

20.1 Introduction
Languages are layered with patterns and processes spanning multiple scales (Patel, Reference Patel2003). Theories of phonology, morphology, and syntax address levels of linguistic analysis, and each one contains layers in terms of nested representations that correspond with smaller to larger linguistic structures across several scales. Phonemes nest within syllables, morphemes within words, and both within phrases; phrases nest within clauses and clauses within sentences.
Prosody is also theorized in terms of multiple levels of linguistic structure that are often expressed in terms of hierarchical structure (Beckman, Reference Beckman1996; Goldsmith, Reference Goldsmith1990; Krivokapić, Reference Krivokapić2014; O’Dell and Nieminen, Reference O’Dell and Nieminen1999; Shattuck-Hufnagel and Turk, Reference Shattuck-Hufnagel and Turk1996; Tilsen and Arvaniti, Reference Tilsen and Arvaniti2013). Starting with the smaller timescales of prosody, the amplitude, duration, and pitch of vocalic and syllabic sounds may be varied for purposes of lexical stress, for example (Fry, Reference Fry1958; Gordon and Roettger, Reference Gordon and Roettger2017). At longer timescales, the same acoustic dimensions may be varied more slowly over phrases, clauses, and sentences as an expression of grammar, emphasis, emotion, and discourse (Bolinger, Reference Bolinger1989). The rhythm and pace of speech may vary with longer-term changes in discourse (Wennerstrom, Reference Wennerstrom2001), and overall patterns of intonation may vary with changes in speech register (Yaeger-Dror, Reference Yaeger-Dror2002). All these timescales are layered together and combined to yield prosodic effects on overt speech.
While prosodic hierarchies are well established as linguistic representations, less is known about the patterns and relationships across the timescales of naturally produced speech that encode prosodic information. For instance, coupled oscillators have been formulated to model rhythmic patterns of activity hypothesized to encode prosodic information (Goswami, Reference Goswami2019; Meyer, Reference Meyer2018; Tilsen, Reference Tilsen2009). Consistent with this hypothesis, speech can be overtly rhythmic, as when items are listed aloud (Schiffrin, Reference Schiffrin1994) or when words and phrases are repeated (Cummins and Port, Reference Cummins and Port1998). Rhythmic patterning can also be found when nursery rhymes are read aloud (Leong and Goswami, Reference Leong and Goswami2015) and in infant-directed speech (Leong et al., Reference Leong, Kalashnikova, Burnham and Goswami2017).
The studies by Leong et al. illustrate some of the advances, and complexities, in measuring prosodic hierarchies in the speech signal. They computed the modulation spectrum for acoustic recordings of speech and divided spectra into frequency bands corresponding to established bands of brain rhythms – delta, theta, and beta/low-gamma bands (also see Chapter 10). They found phase relations between peaks in the amplitude envelopes across different frequency bands, indicating a hierarchical rhythmic organization of the speech signal. Evidence indicates that brain rhythms can entrain to amplitude modulations in these frequency bands (Poeppel and Assaneo, Reference Poeppel and Assaneo2020). While these specialized speech conditions demonstrate the capacity for speech to exhibit regular periodicities (see Tilsen and Arvaniti, Reference Tilsen and Arvaniti2013), the results also indicate that most natural speech conditions do not appear to be so rhythmic (Cummins, Reference Cummins2012) – for instance, Leong et al. (Reference Leong, Kalashnikova, Burnham and Goswami2017) found that adult-directed speech did not exhibit a hierarchical rhythmic organization like infant-directed speech (also see Chapter 14).
The lack of prominent periodicity in most naturally occurring speech signals does not mean there is a lack of temporal structure to carry prosodic information. Some researchers refer to the speech signal as being “quasi-regular,” “quasi-periodic,” or “quasi-rhythmic” (Giraud and Poeppel, Reference Giraud and Poeppel2012; Peelle and Davis, Reference Peelle and Davis2012), but a concentration in energy within a given frequency band does not necessarily entail any amount of regularity or periodicity. Another possibility of temporal structure takes the form of clustering or so-called burstiness in time (Goh and Barabási, Reference Goh and Barabási2008), which means more clustering than expected by a random process. Clustering is common in many human activities, and rhythmic activity can be a special case of temporal clustering at regular intervals, such as the beats of a drum. Nonrhythmic clustering is found in eye movements, for example, where irregular but nonrandom jumps to locations in the visual field are interspersed with periods of fixation composed of shorter microsaccades (Salvucci and Goldberg, Reference Salvucci and Goldberg2000). Similarly, foraging behaviors consist of irregular bouts of exploratory locomotive activities interspersed with relatively stationary periods of intensive local search (Garg and Kello, Reference Garg and Kello2021). Clustering can be completely irregular and aperiodic and still manifest as concentrated energy in a frequency band, the same as a comparable regular, periodic signal.
