


Surveys are fundamental to the measurement of public opinion and behavior, but the deteriorating performance of both pre-election polls (Clinton et al. Reference Clinton2021; Kennedy et al. Reference Kennedy2018) and academic surveys (Jacobson Reference Jacobson2022) has fueled concerns that survey respondents differ from the populations they are meant to reflect (Bailey Reference Bailey2023; Jamieson et al. Reference Jamieson2023). Researchers have proposed several methods to address these concerns. A particularly important approach is multilevel regression and poststratification (MRP; Gelman and Little Reference Gelman and Little1997; Park, Gelman, and Bafumi Reference Park, Gelman and Bafumi2004), which combines regression modeling with poststratification to estimate opinion in populations that were not intentionally sampled.
Despite these improvements, MRP estimates may still suffer from at least three sources of error: (1) nonignorable nonresponse, where respondents differ from nonrespondents in ways not captured by covariates (e.g., Clinton, Lapinski, and Trussler Reference Clinton, Lapinski and Trussler2022); (2) poststratification error, where population targets are proxied or measured with error; and (3) model specification error and sampling variation.
These errors matter: a rich literature uses constituency-level opinion estimates to assess democratic representation, but interpreting discrepancies between public opinion and policy as “democratic deficits” (Lax and Phillips Reference Lax and Phillips2012) requires confidence that these gaps are not artifacts of survey error—confidence that is increasingly difficult to justify (Cohn Reference Cohn2022).Footnote 1
A large literature has proposed MRP-related strategies to improve small-area opinion measurement (Ben-Michael, Feller, and Hartman Reference Ben-Michael, Feller and Hartman2024; Bisbee Reference Bisbee2019; Broniecki, Leemann, and Wuest Reference Broniecki, Leemann and Wuest2022; Bruch and Felderer Reference Bruch and Felderer2023; Caughey and Wang Reference Caughey and Wang2019; Ghitza and Gelman Reference Ghitza and Gelman2013; Goplerud Reference Goplerud2024; Hanretty, Lauderdale, and Vivyan Reference Hanretty, Lauderdale and Vivyan2016; Leemann and Wasserfallen Reference Leemann and Wasserfallen2017; Ornstein Reference Ornstein2020; Rosenman, McCartan, and Olivella Reference Rosenman, McCartan and Olivella2023). We contribute a method that reduces both the bias and variance of MRP estimates by leveraging auxiliary data with known marginals (e.g., election results) to calibrate estimates of correlated outcomes lacking ground truth (e.g., policy attitudes).
The core insight is that because attitudes are correlated across issues, so too are errors in survey-based estimates: if an MRP model overestimates Democratic vote share in a county, it probably also overestimates support for increasing the minimum wage. Our approach jointly models outcomes of interest alongside auxiliary variables with known ground truth, estimating the geographic-level correlations across variables. We then use these estimated correlations to update estimates of target variables based on the observed calibration error for the auxiliary variables with ground-truth data. This approach, which is agnostic as to the source of error, provides larger adjustments for more highly correlated variables. Our method also enables opinion estimation in smaller geographies than those in the survey or poststratification data by applying calibration at a lower, nested level (e.g., precincts within counties). We implement our methods in R software available at http://github.com/wpmarble/calibratedMRP.Footnote 2
We validate our approach using pre-election polling in the 2022 Michigan midterm election. We focus on elections for governor, secretary of state and a ballot proposition on reproductive rights (Proposition 3). Calibrating to the governor race reduces county-level error by about two-thirds in the other elections. Our precinct-level extension reduces error by 60%. Simulations show that the procedure is most helpful when the calibration variable is highly correlated with the outcome of interest, and that it substantially reduces error even with small, highly non-representative samples.
Methodologically, we build on methods for calibrating model-based inferences to known population quantities. MRP researchers commonly use a “logit shift” to adjust discrepancies between known aggregates and model-based estimates (Ghitza and Gelman Reference Ghitza and Gelman2013; Rosenman et al. Reference Rosenman, McCartan and Olivella2023).Footnote 3 We extend this approach by jointly modeling correlated outcomes and exploiting their covariance structure to improve estimates for outcomes with unobserved true values. Our work is also related to efforts to expand poststratification using synthetic targets (Leemann and Wasserfallen Reference Leemann and Wasserfallen2017); our approach sidesteps synthetic poststratification tables entirely, requiring only marginal distributions of auxiliary variables at the geographic level of interest.
1 Survey adjustment using multilevel regression and poststratification
MRP involves three steps. First, researchers use survey data to estimate a regression model predicting an outcome of interest (e.g., opinion and behavior). The regression includes individual- and geographic-level predictors whose joint distribution is known (e.g., from Census microdata). Second, the model predicts the expected outcome for each combination of covariates in the known joint distribution (i.e., each poststratification cell). Third, final estimates are weighted averages of predicted outcomes in each cell. The weights are proportional to population size of the cell.Footnote 4
1.1 Population quantities
Suppose we are interested in public opinion on J binary outcomes. Our estimands
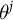 $\theta ^j$
denote the population share holding attitude j. Superscripts index issues; subscripts index groups or individuals. For example,
$\theta ^j$
denote the population share holding attitude j. Superscripts index issues; subscripts index groups or individuals. For example,
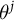 $\theta ^j$
might represent the share of the public who turn out to vote, who vote for the Democrat or who support a policy.
$\theta ^j$
might represent the share of the public who turn out to vote, who vote for the Democrat or who support a policy.
The population is partitioned into a set of cells
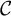 $\mathcal {C}$
, where each cell c is defined by a combination of demographic variables and geography. For example,
$\mathcal {C}$
, where each cell c is defined by a combination of demographic variables and geography. For example,
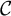 $\mathcal {C}$
might represent every combination of age, race, gender, education and county. Population cell sizes
$\mathcal {C}$
might represent every combination of age, race, gender, education and county. Population cell sizes
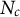 $N_c$
are known from Census data or other sources.Footnote 5 The total population is the sum of cell populations:
$N_c$
are known from Census data or other sources.Footnote 5 The total population is the sum of cell populations:
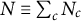 $N \equiv \sum _c N_c$
. The poststratification table is defined by cell-level covariates and cell sizes
$N \equiv \sum _c N_c$
. The poststratification table is defined by cell-level covariates and cell sizes
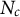 $N_c$
. Because cells are defined by geography, let
$N_c$
. Because cells are defined by geography, let
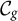 $\mathcal {C}_g$
denote the cells within geography g (e.g.,
$\mathcal {C}_g$
denote the cells within geography g (e.g.,
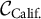 $\mathcal {C}_{\text {Calif.}}$
for California).
$\mathcal {C}_{\text {Calif.}}$
for California).
