

14.1 Introduction
Rhythm is perhaps one of the most perplexing notions in linguistic theory, a theory that has been struggling to accommodate it as a clear construct of language systems, with a relatively coherent function and definition. Rhythm is of major interest in prosodic analysis of speech, but in the mainstream linguistic literature, it has proven to be a less fruitful auditory dimension than pitch, which has long been the focus of intonation studies, aided by the relatively straightforward display of the fundamental frequency (F0) contour.
Rhythm and pitch are major aspects of auditory perception, and are exploited in both music and speech. However, while pitch has relatively similar cognitive goals in both domains (i.e., making use of our specialization in detecting fundamental frequencies in complex harmonic structures), rhythm seems to have different cognitive goals. In music, rhythm is most effectively used to couple oscillations internally with the motor system, as well as externally between agents. In speech, however, rhythm is most effectively used to construct an internal representation of timing effects in the prosody of language systems. This discrepancy between domains has likely contributed to the impression in the linguistic literature that speech rhythm is a highly elusive concept (Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2013; Nolan and Jeon, Reference Nolan and Jeon2014).
In this chapter, we offer a new synthesis of existing theories and findings that relate to rhythm. We take into account evolutionary, physical, cognitive, neurological, musicological, and linguistic aspects of this question in order to paint a holistic picture of rhythm. This synthesis offers a framework for understanding rhythm in a manner that can be shared more coherently across disciplines. The immediate contribution is in explicating rhythm within linguistic contexts, where the notion of musical rhythm seems to have led many studies astray. We present a clear and principled delineation of rhythmic goals in music and in speech. Essentially, we claim that the shared behavior that makes those different goals rhythmic is not the adherence to metronome-like equal intervals (isochrony), which is so characteristic of musical signals, but the shared timescale of temporal integration that both music and speech exploit to different ends.
14.1.1 Speech Rhythm: A Brief Overview
There is a general consensus that some aspects of speech are rhythmic. However, after many decades of research (e.g., Brown, Reference Brown1911; Pike, Reference Pike1945; Abercrombie, Reference Abercrombie1967; Allen, Reference Allen1975; Dauer, Reference Dauer1983; Cummins and Port, Reference Cummins and Port1998; Arvaniti, Reference Arvaniti2009; Nolan and Jeon, Reference Nolan and Jeon2014; Inbar et al., Reference Inbar, Grossman and Landau2020), it is still unclear which units of speech actually play a role in this rhythmicality, the most commonly reported being phonemes, syllables, and stressed syllables. Moreover, it is unclear across the different studies which type of rhythmicality is intended when the notion of rhythm is invoked.
One type of rhythmicality is often referred to with terms such as isochronous, periodic, temporal, coordinative rhythm or beat. It resembles the workings of a clock, characterized by equal intervals between successive events. Another type of rhythmicality is often referred to with terms such as meter, prominence, accentual or contrastive rhythm. It is less bound to an abstract external clock, and it is mostly based on the distinction between weak and strong events in a sequence, promoting the grouping of these events in different ways. While the former type (beat) is based on temporal relations, the latter type (meter) incorporates various dimensions that can contribute to strength. On top of a duration-based distinction, strength also includes the acoustic power, the spectral quality, and the F0 of the events in question (see overviews in Gordon and Roettger, Reference Gordon and Roettger2017, and Baumann and Winter, Reference Baumann and Winter2018).
These two types of rhythmicality are often conflated. This is due to some long-standing assumptions that isochronous relations may hold between the strong members of successive events, rather than between all members in the string. Such ideas gained traction during the second half of the twentieth century, with the widely adopted distinction between syllable-timed and stress-timed languages (e.g., Pike, Reference Pike1945; Abercrombie, Reference Abercrombie1967; Dauer, Reference Dauer1983).
The distinction between stress-timing and syllable-timing has been widely investigated using rhythm metrics (e.g., Low, Reference Low1998; Ramus et al., Reference Ramus, Nespor and Mehler1999; Dellwo, Reference Dellwo, Karnowski and Szigeti2006). Although they have failed to adequately characterize different language types in a systematic manner (e.g., Nolan and Asu, Reference Nolan and Asu2009; Arvaniti, Reference Arvaniti2009, Reference Arvaniti2012; Barry, Reference Barry2010; Lowit, Reference Lowit2014), they have not been abandoned. We return to this classic distinction in our discussion in Section 14.5.
14.1.2 Scope of Current Synthesis
In the following sections we lay the foundations for a holistic proposal. In Section 14.2 we discuss the notion of timescales in perception, and we introduce a theoretical framework for the principled reduction of the perceptual auditory space based on timescales. In Section 14.3 we provide a brief overview of the role of rhythm in prosody, and in Section 14.4 we extend the discussion with theories and findings from the literature on neural oscillations, considering both speech and music, and how they relate to the notion of entrainment. We end with a discussion in Section 14.5.
14.2 Timescales of Perception
The ability to construct a stable and useful representation of the external physical reality is a critical aspect of survival. An inevitable outcome is that perceptual and cognitive systems evolve to optimally capture physical phenomena that can be beneficial to survival. In that sense, the type of events that different species can see and hear were selected in evolution to support each species’ occupation of a specialized niche in a shared ecosystem (Krause, Reference Krause2012).
