


1. Introduction
The rise of generative artificial intelligence (AI) and its transformative impact pose novel legal challenges, ethical dilemmas and even existential risks for global stakeholders (Dwivedi et al. Reference Dwivedi, Hughes, Ismagilova, Aarts, Coombs, Crick, Duan, Dwivedi, Edwards, Eirug, Galanos, Ilavarasan, Janssen, Jones, Kar, Kizgin, Kronemann, Lal, Lucini, Medaglia, Le Meunier-FitzHugh, Le Meunier-FitzHugh, Misra, Mogaji, Sharma, Singh, Raghavan, Raman, Rana, Samothrakis, Spencer, Tamilmani, Tubadji, Walton and Williams2021; Fui-Hoon Nah et al. Reference Fui-Hoon Nah, Zheng, Cai, Siau and Chen2023; Wirtz et al. Reference Wirtz, Weyerer and Geyer2019). Governments, international organisations, multinational corporations and research institutions are continuously issuing diverse regulations, principles, frameworks and strategies in pursuit of global oversight of AI. However, divergent national interests and varied governance stances (Clarke Reference Clarke2019; Smuha Reference Smuha2021) have led to previous international normative outputs focusing predominantly on ethical guidelines, policy documents and technical standards, which typically lack binding consensus (Schiff et al. Reference Schiff, Biddle, Borenstein and Laas2020; Schmitt Reference Schmitt2022; Villarino Reference Villarino2023).
The current global AI regulatory landscape must be understood within the context of the global AI governance regime (Veale et al. Reference Veale, Matus and Gorwa2023). AI’s cross-border externalities (Jonas et al. Reference Jonas, Eva, Markus, Johannes, Mark and Magnus2023) render unilateral state efforts insufficient, prompting calls for broader stakeholder participation in shaping AI regulatory frameworks. Indeed, the very concept of ‘the Global’ is not a pre-existing container for state action, but is itself constructed through various legal and political practices that increasingly transcend territorial boundaries (Rajkovic Reference Rajkovic2025). Terminologically, ‘governance’ extends beyond ‘government’, encompassing not only traditional international bodies but also overlapping, interlinked regional institutions and the growing involvement of non-state actors (Levi-Faur Reference Levi-Faur and Levi-Faur2012). The international AI regulation regime reflects the paradigm of global governance. Current global AI regulations lack a clear central authority or hierarchy (Erman and Furendal Reference Erman and Furendal2022), instead consisting of fragmented, interlocking arrangements built on a patchwork of old and new legal frameworks across jurisdictions, including transnational private standards, best practice initiatives and normative declarations/principles from international organisations (Green and Auld Reference Green and Auld2017; Marchant and Allenby Reference Marchant and Allenby2017). This complex web of norms, produced and enforced by a variety of actors, is a prime example of what the sociologist of law Eugen Ehrlich famously called ‘living law’ (lebendes Recht) – the law that actually dominates social life, often independently of formal state legislation. From this perspective, much of the AI regulatory landscape can be seen as a form of non-state law, emerging from the ‘inner order’ of social associations rather than from sovereign command (Hertogh Reference Hertogh2008a; Hertogh Reference Hertogh2008b; Nelken Reference Nelken2008).
Global norms for regulating AI constitute an evolving and dynamic corpus, largely due to their foundation in international ‘soft law’. Despite critiques of soft law from both positivist and critical legal scholars (Kennedy Reference Kennedy1980; Klabbers 1998; Koskenniemi Reference Koskenniemi2006; Weil Reference Weil1983), its rise in technology governance, coupled with the slow pace of hard law, poses a significant challenge to traditional state-centric international legal studies. Declining extending research to these emerging social realities risks ceding the study of global AI regulation to disciplines like political science, IR or management. Recognising soft law’s potential virtues, modern legal positivists, rationalists and constructivists have integrated its study into their frameworks. For instance, Kratochwil (Reference Kratochwil1991), Onuf (Reference Onuf1985) and Günther (Reference Günther2008) combine legal positivism with sociological approaches, proposing discourse-based methods to understand soft law and international legal systems. Onuf (Reference Onuf1985) applied speech act theory to show that international order, including soft law like UN resolutions, functions as a legal order. Günther (Reference Günther2008), building on Luhmann (Reference Luhmann1995), views international law as a communicative system and a certain form of discourse, arguing that norms become law by adhering to normative principles, thereby encompassing soft law.
How can we characterise this dynamic and evolving international AI governance regime primarily constituted by soft law? Drawing linguistic inspiration from scholars like Onuf and Günther, this paper proposes applying sociosemiotics as a methodological lens. Semiotics has been innovatively applied to legal studies (Balkin Reference Balkin1990; Cheng and Danesi Reference Cheng and Danesi2019; Cheng and Sin Reference Cheng and Sin2008; Jackson Reference Jackson1985; Kennedy Reference Kennedy1991; Kevelson Reference Kevelson1988). Social semiotics specifically focuses on the relationship between signifiers and signified (the meaning-making process) within social behaviour and interaction (Cobley Reference Cobley2010). Within this framework, both texts and social systems are understood as sign systems (Halliday Reference Halliday2014), highlighting sociosemiotics’ role as a meta-discipline for delineating sociocultural phenomena and sign systems (Cobley and Randviir Reference Cobley and Randviir2009). This perspective provides an analytical anchor point for examining the fluid international legal governance of AI. By viewing AI normative texts, the AI governance regime and international society as multilayered sign systems, we can examine the semiotic interplay across discursive, regulatory and social dimensions. This approach enables the deconstruction and reconstruction of AI international regulation, identifying key characteristics of the current regime, revealing the underlying semiotic processes and socio-ideological factors, and helping refine our ethical and legal intuitions on this issue (Balkin Reference Balkin1990).
2. Theoretical framework
This study focuses on AI regulation and first clarifies the characteristics of international AI regulation to demonstrate its alignment with the sociosemiotic framework. A defining feature is its fragmentation, with norms dispersed across distinct international regimes. International regimes constitute patterned behaviour (Haggard and Simmons Reference Haggard and Simmons1987), emphasising the normative dimension of international politics and reflecting the interplay between international politics and law. They comprise issue areas, actors/organisations, norms and decision-making procedures (Krasner Reference Krasner1982). Currently, norms governing AI are widely distributed across regimes like international human rights, telecommunications and trade. Examples include using human rights principles for AI algorithmic accountability frameworks (McGregor et al. Reference McGregor, Murray and Ng2019), regulating cross-border data flows for AI development via telecommunications law (Taylor Reference Taylor2019), and addressing AI’s legal complexities within international trade law (Igbinenikaro and Adewusi Reference Igbinenikaro and Adewusi2024). A dedicated international AI regime remains nascent.
A second characteristic of international AI regulation is its predominance of soft law and lack of hard law. Key actors include inter-governmental organisations (UN, G7, G20, BRICS Alliance, ASEAN) alongside numerous non-governmental and multi-stakeholder bodies (ITU, GPAI, IEEE, ITO). The norms they produce, being primarily non-binding, fit Ehrlich’s classic distinction between the state’s formal ‘norms for decision’ (Entscheidungsnormen) and the society’s ‘living law’ which comprises the actual rules of conduct that people follow (Ehrlich and Ziegert Reference Ehrlich and Ziegert2017). Norms produced are primarily soft law or even ‘ultra-soft law’, with inter-governmental instruments achieving the broadest consensus, exemplified by UNESCO’s Recommendation on the Ethics of Artificial Intelligence, unanimously adopted by all 193 member states. ‘Ultra-soft law’ encompasses self-regulatory industry standards; their technical expertise, filling international legal gaps, may generate strong appeal for compliance. Similar to the Tallinn Manual’s significance for cyber law, standards from bodies like ISO/IEC hold considerable weight and may frame future AI regulatory agendas through path dependency (Villarino Reference Villarino2023).
A third distinctive feature is the plurality of regulatory subjects. This manifests in two ways: first, the diversification of international legal subjects and objects, where individuals and private firms now bear international legal rights, duties and liabilities under indirectly applicable regimes (e.g. international human rights law requiring technical accountability for AI systems (McGregor et al. Reference McGregor, Murray and Ng2019)). Second, diverse actors increasingly participate in the norm-making process of international AI regulation. Legal pluralism and liberalism in IR provide theoretical grounding for extending soft law authorship (Burley Reference Burley1993; Merry Reference Merry1988; Teubner Reference Teubner1991). Globalised AI technology intensifies risk society dynamics (McGrew Reference McGrew and David2004), necessitating regulation by expert committees and epistemic communities for complex, technical global issues. Their ‘ultra-soft law’, due to its expertise, often provides de facto guidance (Evans Reference Evans2014, p. 411), acting as model rules that shape subsequent regulatory agendas. Furthermore, individuals, private firms and NGOs are increasingly visible in international forums/processes. For instance, at the inaugural 2023 AI Safety Summit in London, alongside governments, executives and researchers from leading tech firms like Google and Meta participated, contributing to The Bletchley Declaration.
