


1 Introduction
Ensuring test fairness in educational and psychometric assessments has been a major concern for researchers. A typical approach to ensuring test fairness is through differential item functioning (DIF; Holland & Wainer, Reference Holland and Wainer2012) analysis. DIF occurs when an item’s response function depends on not only the target latent trait to be measured by the item, but also the respondents’ group memberships that are often linked to their demographic characteristics. When DIF is present, the measurement properties of the item differ systematically across groups, leading to measurement bias (Millsap, Reference Millsap2012).
The research on DIF predominantly focuses on the statistical detection of its existence. DIF detection with manifest groups is typically categorized as non-parametric (Cao et al., Reference Cao, Tay and Liu2017; Dorans & Holland, Reference Dorans and Holland1992; Dorans & Kulick, Reference Dorans and Kulick1986; Holland & Thayer, Reference Holland and Thayer1986; Woods et al., Reference Woods, Cai and Wang2013; Zwick et al., Reference Zwick, Thayer and Lewis2000) and parametric (Lord, Reference Lord1977, Reference Lord1980; Raju, Reference Raju1988; Rudner et al., Reference Rudner, Getson and Knight1980; Swaminathan & Rogers, Reference Swaminathan and Rogers1990; Thissen et al., Reference Thissen, Steinberg and Wainer2013). When the comparison groups are unavailable, latent DIF analysis compares how the item functions different across latent groups (Cho & Cohen, Reference Cho and Cohen2010; Cho et al., Reference Cho, Suh and Lee2016b; De Boeck et al., Reference De Boeck, Cho and Wilson2011). More recently, DIF detection methods that do not require predefined group memberships or anchor items have been proposed (Chen et al., Reference Chen, Li, Ouyang and Xu2023; Halpin, Reference Halpin2024; Ouyang et al., Reference Ouyang, Chen, Li and Xu2025; Wallin et al., Reference Wallin, Chen and Moustaki2024). While research has explored methods on handling items with DIF (Cho et al., Reference Cho, Suh and Lee2016a; Liu & Jane Rogers, Reference Liu and Jane Rogers2022), items identified with significant DIF are often removed during item calibration, leading to wasted resources and efforts in their development and administration. Consequently, there has been growing interest in reducing or eliminating DIF, as well as understanding the underlying reasons for why DIF occurs (Ackerman & Ma, Reference Ackerman and Ma2024).
One way to attribute the cause of DIF is multidimensionality, where DIF arises due to the presence of secondary dimensions in the latent space (Ackerman, Reference Ackerman1992; Kok, Reference Kok1988; Shealy & Stout, Reference Shealy and Stout1993). Ideally, differences in the response probabilities solely reflect variations in the latent ability that the item is designed to assess, which is the primary dimension. Secondary latent traits with heterogeneous distributions across subpopulations may also contribute to these differences. These secondary dimensions are called auxiliary if they are intentionally measured by the item, or nuisance otherwise (Roussos & Stout, Reference Roussos and Stout1996). In our examples, computer proficiency is one of such nuisance traits correlated with problem-solving strategies, response time, and the final responses. As we will show in the PIAAC data analysis, age is one of the background variables having substantial DIF for multiple items, part of which is due to differences in computer proficiency among age groups.
The multidimensional IRT (MIRT) model has been used to analyze DIF, where both the target trait and the nuisance trait are used to model item response probabilities (Ackerman, Reference Ackerman1992; Ackerman & Ma, Reference Ackerman and Ma2024; Shan & Xu, Reference Shan and Xu2024; Wang, Zhu, et al., Reference Wang, Zhu and Xu2023). Latent DIF models have also been used to investigate the secondary dimensions, using mixture models to identify latent groups as the secondary dimension and associating it with examinees’ demographic characteristics (Cohen & Bolt, Reference Cohen and Bolt2005; De Boeck et al., Reference De Boeck, Cho and Wilson2011). The multiple-indicator–multiple-cause (MIMIC) model provides another approach from the dimensionality perspective, although only the primary dimension is used (De Boeck et al., Reference De Boeck, Cho and Wilson2011). In a mediated MIMIC model proposed in Cheng et al. (Reference Cheng, Shao and Lathrop2016), a secondary dimension construct (the scale of self-confidence) is used as a potential mediator. Despite these advances, studies that rely only on response data face challenges, particularly when prior knowledge of nuisance traits is limited. Thus, it is of interest to identify the secondary dimensions from data sources beyond the response outcome data.
One data source that presents new opportunities for identifying secondary latent dimensions in DIF analysis is process data (He et al., Reference He, Borgonovi and Paccagnella2021; Li et al., Reference Li, Shin, Kuang and Huggins-Manley2024; Wang, Tang, et al., Reference Wang, Tang, Liu and Ying2023). Process data capture the problem-solving processes as respondents interact with computer-based test items. The respondents’ actions are logged as time-stamped action sequences in computer log files, making process data a detailed record of respondents’ behaviors. Three prominent examples of process data are from the Programme for International Student Assessment (PISA; e.g., OECD, 2012c), the Programme for the International Assessment of Adult Competencies (PIAAC; e.g., OECD, 2012a), and the National Assessment of Educational Progress (NAEP; e.g., Bergner & von Davier, Reference Bergner and von Davier2019). These assessments not only measure skills traditionally tested with paper-and-pencil methods but also evaluate more complex abilities, such as Problem Solving in Technology-Rich Environments (PSTRE). Compared to traditional outcome data that are typically dichotomous (correct/incorrect) or polytomous (partial credit), process data provide more comprehensive information about the respondents’ behaviors toward completing tasks. Process data have been proven useful for accurate assessment (Zhang et al., Reference Zhang, Wang, Qi, Liu and Ying2023), process-incorporated measurement models (Chen, Reference Chen2020; Liang et al., Reference Liang, Tu and Cai2023; Tang, Reference Tang2024; Xiao et al., Reference Xiao, He, Veldkamp and Liu2021; Xiao & Liu, Reference Xiao and Liu2024), strategy and behavioral pattern analysis (Gao et al., Reference Gao, Zhai, Bulut, Cui and Sun2022; He et al., Reference He, Borgonovi and Paccagnella2021, Reference He, Borgonovi and Suárez-Álvarez2023; Ulitzsch et al., Reference Ulitzsch, He and Pohl2022), etc. Process data are potentially a good data source to identify nuisance traits. For example, engagement is an acknowledged nuisance trait (Wise & DeMars, Reference Wise and DeMars2006; Wise & Kong, Reference Wise and Kong2005), and is usually measured by total response time or total number of actions (Sahin & Colvin, Reference Sahin and Colvin2020). The first principal component of features extracted from the 2012 PIAAC process data is highly correlated with engagement (Tang, Wang, He, et al., Reference Tang, Wang, He, Liu and Ying2020). If we are able to identify the secondary dimensions that lead to DIF, we could reduce or potentially remove DIF by appropriately incorporating such a dimension in the scoring rule.
In this article, we propose a novel method for reducing DIF that leverages process data and introduce the corresponding scoring rule that only depends on the respondents’ behaviors. We attribute DIF to multidimensionality and discuss the method within the framework of generalized linear models (GLMs). We assume there is a reasonably accurate estimate of the target latent trait (primary dimension). The nuisance trait is partially predictable by the process data. The key innovation of our approach lies in constructing a surrogate for the nuisance trait using features extracted from process data. This surrogate is formulated as a linear combination of the process data features, with the weights determined by minimizing the maximum-likelihood difference between models with and without the grouping variable. The motivation is to construct a measurement model with the target trait and nuisance trait surrogate, while minimizing the impact of the grouping variable on the measurement model. We show that in the simple case of a linear model (classical test theory), the proposed optimization problem has a closed-form solution. For generalized linear models, the optimization can be solved by well-established numerical methods. We propose a new scoring rule that incorporates both the target latent trait and nuisance trait surrogate that reduces DIF. We stress that the scoring rule is purely based on respondents’ responses. We further propose an iterative method to reduce the dependence on the initial target trait estimate. The effectiveness of this method is demonstrated through simulation studies and a case study.
The rest of the article is structured as follows. Section 2 outlines the methodology of the proposed approach, while Section 3 presents the results of the simulation experiments. In Section 4, we demonstrate a case study using the PIAAC 2012 dataset. Finally, we provide a discussion in Section 5.
2 Method
Consider N independent respondents and their process and outcome responses to one item of interest. Let
 $Y_{i}\in \{0, \dots , C-1\}$
represent the response of the i-th respondent, where C is the number of possible responses. For example, when
$Y_{i}\in \{0, \dots , C-1\}$
represent the response of the i-th respondent, where C is the number of possible responses. For example, when
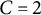 $C=2$
,
$C=2$
,
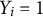 $Y_{i}=1$
indicates correct response and
$Y_{i}=1$
indicates correct response and
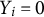 $Y_{i}=0$
indicates otherwise. We use
$Y_{i}=0$
indicates otherwise. We use
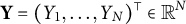 $\mathbf Y=(Y_{1},\dots , Y_{N})^\top \in \mathbb {R}^N$
to denote the vector of responses from all N respondents. We introduce one grouping variable
$\mathbf Y=(Y_{1},\dots , Y_{N})^\top \in \mathbb {R}^N$
to denote the vector of responses from all N respondents. We introduce one grouping variable
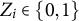 $Z_{i}\in \{0, 1\}$
, where
$Z_{i}\in \{0, 1\}$
, where
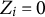 $Z_{i}=0$
represents the reference group and
$Z_{i}=0$
represents the reference group and
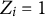 $Z_{i}=1$
represents the focal group. The item is assumed to measure a unidimensional latent trait, denoted by
$Z_{i}=1$
represents the focal group. The item is assumed to measure a unidimensional latent trait, denoted by
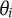 $\theta _i$
for respondent
$\theta _i$
for respondent
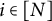 $i\in [N]$
. Let
$i\in [N]$
. Let
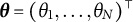 $\boldsymbol \theta =(\theta _1,\dots , \theta _N)^\top $
be the collection of latent traits of all respondents. Additionally, we extract process features
$\boldsymbol \theta =(\theta _1,\dots , \theta _N)^\top $
be the collection of latent traits of all respondents. Additionally, we extract process features
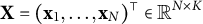 $\mathbf X = (\mathbf x_{1}, \dots , \mathbf x_{N})^\top \in \mathbb {R}^{N\times K}$
from the action sequences of the process data with the multidimensional scaling procedure proposed in Tang, Wang, He, et al. (Reference Tang, Wang, He, Liu and Ying2020), where
$\mathbf X = (\mathbf x_{1}, \dots , \mathbf x_{N})^\top \in \mathbb {R}^{N\times K}$
from the action sequences of the process data with the multidimensional scaling procedure proposed in Tang, Wang, He, et al. (Reference Tang, Wang, He, Liu and Ying2020), where
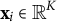 $\mathbf x_{i}\in \mathbb {R}^K$
. Since process features capture most of the useful information of process data when the feature dimension is sufficiently large (Tang, Wang, He, et al., Reference Tang, Wang, He, Liu and Ying2020; Tang, Wang, Liu, et al., Reference Tang, Wang, He, Liu and Ying2020), we will use process features as proxies for the original process data in this work.
$\mathbf x_{i}\in \mathbb {R}^K$
. Since process features capture most of the useful information of process data when the feature dimension is sufficiently large (Tang, Wang, He, et al., Reference Tang, Wang, He, Liu and Ying2020; Tang, Wang, Liu, et al., Reference Tang, Wang, He, Liu and Ying2020), we will use process features as proxies for the original process data in this work.
2.1 Differential item functioning
We adopt a multidimensionality-based DIF framework. In addition to the target trait dimension,
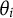 $\theta _i$
, a nuisance trait dimension,
$\theta _i$
, a nuisance trait dimension,
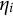 $\eta _{i}$
, also influences the probability of the response. Denote
$\eta _{i}$
, also influences the probability of the response. Denote
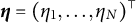 $\boldsymbol \eta =(\eta _{1},\dots , \eta _{N})^\top $
as the vector encompassing the nuisance traits for all respondents. DIF occurs when the item response probability depends on the nuisance trait, and there is a distributional difference of the nuisance trait among the two groups. Conditional on
$\boldsymbol \eta =(\eta _{1},\dots , \eta _{N})^\top $
as the vector encompassing the nuisance traits for all respondents. DIF occurs when the item response probability depends on the nuisance trait, and there is a distributional difference of the nuisance trait among the two groups. Conditional on
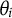 $\theta _i$
,
$\theta _i$
,
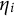 $\eta _{i}$
, and
$\eta _{i}$
, and
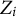 $Z_i$
, it is assumed that
$Z_i$
, it is assumed that
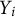 $Y_{i}$
are independently distributed. When the distribution of
$Y_{i}$
are independently distributed. When the distribution of
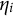 $\eta _{i}$
conditional on
$\eta _{i}$
conditional on
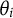 $\theta _i$
differs across the two subgroups, we have
$\theta _i$
differs across the two subgroups, we have
 $$ \begin{align*} p(Y_{i}=y|\theta_i, Z_i=0) = & \int p(Y_{i}=y|\theta_i, \eta_{i}) \cdot p(\eta_{i}|\theta_i, Z_i=0) d\eta_{i} \\ \neq & \int p(Y_{i}=y|\theta_i, \eta_{i}) \cdot p(\eta_{i}|\theta_i, Z_i=1) d\eta_{i} = p(Y_{i}=y|\theta_i, Z_i=1). \end{align*} $$
$$ \begin{align*} p(Y_{i}=y|\theta_i, Z_i=0) = & \int p(Y_{i}=y|\theta_i, \eta_{i}) \cdot p(\eta_{i}|\theta_i, Z_i=0) d\eta_{i} \\ \neq & \int p(Y_{i}=y|\theta_i, \eta_{i}) \cdot p(\eta_{i}|\theta_i, Z_i=1) d\eta_{i} = p(Y_{i}=y|\theta_i, Z_i=1). \end{align*} $$
Therefore, under this multidimensional framework, a unidimensional measurement model leads to DIF.
Specifically, we consider a GLM with the following conditional distribution:
 $$ \begin{align} Y_{i} \sim p(y | \mu_{i}), \quad \text{where}\ \ g(\mu_{i}) = d + a_{0} \theta_i + a_{1} \eta_{i} + \lambda Z_i. \end{align} $$
$$ \begin{align} Y_{i} \sim p(y | \mu_{i}), \quad \text{where}\ \ g(\mu_{i}) = d + a_{0} \theta_i + a_{1} \eta_{i} + \lambda Z_i. \end{align} $$
Here,
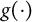 $g(\cdot )$
is the link function with respect to the response mean
$g(\cdot )$
is the link function with respect to the response mean
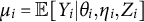 $\mu _{i}=\mathbb {E}[Y_{i} | \theta _i, \eta _{i}, Z_i]$
, and
$\mu _{i}=\mathbb {E}[Y_{i} | \theta _i, \eta _{i}, Z_i]$
, and
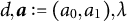 $d, \boldsymbol a:= (a_{0}, a_{1}), \lambda $
are unknown coefficients. When
$d, \boldsymbol a:= (a_{0}, a_{1}), \lambda $
are unknown coefficients. When
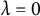 $\lambda =0$
, the distributional difference of
$\lambda =0$
, the distributional difference of
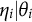 $\eta _{i}|\theta _i$
among the two subgroups is the only DIF source in a unidimensional measurement model. The model specified by (1) is quite general, as we allow
$\eta _{i}|\theta _i$
among the two subgroups is the only DIF source in a unidimensional measurement model. The model specified by (1) is quite general, as we allow
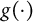 $g(\cdot )$
to take a general form for a wide range of response types, such as binary, polytomous, and continuous responses. For binary responses, the logistic regression model with
$g(\cdot )$
to take a general form for a wide range of response types, such as binary, polytomous, and continuous responses. For binary responses, the logistic regression model with
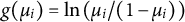 $g(\mu _{i})=\ln \left (\mu _{i} / (1-\mu _{i})\right )$
is referred to as the multidimensional two-parameter logistic (M2PL) IRT model. In addition,
$g(\mu _{i})=\ln \left (\mu _{i} / (1-\mu _{i})\right )$
is referred to as the multidimensional two-parameter logistic (M2PL) IRT model. In addition,
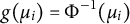 $g(\mu _{i})=\Phi ^{-1}(\mu _{i})$
corresponds to the probit regression model with
$g(\mu _{i})=\Phi ^{-1}(\mu _{i})$
corresponds to the probit regression model with
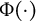 $\Phi (\cdot )$
being the cumulative distribution function of the standard normal distribution. When
$\Phi (\cdot )$
being the cumulative distribution function of the standard normal distribution. When
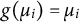 $g(\mu _i)=\mu _i$
, the model becomes a linear regression model for continuous responses.
$g(\mu _i)=\mu _i$
, the model becomes a linear regression model for continuous responses.
2.2 DIF reduction
One of the primary challenges in applying the multidimensionality-based DIF analysis is that the nuisance trait,
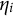 $\eta _{i}$
, is unobserved and is generally difficult to be directly measured. We propose to construct a surrogate for the unobserved nuisance trait and incorporate it in the item response function to correct DIF. Specifically, we aim to build a surrogate,
$\eta _{i}$
, is unobserved and is generally difficult to be directly measured. We propose to construct a surrogate for the unobserved nuisance trait and incorporate it in the item response function to correct DIF. Specifically, we aim to build a surrogate,
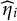 $\widehat \eta _{i}$
, such that DIF is only attributed to the distributional differences in
$\widehat \eta _{i}$
, such that DIF is only attributed to the distributional differences in
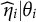 $\widehat \eta _{i}|\theta _i$
, and the conditional probabilities of item responses become approximately equal across different subgroups. Formally, we achieve the following:
$\widehat \eta _{i}|\theta _i$
, and the conditional probabilities of item responses become approximately equal across different subgroups. Formally, we achieve the following:
 $$ \begin{align} p(Y_{i}=y | \theta_i, \widehat\eta_{i}, Z_i=0)\approx p(Y_{i}=y| \theta_i, \widehat\eta_{i}, Z_i=1). \end{align} $$
$$ \begin{align} p(Y_{i}=y | \theta_i, \widehat\eta_{i}, Z_i=0)\approx p(Y_{i}=y| \theta_i, \widehat\eta_{i}, Z_i=1). \end{align} $$
We propose using process data to construct a nuisance trait surrogate, driven by two key motivations. Firstly, process data capture the entire sequence of actions taken by each respondent as they interact with and solve an item, providing a rich source of information on various nuisance traits. Second, process data typically predict the final response with perfect accuracy. By analyzing the respondent’s full sequence of actions, we can infer whether they answered the item correctly or their partial scores. In theory, adding all available process features in the model eliminates DIF. Yet this approach is not ideal as the resulting measurement model solely depends on the process features and provides little information of the target trait.
The core of our proposed method is to identify an optimal linear combination of process features as a surrogate for the nuisance trait
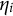 $\eta _{i}$
. Specifically, we consider
$\eta _{i}$
. Specifically, we consider
 $$ \begin{align*}\eta_{i}=\boldsymbol{\omega}^\top \mathbf x_{i}, \end{align*} $$
$$ \begin{align*}\eta_{i}=\boldsymbol{\omega}^\top \mathbf x_{i}, \end{align*} $$
where
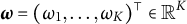 $\boldsymbol {\omega }=(\omega _{1}, \dots , \omega _{K})^\top \in \mathbb {R}^K$
is the weight vector and we assume
$\boldsymbol {\omega }=(\omega _{1}, \dots , \omega _{K})^\top \in \mathbb {R}^K$
is the weight vector and we assume
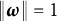 $\|\boldsymbol {\omega }\|=1$
for model identifiability. Our objective in identifying
$\|\boldsymbol {\omega }\|=1$
for model identifiability. Our objective in identifying
 $\boldsymbol {\omega }$
is to minimize a quantity equivalent to the likelihood ratio test statistic,
$\boldsymbol {\omega }$
is to minimize a quantity equivalent to the likelihood ratio test statistic,
 $$ \begin{align} L(\boldsymbol{\omega}) := \max_{d, \boldsymbol a, \lambda} l(d, \boldsymbol a, \lambda) - \max_{d, \boldsymbol a, \lambda=0} l(d, \boldsymbol a, \lambda), \end{align} $$
$$ \begin{align} L(\boldsymbol{\omega}) := \max_{d, \boldsymbol a, \lambda} l(d, \boldsymbol a, \lambda) - \max_{d, \boldsymbol a, \lambda=0} l(d, \boldsymbol a, \lambda), \end{align} $$
where
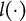 $l(\cdot )$
is the log-likelihood function,
$l(\cdot )$
is the log-likelihood function,
 $$ \begin{align} l(d, \boldsymbol a, \lambda) = \sum_{i=1}^N \log p(Y_{i}|\theta_i, \eta_{i}, Z_i). \end{align} $$
$$ \begin{align} l(d, \boldsymbol a, \lambda) = \sum_{i=1}^N \log p(Y_{i}|\theta_i, \eta_{i}, Z_i). \end{align} $$
Function (3) quantifies how much model fit is increased after adding the grouping variable into the model, thus can be viewed as a quantification of the DIF effect. When there is no DIF exhibited, adding the grouping variable into the model would barely increase the likelihood, and we would expect
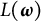 $L(\boldsymbol {\omega })$
to be close to
$L(\boldsymbol {\omega })$
to be close to
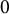 $0$
. This objective function enables us to optimize
$0$
. This objective function enables us to optimize
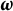 $\boldsymbol {\omega }$
by comparing models with and without the grouping variable, ultimately reducing or removing DIF. Therefore, we propose the estimation of
$\boldsymbol {\omega }$
by comparing models with and without the grouping variable, ultimately reducing or removing DIF. Therefore, we propose the estimation of
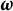 $\boldsymbol {\omega }$
to be the minimizer of the objective function
$\boldsymbol {\omega }$
to be the minimizer of the objective function
 $$ \begin{align} \widehat {\boldsymbol{\omega}} = \arg\min_{\left\lVert{\boldsymbol{\omega}}\right\rVert=1} L(\boldsymbol{\omega)} \end{align} $$
$$ \begin{align} \widehat {\boldsymbol{\omega}} = \arg\min_{\left\lVert{\boldsymbol{\omega}}\right\rVert=1} L(\boldsymbol{\omega)} \end{align} $$
and the nuisance trait surrogate is
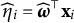 $\widehat \eta _{i}=\widehat {\boldsymbol {\omega }}^\top \mathbf x_{i}$
. We will show that the solution of (5) has a closed-form solution in the linear regression model with one grouping variable (see Section 2.3). In other cases, we can optimize the objective function numerically.
$\widehat \eta _{i}=\widehat {\boldsymbol {\omega }}^\top \mathbf x_{i}$
. We will show that the solution of (5) has a closed-form solution in the linear regression model with one grouping variable (see Section 2.3). In other cases, we can optimize the objective function numerically.
Figure 1 displays the updated measurement model incorporating both the nuisance trait and target trait. With the nuisance trait surrogate, we update the initial estimate of the target trait with the two-dimensional measurement model. Consider the case with J items, among which items
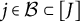 $j\in \mathcal {B}\subset [J]$
exhibit DIF. Suppose the nuisance trait surrogates
$j\in \mathcal {B}\subset [J]$
exhibit DIF. Suppose the nuisance trait surrogates
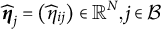 $\widehat {\boldsymbol {\eta }}_j=(\widehat {\eta }_{ij})\in \mathbb {R}^N, j\in \mathcal {B}$
have been estimated for the DIF items, then we obtain the maximum-likelihood estimate (MLE) of the item parameters
$\widehat {\boldsymbol {\eta }}_j=(\widehat {\eta }_{ij})\in \mathbb {R}^N, j\in \mathcal {B}$
have been estimated for the DIF items, then we obtain the maximum-likelihood estimate (MLE) of the item parameters
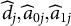 $\widehat {d}_j, \widehat {a}_{0j}, \widehat {a}_{1j}$
with
$\widehat {d}_j, \widehat {a}_{0j}, \widehat {a}_{1j}$
with
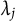 $\lambda _j$
fixed as
$\lambda _j$
fixed as
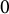 $0$
in (1) for
$0$
in (1) for
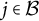 $j\in \mathcal {B}$
, and
$j\in \mathcal {B}$
, and
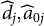 $\widehat {d}_j, \widehat {a}_{0j}$
with
$\widehat {d}_j, \widehat {a}_{0j}$
with
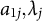 $a_{1j}, \lambda _j$
fixed as
$a_{1j}, \lambda _j$
fixed as
 $0$
for
$0$
for
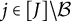 $j\in [J]\backslash \mathcal {B}$
. The target trait estimate is then updated by the MLE
$j\in [J]\backslash \mathcal {B}$
. The target trait estimate is then updated by the MLE
 $$ \begin{align} \widehat{\theta}_i = \operatorname*{\mathrm{argmax}}_{\theta} \sum_{j=1}^J \log p_{ij}(\theta), \end{align} $$
$$ \begin{align} \widehat{\theta}_i = \operatorname*{\mathrm{argmax}}_{\theta} \sum_{j=1}^J \log p_{ij}(\theta), \end{align} $$
where
 $$ \begin{align*} p_{ij}(\theta) & = p(Y_{ij}|\theta, \widehat{\eta}_{ij}, \widehat {d_j}, \widehat{a}_{0j}, \widehat{a}_{1j}, \lambda_j=0), \quad j\in\mathcal{B}, \\ p_{ij}(\theta) & = p(Y_{ij}|\theta, \widehat {d_j}, \widehat{a}_{0j}, a_{1j}=0, \lambda_j=0), \quad j\in [J]\backslash\mathcal{B}. \end{align*} $$
$$ \begin{align*} p_{ij}(\theta) & = p(Y_{ij}|\theta, \widehat{\eta}_{ij}, \widehat {d_j}, \widehat{a}_{0j}, \widehat{a}_{1j}, \lambda_j=0), \quad j\in\mathcal{B}, \\ p_{ij}(\theta) & = p(Y_{ij}|\theta, \widehat {d_j}, \widehat{a}_{0j}, a_{1j}=0, \lambda_j=0), \quad j\in [J]\backslash\mathcal{B}. \end{align*} $$
Measurement model without the intercept.