There are two major conclusions that can be drawn. The first is that the information that travels via sound waves (as well as light waves) is very beneficial to constructing useful representations of reality on earth’s atmosphere. The second ensuing conclusion is that different species focus on the ranges of the spectra of energy waves that are most beneficial to them. Evolution selects the ranges of the spectra that support each species’ successful occupation of a certain niche. Good examples can be gleaned from the auditory system of bats or the visual system of bees, both covering ranges different from humans.
Crucially for us, the spectra of sound waves are temporally distributed in ranges that can be characterized in terms of timescales. All of this is akin to saying that the competition for survival is a determinant force on the timescales in which living brains optimally operate. Humans’ auditory perception and cognition are therefore a manifestation of the spectra of sound waves that we can temporally integrate. The timescales within which we temporally integrate acoustic events were most likely selected at a very early stage in the evolution of our species, to support the most basic needs of survival, such as detecting danger and locating food. Our higher cognitive abilities, such as the capacity for establishing intricate communication systems (i.e., spoken language) and the capacity for creative endeavors (e.g., music), must therefore piggyback on those previously selected timescales of temporal integration that were likely “hardwired” at a prior stage of evolution (see also Meyer, Reference Meyer2018).
14.2.1 Defining Human Auditory Timescales with PRiORS
In this chapter, we make use of a theoretical framework that was introduced in Albert (Reference Albert2023) to provide building blocks for linguistic models that are based on auditory perception. Perceptual Regimes of Repetitive Sound (PRiORS) offers a reduction of auditory perception into its basic primitives, based on distinct behavioral effects of temporal integration in human cognition. It reveals two types of perceptual regimes that operate at different timescales: the temporal regime and the spectral regime. These observations are not entirely new. Similar and related observations have been previously suggested from perspectives that include musicology (Stockhausen, Reference Stockhausen1959), acoustics (Flanagan and Guttman, Reference Flanagan and Guttman1960), cognitive psychology (Warren, Reference Warren1982:80), linguistics (Rosen, Reference Rosen1992; Gibbon, Reference Gibbon2023), and neuroscience (Zatorre et al., Reference Zatorre, Belin and Penhune2002; Chi et al., Reference Chi, Ru and Shamma2005). PRiORS borrows ideas from all of the above in order to present a simplified perception-based synthesis.
The temporal regime in PRiORS dominates the timescale within which we perceive successive acoustic events as isolated events that can be rhythmically related. We can thus sense whether successive discrete events within this timescale can be related, via one of the following scenarios: Events that occur at (relatively) regular (quasi-)isochronous intervals within the timescale of the temporal regime will yield the sensation of a steady beat; we can also perceive whether successive acoustic events within this timescale display dynamic patterns of deceleration or acceleration, that is, whether the interval between successive events decreases or increases; and finally, if intervals between events are randomly distributed within this timescale, these successive acoustic events will be perceived as meandering.
The spectral regime in PRiORS is the timescale within which auditory repetition is too fast to support the perception of isolated events. Instead, we perceive successive acoustic events as a continuous sound. The differences in the rates of repetition at this timescale result in the perception of different spectral details (i.e., different frequencies). We can sense if successive events within this timescale occur in (quasi-)isochronous succession, which will result in a complex harmonic sound, and we can also perceive whether successive events exhibit deceleration or acceleration patterns, such as falling or rising pitch. If successive acoustic events are randomly distributed within this timescale, they will be perceived as aperiodic noise.
The two distinct perceptual regimes in the PRiORS framework should not be confused with the more familiar notions of time and frequency domains in mathematical representations, which lack a perceptual component (see Section 14.2.2). Likewise, they should not be confused with suggestions in the mainstream neurolinguistic literature (e.g., Poeppel, Reference Poeppel2003; Giraud and Poeppel, Reference Giraud and Poeppel2012; Doelling et al., Reference Doelling, Arnal, Ghitza and Poeppel2014; see also Chapters 3 and 5) for different temporal integration windows, whereby spectral detail is linked to phoneme-size intervals (20–50 ms long) and is therefore related to rates of 20–50 Hz. Furthermore, the simple one-dimensional spectral regime in PRiORS should not be confused with the more complex notion of frequency modulation (FM) in speech research (e.g., Teoh et al., Reference Teoh, Cappelloni and Lalor2019; Chapter 23). FM carrier signals exhibit high-frequency oscillations (e.g., the F0 in human vocalization), but FM modulation signals, which are usually the signals of interest in FM configurations, are themselves in the low-frequency range (up to about 8 Hz), which is the rate at which they modulate the high-frequency spectral information. As we shall see below, the spectral regime in PRiORS is inherently distinct and above those rates of oscillation – mostly above 50 Hz.
14.2.2 Time and Frequency Domains
The notion of temporal and spectral regimes echoes the time and frequency domains in mathematical representations, going back to the Fourier transform (Fourier, Reference Fourier1822), which decomposes a time series into a sum of finite series of sine or cosine functions. Note that in most contexts of acoustic analysis, the procedure is referred to as fast Fourier transform (FFT), which is the name given to a wide range of algorithms that perform quick calculations of the Fourier transform (see the overview in Brigham, Reference Brigham1988). FFT allows us to switch the representation of complex natural sounds from the time domain (where all the subcomponents are bundled together) to the frequency domain (where we can represent the distribution of acoustic power of different frequencies at different points in time).
