

1. Introduction
Measuring the degree of semantic similarity between linguistic items has been a great challenge in the field of Natural Language Processing (NLP), a sub-field of Artificial Intelligence concerned with the handling of human language by computers. Over the last two decades, several different approaches have been put forward for computing similarity using a variety of methods and techniques. However, before examining such approaches, it is crucial to provide a definition of similarity: what is meant exactly by the term ‘similar’? Are all semantically related items ‘similar’? Resnik (Reference Resnik1995) and Budanitsky and Hirst (Reference Budanitsky and Hirst2001) make a fundamental distinction between two apparently interchangeable concepts, that is, similarity and relatedness. In fact, while similarity refers to items which can be substituted in a given context (such as cute and pretty)without changing the underlying semantics, relatedness indicates items which have semantic correlations but are not substitutable. Relatedness encompasses a much larger set of semantic relations, ranging from antonymy (beautiful and ugly) to correlation (beautiful and appeal). As is apparent from Figure 1, beautiful and appeal are related but not similar, whereas pretty and cute are both related and similar. In fact, similarity is often considered to be a specific instance of relatedness (Jurafsky Reference Jurafsky2000), where the concepts evoked by the two words belong to the same ontological class. In this paper, relatedness will not be discussed and the focus will lie on similarity.
An explicative illustration of word similarity and relatedness.

In general, semantic similarity can be classified on the basis of two fundamental aspects. The first concerns the type of resource employed, whether it be a lexical knowledge base (LKB), that is, a wide-coverage structured repository of linguistic data, or large collections of raw textual data, that is, corpora. Accordingly, we distinguish between knowledge-based semantic similarity, in the former case, and distributional semantic similarity, in the latter. Furthermore, hybrid semantic similarity combines both knowledge-based and distributional methods. The second aspect concerns the type of linguistic item to be analysed, which can be:
words, which are the basic building blocks of language, also including their inflectional information.
word senses, that is, the meanings that words convey in given contexts (e.g., the device meaning vs. the animal meaning of mouse).
sentences, that is, grammatical sequences of words which typically include a main clause, made up of a predicate, a subject and, possibly, other syntactic elements.
paragraphs and texts, which are made up of sequences of sentences.
This paper focuses on the first two items, that is, words and senses, and provides a review of the approaches used for determining to which extent two or more words or senses are similar to each other, ranging from the earliest attempts to recent developments based on embedded representations.
1.1 Outline
The rest of this paper is structured as follows. First, we describe the tasks of word and sense similarity (Section 2). Subsequently, we detail the main approaches that can be employed for performing these tasks (Sections 3–5) and describe the main measures for comparing vector representations (Section 6). We then move on to the evaluation of word and sense similarity measures (Section 7). Finally, we draw conclusions and propose some suggestions for future research (Section 8).
2. Task description
Given two linguistic items i 1 and i 2, either words or senses in our case, the task consists in calculating some function sim(i 1, i 2) which provides a numeric value that quantifies the estimated similarity between i 1 and i 2. More formally, the similarity function is of the kind:
 $$sim : I \times I \to {\mathbb R} $$
$$sim : I \times I \to {\mathbb R} $$
where I is the set of linguistic items of interest and the output of the function typically ranges between 0 and 1, or between −1 and 1. Note that the set of linguistic items can be cross-level, that is, it can include (and therefore enable the comparison of) items of different types, such as words and senses (Jurgens Reference Jurgens2016).
In order to compute the degree of semantic similarity between items, two major steps have to be carried out. First, it is necessary to identify a suitable representation of the items to be analysed. The way a linguistic item is represented has a fundamental impact on the effectiveness of the computation of semantic similarity, as a consequence of the expressiveness of the representation. For example, a representation which counts the number of occurrences and co-occurrences of words can be useful when operating at the lexical level, but can lead to more difficult calculations when moving to the sense level, for example, due to the paucity of sense-tagged training data. Second, an effective similarity measure has to be selected, that is, a way to compare items on the basis of a specific representation.
Word and sense similarity can be performed following two main approaches:
Knowledge-based similarity exploits explicit representations of meaning derived from widecoverage lexical-semantic knowledge resources (introduced in Section 3).
Distributional similarity draws on distributional semantics, also known as vector space semantics, and exploits the statistical distribution of words within unstructured text (introduced in Section 4).
Hybrid similarity measures, introduced in Section 5, combine knowledge-based and distributional similarity approaches, that is, knowledge from LKBs and occurrence information from texts.
3. Knowledge-based word and sense similarity
Knowledge-based approaches compute semantic similarity by exploiting the information stored in an LKB. With this aim in view, two main methods can be employed. The first method computes the semantic similarity between two given items i 1 and i 2 by inferring their semantic properties on the basis of structural information concerning i 1 and i 2 within a specific LKB. The second method performs the extraction and comparison of a vector representation of i 1 and i 2 obtained from the LKB. It is important to note that the first method is now deprecated as the best performance can be achieved by using more sophisticated techniques, both knowledge-based and distributional, which we will detail in the following sections.
We now introduce the most common LKBs (Section 3.1), and then overview methods and measures employed for knowledge-based word and sense similarity (Section 3.2).
3.1 Lexical knowledge resources
Here we will review the most popular lexical knowledge resources, which are widely used not only for computing semantic similarity, but also in many other NLP tasks.
WordNet. WordNet Footnote a (Fellbaum Reference Fellbaum1998) is undoubtedly the most popular LKB for the English language, originally developed on the basis of psycholinguistic theories. WordNet can be viewed as a graph, whose nodes are synsets, that is, sets of synonyms, and whose edges are semantic relations between synsets. WordNet encodes the meanings of an ambiguous word through the synsets which contain that word and therefore the corresponding senses. For instance, for the word table, WordNet provides the following synsets, together with a textual definition (called gloss) and, possibly, usage examples:
{ table, tabular array } – a set of data arranged in rows and columns ‘see table 1’.
{ table } – a piece of furniture having a smooth flat top that is usually supported by one or more vertical legs ‘it was a sturdy table’.
{ table } – a piece of furniture with tableware for a meal laid out on it ‘I reserved a table at my favorite restaurant’.
{ mesa, table } – flat tableland with steep edges ‘the tribe was relatively safe on the mesa but they had to descend into the valley for water’.
{ table } – a company of people assembled at a table for a meal or game ‘he entertained the whole table with his witty remarks’.
{ board, table } – food or meals in general ‘she sets a fine table’; ‘room and board’.
In the above example, the term tabular array is a synonym for table in the data matrix sense, while mesa is a synonym in the tableland meaning. WordNet makes clear the important distinction between words, senses and synsets: a word is a possibly ambiguous string which represents a single, meaningful linguistic element (e.g., table), a sense is a given meaning of a certain word (e.g., the matrix sense of table, also denoted as table#n#1, table.n.1 or
 ${\rm{table}}_n^1$
to indicate it is the first nominal sense in the WordNet inventory for that word) and a synset is a set of senses all expressing the same concept. A synset has a one-to-one correspondence with a concept, which is purely semantic. A sense (e.g.,
${\rm{table}}_n^1$
to indicate it is the first nominal sense in the WordNet inventory for that word) and a synset is a set of senses all expressing the same concept. A synset has a one-to-one correspondence with a concept, which is purely semantic. A sense (e.g.,
 ${\rm{table}}_n^1$
) uniquely identifies the only synset it occurs in (e.g.,
${\rm{table}}_n^1$
) uniquely identifies the only synset it occurs in (e.g.,
 ${\rm{table}}_n^1$
identifies the 08283156n id in WordNet 3.1 of the synset { table, tabular array }), whereas given a synset S and a word w ∈ S (e.g., the word table in the { table, tabular array } synset), a sense s of w is uniquely identified (i.e.,
${\rm{table}}_n^1$
identifies the 08283156n id in WordNet 3.1 of the synset { table, tabular array }), whereas given a synset S and a word w ∈ S (e.g., the word table in the { table, tabular array } synset), a sense s of w is uniquely identified (i.e.,
 ${\rm{table}}_n^1$
in the example).
