

Building a rich vocabulary in a second language (L2) is essential to gain a sufficient level of L2 proficiency and, therefore, entails a large part of L2 education. According to the lexical quality hypothesis, language ability is facilitated by detailed semantic, phonological, and orthographic representations of words in the mental lexicon (Perfetti & Hart, Reference Perfetti and Hart2002). It has been shown that the strength of L2 lexical representations can be fostered by embedding words in context (Nassaji, Reference Nassaji2003). Thus far, research on vocabulary learning in context has mostly operationalized the semantic informativeness of the context categorically (i.e., semantically supportive vs. nonsupportive contexts) and not as a continuous measure, reflecting also the effects of more subtle distinctions in the semantic support of a context. Besides semantic contextual support, the strength of the learning of L2 lexical representations has been found to be related to word characteristics, such as the degree of L1-L2 overlap between the L2 items to be learned (e.g., Crossley, Salsbury, & McNamara, Reference Crossley, Salsbury and McNamara2012; Dijkstra, Grainger, & van Heuven, Reference Dijkstra, Grainger and van Heuven1999; Pytlyk, Reference Pytlyk2017), the frequency and length of words (Bolger, Balass, Landen, & Perfetti, Reference Bolger, Balass, Landen and Perfetti2008; Elgort, Perfetti, Rickles, & Stafura, Reference Elgort, Perfetti, Rickles and Stafura2015), and learner characteristics, such as prior knowledge and reading ability (e.g., Alderson, Nieminen, & Huhta, Reference Alderson, Nieminen and Huhta2016; Huensch & Ventura, Reference Huensch and Ventura2017; Zhang, Chin, & Li, Reference Zhang, Chin and Li2017). Nevertheless, L2 vocabulary learning has not often been examined as a function of both word and learner characteristics. In the present study, we examined L2 English lexical learning in Dutch adolescents in relation to context, word, and student predictors. English was chosen as the target L2 because it is one of the most commonly taught nonnative languages. The novel contribution of this study is that we used a continuous rather than a categorical measure to reflect the semantic relatedness between a prime and the to-be-learned target word, embedded in the same sentence. Using latent semantic analysis (LSA) scores (Landauer, Foltz, & Laham, Reference Landauer, Foltz and Laham1998) we measured the degree of semantic contextual support of a sentence context. In addition, we operationalized L1-L2 overlap through Levenshtein distance. In this study we related the predictors to three outcomes of L2 vocabulary learning through sentence reading: vocabulary knowledge immediately after learning, learning gain (difference between pretest and immediate posttest of vocabulary knowledge), and rate of forgetting (difference between immediate and delayed posttest of vocabulary knowledge).
CONTEXTUAL SUPPORT IN VOCABULARY LEARNING
One of the key premises of L2 learning is that vocabulary should be acquired in context (Ellis, Reference Ellis2013). Vocabulary learning through a semantic context requires deep processing of words as lexical units, and such learning has been found to result in better storage and retrieval (Nassaji, Reference Nassaji2003). Acquiring vocabulary in an instructed learning setting by reading semantic supportive sentence contexts provides abundant clues of the semantic, orthographic, and syntactic information of words (Beck, McKeown, & McCaslin, Reference Beck, McKeown and McCaslin1983), thus resulting in robust representations of words in the mental lexicon (e.g., Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015; Ma, Chen, Lu, & Dunlap, Reference Ma, Chen, Lu and Dunlap2015). Providing words in a sentence context can also disambiguate unfamiliar phonological contrasts and thus lead to higher lexical specificity as was, for example, demonstrated in L2 learners of Russian (Chrabaszcz & Gor, Reference Chrabaszcz and Gor2017).
In addition to phonology, several studies have demonstrated the importance of semantic contextual support on semantic disambiguation, with different context qualities leading to varying results. Rich, often highly constraining contexts, on the one hand, have a high information load, leading to a limited number of possible interpretations of a word and more specific and strong mental lexical representations. Less rich, often low constraining contexts, on the other hand, include less information, leaving more opportunity to infer the meaning of a word, which may lead to less robust word storage (Ma et al., Reference Ma, Chen, Lu and Dunlap2015) as the initial interpretation may be erroneous. In proficient and less proficient L2 learners, better performance for vocabulary learning was found when target words were embedded in sentences with highly semantically related words, reflecting a higher degree of semantic contextual support (Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015). This effect was largest for highly proficient learners, suggesting that such context effects may (partially) depend on learner characteristics. Furthermore, Beck et al. (Reference Beck, McKeown and McCaslin1983) showed that directive contexts, which were intended to reveal the meaning of a word, provided adult readers with most clues about a word. Daneman and Green (Reference Daneman and Green1986) provided skilled adult readers with contexts that included low-frequency words and showed that vocabulary growth was primarily predicted by semantic cues, spread across the seven categories that were provided. Furthermore, Ma et al. (Reference Ma, Chen, Lu and Dunlap2015) showed that Chinese adults learning English as an L2 had most benefit during vocabulary learning when words were placed in highly constraining sentences.
These studies use word recognition through reading and lexical decision paradigms rather than L2 translation accuracy as an indicator of vocabulary learning and include advanced L2 learners. Furthermore, in experimental settings, L2 vocabulary learning is often assessed only immediately after learning. Long-term effects of L2 vocabulary learning, as operationalized by rate of forgetting in the form of a delayed posttest, are not often addressed. Adlof, Frishkoff, Dandy, and Perfetti (Reference Adlof, Frishkoff, Dandy and Perfetti2016) have shown that both adult and novice first language (L1) learners can acquire and retain new L1 words over time when presented in highly constraining (i.e., semantically supportive) contexts, suggesting lower rate of forgetting when words are placed in such contexts. More important, studies that did focus on the effects of semantic contextual support on (L2) vocabulary learning used categorical measures (i.e., semantically supportive vs. nonsupportive contexts) or other categorizations, such as different types of semantic cues (Daneman & Green, Reference Daneman and Green1986; Ma et al., Reference Ma, Chen, Lu and Dunlap2015). Therefore, these studies do not provide insight into the influence of subtle variations in the semantic contextual support of the context on vocabulary learning. A statistical technique that allows us to gain more insight into the influence of the degree of semantic contextual support on word learning is LSA (Landauer et al., Reference Landauer, Foltz and Laham1998). LSA rests on the assumption that words that often occur in similar contexts are semantically related (the distributional hypothesis), and the LSA score reflects the degree to which this is the case. This computational technique measures the semantic relations between words beyond their direct co-occurrences in the same texts, based on a large corpus of written texts. Previous studies have shown that LSA scores can be used to predict human behavior for example in semantic priming in visual (Landauer & Dumais, Reference Landauer and Dumais1997) or auditory (van de Ven, Tucker, & Ernestus, Reference van de Ven, Tucker and Ernestus2011) lexical decisions, and may therefore also be used to predict vocabulary learning. In the present study, we used LSA as a continuous measure to operationalize semantic contextual support, assuming that higher LSA scores indicated more semantic contextual support.
