




Highlights
What is already known?
-
• In random-effects meta-analysis, standard inverse back-transformations do not recover the mean effect size on the original scale but correspond to the median with the resulting transformation bias increasing with heterogeneity.
-
• Integral back-transformations provide a principled way to obtain the mean effect size on the original scale.
What is new?
-
• We introduce a general formulation of the integral back-transformation for estimating the mean effect size and a corresponding confidence interval.
-
• We emphasize that these methods must be used with caution and should only be applied when the estimand is explicitly the back-transformed mean effect size.
-
• We clarify that standard inverse back-transformations often remain preferable, especially for descriptive purposes, when they are correctly interpreted and reported as back-transformed median effect sizes.
-
• We illustrate and quantify the differences between standard and integral back-transformations using several meta-analytic examples.
Potential impact for RSM readers
-
• The article contains a general methodological discussion of back-transformations in random-effects meta-analysis. An application is possible in all areas of meta-analysis.
-
• Commonly used transformations for different effect sizes, which are used in various research areas, are presented.
-
• Implementations of the back-transformations and the data examples are available in R packages metafor and metadat, respectively.
1 Introduction
Broadly speaking, a meta-analysis consists of quantifying the evidence about some phenomenon of interest (e.g., the size of the difference between a treatment and a comparison group, and the strength of the association between two variables) in terms of an effect size measure (e.g., a risk or odds ratio, and a correlation coefficient) for a set of relevant studies and then summarizing the collection of estimates using appropriate statistical models.
In practice, meta-analyses are applied to various effect size measures, where a normal distribution is typically assumed for the sampling distributions of the individual estimates.Reference Borenstein, Hedges, Higgins and Rothstein1–
Reference Jackson and White3 However, some effect sizes, including, for example, correlation coefficients or those derived from binary data, have a bounded distribution with a variance potentially influenced by their own magnitude. Thus, a normal sampling distribution can hardly be justified for such measures, especially when the sample sizes of the individual studies are not large.Reference Jackson and White3 A commonly used solution is to apply a transformation to the estimates before the analysis, that is, the effect sizes are transformed to a real-valued scale using a continuous, monotonically increasing, and non-linear function. Popular transformations are, for example, Fisher’s r-to-z transformation for correlation coefficients (see Borenstein et al., Chapter 6)Reference Borenstein, Hedges, Higgins and Rothstein1 or the log transformation for risk and odds ratios obtained from
 $2 \times 2$
tables (see Borenstein et al., Chapter 5).Reference Borenstein, Hedges, Higgins and Rothstein1 Subsequently, all estimations are performed based on the transformed values.
$2 \times 2$
tables (see Borenstein et al., Chapter 5).Reference Borenstein, Hedges, Higgins and Rothstein1 Subsequently, all estimations are performed based on the transformed values.
A crucial part of this two-step procedure is the back-transformation, which is nontrivial in a random-effects model, or equivalently, when heterogeneity is modeled. Estimates or confidence intervals (CIs) are not easily interpretable on the transformed scale. The standard procedure is to apply the inverse transformation function to the various quantities of interest (e.g., the mean effect size estimate and the bounds of the corresponding CI). With this article, we want to highlight that such non-linear back-transformations do not in general lead to estimates of the mean effect size on the original (untransformed) scale due to Jensen’s inequality. Instead, the back-transformation process results in an estimate of the median effect size of the back-transformed distribution.
This observation is not new. The handbook of Schmid et al. (see p. 78)Reference Schmid, Stijnen and White2 notes that this back-transformation corresponds to the median. Jackson and WhiteReference Jackson and White3 make a remark regarding the so-called “transformation bias.” However, many researchers dealing with meta-analyses either remain unaware of or overlook this fact. Therefore, erroneous statements are often made and biased estimates of the mean are reported. A detailed discussion in the context of the correlation coefficient in meta-analyses together with a methodological precise solution in the form of an integral back-transformation is given by Hafdahl.Reference Hafdahl4 Strategies to back-transform the bounds of CIs are given as well. This integral back-transformation was included in simulation studies by Welz et al.Reference Welz, Doebler and Pauly5 and also Hafdahl.Reference Hafdahl6
In the present work, we draw attention to methods for the correct back-transformation of the mean for various effect size measures. We also suggest a correct integral back-transformation for transformations that do not map to the whole real scale, such as the variance stabilizing arcsine transformation of proportions based on Anscombe.Reference Anscombe7
Such integral transformations are required to obtain correct estimates of the mean or other higher-order moments. Despite this, we caution analysts against using integral transformations blindly. They are sensitive to uncertainty in the estimation of the degree of heterogeneity and can be highly unstable for unbounded transformations, such as the log transformation. They should only be used when an estimate of the mean is explicitly required by the reporting strategy or when subsequent analyses based on this mean as estimand are performed, that is, additive extrapolations. Furthermore, we discuss an alarming lack of invariance that can be harmful in interpreting results correctly when the transformation lacks point symmetry around a reference value. This also affects statistical inference for the back-transformed mean. We explicitly emphasize that hypothesis tests and CIs should be constructed on the transformed scale, except in cases where a CI for the back-transformed mean effect size is explicitly required.
In this context, we analyze several examples that clarify the risks associated with applying the integral back-transformation. The corresponding data sets contain different outcome structures (proportions, Pearson correlation coefficients, binary
 $2 \times 2$
data, and Cronbach’s
$2 \times 2$
data, and Cronbach’s
 $\alpha $
values), and thus different transformation functions are presented. Furthermore, we quantitatively analyze the differences between the two back-transformations and point to a software implementation of the integral back-transformations for all presented transformations.
$\alpha $
values), and thus different transformation functions are presented. Furthermore, we quantitatively analyze the differences between the two back-transformations and point to a software implementation of the integral back-transformations for all presented transformations.
2 Methods
In this article, we focus on the standard (“normal–normal”) random-effects model for meta-analysis which accounts for between-study heterogeneity by means of a random effect. For the common-effect model, the differences between back-transformations are not present. Consider
 $i = 1, \ldots , k$
available studies with
$i = 1, \ldots , k$
available studies with
 $y_i$
denoting the effect size estimate in the ith study. We assume that some kind of transformation function (e.g., log) was applied to obtain the
$y_i$
denoting the effect size estimate in the ith study. We assume that some kind of transformation function (e.g., log) was applied to obtain the
 $y_i$
values. The transformation function is denoted by
$y_i$
values. The transformation function is denoted by
 $g : D \to V$
. Here,
$g : D \to V$
. Here,
 $D$
corresponds to the possible values of the measured effect size before transformation, and
$D$
corresponds to the possible values of the measured effect size before transformation, and
 $V \subseteq \mathbb {R}$
is often equal to
$V \subseteq \mathbb {R}$
is often equal to
 $\mathbb {R}$
but can also be a subset for certain transformations.
$\mathbb {R}$
but can also be a subset for certain transformations.
The random-effects model is given by
 $$ \begin{align} y_i = \mu + u_i + \varepsilon_i, \end{align} $$
$$ \begin{align} y_i = \mu + u_i + \varepsilon_i, \end{align} $$
where
 $u_i \sim \mathcal {N}(0,\tau ^2)$
and
$u_i \sim \mathcal {N}(0,\tau ^2)$
and
 $\varepsilon _i \sim \mathcal {N}(0,v_i)$
. The study-specific within-study variances
$\varepsilon _i \sim \mathcal {N}(0,v_i)$
. The study-specific within-study variances
 $v_i$
are assumed to be known.
$v_i$
are assumed to be known.