${\rm{table}}_n^1$
in the example).
Synsets are connected via different kinds of relations, the most popular being:
Hypernymy (and its inverse hyponymy), which denotes generalization: for instance, the { table, tabular array } is a kind of { array }, while { table }, in the furniture meaning, is a kind of { furniture, piece of furniture, article of furniture }.
Meronymy (and its inverse holonymy), which denotes a part of relationship: for instance, { table, tabular array } has part { row } and { column }, whereas { table } in the furniture meaning has part, among others, { leg }.
Similarity, which specifies the similarity between adjectival synsets such as between {beautiful} and {pretty}.
Pertainymy and derivationally related form, which connect word senses from different parts of speech with a common root stem, such as that relating { table, tabular array } to the { tabulate } verbal synset, and the same nominal synset to the { tabular } adjectival synset.
Note that some of the above relations are semantic, in that they connect synsets, whereas others, such as the derivationally related form and the pertainymy relations, hold between word senses (i.e., words occurring in synsets). However, it is a common practice, for the purposes of many NLP tasks, to take lexical relations to the semantic level, so as to connect the corresponding enclosing synsets (Navigli and Ponzetto Reference Navigli and Ponzetto2012).
Roget’s thesaurus. Created by the English lexicographer Peter Mark Roget in 1805, the Roget’s thesaurus is a historical lexicographic resource, used in NLP as an alternative to WordNet for knowledge acquisition and semantic similarity (Jarmasz and Szpakowicz Reference Jarmasz and Szpakowicz2003). The Roget’s thesaurus was made available for the first time in 1852 and was one of the resources employed for creating WordNet (Miller et al. Reference Miller, Beckwith, Fellbaum, Gross and Miller1990).
Wikipedia. Started in 2001, Wikipedia Footnote b has become the largest and most reliable online encyclopaedia in the space of a few years and has gained momentum quickly in several NLP tasks, such as text classification (Navigli et al. Reference Navigli, Faralli, Soroa, Lacalle and Agirre2011), Word Sense Disambiguation (WSD) (Navigli, Jurgens, and Vannella Reference Navigli, Jurgens and Vannella2013; Moro and Navigli Reference Moro and Navigli2013), entity linking (Moro and Navigli Reference Moro and Navigli2013) and many others (Hovy, Navigli, and Ponzetto Reference Hovy, Navigli and Ponzetto2013). Wikipedia can be viewed as a lexical knowledge resource with a graph structure whose nodes are Wikipedia pages and whose relations are given by the hyperlinks that connect one page to another. Compared to WordNet, Wikipedia provides three key features which make it very popular in NLP: first, it covers world knowledge in terms of named entities (such as well-known people, companies and works of art) on a large scale; second, it provides coverage of multiple languages, by linking a given page to its counterparts in dozens of other languages, whenever these are available; and third, it is continuously updated.
Wiktionary. Another resource which has become popular in NLP is Wiktionary, a sister project to Wikipedia. Available in almost 200 languages, Wiktionary is a free, Web-based collaborative dictionary that is widely employed in several NLP tasks such as WSD and semantic similarity (Zesch, Müller, and Gurevych Reference Zesch, Müller and Gurevych2008).
BabelNet. Built on top of WordNet and Wikipedia, BabelNet Footnote c (Navigli and Ponzetto Reference Navigli and Ponzetto2012)is the most popular wide-coverage multilingual lexical knowledge resource, used in dozens of tasks among which we cite state-of-the-art multilingual disambiguation (Moro, Raganato, and Navigli Reference Moro, Raganato and Navigli2014), semantic similarity (Camacho-Collados, Pilehvar, and Navigli Reference Camacho-Collados, Pilehvar and Navigli2016) and semantically enhanced machine translation (Moussallem, Wauer, and Ngonga Ngomo Reference Moussallem, Wauer and Ngonga Ngomo2018).
BabelNet is the result of the automatic interlinking and integration of different knowledge resources, such as WordNet, Wikipedia, Wiktionary, Wikidata and other resources. The underlying structure is modelled after that of WordNet: multilingual synsets are created which contain lexicalizations that, in different languages, express the same concept. For instance, the car synset includes, among others, the following lexicalizations (the language code is subscripted):
 $$\left\{ {\mathop {{\rm{car}}}\nolimits_{EN} ,\mathop {{\rm{automatic}}}\nolimits_{EN} ,\mathop {{\rm{macchina}}}\nolimits_{IT} ,\mathop {{\rm{voiture}}}\nolimits_{FR} ,\mathop {{\rm{coche}}}\nolimits_{ES} ,....,\mathop {{\rm{Wagen}}}\nolimits_{DE} } \right\}.$$
$$\left\{ {\mathop {{\rm{car}}}\nolimits_{EN} ,\mathop {{\rm{automatic}}}\nolimits_{EN} ,\mathop {{\rm{macchina}}}\nolimits_{IT} ,\mathop {{\rm{voiture}}}\nolimits_{FR} ,\mathop {{\rm{coche}}}\nolimits_{ES} ,....,\mathop {{\rm{Wagen}}}\nolimits_{DE} } \right\}.$$
The relations interconnecting the BabelNet multilingual synsets come from the integrated resources, such as those from WordNet and Wikipedia (where hyperlinks are labelled as semantic relatedness relations). As a result, similar to WordNet and Wikipedia, BabelNet can also be viewed as a graph and its structure exploited to perform semantic similarity.
3.2 Knowledge-based representations and measures
3.2.1 Earlier attempts
Knowledge-based representations and measures always rely on the availability of LKBs. Earlier efforts aimed at calculating word and sense similarity by exploiting solely the taxonomic structure of an LKB, such as WordNet. The structural information usually exploited by these measures is based on the following ingredients:
The depth of a given concept (i.e., synset) in the LKB taxonomy;
The length of the shortest path between two concepts in the LKB;
The Least Common Subsumer (LCS), that is, the lowest concept in the taxonomical hierarchy which is a common hypernym of two target concepts.
In knowledge-based approaches, computing the similarity between two senses s 1 and s 2 is straightforward, because it involves the calculation of a measure concerning the two corresponding nodes in the LKB graph. When two words w 1 and w 2 are involved, instead, the similarity between them can be computed as the maximum similarity across all their sense combinations:
 $$sim({w_1},{w_2}) = \mathop {\max }\limits_{{s_1} \in Senses({w_1}),\;{s_2} \in Senses({w_2})} sim({s_1},{s_2})$$
$$sim({w_1},{w_2}) = \mathop {\max }\limits_{{s_1} \in Senses({w_1}),\;{s_2} \in Senses({w_2})} sim({s_1},{s_2})$$
where Senses(wi ) is the set of senses provided in the LKB for word wi .
Path . One of the earliest and simplest knowledge-based algorithms for the computation of semantic similarity is based on the assumption that the shorter the path in a specific LKB graph between two senses, the more semantically similar they are. Given two senses s 1 and s 2, the path length (Rada et al. Reference Rada, Mili, Bicknell and Blettner1989) can be computed as follows:
 $$sim({s_1},{s_2}) = {1 \over {length({s_1},{s_2}) + 1}}$$
$$sim({s_1},{s_2}) = {1 \over {length({s_1},{s_2}) + 1}}$$
where we adjusted the original formula to a similarity measure by calculating its reciprocal. Related to this approach, but based on the structural distance within the Roget’s thesaurus (see Section 3.1), a similar algorithm has been put forward by Jarmasz and Szpakowicz (Reference Jarmasz and Szpakowicz2003).
The key idea behind this type of algorithms is that the farther apart the senses of the two words of interest in the LKB are, the lower the degree of similarity between the two words is.
Leacock and Chodorow . A variant of the path measure was proposed by Leacock (Reference Leacock and Chodorow1998), and this computes semantic similarity as:
 $$sim({s_1},{s_2}) = - log{{length({s_1},{s_2})} \over {2D}}$$
$$sim({s_1},{s_2}) = - log{{length({s_1},{s_2})} \over {2D}}$$
where length refers to the shortest path between the two senses and D is the maximum depth of the (nominal) taxonomy of a given LKB (historically, WordNet).