The fragmentation, soft law dominance and plurality of actors in AI regulation transcend the public–private law dichotomy, exhibiting characteristics of social legislation. Current AI-specific regulatory instruments do not conform to any source of international law listed in Article 38(1) of the ICJ Statute (reflecting the sources under the Vienna Convention on the Law of Treaties). As the object of this study, these phenomena necessitate a theoretical framework that: (1) explains AI regulatory signs across multiple regimes; (2) accounts for the dynamic evolution of international AI regulation, with explanatory power for ultra-soft law, soft law and hard law; and (3) interprets the roles of contested legal actors interacting at the international level.
To address the aforementioned research requirements, this paper employs a sociosemiotic framework. Ferdinand de Saussure, the founder of semiotics, divided the structure of signs into signifier (the form carrying meaning) and signified (the concept or meaning) (De Saussure Reference De Saussure, Rivkin and Ryan2004). By limiting his research to linguistics, Saussure characterised the signifier–signified relationship as ‘arbitrary’, while the social, political and cultural factors influencing both were termed extrasemiotic phenomena – precisely the focus of sociosemiotics. Sociosemiotics prioritises analysing the structure of the signifier, its a priori meaning as a sign, and how the union of signifier and signified encodes social reality. This framework treats all semiotic processes as social processes: social processes concern the definition of social actors, relations, structures and procedures, whereas semiotic processes serve as the means through which these definitions are examined, reaffirmed and transformed (Hodge and Kress Reference Hodge and Kress1988).
From a sociosemiotic perspective, all legal terms function as signs, while the international AI governance regime itself constitutes a dynamic semiotic system; the context of semiosis serves as the primary guide for interpretation (Cobley and Randviir Reference Cobley and Randviir2009, p. 2). Diverse forms of AI regulation – including declarations, standards and recommendations – are codified as textual artefacts. As contextualised instantiations of social meaning, these texts manifest the relationship between semantic structures and social context, a relationship subject to sociosemiotic representation (Hymes Reference Hymes1971). Halliday’s tripartite variables explain the semiotic structure of context: the field (the nature of social activity), tenor (participant relationships) and mode (medium of meaning exchange) (Halliday Reference Halliday2014, p. 192). Such tripartite division might cause some overlapping effects, but the configuration of the three elements into register integrates communication with social factors. Consequently, the sociosemiotic framework transcends the fragmentation of international regimes, enabling systematic deconstruction of all regimes through semiotic variables.
Second, sociosemiotics provides a robust framework for interpreting discursive dynamics in international AI governance. Inherently concerned with change and conflict, sociosemiotics focuses on explaining transformations, discontinuities, tensions and contradictions within human interactions and social processes. Sociosemiotics deciphers social constructs – including class stratification, power systems and hierarchies – through its diachronic and synchronic dimensions. When reconstructing the discourse, sociosemiotics reveals how social reality is shaped, constrained and modified (Berger and Luckmann Reference Berger, Luckmann, Longhofer and Winchester2016). The international governance of AI represents a convergence of ethical imperatives, political interests and law-making endeavours. Examining current regulatory discourse through a semiotic lens transcends superficial linguistic manoeuvers, thereby exposing the mutual permeability between morality, politics and law.
A sociosemiotics perspective is adaptive to the plurality of actors and multi-stakeholder dynamics in international AI governance. This framework treats motives (driving sign usage) and interests (guiding sign interpretation) as core factors in meaning production (Hodge and Kress Reference Hodge and Kress1988). Within Halliday’s contextual variables, tenor addresses interpersonal relations, reflecting the ‘participatory’ function of language that encodes status and role hierarchies among actors (Halliday Reference Halliday2014, p. 125). Crucially, the concept of ‘participants’ here denotes not individuals but social actors embedded in institutional contexts and value systems. Through their continuous deconstruction and reconstruction of signs, semantic fluidity emerges. This is manifested in intertextual dynamics across regulatory documents: when successive texts invoke similar terms, the evolving referent of signs progressively re-shapes legal concepts in AI governance.
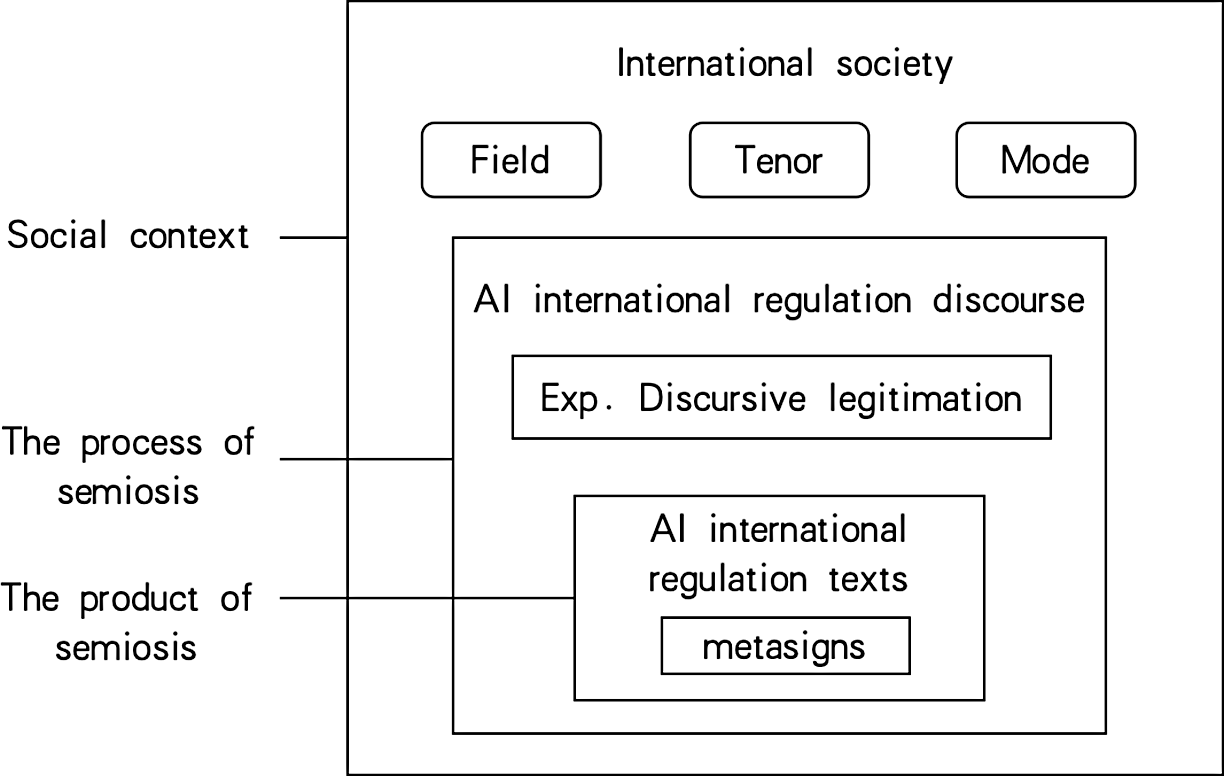
Viewing international AI regulation as a semiotic structure integrates regulatory texts with discursive processes (Hodge and Kress Reference Hodge and Kress1988, p. 262). As Figure 1 illustrates, regulatory texts function as signifiers of governance, where semantic/lexical relations encode critical traces of semiosis. Regulatory discourse operates as the mediating layer between text and social context, simultaneously constituting textual elements and social practices (Fairclough Reference Fairclough2003, p. 45). This discursive dimension, being inherently semiotic, allows critical discourse analysis to dissect legitimisation mechanisms linguistically (Vaara et al. Reference Vaara, Tienari and Laurila2006; Van Leeuwen and Wodak Reference Van Leeuwen and Wodak1999). The social context of AI governance, structured semiotically through field, tenor and mode variables, forms an integrated framework linking situational, discursive and textual strata.
The semiotic structure of international AI regulation.

Figure 1 Long description
The diagram illustrates the semiotic structure of international AI regulation. It is divided into three main sections: social context, the process of semiosis, and the product of semiosis. The social context includes the international society, which is further divided into field, tenor, and mode. The process of semiosis involves AI international regulation discourse, which includes explicit discursive legitimation. The product of semiosis is represented by AI international regulation texts, which contain metasigns. The diagram shows the relationships and flow between these components, emphasizing the complex interplay in the regulation of AI on an international scale.
