


Introduction
Multilingualism is a widespread phenomenon embraced by over half of the world’s population (Bhatia & Ritchie, Reference Bhatia and Ritchie2014). With the number of multilingual speakers increasing rapidly each year (Rocha-Hidalgo & Barr, Reference Rocha-Hidalgo and Barr2023), it is essential to explore how acquiring multiple languages enriches individual experiences and broadens interactions with unfamiliar languages. One area of particular interest is the acquisition of second language (L2) phonology and its impact on processing novel sound sequences. Despite the interest and extensive research, it remains uncertain whether L2 learners have any advantages over monolinguals in the perceptual attainment of the L2 phonotactic specificities. Studies that have examined how exposure to surface consonant sequences resulting from the application of an L2 phonological rule (i.e., vowel devoicing) affects the perception of foreign consonant clusters have been even rarer. This study aims to fill the gap in existing studies by specifically exploring the impact of exposure to Japanese consonant sequences with an intervening voiceless vowel on native English speakers’ perception of foreign consonant clusters, particularly those found in Slavic languages.
There have been relatively few studies dedicated to investigating the influences of bilingualism and L2 learning on the development of the ability to perceive novel phonetic contrasts (for a comprehensive review, see Wang & Nance, Reference Wang and Nance2023; Hirosh & Degani, Reference Hirosh and Degani2018; Cabrelli Amaro & Wrembel, Reference Cabrelli Amaro and Wrembel2016). The motivation behind these studies is based on empirical evidence suggesting that multilingualism positively affects the general cognitive functions of language learners (Quinteros Baumgart & Billick, Reference Quinteros Baumgart and Billick2018; Cenoz, Reference Cenoz2013), including cognitive flexibility and inhibitory control during phonological acquisition (Bartolotti et al., Reference Bartolotti, Marian, Schroeder and Shook2011; Bartolotti & Marian, Reference Bartolotti and Marian2012). However, regarding the abilities to perceptually discriminate novel phonetic contrasts, there is no consensus in the literature on whether L2 learners have any significant advantages over monolinguals. Some studies (e.g., Patihis et al., Reference Patihis, Oh and Mogilner2015; Werker, Reference Werker1986) find no enhanced perceptual sensitivity from learning an additional language. In contrast, other studies (e.g., Antoniou et al., Reference Antoniou, Liang, Ettlinger and Wong2015; Enomoto, Reference Enomoto1994; Missaglia, Reference Missaglia2010; Tremblay & Sabourin, Reference Tremblay and Sabourin2012) have found that L2 learners outperform monolinguals in their ability to learn and perceive novel phonetic contrasts. An interesting case is the study by Onishi (Reference Onishi2016), which examined Korean speakers acquiring English as their L2 and Japanese as their L3. The study found that the participants’ performance in recognizing L3 phonological contrasts correlated with their performance in L2 (English), suggesting that the acquired English phonology improved their perception of Japanese sounds. Additionally, the successful perception of Japanese contrasts, not present in L2 (English) phonology, indicated a general increase in perceptual sensitivity for Korean speakers, attributed to their overall experience in learning foreign languages.
The present study aims to further explore the role of L2 learning in perceptual sensitivity by examining English monolinguals and English-speaking learners of Japanese. Specifically, the study focuses on differences in their perceptions of word-initial stop consonant sequences (#CC-) contrasting with those having a full vowel (#CVC-) or a devoiced vowel (#CV̥C-). Japanese was chosen as the L2 for this study because it exposes learners to word-initial stop sequences with an intervening devoiced vowel. Such phonetic structures acoustically resemble onset stop-stop clusters found in Slavic languages, which Japanese and English phonotactics do not permit. By assessing the abilities of English-speaking learners of Japanese and English monolinguals to discern these phonetic contrasts, this study aims to enhance our understanding of how L2 learning influences the perception of novel contrasts with similar phonetic profiles and to provide valuable insights for future research on bilingualism and L2 phonetic learning.
Japanese vowel devoicing
It is remarkable that Japanese phonotactic grammar prohibits onset consonant clusters, yet similar acoustic sequences frequently surface in the language due to the phonological process of vowel devoicing (Hirayama, Reference Hirayama2009). Vowel devoicing is common in many Japanese dialects and is often claimed to be obligatory in the Tokyo dialect (Hirayama, Reference Hirayama1985). According to Fujimoto (Reference Fujimoto and Kubozono2015), devoicing occurs when an unaccented high vowel (/i/ or /u/) appears between two voiceless obstruents or after a voiceless obstruent word-finally. Based on acoustic studies, such as those by Kimura et al. (Reference Kimura, Kaiki and Kito1998) and Fujimoto (Reference Fujimoto2004), Fujimoto (Reference Fujimoto and Kubozono2015) has reported that vowel devoicing is systematic and most frequent within the voiceless stop-stop (e.g., [ku̥tu] “shoes”), stop-fricative (e.g., [ku̥sa] “grass”), and fricative-stop (e.g., [su̥kuu] “save”) consonantal environments. However, the rate of speech and dialectal variation can also affect the course of the phonological process (for a detailed discussion, see Fujimoto, Reference Fujimoto and Kubozono2015).
Researchers have long been puzzled by the discrepancy between phonological syllabic structure and its surface instantiations when reconciling the Japanese lexical representation of the #CVCV∼ phonological form with “apparent consonant clusters” resulting from vowel devoicing (Hirayama, Reference Hirayama2009, p. 4). Hirayama (Reference Hirayama2009) examined the nature of postlexical versus lexical representation, focusing on the impact of Japanese high vowel devoicing on prosodic units (i.e., syllables and morae). The study questioned whether these units are deleted and if the prosodic inventory changes in the postlexical domain, concluding that both syllable and mora units remain intact, and the prosodic structure does not change post-lexically, with vowels still present despite devoicing. Additionally, Fais et al. (Reference Fais, Kajikawa, Werker and Amano2005) investigated how Japanese native listeners perceive nonsense words that either adhere to or violate the canonical #CVCV∼ phonotactic form due to vowel devoicing, often resulting in “consonant clusters and word-final consonants, apparent violations of that phonotactic pattern” (p. 185). By having native Japanese speakers rate both canonical and noncanonical nonsense words, the study aimed to determine whether listeners’ judgments are influenced more by phonotactic rules or by the frequency of acoustic forms they encounter. The results indicated that listeners’ perceptions are shaped by their implicit understanding of canonical forms and the contexts in which vowel devoicing occurs, rather than strictly adhering to phonotactic constraints.
