


The latent space item response model (LSIRM) integrates latent space models from social network analysis (Hoff et al., Reference Hoff, Raftery and Handcock2002) with item response theory (IRT) from psychometrics, extending traditional IRT by embedding persons and items in a metric, multidimensional latent space. As such, LSIRMs may reveal item–person interactions that generally remain unnoticed in conventional models giving more insights about residual dependencies between persons, between items, and between items and persons. This has been shown valuable in the substantive fields of intelligence (Kang & Jeon, Reference Kang and Jeon2024; Kim et al., 2014), developmental psychology (Go et al., Reference Go, Jeon, Lee, Jin and Park2022), mental health (Jeon & Schweinberger, Reference Jeon and Schweinberger2024), social influence (Park et al., Reference Park, Jin and Jeon2023), national school policy (Jin et al., Reference Jin, Jeon, Schweinberger, Yun and Lin2022), and student monitoring (Jeon et al., Reference Jeon, Jin, Schweinberger and Baugh2021). In addition, extensions of the LSIRM have enabled the analysis of multilevel structured data (Jin et al., Reference Jin, Jeon, Schweinberger, Yun and Lin2022), longitudinal data (Jeon & Schweinberger, Reference Jeon and Schweinberger2024; Park et al., Reference Park, Jeon, Shin, Jeon and Jin2022), and response time data (Jin et al. Reference Jin, Yun, Kim and Jeon2023; Kang & Jeon, Reference Kang and Jeon2024).
Estimation of LSIRMs has been dominated by the fully Bayesian, Markov Chain Monte Carlo (MCMC) estimation scheme by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021), which has been implemented in R (Go et al., Reference Go, Kim and Park2023), JAGS, Stan, NIMBLE (Luo et al., Reference Luo, De Carolis, Zeng and Jeon2023), and Shiny (Ho & Jeon, Reference Ho and Jeon2023). Although valuable due to its flexibility and its facilities for posterior diagnostics, the MCMC routines are numerically demanding, which may hamper (applied) researchers from using the LSIRM in a wide range of settings that may involve large-scale data. In addition, due to the numerical demanding nature of the MCMC approach, model fit comparison is relatively challenging as it involves multiple models to be fit to the data. Although there are alternatives like leave-one-out cross-validation using Pareto smoothing (Vehtari et al., Reference Vehtari, Gelman and Gabry2017), these will still be computationally intensive for models like the LSIRM. Currently, researchers rely on spike and slab priors for model selection (e.g., George & McCulloch, Reference George and McCulloch1997; Ishwaran & Rao, Reference Ishwaran and Rao2005) to compare a given LSIRM with
 $R$
dimensions to a baseline model with
$R$
dimensions to a baseline model with
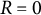 $R=0$
. This approach is feasible in the MCMC framework as it does not increase the computational burden significantly. However, tools to compare multiple competing models that differ in
$R=0$
. This approach is feasible in the MCMC framework as it does not increase the computational burden significantly. However, tools to compare multiple competing models that differ in
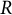 $R$
have not yet been developed.
$R$
have not yet been developed.
Therefore, in this study, we propose different joint maximum likelihood (JML)-based approaches to fit various LSIRMs to data in a fast and efficient way, facilitating large-scale model application and model selection. In the early years of IRT, JML (Birnbaum, Reference Birnbaum, Lord and Novick1968; Lord, Reference Lord1980; Mislevy & Stocking, Reference Mislevy and Stocking1989) was one of the dominant approaches to fit conventional IRT models to data using software packages such as LOGIST (Wingersky, Reference Wingersky and Hambleton1983) and BICAL (Wright & Mead, Reference Wright and Mead1976). As computers were not as fast as nowadays, a desirably practical property of JML was its numerical efficiency. That is, in JML, all parameters are assumed to be fixed effects so that the likelihood function does not include any integrals. These integrals make approaches such as MCMC and marginal maximum likelihood (MML; Bock & Aitkin, Reference Bock and Aitkin1981) relatively time-consuming, as they require numerical approximation due to the lack of a closed form solution. However, over the years, popularity of JML decreased in favor of MML up until recently, when JML was revived in IRT by the work of Chen et al. (Reference Chen, Li and Zhang2019, Reference Chen, Li and Zhang2020) and Bergner et al. (Reference Bergner, Halpin and Vie2022). In this work, the authors developed variations of JML that are suitable for estimation of high-dimensional IRT models on large datasets, which is—even with today’s computers—still challenging for the state-of-the art MCMC and MML approaches. In addition to IRT, some JML approaches have been developed for latent space models for social network analysis. That is, Zhang et al. (Reference Zhang, Xu and Zhu2022) and Ma et al. (Reference Ma, Ma and Yuan2020) focused on a latent space model with high-dimensional covariates and JML estimation of its parameters. In the approach by Zhang et al., the covariates enter the model via a generalized linear latent variable model, whereas in Ma et al., these covariates are included as predictors next to the latent space positions.
As the IRT models estimated by JML are typically high-dimensional, the complexity of these models is commonly managed through regularization. Regularization is a technique originating from ridge regression (Hoerl & Kennard, Reference Hoerl and Kennard1970) in which the regression parameters are pushed to zero to prevent overfitting and to stabilize parameter estimates in the case of multicollinearity. Currently, regularization includes a variety of techniques, such as penalization and constraints on the parameter space, to promote parameter shrinkage (Hastie et al., Reference Hastie, Tibshirani and Friedman2009; Tibshirani, Reference Tibshirani1996) or to improve finite-sample performance (Firth, Reference Firth1993). For example, Chen et al. (Reference Chen, Li and Zhang2019) used constraints on the parameter space to estimate a multidimensional exploratory IRT model, and Bergner et al. (Reference Bergner, Halpin and Vie2022) used
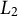 ${L}_2$
penalization of the parameter space of a general family of IRT models for collaborative filtering.
${L}_2$
penalization of the parameter space of a general family of IRT models for collaborative filtering.
In this study, we apply these two regularization strategies, constraining the parameter space and penalizing regions of the parameter space, to provide an efficient and stable JML estimation algorithm for the relatively complex LSIRM model. As the effects of regularization are comparable to the effects of parameter priors on the likelihood function, we will show that our JML-based LSIRM is a special cases of the existing MCMC-based LSIRM, providing a highly comparable but easier to estimate variant of the LSIRM. As MCMC obviously has other practical advantages over JML (e.g., flexibility and full posterior information), we present our JML approach as an extension of the current LSIRM modeling toolbox, not as an alternative.
The models by Zhang et al. (Reference Zhang, Xu and Zhu2022) and Ma et al. (Reference Ma, Ma and Yuan2020) discussed above are related but different from our approach. That is, both Zhang et al. and Ma et al. focused on a unipartite (only modeling one set of nodes, e.g., persons but not items) latent space model without IRT component, and an inner product distance measure. Our model, however, is bipartite, includes an IRT model component, and uses the Euclidean distance. All three of these aspects make our study to face very different challenges in the development of the JML approach. However, besides differences in the underlying model, our estimation approach and that of Zhang et al. and Ma et al. are similar in spirit.
One of the key issues that arises in implementing a maximum likelihood scheme for the LSIRM is that the model can only be identified up to a rotation of the latent space. In the MCMC framework by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021), researchers addressed this problem by post-processing the MCMC chains using Procrustes matching (Gower Reference Gower1975; Sibson, Reference Sibson1979), which involves rotating the latent space to the space from the MCMC iteration with the highest likelihood. Such an approach is infeasible in a maximum likelihood framework. We therefore propose alternative constraints based on the echelon structure from exploratory factor analysis (Dolan et al., Reference Dolan, Oort, Stoel and Wicherts2009; McDonald, Reference McDonald2013). As these constraints are specified a priori, this approach has the advantage that the orientation on which the results are produced is explicitly defined, which facilitates comparisons to other methods.
Thus, using JML, the LSIRM can be estimated in a computationally fast and efficient way, allowing researchers to fit different LSIRM models in a limited amount of time. A resulting advantage that we demonstrate in this study is that the selection of the dimensionality of the latent space can be informed by a
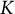 $K$
-fold cross-validation routine (e.g., Bergner et al., Reference Bergner, Halpin and Vie2022; Haslbeck & van Bork, Reference Haslbeck and van Bork2024). As discussed above, it is currently not possible to compare models differing in the dimensions of the latent space. This possibility, therefore, seems a valuable addition to the toolbox of researchers interesting in LSIRM modeling. In addition, we demonstrate how it is straightforward to use our approach to fit LSIRMs to ordinal data in a limited amount of time. Ordinal LSIRM have recently been development in an MCMC framework (see De Carolis et al., Reference De Carolis, Kang and Jeon2025) but are time-consuming to fit.
$K$
-fold cross-validation routine (e.g., Bergner et al., Reference Bergner, Halpin and Vie2022; Haslbeck & van Bork, Reference Haslbeck and van Bork2024). As discussed above, it is currently not possible to compare models differing in the dimensions of the latent space. This possibility, therefore, seems a valuable addition to the toolbox of researchers interesting in LSIRM modeling. In addition, we demonstrate how it is straightforward to use our approach to fit LSIRMs to ordinal data in a limited amount of time. Ordinal LSIRM have recently been development in an MCMC framework (see De Carolis et al., Reference De Carolis, Kang and Jeon2025) but are time-consuming to fit.
The outline of this article is as follows: We first present the LSIRM and discuss MCMC estimation of the model parameters. Next, we present the two JML variants and discuss the constraints needed to solve the rotational indeterminacy of the latent space. Then, we outline the methods for parameter estimation, a generalization to ordinal data, and a cross-validation approach to model selection. In the simulation study, we demonstrate that the accuracy of the parameter recovery of our JML approach is comparable to that of the MCMC approach and that the cross-validation approach successfully selects the correct model in most cases. Next, in two illustrations, we apply a binary LSIRM to a dataset on deductive reasoning and an ordinal LSIRM to a dataset on personality. We end with a general discussion.
1 Latent space item response models
The LSIRM is a statistical model for the dichotomous item responses
 ${X}_{pi}\in \left\{0,\dots C\right\}$
of person
${X}_{pi}\in \left\{0,\dots C\right\}$
of person
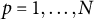 ${p=1,\dots, N}$
on item
${p=1,\dots, N}$
on item
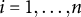 $i=1,\dots, n$
. It is assumed that, after accounting for the main effect of the person by person intercept
$i=1,\dots, n$
. It is assumed that, after accounting for the main effect of the person by person intercept
 ${\theta}_p$
, and for the main effect of the item by item intercept
${\theta}_p$
, and for the main effect of the item by item intercept
 ${\beta}_i$
, the person and item residuals can be embedded in an
${\beta}_i$
, the person and item residuals can be embedded in an
 $R$
-dimensional Euclidean latent space using the
$R$
-dimensional Euclidean latent space using the
 $R$
-dimensional vector of person coordinates
$R$
-dimensional vector of person coordinates
 ${\boldsymbol{z}}_p\in {\mathbb{R}}^R$
and the
${\boldsymbol{z}}_p\in {\mathbb{R}}^R$
and the
 $R$
-dimensional vector of item coordinates
$R$
-dimensional vector of item coordinates
 ${\boldsymbol{w}}_i\in {\mathbb{R}}^R$
. As a result, the conditional probability,
${\boldsymbol{w}}_i\in {\mathbb{R}}^R$
. As a result, the conditional probability,
 $P\left({X}_{pi}=c|{\theta}_p,{\beta}_i,{\boldsymbol{z}}_p,{\boldsymbol{w}}_i\right)$
, is given by
$P\left({X}_{pi}=c|{\theta}_p,{\beta}_i,{\boldsymbol{z}}_p,{\boldsymbol{w}}_i\right)$
, is given by
 $$\begin{align}P\left({X}_{pi}=1|{\theta}_p,{\beta}_i,\gamma, {\mathbf{z}}_p,{\mathbf{w}}_i\right)=\omega \left({\theta}_p+{\beta}_i-\gamma d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)\right),\end{align}$$
$$\begin{align}P\left({X}_{pi}=1|{\theta}_p,{\beta}_i,\gamma, {\mathbf{z}}_p,{\mathbf{w}}_i\right)=\omega \left({\theta}_p+{\beta}_i-\gamma d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)\right),\end{align}$$
where
 $\omega (.)$
is a logistic function,
$\omega (.)$
is a logistic function,
 $\gamma$
is the strictly positive weight parameter, and
$\gamma$
is the strictly positive weight parameter, and
 $d(.)$
is a distance function. Even though
$d(.)$
is a distance function. Even though
 $d(.)$
can be any distance function that obeys to the mathematical principles of reflexivity, symmetry, and triangular inequality (e.g., Chebyshev distance, Minkowski distance, and Manhattan distance), LSIRMs have generally been applied using the Euclidian distance, that is,
$d(.)$
can be any distance function that obeys to the mathematical principles of reflexivity, symmetry, and triangular inequality (e.g., Chebyshev distance, Minkowski distance, and Manhattan distance), LSIRMs have generally been applied using the Euclidian distance, that is,
 $$\begin{align}d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)={\left\Vert {\mathbf{z}}_p-{\mathbf{w}}_i\right\Vert}_2=\sqrt{\sum \limits_{r=1}^R{\left({z}_{pr}-{w}_{ir}\right)}^2},\end{align}$$
$$\begin{align}d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)={\left\Vert {\mathbf{z}}_p-{\mathbf{w}}_i\right\Vert}_2=\sqrt{\sum \limits_{r=1}^R{\left({z}_{pr}-{w}_{ir}\right)}^2},\end{align}$$
where
 ${z}_{pr}$
and
${z}_{pr}$
and
 ${w}_{ir}$
are the
${w}_{ir}$
are the
 $r$
th element of
$r$
th element of
 ${\mathbf{z}}_p$
and
${\mathbf{z}}_p$
and
 ${\mathbf{w}}_i$
, respectively. In the present framework,
${\mathbf{w}}_i$
, respectively. In the present framework,
 $d(.)$
is a distance function; however, it can be any other function that models the relation of the latent space coordinates. For instance, Zhang et al. (Reference Zhang, Xu and Zhu2022) and Ma et al. (Reference Ma, Ma and Yuan2020) used an inner product similarity measure for
$d(.)$
is a distance function; however, it can be any other function that models the relation of the latent space coordinates. For instance, Zhang et al. (Reference Zhang, Xu and Zhu2022) and Ma et al. (Reference Ma, Ma and Yuan2020) used an inner product similarity measure for
 $d(.)$
, which would give
$d(.)$
, which would give
 $d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)={\mathbf{z}}_p^T{\mathbf{w}}_i$
. The advantage of the inner product is that it is of low rank, resulting in tractable theoretical properties of the statistical model. However, the inner product cannot be interpreted as a distance that is undesirable for the present aim. See Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021) for a discussion of the interpretational challenges of the inner product measure in LSIRMs.
$d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)={\mathbf{z}}_p^T{\mathbf{w}}_i$
. The advantage of the inner product is that it is of low rank, resulting in tractable theoretical properties of the statistical model. However, the inner product cannot be interpreted as a distance that is undesirable for the present aim. See Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021) for a discussion of the interpretational challenges of the inner product measure in LSIRMs.
The LSIRM above can be interpreted as a Rasch model (Rasch, Reference Rasch1960) in which the residuals are further modeled using
 ${\mathbf{z}}_p$
and
${\mathbf{z}}_p$
and
 ${\mathbf{w}}_i$
. As a result, the LSIRM can give more insight in local dependencies of the item response data due to interactions between items, interactions between persons, or interactions between items and persons. For instance, such interactions may arise because of some items requiring a more similar response processes than others, some persons sharing a relevant background characteristic more than others (e.g., educational attainment and motivation), and some persons use a different solution strategy on some of the items than others.
${\mathbf{w}}_i$
. As a result, the LSIRM can give more insight in local dependencies of the item response data due to interactions between items, interactions between persons, or interactions between items and persons. For instance, such interactions may arise because of some items requiring a more similar response processes than others, some persons sharing a relevant background characteristic more than others (e.g., educational attainment and motivation), and some persons use a different solution strategy on some of the items than others.
1.1 Estimation
MCMC sampling methods have been developed to fit the LSIRM (see, e.g., Jeon et al., Reference Jeon, Jin, Schweinberger and Baugh2021). By specifying prior distributions for the model parameters presented above, it is possible to estimate an additional nonnegative parameter
 ${\sigma}_{\theta}^2$
, the variance of the person intercept. In addition,
${\sigma}_{\theta}^2$
, the variance of the person intercept. In addition,
 $\log \left(\gamma \right)=\gamma^{\prime }$
is modeled to ensure that
$\log \left(\gamma \right)=\gamma^{\prime }$
is modeled to ensure that
 $\gamma$
is strictly positive. Next, if we collect all
$\gamma$
is strictly positive. Next, if we collect all
 ${\theta}_p$
parameters in the
${\theta}_p$
parameters in the
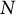 $N$
-dimensional vector
$N$
-dimensional vector
 $\boldsymbol{\unicode{x3b8}}$
and all
$\boldsymbol{\unicode{x3b8}}$
and all
 ${\beta}_i$
parameters in in the
${\beta}_i$
parameters in in the
 $n$
-dimensional vector
$n$
-dimensional vector
 $\boldsymbol{\unicode{x3b2}}$
, and if we denote the full
$\boldsymbol{\unicode{x3b2}}$
, and if we denote the full
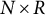 $N\times R$
matrix of stacked
$N\times R$
