


1 Introduction
Classic theories of the survey response in political science (Zaller Reference Zaller1992; Zaller and Feldman Reference Zaller and Feldman.1992) hold that most people have weak preferences on specific policy proposals and so give unstable responses to closed-ended items based on what happens to be at the “top of the head.” Partly due to concerns about top-of-the-head responding and other response artifacts, open-ended items can be a useful complement to their restricted, closed-ended counterparts. They allow for broader reflections of how respondents think about politics and their own beliefs (Feldman and Zaller Reference Feldman and Zaller1992; Kraft Reference Kraft2024; Schuman and Scott Reference Schuman and Scott1987) and can sometimes be used to sidestep closed-ended response style effects (Hobbs and Ong Reference Hobbs and Ong2023).
Open-ended responses have until recently been difficult to analyze at scale, though recent advances in natural language processing now allow for efficient document classification and categorization—with or without supervision from human labels (Gilardi, Alizadeh, and Kubli Reference Gilardi, Alizadeh and Kubli2023; Mellon et al. Reference Mellon, Bailey, Scott, Breckwoldt, Miori and Schmedeman2024; Miller, Linder, and Mebane Reference Miller, Linder and Mebane2020; Yin, Hay, and Roth Reference Yin, Hay and Roth2019). However, these advances have been concentrated in applications where researchers know how documents ought to be evaluated in advance—whether they reference specific constructs or meet specific criteria of interestFootnote 1 —or in supervised settings where differences in word use can be directly linked to an observed outcome such as respondent partisanship. Furthermore, methodological advances do not by themselves address deeper theoretical questions regarding the relationship between the respondent’s underlying attitudes and what they express on a survey. If capturing stable expressions of political attitudes is the goal—which can then inform researchers’ choices regarding what to label—methods for analyzing open-ended responses must be grounded in a theory of the open-ended survey response.
We argue that open-ended survey responses represent top-of-the-head expressions of more general attitudes—much like closed-ended responses. In our theory of the open-ended survey response, respondents first choose a high-level attitude to express in their answer. Because that general attitude may be abstract and difficult to express in words, they then come up with a more specific statement that is easier to communicate. This statement is an incomplete stand-in for a broader attitude—in the language of the closed-ended survey response, a sampled consideration from a underlying attitudinal distribution. Importantly, this means that the ability to accurately and narrowly classify what a respondent happened to say in an open-ended response will not necessarily be the same thing as capturing the broader attitude they expressed (or are likely to express again). The latter requires inferring the more general distributions from which specific statements were sampled—an inherently unsupervised task toward which pre-trained language models have not thus far been oriented. Practically speaking, this involves inferring a range of statements that could be substituted for what someone happened to say without changing what they generally mean—such that we can predict what they are likely to express in response to the same question later on.
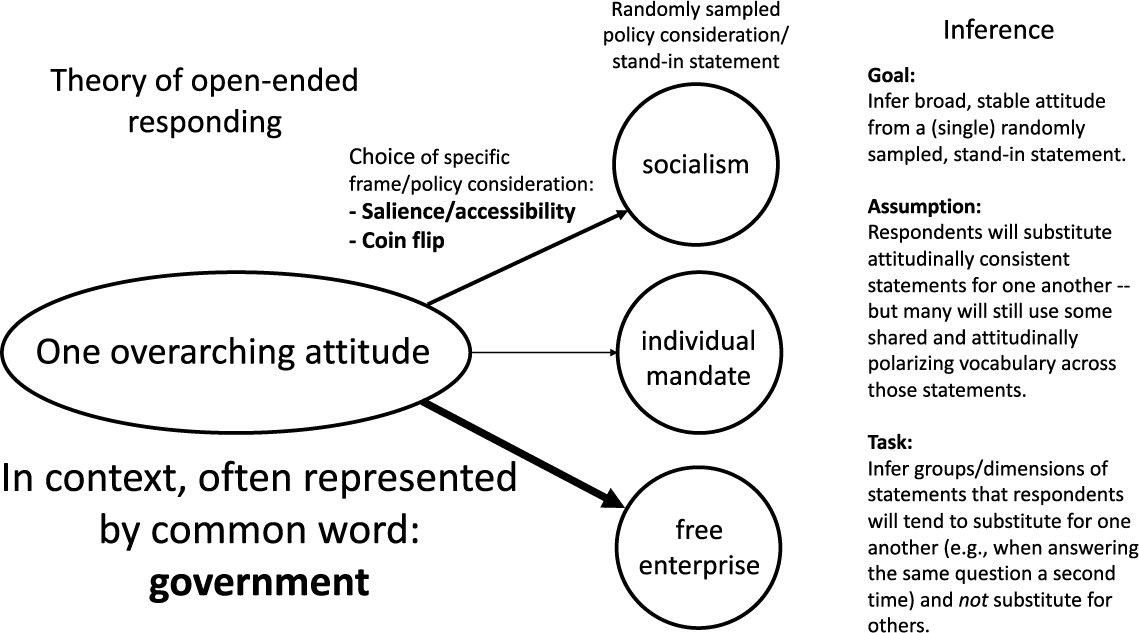
With our theory in mind, we show that it is possible to use text data to infer which elements of open-ended responses are more likely to reflect stable response patterns and, in line with longstanding theories of the survey response in political science, are more likely to reflect the range of political attitudes expressed in a corpus (though not guaranteed to, as we’ll discuss and evaluate). If many respondents use the same words when giving statements, and those words are associated with relatively polarizing sets of less frequently-used words, then those “contextually common” words may provide useful signals of the attitudes being expressed—even if they’d appear vague in more general contexts. In this, we leverage two premises about words used unusually frequently in political contexts: 1) they are re-used across a broad range of more narrow political statements that respondents tend to substitute for each other (and so they can be used to link those statements) and 2) when these words are used in politically distinct ways, they can take on symbolic and polarized meanings. For example, the average meaning of the word “people” in a focused political context may be closer to meanings like “the people”, “working people”, or “ordinary people” than its more general meaning—implying senses of the word that exclude (and place “the people” against) “politicians” and “the rich” (or, in some cases, out-partisans and racial out-groups). Using such a word can both convey meaningful political attitudes and also bridge sets of less common statements.
It is important to clarify that our claim is that contextually common words are particularly useful for inferring distributions of attitudes at the corpus level. At the document level, a person using common rather than rare words to express the same attitude does not necessarily mean that they have a more stable underlying attitude (they might, but that is unrelated). Three different respondents who strongly disapprove of the Affordable Care Act may articulate this disapproval using different specific terms (such as “free enterprise,” “individual mandate,” or “socialism”). We can infer that they intend to convey similar meaning through these terms’ co-occurrence with words used across multiple respondents (such as “government”, as in “big government”).
The usefulness of contextually commonFootnote 2 words may seem counter-intuitive to many text-as-data practitioners. There are almost certainly more rare words that are predictive of attitudes, and in a supervised setting these could be used to classify many specific outcomes. However, this can be easily driven by the far greater number of unique rare words compared to common ones overall (i.e., Zipf’s law) and a resulting base rate fallacy in evaluating the average importance of contextually common versus rare words. It is easy to identify a small number of rare words that are highly correlated with an outcome of interest, even when they are the exception rather than the norm. Without a known filter for uninformative rare words—and (in line with our goals here) a reliable means to link informative terms to more abstract concepts—many rare words will reflect a variety of idiosyncratic considerations that happened to be salient for the respondent at the time (i.e., what a respondent happened to think of when they answered the question), in addition to a core attitude that is more likely to be expressed in repeated measures.
Consistent with this theory, we show that 1) words commonly used to answer a focused open-ended prompt—as well as more prevalent human-coded categories—tend to be more strongly correlated over survey waves than rare ones; and 2) a method explicitly leveraging variation in contextually common word use to infer distributions of (polarized) statements provides efficient quantitative representations of open-ended responses. Our method outperforms other tools, especially topic models, in terms of both test-retest reliability and in predicting high-level groupings of hand labeled political content.
After showing this performance, we provide recommendations for use of our approach—and words of caution. Although the method returns stable dimensions of responses, these dimensions are not guaranteed to conform to researcher expectations (such as recovering a left/right dimension, as many alternate scaling methods for behavioral data aim to—often by training on a subset of a data set that is more likely to be driven by left/right ideology). For example, it is possible for the primary variation in an open-ended response to be communication style, just as a closed-ended responses can be dominated by social desirability or acquiescence bias. As with any automated text method, ours requires in-depth validation of its output. The method also does not reveal all topics that can be labeled in a data set—just the ones that tend to be the most stable over time. As Grimmer, Roberts, and Stewart (Reference Grimmer, Roberts and Stewart2022) note, there is no globally optimal method when it comes to analyzing text as data.