3. Data and methods
To ground the abstract principles of social semiotics in a concrete analysis of legal texts, this study utilises a corpus-assisted methodology. While previous research on AI soft law has compiled valuable datasets (Fjeld et al. Reference Fjeld, Achten, Hilligoss, Nagy and Srikumar2020; Jobin et al. Reference Jobin, Ienca and Vayena2019; Schmitt Reference Schmitt2022), the reliance on purely qualitative methods presents challenges of scale and potential interpretive subjectivity. A corpus-based approach addresses these challenges by enabling the systematic, large-scale analysis of linguistic patterns as an empirical foundation for qualitative interpretation. As an established method in legal linguistics (Cheng et al. Reference Cheng, Sun and Chen2019; Goźdź-Roszkowski Reference Goźdź-Roszkowski2021; Solan and Gales Reference Solan and Gales2017; Vogel et al. Reference Vogel, Hamann and Gauer2018), corpus analysis facilitates the objective identification of keywords, collocational patterns and semantic trends, thereby revealing the underlying structure of a discourse before a more nuanced reading.
The first step in this research was to construct a specialised target corpus. Recognising that the explosive growth of AI soft law makes comprehensive collection nearly impossible, the collection process was based on the Global Partners Digital ‘Navigating the Global AI Governance Landscape’ report.Footnote 1 From their extensive catalogue of initiatives, formal normative documents were identified and then filtered to include only those that explicitly link specific actors to established norms; the set was also updated with key regulations released through 2024. This curated process yielded a target corpus of forty-seven documents representing a snapshot of the core international AI regime, with each document featuring a clear problem domain and institutional anchor (Appendix 1).
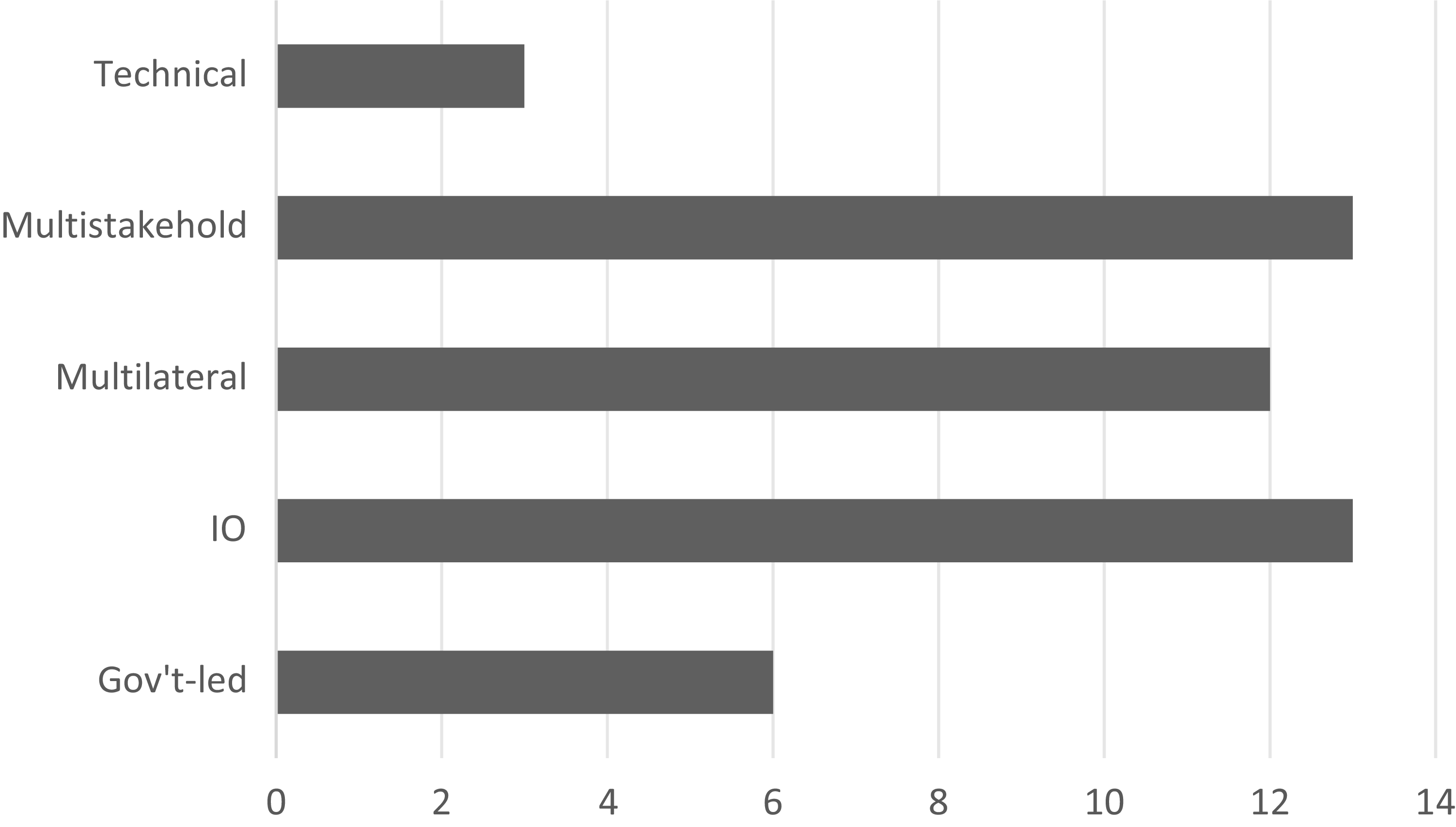
The distribution of drafting institution types is shown in Figure 2. To ensure the comparability of corpus length across document types in the discursive legitimation analysis, excessively long documents such as the EU AI Act were not included in the target corpus. However, the target corpus already includes other EU-issued documents, such as international conventions and advisory soft law files containing similar principles, to ensure the representation of the EU’s perspective. Overall, the target corpus is primarily composed of soft law (such as declarations and recommendations) and ultra-soft law (such as industry standards). Hard law documents mainly include two AI conventions and representative domestic AI laws from influential governments that have binding force and international impact.
Distribution of drafting institutions.

Figure 2 Long description
The horizontal bar graph compares the distribution of drafting institutions across five categories: Technical, Multistakehold, Multilateral, I O, and Gov't-led. The x-axis represents the number of institutions, ranging from 0 to 14. The y-axis lists the categories. The Technical category has a bar extending to approximately 3. The Multistakehold category has the longest bar, extending to 13. The Multilateral category has a bar extending to approximately 12. The I O category also has a bar extending to approximately 13. The Gov't-led category has a bar extending to approximately 6. All values are approximated.
The analytical procedure began with preparing the documents for computational analysis. The forty-seven files were converted to .txt format and imported into AntConc (v. 4.3.1). For comparative analysis, the Corpus of Contemporary American English (COCA) was loaded as a reference corpus, and the Harbin Institute of Technology (HIT) stop word list was applied to exclude function words. Table 1 presents the details of two corpora. The analysis then proceeded in two integrated phases. First, a quantitative keyword analysis was conducted to objectively map the dominant thematic landscape of the regulatory discourse. Subsequently, in a qualitative phase, these computer-identified keywords and their surrounding patterns were examined within their original textual context. This second step involved a sociosemiotic ‘close reading’ to interpret how key terms were used to construct meaning and frame the regulatory problem, allowing for a systematic yet nuanced interpretation of their function.
Corpora information

Table 1 Long description
The table presents information about two corpora, detailing their types, names, and token counts. The first row indicates the target corpus as the Corpus of International Regulations on A I, with 397674 tokens. The second row shows the reference corpus as C O C A, with 9412521 tokens. The table is structured with two columns labeled Type and Tokens, and two rows labeled Target corpus and Reference corpus.
