polychoric model is correctly specified, that is, latent normality holds true for all observations, our estimator and ML estimation are asymptotically equivalent. As such, our proposed estimator can be thought of as a generalized ML estimator that is robust to potential partial model misspecification, due to, for instance (but not limited to), careless responding. We show that our robust estimator is consistent, asymptotically normal, and fully efficient under the polychoric model, while possessing similar asymptotic properties under misspecification, and it comes at no additional computational cost compared to ML.
The partial misspecification framework in this article is fundamentally different from that considered in recent literature on misspecified polychoric models. In this literature (e.g., Foldnes & Grønneberg, Reference Foldnes and Grønneberg2019, Reference Foldnes and Grønneberg2020, Reference Foldnes and Grønneberg2022; Grønneberg & Foldnes, Reference Grønneberg and Foldnes2022; Jin & Yang-Wallentin, Reference Jin and Yang-Wallentin2017; Lyhagen & Ornstein, Reference Lyhagen and Ornstein2023), the polychoric model is misspecified in the sense that all (unobserved) realizations of the latent continuous variables come from a distribution that is nonnormal. Under this framework, which is also known as distributional misspecification, the parameter of interest is the correlation coefficient of the latent nonnormal distribution, and all observations are informative for this parameter. While the distributional misspecification framework led to novel insights regarding (the lack of) robustness in ML estimation of polychoric correlation, the partial misspecification framework of this article can provide complimentary insights regarding the effects of a fraction of uninformative observations in a sample (such as careless responses), which is our primary objective.
Nevertheless, while our estimator is designed to be robust to partial misspecification caused by some uninformative responses, it can in some situations also provide a robustness gain under distributional misspecification. It turns out that if a nonnormal latent distribution differs from a normal distribution mostly in the tails, our estimator produces less biased estimates than ML because it can downweigh observations that are farther from the center.
To enhance accessibility and adoption by empirical researchers, an implementation of our proposed methodology in R (R Core Team, 2024) is freely available in the package robcat (for “ROBust CATegorical data analysis”; Welz et al., Reference Welz, Alfons and Mair2025) on CRAN (the Comprehensive R Archive Network) at https://CRAN.R-project.org/package=robcat. Replication materials for all numerical results in this article are provided on GitHub at https://github.com/mwelz/robust-polycor-replication. Proofs, derivations, and additional simulations can be found in the Supplementary Material.
This article is structured as follows. We start with reviewing related literature (Section 2) followed by the polychoric correlation model and ML estimation thereof (Section 3). Afterward, we elaborate on the partial misspecification framework (Section 4) and introduce our robust generalized ML estimator, including its statistical properties (Section 5). These properties are then examined by a simulation study in which we vary the misspecification fraction systematically, and compare the result to the commonly employed standard ML estimator (Section 6). Subsequently, we demonstrate the practical usefulness in an empirical application on a Big Five administration (Goldberg, Reference Goldberg1992) by Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020), where we find evidence of careless responding, manifesting in differences in polychoric correlation estimates of as much as 0.3 between our robust estimator and ML (Section 7). We then investigate the performance of the estimator under distributional misspecification (Section 8) and conclude with a discussion of the results and avenues for further research (Section 9).
2 Related literature
ML estimation of polychoric correlations was originally believed to be fairly robust to slight to moderate distributional misspecification (Coenders et al., Reference Coenders, Satorra and Saris1997; Flora & Curran, Reference Flora and Curran2004; Li, Reference Li2016; Maydeu-Olivares, Reference Maydeu-Olivares2006). This belief was based on simulations that generated data for nonnormal latent variables via the Vale–Maurelli (VM) method (Vale & Maurelli, Reference Vale and Maurelli1983), which were then discretized to ordinal data. However, Grønneberg & Foldnes (Reference Grønneberg and Foldnes2019) show that the distribution of ordinal data generated in this way is indistinguishable from that of ordinal data stemming from discretizing normally distributed latent variables.Footnote 1 In other words, simulation studies that ostensibly modeled nonnormality did in fact model normality. Simulating ordinal data in a way that ensures proper violations of latent normality (Grønneberg & Foldnes, Reference Grønneberg and Foldnes2017) reveals that polychoric correlation is in fact highly susceptible to distributional misspecification, resulting in possibly large biases (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2020, Reference Foldnes and Grønneberg2022; Grønneberg & Foldnes, Reference Grønneberg and Foldnes2022; Jin & Yang-Wallentin, Reference Jin and Yang-Wallentin2017). Consequently, it is recommended to test for the validity of the latent normality assumption, for instance, by using the bootstrap test of Foldnes & Grønneberg (Reference Foldnes and Grønneberg2020).
Another source of model misspecification occurs when the polychoric model is only misspecified for an uninformative subset of a sample (partial misspecification), where, in the context of this article, the term “uninformative” refers to an absence of relevant information for polychoric correlation, for instance, in careless responses. Careless responding “occurs when participants are not basing their response on the item content,” for instance, when a participant is “unmotivated to think about what the item is asking” (Ward & Meade, Reference Ward and Meade2023). It has been shown to be a major threat to the validity of research results through a variety of psychometric issues, such as reduced scale reliability (Arias et al., Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020) and construct validity (Kam & Meyer, Reference Kam and Meyer2015), attenuated factor loadings, improper factor structure, and deteriorated model fit in factor analyses (Arias et al., Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020; Huang, Bowling, et al., Reference Huang, Bowling, Liu and Li2015; Woods, Reference Woods2006), as well as inflated type I or type II errors in hypothesis testing (Arias et al., Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020; Huang, Liu, et al., Reference Huang, Liu and Bowling2015; Maniaci & Rogge, Reference Maniaci and Rogge2014; McGrath et al., Reference McGrath, Mitchell, Kim and Hough2010; Woods, Reference Woods2006). Careless responding is widely prevalent (Bowling et al., Reference Bowling, Huang, Bragg, Khazon, Liu and Blackmore2016; Meade & Craig, Reference Meade and Craig2012; Ward & Meade, Reference Ward and Meade2023) with most estimates on its prevalence ranging from 10% to 15% of study participants (Curran, Reference Curran2016; Huang et al., Reference Huang, Curran, Keeney, Poposki and DeShon2012; Huang, Liu, et al., Reference Huang, Liu and Bowling2015; Meade & Craig, Reference Meade and Craig2012), while already a prevalence 5%–10% can jeopardize the validity of research findings (Arias et al., Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020; Credé, Reference Credé2010; Welz et al., Reference Welz, Archimbaud and Alfons2024; Woods, Reference Woods2006). In fact, Ward & Meade (Reference Ward and Meade2023) conjecture that careless responding is likely present in all survey data. However, to the best of our knowledge, the effects of careless responding on estimates of the polychoric model have not yet been studied.
Existing model-based approaches to account for careless responding in various models typically explicitly model carelessness through mixture models (e.g., Arias et al., Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020; Steinmann et al., Reference Steinmann, Strietholt and Braeken2022; Ulitzsch, Pohl, et al., Reference Ulitzsch, Pohl, Khorramdel, Kroehne and von Davier2022; Ulitzsch, Yildirim-Erbasli, et al., Reference Ulitzsch, Yildirim-Erbasli, Gorgun and Bulut2022; Van Laar & Braeken, Reference Van Laar and Braeken2022). In contrast, our method does not model carelessness since we refrain from making assumptions on how the polychoric model might be misspecified. Another way to address careless responding is to directly detect them through person-fit indices and subsequently remove them from the sample (e.g., Patton et al., Reference Patton, Cheng, Hong and Diao2019). As a primary difference, our method simultaneously downweights aberrant observations during estimation rather than removing them. We refer to Alfons & Welz (Reference Alfons and Welz2024) for a detailed overview of methods addressing careless responding in various settings.
Conceptually related to our approach, Itaya & Hayashi (Reference Itaya and Hayashi2025) propose a way to robustly estimate parameters in item response theory (IRT) models. Their approach is conceptually similar to ours in the sense that it is based on minimizing a notion of divergence between an empirical density (from observed data) and a theoretical density of the IRT model. Like our approach, they achieve robustness by implicitly downweighting responses that the postulated model cannot fit well. Methodologically, our approach is different from Itaya & Hayashi (Reference Itaya and Hayashi2025) because our method is based on C-estimation (Welz, Reference Welz2024), which is designed specifically for categorical data, while they use density power divergence estimation (DPD) theory (Basu et al., Reference Basu, Harris, Hjort and Jones1998), which is not restricted to categorical data.Footnote 2 A relevant consequence is that our estimator is fully efficient, whereas DPD estimators lose efficiency as a price for gaining robustness. To the best of our knowledge, DPD estimators have not yet been studied for estimating polychoric correlation.
Another related branch of literature is that of outlier detection in contingency tables (see Sripriya et al. (Reference Sripriya, Gallo and Srinivasan2020) for a recent overview). In this literature, an outlier is a contingency table cell whose observed frequency is “markedly deviant” from those of the remaining cells (Sripriya et al., Reference Sripriya, Gallo and Srinivasan2020). This literature is agnostic with respect to the observed contingency table and therefore does not impose a parameterization on each cell’s probability. In contrast, the polychoric correlation model imposes such a parametrization through the assumption of latent bivariate normality. Another difference is that we are not primarily interested in outlier detection, but robust estimation of model parameters.
An alternative way to gain robustness against violations of latent nonnormality is to assume a different latent distribution, for instance, one with heavier tails. Examples from the SEM literature use elliptical distributions (Yuan et al., Reference Yuan, Bentler and Chan2004) or skew-elliptical distributions (Asparouhov & Muthén, Reference Asparouhov and Muthén2016), while Lyhagen & Ornstein (Reference Lyhagen and Ornstein2023), Jin & Yang-Wallentin (Reference Jin and Yang-Wallentin2017), and Roscino & Pollice (Reference Roscino, Pollice, Zani, Cerioli, Riani and Vichi2006) consider nonnormal distributions specifically in the context of polychoric correlation. Furthermore, it is worth pointing out that the term “robustness” is used in different ways in the methodological literature. Here, it refers to robustness against model misspecification. A popular but different meaning is robustness against heteroskedastic standard errors and corrected goodness-of-fit test statistics (e.g., Li, Reference Li2016; Satorra & Bentler, Reference Satorra, Bentler, Eye and Clogg1994, Reference Satorra and Bentler2001, and the references therein), which is, for instance, how the popular software package lavaan (Rosseel, Reference Rosseel2012) uses the term. We refer to Alfons & Schley (Reference Alfons and Schley2025) for an overview of the different meanings of “robustness” and a more detailed discussion.
3 Polychoric correlation
The polychoric correlation model (Pearson & Pearson, Reference Pearson and Pearson1922) models the association between two discrete ordinal variables by assuming that an observed pair of responses to two polytomous items is governed by an unobserved discretization process of latent variables that jointly follow a bivariate standard normal distribution. If both items are dichotomous, the polychoric correlation model reduces to the tetrachoric correlation model of Pearson (Reference Pearson1901). In the following, we first define the model and review ML estimation thereof and then introduce a robust estimator in the next section.
3.1 The polychoric model
For ease of exposition, we restrict our presentation to the bivariate polychoric model. The model naturally generalizes to higher dimensions (see, e.g., Muthén (Reference Muthén1984)).
Let there be two ordinal random variables, X and Y, that take values in the sets
 $\mathcal {X} = \{1,2,\dots ,K_X\}$
and
$\mathcal {X} = \{1,2,\dots ,K_X\}$
and
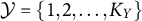 $\mathcal {Y}=\{1,2,\dots ,K_Y\}$
, respectively. The assumption that the sets contain adjacent integers is without loss of generality. Suppose there exist two continuous latent random variables,
$\mathcal {Y}=\{1,2,\dots ,K_Y\}$
, respectively. The assumption that the sets contain adjacent integers is without loss of generality. Suppose there exist two continuous latent random variables,
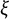 $\xi $
and
$\xi $
and
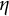 $\eta $
, that govern the ordinal variables through the discretization model
$\eta $
, that govern the ordinal variables through the discretization model
 $$ \begin{align} X= \begin{cases} 1 &\text{if } \xi < a_1,\\ 2 &\text{if } a_1 \leq \xi < a_2,\\ 3 &\text{if } a_2 \leq \xi < a_3,\\ \vdots\\ K_X &\text{if } a_{K_X-1} \leq \xi, \\ \end{cases} \qquad \text{ and } \qquad Y= \begin{cases} 1 &\text{if } \eta < b_1,\\ 2 &\text{if } b_1 \leq \eta < b_2,\\ 3 &\text{if } b_2 \leq \eta < b_3,\\ \vdots\\ K_Y &\text{if } b_{K_Y-1} \leq \eta, \\ \end{cases} \end{align} $$
$$ \begin{align} X= \begin{cases} 1 &\text{if } \xi < a_1,\\ 2 &\text{if } a_1 \leq \xi < a_2,\\ 3 &\text{if } a_2 \leq \xi < a_3,\\ \vdots\\ K_X &\text{if } a_{K_X-1} \leq \xi, \\ \end{cases} \qquad \text{ and } \qquad Y= \begin{cases} 1 &\text{if } \eta < b_1,\\ 2 &\text{if } b_1 \leq \eta < b_2,\\ 3 &\text{if } b_2 \leq \eta < b_3,\\ \vdots\\ K_Y &\text{if } b_{K_Y-1} \leq \eta, \\ \end{cases} \end{align} $$
where the fixed but unobserved parameters
 $a_1 < a_2 < \dots < a_{K_X-1}$
and
$a_1 < a_2 < \dots < a_{K_X-1}$
and
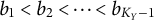 $b_1 < b_2 < \dots < b_{K_Y-1}$
are called thresholds.
$b_1 < b_2 < \dots < b_{K_Y-1}$
are called thresholds.
The primary object of interest is the population correlation between the two latent variables. To identify this quantity from the ordinal variables
 $(X,Y)$
, one assumes that the continuous latent variables follow a standard bivariate normal distribution with unobserved pairwise correlation coefficient
$(X,Y)$
, one assumes that the continuous latent variables follow a standard bivariate normal distribution with unobserved pairwise correlation coefficient
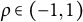 $\rho \in (-1,1)$
, that is,
$\rho \in (-1,1)$
, that is,
 $$ \begin{align} \begin{pmatrix} \xi \\ \eta \end{pmatrix} \sim \text{N}_2 \left( \begin{pmatrix} 0 \\ 0 \end{pmatrix} , \begin{pmatrix} 1 & \rho \\ \rho & 1 \end{pmatrix} \right). \end{align} $$
$$ \begin{align} \begin{pmatrix} \xi \\ \eta \end{pmatrix} \sim \text{N}_2 \left( \begin{pmatrix} 0 \\ 0 \end{pmatrix} , \begin{pmatrix} 1 & \rho \\ \rho & 1 \end{pmatrix} \right). \end{align} $$
Combining the discretization model (3.1) with the latent normality model (3.2) yields the polychoric model. In this model, one refers to the correlation parameter
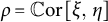 $\rho = \mathbb {C}\mathrm {or} \left [\xi ,\ \eta \right ]$
as the polychoric correlation coefficient of the ordinal X and Y. The polychoric model is subject to
$\rho = \mathbb {C}\mathrm {or} \left [\xi ,\ \eta \right ]$
as the polychoric correlation coefficient of the ordinal X and Y. The polychoric model is subject to
 $d=K_X+K_Y-1$
parameters, namely, the polychoric correlation coefficient from the latent normality model (3.2) and the two sets of thresholds from the discretization model (3.1). These parameters are jointly collected in a d-dimensional vector
$d=K_X+K_Y-1$
parameters, namely, the polychoric correlation coefficient from the latent normality model (3.2) and the two sets of thresholds from the discretization model (3.1). These parameters are jointly collected in a d-dimensional vector
 $$\begin{align*}\boldsymbol{\theta} = \left(\rho, a_1, a_2,\dots, a_{K_X-1}, b_1, b_2, \dots, b_{K_Y-1}\right)^\top. \end{align*}$$
$$\begin{align*}\boldsymbol{\theta} = \left(\rho, a_1, a_2,\dots, a_{K_X-1}, b_1, b_2, \dots, b_{K_Y-1}\right)^\top. \end{align*}$$
Under the polychoric model, the probability of observing an ordinal response
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
at a parameter vector
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
at a parameter vector
 $\boldsymbol {\theta }$
is given by
$\boldsymbol {\theta }$
is given by
 $$ \begin{align} p_{xy}(\boldsymbol{\theta}) = \mathbb{P}_{\boldsymbol{\theta}} \left[ X = x, Y=y \right] = \int_{a_{x-1}}^{a_x}\int_{b_{y-1}}^{b_y} \phi_2\left(t,s; \rho \right)\text{d} s\ \text{d} t, \end{align} $$
$$ \begin{align} p_{xy}(\boldsymbol{\theta}) = \mathbb{P}_{\boldsymbol{\theta}} \left[ X = x, Y=y \right] = \int_{a_{x-1}}^{a_x}\int_{b_{y-1}}^{b_y} \phi_2\left(t,s; \rho \right)\text{d} s\ \text{d} t, \end{align} $$
where we use the conventions
 $a_0=b_0=-\infty , a_{K_X}=b_{K_Y}=+\infty $
, and
$a_0=b_0=-\infty , a_{K_X}=b_{K_Y}=+\infty $
, and
 $$\begin{align*}\phi_2\left(u,v; \rho \right) = \frac{1}{2\pi \sqrt{1-\rho^2}} \exp\left( -\frac{u^2-2\rho uv + v^2}{2(1-\rho^2)} \right) \end{align*}$$
$$\begin{align*}\phi_2\left(u,v; \rho \right) = \frac{1}{2\pi \sqrt{1-\rho^2}} \exp\left( -\frac{u^2-2\rho uv + v^2}{2(1-\rho^2)} \right) \end{align*}$$
denotes the density of the standard bivariate normal distribution function with correlation parameter
 $\rho \in (-1,1)$
at some
$\rho \in (-1,1)$
at some
 $u,v\in \mathbb {R}$
, with corresponding distribution function
$u,v\in \mathbb {R}$
, with corresponding distribution function
 $$\begin{align*}\Phi_2\left(u,v; \rho \right) = \int_{-\infty}^u\int_{-\infty}^v \phi_2\left(t,s; \rho \right)\text{d} s\ \text{d} t. \end{align*}$$
$$\begin{align*}\Phi_2\left(u,v; \rho \right) = \int_{-\infty}^u\int_{-\infty}^v \phi_2\left(t,s; \rho \right)\text{d} s\ \text{d} t. \end{align*}$$
Regarding identification, it is worth mentioning that in the case where both X and Y are dichotomous, the polychoric model is exactly identified by the standard bivariate normal distribution. If at least one of the ordinal variables has more than two response categories, the polychoric model is over-identified, so it could identify more parameters than those in
 $\boldsymbol {\theta }$
.Footnote
3
We refer to Olsson (Reference Olsson1979, Section 2) for a related discussion.
$\boldsymbol {\theta }$
.Footnote
3
We refer to Olsson (Reference Olsson1979, Section 2) for a related discussion.
To distinguish arbitrary parameter values
 $\boldsymbol {\theta }$
from a specific value under which the polychoric model generates ordinal data, denote the latter by
$\boldsymbol {\theta }$
from a specific value under which the polychoric model generates ordinal data, denote the latter by
 $\boldsymbol {\theta }_{\star} = \left (\rho _{\star}, a_{\star,1},\dots , a_{\star,K_X-1}, b_{\star,1}, \dots , b_{\star,K_Y-1}\right )^\top $
. Given a random sample of ordinal data generated by a polychoric model under parameter value
$\boldsymbol {\theta }_{\star} = \left (\rho _{\star}, a_{\star,1},\dots , a_{\star,K_X-1}, b_{\star,1}, \dots , b_{\star,K_Y-1}\right )^\top $
. Given a random sample of ordinal data generated by a polychoric model under parameter value
 $\boldsymbol {\theta }_{\star}$
, the statistical problem is to estimate the true
$\boldsymbol {\theta }_{\star}$
, the statistical problem is to estimate the true
 $\boldsymbol {\theta }_{\star}$
, which is traditionally achieved by the ML estimator (MLE) of Olsson (Reference Olsson1979).Footnote
4
$\boldsymbol {\theta }_{\star}$
, which is traditionally achieved by the ML estimator (MLE) of Olsson (Reference Olsson1979).Footnote
4
3.2 Maximum likelihood estimation
Suppose we observe a sample
 $\{(X_i, Y_i)\}_{i=1}^N$
of N independent copies of
$\{(X_i, Y_i)\}_{i=1}^N$
of N independent copies of
 $(X,Y)$
generated by the polychoric model under the true parameter
$(X,Y)$
generated by the polychoric model under the true parameter
 $\boldsymbol {\theta }_{\star}$
. The sample may be observed directly or as a
$\boldsymbol {\theta }_{\star}$
. The sample may be observed directly or as a
 $K_X\times K_Y$
contingency table that cross-tabulates the observed frequencies. Denote by
$K_X\times K_Y$
contingency table that cross-tabulates the observed frequencies. Denote by