Finally, we extend our method to demonstrate its practical usefulness in tandem and in comparison with common alternatives. We first provide a technique to describe the context-specific and potentially symbolic meanings of common words. We then demonstrate how our method’s output relates to that of tools like topic models and principal component analysis on the latest generation of contextualized embeddings. We find that these off-the-shelf methods —at times and under favorable conditions—recover similar information as ours. However, in our analyses, the most reliable means to find topics and embeddings dimensions with high test-retest reliability and the strongest correspondence with sets of hand labels is to assess correlations with the top dimension of our method’s output.
2 Background
Representative democracy assumes that citizens have meaningful attitudes on political matters that can be communicated to and considered by their representatives (Mansbridge Reference Mansbridge2003; Pitkin Reference Pitkin1967). Without attitudes, and the ability to identify them with some degree of regularity, “democratic theory loses its starting point” (Achen Reference Achen1975).
Early scholars of U.S. public opinion were skeptical that most citizens held political attitudes at all (Converse Reference Converse and Apter1964, Reference Converse and Tufte1970). However, subsequent work (e.g., Achen Reference Achen1975) salvaged the attitude in political science by highlighting a distinction between attitudes in survey respondents’ minds and attitudes measured with (hopefully random) error in surveys. Rather than expecting a one-to-one correspondence between attitudes and survey responses, it is more useful to consider attitudes as unobserved, probabilistic distributions and survey responses as draws from those distributions. Statistical techniques that account for the measurement error inherent to the individual survey response, often by leveraging responses from multiple related items, allow us to learn more about the latent distributions of attitudes that produced them (Ansolabehere, Rodden, and Snyder Reference Ansolabehere, Rodden and Snyder2008; Fowler et al. Reference Fowler, Hill, Lewis, Tausanovitch, Vavreck and Warshaw2023).
2.1 The (Closed-Ended) Survey Response
The dominant model of the survey response in political science, (Zaller’s Reference Zaller1992) Receive, Accept, Sample (RAS) model, incorporates these perspectives to account for empirical regularities in mass opinion research. In this model, individuals receive varying amounts of information about political matters, accept or reject that information based on their political predispositions, and sample from “considerations”—or discrete elements of relevant information—that they have previously accepted when they encounter questions on surveys. The survey response is interpreted as an average of the considerations that were accessible to the respondent when they answered.
Especially for the majority of citizens who do not pay close attention to politics, responses are often constructed on the fly, and based on whichever considerations happen to be available when questions are posed. As many citizens hold considerations that carry divergent implications for matters of public policy—they may, for example, value both freedom and equality (Feldman and Zaller Reference Feldman and Zaller1992) or civil rights and public safety (Nelson, Clawson, and Oxley Reference Nelson, Clawson and Oxley1997) —contextual factors that influence which considerations are made salient can alter responses to similar or even identical questions (Asch Reference Asch1940; Wilson and Hodges Reference Wilson, Hodges, Martin and Tesser1992).
2.2 Open-Ended Responses
The typical mass opinion survey, for which the RAS model was designed, involves closed-ended survey items in which the respondent selects from a pre-determined list of potential answers to each question. Open-ended responses do not similarity limit response options, but the task of mapping articulated responses to underlying attitudes remains challenging. Qualitative categorization of open-ended responses often do not match closed-ended responses to otherwise similar questions (Schuman and Presser Reference Schuman and Presser1979; Schuman and Scott Reference Schuman and Scott1987), and researchers’ interpretations of respondents’ answers can differ from those of the respondents themselves (Glazier, Boydstun, and Feezell Reference Glazier, Boydstun and Feezell2021).
Nonetheless, past (largely qualitative) work on open-ended responses suggests that this mapping is in principle feasible. When posing obscure and almost certainly unfamiliar policy proposals to respondents, Schuman and Presser (Reference Schuman and Presser1980) found that many who could not be said to have a preference on the specific proposal nevertheless tried to use the opportunity to convey a more general attitude.Footnote 3 In their analyses of open-ended responses, Zaller and Feldman (Reference Zaller and Feldman.1992) identified a dizzying number of different “frames of reference” respondents used to approach different policy proposals, but the vast majority of responses had a clearly-identifiable “directional thrust” that reflected their more general disposition.
3 Theory of the Open-ended Survey Response
Our theory of the open-ended response broadly follows the RAS model (Zaller Reference Zaller1992) in that we assume responses represent top-of-the-head expressions of accessible considerations when evaluating the “attitude object” given by a prompt, but differs in the relationship between sampled considerations and the eventual response. In closed-ended responses, some considerations may be more accessible than others, but respondents still average across those that come to mind before selecting a response option. For open-ended responses, we argue that 1) some parts of the responses reflect considerations that are more chronically accessible, and are therefore likely to have served as the starting point for the respondent; 2) it is possible infer these more accessible parts of responses when studying text (even without panel data, though it’s better to have it); and 3) these more accessible considerations better reflect what could be recognized as stable attitudes.
In our model, the respondent begins with an initially drawn directional thrust. They then sample specific, related considerations in order to satisfy the expectations of a composed response, and to communicate their attitude sincerely and efficiently. While some respondents may have more to say than others, they will still not cover every topic they could have discussed and may elaborate on a single, sampled topic consistent with the thrust of their attitude.
In this setting, we expect that words used relatively frequently in the context of the survey prompt (though not necessarily words used frequently across all contexts; see Figure F.1, which shows that these words are moderately common in American English) are likelier than rare words to reflect the directional thrust of responses. This is at least in part because contextually common words are likelier to reflect symbolic language, which allows the respondent to efficiently convey a large amount of topic-dependent meaning. Symbolic language is extremely common in politics, as political elites and the citizens who take cues from them contest and reshape the meaning of particular words and phrases in specific political contexts (Edelman Reference Edelman1985; Lasswell, Lerner, and de Sola Pool Reference Lasswell, Lerner and de Sola Pool1952; Neuman, Just, and Crigler Reference Neuman, Just and Crigler1992). For example, when someone asked to explain why they oppose the Affordable Care Act says that they object to “big government,” we do not necessarily expect that they are articulating a broadly libertarian ideology that would extend to other issue contexts such as military spending. We instead understand their use of the term to symbolize objections to redistribution and new government interventions into the private health insurance market—and we can do so because “government” is mentioned relatively frequently when people express their (negative) attitude toward the Affordable Care Act. There are a variety of different ways people express this more general attitude, and in context we would understand any of these specific expressions to convey a similar meaning.
Especially in short text settings, such as open-ended survey responses, we expect people to rely on symbolic language to express their attitudes efficiently. For example, even if respondents would have trouble precisely defining “big government,” we can still infer what they mean based on how other people tend to use it in similar contexts. Frequently used words that have many context-specific associations, both in terms of words they regularly appear with and words they consistently do not appear with, are therefore likelier to reflect general political attitudes. This intuition is reflected in Figure 1, where multiple related terms are linked through their shared relationship with the word “government”, and we provide example responses in Supplementary Information (SI) Section G.
Inferring broad, stable attitudes from respondents’ individually sampled, stand-in statements. Vocabulary shared across many statements will become contextually common, and some subset will also be attitudinally polarizing. We argue that we can use these words to infer broad, stable attitudes. In doing so, we discount relationships among rare words, but still leverage rare words’ corpus-level associations with more contextually common words.
4 Scoring Common Words
Our approach to inferring attitudes boils down to calculating a score that measures whether a document is ‘about’ a contextually common word—whether or not the word was itself used—and then applying dimensionality reduction to summarize covariation in those “implied word” scores. The goal is to estimate the extent to which one could substitute what the respondent happened to say with other statements without changing what they meant—and through this, infer what statements a respondent could have made consistent with the same general attitude.
Importantly, and in contrast with common practice in many text analysis approaches (e.g., tf-idf weighting), this approach works in part by discarding some information—particularly associations among rare words—that is on average likely to reflect noise rather than signal with respect to stable attitudes. As with most common approaches, including topic models and sentiment analyses, our approach produces a list of words and associated scores on a dimension. It differs in attempting to estimate dimensions and word scores that better reflect stable responses and the underlying attitudes that produced them. Although we develop this theory and method with the English language in mind (and our tests are limited to the US political context), we believe that it can be readily extended, with appropriate validation, to other languages and applied to non-US contexts.Footnote 4
We begin with a fully in-sample method to illustrate our broader points about measurement error and the context-specific and symbolic meanings of common words. We then in Section 7 demonstrate how it can be augmented with pre-trained embeddings to improve both performance and interpretability. It is likely that large language models will eventually outperform methods that rely on in-sample data. However, at present, large language models on their own are unlikely to account for symbolic uses of words that are relatively common across respondents in a fully unsupervised setting—without the researcher providing relevant context and guidance. To maintain our substantive focus, full details of this method are included in the SI (Section B.6, which is an unabridged version of this text; and Appendix Section C, which is an explanation with annotated R code).
