


1. Introduction
Deep neural networks (DNNs) have demonstrated remarkable success at addressing challenging problems in various areas, such as computer vision (CV) [Reference Ren, He, Girshick and Sun1] and natural language processing (NLP) [Reference Sutskever, Vinyals and Le2, Reference Hirschberg and Manning3]. However, as DNN-based systems are increasingly deployed in safety-critical applications [Reference Bender, Gebru, McMillan-Major and Shmitchell4–Reference Dinan, Gavin Abercrombie, Spruit, Dirk Hovy and Rieser9], ensuring their safety and security becomes paramount. Current NLP systems cannot guarantee either truthfulness, accuracy, faithfulness or groundedness of outputs given an input query, which can lead to different levels of harm.
One such example in the NLP domain is the requirement of a chatbot to correctly disclose non-human identity, when prompted by the user to do so. Recently, there have been several pieces of legislation proposed that will enshrine this requirement in law [Reference Kop10, 11]. In order to be compliant with these new laws, in theory the underlying DNN of the chatbot (or the sub-system responsible for identifying these queries) must be 100% accurate in its recognition of such a query. However, a central theme of generative linguistics going back to von Humboldt, is that language is ‘an infinite use of finite means’, i.e there exists many ways to say the same thing. In reality, the questions can come in a near infinite number of different forms, all with similar semantic meanings. For example: “Are you a Robot?”, “Am I speaking with a person?”, “Am i texting to a real human?”, “Aren’t you a chatbot?”. Failure to recognise the user’s intent and thus failure to answer the question correctly could potentially have legal implications for designers of these systems [Reference Kop10, 11].
Similarly, as such systems become widespread in their use, it may be desirable to have guarantees on queries concerning safety critical domains, for example when the user asks for medical advice. Research has shown that users tend to attribute undue expertise to NLP systems [Reference Dinan, Gavin Abercrombie, Spruit, Dirk Hovy and Rieser7, Reference Abercrombie and Rieser12] potentially causing real world harm [Reference Bickmore, Trinh, Olafsson, O’Leary, Asadi, Rickles and Cruz13] (e.g. ‘Is it safe to take these painkillers with a glass of wine?’). However, a question remains on how to ensure that NLP systems can give formally guaranteed outputs, particularly for scenarios that require maximum control over the output.
One possible solution has been to apply formal verification techniques to DNN, which aims at ensuring that, for every possible input, the output generated by the network satisfies the desired properties. One example has already been given above, i.e. guaranteeing that a system will accurately disclose its non-human identity. This example is an instance of the more general problem of DNN robustness verification, where the aim is to guarantee that every point in a given region of the embedding space is classified correctly. Concretely, given a network
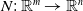 $N_{}: \; {\mathbb {R}}^{m} \rightarrow {\mathbb {R}}^{n}$
, one first defines subspaces
$N_{}: \; {\mathbb {R}}^{m} \rightarrow {\mathbb {R}}^{n}$
, one first defines subspaces
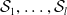 $\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
of the vector space
$\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
of the vector space
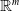 ${\mathbb {R}}^{m}$
. For example, one can define “
${\mathbb {R}}^{m}$
. For example, one can define “
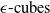 $\epsilon \textrm {-cubes}$
” or “
$\epsilon \textrm {-cubes}$
” or “
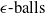 $\epsilon \textrm {-balls}$
”Footnote
1
around all input vectors given by the dataset in question (in which case the number of
$\epsilon \textrm {-balls}$
”Footnote
1
around all input vectors given by the dataset in question (in which case the number of
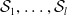 $\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
will correspond to the number of samples in the given dataset). Then, using a separate verification algorithm
$\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
will correspond to the number of samples in the given dataset). Then, using a separate verification algorithm
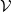 $\mathcal {V}$
, we verify whether
$\mathcal {V}$
, we verify whether
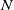 $N_{}$
is robust for each
$N_{}$
is robust for each
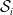 $\mathcal {S}_i$
, i.e. whether
$\mathcal {S}_i$
, i.e. whether
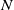 $N_{}$
assigns the same class for all vectors contained in
$N_{}$
assigns the same class for all vectors contained in
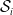 $\mathcal {S}_i$
. Note that each
$\mathcal {S}_i$
. Note that each
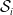 $\mathcal {S}_i$
is itself infinite (i.e. continuous), and thus
$\mathcal {S}_i$
is itself infinite (i.e. continuous), and thus
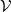 $\mathcal {V}$
is usually based on equational reasoning, abstract interpretation or bound propagation (see related work in Section 2). The subset of
$\mathcal {V}$
is usually based on equational reasoning, abstract interpretation or bound propagation (see related work in Section 2). The subset of
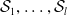 $\mathcal {S}_1, \ldots, \mathcal {S}_l$
for which
$\mathcal {S}_1, \ldots, \mathcal {S}_l$
for which
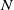 $N_{}$
is proven robust, forms the set of verified subspaces of the given vector space (for
$N_{}$
is proven robust, forms the set of verified subspaces of the given vector space (for
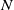 $N_{}$
). The percentage of verified subspaces is called the verification success rate (or verifiability). Given
$N_{}$
). The percentage of verified subspaces is called the verification success rate (or verifiability). Given
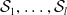 $\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
, we say a DNN
$\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
, we say a DNN
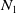 $N_{1}$
is more verifiable than
$N_{1}$
is more verifiable than
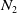 $N_{2}$
if
$N_{2}$
if
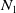 $N_{1}$
has higher verification success rate on
$N_{1}$
has higher verification success rate on
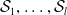 $\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
. Despite not providing a formal guarantee about the entire embedding space, this result is useful as it provides guarantees about the behaviour of the network over a large set of unseen inputs.
$\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
. Despite not providing a formal guarantee about the entire embedding space, this result is useful as it provides guarantees about the behaviour of the network over a large set of unseen inputs.
Existing verification approaches primarily focus on computer vision (CV) tasks, where images are seen as vectors in a continuous space and every point in the space corresponds to a valid image. In contrast, sentences in NLP form a discrete domain,Footnote
2
making it challenging to apply traditional verification techniques effectively. In particular, taking an NLP dataset
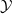 $\mathcal {Y}$
to be a set of sentences
$\mathcal {Y}$
to be a set of sentences
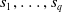 ${s}_1, \ldots, {s}_{q}$
written in natural language, an embedding
${s}_1, \ldots, {s}_{q}$
written in natural language, an embedding
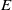 $E$
is a function that maps a sentence to a vector in
$E$
is a function that maps a sentence to a vector in
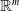 ${\mathbb {R}}^{m}$
. The resulting vector space is called the embedding space. Due to discrete nature of the set
${\mathbb {R}}^{m}$
. The resulting vector space is called the embedding space. Due to discrete nature of the set
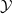 $\mathcal {Y}$
, the reverse of the embedding function
$\mathcal {Y}$
, the reverse of the embedding function
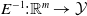 $E^{-1}: {\mathbb {R}}^{m} \rightarrow \mathcal {Y}$
is undefined for some elements of
$E^{-1}: {\mathbb {R}}^{m} \rightarrow \mathcal {Y}$
is undefined for some elements of
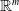 ${\mathbb {R}}^{m}$
. This problem is known as the “problem of the embedding gap”. Sometimes, one uses the term to more generally refer to any discrepancies that
${\mathbb {R}}^{m}$
. This problem is known as the “problem of the embedding gap”. Sometimes, one uses the term to more generally refer to any discrepancies that
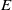 $E$
introduces, for example, when it maps dissimilar sentences close in
$E$
introduces, for example, when it maps dissimilar sentences close in
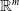 ${\mathbb {R}}^{m}$
. We use the term in both mathematical and NLP sense.
${\mathbb {R}}^{m}$
. We use the term in both mathematical and NLP sense.
Mathematically, the general (geometric) “DNN robustness verification” approach of defining and verifying subspaces of
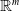 ${\mathbb {R}}^{m}$
should work, and some prior works exploit this fact. However, pragmatically, because of the embedding gap, usually only a tiny fraction of vectors contained in the verified subspaces map back to valid sentences. When a verified subspace contains no or very few sentence embeddings, we say that verified subspace has low generalisability. Low generalisability may render verification efforts ineffective for practical applications.
${\mathbb {R}}^{m}$
should work, and some prior works exploit this fact. However, pragmatically, because of the embedding gap, usually only a tiny fraction of vectors contained in the verified subspaces map back to valid sentences. When a verified subspace contains no or very few sentence embeddings, we say that verified subspace has low generalisability. Low generalisability may render verification efforts ineffective for practical applications.
From the NLP perspective, there are other, more subtle, examples where the embedding gap can manifest. Consider an example of a subspace containing sentences that are semantically similar to the sentence: ‘i really like too chat to a human. are you one?’. Suppose we succeed in verifying a DNN to be robust on this subspace. This provides a guarantee that the DNN will always identify sentences in this subspace as questions about human/robot identity. But suppose the embedding function
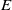 $E$
wrongly embeds sentences belonging to an opposite class into this subspace. For example, the LLM Vicuna [Reference Chiang, Li and Lin14] generates the following sentence as a rephrasing of the previous one: Do you take pleasure in having a conversation with someone?. Suppose our verified subspace contained an embedding of this sentence too, and thus our verified DNN identifies this second sentence to belong to the same class as the first one. However, the second sentence is not a question about human/robot identity of the agent! When we can find such an example, we say that the verified subspace is prone to embedding errors.
$E$
wrongly embeds sentences belonging to an opposite class into this subspace. For example, the LLM Vicuna [Reference Chiang, Li and Lin14] generates the following sentence as a rephrasing of the previous one: Do you take pleasure in having a conversation with someone?. Suppose our verified subspace contained an embedding of this sentence too, and thus our verified DNN identifies this second sentence to belong to the same class as the first one. However, the second sentence is not a question about human/robot identity of the agent! When we can find such an example, we say that the verified subspace is prone to embedding errors.
Robustness verification in NLP is particularly susceptible to this problem, because we cannot cross the embedding gap in the opposite direction as the embedding function is not invertible. This means it is difficult for humans to understand what sort of sentences are captured by a given subspace.
1.1 Contributions
Our main aim is to provide a general and principled verification methodology that bridges the embedding gap when possible; and gives precise metrics to evaluate and report its effects in any case. The contributions split into two main groups, depending on whether the embedding gap is approached from mathematical or NLP perspective.
1.1.1 Contributions part 1: characterisation of verifiable subspaces and general
NLP Verification Pipeline. We start by showing, through a series of experiments, that purely geometric approaches to NLP verification (such as those based on the
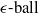 $\epsilon \textrm {-ball}$
[Reference Shi, Zhang, Chang, Huang and Hsieh15]) suffer from the verifiability-generalisability trade-off: that is, when one metric improves, the other deteriorates. Figure 1 gives a good idea of the problem: the smaller the
$\epsilon \textrm {-ball}$
[Reference Shi, Zhang, Chang, Huang and Hsieh15]) suffer from the verifiability-generalisability trade-off: that is, when one metric improves, the other deteriorates. Figure 1 gives a good idea of the problem: the smaller the
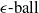 $\epsilon \textrm {-ball}$
s are, the more verifiable they are, and less generalisable. To the best of our knowledge, this phenomenon has not been reported in the literature before (in the NLP context). We propose a general method for measuring generalisability of the verified subspaces, based on algorithmic generation of semantic attacks on sentences included in the given verified semantic subspace.
$\epsilon \textrm {-ball}$
s are, the more verifiable they are, and less generalisable. To the best of our knowledge, this phenomenon has not been reported in the literature before (in the NLP context). We propose a general method for measuring generalisability of the verified subspaces, based on algorithmic generation of semantic attacks on sentences included in the given verified semantic subspace.
An example of verifiable but not generalisable
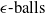 $\epsilon \textrm {-balls}$
(a), convex-hull around selected embedded points (b), hyper-rectangle around same points (c) and rotation of such hyper-rectangle (d) in 2-dimensions. The red dots represent sentences in the embedding space from the training set belonging to one class, while the turquoise dots are embedded sentences from the test set belonging to the same class.
$\epsilon \textrm {-balls}$
(a), convex-hull around selected embedded points (b), hyper-rectangle around same points (c) and rotation of such hyper-rectangle (d) in 2-dimensions. The red dots represent sentences in the embedding space from the training set belonging to one class, while the turquoise dots are embedded sentences from the test set belonging to the same class.