the observed empirical frequency of a response
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
, where the indicator function
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
, where the indicator function ![]() takes value 1 if an event E is true, and 0 otherwise. The MLE of
takes value 1 if an event E is true, and 0 otherwise. The MLE of
 $\boldsymbol {\theta }_{\star}$
can be expressed as
$\boldsymbol {\theta }_{\star}$
can be expressed as
 $$ \begin{align} \widehat{\boldsymbol{\theta}}_N^{\mathrm{\ MLE}} = \arg\max_{\boldsymbol{\theta}\in\boldsymbol{\Theta}} \left\{ \sum_{x\in\mathcal{X}}\sum_{y\in\mathcal{Y}} N_{xy} \log\left(p_{xy}(\boldsymbol{\theta})\right) \right\}, \end{align} $$
$$ \begin{align} \widehat{\boldsymbol{\theta}}_N^{\mathrm{\ MLE}} = \arg\max_{\boldsymbol{\theta}\in\boldsymbol{\Theta}} \left\{ \sum_{x\in\mathcal{X}}\sum_{y\in\mathcal{Y}} N_{xy} \log\left(p_{xy}(\boldsymbol{\theta})\right) \right\}, \end{align} $$
where the
 $p_{xy}(\boldsymbol {\theta })$
are the response probabilities in (3.3), and
$p_{xy}(\boldsymbol {\theta })$
are the response probabilities in (3.3), and
 $$ \begin{align} \boldsymbol{\Theta} = \bigg( \Big(\rho, \big(a_i\big)_{i=1}^{K_X-1}, \big(b_j\big)_{j=1}^{K_Y-1}\Big)^\top \ \Big|\ \rho\in(-1,1),\ a_1 < \dots < a_{K_X-1},\ b_1 < \dots < b_{K_Y-1} \bigg) \end{align} $$
$$ \begin{align} \boldsymbol{\Theta} = \bigg( \Big(\rho, \big(a_i\big)_{i=1}^{K_X-1}, \big(b_j\big)_{j=1}^{K_Y-1}\Big)^\top \ \Big|\ \rho\in(-1,1),\ a_1 < \dots < a_{K_X-1},\ b_1 < \dots < b_{K_Y-1} \bigg) \end{align} $$
is a set of parameters
 $\boldsymbol {\theta }$
that rules out degenerate cases, such as
$\boldsymbol {\theta }$
that rules out degenerate cases, such as
 $\rho = \pm 1$
or thresholds that are not strictly monotonically increasing. This estimator, its computational details, as well as its statistical properties are derived in Olsson (Reference Olsson1979). In essence, if the polychoric model (3.1) is correctly specified—that is, the underlying latent variables
$\rho = \pm 1$
or thresholds that are not strictly monotonically increasing. This estimator, its computational details, as well as its statistical properties are derived in Olsson (Reference Olsson1979). In essence, if the polychoric model (3.1) is correctly specified—that is, the underlying latent variables
 $(\xi , \eta )$
are indeed standard bivariate normal—then the estimator
$(\xi , \eta )$
are indeed standard bivariate normal—then the estimator
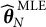 $\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
is consistent for the true
$\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
is consistent for the true
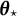 $\boldsymbol {\theta }_{\star}$
. In addition,
$\boldsymbol {\theta }_{\star}$
. In addition,
 $\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
is asymptotically normally distributed with mean zero and covariance matrix being equal to the model’s inverse Fisher information matrix, which makes it fully efficient.
$\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
is asymptotically normally distributed with mean zero and covariance matrix being equal to the model’s inverse Fisher information matrix, which makes it fully efficient.
As a computationally attractive alternative to estimating all parameters in
 $\boldsymbol {\theta }_{\star}$
simultaneously in problem (3.4), one may consider a “2-step approach” where only the correlation coefficient
$\boldsymbol {\theta }_{\star}$
simultaneously in problem (3.4), one may consider a “2-step approach” where only the correlation coefficient
 $\rho _{\star}$
is estimated via ML, but not the thresholds. In this approach, one estimates in a first step the thresholds as quantiles of the univariate standard normal distribution, evaluated at the observed cumulative marginal proportion of each contingency table cell. Formally, in the 2-step approach, thresholds
$\rho _{\star}$
is estimated via ML, but not the thresholds. In this approach, one estimates in a first step the thresholds as quantiles of the univariate standard normal distribution, evaluated at the observed cumulative marginal proportion of each contingency table cell. Formally, in the 2-step approach, thresholds
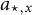 $a_{\star,x}$
and
$a_{\star,x}$
and
 $b_{\star,y}$
are, respectively, estimated via
$b_{\star,y}$
are, respectively, estimated via
 $$ \begin{align} \widehat{a}_{x} = \Phi_1^{-1}\left( \frac{1}{N}\sum_{k=1}^x\sum_{y\in\mathcal{Y}} N_{ky} \right)\qquad\text{and}\qquad \widehat{b}_{y} = \Phi_1^{-1}\left( \frac{1}{N}\sum_{x\in\mathcal{X}}\sum_{l=1}^y N_{xl} \right), \end{align} $$
$$ \begin{align} \widehat{a}_{x} = \Phi_1^{-1}\left( \frac{1}{N}\sum_{k=1}^x\sum_{y\in\mathcal{Y}} N_{ky} \right)\qquad\text{and}\qquad \widehat{b}_{y} = \Phi_1^{-1}\left( \frac{1}{N}\sum_{x\in\mathcal{X}}\sum_{l=1}^y N_{xl} \right), \end{align} $$
for
 $x=1,\dots ,K_X-1$
and
$x=1,\dots ,K_X-1$
and
 $y=1,\dots ,K_Y-1$
, where
$y=1,\dots ,K_Y-1$
, where
 $\Phi _1^{-1}(\cdot )$
denotes the quantile function of the univariate standard normal distribution. Then, taking these threshold estimates as fixed in the polychoric model, one estimates in a second step the only remaining parameter, correlation coefficient
$\Phi _1^{-1}(\cdot )$
denotes the quantile function of the univariate standard normal distribution. Then, taking these threshold estimates as fixed in the polychoric model, one estimates in a second step the only remaining parameter, correlation coefficient
 $\rho _{\star}$
, via ML. The main advantage of the 2-step approach is reduced computational time, while it comes at the cost of being theoretically non-optimal because ML standard errors do not apply to the threshold estimators in (3.6) (Olsson, Reference Olsson1979). Using simulation studies, Olsson (Reference Olsson1979) finds that the two approaches tend to yield similar results in practice—both in terms of correlation and variance estimation—for small to moderate true correlations, while there can be small differences for larger true correlations.
$\rho _{\star}$
, via ML. The main advantage of the 2-step approach is reduced computational time, while it comes at the cost of being theoretically non-optimal because ML standard errors do not apply to the threshold estimators in (3.6) (Olsson, Reference Olsson1979). Using simulation studies, Olsson (Reference Olsson1979) finds that the two approaches tend to yield similar results in practice—both in terms of correlation and variance estimation—for small to moderate true correlations, while there can be small differences for larger true correlations.
Software implementations of polychoric correlation vary with respect to their estimation strategy. For instance, the popular R packages lavaan (Rosseel, Reference Rosseel2012) and psych (Revelle, Reference Revelle2024) only support the 2-step approach, while the package polycor (Fox, Reference Fox2022) supports both the 2-step approach and simultaneous estimation of all model parameters, with the former being the default. Our implementation of ML estimation in package robcat also supports both strategies.
4 Conceptualizing model misspecification
To study the effects of partial model misspecification from a theoretical perspective, we first rigorously define this concept and explain how it differs from distributional misspecification.
4.1 Partial misspecification of the polychoric model
The polychoric model is partially misspecified when not all unobserved realizations of the latent variables
 $(\xi ,\eta )$
come from a standard bivariate normal distribution. Specifically, we consider a situation where only a fraction
$(\xi ,\eta )$
come from a standard bivariate normal distribution. Specifically, we consider a situation where only a fraction
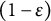 $(1-\varepsilon )$
of those realizations are generated by a standard bivariate normal distribution with true correlation parameter
$(1-\varepsilon )$
of those realizations are generated by a standard bivariate normal distribution with true correlation parameter
 $\rho _{\star}$
, whereas a fixed but unknown fraction
$\rho _{\star}$
, whereas a fixed but unknown fraction
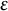 $\varepsilon $
are generated by some different but unspecified distribution H. Note that H being unspecified allows its correlation coefficient to differ from
$\varepsilon $
are generated by some different but unspecified distribution H. Note that H being unspecified allows its correlation coefficient to differ from
 $\rho _{\star}$
so that realizations generated by H may be uninformative for the true polychoric correlation coefficient
$\rho _{\star}$
so that realizations generated by H may be uninformative for the true polychoric correlation coefficient
 $\rho _{\star}$
, such as, after discretization, careless responses, misresponses, or responses stemming from item misunderstanding.
$\rho _{\star}$
, such as, after discretization, careless responses, misresponses, or responses stemming from item misunderstanding.
Formally, we say that the polychoric model is partially misspecified if the latent variables
 $(\xi ,\eta )$
are jointly distributed according to
$(\xi ,\eta )$
are jointly distributed according to
 $$ \begin{align} (u,v) \mapsto G_\varepsilon(u,v) = (1-\varepsilon) \Phi_2\left(u,v; \rho_{\star} \right) +\varepsilon H(u,v), \end{align} $$
$$ \begin{align} (u,v) \mapsto G_\varepsilon(u,v) = (1-\varepsilon) \Phi_2\left(u,v; \rho_{\star} \right) +\varepsilon H(u,v), \end{align} $$
for
 $u,v\in \mathbb {R}$
. Conceptualizing model misspecification in such a manner is standard in the robust statistics literature, going back to the seminal work of Huber (Reference Huber1964).Footnote
5
We therefore adopt terminology from robust statistics and call
$u,v\in \mathbb {R}$
. Conceptualizing model misspecification in such a manner is standard in the robust statistics literature, going back to the seminal work of Huber (Reference Huber1964).Footnote
5
We therefore adopt terminology from robust statistics and call
 $\varepsilon $
the contamination fraction, the uninformative H the contamination distribution (or simply contamination), and
$\varepsilon $
the contamination fraction, the uninformative H the contamination distribution (or simply contamination), and
 $G_\varepsilon $
the contaminated distribution. Observe that when the contamination fraction is zero, that is,
$G_\varepsilon $
the contaminated distribution. Observe that when the contamination fraction is zero, that is,
 $\varepsilon = 0$
, there is no misspecification so that the polychoric model is correctly specified for all observations. However, neither the contamination fraction
$\varepsilon = 0$
, there is no misspecification so that the polychoric model is correctly specified for all observations. However, neither the contamination fraction
 $\varepsilon $
nor the contamination distribution H is assumed to be known. Thus, both quantities are left completely unspecified in practice and
$\varepsilon $
nor the contamination distribution H is assumed to be known. Thus, both quantities are left completely unspecified in practice and
 $\Phi _2\left (u,v; \rho _{\star} \right )$
remains the distribution of interest. That is, we only aim to estimate the model parameters
$\Phi _2\left (u,v; \rho _{\star} \right )$
remains the distribution of interest. That is, we only aim to estimate the model parameters
 $\boldsymbol {\theta }$
of the polychoric model, while reducing the adverse effects of potential contamination in the observed ordinal data. The contaminated distribution
$\boldsymbol {\theta }$
of the polychoric model, while reducing the adverse effects of potential contamination in the observed ordinal data. The contaminated distribution
 $G_\varepsilon $
, on the other hand, is never estimated. It serves as a purely theoretical construct that we use to study the theoretical properties of estimators of the polychoric model when that model is partially misspecified due to contamination.
$G_\varepsilon $
, on the other hand, is never estimated. It serves as a purely theoretical construct that we use to study the theoretical properties of estimators of the polychoric model when that model is partially misspecified due to contamination.
Leaving the contamination distribution H and contamination fraction
 $\varepsilon $
unspecified in the partial misspecification model (4.1) means that we are not making any assumptions on the degree, magnitude, or type of contamination (which is possibly absent altogether). Hence, in our context of responses to rating items, the polychoric model can be misspecified due to an unlimited variety of reasons, for instance, but not limited to careless/inattentive responding (e.g., straightlining, pattern responding, and random-like responding), misresponses, or item misunderstanding.
$\varepsilon $
unspecified in the partial misspecification model (4.1) means that we are not making any assumptions on the degree, magnitude, or type of contamination (which is possibly absent altogether). Hence, in our context of responses to rating items, the polychoric model can be misspecified due to an unlimited variety of reasons, for instance, but not limited to careless/inattentive responding (e.g., straightlining, pattern responding, and random-like responding), misresponses, or item misunderstanding.
Although we make no assumption on the specific value of the contamination fraction
 $\varepsilon $
in the partial misspecification model (4.1), we require the identification restriction
$\varepsilon $
in the partial misspecification model (4.1), we require the identification restriction
 $\varepsilon \in [0, 0.5)$
. That is, we require that the polychoric model is correctly specified for the majority of observations, which is standard in the robust statistics literature (e.g., Hampel et al., Reference Hampel, Ronchetti, Rousseeuw and Stahel1986, p. 67). While it is in principle possible to also consider a contamination fraction between
$\varepsilon \in [0, 0.5)$
. That is, we require that the polychoric model is correctly specified for the majority of observations, which is standard in the robust statistics literature (e.g., Hampel et al., Reference Hampel, Ronchetti, Rousseeuw and Stahel1986, p. 67). While it is in principle possible to also consider a contamination fraction between
 $0.5$
and
$0.5$
and
 $1$
, one would need to impose certain additional assumptions on the correct model to distinguish it from incorrect ones when the majority of observations are not generated by the correct model. Since we prefer refraining from imposing additional assumptions, we only consider
$1$
, one would need to impose certain additional assumptions on the correct model to distinguish it from incorrect ones when the majority of observations are not generated by the correct model. Since we prefer refraining from imposing additional assumptions, we only consider
 $\varepsilon \in [0, 0.5)$
. We discuss the link between identification and contamination fractions beyond 0.5 in more detail in Section E.1 of the Supplementary Material.
$\varepsilon \in [0, 0.5)$
. We discuss the link between identification and contamination fractions beyond 0.5 in more detail in Section E.1 of the Supplementary Material.
Furthermore, as another, more practical reason for considering
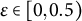 $\varepsilon \in [0,0.5)$
, having more than half of all observations in a sample being not informative for the quantity of interest would be indicative of serious data quality issues. When data quality is unreasonably low, it is doubtful whether the data are suitable for modeling analyses in the first place.
$\varepsilon \in [0,0.5)$
, having more than half of all observations in a sample being not informative for the quantity of interest would be indicative of serious data quality issues. When data quality is unreasonably low, it is doubtful whether the data are suitable for modeling analyses in the first place.
4.2 Response probabilities under partial misspecification
Under contaminated distribution
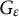 $G_\varepsilon $
with contamination fraction
$G_\varepsilon $
with contamination fraction
 $\varepsilon \in [0, 0.5)$
, the probability of observing an ordinal response
$\varepsilon \in [0, 0.5)$
, the probability of observing an ordinal response
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
is given by
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
is given by
 $$ \begin{align} f_{\varepsilon} \left(x,y\right) = \mathbb{P}_{G_\varepsilon} \left[ X = x, Y=y \right] = (1-\varepsilon) p_{xy}(\boldsymbol{\theta}_{\star}) + \varepsilon \int_{a_{\varepsilon,x-1}}^{a_{\varepsilon,x}} \int_{b_{\varepsilon,y-1}}^{b_{\varepsilon,y}} \text{d} H, \end{align} $$
$$ \begin{align} f_{\varepsilon} \left(x,y\right) = \mathbb{P}_{G_\varepsilon} \left[ X = x, Y=y \right] = (1-\varepsilon) p_{xy}(\boldsymbol{\theta}_{\star}) + \varepsilon \int_{a_{\varepsilon,x-1}}^{a_{\varepsilon,x}} \int_{b_{\varepsilon,y-1}}^{b_{\varepsilon,y}} \text{d} H, \end{align} $$
where the unobserved thresholds
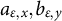 $a_{\varepsilon ,x},b_{\varepsilon ,y}$
discretize the fraction
$a_{\varepsilon ,x},b_{\varepsilon ,y}$
discretize the fraction
 $\varepsilon $
of latent variables for which the polychoric model is misspecified. The thresholds
$\varepsilon $
of latent variables for which the polychoric model is misspecified. The thresholds
 $a_{\varepsilon ,x},b_{\varepsilon ,y}$
may be different from the true
$a_{\varepsilon ,x},b_{\varepsilon ,y}$
may be different from the true
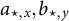 $a_{\star,x},b_{\star,y}$
and/or depend on contamination fraction
$a_{\star,x},b_{\star,y}$
and/or depend on contamination fraction
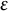 $\varepsilon $
. However, it turns out that from a theoretical perspective, studying the case where the
$\varepsilon $
. However, it turns out that from a theoretical perspective, studying the case where the
 $a_{\varepsilon ,x},b_{\varepsilon ,y}$
are different from the
$a_{\varepsilon ,x},b_{\varepsilon ,y}$
are different from the
 $a_{\star,x},b_{\star,y}$
is equivalent to a case where they are equal.Footnote
6
$a_{\star,x},b_{\star,y}$
is equivalent to a case where they are equal.Footnote
6
The population response probabilities
 $f_{\varepsilon } \left (x,y\right )$
in (4.2) are unknown in practice because they depend on unspecified and unmodeled quantities, namely, the contamination fraction
$f_{\varepsilon } \left (x,y\right )$
in (4.2) are unknown in practice because they depend on unspecified and unmodeled quantities, namely, the contamination fraction
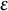 $\varepsilon $
, the contamination distribution H, and the discretization thresholds of the latter. Consequently, we do not attempt to estimate the population response probabilities
$\varepsilon $
, the contamination distribution H, and the discretization thresholds of the latter. Consequently, we do not attempt to estimate the population response probabilities
 $f_{\varepsilon } \left (x,y\right )$
. We instead focus on estimating the true polychoric model probabilities
$f_{\varepsilon } \left (x,y\right )$
. We instead focus on estimating the true polychoric model probabilities
 $p_{xy}(\boldsymbol {\theta }_{\star})$
while reducing bias stemming from potential contamination in the observed data.
$p_{xy}(\boldsymbol {\theta }_{\star})$
while reducing bias stemming from potential contamination in the observed data.
Figure 1 visualizes a simulated example of bivariate data drawn from contaminated distribution
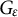 $G_\varepsilon $
, where a fraction of
$G_\varepsilon $
, where a fraction of
 $\varepsilon =0.15$
of the data follow a bivariate normal contamination distribution H (orange dots) with mean
$\varepsilon =0.15$
of the data follow a bivariate normal contamination distribution H (orange dots) with mean
 $(2.5, -2.5)^\top $
, variance
$(2.5, -2.5)^\top $
, variance
 $(0.25, 0.25)^\top $
, and zero correlation, whereas the remaining data are generated by a standard bivariate normal distribution with correlation
$(0.25, 0.25)^\top $
, and zero correlation, whereas the remaining data are generated by a standard bivariate normal distribution with correlation
 $\rho _{\star}=0.5$
(gray dots). In this example, the data from the contamination distribution H primarily inflate the cell
$\rho _{\star}=0.5$
(gray dots). In this example, the data from the contamination distribution H primarily inflate the cell
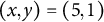 $(x,y) = (5,1)$
after discretization. That is, this cell will have a larger empirical frequency than the polychoric model allows for, since the probability of this cell is nearly zero at the polychoric model, yet many realized responses will populate it. Consequently, due to (partial) misspecification of the polychoric model, an ML estimate of
$(x,y) = (5,1)$
after discretization. That is, this cell will have a larger empirical frequency than the polychoric model allows for, since the probability of this cell is nearly zero at the polychoric model, yet many realized responses will populate it. Consequently, due to (partial) misspecification of the polychoric model, an ML estimate of
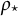 $\rho _{\star}$
on these data might be substantially biased for
$\rho _{\star}$
on these data might be substantially biased for
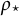 $\rho _{\star}$
. Indeed, calculating the MLE using the data plotted in Figure 1 yields an estimate of
$\rho _{\star}$
. Indeed, calculating the MLE using the data plotted in Figure 1 yields an estimate of
 $\widehat {\rho }_N^{\mathrm {\ MLE}}=-0.10$
, which is far off from the true
$\widehat {\rho }_N^{\mathrm {\ MLE}}=-0.10$
, which is far off from the true
 $\rho _{\star}=0.5$
. In contrast, our proposed robust estimator, which is calculated from the exact same information as the MLE and is defined in Section 5, yields a fairly accurate estimate of
$\rho _{\star}=0.5$
. In contrast, our proposed robust estimator, which is calculated from the exact same information as the MLE and is defined in Section 5, yields a fairly accurate estimate of
 $0.47$
.
$0.47$
.
Simulated data with
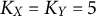 $K_X=K_Y=5$
response options where the polychoric model is misspecified with contamination fraction
$K_X=K_Y=5$
response options where the polychoric model is misspecified with contamination fraction
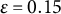 $\varepsilon =0.15$
.
$\varepsilon =0.15$
.
Note: The gray dots represent random draws of
 $(\xi ,\eta )$
from the polychoric model with
$(\xi ,\eta )$
from the polychoric model with
 $\rho _{\star}=0.5$
, whereas the orange dots represent draws from a contamination distribution that primarily inflates the cell
$\rho _{\star}=0.5$
, whereas the orange dots represent draws from a contamination distribution that primarily inflates the cell
 $(x,y)=(5,1)$
. The contamination distribution is bivariate normal with a mean
$(x,y)=(5,1)$
. The contamination distribution is bivariate normal with a mean
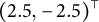 $(2.5,-2.5)^\top $
, variances
$(2.5,-2.5)^\top $
, variances
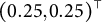 $(0.25, 0.25)^\top $
, and zero correlation. The blue lines indicate the locations of the thresholds. In each cell, the numbers in parentheses denote the population probability of that cell under the true polychoric model.
$(0.25, 0.25)^\top $
, and zero correlation. The blue lines indicate the locations of the thresholds. In each cell, the numbers in parentheses denote the population probability of that cell under the true polychoric model.