2.3 A special case: Linear model with closed-form solution
When the link function g is the identity function, model (1) becomes the linear regression model. As DIF is defined as the group difference of the distribution of Y conditional on the latent trait, we conduct our DIF analysis in the orthogonal subspace of
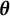 $\boldsymbol \theta $
in the linear model. To be more specific, we consider the residuals of
$\boldsymbol \theta $
in the linear model. To be more specific, we consider the residuals of
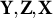 $\mathbf Y, \mathbf Z, \mathbf X$
after regressing on
$\mathbf Y, \mathbf Z, \mathbf X$
after regressing on
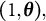 $(1, \boldsymbol \theta ),$
respectively, denoted by
$(1, \boldsymbol \theta ),$
respectively, denoted by
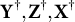 $\mathbf Y^\dagger , \mathbf Z^\dagger , \mathbf X^\dagger $
.
$\mathbf Y^\dagger , \mathbf Z^\dagger , \mathbf X^\dagger $
.
The model with and without the grouping variable can be rewritten as a reduced and a full linear regression model
 $$ \begin{align} \mathbf Y^\dagger & = a_{1}' \boldsymbol {\eta} + \boldsymbol {\epsilon}, \end{align} $$
$$ \begin{align} \mathbf Y^\dagger & = a_{1}' \boldsymbol {\eta} + \boldsymbol {\epsilon}, \end{align} $$
 $$ \begin{align} \mathbf Y^\dagger & = a_{1} \boldsymbol {\eta} + \lambda \mathbf Z^\dagger + \boldsymbol {\delta}, \end{align} $$
$$ \begin{align} \mathbf Y^\dagger & = a_{1} \boldsymbol {\eta} + \lambda \mathbf Z^\dagger + \boldsymbol {\delta}, \end{align} $$
where
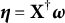 $\boldsymbol \eta = \mathbf X^\dagger \boldsymbol {\omega }$
. If we assume
$\boldsymbol \eta = \mathbf X^\dagger \boldsymbol {\omega }$
. If we assume
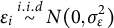 $\epsilon _{i}\stackrel {i.i.d}{\sim } N(0, \sigma _{\epsilon }^2)$
and
$\epsilon _{i}\stackrel {i.i.d}{\sim } N(0, \sigma _{\epsilon }^2)$
and
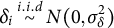 $\delta _{i}\stackrel {i.i.d}{\sim } N(0, \sigma _{\delta }^2)$
, the objective function (3) is equivalent to
$\delta _{i}\stackrel {i.i.d}{\sim } N(0, \sigma _{\delta }^2)$
, the objective function (3) is equivalent to
 $$ \begin{align} L(\boldsymbol{\omega}) = \frac{n}{2} \log(\|\widehat{\boldsymbol \epsilon}\|^2) - \frac{n}{2} \log(\|\widehat{\boldsymbol \delta}\|^2), \end{align} $$
$$ \begin{align} L(\boldsymbol{\omega}) = \frac{n}{2} \log(\|\widehat{\boldsymbol \epsilon}\|^2) - \frac{n}{2} \log(\|\widehat{\boldsymbol \delta}\|^2), \end{align} $$
where
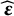 $\widehat {\boldsymbol \epsilon }$
and
$\widehat {\boldsymbol \epsilon }$
and
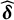 $\widehat {\boldsymbol \delta }$
are the linear regression residuals in (7) and (8). The zero of the objective (9) turns out to have a closed-form expression under some weak conditions, in which case DIF can be fully removed. Without loss of generality, we assume that all the features are orthogonal and scaled, i.e.,
$\widehat {\boldsymbol \delta }$
are the linear regression residuals in (7) and (8). The zero of the objective (9) turns out to have a closed-form expression under some weak conditions, in which case DIF can be fully removed. Without loss of generality, we assume that all the features are orthogonal and scaled, i.e.,
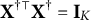 $\mathbf X^{\dagger \top }\mathbf X^\dagger =\mathbf {I}_K$
. This is achieved by principal component analysis in practice. We also assume that
$\mathbf X^{\dagger \top }\mathbf X^\dagger =\mathbf {I}_K$
. This is achieved by principal component analysis in practice. We also assume that
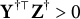 $\mathbf Y^{\dagger \top }\mathbf Z^\dagger>0$
.
$\mathbf Y^{\dagger \top }\mathbf Z^\dagger>0$
.
Proposition 1. Assume that
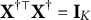 $\mathbf X^{\dagger \top }\mathbf X^\dagger =\mathbf {I}_K$
. Let
$\mathbf X^{\dagger \top }\mathbf X^\dagger =\mathbf {I}_K$
. Let
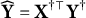 $\widehat {\mathbf Y} = \mathbf X^{\dagger \top } \mathbf Y^\dagger $
and
$\widehat {\mathbf Y} = \mathbf X^{\dagger \top } \mathbf Y^\dagger $
and
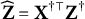 $\widehat {\mathbf Z} = \mathbf X^{\dagger \top } \mathbf Z^\dagger $
. Under the condition that
$\widehat {\mathbf Z} = \mathbf X^{\dagger \top } \mathbf Z^\dagger $
. Under the condition that
 $$ \begin{align} \frac{-\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\|+\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2} < \mathbf Y^{\dagger\top}\mathbf Z^\dagger < \frac{\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| + \widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2}, \end{align} $$
$$ \begin{align} \frac{-\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\|+\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2} < \mathbf Y^{\dagger\top}\mathbf Z^\dagger < \frac{\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| + \widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2}, \end{align} $$
there exists
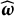 $\widehat {\boldsymbol {\omega }}$
such that
$\widehat {\boldsymbol {\omega }}$
such that
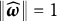 $\left \lVert \widehat {\boldsymbol {\omega }}\right \rVert =1$
and
$\left \lVert \widehat {\boldsymbol {\omega }}\right \rVert =1$
and
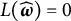 $L(\widehat {\boldsymbol {\omega }})=0$
. Specifically, denote
$L(\widehat {\boldsymbol {\omega }})=0$
. Specifically, denote
 $$ \begin{align*} \alpha = \sqrt{\frac{2\mathbf Y^{\dagger\top}\mathbf Z^\dagger + \|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| - \widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\|}} & , \ \beta = \sqrt{\frac{-2\mathbf Y^{\dagger\top}\mathbf Z^\dagger + \|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| + \widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\|}}, \notag \\ \boldsymbol q_1 = \frac{\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} + \|\widehat{\mathbf Z}\|\widehat{\mathbf Y}}{\left\|\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} + \|\widehat{\mathbf Z}\|\widehat{\mathbf Y} \right\|} & , \ \boldsymbol q_2= \frac{\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} - \|\widehat{\mathbf Z}\|\widehat{\mathbf Y}}{\left\| \|\widehat{\mathbf Y}\|\widehat{\mathbf Z} - \|\widehat{\mathbf Z}\|\widehat{\mathbf Y} \right\|}. \notag \end{align*} $$
$$ \begin{align*} \alpha = \sqrt{\frac{2\mathbf Y^{\dagger\top}\mathbf Z^\dagger + \|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| - \widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\|}} & , \ \beta = \sqrt{\frac{-2\mathbf Y^{\dagger\top}\mathbf Z^\dagger + \|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| + \widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\|}}, \notag \\ \boldsymbol q_1 = \frac{\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} + \|\widehat{\mathbf Z}\|\widehat{\mathbf Y}}{\left\|\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} + \|\widehat{\mathbf Z}\|\widehat{\mathbf Y} \right\|} & , \ \boldsymbol q_2= \frac{\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} - \|\widehat{\mathbf Z}\|\widehat{\mathbf Y}}{\left\| \|\widehat{\mathbf Y}\|\widehat{\mathbf Z} - \|\widehat{\mathbf Z}\|\widehat{\mathbf Y} \right\|}. \notag \end{align*} $$
Then,
 $\widehat {\boldsymbol {\omega }} = \alpha \boldsymbol q_1 + \beta \boldsymbol q_2$
or
$\widehat {\boldsymbol {\omega }} = \alpha \boldsymbol q_1 + \beta \boldsymbol q_2$
or
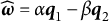 $\widehat {\boldsymbol {\omega }} = \alpha \boldsymbol q_1 - \beta \boldsymbol q_2$
satisfies
$\widehat {\boldsymbol {\omega }} = \alpha \boldsymbol q_1 - \beta \boldsymbol q_2$
satisfies
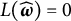 $L(\widehat {\boldsymbol {\omega }})=0$
.
$L(\widehat {\boldsymbol {\omega }})=0$
.
We note that
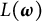 $L(\boldsymbol {\omega })$
has multiple zeros, as established in Proposition 1. We choose
$L(\boldsymbol {\omega })$
has multiple zeros, as established in Proposition 1. We choose
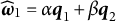 $\widehat {\boldsymbol {\omega }}_1=\alpha \boldsymbol q_1 + \beta \boldsymbol q_2$
over
$\widehat {\boldsymbol {\omega }}_1=\alpha \boldsymbol q_1 + \beta \boldsymbol q_2$
over
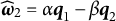 $\widehat {\boldsymbol {\omega }}_2=\alpha \boldsymbol q_1 - \beta \boldsymbol q_2$
for the following reason. When
$\widehat {\boldsymbol {\omega }}_2=\alpha \boldsymbol q_1 - \beta \boldsymbol q_2$
for the following reason. When
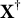 $\mathbf X^\dagger $
predicts
$\mathbf X^\dagger $
predicts
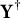 $\mathbf Y^\dagger $
with high accuracy,
$\mathbf Y^\dagger $
with high accuracy,
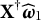 $\mathbf X^\dagger \widehat {\boldsymbol {\omega }}_1$
aligns with the projection of
$\mathbf X^\dagger \widehat {\boldsymbol {\omega }}_1$
aligns with the projection of
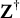 $\mathbf Z^\dagger $
onto the column space of
$\mathbf Z^\dagger $
onto the column space of
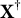 $\mathbf X^\dagger $
, whereas
$\mathbf X^\dagger $
, whereas
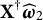 $\mathbf X^\dagger \widehat {\boldsymbol {\omega }}_2$
aligns with the projection of
$\mathbf X^\dagger \widehat {\boldsymbol {\omega }}_2$
aligns with the projection of
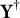 $\mathbf Y^\dagger $
onto the same subspace. As the goal is to reduce DIF, we choose to use
$\mathbf Y^\dagger $
onto the same subspace. As the goal is to reduce DIF, we choose to use
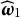 $\widehat {\boldsymbol {\omega }}_1$
over
$\widehat {\boldsymbol {\omega }}_1$
over
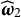 $\widehat {\boldsymbol {\omega }}_2$
. For further details, see the proof of Proposition 1 in the Appendix.
$\widehat {\boldsymbol {\omega }}_2$
. For further details, see the proof of Proposition 1 in the Appendix.
There are several scenarios in which condition (10) holds. The first scenario occurs when
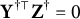 $\mathbf Y^{\dagger \top } \mathbf Z^\dagger = 0$
, which arises if the response and the grouping variable are independent conditional on the target trait, indicating that the item is not a DIF item, and condition (10) is automatically satisfied. The second scenario is when
$\mathbf Y^{\dagger \top } \mathbf Z^\dagger = 0$
, which arises if the response and the grouping variable are independent conditional on the target trait, indicating that the item is not a DIF item, and condition (10) is automatically satisfied. The second scenario is when
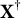 $\mathbf X^\dagger $
has high linear predictability of
$\mathbf X^\dagger $
has high linear predictability of
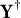 $\mathbf Y^\dagger $
. Specifically, when
$\mathbf Y^\dagger $
. Specifically, when
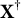 $\mathbf X^\dagger $
predicts
$\mathbf X^\dagger $
predicts
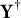 $\mathbf Y^\dagger $
with high accuracy, we find that
$\mathbf Y^\dagger $
with high accuracy, we find that
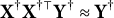 $\mathbf X^\dagger \mathbf X^{\dagger \top }\mathbf Y^\dagger \approx \mathbf Y^\dagger $
, which leads to
$\mathbf X^\dagger \mathbf X^{\dagger \top }\mathbf Y^\dagger \approx \mathbf Y^\dagger $
, which leads to
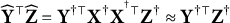 $\widehat {\mathbf Y}^\top \widehat {\mathbf Z}=\mathbf Y^{\dagger \top }\mathbf X^\dagger \mathbf X^{^\dagger \top }\mathbf Z^\dagger \approx \mathbf Y^{\dagger \top } \mathbf Z^\dagger $
, making it straightforward to verify condition (10). This is the case where process data capture the nuisance factors that affect the response. In the simplest case, we assume
$\widehat {\mathbf Y}^\top \widehat {\mathbf Z}=\mathbf Y^{\dagger \top }\mathbf X^\dagger \mathbf X^{^\dagger \top }\mathbf Z^\dagger \approx \mathbf Y^{\dagger \top } \mathbf Z^\dagger $
, making it straightforward to verify condition (10). This is the case where process data capture the nuisance factors that affect the response. In the simplest case, we assume
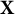 $\mathbf X$
can linearly predict
$\mathbf X$
can linearly predict
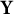 $\mathbf Y$
with full accuracy and let
$\mathbf Y$
with full accuracy and let
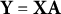 $\mathbf Y = \mathbf X \mathbf A$
with some vector
$\mathbf Y = \mathbf X \mathbf A$
with some vector
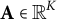 $\mathbf A\in \mathbb {R}^K$
. Then,
$\mathbf A\in \mathbb {R}^K$
. Then,
 $$ \begin{align*}\mathbf Y^\dagger = \mathbf Y-\mathbb{E}[\mathbf Y|\boldsymbol \theta] = \left( \mathbf X-\mathbb{E}[\mathbf X|\boldsymbol \theta]\right)\mathbf A = \mathbf X^\dagger \mathbf A.\end{align*} $$
$$ \begin{align*}\mathbf Y^\dagger = \mathbf Y-\mathbb{E}[\mathbf Y|\boldsymbol \theta] = \left( \mathbf X-\mathbb{E}[\mathbf X|\boldsymbol \theta]\right)\mathbf A = \mathbf X^\dagger \mathbf A.\end{align*} $$
Accordingly, we consider this case to be achievable. The third scenario is when
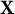 $\mathbf X$
has high linear predictability of
$\mathbf X$
has high linear predictability of
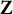 $\mathbf Z$
. Following similar calculations, we conclude that condition (10) is satisfied. With that being said, it is generally difficult to predict
$\mathbf Z$
. Following similar calculations, we conclude that condition (10) is satisfied. With that being said, it is generally difficult to predict
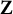 $\mathbf Z$
with process data.
$\mathbf Z$
with process data.
2.4 General cases
The main focus of this article is to reduce the DIF of univariate Z. Nonetheless, we have a brief extension to some simple cases of multi-dimensional Z. While we have previously focused on uniform DIF in a linear factor model with one grouping variable, the proposed method is applicable to other general cases. In what follows, we will shift our focus to addressing non-uniform DIF, continuous covariates, multiple grouping variables, and nonlinear models. The goal is to minimize the objective function (3).
2.4.1 Non-uniform DIF
Non-uniform DIF occurs when not only the intercept parameter, but also the discrimination parameter (the coefficient of
 $\theta _i$
) differs across groups. More specifically, for non-uniform DIF, (1) becomes
$\theta _i$
) differs across groups. More specifically, for non-uniform DIF, (1) becomes
 $$ \begin{align} g(\mu_{i}) = d + a_{0} \theta_i + a_{1} \eta_{i} + \lambda Z_i + \lambda' Z_i\theta_i. \end{align} $$
$$ \begin{align} g(\mu_{i}) = d + a_{0} \theta_i + a_{1} \eta_{i} + \lambda Z_i + \lambda' Z_i\theta_i. \end{align} $$
Non-uniform DIF can be viewed as a special case involving one grouping variable
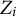 $Z_i$
and a continuous covariate
$Z_i$
and a continuous covariate
 $Z_i\theta _i$
. Therefore, non-uniform DIF is included in the continuous covariates and multiple-group cases discussed below.
$Z_i\theta _i$
. Therefore, non-uniform DIF is included in the continuous covariates and multiple-group cases discussed below.
2.4.2 Continuous covariates
In some applications, DIF is brought by continuous covariates. For instance, in computer-based tests, age is a very important variable. As our proposed method does not require
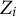 $Z_i$
to be a discrete variable, it is applicable when
$Z_i$
to be a discrete variable, it is applicable when
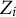 $Z_i$
is a continuous variable. To see this, let
$Z_i$
is a continuous variable. To see this, let
 $Z_i\in \mathbb {R}$
, and we aim to construct
$Z_i\in \mathbb {R}$
, and we aim to construct
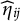 $\widehat {\eta }_{ij}$
such that
$\widehat {\eta }_{ij}$
such that
 $$ \begin{align} p(Y_{i}=y | \theta_i, \widehat\eta_{i}, Z_i)\approx p(Y_{i}=y| \theta_i, \widehat\eta_{i}). \end{align} $$
$$ \begin{align} p(Y_{i}=y | \theta_i, \widehat\eta_{i}, Z_i)\approx p(Y_{i}=y| \theta_i, \widehat\eta_{i}). \end{align} $$
When (12) holds, we expect the objective function (3) to be close to
 $0$
. Therefore, minimizing (3) to reduce DIF is valid for continuous covariates.
$0$
. Therefore, minimizing (3) to reduce DIF is valid for continuous covariates.
2.4.3 Nonlinear models
When the link function
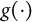 $g(\cdot )$
is not linear, e.g., the M2PL model and the Probit regression model, minimizing the objective function (3) is a nested optimization problem that takes in different forms depending on the model employed. Again, we rely on numerical methods to approximate the solution.
$g(\cdot )$
is not linear, e.g., the M2PL model and the Probit regression model, minimizing the objective function (3) is a nested optimization problem that takes in different forms depending on the model employed. Again, we rely on numerical methods to approximate the solution.
2.4.4 Multiple grouping variables
Sometimes, it is of interest to evaluate DIF over more than one grouping variable (Bauer et al., Reference Bauer, Belzak and Cole2020; Kim et al., Reference Kim, Cohen and Park1995). For cases involving multiple grouping variables, the expression of the objective function in terms of
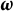 $\boldsymbol {\omega }$
becomes significantly more complex. To address this, we propose an approximation of the objective function for M grouping variables
$\boldsymbol {\omega }$
becomes significantly more complex. To address this, we propose an approximation of the objective function for M grouping variables
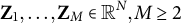 $\mathbf Z_1,\dots , \mathbf Z_M\in \mathbb {R}^N, M\ge 2$
as follows:
$\mathbf Z_1,\dots , \mathbf Z_M\in \mathbb {R}^N, M\ge 2$
as follows:
 $$ \begin{align} L(\boldsymbol{\omega}) = \sum_{m=1}^M L^{(m)}(\boldsymbol{\omega}), \end{align} $$
$$ \begin{align} L(\boldsymbol{\omega}) = \sum_{m=1}^M L^{(m)}(\boldsymbol{\omega}), \end{align} $$
where
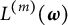 $L^{(m)}(\boldsymbol {\omega })$
is the objective function (3) corresponding to
$L^{(m)}(\boldsymbol {\omega })$
is the objective function (3) corresponding to
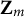 $\mathbf Z_m$
. In general, there is no closed-form solution for the minimizer of (3) or (13) with the presence of multiple grouping variables. Therefore, we rely on numerical methods to approximate the minimizer.
$\mathbf Z_m$
. In general, there is no closed-form solution for the minimizer of (3) or (13) with the presence of multiple grouping variables. Therefore, we rely on numerical methods to approximate the minimizer.
2.5 Procedure
We outline the procedure of the proposed method in a practical setting with J items.
-
1. Suppose we have access to a set of anchor items that are DIF-free, which are used to perform DIF detection on all the items. Suppose DIF has been detected on a subset of items
 $\mathcal {B}\subset [J]$
.
$\mathcal {B}\subset [J]$
. -
2. Obtain an initial latent trait estimate
$\widehat {\boldsymbol {\theta }}^{(0)}$
using the items without DIF. -
3. For each item, perform the proposed method to obtain the nuisance trait surrogates and DIF-corrected model parameters. More specifically, for each item
$j\in \mathcal {B}$
,-
(a) With the initial ability estimate,
$\widehat {\boldsymbol {\theta }}^{(0)}$
, find the minimizer
$\widehat {\boldsymbol {\omega }}_j$
in Equation (5) and obtain the nuisance trait estimate
$\widehat {\boldsymbol \eta }_j=\mathbf X_j\widehat {\boldsymbol {\omega }}_j$
. -
(b) With
$\widehat {\boldsymbol {\theta }}^{(0)}, \widehat {\boldsymbol \eta }_j$
, obtain the item parameter estimates
$\widehat d_j, \widehat {a}_{0j}, \widehat {a}_{1j}$
in (1) with
$\lambda _j$
set to
$0$
, using the full data.
-
-
4. Obtain the updated estimate of
$\theta _i$
with (6), utilizing the nuisance trait surrogates and the calibrated measurement models, denoted by
$\widehat {\boldsymbol {\theta }}^{(1)}$
.
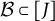
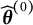