The present chapter considers that while speech signals may have some quasi-regularity/periodicity, prosodic information may also be carried by nonrhythmic, aperiodic clustering in the speech signal across a hierarchy of timescales. There are multiple possible features of the speech signal that might cluster to carry prosodic information. In terms of acoustic energy, for instance, there may be vocalic clusters of peak intensity or peak pitch values interspersed with irregular periods of relative silence or nonpeak/nonvocalic values. Rather than being characterized by specific timescales of activity, speech seems better characterized by activity that might cluster across a range of timescales, from tens of milliseconds to tens of seconds and even longer depending on the speaking conditions. Prosodic information in the form of irregular clustering might be available anywhere in this range, up to discourse-level timescales.
The intensity of acoustic energy is well established as a measure of speech signals that carries prosodic information (Shattuck-Hufnagel and Turk, Reference Shattuck-Hufnagel and Turk1996), and this measure is generally captured by the amplitude envelope that the modulation spectrum is based upon. Periods of intense acoustic energy can be irregularly interspersed with less intense periods and silence, and these periods correspond to rises and falls in the amplitude envelope, respectively. Fluctuations in the amplitude envelope can unfold both quickly and slowly at the same time, reflecting temporal structure across multiple timescales. For instance, Tilsen and Arvaniti (Reference Tilsen and Arvaniti2013) used empirical mode decomposition to analyze temporal structure in the amplitude envelope for syllabic and stress-driven timescales in the speech signal (also see Chapter 16).
The present chapter examines how a measure of hierarchical temporal structure in the amplitude envelope (Falk and Kello, Reference Falk and Kello2017; Kello et al., Reference Kello, Bella, Médé and Balasubramaniam2017) appears to reflect an overall degree of prosodic composition in the speech signal. While similar measures have been advanced in recent years (Ding et al., Reference Ding, Patel and Chen2017; Goswami, Reference Goswami2019), this chapter focuses on an adaptation of Allan Factor analysis (Allan, Reference Allan1966) designed to distill temporal structure across and applied over a relatively wide range of timescales, from phonemic effects on the order of tens of milliseconds to speech rate and turn-taking effects on the order of tens of seconds. The resulting Allan Factor function is agnostic to whether temporal structure is periodic or aperiodic, and it excludes phase information, which means that it does not capture nesting of linguistic units located in specific time intervals. Instead, the function measures the temporal structure around a given timescale in terms of Allan Factor variance (a type of coefficient of variation explained later), and a given signal is hierarchical when temporal structure grows with timescale.
20.2 Hierarchical Temporal Structure
Perhaps the most direct way to realize hierarchical temporal structure is to relate measures of speech activity to the hypothesized nesting of specific phonemes, syllables, and so on being produced. While this approach will yield hierarchical structures, it requires mapping between a physical space of measurement and the symbolic space of linguistic representation. In speech sounds, the physical space of prosody is typically defined in terms of amplitude and duration of periods of acoustic energy, plus durations of periods lacking energy, as well as measures of pitch and spectral frequency. Sounds and silent periods corresponding to specific phonemes and other phonological units may be produced with variations in amplitude, duration, and spectral measures that correspond to prosodic boundaries, contrasts, and features (Hayes, Reference Hayes, Kiparsky and Youmans1989; Langus et al., Reference Langus, Marchetto, Bion and Nespor2012). Also, electrophysiological activity corresponding to speech may similarly express variations in amplitude, duration, and spectral measures of voltage, for instance, that reflect hierarchical processing of language structures (Giraud and Poeppel, Reference Giraud and Poeppel2012).