It is worth addressing that there exist nonnormal distributions of the latent variables
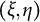 $(\xi ,\eta )$
that, after discretization with the same thresholds, result in the same response probabilities as under latent normality (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2019). This implies that there may exist contamination distributions H and contamination fractions
$(\xi ,\eta )$
that, after discretization with the same thresholds, result in the same response probabilities as under latent normality (Foldnes & Grønneberg, Reference Foldnes and Grønneberg2019). This implies that there may exist contamination distributions H and contamination fractions
 $\varepsilon> 0$
under which the population probabilities
$\varepsilon> 0$
under which the population probabilities
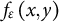 $f_{\varepsilon } \left (x,y\right )$
in (4.2) are equal to the true population probabilities of the polychoric model,
$f_{\varepsilon } \left (x,y\right )$
in (4.2) are equal to the true population probabilities of the polychoric model,
 $p_{xy}(\boldsymbol {\theta }_{\star})$
, that is,
$p_{xy}(\boldsymbol {\theta }_{\star})$
, that is,
 $f_{\varepsilon } \left (x,y\right ) = p_{xy}(\boldsymbol {\theta }_{\star})$
for all
$f_{\varepsilon } \left (x,y\right ) = p_{xy}(\boldsymbol {\theta }_{\star})$
for all
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
. In this situation, the polychoric model is misspecified, but the misspecification does not have consequences because the response probabilities remain unaffected. To avoid cumbersome notation in the theoretical analysis of our robust estimator, we assume consequential misspecification throughout this article, that is,
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
. In this situation, the polychoric model is misspecified, but the misspecification does not have consequences because the response probabilities remain unaffected. To avoid cumbersome notation in the theoretical analysis of our robust estimator, we assume consequential misspecification throughout this article, that is,
 $f_{\varepsilon } \left (x,y\right ) \neq p_{xy}(\boldsymbol {\theta }_{\star})$
for some
$f_{\varepsilon } \left (x,y\right ) \neq p_{xy}(\boldsymbol {\theta }_{\star})$
for some
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
whenever
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
whenever
 $\varepsilon> 0$
. However, it is silently understood that misspecification need not be consequential, in which case there is no issue and both the MLE and our robust estimator are consistent for the true
$\varepsilon> 0$
. However, it is silently understood that misspecification need not be consequential, in which case there is no issue and both the MLE and our robust estimator are consistent for the true
 $\boldsymbol {\theta }_{\star}$
.
$\boldsymbol {\theta }_{\star}$
.
4.3 Distributional misspecification
A model is distributionally misspecified when all observations in a given sample are generated by a distribution that is different from the model distribution. In the context of the polychoric model, this means that all ordinal observations are generated by a latent distribution that is nonnormal. Let G denote the unknown nonnormal distribution that the latent variables
 $(\xi , \eta )$
jointly follow under distributional misspecification. The object of interest is the population correlation between latent
$(\xi , \eta )$
jointly follow under distributional misspecification. The object of interest is the population correlation between latent
 $\xi $
and
$\xi $
and
 $\eta $
under distribution G, for which the normality-based MLE of Olsson (Reference Olsson1979) turns out to be substantially biased in many cases (e.g., Foldnes & Grønneberg, Reference Foldnes and Grønneberg2020, Reference Foldnes and Grønneberg2022; Jin & Yang-Wallentin, Reference Jin and Yang-Wallentin2017; Lyhagen & Ornstein, Reference Lyhagen and Ornstein2023). As such, distributional misspecification is fundamentally different from partial misspecification: In the former, one attempts to estimate the population correlation of the nonnormal and unknown distribution that generated a sample, instead of estimating the polychoric correlation coefficient (which is the correlation under standard bivariate normality). In the latter, one attempts to estimate the polychoric correlation coefficient with a contaminated sample that has only been partly generated by latent normality (that is, the polychoric model). The assumption that the polychoric model is only partially misspecified for some uninformative observations enables one to still estimate the polychoric correlation coefficient of that model, which would not be feasible under distributional misspecification (at least not without additional assumptions).
$\eta $
under distribution G, for which the normality-based MLE of Olsson (Reference Olsson1979) turns out to be substantially biased in many cases (e.g., Foldnes & Grønneberg, Reference Foldnes and Grønneberg2020, Reference Foldnes and Grønneberg2022; Jin & Yang-Wallentin, Reference Jin and Yang-Wallentin2017; Lyhagen & Ornstein, Reference Lyhagen and Ornstein2023). As such, distributional misspecification is fundamentally different from partial misspecification: In the former, one attempts to estimate the population correlation of the nonnormal and unknown distribution that generated a sample, instead of estimating the polychoric correlation coefficient (which is the correlation under standard bivariate normality). In the latter, one attempts to estimate the polychoric correlation coefficient with a contaminated sample that has only been partly generated by latent normality (that is, the polychoric model). The assumption that the polychoric model is only partially misspecified for some uninformative observations enables one to still estimate the polychoric correlation coefficient of that model, which would not be feasible under distributional misspecification (at least not without additional assumptions).
Despite not being designed for distributional misspecification, the robust estimator introduced in the next section can offer a robustness gain in some situations where the polychoric model is distributionally misspecified. We discuss this in more detail in Section 8.
5 Robust estimation of polychoric correlation
The behavior of ML estimates of any model crucially depends on the correct specification of that model. Indeed, ML estimation can be severely biased even when the assumed model is only slightly misspecified (e.g., Hampel et al., Reference Hampel, Ronchetti, Rousseeuw and Stahel1986; Huber, Reference Huber1964; Huber & Ronchetti, Reference Huber and Ronchetti2009). For instance, in many models of continuous variables like regression models, one single observation from a different distribution can be enough to make the ML estimator converge to an arbitrary value (Huber & Ronchetti, Reference Huber and Ronchetti2009; see also Alfons et al. (Reference Alfons, Ateş and Groenen2022) for the special case of mediation analysis). The non-robustness of ML estimation of the polychoric model has been demonstrated empirically by Foldnes & Grønneberg (Reference Foldnes and Grønneberg2020, Reference Foldnes and Grønneberg2022) and Grønneberg & Foldnes (Reference Grønneberg and Foldnes2022) for the case of distributional misspecification. In this section, we introduce an estimator that is designed to be robust to partial misspecification when present, but remains (asymptotically) equivalent to the ML estimator of Olsson (Reference Olsson1979) when misspecification is absent. We furthermore derive the statistical properties of the proposed estimator.
Throughout this section, let
 $\{(X_i, Y_i)\}_{i=1}^N$
be an observed ordinal sample of size N generated by discretizing latent variables
$\{(X_i, Y_i)\}_{i=1}^N$
be an observed ordinal sample of size N generated by discretizing latent variables
 $(\xi ,\eta )$
that follow the unknown and unspecified contaminated distribution
$(\xi ,\eta )$
that follow the unknown and unspecified contaminated distribution
 $G_\varepsilon $
in (4.1). Hence, the polychoric model is possibly misspecified for an unknown fraction
$G_\varepsilon $
in (4.1). Hence, the polychoric model is possibly misspecified for an unknown fraction
 $\varepsilon $
of the sample.
$\varepsilon $
of the sample.
5.1 The estimator
The proposed estimator is a special case of a class of robust estimators for general models of categorical data called C-estimators (Welz, Reference Welz2024), and is based on the following idea. The empirical relative frequency of a response
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
, denoted
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
, denoted

is a consistent nonparametric estimator of the population response probability in (4.2),
 $$\begin{align*}f_{\varepsilon} \left(x,y\right) = \mathbb{P}_{G_\varepsilon} \left[ X = x, Y=y \right] = (1-\varepsilon) p_{xy}(\boldsymbol{\theta}_{\star}) + \varepsilon \int_{a_{\varepsilon,x-1}}^{a_{\varepsilon,x}} \int_{b_{\varepsilon,y-1}}^{b_{\varepsilon,y}} \text{d} H, \end{align*}$$
$$\begin{align*}f_{\varepsilon} \left(x,y\right) = \mathbb{P}_{G_\varepsilon} \left[ X = x, Y=y \right] = (1-\varepsilon) p_{xy}(\boldsymbol{\theta}_{\star}) + \varepsilon \int_{a_{\varepsilon,x-1}}^{a_{\varepsilon,x}} \int_{b_{\varepsilon,y-1}}^{b_{\varepsilon,y}} \text{d} H, \end{align*}$$
as
 $N\to \infty $
(see, e.g., Chapter 19.2 in Van der Vaart (Reference Van der Vaart1998)). If the polychoric model is correctly specified
$N\to \infty $
(see, e.g., Chapter 19.2 in Van der Vaart (Reference Van der Vaart1998)). If the polychoric model is correctly specified
 $(\varepsilon = 0)$
, then
$(\varepsilon = 0)$
, then
 $\widehat {f}_{N}(x,y)$
will converge (in probability) to the true model probability
$\widehat {f}_{N}(x,y)$
will converge (in probability) to the true model probability
 $p_{xy}(\boldsymbol {\theta }_{\star})$
because
$p_{xy}(\boldsymbol {\theta }_{\star})$
because
 $$\begin{align*}f_0(x,y) = p_{xy}(\boldsymbol{\theta}_{\star}), \end{align*}$$
$$\begin{align*}f_0(x,y) = p_{xy}(\boldsymbol{\theta}_{\star}), \end{align*}$$
for all
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
. Conversely, if the polychoric model is misspecified
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
. Conversely, if the polychoric model is misspecified
 $(\varepsilon> 0)$
, then
$(\varepsilon> 0)$
, then
 $\widehat {f}_{N}(x,y)$
may not converge to the true
$\widehat {f}_{N}(x,y)$
may not converge to the true
 $p_{xy}(\boldsymbol {\theta }_{\star})$
because
$p_{xy}(\boldsymbol {\theta }_{\star})$
because
 $$\begin{align*}f_{\varepsilon} \left(x,y\right) \neq p_{xy}(\boldsymbol{\theta}_{\star}) \end{align*}$$
$$\begin{align*}f_{\varepsilon} \left(x,y\right) \neq p_{xy}(\boldsymbol{\theta}_{\star}) \end{align*}$$
for some
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
, since we assume consequential misspecification.
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
, since we assume consequential misspecification.
It follows that if the polychoric model is misspecified, there exists no parameter value
 $\boldsymbol {\theta }\in \boldsymbol {\Theta }$
for which the nonparametric estimates
$\boldsymbol {\theta }\in \boldsymbol {\Theta }$
for which the nonparametric estimates
 $\widehat {f}_{N}(x,y)$
converge pointwise to the associated model probabilities
$\widehat {f}_{N}(x,y)$
converge pointwise to the associated model probabilities
 $p_{xy}(\boldsymbol {\theta })$
for all
$p_{xy}(\boldsymbol {\theta })$
for all
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
. Hence, it is indicative of model misspecification if there exists at least one response
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
. Hence, it is indicative of model misspecification if there exists at least one response
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
for which
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
for which
 $\widehat {f}_{N}(x,y)$
does not converge to any polychoric model probability
$\widehat {f}_{N}(x,y)$
does not converge to any polychoric model probability
 $p_{xy}(\boldsymbol {\theta })$
, resulting in a discrepancy between
$p_{xy}(\boldsymbol {\theta })$
, resulting in a discrepancy between
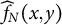 $\widehat {f}_{N}(x,y)$
and
$\widehat {f}_{N}(x,y)$
and
 $p_{xy}(\boldsymbol {\theta })$
.Footnote
7
This observation can be exploited in model fitting by minimizing the discrepancy between the empirical relative frequencies,
$p_{xy}(\boldsymbol {\theta })$
.Footnote
7
This observation can be exploited in model fitting by minimizing the discrepancy between the empirical relative frequencies,
 $\widehat {f}_{N}(x,y)$
, and theoretical model probabilities,
$\widehat {f}_{N}(x,y)$
, and theoretical model probabilities,
 $p_{xy}(\boldsymbol {\theta })$
, to find the most accurate fit that can be achieved with the polychoric model for the observed data. Specifically, our estimator minimizes with respect to
$p_{xy}(\boldsymbol {\theta })$
, to find the most accurate fit that can be achieved with the polychoric model for the observed data. Specifically, our estimator minimizes with respect to
 $\boldsymbol {\theta }$
the loss function
$\boldsymbol {\theta }$
the loss function
 $$ \begin{align} L\left( \boldsymbol{\theta},\ \widehat{f}_{N} \right) = \sum_{x\in\mathcal{X}}\sum_{y\in\mathcal{Y}} \varphi\left(\frac{\widehat{f}_{N}(x,y)}{p_{xy}(\boldsymbol{\theta})}-1\right)p_{xy}(\boldsymbol{\theta}), \end{align} $$
$$ \begin{align} L\left( \boldsymbol{\theta},\ \widehat{f}_{N} \right) = \sum_{x\in\mathcal{X}}\sum_{y\in\mathcal{Y}} \varphi\left(\frac{\widehat{f}_{N}(x,y)}{p_{xy}(\boldsymbol{\theta})}-1\right)p_{xy}(\boldsymbol{\theta}), \end{align} $$
where
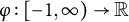 $\varphi : [-1,\infty ) \to \mathbb {R}$
is a prespecified discrepancy function that will be defined momentarily. The proposed estimator
$\varphi : [-1,\infty ) \to \mathbb {R}$
is a prespecified discrepancy function that will be defined momentarily. The proposed estimator
 $\widehat {\boldsymbol {\theta }}_N$
is given by the value minimizing the objective loss over parameter space
$\widehat {\boldsymbol {\theta }}_N$
is given by the value minimizing the objective loss over parameter space
 $\boldsymbol {\Theta }$
,
$\boldsymbol {\Theta }$
,
 $$ \begin{align} \widehat{\boldsymbol{\theta}}_N = \arg\min_{\boldsymbol{\theta}\in\boldsymbol{\Theta}} L\Big(\boldsymbol{\theta}, \widehat{f}_{N}\Big). \end{align} $$
$$ \begin{align} \widehat{\boldsymbol{\theta}}_N = \arg\min_{\boldsymbol{\theta}\in\boldsymbol{\Theta}} L\Big(\boldsymbol{\theta}, \widehat{f}_{N}\Big). \end{align} $$
For the choice of discrepancy function
 $\varphi (z) = \varphi ^{\mathrm {MLE}}(z) = (z+1) \log (z+1)$
, it can be easily verified that
$\varphi (z) = \varphi ^{\mathrm {MLE}}(z) = (z+1) \log (z+1)$
, it can be easily verified that
 $\widehat {\boldsymbol {\theta }}_N$
coincides with the MLE
$\widehat {\boldsymbol {\theta }}_N$
coincides with the MLE
 $\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
in (3.4). In the following, we motivate a specific choice of discrepancy function
$\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
in (3.4). In the following, we motivate a specific choice of discrepancy function
 $\varphi (\cdot )$
that makes the estimator
$\varphi (\cdot )$
that makes the estimator
 $\widehat {\boldsymbol {\theta }}_N$
less susceptible to misspecification of the polychoric model while preserving equivalence with ML estimation in the absence of misspecification.
$\widehat {\boldsymbol {\theta }}_N$
less susceptible to misspecification of the polychoric model while preserving equivalence with ML estimation in the absence of misspecification.
The fraction between empirical relative frequencies and model probabilities with value 1 deducted,
 $$\begin{align*}\frac{\widehat{f}_{N}(x,y)}{p_{xy}(\boldsymbol{\theta})} -1, \end{align*}$$
$$\begin{align*}\frac{\widehat{f}_{N}(x,y)}{p_{xy}(\boldsymbol{\theta})} -1, \end{align*}$$
is referred to as Pearson residual (PR) (Lindsay, Reference Lindsay1994). It takes values in
 $[-1,+\infty )$
and can be interpreted as a goodness-of-fit measure. PR values close to 0 indicate a good fit between data and polychoric model at
$[-1,+\infty )$
and can be interpreted as a goodness-of-fit measure. PR values close to 0 indicate a good fit between data and polychoric model at
 $\boldsymbol {\theta }$
, whereas values toward
$\boldsymbol {\theta }$
, whereas values toward
 $-1$
or
$-1$
or
 $+\infty $
indicate a poor fit because empirical response probabilities disagree with their model counterparts. To achieve robustness to misspecification of the polychoric model, responses that cannot be modeled well by the polychoric model, as indicated by their PR being away from 0, should receive less weight in the estimation procedure such that they do not over-proportionally affect the fit. Downweighting when necessary is achieved through a specific choice of discrepancy function
$+\infty $
indicate a poor fit because empirical response probabilities disagree with their model counterparts. To achieve robustness to misspecification of the polychoric model, responses that cannot be modeled well by the polychoric model, as indicated by their PR being away from 0, should receive less weight in the estimation procedure such that they do not over-proportionally affect the fit. Downweighting when necessary is achieved through a specific choice of discrepancy function
 $\varphi (\cdot )$
proposed by Welz et al. (Reference Welz, Archimbaud and Alfons2024), which is a special case of a function suggested by Ruckstuhl & Welsh (Reference Ruckstuhl and Welsh2001). The discrepancy function reads
$\varphi (\cdot )$
proposed by Welz et al. (Reference Welz, Archimbaud and Alfons2024), which is a special case of a function suggested by Ruckstuhl & Welsh (Reference Ruckstuhl and Welsh2001). The discrepancy function reads
 $$ \begin{align} \varphi(z) = \begin{cases} (z+1) \log(z+1) &\text{ if } z \in [-1, c],\\ (z+1)(\log(c+1) + 1) - c-1&\text{ if } z> c, \end{cases} \end{align} $$
$$ \begin{align} \varphi(z) = \begin{cases} (z+1) \log(z+1) &\text{ if } z \in [-1, c],\\ (z+1)(\log(c+1) + 1) - c-1&\text{ if } z> c, \end{cases} \end{align} $$
where
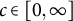 $c\in [0,\infty ]$
is a prespecified tuning constant that governs the estimator’s behavior at the PR of each possible response. Figure 2 visualizes this function for the example choice
$c\in [0,\infty ]$
is a prespecified tuning constant that governs the estimator’s behavior at the PR of each possible response. Figure 2 visualizes this function for the example choice
 $c=0.6$
as well as the ML discrepancy function
$c=0.6$
as well as the ML discrepancy function
 $\varphi ^{\mathrm {MLE}}(z) = (z+1) \log (z+1)$
. Note that deducting 1 in (5.1) and adding it again in (5.3) is purely for keeping the interpretation that a PR close to 0 indicates a good fit. We further stress that although the discrepancy function (5.3) can be negative, the loss function (5.1) is always nonnegative (Welz, Reference Welz2024).
$\varphi ^{\mathrm {MLE}}(z) = (z+1) \log (z+1)$
. Note that deducting 1 in (5.1) and adding it again in (5.3) is purely for keeping the interpretation that a PR close to 0 indicates a good fit. We further stress that although the discrepancy function (5.3) can be negative, the loss function (5.1) is always nonnegative (Welz, Reference Welz2024).
Visualization of the robust discrepancy function
 $\varphi (z)$
in (5.3) for
$\varphi (z)$
in (5.3) for
 $c = 0.6$
(solid line) and the ML discrepancy function
$c = 0.6$
(solid line) and the ML discrepancy function
 $\varphi ^{\mathrm {MLE}}(z) = (z+1) \log (z+1)$
(dotted line).
$\varphi ^{\mathrm {MLE}}(z) = (z+1) \log (z+1)$
(dotted line).