We compare a document-term matrix to a matrix that stands in for the respondent sampling distribution (the range of considerations to sample from) when a document is about an implied word. That matrix contains conditional distributions of co-ocurring words in all responses to the same or closely related promptsi.e., across documents that contain the word “people”, what fraction of (unique) words in those documents was the word x.
To compare documents’ stated words to the implied words’ sampling distributions, we use Bhattacharyya coefficients (which measure overlap in probability distributions) for every word in the corpus. Regardless of whether a document uses the word “people”, we still calculate whether the distribution of words in the document resembles the distribution of words for all other documents in the corpus that did use the word “people.”
Concretely, for a document i, stated word(s) j, and implied word k, the following calculation produces a document similarity score for word k in document i (a word that the document might be “about”):
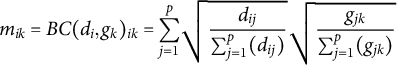 $$\begin{align*}\ m_{ik} = BC(d_{i}, g_{k})_{ik} = {\sum_{j=1}^{p}} \sqrt{\frac{d_{ij}}{\sum_{j=1}^{p}(d_{ij})}} \sqrt{\frac{g_{jk}}{\sum_{j=1}^{p}(g_{jk})}} \end{align*}$$
$$\begin{align*}\ m_{ik} = BC(d_{i}, g_{k})_{ik} = {\sum_{j=1}^{p}} \sqrt{\frac{d_{ij}}{\sum_{j=1}^{p}(d_{ij})}} \sqrt{\frac{g_{jk}}{\sum_{j=1}^{p}(g_{jk})}} \end{align*}$$
where
 $d_{ij}$
is an element in the original document-term matrix (whether word j was used in document i),
$d_{ij}$
is an element in the original document-term matrix (whether word j was used in document i),
 $g_{jk}$
is an element in the corpus conditional word co-occurrence matrix (approximately: of respondents who used the word k, the fraction who also used the word j), and
$g_{jk}$
is an element in the corpus conditional word co-occurrence matrix (approximately: of respondents who used the word k, the fraction who also used the word j), and
 $m_{ik}$
an element in the transformed document-term matrix (whether document i appears to be “about” word k).
$m_{ik}$
an element in the transformed document-term matrix (whether document i appears to be “about” word k).
In Table 1, we illustrate this process for a document that states: “they spend too much”. We compare this document to the conditional distributions of common words in the corpus, using the words people, issues, beliefs, candidates, help, and waste as these words (in our later analyses, we exclude stop words like “they” and “the”). This calculation shows that, although this document does not explicitly use the word waste, the method identifies waste as the most likely “topic” of the sentence.
We illustrate calculations for the transformed document-term matrix. Each row of the transformed matrix is standardized (see text) prior to singular value decomposition. The leading dimension of this method will capture the number of words and use of more common words across documents, and the next will be the first substantive dimension.
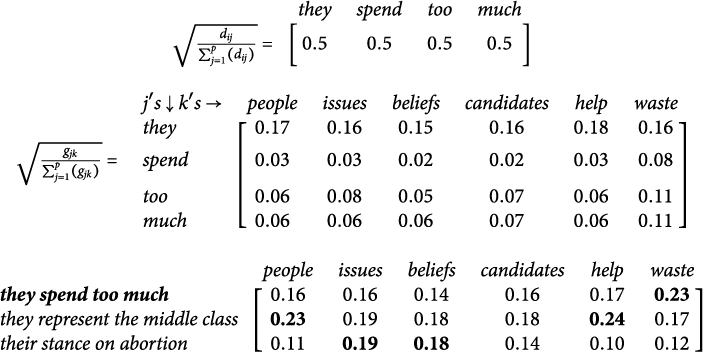
Importantly, this approach will more heavily weight common words than rare words and do so across all of the comparisons (see SI Figure B.2)
To better understand the broad associations of different common words across a corpus, we need to use some form of dimensionality reduction. We use singular value decomposition. Because this captures dominant sources of variation in the data, the singular vectors from this provide the top candidate dimensions that could represent (polarization in) attitudes (after the leading dimension, which captures overall prevalence).
Prior to applying SVD, we standardize the data, weight training data so that each survey wave is treated equally (in the ANES, recent waves are far larger with added online samples), and run SVD only on the q most common words in the corpus. For our analyses below, we restrict q to the number of words whose squared frequency is greater than the average squared frequency. We show in the appendix that we see the same results for word frequencies simply greater than the average frequency. However, with that setting, the dimensions are sometimes highly correlated with each other, which could exaggerate the reliability of the findings.
Resulting word scores are
 $G^\top V$
. Document scores are produced from the matrix multiplication
$G^\top V$
. Document scores are produced from the matrix multiplication
 $D(G^\top V)$
and then standardized so that each observation has a Euclidean norm of one. In this, D represents the document-term matrix, G the standardized word co-occurrence matrix/sampling distribution matrix (truncated to all words’ co-occurrences with common words—so that, after the multiplication
$D(G^\top V)$
and then standardized so that each observation has a Euclidean norm of one. In this, D represents the document-term matrix, G the standardized word co-occurrence matrix/sampling distribution matrix (truncated to all words’ co-occurrences with common words—so that, after the multiplication
 $G^\top V$
, we are able to score uncommon words in our document-term matrix), and V the right singular vectors of singular value decomposition of M, the transformed document-term/“implied word” matrix. We illustrate this process with (working) R code in SI Section C.
$G^\top V$
, we are able to score uncommon words in our document-term matrix), and V the right singular vectors of singular value decomposition of M, the transformed document-term/“implied word” matrix. We illustrate this process with (working) R code in SI Section C.
When listing keywords, we multiply word scores by the square root of words’ frequencies and then report the top words with the largest values on each side of the scale. This multiplication ensures that the keywords reflect the influence of common words on the scaling process, as illustrated in Figure B.2—we treat common and rare words equally when assigning document scores.
4.1 Scoring Common Words with Large Language Models?
It is possible to create a version of the transformed document-term matrix we described in the previous section—whether a document is “about” a common word—using large language model based zero-shot classification. We evaluate the out-of-the-box performance of zero-shot classification by classifying whether a text is “about” the top 1,000 words in each corpus. For this, we use the BART language model (Lewis et al. Reference Lewis2020) fine-tuned on the MNLI corpus, as described in Yin et al. (Reference Yin, Hay and Roth2019) and implemented in the python package “ktrain” (Maiya Reference Maiya2022).Footnote 5 To match the numbering of the implied word method, we label principal components starting at 0—across these methods, the dimension with the largest variance typically captures some form of prevalence. In the SI, we show that using PCA on the last layer of BERT sentence embeddings (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) performs notably worse than zero-shot classification for this purpose.
In the SI, we contrast the common word approach with an approach that emphasizes “response distinctiveness”, meaning responses categorized by how different they seem compared to other responses in a corpus.
4.2 Topic Model Comparison
We compare our method to topic models across many settings of k (the number of topics), since many topic model users will try multiple specifications before settling on a preferred model and, unlike our scaling method, topics are unordered. With this output, we assess the fraction of topics that match the performance of the implied word method on test-retest reliability and hand label correspondence, as well as the extent to which a topic’s correlation with the top dimension of our implied word method predicts the topic’s performance. This evaluates whether topic models tend to produce more unstable outputs than stable ones, and whether our method can be used to improve the selection of more stable topics.
4.3 Hand Label Comparison
If more frequently-used words (for a given prompt) are likelier to reflect the directional thrust of an attitude, text labels corresponding with those words should also be more likely than labels for less-frequent words to be attitude-like. If a hand labeling codebook is iteratively expanded to include more infrequent and narrow statements, which we argue are often randomly selected by respondents to convey a broader directional thrust, this expansion is unlikely to reflect attitudes. Given this, we assess whether common labels are relatively strongly correlated over time than more rare and fine-grained ones.
4.4 Supervised Comparison
To contextualize our results, we compare test-retest reliability and associations with hand labels for the unsupervised method outputs described above with supervised text classifiers. These supervised benchmarks are trained on closed-ended ACA favorability (for the ACA attitudes analyses) and partisanship (for the ANES analyses). For these models, we use a ridge regression on document-term matrices, with lambda selected by cross-validation using the ‘glmnet’ package in R (Friedman et al. Reference Friedman2021).