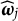
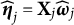
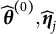


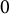


The above procedure requires an initial estimate
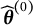 $\widehat {\boldsymbol {\theta }}^{(0)}$
that does not have DIF. In case that DIF-free items are not available, we could apply the above method iteratively. In particular, if
$\widehat {\boldsymbol {\theta }}^{(0)}$
that does not have DIF. In case that DIF-free items are not available, we could apply the above method iteratively. In particular, if
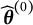 $\kern1.2pt\widehat {\boldsymbol {\theta }}^{(0)}$
is known to have some DIF, we apply the above procedure (steps 1–4) and obtain
$\kern1.2pt\widehat {\boldsymbol {\theta }}^{(0)}$
is known to have some DIF, we apply the above procedure (steps 1–4) and obtain
 $\widehat {\boldsymbol {\theta }}^{(1)}$
. Generally speaking,
$\widehat {\boldsymbol {\theta }}^{(1)}$
. Generally speaking,
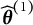 $\widehat {\boldsymbol {\theta }}^{(1)}$
has less DIF than
$\widehat {\boldsymbol {\theta }}^{(1)}$
has less DIF than
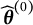 $\widehat {\boldsymbol {\theta }}^{(0)}$
. We set the updated estimate
$\widehat {\boldsymbol {\theta }}^{(0)}$
. We set the updated estimate
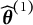 $\widehat {\boldsymbol {\theta }}^{(1)}$
the initial value and apply steps 1–4 and obtain
$\widehat {\boldsymbol {\theta }}^{(1)}$
the initial value and apply steps 1–4 and obtain
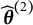 $\widehat {\boldsymbol {\theta }}^{(2)}$
. We could iteratively apply the procedure until some type of convergence is reached. The convergence could be measured by some difference (or similarity) metric between two iterations:
$\widehat {\boldsymbol {\theta }}^{(2)}$
. We could iteratively apply the procedure until some type of convergence is reached. The convergence could be measured by some difference (or similarity) metric between two iterations:
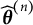 $\widehat {\boldsymbol {\theta }}^{(n)}$
and
$\widehat {\boldsymbol {\theta }}^{(n)}$
and
 $\widehat {\boldsymbol {\theta }}^{(n+1)}$
. In our real data example, we used the sample correlation and two iterations are sufficient. The correlation between
$\widehat {\boldsymbol {\theta }}^{(n+1)}$
. In our real data example, we used the sample correlation and two iterations are sufficient. The correlation between
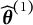 $\widehat {\boldsymbol {\theta }}^{(1)}$
and
$\widehat {\boldsymbol {\theta }}^{(1)}$
and
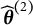 $\widehat {\boldsymbol {\theta }}^{(2)}$
is over
$\widehat {\boldsymbol {\theta }}^{(2)}$
is over
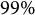 $99\%$
. Researchers may use other metrics depending on the specific scope of their study, such as average difference, maximum difference, general
$99\%$
. Researchers may use other metrics depending on the specific scope of their study, such as average difference, maximum difference, general
 $L_p$
distance, etc.
$L_p$
distance, etc.
3 Simulation studies
We carry out extensive simulation experiments to evaluate the proposed method in this section. The goal is to show that the proposed method is able to minimize the objective function, accurately estimate the nuisance traits and the item parameters, and correct for target trait estimation from the DIF items.
3.1 Simulation settings
We consider three settings with the sample sizes
 $N=$
2,000, 5,000, and 10,000. Among the subjects,
$N=$
2,000, 5,000, and 10,000. Among the subjects,
 $2/3$
are in the reference group and
$2/3$
are in the reference group and
 $1/3$
are in the focal group. We fix the number of items as
$1/3$
are in the focal group. We fix the number of items as
 $J=15$
and consider low, medium, and high proportions of DIF items, that is, 3, 5, and 10 DIF items. We also consider two settings for the DIF parameters
$J=15$
and consider low, medium, and high proportions of DIF items, that is, 3, 5, and 10 DIF items. We also consider two settings for the DIF parameters
 $a_{1j}$
. For small DIF effects,
$a_{1j}$
. For small DIF effects,
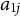 $a_{1j}$
s are uniformly sampled from
$a_{1j}$
s are uniformly sampled from
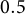 $0.5$
to
$0.5$
to
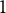 $1$
; for large DIF effects, the range is from
$1$
; for large DIF effects, the range is from
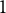 $1$
to
$1$
to
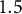 $1.5$
. In summary, there are
$1.5$
. In summary, there are
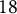 $18$
simulation settings varying in sample size, proportion of DIF items, and DIF effect size. For each simulation setting,
$18$
simulation settings varying in sample size, proportion of DIF items, and DIF effect size. For each simulation setting,
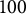 $100$
independent replications are generated. In each replication, we independently sample the target latent trait
$100$
independent replications are generated. In each replication, we independently sample the target latent trait
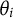 $\theta _i$
from
$\theta _i$
from
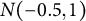 $N(-0.5, 1)$
for the focal group, and
$N(-0.5, 1)$
for the focal group, and
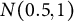 $N(0.5, 1)$
for the reference group. The difficulty parameters
$N(0.5, 1)$
for the reference group. The difficulty parameters
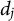 $d_j$
are sampled uniformly from
$d_j$
are sampled uniformly from
 $-1$
to
$-1$
to
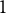 $1$
and the discrimination parameters
$1$
and the discrimination parameters
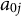 $a_{0j}$
are sampled uniformly from
$a_{0j}$
are sampled uniformly from
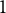 $1$
to
$1$
to
 $2$
. As the generation of process data is challenging, we generate the process data features directly. The number of process data features for each item is fixed at
$2$
. As the generation of process data is challenging, we generate the process data features directly. The number of process data features for each item is fixed at
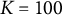 $K=100$
. The process data features
$K=100$
. The process data features
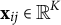 $\mathbf x_{ij}\in \mathbb {R}^K$
are first independently sampled from the multivariate Gaussian distribution
$\mathbf x_{ij}\in \mathbb {R}^K$
are first independently sampled from the multivariate Gaussian distribution
 $N(\boldsymbol {\mu }^{(Z_i)}, \mathbf {I}_K)$
. The mean of the process features depends on the respondent’s group membership. For the reference group,
$N(\boldsymbol {\mu }^{(Z_i)}, \mathbf {I}_K)$
. The mean of the process features depends on the respondent’s group membership. For the reference group,
 $\boldsymbol {\mu }^{(0)}=\mathbf {1}_K$
, and for the focal group
$\boldsymbol {\mu }^{(0)}=\mathbf {1}_K$
, and for the focal group
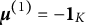 $\boldsymbol {\mu }^{(1)}=-\mathbf {1}_K$
. We then right multiply
$\boldsymbol {\mu }^{(1)}=-\mathbf {1}_K$
. We then right multiply
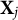 $\mathbf X_j$
with sample
$\mathbf X_j$
with sample
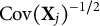 $\text {Cov}(\mathbf X_j)^{-1/2}$
for the process features to have the identity matrix as the covariance. The ground-truth nuisance trait is a linear combination of the process features:
$\text {Cov}(\mathbf X_j)^{-1/2}$
for the process features to have the identity matrix as the covariance. The ground-truth nuisance trait is a linear combination of the process features:
 $\eta _{ij}=\boldsymbol {\omega }_j^\top \mathbf x_{ij}$
, with
$\eta _{ij}=\boldsymbol {\omega }_j^\top \mathbf x_{ij}$
, with
 $\omega _{jk}$
sampled independently from the exponential distribution with rate
$\omega _{jk}$
sampled independently from the exponential distribution with rate
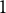 $1$
and
$1$
and
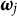 $\boldsymbol {\omega }_j$
’s are scaled to have unit norm. Note that the generated nuisance traits for each item have unit norm. We consider both the linear model and the M2PL model in generating the item responses. As DIF is solely introduced by the distributional difference of the nuisance trait in simulation,
$\boldsymbol {\omega }_j$
’s are scaled to have unit norm. Note that the generated nuisance traits for each item have unit norm. We consider both the linear model and the M2PL model in generating the item responses. As DIF is solely introduced by the distributional difference of the nuisance trait in simulation,
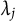 $\lambda _j$
is set to be
$\lambda _j$
is set to be
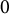 $0$
in (1) when generating the item responses for both models.
$0$
in (1) when generating the item responses for both models.
For the linear factor model, we set the variance of the item response noise as
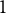 $1$
when generating the item responses. To make sure that the features can almost perfectly predict each item response in the linear model, we add one column of
$1$
when generating the item responses. To make sure that the features can almost perfectly predict each item response in the linear model, we add one column of
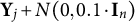 $\mathbf Y_j + N(0, 0.1\cdot \mathbf {I}_n)$
to the generated
$\mathbf Y_j + N(0, 0.1\cdot \mathbf {I}_n)$
to the generated
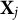 $\mathbf X_j$
for each item j and generate the nuisance traits with the same manner as mentioned above. The initial target trait estimates
$\mathbf X_j$
for each item j and generate the nuisance traits with the same manner as mentioned above. The initial target trait estimates
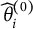 $\widehat \theta _i^{(0)}$
are obtained with factor analysis using responses from the DIF-free items. To construct the nuisance trait, we adopt the closed-form expression of
$\widehat \theta _i^{(0)}$
are obtained with factor analysis using responses from the DIF-free items. To construct the nuisance trait, we adopt the closed-form expression of
 $\widehat {\boldsymbol {\omega }}$
from Proposition 1. For the M2PL model, we generate
$\widehat {\boldsymbol {\omega }}$
from Proposition 1. For the M2PL model, we generate
 $Y_{ij}$
with the link function
$Y_{ij}$
with the link function
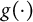 $g(\cdot )$
being the logit function. The initial target trait estimates
$g(\cdot )$
being the logit function. The initial target trait estimates
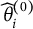 $\widehat \theta _i^{(0)}$
are the MLE estimates using the DIF-free items. The nuisance traits are estimated by solving (5) using the optim function with the L-BFGS-B optimizer in R.
$\widehat \theta _i^{(0)}$
are the MLE estimates using the DIF-free items. The nuisance traits are estimated by solving (5) using the optim function with the L-BFGS-B optimizer in R.
The simulation above corresponds to uniform DIF. In addition, we consider the case with non-uniform DIF so that
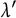 $\lambda '$
in (11) is not zero. Similar simulation settings are adopted except for the generation of process data features. To ensure the existence of non-uniform DIF, the process features
$\lambda '$
in (11) is not zero. Similar simulation settings are adopted except for the generation of process data features. To ensure the existence of non-uniform DIF, the process features
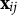 $\mathbf x_{ij}$
are sampled from the multivariate Gaussian distribution
$\mathbf x_{ij}$
are sampled from the multivariate Gaussian distribution
 $N(\boldsymbol {\mu }^{(Z_i)} + \gamma _j \theta _iZ_i, \mathbf {I}_K)$
with
$N(\boldsymbol {\mu }^{(Z_i)} + \gamma _j \theta _iZ_i, \mathbf {I}_K)$
with
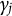 $\gamma _j$
simulated from the exponential distribution with rate
$\gamma _j$
simulated from the exponential distribution with rate
 $1$
.
$1$
.
3.2 Evaluation criteria
We consider five evaluation criteria. Firstly, we check whether the proposed method is able to reduce the objective function value. Specifically, we verify whether zero of (3) is obtained for the linear model with Proposition 1. Secondly, we evaluate the correlation of nuisance trait estimation compared to its ground truth. Thirdly, we calculate the mean squared error (MSE) of the item parameter estimations. In addition, to evaluate measurement reliability after changing the scoring rule, we calculate the Fisher information (FI) of the target trait for the DIF items. For the linear model, target trait FI for the item
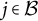 $j\in \mathcal {B}$
is
$j\in \mathcal {B}$
is
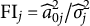 $\text {FI}_j = \widehat {a}_{0j}^2 / \widehat {\sigma }_j^2$
, where
$\text {FI}_j = \widehat {a}_{0j}^2 / \widehat {\sigma }_j^2$
, where
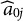 $\widehat {a}_{0j}$
is the estimated coefficient for the target trait and
$\widehat {a}_{0j}$
is the estimated coefficient for the target trait and
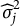 $\widehat {\sigma }_j^2$
is the estimated variance. For the M2PL model,
$\widehat {\sigma }_j^2$
is the estimated variance. For the M2PL model,
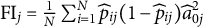 $\text {FI}_j = \frac {1}{N} \sum _{i=1}^N \widehat {p}_{ij}(1-\widehat {p}_{ij}) \widehat {a}_{0j}^2$
, where
$\text {FI}_j = \frac {1}{N} \sum _{i=1}^N \widehat {p}_{ij}(1-\widehat {p}_{ij}) \widehat {a}_{0j}^2$
, where
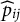 $\widehat {p}_{ij}$
is the estimated response of the logistic model. Last but not least, we consider the between-group sum of squared (SS) bias for target trait estimation using the DIF items. We elaborate more on this evaluation criterion assuming one grouping variable with a focal group and a reference group. Note that this criterion can be easily generalized to multiple grouping variables. For any target trait estimate
$\widehat {p}_{ij}$
is the estimated response of the logistic model. Last but not least, we consider the between-group sum of squared (SS) bias for target trait estimation using the DIF items. We elaborate more on this evaluation criterion assuming one grouping variable with a focal group and a reference group. Note that this criterion can be easily generalized to multiple grouping variables. For any target trait estimate
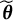 $\widetilde {\boldsymbol {\theta }}$
, define the bias
$\widetilde {\boldsymbol {\theta }}$
, define the bias
 $\boldsymbol {\nu }:=\widetilde {\boldsymbol {\theta }}-\boldsymbol {\theta }$
and denote the mean of bias as
$\boldsymbol {\nu }:=\widetilde {\boldsymbol {\theta }}-\boldsymbol {\theta }$
and denote the mean of bias as
 $\bar \nu :=\frac {1}{N}\sum _{i=1}^N\nu _i$
. Consider the between-group SS for the bias of
$\bar \nu :=\frac {1}{N}\sum _{i=1}^N\nu _i$
. Consider the between-group SS for the bias of
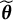 $\widetilde {\boldsymbol {\theta }}$
in analysis of variance (ANOVA):
$\widetilde {\boldsymbol {\theta }}$
in analysis of variance (ANOVA):
 $$ \begin{align} SSB_{\widetilde{\boldsymbol{\theta}}} = N_r \left(\frac{1}{N_r}\sum_{i\in\mathcal{N}_r}\nu_i - \bar\nu \right)^2 + N_f \left(\frac{1}{N_f}\sum_{i\in\mathcal{N}_f}\nu_i - \bar\nu \right)^2, \end{align} $$
$$ \begin{align} SSB_{\widetilde{\boldsymbol{\theta}}} = N_r \left(\frac{1}{N_r}\sum_{i\in\mathcal{N}_r}\nu_i - \bar\nu \right)^2 + N_f \left(\frac{1}{N_f}\sum_{i\in\mathcal{N}_f}\nu_i - \bar\nu \right)^2, \end{align} $$
where
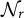 $\mathcal {N}_r$
and
$\mathcal {N}_r$
and
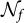 $\mathcal {N}_f$
are the index sets of the reference group and focal group, respectively, and
$\mathcal {N}_f$
are the index sets of the reference group and focal group, respectively, and
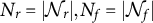 $N_r=|\mathcal {N}_r|, N_f=|\mathcal {N}_f|$
. To illustrate that the proposed method is able to de-bias target trait estimation, we compare the above-defined value for two estimates. The benchmark estimate is the MLE computed using the responses from the DIF items in
$N_r=|\mathcal {N}_r|, N_f=|\mathcal {N}_f|$
. To illustrate that the proposed method is able to de-bias target trait estimation, we compare the above-defined value for two estimates. The benchmark estimate is the MLE computed using the responses from the DIF items in
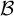 $\mathcal {B}$
, assuming DIF is not present:
$\mathcal {B}$
, assuming DIF is not present:
 $$ \begin{align*} \check\theta_i = \operatorname*{\mathrm{argmax}}_{\theta} \sum_{j\in\mathcal{B}} \log p(Y_{ij} | \theta, \check d_j, \check{a}_{0j}, a_{1j}=0, \lambda_j=0), \end{align*} $$
$$ \begin{align*} \check\theta_i = \operatorname*{\mathrm{argmax}}_{\theta} \sum_{j\in\mathcal{B}} \log p(Y_{ij} | \theta, \check d_j, \check{a}_{0j}, a_{1j}=0, \lambda_j=0), \end{align*} $$
where
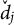 $\check {d}_j$
and
$\check {d}_j$
and
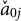 $\check {a}_{0j}$
are calibrated on the DIF items. The second estimate is the MLE computed after DIF-correction:
$\check {a}_{0j}$
are calibrated on the DIF items. The second estimate is the MLE computed after DIF-correction:
 $$ \begin{align*} \widehat\theta_i = \operatorname*{\mathrm{argmax}}_{\theta} \sum_{j\in\mathcal{B}} \log p(Y_{ij} | \theta, \widehat d_j, \widehat{a}_{0j}, \widehat{a}_{1j}, \lambda_j=0), \end{align*} $$
$$ \begin{align*} \widehat\theta_i = \operatorname*{\mathrm{argmax}}_{\theta} \sum_{j\in\mathcal{B}} \log p(Y_{ij} | \theta, \widehat d_j, \widehat{a}_{0j}, \widehat{a}_{1j}, \lambda_j=0), \end{align*} $$
where
 $\widehat {d}_j, \widehat {a}_{0j}$
and
$\widehat {d}_j, \widehat {a}_{0j}$
and
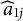 $\widehat {a}_{1j}$
are calibrated on the DIF items with the nuisance trait surrogates. Because of the presence of DIF,
$\widehat {a}_{1j}$
are calibrated on the DIF items with the nuisance trait surrogates. Because of the presence of DIF,
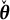 $\check {\boldsymbol {\theta }}$
is expected to be over-estimated within one group, and under-estimated within the other, leading to large values of
$\check {\boldsymbol {\theta }}$
is expected to be over-estimated within one group, and under-estimated within the other, leading to large values of
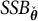 $SSB_{\check {\boldsymbol {\theta }}}$
. With the proposed method, we expect
$SSB_{\check {\boldsymbol {\theta }}}$
. With the proposed method, we expect
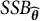 $SSB_{\widehat {\boldsymbol {\theta }}}$
for the corrected estimate to be small compared to
$SSB_{\widehat {\boldsymbol {\theta }}}$
for the corrected estimate to be small compared to
 $SSB_{\check {\boldsymbol {\theta }}}$
for the not-corrected estimate.
$SSB_{\check {\boldsymbol {\theta }}}$
for the not-corrected estimate.
3.3 Simulation results
Figure 2 summarizes the values for the objective function (3) before and after adding the nuisance trait surrogate for the linear and M2PL models, with uniform DIF,
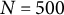 $N=500$
, and large DIF. For complete results of all simulation settings, see Figures B1 and B2 in the Appendix. We are able to minimize the objective function across simulation settings and replications. Specifically, we are able to obtain the zero of the objective function for the linear model. Tables 1 and 2 demonstrate the MSE of the item parameter estimates and the correlation between the ground truth and estimated nuisance traits. We observe that the MSE values are small in magnitude and the nuisance trait estimation correlation is high. It also shows that as the sample size increases, MSE tends to decrease and the nuisance trait correlation tends to increase. On the other hand, larger DIF effects and DIF item proportion lead to larger MSE. For the linear model, the nuisance trait correlation does not change with the sample size. For the M2PL model, it increases with the sample size. Figures B3 and B4 in the Appendix summarize the FI of the target trait
$N=500$
, and large DIF. For complete results of all simulation settings, see Figures B1 and B2 in the Appendix. We are able to minimize the objective function across simulation settings and replications. Specifically, we are able to obtain the zero of the objective function for the linear model. Tables 1 and 2 demonstrate the MSE of the item parameter estimates and the correlation between the ground truth and estimated nuisance traits. We observe that the MSE values are small in magnitude and the nuisance trait estimation correlation is high. It also shows that as the sample size increases, MSE tends to decrease and the nuisance trait correlation tends to increase. On the other hand, larger DIF effects and DIF item proportion lead to larger MSE. For the linear model, the nuisance trait correlation does not change with the sample size. For the M2PL model, it increases with the sample size. Figures B3 and B4 in the Appendix summarize the FI of the target trait
 $\theta $
before and after adding the nuisance trait surrogate for the linear and M2PL models, respectively. We observe an increase in FI of the target trait in the measurement model after correcting for DIF in both models. Furthermore, Figure 3 compares the between-group SS bias of the corrected and not-corrected target trait estimates using the DIF items for the linear and M2PL models. The x-axis corresponds to the estimation without DIF correction, and the y-axis corresponds to the DIF-corrected estimation. The corresponding simulation setting is
$\theta $
before and after adding the nuisance trait surrogate for the linear and M2PL models, respectively. We observe an increase in FI of the target trait in the measurement model after correcting for DIF in both models. Furthermore, Figure 3 compares the between-group SS bias of the corrected and not-corrected target trait estimates using the DIF items for the linear and M2PL models. The x-axis corresponds to the estimation without DIF correction, and the y-axis corresponds to the DIF-corrected estimation. The corresponding simulation setting is
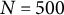 $N=500$
with large DIF; for the complete results, see Figures B5 and B6 in the Appendix. We see that the proposed method is able to correct for the target estimation bias introduced by DIF, as the between-group SS bias is significantly reduced after DIF correction for both models.
$N=500$
with large DIF; for the complete results, see Figures B5 and B6 in the Appendix. We see that the proposed method is able to correct for the target estimation bias introduced by DIF, as the between-group SS bias is significantly reduced after DIF correction for both models.
Values of the objective function before and after adding the nuisance trait surrogate for the linear model (upper) and the M2PL model (lower) with uniform DIF,
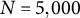 $N=5{,}000$
, and large DIF.
$N=5{,}000$
, and large DIF.

Mean squared error of item parameter estimates and nuisance trait correlation for the linear model with uniform DIF under different simulation settings

Note: The values are averaged across the DIF items and replications.
Mean squared error of item parameter estimates and nuisance trait correlation for the M2PL model with uniform DIF under different simulation settings. The values are averaged across the DIF items and replications

Note: The values are averaged across the DIF items and replications.
Between-group sum of squared bias for target trait estimation for the linear model (upper) and the M2PL model (lower) with uniform DIF,
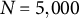 $N=5{,}000$
, and large DIF. The x-axis corresponds to the estimation without DIF correction using the DIF items; the y-axis corresponds to the DIF-corrected estimation using the DIF items.
$N=5{,}000$
, and large DIF. The x-axis corresponds to the estimation without DIF correction using the DIF items; the y-axis corresponds to the DIF-corrected estimation using the DIF items.

Results for non-uniform DIF are deferred to the Appendix. In Figures B7 and B8, we observe an increase in the minimized objective function values for non-uniform compared to uniform DIF, although the proposed method is still able to reduce DIF significantly. Similar results for item parameter and nuisance trait estimation, target trait FI, and between-group SS bias are observed (see Tables B1 and B2 and Figures B9–B12 in the Appendix).
4 Case study
We use the PIAAC 2012 survey data as a case study to demonstrate the effectiveness of our method. Response processes of
 $13$
PSTRE items from
$13$
PSTRE items from
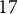 $17$
countries are considered in this study. PIAAC was the first attempt to assess the PSTRE construct on a large scale and as a single dimension. Under the PIAAC framework, PSTRE is defined as the use of digital technology, communication tools, and the internet to obtain and evaluate information, communicate with others, and perform practical tasks (OECD, 2012b). The survey also recorded a broad spectrum of respondents’ background information, such as gender, age, occupation, hourly income, education level, etc. To conduct DIF analysis, we consider age, income, and gender as the demographic grouping variables. We include the process data of 8,398 respondents who answered all 13 items and have no missing value of the three covariates in the study. For age, we use
$17$
countries are considered in this study. PIAAC was the first attempt to assess the PSTRE construct on a large scale and as a single dimension. Under the PIAAC framework, PSTRE is defined as the use of digital technology, communication tools, and the internet to obtain and evaluate information, communicate with others, and perform practical tasks (OECD, 2012b). The survey also recorded a broad spectrum of respondents’ background information, such as gender, age, occupation, hourly income, education level, etc. To conduct DIF analysis, we consider age, income, and gender as the demographic grouping variables. We include the process data of 8,398 respondents who answered all 13 items and have no missing value of the three covariates in the study. For age, we use
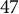 $47$
, which is the
$47$
, which is the
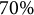 $70\%$
quantile, as the cutoff value to split the samples into younger and older sub-populations. The younger population is treated as the reference group, and the older population is treated as the focal group. For income, we first group the samples by their nationality, and then use the medium income of each nation as the cutoff value. The lower-income and higher-income groups are treated as the focal and the reference groups, respectively. For gender, female is treated as the focal group and male as the reference group.
$70\%$
quantile, as the cutoff value to split the samples into younger and older sub-populations. The younger population is treated as the reference group, and the older population is treated as the focal group. For income, we first group the samples by their nationality, and then use the medium income of each nation as the cutoff value. The lower-income and higher-income groups are treated as the focal and the reference groups, respectively. For gender, female is treated as the focal group and male as the reference group.
Table 3 provides a descriptive summary of the
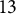 $13$
items, where n is the number of total possible actions,
$13$
items, where n is the number of total possible actions,
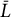 $\bar {L}$
is the average process sequence length, and Correct
$\bar {L}$
is the average process sequence length, and Correct
 $\%$
is the percentage receiving the full credit on each item. When solving for each item, the respondents are presented with one or more simulated informational and communicative (ICT) environments, such as an email inbox, a spreadsheet, a web browser, etc. For example, in item U01a, the respondents are presented with an email inbox interface and are asked to classify the email senders into “can come” and “cannot come” categories based on their email contents. To complete the task, the respondents need to conduct a sequence of clicking, dragging, or typing actions, which are recorded in the log files as process data. In addition, Tables B3 and B4 in the Appendix summarize the mean and standard deviation of the responses by group for each item, for the polytomous responses and binary responses, respectively.
$\%$
is the percentage receiving the full credit on each item. When solving for each item, the respondents are presented with one or more simulated informational and communicative (ICT) environments, such as an email inbox, a spreadsheet, a web browser, etc. For example, in item U01a, the respondents are presented with an email inbox interface and are asked to classify the email senders into “can come” and “cannot come” categories based on their email contents. To complete the task, the respondents need to conduct a sequence of clicking, dragging, or typing actions, which are recorded in the log files as process data. In addition, Tables B3 and B4 in the Appendix summarize the mean and standard deviation of the responses by group for each item, for the polytomous responses and binary responses, respectively.
Summary statistics of
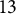 $13$
PIAAC problem-solving items
$13$
PIAAC problem-solving items

Note: Here, n is the number of total possible actions,
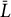 $\bar {L}$
is the average process sequence length, and Correct
$\bar {L}$
is the average process sequence length, and Correct
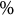 $\%$
is the percentage of correct answers.
$\%$
is the percentage of correct answers.
We use the MDS approach proposed in Tang, Wang, He, et al. (Reference Tang, Wang, He, Liu and Ying2020) to extract item features that approximate the geometric distances defined by a dissimilarity matrix of the action sequences. We set the dimension of features to be
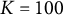 $K=100$
to ensure enough information is retained in the extracted features. To verify that the features contain an adequate amount of information in the process data, we use them to predict the responses with both linear regression and logistic regression. Results show that the extracted features can perfectly predict whether the examine received the full credit of each item with both regression methods. Engagement is often considered a nuisance trait in respondent behavior (Wise & DeMars, Reference Wise and DeMars2006; Wise & Kong, Reference Wise and Kong2005), and one plausible measure of engagement is the length of a respondent’s process sequence. For each item, we randomly sample
$K=100$
to ensure enough information is retained in the extracted features. To verify that the features contain an adequate amount of information in the process data, we use them to predict the responses with both linear regression and logistic regression. Results show that the extracted features can perfectly predict whether the examine received the full credit of each item with both regression methods. Engagement is often considered a nuisance trait in respondent behavior (Wise & DeMars, Reference Wise and DeMars2006; Wise & Kong, Reference Wise and Kong2005), and one plausible measure of engagement is the length of a respondent’s process sequence. For each item, we randomly sample
 $80\%$
of training data to predict the process sequence length with the extracted features using ridge regression, where the ridge parameter is selected with cross-validation on the training data. Figure 4 demonstrates the out-of-sample correlation between the predicted and actual process sequence lengths for each item. It shows that the extracted features are able to predict the sequence length with high accuracy.
$80\%$
of training data to predict the process sequence length with the extracted features using ridge regression, where the ridge parameter is selected with cross-validation on the training data. Figure 4 demonstrates the out-of-sample correlation between the predicted and actual process sequence lengths for each item. It shows that the extracted features are able to predict the sequence length with high accuracy.
Out-of-sample prediction correlation of the process sequence length using the extracted features for each item.