In principle, the temporal regime is congruent with the notion of the time domain, while the spectral regime is congruent with the notion of the frequency domain. However, while the time and frequency domains can independently describe the same event in mathematical terms, the perceptual regimes in PRiORS operate at two mostly distinct and mutually exclusive timescales. The non-overlapping qualia in PRiORS are therefore referred to as temporal and spectral regimes to set them apart from the overlapping time and frequency domains.
14.2.3 Visual FFT-Based Simulations
It is useful to illustrate the distinction between perceptual regimes with a Band-Limited Impulse Train (BLIT) synthesis that produces a train of transient acoustic bursts at adjustable rates (in contrast to continuous sine waves). Each burst is a single impulse, which is the shortest burst a given system can produce (i.e., one sample in digital setups), with equal power across the frequency scale. A perfect impulse has acoustic power over an infinite frequency range, but the impulses in a BLIT are band-limited to human hearing ranges, between approximately 20 and 20k Hz. The BLIT signal can be effectively visualized with standard FFT-based tools that convert signals between time domain and frequency domain representations (see Section 14.2.2).
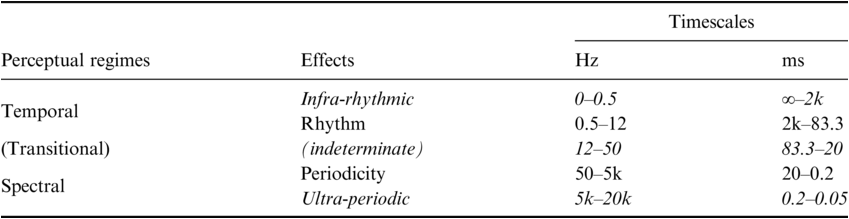
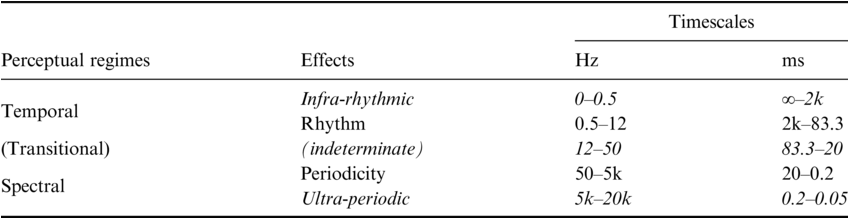
Table 14.1 presents a rough sketch of the relevant timescales of the two perceptual regimes. Within each regime the effects of repetition are termed differently in order to maintain a distinction (although note that they are largely interchangeable in many conventional uses). We use the term Rhythm for the main effect occurring within the timescale of the temporal regime versus Periodicity for the main effect occurring within the timescale of the spectral regime. Table 14.1 also shows the upper and lower boundaries of these temporal integration effects. Repetitions within the temporal regime may be too slow to be integrated as rhythmic (below 0.5 Hz for intervals longer than 2 seconds; see Fraisse, Reference Fraisse1984; Repp, Reference Repp2005; Ulbrich et al., Reference Ulbrich, Churan, Fink and Wittmann2007; Wittmann, Reference Wittmann2011; Farbood et al., Reference Farbood, Marcus and Poeppel2013). Likewise, repetitions within the spectral regime may be too fast to be perceived as periodic (above 5k Hz, given that our auditory system can typically discern pitch up to about 5k Hz; see Ward, Reference Ward1954; Attneave and Olson, Reference Attneave and Olson1971). Furthermore, the switch between regimes does not occur at once. Table 14.1 displays a transitional range between the temporal and the spectral regimes, in which both effects are present but neither is clear enough, resulting in an indeterminate effective sensation.
Perceptual regimes with corresponding effects and timescales (rough sketch). Hz = Hertz (repetitions per second); ms = millisecond (duration of intervals).
Four examples are provided in Figure 14.1, each one with three corresponding visualization panels. The bottom white panel presents a one-second-long waveform (oscillogram) that shows the unipolar transient bursts produced by the BLIT synthesis in the time domain, going from left to right. The number of visible bursts within this one-second interval corresponds to the rate of the BLIT in Hz. The two upper dark panels show FFT-based analyses exhibiting the dispersion of acoustic power across the audible frequency range in the frequency domain.Footnote 1 The middle panel, often called a spectrum or a spectrograph, exhibits a two-dimensional representation of frequency (x-axis) and power (y-axis), while the top panel, which is typically called a spectrogram, exhibits a three-dimensional representation of frequency (x-axis), power (shade), and time (y-axis). The frequency x-axes of the spectrum and the spectrogram are perfectly aligned to facilitate the interpretation of the spectrum in the middle as a “slice,” or a still image of the temporal representation in the spectrogram above it. This means that unlike the more typical configuration, the spectrogram here is moving in time from bottom to top, rather than from left to right.
A BLIT demonstration.
Illustration of perceptual regimes with visual analyses of acoustic impulse trains (BLITs) at different rates and different domains (see text for details).

Figure 14.1 Long description
Four sets (A–D) of three-panel graph representations of auditory impulse signals in the time and frequency domains. In each set, the top two panels are in the frequency domain, showing graphs depicting frequency and power (with time added in the top panel). The bottom panel is a waveform representation in the time domain, showing positive spikes (vertical lines) within a one-second interval. The four sets show different rates of repetition, between 4 – 120 Hertz. The visual representations in the frequency domain demonstrate two distinct effects: isolated events with no spectral structure in A (4 Hertz) vs. continuous sound with harmonic structure in D (120 Hertz). The transitional states between the two distinct effects are depicted in B and C (24 and 40 Hertz respectively).