Furthermore, an ongoing debate in the literature revolves around the nature of the devoiced vowels, particularly whether they are devoiced categorically or via a natural phonetic process arising from a tempo-gestural overlap of laryngeal movements (Fujimoto, Reference Fujimoto and Kubozono2015). The arguments used from both sides of the debate are relevant for the current study as they may shed light on whether listeners can rely on any acoustic information associated with the phenomenon. Crucially, there is no agreement in the literature on whether Japanese vowels are devoiced or deleted completely. Whang (Reference Whang2018) suggests differentiating the absence of the laryngeal gestures (“unphonated”) from the lack of both laryngeal and supralaryngeal vowel gestures (“deleted”) when discussing vowel devoicing. Although studies agree that it is often challenging to characterize devoiced vowels acoustically, Vance (Reference Vance2008) describes them as a short period of voiceless noise between the first-consonant (C1) release burst and the second consonant (C2) closure. Articulatory evidence emerges from photoglottography studies (Sawashima, Reference Sawashima1974; Fujimoto et al., Reference Fujimoto, Murano, Niimi and Kiritani2002) that have shown that during the production of devoiced vowels, the vocal folds are set to vibrate in a mono-modal manner, abducting at a greater extent than when producing voiceless consonants. For example, as reported by Fujimoto et al. (Reference Fujimoto, Murano, Niimi and Kiritani2002), for non-words like /kite/ (but not /kide/ or /kete/), the vocal folds began to abduct at the onset of the voiceless /k/, peaked in the glottal opening at the midpoint of /i/, and adducted only after /t/ offset. According to the researchers, the duration of the glottal abduction during /k/ in [ki̥te] was longer than in [kide], while the devoiced vowel duration was shorter than the voiced counterparts. These findings are consistent with studies (e.g., Whang, Reference Whang2018; Varden, Reference Varden2010; Han, Reference Han1994) reporting that the burst release noise of C1 (non-fricatives) is typically longer when the subsequent vowel is devoiced than voiced in otherwise similar phonetic contexts. As the researchers suggest, such lengthening “provide[s] temporal compensation within a mora” for durational reduction of the devoiced vowel (Han, Reference Han1994, p. 81). Studies also demonstrated that spectral information in C1 burst release noise often contains visible formant frequencies from the following vocalic tongue gestures due to coarticulatory overlap (Whang, Reference Whang2018; Varden, Reference Varden2010; Beckman & Shoji, Reference Beckman and Shoji1984). Thus, the acoustic cues that may facilitate the perceptibility of unphonated vowels are described by the presence of the short, devoiced portion between voiceless consonants, the lengthened duration of C1 burst release noise, and traces of vowel formant structures in C1 spectral energy.
Nonetheless, according to Whang (Reference Whang2018), listeners do not solely rely on the acoustic cues signaling the presence of devoiced vowels. That is, he claims that the recoverability of the sounds depends not as much on the acoustic correlates of vowel devoicing per se (i.e., the bottom-up processing of auditory information) but the listeners’ phonotactic knowledge and the predictability of devoicing patterning (i.e., top-down processing). In the example given by Whang (Reference Whang2018), a major part of Japanese phonotactic knowledge is the absence of consonant clusters and /t, s, h/ alternations before high vowels (i.e., [ t͡ɕi, t͡su], [ɕi, su], and [çi, ɸu], respectively). Hence, the devoiced vowel in [ɸu̥ku] corresponding to /huku/ “clothes” can be easily recoverable from the [ɸ_k] context since /u/ is the only possible underlying vowel. In contrast, high vowels after /k/ are less phonotactically predictable because both [ku̥] and [ki̥] are possible. Accordingly, the researcher claims that when Japanese phonotactics provide a predictable and sufficient environment for a particular devoiced vowel to be recovered by listeners, the vowel has a higher chance of complete deletion.
This is further supported by an articulatory study by Shaw and Kawahara (Reference Shaw and Kawahara2018a) who investigated the lingual articulation of devoiced /u/ vowels in Japanese, focusing on whether they retain their vowel height target. Using electromagnetic articulography, the researchers found that devoiced /u/ vowels sometimes lack a height target, displaying a linear trajectory between flanking consonants. Thus, this suggests that these vowels are not simply devoiced but can be completely absent. The study also observed that the coordination between flanking consonants changes in these cases, indicating a shift from consonant-vowel to consonant-consonant timing, providing articulatory evidence that high vowel deletion in Japanese creates surface consonant clusters. In a subsequent study, Shaw and Kawahara (Reference Shaw, Kawahara, Gallagher, Gouskova and Yin2018b) further showed that the resulting consonant clusters exhibit articulatory stability similar to word-initial consonant clusters in Moroccan Arabic.
While native Japanese speakers can recover devoiced vowels from apparent consonant-consonant sequences using phonotactic predictability and acoustic cues from the ambient phonetic environment, it is unclear how English-speaking L2 learners of Japanese process these sequences. It is natural to assume that Japanese high vowel devoicing, which results in forms that resemble consonant clusters, may pose challenges for L2 learners. For instance, Fais et al. (Reference Fais, Kajikawa, Werker and Amano2005) suggest that L2 learners might misperceive sequences like #CVC- as two consonants (e.g., perceiving /ki∫a/ “train” as [k∫a]). This also raises the question of whether L2 learners may rely on phonotactic likelihood, acoustic cues, or both to detect devoiced vowels. Unlike native Japanese speakers, some L2 learners of Japanese may not be attuned to subtle acoustic cues indicating a devoiced vowel. Additionally, since their native phonotactics license certain onset consonant clusters, English-speaking learners may be prone to perceptual confusion.
Non-native consonant cluster perception by Japanese and English listeners
Numerous studies have explored how listeners perceive non-native consonant clusters and how they attempt to repair such phonological input when their native language phonotactics do not license it. These phonotactic repairs often give rise to a well-studied psycholinguistic phenomenon known as a perceptual illusion, which suggests possible interlanguage phonological interactions (e.g., Leung et al., Reference Leung, Young-Scholten, Almurashi, Ghadanfari, Nash and Outhwaite2021; Davidson & Shaw, Reference Davidson and Shaw2012; Berent et al., Reference Berent, Steriade, Lennertz and Vaknin2007; Kabak & Idsardi, Reference Kabak and Idsardi2007; Matthews & Brown, Reference Matthews and Brown2004; Dupoux et al., Reference Dupoux, Kakehi, Hirose, Pallier and Mehler1999, Reference Dupoux, Pallier, Kakehi and Mehler2001). A common strategy that listeners utilize to repair unattested onset consonant sequences is an external (#əCC-) or an internal (#CəC-) vowel insertion. For example, in Dupoux et al. (Reference Dupoux, Kakehi, Hirose, Pallier and Mehler1999), the researchers conducted a series of discrimination and identification experiments to investigate how listeners’ L1 phonology affects the perception of non-native consonant sequences. The participants were Japanese and French native listeners with no prior experience in L2. They were given non-words with illicit sequences of consonants and an intermediate vowel that varied in duration on a five-step continuum from VCuCV (e.g., ebuzo) to VCCV (e.g., ebzo). While French listeners could not detect the shorter duration vowel, Japanese listeners reported hearing it over 70% of the time even when the stimuli lacked the vowel completely. The authors concluded that because Japanese (unlike French) does not permit consonant clusters, listeners perceive an “illusory vowel” to resolve the phonotactically illegal CC sequences (p. 1568). The subsequent study by Dupoux et al., (Reference Dupoux, Pallier, Kakehi and Mehler2001) showed that the psychoacoustic effect is before the influence of lexical access and happens at a lower level of input processing that is impacted by listeners’ phonotactic constraints. Other studies consistently replicated these results reporting Japanese listeners’ productive vowel epenthesis within various word-medial clusters (e.g., Dupoux et al., Reference Dupoux, Parlato, Frota, Hirose and Peperkamp2011; Kabak & Idsardi, Reference Kabak and Idsardi2007; Matthews & Brown, Reference Matthews and Brown2004).