Research on hierarchically nested structures has been fruitful in advancing our understanding of speech and prosody. That said, it can be difficult to identify phonological units and their occurrence in ongoing speech and brain activity (Port, Reference Port2008). Alternatively, one can quantify the shape and degree of hierarchical temporal structure in acoustic signals without knowledge of the underlying processes or representations (Singh and Theunissen, Reference Singh and Theunissen2003). Perhaps the first study to analyze hierarchical temporal structure in speech was conducted by Voss and Clarke (Reference Voss and Clarke1975). They computed power spectra of amplitude envelopes for radio station signals containing various kinds of speech and music. The envelope captures fluctuations in the amount of acoustic energy recorded over time, and the spectrum quantifies the degree (power) of fluctuation at different frequencies. In a signal with hierarchical temporal structure, power builds up from higher to lower frequencies because smaller units of speech that vary at higher frequencies are nested within larger units of speech that vary at lower frequencies, which are nested within even larger units at even lower frequencies, and so on.
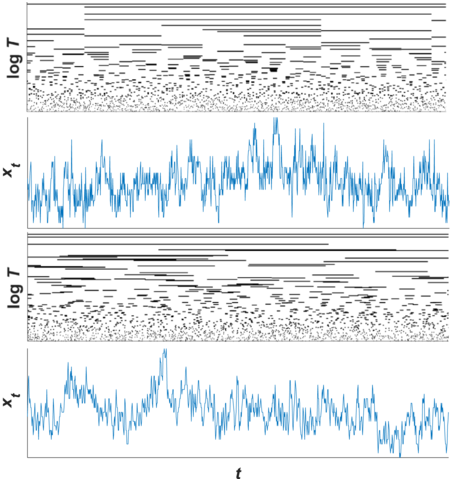
Voss and Clarke (Reference Voss and Clarke1975) found that an inverse relationship between power and frequency known as 1/f scaling (aka 1/f noise), which since has been found across a wide range of neural and behavioral activity (see Kello et al., Reference Kello, Brown and Ferrer-i-Cancho2010). Like hierarchical temporal structure, 1/f scaling is agnostic to whether or not units of speech or music are nested in time (i.e., phase information is removed from the analysis). To illustrate this point, a simple model of nested temporal structure is shown in Figure 20.1 (Kello et al., Reference Kello, Bhat, Turner and Alviar2024). Nesting is created by starting with a long unit interval and then copying and splitting the interval at a random point along its length to create two new intervals. The process is repeated recursively until units reach an arbitrary minimum length.
An illustrative model of hierarchically nested intervals and their summed fluctuations.
In the top graph, one interval spans the entire length of time (x-axis), represented as a horizontal line located at the longest timescale (the highest point on the logarithmic y-axis). The interval is copied and divided at a random point along its length (towards the left in this case). The two resulting intervals remain at their x-axis positions and are plotted at their new corresponding timescales (lengths). The process is repeated recursively until all intervals reach a minimal length. The second graph down plots a series of sums across the nested intervals at each time point. The third graph down shows the same hierarchical intervals but with their locations randomized along the time axis, and the resulting sums are plotted below them.
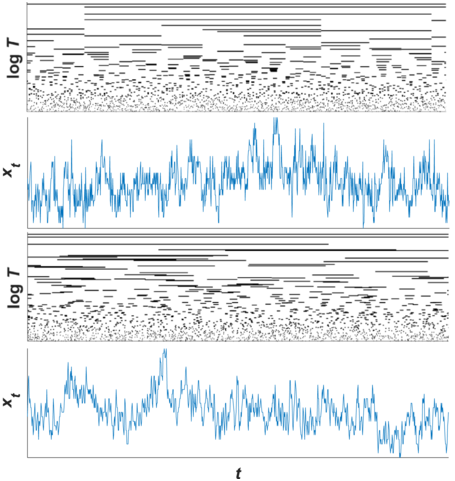
In the top half of the figure, one can see smaller unit intervals repeatedly nested within larger unit intervals across timescales to form hierarchical structures. The structures in this example are aperiodic because intervals are split at randomized points, but structures could instead be made periodic by splitting intervals at their midpoints instead. In the bottom half of the figure, the same unit intervals from above are shown with their phases randomized. Amplitude envelopes are created for nested and phase-randomized intervals by summing the values (all equal to one) of intervals present at each successive time point.
The nesting of structures is destroyed by phase randomization, which changes the resulting fluctuations in their amplitude envelopes. However, both envelopes converge on 1/f scaling because hierarchical temporal structure is preserved, as it does not capture information about specific clusters or nested structures. The same would be true for a periodic version of the model because 1/f scaling is also agnostic to periodicity – it essentially reflects the clustering of amplitudes (power) as a function of frequency.