WORD PREDICTORS OF CONTEXTUAL VOCABULARY LEARNING
A core predictor of the acquisition of lexical representations in contextual L2 vocabulary learning is L1-L2 overlap (Dijkstra et al., Reference Dijkstra, Grainger and van Heuven1999). In the present study, we measured L1-L2 overlap in two ways, by means of cognate status and Levenshtein distance. Words that share orthographic, phonological, and meaning similarities are referred to as cognates. Words with phonological and/or orthographic but no semantic overlap are called false cognates or false friends (Carrol, 1992). For instance, the English word FILM and the Dutch word FILM show complete phonological, orthographic, and semantic overlap, and these words are therefore cognates. In contrast, although the English word SPOT (Dutch: VLEK) shares orthographic similarity with the Dutch SPOT (English: MOCKERY), these words have no semantic overlap and are thus false friends. Cognate status has been shown to contribute significantly to translation variance (de Groot, Reference de Groot1992) and to performance on both forward and backward translation (de Groot, Dannenburg, & van Hell, Reference de Groot, Dannenburg and van Hell1994). Furthermore, evidence was found that there is a benefit of cognate status both in learning and in retrieving vocabulary in university students learning a foreign language (e.g., de Groot & Keijzer, Reference de Groot and Keijzer2000; Lotto & de Groot, Reference Lotto and de Groot1998). However, another study found evidence that lexical items were connected between languages regardless of cognate status in Dutch–English bilinguals (de Groot & Nas, Reference de Groot and Nas1991). Different types of priming experiments were conducted to examine word representations in the bilingual lexicon. The results suggest that cognate status does not necessarily benefit or hamper word representations (de Groot & Nas, Reference de Groot and Nas1991). The use of cognates was shown to foster morphological awareness in Spanish–English bilinguals in fourth up to eighth grade (Hancin-Bhatt & Nagy, Reference Hancin-Bhatt and Nagy1994). In their study, Starreveld, de Groot, Rossmark, and van Hall (2014) examined the cognate effect as a marker of activation of a nontarget language during picture naming with varying sentence contexts. They found that the cognate effect was smaller for high-constraint than for low-constraint sentences.
More subtle differences in cross-linguistic overlap can be measured by calculating the Levenshtein distance (Levenshtein, Reference Levenshtein1966) between two words. This measure reflects the number of insertions, deletions, and substitutions required to edit one word into another. For example, when comparing the English word CLOCK to its Dutch translation KLOK, the Levenshtein distance is 2: the first C is substituted for a K and the second C is deleted. A small Levenshtein distance indicates a large overlap between words, whereas a large distance points to a small overlap. Levenshtein distance has so far only been used as a measure to describe the structure of the mental lexicon and how L1 and L2 words are organized (Dautriche, Mahowald, Gibson, Christophe, & Piantadosi, Reference Dautriche, Mahowald, Gibson, Christophe and Piantadosi2017), and not as a measure to show subtle effects of L1-L2 overlap on L2 vocabulary learning, or in interaction with context characteristics.
Two other, more traditional, predictors that have been used in vocabulary learning research are word frequency (Diependaele, Lemhöfer, & Brysbaert, Reference Diependaele, Lemhöfer and Brysbaert2013) and word length (Whaley, Reference Whaley1978). In lexical decision, which can be seen as a measure of a word’s familiarity (i.e., with acoustic as well as semantic features) or word learning (e.g., Reichle & Perfetti, Reference Reichle and Perfetti2003), processing accuracy and speed are higher for words with relatively high frequencies (Hauk & Pulvermüller, Reference Hauk and Pulvermüller2004).
Frequent words in monolingual settings are, to some extent, used relatively frequently in bilingual translation settings as well (de Groot, Reference de Groot1992). Therefore, it is assumed that L2 learners are more likely to learn words that are relatively frequent in the L1 (Lotto & de Groot, Reference Lotto and de Groot1998). Furthermore, short response times in lexical decision indicate that representations of highly frequent words are more easily accessible from the mental lexicon than low-frequency words (e.g., Adelman, Brown, & Quesada, Reference Adelman, Brown and Quesada2006; Forster, Reference Forster1976; Seidenberg & McClelland, Reference Seidenberg and McClelland1989). However, after controlling for cognate status, de Groot and Keijzer (Reference de Groot and Keijzer2000) found marginal remaining effects of word frequency in experienced foreign language learners. Finally, semantic priming effects were shown to be moderated by word frequency; priming effects are stronger for low- than for high-frequency words (Rayner, Ashby, Pollatsek, & Reichle, Reference Rayner, Ashby, Pollatsek and Reichle2004). Moreover, word length has been shown to be a predictor of lexical decision. Shorter words tend to be processed more quickly and more accurately than longer words, which suggests that these words have stronger lexical representations (Whaley, Reference Whaley1978) and may, hence, be easier to learn. On the one hand, Hauk and Pulvermüller (Reference Hauk and Pulvermüller2004) found that, when looking at the amplitude of neurophysiological responses, relatively long words evoked stronger responses in the early stages (~100 ms after stimulus onset) than did relatively short words during lexical decision. On the other hand, they found stronger responses to short words at later stages (150–360 ms after stimulus onset). These findings suggest that long and short words may be processed in different ways, which may be related to the way these lexical items are stored in the mental lexicon.
Student Predictors of Contextual Vocabulary Learning
Vocabulary learning outcomes vary in students with different characteristics. Prior vocabulary knowledge has been demonstrated to influence word recognition in 8.5- to 13-year-old L1 learners (Nation & Snowling, Reference Nation and Snowling2004). Children with more vocabulary knowledge were better at recognizing structure in novel words (Nation & Snowling, Reference Nation and Snowling1998), but this was not studied specifically in a vocabulary learning setting. Cain, Oakhill, and Lemmon (Reference Cain, Oakhill and Lemmon2004) did find that L1 learners with less vocabulary knowledge had more difficulty acquiring new vocabulary than those with more prior vocabulary knowledge.