Population opinion is a weighted average of cell-level opinion:
 $$ \begin{align} \text{population-level opinion:} \quad &\theta^j \equiv \frac{\sum N_c \theta_c^j}{\sum N_c} \nonumber\\\text{opinion in geography } g{:} \quad &\theta_g^j \equiv \frac{\sum_{c \in \mathcal{C}_g} N_c \theta_c^j}{\sum_{c \in \mathcal{C}_g} N_c}. \end{align} $$
$$ \begin{align} \text{population-level opinion:} \quad &\theta^j \equiv \frac{\sum N_c \theta_c^j}{\sum N_c} \nonumber\\\text{opinion in geography } g{:} \quad &\theta_g^j \equiv \frac{\sum_{c \in \mathcal{C}_g} N_c \theta_c^j}{\sum_{c \in \mathcal{C}_g} N_c}. \end{align} $$
1.2 MRP estimation
MRP estimation proceeds by using survey data to fit a regression model for
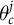 $\theta ^j_c$
as a function of covariates in the poststratification table. The model typically includes geographic intercepts to capture remaining between-geography variation after accounting for individual-level covariates. The model is used to generate predictions
$\theta ^j_c$
as a function of covariates in the poststratification table. The model typically includes geographic intercepts to capture remaining between-geography variation after accounting for individual-level covariates. The model is used to generate predictions
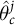 $\hat {\theta }^j_c$
for each cell. After generating opinion estimates for each cell, researchers then poststratify those estimates to the geography of interest—that is, substituting estimates for the population quantities in Equation (1).
$\hat {\theta }^j_c$
for each cell. After generating opinion estimates for each cell, researchers then poststratify those estimates to the geography of interest—that is, substituting estimates for the population quantities in Equation (1).
MRP allows researchers to estimate opinion in geographies that were not intentionally sampled. For example, researchers studying representation may want to know whether policy outcomes accord with public opinion (e.g., Lax and Phillips Reference Lax and Phillips2012; Tausanovitch and Warshaw Reference Tausanovitch and Warshaw2014), but even large surveys are unlikely to have many respondents in any given geography. MRP provides a solution by pooling information across geography and demographics via the regression step and accounting for differences in population composition via the poststratification step.
1.3 Remaining sources of error
The performance of the MRP estimates relies on ignorability: conditional on covariates, representation in the survey is independent of the outcome. Under ignorability and correct model specification, MRP is consistent. To make these assumptions more plausible, recent work has focused on specifying more complex interactions (e.g., Bisbee Reference Bisbee2019; Broniecki et al. Reference Broniecki, Leemann and Wuest2022; Ghitza and Gelman Reference Ghitza and Gelman2013; Goplerud Reference Goplerud2024) and increasing the number of poststratification variables (Leemann and Wasserfallen Reference Leemann and Wasserfallen2017). Still, respondents may differ from non-respondents in unobservable ways. Additionally, attempts to reduce bias by increasing model complexity may be offset by increased variance (Buttice and Highton Reference Buttice and Highton2013; Warshaw and Rodden Reference Warshaw and Rodden2012).
A second source of error arises when the population of interest differs from the population used to construct the poststratification table. An example is estimating the opinions of the electorate using the voting-age population demographics.
Finally, even under ideal conditions, MRP does not guarantee accurate estimates for every geography: model-based estimates that are unbiased overall can still produce sizable errors in specific areas.
2 Calibrating a single outcome to ground-truth data
The quality of MRP inference depends on how well the regression is able to model opinion within each cell. Researchers can sometimes assess error by comparing model-based estimates to known quantities—typically in the context of election surveys. We do not know how particular individuals voted, but we do know election outcomes at various levels of geographic aggregation. Even if predicting opinion in these geographies is not of primary interest, these discrepancies can be used to improve inference for other subgroups.
A popular method of adjusting MRP estimates to account for such error involves adding a geography-specific intercept shift to the modeled probabilities in each poststratification cell.Footnote 6 The values of these geographic intercepts are chosen such that the model-implied vote shares exactly match the known population vote shares in each geographic unit (Ghitza and Gelman Reference Ghitza and Gelman2013, 769). Because the intercept adjustment is applied on the logit scale, this method has been called the “logit shift.”
To formalize this method, suppose we observe the population-level outcome
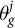 $\theta _g^j$
for some geography g. Given model estimates
$\theta _g^j$
for some geography g. Given model estimates
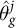 $\hat {\theta }_g^j$
, we calibrate results by adding an intercept shift on the logit scale to the predicted probabilities. The logit shift parameter for geography g on outcome j is the value of
$\hat {\theta }_g^j$
, we calibrate results by adding an intercept shift on the logit scale to the predicted probabilities. The logit shift parameter for geography g on outcome j is the value of
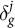 $\delta _g^j$
that solves:
$\delta _g^j$
that solves:
 $$ \begin{align} \underbrace{\theta_g^j}_{\substack{\text{ground truth} \\ \text{for geography } g}} &= \,\, \underbrace{\frac{1}{N_g} \sum_{c \in \mathcal{C}_g} N_c \,\, \overbrace{\text{logit}^{-1}\left(\delta_{g[c]}^j + \text{logit}(\hat{\theta}_c^j) \right)}^{\text{updated estimate for cell } c}}_{\text{updated estimate for geography } g}, \end{align} $$
$$ \begin{align} \underbrace{\theta_g^j}_{\substack{\text{ground truth} \\ \text{for geography } g}} &= \,\, \underbrace{\frac{1}{N_g} \sum_{c \in \mathcal{C}_g} N_c \,\, \overbrace{\text{logit}^{-1}\left(\delta_{g[c]}^j + \text{logit}(\hat{\theta}_c^j) \right)}^{\text{updated estimate for cell } c}}_{\text{updated estimate for geography } g}, \end{align} $$
where
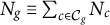 $N_g \equiv \sum _{c \in \mathcal {C}_g} N_c$
is the population of geography g and the notation
$N_g \equiv \sum _{c \in \mathcal {C}_g} N_c$
is the population of geography g and the notation
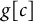 $g[c]$
indicates the geography for cell c. This expression equates the adjusted model-implied outcome to the ground-truth population outcome
$g[c]$
indicates the geography for cell c. This expression equates the adjusted model-implied outcome to the ground-truth population outcome
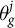 $\theta _g^j$
.
$\theta _g^j$
.
The new cell-level probabilities are generated by applying the geographic offset to the existing probabilities:
 $$ \begin{align} \tilde{\theta}_c^j = \text{logit}^{-1}\left( \delta_{g[c]}^j + \text{logit}(\hat{\theta}_c^j)\right). \end{align} $$
$$ \begin{align} \tilde{\theta}_c^j = \text{logit}^{-1}\left( \delta_{g[c]}^j + \text{logit}(\hat{\theta}_c^j)\right). \end{align} $$
When the updated estimates are poststratified to the geographic level, they exactly match the ground-truth data. When poststratified to other subgroups, the results will generally differ from the uncalibrated MRP results.