An alternative method to the purely geometric approach is to construct subspaces of the embedding space based on the semantic perturbations of sentences (first attempts to do this appeared in [Reference Casadio, Arnaboldi, Daggitt, Isac, Dinkar, Kienitz, Rieser and Komendantskaya16–Reference Zhang, Albarghouthi and D’Antoni19]). Concretely, the idea is to form each
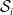 $\mathcal {S}_i$
by embedding a sentence
$\mathcal {S}_i$
by embedding a sentence
 $s$
and
$s$
and
 $n$
semantic perturbations of
$n$
semantic perturbations of
 $s$
into the real vector space and enclosing them inside some geometric shape. Ideally, this shape should be the convex hull around the
$s$
into the real vector space and enclosing them inside some geometric shape. Ideally, this shape should be the convex hull around the
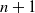 $n+1$
embedded sentences (see Figure 1), however calculating convex hulls with sufficient precision is computationally infeasible for high number of dimensions. Thus, simpler shapes, such as hyper-cubes and hyper-rectangles are used in the literature. We propose a novel refinement of these ideas, by including the method of a hyper-rectangle rotation in order to increase the shape precision (see Figure 1). We will call the resulting shapes semantic subspaces (in contrast to those obtained purely geometrically).
$n+1$
embedded sentences (see Figure 1), however calculating convex hulls with sufficient precision is computationally infeasible for high number of dimensions. Thus, simpler shapes, such as hyper-cubes and hyper-rectangles are used in the literature. We propose a novel refinement of these ideas, by including the method of a hyper-rectangle rotation in order to increase the shape precision (see Figure 1). We will call the resulting shapes semantic subspaces (in contrast to those obtained purely geometrically).
A few questions have been left unanswered in the previous work [Reference Casadio, Arnaboldi, Daggitt, Isac, Dinkar, Kienitz, Rieser and Komendantskaya16–Reference Zhang, Albarghouthi and D’Antoni19]. First, because generalisability of the verified subspaces is not reported in the literature, we cannot know whether the prior semantically-informed approaches are better in that respect than purely geometric methods. If they are better in both verifiability and generalisability, it is unclear whether the improvement should be attributed to:
-
• the fact that verified semantic subspaces simply have an optimal volume (for the verifiability-generalisability trade-off), or
-
• the improved precision of verified subspaces that comes from using the semantic knowledge.
Through a series of experiments, we confirm that semantic subspaces are more verifiable and more generalisable than their geometric counterparts. Moreover, by comparing the volumes of the obtained verified semantic and geometric subspaces, we show that the improvement is partly due to finding an optimal size of subspaces (for the given embedding space), and partly due to improvement in shape precision.
The second group of unresolved questions concerns robust training regimes in NLP verification that is used as means of improving verifiability of subspaces in prior works [Reference Casadio, Arnaboldi, Daggitt, Isac, Dinkar, Kienitz, Rieser and Komendantskaya16–Reference Zhang, Albarghouthi and D’Antoni19]. It was not clear what made robust training successful:
-
• was it because additional examples generally improved the precision of the decision boundary (in which case dataset augmentation would have a similar effect);
-
• was it because adversarial examples specifically improved adversarial robustness (in which case simple
 $\epsilon \textrm {-ball}$
PGD attacks would have a similar effect); or
$\epsilon \textrm {-ball}$
PGD attacks would have a similar effect); or -
• did the knowledge of semantic subspaces play the key role?
Through a series of experiments we show that the latter is the case. In order to do this, we formulate a semantically robust training method that uses projected gradient descent on semantic subspaces (rather than on
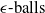 $\epsilon \textrm {-balls}$
as the famous PGD algorithm does [Reference Madry, Makelov, Schmidt, Tsipras and Vladu20]). We use different forms of semantic perturbations, at character, word and sentence levels (alongside the standard PGD training and data augmentation) to perform semantically robust training. We conclude that semantically robust training generally wins over the standard robust training methods. Moreover, the more sophisticated semantic perturbations we use in semantically robust training, the more verifiable the neural network will be obtained as a result (at no cost to generalisability). For example, using the strongest form of attack (the polyjuice attack [Reference Wu, Ribeiro, Heer and Weld21]) in semantically robust training, we obtain DNNs that are more verifiable irrespective of the way the verified sub-spaces are formed.
$\epsilon \textrm {-balls}$
as the famous PGD algorithm does [Reference Madry, Makelov, Schmidt, Tsipras and Vladu20]). We use different forms of semantic perturbations, at character, word and sentence levels (alongside the standard PGD training and data augmentation) to perform semantically robust training. We conclude that semantically robust training generally wins over the standard robust training methods. Moreover, the more sophisticated semantic perturbations we use in semantically robust training, the more verifiable the neural network will be obtained as a result (at no cost to generalisability). For example, using the strongest form of attack (the polyjuice attack [Reference Wu, Ribeiro, Heer and Weld21]) in semantically robust training, we obtain DNNs that are more verifiable irrespective of the way the verified sub-spaces are formed.
As a result, we arrive at a fully parametric approach to NLP verification that disentangles the four components:
-
• choice of the semantic attack (on the NLP side),
-
• semantic subspace formation in the embedding space (on the geometric side),
-
• semantically robust training (on the machine learning side),
-
• choice of the verification algorithm (on the verification side).
We argue that this approach opens the way for more principled NLP verification methods that reduces the effects of the embedding gap; and generation of more transparent NLP verification benchmarks. We implement a tool ANTONIO that generates NLP verification benchmarks based on the above choices. This paper is the first to use a complete SMT-based verifier (namely Marabou [Reference Wu, Isac, Zeljić, Tagomori, Daggitt, Kokke and Barrett22]) for NLP verification.
1.1.2 Contributions part 2: NLP verification pipeline in use: an NLP perspective on the embedding gap
We test the theoretical results by suggesting an NLP verification pipeline, a general methodology that starts with NLP analysis of the dataset and obtaining semantically similar perturbations that together characterise the semantic meaning of a sentence; proceeds with embedding of the sentences into the real vector space and defining semantic subspaces around embeddings of semantically similar sentences; and culminates with using these subspaces for both training and verification. This clear division into stages allows us to formulate practical NLP methods for minimising the effects of the embedding gap. In particular, we show that the quality of the generated sentence perturbations maybe improved through the use of human evaluation, cosine similarity and ROUGE-N. We introduce the novel embedding error metric as an effective practical way to measure the quality of the embedding functions. Through a detailed case study, we show how geometric and NLP intuitions can be put at work towards obtaining DNNs that are more verifiable over better generalisable and less prone to embedding errors semantic subspaces. Perhaps more importantly, the proposed methodology opens the way for transparency in reporting NLP verification results, – something that this domain will benefit from if it reaches the stage of practical deployment of NLP verification pipelines.
Paper Outline. From here, the paper proceeds as follows. Section 2 gives an extensive literature review encompassing DNN verification methods generally, and NLP verification methods in particular. The section culminates with distilling a common “NLP verification pipeline” encompassing the existing literature. Based on the understanding of major components of the pipeline, the rest of the paper focuses on improving understanding or implementation of its components. Section 3 formally defines the components of the pipeline in a general mathematical notation, which abstracts away from particular choices of sentence perturbation, sentence embedding, training and verification algorithms. The central notion the section introduces is that of geometric and semantic subspaces. The next Section 4 makes full use of this general definition, and shows that semantic subspaces play a pivotal role in improving verification and training of DNNs in NLP. This section formally defines the generalisability metric and considers the problem of generalisability-verifiability trade-off. Through thorough empirical evaluation, it shows that a principled approach to defining semantic subspaces can help to improve both generalisability and verifiability of DNNs, thus reducing the effects of the trade-off. The final Section 5 further tests the NLP verification pipelines using state-of-the-art NLP tools, and analyses the effects of the embedding gap from the NLP perspective, in particular it introduces a method of measuring the embedding error and reporting this metric alongside verifiability and generalisability. Section 6 concludes the paper and discusses future work.
2. Related work
2.1 DNN verification
Formal verification is an active field across several domains including hardware [Reference Kroening and Paul23, Reference Patankar, Jain and Bryant24], software [Reference Jourdan, Laporte, Blazy, Leroy and Pichardie25], network protocols [Reference Metere and Arnaboldi26] and many more [Reference Woodcock, Larsen, Bicarregui and Fitzgerald27]. However, it was only recently that this became applicable to the field of machine learning [Reference Katz, Barrett, Dill, Julian and Kochenderfer28]. An input query to a verifier consists of a subspace within the embedding space and a target subspace of outputs, typically a target output class. The verifier then returns either true, false or unknown. True indicates that there exists an input within the given input subspace whose output falls within the given output subspace, often accompanied by an example of such input. False indicates that no such input exists. Several verifiers are popular in DNN verification and competitions [Reference Bak, Liu and Johnson29–Reference Singh, Ganvir, Püschel and Vechev32]. We can divide them into 2 main categories: complete verifiers which return true/false and incomplete verifiers which return true/unknown. While complete verifiers are always deterministic, incomplete verifiers may be probabilistic. Unlike deterministic verification, probabilistic verification is not sound and a verifier may incorrectly output true with a very low probability (typically 0.01%).
Complete Verification based on Linear Programming & Satisfiability Modulo Theories (SMT) solving. Generally, SMT solving is a group of methods for determining the satisfiability of logical formulas with respect to underlying mathematical theories such as real arithmetic, bit-vectors or arrays [Reference Barrett and Tinelli33]. These methods extend traditional satisfiability (SAT) solving by incorporating domain-specific reasoning, making them particularly useful for verifying complex systems. In the context of neural network verification, SMT solvers encode network behaviours and safety properties as logical constraints, enabling rigorous checks for violations of specifications [Reference Albarghouthi34]. When the activation functions are piecewise linear (e.g. ReLU), the DNN can be encoded by conjunctions and disjunctions of linear inequalities and thus linear programming algorithms can be directly applied to solve the satisfiability problem. A state-of-the-art tool is Marabou [Reference Wu, Isac, Zeljić, Tagomori, Daggitt, Kokke and Barrett22], which answers queries about neural networks and their properties in the form of constraint satisfaction problems. Marabou takes the network as input and first applies multiple pre-processing steps to infer bounds for each node in the network. It applies the algorithm ReLUplex [Reference Katz, Barrett, Dill, Julian and Kochenderfer28], a combination of Simplex [Reference Dantzig35] search over linear constraints, modified to work for networks with piece-wise linear activation functions. With time, Marabou grew into a complex prover with multiple heuristics supplementing the original ReLUplex algorithm [Reference Wu, Isac, Zeljić, Tagomori, Daggitt, Kokke and Barrett22], for example it now includes mixed-integer linear programming (MILP) [Reference Winston36] and abstract interpretation based algorithms which we survey below. MILP-based approaches [Reference Cheng, Nührenberg and Ruess37–Reference Tjeng, Xiao and Tedrake39] encode the verification problem as a mixed-integer linear programming problem, in which the constraints are linear inequalities and the objective is represented by a linear function. Thus, the DNN verification problem can be precisely encoded as a MILP problem. For example, ERAN [Reference Singh, Gehr, Mirman, Püschel, Vechev, Bengio, Wallach, Larochelle, Grauman, Cesa-Bianchi and Garnett40] combines abstract interpretation with the MILP solver GUROBI [41]. By the time Branch and Bound (BaB) methodologies are introduced later, it becomes evident that the verification community has effectively consolidated diverse approaches into a unified taxonomy. Modern verifiers, such as
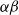 $\alpha \beta$
-CROWN [Reference Xu, Zhang, Wang, Wang, Jana, Lin and Hsieh42, Reference Wang, Zhang, Xu, Lin, Jana, Hsieh and Kolter43], take full advantage of this combination and effectively balance efficiency with precision.
$\alpha \beta$
-CROWN [Reference Xu, Zhang, Wang, Wang, Jana, Lin and Hsieh42, Reference Wang, Zhang, Xu, Lin, Jana, Hsieh and Kolter43], take full advantage of this combination and effectively balance efficiency with precision.
Incomplete Verification based on Abstract Interpretation takes inspiration from the domain of abstract interpretation, and mainly uses linear relaxations on ReLU neurons, resulting in an over-approximation of the initial constraint. Abstract interpretation was first developed by Cousot and Cousot [Reference Cousot and Cousot44] in 1977. It formalises the idea of abstraction of mathematical structures, in particular those involved in the specification of properties and proof methods of computer systems [Reference Cousot45] and it has since been used in many applications [Reference Cousot and Cousot46]. Specifically, for DNN verification, this technique can model the behaviour of a network using an abstract domain that captures the possible range of values the network can output for a given input. Abstract interpretation-based verifiers can define a lower bound and an upper bound of the output of each ReLU neuron as linear constraints, which define a region called ReLU polytope that gets propagated through the network. To propagate the bounds, one can use interval bound propagation (IBP) [Reference Wong and Kolter47–Reference Mirman, Gehr and Vechev50]. The strength of IBP-based methods lies in their efficiency; they are faster than alternative approaches and demonstrate superior scalability. However, their primary limitation lies in the inherently loose bounds they produce [Reference Gowal, Dvijotham, Stanforth, Bunel, Qin, Uesato, Arandjelovic, Mann and Kohli48]. This drawback becomes particularly pronounced in the case of deeper neural networks, typically those with more than 10 layers [Reference Li, Xie and Li51], where they cannot certify non-trivial robustness properties. Other methods that are less efficient but produce tighter bounds are based on polyhedra abstraction, such as CROWN [Reference Zhang, Weng, Chen, Hsieh and Daniel52] and DeepPoly [Reference Singh, Gehr, Püschel and Vechev53], or based on multi-neuron relaxation, such as PRIMA [Reference Müller, Makarchuk, Singh, Püschel and Vechev54]. An abstract interpretation tool CORA [Reference Althoff55], uses polyhedral abstractions and reachability analysis for formal verification of neural networks. It integrates various set representations, such as zonotopes, and algorithms to compute reachable sets for both continuous and hybrid systems, providing tighter bounds in verification tasks. Another mature tool in this category is ERAN [Reference Singh, Gehr, Mirman, Püschel, Vechev, Bengio, Wallach, Larochelle, Grauman, Cesa-Bianchi and Garnett40], which uses abstract domains (DeepPoly) with custom multi-neuron relaxations (PRIMA) to support fully-connected, convolutional and residual networks with ReLU, Sigmoid, Tanh and Maxpool activations. Note that, having lost completeness, they can work with a more general class of neural networks (e.g. neural networks with non linear layers).
Modern Neural Network Verifiers. Modern verifiers are complex tools that take advantage of a combination of complete and incomplete methods as well as additional heuristics. The term Branch and Bound (BaB) [Reference Wang, Zhang, Xu, Lin, Jana, Hsieh and Kolter43, Reference Gehr, Mirman, Drachsler-Cohen, Tsankov, Chaudhuri and Vechev56–Reference Zhang, Wang, Xu, Li, Li, Jana, Hseih and Kolter61] often refers to the method that relies on the piecewise linear property of DNNs: since each ReLU neuron outputs ReLU(
 $x$
) = max{
$x$
) = max{
 $x$
,
$x$
,
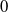 $0$
} is piecewise linear, we can consider its two linear pieces
$0$
} is piecewise linear, we can consider its two linear pieces
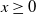 $x\geq 0$
,
$x\geq 0$
,
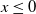 $x\leq 0$
separately. A BaB verification approach, as the name suggests, consists of two parts: branching and bounding. It first derives a lower bound and an upper bound, then, if the lower bound is positive it terminates with ‘verified’, else, if the upper bound is non-positive it terminates with ‘not verified’ (bounding). Otherwise, the approach recursively chooses a neuron to split into two branches (branching), resulting in two linear constraints. Then bounding is applied to both constraints and if both are satisfied the verification terminates, otherwise the other neurons are split recursively. When all neurons are split, the branch will contain only linear constraints, and thus the approach applies linear programming to compute the constraint and verify the branch. It is important to note that BaB approaches themselves are neither inherently complete nor incomplete. BaB is an algorithm for splitting problems into sub-problems and requires a solver to resolve the linear constraints. The completeness of the verification depends on the combination of BaB and the solver used. Multi-Neuron Guided Branch-and-Bound (MN-BaB) [Reference Ferrari, Mueller, Jovanović and Vechev59] is a state-of-the-art neural network verifier that builds on the tight multi-neuron constraints proposed in PRIMA [Reference Müller, Makarchuk, Singh, Püschel and Vechev62] and leverages these constraints within a BaB framework to yield an efficient, GPU-based dual solver. Another state-of-the-art tool is
$x\leq 0$
separately. A BaB verification approach, as the name suggests, consists of two parts: branching and bounding. It first derives a lower bound and an upper bound, then, if the lower bound is positive it terminates with ‘verified’, else, if the upper bound is non-positive it terminates with ‘not verified’ (bounding). Otherwise, the approach recursively chooses a neuron to split into two branches (branching), resulting in two linear constraints. Then bounding is applied to both constraints and if both are satisfied the verification terminates, otherwise the other neurons are split recursively. When all neurons are split, the branch will contain only linear constraints, and thus the approach applies linear programming to compute the constraint and verify the branch. It is important to note that BaB approaches themselves are neither inherently complete nor incomplete. BaB is an algorithm for splitting problems into sub-problems and requires a solver to resolve the linear constraints. The completeness of the verification depends on the combination of BaB and the solver used. Multi-Neuron Guided Branch-and-Bound (MN-BaB) [Reference Ferrari, Mueller, Jovanović and Vechev59] is a state-of-the-art neural network verifier that builds on the tight multi-neuron constraints proposed in PRIMA [Reference Müller, Makarchuk, Singh, Püschel and Vechev62] and leverages these constraints within a BaB framework to yield an efficient, GPU-based dual solver. Another state-of-the-art tool is
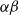 $\alpha \beta$
-CROWN [Reference Xu, Zhang, Wang, Wang, Jana, Lin and Hsieh42, Reference Wang, Zhang, Xu, Lin, Jana, Hsieh and Kolter43], a neural network verifier based on an efficient linear bound propagation framework and branch-and-bound. It can be accelerated efficiently on GPUs and can scale to relatively large convolutional networks (e.g.
$\alpha \beta$
-CROWN [Reference Xu, Zhang, Wang, Wang, Jana, Lin and Hsieh42, Reference Wang, Zhang, Xu, Lin, Jana, Hsieh and Kolter43], a neural network verifier based on an efficient linear bound propagation framework and branch-and-bound. It can be accelerated efficiently on GPUs and can scale to relatively large convolutional networks (e.g.
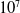 $10^7$
parameters). It also supports a wide range of neural network architectures (e.g. CNN, ResNet and various activation functions).
$10^7$
parameters). It also supports a wide range of neural network architectures (e.g. CNN, ResNet and various activation functions).
Probabilistic Incomplete Verification approaches add random noise to models to smooth them, and then derive certified robustness for these smoothed models. This field is commonly referred to as Randomised Smoothing, given that these approaches provide probabilistic guarantees of robustness, and all current probabilistic verification techniques are tailored for smoothed models [Reference Lecuyer, Atlidakis, Geambasu, Hsu and Jana63–Reference Mohapatra, Ko, Weng, Chen, Liu and Daniel68]. Given that our work focuses on deterministic approaches, here we only report the existence of this line of work without going into details.
Note that these existing verification approaches primarily focus on CV tasks, where images are seen as vectors in a continuous space and every point in the space corresponds to a valid image, while sentences in NLP form a discrete domain, making it challenging to apply traditional verification techniques effectively.
In this work, we use both an abstract interpretation-based incomplete verifier (ERAN [Reference Singh, Gehr, Mirman, Püschel, Vechev, Bengio, Wallach, Larochelle, Grauman, Cesa-Bianchi and Garnett40]) and an SMT-based complete verifier (Marabou [Reference Wu, Isac, Zeljić, Tagomori, Daggitt, Kokke and Barrett22]) in order to demonstrate the effect that the choice of a verifier may bring and demonstrate common trends.
2.2 Geometric representations in DNN verification
Geometric representations form the backbone of many DNN verification techniques, enabling the encoding and manipulation of input and output bounds during analysis. Among these, hyper-rectangles, including
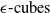 $\epsilon \textrm {-cubes}$
, are the most widely used due to their simplicity and efficiency in over-approximating neural network behaviours [Reference Wong and Kolter47, Reference Gowal, Dvijotham, Stanforth, Bunel, Qin, Uesato, Arandjelovic, Mann and Kohli48].These representations are computationally lightweight, making them highly scalable to large networks. However, they often produce loose approximations, particularly in deeper or more complex architectures, which can limit the precision of the verification results [Reference Gowal, Dvijotham, Stanforth, Bunel, Qin, Uesato, Arandjelovic, Mann and Kohli48]. Other representations, such as zonotopes [Reference Singh, Gehr, Püschel and Vechev53, Reference Gehr, Mirman, Drachsler-Cohen, Tsankov, Chaudhuri and Vechev56, Reference Singh, Gehr, Püschel and Vechev69], offer tighter approximations and better capture the linear dependencies between neurons but at a higher computational cost. Polyhedra-based methods, as employed in tools like DeepPoly [Reference Singh, Gehr, Püschel and Vechev53] and PRIMA [Reference Müller, Makarchuk, Singh, Püschel and Vechev54], provide even more precise abstractions by considering multi-dimensional relationships between neurons. However, these methods trade off efficiency for precision, making them less scalable to large and deep networks. Ellipsoidal representations [Reference Althoff55] are another class of geometric abstractions that provide compact and smooth bounds for neural network outputs. These representations are particularly useful for capturing the effects of continuous transformations in hybrid systems and other control applications. However, operations such as intersection and propagation through non-linear layers can be computationally intensive, which limits their applicability in large-scale neural network verification tasks. The dominance of hyper-rectangles in the field stems from their balance of computational simplicity and generality. Nonetheless, ongoing research continues to explore how alternative shapes, hybrid approaches or adaptive representations might better meet the demands of increasingly complex neural network architectures.
$\epsilon \textrm {-cubes}$
, are the most widely used due to their simplicity and efficiency in over-approximating neural network behaviours [Reference Wong and Kolter47, Reference Gowal, Dvijotham, Stanforth, Bunel, Qin, Uesato, Arandjelovic, Mann and Kohli48].These representations are computationally lightweight, making them highly scalable to large networks. However, they often produce loose approximations, particularly in deeper or more complex architectures, which can limit the precision of the verification results [Reference Gowal, Dvijotham, Stanforth, Bunel, Qin, Uesato, Arandjelovic, Mann and Kohli48]. Other representations, such as zonotopes [Reference Singh, Gehr, Püschel and Vechev53, Reference Gehr, Mirman, Drachsler-Cohen, Tsankov, Chaudhuri and Vechev56, Reference Singh, Gehr, Püschel and Vechev69], offer tighter approximations and better capture the linear dependencies between neurons but at a higher computational cost. Polyhedra-based methods, as employed in tools like DeepPoly [Reference Singh, Gehr, Püschel and Vechev53] and PRIMA [Reference Müller, Makarchuk, Singh, Püschel and Vechev54], provide even more precise abstractions by considering multi-dimensional relationships between neurons. However, these methods trade off efficiency for precision, making them less scalable to large and deep networks. Ellipsoidal representations [Reference Althoff55] are another class of geometric abstractions that provide compact and smooth bounds for neural network outputs. These representations are particularly useful for capturing the effects of continuous transformations in hybrid systems and other control applications. However, operations such as intersection and propagation through non-linear layers can be computationally intensive, which limits their applicability in large-scale neural network verification tasks. The dominance of hyper-rectangles in the field stems from their balance of computational simplicity and generality. Nonetheless, ongoing research continues to explore how alternative shapes, hybrid approaches or adaptive representations might better meet the demands of increasingly complex neural network architectures.
2.3 Robust training
Verifying DNNs poses significant challenges if they are not appropriately trained. The fundamental issue lies in the failure of DNNs, including even sophisticated models, to meet essential verification properties, such as robustness [Reference Casadio, Komendantskaya, Daggitt, Kokke, Katz, Amir and Rafaeli70]. To enhance robustness, various training methodologies have been proposed. It is noteworthy that, although robust training by projected gradient descent [Reference Madry, Makelov, Schmidt, Tsipras and Vladu20, Reference Goodfellow, Shlens and Szegedy71, Reference Kolter and Madry72] predates verification, contemporary approaches are often related to, or derived from, the corresponding verification methods by optimising verification-inspired regularisation terms or injecting specific data augmentation during training. In practice, after robust training, the model usually achieves higher certified robustness and is more likely to satisfy the desired verification properties [Reference Casadio, Komendantskaya, Daggitt, Kokke, Katz, Amir and Rafaeli70]. Thus, robust training is a strong complement to robustness verification approaches.
Robust training techniques can be classified into several large groups:
-
• data augmentation [Reference Rebuffi, Gowal, Calian, Stimberg, Wiles and Mann73],
-
• adversarial training [Reference Madry, Makelov, Schmidt, Tsipras and Vladu20, Reference Goodfellow, Shlens and Szegedy71] including property-driven training [Reference Fischer, Balunovic, Drachsler-Cohen, Gehr, Zhang, Vechev, Chaudhuri and Salakhutdinov74, Reference Slusarz, Komendantskaya, Daggitt, Stewart, Stark, Piskac and Voronkov75],
-
• IBP training [Reference Gowal, Dvijotham, Stanforth, Bunel, Qin, Uesato, Arandjelovic, Mann and Kohli48, Reference Zhang, Chen, Xiao, Gowal, Stanforth, Li, Boning and Hsieh76] and other forms of certified training [Reference Müller, Eckert, Fischer and Vechev77], or
-
• a combination thereof [Reference Casadio, Komendantskaya, Daggitt, Kokke, Katz, Amir and Rafaeli70, Reference Zhang, Albarghouthi and D’Antoni78].
Data augmentation involves the creation of synthetic examples through the application of diverse transformations or perturbations to the initial training data. These generated instances are then incorporated into the original dataset to enhance the training process. Adversarial training entails identifying worst-case examples at each epoch during the training phase and calculating an additional loss on these instances. State of the art adversarial training involves projected gradient descent algorithms such as FGSM [Reference Goodfellow, Shlens and Szegedy71] and PGD [Reference Madry, Makelov, Schmidt, Tsipras and Vladu20]. Certified training methods focus on providing mathematical guarantees about the model’s behaviour within certain bounds. Among them, we can name IBP training [Reference Gowal, Dvijotham, Stanforth, Bunel, Qin, Uesato, Arandjelovic, Mann and Kohli48, Reference Zhang, Chen, Xiao, Gowal, Stanforth, Li, Boning and Hsieh76] techniques, which impose intervals or bounds on the predictions or activations of the model, ensuring that the model’s output lies within a specific range with high confidence.
Note that all techniques mentioned above can be categorised based on whether they primarily augment the data (such as data augmentation) or augment the loss function (as seen in adversarial, IBP and certified training). Augmenting the data tends to be efficient, although it may not help against stronger adversarial attacks. Conversely, methods that manipulate the loss functions directly are more resistant to strong adversarial attacks but often come with higher computational costs. Ultimately, the choice between altering data or loss functions depends on the specific requirements of the application and the desired trade-offs between performance, computational complexity and robustness guarantees.
2.4 NLP robustness
There exists a substantial body of research dedicated to enhancing the adversarial robustness of NLP systems [Reference Zhang, Sheng, Alhazmi and Li79–Reference Dong, Luu, Ji and Liu85]. These efforts aim to mitigate the vulnerability of NLP models to adversarial attacks and improve their resilience in real-world scenarios [Reference Wang, Wang, Wang, Wang and Ye80, Reference Wang, Wang and Yang81] and mostly employ data augmentation techniques [Reference Feng, Gangal, Wei, Chandar, Vosoughi, Mitamura and Hovy86, Reference Dhole, Gangal, Gehrmann, Gupta, Li, Mahamood and Zhang87]. In NLP, we can distinguish perturbations based on three main criteria:
-
• where and how the perturbations occur,
-
• whether they are altered automatically using some defined rules (vs. generated by humans or large language model (LLMs)) and
-
• whether they are adversarial (as opposed to random).
In particular, perturbations can occur at the character, word or sentence level [Reference Cheng, Jiang and Macherey88–Reference Cao, Li, Fang, Zhou, Gao, Zhan and Tao90] and may involve deletion, insertion, swapping, flipping, substitution with synonyms, concatenation with characters or words, or insertion of numeric or alphanumeric characters [Reference Liang, Li, Su, Bian, Li and Shi91–Reference Lei, Cao, Li, Zhou, Fang and Pechenizkiy93]. For instance, in character level adversarial attacks, Belinkov et al. [Reference Belinkov and Bisk94] introduce natural and synthetic noise to input data, while Gao et al. [Reference Gao, Lanchantin, Soffa and Qi95] and Li et al. [Reference Li, Ji, Du, Li and Wang96] identify crucial words within a sentence and perturb them accordingly. For word level attacks, they can be categorised into gradient-based [Reference Liang, Li, Su, Bian, Li and Shi91, Reference Samanta and Mehta97], importance-based [Reference Ivankay, Girardi, Marchiori and Frossard98, Reference Di, Jin, Zhou and Szolovits99] and replacement-based [Reference Alzantot, Sharma, Elgohary, Ho, Srivastava and Chang100–Reference Pennington, Socher and Manning102] strategies, based on the perturbation method employed. Moreover, Moradi et al. [Reference Moradi and Samwald103] introduce rule-based non-adversarial perturbations at both the character and word levels. Their method simulates various types of noise typically caused by spelling mistakes, typos and other similar errors. In sentence level adversarial attacks, some perturbations [Reference Jia and Liang104, Reference Wang and Bansal105] are created so that they do not impact the original label of the input and can be incorporated as a concatenation in the original text. In such scenarios, the expected behaviour from the model is to maintain the original output, and the attack can be deemed successful if the label/output of the model is altered. Additionally, non-rule-based sentence perturbations can be obtained through prompting LLMs [Reference Chiang, Li and Lin14, Reference Wu, Ribeiro, Heer and Weld21] to generate rephrasing of the inputs. By augmenting the training data with these perturbed examples, models are exposed to a more diverse range of linguistic variations and potential adversarial inputs. This helps the models to generalise better and become more robust to different types of adversarial attacks. To help with this task, the NLP community has gathered a dataset of adversarial attacks named AdvGLUE [Reference Wang, Xu and Wang106], which aims to be a principled and comprehensive benchmark for NLP robustness measurements.
In this work we employ a PGD-based adversarial training as the method to enhance the robustness and verifiability of our models against gradient-based adversarial attacks. For non-adversarial perturbations, we create rule-based perturbations at the character and word level as in Moradi et al. [Reference Moradi and Samwald103] and non-rule-based perturbations at the sentence level using PolyJuice [Reference Wu, Ribeiro, Heer and Weld21] and Vicuna [Reference Chiang, Li and Lin14]. We thus cover most combinations of the three choices above (bypassing only human-generated adversarial attacks as there is no sufficient data to admit systematic evaluation which is important for this study).
2.5 Datasets and use cases used in NLP verification
Existing NLP verification datasets. Table 1 summarises the main features and tasks of the datasets used in NLP verification. Despite their diverse origins and applications, the datasets in the literature are usually binary or multi-class text classification problems. Furthermore, datasets can be sensitive to perturbations, i.e. perturbations can have non-trivial impact on label consistency. For example, Jia et al. [Reference Jia, Raghunathan, Göksel and Liang17] use IBP with the SNLI [Reference Bowman, Angeli, Potts, Manning, Màrquez, Callison-Burch and Su119]Footnote 3 dataset (see Tables 2 and 1) to show that word perturbations (e.g. ‘good’ to ‘best’) can change whether one sentence entails another. Some works such as Jia et al. [Reference Jia, Raghunathan, Göksel and Liang17] try to address this label consistency, while others do not.
Summary of the main features of the datasets used in NLP verification

Summary of the main features of the existing NLP verification approaches. In bold are state-of-the-art methods
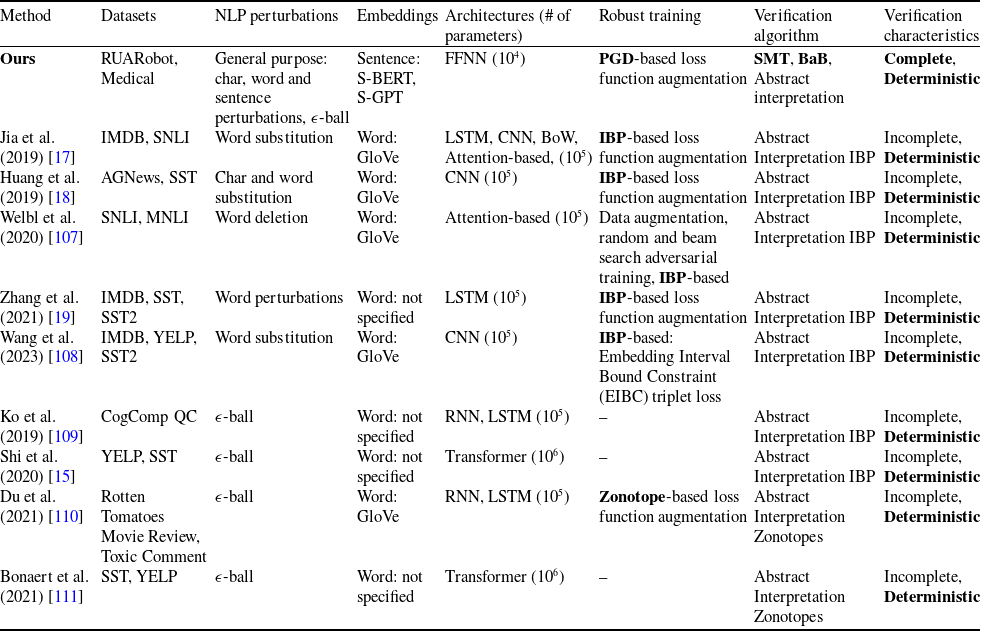
Additionally, we find that the previous research on NLP verification does not utilise safety critical datasets (which strongly motivates the choice of datasets in alternative verification domains), with the exception of Du et al. [Reference Du, Ji, Shen, Zhang, Li, Shi, Fang, Yin, Beyah and Wang110] that use the Toxic Comment dataset [Reference Adam120]. Other papers do not provide detailed motivation as to why the dataset choices were made, however it could be due to the datasets being commonly used in NLP benchmarks (IMDB etc.).
2.5.1 Datasets proposed in this paper
In this paper, we focus on two existing datasets that model safety-critical scenarios. These two datasets have not previously been applied or explored in the context of NLP verification. Both are driven by real-world use cases of safety-critical NLP applications, i.e. applications for which law enforcement and safety demand formal guarantees of “good” DNN behaviour.
Chatbot Disclosure (R-U-A-Robot Dataset [Reference Gros, Li and Yu129]). The first case study is motivated by new legislation which states that a chatbot must not mislead people about its artificial identity [Reference Kop10, 11]. Given that the regulatory landscape surrounding NLP models (particularly LLMs and generative AI) is rapidly evolving, similar legislation could be widespread in the future – with recent calls for the US Congress to formalise such disclosure requirements [Reference Altman, Marcus and Montgomery130]. The prohibition on deceptive conduct act may apply to the outputs generated by NLP systems if used commercially [Reference Atleson131], and at minimum a system must guarantee a truthful response when asked about its agency [Reference Gros, Li and Yu129, Reference Abercrombie, Curry, Dinkar, Rieser and Talat132]. Furthermore, the burden of this should be placed on the designers of NLP systems, and not on the consumers.
Our first safety critical case is the R-U-A-Robot dataset [Reference Gros, Li and Yu129], a written English dataset consisting of 6800 variations on queries relating to the intent of ‘Are you a robot?’, such as ‘I’m a man, what about you?’. The dataset was created via a context-free grammar template, crowd-sourcing and pre-existing data sources. It consists of 2,720 positive examples (where given the query, it is appropriate for the system to state its non-human identity), 3,400 negative examples and 680 ‘ambiguous-if-clarify’ examples (where it is unclear whether the system is required to state its identity). The dataset was created to promote transparency, which may be required when the user receives unsolicited phone calls from artificial systems. Given systems like Google Duplex [Reference Leviathan and Matias133], and the criticism it received for human-sounding outputs [Reference Lieu134], it is also highly plausible for the user to be deceived regarding the outputs generated by other NLP-based systems [Reference Atleson131]. Thus we choose this dataset to understand how to enforce such disclosure requirements. We collapse the positive and ambiguous examples into one label, following the principle of ‘better be safe than sorry’, i.e. prioritising a high recall system.
Medical Safety Dataset. Another scenario one might consider is that inappropriate outputs of NLP systems have the potential to cause harm to human users [Reference Bickmore, Trinh, Olafsson, O’Leary, Asadi, Rickles and Cruz13]. For example, a system may give a user false impressions of its ‘expertise’ and generate harmful advice in response to medically related user queries [Reference Dinan, Gavin Abercrombie, Spruit, Dirk Hovy and Rieser7]. In practice, it may be desirable for the system to avoid answering such queries. Thus, we choose the Medical safety dataset [Reference Abercrombie and Rieser12], a dataset consisting of 2,917 risk-graded medical and non-medical queries (1,417 and 1,500 examples, respectively). The dataset was constructed via collecting questions posted on reddit, such as r/AskDocs. The medical queries have been labelled by experts and crowd annotators for both relevance and levels of risk (i.e. non-serious, serious to critical) following established World Economic Forum (WEF) risk levels designated for chatbots in healthcare [Reference Forum135]. We merge the medical queries of different risk-levels into one class, given the high scarcity of the latter two labels to create an in-domain/out-of-domain classification task for medical queries. Additionally, we consider only the medical queries that were labelled as such by expert medical practitioners. Thus, this dataset will facilitate discussion on how to guarantee a system recognises medical queries, in order to avoid generating medical output.
An additional benefit of these two datasets is that they are distinct semantically, i.e. the R-U-A-Robot dataset contains several semantically similar, but lexically different queries, while the medical safety dataset contains semantically diverse queries. For both datasets, we utilise the same data splits as given in the original papers and refer to the final binary labels as positive and negative. The positive label in the R-U-A-Robot dataset implies a sample where it is appropriate to disclose non-human identity, while in the medical safety dataset it implies an in-domain medical query.
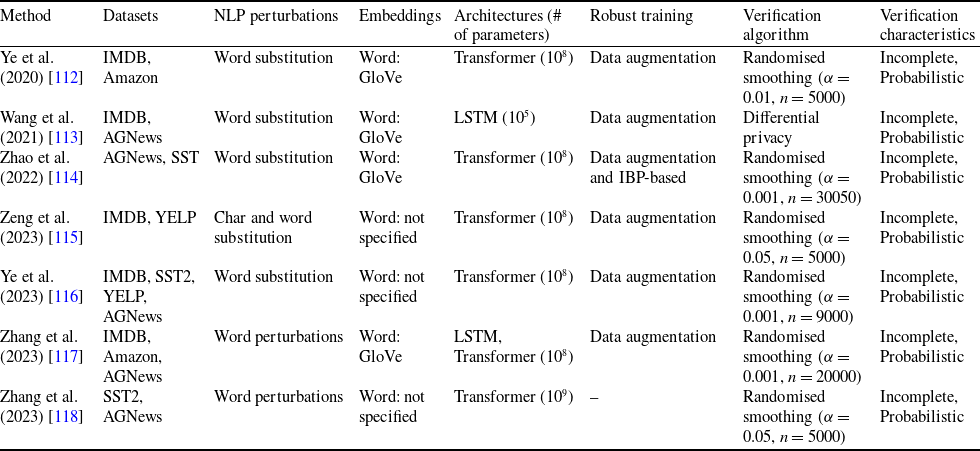
2.6 Previous NLP verification approaches
Although DNN verification studies have predominantly focused on CV, there is a growing body of research exploring the verification of NLP. This research can be categorised into three main approaches: using IBP, zonotopes and randomised smoothing. Tables 2 and 3 show a comparison of these approaches. To the best of our knowledge, this paper is the first one to use an SMT-based verifier for this purpose and compare it with an abstract interpretation-based verifier on the same benchmarks.
Summary of the main features of the existing randomised smoothing approaches
NLP Verification via Interval Bound Propagation. The first technique successfully adopted from the CV domain for verifying NLP models was the IBP. IBP was used for both training and verification with the aim to minimise the upper bound on the maximum difference between the classification boundary and the input perturbation region. It was achieved by augmenting the loss function with a term that penalises large perturbations. Specifically, IBP incorporates interval bounds during the forward propagation phase, adding a regularisation term to the loss function that minimises the distance between the perturbed and unperturbed outputs. This facilitated the minimisation of the perturbation region in the last layer, ensuring it remained on one side of the classification boundary. As a result, the adversarial region becomes tighter and can be considered certifiably robust. Notably, Jia et al. [Reference Jia, Raghunathan, Göksel and Liang17] proposed certified robust models on word substitutions in text classification. The authors employed IBP to optimise the upper bound over perturbations, providing an upper bound over the discrete set of perturbations in the word vector space. Similarly, POPQORN [Reference Ko, Lyu, Weng, Daniel, Wong and Lin109] introduced robustness guarantees for RNN-based networks by handling the non-linear activation functions of complicated RNN structures (like LSTMs and GRUs) using linear bounds. Later, Shi et al. [Reference Shi, Zhang, Chang, Huang and Hsieh15] developed a verification algorithm for transformers with self-attention layers. This algorithm provides a lower bound to ensure the probability of the correct label remains consistently higher than that of the incorrect labels. Furthermore, Huang et al. [Reference Huang, Stanforth, Welbl, Dyer, Yogatama, Gowal, Dvijotham and Kohli18] introduced a verification and verifiable training method with a tighter over-approximation in style of the Simplex algorithm [Reference Katz, Barrett, Dill, Julian and Kochenderfer28]. To make the network verifiable, they defined the convex hull of all the original unperturbed inputs as a space of perturbations. By employing the IBP algorithm, they generated robustness bounds for each neural network layer. Later on, Welbl et al. [Reference Welbl, Huang, Stanforth, Gowal, Dvijotham, Szummer and Kohli107] differentiated from the previous approaches by using IBP to address the under-sensitivity issue. They designed and formally verified the ‘under-sensitivity specification’ that a model should not become more confident as arbitrary subsets of input words are deleted. Recently, Zhang et al. [Reference Zhang, Albarghouthi and D’Antoni19] introduced Abstract Recursive Certification (ARC) to verify the robustness of LSTMs. ARC defines a set of programmatically perturbed string transformations to construct a perturbation space. By memorising the hidden states of strings in the perturbation space that share a common prefix, ARC can efficiently calculate an upper bound while avoiding redundant hidden state computations. Finally, Wang et al. [Reference Wang, Yang, Di and He108] improved on the work of Jia et al. by introducing Embedding Interval Bound Constraint (EIBC). EIBC is a new loss that constraints the word embeddings in order to tighten the IBP bounds.
The strength of IBP-based methods is their efficiency and speed, while their main limitation is the bounds’ looseness, further accentuated if the neural network is deep.
NLP Verification via Propagating Zonotopes. Another popular verification technique applied to various NLP models is based on propagating zonotopes, which produces tighter bounds then IBP methods. One notable contribution in this area is Cert-RNN [Reference Du, Ji, Shen, Zhang, Li, Shi, Fang, Yin, Beyah and Wang110], a robust certification framework for RNNs that overcomes the limitations of POPQORN. The framework maintains inter-variable correlation and accelerates the non-linearities of RNNs for practical uses. Cert-RNN utilised zonotopes [Reference Ghorbal, Goubault and Putot136] to encapsulate input perturbations and can verify the properties of the output zonotopes to determine certifiable robustness. This results in improved precision and tighter bounds, leading to a significant speedup compared to POPQORN. Analogously, Bonaert et al. [Reference Bonaert, Dimitrov, Baader and Vechev111] propose DeepT, a certification method for large transformers. It is specifically designed to verify the robustness of transformers against synonym replacement-based attacks. DeepT employs multi-norm zonotopes to achieve larger robustness radii in the certification and can work with networks much larger than Shi et al.
Methods that propagate zonotopes produce much tighter bounds than IBP-based methods, which can be used with deeper networks. However, they use geometric methods and do not take into account semantic considerations (e.g. do not use semantic perturbations).
NLP Verification via Randomised Smoothing. Randomised smoothing [Reference Cohen, Rosenfeld and Kolter137] is another technique for verifying the robustness of deep language models that has recently grown in popularity due to its scalability [Reference Ye, Gong and Liu112–Reference Zhang, Zhang and Hou118]. The idea is to leverage randomness during inference to create a smoothed classifier that is more robust to small perturbations in the input. This technique can also be used to give certified guarantees against adversarial perturbations within a certain radius. Generally, randomised smoothing begins by training a regular neural network on a given dataset. During the inference phase, to classify a new sample, noise is randomly sampled from the predetermined distribution multiple times. These instances of noise are then injected into the input, resulting in noisy samples. Subsequently, the base classifier generates predictions for each of these noisy samples. The final prediction is determined by the class with the highest frequency of predictions, thereby shaping the smoothed classifier. To certify the robustness of the smoothed classifier against adversarial perturbations within a specific radius centred around the input, randomised smoothing calculates the likelihood of agreement between the base classifier and the smoothed classifier when noise is introduced to the input. If this likelihood exceeds a certain threshold, it indicates the certified robustness of the smoothed classifier within the radius around the input.
The main advantage of randomised smoothing-based methods is their scalability, indeed recent approaches are tested on larger transformer such as BERT and Alpaca. However, their main issue is that they are probabilistic approaches, meaning they give certifications up to a certain probability. In this work, we focus on deterministic approaches, hence we only report these works in Table 3 for completeness without delving deeper into each paper here. All randomised smoothing-based approaches use data augmentation obtained by semantic perturbations.
To systematically compare the existing body of research, we distil an “NLP verification pipeline” that is common across many related papers. This pipeline is outlined diagrammatically in Figure 2, while Tables 2 and 3 provide a detailed breakdown, with columns corresponding to each stage of the pipeline. It proceeds in stages:
-
1. Given an NLP dataset, generate semantic perturbations on sentences that it contains. The semantic perturbations can be of different kinds: character, word or sentence level. IBP and randomised smoothing use word and character perturbations, abstract interpretation papers usually do not use any semantic perturbations. Tables 2 and 3 give the exact mapping of perturbation methods to papers. Our method allows to use all existing semantic perturbations, in particular, we implement character and word-level perturbations as in Moradi et al. [Reference Moradi and Samwald103], sentence-level perturbations with PolyJuice [Reference Wu, Ribeiro, Heer and Weld21] and Vicuna.
-
2. Embed the semantic perturbations into continuous spaces. The cited papers use the word embeddings GloVe [Reference Pennington, Socher and Manning102], we use the sentence embeddings S-BERT and S-GPT.
-
3. Working on the embedding space, use geometric or semantic perturbations to define geometric or semantic subspaces around perturbed sentences. In IBP papers, semantic subspaces are defined as “bounds” derived from admissible semantic perturbations. In abstract interpretation papers, geometric subspaces are given by
$\epsilon$
-cubes and
$\epsilon \textrm {-balls}$
around each embedded sentence. Our paper generalises the notion of
$\epsilon$
-cubes by defining “hyper-rectangles” on sets of semantic perturbations. The hyper-rectangles generalise
$\epsilon$
-cubes both geometrically and semantically, by allowing to analyse subspaces that are drawn around several (embedded) semantic perturbations of the same sentence. We could adapt our methods to work with hyper-ellipses and thus directly generalise
$\epsilon \textrm {-balls}$
(the difference boils down to using
$\ell _2$
norm instead of
$\ell _\infty$
when computing geometric proximity of points); however, hyper-rectangles are more efficient to compute, which determined our choice of shapes in this paper. -
4. Use the geometric/semantic subspaces to train a classifier to be robust to change of label within the given subspaces. We generally call such training either robust training or semantically robust training, depending on whether the subspaces it uses are geometric or semantic. A custom semantically robust training algorithm is used in IBP papers, while abstract interpretation papers usually skip this step or use (adversarial) robust training. See Tables 2 and 3 for further details. In this paper, we adapt the famous PGD algorithm [Reference Madry, Makelov, Schmidt, Tsipras and Vladu20] that was initially defined for geometric subspaces (
$\epsilon \textrm {-balls}$
) to work with semantic subspaces (hyper-rectangles) to obtain a novel semantic training algorithm. -
5. Use the geometric/semantic subspaces to verify the classifier’s behaviour within those subspaces. The papers [Reference Jia, Raghunathan, Göksel and Liang17–Reference Zhang, Albarghouthi and D’Antoni19, Reference Welbl, Huang, Stanforth, Gowal, Dvijotham, Szummer and Kohli107, Reference Wang, Yang, Di and He108] use IBP algorithms and the papers [Reference Shi, Zhang, Chang, Huang and Hsieh15, Reference Ko, Lyu, Weng, Daniel, Wong and Lin109–Reference Bonaert, Dimitrov, Baader and Vechev111] use abstract interpretation; in both cases, it is incomplete and deterministic verification. See ‘Verification algorithm’ and ‘Verification characteristics’ columns of Tables 2 and 3. We use SMT-based tool Marabou (complete and deterministic) and abstract-interpretation tool ERAN (incomplete and deterministic).