matrix of stacked
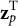 ${\mathbf{z}}_p^{\mathrm{T}}$
vectors by
${\mathbf{z}}_p^{\mathrm{T}}$
vectors by
 $\mathbf{Z}$
, and the full
$\mathbf{Z}$
, and the full
 $n\times R$
matrix of stacked
$n\times R$
matrix of stacked
 ${\mathbf{w}}_i^{\mathrm{T}}$
vectors by
${\mathbf{w}}_i^{\mathrm{T}}$
vectors by
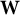 $\mathbf{W}$
, the posterior distribution of the model parameters is given by
$\mathbf{W}$
, the posterior distribution of the model parameters is given by
 $$\begin{align}\begin{aligned} f\left(\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z},\unicode{x3b3}^{\prime },{\sigma}_{theta}^2|\boldsymbol{X}\right)&\propto \left[\prod \limits_{p=1}^N\prod \limits_{i=1}^n{f}_X\left({X}_{pi}|\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z},\unicode{x3b3}^{\prime}\right)\right]\times \left[\prod \limits_{p=1}^N{f}_{\theta}\left({\theta}_p|{\sigma}_{\theta}^2\right){f}_z\left({\mathbf{z}}_p\right)\right]\\& \quad\times \left[\prod \limits_{i=1}^n{f}_w\left({\mathbf{w}}_i\right){f}_{\beta}\left({\beta}_i\right)\right]\times {f}_{\sigma^2}\left({\sigma}_{\theta}^2\right)\times {f}_{\gamma^{\prime }}\left(\gamma^{\prime}\right),\end{aligned}\end{align}$$
$$\begin{align}\begin{aligned} f\left(\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z},\unicode{x3b3}^{\prime },{\sigma}_{theta}^2|\boldsymbol{X}\right)&\propto \left[\prod \limits_{p=1}^N\prod \limits_{i=1}^n{f}_X\left({X}_{pi}|\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z},\unicode{x3b3}^{\prime}\right)\right]\times \left[\prod \limits_{p=1}^N{f}_{\theta}\left({\theta}_p|{\sigma}_{\theta}^2\right){f}_z\left({\mathbf{z}}_p\right)\right]\\& \quad\times \left[\prod \limits_{i=1}^n{f}_w\left({\mathbf{w}}_i\right){f}_{\beta}\left({\beta}_i\right)\right]\times {f}_{\sigma^2}\left({\sigma}_{\theta}^2\right)\times {f}_{\gamma^{\prime }}\left(\gamma^{\prime}\right),\end{aligned}\end{align}$$
where
 ${f}_X(.)$
is the Bernoulli distribution with success probability given by Equation (1), and where
${f}_X(.)$
is the Bernoulli distribution with success probability given by Equation (1), and where
 ${f}_{\theta }(.)$
,
${f}_{\theta }(.)$
,
 ${f}_z(.)$
,
${f}_z(.)$
,
 ${f}_w(.)$
,
${f}_w(.)$
,
 ${f}_{\beta }(.)$
,
${f}_{\beta }(.)$
,
 ${f}_{\sigma^2}(.)$
, and
${f}_{\sigma^2}(.)$
, and
 ${f}_{\gamma^{\prime }}(.)$
are (hyper) prior distributions for, respectively,
${f}_{\gamma^{\prime }}(.)$
are (hyper) prior distributions for, respectively,
 ${\theta}_p$
,
${\theta}_p$
,
 ${\mathbf{z}}_p$
,
${\mathbf{z}}_p$
,
 ${\mathbf{w}}_i$
,
${\mathbf{w}}_i$
,
 ${\beta}_i$
,
${\beta}_i$
,
 ${\sigma}_{\theta}^2$
, and
${\sigma}_{\theta}^2$
, and
 $\gamma^{\prime }$
. In general, the following distributions are used (e.g., Go et al., Reference Go, Kim and Park2023; Jeon et al., Reference Jeon, Jin, Schweinberger and Baugh2021): a univariate normal for
$\gamma^{\prime }$
. In general, the following distributions are used (e.g., Go et al., Reference Go, Kim and Park2023; Jeon et al., Reference Jeon, Jin, Schweinberger and Baugh2021): a univariate normal for
 ${\theta}_p$
with mean 0 and variance
${\theta}_p$
with mean 0 and variance
 ${\sigma}_{\theta}^2$
(as discussed above), a univariate normal for
${\sigma}_{\theta}^2$
(as discussed above), a univariate normal for
 ${\beta}_i$
with mean 0 and variance
${\beta}_i$
with mean 0 and variance
 ${\sigma}_{\beta}^2$
, a multivariate orthogonal standard normal distributions for
${\sigma}_{\beta}^2$
, a multivariate orthogonal standard normal distributions for
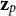 ${\mathbf{z}}_p$
and
${\mathbf{z}}_p$
and
 ${\mathbf{w}}_i$
, an inverse-gamma distribution for
${\mathbf{w}}_i$
, an inverse-gamma distribution for
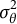 ${\sigma}_{\theta}^2$
with shape parameter
${\sigma}_{\theta}^2$
with shape parameter
 ${a}_{\sigma }$
and scale parameter
${a}_{\sigma }$
and scale parameter
 ${b}_{\sigma }$
, and a normal distribution for
${b}_{\sigma }$
, and a normal distribution for
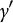 ${\gamma}^{\prime }$
with mean
${\gamma}^{\prime }$
with mean
 ${\mu}_{\gamma }$
and variance
${\mu}_{\gamma }$
and variance
 ${\sigma}_{\gamma}^2$
.
${\sigma}_{\gamma}^2$
.
1.2 Identification
The item and person intercept parameters
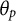 ${\theta}_p$
and
${\theta}_p$
and
 ${\beta}_i$
are readily identified by fixing the prior mean of
${\beta}_i$
are readily identified by fixing the prior mean of
 ${\theta}_p$
to 0 in the above. For
${\theta}_p$
to 0 in the above. For
 ${\mathbf{z}}_p$
and
${\mathbf{z}}_p$
and
 ${\mathbf{w}}_i$
, fixing the
${\mathbf{w}}_i$
, fixing the
 $R$
dimensions to be orthogonal with zero mean and unit variance ensures that the locations of the
$R$
dimensions to be orthogonal with zero mean and unit variance ensures that the locations of the
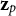 ${\mathbf{z}}_p$
and
${\mathbf{z}}_p$
and
 ${\mathbf{w}}_i$
coordinates are uniquely identified. However, there still exists a rotational indeterminacy. That is, any two of the
${\mathbf{w}}_i$
coordinates are uniquely identified. However, there still exists a rotational indeterminacy. That is, any two of the
 $R$
dimensions of
$R$
dimensions of
 ${\mathbf{z}}_{\boldsymbol{p}}$
and
${\mathbf{z}}_{\boldsymbol{p}}$
and
 ${\mathbf{w}}_i$
can be rotated by an arbitrary angle
${\mathbf{w}}_i$
can be rotated by an arbitrary angle
 $\alpha$
, resulting in a different solution with the same Euclidean distances
$\alpha$
, resulting in a different solution with the same Euclidean distances
 ${\left\Vert {\mathbf{z}}_p-{\mathbf{w}}_i\right\Vert}_2$
and the same data likelihood. In the MCMC framework to fit the LSIRM, this indeterminacy causes each sample from the posterior parameter distribution to be potentially subject to a different rotation. Posterior sample means are therefore confounded and cannot be used as parameter estimates. To solve this issue, researchers rely on Procrustes matching (Gower, Reference Gower1975; Sibson, Reference Sibson1979) in which each posterior sample of
${\left\Vert {\mathbf{z}}_p-{\mathbf{w}}_i\right\Vert}_2$
and the same data likelihood. In the MCMC framework to fit the LSIRM, this indeterminacy causes each sample from the posterior parameter distribution to be potentially subject to a different rotation. Posterior sample means are therefore confounded and cannot be used as parameter estimates. To solve this issue, researchers rely on Procrustes matching (Gower, Reference Gower1975; Sibson, Reference Sibson1979) in which each posterior sample of
 $\mathbf{Z}$
and
$\mathbf{Z}$
and
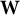 $\mathbf{W}$
is transformed to match a given target, respectively,
$\mathbf{W}$
is transformed to match a given target, respectively,
 ${\mathbf{T}}^{(z)}$
and
${\mathbf{T}}^{(z)}$
and
 ${\mathbf{T}}^{(w)}$
. In general, these target matrices are chosen to be the
${\mathbf{T}}^{(w)}$
. In general, these target matrices are chosen to be the
 ${\mathbf{z}}_p$
and
${\mathbf{z}}_p$
and
 ${\mathbf{w}}_i$
samples from the MCMC iteration with the largest likelihood (Jeon et al., Reference Jeon, Jin, Schweinberger and Baugh2021).
${\mathbf{w}}_i$
samples from the MCMC iteration with the largest likelihood (Jeon et al., Reference Jeon, Jin, Schweinberger and Baugh2021).
1.3 Model selection
For model selection, Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021) proposed the use of a spike and slab prior for
 $\gamma^{\prime }$
. Specifically, instead of a normal prior,
$\gamma^{\prime }$
. Specifically, instead of a normal prior,
 ${f}_{\gamma^{\prime }}(.)$
is specified as a mixture of two normal distributions
${f}_{\gamma^{\prime }}(.)$
is specified as a mixture of two normal distributions
 $$\begin{align*}{f}_{\gamma \prime }(.)=\left(1-\delta \right)\times {f}_{\gamma^{\prime}}^{(0)}\left({\gamma}^{\prime}\right)+\delta \times {f}_{\gamma^{\prime}}^{(1)}\left({\gamma}^{\prime}\right),\end{align*}$$
$$\begin{align*}{f}_{\gamma \prime }(.)=\left(1-\delta \right)\times {f}_{\gamma^{\prime}}^{(0)}\left({\gamma}^{\prime}\right)+\delta \times {f}_{\gamma^{\prime}}^{(1)}\left({\gamma}^{\prime}\right),\end{align*}$$
where
 $\delta \in \left\{0,1\right\}$
is a dichotomous parameter,
$\delta \in \left\{0,1\right\}$
is a dichotomous parameter,
 ${f}_{\gamma^{\prime}}^{(0)}(.)$
is the spike prior with mean
${f}_{\gamma^{\prime}}^{(0)}(.)$
is the spike prior with mean
 ${\mu}_0$
and variance
${\mu}_0$
and variance
 ${\sigma}_0^2$
, and
${\sigma}_0^2$
, and
 ${f}_{\gamma^{\prime}}^{(1)}(.)$
is the slab prior with mean
${f}_{\gamma^{\prime}}^{(1)}(.)$
is the slab prior with mean
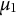 ${\mu}_1$
and variance
${\mu}_1$
and variance
 ${\sigma}_1^2$
. The spike prior mean and variance should be chosen so that the resulting distribution of untransformed
${\sigma}_1^2$
. The spike prior mean and variance should be chosen so that the resulting distribution of untransformed
 $\gamma$
has a mean close to
$\gamma$
has a mean close to
 $0$
and a small variance, while the slab prior mean and variance should reflect the more conventional prior mean and variance. Next, by assuming
$0$
and a small variance, while the slab prior mean and variance should reflect the more conventional prior mean and variance. Next, by assuming
 $\delta$
to be Bernoulli distributed with success parameter
$\delta$
to be Bernoulli distributed with success parameter
 ${\pi}_{\delta }$
, and by specifying a Beta prior for
${\pi}_{\delta }$
, and by specifying a Beta prior for
 ${\pi}_{\delta }$
, parameter
${\pi}_{\delta }$
, parameter
 $\delta$
can be sampled along with the other parameters in the model. Model selection then involves the posterior probability that
$\delta$
can be sampled along with the other parameters in the model. Model selection then involves the posterior probability that
 $\delta$
is equal to 1. If this probability is large (commonly a cutoff of
$\delta$
is equal to 1. If this probability is large (commonly a cutoff of
 $0.5$
is used), it is concluded that the LSIRM with the
$0.5$
is used), it is concluded that the LSIRM with the
 $R$
under consideration accounts better for the data than an IRT model without latent space (i.e., a one-parameter logistic model).
$R$
under consideration accounts better for the data than an IRT model without latent space (i.e., a one-parameter logistic model).
2 Joint maximum likelihood estimation
As discussed, the MCMC estimation scheme above can be time-consuming as sufficient samples need to be drawn from the posterior parameter distribution. To have a fast alternative available, below we present a JML estimation approach to estimate the parameters from the LSIRM. Implementing the LSIRM in a maximum likelihood framework brings specific identification challenges, which we address below. In addition, we discuss a model selection procedure based on
 $K$
-fold cross-validation that is impractical or infeasible for the more time-consuming estimation algorithms, and we present a generalization to ordinal data.
$K$
-fold cross-validation that is impractical or infeasible for the more time-consuming estimation algorithms, and we present a generalization to ordinal data.
In maximum likelihood estimation, the parameters of a statistical model are estimated by maximizing the likelihood of the data for the unknown model parameters. For LSIRM, this would involve the joint log-likelihood function,
 $\log \left({f}_X\left({X}_{pi}|\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z},{\boldsymbol{\unicode{x3b3}}}^{\prime}\right)\right)$
with
$\log \left({f}_X\left({X}_{pi}|\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z},{\boldsymbol{\unicode{x3b3}}}^{\prime}\right)\right)$
with
 ${f}_X(.)$
from Equation (3), summed over items and persons. However, without further constraints, this model is unidentified. First of all, in a JML framework, all parameters are fixed effects so that
${f}_X(.)$
from Equation (3), summed over items and persons. However, without further constraints, this model is unidentified. First of all, in a JML framework, all parameters are fixed effects so that
 ${\sigma}_{\theta}^2$
is not a model parameter as it is absorbed in the
${\sigma}_{\theta}^2$
is not a model parameter as it is absorbed in the
 ${\theta}_p$
estimates. For the same reason,
${\theta}_p$
estimates. For the same reason,
 $\gamma$
is not estimable as it is equivalent to the standard deviation of
$\gamma$
is not estimable as it is equivalent to the standard deviation of
 ${z}_{pk}$
and
${z}_{pk}$
and
 ${w}_{ik}$
. Thus,
${w}_{ik}$
. Thus,
 $\gamma$
is absorbed in the
$\gamma$
is absorbed in the
 ${z}_{pk}$
and
${z}_{pk}$
and
 ${w}_{ik}$
estimates. Therefore, the JML-based LSIRM is given by
${w}_{ik}$
estimates. Therefore, the JML-based LSIRM is given by
 $$\begin{align}P\left({X}_{pi}=1|{\theta}_p,{\beta}_i,{\mathbf{z}}_p,{\mathbf{w}}_i\right)=\omega \left({\theta}_p+{\beta}_i-d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)\right),\end{align}$$
$$\begin{align}P\left({X}_{pi}=1|{\theta}_p,{\beta}_i,{\mathbf{z}}_p,{\mathbf{w}}_i\right)=\omega \left({\theta}_p+{\beta}_i-d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)\right),\end{align}$$
where
 $d(.)$
is the Euclidean distance from Equation (2).
$d(.)$
is the Euclidean distance from Equation (2).
As discussed above, to introduce further sparsity into the model, we consider two different regularization approaches based on either penalizing the joint likelihood or on constraining the maximum norm of the parameter vectors in the joint likelihood. As both regularization effects can be conceived as the effects of prior distributions, we intend to enhance the comparability of the JML results and the MCMC results. Both JML variants are discussed below.
2.1 Penalized joint maximum likelihood
In the first approach referred to as penalized joint maximum likelihood (pJML), we use an
 ${L}_2$
regularization penalty in the likelihood function. Although there are other options possible, we use the
${L}_2$
regularization penalty in the likelihood function. Although there are other options possible, we use the
 ${L}_2$
due to its correspondence to a normal prior. The log-likelihood function we consider is
${L}_2$
due to its correspondence to a normal prior. The log-likelihood function we consider is
 $$\begin{align}\begin{array}{c}\ell \left(\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z},|\mathbf{X}\right)=\sum \limits_{p=1}^N\sum \limits_{i=1}^n\log \left({f}_X\left({X}_{pi}|\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z}\right)\right)-\\ {}\frac{1}{2}\lambda \left(\sum \limits_{p=1}^N{\theta}_p^2+\sum \limits_{i=1}^n{\beta}_i^2+\sum \limits_{i=1}^n\sum \limits_{k=1}^K{w}_{ik}^2+\sum \limits_{p=1}^N\sum \limits_{k=1}^K{z}_{pk}^2\right),\end{array}\end{align}$$
$$\begin{align}\begin{array}{c}\ell \left(\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z},|\mathbf{X}\right)=\sum \limits_{p=1}^N\sum \limits_{i=1}^n\log \left({f}_X\left({X}_{pi}|\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{W},\mathbf{Z}\right)\right)-\\ {}\frac{1}{2}\lambda \left(\sum \limits_{p=1}^N{\theta}_p^2+\sum \limits_{i=1}^n{\beta}_i^2+\sum \limits_{i=1}^n\sum \limits_{k=1}^K{w}_{ik}^2+\sum \limits_{p=1}^N\sum \limits_{k=1}^K{z}_{pk}^2\right),\end{array}\end{align}$$
where
 $\lambda$
is a penalty parameter and
$\lambda$
is a penalty parameter and
 ${f}_X(.)$
is a Bernoulli distribution with success probability given by Equation (4). Although, in the context of predictive accuracy,
${f}_X(.)$
is a Bernoulli distribution with success probability given by Equation (4). Although, in the context of predictive accuracy,
 $\lambda$
can be optimized using cross-validation, here we take
$\lambda$
can be optimized using cross-validation, here we take
 $\lambda$
to be a prespecified parameter reflecting the precision of a zero-centered normal prior distribution. In the remainder of this article, we use
$\lambda$
to be a prespecified parameter reflecting the precision of a zero-centered normal prior distribution. In the remainder of this article, we use
 $\lambda =1$
so that the regularization effect on
$\lambda =1$
so that the regularization effect on
 ${\theta}_p,$
${\theta}_p,$
 ${\beta}_i$
,
${\beta}_i$
,
 ${\mathbf{z}}_p,$
and
${\mathbf{z}}_p,$
and
 ${\mathbf{w}}_i$
is comparable to that of standard normal priors typically used in MCMC estimation of the LSIRM. For instance, in the R package lsirm12pl (Go et al., Reference Go, Kim and Park2023), which we use to compare our results to in the simulation study below, standard normal priors are used by default for
${\mathbf{w}}_i$
is comparable to that of standard normal priors typically used in MCMC estimation of the LSIRM. For instance, in the R package lsirm12pl (Go et al., Reference Go, Kim and Park2023), which we use to compare our results to in the simulation study below, standard normal priors are used by default for
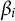 ${\beta}_i$
,
${\beta}_i$
,
 ${\mathbf{z}}_p,$
and
${\mathbf{z}}_p,$
and
 ${\mathbf{w}}_i$
(
${\mathbf{w}}_i$
(
 ${\theta}_p$
has a normal prior with variance
${\theta}_p$
has a normal prior with variance
 ${\sigma}_{\theta}^2$
as discussed above).
${\sigma}_{\theta}^2$
as discussed above).
The resulting approach can be seen as a variant of the Bayesian joint modal estimation approach used by Swaminathan and Gifford (Reference Swaminathan and Gifford1982, Reference Swaminathan and Gifford1985, Reference Swaminathan and Gifford1986) to fit one-, two-, and three-parameter logistic IRT models in a Bayesian framework. That is, Equation (5) is proportional to the log-posterior distribution of the parameters by which its maximum gives joint modal estimates of the parameters (i.e., MAP estimates). Moreover, the pJML approach in Equation (5) is a special case of the MCMC-based LSIRM in Equation (3). That is, fixing
 $\gamma^{\prime }=0$
,
$\gamma^{\prime }=0$
,
 ${\sigma}_{\theta}^2=1, and\;{\sigma}_{\beta}^2=1$
in the logarithm of Equation (3), the MCMC-based LSIRM is equivalent to the pJML model in Equation (5) with
${\sigma}_{\theta}^2=1, and\;{\sigma}_{\beta}^2=1$
in the logarithm of Equation (3), the MCMC-based LSIRM is equivalent to the pJML model in Equation (5) with
 $\lambda =1$
. The key difference that arises in practice is that MCMC focusses on posterior means instead of posterior modes by which the pJML model can be estimated much faster.
$\lambda =1$
. The key difference that arises in practice is that MCMC focusses on posterior means instead of posterior modes by which the pJML model can be estimated much faster.
2.2 Constrained joint maximum likelihood
A next option referred to as constrained joint maximum likelihood (cJML) is to regularize the LSIRM model in Equation (4) by constraining the maximum norm of the person and item parameter vectors to some prespecified value. This approach has been proposed by Chen et al. (Reference Chen, Li and Zhang2019) for JML estimation of the multidimensional two-parameter logistic IRT model. Thus, we constrain the vector of person parameters