Wu and Palmer. In order to take into account the taxonomical information shared by two senses, Wu and Palmer (Reference Wu and Palmer1994) put forward the following measure:
 $$sim({s_1},{s_2}) = {{2 \cdot depth(LCS({s_1},{s_2}))} \over {depth({s_1}) + depth({s_2})}}$$
$$sim({s_1},{s_2}) = {{2 \cdot depth(LCS({s_1},{s_2}))} \over {depth({s_1}) + depth({s_2})}}$$
where the higher the LCS, the lower the similarity between s 1 and s 2.
Resnik. A more sophisticated approach was proposed by Resnik (Reference Resnik1995) who developed a notion of information content which determines the amount of information covered by a certain WordNet synset in terms of all its descendants (i.e., hyponyms). Formally, this similarity measure is computed as follows:
 $$sim({s_1},{s_2}) = IC(LCS({s_1},{s_2}))$$
$$sim({s_1},{s_2}) = IC(LCS({s_1},{s_2}))$$
where IC, that is, the information content, is defined as:
 $$IC(S) = - logP(S)$$
$$IC(S) = - logP(S)$$
where P(S) is the probability that a word, randomly selected within a large corpus, is an instance of a given synset S. Such probability is calculated as:
 $$P(S) = {{\sum\nolimits_{w \in words(S)} {count(w)} } \over N}$$
$$P(S) = {{\sum\nolimits_{w \in words(S)} {count(w)} } \over N}$$
where words(S) is the set of words contained in synset S and all its hyponyms, count(w) is the number of occurrences of w in the reference corpus and N is the total number of word tokens in the corpus.
Lin. A refined version of Resnik’s measure was put forward by Lin (Reference Lin1998) which exploits the information content not only of the commonalities, but also of the two senses individually. Formally:
 $$sim({s_1},{s_2}) = {{2 \cdot IC(LCS({s_1},{s_2}))} \over {IC({s_1}) + IC({s_2})}}$$
$$sim({s_1},{s_2}) = {{2 \cdot IC(LCS({s_1},{s_2}))} \over {IC({s_1}) + IC({s_2})}}$$
Jiang and Conrath. A variant of Lin’s measure that has been widely used in the literature is the following (Jiang and Conrath Reference Jiang and Conrath1997):
 $$sim({s_1},{s_2}) = {1 \over {IC({s_1}) + IC({s_2}) - 2 \cdot IC(LCS({s_1},{s_2}))}}$$
$$sim({s_1},{s_2}) = {1 \over {IC({s_1}) + IC({s_2}) - 2 \cdot IC(LCS({s_1},{s_2}))}}$$
Extended gloss overlaps or Extended Lesk. All of the above approaches are hinged on taxonomic information, which however is only a portion of the information that is provided in LKBs such as WordNet. Other kinds of relations can indeed be used, such as meronymy and pertainymy (cf. Section 3.1). To do this, Banerjee and Pedersen (Reference Banerjee and Pedersen2003) proposed an improvement of the Lesk algorithm (Lesk Reference Lesk1986), which has been used historically in WSD for determining the overlap between the textual definitions of two senses under comparison. The measure designed by Banerjee and Pedersen (Reference Banerjee and Pedersen2003) extends this idea by considering the overlap between definitions not only of the target senses, but also of their neighbouring synsets in the WordNet graph:
 $$sim({s_1},{s_2}) = \sum\limits_{r, r' \in R} \sum\limits_{s \in r({s_1})} \sum\limits_{s' \in r'({s_2})} overlap(gloss(s),gloss(s'))$$
$$sim({s_1},{s_2}) = \sum\limits_{r, r' \in R} \sum\limits_{s \in r({s_1})} \sum\limits_{s' \in r'({s_2})} overlap(gloss(s),gloss(s'))$$
where R is the set of lexical-semantic relations in WordNet, gloss is a function that provides the textual definition for a given synset (or sense), overlap determines the number of common words between two definitions and r(s) provides the set of the other endpoints of the relation edges of type r connecting s.
Wikipedia-based semantic relatedness. One of the advantages of using Wikipedia as opposed to WordNet is the former’s network of interlinked articles. A key hunch is that two articles are deemed similar if they are linked by a similar set of pages (Milne and Witten Reference Milne and Witten2008). Such similarity can be computed with the following formula:
 $$sim(a,b) = 1 - {{log(max(|in(a)|,|in(b)|)) - log(|in(a) \cap in(b)|)} \over {log(|W|) - log(min(|in(a)|,|in(b)|))}}$$
$$sim(a,b) = 1 - {{log(max(|in(a)|,|in(b)|)) - log(|in(a) \cap in(b)|)} \over {log(|W|) - log(min(|in(a)|,|in(b)|))}}$$
where a and b are two Wikipedia articles, in(a) is the set of articles linking to a,and W is the full set of Wikipedia articles. This measure aims at determining the degree of relatedness between two articles, nonetheless when the two articles are close enough (i.e., the value gets close to 1) the computed value can be considered a degree of similarity.
3.2.2 Recent developments
More recent knowledge-based approaches extract vector-based representations of meaning, which are then used to determine semantic similarity. Unlike previous techniques where the main form of linguistic knowledge representation was the LKB itself, in this case a second form of linguistic knowledge representation is involved, namely, a vector encoding. Accordingly, word and sense similarity is computed in two steps:
a vector-based word and sense representation is obtained by exploiting the structural information of an LKB.
the obtained vector representations are compared by applying a similarity measure.
In what follows we overview approaches to the first step, while deferring an introduction to similarity measures to Section 6.
Personalized PageRank-based representations . A key idea introduced in the scientific literature is the exploitation of Markov chains and random walks to determine the importance of nodes in the graph, and this was popularized with the PageRank algorithm (Page et al. Reference Page, Brin, Motwani and Winograd1998). In order to obtain probability distributions specific to a node, that is, a concept of interest, topic-sensitive or Personalized PageRank (PPR) (Haveliwala Reference Haveliwala2002) is employed for the calculation of a semantic signature for each WordNet synset (Pilehvar, Jurgens and Navigli Reference Pilehvar, Jurgens and Navigli2013).
Given the WordNet adjacency matrix M (possibly enriched with further edges, for example, from disambiguated WordNet glosses), the following formula is computed:
 $${v_t} = \alpha M{v_{t - 1}} + (1 - \alpha ){v_0}$$
$${v_t} = \alpha M{v_{t - 1}} + (1 - \alpha ){v_0}$$
where v 0 denotes the probability distribution for restart of the random walker in the network and α is the so-called damping factor (typically set to 0.85). The result of the computation of the above PageRank formula in the topic-sensitive setting (i.e., when v 0 is highly skewed) provides a distribution with most of the probability mass concentrated on the nodes, which are at easy reach from the nodes initialized for restart in v 0. Depending on how v 0 is initialized, an explicit semantic representation for a target word or sense can be obtained. For the target word w, it is sufficient to initialize the components of v 0 corresponding to the senses of w to 1/|Senses(w)| (i.e., uniformly distributed across the synsets of w in WordNet), and 0 for all other synsets. For computing a representation of a target sense s of a word w, v 0 is, instead, initialized to 1 on the corresponding synset, and 0 otherwise. An alternative approach has been proposed (Hughes and Ramage Reference Hughes and Ramage2007) which interconnects not only synsets, but also words and POS-tagged words. Some variants also link synset and words in their definition, and use sense-occurrence frequencies to weight edges. However, this approach is surpassed in performance by purely synset-based semantic signatures when using a suitable similarity measure (Pilehvar et al. Reference Pilehvar, Jurgens and Navigli2013).