For example, researchers studying racially polarized voting may estimate an MRP model, apply the logit shift at the district level to match actual election results and aggregate adjusted estimates to the racial-group level (Kuriwaki et al. Reference Kuriwaki, Ansolabehere, Dagonel and Yamauchi2024). The resulting race-level vote share estimates will differ from their uncalibrated counterparts.
The logit shift is a minimal, geographic-based adjustment that does not distinguish between individuals within the same geography and has been shown to approximate the posterior distribution of cell-level probabilities conditional on the ground truth (Rosenman et al. Reference Rosenman, McCartan and Olivella2023).
Calibration improves estimates only under certain assumptions (Rosenman et al. Reference Rosenman, McCartan and Olivella2023, Section 3). The shift is uniform within each geography, so if the true error is not uniform, calibration may increase error for some cells even as it decreases average error. The uniform-shift assumption is more appropriate for homogeneous geographies. Given residential segregation along political and racial lines (Rodden Reference Rodden2019), the logit shift generally works better at smaller scales.
3 Adjusting multiple outcomes to account for ground-truth data
Discrepancies between model-based predictions and ground-truth data reveal information about the structure of survey-based error across outcomes. We extend the logit shift to multiple outcomes by relying on the fact that errors in one variable are often informative about errors in others. The basic idea is to estimate the correlation between the variables whose true outcomes are known and other variables with unknown ground-truth data. We use these correlations, along with the logit shift parameters for variables with ground-truth data, to estimate the implied logit shifts for other variables.
Consider the task of estimating opinion on increasing income taxes and changing local zoning regulations from a survey that also measures presidential vote choice. Using MRP, we generate population estimates of all three outcomes and apply the logit shift to ensure model-based presidential vote share estimates match actual results.
Our contribution is to note that discrepancies between model-based predictions of vote share and the actual outcome are informative about errors in survey-based estimates of opinion on income taxes and zoning. Of course, opinions on these two issues are not equally correlated with presidential vote choice: vote choice is likely more correlated with attitudes on taxes than on zoning. As a result, the survey error in presidential vote choice is likely more similar to the survey error in tax preferences than in zoning preferences. Our method formalizes this intuition and provides a principled, data-driven method for both estimating this correlation and updating survey estimates to account for this error.
First, we specify a model for all outcomes, including both outcomes of interest (without ground-truth data) and auxiliary variables (with ground-truth data).Footnote 7 The joint model includes random effects for geography that are allowed to correlate across outcomes. This approach is conceptually similar to seemingly unrelated regression (Zellner Reference Zellner1962), in which multiple outcomes are stacked and the error variance is correlated across outcomes within individuals (or, in our case, within geographies). Next, we update estimates of auxiliary variables to ensure they match known population margins using the logit shift method outlined above. Rather than viewing the logit shift as an ad-hoc adjustment, we interpret the sum of the logit shift parameter and the estimated random effect as the realized random effects—the actual geographic-level intercept implied by the ground-truth data.Footnote 8 We then condition on the realized random effects and compute the conditional expectation of the random effects for the target variables. With joint normal random effects, this expectation is a simple linear function of the realized logit shifts for the auxiliary variables, with coefficients determined by the covariance across outcomes.
3.1 Multivariate outcome model
Recall that our estimand is opinion on J issues with true values
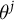 $\theta ^j$
. For each respondent
$\theta ^j$
. For each respondent
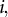 $i,$
we observe binary responses
$i,$
we observe binary responses
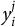 $y_i^j$
and demographic cell membership c. Each cell has a demographic covariate vector
$y_i^j$
and demographic cell membership c. Each cell has a demographic covariate vector
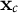 $\mathbf {x}_{c}$
and a geographic covariate vector
$\mathbf {x}_{c}$
and a geographic covariate vector
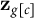 $\mathbf {z}_{g[c]}$
. We model
$\mathbf {z}_{g[c]}$
. We model
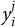 $y_i^j$
using a multivariate logit model with demographic and geographic covariates. We include a random intercept for each geography g. Conditional on covariates, responses across issues are assumed independent.
$y_i^j$
using a multivariate logit model with demographic and geographic covariates. We include a random intercept for each geography g. Conditional on covariates, responses across issues are assumed independent.
The model for each issue j is given by
 $$ \begin{align} \begin{aligned} y^j_i &\sim \text{Bernoulli}(\theta_{c[i]}^j) \quad \text{for } j \in 1, \dots, J\\ \theta_{c}^j &= \text{logit}^{-1}\left( \alpha_{{g}[c]}^j + \mathbf{x}_c'\beta^{j} + \mathbf{z}_{{g}[c]}'\gamma^{j} \right), \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} y^j_i &\sim \text{Bernoulli}(\theta_{c[i]}^j) \quad \text{for } j \in 1, \dots, J\\ \theta_{c}^j &= \text{logit}^{-1}\left( \alpha_{{g}[c]}^j + \mathbf{x}_c'\beta^{j} + \mathbf{z}_{{g}[c]}'\gamma^{j} \right), \end{aligned} \end{align} $$
where
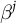 $\beta ^j$
and
$\beta ^j$
and
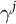 $\gamma ^j$
are vectors of coefficients on the demographic and geographic predictors, respectively. The parameter
$\gamma ^j$
are vectors of coefficients on the demographic and geographic predictors, respectively. The parameter
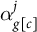 $\alpha _{{g}[c]}^j$
is a random intercept for item j that varies by geography.Footnote 9 To permit partial pooling (Gelman and Hill Reference Gelman and Hill2007), we specify a hierarchical multivariate normal distribution for the random intercepts:
$\alpha _{{g}[c]}^j$
is a random intercept for item j that varies by geography.Footnote 9 To permit partial pooling (Gelman and Hill Reference Gelman and Hill2007), we specify a hierarchical multivariate normal distribution for the random intercepts:
 $$ \begin{align} &(\alpha_{{g}}^1, \alpha_{{g}}^2, \dots, \alpha_{{g}}^J) \sim \text{MultivariateNormal}(\mathbf{0}, \boldsymbol{\Sigma}). \end{align} $$
$$ \begin{align} &(\alpha_{{g}}^1, \alpha_{{g}}^2, \dots, \alpha_{{g}}^J) \sim \text{MultivariateNormal}(\mathbf{0}, \boldsymbol{\Sigma}). \end{align} $$
The covariance matrix
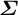 $\boldsymbol {\Sigma }$
, estimated from the data, encodes the within-geography correlation across outcomes after accounting for other model terms. We use
$\boldsymbol {\Sigma }$
, estimated from the data, encodes the within-geography correlation across outcomes after accounting for other model terms. We use
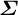 $\boldsymbol {\Sigma }$
to predict logit shifts for outcomes without ground-truth data.
