



Highlights
What is already known?
-
• Network meta-analyses (NMAs) that include treatment–covariate interactions, such as individual participant data (IPD) NMAs, provide relative treatment effects conditional on covariate values.
-
• Treatment hierarchies created from ranking metrics are a popular way to summarize the results of a network meta-analysis.
What is new?
-
• We describe how existing ranking metrics can be easily adapted to provide personalized treatment hierarchies from an IPD NMA.
Potential impact for RSM readers
-
• Practitioners should consider creating tools that can compute ranking metrics in IPD NMAs to support personalized clinical decision-making.
1 Introduction
Network meta-analysis (NMA) is a statistical methodology that facilitates the estimation of relative effects for multiple treatments from a set of clinical trials. A convenient method for summarizing the results of a standard NMA is to construct a treatment hierarchy, that is, a list of the treatments ranked in order of preference. Treatment hierarchies are constructed using ranking metrics that consider the magnitude and uncertainty of relative effect estimates, such as the Surface Under the Cumulative RAnking curve (SUCRA) in Bayesian NMA.Reference Salanti, Nikolakopoulou, Efthimiou, Mavridis, Egger and White1, Reference Salanti, Ades and Ioannidis2 A treatment hierarchy is a desired output of many NMAs.Reference Papakonstantinou, Salanti, Mavridis, Rücker, Schwarzer and Nikolakopoulou3
When effect modifiers are present, incorporating treatment–covariate interactions (TCIs) into the NMA model can reduce heterogeneity and provide more precise estimates.Reference Donegan, Williamson, D’Alessandro, Garner and Smith4– Reference Riley, Dias and Donegan6 TCIs allow the expected relative treatment effects, and therefore treatment hierarchies, to differ between individuals with different covariate values, presenting an opportunity to compute personalized hierarchies. Authors have called for the reporting of treatment hierarchies at different covariate levels when TCIs are included in an NMA,Reference Donegan, Williamson, D’Alessandro, Garner and Smith4– Reference Riley, Debray and Fisher7 but this is rarely done in practice. In this article, we show how Bayesian NMAs with TCIs can produce personalized treatment hierarchies, and demonstrate the methods using a network of studies for major depressive disorder (MDD).
2 Treatment hierarchies in standard NMA models
In a standard NMA with no TCIs, the parameters representing treatment performance are given by
 $\psi _{20}^{(1)}, \psi _{30}^{(1)}, \dots , \psi _{G0}^{(1)}$
, where
$\psi _{20}^{(1)}, \psi _{30}^{(1)}, \dots , \psi _{G0}^{(1)}$
, where
 $\psi _{g0}^{(1)}$
is the expected relative effect of treatment g compared to treatment 1, and the index
$\psi _{g0}^{(1)}$
is the expected relative effect of treatment g compared to treatment 1, and the index
 $0$
indicates that the parameter represents the main effect of the treatment and not an interaction, which will become important in the following section. Additionally, G is the number of treatments in the network, and
$0$
indicates that the parameter represents the main effect of the treatment and not an interaction, which will become important in the following section. Additionally, G is the number of treatments in the network, and
 $\psi _{10}^{(1)} = 0$
. We assume that the expected relative effect of treatment g versus h,
$\psi _{10}^{(1)} = 0$
. We assume that the expected relative effect of treatment g versus h,
 $\psi _{g0}^{(h)}$
, is given by
$\psi _{g0}^{(h)}$
, is given by
 $\psi _{g0}^{(1)}-\psi _{h0}^{(1)}$
for any
$\psi _{g0}^{(1)}-\psi _{h0}^{(1)}$
for any
 $g,h$
in
$g,h$
in
 $1, \dots , G$
. This is referred to as the consistency assumption in NMA literature.Reference Ades, Welton, Dias, Phillippo and Caldwell8 In the remainder of the article, we suppress the superscript
$1, \dots , G$
. This is referred to as the consistency assumption in NMA literature.Reference Ades, Welton, Dias, Phillippo and Caldwell8 In the remainder of the article, we suppress the superscript
 $(1)$
and emphasize that all parameters are relative to treatment 1.
$(1)$
and emphasize that all parameters are relative to treatment 1.
