


1. Introduction
NLP tasks such as morphological segmentation, morpheme tagging, part-of-speech (POS) tagging, and syntactic parsing onto semantic dependencies have been widely investigated for extracting the meaning of a clause. These tasks can be considered to be different stages in reaching semantics: morphological segmentation and morpheme tagging deal with the morphemes inside a word;Footnote a POS tagging captures the words in a particular context, usually in a clause; dependency parsing views each clause as a sequence of words and the relations between them, such as subject, modifier, complement.
In these tasks, morpheme tagging labels each morpheme in a word with the syntactic information of the morpheme in that particular context, for example, person or tense. POS tagging assigns a syntactic category to each word in a context (e.g., noun and adjective). Dependency parsing finds relations such as argument, complement, and adjunct between words in terms of word–word dependencies. Dependency labeling assigns a tag (e.g., subject, object, and modifier) to every dependency relation.
Different aspects of language such as phonology, morphology, parts of speech, and dependency relations of words must be linked to each other to understand the interaction of these tasks.
For example, in Turkish, a plural marker on a noun pluralizes the noun to which it is attached, whereas a plural on the verb—which has the same phonological shape as nominal plural—indicates (as agreement) a plural syntactic subject.
Morphology and phonology interact to bring about the dependencies, and the interaction has implications for syntax. For example, in Tagalog, a verb is not available to surface syntax unless it is inflected for voice or marked for recent past. The phonological shape of the voice morpheme depends on the verb class, to be realized as prefix, infix or suffix. It has been argued that Tagalog’s unvoiced and bare verbs are precategorial, that is, without an identifiable POS (Foley Reference Foley1998). Their POS is determined by an interaction of morphology, phonology, and syntax, which call for joint consideration of these aspects.
Furthermore, the question of context in a clause, that is, left and right neighboring of linguistic elements in an expression, is relevant to morphology in ways that require its involvement from the ground up, rather than as an add-on mechanism serving only morphological disambiguation, which would in most cases disambiguate the morphemes of one word depending on its neighbors. A striking example of an extended role for morphology is from the language Kwakw’ala (Anderson Reference Anderson1992). In this language, nominal morphological markers of case, deictic status, and possession are not marked on the word itself but on the preceding word, as “suffixes” of that word. However, these suffixes bear no morphological relation to their phonological host.Footnote b Therefore, these morphemes need right context beyond their phonological host word to identify the stem of these inflections.
Providing a cross-level contextual information flow as we propose intends to inform higher levels so that a combination of the morpheme, the POS tag and the morpheme tag can use attention to right context. By “cross-level contextual information,” we mean phonological, morphological, syntactic, and semantic (dependency) information considered altogether, for each word, rather than exclusively horizontal (or “cascaded”) information flow, for example, first segmenting each word, then tagging and morphological analysis of each word, then syntax, then semantics. It also means that, for example, syntactic properties of a word not only depends on its own morphological properties but also on morphological properties of words in its context. This is true of all information projected upward, to dependencies.
In the current work, the only aspect we project exclusively horizontally is attention to phonemes of words in morphological tagging.
In the other direction of surface structure, that is, in requiring a left context, we do not have to go far to find striking examples which need left context. It is a fact of English morphosyntax in which “group genitives” show their true syntactic potential by semantically scoping over phrases but phonologically appearing in an unrelated word, for example, Every man I know’s taste in wallpaper is appalling (Anderson et al. Reference Anderson, Brown, Gaby and Lecarme2006). The genitive marker in the example bears no morphological or semantic relation to the word on which it appears. The left context that is needed to determine the semantic argument of the genitive can therefore span many words.
It is with these facts in mind that Anderson et al. (Reference Anderson, Brown, Gaby and Lecarme2006) propose relating word-level inflection to leftmost or rightmost daughters of a syntactic phrase. Clearly, it will require joint consideration of phonology, syntax, morphology, and semantics with the context in mind from the ground up.
In this article, we propose to start doing that by looking at a moving window of words at every level, by changing information flow from horizontally cascaded processes to a cross-level one, from morphological segments up to dependencies for every word in a moving window. This choice addresses agglutinating languages quite naturally, albeit within a limited window.Footnote c
We introduce a joint learning framework for morphological segmentation, morpheme tagging, POS tagging, and dependency parsing, with particular modeling emphasis on agglutinating languages such as Turkish. We have tested our system with other languages as well.
The proposed joint learning is a stronger form of multitask learning. Instead of cascaded horizontal processes which are common in multitasks, we propose a different design. We can motivate the design choices as follows.
In Turkish, morphology is agglutinating. Syntactic information is encoded in inflectional morphemes, which are suffixed to the word. An example is given in Figure 1. In the example, -ı in kapağ-ı-nı indicates possession, which is an inflection. It also reveals that its host word is a nominal. It is in a possessive dependency relation with “book.”
A Turkish clause with labeled dependency relations between morphologically complex words. First line: The orthographic form (“-” is for “null”). Second line: morphological segments. Third line: morphological tags (-GEN=genitive, .3s=3rd person singular, -ACC=accusative, -PAST=past tense). Dependencies in the article are arrowed (head to dependent) and labeled UD dependencies (de Marneffe et al. Reference de Marneffe, Manning, Nivre and Zeman2021).
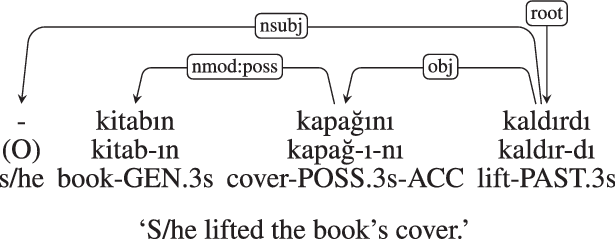
If the stem were a verb, for example, yap-tığ-ı-nı (do-COMP-POSS.3s-ACC) “his/her doing,” the same phonological shape ı would mark agreement with subordinate subject of this verb, rather than possession. This is relevant to choice of dependency. There is no possessive meaning in yaptığ-ı-nı, as can be observed in Ben [[sigara içme-nin] kanser yap-tığ-ı-nı] bilmiyordum (I [cigarette smoking] -GEN.3s cancer do-COMP-POSS.3s-ACC I-not-know) “I did not know that smoking caused cancer.” There is possessive meaning in kapağ-ı-nı. One implication is that their morphological tags must be different, because of differences in semantics.Footnote d
Morphology’s role is crucial and it can be nonlocal in setting up the correct relation of meaning. As we shall see later, in Figures 9(c) and 10, in many cases looking at the previous word is not enough to disambiguate the possessor even in examples where we can determine that the shape has possession semantics; therefore, decoding on this basis alone would not be sufficient (cf. Akyürek, Dayanık, and Yuret Reference Akyürek, Dayanık and Yuret2019). It needs an attention mechanism or its functional equivalent. Therefore, a standard method that involves learning morphology, syntax, and semantics in a horizontal pipeline process would eventually suffer in such circumstances.
Joint learning is a preparation for these concerns. It is defined as learning some related tasks in parallel by using shared knowledge contained in various tasks; therefore, each task can help other tasks to be learned better (Caruana Reference Caruana1997). Representational autonomy of the tasks is the expedient to joint modeling.
We represent distributional meaning in terms of neural vector representations that help to learn some underlying form of a sentence. We use neural character and morpheme representations to learn the word representations for learning POS tags and dependency relations between words. In learning morphological segmentation of words, we aim to obtain a word representation based on morphemes. Recent work shows that representations that are learned from words as separate tokens are not good enough to capture the syntactic and semantic information of words in agglutinating languages because of severe sparsity. Character-level or morpheme-level representations lead to a better prediction of embeddings in such languages (e.g., Üstün, Kurfalı, and Can Reference Üstün, Kurfal and Can2018). Vania and Lopez (Reference Vania and Lopez2017) provide a comparison of word representations. Their results confirm that although character-level embeddings are effective for many languages, they do not perform as well as the models with explicit morphological information. We use both character and morpheme representations in learning POS tags and dependencies.
Our framework is built upon the joint POS tagging and dependency parsing model of Nguyen and Verspoor (Reference Nguyen and Verspoor2018), to which we introduce two more layers for morphological segmentation and morphological tagging. The results show that a unified framework benefits from joint learning of various levels, from morphology to dependencies. Our results with joint learning of morphological tagging and dependency parsing are encouraging compared to the model of Nguyen and Verspoor (Reference Nguyen and Verspoor2018), who model them separately.
The rest of the paper is organized as follows. Section 2 reviews related work in five tasks that we model. Section 3 describes the proposed joint learning framework and the components involved in the architecture. Section 4 presents experimental results and detailed error analysis. A brief section concludes (Section 5).
2. Related work
Adequate treatment of morphology has been one of the long-standing problems in computational linguistics. Some work in the literature deals with it as a segmentation task that only aims to segment each word into its morphemes without identifying the syntactic or semantic role of the morpheme (Goldsmith Reference Goldsmith2001; Creutz and Lagus Reference Creutz and Lagus2007; Can and Manandhar Reference Can and Manandhar2010; Goldwater, Griffiths, and Johnson Reference Goldwater, Griffiths and Johnson2011). Some work deals with morphology as both segmentation and sequence labeling, which is called morphological tagging (Müller et al. Reference Müller, Cotterell, Fraser and Schütze2015; Cotterell and Heigold Reference Cotterell and Heigold2017; Dayanık, Akyürek, and Yuret Reference Dayanık, Akyürek and Yuret2018). POS tagging (Schütze Reference Schütze1993; Clark Reference Clark2000; Van Gael, Vlachos, and Ghahramani Reference Van Gael, Vlachos and Ghahramani2009) and dependency parsing (Kudo and Matsumoto Reference Kudo and Matsumoto2002; Oflazer et al. Reference Oflazer, Say, Hakkani-Tür and Tür2003; Nivre and Nilsson Reference Nivre and Nilsson2005) are well-known tasks in computational linguistics.
In recent years, deep neural networks have been extensively used for all of these tasks. Regarding morphological analysis, Heigold, Neumann, and van Genabith (Reference Heigold, Neumann and van Genabith2017) present an empirical comparison between convolutional neural network (CNN) (Lecun et al. Reference Lecun, Bottou, Bengio and Haffner1998) architectures and long-short-term memory network architectures (LSTMs) (Hochreiter and Schmidhuber Reference Hochreiter and Schmidhuber1997). Character-based architectures are meant to deal with sparsity. LSTMs give slightly better results compared to CNNs. Cotterell and Heigold (Reference Cotterell and Heigold2017) apply transfer learning by jointly training a model for different languages in order to learn cross-lingual morphological features. Shared character embeddings are learned for each language as in joint learning, under a joint loss function. Dayanık et al. (Reference Dayanık, Akyürek and Yuret2018) propose a sequence-to-sequence model for morphological analysis and disambiguation that combines word embeddings, POS tags, and morphological context.
Deep neural networks have also been used for POS tagging. Dos Santos and Zadrozny (Reference Dos Santos and Zadrozny2014) employ both word embeddings and character embeddings obtained from a CNN. Ling et al. (Reference Ling, Dyer, Black, Trancoso, Fermandez, Amir, Marujo and LuÍs2015) introduce a model to learn word representations by composing characters. The open vocabulary problem is addressed by employing the character-level model, and final representations are used for POS tagging. The results are better compared to that of Dos Santos and Zadrozny (Reference Dos Santos and Zadrozny2014).
Joint learning has re-attracted attention in recent years (Sanh, Wolf, and Ruder Reference Sanh, Wolf and Ruder2019; Liu et al. Reference Liu, He, Chen and Gao2019; Li et al. Reference Li, Liu, Yin, Yang, Ma and Jin2020) after the resurgence of neural networks. To our knowledge, there has not been any study that combines morphological segmentation, morpheme tagging, POS tagging, and dependency parsing in a single framework using deep neural networks, especially for morphologically rich languages. There have been various studies that combine some of these taks. Nguyen and Verspoor (Reference Nguyen and Verspoor2018) introduce a model that extends the graph-based dependency parsing model of Kiperwasser and Goldberg (Reference Kiperwasser and Goldberg2016) by adding an extra layer to learn POS tags through another layer of bidirectional LSTM (BiLSTM), which is used as one of the inputs to dependency LSTMs. Yang et al. (Reference Yang, Zhang, Liu, Sun, Yu and Fu2018) propose a joint model to perform POS tagging and dependency parsing based on transition-based neural networks. Zhang et al. (Reference Zhang, Li, Barzilay and Darwish2015) introduce a joint model that combines morphological segmentation, POS tagging, and dependency parsing. The model does not perform morpheme tagging. It is based on randomized greedy algorithm that jointly predicts morphological segmentations, POS tags, and dependency trees. Straka (Reference Straka2018) proposes a pipeline model called UDPipe 2.0 that performs sentence segmentation, tokenization, POS tagging, lemmatization, and dependency parsing. The pipeline framework follows a bottom-up approach without jointly training the tasks. Kondratyuk and Straka (Reference Kondratyuk and Straka2019) extends UDPipe 2.0 with a BERT replacement of embedding and projection layers, which is trained across 75 languages simultaneously.
Our proposed model differs from these models in trying to combine five different tasks in a single learning framework, with the expectation that all five tasks improve by joint modeling, and with cross-level information. The baseline of our framework, Nguyen and Verspoor (Reference Nguyen and Verspoor2018), addresses only POS tagging and dependency parsing. We extend their model with extra layers for morphological segmentation and identification, enabling the model to perform both morphological and syntactic analysis for morphologically rich languages.