Unlike Japanese, English has less strict phonotactic constraints on word-initial consonant clusters and syllable structure, allowing onset consonant sequences such as /s/-stop (e.g., /sp/ in “speak”), stop-liquid (e.g., /pl/ in “play”), and stop-glide combinations (e.g., /kj/ in “cute”). However, English still adheres to sonority-based constraints, such as the Sonority Sequencing Principle and Minimal Sonority Distance (Clements, Reference Clements, Beckman and Kingston1990; Broselow & Finer, Reference Broselow and Finer1991; Blevins, Reference Blevins and Goldsmith1995), which govern permissible combinations based on the sonority hierarchy. Consequently, English does not allow clusters like stop-nasal (/kn/) or stop-stop (/pt/), which are present in Slavic languages, posing perceptual difficulties for English listeners when processing these sequences (e.g., Davidson & Shaw, Reference Davidson and Shaw2012; Berent et al., Reference Berent, Steriade, Lennertz and Vaknin2007). For example, in Pitt’s (Reference Pitt1998) study on processing illegal sound sequences, English listeners were asked to judge whether the non-words they heard (e.g., /tlæ/ vs. /təlæ/) had one or two syllables. The results revealed that English listeners generally perceived two syllables in non-words with an illegal cluster, indicating that phonotactic constraints on the well-formedness of an onset cluster biased their perception by causing them to hear an illusory vowel. Furthermore, Berent et al. (Reference Berent, Steriade, Lennertz and Vaknin2007, Reference Berent, Lennertz, Jun, Moreno and Smolensky2008) compared English and Russian listeners (the phonotactics of the latter licenses a wider range of CC clusters) in their ability to correctly perceive onset consonant clusters that varied in sonority profile (i.e., the direction of sonority change and minimal sonority distance between the segments). Using a syllable counting task in conjunction with response time analysis, Berent et al. (Reference Berent, Steriade, Lennertz and Vaknin2007, Reference Berent, Lennertz, Jun, Moreno and Smolensky2008) reported that native English listeners showed sensitivity to the marked nature of onset clusters, such that onset sequences with a sonority rise (e.g., /pnik/ and /knik/) were perceived more accurately and faster than those with a sonority plateau (e.g., /ktik/ and /pkik/). Additionally, the results indicated that English listeners misperceived phonotactically illegal clusters significantly more often than Russian listeners, tending to categorize illegal sequences and those with an epenthesis (e.g., /lbif/ and /ləbif/) into one group (compared to legal counterparts, like /blif/ and /bəlif/). The authors inferred that perceptual bias toward clusters with epenthesis depends on universal sonority sequencing and language-specific phonotactic constraints. Lee (Reference Lee2011) explored the perceptual sensitivity of English, Korean, and Japanese listeners to English onset clusters formed by initial schwa deletion using nonce words. Her study revealed that English listeners were perceptually sensitive to both the legality of the onset clusters and their sonority profiles, in terms of both accuracy and reaction time, whereas Korean and Japanese listeners showed only partial sensitivity to these differences. Davidson and Shaw’s (Reference Davidson and Shaw2012) study further investigated the role of the manner of articulation of English illicit consonant clusters in relation to the types of perceptual repairs they invoke. In a series of discrimination tasks with native English listeners, the researchers found that perceptual epenthesis in the onset clusters (#CəC) occurred significantly more often when both segments were stop consonants. Sequences other than stop-stop clusters elicited other phonotactic repairs (e.g., external vowel insertion was found in fricative-initial sequences). Furthermore, research has shown that perceptual epenthesis can arise not only phonotactic restrictions but also subtle acoustic-phonetic properties of non-native sequences (Davidson & Wilson, Reference Davidson and Wilson2016; Wilson et al., Reference Wilson, Davidson and Martin2014). In Slavic consonant clusters, acoustic cues such as pre-obstruent voicing, lengthened bursts, or higher burst amplitudes may lead English listeners to hear a schwa-like vowel where none exists. Due to their unfamiliarity with these specific patterns, English listeners are more likely to interpret such acoustic details as reduced vowels, thereby resolving otherwise illicit clusters. This suggests that both phonotactic constraints and fine-grained acoustic variation shape perceptual mapping, increasing the likelihood of illusory vowels. While exposure to phenomena like Japanese high vowel devoicing might enhance sensitivity to similar subtleties, it remains unclear whether such perceptual adjustment gains extend to complex foreign clusters, such as those found in Slavic languages.
The present study
The current study aims to investigate the perception of word-initial stop consonant sequences with an underlying devoiced vowel (#CV̥C-) and without one (#CC-) by monolingual English listeners (ML) and those learning Japanese at an advanced level (AJL) during forced-choice syllable counting task. Specifically, this investigation explores how frequent exposure to #CV̥C- in Japanese may influence their perception of novel #CC- sequences, such as those found in Slavic languages and dialects (e.g., /pt/ in /ˈptɒk/ “bird” and /kp/ in /ˈkpi.na/ “mockery” in Polish, and /kt/ in /kto/ “who” and /pk/ in /ˈpki.dɐ/ “clerk” in Russian and Ukrainian-speaking Jewish communities), which are not part of listeners’ L1 or L2 phonotactics. Although not phonotactically licensed, some of these consonant sequences still surface in English and Japanese due to different phonological processes. In English, the occurrence of onset stop clusters is limited and can result from pre-tonic schwa elision (e.g., potato → [pt]ato; Davidson, Reference Davidson2006). In certain Japanese dialects, these clusters are common due to the phonological high vowel devoicing process (e.g., /kita/ pronounced as [ki̥tɑ]), as discussed earlier. Notably, despite the distinct phonological processes leading to the emergence of such onset stop clusters in the two languages, both Japanese and English speakers have been reported to misperceive voiceless stop clusters in word-initial positions by inserting an illusory vowel within the cluster.
Exposure to Japanese #CV̥C- sequences provides English-speaking learners of Japanese with more frequent encounters with surface CC sequences resulting from regular vowel devoicing between voiceless obstruents. Therefore, we hypothesize that the frequency of exposure to Japanese #CV̥C- sequences may enhance the sensitivity of English-speaking learners of Japanese to surface CC sequences, thereby influencing their perception of novel #CC- sequences. To our knowledge, no previous study has explored how exposure to such surface onset stop clusters, even if resulting from different phonological processes, might impact a language learner’s perception of the onset stop clusters such as those found in Slavic languages. Thus, we seek to address two main research questions:
-
RQ1: How do monolingual English listeners perceive Japanese onset consonant sequences with a devoiced vowel (#CV̥C-)? Are they more likely to perceive these sequences like Slavic voiceless stop consonant clusters (#CC-), which may lead to a repair of this sequence to a #CVC- structure? Alternatively, do they perceive these sequences without undergoing such a repair due to the presence of distinct acoustic cues indicating the presence of the voiceless vowel?
-
RQ2: Does exposure to Japanese phonological structure and the accompanying subtle acoustic cues modify the perceptual abilities of English listeners in discerning phonetic contrasts between initial voiceless stop sequences (#CC-) and analogous sequences containing a full (#CVC-) or a devoiced (#CV̥C-) vowel? If so, how does exposure to Japanese affect perception:
-
-
(a) Do English-speaking learners of Japanese become more sensitive to acoustic cues in novel #CC- sequences and repair them less frequently?
