


1. Introduction
One of the core tenets of saliency theory is that parties do not compete by taking opposing stances on the same issues (Budge and Farlie, Reference Budge and Farlie1983) but that parties emphasize different issues in order to gain electoral support (Dolezal et al., Reference Dolezal, Ennser-Jedenastik, Müller and Winkler2014; Wagner and Meyer, Reference Wagner and Meyer2014; Greene, Reference Greene2016; Seeberg, Reference Seeberg2022). As parties continue to focus on their core issues, the public learns to associate them with those issues (Petrocik, Reference Petrocik1996; Walgrave et al., Reference Walgrave, Lefevere and Tresch2012). Research has consistently shown that when parties convince the public of their problem-solving capacity, they are rewarded electorally (Green and Hobolt, Reference Green and Hobolt2008; Belanger/Meguid, Reference Meguid2008; Green and Jennings, Reference Green and Jennings2012a; Bélanger and Nadeau, Reference Bélanger and Nadeau2015).
One of the key questions in current research on issue ownership is the extent to which public competence ascriptions are malleable (Pope and Woon, Reference Pope and Woon2009; Green and Jennings, Reference Green and Jennings2012b; Meyer and Müller, Reference Meyer and Müller2013; Seeberg, Reference Seeberg2017a). Are parties able to take over issue ownership from their competitors and how frequently does this happen? Are some issues more resistant to issue ownership and issue ownership changes than others? What factors help or impede parties from taking over issue ownership from their competitors? While answers to these questions promise important insights into party competition, current research is hindered by methodological challenges.
First and foremost, researchers often face a data sparsity problem when attempting to take a longitudinal perspective on issue ownership (Seeberg Reference Seeberg2017a). This data sparsity problem is exacerbated by the fact that existing research has predominantly measured issue ownership by calculating the share of respondents who name a particular party as most competent for a particular issue at a particular point in time. By implicitly and implausibly assuming that each issue and each time point is independent, this approach increases the number of data points needed to arrive at reasonable estimates. What is more, such estimates are more vulnerable to random sampling error and fail to account for the inherent uncertainty in measuring public perceptions of issue competence.
To overcome these shortcomings, we introduce a Bayesian multilevel model of issue competence. In modeling issue competence, defined as people’s perceptions of party competence on specific issues, we take inspiration from the work by Green and Jennings on macro-competence (Green and Jennings, Reference Green and Jennings2012b). Green and Jennings argue that it is possible to identify an underlying structure in voters’ perceptions of party competence. Building on this insight, we develop a multilevel framework of issue competence by estimating the macro-competence for each party and treating issue-competence as systematic deviations from the macro-competence. Setting the model up in this way allows us to borrow strength between issues, resulting in more reasonable estimates even for sparsely populated issue categories, while the model also yields uncertainty estimates for the predictions. Furthermore, the proposed model can be flexibly specified to allow for deviations with regard to time or other factors to answer substantive questions of issue ownership, such as how issue ownership changes over time and what factors might cause such changes.
To develop the model of issue competence, we begin with a brief discussion of current conceptualizations and measurement strategies for issue ownership and issue competence. Next, we introduce the issue competence model and discuss possible extensions. For the application, we rely on survey data from the German Longitudinal Election Study (GLES). The application proceeds in three steps. First, we discuss the validity of the estimated macro-competence and issue competence. Second, we present the estimates for the dynamic model specification. Third, we compare the estimates from our model with the results from a more conventional measurement strategy.
Overall, the model yields plausible estimates, which can be summarized as follows. First, the estimated issue competences exhibit high face validity. Second, there is considerable variation with regard to the party competences over time. Third, the model yields more stable and credible estimates of issue competence, whereas a measure based on raw percentages produces markedly more volatile patterns over time.
2. Concepts and measures of issue ownership
The defining characteristic of issue ownership is a clear link between a party and an issue in the minds of voters. Following the work of Petrocik (Reference Petrocik1996), scholars have generally conceived of this link in terms of competence, where some parties are thought to be better at dealing with a particular issue. In a well-known extension of the concept, Walgrave and others have distinguished between a competence dimension and an associative dimension of issue ownership (Walgrave et al., Reference Walgrave, Lefevere and Tresch2012, Reference Walgrave, van Camp, Lefevere and Tresch2016), where the latter refers to a spontaneous association between parties and issues. This distinction relates to measurement difficulties that have plagued research on issue ownership (Lefevere et al., Reference Lefevere, Walgrave, Stubager and Tresch2017; Stubager, Reference Stubager2018). While the underlying conception of issue ownership is similar between surveys—and mostly addressing the competence dimension of issue ownership—we can readily identify a host of survey questions that have been employed to gauge issue ownership in existing research. To ease exposition, we will speak of competence-based issue ownership in the remainder of this paper, not least since this reflects the empirical measure in our case study. Yet, the proposed model can be applied just as easily to estimate associative issue ownership.
We can identify another important distinction in existing research that is not as prominently discussed—the distinction between issue ownership and issue competence. Issue ownership refers to the party that is collectively perceived as most competent for dealing with an issue, while issue competence refers to the attributed party competence, regardless of whether a party is perceived as most competent. While this distinction is irrelevant when studying two-party systems, it is crucial in the study of multi-party systems. As voters tend to name their preferred party as most competent (Walgrave et al., Reference Walgrave, van Camp, Lefevere and Tresch2016; Lefevere et al., Reference Lefevere, Walgrave, Stubager and Tresch2017), large parties are more likely to be assigned the issue owner status than small parties. At the same time, minor competitors often have a strong reputation for specific issues, even when that reputation does not reach the levels of the major parties.