 ${{\boldsymbol{\unicode{x3c4}}}_{\mathbf{1}}}_p=\left[{\theta}_p,{\mathbf{z}}_p\right]$
and the vector of item parameters
${{\boldsymbol{\unicode{x3c4}}}_{\mathbf{1}}}_p=\left[{\theta}_p,{\mathbf{z}}_p\right]$
and the vector of item parameters
 ${{\boldsymbol{\unicode{x3c4}}}_{\mathbf{2}}}_i=\left[{\beta}_p,{\mathbf{w}}_p\right]$
in the following way:
${{\boldsymbol{\unicode{x3c4}}}_{\mathbf{2}}}_i=\left[{\beta}_p,{\mathbf{w}}_p\right]$
in the following way:
 $$\begin{align}{\left\Vert {{\boldsymbol{\unicode{x3c4}}}_{\mathbf{1}}}_p\right\Vert}_2\le {C}_1\;\mathrm{and}\;{\left\Vert {{\boldsymbol{\unicode{x3c4}}}_{\mathbf{2}}}_i\right\Vert}_2\le {C}_2,\end{align}$$
$$\begin{align}{\left\Vert {{\boldsymbol{\unicode{x3c4}}}_{\mathbf{1}}}_p\right\Vert}_2\le {C}_1\;\mathrm{and}\;{\left\Vert {{\boldsymbol{\unicode{x3c4}}}_{\mathbf{2}}}_i\right\Vert}_2\le {C}_2,\end{align}$$
where
 ${C}_1$
and
${C}_1$
and
 ${C}_2$
are the prespecified maximum parameter norms for the person and item parameter vectors, respectively, and
${C}_2$
are the prespecified maximum parameter norms for the person and item parameter vectors, respectively, and
 ${\left\Vert .\right\Vert}_2$
is the Euclidean norm. Thus, if
${\left\Vert .\right\Vert}_2$
is the Euclidean norm. Thus, if
 ${\mathbf{T}}_1$
denotes a matrix of stacked
${\mathbf{T}}_1$
denotes a matrix of stacked
 ${\boldsymbol{\tau}}_{1p}$
vectors and
${\boldsymbol{\tau}}_{1p}$
vectors and
 ${\mathbf{T}}_2$
denotes a matrix of stacked
${\mathbf{T}}_2$
denotes a matrix of stacked
 ${\boldsymbol{\tau}}_{2i}$
vectors, the likelihood function in this approach is given by
${\boldsymbol{\tau}}_{2i}$
vectors, the likelihood function in this approach is given by
 $$\begin{align}\ell \left({\mathbf{T}}_1,{\mathbf{T}}_2|\mathbf{X}\right)=\sum \limits_{p=1}^N\sum \limits_{i=1}^n\log \left({f}_X\left({X}_{pi}|{\boldsymbol{\unicode{x3c4}}}_{1\mathrm{p}},{\boldsymbol{\unicode{x3c4}}}_{2\mathrm{i}}\right)\right)\mathrm{with}\ {\boldsymbol{\unicode{x3c4}}}_{1\mathrm{p}},{\boldsymbol{\unicode{x3c4}}}_{2\mathrm{i}}\;\mathrm{s}.\mathrm{t}.\kern0.36em \mathrm{Equation}\;({6}).\end{align}$$
$$\begin{align}\ell \left({\mathbf{T}}_1,{\mathbf{T}}_2|\mathbf{X}\right)=\sum \limits_{p=1}^N\sum \limits_{i=1}^n\log \left({f}_X\left({X}_{pi}|{\boldsymbol{\unicode{x3c4}}}_{1\mathrm{p}},{\boldsymbol{\unicode{x3c4}}}_{2\mathrm{i}}\right)\right)\mathrm{with}\ {\boldsymbol{\unicode{x3c4}}}_{1\mathrm{p}},{\boldsymbol{\unicode{x3c4}}}_{2\mathrm{i}}\;\mathrm{s}.\mathrm{t}.\kern0.36em \mathrm{Equation}\;({6}).\end{align}$$
For a
 $D$
-dimensional two-parameter logistic IRT model, Chen et al. (Reference Chen, Li and Zhang2019) proposed
$D$
-dimensional two-parameter logistic IRT model, Chen et al. (Reference Chen, Li and Zhang2019) proposed
 ${C}_1={C}_2=5\sqrt{D}$
. As both
${C}_1={C}_2=5\sqrt{D}$
. As both
 ${\boldsymbol{\tau}}_{1p}$
and
${\boldsymbol{\tau}}_{1p}$
and
 ${\boldsymbol{\tau}}_{2i}$
have
${\boldsymbol{\tau}}_{2i}$
have
 $R+1$
dimensions in our LSIRM model, we replace
$R+1$
dimensions in our LSIRM model, we replace
 $D$
by
$D$
by
 $R+1$
. In addition, we use
$R+1$
. In addition, we use
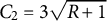 ${C}_2=3\sqrt{R+1}$
for the item parameters and
${C}_2=3\sqrt{R+1}$
for the item parameters and
 ${C}_1=\frac{1}{2}{C}_2$
for the person parameters. Below, we show that these constraints are still less restrictive compared with the MCMC and pJML approaches.
${C}_1=\frac{1}{2}{C}_2$
for the person parameters. Below, we show that these constraints are still less restrictive compared with the MCMC and pJML approaches.
The cJML model in Equation (7) can similarly be conceived as a joint modal estimation approach. To this end, the constraints in Equation (6) are enforced by using priors
 ${f}_{{\boldsymbol{\tau}}_1}(.)$
and
${f}_{{\boldsymbol{\tau}}_1}(.)$
and
 ${f}_{{\boldsymbol{\tau}}_2}(.)$
on
${f}_{{\boldsymbol{\tau}}_2}(.)$
on
 ${\boldsymbol{\tau}}_{1p}$
and
${\boldsymbol{\tau}}_{1p}$
and
 ${\boldsymbol{\tau}}_{2i}$
, respectively. These priors are uniform on an (
${\boldsymbol{\tau}}_{2i}$
, respectively. These priors are uniform on an (
 $R+1$
)-dimensional Euclidean ball with radius
$R+1$
)-dimensional Euclidean ball with radius
 ${C}_1$
for the person parameters and
${C}_1$
for the person parameters and
 ${C}_2$
for the item parameters, that is,
${C}_2$
for the item parameters, that is,
 $$\begin{align}{f}_{{\boldsymbol{\tau}}_1}\left({\boldsymbol{\tau}}_{1p}\right)\propto I\left({\left\Vert \left|{\boldsymbol{\tau}}_{1p}\right|\right\Vert}_2<{C}_1\right)\end{align}$$
$$\begin{align}{f}_{{\boldsymbol{\tau}}_1}\left({\boldsymbol{\tau}}_{1p}\right)\propto I\left({\left\Vert \left|{\boldsymbol{\tau}}_{1p}\right|\right\Vert}_2<{C}_1\right)\end{align}$$
and
 $$\begin{align}{f}_{{\boldsymbol{\tau}}_2}\left({\boldsymbol{\tau}}_{2i}\right)\propto I\left({\left\Vert \left|{\boldsymbol{\tau}}_{2i}\right|\right\Vert}_2<{C}_2\right),\end{align}$$
$$\begin{align}{f}_{{\boldsymbol{\tau}}_2}\left({\boldsymbol{\tau}}_{2i}\right)\propto I\left({\left\Vert \left|{\boldsymbol{\tau}}_{2i}\right|\right\Vert}_2<{C}_2\right),\end{align}$$
where
 $I(.)$
is the indicator function. Although, in this study, we rely on Equation (7), the above joint modal formulation of the cJML model is equivalent and explicates the difference with the pJML and MCMC approaches, both of which use normal priors. Unlike the pJML, the cJML-based LSIRM model is not strictly a special case of the MCMC-based LSIRM with standard normal priors discussed above. However, it is a special case in the more general framework of Equation (3) with
$I(.)$
is the indicator function. Although, in this study, we rely on Equation (7), the above joint modal formulation of the cJML model is equivalent and explicates the difference with the pJML and MCMC approaches, both of which use normal priors. Unlike the pJML, the cJML-based LSIRM model is not strictly a special case of the MCMC-based LSIRM with standard normal priors discussed above. However, it is a special case in the more general framework of Equation (3) with
 $\gamma^{\prime }=0$
and
$\gamma^{\prime }=0$
and
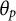 ${\theta}_p$
and
${\theta}_p$
and
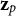 ${\mathbf{z}}_p$
following the prior in Equation (8) and
${\mathbf{z}}_p$
following the prior in Equation (8) and
 ${\beta}_i$
and
${\beta}_i$
and
 ${\mathbf{w}}_i$
following the prior in Equation (9).
${\mathbf{w}}_i$
following the prior in Equation (9).
To see that the cJML approach is the least restrictive approach in terms of parameter regularization, we compare the prior variance across the three approaches. For the MCMC and pJML approaches, all priors have variance 1 (except for
 $\theta$
in the MCMC approach). The variances of the priors in Equations (8) and (9) are
$\theta$
in the MCMC approach). The variances of the priors in Equations (8) and (9) are
 $\frac{C_1^2}{R+3}$
for the person parameters and
$\frac{C_1^2}{R+3}$
for the person parameters and
 $\frac{C_2^2}{R+3}$
for the item parameters. Given our choices for
$\frac{C_2^2}{R+3}$
for the item parameters. Given our choices for
 ${C}_1$
and
${C}_1$
and
 ${C}_2$
above, this results in a prior variance of
${C}_2$
above, this results in a prior variance of
 $4.5$
,
$4.5$
,
 $5.4$
, and
$5.4$
, and
 $6$
for the item parameters and of
$6$
for the item parameters and of
 $1.125,1.35$
, and
$1.125,1.35$
, and
 $1.5$
for the person parameters for
$1.5$
for the person parameters for
 $R=1$
,
$R=1$
,
 $R=2$
, and
$R=2$
, and
 $R=3$
, respectively. These priors are, thus, less informative in terms of prior variance than those of the MCMC and pJML approaches (although differences are small for the person parameters). This will also be illustrated in the simulation study.
$R=3$
, respectively. These priors are, thus, less informative in terms of prior variance than those of the MCMC and pJML approaches (although differences are small for the person parameters). This will also be illustrated in the simulation study.
2.3 Consistency
Traditional unregularized JML is known to be theoretically inconsistent (Andersen, Reference Andersen1973; Haberman, Reference Haberman1977) as asymptotic theory is violated because of the number of parameters increasing with
 $N$
. In this study, it is expected that, due to the known correspondence of our
$N$
. In this study, it is expected that, due to the known correspondence of our
 ${L}_2$
penalization to the effects of normal parameter priors, the finite-sample properties of the JML procedure will improve. However, we are unaware of theoretical proofs of consistency of pJML in the literature, so whether penalized JML is strictly consistent in the asymptotic sense has yet to be established.
${L}_2$
penalization to the effects of normal parameter priors, the finite-sample properties of the JML procedure will improve. However, we are unaware of theoretical proofs of consistency of pJML in the literature, so whether penalized JML is strictly consistent in the asymptotic sense has yet to be established.
For the cJML approach described above, it is known that the procedure is theoretically consistent under a double-asymptotic regime for structured generalized latent factor models (Chen et al., Reference Chen, Li and Zhang2020) and multidimensional unstructured two-parameter IRT models (see Chen et al., Reference Chen, Li and Zhang2019; Chen & Li, Reference Chen and Li2024). Similarly, approaches related to cJML are shown to be consistent for unipartite latent space models with low-rank inner-product distances (Ma et al., Reference Ma, Ma and Yuan2020; Zhang et al., Reference Zhang, Xu and Zhu2022). However, these results do not necessarily apply to the present model due to the unstructured nature of the latent space, the nonlinear and high-rank character of the natural parameter arising from Euclidean distances, and the bipartite nature of our item–respondent interactions. As the JML consistency issues are known to decrease with an increasing number of items (Haberman, Reference Haberman1977), and our simulation study below shows that our JML approaches perform comparable to the existing Bayesian approaches, we believe that any inconsistency (if any) is relatively unproblematic given the aim of the present study.
2.4 Rotation
As discussed above, the distances in Equation (2) are subject to a rotational indeterminacy and can be arbitrarily rotated to produce the same distances. For instance, for
 $R=2$
,
$R=2$
,
 $$\begin{align*}{\mathbf{W}}^{\prime }=\mathbf{W}{\mathbf{R}}^{\mathbf{T}}\;\mathrm{and}\;{\mathbf{Z}}^{\prime }=\mathbf{Z}{\mathbf{R}}^{\mathbf{T}}\end{align*}$$
$$\begin{align*}{\mathbf{W}}^{\prime }=\mathbf{W}{\mathbf{R}}^{\mathbf{T}}\;\mathrm{and}\;{\mathbf{Z}}^{\prime }=\mathbf{Z}{\mathbf{R}}^{\mathbf{T}}\end{align*}$$
with
 $$\begin{align*}\boldsymbol{R}=\left[\begin{array}{@{}cc@{}}\cos r& -\sin r\\ {}\sin r& \cos r\end{array}\right]\end{align*}$$
$$\begin{align*}\boldsymbol{R}=\left[\begin{array}{@{}cc@{}}\cos r& -\sin r\\ {}\sin r& \cos r\end{array}\right]\end{align*}$$
will result in the same Euclidean distances
 $d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)=d\left({\mathbf{z}}_p^{\prime },{\mathbf{w}}_i^{\prime}\right)$
for all
$d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)=d\left({\mathbf{z}}_p^{\prime },{\mathbf{w}}_i^{\prime}\right)$
for all
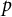 $p$
and all
$p$
and all
 $i$
for any arbitrary angle of rotation
$i$
for any arbitrary angle of rotation
 $r\in \left[-2\pi, 2\pi \right]$
. As discussed above, this problem is solved in an MCMC framework by Procrustes matching in which the samples from the posterior are all transformed to a target solution. As our approaches do not involve posterior samples, we will use specific constraints on
$r\in \left[-2\pi, 2\pi \right]$
. As discussed above, this problem is solved in an MCMC framework by Procrustes matching in which the samples from the posterior are all transformed to a target solution. As our approaches do not involve posterior samples, we will use specific constraints on
 $\mathbf{W}$
to fix
$\mathbf{W}$
to fix
 $\mathbf{W}$
and
$\mathbf{W}$
and
 $\mathbf{Z}$
to an arbitrary rotation without affecting the data likelihood.
$\mathbf{Z}$
to an arbitrary rotation without affecting the data likelihood.
Specifically, the problem of rotational indeterminacy of W and
 $\mathbf{Z}$
is similar to the problem of rotational indeterminacy of the factor loadings and the factor scores in factor analysis (e.g., Jennrich, Reference Jennrich1978). Therefore, we will rely on what is referred to as “echelon rotation” in the factor analysis literature (Dolan et al., Reference Dolan, Oort, Stoel and Wicherts2009; McDonald, Reference McDonald2013). That is, we will fix the
$\mathbf{Z}$
is similar to the problem of rotational indeterminacy of the factor loadings and the factor scores in factor analysis (e.g., Jennrich, Reference Jennrich1978). Therefore, we will rely on what is referred to as “echelon rotation” in the factor analysis literature (Dolan et al., Reference Dolan, Oort, Stoel and Wicherts2009; McDonald, Reference McDonald2013). That is, we will fix the
 $\frac{R\left(R-1\right)}{2}$
elements of the upper triangle of submatrix
$\frac{R\left(R-1\right)}{2}$
elements of the upper triangle of submatrix
 ${\mathbf{W}}_{1:\mathrm{R}-1,1:\mathrm{R}-1}$
to 0. For instance, for
${\mathbf{W}}_{1:\mathrm{R}-1,1:\mathrm{R}-1}$
to 0. For instance, for
 $R=3$
,
$R=3$
,
 $$\begin{align}\mathbf{W}=\left[\begin{array}{@{}ccc@{}}0& 0& {w}_{13}\\ {}{w}_{21}& 0& {w}_{23}\\ {}{w}_{31}& {w}_{32}& {w}_{33}\\ {}\vdots & \vdots & \vdots \\ {}{w}_{n1}& {w}_{n2}& {w}_{n3}\end{array}\right].\end{align}$$
$$\begin{align}\mathbf{W}=\left[\begin{array}{@{}ccc@{}}0& 0& {w}_{13}\\ {}{w}_{21}& 0& {w}_{23}\\ {}{w}_{31}& {w}_{32}& {w}_{33}\\ {}\vdots & \vdots & \vdots \\ {}{w}_{n1}& {w}_{n2}& {w}_{n3}\end{array}\right].\end{align}$$
An advantage of using this constraint compared with Procrustes matching is that the solution is more explicitly defined and comparable across different methods that fit the LSIRM. As for Procrustes matching, the solution depends on the largest likelihood encountered during MCMC sampling, the solution may depend on the sampling scheme, estimation algorithm, or even on random fluctuations within the same method applied to the same dataset. This is unproblematic for a single application as any rotation solution is arbitrary. However, if applications or algorithms need to be compared, using Procrustes matching may confound the comparison. Using echelon rotation, any solution obtained with any estimation algorithm (MCMC or maximum likelihood, but also potential other procedures such as least squares, variational inference, and minorization) can be rotated to the structure above to facilitate comparison.
For
 $R=3$
, the following three rotations are carried out to transform
$R=3$
, the following three rotations are carried out to transform
 $\mathbf{W}$
to an echelon structure:
$\mathbf{W}$
to an echelon structure:
 $$\begin{align}{\mathbf{W}}^{\prime }={\mathbf{W}\mathbf{R}}_{\mathbf{1}}^{\mathbf{T}},{\mathbf{W}}^{\prime \prime }={\mathbf{W}}^{\prime }{\mathbf{R}}_{\boldsymbol{2}}^{\mathbf{T}},\ \mathrm{and}\kern0.24em {\mathbf{W}}^{\prime \prime \prime }={\mathbf{W}}^{\prime \prime }{\mathbf{R}}_3^{\mathbf{T}},\end{align}$$
$$\begin{align}{\mathbf{W}}^{\prime }={\mathbf{W}\mathbf{R}}_{\mathbf{1}}^{\mathbf{T}},{\mathbf{W}}^{\prime \prime }={\mathbf{W}}^{\prime }{\mathbf{R}}_{\boldsymbol{2}}^{\mathbf{T}},\ \mathrm{and}\kern0.24em {\mathbf{W}}^{\prime \prime \prime }={\mathbf{W}}^{\prime \prime }{\mathbf{R}}_3^{\mathbf{T}},\end{align}$$
where
 ${\mathbf{R}}_1$
,
${\mathbf{R}}_1$
,
 ${\mathbf{R}}_2$
, and
${\mathbf{R}}_2$
, and
 ${\mathbf{R}}_3$
are given by
${\mathbf{R}}_3$
are given by
 $$\begin{align}{\mathbf{R}}_1=\left[\begin{array}{@{}ccc@{}}\cos \left({\unicode{x3b1}}_1\right)& 0& \sin \left({\alpha}_1\right)\\ {}0& 1& 0\\ {}-\sin \left({\alpha}_1\right)& 0& \cos \left({\unicode{x3b1}}_1\right)\end{array}\right],\ {\mathbf{R}}_2=\left[\begin{array}{@{}ccc@{}}1& 0& 0\\ {}0& \cos \left({\unicode{x3b1}}_2\right)& \sin \left({\alpha}_2\right)\\ {}0& -\sin \left({\alpha}_2\right)& \cos \left({\unicode{x3b1}}_2\right)\end{array}\right],\ \mathrm{and}\;{\mathbf{R}}_3=\left[\begin{array}{@{}ccc@{}}\cos \left({\unicode{x3b1}}_3\right)& \sin \left({\alpha}_3\right)& 0\\ {}-\sin \left({\alpha}_3\right)& \cos \left({\unicode{x3b1}}_3\right)& 0\\ {}0& 0& 1\end{array}\right].\end{align}$$
$$\begin{align}{\mathbf{R}}_1=\left[\begin{array}{@{}ccc@{}}\cos \left({\unicode{x3b1}}_1\right)& 0& \sin \left({\alpha}_1\right)\\ {}0& 1& 0\\ {}-\sin \left({\alpha}_1\right)& 0& \cos \left({\unicode{x3b1}}_1\right)\end{array}\right],\ {\mathbf{R}}_2=\left[\begin{array}{@{}ccc@{}}1& 0& 0\\ {}0& \cos \left({\unicode{x3b1}}_2\right)& \sin \left({\alpha}_2\right)\\ {}0& -\sin \left({\alpha}_2\right)& \cos \left({\unicode{x3b1}}_2\right)\end{array}\right],\ \mathrm{and}\;{\mathbf{R}}_3=\left[\begin{array}{@{}ccc@{}}\cos \left({\unicode{x3b1}}_3\right)& \sin \left({\alpha}_3\right)& 0\\ {}-\sin \left({\alpha}_3\right)& \cos \left({\unicode{x3b1}}_3\right)& 0\\ {}0& 0& 1\end{array}\right].\end{align}$$
The angles of rotation
 ${\alpha}_1$
,
${\alpha}_1$
,
 ${\alpha}_2$
, and
${\alpha}_2$
, and
 ${\alpha}_3$
can be obtained by standard trigonometry and are given by
${\alpha}_3$
can be obtained by standard trigonometry and are given by
 $$\begin{align}{\alpha}_1=\arctan \left(\frac{w_{11}}{w_{13}}\right),{\alpha}_2=\arctan \left(\frac{w_{12}^{\prime }}{w_{13}^{\prime }}\right),\ \mathrm{and}\;{\alpha}_3=-\arctan \left(\frac{w_{22}^{\prime \prime }}{w_{21}^{\prime \prime }}\right),\end{align}$$
$$\begin{align}{\alpha}_1=\arctan \left(\frac{w_{11}}{w_{13}}\right),{\alpha}_2=\arctan \left(\frac{w_{12}^{\prime }}{w_{13}^{\prime }}\right),\ \mathrm{and}\;{\alpha}_3=-\arctan \left(\frac{w_{22}^{\prime \prime }}{w_{21}^{\prime \prime }}\right),\end{align}$$
where
 ${w}_{ik}^{\prime }$
and
${w}_{ik}^{\prime }$
and
 ${w}_{ik}^{\prime \prime }$
are the elements from the rotated
${w}_{ik}^{\prime \prime }$
are the elements from the rotated
 $\mathbf{W}^{\prime }$
and
$\mathbf{W}^{\prime }$
and
 $\mathbf{W}^{\prime\prime }$
matrices. See Figure 1 for a graphical illustration of the rotation scheme.
$\mathbf{W}^{\prime\prime }$
matrices. See Figure 1 for a graphical illustration of the rotation scheme.
Graphical illustration of the echelon rotation for
 $R=3$
. The dotted arrows indicate the direction of the rotation, the solid dot denotes a specific coordinate
$R=3$
. The dotted arrows indicate the direction of the rotation, the solid dot denotes a specific coordinate
 $\left(x,y\right)$
, and the striped lines give an indication of the new (i.e., rotated) position of the axis connected to the dotted arrow. The angle of rotation is indicated by
$\left(x,y\right)$
, and the striped lines give an indication of the new (i.e., rotated) position of the axis connected to the dotted arrow. The angle of rotation is indicated by
 ${\alpha}_1$
,
${\alpha}_1$
,
 ${\alpha}_2$
, and
${\alpha}_2$
, and
 ${\alpha}_3$
.
${\alpha}_3$
.