-
(b) Do they become more attuned to acoustic cues of voiceless vowels in Japanese #CV̥C- sequences and perceive them as distinct from Slavic #CC- sequences?
-
To answer these questions, the study compares the performance of the subject groups on a syllable counting task, where they had to indicate whether the presented stimulus had two or three syllables. This task has been employed in previous studies (e.g., Pitt, Reference Pitt1998; Berent et al., Reference Berent, Steriade, Lennertz and Vaknin2007, Reference Berent, Lennertz, Jun, Moreno and Smolensky2008; Lee, Reference Lee2011) to assess an individual’s ability to recognize and manipulate the internal structure of words by segmenting them into their constituent syllables. This involves an awareness of the number and boundaries of syllables within a word. Additionally, previous studies have assessed individuals’ sensitivity to non-native phonemic contrasts using listeners’ response latency with slower responses indicating more difficult cognitive processing (Whalen, Reference Whalen1984; Navarra, Sebastián-Gallés & Soto-Faraco, Reference Navarra, Sebastián-Gallés and Soto-Faraco2005). Thus, by investigating these questions, the study aims to shed light on how exposure to a phonological process and its phonetic manifestation in a second language may influence non-native speech perception and the strategies employed by language learners when listening to novel phonetic contrasts.
Methods
Participants
Twenty-four native English listeners were recruited from the main campus of the University of Florida and were divided into two subject groups. The first group (n = 13) consisted of functional monolingual listeners of the American English dialect who do not use a second language in their daily lives and have minimal prior exposure to a foreign language. This group comprised 11 females and 2 males, with an age range from 18 to 21 and a mean age of 19.6. The second group (n = 11) consisted of individuals who were also native listeners of American English but had started studying Japanese after the age of 11 and had since achieved a high intermediate or advanced level. This group included 3 females and 8 males, with an age range from 17 to 22 and a mean age of 20.5. All participants reported having normal hearing and no history of speech, language, learning, or neurological impairments. To ensure linguistic homogeneity within each group, the Language Experience and Proficiency Questionnaire (Marian, Blumenfeld, & Kaushanskaya, Reference Marian, Blumenfeld and Kaushanskaya2007) was administered, assessing participants’ linguistic backgrounds and high intermediate to advanced proficiency level by university standards. Those individuals who were in contact at any level with any Slavic or another language were excluded from the study. Initially, two additional individuals were considered for the advanced Japanese learner group, but were ultimately excluded based on these criteria, resulting in the final sample sizes reported above.
The inclusion criteria for learners of Japanese were based on the completion of Intermediate Japanese 2 (a total of four semesters) and enrollment in Advanced Japanese 1 at the University of Florida. All participants were majoring in Japanese Studies and were learning the language in a formal setting with instructors who were either native speakers or had near-native fluency in Japanese. Since the Tokyo dialect from the greater Kanto region forms the foundation of Standard Japanese and is the dialect taught worldwide in Japanese “broadcasting textbooks” (Fujimoto, Reference Fujimoto and Kubozono2015), we assume that University of Florida students also acquire the Tokyo dialect through interactions with the language variety. Nevertheless, we acknowledge that the individual listeners in our study may vary in their Japanese proficiency and the extent of their daily exposure to the language.
Stimuli
Table 1 presents the set of study stimuli used in the experiment, comprising eighteen disyllabic and trisyllabic non-words. These non-words were designed to reflect three distinct phonotactic patterns—CVC-VCV, CV̥C-VCV, and CC-VCV, which correspond to permissible onset stop consonant sequences observed in English, Japanese, and Slavic languages, respectively.
Experimental stimuli

Specifically, the stimuli varied in the initial two voiceless stop consonants (conditioning Japanese high vowel devoicing), where they were either separated by a full vowel (#CVC-), a devoiced vowel (#CV̥C-), or had no intervening vowel (#CC-). The ending -VCV# (/-ata/) structure remained constant across all stimuli. For convenience in describing the language phonotactic patterns (and for lack of better terms), the stimulus types were labeled English-like (#CVC-), Japanese-like (#CV̥C-), and Slavic-like (#CC-). However, it is important to note that sequences like /putata/ and /supata/ are not exclusive to English but are also permissible in Slavic and Japanese phonotactics, just as Slavic-like sequences /spata/ and /stata/ are legal in English.
The test stimuli included stop-initial sequences (e.g., /putata/, /pu̥tata/, /ptata/), designed to assess participants’ ability to discern different phonotactic patterns. Specifically, English-like stop-initial sequences are permissible for both participant groups, Japanese-like stop-initial sequences are non-native yet familiar for learners of Japanese and novel for English monolinguals, and Slavic stop-initial sequences are novel for both groups. The control stimuli included fricative-initial sequences (e.g., /supata/, /su̥pata/, /spata/), which served to ensure participants’ attentiveness to the experimental task and provided a reference for evaluating the effects of different phonotactic patterns. These fricative-initial sequences conform to the phonotactics of both groups of listeners, with only Japanese-like items being novel for English monolinguals.
All non-words were recorded by a male native Japanese speaker using a high-quality microphone (Blue Yeti Ultimate USB Microphone) at a sampling rate of 44,100 Hz. The model speaker was given specific instructions to correctly produce the onset stop-stop and fricative-stop sequences that are not permitted by Japanese phonotactics. To ensure the quality of the stimuli, the recorded sequences were assessed by a trained phonetician using the Praat software (Boersma & Weenink, Reference Boersma and Weenink2023). For the Slavic-like stop-initial tokens, the burst release noise of the first consonant was verified to remain under 50 ms, consistent with the upper boundary for natural first-consonant stop-burst durations reported by Wilson et al. (Reference Wilson, Davidson and Martin2014) for Russian speakers. In addition, all stop-initial stimuli were confirmed to lack transitional vocoids between the initial two stop segments, as observed in both the acoustic waveform and spectrogram, also aligning with Wilson et al. (Reference Wilson, Davidson and Martin2014). Native English, Japanese, and Russian speakers then selected the most exemplary tokens. Finally, the stimuli were normalized in duration using the Praat software, so that each token had a fixed duration of precisely 600 ms. This normalization was done to prevent listeners from relying on the token duration when identifying their syllable count, thereby focusing solely on the phonological or acoustic features. The final set of stop-initial stimuli varied in their burst release durations across language categories: Slavic-like tokens had a mean of 44 ms (SD = 8 ms), English-like tokens averaged 26 ms (SD = 6 ms), and Japanese-like tokens averaged 104 ms (SD = 20 ms), which was anticipated to be the longest (Whang, Reference Whang2018). Lastly, no additional stimuli were included as filler items.