Figure 14.1(a) (top left) shows a clear rhythmic effect at 4 Hz, indicated by four bursts in the bottom oscillogram panel. A single burst appears with equal power along the (band-limited) frequency range in the spectrum, indicated by the fairly straight horizontal line across the middle panel. Note that the still image shown here captured a moment in time in which the power graph of the spectrum was high. With rhythmic bursts, such as the 4 Hz BLIT in Figure 14.1(a), this graph goes visibly up and down over time. Above it, in the corresponding upper spectrogram panel, a succession of 10 impulses over a short period of time (about 2.5 seconds) is visible as isolated bursts, indicated by the horizontal lines going from bottom to top.Footnote 2
In sharp contrast, Figure 14.1(d) (bottom right) clearly shows tonal behavior at 120 Hz. There are, indeed, 120 bursts in the time domain display of the bottom oscillogram panel, but the isolated bursts are no longer visible in the top spectrogram panel; that is, there are no horizontal lines going from bottom to top across the upper panel. The sensation of isolated discrete bursts transitions into one of continuous sound at these higher rates of repetition. This perceptual effect is reflected by the two FFT-based representations in Figure 14.1(d), which display a signal with the properties of a continuous sound that has a complex harmonic structure. The middle spectrum panel shows a series of “bumps” along the white curve, from left to right, corresponding to a series of continuous energy “poles” in the vertical representations of the upper spectrogram panel. This is a harmonic series in which the rate of repetition of the BLIT synthesis is mapped onto the F0 of the continuous sound (120 Hz in this case).Footnote 3 This demonstrates that at this faster timescale of the spectral regime, the sensation of repetition feeds perceptual effects of continuity and pitch, rather than of discreteness and rhythm.
Between the two regimes, we can observe a transitional range in which effects of both rhythm and periodicity are present, but neither is strong enough to be sufficiently clear. Figures 14.1(b)–14.1(c) demonstrate this transitional range between the two distinct regimes. Figure 14.1(b) (top right) is especially well suited for illustrating the indeterminacy of the transitional range. At a BLIT rate of 24 Hz, the impulses seem to be too fast to support a rhythmic perception of discrete bursts, and, at the same time, too slow to support the perception of a continuous harmonic (pitch-bearing) sound. The upper spectrogram panel of Figure 14.1(b) reflects that by showing a combination of both faint horizontal lines that reflect isolated events in time, as well as faint vertical lines that reflect the emerging harmonic structure of a continuous complex tone (visible also as small corresponding energy fluctuations in the middle spectrum panel).
14.2.4 PRiORS-Derived Hypotheses
14.2.4.1 Universal Aspects of Syllabic Structure
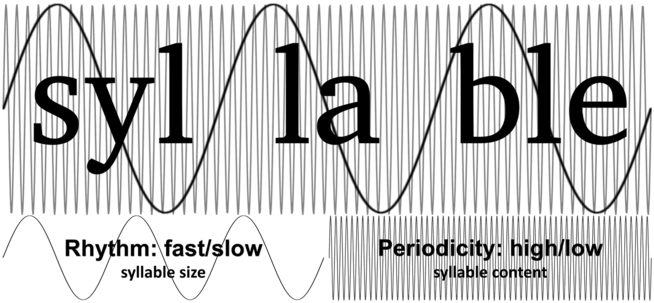
Syllables are abstract units of phonological systems, and they do not easily lend themselves to consistent and straightforward phonetic descriptions in terms of perception.Footnote 4 The PRiORS framework can do a lot of heavy lifting in this regard, by providing the conditions that can explain the evolutionary trajectory of syllables from a perceptual perspective. According to this analysis, syllables were shaped by selection to optimally take advantage of the two perceptual regimes: carrying pitch in the spectral regime and giving rise to dynamic timing relations in the temporal regime (see also Strauß and Schwartz, Reference Strauß and Schwartz2017, and Räsänen et al., Reference Räsänen, Doyle and Frank2018, for proposals that suggest somewhat similar divisions of labor). In other words, syllables universally exploit the spectral regime with an internal segmental makeup that is optimized to carry pitch (namely by the requirement for sonorous nuclei; see Albert and Nicenboim, Reference Albert and Nicenboim2022). At the same time, syllables universally exploit the temporal regime with sizes that give rise to dynamic speech rate effects.Footnote 5 Figure 14.2 illustrates this.
Perceptual regimes and syllables.
Schematic illustration of the relationship between perceptual regimes and syllabic units. Segmental makeup in terms of sonority is related to the spectral regime with high-frequency oscillations within syllables, while syllabic size is related to the temporal regime with low-frequency oscillations between syllables. The ratio between the low- and high-frequency oscillations in this illustration is arbitrarily set to be 1:20. This is a realistic ratio such that if syllables are taken to have a typical average duration of 200 ms (5 Hz), the high-frequency oscillation within it would reflect a typical F0 for adult males at 100 Hz. For simplicity, this generalized illustration shows a single rate at each timescale using a steady phase (isochronous repetitions).