4. Results and discussion
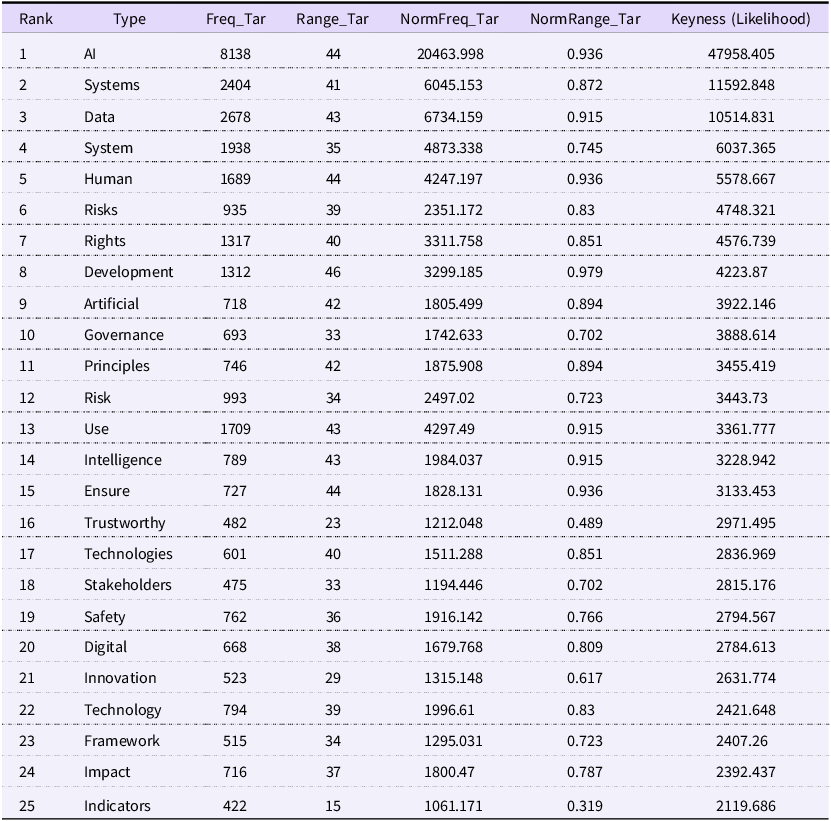
This discussion interprets the findings of our corpus analysis through the lens of social semiotics. Viewing the collected AI normative texts as a form of discourse, we draw upon Hallidayan and Foucauldian perspectives to understand them not as objective statements, but as selective representations of reality. These texts utilise specific semiotic resources – namely, vocabulary – to construct a particular understanding of AI governance. The critical question, therefore, is how the international regulation of AI is being characterised. What specific themes and topics are brought to the forefront through the discourse’s choice of language? To answer this, we turn to the keyword analysis detailed in Table 2. These keywords, generated by comparing our target corpus against the COCA reference corpus, reveal the core thematic structure of the AI regulatory discourse.
Keyword list of target corpus

Table 2 Long description
The table presents a keyword analysis of a target corpus focused on AI governance. It includes 25 rows and 8 columns, with headers for rank, type, frequency target, range target, normalized frequency target, normalized range target, and keyness likelihood. The first row highlights the keyword 'AI' with the highest frequency of 8138 and a keyness of 47958.405. Other notable keywords include 'Systems', 'Data', 'Human', and 'Risks', each with varying frequencies and keyness values. The table provides a detailed comparison of how often these keywords appear in the target corpus versus a reference corpus, indicating their significance in the discourse on AI governance.
The keyword analysis reveals a distinct clustering effect, indicating that international normative documents have converged around a shared set of concepts and principles. Drawing from Van Leeuwen’s social semiotic insight – that discourse selectively represents elements of a social practice – this keyword list highlights the core components prioritised within the quasi-international legal discourse of AI governance. A thematic categorisation of these keywords reveals three primary domains: (1) Core Subjects and Concepts: AI, data, system(s), technology, digital, risk(s) and development; (2) Regulatory Mechanisms and Actions: ensure, governance, framework and stakeholders; (3) Guiding Values and Principles: human, rights, principles, trustworthy, safety and innovation. Based on this categorisation, the foundational values currently driving international AI regulation are human-centricity, trustworthiness, safety and innovation. Admittedly, the analysis also identified other crucial values such as privacy, transparency, accountability, sustainability and explainability. A comprehensive ranking of these normative keywords by their statistical keyness is presented in Table 3.
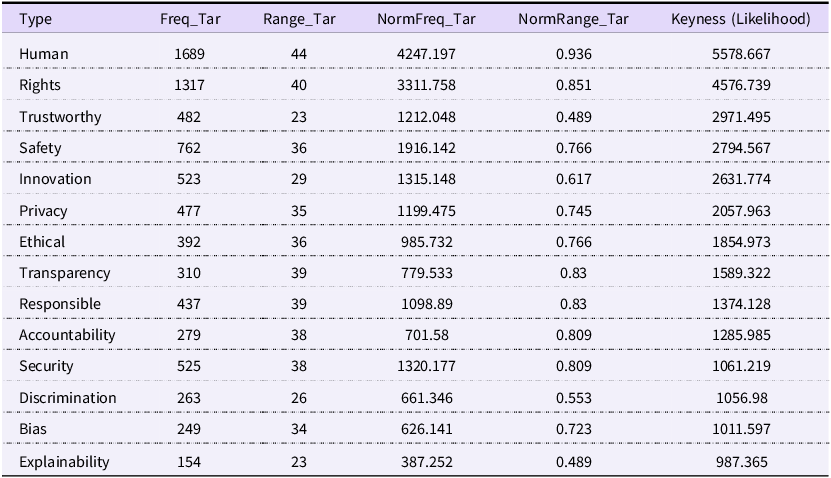
Rankings of values in international AI regulations

Table 3 Long description
The table ranks various values in international AI regulations across six columns: Type, Freq_Tar, Range_Tar, NormFreq_Tar, NormRange_Tar, and Keyness. The table includes 17 rows, each representing a different value such as Human, Rights, Trustworthy, Safety, Innovation, Privacy, Ethical, Transparency, Responsible, Accountability, Security, Discrimination, Bias, and Explainability. Each row provides specific data points for frequency, range, normalized frequency, normalized range, and keyness. Notable trends include high keyness values for Human, Rights, and Trustworthy, indicating their prominence in AI regulations. The table provides a comprehensive statistical analysis of the importance of various values in the context of AI governance.
The keywords related to ethical principles and values reveal a clear hierarchy within the dataset, with certain values receiving significantly more emphasis than others. This finding aligns with the evolving focus of AI principles research. For instance, a landmark qualitative study by Jobin et al. (Reference Jobin, Ienca and Vayena2019) identified eleven ethical principles, noting an emerging global consensus around five core themes: transparency, fairness, non-maleficence, responsibility and privacy. Subsequent research by American scholars highlighted eight principles, adding safety, human control of technology, professional responsibility and human values to the list, which notably signalled a clearer and more prevalent focus on human-centric ethics (Fjeld et al. Reference Fjeld, Achten, Hilligoss, Nagy and Srikumar2020). Similarly, Chinese scholars have summarised various frameworks, including three, four and eight-principle models that primarily feature values such as human-centricity, trustworthiness, accountability, safety, fairness and beneficence.
Among these studies, the classification by Jobin et al. is particularly detailed, covering a comprehensive range of AI legal and ethical principles. Therefore, to systematically assess the hierarchy of values in the current discourse, this study adopted their framework to guide a frequency analysis of the corpus. This approach is methodologically sound, as word frequency in legislative corpora is often used to reveal ideological leanings and policy priorities (Slapin and Proksch Reference Slapin, Proksch, Martin, Saalfeld and Strøm2014). The analysis thus provides an empirical ranking of the main principles currently emphasised in international AI governance.