Although conceptual contributions have clearly understood issue ownership to refer to a collective phenomenon, a surprising number of studies have focused on individual-level perceptions of issue competence and, hence, on highly subjective competence ascriptions. This is particularly evident in studies which have tried to relate issue competences to vote choices (Green and Hobolt, Reference Green and Hobolt2008; Belanger/Meguid, Reference Meguid2008; Lachat, Reference Lachat2014; Bélanger and Nadeau, Reference Bélanger and Nadeau2015). To remain closer to the conceptual foundations of issue ownership research, not least since aggregate perceptions of issue ownership is central to a lot of research in this field, such as the effects of party communication and media coverage on issue competence (Walgrave and De Swert, Reference Walgrave and De Swert2007; Kleinnijenhuis and Walter, Reference Kleinnijenhuis and Walter2014) or the effects of issue competence on media coverage (Hayes, Reference Hayes2008; van der Brug and Berkhout, Reference van der Brug and Berkhout2015; Schwarzbözl et al., Reference Schwarzbözl, Fatke and Hutter2020), we focus on aggregate perceptions of party competence.
One of the areas that has received a lot of interest is measuring the dynamics of issue ownership (Bélanger, Reference Bélanger2003; Brasher, Reference Brasher2009; Pope and Woon, Reference Pope and Woon2009; Green and Jennings, Reference Green and Jennings2012a, Reference Green and Jennings2012b; Meyer and Müller, Reference Meyer and Müller2013; Christensen et al., Reference Christensen, Dahlberg and Martinsson2015). While the majority of studies on dynamic issue ownership have been restricted to case studies, few contributions have moved in a comparative direction (Seeberg, Reference Seeberg2017a, Reference Seeberg2017b, Reference Seeberg2020). One of the main challenges in this field regards data availability and is thus a methodological one. Existing studies have often calculated simple percentages of respondents who name a party as most competent to gauge issue ownership. This approach implicitly assumes that each issue and each time point is independent, which is unreasonable given that public evaluations of party competence on specific issues are likely influenced by past evaluations and by perceptions of their competence on related issues. Consequently, this assumption limits the ability to borrow strength from related observations in estimating issue competence, thereby increasing the number of data points needed for reliable estimates. The problem is further compounded by data sparsity, which is common in studies of issue ownership. As a result, conventional estimates tend to be unstable and susceptible to random error.
Even though many studies have relied on simple percentages, a few contributions have modeled the percentages (Green and Jennings, Reference Green and Jennings2012b; Seeberg, Reference Seeberg2017b). The most elaborate version of such a model is presented by Green and Jennings (Reference Green and Jennings2012b), who rely on Stimson’s dyad ratios algorithm and a smoother for the resulting estimates (cf. Stimson, Reference Stimson2018). While this is undoubtedly more sophisticated than other methodological choices in the field, the individual time periods are nonetheless treated as independent, thus increasing the data requirements.
Consequently, our aim is to introduce a measurement strategy which yields aggregate issue ownership dynamics. By modeling the survey data, we are better able to deal with sparse data, while estimating issue competences that are less prone to noise from random sampling error and account for the underlying uncertainty in measuring issue competence.
3. Modeling issue competence
To develop our model of issue competence, we build on the idea that there is a macro-competence underlying issue-specific competence perceptions, as proposed by Green and Jennings (Reference Green and Jennings2012b). Green and Jennings argue that there is a common structure to issue competence ratings, as voters transfer their perceptions of party competence between issues. While the notion of such an underlying structure in individual issue perceptions is plausible, the macro-competence is not perfectly deterministic for the issue competence ratings either, as even Green and Jennings find that the individual issue ratings correlate with the estimated macro-competence to varying degrees.
Unlike Green and Jennings, we employ a more conventional modeling strategy. When researchers have access to individual-level data, the individual responses can be modeled directly, which has several advantages. Not only do the resulting models readily yield uncertainty estimates, but they can also be easily extended. Essentially, we start by assuming that all individual issue-specific ratings are fully determined by macro-competence and then successively relax this assumption to allow for deviations from the macro-competence with regard to issue and time. By modeling such deviations in a single hierarchical set-up allows borrowing strength between categories, resulting in more reasonable estimates, which is important as the data becomes sparser when multiple categories are being considered at the same time. Terminologically, we will refer to macro-competence when talking about the underlying structure of the issue competence ratings, while the term issue competence will refer to the issue-specific estimates.
Assume we have common survey data, where individuals are asked to name the party that they associate with an issue or that they perceive as most competent at dealing with an issue. A straightforward way to estimate the aggregate-level macro-competence underlying the individual responses is to stack all responses and to model the probability that a particular party is named as most competent. In a two-party system, this would result in a logistic model, which generalizes to a categorical model in a multi-party system. In the latter case, the most competent party 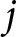 $j$ as rated by individual
$j$ as rated by individual 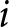 $i$,
$i$, 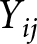 ${Y_{ij}}$, is given by:
${Y_{ij}}$, is given by:
 \begin{equation*}{Y_{ij}}\,\sim\,{\text{Categorical}}\left( {{\pi _{ij}}} \right)\end{equation*}
\begin{equation*}{Y_{ij}}\,\sim\,{\text{Categorical}}\left( {{\pi _{ij}}} \right)\end{equation*} \begin{equation*}{\pi _{ij}} = \,\frac{{{\text{exp}}\left( {{\eta _{ij}}} \right)}}{{\displaystyle\sum_{k = 1}^K {\text{exp}}\left( {{\eta _{ik}}} \right)}}\end{equation*}
\begin{equation*}{\pi _{ij}} = \,\frac{{{\text{exp}}\left( {{\eta _{ij}}} \right)}}{{\displaystyle\sum_{k = 1}^K {\text{exp}}\left( {{\eta _{ik}}} \right)}}\end{equation*} \begin{equation*}{\eta _{ij}} = {\alpha _j}\end{equation*}
\begin{equation*}{\eta _{ij}} = {\alpha _j}\end{equation*} where 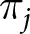 ${\pi _j}$ represents the probability of naming a particular party as most competent, while
${\pi _j}$ represents the probability of naming a particular party as most competent, while 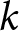 $k$ represents the alternatives. In its most basic form, the model is fully determined by a set of intercepts,
$k$ represents the alternatives. In its most basic form, the model is fully determined by a set of intercepts, 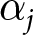 ${\alpha _j}$, which represent the macro-competence of each party. Note that the model treats the individual responses as independent, thus disregarding any individual-level clustering that arises when respondents evaluate party competence on more than one issue. As we are only interested in aggregate-level estimates of party competence, the individual-level clustering should have little effect on the resulting estimates.
