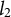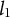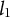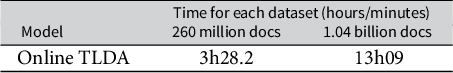1 Introduction
We propose a new method to estimate topic models that is feasible on large-scale data that has theoretical accuracy guarantees. Our approach leverages theoretical insights from Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013) that show that a spectral decomposition approach to topic models scales to large datasets and possesses desirable theoretical properties, such as provable, accurate recovery of the parameters and large-sample consistency. To achieve scale, we show that by demeaning and batching the data, our method estimates topic model outputs for large-scale documents and recovers the same model as Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013), endowing it with the same theoretical guarantees. This approach has many benefits for political scientists, who have used topic modeling methods to study important questions across the discipline, such as studies using text data to study new questions concerning political behavior (Barberá et al. Reference Barberá, Jost, Nagler, Tucker and Bonneau2015; Metzger et al. Reference Metzger, Bonneau, Nagler and Tucker2016; Munger Reference Munger2017) and public opinion (Barberá Reference Barberá2015; Barberá et al. Reference Barberá2019). Text data has been important for new advances in analyzing the evolution of protest movements and social protests (Kann et al. Reference Kann, Hashash, Steinert-Threlkeld and Michael Alvarez2023; Larson et al. Reference Larson, Nagler, Ronen and Tucker2019; Steinert-Threlkeld Reference Steinert-Threlkeld2017; Tillery Reference Tillery2019). New methods for analyzing text data and more accessible data have allowed researchers to explore political communications, agenda setting, and the news media (Barberá et al. Reference Barberá, Boydstun, Linn, McMahon and Nagler2021; Gilardi et al. Reference Gilardi, Kubli, Gessler and Müller2022).
In this article, we contribute to a rich line of methodological research in political science that has innovated and proposed clever frameworks to meet the needs of applied researchers across a wide variety of domains. From best practices and research design frameworks for how to incorporate text (Grimmer and Stewart Reference Grimmer and Stewart2013; Gilardi et al. Reference Gilardi, Kubli, Gessler and Müller2022; King and Hopkins Reference King and Hopkins2010), to approaches to unsupervised methods (Denny and Spirling Reference Denny and Spirling2018), political methodologists are guiding the field in how to best approach this high-dimensional data. Researchers have also introduced new tools for political scientists, including topic models which incorporate metadata (Roberts et al. Reference Roberts2014), computer-assisted techniques in processing texts in both clustering and in comparative settings (Grimmer and King Reference Grimmer and King2011; Lucas et al. Reference Lucas, Nielsen, Roberts, Stewart, Storer and Tingley2015), lexical feature selection (Monroe, Colaresi, and Quinn Reference Monroe, Colaresi and Quinn2017), and crowd-sourcing approaches to measure sophistication (Benoit, Munger, and Spirling Reference Benoit, Munger and Spirling2019). For example, in this article, we study two large-scale political science datasets. First, we study a dataset composed of tweets generated before and during the #MeToo movement to better understand the evolution of collective action and protest movements. The Women’s March in January 2017 was the largest political protest in American history up until that time (Friedersdorf Reference Friedersdorf2017). We also study a dataset of tweets generated after the 2020 Presidential election in order to better understand coordination effects, the loser’s effect, and how online publics react to electoral defeat. These large, dynamic, and unstructured datasets offer new insights into mass politics and how it manifests on online discourse in particular. This is especially helpful where political scientists have been limited to surveys which rely on respondent recall and are generally static in nature.
Importantly, researchers are now collecting text datasets that are larger and larger in scale. For example, there are now numerous studies from different disciplines reporting the use of datasets that contain more than a billion tweets (Dimitrov et al. Reference Dimitrov2020; Hannak et al. Reference Hannak, Anderson, Barrett, Lehmann, Mislove and Riedewald2021; Sinnenberg et al. Reference Sinnenberg2016). However, for large datasets, typical approaches for the estimation of latent Dirichlet allocation (LDA) methods are often computationally impractical and memory inefficient. Data discovery and description techniques for these large data can help inform new theoretical frameworks, establish critical empirical facts, and help establish an empirical foundation for political science researchers to explore with rigorous tools from causal inference frameworks. In this article, we propose a new scalable online tensor LDA (TLDA) method with an end-to-end GPU implementation, ideally suited for the analysis of large text datasets. In summary, we make the following contributions:
-
• LDA with Theoretical Foundations: The method has identifiable and recoverable parameter guarantees and sample complexity guarantees for large data. These theoretical properties provide assurance that under the assumed data generation process and mild regularity assumptions, the method returns accurate results in large data.
-
• Political Science Data Discovery: Our method improves understanding of large corpora at scale and answers questions in real-time about politically salient topics, such as the #MeToo movement and social media activity around the Presidential election in 2020.
-
• Fully Online, Incremental Tensor LDA: Our method can be estimated in real-time without relying on a precomputed dimensionality reduction of the second-order moment. This results in a method that is computationally and memory efficient.
-
• Scaling to Large Corpora: We demonstrate that the method scales linearly by applying our approach to over 1 billion documents, scaling results which we show in the Supplementary Material.
-
• Efficient Implementation with End-to-End GPU Acceleration: In addition to our theoretical contributions, we release a new open-source library alongside this article, which provides an efficient GPU-based implementation of all steps of topic modeling from pre-processing to tensor operations, without costly GPU–CPU exchanges.Footnote 1
To demonstrate the usefulness of our method, we utilize it to analyze the topical development of
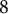 $8$
million tweets concerning #MeToo from September 2017 through December 2019. Using our TLDA method, we can discern clear topical evolution over time through a qualitative study. Notably, as we dynamically grow the corpus of tweets, we find that topics related to politically salient news events are generally ephemeral. In contrast, the topical prominence related to personal testimonies, coordinating protests, and supporting other participants in the #MeToo movement stays persistently prominent as the topics evolve over time. In addition, discussion around counter-#MeToo topics declined in prominence over time, and this discussion was subsumed into one topic by September 2019 (see Figures 1 and 2). In addition to the applications mentioned here, our method can be used to study a wide array of political science questions where large, unstructured data could provide powerful evidence toward extant theories. Providing empirical baselines could also help inform the generation of new theories.
$8$
million tweets concerning #MeToo from September 2017 through December 2019. Using our TLDA method, we can discern clear topical evolution over time through a qualitative study. Notably, as we dynamically grow the corpus of tweets, we find that topics related to politically salient news events are generally ephemeral. In contrast, the topical prominence related to personal testimonies, coordinating protests, and supporting other participants in the #MeToo movement stays persistently prominent as the topics evolve over time. In addition, discussion around counter-#MeToo topics declined in prominence over time, and this discussion was subsumed into one topic by September 2019 (see Figures 1 and 2). In addition to the applications mentioned here, our method can be used to study a wide array of political science questions where large, unstructured data could provide powerful evidence toward extant theories. Providing empirical baselines could also help inform the generation of new theories.
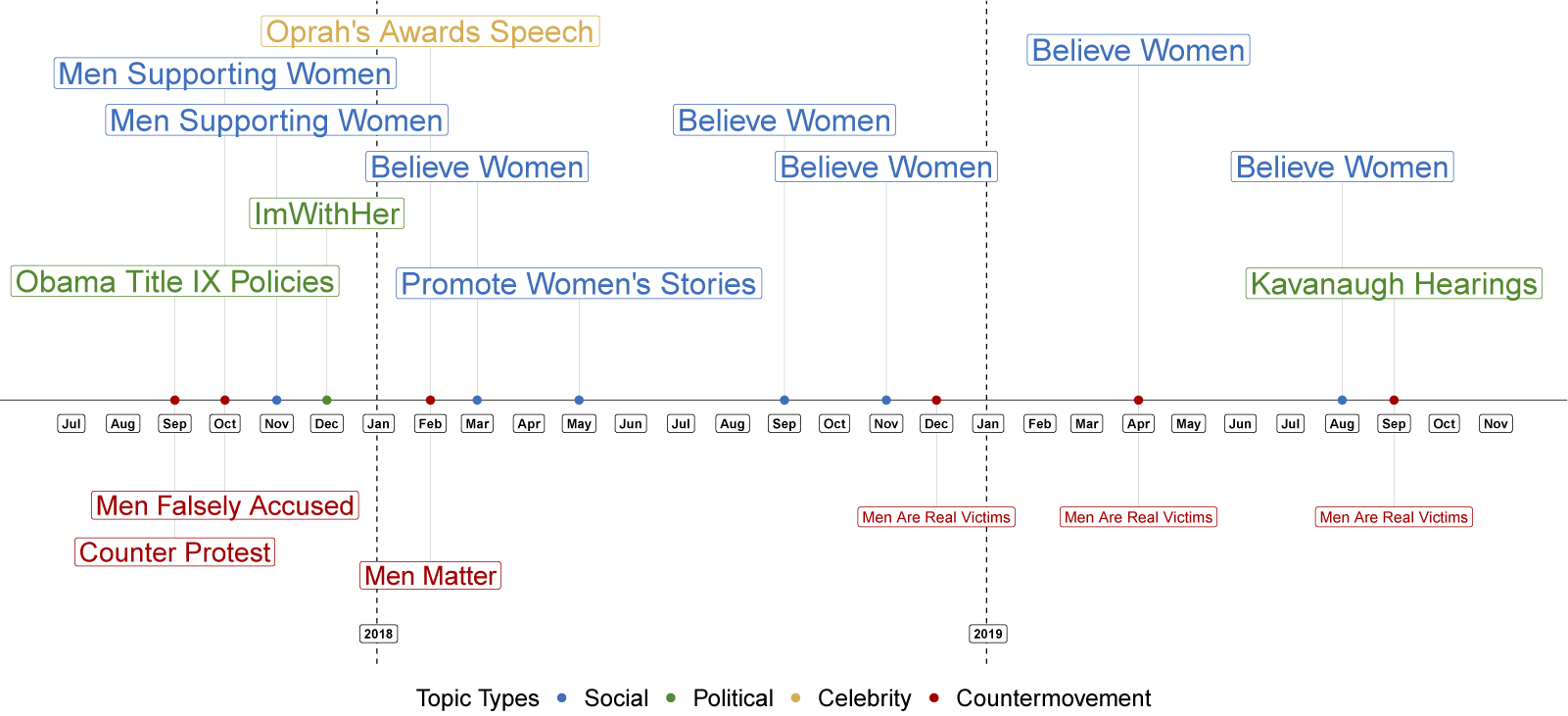
Evolution of the most prominent pro- and counter-movement topics in the #MeToo discussion.
Note: In each iteration of the dynamic analysis described in Section 7.2, we inspect the topics and manually label them, as well as classify them as pro- or counter-#MeToo. We then display the topic in each category with the highest weight
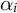 $\alpha _i$
below.
$\alpha _i$
below.

2 Topic Models' Continued Usefulness in Political Science Research
Given the emergence of proprietary large language models (LLMs) and generative AI (ChatGPT and Claude), we demonstrate in this article that online topic model methods provide several advantages to political science researchers, such as being theoretically founded, open-source, and scalable. We emphasize that our methods are designed for data discovery, establishing new empirical facts, and helping to clarify new theoretical frameworks, especially for data that are unstructured. That said, we of course caution applied researchers from blindly applying this (or any) method. We encourage readers to view this method as an important first step to lead to deeper analysis, connecting to additional datasets, and informing new theories, especially where existing data lacked either granularity or real-time dynamics.
2.1 TLDA Provides Theoretical Foundations, Open Sourced Software, and Scalable Estimates
Our method has three key advantages over existing methods. First, our method has important theoretical properties. Neither the most popular LDA approaches based on Blei, Ng, and Jordan (Reference Blei, Ng and Jordan2003) nor LLMs have yet been shown to have these theoretical foundations (Anandkumar et al. Reference Anandkumar, Foster, Hsu, Kakade and Liu2012, Reference Anandkumar, Foster, Hsu, Kakade and Liu2013, Reference Anandkumar, Ge, Hsu, Kakade and Telgarsky2014). Our approach recovers—in feasible computational time—a provable identification guarantee for the topic–word probabilities and sample complexity bounds, as well as a form of statistical consistency in large samples (Anandkumar et al. Reference Anandkumar, Foster, Hsu, Kakade and Liu2012, Reference Anandkumar, Foster, Hsu, Kakade and Liu2013).Footnote 2 These foundations suggest that parameter recovery and large-sample accuracy are achievable when the text data follow a data generation process assumed by LDA, and that the topic–word probability matrix is full rank.
Second, our method is open-source, intentionally designed to be estimated on a wide array of workstations. Although LLMs show tremendous promise as a research method and clearly model human speech patterns more realistically than bag-of-word approaches like we propose, most of the popular LLMs are not open-source, cannot be trained locally without high-end computational resources (Linegar, Kocielnik, and Alvarez Reference Linegar, Kocielnik and Michael Alvarez2023), and demonstrate various social biases with significant implications for research using their model outputs, particularly on prompts concerning gender and race (Bartl, Nissim, and Gatt Reference Bartl, Nissim and Gatt2020; Kocielnik et al. Reference Kocielnik, Prabhumoye, Zhang, Jiang, Alvarez and Anandkumar2023; Nozza, Bianchi, and Hovy Reference Nozza, Bianchi, Hovy and Toutanova2021; Sheng et al. Reference Sheng, Chang, Natarajan, Peng, Inui, Jiang, Ng and Wan2019; Zhao et al. Reference Zhao, Wang, Yatskar, Ordonez and Chang2018). By open-sourcing the training of the model, researchers can better test the sensitivity of their hyperparameter choices, run more robustness checks, and better assess the validity of their model outputs. While LLMs are extremely flexible and powerful and can be fine-tuned to a diverse array of tasks, this flexibility comes at the cost of an unconstrained, high-dimensional parameter space: the prompts needed to define the task that the model will perform. Small changes in these prompts often result in large and unpredictable differences in the model outputs, which make prompt-based methods very challenging to tune and reduce their reliability. The limiting principles of prompt engineering are an area of active research.