4. Distributional word and sense similarity
Knowledge-based approaches can only be implemented if a lexical-semantic resource such as WordNet or BabelNet is available. A radically different approach which does not rely on structured knowledge bases exploits the statistical distribution of words occurring in corpora. The fundamental assumption behind distributional approaches is that the semantic properties of a given word w can be inferred from the contexts in which w appears. That is, the semantics of w is determined by all the other words which co-occur with it (Harris Reference Harris1954; Firth Reference Firth1957).
4.1 Corpora
Distributional approaches rely heavily on corpora, that is, large collections of raw textual data which can be leveraged effectively for computing semantic similarity. In fact, large-scale corpora reflect the behaviour of words in context, that is, they reveal a wide range of relationships between words, making them a particularly suitable resource from which to learn word distributions. These are then used to infer semantic properties and determine the extent of semantic similarity between two words.
The most widely employed corpora for word and sense similarity are:
Wikipedia, one of the largest multilingual corpora employed in several NLP tasks.
UMBC Footnote d (Han and Finin Reference Han and Finin2013), a Web corpus including more than three billion English words derived from the Stanford WebBase project.
ukWaC Footnote e (Ferraresi et al. Reference Ferraresi, Zanchetta, Baroni and Bernardini2008), a 2-billion word corpus constructed using the .uk domain and medium-frequency words from the British National Corpus.
GigaWord Footnote f (Graff et al. Reference Graff, Kong, Chen and Maeda2003), a large corpus of newswire text that has been acquired over several years by the Linguistic Data Consortium (LDC).
4.2 Distributional representations and measures
In the distributional approach, a vector representation typically encodes the behavioural use of specific words and/or senses. Two types of distributional representation can be distinguished:
Explicit representation, which refers to a form of representation in which every dimension can be interpreted directly (e.g., when words or senses are used as the meanings of the vector’s dimensions).
Implicit or latent representation, which encodes the linguistic information in a form which cannot be interpreted directly.
In the case of an explicit representation vector, given a word w and a vocabulary of size N, a feature vector specifies whether each vocabulary entry, that is, each word w′, occurs in the neighbourhood of w. The size of a feature vector can range from the entire vocabulary size, that is, N, to two dimensions referring to the words preceding and succeeding the target word w. In many cases, most frequent words, such as articles, are not included in feature vectors as they do not contain useful semantic information regarding a particular word. Given the feature vector of the target word w, its dimensions can be:
binary values, that is, 0 or 1 depending on whether a specific word co-occurs with the target word or not.
association and probabilistic measures which provide the score or probability that a specific word co-occurs with the target word.
A typical example of a binary-valued explicit vector representation is the so-called one-hot encoding of a word w, which is a unit vector (0, 0, …, 0, 1, 0, …, 0), where only the dimension corresponding to word w is valued with 1. Latent representations, such as embeddings, instead, encode features which are not human-readable and are not directly associated with linguistic items.
In the rest of this section we introduce the two types of representations.
4.2.1 Explicit representations
Early distributional approaches aimed at capturing semantic properties directly between words depending on their distributions. To this end, different measures were proposed in the literature.
Sørensen-Dice index , also known as Dice’s coefficient, is used to measure the similarity of two words. Formally:
 $$sim({w_1},{w_2}) = {{2{w_{1,2}}} \over {{w_1} + {w_2}}}$$
$$sim({w_1},{w_2}) = {{2{w_{1,2}}} \over {{w_1} + {w_2}}}$$
where wi is the number of occurrences of the corresponding word and w 1,2 is the number of co-occurrences of w 1 and w 2 in the same context (e.g., sentence).
Jaccard Index. Also known as Jaccard similarity coefficient, Jaccard Index (JI) is defined as follows:
 $$sim({w_1},{w_2}) = {{{w_{1,2}}} \over {{w_1} + {w_2} - {w_{1,2}}}}$$
$$sim({w_1},{w_2}) = {{{w_{1,2}}} \over {{w_1} + {w_2} - {w_{1,2}}}}$$
which has clear similarities to the Sørensen-Dice index defined above. This measure was used for detecting word and sense similarity by Grefenstette (Reference Grefenstette1994).
Pointwise Mutual Information. Given two words, the Pointwise Mutual Information (PMI) quantifies the discrepancy between their joint distribution and their individual distributions, assuming independence:
 $$PMI({w_1},{w_2}) = log{{p({w_1},{w_2})} \over {p({w_1})p({w_2})}} = log{{D \cdot c({w_1},{w_2})} \over {c({w_1})c({w_2})}}$$
$$PMI({w_1},{w_2}) = log{{p({w_1},{w_2})} \over {p({w_1})p({w_2})}} = log{{D \cdot c({w_1},{w_2})} \over {c({w_1})c({w_2})}}$$
where w 1 and w 2 are two words, c(wi ) is the count of wi , c(w 1, w 2) is the number of times the two words co-occur in a context and D is the number of contexts considered. This measure was introduced into NLP by Church and Hanks (Reference Church and Hanks1990).
Positive PMI. Because many entries of word pairs are never observed in a corpus, and therefore have their PMI equal to log 0 = −∞, a frequently used version of PMI is one in which all negative values are flattened to zero:
 $$PPMI({w_1},{w_2}) = \left\{ {\matrix{ {PMI({w_1},{w_2})} & {\quad {\rm{if}}PMI({w_1},{w_2}) > 0} \cr 0 & {\quad {\rm{otherwise}}} \cr } } \right.$$
$$PPMI({w_1},{w_2}) = \left\{ {\matrix{ {PMI({w_1},{w_2})} & {\quad {\rm{if}}PMI({w_1},{w_2}) > 0} \cr 0 & {\quad {\rm{otherwise}}} \cr } } \right.$$
PPMI is among the most popular distributional similarity measures in the NLP literature.
The above association measures can be used to populate an explicit representation vector in which each component values the correlation strength between the word represented by the vector and the word identified by the component.
We now overview an approach that uses concepts as a word’s vector components.
Explicit Semantic Analysis . An effective method, called Explicit Semantic Analysis (ESA), encodes semantic information in the word vector’s components starting from Wikipedia (Gabrilovich and Markovitch Reference Gabrilovich and Markovitch2007). The dimensionality of the vector space is given by the set of Wikipedia pages and the vector vw for a given word w is computed by setting its i-th component vw,i to the TF-IDF of w in the i-th Wikipedia page pi . Formally:
 $${v_{w,i}} = {\rm{TF}} - {\rm{IDF}}(w,{p_i}) = tf(w,{p_i}) \cdot log{N \over {{N_w}}}$$
$${v_{w,i}} = {\rm{TF}} - {\rm{IDF}}(w,{p_i}) = tf(w,{p_i}) \cdot log{N \over {{N_w}}}$$
where pi is the i-th page in Wikipedia, tf (w, pi ) is the frequency of w in page pi , N is the total number of Wikipedia pages and Nw is the number of Wikipedia pages in which w occurs.
It has been shown that using Wiktionary instead of Wikipedia leads to higher results in semantic similarity and relatedness (Zesch et al. Reference Zesch, Müller and Gurevych2008).
4.2.2 Implicit or latent representations
Latent Semantic Analysis . Latent Semantic Analysis (LSA) (Deerwester et al. Reference Deerwester, Dumais, Furnas and Harshman1990) is a technique used for inferring semantic properties of linguistic items starting from a corpus. A term-passage matrix is created whose rows correspond to words and whose columns correspond to passages in the corpus where words occur. At the core of LSA lies the singular value decomposition of the term-passage matrix which decomposes it into the product of three matrices. The dimensionality of the decomposed matrices is then reduced. As a result, latent representations of terms and passages are produced and comparisons between terms can be performed by just considering the rows of the lower-ranking term-latent dimension matrix.
Word embeddings. In the last few years, LSA has been superseded by neural approaches aimed at learning latent representations of words, called word embeddings. Different embedding techniques have been developed and refined. Earliest approaches representing words by means of continuous vectors date back to the late 1980s (Rumelhart, Hinton, and Williams Reference Rumelhart, Hinton and Williams1988). A wellknown technique which aims at acquiring distributed real-valued vectors as a result of learning a language model was put forward by Bengio (Reference Bengio, Ducharme, Vincent and Jauvin2003). Collobert (Reference Collobert, Weston, Bottou, Karlen, Kavukcuoglu and Kuksa2011) proposed a unified neural network architecture for various NLP tasks. More recently, Mikolov (Reference Mikolov, Chen, Corrado and Dean2013) proposed a simple technique which speeds up the learning and has proven to be very effective.