For the choice
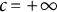 $c=+\infty $
, minimizing the loss (5.1) is equivalent to maximizing the log-likelihood objective in (3.4), meaning that the estimator
$c=+\infty $
, minimizing the loss (5.1) is equivalent to maximizing the log-likelihood objective in (3.4), meaning that the estimator
 $\widehat {\boldsymbol {\theta }}_N$
is equal to
$\widehat {\boldsymbol {\theta }}_N$
is equal to
 $\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
for this choice of c. More specifically, if a PR
$\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
for this choice of c. More specifically, if a PR
 $z = \frac {\widehat {f}_{N}(x,y)}{p_{xy}(\boldsymbol {\theta })}-1$
of a response
$z = \frac {\widehat {f}_{N}(x,y)}{p_{xy}(\boldsymbol {\theta })}-1$
of a response
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
is such that
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
is such that
 $z\in [-1, c]$
for fixed
$z\in [-1, c]$
for fixed
 $c\geq 0$
, then the estimation procedure behaves at this response like in classic ML estimation. As argued before, in the absence of misspecification,
$c\geq 0$
, then the estimation procedure behaves at this response like in classic ML estimation. As argued before, in the absence of misspecification,
 $\widehat {f}_{N}(x,y)$
converges to
$\widehat {f}_{N}(x,y)$
converges to
 $p_{xy}(\boldsymbol {\theta }_{\star})$
for all responses
$p_{xy}(\boldsymbol {\theta }_{\star})$
for all responses
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
, therefore, all PRs are asymptotically equal to 0. Hence, if the polychoric model is correctly specified, then estimator
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
, therefore, all PRs are asymptotically equal to 0. Hence, if the polychoric model is correctly specified, then estimator
 $\widehat {\boldsymbol {\theta }}_N$
is asymptotically equivalent to the MLE
$\widehat {\boldsymbol {\theta }}_N$
is asymptotically equivalent to the MLE
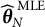 $\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
for any tuning constant value
$\widehat {\boldsymbol {\theta }}_N^{\mathrm {\ MLE}}$
for any tuning constant value
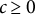 $c \geq 0$
. On the other hand, if a response’s PR z is larger than c, that is,
$c \geq 0$
. On the other hand, if a response’s PR z is larger than c, that is,
 $z> c \geq 0$
, then the estimation procedure does not behave like in ML, but the response’s contribution to loss (5.1) is linear rather than super-linear like in ML (Figure 2). It follows that the influence of responses that cannot be fitted well by the polychoric model is downweighted to prevent them from dominating the fit. The tuning constant
$z> c \geq 0$
, then the estimation procedure does not behave like in ML, but the response’s contribution to loss (5.1) is linear rather than super-linear like in ML (Figure 2). It follows that the influence of responses that cannot be fitted well by the polychoric model is downweighted to prevent them from dominating the fit. The tuning constant
 $c\geq 0$
is the threshold beyond which a PR will be downweighted, so the choice thereof determines what is considered an insufficient fit. The closer to 0 the tuning constant c is chosen, the more robust the estimator is in theory. In Section C of the Supplementary Material, we explore different values of c in simulations and motivate a specific choice that we use for all numerical results in this article, namely,
$c\geq 0$
is the threshold beyond which a PR will be downweighted, so the choice thereof determines what is considered an insufficient fit. The closer to 0 the tuning constant c is chosen, the more robust the estimator is in theory. In Section C of the Supplementary Material, we explore different values of c in simulations and motivate a specific choice that we use for all numerical results in this article, namely,
 $c=0.6$
.
$c=0.6$
.
Note that the discrepancy function
 $\varphi (\cdot )$
in (5.3) may only downweight overcounts, that is, the empirical probability
$\varphi (\cdot )$
in (5.3) may only downweight overcounts, that is, the empirical probability
 $\widehat {f}_{N}(x,y)$
exceeding the theoretical probability
$\widehat {f}_{N}(x,y)$
exceeding the theoretical probability
 $p_{xy}(\boldsymbol {\theta })$
for some cell
$p_{xy}(\boldsymbol {\theta })$
for some cell
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
. One might wonder why undercounts—
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
. One might wonder why undercounts—
 $\widehat {f}_{N}(x,y)$
being smaller than
$\widehat {f}_{N}(x,y)$
being smaller than
 $p_{xy}(\boldsymbol {\theta })$
, resulting in negative PRs—are not downweighted as well. Indeed, the discrepancy function in (5.3) does not change its behavior compared to the MLE for PRs below 0. The empirical frequency
$p_{xy}(\boldsymbol {\theta })$
, resulting in negative PRs—are not downweighted as well. Indeed, the discrepancy function in (5.3) does not change its behavior compared to the MLE for PRs below 0. The empirical frequency
 $\widehat {f}_{N}(x,y)$
is a relative measure, so if a contingency table cell
$\widehat {f}_{N}(x,y)$
is a relative measure, so if a contingency table cell
 $(x,y)$
has inflated counts, the other cells will have reduced values of
$(x,y)$
has inflated counts, the other cells will have reduced values of
 $\widehat {f}_{N}$
. If the discrepancy function would downweight undercounts, there is a risk of downweighting non-contaminated cells simply because these cells have reduced
$\widehat {f}_{N}$
. If the discrepancy function would downweight undercounts, there is a risk of downweighting non-contaminated cells simply because these cells have reduced
 $\widehat {f}_{N}$
values if at least one cell is inflated due to contamination. Such behavior could result in bias since non-contaminated cells are not supposed to be downweighted. We refer to Ruckstuhl and Welsh (Reference Ruckstuhl and Welsh2001, p. 1128) for a related discussion.
$\widehat {f}_{N}$
values if at least one cell is inflated due to contamination. Such behavior could result in bias since non-contaminated cells are not supposed to be downweighted. We refer to Ruckstuhl and Welsh (Reference Ruckstuhl and Welsh2001, p. 1128) for a related discussion.
With the proposed choice of
 $\varphi (\cdot )$
, we stress that our estimator
$\varphi (\cdot )$
, we stress that our estimator
 $\widehat {\boldsymbol {\theta }}_N$
in (5.2) has the same time complexity as ML, namely,
$\widehat {\boldsymbol {\theta }}_N$
in (5.2) has the same time complexity as ML, namely,
 $O\big (K_X\cdot K_Y\big )$
, since one needs to calculate the PR of all
$O\big (K_X\cdot K_Y\big )$
, since one needs to calculate the PR of all
 $K_X\cdot K_Y$
possible responses for every candidate parameter value. Consequently, our proposed estimator does not incur any additional computational cost compared to ML.
$K_X\cdot K_Y$
possible responses for every candidate parameter value. Consequently, our proposed estimator does not incur any additional computational cost compared to ML.
5.2 Statistical properties
We first address what quantity is estimated by the proposed estimator before discussing its asymptotic behavior.
5.2.1 Estimand
The estimand of the estimator
 $\widehat {\boldsymbol {\theta }}_N$
in (5.2) is given by
$\widehat {\boldsymbol {\theta }}_N$
in (5.2) is given by
 $$\begin{align*}\boldsymbol{\theta}_0 = \arg\min_{\boldsymbol{\theta}\in\boldsymbol{\Theta}} L\Big(\boldsymbol{\theta}, f_\varepsilon\Big). \end{align*}$$
$$\begin{align*}\boldsymbol{\theta}_0 = \arg\min_{\boldsymbol{\theta}\in\boldsymbol{\Theta}} L\Big(\boldsymbol{\theta}, f_\varepsilon\Big). \end{align*}$$
This minimization problem is simply the population analog to the minimization problem in (5.2) that the sample-based
 $\widehat {\boldsymbol {\theta }}_N$
solves because the probabilities
$\widehat {\boldsymbol {\theta }}_N$
solves because the probabilities
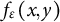 $f_{\varepsilon } \left (x,y\right )$
are the population analogs to the empirical probabilities
$f_{\varepsilon } \left (x,y\right )$
are the population analogs to the empirical probabilities
 $\widehat {f}_{N}(x,y)$
.
$\widehat {f}_{N}(x,y)$
.
If the polychoric model is correctly specified, the estimand
 $\boldsymbol {\theta }_0$
equals the true parameter
$\boldsymbol {\theta }_0$
equals the true parameter
 $\boldsymbol {\theta }_{\star}$
. Indeed, if
$\boldsymbol {\theta }_{\star}$
. Indeed, if
 $\varepsilon = 0$
, then
$\varepsilon = 0$
, then
 $f_0(x,y) = p_{xy}(\boldsymbol {\theta }_{\star})$
for all
$f_0(x,y) = p_{xy}(\boldsymbol {\theta }_{\star})$
for all
 $(x,y)\in \mathcal {X}\times \mathcal {Y}$
, so it follows that the loss
$(x,y)\in \mathcal {X}\times \mathcal {Y}$
, so it follows that the loss

attains its global minimum of zero if and only if
 $\boldsymbol {\theta } = \boldsymbol {\theta }_{\star}$
, for any choice of
$\boldsymbol {\theta } = \boldsymbol {\theta }_{\star}$
, for any choice of
 $c\geq 0$
. Thus, in the absence of contamination, our estimator estimates the same quantity as the MLE, namely, the true
$c\geq 0$
. Thus, in the absence of contamination, our estimator estimates the same quantity as the MLE, namely, the true
 $\boldsymbol {\theta }_{\star}$
. In other words, it obtains the true
$\boldsymbol {\theta }_{\star}$
. In other words, it obtains the true
 $\boldsymbol {\theta }_{\star}$
in population when the model is correctly specified, a property known as Fisher consistency. We refer to Welz et al. (Reference Welz, Archimbaud and Alfons2024) for details.
$\boldsymbol {\theta }_{\star}$
in population when the model is correctly specified, a property known as Fisher consistency. We refer to Welz et al. (Reference Welz, Archimbaud and Alfons2024) for details.
However, in the presence of misspecification (
 $\varepsilon> 0$
), the sampling distribution differs from the model distribution such that the estimand
$\varepsilon> 0$
), the sampling distribution differs from the model distribution such that the estimand
 $\boldsymbol {\theta }_0$
—the parameter that minimizes the loss evaluated at the sampling distribution—is generally different from the true
$\boldsymbol {\theta }_0$
—the parameter that minimizes the loss evaluated at the sampling distribution—is generally different from the true
 $\boldsymbol {\theta }_{\star}$
(cf. White, Reference White1982).Footnote
8
The population estimand being different from the true value translates to biased estimates of the latter as a consequence of the misspecification.
$\boldsymbol {\theta }_{\star}$
(cf. White, Reference White1982).Footnote
8
The population estimand being different from the true value translates to biased estimates of the latter as a consequence of the misspecification.
How much the estimand
 $\boldsymbol {\theta }_0$
differs from the true
$\boldsymbol {\theta }_0$
differs from the true
 $\boldsymbol {\theta }_{\star}$
depends on the unknown fraction of contamination
$\boldsymbol {\theta }_{\star}$
depends on the unknown fraction of contamination
 $\varepsilon $
, the unknown type of contamination H, as well as the choice of tuning constant c in
$\varepsilon $
, the unknown type of contamination H, as well as the choice of tuning constant c in
 $\varphi (\cdot )$
. Mainly, the larger
$\varphi (\cdot )$
. Mainly, the larger
 $\varepsilon $
(more severe misspecification) and c (less downweighting of hard-to-fit responses), the further
$\varepsilon $
(more severe misspecification) and c (less downweighting of hard-to-fit responses), the further
 $\boldsymbol {\theta }_0$
is away from
$\boldsymbol {\theta }_0$
is away from
 $\boldsymbol {\theta }_{\star}$
. Figure 3 illustrates this behavior for the polychoric correlation coefficient at an example misspecified distribution that is described in Section 4.2 and in which the true polychoric correlation under the correct model amounts to
$\boldsymbol {\theta }_{\star}$
. Figure 3 illustrates this behavior for the polychoric correlation coefficient at an example misspecified distribution that is described in Section 4.2 and in which the true polychoric correlation under the correct model amounts to
 $\rho _{\star} = 0.5$
. For increasing contamination fractions, the MLE (
$\rho _{\star} = 0.5$
. For increasing contamination fractions, the MLE (
 $c = +\infty )$
estimates a parameter value that is increasingly farther away from the true
$c = +\infty )$
estimates a parameter value that is increasingly farther away from the true
 $\boldsymbol {\theta }_{\star}$
, where already a contamination fraction of less than
$\boldsymbol {\theta }_{\star}$
, where already a contamination fraction of less than
 $\varepsilon = 0.15$
suffices for a sign flip in the correlation coefficient. Conversely, choosing tuning constant c to be near 0 results in a much less severe bias. For instance, even at contamination fraction
$\varepsilon = 0.15$
suffices for a sign flip in the correlation coefficient. Conversely, choosing tuning constant c to be near 0 results in a much less severe bias. For instance, even at contamination fraction
 $\varepsilon = 0.4$
, the difference between the estimand and the true value is approximately 0.1 or less.
$\varepsilon = 0.4$
, the difference between the estimand and the true value is approximately 0.1 or less.
The population estimand
 $\rho _0$
of the polychoric correlation coefficient for various degrees of contamination fractions
$\rho _0$
of the polychoric correlation coefficient for various degrees of contamination fractions
 $\varepsilon $
(x-axis) and tuning constants c (line colors), for the same contamination distribution as in Figure 1.
$\varepsilon $
(x-axis) and tuning constants c (line colors), for the same contamination distribution as in Figure 1.
Note: The ML estimand corresponds to
 $c=+\infty $
. There are
$c=+\infty $
. There are
 $K_X=K_Y=5$
response options and the true value corresponds to
$K_X=K_Y=5$
response options and the true value corresponds to
 $\rho _{\star} = 0.5$
(dashed line).
$\rho _{\star} = 0.5$
(dashed line).

Overall, finite choices of c lead to an estimator that is at least as accurate as the MLE, and more accurate under misspecification of the polychoric model, thereby gaining robustness to misspecification.
A relevant question is whether the true parameter
 $\boldsymbol {\theta }_{\star}$
can be recovered when
$\boldsymbol {\theta }_{\star}$
can be recovered when
 $\varepsilon> 0$
such that it can be estimated using
$\varepsilon> 0$
such that it can be estimated using
 $\widehat {\boldsymbol {\theta }}_N$
combined with a bias correction term. To derive such a bias correction term, one would need to impose assumptions on the contamination fraction and type of contamination. However, if one has strong prior beliefs about how the polychoric model is misspecified, modeling them explicitly rather than relying on the polychoric model seems more appropriate. Yet, one’s beliefs about misspecification may not be accurate, so attempts to explicitly model the misspecification may themselves result in a misspecified model. Consequently, robust estimation traditionally refrains from making assumptions on how a model may potentially be misspecified by leaving
$\widehat {\boldsymbol {\theta }}_N$
combined with a bias correction term. To derive such a bias correction term, one would need to impose assumptions on the contamination fraction and type of contamination. However, if one has strong prior beliefs about how the polychoric model is misspecified, modeling them explicitly rather than relying on the polychoric model seems more appropriate. Yet, one’s beliefs about misspecification may not be accurate, so attempts to explicitly model the misspecification may themselves result in a misspecified model. Consequently, robust estimation traditionally refrains from making assumptions on how a model may potentially be misspecified by leaving
 $\varepsilon $
and H unspecified in the contaminated distribution (4.1). Instead, one may use a robust estimator to identify data points that cannot be modeled with the model at hand, like the one presented in this article.
$\varepsilon $
and H unspecified in the contaminated distribution (4.1). Instead, one may use a robust estimator to identify data points that cannot be modeled with the model at hand, like the one presented in this article.
5.2.2 Asymptotic analysis
It can be shown that under certain standard regularity conditions that do not restrict the degree or type of possible partial misspecification beyond
 $\varepsilon \in [0,0.5)$
, the robust estimator
$\varepsilon \in [0,0.5)$
, the robust estimator
 $\widehat {\boldsymbol {\theta }}_N$
is consistent for estimand
$\widehat {\boldsymbol {\theta }}_N$
is consistent for estimand
 $\boldsymbol {\theta }_0$
as well as asymptotically normally distributed. Specifically, under said regularity conditions and fixed tuning constant
$\boldsymbol {\theta }_0$
as well as asymptotically normally distributed. Specifically, under said regularity conditions and fixed tuning constant
 $c>0$
, Theorem A.1 in the Supplementary Material establishes that
$c>0$
, Theorem A.1 in the Supplementary Material establishes that
 $$\begin{align*}\widehat{\boldsymbol{\theta}}_N \stackrel{\mathbb{P}}{\longrightarrow} \boldsymbol{\theta}_0, \end{align*}$$
$$\begin{align*}\widehat{\boldsymbol{\theta}}_N \stackrel{\mathbb{P}}{\longrightarrow} \boldsymbol{\theta}_0, \end{align*}$$
as well as
 $$\begin{align*}\sqrt{N}\left(\widehat{\boldsymbol{\theta}}_N - \boldsymbol{\theta}_0\right) \stackrel{\mathrm{d}}{\longrightarrow} \text{N}_d \Big(\boldsymbol{0}, \boldsymbol{\Sigma}\left({\boldsymbol{\theta}_0}\right) \Big), \end{align*}$$
$$\begin{align*}\sqrt{N}\left(\widehat{\boldsymbol{\theta}}_N - \boldsymbol{\theta}_0\right) \stackrel{\mathrm{d}}{\longrightarrow} \text{N}_d \Big(\boldsymbol{0}, \boldsymbol{\Sigma}\left({\boldsymbol{\theta}_0}\right) \Big), \end{align*}$$
as
 $N\to \infty $
, where “
$N\to \infty $
, where “
 $\stackrel {\mathbb {P}}{\longrightarrow }$
” and “
$\stackrel {\mathbb {P}}{\longrightarrow }$
” and “
 $\stackrel {\mathrm {d}}{\longrightarrow }$
” denote convergence in probability and distribution, respectively. The asymptotic covariance matrix has a sandwich-type construction
$\stackrel {\mathrm {d}}{\longrightarrow }$
” denote convergence in probability and distribution, respectively. The asymptotic covariance matrix has a sandwich-type construction
 $$\begin{align*}\boldsymbol{\Sigma}\left({\boldsymbol{\theta}}\right) = \boldsymbol{M}\left( \boldsymbol{\theta} \right)^{-1} \boldsymbol{U}\left( \boldsymbol{\theta} \right) \boldsymbol{M}\left( \boldsymbol{\theta} \right)^{-1}, \qquad\boldsymbol{\theta}\in\boldsymbol{\Theta}, \end{align*}$$
$$\begin{align*}\boldsymbol{\Sigma}\left({\boldsymbol{\theta}}\right) = \boldsymbol{M}\left( \boldsymbol{\theta} \right)^{-1} \boldsymbol{U}\left( \boldsymbol{\theta} \right) \boldsymbol{M}\left( \boldsymbol{\theta} \right)^{-1}, \qquad\boldsymbol{\theta}\in\boldsymbol{\Theta}, \end{align*}$$
where the
 $d\times d$
matrices
$d\times d$
matrices