That is, in the figure, it can be seen that, first,
 ${w}_{i1}$
and
${w}_{i1}$
and
 ${w}_{i3}$
are rotated around
${w}_{i3}$
are rotated around
 ${w}_{i2}$
using angle
${w}_{i2}$
using angle
 ${\alpha}_1$
so that
${\alpha}_1$
so that
 ${w}_{11}^{\prime }=0$
. Next,
${w}_{11}^{\prime }=0$
. Next,
 ${w}_{i2}^{\prime }$
and
${w}_{i2}^{\prime }$
and
 ${w}_{i3}^{\prime }$
are rotated around
${w}_{i3}^{\prime }$
are rotated around
 ${w}_{i1}^{\prime }$
using angle
${w}_{i1}^{\prime }$
using angle
 ${\alpha}_2$
so that
${\alpha}_2$
so that
 ${w}_{12}^{\prime \prime }=0$
. Finally,
${w}_{12}^{\prime \prime }=0$
. Finally,
 ${w}_{i1}^{\prime \prime }$
and
${w}_{i1}^{\prime \prime }$
and
 ${w}_{i2}^{\prime \prime }$
are rotated around
${w}_{i2}^{\prime \prime }$
are rotated around
 ${w}_{i3}^{\prime \prime }$
using angle
${w}_{i3}^{\prime \prime }$
using angle
 ${\alpha}_3$
so that
${\alpha}_3$
so that
 ${w}_{22}^{\prime \prime \prime }=0$
. Final matrix
${w}_{22}^{\prime \prime \prime }=0$
. Final matrix
 ${\mathbf{W}}^{\prime \prime \prime }$
will have the structure in Equation (10). If
${\mathbf{W}}^{\prime \prime \prime }$
will have the structure in Equation (10). If
 ${\mathbf{R}}_{\boldsymbol{0}}={\mathbf{R}}_{\mathbf{3}}\left({\mathbf{R}}_{\boldsymbol{2}}{\mathbf{R}}_1\right)$
is denoted to be the overall rotation matrix, then the same rotation can be applied to
${\mathbf{R}}_{\boldsymbol{0}}={\mathbf{R}}_{\mathbf{3}}\left({\mathbf{R}}_{\boldsymbol{2}}{\mathbf{R}}_1\right)$
is denoted to be the overall rotation matrix, then the same rotation can be applied to
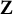 $\mathbf{Z}$
, resulting in
$\mathbf{Z}$
, resulting in
 ${\mathbf{Z}}^{\prime \prime \prime }=\mathbf{Z}{\mathbf{R}}_0^{\mathrm{T}}$
. As noted before, the Euclidean distances of the original parameters from
${\mathbf{Z}}^{\prime \prime \prime }=\mathbf{Z}{\mathbf{R}}_0^{\mathrm{T}}$
. As noted before, the Euclidean distances of the original parameters from
 $\mathbf{W}$
and
$\mathbf{W}$
and
 $\mathbf{Z}$
are equivalent to the Euclidean distances of the rotated parameters from
$\mathbf{Z}$
are equivalent to the Euclidean distances of the rotated parameters from
 $\mathbf{W}^{\prime\prime\prime }$
and
$\mathbf{W}^{\prime\prime\prime }$
and
 $\mathbf{Z}^{\prime\prime\prime }$
, that is,
$\mathbf{Z}^{\prime\prime\prime }$
, that is,
 $d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)=d\left({\mathbf{z}}_p^{\prime \prime \prime },{\mathbf{w}}_i^{\prime \prime \prime \prime}\right)$
for all
$d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)=d\left({\mathbf{z}}_p^{\prime \prime \prime },{\mathbf{w}}_i^{\prime \prime \prime \prime}\right)$
for all
 $p$
and all
$p$
and all
 $i$
. Generalization to any
$i$
. Generalization to any
 $R$
is straightforward and can be practically performed using the algorithm by, for instance, Wansbeek and Meijer (Reference Wansbeek and Meijer2000).
$R$
is straightforward and can be practically performed using the algorithm by, for instance, Wansbeek and Meijer (Reference Wansbeek and Meijer2000).
2.5 Model selection
Owing to its diagnostic character, in many situations, an LSIRM with
 $R=2$
will suffice because of its suitability to visualize the results in
$R=2$
will suffice because of its suitability to visualize the results in
 $2D$
plots. However, if a more statistical informed decision needs to be made about
$2D$
plots. However, if a more statistical informed decision needs to be made about
 $R,$
there are no methods available yet. In a maximum likelihood framework, direct comparison of the models using common fit indices, such as Akaike information criterion and Bayesian information criterion, is challenging because of the ambiguity about the definition of the parameter penalty for models with different dimensions of
$R,$
there are no methods available yet. In a maximum likelihood framework, direct comparison of the models using common fit indices, such as Akaike information criterion and Bayesian information criterion, is challenging because of the ambiguity about the definition of the parameter penalty for models with different dimensions of
 $\mathbf{W}$
and
$\mathbf{W}$
and
 $\mathbf{Z}$
. As we rely on JML estimation, a suitable fit index may be provided by the Joint-likelihood-based information criteria (JIC) by Chen and Li (Reference Chen and Li2022). However, in simulations, it turned out that the JIC only works for our model if the ratio
$\mathbf{Z}$
. As we rely on JML estimation, a suitable fit index may be provided by the Joint-likelihood-based information criteria (JIC) by Chen and Li (Reference Chen and Li2022). However, in simulations, it turned out that the JIC only works for our model if the ratio
 $n/N$
is larger than considered here (see below and Appendix B of the Supplementary Material).
$n/N$
is larger than considered here (see below and Appendix B of the Supplementary Material).
Therefore, we propose a model selection procedure based on
 $K$
-fold cross-validation. Similar procedures have been proposed for model selection among multidimensional two-parameter logistic models (Bergner et al., Reference Bergner, Halpin and Vie2022) and network models, including latent space models (Li et al., Reference Li, Levina and Zhu2020). Specifically,
$K$
-fold cross-validation. Similar procedures have been proposed for model selection among multidimensional two-parameter logistic models (Bergner et al., Reference Bergner, Halpin and Vie2022) and network models, including latent space models (Li et al., Reference Li, Levina and Zhu2020). Specifically,
 ${\mathbf{X}}^{\left(\mathrm{k}\right)}$
denotes the
${\mathbf{X}}^{\left(\mathrm{k}\right)}$
denotes the
 $N\times n$
matrix of data in fold
$N\times n$
matrix of data in fold
 $k=1,\dots, K$
, and
$k=1,\dots, K$
, and
 $Q$
denotes the number of observed elements in
$Q$
denotes the number of observed elements in
 $\mathbf{X}$
. Then, the data in fold
$\mathbf{X}$
. Then, the data in fold
 $k$
,
$k$
,
 ${\mathbf{X}}^{\left(\mathrm{k}\right)}$
, are obtained by randomly selecting
${\mathbf{X}}^{\left(\mathrm{k}\right)}$
, are obtained by randomly selecting
 $\mathrm{floor}\left(\frac{Q}{K}\right)$
elements
$\mathrm{floor}\left(\frac{Q}{K}\right)$
elements
 ${X}_{pi}$
from the full data matrix
${X}_{pi}$
from the full data matrix
 $\mathbf{X}$
without replacement, and assigning these to elements
$\mathbf{X}$
without replacement, and assigning these to elements
 ${X}_{pi}^{(k)}$
in
${X}_{pi}^{(k)}$
in
 ${\mathbf{X}}^{(k)}$
. The elements of
${\mathbf{X}}^{(k)}$
. The elements of
 ${\mathbf{X}}^{(k)}$
that have no value from
${\mathbf{X}}^{(k)}$
that have no value from
 $\mathbf{X}$
assigned are replaced by missing values. As such,
$\mathbf{X}$
assigned are replaced by missing values. As such,
 $\mathbf{X}$
is partitioned in
$\mathbf{X}$
is partitioned in
 $K$
subsamples. If
$K$
subsamples. If
 $Q$
is not a multiple of
$Q$
is not a multiple of
 $K$
, the elements from
$K$
, the elements from
 $\mathbf{X}$
that are yet unselected are assigned to the first
$\mathbf{X}$
that are yet unselected are assigned to the first
 $Q \operatorname {mod}\;K$
folds.
$Q \operatorname {mod}\;K$
folds.
Next, the LSIRM is fit
 $K$
times to the data matrix
$K$
times to the data matrix
 $\mathbf{X}$
, each time leaving out the data from fold
$\mathbf{X}$
, each time leaving out the data from fold
 $k$
by assuming these data to be Missing Completely at Random (Rubin, Reference Rubin1976). Finally, for each of the
$k$
by assuming these data to be Missing Completely at Random (Rubin, Reference Rubin1976). Finally, for each of the
 $K$
results obtained, we determine the predictive accuracy of the LSIRM in predicting the data from fold
$K$
results obtained, we determine the predictive accuracy of the LSIRM in predicting the data from fold
 $K$
. Specifically, we consider three performance metrics.
$K$
. Specifically, we consider three performance metrics.
2.5.1 Unnormalized classification error
The first metric is what we refer to as the unnormalized classification error (
 $UCE$
):
$UCE$
):
 $$\begin{align}UCE={\sum}_{\left(p,i\right)\in {S}^{(k)}}{\sum}_{k=1}^KI\left({X}_{pi}^{(k)}\ne {\dot{X}}_{pi}^{(k)}\right),\end{align}$$
$$\begin{align}UCE={\sum}_{\left(p,i\right)\in {S}^{(k)}}{\sum}_{k=1}^KI\left({X}_{pi}^{(k)}\ne {\dot{X}}_{pi}^{(k)}\right),\end{align}$$
where
 ${S}^{(k)}$
is the set containing all
${S}^{(k)}$
is the set containing all
 $\left(p,i\right)$
combinations for which
$\left(p,i\right)$
combinations for which
 ${X}_{pi}^{(k)}$
is observed in
${X}_{pi}^{(k)}$
is observed in
 ${\mathbf{X}}^{\left(\boldsymbol{k}\right)}$
and
${\mathbf{X}}^{\left(\boldsymbol{k}\right)}$
and
 ${\dot{X}}_{pi}^{(k)}$
is the model predicted score (0 or 1) for
${\dot{X}}_{pi}^{(k)}$
is the model predicted score (0 or 1) for
 ${X}_{pi}^{(k)}$
, that is,
${X}_{pi}^{(k)}$
, that is,
 $$\begin{align}{\dot{X}}_{pi}^{(k)}=\mathrm{round}\left(P\left({X}_{pi}^{(k)}=1|{\theta}_p^{\left(-k\right)},{\beta}_i^{\left(-k\right)},{\mathbf{z}}_p^{\left(-k\right)},{\mathbf{w}}_i^{\left(-k\right)}\right)\right),\end{align}$$
$$\begin{align}{\dot{X}}_{pi}^{(k)}=\mathrm{round}\left(P\left({X}_{pi}^{(k)}=1|{\theta}_p^{\left(-k\right)},{\beta}_i^{\left(-k\right)},{\mathbf{z}}_p^{\left(-k\right)},{\mathbf{w}}_i^{\left(-k\right)}\right)\right),\end{align}$$
where the parameters contain superscript
 $\left(-k\right)$
to denote that the data in
$\left(-k\right)$
to denote that the data in
 ${\mathbf{X}}^{(k)}$
were not used in its estimation. Note that
${\mathbf{X}}^{(k)}$
were not used in its estimation. Note that
 $UCE$
is inversely related to the classification accuracy, which is generally defined as the overall proportion of scores correctly classified as 0 or 1. We focus on classifications error so that smaller values indicate better-performing models, which is better in line with the residual sum of squares that we introduce later (which is naturally smaller for better-performing models). In addition, while the classification accuracy is commonly normalized, we focus on the unnormalized metric to increase the range of the metric and to be better in line with log-likelihood-based metrics, which are typically unnormalized (at least in psychometrics). The disadvantage of using unnormalized metrics is that its exact value is harder to interpret compared with, for example, prediction accuracies. However, prediction accuracies can be very similar across models due to their narrow range and upper bound (which is not necessarily
$UCE$
is inversely related to the classification accuracy, which is generally defined as the overall proportion of scores correctly classified as 0 or 1. We focus on classifications error so that smaller values indicate better-performing models, which is better in line with the residual sum of squares that we introduce later (which is naturally smaller for better-performing models). In addition, while the classification accuracy is commonly normalized, we focus on the unnormalized metric to increase the range of the metric and to be better in line with log-likelihood-based metrics, which are typically unnormalized (at least in psychometrics). The disadvantage of using unnormalized metrics is that its exact value is harder to interpret compared with, for example, prediction accuracies. However, prediction accuracies can be very similar across models due to their narrow range and upper bound (which is not necessarily
 $1$
; see Bergner et al., Reference Bergner, Halpin and Vie2022), and can therefore also be challenging to interpret.
$1$
; see Bergner et al., Reference Bergner, Halpin and Vie2022), and can therefore also be challenging to interpret.
2.5.2 Unnormalized ROC error
The next fit metric proposed is based on the area under the receiver operator curve (ROC). An ROC gives the relation among the true positive rates and the false positive rates of a model across different thresholds in a classification. For a perfect classification, the area under this curve is equal to
 $1$
, indicating that the true positive rate is 1 and the false positive rate is 0. In the present study, we use the area under the ROC curve to see how well the data in a given fold are predicted using the LSIRM as estimated on the remaining folds. As discussed above, we focus on unnormalized metrics for which lower values indicate better model performance; therefore, we focus on the unnormalized ROC error (
$1$
, indicating that the true positive rate is 1 and the false positive rate is 0. In the present study, we use the area under the ROC curve to see how well the data in a given fold are predicted using the LSIRM as estimated on the remaining folds. As discussed above, we focus on unnormalized metrics for which lower values indicate better model performance; therefore, we focus on the unnormalized ROC error (
 $URE$
):
$URE$
):
 $$\begin{align}URE={\sum}_{k=1}^K{N}^{(k)}{n}^{(k)}\left[1-\mathrm{AUC}\left({\mathbf{X}}^{(k)},{\mathbf{P}}^{(k)}\right)\right],\end{align}$$
$$\begin{align}URE={\sum}_{k=1}^K{N}^{(k)}{n}^{(k)}\left[1-\mathrm{AUC}\left({\mathbf{X}}^{(k)},{\mathbf{P}}^{(k)}\right)\right],\end{align}$$
where
 $AUC(.)$
is the function that determines the area under the ROC curve and
$AUC(.)$
is the function that determines the area under the ROC curve and
 ${\mathbf{P}}^{(k)}$
is an
${\mathbf{P}}^{(k)}$
is an
 $N\times n$
matrix containing the model predictions for fold
$N\times n$
matrix containing the model predictions for fold
 $k$
in elements
$k$
in elements
 ${S}^{(k)}$
of that matrix. Similarly to
${S}^{(k)}$
of that matrix. Similarly to
 ${\mathbf{X}}^{(k)}$
, the elements of
${\mathbf{X}}^{(k)}$
, the elements of
 ${\mathbf{P}}^{(k)}$
that are not in
${\mathbf{P}}^{(k)}$
that are not in
 ${S}^{(k)}$
are set to missing.
${S}^{(k)}$
are set to missing.
2.5.3 Residual sum of squares
Finally, we use a metric based on the residual sum of squares (
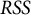 $RSS$
) in the prediction of
$RSS$
) in the prediction of
 ${\mathbf{X}}^{(k)}$
by
${\mathbf{X}}^{(k)}$
by
 ${\mathbf{P}}^{(k)}$
. That is,
${\mathbf{P}}^{(k)}$
. That is,
 $$\begin{align}RSS={\sum}_{\left(p,i\right)\in {S}^{(r)}}{\sum}_{k=1}^K{\left({X}_{pi}^{(k)}-{P}_{pi}^{(k)}\right)}^2,\end{align}$$
$$\begin{align}RSS={\sum}_{\left(p,i\right)\in {S}^{(r)}}{\sum}_{k=1}^K{\left({X}_{pi}^{(k)}-{P}_{pi}^{(k)}\right)}^2,\end{align}$$
where
 ${P}_{pi}^{(k)}$
is element
${P}_{pi}^{(k)}$
is element
 $\left(p,i\right)$
from matrix
$\left(p,i\right)$
from matrix
 ${\mathbf{P}}^{(k)}$
. For the
${\mathbf{P}}^{(k)}$
. For the
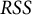 $RSS$
, it also holds that lower values indicate a better-performing model.
$RSS$
, it also holds that lower values indicate a better-performing model.
2.6 Likelihood optimization
We implemented the methods above in the
 $R$
package LSMjml, which is available from CRAN and from www.dylanmolenaar.nl. We use a gradient ascent algorithm to maximize the likelihood in Equation (5) for pJML and in Equation (7) for cJML with
$R$
package LSMjml, which is available from CRAN and from www.dylanmolenaar.nl. We use a gradient ascent algorithm to maximize the likelihood in Equation (5) for pJML and in Equation (7) for cJML with
 $\mathbf{W}$
subject to the echelon structure discussed above. For pJML, parameters
$\mathbf{W}$
subject to the echelon structure discussed above. For pJML, parameters
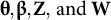 $\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{Z},\ \textrm{and}\ \mathbf{W} $
are updated sequentially by holding the other parameters constant. The likelihood is penalized as shown in Equation (5), with
$\boldsymbol{\unicode{x3b8}}, \boldsymbol{\unicode{x3b2}}, \mathbf{Z},\ \textrm{and}\ \mathbf{W} $
are updated sequentially by holding the other parameters constant. The likelihood is penalized as shown in Equation (5), with
 $\lambda =1$
as discussed above. For cJML, parameter pairs
$\lambda =1$
as discussed above. For cJML, parameter pairs
 $\left[\boldsymbol{\unicode{x3b2}}, \mathbf{W}\right]$
and
$\left[\boldsymbol{\unicode{x3b2}}, \mathbf{W}\right]$
and
 $\left[\boldsymbol{\unicode{x3b8}}, \mathbf{Z}\right]$
are updated alternatingly. The constraints in Equation (6) are introduced by gradient projection (Chen et al., Reference Chen, Li and Zhang2019; Nocedal & Wright, Reference Nocedal and Wright2006, p. 485) in which the parameter values are transformed to comply to Equation (6) after each parameter vector update (if necessary). As both JML procedures are full information, missing data can be accommodated by assuming MAR and summing the log-likelihood over all available data points.
$\left[\boldsymbol{\unicode{x3b8}}, \mathbf{Z}\right]$
are updated alternatingly. The constraints in Equation (6) are introduced by gradient projection (Chen et al., Reference Chen, Li and Zhang2019; Nocedal & Wright, Reference Nocedal and Wright2006, p. 485) in which the parameter values are transformed to comply to Equation (6) after each parameter vector update (if necessary). As both JML procedures are full information, missing data can be accommodated by assuming MAR and summing the log-likelihood over all available data points.
Starting values are based on a preliminary exploratory item factor analysis with
 $R+1$
factors in which the first factor has equal factor loadings for all items and the factor loadings of the remaining
$R+1$
factors in which the first factor has equal factor loadings for all items and the factor loadings of the remaining
 $R$
factors follow an echelon structure. Cai (Reference Cai2010) proposes a similar strategy for multidimensional item factor analysis. However, like Bergner et al. (Reference Bergner, Halpin and Vie2022), we found that, in general, random initialization performs equally well. See Algorithms 1 and 2 below for a description of, respectively, the pJML and cJML procedures using pseudocode.
$R$
factors follow an echelon structure. Cai (Reference Cai2010) proposes a similar strategy for multidimensional item factor analysis. However, like Bergner et al. (Reference Bergner, Halpin and Vie2022), we found that, in general, random initialization performs equally well. See Algorithms 1 and 2 below for a description of, respectively, the pJML and cJML procedures using pseudocode.