Reading comprehension skills have been widely shown to foster vocabulary learning within a semantically supportive context. For example, Ouellete (2006) demonstrated relationships between reading comprehension and both vocabulary breadth and depth in Grade 4 children. Furthermore, 9- to 10-year-old L1 learners with weak reading comprehension skills were found to have more difficulty with vocabulary learning than learners with good reading comprehension skills (Cain et al., Reference Cain, Oakhill and Lemmon2004). In addition, university students who were proficient text comprehenders made larger vocabulary learning gains than poor comprehenders in a study by Elgort and Warren (Reference Elgort and Warren2014).
Exposure to English media outside school has been found to contribute to L2 learning. Kuppens (Reference Kuppens2010) performed a study to examine the influence of self-reported media use on incidental language acquisition in Flanders’ students, in their final year of primary school. This showed a significant influence of the use of subtitled English television on translation accuracy. Students’ media exposure is not limited to television but also comprises listening to English music, reading English texts online, and watching videos (Lindgren & Muñoz, Reference Lindgren and Muñoz2013). Exposure to these English media was shown to be a strong predictor for L2 reading and listening comprehension skills in Dutch 10- to 11-year-olds. Highly proficient adult L2 learners were shown to benefit more from semantic contextual support; however, interactions between learner characteristics, such as prior knowledge or exposure, of novice L2 learners and semantic contextual support remain to be examined.
Present Study
From the research so far, it can be concluded that context, word, and learner factors may predict the learning of L2 vocabulary. Although relations between these factors have been examined (e.g., de Groot & Keijzer, Reference de Groot and Keijzer2000; Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015; Starreveld et al., Reference Starreveld, de Groot, Rossmark and van Hell2014), an attempt to integrate these measures into a single design has not yet been made. Further, both semantic contextual support and cognate status tend to be operationalized categorically rather than continuously. Therefore, the present study aimed to examine context, word, and student predictors of L2 English vocabulary learning in 197 Dutch secondary school students. All students had received English education during primary school and now attended different educational tracks within secondary school: lower and intermediate prevocational education (VMBO-t/Havo), intermediate education (Havo), or higher level and preuniversity education (Havo/VWO). Students were asked to perform a computerized task, consisting of a pretest, learning trials, an immediate posttest, and a delayed posttest. On both pretest and posttests, participants translated cognates, false friends, and control words with different degrees of Dutch–English overlap and varying word frequencies. During learning trials, the students read sentences with these target words. They were instructed to judge the plausibility of these sentences. For each target word, we selected one prime that was strongly related to the target word (i.e., creating a context with relatively high semantic support) and one that was weakly or unrelated to the target word (i.e., creating a context with less semantic support).
We examined context, word, and student predictors of three different L2 vocabulary learning outcomes: vocabulary knowledge at immediate posttest after the vocabulary learning trials; learning gain, operationalized as the difference between pretest and immediate posttest vocabulary knowledge; and rate of forgetting, as reflected by the decrease in vocabulary knowledge between immediate posttest and delayed posttest looking at the prediction of time (immediate or delayed). We were the first to examine the continuous effects of semantic contextual support, as measured by the LSA score of semantic similarity between the prime and the target word that needed to be learned. Another novel contribution was that we examined the influence of L1-L2 form overlap, as reflected by Levenshtein distance on L2 vocabulary learning. The vocabulary knowledge, learning gain, and rate of forgetting were related to word characteristics (L1-L2 overlap, word frequency, and word length) and student characteristics (prior knowledge, reading ability, and exposure to English). The research questions were to what extent the three different L2 vocabulary learning outcomes are explained by
1. semantic contextual support;
2. word characteristics (i.e., cognate status, Levenshtein distance between L1 and L2, word frequency, and word length);
3. student characteristics (i.e., prior vocabulary knowledge via pretest accuracy, reading comprehension, exposure to English media outside school, and learning trials performance via accuracy and reaction times during sentence judgment); and
4. interactions between the aforementioned.
We expected that semantically more supportive contexts (i.e., higher LSA scores for prime and target) would result in a larger knowledge and learning gain (e.g., Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015; Ma et al., Reference Ma, Chen, Lu and Dunlap2015), and in a lower rate of forgetting compared to contexts with less semantically supportive contexts (i.e., lower LSA scores; Adlof et al., Reference Adlof, Frishkoff, Dandy and Perfetti2016), shown by an interaction between time and semantic support. We expected several word characteristics to predict vocabulary learning. We hypothesized that cognates (e.g., de Groot, Reference de Groot1992; de Groot et al., Reference de Groot, Dannenburg and van Hell1994), words with smaller Levenshtein distances (e.g., Dautriche et al., Reference Dautriche, Mahowald, Gibson, Christophe and Piantadosi2017), and highly frequent (e.g., Diependaele et al., Reference Diependaele, Lemhöfer and Brysbaert2013) and shorter words (e.g., Whaley, Reference Whaley1978) would be known best after learning in context, followed by control words, and finally false friends. We also expected larger gains could be made for false cognates, as compared to cognates (e.g., Starreveld et al., Reference Starreveld, de Groot, Rossmark and van Hell2014) and control words. With reference to student characteristics, we hypothesized positive effects of prior vocabulary knowledge (e.g., Nation & Snowling, Reference Nation and Snowling1998), reading comprehension (e.g., Cain et al., Reference Cain, Oakhill and Lemmon2004), task performance, and exposure to English media (Kuppens, Reference Kuppens2010) on the learning outcomes. We examined interactions between context, word, and student characteristics. We expected highly proficient learners (i.e., students with larger prior vocabulary knowledge, and better reading comprehension and/or task performance; e.g., Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015) to benefit more from semantic contextual support (context characteristics). We hypothesized semantic contextual support (context characteristic) to be more important for low-frequency words than for high-frequency words (word characteristics; Rayner et al., Reference Rayner, Ashby, Pollatsek and Reichle2004). Further interactions were explored.
METHOD
Participants
Participants included in this study were 197 Dutch students learning English as an L2 from the seventh grade of three secondary schools in the Netherlands. The sample consisted of 56 students who were in their first year of lower and intermediate prevocational education (VMBO-t/Havo), 30 students in intermediate education (Havo), and 111 students of higher level and preuniversity education (Havo/VWO). The sample comprised 104 boys and 93 girls (mean age=12 years and 8 months, SD=5.04 months).
At the time of testing, the participants had received 5 months of English instruction at secondary school. Most students had also received English instruction at primary school from the fourth grade onward (n=160); the others had received English education before the fourth grade. The majority of the participants spoke Dutch at home with their parents (n=175) and siblings (n=167); some participants spoke Dutch and English (parents n=6; siblings n=5), or Dutch and another language, such as Turkish, German, or Papiamento (parents n=16; siblings n=20).