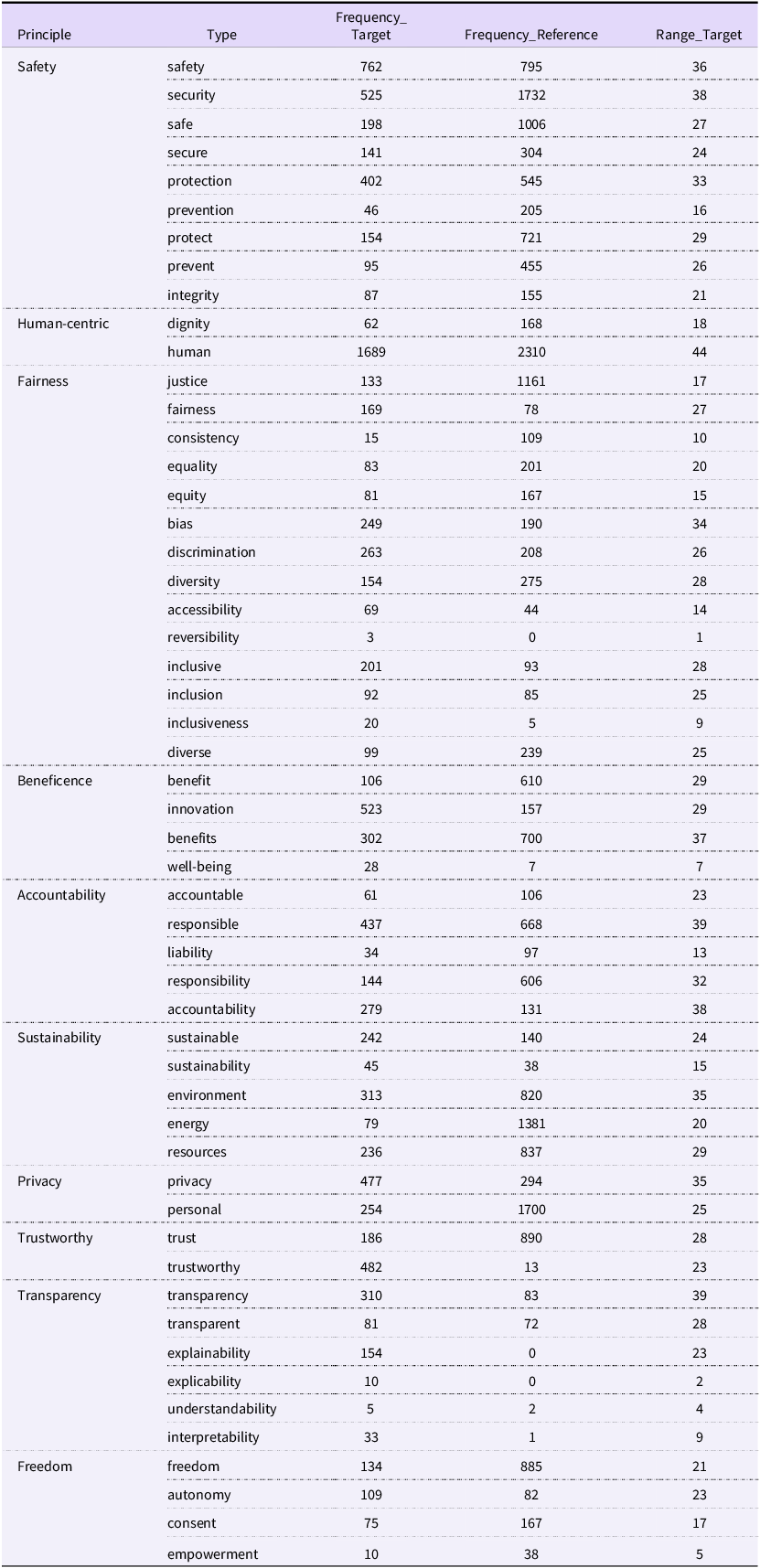
A frequency analysis of the entire corpus reveals that the AI principles cluster into ten primary thematic categories (See Table 4). In descending order of frequency, these are: safety, human-centricity, fairness, beneficence, accountability, sustainability, privacy, trustworthiness, transparency and freedom. This classification largely aligns with the framework proposed by Jobin et al. (Reference Jobin, Ienca and Vayena2019). Most notably, the terms related to the top three principles – safety, human-centric and fairness – appear with a significantly higher frequency than all others.
AI principles related words identified in the target corpus

Table 4 Long description
A table showing the frequency analysis of AI principles related words identified in the target corpus. The table is organized into ten primary thematic categories: safety, human-centricity, fairness, beneficence, accountability, sustainability, privacy, trustworthiness, transparency, and freedom. Each category lists various types of principles along with their frequency in the target and reference corpora, and the range target. The safety category includes types such as safety, security, safe, secure, protection, prevention, protect, prevent, and integrity. The human-centric category includes dignity and human. The fairness category includes justice, fairness, consistency, equality, equity, bias, discrimination, diversity, accessibility, reversibility, inclusive, inclusion, inclusiveness, and diverse. The beneficence category includes benefit, innovation, benefits, and well-being. The accountability category includes accountable, responsible, liability, responsibility, and accountability. The sustainability category includes sustainable, sustainability, environment, energy, and resources. The privacy category includes privacy and personal. The trustworthy category includes trust and trustworthy. The transparency category includes transparency, transparent, explainability, explicability, understandability, and interpretability. The freedom category includes freedom, autonomy, consent, and empowerment. The table provides a detailed comparison of the frequency of these principles in the target and reference corpora, highlighting the most frequently occurring principles.
However, this quantitative ranking has its limits. First, such classifications are not absolute. Existing AI principle frameworks often lack systematicity and uniform expression, and different global actors promote different governance visions. This is evident in our corpus, where the ‘Range’ column in Table 4 shows that the distribution and density of these principle-related terms vary considerably across texts. Second, from a social semiotic perspective, even when a legal term like ‘human rights’ appears as the same signifier, its meaning is dynamic and context-dependent (Cheng et al. Reference Cheng, Cheng and Sin2014). These two factors – inconsistent application across texts and the inherent ambiguity of legal terms – underscore the necessity of moving beyond frequency counts to analyse contextualised meaning. Therefore, the following analysis returns to the source texts to qualitatively examine the use of the three most prominent principle clusters.
4.1. Safety
‘Safety’ stands out as the most prominent and frequently mentioned principle in the entire corpus. To conduct an in-depth analysis of this theme, a set of nine related search terms was compiled, guided by the keywords in both our initial analysis and Jobin et al.’s framework: safe, safety, secure, security, protect, protection, prevent, prevention and integrity. An examination of the collocates for these terms confirmed that their semantic use throughout the corpus consistently falls within the conceptual domain of the safety principle. The emphasis on this theme is quantitatively significant. The combined frequency of these nine terms reaches 2,410 occurrences. Furthermore, their broad distribution across the documents suggests a widespread consensus on the centrality of safety among different types of actors. Specifically, the core term ‘security’ appears in thirty-eight of the forty-seven documents (81 per cent), while ‘safety’ is present in thirty-six (77 per cent).
Within the cluster of terms related to the safety principle, the pairs safety/safe and security/secure are consistently linked, necessitating a clear distinction. A contextual examination of the corpus reveals that safety typically refers to the internal integrity of an AI system and the avoidance of accidental harm, whereas security pertains to its external resilience against attacks. This distinction is explicitly articulated in UNESCO’s Recommendation on the Ethics of Artificial Intelligence, which states that, ‘Unwanted harms (safety risks), as well as vulnerabilities to attack (security risks) should be avoided…’. This conceptual difference is also reflected in their distribution and collocates. Safety appears most frequently in technical, standard-setting documents and its top collocate is function, reinforcing its connection to internal operations. In contrast, security is distributed broadly across all document types, and its most significant collocate is national, pointing to a different set of primary concerns. The prominence of national security suggests that the discourse on AI safety is deeply embedded in a framework of legally protected interests. This securitisation of AI can be understood as part of a broader logic of governance for managing uncertain futures, where principles of precaution, pre-emption and preparedness become central. The focus on ‘safety’ and ‘risk’ in the texts reflects a political desire to anticipate and neutralise potential threats before they materialise, a key feature of contemporary governance imaginaries (Lazaro and Rizzi Reference Lazaro and Rizzi2023). This framework can be conceptualised as a three-tiered model of ‘National Security – Social Security – Individual Security’, an evolution from the traditional Roman law dichotomy of public and private law. In this model, national security is the broadest level, concerning state sovereignty. Social security is the intermediate level, relating to public order and the stability of societal domains. Individual security is the narrowest, encompassing not only traditional personal and property safety but also emerging technological and industrial safety. The development and use of AI implicate all three levels of this security framework, from public interests to private ones. Because the authors in our corpus – ranging from inter-governmental organisations and states to NGOs and private firms – each selectively emphasise different facets of security, the resulting discourse is inherently multi-faceted, regionalised and context-dependent. Consequently, any effort to build a meaningful global consensus must be founded upon a clear acknowledgement of these diverse interests to fully define the principle’s intension and extension. In this context, the ‘safety’ discourse within AI soft law documents can be understood as what the legal sociologist Philip Selznick termed ‘incipient law’ – patterns and claims ‘latent in the evolving social and economic order’ that are highly probable to receive legal recognition in due course. The widespread consensus on safety, emerging from the practices and declarations of both state and non-state actors, forms a normative foundation from which future binding treaties or customary international law on AI safety may evolve. The process of securitisation, therefore, is not just a political manoeuver; it can be seen as a jurisgenerative process where social anxieties about risk are potentially translated into the building blocks of a new legal order.