2.7 Ordered categorical data
With the methods above in place, a generalization to ordered categorical data is straightforward. That is, the LSIRM is formulated as a sequential item IRT model (Tutz, Reference Tutz1990) as follows:
 $$\begin{align}P\left({X}_{pi}\geq h|{\theta}_p,{\beta}_{ic},{\mathbf{z}}_p,{\mathbf{w}}_i\right)=\prod_{c=0}^h\omega \left({\theta}_p+{\beta}_{ic}-d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)\right),\end{align}$$
$$\begin{align}P\left({X}_{pi}\geq h|{\theta}_p,{\beta}_{ic},{\mathbf{z}}_p,{\mathbf{w}}_i\right)=\prod_{c=0}^h\omega \left({\theta}_p+{\beta}_{ic}-d\left({\mathbf{z}}_p,{\mathbf{w}}_i\right)\right),\end{align}$$
where
 ${X}_{pi}\in \left\{0,\dots, {C}_i-1\right\}$
are the ordered categorical item responses and
${X}_{pi}\in \left\{0,\dots, {C}_i-1\right\}$
are the ordered categorical item responses and
 ${\beta}_{ic}$
is the effect of item category
${\beta}_{ic}$
is the effect of item category
 $c=0,\dots, {C}_i-1$
, which are ordered as follows:
$c=0,\dots, {C}_i-1$
, which are ordered as follows:
 $\infty={\beta}_{i0}>{\beta}_{i1}>\dots >{\beta}_{ic}>\dots >{\beta}_{i({C}_i-1)}$
. Note that
$\infty={\beta}_{i0}>{\beta}_{i1}>\dots >{\beta}_{ic}>\dots >{\beta}_{i({C}_i-1)}$
. Note that
 $\gamma =1$
as discussed above.
$\gamma =1$
as discussed above.
This ordinal LSIRM can readily be fit using the methodology discussed above by recoding the
 $N\times n$
data matrix
$N\times n$
data matrix
 $\mathbf{X}$
with order categorical elements
$\mathbf{X}$
with order categorical elements
 ${X}_{pi}\in \left\{0,\dots, {C}_i-1\right\}$
into an
${X}_{pi}\in \left\{0,\dots, {C}_i-1\right\}$
into an
 $N\times \sum _{i=1}^n\left({C}_i-1\right)$
matrix of cumulative binary dummy coded variables
$N\times \sum _{i=1}^n\left({C}_i-1\right)$
matrix of cumulative binary dummy coded variables
 $\mathbf{X}^{\prime }$
with elements
$\mathbf{X}^{\prime }$
with elements
 ${X}_{pij}^{\prime}\in \left\{0,1\right\}$
, for
${X}_{pij}^{\prime}\in \left\{0,1\right\}$
, for
 $j=1,\dots, {C}_i-1$
. Specifically,
$j=1,\dots, {C}_i-1$
. Specifically,
$$\begin{align}{X}_{pij}^{\prime }=1\ \mathrm{if}\ {X}_{pi}\ge j \ \mathrm{and}\ {X}_{pij}^{\prime }=0\ \mathrm{otherwise}. \end{align}$$
For instance, if
 ${C}_i=3$
, this results in
${C}_i=3$
, this results in
 ${X}_{pi}^{\prime }=\left[0,0\right]$
for
${X}_{pi}^{\prime }=\left[0,0\right]$
for
 ${X}_{pi}=0$
,
${X}_{pi}=0$
,
 ${X}_{pi}^{\prime }=\left[1,0\right]$
for
${X}_{pi}^{\prime }=\left[1,0\right]$
for
 ${X}_{pi}=1$
, and
${X}_{pi}=1$
, and
 ${X}_{pi}^{\prime }=\left[1,1\right]$
for
${X}_{pi}^{\prime }=\left[1,1\right]$
for
 ${X}_{pi}=2$
. Now, by treating the variables
${X}_{pi}=2$
. Now, by treating the variables
 ${X}_{pij}^{\prime }$
as dummy items in the binary LSIRM in Equation (18), and by fixing
${X}_{pij}^{\prime }$
as dummy items in the binary LSIRM in Equation (18), and by fixing
 ${w}_{ijr}={w}_{ir}$
for dummy items that correspond to the same original item, fitting the cJML or pJML models to these dummy items will be equivalent to fitting Equation (18) to the original data
${w}_{ijr}={w}_{ir}$
for dummy items that correspond to the same original item, fitting the cJML or pJML models to these dummy items will be equivalent to fitting Equation (18) to the original data
 $\mathbf{X}$
. The estimates of
$\mathbf{X}$
. The estimates of
 ${\beta}_{ij}$
on
${\beta}_{ij}$
on
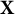 $\mathbf{X}$
’ will correspond to those of
$\mathbf{X}$
’ will correspond to those of
 ${\beta}_{ic}$
in Equation (18) obtained on
${\beta}_{ic}$
in Equation (18) obtained on
 $\mathbf{X}^{\prime }$
. Note that by using the approach above, the number of categories for the item responses is allowed to differ across items.
$\mathbf{X}^{\prime }$
. Note that by using the approach above, the number of categories for the item responses is allowed to differ across items.
3 Simulation studies
3.1 Design
In this simulation study, we focus on parameter recovery of JML approaches proposed in this article. We focus on an LSIRM with
 $R=2$
, as this is arguably the model that is used in practice most. In addition, we focus on binary data to be able to compare the results to the existing MCMC approach, which is only available for binary data. Moreover, the binary model underlies the ordinal model, as discussed above; therefore, the results will apply to the ordinal case as well. We simulate the data using the parameterization in Equations (1) and (2) (including the
$R=2$
, as this is arguably the model that is used in practice most. In addition, we focus on binary data to be able to compare the results to the existing MCMC approach, which is only available for binary data. Moreover, the binary model underlies the ordinal model, as discussed above; therefore, the results will apply to the ordinal case as well. We simulate the data using the parameterization in Equations (1) and (2) (including the
 $\gamma$
parameter). Note that the JML models do not include
$\gamma$
parameter). Note that the JML models do not include
 $\gamma$
as a free parameter as explained above; however, we do simulate data using
$\gamma$
as a free parameter as explained above; however, we do simulate data using
 $\gamma$
to manipulate the effect of the latent space on the data and to demonstrate that
$\gamma$
to manipulate the effect of the latent space on the data and to demonstrate that
 $\gamma$
is indeed absorbed in the
$\gamma$
is indeed absorbed in the
 ${z}_{pr}$
and
${z}_{pr}$
and
 ${w}_{ir}$
JML estimates.
${w}_{ir}$
JML estimates.
We consider two sample sizes:
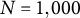 $N=\mathrm{1,000}$
to reflect a more practical setting and
$N=\mathrm{1,000}$
to reflect a more practical setting and
 $N=\mathrm{10,000}$
to study the large sample behavior of the model estimates. We fully cross these sample size conditions with
$N=\mathrm{10,000}$
to study the large sample behavior of the model estimates. We fully cross these sample size conditions with
 $n=24$
(practical setting) and
$n=24$
(practical setting) and
 $n=96$
(large sample). Below, we discuss the true values for the parameters, which are inspired by or equal to the MCMC estimates of the deductive reasoning data analyzed in the illustration section below. Specifically, true values for
$n=96$
(large sample). Below, we discuss the true values for the parameters, which are inspired by or equal to the MCMC estimates of the deductive reasoning data analyzed in the illustration section below. Specifically, true values for
 ${\beta}_i$
are between
${\beta}_i$
are between
 $1.5$
and
$1.5$
and
 $5$
and are identical to the deductive reasoning data estimates. In addition,
$5$
and are identical to the deductive reasoning data estimates. In addition,
 ${w}_{i1}$
are decreasing from
${w}_{i1}$
are decreasing from
 $2$
to
$2$
to
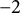 $-2$
in equally sized steps and
$-2$
in equally sized steps and
 ${w}_{i2}$
are between −2 and 2 and randomly assigned to the different items. For the conditions with
${w}_{i2}$
are between −2 and 2 and randomly assigned to the different items. For the conditions with
 $n=96$
, the item parameters from the conditions with
$n=96$
, the item parameters from the conditions with
 $n=24$
are repeated four times. For the person parameters,
$n=24$
are repeated four times. For the person parameters,
 ${\theta}_p$
is specified to follow a normal distribution with mean
${\theta}_p$
is specified to follow a normal distribution with mean
 $0$
and variance
$0$
and variance
 $0.8$
, and
$0.8$
, and
 ${z}_{p1}$
and
${z}_{p1}$
and
 ${z}_{p2}$
are specified to follow a normal distribution with mean 0 and variance, respectively,
${z}_{p2}$
are specified to follow a normal distribution with mean 0 and variance, respectively,
 $0.9$
and
$0.9$
and
 $0.7$
. The correlation between
$0.7$
. The correlation between
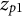 ${z}_{p1}$
and
${z}_{p1}$
and
 ${z}_{p2}$
was specified to be equal to
${z}_{p2}$
was specified to be equal to
 $-0.14$
. Finally,
$-0.14$
. Finally,
 $\gamma$
is equal to 1.7. As the above values are based on the MCMC results from the deductive reasoning data, we also wanted to add a data condition where
$\gamma$
is equal to 1.7. As the above values are based on the MCMC results from the deductive reasoning data, we also wanted to add a data condition where
 $\gamma =1$
to establish how parameter recovery is affected by this parameter. All other parameters in this condition are the same as above. We use
$\gamma =1$
to establish how parameter recovery is affected by this parameter. All other parameters in this condition are the same as above. We use
 $50$
replications for each condition
$50$
replications for each condition
To the data from the different conditions, we fit the LSIRM with
 $R=2$
using both pJML and cJML as discussed above. We also fit the LSIRM using MCMC estimation in the R package lsirm12pl (Go et al., Reference Go, Kim and Park2023). We did so to have a benchmark approach available to compare JML results to. That is, we want to demonstrate that parameter estimates are highly comparable across the different fitting methods after appropriate rotation. The aim of this study is not to show superiority of one method over the other. We used all default settings of lsirm12pl. That is, we relied on 15,000 posterior samples of which 2,500 are burn-in and which is thinned by 5. In addition, the default priors of the package are a standard normal prior for
$R=2$
using both pJML and cJML as discussed above. We also fit the LSIRM using MCMC estimation in the R package lsirm12pl (Go et al., Reference Go, Kim and Park2023). We did so to have a benchmark approach available to compare JML results to. That is, we want to demonstrate that parameter estimates are highly comparable across the different fitting methods after appropriate rotation. The aim of this study is not to show superiority of one method over the other. We used all default settings of lsirm12pl. That is, we relied on 15,000 posterior samples of which 2,500 are burn-in and which is thinned by 5. In addition, the default priors of the package are a standard normal prior for
 ${\beta}_i,{z}_{rp},$
and
${\beta}_i,{z}_{rp},$
and
 ${w}_{ri}$
, a normal prior with mean 0 and variance
${w}_{ri}$
, a normal prior with mean 0 and variance
 ${\sigma}_{\theta}^2$
for
${\sigma}_{\theta}^2$
for
 ${\theta}_p$
, a normal prior with mean
${\theta}_p$
, a normal prior with mean
 $0.5$
and variance
$0.5$
and variance
 $1.0$
for
$1.0$
for
 $\gamma^{\prime }$
, and an inverse-gamma prior with scale and shape 0.001 for
$\gamma^{\prime }$
, and an inverse-gamma prior with scale and shape 0.001 for
 ${\sigma}_{\theta}^2$
.
${\sigma}_{\theta}^2$
.
3.2 Results
As the results do not differ importantly across the different dimensions of
 ${\mathbf{z}}_p$
and
${\mathbf{z}}_p$
and
 ${\mathbf{w}}_i$
, in the below, we focus on
${\mathbf{w}}_i$
, in the below, we focus on
 ${z}_{p1}$
and
${z}_{p1}$
and
 ${w}_{i1}$
. In addition, due to space limitations, in the main text, we mostly provide graphical and verbal displays of the results, but we will make references to tables that can be found in the Supplementary Material.
${w}_{i1}$
. In addition, due to space limitations, in the main text, we mostly provide graphical and verbal displays of the results, but we will make references to tables that can be found in the Supplementary Material.
3.2.1 Parameter recovery
Figure 2 contains the average estimates and standard deviations across replications for
 ${z}_{p1}$
in the cases of
${z}_{p1}$
in the cases of
 $n=24$
and
$n=24$
and
 $n=96$
in the
$n=96$
in the
 $\gamma =1$
and
$\gamma =1$
and
 $\gamma =1.7$
conditions for
$\gamma =1.7$
conditions for
 $N=\mathrm{1,000}$
. In addition, similarly, Figure 3 contains the average estimates and standard deviations across replications for
$N=\mathrm{1,000}$
. In addition, similarly, Figure 3 contains the average estimates and standard deviations across replications for
 ${w}_{i1}$
in the cases of
${w}_{i1}$
in the cases of
 $N=\mathrm{1,000}$
and
$N=\mathrm{1,000}$
and
 $N=\mathrm{10,000}$
in the
$N=\mathrm{10,000}$
in the
 $\gamma =1$
and
$\gamma =1$
and
 $\gamma =1.7$
conditions for
$\gamma =1.7$
conditions for
 $24$
items. In the figures, the true values are the plots on the x-axis and the mean estimates on the y-axis. For the pJML and cJML estimates in the condition
$24$
items. In the figures, the true values are the plots on the x-axis and the mean estimates on the y-axis. For the pJML and cJML estimates in the condition
 $\gamma =1.7$
, the estimates are divided by 1.7, as the
$\gamma =1.7$
, the estimates are divided by 1.7, as the
 $\gamma$
parameter is absorbed in these estimates (as it is not a free parameter in the JML approaches, see above). As can be seen, pJML and MCMC estimates tend to be unbiased up to a shrinkage effect that decreases for increasing
$\gamma$
parameter is absorbed in these estimates (as it is not a free parameter in the JML approaches, see above). As can be seen, pJML and MCMC estimates tend to be unbiased up to a shrinkage effect that decreases for increasing
 $N$
and
$N$
and
 $n$
. For cJML, there is no shrinkage effect noticeable, which is understandable given the constraints used in this approach (Equations (8) and (9)), which operate as uniform priors. Shrinkage of the MCMC estimates diminishes at a higher rate for increasing
$n$
. For cJML, there is no shrinkage effect noticeable, which is understandable given the constraints used in this approach (Equations (8) and (9)), which operate as uniform priors. Shrinkage of the MCMC estimates diminishes at a higher rate for increasing
 $n$
or
$n$
or
 $N$
and
$N$
and
 $\gamma$
compared to pJML especially for
$\gamma$
compared to pJML especially for
 ${z}_{p1}$
.
${z}_{p1}$
.
Plot of the true values of
 ${z}_{1p}$
(x-axis) and the mean estimated values (y-axis) for penalized joint maximum likelihood (pJML), constrained joint maximum likelihood (cJML), and Markov Chain Monte Carlo for 24 and 96 items in the conditions
${z}_{1p}$
(x-axis) and the mean estimated values (y-axis) for penalized joint maximum likelihood (pJML), constrained joint maximum likelihood (cJML), and Markov Chain Monte Carlo for 24 and 96 items in the conditions
 $\gamma =1$
and
$\gamma =1$
and
 $\gamma =1.7$
. In addition,
$\gamma =1.7$
. In addition,
 $N=1,000$
in all plots and the gray vertical lines indicate the range of the estimates within one standard deviation from the mean. Note that the pJML and cJML estimates are divided by the true value of
$N=1,000$
in all plots and the gray vertical lines indicate the range of the estimates within one standard deviation from the mean. Note that the pJML and cJML estimates are divided by the true value of
 $\gamma$
(see the text).
$\gamma$
(see the text).