Materials
Vocabulary learning in context
A computer-based experiment was constructed that consisted of a pretest, learning phase, immediate posttest, and delayed posttest. In all four parts of the task, participants were presented with 96 target words with varying degrees of English–Dutch overlap: cognates (e.g., apple–appel), false friends (e.g., note [Dutch translation: briefje]–noot [English translation: nut]), and control words (e.g., fibre–vezel), along with 20 filler items.
During the pretest, immediate posttest, and delayed posttest, participants translated all targets and fillers from English into Dutch. The English target words appeared on the screen and the students had to type the translations within 8000 ms. In the learning phase, students had to learn the words through reading sentences with different degrees of semantic contextual support and judging their plausibility, after being presented with a Dutch translation of the target word. For each item, we created one semantically supporting context (with a relatively high LSA score) and one semantically less supporting context (with a low LSA score). The LSA scores were retrieved using the pairwise comparison tool from the LSA website at the University of Colorado at Boulder (2003). We used the General Reading Up to First Year of College corpus with 300 factors. The experimental procedure is illustrated in Figure 1. In this figure, prime words were underlined and target words were printed in bold. More information about the selection of primes and sentence construction can be found in the Sentence Contexts section.
Graphic overview of experiment. Primes are underlined, targets are printed in bold, and Dutch translations of the targets are printed in italics.
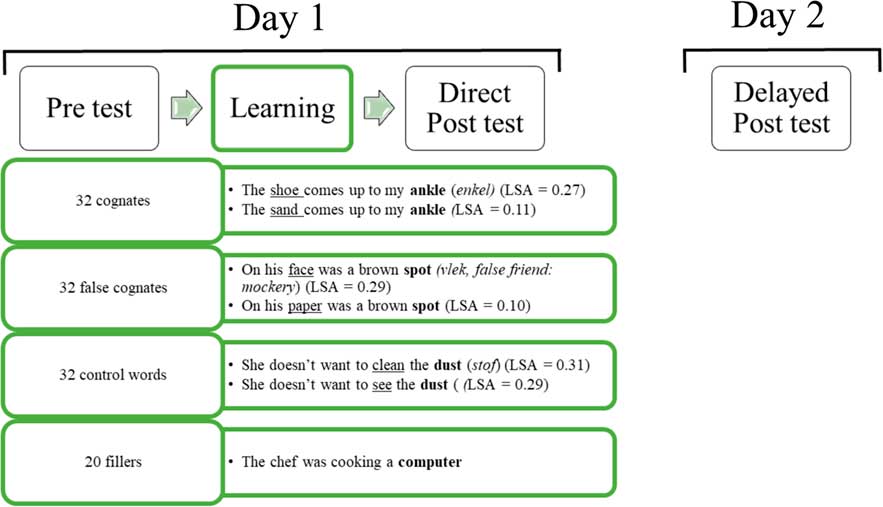
All participants were randomly assigned to a list with either of the two versions of the items, all combined with 20 filler items; the condition of each item had been randomly generated. Thus, the presentation of the sentences in either a semantically supportive or less supportive context was counterbalanced.
To intrinsically motivate participants (Martens, Gulikers, & Bastiaens, Reference Martens, Gulikers and Bastiaens2004), they were told they would be playing a game in which they had to judge sentences on their plausibility. Thus, filler items that were implausible sentences were included in the task, such as: “The flowers were having a fight.” All sentences with target words were plausible. Learning trials were presented as follows for both target and filler items: participants were presented with a fixation cross for 200 ms, followed by an English word and its corresponding Dutch translation (e.g., box–doos), which was shown for 2500 ms. Subsequently, participants were presented with a sentence. Participants were then to decide whether the sentence was plausible or implausible, pressing “A” on the keyboard for a plausible and “L” for an implausible sentence. The sentence was shown for 8000 ms, unless participants responded earlier, in which case the next sentence would appear. The English word and its Dutch translation were presented prior to the context, which allowed learners to construct a lexical entry (if none was available).
Stimuli were presented in a pseudorandom order with the restriction that semantically or phonologically related target words were never presented successively. To facilitate storage of new representations (Perfetti & Hart, Reference Perfetti and Hart2002), all learning trials were audio supported: students heard the English target word, its Dutch translation, and the sentence in which the English target word was embedded. The audio recordings were made using Audacity® version 2.1.2 (Audacity Team, 2015). Stimuli were then extracted by means of Praat (Boersma, Reference Boersma2001). The task was programmed using Delphi XE 5 update 2. A detailed overview of all stimulus characteristics can be found in Appendix A.
TARGET WORDS
Target words were selected comparing words from four studies (Brenders, van Hell, & Dijkstra, Reference Brenders, van Hell and Dijkstra2011; Dijkstra et al., Reference Dijkstra, Grainger and van Heuven1999; Lotto & de Groot, Reference Lotto and de Groot1998; van Hell & Dijkstra, Reference van Hell and Dijkstra2002) with vocabulary lists from the English as a Foreign Language (EFL) method “Stepping Stones.” Sets of words consisting of a cognate, a false friend, and a noncognate were constructed and controlled for word type (e.g., adjectives: wild–glad–near; nouns: apple–note–fibre), length, number of syllables, singular or plural form, and word frequency, based on the English CELEX database (Baayen, Piepenbrock, & van Rijn, Reference Baayen, Piepenbrock and van Rijn1993). The frequency of the target words ranged from 11 to 22,071 (M=1,224.88, SD=2,557.62) and was kept constant across the different word types. Thus, a list of 96 three- to seven-letter nouns, verbs, and adjectives was composed. English–Dutch cognate pairs were constructed based on cross-linguistic similarity in terms of orthography, phonology, and/or semantics. False friend pairs were matched on orthography and/or phonology, but not on semantics. Noncognates were selected if there was no matching orthography and/or phonology and possibly no matching semantics (Dijkstra et al., Reference Dijkstra, Grainger and van Heuven1999). For the cognates, Levenshtein distance (Levenshtein, Reference Levenshtein1966) ranged from 0 to 5 (M=1.44, SD=1.32); for false friends, it ranged from 1 to 7 (M=4.03, SD=1.55), and the range was 2 to 8 for control words (M=4.53, SD=1.45). Cognate status and Levenshtein distance were highly correlated, and therefore these variables were orthogonalized. For the orthogonalization, a linear regression model was fitted with Levenshtein distance as the dependent and cognate status as the independent variable (e.g., see Wurm & Fisicaro, Reference Wurm and Fisicaro2014). The residuals of this model (Levenshtein distanceresid) were used to replace Levenshtein distance as a predictor in the mixed-effects models.