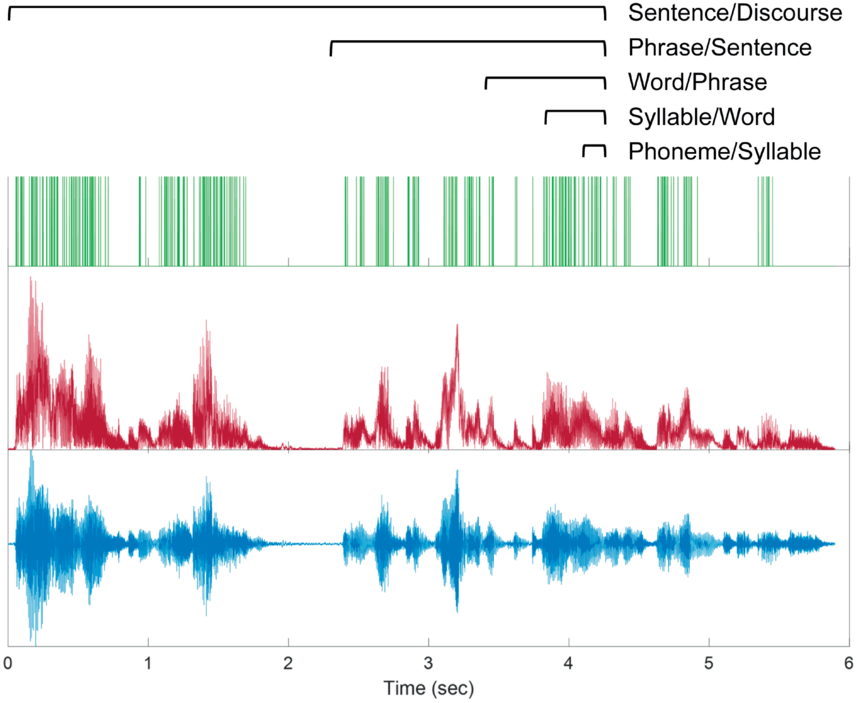
This simple model creates “pure” hierarchical temporal structure that is devoid of the many other factors and influences that combine to create the richness of real speech and music signals. To distill hierarchical temporal structure from real signals, one can convert their amplitude envelopes into series of peaks defined only by their timing – a time series of zeros and ones that is called a point process (see Figure 20.2). Converting amplitude envelopes to point processes focuses analyses on temporal structure per se, and the threshold for identifying peaks can be set to achieve a specified overall rate of peaks that facilitates comparisons across recordings. The rate of peaks is a free parameter that is set to allow for a large dynamic range of peaks per unit time, so that hierarchical temporal clustering in the signal may be expressed as variability in the clustering of peaks. Peaks sometimes roughly correspond to glottal pulses, but they also correspond to aperiodic sounds of sufficient energy and generally any significant concentration of acoustic energy. Also, individual peaks are not intended to capture perceptual events (e.g., they may occur more rapidly than the auditory flicker fusion rate). Instead, clusters of peaks are the basic unit of analysis.
Illustration of Allan Factor analysis.
A speech example of hierarchical temporal structure is shown for the utterance “all we have to decide is what to do with the time that is given to us.” The acoustic waveform is at the bottom, the amplitude envelope in the middle, and peaks of the envelope above the threshold used for Allan Factor analysis. Brackets above show example windows over which peaks are counted and differenced over time to measure clustering. Window sizes roughly correspond to different overlapping linguistic timescales of prosodic temporal structure.