4.5 Using Embeddings to Describe Dimensions and Add Rare Words Back in
After we use common words to identify stable attitudes overall, we can then use recently-developed embeddings to better score individual documents (e.g., more accurately placing uses of rare words on the identified dimension). See Section 7 for details on how we embed the implied word method.
5 Tests and Data
We have proposed a theory of open-ended survey responses and argued that this theory can help us infer attitudes in open-ended survey data. We present multiple tests of this theory, and further consider whether our approach complements rather than solely duplicates closed-ended responses.
First, we compare within-subject response stability over time for common words and the top dimensions of our implied word method to that of rare words and topics. This evaluates whether we have succeeded in identifying broad topics and concepts that respondents will tend to substitute for each other because they are consistent with the same underlying attitude.
Second, we assess whether automated methods that perform well on response stability also capture the political topics chosen by survey administrators, as labeled by human coders. This test, in addition to our analysis connecting our results to past literature, is intended to rule out the possibility that unsupervised outputs that are highly correlated over time merely reflect communication style rather than variation in political content. Qualitative labels were presumably considered politically relevant, potentially important, and not merely a reflection of communication style. In this, we evaluate whether there is an organization of these labels that predict common words’ directional thrust, rather than attempting to predict them label by label. Relevant to our theory, we have argued that the exact statement will often not reflect underlying and stable attitudes, which we illustrate by assessing test-retest reliability of human-coded labels.
Finally, and connecting the findings to past literature in political science, we demonstrate that our method recovers substantively meaningful variation in responses, even in cases where it does not reproduce a closed-ended stance (such as partisanship). If open-ended responses merely reflected closed-ended responses, there would be little point to including them in surveys.
After these tests, we provide an additional analysis that combines our approach with embeddings, and also provide techniques and guidance on how to better describe the content of a dimension, more accurately score documents on that dimension, and assess potential problems in the use of the method—including outliers, corpus “context size”, and potential response style effects.
5.0.1 Data
We use three open-ended survey questions from major U.S. surveys for our primary analyses, in addition to social media posts from Twitter for an auxiliary analysis in the SI (Figures D.1 and D.2). These questions are particularly useful for three reasons. First, panel data is available for all of them. Second, most include qualitative hand-labels chosen by the survey administrators. Third, they each appear in a large number of studies over time.
Specifically, these questions are:
-
• 1) “Could you tell me in your own words what is the main reason you have (a favorable/unfavorable) opinion of the health reform law?” (2009–2018—14,278 responses) For 2009, this question was “What would you say is the main reason you (favor/oppose) the health care proposals being discussed in Congress?”
-
• 2) “Is there anything in particular that you (like/dislike) about the (Democratic/Republican) party? What is that?” (1984–2020—62,798 responses)
-
• 3) “What do you think is the most important problem facing this country today?” (1984–2016—22,983 responses)
The panel data for the two ANES questions come from the small 1992 to 1996 panel study and the much larger 2016 to 2020 panel study. We also have a large sample for the open-ended question about the Affordable Care Act—a panel of respondents in the ISCAP study (Hopkins and Mutz Reference Hopkins and Mutz2022) for the 2016 through 2018 period. However, for the ACA panel and the 2016 to 2020 ANES panel, we do not have hand labels. More details on these data sets and coverage years can be found in Section A.2 of the appendix.
From the available ANES data, we excluded most important problem data from 2020. In 2020, many responses mentioned the COVID-19 pandemic, and, because of the uniqueness of those responses (i.e., little overlap in vocabulary with other years) automated methods assign unique dimensions and topics to 2020 content. Meaning, automated methods produce dimensions and topics that capture whether a response comes from the year 2020. We return to this 2020 data in Sections 7 and 8, however, where we explore extensions and limitations of the method, including a means to assess when an open-ended corpus (or other text corpus) may be too broad for our method to work well.
6 Results
6.1 Correlation Over Time
Attitudes reflect general dispositions that people apply repeatedly when thinking about political matters. Our first tests consider the accessibility of common words and the tendency of respondents to re-use common words, above and beyond what we would expect based on their frequencies. We then evaluate whether common human-coded labels and the common-word based dimensions are more strongly correlated over time than less common labels and topics from topic models.
6.1.1 The Affordable Care Act
The left panel of Figure 2 displays correlations across the 2016 and 2018 waves of the ISCAP study. It compares correlations for specific words, topics, and the top dimensions of our implied word method. We conduct a permutation test (in blue—word correlation with a random panelist in
 $t_2$
) to show that higher overall frequency does not mechanically produce a stronger correlation.
$t_2$
) to show that higher overall frequency does not mechanically produce a stronger correlation.
Top: Correlation in word use, topics, and document scores over time in open-ended survey responses. On average, contextually common words and topics are more correlated than rare words over time. Dotted lines are from unsupervised model dimension correlations. N panelists = 1,094. Bottom: Keywords from first substantive dimension for co-occurrence based implied word method and zero-shot principal components.
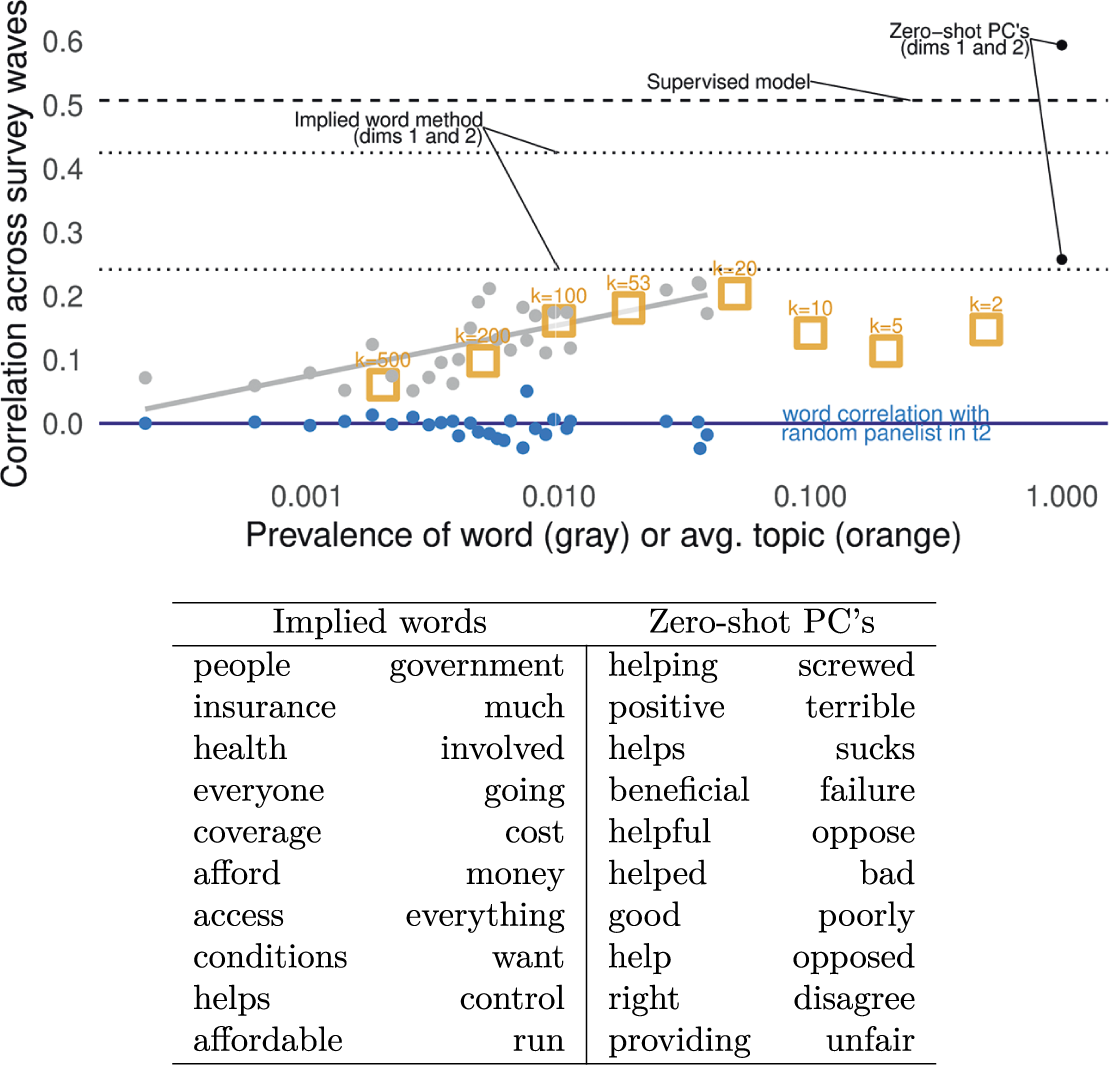
The figure shows that usage of common words, prevalent topics, and the top dimensions of our implied word method are more strongly correlated across waves than rarer words and less prevalent topics. Further, prevalent topics (averaged here, but separated in SI Section E.1 and in ANES analyses below) are on average as correlated within-user as the most common words.