 $\tau ^2 \geq 0$
is called the between-study variance, quantifying the amount of heterogeneity. Again, when no heterogeneity is modeled (
$\tau ^2 \geq 0$
is called the between-study variance, quantifying the amount of heterogeneity. Again, when no heterogeneity is modeled (
 $\tau ^2$
is set or estimated to be zero) no random effects are present and the differences between the back-transformation approaches do not exist. In the commonly applied two-step estimation procedure for random-effects models of this form (see Borenstein et al., Chapter 12),Reference Borenstein, Hedges, Higgins and Rothstein1 the first step involves estimating
$\tau ^2$
is set or estimated to be zero) no random effects are present and the differences between the back-transformation approaches do not exist. In the commonly applied two-step estimation procedure for random-effects models of this form (see Borenstein et al., Chapter 12),Reference Borenstein, Hedges, Higgins and Rothstein1 the first step involves estimating
 $\tau ^2$
. Throughout this article, we use the restricted maximum-likelihood estimator,Reference Viechtbauer8 although this particular choice is not material to the discussion at hand. Let
$\tau ^2$
. Throughout this article, we use the restricted maximum-likelihood estimator,Reference Viechtbauer8 although this particular choice is not material to the discussion at hand. Let
 $\hat {\tau }^2$
denote the corresponding estimate. Subsequently, the mean effect size
$\hat {\tau }^2$
denote the corresponding estimate. Subsequently, the mean effect size
 $\mu $
is estimated via weighted least squares as
$\mu $
is estimated via weighted least squares as
 $$ \begin{align} \hat{\mu} = \frac{\sum_{i=1}^k w_i y_i}{\sum_{i=1}^k w_i} \end{align} $$
$$ \begin{align} \hat{\mu} = \frac{\sum_{i=1}^k w_i y_i}{\sum_{i=1}^k w_i} \end{align} $$
with weights
 $w_i = (v_i + \hat {\tau }^2)^{-1}$
. The CIs for
$w_i = (v_i + \hat {\tau }^2)^{-1}$
. The CIs for
 $\mu $
presented within this article are Wald-type CIs with lower and upper bounds for an
$\mu $
presented within this article are Wald-type CIs with lower and upper bounds for an
 $\alpha $
-level CI defined as
$\alpha $
-level CI defined as
 $(\hat {\mu }^{(l)}, \hat {\mu }^{(u)}) = \hat {\mu } \pm q_{1-\alpha /2}\cdot \text {SE}[\hat {\mu }]$
, where
$(\hat {\mu }^{(l)}, \hat {\mu }^{(u)}) = \hat {\mu } \pm q_{1-\alpha /2}\cdot \text {SE}[\hat {\mu }]$
, where
 $q_{1-\alpha /2}$
denotes the
$q_{1-\alpha /2}$
denotes the
 $(1-\alpha /2)$
-quantile of the standard normal distribution and
$(1-\alpha /2)$
-quantile of the standard normal distribution and
 $\text {SE}[\hat {\mu }] = \left (\sum _{i=1}^k w_i\right )^{-1/2}$
. For the example meta-analyses presented later, we use
$\text {SE}[\hat {\mu }] = \left (\sum _{i=1}^k w_i\right )^{-1/2}$
. For the example meta-analyses presented later, we use
 $\alpha = 0.05$
and hence report 95% CIs.
$\alpha = 0.05$
and hence report 95% CIs.
2.1 Back-transformation
The random-effects model assumes that the true effect sizes
 $\theta _i$
are normally distributed with expected value
$\theta _i$
are normally distributed with expected value
 $\mu $
and variance
$\mu $
and variance
 $\tau ^2$
(i.e.,
$\tau ^2$
(i.e.,
 $\theta _i \sim \mathcal {N}(\mu , \tau ^2)$
). However, the estimates
$\theta _i \sim \mathcal {N}(\mu , \tau ^2)$
). However, the estimates
 $\hat {\mu }$
and
$\hat {\mu }$
and
 $\hat {\tau }^2$
that characterize this distribution apply to the transformed scale. We consider a simple illustrative example in which a log transformation is applied to risk ratios (RR), which corresponds to the special case of the well-known log-normal model. An estimate of
$\hat {\tau }^2$
that characterize this distribution apply to the transformed scale. We consider a simple illustrative example in which a log transformation is applied to risk ratios (RR), which corresponds to the special case of the well-known log-normal model. An estimate of
 $\hat {\mu } = 0.58$
implies that we estimate that the log risk ratio is, on average, equal to 0.58, or equivalently, that the log risk is, on average, 0.58 points higher in the first compared to the second group. Such a finding is difficult to interpret and hence it is common practice to back-transform especially the estimate of the mean effect. Due to Jensen’s inequality,
$\hat {\mu } = 0.58$
implies that we estimate that the log risk ratio is, on average, equal to 0.58, or equivalently, that the log risk is, on average, 0.58 points higher in the first compared to the second group. Such a finding is difficult to interpret and hence it is common practice to back-transform especially the estimate of the mean effect. Due to Jensen’s inequality,
 $g^{-1}(E[\theta _i]) \ne E[g^{-1}(\theta _i)]$
and hence
$g^{-1}(E[\theta _i]) \ne E[g^{-1}(\theta _i)]$
and hence
 $g^{-1}(\hat {\mu })$
is not an estimate of the mean effect on the back-transformed scale. As a result, the value
$g^{-1}(\hat {\mu })$
is not an estimate of the mean effect on the back-transformed scale. As a result, the value
 $\exp (0.58) = 1.79$
cannot be interpreted as indicating that the risk is, on average, 1.79 times higher (or 79% larger) in the first group compared to the second group. The value is the median and not the mean of the asymmetric (here specifically log-normal) distribution of the true effects on the back-transformed scale.
$\exp (0.58) = 1.79$
cannot be interpreted as indicating that the risk is, on average, 1.79 times higher (or 79% larger) in the first group compared to the second group. The value is the median and not the mean of the asymmetric (here specifically log-normal) distribution of the true effects on the back-transformed scale.
However, the mean can be back-transformed via an integral transformation. This has been proposed for correlation coefficients in meta-analyses by HafdahlReference Hafdahl4 and generally works as follows. Assume that
 $V = \mathbb {R}$
holds for our transformation
$V = \mathbb {R}$
holds for our transformation
 $g$
, then the appropriate back-transformation is given by
$g$
, then the appropriate back-transformation is given by
 $$ \begin{align} \psi_g(\mu,\tau^2) = \frac{1}{\tau} \int_{-\infty}^{\infty} g^{-1}(t)\, \, \phi\!\left((t-\mu)/\tau\right)\,dt, \end{align} $$
$$ \begin{align} \psi_g(\mu,\tau^2) = \frac{1}{\tau} \int_{-\infty}^{\infty} g^{-1}(t)\, \, \phi\!\left((t-\mu)/\tau\right)\,dt, \end{align} $$
where
 $\phi (\cdot )$
is the density of the standard normal distribution. Formally, this equation represents the expected value of
$\phi (\cdot )$
is the density of the standard normal distribution. Formally, this equation represents the expected value of
 $g^{-1}(T)$
with
$g^{-1}(T)$
with
 $T$
following a normal distribution with parameters
$T$
following a normal distribution with parameters
 $\mu $
and
$\mu $
and
 $\tau ^2$
. Therefore,
$\tau ^2$
. Therefore,
 $\psi _g(\hat {\mu }, \hat {\tau }^2)$
is an estimate of the mean of the distribution of
$\psi _g(\hat {\mu }, \hat {\tau }^2)$
is an estimate of the mean of the distribution of
 $g^{-1}(\theta _i)$
. For example, suppose
$g^{-1}(\theta _i)$
. For example, suppose
 $\hat {\tau }^2 = 0.041$
in the example above, then
$\hat {\tau }^2 = 0.041$
in the example above, then
 $\psi _g(\hat {\mu } = 0.58, \hat {\tau }^2 = 0.041) = 1.82$
would indicate that the risk is, on average, 1.82 times higher in the first group compared to the second group.
$\psi _g(\hat {\mu } = 0.58, \hat {\tau }^2 = 0.041) = 1.82$
would indicate that the risk is, on average, 1.82 times higher in the first group compared to the second group.
Note that this bias is not present for quantiles of the back-transformed distribution due to the monotonicity of
 $g^{-1}(\cdot )$
. Therefore, since
$g^{-1}(\cdot )$
. Therefore, since
 $\hat {\mu }$
is not only an estimate of the mean but also the median of the distribution of
$\hat {\mu }$
is not only an estimate of the mean but also the median of the distribution of
 $\theta _i$
,
$\theta _i$
,
 $g^{-1}(\hat {\mu })$
is an estimate of the median of the distribution of
$g^{-1}(\hat {\mu })$
is an estimate of the median of the distribution of
 $g^{-1}(\theta _i)$
. Thus, it would be correct to say that in 50% of the cases (studies), the true effect is estimated to be above 1.79 (and below in the other 50% of cases).
$g^{-1}(\theta _i)$
. Thus, it would be correct to say that in 50% of the cases (studies), the true effect is estimated to be above 1.79 (and below in the other 50% of cases).