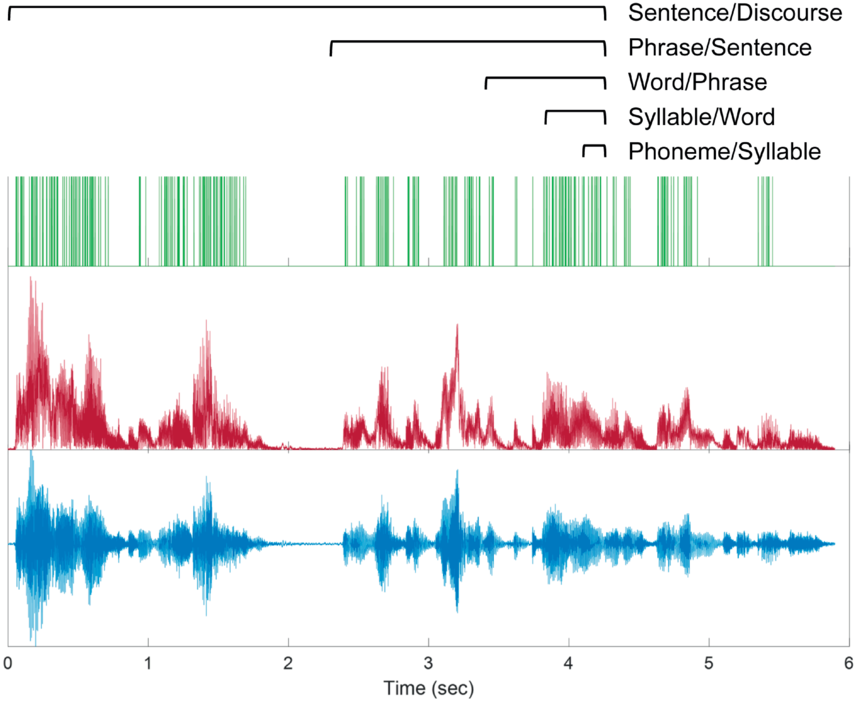
The resulting point processes are submitted to Allan Factor analysis, which quantifies the degree of clustering across the range of available timescales given the time series length and resolution, without identifying individual clusters at any given timescale. Hierarchical temporal structure is expressed in Allan Factor analysis as a positive relationship between timescale and average amount of clustering at that timescale, in logarithmic coordinates. The degree of hierarchical temporal structure can be measured by the logarithmic rate of increase in average clustering.
20.3 Hierarchical Temporal Structure in Speech
Allan Factor analysis has been applied to many hours of speech recordings from several different languages under a range of speaking conditions, including talks and other monologues, rapping, singing, infant-directed speech, computer-generated speech, and conversations in one and two languages (Alviar et al., Reference Alviar, Dale, Kello, Rogers, Rau, Zhu and Kalish2018; Falk and Kello, Reference Falk and Kello2017; Kello et al., Reference Kello, Bella, Médé and Balasubramaniam2017; Schneider et al., Reference Schneider, Ramirez-Aristizabal, Gavilan and Kello2020). The first and foremost result is that speech exhibits a characteristic pattern of hierarchical temporal structure that holds true in all cases, regardless of language spoken or idiosyncrasies of recording conditions.
The pattern is characterized by a relatively steep rise in average clustering as the Allan Factor function goes from timescales of tens of milliseconds to about one second, followed by a tapering in the rate of increase in clustering as timescales extend to tens of seconds (longer timescales require longer recordings of 10+ minutes that are difficult to find or collect). This general pattern of steep-then-tapering suggests that speech exhibits strong hierarchical structure for the timescales over which much of linguistic processing occurs – phonemes, syllables, words, phrases, and short sentences. Clustering subsides as sentences become longer and timescales stretch out to multiple sentences.
The pattern of tapered clustering at longer timescales may be partly due to the lengths of recordings being limited to around four–five minutes. Recordings were generally intended to contain uninterrupted speech signals throughout, which inhibits clustering at the longest timescales measured. Breaks in activity lasting tens of seconds are generally unwanted in audio recordings because there is an expectation of something being recorded. Such breaks may come about naturally under certain conditions, perhaps during casual or intimate conversation for example, but further work is needed to investigate.
While it is possible that tapered clustering may be partly due to recording conditions, results indicate that tapering also varies systematically across individuals, even when they are speaking different languages. Schneider et al. (Reference Schneider, Ramirez-Aristizabal, Gavilan and Kello2020) recorded pairs of Spanish-English bilingual speakers having conversations in the three different language conditions: Spanish, English, and a mixed condition in which one partner spoke Spanish while the other spoke English. Audio recordings were individual to each speaker, which allowed for within-speaker comparisons of hierarchical temporal structure when speaking the same language or different languages. Results showed that variations around the general steep-then-tapered pattern were highly correlated (mean B = 0.77) within speakers, regardless of whether correlations were within Spanish or English, or between the two languages.
These results show that hierarchical temporal structure, as measured by the adaptation of Allan Factor analysis, reflects the speaking style of individuals rather than the specific language or words being spoken. Consistent with this conclusion, Kello et al. (Reference Kello, Bella, Médé and Balasubramaniam2017) found that TED talks all had highly similar patterns of hierarchical temporal structure across seven different languages. When combined with the results from Schneider et al. (Reference Schneider, Ramirez-Aristizabal, Gavilan and Kello2020), the TED talk pattern seems to reflect the consistent style and manner in which TED talks are given. The pattern consists of a specific tilt and bend to the increase in clustering with timescale, which is difficult to interpret on its own. Next, recent studies are reviewed that begin to shed light on how to interpret systematic patterns and variability in hierarchical temporal structure.