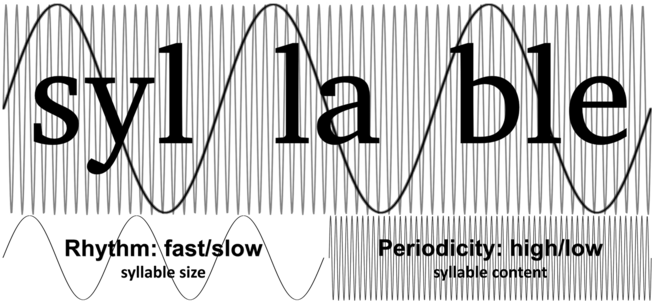
Figure 14.2 Long description
Two overlaid sinus-like wavy lines reflect two simultaneous rates of oscillation that characterize syllables, shown with respect to a superimposed orthographic annotation of a trisyllabic example (the word 'syl-la-ble'). The low frequency oscillation, linked to syllable size, illustrates the concept of rhythm with distinctions between fast vs. slow. The higher frequency oscillation, linked to syllable content, illustrates the concept of periodicity with distinctions between high versus low.
14.2.4.2 Prosodic Effects Are Dynamic
Pitch contours in speech signals are not static but dynamic. They are constantly changing in order to achieve communicative goals. Consider, for example, the periods during a rising pitch contour, in which every period is shorter than the previous one. These degrees of change do not hinder the perception of a coherent rising pitch contour, demonstrating our specialized ability to perceive gradually changing dynamic pitch (Temperley, Reference Temperley2008; Morgan et al., Reference Morgan, Fogel, Nair and Patel2019). As long as these communicatively relevant pitch changes occur within the timescale of the spectral regime – and follow basic Gestalt principles – they invoke a reliable effect in perception.
A similar behavior can be observed for rhythm (e.g., Cope et al., Reference Cope, Grube and Griffiths2012). Rather than exhibiting static isochrony, speech units within the temporal regime exhibit mostly dynamic changes in terms of acceleration and deceleration patterns within certain ranges. These patterns are exploited for communicative goals via prosody, such as chunking the message into phrases, highlighting important information and turn-taking management (see a more detailed non-exhaustive overview in the following Section 14.3).
From a functional linguistic perspective, isochrony is not a useful effect of temporal integration, as it is not immediately clear what purpose this would serve in speech. There are no behaviorally observable isochronous responses to (non-isochronous) spontaneous speech, or, in other words, we do not – and likely cannot – dance to spontaneous speech (see the discussion in Section 14.5.3). This can be contrasted with music, which much more clearly exploits isochrony to achieve certain goals (see Section 14.4.1).
A truly steady isochronous signal – or a quasi-isochronous one, given perceptually negligible jitter – would not be very useful for prosody. Within the spectral regime, that would entail that all the syllables have the same static F0 rate, and within the temporal regime that would entail that all the syllables have the same duration. In fact, it is the constant state of flux in the prosody of spontaneous speech that is critical to effectively exploit the sensations of rhythm and pitch in their respective timescales in speech (see Section 14.3).
14.3 Speech Prosody and Dynamic Speech Rate
More often than not, when the notion of speech rate is invoked, it is meant in the sense of the global speech rate, looking at the ratio between a certain linguistic unit and a given unit of time. This is often measured in terms of the average syllable duration (e.g., Miller et al., Reference Miller, Grosjean and Lomanto1984) or other similar measurements (see Tilsen and Tiede, Reference Tilsen and Tiede2023, for a recent proposal for global speech rate measurements). We explicitly refer here to dynamic speech rate, to express the idea that the tempo of speech is in a constant state of flux (explained in Section 14.2.4.2; also, see Gibbon, Reference Gibbon2023, and Chapter 23 for a related perspective on speech rate dynamics). Unlike global speech rate, dynamic speech rate should be more adequately characterized in terms of a time series trajectory. Few studies have used this type of dynamic speech rate trajectory representation thus far, making the perceptual local speech rate in Pfitzinger (Reference Pfitzinger2001) a notable exception.
One of the most important goals achieved by dynamic speech rate in the prosody of speech is the division of the message into chunks (see Christiansen and Chater, Reference Christiansen and Chater2016, for a functional cognitive account of chunks as crucial units in models of speech processing). Chunking can be achieved by various prosodic effects (e.g., Gee and Grosjean, Reference Gee and Grosjean1984; Price et al., Reference Price, Ostendorf, Shattuck‐Hufnagel and Fong1991; Dilley and Pitt, Reference Dilley and Pitt2010; Reinisch et al., Reference Reinisch, Jesse and McQueen2011), which play a major role in comprehension of speech in real time (see Chapters 17 and 18, and see the debate in Kazanina and Tavano, Reference Kazanina and Tavano2023, and Lo et al., Reference Lo, Henke, Martorell and Meyer2023, about the syntactic and neurological aspects of chunking). Additionally, chunking is essential in turn-taking management to maintain the conversational flow (e.g., Sacks et al., Reference Sacks, Schegloff, Jefferson and Schenkein1978; Wilson and Wilson, Reference Wilson and Wilson2005; Levinson and Torreira, Reference Levinson and Torreira2015; Ogden and Hawkins, Reference Ogden and Hawkins2015; Roberts et al., Reference Roberts, Torreira and Levinson2015).