respectively, are the Hessian matrix of the population loss and the covariance matrix (evaluated at
 $f_{\varepsilon }$
) of the likelihood score function—that is, the gradient of
$f_{\varepsilon }$
) of the likelihood score function—that is, the gradient of
 $\log (p_{XY}(\boldsymbol {\theta }))$
—weighted by stochastic binary weights whether the PR is smaller than or equal to the tuning constant c.Footnote
9
We derive closed-form expressions of the matrices
$\log (p_{XY}(\boldsymbol {\theta }))$
—weighted by stochastic binary weights whether the PR is smaller than or equal to the tuning constant c.Footnote
9
We derive closed-form expressions of the matrices
 $\boldsymbol {M}\left ( \boldsymbol {\theta } \right )$
and
$\boldsymbol {M}\left ( \boldsymbol {\theta } \right )$
and
 $\boldsymbol {U}\left ( \boldsymbol {\theta } \right )$
as well as their properties in Section A of the Supplementary Material.
$\boldsymbol {U}\left ( \boldsymbol {\theta } \right )$
as well as their properties in Section A of the Supplementary Material.
The asymptotic covariance matrix
 $\boldsymbol {\Sigma }\left ({\boldsymbol {\theta }_0}\right )$
of our estimator is unobserved in practice because it depends on the unknown quantities
$\boldsymbol {\Sigma }\left ({\boldsymbol {\theta }_0}\right )$
of our estimator is unobserved in practice because it depends on the unknown quantities
 $\boldsymbol {\theta }_0$
and
$\boldsymbol {\theta }_0$
and
 $f_{\varepsilon }$
. Yet,
$f_{\varepsilon }$
. Yet,
 $\boldsymbol {\Sigma }\left ({\boldsymbol {\theta }_0}\right )$
can be consistently estimated by replacing
$\boldsymbol {\Sigma }\left ({\boldsymbol {\theta }_0}\right )$
can be consistently estimated by replacing
 $\boldsymbol {\theta }_0$
and
$\boldsymbol {\theta }_0$
and
 $f_{\varepsilon }$
by their corresponding consistent estimators
$f_{\varepsilon }$
by their corresponding consistent estimators
 $\widehat {\boldsymbol {\theta }}_N$
and
$\widehat {\boldsymbol {\theta }}_N$
and
 $\widehat {f}_{N}$
, respectively. Details are provided in Section A of the Supplementary Material.
$\widehat {f}_{N}$
, respectively. Details are provided in Section A of the Supplementary Material.
With this limit theory, one can construct standard errors and confidence intervals for every element in
 $\boldsymbol {\theta }_0$
. Importantly, in the absence of contamination (such that
$\boldsymbol {\theta }_0$
. Importantly, in the absence of contamination (such that
 $\boldsymbol {\theta }_0 = \boldsymbol {\theta }_{\star}$
), the asymptotic covariance matrix
$\boldsymbol {\theta }_0 = \boldsymbol {\theta }_{\star}$
), the asymptotic covariance matrix
 $\boldsymbol {\Sigma }\left ({\boldsymbol {\theta }_0}\right )$
of the robust estimator reduces to that of the fully efficient MLE (i.e., inverse Fisher information matrix) as long as
$\boldsymbol {\Sigma }\left ({\boldsymbol {\theta }_0}\right )$
of the robust estimator reduces to that of the fully efficient MLE (i.e., inverse Fisher information matrix) as long as
 $c>0$
. It follows that there is no loss of statistical efficiency when there is no contamination.Footnote
10
Hence, if the polychoric model is correctly specified, the robust estimator and the MLE are asymptotically first- and second-order equivalent. We refer to Section A of the Supplementary Material for a rigorous exposition and discussion of the robust estimator’s asymptotic properties.
$c>0$
. It follows that there is no loss of statistical efficiency when there is no contamination.Footnote
10
Hence, if the polychoric model is correctly specified, the robust estimator and the MLE are asymptotically first- and second-order equivalent. We refer to Section A of the Supplementary Material for a rigorous exposition and discussion of the robust estimator’s asymptotic properties.
5.3 Implementation
We provide a free and open-source implementation of our proposed methodology in a package for the statistical programming environment R (R Core Team, 2024). The package is called robcat (for “ROBust CATegorical data analysis”; Welz et al., Reference Welz, Alfons and Mair2025), and it is available from CRAN (the Comprehensive R Archive Network) at https://CRAN.R-project.org/package=robcat. To maximize speed and performance, the package is predominantly developed in C++ and integrated to R via Rcpp (Eddelbuettel, Reference Eddelbuettel2013). All numerical results in this article were obtained with this package.
The estimator’s minimization problem in (5.2) can be solved with standard algorithms for numerical optimization. In our experience, using an unconstrained version of the quasi-Newton algorithm L-BFGS-B of Byrd et al. (Reference Byrd, Lu, Nocedal and Zhu1995) works fine. However, additional stability might be gained from imposing the boundary constraint on the correlation coefficient and the monotonicity constraints on the thresholds, see (3.5), for which the simplex algorithm of Nelder & Mead (Reference Nelder and Mead1965) for constrained optimization can be used. In our implementation in package robcat, the default behavior is to first try unconstrained optimization via L-BFGS-B. If numerical instability is encountered or a monotonicity constraint is violated, the constrained optimization algorithm of Nelder & Mead (Reference Nelder and Mead1965) is used instead. While this is the default behavior, the package allows users to freely specify any supported optimization routine.
An important user choice is that of the tuning constant c in discrepancy function (5.3). The closer c is to 0, the more robust the estimator will be to possible misspecification of the polychoric model (see, e.g., Figure 3). On the other hand, in the presence of model misspecification, the more robust the estimator is made, the larger its estimation variance becomes. Moreover, if the model is correctly specified, then Welz et al. (Reference Welz, Archimbaud and Alfons2024) shows that the most robust choice,
 $c=0$
, is associated with two drawbacks, namely, asymptotic nonnormality as well as certain finite sample issues. We therefore suggest choosing a value slightly larger than 0. In simulation experiments (see Section C of the Supplementary Material), we find that the estimator is relatively insensitive to the specific choice of
$c=0$
, is associated with two drawbacks, namely, asymptotic nonnormality as well as certain finite sample issues. We therefore suggest choosing a value slightly larger than 0. In simulation experiments (see Section C of the Supplementary Material), we find that the estimator is relatively insensitive to the specific choice of
 $c> 0$
, as long as it is reasonably small (for robustness) yet sufficiently far away from 0 (to avoid the aforementioned issues). The choice
$c> 0$
, as long as it is reasonably small (for robustness) yet sufficiently far away from 0 (to avoid the aforementioned issues). The choice
 $c = 0.6$
thereby yields a good compromise so that we use this value for all applications in this article. However, we acknowledge that a detailed study, preferably founded in statistical theory, is necessary to provide guidelines on the choice of c. We will explore this in future work.
$c = 0.6$
thereby yields a good compromise so that we use this value for all applications in this article. However, we acknowledge that a detailed study, preferably founded in statistical theory, is necessary to provide guidelines on the choice of c. We will explore this in future work.
Furthermore, a two-step estimation procedure like in (3.6) is not recommended for robust estimation. The possible presence of responses that have not been generated by the polychoric model can inflate the empirical cumulative marginal proportion of some responses, which may result in a sizable bias of threshold estimates (3.6), possibly translating into biased estimates of polychoric correlation coefficients in the second stage. Our robust estimator therefore estimates all model parameters (thresholds and polychoric correlation) simultaneously.
6 Simulation studies on partial misspecification
In this section, we employ two simulation studies to demonstrate the robustness gain of our proposed estimator under partial misspecification of the polychoric model. The first simulation design (Section 6.1) is a simplified setting with respect to the partial misspecification, chosen specifically to illustrate the effects of a particular type of contamination with high leverage affecting only a small number of contingency table cells. The second design (Section 6.2) is more involved and considers estimation of a polychoric correlation matrix with a contamination type that scatters in many directions so that nonnormal data points can occur in every contingency table cell. Section 6.3 summarizes findings from additional simulations in the Supplementary Material. For all simulation designs, we perform 5,000 repetitions.
6.1 Individual polychoric correlation coefficient
Let there be
 $K_X=K_Y = 5$
response categories for each of the two rating variables and define the true thresholds in the discretization process (3.1) as
$K_X=K_Y = 5$
response categories for each of the two rating variables and define the true thresholds in the discretization process (3.1) as
 $$\begin{align*}a_{\star,1}=b_{\star,1} = -1.5,\quad a_{\star,2}=b_{\star,2} = -0.5,\quad a_{\star,3}=b_{\star,3}=0.5,\quad a_{\star,4}=b_{\star,4}=1.5, \end{align*}$$
$$\begin{align*}a_{\star,1}=b_{\star,1} = -1.5,\quad a_{\star,2}=b_{\star,2} = -0.5,\quad a_{\star,3}=b_{\star,3}=0.5,\quad a_{\star,4}=b_{\star,4}=1.5, \end{align*}$$
and let the true polychoric correlation coefficient in the latent normality model (3.2) be
 $\rho _{\star}=0.5$
. To simulate partial misspecification of the polychoric model according to (4.1), we let a fraction
$\rho _{\star}=0.5$
. To simulate partial misspecification of the polychoric model according to (4.1), we let a fraction
 $\varepsilon $
of the data be generated by a particular contamination distribution H—which is left unspecified and therefore not explicitly modeled by our estimator—namely, a bivariate normal distribution with mean
$\varepsilon $
of the data be generated by a particular contamination distribution H—which is left unspecified and therefore not explicitly modeled by our estimator—namely, a bivariate normal distribution with mean
 $(2.5,-2.5)^\top $
, variances
$(2.5,-2.5)^\top $
, variances
 $(0.25, 0.25)^\top $
, and zero covariance (and therefore zero correlation). We discretize the realizations of the contamination distribution according to the same thresholds
$(0.25, 0.25)^\top $
, and zero covariance (and therefore zero correlation). We discretize the realizations of the contamination distribution according to the same thresholds
 $a_{\star,1}, \dots , a_{\star,4}, b_{\star,1}, \dots , b_{\star,4}$
as the uncontaminated realizations. This contamination distribution will inflate the empirical frequency of contingency table cells
$a_{\star,1}, \dots , a_{\star,4}, b_{\star,1}, \dots , b_{\star,4}$
as the uncontaminated realizations. This contamination distribution will inflate the empirical frequency of contingency table cells
 $(x,y) \in \{(5,1), (4,1), (5,2)\}$
, in the sense that they have a higher realization probability than under the true polychoric model.Footnote
11
In fact, the data plotted in Figure 1 were generated by this process for contamination fraction
$(x,y) \in \{(5,1), (4,1), (5,2)\}$
, in the sense that they have a higher realization probability than under the true polychoric model.Footnote
11
In fact, the data plotted in Figure 1 were generated by this process for contamination fraction
 $\varepsilon = 0.15$
, and one can see in this figure that particularly cell
$\varepsilon = 0.15$
, and one can see in this figure that particularly cell
 $(x,y) = (5,1)$
is sampled frequently although it only has a near-zero probability at the true polychoric model. The data points causing these three cells to be inflated are instances of negative leverage points. Here, such leverage points drag correlational estimates away from a positive value toward zero or, if there are sufficiently many of them, even a negative value. For intuition, one may think of such points as the responses of careless or inattentive participants whose responses are not based on item content. Although careless responding is only one special case of the unlimited and unrestricted variety of uninformative responses generated by H, we use careless responding as an illustrative running example throughout our simulations.
$(x,y) = (5,1)$
is sampled frequently although it only has a near-zero probability at the true polychoric model. The data points causing these three cells to be inflated are instances of negative leverage points. Here, such leverage points drag correlational estimates away from a positive value toward zero or, if there are sufficiently many of them, even a negative value. For intuition, one may think of such points as the responses of careless or inattentive participants whose responses are not based on item content. Although careless responding is only one special case of the unlimited and unrestricted variety of uninformative responses generated by H, we use careless responding as an illustrative running example throughout our simulations.
For contamination fraction
 $\varepsilon \in \{0, 0.01, 0.05, 0.1, 0.15, 0.2, 0.3, 0.4, 0.49\}$
, we sample
$\varepsilon \in \{0, 0.01, 0.05, 0.1, 0.15, 0.2, 0.3, 0.4, 0.49\}$
, we sample
 $N=1{,}000$
ordinal responses from this data-generating process. We estimate the true parameter
$N=1{,}000$
ordinal responses from this data-generating process. We estimate the true parameter
 $\boldsymbol {\theta }_{\star}$
with our proposed estimator with tuning constant set to
$\boldsymbol {\theta }_{\star}$
with our proposed estimator with tuning constant set to
 $c=0.6$
, the MLE (Olsson, Reference Olsson1979), and, for comparison, the Pearson sample correlation calculated on the integer-valued responses.
$c=0.6$
, the MLE (Olsson, Reference Olsson1979), and, for comparison, the Pearson sample correlation calculated on the integer-valued responses.
Let
 $\widehat {\rho }_N$
be the estimate on a simulated dataset and
$\widehat {\rho }_N$
be the estimate on a simulated dataset and
 $\widehat {\text {SE}}\left (\widehat {\rho }_N\right )$
the estimated standard error of
$\widehat {\text {SE}}\left (\widehat {\rho }_N\right )$
the estimated standard error of
 $\widehat {\rho }_N$
, which is constructed using the limit theory developed in Theorem A.1 in the Supplementary Material. As performance measures, we calculate the average bias of the correlation estimates, the average bias of the standard error estimates (using the standard deviation of the correlation estimates across repetitions as an approximation of the true standard error), as well as coverage and average length of confidence intervals at significance level
$\widehat {\rho }_N$
, which is constructed using the limit theory developed in Theorem A.1 in the Supplementary Material. As performance measures, we calculate the average bias of the correlation estimates, the average bias of the standard error estimates (using the standard deviation of the correlation estimates across repetitions as an approximation of the true standard error), as well as coverage and average length of confidence intervals at significance level
 $\alpha =0.05$
. The coverage is defined as the proportion (across repetitions) of confidence intervals
$\alpha =0.05$
. The coverage is defined as the proportion (across repetitions) of confidence intervals
 $\left [\widehat {\rho }_N\mp q_{1-\alpha /2}\cdot \widehat {\text {SE}}\left (\widehat {\rho }_N\right )\right ]$
that contain the true
$\left [\widehat {\rho }_N\mp q_{1-\alpha /2}\cdot \widehat {\text {SE}}\left (\widehat {\rho }_N\right )\right ]$
that contain the true
 $\rho _{\star}$
, where
$\rho _{\star}$
, where
 $q_{1-\alpha /2}$
is the
$q_{1-\alpha /2}$
is the
 $(1-\alpha /2)$
quantile of the standard normal distribution. The length of a confidence interval is given by
$(1-\alpha /2)$
quantile of the standard normal distribution. The length of a confidence interval is given by
 $2 \cdot q_{1-\alpha /2}\cdot \widehat {\text {SE}}\left (\widehat {\rho }_N\right )$
.
$2 \cdot q_{1-\alpha /2}\cdot \widehat {\text {SE}}\left (\widehat {\rho }_N\right )$
.
Figure 4 visualizes the bias of each estimator with respect to the true polychoric correlation
 $\rho _{\star}$
across the 5,000 simulated datasets. An analogous plot for the whole parameter
$\rho _{\star}$
across the 5,000 simulated datasets. An analogous plot for the whole parameter
 $\boldsymbol {\theta }_{\star}$
can be found in Section D.1 of the Supplementary Material; the results are similar to those of
$\boldsymbol {\theta }_{\star}$
can be found in Section D.1 of the Supplementary Material; the results are similar to those of
 $\rho _{\star}$
. Additional performance measures are shown in Table 1. For all considered contamination fractions, the estimates of the MLE and sample correlation are somewhat similar, which is expected because these two estimators are known to yield similar results when there are five or more rating options and the discretization thresholds are symmetric (cf. Rhemtulla et al., Reference Rhemtulla, Brosseau-Liard and Savalei2012). In the absence of contamination, the MLE and the robust estimator yield accurate estimates. Both estimators are nearly equivalent to one another in the sense that their point estimates, standard deviation, and coverage at significance level
$\rho _{\star}$
. Additional performance measures are shown in Table 1. For all considered contamination fractions, the estimates of the MLE and sample correlation are somewhat similar, which is expected because these two estimators are known to yield similar results when there are five or more rating options and the discretization thresholds are symmetric (cf. Rhemtulla et al., Reference Rhemtulla, Brosseau-Liard and Savalei2012). In the absence of contamination, the MLE and the robust estimator yield accurate estimates. Both estimators are nearly equivalent to one another in the sense that their point estimates, standard deviation, and coverage at significance level
 $\alpha =0.05$
are very similar. However, when contamination is introduced, MLE, sample correlation, and the robust estimator yield noticeably different results. Already at the small contamination fraction
$\alpha =0.05$
are very similar. However, when contamination is introduced, MLE, sample correlation, and the robust estimator yield noticeably different results. Already at the small contamination fraction
 $\varepsilon =0.01$
(corresponding to only ten observations), MLE and sample correlation are noticeably biased, resulting in poor coverage of only about 0.45 and 0.04, respectively. Increasing the contamination fraction to the still relatively small value of
$\varepsilon =0.01$
(corresponding to only ten observations), MLE and sample correlation are noticeably biased, resulting in poor coverage of only about 0.45 and 0.04, respectively. Increasing the contamination fraction to the still relatively small value of
 $\varepsilon = 0.05$
, MLE and sample correlation start to be substantially biased with average biases of
$\varepsilon = 0.05$
, MLE and sample correlation start to be substantially biased with average biases of
 $-0.25$
and
$-0.25$
and
 $-0.28$
, respectively, leading to zero coverage. The biases of these two methods further deteriorate as the contamination fraction is gradually increased. At
$-0.28$
, respectively, leading to zero coverage. The biases of these two methods further deteriorate as the contamination fraction is gradually increased. At
 $\varepsilon \geq 0.15$
, MLE and sample correlation produce estimates that are not only severely biased but also sign-flipped: while the true correlation is positive (0.5), both estimates are negative. In stark contrast, the proposed robust estimator remains accurate throughout nearly all considered contamination fractions. At the small
$\varepsilon \geq 0.15$
, MLE and sample correlation produce estimates that are not only severely biased but also sign-flipped: while the true correlation is positive (0.5), both estimates are negative. In stark contrast, the proposed robust estimator remains accurate throughout nearly all considered contamination fractions. At the small
 $\varepsilon = 0.01$
, the robust estimator is nearly unaffected, while at
$\varepsilon = 0.01$
, the robust estimator is nearly unaffected, while at
 $\varepsilon = 0.15$
, it only exhibits a minor bias of about
$\varepsilon = 0.15$
, it only exhibits a minor bias of about
 $-0.02$
. Even at extreme contamination
$-0.02$
. Even at extreme contamination
 $\varepsilon = 0.4$
, its bias amounts to less than 0.1. In addition, the coverage of the robust method remains above or close to 0.9 for contamination fractions
$\varepsilon = 0.4$
, its bias amounts to less than 0.1. In addition, the coverage of the robust method remains above or close to 0.9 for contamination fractions
 $\varepsilon \leq 0.2$
.
$\varepsilon \leq 0.2$
.
Boxplot visualization of the bias of three estimators of the polychoric correlation coefficient,
 $\widehat {\rho }_N - \rho _{\star}$
, for various contamination fractions in the misspecified polychoric model across 5,000 repetitions.
$\widehat {\rho }_N - \rho _{\star}$
, for various contamination fractions in the misspecified polychoric model across 5,000 repetitions.
Note: The estimators are the robust estimator with
 $c=0.6$
(left), the MLE (center), and the Pearson sample correlation (right). Diamonds represent the respective average bias. The dashed line denotes value 0 and the dotted line
$c=0.6$
(left), the MLE (center), and the Pearson sample correlation (right). Diamonds represent the respective average bias. The dashed line denotes value 0 and the dotted line
 $-\rho _{\star} = -0.5$
, the latter of which indicating a sign flip in the correlation estimate.
$-\rho _{\star} = -0.5$
, the latter of which indicating a sign flip in the correlation estimate.