20.4 Interpretable Variability in Hierarchical Temporal Structure
Abney et al. (Reference Abney, Paxton, Dale and Kello2014) reported the first study to employ Allan Factor analysis adapted for measuring hierarchical temporal structure in speech acoustics. They analyzed conversations from a study by Paxton and Dale (Reference Paxton and Dale2013) in which pairs of individuals engaged in either affiliative conversations (e.g., shared interests in entertainment) or argumentative conversations. The latter were created by pairing individuals who took opposing positions on “hot button” issues such as abortion based on a prior survey, and then instructing them to talk about the issue. The authors analyzed audio recordings of individual speakers as in Schneider et al. (Reference Schneider, Ramirez-Aristizabal, Gavilan and Kello2020), and results showed a similar steep-then-taper pattern, but there was greater hierarchical temporal structure in the longer timescales for conversations versus monologues such as TED talks. The reason is that conversations include more pauses for turn-taking and interacting, which creates clustering, whereas speaking is more continuous in monologues such as TED talks.
Abney et al. (Reference Abney, Paxton, Dale and Kello2014) also found more tapering for affiliative compared with argumentative conversations. This difference indicates that speakers can alter the degree of hierarchical temporal structure based on the mode of conversation. The authors conjectured that the argumentative conditions triggered more formal speech registers that, among other factors, caused speakers to enunciate more carefully and clearly compared with affiliative conversations in which speaking can be looser and more fluid. This conjecture is supported by the finding that hierarchical temporal structure changed in the prosodic timescales of hundreds of milliseconds and longer, rather than more fine-grained phonetic features that speakers may not be able to control. Since this first study, three other studies of speech under varying conditions have found similar effects that corroborate the original conjecture.
First, Kello et al. (Reference Kello, Bella, Médé and Balasubramaniam2017) compared hierarchical temporal structure measured in original TED talk recordings with those created by Google speech synthesis when reading transcripts of the talks. Allan Factor analysis showed that prosodic timescales for synthesized speech were devoid of temporal structure compared with original recordings, in that the Allan Factor function tapered off to a flat line. Given that the same words were spoken in both conditions, this result can be attributed to the failure of speech synthesis (at the time) to use prosody as a channel for communicating meaning and emotion.
Second, Ramirez-Aristizabal et al. (Reference Ramirez-Aristizabal, Médé and Kello2018) found that hierarchical temporal structure in prosodic timescales (and not the faster phonetic timescales) is more tapered for fast versus slow rates of speech. They instructed participants to read off a teleprompter excerpt from a speech by Barack Obama. The speed of the teleprompter was manipulated to be either slower or faster than the pace of the original speech to induce relatively slow versus fast speaking. Also, the original recording of Obama giving the speech was slowed down or sped up using an algorithm for manipulating speech rate without affecting pitch so that the result is relatively natural sounding. For both the algorithm and the teleprompter, tapering was less pronounced for slow speaking and more pronounced for fast speaking. Changing the pace of speaking has several effects of prosody (Jun, Reference Jun2003), but giving a slow and deliberate speech entails greater enunciation compared with “cutting corners” to get through a hasty speech. Indeed, hastened speech is more likely to sound flat, akin to a computerized voice.
Third, Falk and Kello (Reference Falk and Kello2017) analyzed hierarchical temporal structure in recordings of mothers singing a song or telling a story in German to either their infants or adult confederates. Singing or speaking to their infants induced infant-directed speech, whereas doing the same for adults induced adult-directed speech. As one might expect given the prior two studies, hierarchical temporal structure was more pronounced in prosodic timescales (and again not the faster phonetic timescales) for infant-directed versus adult-directed speech (also see Chapter 38). The authors interpreted this result as indicating that mothers exaggerated prosodic information for their infants. Convergent evidence for purposeful exaggeration also came from Boorom et al. (Reference Boorom, Alviar and Zhang2022) who found that adult speech directed at children diagnosed with autism spectrum disorder had greater hierarchical temporal structure compared with typically developing controls. In both cases, exaggeration may serve to grab the child’s attention, and it could also serve to aid speech development and comprehension.