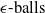


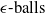
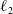
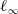
Tables 2 and 3 summarise differences and similarities of the above NLP verification approaches against ours. To the best of our knowledge, we are the first to use SMT-based complete methods in NLP verification and we show how they achieve higher verifiability than abstract interpretation verification approaches (ERAN and CORA) or IBP and BaB (
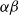 $\alpha \beta$
-CROWN), thanks to the increased precision of the ReLUplex algorithm that underlies Marabou.
$\alpha \beta$
-CROWN), thanks to the increased precision of the ReLUplex algorithm that underlies Marabou.
Furthermore, our study is the first to demonstrate that the construction of semantic subspaces can happen independently of the choice of the training and verification algorithms. Likewise, although training and verification build upon the defined (semantic) subspaces, the actual choice of the training and verification algorithms can be made independently of the method used to define the semantic subspaces. This separation, and the general modularity of our approach, facilitates a comprehensive examination and comparison of the two key components involved in any NLP verification process:
-
• effects of the verifiability-generalisability trade-off for verification with geometric and semantic subspaces;
-
• relation between the volume/shape of semantic subspaces and verifiability of neural networks obtained via semantic training with these subspaces.
These two aspects have not been considered in the literature before.
3 The parametric NLP verification pipeline
This section presents a parametric NLP verification pipeline, shown in Figure 2 diagrammatically. We call it “parametric” because each component within the pipeline is defined independently of the others and can be taken as a parameter when studying other components. The parametric nature of the pipeline allows for the seamless integration of state-of-the-art methods at every stage, and for more sophisticated experiments with those methods. The following section provides a detailed exposition of the methodological choices made at each step of the pipeline.
Visualisation of the NLP verification pipeline followed in our approach.

3.1 Semantic perturbations
As discussed in Section 2.6, we require semantic perturbations for creating semantic subspaces. To do so, we consider three kinds of perturbations—i.e. character, word and sentence level. This systematically accounts for different variations of the samples.
Character and word-level perturbations are created via a rule-based method proposed by Moradi et al. [Reference Moradi and Samwald103] to simulate different kinds of noise one could expect from spelling mistakes, typos, etc. These perturbations are non-adversarial and can be generated automatically. Moradi et al. [Reference Moradi and Samwald103] found that NLP models are sensitive to such small errors, while in practice this should not be the case. Character-level perturbations types include randomly inserting, deleting, replacing, swapping or repeating a character of the data sample. At the character level, we do not apply letter case changing, given it does not change the sentence-level representation of the sample. Nor do we apply perturbations to commonly misspelled words, given only a small percentage of the most commonly misspelled words occur in our datasets. Perturbations types at the word level include randomly repeating or deleting a word, changing the ordering of the words, the verb tense, singular verbs to plural verbs or adding negation to the data sample. At the word level, we omit replacement with synonyms, as this is accounted for via sentence rephrasing. Negation is not done on the medical safety dataset, as it creates label ambiguities (e.g. ‘pain when straightening knee’
 $\rightarrow$
‘no pain when straightening knee’), as well as singular plural tense and verb tense, given human annotators would experience difficulties with this task (e.g. rephrase the following in plural/ with changed tense – ‘peritonsillar abscess drainage aftercare.. please help’). Note that the Medical dataset contains several sentences without a verb (like the one above) for which it is impossible to pluralise or change the tense of the verb.
$\rightarrow$
‘no pain when straightening knee’), as well as singular plural tense and verb tense, given human annotators would experience difficulties with this task (e.g. rephrase the following in plural/ with changed tense – ‘peritonsillar abscess drainage aftercare.. please help’). Note that the Medical dataset contains several sentences without a verb (like the one above) for which it is impossible to pluralise or change the tense of the verb.
Further examples of character and word rule-based perturbations can be found in Tables 4 and 5.
Character-level perturbations: their types and examples of how each type acts on a given sentence from the R-U-A-robot dataset [Reference Gros, Li and Yu129]. Perturbations are selected from random words that have 3 or more characters, first and last characters of a word are never perturbed

Word-level perturbations: their types and examples of how each type acts on a given sentence from the R-U-A-robot dataset [Reference Gros, Li and Yu129].

Sentence-level perturbations. We experiment with two types of sentence-level perturbations, particularly due to the complicated nature of the medical queries (e.g. it is non-trivial to rephrase queries such as this – ‘peritonsillar abscess drainage aftercare.. please help’). We do so by either using Polyjuice [Reference Wu, Ribeiro, Heer and Weld21] or vicuna-13b.Footnote 4 Polyjuice is a general-purpose counterfactual generator that allows for control over perturbation types and locations, trained by fine-tuning GPT-2 on multiple datasets of paired sentences. Vicuna is a state-of-the-art open source chatbot trained by fine-tuning LLaMA [138] on user-shared conversations collected from ShareGPT.Footnote 5 For Vicuna, we use the following prompt to generate variations on our data samples ‘Rephrase this sentence 5 times: “[Example]”.’ For example, from the sentence “How long will I be contagious?”, we can obtain “How many years will I be contagious?” or “Will I be contagious for long?” and so on.
We will use notation
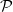 $\mathcal {P}$
to refer to a perturbation algorithm abstractly.
$\mathcal {P}$
to refer to a perturbation algorithm abstractly.
Semantic similarity of perturbations. In later sections we will make an assumption that the perturbations that we use produce sentences that are semantically similar to the originals. However, precisely defining or measuring semantic similarity is a challenge in its own right, as semantic meaning of sentences can be subjective, context-dependent, which makes evaluating their similarity intractable. Nevertheless, Subsection 5.5.2 will discuss and use several metrics for calculating semantic similarity of sentences, modulo some simplifying assumptions.
3.2 NLP embeddings
The next component of the pipeline is the embeddings. Embeddings play a crucial role in NLP verification as they map textual data into continuous vector spaces, in a way that should capture semantic relationships and contextual information.
Given the set of all strings,
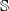 $\mathbb {S}$
, an NLP dataset
$\mathbb {S}$
, an NLP dataset
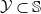 $\mathcal {Y} \subset \mathbb {S}$
is a set of sentences
$\mathcal {Y} \subset \mathbb {S}$
is a set of sentences
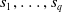 ${s}_1, \ldots, {s}_{q}$
written in natural language. The embedding
${s}_1, \ldots, {s}_{q}$
written in natural language. The embedding
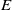 $E$
is a function that maps a string in
$E$
is a function that maps a string in
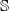 $\mathbb {S}$
to a vector in
$\mathbb {S}$
to a vector in
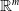 ${\mathbb {R}}^{m}$
. The vector space
${\mathbb {R}}^{m}$
. The vector space
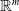 ${\mathbb {R}}^{m}$
is called the embedding space. Ideally,
${\mathbb {R}}^{m}$
is called the embedding space. Ideally,
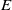 $E$
should reflect the semantic similarities between sentences in
$E$
should reflect the semantic similarities between sentences in
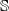 $\mathbb {S}$
, i.e. the more semantically similar two sentences
$\mathbb {S}$
, i.e. the more semantically similar two sentences
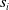 ${s}_i$
and
${s}_i$
and
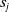 ${s}_j$
are, the closer the distance between
${s}_j$
are, the closer the distance between
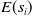 $E({s}_i)$
and
$E({s}_i)$
and
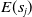 $E({s}_j)$
should be in
$E({s}_j)$
should be in
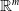 ${\mathbb {R}}^{m}$
. Of course, defining semantic similarity in precise terms may not be tractable (the number of unseen sentences may be infinite, the similarity may be subjective and/or depend on the context). This is why, the state-of-the-art NLP relies on machine learning methods to capture the notion of semantic similarity approximately.
${\mathbb {R}}^{m}$
. Of course, defining semantic similarity in precise terms may not be tractable (the number of unseen sentences may be infinite, the similarity may be subjective and/or depend on the context). This is why, the state-of-the-art NLP relies on machine learning methods to capture the notion of semantic similarity approximately.
Currently, the most common approach to obtain an embedding function
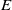 $E$
is by training transformers [Reference Devlin, Chang, Lee and Toutanova139, Reference Reimers and Gurevych140]. Transformers are a type of DNNs that can be trained to map sequential data into real vector spaces and are capable of handling variable-length input sequences. They can also be used for other tasks, such as classification or sentence generation, but in those cases, too, training happens at the level of embedding spaces. In this work, a transformer is trained as a function
$E$
is by training transformers [Reference Devlin, Chang, Lee and Toutanova139, Reference Reimers and Gurevych140]. Transformers are a type of DNNs that can be trained to map sequential data into real vector spaces and are capable of handling variable-length input sequences. They can also be used for other tasks, such as classification or sentence generation, but in those cases, too, training happens at the level of embedding spaces. In this work, a transformer is trained as a function
 $E: \mathbb {S} \rightarrow {\mathbb {R}}^{m}$
for some given
$E: \mathbb {S} \rightarrow {\mathbb {R}}^{m}$
for some given
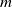 $m$
. The key feature of the transformer is the “self-attention mechanism”, which allows the network to weigh the importance of different elements in the input sequence when making predictions, rather than relying solely on the order of elements in the sequence. This makes them good at learning to associate semantically similar words or sentences. In this work, we initially use Sentence-BERT [Reference Reimers and Gurevych140] and later add Sentence-GPT [Reference Muennighoff141] to embed sentences. Unfortunately, the relation between the embedding space and the NLP dataset is not bijective: i.e. each sentence is mapped into the embedding space, but not every point in the embedding space has a corresponding sentence. This problem is well known in NLP literature [Reference Kugler, Münker, Höhmann and Rettinger142] and, as shown in this paper, is one of the reasons why verification of NLP is tricky. Given an NLP dataset
$m$
. The key feature of the transformer is the “self-attention mechanism”, which allows the network to weigh the importance of different elements in the input sequence when making predictions, rather than relying solely on the order of elements in the sequence. This makes them good at learning to associate semantically similar words or sentences. In this work, we initially use Sentence-BERT [Reference Reimers and Gurevych140] and later add Sentence-GPT [Reference Muennighoff141] to embed sentences. Unfortunately, the relation between the embedding space and the NLP dataset is not bijective: i.e. each sentence is mapped into the embedding space, but not every point in the embedding space has a corresponding sentence. This problem is well known in NLP literature [Reference Kugler, Münker, Höhmann and Rettinger142] and, as shown in this paper, is one of the reasons why verification of NLP is tricky. Given an NLP dataset
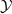 $\mathcal {Y}$
that should be classified into
$\mathcal {Y}$
that should be classified into
 $n$
classes, the standard approach is to construct a function
$n$
classes, the standard approach is to construct a function
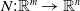 $N_{}: {\mathbb {R}}^{m} \rightarrow {\mathbb {R}}^{n}$
that maps the embedded inputs to the classes. In order to do that, a domain-specific classifier
$N_{}: {\mathbb {R}}^{m} \rightarrow {\mathbb {R}}^{n}$
that maps the embedded inputs to the classes. In order to do that, a domain-specific classifier
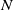 $N_{}$
is trained on the embeddings
$N_{}$
is trained on the embeddings
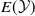 $E(\mathcal {Y})$
and the final system will then be the composition of the two subsystems, i.e.
$E(\mathcal {Y})$
and the final system will then be the composition of the two subsystems, i.e.
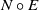 $N_{} \circ E$
.
$N_{} \circ E$
.
3.3 Geometric analysis of embedding spaces
In the recent years, the study of manifold subspaces has gained significant attention in the context of machine learning verification [Reference Althoff55], where the geometry of data regions plays an important role. In this section, we formally define most common subspaces used in verification: convex sets, convex hulls, zonotopes and hyper-rectangles (also known as multi-dimensional intervals), following closely [Reference Althoff55].
Definition 1. (Convex Set). A set
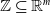 $\mathbb {Z} \subseteq {\mathbb {R}}^{m}$
is said to be convex if, for any two points
$\mathbb {Z} \subseteq {\mathbb {R}}^{m}$
is said to be convex if, for any two points
 $ {x}_1, {x}_2 \in \mathbb {Z}$
, the line segment joining them is entirely contained within
$ {x}_1, {x}_2 \in \mathbb {Z}$
, the line segment joining them is entirely contained within
 $\mathbb {Z}$
. Formally, this means that for all
$\mathbb {Z}$
. Formally, this means that for all
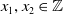 ${x}_1, {x}_2 \in \mathbb {Z}$
and
${x}_1, {x}_2 \in \mathbb {Z}$
and
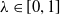 $\lambda \in [0, 1]$
, the points
$\lambda \in [0, 1]$
, the points
 \begin{equation*} \lambda {x}_1 + (1 - \lambda ) {x}_2 \in \mathbb {Z}. \end{equation*}
\begin{equation*} \lambda {x}_1 + (1 - \lambda ) {x}_2 \in \mathbb {Z}. \end{equation*}
In other words, a set is convex if, for any pair of points in the set, the entire segment connecting them lies within the set.
The convex hull of a set is the smallest convex set that contains all the points of the set. It can be seen as the “tightest” boundary enclosing the points.
Definition 2. (Convex Hull). The convex hull of a set
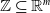 $\mathbb {Z} \subseteq {\mathbb {R}}^{m}$
, denoted by
$\mathbb {Z} \subseteq {\mathbb {R}}^{m}$
, denoted by
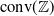 $\text {conv}(\mathbb {Z})$
, is the smallest convex set containing
$\text {conv}(\mathbb {Z})$
, is the smallest convex set containing
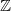 $\mathbb {Z}$
. Formally, it can be defined as:
$\mathbb {Z}$
. Formally, it can be defined as:
 \begin{equation*} \text {conv}(\mathbb {Z}) \,:\!= \left \{ \sum _{i=1}^{p} \lambda _i {x}_i \; \middle | \; {x}_i \in \mathbb {Z}, \; \lambda _i \geq 0, \; \sum _{i=1}^{p} \lambda _i = 1, \; {p} \in \mathbb {N} \right \}. \end{equation*}
\begin{equation*} \text {conv}(\mathbb {Z}) \,:\!= \left \{ \sum _{i=1}^{p} \lambda _i {x}_i \; \middle | \; {x}_i \in \mathbb {Z}, \; \lambda _i \geq 0, \; \sum _{i=1}^{p} \lambda _i = 1, \; {p} \in \mathbb {N} \right \}. \end{equation*}
In other words,
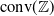 $\text {conv}(\mathbb {Z})$
consists of all finite convex combinations of points in
$\text {conv}(\mathbb {Z})$
consists of all finite convex combinations of points in
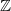 $\mathbb {Z}$
. The construction of the convex hull has a complexity of
$\mathbb {Z}$
. The construction of the convex hull has a complexity of
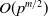 $O({p}^{{m}/2})$
, where
$O({p}^{{m}/2})$
, where
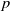 $p$
is the number of points and
$p$
is the number of points and
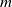 $m$
is the number of dimensions.
$m$
is the number of dimensions.
A zonotope is a geometric shape formed by the Minkowski sum of line segments.
Definition 3. (Zonotope). Given a center
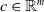 $c \in {\mathbb {R}}^{m}$
and generators
$c \in {\mathbb {R}}^{m}$
and generators
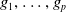 ${g}_1, \ldots, {g}_{p}$
, a zonotope is
${g}_1, \ldots, {g}_{p}$
, a zonotope is
 \begin{equation*} \mathcal {Z} \,:\!= \left \{c + \sum _{i=1}^{{p}} \lambda _i {g}_i \; \middle \vert \; \lambda _i \in [\!-1,1], \forall i \in [1, \ldots, {p}] \right \} \end{equation*}
\begin{equation*} \mathcal {Z} \,:\!= \left \{c + \sum _{i=1}^{{p}} \lambda _i {g}_i \; \middle \vert \; \lambda _i \in [\!-1,1], \forall i \in [1, \ldots, {p}] \right \} \end{equation*}
Zonotopes are computationally more efficient than convex hulls, with a construction complexity of
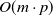 $O({m} \cdot {p})$
, where
$O({m} \cdot {p})$
, where
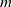 $m$
is the dimensionality and
$m$
is the dimensionality and
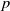 $p$
is the number of generators.
$p$
is the number of generators.
Finally, an interval is a simple shape defined by lower and upper bounds for each dimension, and it is equivalent to a multi-dimensional rectangle (or hyper-rectangle). Intervals are easy to construct with a complexity of
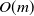 $O({m})$
, where
$O({m})$
, where
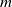 $m$
is the dimensionality, and are often used in verification.
$m$
is the dimensionality, and are often used in verification.
Definition 4. (Interval (aka Hyper-Rectangle)). Given a lower and upper bound
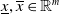 $\underline {x}, \overline {x} \in {\mathbb {R}}^{m}$
such that
$\underline {x}, \overline {x} \in {\mathbb {R}}^{m}$
such that
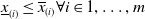 $\underline {x} _{(i)} \leq \overline {x} _{(i)} \forall i \in {1,\ldots, {m}}$
, a multi-dimensional interval
$\underline {x} _{(i)} \leq \overline {x} _{(i)} \forall i \in {1,\ldots, {m}}$
, a multi-dimensional interval
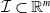 ${\mathcal {I}} \subset {\mathbb {R}}^{m}$
is
${\mathcal {I}} \subset {\mathbb {R}}^{m}$
is
 \begin{equation*} {\mathcal {I}} \,:\!= \left \{{x} \in {\mathbb {R}}^{m} \; \middle \vert \; \underline {x} _{(i)} \leq {x}_{(i)} \leq \overline {x} _{(i)}, \forall i \in [1,\ldots, {m}] \right \} \end{equation*}
\begin{equation*} {\mathcal {I}} \,:\!= \left \{{x} \in {\mathbb {R}}^{m} \; \middle \vert \; \underline {x} _{(i)} \leq {x}_{(i)} \leq \overline {x} _{(i)}, \forall i \in [1,\ldots, {m}] \right \} \end{equation*}
Table 6 summarises the construction complexities of these different shapes. Ideally, convex hulls would be the preferred choice due to their precise and detailed representations of subspaces. However, their computational complexity renders them infeasible in high dimensions. Zonotopes provide a promising alternative, as they are more precise than hyper-rectangles while remaining computationally tractable. Despite their theoretical compatibility with complete verifiers, practical limitations arise because most state-of-the-art verifiers do not support zonotopes. Hyper-rectangles, or intervals, are the simplest to construct and are supported by all verifiers, making them the default choice in many verification pipelines.
Construction complexity for different geometric shapes, where
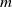 $m$
is the number of dimensions and
$m$
is the number of dimensions and
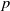 $p$
is the number of points or generators
$p$
is the number of points or generators