3. Joint learning of morphology and syntax
In the base model of Nguyen and Verspoor (Reference Nguyen and Verspoor2018), one component is for POS tagging. It is based on a two-layer BiLSTM (Hochreiter and Schmidhuber Reference Hochreiter and Schmidhuber1997) which encodes sequential information that comes from each word within a sentence. Encoded information is passed through a multilayer perceptron with a single layer that outputs the POS tags. Their second component is for graph-based dependency parsing. It also involves BiLSTM, which learns the features of dependency arcs and their labels by using the predicted POS tags obtained from the POS tagging component, word embeddings, and character-level word embeddings.
The overview of our architecture is shown in Figure 2. We have added one component to learn the morphological segmentation and another to do morphological identification to obtain the morpheme labels. The vectorial representations used in the model are illustrated in Figure 3. We now describe the architecture.
The layers of the proposed joint learning framework. The sentence “Ali okula gitti.” (“Ali went to school”) is processed from morphology up to dependencies.
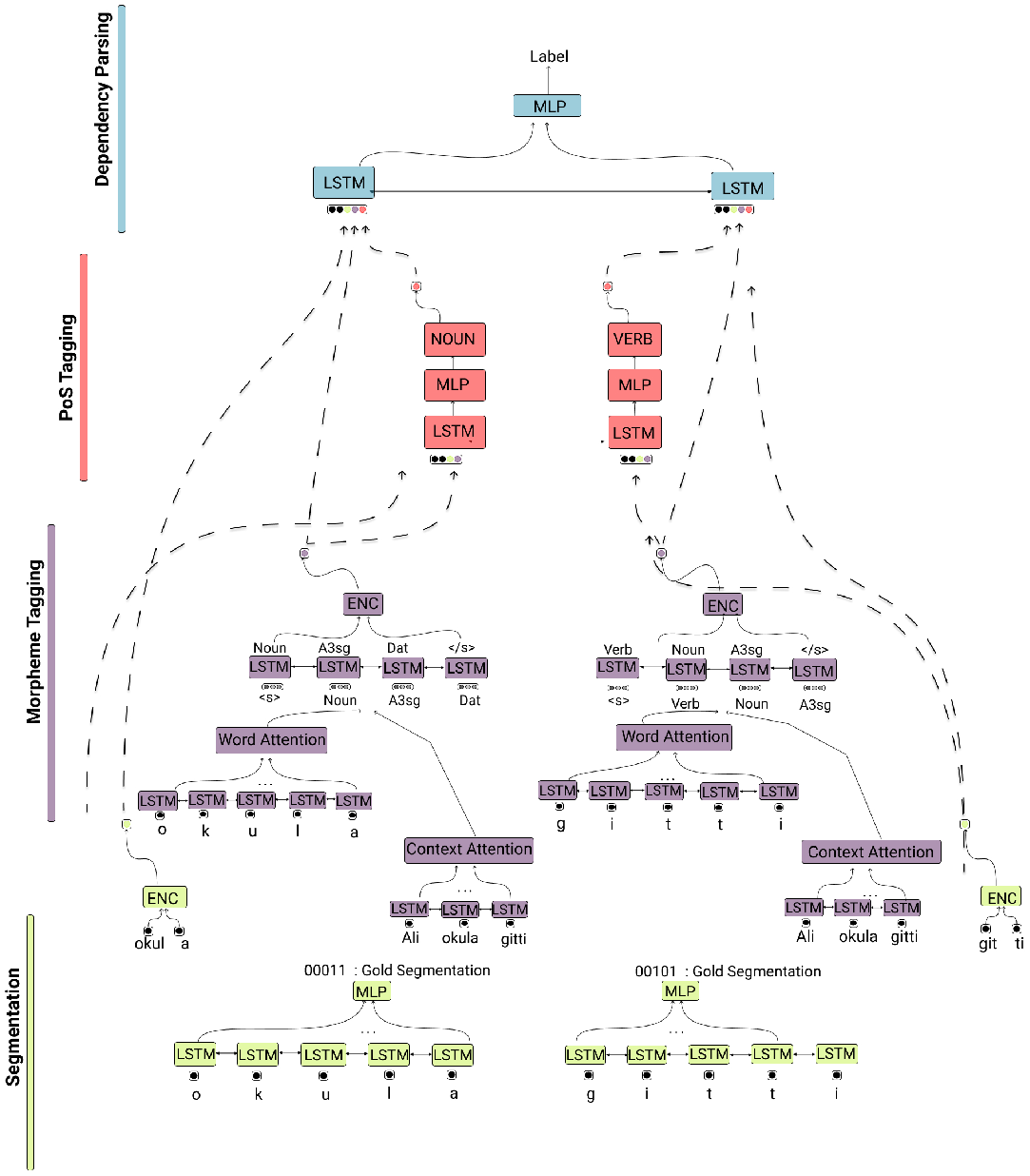
The layers of the proposed joint learning framework working on the sentence “okula gitti” (“(he/she) went to school”). The vectors c, w, e, mt, s, and p denote character, word, concatenated character and word, morphological tag, segment, and POS tag, respectively.
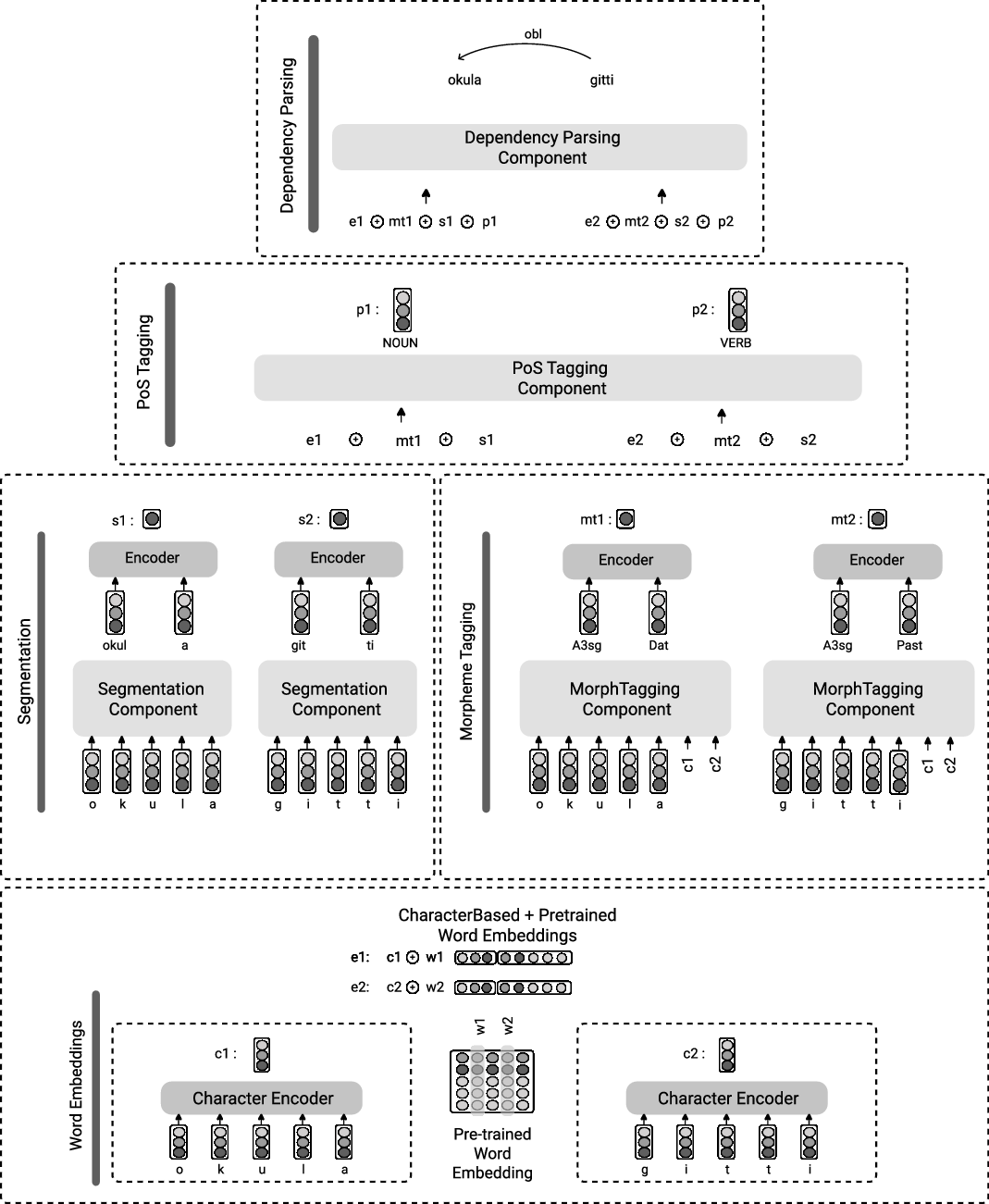
3.1 Morphological segmentation
The lowest-level component in our joint learning framework performs segmentation, which uses characters as proxies for phonological shape. For agglutinating languages, in particular, the task is to make the segmentation morphologically salient, that is, corresponding to a morph. The overall sub-architecture of the segmentation component is given in Figure 4. A BiLSTM (BiLSTM
 $_{\textrm{seg}}$
) which encodes characters in a word is used to learn the sequential character features for segment boundaries. We feed this BiLSTM with one hot character encoding of each character in the word. A latent feature vector
$_{\textrm{seg}}$
) which encodes characters in a word is used to learn the sequential character features for segment boundaries. We feed this BiLSTM with one hot character encoding of each character in the word. A latent feature vector
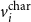 $v_i^{\textrm{char}}$
for a character
$v_i^{\textrm{char}}$
for a character
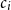 $c_i$
(
$c_i$
(
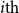 $i{\textrm{th}}$
character in the word) is learned as an output of the BiLSTM at a time step:
$i{\textrm{th}}$
character in the word) is learned as an output of the BiLSTM at a time step:
 \begin{equation} v_i^{\textrm{char}} = \textrm{BiLSTM}_{\textrm{seg}}(e_{1:n},i)\end{equation}
\begin{equation} v_i^{\textrm{char}} = \textrm{BiLSTM}_{\textrm{seg}}(e_{1:n},i)\end{equation}
where
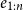 $e_{1:n}$
denotes a sequence of one hot vectors for each character in the word.
$e_{1:n}$
denotes a sequence of one hot vectors for each character in the word.
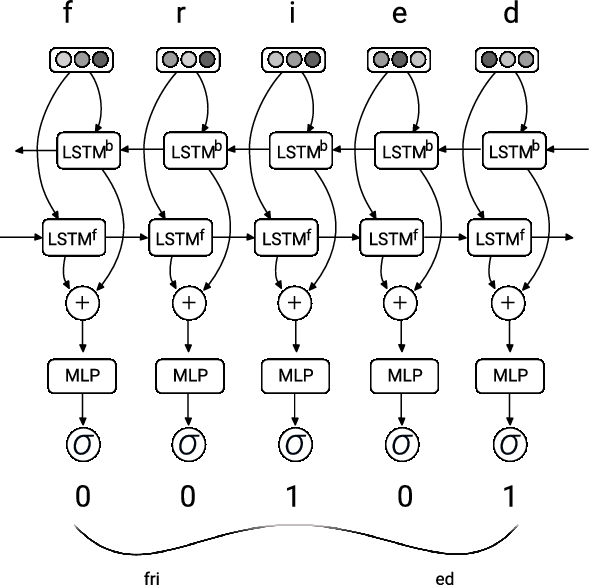
The sub-architecture of the morphological segmentation component. The one hot vector of each character of a word is fed into a BiLSTM. The resulting vector obtained from each state of the BiLSTM is fed into a multilayer perceptron with one hidden layer and with a sigmoid activation function in the output layer. The output of the sigmoid function is a value between 0 and 1, where 1 corresponds to a segment boundary and 0 indicates a non-boundary. In the example, there is a boundary after the character i, that is, 1 is the output from the MLP at that time step.