A corresponding CI for the mean effect size is given by the integral transformed bounds
 $\psi _g(\hat {\mu }^{(l)}, \hat {\tau }^2)$
and
$\psi _g(\hat {\mu }^{(l)}, \hat {\tau }^2)$
and
 $\psi _g(\hat {\mu }^{(u)}, \hat {\tau }^2)$
. CIs for the median effect size can again be obtained by applying the inverse back-transformation to the bounds
$\psi _g(\hat {\mu }^{(u)}, \hat {\tau }^2)$
. CIs for the median effect size can again be obtained by applying the inverse back-transformation to the bounds
 $g^{-1}(\hat {\mu }^{(l)})$
and
$g^{-1}(\hat {\mu }^{(l)})$
and
 $g^{-1}(\hat {\mu }^{(u)})$
due to the monotonicity. Ambiguities due to one-sided transformation bias for certain transformations that are not point-symmetric around a specific neutral value may arise when using the proposed CI for the back-transformed mean as a basis for hypothesis testing. These issues are discussed in detail and illustrated with an example in Sections 3 and 4. Therefore, we generally recommend performing testing on the transformed scale where the normal–normal model is originally assumed. For the CI based on the
$g^{-1}(\hat {\mu }^{(u)})$
due to the monotonicity. Ambiguities due to one-sided transformation bias for certain transformations that are not point-symmetric around a specific neutral value may arise when using the proposed CI for the back-transformed mean as a basis for hypothesis testing. These issues are discussed in detail and illustrated with an example in Sections 3 and 4. Therefore, we generally recommend performing testing on the transformed scale where the normal–normal model is originally assumed. For the CI based on the
 $g^{-1}$
back-transformation corresponding to the median, such problems do not occur. It can be considered equivalent to conducting a test of the median on the transformed scale.
$g^{-1}$
back-transformation corresponding to the median, such problems do not occur. It can be considered equivalent to conducting a test of the median on the transformed scale.
2.2 Back-transformation for transformations with different ranges
There are also transformations with
 $V \subsetneq \mathbb {R}$
. For example, the range of values transformed by the arcsine transformation is
$V \subsetneq \mathbb {R}$
. For example, the range of values transformed by the arcsine transformation is
 $V=[0, \pi /2] \subsetneq {\mathbb {R}}$
. In these cases, the normality assumption on the transformed scale is questionable. An advantage of the arcsine transformation, and a reason for its continued use is its variance stabilizing property.Reference Anscombe7
$V=[0, \pi /2] \subsetneq {\mathbb {R}}$
. In these cases, the normality assumption on the transformed scale is questionable. An advantage of the arcsine transformation, and a reason for its continued use is its variance stabilizing property.Reference Anscombe7
Due to the restricted range, an integration as in Equation (2.3) is no longer meaningful to estimate the back-transformed mean effect. In practice, the probability that lies outside of the restricted range is ignored, and therefore a truncated normal distribution is obtained. Therefore, we propose the following integral transformation for general transformations
 $g:D\to V\subseteq \mathbb {R}$
:
$g:D\to V\subseteq \mathbb {R}$
:
 $$ \begin{align} {\psi}_g(\mu, \tau^2) = \frac{1}{\tau}\int_a^b g^{-1}(t)\, \frac{\phi\!\left((t-\mu)/\tau\right)}{\Phi((b - \mu)/\tau) - \Phi((a- \mu)/\tau)}\, dt, \end{align} $$
$$ \begin{align} {\psi}_g(\mu, \tau^2) = \frac{1}{\tau}\int_a^b g^{-1}(t)\, \frac{\phi\!\left((t-\mu)/\tau\right)}{\Phi((b - \mu)/\tau) - \Phi((a- \mu)/\tau)}\, dt, \end{align} $$
where
 $\Phi $
denotes the cumulative distribution function of a standard normal distribution. The integration limits are defined as
$\Phi $
denotes the cumulative distribution function of a standard normal distribution. The integration limits are defined as
 $a = \inf V$
and
$a = \inf V$
and
 $b = \sup V$
. In the special case
$b = \sup V$
. In the special case
 $V = \mathbb {R}$
, Equation (2.4) reduces to Equation (2.3).
$V = \mathbb {R}$
, Equation (2.4) reduces to Equation (2.3).
This implies that the assumed normal distribution, which is not strictly accurate, is truncated and subsequently rescaled to the range specified by the transformation function. Therefore, in cases with
 $V \subsetneq \mathbb {R}$
, we are not estimating
$V \subsetneq \mathbb {R}$
, we are not estimating
 $\mathbb {E}[g^{-1}(\theta _i)]$
with
$\mathbb {E}[g^{-1}(\theta _i)]$
with
 $\theta _i \sim \mathcal {N}(\mu , \tau ^2)$
as implied by the model from Equation (2.1) but with
$\theta _i \sim \mathcal {N}(\mu , \tau ^2)$
as implied by the model from Equation (2.1) but with
 $\theta _i \sim \textit {TN}(\mu ,\tau ^2;a,b)$
. Here,
$\theta _i \sim \textit {TN}(\mu ,\tau ^2;a,b)$
. Here,
 $\textit {TN}(\cdot ;a,b)$
denotes the truncated normal distribution on the interval
$\textit {TN}(\cdot ;a,b)$
denotes the truncated normal distribution on the interval
 $[a,b]$
. In many cases, especially when dealing with skewed distributions, the implicitly assumed distribution on the back-transformed scale can exhibit complex and non-intuitive shapes. Moreover, truncation introduces an additional bias when unequal probability masses are ignored on the left- and right-hand side of the distribution. It should also be noted that, due to truncation, the back-transformation via
$[a,b]$
. In many cases, especially when dealing with skewed distributions, the implicitly assumed distribution on the back-transformed scale can exhibit complex and non-intuitive shapes. Moreover, truncation introduces an additional bias when unequal probability masses are ignored on the left- and right-hand side of the distribution. It should also be noted that, due to truncation, the back-transformation via
 $g^{-1}$
does not yield the median of the
$g^{-1}$
does not yield the median of the
 $\textit {TN}$
distribution.
$\textit {TN}$
distribution.
2.3 Specific transformations and R support
A comprehensive overview of commonly used transformations can be found in Table 1. Both, the standard inverse and the integral back-transformation, are implemented for all of these transformations in the R package metafor.Reference Viechtbauer9 The software name of the integral back-transformation function is denoted within the table. The respective functions for the standard
 $g^{-1}(x)$
transformations have the same name without the appended .int. For some transformations, a closed form of the integral back-transformation exists. For example, the log transformation leads to
$g^{-1}(x)$
transformations have the same name without the appended .int. For some transformations, a closed form of the integral back-transformation exists. For example, the log transformation leads to
 $\psi _{\log }(\mu , \tau ^2) = \exp \left (\mu + \tau ^2/2 \right )$
. Otherwise, the integral in Equations (2.3) or (2.4) can be calculated numerically.
$\psi _{\log }(\mu , \tau ^2) = \exp \left (\mu + \tau ^2/2 \right )$
. Otherwise, the integral in Equations (2.3) or (2.4) can be calculated numerically.
Overview of commonly used transformations and their back-transformations

Note: is the
 $\Phi $
cumulative distribution function of the standard normal distribution.
$\Phi $
cumulative distribution function of the standard normal distribution.
Other listed transformations are the logit, probit, and arcsine transformations. These are particularly useful for proportions and probabilities. Furthermore, Fisher’s r-to-z transformation for correlations is included. Another effect size of interest is Cronbach’s
 $\alpha $
, a measure of internal consistency that indicates how well the items in a test or questionnaire reliably measure the same underlying construct. It is often a component of meta-analysis in psychology and requires special transformations due to its often skewed distribution, especially with small samples. We added two common transformations for Cronbach’s
$\alpha $
, a measure of internal consistency that indicates how well the items in a test or questionnaire reliably measure the same underlying construct. It is often a component of meta-analysis in psychology and requires special transformations due to its often skewed distribution, especially with small samples. We added two common transformations for Cronbach’s
 $\alpha $
, the first based on Hakstian and WhalenReference Hakstian and Whalen10 (AHW) and the second based on BonettReference Bonett11 (ABT). Note that the versions of these two transformations differ slightly from their original formulations to ensure that
$\alpha $
, the first based on Hakstian and WhalenReference Hakstian and Whalen10 (AHW) and the second based on BonettReference Bonett11 (ABT). Note that the versions of these two transformations differ slightly from their original formulations to ensure that
 $g(x)$
remains a monotonically increasing function in
$g(x)$
remains a monotonically increasing function in
 $\alpha $
.Reference Viechtbauer9 Of the transformations reported, those with a bounded
$\alpha $
.Reference Viechtbauer9 Of the transformations reported, those with a bounded
 $V$
are the arcsine, AHW, and ABT transformations.