The chunking function of dynamic speech rate is often studied in terms of prosodic boundary phenomena (Schubö et al., Reference Schubö, Zerbian, Hanne and Wartenburger2023), which are generally assumed to be present in all languages, regardless of their typology (Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2010). One of the most commonly researched aspects is (progressive) domain final lengthening (Klatt, Reference Klatt1976; Cummins, Reference Cummins1999; White, Reference White2002, Reference White2014; Kohler, Reference Kohler2003; Paschen et al., Reference Paschen, Fuchs and Seifart2022). Domain final lengthening involves deceleration in articulation when approaching a prosodic boundary, something that can be found in movement in general (Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2007). Despite the mechanical explanations (along with others relating to planning of upcoming phrases), domain final lengthening interacts with the phonology of the language it operates on, leading to language-specific differences in the domain, scope, and execution of this lengthening (Paschen et al., Reference Paschen, Fuchs and Seifart2022).
Another, less investigated aspect of chunking is often studied in terms of acceleration at the beginning of a prosodic domain, referred to as initial rush, anacrusis, or phrase-initial acceleration (Cruttenden, Reference Cruttenden1997; Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2010). This is particularly commonly (but not exclusively) reported in languages with (final or right-branching) lexical stress, with unstressed syllables being rapidly produced at the beginning of the domain.
The temporal integration of events at the timescale of the temporal regime can also be exploited via silent gaps in the sequence, which are usually considered as pauses in prosodic analyses. Pauses serve as strong cues to demarcation of phrasal units, which can also promote effective chunking of speech (e.g., Grosjean, Reference Grosjean1979; Duez, Reference Duez1982, Reference Duez1985; Gee and Grosjean, Reference Gee and Grosjean1984; Heldner and Edlund, Reference Heldner and Edlund2010), and they appear to be more common in slow speech (Trouvain and Grice, Reference Trouvain and Grice1999).
Furthermore, dynamic speech rate is sometimes used to mark the distinctive status of a certain phrase in the stream of speech. Phrases that are part of a self-repair strategy (Schegloff et al., Reference Schegloff, Jefferson and Sacks1977; Levelt and Cutler, Reference Levelt and Cutler1983; Dingemanse and Floyd, Reference Dingemanse, Floyd, Enfield, Kockelman and Sidnell2014) make a good case in point as they have already been found to be systematically employing speech rate cues (Plug, Reference Plug2016).
Dynamic speech rate can also be used to highlight informative parts of the message: Slowing down allows for more precise articulation of the individual sounds (hyperarticulation) (Lindblom, Reference Lindblom, Hardcastle and Marchal1990) and for an intonation contour to be produced in full (Grice et al., Reference Grice, Savino and Roettger2018). Conversely, less informative parts can be speeded up with reduction in the segmental domain (Cohen Priva, Reference Cohen Priva2017; Hall et al., Reference Hall, Hume, Jaeger and Wedel2018) as well as a possible truncation of intonation contours (Rathcke, Reference Rathcke2013). Domain final lengthening and accentual lengthening can coexist, indicating a cumulative effect (Turk and White, Reference Turk and White1999).
14.4 Neural Perspectives
14.4.1 Entrainment in Music
Unlike spontaneous speech, music tends to exhibit a steady (quasi-)isochronous beat (e.g., Bolton, Reference Bolton1894; Fraisse, Reference Fraisse1963; Repp, Reference Repp2005; Bispham, Reference Bispham2006, Reference Bispham, Doffman, Payne and Young2021; Fitch, Reference Fitch, Rebuschat, Rohrmeier, Hawkins and Cross2012; Grahn, Reference Grahn2012). In this respect, the notion of entrainment is often invoked to describe how listening to music may involve the phase-locking of neural activity to the external musical signal (e.g., Merker et al., Reference Merker, Madison and Eckerdal2009; Phillips-Silver et al., Reference Phillips-Silver, Aktipis and Gregory2010; Nozaradan et al., Reference Nozaradan, Peretz and Mouraux2012; Doelling et al., Reference Doelling, Assaneo, Bevilacqua, Pesaran and Poeppel2019). Entrainment makes perfect sense in cases where an external isochronous beat promotes motor coordination in synchrony, such as dancing, tapping, nodding, and so on (see Repp, Reference Repp2005; Ravignani et al., Reference Ravignani, Bowling and Fitch2014; Kotz et al., Reference Kotz, Ravignani and Fitch2018), even in the absence of actual motor response (Chen et al., Reference Chen, Penhune and Zatorre2008). Entrainment to a musical rhythm is not only useful to internally couple one’s motor system with an external clock; it also allows coupling oscillations across different agents who share the same space. The goal of isochrony in this case is to achieve this type of system(s)-wide phase-locking, which many researchers equate with rewarding goals such as rapid social bonding, social cohesion, and even pain relief (Wiltermuth and Heath, Reference Wiltermuth and Heath2009; Cohen et al., Reference Cohen, Ejsmond-Frey, Knight and Dunbar2010; Kokal et al., Reference Kokal, Engel, Kirschner and Keysers2011; Bowling et al., Reference Bowling, Herbst and Fitch2013; Tarr et al., Reference Tarr, Launay and Dunbar2016; Savage et al., Reference Savage, Loui and Tarr2021).