3.4 Working with embedding spaces: our approach
We now formally define geometric and semantic subspaces of the embedding space. Our goal is to define subspaces on the embedding space
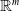 ${\mathbb {R}}^{{m}}$
by using an effective algorithmic procedure. We will use notation
${\mathbb {R}}^{{m}}$
by using an effective algorithmic procedure. We will use notation
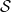 $\mathcal {S}$
to refer to a subspace of the embedding space. Recall that an hyper-rectangle of dimension
$\mathcal {S}$
to refer to a subspace of the embedding space. Recall that an hyper-rectangle of dimension
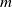 $m$
is a list of points
$m$
is a list of points
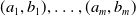 $(a_1,b_1), \ldots, (a_{m}, b_{m})$
such that a point
$(a_1,b_1), \ldots, (a_{m}, b_{m})$
such that a point
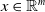 $x \in {\mathbb {R}}^{m}$
is a member if for every dimension
$x \in {\mathbb {R}}^{m}$
is a member if for every dimension
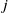 $j$
we have
$j$
we have
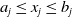 $a_j \leq x_j \leq b_j$
.
$a_j \leq x_j \leq b_j$
.
We start with an observation that, given an NLP dataset
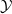 $\mathcal {Y}$
that contains a finite set of sentences
$\mathcal {Y}$
that contains a finite set of sentences
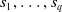 ${s}_1, \ldots, {s}_{q}$
belonging to the same class, and an embedding function
${s}_1, \ldots, {s}_{q}$
belonging to the same class, and an embedding function
 $E: \mathbb {S} \rightarrow {\mathbb {R}}^{m}$
, we can define an embedding matrix
$E: \mathbb {S} \rightarrow {\mathbb {R}}^{m}$
, we can define an embedding matrix
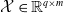 $\mathcal {X} \in {\mathbb {R}}^{{q} \times {m}}$
, where each row
$\mathcal {X} \in {\mathbb {R}}^{{q} \times {m}}$
, where each row
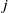 $j$
is given by
$j$
is given by
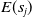 $E(s_j)$
. We will use the notation
$E(s_j)$
. We will use the notation
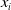 $x_i$
to refer to the
$x_i$
to refer to the
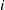 $i$
th element of the vector
$i$
th element of the vector
 $x$
, and
$x$
, and
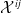 $\mathcal {X}^{ij}$
to refer to the element in the
$\mathcal {X}^{ij}$
to refer to the element in the
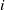 $i$
th row and
$i$
th row and
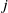 $j$
th column of
$j$
th column of
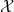 $\mathcal {X}$
. Treating embedded sentences as matrices, rather than as points in the real vector space, makes many computations easier. We can therefore define a hyper-rectangle for
$\mathcal {X}$
. Treating embedded sentences as matrices, rather than as points in the real vector space, makes many computations easier. We can therefore define a hyper-rectangle for
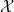 $\mathcal {X}$
as follows.
$\mathcal {X}$
as follows.
Definition 5. (Hyper-rectangle for an Embedding Matrix). Given an embedding matrix
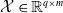 $\mathcal {X} \in {\mathbb {R}}^{{q} \times {m}}$
, the
$\mathcal {X} \in {\mathbb {R}}^{{q} \times {m}}$
, the
 $m$
-dimensional hyper-rectangle for
$m$
-dimensional hyper-rectangle for
 $\mathcal {X}$
is defined as
$\mathcal {X}$
is defined as
 \begin{equation*} \mathbb {H}(\mathcal {X}) \,:\!= \{ (\min \nolimits _{i=0}^{{q}}\mathcal {X}^{ij}, \, \max \nolimits _{i=0}^{{q}}\mathcal {X}^{ij}) \mid j \in [1, \ldots, {m}] \} \end{equation*}
\begin{equation*} \mathbb {H}(\mathcal {X}) \,:\!= \{ (\min \nolimits _{i=0}^{{q}}\mathcal {X}^{ij}, \, \max \nolimits _{i=0}^{{q}}\mathcal {X}^{ij}) \mid j \in [1, \ldots, {m}] \} \end{equation*}
Therefore given an embedding function
 $E: \mathbb {S} \rightarrow {\mathbb {R}}^{m}$
, and a set of sentences
$E: \mathbb {S} \rightarrow {\mathbb {R}}^{m}$
, and a set of sentences
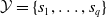 $\mathcal {Y} = \{{s}_1, \ldots, {s}_{q}\}$
, we can form a subspace
$\mathcal {Y} = \{{s}_1, \ldots, {s}_{q}\}$
, we can form a subspace
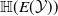 $\mathbb {H}(E(\mathcal {Y}))$
by constructing the embedding matrix, as described above, and forming the corresponding hyper-rectangle. To simplify the notation, we will omit the application of
$\mathbb {H}(E(\mathcal {Y}))$
by constructing the embedding matrix, as described above, and forming the corresponding hyper-rectangle. To simplify the notation, we will omit the application of
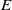 $E$
and from here on simply write
$E$
and from here on simply write
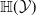 $\mathbb {H}(\mathcal {Y})$
.
$\mathbb {H}(\mathcal {Y})$
.
The next example shows how the above definitions generalise the commonly known definition of the
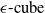 $\epsilon \textrm {-cube}$
.
$\epsilon \textrm {-cube}$
.
Example 1. (
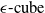 $\epsilon \textrm {-cube}$
and
$\epsilon \textrm {-cube}$
and
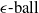 $\epsilon \textrm {-ball}$
). One of the most popular terms used in robust training [71] and verification [70] literature is the
$\epsilon \textrm {-ball}$
). One of the most popular terms used in robust training [71] and verification [70] literature is the
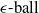 $\epsilon \textrm {-ball}$
. It is defined as follows. Given an embedded input
$\epsilon \textrm {-ball}$
. It is defined as follows. Given an embedded input
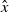 $\hat {x}$
, a constant
$\hat {x}$
, a constant
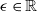 $\epsilon \in {\mathbb {R}}$
, and a distance function (
$\epsilon \in {\mathbb {R}}$
, and a distance function (
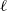 $\ell$
-norm)
$\ell$
-norm)
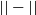 $|| - ||$
, the
$|| - ||$
, the
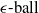 $\epsilon \textrm {-ball}$
around
$\epsilon \textrm {-ball}$
around
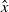 $\hat {x}$
of radius
$\hat {x}$
of radius
 $\epsilon$
is defined as
$\epsilon$
is defined as
 \begin{equation*} \mathbb {B}(\hat {x}, \epsilon ) \,:\!= \{x \in {\mathbb {R}}^{m} : ||\hat {x} - x|| \leq \epsilon \}. \end{equation*}
\begin{equation*} \mathbb {B}(\hat {x}, \epsilon ) \,:\!= \{x \in {\mathbb {R}}^{m} : ||\hat {x} - x|| \leq \epsilon \}. \end{equation*}
In practice, it is common to use the
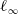 $\ell _{\infty }$
norm, which results in the
$\ell _{\infty }$
norm, which results in the
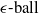 $\epsilon \textrm {-ball}$
actually being a hyper-rectangle, also called
$\epsilon \textrm {-ball}$
actually being a hyper-rectangle, also called
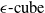 $\epsilon \textrm {-cube}$
, where
$\epsilon \textrm {-cube}$
, where
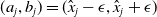 $(a_j, b_j) = (\hat {x} _j - \epsilon, \hat {x} _j + \epsilon )$
. Therefore, our construction
$(a_j, b_j) = (\hat {x} _j - \epsilon, \hat {x} _j + \epsilon )$
. Therefore, our construction
 $\mathbb {H}$
is a strict generalisation of
$\mathbb {H}$
is a strict generalisation of
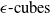 $\epsilon \textrm {-cubes}$
. We will therefore use the notation
$\epsilon \textrm {-cubes}$
. We will therefore use the notation
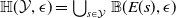 $\mathbb {H}(\mathcal {Y}, \epsilon ) = \bigcup _{{s} \in \mathcal {Y}} \mathbb {B}(E({s}),\epsilon )$
to refer to the set of
$\mathbb {H}(\mathcal {Y}, \epsilon ) = \bigcup _{{s} \in \mathcal {Y}} \mathbb {B}(E({s}),\epsilon )$
to refer to the set of
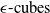 $\epsilon \textrm {-cubes}$
around every sentence in the dataset.
$\epsilon \textrm {-cubes}$
around every sentence in the dataset.
Of course, as we have already discussed in the introduction and Figure 1, hyper-rectangles are not very precise, geometrically. A more precise shape would be a convex hull around
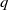 $q$
given points in the embedding space. Indeed literature has some definitions of convex hulls [Reference Barber, Dobkin and Huhdanpaa143–Reference Jia, Wang, Shao, Long, Zhou and Wang145]. However, none of them is suitable as they are computationally too expensive due to the time complexity of
$q$
given points in the embedding space. Indeed literature has some definitions of convex hulls [Reference Barber, Dobkin and Huhdanpaa143–Reference Jia, Wang, Shao, Long, Zhou and Wang145]. However, none of them is suitable as they are computationally too expensive due to the time complexity of
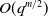 $O({q}^{{m}/2})$
where
$O({q}^{{m}/2})$
where
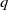 $q$
is the number of inputs and
$q$
is the number of inputs and
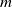 $m$
is the number of dimensions [Reference Barber, Dobkin and Huhdanpaa143]. Approaches that use under-approximations to speed up the algorithms [Reference Sartipizadeh and Vincent144, Reference Jia, Wang, Shao, Long, Zhou and Wang145] do not work well in NLP scenarios, as under-approximated subspaces are so small that they contain near zero sentence embeddings.
$m$
is the number of dimensions [Reference Barber, Dobkin and Huhdanpaa143]. Approaches that use under-approximations to speed up the algorithms [Reference Sartipizadeh and Vincent144, Reference Jia, Wang, Shao, Long, Zhou and Wang145] do not work well in NLP scenarios, as under-approximated subspaces are so small that they contain near zero sentence embeddings.
3.4.1 Exclusion of unwanted sentences via shrinking
Another concern is that the generated hyper-rectangles may contain sentences from a different class. This would make it unsuitable for verification. In order to exclude all samples from the wrong class, we define a shrinking algorithm
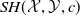 $SH(\mathcal {X}, \mathcal {Y}, {c})$
that calculates a new subspace that is a subset of the original hyper-rectangle around
$SH(\mathcal {X}, \mathcal {Y}, {c})$
that calculates a new subspace that is a subset of the original hyper-rectangle around
 $\mathcal {X}$
, that only contains embeddings of sentences in
$\mathcal {X}$
, that only contains embeddings of sentences in
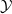 $\mathcal {Y}$
that are of class
$\mathcal {Y}$
that are of class
 $c$
. Of course, to ensure this, the algorithm may have to exclude some sentences of class
$c$
. Of course, to ensure this, the algorithm may have to exclude some sentences of class
 $c$
. The second graph of Figure 3 gives a visual intuition of how this is done.
$c$
. The second graph of Figure 3 gives a visual intuition of how this is done.
An example of hyper-rectangle drawn around all points of the same class (a), shrunk hyper-rectangle
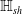 $\mathbb {H}_{sh}$
that is obtained by excluding all points from the opposite class (b) and clustered hyper-rectangles (c) in 2-dimensions. The red dots represent sentences in the embedding space of one class, while the blue dots are embedded sentences that do not belong to that class.
$\mathbb {H}_{sh}$
that is obtained by excluding all points from the opposite class (b) and clustered hyper-rectangles (c) in 2-dimensions. The red dots represent sentences in the embedding space of one class, while the blue dots are embedded sentences that do not belong to that class.

Formally, for each sentence
 $s$
in
$s$
in
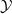 $\mathcal {Y}$
that is not of class
$\mathcal {Y}$
that is not of class
 $c$
, the algorithm performs the following procedure. If
$c$
, the algorithm performs the following procedure. If
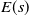 $E({s})$
lies in the current hyper-rectangle
$E({s})$
lies in the current hyper-rectangle
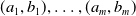 $(a_1, b_1), \dots, (a_{m}, b_{m})$
, then for each dimension
$(a_1, b_1), \dots, (a_{m}, b_{m})$
, then for each dimension
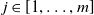 $j \in [1, \dots, {m}]$
we compute the distance whether
$j \in [1, \dots, {m}]$
we compute the distance whether
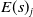 $E({s})_j$
is closer to
$E({s})_j$
is closer to
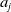 $a_j$
or
$a_j$
or
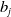 $b_j$
. Without loss of generality, assume
$b_j$
. Without loss of generality, assume
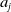 $a_j$
is closer. We then compute the number of sentences of class
$a_j$
is closer. We then compute the number of sentences of class
 $c$
that would be excluded by replacing
$c$
that would be excluded by replacing
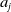 $a_j$
with
$a_j$
with
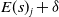 $E({s})_j+ \delta$
in the hyper-rectangle where
$E({s})_j+ \delta$
in the hyper-rectangle where
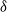 $\delta$
is a small positive number (we use
$\delta$
is a small positive number (we use
 $e^{-100}$
). This gives us a penalty for each dimension
$e^{-100}$
). This gives us a penalty for each dimension
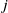 $j$
, and we exclude
$j$
, and we exclude
 $s$
by updating the hyper-rectangle in the dimension that minimises this penalty. The idea is to shrink the hyper-rectangle in the dimensions that exclude as few embedded sentences from the desired class
$s$
by updating the hyper-rectangle in the dimension that minimises this penalty. The idea is to shrink the hyper-rectangle in the dimensions that exclude as few embedded sentences from the desired class
 $c$
as possible.Footnote
6
$c$
as possible.Footnote
6
3.4.2 Exclusion of unwanted sentences via clustering
An alternative approach to excluding unwanted sentences is to split the dataset up by clustering semantically similar sentences in the embedding space and then compute the hyper-rectangles around each cluster individually, as shown in the last graph of Figure 3. In this paper, we will use the k-means algorithm for clustering. We will use the notation
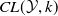 $CL(\mathcal {Y}, k)$
to refer to the
$CL(\mathcal {Y}, k)$
to refer to the
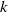 $k$
-clusters formed by applying it to dataset
$k$
-clusters formed by applying it to dataset
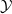 $\mathcal {Y}$
. While in our experiments we have found this is often sufficient to exclude unwanted sentences, it is not guaranteed to do so. Therefore, this method is combined with the shrinking algorithm in our experiments.
$\mathcal {Y}$
. While in our experiments we have found this is often sufficient to exclude unwanted sentences, it is not guaranteed to do so. Therefore, this method is combined with the shrinking algorithm in our experiments.
3.4.3 Eigenspace rotation
A final alternative and computationally efficient way of reducing the likelihood that the hyper-rectangles will contain embedded sentences of an unwanted class is to rotate them to better align to the distribution of the embedded sentences of the desired class in the embedding space. This motivates us to introduce the Eigenspace rotation.
To construct the tightest possible hyper-rectangle, we define a specific method of eigenspace rotation. As shown in Figure 1 (C and D), our approach is to calculate a rotation matrix
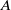 $A$
such that the rotated matrix
$A$
such that the rotated matrix
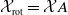 $\mathcal {X}_{\text {rot}} = \mathcal {X} A$
is better aligned with the axes than
$\mathcal {X}_{\text {rot}} = \mathcal {X} A$
is better aligned with the axes than
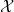 $\mathcal {X}$
, and therefore
$\mathcal {X}$
, and therefore
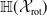 $\mathbb {H}(\mathcal {X}_{\text {rot}})$
has a smaller volume. By a slight abuse of terminology, we will refer to
$\mathbb {H}(\mathcal {X}_{\text {rot}})$
has a smaller volume. By a slight abuse of terminology, we will refer to
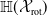 $\mathbb {H}(\mathcal {X}_{\text {rot}})$
as the rotated hyper-rectangle, even though strictly speaking, we are rotating the data, not the hyper-rectangle itself. In order to calculate the rotation matrix
$\mathbb {H}(\mathcal {X}_{\text {rot}})$
as the rotated hyper-rectangle, even though strictly speaking, we are rotating the data, not the hyper-rectangle itself. In order to calculate the rotation matrix
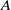 $A$
, we use singular value decomposition [Reference Klema and Laub146]. The singular value decomposition of
$A$
, we use singular value decomposition [Reference Klema and Laub146]. The singular value decomposition of
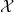 $\mathcal {X}$
is defined as
$\mathcal {X}$
is defined as
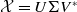 $\mathcal {X} = U \Sigma V^*$
, where
$\mathcal {X} = U \Sigma V^*$
, where
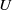 $U$
is a matrix of left-singular vectors,
$U$
is a matrix of left-singular vectors,
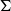 $\Sigma$
is a matrix of singular values and
$\Sigma$
is a matrix of singular values and
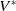 $V^*$
is a matrix of right-singular vectors and
$V^*$
is a matrix of right-singular vectors and
 $\cdot ^*$
denotes the conjugate transpose. Intuitively, the right-singular vectors
$\cdot ^*$
denotes the conjugate transpose. Intuitively, the right-singular vectors
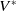 $V^*$
describe the directions in which
$V^*$
describe the directions in which
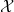 $\mathcal {X}$
exhibits the most variance. The main idea behind the definition of rotation is to align these directions of maximum variance with the standard canonical basis vectors. Formally, using
$\mathcal {X}$
exhibits the most variance. The main idea behind the definition of rotation is to align these directions of maximum variance with the standard canonical basis vectors. Formally, using
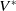 $V^*$
, we can compute the rotation (or change-of-basis) matrix
$V^*$
, we can compute the rotation (or change-of-basis) matrix
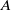 $A$
that rotates the right-singular vectors onto the canonical standard basis vectors
$A$
that rotates the right-singular vectors onto the canonical standard basis vectors
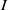 $I$
, where
$I$
, where
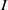 $I$
is the identity matrix. To do this, we observe that
$I$
is the identity matrix. To do this, we observe that
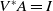 $V^*A = I$
implies
$V^*A = I$
implies
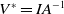 $V^* = IA^{-1}$
, which implies
$V^* = IA^{-1}$
, which implies
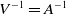 $V^{-1} = A^{-1}$
, and thus
$V^{-1} = A^{-1}$
, and thus
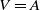 $V = A$
. We thus obtain
$V = A$
. We thus obtain
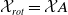 $\mathcal {X}_{rot} = \mathcal {X} A$
as desired. All hyper-rectangles constructed in this paper are rotated.
$\mathcal {X}_{rot} = \mathcal {X} A$
as desired. All hyper-rectangles constructed in this paper are rotated.
3.4.4 Geometric and semantic subspaces
We now apply the abstract definition of a subspace of an embedding space to concrete NLP verification scenarios. Once we know how to define subspaces for a selection of points in the embedding space, the choice remains how to choose those points. The first option is to use
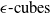 $\epsilon \textrm {-cubes}$
around given embedded points, as Example1 defines. Since this construction does not involve any knowledge about the semantics of sentences, we will call the resulting subspaces geometric subspaces. The second choice is to apply semantic perturbations to a sentence in
$\epsilon \textrm {-cubes}$
around given embedded points, as Example1 defines. Since this construction does not involve any knowledge about the semantics of sentences, we will call the resulting subspaces geometric subspaces. The second choice is to apply semantic perturbations to a sentence in
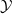 $\mathcal {Y}$
, embed the resulting sentences, and then define a subspace around them. We will call the subspaces obtained by this method semantic perturbation subspaces, or just semantic subspaces for short.
$\mathcal {Y}$
, embed the resulting sentences, and then define a subspace around them. We will call the subspaces obtained by this method semantic perturbation subspaces, or just semantic subspaces for short.
We will finish this section with defining semantic subspaces formally. We will use
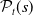 ${\mathcal {P}}_{{t}}({s})$
to denote an algorithm for generating sentence perturbations of type
${\mathcal {P}}_{{t}}({s})$
to denote an algorithm for generating sentence perturbations of type
 $t$
, applied to an input sentence
$t$
, applied to an input sentence
 $s$
in a random position. In the later sections, we will use
$s$
in a random position. In the later sections, we will use
 $t$
to refer to the different types of perturbations illustrated in Tables 4 and 5, e.g. character-level insertion, deletion, replacement. Intuitively, given a single sentence we want to generate a set of semantically similar perturbations and then construct a hyper-rectangle around them, as described in Definition5.
$t$
to refer to the different types of perturbations illustrated in Tables 4 and 5, e.g. character-level insertion, deletion, replacement. Intuitively, given a single sentence we want to generate a set of semantically similar perturbations and then construct a hyper-rectangle around them, as described in Definition5.
This motivates the following definitions. Given a sentence
 $s$
, a number
$s$
, a number
 $b$
and a type
$b$
and a type
 $t$
, the set
$t$
, the set
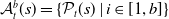 $\mathcal {A}^{{b}}_{{t}}({s}) = \{ {\mathcal {P}}_{{t}}({s}) \mid i \in [1, {b}] \}$
is the set of
$\mathcal {A}^{{b}}_{{t}}({s}) = \{ {\mathcal {P}}_{{t}}({s}) \mid i \in [1, {b}] \}$
is the set of
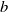 $b$
semantic perturbations of type
$b$
semantic perturbations of type
 $t$
generated from
$t$
generated from
 $s$
. We will use the notation
$s$
. We will use the notation
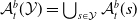 $\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}) = \bigcup _{{s} \in \mathcal {Y}} \mathcal {A}^{{b}}_{{t}}({s})$
to denote the new dataset generated by creating
$\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}) = \bigcup _{{s} \in \mathcal {Y}} \mathcal {A}^{{b}}_{{t}}({s})$
to denote the new dataset generated by creating
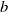 $b$
semantic perturbations of type
$b$
semantic perturbations of type
 $t$
around each sentence.
$t$
around each sentence.
Definition 6. (Semantic Subspace for a Sentence). Given an embedding function
 $E: \mathbb {S} \rightarrow {\mathbb {R}}^{m}$
, the semantic subspace for a sentence
$E: \mathbb {S} \rightarrow {\mathbb {R}}^{m}$
, the semantic subspace for a sentence
 $s$
is the subspace
$s$
is the subspace
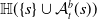 $\mathbb {H}(\{s\} \cup \mathcal {A}^{{b}}_{{t}}({s}))$
. We will refer to a set of such semantic hyper-rectangles over an entire dataset
$\mathbb {H}(\{s\} \cup \mathcal {A}^{{b}}_{{t}}({s}))$
. We will refer to a set of such semantic hyper-rectangles over an entire dataset
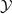 $\mathcal {Y}$
as
$\mathcal {Y}$
as
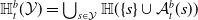 $\mathbb {H}_{{t}}^{{b}}(\mathcal {Y}) = \bigcup _{{s} \in \mathcal {Y}} \mathbb {H}(\{s\} \cup \mathcal {A}^{{b}}_{{t}}({s}))$
.
$\mathbb {H}_{{t}}^{{b}}(\mathcal {Y}) = \bigcup _{{s} \in \mathcal {Y}} \mathbb {H}(\{s\} \cup \mathcal {A}^{{b}}_{{t}}({s}))$
.
Example 2. (Construction of Semantic Subspaces). To illustrate this construction, let us consider the sentence
 $s$
: “Can u tell me if you are a chatbot?”. This sentence is one of
$s$
: “Can u tell me if you are a chatbot?”. This sentence is one of
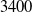 $3400$
original sentences of the positive class in the dataset. From this single sentence, we can create six new sentences using the word-level perturbations from Table
5
to form
$3400$
original sentences of the positive class in the dataset. From this single sentence, we can create six new sentences using the word-level perturbations from Table
5
to form
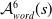 $\mathcal {A}^{6}_{word}({s})$
. Once the seven sentences are embedded into the vector space, they form the hyper-rectangle
$\mathcal {A}^{6}_{word}({s})$
. Once the seven sentences are embedded into the vector space, they form the hyper-rectangle
 $\mathbb {H}(\{s\} \cup \mathcal {A}^{6}_{word}({s}))$
. By repeating this construction for the remaining
$\mathbb {H}(\{s\} \cup \mathcal {A}^{6}_{word}({s}))$
. By repeating this construction for the remaining
 $3399$
sentences, we obtain the set of hyper-rectangles
$3399$
sentences, we obtain the set of hyper-rectangles
 $\mathbb {H}_{word}(\mathcal {Y})$
for the dataset.
$\mathbb {H}_{word}(\mathcal {Y})$
for the dataset.
Given a sentence
 $s$
, we embed each sentence in
$s$
, we embed each sentence in
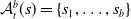 $\mathcal {A}^{{b}}_{{t}}({s}) = \{ {s}_1, \dots, {s}_{b}\}$
into
$\mathcal {A}^{{b}}_{{t}}({s}) = \{ {s}_1, \dots, {s}_{b}\}$
into
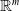 ${\mathbb {R}}^{{m}}$
obtaining vectors
${\mathbb {R}}^{{m}}$
obtaining vectors
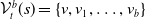 $\mathcal {V}^{{b}}_{{t}}({s}) = \{v, v_1, \ldots, v_{b}\}$
where
$\mathcal {V}^{{b}}_{{t}}({s}) = \{v, v_1, \ldots, v_{b}\}$
where
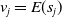 $v_j = E({s}_j)$
.
$v_j = E({s}_j)$
.
3.4.5 Measuring the quality of sentence embeddings
One of our implicit assumptions in the previous sections is that the embedding function
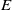 $E$
maps pairs of semantically similar sentences to nearby points in the embedding space. In Section 5.5.2, we will evaluate the accuracy of this assumption using cosine similarity. This metric measures how similar two vectors are in a multi-dimensional space by calculating the cosine of the angle between them:
$E$
maps pairs of semantically similar sentences to nearby points in the embedding space. In Section 5.5.2, we will evaluate the accuracy of this assumption using cosine similarity. This metric measures how similar two vectors are in a multi-dimensional space by calculating the cosine of the angle between them:
 \begin{equation*} \text {CoS}(v_1, v_2) = \frac {v_1 \cdot v_2}{\|v_1\| \|v_2\|} \end{equation*}
\begin{equation*} \text {CoS}(v_1, v_2) = \frac {v_1 \cdot v_2}{\|v_1\| \|v_2\|} \end{equation*}
where
 $\cdot$
is the dot product and
$\cdot$
is the dot product and
 $\|v\| = \sqrt {v \cdot v}$
. The resulting value ranges from
$\|v\| = \sqrt {v \cdot v}$
. The resulting value ranges from
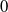 $0$
to
$0$
to
 $1$
. A value of
$1$
. A value of
 $1$
indicates that the vectors are parallel (highest similarity), while
$1$
indicates that the vectors are parallel (highest similarity), while
 $0$
means that the vectors are orthogonal (no similarity).
$0$
means that the vectors are orthogonal (no similarity).
3.5 Training
As outlined in Section 2.3, robust training is essential for bolstering the robustness of DNNs; without it, their verifiability would be significantly diminished. This study employs two robust training methods, namely data augmentation and a custom PGD adversarial training, with the goal of discerning the factors contributing to the success of robust training and compare the effectiveness of these methods.
Data Augmentation. In this training method, we statically generate semantic perturbations at the character, word and sentence levels before training, which are then added to the dataset. The network is subsequently trained on this augmented dataset using the standard stochastic gradient descent algorithm.
Adversarial Training. In this training method, the traditional projected gradient descent (PGD) algorithm [Reference Madry, Makelov, Schmidt, Tsipras and Vladu20], is defined as follows. Given a loss function
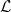 $\mathcal {L}$
, a step size
$\mathcal {L}$
, a step size
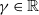 $\gamma \in {\mathbb {R}}$
and a starting point
$\gamma \in {\mathbb {R}}$
and a starting point
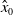 $\hat {x} _0$
then the output of the PGD algorithm
$\hat {x} _0$
then the output of the PGD algorithm
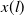 $x(l)$
after
$x(l)$
after
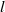 $l$
iterations is defined as:
$l$
iterations is defined as:
 \begin{align*} x(0) &= \hat {x} _0\\ x(t+1) &= \textrm {proj}_{\mathcal {S}}\Big {[}x(t) + \gamma \cdot \text {sign}(\nabla _{x(t)} \mathcal {L}(x(t), y))\Big {]} \end{align*}
\begin{align*} x(0) &= \hat {x} _0\\ x(t+1) &= \textrm {proj}_{\mathcal {S}}\Big {[}x(t) + \gamma \cdot \text {sign}(\nabla _{x(t)} \mathcal {L}(x(t), y))\Big {]} \end{align*}
where
 $\textrm {proj}_{\mathcal {S}}$
is the projection back into the desired subspace
$\textrm {proj}_{\mathcal {S}}$
is the projection back into the desired subspace
 $\mathcal {S}$
. In its standard formulation, the subspace
$\mathcal {S}$
. In its standard formulation, the subspace
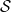 $\mathcal {S}$
is often an
$\mathcal {S}$
is often an
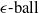 $\epsilon \textrm {-ball}$
(for some chosen
$\epsilon \textrm {-ball}$
(for some chosen
 $\epsilon$
).
$\epsilon$
).
In this work, we modify the algorithm to work with custom-defined hyper-rectangles as the subspace. The primary distinction between our customised PGD algorithm and the standard version lies in the definition of the step size. In the conventional algorithm, the step size is represented by a scalar
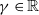 $\gamma \in {\mathbb {R}}$
therefore representing a uniform step size in every dimension. In our case the width of
$\gamma \in {\mathbb {R}}$
therefore representing a uniform step size in every dimension. In our case the width of
 $\mathbb {H}$
in each dimension may vary greatly, therefore we transforms
$\mathbb {H}$
in each dimension may vary greatly, therefore we transforms
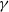 $\gamma$
into a vector in
$\gamma$
into a vector in
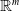 ${\mathbb {R}}^{m}$
, allowing the step size to vary by dimension. Note that the dot
${\mathbb {R}}^{m}$
, allowing the step size to vary by dimension. Note that the dot
 $\cdot$
between
$\cdot$
between
 $\gamma$
and
$\gamma$
and
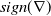 $sign(\nabla )$
becomes an element-wise multiplication. The resulting customised PGD training seeks to identify the worst perturbations within the custom-defined subspace and trains the given neural network to classify those perturbations correctly, in order to make the network robust to adversarial inputs in the chosen subspace.
$sign(\nabla )$
becomes an element-wise multiplication. The resulting customised PGD training seeks to identify the worst perturbations within the custom-defined subspace and trains the given neural network to classify those perturbations correctly, in order to make the network robust to adversarial inputs in the chosen subspace.
3.6 Choice of verification algorithm
As stated earlier, our approach in this study involves the utilisation of cutting-edge tools for DNN verification. Initially, we employ ERAN [Reference Singh, Gehr, Püschel and Vechev69], a state-of-the-art abstract interpretation-based method. This choice is made over IBP due to its ability to yield tighter bounds. Subsequently, we conduct comparisons and integrate Marabou [Reference Wu, Isac, Zeljić, Tagomori, Daggitt, Kokke and Barrett22], a state-of-the-art complete verifier. This enables us to attain the highest verification percentage, maximising the tightness of the bounds. Additionally, we incorporate
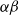 $\alpha \beta$
-CROWN [Reference Xu, Zhang, Wang, Wang, Jana, Lin and Hsieh42, Reference Wang, Zhang, Xu, Lin, Jana, Hsieh and Kolter43], the best-performing verifier in the International Verification of Neural Networks Competition (VNN-COMP) 2024 competition, known for its efficiency in linear bound propagation and branch-and-bound techniques. Moreover, we utilise CORA [Reference Althoff55], an abstract interpretation-based verifier that supports zonotope-based verification, allowing us to compare hyper-rectangles and zonotopes in our verification experiments. We will use notation
$\alpha \beta$
-CROWN [Reference Xu, Zhang, Wang, Wang, Jana, Lin and Hsieh42, Reference Wang, Zhang, Xu, Lin, Jana, Hsieh and Kolter43], the best-performing verifier in the International Verification of Neural Networks Competition (VNN-COMP) 2024 competition, known for its efficiency in linear bound propagation and branch-and-bound techniques. Moreover, we utilise CORA [Reference Althoff55], an abstract interpretation-based verifier that supports zonotope-based verification, allowing us to compare hyper-rectangles and zonotopes in our verification experiments. We will use notation
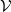 $\mathcal {V}$
to refer to a verifier abstractly.
$\mathcal {V}$
to refer to a verifier abstractly.
4. Characterisation of verifiable subspaces
In this Section, we provide key results in support of Contribution 1 formulated in the introduction:
-
• We start with introducing the metric of generalisability of (verified) subspaces and set-up some baseline experiments.
-
• We introduce the problem of the verifiability-generalisability trade-off in the context of geometric subspaces.
-
• We show that, compared to geometric subspaces, the use of semantic subspaces helps to find a better balance between generalisability and verifiability.
-
• Finally, we show that adversarial training based on semantic subspaces results in DNNs that are both more verifiable and more generalisable than those obtained with other forms of robust training.
4.1 Metrics for understanding the properties of embedding spaces
Let us start with recalling the existing standard metrics used in DNN verification. Recall that we are given an NLP dataset
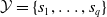 $\mathcal {Y} = \{{s}_1, \ldots, {s}_q\}$
, moreover we assume that each
$\mathcal {Y} = \{{s}_1, \ldots, {s}_q\}$
, moreover we assume that each
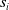 ${s}_i$
is assigned a correct class from
${s}_i$
is assigned a correct class from
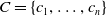 $C = \{ {c}_1, \ldots, {c}_n\}$
. We restrict to the case of binary classification in this paper for simplicity, so we will assume
$C = \{ {c}_1, \ldots, {c}_n\}$
. We restrict to the case of binary classification in this paper for simplicity, so we will assume
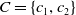 $C = \{ {c}_1, {c}_2\}$
. Furthermore, we are given an embedding function
$C = \{ {c}_1, {c}_2\}$
. Furthermore, we are given an embedding function
 $E: \mathbb {S} \rightarrow {\mathbb {R}}^m$
, and a network
$E: \mathbb {S} \rightarrow {\mathbb {R}}^m$
, and a network
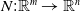 $N_{}: {\mathbb {R}}^{m} \rightarrow {\mathbb {R}}^{n}$
. Usually
$N_{}: {\mathbb {R}}^{m} \rightarrow {\mathbb {R}}^{n}$
. Usually
 $n$
corresponds to the number of classes, and thus in case of binary classification, we have
$n$
corresponds to the number of classes, and thus in case of binary classification, we have
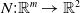 $N_{}: {\mathbb {R}}^{m} \rightarrow {\mathbb {R}}^2$
. An embedded sentence
$N_{}: {\mathbb {R}}^{m} \rightarrow {\mathbb {R}}^2$
. An embedded sentence
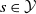 ${s} \in \mathcal {Y}$
is classified as class
${s} \in \mathcal {Y}$
is classified as class
 $c$
if the value of
$c$
if the value of
 $c$
in
$c$
in
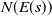 $N_{}(E({s}))$
is higher than all other classes.
$N_{}(E({s}))$
is higher than all other classes.
Accuracy. The most popular metric for measuring the performance of the network is the accuracy of
 $N_{}$
, which is measured as a percentage of sentences in
$N_{}$
, which is measured as a percentage of sentences in
 $\mathcal {Y}$
that are assigned to a correct class by
$\mathcal {Y}$
that are assigned to a correct class by
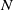 $N_{}$
. Note that this metric only checks a finite number of points in
$N_{}$
. Note that this metric only checks a finite number of points in
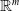 ${\mathbb {R}}^{m}$
given by the dataset.
${\mathbb {R}}^{m}$
given by the dataset.
Verifiability. A verifier
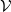 $\mathcal {V}$
takes a network
$\mathcal {V}$
takes a network
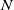 $N_{}$
, a subspace
$N_{}$
, a subspace
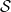 $\mathcal {S}$
and its designated class
$\mathcal {S}$
and its designated class
 $c$
as an input, and outputs 1 if it can prove that
$c$
as an input, and outputs 1 if it can prove that
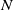 $N_{}$
assigns all points in the subspace
$N_{}$
assigns all points in the subspace
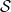 $\mathcal {S}$
to the class
$\mathcal {S}$
to the class
 $c$
and 0 otherwise. Consider a verification problem with multiple subspaces
$c$
and 0 otherwise. Consider a verification problem with multiple subspaces
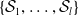 $\{ \mathcal {S}_1, \ldots, \mathcal {S}_{l} \}$
, where all the points in each subspace should be assigned to a specific class
$\{ \mathcal {S}_1, \ldots, \mathcal {S}_{l} \}$
, where all the points in each subspace should be assigned to a specific class
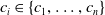 $c_i \in \{ {c}_1, \ldots, {c}_n\}$
. In the literature, the most popular metric to measure success rate of the given verifier on
$c_i \in \{ {c}_1, \ldots, {c}_n\}$
. In the literature, the most popular metric to measure success rate of the given verifier on
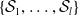 $\{ \mathcal {S}_1, \ldots, \mathcal {S}_{l} \}$
is verifiability:
$\{ \mathcal {S}_1, \ldots, \mathcal {S}_{l} \}$
is verifiability:
Definition 7. (Verifiability). Given a set of subspaces
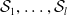 $\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
each assigned to classes
$\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
each assigned to classes
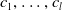 ${c}_1, \ldots, {c}_{l}$
, then the verifiability is the percentage of such subspaces successfully verified:
${c}_1, \ldots, {c}_{l}$
, then the verifiability is the percentage of such subspaces successfully verified:
 \begin{equation*} \mathcal {W}(\mathcal {S}_1, \ldots, \mathcal {S}_{l},{c}_1, \ldots, {c}_{l}) = \frac {\sum _{i = 0}^{{l}} \mathcal {V}(N_{}, \mathcal {S}_i, {c}_i)} {{l}} \end{equation*}
\begin{equation*} \mathcal {W}(\mathcal {S}_1, \ldots, \mathcal {S}_{l},{c}_1, \ldots, {c}_{l}) = \frac {\sum _{i = 0}^{{l}} \mathcal {V}(N_{}, \mathcal {S}_i, {c}_i)} {{l}} \end{equation*}
All DNN verification papers that study such problems report this measure. Note that each subspace contains an infinite number of points.
However, suppose we have a subspace
 $\mathcal {S}$
that verifiably consists only of vectors that are assigned to a class
$\mathcal {S}$
that verifiably consists only of vectors that are assigned to a class
 $c$
by
$c$
by
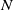 $N_{}$
. Because of the embedding gap, it is difficult to calculate how many valid unseen sentences outside of
$N_{}$
. Because of the embedding gap, it is difficult to calculate how many valid unseen sentences outside of
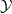 $\mathcal {Y}$
will be mapped into
$\mathcal {Y}$
will be mapped into
 $\mathcal {S}$
by
$\mathcal {S}$
by
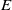 $E$
, and therefore how much utility there is in verifying
$E$
, and therefore how much utility there is in verifying
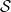 $\mathcal {S}$
. In an extreme case, it is possible to have 100% verifiability and yet the verified subspaces will not contain any unseen sentences.
$\mathcal {S}$
. In an extreme case, it is possible to have 100% verifiability and yet the verified subspaces will not contain any unseen sentences.
Generalisability. Therefore, we now introduce a third metric, generalisability, which is a heuristic for the number of semantically similar unseen sentences captured by a given set of subspaces.
Definition 8. (Generalisability). Given a set of subspaces
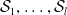 $\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
and a target set of embeddings
$\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
and a target set of embeddings
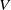 $V$
the generalisability of the subspaces is measured as the percentage of the embedded vectors that lie in the subspaces:
$V$
the generalisability of the subspaces is measured as the percentage of the embedded vectors that lie in the subspaces:
 \begin{equation*} R\mathcal {G}^{}_{}(V, \mathcal {S}_1, \ldots, \mathcal {S}_{l}) = \frac {|V \cap \bigcup _{i = 1}^{{l}} \mathcal {S}_i |}{| V |} \end{equation*}
\begin{equation*} R\mathcal {G}^{}_{}(V, \mathcal {S}_1, \ldots, \mathcal {S}_{l}) = \frac {|V \cap \bigcup _{i = 1}^{{l}} \mathcal {S}_i |}{| V |} \end{equation*}
In this paper, we will generate the target set of embeddings
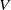 $V$
as
$V$
as
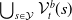 $\bigcup _{{s} \in \mathcal {Y}} \mathcal {V}^{{b}}_{{t}}({s})$
where
$\bigcup _{{s} \in \mathcal {Y}} \mathcal {V}^{{b}}_{{t}}({s})$
where
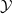 $\mathcal {Y}$
is a dataset,
$\mathcal {Y}$
is a dataset,
 $t$
is the type of semantic perturbation,
$t$
is the type of semantic perturbation,
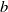 $b$
is the number of perturbations and
$b$
is the number of perturbations and
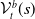 $\mathcal {V}^{{b}}_{{t}}({s})$
is the embeddings of the set of semantic perturbations
$\mathcal {V}^{{b}}_{{t}}({s})$
is the embeddings of the set of semantic perturbations
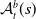 $\mathcal {A}^{{b}}_{{t}}({s})$
around
$\mathcal {A}^{{b}}_{{t}}({s})$
around
 $s$
generated using
$s$
generated using
 ${\mathcal {P}}_{t}$
, as described in Section 3.4.
${\mathcal {P}}_{t}$
, as described in Section 3.4.
Note that
 ${\mathcal {P}}_{t}$
can be given by a collection of different perturbation algorithms and their kinds. The key assumption is that
${\mathcal {P}}_{t}$
can be given by a collection of different perturbation algorithms and their kinds. The key assumption is that
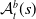 $\mathcal {A}^{{b}}_{{t}}({s})$
contains valid sentences semantically similar to
$\mathcal {A}^{{b}}_{{t}}({s})$
contains valid sentences semantically similar to
 $s$
and belonging to the same class. Assuming that membership of
$s$
and belonging to the same class. Assuming that membership of
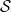 $\mathcal {S}$
is easy to compute, then this metric is also easy to compute as the set
$\mathcal {S}$
is easy to compute, then this metric is also easy to compute as the set
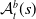 $\mathcal {A}^{{b}}_{{t}}({s})$
is finite and of size
$\mathcal {A}^{{b}}_{{t}}({s})$
is finite and of size
 $b$
, and therefore so is
$b$
, and therefore so is
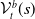 $\mathcal {V}^{{b}}_{{t}}({s})$
. Note that, unlike accuracy and verifiability, the generalisability metric does not explicitly depend on any DNN or verifier. However, in this paper, we only study generalisability of verifiable subspaces, and thus the existence of a verified network
$\mathcal {V}^{{b}}_{{t}}({s})$
. Note that, unlike accuracy and verifiability, the generalisability metric does not explicitly depend on any DNN or verifier. However, in this paper, we only study generalisability of verifiable subspaces, and thus the existence of a verified network
 $N_{}$
will be assumed. Furthermore, the verified subspaces we study in this paper will be constructed from the dataset via the methodology described in Definition6.
$N_{}$
will be assumed. Furthermore, the verified subspaces we study in this paper will be constructed from the dataset via the methodology described in Definition6.
4.2 Baseline experiments for understanding the properties of embedding spaces
The methodology defined thus far has given basic intuitions about the modular nature of the NLP verification pipeline. Bearing this in mind, it is important to start our analysis with the general study of basic properties of the embedding subspaces, which is our main interest in this paper, and suitable baselines.
Benchmark datasets will be abbreviated as “RUAR” and “Medical”. We use
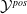 $\mathcal {Y}^{pos}$
to refer to the set of sentences in the training dataset with a positive class (i.e. a question asking the identity of the model, and a medical query, respectively), and
$\mathcal {Y}^{pos}$
to refer to the set of sentences in the training dataset with a positive class (i.e. a question asking the identity of the model, and a medical query, respectively), and
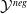 $\mathcal {Y}^{neg}$
to refer to the remaining sentences. For a benchmark network
$\mathcal {Y}^{neg}$
to refer to the remaining sentences. For a benchmark network
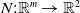 $N: {\mathbb {R}}^m \rightarrow {\mathbb {R}}^2$
, we train a medium-sized fully-connected DNN (with 2 layers of size (128, 2) and input size 30) using stochastic gradient descent and cross-entropy loss. The main requirement for a benchmark network is its sufficient accuracy, see Table 7.
$N: {\mathbb {R}}^m \rightarrow {\mathbb {R}}^2$
, we train a medium-sized fully-connected DNN (with 2 layers of size (128, 2) and input size 30) using stochastic gradient descent and cross-entropy loss. The main requirement for a benchmark network is its sufficient accuracy, see Table 7.
Mean and standard deviation of the accuracy of the baseline DNN on the RUAR and the medical datasets. All experiments are replicated five times