The latter possibility leads to the hypothesis that hierarchical temporal structure may vary as a function of the degree of prosodic composition – that is, the presence and distinctiveness of prosodic boundaries and units as expressed in the speech signal. As with prosody in general, hierarchical temporal structure is hypothesized to carry information about meaning, intention, emotion, mode of interaction, and other possible channels of communication and coordination. On this hypothesis, tapering in hierarchical temporal structure occurs when these layers are less composed.
As a further test of the composition hypothesis, Kello et al. (Reference Kello, Bella, Médé and Balasubramaniam2017) tested whether different kinds of music might also vary in their degree of layering of temporal structure. The authors applied the same Allan Factor method of analysis to four different categories of music – contemporary pop, rap, jazz improvisation, and classical symphonies. The composition hypothesis predicts that symphonies should have the greatest degree of nested clustering because composers explicitly add layers of structure for each of the instruments. Results bore out the prediction, in that nested clustering increased steadily across all measured timescales, as in 1/f scaling, but only for classical music. By contrast, rap and popular music had bends in their Allan Factor functions that reflected their beat structure. More interestingly, jazz showed a degree of tapering in the longer timescales that was remarkably similar to the tapering for recordings of conversations. Jazz improvisation has been likened to a conversation among musicians (Sawyer, Reference Sawyer, Miell, MacDonald and Hargreaves2005), but heretofore there was little if any quantitative evidence for the comparison. The Allan Factor results support an underlying connection between prosody and music hypothesized in previous studies (Patel et al., Reference Patel, Peretz, Tramo and Labreque1998).
20.5 Conclusions
This chapter reviewed a growing body of evidence that speakers can control the rate of growth of temporal structure with timescales, referred to as the degree of hierarchical temporal structure. Evidence indicates that this control governs the amount of prosodic structure and composition in speech, possibly through a relative sharpening or blurring of prosodic units and boundaries. Studies show that the degree of hierarchical temporal structure reflects the difference between more hastened versus measured rates of speech (Ramirez-Aristizabal et al., Reference Ramirez-Aristizabal, Médé and Kello2018), more informal versus formal speech registers (Abney et al., Reference Abney, Paxton, Dale and Kello2014), adult-directed versus infant-directed speech (Falk and Kello, Reference Falk and Kello2017), and monologues versus dialogues (Kello et al., Reference Kello, Bella, Médé and Balasubramaniam2017).
A similar control parameter also appears in analyses of musical recordings in which the more layered compositions of classical music have greater degrees of hierarchical temporal structure compared with contemporary popular music and other less layered forms of music (Kello et al., Reference Kello, Bella, Médé and Balasubramaniam2017). Taken together, these studies suggest that listeners can distinguish degrees of hierarchical temporal structure, and speakers may vary this control parameter to signal different modes of communication to interlocutors (Alviar et al., Reference Alviar, Dale, Dewitt and Kello2020), and aid speech development and comprehension (Abney et al., Reference Abney, Warlaumont, Oller, Wallot and Kello2017; Boorom et al., Reference Boorom, Alviar and Zhang2022).
Hierarchical temporal structure such as classical music has been found in recordings of thunderstorms as well, and Allan Factor functions for human conversations were like those for improvisational jazz as well as vocalizations of killer whales communicating in groups. These results indicate that prosodic and hierarchical temporal structure can be composed by people, animals, or natural causes (Ravignani et al., Reference Ravignani, Dalla Bella and Falk2019). Hierarchical temporal structure serves to situate prosodic composition and structure in the broader context of language, music, and vocal communication.
Summary
Prosody is defined over several layers of hierarchical temporal structure. A growing number of studies indicate that variations in prosodic information correspond to variations in temporal clustering of acoustic energy as a function of timescale. Speakers can control hierarchical temporal structure in prosodic timescales for various reasons, including who is being addressed and under what circumstances.
Implications
Prosodic structure is sometimes considered as periodic, and linguistic hierarchies are often represented in terms of nested structures, but hierarchical temporal structure in the range of prosodic timescales may also be aperiodic and not necessarily nested.
Gains
Studies of hierarchical temporal structure may help to link prosody with music, animal vocalizations, and other temporal structures in nature such as 1/f scaling. They may also illuminate mechanisms of control in communication and provide a broad basis for linking measures of cortical activity with speech activity.

 Open access
Open access