$\boldsymbol {\Sigma }$
to predict logit shifts for outcomes without ground-truth data.
This model nests the traditional approach of estimating separate regressions for each outcome. This approach corresponds to constraining
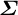 $\boldsymbol {\Sigma }$
to be diagonal—sharing no information about geographic random effects across outcomes.
$\boldsymbol {\Sigma }$
to be diagonal—sharing no information about geographic random effects across outcomes.
3.2 Calibration procedure
We reinterpret the logit shift as the residual between the estimated random effect
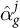 $\hat {\alpha }_{g}^j$
and the realized geographic intercept. Substitute Equation (4) into the expression for the updated cell-level probabilities after calibration in Equation (3):
$\hat {\alpha }_{g}^j$
and the realized geographic intercept. Substitute Equation (4) into the expression for the updated cell-level probabilities after calibration in Equation (3):
 $$ \begin{align*} \tilde{\theta}^{j}_c &= \text{logit}^{-1}\left(\delta_{g[c]}^j + \text{logit}(\hat{\theta}_c^j) \right) \\ &= \text{logit}^{-1}\left(\smash{\underbrace{\delta_{g[c]}^j + \hat{\alpha}_{{g}[c]}^j}_{\text{realized intercept}}} + \mathbf{x}_c' \hat{\beta}^{j} + \mathbf{z}_{g[c]}' \hat{\gamma}^{j} \right). \end{align*} $$
$$ \begin{align*} \tilde{\theta}^{j}_c &= \text{logit}^{-1}\left(\delta_{g[c]}^j + \text{logit}(\hat{\theta}_c^j) \right) \\ &= \text{logit}^{-1}\left(\smash{\underbrace{\delta_{g[c]}^j + \hat{\alpha}_{{g}[c]}^j}_{\text{realized intercept}}} + \mathbf{x}_c' \hat{\beta}^{j} + \mathbf{z}_{g[c]}' \hat{\gamma}^{j} \right). \end{align*} $$
Because the updated probabilities ensure that model-implied geographic estimates match observed ground truth, the logit shift
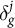 $\delta ^j_g$
can be interpreted as the residual between the estimated intercept
$\delta ^j_g$
can be interpreted as the residual between the estimated intercept
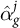 $\hat {\alpha }_g^j$
and the realized intercept
$\hat {\alpha }_g^j$
and the realized intercept
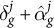 $\delta ^j_g + \hat {\alpha }_g^j$
.
$\delta ^j_g + \hat {\alpha }_g^j$
.
This perspective suggests a method for predicting logit shifts for outcomes with unknown ground truth. We invoke a covariance equivalence assumption: the covariance of
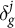 $\delta _g^j$
equals the covariance of geographic random intercepts estimated from the survey. More formally, we assume
$\delta _g^j$
equals the covariance of geographic random intercepts estimated from the survey. More formally, we assume
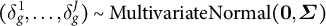 $(\delta _g^1, \dots , \delta _g^J) \sim \text {MultivariateNormal}(\mathbf {0}, \boldsymbol {\Sigma })$
, where
$(\delta _g^1, \dots , \delta _g^J) \sim \text {MultivariateNormal}(\mathbf {0}, \boldsymbol {\Sigma })$
, where
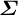 $\boldsymbol {\Sigma }$
is the same as in Expression (5). The upshot of this assumption is that we can use the survey to estimate the correlation in realized random effects.Footnote 10
$\boldsymbol {\Sigma }$
is the same as in Expression (5). The upshot of this assumption is that we can use the survey to estimate the correlation in realized random effects.Footnote 10
We observe logit shifts for the auxiliary variables with ground-truth data. Denote the vector of observed logit shifts
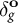 $\delta _g^{\mathbf {o}}$
and the vector of unknown logit shifts
$\delta _g^{\mathbf {o}}$
and the vector of unknown logit shifts
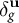 $\delta _g^{\mathbf {u}}$
. Conditional on the observed shifts, the expected value of unobserved logit shifts has a linear formFootnote 11:
$\delta _g^{\mathbf {u}}$
. Conditional on the observed shifts, the expected value of unobserved logit shifts has a linear formFootnote 11:
 $$ \begin{align} E[\delta_g^{\mathbf{u}} \mid \delta_g^{\mathbf{o}}] &= \boldsymbol{\Sigma}_{\mathbf{uo}} \boldsymbol{\Sigma}_{\mathbf{oo}}^{-1} \delta_g^{\mathbf{o}}. \end{align} $$
$$ \begin{align} E[\delta_g^{\mathbf{u}} \mid \delta_g^{\mathbf{o}}] &= \boldsymbol{\Sigma}_{\mathbf{uo}} \boldsymbol{\Sigma}_{\mathbf{oo}}^{-1} \delta_g^{\mathbf{o}}. \end{align} $$
In this equation,
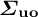 $\boldsymbol {\Sigma }_{\mathbf {uo}}$
is the cross-covariance in random effects between the unobserved and observed elements and
$\boldsymbol {\Sigma }_{\mathbf {uo}}$
is the cross-covariance in random effects between the unobserved and observed elements and
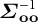 $\boldsymbol {\Sigma }_{\mathbf {oo}}^{-1}$
is the inverse of the covariance of the observed elements. This expression follows from the properties of the multivariate normal distribution (Eaton Reference Eaton2007, 116).
$\boldsymbol {\Sigma }_{\mathbf {oo}}^{-1}$
is the inverse of the covariance of the observed elements. This expression follows from the properties of the multivariate normal distribution (Eaton Reference Eaton2007, 116).
In other words, the logit shift parameters for the outcomes without ground-truth data are a linear combination of the logit shifts for the outcomes with calibration data. The coefficients in this linear combination depend on the covariance in the geographic random effects across outcomes, with higher weights going to the logit shift of outcomes with higher covariance.
To build intuition, consider the case of a single observed auxiliary outcome (
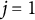 $j=1$
) and a single unobserved outcome (
$j=1$
) and a single unobserved outcome (
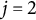 $j=2$
). The predicted logit shift is
$j=2$
). The predicted logit shift is
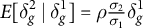 $E[\delta ^2_g\mid \delta _{g}^{1}] = \rho \frac {\sigma _{2}}{\sigma _1} \delta _g^1$
, where
$E[\delta ^2_g\mid \delta _{g}^{1}] = \rho \frac {\sigma _{2}}{\sigma _1} \delta _g^1$
, where
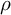 $\rho $
is the correlation between random effects and
$\rho $
is the correlation between random effects and
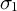 $\sigma _1$
,
$\sigma _1$
,
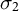 $\sigma _{2}$
are their standard deviations. The correlation controls the magnitude, while the ratio of standard deviations corrects for scale differences. If
$\sigma _{2}$
are their standard deviations. The correlation controls the magnitude, while the ratio of standard deviations corrects for scale differences. If
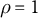 $\rho = 1$
, the logit shift for the unobserved outcome equals the observed shift (up to a scale adjustment). If
$\rho = 1$
, the logit shift for the unobserved outcome equals the observed shift (up to a scale adjustment). If
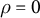 $\rho = 0$
, the observed shift is uninformative and no adjustment is made.
