


Background
Central lines are frequently used in inpatient care, often for extended durations. However, they come with the risk of central line associated blood stream infections (CLABSI). CLABSIs extend hospital stay, increase mortality Reference Elangovan, Lo, Xie, Mitchell, Graves and Cai1 and can increase the cost of admission by 25,000–55,000 US dollars. Reference Yu, Jung and Ai2 Removal of unnecessary central lines, central lines that are not essential for current medical care, is a key component of CLABSI prevention; Reference Buetti, Marschall and Drees3 one method to achieve this is prospective audit and feedback, which is effective, but resource intensive and rarely systematically evaluated. Reference Beville, Heipel, Vanhoozer and Bailey4
Large language models (LLMs) are systems capable of rapidly analyzing substantial amounts of data to perform high level tasks. LLMs have the potential for high-volume healthcare data extraction and report generation. Reference Fahim, Hasani, Kabba and Ragab5 These characteristics make LLMs a promising tool in the field of infection prevention. However, LLMs can present misinformation (e.g., “hallucinations”) and struggle with the nuances of clinical medicine. Reference Bedi, Liu and Orr-Ewing6 There has been little evaluation of LLMs with real patient scenarios to date in infection prevention. We used a secure LLM to evaluate unnecessary central lines in a large academic medical center.
Methods
Study setting and design: Stanford Health Care is a 700-bed academic medical center in Northern California. Recently, a secure LLM with gpt-4.1-mini (ChatEHR) was integrated within the EHR. We conducted a prospective study from October to November 2025.
Reference standard (expert review): The vascular access team conducts daily active central line necessity assessments within three general medicine units. It is performed by manual EHR chart review using criteria based on published literature (Supplement 1). The vascular access team performs audit and feedback by discussing removal of identified unnecessary lines with providers. For units without routine assessments, the same criteria were applied by expert reviewers performing manual EHR chart review, but audit and feedback was not performed in these cases.
Index test (ChatEHR): Using a standardized prompt (Supplement 2), ChatEHR was asked to determine whether each central line was unnecessary on that calendar day based on predefined criteria. For each case, the model received EHR data from the preceding seven days, including clinical notes, laboratory results, vital signs, medications, and orders. The model was run with a temperature of 0.1 and deployed within Stanford Health Care’s secure Microsoft Azure environment. ChatEHR did not perform dynamic retrieval of selected records at inference time. Rather, available patient data within the specified time window were passed directly to the LLM; when those data exceeded the allowable context length, they were partitioned into smaller chunks and analyzed separately. The same prompt, sources, and input data window were applied to all cases.
Analysis: We compared ChatEHR classification of unnecessary versus necessary to the expert review on a per-line per-day basis. We calculated sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) with 95% confidence intervals.
Results
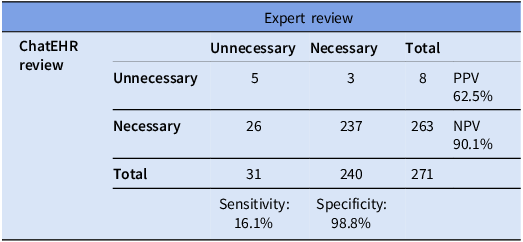
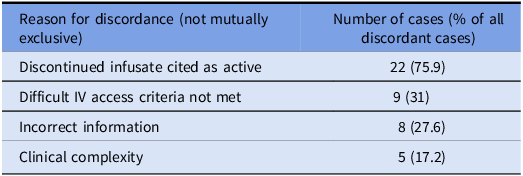
We evaluated 271 central lines (111 PICCs, 82 implanted ports, 65 tunneled central lines, 12 non-tunneled central lines, and 1 pulmonary artery catheter). The reference standard classified 31 (11%) as unnecessary and 240 (89%) as necessary. ChatEHR identified 5 out of 31 unnecessary lines (sensitivity 16.1%) and correctly classified 237 out of 240 necessary lines (specificity 98.8%). The PPV was 62.5% and the NPV was 90.1% (Table 2). Discordant classifications occurred in 29 cases: ChatEHR classified 26 lines as necessary that were unnecessary (false negatives), and 3 lines as unnecessary that were necessary (false positives). Among discordant cases, 75% (n = 22) were PICCs, 10% (n = 3) were non-tunneled central lines, 7% (n = 2) were tunneled central lines, and 7% (n = 2) were implanted ports. Reasons for discordance (these were not mutually exclusive as ChatEHR frequently cited multiple reasons in same response) were clustered into four categories: (1) a discontinued infusate still cited as active occurred in 22 cases, (2) difficult IV access cited when criteria were not met occurred in 9 cases, (3) incorrect statements inconsistent with chart data occurred in 8 cases, and (4) clinical complexity requiring contextual judgment caused the discordance in 5 cases (Table 1; detailed examples in Supplement 3).
Diagnostic performance of ChatEHR for identifying unnecessary central lines

Discordant cases

Discussion
To our knowledge, this is the first study using an LLM integrated within the EHR to assess unnecessary central lines. Our evaluation used actual patient data in real-time. We found that the LLM quickly reviewed large volumes of clinical information and achieved a high specificity for unnecessary central lines. ChatEHR could be deployed as an surveillance method to evaluate for the presence of central lines that are unnecessary in settings where human review is not feasible.
ChatEHR had a specificity of 99% for detecting unnecessary central lines, thus rarely incorrectly classified an appropriate line as unnecessary. However, it had a sensitivity of 16%, and was unable to identify many unnecessary central lines. Similar to other evaluations of LLMs in infection prevention for detection of CAUTI, CLABSI and appropriate blood cultures, there is an imbalance between sensitivity and specificity. Reference Rodriguez-Nava, Egoryan, Goodman, Morgan and Salinas7–Reference Rodriguez-Nava, Keyes and Ambers9 This was a limitation of ChatEHR and may be one of other generic LLMs as well in the field of infection prevention. The most frequent reason for discordance was ChatEHR’s failure to utilize the current clinical scenario, and the second most frequent reason was failing to fulfill detailed criteria of the prompt. Increased sensitivity may be gained with additional training of the models to reflect the most recent data and to strictly adhere to requirements in the prompt. Incorrect information about how a medication was administered was also a flaw and having the LLM repeat the task to check itself might improve accuracy. Perhaps with enough training it will improve in nuanced clinical cases, although this is a daunting feat given the complexity of medical practice.
Our study has several limitations. It was conducted at a single center using ChatEHR, which may differ from LLMs available at other institutions. Different parameters of LLM prompts will yield variable results, and although we considered one week of data appropriate for the current clinical situation, results may differ if a different time frame is used. Additionally, there is a subjective component to the determination of unnecessary central lines, and our criteria may vary from what is used at other institutions. Despite limitations, our study adds to the evolving understanding of the rapidly progressing field of AI in medicine.
Ideally, clinical teams would review central line necessity daily; however, changing clinical scenarios and competing priorities often necessitate a secondary auditing process to support device-necessity review. Secondary audits are challenging for healthcare systems with options often being resource intensive; these manual reviews may not be realistic for units or institutions as a whole. Although LLMs cannot identify all unnecessary central lines, it could increase detection in areas where manual review is not possible. LLMs have the potential to review many more patients than feasible with the current practice of manual review, emphasizing that LLMs may become a valuable tool for review of devices that ultimately aides in healthcare-associated infection reduction.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/ice.2026.10462.
Acknowledgements
We thank the Stanford University Center for Digital Health for funding this study. The authors report no conflicts of interest related to this work.



 Open access
Open access