Plot of the true values of
 ${w}_{1i}$
(x-axis) and the mean estimated values (y-axis) for penalized joint maximum likelihood (pJML), constrained joint maximum likelihood (cJML), and Markov Chain Monte Carlo for
${w}_{1i}$
(x-axis) and the mean estimated values (y-axis) for penalized joint maximum likelihood (pJML), constrained joint maximum likelihood (cJML), and Markov Chain Monte Carlo for
 $N=\mathrm{1,000}$
and
$N=\mathrm{1,000}$
and
 $N=\mathrm{10,000}$
in the conditions
$N=\mathrm{10,000}$
in the conditions
 $\gamma =1$
and
$\gamma =1$
and
 $\gamma =1.7$
. In addition,
$\gamma =1.7$
. In addition,
 $n=24$
in all plots and the gray vertical lines indicate the range of the estimates within one standard deviation from the mean. Note that the pJML and cJML estimates are divided by the true value of
$n=24$
in all plots and the gray vertical lines indicate the range of the estimates within one standard deviation from the mean. Note that the pJML and cJML estimates are divided by the true value of
 $\gamma$
(see the text).
$\gamma$
(see the text).

In Supplementary Table A1, the mean absolute bias (MAB), the variance (VAR), and the mean squared error (MSE) of the estimates for person parameters
 ${z}_{1p}$
and
${z}_{1p}$
and
 ${\theta}_p$
averaged over persons are reported. To separate the shrinkage effects from these statistics, for each parameter, the estimates are scaled to have a standard deviation equal to that of the true parameters. The recovery of the standard deviation of the estimates is studied separately later.
${\theta}_p$
averaged over persons are reported. To separate the shrinkage effects from these statistics, for each parameter, the estimates are scaled to have a standard deviation equal to that of the true parameters. The recovery of the standard deviation of the estimates is studied separately later.
The most important result is that for all three methods, the MAB, VAR, and MSE decrease for
 ${z}_{p1}$
and
${z}_{p1}$
and
 ${\theta}_p$
for an increasing number of items,
${\theta}_p$
for an increasing number of items,
 $n$
. In addition, pJML performs comparable to MCMC especially for larger
$n$
. In addition, pJML performs comparable to MCMC especially for larger
 $N$
and
$N$
and
 $n$
. For cJML, the VAR and MSE are slightly higher compared with cJML and MCMC, particularly in conditions with smaller
$n$
. For cJML, the VAR and MSE are slightly higher compared with cJML and MCMC, particularly in conditions with smaller
 $N$
and
$N$
and
 $n$
.
$n$
.
Supplementary Table A2 contains the MSE, VAR, and MAB for item parameters
 ${w}_{i1}$
and
${w}_{i1}$
and
 ${b}_{i1}$
averaged over items. For all three methods, these statistics decrease for both
${b}_{i1}$
averaged over items. For all three methods, these statistics decrease for both
 ${w}_{i1}$
and
${w}_{i1}$
and
 ${b}_i$
for an increasing sample size,
${b}_i$
for an increasing sample size,
 $N$
. One exception is for the estimates of
$N$
. One exception is for the estimates of
 ${b}_i$
for pJML in the
${b}_i$
for pJML in the
 $\gamma =1$
condition where the VAR increases slightly. Similar as for the person parameters, for
$\gamma =1$
condition where the VAR increases slightly. Similar as for the person parameters, for
 ${w}_i$
, pJML performs comparable to MCMC especially for larger
${w}_i$
, pJML performs comparable to MCMC especially for larger
 $N$
and
$N$
and
 $n$
. For cJML, the VAR and MSE are slightly higher compared with cJML and MCMC particularly in conditions with smaller
$n$
. For cJML, the VAR and MSE are slightly higher compared with cJML and MCMC particularly in conditions with smaller
 $N$
and
$N$
and
 $n$
. For
$n$
. For
 ${b}_i$
, results are generally somewhat better for MCMC in the case of smaller
${b}_i$
, results are generally somewhat better for MCMC in the case of smaller
 $N$
,
$N$
,
 $n$
, and
$n$
, and
 $\gamma$
.
$\gamma$
.
Next, we focus on accuracy of the standard deviation of the estimates. As the variance of these standard deviations is very small, we only report the mean bias in Supplementary Table A3. Previously, we focused on the MAB to prevent biasing effects from canceling out across items or persons. However, here, the mean bias is more interesting as it gives an indication of the direction of the effect. That is, a mean bias smaller than 0 indicates shrinkage of the parameter estimates, whereas a mean bias larger than 0 indicates increased parameter variability. In addition, as we are not aggregating over persons or items, effects cannot cancel out.
As the standard deviations of the parameters are not explicit model parameters for pJML and cJML, and these parameters are fixed for MCMC (except for
 ${\sigma}_{\theta}^2$
), the mean bias of the standard deviations has been determined by focussing on the theoretically expected standard deviation. For MCMC, the expected standard deviation is the standard deviations of the true values used to simulate the data (see above). For pJML and cJML, the expected value of
${\sigma}_{\theta}^2$
), the mean bias of the standard deviations has been determined by focussing on the theoretically expected standard deviation. For MCMC, the expected standard deviation is the standard deviations of the true values used to simulate the data (see above). For pJML and cJML, the expected value of
 $SD\left({w}_{1i}\right)$
and
$SD\left({w}_{1i}\right)$
and
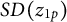 $SD\left({z}_{1p}\right)$
are, respectively,
$SD\left({z}_{1p}\right)$
are, respectively,
 $\gamma \times SD\left({w}_{1i}\right)$
and
$\gamma \times SD\left({w}_{1i}\right)$
and
 $\gamma \times SD\left({z}_{1p}\right)$
as
$\gamma \times SD\left({z}_{1p}\right)$
as
 $\gamma$
is expected to be absorbed in
$\gamma$
is expected to be absorbed in
 ${w}_{1i}$
and
${w}_{1i}$
and
 ${z}_{1p}$
as discussed above. For
${z}_{1p}$
as discussed above. For
 $SD$
(
$SD$
(
 ${b}_i$
) and
${b}_i$
) and
 $SD\left({\theta}_p\right)$
, the expected values are the standard deviations of the true values used to simulate the data. The results show that, as was already concluded from Figures 2 and 3, shrinkage effects are present for pJML and MCMC with slightly negative biases that decrease for increasing
$SD\left({\theta}_p\right)$
, the expected values are the standard deviations of the true values used to simulate the data. The results show that, as was already concluded from Figures 2 and 3, shrinkage effects are present for pJML and MCMC with slightly negative biases that decrease for increasing
 $N$
and
$N$
and
 $n$
. This decrease generally follows a higher rate for MCMC compared with pJML. For cJML, the estimates are mostly associated with increased variability with positive biases that decrease for increasing
$n$
. This decrease generally follows a higher rate for MCMC compared with pJML. For cJML, the estimates are mostly associated with increased variability with positive biases that decrease for increasing
 $N$
and
$N$
and
 $n$
.
$n$
.
3.2.2 Estimation time
Figure 4 contains a bar plot of the mean estimation time of the different approaches for
 $\gamma =1$
in minutes. For
$\gamma =1$
in minutes. For
 $\gamma =1.7$
, pJML and cJML are even faster, while MCMC is about as fast (see Supplementary Table A4). It can be concluded that pJML is the fastest, and MCMC is the slowest. These averages are just given as an indication; the comparison between cJML/pJML and MCMC may not be fully fair as the settings for the MCMC routine (e.g., number of samples) may be tuned in specific conditions so that the average times shown in the figure are an overestimate. However, looking at the number of samples you can take from the posterior parameters in the average time pJML took to converge (also in the figure), it is clear that the JML-based approaches require a substantial smaller amount of time. As discussed, this brings possibilities for establishing model fit, which are discussed below.
$\gamma =1.7$
, pJML and cJML are even faster, while MCMC is about as fast (see Supplementary Table A4). It can be concluded that pJML is the fastest, and MCMC is the slowest. These averages are just given as an indication; the comparison between cJML/pJML and MCMC may not be fully fair as the settings for the MCMC routine (e.g., number of samples) may be tuned in specific conditions so that the average times shown in the figure are an overestimate. However, looking at the number of samples you can take from the posterior parameters in the average time pJML took to converge (also in the figure), it is clear that the JML-based approaches require a substantial smaller amount of time. As discussed, this brings possibilities for establishing model fit, which are discussed below.
Bar plot of the mean estimation time in minutes for penalized joint maximum likelihood (pJML), constrained joint maximum likelihood, and Markov Chain Monte Carlo for the different conditions and
 $\gamma =1$
. The error bars indicate one standard deviation. The numbers indicate the rounded number of samples you can take from the posterior parameters in the average time pJML took to converge (after thinning in brackets).
$\gamma =1$
. The error bars indicate one standard deviation. The numbers indicate the rounded number of samples you can take from the posterior parameters in the average time pJML took to converge (after thinning in brackets).