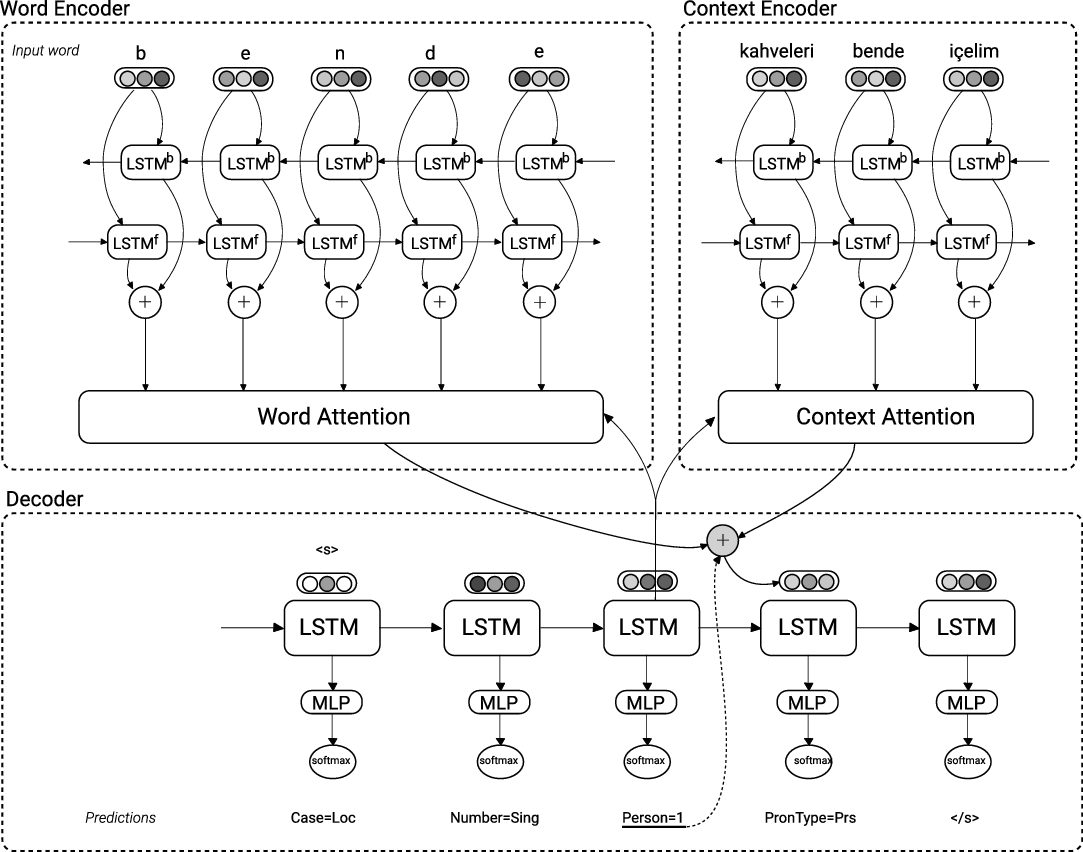
The encoder–decoder sub-architecture of the morphological tagging component. The top part is the encoder and the bottom part is the decoder. The example is “kahveleri bende içelim” (“let’s drink coffee at my place”).
Each output vector is reduced to a single dimension by a multilayer perceptron (MLP) with one hidden layer to predict a segment boundary at a given step:
 \begin{equation} \hat{y_i} = \textrm{sigmoid}\left( \textrm{MLP}_{\textrm{seg}}\left(v_i^{\textrm{char}}\right)\right)\end{equation}
\begin{equation} \hat{y_i} = \textrm{sigmoid}\left( \textrm{MLP}_{\textrm{seg}}\left(v_i^{\textrm{char}}\right)\right)\end{equation}
where
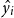 $\hat{y_i}$
denotes prediction probability of being a segment boundary after the
$\hat{y_i}$
denotes prediction probability of being a segment boundary after the
 $i{\textrm{th}}$
character in the word. MLP has one sigmoid output that predicts whether there is a segment boundary at a time step. 1 indicates that there is a segment boundary after the character and 0 indicates that the word will not be split at that point.
$i{\textrm{th}}$
character in the word. MLP has one sigmoid output that predicts whether there is a segment boundary at a time step. 1 indicates that there is a segment boundary after the character and 0 indicates that the word will not be split at that point.
The sigmoid is a continuous function. We use it for binary tagging, where a value above
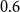 $0.6$
refers to a morpheme boundary and a value below
$0.6$
refers to a morpheme boundary and a value below
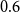 $0.6$
refers to a non-boundary during testing. Therefore, we amplify the values above the threshold to predict a segmentation boundary during testing. However, we sample a segmentation boundary during training based on a probability value sampled randomly.
$0.6$
refers to a non-boundary during testing. Therefore, we amplify the values above the threshold to predict a segmentation boundary during testing. However, we sample a segmentation boundary during training based on a probability value sampled randomly.
Based on the predicted outputs for each position inside the word, we compute the loss defined by binary cross-entropy as follows for Y number of characters inside a word:
 \begin{equation} \mathscr{L}_{ \textrm{seg}} = -\sum_{i=1}^Y \left(y\: \textrm{log}(\hat{y_i})-(1-y) \textrm{log}\left(1-\hat{y_i}\right)\right)\end{equation}
\begin{equation} \mathscr{L}_{ \textrm{seg}} = -\sum_{i=1}^Y \left(y\: \textrm{log}(\hat{y_i})-(1-y) \textrm{log}\left(1-\hat{y_i}\right)\right)\end{equation}
where
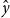 $\hat{y}$
denotes the predicted segmentation and y denotes the gold segmentation.
$\hat{y}$
denotes the predicted segmentation and y denotes the gold segmentation.
3.2 Morphological tagging
The second additional component in the model is for morphological tagging. We use an encoder-decoder model which takes each word as input, encodes the characters of the word along with the context of the word, and performs decoding by generating the morpheme tags of the word.
Decoding is performed in a sequential manner by predicting morpheme tags of a word one by one using LSTM. However, this sequential generation may not refer to the actual order of morphemes in a word. It reveals the correspondent morpeme tags within a word regardless of their position. Therefore, decoding is not tied to agglutination, and portmanteau, circumfixation and lexically marked differences in a word are representable (e.g., run/ran).
The overall sub-architecture of the morphological tagging component is depicted in Figure 5. Here, we define a two-layer BiLSTM for the character encoder, where each character is encoded as a vector which is the output of that time step in BiLSTM that involves all the sequential information to the right and left of the current character, denoted as
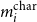 $m_i^{\textrm{char}}$
:
$m_i^{\textrm{char}}$
:
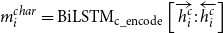 \begin{equation} {m_i^{char}} = \textrm{BiLSTM}_{\textrm{c}\_{\textrm{encode}}}\left[\overrightarrow{h^c_{i}}:\overleftarrow{h^c_{i}}\right]\end{equation}
\begin{equation} {m_i^{char}} = \textrm{BiLSTM}_{\textrm{c}\_{\textrm{encode}}}\left[\overrightarrow{h^c_{i}}:\overleftarrow{h^c_{i}}\right]\end{equation}
where
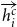 $\overrightarrow{h^c_{i}}$
is the forward representation and
$\overrightarrow{h^c_{i}}$
is the forward representation and
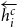 $\overleftarrow{h^c_{i}}$
is the backward representation obtained for the
$\overleftarrow{h^c_{i}}$
is the backward representation obtained for the
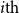 $i{\textrm{th}}$
character in the current word. In order to decode a token into a morphological tag through the decoder, we apply an attention mechanism to learn which characters in the actual word have more impact on the current tag that will be generated by the decoder.
$i{\textrm{th}}$
character in the current word. In order to decode a token into a morphological tag through the decoder, we apply an attention mechanism to learn which characters in the actual word have more impact on the current tag that will be generated by the decoder.
We estimate the weight of each character
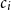 $c_i$
on each decoded token
$c_i$
on each decoded token
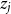 $z_j$
as follows, which is normalized over all characters in the original word:
$z_j$
as follows, which is normalized over all characters in the original word:
 \begin{equation} \alpha_{ji} = \frac{\textrm{exp}\left( \textrm{score}\left(c_i, z_j\right)\right)}{\Sigma_{y'=1}^{Y}\textrm{exp}\left( \textrm{score}\left(c^{\prime}_i, z_j\right)\right)}\end{equation}
\begin{equation} \alpha_{ji} = \frac{\textrm{exp}\left( \textrm{score}\left(c_i, z_j\right)\right)}{\Sigma_{y'=1}^{Y}\textrm{exp}\left( \textrm{score}\left(c^{\prime}_i, z_j\right)\right)}\end{equation}
Y is the length of the encoded word. The unnormalized
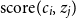 $\textrm{score}(c_i, z_j)$
that measures how much contribution each character has on the output tokens is computed with the relation between the encoded character
$\textrm{score}(c_i, z_j)$
that measures how much contribution each character has on the output tokens is computed with the relation between the encoded character
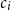 $c_i$
and the decoded state
$c_i$
and the decoded state
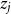 $z_j$
as follows:
$z_j$
as follows:
 \begin{equation} \textrm{score}\left(c_i, z_j\right) = v_1 \cdot \textrm{tanh} \left(\left[W_1 m_i^{\textrm{char}}\right]; \left[W_2 z_j\right]\right)\end{equation}
\begin{equation} \textrm{score}\left(c_i, z_j\right) = v_1 \cdot \textrm{tanh} \left(\left[W_1 m_i^{\textrm{char}}\right]; \left[W_2 z_j\right]\right)\end{equation}
where
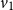 $v_1$
,
$v_1$
,
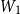 $W_1$
, and
$W_1$
, and
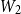 $W_2$
are the parameters to be learned during training. This is a one-layer neural network that applies tanh function to its output. It corresponds to the attention mechanism for the character encoder.
$W_2$
are the parameters to be learned during training. This is a one-layer neural network that applies tanh function to its output. It corresponds to the attention mechanism for the character encoder.
Once the weights are estimated, the total contribution of all characters to the current word is computed as the weighted sum of each character at time step t:
 \begin{equation} c_t = \Sigma_s \alpha_{ts} m_s^{\textrm{char}}\end{equation}
\begin{equation} c_t = \Sigma_s \alpha_{ts} m_s^{\textrm{char}}\end{equation}
where
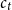 $c_t$
is the attended word characters of the current word that will be one of the inputs to the decoder.
$c_t$
is the attended word characters of the current word that will be one of the inputs to the decoder.
For the word encoder, we define a second one-layer BiLSTM, where each context word is encoded as a vector,
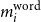 $m_i^{\textrm{word}}$
:
$m_i^{\textrm{word}}$
:
 \begin{equation} m_k^{\textrm{word}} = \textrm{BiLSTM}_{\textrm{w}\_{\textrm{encode}}}\left[\overrightarrow{h^w_{k}}:\overleftarrow{h^w_{k}}\right]\end{equation}
\begin{equation} m_k^{\textrm{word}} = \textrm{BiLSTM}_{\textrm{w}\_{\textrm{encode}}}\left[\overrightarrow{h^w_{k}}:\overleftarrow{h^w_{k}}\right]\end{equation}
where
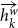 $\overrightarrow{h^w_{k}}$
is the forward representation and
$\overrightarrow{h^w_{k}}$
is the forward representation and
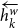 $\overleftarrow{h^w_{k}}$
is the backward representation obtained from the
$\overleftarrow{h^w_{k}}$
is the backward representation obtained from the
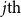 $j{\textrm{th}}$
context word in the current sentence. The input to BiLSTM
$j{\textrm{th}}$
context word in the current sentence. The input to BiLSTM
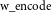 $$_{{\rm{w}}{\_}{\rm{encode}}}$$
is generated by another BiLSTM that processes the characters of each word and produces a character-level word embedding of a given word using character embeddings. Another attention mechanism is used for encoding the context to predict the correct morphological tags based on the context, thereby enabling morphological disambiguation. To this end, we estimate the weight of each context word
$$_{{\rm{w}}{\_}{\rm{encode}}}$$
is generated by another BiLSTM that processes the characters of each word and produces a character-level word embedding of a given word using character embeddings. Another attention mechanism is used for encoding the context to predict the correct morphological tags based on the context, thereby enabling morphological disambiguation. To this end, we estimate the weight of each context word
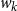 $w_k$
(including the current word) on each decoded token
$w_k$
(including the current word) on each decoded token
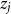 $z_j$
as follows, which is normalized over all words in the sentence:
$z_j$
as follows, which is normalized over all words in the sentence:
 \begin{equation} \alpha_{jk} = \frac{\textrm{exp}\left( \textrm{score}\left(w_k, z_j\right)\right)}{\Sigma_{i'=1}^{N}\textrm{exp}\left( \textrm{score}\left(w^{\prime}_k, z_j\right)\right)}\end{equation}
\begin{equation} \alpha_{jk} = \frac{\textrm{exp}\left( \textrm{score}\left(w_k, z_j\right)\right)}{\Sigma_{i'=1}^{N}\textrm{exp}\left( \textrm{score}\left(w^{\prime}_k, z_j\right)\right)}\end{equation}
where N denotes the number of words in the sentence. The unnormalized score
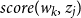 $score(w_k, z_j)$
that measures how much contribution each context word has on the output tokens is computed based on the encoded word
$score(w_k, z_j)$
that measures how much contribution each context word has on the output tokens is computed based on the encoded word
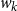 $w_k$
. The resulting decoded state
$w_k$
. The resulting decoded state
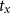 $t_x$
is defined as follows:
$t_x$
is defined as follows:
 \begin{equation} \textrm{score}\left(w_k, z_j\right) = v_2 \cdot \textrm{tanh} \left(\left[W_3 {m_k^{\textrm{word}}}\right]; \left[W_4 z_j\right]\right)\end{equation}
\begin{equation} \textrm{score}\left(w_k, z_j\right) = v_2 \cdot \textrm{tanh} \left(\left[W_3 {m_k^{\textrm{word}}}\right]; \left[W_4 z_j\right]\right)\end{equation}
where
 $v_2$
,
$v_2$
,
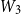 $W_3$
, and
$W_3$
, and
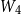 $W_4$
are the parameters to be learned during training. This is a one-layer neural network that applies tanh function to its output. It is the attention mechanism for the context encoder.
$W_4$
are the parameters to be learned during training. This is a one-layer neural network that applies tanh function to its output. It is the attention mechanism for the context encoder.
Once the weights are estimated, the total contribution of all words in the sentence is computed as the weighted sum of each word at time step t:
 \begin{equation} wv_t = \Sigma_s \alpha_{ts} {m_s^{\textrm{word}}}\end{equation}
\begin{equation} wv_t = \Sigma_s \alpha_{ts} {m_s^{\textrm{word}}}\end{equation}
where
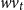 $wv_t$
is the attended context words that will be another input to be fed into the decoder.