Procedure
Participants completed the task in a controlled lab setting, listening to stimulus tokens that were presented auditorily through professional monitoring headphones (SRH840, Shure, Niles, IL, USA) in a sound-attenuated booth. The stimuli were presented using PsychoPy software (Peirce, Reference Peirce2007) because of its flexibility in designing psycholinguistic experiments, precise control over stimulus presentation timing, and accurate measurement of response times from key presses. The stimuli were presented in a pseudorandom order to avoid any systematic biases. During each trial, the letters “S” and “L” were displayed on the computer screen, positioned on the left and right sides, respectively. Participants were instructed to initiate a key press response by pressing the “S” key on the laptop keyboard with the left hand if they perceived the stimulus as having two syllables, and the “L” key with the right hand if they heard three syllables. They had a maximum of 3 seconds to respond before the next trial was presented. If no response was made within the allocated time, the software moved to the next trial. To familiarize participants with the task, they first completed practice trials using five non-experimental tokens (/pulata/, /plata/, /kulata/, /klata/, /sulata/), each repeated twice in random order, prior to the main experiment. Feedback was not provided during the practice trials. The main experiment was divided into two blocks, with a 10-minute break between blocks to prevent fatigue and ensure sustained attention. In the first block, there were nine fricative-initial (control) and nine stop-initial (test) stimulus items, each repeated 10 times, resulting in a total of 180 items in the block. The second block comprised the same nine fricative-initial items from the first block and nine different test stimulus items, not used in the first block, again repeated 10 times per stimulus item, totaling 180 items in the block. Participants’ responses and response times were automatically recorded by the PsychoPy software. The entire experiment lasted approximately 35 minutes.
Data analysis
The primary objective of this experiment was to examine the influence of participants’ language experience group (ML vs. AJL), the type of stimuli language pattern (English-like vs. Japanese-like vs. Slavic-like), stimuli condition (test vs. control), and the interactions of the factors on listeners’ perception of syllable count. Stimuli starting with a /t/ stop (e.g., /tupata/, /tu̥pata/, and /tpata/) were excluded from the analyses due to an affrication of alveolar stops preceding high vowels in Japanese (Pintér, Reference Pintér and Kubozono2015). Consequently, 300 responses (10 repetitions for 12 test and 18 control stimulus items) were collected from each of the 24 participants, resulting in a total of 7,200 responses. However, some participants did not respond in certain trials, yielding only 7,162 tokens for analysis.
The results are reported based on two analyses: (1) a generalized mixed-effects logistic regression analysis of binary syllable judgment responses, and (2) a linear mixed-effects regression analysis of response times.
For the binary response analysis, a series of mixed-effects logistic regression models were employed with a binomial distribution and logit link function, modeling participants’ perception of each stimulus token as either having two syllables (coded as 0) or three syllables (coded as 1). The model incorporated several fixed factors—subject group (using ML as the reference level), type of stimulus language (with English-like as the reference level), and stimulus condition (with the control stimulus type as the reference level)—as well as their three-way interaction, using treatment coding. To account for individual variability in the data, the model’s random structure included both subjects and items as random intercepts and by-subject slopes for stimuli language and condition factors. Initially, the model included an interaction term for language and condition slopes, but this led to singular fit warnings. Consequently, this term was omitted. Thus, the final formula of the model was: Response ∼ Group × Language × Condition + (1 + Language + Condition | Subject) + (1 | Item).
To assess the contribution of each fixed factor in explaining the variance in the data, we applied the likelihood ratio test by comparing nested models—one with and one without the fixed effects of interest. The difference in log-likelihoods between the two models was used to test whether the inclusion of the fixed effects significantly improved the model fit. Post hoc analyses using estimated marginal means with Tukey HSD correction for multiple comparisons were conducted to examine pairwise differences among fixed factor levels and their interactions.
The second dependent variable examined in this study was response time, representing the time lag between the onset of auditory stimuli and participants’ keyboard responses. To ensure robust statistical analysis of the effect of fixed factors on response times, data outliers were removed (2 standard deviations away from each group mean), resulting in the removal of approximately 5.95% of data points. Additionally, a square root transformation was applied to the response time data to reduce right-skewed distribution, thereby normalizing it, and improving the validity of the statistical assumptions for regression analyses. Subsequently, a linear mixed-effects regression model was used to investigate the effects of the fixed factors on the transformed response time. As in the previous analysis, the linear mixed-effects regression model included fixed factors of groups, language, conditions, and the three-way interaction of the terms. This model also accounted for potential variability associated with individual subjects and different experimental items by including them as random intercepts as well as stimuli language and condition types as by-subject slopes. Post hoc analyses using estimated marginal means were conducted to examine pairwise differences between levels of each of the fixed factors, and the Tukey HSD method was utilized to adjust for multiple comparisons.
All statistical analyses were performed using R version 4.3.1 (R Development Core Team, 2023). Data management utilized the tidyverse package (Wickham et al., Reference Wickham, Averick, Bryan, Chang, McGowan, François, Grolemund, Hayes, Henry, Hester, Kuhn, Pedersen, Miller, Bache, Müller, Ooms, Robinson, Seidel, Spinu, Takahashi, Vaughan, Wilke, Woo and Yutani2019), while visualization was carried out with the ggplot2 package (Wickham, Reference Wickham2016) and the ggpattern package (FC & Davis, Reference FC and Davis2022). The fitting of mixed-effects logistic and linear regression models was accomplished using the lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015), and the p-values were obtained using the lmerTest package (Kuznetsova et al., Reference Kuznetsova, Brockhoff, Rune and Christensen2017). Subsequently, post hoc analyses were conducted using the emmeans package (Lenth, Reference Lenth2023) to derive estimated marginal means.
Results
Proportion of syllable count responses
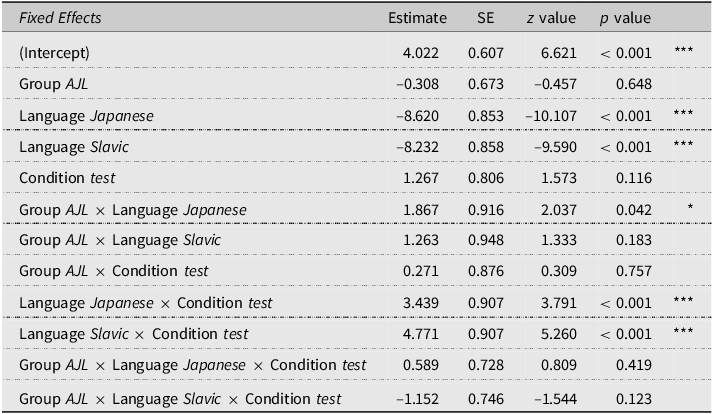
Table 2 summarizes the results obtained from the best-fitting model (reported on the log-odds scale) for the binary responses (2 vs. 3 syllables) modeling the effects of group, language, condition, and their interactions on participants’ perception of syllable count.
Summary of the mixed-effects logistic regression model for 3 vs. 2 syllable response proportions (N = 7162), with reference levels for fixed factors: group = ML, language = English, and condition = control
Sig. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1.
For the effect of the subjects’ linguistic background, model comparisons between a model with and without the group factor revealed a statistically significant main effect (χ2(6) = 27.73, p < 0.001). A separate model comparison revealed that the inclusion of language (χ2(8) = 77.82, p < 0.001) also improved the model’s fit. Further pairwise comparisons using estimated marginal means, showed that averaged across subject groups and stimulus conditions, listeners were more likely to perceive stimuli with English-like patterns as having three syllables compared to both Japanese-like (β = 5.819, SE = 0.586, p < 0.001) and Slavic-like patterns (β = 5.503, SE = 0.596, p < 0.001). This is expected given that there is a full intervening vowel between C1 and C2 (e.g., /putata/ and /supata/) in the English-like stimuli. Additionally, the inclusion of condition (χ2(6) = 56.34, p < 0.001) and the interaction term involving the three fixed factors (χ2(7) = 42.38, p < 0.001) significantly improved the model’s fit. Please refer to the Supplementary Materials for more detailed descriptive and inferential statistics.