Word2vec. Undoubtedly, the most popular yet simple approach to learning word embeddings is called word2vec (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013). Footnote g As in all distributional methods, the assumption behind word2vec is that the meaning of a word can be inferred effectively using the context in which that word occurs. Word2vec is based on a two-layer neural network which takes a corpus as input and learns vector-based representations for each word. Two variants of word2vec have been put forward:
(1) continuous bag of words (CBOW), which exploits the context to predict a target word;
(2) skip-gram, which, instead, uses a word to predict a target context word.
Focusing on the skip-gram approach, for each given target word wt , the objective function of the neural network is set to maximize the conditional probabilities of the words surrounding wt in a window of m words. Formally, the following log likelihood is calculated:
 $$J(\theta ) = - {1 \over T}\sum\limits_{t = 1}^T \sum\limits_{ - m \le j \le m{\kern 1pt} :{\kern 1pt} j \ne 0} log(p({w_{t + j}}|{w_t}))$$
$$J(\theta ) = - {1 \over T}\sum\limits_{t = 1}^T \sum\limits_{ - m \le j \le m{\kern 1pt} :{\kern 1pt} j \ne 0} log(p({w_{t + j}}|{w_t}))$$
where T is the number of words in the training corpus and θ are the embedding parameters. Word2vec can be viewed as a close approximation of traditional window-based distributional approaches.
A crucial feature of word2vec consists in preserving relationships between vectors such as analogy. For instance, London UK + Italy should be very close to Rome. Standard word2vec embeddings are available in English, obtained from the Google News dataset. Embeddings for dozens of languages can also be derived from Wikipedia or other corpora.
fastText. Recently, an extension of word2vec’s skip-gram model called fastText Footnote h has been proposed which integrates subword information (Joulin et al. Reference Joulin, Grave, Bojanowski and Mikolov2017). A key difference between fastText and word2vec is that the former is capable of building vectors for misspellings or out-of-vocabulary words. This is taken into account thanks to encoding words as a bag of character n-grams (i.e., substrings of length n) together with the word itself. For instance, to encode the word table, the following 3-grams are considered: { <ta, tab, abl, ble, le > } ∪ { <table > }. Thanks to this, compared to the standard skip-gram model, the input vocabulary includes the word and all the n-grams that can be calculated from it. As a result, the meanings of prefixes and suffixes are also considered in the final representation, therefore reducing data sparsity. fastText provides ready sets of embeddings for around 300 languages, which makes it appealing for multilingual processing of text. Footnote i
GloVe. A key difference between LSA and word2vec is that the latter produces latent representations with the useful property of preserving analogies, therefore indicating appealing linear substructures of the word vector space, whereas the former takes better advantage of the overall statistical information present in the input documents. However, the advantage of either approach is the drawback of the other. GloVe (Global Vectors) Footnote j addresses this issue by performing unsupervised learning of latent word vector representations starting from global word–word co-occurrence information (Pennington, Socher, and Manning Reference Pennington, Socher and Manning2014). At the core of the approach is a counting method which calculates a co-occurrence vector counti for a word wi with its j-th component counting the times wj co-occurs with wi within a context window of a certain size, where each individual count is weighted by 1/d, and d is the distance between the two words in the context under consideration. The key constraint put forward by GloVe is that, for any two words wi and wj :
 $$v_i^T{v_j} + {b_i} + {b_j} = log(coun{t_{i,j}})$$
$$v_i^T{v_j} + {b_i} + {b_j} = log(coun{t_{i,j}})$$
where vi and vj are the embeddings to learn and bi and bj are scalar biases for the two words. A least square regression model is then calculated which aims at learning latent word vector representations such that the loss function is driven by the above soft constraint for any pair of words in the vocabulary:
 $$J = \sum\limits_{i = 1}^V \sum\limits_{j = 1}^V f(coun{t_{i,{\kern 1pt} j}})(w_i^T{w_j} + {b_i} + {b_j} - log(coun{t_{i,{\kern 1pt} j}}{))^2}$$
$$J = \sum\limits_{i = 1}^V \sum\limits_{j = 1}^V f(coun{t_{i,{\kern 1pt} j}})(w_i^T{w_j} + {b_i} + {b_j} - log(coun{t_{i,{\kern 1pt} j}}{))^2}$$
where f (counti, j ) is a weighting function that reduces the importance of overly frequent word pairs and V is the size of the vocabulary. While both word2vec and GloVe are popular approaches, a key difference between the two is that the former is a predictive model, whereas the latter is a count-based model. While it has been found that standard count-based models such as LSA fare worse than word2vec (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013; Baroni, Dinu, and Kruszewski Reference Baroni, Dinu and Kruszewski2014), Levy and Goldberg (Reference Levy and Goldberg2014) showed that a predictive model such as word2vec’s skip-gram is essentially a factorization of a variant of the PMI co-occurrence matrix of the vocabulary, which is countbased. Experimentally, there is contrasting evidence as to the superiority of word2vec over GloVe, with varying (and, in several cases, not very different) results.
SensEmbed. Word embeddings conflate different meanings of a word into a single vector-based representation and are therefore unable to capture polysemy. In order to address this issue, Iacobacci et al. (Reference Iacobacci, Pilehvar and Navigli2015) proposed an approach for obtaining embedded representations of word senses called sense embeddings. To this end, first, a text corpus is disambiguated with a state-of-the-art WSD system, that is, Babelfy (Moro et al. Reference Moro, Raganato and Navigli2014); second, the disambiguated corpus is processed with word2vec, in particular with the CBOW architecture, in order to produce embeddings for each sense of interest.
AutoExtend. An alternative approach put forward by Rothe and Schütze (Reference Rothe and Schütze1995) takes into account the interactions and constraints between words, senses and synsets, as made available in the WordNet LKB, and – starting from arbitrary word embeddings – acquires the latent, embedded representations of senses and synsets by means of an autoencoder neural architecture, where word embeddings are at the input and output layers and the hidden layer provides the synset embeddings.
Contextual Word Embeddings. Recent approaches exploit the distribution of words to learn latent encodings which represent word occurrences in a given context. Two prominent examples of such approaches are ELMo (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018) and BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018). These approaches can be employed for tasks such as question answering, textual entailment and semantic role labelling, but also in tasks such as Word in Context (WiC) similarity (Pilehvar and Camacho-Collados Reference Pilehvar and Camacho-Collados2019). While such approaches could potentially be used to produce word representations based on the vectors output at their first layer, their main goal is to work on contextualized linguistic items.
5. Hybrid word and sense similarity
Recently, some approaches have been put forward which bring together knowledge-based and distributional similarity by combining the knowledge provided in LKBs and the occurrence information obtained from texts. The key advantage of such approaches is their ability to embed words and meanings in the same vector space model.
Salient Semantic Analysis . A development along the lines of Explicit Semantic Analysis (cf. Section 4.2.1) has been put forward which exploits the hyperlink information in Wikipedia pages to determine the salience of concepts (Hassan and Mihalcea Reference Hassan and Mihalcea2011). Specifically, given a Wikipedia page and a hyperlink, all the occurrences of its surface form (i.e., the hyperlinked text) are searched across the page and the sense annotations propagated to those occurrences. Additional non-linked phrases in the page are tagged with a Wikification system. A semantic profile for each page is then created by building a PMI vector of the co-occurrences of each term with the concept of interest in the entire Wikipedia corpus. Since Salient Semantic Analysis relies not only on the distribution of words occurring in Wikipedia pages, but also on the usage of the Wikipedia sense inventory and the manual linking of salient concepts to Wikipedia pages, this technique can be considered both distributional and knowledge-based.