${\alpha _j}$, which represent the macro-competence of each party. Note that the model treats the individual responses as independent, thus disregarding any individual-level clustering that arises when respondents evaluate party competence on more than one issue. As we are only interested in aggregate-level estimates of party competence, the individual-level clustering should have little effect on the resulting estimates.
One of the main advantages of setting the model up this way is that it allows for flexible extensions to account for group-specific deviations. The first deviation we will consider concerns differences in parties’ perceived competence across issues. While it is plausible that voters form perceptions of parties’ issue competence based on their overall competence, they are likely to hold more specific views about which parties are more or less competent on particular issues. For example, we might expect that voters are more aware of party competences on more politically salient issues. Their perception should also be clearer when parties address an issue more frequently, while voters should generally have a more nuanced sense of the issue competences of larger parties. By incorporating such issue-specific deviations from parties’ macro-competence, our model can estimate the perceived party competence on different issues. Specifically, we generalize the linear model component to include random intercepts for issue 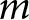 $m$, one for each party
$m$, one for each party 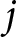 $j$,
$j$, 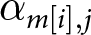 ${\alpha _{m\left[ i \right],j}}$:
${\alpha _{m\left[ i \right],j}}$:
 \begin{equation*}{\eta _{ijm}} = {\alpha _j} + {\alpha _{m\left[ i \right],j}}\end{equation*}
\begin{equation*}{\eta _{ijm}} = {\alpha _j} + {\alpha _{m\left[ i \right],j}}\end{equation*} The impact of the random intercepts on the predicted issue competence depends on the number of observations we have for a particular issue category and how distinct the response patterns are for a particular issue area relative to the macro competence. If a sufficient number of voters evaluate party competences systematically better or worse on some of the issues, this would result in non-zero terms for the issue-specific intercepts. Otherwise, the model remains unchanged. Notably, the metric of interest for all the model variants is the predicted party competence, 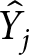 ${\hat Y_j}$, adjusted for grouping factors. In this case, the relevant grouping factor is issue
${\hat Y_j}$, adjusted for grouping factors. In this case, the relevant grouping factor is issue 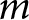 $m$, resulting in
$m$, resulting in 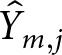 ${\hat Y_{m,j}}$.
${\hat Y_{m,j}}$.
The next grouping factor is the time period 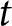 $t$, which allows the model to account for temporal dynamics in public perceptions of issue competence. To capture the temporal and issue-specific temporal dynamics in competence evaluations, we include a set of random intercepts for time period
$t$, which allows the model to account for temporal dynamics in public perceptions of issue competence. To capture the temporal and issue-specific temporal dynamics in competence evaluations, we include a set of random intercepts for time period 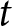 $t$ and random intercepts for issue
$t$ and random intercepts for issue 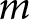 $m$ at time period
$m$ at time period 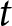 $t$,
$t$, 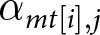 ${\alpha _{mt\left[ i \right],j}}$, which allows for varying trajectories of issue competence over timeFootnote 1:
${\alpha _{mt\left[ i \right],j}}$, which allows for varying trajectories of issue competence over timeFootnote 1:
 \begin{equation*}{\eta _{ijmt}} = {\alpha _j} + {\alpha _{m[i]}}_{,j} + {\alpha _t}_{[i],j} + {\alpha _{mt[i]}}_{,j}\end{equation*}
\begin{equation*}{\eta _{ijmt}} = {\alpha _j} + {\alpha _{m[i]}}_{,j} + {\alpha _t}_{[i],j} + {\alpha _{mt[i]}}_{,j}\end{equation*}One concern when introducing grouping factors is that data become increasingly sparse, making estimates more susceptible to random sampling error. This may cause neighboring estimates to fluctuate in implausible ways as they are driven by random noise rather than meaningful variation. A reasonable extension of the model is to explicitly incorporate time dependencies, which can provide more information and, hence, more stability to the model, as shown in Appendix B. However, in our application, incorporating time dependencies did not substantially improve model fit or predictive performance compared to the simpler specification without time dependencies. Therefore, we will present the results from the simpler model in the following analysis.
Before moving to the application, it is worth emphasizing that the proposed approach does not challenge the established conceptualization or measurement of issue competence as the share of voters who consider a party as most competent on a given issue at a given point in time. On the contrary, our intention is to build on this measure. While the conventional approach has intuitive appeal and a clear conceptual link to issue competence, it is vulnerable to data sparsity—an issue that becomes especially problematic when researchers seek to track issue competence over time, often leading to implausible results. Our model incorporates information from other issue areas and time periods, thereby producing more reasonable and stable estimates of issue competence when data are sparse. In other words, if there is enough data about perceived party competence in a particular issue area at a particular point in time, this information should be sufficient to calculate reasonable shares of perceived issue competence, and our model would produce estimates that should differ little from the raw percentages. If the data are more sparse, however, the estimates will be more strongly influenced by macro-competence, since there is too little information to calculate reasonable shares of perceived party competence on a particular issue.