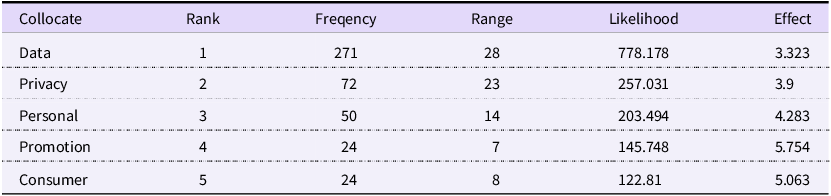
‘Protection’ is another key term within the safety principle, revealing the primary objects of this concern. The collocation results for protection (Table 5) are dominated by data, privacy, personal and consumer, outlining a clear focus on safeguarding the data and privacy of individuals. This focus is consistently reinforced in the source texts, such as the G20’s call to ‘promote the protection of privacy and personal data’ and UNESCO’s mandate that data processing must align with ‘data protection and data privacy’ laws and principles. Beyond what is protected, the discourse reveals a crucial insight into how protection is framed. Drawing on Foucault’s (Reference Foucault2013) concept of discourse as a socially constructed knowledge and Van Leeuwen’s (Reference Van Leeuwen2005) notion of ‘substitution’, we can observe a key discursive strategy at play: nominalisation. Van Leeuwen argues that replacing verbs (doing) with nouns (being) objectifies an issue, framing it as a settled state. This is precisely what occurs here: the nominalised forms protection and prevention appear with far greater frequency than their verb counterparts protect and prevent. This suggests the discourse treats data and privacy protection not as an ongoing action to be advocated for, but as an already established consensus – a static feature of the governance landscape. This discursive emphasis on protection, however, exists in tension with the practical reality of AI development, where the collection and use of data serve as the technology’s essential fuel. While data, algorithms and computing power are all core elements of AI, massive datasets are what enabled the recent ‘emergent intelligence’ in models like ChatGPT, whose core algorithms have existed for years. A final analysis of the word data itself within our corpus confirms the discursive priority: protection co-occurs with data far more frequently than terms related to data utilisation, such as collection, training, sharing or processing. This suggests a central finding: while data use is paramount for technological advancement, data protection appears to constitute the core theme of the regulatory discourse.
Top collocations of ‘protection’

Table 5 Long description
The table presents the top collocations of the term protection, focusing on data, privacy, personal, promotion, and consumer. It includes six columns: collocate, rank, frequency, range, likelihood, and effect. The collocate column lists the terms data, privacy, personal, promotion, and consumer. The rank column shows their respective ranks from 1 to 5. The frequency column indicates how often each term appears, with data having the highest frequency at 271 and promotion and consumer tied at 24. The range column shows the distribution of these terms, with data having the widest range at 28 and promotion the narrowest at 7. The likelihood column measures the statistical likelihood of these terms appearing with protection, with data having the highest likelihood at 778.178 and consumer the lowest at 122.81. The effect column shows the impact of these collocations, with promotion having the highest effect at 5.754 and data the lowest at 3.323.
The pronounced emphasis on ‘safety’ is one of this study’s most striking findings. In contrast to earlier analyses of global AI governance datasets, the safety principle is now discussed more frequently, suggesting a new global consensus on its importance. This evolution can be understood through Balkin’s (Reference Balkin1990) concept of ‘ideological drift’. Balkin argues that as political and legal concepts are expressed through signs, their ideological leanings can shift over time as those signs are iterated in new contexts. The rising prominence of ‘safety’ thus demonstrates this diachronic function of signs, where the discourse around AI principles has evolved in just a few years.
Furthermore, the critical nature of social semiotics can reveal previously unrecognised conflicts and prompt a reassessment of existing intuitions. Paul’s (Reference Paul2023) semiotic study of the EU AI Act provides a powerful recent example. Paul deconstructs the EU’s ‘risk-based’ approach, arguing – based on legislative analysis and expert interviews – that the risk classifications were not objective but were rather a ‘political decision and value statement’. This framing was a strategic discursive choice that allowed the EU’s regulatory framework to ‘stand out’ in the global competition over AI norms. Similarly, the discursive construction of the ‘safety’ principle in our corpus merits critical reflection. A sociosemiotic perspective prompts further questions: how, precisely, was the regulation of AI ‘securitized?’ Whose viewpoints does this safety-centric discourse represent and amplify? And through what semiotic processes was this principle generated and propagated?
While fully answering these questions requires more contextual material, the current international political climate offers potential explanations. One is the broader trend of ‘pan-securitization’, where numerous international issues are framed through a security lens. For a disruptive technology like AI, a ‘safety narrative’ offers international actors more control than a ‘development narrative’. Second, the still-maturing international AI regime is heavily influenced by the domestic laws of first-mover jurisdictions, and these legal systems have themselves been observed to be undergoing a clear securitisation process (Mügge Reference Mügge2023; Zeng Reference Zeng2021).
4.2. Human-centric
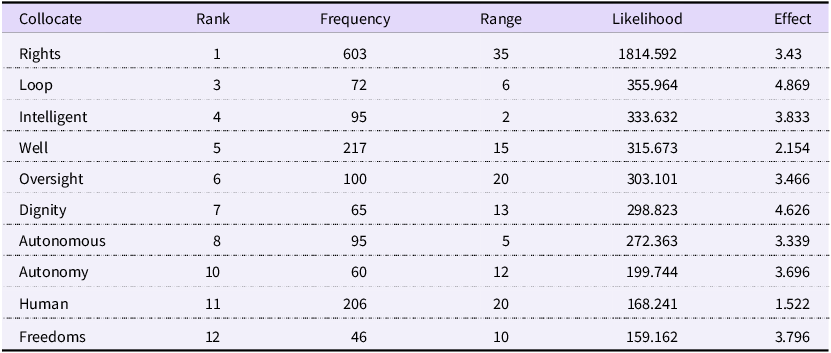
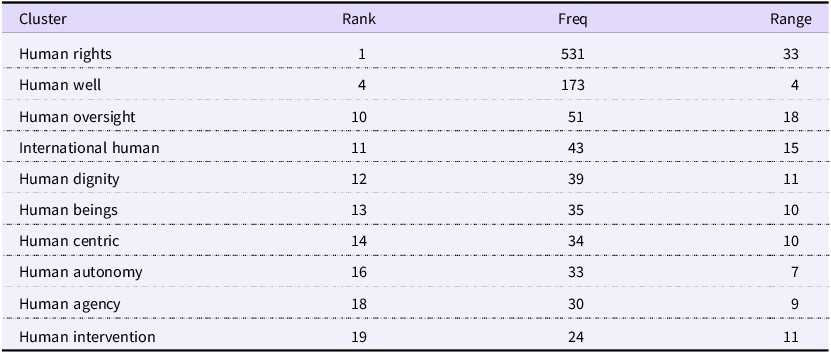
Alongside safety, a human-centric approach emerges as one of the most significant principle themes in the corpus. This is immediately evident from the prominence of the keyword human, which, with a frequency of 1,686, is the most common of all principle-related terms. Its statistical keyness is second only to keywords that refer to AI itself. A qualitative review of the corpus shows that human combines with other words to form a rich semantic network encompassing concepts like rights, dignity and well-being. Therefore, this analysis uses the term ‘human-centric’ – a label common in both international law and contemporary AI ethics scholarship (Amariles and Baquero Reference Amariles and Baquero2023; Rožanec et al. Reference Amariles and Baquero2023) – as an umbrella concept to encapsulate the diverse principles revolving around the keyword human. To deconstruct this concept, a collocate analysis of human was performed, with the results presented in Table 6. Additionally, the Cluster function was used to identify common two-word phrases (n-grams) involving human, as shown in Table 7.
Top collocations of ‘human’

Table 6 Long description
The table presents the top collocations of the keyword human, detailing their rank, frequency, range, likelihood, and effect. It includes twelve rows and five columns. The columns are labeled Collocate, Rank, Frequency, Range, Likelihood, and Effect. The collocates listed are Rights, Loop, Intelligent, Well, Oversight, Dignity, Autonomous, Autonomy, Human, and Freedoms. Each row provides specific values for these collocates. For example, Rights has a rank of 1, a frequency of 603, a range of 35, a likelihood of 1814.592, and an effect of 3.43. The table highlights the prominence of these collocates in relation to the keyword human, showing their statistical significance and frequency of occurrence.
Top clusters of ‘human’

Table 7 Long description
The table presents data on top clusters of human, listing their rank, frequency, and range. It includes clusters such as Human rights, Human well, Human oversight, International human, Human dignity, Human beings, Human centric, Human autonomy, Human agency, and Human intervention. Each cluster is ranked from 1 to 19, with frequencies ranging from 531 to 24 and ranges from 33 to 11. The table provides a detailed comparison of these clusters based on their frequency and range.
The analysis of human’s collocates in Table 6 and word clusters in Table 7 reveals that the ‘human-centric’ principle encompasses two primary dimensions. The first dimension concerns the relationship between humans and AI systems. A contextual examination of key collocates like loop, oversight and autonomy confirms that their semantic use consistently points to human interaction with and control over AI. This theme is further reinforced by the prominence of two-word clusters such as human agency and human intervention. The second dimension is an emphasis on human values, highlighted by collocates like dignity, freedoms and well-being. Within this dimension, the most significant finding is the deep integration of the international human rights framework. The high co-occurrence score of the collocate rights, combined with the statistical prominence of the cluster human rights, demonstrates that international human rights law has become a foundational component of the current AI regulatory discourse.