$wv_t$
is the attended context words that will be another input to be fed into the decoder.
The input of the decoder for each time step t is therefore the concatenation of the embedding of the morpheme tag produced in the last time step
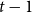 $t-1$
, the weighted sum of the BiLSTM outputs of both word encoder and context encoders:
$t-1$
, the weighted sum of the BiLSTM outputs of both word encoder and context encoders:
 \begin{equation} f_t = c_t \circ wv_t \circ z_{t-1}\end{equation}
\begin{equation} f_t = c_t \circ wv_t \circ z_{t-1}\end{equation}
The decoder is a unidirectional LSTM with the output at each time step t:
 \begin{equation}\begin{split} {d_t^{\textrm{token}}} & = \textrm{LSTM}_{\textrm{decode}}(f_{1:Y},t) \\[3pt] \hat{y_t} & = \textrm{softmax}\left(\textrm{MLP}_{\textrm{mtag}}\left({d_t^{\textrm{token}}}\right)\right) \end{split}\end{equation}
\begin{equation}\begin{split} {d_t^{\textrm{token}}} & = \textrm{LSTM}_{\textrm{decode}}(f_{1:Y},t) \\[3pt] \hat{y_t} & = \textrm{softmax}\left(\textrm{MLP}_{\textrm{mtag}}\left({d_t^{\textrm{token}}}\right)\right) \end{split}\end{equation}
where
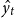 $\hat{y_t}$
is the predicted morpheme tag at time step t; the
$\hat{y_t}$
is the predicted morpheme tag at time step t; the
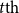 $t{\textrm{th}}$
morpheme tag generated for the current word. The output of each decoder state is fed into a one-layer MLP with a softmax function to predict the next morpheme tag.
$t{\textrm{th}}$
morpheme tag generated for the current word. The output of each decoder state is fed into a one-layer MLP with a softmax function to predict the next morpheme tag.
Finally, categorical cross-entropy loss is computed for each position in the decoder. The morphological tagging loss (
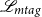 $\mathscr{L}_{mtag}$
) is
$\mathscr{L}_{mtag}$
) is
 \begin{equation}\begin{split}\mathscr{L}_{mtag} = - \sum_{t}^\mathbb{Y} y_{t} \log(\hat{y_t})\end{split}\end{equation}
\begin{equation}\begin{split}\mathscr{L}_{mtag} = - \sum_{t}^\mathbb{Y} y_{t} \log(\hat{y_t})\end{split}\end{equation}
3.3 Word vector representation
We use word-level, character-level, and morpheme-level word embeddings for both POS tagging and dependency parsing. Word-level word embeddings are pretrained from word2vec (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013). We learn the character embeddings through a BiLSTM. The output of the BiLSTM is used for character-level word embeddings.
For the morpheme-level embeddings, we have two types. One is generated from actual morphemes. The other one is generated from morpheme tags. For the embeddings of the actual morphemes, we use morph2vec (Üstün et al. Reference Üstün, Kurfal and Can2018) to pretrain the morpheme embeddings. Once the morpheme embeddings are learned, we use a BiLSTM that encodes each morpheme embedding to predict the morpheme-level word embeddings. We use another character BiLSTM for the unseen morphemes that are fed with character embeddings. For the embeddings of the morpheme tags, we randomly initialize the morpheme tag embeddings, where the morpheme tags are predicted by the morpheme tagging component described above.
The final vector
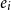 $e_i$
for the
$e_i$
for the
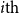 $i{\textrm{th}}$
word
$i{\textrm{th}}$
word
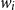 $w_i$
in a given sentence
$w_i$
in a given sentence
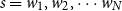 $s = w_1,w_2,\cdots w_N$
is
$s = w_1,w_2,\cdots w_N$
is
 \begin{equation} e_i = e_{w_i}^{(w)} \circ e_{w_i}^{(c)} \circ e_{w_i}^{(m)} \circ e_{w_i}^{(mt)}\end{equation}
\begin{equation} e_i = e_{w_i}^{(w)} \circ e_{w_i}^{(c)} \circ e_{w_i}^{(m)} \circ e_{w_i}^{(mt)}\end{equation}
where
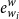 $e_{w_i}^{w}$
is the word-level word embedding,
$e_{w_i}^{w}$
is the word-level word embedding,
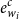 $e_{w_i}^{c}$
is the character-level word embedding,
$e_{w_i}^{c}$
is the character-level word embedding,
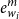 $e_{w_i}^{m}$
is the morpheme-level word embedding, and
$e_{w_i}^{m}$
is the morpheme-level word embedding, and
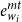 $e_{w_i}^{mt}$
is the encoding of the sequence of morpheme tags for the given word.
$e_{w_i}^{mt}$
is the encoding of the sequence of morpheme tags for the given word.
3.4 POS tagging
We use a BiLSTM to learn the latent feature vectors for POS tags in a sentence. We feed the sequence of vectors
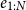 $e_{1:N}$
for the sentence to BiLSTM
$e_{1:N}$
for the sentence to BiLSTM
 $_\textrm{POS}$
. The output of each state is a latent feature vector
$_\textrm{POS}$
. The output of each state is a latent feature vector
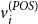 $v_i^{(POS)}$
that refers to the feature vector of the
$v_i^{(POS)}$
that refers to the feature vector of the
 $i{\textrm{th}}$
word
$i{\textrm{th}}$
word
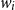 $w_i$
in the sentence:
$w_i$
in the sentence:
 \begin{equation} {v_i^{\textrm{POS}}} = \textrm{BiLSTM}_{\textrm{POS}}(e_{1:n},i)\end{equation}
\begin{equation} {v_i^{\textrm{POS}}} = \textrm{BiLSTM}_{\textrm{POS}}(e_{1:n},i)\end{equation}
In order to predict the POS tag of each word, we use an MLP with softmax output function similar to the joint model of Nguyen and Verspoor (Reference Nguyen and Verspoor2018):
 \begin{equation} \textrm{P}\hat{\textrm{O}}\textrm{S}_{\it i} = {\textrm{arg} \,{max} \atop {T}} \textrm{softmax}\left(\textrm{MLP}_{\textrm{POS}}\left(v_i^{POS}\right)\right)\end{equation}
\begin{equation} \textrm{P}\hat{\textrm{O}}\textrm{S}_{\it i} = {\textrm{arg} \,{max} \atop {T}} \textrm{softmax}\left(\textrm{MLP}_{\textrm{POS}}\left(v_i^{POS}\right)\right)\end{equation}
where POS
i
denotes the predicted POS tag of the
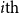 $i{\textrm{th}}$
word in the sentence and T is the set of all POS tags. We use the categorical cross-entropy loss
$i{\textrm{th}}$
word in the sentence and T is the set of all POS tags. We use the categorical cross-entropy loss
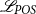 $\mathscr{L}_{POS}$
.
$\mathscr{L}_{POS}$
.
 \begin{equation}\begin{split}{\mathscr{L}_{POS}} = - \sum_{t}^\mathbb{Y} POS_{t} \log(\hat{POS_{t}})\end{split}\end{equation}
\begin{equation}\begin{split}{\mathscr{L}_{POS}} = - \sum_{t}^\mathbb{Y} POS_{t} \log(\hat{POS_{t}})\end{split}\end{equation}
where POS t is the gold POS tag.
3.5 Dependency parsing
We employ a BiLSTM (BiLSTM
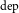 $_\textrm{dep}$
) to learn the dependency latent feature vectors for dependency relations between words. We feed BiLSTM
$_\textrm{dep}$
) to learn the dependency latent feature vectors for dependency relations between words. We feed BiLSTM
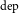 $_\textrm{dep}$
with the POS tag embeddings and the word embeddings
$_\textrm{dep}$
with the POS tag embeddings and the word embeddings
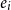 $e_i$
. Once the POS tags are predicted, we represent each POS tag with a vector representation
$e_i$
. Once the POS tags are predicted, we represent each POS tag with a vector representation
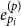 $e_{p_i}^{(p)}$
, which is randomly initialized. The final input vector representations are defined as follows for the dependency parsing component:
$e_{p_i}^{(p)}$
, which is randomly initialized. The final input vector representations are defined as follows for the dependency parsing component:
 \begin{align} x_i = e_{p_i}^{(p)} \circ e_i\qquad\qquad\qquad\quad\qquad\end{align}
\begin{align} x_i = e_{p_i}^{(p)} \circ e_i\qquad\qquad\qquad\quad\qquad\end{align}
 \begin{align} = e_{p_i}^{(p)} \circ e_{w_i}^{(w)} \circ e_{w_i}^{(c)} \circ e_{w_i}^{(m)} \circ e_{w_i}^{(mt)}\end{align}
\begin{align} = e_{p_i}^{(p)} \circ e_{w_i}^{(w)} \circ e_{w_i}^{(c)} \circ e_{w_i}^{(m)} \circ e_{w_i}^{(mt)}\end{align}
We feed the sequence of vectors
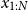 $x_{1:N}$
into BiLSTM
$x_{1:N}$
into BiLSTM
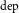 $_\textrm{dep}$
. Latent feature vectors
$_\textrm{dep}$
. Latent feature vectors
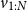 $v_{1:N}$
are obtained from BiLSTM
$v_{1:N}$
are obtained from BiLSTM
 $_\textrm{dep}$
:
$_\textrm{dep}$
:
 \begin{equation} v_k = \textrm{BiLSTM}_{\textrm{dep}}\left[\overrightarrow{h^d_{k}}:\overleftarrow{h^d_{k}}\right]\end{equation}
\begin{equation} v_k = \textrm{BiLSTM}_{\textrm{dep}}\left[\overrightarrow{h^d_{k}}:\overleftarrow{h^d_{k}}\right]\end{equation}
where
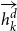 $\overrightarrow{h^d_{k}}$
is the forward representation and
$\overrightarrow{h^d_{k}}$
is the forward representation and
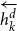 $\overleftarrow{h^d_{k}}$
is the backward representation obtained from the output of the kth state in BiLSTMdep.
$\overleftarrow{h^d_{k}}$
is the backward representation obtained from the output of the kth state in BiLSTMdep.
To predict the dependency arcs, we follow Nguyen and Verspoor (Reference Nguyen and Verspoor2018) and McDonald, Crammer, and Pereira (Reference McDonald, Crammer and Pereira2005). Features are enriched with morpheme embeddings obtained from morph2vec (Üstün et al. Reference Üstün, Kurfal and Can2018). The arcs are scored by an MLP that produces a score denoted by
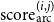 ${\textrm{score}}_{\textrm{arc}}^{(i,j)}$
with a single output node:
${\textrm{score}}_{\textrm{arc}}^{(i,j)}$
with a single output node:
 \begin{equation} \textrm{score}_{\textrm{arc}}{(i,j)} = \textrm{MLP}_{\textrm{arc}}\left(v_i \circ v_j \circ \left(v_i \ast v_j\right) \circ |v_i-v_j|\right)\end{equation}
\begin{equation} \textrm{score}_{\textrm{arc}}{(i,j)} = \textrm{MLP}_{\textrm{arc}}\left(v_i \circ v_j \circ \left(v_i \ast v_j\right) \circ |v_i-v_j|\right)\end{equation}
The MLP consists of a pointer network (Figure 6) which predicts whether two words in a sentence have a dependency relation or not.
The pointer network which is used to predict a dependency score between words in a sentence. Some Turkish dependencies are shown for exemplifying head-dependent relations.