At the same time, in terms of interpretation and inference, proprietary LLM model weights, trained parameters, and specifics of training data are hidden from public view. For commercial LLMs, the model underpinnings and mechanics are areas of active research by those developing the LLMs. While it is possible for researchers to fix a particular version of an LLM to use in their research, it is not transparent to users how fixed any particular version of a commercial LLM might be. Unlike some proprietary models, our mathematical underpinnings are clearly and openly communicated and replicated, and the implementation itself is transparent and open source—previous versions are archived and available for reproduction purposes. Relatedly, due to their generative objective, commercial LLMs have been shown to “hallucinate,” to literally shift their responses to prompts to completely different topics and subjects; by construction, our method will not hallucinate. Finally, by implementing a batched, streaming version of our method, researchers are freed from memory constraints that otherwise plague traditional unsupervised methods with large text corpora.
Third, both LLMs and supervised methods impose substantive financial resource hurdles that serve as barriers to their use by many researchers—hand labeling is expensive and proprietary LLM API calls can be extremely costly at scale. Furthermore, in applications where the entire population of documents contains valuable information, down-sampling may not be a viable solution to this cost. For example, 10,000 documents in a 200 million document sample (0.005%) might comprise a cogent and important topic, say congressional speeches opposing war, but due to sampling, such a critical topic may not be identified at all if only a few thousand documents are sampled. For both replication purposes and ready access to applied researchers, we hope our method allows political scientists to more readily answer questions of pressing concern, making more widespread use of large-scale text corpora numbering in the millions and billions of documents.
3 Building on Methodological Innovations in Political Science and Computer Science
In this section, we explain how we build from the foundation of two existing literatures. In the first case, we will leverage insights to build upon existing popular methods for topic models in political methodology. Second, we will contribute to a robust computer science literature on scalable LDA and Tensor LDA methods by proposing a GPU end-to-end pipeline for accurate and scalable open-source topic modeling.
3.1 Theoretical Guarantees Build on Existing Political Science Methods
Our contribution to the political methodology literature is to introduce topic model techniques from computer science that have statistical theoretical foundations. To cluster and analyze large text datasets, political science researchers make widespread use of unsupervised topic models, which do not always have parameter recovery and accuracy guarantees (Anandkumar et al. Reference Anandkumar, Foster, Hsu, Kakade and Liu2012, Reference Anandkumar, Foster, Hsu, Kakade and Liu2013). Among them, a popular model is LDA (Blei et al. Reference Blei, Ng and Jordan2003; Hoffman, Bach, and Blei Reference Hoffman, Bach, Blei, Lafferty, Williams, Shawe-Taylor, Zemel and Culotta2010). This workhorse model can extract important information without requiring labeling or prior knowledge and has been used to analyze datasets across the social sciences, including studies on coordination among social movements, strategic communication of political elites, news dissemination, and the detection of toxic online behavior (Grimmer, Roberts, and Stewart Reference Grimmer, Roberts and Stewart2022; King and Hopkins Reference King and Hopkins2010; Lauderdale and Clark Reference Lauderdale and Clark2014). Also popular is the structural topic model (STM), which is closely related to LDA (Roberts et al. Reference Roberts2014; Roberts, Stewart, and Tingley Reference Roberts, Stewart, Tingley and Alvarez2016). These methods are popular due to the feasibility and easy implementation, but they often do not scale well to large datasets, so we turn to the computer science literature, where scale is key to unlocking new frontiers in research.
3.2 Feasible Improvements for Existing Scalable LDA
There have been numerous efforts to make LDA more scalable. Specifically, Yu et al. (Reference Yu, Hsieh, Yun, Vishwanathan and Dhillon2015) develop a method for faster sampling and distributing computation across multiple CPU cores. More recently, efficient GPU LDA implementations have been proposed: some have developed improved GPU workload partitioning (Wang et al. Reference Wang, Liu, Gaihre and Yu2023; Xie et al. Reference Xie, Liang, Li and Tan2019), while Wang et al. (Reference Wang, Liu, Gaihre and Yu2023) developed a new branched sampling method. However, all of these implementations rely on traditional LDA methods based on Gibbs sampling, variational Bayes, or expectation maximization. The parallelization and scalability of these methods are inherently algorithmically challenging, as they are limited significantly by the sampling required to estimate the topics. Furthermore, unlike our method, these implementations are not available open-source, so they cannot be used easily by applied researchers.
Runtime of our TLDA method on GPU for 260 million and 1.04 billion documents using the COVID dataset.

Note: None of the previous LDA methods scale to billions of documents.
Therefore, instead of relying on traditional LDA methods, we leverage tensor methods (Kolda and Bader Reference Kolda and Bader2009), which are embarrassingly parallel and have been proposed in order to scale to larger datasets (Papalexakis, Faloutsos, and Sidiropoulos Reference Papalexakis, Faloutsos and Sidiropoulos2016; Sidiropoulos et al. Reference Sidiropoulos, De Lathauwer, Fu, Huang, Papalexakis and Faloutsos2017). Using tensor methods, it is possible to learn latent variable models with accuracy guarantees under mild regularity conditions (Anandkumar et al. Reference Anandkumar, Ge, Hsu, Kakade and Telgarsky2014; Janzamin et al. Reference Janzamin, Ge, Kossaifi and Anandkumar2019). In particular, Tensor LDA relies on the computation of third-order moments, i.e., the three-way co-occurrence of words, and decomposes them to recover the topics. This approach has been shown to have similar performance as traditional LDA (Huang et al. Reference Huang, Niranjan, Hakeem and Anandkumar2015), which we also demonstrate empirically in the results of this article.
However, previous implementations of these tensor methods are limited by (1) the explicit construction of the second- or third-order moments and (2) a lack of hardware acceleration due to being developed either entirely for CPU or with a costly exchange between CPU and GPU. In particular, researchers have developed tensor LDA methods that face memory constraints due to the computation of high-dimensional low-order tensors (Anandkumar et al. Reference Anandkumar, Foster, Hsu, Kakade and Liu2012, Reference Anandkumar, Foster, Hsu, Kakade and Liu2013, Reference Anandkumar, Ge, Hsu, Kakade and Telgarsky2014). Further, these methods only run on CPU and do not benefit from hardware acceleration on GPU. But Huang et al. (Reference Huang, Niranjan, Hakeem and Anandkumar2015) developed a stochastic tensor gradient descent (STGD) approach to estimate the third-order decomposition, allowing for further scaling of the method. However, this method has CPU–GPU exchange and relies on the explicit construction of the second-order moment, so it cannot be run fully online. Similarly, Swierczewski et al. (Reference Swierczewski, Bodapati, Beniwal, Leen and Anandkumar2019) proposed a method for learning the third-order decomposition using alternating least squares but is limited by a CPU-based implementation.
By contrast, we derive an efficient centered, online version of the TLDA that scales linearly to any dataset size (with constant memory). We provide evidence supporting this claim in Table 1. We provide an end-to-end GPU-accelerated implementation that will be open-sourced along with this article to enable its application to any dataset by other researchers.
4 How to Achieve Scalable Tensor LDA
We provide a summary overview of our method in Figure 3. As documents are provided as input to our TLDA pipeline, they are first pre-processed and converted into bag-of-words vectors. The key to TLDA methods is to perform no more dimension reduction than needed to ensure the method has theoretical accuracy guarantees, but to perform enough dimension reduction to achieve scale. Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013) demonstrated that two dimension reductions will produce accurate results. Similarly, our method takes the document–topic frequency matrix and takes the average word frequency across documents. We call this average
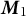 $\boldsymbol {M}_{1}$
, the first moment. Then, we can demean the data and by doing so, we automatically update the model as we stream in new documents. Demeaning the data is a very powerful tool for reducing computational complexity because it cancels out very ugly off-diagonal terms for the higher-order moments that we calculate in our model. By canceling out these terms, we can now stream data into the method and automatically update the results. Computer scientists call this an online update, terminology we adopt here and throughout the text (online centering and update of
$\boldsymbol {M}_{1}$
, the first moment. Then, we can demean the data and by doing so, we automatically update the model as we stream in new documents. Demeaning the data is a very powerful tool for reducing computational complexity because it cancels out very ugly off-diagonal terms for the higher-order moments that we calculate in our model. By canceling out these terms, we can now stream data into the method and automatically update the results. Computer scientists call this an online update, terminology we adopt here and throughout the text (online centering and update of
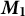 $\boldsymbol {M_1}$
in Figure 3). We then perform our first dimension reduction on the word co-occurrence matrix
$\boldsymbol {M_1}$
in Figure 3). We then perform our first dimension reduction on the word co-occurrence matrix
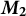 $\boldsymbol {M_2}$
to find singular values, so we can use them to transform (“whiten”) the data. Whitening is a linear transformation that reduces the dimensionality of the data from the number of words to the number of topics.Footnote 3 The word-occurrence matrix simply records how many times words occur together in the corpus. Then, rather than directly compute the singular values for the word-occurrence matrix to get the whitening values, we can implicitly calculate them by performing PCA on the demeaned (centered) data,
$\boldsymbol {M_2}$
to find singular values, so we can use them to transform (“whiten”) the data. Whitening is a linear transformation that reduces the dimensionality of the data from the number of words to the number of topics.Footnote 3 The word-occurrence matrix simply records how many times words occur together in the corpus. Then, rather than directly compute the singular values for the word-occurrence matrix to get the whitening values, we can implicitly calculate them by performing PCA on the demeaned (centered) data,
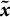 $\boldsymbol {\tilde {x}}$
(online whitening and update of
$\boldsymbol {\tilde {x}}$
(online whitening and update of
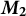 $\boldsymbol {M_2}$
in Figure 3). Now, we take the whitening values and use them to transform the demeaned (centered) data. This “whitening” step reduces the size of the data from
$\boldsymbol {M_2}$
in Figure 3). Now, we take the whitening values and use them to transform the demeaned (centered) data. This “whitening” step reduces the size of the data from
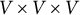 $V\times V \times V$
(number of words by number of words) to
$V\times V \times V$
(number of words by number of words) to
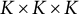 $K \times K \times K$
, the number of topics. This vastly reduces the size of the problem because in every real-world application, the number of topics will be vastly smaller than the number of words. Having performed this transformation, our data have been reduced from size
$K \times K \times K$
, the number of topics. This vastly reduces the size of the problem because in every real-world application, the number of topics will be vastly smaller than the number of words. Having performed this transformation, our data have been reduced from size
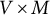 $V\times M$
to size
$V\times M$
to size
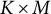 $K \times M$
. We now compute the “whitened” analog of the word tri-occurrence matrix,
$K \times M$
. We now compute the “whitened” analog of the word tri-occurrence matrix,
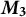 $\boldsymbol {M_3}$
, which is
$\boldsymbol {M_3}$
, which is
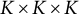 $K \times K \times K$
. We then find the eigenvalues of this
$K \times K \times K$
. We then find the eigenvalues of this
 $K \times K \times K$
object, which after some algebraic transformations, we show are equivalent to the topic model outputs from LDA (the unwhitened, uncentered learned factor in Figure 3).
$K \times K \times K$
object, which after some algebraic transformations, we show are equivalent to the topic model outputs from LDA (the unwhitened, uncentered learned factor in Figure 3).
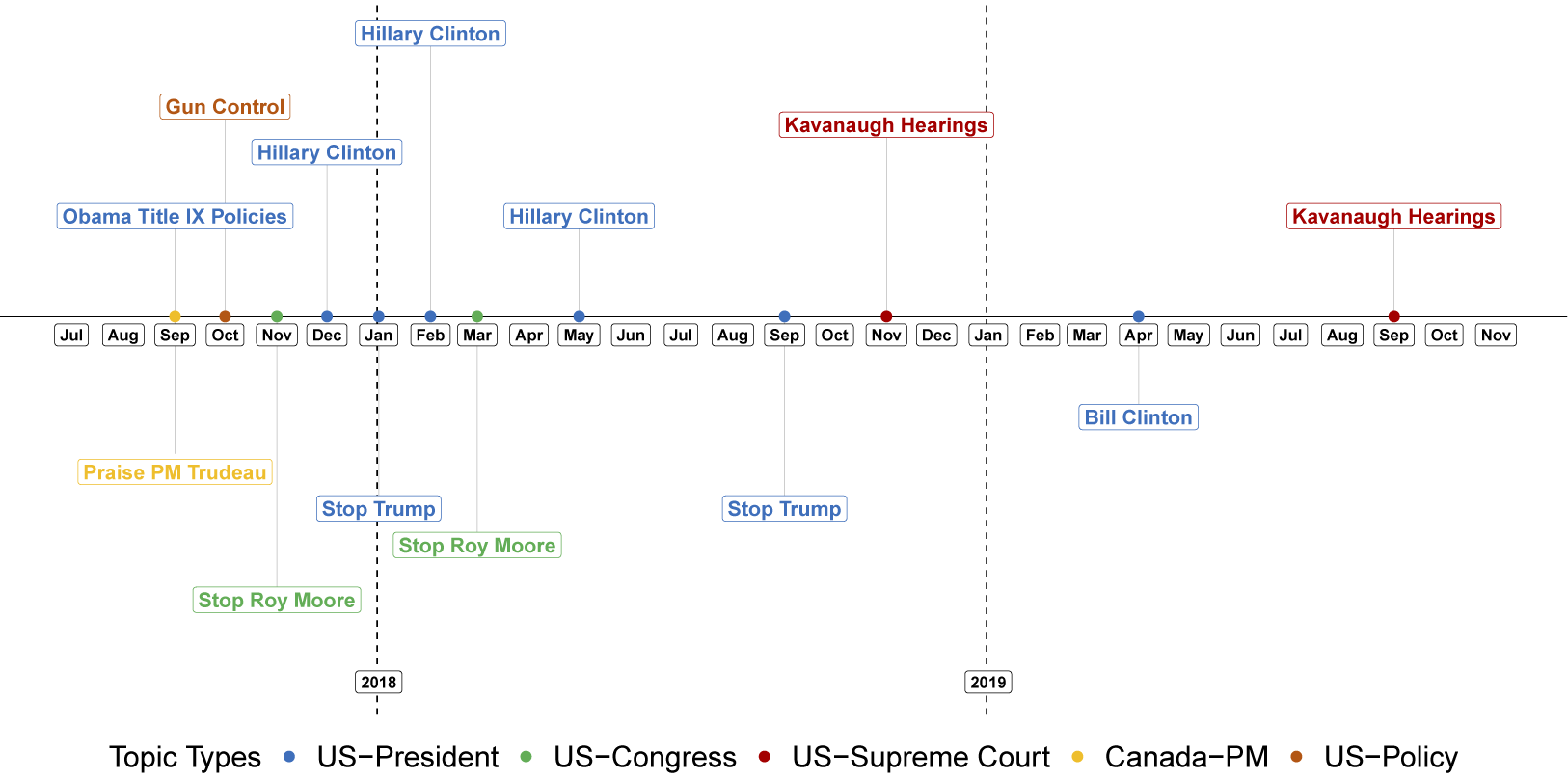
Evolution of most prominent political topics in the #MeToo discussion.