SUCRA values are calculated from the relative effects to obtain a treatment hierarchy that is relevant to the population represented by the NMA. The SUCRA value for treatment g is calculated in a standard Bayesian NMA as
 $$ \begin{align} \text{SUCRA}(g) &= \frac{\sum_{s = 1}^{G-1} \sum_{r = 1}^s p_{gr}}{G-1} \notag \\ &= \frac{G - \text{E}\left[rank(g)\right]}{G-1}, \end{align} $$
$$ \begin{align} \text{SUCRA}(g) &= \frac{\sum_{s = 1}^{G-1} \sum_{r = 1}^s p_{gr}}{G-1} \notag \\ &= \frac{G - \text{E}\left[rank(g)\right]}{G-1}, \end{align} $$
where
 $p_{gr}$
is the probability that treatment g takes rank r, that is, it has a more favorable response than exactly r treatments, and
$p_{gr}$
is the probability that treatment g takes rank r, that is, it has a more favorable response than exactly r treatments, and
 $\text {E}\left [rank(g)\right ]$
is the average rank of treatment g.Reference Salanti, Ades and Ioannidis2,
Reference Rücker and Schwarzer9
$\text {E}\left [rank(g)\right ]$
is the average rank of treatment g.Reference Salanti, Ades and Ioannidis2,
Reference Rücker and Schwarzer9
SUCRA values can be computed in a standard Bayesian NMA using samples from the posterior distribution. Assume that we have a sample of size M from the posterior distribution of
 $\psi _{10} = 0, \psi _{20}, \dots , \psi _{G0}$
, and let
$\psi _{10} = 0, \psi _{20}, \dots , \psi _{G0}$
, and let
 $\psi _{g0}{}_{(m)}$
represent the value of
$\psi _{g0}{}_{(m)}$
represent the value of
 $\psi _{g0}$
in the
$\psi _{g0}$
in the
 $m^{\text {th}}$
posterior sample. Note that
$m^{\text {th}}$
posterior sample. Note that
 $\psi _{10} = 0$
by definition for every posterior sample. Then we can calculate SUCRA values as follows:
$\psi _{10} = 0$
by definition for every posterior sample. Then we can calculate SUCRA values as follows:
-
1. For each sample
 $m = 1, \dots , M$
and each treatment
$g = 1, \dots , G$
, determine the treatment rank according to where
$$ \begin{align*} rank(g)_{(m)} = G - \sum_{h \neq g} I\left\{\psi_{g0}{}_{(m)}> \psi_{h0}{}_{(m)}\right\}, \end{align*} $$
$I\{\cdot \} = 1$
when
$\cdot $
is true and
$0$
otherwise.
$m = 1, \dots , M$
and each treatment
$g = 1, \dots , G$
, determine the treatment rank according to where
$$ \begin{align*} rank(g)_{(m)} = G - \sum_{h \neq g} I\left\{\psi_{g0}{}_{(m)}> \psi_{h0}{}_{(m)}\right\}, \end{align*} $$
$I\{\cdot \} = 1$
when
$\cdot $
is true and
$0$
otherwise.
-
2. Calculate the average rank for each treatment,
$$ \begin{align*} \text{E}\left[rank(g)\right] = \frac{1}{M}\sum_{m = 1}^M rank(g)_{(m)}. \end{align*} $$
-
3. Calculate
$\text {SUCRA}(g)$
using
$$ \begin{align*} \text{SUCRA}(g) = \frac{G-\text{E}\left[rank(g)\right]}{G-1}. \end{align*} $$









The SUCRA of treatment g in a standard NMA is interpreted as the proportion of competing treatments that g is expected to beat,Reference Salanti, Ades and Ioannidis2 or the inverse-scaled average rank of treatment g,Reference Rücker and Schwarzer9 when it is employed in the population represented by the NMA. The resulting treatment hierarchy is not personalized to any particular patient and depends on the covariate distribution in the population.Reference Phillippo, Dias and Ades10
3 Treatment hierarchies in NMA models with TCIs
TCIs can be estimated using aggregate data NMA models with meta-regression and Individual Participant Data (IPD) NMA models, including recently proposed Individualized Treatment Rule (ITR) NMA models.Reference Riley, Lambert and Staessen11, Reference Shen, Moodie and Golchi12 In Supplementary Section S1, we describe the suitability of each model type for creating personalized treatment hierarchies. Briefly, we do not recommend using aggregate data NMA meta-regression to create personalized treatment hierarchies due to its risk of ecological bias and confounding.Reference Riley, Lambert and Staessen11, Reference Donegan, Williamson, D’Alessandro and Smith13– Reference Schmid, Stark, Berlin, Landais and Lau15 IPD NMA can be used to produce personalized treatment hierarchies when care is taken in specifying the model.Reference Riley, Dias and Donegan6, Reference Riley, Debray and Fisher7, Reference Hua, Burke, Crowther, Ensor, Tudur Smith and Riley16