Novel Approach to a Semantically-Aware Representation of Items. As described previously, a knowledge-based approach such as PPR obtains a vector representation for each synset in a WordNet-like graph, which contains semantic information consisting mostly of a prescribed nature, that is, the kind of information that can be found in a dictionary. Instead, to create vectors that account for descriptive information about the concept of interest, a Novel Approach to a Semantically-Aware Representation of Items (NASARI) has been put forward by Camacho-Collados et al. (Reference Camacho-Collados, Pilehvar and Navigli2016). This approach exploits the distributional semantics of texts which describe the concept. For this purpose, given a target concept c = (p, S) identified by the pair of Wikipedia page p and WordNet synset S which are linked in BabelNet (cf. Section 3.1), two steps are carried out. First, the contextual information for c is collected according to the following equation:
 $${{\cal T}_{\rm{c}}} = {{\cal L}_{\rm{p}}} \cup {\cal B}({{\cal R}_{\rm{S}}})$$
$${{\cal T}_{\rm{c}}} = {{\cal L}_{\rm{p}}} \cup {\cal B}({{\cal R}_{\rm{S}}})$$
where 𝒯c is the contextual information for a specific concept c = (p, S), ℒp is the set of Wikipedia pages containing the page p and all the pages pointing to p, ℬ is a function which maps each WordNet synset S to the corresponding Wikipedia page p, ℛS is a set of synsets which contains S and all its related, that is, connected, synsets. Second, the contextual information 𝒯 c is encoded in a lexical vector representation. After tokenization, lemmatization and stopword removal, a bag of words is created from the Wikipedia pages in ℒp. Lexical specificity is used for the identification of the most characteristic words in the bag of words extracted (Lafon Reference Lafon1980). As a result, a lexical vector is created which represents c.
In order to overcome the sparseness which can occur in such lexical vector representation, two additional versions of NASARI vectors are provided:
semantic vectors: a synset-based representation is created whose dimensions are not potentially ambiguous words, but concepts (represented by synsets): for each word w in the bag of words of concept c, the set of all hypernyms in common between pairs of words in the vector is considered (e.g., table, lamp and seat are grouped under the hypernym { furniture, piece of furniture, article of furniture }) and encoded in a single dimension represented by that common hypernym. Finally, lexical specificity is calculated in order to determine the most relevant hypernyms that have to be encoded in the vector representation. The weight associated with each semantic dimension is determined by computing lexical specificity on the words grouped by each hypernym as if they were a single word in the underlying texts.
embedded vectors: an alternative representation, which is latent and compact, rather than explicit like the semantic vectors, is also provided in the NASARI framework. Starting from the lexical vector vlex (S) of a synset S, the embedded vector e(S)of S is computed as the weighted average of the embeddings of the words in the lexical vector. Formally:
(22) $$e(s) = {{\sum\nolimits_{w \in {v_{lex}}(S)} {rank{{(w,{v_{lex}}(S))}^{ - 1}}e(w)} } \over {\sum\nolimits_{w \in {v_{lex}}(S)} {rank{{(w,{v_{lex}}(S))}^{ - 1}}} }}$$
$$e(s) = {{\sum\nolimits_{w \in {v_{lex}}(S)} {rank{{(w,{v_{lex}}(S))}^{ - 1}}e(w)} } \over {\sum\nolimits_{w \in {v_{lex}}(S)} {rank{{(w,{v_{lex}}(S))}^{ - 1}}} }}$$
where e(w) is the word embedding (e.g., a word2vec embedding) of w and rank(w, vlex (S)) is the ranking of word w in the sorted vector vlex (S).

DeConf. The main idea behind de-conflated semantic representations (DeConf) (Pilehvar and Collier Reference Pilehvar and Collier2016) is to develop a method for obtaining a semantic representation which embeds word senses into the same semantic space of words, analogously to the NASARI embedded vectors. At the core of this approach lies the computation of a list of sense-biasing words for each word sense of interest which is used to ‘bend’ the sense representations in the right direction. Specifically, DeConf is computed in two steps:
identification of sense-biasing words, that is, a list of words is extracted from WordNet which most effectively represent the semantics of a given synset S. Such list is obtained by, first, applying the PPR algorithm to the WordNet graph with restart on S and, second, progressively adding new words from the WordNet synsets sorted in descending order by their PPR probability.
learning a sense representation, calculated for a target sense s of a word w as follows:
(23)
$${v_s} = {{\alpha {v_w} + \sum\nolimits_{b \in {B_s}} {{\delta _s}(b){v_b}} } \over {\alpha + \sum\nolimits_{b \in {B_s}} {{\delta _s}(b)} }}$$
whose numerator is an average of the word embedding vw weighted with a factor α and the embeddings of the various words in the list Bs of sense-biasing words calculated as a result of the first step, and weighted with a function δs (b) of their ranking in the list.

6. Measures for comparing vector-based representations
In this section, we focus on the main measures which are employed widely whenever two or more vector-based representations have to be compared for determining the degree of semantic similarity. The following measures are used in knowledge-based and distributional approaches, whenever they resort to vector-based representations.
Cosine similarity. Widely used for determining the similarity between two vectors, the cosine similarity is formalized as follows:
 $$sim({w_1},{w_2}) = {{{w_1} \cdot {w_2}} \over {\parallel {w_1}\parallel \parallel {w_2}\parallel }} = {{\sum\limits_{i = 1}^n {w_{1{\rm{i}}}}{w_{2{\rm{i}}}}} \over {\sqrt {\sum\limits_{i = 1}^n w_{1{\rm{i}}}^{{\kern 1pt} {\kern 1pt} {\kern 1pt} 2}} \sqrt {\sum\limits_{i = 1}^n w_{2{\rm{i}}}^{{\kern 1pt} {\kern 1pt} {\kern 1pt} 2}} }}$$
$$sim({w_1},{w_2}) = {{{w_1} \cdot {w_2}} \over {\parallel {w_1}\parallel \parallel {w_2}\parallel }} = {{\sum\limits_{i = 1}^n {w_{1{\rm{i}}}}{w_{2{\rm{i}}}}} \over {\sqrt {\sum\limits_{i = 1}^n w_{1{\rm{i}}}^{{\kern 1pt} {\kern 1pt} {\kern 1pt} 2}} \sqrt {\sum\limits_{i = 1}^n w_{2{\rm{i}}}^{{\kern 1pt} {\kern 1pt} {\kern 1pt} 2}} }}$$
where w 1 and w 2 are two vectors to be compared. The above formula determines the closeness of the two vectors by calculating the dot product between them divided by their norms.
Weighted overlap. This measure (Camacho-Collados et al. Reference Camacho-Collados, Pilehvar and Navigli2016) compares the similarity between vectors in two steps. First, a ranking of the dimensions of each vector is calculated. Such ranking considers only dimensions with values different from 0 for both vectors, assigning higher scores to more relevant dimensions. Second, it sums the ranking of the two vectors normalized by a factor which computes the best rank pairing. The weighted overlap is formalized as follows:
 $$WO({v_1},{v_2}) = {{\sum\nolimits_{q \in O} {{{(r_q^1 + r_q^2)}^{ - 1}}} } \over {\sum\nolimits_{i = 1}^{|O|} {{{(2i)}^{ - 1}}} }}$$
$$WO({v_1},{v_2}) = {{\sum\nolimits_{q \in O} {{{(r_q^1 + r_q^2)}^{ - 1}}} } \over {\sum\nolimits_{i = 1}^{|O|} {{{(2i)}^{ - 1}}} }}$$
where O indicates the set of overlapping dimensions and
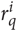 $r_q^i$
refers to the ranking of the q-th dimension of vector vi
(i ∈{1, 2}). While cosine similarity is applicable to both latent and explicit vectors, Weighted Overlap is suitable only for explicit and potentially sparse vectors which have humaninterpretable components, like in the knowledge-based vector representations produced with PPR or NASARI (see Sections 3.2.2 and 5).