SENTENCE CONTEXTS
Sentences were constructed taking several aspects into account. Sentences consisted of a semantic prime preceding the target word to be learned. Prime words were selected based on semantic relatedness with the target word using LSA (University of Colorado at Boulder, 2003), thus indicating the degree of semantic contextual support. LSA computes a score ranging from –1 to +1, where a higher score indicates that words are more likely to occur in similar texts (i.e., measured beyond first-order co-occurrences). On the basis of the distribution of words across different texts, words are placed in a vector space. The LSA score was computed by taking the cosine of the angle between the vectors for the primes and the targets. Similar to the target words, we verified that the primes were familiar to the participants on the basis of the Dutch EFL method “Stepping Stones.” For each sentence, a prime was selected that was closer to 0 and a prime that was closer to 1 compared to the target. LSA scores differed significantly for the highly related prime (M=0.46) and the less related prime (M=0.099), t (112.21)=21.68, p<.0001, d=3.21. The frequencies of the primes ranged from 33 to 111,471 (M=3,157.84, SD=8,860.41), based on the English CELEX database (Baayen et al., Reference Baayen, Piepenbrock and van Rijn1993). We aimed to keep prime frequencies comparable to target frequencies. The primes were always placed in or near sentence-initial position, while the targets were always placed in sentence-final position (similar to Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015). The distance between primes and targets ranged from 1 to 5 words (M=2.57, SD=0.93) and was similar across word categories and conditions, as was sentence length, which ranged from 4 to 10 words (M=6.55, SD=1.07).
Reading comprehension
A measure often used for reading comprehension is a cloze task or a gap text (e.g., Gellert & Elbro, Reference Gellert and Elbro2013; Keenan & Meenan, Reference Keenan and Meenan2014). This measure required completing a text in which words had been omitted. An exam text for lower and intermediate prevocational education was selected (van Gelderen et al., Reference van Gelderen, Schoonen, de Glopper, Hulstijn, Simis, Snellings and Stevenson2004), and every seventh word was omitted and replaced by a blank line. The omitted words were listed below the text, and children were instructed to write down each word on the correct line. Reliability of this task was α=0.943.
Questionnaire
Students were asked to complete a questionnaire in order to measure their linguistic background and exposure to English. Participants were asked to indicate their exposure to English media outside school, answering the questionnaire with a 7-point Likert scale. They were asked how often (1=never to 7=daily) and how long (1=never to 7=5 hours or more) they played English video games, read English books or texts, watched English television programs or films, watched online videos in English, and listened to English music.
Procedure
For this study, a convenience sample was used, consisting of three schools that were contacted by the first author and agreed to participate. The students’ parents or guardians received an information letter and provided passive consent, with active consent being received from the students.
Participants completed two 50-min sessions. In the first session, the pretest, learning phase, and immediate posttest were carried out in a classroom setting. In the second session, the delayed posttest was performed, followed by the questionnaire to assess student predictors and the cloze test. Stimuli were presented on a white screen printed in black lowercase letters. The questionnaire and cloze test were paper-and-pencil tasks.
During the first session, students were told that they were testing an English video game called “It’s raining rabbits all day.” They received an instruction about the game. First, they were told that they had to make plausibility judgments during the game. During a familiarization phase, participants were asked to provide plausibility judgments for several clear examples of plausible and implausible sentences. Second, we explained to the participants that, to help them with the plausibility judgments, they would first see the translation of one English word (the target) from the sentence and its Dutch translation. Thus, for each trial, participants would first see an English target word with its Dutch translation, followed by a full English sentence in which this word was embedded, and they were instructed to provide a plausibility judgment for this sentence. Third, participants were instructed to work individually, and as quietly, quickly, and accurately as possible. After the instruction, they were allowed to ask questions. The delayed posttest was administered a day after Session 1.
Analyses
The data were analysed in R (version 3.3.1) by means of generalized linear mixed-effects models in lme4 (Bates, Maechler, Bolker, & Walker, Reference Bates, Maechler, Bolker and Walker2015) using contrast coding for factors (Jaeger, Reference Jaeger2008), and with the logit link function (e.g., Breslow & Clayton, Reference Breslow and Clayton1993; Jaeger, Reference Jaeger2008). To control for multicollinearity and possible normality distribution violations, all continuous variables were standardized and centered (Belsley, Kuh, & Welsh, Reference Belsley, Kuh and Welsh1980). One control item needed to be excluded from the analyses, because of a mismatch between the audio recording and the displayed sentence, resulting in 32 cognates, 32 false cognates, and 31 control word items. We created three models that all had binomial dependent variables per participant for each item: one for translation accuracy, that is, vocabulary knowledge at immediate posttest (correct/incorrect); a second model for learning gain (learning gain/no learning gain), as operationalized by the difference between pretest and posttest vocabulary knowledge; and a third model for rate of forgetting in which we measured translation accuracy at the immediate and delayed posttest (correct/incorrect) and forgetting could be measure by testing for main effects of and interactions with the variable time. We determined the final mixed-effects models by means of model selection, in which predictors were removed if they did not attain significance at the 5% level. Model selection took place in three separate steps. We determined the significant fixed effects, followed by the random effects (student and word), and the random slopes (i.e., interactions between the fixed and random effects). Variables and interactions were added successively to lead to a converging model with increased model fit. Chi-square tests were used to examine whether inclusion of a variable led to a significantly better model fit. We also ensured that these models then contained lower Akaike information criterion values. To construct the fixed-effects section of the mixed model, variables were added successively, based on preliminary considerations. Once the fixed-effects section was complete, the inclusion of random slopes for the fixed effects was tested using chi-square tests (Baayen, Reference Baayen2008). We report one-tailed significance values for directed hypotheses and two-tailed values for explorative analyses. Effect size is indicated by beta coefficients and their corresponding confidence intervals: large betas indicate a large effect size, and narrow confidence intervals point to more precision as compared to broad confidence intervals.
RESULTS
Descriptives
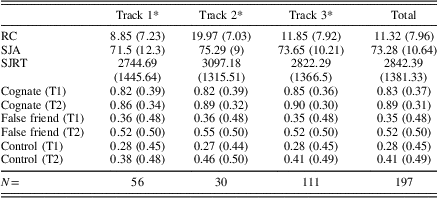
The descriptive statistics are presented in Table 1, including means and standard deviations of student characteristics and both pretest and posttest accuracy, tabulated by cognate status across the different educational tracks.