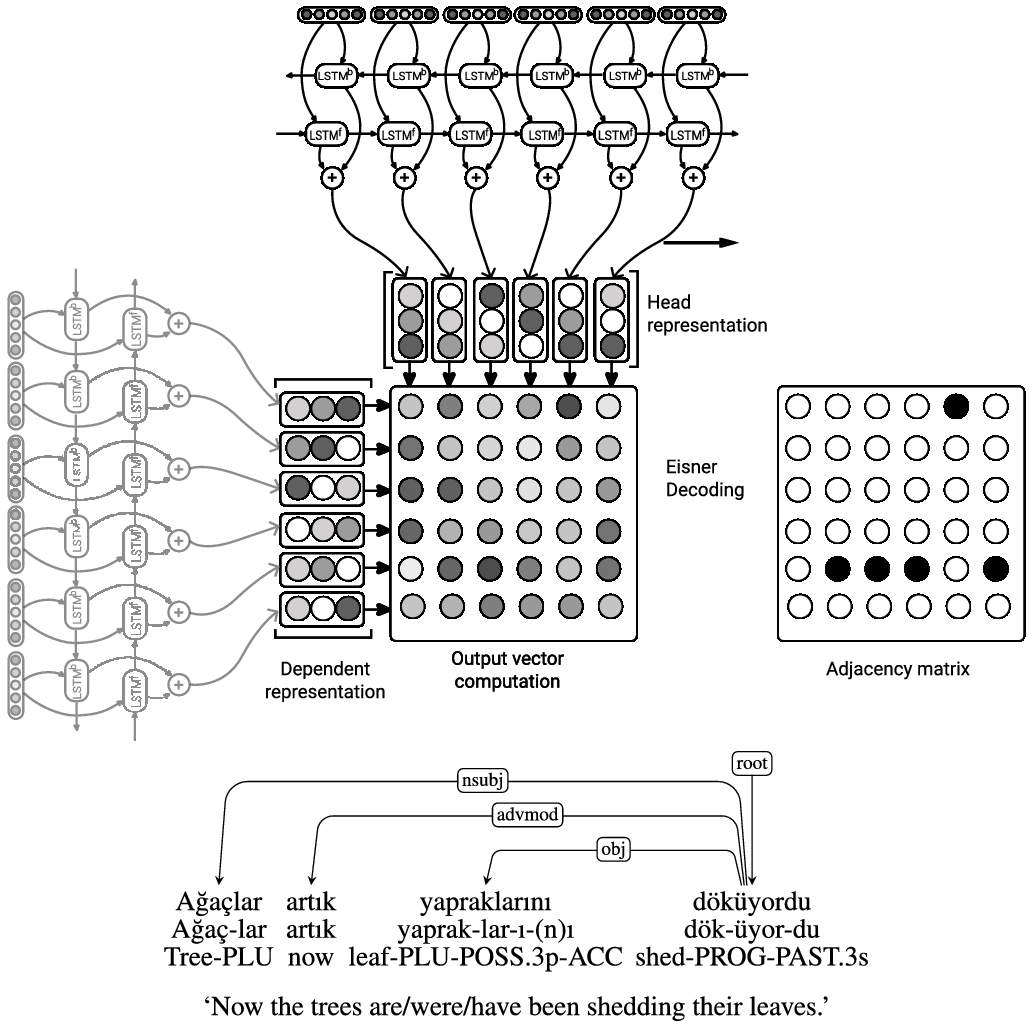
Once the scores are predicted, we use the decoding algorithm of Eisner (Reference Eisner1996) to find the projective parse tree with the maximum score:Footnote e
 \begin{equation} \textrm{score(s)} = {\textrm{arg}} \, {max}_{\hat{t}\in T(s)} \sum_{(h,m)\in \hat{t}} {\textrm{score}}_{\textrm{arc}}(h,m)\end{equation}
\begin{equation} \textrm{score(s)} = {\textrm{arg}} \, {max}_{\hat{t}\in T(s)} \sum_{(h,m)\in \hat{t}} {\textrm{score}}_{\textrm{arc}}(h,m)\end{equation}
where h denotes the head word of the dependency, m denotes the modifier word,
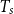 $T_s$
is the set of all possible parse trees for the sentence s, and
$T_s$
is the set of all possible parse trees for the sentence s, and
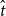 $\hat{t}$
is the parse tree with the maximum score.
$\hat{t}$
is the parse tree with the maximum score.
We also predict the labels for each arc with another MLP, which is MLP
 $_\textrm{rel}$
, with softmax output. An output vector
$_\textrm{rel}$
, with softmax output. An output vector
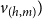 $v_{(h,m)})$
is computed for an arc (h,m):
$v_{(h,m)})$
is computed for an arc (h,m):
 \begin{equation} v_{(h,m)} = \textrm{MLP}_{\textrm{rel}}\left(v_h \circ v_m \circ \left(v_h \ast v_m\right) \circ |v_h-v_m|\right)\end{equation}
\begin{equation} v_{(h,m)} = \textrm{MLP}_{\textrm{rel}}\left(v_h \circ v_m \circ \left(v_h \ast v_m\right) \circ |v_h-v_m|\right)\end{equation}
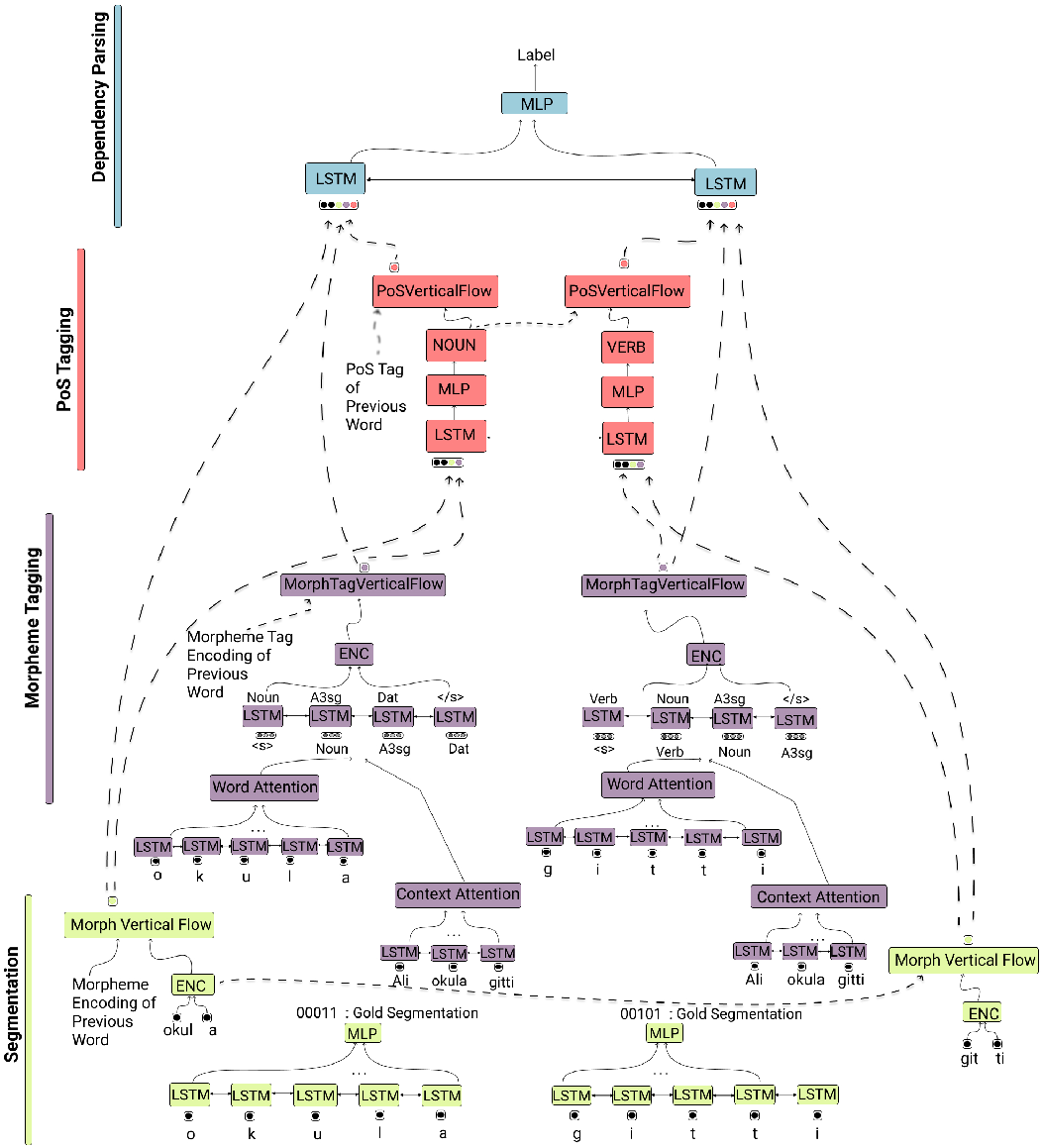
3.6 Cross-level contextual information flow
In the architecture which we have described so far, every time step in each layer is fed with only that time step’s output obtained from one layer below.
We further investigate data sharing between the layers in various time steps. For this, we incorporate contextual information from the previous word into the input of the layers for the current word, by adding contextual information obtained from morpheme tagging encoding and morpheme encoding of the previous word to POS and dependency layers of the current word. Similarly, we incorporate POS tagging encoding of the previous word into the dependency layer of the current word. An illustration of the cross-level contextual information flow is in Figure 7.
An illustration of the overall architecture with the cross-level contextual information flows between layers, using the example “Ali okula gitti.” (“Ali went to school”).
We do this by various methods. One of the methods is weighted sum:
 \begin{equation} e^{\prime}_{w_i} = \alpha_{1} e_{w_{i-1}} + \alpha_{2} e_{w_{i}}\end{equation}
\begin{equation} e^{\prime}_{w_i} = \alpha_{1} e_{w_{i-1}} + \alpha_{2} e_{w_{i}}\end{equation}
where
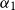 $\alpha_1$
and
$\alpha_1$
and
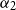 $\alpha_2$
are weights in combining the encoding of the previous word
$\alpha_2$
are weights in combining the encoding of the previous word
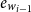 $e_{w_{i-1}}$
and encoding of the current word
$e_{w_{i-1}}$
and encoding of the current word
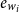 $e_{w_{i}}$
. The updated encoding of the current word is denoted by
$e_{w_{i}}$
. The updated encoding of the current word is denoted by
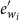 $e^{\prime}_{w_i}$
.Footnote f The encodings may correspond to either morpheme-based word embeddings, morpheme tag encodings, or POS tag encodings of words, depending on which layer the cross-level contextual information flow applies.
$e^{\prime}_{w_i}$
.Footnote f The encodings may correspond to either morpheme-based word embeddings, morpheme tag encodings, or POS tag encodings of words, depending on which layer the cross-level contextual information flow applies.
The second method is elementwise multiplication between the encoding of the previous word and the encoding of the following word:
 \begin{equation} e^{\prime}_{w_i}= e_{w_{i-1}} \odot e_{w_{i}}\end{equation}
\begin{equation} e^{\prime}_{w_i}= e_{w_{i-1}} \odot e_{w_{i}}\end{equation}
In the third method, we experimented with contextual information by using MLP to let the full joint model learn how to combine the encodings of successive words:
 \begin{equation} e^{\prime}_{w_i} = \textrm{MLP}_{\textrm{ver}}\left( e_{w_{i-1}} \circ e_{w_{i}}\right)\end{equation}
\begin{equation} e^{\prime}_{w_i} = \textrm{MLP}_{\textrm{ver}}\left( e_{w_{i-1}} \circ e_{w_{i}}\right)\end{equation}
First, the encodings of the previous and the current word are concatenated, then fed into a one-layer MLP. The parameters of the MLP are learned jointly with the model.
In the fourth method, we employed a concatenative (or additive) attention network to learn the weights of the contextual information automatically. We used a fixed size window for the history to estimate the weights.Footnote g The weight of a previous word is estimated as:
 \begin{equation} \alpha_{i} = \frac{exp( {{\textrm{score}}(w_{i-1}, x_i))}}{\Sigma^{Y}exp( {{\textrm{score}}(w', x_i))}}\end{equation}
\begin{equation} \alpha_{i} = \frac{exp( {{\textrm{score}}(w_{i-1}, x_i))}}{\Sigma^{Y}exp( {{\textrm{score}}(w', x_i))}}\end{equation}
where
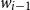 $w_{i-1}$
is the previous word,
$w_{i-1}$
is the previous word,
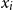 $x_i$
is the encoding of the ith token (particularly, the POS tag or the dependency relation), and Y is the set of context words (including the current word itself). Therefore,
$x_i$
is the encoding of the ith token (particularly, the POS tag or the dependency relation), and Y is the set of context words (including the current word itself). Therefore,
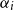 $\alpha_{i}$
gives the relevance of
$\alpha_{i}$
gives the relevance of
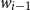 $w_{i-1}$
for
$w_{i-1}$
for
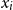 $x_i$
in that layer. The unnormalized score
$x_i$
in that layer. The unnormalized score
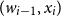 $(w_{i-1}, x_i)$
that estimates the weight of each context word is defined as follows:
$(w_{i-1}, x_i)$
that estimates the weight of each context word is defined as follows:
 \begin{equation} \textrm{score}_1\left(w_{i-1}, x_{i}\right) = v_3 \cdot \textrm{tanh} \left(\left[W_4 {e_{w_{i-1}}}\right]; \left[W_5 x_i\right]\right)\end{equation}
\begin{equation} \textrm{score}_1\left(w_{i-1}, x_{i}\right) = v_3 \cdot \textrm{tanh} \left(\left[W_4 {e_{w_{i-1}}}\right]; \left[W_5 x_i\right]\right)\end{equation}
where
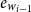 $e_{w_{i-1}}$
is the encoded information of
$e_{w_{i-1}}$
is the encoded information of
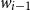 $w_{i-1}$
(either with morphemic information, morpheme tags, or POS tags) that is obtained from a lower layer to be fed into an upper layer, and
$w_{i-1}$
(either with morphemic information, morpheme tags, or POS tags) that is obtained from a lower layer to be fed into an upper layer, and
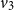 $v_3$
,
$v_3$
,
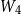 $W_4$
, and
$W_4$
, and
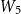 $W_5$
are the parameters to be learned during training. Once the weights are learned, max pooling is applied for the final encoding that will be fed into the upper layer.
$W_5$
are the parameters to be learned during training. Once the weights are learned, max pooling is applied for the final encoding that will be fed into the upper layer.
In the fifth method, we used a dot-product attention model. The unnormalized score
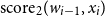 ${\textrm{score}}_2(w_{i-1}, x_i)$
, which estimates the weight of each context word is defined as follows:
${\textrm{score}}_2(w_{i-1}, x_i)$
, which estimates the weight of each context word is defined as follows:
 \begin{equation} \textrm{score}_2(w_{i-1}, x_{i}) = x_{i}^{T} \cdot e_{w_{i-1}}\end{equation}
\begin{equation} \textrm{score}_2(w_{i-1}, x_{i}) = x_{i}^{T} \cdot e_{w_{i-1}}\end{equation}
We also employed CNNs to blend the contextual information using convolution and pooling layers along with a rectifier unit.