Promisingly, the first substantive dimension from PCA on the zero-shot “implied word” matrix out-performs all other approaches in test-retest reliability. However, as shown in the keywords table below in Figure 2, this performance appears to be driven by the zero-shot model’s ability to detect sentiment—reflecting generally positive or negative words that we would not expect to vary across political contexts. Recall that this open-ended question followed a closed-ended question regarding favorability toward the ACA. Reproducing this sentiment adds little additional information to the closed-ended response. By contrast, the first dimension that emerges in our approach recovers substantive differences in how respondents think about the Affordable Care Act—spanning concerns about the role of government, on the one hand, and access to affordable health care on the other.
6.1.2 The “Most Important Problem”’ and Partisan Likes/Dislikes
We next compare approaches using open-ended responses that are less strongly related to partisanship than the ACA.Footnote 6
Figure 3 displays within-subject correlations in the 1992–1996 and 2016–2020 ANES panels for a supervised text model, the most frequent human-coded categories ordered by prevalence, the implied word method, zero-shot principal components, and topics from several models with different settings of k (the number of topics). ‘Keywords’ in the 2016–2020 panel combined multiple search terms—e.g., abortion represents a search for “abortion—prolife—prochoice—pro-choice—pro-life—right to choose—roe.” We were able to analyze these keywords in this 2016-2020 analysis because the 2016–2020 panel is much larger than the 1992–1996 panel. There are no hand labels for years 2016 and 2020.
Each measure is ordered by prevalence (hand labels), correlation with the implied word method (topics), or variance explained (automated methods). 1992–1996: N panelists = 193 (party likes/dislikes); N panelists = 270 (most important problem). 2016-2020: N panelists = 2,053 (party likes/dislikes).
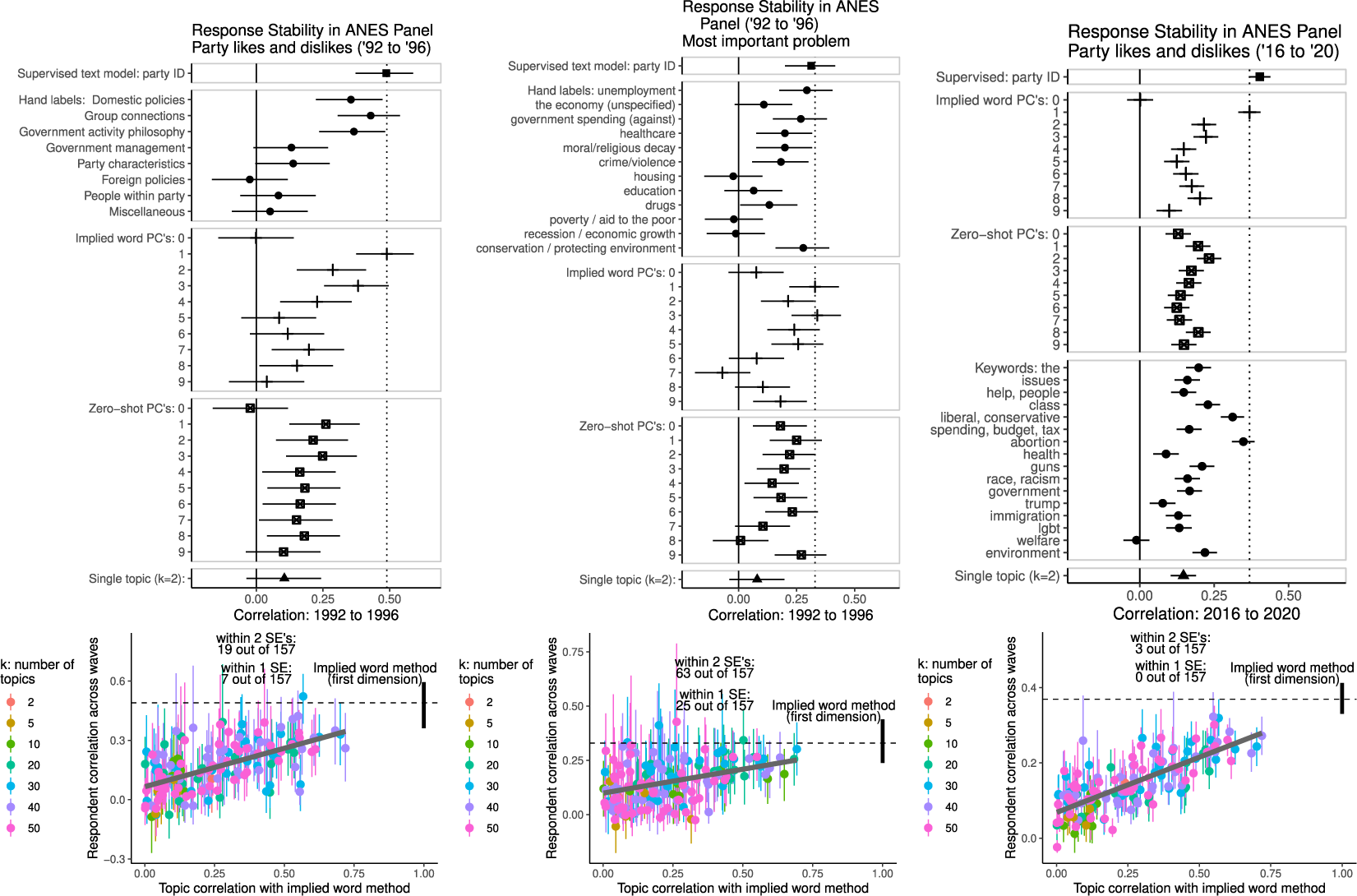
These comparisons illustrate two key points. First, the principal components from zero-shot classification are less reliable than the most prevalent labels and the top dimension of the implied word method. This method appears to discover variation in responses that might be meaningful in more general contexts, but that does not predict re-use across survey waves. Keyword tables for zero-shot PCA output are in SI Tables E.4 and E.6. Second, the most strongly correlated dimensions from our (unsupervised) implied word method are on par with a supervised text model trained to predict 7 point partisan identification. In the comparison to topics models, a few of the topics perform as well as the implied word method, but they are rare and tend to those most highly correlated with the first dimension of the implied word method.
In SI Section E.3, we further illustrate our topic model findings using a subset of topics, from a model with 69 topics, that we deemed to be especially coherent. There, again, we show that topics—whether or not they have coherent sets of keywords—are often not very strongly correlated within-individual over time.
6.2 Higher Order Structure for Coding Schemes
We next consider associations with human-coded labels of political content. This assesses whether the implied (common) word dimensions and other unsupervised outputs might merely reflect communication style, rather than both being highly correlated over time while also reflecting structured variation in substantive political content.
We do not assess whether we can automate the hand labeling of responses. We have already evaluated whether hand labels themselves were highly correlated over time. For those tests, most of the texts were already hand labeled and a perfect supervised method would merely reproduce those labels.
6.2.1 The Affordable Care Act
In Figure E.1 in the appendix, we show that the ACA attitude text dimensions with high test-retest reliability (from both our implied word method and its zero-shot analog) also correspond with labels assigned by survey administrators. They do not merely reflect writing styles.
6.2.2 The “Most Important Problem” and Partisan Likes/Dislikes
Figure 4 displays the multiple R (the bootstrapped 95% confidence interval) for each dimension of each measure studied in the test-retest analysis. This assesses whether we can predict the automated measure using the human-coded labels, restricted to labels that appear at least 10 times and over 8 waves (leaving the remaining labels as a reference group). We consider whether the combination of human-coded labels is likely to be politically meaningful in the next section.
Do more prevalent topics and the top implied word dimensions merely reflect communication style? Or do they reflect variation in politically meaningful content? This analysis tests correspondence between automated methods and combinations of ANES hand labels for categories of political content—multiple R (bootstrapped 95% confidence interval) for each dimension of each measure studied in the test-retest analysis. In each regression, the dependent variable is the automated text analysis output and dependent variables are dummies for hand labels. N respondents = 8,787 (party likes/dislikes, 1984–2004); N respondents = 11,776 (most important problem, 1984–2000). Figure E.5 further shows strong associations between issue preferences and the top implied word dimension, with divergence from party-line stances on social versus economic issues.

This figure shows that, again, the top dimensions produced by the implied word method tend to be strongly correlated with the human-coded labels, and at a level on par with a supervised model using the text to predict party identification. Similar to the test-retest analysis, some topics also carry relatively strong associations with the human-coded labels, although this pattern is less consistent and tends to appear for topics more strongly correlated with the first dimension of the implied word method.