Note: In each iteration of the dynamic analysis detailed in Section 7.2, we inspect the topics, manually label them, and classify them as political or not political. We display the political topic with the highest weight
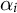 $\alpha _i$
below.
$\alpha _i$
below.

Here, we propose several improvements over previous work to enable scaling the TLDA to billions of documents. First, we reduce the computation complexity of the second- and third-order cross moments; we derive them on centered data. Second, we incrementally estimate PCA on the centered documents. We take these principal components and use them to implicitly form the decomposition of the second-order moment.Footnote 4 We derive a simplified, batched gradient update, leading to efficient recovery of the decomposition of the third-order moment. We jointly learn all moments online by updating the mean, PCA, and third-order decomposition in one pass, instead of relying on a precomputed dimensionality reduction of the second-order moment.
Crucially, we prove that the original topics computed in prior spectral LDA work can be recovered from the topics produced by our method with a simple post-processing step. As a result, our method enjoys the theoretical benefits of spectral LDA while significantly reducing its computational complexity. After finding the topic distribution over words, we employ standard variational inference (VI) to recover document-level parameters. We propose an efficient implementation on GPU within the TensorLy framework, which can easily scale to very large datasets. We preview the substantive results of this method, displaying the most prominent topics over time as identified by the learned weights, which is possible thanks to our tensor-based approach (Figure 3).
Overview of our approach.
Note: As batches of documents arrive, incrementally, they are first pre-processed (they are stemmed, tokenized, and the vocabulary is standardized). We then create a dataset of the counts for each word in each document. We then find the average number of times each word appears in each document (the average word occurrence, which is the first moment
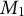 $M_1$
) and subtract the value of
$M_1$
) and subtract the value of
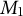 $M_1$
from our existing word-frequency matrix. The resulting document term matrix is our centered dataset, X (Section 4.1). We then perform a singular value decomposition on the centered data, X, to recover whitening weights without ever needing to calculate
$M_1$
from our existing word-frequency matrix. The resulting document term matrix is our centered dataset, X (Section 4.1). We then perform a singular value decomposition on the centered data, X, to recover whitening weights without ever needing to calculate
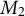 $M_2$
, directly. This saves computational overhead while being mathematically equivalent. We then use these whitening weights to transform the centered data, X, which can be done incrementally (Section 4.3). Finally, we construct the whitened equivalent of the third-order moment,
$M_2$
, directly. This saves computational overhead while being mathematically equivalent. We then use these whitening weights to transform the centered data, X, which can be done incrementally (Section 4.3). Finally, we construct the whitened equivalent of the third-order moment,
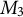 $M_3$
, which is updated, directly in this factorized form (Section 4.4). This learned factorization can be directly unwhitened and uncentered to recover the classic solution to TLDA (Section 1) and recover the topics and their associated word probabilities (Section 4.6).
$M_3$
, which is updated, directly in this factorized form (Section 4.4). This learned factorization can be directly unwhitened and uncentered to recover the classic solution to TLDA (Section 1) and recover the topics and their associated word probabilities (Section 4.6).

4.1 Computing the Centered Cumulants
In this section, we provide a technical overview of the method. For a summary of our notation and the mathematical background for the method, please refer to the Supplementary Material (Table A1). We begin by introducing the model, the data generation process, and the estimation routine.
The data are a corpus of documents which we note in the following way. Let the data be a document term matrix
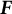 $\boldsymbol {F}$
with rows
$\boldsymbol {F}$
with rows
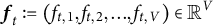 ${\boldsymbol {f}}_t := (f_{t, 1}, f_{t, 2},. .. , f_{t, V}) \in \mathbb {R}^{V}$
denoting the vector of word counts for the t-th document, where V is the number of words in the vocabulary, and let N be the number of documents. Finally, we will let K denote the total number of topics and h be the topic labels. Then, the first-order moment is
${\boldsymbol {f}}_t := (f_{t, 1}, f_{t, 2},. .. , f_{t, V}) \in \mathbb {R}^{V}$
denoting the vector of word counts for the t-th document, where V is the number of words in the vocabulary, and let N be the number of documents. Finally, we will let K denote the total number of topics and h be the topic labels. Then, the first-order moment is
 $$ \begin{align} {\boldsymbol{M}}_1 := \frac{1}{N}\sum_{i=1}^N {\boldsymbol{f}}_i. \end{align} $$
$$ \begin{align} {\boldsymbol{M}}_1 := \frac{1}{N}\sum_{i=1}^N {\boldsymbol{f}}_i. \end{align} $$
Our first innovation is to center the data by forming
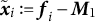 $\tilde{{\boldsymbol{x}}}_i := {\boldsymbol{f}}_i - {\boldsymbol{M}}_1$
. Given this set-up, we can simplify the usual moments for spectral LDA (see Anandkumar et al. Reference Anandkumar, Foster, Hsu, Kakade and Liu2012, Reference Anandkumar, Foster, Hsu, Kakade and Liu2013, Reference Anandkumar, Ge, Hsu, Kakade and Telgarsky2014, as well as Section 1.2 of the Supplementary Material). This is because the diagonalization terms in
$\tilde{{\boldsymbol{x}}}_i := {\boldsymbol{f}}_i - {\boldsymbol{M}}_1$
. Given this set-up, we can simplify the usual moments for spectral LDA (see Anandkumar et al. Reference Anandkumar, Foster, Hsu, Kakade and Liu2012, Reference Anandkumar, Foster, Hsu, Kakade and Liu2013, Reference Anandkumar, Ge, Hsu, Kakade and Telgarsky2014, as well as Section 1.2 of the Supplementary Material). This is because the diagonalization terms in
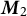 $\boldsymbol{M}_2$
and
$\boldsymbol{M}_2$
and
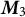 $\boldsymbol{M}_3$
become
$\boldsymbol{M}_3$
become
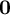 $\mathbf {0}$
in expectation, as the first moment is now
$\mathbf {0}$
in expectation, as the first moment is now
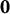 ${\boldsymbol {0}}$
for the centered data matrix
${\boldsymbol {0}}$
for the centered data matrix
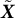 $\tilde {\boldsymbol {X}}$
. This vastly reduces the number of off-diagonal calculations required to estimate the higher-order moments.
$\tilde {\boldsymbol {X}}$
. This vastly reduces the number of off-diagonal calculations required to estimate the higher-order moments.
By removing the corresponding terms that are now
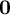 $\mathbf {0}$
in expectation from the expression of the moments in Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013), we now have the following simplified empirical moments for the centered data
$\mathbf {0}$
in expectation from the expression of the moments in Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013), we now have the following simplified empirical moments for the centered data
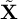 $\tilde {\mathbf {X}}$
, where
$\tilde {\mathbf {X}}$
, where
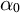 $\alpha _{0}$
is the topic mixing parameter
$\alpha _{0}$
is the topic mixing parameter
 $$ \begin{align} \tilde{\mathbf{M}}_2 &:= \frac{(\alpha_{0} +1)}{N}\sum_{t=i}^N \tilde{{\boldsymbol{x}}}_i \otimes \tilde{{\boldsymbol{x}}}_i \end{align} $$
$$ \begin{align} \tilde{\mathbf{M}}_2 &:= \frac{(\alpha_{0} +1)}{N}\sum_{t=i}^N \tilde{{\boldsymbol{x}}}_i \otimes \tilde{{\boldsymbol{x}}}_i \end{align} $$
 $$ \begin{align} \tilde{\mathbf{M}}_3 &:= \frac{(\alpha_{0} + 1)(\alpha_{0} + 2)}{2N}\sum_{i=1}^N \tilde{{\boldsymbol{x}}}_i \otimes \tilde{{\boldsymbol{x}}}_i \otimes \tilde{{\boldsymbol{x}}}_i,\end{align} $$
$$ \begin{align} \tilde{\mathbf{M}}_3 &:= \frac{(\alpha_{0} + 1)(\alpha_{0} + 2)}{2N}\sum_{i=1}^N \tilde{{\boldsymbol{x}}}_i \otimes \tilde{{\boldsymbol{x}}}_i \otimes \tilde{{\boldsymbol{x}}}_i,\end{align} $$
where
 $\otimes $
is the Kronecker product.
$\otimes $
is the Kronecker product.
Following Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013), we know that the moments for the centered data can be factorized as
 $$ \begin{align} \mathbb{E}_{ } \boldsymbol{ \big[ }\, { \tilde{{\boldsymbol{M}}}_1 } \,\boldsymbol{ \big] } &:= {\boldsymbol{0}} \end{align} $$
$$ \begin{align} \mathbb{E}_{ } \boldsymbol{ \big[ }\, { \tilde{{\boldsymbol{M}}}_1 } \,\boldsymbol{ \big] } &:= {\boldsymbol{0}} \end{align} $$
 $$ \begin{align}\mathbb{E}_{ } \boldsymbol{ \big[ }\, { \tilde{\boldsymbol{M}}_2 } \,\boldsymbol{ \big] } &:= \sum_{i=1}^K \frac{\alpha_{i}}{\alpha_{0}} {\boldsymbol{{\boldsymbol{\nu}}}}_i \otimes {\boldsymbol{\nu}}_i\end{align} $$
$$ \begin{align}\mathbb{E}_{ } \boldsymbol{ \big[ }\, { \tilde{\boldsymbol{M}}_2 } \,\boldsymbol{ \big] } &:= \sum_{i=1}^K \frac{\alpha_{i}}{\alpha_{0}} {\boldsymbol{{\boldsymbol{\nu}}}}_i \otimes {\boldsymbol{\nu}}_i\end{align} $$
 $$ \begin{align}\mathbb{E}_{ } \boldsymbol{ \big[ }\, { \tilde{\boldsymbol{M}}_3 } \,\boldsymbol{ \big] } &:= \sum_{i=1}^K \frac{\alpha_{i}}{\alpha_{0}} {\boldsymbol{\nu}}_i \otimes {\boldsymbol{\nu}}_i \otimes {\boldsymbol{\nu}}_i, \end{align} $$
$$ \begin{align}\mathbb{E}_{ } \boldsymbol{ \big[ }\, { \tilde{\boldsymbol{M}}_3 } \,\boldsymbol{ \big] } &:= \sum_{i=1}^K \frac{\alpha_{i}}{\alpha_{0}} {\boldsymbol{\nu}}_i \otimes {\boldsymbol{\nu}}_i \otimes {\boldsymbol{\nu}}_i, \end{align} $$
where
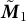 $\tilde {{\boldsymbol {M}}}_1$
,
$\tilde {{\boldsymbol {M}}}_1$
,
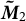 $\boldsymbol {\tilde {M}}_2$
, and
$\boldsymbol {\tilde {M}}_2$
, and
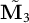 $\tilde {\mathbf {M}_3}$
are the first, second, and third moments of the centered data, and
$\tilde {\mathbf {M}_3}$
are the first, second, and third moments of the centered data, and
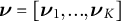 $\boldsymbol {\nu } = [{\boldsymbol {\nu }}_1,. .. , {\boldsymbol {\nu }}_K]$
, the learned decomposition of
$\boldsymbol {\nu } = [{\boldsymbol {\nu }}_1,. .. , {\boldsymbol {\nu }}_K]$
, the learned decomposition of
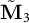 $\tilde {\mathbf {M}}_3$
. Note that we use the centered analog from Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013), which showed that the singular value decomposition of the third-order moment tensor yields estimates for the LDA model parameters.
$\tilde {\mathbf {M}}_3$
. Note that we use the centered analog from Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013), which showed that the singular value decomposition of the third-order moment tensor yields estimates for the LDA model parameters.
Finally, to recover the actual topic–word probability matrix as derived in Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013) using the topics computed from the centered data, we prove Theorem 1, demonstrating that the ground-truth factors can be recovered by de-centering the factors from the centered ones.
Theorem 1 Given the factors
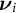 ${\boldsymbol {\nu }}_i$
learned from the centered data, we show that
${\boldsymbol {\nu }}_i$
learned from the centered data, we show that
 $$ \begin{align*}\mathbb{E}[\mathbf{M}_3] = \sum_{i = 1}^K \frac{\alpha_i}{\alpha_0} ({\boldsymbol{\nu}}_i + \boldsymbol{M}_1) \otimes ({\boldsymbol{\nu}}_i + \boldsymbol{M}_1) \otimes ({\boldsymbol{\nu}}_i + \boldsymbol{M}_1).\end{align*} $$
$$ \begin{align*}\mathbb{E}[\mathbf{M}_3] = \sum_{i = 1}^K \frac{\alpha_i}{\alpha_0} ({\boldsymbol{\nu}}_i + \boldsymbol{M}_1) \otimes ({\boldsymbol{\nu}}_i + \boldsymbol{M}_1) \otimes ({\boldsymbol{\nu}}_i + \boldsymbol{M}_1).\end{align*} $$
That is, the true third-order cumulant can be recovered directly by re-centering the factors of the decomposition of the centered cumulant, indicating that the vectors
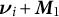 ${\boldsymbol {\nu }}_i + \boldsymbol {M}_1$
are equivalent to the ground-truth factors from Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013).
${\boldsymbol {\nu }}_i + \boldsymbol {M}_1$
are equivalent to the ground-truth factors from Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2013).
For the proof, see Section 1.3 of the Supplementary Material.