4. Perceptions of party competence in Germany
For an application of the model, we need data on the perception of parties’ issue competences, which we take from the GLES (Weßels et al., Reference Weßels, Rattinger, Roßteutscher and Schmitt-Beck2014; Schoen et al., Reference Schoen, Roßteutscher, Schmitt-Beck, Weßels and Wolf2017; Schmitt-Beck et al., Reference Schmitt-Beck, Roßteutscher, Schoen, Weßels and Wolf2022). Parties’ issue competences are collected by the GLES as part of the Most Important Problem (MIP) question, where respondents are asked to identify the issues they consider most important and the parties they believe are most competent at addressing those issues. In terms of the distinction between competence issue ownership and associative issue ownership (Walgrave et al., Reference Walgrave, Lefevere and Tresch2012, Reference Walgrave, van Camp, Lefevere and Tresch2016), the question clearly falls on the competence side of issue ownership.
There are two main benefits of relying on the GLES data. First, the competence question was included in all GLES surveys in a consistent manner since the 2009 federal election, enabling an analysis of all individual-level responses in a comprehensive model. Second, the GLES has fielded a large number of surveys, even between federal elections, allowing a detailed perspective on issue competence dynamics. Specifically, due to the wealth of data, we are able to estimate biannual models with 28 time points between 2009 and 2023. An overview of the datasets underlying the analysis is provided in Table A1 in Appendix A.
Most surveys asked respondents to name the most and second most important problem, as well as the parties they perceive as the most competent at addressing those problems. Earlier surveys asked respondents to name the three most important problems and the most competent parties. For the analysis, we created a dataset of all responses, along with the necessary meta information. Each respondent can thus appear up to three times in the dataset. Several GLES surveys had a panel structure, where individuals were interviewed multiple times. In those cases, we only included the first interview in the dataset to avoid giving too much weight to the perceptions of respondents who were repeatedly surveyed. As a practical matter, it should make little difference, given the large number of respondents at roughly 100,000 individuals overall. We focus on the issue competences of the six parties in the 19th German Bundestag (2017–2021), the center-right CDU/CSU, the center-left SPD, the left-wing Grüne, the economically liberal FDP, the far-left Die Linke, as well as the far-right AfD. All responses that did not name one of the six main parties in the German party system as most competent were discarded.
As the MIP question had an open response format, the GLES team assigned the responses to a coding scheme specifically designed for classifying German politics. For the present analysis, we reassigned the GLES codes to the coding scheme of the Comparative Agendas Project (CAP; Baumgartner et al., Reference Baumgartner, Breunig and Grossman2019), specifically the German variant of the coding scheme (Breunig et al., Reference Breunig, Guinaudeau and Schnatterer2023), which allows associating the results from this analysis to other datasets classified according to the CAP coding scheme.Footnote 2 Some responses could not be assigned to a single category. In such cases, the GLES team assigned the response to multiple categories. In creating the dataset, we only used the first assigned category, as this category likely reflects the dominant issue in the response.Footnote 3
While the two-step data collection results in at most three responses per interviewee, the major benefit of this data collection strategy is that we are able to gauge issue competences for an unusually large number of issues. When respondents are explicitly asked to name the most competent party on specific issues, there is a practical limit as to how many issues can be presented to respondents. Therefore, existing research has typically been limited to studying issue ownership regarding few issues (Walgrave et al., Reference Walgrave, van Camp, Lefevere and Tresch2016; Stubager, Reference Stubager2018; Seeberg, Reference Seeberg2020).Footnote 4
The benefit of being able to study a wide range of issues comes at the price that not every respondent provides their views on all issues. As the subset of respondents who view a particular issue as important is potentially quite different from the average voter, we only get issue competence ratings for a politically skewed sample. In other words, relying on individuals’ responses at face value likely results in unbalanced samples between issues. To provide an example, while there are potentially a lot of CDU/CSU voters in the dataset, few might mention Welfare as the most important problem. As a consequence, left-leaning voters are likely overrepresented among those who perceive Welfare as Germany’s most important problem, leading to an artificially depressed number of respondents who view the CDU/CSU as most competent at dealing with Welfare matters. This problem becomes increasingly pronounced for issues that are either less salient to the general public or are strongly associated with specific partisan constituencies.