4.1 DIF existence
The proposed procedure assumes that we have access to the ground-truth target trait values. However, these target traits are unknown and need to be estimated in practice. To obtain initial estimates of the target traits, we utilize the responses to all
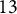 $13$
items. We then use these target trait estimates to identify DIF items. For the linear model, the latent traits are estimated by performing maximum-likelihood factor analysis on the response data. For the M2PL model, the link function
$13$
items. We then use these target trait estimates to identify DIF items. For the linear model, the latent traits are estimated by performing maximum-likelihood factor analysis on the response data. For the M2PL model, the link function
 $g(\cdot )$
in Equation (1) is the logit function, and the reduced model without the nuisance trait is calibrated by maximizing the marginal likelihood using the expectation–maximization algorithm (Bock & Aitkin, Reference Bock and Aitkin1981). The initial estimation
$g(\cdot )$
in Equation (1) is the logit function, and the reduced model without the nuisance trait is calibrated by maximizing the marginal likelihood using the expectation–maximization algorithm (Bock & Aitkin, Reference Bock and Aitkin1981). The initial estimation
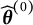 $\widehat {\boldsymbol {\theta }}^{(0)}$
is the MLE estimate after item calibration.
$\widehat {\boldsymbol {\theta }}^{(0)}$
is the MLE estimate after item calibration.
Table 4 summarizes the DIF detection results using the initial trait estimate
 $\widehat {\boldsymbol {\theta }}^{(0)}$
. For the age variable,
$\widehat {\boldsymbol {\theta }}^{(0)}$
. For the age variable,
 $12$
out of
$12$
out of
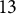 $13$
items are detected to have uniform DIF with both the linear model and the logistic model. For the income variable, five items have uniform DIF with both models. For the gender variable,
$13$
items are detected to have uniform DIF with both the linear model and the logistic model. For the income variable, five items have uniform DIF with both models. For the gender variable,
 $5$
are uniform-DIF items with the linear model and
$5$
are uniform-DIF items with the linear model and
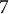 $7$
with the logistic model.
$7$
with the logistic model.
DIF detection results without the nuisance trait

Note: Bold text indicates statistical significance under the
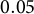 $0.05$
significance level.
$0.05$
significance level.
4.2 DIF correction
We implement the proposed method to estimate the nuisance traits with the extracted process features, and to correct for DIF effects. For the linear model, we use the closed-form expression in Proposition 1 as the estimate, while for the M2PL model, the nuisance traits are estimated by solving (5) using the optim function with the L-BFGS-B optimizer in R. We also apply the iterative method in Section 2.5, the correlations between
 $\widehat {\boldsymbol {\theta }}^{(1)}$
and
$\widehat {\boldsymbol {\theta }}^{(1)}$
and
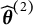 $\widehat {\boldsymbol {\theta }}^{(2)}$
are over 99%.
$\widehat {\boldsymbol {\theta }}^{(2)}$
are over 99%.
Figure 5 includes the boxplots of the objective function (3) with and without the nuisance trait surrogate for the three grouping variables. We see that the estimated nuisance traits serve the purpose of minimizing the objective functions for both models. Table 5 demonstrates the sample mean FI of the target trait
 $\theta $
before and after adding the nuisance trait surrogate
$\theta $
before and after adding the nuisance trait surrogate
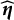 $\widehat {\boldsymbol \eta }$
for items that exhibit DIF. We see that the FI increases in the linear model by adding the nuisance trait surrogate. For the M2PL model, we observe a moderate reduction for most items, and a significant reduction for items U06b and U07. For these two items, adding the nuisance trait surrogate significantly increases the prediction accuracy of the item response. The boxplots of the objective function with and without the nuisance trait when two grouping variables are present can be found in Figure B13 in the Appendix. We see that the estimated nuisance traits are able to minimize the objective function with two grouping variables. For the case study, we do not have access to the ground-truth target trait or a reliable unbiased estimator of the target trait as many items exhibit DIF. Therefore, we do not compare the between-group SS bias for the target trait estimates before and after DIF correction.
$\widehat {\boldsymbol \eta }$
for items that exhibit DIF. We see that the FI increases in the linear model by adding the nuisance trait surrogate. For the M2PL model, we observe a moderate reduction for most items, and a significant reduction for items U06b and U07. For these two items, adding the nuisance trait surrogate significantly increases the prediction accuracy of the item response. The boxplots of the objective function with and without the nuisance trait when two grouping variables are present can be found in Figure B13 in the Appendix. We see that the estimated nuisance traits are able to minimize the objective function with two grouping variables. For the case study, we do not have access to the ground-truth target trait or a reliable unbiased estimator of the target trait as many items exhibit DIF. Therefore, we do not compare the between-group SS bias for the target trait estimates before and after DIF correction.
Comparing the objective function value with and without the nuisance trait surrogate for the linear model (left) and the M2PL model (right) with one grouping variable.

Sample mean Fisher information for
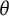 $\theta $
with and without nuisance trait surrogate, for three grouping variables and two models
$\theta $
with and without nuisance trait surrogate, for three grouping variables and two models

Note: Only the values corresponding to the DIF items are present.
As an illustration, we consider item U01a and the M2PL model to interpret the results for the age variable. After obtaining the estimated nuisance traits, we update the estimation of the target trait as
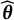 $\widehat {\boldsymbol \theta }$
by solving Equation (6). Recall that DIF arises when the functioning of the response differs given the latent trait. Therefore, we study the characteristics of the residual nuisance trait given the target trait, i.e.,
$\widehat {\boldsymbol \theta }$
by solving Equation (6). Recall that DIF arises when the functioning of the response differs given the latent trait. Therefore, we study the characteristics of the residual nuisance trait given the target trait, i.e.,
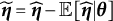 $\widetilde {\boldsymbol \eta }=\widehat {\boldsymbol \eta } - \mathbb {E}[\widehat {\boldsymbol \eta }|\boldsymbol \theta ]$
. To interpret why DIF occurs in item U01a, we check the original process sequences corresponding to the minimum and maximum values of
$\widetilde {\boldsymbol \eta }=\widehat {\boldsymbol \eta } - \mathbb {E}[\widehat {\boldsymbol \eta }|\boldsymbol \theta ]$
. To interpret why DIF occurs in item U01a, we check the original process sequences corresponding to the minimum and maximum values of
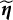 $\widetilde {\boldsymbol \eta }$
, and find that the usage of using drag/drop actions is related to the value of the residual nuisance trait. To verify this assumption, we calculate the correlation between
$\widetilde {\boldsymbol \eta }$
, and find that the usage of using drag/drop actions is related to the value of the residual nuisance trait. To verify this assumption, we calculate the correlation between
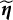 $\widetilde {\boldsymbol \eta }$
and whether drag/drop actions are used, which achieves
$\widetilde {\boldsymbol \eta }$
and whether drag/drop actions are used, which achieves
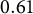 $0.61$
. And the correlation between
$0.61$
. And the correlation between
 $\widetilde {\boldsymbol \eta }$
and the number of drag/drop actions achieves
$\widetilde {\boldsymbol \eta }$
and the number of drag/drop actions achieves
 $0.49$
. These results suggest that the estimated nuisance variable can indicate the intensity of using drag/drop actions. Furthermore, the item response accuracy is
$0.49$
. These results suggest that the estimated nuisance variable can indicate the intensity of using drag/drop actions. Furthermore, the item response accuracy is
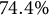 $74.4\%$
among the group that used drag/drop actions, versus
$74.4\%$
among the group that used drag/drop actions, versus
 $26.3\%$
among those that did not use drag/drop actions. Figure 6 demonstrates the density plots of the residual nuisance trait
$26.3\%$
among those that did not use drag/drop actions. Figure 6 demonstrates the density plots of the residual nuisance trait
 $\widetilde {\boldsymbol \eta }$
among the “older”/“younger” groups, and among the groups that did or did not use drag/drop actions. A possible interpretation of this phenomenon is that more senior individuals might be less familiar with this type of drag-and-drop mouse usage. It is also possibly more error-prone for more senior individuals to move emails using drag-and-drop actions because of the small font size in the email interface and the narrow distances between email folders. Among the individuals who used drag/drop actions,
$\widetilde {\boldsymbol \eta }$
among the “older”/“younger” groups, and among the groups that did or did not use drag/drop actions. A possible interpretation of this phenomenon is that more senior individuals might be less familiar with this type of drag-and-drop mouse usage. It is also possibly more error-prone for more senior individuals to move emails using drag-and-drop actions because of the small font size in the email interface and the narrow distances between email folders. Among the individuals who used drag/drop actions,
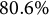 $80.6\%$
of the younger population had correct responses, while the percentage for the older population is only
$80.6\%$
of the younger population had correct responses, while the percentage for the older population is only
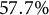 $57.7\%$
.
$57.7\%$
.
On the left: density plot of the residual nuisance trait
 $\widetilde {\boldsymbol \eta }$
among the “old” group and the “young” group. On the right: density plot of the residual nuisance trait
$\widetilde {\boldsymbol \eta }$
among the “old” group and the “young” group. On the right: density plot of the residual nuisance trait
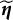 $\widetilde {\boldsymbol \eta }$
among the group that used drag/drop actions and those that did not.
$\widetilde {\boldsymbol \eta }$
among the group that used drag/drop actions and those that did not.