$r_q^i$
refers to the ranking of the q-th dimension of vector vi
(i ∈{1, 2}). While cosine similarity is applicable to both latent and explicit vectors, Weighted Overlap is suitable only for explicit and potentially sparse vectors which have humaninterpretable components, like in the knowledge-based vector representations produced with PPR or NASARI (see Sections 3.2.2 and 5).
7. Evaluation
We now describe how to evaluate and compare measures for word and sense similarity. We distinguish between:
in vitro or intrinsic evaluation, that is, by means of measures that assess the quality of the similarity compared to human judgments (Section 7.1), and
in vivo or extrinsic evaluation, that is, where the quality of a similarity approach is evaluated by measuring the impact on the performance of an application when integrating such approach therein (Section 7.2).
In vitro evaluation may suffer from several issues, such as the subjectivity of the annotation and the representativeness of the dataset. In contrast, in vivo evaluation is ideal, in that it shows a clear effectiveness on a separate application.
7.1 In vitro evaluation
We introduce the key measures used in the literature in Section 7.1.1 and overview several manually annotated datasets to which the measures are applied in Section 7.1.2.
7.1.1 Measures
The quality of a semantic similarity measure, be it knowledge-based or distributional, is estimated by computing a correlation coefficient between the similarity results obtained with the measure and those indicated by human annotators. Different measures can be employed for determining the correlation between variables. The two most common correlation measures are: Pearson’s coefficient and Sperman’s rho coefficient.
Pearson correlation coefficient. The Pearson correlation coefficient, also called Pearson productmomentum correlation coefficient, is a popular measure employed for computing the degree of correlation between two variables X and Y:
 $$r = {{cov(X,Y)} \over {{\sigma _X}{\sigma _Y}}}$$
$$r = {{cov(X,Y)} \over {{\sigma _X}{\sigma _Y}}}$$
where cov(X, Y) is the covariance between X and Y, and σX is the standard deviation of X (analogously for Y). For a dataset of n word pairs for which the similarity has to be calculated, the following formula is computed:
 $$r = {{\sum\nolimits_{i = 1}^n {({x_i} - \overline x )({y_i} - \overline y )} } \over {\sqrt {\sum\nolimits_{i = 1}^n {{{({x_i} - \overline x )}^2}} } \sqrt {\sum\nolimits_{i = 1}^n {{{({y_i} - \overline y )}^2}} } }}$$
$$r = {{\sum\nolimits_{i = 1}^n {({x_i} - \overline x )({y_i} - \overline y )} } \over {\sqrt {\sum\nolimits_{i = 1}^n {{{({x_i} - \overline x )}^2}} } \sqrt {\sum\nolimits_{i = 1}^n {{{({y_i} - \overline y )}^2}} } }}$$
where the dataset is made up of n word pairs
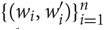 $\{ ({w_i},{w'_i})\} _{i = 1}^n$
, xi
is the similarity between wi
and w′
i
computed with the similarity measure under evaluation, yi
is the similarity provided by the human annotators for the same word pair and
$\{ ({w_i},{w'_i})\} _{i = 1}^n$
, xi
is the similarity between wi
and w′
i
computed with the similarity measure under evaluation, yi
is the similarity provided by the human annotators for the same word pair and
 $\overline x$
is the mean of all values xi
.
$\overline x$
is the mean of all values xi
.
Spearman’s rank correlation. In determining the effectiveness of word similarity, the Pearson correlation coefficient has sometimes been criticized because it determines how well the similarity measure fits the values provided in the gold-standard, humanly produced datasets. However, it is suggested that for similarity it might be more important to determine how well the ranks of the similarity values correlate, which makes the measure non-parametric, that is, independent of the underlying distribution of the data. This can be calculated with Spearman’s rank correlation, which is Pearson’s coefficient applied to the ranked variables rankX and rankY of X and Y. Given a dataset of n word pairs as above, the following formula can be computed:
 $$\rho = 1 - {{6\sum\nolimits_{i = 1}^n {{{(rank({x_i}) - rank({y_i}))}^2}} } \over {n({n^2} - 1)}}$$
$$\rho = 1 - {{6\sum\nolimits_{i = 1}^n {{{(rank({x_i}) - rank({y_i}))}^2}} } \over {n({n^2} - 1)}}$$
where rank(xi ) is the rank value of the i-th item according to the similarity measure under evaluation and rank(yi ) is the rank value of the same item according to the overall ranking of similarity scores provided by human annotators in the evaluation dataset.
7.1.2 Datasets
Several datasets have been created as evaluation benchmarks for semantic similarity. Here we overview the most popular of these datasets.
Rubenstein & Goodenough (RG-65) and its translations . A dataset made up of 65 pairs of nouns selected to cover several types of semantic similarities was created by Rubenstein and Goodenough (Reference Rubenstein and Goodenough1965). Annotators were asked to assign each pair with a value between 0.0 and 4.0 where the higher the score, the higher the similarity. Due to the paucity of datasets in languages other than English, some of these datasets have been entirely or partially translated into various languages obtaining similar scores, including German (Gurevych Reference Gurevych2005), French (Joubarne and Inkpen Reference Joubarne and Inkpen2011), Spanish (Camacho-Collados, Pilehvar, and Navigli Reference Camacho-Collados, Pilehvar and Navigli2015), Portuguese (Granada, Trojahn, and Vieira Reference Granada, Trojahn and Vieira2014) and many other languages (Bengio et al. 2018).
Miller & Charles (MC-30). From these 65 word pairs, Miller and Charles (Reference Miller and Charles1991) selected a subset of 30 noun pairs, dividing it into three categories depending on the degree of similarity. Annotators were asked to evaluate the similarity of meaning, thus producing a new set of ratings.
WordSim-353 . To make available a larger evaluation dataset, Finkelstein et al. (Reference Finkelstein, Gabrilovich, Matias, Rivlin, Solan, Wolfman and Ruppin2002) elaborated a list of 353 pairs of nouns representing different degrees of similarity. To distinguish between similarity and relatedness pairs and set a level playing field in the evaluation of approaches which perform best in one of the two directions, WordSim-353 was divided into two sets (Agirre et al. Reference Agirre, Alfonseca, Hall, Kravalova, Paşca and Soroa2009), one containing 203 similar pairs of nouns (WordSim-203) and one containing 252 related nouns (WordRel-252). Footnote k
BLESS . One of the first datasets specifically designed to intrinsically test the quality of distributional space models is BLESS. This dataset includes 200 distinct English nouns and, for each of these, several semantically related words (Baroni and Lenci Reference Baroni and Lenci2011).
Yang and Powers (YP). Because traditional datasets work with noun pairs, Yang and Powers (Reference Yang and Powers2006) released a verb similarity dataset which includes a total of 144 pairs of verbs.
SimVerb-3500. To provide a larger and more comprehensive gold standard dataset for verb pairs, Gerz et al. (Reference Gerz, Vulić, Hill, Reichart and Korhonen2016) produced a resource providing scores for 3500 verb pairs.
MEN. Bruni et al. (Reference Bruni, Tran and Baroni2014) released a dataset of 3,000 word pairs with semantic relatedness ratings in the range [0, 1], obtained by crowdsourcing using Amazon Mechanical Turk.
Rel-122. A further dataset for semantic similarity was proposed by Szumlanski (Reference Szumlanski, Gomez and Sims2013) who compiled a new set including 122 pairs of nouns.
SimLex-999. One of the largest resources providing word similarity scores was produced by Hill (Reference Hill, Reichart and Korhonen2015). This dataset distinguishes clearly between similarity and relatedness by assigning related items with lower scores. Furthermore, it contains a large and differentiated set of adjectives, nouns and verbs, thus enabling a fine-grained evaluation of the performance.
Cross-lingual datasets. Camacho-Collados et al. (Reference Camacho-Collados, Pilehvar and Navigli2015) addressed the issue of comparing words across languages by providing fifteen cross-lingual datasets which contain items for any pair of the English, French, German, Spanish, Portuguese and Farsi languages. More data aimed at multilingual and cross-lingual similarity were made available at SemEval-2017 (Camacho-Collados, Pilehvar, and Navigli Reference Camacho-Collados, Pilehvar and Navigli2017).