To address such partisan effects on issue selection and the possible partisan imbalances between issues, we extend the model to incorporate the party identification (PID) of the respondents into the estimation of party issue competence. Specifically, in addition to the party-specific intercepts and the random intercepts for issue 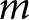 $m$, time
$m$, time 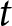 $t$, and for issue
$t$, and for issue 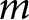 $m$ at time
$m$ at time 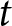 $t$, we add a series of fixed terms for PID
$t$, we add a series of fixed terms for PID 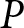 $P$, one set for each party
$P$, one set for each party 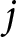 $j$ as response category. Along with a PID for one of the six main parties in the German party system, we add a seventh category for voters with no (stated) PID. A CDU/CSU PID constitutes the reference category. Based on this model, we predict the issue competence perceptions for respondents with the various PIDs. Formally, the extended model has the following form:
$j$ as response category. Along with a PID for one of the six main parties in the German party system, we add a seventh category for voters with no (stated) PID. A CDU/CSU PID constitutes the reference category. Based on this model, we predict the issue competence perceptions for respondents with the various PIDs. Formally, the extended model has the following form:
 \begin{equation*}{\eta _{ijmt}} = {\alpha _j} + {\alpha _{m\left[ i \right],j}} + {\alpha _{t\left[ i \right],j}} + {\alpha _{mt\left[ i \right],j}} + \mathop \sum \limits_{p = 1}^P {\beta _{p,j}} \cdot {X_{{\text{p}},i}}\end{equation*}
\begin{equation*}{\eta _{ijmt}} = {\alpha _j} + {\alpha _{m\left[ i \right],j}} + {\alpha _{t\left[ i \right],j}} + {\alpha _{mt\left[ i \right],j}} + \mathop \sum \limits_{p = 1}^P {\beta _{p,j}} \cdot {X_{{\text{p}},i}}\end{equation*} To estimate issue ownership, we weight the issue competence ratings for the different PID categories with their factual prevalences in the data. Specifically, we predict the competence of party 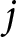 $j$ on issue
$j$ on issue 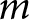 $m$ at time period
$m$ at time period 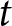 $t$ among voters with PID
$t$ among voters with PID 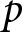 $p$, denoted
$p$, denoted 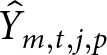 ${\hat Y_{m,t,j,p}}$, and multiply this estimate by the number of respondents with PID
${\hat Y_{m,t,j,p}}$, and multiply this estimate by the number of respondents with PID 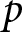 $p$ in the dataset,
$p$ in the dataset, 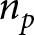 ${n_p}$. This process is repeated for all
${n_p}$. This process is repeated for all 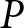 $P$ PIDs. The weighted competence score for party
$P$ PIDs. The weighted competence score for party 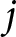 $j$ on issue
$j$ on issue 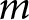 $m$ is then calculated by summing all partisan evaluations and dividing by the total number of observations in the dataset. Formally, the weighted competence for party
$m$ is then calculated by summing all partisan evaluations and dividing by the total number of observations in the dataset. Formally, the weighted competence for party 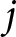 $j$ on issue
$j$ on issue 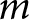 $m$ at time period
$m$ at time period 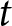 $t$ is calculated as:
$t$ is calculated as:
 \begin{equation*}{\hat Y_{m,t,j,{\text{weighted}}}} = \frac{{\displaystyle\sum_{p\, = \,1}^P \left( {{{\hat Y}_{m,t,j,\,p}} \cdot {n_p}} \right)}}{n}\end{equation*}
\begin{equation*}{\hat Y_{m,t,j,{\text{weighted}}}} = \frac{{\displaystyle\sum_{p\, = \,1}^P \left( {{{\hat Y}_{m,t,j,\,p}} \cdot {n_p}} \right)}}{n}\end{equation*}All models were estimated using Markov Chain Monte Carlo in Stan (Carpenter et al., Reference Carpenter, Gelman, Hoffman, Lee, Goodrich, Betancourt, Brubaker, Guo, Li and Riddell2017).Footnote 5 We assume the following priors:
 \begin{equation*}{\alpha _j}\,\sim\,{\text{Normal}}\left( {0,2} \right)\end{equation*}
\begin{equation*}{\alpha _j}\,\sim\,{\text{Normal}}\left( {0,2} \right)\end{equation*} \begin{equation*}{\beta _{p,j}}\sim{\text{Normal}}\left( {0,2} \right)\end{equation*}
\begin{equation*}{\beta _{p,j}}\sim{\text{Normal}}\left( {0,2} \right)\end{equation*} \begin{equation*}{\alpha _{m,j}}\,\sim\,{\text{Normal}}\left( {0,{\sigma _m}} \right)\end{equation*}
\begin{equation*}{\alpha _{m,j}}\,\sim\,{\text{Normal}}\left( {0,{\sigma _m}} \right)\end{equation*} \begin{equation*}{\sigma _m}\,\sim\,{\text{Half - Cauchy}}\left( {0,2} \right)\end{equation*}
\begin{equation*}{\sigma _m}\,\sim\,{\text{Half - Cauchy}}\left( {0,2} \right)\end{equation*} \begin{equation*}{\alpha _{t,j}}\,\sim\,{\text{Normal}}\left( {0,{\sigma _t}} \right)\end{equation*}
\begin{equation*}{\alpha _{t,j}}\,\sim\,{\text{Normal}}\left( {0,{\sigma _t}} \right)\end{equation*} \begin{equation*}{\sigma _t}\,\sim\,{\text{Half - Cauchy}}\left( {0,2} \right)\end{equation*}
\begin{equation*}{\sigma _t}\,\sim\,{\text{Half - Cauchy}}\left( {0,2} \right)\end{equation*} \begin{equation*}{\alpha _{mt,j}}\,\sim\,{\text{Normal}}\left( {0,{\sigma _{mt}}} \right)\end{equation*}
\begin{equation*}{\alpha _{mt,j}}\,\sim\,{\text{Normal}}\left( {0,{\sigma _{mt}}} \right)\end{equation*} \begin{equation*}{\sigma _{mt}}\,\sim\,{\text{Half - Cauchy}}\left( {0,2} \right)\end{equation*}
\begin{equation*}{\sigma _{mt}}\,\sim\,{\text{Half - Cauchy}}\left( {0,2} \right)\end{equation*}The parameters for the response category CDU/CSU are constrained to be zero in all models. We ran each model with four chains and 2,000 iterations each, where the first 1,000 iterations from each chain were discarded as burn-in. The model diagnostics show good convergence.
5. Static issue competence
We first estimate the basic model without random intercepts to examine the static overall perception of party competence. The results are presented in Model 1 in Table 1, which only includes the party intercepts to capture their static macro-competence. Model 2 adds fixed effects for respondents’ PID. Model 3 introduces issue random intercepts to the baseline model to estimate static issue competences. Finally, Model 4 includes both the PID parameters and the issue random intercepts, allowing us to estimate parties’ static issue competence while accounting for potential partisan issue selection biases.
Models for static competence

The party intercepts in Model 1 represent the static macro-competences, which can be viewed as the underlying structure shaping individuals’ perceptions of parties’ competences. The values broadly reflect the electoral strengths of the German parties. All party fixed effects are lower than the CDU/CSU baseline, with the SPD exhibiting the closest parameter as the CDU/CSU. This suggests that respondents perceive the CDU/CSU as the most competent party overall, followed by the SPD. Given that party supporters are more likely to name their preferred party as most competent (Walgrave et al., Reference Walgrave, van Camp, Lefevere and Tresch2016; Lefevere et al., Reference Lefevere, Walgrave, Stubager and Tresch2017), the fixed effects broadly reflect the distribution of party support in the German electorate.