Notice that the majority of the items have some level of DIF. We apply the DIF correction method iteratively and found that the final estimates of
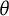 $\theta $
between iteration 1 and iteration 2 are over
$\theta $
between iteration 1 and iteration 2 are over
 $99\%$
. To keep the illustration simple, we only report the results of iteration 1.
$99\%$
. To keep the illustration simple, we only report the results of iteration 1.
5 Discussion
Test fairness is a prominent concern within psychometric and educational research, and DIF analysis is a commonly practiced approach to ensure test fairness. When the distributions of the item response differ among two or more groups conditional on the target trait(s), DIF arises. Development of high-quality operational test items is costly, yet in practice, items identified with significant DIF effects are often discarded. In this article, we propose a method to “de-bias” items that are detected with DIF by incorporating data beyond item responses. We utilize the rich information contained in item process data, which capture the whole response processes of respondents when they interact with computer-based items. Specifically, we attribute DIF to multidimensionality, where nuisance traits with heterogeneous sub-group distributions also affect the item responses, besides the target trait to be measured. To uncover the unobserved nuisance trait, we propose to minimize the maximum-likelihood difference of the models with and without the grouping variable. In the simple case with linear regression models and one grouping variable, there is a closed-form solution to the proposed optimization problem. Simulation studies and a real data case study demonstrate the effectiveness of the proposed method.
Some limitations do exist in the current method. Firstly, the assumption that DIF stems from multidimensionality may not hold, as DIF may arise from other forms of model misspecification (Huang et al., Reference Huang, Bolt and Lyu2024). Our study focuses on how process data help capture additional latent traits contributing to DIF within the multidimensionality framework. The amount of DIF reduction is limited to the portion that is caused by nuisance attributes and their predictability by the process data. Secondly, introducing the nuisance trait into the model might reduce measurement reliability, as suggested in some decrease in the FI for the target variable in the case study. It is of interest to study if a weighted summation of the maximum-likelihood reduction as in (3) and model liability quantification, such as the FI, would be appropriate as the new objective function. Thirdly, our proposed method relies on identifying a set of DIF-free or anchor items to identify the DIF items. In the case study, the initial targets are estimated assuming that all the items are DIF-free, and then utilized for DIF detection. However, this approach might be prone to bias when the influence of DIF on the initial trait estimation is significant. In the future, we are interested in more sophisticated DIF detection methods, such as item purification with stepwise model selection (Candell & Drasgow, Reference Candell and Drasgow1988; Kopf et al., Reference Kopf, Zeileis and Strobl2015a, Reference Kopf, Zeileis and Strobl2015b). In addition, we can bypass the tedious iterative purification procedure by employing methods similar to the covariate-adjusted model with regularization (Ouyang et al., Reference Ouyang, Cui, Tan and Xu2024; Wang, Zhu, et al., Reference Wang, Zhu and Xu2023), where the anchor item identification and latent trait estimation are carried out simultaneously. However, model identifiability must be carefully examined, as existing methods in the literature cannot be directly applied to our setting. Last but not least, process features are extracted from the action sequences and then utilized to linearly model the nuisance trait. However, a non-linear relationship between the nuisance trait and process data can be approximated by a neural network. Furthermore, it is generally difficult to systematically obtain interpretations of the nuisance traits. This is mostly because those traits are often unique to items and Z and thus not repeatedly measurable by multiple items. This is one of the limitations of the current method.
Acknowledgements
ChatGPT is used to polish certain parts of the writing. The authors take responsibility for the content of the article.
Funding statement
This research is supported in part by NSF SES-2119938.
Competing interests
The authors declare none.
Appendix A: Mathematical derivations
A.1. Proof of Proposition 1.
Recall that
 $\mathbf Y^\dagger , \mathbf Z^\dagger , \mathbf X^\dagger $
are, respectively, the residuals of
$\mathbf Y^\dagger , \mathbf Z^\dagger , \mathbf X^\dagger $
are, respectively, the residuals of
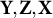 $\mathbf Y, \mathbf Z, \mathbf X$
after regressing on
$\mathbf Y, \mathbf Z, \mathbf X$
after regressing on
 $(1,\boldsymbol {\theta })$
. Regress
$(1,\boldsymbol {\theta })$
. Regress
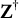 $\mathbf Z^\dagger $
on
$\mathbf Z^\dagger $
on
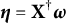 $\boldsymbol \eta =\mathbf X^\dagger \boldsymbol {\omega }$
:
$\boldsymbol \eta =\mathbf X^\dagger \boldsymbol {\omega }$
:
 $$ \begin{align*} \mathbf Z^\dagger = \beta \boldsymbol \eta + \boldsymbol \epsilon_Z, \end{align*} $$
$$ \begin{align*} \mathbf Z^\dagger = \beta \boldsymbol \eta + \boldsymbol \epsilon_Z, \end{align*} $$
and obtain the residuals
 $\widehat {\boldsymbol \epsilon }_Z := \mathbf Z^\dagger - \widehat {\beta }\boldsymbol \eta $
with
$\widehat {\boldsymbol \epsilon }_Z := \mathbf Z^\dagger - \widehat {\beta }\boldsymbol \eta $
with
 $\widehat \beta $
as the ordinary least squares (OLS) estimate. Specifically, since
$\widehat \beta $
as the ordinary least squares (OLS) estimate. Specifically, since
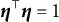 $\boldsymbol \eta ^\top \boldsymbol \eta =1$
with
$\boldsymbol \eta ^\top \boldsymbol \eta =1$
with
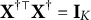 $\mathbf X^{\dagger \top }\mathbf X^\dagger =\mathbf {I}_K$
and
$\mathbf X^{\dagger \top }\mathbf X^\dagger =\mathbf {I}_K$
and
 $\boldsymbol {\omega }^\top \boldsymbol {\omega } = 1$
, we have
$\boldsymbol {\omega }^\top \boldsymbol {\omega } = 1$
, we have
 $$ \begin{align} & \widehat\beta =\frac{\mathbf Z^{\dagger\top}\boldsymbol \eta}{\boldsymbol \eta^\top \boldsymbol \eta}=\mathbf Z^{\dagger\top} \boldsymbol \eta, \notag \\ & \widehat{\boldsymbol \epsilon}_Z = \mathbf Z^\dagger - \boldsymbol \eta \mathbf Z^{\dagger\top}\boldsymbol \eta. \end{align} $$
$$ \begin{align} & \widehat\beta =\frac{\mathbf Z^{\dagger\top}\boldsymbol \eta}{\boldsymbol \eta^\top \boldsymbol \eta}=\mathbf Z^{\dagger\top} \boldsymbol \eta, \notag \\ & \widehat{\boldsymbol \epsilon}_Z = \mathbf Z^\dagger - \boldsymbol \eta \mathbf Z^{\dagger\top}\boldsymbol \eta. \end{align} $$
Similarly, obtain the OLS estimates for (7):
 $$ \begin{align} & \widehat{a}^{\prime}_1 = \frac{\mathbf Y^{\dagger\top} \boldsymbol \eta}{\boldsymbol \eta^\top \boldsymbol \eta} = \mathbf Y^{\dagger\top} \boldsymbol \eta, \notag \\ & \widehat{\boldsymbol \epsilon} = \mathbf Y^\dagger - \boldsymbol \eta \mathbf Y^{\dagger\top} \boldsymbol \eta , \end{align} $$
$$ \begin{align} & \widehat{a}^{\prime}_1 = \frac{\mathbf Y^{\dagger\top} \boldsymbol \eta}{\boldsymbol \eta^\top \boldsymbol \eta} = \mathbf Y^{\dagger\top} \boldsymbol \eta, \notag \\ & \widehat{\boldsymbol \epsilon} = \mathbf Y^\dagger - \boldsymbol \eta \mathbf Y^{\dagger\top} \boldsymbol \eta , \end{align} $$
and the residuals
 $\widehat {\boldsymbol \delta }=\mathbf Y^\dagger - \widehat {a}_1 \boldsymbol \eta - \widehat {\lambda } \mathbf Z^\dagger $
for (8).
$\widehat {\boldsymbol \delta }=\mathbf Y^\dagger - \widehat {a}_1 \boldsymbol \eta - \widehat {\lambda } \mathbf Z^\dagger $
for (8).
It is straightforward to show that
 $$ \begin{align*} \widehat{\boldsymbol \epsilon} = \widehat{\lambda} \widehat{\boldsymbol \epsilon}_Z + \widehat{\boldsymbol \delta}, \quad \widehat{\lambda} = \frac{\widehat{\boldsymbol \epsilon}^\top \widehat{\boldsymbol \epsilon}_Z}{\|\widehat{\boldsymbol \epsilon}_Z\|^2}. \end{align*} $$
$$ \begin{align*} \widehat{\boldsymbol \epsilon} = \widehat{\lambda} \widehat{\boldsymbol \epsilon}_Z + \widehat{\boldsymbol \delta}, \quad \widehat{\lambda} = \frac{\widehat{\boldsymbol \epsilon}^\top \widehat{\boldsymbol \epsilon}_Z}{\|\widehat{\boldsymbol \epsilon}_Z\|^2}. \end{align*} $$
Therefore,
 $$ \begin{align*} \|\widehat{\boldsymbol \epsilon}\|^2 - \|\widehat{\boldsymbol \delta}\|^2 = \widehat{\lambda}^2 \|\widehat{\boldsymbol \epsilon}_Z \|^2= \frac{(\widehat{\boldsymbol \epsilon}^\top \widehat{\boldsymbol \epsilon}_Z)^2}{\|\widehat{\boldsymbol \epsilon}_Z\|^2}. \end{align*} $$
$$ \begin{align*} \|\widehat{\boldsymbol \epsilon}\|^2 - \|\widehat{\boldsymbol \delta}\|^2 = \widehat{\lambda}^2 \|\widehat{\boldsymbol \epsilon}_Z \|^2= \frac{(\widehat{\boldsymbol \epsilon}^\top \widehat{\boldsymbol \epsilon}_Z)^2}{\|\widehat{\boldsymbol \epsilon}_Z\|^2}. \end{align*} $$
To obtain the zero of (9) is equivalent to obtaining the zero of
 $\widehat {\boldsymbol \epsilon }^\top \widehat {\boldsymbol \epsilon }_Z$
. Denote
$\widehat {\boldsymbol \epsilon }^\top \widehat {\boldsymbol \epsilon }_Z$
. Denote
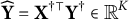 $\widehat {\mathbf Y} = \mathbf X^{\dagger \top } \mathbf Y^\dagger \in \mathbb {R}^{K}$
and
$\widehat {\mathbf Y} = \mathbf X^{\dagger \top } \mathbf Y^\dagger \in \mathbb {R}^{K}$
and
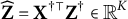 $\widehat {\mathbf Z} = \mathbf X^{\dagger \top } \mathbf Z^\dagger \in \mathbb {R}^K$
. With
$\widehat {\mathbf Z} = \mathbf X^{\dagger \top } \mathbf Z^\dagger \in \mathbb {R}^K$
. With
 $\boldsymbol \eta =\mathbf X^\dagger \boldsymbol {\omega }, \mathbf X^{\dagger \top }\mathbf X^\dagger =\mathbf {I}_K$
,
$\boldsymbol \eta =\mathbf X^\dagger \boldsymbol {\omega }, \mathbf X^{\dagger \top }\mathbf X^\dagger =\mathbf {I}_K$
,
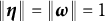 $\left \lVert \boldsymbol \eta \right \rVert =\left \lVert \boldsymbol {\omega }\right \rVert =1$
, plugging in (A.1) and (A.2) yields
$\left \lVert \boldsymbol \eta \right \rVert =\left \lVert \boldsymbol {\omega }\right \rVert =1$
, plugging in (A.1) and (A.2) yields
 $$ \begin{align*} \widehat{\boldsymbol \epsilon}^\top \widehat{\boldsymbol \epsilon}_Z & = (\mathbf Y^\dagger - \mathbf X^\dagger \boldsymbol{\omega} \mathbf Y^{\dagger\top} \mathbf X^\dagger \boldsymbol{\omega} )^\top (\mathbf Z^\dagger - \mathbf X^\dagger \boldsymbol{\omega} \mathbf Z^{\dagger\top} \mathbf X^\dagger \boldsymbol{\omega}) \\ & = \mathbf Y^{\dagger\top} \mathbf Z^\dagger - \widehat{\mathbf Y}^\top \boldsymbol{\omega} \widehat{\mathbf Z}^\top \boldsymbol{\omega} - \boldsymbol{\omega}^\top \widehat{\mathbf Y}^\top \boldsymbol{\omega}^\top \widehat{\mathbf Z}^\top + \boldsymbol{\omega}^\top \widehat{\mathbf Y} \boldsymbol{\omega}^\top \boldsymbol{\omega} \widehat{\mathbf Z}^\top \boldsymbol{\omega} \\ & = \mathbf Y^{\dagger\top} \mathbf Z^\dagger - \boldsymbol{\omega}^\top \widehat{\mathbf Y} \widehat{\mathbf Z}^\top \boldsymbol{\omega}\\ & = \boldsymbol{\omega}^\top \left(\mathbf Y^{\dagger\top} \mathbf Z^\dagger \cdot \mathbf{I}_K - \frac{\widehat{\mathbf Y} \widehat{\mathbf Z}^\top + \widehat{\mathbf Z} \widehat{\mathbf Y}^\top}{2}\right) \boldsymbol{\omega} \\ & := \boldsymbol{\omega}^\top \mathbf A \boldsymbol{\omega}, \end{align*} $$
$$ \begin{align*} \widehat{\boldsymbol \epsilon}^\top \widehat{\boldsymbol \epsilon}_Z & = (\mathbf Y^\dagger - \mathbf X^\dagger \boldsymbol{\omega} \mathbf Y^{\dagger\top} \mathbf X^\dagger \boldsymbol{\omega} )^\top (\mathbf Z^\dagger - \mathbf X^\dagger \boldsymbol{\omega} \mathbf Z^{\dagger\top} \mathbf X^\dagger \boldsymbol{\omega}) \\ & = \mathbf Y^{\dagger\top} \mathbf Z^\dagger - \widehat{\mathbf Y}^\top \boldsymbol{\omega} \widehat{\mathbf Z}^\top \boldsymbol{\omega} - \boldsymbol{\omega}^\top \widehat{\mathbf Y}^\top \boldsymbol{\omega}^\top \widehat{\mathbf Z}^\top + \boldsymbol{\omega}^\top \widehat{\mathbf Y} \boldsymbol{\omega}^\top \boldsymbol{\omega} \widehat{\mathbf Z}^\top \boldsymbol{\omega} \\ & = \mathbf Y^{\dagger\top} \mathbf Z^\dagger - \boldsymbol{\omega}^\top \widehat{\mathbf Y} \widehat{\mathbf Z}^\top \boldsymbol{\omega}\\ & = \boldsymbol{\omega}^\top \left(\mathbf Y^{\dagger\top} \mathbf Z^\dagger \cdot \mathbf{I}_K - \frac{\widehat{\mathbf Y} \widehat{\mathbf Z}^\top + \widehat{\mathbf Z} \widehat{\mathbf Y}^\top}{2}\right) \boldsymbol{\omega} \\ & := \boldsymbol{\omega}^\top \mathbf A \boldsymbol{\omega}, \end{align*} $$