Means and standard deviations (in parentheses) of reading comprehension (RC), sentence judging accuracy (SJA), reaction time (SJRT), and proportion of words correct on pretest (T1) and posttest (T2) tabulated by cognate status, and across different tracks

Note: *Track 1=prevocational, track 2=intermediate, track 3=preuniversity.
We first assessed whether actual vocabulary learning took place. This was the case, as a significant difference between pretest and posttest accuracy was found, χ² (1, N=142)=42.55, p<.0001. The effect size (Φ coefficient) for this effect was 0.55, which can be considered a large effect (Ellis & Steyn, Reference Ellis and Steyn2003). This indicated that, in general, students’ posttest accuracy was higher than their pretest accuracy, and a learning effect had occurred. Although there was a significant overall difference between pretest and immediate posttest accuracy, a ceiling effect was present for cognates. Furthermore, we examined the possible presence of a speed–accuracy trade-off during the sentence reading trials. There was a significant, yet small, correlation between sentence judgment accuracy and sentence judgment reaction time, r=.10, p<.0001. This indicates students were less accurate in their sentence judgment when they had faster reaction times.
After this, we fitted three different models, using mixed-effects regression, to examine the effect of context, word, and student predictors on the three learning outcomes: vocabulary knowledge at immediate posttest, learning gain (difference between pretest and immediate posttest vocabulary knowledge), and rate of forgetting (vocabulary knowledge at immediate posttest and delayed posttest). For all models, the model intercept indicates the model prediction holds when all variables have the intercept value; that is, the intercept levels for factors, and the standardized means for numeric variables.
Predictors of vocabulary knowledge
We created a model for vocabulary knowledge at immediate posttest, to examine the vocabulary knowledge after the sentence judgment during the learning trials. To analyze the results, in the vocabulary knowledge model we used immediate posttest accuracy as the dependent variable. The following independent variables were included: semantic contextual support (as indicated by LSA scores; higher LSA scores pointed to a larger semantic overlap between prime and target and thus larger semantic contextual support), prior vocabulary knowledge (i.e., pre–test accuracy), reading comprehension (scores on a written cloze task), sentence judgment accuracy (during the learning phase), sentence judgment reaction time (reaction times during the learning phase), cognate status (cognates on the intercept), Levenshtein distance resid (after controlling for cognate status), and target frequency. An overview of the influence of the relevant variables on vocabulary knowledge at pretest can be found in Table 2. A summary of the final model for vocabulary knowledge at immediate posttest is presented in Table 3.
Summary of a generalized linear mixed-effects model predicting vocabulary knowledge at pretest

Note: aTested one-tailed.
Summary of a generalized linear mixed-effects model predicting vocabulary knowledge at immediate posttest

Note: aTested one-tailed.
There were main effects of semantic contextual support, pretest accuracy, reading comprehension, sentence judgment accuracy and reaction time, cognate status, Levenshtein distance, and target frequency on vocabulary knowledge, as reflected by immediate posttest accuracy. Main effects of variables that were also included in an interaction (i.e., pretest accuracy, sentence judgment accuracy and reaction time, and target frequency) are discussed below, together with the interactions.
Semantic contextual support and vocabulary knowledge
We examined whether vocabulary knowledge at immediate posttest could be explained by semantic contextual support. As can be seen in Table 3, there was a significant positive main effect of semantic contextual support, b=0.078, 95% confidence interval (CI) [0.024, 0.131]. This indicates that the vocabulary knowledge was higher for target words placed in a sentence context that included a prime that had a strong semantic relation with the target (higher LSA scores and thus higher semantic contextual support). When the target word was placed in a sentence context with a less strongly related semantic prime (lower LSA scores and thus lower semantic contextual support), vocabulary knowledge was lower.
Word characteristics and vocabulary knowledge
Furthermore, we investigated to what extent vocabulary knowledge was influenced by word characteristics, namely, cognate status, Levenshtein distance, and word frequency. There were main effects of all word predictors. Regarding cognate status, students knew fewer false friends, b=–1.787, 95% CI [–2.482, –1.093] and control words, b=–2.748, 95% CI [–3.449, –2.064] compared to cognates at the immediate posttests. Students knew fewer control words than false cognates, b=–0.960, 95% CI [–1.629, –0.291] at the immediate posttest. We controlled for multiple comparisons with a Bonferroni correction. Furthermore, immediate posttest accuracy was larger for words with smaller Levenshtein distances, b=–0.806, 95% CI [–1.175, –0.437]. This indicates larger vocabulary knowledge at immediate posttest for English words that were more similar to their Dutch translations.
Student characteristics and vocabulary knowledge
In addition, to examine the effects of student characteristics pretest accuracy, reading comprehension, sentence judgment accuracy, and reaction time were included in the model. The addition of the predictors education level, native language, and exposure to English media did not improve model fit. There were main effects of pretest accuracy, reading comprehension, and sentence judgment accuracy, but the main effect of sentence judgment reaction time was not significant. The main effect of reading comprehension, as is shown in Table 3, indicated that students with stronger reading comprehension skills had larger vocabulary knowledge at immediate posttest than those with lower reading comprehension skills, b=0.472, 95% CI [0.270, 0.674].
Interactions
We explored whether there were any two-way interactions between context, word, and student characteristics associated with vocabulary knowledge. There was a two-way interaction between sentence judgment accuracy (student characteristic) and sentence judgment reaction time (student characteristic), and there was a two-way interaction between pretest accuracy (student characteristic) and target frequency (word characteristic). The two-way interaction between sentence judgment accuracy and sentence judgment reaction time, b=–0.093, 99% CI [–0.15, –0.038] showed that higher sentence judgment accuracy scores lead to higher posttest accuracy. This effect was smaller when sentence judgment reaction times were also slower. This means that students with higher sentence judgment accuracy overall had higher posttest accuracy than those with lower sentence judgment accuracy, but only if they were quick enough at performing the sentence judgment. The two-way interaction between pretest accuracy and target frequency indicated that higher word frequencies lead to higher vocabulary knowledge, and this relationship was even stronger for students with high pretest accuracy, b=0.542, 99% CI [0.251, 0.833]. No other interactions were found.