Results for the robust estimator with
 $c=0.6$
, the MLE, and the Pearson sample correlation, for various contamination fractions across 5,000 simulated datasets
$c=0.6$
, the MLE, and the Pearson sample correlation, for various contamination fractions across 5,000 simulated datasets

Note: The true polychoric correlation coefficient is
 $\rho _{\star}=0.5$
. We compute the average of point estimates
$\rho _{\star}=0.5$
. We compute the average of point estimates
 $\widehat {\rho }_N$
of the polychoric correlation coefficient, the average bias (
$\widehat {\rho }_N$
of the polychoric correlation coefficient, the average bias (
 $\widehat {\rho }_N - \rho _{\star}$
), the standard deviation of the
$\widehat {\rho }_N - \rho _{\star}$
), the standard deviation of the
 $\widehat {\rho }_N$
(SE; an approximation of the true standard error), the average standard error estimate
$\widehat {\rho }_N$
(SE; an approximation of the true standard error), the average standard error estimate
 $\widehat {\text {SE}}$
, the corresponding average bias (
$\widehat {\text {SE}}$
, the corresponding average bias (
 $\widehat {\text {SE}} - \text {SE}$
), confidence interval coverage with respect to the true
$\widehat {\text {SE}} - \text {SE}$
), confidence interval coverage with respect to the true
 $\rho _{\star}$
at nominal level 95%, and the average length of the respective confidence intervals.
$\rho _{\star}$
at nominal level 95%, and the average length of the respective confidence intervals.
It is worth noting that the confidence intervals of the robust estimator grow wider with increasing contamination fraction
 $\varepsilon $
. We also observe that the standard deviation of the robust estimates over the repetitions grows similarly. This indicates that the derived asymptotic distribution used to estimate standard errors matches well with the simulated distribution of the estimator across the repetitions. Indeed, the bias of standard error estimation remains at near-zero for the robust estimator, except for extremely large contamination fractions (
$\varepsilon $
. We also observe that the standard deviation of the robust estimates over the repetitions grows similarly. This indicates that the derived asymptotic distribution used to estimate standard errors matches well with the simulated distribution of the estimator across the repetitions. Indeed, the bias of standard error estimation remains at near-zero for the robust estimator, except for extremely large contamination fractions (
 $\varepsilon \geq 0.4$
). We investigate this in more detail in Section D.1 of the Supplementary Material.
$\varepsilon \geq 0.4$
). We investigate this in more detail in Section D.1 of the Supplementary Material.
6.2 Polychoric correlation matrix
The goal of this simulation study is to robustly estimate a polychoric correlation matrix, that is, a matrix comprising of pairwise polychoric correlation coefficients. The simulation design is based on Foldnes & Grønneberg (Reference Foldnes and Grønneberg2020).
Let there be r observed ordinal random variables and assume that a latent variable underlies each ordinal variable. In accordance with the multivariate polychoric model (e.g., Muthén, Reference Muthén1984), the latent variables are assumed to jointly follow an r-dimensional normal distribution with mean zero and a covariance matrix with unit diagonal elements so that the covariance matrix is a correlation matrix. Each individual latent variable is discretized to its corresponding observed ordinal variable akin to the discretization process (3.1).
Following the five-dimensional simulation design in Foldnes & Grønneberg (Reference Foldnes and Grønneberg2020), there are
 $r=5$
ordinal variables with a polychoric correlation matrix as in Table 2 such that the pairwise correlations vary from a low 0.2 to a moderate 0.56.Footnote
12
For all latent variables, the discretization thresholds are set to, in ascending order,
$r=5$
ordinal variables with a polychoric correlation matrix as in Table 2 such that the pairwise correlations vary from a low 0.2 to a moderate 0.56.Footnote
12
For all latent variables, the discretization thresholds are set to, in ascending order,
 $\Phi _1^{-1}(0.1) = -1.28,\ \Phi _1^{-1}(0.3) = -0.52,\ \Phi _1^{-1}(0.7) = 0.56$
, and
$\Phi _1^{-1}(0.1) = -1.28,\ \Phi _1^{-1}(0.3) = -0.52,\ \Phi _1^{-1}(0.7) = 0.56$
, and
 $\Phi _1^{-1}(0.9) = 1.28$
, such that each ordinal variable can take five possible values. A visualization of the implied distribution of each ordinal variable can be found in Figure 5 in Foldnes & Grønneberg (Reference Foldnes and Grønneberg2020).
$\Phi _1^{-1}(0.9) = 1.28$
, such that each ordinal variable can take five possible values. A visualization of the implied distribution of each ordinal variable can be found in Figure 5 in Foldnes & Grønneberg (Reference Foldnes and Grønneberg2020).
Correlation matrix of
 $r=5$
latent variables as in Foldnes & Grønneberg (Reference Foldnes and Grønneberg2020)
$r=5$
latent variables as in Foldnes & Grønneberg (Reference Foldnes and Grønneberg2020)

Note: In line with the multivariate polychoric correlation model (e.g., Muthén, Reference Muthén1984), the latent variables are jointly normally distributed with mean zero and this correlation matrix as covariance matrix.
Absolute average bias (top) and confidence interval coverage (bottom) at nominal level 95% (dashed horizontal lines) of the robust estimator with
 $c=0.6$
(left) and the MLE (right) for each unique pairwise polychoric correlation coefficient in the true correlation matrix (Table 2), expressed as a function of the contamination fraction
$c=0.6$
(left) and the MLE (right) for each unique pairwise polychoric correlation coefficient in the true correlation matrix (Table 2), expressed as a function of the contamination fraction
 $\varepsilon $
(x-axis).
$\varepsilon $
(x-axis).
Note: Results are aggregated over 5,000 repetitions.

As contamination distribution, we choose an r-dimensional Gumbel distribution comprising of mutually independent Gumbel marginal distributions, each with location and scale parameters equal to 0 and 3, respectively. To obtain ordinal observations, the unobserved realizations from this distribution are discretized via the same threshold values as realizations from the model (normal) distribution. As such, the uninformative ordinal observations generated by this contaminated distribution emulate the erratic behavior of a careless respondent. Unlike in the previous simulation design (Section 6.1), the uninformative responses are not concentrated around a few response options, but may occur in every response option.
For contamination fraction
 $\varepsilon \in \{0, 0.01, 0.05, 0.1, 0.15, 0.2, 0.3, 0.4, 0.49\}$
, we sample
$\varepsilon \in \{0, 0.01, 0.05, 0.1, 0.15, 0.2, 0.3, 0.4, 0.49\}$
, we sample
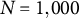 $N=1{,}000$
ordinal five-dimensional responses from this data-generating process and use them to estimate the polychoric correlation matrix in Table 2 via our robust estimator (again with tuning constant
$N=1{,}000$
ordinal five-dimensional responses from this data-generating process and use them to estimate the polychoric correlation matrix in Table 2 via our robust estimator (again with tuning constant
 $c=0.6$
) as well as the MLE.
$c=0.6$
) as well as the MLE.
Figure 5 visualizes the absolute average bias as well as confidence interval coverage at 95% nominal level (calculated over the 5,000 repetitions) of the robust estimator and the MLE for each pairwise polychoric correlation coefficient. As expected, when the model is correctly specified (
 $\varepsilon = 0$
), both estimators coincide with accurate estimates. However, in the presence of contamination (
$\varepsilon = 0$
), both estimators coincide with accurate estimates. However, in the presence of contamination (
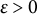 $\varepsilon> 0$
), the two estimators deviate. The MLE exhibits a notable bias for all correlation coefficients, which increases gradually with increasing contamination fraction. The magnitude of the bias tends to be larger for pairs with larger true correlation, such as
$\varepsilon> 0$
), the two estimators deviate. The MLE exhibits a notable bias for all correlation coefficients, which increases gradually with increasing contamination fraction. The magnitude of the bias tends to be larger for pairs with larger true correlation, such as
 $0.56$
for pair
$0.56$
for pair
 $(2,1)$
, than for pairs with weaker true correlation, such as
$(2,1)$
, than for pairs with weaker true correlation, such as
 $0.20$
for pair
$0.20$
for pair
 $(5,4)$
. In addition, coverage of the MLE drops quickly for many pairs and gradually for the remaining ones. Conversely, the robust estimator remains nearly unaffected for a broad range of contamination fractions for each correlation coefficient (
$(5,4)$
. In addition, coverage of the MLE drops quickly for many pairs and gradually for the remaining ones. Conversely, the robust estimator remains nearly unaffected for a broad range of contamination fractions for each correlation coefficient (
 $\varepsilon \leq 0.2$
or
$\varepsilon \leq 0.2$
or
 $\varepsilon \leq 0.3$
depending on the variable pair), with bias only somewhat increasing afterward. Furthermore, its coverage remains close to 0.9 or higher even at the high contamination fraction of
$\varepsilon \leq 0.3$
depending on the variable pair), with bias only somewhat increasing afterward. Furthermore, its coverage remains close to 0.9 or higher even at the high contamination fraction of
 $\varepsilon = 0.3$
. This reflects the excellent performance of the proposed estimator with respect to robustness to uninformative responses. Section D.2 of the Supplementary Material contains additional evaluations. In essence, the robust estimator yields accurate standard errors, but its confidence intervals tend to be wider than those of the MLE in the presence of contamination.
$\varepsilon = 0.3$
. This reflects the excellent performance of the proposed estimator with respect to robustness to uninformative responses. Section D.2 of the Supplementary Material contains additional evaluations. In essence, the robust estimator yields accurate standard errors, but its confidence intervals tend to be wider than those of the MLE in the presence of contamination.
We stress that polychoric correlation matrices need not be positive definite (e.g., Mair, Reference Mair2018, p. 22), although all estimated polychoric correlation matrices in this simulation turned out positive definite. If an estimated polychoric correlation matrix is not positive definite, one may opt to apply a smoothing procedure like in Yuan et al. (Reference Yuan, Wu and Bentler2011) or Bock et al. (Reference Bock, Gibbons and Muraki1988).
6.3 Discussion and additional simulation experiments
The two simulation studies above demonstrate that already a small degree of partial misspecification due to uninformative responses, such as careless responses, can render the commonly employed MLE unreliable, while the proposed robust estimator retains good accuracy and coverage even in the presence of a considerable number of uninformative responses. On the other hand, when the polychoric model is correctly specified, the MLE and the robust estimator produce equivalent estimates.
To further evaluate our robust estimator and investigate its limitations, we conduct additional simulation experiments in Section E of the Supplementary Material.
The first experiment, described in Section E.2 of the Supplementary Material, is a generalization of the design in Section 6.1 with different mean shifts in the contamination distribution H. For small mean shifts, the proposed estimator does not improve upon the MLE, but the bias of both estimators remains reasonable. The larger the mean shift, the larger the detrimental effect on the MLE and the higher the robustness gain of our proposed estimator.
The second experiment, described in Section E.3 of the Supplementary Material, focuses on correlation shifts in the contamination distribution H. Specifically, the contamination distribution is the same as the true model distribution except for a sign-flipped correlation coefficient
 $-\rho _{\star}$
. For moderate correlation
$-\rho _{\star}$
. For moderate correlation
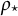 $\rho _{\star}$
, the proposed estimator does not improve upon the MLE due to substantial overlap between the true model distribution and the contamination. However, the gain in robustness increases substantially for higher correlation coefficients
$\rho _{\star}$
, the proposed estimator does not improve upon the MLE due to substantial overlap between the true model distribution and the contamination. However, the gain in robustness increases substantially for higher correlation coefficients
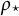 $\rho _{\star}$
. We expect the gain in robustness to increase for a higher number of response options and decrease for fewer response options. In the most extreme case of two dichotomous rating variables, no improvement can be expected.
$\rho _{\star}$
. We expect the gain in robustness to increase for a higher number of response options and decrease for fewer response options. In the most extreme case of two dichotomous rating variables, no improvement can be expected.
7 Empirical application
We now demonstrate our proposed method on empirical data by using a subset of the 100 unipolar markers of the Big Five personality traits (Goldberg, Reference Goldberg1992).
7.1 Background and study design
Each marker is an item comprising a single English adjective (such as “bold” or “timid”) asking respondents to indicate how accurately the adjective describes their personality using a 5-point Likert-type rating scale (very inaccurate, moderately inaccurate, neither accurate nor inaccurate, moderately accurate, and very accurate). Here, each Big Five personality trait is measured with six pairs of adjectives that are polar opposites to one another (such as “talkative” vs. “silent”), that is, 12 items in total for each trait. It seems implausible that an attentive respondent would choose to agree (or disagree) to both items in a pair of polar opposite adjectives. Consequently, one would expect a strongly negative correlation between polar adjectives if all respondents respond attentively (Arias et al., Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020).
Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020) collect measurements of three Big Five traits in this way, namely, extroversion, neuroticism, and conscientiousness.Footnote
13
The sample that we shall use, Sample 1 in Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020), consists of
 $N=725$
online respondents who are all U.S. citizens, native English speakers, and tend to have relatively high levels of reported education (about 90% report to hold an undergraduate or higher degree). Concerned about respondent inattention in their data, Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020) construct a factor mixture model for detecting inattentive/careless participants. Their model crucially relies on response inconsistencies to polar opposite adjectives and is designed to primarily detect careless straightlining responding. They find that careless responding is a sizable problem in their data. Their model finds evidence of straightliners, and the authors conclude that if unaccounted for, they can substantially deteriorate the fit of theoretical models, produce spurious variance, and overall jeopardize the validity of research results.
$N=725$
online respondents who are all U.S. citizens, native English speakers, and tend to have relatively high levels of reported education (about 90% report to hold an undergraduate or higher degree). Concerned about respondent inattention in their data, Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020) construct a factor mixture model for detecting inattentive/careless participants. Their model crucially relies on response inconsistencies to polar opposite adjectives and is designed to primarily detect careless straightlining responding. They find that careless responding is a sizable problem in their data. Their model finds evidence of straightliners, and the authors conclude that if unaccounted for, they can substantially deteriorate the fit of theoretical models, produce spurious variance, and overall jeopardize the validity of research results.
Due to the suspected presence of careless respondents, we apply our proposed method to estimate the polychoric correlation coefficients between all
 $\binom {12}{2}=66$
unique item pairs in the neuroticism scale to obtain an estimate of the scale’s (polychoric) correlation matrix. The results of the remaining two scales are qualitatively similar and are reported in Section F of the Supplementary Material. We estimate the polychoric correlation matrix via the MLE and via our proposed robust alternative with tuning parameter
$\binom {12}{2}=66$
unique item pairs in the neuroticism scale to obtain an estimate of the scale’s (polychoric) correlation matrix. The results of the remaining two scales are qualitatively similar and are reported in Section F of the Supplementary Material. We estimate the polychoric correlation matrix via the MLE and via our proposed robust alternative with tuning parameter
 $c=0.6$
. As a robustness check, we further investigate the effect of the choice of c.
$c=0.6$
. As a robustness check, we further investigate the effect of the choice of c.
7.2 Results
Figure 6 visualizes the difference in absolute estimates for the polychoric correlation coefficient between all 66 unique item pairs in the neuroticism scale. For all unique pairs, our method estimates a stronger correlation coefficient than the MLE. The differences in absolute estimates on average amount to 0.083, ranging from only marginally larger than zero to a substantive 0.314. For correlations between polar opposite adjectives, the average absolute difference between our robust method and the MLE is 0.151. The fact that a robust method consistently yields stronger correlation estimates than the MLE, particularly between polar opposite adjectives, is indicative of the presence of leverage points, which drag negative correlation estimates toward zero, that is, they attenuate the estimated strength of correlation. Here, such leverage points could be the responses of careless respondents who report agreement or disagreement to both items in item pairs that are designed to be negatively correlated. For instance, recall that it is implausible that an attentive respondent would choose to agree (or disagree) to both adjectives in the pair “envious” and “not envious” (cf. Arias et al., Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020). If sufficiently many such respondents are present, then the presumably strongly negative correlation between these two opposite adjectives will be estimated to be weaker than it actually is.
Difference between absolute estimates for the polychoric correlation coefficient of the robust estimator with
 $c=0.6$
and the MLE for each item pair in the neuroticism scale, using the data of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020).
$c=0.6$
and the MLE for each item pair in the neuroticism scale, using the data of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020).
Note: The items are “calm” (N1_P), “angry” (N1_N), “relaxed” (N2_P), “tense” (N2_N), “at ease” (N3_P), “nervous” (N3_N), “not envious” (N4_P), “envious” (N4_N), “stable” (N5_P), “unstable” (N5_N), “contented” (N6_P), and “discontented” (N6_N). For the item naming given in parentheses, items with identical identifier (the integer after the first “N”) are polar opposites, where a last character “P” refers to the positive opposite and “N” to the negative opposite. The individual estimates of each method are provided in Table F.2 in the Supplementary Material.

To further investigate the presence of careless respondents who attenuate correlational estimates, we study in detail the adjective pair “not envious” and “envious,” which featured the largest discrepancy between the ML estimate and the robust estimate in Figure 6, with an absolute difference of 0.314. The results of the two estimators and, for completeness, the sample correlation, are summarized in Table 3. The ML estimate of
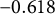 $-0.618$
and sample correlation estimate of
$-0.618$
and sample correlation estimate of
 $-0.562$
for the (polychoric) correlation coefficient seem remarkably weak considering that the two adjectives in question are polar opposites. In contrast, the robust correlation estimate is given by
$-0.562$
for the (polychoric) correlation coefficient seem remarkably weak considering that the two adjectives in question are polar opposites. In contrast, the robust correlation estimate is given by
 $-0.925$
, which seems much more in line with what one would expect if all participants responded accurately and attentively (cf. Arias et al., Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020).
$-0.925$
, which seems much more in line with what one would expect if all participants responded accurately and attentively (cf. Arias et al., Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020).
Parameter estimates and standard error estimates (
 $\widehat {\text {SE}}$
) for the correlation between the neuroticism adjective pair “not envious” and “envious” in the data of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020), using the robust estimator with
$\widehat {\text {SE}}$
) for the correlation between the neuroticism adjective pair “not envious” and “envious” in the data of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020), using the robust estimator with
 $c=0.6$
, the MLE, and the Pearson sample correlation
$c=0.6$
, the MLE, and the Pearson sample correlation