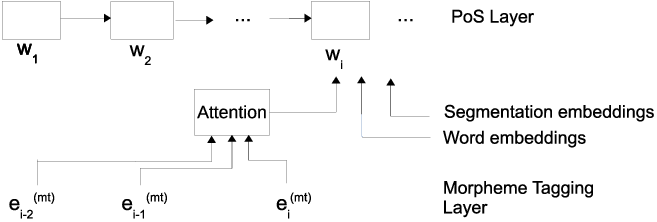
An illustration of the attention network that allows cross-level contextual information flow for two previous words is given in Figure 8. The figure shows the attention network between the POS layer and morpheme tagging layer, where
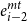 $e_{i-2}^{mt}$
and
$e_{i-2}^{mt}$
and
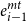 $e_{i-1}^{mt}$
correspond to the previous two words but particularly to their morpheme tags and
$e_{i-1}^{mt}$
correspond to the previous two words but particularly to their morpheme tags and
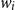 $w_i$
is the current word with a POS tag
$w_i$
is the current word with a POS tag
 $p_i$
. Therefore, the attention network learns how the morpheme tags of two previous words affect the POS tag of the current word. We generalize it further to a larger context to the left and right, and between various layers in the architecture. A similar cross-level contextual information flow is also built between dependency layer and morpheme tagging layer, or dependency layer and segmentation layer; or POS tagging layer and segmentation layer. Attention is replaced with all the methods mentioned (weighted sum, elementwise multiplication, MLP, concatenative attention, dot-product attention, and CNN), to combine the contextual information in each layer to feed into upper layer.
$p_i$
. Therefore, the attention network learns how the morpheme tags of two previous words affect the POS tag of the current word. We generalize it further to a larger context to the left and right, and between various layers in the architecture. A similar cross-level contextual information flow is also built between dependency layer and morpheme tagging layer, or dependency layer and segmentation layer; or POS tagging layer and segmentation layer. Attention is replaced with all the methods mentioned (weighted sum, elementwise multiplication, MLP, concatenative attention, dot-product attention, and CNN), to combine the contextual information in each layer to feed into upper layer.
An illustration of morpheme tag cross-level contextual information flow between POS layer and morpheme tagging layer. The context contains only two previous words in the example. The POS layer also takes the morpheme segmentation embeddings and word embeddings which are also based on their own attention networks; they are excluded from the figure for the sake of simplicity.
3.7 Model training
In the proposed joint learning framework, each component has its own error that contributes to the total loss of the model
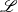 $\mathscr{L}$
:
$\mathscr{L}$
:
 \begin{equation} \mathscr{L} = {\mathscr{L}_{\textrm{seg}}}+ {\mathscr{L}_{\textrm{mtag}}} + {\mathscr{L}_{\textrm{POS}}} + {\mathscr{L}_{\textrm{arc}}} + {\mathscr{L}_{\textrm{rel}}}\end{equation}
\begin{equation} \mathscr{L} = {\mathscr{L}_{\textrm{seg}}}+ {\mathscr{L}_{\textrm{mtag}}} + {\mathscr{L}_{\textrm{POS}}} + {\mathscr{L}_{\textrm{arc}}} + {\mathscr{L}_{\textrm{rel}}}\end{equation}
We use training and validation corpora to train the model. During training, at each epoch, the model is first trained by Adaptive Moment Estimation (Adam) optimization algorithm (Kingma and Ba Reference Kingma and Ba2015). Then, per-token accuracy is calculated using the validation set. At every tenth epoch, all momentum values are cleared in the Adam Trainer. We applied step-based learning rate decay and early stopping.
3.8 Realization
We implemented our model in DyNet v2.0 (Neubig et al. Reference Neubig, Dyer, Goldberg, Matthews, Ammar, Anastasopoulos, Ballesteros, Chiang, Clothiaux, Cohn, Duh, Faruqui, Gan, Garrette, Ji, Kong, Kuncoro, Kumar, Malaviya, Michel, Oda, Richardson, Saphra, Swayamdipta and Yin2017), a dynamic neural network toolkit. The implementation of the model is publicly available at https://github.com/halecakir/JointParser. For the morphological segmentation component, we split each token into characters. We represent each character with a 50-dimensional character embedding. Using characters as input, we build a BiLSTM with 50-dimensional unit size to encode the character context. We feed an MLP with a sigmoid output that has an output size of 1 with the encoded characters to capture the segment boundaries.
Based on the segmentation probabilities obtained from the MLP, we created a morpheme list that makes up the input word. We encode morphemes with 50-dimensional embeddings. We feed another BiLSTM with 50-dimensional units to encode each input morpheme. We concatenate the 200-dimensional word-level word embeddings, 50-dimensional character-level word embeddings, and 100-dimensional morpheme-level word embeddings for the final word representation.
For the morpheme tagging component, we use a two-layered BiLSTM with 128-dimensional unit size to encode the character context. The decoder is also based on a two-layered BiLSTM with 128-dimensional unit size that is fed with the attended characters that are encoded by the encoder.
For the POS tagging component, we use a two-layered BiLSTM with 128-dimensional unit size to encode the word context. We feed the output of the word context into an MLP with a softmax activation function and 100-dimensional hidden unit size. The output size of the MLP is equal to the number of distinct POS tags in a language. Softmax gives the probability vector for the POS categories. We use the negative log-likelihood function as a loss function for the POS tagging component.
For the dependency parsing component, we use a two-layered BiLSTM with 128-dimensional unit size and a pointer network with 100-dimensional hidden unit size.Footnote h We use negative log-likelihood function for training.
We adopt dropout to penalize some random weights to zero and observed significant improvement when we applied dropout with a rate of 0.3 after each LSTM.
4. Experiments and results
We have tested the system in various languages. First, we report Turkish results.
4.1 Turkish data
We used the UD Turkish Treebank for both training and evaluation. The dataset is a semi-automatic conversion of the IMST Treebank (Sulubacak et al. Reference Sulubacak, Gokirmak, Tyers, Çöltekin, Nivre and Eryiğit2016), which is a re-annotated version of the METU-Sabancı Turkish Treebank (Oflazer et al. Reference Oflazer, Say, Hakkani-Tür and Tür2003). All of the three treebanks share the same raw data, with 5635 sentences from daily news reports and novels.
For the pretrained word embeddings, we use pretrained 200-dimensional word embeddings trained on Boun Web Corpus (Sak, Güngör, and Saraçlar Reference Sak, Güngör and Saraçlar2008) provided by CoNLL 2018 Shared Task. We also pre-train morph2vec (Üstün et al. Reference Üstün, Kurfal and Can2018) to learn the morpheme embeddings on METU-Sabancı Turkish Treebank. We obtain the gold segments from rule-based Zemberek (Akın and Akın Reference Akn and Akn2007), to train the segmentation component by disambiguating segmentation of a word in the given context in METU-Sabancı Treebank. Each word token then has only one interpretation.
4.2 Turkish results
We performed several experiments with the alternating components of the proposed model. All models are trained jointly with a single loss function. Depending on the examined joint tasks, we excluded either morpheme tagging or segmentation or both tasks from the full model. We observed how the lower levels that correspond to morpheme tagging and segmentation tasks affect the upper levels that refer to POS tagging and dependency parsing.
We followed the standard evaluation procedure of CoNLL 2018 shared task defined for dependency parsing, morphological tagging, and POS tagging. For the POS tagging, we evaluated our results with an accuracy score that is the percentage of the correctly tagged words. For the dependency parsing task, we present two different evaluation scores: labeled attachment score (LAS) and unlabeled attachment score (UAS). The attachment score is the percentage of the words that have the correct head and the dependency arc. LAS measures the percentage of the words that have the correct head with the correct dependency label, whereas UAS only measures the percentage of the words that have the correct head without considering the dependency labels.
We evaluate segmentation results also for accuracy, which is the percentage of the correctly segmented words. We evaluate morpheme tagging with an accuracy measure, which is in this case the percentage of correctly tagged words. We evaluate morpheme tagging based on all of the morpheme tags that each word bears. We assume that all the morpheme tags of the word must be correct in order to count the word as correctly tagged. It is labeled FEATS in the tables (universal morphological tags).
Because gold segments are not provided in the CoNLL datasets, we segmented the test set with Zemberek morphological segmentation tool of Akın and Akın (Reference Akn and Akn2007) and evaluated training based on Zemberek results. Therefore, our segmentation results are computed relative to Zemberek.
All the results obtained for the proposed models of Turkish are given in Table 1. We compare them with the joint POS tagging and dependency parsing model of Nguyen and Verspoor (Reference Nguyen and Verspoor2018), which is the base model for us. Recall that it has two layers, given as POS-DEP (Baseline) in the table. Our baseline with these two layers only approximately replicate the results of Nguyen and Verspoor (Reference Nguyen and Verspoor2018). We obtained an UAS score of 70.42% and a LAS score of 62.71% from the baseline model. The results of the baseline in Table 1 are obtained using Nguyen and Verspoor (Reference Nguyen and Verspoor2018)’s own implementation. However, we have been unable to replicate their reported scores identically, possibly due to some minor parametric differences because of hyperparameters. POS tagging accuracy is the highest with 94.78% when all the components (i.e., addition of morpheme tagging and morphological segmentation) are included in a full joint model. The same also applies to UAS, LAS, morpheme tagging accuracy, and segmentation accuracy, which are the highest when all the components are adopted in the model. This shows that all the layers in the model contribute to each other during learning.
Experimental results for different joint models
Ours being the first attempt to combine five tasks in a single joint model, we compare the performance of each component separately with different models. Results of dependency parsing are in Table 2. The table shows the UAS and LAS scores of different dependency parsing models. We compare our results with the joint POS tagging and dependency parsing model by Nguyen and Verspoor (Reference Nguyen and Verspoor2018), with the winning contribution to CoNLL 2018 shared task that incorporates deep contextualized word embeddings (Che et al. Reference Che, Liu, Wang, Zheng and Liu2018), with the horizontal pipeline system that performs tokenization, word segmentation, POS tagging, and dependency parsing by Qi et al. (Reference Qi, Dozat, Zhang and Manning2018), with the tree-stack LSTM model by Kırnap, Dayanık, and Yuret (Reference Kırnap, Dayanık and Yuret2018), and with the dependency parser that incorporates morphology-based word embeddings proposed by Özateş et al. (2018).
Comparison of Turkish dependency parsing results with other models

The results show that our model has nontrivial improvement on the baseline model of Nguyen and Verspoor (Reference Nguyen and Verspoor2018). Moreover, our model outperforms most of the models that participated in CoNLL 2017 and CoNLL 2018. The only models that perform better than our model are the ones proposed by Che et al. (Reference Che, Liu, Wang, Zheng and Liu2018) and Qi et al. (Reference Qi, Dozat, Zhang and Manning2018). Their models give a UAS score of 72.25% and 71.07%, LAS score of 66.44% and 64.42%, respectively, whereas our model gives a UAS score of 71.00% and LAS score of 63.92%. Our UAS score is competitive with the deep contextualized model by Che et al. (Reference Che, Liu, Wang, Zheng and Liu2018); however, there is a 2.5% difference in the LAS scores of the two models. As the authors of that work also state, deep contextualized word embeddings (BERT, Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) affect parsing accuracy significantly.
Apart from the usage of contextualized word embeddings, our base model is similar to their model. Our full model performs morpheme tagging and morphological segmentation additionally. Qi et al. (Reference Qi, Dozat, Zhang and Manning2018) presents another prominent model which competed in CoNLL shared task 2018. They were placed second in the shared task with their UAS and LAS scores. Similar to our model, they also introduce a neural pipeline system that performs tokenization, segmentation, POS tagging, and dependency parsing. Their architecture is similar to ours, differently they use biaffine classifier for POS tagging similar to that of Dozat and Manning (Reference Dozat and Manning2017).
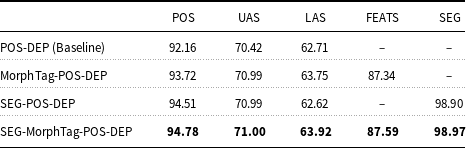
The comparison of our POS tagging results with other POS tagging models is given in Table 3. We compare our model with Che et al. (Reference Che, Liu, Wang, Zheng and Liu2018), Qi et al. (Reference Qi, Dozat, Zhang and Manning2018), Özateş et al. (Reference Özateş, Özgür, Gungor and Öztürk2018), and Kırnap et al. (Reference Kırnap, Dayanık and Yuret2018). Our model outperforms other models with an accuracy of 94.78% performing similar to Che et al. (Reference Che, Liu, Wang, Zheng and Liu2018), which uses deep contextualized word embeddings.
The comparison of the Turkish POS tagging results with other models
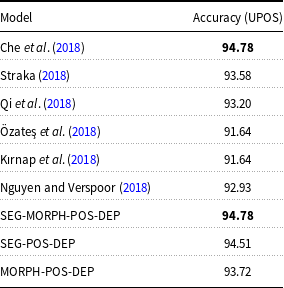
The comparison of our morphological tagging results (FEATS) with other models is given in Table 4. We compare our model with Straka (Reference Straka2018), Dayanık et al. (Reference Dayanık, Akyürek and Yuret2018), Che et al. (Reference Che, Liu, Wang, Zheng and Liu2018), Qi et al. (Reference Qi, Dozat, Zhang and Manning2018), Özateş et al. (Reference Özateş, Özgür, Gungor and Öztürk2018), and Kırnap et al. (Reference Kırnap, Dayanık and Yuret2018). The best performing model is by Straka (Reference Straka2018) with an accuracy of 91.25%. It is worth mentioning that none of these models performs a joint learning for morphological tagging. Our model is the only joint model that performs morphological tagging along with other syntactic tasks. The results are very competitive with other models although they fall slightly behind them.