3.2.3 Cross-validation
We conducted additional simulations to test the appropriateness of our proposed
 $K$
-folds cross-validation procedure. The full description of this study and the results can be found in Appendix B of the Supplementary Material. The main results indicate that cross-validation with the UCE, URE, and RSS metrics as proposed above can distinguish well between the models for
$K$
-folds cross-validation procedure. The full description of this study and the results can be found in Appendix B of the Supplementary Material. The main results indicate that cross-validation with the UCE, URE, and RSS metrics as proposed above can distinguish well between the models for
 $\gamma =1$
, irrespective of the number of items, the number of persons, or the number of folds considered. For the smaller data scenario (
$\gamma =1$
, irrespective of the number of items, the number of persons, or the number of folds considered. For the smaller data scenario (
 $N=\mathrm{1,000}$
,
$N=\mathrm{1,000}$
,
 $n=24$
), the
$n=24$
), the
 $UCE$
has difficulties, correctly identifying the
$UCE$
has difficulties, correctly identifying the
 $R=1$
model for five folds (true positive rate of 0
$R=1$
model for five folds (true positive rate of 0
 $.66$
). However, using
$.66$
). However, using
 $10$
folds, the true positive rate increases to 0.78, which is more acceptable. For
$10$
folds, the true positive rate increases to 0.78, which is more acceptable. For
 $\gamma =1.7$
, all true positives were at least 0.98, with one exception of a true positive of 0.86 for the
$\gamma =1.7$
, all true positives were at least 0.98, with one exception of a true positive of 0.86 for the
 $UCE$
when
$UCE$
when
 $R=1$
and
$R=1$
and
 $K=5$
.
$K=5$
.
It should be noted that our cross-validation procedure tends to overselect, and not underselect. That is, although, in general, the correct model is picked most of the times, if an incorrect model is being selected, it is always a model with a larger
 $R$
than the true model. This is a known property of cross-validation in general (see Li et al., Reference Li, Levina and Zhu2020), but it should be kept in mind when using cross-validation for dimensionality selection.
$R$
than the true model. This is a known property of cross-validation in general (see Li et al., Reference Li, Levina and Zhu2020), but it should be kept in mind when using cross-validation for dimensionality selection.
3.3 Conclusion
In general, our cJML and pJML estimation approaches perform as intended. The parameter recovery is comparable to that of MCMC with some minor differences in specific conditions due to differences in the priors and restrictions imposed. The cJML estimates are generally more variable because of the constraints in this approach being the least restrictive among the three approaches. However, it should be noted that in practice,
 ${C}_1$
and
${C}_1$
and
 ${C}_2$
may be chosen by cross-validation, which may decrease parameter variability. The pJML approach is generally faster than cJML, with MCMC being slower than the JML approaches. Finally, the cross-validation procedure works well in selecting the number of dimensions of the latent space.
${C}_2$
may be chosen by cross-validation, which may decrease parameter variability. The pJML approach is generally faster than cJML, with MCMC being slower than the JML approaches. Finally, the cross-validation procedure works well in selecting the number of dimensions of the latent space.
4 Illustration 1: dichotomous data
4.1 Data
In this section, we analyze the scores of
 $N=418$
children to 24 items from a Piagetian syllogistic deductive reasoning test (see Spiel et al., Reference Spiel, Glück and Gösslers2001). These data have previously been analyzed using an MCMC LSIRM by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021). In the present application, we use these data to illustrate the similarities between the results of JML and MCMC after appropriate rotation. In addition, Jeon et al. tested the fit of an
$N=418$
children to 24 items from a Piagetian syllogistic deductive reasoning test (see Spiel et al., Reference Spiel, Glück and Gösslers2001). These data have previously been analyzed using an MCMC LSIRM by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021). In the present application, we use these data to illustrate the similarities between the results of JML and MCMC after appropriate rotation. In addition, Jeon et al. tested the fit of an
 $R=0$
LSIRM against an
$R=0$
LSIRM against an
 $R=2$
LSIRM using the spike and slab prior approach discussed above. Here, we verify these results using the present cross-validation approach with
$R=2$
LSIRM using the spike and slab prior approach discussed above. Here, we verify these results using the present cross-validation approach with
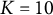 $K=10$
and extend these results by also considering
$K=10$
and extend these results by also considering
 $R=1$
and
$R=1$
and
 $R=3$
. In addition, we explore the results of the
$R=3$
. In addition, we explore the results of the
 $R=3$
model. Models are fit using the same methods and settings as discussed for Simulation Study 1.
$R=3$
model. Models are fit using the same methods and settings as discussed for Simulation Study 1.
4.2 Results
We first consider the LSIRM with
 $R=2$
as studied by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021) in an MCMC framework. After the rotation of the MCMC results to an echelon structure, correlations among the parameter estimates across the different approaches are close to 1.0 (i.e., at least 0.989 for the MCMC—JML parameter estimate correlations) or practically 1.0 (i.e., at least 0.999 for the pJML and cJML parameter estimate correlations). We, therefore, only consider the pJML results below.
$R=2$
as studied by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021) in an MCMC framework. After the rotation of the MCMC results to an echelon structure, correlations among the parameter estimates across the different approaches are close to 1.0 (i.e., at least 0.989 for the MCMC—JML parameter estimate correlations) or practically 1.0 (i.e., at least 0.999 for the pJML and cJML parameter estimate correlations). We, therefore, only consider the pJML results below.
Table 1 contains the results of the cross-validation for models with
 $R=0,$
$R=0,$
 $R=1$
,
$R=1$
,
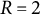 $R=2$
,
$R=2$
,
 $and\;R=3$
. As can be seen, the
$and\;R=3$
. As can be seen, the
 $UCE$
and
$UCE$
and
 $RSS$
select the
$RSS$
select the
 $R=2$
model to be the best fitting, whereas the
$R=2$
model to be the best fitting, whereas the
 $URE$
favors the
$URE$
favors the
 $R=3$
model. As Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021) considered an
$R=3$
model. As Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021) considered an
 $R=2$
model, we here also explore if an
$R=2$
model, we here also explore if an
 $R=3$
model will give some additional insights. First, in Figure 5, the
$R=3$
model will give some additional insights. First, in Figure 5, the
 ${\mathbf{w}}_i$
and
${\mathbf{w}}_i$
and
 ${\mathbf{z}}_p$
estimates are plotted for an
${\mathbf{z}}_p$
estimates are plotted for an
 $R=2$
LSIRM. The figure is highly comparable to Figure 8a of Jeon et al., up to a difference in orientation due to the differences in rotation between pJML and MCMC. Following Jeon et al., we label the four item clusters that are observed as “I1” to “I4” in the figure. These are interpreted as, respectively, concrete complex inference items, abstract and counterfactual logical fallacy items, bi-conditional items, and complex algebra items.
$R=2$
LSIRM. The figure is highly comparable to Figure 8a of Jeon et al., up to a difference in orientation due to the differences in rotation between pJML and MCMC. Following Jeon et al., we label the four item clusters that are observed as “I1” to “I4” in the figure. These are interpreted as, respectively, concrete complex inference items, abstract and counterfactual logical fallacy items, bi-conditional items, and complex algebra items.
Model fit indices as based on a 10-fold cross-validation.

Note: For each metric, the smallest value is in boldface.
 $RSS$
, residual sum of squares;
$RSS$
, residual sum of squares;
 $UCE$
, unnormalized classification error;
$UCE$
, unnormalized classification error;
 $URE$
, unnormalized ROC error.
$URE$
, unnormalized ROC error.
Plot of the estimates of vector
 ${\mathbf{w}}_i$
from an
${\mathbf{w}}_i$
from an
 $R=2$
model for all items. I1–I4 are the item groups identified by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021).
$R=2$
model for all items. I1–I4 are the item groups identified by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021).

Next, we fit an
 $R=3$
LSIRM. Figure 6 contains a three-dimensional plot of the estimates of
$R=3$
LSIRM. Figure 6 contains a three-dimensional plot of the estimates of
 ${\mathbf{w}}_i$
from this model. We first focus on an orientation of the view of the plot in which variability on dimension 1 (
${\mathbf{w}}_i$
from this model. We first focus on an orientation of the view of the plot in which variability on dimension 1 (
 ${w}_{i1}$
) is mostly masked to show the correspondence with the
${w}_{i1}$
) is mostly masked to show the correspondence with the
 $R=2$
plot in Figure 5. It is important to note that by using the echelon restrictions in the way illustrated in Equation (10), the first dimension from an
$R=2$
plot in Figure 5. It is important to note that by using the echelon restrictions in the way illustrated in Equation (10), the first dimension from an
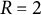 $R=2$
model corresponds to the second dimension in an
$R=2$
model corresponds to the second dimension in an
 $R=3$
model. Therefore, we masked dimension 1 in Figure 6 to show the correspondence to Figure 5. As these figures indeed correspond, we now demonstrate the differences on the first dimension in Figure 7. As can be seen, an additional item cluster seems to arise splitting cluster I2 into l2a and l2b where I2a are items 10, 11, 14, and 15, and I2b are items 18, 19, 22, and 23. In Figure 8, we next add the estimates of
$R=3$
model. Therefore, we masked dimension 1 in Figure 6 to show the correspondence to Figure 5. As these figures indeed correspond, we now demonstrate the differences on the first dimension in Figure 7. As can be seen, an additional item cluster seems to arise splitting cluster I2 into l2a and l2b where I2a are items 10, 11, 14, and 15, and I2b are items 18, 19, 22, and 23. In Figure 8, we next add the estimates of
 ${\mathbf{z}}_p$
to the three-dimensional plot. This figure illustrates that persons differ in their proximity to the different item clusters, with the I3 items (blue) being more isolated, for instance, compared with the I1 items (red).
${\mathbf{z}}_p$
to the three-dimensional plot. This figure illustrates that persons differ in their proximity to the different item clusters, with the I3 items (blue) being more isolated, for instance, compared with the I1 items (red).
Plot of the estimates of vector
 ${\mathbf{w}}_i$
from an
${\mathbf{w}}_i$
from an
 $R=3$
model for all items. The view has been adjusted to demonstrate correspondence with the results for the
$R=3$
model for all items. The view has been adjusted to demonstrate correspondence with the results for the
 $K=2$
model, which lacks dimension 1 (see the text).
$K=2$
model, which lacks dimension 1 (see the text).

Plot of the estimates of vector
 ${\mathbf{w}}_i$
from an
${\mathbf{w}}_i$
from an
 $R=3$
model for all items. The view has been chosen to demonstrate the differences across dimension 1.
$R=3$
model for all items. The view has been chosen to demonstrate the differences across dimension 1.

Same as Figure 7, but with the estimates of
 ${\mathbf{z}}_p$
added.
${\mathbf{z}}_p$
added.

4.3 Conclusion
The main purpose of this real data analysis was to illustrate our JML-based approach on real data. A cross-validation indicated that an
 $R=2$
model seems, indeed, appropriate for the deductive reasoning task analyses by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021) using an MCMC approach. As results indicated that there may be variability on an additional dimension, we explored a three-dimensional model and found some differences among the items in the three-dimensional space.
$R=2$
model seems, indeed, appropriate for the deductive reasoning task analyses by Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021) using an MCMC approach. As results indicated that there may be variability on an additional dimension, we explored a three-dimensional model and found some differences among the items in the three-dimensional space.
5 Illustration 2: ordered categorical data
5.1 Data
In this section, we illustrate the application of the present methodology to the analysis of ordinal data. To this end, we analyze data from the Adjective Check List (ACL; Gough & Heilbrun, Reference Gough and Heilbrun1980). The original ACL consists of 300 adjectives for which respondents need to indicate on a 5-point scale to what degree the adjective describes the personality of the respondent. The item scores of 433 students on an adapted version of the ACL is available as part of the Mokken package in R (Van der Ark, Reference Van der Ark2007). Here, we focus on the Communality and the Dominance scale, which both consist of 10 items. We fit the ordinal LSIRM in Equation (18) to each scale separately using the cumulative binary dummy coding approach described above. We focus on
 $R=2$
for ease of interpretation and visualization. The contraindicative items (indicated by an asterisk in the item name in the presentation of the results) are reversely coded. For the item “reliable” from the Communality scale, respondents did not use the lowest response category. Therefore, this item only has three threshold parameters, and all other items have four threshold parameters.
$R=2$
for ease of interpretation and visualization. The contraindicative items (indicated by an asterisk in the item name in the presentation of the results) are reversely coded. For the item “reliable” from the Communality scale, respondents did not use the lowest response category. Therefore, this item only has three threshold parameters, and all other items have four threshold parameters.
5.2 Results
Item parameter estimates for
 ${\beta}_{ic}$
and
${\beta}_{ic}$
and
 ${\boldsymbol{w}}_i$
of the ordinal LSIRM can be found in Supplementary Table C1. In Figure 9, the latent space, including
${\boldsymbol{w}}_i$
of the ordinal LSIRM can be found in Supplementary Table C1. In Figure 9, the latent space, including
 ${\boldsymbol{z}}_p$
, is displayed for the two scales. For the item positions
${\boldsymbol{z}}_p$
, is displayed for the two scales. For the item positions
 ${\boldsymbol{w}}_i$
, the figure contains 99% confidence ellipses based on bootstrapped standard errors using 1,000 samples. Even though the scales are intended to be unidimensional, as can be seen from the figure, for both scales, the items seem to meaningfully cluster. For instance, for the Communality scale, omitting the “unscrupulous*” and “honest” items that have relatively large standard errors, three clusters arise: the “unintelligent*” item on the on side, which is apart from all the other items; the “reliable”–“dependable” cluster; and a cluster with among others “cruel*” and “unfriendly*.” Items within a cluster are close to each other while being further away from the other clusters. For the Dominance scale, something similar is observed, omitting the “timid*” item, which has a relatively large standard error, “dreamy*” stands out as it is apart from most of the items, while “dominant,” “strong,” and “enterprising” form a cluster, and the other items form a separate cluster. “Apathic*” is separate but in the middle of the three clusters.
${\boldsymbol{w}}_i$
, the figure contains 99% confidence ellipses based on bootstrapped standard errors using 1,000 samples. Even though the scales are intended to be unidimensional, as can be seen from the figure, for both scales, the items seem to meaningfully cluster. For instance, for the Communality scale, omitting the “unscrupulous*” and “honest” items that have relatively large standard errors, three clusters arise: the “unintelligent*” item on the on side, which is apart from all the other items; the “reliable”–“dependable” cluster; and a cluster with among others “cruel*” and “unfriendly*.” Items within a cluster are close to each other while being further away from the other clusters. For the Dominance scale, something similar is observed, omitting the “timid*” item, which has a relatively large standard error, “dreamy*” stands out as it is apart from most of the items, while “dominant,” “strong,” and “enterprising” form a cluster, and the other items form a separate cluster. “Apathic*” is separate but in the middle of the three clusters.
Graphical representation of the ordinal latent space item response model in application 2 for the Communality scale (left) and the Dominance scale (right) of the ACL. The red dots represent the item locations
 ${\boldsymbol{w}}_i$
, and the gray dots represent the person locations
${\boldsymbol{w}}_i$
, and the gray dots represent the person locations
 ${\boldsymbol{z}}_p$
. The ellipses around the item locations give the range of the 99% confidence intervals. The location of the first item (“reliable” in Communality scale and “apathic” in the Dominance scale) is indicated by a star instead of a dot as
${\boldsymbol{z}}_p$
. The ellipses around the item locations give the range of the 99% confidence intervals. The location of the first item (“reliable” in Communality scale and “apathic” in the Dominance scale) is indicated by a star instead of a dot as
 ${w}_{11}$
is fixed to 0 for this item, and a 99% confidence line is displayed for this item.
${w}_{11}$
is fixed to 0 for this item, and a 99% confidence line is displayed for this item.