In an NMA model that includes TCIs, the interpretation of the parameter
 $\psi _{g0}$
does not correspond to the expected relative effect on average in the population. Instead,
$\psi _{g0}$
does not correspond to the expected relative effect on average in the population. Instead,
 $\psi _{g0}$
corresponds to the expected relative effect of treatment g compared to treatment 1 in the reference group. To illustrate, suppose there are Q effect-modifying covariates included as TCIs in an NMA model. The expected relative effect of treatment g versus treatment 1 for an individual with covariate values
$\psi _{g0}$
corresponds to the expected relative effect of treatment g compared to treatment 1 in the reference group. To illustrate, suppose there are Q effect-modifying covariates included as TCIs in an NMA model. The expected relative effect of treatment g versus treatment 1 for an individual with covariate values
 $X_1 = x_1, X_2 = x_2, \dots , X_Q = x_Q$
is given by
$X_1 = x_1, X_2 = x_2, \dots , X_Q = x_Q$
is given by
 $$ \begin{align} \psi_{g0} + \psi_{g1} x_1 + \psi_{g2} x_2 + \dots + \psi_{gQ} x_Q, \end{align} $$
$$ \begin{align} \psi_{g0} + \psi_{g1} x_1 + \psi_{g2} x_2 + \dots + \psi_{gQ} x_Q, \end{align} $$
where
 $\psi _{g1}, \dots , \psi _{gQ}$
are the coefficients representing the interaction between each covariate and treatment g compared to treatment 1, that is,
$\psi _{g1}, \dots , \psi _{gQ}$
are the coefficients representing the interaction between each covariate and treatment g compared to treatment 1, that is,
 $\psi _{gq}, q> 0$
is the change in the relative effect of treatment g compared to treatment 1 for a one unit increase in covariate q, and
$\psi _{gq}, q> 0$
is the change in the relative effect of treatment g compared to treatment 1 for a one unit increase in covariate q, and
 $\psi _{g0}$
is the expected relative effect when all
$\psi _{g0}$
is the expected relative effect when all
 $x_1, \dots , x_Q$
equal 0.
$x_1, \dots , x_Q$
equal 0.
Now, consider creating a treatment hierarchy from a model that includes TCIs. If we were to use only
 $\psi _{g0}$
,
$\psi _{g0}$
,
 $g = 1, \dots , G$
to create the hierarchy for such a model, the hierarchy would apply to patients whose covariate values are all equal to zero. The hierarchy will be meaningless for patients with a different covariate profile. Clearly, for a treatment hierarchy to be meaningful in an NMA with TCIs, it should be intentionally created for a particular set of covariate values.
$g = 1, \dots , G$
to create the hierarchy for such a model, the hierarchy would apply to patients whose covariate values are all equal to zero. The hierarchy will be meaningless for patients with a different covariate profile. Clearly, for a treatment hierarchy to be meaningful in an NMA with TCIs, it should be intentionally created for a particular set of covariate values.
Let
 $\text {E}\left [rank(g)\mid x_{1}, \dots , x_Q\right ]$
be the average rank of treatment g given covariates
$\text {E}\left [rank(g)\mid x_{1}, \dots , x_Q\right ]$
be the average rank of treatment g given covariates
 $x_{1}, \dots , x_Q$
. The average ranks are determined using the expected relative effects defined in equation (3.1). They can be calculated using samples from the posterior of
$x_{1}, \dots , x_Q$
. The average ranks are determined using the expected relative effects defined in equation (3.1). They can be calculated using samples from the posterior of
 $\psi _{gq}$
,
$\psi _{gq}$
,
 $g = 1, \dots $
, G and
$g = 1, \dots $
, G and
 $q = 0$
,
$q = 0$
,
 $\dots $
, Q
$\dots $
, Q
-
1. For each sample
$m = 1, \dots , M$
and each treatment
$g = 1, \dots , G$
, determine the expected relative treatment effect given
$x_{1}, \dots , x_Q$
via and
$$ \begin{align*} RE_{1g}{}_{(m)}(x_{1}, \dots, x_Q) = \psi_{g0}{}_{(m)} + \psi_{g1}{}_{(m)} x_1 + \psi_{g2}{}_{(m)} x_2 + \dots + \psi_{gQ}{}_{(m)} x_Q \quad \text{for } g = 2, ..., G, \end{align*} $$
$RE_{11} {}_{(m)}(x_{1}, \dots , x_Q) = 0$
, where
$RE_{1g} {}_{(m)}(x_{1}, \dots , x_Q)$
represents the expected relative effect of treatment g versus 1 given covariates
$x_{1}, \dots , x_Q$
in sample m.