where
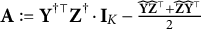 $\mathbf A:= \mathbf Y^{\dagger \top } \mathbf Z^\dagger \cdot \mathbf {I}_K - \frac {\widehat {\mathbf Y} \widehat {\mathbf Z}^\top + \widehat {\mathbf Z} \widehat {\mathbf Y}^\top }{2}$
. In the above calculation, notice that
$\mathbf A:= \mathbf Y^{\dagger \top } \mathbf Z^\dagger \cdot \mathbf {I}_K - \frac {\widehat {\mathbf Y} \widehat {\mathbf Z}^\top + \widehat {\mathbf Z} \widehat {\mathbf Y}^\top }{2}$
. In the above calculation, notice that
 $\boldsymbol {\omega }^\top \widehat {\mathbf Y}^\top $
and
$\boldsymbol {\omega }^\top \widehat {\mathbf Y}^\top $
and
 $\boldsymbol {\omega }^\top \widehat {\mathbf Z}^\top $
are numbers and therefore we could exchange order and take transpose when necessary. Consider the eigenvalue decomposition of
$\boldsymbol {\omega }^\top \widehat {\mathbf Z}^\top $
are numbers and therefore we could exchange order and take transpose when necessary. Consider the eigenvalue decomposition of
 $\mathbf A$
:
$\mathbf A$
:
 $\mathbf A = \mathbf Q \mathbf S \mathbf Q^\top $
, where
$\mathbf A = \mathbf Q \mathbf S \mathbf Q^\top $
, where
 $\mathbf Q = (\boldsymbol q_1, \dots , \boldsymbol q_{K})\in \mathbb {R}^{K\times K}$
,
$\mathbf Q = (\boldsymbol q_1, \dots , \boldsymbol q_{K})\in \mathbb {R}^{K\times K}$
,
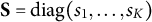 $\mathbf S=\text {diag} (s_1, \dots , s_K)$
, and
$\mathbf S=\text {diag} (s_1, \dots , s_K)$
, and
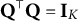 $\mathbf Q^\top \mathbf Q=\mathbf {I}_K$
. By the property of matrix
$\mathbf Q^\top \mathbf Q=\mathbf {I}_K$
. By the property of matrix
 $\mathbf A$
, there are closed-form expressions of its two eigen vectors and K eigenvalues. Specifically,
$\mathbf A$
, there are closed-form expressions of its two eigen vectors and K eigenvalues. Specifically,
 $$ \begin{align*} \boldsymbol q_1 = \frac{\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} + \|\widehat{\mathbf Z}\|\widehat{\mathbf Y}}{\left\|\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} + \|\widehat{\mathbf Z}\|\widehat{\mathbf Y} \right\|} & , \ \boldsymbol q_2= \frac{\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} - \|\widehat{\mathbf Z}\|\widehat{\mathbf Y}}{\left\| \|\widehat{\mathbf Y}\|\widehat{\mathbf Z} - \|\widehat{\mathbf Z}\|\widehat{\mathbf Y} \right\|}, \\ s_1 = \mathbf Y^{\dagger\top} \mathbf Z^\dagger - \frac{\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| + \widehat{\mathbf Y}^\top\widehat{\mathbf Z}}{2} & , \ s_2 = \mathbf Y^{\dagger\top} \mathbf Z^\dagger + \frac{\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| - \widehat{\mathbf Y}^\top\widehat{\mathbf Z}}{2}, \\ s_3=\dots & =s_K = \mathbf Y^{\dagger\top} \mathbf Z^\dagger. \end{align*} $$
$$ \begin{align*} \boldsymbol q_1 = \frac{\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} + \|\widehat{\mathbf Z}\|\widehat{\mathbf Y}}{\left\|\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} + \|\widehat{\mathbf Z}\|\widehat{\mathbf Y} \right\|} & , \ \boldsymbol q_2= \frac{\|\widehat{\mathbf Y}\|\widehat{\mathbf Z} - \|\widehat{\mathbf Z}\|\widehat{\mathbf Y}}{\left\| \|\widehat{\mathbf Y}\|\widehat{\mathbf Z} - \|\widehat{\mathbf Z}\|\widehat{\mathbf Y} \right\|}, \\ s_1 = \mathbf Y^{\dagger\top} \mathbf Z^\dagger - \frac{\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| + \widehat{\mathbf Y}^\top\widehat{\mathbf Z}}{2} & , \ s_2 = \mathbf Y^{\dagger\top} \mathbf Z^\dagger + \frac{\|\widehat{\mathbf Y}\|\|\widehat{\mathbf Z}\| - \widehat{\mathbf Y}^\top\widehat{\mathbf Z}}{2}, \\ s_3=\dots & =s_K = \mathbf Y^{\dagger\top} \mathbf Z^\dagger. \end{align*} $$
Under assumption (10), we have
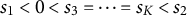 $s_1 < 0 <s_3=\dots =s_K<s_2$
. Let
$s_1 < 0 <s_3=\dots =s_K<s_2$
. Let
 $$ \begin{align*} \alpha = \sqrt{\frac{s_2}{s_2-s_1}}, \ \ \beta = \sqrt{\frac{-s_1}{s_2-s_1}} \end{align*} $$
$$ \begin{align*} \alpha = \sqrt{\frac{s_2}{s_2-s_1}}, \ \ \beta = \sqrt{\frac{-s_1}{s_2-s_1}} \end{align*} $$
and
 $$ \begin{align*}\widehat{\boldsymbol{\omega}} = \alpha\boldsymbol q_1 + \beta\boldsymbol q_2 \text{ or } \alpha\boldsymbol q_1 - \beta\boldsymbol q_2,\end{align*} $$
$$ \begin{align*}\widehat{\boldsymbol{\omega}} = \alpha\boldsymbol q_1 + \beta\boldsymbol q_2 \text{ or } \alpha\boldsymbol q_1 - \beta\boldsymbol q_2,\end{align*} $$
then we have
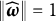 $\left \lVert \widehat {\boldsymbol {\omega }}\right \rVert =1$
and
$\left \lVert \widehat {\boldsymbol {\omega }}\right \rVert =1$
and
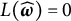 $L(\widehat {\boldsymbol {\omega }})=0$
.
$L(\widehat {\boldsymbol {\omega }})=0$
.
We notice that
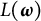 $L(\boldsymbol {\omega })$
has more than one zero. We choose
$L(\boldsymbol {\omega })$
has more than one zero. We choose
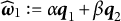 $\widehat {\boldsymbol {\omega }}_1 := \alpha \boldsymbol q_1 + \beta \boldsymbol q_2$
over
$\widehat {\boldsymbol {\omega }}_1 := \alpha \boldsymbol q_1 + \beta \boldsymbol q_2$
over
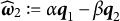 $\widehat {\boldsymbol {\omega }}_2 := \alpha \boldsymbol q_1 - \beta \boldsymbol q_2$
because of the following geometric interpretations. We further write the scaled versions of
$\widehat {\boldsymbol {\omega }}_2 := \alpha \boldsymbol q_1 - \beta \boldsymbol q_2$
because of the following geometric interpretations. We further write the scaled versions of
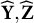 $\widehat {\mathbf Y}, \widehat {\mathbf Z}$
as
$\widehat {\mathbf Y}, \widehat {\mathbf Z}$
as
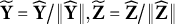 $\widetilde {\mathbf Y}=\widehat {\mathbf Y} / \|\widehat {\mathbf Y}\|, \widetilde {\mathbf Z}=\widehat {\mathbf Z} / \|\widehat {\mathbf Z}\|$
. Without loss of generality, we have assumed that
$\widetilde {\mathbf Y}=\widehat {\mathbf Y} / \|\widehat {\mathbf Y}\|, \widetilde {\mathbf Z}=\widehat {\mathbf Z} / \|\widehat {\mathbf Z}\|$
. Without loss of generality, we have assumed that
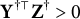 $\mathbf Y^{\dagger \top }\mathbf Z^\dagger>0$
. We consider the case where
$\mathbf Y^{\dagger \top }\mathbf Z^\dagger>0$
. We consider the case where
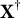 $\mathbf X^\dagger $
can almost perfectly predict
$\mathbf X^\dagger $
can almost perfectly predict
 $\mathbf Y^\dagger $
. Then,
$\mathbf Y^\dagger $
. Then,
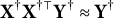 $\mathbf X^\dagger \mathbf X^{\dagger \top }\mathbf Y^\dagger \approx \mathbf Y^\dagger $
, which leads to
$\mathbf X^\dagger \mathbf X^{\dagger \top }\mathbf Y^\dagger \approx \mathbf Y^\dagger $
, which leads to
 $$ \begin{align} \widehat{\mathbf Y}^\top \widehat{\mathbf Z} = \mathbf Y^{\dagger\top} \mathbf X^\dagger \mathbf X^{\dagger\top} \mathbf Z^\dagger \approx \mathbf Y^{\dagger\top}\mathbf Z^\dagger>0. \end{align} $$
$$ \begin{align} \widehat{\mathbf Y}^\top \widehat{\mathbf Z} = \mathbf Y^{\dagger\top} \mathbf X^\dagger \mathbf X^{\dagger\top} \mathbf Z^\dagger \approx \mathbf Y^{\dagger\top}\mathbf Z^\dagger>0. \end{align} $$
Denote the angle between
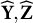 $\widehat {\mathbf Y}, \widehat {\mathbf Z}$
as
$\widehat {\mathbf Y}, \widehat {\mathbf Z}$
as
 $\Delta $
, which is also approximately the angle between
$\Delta $
, which is also approximately the angle between
 $\mathbf Y^\dagger , \mathbf Z^\dagger $
. By assumption,
$\mathbf Y^\dagger , \mathbf Z^\dagger $
. By assumption,
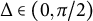 $\Delta \in (0, \pi /2)$
.
$\Delta \in (0, \pi /2)$
.
Rewrite
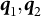 $\boldsymbol q_1, \boldsymbol q_2$
as
$\boldsymbol q_1, \boldsymbol q_2$
as
 $$ \begin{align*} \boldsymbol q_1 = \frac{\widetilde{\mathbf Y} + \widetilde{\mathbf Z}}{\left\lVert\widetilde{\mathbf Y} + \widetilde{\mathbf Z}\right\rVert}, \quad \boldsymbol q_2 = \frac{\widetilde{\mathbf Y} - \widetilde{\mathbf Z}}{\left\lVert\widetilde{\mathbf Y} - \widetilde{\mathbf Z}\right\rVert}. \end{align*} $$
$$ \begin{align*} \boldsymbol q_1 = \frac{\widetilde{\mathbf Y} + \widetilde{\mathbf Z}}{\left\lVert\widetilde{\mathbf Y} + \widetilde{\mathbf Z}\right\rVert}, \quad \boldsymbol q_2 = \frac{\widetilde{\mathbf Y} - \widetilde{\mathbf Z}}{\left\lVert\widetilde{\mathbf Y} - \widetilde{\mathbf Z}\right\rVert}. \end{align*} $$
By (A.3), we also notice that
 $$ \begin{align*} \frac{-s_1}{\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} \approx \frac{-\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} + \frac{1}{2} + \frac{-\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} = \frac{1-\cos(\Delta)}{2} = \sin^2\left(\frac{\Delta}{2}\right), \end{align*} $$
$$ \begin{align*} \frac{-s_1}{\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} \approx \frac{-\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} + \frac{1}{2} + \frac{-\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} = \frac{1-\cos(\Delta)}{2} = \sin^2\left(\frac{\Delta}{2}\right), \end{align*} $$
 $$ \begin{align*} \frac{s_2}{\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} \approx \frac{\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} + \frac{1}{2} - \frac{-\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} = \frac{1+\cos(\Delta)}{2} = \cos^2\left(\frac{\Delta}{2}\right). \end{align*} $$
$$ \begin{align*} \frac{s_2}{\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} \approx \frac{\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} + \frac{1}{2} - \frac{-\widehat{\mathbf Y}^\top \widehat{\mathbf Z}}{2\|\widehat{\mathbf Y}\| \|\widehat{\mathbf Z}\|} = \frac{1+\cos(\Delta)}{2} = \cos^2\left(\frac{\Delta}{2}\right). \end{align*} $$
Therefore,
 $$ \begin{align*} \widehat{\boldsymbol{\omega}}_1 = \alpha \boldsymbol q_1 + \beta \boldsymbol q_2 \propto \cos\left(\frac{\Delta}{2}\right) \boldsymbol q_1 + \sin\left(\frac{\Delta}{2}\right) \boldsymbol q_2, \\ \widehat{\boldsymbol{\omega}}_2 = \alpha \boldsymbol q_1 - \beta \boldsymbol q_2 \propto \cos\left(\frac{\Delta}{2}\right) \boldsymbol q_1 - \sin\left(\frac{\Delta}{2}\right) \boldsymbol q_2. \end{align*} $$
$$ \begin{align*} \widehat{\boldsymbol{\omega}}_1 = \alpha \boldsymbol q_1 + \beta \boldsymbol q_2 \propto \cos\left(\frac{\Delta}{2}\right) \boldsymbol q_1 + \sin\left(\frac{\Delta}{2}\right) \boldsymbol q_2, \\ \widehat{\boldsymbol{\omega}}_2 = \alpha \boldsymbol q_1 - \beta \boldsymbol q_2 \propto \cos\left(\frac{\Delta}{2}\right) \boldsymbol q_1 - \sin\left(\frac{\Delta}{2}\right) \boldsymbol q_2. \end{align*} $$
Therefore,
 $\widehat {\boldsymbol {\omega }}_1$
aligns with
$\widehat {\boldsymbol {\omega }}_1$
aligns with
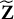 $\widetilde {\mathbf Z}$
and
$\widetilde {\mathbf Z}$
and
 $\widehat {\boldsymbol {\omega }}_2$
aligns with
$\widehat {\boldsymbol {\omega }}_2$
aligns with
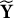 $\widetilde {\mathbf Y}$
(see Figure A1 for geometric interpretations). Furthermore,
$\widetilde {\mathbf Y}$
(see Figure A1 for geometric interpretations). Furthermore,
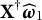 $\mathbf X^\dagger \widehat {\boldsymbol {\omega }}_1$
aligns with
$\mathbf X^\dagger \widehat {\boldsymbol {\omega }}_1$
aligns with
 $\mathbf X^\dagger \mathbf X^{\dagger \top }\mathbf Z^\dagger $
, which is the projection of
$\mathbf X^\dagger \mathbf X^{\dagger \top }\mathbf Z^\dagger $
, which is the projection of
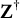 $\mathbf Z^\dagger $
onto the column space of
$\mathbf Z^\dagger $
onto the column space of
 $\mathbf X^\dagger $
. Similarly,
$\mathbf X^\dagger $
. Similarly,
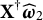 $\mathbf X^\dagger \widehat {\boldsymbol {\omega }}_2$
aligns with the prediction of
$\mathbf X^\dagger \widehat {\boldsymbol {\omega }}_2$
aligns with the prediction of
 $\mathbf Y^\dagger $
by
$\mathbf Y^\dagger $
by
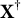 $\mathbf X^\dagger $
. We choose to select
$\mathbf X^\dagger $
. We choose to select
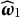 $\widehat {\boldsymbol {\omega }}_1$
as the goal is to reduce DIF instead of using the process features to predict the response.
$\widehat {\boldsymbol {\omega }}_1$
as the goal is to reduce DIF instead of using the process features to predict the response.
Geometric illustration for the proof of Proposition 1.