Following from Theorem 1, we have
 $$ \begin{align*} \mathbb{E}_{ } \boldsymbol{ \big[ }\, { \mathbf{M}_3 } \,\boldsymbol{ \big] } &= \sum_{i = 1}^K \frac{\alpha_i}{\alpha_0} ({\boldsymbol{\nu}}_i + {\boldsymbol{M}}_1) \otimes ({\boldsymbol{\nu}}_i + {\boldsymbol{M}}_1) \otimes ({\boldsymbol{\nu}}_i + {\boldsymbol{M}}_1) \\ &= \sum_{i = 1}^K \frac{\alpha_i}{\alpha_0} {\boldsymbol{\mu}}_i \otimes {\boldsymbol{\mu}}_i \otimes {\boldsymbol{\mu}}_i, \end{align*} $$
$$ \begin{align*} \mathbb{E}_{ } \boldsymbol{ \big[ }\, { \mathbf{M}_3 } \,\boldsymbol{ \big] } &= \sum_{i = 1}^K \frac{\alpha_i}{\alpha_0} ({\boldsymbol{\nu}}_i + {\boldsymbol{M}}_1) \otimes ({\boldsymbol{\nu}}_i + {\boldsymbol{M}}_1) \otimes ({\boldsymbol{\nu}}_i + {\boldsymbol{M}}_1) \\ &= \sum_{i = 1}^K \frac{\alpha_i}{\alpha_0} {\boldsymbol{\mu}}_i \otimes {\boldsymbol{\mu}}_i \otimes {\boldsymbol{\mu}}_i, \end{align*} $$
where
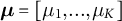 ${\boldsymbol {\mu }} = [\mu _1,. .. , \mu _K]$
and
${\boldsymbol {\mu }} = [\mu _1,. .. , \mu _K]$
and
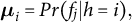 ${\boldsymbol {\mu }}_i = Pr (f_j | h = i),$
where
${\boldsymbol {\mu }}_i = Pr (f_j | h = i),$
where
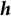 ${\boldsymbol {h}}$
are the set topic labels, i is the i’th topic, and j is the j’th word in the vocabulary. In other words,
${\boldsymbol {h}}$
are the set topic labels, i is the i’th topic, and j is the j’th word in the vocabulary. In other words,
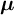 ${\boldsymbol {\mu }}$
is the topic word matrix of the uncentered data
${\boldsymbol {\mu }}$
is the topic word matrix of the uncentered data
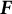 $\boldsymbol {F}$
.
$\boldsymbol {F}$
.
4.2 Batched Implementation Enables Arbitrary Scaling
In the sections below, we present a batched implementation for TLDA. Each moment is individually calculated incrementally as we feed in data to the method, and then we estimate the topic–word probabilities using stochastic gradient descent.
In the section that follows the online decomposition for the second and third moments, we present a fully online implementation, which we recommend for very large datasets on the scale of billions of documents. For such datasets, the individual contribution of one data point is extremely small, so we average over many documents with minimal loss to accuracy given the enormous gains to scale.Footnote 5 In practice, this means we can iterate through the documents just once to still achieve our convergence criteria and to achieve accurate inference. As a byproduct of this implementation, we can then update the model by streaming new data points into the training API, giving a means to offer a fully online version of the model as part of this library.
4.3 Online Decomposition of the Second Moment
As a function of centering the data, our method streamlines the pipeline that Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2012) proposes for calculating the second moment and the whitening matrix. Specifically, instead of constructing
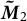 $\boldsymbol {\tilde {M}}_2$
, which is very memory-intensive for large data, we implicitly form
$\boldsymbol {\tilde {M}}_2$
, which is very memory-intensive for large data, we implicitly form
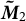 $\boldsymbol {\tilde {M}}_2$
by computing a singular value decomposition of the centered data matrix.
$\boldsymbol {\tilde {M}}_2$
by computing a singular value decomposition of the centered data matrix.
Using the singular values and singular vectors from the centered data, we construct a whitening matrix
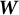 $\boldsymbol {W}$
such that
$\boldsymbol {W}$
such that
 $$ \begin{align} \boldsymbol{W}^{\top} \boldsymbol{\tilde{M}}_2 \boldsymbol{W}=I. \end{align} $$
$$ \begin{align} \boldsymbol{W}^{\top} \boldsymbol{\tilde{M}}_2 \boldsymbol{W}=I. \end{align} $$
We let D be the whitening dimension size. We note that from Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2012, Reference Anandkumar, Foster, Hsu, Kakade and Liu2013, Reference Anandkumar, Ge, Hsu, Kakade and Telgarsky2014), letting
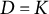 $D = K$
is sufficient to compute the third-order decomposition, although a slightly larger D can be chosen to improve the dimensionality reduction. Then, from the centered data, we have
$D = K$
is sufficient to compute the third-order decomposition, although a slightly larger D can be chosen to improve the dimensionality reduction. Then, from the centered data, we have
 $$ \begin{align*}\boldsymbol{W} = \frac{\sqrt{\alpha_0+1}}{N} \boldsymbol{U}\, \boldsymbol{\Sigma}^{-\frac{1}{2}},\end{align*} $$
$$ \begin{align*}\boldsymbol{W} = \frac{\sqrt{\alpha_0+1}}{N} \boldsymbol{U}\, \boldsymbol{\Sigma}^{-\frac{1}{2}},\end{align*} $$
where
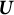 $\boldsymbol {U}$
and
$\boldsymbol {U}$
and
 $\boldsymbol {\Sigma }$
(the variance matrix of the centered data) are the top D singular vectors and singular values of the centered data, obtained through computing the PCA of
$\boldsymbol {\Sigma }$
(the variance matrix of the centered data) are the top D singular vectors and singular values of the centered data, obtained through computing the PCA of
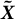 $\boldsymbol {\tilde {X}}$
, which is equivalent to its SVD since the data are centered.
$\boldsymbol {\tilde {X}}$
, which is equivalent to its SVD since the data are centered.
Then, the
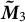 $\boldsymbol {\tilde {M}}_3$
tensor is implicitly formed using the whitened counts of the centered data. Whitening renders the tensor symmetric and orthogonal (in expectation). Most importantly, it reduces the dimensionality of the third moment from size
$\boldsymbol {\tilde {M}}_3$
tensor is implicitly formed using the whitened counts of the centered data. Whitening renders the tensor symmetric and orthogonal (in expectation). Most importantly, it reduces the dimensionality of the third moment from size
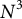 $N^3$
to
$N^3$
to
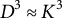 $D^3 \approx K^3$
, where K is the number of topics. Given the nature of speech in social environments, the number of topics will almost always be at least an order of magnitude smaller than the number of words.
$D^3 \approx K^3$
, where K is the number of topics. Given the nature of speech in social environments, the number of topics will almost always be at least an order of magnitude smaller than the number of words.
To estimate the implicit third moment, the method calculates the whitened counts
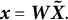 $\boldsymbol {x} = \boldsymbol {W} \boldsymbol {\tilde {X}}.$
We will use these whitened counts to construct the implicit third-order tensor. Using that implicit tensor, the method utilizes stochastic gradient descent to find the spectral decomposition of the third-order moments.
$\boldsymbol {x} = \boldsymbol {W} \boldsymbol {\tilde {X}}.$
We will use these whitened counts to construct the implicit third-order tensor. Using that implicit tensor, the method utilizes stochastic gradient descent to find the spectral decomposition of the third-order moments.
4.4 Online Learning of the Third Moment
Here, we formulate the TLDA framework in a vectorized form, solving for a batch of data, resulting in a much more efficient implementation. Let
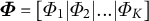 ${\boldsymbol {\Phi }} = [\Phi _1|\Phi _2|. .. |\Phi _K]$
be the eigenvectors of the third-order moment for the whitened, centered data. We note that each eigenvector
${\boldsymbol {\Phi }} = [\Phi _1|\Phi _2|. .. |\Phi _K]$
be the eigenvectors of the third-order moment for the whitened, centered data. We note that each eigenvector
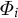 $\Phi _i$
is of length D and denote the full sample size as N.
$\Phi _i$
is of length D and denote the full sample size as N.
Now, note that the decomposition of the third-order moment for the whitened, centered data
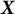 $\boldsymbol {X}$
(of size
$\boldsymbol {X}$
(of size
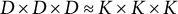 $D \times D \times D \approx K \times K \times K$
) is
$D \times D \times D \approx K \times K \times K$
) is
 $$ \begin{align*}\boldsymbol{T} = \sum_{i \in K} {\boldsymbol{\Phi}}_i \otimes {\boldsymbol{\Phi}}_i \otimes {\boldsymbol{\Phi}}_i.\end{align*} $$
$$ \begin{align*}\boldsymbol{T} = \sum_{i \in K} {\boldsymbol{\Phi}}_i \otimes {\boldsymbol{\Phi}}_i \otimes {\boldsymbol{\Phi}}_i.\end{align*} $$
With the whitened tensor in hand, the method follows Huang et al. (Reference Huang, Niranjan, Hakeem and Anandkumar2015) in implementing a batched STGD algorithm for tensor CP decomposition.
Specifically, we consider a mini-batch of
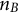 $n_B$
centered and whitened samples
$n_B$
centered and whitened samples
 ${\boldsymbol {x}}_1, \ldots {\boldsymbol {x}}_{n_B}$
, which we collect in a matrix
${\boldsymbol {x}}_1, \ldots {\boldsymbol {x}}_{n_B}$
, which we collect in a matrix
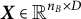 $\boldsymbol {X} \in \mathbb {R}^{n_B \times D}$
. We want to learn a tensor factorization of the third-order whitened and centered cumulant:
$\boldsymbol {X} \in \mathbb {R}^{n_B \times D}$
. We want to learn a tensor factorization of the third-order whitened and centered cumulant:
 $$ \begin{align} \tilde{\boldsymbol{M}}_3 = & \,\, \frac{(\alpha_0 + 1)(\alpha_0 + 2)}{2N} \sum_{n=1}^N {\boldsymbol{x}}_n \otimes {\boldsymbol{x}}_n \otimes {\boldsymbol{x}}_n\nonumber \\ = & \,\, \frac{(\alpha_0 + 1)(\alpha_0 + 2)}{2N} \sum_{n=1}^N {\boldsymbol{x}}_n \otimes^3. \end{align} $$
$$ \begin{align} \tilde{\boldsymbol{M}}_3 = & \,\, \frac{(\alpha_0 + 1)(\alpha_0 + 2)}{2N} \sum_{n=1}^N {\boldsymbol{x}}_n \otimes {\boldsymbol{x}}_n \otimes {\boldsymbol{x}}_n\nonumber \\ = & \,\, \frac{(\alpha_0 + 1)(\alpha_0 + 2)}{2N} \sum_{n=1}^N {\boldsymbol{x}}_n \otimes^3. \end{align} $$
We are trying to learn a rank-K CP factorization with factors
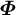 ${\boldsymbol {\Phi }}$
of
${\boldsymbol {\Phi }}$
of
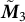 $ \tilde {\boldsymbol {M}}_3$
such that
$ \tilde {\boldsymbol {M}}_3$
such that
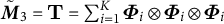 $\tilde {\boldsymbol {M}}_3 = \mathbf {T} = \sum _{i=1}^K {\boldsymbol {\Phi }}_i \otimes {\boldsymbol {\Phi }}_i \otimes {\boldsymbol {\Phi }}_i $
. In other words, we solve the following optimization problem:
$\tilde {\boldsymbol {M}}_3 = \mathbf {T} = \sum _{i=1}^K {\boldsymbol {\Phi }}_i \otimes {\boldsymbol {\Phi }}_i \otimes {\boldsymbol {\Phi }}_i $
. In other words, we solve the following optimization problem:
 $$ \begin{align} \operatorname*{\mbox{arg min}}_{{\boldsymbol{\Phi}};\, ||{\boldsymbol{\Phi}}_i||_F^2=1} \underbrace{|| \tilde{\boldsymbol{M}}_3 - \mathbf{T} ||_F^2}_{\text{reconstruction loss}} + \underbrace{ \frac{(1 + \theta)}{2} || \mathbf{T} ||_F^2}_{\text{orthogonality loss}}. \end{align} $$
$$ \begin{align} \operatorname*{\mbox{arg min}}_{{\boldsymbol{\Phi}};\, ||{\boldsymbol{\Phi}}_i||_F^2=1} \underbrace{|| \tilde{\boldsymbol{M}}_3 - \mathbf{T} ||_F^2}_{\text{reconstruction loss}} + \underbrace{ \frac{(1 + \theta)}{2} || \mathbf{T} ||_F^2}_{\text{orthogonality loss}}. \end{align} $$
In plain words, we minimize the reconstruction loss while inducing orthogonality on the decomposition factors. This can be seen by noting that the factors (and therefore the rank-1 components) are normalized, meaning the Frobenius norm of the second term simplifies to only the inner product between the components.