$\rho = 0$
, the observed shift is uninformative and no adjustment is made.
3.3 Assumptions and limitations
In this section, we discuss several points related to the covariance equivalence assumption, which we rely on to derive the estimator.
First, this assumption could be violated if respondent correlations differ from those in the population. For example, because survey respondents are often highly educated and more politically interested than the public, their attitudes may be more correlated across issues than those of the general public (Freeder, Lenz, and Turney Reference Freeder, Lenz and Turney2018; Hopkins and Gorton Reference Hopkins and Gorton2023; Marble and Tyler Reference Marble and Tyler2022). Although strong, this assumption is almost certainly better than the traditional MRP default, which implicitly assumes no correlation. Other weighting methods make similar assumptions: raking, for example, can over-correct when the sample correlation between an underrepresented group and the outcome exceeds the population correlation.
Second, the scale of the random effects estimated in the survey might differ from the scale of the true intercept shifts needed for calibration. This form of error affects inferences only when there is differential error in the survey-based estimate of the variances in
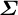 $\boldsymbol {\Sigma }$
across outcomes. To be more precise, consider the scale-correlation factorization of
$\boldsymbol {\Sigma }$
across outcomes. To be more precise, consider the scale-correlation factorization of
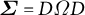 $\boldsymbol {\Sigma } = D \Omega D$
, where
$\boldsymbol {\Sigma } = D \Omega D$
, where
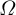 $\Omega $
is the correlation matrix and
$\Omega $
is the correlation matrix and
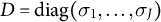 ${D = \text {diag}(\sigma _1, \dots , \sigma _J)}$
are standard deviations. If our estimate of each element of D is off by a common factor, such that
${D = \text {diag}(\sigma _1, \dots , \sigma _J)}$
are standard deviations. If our estimate of each element of D is off by a common factor, such that
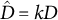 $\hat {D} = k D$
for a scalar k, then the point estimates of our method are unaffected, but if different elements of D are estimated with differential error, it could lead to over- or under-updating.
$\hat {D} = k D$
for a scalar k, then the point estimates of our method are unaffected, but if different elements of D are estimated with differential error, it could lead to over- or under-updating.
Appendix F of the Supplementary Material discusses these points further and provides empirical evidence for the plausibility of the covariance equivalence assumption in our application.
3.4 Estimation
Estimation proceeds by first fitting the multivariate model in Equations (4) and (5) to survey data. Next, we poststratify and calculate logit shifts for outcomes with ground truth following Equation (2). Finally, we apply Equation (6) to update the remaining outcomes.
The simplest option is a plug-in estimator for
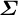 $\boldsymbol {\Sigma }$
(e.g., the MLE or posterior mean). In our application, we adopt a fully Bayesian approach. For each posterior draw, calculate logit shifts for observed outcomes; predict implied shifts for unobserved outcomes; update unobserved outcomes; and, finally, poststratify. We summarize results using the posterior mean. See Appendix A of the Supplementary Material for a formal description.Footnote 12
$\boldsymbol {\Sigma }$
(e.g., the MLE or posterior mean). In our application, we adopt a fully Bayesian approach. For each posterior draw, calculate logit shifts for observed outcomes; predict implied shifts for unobserved outcomes; update unobserved outcomes; and, finally, poststratify. We summarize results using the posterior mean. See Appendix A of the Supplementary Material for a formal description.Footnote 12
3.5 Comparison with alternative approaches
Our procedure uses observed estimation error in a subset of outcomes to adjust others. Several alternative approaches exist, which we briefly discuss here and more fully in Appendix D of the Supplementary Material.
First, classic weighting methods like raking can use known margins as weighting targets. But, without an outcome model, the survey must contain respondents from each geographic unit, making it infeasible for estimating opinion in small subgroups. Second, known margins can be included as geographic predictors in the regression. This approach likely improves estimates, but it does not guarantee that they match known margins. Our calibration procedure can be applied in conjunction with this approach to reduce remaining error. Third, researchers can generate synthetic poststratification tables (MRsP; Leemann and Wasserfallen Reference Leemann and Wasserfallen2017). The Supplementary Material discusses two variants: assuming conditional independence between demographics and the calibration variable (“conventional MRsP”) or using a first-stage calibrated MRP model as the poststratification table for a second stage (“chained calibrated MRP”). Our approach sidesteps the need to impute this poststratification table, and instead estimates multiple outcomes jointly.
3.6 Extension to hyperlocal geography
Our approach can be extended to smaller geographies lacking poststratification data but with ground-truth calibration data. For example, we can use it to estimate opinion in precincts, where election results are available but poststratification data are not. To do so, we initialize precinct-level predictions to their corresponding county-level values. We then calibrate using observed precinct-level vote share, assuming the precinct-level correlation structure matches the estimated county-level structure. While this assumption need not hold—particularly if there is significant heterogeneity across precincts within counties—in our application it performs well. This extension enables hyperlocal opinion estimation even without poststratification data or fine-grained geographic identifiers in the survey. Appendix H of the Supplementary Material describes this extension further and validates its performance.
4 Validation in Michigan elections in 2022
The primary use case for this method is measuring public opinion on policy issues. Evaluating the method requires: (1) a policy issue with available ground-truth data and (2) a survey measuring that issue alongside variables suitable for calibration.
We evaluate the method using pre-election polling of the 2022 Michigan midterm election. This election featured a referendum concerning abortion rights (Proposition 3) alongside races for Governor and Secretary of State. We calibrate to ground-truth Governor and Secretary of State results and evaluate how this changes estimates of Proposition 3 opinion.
We use data from an original survey conducted via SurveyMonkey in fall 2022.Footnote 13 Respondents were recruited via a river sample: users who completed any SurveyMonkey survey during this period were invited to take a survey on the 2022 midterm elections. We have
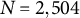 $N = 2{,}504 $
Michigan respondents who answered all demographic and outcome questions. Appendix B of the Supplementary Material contains details of this case and survey.
$N = 2{,}504 $
Michigan respondents who answered all demographic and outcome questions. Appendix B of the Supplementary Material contains details of this case and survey.
4.1 Validation approach
We model vote choice for the three statewide elections (alongside other opinions) as a function of respondent- and county-level predictors. We first generate uncalibrated county-level estimates by poststratifying on the joint distribution of county demographics. We then calibrate to observed county-level margins for the Governor and Secretary of State races and assess how this changes estimation error.