Appendix B: Additional tables and figures
B.1. Simulation with uniform DIF
Objective function value before and after adding the nuisance trait surrogate for the linear model with uniform DIF under different simulation settings.

Objective function value before and after adding the nuisance trait surrogate for the M2PL model with uniform DIF under different simulation settings.

Fisher information of
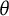 $\theta $
in the measurement model before and after adding the nuisance trait surrogate for the linear model with uniform DIF under different simulation settings.
$\theta $
in the measurement model before and after adding the nuisance trait surrogate for the linear model with uniform DIF under different simulation settings.

Fisher information of
 $\theta $
in the measurement model before and after adding the nuisance trait surrogate for the M2PL model with uniform DIF under different simulation settings.
$\theta $
in the measurement model before and after adding the nuisance trait surrogate for the M2PL model with uniform DIF under different simulation settings.

Between-group sum of squared bias for target trait estimation for the linear model with uniform DIF under different simulation settings. The x-axis corresponds to the estimation without DIF correction using the DIF items; the y-axis corresponds to the DIF-corrected estimation using the DIF items.

Between-group sum of squared bias for target trait estimation for the M2PL model with uniform DIF under different simulation settings. The x-axis corresponds to the estimation without DIF correction using the DIF items; the y-axis corresponds to the DIF-corrected estimation using the DIF items.

B.2. Simulation with non-uniform DIF
Mean squared error of item parameter estimates and nuisance trait correlation for the linear model with non-uniform DIF under different simulation settings

Note: The values are averaged across the DIF items and replications.
Mean squared error of item parameter estimates and nuisance trait correlation for the M2PL model with non-uniform DIF under different simulation settings

Note: The values are averaged across the DIF items and replications.
Objective function value before and after adding the nuisance trait surrogate for the linear model with non-uniform DIF under different simulation settings.

Objective function value before and after adding the nuisance trait surrogate for the M2PL model with non-uniform DIF under different simulation settings.

Fisher information of
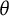 $\theta $
in the measurement model before and after adding the nuisance trait surrogate for the linear model with non-uniform DIF under different simulation settings.
$\theta $
in the measurement model before and after adding the nuisance trait surrogate for the linear model with non-uniform DIF under different simulation settings.

Fisher information of
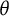 $\theta $
in the measurement model before and after adding the nuisance trait surrogate for the M2PL model with non-uniform DIF under different simulation settings.
$\theta $
in the measurement model before and after adding the nuisance trait surrogate for the M2PL model with non-uniform DIF under different simulation settings.

Between-group sum of squared bias for target trait estimation for the linear model with non-uniform DIF under different simulation settings. The x-axis corresponds to the estimation without DIF correction using the DIF items; the y-axis corresponds to the DIF-corrected estimation using the DIF items.

Between-group sum of squared bias for target trait estimation for the M2PL model with non-uniform DIF under different simulation settings. The x-axis corresponds to the estimation without DIF correction using the DIF items; the y-axis corresponds to the DIF-corrected estimation using the DIF items.

B.3. Case study
The mean and standard deviation of the polytomous responses by group for each item

Note:
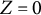 $Z=0$
corresponds to the reference group, and
$Z=0$
corresponds to the reference group, and
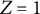 $Z=1$
corresponds to the focal group.
$Z=1$
corresponds to the focal group.
The mean and standard deviation of the binary responses by group for each item

Note:
 $Z=0$
corresponds to the reference group, and
$Z=0$
corresponds to the reference group, and
 $Z=1$
corresponds to the focal group. To convert the polytomous responses to binary responses, we treat the full score as correct (
$Z=1$
corresponds to the focal group. To convert the polytomous responses to binary responses, we treat the full score as correct (
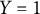 $Y=1$
), and other values as incorrect (
$Y=1$
), and other values as incorrect (
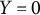 $Y=0$
).
$Y=0$
).
Comparing the objective function value with and without the nuisance trait surrogate for the linear (left) and the M2PL model (right) with two grouping variables.

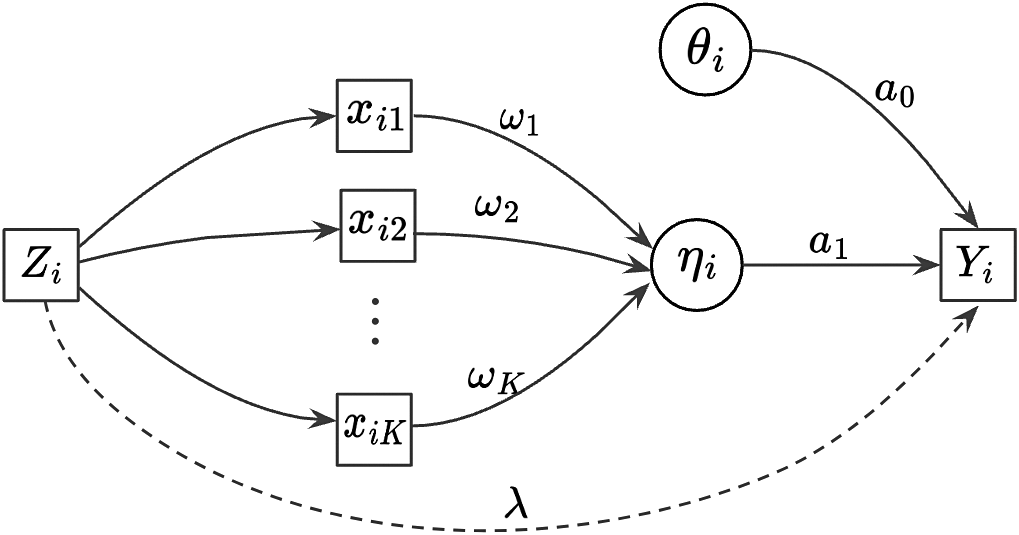


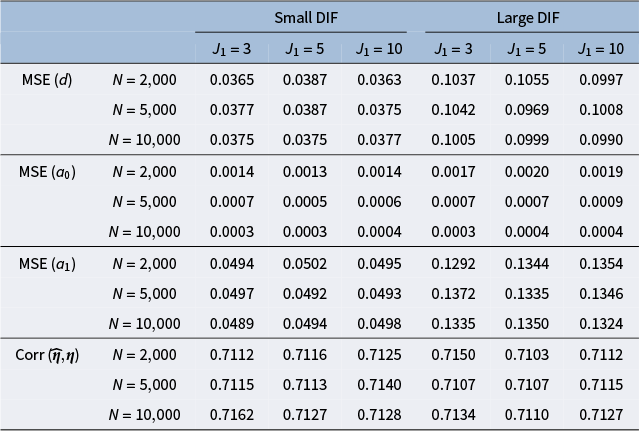
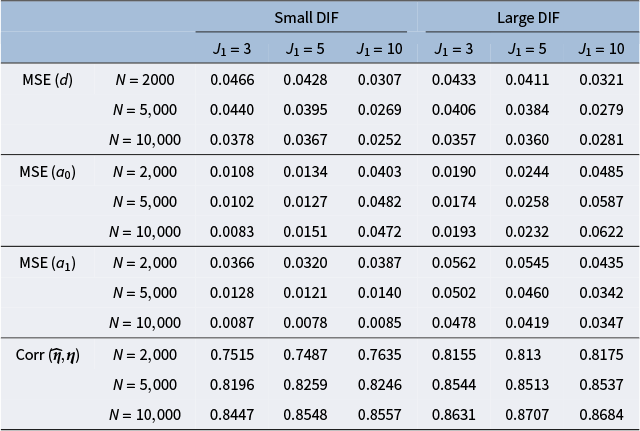