-
2. For each sample
$m = 1, \dots , M$
and each treatment
$g = 1, \dots , G$
, determine the treatment rank according to
$$ \begin{align*} rank(g)_{(m)} = G - \sum_{h \neq g} I\left\{RE_{1g} {}_{(m)}(x_{1}, \dots, x_Q)> RE_{1h} {}_{(m)}(x_{1}, \dots, x_Q)\right\}. \end{align*} $$
-
3. Calculate the average rank for each treatment given the covariates,
$$ \begin{align*} \text{E}\left[rank(g)\mid x_{1}, \dots, x_Q\right] = \frac{1}{M}\sum_{m = 1}^M rank(g)_{(m)}. \end{align*} $$
-
4. Calculate
$\text {SUCRA}(g)$
using
$$ \begin{align*} \text{SUCRA}(g) = \frac{G-\text{E}\left[rank(g)\mid x_{1}, \dots, x_Q\right]}{G-1}. \end{align*} $$













The treatment hierarchy produced in this way is personalized to a patient with the covariate profile defined by
 $x_{1}, \dots , x_Q$
.
$x_{1}, \dots , x_Q$
.
4 Example: Pharmacological treatments for MDD
We illustrate the use and impact of personalized treatment hierarchies using data from three studies investigating treatment for MDD. A systematic review process was not followed to select the studies; rather, the studies were selected based on the availability of IPD. Details on the study designs are given in Supplementary Section S2. The data provide information on six pharmacological treatments: Bupropion, Citalopram + Bupropion, Citalopram + Buspirone, Escitalopram, Sertraline, and Venlafaxine. The response is defined as the negative of the 17-question Hamilton Rating Scale for Depression (HRSD-17), so that larger values are preferred. The following covariates, considered to be potential effect modifiers for depression, were included as TCIs in the analysis: age, sex, marital status, years of education, employment status, household size, age of depression onset, number of depressive episodes, chronicity of current MDD episode, and HRSD-17 before receiving any treatment in the study.Reference Kessler, van and Wardenaar17, Reference Perlman, Benrimoh and Israel18 We fit a two-stage common effect Bayesian ITR NMA model with IPD to estimate expected relative treatment effects in the MDD network,Reference Shen, Moodie and Golchi12 described in detail in Supplementary Section S3.