For the choice of benchmark subspaces, we use the following two extreme sets of geometric subspaces:
-
1. the singleton set containing the maximal subspace
$SH(\mathbb {H}(\mathcal {Y}^{pos}))$
around all embedded sentences of the positive class
$pos$
in
$\mathcal {Y}$
. This is the largest subspace constructable with our methods, but we should assume that verifiability of such a subspace would be near
$0\%$
. It is illustrated in the first graph of Figure 3. -
2. the set of minimal subspaces
$\mathbb {H}(\mathcal {Y}^{pos}, 0.005)$
given by
$\epsilon \textrm {-cubes}$
around each embedded sentence of class
$pos$
in
$\mathcal {Y}$
, where
$\epsilon = 0.005$
is chosen to be sufficiently small to give very high verifiability. This is illustrated in the first graph of Figure 1.
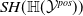
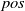
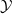
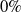
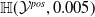
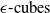
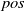
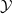
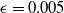
We first seek to understand the geometric properties (e.g. volume,
 $\epsilon$
values) and verifiability figures for these two extremes.
$\epsilon$
values) and verifiability figures for these two extremes.
4.3 Verifiability-generalisability trade-off for geometric subspaces
The number and average volume of the hyper-rectangles that will make up our verified subspaces are shown in Table 8. Generally, we use the following naming convention for our experiments:
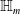 $\mathbb {H}_{m}$
denotes a hyper-rectangle obtained using a method
$\mathbb {H}_{m}$
denotes a hyper-rectangle obtained using a method
 $m$
. For example, RUAR dataset contains
$m$
. For example, RUAR dataset contains
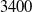 $3400$
sentences of the positive class, and therefore the experiment
$3400$
sentences of the positive class, and therefore the experiment
 $\mathbb {H}_{\epsilon = 0.005}$
consisting of generating hyper-cubes around each positive sentence results in
$\mathbb {H}_{\epsilon = 0.005}$
consisting of generating hyper-cubes around each positive sentence results in
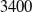 $3400$
hyper-cubes. Using clustering, we obtain a set of
$3400$
hyper-cubes. Using clustering, we obtain a set of
 $50$
,
$50$
,
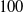 $100$
,
$100$
,
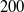 $200$
,
$200$
,
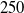 $250$
clusters denoted as
$250$
clusters denoted as
 $\mathbb {H}_{50}$
–
$\mathbb {H}_{50}$
–
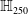 $\mathbb {H}_{250}$
and using the shrinking algorithm we obtain
$\mathbb {H}_{250}$
and using the shrinking algorithm we obtain
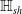 $\mathbb {H}_{sh}$
.
$\mathbb {H}_{sh}$
.
Sets of geometric subspaces used in the experiments, their cardinality and average volumes of hyper-rectangles. All shapes are eigenspace rotated for better precision

Notice the consistent reduction of volume in Table 8, from
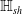 $\mathbb {H}_{sh}$
to
$\mathbb {H}_{sh}$
to
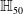 $\mathbb {H}_{50}$
-
$\mathbb {H}_{50}$
-
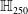 $\mathbb {H}_{250}$
and ultimately to
$\mathbb {H}_{250}$
and ultimately to
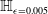 $\mathbb {H}_{\epsilon =0.005}$
. There are several orders of magnitude between the largest and the smallest subspace.
$\mathbb {H}_{\epsilon =0.005}$
. There are several orders of magnitude between the largest and the smallest subspace.
4.3.1 Verifiability of geometric subspaces
Next, we pass each set of hyper-rectangles and the given network to the ERAN verifier and measure verifiability. Table 9 shows that, as expected, the shrunk hyper-rectangle
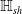 $\mathbb {H}_{sh}$
achieves 0% verifiability, and the various clustered hyper-rectangles (
$\mathbb {H}_{sh}$
achieves 0% verifiability, and the various clustered hyper-rectangles (
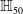 $\mathbb {H}_{50}$
,
$\mathbb {H}_{50}$
,
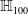 $\mathbb {H}_{100}$
$\mathbb {H}_{100}$
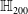 $\mathbb {H}_{200}$
,
$\mathbb {H}_{200}$
,
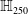 $\mathbb {H}_{250}$
) achieve at most negligible verifiability. In contrast, the baseline
$\mathbb {H}_{250}$
) achieve at most negligible verifiability. In contrast, the baseline
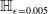 $\mathbb {H}_{\epsilon =0.005}$
achieves up to
$\mathbb {H}_{\epsilon =0.005}$
achieves up to
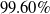 $99.60\%$
verifiability. This suggests that
$99.60\%$
verifiability. This suggests that
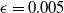 $\epsilon =0.005$
is a good benchmark for a different extreme. Table 8 can give us an intuition of why
$\epsilon =0.005$
is a good benchmark for a different extreme. Table 8 can give us an intuition of why
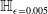 $\mathbb {H}_{\epsilon =0.005}$
has notably higher verifiability than the other hyper-rectangles: the volume of
$\mathbb {H}_{\epsilon =0.005}$
has notably higher verifiability than the other hyper-rectangles: the volume of
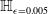 $\mathbb {H}_{\epsilon =0.005}$
is several orders of magnitude smaller. We call this effect low verifiability of the high-volume subspaces.
$\mathbb {H}_{\epsilon =0.005}$
is several orders of magnitude smaller. We call this effect low verifiability of the high-volume subspaces.
Verifiability of the baseline DNN on the RUAR and the medical datasets, for a selection of geometric subspaces; using the ERAN verifier

Tables 8 and 9 suggest that smaller subspaces are more verifiable. One may also conjecture that they are less generalisable (as they will contain fewer embedded sentences). We now will confirm this via experiments; we are particularly interested in understanding how quickly generalisability deteriorates as verifiability increases.
4.3.2 Generalisability of geometric subspaces
To test generalisability, we algorithmically generate a new dataset
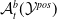 $\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{pos})$
containing its semantic perturbations, using the method described in Section 3.1. The choice to use only positive sentences is motivated by the nature of the chosen datasets – both Medical and RUAR sentences split into:
$\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{pos})$
containing its semantic perturbations, using the method described in Section 3.1. The choice to use only positive sentences is motivated by the nature of the chosen datasets – both Medical and RUAR sentences split into:
-
• a positive class that contains sentences with one intended semantic meaning (they are medical queries, or they are questions about robot identity); and
-
• a negative class that represents “all other sentences” These “other sentences” are not grouped by any specific semantic meaning and therefore do not form one coherent semantic category.
However, Section 5 will make use of
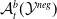 $\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{neg})$
in the context of discussing the embedding error of verified subspaces.
$\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{neg})$
in the context of discussing the embedding error of verified subspaces.
For the perturbation type
 $t$
, in this experiment we take a combination of the different perturbations algorithmsFootnote
7
described in Section 3.1. Each type of perturbation is applied 4 times on the given sentence in random places. The resulting datasets of semantically perturbed sentences are therefore approximately two orders of magnitude larger than the original datasets (see Table 10) and contain unseen sentences of similar semantic meaning to the ones present in the original datasets described in Section 3.1. Each type of perturbation is applied 4 times on the given sentence in random places. The resulting datasets of semantically perturbed sentences are therefore approximately two orders of magnitude larger than the original datasets (see Table 10) and contain unseen sentences of similar semantic meaning to the ones present in the original datasets
$t$
, in this experiment we take a combination of the different perturbations algorithmsFootnote
7
described in Section 3.1. Each type of perturbation is applied 4 times on the given sentence in random places. The resulting datasets of semantically perturbed sentences are therefore approximately two orders of magnitude larger than the original datasets (see Table 10) and contain unseen sentences of similar semantic meaning to the ones present in the original datasets described in Section 3.1. Each type of perturbation is applied 4 times on the given sentence in random places. The resulting datasets of semantically perturbed sentences are therefore approximately two orders of magnitude larger than the original datasets (see Table 10) and contain unseen sentences of similar semantic meaning to the ones present in the original datasets
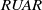 $RUAR$
and
$RUAR$
and
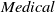 $Medical$
.
$Medical$
.
Generalisability of the selected geometric subspaces
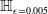 $\mathbb {H}_{\epsilon =0.005}$
,
$\mathbb {H}_{\epsilon =0.005}$
,
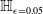 $\mathbb {H}_{\epsilon =0.05}$
and
$\mathbb {H}_{\epsilon =0.05}$
and
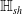 $\mathbb {H}_{sh}$
, measured on the sets of semantic perturbations
$\mathbb {H}_{sh}$
, measured on the sets of semantic perturbations
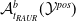 $\mathcal {A}^{{b}}_{{t}_{RAUR}}(\mathcal {Y}^{pos})$
and
$\mathcal {A}^{{b}}_{{t}_{RAUR}}(\mathcal {Y}^{pos})$
and
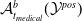 $\mathcal {A}^{{b}}_{{t}_{medical}}(\mathcal {Y}^{pos})$
$\mathcal {A}^{{b}}_{{t}_{medical}}(\mathcal {Y}^{pos})$

Table 10 shows that the most verifiable subspace
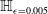 $\mathbb {H}_{\epsilon =0.005}$
is the least generalisable. This means
$\mathbb {H}_{\epsilon =0.005}$
is the least generalisable. This means
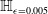 $\mathbb {H}_{\epsilon =0.005}$
may not contain any valid new sentences apart from the one for which it was formed! At the same time,
$\mathbb {H}_{\epsilon =0.005}$
may not contain any valid new sentences apart from the one for which it was formed! At the same time,
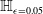 $\mathbb {H}_{\epsilon =0.05}$
has up to
$\mathbb {H}_{\epsilon =0.05}$
has up to
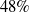 $48\%$
of generalisability at the expense of only up to
$48\%$
of generalisability at the expense of only up to
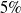 $5\%$
of verifiability (cf. Table 9). The effect of the generalisability vs verifiability trade-off can thus be rather severe for geometric subspaces.
$5\%$
of verifiability (cf. Table 9). The effect of the generalisability vs verifiability trade-off can thus be rather severe for geometric subspaces.
This experiment demonstrates the importance of using the generalisability metric: if one only took into account the verifiability of the subspaces one would choose
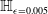 $\mathbb {H}_{\epsilon =0.005}$
, obtaining mathematically sound but pragmatically useless results. We argue that this is a strong argument for including generalisability as a standard metric in reporting NLP verification results in the future.
$\mathbb {H}_{\epsilon =0.005}$
, obtaining mathematically sound but pragmatically useless results. We argue that this is a strong argument for including generalisability as a standard metric in reporting NLP verification results in the future.
4.4 Verifiability-generalisability trade-off for semantic subspaces
The previous subsection has shown that the verifiability-generalisability trade-off is not resolvable by geometric manipulations alone. In this section we argue that using semantic subspaces can help to improve the effects of the trade-off. The main hypothesis that we are testing is: semantic subspaces constructed using semantic-preserving perturbations are more precise, and this in turn improves both verifiability and generalisability.
We will use the construction given in Definition6. As Table 11 illustrates, we construct several semantic hyper-rectangles on sentences of the positive class using character-level (
 $\mathbb {H}_{char}$
,
$\mathbb {H}_{char}$
,
 $\mathbb {H}_{del.}$
,
$\mathbb {H}_{del.}$
,
 $\mathbb {H}_{ins.}$
,
$\mathbb {H}_{ins.}$
,
 $\mathbb {H}_{rep.}$
,
$\mathbb {H}_{rep.}$
,
 $\mathbb {H}_{repl.}$
,
$\mathbb {H}_{repl.}$
,
 $\mathbb {H}_{swap.}$
), word-level (
$\mathbb {H}_{swap.}$
), word-level (
 $\mathbb {H}_{word}$
) and sentence-level perturbations (
$\mathbb {H}_{word}$
) and sentence-level perturbations (
 $\mathbb {H}_{pj}$
). The subscripts
$\mathbb {H}_{pj}$
). The subscripts
 $_{char}$
and
$_{char}$
and
 $_{word}$
refer to the kind of perturbation algorithm, while
$_{word}$
refer to the kind of perturbation algorithm, while
 $_{del.}$
,
$_{del.}$
,
 $_{ins.}$
,
$_{ins.}$
,
 $_{rep.}$
,
$_{rep.}$
,
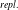 $_{repl.}$
,
$_{repl.}$
,
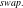 $_{swap.}$
and
$_{swap.}$
and
 $_{pj}$
refer to the type of perturbation, where pj stands for Polyjuice (see Section 3.1). Notice comparable volumes of all these shapes, and compare with
$_{pj}$
refer to the type of perturbation, where pj stands for Polyjuice (see Section 3.1). Notice comparable volumes of all these shapes, and compare with
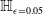 $\mathbb {H}_{\epsilon =0.05}$
.
$\mathbb {H}_{\epsilon =0.05}$
.
Sets of semantic subspaces used in the experiments, their cardinality and average volumes of hyper-rectangles. All shapes are eigenspace rotated for better precision

4.4.1 Verifiability of semantic subspaces
We pass each set of hyper-rectangles and the network
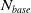 $N_{base}$
to the verifiers ERAN and Marabou to measure verifiability of the subspaces. Table 12 illustrates the verification results obtained using ERAN. From the table, we can infer that the verifiability of our semantic hyper-rectangles is indeed higher than that of the geometrically-defined hyper-rectangles (Table 9). Furthermore, our semantic hyper-rectangles, while unable to reach the verifiability of
$N_{base}$
to the verifiers ERAN and Marabou to measure verifiability of the subspaces. Table 12 illustrates the verification results obtained using ERAN. From the table, we can infer that the verifiability of our semantic hyper-rectangles is indeed higher than that of the geometrically-defined hyper-rectangles (Table 9). Furthermore, our semantic hyper-rectangles, while unable to reach the verifiability of
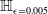 $\mathbb {H}_{\epsilon =0.005}$
, achieve notable higher verification than its counterpart of comparable volume
$\mathbb {H}_{\epsilon =0.005}$
, achieve notable higher verification than its counterpart of comparable volume
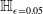 $\mathbb {H}_{\epsilon =0.05}$
. From this experiment, we conclude that not only volume, but also precision of the subspaces has an impact on their verifiability.
$\mathbb {H}_{\epsilon =0.05}$
. From this experiment, we conclude that not only volume, but also precision of the subspaces has an impact on their verifiability.
Verifiability of the baseline DNN on the RUAR and the medical datasets, for a selection of semantic subspaces; using the ERAN verifier

Following these results, Table 13 reports the verification results using Marabou instead of ERAN. As shown, Marabou is able to verify up to
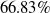 $66.83\%$
(
$66.83\%$
(
 $\mathbb {H}_{rep.}$
), while ERAN achieves at most
$\mathbb {H}_{rep.}$
), while ERAN achieves at most
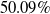 $50.09\%$
. This shows that Marabou outperforms ERAN. This is most likely due to the fact that Reluplex algorithm of Marabou achieves better precision on ReLU networks, that we use. Overall, the Marabou experiment confirms the trends of improved verifiability shown by ERAN and thus confirms our hypothesis about importance of shape precision.
$50.09\%$
. This shows that Marabou outperforms ERAN. This is most likely due to the fact that Reluplex algorithm of Marabou achieves better precision on ReLU networks, that we use. Overall, the Marabou experiment confirms the trends of improved verifiability shown by ERAN and thus confirms our hypothesis about importance of shape precision.
Verifiability of the baseline DNN on the RUAR and the medical datasets, for a selection of semantic subspaces; using the Marabou verifier