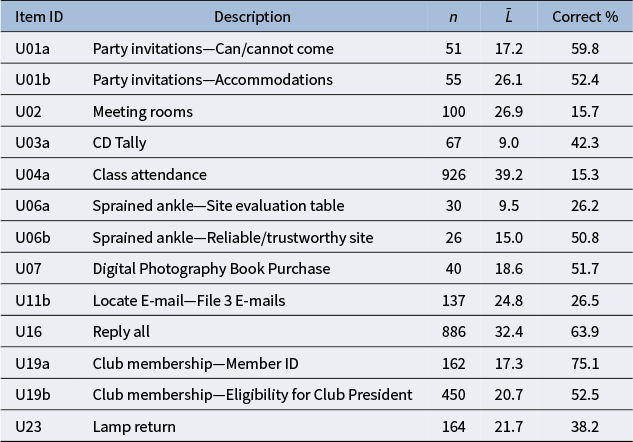

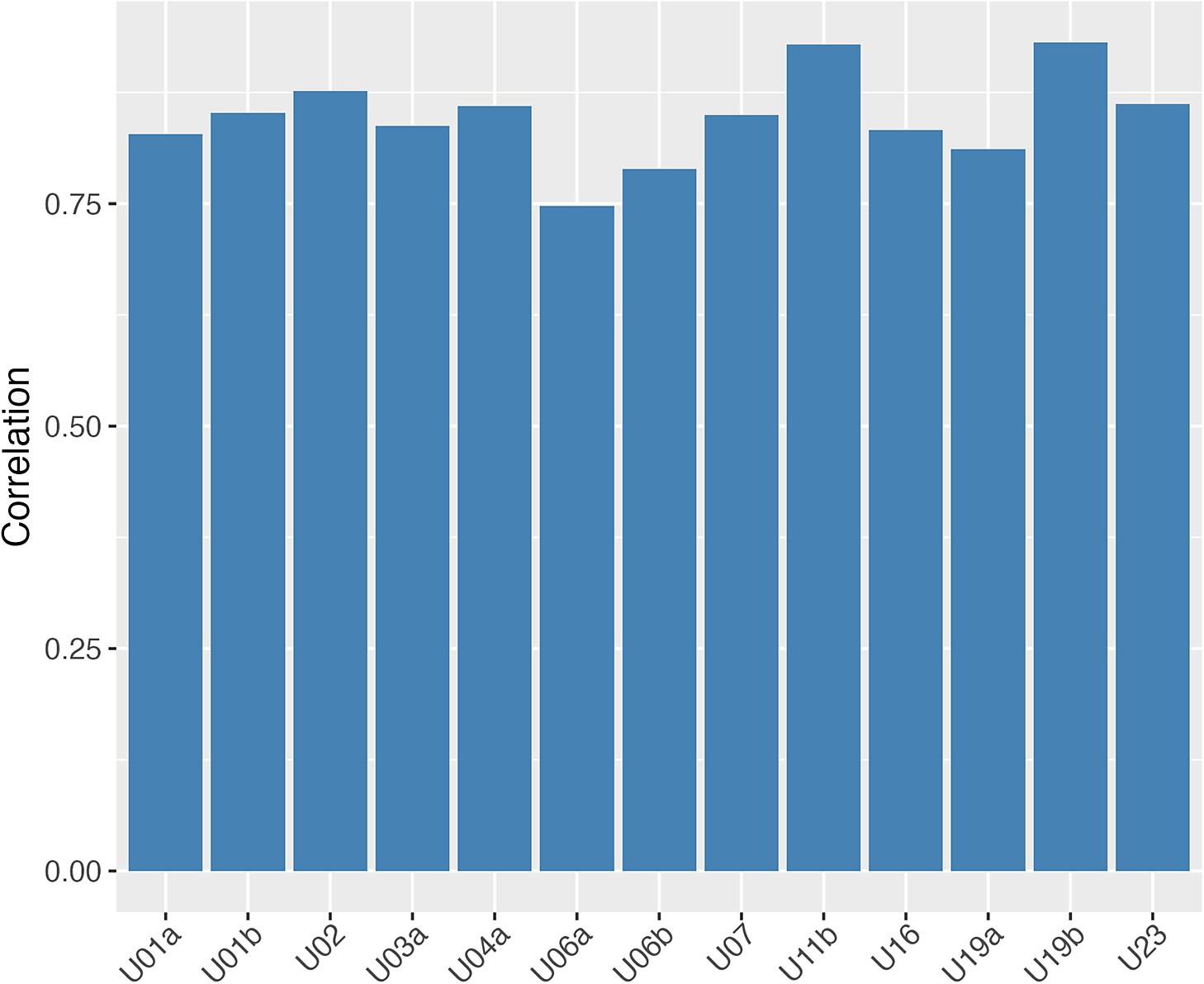
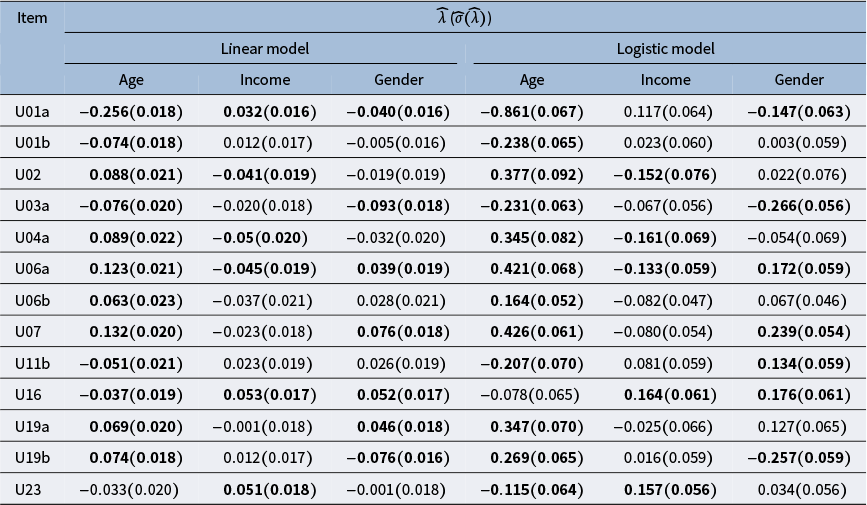
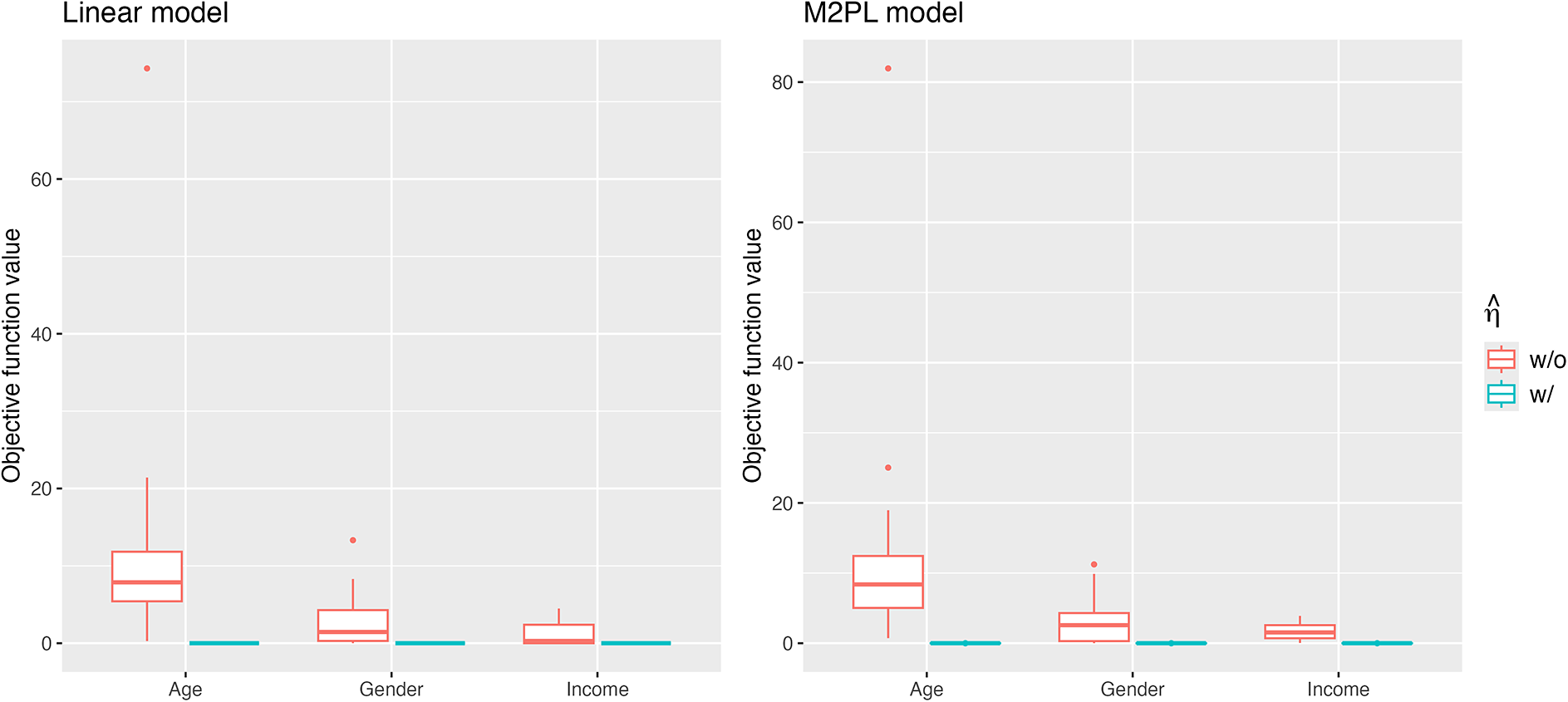
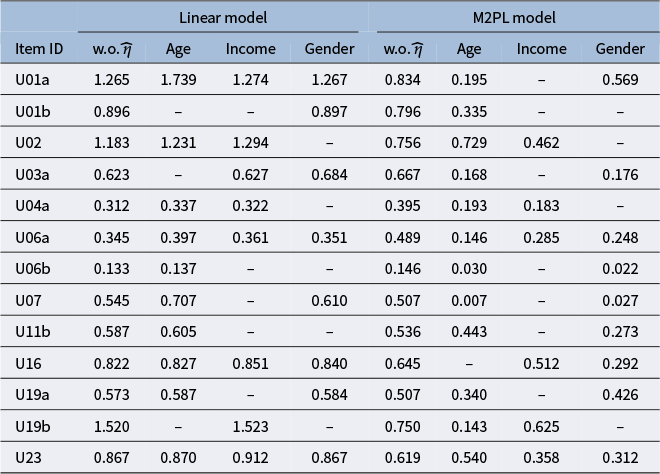

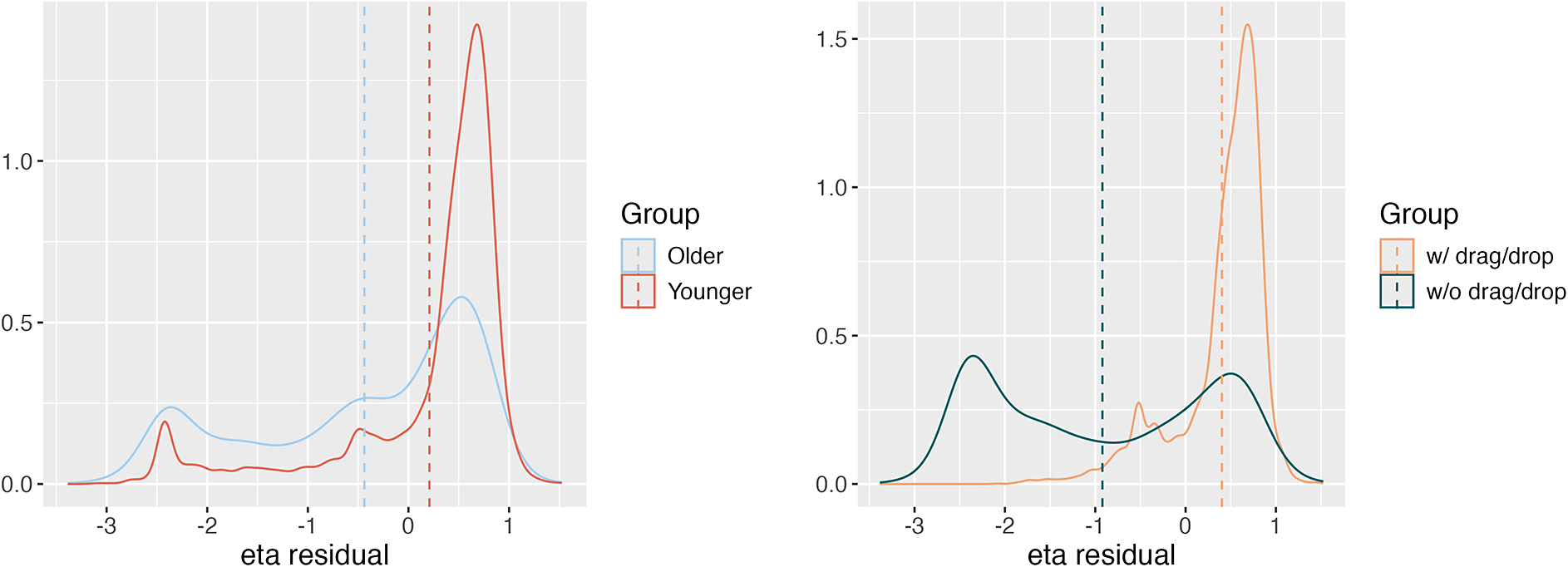


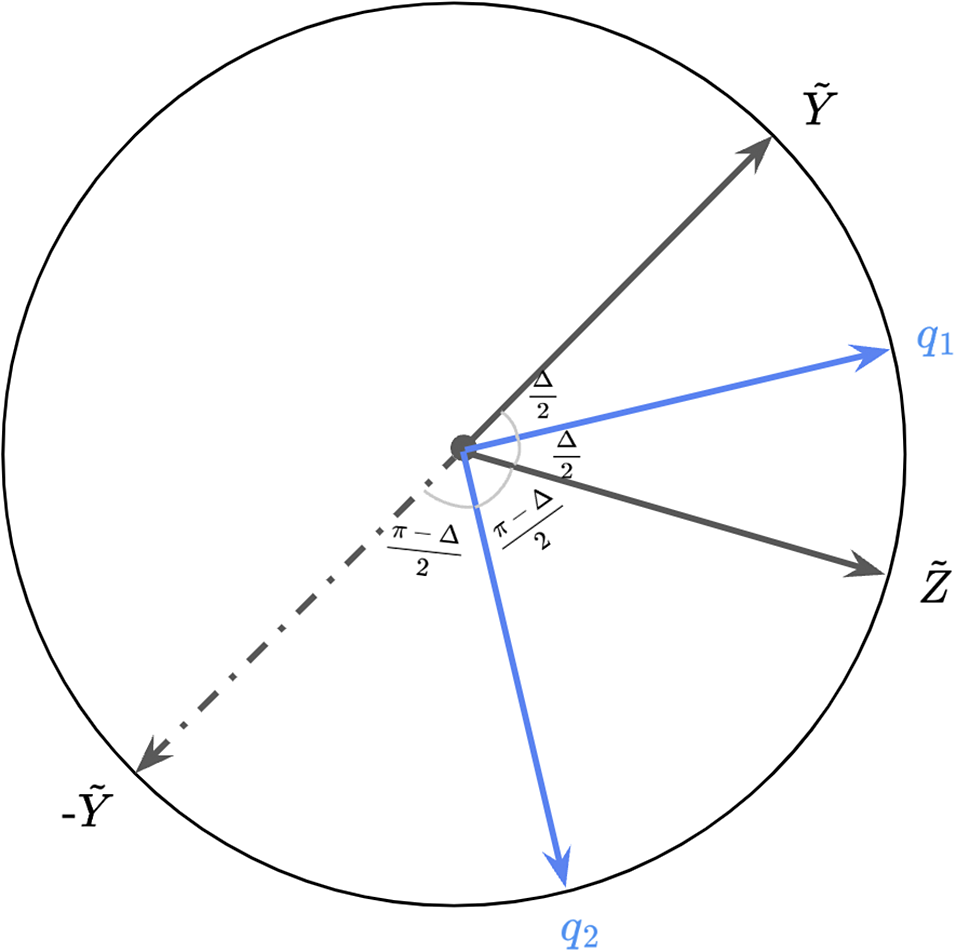








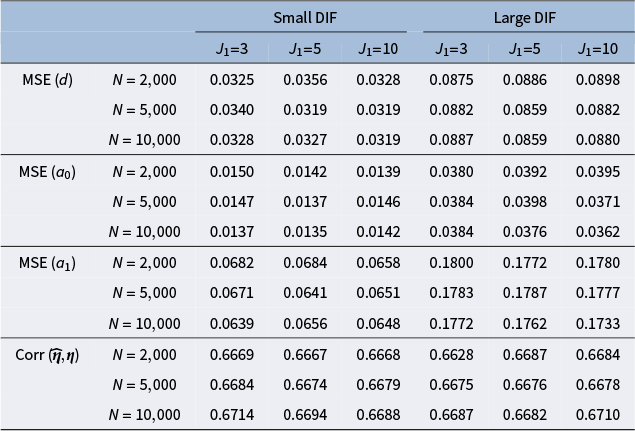
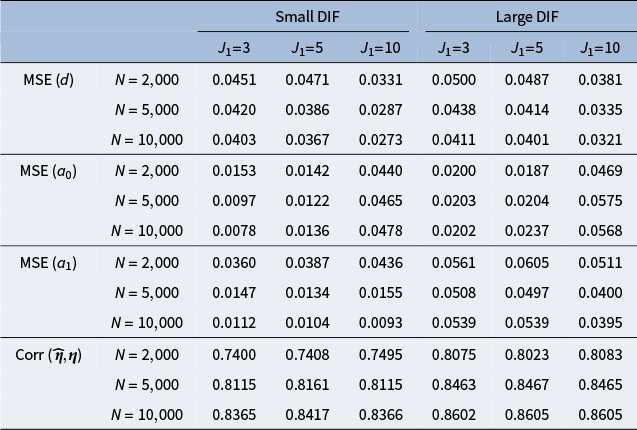








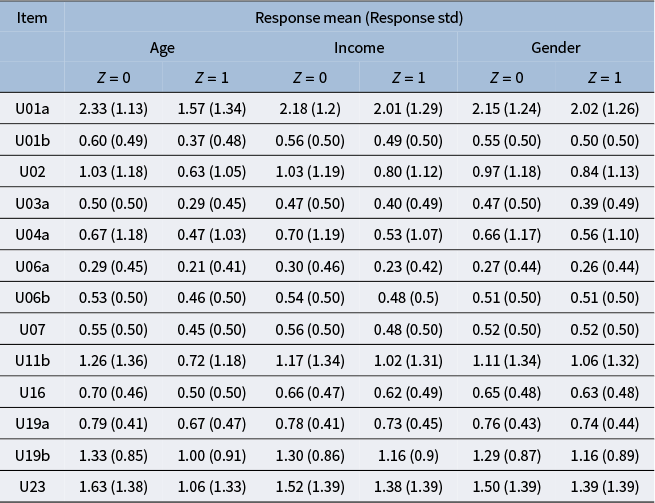
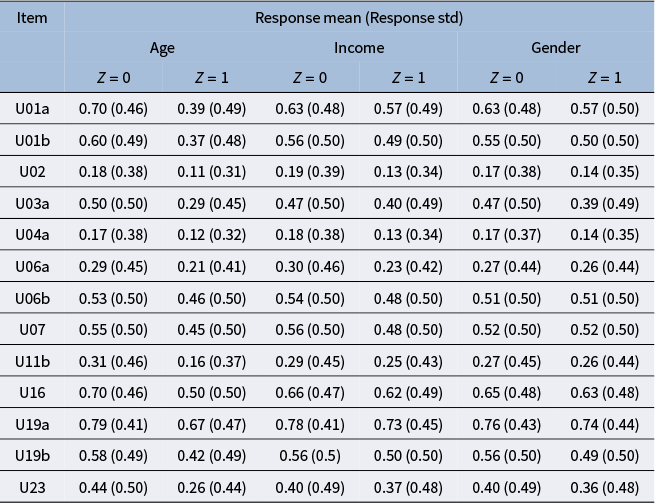
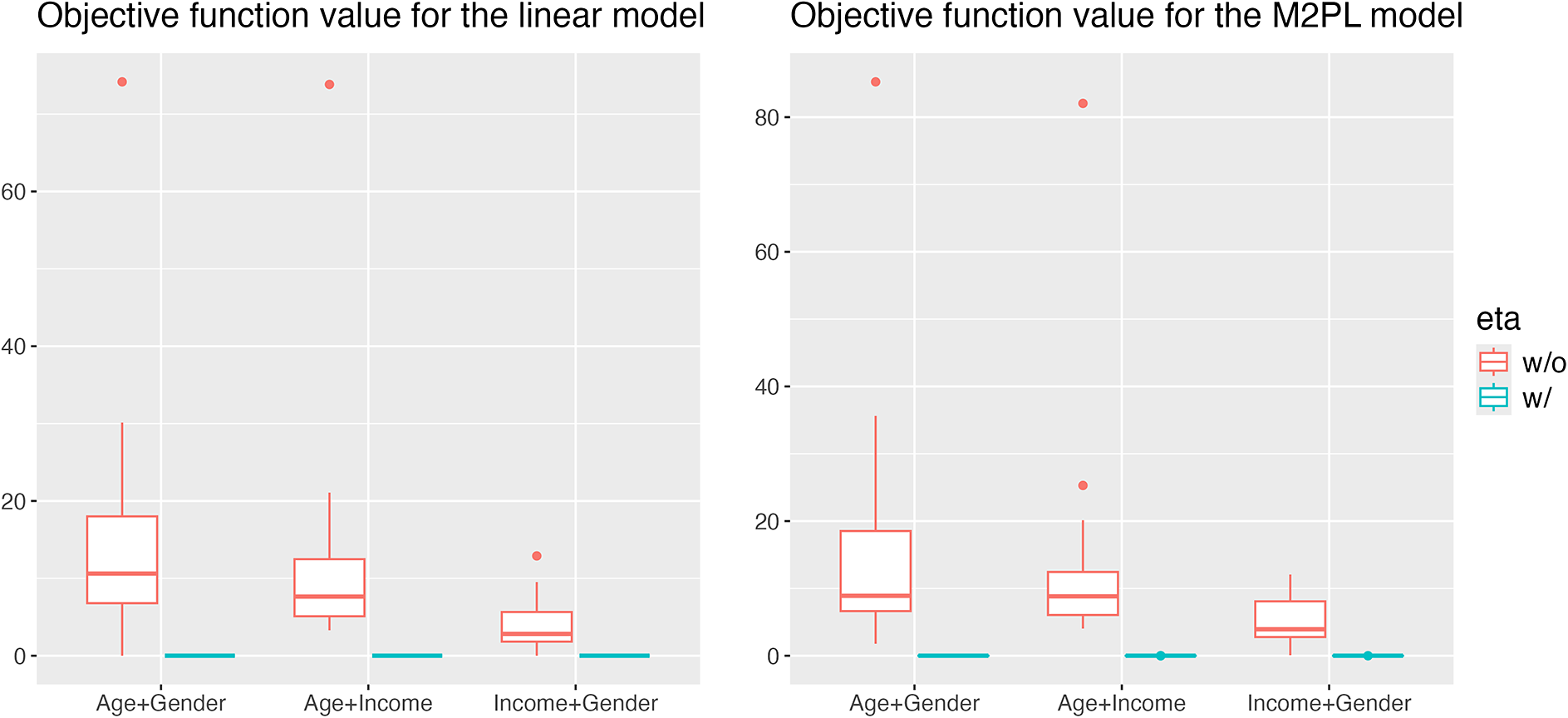

 Open access
Open access