For the person positions, respondents are scattered across the clusters, with some persons have an estimate closer to, for example, the “reserved*–withdrawn*” item cluster than to other items. Respondents near the origin of the coordinate system (0,0) score high or low on all items (which could be inferred from their
 ${\theta}_p$
estimate).
${\theta}_p$
estimate).
5.3 Conclusion
We demonstrated the viability of the ordinal LSIRM on a real dataset. In practice, results like the above can be used to make profiles. For instance, using the adjectives check list above, in job applicant selection, one may want to aim for respondents close to the “enterprising” and “strong” items, but also to the shy* and timid* items, while not necessarily close to the “dreamy*” item. Using the present approach such distances between persons and items can readily be interpreted. Other statistical methods like factor analysis are valuable but serve different purposes compared with the latent space approach adopted here. That is, factor analysis parameters cannot be interpreted in terms of item–person distances as in factor analysis triangular inequality is violated. For a more elaborate discussion on the differences, see Jeon et al. (Reference Jeon, Jin, Schweinberger and Baugh2021).
6 Discussion
In this study, we proposed regularized JML estimation to fit the LSIRM to data. A key advantage is that the estimation is fast, which hopefully facilitates the use of these models by the applied researcher. Owing to its fast nature, model selection can be conducted using
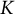 $K$
-folds cross-validation, which is valuable as such model selection tools are still relatively limited in the LSIRM literature.
$K$
-folds cross-validation, which is valuable as such model selection tools are still relatively limited in the LSIRM literature.
These advantages come at the cost of reduced information about the posterior parameter distribution. That is, the MCMC approach results in estimates of the full posteriors parameter distributions, while, as discussed, the estimates in our approach can be conceived as MAP estimates (e.g., Swaminathan & Gifford, Reference Swaminathan and Gifford1985). Our approach does not give such detailed information about the shape of the posterior parameter distributions. In the illustration section, we bootstrapped the standard errors, but this increases the computational burden. The observed and expected information matrices may be useful in obtaining uncertainty measures; however, for our approach, the theoretical properties of these matrices are strictly unknow. At best, they give a local approximation if the posterior is normal near its mode. As MCMC can account for any form of the parameter distribution in principle, MCMC is superior in its measures of parameter uncertainty. Therefore, as noted earlier, we do not view our approach as a replacement for existing LSIRM modeling tools, but rather as an extension. For example, when uncertainty measures are of primary importance, MCMC estimation remains preferable. Conversely, if the main goal is to visualize latent space positions or determine the dimensions of the latent space, our JML-based approaches are recommended.
As discussed in this article, traditional JML estimation as proposed by Birnbaum (Reference Birnbaum, Lord and Novick1968) is known to be asymptotically inconsistent (e.g., Haberman, Reference Haberman1977). For a multidimensional unstructured two-parameter logistic model, Chen et al. (Reference Chen, Li and Zhang2019) proofed JML to be consistent in the double asymptotic sense under appropriate constraints. As mentioned, we did not study such theoretical consistency for our approach. However, the simulation results suggest that parameter bias decreases for increasing number of items and sample size. Moreover, theoretical consistency was not our main objective in this study. That is, we studied JML as a less time-consuming complement to the existing MCMC procedures but with comparable results. In that respect, our approach performs as desired. It should be noted, however, that our implementation of the constrained JML approach uses the results from Chen et al. (Reference Chen, Li and Zhang2019), which are known to be asymptotically consistent in the average sense (the overall MSE approaches 0). For entry-wise consistency (i.e., MSE approaches 0 for each parameter), additional post processing steps are needed (see Chen and Li, Reference Chen and Li2024). Here, we did not consider such post processing, but we note that our approach is equally amenable to such a treatment.
Supplementary material.
To view supplementary material for this article, please visit http://doi.org/10.1017/psy.2025.10068.
Disclosure of use of AI tools
In this research, ChatGPT has been used to assist in literature searches and some minor writing edits.
Funding statement
There are no funders to report for this submission. Open access funding provided by University of Amsterdam.
Competing interests
The authors declare no competing interests.





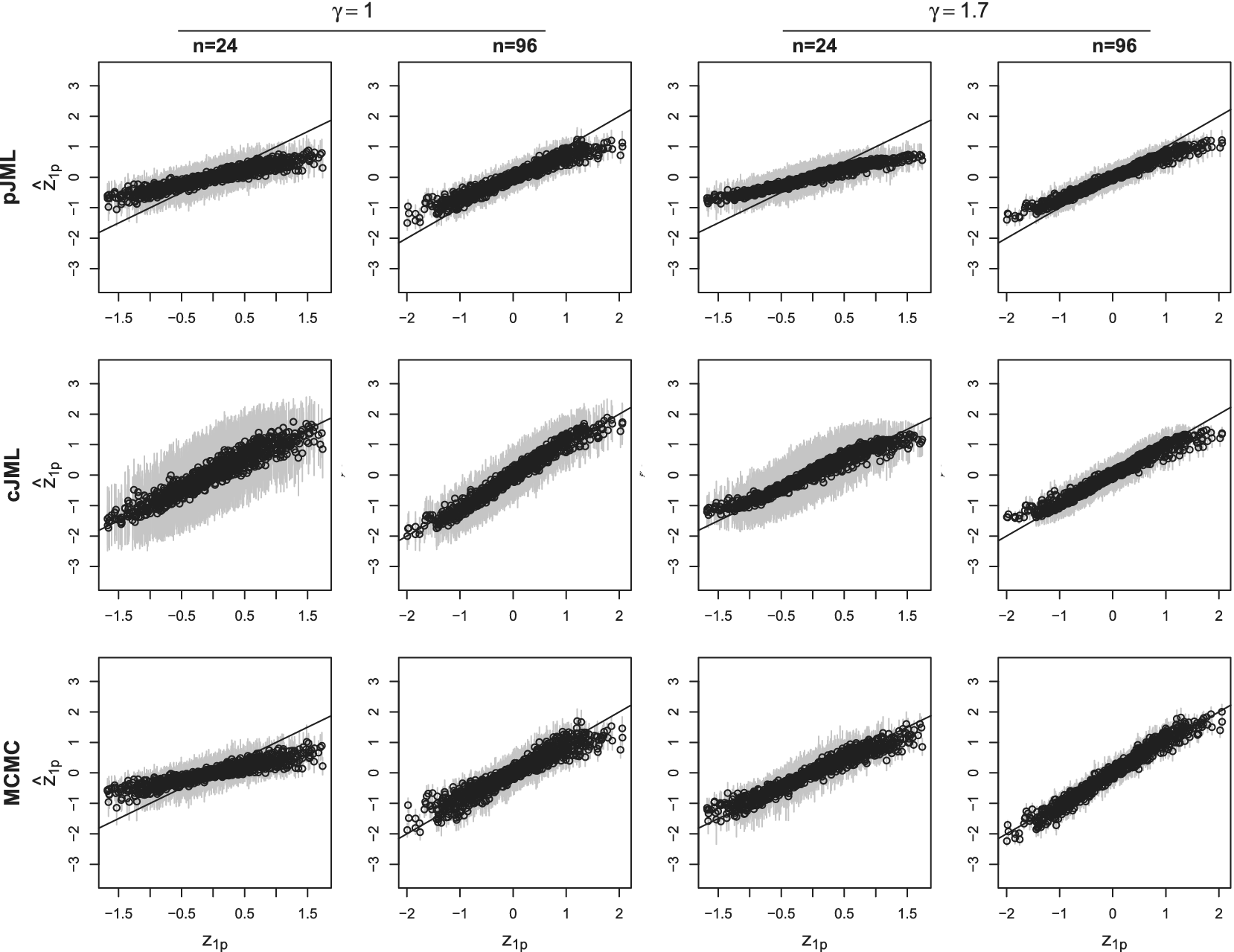





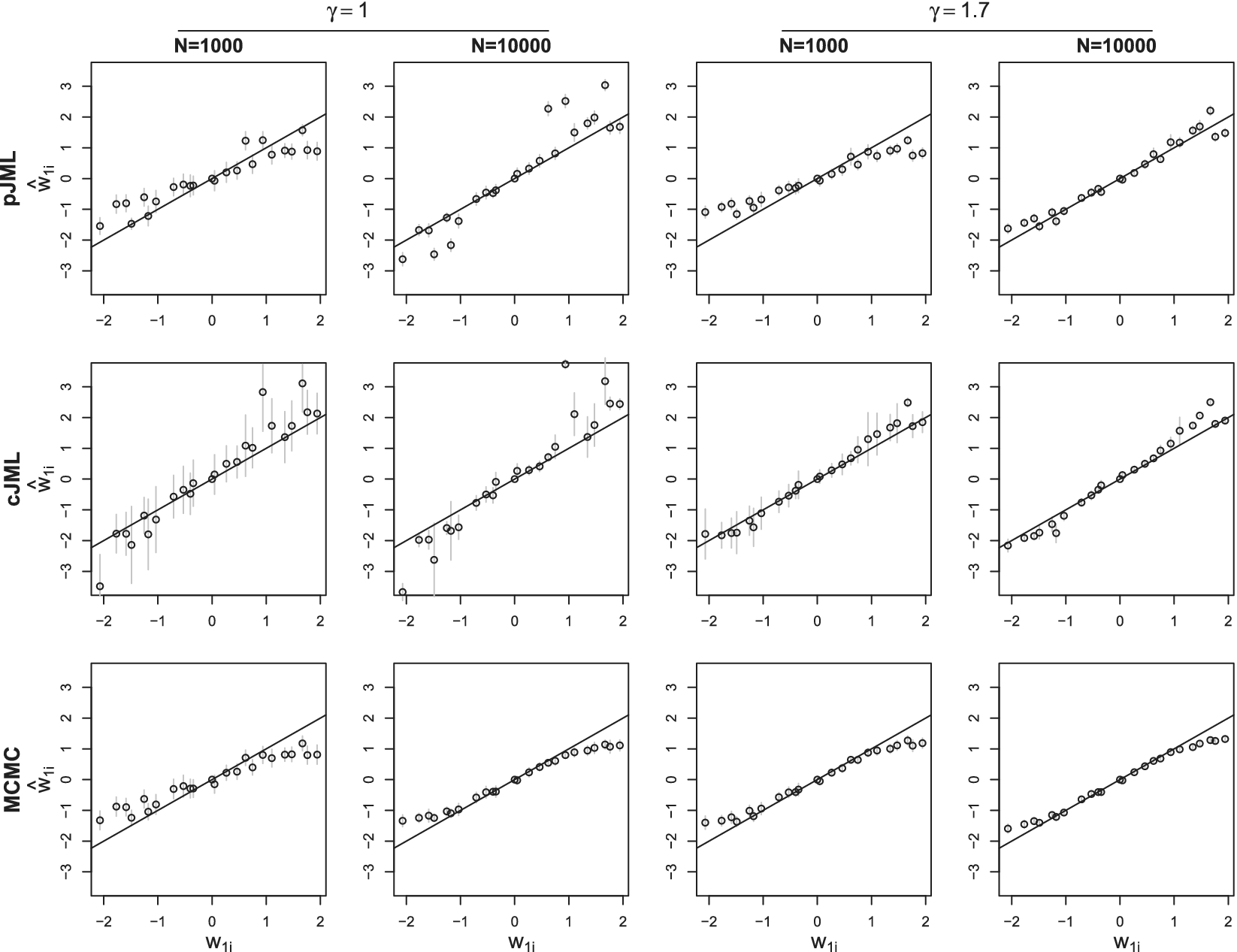







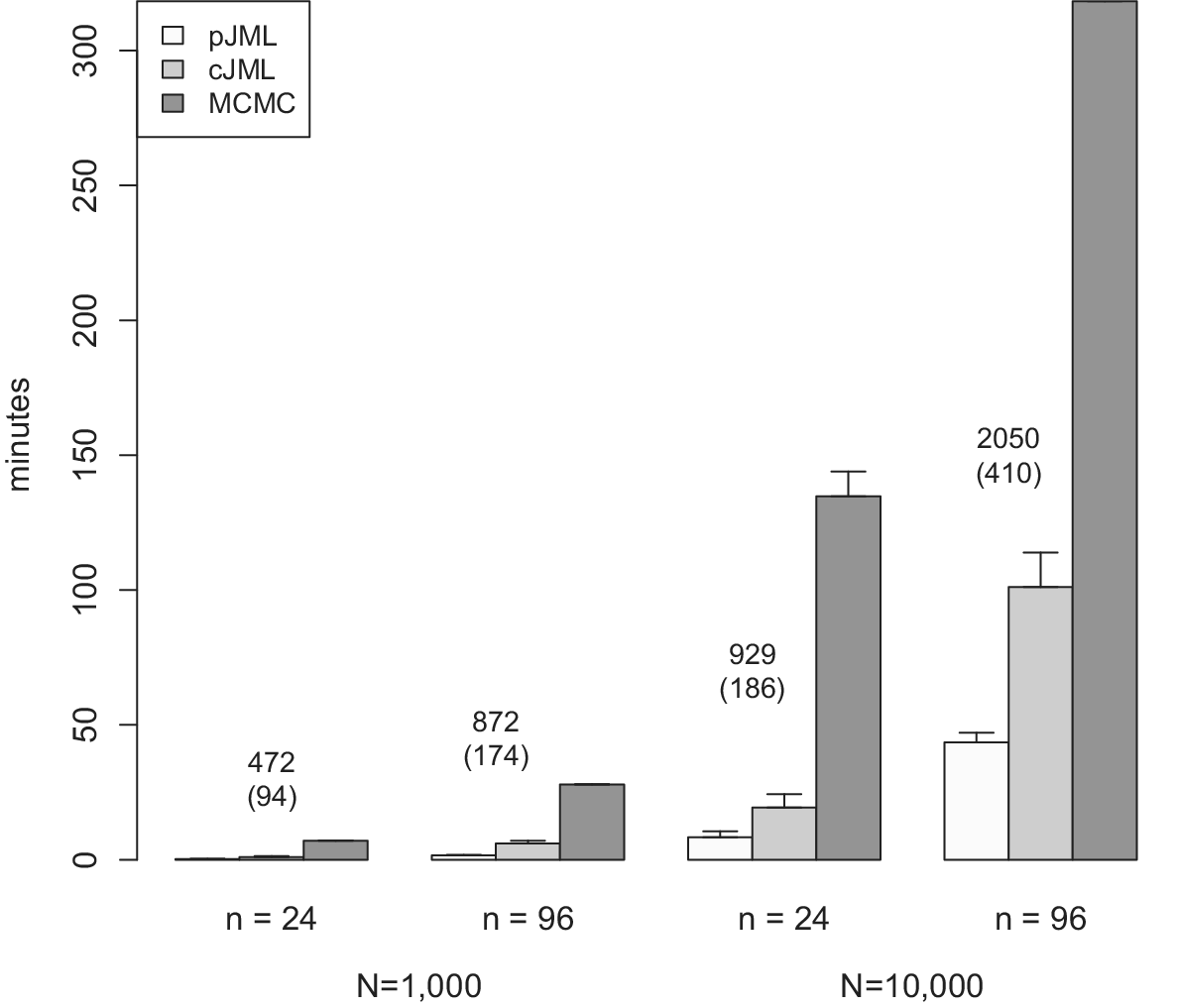

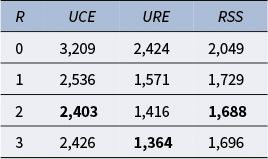



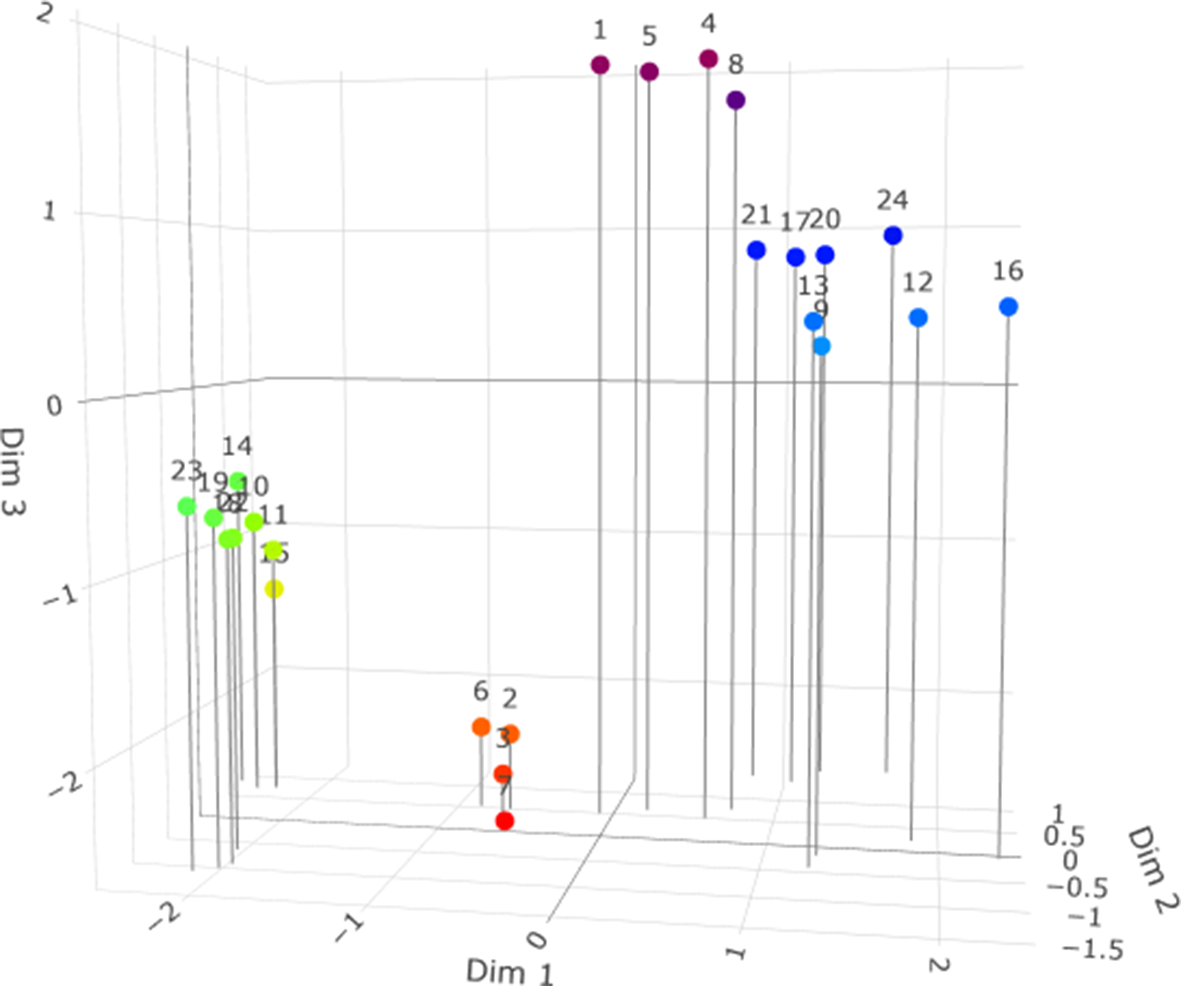














 Open access
Open access