The problem in equation (9) thus simplifies to
 $$ \begin{align} \operatorname*{\mbox{arg min}}_{{\boldsymbol{\Phi}};\, ||{\boldsymbol{\Phi}}_i||_F^2=1} & \frac{(1 + \theta)}{2} || \sum_{i=1}^K {\boldsymbol{\Phi}}_i \otimes^3 ||_F^2 \\ \nonumber - & \langle {\sum_{i=1}^K {\boldsymbol{\Phi}}_i \otimes^3}, { \frac{(\alpha_0 + 1)(\alpha_0 + 2)}{2N} \sum_{n=1}^N {\boldsymbol{x}}_n \otimes^3 } \rangle.\end{align} $$
$$ \begin{align} \operatorname*{\mbox{arg min}}_{{\boldsymbol{\Phi}};\, ||{\boldsymbol{\Phi}}_i||_F^2=1} & \frac{(1 + \theta)}{2} || \sum_{i=1}^K {\boldsymbol{\Phi}}_i \otimes^3 ||_F^2 \\ \nonumber - & \langle {\sum_{i=1}^K {\boldsymbol{\Phi}}_i \otimes^3}, { \frac{(\alpha_0 + 1)(\alpha_0 + 2)}{2N} \sum_{n=1}^N {\boldsymbol{x}}_n \otimes^3 } \rangle.\end{align} $$
This can be equivalently written in matrix form using the Khatri–Rao product:
 $$ \begin{align} \operatorname*{\mbox{arg min}}_{{\boldsymbol{\Phi}};\, ||{\boldsymbol{\Phi}}_i||_F^2=1} & \,\, \frac{(1 + \theta)}{2} || {\boldsymbol{\Phi}} \left({\boldsymbol{\Phi}} \odot {\boldsymbol{\Phi}}\right)^{\top} ||_F^2 \\ \nonumber & - \frac{(\alpha_0 + 1)(\alpha_0 + 2)}{2n} \langle {{\boldsymbol{\Phi}} \left({\boldsymbol{\Phi}} \odot {\boldsymbol{\Phi}}\right)^{\top}}, { \boldsymbol{X}^{\top} \left( \boldsymbol{X} \odot \boldsymbol{X} \right) } \rangle. \end{align} $$
$$ \begin{align} \operatorname*{\mbox{arg min}}_{{\boldsymbol{\Phi}};\, ||{\boldsymbol{\Phi}}_i||_F^2=1} & \,\, \frac{(1 + \theta)}{2} || {\boldsymbol{\Phi}} \left({\boldsymbol{\Phi}} \odot {\boldsymbol{\Phi}}\right)^{\top} ||_F^2 \\ \nonumber & - \frac{(\alpha_0 + 1)(\alpha_0 + 2)}{2n} \langle {{\boldsymbol{\Phi}} \left({\boldsymbol{\Phi}} \odot {\boldsymbol{\Phi}}\right)^{\top}}, { \boldsymbol{X}^{\top} \left( \boldsymbol{X} \odot \boldsymbol{X} \right) } \rangle. \end{align} $$
By taking the derivative with respect to the decomposition factor
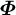 ${\boldsymbol {\Phi }}$
, we get
${\boldsymbol {\Phi }}$
, we get
 $$ \begin{align} \frac{\partial{\mathcal{L}}}{\partial{{\boldsymbol{\Phi}}}} = 3(1 + \theta) {\boldsymbol{\Phi}} ({\boldsymbol{\Phi}}^{\top}{\boldsymbol{\Phi}} * {\boldsymbol{\Phi}}^{\top}{\boldsymbol{\Phi}}) - \frac{3(\alpha_0 + 1)(\alpha_0 + 2)}{2n} \boldsymbol{X}^T (\boldsymbol{X}{\boldsymbol{\Phi}}*\boldsymbol{X}{\boldsymbol{\Phi}}). \end{align} $$
$$ \begin{align} \frac{\partial{\mathcal{L}}}{\partial{{\boldsymbol{\Phi}}}} = 3(1 + \theta) {\boldsymbol{\Phi}} ({\boldsymbol{\Phi}}^{\top}{\boldsymbol{\Phi}} * {\boldsymbol{\Phi}}^{\top}{\boldsymbol{\Phi}}) - \frac{3(\alpha_0 + 1)(\alpha_0 + 2)}{2n} \boldsymbol{X}^T (\boldsymbol{X}{\boldsymbol{\Phi}}*\boldsymbol{X}{\boldsymbol{\Phi}}). \end{align} $$
We then update the factor via batched stochastic gradient update:
 $$ \begin{align} {\boldsymbol{\Phi}}_{t+1} = {\boldsymbol{\Phi}}_{t} - \beta \frac{\partial{\mathcal{L}}}{\partial{{\boldsymbol{\Phi}}}}, \end{align} $$
$$ \begin{align} {\boldsymbol{\Phi}}_{t+1} = {\boldsymbol{\Phi}}_{t} - \beta \frac{\partial{\mathcal{L}}}{\partial{{\boldsymbol{\Phi}}}}, \end{align} $$
with
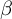 $\beta $
as the learning rate.
$\beta $
as the learning rate.
4.5 Fully Online Implementation
In a fully batched implementation above, the method relies on computing each higher-order moment sequentially, even though each moment is individually learned online. By contrast, in the fully online version of our TLDA method presented here, we learn both moments by jointly learning both the second- and third-order moments online.Footnote 6 We first find initial values for the factors by running the batched TLDA to convergence on a small portion of the data. Then, when given a new batch of data, we first update
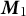 $\boldsymbol {M}_1$
, then update the incremental PCA (and use the new version of the PCA to whiten the data), and finally perform a gradient update of the third-order moment using the new batch of whitened data. As a result, we can update the third-order moment decomposition only using the new batch without looping through any prior data. This is in contrast to the batched version of our method, where we loop through the entire dataset three times to compute the first-order moment, second-order moment decomposition, and third-order moment decomposition, respectively.
$\boldsymbol {M}_1$
, then update the incremental PCA (and use the new version of the PCA to whiten the data), and finally perform a gradient update of the third-order moment using the new batch of whitened data. As a result, we can update the third-order moment decomposition only using the new batch without looping through any prior data. This is in contrast to the batched version of our method, where we loop through the entire dataset three times to compute the first-order moment, second-order moment decomposition, and third-order moment decomposition, respectively.
Although we only perform one gradient descent step per batch of data in this version of the method, we expect that for large datasets, there are sufficiently many documents so that this does not significantly impact the quality of the factors produced.Footnote 7 We use online LDA to obtain topic coherence values that are similar to or better than existing methods.
4.6 Recovering the Topic Model Parameters
Once we have learned the factorized form
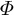 $\Phi $
of the third-order moment, we describe how we recover the uncentered, unwhitened moment to recover the topics. First, we obtain
$\Phi $
of the third-order moment, we describe how we recover the uncentered, unwhitened moment to recover the topics. First, we obtain
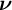 $\boldsymbol {\nu }$
, the estimate of the decomposition of
$\boldsymbol {\nu }$
, the estimate of the decomposition of
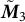 $\tilde {\boldsymbol {M}}_3$
, by unwhitening the components
$\tilde {\boldsymbol {M}}_3$
, by unwhitening the components
 $\Phi $
of the decomposition:
$\Phi $
of the decomposition:
 $$ \begin{align*}\boldsymbol{\nu} = \boldsymbol{W}^{T^{\dagger}} \boldsymbol{\Phi},\end{align*} $$
$$ \begin{align*}\boldsymbol{\nu} = \boldsymbol{W}^{T^{\dagger}} \boldsymbol{\Phi},\end{align*} $$
where
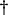 $\dagger $
denotes the pseudo-inverse. Using this, we can find
$\dagger $
denotes the pseudo-inverse. Using this, we can find
 $$ \begin{align*}\alpha_i = \gamma^2{\boldsymbol{\nu}}_i^{-2}.\end{align*} $$
$$ \begin{align*}\alpha_i = \gamma^2{\boldsymbol{\nu}}_i^{-2}.\end{align*} $$
Here,
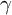 $\gamma $
is a scaling factor such that
$\gamma $
is a scaling factor such that
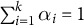 $\sum _{i=1}^k \alpha _i = 1$
.
$\sum _{i=1}^k \alpha _i = 1$
.
As derived in Theorem 1, we can then re-center
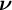 $\boldsymbol {\nu }$
to compute the estimate for the uncentered topic–word probabilities
$\boldsymbol {\nu }$
to compute the estimate for the uncentered topic–word probabilities
 $$ \begin{align*}{\boldsymbol{\mu}}_i = {\boldsymbol{\nu}}_i + \boldsymbol{M}_1.\end{align*} $$
$$ \begin{align*}{\boldsymbol{\mu}}_i = {\boldsymbol{\nu}}_i + \boldsymbol{M}_1.\end{align*} $$
5 The TensorLy-LDA Package
Along with this article, we release a new Python package that provides an efficient, end-to-end GPU-accelerated implementation of our proposed online Tensor LDA.Footnote 8 We used that implementation for all experiments in this article. It consists of two main steps: an efficient pre-processing module that uses RAPIDS and a module that builds on top of TensorLy to learn the higher-order cumulants.
Our entire Tensor LDA method is end-to-end GPU accelerated and implemented on the Nvidia RAPIDS Data Science Framework, a GPU-based architecture for data analysis in python (RAPIDS Development Team 2018), as well as the TensorLy library, a high-level API for tensor methods in Python (Kossaifi et al. Reference Kossaifi, Panagakis, Anandkumar and Pantic2019). First, the data are pre-processed, on GPU, using RAPIDS. After the data have been pre-preprocessed, all tensor operations are performed using the TensorLy library, which is used to learn the third-order cumulant in factorized form directly. RAPIDS is used for learning the second-order cumulant through incremental PCA. The result is an end-to-end GPU implementation of a large-scale topic model with no CPU–GPU exchange. We empirically establish our implementation in the next section through thorough experiments and demonstrate large speedups over previous works.
The library provides all the tools to run our method on an actual dataset. To facilitate adoption by practitioners, it comes with a thorough online documentation and interactive examples. Both the examples and an extensive suite of unit tests are run dynamically after any change in the codebase through a continuous integration suite to ensure correctness.
5.1 Input and Output
The method takes a data matrix where each entry is the centered word frequencies for each of V words for N documents. Each column represents a word in the dataset and each row is a document, for a matrix of size
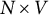 $N\times V$
. The method produces two key outputs: first, the topic–word matrix and second, the learned weights,
$N\times V$
. The method produces two key outputs: first, the topic–word matrix and second, the learned weights,
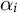 $\alpha _i$
. These outputs can be fed as inputs into a standard VI method that calculates the topic–document matrix, as well. We have included a standard VI method in our API so users can calculate the document–topic matrix for their applications.
$\alpha _i$
. These outputs can be fed as inputs into a standard VI method that calculates the topic–document matrix, as well. We have included a standard VI method in our API so users can calculate the document–topic matrix for their applications.
Hyperparameter Tuning
There are several hyperparameters standard to LDA and STGD methods that are under researcher discretion. Users are encouraged to check that the default parameters are appropriate for their application.
-
1. Number of topics k: number of learned clusters. Should be optimized by a researcher.
-
2. Topical mixing,
 $\alpha _0$
: The level of mixing believed to be in the documents. Closer to
$0$
is no mixing and closer to
$\infty $
means fully mixed documents.
$\alpha _0$
: The level of mixing believed to be in the documents. Closer to
$0$
is no mixing and closer to
$\infty $
means fully mixed documents. -
3. Learning rate
$\beta $
. How much to allow new batches of data to contribute to the factor update. Needs to be tuned for stable convergence (if convergence is too slow, increase it. If topics appear noisy or nonsensical, decrease it). -
4. Orthogonality penalty
$\theta $
: How much separation you expect between topics. If topical mixtures appear too similar, increase this parameter. If topics are incoherent or convergence is unstable, decrease it.
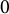
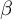
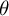
Recommendations for Data Pre-Processing
By pre-processing the data on the Rapids GPU framework, we alleviate a crucial bottleneck in the practicability of LDA on large datasets. Although pre-processing has been shown to be critical to producing valid results, especially in social science contexts (Grimmer and Stewart Reference Grimmer and Stewart2013), existing frameworks for topic models often entail expensive CPU–GPU exchange. Having overcome this bottleneck, we follow best practices suggested by Grimmer and Stewart (Reference Grimmer and Stewart2013) and summarized in King and Hopkins (Reference King and Hopkins2010); we optimize feature selection by stemming and tokenizing the data. The political science literature has found that for non-noisy inference on text data, we want neither too few common features such that there is no variation amongst documents nor too many uncommon features such that there are no distinguishable clusters.
We follow this process to arrive at our final set of features:
-
• Remove any document shorter than three non-unique words.
-
• Stem all words to remove word endings using a Porter Stemmer.
-
• Identify bigrams in the data.
-
• Trim the features: exclude any features appearing in fewer than the lower bound that scales with the number of documents of the document and more than the upper bound that scales with the number of documents.
The political science literature has intensively explored the sensitivity of critical substantive findings to pre-processing. King and Hopkins (Reference King and Hopkins2010) find that the consensus in the social science literature is that brute force unigram-based methods, with rigorous empirical validation, will typically account for the majority of the available explanatory power in the data. So long as pre-processing captures all relevant features, our inferences derived from NLP can be used to analyze social phenomena. However, King and Hopkins (Reference King and Hopkins2010) note that the tuning of pre-processing choices generally depends on the nature of the application. In all of the applications presented in this article, our unit of observation is a tweet, an inherently short document limited to 270 characters. Finally, following standard practice for topic models, we stem words to their base root so that the core meaning of these words is captured by only one token. In previous applications, this has been shown to both improve computational tractability and clarify the substantive analysis of text data.
5.2 Package Availability
The package is fully open-source as part of the TensorLy (Kossaifi et al. Reference Kossaifi, Panagakis, Anandkumar and Pantic2019) project, under the BSD-3 license, which makes it suitable for any use, academic or industrial. It is well tested and has extensive documentation.
6 Simulations
6.1 Parameter Recovery and Comparison to Previous TLDA Methods
In this section, we demonstrate that our method results in gains in accuracy, topic correlation, and speed in comparison to existing TLDA methods in a simulated setting. We use the traditional LDA Data Generation Process for generating the simulated data (see Section 1.4 of the Supplementary Material and Blei et al. Reference Blei, Ng and Jordan2003). We present a comparison to two key existing versions of the TLDA method: (1) the spectral decomposition algorithm in Anandkumar et al. (Reference Anandkumar, Foster, Hsu, Kakade and Liu2012, Reference Anandkumar, Foster, Hsu, Kakade and Liu2013, Reference Anandkumar, Ge, Hsu, Kakade and Telgarsky2014) and (2) the SGD-based TLDA derived in Huang et al. (Reference Huang, Niranjan, Hakeem and Anandkumar2015), in which the third-order moment is computed online. To do so, we show comparisons of all three TLDA methods on synthetic data. Due to the small scale of the synthetic experiment (20,000 documents), we run the batched version of our method.
As a result, through this process, we obtain ground-truth factors that adhere to the assumptions of LDA. By running TLDA on the synthetic document vectors, we can then compare each factor in the learned topic–word matrix to the corresponding factor in the generated ground-truth topic–word matrix by computing their correlation.