Furthermore, the presence of significant interactions between group and language, and between group, language, and condition factors suggests that the influence of language type on syllable perception may vary depending on participants’ language experience and the type of stimulus condition. Figure 1 demonstrates the interplay between language background and the perception of the syllable count of stimuli tokens following different phonotactic patterns.
Comparison of response proportions between ML and AJL groups across stimulus language patterns and stimulus condition types during syllable judgment task. Higher response proportions reflect a higher preference of 3 over 2 syllables. The error bars represent ±1 SE.

To better understand the interactions, post hoc tests were conducted with pairwise comparisons for the group × language × condition interaction. No significant group difference was observed when counting syllables of the Slavic-like stimuli, either in the control (β = –0.955, SE = 0.802, p = 0.234) or test condition (β = –0.074, SE = 0.986, p = 0.941), indicating that the AJL group’s exposure to Japanese did not affect their perception of Slavic-like word-initial consonant clusters. However, a significant difference between the two subject groups emerged when counting Japanese-like stimuli syllables in the control condition (β = –1.559, SE = 0.669, p = 0.020) and the test condition (β = –2.419, SE = 0.825, p = 0.003). This suggests that the AJL group’s prior experience with Japanese influenced their perception of word-initial consonants with a devoiced vowel. Specifically, exposure to a devoiced vowel in Japanese significantly increases the frequency of three-syllable counts. Next, we examined the comparison of stimulus language type within each group and condition. As also shown in Figure 1, both the ML and AJL groups showed a significant difference between English-like and Japanese-like stimuli in both the control (ML: β = 8.620, SE = 0.853, p < 0.001; AJL: β = 6.753, SE = 0.868, p < 0.001) and test (ML: β = 5.180, SE = 0.835, p < 0.001; AJL: β = 2.724, SE = 0.885, p < 0.01) conditions. Specifically, for both sets of stimuli, both groups reported hearing more three syllables than two syllables in the English-like than in the Japanese-like stimuli. Similarly, both groups perceived a significantly higher number of 3 syllables in the English-like than in the Slavic-like stimuli in both the control (ML: β = 8.232, SE = 0.858, p < 0.001; AJL: β = 6.969, SE = 0.892, p < 0.001) and test (ML: β = 3.461, SE = 0.853, p < 0.001; AJL: β = 3.351, SE = 0.903, p < 0.001) conditions. Crucially, the ML but not the AJL group had significantly more 3-syllable responses for the Slavic-like than for the Japanese-like stimuli in the test condition (ML: β = –1.719, SE = 0.577, p < 0.01; AJL: β = 0.626, SE = 0.596, p = 0.545). However, there was no significant difference between the number of syllables heard in the Japanese-like and the Slavic-like stimuli for either group in the control condition (ML: β = –0.388, SE = 0.702, p = 0.845; AJL: β = 0.216, SE = 0.667, p = 0.944). These results indicate that a higher number of three-syllable responses were reported in the English-like stimuli compared to the non-English-like stimuli, but there was no statistically significant difference between the two non-English-like (non-native) stimuli, except for the observation that monolingual listeners were significantly more likely to perceive 3 syllables in the stop-initial Slavic-like stimuli when compared to the Japanese-like stimuli.
Finally, when comparing stimulus conditions within each group and language types of stimuli, significant differences were observed for both the Japanese-like stimuli (ML: β = –4.710, SE = 0.742, p < 0.001; AJL: β = –5.570, SE = 0.756, p < 0.001) and the Slavic-like stimuli (ML: β = –6.040, SE = 0.753, p < 0.001; AJL: β = –5.160, SE = 0.765, p < 0.001), as expected. Specifically, more three syllables were heard in the test stimulus set than in the control set, further supporting the effects of familiar (fricative-stop onset clusters) versus foreign (stop-stop onset clusters) on the number of syllables heard.
Response time
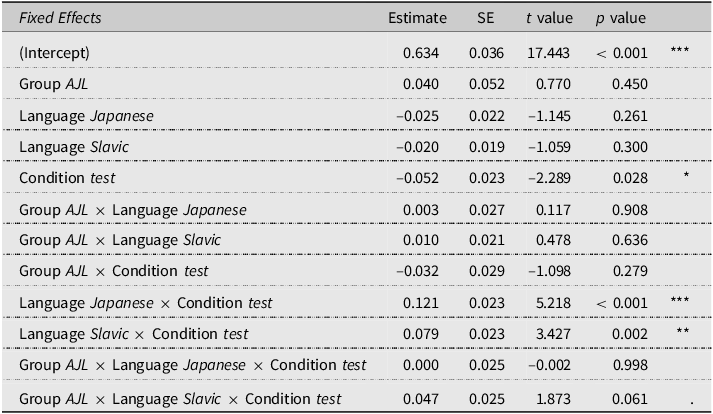
The mixed-effect linear regression results are summarized in Table 3. The analysis evaluated the impact of the same fixed factors as in the analysis of response syllable count proportions but on square root transformed response time data.
Summary of the linear mixed-effects model for transformed response times (N = 6736), with reference levels for fixed factors: group = ML, language = English, and condition = control
Sig. codes: 0 “***” 0.001 “**” 0.01 “*” 0.05 “.” 0.1 “ ” 1.
Firstly, the inclusion of the subject group factor indicated no difference in model fit (χ2(6) = 10.14, p = 0.119). However, there was a significant main effect in improving the model’s fit when comparing a model with and without the stimulus language factor (χ2(8) = 39.16, p < 0.001), stimulus condition (χ2(6) = 30.29, p < 0.001), the interaction of stimulus language and condition factors (χ2(4) = 29.66, p < 0.001), and the interaction between the three fixed factors (χ2(7) = 34.67, p < 0.001). To explore these interactions further, post hoc analysis using estimated marginal means with Tukey HSD corrections for multiple comparisons was performed with pairwise comparisons of the square root transformed response times between different combinations of subject groups, stimulus language patterns, and conditions. Both the ML and AJL groups had longer responses for the test condition of Japanese-like stimuli compared to English-like stimuli (ML: β = –0.096, SE = 0.022, p < 0.001; AJL: β = –0.099, SE = 0.024, p < 0.001). Similarly, both subject groups showed a significantly longer response time in the test condition of Slavic-like stimuli (ML: β = –0.060, SE = 0.019, p < 0.01; AJL: β = –0.116, SE = 0.020, p < 0.001) compared to the English-like stimuli, as illustrated in Figure 2.
Transformed response times (in sec) comparison for ML and AJL groups by stimulus language pattern and stimulus condition types in a syllable judgment task. The error bars represent ±1 SE.