$V$
are the arcsine, AHW, and ABT transformations.
3 Analysis of the difference between both back-transformations
As noted above, the interpretation of
 $g^{-1}(\hat {\mu })$
as the estimated mean effect size is incorrect. Compared with the correct back-transformation
$g^{-1}(\hat {\mu })$
as the estimated mean effect size is incorrect. Compared with the correct back-transformation
 $\psi _g(\hat {\mu }, \hat {\tau }^2)$
, the resulting transformation difference can be quantified by
$\psi _g(\hat {\mu }, \hat {\tau }^2)$
, the resulting transformation difference can be quantified by
 $g^{-1}(\hat {\mu }) -\psi _g(\hat {\mu }, \hat {\tau }^2)$
. This, sometimes called transformation bias,Reference Jackson and White3 is influenced by both the degree of heterogeneity and the shape of the transformation function at the point
$g^{-1}(\hat {\mu }) -\psi _g(\hat {\mu }, \hat {\tau }^2)$
. This, sometimes called transformation bias,Reference Jackson and White3 is influenced by both the degree of heterogeneity and the shape of the transformation function at the point
 $\hat {\mu }$
.
$\hat {\mu }$
.
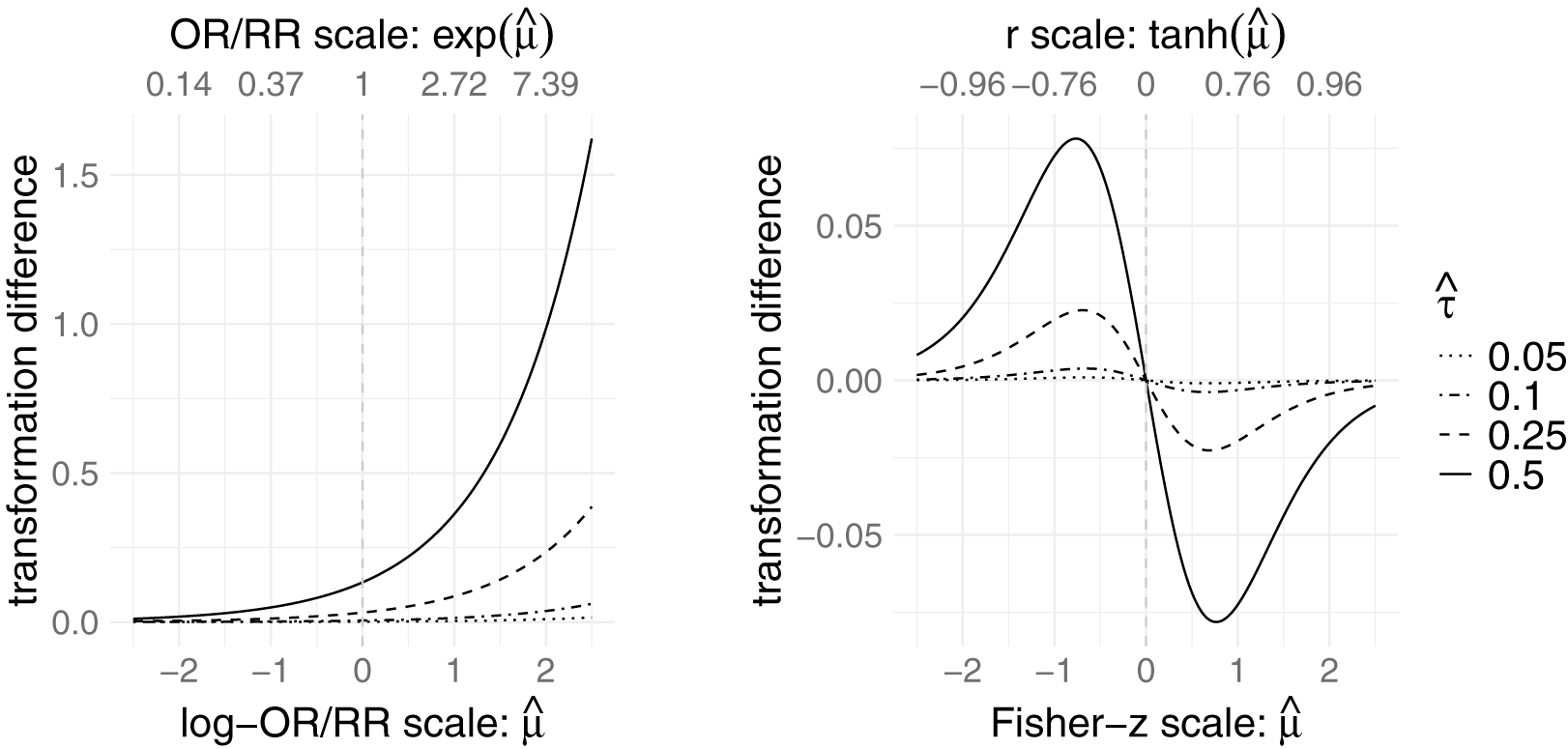
Figure 1 visualizes the difference for the log transformation (left plot) and Fisher’s r-to-z transformation (right plot) as a function of
 $\hat {\mu }$
(and
$\hat {\mu }$
(and
 $g^{-1}(\hat {\mu })$
) for different values of
$g^{-1}(\hat {\mu })$
) for different values of
 $\hat {\tau }$
. In analyzing these plots, two properties require particular attention: boundedness of the bias and point symmetry around the origin. The r-to-z transformation is an example that exhibits both properties, whereas the log transformation does neither.
$\hat {\tau }$
. In analyzing these plots, two properties require particular attention: boundedness of the bias and point symmetry around the origin. The r-to-z transformation is an example that exhibits both properties, whereas the log transformation does neither.
Visualization of the transformation difference
 $\psi _g(\hat {\mu }, \hat {\tau }^2) - g^{-1}(\hat {\mu })$
for the log transformation (left) and r-to-z transformation (right).
$\psi _g(\hat {\mu }, \hat {\tau }^2) - g^{-1}(\hat {\mu })$
for the log transformation (left) and r-to-z transformation (right).

For transformations defined over bounded D, the transformation bias is also bounded, and thus generally less extreme. For example, under the r-to-z transformation, the absolute value of the bias is limited for any fixed
 $\hat {\tau }$
(see the right panel in Figure 1). In contrast, the log transformation, which is defined over the positive real numbers, exhibits an exponentially increasing difference as
$\hat {\tau }$
(see the right panel in Figure 1). In contrast, the log transformation, which is defined over the positive real numbers, exhibits an exponentially increasing difference as
 $\hat {\mu }$
grows (see the left panel in Figure 1). For the log transformation, it is possible to present the integral back-transformation and based on this also the transformation difference in a closed form (see Section 2.3). The relative increase in transformation difference is equal to
$\hat {\mu }$
grows (see the left panel in Figure 1). For the log transformation, it is possible to present the integral back-transformation and based on this also the transformation difference in a closed form (see Section 2.3). The relative increase in transformation difference is equal to
 $\exp (\hat {\tau }^2/2)$
and is therefore sensitive to the possibly imprecise estimation of
$\exp (\hat {\tau }^2/2)$
and is therefore sensitive to the possibly imprecise estimation of
 $\tau $
, even more than the rest of the analysis. This represents a critical limitation of using the integral back-transformation in this setting. With such unbounded transformations, the integral back-transformation can become unstable and a careful decision for the choice of the back-transformation is needed. This is further illustrated in the two examples in the following section (see Section 4; Figures 2 and 3).
$\tau $
, even more than the rest of the analysis. This represents a critical limitation of using the integral back-transformation in this setting. With such unbounded transformations, the integral back-transformation can become unstable and a careful decision for the choice of the back-transformation is needed. This is further illustrated in the two examples in the following section (see Section 4; Figures 2 and 3).