The comparison of the Turkish morphological tagging results (FEATS) with other models
4.3 The effect of cross-level contextual information flow
The cross-level contextual information flow has been investigated with the following methods: weighted sum, elementwise multiplication, MLP, and attention network. We include only the previous word as context in weighted sum, elementwise multiplication, and MLP, and we incorporate various lengths of contextual information both from left and right in the attention mechanism.
The results of the proposed methods for cross-level contextual information flow on Turkish are given in Table 5. Highest results are obtained with basic dot-product attention.
The results of cross-level contextual information flow on Turkish
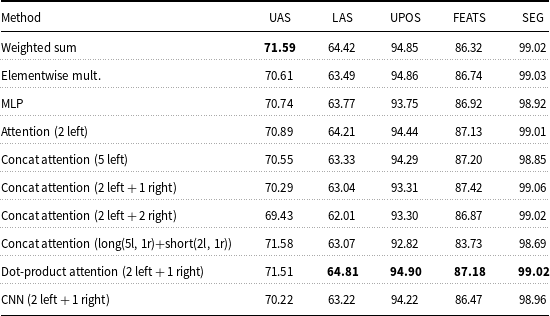
Attention networks resolve the issue of manual weight assignment by learning the weight of each context word automatically during training. However, attention with concatenation requires a separate development set for hyperparameter tuning to find the optimum weights for the contextual words. Therefore, it has to be performed for every language and dataset separately using a development set, which is preferably different than the training dataset. We incorporated various lengths of contextual knowledge both for left and right context. For a smaller context, we incorporated two previous words; and for a larger context, we incorporated five previous words. The results obtained from two previous words are comparably lower than that of five previous words. We also incorporated right context with one and two following words including previous words as well. The results with smaller context again performs better than a larger context. This could be due to various lengths of sentences in dataset where there is not enough history for especially larger contexts.
We split the dataset for training and test sets to include various lengths of contextual knowledge for shorter (having less than 10 words) and longer sentences (having 10 or more words). We used five words in the left and one word on the right for longer sentences and used two words in the left and one word on the right for shorter sentences. The overall results are comparably better than that of using a fixed length of context for all sentences, especially in dependency parsing. However, POS tagging and morphological tagging results fall behind that of using a fixed amount of context. This could be due to the size of the training sets when split. However, it still shows that using a larger context indeed helps at the syntactic level.
4.4 Results on English, Czech, Hungarian, and Finnish
There is nothing in our system which is specific to Turkish. We have applied our joint system to other languages, where we use Universal Dependencies v2.3 corpora. The results for English, Czech, Hungarian, and Finnish are given in Table 6. We excluded the morphological segmentation layer from the joint model for these experiments, since gold morphological segmentations are not available for these languages; only morphological tags are available in UD treebanks.
The results of joint model on other languages (English, Czech, Hungarian, and Finnish) with (w) and without (w/o) cross-level contextual information flow. The bold ones are the highest scores for the given language
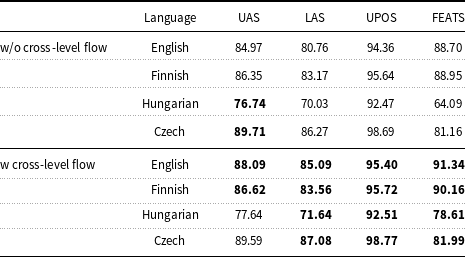
We performed experiments both without using cross-level contextual information flow and with using attention mechanism for the cross-level information flow. We used only previous two words for the contextual information, since the highest scores are obtained from this setting on Turkish. We applied concatenative attention network for English, Hungarian, and Czech, dot-product attention for Finnish due to the highest evaluation scores.
As can be seen from the results, the cross-level contextual information flow considerably improves the results in all languages. The results demonstrated a substantial improvement, especially in English LAS and Hungarian FEATS.
We compared the highest scores obtained in these languages with other state-of-the-art participated in CoNLL Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies (Zeman and Hajič Reference Zeman and Hajič2018). The results are given in Table 7. There are 26 participants who shared their results on the given languages. We only compared our scores with the top five systems participated in the shared task. We also provide the scores of Nguyen and Verspoor (Reference Nguyen and Verspoor2018) to show the improvement obtained by the joint model and cross-level contextual information flow.
Comparison to other models on English, Czech, Hungarian, and Finnish

Our joint model outperforms all other participants in English for both UAS and LAS. Although we have a significant improvement over the baseline model by Nguyen and Verspoor (Reference Nguyen and Verspoor2018) in Finnish, Hungarian, and Czech, our model falls behind the top scores in other languages. However, the joint model still performs well on other languages when all participants in the shared task are considered. For example, our model is ranked 11th in Finnish, 13th in Hungarian, and 14th in Czech according to LAS scores; 10th in Finnish, 13th in Hungarian, and 15th in Czech according to UAS scores; 5th in English, 10th in Finnish, and Hungarian, 6th in Czech according to universal POS (UPOS) scores.
4.5 Error analysis for Turkish
We explored the errors made by the proposed model variations in greater detail in one language, Turkish. The following experiments aim to classify parsing errors with respect to structural properties of the dependency graphs. In all experiments, four different joint models have been trained and tested with the standard split of Turkish IMST universal dependencies.Footnote i Error analysis has been carried out using four properties: sentence length, projectivity, arc type, and POS.
4.5.1 The effect of sentence length
We first try to see the effect of sentence length on the robustness of the four model variations. For that purpose, the test data have been divided into equally sized sentence length intervals. The interval length is 10. The UAS and LAS scores according to different sentence lengths are given in Tables 8 and 9, respectively. It can be seen that the longer the sentences are, the lower both scores are for all model variations. However, MorphTag-POS-DEP and SEG-MorphTag-POS-DEP models perform rather well in shorter sentences (with length 0–20) with regard to both UAS and LAS.
LAS by length

UAS by length
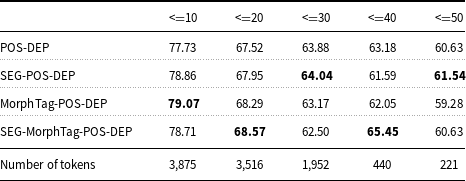
What is interesting about the scores is that the models that have higher UAS and LAS scores in shorter sentences are worse in longer sentences (length 30–50). Parsing errors gradually increase as the sentence length increases. In literature, a similar outcome has been reported for other languages, for example, for English and Vietnamese (McDonald and Nivre Reference McDonald and Nivre2007; Van Nguyen and Nguyen Reference Van Nguyen and Nguyen2015).
4.5.2 Effect of projectivity
This effect concerns dependencies.
An arc in a dependency tree is projective if there is a directed path from the head word to all the words between the two endpoints of the arc, and therefore there are no crossing edges in the dependency graph. Projectivity is less of a problem in languages with more strict order such as English. However, non-projective trees can be seen more frequently in languages such as Czech, German and Turkish. Table 10 shows some statistics about the test set. Turkish being a free order language, the number of non-projective dependency graphs is quite significant.
Statistics about test partition of Turkish IMST universal dependencies

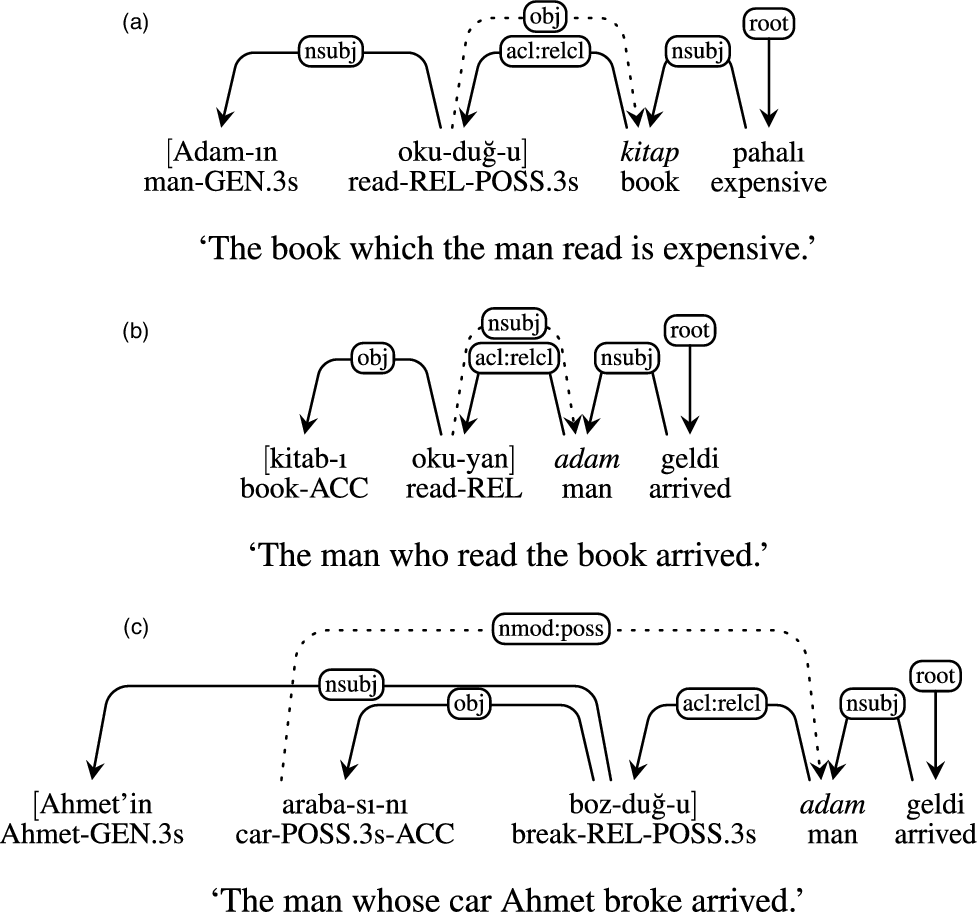
However, it is not only relatively free word order in languages such as Turkish that leads to various number of non-projective dependencies. Turkish root relativization may be nested Figure 9(a)–(b), or crossing Figure 9(c), without manipulating free word order effects.
In the case of long-range dependencies crossing clause boundaries, Turkish is always crossing, as can be seen from Figure 10; therefore, a dataset that contains abundance of such examples would afford very little chance of adequate coverage when non-projective dependencies are eliminated.
There is no limit to crossings in Turkish, because there is no limit to long-range relativization. N-level embedded complementation in an expression requires n crossings to capture the dependency relation of the extracted element with its verb, as shown in Figure 10. Therefore, there is no such thing as mildly non-projective Turkish long-range relative clause dependency (cf. Kuhlmann and Nivre Reference Kuhlmann and Nivre2006).
Dependencies in Turkish relative clauses (in brackets), and with the relativized noun (in italic). They are (a) root-clause object relativization; (b) root-clause subject relativization; (c) relativization out of possessive NPs, here from “man’s car”: “adam-GEN.3s araba-POSS.3s.” Dotted edges indicate which dependency relation “acl:rel” dependency is expected to capture.
Unbounded dependencies in Turkish relative clauses (in brackets), and with the relativized noun (in italic). They are (a) long-range subject relativization and (b–c) long-range object relativization. Dotted edges indicate which dependency relation “acl:rel” dependency is expected to capture.
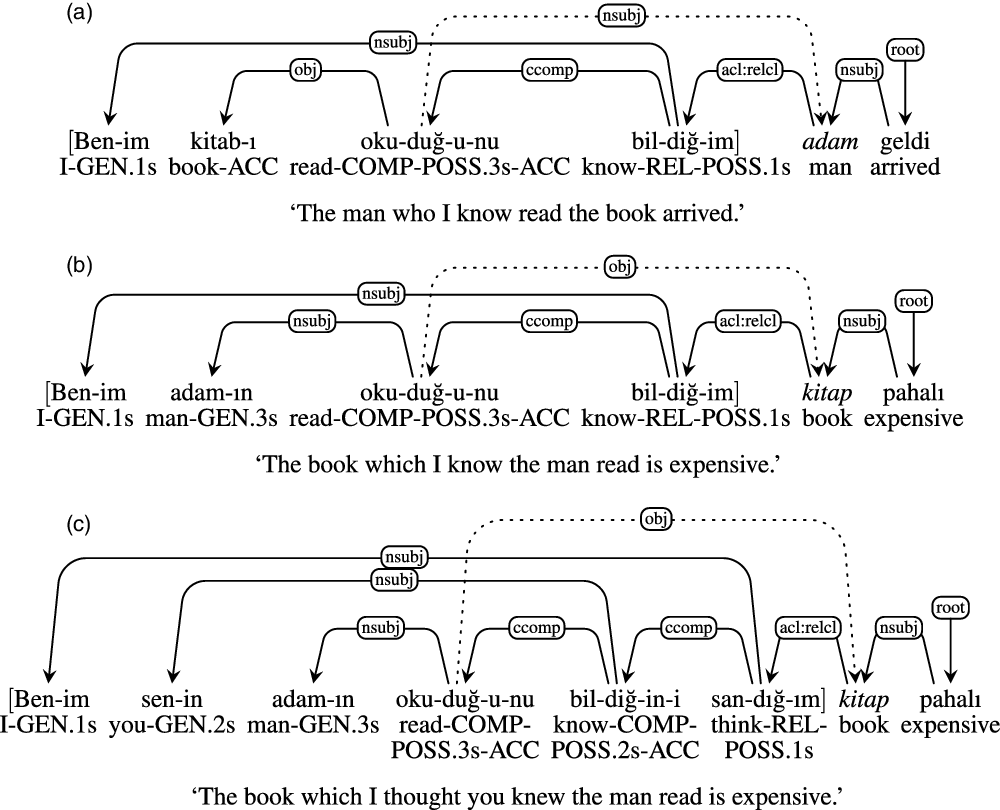
We point out that filtering out crossing dependencies for evaluation as, for example, done by Sulubacak and Eryiğit (Reference Sulubacak and Eryiğit2018) would take away a lot of non-crossing dependencies as well, so all kinds of parsers, projective and non-projective, would be affected by this elimination in their training and performance in simpler cases.