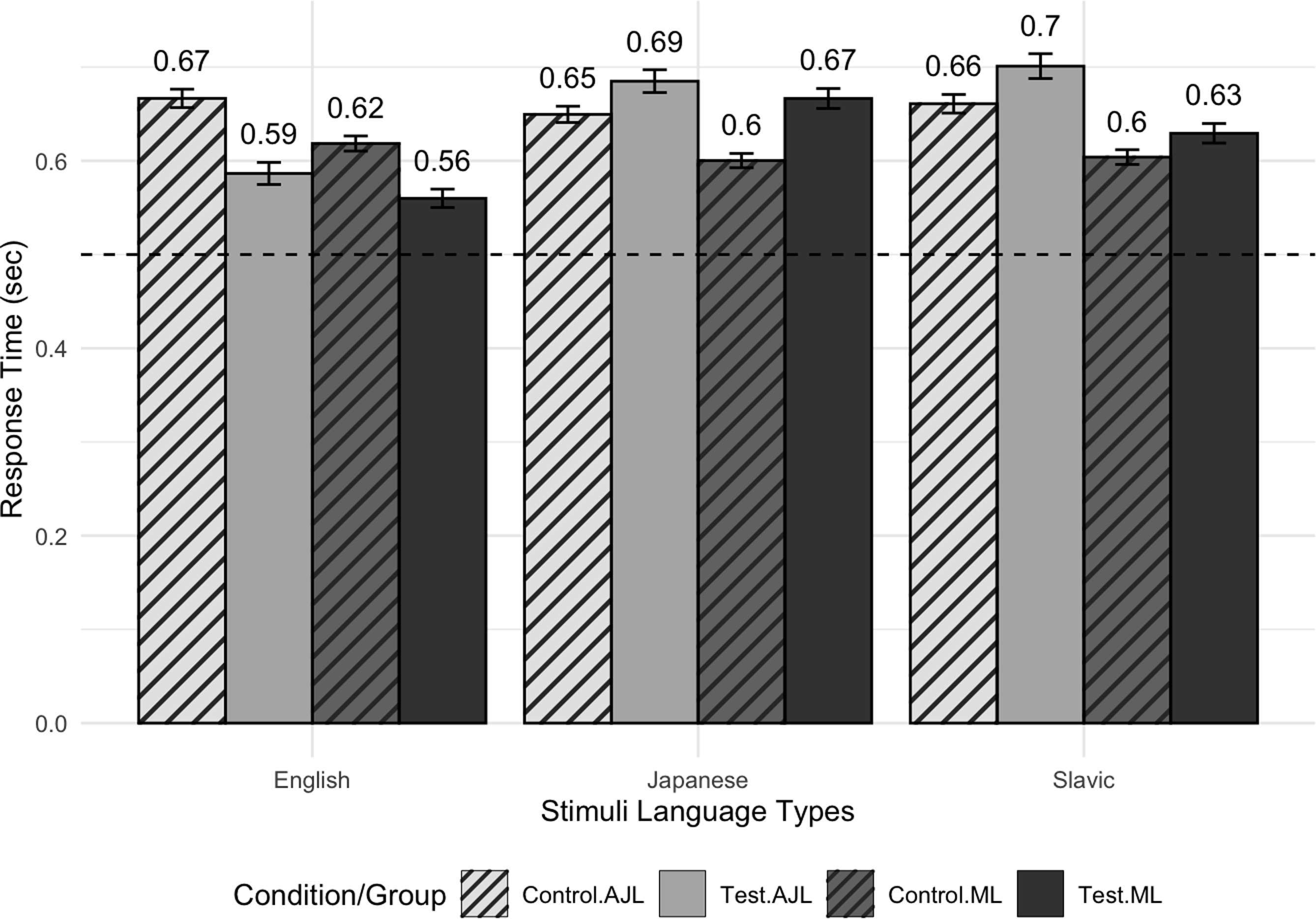
When comparing the control and test stimulus conditions within the levels of the subject group and the stimuli language type factors, significantly longer response times were found for the control than the test English-like stimuli (ML: β = 0.052, SE = 0.023, p < 0.05; AJL: β = 0.083, SE = 0.024, p < 0.001). In contrast, only the ML group showed longer response times for the test than for the control stimulus condition with Japanese-like stimuli (β = –0.069, SE = 0.023, p < 0.01), while the AJL group did not reach statistical significance (β = –0.038, SE = 0.024, p = 0.115). However, no significant difference was observed between the Slavic control and test stimuli for either group (ML: β = –0.028, SE = 0.023, p = 0.216; AJL: β = –0.043, SE = 0.024, p = 0.075). No other statistically significant differences in response time were observed.
Discussion
The present study aimed to build upon previous research (e.g., Davidson & Shaw, Reference Davidson and Shaw2012; Davidson, Reference Davidson2011; Berent et al., Reference Berent, Steriade, Lennertz and Vaknin2007; Dupoux et al., Reference Dupoux, Kakehi, Hirose, Pallier and Mehler1999) on non-native speech perception, focusing on the difficulties faced by L2 listeners when encountering unfamiliar sound sequences. These difficulties arise due to the listeners’ reliance on their language-specific phonetic and phonological knowledge to process and categorize novel phonotactic patterns. To explore this further, we designed our study around the acoustic similarity of input sound sequences in the context of perceiving non-native and novel contrasts, which can often lead to perceptual confusion and illusions (Davidson & Shaw, Reference Davidson and Shaw2012). The high resemblance between the acoustic characteristics of native and similar non-native (L2) and novel sound sequences presents a significant challenge for listeners to differentiate between them, often causing them to map unfamiliar sequences onto the familiar native phonological templates. Consequently, listeners tend to confuse sequences with low phonotactic probability with those of high phonotactic probability in their native language, thereby erasing the subtle contrasts (Davidson & Shaw, Reference Davidson and Shaw2012; Dupoux et al., Reference Dupoux, Parlato, Frota, Hirose and Peperkamp2011).
To achieve the study’s objective, we examined the perceptual ability of English monolinguals and advanced learners of Japanese in processing non-native sound sequences, focusing on three phonologically contrasting patterns: English-like (#CVC-), Japanese-like (#CV̥C-), and Slavic-like (#CC-) word-initial sequences. Despite both English and Japanese phonotactic grammar prohibiting onset stop-stop consonant clusters, similar acoustic structures emerge in both languages due to specific linguistic processes (e.g., English pre-tonic schwa deletion and Japanese vowel devoicing). Nevertheless, listeners tend to repair input word-initial stop-stop sequences (like those in Slavic languages) by inserting a vowel-like segment within the cluster, leading to confusion with phonotactically more probable native stop-vowel-stop sequences (#CC- ∼ #CVC-). While previous research has extensively investigated how English listeners process initial stop clusters, there is a gap in understanding how listeners process acoustically similar sequences caused by Japanese vowel devoicing. Additionally, the study aims to explore whether English listeners’ experience with Japanese phonological grammar can influence their perception of stop-stop sequences, thereby making L2 listeners more sensitive to novel phonetic contrasts.
In the context of our first research question, the results of the forced-choice syllable counting task showed that monolingual English listeners perceive non-native stop-initial sequences differently: they were significantly less likely to perceive the Japanese-like tokens as having three syllables compared to the Slavic-like sequences. Specifically, the mean proportion of hearing an illusory vowel within initial stop sequences with a devoiced vowel was 53% (95% CI = [0.488, 0.574]), while it was 72% (95% CI = [0.686, 0.763]) for stop-stop onsets without the vowel. Both proportions were significantly lower compared to perceiving a full vowel between two stop consonants (i.e., the English-like stimuli). However, both proportions remained above a 50% chance level and were significantly higher than the perception of two syllables, as demonstrated by comparison with the control condition, which involved fricative-initial stimuli. The gradient difference in perception responses indicates that English listeners’ perception of unattested stop sequences is not solely governed by top-down phonological processing (i.e., phonotactics) but may also be affected by the acoustic characteristics of the input. The findings are in line with previous studies on non-native phonotactics perception (Davidson & Wilson, Reference Davidson and Wilson2016; Davidson, Reference Davidson2007, Reference Davidson2011), suggesting that fine acoustic details in the input modulate listeners’ perception of unattested onset consonant sequences. However, as monolingual listeners perceived Japanese-like CV̥C-VCV tokens as having two syllables more often than Slavic CC-VCV tokens, the acoustic effect is likely less pronounced than the top-down, phonotactic effects. This is likely due to their unfamiliarity with the acoustic cues associated with an intervening voiceless vowel in the Japanese-like tokens.