We supplement these tests ruling out mere communication style effects in Section 8.
6.3 Novelty, Correspondence with Political Science Theory, and Political Context
We now turn to the question of whether dimensions of the method that are correlated over time and that can be predicted by human-coded labels are a) politically meaningful and b) “novel”.
In Table 5, we show the associations between the first dimension and the non-collapsed ANES human-coded labels of the likes and dislikes open-ended responses. The first dimension reflects issue-based versus group-based justifications for party likes and dislikes. These labels are from the same analysis as in Figure 4, where the dependent variable was the text measure and the independent variable was an indicator representing each label. These are ordered by the value of their regression coefficients.
Average party likes/dislikes response in the ANES over time—first dimension of the implied word method. More negative is more issue focused and more positive is more group focused. Hand labels are largest magnitude coefficients from the regression analysis in Figure 4. Responses have become more issue focused over time, in line with research on partisan polarization (Webster and Abramowitz Reference Webster and Abramowitz2017) and issue constraint (Hare Reference Hare2022).
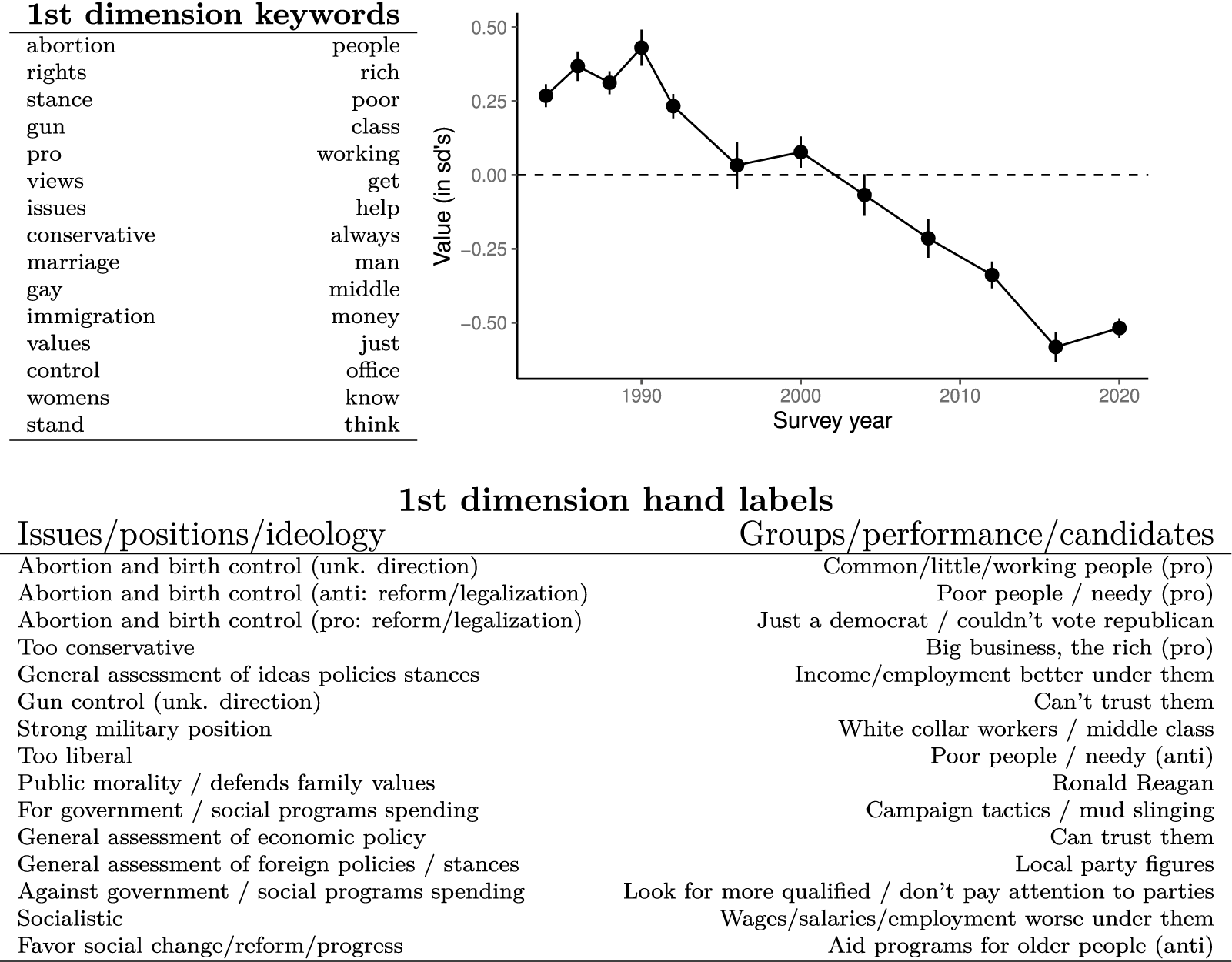
This is notable because it closely corresponds with the higher “levels of conceptualization” Converse (Reference Converse and Apter1964) identified in qualitative interviews with members of the mass public regarding the bases on which they evaluated political objects. In analyzing these interviews, Converse differentiated “ideologues” and “near-ideologues” who referenced abstract concepts along the liberal-conservative spectrum when articulating their likes and dislikes of parties and candidates from those who evaluated these objects with respect to particular social groups. Here, the first dimension of the likes and dislikes differentiates respondents who reference policy issues with clear ideological valence (abortion, gun control, immigration, e.g.,) and ideological concepts themselves (conservative) from those who reference more general class distinctions and distributive politics (rich, poor, working/middle class, help).
In Figure 5, we show that responses in the ANES have shifted on this dimension over time. Compared to responses from 1984 through 1992, open-ended responses about party likes and dislikes in 2012 through 2020 were far more likely to mention issue-based/ideological likes and dislikes over group (in this data, largely based on income), performance, and candidate-based concerns. This is consistent with work showing increases in issue-based polarization (Webster and Abramowitz Reference Webster and Abramowitz2017) and issue constraint (Hare Reference Hare2022) over this time period, and extends these findings to suggest that a greater share of citizens are evaluating political parties and candidates in ideological terms.
7 Using LLM’s to Better Describe Dimensions and Score Documents
Our “implied word” method identifies dimensions in text that tend to be highly correlated over time—consistent with a method that identifies topics/concepts that can be substituted for each other in an attitudinally consistent way. However, without pre-existing hand labels, it may be challenging to efficiently describe the contents of a dimension to the reader of an article who may not have access to many of the texts to read themselves, since our method relies on context-specific and potentially symbolic meanings of words.
Given this problem, we developed a generative AI and embedding technique for generating more descriptive labels for dimensions. We use generative AI to produce labels for each document in our corpus, prompting ChatGPT 3.5 (through an institutional account on the Microsoft Azure platform, which provides greater data privacy assurances than OpenAI’s platform) to provide a few topical categories for each open-ended response (see SI Section H.1 for prompt). From there, we used OpenAI’s v3 large embeddings (through Azure), which they released in January 2024 (during review of this paper), to embed each of those topical categories – submitting each open-ended response and a prompt (see SI Section H.2 for prompt) to the embedding API for a document-level embedding.
To embed the open-ended responses on our implied word dimension, we multiply the centered document implied word scores by the document embeddings and then average the embeddings (i.e., an average for each 3,072 embedding dimensions) across all documents for an embedded version of our implied word scores. We then calculate the cosine similarity for each category embedding and the implied word embedding vector. The labels for each dimension are then those with the top 100 most positive and most negative cosine similarities. We provide R code to reproduce this process at the end of our code walk-through in SI Section C.