We computed personalized treatment hierarchies using SUCRA for two hypothetical patients, Patient A and Patient B, each with unique covariate profiles: Patient A is employed while Patient B is unemployed, Patient A has experienced three or fewer depressive episodes while Patient B has experienced more than three, Patient A is male and Patient B is not, and Patient A lives in a household with two more members than Patient B. The specific covariate values for each patient are described in Supplementary Section S3.3.
4.1 Results
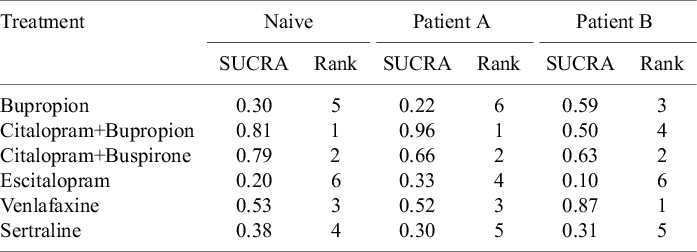
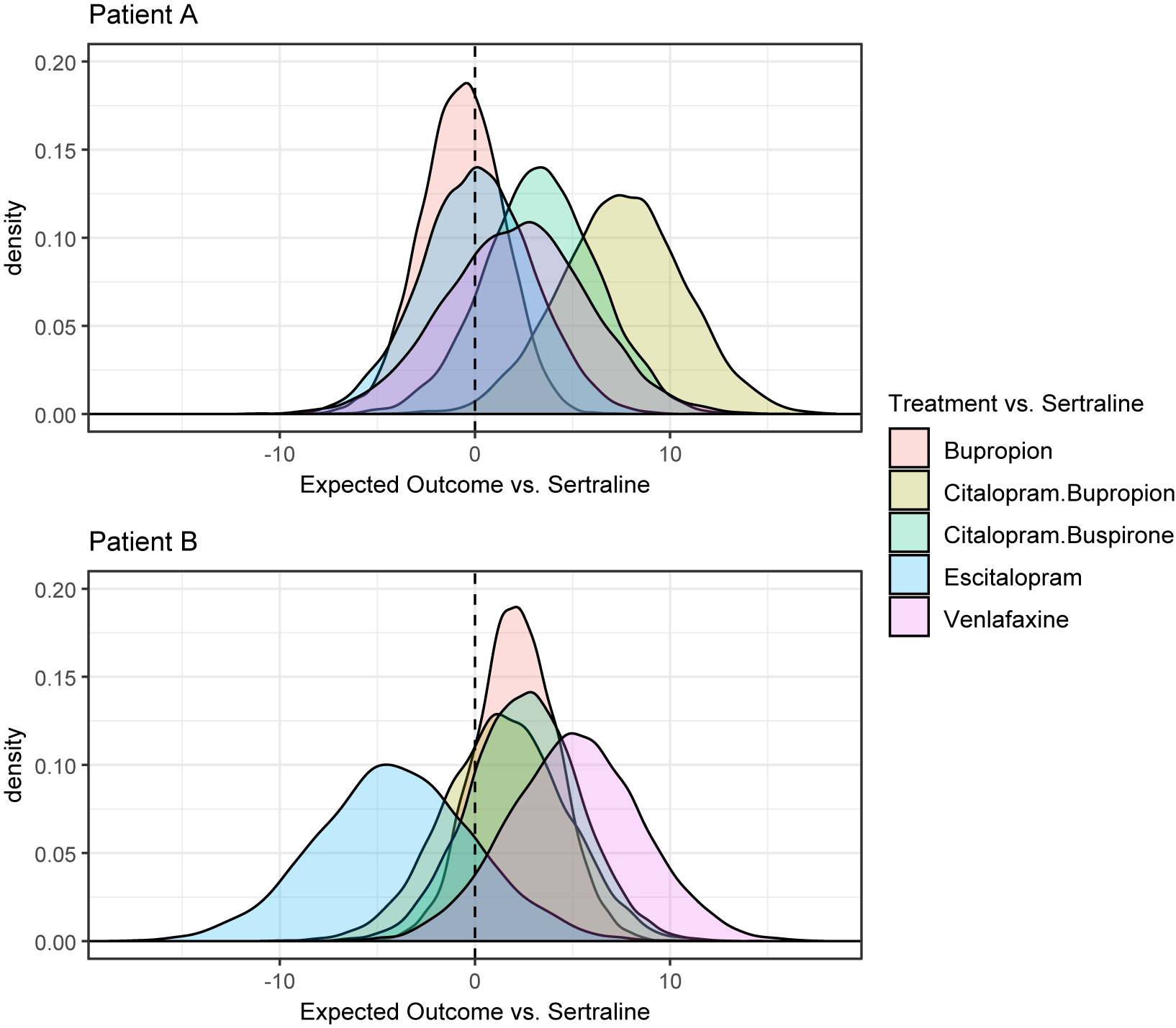
A plot showing point estimates and 95% credible intervals for treatment effects and TCIs is shown in Supplementary Section S3.4. All credible intervals contain zero. This is not too surprising, since only three studies were included in the analysis. In Figure 1, we show the posterior distribution of the expected relative effects as defined in equation (3.1) of each treatment compared to Sertraline for Patients A and B. It is clear that there are differences in the posterior densities between the patients. The SUCRA values for Patients A and B reflect the differences in the posteriors, and are compared in Table 1. For example, Citalopram + Bupropion is ranked first for Patient A, while it is ranked only fourth out of the six treatments for Patient B. Table 1 also compares the SUCRA and treatment rankings that would result from using a naive method that only considered the main treatment effects,
 $\psi _{g0}$
. The naive method gives the same hierarchy for both patients, and this differs from both personalized hierarchies, particularly for Patient B, who deviates more from the reference profile.
$\psi _{g0}$
. The naive method gives the same hierarchy for both patients, and this differs from both personalized hierarchies, particularly for Patient B, who deviates more from the reference profile.
SUCRA values and ranking of each treatment using a naive nonpersonalized approach, and using a personalized approach for Patient A and Patient B

Posterior distributions of the relative effects of each treatment for Patients A and B.

5 Discussion
Personalized treatment hierarchies can be computed from IPD NMA models that include TCIs. We demonstrated the methods using an ITR NMA of treatments for MDD, where the TCIs were selected based on previous studies on MDD effect modifiers. The posterior distributions of the expected relative effects changed for different patient profiles and resulted in different treatment hierarchies, suggesting possible value in personalizing recommendations.