4.4.2 Generalisability of semantic subspaces
It remains to establish whether the more verifiable semantic subspaces are also more generalisable. Whereas Table 10 compared the generalisability of
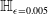 $\mathbb {H}_{\epsilon =0.005}$
and
$\mathbb {H}_{\epsilon =0.005}$
and
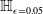 $\mathbb {H}_{\epsilon =0.05}$
with that of
$\mathbb {H}_{\epsilon =0.05}$
with that of
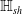 $\mathbb {H}_{sh}$
, Table 14 compares their generalisability to the most verifiable semantic subspaces,
$\mathbb {H}_{sh}$
, Table 14 compares their generalisability to the most verifiable semantic subspaces,
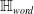 $\mathbb {H}_{word}$
and
$\mathbb {H}_{word}$
and
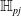 $\mathbb {H}_{pj}$
. It shows that these semantic subspaces are also the most generalisable among the verifiable subspaces, containing, respectively,
$\mathbb {H}_{pj}$
. It shows that these semantic subspaces are also the most generalisable among the verifiable subspaces, containing, respectively,
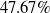 $47.67\%$
and
$47.67\%$
and
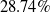 $28.74\%$
of the unseen sentences. Note that among all the experiments, only
$28.74\%$
of the unseen sentences. Note that among all the experiments, only
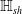 $\mathbb {H}_{sh}$
has higher generalisability, but its verifiability is 0.
$\mathbb {H}_{sh}$
has higher generalisability, but its verifiability is 0.
Generalisability of the selected geometric subspaces
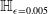 $\mathbb {H}_{\epsilon =0.005}$
and
$\mathbb {H}_{\epsilon =0.005}$
and
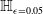 $\mathbb {H}_{\epsilon =0.05}$
and the semantic subspaces
$\mathbb {H}_{\epsilon =0.05}$
and the semantic subspaces
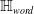 $\mathbb {H}_{word}$
and
$\mathbb {H}_{word}$
and
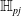 $\mathbb {H}_{pj}$
, measured on the sets of semantic perturbations
$\mathbb {H}_{pj}$
, measured on the sets of semantic perturbations
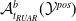 $\mathcal {A}^{{b}}_{{t}_{RUAR}}(\mathcal {Y}^{pos})$
and
$\mathcal {A}^{{b}}_{{t}_{RUAR}}(\mathcal {Y}^{pos})$
and
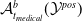 $\mathcal {A}^{{b}}_{{t}_{medical}}(\mathcal {Y}^{pos})$
. Note that the generalisability of
$\mathcal {A}^{{b}}_{{t}_{medical}}(\mathcal {Y}^{pos})$
. Note that the generalisability of
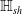 $\mathbb {H}_{sh}$
(Table 10
), despite it having the volume 19 order of magnitudes bigger, is only
$\mathbb {H}_{sh}$
(Table 10
), despite it having the volume 19 order of magnitudes bigger, is only
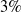 $3\%$
greater than
$3\%$
greater than
 $\mathbb {H}_{word}$
$\mathbb {H}_{word}$

We thus infer that using semantic subspaces is effective for bridging the verifiability-generalisability gap, with precise subspaces performing somewhat better than
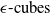 $\epsilon \textrm {-cubes}$
of the same volume; however both beating the smallest
$\epsilon \textrm {-cubes}$
of the same volume; however both beating the smallest
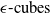 $\epsilon \textrm {-cubes}$
from Section 4.2 of comparable verifiability. Bearing in mind that the verified hyper-rectangles only cover a tiny fraction of the embedding space, the fact that they contain up to
$\epsilon \textrm {-cubes}$
from Section 4.2 of comparable verifiability. Bearing in mind that the verified hyper-rectangles only cover a tiny fraction of the embedding space, the fact that they contain up to
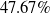 $47.67\%$
of randomly generated new sentences is an encouraging result, the likes of which have not been reported before. To substantiate this claim, we define the training embedding space as the hyper-rectangle that encloses all sentences on the dataset. We show in Table 15 the percentage of the ‘training embedding space’ covered by our best hyper-rectangles
$47.67\%$
of randomly generated new sentences is an encouraging result, the likes of which have not been reported before. To substantiate this claim, we define the training embedding space as the hyper-rectangle that encloses all sentences on the dataset. We show in Table 15 the percentage of the ‘training embedding space’ covered by our best hyper-rectangles
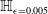 $\mathbb {H}_{\epsilon =0.005}$
,
$\mathbb {H}_{\epsilon =0.005}$
,
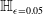 $\mathbb {H}_{\epsilon =0.05}$
,
$\mathbb {H}_{\epsilon =0.05}$
,
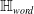 $\mathbb {H}_{word}$
and
$\mathbb {H}_{word}$
and
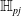 $\mathbb {H}_{pj}$
.
$\mathbb {H}_{pj}$
.
Total volume and percentage of the training embedding space covered by our best hyper-rectangles. The total volume of the training embedding space for RUAR is
 $6.14e-5$
, and for medical is
$6.14e-5$
, and for medical is
 $1.43e-5$
$1.43e-5$

4.5 Adversarial training on semantic subspaces
In this section, we study the effects that adversarial training methods have on the verifiability of the previously defined subspaces in Tables 8 and 11. By comparing the effectiveness of the different training approaches described in Section 3.5, we show in this section that adversarial training based on our new semantic subspaces is the most efficient. Three kinds of training are deployed in this section:
-
1. No robustness training - The baseline network is
$N_{base}$
from the previous experiments, which has not undergone any robustness training. -
2. Data augmentation. We obtain three augmented datasets
$\mathcal {Y} \cup \mathcal {A}^{5}_{char}(\mathcal {Y}^{pos})$
,
$\mathcal {Y} \cup \mathcal {A}^{6}_{word}(\mathcal {Y}^{pos})$
and
$\mathcal {A}^{5}_{pj}(\mathcal {Y}^{pos})$
where
$\mathcal {A}^{}_{}(\cdot )$
is defined in Section 4.4. The subscripts char and word denote the type of perturbation as detailed in Tables 4 and 5, while the subscript pj refers to the sentence level perturbations generated with Polyjuice. We train the baseline architecture, using the standard stochastic gradient descent and cross entropy loss, on the augmented datasets, and obtain DNNs
$N_{char-aug}$
,
$N_{word-aug}$
and
$N_{pj-aug}$
. -
3. PGD adversarial training with geometric and semantic hyper-rectangles. Instead of using the standard
$\epsilon \textrm {-cube}$
as the PGD subspace
$\mathcal {S}$
, we use the various hyper-rectangles defined in Tables 8 & 11. We refer to a network trained with the PGD algorithm on the hyper-rectangle associated with experiment
$\mathbb {H}_{name}$
as
$N_{name-adv}$
. For example, for the previous experiment
$\mathbb {H}_{sh}$
, we obtain the network
$N_{sh-adv}$
by adversarially training the benchmark architecture on the associated subspace
$\mathcal {S} = SH(\mathbb {H}(\mathcal {Y}^{pos}), \mathcal {Y}, {c}^{pos})$
.
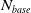
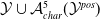
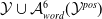
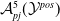
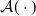
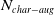
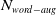
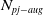
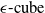
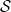
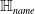
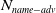
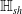
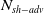
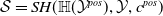
See Tables 16 & 17 for full listing of the networks we obtain in this way. We call DNNs of second and third type robustly trained networks. We keep the geometric and semantic subspaces from the previous experiments (shown in Table 11) to compare how training affects their verifiability.
Accuracy of the robustly trained DNNs on the RUAR and the medical datasets.
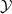 $\mathcal {Y}$
stands for either RUAR or medical depending on the column
$\mathcal {Y}$
stands for either RUAR or medical depending on the column

Accuracy of the DNNs trained adversarially on the RUAR and the medical datasets

Following the same evaluation methodology of experiments as in Sections 4.2 and 4.4.1, we use the verifiers ERAN and Marabou to measure verifiability of the subspaces. Table 16 reports accuracy of the robustly trained networks, while the verification results are presented in Tables 18 and 19. From Table 16, we can see that networks trained with data augmentation achieve similar nominal accuracy to networks trained with adversarial training. However, the most prominent difference is exposed in Tables 18 and 19: adversarial training effectively improves the verifiability of the networks, while data augmentation actually decreases it.
Verifiability of the robustly trained DNNs on the RUAR and the medical datasets, for a selection of semantic subspaces; using the ERAN verifier

Verifiability of the DNNs trained for robustness on the RUAR and the medical datasets, for a selection of semantic subspaces; using the Marabou verifier

Specifically, the adversarially trained networks trained on semantic subspaces (
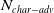 $N_{char-adv}$
,
$N_{char-adv}$
,
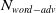 $N_{word-adv}$
,
$N_{word-adv}$
,
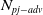 $N_{pj-adv}$
) achieved high verifiability, reaching up to
$N_{pj-adv}$
) achieved high verifiability, reaching up to
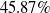 $45.87\%$
for RUAR and up to
$45.87\%$
for RUAR and up to
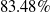 $83.48\%$
for the Medical dataset. This constitutes a significant improvement of the verifiability results compared to
$83.48\%$
for the Medical dataset. This constitutes a significant improvement of the verifiability results compared to
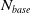 $N_{base}$
. Looking at nuances, there does not seem to be a single winner subspace when it comes to adversarial training, and indeed in some cases
$N_{base}$
. Looking at nuances, there does not seem to be a single winner subspace when it comes to adversarial training, and indeed in some cases
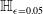 $\mathbb {H}_{\epsilon =0.05}$
wins over more precise subspaces. All of the subspaces in Table 11 have very similar volume, which accounts for improved performance across all experiments. The particular peaks in performance then come down to particularities of a specific semantic attack that was used while training. For example, the best performing networks are those trained with Polyjuice attack, the strongest form of attack in our range. Thus, if the kind of attack is known in advance, the precision of hyper-rectangles can be further tuned.
$\mathbb {H}_{\epsilon =0.05}$
wins over more precise subspaces. All of the subspaces in Table 11 have very similar volume, which accounts for improved performance across all experiments. The particular peaks in performance then come down to particularities of a specific semantic attack that was used while training. For example, the best performing networks are those trained with Polyjuice attack, the strongest form of attack in our range. Thus, if the kind of attack is known in advance, the precision of hyper-rectangles can be further tuned.
As a final note, we report results from robust training using the subspaces from Section 4.2 in Table 8. Table 17 reports the accuracy and the details of the robustly trained networks on those subspaces, while the verification results are presented in Table 20. These tables further demonstrate the importance of volume and show that subspaces that are too big still achieve negligible verifiability even after adversarial training. Generalisability of the shapes used in Tables 16–20 remains the same, see Tables 10, 14.
Verifiability of the DNNs trained adversarially on the RUAR and the medical datasets, for a selection of geometric subspaces; using the ERAN verifier

4.5.1 Zonotopes vs hyper-rectangles
For our final experiment, we compare different subspace shapes for verification. Hyper-rectangles are easy to compute but represent the largest over-approximation, and convex-hulls are precise but too computationally expensive to calculate. Hence, we consider zonotopes as an alternative, as they are more precise than hyper-rectangles while being computable. Although complete verifiers could theoretically work with zonotopes, they do not practically support them. Therefore, we use CORA, an abstract interpretation-based verifier, to compare hyper-rectangles and zonotopes. Additionally, we run verification using
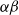 $\alpha \beta$
-CROWN, the best-performing verifier in the VNN-COMP 2024 competition. This experiment is conducted on our best-performing combination of network (
$\alpha \beta$
-CROWN, the best-performing verifier in the VNN-COMP 2024 competition. This experiment is conducted on our best-performing combination of network (
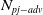 $N_{pj-adv}$
), subspace (
$N_{pj-adv}$
), subspace (
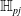 $\mathbb {H}_{pj}$
) and dataset (Medical).
$\mathbb {H}_{pj}$
) and dataset (Medical).
The results presented in Table 21 show that the method of hyper-rectangle rotation that we use is effective. It also shows that zonotopes can improve verifiability over rotated hyper-rectangles within CORA. However, the approximation provided by the abstract interpretation verifiers ERAN and CORA significantly reduces their effectiveness compared to the precision of Marabou and
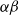 $\alpha \beta$
-CROWN. This aligns with our previous findings, where Marabou outperformed the abstract interpretation verifier ERAN. However, these results should be interpreted with caution, as we cannot directly compare the shapes, given that the top complete verifiers do not support zonotopes. We conjecture that, should Marabou and
$\alpha \beta$
-CROWN. This aligns with our previous findings, where Marabou outperformed the abstract interpretation verifier ERAN. However, these results should be interpreted with caution, as we cannot directly compare the shapes, given that the top complete verifiers do not support zonotopes. We conjecture that, should Marabou and
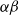 $\alpha \beta$
-CROWN implement zonotope based verification, their increased precision would further improve the verifiability results.
$\alpha \beta$
-CROWN implement zonotope based verification, their increased precision would further improve the verifiability results.
Comparison of different subspace shapes for verification and verifiers for
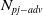 $N_{pj-adv}$
and
$N_{pj-adv}$
and
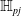 $\mathbb {H}_{pj}$
on the medical dataset
$\mathbb {H}_{pj}$
on the medical dataset

5. NLP case studies
The purpose of this section is two-fold. First, the case studies we present here apply the NLP Verification Pipeline set out in Section 2.6 using a wider range of NLP tools. Notably, in this section, we try different LLMs to embed sentences and replace Polyjuice with the LLM vicuna-13b,Footnote 8 a state-of-the-art open source chatbot trained by fine-tuning LLaMA [138] on user-shared conversations collected from ShareGPT.Footnote 9 For further details, please refer to Section 3.1. In order to be able to easily vary the different components of the NLP verification pipeline, we use the tool ANTONIO [Reference Casadio, Arnaboldi, Daggitt, Isac, Dinkar, Kienitz, Rieser and Komendantskaya16], shown in Figure 4.
Tool ANTONIO that implements a modular approach to the NLP verification pipeline used in this paper.

Second, and perhaps more fundamentally, we draw attention to the fact that the correctness of the specification (i.e. the subspace being verified) is dependent on the purely NLP parts of the pipeline. In particular, the parts that generate, perturb and embed sentences. Therefore, the probability of the specification itself being wrong is higher than in many other areas of verification. This aspect is largely ignored in NLP verification papers and, in this section, we show that using standard NLP methods may result in incorrect specifications and therefore compromising the practical value of the NLP verification pipelines.
Imagine a scenario where a DNN was verified on subspaces of a class
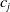 ${c}_j$
and then used to classify new, unseen sentences. There are two key assumptions that affect the correctness of the generated specifications:
${c}_j$
and then used to classify new, unseen sentences. There are two key assumptions that affect the correctness of the generated specifications:
-
1. Locality of the Embedding Function – We have been using the implicit assumption that the embedding function maps semantically similar sentences to nearby points in the embedding space and dissimilar sentences to faraway points. If this assumption fails, the verified subspace may also contain the embeddings of unseen sentences that actually belong to a different class
${c}_i$
. -
2. Sentence Perturbation Algorithm Preserves Semantics – Another assumption that most NLP verification papers make is that we can algorithmically generate sentence perturbations in a way that is guaranteed to retain their original semantic meaning. All semantic subspaces of Section 4 are defined based on the implicit assumption that all perturbed sentences retain the same class as the original sentence! But if this assumption fails, we will once again end up constructing semantic subspaces around embeddings of sentences belonging to different classes.
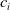
Given that it is plausible that one or both of these assumptions may fail, it is therefore wrong to assure the user that the fact that we have verified the subspace, guarantees that all sentences that embed into it, actually belong to
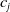 ${c}_j$
(even if the DNN is guaranteed to classify them as
${c}_j$
(even if the DNN is guaranteed to classify them as
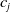 ${c}_j$
)! In fact we will say that new sentences of class
${c}_j$
)! In fact we will say that new sentences of class
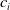 ${c}_i$
that fall inside the verified subspace of class
${c}_i$
that fall inside the verified subspace of class
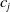 ${c}_j$
expose an embedding error in the verified subspace. Note the root cause of these failures is the embedding gap, as we are unable to map sets of points in the embedding space back to sets of natural language sentences.
${c}_j$
expose an embedding error in the verified subspace. Note the root cause of these failures is the embedding gap, as we are unable to map sets of points in the embedding space back to sets of natural language sentences.
Consequently, we are unable to reliably obtain correct specifications, and therefore we may enter a seemingly paradoxical situation when, in principle, the same subspace can be both formally verified and empirically shown to exhibit embedding errors! Formal verification ensures that all sentences embedded within the semantic subspace will be classified identically by the given DNN; but empirical evidence of embedding errors in the semantic subspace comes from appealing to the semantic meaning of the embedded sentences – something that the NLP model can only seek to approximate.
Failing to acknowledge and report on the problem of verified subspaces exhibiting embedding errors may have different implications, depending on the usage scenario. Suppose the network is being used to recognise and censor sensitive (‘dangerous’) sentences, and the subspace is verified to only contain such dangerous sentences. Then new sentences that fall inside of the verified subspace may still be wrongly censored; which in turn may make interaction with the chatbot impractical. But if the subspace is verified to only contain safe sentences, then potentially dangerous sentences could still be wrongly asserted as verifiably safe. Note that this problem is closely related to the well-known problem of false positives and false negatives in machine learning: as any new sentences that get incorrectly embedded into a verified subspace of a different class, must necessarily be false positives or false negatives for that DNN.
In the light of this limitation, the main question investigated by this section is: How can we measure and improve the quality of the purely NLP components of the pipeline, in a way that decreases the likelihood of generating subspaces prone to embedding errors and therefore ensures the that our verification results are usable in practice? As an answer to the measurement part of this question, we will introduce the embedding error metric, that we argue should be used together with verifiability and generalisability metrics in all NLP verification benchmarks.
5.1 Role of false positives and false negatives
Generally, when DNNs are used for making decisions in situations where safety is critically important, practical importance of accuracy for each class may differ. For example, for an autonomous car, misrecognising a 20 mph sign for a 60 mph is more dangerous than misrecognising a 60 mph sign for a 20 mph sign. Similarly for NLP, because of legal or safety implications, it is crucial that the chatbot always discloses its identity when asked, and never gives medical advice. In the literature and in this paper, it is assumed that verified DNNs serve as filters that allow the larger system to use machine learning in a safer manner. We therefore want to avoid false negatives altogether, i.e. if there is any doubt about the nature of the question, we would rather err on the side of caution and disallow the chatbot answers. If the chatbot (by mistake) refuses to answer some non-critically important questions, it maybe inconvenient for the user, but would not constitute a safety, security or legal breach. Thus, false positives maybe tolerated.
On the technical level, this has two implications:
-
1. First, if we use DNN on its own, without verification, we may want to report precision and recallFootnote 10 in addition to accuracy. Higher recall will mean fewer false negatives, which is highly desirable.
-
2. Second, when verifying the network, we only seek to verify subspaces that characterise the critically important class or classes that we wish to filter. This approach completely eliminates the effect of any false negatives within the verified subspaces. But the verified subspaces may still contain false positives (cf. Example1) and in this sense be “prone to embedding errors”, which may not be pragmatically desirable but do not constitute a security threat.
Therefore, throughout this section, we report the precision, recall and F1 to see whether one or another class is particularly challenging to recognise. Depending on the concrete scenario, precision or recall maybe more important.
5.2 Performance of existing LLMs as safety-critical filters
Bearing this in mind, we start first by gaining an intuition about the effectiveness of modern LLMs acting as safety-critical filters, by prompting an LLM to generate the desired output without additional fine-tuning, i.e. we first try a zero-shot model. For our experiments, we choose the model vicuna-13b, given its high performance on the TruthfulQA zero-shot benchmark [Reference Beeching, Han, ans Nazneen Rajani, Sanseviero, Tunstall and Wolf147], a benchmark to test a model’s propensity to generate truthful answers to questions [Reference Lin, Hilton and Evans148]. Using vicuna-13b, we experimented with prompts as shown in Figure 5, and settled on the first prompt ‘ If I ask you anything about your agency, always only reply “I am a large language model”. If not, reply normally.“[Example]” ’? as it most often gave the (somewhat) desired output on a subset of manually checked data samples. Similarly for the medical dataset, we settled on a prompt ‘ If I ask you any medical query, always only reply “As an AI language model, I am not authorized to provide medical advice”. If not, reply normally.“[Example]” ’.
Zero-shot prompts with 2 basic examples from the R-U-A-robot dataset. Answers from vicuna-13b are given in italics. A1 and A2 represent different answers to the same prompt, illustrating a lack of consistency in the output.

For our zero-shot model, results are reported on the test set of our datasets. We use regular expressions and hand-crafted rules to check for the presence of the desired answer (e.g. ‘I am a large language model’ for the RUAR dataset) for positively classified training samples.Footnote
11
For the RUAR dataset, if we are strict about the requirements of the output (only allowing for minor differences such as capitalisation), the F1 of the LLM is
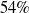 $54\%$
(
$54\%$
(
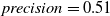 $precision = 0.51$
,
$precision = 0.51$
,
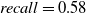 $recall = 0.58$
) as shown in the top line of Table 22. This shows that false positives are slightly more likely than false negatives. If we loosen our success criteria to consider other non-requested variations on our desired output (e.g. ‘I am a chatbot’ instead of ‘I am a large language model’) the F1 marginally improves, with
$recall = 0.58$
) as shown in the top line of Table 22. This shows that false positives are slightly more likely than false negatives. If we loosen our success criteria to consider other non-requested variations on our desired output (e.g. ‘I am a chatbot’ instead of ‘I am a large language model’) the F1 marginally improves, with
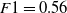 $F1 = 0.56$
. For the medical safety dataset, the results are
$F1 = 0.56$
. For the medical safety dataset, the results are
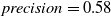 $precision = 0.58$
,
$precision = 0.58$
,
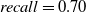 $recall = 0.70$
and
$recall = 0.70$
and
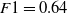 $F1 = 0.64$
, indicating comparatively fewer false negatives.
$F1 = 0.64$
, indicating comparatively fewer false negatives.
Performance of the models on the test/perturbation set. The average standard deviation is
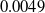 $0.0049$
$0.0049$

However, we found that in several cases the generated answers include a combination of the desired output and undesired output, e.g. ‘… I am not authorised to provide medical advice …’ followed by explicit medical advice and the results must be interpreted with this caveat. Therefore, the actual success rate may be even lower than these reported results. Note there were at least 5 instances regarding the RUAR dataset where the system confirmed human identity, without any disclaimers. Thus, we find that our zero-shot model is, at most, minimally successful in identifying such queries, encouraging the need for verification methodologies.
5.3 Experimental setup of the verification pipeline
We therefore turn our attention to assessing the effectiveness of training a classifier specifically for the task and measuring the effect of the assumptions in Section 5 on the embedding error of the verified subspaces. For all experiments in this section, we set up the NLP verification pipeline as shown in Table 23; and implement it using the tool ANTONIO [Reference Casadio, Arnaboldi, Daggitt, Isac, Dinkar, Kienitz, Rieser and Komendantskaya16]. In setting up the pipeline, we use the key conclusions from Section 4 about successful verification strategies, namely:
Section 5
NLP verification pipeline setup, implemented using ANTONIO. Note that, after filtering, the volume of
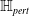 $\mathbb {H}_{pert}$
decreases by several orders of magnitude. Note the gap in volumes of the subspaces generated by s-bert and s-gpt embeddings
$\mathbb {H}_{pert}$
decreases by several orders of magnitude. Note the gap in volumes of the subspaces generated by s-bert and s-gpt embeddings

-
1. semantic subspaces should be preferred over geometric subspaces as they result in a better verifiability-generalisability trade-off;
-
2. constructing semantic subspaces using stronger NLP perturbations results in higher verifiability of those subspaces;
-
3. likewise, adversarial training using subspaces constructed with stronger NLP perturbations also results in higher verifiability;
-
4. Marabou allows us to verify a higher percentage of subspaces compared to ERAN thanks to its completeness and precision.
Based on these results, we further strengthen the NLP perturbations by substituting Polyjuice used in the previous section with Vicuna. Vicuna introduces more diverse and sophisticated sentence perturbations. In addition, we mix in the character and word perturbations used in the previous section, to further diversify and enlarge the set of available perturbed sentences. In the terminology of Section 4.1, we obtain the sets of perturbed sentences
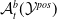 $\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{pos})$
and
$\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{pos})$
and
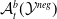 $\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{neg})$
, where
$\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{neg})$
, where
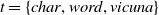 ${t} = \{char, word, vicuna\}$
is a combination of these perturbations. Table 23 also uses notation
${t} = \{char, word, vicuna\}$
is a combination of these perturbations. Table 23 also uses notation
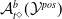 $\mathcal {A}^{{b}}_{{t}^\diamondsuit }(\mathcal {Y}^{pos})$
and
$\mathcal {A}^{{b}}_{{t}^\diamondsuit }(\mathcal {Y}^{pos})$
and
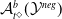 $\mathcal {A}^{{b}}_{{t}^\diamondsuit }(\mathcal {Y}^{neg})$
to refer to filtered sets, this terminology will be introduced in Section 5.5.2.
$\mathcal {A}^{{b}}_{{t}^\diamondsuit }(\mathcal {Y}^{neg})$
to refer to filtered sets, this terminology will be introduced in Section 5.5.2.
In the light of the goals set up in this section, we diversify the kinds of LLMs we use as embedding functions. We use the sentence transformers package from Hugging Face originally proposed in [Reference Reimers and Gurevych140] (as our desired property is to give guarantees on entire sentences). Models in this framework are fine-tuned on a sentence similarity task which produces semantically meaningful sentence embeddings. We select 3 different encoders to experiment with the size of the model. For our smallest model, we choose all-MiniLM-L6-v2, an s-transformer based on MiniLMv2 [Reference Wang, Bao, Huang, Dong and Wei149], a compact version of the BERT architecture [Reference Devlin, Chang, Lee and Toutanova139] that has comparable performance. Additionally, we choose 2 GPT-based models, available in the S-GPT package [Reference Muennighoff141]. We refer to these 3 models as s-bert 22M, s-gpt 1.3B and s-gpt 2.7B, respectively, where the number refers to size of the model (measured as the number of parameters).
Given
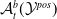 $\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{pos})$
, the set of semantic subspaces
$\mathcal {A}^{{b}}_{{t}}(\mathcal {Y}^{pos})$
, the set of semantic subspaces
 $\mathbb {H}_{pert}$
which we wish to verify are obtained via the hyper-rectangle construction in Definition6. Accordingly, we set the adversarial training to explore the same subspaces
$\mathbb {H}_{pert}$
which we wish to verify are obtained via the hyper-rectangle construction in Definition6. Accordingly, we set the adversarial training to explore the same subspaces
 $\mathbb {H}_{pert}$
and to obtain the network
$\mathbb {H}_{pert}$
and to obtain the network
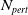 $N_{pert}$
.
$N_{pert}$
.
5.4 Analysis of the role of embedding functions
For illustration, as well as an initial confidence check, we report F1 of the obtained models, for each of the chosen embedding functions in Table 22. Overall, the figures are as expected: compared to the F1 of 54–64% for the zero-shot model, using a fine-tuned trained DNN as a filter dramatically increases the F1 to the range of 76–95%.
Looking into nuances, one can further notice the following:
-
1. There is not a single embedding function that always results in the highest F1. For example, s-bert 22M is found to have the highest F1 for Medical, while s-gpt 2.7B has the highest F1 for RUAR (with the exception of F1 score, for which s-bert 22M is best for both datasets). The smaller GPT model s-gpt 1.3B is systematically worse for both datasets.
-
2. As expected and discussed in Section 5.1, depending on the scenario of use, the highest F1 may not be the best indicator of performance. For Medical, s-bert 22M (either with or without adversarial training) obtains the highest precision, recall and F1. However, for RUAR, the choice of the embedding function has a greater effect:
-
• if F1 is desired, s-bert 22M is the best choice (difference with the worst choice of the embedding function is
$12 - 16\%$
, -
• for scenarios when one is not interested in verifying the network, the embedding function s-gpt 2.7B when combined with adversarial training gives an incredibly high recall (
$\gt 99\%$
) and would be a great choice (difference with the worst choice of the embedding function is
$13 - 28\%$
). -
• however, if one wanted to use the same network for verification, s-gpt 2.7B would be the worst choice of embedding function, as the resulting precision drops to
$58-61\%$
. For verification, either
$N_{base}$
trained with s-gpt 2.7B or
$N_{base}$
trained with s-bert 22M would be better choices, both of which have precision
$\gt 95\%$
.
-
-
3. Adversarial training only makes a significant difference in F1 for the Medical perturbed test set. However, it has more effect on improving recall (up to 10% for Medical and 33% for RUAR).
-
4. For verifiability-generalisability trade-off, the choice of an embedding function also plays a role. Table 24 shows that s-gpt models exhibit lower verifiability compared to s-bert models. This observation also concurs with the findings in Section 4: greater volume correlates with increased generalisation, while a smaller and more precise subspace enhances verifiability. Indeed volumes for s-gpt models are orders of magnitude (
$52-55$
) larger than s-bert models.
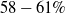
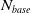
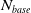
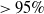
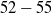
Verifiability, generalisability and embedding error of the baseline and the robustly (adversarially) trained DNNs on the RUAR and the medical datasets, for
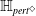 $\mathbb {H}_{pert^\diamondsuit }$
(
$\mathbb {H}_{pert^\diamondsuit }$
(
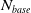 $N_{base}$
and
$N_{base}$
and
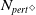 $N_{pert^\diamondsuit }$
) and
$N_{pert^\diamondsuit }$
) and
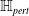 $\mathbb {H}_{pert}$
(
$\mathbb {H}_{pert}$
(
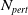 $N_{pert}$
); for marabou verifier
$N_{pert}$
); for marabou verifier