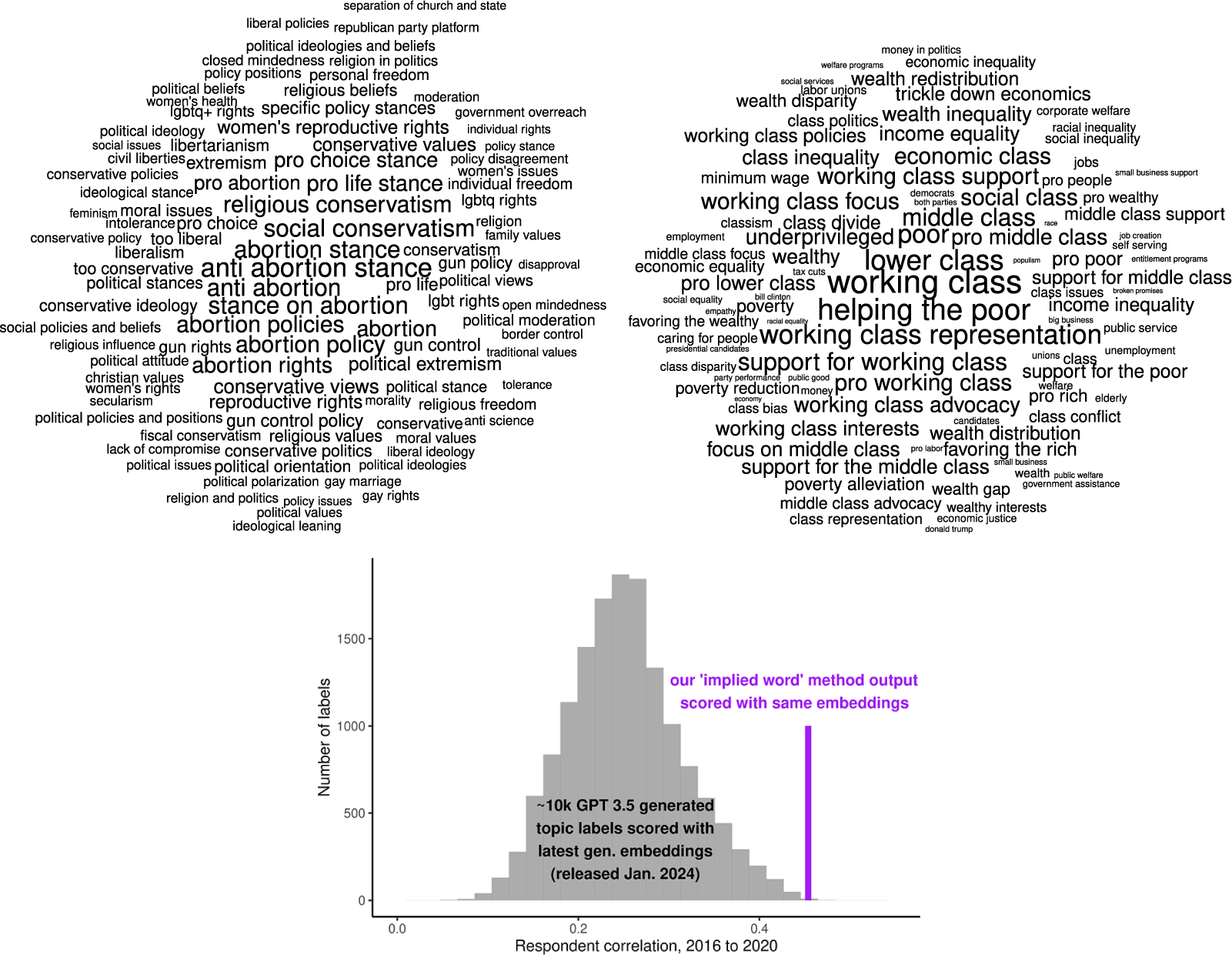
We illustrate these categories for the first dimension of the party likes and dislikes data in the top panels of Figure 6. These are consistent with hand labels, though with more labels differing on social versus economic dimensions than the hand labels and with less of a candidate focus on the representation side of the output. The candidate focus is prominent in the embedded output again in the 2016 re-analysis described below, as shown in the labels in top panels of SI Figure H.2.
The top panels of this figure display the topic labels with the largest positive and negative cosine similarities for the embedding of our implied word method’s first dimension, sized by relative cosine similarity. These labels are useful because our method relies on context-specific and potentially symbolic meanings of words, and lists of those words can be difficult to interpret in isolation. The bottom panel of this figure displays 2016-2020 respondent correlations for scores of approximately 10,000 topic labels generated by GPT 3.5 on the party likes and dislikes data, and the corresponding correlation for the embedded version of our method. Because these labels’ embedding scores are not stochastic, lower correlations reflect changes in the respondents’ answers across waves.
7.1 Using Embeddings to Better Score Implied Words Dimensions at the Document Level
Once we have embedded our implied word dimension, it is straightforward to then ask whether this embedded version has the same or better performance than the original. This matters because we change the meaning of a dimension somewhat after this embedding process, but we are likely to have more accurately scored documents on the implied word dimensions (i.e., our method focuses on finding a reliable dimension in aggregate, but may exhibit high variance at the document-level). With the implied word embedding described above, we then score each document on that embedded dimension by calculating each document embedding’s cosine similarity with the implied word embedding (a separate embedding for each dimension of the implied word method output—though we focus in the main text on dimension 1).
We test this in Figure 7, where we find equal or improved performance for the latest generation embeddings (and much poorer performance for the older generation, represented by BERT). Further, when the embedding process is successful, PCA on those embeddings tends to perform relatively well—and not very far below the performance of the embedded implied word method in terms of test-retest reliability. Unfortunately, we cannot verify that these embeddings will work well across all contexts, however—and this may be difficult to assess ahead of time, since training data details are not public for these models, even to our knowledge the latest generation of “open-source” models. We suspect that the data sets we analyze here, or online conversations closely related to them, are now relatively likely to be included in LLM training data.
In the top panels of this figure, we display test-retest correlations for the first dimension of our embedded version of our method, along with the first PCA dimension on BERT and OpenAI v3 embeddings (top 10 dimensions and hand label analyses shown in SI Sections H.5 and H.6). In the bottom panel of this figure, correlations in square root word frequencies, and so contextually common words and their associates, diverge in 2020 for the most important problem question, but are still similar to those in 2016. Black circles around the points indicate survey waves that are 4 years or fewer apart.
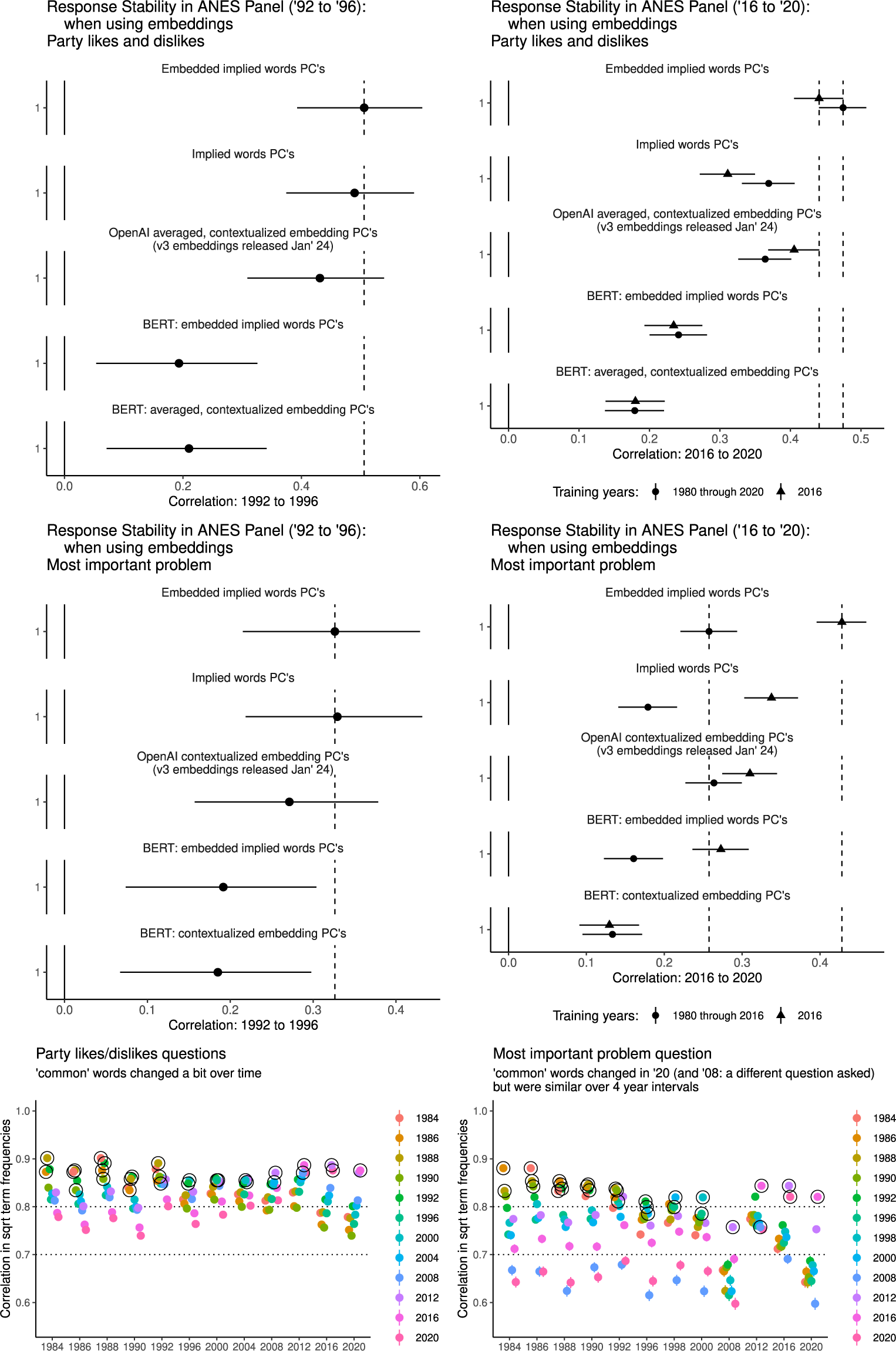
For the test in 2020, the most important problem question was challenging to analyze because so many responses mentioned the COVID-19 pandemic. It was excluded from our earlier analyses and training data for the most important problem because of this. However, we discovered that over a shorter 4 year interval (rather than close to 40 years), even with a pandemic, the difference between 2016 (only) and 2020 in terms of common word use (i.e., correlation in square root word frequencies) was no larger than other 4 year periods (bottom panels of Figure 7—see next section for more discussion of this test). Given this, we retrained our implied word method using just 2016 as training data for both ANES questions. This gave us an extra test for our added, latest generation embedding analyses, and also allowed us to better compare test-retest reliability with cross question test-retest reliability (see below).