Individual-level predictors include age, race, gender and education, with interactions between race
 $\times $
education and nonwhite
$\times $
education and nonwhite
 $\times $
education
$\times $
education
 $\times $
age. County-level predictors are percent nonwhite, percent Hispanic/Latino, percent college-educated, median income and 2020 Biden two-party vote share. The specification includes county-level random intercepts correlated across outcomes, which provide the basis for our adjustment. Further modeling details, including R code, are included in Appendix B of the Supplementary Material.Footnote 14
$\times $
age. County-level predictors are percent nonwhite, percent Hispanic/Latino, percent college-educated, median income and 2020 Biden two-party vote share. The specification includes county-level random intercepts correlated across outcomes, which provide the basis for our adjustment. Further modeling details, including R code, are included in Appendix B of the Supplementary Material.Footnote 14
We produce two sets of adjusted results: the first calibrates Secretary of State and Proposition 3 using gubernatorial results; the second calibrates Proposition 3 using both gubernatorial and Secretary of State results.
Because we calibrate to two-party vote share, the calibration implicitly targets the electorate rather than the population. The approach can target the population instead by including turnout as a calibration variable—that is, calibrating to Democratic vote share, Republican vote share and aggregate turnout as functions of total population. We take this approach in a simulation study in Appendix I of the Supplementary Material. Researchers should take care in specifying the population of interest—which depends on the substantive research question—and ensuring that the calibration variables are measured accordingly.
4.2 Validation results
Calibration substantially reduces error: average absolute error for Secretary of State and Proposition 3 falls by
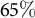 $65\%$
and
$65\%$
and
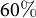 $60\%$
, respectively.
$60\%$
, respectively.
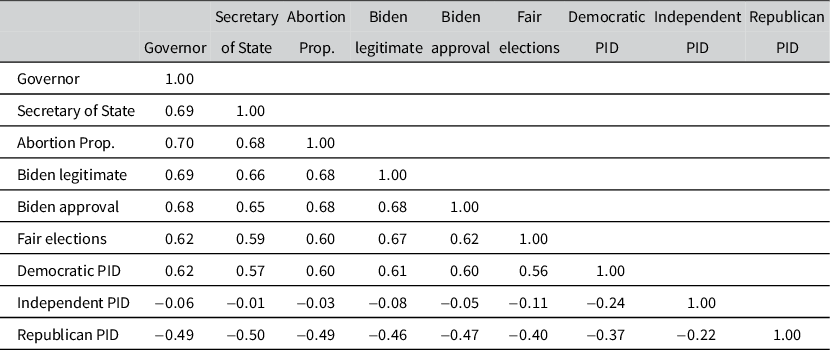
Table 1 reports correlations between county-level random intercepts across outcomes. This matrix measures residual within-county correlation on the logit scale after accounting for covariates.
Correlation of county intercepts across outcomes, Michigan 2022

Note: Posterior mean correlations between county random intercepts across survey outcomes.
Consistent with partisan and geographic sorting, county intercept correlations are relatively high across outcomes. The sole exception is independent party identification, which is largely unrelated to other county-level opinions.
Despite these high average correlations, Table 1 reveals interesting variation. For example, the residual geographic correlation between governor vote choice and belief that Biden won legitimately is just below
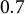 $0.7$
, but the correlation between governor vote choice and Republican party identification is about
$0.7$
, but the correlation between governor vote choice and Republican party identification is about
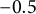 $-0.5$
. Calibrating to gubernatorial results will thus produce a smaller update for party identification than for beliefs about Biden’s legitimacy. In short, gubernatorial vote choice carries more information about opinions on Biden’s legitimacy than about party identification. This is consistent with the specifics of the race: Republican gubernatorial candidate Tudor Dixon denied Biden’s 2020 victory, alienating some Republicans (Ulloa Reference Ulloa2022).
$-0.5$
. Calibrating to gubernatorial results will thus produce a smaller update for party identification than for beliefs about Biden’s legitimacy. In short, gubernatorial vote choice carries more information about opinions on Biden’s legitimacy than about party identification. This is consistent with the specifics of the race: Republican gubernatorial candidate Tudor Dixon denied Biden’s 2020 victory, alienating some Republicans (Ulloa Reference Ulloa2022).
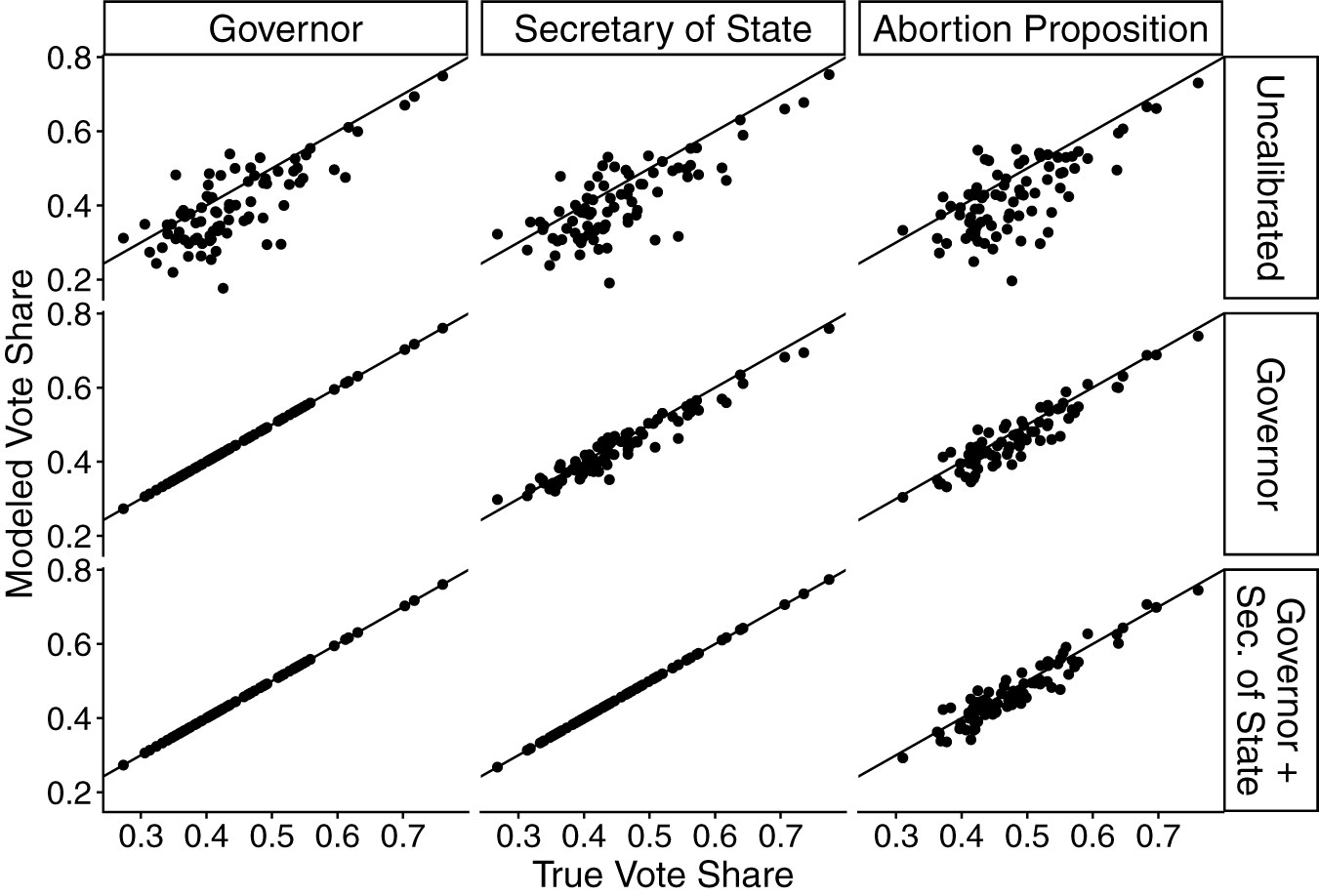
Using these correlations, we calibrate to outcomes with known county-level values. Figure 1 plots true county-level vote share against: (1) uncalibrated MRP estimates; (2) estimates calibrated to gubernatorial results; and (3) estimates calibrated to both gubernatorial and Secretary of State results.