Additionally, the transformation difference of the r-to-z transformation is point-symmetric around the origin. This property is not shared by transformation functions that lack point symmetry around a neutral value depending on the effect size, namely, transformations for which symmetry around the midpoint of the effect-size domain does not hold. Formally, point symmetry around a midpoint
 $c$
is defined by
$c$
is defined by
 $g(c+x) = -g(c-x)$
for all
$g(c+x) = -g(c-x)$
for all
 $x \in [0, c-a)$
, where
$x \in [0, c-a)$
, where
 $[a,b]$
denotes the domain and
$[a,b]$
denotes the domain and
 $c = a + (b-a)/2$
. This notion of point symmetry should not be confused with the symmetry defined for transformations of probabilities via
$c = a + (b-a)/2$
. This notion of point symmetry should not be confused with the symmetry defined for transformations of probabilities via
 $g(p) + g(1 - p) = \text {const}$
, which relates to invariance under exchanging events and non-events rather than exchanging groups.Reference Rücker, Schwarzer, Carpenter and Olkin12
$g(p) + g(1 - p) = \text {const}$
, which relates to invariance under exchanging events and non-events rather than exchanging groups.Reference Rücker, Schwarzer, Carpenter and Olkin12
As a consequence, invariance of point estimates and inference can be violated due to the integral back-transformation. This can lead to problematic and counterintuitive results, that is, when inverting effect sizes. A particularly illustrative example involves the log transformation of odds ratios (ORs) when testing for the presence of a treatment effect. A commonly tested
 $H_0$
states that the mean OR is equal to one. Due to the skewness of the distribution on the exponentially back-transformed scale and the resulting systematic (rightward) transformation bias, the test outcome can depend on whether ORs are defined in one direction or its inverse. This issue is described in more detail in the applied example in Section 4.2.
$H_0$
states that the mean OR is equal to one. Due to the skewness of the distribution on the exponentially back-transformed scale and the resulting systematic (rightward) transformation bias, the test outcome can depend on whether ORs are defined in one direction or its inverse. This issue is described in more detail in the applied example in Section 4.2.
Therefore, we do not recommend conducting hypothesis tests for the back-transformed mean and suggest constructing CIs only when they are explicitly required. This applies to transformations exhibiting the described asymmetry. Alternative approaches can be employed either by formally conducting inference for the mean on the transformed scale or by performing a standard median-based test using the inverse transformation
 $g^{-1}$
.
$g^{-1}$
.
Equivalent plots of the transformation difference for all other transformations, which are listed in Table 1, are provided in Section A of the Supplementary Material. When comparing the transformation difference for the logit and probit transformation, it can be seen that the absolute difference of the logit transformation is larger across almost all combinations of
 $\hat {\mu }$
and
$\hat {\mu }$
and
 $\hat {\tau }$
. The same applies for the difference of the AHW transformation compared with the difference of the ABT transformation. A direct comparison of the arcsine transformation with the logit and probit transformation is not meaningful due to the differing ranges of the transformations and the associated slight variation in the interpretation of
$\hat {\tau }$
. The same applies for the difference of the AHW transformation compared with the difference of the ABT transformation. A direct comparison of the arcsine transformation with the logit and probit transformation is not meaningful due to the differing ranges of the transformations and the associated slight variation in the interpretation of
 $\psi _g$
.
$\psi _g$
.
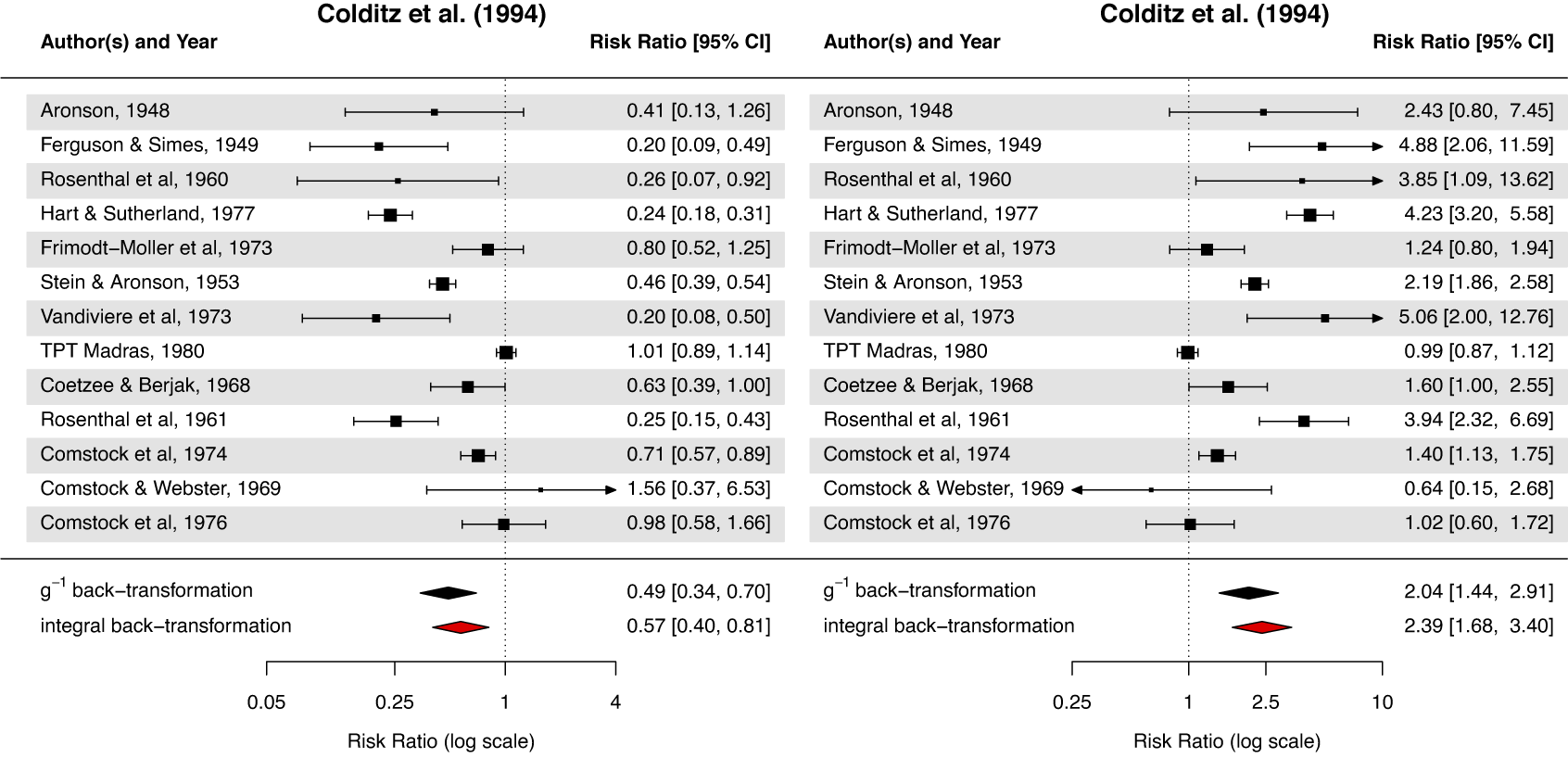
Forest plots for the Colditz et al. meta-analysisReference Colditz, Brewer and Berkey15 with the standard
 $g^{-1}$
and integral back-transformations;
$g^{-1}$
and integral back-transformations;
 $\hat {\tau } = 0.56$
; definitions of the RR: vaccinated over control (left) and control over vaccinated (right).
$\hat {\tau } = 0.56$
; definitions of the RR: vaccinated over control (left) and control over vaccinated (right).

4 Data application
To illustrate the impact of transformation difference and demonstrate the application of different types of transformations, we re-analyzed several data sets with different effect sizes. We begin by presenting two case studies applying the log transformation, which, as described in Section 3, can induce particularly extreme transformation difference and also conflicting test results for tests based on back-transformed CIs. The first data set (Section 4.1) exhibits a moderate, commonly observed level of heterogeneity, where a noticeable transformation difference is already evident. The second data set (Section 4.2) displays an extremely high level of heterogeneity, illustrating the issue of divergent test decisions, which has been discussed in Section 3. Additional examples including the usage of further effect sizes and corresponding transformations are summarized in Section 4.3. All analyzed data sets are available in the R package metadat.Reference Viechtbauer, White, Noble, Senior and Hamilton13 All analyses were conducted in R 14 (version 4.5.1) using the package metafor.Reference Viechtbauer9 The corresponding R script can be found in the Supplementary Material.