We designed the joint-task cross-level contextual information flow with these considerations in mind, so that all kinds of dependencies when available in standard datasets for evaluation can be modeled. Adding attention along with cross-level contextual information handling must be regarded as the first-step toward handling such data with dependencies when they are available, which would allow a meaningful comparison of dependency parsing with, for example, CCG parsing (Hockenmaier and Steedman Reference Hockenmaier and Steedman2007; Çakıcı, Steedman, and BozşahinReference Çakıcı, Steedman and Bozşahin2018), where so-called non-projectivity is handled by bounded function composition on complement clauses.
We hope that our sticking to dependency parsing for the moment may help assess current state of the art and provide a prospect for the future with such kind of data. In particular, we suggest reporting constructions by genera (control, suboordination, relativization, coordination, etc.), cross-listed by bounded and long-range dependencies, as also pointed out by Hockenmaier and Steedman (Reference Hockenmaier and Steedman2007). Without such standardizations, significance tests for improvement or degradation over datasets would not reveal much about what is learned about a language in a model.
Figure 11 gives the percentages of projective and non-projective trees according to sentence length. The results show that as the complexity of sentence increases; therefore, the length, the probability of generating non-projective trees also increases. The number of projective trees is higher for the sentence lengths smaller than 30. The number of non-projective trees is higher for the sentence lenghts greater than 40. For example, for all the sentences that are longer than 50, the dependency tree is non-projective.
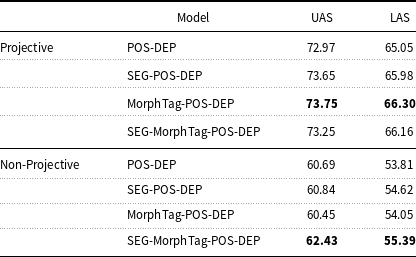
We analyze the labeled and unlabeled accuracy scores obtained from the projective and non-projective trees in testing. As can be seen in Table 11, the MorphTag-POS-DEP model outperforms other models both for labeled and unlabeled dependency arcs in projective trees. However, for the non-projective trees, the SEG-MorphTag-POS-DEP model outperforms other models. We aim in the long run for wide-coverage systems with reasonable approximation of semantics; therefore, we take it as a good sign that the full model is responsive to non-projective, therefore more complex sentences.
4.5.3 The effect of constructions
Finally, we analyze the syntactic properties of dependency relations based on their POS labels obtained from different models. We compare the results based on dependent word’s POS tag to see whether it plays a role in the accuracy of dependencies. Following McDonald and Nivre (Reference McDonald and Nivre2007), we make use of coarse POS categories instead of UPOS categories in order to observe the performance differences between the models in loss of useful syntactic information. In coarse POS categories, nouns include nouns and proper nouns, pronouns consist of pronouns and determiner, and verbs include verbs and auxiliary verbs.
UAS and LAS accuracies of the four models are given in Tables 12 and 13, respectively for the coarse POS categories. As can be seen from Table 12, there is a slight improvement of UAS in conjunctions (CONJ), and substantial improvement in verbs (VERB) and adpositions (ADP) in the SEG-MorphTag-POS-DEP model. The MorphTag-POS-DEP model captures the unlabeled arcs for the adjective (ADJ) and adverb (ADV) dependents better compared to other models. The scores also show that there is a slight increase in the unlabeled accuracy for the noun (NOUN) and pronoun (PRON) dependents in the SEG-POS-DEP model. The POS-DEP model does not outperform other models for any of the POS categories. Only the UAS score for the adverb dependents is the same as the one obtained from the MorphTag-POS-DEP. LAS and UAS scores are given for all dependency relations in Tables A1 and A2, respectively, in Appendix A.
Results for projective and non-projective sentences
The overall results show that each component in the model has an impact on the UAS scores for different POS categories of the dependents, and the full joint model that includes all the components has a higher overall UAS accuracy for different dependent word’s POS categories.
Projective and non-projective tree percentages grouped by the sentence length.
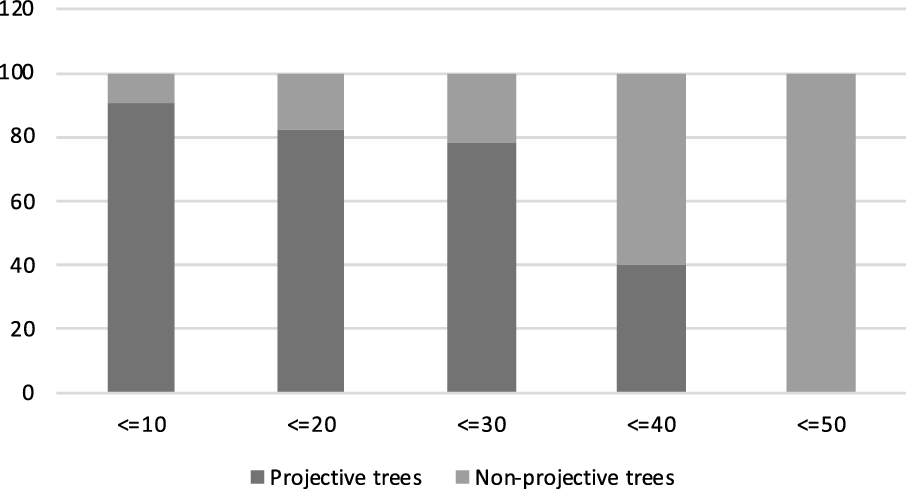
As can be seen from Table 13, the SEG-MorphTag-POS-DEP model tends to be more accurate in nouns (NOUN) and conjunctions (CONJ). With the addition of morpheme tags, the MorphTag-POS-DEP model has higher LAS accuracies for adjectives (ADJ), adverbs (ADV), and verbs (VERB). There is a considerable improvement of LAS in adpositions (ADP) after incorporating segmentation information in the joint SEG-POS-DEP model; however, the SEG-POS-DEP model does not outperform other models for other POS categories. The only POS category where the POS-DEP model outperforms other models is pronouns (PRON), which can be a sign that pronouns are usually not inflected and the morph tags and segmentation do not contribute much for the pronoun category.
UAS by coarse POS categories
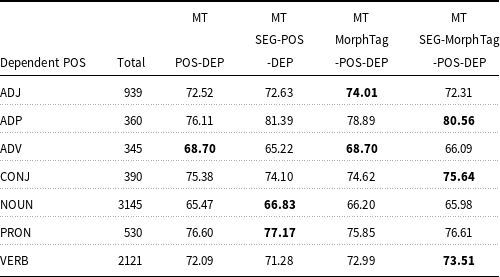
LAS by coarse POS categories
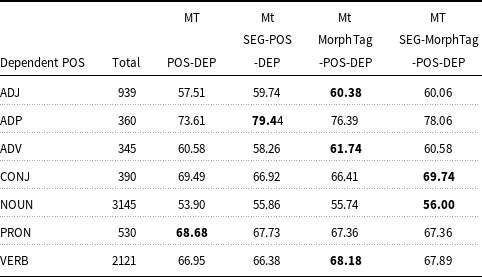
4.6 Ablation
In order to measure the contribution of components in the model, we remove one component tentatively, and test. It is an ablation analysis, and, in the previous sections, we have done a coarse version of it.
There is also another version of ablation analysis that measures the influence of the individual components in the model by incrementally replacing the component with their gold annotations. This version of ablation analysis is reported by Qi et al. (Reference Qi, Dozat, Zhang and Manning2018). Using this approach, researchers have been able to decide whether an individual component is useful for higher-level tasks and estimate the limitations of their studies under perfect conditions. This way, the errors that flow through the network from different components are filtered out to measure the actual effect of each component on the final scores.
The results obtained from the pipeline ablation analysis of the joint model are given in Table 14. The first row gives the results of the full joint model without gold annotations. In the second row (POS-MorphTag-GoldSEG-DEP), the morpheme segmentation component is replaced with the gold morphological segments rather than predicting them, and the rest of the components are left as they are. In the third row (POS-GoldMorphTag-SEG-DEP), the morphological tagging component is replaced with the gold morpheme tags.
Pipeline ablation results
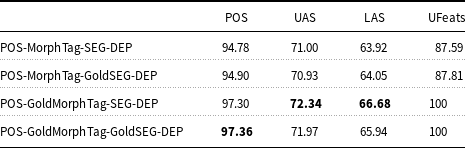
Finally, both morpheme segmentation and morphological tagging components are replaced with their gold annotations in the fourth row (POS-GoldMorphTag-GoldSEG-DEP). The results show that using the gold morpheme tags contributes to the dependency scores the most. However, the highest improvement is obtained when both gold morphological segmentations and gold morpheme tags are incorporated into the model for POS tagging. We are encouraged by this result because of our motivation to add morpheme information to joint learning from the beginning.
When individual components are replaced with the gold annotations incrementally, from bottom tasks to the upper layers, there is still a huge gap between the ablation scores and the gold scores. This is where linguistic theories can fill in the gap, for morphology, phonology, and syntax, by narrowing the solution space of every task of a joint model.
5. Conclusion and future work
We presented a joint learning framework for learning POS tagging, morphological tagging, morphological segmentation and dependency parsing to the extent of obtaining dependency relations of who does what to whom. We use a deep neural architecture where each layer learns a specific level, and this knowledge is shared through other layers.
The results show that using morphological knowledge such as morpheme tags and morphs themselves improve both dependency parsing and POS tagging. Morphemic knowledge plays an important role in morphologically rich languages.
Applying deep contextualized word embeddings such as BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) or Elmo (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018) remain as a future goal in this work. We plan to replace the LSTMs with self-attention mechanisms of variable reach at the levels of the current architecture, as a controlled means of extending the context. We believe that using self-attention mechanism instead of LSTMs will handle the long-term dependencies better, especially in longer sentences, and in larger left and right contexts.
Acknowledgments
This research has been supported by Scientific and Technological Research Council of Turkey (TUBITAK), project number EEEAG-115E464.
A. Appendix
LAS by dependency relation
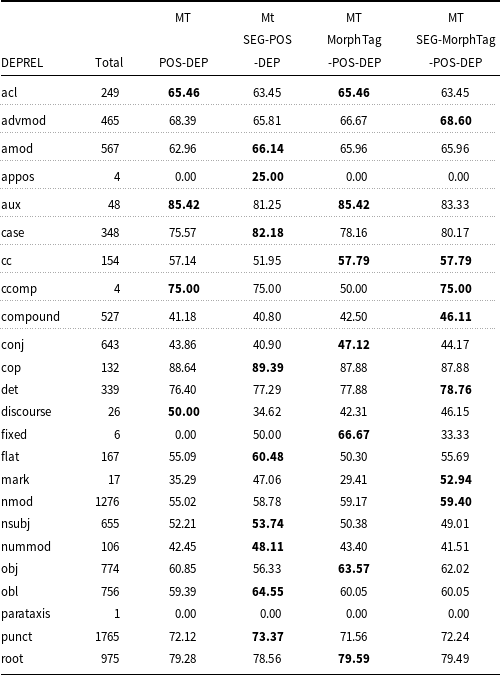
UAS by dependency relation
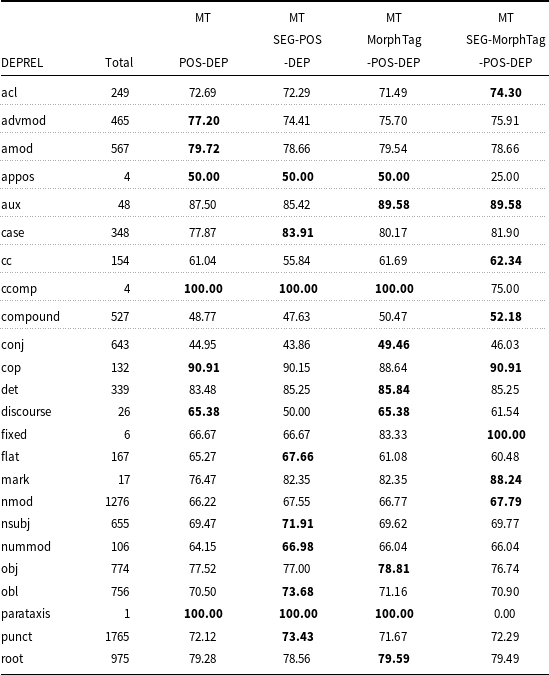
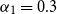
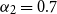




























 Open access
Open access