We caution against relying on the statistical significance of TCI parameters to decide when it would be beneficial to create personalized treatment hierarchies. First, TCIs that exist in practice but have not yet been estimated precisely enough to reach statistical significance are still important to include in the model, and a personalized treatment hierarchy could be useful in this context. Additionally, although the
 $\psi _{gq}$
parameters may not be statistically significantly different from zero, these parameters represent interactions compared to the reference treatment, and it is possible that other interaction terms may be statistically significant for other treatment comparisons, for example, the credible interval for the interaction of age with Bupropion versus Sertraline may contain zero, but the credible interval for the interaction of age with Bupropion versus Venlafaxine may be well away from zero. Therefore, an interaction that does not seem important at first glance may indeed be important for other treatment comparisons.
$\psi _{gq}$
parameters may not be statistically significantly different from zero, these parameters represent interactions compared to the reference treatment, and it is possible that other interaction terms may be statistically significant for other treatment comparisons, for example, the credible interval for the interaction of age with Bupropion versus Sertraline may contain zero, but the credible interval for the interaction of age with Bupropion versus Venlafaxine may be well away from zero. Therefore, an interaction that does not seem important at first glance may indeed be important for other treatment comparisons.
On the other hand, including TCIs that do not exist in practice will increase the variance of the posterior distribution of conditional relative effects without improving the accuracy of treatment recommendations. The use of the SUCRA ranking metric to create the hierarchy will mitigate the additional variance to some extent, as SUCRA summarizes the entire posterior distribution of relative effects,Reference Chiocchia, Nikolakopoulou, Papakonstantinou, Egger and Salanti19 but personalized treatment hierarchies may still be misleading if the included TCIs do not exist. For this reason, we believe personalized treatment hierarchies should be created when there is additional reason to believe that the included TCIs do exist in practice, besides only the NMA results at hand.
We focused on creating treatment hierarchies from the expected relative effects. In random-effects NMA models, treatment effects and interactions are allowed to vary across studies, and a personalized treatment hierarchy that better reflects uncertainty could be obtained by considering this additional predictive variability. A Bayesian approach to creating predictive treatment hierarchies in standard NMAs has been proposedReference Rosenberger, Duan, Chen and Lin20 and could be adapted to personalized treatment hierarchies.
We echo previous calls to report treatment hierarchies for different covariate profiles when possible and when there is evidence that TCIs exist.Reference Donegan, Williamson, D’Alessandro, Garner and Smith4– Reference Riley, Debray and Fisher7 If many covariates are effect modifiers, it may not be feasible to report hierarchies for all covariate patterns of interest. Some recent IPD NMAs have included online tools that allow individuals to compute expected relative effects for custom covariate values to aid in decision-making.Reference Karyotaki, Efthimiou and Miguel21, Reference Furukawa, Suganuma and Ostinelli22 With little additional effort, personalized treatment hierarchies could be included in the output of such tools. We encourage researchers conducting IPD NMAs to consider creating tools that can provide personalized treatment hierarchies to support clinical decision-making.
Acknowledgments
Data and/or research tools used in the preparation of this manuscript were obtained from the National Institute of Mental Health (NIMH) Data Archive (NDA). NDA is a collaborative informatics system created by the National Institutes of Health to provide a national resource to support and accelerate research in mental health. Dataset identifier(s): #2199 (EMBARC), #2153 (REVAMP), #2148 (STAR*D). This manuscript reflects the views of the authors and may not reflect the opinions or views of the NIH or of the Submitters submitting original data to NDA.
Author contributions
Conceptualization: A.W., E.E.M.M.; Data curation: A.W.; Formal analysis: A.W.; Methodology: A.W.; Software: A.W.; Supervision: E.E.M.M.; Visualization: A.W.; Writing—original draft: A.W.; Writing—review and editing: A.W., E.E.M.M.
Competing interest statement
The authors declare that no competing interests exist.
Data availability statement
Code and data to reproduce the results in this article are available at https://doi.org/10.5281/zenodo.19007228.
Funding statement
A.W. is supported by the Natural Sciences and Engineering Research Council of Canada (Grant No. PDF-598932-2025). E.E.M.M. is a Canadian Institutes of Health Research Canada Research Chair (Tier 1) in Statistical Methods for Precision Medicine.
Ethical standards
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.
Supplementary material
To view supplementary material for this article, please visit http://doi.org/10.1017/rsm.2026.10089.



 Open access
Open access