4.1 Detailed case study on log transformations for Colditz et al.
We illustrate the use of the log transformation with two data sets reporting
 $2 \times 2$
contingency data. One of these is the data set from Colditz et al.,Reference Colditz, Brewer and Berkey15 which includes studies on the effectiveness of the Bacillus Calmette–Guérin vaccine against tuberculosis (TB). Reported are the numbers of TB-positive cases in the vaccinated and unvaccinated groups (“tpos” and “cpos,” respectively), as well as the numbers of TB-negative cases in both groups (“tneg” and “cneg”). The analysis is carried out using the log transformation applied to the RR, which are defined as:
$2 \times 2$
contingency data. One of these is the data set from Colditz et al.,Reference Colditz, Brewer and Berkey15 which includes studies on the effectiveness of the Bacillus Calmette–Guérin vaccine against tuberculosis (TB). Reported are the numbers of TB-positive cases in the vaccinated and unvaccinated groups (“tpos” and “cpos,” respectively), as well as the numbers of TB-negative cases in both groups (“tneg” and “cneg”). The analysis is carried out using the log transformation applied to the RR, which are defined as:
 $\text {RR} = (\text {tpos} / (\text {tpos} + \text {tneg})) / (\text {cpos} / (\text {cpos} + \text {cneg}))$
. A resulting forest plot is shown in Figure 2 (left plot). The parameter estimates before back-transformation are
$\text {RR} = (\text {tpos} / (\text {tpos} + \text {tneg})) / (\text {cpos} / (\text {cpos} + \text {cneg}))$
. A resulting forest plot is shown in Figure 2 (left plot). The parameter estimates before back-transformation are
 $\hat {\mu } = -0.71$
and
$\hat {\mu } = -0.71$
and
 $\hat {\tau } = 0.56$
. Using the integral back-transformation, the estimated mean effect size and its CI are 0.57 [0.40, 0.81], while the results obtained applying
$\hat {\tau } = 0.56$
. Using the integral back-transformation, the estimated mean effect size and its CI are 0.57 [0.40, 0.81], while the results obtained applying
 $g^{-1} (= \exp )$
are 0.49 [0.34, 0.70].
$g^{-1} (= \exp )$
are 0.49 [0.34, 0.70].
In principle, the treatment comparison can also be defined inversely. The right panel of Figure 2 shows the forest plot for the same data set using inversely defined risk ratios
 $\text {RR} = (\text {cpos} / (\text {cpos} + \text {cneg})) / (\text {tpos} / (\text {tpos} + \text {tneg}))$
. The raw estimates and CI bounds as well as the absolute transformation difference increase largely because of the asymmetrical nature of the transformation or equivalently the skewness of the log-normal distribution. The results using the integral back-transformation are 2.39 [1.68, 3.40], while those using the inverse back-transformation are 2.04 [1.44, 2.91].
$\text {RR} = (\text {cpos} / (\text {cpos} + \text {cneg})) / (\text {tpos} / (\text {tpos} + \text {tneg}))$
. The raw estimates and CI bounds as well as the absolute transformation difference increase largely because of the asymmetrical nature of the transformation or equivalently the skewness of the log-normal distribution. The results using the integral back-transformation are 2.39 [1.68, 3.40], while those using the inverse back-transformation are 2.04 [1.44, 2.91].
Importantly, this numerical example clearly demonstrates that the integral back-transformation is not invariant to a reversal of the comparison direction, such that exchanging treatment and control does not generally lead to reciprocal effect estimates. In the forest plot, this is reflected by the fact that the red diamond is the only element that is not mirrored at the vertical line at one. To further illustrate the relevance of this issue, the following section presents an additional example in which extreme heterogeneity amplifies this problem.
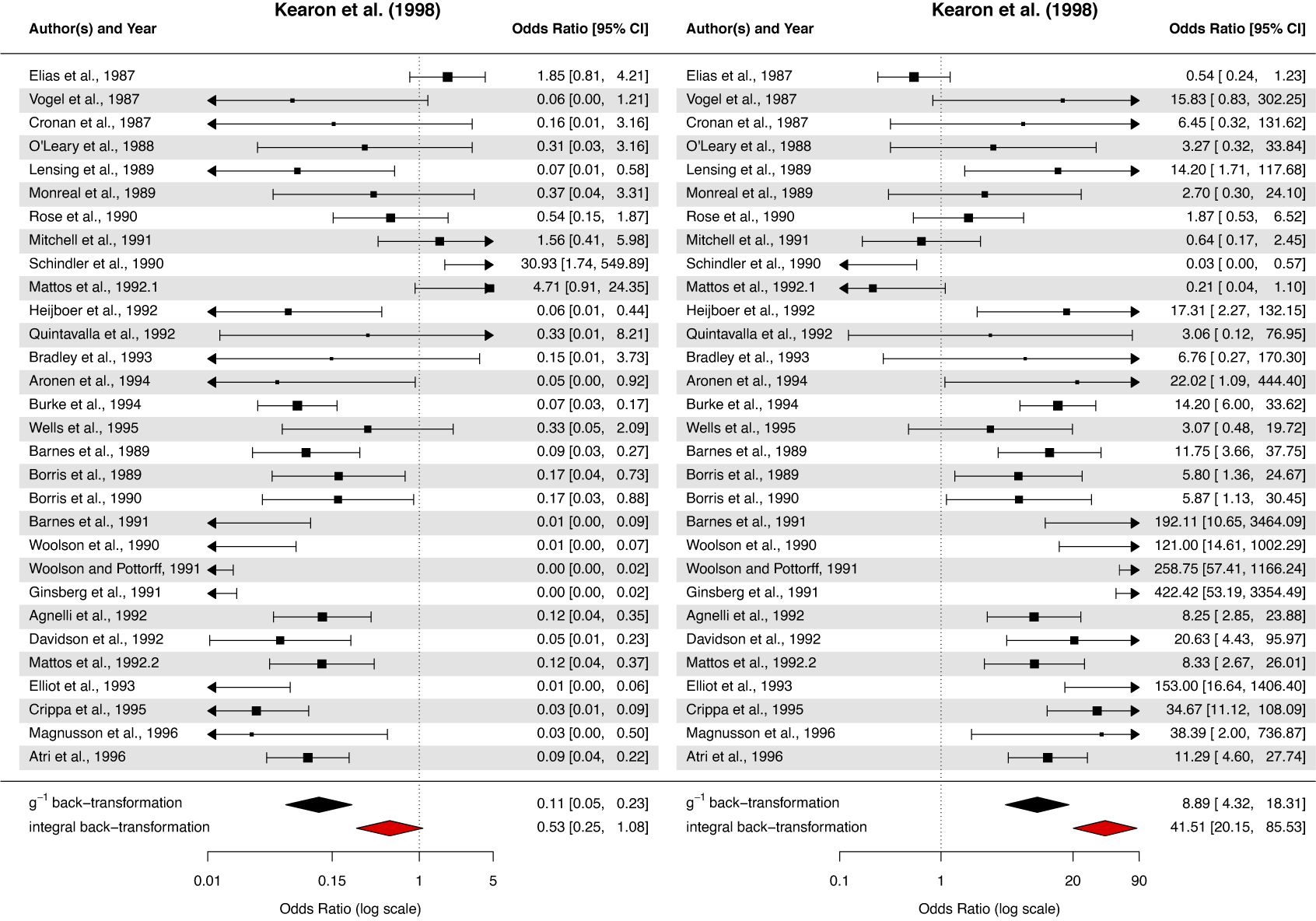
4.2 Detailed case study on log transformations for Kearon et al.
We re-analyzed an additional meta-analysis containing
 $2 \times 2$
contingency tables by Kearon et al.Reference Kearon, Julian, Newman and Ginsberg16 on the precision of venous ultrasound for the diagnosis of deep venous thrombosis. The results indicate an extreme level of heterogeneity. As a result, the transformation bias is larger, and additionally, inconsistent CI results are obtained. A detailed investigation of the sources of heterogeneity and a medical justification for conducting a meta-analysis on these heterogeneous data is not within the scope of this re-analysis.