7.2 In vivo evaluation
An alternative way of evaluating and comparing semantic similarity measures is by integrating them into an end-to-end application and then measuring the performance change (hopefully, the improvement) of the latter compared to the baseline performance. Word and sense similarity are, indeed, intermediate tasks that lend themselves to the integration into an application. Among the most popular applications we cite:
(1) Information retrieval: word similarity has been applied historically to Information Retrieval (IR) since the development of the SMART system (Salton and Lesk Reference Salton and Lesk1968). More recent work performs IR using ESA (Gabrilovich and Markovitch Reference Gabrilovich and Markovitch2007), or employs similarity in geographic IR (Janowicz, Raubal, and Kuhn Reference Janowicz, Raubal and Kuhn2011), in semantically enhanced IR (Hliaoutakis et al. Reference Hliaoutakis, Varelas, Voutsakis, Petrakis and Milios2006) and domain-oriented IR (Ye et al. Reference Ye, Shen, Ma, Bunescu and Liu2016).
(2) Text classification: word similarity has also been used for classification since the early days (Rocchio Reference Rocchio1971). More recently, word embeddings have been used to compute the similarity between words in the text classification task (Liu et al. Reference Liu, Huang, Gao, Wei, Tian and Liu2018). Topical word, that is, contextbased, representations (Liu et al. Reference Liu, Liu, Chua and Sun2015) and bag-of-embeddings representations (Jin et al. Reference Jin, Zhang, Chen and Xia2016) have also been proposed which achieve performance improvement in text classification: NASARI embeddings have been used to create rich representations of documents and perform an improved classification of text (Sinoara et al. Reference Sinoara, Camacho-Collados, Rossi, Navigli and Rezende2019).
(3) Word sense disambiguation: in order to choose the right sense of a given word, the similarity between sense vector representations, such as those available in NASARI, and the other words in the context has been computed (Camacho-Collados et al. Reference Camacho-Collados, Pilehvar and Navigli2016). Word similarity has been employed also in the context of word sense induction, that is, the task of automatically determining the senses of words (Schütze Reference Schütze1998), with the creation of the so-called multi-prototype embeddings (Tian et al. 2014; Liu et al. Reference Liu, Liu, Chua and Sun2015; Pelevina et al. Reference Pelevina, Arefyev, Biemann and Panchenko2016).
(4) Text summarization: word similarity has been used to determine the correlation between summary pairs (Lin and Hovy Reference Lin and Hovy2003).
(5) Machine translation: word similarity has been proposed as a tool to improve the wellknown issues with the n-gram overlap-based evaluation performed with the BLEU score (Banerjee and Lavie Reference Banerjee and Lavie2005; Castillo and Estrella Reference Castillo and Estrella2012).
(6) Synonym identification: word and sense similarity have been used in the literature (Pilehvar et al. Reference Pilehvar, Jurgens and Navigli2013) to determine the best synonym in the TOEFL synonymy recognition task (Landauer and Dumais Reference Landauer and Dumais1997).
(7) Coreference resolution: word similarity has been used for anaphora resolution (Gasperin and Vieira Reference Gasperin and Vieira2004); in a more complex coreference resolution system, measures of semantic relatedness have been used as features for classifying referring expressions (Strube and Ponzetto Reference Strube and Ponzetto2006).
(8) Malapropism detection: semantic similarity has been employed to detect and correct malapropisms (Budanitsky and Hirst Reference Budanitsky and Hirst2006), that is, real-word spelling errors.
(9) Dictionary linking: a key effort in electronic lexicography and related fields concerns linking dictionary entries. This can be done by determining the similarity between senses in different entries of two dictionaries (Pilehvar, Jurgens, and Navigli Reference Pilehvar, Jurgens and Navigli2014). In like manner, sense clustering can be performed to reduce the dictionary granularity based on semantic similarity between concepts (Navigli Reference Navigli2006).
8. Conclusions and future directions
Similarity is at the core of NLP, in that all kinds of linguistic items need to be compared to perform tasks at all levels. In this article we have provided an overview of semantic similarity at the word and sense level. We have introduced the two main approaches to similarity, that is, the knowledge-based approach and the distributional approach, including recent developments based on neural networks, and we have described the various evaluation settings, including the most popular datasets in the field.
The reader might be wondering when and why sense representations should be preferred over word representations. There are several points to consider when facing this choice, which are the following:
(1) sense representations are preferable in any case if they improve the performance in word similarity tasks (cf. Section 7).
(2) sense representations provide linkage to existing lexical knowledge resources such as WordNet and BabelNet, in some cases performing disambiguation implicitly (Pilehvar et al. Reference Pilehvar, Jurgens and Navigli2013; Camacho-Collados et al. Reference Camacho-Collados, Pilehvar and Navigli2016).
(3) meaning representations often enable multilingual or cross-lingual similarity without the need either to retrain the word embeddings or to use bilingual/multilingual lexical embeddings, which work well with predominant senses, but less so with infrequent meanings.
There are several promising directions in which word and sense similarity can develop. The first, and probably the most important, is multilinguality: being able to compare linguistic items in multiple languages is still understudied, even though recent developments in bilingual and multilingual embeddings are very promising (Ammar et al. Reference Ammar, Mulcaire, Tsvetkov, Lample, Dyer and Smith2016; Smith et al. Reference Smith, Turban, Hamblin and Hammerla2017; Conneau et al. 2018). More interestingly, being able to contrast words and senses across languages, that is, by pairing items in different languages, might boost current new developments in fields such as machine translation (Lample et al. Reference Lample, Ott, Conneau, Denoyer and Ranzato2018; Artetxe, Labaka, and Agirre Reference Artetxe, Labaka and Agirre2018).
A second important direction is the creation of solid benchmarks for evaluating linguistic items at different levels. Currently, there are several datasets of different types. Unfortunately, not all datasets contain the same kind of information. For instance, some are more geared towards measuring the degree of similarity between pairs, while still others more towards relatedness, others mix the two kinds of correlation in the same data. It is not obvious whether a solid in-vitro evaluation benchmark would be better than a single effective end-to-end application, probably because similarity measures tend to behave differently depending on the task and the nature of the data under study.
Importantly, we have seen that similarity is in many cases achieved with two ingredients: an effective representation of the linguistic item and a measure that exploits that representation to determine similarity. As the two main approaches to similarity tend to use different kinds of information, we believe strongly that a key further research direction should be to achieve a tighter integration of knowledge with distributional semantics, that is, to enhance neural architectures with explicit knowledge. This can be achieved, on the one hand, by leveraging multilingual lexicalsemantic knowledge resources such as BabelNet, and, on the other hand, by learning relationships between distributional information in multiple languages, such as multilingual embeddings which share the same semantic vector space.
A final important direction, related to the above point, concerns the adaptability of the similarity approaches to different domains, tasks and applications. This direction is underexplored and calls for more investigation in order to establish the extent to which representations and measures have to be adapted to each new need (Bollegala, Maehara, and Kawarabayashi Reference Bollegala, Maehara and Kawarabayashi2015; Prathusha, Liang, and Sethares Reference Prathusha, Liang and Sethares2018; Yang, Lu, and Zheng Reference Yang, Lu and Zheng2019).
9. Further reading
For additional information on the topic, we refer the reader to other surveys in word similarity (Mihalcea, Corley, and Strapparava Reference Mihalcea, Corley and Strapparava2006) and relatedness (Zhang, Gentile, and Ciravegna Reference Zhang and Ciravegna2013), word and sense embeddings (Camacho-Collados and Pilehvar Reference Camacho-Collados and Pilehvar2018) and semantic vector space models (Turney and Pantel Reference Turney and Pantel2010).
Acknowledgements
This work was funded by the ELEXIS project (contract no. 731015) under the European Union’s Horizon 2020 research and innovation programme.


 Open access
Open access