Model 2 underscores the benefit of including respondents’ PID to estimate party competences. Including the party affiliation of voters dramatically improves our ability to predict which party respondents perceive as most competent, as evidenced by the substantial improvement in model fit. The PID parameters represent the changes in the perceived macro-competences of the parties by party supporters. The parameters all have plausible magnitudes, in that party supporters exhibit the highest parameter estimates for their preferred party. For example, Die Linke supporters exhibit the largest parameter value for the macro-competence of Die Linke, indicating that Die Linke supporters tend to perceive Die Linke as more competent than the supporters of the other parties. Figure A1 in the Appendix shows that partisans rate their own party as more competent than others do, especially supporters of Die Linke and the AfD. The in-group premium underscores the importance of accounting for respondents’ partisan identity when measuring party competence. Even beyond this obvious expectation, the parameters show strong face validity, as party supporters exhibit higher parameter values for ideologically similar parties. For example, while the SPD parameter value is highest for SPD supporters in Model 2, the values for Grüne supporters and Die Linke supporters are also sizeable, whereas AfD supporters and FDP supporters are much less likely to select the SPD as most competent.
The standard deviations of the random intercepts displayed at the bottom of Table 1 for Models 3 and 4 indicate a notable degree of variation in perceived party competence between issues (see Table A3 in the Appendix for a presentation of all random intercepts for each issue and party). This suggests that parties are perceived as more competent than their average competence on some issues and less competent on others. The extent of the variability in parties’ perceived competence across issues differs considerably between parties. Grüne, Die Linke, and AfD exhibit stronger variation in their issue-level intercepts, whereas SPD and FDP show more limited variation. Table A3 documents how parties’ perceived competence varies across issues, and the pattern aligns with expectations. Grüne, Die Linke, and the AfD are evaluated much more strongly on issues they emphasize (e.g., environment, welfare, immigration). By contrast, broader programmatic parties such as the SPD and the FDP also show issue-specific differences, but the dispersion is comparatively modest, yielding more even competence profiles. This pattern nicely aligns with the niche party character of the former three parties (cf. Meguid, Reference Meguid2008; Wagner, Reference Wagner2012). Evidently, the emphasis on fewer issues is mirrored in public perceptions. Notably, the estimated values for macro-competence and the fixed effects for PID remain largely consistent between Models 2 and 4, despite a slight increase in the variability of the issue-level random intercepts in the model that includes PIDs.
Figure 1 presents the predicted static issue competences based on Model 4, providing further face validity for the performance of the model (see Table A4 in the Appendix for the specific numeric values). Each value represents the predicted share of voters who consider a party as most competent on a given issue. For instance, a value of 0.411 for the CDU/CSU on Macroeconomics indicates that, on average, 41.1 percent of voters are predicted to view the CDU/CSU as the most competent party on this issue. The predicted values align well with established views of the German party system. For example, the center-right CDU scores highly in areas such as Law and Crime, Domestic Commerce, International Affairs, and Macroeconomics, whereas the center-left SPD has higher competence values in social matters, such as Housing, Labor, Welfare, and Education. The predicted values for the minor parties are also consistent with expectations. The left-leaning Grüne demonstrates high competence in Energy, Civil Rights, and Transportation, along with exceptionally high competence in Environment. The economically liberal FDP is perceived as strong in Domestic Commerce and Macroeconomics. The far-left Die Linke is viewed as competent in the fields of Welfare, Housing, Defense, and Civil Rights. The party’s high competence in Defense can be attributed to its strong anti-war stance. Finally, the far-right AfD exhibits high values in Law and Crime and Immigration, the latter of which can be attributed to its anti-immigration position.
Static issue competences along with 95 percent credible intervals.

6. Dynamic issue competence
Having shown that the proposed model generates plausible estimates for static macro-competence and static issue competence, we now incorporate the temporal effects into the model to measure the dynamic issue competence of parties. To that end, Table A2 in Appendix A presents the results from a model that includes the PID parameters along with random intercepts for issue, time, and the interaction between time and issue, where time is added in biannual increments. As shown in Table A2, the inclusion of random intercepts for time and for the issue–time interaction further improves model fit.
We present the results for two issue categories in Figure 2. The left figure shows the estimated party competence for the issue of Health, the right figure shows the estimated competence for the issue of Immigration. A few observations stand out. First, on the issue of Health, CDU/CSU and SPD alternate as the most competent party over time. Notably, CDU/CSU received a strong boost in 2020 at the onset of the COVID-19 pandemic, a surge that gradually dissipates over time. These gains come at the expense of the coalition partner SPD. This likely reflects the fact that CDU/CSU held both the chancellorship and the federal health ministry when the pandemic started, thus benefiting from its association with the national COVID response.
Examples of biannual issue competences.

The issue of Immigration, presented in the right panel of Figure 2, provides a similarly interesting case. While the AfD’s perceived competence has generally increased over the course of the observation period, this trend is especially pronounced in the area of Immigration. By 2018, the AfD had surpassed the CDU/CSU, positioning itself as the issue owner on Immigration. Notably, there is a clear contrast between the party’s estimated competence on the two issues. The AfD saw a significant increase in its perceived competence on Immigration from the mid-2010s, but this boost is not reflected in its estimated competence on health matters. Conversely, the CDU/CSU’s surge in health-related competence in 2020 is not mirrored in its performance on immigration. These different patterns provide additional validity to our findings and suggest that respondents hold at least partially issue-specific perceptions of party competence.