$2 \times 2$
contingency tables by Kearon et al.Reference Kearon, Julian, Newman and Ginsberg16 on the precision of venous ultrasound for the diagnosis of deep venous thrombosis. The results indicate an extreme level of heterogeneity. As a result, the transformation bias is larger, and additionally, inconsistent CI results are obtained. A detailed investigation of the sources of heterogeneity and a medical justification for conducting a meta-analysis on these heterogeneous data is not within the scope of this re-analysis.
Forest plots for the Kearon et al. meta-analysisReference Kearon, Julian, Newman and Ginsberg16 with the
 $g^{-1}$
and integral back-transformations;
$g^{-1}$
and integral back-transformations;
 $\hat {\tau } = 1.76$
; definitions of the OR: positive over negative patients (left) and negative over positive patients (right).
$\hat {\tau } = 1.76$
; definitions of the OR: positive over negative patients (left) and negative over positive patients (right).

We denote the deep venous thrombosis cases and non-cases based on the contrast venography classification as: true positives (“tp”), false positives (“fp”), true negatives (“tn”), and false negatives (“fn”). In our case study, a log transformation is applied to the diagnostic ORs, which compare the odds of a correct classification for positive cases with those for negative cases. The OR is defined as
 $\text {OR} = (\text {tp} \cdot \text {fn}) / (\text {fp} \cdot \text {tn})$
. There are two studies with, in relation, extremely large ORs (Schindler et al. with OR = 30.39 and Mattos et al. with OR = 4.71). This leads to a large and imprecise estimate of
$\text {OR} = (\text {tp} \cdot \text {fn}) / (\text {fp} \cdot \text {tn})$
. There are two studies with, in relation, extremely large ORs (Schindler et al. with OR = 30.39 and Mattos et al. with OR = 4.71). This leads to a large and imprecise estimate of
 $\hat {\tau } = 1.76$
. As discussed in Section 3, this large and imprecisely estimated value has a drastic impact on the integral back-transformation.
$\hat {\tau } = 1.76$
. As discussed in Section 3, this large and imprecisely estimated value has a drastic impact on the integral back-transformation.
A corresponding forest plot can be found in Figure 3 (left plot). The results of the two back-transformations differ strongly: 0.11 [0.05, 0.23] for the standard inverse back-transformation and 0.53 [0.25, 1.08] for the integral one. Since the CI contains “1” only in the integral transformation case, this would even lead to a different test decision when interpreting the CIs as a test for the mean OR for venography classification accuracy for cases versus non-cases (the inverse back-transformation and CI for the median confirm the effect, the integral back-transformation and CI for the mean do not).
When using the inverse definition of the OR (
 $\text {OR} = (\text {fp} \cdot \text {tn}) / (\text {tp} \cdot \text {fn})$
), the difference between the estimates of the two back-transformation methods becomes even larger. The results are visualized in the right plot of Figure 3 (8.89 [4.32, 18.31] for the inverse back-transformation and 41.51 [20.15, 85.53] for the integral back-transformation). In this case, both CIs confirm the effect. For the
$\text {OR} = (\text {fp} \cdot \text {tn}) / (\text {tp} \cdot \text {fn})$
), the difference between the estimates of the two back-transformation methods becomes even larger. The results are visualized in the right plot of Figure 3 (8.89 [4.32, 18.31] for the inverse back-transformation and 41.51 [20.15, 85.53] for the integral back-transformation). In this case, both CIs confirm the effect. For the
 $g^{-1}$
transformation, this is consistent with the result based on the inverse OR definition (left plot). However, for the integral transformation, which corresponds to the correct test for the back-transformed mean, the problem described in Section 3 arises. Due to the one-sided bias and the skewness of the back-transformed distribution, the test, based on the back-transformed CI, differs when using the inverse OR.
$g^{-1}$
transformation, this is consistent with the result based on the inverse OR definition (left plot). However, for the integral transformation, which corresponds to the correct test for the back-transformed mean, the problem described in Section 3 arises. Due to the one-sided bias and the skewness of the back-transformed distribution, the test, based on the back-transformed CI, differs when using the inverse OR.
Even though there is often a prescriptive direction used in the definition of the odds or risk ratio (i.e., intervention vs. comparator as recommended in Chapter 6.4 of the Cochrane HandbookReference Higgins, Li, Deeks, Higgins, Thomas and Chandler17), this inconsistency is alarming. This is severe especially in test decisions but also for regular point estimates. As noted at the end of Section 3, we therefore recommend performing all tests on the transformed scale or use the standard back-transformation and then conduct a test for the back-transformed median (and interpret it as such). Thus, hypothesis tests for the back-transformed mean should not be conducted, and CIs should only be reported when they are explicitly required.
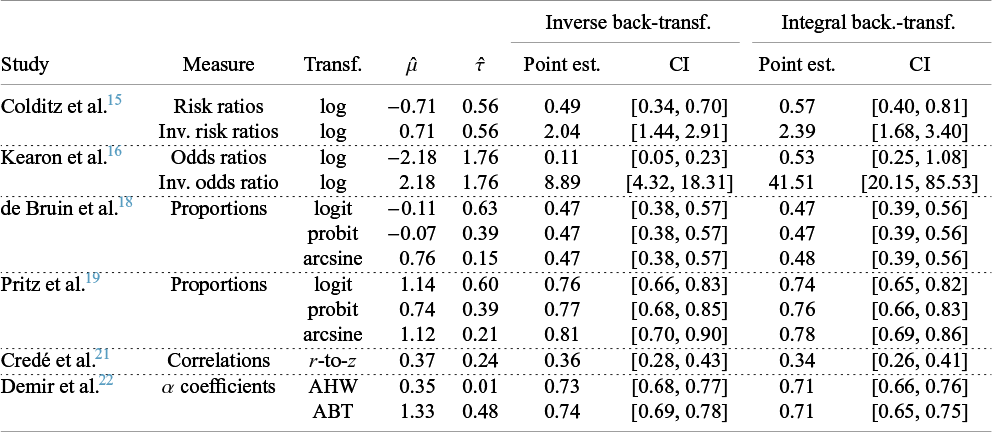
4.3 Overview of case studies for different types of transformations
An overview of the results when applying the two log transformations from the previous sections and the other transformations for several additional case studies can be found in Table 2. The corresponding effect measures and transformations are indicated. In addition, estimates of
 $\hat {\mu }$
and
$\hat {\mu }$
and
 $\hat {\tau }$
are reported. The corresponding forest plots can be found in Section B of the Supplementary Material.
$\hat {\tau }$
are reported. The corresponding forest plots can be found in Section B of the Supplementary Material.
Re-analyzed data sets with different effect measures and transformations with results separated for the standard inverse and the integral back-transformation

Proportions are analyzed in two studies (de Bruin et al.Reference de Bruin, Viechtbauer, Hospers, Schaalma and Kok18 and Pritz et al.Reference Pritz, Zhou and Brizendine19). The first study summarizes results from control groups in trials investigating antiviral therapies. The proportion of patients with an undetectable viral load in standard care groups is used for this meta-analysis. The second study includes research on the effectiveness of hyperdynamic therapy for treating cerebral vasospasm. The data set, originally compiled by Pritz et al.,Reference Pritz, Zhou and Brizendine19 is available through Zhou et al.Reference Zhou, Brizendine and Pritz20 The proportions analyzed refer to the share of patients who showed improvement following the therapy. We applied the logit, probit, and arcsine transformations to both data sets. A larger transformation effect was observed for Pritz et al.Reference Pritz, Zhou and Brizendine19 due to the different size of
 $\hat {\mu }$
.
$\hat {\mu }$
.
An example of the application of Fisher’s r-to-z transformation on correlation coefficients is provided using the data set from Credé et al.Reference Credé, Roch and Kieszczynka21 This analysis explores the relationship between class attendance and grade point average among college students. Furthermore, the AHW and ABT transformations are applied to the data set from Demir et al.,Reference Demir, Öz, Aral and Gürsoy22 which investigates the reliability of the Mother-to-Infant Bonding Scale. Reliability is assessed using the reported coefficients of Cronbach’s
 $\alpha $
. The results indicate that the transformation bias was more pronounced in the case of the ABT transformation.