County-level MRP results, Michigan 2022 elections.
Note: The x-axis shows the true county-level Democratic/pro-choice vote share and the y-axis shows model-based estimates. The top row shows uncalibrated MRP estimates, the middle row shows estimates calibrated to the Governor race and the bottom row shows estimates calibrated to Governor and Secretary of State races.

The top row shows that uncalibrated MRP underestimates Democratic vote share in the gubernatorial and Secretary of State races, as well as the pro-choice position in Proposition 3. Moreover, there is evidence of heteroskedasticity, with more variation in polling errors in less-Democratic counties. Some errors in less-Democratic counties exceed 10 percentage points.
The second row shows the effect of calibrating to gubernatorial results, showing a dramatic improvement in accuracy. By construction, calibrated gubernatorial vote shares perfectly match actual outcomes (far left). The center and right panels show that Secretary of State and Proposition 3 predictions also improve substantially. Calibrated estimates are closer to the 45-degree line and heteroskedasticity is greatly reduced.
The final row shows calibration using both Governor and Secretary of State results. As the panel in the lower-right reveals, the doubly-calibrated estimate is slightly improved relative to the estimates calibrated using only the gubernatorial results. The mild gains likely reflect the similar relationships both elections have with Proposition 3 support. The correlation of county intercepts between the Governor and Secretary of State races was nearly 0.7, indicating that the latter race adds relatively little additional information.
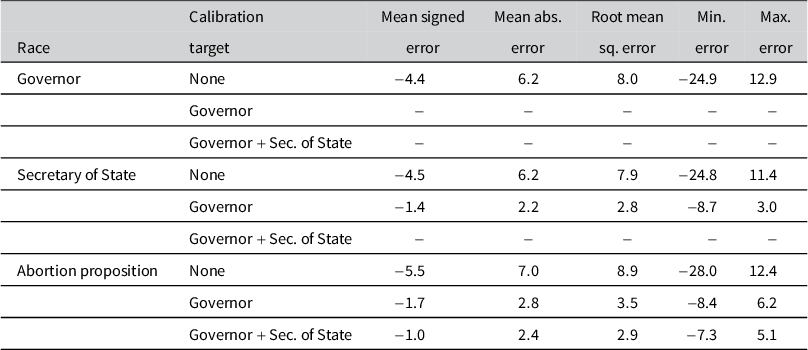
Table 2 summarizes these results by calculating the mean signed error, the mean absolute error (MAE), the root mean squared error (RMSE) and the range of errors across counties. Each panel has three rows: uncalibrated MRP, calibrated to Governor and calibrated to both Governor and Secretary of State.
County-level errors, Michigan 2022 elections

Note: Entries in the table show the county-level error associated with uncalibrated and calibrated MRP vote share estimates for the Democrat/pro-choice outcome. The first row for each race is the error when using uncalibrated MRP; the second row is the error when calibrating to the Governor outcomes and the third row is the error when calibrating to both the Governor and Secretary of State outcomes.
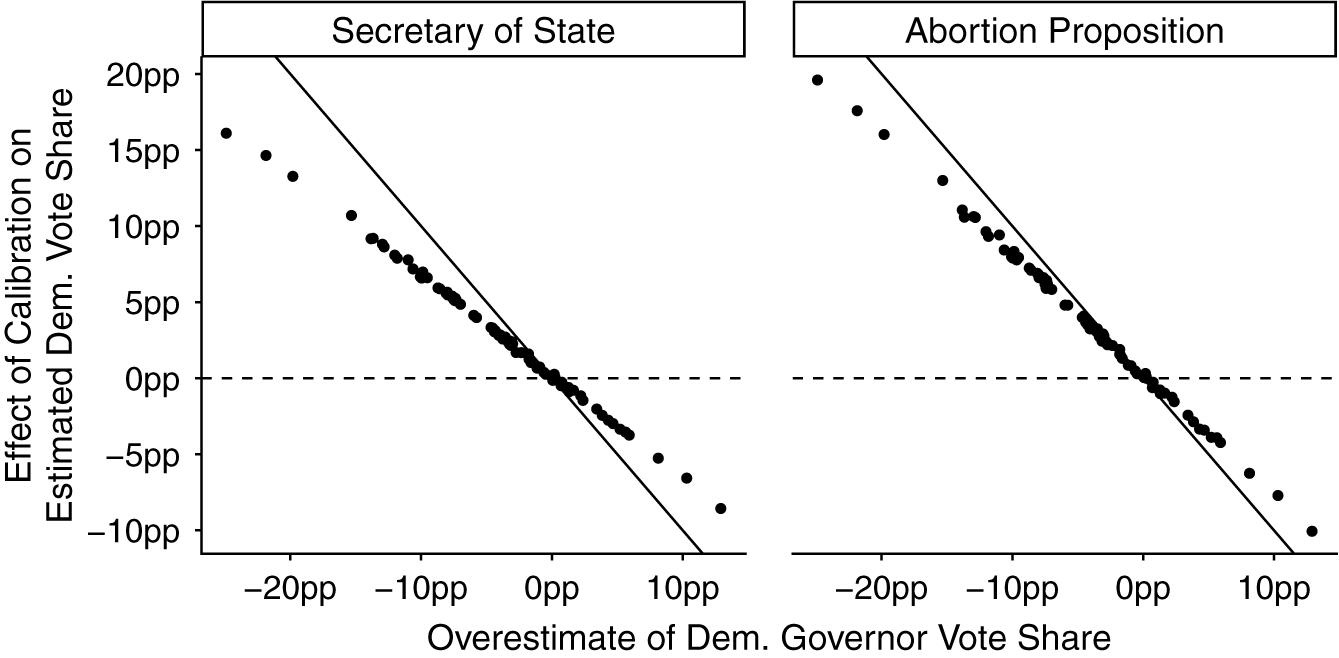
Change in county-level estimates from calibration to Governor results.