Predictors of learning gain
In addition to vocabulary knowledge, we wanted to examine the learning gain between pretest and posttest. We created an additional model for which we recoded the accuracy scores across time (from pretest to posttest). Learning gain was coded as “0” when either the response on both pretest and posttest was incorrect or when the response was correct at pretest but incorrect at the posttest. When the response on the pretest was incorrect but correct on the posttest, the learning gain was coded as “1.” Responses that were correct at both pretest and posttest were excluded from the analyses. We included the following independent variables: semantic contextual support, reading comprehension, sentence judgment accuracy, sentence judgment reaction time, cognate status, and Levenshtein distance resid . The variable target word frequency was no longer significant. A summary of the final model is presented in Table 4.
Summary of a generalized linear mixed-effects model predicting learning gain

Note: aTested one-tailed.
There were main effects of semantic contextual support, reading comprehension, sentence judgment accuracy, cognate status, and Levenshtein distance. The main effect of semantic contextual support was similar to the effect in the vocabulary knowledge model, b=0.086, 95% CI [0.027, 0.145]. This provides evidence that larger semantic contextual support results in larger learning gains. The influence of the included word and student predictors in this learning gain model was also similar to the influence of these predictors in the vocabulary knowledge model. Finally, there was an interaction between the sentence judgment accuracy and reaction time, b=–0.110, 95% CI [–0.171, –0.049].
Predictors of rate of forgetting
We created a model to look at rate of forgetting to see how well the newly learnt vocabulary was retained. In this model, the dependent variable was accuracy on immediate posttest and delayed posttest. The independent variables included in this model were time (immediate posttest vs. delayed posttest), semantic contextual support, reading comprehension, sentence judgment accuracy, sentence judgment reaction time, cognate status, Levenshtein distance resid , and target frequency. A summary of the final model can be found in Table 5.
Summary of a generalized linear mixed-effects model predicting rate of forgetting

Note: aTested one-tailed.
There were main effects of time, reading comprehension, sentence judgment accuracy, cognate status, Levenshtein distance, and target frequency. However, as opposed to vocabulary knowledge at immediate posttest, there was no longer a main effect of contextual support. Hence, rate of forgetting does not appear to be influenced by contextual support. As there was no significant negative effect of contextual support either, this suggests that there are long-term effects of LSA on word learning (similar to the short-term effects established in models above). The main effect of time indicated that students knew fewer words at the delayed posttest than at the immediate posttest, b=0.122, 95% CI [0.021, 0.223] and forgetting took place. We explored the interactions between time and the other variables. However, including these interactions did not improve model fit.
DISCUSSION
The present study investigated the effects of semantic contextual support and various word and student characteristics, and their interactions on L2 vocabulary learning outcomes (vocabulary knowledge, learning gain, and rate of forgetting) obtained by means of a computerized L2 vocabulary learning task in context in Dutch seventh-grade students. We addressed the effects of semantic contextual support on L2 vocabulary learning outcomes using a continuous measure (LSA; Landauer et al., Reference Landauer, Foltz and Laham1998) for the first time, rather than a categorical measure of semantic relatedness in a vocabulary learning study. We found stronger learning gains for more supportive contexts, in line with previous research (Beck et al., Reference Beck, McKeown and McCaslin1983; Chrabaszcz & Gor, Reference Chrabaszcz and Gor2017; Daneman & Green, Reference Daneman and Green1986; Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015; Ellis, Reference Ellis2013; Howard & Kahana, Reference Howard and Kahana2002; Ma et al., Reference Ma, Chen, Lu and Dunlap2015; Nassaji, Reference Nassaji2003). Whereas these studies had more exposure trials (e.g., Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015), we demonstrated the effects of semantic contextual support even in vocabulary learning with merely a single exposure in a sentence context. In addition, we showed that the rate of forgetting was not influenced by semantic contextual support. This suggests that there are long-term effects of LSA on word learning (similar to the short-term effects established for vocabulary knowledge and learning gain). Previous studies already showed an effect of contrasting contexts (e.g., Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008). Here, we provided evidence that even subtle semantic variations can make a difference for L2 vocabulary learning outcomes, in an understudied group of L2 learners: adolescents in secondary school.
Further, we found partial evidence of the influence of word characteristics, including L1-L2 overlap, on L2 vocabulary knowledge and learning gain. Regarding L1-L2 overlap, we found that L2 vocabulary learning outcomes differed across words with varying cognate status. Cognates were easier to translate and retain, compared to both false friends and control words, which is in line with previous studies (de Groot, Reference de Groot1992; de Groot et al., Reference de Groot, Dannenburg and van Hell1994; Dijkstra et al., Reference Dijkstra, Grainger and van Heuven1999; Hancin-Bhatt & Nagy, Reference Hancin-Bhatt and Nagy1994). However, previous studies also demonstrated that false cognates were harder to recognize or learn than control words. Possibly, the control words were too difficult for the inexperienced L2 learners in the present study after all. It has previously been shown that the cognate facilitation effect is reduced for highly proficient L2 learners (Bultena, Dijkstra, & van Hell, Reference Bultena, Dijkstra and van Hell2014). However, we did not replicate this finding, which may be explained by the fact that we used a reading comprehension task instead of a fluency or standardized vocabulary task as a measure of English proficiency. These measures may also reflect English proficiency in a different way than in the study by Bultena et al. (Reference Bultena, Dijkstra and van Hell2014). Furthermore, cognate facilitation effects have been shown to depend on task demands; Bultena et al. (Reference Bultena, Dijkstra and van Hell2014) used a self-paced reading task and eye movements, whereas we used sentence verification and word typing. Thus, the difference in task demands between self-paced reading on the one hand (Bultena et al., Reference Bultena, Dijkstra and van Hell2014) and sentence verification, as was used in our study, where the entire sentence was presented at once, on the other, may explain this difference in results. The second measure for L1-L2 overlap was Levenshtein distance, which also predicted L2 vocabulary learning outcomes, after controlling for cognate status. Words with smaller Levenshtein distances were easier to learn compared to words with larger Levenshtein distances. This measure has been used to reveal the structure of the mental lexicon (Dautriche et al., Reference Dautriche, Mahowald, Gibson, Christophe and Piantadosi2017), but has not before been examined as a predictor for L2 vocabulary learning outcomes. Apparently, Levenshtein distance can be used to predict variability in L2 vocabulary learning outcomes due to lexical cross-linguistic influences. We are the first to show the effect of Levenshtein distance on L2 vocabulary learning outcomes. We found no effect of word length, whereas previous studies do point toward the predictive effect of word length on L2 vocabulary learning (Hauk & Pulvermüller, Reference Hauk and Pulvermüller2004; Whaley, Reference Whaley1978). It has been argued that this effect is hard to disentangle from word frequency (e.g., Hauk & Pulvermüller, Reference Hauk and Pulvermüller2004). On the one hand, short words are possibly easier to remember, but on the other hand, short words are also more easily confused with other words than longer words. Whereas we found an effect of target frequency on vocabulary knowledge, this did not persist in the learning gain model. Possibly, this is because words that were translated correctly during the pretest and posttest were omitted, and these words typically had high frequencies (and were often cognates). Hence, there was not only a reduction of statistical power in the learning gain model but also a reduction in terms of the variability in word frequency in this model. We did not find any interactions between time and the other variables for rate of forgetting. This suggests that although forgetting takes place, this effect is not mediated by any of the other variables.