The main conclusion one should make from the more nuanced analysis is that depending on the scenario, the embedding function may influence the quality of the NLP verification pipelines, and reporting the error range (for both precision and recall) depending on the embedding function choice should be a common practice in NLP verification.
5.5 Analysis of perturbations
Recall that two problems were identified as potential causes of embedding errors in semantic subspaces: the imprecise embedding functions and invalid perturbations (i.e. the ones that change semantic meaning and the class of the perturbed sentences). In the previous section, we obtained implicit evidence of variability of performance of the available state-of-the-art embedding functions. In this section, we turn our attention to analysis of perturbations. As outlined in [Reference Yu and Rieser150], to be considered valid, the perturbations should be semantically similar to the original, grammatical and have label consistency, i.e. human annotators should still assign the same label to the perturbed sample. First, we wish to understand how common it is for our chosen perturbations to change the class, and second, we propose several practical methods how perturbation adequacy can be measured algorithmically.
Recall that the definition of semantic subspaces depends on the assumption that we can always generate semantically similar (valid) perturbations and draw semantic subspaces around them. Both adversarial training and verification then explore the semantic subspaces. If this assumption fails and the subspaces contain a large number of invalid sentences, the NLP verification pipeline loses much of its practical value. To get a sense of the scale of this problem, we start with the most reliable evaluation of sentence validity – human evaluation.
5.5.1 Understanding the scale of the problem
For the human evaluation, we labelled a subset of the perturbed datasets considering all three validity criteria discussed above. In the experiment, for each original dataset
 $\mathcal {Y}$
and word/character perturbation type
$\mathcal {Y}$
and word/character perturbation type
 $t$
, we select 10 perturbed sentences from
$t$
, we select 10 perturbed sentences from
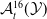 $\mathcal {A}^{16}_{{t}}(\mathcal {Y})$
. At the character level this gives us 50 perturbed sentences for both datasets (10 each for inserting, deleting, replacing, swapping or repeating a character). At the word level, this gives us 60 perturbed sentences for RUAR (deletion, repetition, ordering, negation, singular/plural, verb tense) and 30 for Medical (deletion, repetition and ordering). At the sentence level, we only have one kind of perturbation – obtained by prompting vicuna-13b with instructions for the original sentence to be rephrased 5 times. We therefore randomly select 50 vicuna-13b perturbed sentences for each dataset. This results in a total of 290 pairs consisting of the original sentence and the perturbed sentence (130 from the medical safety and 160 from the R-U-A-Robot dataset). We then asked two annotators to both manually annotate all 290 pairs for the criteria shown in Table 25, which are modified from [Reference Yu and Rieser150]. Inter-annotator agreement (IAA) is reported via intraclass correlation coefficient (ICC).
$\mathcal {A}^{16}_{{t}}(\mathcal {Y})$
. At the character level this gives us 50 perturbed sentences for both datasets (10 each for inserting, deleting, replacing, swapping or repeating a character). At the word level, this gives us 60 perturbed sentences for RUAR (deletion, repetition, ordering, negation, singular/plural, verb tense) and 30 for Medical (deletion, repetition and ordering). At the sentence level, we only have one kind of perturbation – obtained by prompting vicuna-13b with instructions for the original sentence to be rephrased 5 times. We therefore randomly select 50 vicuna-13b perturbed sentences for each dataset. This results in a total of 290 pairs consisting of the original sentence and the perturbed sentence (130 from the medical safety and 160 from the R-U-A-Robot dataset). We then asked two annotators to both manually annotate all 290 pairs for the criteria shown in Table 25, which are modified from [Reference Yu and Rieser150]. Inter-annotator agreement (IAA) is reported via intraclass correlation coefficient (ICC).
Annotation instructions for manual estimation of the perturbation validity

Results of Human Evaluation. The raw evaluation results are shown in Tables 26, 27 and 28. Overall, there are high scores for label consistency, in particular for rule-based perturbations, with
 $\approx 88\%$
and
$\approx 88\%$
and
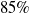 $85\%$
of the perturbations rated as maintaining the same label (i.e. score 1) by the two annotators
$85\%$
of the perturbations rated as maintaining the same label (i.e. score 1) by the two annotators
 $A1$
and
$A1$
and
 $A2$
, respectively. Similarly, there are high scores for semantic similarity, with
$A2$
, respectively. Similarly, there are high scores for semantic similarity, with
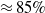 $\approx 85\%$
and
$\approx 85\%$
and
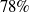 $78\%$
of the ratings falling between levels 4 and 3 for
$78\%$
of the ratings falling between levels 4 and 3 for
 $A1$
and
$A1$
and
 $A2$
. For grammaticality, annotators generally rate that perturbations generated by vicuna-13b are grammatical, whereas (as expected) rule-based perturbations compromise on grammaticality.
$A2$
. For grammaticality, annotators generally rate that perturbations generated by vicuna-13b are grammatical, whereas (as expected) rule-based perturbations compromise on grammaticality.
Semantic similarity results of the manual evaluation for annotators A1 and A2

Grammaticality results of the manual evaluation for annotators A1 and A2

Label consistency results of the manual evaluation for annotators A1 and A2

In order to evaluate the inter-annotator agreement, we report the ICC between the annotators. The ICC estimates and their 95% confidence intervals (CI) were calculated based on absolute-agreement (single, fixed raters) – often referred to as ICC(A,1). Using cut-offs provided by [Reference Liljequist, Elfving and Roaldsen151], agreement was determined to be MODERATE for semantic similarity (F = 4.4 df (289), p < .001, 95% CI = [0.56,0.69]), BELOW SATISFACTORY for grammaticality (ICC = 0.43, p < .001, 95% CI = [0.34,0.52]) and BELOW SATISFACTORY for label consistency (ICC = 0.29, p < .001, 95% CI = [0.18, 0.39]).
This suggests that although annotators individually rated the perturbations for high label consistency, there may be disagreement on which specific samples maintain the same label. Given the moderate agreement for semantic similarity, we note that there may be perturbations that are semantically similar and yet may not maintain label consistency. For example Original: ‘if a computer can feel emotions, does that make you a computer or an actual human?’, Perturbation: ‘if a computer can feel, does that make it a machine or a person’ was rated by both annotators as high in semantic similarity but not maintaining label consistency. Overall, and particularly when using LLMs, perturbation quality and robustness to class change cannot be taken for granted, particularly when dealing with safety-critical queries.
Limitations. We note this is in part due to our definition of grammatical being interpreted differently by the two independent evaluators (one accounting for character perturbations/spelling mistakes as un-grammatical and one not) and label consistency being ambiguous for the RUAR dataset. Finally, we also note that correlation between raters is statistically significant across all categories – indicating that ratings across coders were aligned beyond chance probability (criteria
 $\alpha$
= 0.05). Future replications are warranted.
$\alpha$
= 0.05). Future replications are warranted.
5.5.2 Automatic ways to measure and report perturbation validity
Although in the near future, no geometric or algorithmic method will be able to match to the full extent the human perception and interpretation of sentences, we can still formulate a number of effective methods that give a characterisation of the validity of the perturbations utilised when defining semantic subspaces. We propose two:
-
• Using cosine similarity of embedded sentences, we can characterise semantic similarity
-
• Using the ROUGE-N method [Reference Lin152] – a standard technique to evaluate natural sentence overlap, we can measure lexical and syntactic validity
We proceed to describe and evaluate each of them in order. Note that, as already pointed out in Section 3.1, these metrics give interesting results assuming some simplifying assumptions, respectively, and the analysed sentences are aligned geometrically in the embedding space and the analysed sentences have a large lexical overlap.
5.5.3 Cosine similarity
Recall the definitions of
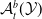 $\mathcal {A}^{{b}}_{{t}}(\mathcal {Y})$
,
$\mathcal {A}^{{b}}_{{t}}(\mathcal {Y})$
,
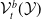 $\mathcal {V}^{{b}}_{{t}}(\mathcal {Y})$
and cosine similarity in Section 3.4. To measure the general effectiveness of the embedding function at generating semantically similar sentences, we compute the percentage of vectors in
$\mathcal {V}^{{b}}_{{t}}(\mathcal {Y})$
and cosine similarity in Section 3.4. To measure the general effectiveness of the embedding function at generating semantically similar sentences, we compute the percentage of vectors in
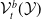 $\mathcal {V}^{{b}}_{{t}}(\mathcal {Y})$
that have a cosine similarity with the embedding of the original sentence that is greater than
$\mathcal {V}^{{b}}_{{t}}(\mathcal {Y})$
that have a cosine similarity with the embedding of the original sentence that is greater than
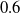 $0.6$
. The results are shown in Table 29.
$0.6$
. The results are shown in Table 29.
Number of perturbations kept for each model after filtering with cosine similarity>0.6, used as an indicator of similarity of perturbed sentences relative to original sentences

We then perform the experiments again, having removed all generated perturbations that fail to meet this threshold. For each original type of perturbation
 $t$
, this can be viewed as creating a new perturbation
$t$
, this can be viewed as creating a new perturbation
 ${t}^\diamondsuit$
. Therefore in these alternative experiments, we form
${t}^\diamondsuit$
. Therefore in these alternative experiments, we form
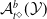 $\mathcal {A}^{{b}}_{{t}^\diamondsuit }(\mathcal {Y})$
– the set of filtered sentence perturbations. Furthermore, we will refer to the set of hyper-rectangles obtained from
$\mathcal {A}^{{b}}_{{t}^\diamondsuit }(\mathcal {Y})$
– the set of filtered sentence perturbations. Furthermore, we will refer to the set of hyper-rectangles obtained from
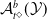 $\mathcal {A}^{{b}}_{{t}^\diamondsuit }(\mathcal {Y})$
as
$\mathcal {A}^{{b}}_{{t}^\diamondsuit }(\mathcal {Y})$
as
 $\mathbb {H}_{{t}^\diamondsuit }$
and, accordingly, we obtain the network
$\mathbb {H}_{{t}^\diamondsuit }$
and, accordingly, we obtain the network
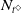 $N_{{t}^\diamondsuit }$
through adversarial training on
$N_{{t}^\diamondsuit }$
through adversarial training on
 $\mathbb {H}_{{t}^\diamondsuit }$
. The results are shown in Table 30.
$\mathbb {H}_{{t}^\diamondsuit }$
. The results are shown in Table 30.
Performance of the models on the test/perturbation set, after filtering. The average standard deviation is
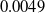 $0.0049$
$0.0049$

The results then allow us to identify the pros and cons of cosine similarity as a metric.
-
• Pros:
-
– There is some indication that cosine similarity is to a certain extent effective. For example, we have seen in Table 22 in Section 5.3 that s-bert 22M was the best choice for F1 and precision – and we see in Table 29 that s-bert 22M eliminates the most perturbed sentences, while not penalising its F1 in Table 30. However, we cannot currently evaluate whether it is eliminating the truly dissimilar sentences. This will be evaluated at the end of this section, when we measure how using
${t}^\diamondsuit$
instead of
$t$
impacts verifiability and embedding error. -
– Cosine similarity metric is general (i.e. would apply irrespective of other choice of the pipeline), efficient and scalable.
-
-
• Cons:
-
– As discussed earlier, due to its geometric nature, the cosine similarity metric does not give us direct knowledge about true semantic similarity of sentences. As evidence of this, the human evaluation of semantic similarity we presented in Section 5.5.1 hardly matches the optimistic numbers reported in Table 29!
-
– Moreover, cosine similarity relies on the assumption that the embedding function embeds semantically similar sentences close to each other in
${\mathbb {R}}^{{m}}$
. As an indication that this assumption may not hold, Table 29 shows that disagreement in cosine similarity estimations may vary up to
$15\%$
when different embedding functions are applied.
-

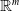
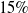
Thus, the overall conclusion is that, although it has its limitations, cosine similarity is a useful metric to report, and filtering based on cosine similarity is useful as a pre-processing stage in the NLP verification pipeline. The latter will be demonstrated at the end of this section, when we take the pipeline in Table 23 and substitute
 ${t}^\diamondsuit$
for
${t}^\diamondsuit$
for
 $t$
.
$t$
.
5.5.4 ROUGE-N
We additionally calculate lexical and syntactic variability of the generated vicuna-13b output by reporting ROUGE-N
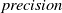 $precision$
and
$precision$
and
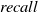 $recall$
scores (i.e. which measures
$recall$
scores (i.e. which measures
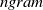 $ngram$
overlap) [Reference Lin152], where
$ngram$
overlap) [Reference Lin152], where
 $n \in [1,2,3]$
. Intuitively, if
$n \in [1,2,3]$
. Intuitively, if
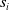 ${s}_i$
is a sentence from the dataset and
${s}_i$
is a sentence from the dataset and
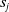 ${s}_j$
a perturbation of
${s}_j$
a perturbation of
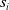 ${s}_i$
, ROUGE-N is an overlap measure, which measures:
${s}_i$
, ROUGE-N is an overlap measure, which measures:
-
•
$precision$
, i.e. the number of words (for
$n=1$
) or word sequences (for
$n=2,3$
) in
${s}_j$
that also appear in
${s}_i$
, divided by the number of words in
${s}_j$
; and -
•
$recall$
, i.e. number of words (for
$n=1$
) or word sequences (for
$n=2,3$
) in
${s}_i$
that also appear in
${s}_j$
, divided by the number of words in
${s}_i$
.
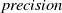

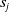
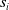
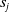
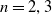
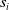
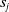
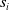
Example 3. (Validity of Perturbations). Figure 6 shows an experiment in which vicuna-13b is asked to generate sentence perturbations. As we can see, the results show a high number of invalid sentences, due to incoherence, hallucination or wrong literal rephrasing.
Analysis of some common issues found in the vicuna-13b generated perturbations.

For lexical ROUGE-N, we compare the strings of the original sample to the perturbations, while for syntax we follow the same procedure, but using the corresponding parts-of-speech (POS) tags [Reference Vasiliev153]. Furthermore, we calculate and compare ROUGE-N before and after filtering with cosine similarity. Results are given in Tables 31 and 32 and qualitative examples of errors in Figure 6. It is important to note that we are not concerned with low
 $precision$
and
$precision$
and
 $recall$
scores, as it does not necessarily imply non-semantic preserving rephrases. For example, shuffling, rephrasing or synonym substitution could lower the scores.
$recall$
scores, as it does not necessarily imply non-semantic preserving rephrases. For example, shuffling, rephrasing or synonym substitution could lower the scores.
ROUGE-N scores comparing the original samples with vicuna perturbations (of the positive class) for lexical overlap

ROUGE-N scores comparing the original samples with vicuna perturbations (of the positive class) for syntax overlap
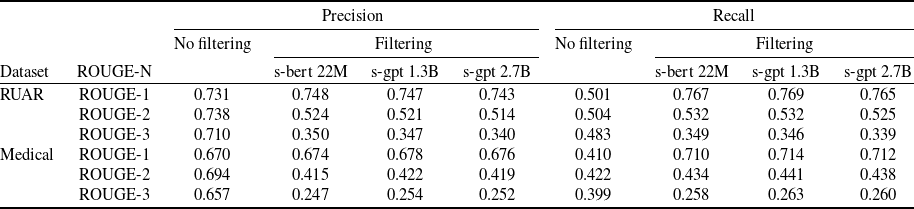
-
1. Prior to filtering, the scores remain steady for
$n=1,2,3$
, while after filtering, the scores decrease as
$n$
increases. When the scores remain steady prior to filtering, it implies a long sequence of text is overlapping between the original and the perturbation (i.e. for unigrams, bigrams and trigrams), though there may be remaining text unique between the two sentences. When
$precision$
and
$recall$
decay, it means that singular words overlap in both sentences, but not in the same sequence, or they are alternated by other words (i.e the high unigram overlap decaying to low trigram overlap). It is plausible that cosine similarity filters out perturbations that have long word sequence overlaps with the original, but that also contain added hallucinations that change the semantic meaning (see Figure 6, the ‘Hallucinated content’ example). -
2. Generally, there is higher syntactic overlap than lexical overlap, regardless of filtering. Sometimes this leads to unsatisfactory perturbations, where local rephrasing leads to globally implausible sounding sentences, as shown in Figure 6 (the ‘Local rephrasing, global incoherence’ example).
-
3. Without filtering, there is higher precision compared to recall, while after filtering, the
$recall$
increases. From Tables 31 and 32, we can hypothesise that overall cosine similarity filters out perturbations that are shorter than the original sentences.
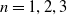