Regarding the human–AI relationship, the corpus reveals a strong emphasis on human control over technology. This control manifests as: human oversight of automated decisions; human independence within the decision-making loop (ensuring autonomy and agency); and the capacity for direct human intervention. The concept of ‘oversight’ primarily refers to the human review of an AI system’s decisions, typically conducted ex post to correct outcomes. This requires that humans retain effective autonomy, as noted in the Principles for Responsible AI Innovation: ‘human control and oversight are the ability and opportunity for humans to adequately supervise, engage and interfere with an AI system… law enforcement agencies are advised to verify that… humans have the last word’. Documents like the Blueprint for an AI Bill of Rights further specify that such oversight should be enhanced in sensitive domains like the criminal justice system, employment and health care. However, despite this emphasis, the requirements for human oversight are often described in general terms, lacking detailed scenarios or clear hierarchical rules. This is reflected in practice, where legal professionals acknowledge the necessity of verifying AI-generated outputs to mitigate risks like ‘hallucinations’, but formal training on how to do so remains scarce. The reliance on human oversight, therefore, becomes a matter of individual professional responsibility rather than a systematically implemented rule (Terzidou Reference Terzidou2025). Different documents propose varying levels of review, typically based on risk. For example, the EU’s Ethics Guidelines for Trustworthy AI notes that oversight can be required ‘in varying degrees… depending on the… application area and potential risk’, and operationalises this through a questionnaire-style self-assessment list. While flexible, this approach delegates the interpretation of oversight intensity and mechanisms to the implementing entity. This may lead to a diversification of standards in practice, undermining the goal of achieving international consensus. Such vagueness is characteristic of the current international AI regime, which is dominated by non-binding soft law instruments (Elias and Lim Reference Elias and Lim1997). This implementation challenge is rooted in the nature of international legal communication. As a cultural semiotic system, international law must be interpreted by a diverse global community (the ‘receivers’) who may not share the same context as the drafters (the ‘senders’). The comparability and effectiveness of any legal regime depend on a shared interpretation of meaning (Anne et al. Reference Anne, Matulewska and Cheng2020). The inherent ambiguity of soft law, while inclusive, exacerbates this problem, as it can lead to divergent practices that reduce comparability. Therefore, from the perspective of ensuring clear semiotic communication and robust dialogue, hard law mechanisms – such as the Council of Europe’s Framework Convention on Artificial Intelligence – represent a crucial path forward for achieving a more thoroughly negotiated and stable consensus.
In the human–AI relationship, the concepts of human independence, oversight and control are tightly interwoven. The keyword loop, for instance, is central to a tripartite classification found in roughly a quarter of the documents: human-in-the-loop, human-over-the-loop and human-out-of-the-loop, which represent escalating levels of automation and risk.Footnote 2 A core tenet of human independence is that even in human-out-of-the-loop scenarios, a person retains the ability to exit the automated process. In the corpus, this capacity is represented by human autonomy and human agency. The Ethics Guidelines for Trustworthy AI define human agency as the ability for users to ‘make informed autonomous decisions regarding AI systems’, while UNESCO’s Recommendation on the Ethics of Artificial Intelligence links human autonomy and human agency directly to the protection of human dignity. However, the principles of control and intervention reveal a significant tension at the heart of AI governance. While regulatory texts call for human control, technical standards often define autonomous systems in contradictory terms. For example, the IEEE Recommended Practice for Assessing the Impact of Autonomous and Intelligent Systems on Human Well-Being defines an intelligent system as one that can ‘carry out some task with or without limited human intervention capable of decision making by independent inference’. This characterisation of AI as inherently free from intervention directly conflicts with the human-centric demand for control. This contradiction likely stems from what appears to be one of the deepest conflicts within AI regulation: the tension between development and safety. This development-versus-safety conflict brings the second dimension of the human-centric principle – human values – into sharp focus. On the other side of the risks posed by AI is its immense potential to benefit society; collocates of human show that ‘development’ and ‘well-being’ are also treated as key legal interests. The governance challenge, therefore, is a fundamental value conflict between the legal interest of safety and that of development. As long as different legislative contexts prioritise these competing values differently, the formation of an effective and stable global consensus will remain a significant challenge.
One of the most significant findings relating to the human-centric principle is the widespread integration of the international human rights law (IHRL) framework, mentioned in thirty-three of the forty-seven documents. This trend is not isolated to AI governance; it is part of a broader ‘transnational human rights’ movement where international norms, constitutional rights and humanitarian law increasingly interact and shape both state and non-state action (Klug Reference Klug2005). This is supported by the high statistical keyness of the terms human and rights and the frequent human rights law cluster. The contextual analysis shows that human rights has a dual meaning: it refers both to core values, often listed with dignity and fundamental freedoms, and to the formal legal framework itself. These two meanings are tightly linked; when documents elaborate on values, they consistently align them with IHRL. For instance, the Principles for Responsible AI Innovation states that its concepts ‘are derived from the Universal Declaration of Human Rights’, while other reports use specific ICCPR articles to define principles like non-discrimination, directly aligning AI ethics with established human rights law. The broad application of IHRL signals a growing recognition of its utility for AI governance. The IHRL framework provides a mature, systematic and universal methodology for assessing and regulating AI, built on decades of global consensus and already integrated into national legal systems (Rodrigues Reference Rodrigues2020). Its suitability stems from its focus on human dignity and its clear delineation of state and private sector responsibilities (Donahoe and Metzger Reference Donahoe and Metzger2019). The direct applicability of this framework is clear when mapping cornerstone documents like the Universal Declaration of Human Rights (UDHR) to key AI principles. For example, the UDHR’s principles of equality and non-discrimination (Article 2) directly address AI fairness; the rights to remedy and due process (Articles 8–11) provide a foundation for transparency and accountability; and the right to privacy (Article 12) anchors data protection requirements. Ultimately, the relationship between the nascent discourse of AI regulation and the established IHRL framework can be understood as a form of ‘manifest intertextuality’ (Fairclough Reference Fairclough1992). The two function as interconnected legal semiotic systems at the international level. The semiotic meaning of AI regulation is endowed and specified through its dialogue with IHRL. Concurrently, the semiotic meaning of the human rights framework is itself reinterpreted and enriched as it is applied to the new and complex problem domain of artificial intelligence, suggesting a dynamic and mutually constitutive relationship.
4.3. Fairness
As one of the three most significant principles revealed in the corpus, fairness is distinguished by having the richest set of associated keywords, indicating its broad semantic range. The centrality of this theme is underscored by the fact that its antithesis, discrimination, is mentioned in thirty-four of the forty-seven documents. The keywords encompassed by this principle include fairness, justice, equality, diversity, inclusion, consistency, accessibility, unbiased and non-discrimination. As a deontological principle, fairness is an essential requirement for ‘AI for good’. However, it is also notoriously vague, containing multiple, often competing, meanings that can lead to value conflicts. This presents a challenge for purely qualitative analysis, as noted in the Artificial Intelligence Risk Management Framework: ‘Standards of fairness can be complex and difficult to define because perceptions of fairness differ among cultures and may shift depending on application’. To navigate this complexity, this study utilises corpus methods (frequency and keyness calculations) to distil the ‘greatest common denominator’ from the discourse across the extensive document set. Based on semantic proximity, keywords under principles of fairness in Table 4 can be grouped into four primary thematic categories: (1) Non-discrimination and Non-bias (non-discrimination, unbiased); (2) Fairness and Justice (fairness, justice, equity); (3) Equality and Accessibility (equality, accessibility, with equity also being relevant); and (4) Diversity and Inclusion (diversity, inclusion). Based on a ranking of their combined frequency and keyness, ‘Non-discrimination and Non-bias’ emerges as the most significant dimension of the fairness principle. This is followed, in order, by ‘Fairness and Justice’, ‘Diversity and Inclusion’ and finally ‘Equality and Accessibility’. The following analysis will further examine these quantitative discourse results.