Note: The y-axis plots the difference between calibrated and uncalibrated county-level estimates for Secretary of State and the abortion proposition. The x-axis shows the county-level error in the Governor’s race before calibration where positive values indicate overestimating the support for Democratic incumbent Gretchen Whitmer.

Calibrating to the Governor race reduces mean signed error in the Secretary of State race from
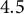 $4.5$
percentage points in the Republican direction to just
$4.5$
percentage points in the Republican direction to just
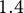 $1.4$
points—a reduction of
$1.4$
points—a reduction of
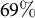 $69\%$
. MAE and RMSE both fall by nearly two-thirds and the error range shrinks dramatically, from
$69\%$
. MAE and RMSE both fall by nearly two-thirds and the error range shrinks dramatically, from
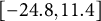 $[-24.8,11.4]$
to
$[-24.8,11.4]$
to
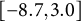 $[ -8.7, 3.0]$
.
$[ -8.7, 3.0]$
.
Proposition 3 results show modest additional gains from calibrating to multiple outcomes. The MAE is reduced from
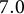 $7.0$
to
$7.0$
to
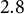 $2.8$
percentage points when calibrating to the Governor results—a reduction of
$2.8$
percentage points when calibrating to the Governor results—a reduction of
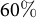 $60\%$
. Jointly calibrating to both races further reduces the MAE to
$60\%$
. Jointly calibrating to both races further reduces the MAE to
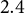 $2.4$
percentage points. Maximum and minimum errors are also greatly reduced by calibrating to both races.
$2.4$
percentage points. Maximum and minimum errors are also greatly reduced by calibrating to both races.
To visualize the nature of the calibration, Figure 2 plots the effect of calibration in the Secretary of State and abortion proposition against the baseline error in estimates for Governor.Footnote 15 The x-axis shows the gubernatorial overestimate; the y-axis shows the change in estimates after calibration.
The pattern is intuitive: where standard MRP overestimates gubernatorial Democratic vote share, other estimates are revised downward. Most points fall below 0 on the x-axis—indicating that baseline MRP underestimates Democratic vote share. Consequently, most observations fall above 0 on the y-axis.
The slope reflects the cross-race correlations. One-for-one adjustment would place points on the 45-degree line. The observed slope is flatter, reflecting imperfect correlations across races. The fact that the left-hand panel has a flatter slope than the right-hand panel reflects the lower correlation between the Governor and Secretary of State races than between the Governor race and the abortion proposition.
In sum, we find that our calibrated MRP approach can significantly improve estimates of small-area opinion. We compare our approach to alternatives in Appendix E of the Supplementary Material, finding that our method outperforms alternatives in this setting. In Appendix J of the Supplementary Material, we also show the effect of calibration on party identification—an outcome with no ground-truth data in Michigan.
5 Conclusion and implications
Estimates of public opinion are critically important for assessing representation, accountability and democratic legitimacy. But inferences based on comparing constituency-level opinion to policy outcomes require accurate, fine-grained measures of public opinion—measures that are increasingly difficult to obtain given declining response rates and growing nonignorable nonresponse. As a result, it is often unclear whether discrepancies between public opinion and policy reflect failures of representation or failures of polling.
We propose a method that limits the impact of survey errors on small-area opinion estimates by leveraging auxiliary data with known ground truth. Building on the logit shift calibration framework common in MRP, we extend the approach to multiple correlated outcomes. The key insight is that discrepancies between model-based and ground-truth estimates for auxiliary variables (e.g., election results) are informative about likely survey errors for correlated outcomes for which no ground truth exists (e.g., policy attitudes). We propose a principled calibration method building on this intuition. The calibration is driven by geographic random effect correlations estimated from a joint model of all outcomes. The method produces larger adjustments for more highly correlated variables. We also show how this approach can be extended to hyperlocal geographies lacking poststratification data, such as precincts, by calibrating to ground-truth margins at the lower level (Appendix H of the Supplementary Material).
Using pre-election polling from the 2022 Michigan midterm, we demonstrate that calibrating county-level MRP estimates to gubernatorial results reduces error by as much as two-thirds. We find similar gains when extending the approach to precinct-level results.
A key benefit of our approach is that it can correct for multiple sources of survey error—nonignorable nonresponse, model misspecification and errors in poststratification data—without requiring researchers to decompose the contribution of each source. As demonstrated by simulations in Appendix I of the Supplementary Material, our calibration procedure is most beneficial when the calibration variable is strongly correlated with the outcome of interest and when nonignorable nonresponse is present. Even with small, highly nonrepresentative samples, calibration substantially reduces error for correlated outcomes.
The method relies on the covariance equivalence assumption, which states that the geographic correlation structure estimated from the survey reflects the population-level correlations. In Appendix F of the Supplementary Material, we demonstrate the plausibility of this assumption in our validation setting. Of course, this assumption may not always hold, particularly if survey respondents’ attitudes are more correlated than those of nonrespondents. However, the alternative—standard MRP without calibration—implicitly assumes that observed errors in auxiliary variables are completely uninformative about errors in other outcomes. Our approach is likely to improve estimates even when the assumption is not perfectly met.
By providing researchers with a principled method for incorporating known population quantities into MRP estimates, we help ensure that substantive conclusions based on small-area opinion measures are robust to survey error. The method complements existing MRP tools. Finally, our method can be implemented using our accompanying R package, calibratedMRP.
Acknowledgements
For helpful comments, we thank Larry Bartels, Devin Caughey, Shira Mitchell, Jacob Montgomery, John Sides, Matt Tyler and panelists at APSA.
Funding statement
The survey reported here was funded by the Program for Opinion Research and Election Studies at the University of Pennsylvania.
Data availability statement
A reproducible run of all numeric results in this article is archived on Code Ocean at http://doi.org/10.24433/CO.4609952.v2. Replication materials are also available on Dataverse at https://doi.org/10.7910/DVN/LGISTM (Marble and Clinton Reference Marble and Clinton2026). An R package implementing methods proposed in this article is available for download at http://github.com/wpmarble/calibratedMRP and key functionality is demonstrated in Appendix C of the Supplementary Material.
Ethical standards
The IRB at the University of Pennsylvania deemed the survey exempt from review under Protocol No. 852133.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/pan.2026.10044.
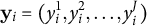
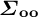



 Open access
Open access