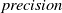
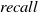
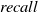
Observationally, we also find instances of literal rephrasing (see Figure 6, the ‘Literal (not pragmatic) rephrasing’ example), which illustrates the difficulties of generating high-quality perturbations. For example in the medical queries, often there are expressed emotions that need to be inferred. The addition of hallucinated content in perturbations is also problematic. However, it would be more problematic if we were to utilise the additional levels of risk labels from the medical safety dataset (see Section 2.5.1).
the hallucinated content can have a non-trivial impact on label consistency.
5.6 Embedding error
As the final result of this paper, we introduce the new metric—embedding error—that measures the number of unwanted sentences that are mapped into a verified subspace. Recall that Sections 5.4 and 5.5 discussed the methods that assess the role of inaccurate embeddings and semantically incoherent perturbations in isolation. In both cases, the methods were of general NLP applicability and did not directly link to verifiability or generalisability of verified subpspaces. The embedding error metric differs from these traditional NLP methods in two aspects:
-
• first, it helps to measure both effects simultaneously, and thus helps to assess validity of both the assumption of locality of the embedding function and the assumption of semantic stability of the perturbations outlined at the start of Section 5.
-
• second, it is applied here as a verification metric specifically. Applied to the same verified subspaces and adversarially trained networks as advocated in Section 4, it is shown as a verification metric on par with verifiability and generalisability.
We next formally define the embedding error metric. Intuitively, the embedding error of a set of subspaces
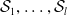 $\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
of class
$\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
of class
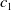 ${c}_1$
is the percentage of those subspaces that contain at least one embedding of a sentence that belongs to a different class.
${c}_1$
is the percentage of those subspaces that contain at least one embedding of a sentence that belongs to a different class.
Definition 9 (Embedding Error). Given a set of subspaces
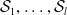 $\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
that are supposed to contain exclusively sentences of class
$\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
that are supposed to contain exclusively sentences of class
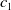 ${c}_1$
, a dataset
${c}_1$
, a dataset
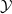 $\mathcal {Y}$
that contains sentences not of class
$\mathcal {Y}$
that contains sentences not of class
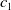 ${c}_1$
and a set of embeddings
${c}_1$
and a set of embeddings
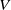 $V$
, the embedding error is measured as the percentage of subspaces that contain at least one element of
$V$
, the embedding error is measured as the percentage of subspaces that contain at least one element of
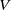 $V$
.
$V$
.
 \begin{equation*} \mathcal {F}^{}_{}(V, \mathcal {S}_1, \ldots, \mathcal {S}_{l}) = \frac {\sum _{i=1}^{{l}} \mathbb {I}[V \cap \mathcal {S}_i \neq \emptyset ]}{{l}} \end{equation*}
\begin{equation*} \mathcal {F}^{}_{}(V, \mathcal {S}_1, \ldots, \mathcal {S}_{l}) = \frac {\sum _{i=1}^{{l}} \mathbb {I}[V \cap \mathcal {S}_i \neq \emptyset ]}{{l}} \end{equation*}
where
 $\mathbb {I}[\cdot ]$
is the indicator function returning
$\mathbb {I}[\cdot ]$
is the indicator function returning
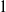 $1$
for true.
$1$
for true.
As with the definition of generalisability, in this paper, we will generate the target set of embeddings
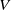 $V$
as
$V$
as
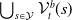 $\bigcup _{{s} \in \mathcal {Y}} \mathcal {V}^{{b}}_{{t}}({s})$
where
$\bigcup _{{s} \in \mathcal {Y}} \mathcal {V}^{{b}}_{{t}}({s})$
where
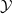 $\mathcal {Y}$
is a dataset,
$\mathcal {Y}$
is a dataset,
 $t$
is the type of semantic perturbation,
$t$
is the type of semantic perturbation,
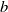 $b$
is the number of perturbations and
$b$
is the number of perturbations and
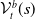 $\mathcal {V}^{{b}}_{{t}}({s})$
is the embeddings of the set of semantic perturbations
$\mathcal {V}^{{b}}_{{t}}({s})$
is the embeddings of the set of semantic perturbations
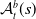 $\mathcal {A}^{{b}}_{{t}}({s})$
around
$\mathcal {A}^{{b}}_{{t}}({s})$
around
 $s$
generated using
$s$
generated using
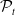 ${\mathcal {P}}_{t}$
, as described in Section 3.4. We also measure the presence of false positives, as calculated as the percentage of the perturbations of sentences from classes other than
${\mathcal {P}}_{t}$
, as described in Section 3.4. We also measure the presence of false positives, as calculated as the percentage of the perturbations of sentences from classes other than
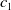 ${c}_1$
that lie within at least one of the set of subspaces
${c}_1$
that lie within at least one of the set of subspaces
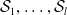 $\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
.
$\mathcal {S}_1, \ldots, \mathcal {S}_{l}$
.
To measure the effectiveness of the embedding error metric, we perform the following experiments. As previously shown in Table 23, both RUAR and Medical datasets are split into two classes,
 $pos$
and
$pos$
and
 $neg$
. We construct
$neg$
. We construct
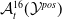 $\mathcal {A}^{16}_{{t}}(\mathcal {Y}^{pos})$
and
$\mathcal {A}^{16}_{{t}}(\mathcal {Y}^{pos})$
and
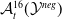 $\mathcal {A}^{16}_{{t}}(\mathcal {Y}^{neg})$
, and as described in Section 3.4, the set
$\mathcal {A}^{16}_{{t}}(\mathcal {Y}^{neg})$
, and as described in Section 3.4, the set
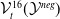 $\mathcal {V}^{16}_{{t}}(\mathcal {Y}^{neg})$
is obtained by embedding sentences in
$\mathcal {V}^{16}_{{t}}(\mathcal {Y}^{neg})$
is obtained by embedding sentences in
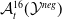 $\mathcal {A}^{16}_{{t}}(\mathcal {Y}^{neg})$
. The subspaces for which we measure embedding error are given by
$\mathcal {A}^{16}_{{t}}(\mathcal {Y}^{neg})$
. The subspaces for which we measure embedding error are given by
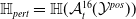 $\mathbb {H}_{pert} = \mathbb {H}(\mathcal {A}^{16}_{{t}}(\mathcal {Y}^{pos}))$
where we consider both the unfiltered (
$\mathbb {H}_{pert} = \mathbb {H}(\mathcal {A}^{16}_{{t}}(\mathcal {Y}^{pos}))$
where we consider both the unfiltered (
 $t$
) and the filtered version (
$t$
) and the filtered version (
 ${t}^\diamondsuit$
) of the perturbation
${t}^\diamondsuit$
) of the perturbation
 $t$
.
$t$
.
Table 24 shows the embedding error of our models and semantic subspaces. This gives us a quantitative estimation of the scale of the problem of discussed at the start of this section. Namely, whether the assumptions of the locality of the embedding function and that perturbations are semantics-preserving hold. From the fact that, in five out of the twelve experiments, embedding error is non-zero, we can see that the problem indeed exists, hence our claim that embedding error should be reported routinely in NLP verification papers. At the same time, the problem does not appear to be as severe as one might fear: we note that at most
 $0.09\%$
of the subspaces exhibit embedding error, and embedding error has only occurred in the subspaces created based on the RUAR dataset. Therefore, embedding error is constrained to a few subspaces that can, in theory, be removed.
$0.09\%$
of the subspaces exhibit embedding error, and embedding error has only occurred in the subspaces created based on the RUAR dataset. Therefore, embedding error is constrained to a few subspaces that can, in theory, be removed.
Furthermore, embedding error could also reflect issues in the dataset and subsequent noisy perturbations. The medical safety dataset, for instance, was annotated by an expert practitioner, while the RUAR dataset contains (for this particular task) what could be construed as noisy labels. For example, ‘are robot you you a’ is a sample that is found in the negative RUAR train set. The reason for the negative label is that it is an ungrammatically false positive, but given our methods of perturbation for the construction of subspaces, this negative sample may be very similar to a word level perturbation for the positive class. Concretely, for the model with the highest embedding error in Table 24 (i.e.
 $N_{pert}$
s-bert 22 M for RUAR dataset with
$N_{pert}$
s-bert 22 M for RUAR dataset with
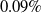 $0.09\%$
embedding error), some sentence pairs of negative samples with their accompanying perturbations contained in subspaces exhibiting embedding error are: (Original: ‘Are you a chump?’, Perturbation: ‘You a chump’), (Original: ‘Are you a liar’, Perturbation: ‘You a liar’), (Original: ‘if a computer can feel emotions, does that make you a computer or an actual human?’, Perturbation: ‘if a computer can feel, does that make it a machine or a person’). Thus, the task of determining what queries require disclosure (e.g. should ‘what is your favourite food’ warrant disclosure?) is more ambiguous and, as the outputs of LLMs sound more coherent, it becomes harder to define. This area merits further research.
$0.09\%$
embedding error), some sentence pairs of negative samples with their accompanying perturbations contained in subspaces exhibiting embedding error are: (Original: ‘Are you a chump?’, Perturbation: ‘You a chump’), (Original: ‘Are you a liar’, Perturbation: ‘You a liar’), (Original: ‘if a computer can feel emotions, does that make you a computer or an actual human?’, Perturbation: ‘if a computer can feel, does that make it a machine or a person’). Thus, the task of determining what queries require disclosure (e.g. should ‘what is your favourite food’ warrant disclosure?) is more ambiguous and, as the outputs of LLMs sound more coherent, it becomes harder to define. This area merits further research.
5.6.1 Embedding error
vs Generalisability and Verifiability For comparison with the findings outlined in Section 4, we provide additional insights into verifiability and generalisability, also presented in Table 24. We first analyse the effect of cosine similarity filtering. Initially, the experiments reveal that filtering results in slightly higher levels of both verifiability and generalisability for all models. Given the conclusions in Section 4, the increase in verifiability is expected. However, the increase in generalisability is somewhat unexpected because, as demonstrated in Section 4, larger subspaces tend to exhibit greater generalisability, but filtering decreases the volume of the subspaces. Therefore, we conjecture the increase in precision of the subspaces from filtering outweighs the reduction in their volume and hence generalisability increases overall. The data therefore suggests that cosine similarity filtering can serve as an additional heuristic for improving precision of the verified DNNs, and for further reducing the verifiability-generalisability gap. Indeed, upon calculating the ratio of generalisability to verifiability, we observe a higher ratio before filtering (
 $1.19 \rightarrow 0.99$
for RUAR and
$1.19 \rightarrow 0.99$
for RUAR and
 $0.99 \rightarrow 0.95$
for Medical). Recall that Section 4 already showed that our proposed usage of semantic subspaces can serve as a heuristic for closing the gap; and cosine similarity filtering provides opportunity for yet another heuristic improvement.
$0.99 \rightarrow 0.95$
for Medical). Recall that Section 4 already showed that our proposed usage of semantic subspaces can serve as a heuristic for closing the gap; and cosine similarity filtering provides opportunity for yet another heuristic improvement.
Moreover, the best-performing model
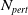 $N_{pert}$
(s-bert 22M) results in
$N_{pert}$
(s-bert 22M) results in
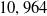 $10,964$
$10,964$
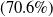 $(70.6\%)$
medical perturbations and
$(70.6\%)$
medical perturbations and
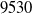 $9530$
$9530$
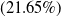 $(21.65\%)$
RUAR perturbations contained in the verified subspaces. While
$(21.65\%)$
RUAR perturbations contained in the verified subspaces. While
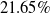 $21.65\%$
of the
$21.65\%$
of the
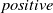 $positive$
perturbations contained in the verified subspaces for the RUAR dataset may seem like a low number, it still results in a robust filter, given that the
$positive$
perturbations contained in the verified subspaces for the RUAR dataset may seem like a low number, it still results in a robust filter, given that the
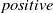 $positive$
class of the dataset contains many adversarial examples of the same input query, i.e. semantically similar but lexically different queries. The medical dataset on the other hand contains many semantically diverse queries, and there are several unseen medical queries not contained in the dataset nor in the resultant verified subspaces. However, given that the subspaces contain
$positive$
class of the dataset contains many adversarial examples of the same input query, i.e. semantically similar but lexically different queries. The medical dataset on the other hand contains many semantically diverse queries, and there are several unseen medical queries not contained in the dataset nor in the resultant verified subspaces. However, given that the subspaces contain
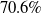 $70.6\%$
of the
$70.6\%$
of the
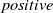 $positive$
perturbations of the medical safety dataset, an application of this could be to carefully curate a new dataset containing only queries with critical and serious risk-level labels defined by the World Economic Forum for chatbots in healthcare (see Section 2.5.1 and [Reference Forum135]). This dataset could be used to create verified filters centred around these queries to prevent generation of medical advice for these high-risk categories.
$positive$
perturbations of the medical safety dataset, an application of this could be to carefully curate a new dataset containing only queries with critical and serious risk-level labels defined by the World Economic Forum for chatbots in healthcare (see Section 2.5.1 and [Reference Forum135]). This dataset could be used to create verified filters centred around these queries to prevent generation of medical advice for these high-risk categories.
Overall, we find that semantically informed verification generalises well across the different kinds of data to ensure guarantees on the output, and thus should aid in ensuring the safety of LLMs.
6. Conclusions and future work
Summary. This paper started with a general analysis of existing NLP verification approaches, with a view of identifying key components of a general NLP verification methodology. We then distilled these into a “NLP Verification Pipeline” consisting of the following six components:
-
1. dataset selection;
-
2. generation of perturbations;
-
3. choice of embedding functions;
-
4. definition of subspaces;
-
5. robust training;
-
6. verification via one of existing verification algorithms.
Based on this taxonomy, we make concrete selections for each component and implement the pipeline using the tool ANTONIO [Reference Casadio, Arnaboldi, Daggitt, Isac, Dinkar, Kienitz, Rieser and Komendantskaya16]. ANTONIO allowed us to mix and match different choices for each pipeline component, enabling us to study the effects of varying the components of the pipeline in a algorithm-independent way. Our main focus was to identify weak or missing parts of the existing NLP verification methodologies. We proposed that NLP verification results should report, in addition to the standard verifiability metric, the following:
-
• whether they use geometric or semantic subspaces, and for which type of semantic perturbations;
-
• volumes, generalisability and embedding error of verified subspaces.
We finished the paper with a study of the current limitations of the NLP components of the pipeline and proposed possible improvements such as introducing a perturbations filter stage using cosine similarity. One of the major strengths of the pipeline is that each component can be improved individually.
Contributions. The major discoveries of this paper were
-
• In Section 4, we proposed generalisability as a novel metric and showed that NLP verification methods exhibit a generalisability-verifiability trade-off. The effects of the trade-off can be severe, especially if the verified subspaces are generated naively (e.g. geometrically). We, therefore, strongly believe that generalisability should be routinely reported as part of NLP verification pipeline.
-
• In Sections 4 and 5, we showed that it is possible to overcome this trade-off by using several heuristic methods: defining semantic subspaces, training for semantic robustness, choosing a suitable embedding function and filtering with cosine similarity. All of these methods result in the definition of more precise verifiable subspaces, and all of them can be practically implemented as part of NLP verification pipelines in the future. This is the main positive result of this paper.
-
• In Section 5, we demonstrated that there are two key assumptions underlying the definition of subspaces that cannot be taken for granted. First, the LLMs, used as embedding functions, may not map semantically similar sentences to similar vectors in the embedding space. Second, our algorithmic methods for generating perturbations, whether by LLMs or otherwise, may not always be semantically-preserving operations. Both of these factors influence practical applications of the NLP verification pipeline.
-
• In Section 5, we demonstrated that even verified subspaces can exhibit semantic embedding errors: this effect is due to the tension between verification methods that are essentially geometric and the intuitively understood semantic meaning of sentences. By defining the embedding error metric and using it in our experiments, we demonstrated that the effects of embedding errors do not seem to be severe in practice, but this may vary from one scenario to another. It is important that NLP verification papers are aware of this pitfall and report embedding error alongside verifiability and generalisability.
Finally, we claim as a contribution, a novel, coherent, methodological framework that allows us to include a broad spectrum of NLP, geometric, machine learning and verification methods under a single umbrella. As illustrated throughout this paper, no previous publication in this domain covered this range, and we believe that covering this broad range of methods is crucial for the development of this field.
Limitations and the Role of the Embedding Gap. In this paper, we have shown the effect of the embedding gap in the NLP verification domain. In Section 4.1, we introduced the generalisability metric (Definition8) to estimate how well subspaces capture semantically similar yet unseen sentences, providing a quantitative lens to examine this challenge. Sections 4.3 and 4.4 demonstrated that geometric subspaces struggle with the verifiability-generalisability trade-off, while semantic subspaces, constructed using semantic-preserving perturbations, show promise in mitigating the embedding gap by better aligning with data semantics.
The embedding gap is not unique to NLP and manifests itself nearly in every domain where machine learning is applied. For example, in CV, the geometric definition of an
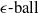 $\epsilon \textrm {-ball}$
can include perturbations that no longer semantically resemble the original image (e.g. distortions that transform a given image into something unrecognisable). In the verification of neural network controllers, possible discrepancies arise between interpretation of neural network inputs, such as velocity, distance, angle (i.e. have physical interpretation) and the way in which the neural network treats them as normalised input vectors [Reference Daggitt, Kokke, Atkey, Slusarz, Arnaboldi and Komendantskaya154, Reference Cordeiro, Daggitt, Girard-Satabin, Isac, Johnson, Katz and Wu155]. In NLP, the gap is amplified by the use of LLMs to map discrete sentences into continuous vector spaces. This process lacks a one-to-one correspondence between semantics and embeddings, exacerbating the challenge.
$\epsilon \textrm {-ball}$
can include perturbations that no longer semantically resemble the original image (e.g. distortions that transform a given image into something unrecognisable). In the verification of neural network controllers, possible discrepancies arise between interpretation of neural network inputs, such as velocity, distance, angle (i.e. have physical interpretation) and the way in which the neural network treats them as normalised input vectors [Reference Daggitt, Kokke, Atkey, Slusarz, Arnaboldi and Komendantskaya154, Reference Cordeiro, Daggitt, Girard-Satabin, Isac, Johnson, Katz and Wu155]. In NLP, the gap is amplified by the use of LLMs to map discrete sentences into continuous vector spaces. This process lacks a one-to-one correspondence between semantics and embeddings, exacerbating the challenge.
This problem is fundamental for machine learning methods deployed in NLP: they always rely on an “embedding function” that maps sentences into real vectors (on which machine learning algorithms operate). There is an implicit assumption that the embedding function works in a way that semantic similarity of sentences is reflected in geometric proximity of their embeddings. However, as general semantic similarity of sentences is not effectively computable, there is no hope that a perfect embedding function will ever be defined. Fundamentally, this is exactly the reason why machine learning (and not symbolic) approaches to NLP proved to be successful: they operate on the assumption that the embedding function is imperfect. As a consequence, any verification pipeline for NLP must include metrics that measure potential embedding errors. Section 5.6 of this paper is entirely devoted to defining this problem in mathematically precise terms and proposing an effective metric for measuring and reporting the severity and effects of the embedding errors.
This paper aims to quantify and address the embedding gap in the NLP domain. For better quantifying the effect of the embedding gap, we proposed precise metrics, such as verifiability, generalisability, and embedding error, and showed their interplay. This better understanding of the problem gave rise to our main positive result: the method that empirically reduces the effect of the embedding gap. While our findings mark progress, further research is needed to better align geometric representations with semantic meaning, especially in NLP contexts.
Future Work. Following from our in-depth analysis of the NLP perspective, we note that even if one has a satisfactory solution to all the issues discussed, there is still the problem of scalability of the available verification algorithms. For example, the most performant neural network verifier,
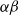 $\alpha \beta$
-Crown [Reference Wang, Zhang, Xu, Lin, Jana, Hsieh and Kolter43], can only handle networks in the range of tens of millions of trainable parameters. In contrast, in NLP systems, the base model of BERT [Reference Devlin, Chang, Lee and Toutanova139] has around 110 million trainable parameters (considered small compared to modern LLMs—with trainable parameters in the billions!). It is clear that the rate at which DNN verifiers become more performant may never catch up with the rate at which LLMs become larger. Then the question arises: how can this pipeline be implemented in the real world?
$\alpha \beta$
-Crown [Reference Wang, Zhang, Xu, Lin, Jana, Hsieh and Kolter43], can only handle networks in the range of tens of millions of trainable parameters. In contrast, in NLP systems, the base model of BERT [Reference Devlin, Chang, Lee and Toutanova139] has around 110 million trainable parameters (considered small compared to modern LLMs—with trainable parameters in the billions!). It is clear that the rate at which DNN verifiers become more performant may never catch up with the rate at which LLMs become larger. Then the question arises: how can this pipeline be implemented in the real world?
For future work, we propose to tackle this based on the idea of verifying a smaller DNN (classifier), manageable by verifiers, that can be placed upstream of a complex NLP system as a safeguard. We call this a filter (as mentioned in Section 3 and illustrated in Figure 2), and Figure 7 shows how a semantically informed verified filter can be prepended to an NLP system (here, an LLM) to check that safety-critical queries are handled responsibly, e.g. by redirecting the query to a tightly controlled rule-based system instead of a stochastic LLM. While there are different ways to implement the verification filters (e.g. only the verified subspaces), we suggest utilising both the verified subspaces together with the DNN as the additional classification could strengthen catching positives that fall outside the verified subspaces, thus giving stronger chances of detecting the query via both classification and verification.
In this figure, we show how a prepended, semantically informed verified filter added to an NLP system (here, an LLM), can check that safety-critical queries are handled responsibly, e.g. by redirecting the query to a tightly controlled rule-based system instead of a stochastic LLM.

We note that the NLP community has recently proposed guardrails, in order to control the output of LLMs and create safer systems (such as from Open AI, NVIDIA and so on). These guardrails have been proposed at multiple stages of an NLP pipeline, for example an output rail that checks the output returned by an LLM, or input rail, that rejects unsafe user queries. In Figure 7, we show an application of our filter applied to the user input, which thus creates guarantees that a subset of safety critical queries are handled responsibly. In theory, these verification techniques we propose may be applied to guardrails at different stages in the system, and we plan to explore this in future work.
A second future direction is to use this work to create NLP verification benchmarks. In 2020, the International Verification of Neural Networks Competition [Reference Brix, Müller, Bak, Johnson and Liu156] (VNN-COMP) was established to facilitate comparison between existing approaches, bring researchers working on the DNN verification problem together and help shape future directions of the field. However, for some time, the competition still lacked NLP verification benchmarks [Reference Brix, Bak, Liu and Johnson157]. In 2024, we contributed a first NLP benchmark to VNN-COMP, using the methodology of this paper, and the tool ANTONIO [Reference Brix, Bak, Johnson and Wu158]. We intend to use this work for creating NLP verification benchmarks for future editions, to spread the awareness and attention to this field.
Acknowledgements
The authors acknowledge Vinay Krupakaran for his help in the manual annotation of the perturbed sentences and Daniel Kienitz for his help with the eigenspace rotation.
Funding
The authors acknowledge support of EPSRC grant AISEC EP/T026952/1 and NCSC grant `Neural Network Verification: in search of the missing spec'. The first author acknowledges the James Watt Scholarship awarded by the Heriot-Watt University.
Competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
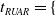
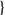
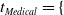
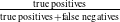
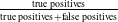
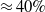


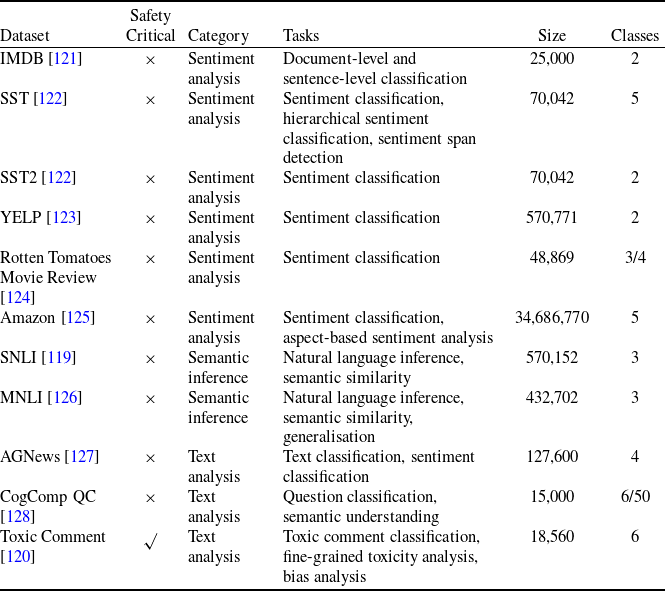
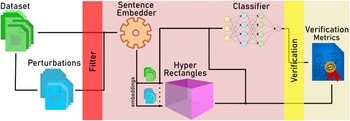

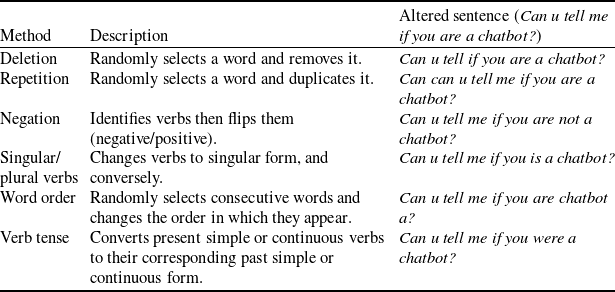






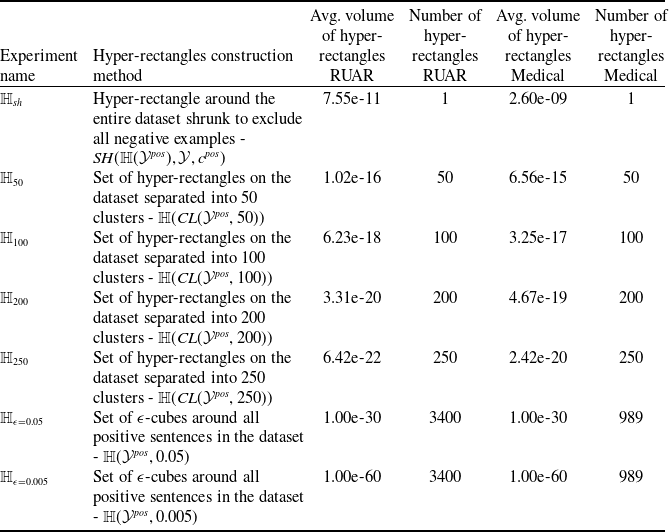

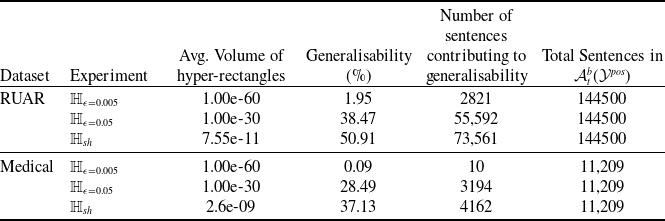





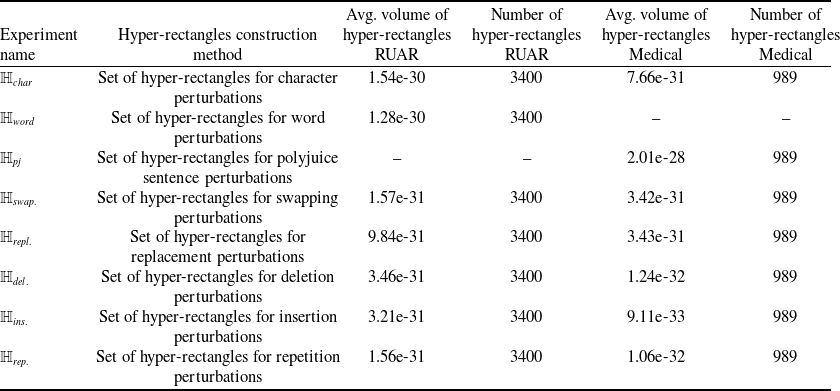


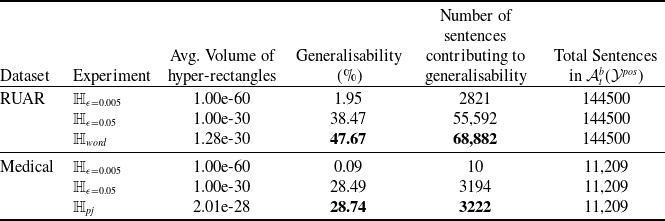









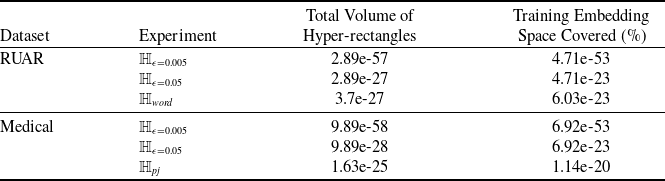


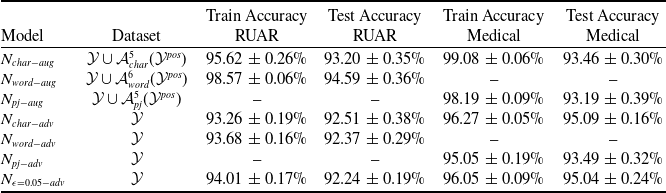

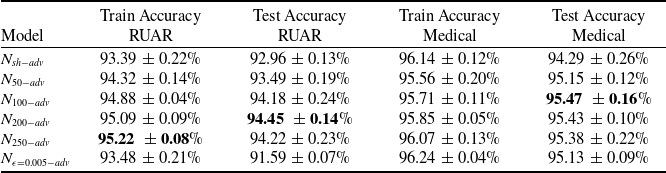
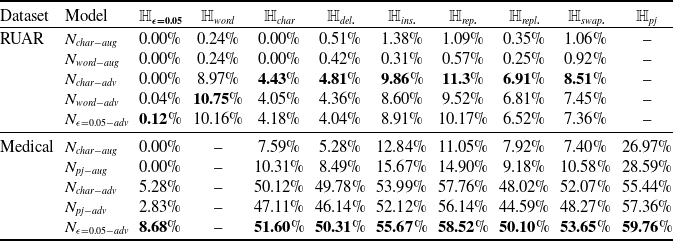
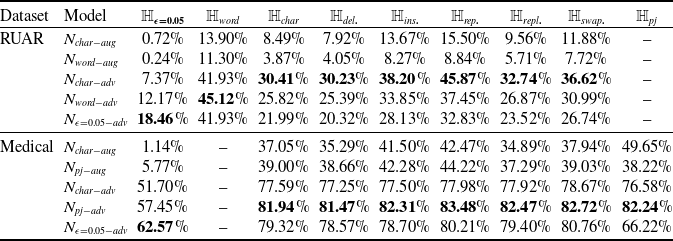
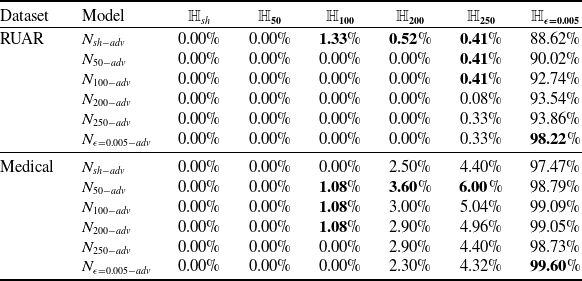





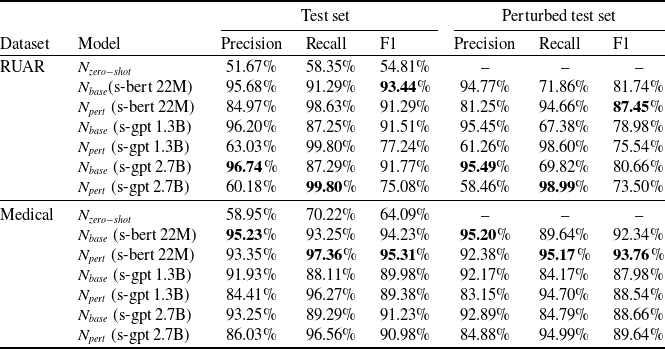

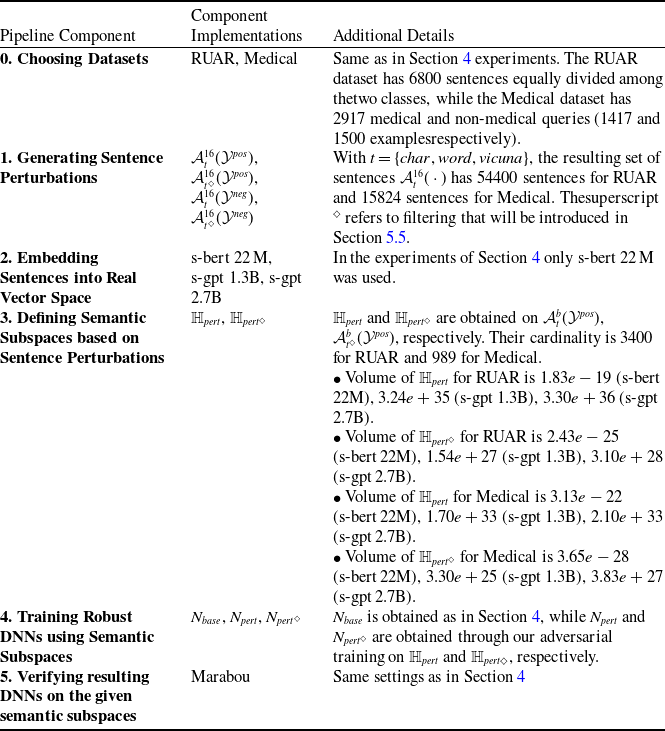

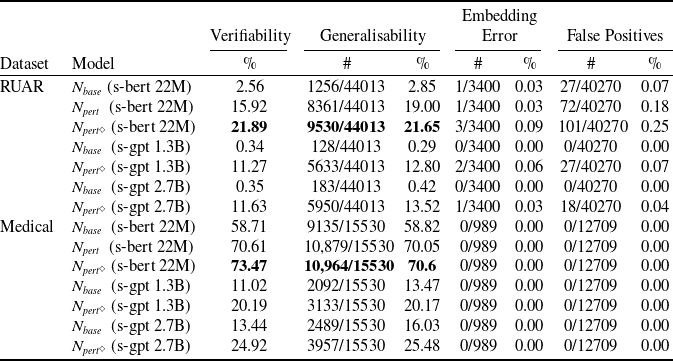






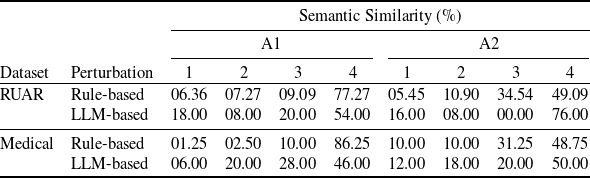
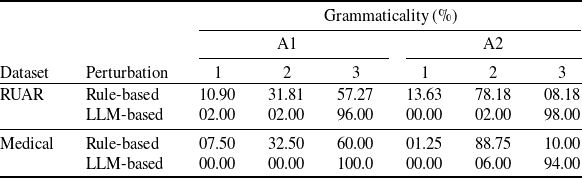
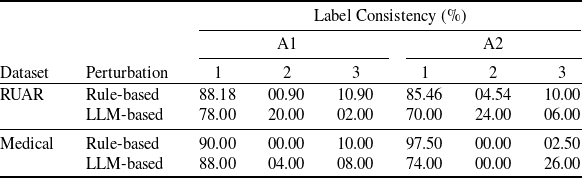
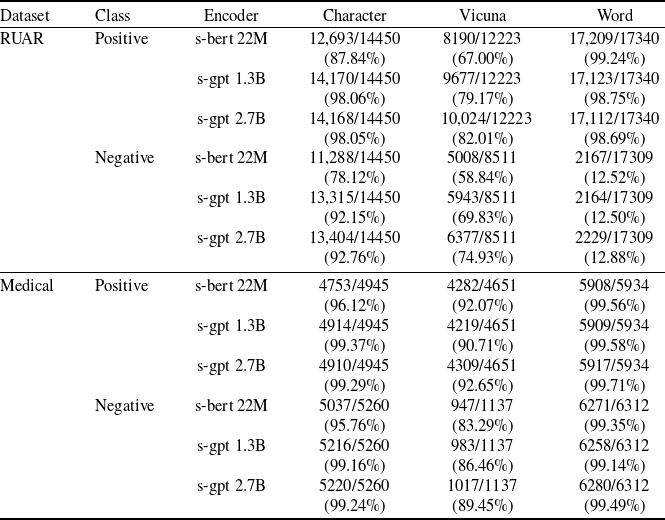
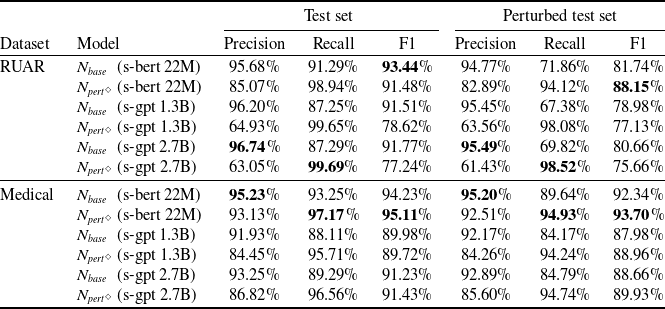


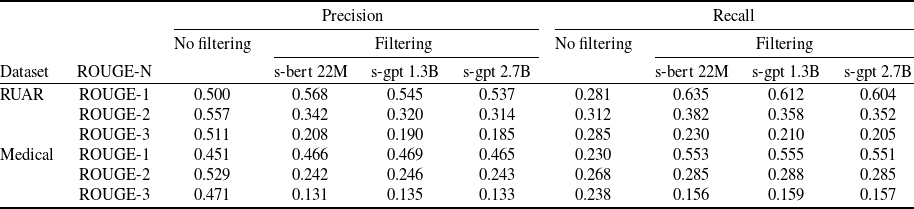
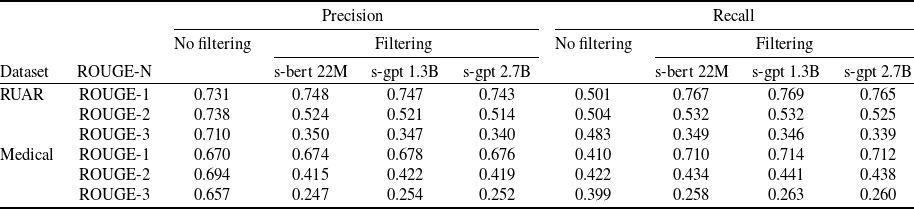


 Open access
Open access