We also calculated the raw proportion of respondents who named the parties as most competent at handling specific issues—a measure that has often been used in the literature as an indicator for issue competence. To compare our model-based estimates with the raw percentages, we focus on less common issues, Transportation and Housing, as our model is designed to deal with data sparsity and the resulting random sampling error, which is more pronounced for issues where fewer respondents provide evaluations of party competence. In addition to these data-sparse issues, we also compare our model-based estimates with the raw percentages for two data-rich cases, Die Linke on Welfare and AfD on Immigration, to illustrate how our model performs under data-rich conditions. The results are shown in Figure 3.
Comparison between the model predictions and the raw estimates of issue competence for two data-sparse and two data-rich cases. (a) CDU/CSU: Transportation (data-sparse). (b) SPD: Housing (data-sparse). (c) Die Linke: Welfare (data-rich). (d) AfD: Immigration (data-rich).


As shown in Figure 3(a) and (b), the conventional measure of issue competence is more erratic and sensitive to short-term fluctuations in public opinion. For example, the raw proportions of the CDU/CSU’s competence in Transportation in Figure 3(a) exhibit sharp reversals within short time spans. Specifically, the share of voters who consider the CDU/CSU as most competent in the area of transportation drops from well over 60 percent in the first half of 2010 to zero in the second half of 2010, followed by an immediate rebound in the mid-2010s. These swings suggest implausible volatility in public opinion, which is difficult to reconcile with political developments or shifts in party position. They also contradict theoretical conceptions of issue ownership. A similar pattern is evident for the SPD’s competence on Housing. Raw estimates fluctuate abruptly and sometimes reverse direction without any discernible political cause. In our model-based estimates, the SPD remains the most competent party on Housing throughout the period of observation, although it often competes with the CDU/CSU within the 95 percent credible interval.
The erratic dynamics in the unmodeled measure of issue competence likely result from random sampling error and data sparsity, rather than reflecting meaningful changes in public opinion. For example, in the 2010 surveys, only eight respondents provided an evaluation of party competence on transportation. Such small numbers create the appearance of a 60-point collapse in competence within a six-month time span. The volatility in issue competence also contributes to erratic shifts in issue ownership. In the raw data, issue ownership changes no less than 16 times over the course of the observation in the area of transportation, often accompanied by dramatic gains and losses, as shown in Figure C2 in the Appendix. By contrast, our model predicts only four changes in issue ownership, with more gradual shifts in parties’ perceived competence on the issue (see Figure C3 in the Appendix). The more stable patterns of ownership in our model align better with the literature which views issue ownership as a relatively stable property (Seeberg, Reference Seeberg2017a), although our results suggest that public perceptions of issue competence are somewhat more malleable than previously assumed. We return to this point in the conclusion.
While the comparison demonstrates that our proposed model provides a plausible alternative to conventional percentage-based measures under conditions of data sparsity, it should be noted that when a sufficient number of responses about perceived party competence in a particular issue area at a given point in time is available, this information should be sufficient to calculate reasonable shares of perceived issue competence, where the model estimates should differ little from the raw percentages. This is demonstrated in Figure 3(c) and (d), which compares the predicted values with the raw measure for Die Linke’s issue competence on Welfare and AfD’s issue competence on Immigration. In these well-populated issue areas, where each party received the greatest number of responses with the mean numbers of responses being 160.46 and 192.14 per time point, respectively, the predicted values closely align with the raw measures.
Lastly, it should be noted that the problem of small numbers of responses for issue competence is not confined to few issues. Even though we use the GLES data, which has fielded many surveys over the course of the observation period with consistent survey questions (see Table A1 in the Appendix), 16.6 percent of the raw estimates are based on fewer than ten responses, and the median number of respondents per estimate is only twelve (for the full distribution, see Figure C1 in the Appendix). This clearly illustrates the problem of data sparsity when researchers measure issue competence over time. The problem becomes even more pronounced when researchers further disaggregate party competence, for example, by geography. Such low numbers of responses, and the volatility they produce, raise serious concerns about both the face validity and the analytical utility of the raw measure. In contrast, by modeling issue-specific deviations from parties’ macro-competence within a unified framework, our model-based estimates produce more stable estimates which better align with theoretical expectations and political developments, as it incorporates data from other issue areas and other time periods. Overall, the model offers a plausible alternative to conventional percentage-based measures and contributes to more robust empirical analyses.
7. Conclusion
While issue salience and issue ownership are crucial concepts in the study of party competition, the former has received much more attention in empirical research than the latter. Whereas issue salience refers to the importance that parties ascribe to particular issues, issue ownership relates to public perceptions of what issues parties are associated with or what issues they are perceived as competent at dealing with (Walgrave et al., Reference Walgrave, Lefevere and Tresch2012, Reference Walgrave, van Camp, Lefevere and Tresch2016). While the two concepts are undoubtedly related, they are far from identical, such that the strong emphasis on issue salience over issue ownership constitutes an imbalance in current research on party competition.
Arguably, the main reason for this imbalance is that political scientists are far better at measuring issue salience than issue ownership (cf. Wagner and Meyer, Reference Wagner and Meyer2014). Given the ever more widely available digitized text and the ever more refined techniques for automated text analyses (Grimmer et al., Reference Grimmer, Roberts and Stewart2021, Reference Grimmer, Roberts and Stewart2022), scholars have developed a nuanced sense of which issues parties care about and which issues parties emphasize in their communication (e.g., Abou-Chadi and Orlowski Reference Abou-Chadi and Orlowski2016; Dolezal et al., Reference Dolezal, Ennser-Jedenastik, Müller and Winkler2014; Klüver and Spoon, Reference Klüver and Spoon2016).