14.4.2 Entrainment in Speech
Recent decades have seen an influx of studies that link language processing with neural activity within a range of low-frequency oscillations (see reviews in Meyer, Reference Meyer2018; Myers et al., Reference Myers, Lense and Gordon2019; Poeppel and Assaneo, Reference Poeppel and Assaneo2020). This is largely in line with the entire effective rhythmic range of the temporal regime in PRiORS, at about 0.5–12 Hz (Keitel et al., Reference Keitel, Gross and Kayser2018). Central among these are Theta band oscillations (about 4–8 Hz) that correspond to syllable-size events. Frequencies above and below the Theta band are likewise often linked with units below and above the syllable, respectively (e.g., Delta band oscillations at about 0.5–4 Hz are often linked with words/phrases; see Inbar et al., Reference Inbar, Grossman and Landau2020; Rimmele et al., Reference Rimmele, Poeppel and Ghitza2021; Chapter 15).
The majority of the literature on the link between brain oscillations and speech makes two (implicit or explicit) assumptions: (i) that the mechanism at play is entrainment, whereby the rate of internal oscillations phase-lock to the external speech stimulus (exogenous neural oscillation); and (ii) that this phase-locking procedure facilitates and improves comprehension in general, under the assumption that the rate of activity in the brain can be equated with the rate of attention allocation when processing incoming information (see, for example, Large and Jones, Reference Large and Jones1999; Ghitza, Reference Ghitza2011; Peelle and Davis, Reference Peelle and Davis2012; Doelling et al., Reference Doelling, Arnal, Ghitza and Poeppel2014; Goswami, Reference Goswami2018).
With regards to the first assumption, a growing number of voices among the researchers in the field have been calling for a revised understanding of the notion of entrainment in the case of brain oscillations that respond to speech (see Cummins, Reference Cummins2012; Breska and Deouell, Reference Breska and Deouell2017; Haegens and Golumbic, Reference Haegens and Golumbic2018; Rimmele et al., Reference Rimmele, Morillon, Poeppel and Arnal2018; Kotz et al., Reference Kotz, Ravignani and Fitch2018; Meyer et al., Reference Meyer, Sun and Martin2019, Reference Meyer, Sun and Martin2020). For example, Cummins (Reference Cummins2012) claims that entrainment and phase-locking are not adequate descriptions for the tracking of spontaneous speech, which is essentially non-isochronous. Meyer et al. (Reference Meyer, Sun and Martin2019) suggest the term intrinsic synchronicity as a separate process from classic entrainment, to cover cases in which the external signal is non-isochronous yet linked to relatively isochronous internal oscillations (endogenous neural oscillations).
The second assumption regarding the direct link between brain oscillations and comprehension should also be questioned. Such a link between oscillations and comprehension via rate of attention seems to reflect a computer metaphor of the mind (e.g., Searle, Reference Searle, Gill, Göranzon and Florin1990; Spivey, Reference Spivey2007): The frequency of the oscillations in this type of explanation is likened to the sample rate in digital systems, where the resolution of the sample rate determines the resolution of the obtained signal. While this is not implausible, there seem to be other links to speech comprehension via prosody that would benefit from the time-keeping capability of internal oscillations, without the need to resort to new theoretical entities.
As briefly summarized above in Section 14.4.1, music tends much more than speech to exploit the timescale of the temporal regime to produce isochronous signals that promote the phase-locking of motor systems. This is arguably one of the major effects of the musical experience as a social phenomenon. Non-isochronous beats in music destroy this effect. Likewise, speech tends much more than music to exploit the timescale of the temporal regime to produce non-isochronous (yet dynamically changing) signals that are designed to use changes in speech rate to create prosodic effects. Isochronous rhythm in speech is devoid of this communicative dimension of the language sound system (but see the discussion in Section 14.5.3 for specific roles isochrony may play in the prosodic repertoire of languages).
In our current proposal, we argue along with others that entrainment in music cannot be the same as entrainment in speech perception. Speech does not have the same goal that music has in terms of social bonding via syncing of the motor systems to external signals (see Section 14.5.3). We add to that a skeptical view towards the second assumption in its simplistic form. When processing speech, brain oscillations should allow us to perceive the dynamic timing patterns in speech rate, which, in turn, enrich and facilitate comprehension via prosody (see Glushko et al., Reference Glushko, Poeppel and Steinhauer2022). This seems like a stronger explanation than the currently dominant attention-based explanation, which is modeled in terms of digital sampling.
14.5 Discussion
14.5.1 Isochrony, Where Are You?
In music, the isochronous element is typically in the external signal such that the internal brain oscillations can entrain to it (exogenous neural oscillations). This is essential for achieving some of the most powerful goals that music can achieve – rapid social bonding and group coherence via coupled oscillations.
In speech processing, the relatively isochronous element comes from the brain oscillations themselves (endogenous neural oscillations), such that the external and temporally dynamic speech can be measured internally. This is essential for achieving communicative goals via prosody (see Section 14.3) by obtaining a mental representation of timing patterns (for models of internal clocks, see Treisman, Reference Treisman1963; Church, Reference Church1984; Wittmann, Reference Wittmann2013; Allman et al., Reference Allman, Teki, Griffiths and Meck2014; Paton and Buonomano, Reference Paton and Buonomano2018).
The proposed description that assumes that (quasi-)isochrony in speech is internal rather than external fits well with some prominent critical reviews on the topic of rhythm in the linguistic literature. Having found no convincing case for isochrony in speech signals, Lehiste (Reference Lehiste1977) suggested that isochrony in speech may be projected from perception. Likewise, Nolan and Jeon (Reference Nolan and Jeon2014) suggested that isochrony may be a metaphor that we project onto speech in perception. These intuitive descriptions are in line with the current proposal.