With respect to the role of student characteristics, our hypothesis was partly confirmed; we found that prior vocabulary knowledge contributed to vocabulary knowledge. This corroborates the previous finding that students with a larger prior vocabulary were better at recognizing novel word structures (Nation & Snowling, Reference Nation and Snowling1998). Reading comprehension was found to be a predictor of all three L2 vocabulary learning outcomes. Students with good reading comprehension skills also made larger gains. This is in line with previous studies that showed that poor comprehenders performed weakly on making inferences from text (e.g., Cain et al., Reference Cain, Oakhill and Lemmon2004). Exposure to English media did not contribute to L2 vocabulary learning outcomes. English exposure may have already been reflected in reading comprehension skills (Kuppens, Reference Kuppens2010), and media exposure does not appear to have an additional influence on L2 vocabulary learning outcomes on top of reading comprehension. Our findings were similar across different educational tracks and in students with varying linguistic backgrounds.
There was evidence of interactions between the aforementioned variables. We found that L2 vocabulary learning outcomes were higher for students with higher sentence judgment accuracies, but only when they also responded relatively quickly. The influence of task performance in general had been shown previously (Sense, Meijer, & van Rijn, Reference Sense, Meijer and van Rijn2016), and here we specifically demonstrated the influence of within-task behavior on later vocabulary learning outcomes. A speed–accuracy trade-off may have induced students to make more mistakes during sentence judgment when they had low reaction times. Furthermore, the relationship between sentence verification and reading comprehension in Dutch EFL learners was previously demonstrated (van Gelderen et al., Reference van Gelderen, Schoonen, de Glopper, Hulstijn, Simis, Snellings and Stevenson2004). However, we demonstrated the unique contribution of sentence judgment speed combined with accuracy to L2 vocabulary learning outcomes. Regarding word frequency, Monaghan, Chang, Welbourne, and Brysbaert (Reference Monaghan, Chang, Welbourne and Brysbaert2017) found that vocabulary size can reduce frequency effects in lexical processes. We found that higher word frequency resulted in higher vocabulary knowledge at immediate posttest, especially when prior vocabulary knowledge was relatively high. This could be explained by the fact that we had already found a ceiling effect on the pretest for cognates. Students had already correctly translated many of the cognates before the vocabulary learning task, leaving less room for improvement. We did not find any interactions between contextual support and any of the other predictors, in contrast with previous studies. This could be due to the fact that single exposures during vocabulary learning were utilized in the present study, whereas other studies (e.g., Elgort et al., Reference Elgort, Perfetti, Rickles and Stafura2015) used repeated exposure trials. This could also be due to the preexposure to the target words, which was included to allow learners to create a lexical entry (if there was none). The fact that we did not find any two-way interactions between context and word predictors or student predictors suggests that students benefit from contextual support, regardless of their proficiency and word predictors.
There are several matters that may have limited the study. First, we used pretest accuracy as a measure for prior vocabulary, and no standardized vocabulary measure was taken into account. This may have affected the results, as students showed ceiling effects for cognates on prior vocabulary knowledge. A standardized vocabulary test could be used in future research as a predictor for vocabulary learning. Second, we used a cloze task to measure reading comprehension. It may be argued that reading text passages and answering comprehension question is more representative for vocabulary learning through sentence verification. Third and finally, though we contributed to the literature of vocabulary learning through a single exposure, it would be useful to know what the effect is of several exposure trials on L2 vocabulary learning and the rate of forgetting in adolescents. This has been shown to be effective in other age groups as well (e.g., Bolger et al., Reference Bolger, Balass, Landen and Perfetti2008).
Based on this study we have suggestions for further research. First, it would be interesting to look at the influence of repeated exposure to a word and subtle semantic contextual support differences to get closer to a natural situation in which L2 learners encounter words repeatedly and possibly in different ways. Second, it might be interesting to administer another delayed posttest. In the present study, the delayed posttest was administered a day after the vocabulary learning task and the immediate posttest. Differences between educational tracks might also be explained by this delayed posttest. It is possible that short-term results appear similar across educational tracks, but differences emerge a longer period of time after the intervention, as words are harder to consolidate for students in the lower tracks. The addition of another test may show more individual differences in vocabulary learning consolidation. Third and finally, concentration (Bialystok, Reference Bialystok2015) or L1 fluency (Alderson et al., Reference Alderson, Nieminen and Huhta2016; Huensch & Ventura, Reference Huensch and Ventura2017) could be relevant to take into account in L2 vocabulary learning as student characteristics.
The practical implications of this study are that a semantic supportive context benefits L2 vocabulary acquisition. This can be useful for teachers in secondary education. In addition, L2 vocabulary learning methods should focus on words with different degrees of Dutch–English overlap. Finally, individual learners’ characteristics can be taken into account to signal possible difficulties and utilize strengths in L2 vocabulary learning.
In conclusion, we were the first to show that L2 study materials containing more semantic supportive contexts and materials with a focus on words with small L1-L2 overlap are most effective for L2 vocabulary learning outcomes.
APPENDIX A
Stimuli used in the word learning experiment. For each item, the English target word, its Dutch translation, the phonetic transcription of the Dutch cognate or false friend, Levenshtein distance (LD), target word frequency, target word length, and two primes, and corresponding sentences with varying semantic distances (LSA) between primes and targets are displayed.

ACKNOWLEDGMENTS
This research was supported by Grant nr 405-14-304 from the NRO Programme Council for Educational Research (PROO). We thank all university students, participants, schools, and staff that helped to make this project possible. We would also like to thank Hubert Voogd from the Technical Support Group, Faculty of Social Sciences, Radboud University, for his valuable technical support in the creation of the experiment. Finally, we thank Bernard Westwell for his useful advice.






 Open access
Open access