By contrast, estimating issue ownership requires survey data, which is often sparse, especially when our interest lies in estimating issue ownership dynamics. By frequently relying on simple percentages, previous studies have needed more data to estimate issue ownership structures for every issue and time point. The resulting estimates are more prone to random sampling error, while also not providing a sense of the uncertainty associated with the estimates. As a result, the conventional measure of issue competence suffers from volatility which results from random sampling error rather than meaningful changes in public opinion.
To overcome these challenges, we have argued that it is possible to make better use of the available survey data than in the past. We have proposed a Bayesian multilevel model for estimating the issue competence of parties. The idea was to model all available competence ratings in a common model and to treat issue-specific and/or time-specific competence ascriptions as deviations from parties’ macro-competence. The main benefit of this model set-up is that we are able to generate plausible estimates with fewer data points, as the model is able to borrow strength between the different categories (cf. Park et al., Reference Park, Gelman and Bafumi2004; Caughey and Warshaw, Reference Caughey and Warshaw2015). Our modeling strategy builds on the idea of macro-competence, proposed by Green and Jennings (Reference Green and Jennings2012b), while flipping the idea on its head. Whereas Green and Jennings are interested in parties’ macro-competence, which they estimate by aggregating parties’ issue-specific competences, our modeling strategy starts with parties’ macro-competence to arrive at their issue competences.
Overall, our analysis demonstrates a meaningful degree of face validity in the model’s predicted estimates. Compared to the raw estimates, which tend to be more volatile, our model captures more stable and interpretable trends in perceived issue competence. In addition, incorporating uncertainty around the estimates adds further value to our approach. While the importance of accounting for measurement uncertainty has long been emphasized in the measurement literature, it has received relatively little attention in applications that measure political science concepts such as issue competence.
Still, we would like to emphasize that our paper does not argue that all researchers should shift from using raw percentages to model-based estimates, nor that our model should become the default approach in studies of dynamic issue ownership. Rather than opposing the use of raw percentages to measure issue competence or issue ownership, our model builds on this measure while addressing the data sparsity problem which often arises in such research but has received insufficient attention. When researchers have sufficient data to estimate the issue competence of parties with raw percentages, the benefits of using our model are limited, as its predictions differ little from the raw values. Yet data sparsity is a common challenge, particularly for minor parties or less prominent issues, and it becomes even more pronounced when researchers attempt to measure issue competence in a disaggregated way, such as by time or region. In this context, our model offers a promising alternative to raw percentages, which are highly vulnerable to sparsity and the resulting volatile dynamics in estimates of issue competence.
Another alternative to address the data sparsity problem would be to change the data collection process. Instead of the commonly used two-step format—first asking respondents which issues they consider most important for the country and then asking which party they consider most qualified at handling those issues—surveys can directly query respondents about their perceptions of the most competent party across all issues of interest. This approach does away with problems of data sparsity and random sampling error by providing sufficient information to estimate party competence. While practical constraints limit the number of issues that can realistically be presented to respondents, the benefits of directly asking about competence across all issues of interest outweigh the limitations. In practice, however, we are not aware of any longitudinal study that has consistently employed this question format, which makes our proposed model a viable alternative for mitigating random sampling error in less-populated issues under the common two-step survey design.
Substantively, the analyses provided strong evidence that issue ownership is malleable and can change based on public evaluations of how parties manage specific issues. For example, the significant increase in the CDU/CSU’s perceived competence on health during the COVID-19 pandemic reflects its central role in managing the crisis. Likewise, the AfD’s growing perceived competence on immigration, particularly following the 2015 refugee crisis, illustrates how political events and a party’s strategic focus on an issue can shape public perceptions of which parties are most competent at dealing with an issue. This degree of malleability is noteworthy because, while studies relying on raw data often show substantial variability over time (e.g., Meyer and Müller, Reference Meyer and Müller2013)—variability that may reflect random sampling error rather than meaningful shifts—more recent work by Seeberg (Reference Seeberg2017a) observes greater stability in issue ownership by modeling responses in a conventional regression framework. Our work represents a middle ground between the two extremes: we ensure stability by borrowing strength across issue categories, while still allowing for dynamic shifts when supported by the data. Therefore, although we observe more shifts in issue ownership than is currently assumed in the literature, we recognize that this may partly reflect our focus on competence ratings, whereas associative issue ownership is likely to be more stable over time (cf. Walgrave et al., Reference Walgrave, van Camp, Lefevere and Tresch2016).
Future research should seek to apply the model in other contexts. While there is no consistent survey measure for issue ownership (Therriault, Reference Therriault2015; Lefevere et al., Reference Lefevere, Walgrave, Stubager and Tresch2017; Stubager, Reference Stubager2018), the model is sufficiently general to be used with different types of survey questions on issue ownership, including associative issue ownership. There is no reason to expect that the core logic of estimating parties’ issue competences as deviations from their macro-competence would not apply in other settings.
Future research can also apply the model to study issue ownership in other countries, particularly those with more limited data. One important caveat is that, although the model generally performs well with sparse data, the data requirements increase substantially with the inclusion of grouping factors. Therefore, as a practical matter, researchers should carefully weigh the costs and benefits of adding complexity to the model. Nevertheless, we hope that this contribution will open up new opportunities to incorporate public perceptions of issue competence into a wider range of research projects and renew scholarly attention for the important role of competence ascriptions in shaping party competition.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/psrm.2025.10074.
Acknowledgements
We are grateful to Kolja Hiebl for excellent research assistance. We thank Henrik Bech Seeberg, Denis Cohen, Jane Green, Tilko Swalve, and Constantin Wurthmann for their feedback on this project.
Data availability statement
Replication data for this study are available on the Harvard Dataverse.
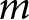
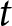







 Open access
Open access