Note: Each adjective item has five answer categories. Note that the Pearson sample correlation does not model thresholds.
To study the potential presence of careless responses in each contingency table cell
 $(x,y)$
for item pair “not envious” and “envious,” Table 4 lists the PRs at the robust estimate, alongside the associated model probabilities and empirical relative frequencies.Footnote
14
A total of six cells have extremely large PR values of higher than 1,000, and, in addition, five cells have a PR of higher than 9, and one cell has a PR of higher than 4. Such PR values are far away from the ideal value 0 at which the model would fit perfectly, thereby indicating a poor fit of the polychoric model for such responses. It stands out that all such poorly fitted cells are those whose responses might be viewed as inconsistent. Indeed, response cells
$(x,y)$
for item pair “not envious” and “envious,” Table 4 lists the PRs at the robust estimate, alongside the associated model probabilities and empirical relative frequencies.Footnote
14
A total of six cells have extremely large PR values of higher than 1,000, and, in addition, five cells have a PR of higher than 9, and one cell has a PR of higher than 4. Such PR values are far away from the ideal value 0 at which the model would fit perfectly, thereby indicating a poor fit of the polychoric model for such responses. It stands out that all such poorly fitted cells are those whose responses might be viewed as inconsistent. Indeed, response cells
 $(x,y) \in \{(1,1), (1,2), (2,1), (2,2)\}$
indicate that a participant reports that neither “not envious” nor “envious” characterizes them accurately, which are mutually contradicting responses, while for response cells
$(x,y) \in \{(1,1), (1,2), (2,1), (2,2)\}$
indicate that a participant reports that neither “not envious” nor “envious” characterizes them accurately, which are mutually contradicting responses, while for response cells
 $(x,y) \in \{(4,4), (4,5), (5,4), (5,5)\},$
both adjectives characterize them accurately, which is again contradicting. As discussed previously, such responses might be due to careless responding. The robust estimator suggests that such responses cannot be fitted well by the polychoric model and subsequently downweighs their influence in the estimation procedure by mapping their PR with the linear part of the discrepancy function
$(x,y) \in \{(4,4), (4,5), (5,4), (5,5)\},$
both adjectives characterize them accurately, which is again contradicting. As discussed previously, such responses might be due to careless responding. The robust estimator suggests that such responses cannot be fitted well by the polychoric model and subsequently downweighs their influence in the estimation procedure by mapping their PR with the linear part of the discrepancy function
 $\varphi (\cdot )$
in (5.3). Notably, also cells
$\varphi (\cdot )$
in (5.3). Notably, also cells
 $(x,y) \in \{(1,3), (3,1), (3,5), (5,3)\}$
are poorly fitted. These responses report (dis)agreement to one opposite adjective, while being neutral about the other opposite. It is beyond the scope of this article to assess whether such response patterns are also indicative of careless responding, but the robust estimator suggests that such responses at least cannot be fitted well by the polychoric model with the data of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020).
$(x,y) \in \{(1,3), (3,1), (3,5), (5,3)\}$
are poorly fitted. These responses report (dis)agreement to one opposite adjective, while being neutral about the other opposite. It is beyond the scope of this article to assess whether such response patterns are also indicative of careless responding, but the robust estimator suggests that such responses at least cannot be fitted well by the polychoric model with the data of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020).
Empirical relative frequency (top), estimated response probability (center), and Pearson residual (PR) (bottom) of each response
 $(x,y)$
for the item pair “not envious” (X) and “envious” (Y) in the measurements of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020) of the neuroticism scale
$(x,y)$
for the item pair “not envious” (X) and “envious” (Y) in the measurements of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020) of the neuroticism scale

Note: Estimate
 $\widehat {\boldsymbol {\theta }}_N$
was computed via the robust estimator with tuning constant
$\widehat {\boldsymbol {\theta }}_N$
was computed via the robust estimator with tuning constant
 $c=0.6$
. The complete PR values are provided in Table F.5 in the Supplementary Material.
$c=0.6$
. The complete PR values are provided in Table F.5 in the Supplementary Material.
As a robustness check on the role of tuning constant c, Figure 7 visualizes the point estimate
 $\widehat {\rho }_N$
of the polychoric correlation between the item pair “not envious” and “envious” for various values of c. The point estimate stays relatively constant for c between 0 and 0.75, with
$\widehat {\rho }_N$
of the polychoric correlation between the item pair “not envious” and “envious” for various values of c. The point estimate stays relatively constant for c between 0 and 0.75, with
 $\widehat {\rho }_N$
ranging between
$\widehat {\rho }_N$
ranging between
 $-0.95$
and
$-0.95$
and
 $-0.92$
. Just after
$-0.92$
. Just after
 $c=0.75$
,
$c=0.75$
,
 $\widehat {\rho }_N$
abruptly jumps to about
$\widehat {\rho }_N$
abruptly jumps to about
 $-0.85$
, before it stabilizes again and slowly transitions to the ML estimate of
$-0.85$
, before it stabilizes again and slowly transitions to the ML estimate of
 $-0.62$
(see Table 3) for
$-0.62$
(see Table 3) for
 $c \rightarrow \infty $
. Since
$c \rightarrow \infty $
. Since
 $\widehat {\rho }_N$
very slowly approaches the value of the ML estimate, we only visualize choices of c up to 2 in Figure 7. The instability of the estimate around
$\widehat {\rho }_N$
very slowly approaches the value of the ML estimate, we only visualize choices of c up to 2 in Figure 7. The instability of the estimate around
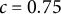 $c=0.75$
suggests that c should be chosen below this value to avoid disproportionate influence of poorly fitting cells. For the broad range of
$c=0.75$
suggests that c should be chosen below this value to avoid disproportionate influence of poorly fitting cells. For the broad range of
 $c \leq 0.75$
, we obtain a robust finding of “not envious” and “envious” having a very strong negative correlation after accounting for likely careless responding.
$c \leq 0.75$
, we obtain a robust finding of “not envious” and “envious” having a very strong negative correlation after accounting for likely careless responding.
Estimates of the polychoric correlation between the items “not envious” and “envious” in the data of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020) for various choices of the tuning constant c (x-axis).
Note: The dashed vertical line marks the default value of
 $c=0.6$
.
$c=0.6$
.

Overall, leveraging our robust estimator, we find evidence for the presence of careless respondents in the data of Arias et al. (Reference Arias, Garrido, Jenaro, Martinez-Molina and Arias2020). While they substantially affect the correlation estimate of the MLE, amounting to about
 $-0.62$
, which is much weaker than one would expect for polar opposite items, our robust estimator can withstand their influence with an estimate of about
$-0.62$
, which is much weaker than one would expect for polar opposite items, our robust estimator can withstand their influence with an estimate of about
 $-0.93$
and also help identify them through unreasonably large PR values. On a final note, our findings from the empirical application align remarkably well with those of the simulation from Section E.3 of the Supplementary Material, therefore strengthening their validity. We provide a detailed discussion of this similarity in Section E.3.3 of the Supplementary Material.
$-0.93$
and also help identify them through unreasonably large PR values. On a final note, our findings from the empirical application align remarkably well with those of the simulation from Section E.3 of the Supplementary Material, therefore strengthening their validity. We provide a detailed discussion of this similarity in Section E.3.3 of the Supplementary Material.
8 Estimation under distributional misspecification
The simulation studies in Section 6 have been concerned with a situation in which the polychoric model is misspecified for a subset of a sample (partial misspecification). However, as outlined in Section 4.3, another misspecification framework of interest is that of distributional misspecification where the model is misspecified for the entire sample. Suppose that instead of a bivariate standard normal distribution, the latent variables
 $(\xi , \eta )$
jointly follow an unknown and unspecified distribution G. In this framework, the object of interest is the population correlation between
$(\xi , \eta )$
jointly follow an unknown and unspecified distribution G. In this framework, the object of interest is the population correlation between
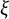 $\xi $
and
$\xi $
and
 $\eta $
under distribution G, that is,
$\eta $
under distribution G, that is,
 $\rho _G = \mathbb {C}\mathrm {or}_{G} \left [\xi ,\ \eta \right ]$
, rather than a polychoric correlation coefficient. Estimators for such situations where the population distribution G is nonnormal have been proposed by Lyhagen & Ornstein (Reference Lyhagen and Ornstein2023), Jin & Yang-Wallentin (Reference Jin and Yang-Wallentin2017), and Roscino & Pollice (Reference Roscino, Pollice, Zani, Cerioli, Riani and Vichi2006).
$\rho _G = \mathbb {C}\mathrm {or}_{G} \left [\xi ,\ \eta \right ]$
, rather than a polychoric correlation coefficient. Estimators for such situations where the population distribution G is nonnormal have been proposed by Lyhagen & Ornstein (Reference Lyhagen and Ornstein2023), Jin & Yang-Wallentin (Reference Jin and Yang-Wallentin2017), and Roscino & Pollice (Reference Roscino, Pollice, Zani, Cerioli, Riani and Vichi2006).
8.1 Distributional vs. partial misspecification
Huber and Ronchetti (Reference Huber and Ronchetti2009, p. 4) note that, although conceptually distinct, robustness to distributional misspecification and partial misspecification are “practically synonymous notions.” Hence, despite distributional misspecification not being covered by the partial misspecification framework under which we study the theoretical properties of our proposed estimator, our estimator could still offer a gain in robustness compared to the MLE of the polychoric model under distributional misspecification. Specifically, the robust estimator may still be useful if the central part of the nonnormal distribution G is not too different from a standard bivariate normal distribution. Intuitively, if the difference between G and a standard normal distribution is mainly in the tails, G can be approximated by a contaminated distribution as in (4.1), with the standard normal distribution covering the central part and some contamination distribution H covering the tails. The polychoric MLE tries to treat influential observations from the tails—which cannot be fitted well by the polychoric model—as if they were normally distributed, resulting in a possibly large estimation bias. In contrast, the robust estimator uses the normal distribution only for observations from the central part—which may fit the polychoric model well enough—and downweights observations from the tails. Thus, as long as such a contaminated normal distribution is a decent approximation of the nonnormal distribution G, the robust estimator should perform reasonably well. However, if G cannot be approximated by such a contaminated normal distribution, neither the polychoric MLE nor our estimator can be expected to perform well. Overall, though, our estimator could offer an improvement in terms of robustness to distributional misspecification.
In the following, we perform a simulation study to investigate the performance of our estimator when the polychoric model is distributionally misspecified.
8.2 Simulation study
To simulate ordinal variables that were generated by a nonnormal latent distribution G, we employ the VITA simulation method of Grønneberg & Foldnes (Reference Grønneberg and Foldnes2017). For a pre-specified value of the population correlation
 $\rho _G$
, the VITA method models the latent random vector
$\rho _G$
, the VITA method models the latent random vector
 $(\xi ,\eta )$
such that the individual variables
$(\xi ,\eta )$
such that the individual variables
 $\xi $
and
$\xi $
and
 $\eta $
both possess standard normal marginal distributions with population correlation set equal to
$\eta $
both possess standard normal marginal distributions with population correlation set equal to
 $\rho _G = \mathbb {C}\mathrm {or}_{G} \left [\xi ,\ \eta \right ]$
, but are not jointly normally distributed. Instead, their joint distribution G is equal to a pre-specified nonnormal copula distribution, such as the Clayton or Gumbel copula. Grønneberg & Foldnes (Reference Grønneberg and Foldnes2017) show that discretizing such VITA latent variables yields ordinal observations that could not have been generated by a standard bivariate normal distribution, thereby ensuring proper violation of the latent normality assumption.
$\rho _G = \mathbb {C}\mathrm {or}_{G} \left [\xi ,\ \eta \right ]$
, but are not jointly normally distributed. Instead, their joint distribution G is equal to a pre-specified nonnormal copula distribution, such as the Clayton or Gumbel copula. Grønneberg & Foldnes (Reference Grønneberg and Foldnes2017) show that discretizing such VITA latent variables yields ordinal observations that could not have been generated by a standard bivariate normal distribution, thereby ensuring proper violation of the latent normality assumption.
To investigate the robustness of our estimator to distributional misspecification, we use the VITA implementation in package covsim (Grønneberg et al., Reference Grønneberg, Foldnes and Marcoulides2022) to generate draws of the latent variables
 $(\xi ,\eta )$
such that the latent variables are jointly distributed according to a Clayton copula G with population correlation
$(\xi ,\eta )$
such that the latent variables are jointly distributed according to a Clayton copula G with population correlation
 $\rho _G \in \{0.9, 0.3\}$
(see Figure 8 for visualizations). Following the discretization process (3.1), we discretize both latent variables via discretization thresholds
$\rho _G \in \{0.9, 0.3\}$
(see Figure 8 for visualizations). Following the discretization process (3.1), we discretize both latent variables via discretization thresholds
 $$ \begin{align*} \begin{array}{r r r r r} a_1 = -1.5, & a_2 = 0,& a_3 = 0.5, &a_4 = 1, & \quad \text{and}\\ b_1 = -1, & b_2 =1,& b_3 =1.5, &b_4 =2, & \end{array} \end{align*} $$
$$ \begin{align*} \begin{array}{r r r r r} a_1 = -1.5, & a_2 = 0,& a_3 = 0.5, &a_4 = 1, & \quad \text{and}\\ b_1 = -1, & b_2 =1,& b_3 =1.5, &b_4 =2, & \end{array} \end{align*} $$
such that both resulting ordinal variables have five response options each. We generate
 $N=1{,}000$
ordinal responses according to this data generation process and compute across 5,000 repetitions the same estimators and performance measures as in the simulations in Section 6.
$N=1{,}000$
ordinal responses according to this data generation process and compute across 5,000 repetitions the same estimators and performance measures as in the simulations in Section 6.
Bivariate density plots of the standard normal distribution (left) and Clayton copula with standard normal marginals (right), for population correlations 0.9 (top) and 0.3 (bottom).

Figure 9 visualizes the bias of the robust estimator and the polychoric MLE under both Clayton copulas across the repetitions.Footnote
15
For correlation 0.9, the polychoric MLE exhibits a noteworthy bias, whereas the robust estimator remains accurate, albeit with a larger estimation variance as compared to most simulation configurations of partial misspecification (cf. Section 6). Conversely, for the weaker correlation 0.3, both estimators are fairly accurate with average biases of about
 $-0.015$
. Table 5 contains additional performance measures regarding inference. For
$-0.015$
. Table 5 contains additional performance measures regarding inference. For
 $\rho _G = 0.3$
, the average standard error estimate of the robust method is accurate, but for
$\rho _G = 0.3$
, the average standard error estimate of the robust method is accurate, but for
 $\rho _G = 0.9$
, it notably overestimates. We therefore also computed the median of the standard error estimates in the latter case: at 0.017, it is fairly close to the true standard error of 0.014. It turns out that there is a small number of simulated datasets with a large majority of empty cells in the contingency table, resulting in numerical instability of the standard error estimates and inflating their average. As discussed in Section 4.3, distributional misspecification is not covered by our partial misspecification framework, so it is not surprising that standard errors derived under partial misspecification are not always valid. Bootstrap inference may therefore be an attractive alternative. Nevertheless, unlike the polychoric MLE with coverage of only about 13% for
$\rho _G = 0.9$
, it notably overestimates. We therefore also computed the median of the standard error estimates in the latter case: at 0.017, it is fairly close to the true standard error of 0.014. It turns out that there is a small number of simulated datasets with a large majority of empty cells in the contingency table, resulting in numerical instability of the standard error estimates and inflating their average. As discussed in Section 4.3, distributional misspecification is not covered by our partial misspecification framework, so it is not surprising that standard errors derived under partial misspecification are not always valid. Bootstrap inference may therefore be an attractive alternative. Nevertheless, unlike the polychoric MLE with coverage of only about 13% for
 $\rho _G = 0.9$
, the robust estimator maintains high coverage of over 90%.
$\rho _G = 0.9$
, the robust estimator maintains high coverage of over 90%.
Results for the robust estimator with
 $c=0.6$
and the polychoric MLE across 5,000 simulated datasets under distributional misspecification via a Clayton copula with true population correlation
$c=0.6$
and the polychoric MLE across 5,000 simulated datasets under distributional misspecification via a Clayton copula with true population correlation
 $\rho _G\in \{0.9, 0.3\}$
$\rho _G\in \{0.9, 0.3\}$

Note: See Table 1 for explanatory notes on the performance measures.
Boxplot visualization of the bias of the robust estimator and the polychoric MLE,
 $\widehat {\rho }_N - \rho _G$
, under distributional misspecification via a Clayton copula with correlation
$\widehat {\rho }_N - \rho _G$
, under distributional misspecification via a Clayton copula with correlation
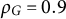 $\rho _G = 0.9$
(left) and
$\rho _G = 0.9$
(left) and
 $\rho _G = 0.3$
(right), across 5,000 repetitions.
$\rho _G = 0.3$
(right), across 5,000 repetitions.
Note: Diamonds represent the respective average bias. The tuning constant of the robust estimator is set to
 $c=0.6$
.
$c=0.6$
.

These results suggest that at least for point estimation, the Clayton copula with correlation 0.9 might be reasonably approximable by a contaminated normal distribution where the normal distribution covers the center of the probability mass and some contamination distribution covers the tails (cf. Section 8.1). Indeed, Figure 8 indicates that the normal distribution and Clayton copula at correlation 0.9 seem to behave similarly in the center, but deviate from one another toward the tails. On the other hand, at correlation 0.3, the two densities do not appear to be drastically different from one another, which may explain why both the polychoric MLE and the robust estimator work reasonably well for such distributional misspecification. If the latent distribution is not too different from a normal distribution, then the polychoric model may offer a satisfactory fit despite being technically misspecified.
Overall, this simulation study demonstrates that in some cases of distributional misspecification, robustness can be gained with our estimator, compared to the polychoric MLE. However, it also demonstrates that there are cases of distributional misspecification for which the polychoric MLE still works quite well such that the robust estimator offers little gain. Nevertheless, the fact that in some situations robustness can be gained under distributional misspecification represents an overall gain in robustness.
9 Discussion and conclusion
We consider a situation where the polychoric correlation model is potentially misspecified for a subset of responses in a sample, that is, a set of uninformative observations not generated by a latent standard normal distribution. This model misspecification framework, called partial misspecification here, stems from the robust statistics literature, and a relevant special case is that of careless respondents in questionnaire studies. We demonstrate that ML estimation is highly susceptible to the presence of such uninformative responses, resulting in possibly large estimation biases and low coverage of confidence intervals.
As a remedy, we propose an estimator based on the C-estimation framework of Welz et al. (Reference Welz, Archimbaud and Alfons2024) that is designed to be robust to partial model misspecification. Our estimator generalizes ML estimation, does not make any assumption on the magnitude or type of potential misspecification, comes at no additional computational cost, and possesses attractive statistical guarantees, such as asymptotic normality. It furthermore allows to pinpoint the sources of potential model misspecification through the notion of PRs. Each possible response option is assigned a PR, where values substantially larger than the ideal value 0 imply that the response in question cannot be fitted well by the polychoric correlation model. In addition, the methodology proposed in this article is implemented in the free open-source package robcat (Welz et al., Reference Welz, Alfons and Mair2025) for the statistical programming environment R and is publicly available at https://CRAN.R-project.org/package=robcat.
Although not covered by our partial misspecification framework, we also discuss how and when our estimator can offer a robustness gain (compared to the polychoric MLE) when the polychoric model is misspecified for all observations, which has been a subject of interest in recent literature. In essence, there can be a robustness gain if the latent nonnormal distribution that generated the data can be reasonably well approximated by a contaminated normal distribution where the normal distribution reflects the central part and some unspecified contamination distribution reflects the tails.
We verify the enhanced robustness and theoretical properties of our robust estimator in simulation studies. Furthermore, we demonstrate the estimator’s practical usefulness in an empirical application on a Big Five administration, where we find compelling evidence for the presence of careless respondents as a source of partial model misspecification.
However, our estimator depends on a user-specified choice of a tuning constant c, which governs a tradeoff between robustness and efficiency in case of misspecification. While simulation experiments suggest that the choice
 $c=0.6$
provides a good tradeoff and estimates do not change considerably for a broad range of finite choices of c, a detailed investigation on this tuning constant needs to be carried out in future work. As an alternative, one could consider other discrepancy functions that do not depend on tuning constants, like the ones discussed in Welz et al. (Reference Welz, Archimbaud and Alfons2024). As practical guidelines, we recommend always comparing robust estimates to that of ML and running the robust estimator for various choices of c, like in Figure 7. Doing so not only helps assess the estimates’ stability, but also the severity of (partial) model misspecification. If the ML and robust estimates strongly differ, one may want to opt for choices of
$c=0.6$
provides a good tradeoff and estimates do not change considerably for a broad range of finite choices of c, a detailed investigation on this tuning constant needs to be carried out in future work. As an alternative, one could consider other discrepancy functions that do not depend on tuning constants, like the ones discussed in Welz et al. (Reference Welz, Archimbaud and Alfons2024). As practical guidelines, we recommend always comparing robust estimates to that of ML and running the robust estimator for various choices of c, like in Figure 7. Doing so not only helps assess the estimates’ stability, but also the severity of (partial) model misspecification. If the ML and robust estimates strongly differ, one may want to opt for choices of
 $c>0$
not too far from 0 to achieve larger robustness gains.
$c>0$
not too far from 0 to achieve larger robustness gains.
A practical consideration of polychoric correlation is computing time. Our estimator simultaneously estimates all model parameters (i.e., correlation coefficient and thresholds) for robustness reasons, hence, it is computationally more intensive than the non-robust two-stage approach of Olsson (Reference Olsson1979). To alleviate the computational burden, our implementation in package robcat is written in fast and efficient C++ code. Furthermore, its default behavior first tries a fast unconstrained numerical optimization routine, which in our experience almost always suffices and executes in about half a second for five-point rating variables on a regular laptop. For estimating polychoric correlation matrices, package robcat supports parallel computing to keep computation time low. Since our method generalizes ML and has the same time complexity, these functionalities also provide a fast implementation of the MLE.
The methodology proposed in this article suggests a number of extensions. For instance, one could use a robustly estimated polychoric correlation matrix in SEMs to robustify such models and their fit indices against misspecification. Similar robustification could be achieved in, for instance, but not limited to, principal component analyses, multidimensional scaling, or clustering. In addition, the theory of Welz et al. (Reference Welz, Archimbaud and Alfons2024) may allow to pinpoint possible sources of model misspecification on the individual response level. That is, it may enable the derivation of statistically sound cutoff values for PRs in order to detect whether a given response can be fitted well by the polychoric correlation model. We leave these avenues to further research.
Overall, our novel robust estimator could open the door for a new line of research that is concerned with making the correlation-based analysis of rating data more reliable by reducing dependence on modeling assumptions.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/psy.2025.10066.
Data availability statement
Replication files are publicly available on GitHub at https://github.com/mwelz/robust-polycor-replication.
Acknowledgements
We thank Patrick Groenen, Steffen Grønneberg, and Jonas Moss for valuable feedback. We further thank the associate editor and three anonymous reviewers, whose comments led to a substantially improved paper. This article is based on Chapter 3 of M.W.’s Ph.D. thesis.
Author contributions
Conceptualization: M.W., P.M., and A.A.; Formal analysis, Methodology, Software, and Writing—original draft: M.W.; Visualization: M.W. and A.A.; Writing—review and editing: M.W., P.M., and A.A.; Funding acquisition: A.A. All authors approved the final submitted draft.
Funding statement
This research was supported by a grant from the Dutch Research Council (NWO), research program Vidi (Project No. VI.Vidi.195.141).
Competing interests
The authors declare none.
Ethical standards
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.


