However, the topics in the learned topic–word matrix can be in any order, so we limit the number of topics to
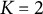 $K = 2$
and use the permutation that maximizes the average correlation to the ground truth. We use parameters
$K = 2$
and use the permutation that maximizes the average correlation to the ground truth. We use parameters
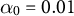 $\alpha _0 = 0.01$
and whitening size
$\alpha _0 = 0.01$
and whitening size
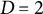 $D = 2$
for all TLDA methods, as well as learning rate
$D = 2$
for all TLDA methods, as well as learning rate
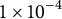 $1 \times 10^{-4}$
for the SGD-based TLDA and our method. Table 2 shows the correlation between the learned and ground-truth factors in corpora with
$1 \times 10^{-4}$
for the SGD-based TLDA and our method. Table 2 shows the correlation between the learned and ground-truth factors in corpora with
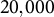 $20,000$
documents. The results are averaged over ten random seeds for each combination of parameters. This table illustrates that under a variety of vocabulary sizes, our method is more accurate than existing tensor methods, as evidenced by the higher mean and lower standard deviation of correlations among all runs.
$20,000$
documents. The results are averaged over ten random seeds for each combination of parameters. This table illustrates that under a variety of vocabulary sizes, our method is more accurate than existing tensor methods, as evidenced by the higher mean and lower standard deviation of correlations among all runs.
Comparison of topic recovery on synthetic data for various TLDA methods.

Note: (1) Anandkumar et al. (Reference Anandkumar, Ge, Hsu, Kakade and Telgarsky2014); (2) Huang et al. (Reference Huang, Niranjan, Hakeem and Anandkumar2015); and (3) Our method. The method achieving the highest average correlation and lowest standard deviation among the correlations is bolded at each vocabulary size.
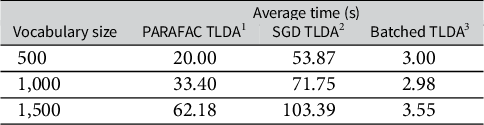
In Table 3, we compare the average runtime of the three TLDA methods for the synthetic data experiments in Table 2. In Table A4 in the Supplementary Material, we also compare against other scalable LDA methods—we note our TLDA method compares favorably and that none of the methods against which we compare have theoretical accuracy guarantees. We run this analysis on the CPU due to the relatively small scale of the experiment. Our version of the TLDA method results in a runtime that is between 6 and 20 times faster than the existing TLDA methods. Furthermore, as shown in Table 3, as the vocabulary size increases, the runtime of our method increases its relative speed advantage over the others. This demonstrates the value of the simplifications we introduce in the method section; we significantly outperform the existing TLDA methods in terms of runtime while also making non-trivial gains in accuracy.
Comparison of CPU runtime on synthetic data for various TLDA methods.
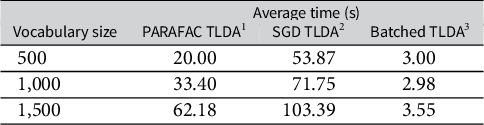
Note: (1) Anandkumar et al. (Reference Anandkumar, Ge, Hsu, Kakade and Telgarsky2014); (2) Huang et al. (Reference Huang, Niranjan, Hakeem and Anandkumar2015); and (3) Our method.
7 Applications
In this section, we demonstrate the scalability of our method by applying it to two large-scale Twitter datasets—concerning the #MeToo movement and the 2020 U.S. Presidential elections. These applications present analyses of important datasets that political scientists might wish to use to study collective action, political behavior, gender politics, election misinformation, and many other theoretically- and substantively-important topics. But analyses like these would have been infeasible or perhaps impossible due to the large size of the data (as we demonstrate below) without methods like TLDA.
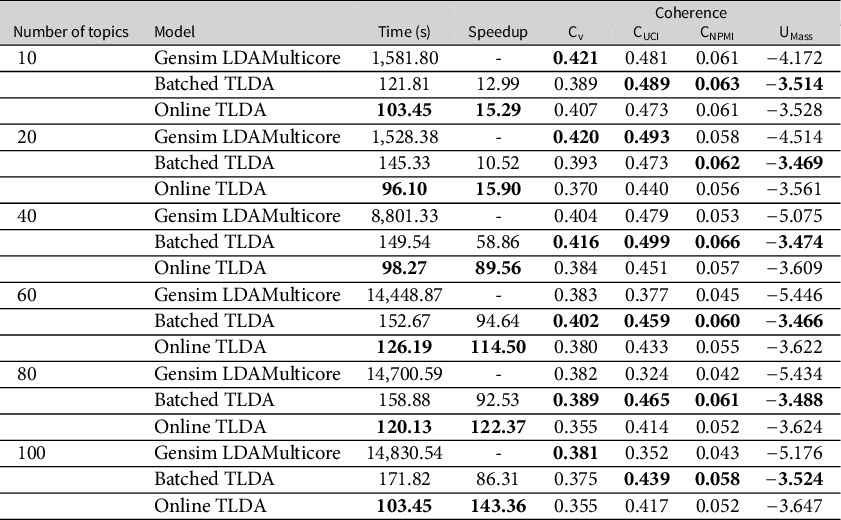
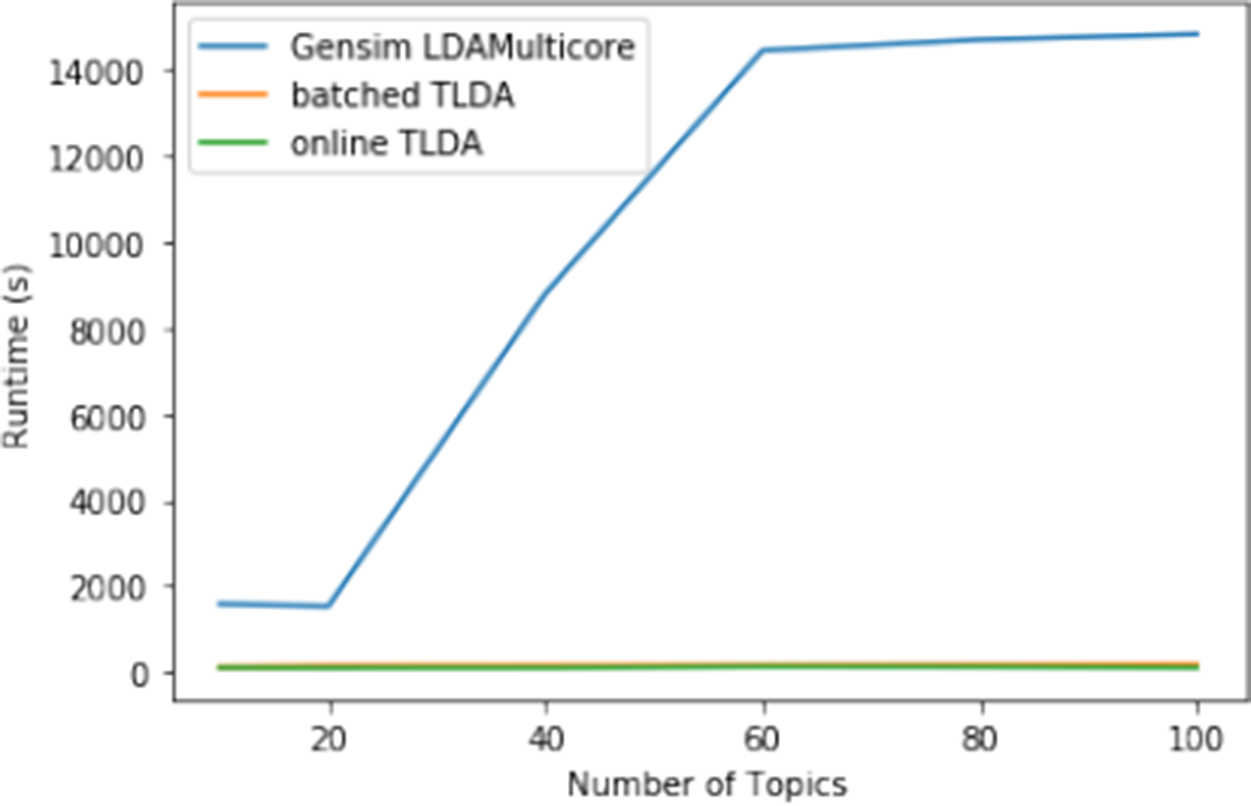
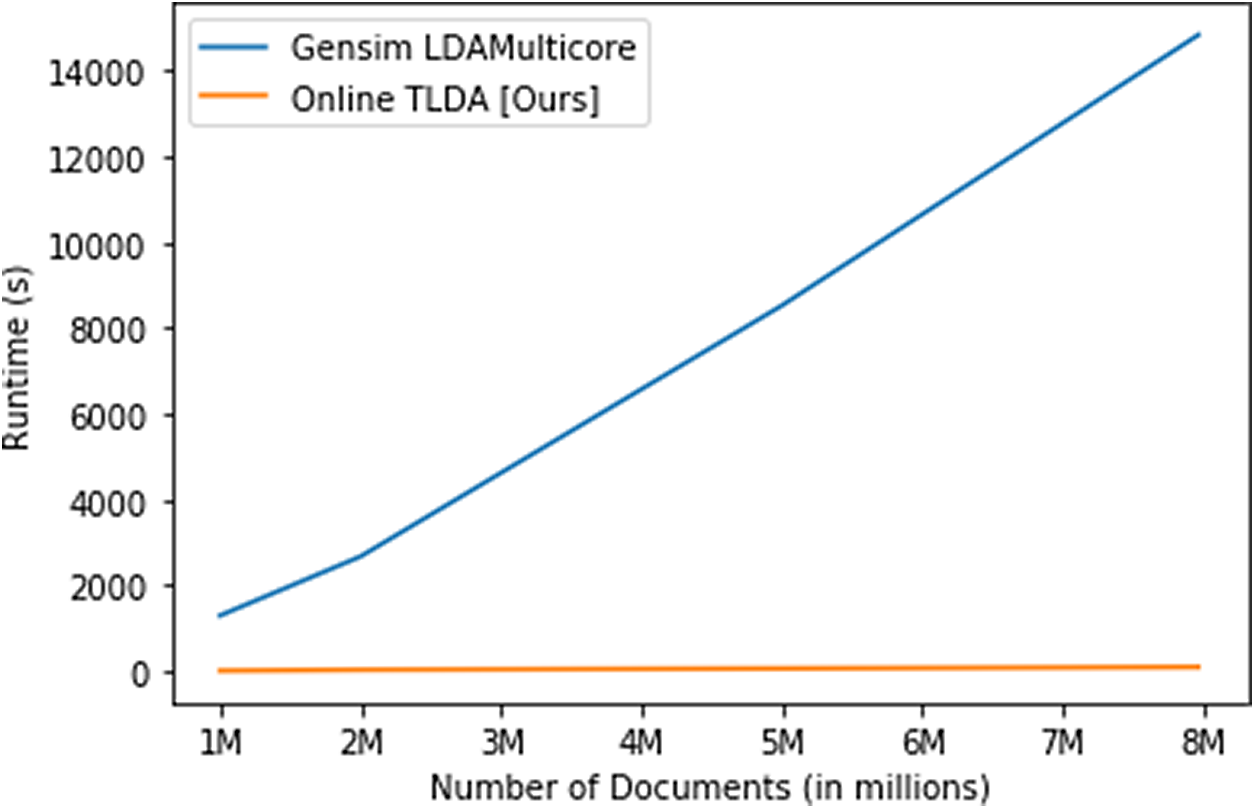
The #MeToo dataset comprises 7.97 million tweets related to the political and social discussion surrounding #MeToo. We conduct thorough ablation studies using the #MeToo dataset and empirically demonstrate that the runtime of our method scales linearly as the number of documents increases and is nearly constant as the number of topics increases. We compare the runtime and topic coherence to a popular off-the-shelf model to show that our online method is 15
 $\times $
–140
$\times $
–140
 $\times $
faster than previous methods while achieving similar or better coherence.Footnote 9 Additionally, we show the practical utility of our method for applied researchers by using it to dynamically analyze the evolution of the #MeToo dataset over time. We show qualitative evidence of topical evolution in the discussion around the social movement and political coordination on social media.
$\times $
faster than previous methods while achieving similar or better coherence.Footnote 9 Additionally, we show the practical utility of our method for applied researchers by using it to dynamically analyze the evolution of the #MeToo dataset over time. We show qualitative evidence of topical evolution in the discussion around the social movement and political coordination on social media.