8 Evaluating Style Effects, Corpus Context Size, and Outliers
Below, we use the two open-ended questions in the ANES to further assess possible style effects. If our first dimensions represent communication style only, then we might observe strong correlations over time between different questions. Figure 8 shows that high test-retest reliability across our first dimensions applies only to test-retest on the same open-ended question. In the 2016–2020 panel, the second dimension of the most important problem implied word scores is more strongly correlated with the first dimension of the likes/dislikes scores (slightly over 0.1 and higher than the null of 0.02).
Within-question and cross-question wave-to-wave correlation coefficients. N 1992 post-election most important problem to 1996 pre-election party likes/dislikes: 217. N 2016 post-election most important problem to 2020 pre-election party likes/dislikes: 2306. 2016-2020. Note that the 2016–2020 analysis is based on the implied word method trained on 2016 (see text on “context window” and pandemic related issues in the most important problem analyses). The dotted line indicates the null value of a normed correlation coefficient Green et al. (Reference Green, Hobbs, Avila, Rodriguez, Spirling and Stewart2024).

This test is not definitive—ideally, we would have a method that would be able to capture shared political content across multiple questions, including these questions. We thank a reviewer for this broad recommendation, although we recognize that completely unrelated questions or a political versus non-political question would be preferable.
Next, because the method relies on uses of common words and associations between rare words and common words, we can end up with rare terms that have not been very accurately scored on our dimensions, leading to outliers in the document-level scores. This issue can be corrected by using embeddings (if we are willing to trust the performance of often opaque embeddings)—or we can simply assess potential outliers visually by plotting and looking for outlying observations in word scores and document scores.
Last, the context covered in some corpora may be too large for our method to work well—for example, when what is contextually common for one subset of the data is not contextually common for the other. For this, we can split the data on some variable that may drive overly large context size (and a contrast that we know we do not want the method to identify—e.g., pandemic versus non-pandemic years) and assess the correlation in word frequencies across that contrast. We showed this in Figure 7 where, indeed, we find that 2020 is dramatically different from other years in the most important problem data set.
9 Discussion
Advances in natural language processing have made it possible to organize and code open-ended survey responses inexpensively at scale. However, improvements in the speed and accuracy with which researchers can label texts (and in many different ways) are more useful for some tasks than others. These tools can be transformative if and when they allow researchers to tackle more fundamental challenges in measurement.
Toward this goal, we suggest that the key insights of studies on attitudes in closed-ended responses (Achen Reference Achen1975; Ansolabehere et al. Reference Ansolabehere, Rodden and Snyder2008; Converse Reference Converse and Apter1964; Zaller Reference Zaller1992) should be applied to the study of open-ended responses. Respondents have many different, narrow ways to express a broad attitude regarding a specific prompt. This being the case, the ability to efficiently categorize what was said in a single document—i.e. the task for which off-the-shelf large language models are extremely useful at present—is not the same thing as capturing the underlying attitude that document is expressing (and that a respondent is likely to express again), which is often what researchers are more interested in doing.
However, we argue that this task is not wholly intractable. Despite randomness in parts of their answers, if respondents start with a directional thrust, we still expect them to choose some words that reflect more generalizable meaning. This has two key implications for future work concerning attitudes in short text documents such as open-ended survey responses. First, observing how multiple respondents respond to the same prompt is important for capturing the symbolic elements of language that can be used to communicate attitudes. Second, contextually common words (and, more abstractly, common concepts used when responding to a prompt) will be more useful than rare words for inferring distributions of attitudes.
Our tests support this argument. Contextually common words and text dimensions summarizing variation in how much texts are (symbolically) “about” common words show high within-subject correlation over time and can be predicted by human-labeled categories. Without fine-tuning to better capture the symbolic meanings of words in local (i.e., in-sample) context, the output of large language models is less informative of attitudes—even for dimensions of such output that capture a large amount of between-subject variation. In contrast, the output from our implied word method—which can then be augmented with pre-trained embeddings—efficiently accomplishes this unsupervised inferential task, reproducing findings (such as Converse’s “levels of conceptualization”) that would otherwise require labor-intensive qualitative analyses of open-ended responses, and would be difficult to elicit in either a closed-ended setting or by using standard topic modeling approaches.
Reducing the costs (in both time and financial expense) of analyzing open-ended responses is important given their usefulness for understanding political attitudes. In studying attitudes, we are interested in understanding how some attitude object, like an issue or party, is represented in the mind of a respondent. Issues and parties change over time, both in terms of their content and members but also in what they represent to the public. If we use only closed-ended questions to ask about them, then the same responses, especially at different time points, can mean very different things. The Democratic and Republican parties in the 1980’s had different platforms and priorities than they do today—and someone who voted for a party then was voting for a different type of representation than they are now. Open-ended questions allow us to extract evaluations of attitude objects that are broader than closed-ended ones in the sense that we can understand both whether a person supports or opposes an issue or party and also what that issue or party means to them.
Open-ended responses are also useful relative to other forms of free form text because, in principle, studying attitudes in the open-ended survey setting should be much more straightforward than in general text. The open-ended question prompt provides a common attitude object for respondents to evaluate. Without a prompt to focus responses, we would need to first identify an attitude object (whatever someone chooses to discuss and evaluate in a document) and then attempt to infer their corresponding attitude. Even beyond that, there can be substantial selection bias in who chooses to publicly articulate their political views (e.g., on social media), including why they like or dislike a political party.
A primary recommendation for developing qualitative codebooks is that researchers should read either all or a relatively large, random sample of the texts to better understand the in-context associations of common words. And, although crowd-sourced ratings of topic/keyword cluster quality based on the (potentially out-of-context) semantic coherence of cluster keywords (Ying, Montgomery, and Stewart Reference Ying, Montgomery and Stewart2022) can be helpful, coherence ratings can still be unrelated to the usefulness of a topic as a measure of a stable attitude. Similarly because of respondent-driven measurement error that can lead to high coherence without high response stability, we suggest striking a balance between inter-rater reliability and observed or anticipated test-retest reliability.
Last, we cannot over-emphasize the importance of high-quality data—especially panel data. More panel data will be needed to further advance our understanding of open-ended survey responses, and panel data built on probability samples is usually extremely expensive. The need to ensure that written responses are not produced by AI only increases their cost. We hope that the framework provided here can help justify that expense.
Acknowledgments
We thank Dan Hopkins, Connor Jerzak, Kenny Joseph, Jen Pan, and Molly Roberts for their helpful feedback on this project.
Competing Interests
The authors have no competing interests to report.
Funding Statement
Data collection for the ISCAP panel was supported by the Russell Sage Foundation (awards 94-17-01 and 94-18-07—PI Hopkins, co-PI Hobbs).
Data Availability Statement
Replication code for this article has been published in Code Ocean, a computational reproducibility platform that enables users to run the code, and can be viewed interactively at https://doi.org/10.24433/CO.1205164.v1 Hobbs and Green (Reference Hobbs and Green2024a). A preservation copy of the same code and data can also be accessed via Dataverse at https://doi.org/10.7910/DVN/FSK6NZ Hobbs and Green (Reference Hobbs and Green2024b).
Ethical Standards
Data collection for the ISCAP panel was evaluated by the Cornell University IRB (protocol 1809008257, exempt).
Supplementary Material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2024.23.












 Open access
Open access