The findings from our second research question extend this conjecture by revealing that Japanese learners perceived more three-syllable sequences than monolinguals in both the Japanese-like control and test stimuli. This suggests that learners may be more attuned to the acoustic properties of intervening voiceless vowels, such as those present in lengthened C1 burst release noise. Notably, AJL participants discerned significantly more three-syllable counts in the test condition. The larger difference between the two groups in the test compared to the control stimuli suggests that the acoustic properties of an intervening voiceless vowel are more readily detected in stop-initial sequences than in fricative-initial sequences, or that phonological repairs are more frequently triggered in phonotactically illegal sequences than in phonotactically legal ones. The group difference in perceiving Japanese-like sequences may be due to different approaches to integrating phonotactic grammar with acoustic signals, aligning with prior research (Antoniou et al., Reference Antoniou, Liang, Ettlinger and Wong2015; Altenberg, Reference Altenberg2005; Enomoto, Reference Enomoto1994). Specifically, exposure to a language like Japanese, which restricts the occurrence of onset consonant clusters, may condition learners to adhere more firmly to the combined phonotactic constraints of both languages. This, in turn, can lead to a reduced reliance on acoustic input, resulting in less perceived variation in the acoustic signal. In this scenario, learners might recognize the vowel between initial stop segments not necessarily from acoustic cues but due to the increased phonotactic likelihood of a vowel appearing in that specific phonetic context. However, the exact mechanism remains uncertain, and whether AJL listeners rely on acoustic cues or enhanced markedness constraints (or a combination of both) is still a subject for future research.
Another significant finding from the syllable judgment experiment was that monolingual listeners and Japanese learners did not differ in their responses when identifying Slavic-like onset stop-stop sequences. This suggests that exposure to a language that phonologically does not allow stop-stop sequences, but which are still realized phonetically, does not enhance the perceptual ability of English listeners to correctly identify these sequences without experiencing an illusory vowel. The finding aligns with some previous studies investigating the impact of bilingual training on perceiving novel phonetic distinctions. For instance, Tremblay and Sabourin (Reference Tremblay and Sabourin2012) found no difference among groups in their ability to distinguish between novel non-native contrasts before training, and in a study by Altenberg (Reference Altenberg2005), L2 learners did not show an advantage compared to monolinguals in perceiving unattested phonetic contrasts. Likewise, a study by Archila-Suerte et al. (Reference Archila-Suerte, Bunta and Hernandez2016) investigated whether bilingualism or general perceptual abilities influenced the learning of new speech sounds. The results indicated that individuals with advanced ability to learn novel speech sound contrasts performed better in discriminating pseudowords, as evidenced both behaviorally and neurophysiologically, with increased activity in the superior temporal gyrus, suggesting that individual ability is more influential in speech sound learning than bilingual experience alone.
The response time data complement the syllable count data. The significantly longer response times for both Japanese-like (ML: Mean = 0.67 s, CI = [0.646, 0.687]; AJL: Mean = 0.69 s, CI = [0.661, 0.709]) and Slavic-like (ML: Mean = 0.63 s, CI = [0.609, 0.650]; AJL: Mean = 0.70 s, CI = [0.675, 0.727]) stimuli compared to native ones (ML: Mean = 0.56 s, CI = [0.541, 0.579]; AJL: Mean = 0.59 s, CI = [0.563, 0.610]) by both groups indicate that monolinguals and AJL experience increased cognitive load when processing language stimuli that are structurally less familiar to them (cf. Berent et al., Reference Berent, Steriade, Lennertz and Vaknin2007, Reference Berent, Lennertz, Jun, Moreno and Smolensky2008; Lee, Reference Lee2011). Additionally, a significant difference in response times between control and test conditions for Japanese-like stimuli in the monolinguals but not in the learner’s group may be attributed to monolinguals’ lack of experience with Japanese and a more cautious approach in discerning the presence of an intervening vowel. In contrast, the absence of significant differences in response times between Slavic-like test and control conditions in both groups implies equally challenging cognitive processing in response to unfamiliar sequences. For English-like stimuli, the longer response times in control conditions for both groups were unexpected and could reflect a degree of over-familiarity, leading to less automatic processing, or perhaps a more careful consideration of stimuli due to participants’ expectations based on their language proficiency.
Overall, these results underscore the influence of language experience and structural similarity on language processing efficiency and highlight the need for further research into the cognitive mechanisms that underpin language learning and processing across different structurally similar language groups.
Conclusion
The current study investigated how English speakers process non-native sound sequences with a devoiced vowel surfacing as consonant clusters and whether prolonged exposure to a second language, specifically Japanese, alters native English listeners’ perception of phonotactically illicit non-words. We employed a forced-choice syllable judgment task to evaluate participants’ ability to accurately identify three phonologically contrasting sequences. Our findings revealed that monolingual English listeners showed a significant difference in perceiving Japanese-like sequences with devoiced vowels with lower rates of perceptual illusions compared to Slavic-like sequences. Moreover, linguistic experience played a significant role in identifying the syllable count of Japanese-like tokens. Advanced learners of Japanese were significantly more likely to label these tokens as having three syllables compared to monolingual English listeners, indicating that exposure to Japanese either enhanced their ability to recover the devoiced vowel from acoustics or enhanced phonological constraints on syllable onset acceptability. Nevertheless, the study also highlighted the complexity of non-native speech perception, as both groups of participants demonstrated no difference in perception of Japanese-like and Slavic-like stimuli, despite linguistic experience. This indicates that exposure to a language like Japanese, where stop-stop clusters are not phonologically permissible but occur as acoustically similar sequences, does not enhance English listeners’ ability to correctly identify these sequences without inserting an illusory vowel. Importantly, the study does not fully account for individual differences in Japanese proficiency and daily language use, which may influence perception outcomes. Future research should incorporate more detailed assessments of language exposure and proficiency to better understand their impact on non-native speech perception. The findings contribute to our understanding of how language experience shapes speech perception and may inform second language acquisition strategies by highlighting the role of phonological exposure in perceptual processing. Future research in this area may further elucidate the underlying mechanisms of non-native speech perception and shed light on the cognitive processes involved in the acquisition and processing of phonological information from multiple linguistic backgrounds.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0142716425000116
Replication package
All research materials, data, and analysis code are available at https://osf.io/mgujs/.
Acknowledgements
We wish to express our profound gratitude to the faculty members of the University of Florida’s Japanese Studies, particularly Dr. Ann Wehmeyer and Ryosuke Sano, for their invaluable support and assistance in the recruitment of participants for this study.
Funding
This research did not receive any specific grants from public, commercial, or not-for-profit funding agencies.
Competing interests
The authors declare none.








 Open access
Open access