Non-discrimination and the prevention of bias represent the most significant dimension of the fairness principle, with discussions of bias found in thirty-four of the forty-seven documents and non-discrimination in twenty-six. The discourse is primarily concerned with algorithmic bias, which is defined as ‘systematic and repeatable errors in a computer system that create unfair outcomes’ in the Assessment List for Trustworthy AI. The root causes are identified as flawed or unrepresentative training data and poor algorithmic design. As many documents note, the harms of such bias are amplified in sensitive domains, with frameworks like the AI Safety Governance Framework stating that ‘poor-quality datasets can lead to biased or discriminatory outcomes… regarding ethnicity, religion, nationality and region’. However, a key limitation of the current discourse is that it concentrates on bias as a problem to be avoided rather than articulating a clear, operational vision for an unbiased AI system. This stems from the semantic uncertainty of the term bias itself. Most texts address discrimination in general terms, often using vague modifiers like harmful, unjust or unintended. Even the most precise definitions, such as that in the EU’s Ethics Guidelines, offer only a broad framing of bias as ‘an inclination of prejudice towards or against a person, object, or position’, without providing concrete operational criteria. This lack of specificity can be explained by the inherent distinction between the legal and moral dimensions of discrimination. The moral understanding of bias is often unstable and subject to rapid semantic shifts based on social trends. Law, adhering to a principle of contraction, is inherently cautious about codifying such fluid moral concepts. This challenge, combined with the fact that the meaning of bias is spatiotemporally dependent – varying significantly across different regions and legal cultures – results in a principle that is widely endorsed in theory yet lacks the concrete substance required for effective legal practice.
The collocation analysis shows that fairness and justice are core components of the broader fairness principle, frequently appearing alongside non-discrimination. Similar to the other concepts, it has multiple meanings. Documents like A pro-innovation approach to AI regulation acknowledge this complexity, suggesting that fairness should be interpreted in line with existing legal frameworks such as human rights law. A particularly useful approach, proposed in the EU’s Ethics Guidelines for Trustworthy AI and supported by a contextual review of the corpus, is to divide the concept into substantive fairness and procedural fairness. Substantive fairness, though often defined in general terms, appears widely. For example, the Principles for Responsible AI Innovation defines it as ensuring ‘a just and non-discriminatory treatment of individuals and groups and a contribution to a more equitable society’. Procedural fairness complements this by safeguarding individual recourse. The same documents emphasise that procedural fairness ‘requires that agencies safeguard people’s ability to contest decisions supported by AI systems and to be compensated if such decisions are harmful to them’. This distinction highlights a key dynamic: because the concept of fairness and justice in legislative documents remains generalised and slow to evolve, enforcement and judicial action often take the lead in guaranteeing fairness in the AI domain. However, a significant gap remains, as these enforcement-led approaches currently lack effective, detailed guidance on how to reconcile the competing values of fairness and innovation.
Inclusion, primarily represented by the keywords diversity and inclusion, which often appear together, is another important dimension of the fairness principle. A contextual analysis reveals that inclusion is applied in two primary scenarios. The first is inclusion in the design of AI systems, which requires that development processes be multi-faceted and participatory. As the EU’s Ethics Guidelines for Trustworthy AI states, ‘It is critical that… the teams that design, develop, test and maintain… these systems reflect the diversity of users and of society in general’, including different genders, races, nationalities and cultures. This extends beyond the design teams to also consider the diversity of the technology’s intended audience. Furthermore, organisations are called upon to support this participation, with the Partnership on AI noting that ‘committing organizational resources demonstrates a different level of dedication to pursuing inclusively… developed technology’. The second scenario is the inclusive sharing of AI’s benefits. This interpretation of inclusion is widely mentioned throughout the corpus and serves to link the principle of fairness with the broader goals of human-centricity and trustworthy AI. For example, the OECD’s Policy and Investment Recommendations for Trustworthy AI explains inclusion as ensuring that all people can benefit from artificial intelligence and that it contributes to social well-being.
Finally, the cluster of words represented by ‘equality’ has a certain semantic similarity to ‘fairness and justice’, but from the context of the signs, equality has a different use case compared to ‘fairness’. ‘Equality’ is more absolute, meaning that regardless of whether the situations of different groups are similar, they should receive the same opportunities and protection, whereas fairness is more about adapting to local conditions, focusing on guaranteeing the treatment and opportunities of similar groups. In the corpus, the most common collocates of ‘equality’ include ‘race’, ‘gender’, ‘dignity’, ‘economic’ and ‘rights’. Taking ‘race’ and ‘gender’ as examples, even if there are large differences between individuals, they are ‘absolute’ equality matters in the AI context. In addition, the principle of ‘equality’ is often mentioned together with the principle of ‘non-discrimination’, but at the semantic level, the principle of ‘equality’ goes a step further than the principle of ‘non-discrimination’. In the AI context, non-discrimination still retains the possibility of treating different situations differently based on objective reasons, whereas equality means applying the same rules – for example, the same algorithm rules – so that all groups have equal rights to information, data, knowledge, market access and the distribution of utility (Yu Reference Yu2020). In the corpus documents, equality in the AI context mainly includes three aspects: equality from a human rights perspective (race, gender), equality in the accessibility of technology and equality in sharing the results of AI technology. For example, the Recommendation on the Ethics of Artificial Intelligence released by UNESCO mentions that the goals of the recommendation include equality from a human rights perspective, ‘to protect, promote and respect human rights and fundamental freedoms, human dignity and equality, including gender equality’, as well as equality in accessing AI knowledge and in sharing the results of AI development, ‘to promote equitable access to developments and knowledge in the field of AI and the sharing of benefits’.
5. Conclusion
From a social semiotic perspective, this paper presents a systematic analysis of consensus-building and legitimisation within the global governance of AI. Based on a corpus of forty-seven international normative documents, this study identifies three primary characteristics of the current landscape: a fragmented regulatory architecture, a normative system dominated by soft law and the dynamic participation of multiple actors. The analysis reveals that the three core principles of ‘safety’, ‘human-centricity’ and ‘fairness’ form a cross-textual consensus through semiotic expression. ‘Safety’ constructs a hierarchical framework of legally protected interests, from the national to the individual level; ‘human-centricity’ emphasises technological controllability through signs like ‘human rights’ and ‘oversight’; and ‘fairness’ seeks to balance social justice through discourses of ‘non-discrimination’ and ‘diversity’.
However, the pervasive use of nominalisation in these soft law texts (e.g. ‘protection’ instead of ‘to protect’), while effective at building surface-level consensus, also exposes a core tension between this emerging ‘living law’ and the state’s formal ‘norms for decision’. This ambiguity undermines practical enforcement, leading to fragmented standards and interpretive disagreements during implementation. The social semiotic framework further demonstrates that these governance texts are not merely technical products but are also mappings of global power relations. For instance, the prevalence of ‘securitization’ discourse reflects the risk-control imperatives of sovereign states in technological competition, a logic of governance increasingly shaped by a desire to pre-empt uncertain futures. At the same time, the frequent citation of the ‘human rights framework’ highlights a strategy by non-state actors to contest discursive power using established legal signs, a process central to the formation of transnational legal fields.
At a theoretical level, this study offers a certain contribution by moving beyond the traditional hard law–soft law dichotomy. By treating AI governance texts as a dynamic semiotic system, it demonstrates how a new transnational legal order for AI is being constructed, one characterised by the features of legal pluralism. This approach aligns with socio-legal scholarship that emphasises ‘living law’ over state-centric models and aims to contribute an analytical tool for understanding the legitimisation of technology governance. The challenge for the future of international law, therefore, is whether and how this vibrant, pluralistic ‘living law’ of AI governance will be integrated and made accountable through more robust legal mechanisms, without stifling the innovation and multi-stakeholder collaboration that gave it rise.
It must be acknowledged that this study is limited by the timeliness of its corpus and sample size, and has not fully captured the impact of rapid technological iteration on governance discourse. Furthermore, an analysis of non-textual semiotic practices awaits future research. Such research could be expanded to include multimodal signs (e.g. images, algorithmic code) or to track the chronological evolution of these norms, offering a more comprehensive response to the globality and complexity of AI governance. In addition, as global AI legislation evolves and more comparable soft law and hard law corpora become available, this move beyond the dichotomy can evolve into comparative research within these respective datasets, seeking to bridge and reconcile the potential value differences that may exist between them.
Overall, the global regulation of AI is not merely a technical challenge but a profound semiotic and legal process laden with political and moral disagreements. A durable balance between common human values and technological transformation can only be achieved by embracing difference within consensus and upholding fundamental principles amid innovation, recognising the complex interplay between the living law of society and the formal law of states.
Acknowledgements
This work was supported by the National Social Science Fund of China (No. 24BYY151) under the project “Corpus-based Research on Cyber Security Discourse System”. We would like to express our sincere gratitude to the anonymous reviewers for their inspiring feedbacks and encouraging comments.
Competing interests
No competing interests.
Appendix A: List of international regulations on AI governance



 Open access
Open access