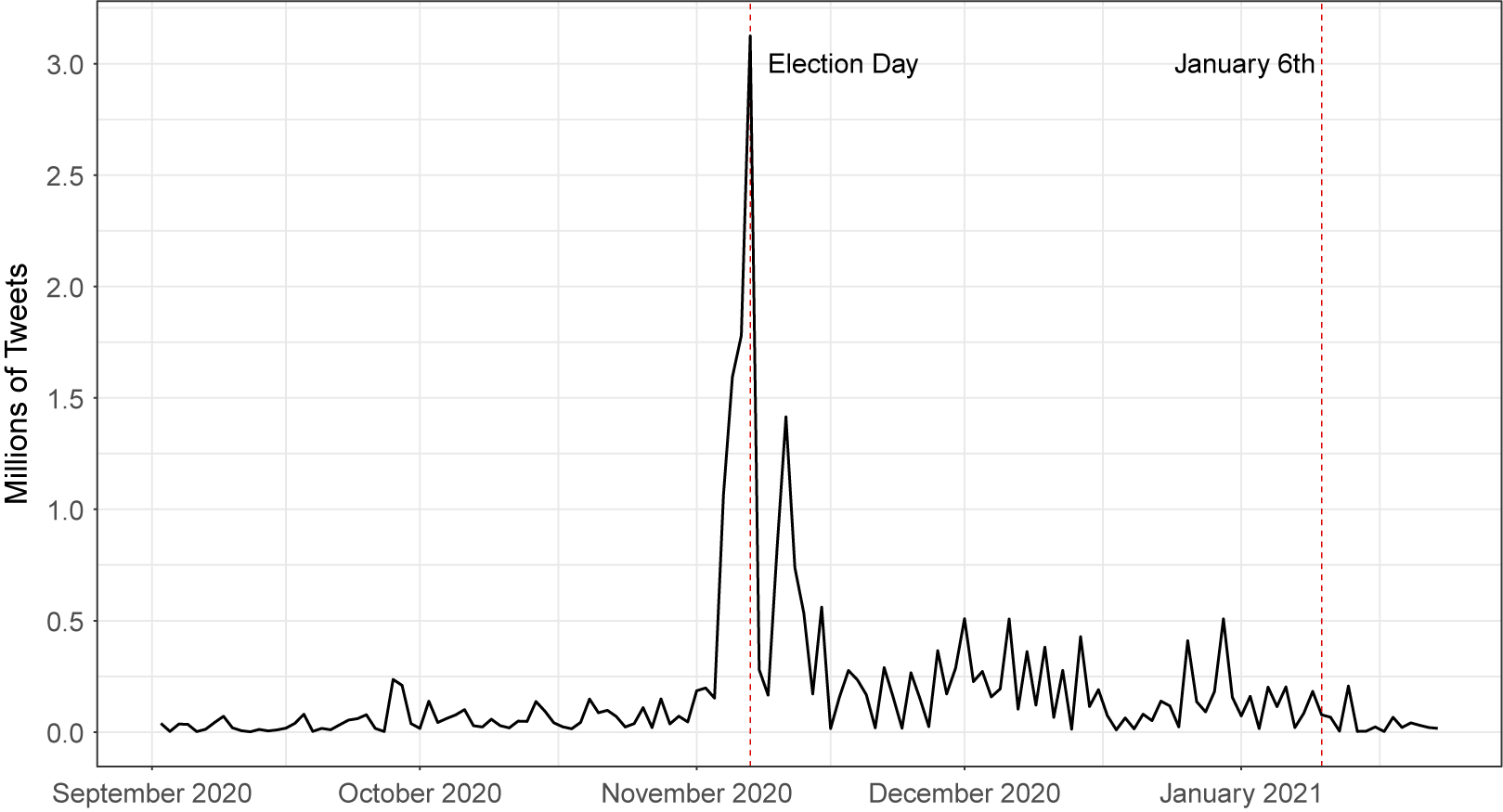
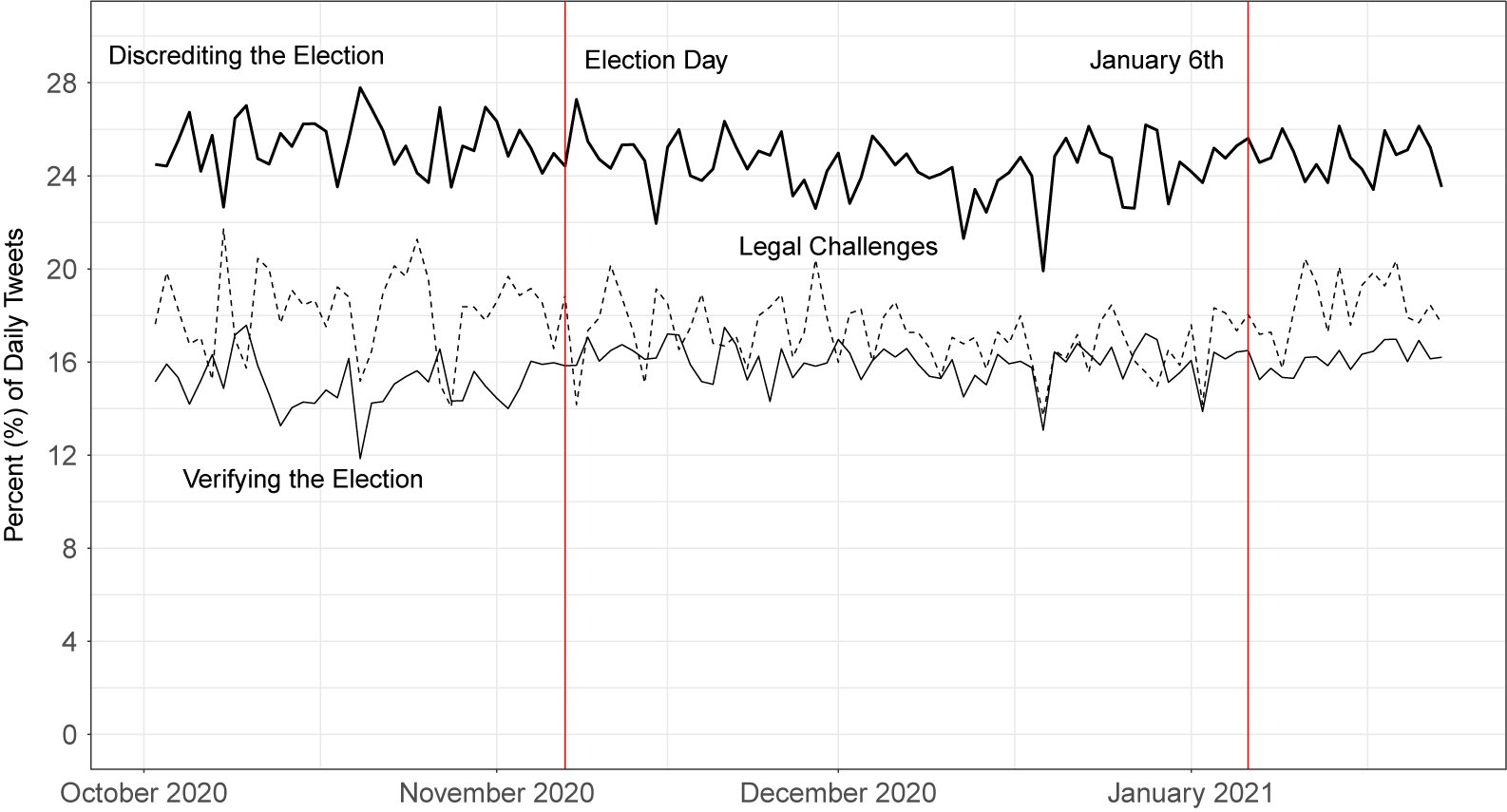
The second application uses a dataset of approximately 29 million tweets that were collected during the 2020 presidential election, regarding the conduct of the election. We show below that our method can process and analyze these data quickly and efficiently, generating interesting topic modeling results that could shed light on important political science questions.
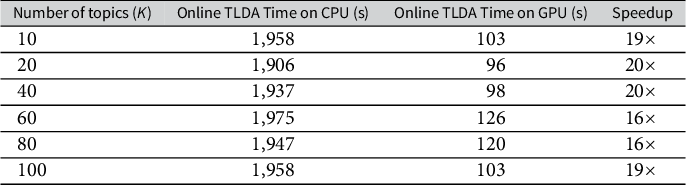
Finally, in the Supplementary Material, we analyze a third dataset that contains over 260 million tweets related to COVID-19, collected in real-time using keywords from the Twitter streaming API. We show that our method produces coherent estimates in under 3.5 hours on this dataset, and in under 13.5 hours on a simulated 1.04 billion document dataset created using these COVID-19 data. Thus, we demonstrate that our method is effective for unsupervised analysis of large-scale data on the order of billions of documents.
7.1 The #MeToo Movement: Scaling, Ablation, and Substantive Studies
7.1.1 Studying Mass Movements and Collective Action with Large-Scale Datasets
The #MeToo movement is a prolific women’s rights movement that gained traction extremely quickly on Twitter in October 2017, with over 7.9 million tweets containing the #MeToo hashtag from October 2017 to October 2018 alone (Brown Reference Brown2018). This movement is an important example of what Clark-Parsons has termed “Network Feminism,” where social media platforms have become a crucial organizational tool for mobilization of social and political movements (Clark-Parsons Reference Clark-Parsons2022).
Going back to the early theoretical work of Mancur Olson, studying social movements and protest politics as a lens for collective action has been an important literature in political science (Olson Jr. Reference Olson1971). In particular, researchers have long tried to understand the political origins of protest politics and mass movements, because as Olson noted, participation can be costly and the results of participation can be difficult for individuals to assess.
Studying how mass movements and protest politics arise, how they are organized, and how they are sustained in the long run, is also complicated by a lack of available data. Movements and protests arise quickly, and authorities often act to stop and prevent protesting and organizing, which means in many cases that political scientists cannot often collect data about protests and movements. Surveys of protest participants can be done after the fact, but they can be difficult to find, difficult to persuade to participate in a survey, and their survey responses may be inaccurate with the passage of time. Thus, much of the literature has resorted to case studies of historical examples (Chong Reference Chong1991).
In recent years, the use of social media by protest and movement participants has sparked new research about collective action, specifically regarding protests and mass movements. By collecting data from participants in the protests, while they are protesting or acting collectively, has proven to be an important way to generate datasets to test existing theories, for example, about the Arab Spring or Black Lives Matter movements (Kann et al. Reference Kann, Hashash, Steinert-Threlkeld and Michael Alvarez2023; Steinert-Threlkeld Reference Steinert-Threlkeld2017).
In a similar way, the tweets related to #MeToo thus provide rich data for investigating the evolution of a modern social movement initiated by online discussions on social media. What topics engaged participants in the #MeToo movement? Did the topics of conversation change over the course of the movement? Can the language of social media conversations help us determine the motivations of participants in the movement, where they motivated by self-interest or collective concerns? These data can be crucial for understanding this important social and political movement, and for testing theories about how movements like these arise and are sustained.
We analyze the topics present in a corpus of #MeToo tweets collected from January 2017 to September 2019, which contains 7.97 million tweets after pre-processing. Figure 4 shows the initial proliferation of tweets in January 2017 related to the Women’s March and Movement, as well as the viral growth of the #MeToo movement in September and October 2017.
Tweets per month in the #MeToo data, in millions.

7.1.2 Pre-Processing
We follow the standard pre-processing framework outlined earlier in the article, which we note takes only 178 seconds on GPU using RAPIDS. The #MeToo Twitter data are high-frequency, and there are orders of magnitude many more observations than in existing datasets analyzed in applications in the social science literature. Thus, we set a very low lower bound for pruning words—words need only appear in 0.002% of documents to be included in the #MeToo data. Higher thresholds would dramatically reduce the number of features such that there was no variation in the document structure. Any lower and many features which only appear in a handful of documents would be essentially noise. These are proper nouns, such as usernames, typos, nonsensical words, or words that are not common enough to help define meaningful clusters. At the same time, we exclude words that appear in more than 50% of the documents. This only amounts to removing 50 words, many of which are so common as not to be useful in delineating a topic due to lack of variation (as they appear in every document). We arrive at 1,837 words, more than enough to pin down meaningful topics. Changing this cutoff to 70%, 80%, or 90% does not significantly change the number of words in the vocabulary. Still, we stick to the more restrictive cutoff because many common words would otherwise dominate every topic, hindering the interpretability of the model. We also ensure that words occur in at least 0.002% of documents, so idiosyncratic words that explain slight variation in the data are excluded. These words might appear in only one or two documents, which is far too infrequently to pin down substantive topics. Finally, following standard practice, we stem words by cutting off verb and noun endings so that base words will carry the same semantic meaning.
7.1.3 #MeToo Scaling and Convergence Speed Comparison
In this set of results, we first run the batched and online versions of our TLDA method on the entire #MeToo Twitter dataset on one GPU core to analyze how quickly both versions of our approach converge with varying numbers of topics. We then compare the scaling of our TLDA method to that of Gensim by computing convergence time on subsets of the #MeToo dataset containing 1M, 2M, 5M, and 7.97M documents.
Full #MeToo Timing Comparison
To choose the optimal parameters for our method, we run an extensive grid search over the number of topics K, whitening sizes D, topic mixing parameters
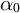 $\alpha _0$
, and learning rates
$\alpha _0$
, and learning rates
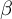 $\beta $
. For each number of topics, we determine the optimal parameters by finding the parameter combination with the highest mean coherence score across all metrics. For
$\beta $
. For each number of topics, we determine the optimal parameters by finding the parameter combination with the highest mean coherence score across all metrics. For
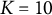 $K = 10$
, we report the 20 top words for the batched model with the best parameters in Table A2 in the Supplementary Material. We include the parameters used for each number of topics in Table A6 in the Supplementary Material.
$K = 10$
, we report the 20 top words for the batched model with the best parameters in Table A2 in the Supplementary Material. We include the parameters used for each number of topics in Table A6 in the Supplementary Material.
Using these optimal parameters, we run the batched and online versions of our model to convergence and provide a benchmark comparison of speed and coherence on GPU to the most popular off-the-shelf CPU-based LDA method, Gensim LDAMulticore, which is fully parallelized (Rehurek and Sojka Reference Rehurek and Sojka2011). For the Gensim LDA model, we keep all default parameters, except we increase the number of passes and iterations until the coherence of the model converges for each specified number of topics. We include the final parameters used in Table A7 in the Supplementary Material. We compute the coherence measures using the Gensim CoherenceModel library by providing the
 $20$
top words in each topic and using the default parameters for each coherence measure.
$20$
top words in each topic and using the default parameters for each coherence measure.
In the Supplementary Material, we also compare how our methods scale against other state-of-the-art LDA methods (see Table A4 in the Supplementary Material). In particular, we analyze LightLDA (Yuan et al. Reference Yuan2015) and WarpLDA (Chen et al. Reference Chen, Li, Zhu and Chen2016), both of which purport tremendous increases in scale. We note neither method offers the accuracy guarantees of TLDA, nor are they actively maintained as part of a larger suite of packages (such as Gensim’s LDAMulticore or Tensorly’s TLDA, presented here). We note in any case that our method outperforms both in terms of time, even without the theoretical guarantees of our method (Anandkumar et al. Reference Anandkumar, Foster, Hsu, Kakade and Liu2013).Footnote 10 We also note that there are many other methods purporting to perform topic modeling at scale. As far as our review of them can determine, none purport to have the accuracy guarantees of our method, nor have they been widely adopted. For this reason, we focus our analysis on Gensim’s implementation, which is, by far, the most popular and widely adopted.