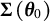













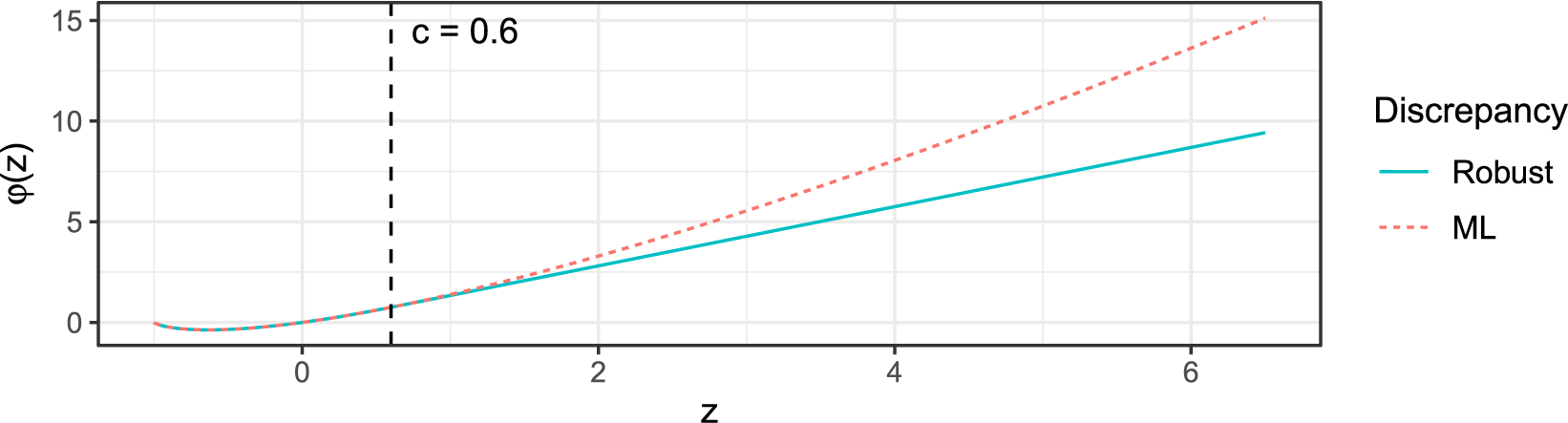



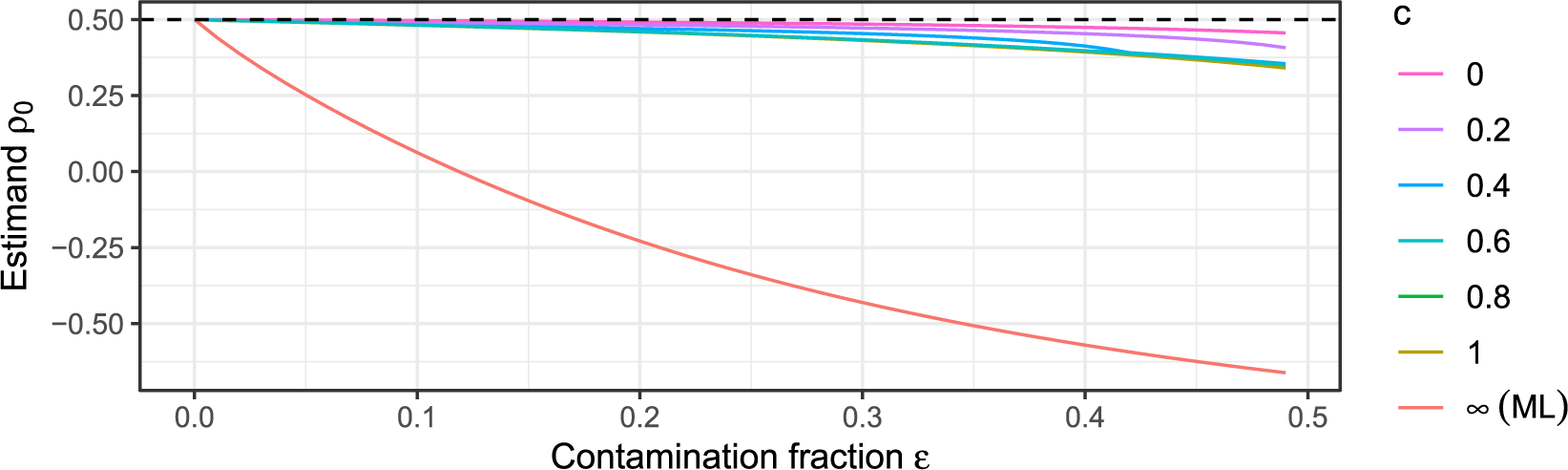





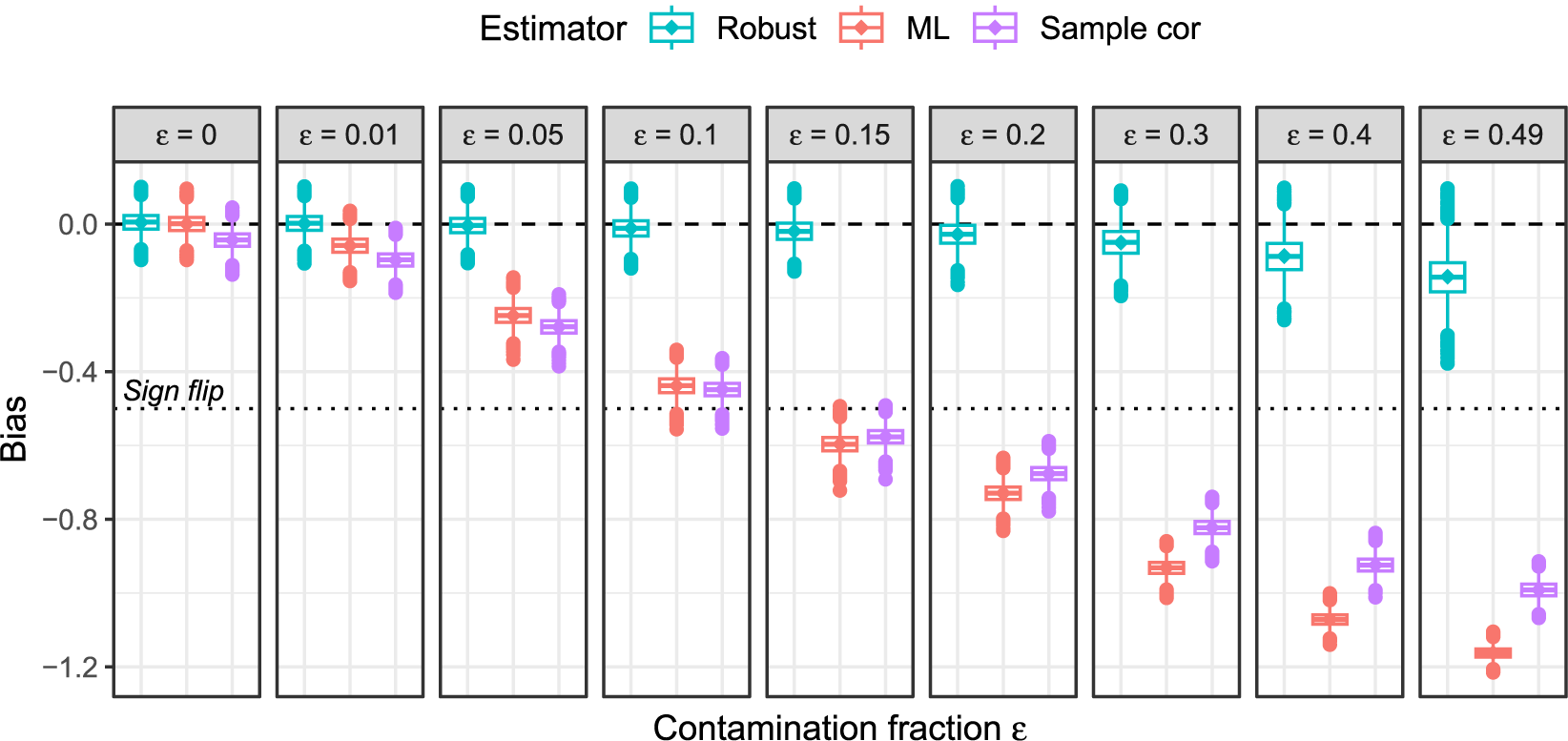






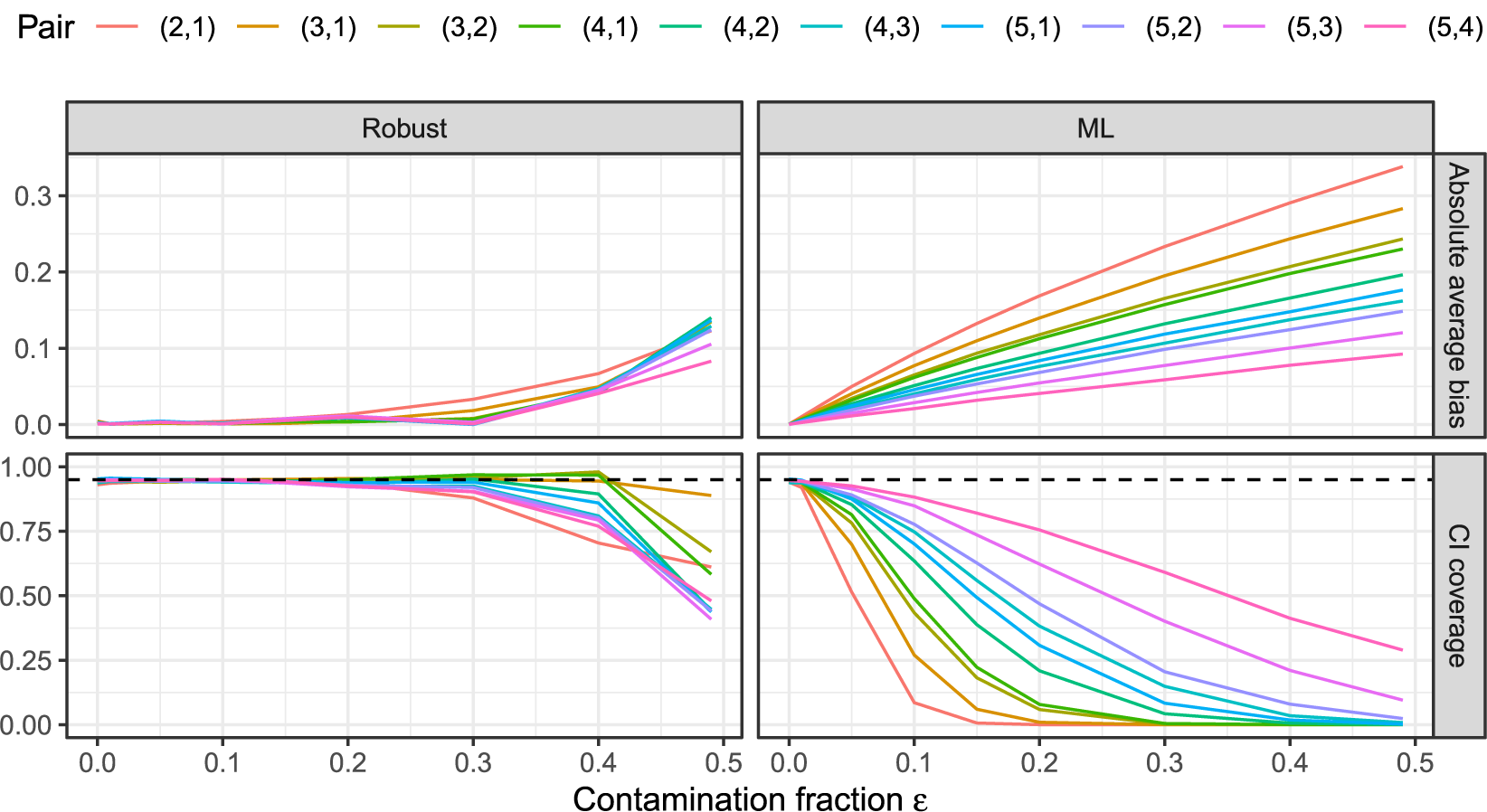



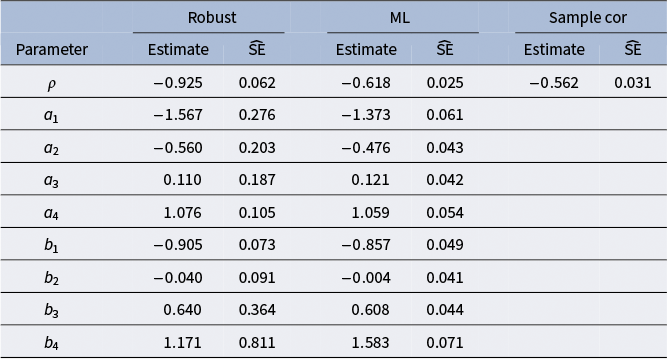




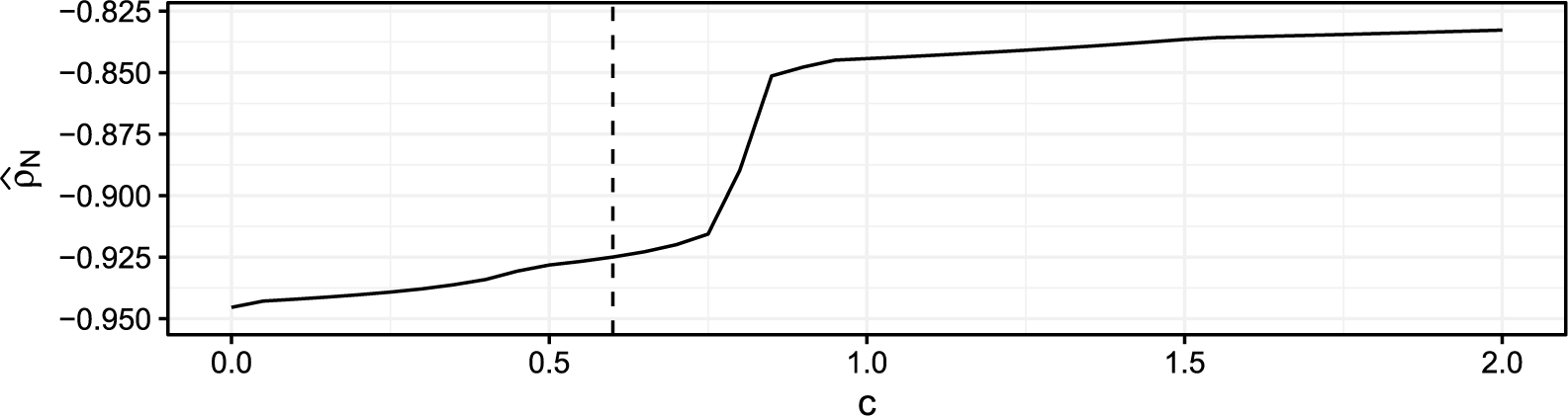

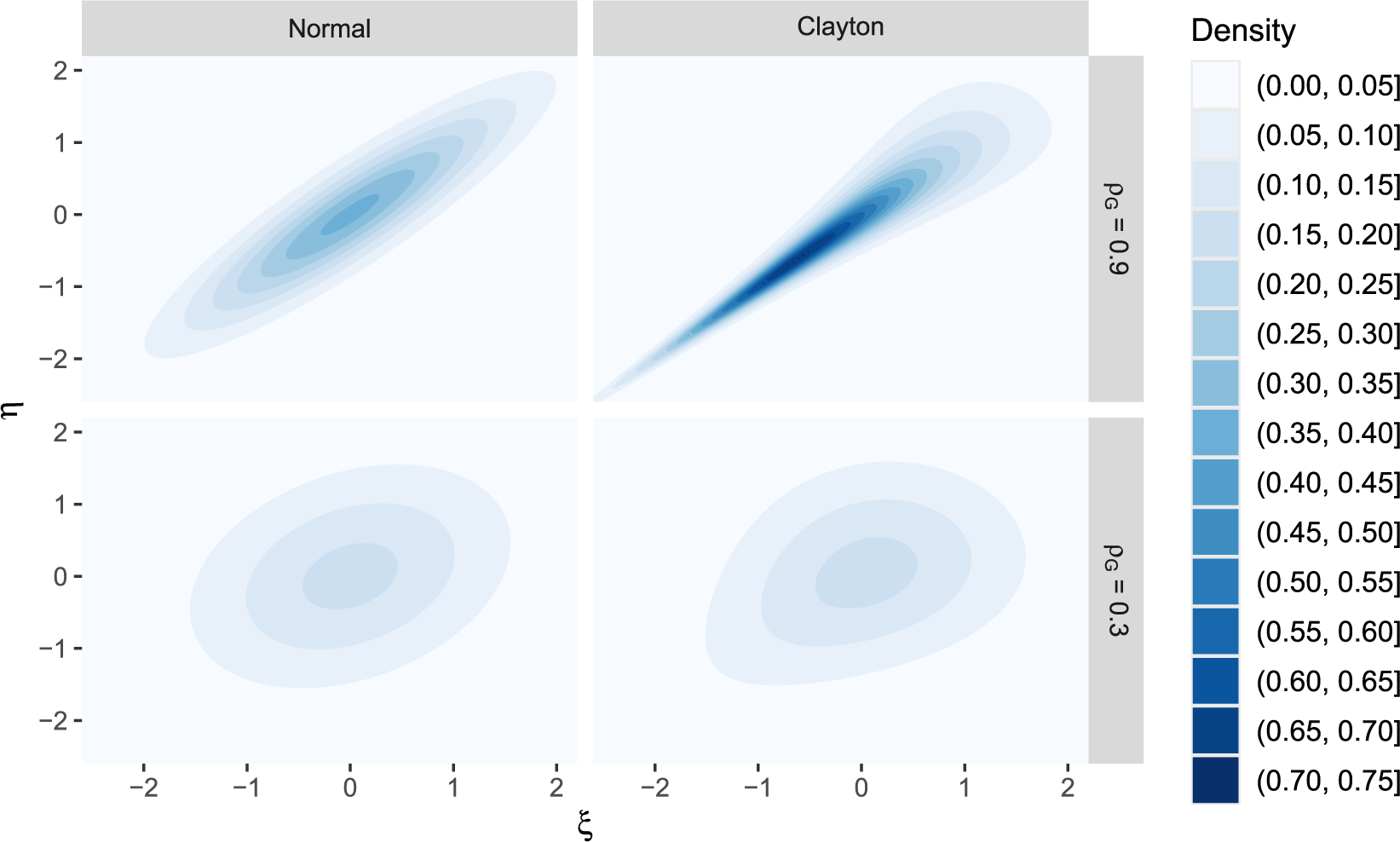









 Open access
Open access