$\alpha $
. The results indicate that the transformation bias was more pronounced in the case of the ABT transformation.
5 Summary and discussion
Meta-analyses commonly involve transformations of effect sizes to approximate a normally distributed sampling distribution. These transformations are typically followed by back-transformations to return the results to the original scale for easier interpretation. However, the standard approach, applying the inverse of the transformation function, yields the median of the distribution of effects on the back-transformed scale rather than its mean.
The first key message of this article is therefore conceptual. Interpreting the result of a standard inverse back-transformation as a mean effect size is incorrect. While the use of the inverse transformation is not inappropriate, the resulting estimate must be explicitly interpreted and reported as a median effect size, representing the typical value of the distribution of true effects.
The second key message concerns estimation of the mean on the original scale. We presented an integral back-transformation aiming for this mean. We generalized this approach to arbitrary effect size transformations and proposed a modification that is also valid for transformations with a bounded range. While this approach is methodologically correct in targeting the mean, it entails several issues and must be applied with caution. These issues are sensitivity to the estimation of
 $\tau ^2$
and the occurrence of inverse results for inversely defined effect sizes. This lack of invariance is present when the transformation is not point-symmetric around an effect-size-specific neutral value.
$\tau ^2$
and the occurrence of inverse results for inversely defined effect sizes. This lack of invariance is present when the transformation is not point-symmetric around an effect-size-specific neutral value.
The discrepancy between standard inverse and integral back-transformations depends on both the shape of the transformation function and the degree of between-study heterogeneity, as quantified by
 $\tau ^2$
. This relationship is illustrated in this article across several effect size measures and transformations. In particular, transformation difference can be substantial for transformation functions with unbounded domains, such as the log transformation applied to ratio measures.
$\tau ^2$
. This relationship is illustrated in this article across several effect size measures and transformations. In particular, transformation difference can be substantial for transformation functions with unbounded domains, such as the log transformation applied to ratio measures.
The integral back-transformation not only enables estimation of the mean effect size on the original scale, but also provides a formally valid basis for conducting hypothesis tests targeting this mean. Such tests can be defined by applying the integral back-transformation directly to the CI bounds on the transformed scale. However, we generally recommend performing statistical tests on the transformed scale, where the normality assumption for the distribution of true effects is originally specified. Equivalent test results are obtained from CIs for the back-transformed median, which can be constructed using the standard inverse transformation applied to the confidence limits on the transformed scale.
We emphasize that, even if the mean effect size on the original scale is the primary target, directly averaging the untransformed study-specific estimates is generally neither equivalent nor advisable. The rationale for working on a transformed scale is to better satisfy model assumptions and thereby ensure statistically sound estimation and inference. In particular, transformations are chosen such that both the distribution of true effects and the corresponding sampling distributions are closer to normality, while also stabilizing the variance across studies. The integral back-transformation should therefore be understood as a way to recover the mean effect on the original scale after fitting the model under these more appropriate conditions.
For transformations where the range of
 $g$
is not equal to
$g$
is not equal to
 $\mathbb {R}$
(
$\mathbb {R}$
(
 $V \subsetneq \mathbb {R}$
, e.g., for the arcsine transformation), the integral transformation cannot be applied directly since the probability distribution of the fitted normal distribution extends
$V \subsetneq \mathbb {R}$
, e.g., for the arcsine transformation), the integral transformation cannot be applied directly since the probability distribution of the fitted normal distribution extends
 $V$
. If this issue is ignored, formally, a truncated normal distribution is back transformed. We describe this truncation-based approach and introduce a corresponding integral back-transformation. The truncation approach generally leads to biased results. A possible alternative, that is potentially less biased, is clipping, where the irregular probability mass is assigned as point mass to the respective boundary of
$V$
. If this issue is ignored, formally, a truncated normal distribution is back transformed. We describe this truncation-based approach and introduce a corresponding integral back-transformation. The truncation approach generally leads to biased results. A possible alternative, that is potentially less biased, is clipping, where the irregular probability mass is assigned as point mass to the respective boundary of
 $V$
. However, it must be noted that this also implies a different formal distributional assumption.
$V$
. However, it must be noted that this also implies a different formal distributional assumption.
In addition, it should be noted that models assuming other distributions for the true effectsReference Lee and Thompson23,
Reference Noma, Nagashima, Kato, Teramukai and Furukawa24 are equally affected by the issues discussed in the present article. In this case, the normal density in Equation (2.3) needs to be replaced with whatever distribution is assumed for the true effects. Moreover, models using “exact likelihoods” (e.g., when modeling the counts of
 $2 \times 2$
tables via binomial and Poisson distributions) also typically assume a (normal) distribution of true effects on a transformed scale.Reference Jackson, Law, Stijnen, Viechtbauer and White25,
Reference Bagos and Nikolopoulos26 Therefore, to obtain the mean of the untransformed distribution, the integral back-transformation should also be used.
$2 \times 2$
tables via binomial and Poisson distributions) also typically assume a (normal) distribution of true effects on a transformed scale.Reference Jackson, Law, Stijnen, Viechtbauer and White25,
Reference Bagos and Nikolopoulos26 Therefore, to obtain the mean of the untransformed distribution, the integral back-transformation should also be used.
This article describes the issue in the context of frequentist statistics. A similar principle naturally applies in a Bayesian setting.Reference Röver27 When the mean of the posterior samples is computed, it can be back-transformed using either back-transformation. Applying the inverse transformation yields the median. Using the integral transformation in combination with a variance estimate results in the mean. This is identical to directly back-transforming the posterior samples and subsequently computing the median or mean on the original scale.
6 Practical guidance
Importantly, the choice between the two back-transformations should be guided by the analyst’s underlying goal. When the objective of a meta-analysis is primarily descriptive, and interest focuses on a central or typical effect, the median effect size obtained via the standard inverse back-transformation is often preferable. This approach is comparatively robust in the presence of strong skewness on the original scale and substantial between-study heterogeneity. Moreover, it is less sensitive to imprecision in the estimation of the between-study variance parameter
 $\tau ^2$
as the corresponding back-transformation function is independent of it.
$\tau ^2$
as the corresponding back-transformation function is independent of it.
In contrast, the integral back-transformation is particularly important when the target estimand is explicitly defined as a mean effect size. This includes reporting strategies that require mean effects by definition, comparisons with primary or secondary studies reporting means on the original scale, and applications in which the meta-analytic result is used as input for further linear calculations. Examples for this are additive projections, such as determining expected event counts based on pooled proportions or extrapolating average treatment costs. Similarly, secondary statistical analyses and decision-theoretic frameworks that rely on optimality properties defined in terms of expectations necessitate the use of a mean-based back-transformation. Thus, from a practical perspective, the estimand should be chosen deliberately and reported transparently. In cases of doubt, it is safer to use the standard inverse transformation and to correctly report the resulting estimate as a median.
Acknowledgements
We would like to thank the reviewers and the Associate Editor for their constructive comments, which contributed significantly to improving the quality of this work.
Author contributions
Conceptualization: J.-B.I. and W.V.; Data curation: J.-B.I.; Formal analysis: J.-B.I. and W.V.; Funding acquisition: M.P.; Investigation: J.-B.I. and W.V.; Methodology: J.-B.I., M.P., and W.V.; Project administration: M.P. and W.V.; Software: J.-B.I. and W.V.; Supervision: M.P. and W.V.; Visualization: J.-B.I.; Writing—original draft: J.-B.I.; Writing—review and editing: J.-B.I., M.P., and W.V.
Competing interests statement
The authors declare that no competing interests exist.
Data availability statement
All materials, including the Supplementary Material document, the R scripts for reproducing the analyses and examples, as well as all referenced figures, are openly available via the repository at https://doi.org/10.17877/TUDODATA-2026-7UFBJF. The datasets used for the analysis are accessible through the R package metadat.Reference Viechtbauer, White, Noble, Senior and Hamilton13
Funding statement
All authors were supported by the German Research Foundation (DFG) project, Grant No. 413270747.
Disclosure of use of AI tools
During the preparation of this manuscript, we used the ChatGPT 4o model from OpenAI for minor language edits, aiming to enhance readability. After using this tool/service, the authors reviewed and edited the content as needed and take full responsibility for the content of the proposal.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/rsm.2026.10096.









 Open access
Open access