As shown in Table 4, we find that the batched version of our method, running on a single GPU, achieves 10
 $\times $
–95
$\times $
–95
 $\times $
speedup over Gensim running in parallel on 79 CPU cores. The online version running on a single GPU achieves a 15
$\times $
speedup over Gensim running in parallel on 79 CPU cores. The online version running on a single GPU achieves a 15
 $\times $
–143
$\times $
–143
 $\times $
speedup over Gensim run in parallel on 79 CPU cores. Notably, our method has a relatively constant convergence speed and consistent coherence for all numbers of topics. On the other hand, as the number of topics increases, the convergence time for the Gensim model increases nonlinearly and the final coherence score to which it converges decreases significantly. The runtime comparison as the number of topics increases is visualized in Figure 5. As these results indicate, our method is especially useful for analyzing larger numbers of topics, thanks to the near-constant scaling of convergence time as the number of topics increases: for more than 60 topics, our method is over 100
$\times $
speedup over Gensim run in parallel on 79 CPU cores. Notably, our method has a relatively constant convergence speed and consistent coherence for all numbers of topics. On the other hand, as the number of topics increases, the convergence time for the Gensim model increases nonlinearly and the final coherence score to which it converges decreases significantly. The runtime comparison as the number of topics increases is visualized in Figure 5. As these results indicate, our method is especially useful for analyzing larger numbers of topics, thanks to the near-constant scaling of convergence time as the number of topics increases: for more than 60 topics, our method is over 100
 $\times $
faster on GPU than the fully parallelized Gensim CPU LDA method.
$\times $
faster on GPU than the fully parallelized Gensim CPU LDA method.
TLDA convergence timing comparison on the full #MeToo dataset.

Note: See Rehurek and Sojka (Reference Rehurek and Sojka2011) for details about Gensim LDA Multicore and Röder, Both, and Hinneburg (Reference Röder, Both and Hinneburg2015) for the coherence metrics.
Runtime comparison for TLDA on GPU vs. Gensim for the full #MeToo corpus and varying numbers of topics.
Note: This shows that the runtime of our method scales nearly constantly with respect to the number of topics, while Gensim scales more than linearly.

Scaling Study
We fit our TLDA method for 10, 20, 40, 60, 80, and 100 topics on four subsets of the #MeToo movement containing 1, 2, 5, and 7.97 million tweets. We keep the same vocabulary and optimal parameters from the full #MeToo timing comparison while running the model on each of these subsets. As seen in Figure 6, which displays the TLDA fit time (excluding preprocessing) for 100 topics, the convergence time for our method scales linearly with the number of documents on the GPU, while the convergence time for the Gensim LDAMulticore method increases significantly faster. Combined with our empirical finding from the full-scale #MeToo study that our method scales nearly constantly with the number of topics, this indicates that it is feasible to run both the batched and online versions of our method on even larger data. We include the plots for the remaining number of topics in Figure A2 in the Supplementary Material.
TLDA vs. Gensim fitting time.
Note: We compare the time to fit Gensim’s LDAMulticore and our online TLDA, not including pre-processing, for 100 topics. We plot the runtime in seconds as a function of the size of the subset from the #MeToo dataset, from 1 million to 7.97 million tweets.

7.1.4 CPU Ablation Study
To demonstrate the benefits of our GPU implementation, we perform an ablation study comparing CPU and GPU TLDA runtime.
As shown in Table 5 (which does not include pre-processing time), we find that the CPU version of our method has relatively constant runtime with respect to the number of topics and takes under 1 hour to converge for each number of topics on the full #MeToo dataset. Furthermore, we perform an empirical scaling study (see Figure A3 in the Supplementary Material), in which we confirm that the convergence time of our method scales linearly with the number of topics on CPU as well as on GPU. These results indicate that our method is feasible to use on CPU for datasets on the scale of tens of millions of documents for researchers who do not have access to GPU machines. However, the GPU implementation results in significant gains in TLDA convergence speed and allows for scaling to hundreds of millions and billions of documents.
Comparison of CPU and GPU runtime on the #MeToo dataset (7.97 million tweets).
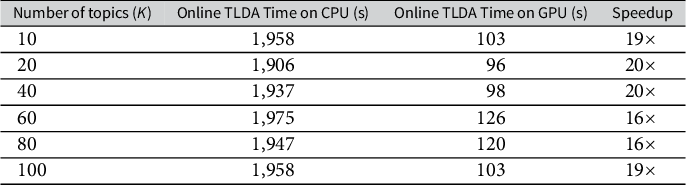
7.2 Qualitative Analysis of the #MeToo Movement
Finally, we present a full-scale analysis of the evolution of two years of #MeToo Twitter discussion over time. Previous studies have shown the importance of accounting for the dynamic nature of conversation in the #MeToo movement (Liu et al. Reference Liu, Srikanth, Adams-Cohen, Alvarez and Anandkumar2019), and here we analyze the topical development of tweets concerning #MeToo from just before the start of the movement in August 2017 through September 2019. Understanding the topical development of the #MeToo movement would be important for scholars who wish to test theories about how social movements organize online, for studies of feminism or gender politics, for two examples.
To develop this dynamic analysis, we iteratively grow the corpus of tweets and estimate the TLDA model. That is, first, we fit the model on August and September 2017 data to capture the discussion immediately preceding the time when #MeToo discussion went viral on Twitter. Then, we add the next month and estimate the entire model again. We repeat this process for each subsequent month until we reach the end of the dataset. In Figure 1, we report the topic for selected months with the largest weight
 $\alpha _i$
for both pro- and counter-#MeToo topics. We call these topics the most prominent. The relative size of the labels indicates the relative prominence of the respective topics. In Figure 2, we report the political topic with the largest
$\alpha _i$
for both pro- and counter-#MeToo topics. We call these topics the most prominent. The relative size of the labels indicates the relative prominence of the respective topics. In Figure 2, we report the political topic with the largest
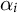 $\alpha _i$
, which we call the most politically salient.
$\alpha _i$
, which we call the most politically salient.
This approach leads to three key qualitative findings: first, topics related to politically salient news events are generally ephemeral, changing often as we grow the dataset over time. In contrast, topical prominence related to personal testimonies, coordinating protests, and supporting other participants in the #MeToo movement is persistent over time. Third, discussion around counter-#MeToo topics declines in prominence over time and is subsumed into one topic by September 2019. These findings suggest avenues for the study of the temporal evolution of political and social coordination in mass movements, especially on social media, as most research using this type of data to study social movements has not examined the longer-term dynamics of these forms of political engagement (Jost et al. Reference Jost2018; Steinert-Threlkeld Reference Steinert-Threlkeld2017). Moreover, these results indicate that dynamic changes in topic evolution on social media may be in response to changing news events, another area ripe for new research using large social media and news media datasets using methods like TLDA.
7.3 Election 2020: Elite Political Communication and the Losers’ Effect
In this second application, we look at another source of real-time social media data relevant to how political elites communicate with and coordinate their supporters, especially in the face of electoral defeat. A peaceful transfer of power is a necessary indicator of a healthy democracy. Studies into how political elites respond to electoral defeat offer critical insights into how democracies persist, even in polarized or politically fraught periods of history. In light of the 2020 election, longstanding questions around how politicians organize their supporters around election were especially salient. Previous studies into political anger and the losers’ effect have relied on survey-based evidence, and produced valuable insights into voter psychology and political behavior (Craig et al. Reference Craig, Martinez, Gainous and Kane2006; Sinclair, Smith, and Tucker Reference Sinclair, Smith and Tucker2018); however, these methods are static and rely on recalled emotions after an election. Building on this important work, our methodology allows researchers to study how a politician coordinates with his or her politically engaged supporters online. With this type of data, we can study online political behaviors in real-time—President Trump was active online and especially on Twitter (Li et al. Reference Li, Cao, Adams-Cohen, Michael Alvarez, Ceolin, Caselli and Tulin2023), so these conditions allow us to better understand how electoral losers respond to electoral defeat. For policy makers, such methods might allow for real-time detection of the spread of effective attempts to inform the public, while highlighting messaging that angers, rather than informs, the voting public.
As with #MeToo, this data was collected based on a keyword search employing the social media data collection techniques in Cao, Adams-Cohen, and Alvarez (Reference Cao, Adams-Cohen and Michael Alvarez2021) and Li et al. (Reference Li, Cao, Adams-Cohen, Michael Alvarez, Ceolin, Caselli and Tulin2023). The data are lightly structured, so our method can offer insights into the latent structure of this politically engaged demographic: online supporters. In this case, a comprehensive collection of tweets related to keywords related to the administration of the 2020 Presidential election served as the basis of the data collection. Overall, the data are composed of 29,711,862 tweets collected from September 1, 2020 through the Inauguration on January 20, 2021. These data were collected in real time as the tweets were being posted. In large part thanks to this real-time collection of data, we were able to capture many tweets prior to their being deleted or moderated, giving us an unfiltered look at social media activity during a critical period in American electoral politics.
In Figure 7, we report the daily number of tweets collected by our keyword search. The data are most voluminous on November 4th, the day of the election, with nearly 3 million election-related tweets. There is a second peak of just under 1.5 million tweets on November 7th, the day the media outlets declared Joe Biden the winner of the election. Activity remains high following the election with nearly 250 thousand to 500 thousand tweets following the election.
Number of tweets per day.

The TLDA framework offers potential new insights as a data discovery method for a critically important area of political science—how the public and politicians organize messaging surrounding the legitimacy of elections on social media. Large-scale social media data concerning the legitimacy of the election are particularly suited for the TLDA framework because discerning meaningful structure from these data would be impractical without automated methods. More than merely large, the data are unstructured because they are directly collected in real-time from people’s authentic online thoughts. In terms of generating new theories about the role of online behavior in disseminating information about the election amplifying the loser’s effect, actively organizing political supporters, and its direct role in helping to coordinate the rally and riots on January 6th, a data discovery method like TLDA is the most computationally feasible way to study these data real-time and at scale.
7.4 Qualitative Analysis of Trump-Related Social Media Activity in the 2020 Election
We now report an analysis based on the outputs of our TLDA analysis—we hope this serves as an example of how political scientists might employ our framework to engage in data discovery for unstructured data at large scale. We report descriptive findings on a full population of tweets covering a topic of critical importance to students of political behavior and electoral politics. To that end, we recover 30 topics overall. For this analysis, we classify the topics into three main categories based on the following criteria: of the discovered topics, we find three broadly related categories: discrediting the election, discussing legal challenges to the election, and tweets verifying the election result.
Notably, in Figure 8, we observe relative stability in the daily share of tweets belonging to each category both across time and between the relative share of each of the categories. We see that tweets discrediting the election account for 25% of all tweets on average, with a relative peak on January 6th. We see that in the days after January 6th, the share of tweets related to verifying the election results actually drops.
Topical composition over time: In this figure, we report the average share of tweets belonging to one of three main categories of topics with a greater than 90% probability.

7.4.1 Pre-Processing
Following the same pre-processing as for the #MeToo data (i.e., we removed all words that appear in fewer than 0.002% of documents and in more than 50% of documents), we generate a vocabulary of 3,788 words. As in the case of the #MeToo analysis, we perform all pre-processing using the Rapids GPU Framework. We note that preprocessing the entire dataset takes only 3,661 seconds (or 1.02 hours).
7.4.2 Timing
In addition, to demonstrate that our method can scale to billions of documents, we use a large COVID dataset to simulate a dataset of
 $1,043,009,932$
documents. To do so, we loop through the entirety of the data four times and update the online version of the method on each batch once within each iteration. We report full results in the Supplementary Material.
$1,043,009,932$
documents. To do so, we loop through the entirety of the data four times and update the online version of the method on each batch once within each iteration. We report full results in the Supplementary Material.
In Table 1, we show that the model converges in 3.47 hours. We include the top 20 words from each topic and word clouds for the top 3 topics in Section 1.5 of the Supplementary Material to illustrate that our model produces coherent topics. We also find that our method scales linearly to the simulated data, as it takes 13.16 hours to analyze 1.04 billion documents. This illustrates the feasibility of using our method for tuning, estimating, and analyzing topic models on social media data at a large scale.
8 Conclusion
Applied researchers have access to larger and larger datasets of text information. These datasets may come from social media platforms like Twitter, Reddit, or Facebook (Steinert-Threlkeld Reference Steinert-Threlkeld2018), congressional speeches, news media archives, legislative text, campaign websites, and senatorial memos. These data sources are being used for critical new studies in political science, across a variety of topics, including political behavior, political opinion, protest movements, legislative agendas, and collective action. Other large and complex text datasets are being compiled and used in the humanities (Dennis-Henderson Reference Dennis-Henderson2020). The widespread availability of unique and high-dimensional text data is opening new doors for applied researchers in the field.
However, off-the-shelf methods, such as LDA, are computationally inefficient and unusable for analyzing large, high-dimensional text datasets. Our approach provides a feasible scale and a method with theoretical foundations for its statistical properties. This compares favorably, as we noted earlier, with proprietary LLMs. New LLM methods show increasing promise, but yet pose lingering challenges for academic researchers, including a lack of strong statistical theoretical foundations. We hope in future research to show that these statistical properties serve as a foundation for further validation of the quantities of interest researchers aim to study.
In this article, we proposed an efficient and theoretically-founded TLDA approach for estimating topic models, which we have shown can be fitted on large text datasets many orders of magnitude faster than existing off-the-shelf topic modeling methods. Our implementation of the TLDA method builds on the TensorLy library. We aim to democratize the analysis of large-text datasets by offering a method that scales on both GPU and CPU, is fully open-source, and whose mathematical underpinnings are clearly communicated. We hope the wide availability of this method will enable new lines of research on previously out-of-reach scales.
Acknowledgments
The authors thank Ryan P. Kennedy, Patrick T. Brandt, and the participants at the 2024 “TexMeth” Workshop for their comments and suggestions. Some of S.K.’s work on this project was supported by Summer Undergraduate Research Fellowships from Caltech. We thank the Anima AI + Science Lab and the Alvarez Lab for their comments and feedback.
Data Availability Statement
Replication code for this article is available via Dataverse at Ebanks et al. (Reference Ebanks, Anandkumar, Kossaifi, Sara and Alvarez2025) at https://doi.org/10.7910/DVN/OKPRJG.
Author Contributions
Conceptualization: S.K., D.E., J.K., A.L., R.M.A., and A.A.; Data collection and curation: S.K., D.E., and R.M.A.; Formal analysis: S.K., D.E., J.K., A.L., and A.A.; Funding acquisition: R.M.A. and A.A.; Methodology: S.K., D.E., J.K., A.L., R.M.A., and A.A.; Project administration: R.M.A. and A.A.; Software: S.K., D.E., and J.K.; Writing and editing: S.K., D.E., J.K., A.L., R.M.A., and A.A.
Supplementary Material
The supplementary material for this article can be found at https://doi.org/10.1017/pan.2025.10024.