Rhythm, as we understand it here, is the main effect of temporal integration at the timescale of the temporal regime (roughly 0.5–12 Hz).Footnote 6 Isochrony is not what defines rhythm – it is one of the goals that rhythm can achieve. In music, this goal requires external sources, while in speech, isochrony needs to be sourced internally, since it is likely serving as the baseline measurement for mental representation of dynamic speech rate effects in prosodic perception.
14.5.2 Meter Is Independent of Isochrony
Meter (or contrastive rhythm) is therefore not a relationship that needs to be tied to isochrony. Any sequence of elements that can be grouped via temporal integration (i.e., that fall within the relevant timescale of the temporal regime) can be in a strong–weak relationship, regardless of whether they are temporally equidistant or not. This more nuanced understanding can also provide an explanation for the continued prevalence of one of the most contested notions in the literature on rhythm and speech, namely the notions of stress-timing versus syllable-timing (Pike, Reference Pike1945; Dauer, Reference Dauer1983). In our proposed understanding of rhythm, it is possible to extract timing patterns from all successive syllabic units as much as it is possible to extract such patterns more selectively from the string of strong syllables only. Again, this should not entail that the units (either all syllables or just the stressed ones) are equidistant, only that they are in a rhythmically relevant relationship within the timescale of the temporal regime.
For example, languages such as English, that include many weak syllables next to strong ones, can plausibly use the strong syllables (either all stressed syllables or just the primary stressed ones) to signal dynamic change in speech rate. Languages such as French, with phrase-final prominence, may tune to this phrasal position for similar effects, while languages with no apparent prominence asymmetries may likely signal speech rate patterns using all the syllables (or moras) in the stream of speech.
14.5.3 Isochrony between Music and Speech
We make a distinction between speech in spontaneous communication scenarios and speech types that incorporate musical aspects, which may include prayers, mantras, chants, poems, nursery rhymes, freestyle rap, and many other types of belief-based and/or artistic expressions (see Leong and Goswami, Reference Leong and Goswami2015; Fuchs and Reichel, Reference Fuchs and Reichel2016; Davis, Reference Davis2017; Cummins, Reference Cummins2018; Danner et al., Reference Danner, Krivokapić and Byrd2021). All the latter tend to incorporate quasi-isochrony that should be related to the musical aspect of these complex fusions between music and speech. The nature of the compromise in the vast majority of music and speech fusions is such that speech gives way to musical isochrony.
Speaking intentionally in a quasi-isochronous rhythm can be attested as part of the repertoire of intonation patterns of at least some languages. In English, for example, a tendency to make strong syllables equidistant can often characterize the intonation pattern of lists (e.g., alignment of p-centers; see Morton et al., Reference Morton, Marcus and Frankish1976; Couper-Kuhlen, Reference Couper-Kuhlen1993). Likewise, quasi-isochrony can be attested in declarations in public speeches and statements (e.g., see White’s Reference White2014:45 analysis of Bill Clinton’s statement). Here, again, the task of the listener does not appear to be entrainment to the rhythm in the speech signal in order to couple oscillations between their own motor system and the external auditory signal. It seems more likely that the task of the listener is to infer the timing relations such that a “sing-song” effect can arise (which in turn might make the message more appealing and/or long-lasting in memory, due to its atypical “musicality”).
The speech-to-song illusion (Deutsch et al., Reference Deutsch, Henthorn and Lapidis2011) shows that stretches of spontaneous speech can be perceived as music when a certain portion is repeated in a loop (various factors, such as the size of the loop, the number of repetitions, and the segmental makeup of the looped speech, can affect the strength of this illusion; see Rathcke et al., Reference Rathcke, Falk and Dalla Bella2021a). This is of interest in the context of the current synthesis because a looped auditory signal is, in fact, isochronous at the level of the entire loop size, and it can become “musical” as soon as the structure of the repeating pattern is revealed in perception (see tapping to speech in Rathcke et al., Reference Rathcke, Lin, Falk and Bella2021b). The invisible boundaries between music and speech are brought to light in this illusion and they imply that isochrony is at the heart of the distinction between music and speech in perception (rather than being what they both share).
Seen this way, speech rhythm is not such an elusive concept after all. We suggest that rhythm is the timescale within which temporal relationships between isolated events are perceived. While music tends to use this timescale to promote phase-locking to an external clock, speech rather exploits it to achieve a mental representation of dynamic speech rate in prosody.
Summary
Rhythm is the timescale within which temporal relationships between isolated events are perceived. While music tends to use this timescale in terms of isochrony to promote phase-locking to an external clock, speech rather exploits the rhythmic timescale to achieve a mental representation of dynamic speech rate.
Implications
Speech rhythm is too irregular to be described using isochrony and entrainment. Instead, speech rhythm should be understood in terms of dynamic speech rate, which is an important aspect of speech prosody, serving major communicative goals such as chunking the signal, highlighting newsworthy information, and turn-taking.
Gains
We provided a principled framework for understanding temporal relations in the auditory domain in relation to music and speech. For speech, this framework can help linguists focus on the rhythmic properties employed in communication, and helps neuroscientists appreciate how prosody, in particular speech rate, facilitates comprehension via neural oscillations.


 Open access
Open access